#✨|sdxl
1 messages · Page 135 of 1
well i find DB many times better

but finding correct parameters took 66 trainings 🙂


looks like the work was worth it. it looks really great!
@cyan crown qrmonster i found is 7-8 years old. What is the name of that thing for qr codes for 1.5? do you know, or link?
@shy kelp try chaiNNer, but scaling latent space can be more effective probably.
yep
i should do same for LoRA too
@cyan crown o.k. found it on hugginface



sdxl already has canny, depth, scribble, openpose, and recolor controlnets


For those curious. Here's peak load speed of SDXL models on sn850 gen 4, vs SX8200 pro gen 3 budget

used rush from doors roblox as control trait using sdxl model in playground ai, results was pretty neat



Lot of things to learn. Hope i manage it 🙂



I've been trying to create my own Controlnet-lllite pose model as the existing ones are not that inuative to use and its getting promising despite the short training.
First two images are with the input "mask" overlaid on the output images. And the last two are them seperate. Given my limited training data (8 pairs) it can't do all poses but I'm happy for something that took about 2 hours of training.




It is supposed to only pose hands, but it decides that a foot passes as a hand when needed.
so good!



is there any way to apply a color scheme ?
.....I'm trying
but can't reach the exact tonality

this is what i want
this what I get with prompt

not the composition, just tonality
It depends on how complicated the subject is.
will SDXL also have something like this? https://twitter.com/RisingSayak/status/1705223295539519858
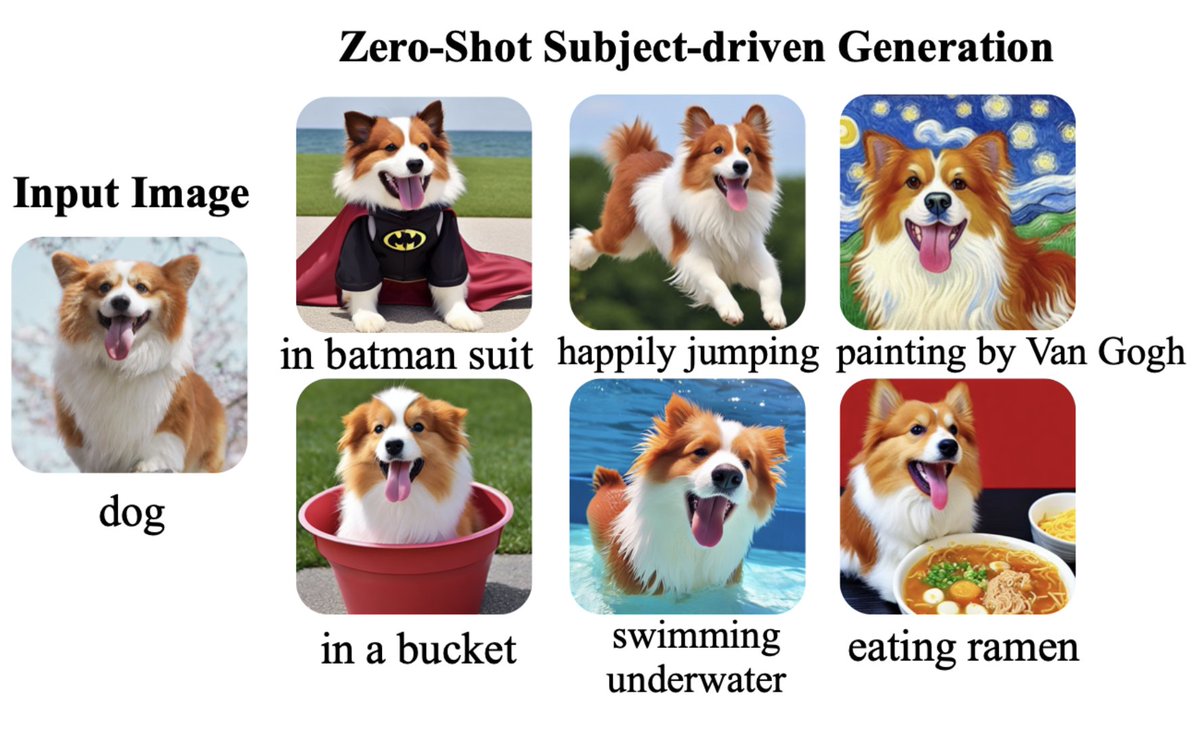
How about a fresh new pipeline in 🧨 diffusers!
We now have BLIP Diffusion from @SFResearch, thanks to @ayush_tues ❤️
We can now enable ZERO-SHOT subject-driven generation and transfer style from images using ControlNets 🔥

4 hours to stickers end. Shouldnt we contribute?
I will try, but i will for sure spoil everything, there should be some categories but i see only BOTOs contribution.... Help me pick one so at least two ppl contribute 😄








I like the lion cats for sure the last one cute tail.
Before/After fun with ControlNet





First two look super similar almost identical but the last two change the face too much
Still great looking
Yeah...I think face detailer kinda got too much ahold of that 2nd one, but I like it enough to keep it.
I just think it's fun to take something made in a model of one type and then pull that forward into other models (or in this case a merge of 3 other models: JuggernautXL, FoddaXL, & TalosProject
Ayo you in here too!? Lmao hello
Am i doing it right?



Here's looking at you !

they watching you!


It says its extended to next week Friday
i got notice it ends in 4 hours, so o.k. probably they extended it
@noble shoal #1072240143521554592 message
Ok, i have added 3 to the reaction submissions
Hai! I've been here for a year and 4 days 
We've been here both for a year this month and first seeing eachother first now lol
I think you have very nice submission @noble shoal
Oh, thank you very much 
Lmao





hairy sushi (watch closely)

somewhere over the rainbow
Yes.
What do you guys think of this paper ? Can it be implemented with SDXL also ?
https://github.com/ChenyangSi/FreeU

GitHub
FreeU: Free Lunch in Diffusion U-Net. Contribute to ChenyangSi/FreeU development by creating an account on GitHub.
don't think SDXL really needs it tbh
Did you ever release your ipadater remix workflow? I wanted to try it 🤞
no, I won't be doing that any time soon. something new released, and it doesn't use SDXL.. I won't be releasing anything IPA related until we figure out how to achieve this with SDXL.

I hope quality is great with this level of control.
yeah, I did manage to get a little close to it with this:

but it's not even close to what's demonstrated in that paper
so we must figure out how to implement that into SDXL
Don’t know much about the technical but asides from IPA weight, is there a way the features so you just get the style and not both composition and style
It’s the one thing that can make it replace Loras
Does this use controlnet?
no, it's goal is to do zero-shot driven gen
I mean your Minecraft generation
but it's nowhere near BLiP diffusion like demonstrated here
so, yeah, BLiP diffusion is open source, luckily- so we might be able to learn how to achieve that level on SDXL
Thought about making something similar to yours but I’m worried I will spend the whole weekend failing lol
when it comes to quality of images; nothing really gets close to SDXL, but that's it, SDXL can't do any of this yet
so if we figure that out for SDXL, we should be golden
Sdxl is quite good. It’s the easy prompting and diversity of styles I really like. Never liked very long prompts
For SAI’s model at least
for sure. when it comes to pure txt2img; no doubt SDXL is the best. but when it comes to stuff like zero-shot subject generation, not possible yet..
I used to be 100% sure about that before but not that certain anymore 😅
I get the MJ magazine’s and always try some prompts from it but it doesn’t always go my way
I'd blame your inference if MJ feels better for you.. I always try prompts from MJ and SDXL never fails to beat MJ in their own prompts..
iC2 style chair design/silver pipe/various logos and labels/black and silver mixture/in the style of Tom sachs/low back seat


Let me know if you can come close.
When I can run MJ on my own pc, let me know

The conversation really isn’t about that. I will always root for opensource/ self hosting. But I said I started to realize there are cases in which I just couldn’t beat MJ in terms of adherence to prompt.
I'm loading ComfyUI real quick, I never saw MJ be better than SDXL in anything really.. give me a sec

I really will like to gain some knowledge out of this perhaps from a workflow perspective. I have a vanilla setup in terms of node construction. So perhaps you will actually figure this prompt
Could you guys recommend a way to add more detail to a scene like this:




Yes it can and SDXL absolutely will benefit from it. 😮



why tf is everyone saying this here?
because people are clicking on the link
so stupid

Remove the photography terms like "bokeh", because they cause blur. Remove all the negative prompts, because negative prompts always lower SDXL's level of detail. Remove the specific video game names, because specific names (e.g., "Gears of War", "Elton John", "Louvre") always force SDXL into a narrower region of its data; they hurt quality and drop detail.
Add these words: ashes, ruined buildings, scorched earth, metal debris, concrete debris, barbed wire, dust, haze, exposed rock formations, tumbleweeds, ancient, volumetric lighting, machinery debris
(Or, in general, words describing the details you want to see.)

Thank you
yeah, big negative prompts limit SDXL's capabilities, you usually just write "nsfw, painting, drawing, sketch, cartoon, manga, watermark, signature, label" or even that's too much
Aaah! I thought this was delicious sushi and then realized someone replace my nori with felt. 😱
A very hard full body shot via SDXL DreamBooth
And I didn't even have any full body in training set
1024x1024 native


Honestly, I avoid negative prompts as much as I can, including "painting". Paintings come with compositional beauty that you don't find in photographs. It's much more effective to use things like "photorealistic" in the positive prompt. (I do have to resort to negative prompts though if SDXL insists on giving me styles and subjects I don't want.)
there is a great Lora for "artist"
What's your take on (masterpiece:1,2),best quality, masterpiece, highres, original, extremely detailed wallpaper,(extremely detailed CG:1.2),?

try one with and one without and make your own conclusion
I just made a version of my AIT workflow that has a styles feature so I can just make 4 word prompts and still make masterpieces
For sure, just trying to get a more technical answer.
eat up!

When it comes to prompting, there's not really any set in stone methodology yet.
Using "masterpiece" twice seems pointless.
"masterpiece" also assumes the images trained which were tagged as "masterpiece" were actually of "masterpiece" quality.
So, as everyone has mentioned, it seems to be a pretty limiting term
"detailed" does a lot, and CG helps remove background blur. I think I tested "highres" and found out it was less effective than 8k. "wallpaper" and "masterpiece" have strong effects, so try your prompt with and without them to see which you prefer. "best quality" does nothing. I've never tested "original", but I will now! Thank you. 🙂
Thanks for your time!


I want to punch it

Owlcat. 🙂
Did you try the prompt?
no, what was it again?
iC2 style chair design/silver pipe/various logos and labels/black and silver mixture/in the style of Tom sachs/low back seat
I used IPA and put death stranding inspired in the prompt lol didn’t bother using the original prompt












I like the fourth one a lot. Did you have to work on the prompt?
on those I just wrote sci-fi chair, on the last ones I posted I used that actual prompt, can't say I'm disappointed, SDXL really nails that
When I tried it MJ it gives similar result to yours. I don’t know how the user in the magazine got that variant with brand logos.
I’d like to see what your IPA workflow can do though
comparing MJ to SDXL when it comes to pure txt2img is insulting SDXL, even parameter wise SDXL is like times 3 bigger =\
the only thing I can see MJ possibly beating SDXL in is probably zeroshot subject, the SDXL image blend workflow on the other hand; can easily beat MJ most of the time
Post some blend, I am curious 😅




This is the first one I saw that got me interested 🤝
hmm, real pixar looks interesting




they really are pirates haha
Yarrrrrrrr. 🙂
and the titanic is AMD somewhere in the bottom of the ocean in that gen
AMD is all cool if you just want raster for now.
Anything else team green still rocks and they know it.

I'd love to see Nvidia get destroyed by AMD one day, Nvidia needs to be put in their place, they grew too greedy recently
neat

that's not my point. I meant that Nvidia are cucking the 4000 series because no competition. if they would have competition, prices will go down and VRAM won't be cucked
Yes i skip the 40 series here.
Main rig on 3090.
Cause it was even more fun to test dual GPU amd far cheaper to step over.
if the 4000 series would have sane prices like Nvidia used to have and they won't make the VRAM use tech from over a decade ago, I won't be angry- but that's not the case.

so, if AMD will get back up there it will automatically make the 5000 series better and cheaper due to competition
the 4070 ti 16gb looks good but idk the price maybe 600$?
that GPU doesn't exist
but they said soon tm
I have a 4070ti, only 12gb
one of my favorite generations this week 

fuck that, I will go in their walls if they won't give a refund to people with 4070ti after they give it 16gb
Because for sure if you have like a PCIe3 bor for example.
I dont say you should use a 40 serie if you do, but people do.
And downgrade theirselfs lol.
It is is a massive crap show.
i also checked 3070 ti and it has 256 bit bus,they really cucked the 4000 series
3070 ti is good but the one and only thing about it, is it has GDDR6X buts only 8 so quite eh not useful.
they did, if VRAM on all the 4000 series except for 4090 goes over 90% speed decreases in ~90%
the 3000 doesn't get effected when VRAM gets full
why? because the VRAM doesn't use tech from 2012
fuck Nvidia for that
Best always been to buy top cards.
Say you had 4 ram slots and you fit them all with 8 GB RAM.
Then u need to upgrade and ditch 2. 😉
While in first place you could have better went for the higher budget to safe money later so it is for GPU's.
You dont wanna eject em to much eh.
Swapping them costs time and money. 🙂
idk, I might get a refund on my 4070ti and save for when Nvidia would be more sane
if only i could find an used titan rtx for like 500$ 😔
Get a 3090 instead.
yeah, it doesn't matter how dirty it is, the chip is the same chip- nothing cleaning shit can't do
i thought i could find an used rtx titan cheaper than a 3090 since its older but looks like no 😔 at least not now on ebay
isn't titan rtx from 2000 series?
yea
TItan and Tesla are fun but I think best way to go instaed is 3090 / ti / 4090.
These have kinda over shadowed these cards. 🙂
ppl in ebay really chargin 700 and 800 $ for a titan rtx when 3090 is around the same price and faster
😉
Because I think peopel in the titan GPU age are not willing to let go to what they have spent for it.
This seems a lot more doable for ex 3090 owners.
As most when kicking them out upgrade for a 4090.
Look at the 3060 lol.
It used to cost like 2 arms and 4 legs in the miner times.
But now no longer you can buy it for like a bucket of rabbit food.
Inflation plays a big part in it.
🙂

yea they prob think its a collectors item🧐
To bad for them buy something else. 🙂
well if nvidia kills titan lineup it will prob become a collectors item even more expensive if its sealed

Not bad tho. 🙂
not nice modular i done it on comfyui
still on comfyui

a last

some clive barker way ring on my try on comfy

exiftool is like png info tool eatch image have informations =)
I swear the air keeps drinking my beer.


ha changé le processeur
=) sd 1.55

idem

en karras
avec texture inversion d'une autre entité makima


vache c'est détaillé
🙂
la derniere de faite sur makima si je la retrouve
mdr 35 minutes de rendu

Chouette en tous cas ce partage =)
j ne sais pas comment aider les équipes ca avance tellement vite
Je ne comprends pas un seul mot de cette langue mais merci allez Google traduire des choses comme celle-ci ne sont plus un problème mdr. 🙂
pas mal de controlnet perde pied sur la 1.6, sur la 1.5 ou plus c'est du betton
man, was starting to think I lost it with my gens, past couple days been fighting extra hard to get a good image. Still could, but just seemed I lost my touch.
Turns out when I was building out my main workflow and added back in the LORA nodes, I accidentally left them on a random lora, not the offset one. So it was affecting all my images.
Relieving yet frustrating at the same time
Phew. 🙂
this is why comfyui is suited towards being a backend and not a frontend
could have just as easily been done on a frontend ui, the two naming schemes for the lora looked very similar.
Was just simply my oversight
What is? 🙂

the way automatic and sdnext both do it is the lora is prompted and not a setting. They used to do it with a programmer UI style where you had to go into the settings and select an option from a menu, but it made no sense for actual creative work.
UI's designed to be front ends are just better for creativity. I look forward to SDFX because they're hyping actual studio UX design on top of comfy. SD Swarm is coming along well too
swarm has the follow of programmer UI invading stuff too. like selecting loras from a drop down

Stable Diffusion XL (SDXL) DreamBooth is nothing like I have seen before. Even with a bad training dataset (this is on purpose so that I can find the best…
What are the requirements to run DreamBooth training for SDXL?
this swarm thing is really cool! it allows me to use my normal AIT workflow to keep the speeds I'm used to, but have it be a fancy interface
any idea how to make it work with batch sizes?
how'd you get the ui to use the loaded workflow? whenever i go back to ui mode it uses it's own internal one
idk, when it uses ComfyUI as a backend it just translates the workflow to a simple UI that is identical in performance and functionality- except it gets rid of batch size
might not be using ait and the speeds of it's internal workflow is just fast
no, it's identical. I looked in my backend, and output image metadata, it's using the AIT workflow
that's how it looks like when my workflow is being used

it's that, but for some reason Swarm doesn't do batch size?
i dont get the hype for ait. 14 seconds but it's using a gan for scaling. kind of a cheat and it can be seen in the image quality. working with it is just so much more of a technical challenge wrestling with quality trade offs instead of a creative process. if you don't use a gan and just go latent upscaling and loras, does it help?
nah, AIT is just faster. if it effected your outputs you're using it wrong. trust me, I have a lot of experience with this
i'm looking at yours. i can tell a gan was on the finsihed product
?

gan galore here

this works really well. idk what do you want

Ill tell you one thing and it is: soya sauce is freaking master.
sdxl do work really well i know. i just think the ait layer is kind of a snake oil and might be doing less than you think. it's always a wrestle with quality vs speed. with or without ait.
with ait it just seems to have a lot more technical hurdles in the same battle
there's all sorts of gan artifact on that image up close. i think that's where all the speed gains are coming from. the gan doing a lot of the heavy lifting instead of diffusion
you wouldn't know AIT was used here if I wouldn't say that, it seems you're just stuck on the idea of optimizations always being a tradeoff, which might be true in some cases. but not really on this one
it's the gan i see
I guess I'm blind then.. =\ , you're seeing something we don't
i don't use gan upscaling in my workflows because they produce really sloppy artifacts


coolest 4090 model










You really turned that prompt into a gem
thats just a real pic of your dogg 🐶


24 GB card for best settings. 16 can run too
whoopsie!













these cave images are generated right?
they are good enough to make me question... so, they are very good imo
Fourth in my series, with each one being a different type of animation style.


this is what i call a good prompt


Thanks, so the average person kind of have to train in the cloud here.



looking hungry
tasty burger

am getting hungry now
yep. it would cost like 1$ to train
max 2$ - RTX 3090 is sufficient 35 cent hour on RunPod
It's mostly that I find cloud training a bit inconvinient, though the longer training sessions the less of a problem it becomes.
almost 🙂


looks like the little hand from the scary movie



my honest reaction



hello ladies




he's becoming one with the stench bog or whatever that is
he looks like a manatee 🤣
naughty kitty!

very rarely it add legs 🙂 Makes feeling of motion


he looks like this is his favorite treat

ill eat it after im done with shower

idk what happened to him here


input these images

got these

well 3 left ones above
as you may have deduced


\

How was the pull to the right fixed?
man, I have a real goofy setup, but it's working. I'm actually not entirely sure. need to investigate more
I'm using dynamic thresholding with it which took a while to tune
Try fiddling with the clip crop numbers, that's what I've been testing out

I think the vast majority of the time they should stay zerod, but want to test on one's that are off to the right when zerod, then changing the width crop to 256 or something


trying to figure out the nan errors that cause it to break somewhere in the chain. well maybe not the source cause, but how to work around it

that's the same everything with a little tweak

trying some different approaches, but this one might actually work. it'd be on a case by case basis though since it happens randomly depending on seed number and a million other things

nice balls


this pumpking reminds me very Jack Nicholson 🙂


When your neck is broader than my waist you know you are in the presence of a giga chad

Not sure if it works for SDXL though
it does
what is it?
the operation is super simple. Works on any unet though the idea of it being good on all unets is questionable. Curious to see some experimentation with it
in the unet the decoder blocks take in a concatenated tensor of both the info from the skip connections passing along encoder info and the tensor directly from the block before it. This suggests the values are not weighted optimally in training and so applying a small multiplier to give more important to the decoder block outputs gives a better image
little more nuance to where/how its applied but that is the gist

I will try it out
left: without, right: with


looks cleaner
sample of 1
I'll do some more testing
looks like its made out of plastic

I am always a bit skeptical of single value changes being an all around improvement in any model. Though it might reveal so interesting stuff if it turns out to be the case, or at least often enough to merit some thought on the weightings
Apart from training have you tried tweaking block weights to improve the image quality?





what cfg does it used?
5
seen some interesting stuff directly modifying cross/self attention weights. I have played plenty with modifying various weights in the models 1 at a time to see how each part tends to effect outputs. Sometimes freezing parts of a model and training pieces specifically can improve or help smooth out things esp when trying to teach models new stuff, though when aiming generally tweaking stuff tends to have some trade offs, usually as well if something "just works" I figure its something good to learn from and might be applicable in training to just correct for it haha
Could you try 3.5 with freeU
maybe in animation as well? and if so I could be filled in at least to a point of understanding the mechanics you speak of

I've been playing around with block merges when adding loras I've trained, since that's the only way I know how to 'fine tune' SDXL. One thing I noticed, but not sure if true, is some blocks might be linked, e.g. if you set their weights differently you end up with weird artifacts (confetti on the face, blue face, circle on the cheek)
I mean thats def a great way of going about trying stuff! 😄 Curious which blocks you found to be linked haha
gotta find the images now 😄
in 4 & 5
same, different, different



now when you say 4/5 how are you going about changing these?
3.5







like this

ah hmm interesting.. They are the main blocks on input layer 2 and should be able to take dif weights but they are processing basically the portion of the latent back to back

I guess it might make sense that the blocks accounting for each layer if shifted enough might not play as next with the part next to them
Yeah I noticed the loras I trained seemed to be mainly affecting the IN blocks 4 - 8 and OUT 0 & 1
ah yea that makes total sense, those are where the transformers are which are where loras operate. Out 0/1 are the two biggest transformers at the lowest latent size in the unet (besides mid as well) making up the bulk of the composition and color so it makes sense there. You should get some effect on 2-5 as well on our but dimishing only affecting smaller details
also 6 IN you can skip for reg old loras haha. Its just a downres cnn
I think the anime lora I trained was almost all in 6?
I'll have to find those pics haha
was it a locon?
that would affect it
but still not too much happenin there besides downresing to the next layer



4,5,6 here

just normal lora
correction, it was IN 8

@sour obsidian with just IN 8 being applied, anime off, anime on


I've been going to strange corners of the latent space myself
aha yea that makes a lot of sense then 😄 Final encoder supplying its skip connection output to the first big ol decoder block. very important block in the chain
yea that looks awesome ❤️
really clean
other blocks changed little things, but the style definitely was in 8
it can be hard to add in new data without changing the model too much
yea thats a tough challenge in general, esp at smaller scales. The models are so fluid haha
I was trying to get the eyes fixed, but it would make the poses all weird, random missing limbs

why can't we just ask the model which weights to train on? 😄
just gotta know how to ask it
make to use "please" and "thank you" when asking too

yea though balancing is quite a challenge haha. In some sense the data and loss functions are the ask  the response is very akin to the monkeys paw riddles, where you get all sorts of unexpected outcomes haha
the response is very akin to the monkeys paw riddles, where you get all sorts of unexpected outcomes haha


What would you guys reccomend as the best detail processor for environments / landscape?

I'm still new to all the training, the loss chart in tensorboard would be related to the images it's training on at the time? As it moves through the training data there are peaks and troughs because it's not looking at all images at the same time? If so, would be good to know which images it's struggling with
I think it just hits spots that it has a harder time working through?
you are definitely making some interesting and cool images with unusual textures

I've been using this one that masslevel recommended to me
still trying to figure things out. like to mess with things I barely understand and see how far I can go before they break
yeah me too, I just constantly tweak things and go by gut feel, because I have no idea what any of it means 😄
doing weird things with the pooled output in conditioning. split the stream in two, do different things to each stream, concatenate. not sure what I'm achieving exactly. but seems to add something
Thank you, noob question, after putting it in my upscalers I don't have access to it?


did you click the refresh button on the menu?
Restarted comfy as well.
refresh the webpage?

did you drag an image/load an image you created before into comfy?

yea though loss on diffusion models is really funky and tends to be a poor indicator. Honestly I just print many many samples and compare a mix of same prompt/inference and random prompt over time once loss is platued. Also seen various people using models like Dino to do image evals but thats a bit more complex to set up haha. And ofc there is our little bot here which we have used before with the a/b for evals as well. So much of late stage diffusion model training is by feel and preference and really understanding your data and how it will likely be interpreted, from your anime tune it seems like you already got a good feel for it. Lots of playing and figuring out what is best for your stuff
Just did a full refresh of the workspace (cleared and dragged the custom workspace back in)
I have the upscaler in the correct directory, right?

aight, it's that time again, time to go do some highres renders so i can make a nice showcase on the model update ^^



So in Searge workflows, I had to manually set the new detail preprocessor for it to pick up, is this a bug or intentional for from the one who wrote this workflow?

Also thank you this is pretty much what I was looking for

three where?!
The voice actor died, so they won't be making a three.
oh no, gordon freeman's voiceactor died?! 🤣

gordon
the va that did the voice for claude from gta also died, rip 🙏 😔
One final question for upscalers, where would you guys reccomend to put this one?






my man just fused with the bed

lovely
let's see what sort of beautiful music he'll add to the mix


really captures the essence of your image here
ballsy 🤣
 i want a 4090
i want a 4090well, ok

cutie

nice
speaking of cuties

ooh those pucker lips

they're having such a good time

hes not happy about it

She's indifferent about it



does comyui support postive prompts like (daylight:-1)? or is there any other way i can get away with negative prompts in my positive prompt encoder
oh no

that should work
oh man ive always wanted to do it but thought it should work 😄 makes my wildcards easier to do
does anyone uses colab for generating sdxl? also i want to use the models from civitai, is that possible?
I'm pretty sure it's banned unless you pay for compute credits
hmmm is it? cuz using a1111 locally, when generating it took ages for me lol


I tried it and it didn't work :\
yeah im not getting great success with it either
I'm losing a lot of detail when I try and inpaint my image, same settings just a slightly different prompt, the area you see hasn't been masked, the one on the left is the inpainted image, the one on the right is the original. Anyone know a fix?

man that sucks, there seems to be no way to combine positive and negative prompt into a wildcard
@slender coral how about only masked? But supposing you know...
Sorry I don't understand. This is the masked area.

o.k. and you are in comfui? Is there option to only affect masked area? In A1111 there is. Anyway it is quite large mask.
The issue is it's not just effecting the masked areas, it's effecting the overall image, in turn lowering the entire quality.
hm in a1111 it used to work. Do not you using lossy image format?

Lossy would be for encoding, I don't think that's the issue.
i dont think eighter
masked-full, what is other option?

hm... and how about lower mask blur when it is affecting whole area?
I'll try but 8 shound't be changing it this much (3rd time running the inpaint) it looks like a painting now:

which cn model should we use to get these kinda images?

That just looks like a image to image prompt.
its qrmonster?
could be.
#✨|sdxl message
@ionic dragon
probably but according person used to use it is qr monster best
anything for sdxl?
i realy dont know. probably posible with canny or depth.
That's just a image to image transfer
which depth map can detect facial features?

no
I'm 90% sure it's just converting that to grayscale and then preforming a image to image.
it is in controlnet, and i checked in temp it create b&w image in this case Trump. It made very interesting results, so i dont care what is behind it 🙂
I made a @glad grove LoRA. Something is wrong with me.

he looks so handsome 🫡

ai robot painter is Sioux! 🙂

can you please share
what should i share?
I did it in 1.5 with qr monster from huggingface
oh ok
the output
oh it was bad. mmnt
I am pretty sure you can find 1 or 2 models on Civit.ai 😅

i can recognize hand, problem is i put there that man
#🤝|tech-support message
here are links to 1.5 CN
yeah i can
whats the difference 1.5 and sdxl? Isnt it just model? I mean you can have two installation 1.5 and SDXL and you can do anything
probably canny can work for you better @ionic dragon or cant?
inpainting can always affect other parts of the image. To avoid that, you have to blend in the inpained image into the original one
in Comfy you do that with the ImageMaskComposite Node
im installing 1.5
i dont think so





Ai is painting on blue canvas with white color 🙂

see, true art has no limits!
🙂

@floral island it is lora? i like it.
aha 🙂
i managed to fix the horns/swirlies a bit
making the image output a lot more pleasing








AUTOMATIC1111 SDXL and Nik Filters










NB this is not intended to be an egg sucking granny exercise 🙂
a quick & dirty comparison ComfyUI workflow showing the differences Conditioning & noise generation methods make to the final image.
Uses common inputs to generate 3 comparison images.
May help those trying to understand why they cant always replicate other peoples images from places such as CivitAI
Requires
https://github.com/BlenderNeko/ComfyUI_ADV_CLIP_emb
&
https://github.com/ltdrdata/ComfyUI-Inspire-Pack

Thank you

anyone got different results in inference on auto11 than comfy using some LoRA's?
LoRAs in CUI are so different to when I use in A1111 - e.g. Underwater LoRA, 1960's LoRA ...
ok. how so?
and do you know why?
most likely for the same reason that A1111 & ComfyUI convert your text inputs erc differently as per #✨|sdxl message
All comes down to the method used to interpret things
so how do we fix this?
how can I train a LoRA and get at least similar results?
This is Stable Diffusion, This is The Way

ie there's more than one way to skin a cat
think of A1111 & ComfyUI as translation programs , not all translation programs translate the same way
yes, but how can I then train my LoRA's and get at least similar results?
these are similar results
oh that I can't answer, I dont bother with training LORAs . Merely pointing out that things are "different" for reasons which essentially come down to core coding choices int he different UIs 🙂
I think it's just the prompt weighting that is differently handled in comfy and auto111
nope
my glitch lora on auto11 vs comfy (I know res is different but we have tested with the same, just happen to have these two image):
auto11:

ComfyUI makes the Underwater LoRA very shiny - in A1111 its quite matte and dull
comfy:

you use Euler?
But don't know why that shd be
cause ancestral samplers are always instable
have you tried alternate LORA nods in COmfyUI or just theone?

dat tiny leg tho
yeah 😦
Ancestral Samplers change the output as and when you change the iteration number. Non-Ancestral Samplers change as and when you adjust the CFG ... not an exact science, but valuable information
why not same resolution?


I have about 20 LoRAs I use in both ComfyUI and A1111 - what is an alternate LoRA node?
its an alternae node for Loading loras lol
These are the options I seem to have from different node packs Ive installed.
TBH I rarely use LORAs so no idea if they do anything different

DPM++ SDE Karras
What a fun time to be alive. As if finetuning had no issues before.
@soft zealot does comfy handle token order the same way auto11 does: stronger influence the earlier they show in the prompt?
pass what I know is in one of the links in my earlier message

theres a write up here on the differing methods used by the differing UIs

GitHub
ComfyUI node that let you pick the way in which prompt weights are interpreted - GitHub - BlenderNeko/ComfyUI_ADV_CLIP_emb: ComfyUI node that let you pick the way in which prompt weights are interp...
ok, but you have no quick answer to the word order in prompts?
no
ok. thanks
Looking for advice, please.
The dreamstudio sometimes blurs images it creates that it deems inappropriate.
I'm concerned that the API calls we are utilizing in our app might sometimes return blurred images to our users.
Is this something that happens? (only experienced in Dreamstudio so far)
And if so, is there anything that can be done to have these instances return an error, rather than a blurred image?
TIA!
run your own server with your own SD instance on that isnt censored
Thanks for the suggestion @soft zealot That is a bit beyond us
We're using rest API, so was hoping to find a solution for that
Maybe ask in #1025467151206854736
Most of us here generate locally
@glad grove Do you think somebody would vote for that in the Sticker-Scrapbook event? 🤔

i will vote for sensei 🫡
Ok, then its officially submitted





@ionic dragon
just trying, This both are same famous painting. Without preprocessor


i didnt get you
we didnt talk about qrmonster today?

@floral island my answer, but you have nice star in the middle

same prompt? 😮
nope, walpaper made earlier. Got just impression it is related 🙂
@floral island in this picture should be prompt

ah, don't have comfy opened 🙂
np
Thanks @noble shoal
medieval spiderman , thunder armour , rising voltage electricity discharge













@uncut gull lora?
No, just experimenting with prompts.
so it looks superb then. plastical gold, pearls 👍







It's so detailed. (The full one on the right is a 4096*4096 image.) Really makes me want to make a game.


very nice upscale ❤️
latent space upscale?
It's actually img2img with the tiling script in A1111, with the 4x-UltraSharp upscale and 0.51 denoising. (Probably any upscaler would work fine though, since you're running denoising and re-generating.)
once denoising it seems to be latent space. I will try something if i can.
Yeah you definitely get the added detail like latent upscale. Completely different from just ESRGAN or something.
yes
There is on steam overpriced app to let you make card game 😄 , or you can do something for tabletop simulator 🙂
I've been doing game design since middle school. How I first got into programming. But the kind of uber-insanely-high-quality resources you can get out of SDXL with just a few weeks of work have just been eating at me. You can't just make anything obviously. No way to animate this quality. But if you had the right premise... I really want to figure out something that would work.


is there already a tiling script for SDXL?
Works. (Just found out an hour ago though.)

some electronic flowers made with the CircuitCraft LoRA by @stone fossil (base SDXL model)




or in general: what are your upscaling strategies? I have the feeling SDXL is not good in upscaling. Doing img2img on gigh res images often looks blurry and low detail. Maybe I do something wrong, though
and it is using SDXL, not SD 1.5?
is there a SDXL tiling script for comfyui?
I mean, check out the results I just got. Click on the image on the right and "open in browser". It's 4096*4096, and the detail is just beautiful. It's SDXL CrystalClear.
I don't use ComfyUI unless there's something A1111 just can't do, so I can't help you there, sorry.
anybody know if plans CN qrmonster for sdxl? Trying understand it but it is SD theme then
wee, new model is up 😄 https://civitai.com/models/148871?modelVersionId=168123

from the owner of the repo, August12:
No plans for 2.1, but I'm in the process of making a XL version.
The 768x768 images are made with 1.5, it works well.
@indigo vine thank you very much. i dont search on github if there, because qrmonster i found there was 8 years old.
Thank you!
I found it in the repo on huggingface. And if you want to play with 1.5, this basic setup helped me a lot: https://huggingface.co/monster-labs/control_v1p_sd15_qrcode_monster/discussions/28










nice
"i'm in a good establishment, stop horsing around" -> said the unicorn


is there a way to use 2 different characters (loras) on the same image in sd 1.5?
regional prompter or latent couple
pixel perfect is something less demanding?
Moderately successful 8K*8K upscale. There's some tile banding on the soft gradients in the background rays. (But Discord limits images to 4000x4000, so you can't see my beautiful 8K render.)



does that work with loras?
i think there's a latent couple that supports it, and i think i read regional prompter does it too, but i never use loras ever so... uhh..
don't take my words for granted
but i do think it's possible
allright thanks 🙂
Oh wait no! It's A1111 that exports JPEGs as 4000x4000! This might work. 8K render. (Yep! It worked. So much detail! 🤩 )

stupid question but is there a way to merge loras together?
Mathematically, yes. I don't think you can do it in A1111 though. (Even if the loras are on different layers and use different precisions, you can always convert and merge somehow.)




wicked good. you can see great deets in the iridescence of the pearl colors
I know right! Those little flecks of gold and rainbow light. And the seams really don't show up except in the background. (I doubt this level of detail would work for a face portrait, but I might try that in a bit.)
can comfyUI properly sort models by version? Like SDXL, and one for SD 1.5
Just put them in different folders

thats a hard detail to train for. the physical lines in holographic foils

Perfect!
comes out really well here
@eternal fogYou wouldn't happen to know if there's a plugin/node/extension that can show image previews of models next to the names?
As that's a feature i dearly miss from automatic
Not that I know of, but I've never looked
Has anyone had a play around with FreeU on SDXL?
It only has those lines because of the necessity of stamping though, right? I have flat / non-textured foil for my Cricut Maker right here on my shelf.
yeah. manufacturing artifacts
they're the subtle kind of details that make things "realistic" ❤️
Found one for those who wants it as well :D

GitHub
Enhancements & experiments for ComfyUI, mostly focusing on UI features - GitHub - pythongosssss/ComfyUI-Custom-Scripts: Enhancements & experiments for ComfyUI, mostly focusing on UI features

not so difficult to do, just a few lines of python code. But I think kohya_ss can already do that for you
FreeU seems to give SDXL way too much contrast using the settings they have on the github page.
Left to right is base SDXL, SD1.4 FreeU Parameters, SD2.1 FreeU Parameters.



I don't get what FreeU does to SDXL?
Yeah I dunno. Doesn't seem to do anything good with the listed parameters.
does it change architecture?
Guess I could just try randomly change stuff and see if it does anything that looks good
I don't understand the code enough to tell
cswađš u < 0, hy C:\Users\User\Desktop\ComfyUI_windows_portable\ComfyUI\outpute
Changes the weights or something from what sdxl was trained at
It was described a bit yesterday in this channel
its supposed to be way better approach at understanding prompts and turning them into quality images by doing something to the unet. similar to the cfg scaling i think.
i'm probably wrong
heck no. this might imply I would need to provide more AIT modules for that
or just give up on AIT to use it
Here starts the conversation #✨|sdxl message
same situation with controlnet isn't it? ait fails when extra networks tie in
not really, CNET isn't hard to use with AIT
I even managed to use IPA with AIT
weird. if ait is even in the custom nodes folder, controlnet won't work for me
i tried it last week most recently
likely conflicts with your inference's commits
I use a commit from a month ago, so idk how it works with the latest ones
yeah. it's a technical challenge to deal with. very fragile library. i tend to always update to the newest versions and ride the wave
I first read ALL the papers before I change anything with my inference, and even have backups of the backups
I've had so many bad experiences with stuff like this
I also always use Conda for it to be even more reliable, so I don't need to handle the VENV myself
ah i see yeah thanks
FreeU explanation:
TLDR; It makes all diffuser-based AIs fundamentally better, no matter what you're doing. Sound, video, images, code, text. In all cases for all applications. With no downsides, with no compatibility problems, no retraining. Just flat out better.
Background: There's a thing called "skip connections" discovered a while back that also makes all diffuser-based AIs fundamentally better in all cases for all applications. SDXL uses skip connections. (All modern diffusers do.)
Short story: Skip connections work, but the researchers discovered they have a side effect. This algorithm fixes that side effect.
Details:
- The researchers found a way to "look inside" the u-net while it was running. That was the first big breakthrough. (Fourier transform graphs of the noise.)
- They tested what the different parts of the u-net were doing. (We've known for years that "skip connections" improve diffusers, but we never knew why.)
- They realized the "backbone" was doing structural stuff (like eyes, faces, fingers, windows, etc.) and the "skip-connections" were doing textures (like skin, hair, leather, etc.)
- They wrote a function that amplifies half of the channels of the backbone (it has 4 channels if you're not inpainting), and they wrote a second function that "sharpens" the skip connections.
- Profit!!!
It only seems to work "better" with the correct settings though and there aren't any released settings for SDXL. And out of the box it certainly isn't better.
Did you test it? Bad settings should just mean you get "smoothed-out" textures. It should still result in far fewer glitches, better anatomy, better poses, better proportions, etc.
I'm messing around with it and it's blowing out the image contrast a lot
What parameters do you have to mess with? (I don't have it, and I'm in the middle of a render.)
This is the info they give on the github page
b1: 1.2, b2: 1.4, s1: 0.9, s2: 0.2
SD2.1
b1: 1.1, b2: 1.2, s1: 0.9, s2: 0.2
Range for More Parameters
When trying additional parameters, consider the following ranges:
b1: 1 ≤ b1 ≤ 1.2
b2: 1.2 ≤ b2 ≤ 1.6
s1: s1 ≤ 1
s2: s2 ≤ 1


The awful looking one is with the SD1.4 parameters
What's the low-contrast one? Turned off?

i see a lot of hype for free u. i don't know why. it just looks liek more knobs with hand waiving explanations. Quality examples just look like regular examples but cherry picked
It's because from the paper it looks "better" with no extra performance loss
So people are interested
when i use it i get more of the same and once again, prompting is king. a good prompt makes good results. bad prompts make bad results.
it's literally called free lunch. the paper seems like a lot of hype for what amounts to more of the same
Could you stick to 1024*1024? Have you tried just lowering the CFG? And could you do a prompt that tends to show off glitches:
Woman writing in a journal with a fountain pen, sitting at a cafe table, crowded busy street, crowd of people, sunlight
I don't understand the details of the paper, so I can't say much other than what I see when I try and make an image with it.
not at home right now where i have it set up. will experiment more with it as its getting more attention. i do want to try to find the quality gains being hyped
My render just finished. May I ask where / how you got it?
on mine CFG is 4, so I can't really go much lower
true
Where did IPXL_v2 LoRA come from? And what can it do? 🙂
It's built into ComfyUI, just look in the "for Testing" nodes
Thanks, will update and look for it.
this
Left off, right on


Sorry other way around
Right looks worse to me in this case.
I do have similar thoughts to iceycold, it's just another button that might make images look better, but it might make images look worse as well
Same as changing the seed, or noise or anything else.
It's not random. It specifically improves structural information at the cost of high-frequency texture information.
Doesn't look like it has there. Maybe it doesn't work as well with SDXL and that's why they've not provided any parameters.
I'm wondering if it can be used to render a base image, then img2img that for texture.
This image is too simple for it to do anything. You need things where SDXL tends to mess up and glitch on the structure. (In order to test it. Obviously I'm not saying it definitely works. I just really want to know.)




Well, I can see the difference. The hands are the most important thing to me, and it messed those up worse. But there are so many other changes...
They look very similar in composition to me, in this these ones the contast is better, but the structure is similar.
just seems like a slightly different random seed to me
you can look at all the differences and make subjective opinions about them being better or worse. i dont see it though. it just looks like it came out slightly differently
prompting is king
it seems like it manipulates stuff in the background a bit
SDXL, right?
Yeah
can you test if it's compatible with AIT or needs new modules?
I JUST WANT AN SDXL WORKFLOW THAT WORKS. Why are all of these offering a million features I will never use with 5 to 10 custom nodes I have to go hunting somewhere for?
I made a workflow that uses AIT if that's what you're looking for. it also has a styles feature
Seems to work with AIT
It produces a completely different result though
No, I want no extra features, not more features.
Left is without AIT, right is with. Exact same settings.


So looks like it runs, but doesn't work properly.
odd
idk then
if it doesn't improve SDXL I'm not touching it
I guess it's sort of helped here
Left is FreeU off and right is FreeU on


But I still feel like you could just get that by trying different seeds
It makes some things pop a bit more


it makes it look less realistic imo
Yeah in that case it has
It does seem like it can make the shape of things better sometimes


But it's also making it look more like an art piece than a photo
I like the normal one better here too, right looks like it's drawn
Yeah
you can tell it's the same seed though
Absolutely yeah
if you flip between them, the shapes are similar
Got it working! Tests in just a second.
it's a small yet big difference, but I can objectively say it's kinda worse
I don't know why it's making it loo more drawn
Messing with the settings a bit I can sort of remove that drawn look

Okay! This is a classic glitch: SDXL is just incapable of making people hold swords. Until now!
The first one is normal SDXL. There are 0% correctly held swords:

And now... with FreeU! We get 50% correctly held swords. 😄

But it's got overbaked contrast
Yeah, I'll work on that after I test some more stuff. I'm just really interested in what structures in can fix right now.


again, you can tell it's the same seed
just the FreeU one looks less realistic
It looks better than before now I've messed with a few values
it's still not as realistic as without
the bushes look more artificial
It's because it's like it's pumped up the colour of them
Glitch #2! SDXL can't do wings. It always messes up the placement.

And, with FreeU, it does just as bad. (Well, technically two of these are slightly better, but not worth the change.)

lol
i'd say worse, the colors got fucked


Ignoring the colors, because it's not worth adjusting the settings unless it makes enough of a difference. Testing still. (The only improvement FreeU is supposed to make is to features like this.)
I think the right one looks a bit better closer up, but then the background looks weird
I know what this reminds me of now!
remember when SD2 released? the colors also looked like this
It makes text accuracy worse, so I'm guessing text isn't on the backbone's features.


Let me see what it does to an anime model, because they tend to have a lot more weird shapes and stuff that SDXL makes
I think the model called "juggernautV2" doesn't have those issues

kind of interesting
prompt "a warrior holding a sword fighting with dragon"



with freeU default setting
It doesn't help with a painter holding a paintbrush either. I guess I'll mess with the settings...
Doesn't seem to help with holding guns either
It seems more different, than "better" at the moment with SDXL
for me all this images look much worse. As if you used way too high cfg
Yeah it absolutely blows out the contrast
I also don't get the reasoning behind it
"SDXL can't do" ... works fine. prompt issues

that's eular a 30 steps with base 1.0
the weighting between skip connection and previous block is learned during training, why changing it at inference?
I mean yes, you can always experiment and sometimes there are interesting effects.
I'm calling it. This is useless. The paper's authors are full of it.
I could've been upscaling beautiful pearlescent stuff for the last hour.
I think it works better with anime models
It makes the colours pop more
I'm just playing with the parameters, I think I've made it look a little better for this prompt by using parameters outside their recommended numbers,
so, what's FreeU? i've been looking through this server for some time, I keep seeing FreeU followed by a horrible, saturated image, why do people use it?
It's a new thing that was released, so we are testing it out
it's new and the authors are doing a lot of hype about it. weird claims about "free lunch" and quality boosts, with cherry picked examples

SEGA: https://amzn.to/3XMS9GS
MORE VIDEOS ☞ SUBSCRIBE - http://www.youtube.com/gamesyouloved
☞ WEBSITE - http://www.gamesyouloved.com
☞ FACEBOOK - http://www.facebook.com/gamesyouloved
☞ TWITTER - http://twitter.com/gamesyouloved
☞ INSTAGRAM - http://instagram.com/gamesyouloved
if these are cherrypicked i dont want to see the non cherrypicked examples

lol blast processing was actually real
there is a XL QR out there https://huggingface.co/Nacholmo/controlnet-qr-pattern-sdxl

(not HIRES)

whaa I was trying sd2.0 qr one, but could it going


{kind=link}
right loses a lot of details
It loses some background stuff, it seems to be what one of the sliders does
This was the next seed


what threw me was the claims of discovering fourier transforms to look into the inner workings of the unet. it threw up bs alarms to me.
Can I use this with ComfyUI?
idk, shit is slow as hell though

what do Hires add?
make it more detailed, idk
have you tried the SD2.0 one?
if you mean this one then yeah
do you get good results?
yeah, better than this sdxl one that is struggling
one of em

realistic pixar

Yeah, that's how I feel about Pixar's latest movies too.
where are the rated R pixar movies where it's uncanny realistic look now catered to adults who grew up on pixar movies as kids 
LOL okay well, let's see what we get from AI video in a couple years. 🙂

few more months
its just an unfortunate truth of the internet. ideas accelerate and they often spin off towards hedonistic tendencies
ngl, i am not a fan of the jittery ai videos
i was toying with animatediff's cli tools. there is a branch with prompt travelling and controlnet
I'm not going to mess with this SDXL QR till its fleshed out more, I look forward to other controlnets for sdxl also. like DW Pose
mine
win
@shy kelp its cool but 2 many changes ,if you could steady the style,maybe a fixed background
30 minutes for this hires? 😭

ComfyUI would be faster
@shy kelp Can you tell me about T2i and what makes it different?
@uncut gull Give FreeU a try with these settings, do you think it's "better"?

i do not know lol
(1m34s (NOT SDXL))

have you got Scribble to work?
The bottom "STuvwxyz "look good they all should look like that
it not bad thou, the place is like a Quarry or something
,you could run your video thru runways rotoscope tool to get a fixed background
i've got stable swarm setup here at my friends with his 4080. it has the new freeu tools. they just feel like seed variations. quality increases are sometimes there, and sometimes worse. generation times are 2 seconds longer with freeu on.
its a whole lot of snake oil over here too. its kind of a waste of time
LOL you're not doing enough to make any difference IMO. But I'm sticking to my shiny renders for now.
do i have to pay for runways or is there a watermark?
It does make a difference, but it seems to depend highly on the prompt
I do agree with iceycold though, you can get the same stuff with a seed variation, for example, can you tell which of these is the original, the FreeU and just a normal seed variation



often with quality gain claims, it's just cherry picking and what the real champ of the day is prompting. Prompting is always king.
@shy kelp its credits and they give you so many free 150 i think ,you have to run on chrome browser for some reason
i think a big part of it is the need to defend doctorates. competitive academic spaces. maybe thats where the hype claims come from.
is this the one without freeu?

Yeah
fresh off the gpu
i could tell because a lot of the finer details got deleted in the other images lol
3rd image i think has the best details
Yeah I don't think I'll use it. It doesn't really add anything and I have enough knobs to turn to make it do different things
the differences are so slight that i don't think it can be qualified as a distinct improvement