
#🤝|tech-support
1 messages · Page 78 of 1
shot in the dark but least it says point blank "you no longer need to manually install openvino" so i can be sure im getting my boost here . . . had my sight set on stable boy but if idk whether i gots openvino or not for sure . . . or, fingers crossed, i get best of all worlds
only now idk how to compile from source code so . . . and that looks like only option for this thing
anyhow, ill be bck to bitch more later, count on it 😛 til then, yall be well 🙂
anyone can tell me how i might put together that source code there for them openvino-ai-plugins-gimp 2.99 r2? im on windows btw
i would just download from the green button on that other page related but i dont trust id be getting the very newest there
GitHub
GIMP AI plugins with OpenVINO Backend. Contribute to intel/openvino-ai-plugins-gimp development by creating an account on GitHub.
clone with git
git clone https://github.com/intel/openvino-ai-plugins-gimp.git
and run
install.bat
or download from https://github.com/intel/openvino-ai-plugins-gimp/releases/tag/v2.99-R2
unzip and run install.bat

GitHub
v2.99-R2
This is the second official release of OpenVINO™ AI Plugins for GIMP.
Updates:
Updated all the plugins to use OpenVINO™ 2024.0 API
Removed old plugins
Added power modes (Balanced, Best P...
anyone know how to put stable diffusion on taskbar
give a detailed instruction on how to enlarge the finished photo in resolution? I have an order to increase the quality and resolution of the photo. How do I do this?
easy
create a shortcut
https://www.easytechguides.com/pin-a-batch-file-to-the-taskbar-or-start-menu-in-windows-10/
but be sure to add full path to your stabile diffusion folder in start in
for example
c:\ai\stable-diffusion-webui

- create a shortcut like described in the link (let it be on the desktop)
- right click the shortcut and end find "start in" field and add the full path to folder
- try to open it
- if it works add to taskbar as described in the link
where your webui-user.bat is?
C:\Users\HIGHDEEUHH\Documents\StableDiffusionAuto11111
than put that in start in
this is the target url to desktop shortcut webui
C:\Users\HIGHDEEUHH\Desktop\webui-user - Shortcut.lnk

C:\Users\HIGHDEEUHH\Documents\StableDiffusionAuto11111
put that as target?

cmd /c "C:\Users\HIGHDEEUHH\Documents\StableDiffusionAuto11111" ?
cmd /c "C:\Users\HIGHDEEUHH\Documents\StableDiffusionAuto11111\webui-user.bat"
ok
and C:\Users\HIGHDEEUHH\Documents\StableDiffusionAuto11111
in start in

i guess
i am using windows only when i need 🙂
a few times a year
i forgot many things since i first switched to linux, than to macos
@vocal burrow@ornate elk check out this
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16113
I accidentally stumbled upon this bug, while i was testing https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/16092
😳

GitHub
Checklist The issue exists after disabling all extensions The issue exists on a clean installation of webui The issue is caused by an extension, but I believe it is caused by a bug in the webui The...
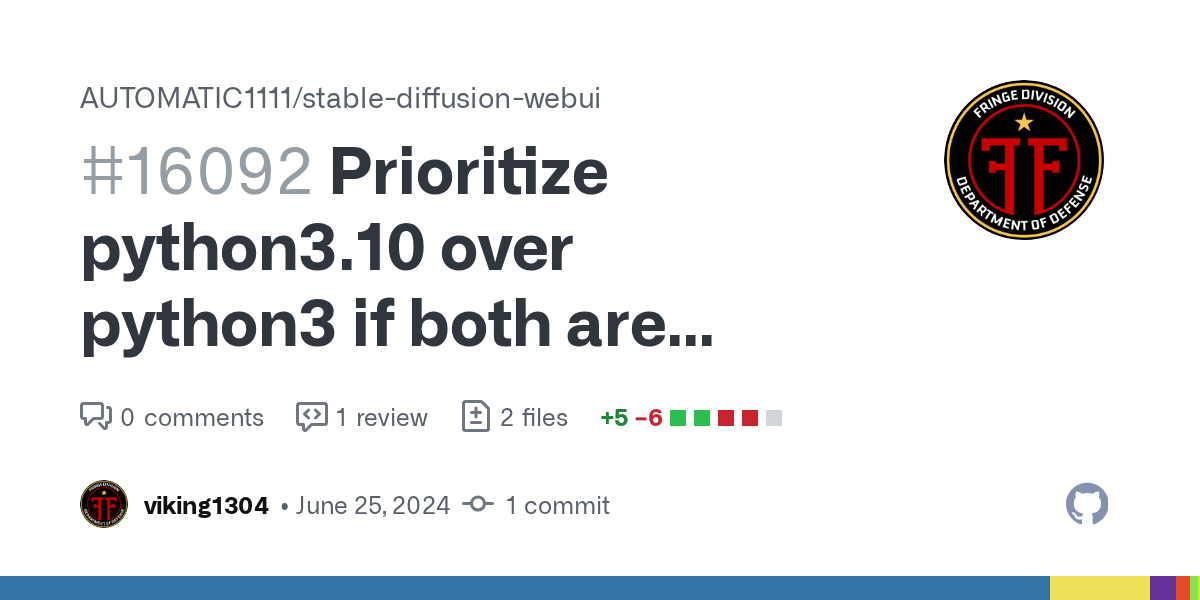
GitHub
Description
prioritizes python3.10 over python3 if both are available
ensure that a specified Python version is available; otherwise, fallback to python3
removes redundant code from mac specific v...
There are changes since Zluda release in February, you can generate pretty fast on windows now
Also WSL2 beta dropped a few days ago
Very interesting find!
having lag spikes mid loading and when its about to be do loading , there for a short time
I'll try it , thank you so much
Hello everyone, can someone help me I'm trying to use ComfyUI on Windows 11. My problem more specifically is with the custom_nodes in the ComfyUI-Manager. I include an image so you can see the problem. As you can see by ComfyUI-Manager it says "Try Update" I have tried clicking this and it gives me the option to restart the server which I click on but after it restarts the same problem is still there. Also "ComfyUI Impact Pack" has a conflict warning and so do other things if I scroll down. When I click on the triangle with the exclamation mark associated with "ComfyUI Impact Pack" I get the following message "【ComfyUI Impact Pack】Conflicted Nodes (1)
SAMLoader [ComfyUI-YOLO]"

Why does the default inpainting model recreate the wood texture well? But dreamshaper inpainting and realisticvision inpainting cant?
Same settings/seeds. Only ckpt are changed.
Is my UI bugged?



i removed venv, relaunched ./webui.sh and in a few seconds, it was running
and i was like 🤯
i tried few more times, with same result
then i checked libraries in venv and there were pip and setup tools
everyting else was installed globally
worst part is that based on the log everything works fine, and venv is created and activated 🙂
does forge have a venv folder?
Does anyone here know why SDXL inpainting models look so bad while inpainting in Gorge webui? It blurs the edges of the inpainted area.
It has been driving me crazy ever since SDXL got inpaint models. Is there a trick that i should be doing or something? xD
[8:23 PM]
(I've also tried using it with the soft inpainting enabled and disabled. Also with both high and low mask blurring too.)
if you are using "one-click" package than no
if you are cloned from git, than it is
i need to update ultralytics, is there no venv?

shit man thanks for the effort
oh ig "environment" is the one
no
wait
you have two folders
system and webui
go to system

it has 3 folders there
go to python
and do pip install or whatever
thats it
gimme a sec testing it now

Hey install python 3.10.11 64bit
Check "add python to path"
Then delete the venv folder and relaunch the webui-user.bat
how do I do the ''add python to path''
I'm struggling with that right now
there is no activate script in Scripts for some reason
what python version did you installed before?
idk how else to activate the venv
3.10.6 but I uninstalled it to get 3.10.11
like you said
you do not have venv, so no activate
just run pip from the folder python
then run the installer once
and then run it again, select Modify, Next, and check "add python to environment variables"
it has its own python in that folder
alright im trying it
I just did it now what?
delete the venv folder if there is one
if not then relaunch the webui-user,bat
Installing something right now I'll let you know what happens later, thanks for helping me
😃
no problem, also dont forget to add the performance launch arsg later
depending on whats your gpu
having lag spikes mid loading and when its about to be do loading , there for a short time
need help
more information please, webui version, webui-uer.bat content, gpu model, txt2img settings, cmd log
Quick easy question: I am using img2img where I am changing the character in the image to another character with a lora. I am happy with most of the output, but the eyes are usually the spot where it fails noticeably. I normally go into Photoshop and manually edit them, but is there a way to like... inpaint just the face / eyes to improve them?
yep there is an extension exactly for that called Adetailer
Oh perfect I'll check that out, thank you!
np!
is it possible to like merge 2 character loras and make it so the lora generates images with the characters in one photo
you mean you want two different characters based on loras in one image?
thats possible with the Regional Prompter Extensions. After installing it check this out:
#🤝|tech-support message
anything like this for comfyui? also this only really works when they dont interact, right?…
kissing and hugging is easier, the rest not doable, idk if there is a node for comfyui
how come is it easier?
easier than other poses
sry
normal standing or sitting and not interacting is the easiest
then comes kissing, hugging, which can be done too
and everything beyond that is not easy or doable
guys any of you have this option enabled?
is sd3 coming to Dreams?
Wouldn't that make it Nightmares?
no that was Joe Bidens debate
It's not his fault he slept through it.
but his eyes were too wide open to be asleep
We'll see how well you debate when you're 182 years old.
Quick question for anyone who knows about lora training...I use buckets, and all of my images are above 1024x1024, but when I look in the command window of kohya ss, I can see that it's making a bucket of 960x960 for some of my images. Is that normal or will it affect my training somehow? I never noticed it before today.
Trump didn't even attend the correct debate, though. The one he was answering the questions for was the world that exists inside his head.
It's a good thing that a presidential debate isn't the actual measure of capability in the position. It's also a good thing that the position isn't nearly as powerful as a lot of people think it is.
(But this is #🤝|tech-support, so I won't continue to post on this topic after this; I just wanted to ensure the counterpoint was made. Life is best when there's a balance.)
idk what your saying...i just want to know if sd3 is in Dreams now
Oh, I think you know what I'm saying.
no i dont...even cnn and msnbc stated Biden is lost, he will not be the dem candidate...sorry to burst your dreamz
We'll see come November. ✌️
ye!
yo soo the bug is still here @ornate elk 😦

its just stuck like that
its weird if i press enter on the cmd it fixes it but i dont think its suppose to work this way
you paused the cmd by clicking on it xD
pressing space unpause it again
you can see that also at this white block
lol
thanks man
but it did fix most of the other bug stuff after i did what u told me
soo thanks for that as well
perfect, no problem 🙂
I am sorry for a really silly question, but my python is updated to 3.10, yet I am getting an error saying I am using 3.8.2... is there any way I can rectify this issue?
you can uninstall 3.8 if not needed then run the python 3.10.11 installer again and click modify, next, and check "add python to environment variables"
then delete the venv folder and relaunch the webui-user.bat
I think that did it... lets see if this works this time
While I am waiting on this install, why is A1111 a web UI? Why not its own GUI application? Maybe I am dumb but I think that'd be cool
Or, does running A1111 essentially mean I run it personally and I can generate as much stuff as possible and negate the need for credits?
Something strange is happening
What's that?
For some reasons

one model is working but all the others aren't

they load grey images
loras appear in the web folder but do not have any result when I click and add them to the prompt tired inlcuding trigger words and exluding trigger words.
Good morning from France anyone 🇫🇷 !
I have some troubles with my installation of Automatic1111, It's kinda weird, each time I load a model into my instance, the model load into my VRAM but stays un RAM too  , if load 3 models, my ram is saturated and in have to kill my process et reload anything.
, if load 3 models, my ram is saturated and in have to kill my process et reload anything.
I'm running Automatic1111 on "Pop!_OS" with Nvidia drivers, the latest version, on a GTX 1080 Ti, the CPU / MB / RAM is old too, but good enough :p
Does anyone have any idea how to fix this huge annoyance ? 
tryna run sd locally and this is popping up. using amd gpu running automatic111 any idea what i should do ?

@karmic crown yeah so after playing with A1111 yesterday, it's doing the job on my M1 Pro but for iterating quick and experimenting the workflow is a bit slow indeed haha
@fossil tendon show me your webui-user.sh
#!/bin/bash
#########################################################
# Uncomment and change the variables below to your need:#
#########################################################
# Install directory without trailing slash
#install_dir="/home/$(whoami)"
# Name of the subdirectory
#clone_dir="stable-diffusion-webui"
# Commandline arguments for webui.py, for example: export COMMANDLINE_ARGS="--medvram --opt-split-attention"
#export COMMANDLINE_ARGS=""
export COMMANDLINE_ARGS="--skip-torch-cuda-test --opt-sub-quad-attention --upcast-sampling --no-half-vae --use-cpu interrogate"
# python3 executable
#python_cmd="python3"
# git executable
#export GIT="git"
# python3 venv without trailing slash (defaults to ${install_dir}/${clone_dir}/venv)
#venv_dir="venv"
# script to launch to start the app
#export LAUNCH_SCRIPT="launch.py"
# install command for torch
#export TORCH_COMMAND="pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113"
export TORCH_COMMAND="pip install --pre torch torchvision --index-url https://download.pytorch.org/whl/nightly/cpu"
# Requirements file to use for stable-diffusion-webui
#export REQS_FILE="requirements_versions.txt"
# Fixed git repos
#export K_DIFFUSION_PACKAGE=""
#export GFPGAN_PACKAGE=""
# Fixed git commits
#export STABLE_DIFFUSION_COMMIT_HASH=""
#export CODEFORMER_COMMIT_HASH=""
#export BLIP_COMMIT_HASH=""
# Uncomment to enable accelerated launch
#export ACCELERATE="True"
# Uncomment to disable TCMalloc
#export NO_TCMALLOC="True"
###########################################
I didn't change anything
i was just thinking about it while looking at the discord's tab seeing the "sd3" and "sdxl" chans and remembered you said something about sdxl being slower than 1.5
when you install a1111 it automatically download and install default 1.5 model
tbh i totally forgot about that detail, was just downloading models from civitai and didn't really pay attention if it was xl or 1.5 😅
so that may have caused slowness too
show me the model name
or link
even better
you can try this:
export COMMANDLINE_ARGS="--skip-torch-cuda-test --opt-sub-quad-attention --upcast-sampling --no-half-vae --medvram-sdxl --use-cpu interrogate"
this will use medvram only for sdxl models
Oh yeah I see, it's written in the model details
yes
do not use 40 steps, use 20
it is enough
disable upscaler, upscale only images you are satisfied with
yep this i figured it out haha
try LCM, turbo and lightning models, they work "faster", since they require less steps
so i should focus on checkpoints/loras with base model being SD 1.5 and not XL ?
you can get great images in just 8 steps
I generally read the recommendations on the model's page
you can use xl, but be sure to add that parameter i send
for Realistic Vision for example they say 4-6 steps
but do not try with sde++ and 40 steps + upscaler
alright, i just add the parameter and relaunched the webui
when applying changes to reload fully i just relaunch webui.sh right ?
close the terminal (or use CTRL+C), and run it again
it is CTRL, not COMMAND
try this model

This my first full LCM model. Its also the first model of the NextGenXL version of Hephaistos. Its trained on a merge of Hephaistos and Colossus Pr...

that image is created with 9 steps as you can see
and it looks amazing
yes i try to be mindful of the steps, it seems like some models are optimised for lower steps count
i need to go now
thanks for your help! much appreciated
Exactly that
Hey, wb, what video upscaler?
Hey you need to edit the webui-user.sh
At the line commandline_args=
You need to add: --xformers --medvram-sdxl --no-half-vae
Then save and relaunch
What's your GPU?
I'm on Linux, I have edited the webui-user.sh, but doesn't work
When I launch le instance, I see the command line args loading 😉
Then they should work
For SD on Linux you also need a large swapfile.
Especially when using sdxl models
Also 32gb ram min or an equivalent swapfile
Ah okay
But 20gb swap seems okay.
What you can check too is a setting in the webui where it states how many models should stay in RAM
Oh sorry
Picture
I’m just tearing apart videos frame by frame and upscaling it image by image
Ah okay, and what upscaler doesn't work?
Can I add --lowram ?
Yes you can try that
Ngl Idr atp
I haven’t tested it since I got back
And it’s 2am rn so I don’t wanna get back on
I’ll try again tomorrow lol
Alright okay ^^
Sorry but I cannot find it :/
Well with the args, I cannot generate more than 2 imgs, before max out RAM and SWAP and the process crash
Without any args, I only have the problem when loading the models
I've tried "--disable-model-loading-ram-optimization" too
With args when I start the webui.sh, I'm already at 10Gb+ RAM used and 3Gb+ SWAP
Without 3.18Gb RAM / 1.56Gb SWAP
Thats normal when using an sdxl or pony model
So I can't run args ? 
Yeah
For the test without the args I've commented the line to "remove" them, and I remove the "#" for enabling the line (save and relaunch too)
Maybe I'ts just my hardware, too old to run this type of workload, dunno
Has the automatic111 update for SD been released?
Check if the webui lists xformers at the bottom
Please help me. I have a photo from the Internet in poor quality, is it possible to increase the image resolution using SD?
Can I have more details, please?
Sorry but sure to understand :/
If you are talking about what said the terminal at launch, I have a line saying : "No module 'xformers' . Proceeding without it."
hmu if any1 comes accross an xl brightness control
Then its not working
Can you screenshot the webui-user.sh commandline_args?
You have uncommented the example too?
Better remove it
Thats why it won't work
It's like that by default, but ok
Oh okay, maybe my view on mobile screen crops it in a weird way
Ah yeah, maybe ^^
Try to install xformers manually into the venv
go to the webui directory
source ./venv/bin/activate
cd repositories
git clone https://github.com/facebookresearch/xformers.git
cd xformers
git submodule update --init --recursive
pip install -r requirements.txt
pip install -e .
GitHub
Hackable and optimized Transformers building blocks, supporting a composable construction. - facebookresearch/xformers
Also is your webui updated?
What version are you on?
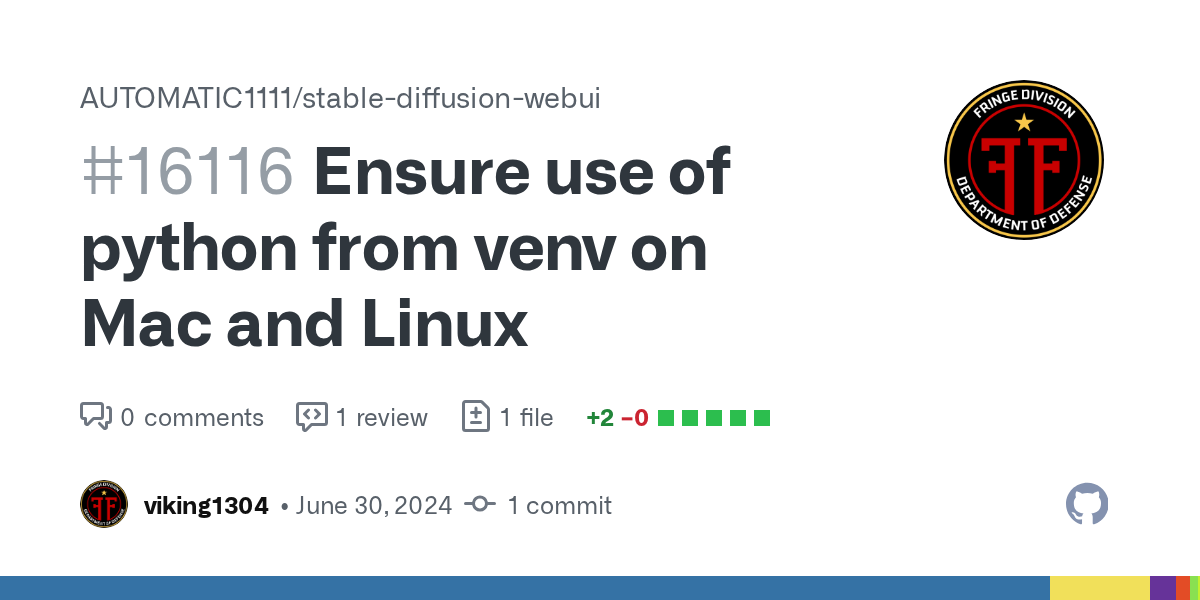
GitHub
Description
If the user sets the full path to the Python executable in webui-user.sh, venv will be created as usual. Everything will work and look normal, but all packages will be actually installe...
FIXED 🥳
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
xformers 0.0.23.post1 requires torch==2.1.2, but you have torch 2.3.1 which is incompatible.
torchvision 0.16.2+cu121 requires torch==2.1.2, but you have torch 2.3.1 which is incompatible.
Successfully installed nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-8.9.2.26 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.20.5 nvidia-nvjitlink-cu12-12.5.40 nvidia-nvtx-cu12-12.1.105 torch-2.3.1 triton-2.3.1
[notice] A new release of pip is available: 23.0.1 -> 24.1.1
[notice] To update, run: pip install --upgrade pip
(venv) ai@pop-os:~/SD/stable-diffusion-webui/repositories/xformers$
Can someone kill me ? please ?
actually wait
Too late x)
Yep
did you set torch command in webui-user.sh?
sorry i was busy with something, didnt read all of your messages
What's that ? x)
No worries
in your stable-diffusion-webui folder you have a file webui-user.sh
Yes, I'm on it
lines 27 and 28 looks like this
# install command for torch
#export TORCH_COMMAND="pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113"`
or you have something else there?
Exactly the same
give me a second to see what it actually use for your system
Anyone know why my ponyrealism output is so bad?
This is the output I'm getting
File "C:\Users\User\Documents\Stable Diffusion\webui\venv\lib\site-packages\gradio\routes.py", line 488, in run_predict
output = await app.get_blocks().process_api(
File "C:\Users\User\Documents\Stable Diffusion\webui\venv\lib\site-packages\gradio\blocks.py", line 1434, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "C:\Users\User\Documents\Stable Diffusion\webui\venv\lib\site-packages\gradio\blocks.py", line 1335, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File "C:\Users\User\Documents\Stable Diffusion\webui\venv\lib\site-packages\gradio\components\gallery.py", line 197, in postprocess
file_path = str(utils.abspath(file))
File "C:\Users\User\Documents\Stable Diffusion\webui\venv\lib\site-packages\gradio\utils.py", line 938, in abspath
if is_symlink or path == path.resolve(): # in case path couldn't be resolved
File "C:\Users\User\AppData\Local\Programs\Python\Python39\lib\pathlib.py", line 1215, in resolve
s = self._flavour.resolve(self, strict=strict)
File "C:\Users\User\AppData\Local\Programs\Python\Python39\lib\pathlib.py", line 215, in resolve
s = self._ext_to_normal(_getfinalpathname(s))
OSError: [WinError 123] The filename, directory name, or volume label syntax is incorrect: 'outputs\txt2img-images\2024-06-30\00001-475401799.png?1719742543.8466835'

ok, change that line to be like this
export TORCH_COMMAND="pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118"
deactivate venv and then delete venv folder
run ./webui.sh
it will create a new venv for you
this should isntall torch 2.3.1 with cuda 118
if that does not work, we will try some older version
"?" and some other characters cannot be used in a filename
'00001-475401799.png?1719742543.8466835'
i am 99% you didnt set that yourself
Correct
The file saves regularly in the folder though, and the image quality is much lower than expected, as seen above
that is the reason for an error, but what is the cause... i really have no idea
It's def the reason for the filename error output, though would it be the reason for the image being so blotchy?
it should not be realted at all, but there might be something that is not working correctly and cause both problems
ERROR: Cannot activate python venv, aborting...
At the execution of the webui.sh :/
give me a second
show me the result of this
echo -e "\nInstalled python versions:";for v in {10..12}; do if command -v python3."${v}" &> /dev/null;then python_version="$(python3."${v}" --version)";python_path="$(which python3."${v}")";echo -e " \033[34m${python_version#*[[:space:]]}\033[0m: ${python_path}";fi;done;if command -v python3 &> /dev/null;then p3="$(python3 --version)";echo -e "\nDefault Python version: \033[34m${p3#*[[:space:]]}\033[0m";fi
it should be something like this
Installed python versions:
3.10.14: /opt/homebrew/bin/python3.10
3.12.4: /opt/homebrew/bin/python3.12
Default Python version: 3.12.4
Installed python versions:
3.10.12: /usr/bin/python3.10
Default Python version: 3.10.12
that looks fine
where can I find the best stable diffusion? is stable diffusion 3 free?
run those one by one
which python
which python3
which pip
which pip3
and show me what you have
Anyone have any idea what might be adding the ? and numbers after the .png? I've checked the output formatting and it's regular
try to disable extensions and to run generation with just a model and all extensions disabled
if that works, than some of the plugins make a problem
which python : Nothing
which python3 : /usr/bin/python3
which pip : Nothing
which pip3 : Nothing
which python3.10 : /usr/bin/python3.10
which pip3.10 : Nothing
No worries ^^
ok, do this
python3 -m ensurepip --upgrade
and try
which pip3
again after that
if that works
which pip3.10
should work too
I got "/usr/bin/python3: No module named ensurepip"
can you please reinstall python?
pip does not work for you
Okay

Pop!_OS is a popular operating system based on Ubuntu, and like most operating systems, it comes with a default version of Python installed. However, you may want to install a newer version of Python or multiple versions of Python on your system for different purposes. Python is a popular programming language that is widely used
you can use ppa:deadsnakes/ppa
i use that on ubuntu
Hmm.. Getting the same issue w all extensions disabled
try another model
I did, tried a few and all gave the same issue
your webui might be corruptet, try to update
Do you think I need to try a full 1111 reinstall? Would suck
just do git pull
Funny bc I just did a git pull right before this session
So maybe the update itself is the corruption?
ok show me git status
Did a git pull via the user ui bat
Sorry for the noob level knowledge here, where do I find that?
I cannot remove the current Python
blah...
Well I want to trash all this and restart form scratch
how about
sudo apt install --reinstall python3
Hmm... I may have messed something up...
PS C:\Users\User\Documents\Stable Diffusion\webui> git status
On branch master
Your branch is up to date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: webui-user.bat
no changes added to commit (use "git add" and/or "git commit -a")
PS C:\Users\User\Documents\Stable Diffusion\webui>
Oh ahaha maybe I didn't mess it up then
that is really strange
I'll show you what the inside of my webui-user.bat looks like
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--autolaunch --medvram --xformers --no-half --disable-nan-check
call git pull
call webui.bat
Reinstalled but nothing when I type : which pip3.10 and which pip3
add --disable-all-extensions (you will remove it later)
and run again
python3 -m pip --version
is this works?
/usr/bin/python3: No module named pip
python3 -m pip install --upgrade pip
It's the same : /usr/bin/python3: No module named pip
IDK Why
i see now, that was stupid sugestion
python3 -m ensurepip --version
is this working
Sadly not, same as last time : /usr/bin/python3: No module named ensurepip
install 3.11 from deadsnakes/ppa
that will have all the things you need
Same issue
when you install that and confirm that both
python3.11 and pip3.11 works
you will need to add this to your webui-user.sh
python_cmd="python3.11"
its in line 16
delete venv and rerun webui-user.bat
it will create new one
any change?
I've installed the version 3.11 and when I "python3 --version" : "Python 3.10.12"
its ok
ERROR: Could not find a version that satisfies the requirement torch==2.1.2 (from versions: 2.2.0, 2.2.0+cu121, 2.2.1, 2.2.1+cu121, 2.2.2, 2.2.2+cu121, 2.3.0, 2.3.0+cu121, 2.3.1, 2.3.1+cu121)
ERROR: No matching distribution found for torch==2.1.2
python3.11 --version
Python 3.11.9 🙂
you are using pyton3.12
you need python 3.10
How do I downgrade that?
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
just download the right version
So I don't have to deacticate 3.12?
and pip3.11 --version (please tell me that it works)
i have all versions from 3.8 -3.12 🙂
i need them for diffrent tests
ai@pop-os:~/SD/stable-diffusion-webui$ pip3.11 --version
Command 'pip3.11' not found, did you mean:
command 'pip3.10' from deb python3-pip (22.0.2+dfsg-1ubuntu0.3)
Try: sudo apt install <deb name>
ai@pop-os:~/SD/stable-diffusion-webui$ pip3.10 --version
Command 'pip3.10' not found, but can be installed with:
sudo apt install python3-pip
Well... If that's not "F" up
whats your gpu?
never use --disable-nan-check
After the install :
ai@pop-os:~/SD/stable-diffusion-webui$ pip3.11 --version
Command 'pip3.11' not found, did you mean:
command 'pip3.10' from deb python3-pip (22.0.2+dfsg-1ubuntu0.3)
Try: sudo apt install <deb name>
ai@pop-os:~/SD/stable-diffusion-webui$ pip3.10 --version
pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)
ai@pop-os:~/SD/stable-diffusion-webui$
note to self: "some c.... distributions have a f.... python3-pip package" 😱
3080 12gb
Getting the same error after installing 3.10
then remove --no-half --disable-nan-check and change --medvram to --medvram-sdxl
i told him to remove venv and now cannot install torch 2.1.2
so it he is obviously on 3.12
oh wait
sorry
didnt notice this
@ornate elk remember this, when someone else start pulling hair off becuse he cannot install pip
@drifting pendant try again now
but without 3.11 in webui-user.sh
just commend that line (add # at the begining)
we finally fixed your 3.10 installation
Output I'm getting:
The Python error, then:
[notice] A new release of pip is available: 24.0 -> 24.1.1
[notice] To update, run: C:\Users\User\Documents\Stable Diffusion\webui\venv\Scripts\python.exe -m pip install --upgrade pip
Traceback (most recent call last):
File "C:\Users\User\Documents\Stable Diffusion\webui\launch.py", line 48, in <module>
main()
File "C:\Users\User\Documents\Stable Diffusion\webui\launch.py", line 39, in main
prepare_environment()
File "C:\Users\User\Documents\Stable Diffusion\webui\modules\launch_utils.py", line 380, in prepare_environment
run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)
File "C:\Users\User\Documents\Stable Diffusion\webui\modules\launch_utils.py", line 115, in run
raise RuntimeError("\n".join(error_bits))
RuntimeError: Couldn't install torch.
Command: "C:\Users\User\Documents\Stable Diffusion\webui\venv\Scripts\python.exe" -m pip install torch==2.1.2 torchvision==0.16.2 --extra-index-url https://download.pytorch.org/whl/cu121
Error code: 1
Press any key to continue . . .
Maybe it was when I try this, everything was broken
sudo apt install python3.10 python3.10-venv python3.10-dev
do this first
Please share the full cmd log
ERROR: Cannot activate python venv, aborting...
Already up to date.
venv "C:\Users\User\Documents\Stable Diffusion\webui\venv\Scripts\Python.exe"
INCOMPATIBLE PYTHON VERSION
This program is tested with 3.10.6 Python, but you have 3.12.3.
If you encounter an error with "RuntimeError: Couldn't install torch." message,
or any other error regarding unsuccessful package (library) installation,
please downgrade (or upgrade) to the latest version of 3.10 Python
and delete current Python and "venv" folder in WebUI's directory.
You can download 3.10 Python from here: https://www.python.org/downloads/release/python-3106/
Alternatively, use a binary release of WebUI: https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre
Use --skip-python-version-check to suppress this warning.
1/2

GitHub
The webui.zip is a binary distribution for people who can't install python and git.
Everything is included - just double click run.bat to launch.
No requirements apart from Windows 10. NVIDIA o...
Python 3.12.3 (tags/v3.12.3:f6650f9, Apr 9 2024, 14:05:25) [MSC v.1938 64 bit (AMD64)]
Version: v1.9.4
Commit hash: feee37d75f1b168768014e4634dcb156ee649c05
Installing torch and torchvision
Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/cu121
ERROR: Could not find a version that satisfies the requirement torch==2.1.2 (from versions: 2.2.0, 2.2.0+cu121, 2.2.1, 2.2.1+cu121, 2.2.2, 2.2.2+cu121, 2.3.0, 2.3.0+cu121, 2.3.1, 2.3.1+cu121)
ERROR: No matching distribution found for torch==2.1.2
[notice] A new release of pip is available: 24.0 -> 24.1.1
[notice] To update, run: C:\Users\User\Documents\Stable Diffusion\webui\venv\Scripts\python.exe -m pip install --upgrade pip
Traceback (most recent call last):
File "C:\Users\User\Documents\Stable Diffusion\webui\launch.py", line 48, in <module>
main()
File "C:\Users\User\Documents\Stable Diffusion\webui\launch.py", line 39, in main
prepare_environment()
File "C:\Users\User\Documents\Stable Diffusion\webui\modules\launch_utils.py", line 380, in prepare_environment
run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)
File "C:\Users\User\Documents\Stable Diffusion\webui\modules\launch_utils.py", line 115, in run
raise RuntimeError("\n".join(error_bits))
RuntimeError: Couldn't install torch.
Command: "C:\Users\User\Documents\Stable Diffusion\webui\venv\Scripts\python.exe" -m pip install torch==2.1.2 torchvision==0.16.2 --extra-index-url https://download.pytorch.org/whl/cu121
Error code: 1
Press any key to continue . . .
2/2
i misread your message, sorry, i tough it is about the package
Uninstall Python 3.12, its not compatible.
Then install python 3.10.11 64bit
Then delete the venv folder
Then relaunch the webui-user.bat
@drifting pendant try
sudo apt install virtualenv
sudo apt install python3-virtualenv
one of those should work
Installed this one : Same
Alerady installed, Same, I try to reinstall it RN
Same
can you please rename folder with stablediffusion to anything else like sd-bkp
and do this
wget -q https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.sh
./webui.sh
now you have all python components including venv and pip
so try again
Getting this now: Already up to date.
Couldn't launch python
exit code: 9009
stderr:
'python' is not recognized as an internal or external command,
operable program or batch file.
Launch unsuccessful. Exiting.
Press any key to continue . . .
i ❤️ those spammers
Repport ?
I'm making a backup of my models and I do that ASAP thx
Run the Python 3.10.11 installer again.
Select Modifiy
Click next,
check "add python to environment variable's"
Then relaunch the webui-user.bat
I'm runing it I have "No module 'xformers'. Proceeding without it."
I can run SD again
ok
so now you need xformers
but..
wait now
ls -l venv/lib/python3.10/site-packages
show me what you have there
transformers-4.30.2 is there
do not install anything else
you just need different paramers in webui-user.sh
line 13
#export COMMANDLINE_ARGS=""
it needs to be
export COMMANDLINE_ARGS="--xformers"
start with that
what is your GPU?
I have a bunch of images i generated that i want to use for training, is there any way of extracting the prompt from the meta data and putting it in a txt?
A humble 1080Ti
@ornate elk what params should be used for 1080Ti? --xformers --medvram? or what
i only know parameters for macs by heart 🙂
sorry
had a 1070 a while ago, those args worked for me
id definitely use them
I've just RTFM of @ornate elk 
And yes
UMMAGAD : Applying attention optimization: xformers... done.
at least i learned something - python packages for popos are c... 😂
following zluda instalation proccess on w11
just wanted to confirm if web-user.bat commands are as planned

is everything ok?
looks fine, but you can remove space between = and --
ok
me too, thanks for all you have done !
looks fine
@karmic crown @ornate elk If I can help for anything, tell me guys.
btw, I've tried following this tutorial before some months ago, but ended up giving up halfway
60% of my problem has been solved, thank you! The filenaming issue is gone. However, I'm still getting the issue of images looking wrong. I've attached an example image from civitai, and my recreation using png info, which is coming out just looking underdeveloped?
is there any way I can confirm that AMD HIP SDK 5.7 is correctly installed?
or would you guys just recommend to delete it and do a fresh install or smt


cute
better go to #📝|prompting-help for further help
One last question, what model can I run on this GPU W/O corrupting anything ? Like SDXL / SD1.5 / any Pony ?
Does the seize of the model in GB matter ?
If you installed it, and added it to path it should work.
Also for your card you need the custom rocm library files
And a PC restart after that
always use the smallest model first
usually it is marked as pruned fp16
if that works great
smaller filesizes, less memory usage...
pruned fp16 1.5 models are around 2GB, and sdxl around 6.5GB
Seems logic, and this what I've observed, I don't want to make any mistakes anymore, thanks
you can try using lightning and turbo based models to get images with less steps, which be "faster" since it will take less time
One other thing, If I play with SDXL I have to lower the render resolution, for VRAM sake
To get the same image like on civitai is not alwaye possible but make sure you do it like this:
On the image in civitai click on the blue copy prompt Settings button.
Then paste that into the positive prompt.
After that Click on the blue/white arrow at the right.
It should now apply everything automaticly.
Then generate.
Thank you!
he was using the different version of a model, we figured that out in #📝|prompting-help
Well, everything is working like a charm, thanks again !
it could be faster it you os was normal 😂
the problem is I that I installed it months ago
just wanted to check out if everything is fine
I don't even remeber if I uninstalled it or not
All "because" of this video : https://www.youtube.com/watch?v=Wjrdr0NU4Sk
But thanks to Him I was able to start something

Ready to get a job in IT? Start studying RIGHT NOW with ITPro: https://go.acilearning.com/networkchuck (30% off FOREVER) *affiliate link
Discover how to set up your own powerful, private AI server with NetworkChuck. This step-by-step tutorial covers installing Ollama, deploying a feature-rich web UI, and integrating stable diffusion for image...
i would ALWAYS choose ubuntu for server
then check the system control pannel
if you have this

ok
I'm more a debian guy, but I understand in this case
BTW I have some "CPU leak" (wierd RAM usage / overload) when I load models, but this is wayyyyy better than before, still strange
try --disable-model-loading-ram-optimization
I've mistaken, the load seems stable, "high", but stable, last time I've tried this it was on a server with 256Go of RAM, so... 10Gigs of load was kinda nothing
@crude trellis let me know hows it going

yup
they're here

now I should check if zluda is in PATH right?
how do I confirm that?
by looking into the path environment settings. the step is listed in the guide
@crude trellis



yes


no wait
you have clicked on the PATH at the user variables
you need to add them to the system variables path

strange
scroll down a bit
there is no Path on system variables
oh really?

ok
going for step 4 now
done
gonna restart my PC now and see if it worked
(lets hope it does)
done

@ornate elk
wrong python version
uninstall python 3.12
install python 3.10.11 64bit
check "add python to path"
delete the venv folder
relaunch tghe webui-user.bat
ok
where can I check "add python to path"?
if its not there, relaunch the python installer, click modify, next, check "add python to system veriables"

Is there a mobile site where you can generate images.
next
oh
there it is
deleted venv
lets see how it goes
does this part usually take this long?


-_-
does anyone know how SD interprets it if I mistyped a lora prompt with a comma? i.e. <lora:model:0,6>
do you have COMMANDLINE_ARGS= correctly set?

did you run webui-user.bat or webui.bat?
webui-user.bat
you need to run webui-user.bat
hmm
strange
we need that switch for macs, but for zluda it should not be there
@ornate elk do you think this could be related to not having Path in System variables?
did you git cloned the webui today?
because yours is still called directml at the end
then please do a fresh install
ok
i know its been a long time but this helped me so much, i've got my hair falling off! thanks!
Anyone knows how to fix the halo/blur edges effect for inpainting with Automatic1111?
what are your settings
@ornate elk it opened!!

so does this means its working 100% or do I need to do some more stuff
nice! now you only need to gen the first image
it will take 15-40 minutes
check the cmd for any error

ohhh
download this model:
https://civitai.com/models/4384/dreamshaper
put it into the models/stable-diffusion folder
then delete the 1.5 ema pruned model
then relaunch
ok
after generating the first image, how long does it usually take to gen?
seconds
maybe 1 minute with sdxl but seconds with 1.5 models
then it depends on the extensions used and resolution too
btw would 500x700 be considered a large resolution?
that would take longer
no thats a normal resolution for 1.5 models (512x768) and would take seconds
great
trying to generate something now using dreamshaper
last cmd message was this
does this means its on the generation proccess?
yes, it wont show anything until the zluda load is done
the generate button should be grayed out
then its working
just let it load until you get an image 🙂

can you screenshot the whole cmd too?
just to be sure there is no error before dogetexx

perfect
thats really great to hear, directml used to take minutes and I always had some vram problems
like messages saying that I dont got enough vram
but i have 12gb
yes that wont happen with zluda that fast
less vram usage and faster generation speed
and if you install the tiled vae extension later you can also upscale without problems
guys, out of curiosity, what's the average budget for a good pc to do only SD? I am a Apple guy so I have absolutely no idea about pc hardware and how much it costs
I followed the directions on Github to install Stable Diffusion and everything appears to have installed properly, except the command prompt dissappears after running the webui-user.bat file. I see it perform nummerous functions on the command line. then closes. I'm trying to run on Window 11 with an AMD RX 7900 XT. I would really appreaciate any help on opening and running Stable Diffusion.
Hey I have the same card, did you followed my guide?
I'm not sure, I would appreciate a link. I used the info on Github.
Looking at the terminal, it may be because I am using Python 3.12.4
Do I need to downgrade python, or will it run on the current version?
You need to downgrade
3.10.11 64bit is good
Here is the guide:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Installation-Guides#amd-automatic1111-with-zluda
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
Thank you so much. I will downgrade my python then try again.
@ornate elk it worked!!!
thank you so much
seriously
you're amazing
if I install models and loras
I'll have to restart SD and wait 40 mins again so i can use them?
I fixed it, by using a normal base model + controlnet inpainting.
Was using an inpainting model, and it keeps creating halo/blurs around the inpainted mask.
Only sd 1.5 inpainting worked. But controlnet fixed that now.
or will they be available instantly?
No they will be available instantly
No problem, have fun 🙂
@fading heron let me know if it worked or if you need help
people talk about sd 1.5 and 1.0 can someone help me understand what thats all about? I just downloaded the latest web ui version. Should I be doing something else for better results ? and if so how
Hey, you need to download community models from Civitai.com
These give much better results than the default 1.5 model
For example try Dreamshaper v8
ty for the info. One other question @ornate elk I downloaded a lora but when i inset it <> into the prompt and or use the trigger words nothing seems to happen. What might I be doing wrong?
-- for further context I installed the loras in stable-diffusion-webui -> models / Lora
the lora needs to be compatible with the model
on civitai you always see the "based on" in the info box, there you see if its for 1.5 or sdxl or pony
ty @ornate elk
@karmic crown in case you also know about pc hardware and not only macs 🙂
at least nvidia 3070, ideally 4070 or better
i used to work in pc shop 20 years ago, but i switched to web and software development 🙂
maybe it is better ask in #💬|general-chat since some people who are there do not come here 🙂
sure, will do! I thought it was more of a tech related topic that's why i posted here
only for SD can mean anything. you can use SD with a 4gb gpu but its not great
best is to go for a gpu with 12gb vram or more from nvidia
he has working m1, so nothing with less with 12gb or he will waste money
yes, need something faster than my m1
i guess 3070 with 12GB would be enough to feel a real difference
3070 has 8gb
few times faster
which one is with 12GB? 4070?
but even 3070 with 8GB is much faster than that m1
SD WebUI Benchmark Data; Author: Vladimir Mandic
find what you can tolerate
basically i don't want to wait minutes when generating regular images (by regular i mean without upscaling)
to have a fluid worklow when working on images

this is fine
its few times faster than my m3 pro
3070 Ti
this means about 4 seconds per 40 steps 🙂
that sounds about right
and regarding the rest of the pc? cpu/ram? any recommended brands?
i guess 16GB is reasonable
if you do not plan to use that for many other things
cpu, i guess some ryzen
i would not waste money on intel
definitly amd ryzen
i guess ryzen 5 would be enough, right?
nope, the m1 pro is for software development (i do iOS dev) and I have my synology server, I do not need another machine at all, only for SD
cool, so amd ryzen, 16gb ram, 370ti
then 16GB it is
i will search for that and see what i find, maybe will post on general later to have other people opinion
@fossil tendon pleas dm me, i have to ask you something aboug ios emulator in xcode
Hey i am wondering if there are any ideas to how to modify images with the prompts by describing the operation rather than the output. For example using a image of a robot and a prompt "add an arm" rather then the detailed original prompt extended with the total number of arms "high tech robot, red, photorealistic ..., three arms" and so on. Are there models that are capable or this? In specific cases i got the desired output, but most often the outputs seamed random, especially when asking for "remove XY" it adds the XY and so on

Switch to a compatible model
Then reload the loras
Got a noob Python question- For those of you running Windows and who have multiple installs of Python - How are you handling the system paths for each instance/version? Due to application requirements I've now amassed 4 separate versions and it has become a proper PITA to have to dig through every program and manually set a "python=" variable due to most applications and scripts just assuming "python=python" will pull the correct version.
Is there a way in System Variables to set paths to a specific python path/install that only is traced if executed in a certain directory? So depending on what folder/directory you attempt to execute python from it will grab a certain path/version?
if it's me, i only have the path to the version of python i'm using configured. and if i have to use a different version, i'm going to change the pathstatement to that version.
Are you saying you change the path statement in the system/user variables or in the script's variables? If the former, that's basically what I'm doing now but when bouncing back and fourth between scripts it gets cumbersome to keep swapping it
hello, for some reason when I try to create a new hypernetwork, and train it I receive this error:
Applying attention optimization: xformers... done.
*** Error completing request
*** Arguments: ('task(o25gm3oq98g3eiv)', 'LTAI', '0.0001', 1, 1, 'C:\\Users\\anriq\\Downloads\\AI_test\\LT\\treinotxt', 'textual_inversion', 512, 512, False, 2500, 'disabled', '0.1', True, 0, 'once', False, 250, 500, 'hypernetwork.txt', False, '', '', 20, 'DPM++ 2M', 7, -1, 512, 512) {}
Traceback (most recent call last):
File "C:\Users\anriq\Desktop\StableDiffusion\stable-diffusion-webui\modules\call_queue.py", line 57, in f
res = list(func(*args, **kwargs))
File "C:\Users\anriq\Desktop\StableDiffusion\stable-diffusion-webui\modules\call_queue.py", line 36, in f
res = func(*args, **kwargs)
File "C:\Users\anriq\Desktop\StableDiffusion\stable-diffusion-webui\modules\hypernetworks\ui.py", line 25, in train_hypernetwork
hypernetwork, filename = modules.hypernetworks.hypernetwork.train_hypernetwork(*args)
File "C:\Users\anriq\Desktop\StableDiffusion\stable-diffusion-webui\modules\hypernetworks\hypernetwork.py", line 483, in train_hypernetwork
hypernetwork.load(path)
File "C:\Users\anriq\Desktop\StableDiffusion\stable-diffusion-webui\modules\hypernetworks\hypernetwork.py", line 250, in load
self.layer_structure = state_dict.get('layer_structure', [1, 2, 1])
AttributeError: 'NoneType' object has no attribute 'get'
I can only train old hypernetworks models, someone can help me ?
i would change it in my system variables. but that's just me, personally. mostly i only use one version, so using other verions is going to be a rare thing
Hi, why my pc use the tiled version of vae, even if i have enought ram?
In automatic1111
rx6600
anyone here familiar with openvino?
Hey, I've also had the same issue as Frusto where some LoRA models were not visible, but I checked an option and now all the LoRA models are visible. Do you know which option that is to desactivate it again?
Nvm i already found the option lol
Follow my Automatic1111 with ZLUDA guide from the pinned messages of this channel
works flawlessly even tried different models and no issues. thanks heaps !!!
Hey, is A1111 still on Python 3.10.6 ? or is it possible to update to .. 3.11 ?
Hi, why my pc use the tiled version of vae, even if i have enough ram with automatic1111?
Since i didnt get any response ill repost my question - any kind of hints are appreciated: Hey i am wondering if there are any ideas to how to modify images with the prompts by describing the operation rather than the output. For example using a image of a robot and a prompt "add an arm" rather then the detailed original prompt extended with the total number of arms "high tech robot, red, photorealistic ..., three arms" and so on. Are there models that are capable or this? In specific cases i got the desired output, but most often the outputs seamed random, especially when asking for "remove XY" it adds the XY and so on
Perfect, no problem 🙂
Where do you see that it tiles the VAE?
Yes A1111 works still the best with 3.10.11 64bit
I import the image in comfyui
i have 12gb of vram
And do you have a VAE tiling node? Or where do you see that it gets tiled ?
When i import the image that i have generated make with automatic1111, in comfyui

Could be here the problem?
Could i fix it?
Ok thanks a lot
hi everyone, could anyone can tell me that how deploy the stable diffusion 3 in colab with colab GPU but the API? thank you very much.


getting this issue on a1111

What's the full cmd log?
Well I tried running the update.bat and now its installing some requirements
when I tried windows run
again
Hey, I'm getting an issue in the DreamBooth extension (full log in link below) that basically amounts to "cannot load because keys are missing", and then at the very end, "Please make sure to pass low_cpu_mem_usage=False and device_map=None if you want to randomly initialize those weights or else make sure your checkpoint file is correct.'."
I've tried the solutions I've found online, with multiple models, but nothing has worked.
I'm currently trying with the HelloWorld and Juggernaut models.
I previously got the "diffusion_pytorch_model" missing in working folder error, and got past that by downloading the pytorch model from the huggingface repo. Not sure whether it has anything to do with this?
Tried posting in the DreamBooth extension discord but I'm not sure whether it's active.
Full log: https://justpaste.it/7pv72
is it fixed now?
dont use Dreambooth, use Kohya_ss for training models or Loras
or OneTrainer
Im trying to get onetrainer working, i seem to be getting repeated errors when trying to use a non official model
tried using a file saved locally and a huggingface hosted file
what am i doing wrong? I keep getting errors when i start training
can you screen shot and post the errors?
hi, hope your doing good.
I followed the guide you sent me and downgraded my python to 3.10.11, but now I am getting a no python found error.
I tried reinstalling python and made sure that the "add to Path" box was checked. Do you have any idea why this could be happening. Sorry to bother you.
Have you deleted the venv again too?
no, I'm not sure I know what that is. Actually I'm sure I don't know what that is.
@knotty turret welcome, try here with tech questions
ok
no, I'm not sure I know what that is. Actually I'm sure I don't know what that is.

I don't have that directory in my c:\SD-ZLUDA directory
thought you were running auto1111, idk about zluda, might as well wait for cs1o
Hey, thanks for trying.
Go into the stable-diffusion-webui-amdgpu folder and delete the venv folder
I'm in that directory, but that folder does not exist.
I'm in that directory, but that folder does not exist.
Hey! Quick question (sorry if it was answered already - it probably was): In ComfyUI, do I have to tag a lora in positive prompt if im using a lora loader node?
Then relaunch the webui-user.bat
If it wont work, relaunch the python installer, select modify, next, ans check "add python to environment variable's"
I verified that the "add python to ..." was checked when I ran the installer. I ran webui with the arguments
--ckpt-dir "Path/to/models/stable-diffusion" --lora-dir "Path/to/models/lora" --controlnet-dir "..." --embeddings-dir "..."
did you add python to your system path?
result was couldn't launch python exit code 9009
it should be, could you tell me how to verify?
windows or mac?
windows 11
windows 11
read through this https://www.c-sharpcorner.com/article/how-to-addedit-path-environment-variable-in-windows-11/

In this article, I will let you know about ways by which you can add or edit the path environment variable in windows 11.
i will, thank you
welcome
Thank you so much, I had to add the python directory to PATH. It
It's downloading and installing. Fingers crossed
It was the Path variable. Sorry for the trouble. Thank you so much for your help.
no trouble at all 🙂 happy it's working for you now.
It's working!!!
Nice to meet you,
I'm currently using stable diffusion forge, is there an extension that separates Lora's description area?
I've used forge-couple, but it doesn't work well for very complex things. If there are other extensions, I would like to know about them.
i've been having decent luck with cutting down on some prompt bleeding and lora control by simply utilizing some of the lora tags within the adetailer prompts....lots of adetailer models to sift through on civit. just a thought. havent tried much in the way of extentions but this is worth checking out:

Reddit
Explore this post and more from the StableDiffusion community
i would love to hear some feedback on LoraCTL if you end up working with it, good luck mate
Hello
howdy drake
Is fine-tuning not available through the API? https://platform.stability.ai/sandbox/fine-tuning
Thanks, I'll give that a go!
Hi all, new here, I am looking to purchase a gtx 1660 super 6gb GPU. Have the known issues of black/green screen output in SD been fixed or not?
I can still cancel my order, so any help/response on above will be greatly appreciated
Hi there! I'm unable to cancel my subscription to Stable Audio, I submitted a ticket almost a month ago and no answer. When I try to access my profile page or the pricing page there's a loading spinning wheel but nothing else happens.....any help???
A Gtx1660 is the worst GPU for using SD, as this GPU doesn't support half float point (fp16)
Everything will take longer and needs more vram
But the black output is no problem anymore
i am trying to install it and i cant get it to work... can someone help me please
cf pinned guides
Hello! Iam trying to install SD and had first to install Swarm, right? so i installed it but i cant find the folder
Oh nevermind its working now
SD is almost working but it says "Backends are still loading on the server..." and (Git failed to load)
I did all the steps from Reddit
You don't need Swarm to use SD, but you can. Its one of many stable diffusion webuis
It says i didnt clone from git or something like that
Do you recommend using something else?
Yea if your new start with Automatic1111.
You'll find the installation guide in the first link from the pinned messages.
Do i have to install Python?
Because when i run it, it says Couldn't launch python
Couldn't launch python
exit code: 9009
stderr:
Python was not found; run without arguments to install from the Microsoft Store, or disable this shortcut from Settings > Manage App Execution Aliases.
Launch unsuccessful. Exiting.
Press any key to continue . . .
Ohh i have 3.12
Thats not compatible, you can uninstall it
I have installed Python 3.10.11 64bit now and Git but its still not working
Python was not found; run without arguments to install from the Microsoft Store, or disable this shortcut from Settings > Manage App Execution Aliases.
What does this mean?
It does say amd, but i dont have amd
Thats normal, amd is not related to amd brand in this case
Run the installer again.
Click Modify, Click next, check "add python to environment variables"
Thanks : ) its working now
Which folder would you put an embedding saved as a safetensors in? I have it in the regular SD folder, but the output is coming up as plain grey
Now it says this: AttributeError: 'NoneType' object has no attribute 'lowvram'
Example of output. Here's the PNG info from it:
parameters
AIMe man taking a selfie on a sidewalk
Steps: 20, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 2.5, Seed: 331226645, Size: 832x1216, Model hash: 5b10498158, Model: AIMe, Clip skip: 2, Downcast alphas_cumprod: True, ComfyUI Workflows: {}, Version: v1.9.4

Its now working by removing " --no-half-vae"
Delete the 1.5 EMA pruned model from models/stable-diffusion and instead download the Dreamshaper v8 model from Civitai.com.
Put that into models/stable-diffusion folder ans then relaunch.
https://civitai.com/models/4384/dreamshaper

DreamShaper - V∞! Please check out my other base models , including SDXL ones! Check the version description below (bottom right) for more info and...
Thats strange, what's your gpu?
Embeddings folder
It's not appearing in the textual inversions when I put it there
Since i didnt get any response ill repost my question one last time - any kind of hints are appreciated: Hey i am wondering if there are any ideas to how to modify images with the prompts by describing the operation rather than the output. For example using a image of a robot and a prompt "add an arm" rather then the detailed original prompt extended with the total number of arms "high tech robot, red, photorealistic ..., three arms" and so on. Are there models that are capable or this? In specific cases i got the desired output, but most often the outputs seamed random, especially when asking for "remove XY" it adds the XY and so on
Have you tried using inpainting?
rtx 4090
my problem with inpainting is that i only found solutions where you manually have to create masks and i was hoping for a solution where the model can do this alone, so the result is not as human dependant
i am generating multiple versions of images simultanuously and ideally want the ai to merge the results into one on its own in the end
i was even thinking about just training a small model with all images that should be merged and then running this model and generating only one image (which hopefully contains the most commen attributes from all) - but this seams to be overkill for the desired goal
Okay then you only need --xformers
anyone have this problem? The result messing up when I used any lora
This is a depth lora. Better to show how its mess up.

original

Already reinstall sd/reboot computer
Hey there is a model and function called Instruct pix2pix that can do this type of stuff. But its not to powerful
Try reducing the lora weight
But why using a depth lora when there are Controlnet depth models?
just used to show you the problem.
lora weight is default 20
I tried 20-30
still not work
I used the same setting to gen yesterday. Its ok. But it suddenly mess up
What webui do you use?

I have already use sd half year. First time have this problem
It is a bug I think. Not prompt or setting problem
I reinstall sd and keep everything default
just simple change the model and lora
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/7851
I have same problem from this post

GitHub
Is there an existing issue for this? I have searched the existing issues and checked the recent builds/commits What happened? Whenever I try and use a Lora, it messes up right at the end. I have no...
anyone knows how to merge 2 sdxl models through commandline no webuis?
What's your webui version?
What's your GPU and what's inside your webui-user.bat?
Made another one using the embedding preset and it shows up now, but doesn't seem to be affecting the result at all. Is there some keyword or setting I should be using that I don't know of? Currently clicking the embedding in the GUI before generating
maybe I gen too much makes my gpu broken?
Scroll down to the bottom of the browser
There you see the version numbers
Of torch, xformers and the webui
For embeddings you only need to include the embedding name In the prompt
version: v1.9.3 • python: 3.10.8 • torch: 2.0.1+cu118 • xformers: 0.0.19 • gradio: 3.41.2 • checkpoint: be1d90c4ab
thank you i will look into that
Hmmm... do you know of a generic reason it might not be doing anything? I trained it on images of me, but the people being generated look nothing like me at all
OK your torch and xformers version is a bit old.
You can try to delete the venv folder and relaunch the webui-user.bat.
That should download the latest torch and xformers.
Hi 👋 is anyone using sdwebui API faced this issue on 1.9.4?
Looks like when we use --api --nowebui, it initializes FastAPI, however I get 404 for sdapi/v1/txt2img endpoint.
2024-07-02T13:23:09.211831145Z Startup time: 8.3s (import torch: 3.3s, import gradio: 0.7s, setup paths: 0.9s, initialize shared: 0.2s, other imports: 0.7s, load scripts: 1.7s, lora_script.py: 0.9s). 2024-07-02T13:23:09.247048698Z INFO: Started server process [8] 2024-07-02T13:23:09.247170051Z INFO: Waiting for application startup. 2024-07-02T13:23:09.247527519Z INFO: Application startup complete. 2024-07-02T13:23:09.249085056Z INFO: Uvicorn running on http://0.0.0.0:3000 (Press CTRL+C to quit) 2024-07-02T13:23:09.282696391Z Creating model from config: /stable-diffusion-webui/configs/v1-inference.yaml 2024-07-02T13:23:09.415919820Z INFO: 127.0.0.1:50820 - "GET /sdapi/v1/memory HTTP/1.1" 200 OK 2024-07-02T13:23:10.067623378Z INFO: 127.0.0.1:50822 - "POST /sdapi/v1/txt2img HTTP/1.1" 404 Not Found
And giving just the embedding name with nothing else resulted in this 

this one?

What do you launch normaly?

Hello all, I have a 3070 and 3060ti, is there a guide to have the webui use both cards on Linux? A lot of the information I've found on Google is not explicitly helpful.
I dont think so.
Can you generate normal images without using a lora?
Hey, you would need to use two separate webui instances
yes. No problem if not using lora
Okay, and if you use an other lora ?
Or try educe the lora weight by changing the lora:loraname:1 to 0.5 ?
Also you need to use a negative prompt
But I use lora:1 have no problem before
Not every lora will work with :1
lower the lora will make my result different
I used that those lora for a long time.
Some loras are overtrained and need a lower value
You have an example of an good image with the same settings?
wait
So I can check the metadata



Okay, but for that image you used a negative prompt
That helps getting non corrupt images
Drop the image into the PNG-Info tab and you see the settings you used.
I know that is different prompt, but those 2 prompt I had used for a long time. I know they are works before.
this one with same prompt and steps

i'm wondering if someone can help me. for starters i'm using automatic1111 webui, and when i run it with webui.sh, the ui runs but any models besides pruned v1.5 doesn't show when i refresh the stable diffusion checkpoint. also I install xformers but it doesn't detect it in my system
Hello community, I am a beginner currently
studying how to run Stable Diffusion on a Mac M2 8G by Core ML. I successfully managed to run it and attempted to add a module called Cetus Mix for use. However, I always end up with an image that is completely filled with noise, no matter what prompts I use.
Please give me some advice I would be appreciated
ie. Both the stable diffusion model and the Cetus Mix mod all at version 1.5 and converted to core ml (mlpackage/ modelc)



guys anyone know how i can use or find the model PonyXL but i want to use it with FP16
its a thing i can change in sd? idk
forget core ml and converting models
install https://github.com/AUTOMATIC1111/stable-diffusion-webui
but use my installation script https://github.com/viking1304/a1111-setup
you might need some parameter tweaking after that, because you have 8GB

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
GitHub
Simple and easy Stable Diffusion WebUI (Automatic1111) and Forge install script for Mac - viking1304/a1111-setup
sup, is there a reason why my stabble is very slow ? maybe is my wifi ? or my gpu is dead ? i updated driver too
sorry for the late response, turns out i had to select sdxl in the top right
ah. okay. glad you got it figured out
got another question now, where do i adjust steps?
steps?
sorry meant repeats
here are the docs https://github.com/Nerogar/OneTrainer/blob/master/docs/QuickStartGuide.md you might want to book mark that and refer to it as you go

GitHub
OneTrainer is a one-stop solution for all your stable diffusion training needs. - Nerogar/OneTrainer
ty
welcome
you need to add --xformers to the webui-user.sh at the line commandline_args=
and outcomment it
pony is fp16
hey, whats your gpu?
GTX 1080 NVIDIA
@ornate elk have you tried running sd3 with a1111 after the webui update?
then you have to edit the webui-user.bat
at the line Commandline_ARGS=
you need to add: --xformers --medvram-sdxl --no-half-vae
then save and relaunch the webui-user.bat
nope
there is a reddit post https://www.reddit.com/r/StableDiffusion/comments/1dh0z5v/sd3_support_has_been_added_to_automatic1111/?rdt=40700 but im using comfyui
Reddit
Explore this post and more from the StableDiffusion community
like that ?

oh your using forge
yeah
GitHub
Simple and easy Stable Diffusion WebUI (Automatic1111) and Forge install script for Mac - viking1304/a1111-setup
this ?
okay will try, ty
no problem 🙂 there you need the --xformers --medvram-sdxl --no-half-vae
at the line set Commandline_ARGS=
in the wbeui-user.bat
just updated a1111 but something is broken when i go to load sd3 model
ok ty man
thats old news, it was available since a few days in the sd3 testing branch. and its still not in the stable release
i only will test it when its stable
because right now there are a lot of things that have to be fixed
ahhh that explains it why its broken when i tried it now
@ornate elki got 3.11 python, is there any prob with this btw ?
its not recommended but some Users said it will work with 3.11 too
if not you can downgrade always later

ah rlly?
lol tried to convert it to fp16
where i can check it
if its a 6gb file its already in fp16 format
ok
btw right now i using webui forge because i cant load sdxl models on a1111. For the lastest update do you think still worth keep webuiforge? or try to make something to use normal a1111 sd
that is for macOS only
whats your gpu?
rtx2060
should work in auto1111 too with --xformers --medvram --no-half-vae in the webui-user.bat
also you need 16gb Ram
oops okay lol
ok but there any advantage using WebUi Forge?
its better back to a1111?
nope, since forge will undergoy changes and wont get any updates for normal users, its only advantage is that the current outdated version has a good performance on lower end gpus
in your opinion for the rtx2060 forge or a1111
i would go with auto1111, but you can also have both installed
"also have both installed" yeah good ideia
i gonna do it thx man
let mt try this see if work
@ornate elk tried to generate image

the model loads fine now but cant generate images for some reason
what was the resolution you tried?
832 x 1216

can you tray 768x1024 ? as reolsuiotn
ok
but restart the webui-user.bat before trying
Ok
Forge is obsolete now??
I did not know this damn
I was gonna reinstall it too lol guess I should just switch back to A1111?
GitHub
Hi forge users, Today the dev branch of upstream sd-webui has updated many progress about performance. Many previous bottlenecks should be resolved. As discussed here, we recommend a majority of us...
for normal users yes, it will be a test webui in future to test new techniques (that are not cmpatible with extensions and stuff)