#DeepSeek-R1 and DeepSeek-R1-Zero
2516 messages · Page 3 of 3 (latest)

ooh Together
Hmm... still working for me, even when I pin to Together
do you want me to print out exactly what's going over the wire?
Can you try a prompt like "9.11 and 9.9, which one is larger? Please THINK!"?
ok
it looks correct in the console -- reasoning should not be None if it produced the think tag
definitely it's thinking - it just doesn't seem to be wrapping it in <think></think>
we detects the think section and pull it into the reasoning field of the delta
So you shouldn't see the <think> tag from our API
take a look at the sample
Hmmm looks sus for sure, let me double check
in the mean time, if you do stream: true, does it work?
I don't know how to process a stream in python - do you have an example?

OpenRouter Documentation
Learn how to implement streaming responses with OpenRouter's API. Complete guide to Server-Sent Events (SSE) and real-time model outputs.
I switched back to /chat/completions and it worked this time, from DeepInfra
without streaming right?
without streaming
it worked again, also from DeepInfra
is there a way to force it to Together so I can verify if it doesn't work on Together?
how can I force it?

OpenRouter Documentation
Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
Something like this (in TS):
body: JSON.stringify({
'model': 'mistralai/mixtral-8x7b-instruct',
'messages': [
{
'role': 'user',
'content': 'Hello'
}
],
'provider': {
'order': [
'OpenAI',
'Together'
],
'allow_fallbacks': false
}
}),
We will add some Python docs for this soon cc @cerulean lotus
ok it's working now, for both Together and DeepInfra (intermittently, at least)
I will just check for null or empty reasoning and retry
Thank you for helping me
I need to get it training on 72b, and also I need to get a RL pipeline set up. (Pretty sure Dolphin-R1-24b would be much better if I used RL to tame its <think> block)
2% of responses have no reasoning - That's not too bad

occasionally there's no "choices" in the response

Reason API error: Response ended prematurely
Reason API error: Response ended prematurely
Reason API error: Response ended prematurely
Reason API error: Response ended prematurely
Processing samples: 3%|█▋ | 1514/47532 [32:58<21:57:27, 1.72s/it]Reason API error: Response ended prematurely
Reason API error: Response ended prematurely
getting a lot of these "Response ended prematurely" and a few of
Reason API error: HTTPSConnectionPool(host='openrouter.ai', port=443): Max retries exceeded with url: /api/v1/chat/completions (Caused by SSLError(SSLError(1, '[SSL: SSLV3_ALERT_BAD_RECORD_MAC] sslv3 alert bad record mac (_ssl.c:2570)')))
looking
What client are you using btw?
is it just this raw request.post?
yes
im still, sometimes, getting empty replies from deepseek api provider for r1. is that just cause theyre refusing to reply? sillytav problems? or api problems?
I'm using the deepseek-ai/DeepSeek-R1 API and need providers with a throughput of at least 25 t/s. However, provider performance constantly changes, and some providers, like Nebius Studio, use different model names (e.g., "deepseek-ai/DeepSeek-R1-FAST"), making it difficult to ensure I'm always using the fastest available option.
Right now, API provider routing only allows filtering by provider name, which isn't enough for my needs. I want a way to automatically route requests to any R1 provider that meets my throughput requirement, without manually updating the provider list.
A better solution would allow filtering providers by throughput, uptime, max context, max output and pricing instead of just excluding them by name.
We have this now!
Lots of provider routing options here: https://openrouter.ai/docs/features/provider-routing
OpenRouter Documentation
Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
most recently, we have sort, which lets you sort by throughput, latency, price, etc.
we also have a max_price param: https://openrouter.ai/docs/api-reference/parameters#max-price
let me know if this begins to fill the requests / features you hope to see.
That works. One suggestion: emphasize displaying each provider's uptime % in the analysis. Uptime % is a crucial metric, but it isn't currently shown on the model page, nor can we sort by it through API calls. Thank you!
isn't the whole point of openrouter is that it routes away from downtime without any work on your part
I see the value of automatic fallback, but in my case, my app relies on chained API calls, data transformations, and long-running processes. Each fallback adds latency and increases processing time. If I can proactively avoid providers with frequent failures, I can minimize disruptions and ensure a more efficient experience for my users. Having uptime data would allow me to make smarter routing decisions upfront, reducing the need for fallbacks in the first place.
isn't the whole point of openrouter is that it routes away from downtime without any work on your part

Each fallback adds latency and increases processing time
not true! we keep track of how providers are doing and skip them without adding latency if they're unreliable. like @vocal raven said above
Download the model weights on our HuggingFace Repo or consider using the model via our Sonar API.
HuggingFace Repo: https://t.co/9HK9mQGKQ1
Can we have R1 1776 from sonar api to Openrouter?
But how is a provider determined to be unreliable? By detecting failed API calls, right? That means failures have to happen first. And unless OpenRouter calls all providers simultaneously, which would be inefficient, the fallback provider is only called after the first one fails, introducing delays. This has happened to me many times, and it's obvious that making one call takes less time than making two or more sequentially. I’m not saying the fallback system is wrong, I think it’s great. But since a provider can only be detected as failing after it fails, the system could be even more efficient if provider uptime were disclosed and sorting by it was possible through the API.
Past returns do not guarantee future returns
On your application side, having logic which retries OpenRouter means you get the routing functionality and the "retry" will then be resolved by OR to a working provider. Only need the one set of API settings in your application.
If you are really mission critical, need to build in logic that means if for whatever reason OR goes down (eg domain hijacking), it goes to some other endpoint for a request.
Past failures don’t guarantee future ones, but probability matters. A provider with lower uptime has a higher chance of failing, and uptime % is a good indicator of that probability. I already have a retry system, but retrying increases latency for my users. I’m just suggesting a way to reduce the chances of needing a retry in the first place, regardless of whether it’s OpenRouter internally handling the retry or me. Thanks for sharing your thoughts!
might be cool to be able to route to providers with at least e.g. 50 tokens/s speed, but use default prio, or price prio
so like a custom speed floor
Publishing more data would be great, I agree.
cc @cedar sentinel

Can you log the provider as well? We return it as provider_name
Or are you pinning it to a known set
on my next subset I will (I don't wanna throw away my progress)
you should consider batches
Hi,
I’ve noticed that R1 is currently returning many errors, as shown on the uptime page. In my app, this causes long-chained API calls to fail, leading to financial losses when expensive processes fail before completion.
To prevent this, I suggest adding an API endpoint to check the current uptime of each model. This would allow apps like mine to monitor uptime and take preventive action. For example, if uptime drops below 90%, I would display a message to users informing them that workflows are temporarily unavailable, preventing them from starting processes that are likely to fail.
This feature would help developers reduce failed requests and unnecessary costs while improving user experience.
Thanks for considering this!
Are you pinning to any provider in particular?
My providers array order is: "Fireworks",
"Together",
"Nebius"
Deepseek is ignored.
Fallbacks are enabled. max_price is 8 for both prompt and completion. sort by throughput is enabled.
there are ways you can make your application more resilient immediately, staging (send a partial canned response to the user implying thought, or a loadinwheel) while you retry in the background, having a HA fallback mechanism to azure or vertex etc. 98% uptime means 200 of every 10000 will fail, so you know they will fail
using data from OR is slower than having an immediate path for your program to go down in case of API failure
within OR you could set it up to fallback to one of their highly available models, and if it has fallen back as shown in the response, you can request again for the actual R1 response
Thank you for sharing your ideas!
I have OpenRouter’s fallback mechanism enabled, and I already have a retry system that calls OpenRouter again when an error is detected.
However, the issue is more complex than just handling explicit errors. Some failed API calls don’t return an error at all, making it difficult to detect programmatically. For example, I received the following response:
{ "result": { "id": "gen-1739998011-kBgJfDmW76mQtvtdyK4L", "model": "deepseek/deepseek-r1", "usage": { "total_tokens": 5623, "prompt_tokens": 5619, "completion_tokens": 4 }, "object": "chat.completion", "choices": [ { "index": 0, "message": { "role": "assistant", "content": "[-1]", "refusal": null }, "logprobs": null, "finish_reason": "stop", "native_finish_reason": "stop" } ], "created": 1739998011, "provider": "DeepInfra" } }
The [-1] response is clearly incorrect and not at all what the model should have returned. This isn’t a prompt engineering issue but rather a problem with degraded responses from the model.
These kinds of errors tend to happen more frequently when uptime is lower, suggesting that the providers available are more likely to be operating at degraded capacity rather than failing outright. Having an uptime API would help my app prevent initiating workflows during these degraded states, where failures are harder to detect.
please vote: #announcements message
yeah I get you, you could detect for something that is wrong unless you ever expect answers <4 characters? there is client side logic like that or checking against a local dictionary for if words have actually been returned. character account is simpler
deepinfra hasn't been my favourite but staff wouldn't have brought it back without serious testing. you shouldnt be billed for a response like that imo
Checking characters might detect some errors, not the ideal solution though.
Yeah I don't have Deepinfra in my providers array, it was called by a fallback. I agree, but what's more important for me is to be able to avoid this kind of errors from occuring. Model uptime tracking via API would help a lot
we're actually in the middle of revamping our downtime avoidance system, so this is timely!
but this overhaul is more geared towards request statuses returned from upstream (4xx/5xx) and dynamically routing around outages better than we do today
in your case here tho, it looks like our response status tracking won't help much. since it was a "successful" request with 200 status and a non-error finish reason. our uptime stats won't necessarily cover "quality" of outputs
for this sort of thing, we're in the early phases of planning some continuous evals that will penalize providers that consistently output garbage. still more thinking to do on it though, to try and differentiate bad sampling parameters from bad providers
my hobby account with sambanova just got API access for the full R1, maybe it is becoming more generally available...
What kind of context limit?
Only 4K
Supposing that FP8 variants of R1 are a little faster but dumber(?) than those without the "FP8" (so FP16?), is there a way to set the ":nitro" shortcut excluding the FP8 variants?
honestly everyone is fp8, this is what deepseek recommends. The others just have not declared it
Ah, very interesting. Thanks!
PS: I also found that there's a quantization filter setting: https://openrouter.ai/docs/features/provider-routing#quantization
Excellent, they have improved the docs a lot so great that you found it
Fp8 is the highest quant. There is no fp16 or anything
R1 and v3 were natively trained in fp8
This sounds good. However, please consider adding a GET API endpoint to retrieve:
Overall uptime % of a model – When general uptime is low, the model tends to return more garbage responses from the available providers. This is especially critical for our use case since we rely on long-chained API calls, where failures mid-process result in financial losses and wasted compute. Having this data available via API would allow us to proactively prevent workflows when the model is in a degraded state.
Uptime % of a model for a specific provider – Some providers may perform worse than others, and low provider-specific uptime would allow us to dynamically avoid routing requests to unstable providers. This helps reduce latency caused by sending requests to failing providers and having to retry them multiple times.
This is a very simple feature with huge benefits—uptime data is already available on the frontend, so making it accessible via an API endpoint should be straightforward while significantly improving reliability for developers.
Thanks for all your feedback, it's very valuable
it might be you're using json response format, and "[-1]" is a valid json. Using json format for R1 will make the output quality bad, because it's trained to start with <think> tokens.
Someone opened a PR on the R1 HF repo enabling using prefix=True with a modified chat template https://huggingface.co/deepseek-ai/DeepSeek-R1/discussions/158
cc @peak flame


this is why we have inconsistency.
providers are deviating from the standard template.
neuralmagic's problem.
ideal or no - EVERYONE should use the official template, and workaround that (by inserting a fake <think> token on the client side) if necessary, otherwise chaos ensues.


my personal workaround is to use the official tokenizer, and tokenize the prompt myself, then call the completions endpoint
Surely you mean you apply the chat template
Surely you don't actually convert the text into a series of IDs
reason_tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Llama-70B")
tokenized_input = reason_tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
)
nontokenized_input = reason_tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
prompt_tokens = tokenized_input.numel()
allowed_completion_tokens = max_tokens - prompt_tokens
final_max = min(allowed_completion_tokens, max_tokens)
final_max = max(final_max, 1) - 1
response = requests.post(
url="http://localhost:4000/v1/completions",
data=json.dumps({
"model": "r1-distill-70b",
"prompt": nontokenized_input,
"temperature": 0.5,
"max_tokens": final_max
})
).json()
I use tokenized to count the tokens, to properly set the max_tokens
I use non-tokenized to pass to the completions endpoint.
(and it's kind of insane that we need to tokenize the input on the client side like this, just to figure out how to set max_tokens)
why do you need to set max_tokens?
we're working on doing this automatically
cc @bright portal
because otherwise, a default value (typically 8k) is used.
is that too large for you?
I want 32k
ah
why not just set max_tokens: 32k then? max tokens is the max completion tokens, not the whole thing
because then I get error "you requested blabal but the prompt + 32k is greater than the 32k the model can provide"
I worked around it, anyway 🙂
the important thing to note is some providers of R1-Distill-70b are removing the <think> from the prompt template
(which causes it to generate a <think> token - when it wants to)
right that is separate and something we're working on
as opposed to the default which forces a <think> token (but then it doesn't generate one)
FYI, I'm getting a number of rambling never-ending <think> (entire 32k with never an answer) I guess it is temperature related
maybe 1% of requests
I can try dropping temperature to .4 or .3
H
Thank you so much for looking into this
That would be great too
I talked to the Fireworks people about not being able to prefill with their R1 API. Seems like they will come up with a fix. I mentioned https://huggingface.co/deepseek-ai/DeepSeek-R1/discussions/158
but I am not sure what fix they will come up with.
Mon/Tues
@rocky heron @bright portal @peak flame
great job cluing in these amateurs
There's no amateurs here
@pearl parcel are any providers using the updated chat template? The ones I tested seemed to still be using the old one
(i.e. the one without <think>)
according to the current tokenizer published by deepseek {"content":"hi","role":"user"} -> '<|begin▁of▁sentence|><|User|>hi<|Assistant|><think>\n'
it doesn't look like R1 providers are doing this yet tho?
Most are using the neuralmagic fp8 out of the box
ah ok, just saw your PR on their repo, hopefully they update it
They fixed it

Just a matter of everyone updating their models 😅 and then mitigating the lack of <think> in the response that the UI depends on
cool, I'll check again in a few days then
hopefully providers will update their deployments
For now I am using this template and the completion endpoint (instead of chat completion) in order to prefill thinking... https://huggingface.co/deepseek-ai/DeepSeek-R1/discussions/158
https://www.perplexity.ai/page/china-launches-underwater-comp-_SRMVJXjQc2LLmJsq2_2zQ
whale literally computing underwater
based?

Perplexity AI
China has deployed an underwater intelligent computing cluster off the coast of Hainan, delivering processing power equivalent to 30,000 high-end gaming PCs...
I don't know where this comes from, but their uptime is starting to be fixed though we still can't purchase credits directly.
https://zzzzzzz.grafana.net/public-dashboards/88296a8e74c14dae8f839c2b9973214b
Few days later edit: Whoops, they're getting intermittent down times again.

is it better than https://en.wikipedia.org/wiki/Project_Natick

Project Natick was an experimental data center that underwent research and development by Microsoft. Microsoft deployed its first undersea data center prototype in August 2015. It subsequently deployed and retrieved a "shipping-container" sized data center off the coast of the Northern Isles in 2018. Microsoft subcontracted Naval Group to spearh...
FYI, slowly rolling out an update to how we handle thinking generations on ALL R1 models. They will now consistently think, and prefill will now consistenly work.
right now, whenever I use Deepinfra or Nebius AI Studio, the reason and context are just two different versions of a reply or sometimes it looks like the first half of the context is in reasoning...but there's no "reasoning" in reasoning.
Deepseek (the source) is still returning it correctly. Does this have something to do with your changes? Did something change that ST hasn't caught up on perhaps?
rest in peace hyperbolic:deepseek/deepseek-r1-zero

Hmm, I'm very interested in knowing what you guys did to make prefill work consistently...

Deepseek R2 is arriving early.
👀 👀 🍿

that is interresting source please link

The prices listed below are in unites of per 1M tokens. A token, the smallest unit of text that the model recognizes, can be a word, a number, or even a punctuation mark. We will bill based on the total number of input and output tokens by the model.
So I just got this from DeepSeek. I know this would apply if we user our own API, but I wonder if the discount would apply through OR (assuming using the deepseek provider and not one of the others)

Yeah if you use your own key through OR, you'd get the discounted pricing.
I figured that, but what if we use OR's deepseek provider
If you set a Deepseek API key in OR settings, you don't pay anything for the token to openrouter, but you pay 5% of the normal cost as a transaction fee: https://openrouter.ai/docs/use-cases/byok

OpenRouter Documentation
Learn how to use your existing AI provider keys with OpenRouter. Integrate your own API keys while leveraging OpenRouter's unified interface and features.
Make sure you monitor your usage, as when the deepseek provider is unavailable with your key, it will retry with your credits, and you would pay OR for the token.
(setting your deepseek key does not guarantee it will be used, just beware)
This doesn't answer my question. Setting aside the BYOK. If I use DeepSeek v3 or DeepSeek-R1 through OR (making sure I use the actual DeepSeek provider when doing so since both models have many providers), will the discount be applied. That's what I'm asking.
Not at this time. We don't support their pricing discounts
because its technically not possible atm or because you just want to make 75% more cash during those few hours ?
if its a technical thing - i can understand that this can get hairy / specially on provider level
we don't have the code support for it
ya that is cool - here is a recommendation that may is a easyer implemenation - weekly refunds of the over charging happening for that 1 provider .. in a given timeframe
so charge full
but refund the delta once a week or a month
should be a fairly easy processing step / and doesnt need to be changed during proxy passing
just fruit for thought
since transaction logs are stored anyway
i think that would be the happy tadeoff
not sure what alex or the rest of the team thinks
According to this, R1 supports response format. Is this wrong?

But we're still getting
their discounts
right?
Especially if I'm using a custom integration key?
You only get their time-based discount if a generation is going through your own API key, in which case you are billed at what they bill you at, including discounts. And our 5% fee comes from the discounted rate.
otherwise, no, it's the standard non-discounted rates, at all times, through OpenRouter
Amazing i'm using my own API key
beautiful, ya'll are goated thank u!!
(<t:1740673800:t> - <t:1740616200:t>)
i really hope you can implement this soon
At this time, it is not a high priority item for us, but we are planning to support it at some point.
I can imagine it isn't exactly straight forward, since it is time based, but I wonder if other providers will do similar things as a way to differentiate themselves
Yeah the thinking on our end is we should have some dynamic pricing capabilities that can normalize across providers / models / implementation details, instead of a one-off
yeah, completely makes sense
as someone mentioned, if it was a big enough deal could do retroactive manual (with scripts) refunds when users would have got the discount
but likely not a huge deal
or make a cron job to change the pricing at a fixed time every day
that way the openrouter.ai price is updated too
well that could be prone for issues, since there could be timing issues
wdym?
are you saying it might lag behind?
just slight differences between when things actually switch on the provider side, or the cron job failing and the price staying wrong for too long
I personally am not a fan of cron jobs for core infra like that
well i don't think anything could fix the provider lagging behind
no way to know that afaik
(response's usage is just token info, no price info)
yeah, though depending on setup, a tighter integration with a provider might be a better option, e.g. where the provider can tell openrouter the price is changed
but that precludes that they care about openrouter 😄
🎯
the retro active refund would be the easy part
as you run it once a month
i dont care if i overpay for 1 provider
if i know i get the money eventually back
going byok defeats a bit of the purpose of holding funds with or
- its just 1 provider anyway / but the savings are nice .. difference if you spend 1000 bucks or 250 on a bigger synth gig
if you get the allocation that is
DeepInfra added a faster endpoint for R1 at $2/$6 (fp4 quantized) https://x.com/DeepInfra/status/1894866880160244163
🚀 Exciting news! @DeepInfra just dropped Deepseek R1 Turbo—blazing fast at up to 40 tokens per second!
🔥 Runs on Nvidia B200 GPUs
💰 Pricing: $2/$6 per 1M tokens
📍 Hosted in the US 🇺🇸
Try it now on DeepInfra! As always - the best price.
max 32k context window though
as chatty in reasoning as r1 is, lol
FP4 though, then Nebius is much better.

this is up now
Okay now we're talking, 150tps, just need to ge that context window up.
Now I can't use the original (fp8) deepinfra, they have the same provider id (deepinfra) it seems
It's more expensive and has lower quality
you can sort by price
OpenRouter Documentation
Route AI model requests across multiple providers intelligently. Learn how to optimize for cost, performance, and reliability with OpenRouter's provider routing.
Any way to just select the provider manually?
You can select the DeepInfra provider, but unfortunately we don't have a way to let you select the specific endpoint at this time. Your best bet is to sort by price and select DeepInfra, and if you really want to avoid getting any other endpoints, you can disable fallbacks. All of this should be in the docs I linked.
We know this is not a good experience, on our roadmap to fix.
Can this setting be more agressive?
I have it set to use the cheaper version but the much pricier version is still replying. almost half of the time.
I rather have a generation failing sometimes than paying 10 times the price.

that's a valid point! the platform defaults tries to guarantee a generation (so it falls back). You should be able to disable fallbacks in your API calls.
I looked onto it and reached this conclusion:
In my opinion, this is a bit out of touch to the fact a lot of users using open router aren't developers.
The majority of apps don't give this deep level of customization of API calls in their UI. I use mostly for roleplay, but I also saw here, that even extremely widely used apps like cline don't allow to disable fallbacks.
I really think that this should be an option handled on openrouter settings.
I would love if this can be looked into. Because while its true that there is the free version for deepseek, 1- I never take free stuff for granted and 2- It fails more often than the cheapest paid.
This is good feedback, thank you!
Perhaps you should make the "Turbo" variant a sperate model in the list that way it has to be explicitly selected (similar to how Nitro versions are separate though I know that's not the same thing)
nitro is no longer separate
everything is in one list
makes sense if you consider that the goal is load balancing
Hi, it looks like sometimes when the reasoning segment in the "raw" R1 response is empty (having things like <think></think>), OpenRouter cannot recognize the text after it as result: it still thinks the tokens after </think> are reasoning tokens.
Also... it could be a good if we could customize the reasoning prefill, like forcing R1 to think in a certain language (prefill <think>OK vs <think>好的).
shame indeed.
just gonna drop this for all the non-deepseek providers

$0.55/2.19 is enough for them, why isn't it enough for you
DeepSeek provider demands collecting prompts, then the pricing is reasonable.
Non-DeepSeek providers with higher pricing, claim they do not collect anything, but who knows?
I don't believe the cost here has revenue from data sharing pre subtracted
I think the other ones just haven’t got used to the new pricing regime yet. Before it was pricing like o1 and Sonnet, prices where clearly there is a very healthy markup. They probably think “oh well $8 output is cheap then” but it’s not.
Each H800 node delivers an average throughput of ~73.7k tokens/s input (including cache hits) during prefilling or ~14.8k tokens/s output during decoding.
whereas vLLM on a H200 node delivers 1.4k tokens/s output at best at low context. Current inference engines are doing at least 10x lower throughput compared to DeepSeek's inferencing.

With a 500%+ margin at their current prices too, eh
Clearly just slapping vllm on a cloud rented instance isn't really good enough to be a competitive service provider.
It just wasn't as noticable before because while I'm sure OAI/Anthropic do have optimized deployments, they are receiving a lot of markup on their $15/output pricing (or $150 for OAI recently lol).
BREAKING DeepSeek just let the world know they make $200M/yr at 500%+ profit margin.
Revenue (/day): $562k
Cost (/day): $87k
Revenue (/yr): ~$205M
This is all while charging $2.19/M tokens on R1, ~25x less than OpenAI o1.
If this was in the US, this would be a >$10B company.

this doesn't account for recouping upfront investments and as they stated, most people don't pay (they don't even a paid payment plan on their site, so it's just API calls).
upfront investments? this is assuming they lease the h800s
I saw some estimates of their value at something like 80b if it was a USA company (though a big range like 1-160b). China business world is extremely different to the USA though.
could make if all is billed - webapp and mobile are not billeg
so i think they are breaking even
paying US tech companies means that at least half of what you paid is going to the pockets of billionaires and shareholders, this wont change anytime soon, THEY aren't willing to change it.
was the deepseek integration changed that it wont supply the thinking traces by default anymore ?
was it ever provided "by default"? I always received it with include_reasoning in the reasoning field.
deepseek's inference efficiency won't be achieved by the other api providers unless they plan to invest a lot of nodes to implement the full EP implementation with separate processing for prefill and decode
it was ..
just need to patch st now i guess
hey all, been using deepseek-r1 in production through open router.
I have json as the response format and require_parameters = True, and it still routes me to Together which doesnt even support json format. Places like fireworks have a post processing json forcer even for models that dont natively support it so im just wondering why I am still getting routed to non-json-supporting providers or if anyone has gotten around this?
edit: I opened a help thread here https://discordapp.com/channels/1091220969173028894/1346285793953583187
I've noticed there is a difference in the response quality between the free and paid versions, is this due to the provider or the money?
both
the provider takes no money so you get what you pay for
Makes sense
which makes sense considering each of their deployment is 320+32 H800s, the standard 8*H200 deployment would be very wasteful as there are a lot of overheads with shifting the weights back and forth
Anyone know provider that serve deepseek r1 zero? hyperbolic has stop serving it.
That model are really good if you trying to get data for whatever you need, yes it's harder to read and understand but for true thinking trace is actually quite unique.
Nobody that we know of atm but we’re trying to incentivize one to start up
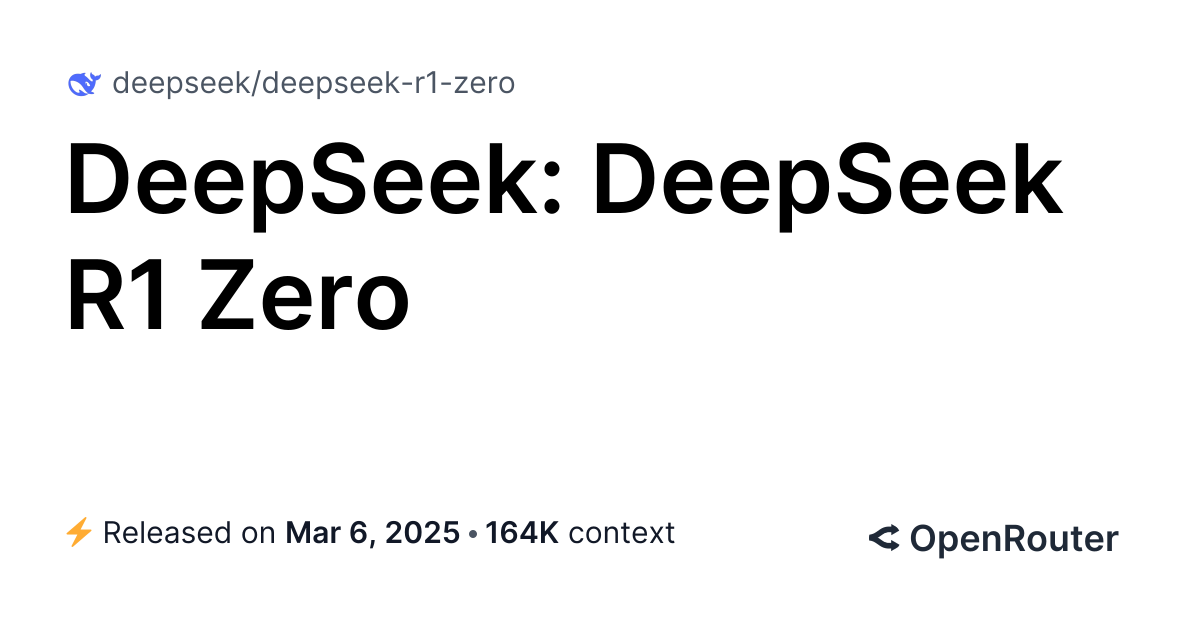
DeepSeek-R1-Zero is a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step. It's 671B parameters in size, with 37B active in an inference pass. Run DeepSeek R1 Zero (free) with API
^
cc @rigid nova
I can't get R1 Zero to stop outputting \boxed{}.
does this have tooling ?
It's coming from deepseek original RL, nothing can't be done with it. I think
Thanks 🙏
Some data stuff
Even with fiddles of parameters?
🥺 🔀🩶
long reasoning and slow tps; normally it takes 2 mins to finish a turn 🤣

I'm getting an annoying number of 0 tokens out of Nebius for R1. The other providers seem fine.
its more annoying when they deduct the input when we dont get any output
you are not currently charged for 0 output tokens - #announcements message
will flag to nebius that this is a significant issue
Seems like MiniMax is returning 0 output tokens all the time now. Some examples from my logs:
{"status_code": 200, "response": {"id": "gen-1741365750-tmyFfnakL1ErupeZdIGM", "provider": "Minimax", "model": "deepseek/deepseek-r1", "object": "chat.completion", "created": 1741365750, "choices": [{"logprobs": null, "index": 0, "message": {"role": "assistant", "content": "", "refusal": null, "reasoning": null}}], "usage": {"prompt_tokens": 2774, "completion_tokens": 0, "total_tokens": 2774}}}
{"status_code": 200, "response": {"id": "gen-1741365750-IC24jkzeA5Vf625itjxD", "provider": "Minimax", "model": "deepseek/deepseek-r1", "object": "chat.completion", "created": 1741365750, "choices": [{"logprobs": null, "index": 0, "message": {"role": "assistant", "content": "", "refusal": null, "reasoning": null}}], "usage": {"prompt_tokens": 2843, "completion_tokens": 0, "total_tokens": 2843}}}
Prefill + stop string ["\\boxed{"] to turn R1 Zero into a more conventional non-thinking model (but then what's the point). For RP at least, since the response is easily just (response) \boxed{(response)}. Temp 1.3+. 😆
But I think R1 is still better.
Indeed. Deepseek is better now, Can't believe t.
why is it better?
No 0 tokens. And response time improved
this shouldn't be happening - we insure all the zero-output requests for deepseek. did you notice otherwise?
from Novita specifically, or from other providers?
Deepseeks is not returning 0 tokens, Nebius is.
@woven chasm can you provide any generation IDs? From our metrics, it's not a large % of requests
Are you setting max_tokens?
1024
Do you see reasoning tokens in your activities page? 1024 is typically too low to get actual completion (non-reasoning) tokens
thanks let me look
To the same effect.
can you screenshot your activity tab? It seems in our logs we are getting some tokens back

Mmm. As we spoke I'm trying to use it. This is what I'm getting with Deepseek

And this with Nebius

Same prompts. See the difference in output tokens? I believe its thinking, but not passing the results.
hmm yeah that is strange. If you click to expand on the Nebius generations on the righthand side there, and view the token counts / raw metadata, do you see reasoning tokens?
4504 prompt 131 completion,
incl. 128 reasoning
4500 prompt 133 completion,
incl. 130 reasoning
Maybe related, I did 500 requests to Nebius, 7 of those have empty content field but full reasoning field.
Mmm. I'm seeing error while passing 'max_price', such as this:
{
"max_tokens": 8124,
"temperature": 0.7,
"top_p": 0.95,
"presence_penalty": 0.5,
"frequency_penalty": 1.7,
"stop": ["#"],
"n": 1,
"tools": [],
"tool_choice": "auto",
"max_price": {
"prompt": 1,
"completion": 3
}
}
what's the error message?
Got an unexpected keyword argument 'max_price'
It worked until it didnt
API parameter 'exclude' doesnt seem to work either. This with QWQ paid version
Yup. Reasonin effort as this:
"reasoning": {
"effort": "high",
"exclude": true # Use reasoning but don't include it in the response
}
Doesnt work for me.
AsyncCompletions. create() got an unexpected argument 'reasoning'
The same as with 'max_price'
This parameters work fine:
{
"max_tokens": 8124,
"temperature": 0.7,
"top_p": 0.95,
"presence_penalty": 0.5,
"frequency_penalty": 1.7,
"stop": ["#"],
"n": 1,
"tools": [],
"tool_choice": "auto",
}
You're using the openai client @woven chasm ? You'll need to pass the reasoning and max_price params etc through extra_body
OpenAI client, yes. And this shows my ignorance. Guess I have to find out what extra_body is.
Thank you. Will find out what it is and how to use it. A pointer would be helpful, but you dont have to do that.
yes one moment
model="deepseek/deepseek-r1",
messages=[{"role": "user", "content": prompt}],
extra_body={
"include_reasoning": True,
"max_price": {"prompt": 0.9, "completion": 2.4}
},
stream=True
)```something like that
so max_price, reasoning, exclude, can all go here
Yes, I looked for the information and fixed my json. Today I learned something thanks to you.
So @formal nest, no idea about the '0 tokens' issue I had with Nebius?
I unfortunately don't see major (>0.5%) occurences of actually 0 completion tokens in my metrics, I can take another look at your account logs though
If you could I would be grateful. Its annoying.
yeah absolutely. Little busy right now but will review later
Thanks!
I didn't notice that with deepseek but maybe when I use minimax model few days ago.
request model

very aggressive, argumentative, angsty, using the same phrases like "the beer tastes like regret and disappointment", eventually making characters act like lunatics
I agree, I choose 12B models over R1 unless I want complete physco
12B?
Are you serious?
For heaven's sake, de gustibus non est disputandum, but only if you use WizardLM-2 8x22B do you realize that you are in a much more advanced era.
I retired WizardLM-2 8x22B user, too much positivity
Minimax has worked pretty well for me. If R1 starts going into a loony place, I rectify it with Minimax for one or two generations and it kind of goes back to normal. I haven't used any other models recently. They're so predictable and almost one-directional.
why minimax im curious? i assume for the context length but thought google would be a better option
what have you found its strengths to be
Gemini is moderated while minimax is not. Otherwise it would be my no 1 model. Minimax passes the strawberry test and follows the prompt and it's slow in progression of the story.
useful to know - been trying to find the right model to pair with R1.
R1 starts with genius and then progresses slowly towards insanity on so many genres
R1 Zero Chutes returning 0 output on all prompts now, no error.
checking
R1 zero is also a good pair to r1 its way less evil.
the issue is that chutes half of the time don't return reply and when it returns, the reply is in weird formatting.
I don't like wizard 8x22B too, it is smart, but its too... nice.
thanks for the minimax sugestion, i've been using deepseek v3 as a swipe mixup, but the tendency that v3 has to repeat paragraphs do gets annoying.
Edit:
Ok, yeah, no. after 2 weeks trying Both Minimax and Hermes 3 405b, deepseek v3 still delivers the best responses, being the best pair to R1. they both can be as repetitive as v3 if you allow them. But v3 has a greater character personality adherence and understanding of the chat history.
OK, responses are back.
thanks for flagging
Can you even use Zero for RP? I get nonsense each time. Not even proper sentences. Also try Hermes 3 405b to mix things up. Even better than Minimax, depending on what you want.
Zero turns into a normal model with a prefill to skip the thinking block and ["\\boxed{"] stopping string. Word salad is rare to me (once in 25 today), goes away on swipe. Didn't try long context. TC without instruct sequences happens to be okay too. "Issue" is there are better RP models.
Is there a way to prompt or prefill to somewhat reliably prevent it from thinking too much or at all
openrouter chat has a slider for thinking slider token budget
if the app your're using don't support this, I think the easiest way to avoid it overthinking is making the prompt as clear as possible so it doesn't have many "but wait!" moments.
I'll assume chub, (mutual servers) So make your system prompt and anything that sets (How it should behave) as simple and without contradictions as possible. You can be descriptive as you want in character details and appearance, but in telling it HOW it should behave, be as simple as possible.
This is not only to avoid r1 overthinking, and hitting chub's 2048 output limit while still on the thinking phase, but because R1 focus A LOT on HOW it should behave, put too much "how" and it will overshadow the rest of your character. (Afterall thats exacly what the thinking phase does, focus on "how" to respond)
@half sapphire (forgot to quote reply)
Wait how is that applied on the API side
like is that a param?
that, I have no idea, I know there is this feature on openrouter chat when selecting r1, so the model probably supports it.
But in any case, I think jailbreaks only make it spend more tokens reasoning, and prefill sometimes just don't work or make it skip the reasoning phase completely.
👀 DS docs says "soon"

👀
question, the endpoints that don't disclose if they use fp4 and fp8 is because you may be routed to a gpu that can use either quantization? Or simply because they don't provide this information to openrouter?
latter, we don't know
Fireworks has dropped their pricing to $0.55/$2.19 on their new basic deployment (deepseek-r1-basic) https://fireworks.ai/blog/fireworks-ai-developer-cloud
old $3/$8 pricing applies to their existing fast model (deepseek-r1)
cc @formal nest

Faster, more efficient DeepSeek on the Fireworks AI Developer Cloud
Discover how Fireworks AI Developer Cloud accelerates AI innovation with faster, optimized DeepSeek R1 deployments. Learn about new GPU options, improved speed, and enhanced developer tools for efficient, scalable AI solutions.
oh, very nice!!
thats 2 providers now with a "fast" end point that it more expensive. Any idea what the difference is?
faster token generation speed
yeah I know that I was more thinking whats the difference in underlying deployment
GPU count, or quantizing then marking up just for stability
yeah thats the thing though, more gpu should mean faster yes, but also larger scale deploy so also cheaper/more efficient
hey anyone else not getting any content from r1 calls? Using fireworks. Reasoning works, then i get the "stop" finish reason, then absolutely no content. this is no matter what i do with prompting
Just confirmed, the content is being sent in the reasoning field from openrouter
Which provider is this btw? -- sometime, reasoning might eat up all the context

okay let me keep investigating here and make sure my ducks are in a row
json mode btw
I wasn't changing anything just fired up the ol app and getting this prob. Some more details,
heres my object im sending
response = client.chat.completions.create(
model="deepseek/deepseek-r1",
messages=...,
stream=True,
response_format={'type': 'json_object'},
extra_body={
"provider": {
"require_parameters": True,
'order': [
'Fireworks'
],
'allow_fallbacks': False
}}
then what happens is, i start recieving reasoning data that is just my json object that should be in content. I dont recieve any actual reasoning. Then i receive no content, and a finish reason "stop". This is consistently happening. am i crazy? lol is it replicable?
I commented out json and switched to SambaNova and it resolved.
I switched to Fireworks and disabled json format and it also worked.
It appears to be an issue with Fireworks's JSON mode (they are the only people i think that have json mode for deepseek through some proprietary method)
to be clear the issue is: 1- no actual reasoning data and 2 content appearing in reasoning, when in json mode
@weak salmon I believe thats an error since json_format wont really work with R1. We should disable allowing users to send that.
@jovial flame That would be extremely disappointing, considering fireworks literally supports it
It seems like there is currently no way to specify routing to the non-basic Fireworks?
This is also the same for other multi-version cases, so I think the "provider label" could be exposed to the endpoints API, and specifiable as the routing parameter.
haha youre the best i really appreciate it. It seems they came out with a new R1 model so it may have mixed their stuff up.
I enconter the same problem, any one have any idea how to use fireworks fast version of deepseek R1 model?
still waiting for offhours discounts
The crypto providers are still setting themselves up to float, but there are now very cheap options like fireworks who have a basic endpoint now
yeah tbf the cheap ones are getting faster and the fast ones are getting cheaper
Klusterai and others do batch processing for a discount
Hello everyone, my question may seem simple and obvious, but I'm just getting the hang of it, so far I can't figure out what's the matter. For some reason, R1 is constantly randomizing the answers in terms of reasoning. He can process the request correctly and separately issue "reasoning", separately "content". Maybe "reasoning" just doesn't fill it out and write a response normally. Or maybe, for some reason, insert the reasoning itself into the "content", i.e. literally the course of your thoughts, has anyone encountered this? Calling like this:
first_model = "deepseek/deepseek-r1"
models_to_try = ["openai/o3-mini-high", "anthropic/claude-3.7-sonnet:thinking"]
#
extra_body = {
"models": models_to_try,
"provider": {
"order": ["Fireworks", "Novita", "Nebius", "DeepSeek"],
"ignore": ["DeepInfra"],
"allow_fallbacks": False
}
}
response_data = await global_variables.ai_client.chat.completions.create(
model=first_model,
extra_body=extra_body,
messages=data_for_requests["messages"],
temperature = 0.4,
max_tokens=20000
)
don't set model and models at the same time
just make one models sorted by preference
aside from that idk why content and reasoning would be inverted...
maybe you should go to https://openrouter.ai/activity and send a screenshot and request id of one of the requests with inverted content/reasoning
hey it works again, just wanted to say thanks for your fast response if you did that! Appreciate it
it seems that I just accidentally found the reason, the fact was that the request was not in English, as soon as I started writing exclusively all requests in English, everything fell into place.😐
edit - sorry for the early props , i was wrong, its still broken in the same way ~ Im going to open up a thread. my whole app is just kinda down because of this
yes somed way to repro would be good
okay just opened a thread and sent repro object from my tests. Going to hook up to fireworks directly and see if its a prob with them on their side too
With Targon (from ST) I am getting broken responses - returning only
<Tool Response>
Chutes is working perfectly.
First time I have seen this issue from Targon. Others I have spoken with seeing the same.
V2 wen?
Jul 17, 2024
i think i only get 1% of the humor. why such a specific date? I don't get ittt 😭 🥜🤏🧠
that was when deepseek v2 launched
sorry
im being pedantic
I read May 2024 on googe tho :(
I'm still behind u i think

Is deepseek zero more knowledgeable than r1?
I just gave it a knowledge test for eye colors of characters, and it consistently did better than R1.
What else is deepseek zero better at? wow.
Being less censored
Hmm. Maybe that's it. I was wondering about more niche things but I suppose thats a plus.
It has the highest unncensored score on dubesor.de.. I wonder what the Venice chatbot would get
It's build upon base without instructions, so it's the purest form of RL
When you didn't put human bias the model optimize it self, better in many aspect but worse in aspect that human care.
Because it's hard to read and hard to understand but it's actually high quality
To bad hyperbolic stop hosting it, and I don't like chutes hosting
If I remember correctly, DeepSeek Zero is a base model instead of a instruction-tuned model. So it should be better at completing sentences.
But last time I tried, it just starts solving math equations randomly out of no where.
Zero is almost further back than a base model
It's a base model run through totally unstructured reinforcement learning on verifiable problems.
I think they very gently showed it what a thinking step looks like, but that's about it. It will apparently switch languages mid-thought sometimes, or use tokens seemingly unrelated to words
normal R1 will also switch languages mid-thought, but it was mostly mitigated via penalty in reward during post-training
Interesting, haven't seen it do that yet. Interpretability is cool, but I also love the idea of seeing raw thoughts
I didn't notice that. It does use messier thought chains for sure (not rephrased to be more human friendly), but it was completely usable in my testing. #1330820209812050002 message It understood and tackled all problems, without producing gibberish.
They mentioned it in their paper, but I'm not sure how common it is
Someone leak when R2 releases 
🤔


"As ai race heats up" I dunno man
It's been pretty hot for a while
It's not heating up
Is new R1 available on DeepSeek API?
Finally, DeepSeek R1 2!
Yes
Need on OpenRouter
@formal nest deepseek did a silent upgrade (again)

Source: here
The announcement says that the new R1 is live
Are you crying or are you laughing? /tease
yeah we hit their deepseek-reasoner endpoint so you can just route to deepseek direct and use the upgrade
Did DeepSeek make an endpoint for the old one?
Nope
Oh, no
You don't like the new one?
I have an unhinged roleplay bot running on R1 for a server, just scared that this will change the personality
As an alternative, you can use the free DeepSeek R1 providers
Or cough up more money and use the other paid providers
Test if the personality changed before switching providers
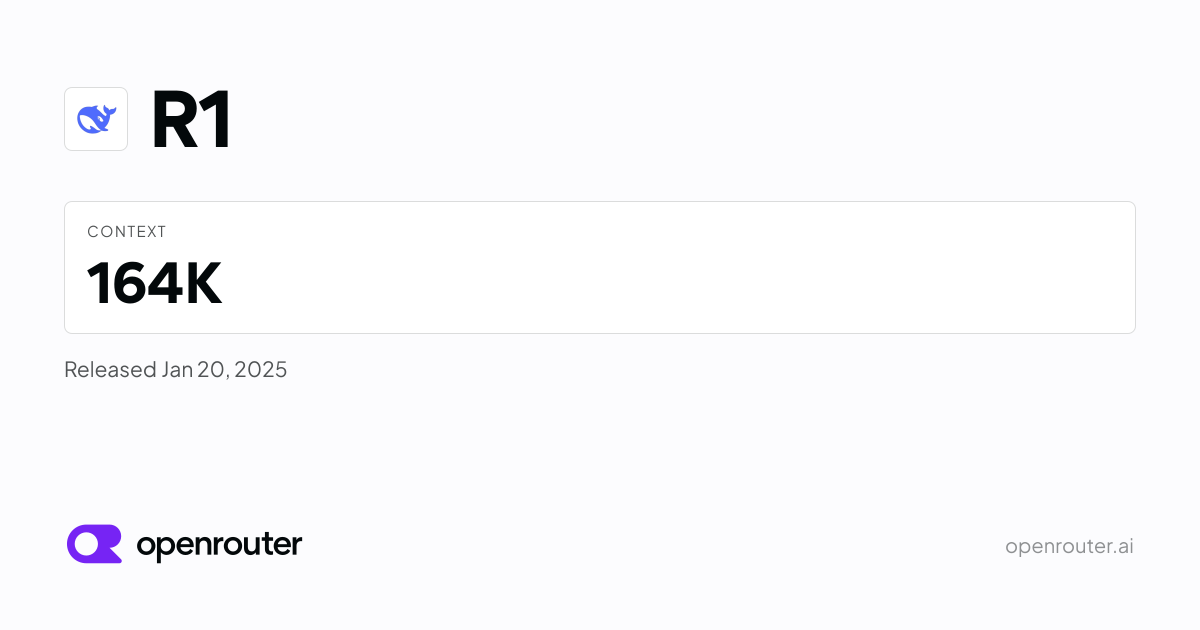
DeepSeek R1 is here: Performance on par with OpenAI o1, but open-sourced and with fully open reasoning tokens. It's 671B parameters in size, with 37B active in an inference pass. Run R1 (free) with API
did they also update the api or just their web platform?
Both
The inner reasoning for this new R1 is very interesting to watch
It seems more articulate than before
they improved the CoT alot
can't wait for the new thread here 🤓
of course it still thinks it's ChatGPT lol

Is the new version still open-weights? Presumably we'll get it via 3rd party providers at some point?
Weights aren't out (yet)
where does it say it's out for API 👀
According to everyone, R1.5 feels different. I want more objective data showing performance
I haven't tried that same prompt with regular R1
need bench before & after today
Parasail's R1 seems slightly worse
Nvm not slightly
Some chess pieces can't move at all
Definitely an improvement
Wonder if the writing capabilities will be better or worse.
https://huggingface.co/deepseek-ai/DeepSeek-R1-0528
it's up, no details yet

They always update the details later
Ok r we sure the API updated on their Provider?
@formal nest sorry for the quick ping, seeing if u know if their API updated to the new one
it would be in-line for them to just update the API endpoint, thats what they did before every time, an in-place update.
big question i guess is did they do it yet

{kind=link}
Yeeeaaahhh
Does that mean no r2 or v4?
:(
Cuz ye, the model is cool and all but
Anthropic and google have gone way beyond
I’m just waiting for dubesor lol
I think it is same as before
2 providers already up
They did
same
well, that'll be a few hours.. I estimate 12ish or so
Can you ping me when you finish the benchmarks? (dont worry if you forget to ping me lol)
do we need an @ dubesor-benchmark-enjoyer role
you can only get the role if you give dubesor an OR key to bench with
Yes we do
That’s why you’re the GOAT! The GOAT!
🤣 Naw I have rejected keys in the past. But if you wanna contribute data to e.g. the chess leaderboard, just play using your own keys... I incorperate the data of any finished match and thus far I have spent ~$300 on the chess data alone 😦
300 $ is insane
there's ya ping
Thank ee very much
When will OpenRouter support tool calling on R1-0528 like DeepSeek API does? @rocky heron 🙏🏻
DeepSeek is not able to review images right?
Correct
Is there tool call support with R1? I know R1 v2 supports it, but some folks are saying it isn't supported with OR yet. Is this true?
R1 the model doesn't support tool calling afaik
R1 v2 explicitly mentions tool calling support though
Yup, I'd love to be able to use its tool calling capabilities through OR
sorry for resurrecting a dead thread, but fyi we have this on a per-endpoint basis now:
https://openrouter.ai/docs/api-reference/list-endpoints-for-a-model#response.body.data.endpoints.uptime_last_30m
https://openrouter.ai/api/v1/models/anthropic/claude-sonnet-4/endpoints

I just got this email which looks interesting

Ooo
Nice
Is it the 1bit architecture or is it the Xeon stuff
I am getting more info from them. probably will make a blog post / newsletter post on this. will share more when i have info. they have api but need to request.