#🆕|sd3
1 messages · Page 127 of 1
and this.
it's not a matter of taste, samplers are either better or worse
more accurate or less accurate
the terms better and worse are comparison terms that make something different to every single person. so are the terms accurate and less accurate. comparison terms. who decides what 0 for accurate is? maybe what I consider accurate and what you do are nothing close to the same - you won't be satisfied with less than 32 decimal places and i'm fine with just 4
Yikes I forgot how good mochi is, especially for an open model.
you generated all those yourself?
These are generated from genmo, the official website. According to an employee, website uses 200steps, full precision, and an upscaler. Uses the open model.
I obviously can’t run the full precision one so I use genmo.
lol that's ridiculous
this is a really good point
essentially the way the field seems to deal with this is by putting all of those things inside a box of "human preferences"
no wonder it looks so good thhx i was wonderinig what they were doing and why my stuuff looks like garbo and theiris looks so pristine
so it's not that they're generating at 2x the resolution they're upscaling, i tried generating at 2x the resolution of 480x840 and my stuff crashed after 90 minutes, that made me sad lol
and then having a subsection of the paper/presentation/docs that deals with the "human preferences" benchmarks
separate to the objective metrics
I actually think the preference studies are more valuable a lot the time, they are just rarer as they are expensive to make
Yeah quantization drops quality considerably. Even fp32 to bf16 drops quality. And yeah they use an upscaler.
i'm still of the opinion that all of their benchmarks are worthless. for LLM's if you want to know whether it's thinking as well as a human, give it the same tests you give humans - give it the mensa test. for AI image generators, all that matters is whether the person using it likes what it's creating or not
for art yeah but for example for inpainting you might wanna have a technical metric
or for something like "how well does this canny control net match the input image"
there's a very specific prompt someone used and posted their vidieo for it on Genmo's discord, I tried to recreate it locally and I tried a bunch of settings even res_3s and 5s and I never managed to hit that level of coherencyy it had
this is two of the 'best' ones


They probably use some sort of llm enhancer too, I didn’t ask anything about that though.
i think there is an option on the website to level up your prompt right? like a toggle switch maybe?
the point though is that what each person thinks is best isn't what other people think is best. so while there can be suggestions of how to achieve X or Y or whatever, they are jsut that. suggestions.
Hmm not sure, let me check.
Nope, they have the option to use mochi or their legacy model(before mochi was released). And seed
most of the ML tasks that come up on discord are ones with qualitative/subjective objectives so yeah
with statistical models or quant models its more common to have something be outright correct or incorrect
you could accomplish almost the same thing by having meta.ai just revise your prompt
1+1=2(sometimes)
okay the prompt was:
A close-up cinematic shot of the protagonist’s face, rain dripping from their determined expression under the glow of neon city lights. Their eyes, sharp and focused, reflect the faint blue hue of a glowing blade they grip tightly in the foreground. Raindrops streak across the lens in slow motion, with subtle steam rising from the wet ground below, framing the intense moment in vivid detail.
and I remember loading it and I got a negative prompt out of the file:
Flat composition, overexposed lighting, unrealistic or cartoonish details, harsh shadows, pixelation, grainy textures, unnatural movements, static framing, cluttered background, artificial colors, poor depth of field, low resolution, jittery camera motion, lack of cinematic contrast, dull expressions, poorly blended lighting effects, unbalanced composition, unconvincing water effects, stiff posture, and unrealistic reflections.
But I'm on the website and I'm seein there is no field for negative prompt.... so i think its fair to say it was indeed rewritten and had the negative prompt injected
I don't like it when they rewrite prompt
when it comes to sampling, it pretty much just verifies that they didn't fuck something up with their analysis imo
there's nothing to be gained from inaccuracy, the only debate is about how much you lose, really
here's what genmo.ai came up with
or wait maybe he ran it locally? bc i see its an mp4 file and its only 1 second, genmo.ai wouldn't have made that file
that is the case currently yeah that humans prefer more accurate sampling on average
but we should check that result every now and then lol
can't take it for granted
yeah, i presume that's why they do it, to verify that there's nothing screwball
I have a SD3.5M Diffusers question, if anyone can help, greatly appreciated.
I can only seem to find FlowMatchEulerDiscreteScheduler and FlowMatchHeunDiscreteScheduler for SD3.5M but they both give a brighter result than the Euler from comfy results. Any idea why my comfy results are prettier (deeper, less bright overall and slightly better contrast?
I'm using Euler + simple for both
pipe.scheduler = FlowMatchEulerDiscreteScheduler.from_config(
pipe.scheduler.config,
timestep_spacing="trailing",
shift=3.0
)
there are so many differences between comfy and diffusers
in terms of the underlying system
its not worth trying to get the exact same output
No not the same per se, but it seems my diffusers output is always sightly too bright and I can't find the right settings to tweak.
I only see Euler and Heun for example and switching to trailing does barely anything
genmo's website, positive prompt
the cool things is the large model does run on my machine even if it is slower, i thiink that other guy was just lucky with his seed bc the reference video stiil looks better than this one
kling
just say 'no' to negative prompts
yeah it naiiled it really well
ran your prompt through SD3.5 large, then animated it in kling
i feel the format fits better in landscape but nontheless i still like this one over Kling's even
negative prompts - are a bad idea
got news you will really like
there is a paper which seems to have solved negative prompts
they found a way to automate making a negative prompt that is way more optimal than normal ones
and it can boost image quality on any image apparently
https://arxiv.org/abs/2411.05473
i like her eye movement near the end
the only solution for negative prompts is to get rid of them totally
im not a fan of negative prompts, i rather do without them entirely, but i do see the value for people who use them, sometmes there's no other way but to need a negative prompt
its like turning a toy boat by pushing the back rather than pushing the front
i wouldn't have a problem with it if they were used correctly, but most of the time they are used by people that don't know what they are for, they are used incorrectly, the results are not what the individual wants, and then they're hunting people down to demand tech support and refusing to listen
yeah the massive Civit negatives I know what you mean
so ur tellin my my word pasta of bad fingers, mutated anatomy, etc are awful eh? hah yeah right!
also this has gotta be the highest quality output of anything AI ive seen so far
is there sd3 for a1111?
i think a1111 has sd3.5 support
do i install flux just like any other model for automatic1111?
very interesting
Hi everyone! I'm using Stable Diffusion 3.5 with Diffusers, but I'm a bit confused about the scheduler and sampler options. I only seem to find FlowMatchEulerDiscreteScheduler and FlowMatchHeunDiscreteScheduler. SwarmUI and ComfyUI have more choices like SGM, DDM, DPM++, etc. When I try using schedulers from SDXL, I get messed up images.
What are my actual options for schedulers and samplers with SD 3.5 and Diffusers? Thanks!
Why are images with the same settings, always brighter with Diffusers compared to Comfy? (same seed etc, both EulerDiscrete with simple sampler)


one really significant difference I noticed between diffusers and comfy is the T5 prompt length
For Flux-dev the T5 prompt should be 512 tokens in length
but Comfyui seem to use 256 instead
it's an error on comfyui, or maybe a feature cause they might noticed it works better? I don't know
SD35L fp8 using controlnet now


oh thanks a lot, I need to look into this
really don't want it to be splitting my prompt like that
I don't know... I find the Flux default behaviour also strange. Having a, say, 80 token prompt but using 512 tokens without proper attention masking
I just wish everything was explicit and documented
the attention masking issue is an interesting one yeah, cos in LLM world people do tend to use attention masking properly when fine tuning T5
I guess in Flux they don't do it cause its a "waste of compute". Instead, Flux is using the empty tokens as registers
however, I wonder if it does effect quality and introduces artifacts in the generation
in particular if you vary between long or short prompts
I think its possible yeah
been trying to read about that but its hard to get a definitive answer
Sana used Gemma 2 2B which is a fantastic model for its size, might be a good trend
T5 doesn't do so well for other languages, whereas the Chinese models that tend to use GLM, or Sana with Gemma, do okay with translating prompts
Did you make the blur one work yet?
when it comes to architecture my opinion is Omnigen is the way to go
or similar like Meta Chameleon
the problem with Gemma and other decoder-only structures is that it's task is to predict the next tokens, so it models the embedding in a way to achieve this task
so if you give it a prompt "A cat with black fur", then it will try to autocomplete the sentence, adding certain token probability distributions to the embeddings like ("playing", "sleeping", "eating", whatever a black cat is doing)
i tried all 3, depth canny and blur, i liked canny best, blur seems really hard to control
in Sana they try to get around this problem by adding a prefix to the image prompt like "The following is an image caption. Summarize and describe the image of this caption")
decoder only models still often underperform yeah
Kaggle competitions are often still won by simple ensembles of flan-t5-xxl and DeBERTa-V3-large
not stuff like GPT 4
Yeah I couldnt get anything useful out of the blur one
i was thinking blur was like redux too
i noticed the default canny settings for the workflow of 0.1/0.8 are too vague I had better luuk with 0.1/0.2 instead
I see what you are saying, next token prediction is problematic for creating embeddings for DiTs/Unets, relative to masked word prediction
cos with masked word prediction its not specifically trying to predict the word at the end
yes
its the same with text classifiers really, even now
I'm also not sure if we really need better text models. T5 is quite powerfull already
I wish one of the big companies trained a bigger and better version of DeBERTa-V3-large
the issue is rather that the latent space of T5 is really huge and there are not enough training data for models like Flux to really learn from this latent space
for the task it is currently doing in Flux, T5 is easily good enough yeah
I think they could easily get 2-3 more years out of simply scaling DiTs
cos we are only 6 months in to that trend really
in the long run as hardware improves something like omnigen makes more sense in terms of scaling
the end game for transformers, just one giant transformer that does everything, across modalities
@dry wave @bitter hearth I found a project yesterday that essentially uses qwen as ollama would
https://github.com/ZHO-ZHO-ZHO/ComfyUI-Qwen/tree/main
here's the workflow:
I think this could be a good starting of point to integrate the new QWENVL version, especially since it supports Qwen2-7B-Instruct which is the exact model the other projet uses


that node also outputs tokenizer, I'm thinking loading the model was half the battle that solves that piece
I was looking at this part of the code from the qwen2vl+flux project I think I would need to turn this piece into a node:
def process_image(self, image):
message = [
{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": "Describe this image."},
]
}
]
text = self.qwen2vl_processor.apply_chat_template(message, tokenize=False, add_generation_prompt=True)
with torch.no_grad():
inputs = self.qwen2vl_processor(text=[text], images=[image], padding=True, return_tensors="pt").to(self.device)
output_hidden_state, image_token_mask, image_grid_thw = self.qwen2vl(**inputs)
image_hidden_state = output_hidden_state[image_token_mask].view(1, -1, output_hidden_state.size(-1))
return image_hidden_state, image_grid_thw
so the node would input image from load image, and Qwen2 from that ModelLoader and then perform this operation to return the image_hidden_state
oh yeah I've been using qwen in comfy already there's quite a few node packs that do that
its useful, having an llm in comfy in node form
yeah it does produce a noticable boost in quality but i think the whole shitck of qwen2vl is that rather than doing this:
input prompt > LLM > output text > Clip text encode
it can do this:
input image > VLM > output conditoning > merge with clip text encode
considering qwen2 is multimodal, using it only as an LLM and not taking advantage of it's VLM capabilities is like underusing it
you can't do this without training a new model to sit in between qwen and the Dit
I mean gemma 2b is a better option, in the Sana paper, it outperforms it in everything basically. Its faster, uses less vram, and is better quality.
they already did that, it's a file called t5_embedder.pt part of the source
I am not sure what you are referring to
this thing dude: https://github.com/erwold/qwen2vl-flux/tree/main
I'm still thinkng of how I can use that in comfy w/o running their code lol
wow these examples in their technical report are by far the best style transfer I have seen
with the exception of training checkpoints and loras
How much control tools does cogvideox get lol, https://github.com/PKU-YuanGroup/ConsisID
Example vids
Left pic(original face), Right vid is generated


this one is really good
I didn't realise cog was this good
I dismissed it initially cos it couldn't make R2D2 move forward, but that's a niche thing, I underestimated it
;) it's euler all over again
lol yeah
original pic left, above right is ConsisId(uses cogvideox), below right is sota closed source at this task(vidu)

I prefer cog there
Vidu even has a paper, and quality seems really amazing but is closed source. Nice that open source is catching up.
yeah it may well be that they have caught up to sora now
when sora leaked this week, a few of the people who used it said that it was worse than kling/minimax
and so mochi is close to kling/minimax
so maybe close to sora
I feel the sora museum flythrough was particularly good but maybe heavy cherry picking was done there
which vid, mochi is amazing at drone flythroughs, better then closed source even imo.

Explore a stunning museum fly-through with Sora, an open AI, as your guide. This immersive experience will leave your mind-blown. I am convinced that education should be accessible to everyone, not just the rich, so allowing everyone to see the best of humanity is key. See the power of generative AI in action and discover new perspectives on ar...
ok let me try something similar with mochi, one thing impressive with sora is the 1min videos though, even closed source models don't reach that long. cogvideox does have a way to extend videos better then just extending with img2vid though, but quality is a bit lower
I dont know how is possible to reach 1mn of video
I just find a new model that do the same https://youtu.be/PhlgC-bI5SQ?si=dKDq8ubIbgJ2smoy

Bring your identity to life with just your words. If you can describe it, you can now visualize it. Introducing Identity-Preserving Text-to-Video Generation, powered by ConsisID. Discover more at https://github.com/PKU-YuanGroup/ConsisID.
final frame technique
svdquants is a magic
a bit lower quality but more than 2x speedup
schnell from 21s down to 8s and vram consumption under 8gb
on rtx 3060
wow nice
its great yeah
I am not sure on Ada/Hopper if it is faster or slower than FP8-fast with torch.compile, or TensorRT
am currently testing that sort of thing
but for RTX 3060 SVDQuant is certainly the best choice
super cool, finally some speeds
would be even cooler to have dev + 8 step lora in svdq
and sd3.5
I didn't know it would work on 3060 ```We currently support only NVIDIA GPUs with architectures sm_86 (Ampere: RTX 3090, A6000), sm_89 (Ada: RTX 4090), and sm_80 (A100). See this issue for more details.
from here https://github.com/mit-han-lab/nunchaku
its good to see that it will work on more GPUs
thankfully, 3060 has compute capability 8.6 (sm_86)
Yeah, I was impressed when I saw the article, I saw that it could work with models like cogvideoX or mochi, I'm looking forward to cogvideoX support personally
but the roadmap didn't seem to have changed for weeks
I hope to see progress soon because it would be a shame not to go all the way, it looks really promising, I haven't seen anyone talking about it yet
Everyone missed it, I have been waiting comfy support since release...
To be fair, comfy team had tons of work with day 1 support and developing app
But still, this need attention, maybe worth to make post in stablediffusion reddit...
realtime videogame filter 

Compiling shaders please wait

What is SVDquants? Link?
For any interested, this was posted in Ideogram Discord today:
mno — Today at 6:27 PM
Hi , Here is our Black Friday Sale :
50% off Ideogram Basic: just $4 for the first month or $42 for the first year.
50% off priority credit top-ups: only $2 for 100 priority credits that roll over beyond billing cycles, as long as your subscription remains active.
Use code BlackFriday at checkout. Taxes may apply. Offer ends Dec 5, 11:59 PM PT.

yeah, sd3 turbo is making good starter images and it's really running with it
Amazing
ltxv was trained on compressed videos if you want to solve the problem of static videos in i2v you can compress the reference image https://www.reddit.com/r/StableDiffusion/s/YHoknAp5vK
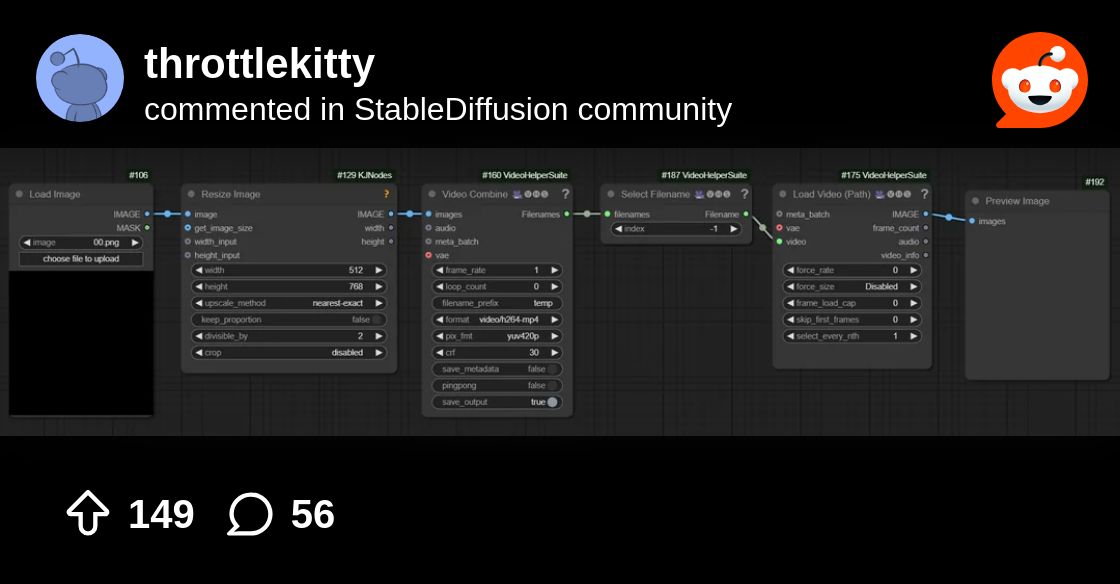
Reddit
Explore this conversation and more from the StableDiffusion community
The image need to bee blur
SD35L

original repo, however, I failed to install that due to lack of knowledge:
https://github.com/mit-han-lab/nunchaku
But this fork was successful:
https://youtu.be/P46Cjw0MSzo?si=RpY7tySTzfo0AK_t
https://github.com/newgenai79/nunchaku

GitHub
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models - mit-han-lab/nunchaku

Nunchaku / SVDQuant
https://github.com/mit-han-lab/nunchaku
Installation guide
https://drive.google.com/file/d/1qtr00-PusMrbdNz5mBs7bCh_THg5VufG/view?usp=sharing
#AI #StableDiffusion #TechInnovation #ArtificialIntelligence #DeepLearning #AIExploration #TechEnthusiast #CreativityInAI #StableAIHub #AICommunity #InnovationHub #TechBreakthroughs #...

GitHub
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models - newgenai79/nunchaku
帮我设计一个logo,要求要有"Aether Link",然后像素在320*320,小于3M
Thanks. I guess the question is whether this retains quality of Dev, or is deeply lossy like fp8
indeed lossy, checkpoint is about 6gb - comparable to quant 4 in size
That would have a lot to do with the ability to work with less RAM as well as render speeds
their quantization mothed works with encoder too, so doesn't take much memory either
The thing is, I'm not really very open to big quality sacrifices. For me the entire point of a large model like SD3.5L or Flux is the large model quality. Once you start butchering that in the name of speed you also begin to drop to the quality of smaller models. If I wanted that, I'd just use a smaller model to begin with, and not some dumbed down large model.
3.3x speedup for dev 20steps is crazy
From 100s to 28s
Maybe not that necessary if you have 3090\4090 but for me it is a huge deal, and it still does hands and smart so it is better than sdxl despite similar sizes
I have a laptop 4060
I also know what I can get from all the models. I don't mass produce images. And when I make one, I want that quality I see. I can wait a bit to get the best
that is fine
I like experimenting
oh so do I, and I love trying the new tools, controlnets and more. Not to mention models and LoRAs
and I love SD3.5L too. Make no mistake. We may be talking Flux here, but they are all super cool
Same, I have been playing with 3.5m a lot
However I don't see any success with finetuning yet, which makes me think Stability has to step in
I thinks is very helpfull for video models
Because actual quants make big quality loss
I read the paper and they said you dont need to train a lora again for the quants
The lora works with svdquant
that is a interesting idea. you put your positive promt in the negative let it generate and then deskibe this image in the acual negative

Yes its an increase in quality as well compared to bnb4bit and gguf4bit, seemed somewhat similar quality to fp8, sometimes better. Uses less vram then gguf4bit, bnb4bit and is way faster. Supports lora loading as well which gguf4bit/bnb4bit don't.

@errant dust do you use cmfyui?
I do
Sorry, was looking into BF deals on the horizon and buff the laptop
which I already has a buyer
(my old one that is)
for better rendering and video editing
There are some exceptional deals right now. Will see if the one I have highlighted can be beat
HP Newest Victus 16.1 Ryzen 7 RTX 4070 Premium Gaming Laptop, 16.1" FHD 144Hz, AMD Ryzen 7 8845HS (Beats i7-1355U), NVIDIA GeForce RTX 4070, 64GB DDR5 RAM, 2TB SSD, HDMI, Wi-Fi 6, Windows 11 Pro for $1266
which is right at the limit of my budget but fine
hint: use "small person" in your prompt
I think if you’re in the hunt for a good deal on a laptop then do what I did. If you live in the states use best buy to look through the returned inventory. I got lucky I bought a laptop rated quality: fair when really I’d consider it excellent
For $1400 it’s i9 4070 FHD. It came with 1tb and 16gb but I’ve since upgraded it to 6tb and 32gb, msrp on it was like $2200
Actually, I found a more attractive deal already. And this one is it. It has a 20-core CPU, 4070, 32GB Ram (this last is a minimum requirement for my work), but also three magic words: "Cherry Mechanical Keyboard"
Only 1TB SSD, but I can add 1 I have spare anyhow. That much is easy
As I live off my writing more than anything, the KB is just magic to my ears.
For any curious: https://www.dell.com/en-us/shop/dell-laptops/g16-gaming-laptop/spd/g-series-16-7630-laptop/useghbts7630hcwn

Dell
Play your favorite games on a Dell 16 inch gaming laptop with the latest Intel alongside a powerful NVIDIA GPU. View on Dell.com.
Yeah sometimes it’s small things like that which turn into dealbreakers, for me I require a numeric pad won’t get a laptop without one
Believe it or not, I actually place my wireless mechanical KB on top of my laptop (my current one) for my writing. Heh.
It's a sight
Checking your laptop it’s newer cpu, same GPU, more ram, but I’d never get it unless there’s an option to upgrade the display, QHD is way too sucky
I will disagree. I had a 4k laptop and hated it. The pixel size is way too small natively, so you either increase the scaling a ton, or reduce resolution, in which case: why bother?
Sorry I’m mistaken, QHD is fine, FHD is not fine lol
And yes I agree, my previous laptop was 4K and I did not enjoy it, I did enjoy the touch screen tho I do miss that
Yeah my current laptop is QHD, mental derp
I also do a ton of video editing, so the RAM is not optional. The minute you have enough moving parts, clips, sound, and so on, insufficient RAM can be crippling
(Just YT stuff, but you'd be amazed at how much RAM the editors demand once you start micromanaging it enough)
Same goes for AI, 32gb helps a lot for making images quickly
I well know. 🙂 The 4070 is dual purpose. It also serves to run some of the large NNs I use in chess
Mechanical KB in laptop. Ahhhhhh...
lol
The difference between the 4070 and the next tier up being 16gb of vram is really expensive too in a laptop. Like it costs at least $1000 more for any laptop with 16gb vram. You can’t get one for under $2200 that was way out of my budget so I settled for 4070
Yeah, the 4080 has 12, and cosst a nifty 500 more, and let's not even mention the 4090s with 16
Considering it’s Black Friday maybe you could get a 16gb one for real cheap? You should def check best buy they might even have that cherry keyboard one as a return
As much as I love the idea, it is simply outside my scope
well, I will absolutely be open to whatever comes my way on BF
not pulling trigger yet. Just lining up the prime options
I live in Brazil, but have family coming from US in ten days and staying here for a month, so....
Go to best buy.com and look for the open box items in their area and check that inventory
I farted
Thank you for using comcom analytics.
"comcom analytics" supports all community managers (moderators and server owners) by stats, visualization, and analytics.
If you have any questions, feel free to ask us!
Your dashboard
Help
Support server
Other languages
en: help
ja: help Japanese
@halcyon yarrow I ended up finding this for $1078 (tax included)
that seems nice yeah
I feel like with GGUF smaller hardware is now viable
I went from renting L40s to renting 3060s
You gave me the idea though. I found it in the Dell Outlet store which has some insane BF discount coupons (BLACKFRIDAY17).
The fact the Outlet also does not charge tax made a big diff
are you in austin?
Rio de Janeiro
there's a dell outlet down there?
Hola
Select the options you want, put the item in the Checkout and apply the coupon BLACKFRIDAY17. the price will be severely reduced AND have no tax appended
Brazil has a huge economy, if a north america company with international reach isnt in Brazil it should be considered a failure on the international front
Dell exists in Brazil just fine. The problem is that all electronics are severely upmarked
Here in Brazil the machine I paid 1078 dollars for would come out to some 3500-4000
Wow
If you can find it at all. Top end tech is a rarity. But it makes sense. The markup is not even taking into account relative incomes
It isn't a big issue for me though. Aside from just bringing things back myself, I have family regularly staying here. Such as next week, heh.
Fam coming in from US that is
its good to get a GPU I think
cloud is too tiring
huggingface and civit download speeds are not always the same speed on one day as on the next day 🤔
but getting private storage like google drive or backblaze is tricky cos it takes money that could have gone to GPUs
okay. cause the only dell outlet i was aware of was the store next to the dell plant in austin
is texas becoming a big tech place now like california is?
I don't follow US stuff too closely but I heard that
has been for years

ah okay
help
help
Help me generate a colored icon that represents the generation of asset inventory tables and the printing of asset labels








That's Mangled Merge Flux V1 + a lora I am in the middle of training for macro photography/etymology
anyone use flux outpaint much? I'm not sure I am understanding how to use it correctly

flux doesn't seem to like outpainting only in a single direction or something 😄


Entomology sorry
working on it now. In the meantime...






This one is with my lora at 100%
"a macro photograph, a chubby lady that looks like a lady bug and she looks stylish and rich"

This is the base model alone with the lora at 0%. Working on 45%.

I didn't see much of a change at 45% but here is 70% lol. I'm gonna try 80.

80%

Looking for that sweet spot. Here's 93%. LOL

getting close at 93.9%

yeah, It's interesting to see the transition though.





austin texas is. the rest of texas has been the electronics components and semiconductor center for 60 years. see texas instruments and mouser.

dallas is where all the major computer companies are at. Austin is where Dell and IBM are/were - and steve jackson games
there is a lot more going on in Austin than IBM/DELL.
also oracle and apple
HPE is in dallas, austin, houston
Create an image for a clothing store called branded_items that should show silhouettes of clothing frozen in ice cubes.
New shuttle 3.1 is great, has more detail then 3.0 for sure. This is 4steps, 2048x1024 with just Euler discrete

look closer, its kinda not good
the lines, ive had them pop out for unknown reasons also
1448x1448 was the recommendation for maximal generating size
Not sure, outpainting would be a option too


This is natively generated, I didn't upscale it.
4096x4096 expect problems
It can generate as high as 2048x2048 but you get weird artifacts, shuttle3/3.1 is better at native generation at higher-res.
my shuttle starting point is 1536x1024
Yeah also shuttle needs really low steps so its very fast since its a finetune of schnell, 4 is usually a good spot.
i think i found a comfyui bug maybe, didnt look if known, but like with the shuttle models if i gen on one and switch to the other it crashes, i think hitting the unload buttons prevents that maybe
Well i tried the shuttle model 7 steps 11 steps 60 steps and 100 steps. I love how all steps above ten work as refiner




this is a workflow i modified for shuttle 3, i love it, doesn't really give the same results with 3.1, almost seems like it needs more steps now, its a handful of 2 steps that ends in a 8MP image


I mean not too bad for 1step with Flux.1 schnell, euler discrete, 2048x1024



Yeah shuttle 3.1 seems to need 4+ steps, shuttle3.0 works with as low as 1step
Thank you for using comcom analytics.
"comcom analytics" supports all community managers (moderators and server owners) by stats, visualization, and analytics.
If you have any questions, feel free to ask us!
Your dashboard
Help
Support server
Other languages
en: help
ja: help Japanese




nice, I use the same TTP_Toolset workflow I just arrange it differently LOL

it works the same, I just replaced the tiling method with ComfyUI_SimpleTiles, added ColorPallete from ComfyUI-APQNodes, some post-processing from ComfyUI_LayerStyle and the new depth map thing
I removed the texture detailer section which was probably a mistake
hey.. Do you guys have advice for me like how can i extract patterns from images. I mean which techniques should i use for it. For example this image i liked the tshirt pattern

you are lucky because the best tool for this came out recently https://github.com/kaibioinfo/ComfyUI_AdvancedRefluxControlif you scroll down to "Masked Conditioning Images" you can see he used it to extract the floral pattern from the clothes
its essentially exactly what you are asking for
you are hero
no problem 🙂
ahh i only use with flux right
yeah
this hurts my brain 😄
what GPU do you have

ah yeah 3090 isn't great it can't take full advantage of FP8 matmul
would try downloading clip vision again
but idk the keyword for research
just search for diffusion
i downloaded from manager
would recommend not using manager
ah
and just using git and wget
now im trying to download with wget sigclip
also try several different sites
sadly it is very common for people to upload broken models
or to mess with the model in some way e.g. pruning
or heavily quantising without telling you
its kinda hard to get pure versions of models sometimes
not sure, would ask on comfy discord or banodoco



I like the style, looks a bit like book cover you could have on the old days 
really nice artstyle yeah
Really want to try SD3, but too lazy to setup another docker image, and it's seems not compatible with current ComfyUI setup i have (despite being latest)
its rough setting up docker instances yeah
TBH most workflows are not model agnostic, its the reason why I have only used 3 models ever (SD 1.5 -> SDXL -> Flux)
is there any custom nodes to join images like top bottom left right
Explain please
i was told that 3.5 large will fit 4090, but i see its cant load the model due to insufficiant memory, why is that? is there something special to do?
be ware of this "supporter", its a thief
I have custom node to do that on specific purpose. But it only join images on right and bottom
anyone have python example how to run sd3.5large on 4090?
I've just created for myself to each edge
Do you own crystools
i have it installed, if that's what you mean?
Your name
oh. nope. not the developer
How is sd3.5 finetuning right now? Is it begins figuring out?
Why would you use two comfy? You could just use another tab
do u have a code example?
i only see comfyUI
i dont use windows, i need it in python
i use sd commercialy with liscence, thats why i need it in code, where can i find that backend?
oh its in python also... didnt know that.. thanx! will try that
yea cuz queue using 100% of gpu
ill just call the functions directly
i also run rest, anyway, ill take a look
ill probably call it from another python
blaaahhhhh RuntimeError: operator torchvision::nms does not exist
ill work it out... thanx!
no thats version stuff.. ill reinstall packages...
@halcyon yarrow everything is perfect, you helped me alot! Thanx!
Oh nice, a way to enhance quality(more detail, diverse, and overall better) of mochi-1/open-sora/svd: https://junhahyung.github.io/STGuidance/
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling
I'm looking for a flux model that won't OOM my system and work decent in quality/speed, for 12 GB VRAM
this would be fine flux.1-lite-8B-alpha-Q4_K_S.gguf https://huggingface.co/city96/flux.1-lite-8B-alpha-gguf/tree/main
offload text encoders before loading DiT
great ty! I was testing one you share for other user and it took like ages to load and generated, and the it went literally OOM in Comfy (didnt generate)
I'll test those ones, thanks
the memory management in Comfy has never worked for me on any GPU
not sure if I have always had a setting wrong
but its pretty rough
depends on the situation
TCD works well with eta and only 8 steps
for the most part eta is for 40 steps plus
I also think flux gets harmed by it
I think people who are not making photos like the results but for image quality I think it is a negative
oh there's no point in taking into account recommendations
yeah I remember
I don't follow video but that's the best sound sync I have seen
might be okay yeah
wouldn't do it personally but it could work
0 eta before 40 steps
is the main thing
if you are able to schedule it then you also want the eta to decay
but that might be too complex for this project
flux can handle low steps with a bit of noise better
2m handles noise less well at low steps than 2s
yeah it's good to keep it real low for anything with only 20 steps, if not zero
30 is kinda where SDE starts to clearly become better than ODE
there is a bit of nuance especially for flux
you can do a little bit at low steps
40+, unleash the noise for sure
I don't know why but TCD lora with TCD sampler
can do high eta at like 8 steps and it goes fine
something very different is happening there
99% of my images have been with TCD, until flux era
its the acceleration lora with the highest complexity score
which is why I like it
its kinda not relevant now we have Shuttle Diffusion doing like 2560x2560 in 3 steps
yea that's def not enough steps for 2m
you can kinda get away-ish with res_2s at 10-15
are you willing to use turbo lora
it is compatible with other loras
bare in mind 15 steps of res_2s takes the time of 30 steps of res_2m

lol
else (cross.eyes.=="true");
I think its an improvement
eta = 0.20 at 30-40 steps might be a bit rough
its good to experiment anyway
with the res samplers you can generally get away with that once you get to 30 steps
espec with flux
tbh the most important thing might be how many steps you run with a low noise level, as opposed to the total number of steps
insofar as mutations and crazy shit are concerned
if you cut the eta down after a certain number of steps it can be helpful
so like... if you're runinng 30 steps, steps 0-10 might have eta 0.5,
11-20 eta 0.2
21+ 0
this would start at eta = 0.5 and follow that plot

and then it should fill in the rest with 0s
np
yeah thats in the newest version
its in the manager now too fyi
though honestly i think it's good to handle it with git cuz you can git reset --hard so easily to hop around versions
i don't do funny stuff with requirements.txt so you wont break dependencies doing that with my repo
it's kinda easier to use git anyway if you have docker
cos it just goes in the provisioning script
if you are updating or installing anything on a live server after provisioning script ends that's a mistake
main cloud advice I have is don't pay for storage
it works out better to download each time
civit download is so slow that it would be kinda hard to hit 1TB
i think there are also other type of bandwidth rules, i drop speed for chunks of time than its back to zippy for a bit
its either i get full saturation or 3mbit
ya so have i, but i have had extreme slow downs also. i dont know why, them, me, isp, who knows
Bit late, but better late than never,
There is a good guide
https://stabilityai.notion.site/Stable-Diffusion-3-5-fine-tuning-tutorial-11a61cdcd1968027a15bdbd7c40be8c6

Stability.ai on Notion
Interested in generating images like this from SD3.5 Large?
thanks, I had success with loras but I don't see big finetunes on civitai and some people say it is hard to tune too
sd35m, euler vs gauss-legendre SDE


SD3 Medium may be much easier to finetune performance wise

#Midjourney
Wf should be embedded but yeah it's from the new version
In numerical analysis and scientific computing, the Gauss–Legendre methods are a family of numerical methods for ordinary differential equations. Gauss–Legendre methods are implicit Runge–Kutta methods. More specifically, they are collocation methods based on the points of Gauss–Legendre quadrature. The Gauss–Legendre method based on s points ha...
Thank you for using comcom analytics.
"comcom analytics" supports all community managers (moderators and server owners) by stats, visualization, and analytics.
If you have any questions, feel free to ask us!
Your dashboard
Help
Support server
Other languages
en: help
ja: help Japanese
I used Flux Redux and used a ComfyUI workflow as one of the 2 input images 😄

haha the noodles
that's so cool
legendary version of gaussian noise sounds cooler than what Gauss–Legendre actually is LOL
Amazing new text to video model, definitely better then mochi-1 and probably sota. It can even do text very accurately: https://huggingface.co/tencent/HunyuanVideo

are there samples
The size though, lol. 13b params and 8b text encoder
ah nice
They have GitHub examples too, the beginning samples are things that can mochi do but in the end, quality is really amazing
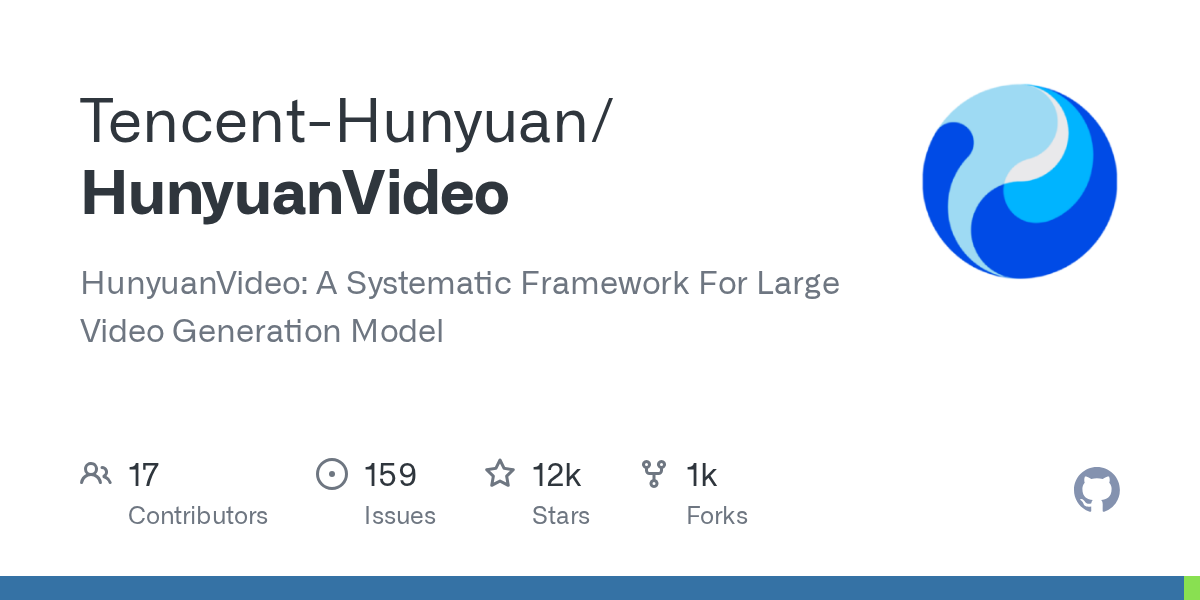
GitHub
Contribute to Tencent/HunyuanVideo development by creating an account on GitHub.
its Hunyuan so it has potential
I don't follow anime stuff, is Illustrious the new big thing?
there's this NoobAI thing too
I think its Illustrious-based but not sure
it has V-pred and ZTSNR which is awesome
oh awesome there's a paper thanks
I'd like to try Pony and Illustrious for photorealistic sci-fi and fantasy
I'd have to hide my workflows for those so I don't get criticised for using Pony LOL
yeah 2MP is good for SDXL
does remix meant img to img
stock SD3.5 does mostly look better than stock flux yeah
Did you check the ghost example and the text painting example, mochi has issues with large amounts of motion where it has distortion.
A nice thing is that according the their paper, with shifting scheduler and high shift, you can get good quality with even 10 steps.
ah okay yeah
I've been working on exactly that
this is for flux but will do for SD 3.5 as well

its not done yet it needs better depth map engine and more control nets
depth maps get way better than this but IDK how yet
the downstairs did okay
but the depth map broke for the back wall
and the side walls are going funny cos my depth map is not smooth
the gradient has lines and it things the lines are a physical feature
canny is way stronger yeah
the reason I prefer depth is that I want it to creatively add stuff
but only a little bit
yeah that helps as well
seen people refining flux with SD35L
interesting
when I am doing long generation workflows I always end with SD 1.5 unet, sent to SD3M VAE using latent interposer
i made this complex system where loras are categorized by an LLM and then an LLM picks the best categories for a given promptthis is a great idea
the first part I'm saying I upscale with SD 1.5
do you know this thing https://github.com/city96/SD-Latent-Interposer
it lets you pass latents around
the crucial thing is to only use 16 channel VAEs
with this you can send SD 1.5, SDXL and Cascade images to SD3M VAE
also lets you get the image from Flux into the older models without using their VAE encode
its an improvement
@halcyon yarrow just wanted to say thanx again! it is now in our production, and thats just WOW! it works about X2 times faster on 4090 than on A100 !!
i work at evmux.com , part of our service includes ai images for streams
and yeah, its on the backend now
i connect to comfy websocket for the progress and result and call the comfy api on /prompt by rest
basically like teir UI is doing, but on the server side
yeah, works great
currently im just waiting for the 'executed' event, in the future will expand
im not saving, im using the preview and sending it as the result, i dont want images to be saved on the server
that shouldnt happen... we are running on many data centers
and losing it is not a big deal if its super rare, it will just retry
exactly
async def handle_message(self, msg):
data = json.loads(msg)
if 'type' in data and data['type'] == 'executed':
data = data['data']
if data['prompt_id'] in self.waiting_requests:
fut = self.waiting_requests[data['prompt_id']]
try:
if 'audio' in data['output']:
fut.set_result(data['output']['audio'][0]['filename'])
else:
fut.set_result(data['output']['images'][0]['filename'])
asyncio.create_task(self.clear_request(data['prompt_id']))
except Exception as e:
stackTrace = traceback.format_exc()
print(stackTrace)
fut.set_result(False)
and also added the stable audio, maybe we will add it to
yeah, and then i see it in /api/view?filename={filename}&type=temp
i just call it as the ui do, with randomizing seed
yeah, copied it from the request in the browser and using it as template changing seed and prompt
async def draw(self, prompt, neg_prompt, width, height):
request = create_draw_request(self.client_id)
request['prompt']['3']['inputs']['width'] = width
request['prompt']['3']['inputs']['height'] = height
request['prompt']['6']['inputs']['text'] = prompt
request['prompt']['7']['inputs']['text'] = neg_prompt
res = await self.do_post('/api/prompt', request)
fut = Future()
self.waiting_requests[res['prompt_id']] = fut
return res['prompt_id'], fut
create_draw_request is the template
i currently have workflow to keep 2 models in the vram, the sd3l and the stable audio, pretty cool
we need speed so we just use 1 flow on each 4090, loading the model takes time
We just need to generate pics so actually its the same flow
Couldn't get Hunyuan vid to work with low vram, but other people's gens in banadaco discord are amazing. It's also better at nsfw then mochi/cogvideox from their testing.
and these are with fp8 quantized and lower-res versions if I'm not mistaken.
This is what it produced with the will smith eating spaghetti prompt and this is again with the fp8 quantized and lower-res versions. Doesn't know who will smith is but the spagetthi eating is near-perfect. Even with quantization, it produces better quality then full quality Mochi-1 from genmo with a upscaler.
Hope some more optimized code comes soon.
16gb lol but I didn’t try with low vram, maybe that could work
It's always a gamble to click on ai videos of people eating

It knows Donald trump at least
What is this model called
New open source video gen model that came today: https://huggingface.co/tencent/HunyuanVideo
The only problem is that it’s very slow locally since it’s not fully optimized yet and is 13b params with an 8b llm text encoder. Requires 24gb vram right now, but probably will go down.
To generate longer videos do you need more vram or only take longer?
Using what method
5sec is the real limit but it should be theoretically possible to extend it, Kijai the goat made a way to extend CogVideoX vids from 6sec to as long as you want.
But short answer, no, not right now.
You could also probably extend with image2vid but that’s not out yet, I believe it was the end of this month in their plan.
So it would just take longer if it was possible
I was wondering if the AI as it generates more frames it had to keep what was in the past in it's memory or something
a lot of methods to extend AI video are just starting a second run through the model
in those situations it has no "memory" of what came before, just a keyframe it was given
It also knows fork and spaghetti 😛
I think its too early for video really








I no longer have time to test everything, let alone conduct full-scale, in-depth experiments.
There are now more video generators than image generators.
I'm having too many problems trying to install the required packages to get this to work (mainly triton), so I gave up 😦
Not sure if that's because it's limited in the Windows portable version...?
does anyone know if sd3.5 large knows japanese?


Honestly, I think it’s kind of the exact opposite. We have so many options, and great models.
CogVideoX is like sd1.5 of the video models, with so much support and control(Lora’s, dimensionx, control net, fun models, multiple aspect ratios, rf-inversion, rf-edit, image2vid, trajectory, consisid)
Ltxv is crazy fast, and now we know some hacks to make it great quality as well. It takes like 10sec to generate a 5sec video.
Also, mochi is already sd3.5 large prompt following level and generates excellent videos. Mostly for realistic and cartoonish style.
Hunyuan vid seems to be trained on many styles for a video model, it knows lots of art styles/anime styles/cartoon styles for a video model surprisingly, and is excellent quality.
Hunyuan video is surprisingly flexible too, it was trained on 5sec videos and a specific res, but it can do lower res, and even 10sec videos
This is a pretty dramatic gen 😆
This model is amazing , i wish one day there are a way to reduce memory usage and increase inference speed
I can't wait to see ltx v paper to discover what they do for the optimization
Yeah same, I’m also waiting for ltxv1.0.
There was a trick to increase quality, by encoding the image with a specific video encoder and decoding so it had a video film grain. That would improve quality considerably for Ltxv.
Is that the new ltg paper ?
No that was just a trick the ltxv team found since Ltxv was trained on such videos mostly with that specific video film grain. So it results in better quality.
Ho , that's smart
i tried stg in comfyui with ltx , the quality increase is amazing
but i can't do img2vid
Why?
i dont know how to modifiy nodes for i2v
but you can probably do i2v without issues
I probably followed the same instructions. I got as far as trying to install the Triton wheel, but I keep getting the same error: ERROR: triton-3.1.0-cp39-cp39-win_amd64.whl is not a supported wheel on this platform.
doing the setup for stuff is always super hard
I almost never manage to get everything setup to reach maximum flux speed on a server
I've only managed it like twice
I have CUDA and VS installed, the path is set for cl.exe, but still no luck.
12.6 is quite a spicy CUDA version, I mostly see 12.1 for diffusion stuff
it might be okay though
sage is big boost sometimes
mostly for video
much better yeah
fp32 files need double vram
filled vram
Trying, but it's slow going... Building wheel for flash_attn (setup.py) ... -
Does it do i2v as well then?
What?!?!?!?!


😔
I mostly meant cost-wise
quality-wise I think mochi and Hunyuan are there now
Flux used to be slow for me but with Nunchaku and 2-step Shuttle, Flux is fast now
but with video I'd go back to being slow again
Yeah that’s an issue but it’s kinda understandable because you basically have to generate like a 100 frames for a 5 second video. I think we definitely need low step models now, like even 8step would be amazing.
Thank you for using comcom analytics.
"comcom analytics" supports all community managers (moderators and server owners) by stats, visualization, and analytics.
If you have any questions, feel free to ask us!
Your dashboard
Help
Support server
Other languages
en: help
ja: help Japanese
Nice, you made it work with low vram? I have to try it with that. It looks decent with that old retro look.
3.5hrs later...I GIVE UP!!
error: command 'C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v12.6\\bin\\nvcc' failed with exit code 4294967295
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for flash_attn
Running setup.py clean for flash_attn
Failed to build flash_attn
ERROR: ERROR: Failed to build installable wheels for some pyproject.toml based projects (flash_attn)
Hunyuan is clearly trained on a lot of anime😆
I’m on my phone right now, and my pc is at my home so can’t run it right now locally.
Yeah it’s probably trained on a large amount of anime videos, it seems to beat any other video model in its diversity of styles.
Mochi is decent at anime but has very little styles, CogVideoX isn’t too great with anime.
Ltxv with stg guidance btw is pretty good too and really fast.
Prompt?
It has a different prompting style then most other models, it actually likes concise 1-2 sentences abt the vid.
And some Ltxv i2v examples with the video compression strategy and stg, it’s surprisingly good.
this is great
are you using fp8 or fp16 T5?
Where you find the i2v workflow ?
How you added the stg ?
Is like skip layer guidence for video models
30 iirc
I love ltxv cause its super fast
not real time fast but still very very fast
I love hunyuan but I don't want to generate MSDOS level resolutions just to run it
yeah
when you use stg it modify the ltxv model : https://github.com/logtd/ComfyUI-LTXTricks/issues/6
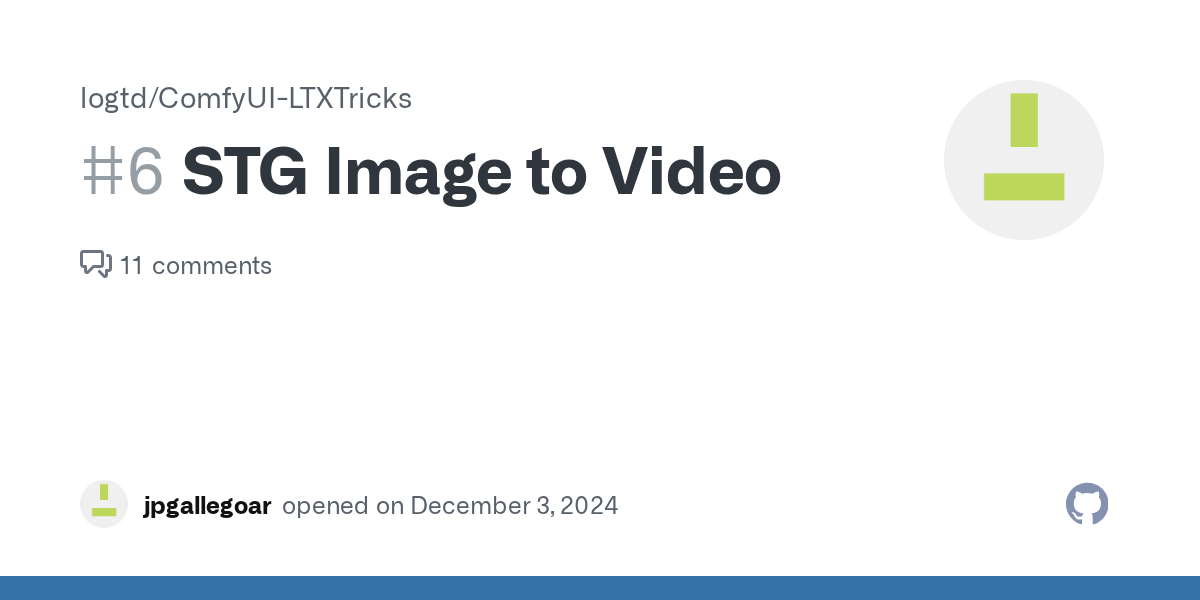
GitHub
Thank you for supporting STG so quickly! One question, I can't get it to work with image to video. The output video has nothing to do with the image, only the prompt. Have you any idea how to g...
you can resolve with "ltx add latent guide" node
It weird to say permanently, it modifies the loaded model, it will back to normal once you clean the loaded model
my bad , sorry
If you use the node "modify LTX model", even in another workflow, it will break the I2V unless you clean the loaded model property or restart Comfy. You may use the ltx add latent guide node to make it work again, but you will be using the modified model even if you current workflow don't use the modify model node.
why i get this error : The expanded size of the tensor (17) must match the existing size (18) at non-singleton dimension 3. Target sizes: [1, 128, 1, 17, 23]. Tensor sizes: [128, 1, 18, 23] ?
one inputs are not compatible with the other, we need to know the workflow
According to my first tests this perturbed attention for LTX is game changing in I2V
wow that looks amazing! you got it to work with pertrubed?
The perturbed is what you call STG, right?
stg is different, but its actually similar(same?) thing as skip layer guidance from stability according to comfyanon.
In the LTX Tricks page says STG but the nodes are those, that's why i'm confused. But yes, i made this node to work with i2v

With and without
yeah with clearly seems much more realistic and better
From what I understood from a previous post you also used it, right? The Javier Bardem one
The workflow is too big since i'm doing 4 videos at times and combining them but you just need this node

Lots of nice example workflows for ltxv including with stg: https://github.com/logtd/ComfyUI-LTXTricks/tree/main/example_workflows
You can't do side by side with i2v anyway. It changes the model for both
Once you use the "modify model node", you need to flush de model or restart comfyui

i dont get errors anymore , is this right ?
Without and With
i get more consistency with ltg


Looks correct (except the height and width were inverted, you should connect those nodes' inputs), I don't know about the performance of the fp8 clip or using only 20 steps
thanks , i corrected this
https://huggingface.co/SG161222/RealVis_Medium_1.0b
sd3.5 medium finetune

ltg seems to get more motion on video
anatomy is better but yet not enough, also it works with higher cfg now

@bitter hearth you are being watched

girl with white skirt
hallo, i am new to Stable diffusion 3.5
is it possible to train a Lora for it (i know you can for 1.5 and XL)
BTW. I have a little over 10k images in my dataset now. I have a few last things to wrap up this weekend with it and then I'm gonna fine tune next week.
I have heard of it, but haven't messed around with it. It has a color palette option right? I think that's pretty cool.
if you like color palette someone made a node for flux that works https://github.com/AIPOQUE/ComfyUI-APQNodes
its cool cos it didn't require training
they found colors the model already knows then they convert your color palette to the nearest ones
lol nice
anyone using sd forge? they have rly good upscale when generating image but i cant upscale any of my older pics good with img2img/extras. whats the current method on forge?
Nice! Yeah, I'm not really trying to train on millions of images or anything. I like the smaller yet more selective type for now. I will build up on it over time. Maybe go for another fine tune when I have 30k images.
img2img, script, sd upscale
tried that it takes like 4 seconds and doesnt add any quality, idk not working for me
No that's pretty cool. Is there a link to the original? Ide like to look into it more.
It is working normally here
got it working cheers, half my upscalers aren't working for some reason, but the same ones did when i used on generated image
¯_(ツ)_/¯
Reddit
Explore this post and more from the StableDiffusion community
anyone recall a website or hugging space that allows you to upload a short video animation and then an image, and it will try to animate your image in the same way the video is?
yes. it's very easy to train for
Bruh hunyuan text to video is completely uncensored. It can probably compete with ponyxl in that department.
What the hell did Tencent train it with lol
woahhh
wow that's a major improvement
i do with an 11gb card in comfy
I have 12gb
I dont see any difference between fp8 and fp16 with ltxv
is it possible to run hunyuan with 12gb vram?
no I am not asking due to certain message before
@halcyon yarrow ran it in 8gb vram so probably yes, not sure
thanks

sd3.5 large to create the image, kling to animate it
really liked how the final effect came out

The Verge
OpenAI has 12 days of Christmas planned.
with what?
to put it to the test
only if the model is grok ;)
Noooo!
Richard, how did you manage to run hunyuan video? I can't even load text encoder with 12gb 😦
I did, with those settings:

it needs around 18gig vram at least, i believe.
thanks, but sadly, I can't go past "(Down)Load HunyuanVideo TextEncoder" node, it just goes out of vram. Is there a way to offload to cpu or force using shared memory?
How much ram do you have?
flux fp16 needs 24gb but I can run it with offloading
32gb
Same as me. It's not the problem.
are you using Comfy? or something else?
Comfy.
you might ask in the #🧣|comfy-ui channel, or on his discord
I'll wait for wrapped to mature, for now
I've had loads of trouble on 32GB DRAM servers
I'm saying DRAM not VRAM here
would recommend 64GB DRAM
if you can, then 128GB, but 64GB is mostly ok
they killed Richard

from comfy's newest annoucement: ComfyUI now natively supports masking and scheduling of LoRA and model weights. This works for all LoRAs and models - as long as the LoRAs and models are not of conflicting architectures. The full blog post is here: https://blog.comfy.org/masking-and-scheduling-lora-and-model-weights/

Comfy Org Blog
As of Monday, December 2nd, ComfyUI now supports masking and scheduling LoRA and model weights natively as part of its conditioning system. It is compatible with all models. The update also has an extensive ModelPatcher rework and introduction of wrappers and callbacks to make custom node implementations require less hacks,
i thought that was implemented already 🤔
they just made the announcement today - so maybe you saw a beta test something?
it was but you needed nodes, this is native support
yeah custom node makes thing pissible
I can run HunyuanVideo now but all I get is black video, anyone had similar issue?
its been doable in various ways for a long time
this is essentially another way of doing it
i just tested sd3.5M is realy great

what is the best upscale model ?

closed source is the topaz gigapixel one
open source typical ones are StableSR, CCSR and SUPIR
there is a newer one that slightly beats SUPIR maybe can't remember the name
but SUPIR has been slightly broken into its components by Kijai, for ComfyUI so I think that is still a better choice
if you wanted the image to not change as much then openmodeldb is the place to go
thanks very much for the information ! @bitter hearth
I think this one right: https://huggingface.co/InstantX/InstantIR
thanks yeah that was it
thanks !

GitHub
I was able to get this working this morning, and generated a few videos. But suddenly out of the blue, all of my outputs are solid black. Why would this be? I'm not getting any error codes or a...
Has anyone else faced this problem? If so, how did you resolve it?
same, don't know solution yet
installing sage attention solved it
I am able to do 41 frames at 512x320 with 35steps in 290 seconds on rtx3060
wish svdquants worked with this model
would be even faster
it may well work
it is actually great even at 512x320 fp8, we need video upscale now
nvidia put svdquant on their tensorRT roadmap too so there could be another speedup there
hope not only for 50 series
I would say that it should be possible to make TensorRT engine for that on older GPUs
but its Nvidia so you never know 
TRT works super fine with sdxl on 3060 at least, but nvidia is nvidia
Yea, I can tell, hunyuan did not filter training data 😂
could just be that for the optiimization to work, it needs hardware support. Like they made the raytracing exclusive to RTX cards and people were like "Ughghhn monopoly and shenanigans!" but then they pushed a version that worked on GTX and without the hardware support it just wasn't good.
Sometimes instruction sets on the chip are crucial to make a routine performant. The optimization might not be effective if it's done on the fly in software.
Sort of like how fp8 isn't slow on ada cards, but it is on older models. That's because the hopper transformer engine with it's hardware fp8 support facilitates it.
SVDQuants are finaly avaible in comfyui ! 🤯 https://www.reddit.com/r/StableDiffusion/s/dRiI1yR1R0
Reddit
Explore this post and more from the StableDiffusion community
awesome

git clone?
yess
hopefully will be sorted out soon if so
i copied the nodes files to custom nodes but it doesn't works
you need to install with anaconda
it doesn't make sense , you have to install nunchaku with conda environement but how comfyui is suposed to find them ?


304x256 16 frames Hunyuan video s about all i can do 😂
did you install triton correctly? 
Use block swap, you can do 49 frames 1280x720 at 12-13gb vram. Will be slower though.



Switti is so fast and pretty decent, I would say sdxl quality, slightly better?
really good impressionist paintings
works in comfy?


hmm great hands but doesn't look like Flux, what model is that?
pin stable diffusion? pinterest.com/pin/864902303412978889
@bitter hearth I thought SUPIR and InstanIR were upscale models like
Why are those two so much bigger? Am I missing something?

diffusion ones are larger
@bitter hearth are there any new great upscale models that are better than the ones in my screenshot. mainly for photo quality and sometimes anime stuff
the Nomos2 ATD
the input needs to be very high quality
so sometimes the other ATD models are better
I'll give it a try. Just got everything running on Ubuntu. Got a new 4tb nvme, pulled out the windows nvme, installed ubuntu, put the windows nvme back in so no bootloader or grub files ended up on windows disk and I can now use either one. Got docker running for open-webui, installed ollama, got ComfyUI running. And I have to say everything runs so much better on linux.
@bitter hearth Anyways, have a good night. I'm off to bed, gotta go to work in about 5 hours.
night
yo
Thank you for using comcom analytics.
"comcom analytics" supports all community managers (moderators and server owners) by stats, visualization, and analytics.
If you have any questions, feel free to ask us!
Your dashboard
Help
Support server
Other languages
en: help
ja: help Japanese

SORA generates videos. This is the first review.
Get up to 40% off on last minute gifts at https://ridge.com/MKBHD
The (real) birding video: https://youtu.be/FjUEHdWU2Vw?si=KncheffCaMT6hK5k
MKBHD Merch: http://shop.MKBHD.com
Tech I'm using right now: https://www.amazon.com/shop/MKBHD
Playlist of MKBHD Intro music: https://goo.gl/B3AWV5
~
h...
Yeah sora finally released, lot of weird restrictions though like i2v can’t have humans?
Honestly, open source is surprisingly close to it and MiniMax is comparable to it(better in physics but sora has better aesthetic)
sora is probably a monster that isnt worth the power bills to run, its the openai way
quantity not quality
We’ll see how it goes. For me, DALL-E 3 is still an unmatched generator. Almost a year has passed, and no model has come close to its understanding of complex scenarios and concepts. The only and biggest downside is its strict censorship. I’m hoping for the growth of decentralized AI—it's the only way regular users can compete with big corporations.
heh


😂
Hmm flux/sd3.5 large should be miles ahead even in prompt following, not even close, can you provide an example prompt that dalle3 does well but not flux/sd3.5 large?
dalle3 is completely outdated, and has very large biases too that are even worse then flux
Everyone is entitled to their own opinion.
Oh yeah aesthetic wise, yeah everyone has different preferences but I'm talking about text, prompt following, image quality, styles, humans is where both models are better.
Have you generated a lot in DALL-E?
alright amount, I don't use it now often but a few weeks ago, I generated 2-3 imgs per day and compared to other models sometimes too.
I’ve generated around 100,000 images.
flux prompting is on par with Dall-e imo. And then you can make it comprehend what you mean with a lora. i can't speak towards sd3.5 as much. there's also omost which uses an LLM to form a regional prompt structure and generate complex images.
local solutions are not only as good, but they give more tools to leverage with. The level of contorl you have is far superior.
I’ve seen what DALL-E 3 is capable of if you dive deeper into its dark subconscious.
lol it has no subconsious
its probably a form of expression
dalle3 uses an llm to enhance your prompt, maybe thats the reason why you think its better? use something similar with flux and you will definitely get better results then dalle3 for sure.
yeah it absolutely does use an LLM to change your prompt
expressions that anthropomorphise models show a fundamental misunderstanding of the tools.
I prefer flux (pixelwave especially) over DALLE3 any day of the week
DALLE3 is good for like... powerpoint presentations I guess
it must have some style or substance in it if you prompt for it, but I just don't like the images it produces
and besides its a service, I like offline
even the simplest aux tools like inpainting are unavailable
bruh
hell you can't even adjust the number of steps
The new sora is uh interesting, from orabazes
Hunyuan T2V which is open source(not even full quality, the fp8 lower quality version and less frames which makes it lower quality)
can it really be called a new sora with only 3 second attention span?
No it can do more, it was just less frames to save vram. and that was an old video, lots of improvements came and now its possible to make high res videos in just 12gb vram.
i'm sure it can do more, but each 3 seconds will be a sepearate attention context
point is, sora seemingly has no attention seams. it's in another class and it's hard to compare models with that short attention span to it
I finally installed it too, and I’m genuinely surprised. Yes, the quality doesn’t quite reach corporate models, but the complete freedom is incredibly satisfying. I’m amazed that such an uncensored model was released as open-source.
No, the normal generation is 5s like sora on the plus plan, you can just do less frames to save vram at the cost of quality. Not required now mostly, lots of optimizations have come.
It even works with vids as long as 10sec but 5sec is the most stable(without seperate gens)
that limitation is put there for payment purposes. it's artificial. Sora can do many minute long videos, even if they're not offered on the plan you have.
i get it though. sora is the brand name. eveyrone wants to be sora. so you call it "the new sora" or "the sora killer"
Limited to 1minute according to the paper, not more, but yeah everyone calls new video models sora killer because basically sora started the hype.
I think too that Dalle is still smarter than flux or sd3.5, and not just for a little
so provide an example
if there's not a little, that implies theres a lot. so it should be easy
I have none, it is just from my experiece
figures
Can you explain though, I tested both on several different prompts like blue dog/image-grid and more. Even on benchmarks, they outperform dalle3.
Flux Dev beats Dalle by 0.01 in the GenEval benchmark
that's within margin of error

this is from the Playground v3 paper
I found it understand complex/crazy concepts better than anything else, but as there are conflicting opinions, I should retest
found a much better table
from the Sana paper
this time Dalle 3 and Flux Dev are exactly even on GenEval, and Dev is 0.5 ponts higher in DPG

to me its not an apples to apples comparison, Dalle should be thought of as a complex workflow, not a single model
These are all synthetic tests. I never pay attention to them. Any tool needs to be deeply tested to understand its hidden capabilities and limits.
you can make your own benchmark dataset if you want
its quite tricky though as you would want it to be well balanced in terms of the distribution of entities, attibutes, spatial relations and non-spatial relations across the prompt dataset
and then you would want to run at least 1k prompts on it
was funny to me when there was a benchmark model people were all about called "chad" or something. It was trained on all tons of gigachad images. so people were like "this prompt works better because my classifier model rates it higher" but it was just cause it looked more gigachadish... which is far from realistic
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/1831 this one it got really popular for a quick minute before people realized what it was actually ranking towards

GitHub
SD Chad - Stable Diffusion Aesthetic Scorer Have been using SD to create art for the last month, finding a template that works across prompt, seed, settings, and then creating 100s of images from i...
Some sora vids generated by orabazes, so far quality is pretty good but MiniMax might be a better option especially since sora 1024p with 10sec is 200$ price
you also can't generate videos with people in them if you don't pay for that 200 dollar plan - theoretically media did a very nice review of it earlier on his youtube
Anyone doing anything interesting in ComfyUI these days?
Hello all, thought I would check in, wondering if the newest SD is able to render hands/fingers in front of faces without messing up the face behind the fingers?
/fingers
mr
Hello guys. I'm a dev agency and I'm developing a flux workflow to create head shot image, and especially that I will deploy the workflow onto the web app so that we can monetize it. After I talked about that idea, a lot of guys have been texting me and asking me to build web app for them, which I think is a great way to earn money from your workflow.
I think there are a lot of people here have cool workflow and want to make it into a web app, launch it to a thousand of users and make money but don't know how to build it. If you are thinking about it and need any help, let me know, I will support nicely :).
for example we are deploying this workflow onto our server

great thing wish you best luck!
But to use flux you need a licence but i guess you know that
Yup, we are using the flux.schnell
flux.dev is non-commercial license so we do not use that

Google
Our new quantum chip demonstrates error correction and performance that paves the way to a useful, large-scale quantum computer.
🤔
can you use loras for SD 3.5 in comfyUI yet?
I can't get it to work
can somebody help pleassseeee
Mmaudio with Hunyuan t2v is pretty amazing, both are open source
Whoa ! I was looking for a vid2audio generator
https://www.runninghub.cn/post/1837756005856821249
very clean character sheet but i cant get it to work, if anyone interested in trying it and gets it working maybe they can give a hand xd
ComfyUI Workflow - 多角度一致性写实人物_基础版此工作流可以生成写实风格的一致性多角度人物1. 自定义你的男性/女性角色,包括性别、年龄、国籍、头发、服装种类等多个自定义类型2. 上传参考动作图3. 描述背景,如果不需要背景可以输入 simple background4. 生成女性选择1,男性选择2,默认放大1.5倍enjoy!作者微信:xdtr6688
That's easy enough: A large pizza with a world map made from pizza toppings.
you actually don't need a commercial license to use the outputs of flux dev. you only need the license to offer the model on a service.
i know you fall into the latter category, i'm just clarifying
Yeah mmaudio is truly amazing, and with hunyuant2v, this thing is ridiculous
Need some more examples of this, pretty neat!
there's a busker guy in the city i grew up in who fiddles in a vader costume. It's extreme. i've loved him for years and always throw some coin in his hat
https://www.youtube.com/watch?v=dVKwiJkc8OI he's still at it looks like

darth fiddler is a street artist in victoria bc
wow this is cool!
new model dropped weights
https://github.com/lehduong/OneDiffusion?tab=readme-ov-file
GitHub
Contribute to lehduong/OneDiffusion development by creating an account on GitHub.
Nice, 3d multi view thing looks pretty interesting and seems very small.
ooh it takes SEGs
the SD 1.5 SEG control net was really nice
acts a bit like tile for layout but it lets the model be a bit more free
I think a model like this is what will be the thing that will dethrone Flux next year
a big transformer with lots of control stuff
@bitter hearth I still can't figure out custom sigmas 😉 ,seems to be a bit above my skill level. I also can't really find anything online that refers to them or how to use them.

this is what a linear schedule of custom sigmas for Flux would look like:
1.0, 0.8, 0.6, 0.4, 0.2, 0.0,
its just a list of numbers that goes down to zero
GitHub
Contribute to kijai/ComfyUI-MMAudio development by creating an account on GitHub.
how are you generating these videos? On the hunyuan page they say you need at least 45 GB VRAM. Do you use an external gpu, or can you quantize hunyuan to use <24GB?
Yes you can use fp8 quantization and even block swap to fit in 12gb vram.
nice, should try it. Is there a tutorial anywhere for comfyui?
keep an eye out for FP4/Int4 stuff
cos that's getting more common now (its half the VRAM and up to twice the speed of FP8)
I can't run mmaudio , i have torch issues
I had torch issues with SD 1.5 today lol
its so hard juggling dependencies and docker containers
Cannot import ComfyUI-MMAudio module for custom nodes: No module named 'torch.nn.attention'
what is the module torch.nn.attention and wich version has this module ?
Not sure abt tutorial but here is the node with some example workflows, https://github.com/kijai/ComfyUI-HunyuanVideoWrapper
thx
resolved , mmaudio works only with torch and torchaudio 2.5.1 version and cuda 1.24
nodes requireing specific versions of dependencies. that's pretty sussy considering how vulnerable packaging infrastructure is.
wasn't it a video node thatpeople were excited about that was the first big security breach on comfyui?
the latest was a specific pypy package that was used on a hundred different nodes
yeah is annoying , i have chance because i dont use lot custom nodes
Kijais nodes are 100% trustable, he makes the first and usually best nodes for every new video model(CogVideoX, mochi, hunyuan) and everyone mostly uses his nodes for video models.
Analyzing the two images, is there a clear winner?


yeh but the infrastructure around it isn't.
running free scripts natively out of excitement is never a smart decision
Also, Kijais whoever they are, is just an online account. Anyone could get access to it. It could always be compromised

wow that is cool. but i wish that they would have model offloading. and the option to runn the vlm on the cpu with lamma cpp or something. because nobody has so much vram. but i will try to caption it by hand for now. whatever that means
great thing about weights is that anyone can take the code and reform it to use the weights the way they want to
really don't think its worth CPU offloading, or running models on CPU
would be better to pick smaller models that fit in your VRAM
anything can be compromised, probably best to stay away from computers in general
the app your typing on was compromised
there's been seven cases of malware this year in the ecosystem, have been keeping count
I keep it sandboxed in docker containers on cloud personally
we are talking about captioning a image that is very fast so its worth it to run on the cpu. the main model shul of corse be on the gpu. also ofloading works quite well.
You can probably just use florence2/moondream2. You don't need the captioner, it just makes it more automated instead of hand writing captions.
Florence2/moondream2 are really fast and good quality and use very little vram(4gb or less?), definitely better options then molmo/llava.
its hard to know what speeds people are used to
it might be fast relative to things you have done before
it will take a few seconds
yes the ui is just a bit confusing. and i am not 100% sure if i am using it corectly
ok but this is no good when my image gen is under 1 second, for example
its not. the image generation takes like 30s on a 3090
oh for this new model yeah I just mean for what I have done before
I wouldn't find a few seconds that fast
there are levels of risk and levels of compromise. nothing is black and white like that.
i dont install custom discords hacks for instance. i have the app installed but i haven't loaded it for many months. i typically use discord in a chrome tab
Awww ❤️ After i popped in on you lol. The guitar mastah.
can SD3 be used in a1111/forge yet?






Sd3.5 large ?
yeah 🙂
Is realy good for styles and colors
yeah, i like the aesthetics of sd3.5 way better than flux
Yeah by far
and i used some new tricks i picked up from one of the capabilities of ollama and an idea by qwq (LLM model)
make the LLM output json, and have it a dedicated field for reasoning when interpreting a prompt, but make another field the output prompt: it'll listen REALLY well
and with sd3.5L having the proper formatting for t5, clipl and clipg really helps too
if clipl goes over 75 tokens the image goes wonky fast
ho , i never tried reasonning models
first, qwq is actually really amazing, but i figured, why not try with something like mistral, or any other small models
and even that works, if they have a little bit of "private" space where they can lay out things for themselves before atcualyl making the prompt seems to help a lot
example from mistral-small-22b:"
"T5": "A desolate battlefield strewn with discarded armor, each piece lined with glinting silver, lies amidst cyanide-tainted earth that shimmers in an eerie blue hue. The ground is scorched and barren, devoid of life except for the remnants of a destructive dance. Swords and shields are scattered haphazardly, as if left behind by an army in haste. The sky above is darkened by a churning storm, with lightning striking down ruthlessly, casting long, ominous shadows across the bleak landscape.",
"CLIPG": "battlefield, silver armor, cyanide ground, scattered weapons, dark storm",
"CLIPL": "A grim battlefield littered with silver-lined armor and discarded weapons on cyanide-tainted earth, under a threatening stormy sky.",
"Artstyle": "Dark Romanticism"}```before, that part that got in the front would end up in parts of the prompt that would be submitted, so now it really gives better visual only representations
intersting , i will try it and share the results
pull my image for the systemprompt and nodes used tho, you need some formatting tricks to get it to work properly
and unfortunately qwq fails at making json if the systemprompt is too big
in forge yess but i controlnet and so one dont work , so i use it in ComfyUI
I prefer Medium personally, both because it supports higher initial generation resolutions, and also because it can actually work properly in a traditional hi-res-fix context
Like e.g. SD 1.5 was perfectly capable of genning at 512 at then refining the image at 1024 once upscaled with ESRGAN or whatever
But 3.5 Large cannot do that (or really any sort of img2img) even for some reason, it creates noticeable artifacting at any denoise strength
3.5 Medium however goes back to behaving like you'd expect in that context
So it's just better IMO
Only thing I don't like about 3.5 is that both Large and Medium lean towards extremely desaturated grayish kind of images, as though "smoke, fog, haze" was always in the positive prompt or something
In contrast 3.0 didn't have that problem at all
i don't feel smoke, fog, haze are a part of 3.5l




