
#✨|sdxl
1 messages · Page 180 of 1
So we all just moving back to xl?

@half gyro traffic being hell, still omw back




All in 3.5K, full view recommended




Amabie Yokai:








futura concept nice



Hello everyone, can anyone suggest me why my generation of mask is not applying on the left side of the image. I am keeping the dimensions - 1016 x 504 but there is this left black patch that is coming again and again



SDXL BETA BOT


Hey guys, I have a questions regarding the licensing of AI images. Can I license the images generated by stabilityai/stable-diffusion-xl-base-1.0 under a Creative Commons license (CC-0-1.0, CC-BY-4.0 or CC-BY-SA-4.0)?
The stable-diffusion-xl-base-1.0 model is licensed under CreativeML Open RAIL++-M License. Thank you!
Sounds good, Thank you! I will contact them, do you know how long usually I can get a reply from them?
No worries, thanks for the help!!
I'm pretty sure that the images created by SDXL are public domain.
There is no ownership of them.
It's the same license on the model.
Anyway, best to read and interpret yourself: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md
Whatever that means: "The Output You Generate. Except as set forth herein, Licensor claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License."
😄
Interesting, so I guess it means we can use the generated image whatever we want?
That used to be the case, but I'm not sure now that they've introduced the creators license.
Trypophobia intensifies...
I am only going to use the model for non-commercial use, and no money change, so I guess I should be able to license them?
but then they also give an example:
Imagine a company wants to use your model in order to develop a version for a commercial chatbot. The company accesses the model, modifies it, and finetunes it to be the technical backbone of the chatbot app. Firstly, these actions will be governed by the OpenRAIL license. Secondly and worth to note, according to the terms defined in the OpenRAIL License this is considered a derivative of the Model. Thus, the use of the chatbot will be governed by the use-based restrictions defined in the OpenRAIL license, and accordingly, when commercializing the new version of the Model by means of a commercial license (or any other type of legal agreement), the latter will have to integrate these use-based restrictions as part of the subsequent license.
I guess it is pretty complex, haha. Thank you!




He uses the faces of his enemies as armour.

Yo how do i generate stuff?
...or #artisan-faq


"How do we drive this thing?"




Hey, does anymore know the rate limits for inference API for Stable diffusion XL model on hugging face?


All very cool stuff ❤️ Do you apply some kind of DOF in post?
No
Spot the hidden spycam










Medieval Iron Man

Zoom in on the deets

What's the problem with hands anyway? 🤷🏻♂️

how are you doing text with sdxl? these look pretty good
mind sharing it?
yeah just realized lol
thank you
Zoom in on the deets
the consistency and clarity is sd3 level, if not better (sd3 struggles with other details of the image sometimes)
How all that jewellery above was made

imma try it once i get home
im at work rn
i haven't used any text loras before
oh definitely
thank you
i usually use dreamshaper XL, hope it'd work fine with that


lord
whats your gpu?
4090
24G?
Yes
Damn


@meager canopy Very first test with hidiffusion. 4kx4k

I mean aside from the hands, kinda cool

: DD




I think you got a world record here
So funny
But very interesting image
Lol yeah. 4x the resolution, 4x the fingers!
At least it doesn't mess up faces. Tweaked it a bit, will see whedre it goes 😛















Did the mods leave or something?


For A1111 and Forge users :
https://www.reddit.com/r/StableDiffusion/comments/1dkh5cv/a1111_forge_improve_your_images_with_a_single/
I finally wrote a post about this


Off to dreamland

is there an inpaint controlnet model for SDXL?

several


Can anyone that knows how to finetune loras in particular about captioning images take a look at #🔧|finetune for me please.






modern hotel lobby
good morning


/gile





A small white cat
Like this?

More like this?









That shoe tho its in an interesting place. If you quint... 
👋 .













They're having the best time. 🙂
Futuristic steampunk warrior in dynamic pose, bright neon blue energy illuminating surroundings, fighting oversized, animated evil fruit in a chaotic grocery store, intricate mechanical armor glowing with blue circuits, swinging a plasma blade, anthropomorphic apples with fierce expressions, bananas with menacing grins, flying strawberries with sharp teeth, aisles filled with overturned products, flickering fluorescent lights casting eerie shadows, shelves toppled over in the background.



- Model introduction: The large model trained for Pixar style can output the feeling of Pixar 3D, which is similar to the Q version style of Bubble...
It's ella with that sd 1.5 checkpoint, then cutejack 0.3 on civit as a refiner
I was playing around with various sd 1.5 checkpoints the other day and it's by far the most prompt following with Ella that I've come across across so far. Was using juggernaut reborn before this.
I just don't get good images from Ella, at all! Must be my workflow 😄



These have been improved with controlnet tile too!

Look at these full screen! 😎

.


\dream
\dream 该项目位于迪拜酋长国谢赫扎伊路AL SAFOUH地区,是业主投资建设的超高层五星级酒店公寓项目,该项目设计为2B+G+M+7P+GYM+14 HOTEL+SERVICE+27 HOTEL APARTMENT+SERVICE+ROOF层,占地面积为5072.7平方米,总建筑面积为96298.3平方米,建筑高度226米。设计一个高大威猛的中铁建塔吊来施工这个建筑
该项目位于迪拜酋长国谢赫扎伊路AL SAFOUH地区,是业主投资建设的超高层五星级酒店公寓项目,该项目设计为2B+G+M+7P+GYM+14 HOTEL+SERVICE+27 HOTEL APARTMENT+SERVICE+ROOF层,占地面积为5072.7平方米,总建筑面积为96298.3平方米,建筑高度226米。设计一个高大威猛的中铁建塔吊来施工这个建筑





Sure, here's my workflow. 2 stages of ella, then a stage or 2 of sdxl refinement. you'll need the extra samplers custom nodes, and i'm using the resolution selector from pixart.

I find that the res_momentumized samplers do especially well with fingers and hands.
Nice, thanks! 🙂










I like these 😊




Anyone in here using allor by any chance?
New project I am working on using SDXL for characters - 24/7 always on live stream of historical figures reacting to twitter live: https://www.twitch.tv/timelesstakes

Twitch
TimelessTakes Live 24/7 | AI Einstein, Jobs, Monroe & MJ React to Twitter
/create


Being very wealthy would make contemplating mortality too unbearable.












Not very good as-is, but there are some nice merges.

\dream generate image of hours




Cascade/pixart


💯


I would go sd3 for environments. It really shines in backgrounds and landscapes without characters.
the new Juggernaut XI is great for landscapes I spent a while with it today







Wow really cool stuff
Midsummer \o/













👋 .

@timid garnet Yo! Can you link me that article you wrote on your a1111 workflow. Can't find it back
This
Was curious, but no one seems to care ahah
sdxl flash from sd community, 3 word prompt, 8 steps in 10 secs on A100, fast asf and not bad

Imagine a powerful Viking, adorned in traditional fur-lined armor, engaged in an epic struggle. On one side, he grapples with a fierce bear, its claws extended, while on the other side, a majestic lion roars, teeth bared in defiance. The Viking's stance is resolute, muscles tense with effort, encapsulating the raw intensity of the battle between man and beast. The lines capture the dynamic motion and strength of each participant, evoking the ancient clash of bravery and ferocity
Using SDXL to generate avatars for a 24/7 livestream of Michael Jackson, Marilyn Monroe, Einstein, and Steve Jobs reacting to a live twitter feed. Fully AI generated conversations and interacting with chat: https://www.twitch.tv/timelesstakes

Twitch
TimelessTakes Live 24/7 | AI Einstein, Jobs, Monroe & MJ React to Twitter 🔴 Ask Them Anything in Chat!
Here is the image you requested.

Automated SD to Photoshop node/plugin - SDXL Models = Mobius, NightVision XL and Albedo XL




My upscale is always, more or less, washing the colors (contrast)... I'm struggling to understand what's going on here...
Visual and obvious example :


Is it only cause of the upscaler ? (foolhardy)
Yeah it comes from upscaling. In comfy I use a color match node, that takes the constrasts and saturation from base image and applies it to the final output. No idea how to do it in A1111 though
There is a color match setting too, but it's just enable/disable, and pretty meh
foolhardy / 4xNomos8kDAT


Best way to upscale imo is using a tiny bit of hallucination ontop, for additional resampling
Not much, just to trigger it
hallucination ? 🤔
Well running it through a sampler again changing the noise just a tiny bit. Basically like magnific, just with low settings
Just googled real quick, in A1111 what I mean is this

Similar to Krea and Magnific but offline using Stable Diffusion. Just follow these steps and enhance a low resolution image better than you ever thought possible.
If you need to install Controlnet and Automatic1111, please check my video and written descriptions here:
https://www.hallett-ai.com/getting-started-free
Links from the Video
...
Well i'm using ultimate sd upscale after the txt2img part with extra noise. The pics are split in 9 tiles and get 25+ additional steps
Yeah but those are upsacle steps, what I mean is re-rendering with a sampler. Just watch the vid, you'll see what I mean
Totally what i'm doing. But i'm also adding extra noise, for details to emerge further.
I'm using a 0.46 denoize.
ah, he's using CN
I can't
vram limited
As i didn't test, i'm not sure what the tile CN add to the process
This is just the USDU part :
foolhardy / 4xNomos8kDAT


This is not bad

DAT models are soooo long

flatworld 🙂
🤨





differences between 0001: Higher saturation Brighter More dynamic uses 2 loras trained by me: - QEW: https://civitai.com/models/470285/qew-quasarca...

prompt blend with gradients



Did I break Luma?
Haha nice animation

Imagine getting 10 hours of queue for static animation 

Scrolling the gallery. I love this one







"Get Gud Skilz!!!" ™

👋 .

Wow!!! This CFG++ is really making a difference - REALLY!!! Incredible!!! Just drop the CFG from 8 to about 2.5 or 3 before you start!!!
I can't see any way to set steps from/to with the custom sampler, so I'll wait until it's part of the other samplers.
Ollama Up Baby!

Get friendly with an LLM! "Get Gud Skilz!" ™ Using CFG++




You may be doing overkill if you implement CFG++ with a ReFINER
It's not good for anything realistic.
Not from what I've tried so far anyway.
Drop the CFG right down ... and use realistic models like NightVisionXL or RealVis
I use low CFG all the time, even at 2.0 it's not so good.
The premiere of "The Lion King"





some new pictures from the last couple days 🙂
the first picture you mean ? it was kinda an experiment with comfyui and an unexpected result
it's an s-kite
or are pure-xxl, not 100% sure
it's been a while 🙂
yeah, it's a pure xxl
and it does pull like a truck 🙂
it's an ancient thing 🙂 i doubt there's many people left flying those
🙂 it's like not from this millenium
it's a fun-flight, you cannot really kiteboard/buggy with it, but in low winds it flies astonishingly stable
i still have a lot of old kites down in my (very dry) cellar, i dont really get to fly much in the last years
got some fun stuff 🙂 a c-quad 8.5, a 20er stacker of speedwings, two big s-kites
a 12qm power lifter
should check my cellar again these days
those were fun, too 🙂
You don't seriously think that looks realistic, do you?! 😄
Sorry, I am mainly an artist - everything looks 'realistic' in strictly artistic terms!
But it ain't photographic realism, no!
CFG++ is a fine arrow to string to your bow - at least at "Torcello Towers" it is!! LOL
Try 0.4!


"I currently have a drawing task, which involves creating a picture for a child's name, specifically for the name '田羽靖'."







I'm dying, i can't use adetailer anymore with Ultimate SD Upscale 

why?
50$ gift
steamcommunity.com/gift/2918J0193717
It's bugged since i updated something. Not sure if it's an extension or the webui/
If you try to enable :
-Soft inpainting
-ADetailer
-Ultimate SD Upscale
in img2img, the first tile will be processed, then return in a black image.
Then you just process the black image.
This is quite devastating for my "workflow"
I'm using a1111*
Are there any compltley free Stable Diffusion models?


All SD models are on Civitai or Huggingface and are free.
whats the link
Explore thousands of high-quality Stable Diffusion models, share your AI-generated art, and engage with a vibrant community of creators

If downloading a model on Civitai do I have to connect to the official SD API to run them?
SDXL racer 😀

nice retro lighting


you can try "green and red neon glow"
ah okay thanks
low cfg also helps to increase the foggy stuff
yeah I use low cfg almost always now
because low cfg also helps get softer skin

yeah I'm staying SDXL mostly for a while
I think I only like models after a lot of fine tuning
it took me a long time to leave SD1.5 even
Totally agree 🙂
I switched to SD2.1 it was not the best in the world but could do proper 1024x1024
I actually skipped SD2 and SD2.1
I might go back some time
and see how they are
cos maybe for certain subjects they have a unique look

you didnt miss too much. Overall it was not that good. But there was nothing better. Try Illuminati 1.1 it can make very unique stuff

This shit knows proper details.
which checkpoint is this

Welcome to Illuminati Diffusion v1.1! This state-of-the-art text-to-image diffusion model is fine-tuned to produce high-quality, aesthetically plea...
ah ok
Yeah this one is a good one 2.1
realvis is already my main model lol
Very good choice 🙂
For illuminati you also need the 3 embeddings
they fix the model problems
provide on that page 🙂
then just check the examples



Dalle also does better in the rain and fog
I think rain and fog are good ways to make models more real

I don't know DallE that much and prefer local stuff 🙂


Hm how do I get a casual look in my images? like someone shot it on its crappy phone instead super high quality studio photos ? "shot on iphone" and similar doesn't really work. "Polaroid" gives some believable results. But is there something even better ?









cascade




Cascade




I use them in my iPad on the app draw things it’s free runs sd great
also cascad

Beautiful 😻
Cascade




idk if you're able to run comfyui but i got some nodes that are getting crazy shit outta it

Do you mind giving me the flow to try?
sure, no prob, you'll need the nodes https://github.com/ClownsharkBatwing/RES4LYF

GitHub
Contribute to ClownsharkBatwing/RES4LYF development by creating an account on GitHub.
git clone https://github.com/ClownsharkBatwing/RES4LYF
^run that in your custom_nodes folder
GitHub
Contribute to ClownsharkBatwing/RES4LYF development by creating an account on GitHub.
then cd into it, and type "pip install -r requirements.txt"
okay. I'll figure this out.
How many gigs do you think this will take up after full setup?
@copper kraken
of vram or disk space?
disk
for disk space, nothing beyond what you need for cascade itself, unless you want to use my lora, that's about 700mb i think




And ppl asking for bots 😂 images I still have some of ur funny images saved
oh god i miss the prompt zombies
😂
we made a sport out of it
i wish we still had that cascade channel
there's what, like 7 or 8 of us that are using it daily now at least?
Me too found one

hahaha
Yes u me and Mack I don’t really recognize anyone else
Least I give u credit thou had to save them good times

It does horror so good
it does... this was something generated from my paint lora
Best free model
so that's a 3D paint sculpture
yeah, for real
it got overlooked cuz the SD3 anouncement came a week after cascade was announced
Yes I’ll have to go digging but I did save some of ur work
Yes and XL too
They all released with in a week and we lost the bots
Now there’s way more drama
Good question kinda got hidden with Cascade and sd3
this was 100% me when i saw how nasty things were getting in the sd3 chan

seems to be calming down now though
Yes same Mack and I were getting annoyed because the time kept going up and ppl acted rage 😡 with out reading and knowing anything about the model … insane to see that much drama
Worse part it was over one prompt
i mean... a lot of it was funny at first... but then it turned really mean
😂 like seriously ppl all this over grass 😂
does sd3 have some big issues? yup, but jeez, keep your humor ppl and don't get so serious like you're actually going to die because your free AI art model isn't what you hoped it'd be
Yeah very mean
Cascade is better
My fave SD model and I agree
Not that I hate on sd3 just knew hands were gonna be a issue
Called it from day one
yeah
i think the big challenge is going to be learning how to wrangle a three text encoder model
from a training perspective in particular
i'm trying training experiments every night... getting SOME Results, but nothing terribly exciting yet
I’ll share my horror with u if that helps because right now it’s trial and error
it's ridiculously good at illustrations and paintings

better than any model i've tried
🤗 nice images



Use for many different things as it was trained on nightmare fuel, but is not limited to just that. Feeling generous? https://www.buymeacoffee.com/...



I have an issue with SDXL models
I'm on a new PC (3060 laptop), installed Auto1111, and my generations times are inconsistent
These are my .bat arguments:
set COMMANDLINE_ARGS=--medvram --medvram-sdxl --xformers --no-half-vae
I've gotten 1it/s on some generations and 2s/it on others
see if you have the same problem with comfyui or stableswarm
Exact same generation settings for both
Even the seed was exactly the same
512x512, 20 step, 7 CFG, I know 512x512 isn't recommended for XL but I'm just testing this GPU
Essentially same image generations vary from 20 seconds to 1 minute+, it's odd
I'll try SwarmUI now
Around 25 seconds with SwarmUI with the same generation settings
is it consistent now
Wait, SwarmUI was using 1024x1024 instead of 512x512
I entered 512x512 and now it's 10 seconds
Significantly faster
yep
a1111 is slow as f
stick with swarmUI if you can, it's gonna be getting lots of upgrades
I've done it 5 times with various prompts and each generation time is consistent





pls share more on this prompting?
Removing --medvram-sdxl from Auto1111 did help generation speed for some reason, but it's still 2 times slower than Swarm
we're looking to put guides together so results from any experiments are helpful and we'll be grateful
cool! yeah, i can get some stuff together for ya tomorrow.
Oh god, now I'm getting 35s/it on Auto1111, I'll enable medvram-sdxl again
i'm getting a significant shift in style now - it took a ton of steps, but it looks pretty awesome now and tehn with the right captions... haven't figured out how to make it reliable
the prompt there is some shuffled components of captions for the training set for the lora i was using for that (cascade)
the biggie is the sampling strategy
i took the RES sampler from @lyric grove 's awesome extra samplers node pack and threw on tons of bells and whistles that allow scheduling every parameter throughout every step of the diffusion process
there's very real benefits from that, i've found
Even with this argument, I'm getting 33s/it, I think 6GBs of VRAM is just not feasible with SDXL on Auto1111

yeah, honestly, best thing you can do is just switch to comfyui or swarmui
they're going to be much better supported in the future, and they're better right now in almost every way
Cinematic photograph of a menacing plant with spiked petals and blood-red sap dripping down, set in a dimly lit, dense forest, the sharp contrast between the vibrant red sap and the dark green foliage, detailed textures of the plant’s spiky petals and leaves, creating a chilling, eerie mood.













cascade? good stuff

yee












Sd runs better on cuda sounds like u do not have that https://stealthoptional.com/tech/stable-diffusion-runtime-error-how-to-fix-cuda-out-of-memory-error-in-stable-diffusion/

Stealth Optional
If the Stable Diffusion runtime error is preventing you from making art, here is what you need to do. Try these tips and CUDA out of memory error will be a thing of the past.







A young adventurer wearing a headband and boots holding glowing blue spiked fruits illuminated by the warm light of a setting sun vibrant, high above jagged rocky cliffs fierce dragon-like creatures with sharp teeth and colorful scales snarling, broken shards of rock and fruit suspended in the air, dramatic clouds swirling in the sky a sense of tension and exhilaration.




The fact that the poor kids prosthetic leg is breaking down is just another insight into a dysfunctional and dystopian health care system 😆
Cascade







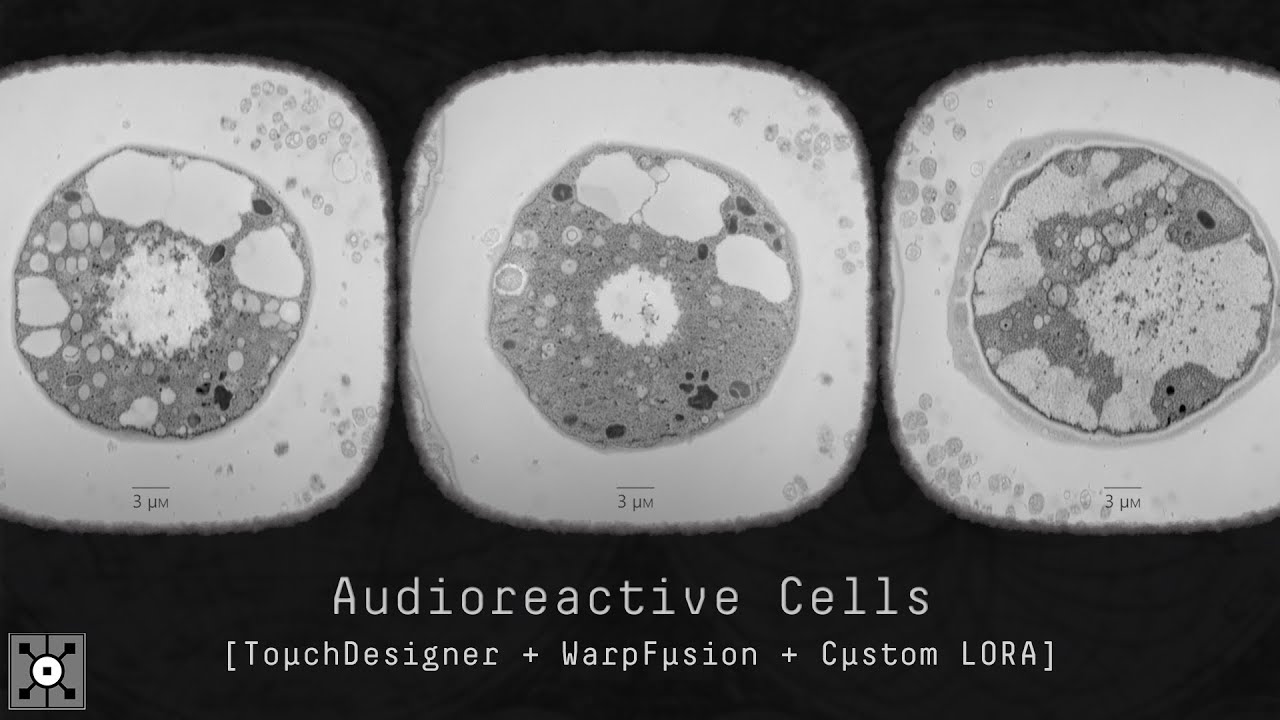
I've been experimenting with SD model fine-tuning for these past few weeks, and this one right here strike me as a hella-interesting one. Hopefully it does for you aswell.
This new system includes: TouchDesigner audio-reactive system ➜ SD/WP parameter configuration files ➜ Custom LORA [Electron Microscopy Style]
You can access these, plus many...
Finally tweaked my upscale. Need your impression peeps.
https://imgsli.com/Mjc0NTQx/1/2

Raw vs Old upscale vs New upscale
Click on the link for the comparison with a slider and the images choices. The raw output is there, for reference.
I need to manage again the contrast. Need to think about it. Probably a prompt issue.
💖 🤖 Strong results have put Boltning Hyper D into 2nd place on the SDXL Top 10 model list. It did pretty well with photorealism too 💗 🥳 https://docs.google.com/spreadsheets/d/1IYJw4Iv9M_vX507MPbdX4thhVYxOr6-IThbaRjdpVgM/edit?usp=sharing

Google Docs
General Prompt Adhere
Support Grockster - Click Here to Donate,One-on-One AI Training / Support Session,
Don’t quote me but I believe it’s 2

Neither is very sharp and clear, but I like this little addition 😄

Mind sharing the prompt for this please?





A lot going on in this one! 😄


i like the extra saber blades just for good measure.
AI: "star wars means lightsaber blades, a lot of them everywhere"




Images of people performing different types of cold therapy (cold showers, ice baths, cryotherapy).
Here’s the image you asked for












that's cool as F







Letter
Hey, here it is. May be random with another model lol
prompt:Photo of an amazingly beautiful creature with flowing white hair towering over a forest floor, its fur barely covering the delicate scales. Behind her lies stone staircases and ancient trees filled for miles above shorelines as rain fills each path to catch fish before it reaches, 2000s vintage RAW photo, photorealistic, film grain, candid camera, color graded cinematic, eye catchlights, atmospheric lighting, natural, shallow dof, High level of detail to create a photographic-like image, focusing on lighting, realistic textures, hyperdetailed. steps:40 width:832 height:1216 guidance_scale:5.0 sampler:DPM++ 3M SDE scheduler:exponential seed:1589594602 data_model:ZavyChromaXL negative_prompt:NSFW, nude, naked

Thanks! I think it's interesting seeing how it varies between models 🙂

I need something to automatically tweak the contrast/colors in a1111
Boring, my pics are so washed out when i try to improve my upscale...

prompt: "creature with multiple large eyes and sharp teeth, the scene is whimsical yet detailed, surrounded by lush green leaves and smaller golden blooms, a creepy"
The prompt is a little confusing for AI 😄

I changed it a bit

Got one like this, nice















what model is this??
Cascade




Yeah 70s muscle car rocks. I agree it could be a little better, but it's so amazing, pure prompt no lora. I cant complaint bro.
haha dont worry bro 🙂

Did this one too


CSBW wf









CSBW w/f








realvis xl lightning with ncp dpo lora is just insane! i didnt even add anything crazy to my prompt
prompt is
masterpiece, high quality, 8k, best quality, an horse in the space

Hello chat, im new here. I guess this channel is for all kinds of sdxl models?
i believe so
Still love what you can do with SDXL.

I still love sd15, but mainly use sdxl. and try sd3 a little
No good finetunes of cascade, that’s the problem.
Cascade base is def a lot better then sdxl base tho. Really good text too
and the reason for that... is cuz everyone thought sd3 was gonna be the next big thing
it trains more easily than sdxl, and now i just showed that the talk about training B being useless is false - it really is all you need to add that bit of polish
i'm getting better generations than i've gotten with sdxl now
You gotta try sdxl with this new dpo Lora tho. The detail is insane.

New technique tho, it just came out today I think
Bit different then the original sdxl dpo Lora’s but this improves quality massively. The original sdxl dpos were ok-ok
depends what you're aiming for, i s'pose
to me a lot of those examples look kinda cooked
but i go for a different style myself 🙂
Yeah true, imo I like these Lora’s too. They kinda make sdxl do real art

nice!

After having released Childhood Nightmares, I immediately started working on Sparklies Glowums to cleanse my mind. Use the weight as a slider for v...


If you want a little more vitality, a little younger flat wind illustration vertical











Cascade 🙂


Yes, but it's only using a captioner

Why?


You mean, training for that stuff you may want to use in the future?
Once I post on Discord I delete the image locally, so what's here is the only version of what I made 😄
If it helps build the models of the future, then I'm glad it goes to good use.
It's all clean here 🤷🏻♂️
蔷薇花
I am in nearly 90 discords, i like control over any traces i might have left anywhere.
Casacde




Cascade.



Characters:
Boy:
Attire: Wearing a light-colored short-sleeved shirt, sturdy khaki pants, hiking shoes with rubber details for grip, and an olive green travel backpack with side pockets.
Appearance: He has short, dark hair slightly tousled by the jungle breeze. His face is lightly tanned, with a neatly trimmed short beard. He is tall and athletic.
Pose: Holding the girl's han, he looks forward with a slight smile, his gaze full of curiosity for the adventure ahead.
Girl:
Attire: She wears a light-colored tank top, comfortable yet durable trekking pants, robust hiking shoes, and a colorful backpack with floral details.
Appearance: Her long dark hair is gathered in a ponytail for convenience, with some strands delicately falling on her face. She is slender and has an energetic and determined expression.
Pose: Holding the boy's hand affectionately, she has a slight expression of wonder. Her gaze is directed sideways, curious to explore the surrounding jungle.
Setting:
Amazon Jungle:
Vegetation: The environment is dominated by majestic trees with massive trunks and exposed roots, adorned with hanging vines. The foliage is dense and varied, featuring tropical plants with large, vibrant leaves and colorful flowers scattered throughout.
Extra Details: Colorful butterflies flutter among the trees, while rays of sunlight filter through the canopy, creating patterns of light and shadow on the ground. A narrow trail disappears into the vegetation, inviting discovery of hidden wonders within the jungle.
Composition:
Character Placement: The boy and girl are at the center of the illustration, walking away from the viewer into the jungle. Their left hands are clasped firmly, conveying a sense of unity and shared adventure.
Background: The jungle fills the entire background of the image, imparting a sense of depth and mystery. Tall trees and dense foliage envelop the characters, while the atmosphere is imbued with excitement for the impending exploration.

well, that makes it suck extra badly that #stable-cascade is gone






China's Loong Boat Festival, the background is three giant mountain Zongzi, surrounded by clouds, Loong Boat racing, Loong Boat moving on the water, the river winding from the huge mountain Zongzi to the distance, the background is misty mountains, rich in details, daytime, fairy fog, clouds, movie lighting, super high quality, super high resolution, ultra high definition, ultra clear details, 8K, HDR, Chinese style
Here is the image you requested.

the problem is it's all already gone and fruitt refuses to make them available again for whatever reason
thanks
Now that's a painting. Really good simplification.

Can't really get people with a painterly feel though. This is too good.

I know there are infinite models. I'm using CreaPrompt Hyper/Lightning v4 at 4 steps, with no hires fix. Maybe could get better results with a painting or art model, or a lora.
Scrolling through Civitai, all the paint models and loras have the same problem: The face colors are too subtle / realistic. No painter could blend this many shades this perfectly over such tiny surface changes.
Doesn't really matter anyway. I was just curious. Maybe someone could figure it out.
I mean the changes from pink to yellow to green on the skin of her face. Those subtle hue shifts are impossible with just blending pigments.
full body shot, miumiu fashion show, irregular shape, morden chinese digital style
Yeah. Reference from Gurney. You can try to paint those colors, but they'll never look as subtle and smooth as real life. SDXL is just too good at those gradients.

You don't seem to get what I'm talking about. Maybe you can't see it.
Pigments are exactly 1 hue. When you blend between two pigments, one hue fades out, and the other hue fades in. You can't add any other hues in there. It's physically impossible.
That has blue, pink, yellow, and green, but they're all blended over a huge, smooth area independent of the brush-stroke impressions.




dog, excited, happy expression, spacesuit, helmet, oxygen mask, floating, space, planets, cinematic, full-body, 4K, 9:16 aspect ratio, photorealistic, detailed, vibrant colors, majestic, otherworldly, visually stunning, classic composition, masterpiece, exquisite, color correction, amazing visual effects, intricate details, sharp focus, super high effect, HD, 16k --ar 9:16 --v 6.0
Here is the image you requested.

Mobius checkpoint










Stumbled upon a cool prompt prefix: unreal engine,c4d renderer,high resolution,Octane render, iconic bird view top shot of a







Hi everyone. I want to create female face shapes that are different from the same shape that sdxl always uses. What kind of words do you suggest using to modify face shape? I tried 'diamond shaped face" or "heart shaped face" type prompts but they seem to either not work or to put pictures of hearts on her cheeks. My overall plan is to make images then turn them into a lora for an original character. Any suggestions appreciated
That is a good idea. I have used controlnet but never tried doing that
Im trying to build an australian girl but the model doesnt understand that face shape.
I initially tried making a lora of instagram girls with that face but their camera quality is too bad
Those are the kind of words I was after
There are 100 breast slider loras but no face slider loras like youd find in skyrim
you have been posting some cool as fuck shit





Sorry guys. But i have a question regarding SDXL inpainting. Particularly in ForgeUI v #🤝|tech-support message




Here is the image with Lora you requested

made a decent amount of progress on cascade stuff btw










@gloomy lark @iron rover i combined your two images with cascade clipvision


Here is the image you requested.





Turbodong, is that you?





"Y'all need jesus, and I'm fresh out."

That’s so awesome 😎
That’s so awesome 😎 … I love ur stuff … I merged 3 horror artist together , using Cascade came out so good… artist Hp love craft , Wes craven and H.R. Giger






@vestal breach Can you ban the spamming bot please? ☝🏻






Good old base SDXL

Those are some great ones
Loooove creepy and weird









Erstelle mir einen Charakter aus dem Film Alles steht Kopf der für die Emotion zwang steht






Yesss add me on here we can collab I mainly do dark horror fantasy art
done 🙂




I converted one of my models to CosXL. You can get some interesting results when you mix the Original model with the CosXL clip. From left to right, Original model, Converted CosXL model, Original model + CosXL Clip.



I usually set output blocks 0-4 at 0.01 and don't use the cosxl clip at all because everything in the more recent advanced models is better.
yeah, i thought that was interesting that it didn't really make my converted model any darker, but the outputs are COMPLETELY different, which I kinda like.
yeah, they're compeltely different because the clip and training is very different than standard sdxl base.
models like mobius and aventishorizon etc that have been trained on really good GPT created captions and others are all going to be more prompt following than cosxl
I also noticed merging loras into it doesn't really work out
I found in a/b comparisons, using the cosxl generally made the model dumber to put a blunt end on it.
yeah, things that should be photographic are coming out as paintings which i thought was odd.
until I realized I didn't need to bring any of that into the merge, and could leave hte clip behind, and only have 0.01 for the output blocks, preserving the most of the original
yeah, loras are based on sdxl base. unfortunately cosxl is effectively a different base model.
they really should have just released a version of sdxl base that ignores the brightness/darkness limitations.
yeah. what're you're thoughts on mobius? i've seen it get a lot of hate and doubt



Both good, though SDXL seems just a tad better.
It didn't get black and white either. things seem further away in it too, which can be good. trying some merges out on it.





my favorite sdxl at this point is mobius with an aventishorizon refiner stage.
@vast galleon some mobius from today.






nice






mobius is nice, but whats going to be really useful is the training strategy they use. mobius as a model itself is decent but isnt some model that beats every other model.
why is there harley quinn in the bottom lol, and what prompt?
My watermark says my name too
I do that not to only share here but also on deviant art and fb etc
I merged it's clip slightly with the model I'm working on, in addition to the clip from the converted CosXL model I made. The differences are small, but it improves some things slightly.
nice, i cant wait for the mobius training strategy. If what they say is really true, then it can really improve sdxl generation.

pony i guess? I never really got good results with pony. Any settings you recommend?

yeah it definitely seems a lot better then other sdxl model with poses, il try it with those loras
Pony Diffusion v6 xL if u are looking for similar results as me as for the horror side like mine that’s actually me drawing by hand adding in the sfx
But u can cut the prompt down use the trigger words and say no to nsfw
I’m like u I’m not into that type of art either just love the poses
Great for horror when I draw
Don’t forget to change the dress color and hair that’s how I got Cinderella and Belle is obviously the Lora
yeah example images show how good it is, is it also good for prompt following compared to models like proteus or just other sdxl finetunes?
for realistic things, i guess this is better?
https://civitai.com/models/372465/pony-realism?modelVersionId=534642

⚠️ Please read the description 🏋️♀️ For training LoRas using the model go here ♻️ v2.1 Is a major rework of the model. Main version has the most detail ...
Thank u I will def do that…
Meaning check it out yesss it’s perfect with bodies and I’m not knocking sd3 but it’s great for what we want none nsfw
But I do love Cascade too!
Gonna be dropping Mangled Merge XL V3 in the next few days. 1800 loras merged. The last 600 were using the DARE/TIES method. So far it seems capable of both photorealism and pretty good 2D.













create a image of fantacy race inspired from snakemen
Here’s the image u requested

Spider girl Jasmine





















Those war scenes are gritty for real

that's beautiful

anyone know how i can use two shot/latent coupling for sdxl?
whats the best overall sdxl model for human anatomy and overall except pony?













Might be useful to many here: https://www.magicflow.ai/insights/read/sdxl-realistic-keywords

SDXL is great for realistic photos, learn how some keywords make it even better while some do not.





🚀 🍪 Congrats to @mellow tendon who's JibMix has entered the realm of the SDXL Top 10! Nice rich model! 🤘 💖 https://docs.google.com/spreadsheets/d/1IYJw4Iv9M_vX507MPbdX4thhVYxOr6-IThbaRjdpVgM/edit?usp=sharing

Google Docs
General Prompt Adhere
Support Grockster - Click Here to Donate,One-on-One AI Training / Support Session,



Really only beaten by sd3 8b on the api
They recently released 1.1 of hunyuan which improved things, and 1.2 is coming shortly.
Photorealism is boring. None of the stuff I do makes sense in a photorealistic setting.
although I guess I could rephrase the trumptopus as photorealistic, let's see.

so that's sd3 8b with multiple photo realistic keywords. it refuses to do it.
SD3 goes way more photo realistic than this
you've gotta get the famous guy out of the test LOL
its triggering the censorship probably
here is a good example of sd3
https://old.reddit.com/r/StableDiffusion/comments/1dlvaej/sd3_can_make_real_instagram_photo_somtime/

Reddit
Explore this post and more from the StableDiffusion community
another from hunyuan/refined




more hunyuan/realvis
there's basically no detail at all on their face
I don't understand how that compares to this at all https://old.reddit.com/r/StableDiffusion/comments/1dlvaej/sd3_can_make_real_instagram_photo_somtime/
Reddit
Explore this post and more from the StableDiffusion community


Bring that certain classic film look to your prompts with Classic_Film_Look_XL. Feeling generous? https://www.buymeacoffee.com/generalawareness
Is it the new Hunyuan v1.2?
AI bg changer:




generate image of a art model front facing with hands on waist half clothed posing for artist
generate image of a art model front facing with hands on waist half clothed posing for artist ✨ | sdxl
I made 8 different images with the SD A1111 Photoshop Plugin - and cut+pasted into this composite


Man, your images (not only these ones but since weeks) has been so freaking cool 👏
Oh yeah??? Your lately image has been using your new checkpoint ?
Hunyuan 1.1. Apparently they released 1.2 right after I went to bed for the night. 🙂
It was uploaded 3 days ago, but I've not managed to get it running in Comfy yet

This implies last night
There was a captioner, but this is the image model.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
They keep releasing stuff constantly
Maybe I've downloaded the wrong stuff, and that's why it won't work.
Oh ok you're right. Well, ultimately we want the distilled anyway. 🙂 it's better quality for the same steps.
The model file is double the size, but it's "faster", but higher quality if you keep the same higher number of steps
So I'm doing 25 steps of ddim/ddim-uniform, but with distilled you could do 13 if you wanted to. I use that extra speed to just keep it at 25
I deleted my original install, and can' remeber what goes where now 🤷🏻♂️
this is the workflow I'm using currently. So the hunyuan 1.2 distilled is in safetensors format. that's good compared to the old pickle, but the city 96 extra models nodes don't work with that, so I'll have to ask them about updating the nodes.
Which directories the models go into 🙂
GitHub
Support for miscellaneous image models. Currently supports: DiT, PixArt, HunYuanDiT, MiaoBi, and a few VAEs. - city96/ComfyUI_ExtraModels
if you go here, and scroll down to hunyuandit, it'll get you going with the right files and directories. i'd say that you want to search for the hunyuan 1.1 distilled model though and put that in there instead of 1.0
Ah yes! Thanks 🙂