#🆕|sd3
1 messages · Page 74 of 1
sigma



prompt ?
Is this possible to finetune FLux?
should be. they're weights. we'll see
I used too much CADS and got a chonky cat on the left

no prob. photoshop was rpolly killing you
was gonna work on dataset building but flux happened and a few other things too. tommorrow chore i guess
An atmospheric HDR 8k digital octane render, a living house with a worn, wooden facade, overgrown with vines and moss, walks through the modern city, its foundation roots splayed out like legs, windows blinking like eyes, chimney puffing out smoke like breath, intricate details, rich textures, warm lighting, long shadows, vibrant colors, dynamic movement, surreal atmosphere

yea i had a bunch of coding and reverse engineering stuff planned for today
got literally nothing done
well actually i read half a page of a paper
lol
@sacred jewel if you've got windows 11 and a cpu with an integrated gpu, you can go into windows settings and makes ure the ps.exe uses the integrated one
i just wanted to add cascade to my own personal use discord bot, now there's this 🤣
sigma

tbh i was annoyed about all the flux talk in sd3 but.. i get it now
flux is king yes
it's super off topic, but asking for a 3rd party models channel is prob too much since even cascade is blocked
i'm liking this prompt better in sigma
they're build from the same parts right? but.. sd3 an flux


here is schnell 4 steps

SD3

And we don't need any code to be released?
lol
after the first WOW moments, i still kinda like sd3-8b looks better overall i think, it just reacts more to styles which i kinda value more than prompt adherence when the difference is relatively small (but maybe next week flux is figured out how to get more broad styles out of it, still early)
diffusers team will figure it out
there's more coming too surely. i think they have people udner nda who have been working on things. there seems to be lots of knowledge about the model that's been seeded around

training or inference?
inference as usual
we're talking about training
sd3.1 would save me from buying a gpu to run flux
they usually don't give that out. Its also not of huge interest for the community
ok
we would use different training code anyways with our consumer hardware
can you even train the full flux model on a 4090
nvm can't train for sure, it takes massive amounts of vram
you can barely load it into vram
was thinking more about things like lora
you have to quantise it to get it run
My PC is somehow not dying if i use 50gb of my SSDs as swap

Now the vae gets processed in 5 seconds instead of 120
sd3

DMD2

FluxPony
dmd2 ?
yeah
what is it
https://huggingface.co/tianweiy/DMD2 the unet

new model ?
newish
schnell

new clip encoder for flux that has guidance* (not 100% sure if it's cfg as we know, havent tested yet) in it https://github.com/comfyanonymous/ComfyUI/commit/a531001cc772305364a319a760fcd5034e28411a
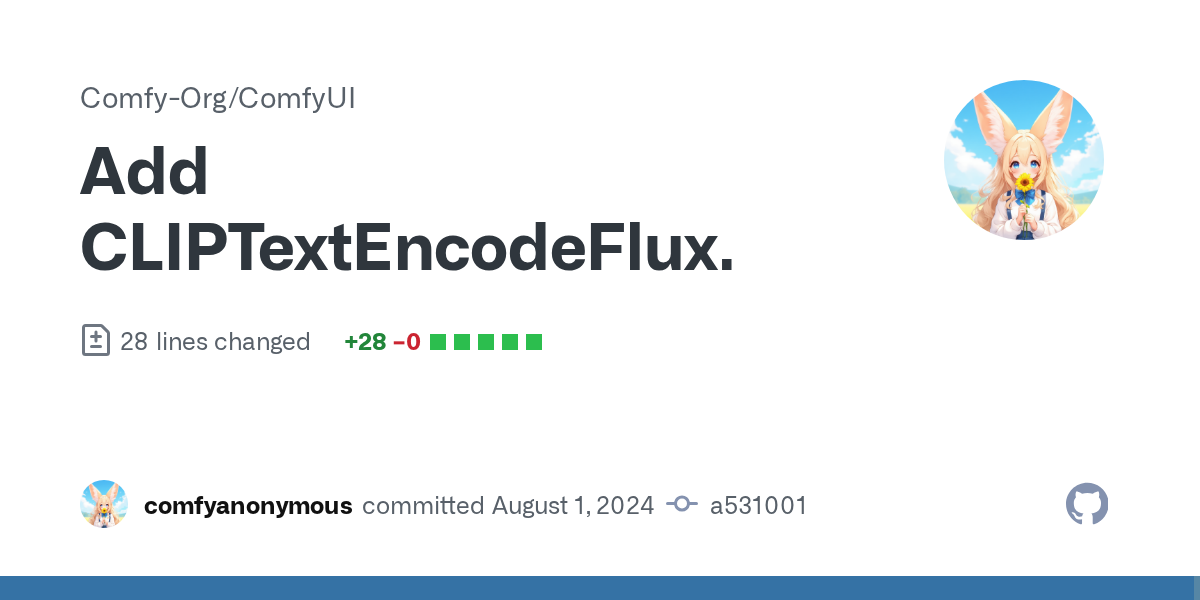
"clip_l": ("STRING", {"multiline": True, "dynamicPrompts": True}), "t5xxl": ("STRING", {"multiline": True, "dynamicPrompts": True}), "guidance": ("FLOAT", {"default": 3.5, "min": 0.0, "max": 100.0, "step": 0.1}),
What speeds are people getting with flux schnell? I have a 24 gb 4090 and I’m barely getting -40 s / it. Seems slow. But I’m using the workflow from the example blog. Is that what people are seeing?
use a smaller t5
use the fp8 one from sd3
about 8-9 s / it, but it takes more time loading the models than actually doing the iterations 🥹
comfyui is crashing instantly when using flux and the default workflow that comes with it, does anyone know what to do? RTX 4070TI Super 16gb, 32gb ddr5 ram
there should be enough to make it run
Ya it’s a shock seeing it load the model in “lowvram mode”. I have 24gb man. Use them!
Use --lowvram in the launcher, even with a 3090/4090 you gotta use that
thanks :) do you know how i can do that?
the model is massive, it's roughly 23gb for the transformer ALONE
not counting the t5
i did NOT realize that
5-7s/it on rtx 3060 with exmple workflow on flux dev
that's crazy
its a 12b model
Right click the comfyui_run nvidia.bat and click edit, and add this "--highvram"
its him... goku...

also, make sure to update it again, there were some comfy pushes for memory management
flux vs sd3

hehe
@acoustic kite It should look like this

the future of personal ball computing

ohh okay thank you so much, let me see if it still crashes
yeah im testing it now after the memory management update, it's capping out almost all my vram now, before it was only using like 6gb out of 8gb
home gpus this gen be like

switched to fp8 flux dev and fp8 T5 and no more low vram or unloading models on 4090

FYI: The guidance on the new CLIPTextEncodeFlux node doesn't seem to do anything yet, or maybe it doesn't work with the schnell model
get it?

whats the quality drop form 16 to 8 if any?
little visual pun because pillows are stuffed full
havent really run any comparisons yet
it made my whole pc crash at first 😂 i think it's doing better now
thank you so much
too fun. just toooo fun

I may have solved the slow generation. In the load diffusion model node, the example sets the weight dtype to “default”. Setting it to fp8_e5m2 or fo8_e4m3fn gets images down from 200 seconds per image to 3 seconds. No idea what those options are though lol
Lol i hope it works good 😅
it's a bit slow at 4.9s/it but i think the prompt adherence is crazy good lol
nevermind it doesn't like me 😂

interesting, maybe that means i'll finally be able to run it
wow this is very cool
Can flux images be used commercially or is it just for fun?
the gpu we need

Did it work after this? press f5 on comfy if it doesnt load
stolen from 4chan, i gotta try this prompt

it works if i use fp8_e5m2 instead of default, default just crashes


diamond is after TI

everything about this card is better than current cards. prove it wrong

power consumption 😁
we'll have the ice cube in the ocean by then its all good
Oof


minecraft from wish 😂
New toy in our hands😌
SD3.1 wip, when ?
Im trying to get it, almost there, only the hud remains

looks great so far
i'm about to make a 2048x2048 image
but it takes such a long time 😂
R u guys trying to make Minecraft in sd😂
no i'm making gta 6 before it releases haha

there we go, i guess it sort of works lol
what romt did you use?
yeah sd3 8b wins by a mile
what is that?
xD
Wait i stole that image, idk the prompt they used or the settings
oh
it's true
to go around this i'm upscaling it and then i can use a positive and negative prompt
but it doesn't really work, only if you don't want a certain style
maybe perp neg works?
this one? will test it rn 😄


left 1024x1024, right 2048x2048 :)
very nice
ty
almost XD


@bitter hearth sadly this one didn't work :(
this is what came out of it when trying to add a negative prompt

this looks sick man
instant VHS lora

2048x2048 image.
sampler: euler
scheduler: beta
steps: 30
prompt: gta 6 gameplay footage, letters on tyres saying "michelin", license plate saying "GTA 6", realistic, background characters
sampler: euler
scheduler: beta
steps: 16
positive prompt in upscaler: gta 6 gameplay footage, letters on tyres saying "michelin", license plate saying "GTA 6", realistic, background characters
negative prompt in upscaler: anime, cartoon, deformed body parts, misspelled words, watermark
is SD3-Universal an improvement over SD3?
i'm not sure what the improvement is but there is definitely an improvement imo
it's just overall looking better
ill try it
okay 😄


flux is the new crysis engine
Make sure you switch down to the fp8 weights and Text encoder, went from 10 mins to 25 seconds on my 3090 after that.
512x512 test at 12 samples

thank you this was the only thing that worked, my pc shat itself trying to use fp16 😭


1424x2048, nice to see flux holding up really well at higher resolutions out of the box.


this is what alarm clocks really look like
thats perp neg yeah
not sure if it works with SD3
i pinged you a bit later, it sadly didn't work :(
I made a bunch (woth mj) using reference images which were screenshots from the leaked video. It worked really well!
@bitter hearth this was the result
thanks for the tip!!
i tried using controlnet with flux and it didn't like that either, hopefully in the future though
yeah i didnt even try... but i sure hope well get controlnets for it and ip adapters. imagine flux with sdxl community support
one off images are good enough - next consistency and next how to make them move, once we get 5-10 seconds of actual consistent img to video. we can make movies
This was 7 months ago, probably better now and SD also now:
https://www.deviantart.com/uniquecharacters93/gallery?q=Gta

you know what's weird? vram use goes way up with the most recent update of comfyui for this shit
i reverted to an older commit and manually added the new clip text encode node and now i can generate at 2048x1024 without oom
very easy fix
git reset --hard 2f88d19
why is flux able to handle more resolution?
won't wreck any models, data, outputs, etc, will just un-update
with the current repo i can't gen past 1536x768
now i'm back to 2048x1024
literally twice the pixels with the same vram
smart science
it doesnt seem to do the weird distortions on the edges like sd3 when you try to gen huge images, it just does some screen door/pixelation effect when you push resolution too far
maybe flux uses a different way of doing positional embeddings compared to sd3 or just conditioned on higher res images
part of the reason I want to know is
if it shrinks or compresses the latent like hi-diffusion, deep shrink, cascade or ultrapixel
that compression has some side effects
I'm not saying latent compression should not be done, it seems like a good solution, but you do take a hit to the composition
go read the paper
ok thanks I should just read the paper yeah
I do hope they managed to do it
without compressed latent like the other high res solutions
but if there's some compression that's fine I will still use it
in case you don't have the main link https://blackforestlabs.ai/announcing-black-forest-labs/

Today, we are excited to announce the launch of Black Forest Labs. Deeply rooted in the generative AI research community, our mission is to develop and advance state-of-the-art generative deep…
 can it balls
can it balls
thanks
somehow made a breakthrough
and R2D2 got his long legs out
not sure if its the seed, the sampler or CADS that did it
never seen SD3 do this before

thx!! where can i write this?
sorry i meant to ask if this was with comfyui?
you gotta pull up a command line and get into your comfyui folder
ohh okay i just typed it in the default location lol
yeah that's to roll back to the version from earlier today that seems to be better with vram

on L2 discord
someone used the C++ version of SDXL, with a library that uses the VRAM as a storage system on linux, so they could bake the model into the VRAM
it seemed cool
nice, got a wf version?
this was in the comfyui folder

sorry i'm probably missing something 😆
wait what?
oh maybe you're on the portable
I will go find
ohhh yeah i am
ok
balls
the technical paper comes later thats just an announcement.

did you happen to read it?
yeah. they give links to all the research they used to build it. papers for other projects. then say theirs will come soon
go check
and a lot of technical information.
guess i have a higher bar for what constitutes a paper
for what he wants, all he has to do is what emad told someone else earlier today 'go read the SD3 paper"
Cyberpunk Venetian carnival, holographic masks, bioluminescent canals, floating neon gondolas, crystal skyscrapers in the background, steampunk clockwork pigeons, quantum aurora borealis in the sky, fractal fireworks, hyper-detailed fabric textures on futuristic Renaissance costumes, zero-gravity confetti, time-distortion ripples in the air, AI-powered street performers, 8K resolution, photorealistic rendering


Does sd3 curently work in auto?
yes but these images are not sd3
yeah but its innefficient and if you intend to use t5 enc with it, use comfy
i.e. - not very well

Classic case of noodle denial.
Everyone goes through that phase before giving in.
i lean towards a111 where the memory isn't a problem. but t5 breaks the bank and needs to be cached. last i tried it wouldn't do it that way
the man who took over reforge is working on the core of it, to enable sd3 support from upstream to bypass the unet patcher part of forge, last i looked
Flux can do the Pixar horrible movie titles meme.
powerful new earth shaking tool is released. Internet uses it to make memes


logo Typography "I Love Samplers" with design elements and artistic flair, background is various noise patterns mixed with dj mixing boards

it does good typography as well
i was getting errors stuffing it with alot of text, but ya its pretty good
The Hellstar Remina prompt attempts. The first image is the original by Junji Ito. The second is another original, Remina eating a planet. The others are by Flux Pro. I got it first time. I couldn't do this with SD.
Prompt is:
a giant hellish planet with a giant eye looking surprised at the viewer and a deformed mouth with a tentacle tongue licking the planet, horror by Junji Ito
And slight variations of this prompt, and tests with different intervals.















Very cool!! i love junji ito's artwork
He is a master of creative horror. I love the fact that in this story the whole apocaliptic ordeal (Remina getting to Earth) starts right in the first few pages.


When release SD3.1



incredible isnt it?
i tried my ideogram promts on flux and even on schnell they came out way better
I'm not gonna go there...
I am testing with Dev; I haven't tried with Schnell yet

2 weeks


SD3 can't compare with flux





Flux is looking promising!
a glass ball half full of red liquid is to the left of a glass square that contains blue liquid. To the right of them is a green glass bottle


try to put persons in positions.
flux does burning cars better then SD3



holy molly these really look real, its harder and harder to spot ai
Does the clip names match the ones you downloaded?
i dont think so
i only downloading the check point from hugging face

thats the issue, if your downloading the checkpoint with the clips then you don't need a triple Clip loader
just the checkpoint node
hello every one
i suppose checkpoint from hugging face already have clip inside right? should i remove the triple clip loader?
i try sd3 frist time with workflow provided on that library
hi
If you downloaded the SD3_medium_incl_clips_T5xxlfp8 or SD3_medium_incl_clips then you don't need a triplecliploader
i have this SD3_medium_incl_clips
how much Vram and ram does your system have?, since T5xxl is pretty important to get a good image out of SD3
i just testing with sd3 meidum incl

i can run it but another problem come up
32gb ram and 8g vram mobile gpu rtx4070
Is this the latest version of comfyui?
yes brother i havnt running comfyui for months i just updating all nodes and comfyui itslef while ago
i dont really understand such technical issue so i dont know where to start looing for this problem

this is how it look like
Try clicking on sd3_medium in the load checkpoint node and try switching to SD3_medium_incl_clips
omg i click wrong checkpoint
hahaha
thinking it was SD3_medium_incl_clips
yes it running already
thank you very much mate

yep thats the issue, the cliptextencode node couldn't tokenize your prompt since there wasn't any clips
yes
@dreamy egret by the way how good is this SD3_medium_incl_clips_T5xxlfp8?
sigh even 8gb not enough

You pinged the wrong guy but SD3_medium_incl_clips_T5xxlfp8 is way better since it has T5xxl in it
😅 how much vram i need?
I think at least 12? but i might be wrong
since it been a while since i ran SD3
well i least we got 50s family the end of the year or next year Q1
it will bring older series prices down
Yeah i hope so but considering the RTX 3090 is still expensive, i dont think it will
You can run it, but it will take you over 6 minutes per image
i think it can if only SD3_medium_incl_clips
will see
TI and super is the way to go
no sd3 runs fine and very fast with it
the minimum vram requirement for Flux Schnell and Flux dev is at least 16gbs of vram
and the recommended is 24gbs of vram
sure but with paging to ssd and ram might do it in fp8
i am not saying that you can't run it, you can but it will take you a long time to generate one image
i know, but i want to know how much
someone said with 8gbs of vram it took them five minutes per image
it would be way faster if we can use align your steps or something else for it
what is this flux something?
also i'm running xformers which is more optimized for shitty gpu
Flux is a new opensource SOTA text to image model that is 12B parameters made by black forest labs, it beats SD3 by a long shot
what the .... it sound so awesome but why i never heard of them?
since it was just released yesterday
what you even want to make with 12B para
and it came out of nowhere, they didn't tease the model
i mean it a big thing and never hear any news regarding that before hahaha unless they want to be a dark horses
nobody heard of or even knew who black forest labs were before Flux's release
free for use?
Flux has three versions, a pro version which is closed source and only useable through a API and Flux Dev version which is free and opensource and a small Flux schnell model which is also free and opensource
they have a playground to use flux pro for free (20 images per day for the pro version) https://fal.ai/models/fal-ai/flux-pro

The pro version of FLUX.1, served in partnership with BFL
i see what is the community reaction it sus for such hot potato come out of no where
Flux Dev version can run locally?
both the dev and the schnell versions yes
and the ironic thing about black forest labs is that the guys behind it is the same guys behind Stable diffusion (People who left stability ai)
that nice gonna try it later
im glad that the one working on it have real abilities
the open models are bad at paintings - or we haven't found the right prompt for them
besides that the model is great
it gets hands right literally every time xD
it even can make people holding swords or axes correctly
cant ask that much for something that is free, but yeah it still have a lot of room to growth since it was a new model
and it can make women lying on grass 😛
I can run it with 12.
why grass?
You're new here huh?
how big is the model sizes?
23GB!
i know sd3 have problem with that but you can test it with women lying every where right?
I'm not sure if it's possible to train loras for such a huge model on consumer hardware
it was ja joke. I just wanted to say Flux can do human anatomy very well
I wodner when flux gets a slot on civitai
it sometimes struggles with feets, but everything else seems perfect
hopefully they realease smaller model thought not all people that run such big model locally for any serious work
yes it can the hands of flux are magnificent
yes, I hope that, too...
no more 
I living my life over here with two RTX 3090s
nah i plan on getting the RTX 5090
nah, I guess things will develop as they did with llms
there will be bigger and bigger t2i models
that good to but for common people 70s is a good middle ground
and then somebody shows that a 6b model can do better than a 70b model with right training
with the amount of companies producing open source text to image models, the scene is looking more and more like the early days of the Opensource LLM scene
race to the moon. more player competing more better for us
Like you have pixart and HunyuanDiT and auraflow and now you have black forest labs with their flux models, SAI has real competition now, they need to step up their game
and now black forest labs is even making a open source SOTA text to video model
dont forget Kolors
I mean, SAI is a company, what counts (besides money) is the people behind it
168s for 4 step with schnell. I have a 6gb vram mobile gpu and 16gb of vram


who is left on sai? All good people left
speaking about video model, hvnt really payng attention for this area. which model is the greatest right now?
you have Kling and gen 3 and luma
My two favorite models are Kling and Gen 3
I find it best to do Image to video using Kling
that awesome something good doesnt come that easy, just looking at her finger precision 2-3mnts waiting time is worths it. as long the model very accurate with the prompt given you dont really need trying that much for good result
until we cant get at least 5--10 seconds of real consistent images its useless for anythign other than pschedellic imagery or stock footage
i will try them later
yes those were the first two generation with euler. Trying other samplers now, dpmpp 2m is my favorite so i think i can get better looking images with it
both of them run locally?
did you guys test the schedulers ?
nah both are closed source
wait what webui you use to run flux?
right now in comfyui, will test later on swarmui

thanks
168s is not that bad considering the quality the model outputs with only 4 steps
For some reason schnell does paintings better then pro or Dev
come back 1 months after sd3 release and now learning it wasnt a hot potato any longer hahaha
agree
it does
i guess pro and dev are more for realism...
which is weird, why does a small model outperform its bigger counterpart on something so specific and simple?
😭
I only tried dev so far. i don't want to waste 50gb memory for both
it's not smaller
fp8 variants are here
i downloaded both but only tried shnell
it's distilled more, who knows
both dev and schnell are distilled model. Maybe schnell had more paintings in it's training data
wait this is not the model repo
some youtuber did a live flux session and dev is muc nicer than shnell
does dev do good images with low steps like 4-8 ?
ah yes.... 😄
dev needs around 10-20 steps I would say
just like how the subreddit was taken over by Flux
schnell is the fast one
Reddit puke
schnell=German word for fast 😉
schnell why i cant find this model i want to download
here is the huggingface repo https://huggingface.co/black-forest-labs/FLUX.1-schnell

dpmpp 2m sampler on 4 steps. Not bad.

do i need all those 3 file?

a stunning artist depiction of a sexy woman made of the cosmos. Her body is made stars, nebulae and she is playing the guitar
fucked up on the prompt, but okay for a first test
the hands, OMG
why her upper body not ethereal with cosmos?
I think you need the two files that end with .sft
4 steps dude, with a shitty prompt. Need to make a better prompt
but dam that guitar look good
flux dev absolutely rocks, this is 40 steps

that trump look handsome
@signal shuttle wait are all flux model dev schell all 24gb in size?
its so amazing that like out of nowhere a model like this comes. its mind boggling how good it is. if it does get finetunes and controlnets its like perfect. i really am impressed
yes i think so
I really want to download the schnell version but i cant be bothered to download it with my amazing 500Kbs internet speed
I'm affraid all other models are dead when compared to this. Perfect anatomy most of the time
have you try it with dept and canny controlnet? can it run
you could hear genuine amazement in Nerdy Rodents voice lol
download the fp8 version it's only 11. something gb
Nerdy Rodent did a fantastic video on it
i havent tried it with any contorlnets or loras or even any workflows yet
dam even this feel slow for me

that will take me overnight to download
yes
where ?
your lucky it only takes you half an hour, it took me the entire night to download Flux dev
this model is the perfect gift, it isn't even Christmas
ikr!
dev or schell ?
i wont try overnight download it always went shit midway

schell 8fp that you talking about

Can it work for flux with 3060 ti 8g ram
it works with mine 2060 6gb vram and 16gb ram
just slow buddy
but go for it
wash your feet with flux right now
i get 90 seconds 1024/1024 on 3060 rtx 12gb vram and 32 gb ram
Flux dev gets me 50 seconds on 1024/1024 with 30 steps on a RTX 3090 with 128 gbs of ram
when the model loading is done and first image is genned. The other images take 160s each to gen in 4 steps
Pretty insane after saw the example with flux
right anyone willing to share some workflow for flux schnell that i can try?
the initial time with model loading and first image takes 300s
comfyui has one in examples
have you try intricate design image with flux?
landsacpe
just tested it, will try other prompts after. Now i'm testing settings
How long do you think it will take until the mods come in here and tell us we can't talk about Flux anymore
aerial view, never ending futuristic wall strecthing into horizon, intricate design, highly detailed
much better then dead channel
make a flux channel then! its your destiny
i hope they come and tell us don't talk about flux anymore because we have brought you sd3.1 and enjoy.
you can replace cascade channel with flux
You can't talk about models other than sd3 in the sd3 channel
👍
Did it first
That and balls.
what is this

My profile
lmao wtf
oh you write it by yourself right
:))))
🤣
looool
 exposing me
exposing me
he talks about balls everywhere so he gets banned

well... his taste is heavy
that ball is shiny
white cat in black hat on red dog in blue shoes

Correct aspect I'm dumb

add black and blue spot for the cat and tiger spot for the dog
I must amdit these are some fine balls.
Im out of dad jokes about balls
no worries take rest and come back again tomorrow with more balls... cough i mean with more vigor
Can flux schenell generate images with 2000's aesthetics ?
AESTHETICS.
never try, have you try it already?

hey
Go and touch the ball to see the truth
can you make the Death Star? its basically a giant ball XD
Heastheticks
hehe
I have no clue if sd3 knows that, or if I even know that

No ship that small has a cloaking device!
best samplers for flux ?


😏
I just tested the distiled model , i am suprised he understand correctly the style
how far? 100%?
can you share
Maybye 70%
lemme see and judge
prompt :144p, vhs filter, image noise, low resolution, jpg artifact, , nostalgia, photo from the 2000s, a dark living room, shadows, lamps, sofas, overturned chairs

for a distiled model is too good
this is flux?
yess
last prompt get ingnored
the distiled model has less prompt understanding ?
pretty good
i love this one

144p, vhs filter, image noise, low resolution, jpg artifact, , nostalgia, 1990s photo, a field next to the entrance, houses, streets, electricity pylons, tall grass, starry brown night sky, red moon, black clouds
how many gb i nedd for flux.1 dev model ?

😮
i will take one month to install it lol
16gbs of vram with the fp8 version and at least 32 gbs of ram to run it somewhat fast and not having to wait 3 minutes per image
i have 12gb vram 😔
hm, I currently try the SCHNELL version
more than enough, how much ram?
the results look so much worse than on DEV. I wonder if I do something wrong...
16gb
i have 32 and comfy maxes it out
maybe youll max out too but last longer, you shoudl still try
Dev looks way better than shnell
So you are not doing anything wrong i think
hm, okay, then I can delete it xD It's not worth the speedness
i will try it
Schnell is more for like artistic styles, dev trys to inject realism into every prompt
what is the lowest step to get something good in dev ?
what ist the problem brother?
I always use 20 steps, but I think you can go much lower
People recommend 20, in my case i use 40

so not worth it for me
with 3090 I get an image in 20-30 seconds - which is totally fine for me
if I would have to wait over a minute I would agree
I love using Flux dev

what's the prompt?
do you have any solution brother? @signal shuttle
I don't use comfyui for flux but I guess you have to download the T5 and CLIP text encoders
what about 12 steps with dev ? Can someone try it ? I want to see if it's worth downloading for me
"Field next to entrance with houses and streets, nostalgic 1990s VHS camcorder footage, extreme low resolution 144p, heavy image noise, visible VHS tracking lines, severe JPEG compression artifacts, desaturated colors, grainy texture, blown-out highlights, electricity pylons silhouetted against starry sepia-toned night sky, oversaturated red moon, ominous black clouds, tall grass in foreground, lo-fi aesthetic, CRT TV scan lines, time-worn visual degradation, analog video glitches, muted palette, soft focus, light leaks, chromatic aberration" it didn't follow my entire prompt but it gave me something good so eh
yeah, my feeling is that if you give it long prompts it starts to miss a lot of things
The names in the node don't match with names of the files you downloaded
but there is no other files i can download on hugging face page for schnell'
I hear 20
T5 and CLIP-L are the same you use for SD3
or PixArt, or SD 1.5
did you missplace the files then?, because that error comes up when the file either is not named correctly or doesn't exist
i download this one i place on vae and another on checkpoint

i have t5
the other on unet folder
which one?
the big model
did you download Clip_l and T5xxl?
Wait is Flux not a DiT model but a Unet one?
here i place on check point folder

i dont know about clip_l that you refering to
wait so not on checkpoint folder?
it's a dit, just comfy that wants to keep everything on one node
no
this good?

you need to download Clip_L
where to find this model brother?
clip goes into clip vae into vae and models into unet
t5 go to?
but there is no clip vae folder

Reddit
Explore this post and more from the StableDiffusion community
i got it
Is there a difference between the flux and sd3 clip_l encoders?
to be safe just use this https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main

yes
where should i place this?
this right?

that is not the correct one
yes the clip_l one
you need t5 separate and clip l separate
Download clip_l.safetensors and one of T5 Encoders: t5xxl_fp16.safetensors or t5xxl_fp8_e4m3fn.safetensors. Both are going into \models\clip
last one?

yeah if you don't have enough vram like me, or take the bigger model if you do
Fp8 if you have low vram and low ram fp16 if you have a beefy computer
i see fp8 then i use laptop
This excitement around FLUX is amazing. Everyone is pleasantly surprised. I think most people will forget about SD3 2B now.
what is a beefy computer? fp16 would be already 24gb. You would need two gpus to do something with it
12B and 2B
well i have two rtx 3090s with a 128gbs of ram so i dont have a issue running it
i won't if they release a decent sd3.1
I know xD I just say: with a normal setup you cannot run it without 8b
Could you please advise which LLM model is best to use with Comfy for prompt enhancement?
open source or closed source?
open source
llama 3.1 ?
quantize it to 4bit and it should be decent
I understand that it's possible to switch the LLM to the processor?
Using gguf models with llama cpp or kobold cpp will always use the cpu
Thanks
you can use it with ollama
Ollama uses the gpu doesn't it?
i think you can do both, but i thought he wanted to have llama 3 on comfyui
so ollama i'm afraid
i don't know if there is another way to have it inside comfyui
It's still interesting to know how many parameters DALL-E 3 has.
no matter how many it have with that kind of restriction i wont even bother looking at dall e 3

i love flux

in contrast to SD the text does not look like photoshopped
what the hell almost 10lit

what gpu?
it dont take much time generaing but take a lot of time loading the model to gpu xd
I hope that soon we will see tunings and upgrades for FLUX.
I hope this doesn't turn out to be too expensive or too restrictive to train, i just hope this doesn't turn out like deepfloyd's "IF" model
flux good with long prompt?
why it keep making small child for me
did you use schnell or dev?
schnell
What prompt did you try to use that kept generating a small child for you?
Image is a digital illustration of a young woman with a fair complexion and short, dark hair. She is dressed in a medieval-inspired outfit consisting of a white blouse with a high collar and a black ribbon tie, a dark green cape, and a high-waisted, knee-length black skirt with a lace-up front. She also wears black tights and white shoes. The character has a delicate and refined appearance, with large, expressive eyes and a calm expression. The overall style is reminiscent of fantasy or historical-themed artwork, with a focus on detailed clothing and a soft color palette.

just testing with civitai prompt
3 attempt all result is a child half her size
even when i add young adult it same
give me a second, let me try that prompt
good luck
i get this when using your prompt using dev

3 attempt on my side is half body shot
cant understand why it become small child thought
one from civitai with same prompt with flux


i think it is because you used the term "Young woman" in your prompt, here is the image when i removed young

does flux have some filter?
love the aethetics of this prompt (sd3 8b)

no it doesn't, i made some wild stuff with it so no
i think it is just because your using schnell with a low step count
flux pro for comparison, meh

low step huh, i will try it with different step
how many step for this? i just 7 last time
but the image is more coherent with flux pro then SD3 8B
hell nah
who in the hell holds a sword with a stick?
just use 28 for a small test
this is good
i loved the aesthetics, it can deffinetly hold the sword properly look (not cherrypicked)


can SD3 get a map of north America in the background right without it being a mess?

let me try, prompt pls?
you have to remember sd3 8b is still an old undertrained model
a military emblem showing GLIF FORCE 1, empty white background, clean and uncluttered, military emblem, clear outlines and borders, do not show anything but the emblem against isolated white background
thx
first output, it's what you asked

here is two of my favourite plane images made with flex dev


The lines are so solid and consistent even with perspective. 😊
take a look at my image and your image and tell me which is more coherent?
the text looks worse on SD3
mine follows the prompt better, yours added thinks you didn't ask for and sd3 is still an undertrained model

followed the prompt better?, it gave me what i asked from it, a military emblem with Glif force 1 written on it, it just made the image look cooler
I posted some tests including prompts in the SDXL channel. Testing for physics. I'd love to see how SD3 handles them. I was just comparing SDXL.
(I was running FluxDev fp8 on a 4090, 20 seconds per image. Not great, but fast enough to experiment.)
it added so much you didn't ask for
alr let me test some of these
It add that much because i suck at prompting, if i had given it a better prompt with much more instructions then it would've given me exactly that, and i was using 1.5 guidance becuase i wanted to test out how low i can get
the problem is not your prompt it added unnecessary things
of course it add unnecessary things, try using SD3 on 1.5 guidance scale and tell me it doesn't add unnecessary things
i was surprised it even gave me the text
@icy drift it struggles with mirrors, at least it got the text right

@icy drift can't do the dice, it does 5's not 6's lol, interesting

@icy drift

@signal shuttle right to left 28 step > 12 step

same prompt just removing word young
all child sigh
Yeah you can see some reflection in the marble below it, "NIIKBOK" or something.
lol yeah
i still prefer sd3 8b for aesthetics, it's almost the same as mj 6 or 6.1 (you'll need an insane prompt tho)
sd3 8b


The girl-reflection here is what I've come to expect from all models until FluxDev. It's the same girl with the same outfit, and they're standing side-by-side. But the lighting is flipped. Leftmost girl has light coming from right, and so does her twin. FluxDev isn't exactly photo-real, but it really is trying to do a sort of copy-paste flip. It surprised me.
has anybody tried quantizing the flux transformer with quanto? 
been running for almost an hour here now, not sure if stuck or churning
I got a quant from HF, didn't try myself.
yes that's pretty good
yes

uhhh really? is that in qint8 or 4?
sd3 8b


can you link it? I only saw the normal fp8 quant, I don't think that's done with quanto
I don't even know what quanto is. Asking the wrong guy.
okay nevermind, I'm guessing you mean the model from kijai then?
Isn't quanto for llms?
sd3 8b

guys, what do you think, is tensorrt for Flux possible?
not only, hf made a blog post about quantizing diffusion models yesterday
cause it is literaly free speedup
huh, i need to read that
sd3 8b

what was the prompt for this one?
A photo of an orange cat diving into a pool at the Paris Olympic games, with "Paris" written on one side and "2024" in a vibrant blue color with some black elements, Olympic rings taken with a Nikon d850 with a wide-angle lens, f/2.6 aperture, high shutter speed. The competition was filled with excitement as spectators watched from their seats. In front of them stood three high podiums, each decorated to represent different sports events like swimming or gymnastics. This moment captured a tense but joyous atmosphere.
even mj struggles with this one

another one
Is SD3 better than DALL .E?
depends on which things
SD3 is trash
the closed source 8b? maybe, the opensource very bad 2B? absolutely not

flux first try

My hardware does not allow to cherrypick
or my patience

There's no point in arguing about it. It's pretty clear to me that FLUX is miles ahead of SD3 in every way.


Can SD3 do this? (Made with flux)

prompt?
Minecraft screenshot of a battleship, pixelated 3D render, isometric view, blocky aesthetic, voxel-based graphics, retro gaming nostalgia, low-resolution textures, cubic architecture, digital sandbox style, vibrant primary colors, orthographic projection, 8-bit inspired design, procedurally generated seascape, minimalist game art, simplified naval warfare representation,

thx
btw flux works with the aligned scheduler

schnell?
yes i have not tried the dev yet, but tell me if you do
/credits
Would you look at that camenduru made a IMG2IMG workflow for Flux comfyui

Reddit
Explore this post and more from the StableDiffusion community
best thing i could get, i think your prompt needs a bit of working bc it's contradictory

flux is the goat 💪
Well doesn't that mean that flux understood the prompt better?
you specified for a minecraft isometric pixelated style, all of thesse things contradict eachother let me try repromting it
here's one with the isometric style btw

Can we encode the image with the clip model instead and concat the conditioning? That way we can talk to the model about the image instead of just generating a variant.
You convert the image to tokens in the prompt. I know we've done it for other models before.
@signal shuttle reprompting it can do it much better

That doesn't look like a ingame screenshot from Minecraft
- flux didn't get the naval warfare ship right
neither yours
it followed the prompt better tho


now this looks more like a vanilla minecraft screenshot

looks like sildurs shaders lol

I have been using Flux Dev let me just switch to Flux pro and see how it compares
ok
(Unrelated image but i made it using Flux dev)

can you give me the new prompt you made?
Flux dev couldn't do trading cards at all for me. That's just dataset though. Loras are perfect for missing data, they just can't improve the models basic IQ very much at all.
It might not have UI stuff or game stuff. Try some more prompts.
Minecraft screenshot of a battleship, 3D render, blocky aesthetic, voxel-based graphics, cubic architecture, digital sandbox style, vibrant primary colors, orthographic projection, procedurally generated seascape, minimalist game art, simplified naval warfare representation
I really hope we will be able to train Loras on 24gb 😢
Uhm... Hmm.
this is flux pro, pretty good

Are there wave shaders for MC? That would be cool.
yes there's a wave mod, i think it's on the physics mod

damn these shaders look good look at those clouds
3.5 guidance with 40 steps
another flux pro one

I have 6 new physics problems to test when I get home. So exciting!
I haven't had to think up new tests since we got SDXL. Nothing ever passed my testset until Flux. 😊

"This lets you adjust the guidance on the dev model which is a parameter
that is passed to the diffusion model."
https://github.com/comfyanonymous/ComfyUI/commit/eca962c6dae395cab1258456529030880c188734

GitHub
This lets you adjust the guidance on the dev model which is a parameter
that is passed to the diffusion model.

I currently use it in diffusers only. Did anyone tried if inpainting works in comfyui? Might be a reason to swicth
it does
works surprisingly well too vs sdxl
nice 🤩
yup
now, please make a few controlnets and ipadapters black-forest-lab! ;D
i did some tests with 100% denoise and didn't end up with visible edges or anything like that
yeah i think ipadapter could be huge here
12b is obviously too much for us to train style loras on consumer hardware
if we could use the style ipadapter stuff here, it'd fill one of the biggest gaps this model has (artist styles)
yeah. Although I still have hopes that training loras on the quantized model might be possible... We will see
yes
text you didn't specify tends to be hilarious, this is no different 😂

enal teepee weack axy leack 😂

How to use it?
It's different than the defualt guider node... no model input. I assume a different workflow?
you don't use it. it's added support for flux. you update comfy, and then if you use flux in comfy, it knows what to do with it
Herrison Fiat?

Hmmm... I am lost then 😦

😄 😄 😄
It's a stolen prompt 😛
if you'e trying to run flux in comfy, be aware that it's HUGE - you're going to need more than 16g vram
Nah. I'm running with 10gb. It just slow
i am THIS CLOSE to losing any potential future job 😂

Is possible to run flux.1 dev localy with 12gb vram and 32 ram ?
Lessgoo
i get 1.19s/it with 16gb vram and 32gb ddr5 ram for reference
whoa
fp8 e4m3fn


i mean if you want any sort of reasonable generation time
how long do you want to wait for each generation?
Me? you may have been tryign to reply to another 😄 .... I have a 4090 and 64GB RAM...
That being said, I did still have small issues with Photoshop running at the same time and also a Google Chrome tab eating up enough VRAM to put me over the edge. Ffux definitely likes a very empty 34GB VRAM 😛

i was, yeah, discord must have jumped the text scroll and i got the wrong message to reply to - and it does. that's the current conversation topic on Latent Vision 2 discord
It's relatively faster than SD3 since i don't need to generate 10 imagens to get 9 shit and 1 half-shit
if you're still having to do 10 images and only getting a couple that are good while using SD3, you don't have a clue what you're doing. i do at the most 4 and get exactly what I want, usualy in all 4
and they're high quality, and excellent images
Yes. Whatever. I won't fall for your trolling
woman laying on grass doing absolutely nothing but looking like she has blown up...

i'm not trolling you, you just don't know how to use SD3 correctly
Generate something like this

i've only gone into great detail on this discord about exactly why it's 1. not just females, and 2. why that happens. so did lykon. you can search for it.
if you consider that good, you should probalby just stick with using sd 1.5
I found out that there is not reason to use fp8 weight dtype, it only slowdowns generation and reduces quality on rtx 3060 at lest
correct number of fingers, grabbing an object, belt isn't doing anything weird. it's good
btw it is good at 512px
if i use fp16 it crashes
rtx 4070ti super 16gb vram, 32gb ddr5 ram
Can't do, right?
absolutely dies and crashes
Shouldn't be like that, here is mine:
rtx 3060 12gb vra, 32gb 3200mhz ram,
flux.1 dev, 1024px, 20steps
100s generation, 60s text encoding
weight dtype - default
fp8 version of T5 encoder
like this? 😄

gib 😮
yea
thanks i'll try it - i fear the worst though, normally it crashes instantly with no error code
do you have a pagefile? because it maxes all my 32gb, pagefile could be a savior here)
I remember comfy completely colapsing when I had 16gb without pagefile on sdxl workflows
that might help - what is it? 😄 it also maxes out my 32gb

as you see here it just crashes instantly
weight dtype to fp8, did you try?
not going to bother with YOUR trolling. go back to 1.5, which is what you're good at.
you are mean and usually wrong also
that's what i did before and it ran fine but cds said this: "#🆕|sd3 message" was better
You're not good even at trolling
yea but you have to make it better for you...
CFG 15

check how to add pagefile, it might really help
CFG 7

i wasn't trolling. i stated facts. you, on the other hand, really need to learn how to use the program before you complain it can't do what it very obviously can do
dude, just shut up
Anyone know how many images Flux trained on?
thanks, do you know what i should search for in order to find it? i'm not quite sure where to add it or what it should look like - thanks 🙏
listen you cant use Flux with 16GB, your gonna need more, one of your facts, mreanwhile people using it with 8GB
yea but it is possible with default on 32gb and 12gb vram, so no quality decrease and time increase
If you can do a good hand holding a sword with SD3, why don't you just do?
oh wait i just noticed now, you also using upscale on top of that, lol
facts without evidence are opinions
you haven't really proved anything
becuase, child, i don't have to. go back and play with your toys
and you stay out of this

hmm il try tonight, im still testing combinations
I mean, they are the same guys who made SD3, so I think training sets might be similar
this channel is packed with a massive number of images all doing exactly what he says SD3 cant' do, and are proof enough that he doesn't know what he's doing. just scroll through it if you want that proof
no one's going to play your little game and go run off and make you proof you will then diss and complain about
people dont emulate you because they dont want to have outputs like you...
i know i dont
That face on the left lmao
check something like "how to set paging file windows 10"
did you try flux? :3
Only a bit
can't wait for 8b sd3
oh okay ty 😄
Anyone know how much vram it takes for flux?
all
As in not needing a work around
16gb at least. Some people say they can do it with less
but it will take much time then
the discussion on L2 discord is that you want more than 16g vram if you don't want to wait quite a while for each gen. it's huge
Perfect, 4080 should work then
Ah shit
yea full quality dev version runs on 3060 for 100s and text encoding is about 60s on my poor r5 5600
Here I was proud of my fast sdxl gens 😦

wait... i actually didnt try,... do you need the t5? what if you just use the clip_l, is it gonna work?
it's much better than SDXL in text understanding and anatomy
regarding "anatomy" (or in general: structureness of the image) it's the best model I saw so far
like hands are almost perfect most of the time. Hands holding stuff works at least in majority of the cases
put it between the clip text encode and the basic guider.
background looks clean and not messy
Serves stability right, hope black forest doesn't do the same shit this company did
there's people on twitter saying 3.1 will be better then Flux, and sharing images of SD 3.1 wip model
How are they?
SD3 team has shared some generated results from the WIP training SD3.1 (not done training yet). comparing them with Robin's Flux 3.1 Pro using the same prompts. The 3.1 model is almost on par with Flux Pro in terms of quality, but it's nearly 5 times smaller, with only 2.5b

Twitter
what the model is not good at is paintings, or styles in general
like it can do anime and comics, but if you ask for specific styles or artists it is usually not good in that
Yeah hope we get some good fine tunes
is there any info about finetuning Flux?
Schnell is allowed I think
I am worrying that it is not possible
not dev?
the typical SAI bullshit as usual
Both Dev and Schnell are finetunable, its just with Dev that you can't sell said finetune
like none of the images is good for assessing model performance. Probably all of them are cherry picked anyways
schnell at 512x512 is manageable, i get 2.7it/s with 16gb vram and 32gb ram
good one
we can make extremely good looking images with SDXL or even with SD 1.5 that look as good as Flux or Midjourney images. But as soon as we ask for something simple as a knight holding a sword these models fail miserably
or use said finetune to train a model that is competitive with Flux
so if anyone want to convince that his model is good he should show images that are challenging for existing models
Uncensored tests I did yesterday. I don't consider these NSFW, they're the tamest stuff possible. But it's the first model in ages that I consider uncensored. (And this is plenty for anything I want out of a model.) Obviously I added the red blocks. It was the only anatomically perfect David I have ever seen.


Does civit count as selling?
woman lying on grass is gonna be the first test from now on LOL
try gymnast doing a headstand, usually upside down stuff confuses the models
@icy drift did you try tcg cards 😮
problem with Flux is its so huge it will be difficult to finetune... I mean, in theory it should be still possible if you train a lora only on the last k layers of the model or similar. But yeah, I guess some people will have to implement really efficient finetuning scripts for that to make that happen
Yes not in the dataset at all as far as I can tell. It can do the art, but "TCG" and related terms do nothing. Loras needed.
perhaps the next GPU gen will feature 128gb vram and none of these concerns will hold true
pictures of dogs and landscapes were not the reason sai got backlash. Show us humans in different poses holding swords and other things but of course also, a woman laying on grass.
Btw what size is sd3
ah yes 128gb vram, so we can finally run those 400B llm models LOL
i feel u
2b(just the mmdit part), the text encoder is pretty massive tho thats like 3b i think
Llama 3.1 405B, the largest model in Meta's Llama 3.1 family, is approximately 854GB in size when using full 16-bit precision
damn son
just have to use 1 bit quantization(:
yes all problems solved
Black hole happens
run flux, 405b on cpu
pc gonna explode
llama 400b as text encoder 💀

oh is this possible to quantize T5 even more? It takes too long on my cpu
flux is pretty okay at doing headstands

generation so slow, you get one word per year
first try, not cherry picked
whats that game where you have to put hand and feet on different colors in a group
The diminishing returns though lol....
twister?

nice as..thetics
yes 4bit, you can even remove it if you are using sd3 but quality will suffer(slightly). You can remove it with flux as well but quality will horribly drop i think.
hahaha 4gb vram.. are you ever gonna upgrade? 😦
twister in flux
