#✨|sdxl
1 messages · Page 142 of 1
you can tell by the way it diffuses, plus- when OpenAI where still somewhat sane the papers explained how pixel diffusion works
that's how Kandisky exists
they used those papers from when they were public
nah, when it comes to things like realism, Dall-e doesn't even come close to SDXL.. again, pixel diffusion has it's own advantages and disadvantages over latent diffusion
It's way less efficient and, and much more "mechanical"

gopro action photo of a man swimming with his dog in rio negro costa rica, extreme wide angle, close-up, highly detailed, sharp focus, shallow dof, glinstering water, bokeh, hq, uhd, hdr, '#photography, man and dog swimming, ntional geographic, awardwinning
the prompt is taken from #🏅|pantheon message
left is sdxl, right is dall-E 🙂


you say this can do more than just two images?
You can technically put in as many as you want
Just batch them together and put them into the IPAdapter
SDXL images arent 300px^2
they're 1024 x 1024 actually 😄
the stylistic prompt doesn't seem to do anything

this is cool, but the hard part is taming it
first try would be something like "pixel-art, detailed cyber punk city, neon lights, 16bit"


sdxl seems to be missing the man 🤔
AI art will keep these pixels burning https://www.theguardian.com/music/2023/sep/30/u2-review-an-utterly-astonishing-admirably-raw-vegas-extravaganza https://www.theguardian.com/music/2023/sep/30/u2-review-an-utterly-astonishing-admirably-raw-vegas-extravaganza


the Guardian
Playing Achtung Baby interspersed with other hits, the band use slick LED displays to eye-popping effect while remaining unpredictable




I put all my latent space in this little box I have.

sdxl seems to having an upper hand with respect to the 16 bit part, I think? 🤔
not sure
how does an actual 16 bit pixel art image look like?
the lower the amount of pixels in the pixel art is, the higher the chance of dalle doing better imo
i would think that the last one is not so far off
I also have a box like that

I call it- "my GPU"
seems like it

bit grainy. but I really like this one 😄

pixel-art, detailed cyber punk city, neon lights, 32bit, 3d city

you can instantly tell it's not sd
really good
it is. I think sdxl has a bit of catching up to do 🙂
hard to do when for it to catch up it needs a latent language model the size of gpt-4, I don't think they ever will sadly

Ah yes, the General Purpose (Storage) Unit
this is what I get with SDXL, idk. SDXL is opensource, so it's still infinitely better

that sounds like some FTB modded minecraft bullshit haha













anyone good at making simple workflows with controlnet that might work well with user drawings?


results subpar
SDXL has Canny, Sketch or lineart

That looks like it's applied wrong

most likely haha
Or are you trying to put the drawing back over the top of the image?
nope, just trying to use the drawing as a fill in for the generation, i'm just an idiot 🙂
there's a 100% chance i'm doing it wrong
but my html/javascript/python web scripts are all working, so that's a plus LOL
Everyone likes scuffed shrek



might try using 1.5 with a sketch controlnet model, then using the results with sdxl canny
Try lower the Controlnet strength, it's above 1, which generally causes weird issues.

lol, just made you a new one. looks good though


so close, yet so far away 🙂 will keep experimenting, appreciate the tips
may need to try the ipadapter stuff, dunno
if you have any questions on that don't hesitate to ask. it's really wonky stuff
IPAdapter won't do what your wanting

what is the easiest way of using two loras for two different people without inpainting in sdxl?
really just need to find something that'll recognize what the sketch is going for
to be fair, there's isnt' much better =p
regional prompting
basically having each lora applied to only a certain portion of the image

thanks I'll look into it, really should be made easier by just saying the two people and sd just figuring out
if you're using a1111 just look for a regional prompting extension. shouldn't be too complicated. the ai currently isn't very good at that sort of thing on it's own
so it just sort of mixes everything together in one big pot



Golden Octopus
I don't think it wants to be friends




crazy difference this is the same prompt, left in sdxl and right in dall-e 3


looks like dall e actually integrates everything into the background instead of slapping it on top like sdxl does

I'm curious if anyone knows of a service to train loras. Even if it's a paid service. When I look up how to do it and I get a 48 minute video, it's discouraging.

I hate it, man. so hard to find quality info
I train loras all the time, for any questions I might be able to help
there are quite a few options for paid services online though. colab is alright, but they aren't big on guis
SDXL needs better prompting, but delivers better quality
I have seen paid services that still require you to set up everything
Ideally, I would either be able to pull a few gits and run it for free, or cheap... or just send an individual like 80 pictures and they do it for me for money
honestly, not vouching for the quality of the service, but there are optionso on runpod
@woeful patio do you run it locally or online?
and they're the pretty simplish interfaces
I run it online through google collab, costs a couple of bucks
If you have images with .txt prompts you can send them to me and I'll make a lora for you
there will never be a concensus on anything in this realm
You can make them locally if you have a decent enough PC. It's not that difficult to set up. Just need at least 10GB VRAM for SDXL
lol i mean if you ask everyone what the best way to run sdxl is, you will have a lot of people say a1111 or comfy, and thats enough to point me in the right direction
unfortunately i have a 3070
weird to feel like a 3060 would be an upgrade for this
how bad is the runpod set up?
I made a quick guide
video guide

🎉 Welcome to a brand-new tutorial where we unlock the potential of generative AI technologies with SDXL and LORA styles!
In this video, we delve deep into the world of AI generative technologies, guiding you step by step on how to train your very own LORA style using the kohya_ss tool and the RUNPOD cloud service
- Go to https://www.runpod.io/...
damn bastard, i drew where to put the pumpkin lol, why add more around the outline hah

word, thank you for making this. this is the shortest video i have seen on the subject lol
I only watch youtube videos if they don't have the clickbait creepy thumbnail
it's very basic.... not explaining all the parameters
just a quick startup with also a Json in the video description
on average
you know which subject has quality youtube videos? auto repair. no frills. these dudes aren't trying to become influencers. their camera work isn't always top quality but they're very helpful
I've been able to make ok ones in about 30 - 45 minutes on a 3080
50 images 4090 and 256 network dim is 2hrs
they charge by the hour
you could rent 8 h100s for 35 an hour
if you want 640gb of vram
and a terabyte of regular ram
the problem is downloading
nah
it's slow
you just send it to the runpodctl colab
using terminal
it's stupid you have to take that step, but it works
nut you need a google cloud account or just google drive?
no need for a cloud account for that
it's a colab notebook that's setup to receive the files
and puts them on your google drive
need a drive of course
I'll try next time
i love how I bought 8gb 3070 a month before sdxl came out 😦
I did the same with a fairly high end laptop. was on the fence with desktop or laptop
figured just get a laptop that can game, that'll be great
LOL
I got my 3070 at launch
felt super cool
now I cant do what I want to do with my mf gpu
I've 4070 12GB it's good for SDXL, but not for training
can it train?
too slow
i hear u need 12gb vram to train at all
word
well that is actually encouraging for me
cause i know for a fact i cant afford to do it locally now
andreac: if you want to do what I'm talking about this is the colab notebook. it has the instructions, but super simple https://colab.research.google.com/drive/1ot8pODgystx1D6_zvsALDSvjACBF1cj6?usp=sharing

thanks

need to do it through the web terminal I believe
no problem for terminal
thanks for the info everybody

Dog face or worry face?









this may be my problem i'm starting to think, why does control net see a thick line as a double outline?


can clearly see the 2nd outline



Because Canny is edge detection. There are 2 edges on a thick line; the inside edge and the outside edge.
If you want to do what you're doing differently, fill in the white space around the eyes and mouth with black.
Then no edges will be detected until you get to the white eyes and inside of the mouth.

clean!!!!!!!!!!!!!!!!

yeah these are super


waka waka


the joker, (batman's nightmare, surreal bat phobia, by Tim Burton and Lucasfilm, voyeurism:1.2), (horror, coherent, intricate detail, victorian gotham city setting background, dawn light, natural light:1.3)


awesome







Steam Punk Lord, cybersteampunk
Steam Punk Lord Batman, cyber steampunk, style of comic book cover illustration, 1995, (POV:1.3), (batman's nightmare, surreal bat phobia, by Tim Burton and Lucasfilm, voyeurism:1.2), (horror, coherent, intricate detail, (victorian gotham city:1.3) setting background, dawn light, natural light:1.3)


Uncle Fester?





Fun result from IPA:




it's all there 
bat parlor

(vermeer lighting), male (SteamPunk Lord Batman, cyber steampunk) planning, Bat Cave Parlor setting, style of Caravaggio, 1987, (POV:1.3), (batman's nightmare, surreal bat phobia, by Tim Burton and Lucasfilm, voyeurism:1.2), (horror, coherent, intricate detail, (victorian gotham city:1.3) setting background, dawn light, natural light, crystal clear, extreme detail


wow the photo look and materials in this are awesome

Thank you. Just playing around with some stuff.












:/











cloudy hair (and demo of the cropping settings (center, top, left, right + offset)










haha. you're still at it 😄
@icy brook mainly improved my workflow in the last few hours and still using the cloud style for tests :)







is this with @icy brook's lora?
No



"The Girl on Fire"



great video about using the ip adapter (by the developer of ip adapter plus): https://www.youtube.com/watch?v=7m9ZZFU3HWo
(shows img2img, inpainting, upscaling, different models, etc.)

Everything you need to know about using the IPAdapter models in ComfyUI directly from the developer of the IPAdapter ComfyUI extension.
👉 You can find the extension "ComfyUI_IPAdapter_plus" on github here: https://github.com/cubiq/ComfyUI_IPAdapter_plus
00:00 Introduction
01:33 Basic Workflow
05:55 IPAdapter Plus Model
07:32 Prepping Images
09...
but only for comfy?
@icy brook yes, comfy only. as he explains the features and usage of his node.

Yeah 😀
dalle3 seems kinda really disappointing for most things. it's just good at the few flashy things like text and prompt accuracy. for a lot of prompt outputs though i even prefer dalle2
like for example?
@glad grove dalle3 (left) seems to try to go more realistic/overly detailed by default instead of painterly/handdrawn of dalle2 (right). and no prompting or negative prompting seems to fix the styling.


i mean left still obviously isn't hyperrealistic, but it tries to still be fake realistic in terms of detail even when prompted for simplistic painting

Digital art?
I've noticed a lot of these focus on SD 1.5 for some reason, even though SDXL is just better.
That Nerdy Rodent has done videos about it as well, but only SD 1.5
the workflow is the same, so you can use everything he shows for sdxl. there's a sdxl section too, where he recommends the vit-h model
i tried prompting for 'digital art' as well @slender coral
Oh yeah I know how it all works, just an observation.
Unfortunately his nodes use more VRAM for me than the alternative nodes. Even though he claims his use less on his page.
And that noise option seems to wreck the outputs with the SDXL Plus model. It did make them better on the regular IPAdapter Model.
I can't stop getting texts of what it is 😄

SDXL does that too, I'm guessing your asking for a barrel of moonshine. So it's doing just that. Giving you a barrel, labelled that it's moonshine 🙂
I usually don't get it this bad, and negatives usually fix it.
Are you changing the empty latent image size to SDXL sizes? SDXL will not look good at the smaller resolutions
Of course lol.
It's just his noise option with the IPAdapter Plus model. Must be down to how it works, but it pulls away from the subject when you use the noise option. With the regular SDXL Model it made them better.

But it's it using more VRAM that's why I don't use his nodes
IPAdapter Plus uses between 9.8 and 10.2 GB VRAM, on average the other IPAdapter nodes cross 10GB less often, so get faster average speeds when I only have 10GB VRAM

is there a way to make sdxl generate more images?
You mean more at once? Up the batch size.
what do you mean by wrecked? guess it depends on the subject and style.
here is the same seed with and without noise with the sdxl plus model:
left with noise:


I've found on SDXL Plus it changes the outputs too much compared to regular.

This is very good for variations https://github.com/chrisgoringe/cg-noise
Plug your empty latent into the Hijack node, then the hijack node into the ksampler And then on the other side of the ksampler plug that into unhijack and then the vae decode. It lets you do variations of a single render.


What do you mean. You just up the variation weight to get slightly different images.
Literally just a slider
is there a version for a1111
Doesn't that have a variation option built in? It's been a while since I used it.
not that i can find
all i found was thishttps://www.reddit.com/r/StableDiffusion/comments/125hosf/image_variations_support_added_to_automatic1111/

Reddit
Explore this post and more from the StableDiffusion community
oh
looks interesting. maybe i'll add that to my workflow instead of the base / base + refiner option. a second variation with reduced render time would be nice.
why is this store selling el caminos

@eternal fog what do those unclip nodes in your ip adapter workflow (the one you posted earlier) do?

i think hes lost

Are you asking what unCLIP does in general or specifically about how he has them setup in his workflow?
@native knot in general and in context with ip adapter.
It's pulling concepts from the given image(s) for use in variation of the new image.
Does anyone here use 1111 still with XL?
I just went back to it for a 1.5 model that was built around 1111. I realized how much I liked 1111 because of how I can go from model to model in image2image.
I'd imagine use with IPA would simply assist IPA.
They can be used to try and adjust the weight of the images that are being put into the IPAdapter. As your feeding in multiple images into 1 IPAdapter node.
By adjusting the noise level, right?
It's basically a workaround for me not having enough VRAM to use multiple IPAdapter Nodes.
More it's adjusting the conditioning to suit those images
It's kind of like putting in a prompt similar to the IPAdapter images.
So I was right that it's being used as an assist to IPA.
I can't remember what fixed the issue.
In this case yeah. So if the IPAdapter focuses too much on 1 image, you can use that to try get it to go the other way
The alternative is buy a 4090 XD
Which i'm still tempted to do
so unclip is creating text based extensions to your manual prompt based on the input images?
If you put a prompt in yes, but you don't have to use a prompt.
I can try do an example, give me a few minutes.
is this similar to what this website does?
https://huggingface.co/spaces/fffiloni/CLIP-Interrogator-2

No because unclip doesn't directly create text prompts. It's pretty complicated and beyond what I understand, but it apparently gets "Concepts" from the images. So it's similar to IPAdapter in a way. But instead of modifying the model, it modifies the conditioning.
It doesn't always work how you'd expect however and I'm guessing you will get better results if you can spare the VRAM for multiple IPAdapters.
But I've put these 2 images into IPAdapter in a batch


And I run it without a text prompt
I get this

It's mostly just the robot dude. For whatever reason IPAdapter doesn't take much attention to the other image in this case.
If I give the none robot dude image a bunch of weight in the unCLIPNode you get this

So it's pushed the car part of the image a lot, however it's not taken to the style.

That's because it's not acting on the model, iirc.
Right?
Well the reason it decides to mainly get the robot dude I'm not sure. Just IPAdapter seems to prefer that image when they are put in a batch together.
When you add unCLIP weight to the old car game, It's looking at the concept, which is a car on a road with some buildings and trees and applying it like text conditioning.
Right. I don't think it can glean the "style" from the image, per se.
Yeah not in this case
But if you really wanted that then I can put just the car game though IPAdapter and unclip the robot dude and

That came through nice.
Text prompts are more powerful though
(do this one lol)
That's with "Male Cyborg in yellow armor standing in the street" as the prompt

How do you unclip just the robot dude?
Only feed the 1 image into the IPAdapter, but keep feeding the robot through the unclip node.
IPAdapter and unCLIPConditioning are completely separate so you can do what you want with either.
yes, looks like it's more like detecting the content/objects, as the result is far from the pixelated video game image. guess i will have to try that out. maybe it's worth to add to the workflow.
kaizu in this style would look like Rampage World Tour
I think if you had 2 IPAdapters you might get a better result, I can try but it will take ages to render.
That's what I ran into....just forever s/it.
Yeah it uses like 12GB VRAM
Add cnet to that and it's even longer.
So it's like 2 minutes to render, instead of a few seconds
then buy one
For training what is the perfect amount of images?
Nvidia need to fuck off with the stupid price they are charging for them
Nah...gotta pay down some other stuff. Too many expenses.
You
You'll pay it.
Actually I just tried this and it still favours the dude. It might be because the source model favours people more.
I put smart shades up in the house this year, need to pay those off. Almost halfway. Need new carpet next.
As most models do.
In fact, most models heavily favor women over men, so working to get some things done that take the shape of a woman without it actually being a woman can be incredibly tough on some models without a LoRA.
You didn't need smart shades, you needed to generate images.
You underestimate how awesome smart shades are. I programmed everything up with Home Assistant so that when both my spouse and I are out of the bed for 10 minutes after 7am it turns off the sound machine and opens all the shades in the house to the precise place we want them. Then, at night, they just close up on their own as we wish while various lights kick on.
I have smart shades, they are too slow 😄
I also don't trust any iOTs hooked up to my house but some people don'tmind.
Not sure how to do that since it wants a clip vison
Home Assistant is self-hosted.
4090's are basically room heaters too, they can save you money in winter 😄
two ip adapters in chained mode:
0.5/0.5 / 0.25/0.75 / 0.75/0.25 weight + 2 source images:





IPAdapter doesn't use CLIP Conditioning.
If you are using the workflow I put in, just take the 2nd image out of the image batch, then it will still be connected to the unCLIP but not the IP Adapter.
Try it without chaining and just sending a batch of all the images to 1 adapter. It doesn't actually seem to make that much difference.
you can't set individual weights in batch mode
it did change for sure
What would you lads reccomdend for the perfect amount of traning images?
I know, it depends entirely on input images. But even changing the weights didn't do much for my example images.
How long is a piece of string 🙂
I've made LoRAs with a single image that worked surprisingly well.
It all depends on the quality of your images really.
Depends
quality and style, or subject, or concept
this is batch mode with 1.0 weight (as you have to add the 0.5+0.5 weights to get a similar result in batch mode):

Object
Just in general 20-50?
Was that because of the base checkpoint?
Subject/Object can be as low as 6
It was just the base SDXL Checkpoint
seen 1 before but 6-15 is good
for styles I like 20-30 but concepts I still don't get what that even is but heard 50-100
more is not always better, btw
Lord Batman





50/50, 75/25, 25/75 (weights) - same seed, no text prompt




Nice. It does work well if you can afford the VRAM. I can do similar, but I tink it's a bit more work to get it right with only the 1.

that's why i prefer chained mode, as it gives much more control than batch mode, even if the developer of the node recommends batch mode
Yeah, hopefully they can reduce the VRAM usage.
how much vram do you have?
And it shows.
the latest update of ip adapter plus allows you to create pre-encoded images to save vram. you can save them and re-use them.
Generation slows to a crawl.
Would it actually save much VRAM though
It still needs to load them into VRAM to run them
And you'd still need two IPAdapters
i don't know if the models are unloaded anyway. but in his video he said something about 4gb of vram you can save (don't know if it's in total or per image)
He says "Hopefully the Clip Vision Encoder is unloaded" I'll give it a test.
But his example he's using batch and not multiple adapters.
yes, he doesn't like chained mode, but he might add weight option for batch mode
I wonder how you'd do that. I've seen him asking about stuff like that on the main IPAdapter github.
imo results of both modes are very similar if you adjust the weights. as chained mode adds all weights you have to use lower values per image. sometimes i even got almost the same image from both modes, after adjusting the weights (only if both used the same weight in chained mode of course).
so if you have enough vram there's little reason to use batch mode
Ideas on why this wouldn't be filling the full image? a racoon human , full character view , Epic background

Probably so it can get more of the "Epic Background" you've prompted into the image.
as epic as unreal 1 on a pentium 1 cpu :)


yes, mentioning a background will often result in zooming out from the main subject
😂

maybe add closeup as counter-measure or just run enough seeds to get some that are closer to the character.
I'd like the full character.
try a very low strength control net depth or canny with a character that fills out the whole image.
Do you know where that would be?

this should force what you want. just have to play around with strenght and end step
maybe in "operating mode". at least that's where i have control net in my workflow.
or if there is no control net you could try img2img with a low img strength and an input image that has the position/size of the character you want. you would also have to find out the optimal strength, so the image is not visible in the result but strong enough to direct the position/size.




hes a natty

hahaha
100% natural full vegan just by going to the gym 2hrs a day


i dont bite

SDXL models, what do you people use?
protovision
I've been using an older Dynavision, and Niji XL special edition. I have to get a few others, juggernaut xl is one

idk what happened here

fed it after midnight by the looks of it
hes mutating
here is an example how control net depth with low strength can force a charcter to full screen:





greetings

anyone know how to keep Comfy from adding numbers to the end of the filename in the save node?
tried a primitive but still tags the number at the end
what model
use the save image node from mickey pack.
thanks JPS
the dall
many of these pockets have snacks

ok

genious, ty sir!

if ur referring to dalle 3 are u sure thats allowed here

Brotha gotta eat

American actor Steven Seagal visited Belarus President Alexander Lukashenko at his official residence in Minsk on Wednesday (August 24).
The Hollywood star received a warm welcome. The country's leader treated him to home-grown carrots and watermelons and invited him for dinner.
What are the top stories today? Click to watch: https://www.youtu...
he loves carrots


Solid Rat





I just noticed there is no path defined for diffusers in comfyui's extra_model_paths.yaml file, only a checkpoints: line under a111:, is there a way to use diffusers (and is there a difference doing it)?

After looking at Civ, I couldn't find any good UI/UX loras for 1.0, anyone know any?
meant to be a ghost taking a shower


I got it guys, the hardest image to prompt for

😄 what was the prompt?
take a guess
small anime girl in white void
same prompt that gave me this, funny enough. Just added a different "style" to it.

(obfuscated the nsfw part)
This is very hard in SD pure prompting, specifically the composition
almost



woops, kicked on my IPA process on accident with that same prompt 🤣

电竞房
how do i get 3/4 front view always on my characters?
prompting sometimes gets what you want.
Or openpose if you want a specific pose
done

example

that's not 3/4
like you know in those side scroller games
its awlays little angled the face
its not totally side
3/4 pose if you're trying to prompt for that will be cutting off around the knees if followed exactly
otherwise, if you're looking for that you described, try prompting "in the style of X game" or "looking away" or something like that.


finally! yay comfyUI and python/java, bed finally






t2i canny + IPAdapter

@soft zealot I really like the cruiser weight workflow... So far excellent results and thats without even getting into the controlnet or revision and ipadapter sections... I do see a lot of great notes on how to use the different nodes... However I was wondering if you have an in depth manual somewhere that I can read, I didn't see an actual manual when I downloaded the workflow? If not that's fine... When I wake up later I might have a few questions for you... I will try to keep questions to a minimum. Great work though. great results.
These double exposure-esque photo's have been fun trying to prompt for.
I'll leave it a mystery for the time being

and this was a unique outcome

Cheers ears. On a “manual” the short answer (especially as I’m on my phone ) is “ there is no manual and there are no plans for one. Let me rewind………..leaving aside the “advanced” features a key focus for me was simply to take a basic workflow and then (within the limits of ComfyUI) build it as a useable daily interface where everything need for basic image generation is logically(to my mind at least lol) laid out. I think for the more advanced bits I e mostly linked to source where I’ve borrowed them from. I don’t mind questions,just don’t ask one that’s answered in the notes already lol
oh and ask questions in the open rather than via DM as its all pretty generic and others may b eable to answer
Going to release my inkdrawing lora later this day. 😏


oh that looks nice! I'm looking forward to trying it out

Thanks
is the paper texture part of the fine-tuning?
It is, kinda. I have tried to get it as much as possible out of my scans, but it keeps showing in the generations. I dont mind it
no I think it's great. looks realistic
For just showing pictures its totally fine. For print it would need a bit of postprocessing. But yeah, i am getting some awesome results imho

yeah. I mean that should be easily removable with some blending 😉
looks very clean
Hey guys, I'm trying to load SDXL in jupyter notebooks and I keep getting:
Encountered %!d(MISSING) file(s) that may not have been copied correctly on Windows:
unet/openvino_model.bin
See: git lfs help smudge for more details.
anyone know why
Im' using paperspace
any math genius in the house? i need help with a crop/resize node i want to develop. guess i can figure it out myself somehow, but it will take hours, while a math wizard would probably solve the problem within minutes or even seconds.
here's the task: input is the current size of an image (width and height), a target width and height and an offset value for both axis. output should be a resized and cropped image that keeps the aspect ratio of the content without stretching.
problem is you have to consider different cases: target width and height could be smaller or larger than the current size (there could be even cases where one axis has a larger target size and the other one a smaller target size) and the offset value could be too large, so there has to be some correction for that case.
i need a way to calculate x,x2,y,y2 for the cropping.

what i figured out is that the cropping box has to have the same aspect ratio as the target image. and i have to figure out if the image has to be cropped in width or in height.
PM'd you a "possible" solution
btw. if you want to fix AITemplate after the latest ComfyUI updates and until the official AIT repo has been updated, this fork works for me: https://github.com/asagi4/AIT/tree/hacks




PixelWave: Where Every Pixel Tells a Story 🌊 This is model that leans more towards photography. Neutral whites. Improved hands, hair and skin. No n...
New version of PixelWave just released 🙂
congrats! it looks great 🙂
Downloading now so I can give it a run.
Congrats!
I was wondering why there are official GitHub repositories for SD 1.x and SD 2.x with python scripts to run them, but none for for SDXL.
There are various wrappers and frontends which can work with SDXL models but no official reference implementation as in the previous versions, or so it seems.
I'm still not sure why that is.
That, and the different naming, make it seem like it's a different "category" than SD 1.x and SD 2.x, not simply the next version which supersedes SD 2.x.
Does anyone here have an answer to that question?


reference repo for the model arch is https://github.com/Stability-AI/generative-models recommended inference core is https://github.com/comfyanonymous/ComfyUI


Damn...I am impressed that SDXL knows the term midsommar. I happened to toss it in to change the look of something and it went from this (left) to that (right).



Thanks. I'm familiar with that.
Totally kewl
SDXL Promt
dream prompt: Airship (Zeppelin Aircraftcarrier:1.5), (stealth:1.1),(submarine:1.1),sharp,high detail,atmospheric lighting,(straight diagonal lines:1.6),vector art, style: Digital Art negative_prompt: chaotic,noise,blur,bloom,shiny,over saturated,strange,chaos,unsharp,hero,buildings,groups,text,watermark,sign,symbols,Alphabet,simple,comic,ropes,many,ships,Columns,dock,sketch,(abstract:0.4),real,
first is the SDXL image than Dall-E-3
1.

than dallE3 2.

and its not open source



can i have your workflow, it is amazing

There's a simple version of it here
#✨|sdxl message
SDXL A1111 using Base and Refiner from Huggingface. Also a few of my own textual inversions (not made using SDXL)





I keep lookingto see if SAI bought out Dall-E or if I am in the wrong discord. Nope, to both.

Shameless Self-advertising. Released Inkdrawing v1
https://civitai.com/models/154918/sdxl-inkdrawing

SDXL Inkdrawing is a LoRA that transforms your prompts into rough black ink sketches on a paper texture background. Whether you want to create a po...



going in sd Comfyui is pain now 😦
This will be my new lora, ive managed to obtain a database of 1400+ van Gogh images where about 60 need upscaling.
After I hand caption each and every one of them as useual I will pick out the best dump Prod vs Ada and release it. 🙂
AUTOMATIC1111 SDXL using DynaVision XL as Base






there is nice source @stone fossil
http://laion-aesthetic.datasette.io/laion-aesthetic-6pls/
have you checked it?
I think mine is fine dw. 🙂 thanks tho! ❤️
o.k. i think this is what is included in SDXL probably. Very good to listing in it. <- if right 🙂

I got the name tags and the year tags.
Could not be better.
I will dirty blip them.
To get the tag(s) in there and then by hand go over 1 by 1 hehe.
Place the name in there of the official date and the name.
Fill in / remove what should not be there and then go.
But this time also seperating styles.
Shit i thought you wanted to write a detailed caption for 1600 images. Hell, i am exhausted after doing that for 80 images

But you will see that when you properly caption stuff it will also be more easty to implement stuff or replace stuff.
Say backdrops for example.
If you never define one in a caption its kinda not good.




Batgogh!


https://scontent-hkt1-2.xx.fbcdn.net/v/t39.2365-6/10000000_210375442059452_321995130515097708_n.pdf?_nc_cat=105&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=5acdOVeMx-cAX9ygXLj&_nc_ht=scontent-hkt1-2.xx&oh=00_AfBS2izeW8gtgd8NjqKzQTfDW79rwkKE_32iYFkg0Two5w&oe=651E7F0D Could we use 32 channels VAE for SDXL?








got it. my crop&resize node is working with some help from aimingfail, bing and chat gpt and fixing all the bugs the AI made:

Noice ❤️





DE3 is impressive, yet there are stuff where SDXL does a better job. So I'm not afraid that Open image models will be completely outcompeted yet
how dalle 3 is so good, can sdxl compete?
A1111 SDXL




DE3 struggles with variance, despite using 4 different seeds, you might end up with the exact same composition in all 4 images while SDXL will give more variation. Which apperently is a weakness with the type of text to image model that OpenAI is using here.

It's well known that small scale finetunes can outperform the base model. Any tl;dr about what's novel about this research?
Hmm, yeah I see that base isn't doing too well with Pikachu Van Gogh so a LoRA is probably helpful if you want it to look really good.


It introduce more channels VAE could reconstruct better result in small detail. For example, load an image and output it via 4 channels vae. It failed to recontruct on the small detail. Image 4 is the example from the emu paper.




dall-e 3 is having a rough time

i am loyal 🙂

I noticed yesterday that the wait estimate for DE3 was a lie, just refresh and it will be ready a lot sooner.
Sounds like it is your VAE that is freezing up Marksouls.

Thanks.
I'm testing my pose controlnet and something went wrong with Pikachu.


nice paper texture 👍
would be nice with an image of a film noir detective smoking in his office with the window blinds half shut
Thank you, it was an accident. Nice idea with the detective. Let me try
that's not an accident 🙂 if that's the case it was the right wrong choice
Close

congrats to the release!
Thanks, now you can play with it
new version of my workflow with the new crop/resize node used for img2img + inpainting and some other minor improvements (for example separate models for image adapter and revision, so you can mix revision and vit-h ip adapter models)
https://i.imgur.com/4DedNov.jpg
https://github.com/JPS-GER/JPS-ComfyUI-Workflows
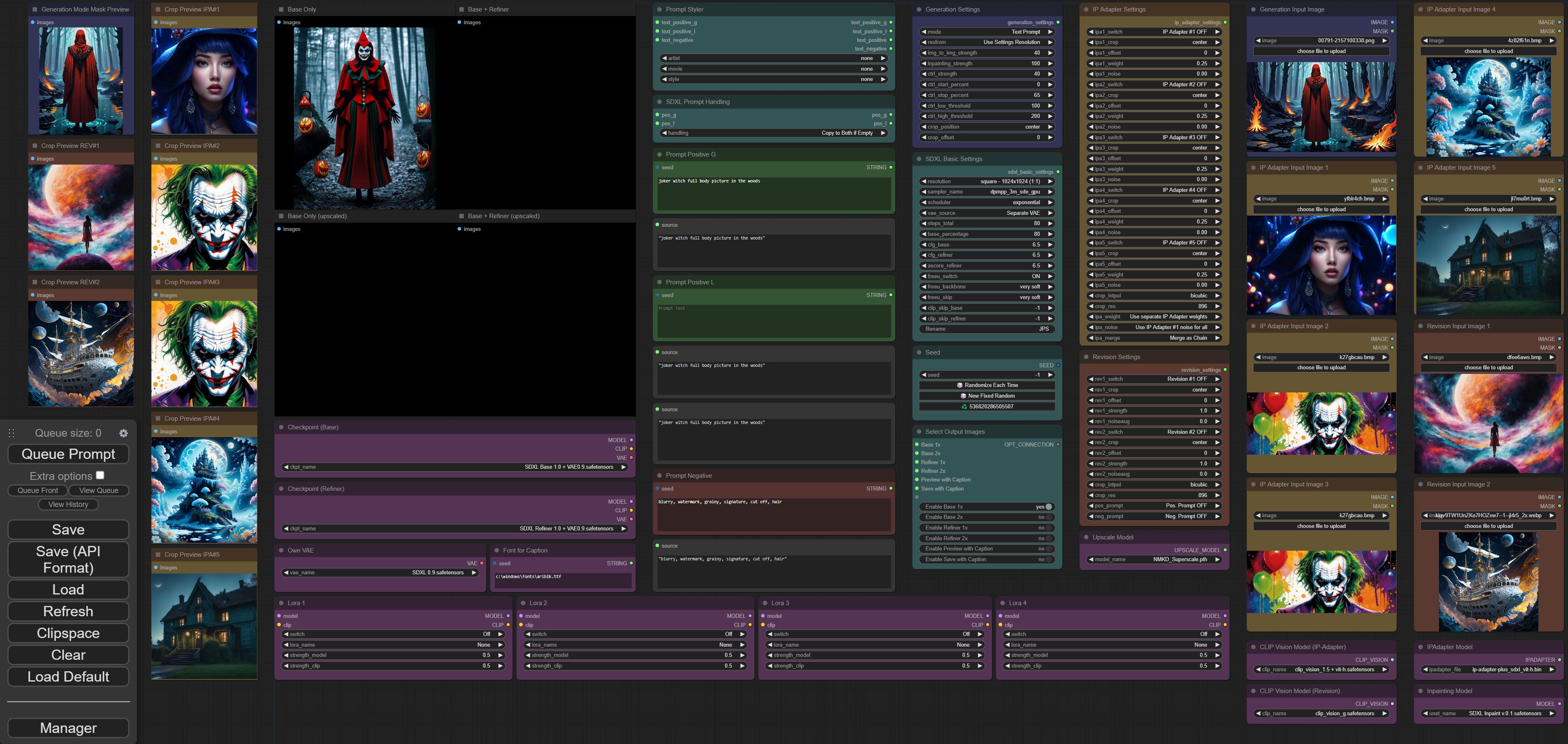
GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
it's still fitting and is useable on my 42 oled. don't know how smaller displays will handle it. :)
Any eta for controlnet tile for xl so I can finally use adetailer?



cool
So sad, i have my menu bar on the right side. Guess i have to search for another workflow then.
You just gave me an idea to try with IPAdapter




It works with coins too






Using people removes the stamp effect somewhat, but it keeps the crown lmao





get a larger screen and you can place your menu bar anywhere :)
and it's still cheaper than a 4090.

I don't believe you. Going to get an ultrawide.


Just figured out that my inkdrawing lora also supports color, if you ask for it....and its awesome (self-advertisement)




You're welcome 😅
I want to try use the LoRA with IPAdapter, but it's going to wreck my VRAM 😢
I'm sure you all remember that great basketball player Michael Joran

DallE3

SDXL

idk, not only it's closed source; it also doesn't seem as good as SDXL

lmao

oh that's cool lol These two mixed



Even better when mixed with one of @noble shoal ink images

Does anyone know how to generate a Minecraft character in high quality in SDXL?


Put it back through with a text prompt and you can even have someone model it

Now you only have to put it on a website, let it produce and sell it. Profit.
lol, I'm sure there's existing products like that. Maybe not on a turtleneck sweater though
minecraft always worked out of the box
Real nice image nevertheless!
Yeah...thought it was hilarious with the combination of the face that's wrong with the name.



there is some stamp lora?
short story comic strip made with SDXL Inkdrawing by @noble shoal
Model: Base SDXL 1.0
the full comic strip here: #🌠|show-and-tell message




It's putting a stamp into IPAdapter
This is the source image

aha o.k. thank you @eternal fog
i am angry on ComfyUI now, so i am in sdxl in A1111
SDXL do nice we call those edges small teeths.
I accidentally made a Bird Plane

🙂









with no plastical surgery?
It gets so close
makes for great humor sometimes
i ask for saab 900 and i get a volvo





like how edge moreless match















Imagine if it got it right though
That would be 

i know one thing weird results combine arnold with elephants



















i want 20 pieces, and got 100 pieces





thers shades of Jag in there as well


Raid. Shadow legends.
















@vital ermine you take my idea sooner then i got chance show something 😄
LOL




tried to play with DT in it, but not good result, but can be relaxing shaking with him


little vibe of Lancia 037
bmw m1 for you



dunno what i'm doing






hmmm.... lets see if we can add a bit more variation


heh. getting there









did you copy my prompt? 😮
oh yeah! this is what i wanted 😮

keep. generating. comrad.


C3-P0-IM
Very good for DKWYD!!!!!
dkwyd?
Don't Know What You're Doing! 🙂
well... actually i know very damn well what i'm doing: abstract absurdism ADDCOM {2::__songmaster__|2::art by __artists__| } ADDROW {2::__songmaster__|2::art by __artists__| } ADDCOL {2::__songmaster__|2::art by __artists__| } ADDCOL {2::__songmaster__|2::art by __artists__| } ADDROW {2::__songmaster__|2::art by __artists__| }
except, i have TOTALLY no idea what the outcome will be

Oh, I thought you mentioned that very pretty girl's face "dunno what I'm doing" 🙂
Is this like X,Y prompting?
excel
that's for regional prompting
that's just cracking up my usual level of randomness with more levels or random entropy
just how i like it 🙂
it works so well for controlling composition and detail, and images not flying off the rails
Entropy! You can get pills for that 😄
digital photography, Can I take another step? I've done everything I can. All the people that I see, they will never understand If I find a way to change, if I step into the light Then I'll never be the same and it all will fade to white
but at the same time just a single verse with the right medium, can make such nice images

I just installed IPAdapter/ClipVision on my ComfyUI - gonna be busy tomorrow setting it all up ...
Sounds like a song ...

i'm pretty sure it's from a song
it's in my songmaster file
ah, it's from the english version of bad apple





Snoop Dog-Gogh







@noble shoal I posted some images on your release page: https://civitai.com/models/154918/sdxl-inkdrawing
Thanks for creating the LoRA! Very inspiring 🙂

I was wondering how to get the face detailer to work? I think its being bypassed at the moment. Does this have to do with the "dummy" nodes on the left?


remeber what I said abiout answers being in the notes

@noble shoal forgot to add the title image - moment 😄

yep I missed that first switch... It was on 1... now its on 2.. thank you
Hope to see more comics from you in the future. The creation was just luck, because I found an old dutch comic book from the 60s at a flea market. Immediately fell in love with the style.
I did what? 😬
great idea and the results look really good 🙂
I<--- forgot to add a title image to the comic strip gallery post 😉 reuploading the images shortly
Ohhh. I thought I had that moment. That would be shit to not have a title page image.
no, you're good 😄

nice details
Thank you both
Prompting can go from Kindergarten level all the way to Ph.D level.
It is an art all unto itself

hahaha





I must have messed something up when I was setting this up... What is this supposed to connect to?



reopen m8ine from the v4.2 zip file and satart again.
Thats something you've added fiddling around

needs a ear bleeding
You can try for yourself once I release the lora lol.
lol
fixed.



@noble shoal ok posted and I generated this title image for it 😉 civitai is still processing it so it will hopefully show on the page soon















Seems to do a good job. It's easy to influence colors with an img2img workflow just by using a little less than 100% denoising.

Is there any documentation on the new scheduler stuff in comfy? Like what to use sigmas for?













The galaxy is on Orion's belt.

Cats are awesome. 🙂
These are agents SD and XL here to see you.

what movie was that from again?
See above.

I havent used sdxl since release week, what kind of workflow and models are people running now? on comfyUI atm
I stack proto as base then dream shaper as refiner.
I just had the best idea...need to make some adjustments, but damn.










{kind=link}
@oak ice (cycle rickshaw batmobile:1.3), Batman, victorian beijing, ( POV:1.3),(adult, night time, horror), 1983, (extremely detailed depth), style of Antoine Blanchard, highly detailed, style of comic book cover illustration, inspired by William Brodie
more fire


A series of 12