
#✨|sdxl
1 messages · Page 165 of 1












🔥
Pixel Wave 07 - Negative Prompt Be Gone! 🪄 TRY WITHOUT NEGATIVE PROMPT FOR BEST RESULTS! The latest version of PixelWave with better cohesion, deta...
New PixelWave out 🙂










0.8 seems a good value for strenght. This template is designed to create crazy portraits. If you use it for other types of images it will work, but...
Wow channels quiet today
All discords are eerily quiet. Might be the winter storm but I didn't hear of massive outages.






idk if this has been asked but does dreamstudio website use the sdxl with vae or without?
ahh..but the huggingface page shows a base version and vae version
what's the difference
I don't know exactly what you mean, but there are several deployments with different vaes. There is the SDXL 0.9 VAE and the SDXL 1.0 VAE. Latter was buggy, therefore they deployed the model with the 0.9 VAE
this is what i was referring to
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main


As per the previous post by @rustic garnet , they're just two different versions of VAE.

I'm weirdly anxious, the bot has had really good phases, but the last days it was like all progress was removed one layer at a time. fingers crossed we get the good model 🤞
my new "Everything All At Once" workflow is available on github now: https://github.com/JPS-GER/JPS-ComfyUI-Workflows
Major features: 4x IPA, single color and RGB masks for IPA, Unsampler, Classic Image to Image, ControlNet, Upscaling with IPA, two different inpainting techniques

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.























For free



I've been interested in Turbo for some time, but all I see is drawings/plastic like generations, is that all it can do ? Nothing Photorealistic ?






Thanks 👍🏻 how did you do it?
just img2img'ed it
how is the seed generated? is it random @tepid needle
I proudly present to you Demons. Demon-ify your prompts, but, as you see in two of my images, they do not all have to have demons in them if you wo...



wow

For your pleasure, I bring to you Edifice. Although, the name is for a large, imposing building, this far exceeds that as you will find when you us...




Yoga scene, products occupy 30% of the screen

Portrait Master v2.3 in ComfyUI Juggernaut model








A fuller body (I added "Jumping Pose" to the lists/MODEL POSE list)






Men







Reddit
Explore this conversation and more from the comfyui community
Random Landscape Generator in A1111












Portrait Master Full Body and Legs

I just copied the image and changed what was wrong
What is the wildcard prompt?
Ah, found it

Cool
You need to change the permissions so we can access it
Just click and it'll authorise anyone with the link
Rolling Dynamic Prompt for Cars A1111









Just a friendly reminder to everyone.
Be careful about giving your email address out to people on the internet. Such sharing methods send your email address to whomever shared the link.

OK, it'll work now 🙂









The car prompt is open access now. Enjoy!
Thank you! I saw it
I haven't used this Dynamic Prompting since SDXL came along - I am surprised by the spectacular results!!!
Dynamic Prompting always makes for a ton of fun, because you never know what to expect—it also can be a great jumping off point for stories and other types of settings
Welcome to Graffiti. This has its own artful twist to the stock graffiti, and what it does based upon the weight, and prompt, chosen. Feeling gener...
some test images of the latest "everything all at once" workflow (v1.1 beta)









Everything All At Once Workflow 1.1 - https://github.com/JPS-GER/JPS-ComfyUI-Workflows/tree/main






Behold Enhanced. I don't wish to spoil the fun, and mystery, I will let you experience it for all of its glory yourself. Tweak the weight as needed...










Afro Centric. Let's MAGA (Make Afros Great Again). Feeling generous? https://www.buymeacoffee.com/generalawareness

When working in landscape (vs portrait) with SD XL I get a much different generation quality, like it is more grainy and deformed.
It is like it always lacks resolution. When using Hi-Resfix, it stay kind of grainy, except not in the part where Adetailer worked on the face, which has nice resolution. It seems like I need to inpaint the other sections to get a nice texture, like the one in the face. (PS: I've been tweaking hi-res fix until it delivers a much better result, but it seem to have a limit).
I guess it has to do in part with the resolution that it takes more screen with less resolution, but there is something in the generation results. Maybe just creating in landscape would need another set of prompt, loras, sampler, etc, as it generates really different than portrait generation.
Maybe I need to outpaint portrait generations to get a good looking generation in portrait
pretty amazing realistic.
thanks






ComfyUI Portrait Master 2.3










surrealism,model temperament,(from_side:1.3),studio
light and shadow,simple pure gray white background image(evening_gown:1.3),necklace,perfect contour,(diamond earrings:
1.3),(pearl earring:0.8),touch the back neck with your hand,

Portrait Master
















WAy to go - but PM lets you set weights easily - and its fun too 🙂
It was fun, but I find it too limiting. Is it your node/creation?
Not my node/creation, but as I say, u can easily adjust the weights for each prompt term

Sousou no Frieren, right? (「葬送のフリーレン」のフリーレンさんでしょう?スクリーンショットみたいです!)







Playing in the snow in BC Canada


It's Official! WildCardX + RunDiffusion. Go Check it out. Kindly share here on what you guys think about it. Good Vibes everyone. https://civitai.com/models/239561/wildcardx-xl



It's Finally Here!!! WildCardX + RunDiffusion For business inquires, commercial licensing, custom models, and consultation contact me under mr.frie...
I bring to you SciFi. Use with the activation word, and sometimes without, with various weights for both to achieve the best generation. Feeling ge...
this is insane, the amount of time and effort is incredible, ty JPS









is it true that SD will understand 2 word negatives as 2 separate things?
e.g.
low quality,
would be understood as "low" and separately "quality" ?
no
negative prompts work exactly like positive prompts
thus, it understands "low quality" as one thing, but it's text understanding is also limited as in positive prompts (e.g. words may blend over and so on)


anybody knows what nodes allow to extract lora from substraction of finetuned model from base model in comfyui
@heady vale these are real hand , aren't?










Another very strange lora. To obtain the same effect of the samples use this prompt (or jyst have fun and experiment) : impactful color paint of .....


Wow!!!
AUTOMATIC1111 using Dynamic Prompts - blended from one for cars; one for landscapes; and one for haute couture/high fashion. I am adding a further 20 high fashion styles to cover all bases, so to speak.










(One of them might have an "extra leg!!!" 😄 )
its only text2image
A post by general_awareness. Tagged with colorful, vibrant, and dragon.








I bring to you Silent Film that makes your prompt appear as it would have 100 years ago in a film. Feeling generous? https://www.buymeacoffee.com/g...

you mean Microsoft Copilot? how you used it for?

@naive ginkgo for Android: Go to playstore, search for "copilot", download the app, give the permission, enable GPT-4, ask for image generation with the specific prompt.......and that's it

I see.. I don't have acces to android store, but it's a MS Copilot, so the image should be created by DALL·E 3 🙂
Yes

still can't make it generate head and shoulders portrait shot 😕 there's (Head and shoulders portrait:1.6) at the first place in prompt but still making this face close ups 😕

Try some combinations of, medium shot, upper torso, close-up vs portrait
In one prompt?
Sure, like medium shot, upper torso
Sometimes you have to play around with it, use weightings, or in some cases controlnet
Or put close-up in the negative
Thanks, will try it 🙂
I know some people are thinking the next version of this might be called SDXL2, but I'm advocating we just advance one of the letters and call it SEXL.

I have been using Portrait Master on ComfyUI to do head and shoulders, full body etc etc






Head & Shoulders Portrait Master








I'm using a controlnet for depth in ComfyUI/Portrait Master - with my 8Gb VRAM RTX2070 - it's taking between 2 and 3 hours to produce a 1024x1024 head and shoulders picture. But! The 3D effect - the reality of the pircture produced - is astonishing!!!
2/3rds processed ...

What do you mean by this? Could you describe it a bit more what you’re doing with the controlnet?
The Controlnet for Depth should use a picture with obvious depth - leading lines converging in the distance, or similar. This depth-map is then applied to the Pose Controlnet - so that the face (head and shoulders) then takes on the apsect of the depth-controlnet, giving it that classic 3D look. But on an underpowered GPU (8Gb VRAM) like mine, it is taking about 3 hours to make this astonishing picture
The Pose Controlnet shows a face plainly looking to camera. The Depth Controlnet shows a panorama with a deep sense of perspective - leading lines way out to the horizon. This depth (forget that it's Venice) then lends itself to the final picture of the woman.

I set Portrait Master at Head & Shoulders, and an OverWeight character










1.0 strenght seems to work fine. Suggested prompt : dark photo of ........... lora:Into_Darkness:1.0, 35mm cinematic , film, bokeh, profess...










0.8 is a good strenght no trigger word This style combines fluid dynamism with sharp detail, characterized by its luminous and soft-focus effects. ...
Damn Andrea you're pumping out the LoRa's!
I present Glowing Edges. Use from -1 to 1 weight and use it with, and without, the activations words for varying effects. Feeling generous? https:/...
I want to use img2img to generate an animated image from the original image. Is there any plug-in that can do this?
Question, im currently generating satellite images in SDXL, in A1111 I use inpaint and prompt "Burning buildings, smoke, fire" on the mask. SDXL just keeps generating different sort of buildings but no burning buildings. What am i doing wrong

You'd need to share the full settings of what you're doing before you can get an intelligent answer, otherwise everyone will just be guessing.
same prompt, same steps (10), different CFG (2, 3, 4)



same prompt, same CFG (4), different steps (10, 15, 20, 25)





still nothing 😦 put (medium shot:1.3), (upper torso:1.3), (upper boddy), C size breast to prompt and close up portrait to negative and still just the face 😕

I changed the pose descriptions in the list files
Standing pose, running pose, jumping pose
Shot type - full body and legs, sideways, standing, one-legged etc
Are you using "Portrait Master"?
Just loaded your workflow from the image and see you're not.
@frigid lintel, I changed the model, adjust the positive prompt a little and improved the negative. KSampler settings also tweaked...is this what you wanted?


Details are in the meta anyway.



You could also change the latent size to 896x1152





Hi, could we relax on the well endowed women pls and ty #✍🏼|rules-and-tos
Sorry, but I didn't see these as breaking any rules. They're not nude or sexualised, I was just assisting with a technique for moving the viewing position.
Hmm, I see no sexualized images or poses 🤔
Woah those are just portraits and GTM was explaining the technicals more than showing off 'well endowed women' . The rules and tos are about no porn only, nothing about portraits of attractive people. This seems liike a bit of a power flex and i don't think the literal server admin should be dropping bombs like this about rules. Extending their meaning much further than they should ever be. If you don't want any women posted ever, say that in the rule instead of being vague and threatening action against a respected community member out of the blue.
Literally just portraits.
Whoa now. Telling an admin how to do their job in an antagonistic way never ends well. NSFW content is clearly stated in the rules and that's what's being referred to.
By ESRB standards, I'd classify some of the images above as "partial nudity" since much of the breast is being shown. That's clearly nsfw, and since nsfw content is always a scale, it's up to the mods and admins to police as they see fit.
This is a great community, and there's tons of content we can post and ways to test that remain well within the bounds of what's allowed on this server and Discord as a whole. Let's keep things civil and awesome, shall we?
.
Have a nice wallpaper.

yeah wasn't trying to power trip- just usually this kind of stuff gets reported across all channels bc exposed breast
thanks @ocean ermine (:
it's a perfectly good call. It is a sexualized position, why do we want to change the camera point of view to see more b00bs? technically it's fair, it's OK but it is what it is, boobs, on other channels, just that calls for a small timeout
she didn't do that, just called it


when you open your post with a passive aggressive threat, the well is immediately poisoned.
The ESRB says any game in the M category is porn then, if thats the standard for what pornographic/nsfw means. Bit of an exageration.
an admin pointing at the rules is a threat. So i guess women not covered up modestly enough is under that rule. Should probably clarify that, because assuming everyone thinks a bikini is porn, it's not
an admin pointing at the rules is a threat
...to you. I think we're good to move on. Wasn't meant to provoke a back and forth here.
It wasn't a threat, as I hold no power here. Just trying to help point the chat in a more positive direction. NSFW ≠ Porn, it means it's not safe for work. Partial nudity with ESRB falls into T for Teen categories, not mature.
and yet , stating things don't end well, is supposed to mean what?
sit back down flava

legendary hype man of public enemy. cultural references


https://civitai.com/models/277328/zerg-style-sdxl-lora
New LoRA for you guys to play with!
If you want ^^



It creates images in the style of the Zerg folk of starcraft 2. If you like my LoRA i would really appreciate a review with : ⭐⭐⭐⭐⭐ I recommend str...
Prompt: cat, Beautiful, cute, exotic, big, opulent creature, large, beautiful eyes art by Cheryl Griesbach and jasmine becket griffith, luis royo an ultra hd detailed, hyperrealistic painting, digital art, Jean-Baptiste Monge style, bright, beautiful, splash, Glittering, cute and adorable, fluffy, filigree, extremely magic, surreal, fantasy, digital art, wlop, artgerm and james jean, Broken Glass effect, with dark, mystic background, stunning, something that even doesn't exist, mythical being, energy, molecular, textures, iridescent and luminescent scales, breathtaking beauty, pure perfection, divine presence, unforgettable, impressive, breathtaking beauty, Volumetric light, auras, rays, vivid colors reflects


Solovey the Robber, "Ilya Muromets and Nightingale the Robber" (mysterious:1.3), (elusive:1.2), (enchanted sword:1.1), (stealthy pose:1.2), (fair skin:1.4), (blue eyes:1.2), (black hair:1.4), (messy hair:1.3), (athletic build:1.3), (hood:1.4), (thief outfit:1.3), (black boots:1.2), (enchanted forest:1.1), (dense forest:1.1), (Russian folklore:1.3), (moonlight:1.3), (2D:1.1), (anime:1.4), (by Ivan Bilibin:1.1), (vibrant colors), (double exposure:1.4), (high quality:1.4)
Все прочитал

thank you 👍🏻 I wasn't using Portrait master in this one, since wanted to learn how to prompt it manualy 🙂 I tryied using your settings just with my model and it moved a bigger further but still isn't "upper half".. but definitelly better than it was before, so thank you for pointing me to the right direction with prompting 🙂

Weren't you just trying to get head and shoulders?
[PAID COLLAB] I’m looking for someone good in prompting, able to work with realistic male/female face and body generation.
You can send me a friend request to discuss about details.
[PAID JOB]
Prompt:Woodrow
yeah I was, you're right 🙂 so in this POV it generated well 🙂
I bring to you Sketch Outline. Use as a positive, or a negative, with various weights to get your desired results. Feeling generous? https://www.bu...

Spoilered zombie. Some of these are old.









I like that zombie one for sure
What has a lycoris got that a lora doesn't?
Woman in swimsuit, white, high heel sandals, beautiful
Released version 2.0 today. It's what I've been using to create images the past few weeks...
https://civitai.com/models/240590/ultimateblendxl
This is a new merge that I have just finalised. There were several models that I really liked the results of, but I didn't want to have to keep swa...
there is one variant of lora that patches not only the attention layers but also the resnet layer - I think it's called Locon or so (con for convolutional).
Then there is another variant of lora that does use a hadanard product over factorizes matrizes, I think that's what called lycoris. However, I don't think that this has any advantage over normal loras and there was never any evaluation of it, so I wouldn't use that.
I think the reasoning behind it was that you can put more information into the lora - however, the whole sense of lora is to be parameter efficient, aka using fewer information to prevent overfitting







I cannot use bot chanels
You have stated a fact.
There’s a channel called #1047610792226340935 , just clicking that and reading solves many questions






#ProtectTaylorSwift
...just kidding.

Play with the weight for a little help to a complete change over. Feeling generous? https://www.buymeacoffee.com/generalawareness

bot 没有权限怎么解决呢
er shorter
this wasn't intended but is quite interesting after all 😄

Hoi, is there a use for these tokenizers, schedulers and whatnot that is along with the model?

just download the model, ending in ".safetensors"
maybe the .vae if it's custom but sdxl regular vae should be fine
Aye, i know to just get the model, just curious what the other folders and files are for
those are the parts a model is made of, you don't need that unless you plan on training or developing
for specific info about what samplers, schedulers and all that is there's a lot on info on the web, the stable diffusion sub reddit has a lot of that https://www.reddit.com/r/stablediffusion/wiki/tutorials/

Reddit
/r/StableDiffusion is back open after the protest of Reddit killing open API access, which will bankrupt app developers, hamper moderation, and exclude blind users from the site.
More info: https://rtech.support/docs/meta/blackout.html#what-is-going-on
Discord: https://discord.gg/4WbTj8YskM
Check out our new Lemmy instance: https://lemmy.dbze...
it's just a different format, the loose files all work with diffusers
I bring to you Asian. This will Asian-ify your prompt. Feeling generous? https://www.buymeacoffee.com/generalawareness
This AI Paper from ETH Zurich, Google, and Max Plank Proposes an Effective AI Strategy to Boost the Performance of Reward Models for RLHF (Reinforcement Learning from Human Feedback) https://www.reddit.com/r/machinelearningnews/comments/1aclwdq/this_ai_paper_from_eth_zurich_google_and_max/
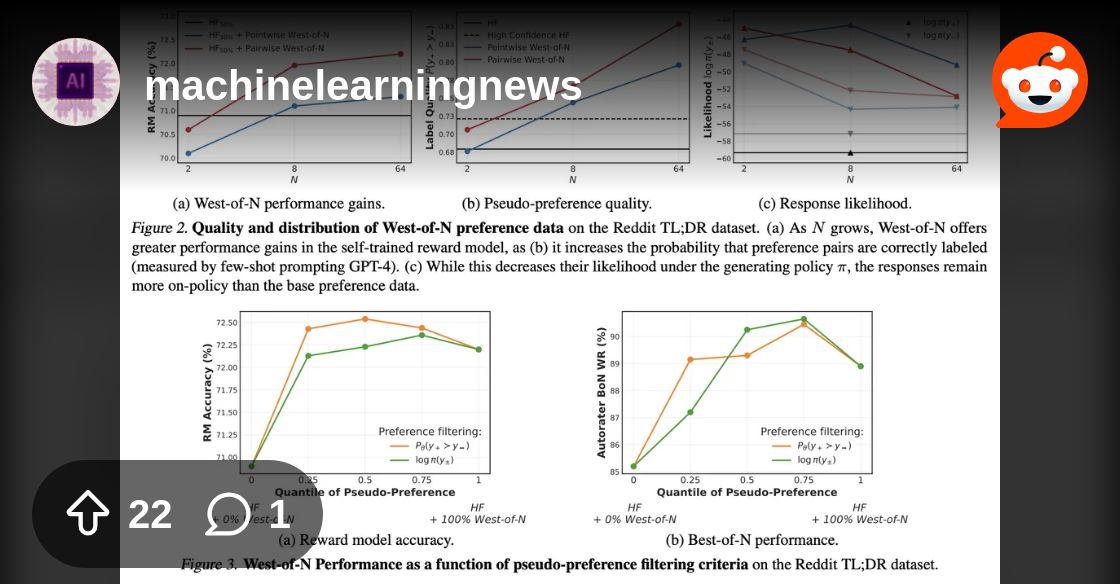
Reddit
Explore this post and more from the machinelearningnews community


教程
Is that a concept art LoRA?
https://civitai.com/models/282340?modelVersionId=317820
Rembrandt ∞ SD XL 1.0 - Timeless Madness
Introducing Rembrandt ∞, a Lora model that captures the timeless spirit of Rembrandt's masterpieces.
Simply use the triggerword "r3mbr4ndt," and watch as your images seamlessly transform into the realm of classic Rembrandt artistry.
Rembrandt ∞ is trained on a very large dataset with far over 1.000 images, at 20,000 steps of carefully curated content.
All example images are made with ComfyUI using Paradox 2.0 base model: https://civitai.com/models/218300/paradox-2-sd-xl-10
The graphs for the example images are made by piscabo and use Deep Cache for blazing fast rendering.
Rembrandt ∞ SD XL 1.0 - Timeless Madness Introducing Rembrandt ∞, a Lora model that captures the timeless spirit of Rembrandt's masterpieces. Simpl...
Paradox 2 empowers you to use unique content while offering even more control over your creations by generating exactly what you request. Unlike mo...
Which sampler in your experience gives the best result at many (100-150) steps?
dpmpp 3 is the most greedy for steps while actually still giving a benefit
but results differ for samplers from model to model
This "DPM++ 3" sampler feels weird, like it randomly chooses which parts of a prompt to emphasize, while "Euler a" just averages any long prompt.
Tom Hanks as an early racecar driver.

James Spader as an experimental stealth jet pilot.

Sting as a villain in an early Rocky movie.



Ancestral samplers (Euler_Ancestral) tend to change the output when changing the number of iterations. The non-Ancestral samplers change more based on the cfg value.
does anybody know where to find controlnet normal for sdxl?

GitHub
WebUI extension for ControlNet. Contribute to Mikubill/sd-webui-controlnet development by creating an account on GitHub.

ComfyUI and OpenPose inside Portrait Master 2.3




hey this cool how did you put them next to each other? openpose?
just prompted for two people
thanks
Site cannot provide a secure certificate!!!!!
It's spammed on loads of channels, don't touch it!










A 80’s style album art with a female silver surfer titled come home

I made this
https://huggingface.co/spaces/FumesAI/Best-Image-Models-Demo
It has
*sdxl
*fooocus
*dream shaper xl turbo
*proteus 0.2
*pixart alpha
*playground v2
*anything v4 https://huggingface.co/spaces/FumesAI/Best-Image-Models-Demo

Cool!!!
Some results (using Pixart)







Foooocus (Best) does rarely supply any output - place-holders, but no pictures - (I did get one picture out of 10 or so tries!)
Thanks ✨
I see it has problem connecting with server will fix it soon
[FIXED]











Hi! I'm trying to make a barebones SDXL img2img workflow that uses ControlNets in ComfyUI. I've followed some tutorials, but for some reason, my controlnets don't seem to apply at all. I feel like I must be making a dumb mistake. Could someone help me get this working?

Not sure about how those nodes work, but your bottom stack node is switched off it appears
More eyes are always better lol
Baphomet is a dangerous demon, sitting on his throne. many humans worship him and prostrate themselves before him. Baphomet turned them away from God towards him... Photo HD, realistic

the Sun and the Moon orbit above a completely flat Earth with no apparent limits for humans... HD

Satan curses him on his ark which is on the water, gives orders to his army of demons to sow trouble in the world, among human beings

the pharaoh in front of the pyramids, at his side a being with the head of a man with horns curved backwards and a hairy body and winged elephants guided by Satan the cursed in front of a people of frightened slaves... HD






Nuralink subject 1:





Neuralink subject 2:

















/Dream:

Hi
I present to you Haunting Steampunk where everything is a bit more gloomy. This can be used with three activation methods: steampunk, haunting, hau...
/help

Hi, I'm trying the IPAdapter for the first time and I need some help. Why does the image has so little quality? Lot of distortion, lacking details etc. And is it just me, or the final image seems like the head is a bit too big for the body, resulting it looks like a baby?



your workflow image is zoomed out too much. can't read any text/settings.
this should contain the workflow 😉

#✨|sdxl Lord Shiva psychedelic art style realistic looking angry and calm avatar and very highly detailed, lumination, contrast dark theme, full body portrait, symmetry in face, and very charming face, full of inner glow and charisma,
also this one is quite poor in quality terms.. not even talking about the background looking like sh*t 😦 workflows are included in the pictures.


Use NightVisionXL as a checkpoint - it does superlative portraits
Will try 👍🏻 will it improve the head-body proportions as well? Or the background quality?
This IPAdapter by Scott Detweiler is cool, and better than yours I suspect

W/flow inside PNG
Thanks, will try when I get back home to my PC..
I have a workflow (when I root about and find it) which stops the subject being off-centre!
LCM LoRA Weights Portrait Master







is there an XL model that gives diversity on woman's faces? the ones I am using all do the same face constantly

Question: does anyone have wenquanlu's HandRefiner working in a ComfyUI workflow for SDXL?
I can't get any xl model to run they all freeze or crash when I load them and if they are loaded they crash auto1111 when generating
any idea how to get this fixed?
please try this at #🤝|tech-support
thx will do




Can anyone suggest better upscale settings for it to look better, getting some artifacting:




A rotating large red lantern with a lucky character on it, and the inside of the lantern shines brightly
Has anybody setup ComfyUI-ID yet? Did it break your ComfyUI Setup at all?
I like the early 2000s screenshots @wet nacelle . 🙂
Once we get cohesive animation/sprite sheets, it's on!
What is it? Do you mean InstantID in ComfyUI?
I have that working
ZHO ZHO ZHO version? Or the 'official' one?
Hi, is there some good rule of thumb about KSampler settings, especifically Sampler and Scheduler? The CFG and Steps are quite straightforward, but I'm still not sure about the Sampler and Scheduler? 🤯
is stable still in business? i mean do they ever make new models or things?
Yes, they're still in business. SDXL Turbo and SVD are both recent new things.
All ancestral samplers respond to iteration number. (E.g. Euler_A) Other samplers respond to CFG. This is not exclusively the case; but you can try for yourself.



@south horizonIF yo want I think you can just save the image and send it into comfy UI workflow.
NOPE!!!!
WAIT
You need these images in the order I sent them. Image one will have a weight of 1.23. Image 2 will have a weight of 0.93


qqqqqqqqqqqqqqqqqqqqqman


is it normal for SDXL generations to take 30 minutes on a GTX 1070 8GB? (30 steps, 1024x1024)
I have 8Gb 2070 - takes 40 seconds
Are you running other apps which are claiming memory and other resources?
I am getting this ERROR - cannot import name 'id_tensor_storage' from 'transformers.pytorch_utils' (C:\Users\xxxx_\AppData\Local\Programs\Python\Python310\lib\site-packages\transformers\pytorch_utils.py)
hm, good point, guess I'll try killing off some of them since looking at how it is without automatic1111 open I'm sitting at around 3.5 GB of memory used now that you mention it
If adobe cloud is running turn it off
The only problem I had was because I put the antelopev2 models into the main models directory, and not the one within the custom nodes folder.
I don't use that; most of it seems to have been firefox, though honestly I really wish task manager would let me break down applications by GPU memory usage :/
oh I found it in task manager details nvm
Yeah I was gonna say go through task manager and start closing… that’s what I am about to do as well… gonna run my template through SD
Computers are sensitive with the GPU and Stable and adobe use a lot of memory
oh there we go

yeah I guess I have to be really aggressive in cutting down on what's using up my GPU memory
💯
This model it would seem must be d/loaded every time ... so perhaps there is an external block at "the hub" - it can take up to 45 minutes to do one so-so picture!!!
It shouldn't do. Once you have the model, it doesn't change.
I've posted the ERROR at GitHub ... so will wait until someone will answer. Code Crafters Corner at YouTube does some painstakingly patient, clear and concise tutorials - I've been following his work in installing InstantID.
I followed the instructions in GitHub and got it working.
There is an LCM version available too ... https://github.com/InstantID/InstantID (not ZHO ZHO ZHO version)


GitHub
InstantID : Zero-shot Identity-Preserving Generation in Seconds 🔥 - GitHub - InstantID/InstantID: InstantID : Zero-shot Identity-Preserving Generation in Seconds 🔥
I will try this non-ZHO version . . .
How fast are your generations/how much VRAM are you using?
After "warmup" it takes under 13 secs per image with a 4090
It's not perfect though! 🤣

Prompt executed in 8.37 seconds


图片
Hello, is it normal I have generating speed about 2 it/sec on SDXL 1024x1024 with RTX 3060Ti? Or is there some problem?




I have no mouth and I must scream!
what is that about?
Just use the workflow and figure it out yourself.
It's Clip.
oh I don't use Comfy these days, crashes a lot for me and stutter my PC, I use Automatic1111
K
s
girl
its ok


Photomaker in ComfyUI (Disney Character)






Photomaker in ComfyUI (Photographic) I'm loving how Photo Maker understands framing, vanishing point/leading lines, and dof!!!






bdhejee
Photomaker in ComfyUI (Comic Book)






ok but how about dpm++, dpm++ 2m, dpm++ sde, sde 2m, 3m etc. ? I know just that the ancestral models are not converging, so adding more steps may not bring better results.. but what about the others non ancestral?
In general, Ancestral responds to iterations (and the response may/may not be better!); the others are more influenced by CFG - try and prove it for yourself! 🙂
have you found the workflow? 🙂 I downloaded the NightVisionXL and it seems to have a slightly better results in terms of the head/body proportions, but still needs lots of work on details and some bad artifacts (hands etc.)



and this is quite interesting and really don't know why it happened 😄 although it seems to have quite detailed face under the artifacts..




Might be bad VAE - try 560000-ema-pruned or 840000-ema-pruned as a VAE
it's the baked one and it did that only in one itteration, before that it was ok..
Even so, give it a try ...
ok
in the meantime trying different samplers and schedullers.. seems the "dpmpp 3m sde" and "dpmpp 3m sde gpu" gives the most realistic outputs, but one add a really sharp lights and shadows and the second one left there some pink artifact..



1
This w/flow by NerdyRodent is worth a try - uses all sorts of nodes to ensure proper cropping and centring etc
Google Docs
Photomaker is quite happy doing 2048x2048 natively!!! Wow!








playing around with CFG / steps settings 😄

@peak dove which is the new ip adapter, which could mimick the style from a reference image and return image in similar style?
GitHub
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate images with image prompt. - GitHub - tencent-ailab/IP-Adapter: The image prompt adapter is des...
is it this one?
any idea what's wrong with this upscale workflow? there must be some dumb mistake I'm overlooking 😕 workflow included in the .png


InstantID is good; but it is even better when linked to Photomaker AND IPAdapter+
im not looking for faceswap
im looking for style recreation
InstantID can take over 30 minutes on a so-so GPU - but I have seen someone say that his 4090 it takes only 15 seconds!!!
Photomaker using Controlnet
can instant ID also mimick the style or is it just for face reference?
See this Video for InstantID

Learn step-by-step how to install the InstantID implementation in ComfyUI, troubleshoot errors and workflow.
In this video I help you learn how to install the unofficial InstantID implementation in ComfyUI. We will be using Python 3.10 and creating a virtual environment to avoid dependency conflicts.
The steps include installing Python 3.10, ...
a tall, muscular Native American with blue tribal tattoos and blue eyes, masculine, virile, serious format:Image






Cool!


#InstantID #Photomaker #tiktok #animateanyone #comfyui #comfy #ai #StableDiffusion
Instant-ID another IP adaptor portrait stylizer
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
SOCIAL MEDIA LINKS!
✨ Support my (・‿・)ノ⌒:・゚✧
character available at https://ko-fi.com/impactframes/shop
SD related https://civitai.com/user/impactframes
▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬...
will check it

Photography like David Hockney

/ dream cat
I've seen it on NV791 too when I have something that adds to the text encoders that's been trained a bit too hard. I guess that socal has pushed the models text encoders quite far.





Super!











Use prompt like mosaic of .... roman mosaic of ...... This style of mosaic is known as the Roman mosaic, a type of artwork commonly used during the...
How to make prompts? New here.

Is there segment anything model for SDXL?
What is a good SDXL model for doing more artistic stuff? So far im only using juggernaut XL and that one is better for realism
Hi, could some of you give me some guidance for great AI image? Like what are the basic steps you do in order to get the best result? Choosing the right model, fine tuning the prompt, sampler settings etc. but what next? When you got some decent basic image from the previous steps, what to do next to get the stunning result? There are tons of tutorials online for some specific techniques, but I haven't found a single beginner go-to guide. Would any of you be so kind and help me? 🙂
What ui do you use to render and what kind of images are you trying to render?
@naive ginkgo Incase i didnt notice your message dm me. I am at work atm. Will reply to you when i can.
I liked Proteus and OpenDalle, but they are now under a non-comercial lience if thats an issue. ooh, and don't underestimate what the original models can do if you're not after realism.
CounterfeitXL and UnstablediffusersXL
thanks for the recommendations
can you please solve the error
There is not enough GPU video memory available! using sdxl having amd gpu 12gb and comfyui
It you run it using fp16 with vae_tiling 12Gb is plenty, assuming your running roughly 1024x1024. You'll need madebyollin's vae thats fixed for working in fp16. I don't use ComfyUI but I'm assuming it has those options somewhere and your GPU can do fp16.
How can they protect themselves from people using the model in commercial purpose?
I'd guess the same way any licence is enforced, court of law.
Now how successful that would be, and if that licence would cover output or just the use of model in a commercial front-end / API
or if they'd actually attempt of enforce it, I honestly don't know.
@peak dove how images would it take to finetune a based on a style?
i want to train a lora on Kurzgesagt style
Huh, could you share that workload? Got me curious to test it :P
Sorry I do not know
Python main.py --force-fp16
I present to you, Glow Lines. Play with the weight for both model and clip weight from negative to positive with this one.

thats kinda awesome 😄
I like Albedobase, UnstablediffusersXL is just a mess
is sdxl turbo 1024 also?

its based on 1.5
im looking for sdxl
dark cyberpunk

I know I was just showing at least it was available. You can use what they did to train it.
nope, 512x512. There are Turbo merges, though, which are 1024x1024, but they need a few more steps than vanilla turbo (like Dreamshaper Turbo needs 6 steps instead of 1)
PhotoMaker





Hi, what is the best upscale method in ComfyUI? Or does it depends on the use case? I mean latent, non-latent, controlnet assisted etc.

a woman sitting on top of a wooden table next to a window, computer graphics by Nagasawa Rosetsu, dribble, plasticien, anime, sensual, photo
naw
Can you generate like this one

nope
Who are you
GOD!
Done in PhotoMaker inside ComfyUI - a woman sitting on top of a wooden table next to a window, computer graphics by Nagasawa Rosetsu, dribble, plasticien, anime, sensual, photo


This is too much beautiful
a woman in a blue dress posing for a picture, a photorealistic painting by Lü Ji, cgsociety, rococo, ultra detailed, anime, detailed
PhotoMaker - a woman in a blue dress posing for a picture, a photorealistic painting by Lü Ji, cgsociety, rococo, ultra detailed, anime, detailed

























Could someone recommend something so I can stop getting blowout like this on my upscales?





hi, what do you use in ComfyUI to pick a image from batch to send it to pipe and work on down the line in the workflow?



football

hi, any idea what to do more to have better hands? this workflow provides quite random output.. once it's ok-ish second it's worse than the original image 😦 full workflow is included in png





SDXL in AUTOMATIC1111 using some home-made textual inversions (embeddings) Model = DynaVisionXL






https://i.postimg.cc/vMz3bq7b/JPS-202402041732-001.png
https://i.postimg.cc/bpmCHCd3/JPS-202402041631-001.png
https://i.postimg.cc/4fRBNjFN/JPS-202402041609-001.png















Anyone got any good model suggestion + settings for getting sharp, detailed img2img results?
NightVisionXL is excellent for sharp output
It does not require a Refiner
And has baked vae
50+ iterations, CFG6+ for sharpness
Myst if it were an open-world MMORPG:









https://i.postimg.cc/xf0c176v/JPS-202402041835-001.png
https://i.postimg.cc/mRpNKNrX/JPS-202402041856-001.png


https://i.postimg.cc/4yjkv42y/JPS-202402041935-001.png
https://i.postimg.cc/nzL6696M/JPS-202402041938-001.png





Woodland Abomination:

what comfy ui workflows do you guys use/
My own. ComfyUI is best when you understand what you're doing. (That's not to say that there aren't great workflows out there made by plenty of talented individuals.)






hi, do you use some special model for inpainting, or do you use the standard checkpoint? Yesterday I found out there are models made specifically for inpainting, but is it necessary?
https://i.postimg.cc/bNxhmvBQ/JPS-202402051008-001.png
https://i.postimg.cc/KvwMDJCK/JPS-202402051109-001.png
https://i.postimg.cc/fTJdd6qn/JPS-202402051036-001.png




a bottle


boom















you've been visited by the strawberry man




Photomaker (version by ZHO-ZHO-ZHO)








I hope it's ok to do a shameless plug for a LoRA I made on the dark fantasy theme if anyone want to try it out.
https://civitai.com/models/293532
Welcome to the dark gothic fantasy LoRA for SDXL, a specialized module designed to enhance your creative journey with deep, immersive gothic and fa...
Style templates are included in a zip file if you want to use them.
Alphonse Mucha as photographer:




Migraines:

valentine's day creative
Nice prompt 🙂












Hi, I tried outpainting with basic workflow from https://comfyanonymous.github.io/ComfyUI_examples/inpaint/ but the result images aren't quite good. You can see the blend lines and even the surroundings don't match quite nice. The anime one is better but still far from good. Is there something to do better in order to get nicer results? 🙂





a woman in a blue dress posing for a picture, a photorealistic painting by Lü Ji, cgsociety, rococo, ultra detailed, anime, detailed
a person wearing a hoodie standing in front of graffiti, graffiti art, inspired by Tim Doyle, deviantart, street art, skull bones, cyan and orange, hd vector art, street art:2 masterpiece, spooky cartoon skull, iphone background






😛
😁






























🤣








Interesting fact; look what the hand model detected and enhanced...

Never tells the truth...





Galaxy what workflow you using?
ComfyUI Photomaker - the last two are basically "somebody's gotta do it!!!" 😄










When you drop your iPhone in the john!!!




Grrrrl








Waiting for Love!







Just something I threw together. It's similar to the latest one I posted on civitai, just a bit more evolved.
create a poster "Safety in a war zone" where the rules are expressed by a character, i.e. a comic book instruction.
When you drop your iPhone in the john!!!
It's better if the prompts are also added along with the images























Can someone reccomend sdxl models for 2d but not necesarily anime?

Paradox 2.
😄
thanks
Nah thats kinda cheating cause thats mine but you could check: Juggernaut / Dreamshaper / Proto. 🙂
juggernaugt is giving me more phooreal even when prompting for cartoon
i use dynavision but its a little too pixar
My model allows more into the cartoon realm imo.

Was checking out one of my new lora's with P2.
Quite fun lolz.
your model gives me: NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
do i need to restart auto?
anyone here that knows a good model that allows me to make an image like the inbetween the black lines? im new to stable diffusion

you can use inpainting, the model doesn't effect that abillity
nvm it works
No idea mate works here properly in many instanses.

your model is giving too "low poly" for me, doing one character
For me it is fine. 🙂








Welcome to Dystopia Use Dystopic image of 0.8 is a good strenght See samples for better prompts. "Welcome to Dystopia" is a grim vision of the futu...




















Use with 0.8 strenght. Prompt like "Dark Manga of" or "Dark Anime of". The style of "dark anime " typically embodies a visually striking and intens...







The cat was right.
Coming to theaters near you.









This is a unique style. The goal is not to produce sharp images, but exactly to give a feeling of continuous movement. Use movement words to achiev...

No, it's an AI art. I promise. Really, I don't even own any paper. Why don't you believe me???

what the heck lol
Has anyone found a scribble/sketch ControlNet model that works well with SDXL? The only one that’s worked for me was limited to a cartoon style.
cat

Ever wondered how to bring your sketches to life? Join us today as we unlock the magic of Stable Diffusion and ControlNet.
In this tutorial, we'll walk you through the process step by step. Starting with a blank canvas in Photoshop, we'll utilize vertical symmetry, a trusty pencil-looking brush, and the power of a Wacom tablet to sketch our ide...
That’s very helpful, thanks! It shows him using Canny, not Scribble/Sketch though. I’ll try it and see if it can still achieve the results I’m looking for.


能用AI生成一个用虾摆盘的图片吗 摆成个龙的形








#dream
hi guys how to create the image --what to type to input the prompt please help

小孩

@meager canopy 1



everything is getting washed out towards the end, how do I fix this


Higher res, upscaling. 🤷🏻♂️
how is everyone getting such good images
I've never gotten anything that good lol
upscaling through SD itself?
Yes
wait where is the upscale tab lol

Don't have them stretch so far away 🤣


lol what was your prompt for that, much nicer!
rows of tulips growing in a field, red yellow purple
let me try that
btw, what GPU are you using/how many seconds per image?
I get about 17 seconds per image
4090, and the time is irrelevant because the workflow will be completely different. It's about 13 secs anyway.
rows of tulips growing in a field, red yellow purple, a small village and church in the distance

Without the vignette

Prompt executed in 13.28 seconds
13? hmm odd Im on a 4050 and get 17 lol
this is with that same prompt

I must have some wrong settings
Compare the output though
how does a different GPU improve the quality... isnt it ujst doing the calculations?
you using comfy?
Mine are 1728x1344 res
Yes
upscaled or original?
im using a111, I should try comfy too
how many GBs more is comfy?
No idea, but I'd expect it to be less space for base install.
This is an improvement on the first one you posted. The model choice can also make a difference.
wdym, arent we all using xl turbo?
No way! 😄
I always use my own model, it's given me far better results than anything else https://civitai.com/models/240590/ultimateblendxl
This is a new merge that I have just finalised. There were several models that I really liked the results of, but I didn't want to have to keep swa...
I just don't get the same quality from turbo models.
rows of tulips growing in a field, red yellow purple, a small village and church in the distance





tried comfy
its 50+ GB lol i mean tf
and it crashed my system so... back to a111
stupid me uninstalled a111 after setting up ccommfy before testing comfy lol
reinstalling a111 lol
Im surprised it's that large. I can't tell because I have about 30 models, plus sub models for control net etc.
Put all your models in a folder shared between A1111 and ComfyUI. That way the ComfyUI install will be a lot smaller should the models still be on disc?
My ComfyUI with all models, vae, custom nodes, ipadapters etc etc comes to 450Gb
But the models make up 250Gb of that, and in a shared folder so that A1111 can also use them
how many gb is that lol
wow lol
i turned on xformers and medvram
is it just me or is this better

upscale...

is the upscale actually bette?
Custom Nodes folder is also very large


It looks better than the 1st image you posted. Now try the prompt that adds the village and church in the distance
That will shift the perspective
Hey can somebody send their best picture generated so far?
Define "best picture"

The one that u think is the best in ur own opinion
Just scroll through the channels on here and you decide. I don't keep any of my images.
you dont lol?
im going to try dreamshaper
I just wanted to see how other people opinions are
BTW u guys run these machines on ur own PCs or using servers for them?
How about a server that is my own machine.
either work but most of us using our own PCs
true lol



No,why? What would I do with them? I share them and then delete... or sometimes just delete 🤣
lol
you dont sell thme?
Do you keep any images as a workflow save or do you do json?
No
wait so why do you guys create AI images, just for fun/entertainment?
Yes???
I save a workflow and keep some of the better prompts on a discord server.
ok, makes sense
Is an addiction 😎
A lot of us have been interested in this type of tech for years. We just use it and watch it evolve over time.
I save all of my images and sift through hundreds of them just to find the workflow that I used the other day.
I know that I don't need to do this.

i kind of feel that way lol
I really do

That's a bit harsh.
relax
I already sent my message. I said what I wanted to say.
no lol
And I deleted it
nice
no use being so rude over something like this- make pretty images and have fun
Hi
Don't care. he got to see it and respond.
I get ya
Where are the images created please?
#1047610792226340935 read there

why do you always post that picture lol
Because the bot is down, and people keep asking
oh lol
we need a new version, though...



di down 🙂

I only made it yesterday! 🤣
hehe... well, at the speed at which AI is proceeding



question for images, I want all of my generations to output 1920x1080, could someone show me the nodes or workflow to achieve that? having some issues with my upscaler.


In case anyone else is looking for a good Sketch ControlNet model, t2i-adapter_diffusers_xl_sketch seems good so far
A new comfy-ui channel was just created yesterday, so we can please keep this channel limited to SDXL and you can find answers much faster. 🙂
Hello! Anyone know what checkpoint and/or lora have been used to create these images? Much appreciated!

Search, or check to see if the prompt information was embedded in the images you want or reach out to the prompter.
Explore thousands of high-quality Stable Diffusion models, share your AI-generated art, and engage with a vibrant community of creators
Unfortunately it's not, it seems all pinterest images lack any information and I don't know who the main prompter is since many accounts share similarly generated images
They're so pretty and aesthetic but I have no idea how they're generated
Then just search 'neon; on civ
Not really you just have to learn.
Just look up on civ, and watch tuts.
You can learn pretty quick, but it takes months to master.
I paid to get a tutor.
I do know how to create and such I have been using it for months but I don't know about the neon feature or whatever you mentioned. But thanks anyway, I'll figure it out.

Generate images with a neon/colorful style with this embedding! This is a basic embedding that can make your images have a neon/cyberpunk style wit...
Neon_Dreams (LORA) Feels likea style of cyberpunk, it's not directly ONE artist and it's not directly ONE style. Works on MANY models, and largely ...
maybe it's cartoon?
I don't know you'd have to look for loras you like
Ohhhh I see what you mean, those are all beautiful
What I'm looking for is more comic style?
I searched all of civitai and I didn't get the exact thing
I got close enough after hours of testing out several loras and checkpoints
But can't seem to get the exact one yet, especially since mixing too many things causes issues in final results
It looks like there's a comic lora
There are several!
Play with your loras, you need to play with the weights
Just not ones that help create the ones I see on pinterest
I've found there's no one size fits all solution.
Yup





I recommend keeping the weight under 0.5 for most textures, otherwise you might end up with a simple cube, blob, sphere, etc. rather than the chara...
I wanted to tackle the imposible, to fix those stairs. Took a lot of generation but I was tired of bad geometry xD


There is some artifacts but I was hoping they got fix in the next upscale
Here on this part of the image I want to correct the sofa so I perfectly put in the center and give enough context



create a logo using two colors and in initials SSG
No.
(There is no bot here.)
It's an anatomical drawing of the body of a spachishup.

And another sparachiip.

Fourteen subjects in one prompt?
classical art oil painting of a woman surrounded by props: holding baby in arms, wearing blue silk, with a puppy dog at her feet, a wood table, a wide open window, a globe, a skull, hanging curtains, paintings hanging on the wall, a pile of books, a peacock, magic glowing crystals, alchemical potions in flasks
14: Woman, baby, silk, dog, table, window, globe, skull, curtains, paintings, books, peacock, crystals, potions
Did it miss anything? 🙂
ProteusV0.2 https://huggingface.co/dataautogpt3/ProteusV0.2
75 steps, hires fix 1024->1280, With CADS and AgentAttention
I picked the best render out of 16.


Had to try that prompt with my model 🤣
https://civitai.com/models/240590/ultimateblendxl



This is a new merge that I have just finalised. There were several models that I really liked the results of, but I didn't want to have to keep swa...
The dawning of "Ghost Rider"


nothing missed but lot of duplication
No harm in having "spares" 😉
Woah. Let's not be picky. Just finding a prompt where it misses nothing is a huge challenge. It's not like the model can actually handle any old 14 subjects. Not even GPT-4 can do anything close to that.
16 subjects: woman, flowers, vase, kimono, mandolin, bed, canopy, chest, snake, sconces, smoke, painting, candle, rug, statue, painted ceiling
classical art oil painting of a woman surrounded by props: bouquet of flowers in a vase, wearing a kimono, with a mandolin, snake coiled on floor, bed with canopy curtains, burning candlestick in a candelabra, treasure chest dresser, incense sconces, smoking vapor wisps, painting on wall, persian rug on floor, clay statue figurine, fresco painted ceiling
Same settings, best out of 4 generations. (I'm playing with these prompts a lot, rearranging things and taking out subjects it just refuses to recognize.)

yeah I wasn't saying that in a mean way. I agree it's really hard 👍 .The only times I felt I really had control with my prompts was by using regional prompting in A111.
True. 😮💨 Prompt-following has improved immensely since SD 1.5, but I love every bit of progress our beloved, amazing, beautiful researchers can give us. The guy making this Proteus (and related) models has been trying to make the model follow prompts better.
Yeah, lot of work is made by the community 👍 . In an other field, I wanted to search something in LAION5B today and stumbled on this:
Spawning is temporarily suspending LAION-5B search results until we are confident that links to CSAM material found by Stanford researchers have been removed from that dataset.
I think there is also some improvement that will be made on the training material. In the paper linked with this statement, it shows how some cleanup is needed:
Image label accuracy: From initial testing, we found most positive PhotoDNA hits
were not labeled with text that was strongly indicative of CSAM; i.e., actual
CSAM entries in the dataset may have generic‐sounding labels while explicit
material depicting adults may commonly have ambiguous indicators of
youth (teen, schoolgirl, twink, etc). The text descriptions for the majority of
initial PhotoDNA hits used generic captions that could apply to either legal
or illegal material; therefore we conclude that at least for English language
material, text descriptions are of limited utility for identifying CSAM

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
/me message:apple
With the below can you please make it brighter and blue sky, with the people facing forward. we want the people to be adults from all walks of life 30 - 60 years old.
This image is a very colorful and vibrant scene related to Chinese culture, with traditional costumes and decorations. There was a man wearing a green and yellow traditional robe. To the left of the man, there is a small statue of a smiling creature holding a bowl. On the right side of the picture, there is a large, detailed dragon with brown fur and blue-green scales; it looks very alive. On the table in front of the man, there are various items, including candles, oranges on a plate, an incense burner, and something less clear. Above are red lanterns hanging from ropes; they bring a warm light to the scene. In the background, there are some intricate paintings or murals depicting another dragon and a flying figure, surrounded by clouds.
There's no bot #1047610792226340935
anyone interested in a Seinfeld Style lora? Trained one last night, testing it with dwayne johnson and its making him into a miniature costanza at high weights, bad hairline at medium weights but still captures the seinfeld era aesthetic pretty well with a neutral sdxl model






I think I may train a more compelx model that has a photo from every scene in every episode just gotta find the screen caps for it
currently only trained this model from about 48 photos from random seinfeld screen caps i found on the internet
still captures the camera styles pretty well and the overall aesthetic what do you think
create an image of imran khan standing in wrestling ring with nawaz sharif.