
#🆕|sd3
1 messages · Page 119 of 1
Me neither :/









A crane is flying over a lake at dusk. Yep. That's a crane.











hahah
it's nothing like my workflows from before i started coding stuff for this
at least
some of those had 500+ nodes
ypeah





all SD35M






Flux RF Inversion - Style Transfer










Impressionist art "is noise!"






generating my ass off over here 😛

lol at this one

these are all one shot
i generated overnight, i'm picking probably one out of two or three here
here's 9 consecutive

















what gpu are you using? that's a good first q
so i know what settings will make you feel like the universe is ending from age
k
i'd try these first, with eta = 0.5, 0.25, and 0 for ODE

for SDE it might be better at 0.25 vs 0.5, not sure
SD3.5 behaves quite differently with noise vs flux. not necessarily better or worse but it absolutely responds differently, it's interesting
SDE will take the same amount of time (or should)
the only thing that makes SDE a SDE not ODE, is that it adds a bit of noise after each step
what i just sent should
but def play with it a bit
it's worth having different configs if it gets you better results, that's "fine tuning" your inference params and is very much worthwhile imo 🙂
ahhh sharksampler doesn't really do a whole lot of crazy stuff, it really just gives you extra noise options
clownsampler/samplerRK (they're the same thing) is where the fancy stuff is
i use clown and shark
clown connects to shark... i named em that cuz ppl were getting confused about which sampler went in which order
yup, SDE just means that eta or eta_var are greater than 0.0
eta and eta_var tell it how much noise to add after each step
no prob
i'd generally start with eta thats less than 1.0 btw
oh, you probably need to update
i added that recently
use "git pull" in the folder and it'll update
definitely
it's really fast, you're on (presumably) a slow card if you have 8gb vram
res_2s will run at the same speed as dpmpp_2s_ancestral and dpmpp_sde
Surprisingly res_3m was faster than 2m i may have broke something
they should be the same speed
what i would recommend is using one or the other
eta_var = 0.5 or 1.0 as a first value to try for that
with eta = 0.0
and then try eta_var = 0.0 and eta = 0.25 or 0.5
def try a few with a couple prompts and see what you like best
there's no correct value or anything, i'd just keep eta < 1.0 for first tests. with noise mode = hard, eta =1.0 is the breaking point, the math won't work so you'll get a black image
😮💨 OmniGen is broken in my Comfy again and nothing I try fixes it. Why is this node so fragile?
not sure you'll just have to see what you're getting
all custom nodes are fragile. i try to play in stock comfyui as much as i can. if you do use custom nodes, freeze your version of comfyui and never update it after you get all the nodes working. only update when you have vetted things. This will be your "Long Term Support" stable install location. The one you update everytime you start should have minimal custom extensions and stay as stock as possible
same rules for modding games
@dusky thistle do you have a discord?
when clicking on either of the workflow images in the readme

it's what 3 WOULD have been if 1. the community hadn't gotten so toxic about not getting a release yet and 2. the community hadn't started saying that SAI wasn't going to opensource anything, any more. the community, here on discord, was so toxic and demanding that they got handed an unfinished beta test model - and then didn't like being told that's what they got becaue they wouldn't be patient and wait till it was done
Well, since you are a part of “the community” I thank you for shouldering the blame. I on the other hand won’t be gaslit.  and thank you for turning a positive message negative and aggressive helps a lot.
and thank you for turning a positive message negative and aggressive helps a lot.
i'm not one of the people - most of whom thankfully are no longer here - that were the issue. and i didn't turn a positive message into a negative, nor gaslight you. i stated the same fact that's been stated over and over. it was clearly stated when it was released why it was being released - and the community did the same thing then they had been doing - try to burn this discord down, with some literally trying to see if they could destroy SAI as well.
ye if anything crystal was pretty much always the one being attacked by the toxic folks simply for pushing back on the negativity lmao
big props
Where can I find inpainting and img2img comfyui workflows for 3.5 large?
you might see what's been posted in the #🧣|comfy-ui channel







Flux RF Inversion





I got it figured out. I've added the safetensors FP8 up here:
https://huggingface.co/ManglerFTW/Mangled_Merge_Flux_V1_Dedistilled/tree/main

wtf, that' sweird...
don't have my own server, nah, just hang here and on L3
you need a discord :)
Yup. It's this one. The hugging face link it just for extra quants.
there's a comfy node too
https://github.com/comfyanonymous/ComfyUI
personally I perfer tonemap and/or skimmed CFG
808

GitHub
Dynamic Thresholding (CFG Scale Fix) for Stable Diffusion (SwarmUI, ComfyUI, and Auto WebUI) - mcmonkeyprojects/sd-dynamic-thresholding
Not a lot actually. I didn't really try to focus it on NSFW but there are some in there. The main thing with the loras was to grab any that looked good and were ok to merge by the creator.
few more thresholding options here too https://github.com/Clybius/ComfyUI-Latent-Modifiers
These setting work pretty well for me. I usually change the mimic scale between 1 and 3.5 and keep the ksampler CFG at 5.

You can always add them in, this model works with loras.
I actually have to update that list now that you mention it... one moment
ok if you refresh the list all 808 are on there now.
Same. It needed help which is why I merged it in. 🙂
I don't mean to nitpick but you mostly want increasing CFG (like cosine up) rather than decreasing CFG (like cosine down)
I will play with it. Those settings were originally being used on a non dedistilled model.
for what its worth I've enjoyed both up and down but up is more supported in papers
the reason is CFG does more damage early on, when the cond and uncond disagree more
anyone here use comfyui? i need some help troubleshooting an issue regarding rhthree's comfyui nodes
in some ways, sure. But I merged them in a way to try and limit that. Basically I took Pixelwave and Nyanko7's model and merged them 60PW/40Nyanko, then took MMMagic and MMMatrix 50/50 and merged that 50/40 with fluxbooru and then merged those 2 together 50/50.
60PW/40Nyanko
I am getting this error @silver sluice

I think it depends on the sampler. I use deis which I set between 20 and 30. But it's also good with dpmpp 2s ancestral / SGM Uniform at 15 steps.
genius @silver sluice i just deleted this folder called glob and that seemed to eliminate a bit of the issue, thanks
yeah, play around with it
I have noticed loras do better with more steps. Sometimes 15 steps isn't nearly enough.
what did you like about flux de distill?
Different output than the normal flux style.
I merged in 808 loras and still couldn't get rid of the "Flux Style"
Yeah, people and animals look too plastic and 2D is too polished.
Im gonna use this model and finetune on top of it.
It all depends on if creator allows merges.
yup
if it's got this sign, it means no merges.

i blame booru lol
3 of 4 are asian lol
she does in the 60 step

there is also flan
which one?
I tried Flan today but I didn't do an A/B comparison
it was good though
lol yeah
Sweet! What's the list?
Any better supported training tools for SD3.5? I am finetuning Flux right now, cause it gives incredible results. I'd love to train SD3.5 if there are better options to train now
jesus fucking christ they are more baked than snoop dog
testing now
that redhead with the camel hoof
It's still funny that even with all the merging and training involved in this model. It still gives sleight butt chins.
yes
Yeah, I'm not sure about fluxbooru, but I know nyanko7's model wasn't trained to go past 3.5

Yup it's Fluxbooru's fault lol
OK. My next project it gonna be fine tuning off of this. Working on building my data set. I need to make a tool that allows me to skim through all the captions and make corrections. I don't have a lot of $$$ for compute so I'm going for the smaller but really good dataset option.
Currently inferencing FP16 flux dev on an 8GB GPU with a messily 1GB/s PCIE connection... Taking 25s/it lmaooo
https://civitai.com/models/686704/flux-dev-to-schnell-4-step-lora this might help. I got pretty good outputs on 4 steps from it.
I'm validating a fine-tune, so I can't add any additional things
gotcha
Training on a 3090, validating on my 3060ti
hows the training part working for you? I also have a 3090 and intend to train on that. I was gonna use simple tuner for it.
not the place for this prompt
I only just started fine-tuning. I'm friends with Mikey, the guy who made pixel wave, and he was giving me some training insights. It's absurdly slow haha
Thank god
no
Uhg, simple tuner. I always get a migraine when I see people mention it
I just tested my fientune at 3k, and it actually is fixing some issues in flux, but its sooooooo slow lmaoooo









wow
really like the last one with the guy with the horns
yaaayy!! goat!
so Omni is in comfy now?
Much ❤️ to the SD team. It's great you can get these results without any refining or upscaling.


@dusky thistle @bitter hearth i finished the sampler/scheduler compare sheet - do you want a copy?


sure, always interesting in more data
DM sent

do you know how many layers SD3.5 medium has?
24






Display an e-commerce interface with Shopify and WordPress logos, emphasizing a smooth checkout experience. Use a cool blue and green gradient in the background. Overlay text reads: “Seamless E-commerce Solutions for Your Business.” Show a shopping cart interface with bright accents in green and teal, and ensure sleek UI elements.
Hi All, I updated my SDXL DaVinci Ink Sketch LoRA for SD3.5 using Ostris' AI-toolkit. I think it came out pretty well.








You can find it on Civitai here if you want to give it a try. https://civitai.com/models/212322/da-vinci-ink-sketch
It's more DaVinci's notebooks with a biomechanical twist.



depth is amazing but why is it hazy?
Onetrainer pushed out an update that made onetrainer support efficient ram offloading which means you can train SD 3.5M on 1024px images with only 4gbs of vram
no way 4gb for 3.5m?
much appreciated, thank you
thats all?
Yes
That all
Reddit
Explore this post and more from the StableDiffusion community
damn going to have to create a dataset
anyone know how to start?
this is bonkers
start by deciding what that lora is for - remember, if you can get what you want with a prompt, don't waist the compute on a lora
Onetrainer is easy to use for beginners, it has a nice user friendly UI, I recommend you to read the instructions on their github to start using it https://github.com/Nerogar/OneTrainer

GitHub
OneTrainer is a one-stop solution for all your stable diffusion training needs. - Nerogar/OneTrainer
thank you
want to train the whole model on multiple subjects/ styles
not a lora
not what onetrainer is for - and that's going to be expensive
that's a fine tuned checkpoint
you cant finetune with onetrainer?
do you honestly need to? the point of a lora is to be able to train a small item that doesn't cost much and specifically updates the model's weights for specific information instead of spending the funds necessary to retrain the entire model
No you can fine tune a full checkpoint on 4gbs of vram one trainer just very very slow
see you in three months
i don't want that electric bill
I am having a blast with sd3.5m doras
they are not perfect yet, maybe due to undertrained base but it learns anything, I like it
and the interesting part is I trained dora for 6k steps with lr 0.001 at 512px and it did not overbake at all and works at 1024px, only some details not accurate
Jokes on you, my government pays my electricity bills
but do they pay @untold valley 's electric bills?
but you can do it in OT
why is it expensive/time consuming, wasnt 1.5 trainings done in like 2 hrs or so?
shouldnt take more than like 3-4 days for sd3.5?
I remember finetunning takes only 2 time longer than lora but I may be wrong

3.5M should be in Theory faster to train then SDXL since 3.5M is smaller then SDXL in parameter size



sd3.5m - 2.5
sdxl - 2.6
not really smaller)

1.5 isn't 3.5
not all params cost the same to train
attention can be hard on the gpu
and 3.5 doesn't use the same architecture as 1.5
@dusky thistle prompt: portrait of a cougar in the moonlit winter snow, euler_ancestral+linear_quadratic, layer 4 only vrs all layers


here kitty
pretty kitty
just amazed at how much of the final result is present in that one layer



Flux RF Inversion Style Transfer

i have two gpu's one with vram 12 gb on with 16 gb. is there any possibility to run stable diffusion using these two. its would be a great help. i am new learner .

Flux RF Inversion Style Transfer









yes please, that would be great
Flux RF Inversion Style Transfer












This doesn’t even look ai. Best ive seen.









I'm currently exploring the Detail Daemon. That looks like it's gonna be next on my list of things to try out.
I wonder if that's 2 gpus through SLI or through a network. Can 2 different GPUs connect through SLI?
I can't speak for this, but in chess it is possible to leverage more than one GPU without SLI. Rigs with 4-8 GPUs exist
Naturally, the software must be written to allow this, but SLI need not be involved.
Detail Daemon is legit
I do it by other means, using SDE sampling with scheduled S_noise, and also adding noise using latentmegamodifier node, but its similar idea
its all just noise injection at the end of the day
So after a bunch of testing with SD3.5L, I will say this much: for artwork and whatnot, I like dpmpp_2s_ancestral a lot. Very different output, but often the prettier.
in Comfy dpmpp_2s_ancestral is the best out of the default samplers for Flux and SD3.5 yeah
SOme things SD3.5 just sucks at, but the same is true of other models, and possibly LoRAs can improve this. So not a general slam of it by any means as I really really like SD3.5 for some things.
Def give my sampler nodes a shot
It blows dpmpp 2s ancestral out of the water for versatility and max quality
And also has faster options
After many testing on sd3.5m, it is very hard to learn the detail accurately.
I am open to trying. You have a WF I can use or link for the node?
Yep give me a sec here and I'll get you one
Today for example is my uncle's birthday. He is 63 and is a known surfer and taekwondo blackbelt (gold in senior division of World Cup). So I asked both to produce images with same prompt. SD3.5 gave me this (and 3 more tries were no better). A third also by Flux shows a typo but nice creativity in text style.



And yes, I asked for a cartoon style
with candles in the shape of 63
Thank you for using comcom analytics.
"comcom analytics" supports all community managers (moderators and server owners) by stats, visualization, and analytics.
If you have any questions, feel free to ask us!
Your dashboard
Help
Support server
Other languages
en: help
ja: help Japanese
https://github.com/ClownsharkBatwing/RES4LYF here's the repo... getting really close to ready to throw up some documentation and get added to the manager
GitHub
Contribute to ClownsharkBatwing/RES4LYF development by creating an account on GitHub.
here's an img2img workflow with two different methods

Many thanks. I will try in Flux first and then in SD
here's txt2img

the node should have tooltips that give some basic idea of what the options do though i'll be adding more detailed documentaiton later
the first two options to play with are the sampler type:

for starters, i'd play with res_2m, res_2s, res_3s
res_2m runs as fast as euler, 2s runs as fast as dpmpp_2s_ancestral, res_3s is somewhat slower but higher quality
the other param to play with at first is eta. set it to 0.0 and it'll be an ODE, anything greater than 0.0 is an SDE (adds noise after each step). values like 0.25 or 0.5 are good starters, if noise mode is hard (default) then eta = 1.0 is by definition the point where the math blows up so it has to be less than 1.0 for that
I could only get noise mode soft working for SDXL
and only eta no eta var
this may have been due to that weird bug though where my sampler was still called RKsampler instead of Clown though
i fixed hard, it should work now
i had done something profoundly stupid with the noise scaling for sdxl lol
lol ah okay nice
I tried the Res_3m in ODE form and it converged really, really fast
much faster than UniPC
so I'm pretty happy with that
for Res_3s I had to use 120 steps for it to finish improving, but the image was probably the best SDXL image I have made
so the repo seems good
as a side note, unipc seems to not work with sd3.5m 🤔
How do I connect the VAE? I am using SD3.5 GGUF, so VAE is not embedded AFAIK. I added the Load VAE node but it refuses to connect to the VAE output
nvm. It was minimized
Sounds good. I got a spare 3060Ti. I might look into leveraging it. Might need a beefier power supply though.
awesome 🙂
should be even better with that hard noise, i think
just a lil bit of it
i'm gonna add nodes for scheduling params soon, so you'll be able to do stuff like tail off noise at the end, etc
ah yeah that would be good
in terms of noise flavours to add as ancestral noise I liked Brownian, Uniform or high frequency power noise

perlin is real interesting too
and the pyramid ones... especial pyramid bilinear, and hires pyramid bicubic
ah okay thanks
I do remember some of the pyramid ones were nicely unhinged
with galaxy bottle prompt there wasn't even a bottle but there was a weird Japanese pagoda
hahah wow
yeah what i'm usually looking out for is a change in the visual style... as in, toward something more or less saturated, or toward a painting/illustration style or back toward photographic
that, and the complexity of the composition: subject front and center, or in the background off to the side
ah my goal with noise is always to make crazy stuff happen
well also add detail
really high strengths of Vector Sculptor node are great for creativity
it adds or subtracts nearby tokens to your prompt automatically
probably the worst possible thing for precise work though
Try ReCraft - it has superlative text capabilities
I noticed ideogram has good text also
I suspect the private models are using large text encoders, they may as well
i don't think i ever got that to do anything
but i don't think i put much effort into it
the node's limits are way too low
you have to crank it right up
also I was leaving the negative stationary and normalising both by "mean"
this example was good

Ideogram has long had the best text of all. Now they have serious competition by Flux for less Graphic Design work.
However their new model in terms of imagery impresses me a lot less
Ideogram probably has best text yeah, I agree
I was hoping for a new Pixart model but they made Sana instead this year



the situation is kinda dire
there are only 3 modern models with MIT or Apache 2.0 licenses
Lumina, Auraflow and Schnell
I've been preparing for a big fine tune but I am not sure which one of the three to pick
is it hard to hooks this up to Flux?
nope, you can use the same WF
just switch to loading the flux checkpoints, vae, and text encoders 🙂
dual clip loader instead of tri clip loader, etc
img2img Flux RF Inversion



Ok, I did that. I disabled the Negative prompt and the SD35 model somethingsomething
should work great with flux, i actually originally wrote this code to work with that and was then very happy to see SD3.5 came out and worked fantastic with it (absolutely love SD3.5 tbh)
oh, yea, and then you need the guidance node too
with enough whacky noise, inpainting and refiner passes
you can kinda make Schnell look good
its still not the level of Dev though but not as bad as the Schnell from launch day
What about the Conditioning Zero node? Leave it or remove it?
doesn't matter too much now since you should set cfg = 1.0 with flux, unless you don't want to use the distilled guidance and want to use cfg... which 95% of ppl don't want to do, myself inculded usually
takes too damn long, and the quality degrades quite a bit, i only turn off flux guidance and turn on cfg if i'm desperate to get a certain look that the distilled flux guidance is forcing to happen
the question I had was this:

I quite liked flux with CFG
its extremely dependent on the nodes you used to fight the CFG burn

ReCraft better at long strings of text
not bad yeah
that's a nod to one of my players in an old GURPS game - he made a superhero that was normally just a coat, a hat, and a pair of sunglasses. but if you hung them all on the same hanger, then they activated and turned into a superhero
I am yet in testing fun shit but so far had good results (ignoring anatomy and consistency as it is not lora's fault), all loras been detailed and flexible. likeness was fine. And great results with 512px training which scaled to 1024 greatly, even to fullhd with little padding artifacts
however I am not sure about lr yet, it takes more steps than sdxl and I was not able to overcook model yet, even with lr 0.001 at 512px
I tried to overfit one image to the model with prodigy. The lr raised to 0.011 end up with 0.007 step loss but the image still couldn't reconstruct perfectly. Some small detail messed up. Overall is reconstructed.
maybe it overfits by messing up structure instead of looking "overbaked" and reconstructing image? I had one run where after certain steps proportions became more and more distorted
The structure is reconstructed, including hand, anatomy, etc, but some small part of image doesn't reconstruct correctly.
gonna test more...
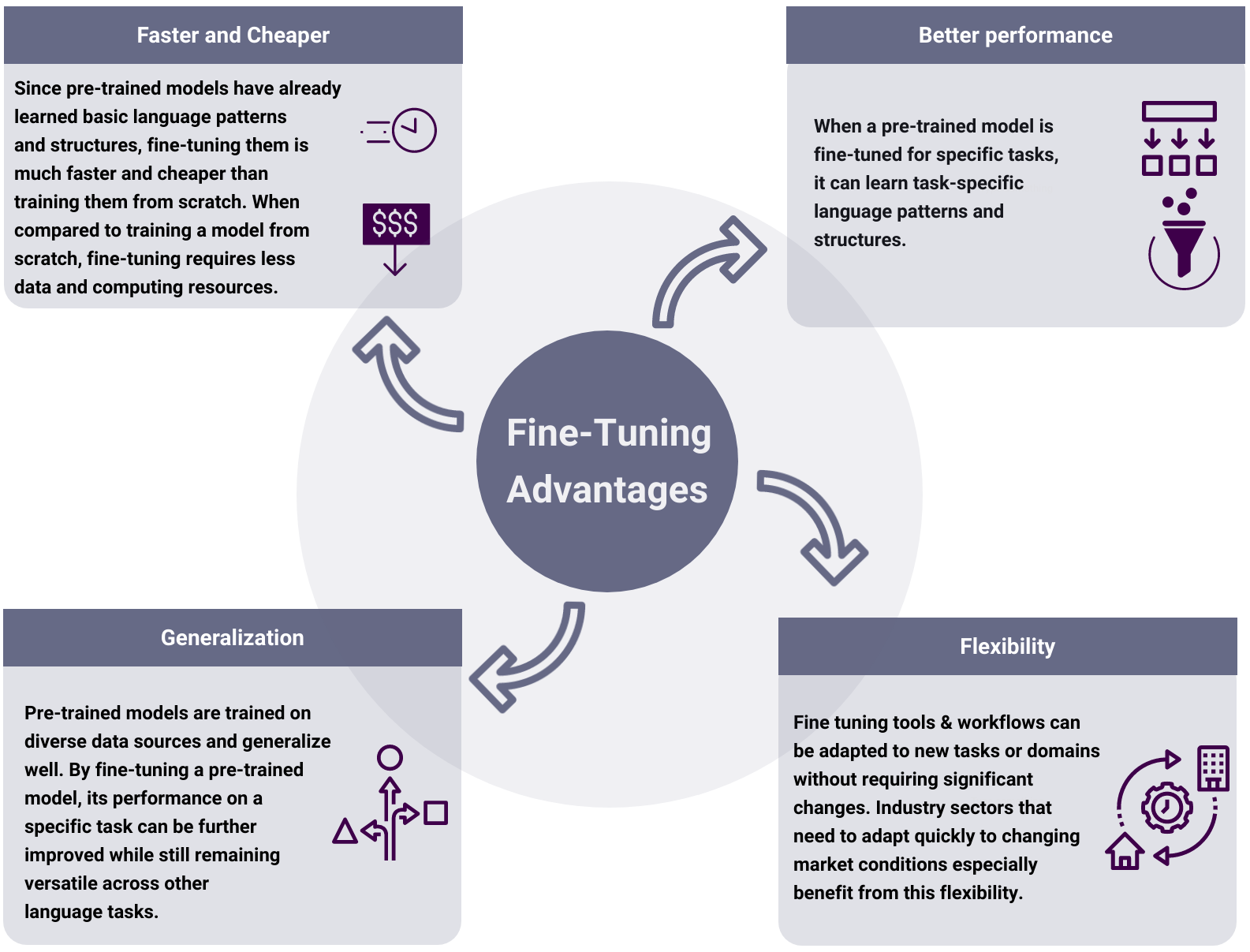
The growing prevalence of large language models (LLMs) has spurred a demand for customization to suit specific tasks and domains. As I’ve noted in previous work, tailoring LLMs to unique needs can significantly enhance performance and cost-efficiency, particularly when striving for higher accuracy in specific applications. Fine-tuning LLMs allow...
One image learned around 12,000 time to get 0.007 using prodigy. Many repeats and epoch.
we need Furkan to test all parameters 😆
For comfyui is there a way to use an older version of the frontend? the updated one is kinda jacky for me.
You always need different parameters with different dataset.
he'd probably find the project interesting, and he does a good job with that sort of stuff - you should suggest it to him
He already planned to do this, just waiting for tools to mature
I cannot say whether it is better or not, need more testing no doubt, but overall good stuff, and I will say that the birthday banner was clearly much better using your WF
it's gonna be more accurate overall in the end
with the right settings you can replicate dpmpp_2s_ancestral exactly
RES is basically dPMPP with some fixes to problems with the math
my birthday banners with the standard WF in SD3.5 were crap. These are not
I used res3 each time as you said it would be a bit slower but better
I would only switch for potential better
I have no clue about the various math options. I put all in Brownian, but it was a mental lottery
and switched linear Quadratic for SGM
what is noise mode Hard, Soft, and so on?
and do you have a suggested choice?
Go to Settings and disable the new gui
What isn't working or don't you like?
I'd assume the girl is not 'it'
the spectre is young
if you're trying to generate this, you need to use the Artisan channels, and you need to read the information in this channel #artisan-faq first
it's paid only?
No, but this channel is for pics of cats and chess pieces.
















Did not expect an ambulance on the second one lmao
neither did sd3.5, did 4 gens in 3 the ambulance turned out too realistic 🤡
Lmao
A confusing timeline, to be sure:




yeah the idea of SLG is sound
its not gonna be on the same level as PAG on the Unets but its similar
I think i missed the class on PAG, but compare the images above.
if you're looking for a place to generate with 3.5 that has free accounts, you should take a look at mage.space
rendering only layer 7, scale 1 vrs skipping layer 7, scale 1


try switching your sampler to euler_ancestral, and your scheduler to linear_quadratic

im alternating between that and res 3, i think im liking eulera^2 for people and res 3 for everything else, euler ads more details works great but for like plain stuff res gets accurate/sharp but no thrills/extra details.
What model is that? 👀

@dusky thistle scale 1 vrs scale 2 vrs scale 3



rendering just layer 8

I figured it out had to run a argument first.
The newer versions are very bad when i run comfy to my phone.
they change how much noise is used in the beginning or end
SD3.5Medium.
soft and softer start strong and drop off fast, and faster
hard is a constant amount based on a fraction of the current noise level
generalyl, best has been with hard and eta = 0.25 up to 0.5
Woah this is amazing to look at. Scales apear to be exponential. Less is more maybe perhaps.
At scale 3 cannot tell there’s even a leopard there.
1 and 2 still can make out the image
i'm sure that you can refine it farther, scales can have decimal points. i'm just doing a rough compare sheet on this
some layers appear to have a much greater effect on the image, than others
Was told 4 is compositional layer and 7,8,9 is finer details like hands feet.
not what i'm finding. i'm going through this, right now, one layer at a time
when i get this sheet finished, and it will take me a few days, i'll post the link
That’s will be great to look at. I do wonder how many total layers there are.
24
Model Description: This model generates images based on text prompts. It is a Multimodal Diffusion Transformer (https://arxiv.org/abs/2403.03206) with improvements that use three fixed, pretrained text encoders, with QK-normalization to improve training stability, and dual attention blocks in the first 12 transformer layers.
Maybe first 12 are the most important
they are definitely important, and qk-norm is extremely important
arXiv.org
Low-resource language translation is a challenging but socially valuable NLP task. Building on recent work adapting the Transformer's normalization to this setting, we propose QKNorm, a normalization technique that modifies the attention mechanism to make the softmax function less prone to arbitrary saturation without sacrificing expressivity. S...

The pain in the but is that many layers affect other layers. Learned that trying to big brain model merging by layers a while ago. And when you get humans good sometimes that messes up animals or shapes or landscapes. It’s not as easy as bad hands? Adjust this lever. That sheet should be really handy.
layer 9 - scale 3 vrs scale 2 vrs scale 1



would suggest keeping scale between 1 and 2
really neat to see it visualized i will say
I finally rest and watch the sun rise on a grateful universe.

:) yeah. i have to have a visual - i can't just look at the math and see what it's doing
Been having fun exploring SD3.5L for the last few days. These are some of my favorite gens so far.










@untold valley rendering just layer 11. scale 31 vrs scale 2 vrs scale 1



skipping just layer 11

this one is interesting, seems to be affecting color in a big way
it is. if you look at the three with only 11 skipped you can see a definate red shift by scale 3
some details too, the whiskers now all look normal.
look at the trees and background
thsi is very cool, so far layer 11 seems to improve the details over the whole image better than all others
this is goign to be a fairly indepth sheet. right now i'm doing the single layer compares - with this layer skipped, with this layer rendered. i'll do that for at least 3 different prompts. then i'll do compares with 2 layers skipped and rendered. and with three - we'll see if i go farther than that
layer 12 - scale 3 vrs scale 2 vrs scale 1



no background, at all. amost no foreground. just the subject
hey that one looks exactly like the image
skipping layer 12

the higher ur going the weirder noise is getting in the sense noise is stronger?
yeah. as scale increases, the noise increase. that doesn't mean it's bad, because injected noise can help refine the details
look at the slope of the back, too
foreground became 2d
so far, every single layer does do things, there aren't any layers that don't - it's learning exctly what effect each has, and how you want to set the values in order to tweak.
and that's the first 12. so now i work on the second 12 and see what's going on with them
hopefully its not diminishing results from here on out
This is a picture of a perfume, add a background to it

layer 13 - scale 3 vrs scale 2 vrs scale 1



if you want to generate in this discord, you have to do it in the Artisan channels, and you need to start by reading the information in #artisan-faq that channel
this one is confusing
Hello guys
why so?

from nothing to scale 3 bam full image without background
second set of 12 layers - i can make assumptions what they are doing but i'd rather not
Errrm I have a question for SD3.5 runners
what's the question?
 wh sd3.5 is not much better than sd3?
wh sd3.5 is not much better than sd3?
I tried the sd3.5 large i expected it to be much better but yet my hopes are down for sai
Flux is still better specially the new 1.1 and also red panda is here
a couple of things, jack. 1. better is a compareison word - it means nothing if you dont' compare stuff - so what are you expecting
what is the big difference between sd3 and sd3.5
and 2. do not come in here and try to start a battle over sd3 and flux
Now that's not what i'm saying i just want to know what are the changes or improvements over sd3 ?
I'm talking about 3.5 large vs 3 large 8b
it still doing the anatomy wrong
did you have questions about comfy?
I'm not saying sd3 is bad but it's still good with creative styles and text rendering and realism
But this is in the comfy channel i'm talking about sd3 vs sd3.5 large
yeah, but you started out by saying you had questions about comfy
you need to try SD3.5 Medium, its works exceptionally well and is more atristically apt than 3.0 or 3.5large. its got styles and does text, follows prompts better than flux.
Errm yes
But this is not the right channel for it 
I didn't try 3.5 medium tbh but is it better in anatomy ?
because most of the images i could get out of sd3.5 are not usable anywhere
🥲 💔.
so here's the deal - sd3.x is a base model. if you are having issues with people in cerain poses it is trainable. and you should train a lora for those poses
yes, and you can push it very far in that area i think u may be leaning.
It's not i'm leaning it's just like not everything good is good until the end some other models are better but they might be slower , harder to train , have different style of art
3.5m is good trust
I will try it out <3 thanks 

3.5 large and 3.5 medium are 2 of the most easily trained models out there. they're also incredibly easy to steer in the diredction you want them to go with just prompts. they're almost effortless to use.
the first lora for 3.5 large came out within a few hours, literally, of it's release
Yes that's what I'm saying but i don't have much experience in training models I'm not very into this specific area that much since i'm new to get deep into AI further than just running the model itself
there are quite a few on civitAI now, and https://huggingface.co/models?other=base_model:adapter:stabilityai/stable-diffusion-3.5-large a large number on huggingface

sdxl had full trained models on release. that is a whole other story tho.
and if you want to try your hand at training, there are a lot of people in this discord that can walk you through the steps
I'll wait for someone in the comfyui section I've H100 so I'm trying to play with it a little bit
But i noticed that sdxl models are lightning fast to run than other models for example flux
sd3.5 has a turbo version.
Yeah i noticed that one but the sd3.5 runs fast i just had to get that clip_g thing
that's one of the encoders. you should be using 3 encoders with sd3.5. flux only uses 2
yeah clip_l clip_g and the t5xxl
flux uses clip_l and t5xxl
but there is another version of flux called nf4 it's all vae and encoders included you don't add anything
I really love what we have as a technology right now
I mean who could imagined that in two years we would reach this point
Ai era
for sd3.X - clip_G is the workhorse encoder. it drives the entire process
@craggy crest one of these is res3 the other is eulerA lin-quad


not about to guess which is which
euler left res 3 right
you so need to go animate that
after we finish messing around with "optimal" settings lol
so in a month or two?
yeah sounds ab right, then thers a new lates and greates model
the push is really on the video side of stuff right now.
ill save video when i get a 5090 rofl im genning on a 1080ti

prompt: world of warcraft elven druid
what is the seed ?
not a clue.
I will try with sd3.5 medium
you should probably download the workflows that were released for it from the SAI page, and play around with the one that has SLG (skip layer guidance) - ask @untold valley to tell you about that




@low inlet so was sd3.5M better or nah?
got some more samplers added to ClownSampler... all the deis ones

28 samplers running with the same code
any that are better than euler a, res 3?
i know better is subjective but those two stick out for sd3.5m
why is it that out of most samplers it almost always puts out great work?
it's the equivalent of... you need to get to a distant mountain you can see, so you start walking directly at it without looking to see if there's any cliffs coming up
i dont understand
as in grain or distortions?
both
if you want euler speed, use res_2m
if you want euler_a speed with the ancestral part, use eta = 0.25 or 0.5 with res_2m
it's a significantly more accurate sampler
once you go to stuff like res_2s or 3s it starts getting waaaay more accurate
you'll notice too euler tends to have a dusty look pretty often cuz it's not developing the details as well as a more accurate sampler
you'll see more hazy images more often
things with incoherent small details that don't make as much sense
i also got masks working with the img2img stuff, really good results with that



with a mask over the clock face



my brain is hurting, been doing comparisons and while euler a doesn't often follow prompt as well as res 3, it makes it better quality, res 3 leaves me with like a smudged look, though it does understand prompt way better.
are you using res_3m?
the multistep one will have more issues with sd35M
cuz what the 3m one is doing, is using the previous two steps to improve the guess for the next step
with low step counts, and for whatever reason, sd35M has some issues with that
i'm only using those when i'm going for that look
2m is more stable
hahah no worries
if you want the crazy quality, it's 2S and 3S
what's cool is SD35M is pretty stable with the outputs
euler a, then res_3m, and 3s yikes lol

so what i've been doing is scoping out seeds with res_2m, and if i find something i reallllllly like, i set it to res_3S, with implicit_steps = 1 and go get a snack
whoa your card must be really slow dang
1080ti 
sell a passenger door from your car if you have one, the stereo, some seats, get yourself a 4090
might go up
they stopped making the 4090s i think
and the supply of 5090s will be scarce for a while i'm sure
that might put pressure on the 3090 market
That did not occur to me that could happen
Yeah because it's doing 2x and 3x as much work per step. Like 30 steps with a _3s sampler will take as long as 90steps with euler. But they definitely do usually come out better than if you just ran something with ruler at 90 steps.
yup
been exploring that stuff in depth

got lots of SDE modes working too
with RF
big gains in quality and coherence with that for sure
But the tradeoff is far longer inference times
I prefer to be able to experiment at a faster rate and then try to switch to a higher quality sampler in the same family of solvers to get roughly the same image, but higher quality if that makes sense
yea that's pretty much what i do
fortunately RF gives stable enough outputs you can usually just swap samplers like that and not get a totally different output
espec since i've got everything implemented under the same framework here, there's no weirdness with implementations changing from one sampler to the next
ultimately even better obv is just to go nuts with the hardware and get the best of both
hoping the 5090 fits well enough to do a dual rig
it'd be nice to have one for pos and one for neg conditioning... get 45k cuda cores ripping away at a single latent lol
ive got 3.5k cuda cores take it or leave it? 
uhmm not really i didn't test much with it as i moved to the animate section now i'm trying moochi




@craggy crest Flux is exceptionally good at learning really varried and creative art styles en masse, so I wanna see if SD3.5 is even more flexible and capable. I know its gonna take way more compute to get it to the same level, but we have access to a monumental amount of compute this time around, so 😅
you won't listen to me, so i'm not going to bother with much of a response other than to say 'learn to prompt'

I am not even sure why that response is there. Learning to prompt has nothing to do with wanting to drop millions of steps worth of training onto SD3.5
not even Sytan is immune to crystalwizard
because what you're setting off to do is 100% unnecessary
why, because SD3.5 is perfect out of the box with no deformtations or gaps in knowledge?
every model can be better
no, but you don't need toi make a huge massive thing when you could make a few specific small loras for just the data that you actually need
and then you can sell each of them. - 6 or 7 products instead of just one
The goal is to make a much more stable base that is more robust, like Pony, but less... janky at the start 😅
pony is garbage. if that's what you want, have fun
a 3.5 tune that can make this level of coherent information out of the box, like flux can

3.5, with the right prompt, can do that with the base model
coherently? I would seriously love to be proven wrong if you wanna try to generate it. I have low expectations and experiences with SD3.5, which is why we are willing to put time and money into fixing it up considerably
yeah, coherently. and yeah, i've done plenty just like it and no, i'm not going to run off and create stuff for you to then pick apart and come up with stuff you don't like even though it might match yours exactly
go waste your compute power doing unnessary training and jumping through hoops

uh, ok then? I guess you're not really serious about changing my perception of SD3.5 then, which is fine, cause I don't need to be tricked into liking things
ya you do
i gave up on that way back there when it became obvious you weren't actually interested
I have high hopes for what we will be able to do with SD3.5, which is all I need
you won't. because you're a flux person and you will only be happy if you turn 3.5 into flux
for future reference. I hate flux's aesthetics and looks out of the box with a flaming passion. I only like flux because its been exceptionally easy and reliable to train. Thats all I like about it

I think its too big, too slow, overbloated, I held off from using it for months cause I thought it was a failure to the community. I don't like flux. I tolerate it

that statement there ' flux is exceptionally easy and reliable to train' has got to be the silliest thing i've ever heard anyone say
I am still very interested in jumping to SD3.5 when I seem more accessible training tools, strictly just because medium is so much smaller
@dusky thistleWould yo say you have had an easy time training Flux?
i wonder why all the experineced devs have had to fight so hard to get flux to train at all when you can jsut breeze along with it
it is very trainable in onetrainer rn
nah, i wouldn't say so
i think it's really easy to get tantalizing results
oh really? Thats dope and good to know. Finally something thats not simple tuner
it picks up on character likeness very easily, and it's easy to shake some stuff loose with just a couple thousand steps from the model
yeah, thats fair enough honestly, I can see that much
but it's very difficult to teach it a lot of diverse concepts without it losing a bunch of stuff too
you can also use luca taco's trainer for 3.5 large and medium

is that available for local yet, or still no?
he only puts stuff out on replicate

yeah, thats fair enough honestly. I started doing very low LR training on it like my friend did, and found it was rapidly improving, and prompt adherence got way better in no time
I was having issues with using higher LR's and getting good results which would then hit a wall and prompt adherence would fall apart. Turns out that just cause flux CAN stay coherent for a while at very high LR's, doesn't mean the damage doesn't add up lmao
way back there, @gusty trail told you to use prodigy

this needs to be a book cover
quick q what scheduler for res_2m
depends on the model, and what you're doing to some degree, but i gotta say, quadratic has been pretty damn good
next up has been beta scheduler with alpha = 0.5, beta = 0.7
cougar moon


these are all sd35L
Acrylic illustration depicting a vast landscape with a sprawling pink-blossomed tree, intricate texture of bark, lone figure with sketchbook, delicate waterfalls cascading over rocky cliffs, distant cityscape of towering spires, afternoon glow enhancing warm tones, crisp horizon with cumulus clouds, moon faintly visible, gentle wind hinted by drifting petals, vibrant greenery patches, heightened contrast adding depth and dimension, invoking inspiration.
I love the diverse styles my friends Flux tune is able to do, which is why I wonder if the same amount of time and training put into SD3.5 would yield even better results








thank you, i learned my lesson on euler a and what you meant about the mountain. it was just not obvious to me
every single one of those can be done with 3.5L and 3.5M without fine tuning
it's not exactly easy to figure out wtf any of this stuff means, tbh
there's no nice textbook on it that's easy to read or anything like that
You can have the prompts if you wanna try, but we all know you're not gonna "waste your compute" on it lol
and all the information online is polluted by huge amounts of misinformation from authorative sounding sources that don't know wtf they're talking about
did you look at any of the images clownshark jsut made you?
here is 1000 million settings and variables go figure it out
and then the sources that do know what they're talking about... tend to only share their thoughts in papers, where you gotta get past all the notation and terminology, so there is def a barrier
oh, i didn't realize thats what he was doing


the general aesthetic is kinda there, but man the coherence is not
which is why, again, I think longer training on it will be very beneficial with how diverse it already is
left hand looks like a foot

i say go for it Sytan then share ur model with me
;) look at the workflow in mine
Our goal is for it to be all available to the public if things go well so, yeah!
told you that's what you'd do. they are more coherent than yours was

to be fair, the SD3.5 ones are a lot lower resolution, so maybe thats where the discrepancy is for me
no comment
yup, boost resolution and things resolve better
gotta generate at the same res to make a fair comparison
My friend did show me these SD3.5 gen's a few days back and I was really impressed with how textured they are




add the term cubism into your prompt
I don't have any way to gen with SD3.5 at the moment, but if/when I do, I will mess around with that
@dusky thistle don't know if you saw this yesterday, but there are 24 layers in 3.5medium
wow, lotta layers for a small model
https://www.runcomfy.com/comfyui-web yes you do
RunComfy
Use ComfyUI online for free without installation required, easily build a Stable Diffusion workflow, and generate images in seconds.
I meant as in I didn't want to deal with it lol
hmmm
I have comfy and the resources to run it, I just don't want to right now
I think I am gonna go mess with SD3.5 training in one trainer though


oooo, I love the colors on this one. I am a sucker for good color grading haha
that one looks much more coherent than the other one you sent for sure
so you like more saturated stuff then
I like that one much more for sure
it depends on the style more so, but that one I think looks really good with those colors
my tastes are very very dynamic when it comes to stuff like that
I am assuming these are all large gens?
had a discussion one night with @bitter hearth - and what it boiled down to - images only look like photos to him if he can see film grain. even digital photos, without film grain, don't look like photos to him. that's a personal taste, but valid. so maybe you need to identfy what it is you actually are looking for in an image
You know what... I could set up a direct comparison between my friends model and SD3.5 to see how they fair against each other. I am sure SD3.5 is still stronger in some ways, but I would be really curious to see how far his model has diversified flux
I don't have one factor things like that in my preferences typically, but there are some specific things I want when I am generating photographs, at least


medium gens are more "refined" ready to go than large. medium is really surprising. large needs large more training tbh, medium needs a push and a tiny teapot nsfw for the uhh scientist and doctors
sweepy time
large is exactly what it's supposed to be. its training is fine. medium is deliberately more artsy
yeah they're complementary imo
they are, yes
Thats what I predicted would be the case several months ago, so I am glad to hear that 😅
I never thought large was gonna be very good, my eggs were always in Mediums basket because of density and easy of access for people on lower end hardware to train and run it, meaning much more support and iteration
I shouldn't say very good
I should say viable in the long term compared to medium and its accessibility
i'm really sick and tired of hearing you say this
idk how much it helps having a model be small so more ppl can train it
tbh, most ppl just train trash
yeah. or train stuff that's unnecessary
that is true, but there are also people who train good who haven't been able to
the really good finetunes take a lot of prep and usually a lot of hardware
it's not something ppl can make a serious contribution toward by screwing around casually in their freetime for a couple hours a month
and plus, you can take on way bigger projects with a model 1/4th the size, which is what I really am excited about
and someone that knows what they are doing - which 90% of those out there training... don't
so you get civitAI packed with loras that all do the same anime girl in states of undress
i remember how eye opening it was seeing some of the datasets ppl shared
captions were literally shit like "dog"
the end. dog. lol
yeah, i am tired of that for sure. But there is also good that comes with it as well
the more people training, I mean
I did a couple of Sdxl loras for faces - male and female, one each - and genereated all the images for the data sets on thispersondoesnotexist
and then cleaned them all up in photoshop
several hundred each
they came out good
A more accessible model means that people who didn't previously have the means can contribute, and there are a lot of very smart people who don't have a lot of money or resources
One of my closest friends works with a SOTA Audio training company for AI generated audio and she works with 10+ H100 systems, and she herself only has a RTX 3070 and can't really afford more because of medical issues
ordinary looking people
Yeah, I am all for more ordinary looking people
that is what 3.5 IS
I know, thats what I am saying
but that doesn't mean that people wont' still make the same anime girl in various states of undress
Thats why I am saying I think 3.5 medium will get a lot more support because its easier and faster to run
oh of course not, that well never not happen
I don't mind waiting a long time for a training or inference if the result is worth it, but lots of people would rather have a much faster result than wait that long

like on a 6GB card. I can only imagine the speed difference of large vs medium for that. Its gotta be at least like 10x faster
the cat is medium. comments?
not on my machine. speed's about the same
I don't see any major issues, just needs a better photographic style tune and thats honestly pretty great
its a base model, its meant to be trained more in specific directions
i'm not tuning a model that is perfectly good without it.
agreed. but i'm doing some very specific tests on medium right now

that cat means business!
yeah, and if you like it how it is, then thats great man. I personally wanna have more of a photographic/professional shot look, which means I will just train that in myself 😅
that's masked unsampling
i think im' gonna make a node that allows you to interpolate from one mask to another throughout the diffusion process
I will say, that image looks a hell of a lot better than what flux dev base would do lmfaoooo
dude, i was shooting photos professsionally before you were born. you have a specific look you like, that doesn't mean everything you don't like isn't professional quality
maybe make the weight between the two determined by the sigmas
While I don't agree with what crystalwizard is saying at all, if you want your idea of professional photo quality you should just drop the image in Lightroom and twist few settings instead of finetuning a model.
prompt: portrait of a cougar in the moonlit winter snow
its not an editing thing, its a composition/detail thing
output from my flux tune (downsampled cause noise issues 😅)

someone was asking about masks the other day. wonder if that would have solved their issue
that's really washed out

finally lol

yes.
oh god
so you think the left looks more like a real pic than the right?


takea really good look at this, @winged seal - it's massively washed out, or over exposed if you like
i think the photographer that shot the cat on the right didn't white balance his camera

what does white balance have to do with anything?
it's missing the clown hat
this is great lmao
these damn shark cats are fn everywhere in my area
the man's a photographer and doesn't understand what i'm saying?
the charks
No, I know what you are saying, I just don't know what you mean. Do you mean a neutral white is the wrong white balance, or did you mean its overexposed?
just go fix it
fix what? lmao
the white balance is 5k neutral
do you think the image is too warm, or too cool?
I do get if you think its too overexposed for night time tho, cause yeah, that is really bright for night lmao
its that thing when light hits the snow and messes up colors and stuff
the details are lost, the cat blends into the background, the entire image has a number of issues
and moonlight doesn't have a warm cast to it
Yeah, that much is fair, I will say
but yeah, I guess national geographic is bad at taking pictures
cat mask

cat mask :3
looks like a gremlin haha
but yeah, that picture of that puma is a real photograph by national geographic. its not dark or cool cause its during the day 😅
I'm gonna mess with SD3.5 medium after all
Anybody have any recommended comfy workflows for 3.5?
I have seen tons floating around
i hope they didn't pay the photographer cause it's lousy
they USED to be good. if this is what they are publishing now, they've really gone down hill
not the workflows i just posted in the images i posted - or, maybe those
those have SLG though, and i'm not sure you want to play with that yet
oh, I didn't realize you were posting with workflow
I heard that Medium does better with higher resolutions that large, is that true?
every image i post, that came out of comfy, has embedded workflow. just click to open, click open in browser, then right clidk and save as
ask @dusky thistle - i haven't done any work on that end at all.
I know how to do it, I just didn't realize you were purposely sharing that. i didn't want to just take somebodys workflow without asking, thats rude lmao
anything i post out, i post for others to use
fair enough, I'll remember that
in fact, if i put it online, i also put it into public domain right then. use it if you want to
the real magic of most workflows is just learning how the nodes work
yeah
it's just appyling ppls code
Solid.

I made that really popular workflow for SDXL when it came out, and then I kinda stopped sharing my more advanced workflows cause man, it was too much to keep up with. I was not ready for all of those people asking me stuff
i do as well - if i can help someone grow, cool. if they take an image i did, and sell it - good, i helped make their day better.
i can make more, and maybe they will improve their own skills
or at least afford a cup of coffee
Comfy workflows might just be completely broken in a week after publishing it anyway, especially if they rely on some more interesting nodes.
holy shit medium is small lmfaooo
did you download it from the SAI page on huggingface?
got too used to working with 24GB plus models
I'm planning on using it with GGUF to save as much memory as possible, why, whats up?
that's where the example workflows are, too
ok cool, thanks for the heads up
jeez, people on 4GB cards should be able to run medium just fine
i believe they have been
Q5 T5XXL, Q4 medium, and it should be very close to full accuracy if its anything like flux/large
unlike flux - sd3.5 has qknorm
that helps with color issues, right?
it helps with stability
arXiv.org
Low-resource language translation is a challenging but socially valuable NLP task. Building on recent work adapting the Transformer's normalization to this setting, we propose QKNorm, a normalization technique that modifies the attention mechanism to make the softmax function less prone to arbitrary saturation without sacrificing expressivity. S...
well then maybe it can go even lower. Flux works down to Q3 with minimal issues as is, so if it can work even smaller, thats dope
oh righttt, network saturation, not image saturation. Thats why I remembered "color issues" lmao
take a minute and go read the paper
@dusky thistle scale 2 - rendered layer 19 only

and scale 1, layer 19 only

Did a very very fast skim over the headlines and some of the charts. Looks like a sort of built in error correction which helps fix small misalignments that can compound over the entire forward pass of the network?
Sounds... Very useful, actually haha
if I got that completely wrong, my bad 😅
I am not in much of a reading mood at the moment
ohhh wait, I have my old very very good SD3.0 Medium workflow I used for a while that a friend gave me. I got incredible results with that. i should see if I can dust it off and get it working again
you doing a sort of masked/segmentational refined inpainting?
oh right, SD3.5 needs more steps than I am used to. i need to remember that before I have issues with it lmao
i'm putting a spreadsheet together for how SLG works.
sounds good, I am curious. I have heard the name thrown around a lot, but not seen any real examples of what it does
you can go lower, but i stick around 32 to 40 steps, and cfg 3.5 to 4
sounds good. Its not gonna be very slow to inference, luckily haha
slg - skip layer guidance. you skip some of the layers - from 1 to however many. which is what the images i've been posting are part of.
you do that to tweak the look or adjust things like hands that aren't quite right. it's experimental, but was include din 3.5 for people to work with if they wanted to
very interesting. thats actually effectively how Flux Lite was made. They cut out a good chunk of the layers that were found to affect outputs minimally, which makes it full compatible with dev for training, but only 8B params instead of 12b, which makes it a lot faster
as an example. this is skipping layer 19. with scale at 2 and with scale at 3


Oh, i like the way that improves the textures and dynamics of the image. very interesting
scale can take decimal points but i'm just doing three renders - scale 1, scale 2, scale 3


look at those two, and then look at this one. this is scale 1

that's all that's changed, jsut the value for scale
very nice. Its starting to have actual detail in the background which is what I am usually after in my trainings
lite on the left vs my most recent training of it on the right. Background fidelity is always one of the first things I greatly improve/fix in models
Prompt: A wide photograph of a blue pug wearing a pair of sun glasses with its tongue out while laying down on a beach in Peurto Rico. Behind it are various colorful Mexican inspired houses in various shades and hues.

to repeat myself - you don't need to train anything, you just need to learn how to use 3.5 correctly.
yeah but the dog is blues clues
While your image does look better and closer to what I am after, its still nothing like what I want. Training will definitely still be something I am aiming for
the prompt asks for that. This training I did greatly improved the prompt adherence of Flux lite


A photograph of a carved pumpkin that is smiling with a purple and silver witch hat on and a broom to the right side. The Pumpkin has round eyes and a single tooth on the bottom right side. Behind the pumpkin is a forest of autumn trees and leaves at dusk, dark, cinematic, jack o lantern

you can see there, the training improved the background, lighting, prompt adherence, a whole bunch. it was a great little test
background looks pretty solid, very nice
Found a nice little perch here

dog isn't blue, but eh, base flux doesn't get that either lmao
photoshoot tired the dog out

yeah, hes melting haha
nothing a treat wouldn't fix
that hat looks fantastic, totally missed the tooth tho, and the background is super artificial. But its stuff like that I wanna train to be better, so its no big deal. I am impressed with these results as they are
That hat especially looks really damn good
gives me hope for pulling out a more photographic alignment with some training
is that still medium?
cause if so, those results look wayyyyy better than what I saw of large
large
my pumpkin also looks like a real pumpkin - yours not so much
the weakest thing in that image is for sure the super artificial background gaussian blur, but all base models have that it seems lmao
possibly. maybe somene had the wrong sampler/scheduler pair or something
yeah, teh pumpkin looks solid too
this is 3.5?

trying to use a lora that wasn't trained for the model you've got loaded?

tail's attached in a strange spot
It is SD3.5 turbo, for the initial image, and then refined with Flux
Some very short broom handles in these images

it's got no hands, so that probably doesn't bother it









If she bit you? Yes!
A few holiday snaps.


















Werf!
@craggy crest You here? Got a question
just curious what causes SD3.5 to look super messy/splotchy. Is that something I am messing up myself?
its super compressed and weird and splotchy whenever I try to generate pictures of people

it doesn't look as bad there
is this M or L

I don't think DiTs work well around 2B param
Hunyuan-DiT also has issues
plenty of smaller ones worked fine and trained well
could you give an example?
Pixart Sigma was great for training. It wasn't SOTA, but it didn't have any issues like this
and that was 900M
ahhhh right, SD3.5 doesn't inference as fast as I would assume cause it has CFG, right
hmm I don't agree about Pixart Sigma
yeah, its getting worse, hmmm

I don't think there is a 2B DiT that I feel achieved a high level of aesthetics
I am not sure it is possible
I mean, the original 3.0 Medium had absolutely fantastic photographic capabilities without these issues. I might have something set up wrong
the original 3.0M did have better textures than this yeah
LoL are those stretch marks?
no, its compression artifacts lmao
I changed the subject of the prompt and its looking better now
wow, look at that lip bite lmfao

since you can fit Flux Dev or SD 3.5L on GPUs with 8GB VRAM, I think smaller DiTs are fairly niche models
they could have some use for mobile or edge applications
I have high VRAm and I much prefer small models, cause they are way faster, more efficient, and more accessible to other people
I agree with one but not the other
3.5M definitely more accessible, for people in the 1-4GB VRAM range
its not that much faster though, the 8B pruned version of Flux dev runs at 50% of the speed of 3.5M
not requiring a negative gives 2x speed up for Flux which closes the gap
and you can fit 8B flux on 6-8GB VRAM GPUs, which is most of the market