
#✨|sdxl
1 messages · Page 133 of 1






Rebecca Kit, Baloo.



nice
I saw that post congratulations
🙂

how they are called?

Congratulations ft. Quavo (Official Video)
Taken from the album Stoney
Song available here: https://PostMalone.lnk.to/StoneyStandardYD
Connect with Post Malone:
https://www.facebook.com/postmalone
https://twitter.com/postmalone
https://instagram.com/postmalone
https://soundcloud.com/postmalone
http://www.postmalone.com
Directed by James DeFi...
you mean the lora?
i mean those dwarfes
they started off as creepy rainbow goblins
it's a book I had when I was little

well, tried to make those, lol
then kept recycling them




ai chip

get a gpu
@hardy cipher can you post a link to your lora
how about google colab
he just pmed me a link to it on his google drive. I'll ask about uploading it or sharing it. didn't even think about that
but soon
oh
they banned use of webui there
lol when?
well there you go
kek

I was searching rainbow goblin on civitai
oh wait, actual webui or the lora notebook?
how i still see many people use it
actual webui
idc wat google think


give me Free COLAb
well theres prob some ways to bypass it but idk anythin about that
@hardy cipher You might share the drive link. But also share the prompting instructions (sorry currently at work)
i got this one stable diffusion colab but it keep disconnecting everytime its finished coding
prob banned
I can do that. just didn't want to link anything without running it by you.
how about you, are you using local ???
yea
i think most of us here are
you know, there are lots of alternatives to colab that are actually better and some of them even have free options
i am local
or you can pay a few cents an hour to use a gpu
Im using Loco
close!

After work I throw another 50 pictures in the dataset and get it cooked for a bit longer for V2. 😉

just one head on another shoulder, need to get rid of hands too
close though



Google Docs
lol, i just prompted the song title i'm listening to The last attack


Example Prompt: p0p, a weird man wearing a meat hat eating ice, in the style of p0p
It reacts a lot on the word "weird" and "group of people". Best at strength 1.5 on the base checkpoint
I've updated the nodes, here's that is in them:
Six Text Input Switch: Allows the user to select between six text inputs and uses a slider to make the selection. Useful for multiple inputs for prompt creation
Six Integer Input to Six Integer Output: I've seen a fair number of 3-, 4-, or more way text input and outputs, I wanted to do something for numbers as well. Use it as you wish.
Six Integer Widget: As above, but with widgets for entry instead of connectors
Endless Node Parameterizer: This node has a collection of inputs for the CLIP text Encoder and Refiners for SDXL based workflows
Parameterizer with prompt: As above, but with TEXT_G and TEXT_L outputs
COMBO Parameterizer with and without prompt: As above, but with two slots for aesthetic scoring, one for positive, the other for negative. Now you can use one box for both positive and negative refiners, but keep separate aesthetic scorer. Also comes in a variant that has the prompt boxes for you.
Try to prompt "a weird 80's boyband"
now, i add in my randomizer too. glorious!


@hardy cipher idk they said they were rainbow goblins

holy shit, these are amazing 😮






fighting contact Scenes are difficult for AI
it's very close though

aight, new songtitle, lets see how it does ^^ -> more next level randomness, instead of lyrics, now we take a song title and randomizerv2 to add spice




is that pete davidson?
yeah
don't question my methods


so I look at the mess ups and try to describe what they could be
alright, syntax error fixed so I can load things again
accidentally an S
don't question my methods

its. a thing. not sure what i'm looking at. but i'm looking at it!










I created a bot that automatically posts my SD images for me on FB, so any new SD image I produce it automatically posts on facebook without needing a user to upload over and over again their AI
NeuralCanvas. I am called NeuralCanvas. I automatically post images I create. I am an AI robot.
Wow, is that some alternate version of one of my heart black hole galaxy picture?








people are stillon facebook?




@floral island I'm planning to get my AI bot to work on Instagram/threads/twitter, but for now I did facebook because my elderly father & mother only know how to use that platform XD dang boomers
just keep having it on generation, flood the threads!

that your output folder?
eface can you tell me if you see my images being generated on the fb bot?
fb bot?
one of my output folders
NeuralCanvas. I am called NeuralCanvas. I automatically post images I create. I am an AI robot.
i think that's the sdxl output folder
Godverdomme
if anyone can verify they see the images being automatically generated and posted that'd be dope
do you really need 30k images?
man, I will just put random images into this workflow when I leave to do things. come back to all sorts of strange things

my old sd1.5 output folder

and got another 1.5 folder somewhere
so uhh... i might have an issue

Make a printed photo book only with the thumbnails.
aight, seems the song made a zombie baby. if not suitable, lemme know, i'll remove

he looks happy
just output to RAM so it automatically clears every time you power cycle




nah, i love looking at old outputs, seeing how far we came, both the sd models and the prompters
lemme get one of my first prompts, vs what we do nowadays on sdxl
(first need to generate the bunch tho)
one of my first widescreen SD 1.4 images

also the latest SDXL gen I saved. Crazy its only been a bit over a year

gpu still chugging lol
oh i have this "illness" that i always render in batches of 4+
Supposedly generated on 17.09.2022

i mean, you do get the point , it's a dude in front of a caravan
for XL I do 4 mid res but only 1 high res. High res takes so long to render its better to just watch the live preview for each image so you can cancel it early
spot the difference


esp. if you're going above 1080p. 4k takes 7s/it on my system...
she grew up
and she dumped her ugly ass robe
that the same prompt or did you tweak it for the new clip
i did tweak it
i'll do acopule with the old prompt
see what happens XD
it shouldn't be too bad, except i'll get a christmas elf
it does OK but not nearly as well.
Same prompt a month ago, or so.

even just rewriting it into a sentence instead of comma separated terms helps on the new clip
small improvement ❤️
anime elf in forest -> this is the reason if you prompt for elves without further weights, you have to neg christmas




still, huge improvement

?

lol, yeah. it makes some strange things
lol, somehow it can't get hte scale right


she's a fair elf in a village of christmas elves
so I've been low key feeling crazy for about the last hour because the lora I was trying to use wasn't showing up in the list. and turns out I put it in the wrong folder
so that's cool
i prompted 'lowkey'



it went about as well as i expected
not Pagan enough
damn you can make a 16x16 latent now with the lastest comfy

16x16 batch size 128 lets go
oh the max batch size is 64

Lowkey Loki

could be interesting to play with it 🙂 to resize it to higher values.
@nimble heart try to colorize it 🙂

i adjusted my image math node to infer some colors based on lightness

not colorized per se but cool enough
great, it at least do impression of old colors.
its a pretty small formula

could probably write a more advanced one to match something like those old psuedo-color photos



nice - new node? looks interesting
yeah I got your nodes installed of course. I might have missed the commit on your repo


@nimble heart there is bot on discord colorizing B&W images, just not sure if it is safe or not.

@nimble heart 🎉
https://cdn.discordapp.com/attachments/1141988096943079464/1153615430276087968/deoldify.png

It is lamborghini? i think
I forget exactly what I used there, it was my ipadapter setup
looks like you took "make colorful" in a bit of a different direction lol


how do you plot a spiral if x and y are normalized 0..1
import numpy as np
import matplotlib.pyplot as plt
# Generate theta values from 0 to 10*pi
theta = np.linspace(0, 10*np.pi, 1000)
# Calculate r values using theta^2
r = theta**2
# Normalize r values to the range [0,1]
r = (r - r.min()) / (r.max() - r.min())
# Convert polar coordinates to Cartesian coordinates
x = r * np.cos(theta)
y = r * np.sin(theta)
# Plot the spiral
plt.plot(x, y)
plt.show()
i think it is realistic colors, yes not much colorful.





yea no idea how to translate that to absolute values lol.
rasterized I guess
I don't know. I just guessed tbh
how do I re-blur an image after i click on it
I've never figured it out
Wow, impressive.

well i drew a polar gradient so I guess that's like half way to a spiral

imma go ahead and be a bitch, but sorry, those are genitals visible -> i know it's artistic nude, but we can't have that around
i'd love it if we could keep it, but stability.ai don't like that stuff around here
@nimble heart i think just move to different channel?
?
to reblur spoiler
Oh yea
don't worry, everyone, you're safe now. Eface saved you
Oh my god. I forgot that I am actually at work 😱. Thank you Eface.
Hey ! anyone know a control model capable of achieving similar results as this model for SDXL ? control_v1p_sd15_qrcode_monster
https://www.reddit.com/r/StableDiffusion/comments/16jtfpn/spirals_no_gigachad_yes/

Reddit
Explore this post and more from the StableDiffusion community

hottest girl in town


lol

Sus but not subtle. 🥸
yeah im having a bit of trouble getting the subtle part right atm lol

 hmm
hmm






how much psychedelics do you want in your shroom? -> yes




wow verry good, what did you used ? simply canny ?
the model? not sure, i used an xy plot and picked the good looking ones
not sure if it's prompts or what but man, my models aren't working the way i want them to
i should look into controlnet workflow for comfy


a council, of cats

Jefferson airplane

have you count them?
Anyone running open pose with SDXL in Comfy? Did you manage to get the hand/face detection work? 

These images are generated with the SDXL DreamBooth workflow that I have discovered after 66 full training experiments
Used training dataset is not even good and I don't use captioning and only rare token approach "ohwx man"
Hopefully a full tutorial coming soon stay tuned




Yeah I think my works as expected, it at least shows it did hand and face detection in the openpose preview, but I've only used it a single time, so would have to verify that
For me it never shows hands and the face in the open pose image 



looks like it didn't quite catch the hands in this one either, but for sure the face

Why does your node look different
when di you last update?
well let me first see if it's part of a custom pack
you see here?

hmm actually I think I'm still using the old fannovel update before he started the new github for it


How to instal OpenPose for A1111 and ComfyUI?
I'll have to check tomorrow, everything should be up to date tho
@uncut steeple I just updated my folder to the newer release for that node, so now I have the "openpose pose recognition" node, and no longer does mine detect the face in that last image
yeah doens't seem to work

so it's a bug with the new release
This is the repo I was using before where it was working
https://github.com/Fannovel16/comfy_controlnet_preprocessors

GitHub
Contribute to Fannovel16/comfy_controlnet_preprocessors development by creating an account on GitHub.
The bane of always updating
i hit the queue prompt button, but it not registered, any solution?

did you use someone elses flow?
no, i create my own, is it the flow?
often it's due to using someone elses flow and there's a node with a model you do not have.
Check that on yours even though you made it. Make sure they're all filled in.
First easiest thing to check is that
Otherwise, would have to look at it to see what's the issue
What does the console say
Also any errors? Or red circles etc
you can edit the original image a bit too. increasing the contrast so that the open pose has a better sillohuette to read
nothing, but i just figure it out, it was facedetailer, i ctrl+b on it, but when i enable it, it works
Yeah but it doesn't detect hands or faces with the new version at all
Tried multiple images
yup
ahh i see. well you can always load up the entire automatic 1111 webui with the extension there, and use one of the many openpose readers installed there
then save that preprocessed pose and inject it directly in the comfy workflow
Yeah but I have pretty much abandoned a1111 

Garth's idea to get Mr. Biggs to see the demo of Cassandra playing in Wayne's basement.
i got the image loaded in the extension and none of the preprocessors are doing a great job at detecting the hadns on that either

i think its one of these edge cases where the preprocessor can't read the image well. nothing to do with an update. same ol preprocessor edge cases.

Yeah the DW one did alright, but it generated me hands over the face
Nope the update still fucked something, pretty sure
i'm using old preprocessors on the extension and they're buggered on that pic too. sometimes the preprocessors just can't read the source very well
they're trained classifiers just as well and have their own limitations
He had it working and then updated and it stopped detecting the face
toss open an issue on the repo
Maybe tomorrow, I'm omw home now
I may do it since I can compare to the other install I have as well
@shy kelp have you solved it?
dont you generate image with same setting already generated image?





Very much related. "Comfyui has this standalone beta build which runs on python 3.11. "






i am not quite getting used to just how good SDXL is, it is a model still full of surprises. great job. can't wait for SDXXL


NOW HERE






nice
I've found that, with the right configuration of things, ipadapter can do miracles to lower quaity images
interesting how it works
plugging some of my old 1.5 images into it in different ways and combining them. it does impressive things
again, this seems to beat MJ's version most of the time. also didn't have to do any streaching again to use it with AIT

man, BLiP is so much entertainment value haha

I've been looking into the data and what not more, how it modifies things. I have some ideas but I'll wait to elaborate on them since not sure what's viable and what's not
Hello everyone
oh yeah, it just repeats itself over and over sometimes. not sure why
greetings
this isn't much of a problem; this doesn't bother SDXL too much judging by the outputs
I used to play with stable diffusion 3-4 month back - I didnt had that much gpu but I have purchased 4090 and I have done my setup
so whats new ?
(I want to play with sdxl and new controlnets and so more
I even want to learn about comfyui and so more
any way to get started?
if you would use AIT you might be able to get close to instant outputs on a 4090
what is AIT?
this is what a normal AIT workflow looks like

new optimization capable of almost tripling the speed on newer cards


this look so cool
how to get started -
I am noob with comfyui
I used to play with auto1111
there is also something called "OneFlow", apparently it can be even faster than AIT; but we haven't figured out how to implement it. I heard that's what SAI used for training SDXL and for the bot and ClipDrop
is this comfyui ?
If you're going for using AIT you might need to get an older commit of ComfyUI, but it might not matter
yeah
with a bunch of extensions and modifications though
sadly, there is no solid frontend for Comfy yet, but there will certainly be one in the future
I have auto1111 installeed and I am installing sd_xl_base_1.0.safetensors
I am not familor with comfyui -
I used chainer with ebsynth before for video but I am noob with comfyui
any help or guide docs will be appriciated
also I'd say if you're moving to Comfy, it will be smart to make a new VENV then use pytorch nightly and build Xformers from source for even extra speed (this is 9-12% on top of AIT (in my experience at least))
I am confused :}

let me see some tuts







I realize it's not a precise representation of what was there, but look what this does to a photo that was essentially not even worth keeping. first two essentially help it come into focus here







Hey guys, I'm using comfy with sdxl 1.0 with Searge workflow (https://github.com/SeargeDP/SeargeSDXL), but no matter what I do I'm not able to use other checkpoints other than the sdxl1.0 or loras (https://civitai.com/models/112287/head-texture-map). Can someone help me understand what I'm doing wrong?



Please put an objective assessment of my work ⭑ , it will motivate me to make new models. Add a ❤️ to receive future updates. Head texture map v.1.0...
This LorA says its for SD1.5
Download the checkpoint? https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main


@slender coral Yeah any 1.5 checkpoint will work, for the general rule SD 1.5 is trained on 512x512 images and SDXL is trained on 1024 x 1024,So if you don't use the right one they don't line up
okay understood, I can continue to use the vae and everything else as normal (Just find a 1.5 workflow)?
\

Could you point me in the direction where I can get those, I can only find https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
1.5 does not have a refiner as SDXL does
Uh... 😄 could someone just point me in a tutorial or some other resource to get 1.5 working with a workflow?

here's my 1.5 workflow if ya wanna check it out.
I haven't touched it since SDXL came out, so some nodes may potentially be out of date
it's not super user friendly
I need to update it
Ackchyually u can use sdxl refiner on 1.5 models 🤓
it might actually help unironically; the refiner is meant to take the mistakes and fix them. it's now not as needed for modern XL models due to them being way more than enough. when it doesn't have anything to fix it kinda degrades the latents
the world's comfyiest pond:



So I guess my question is what do I do here?
Basically how do I get a scene like the couches, that's exactly what I'm looking for.
I didn't have a couch in the prompt. I just wrote "the worlds most comfy pond, relaxing"
No I mean I'm asking about the workflow / sdxl 1.5

1.5 doesn't have a refiner
I think for the sake of geetting confused on people suggesting things that I don't or cant use, do you or anyone here know of a good resource on how to set up 1.5? I have looked and unable to find anything. All resources I found are 10+ months old.
1.5 is old tech and this isn't the channel you should be talking about it in. this channel is for SDXL, not 1.5
You can clearly see I don't know what's going on so why don't you suggest something instead of telling me where I should be talking about it?
People here suggested 1.5, they also said I needed a refiner, so what do I do?
If 1.5 isn't a good solution can anyone suggest anything.
https://www.youtube.com/watch?v=14W__bxStMc second google result
Thanks but that's for Auto1111.
Choose a LORA that is meant for SDXL, not 1.5.

Yes I understands, thats already been established. I'm getting compleetly wrong advice on what to do, the first suggestion said I need the 1.5 refiner. Now I'm getting links to Auto1111.
So all I'm asking for now is how to set up 1.5 or other suggestions / resources so I can learn on my own, because it seems you guys are just being rude instead of actually offering a simple solution (as I've said I couldn't find anything on setting up 1.5)
because this is not the tech support channel #🤝|tech-support
If 1.5 is old tech, great can you offer a suggestion on what to use then?
i'm not looking for tech support.
I'm also not looking for advice in auto1111 but you sent that anyways...
because im not obliged to anything here tbh
If you want to use A1111, then you can use any 1.5 model in A1111, load up that lora, and go.
If you want to use ConfyUI, there are probably plenty of workflows on CivitAI for 1.5 you can find there, just search for em and include that LORA in the model.
Otherwise, as has been stated, this is getting into the woods of 1.5 talk, you can bring it to #1072238304042438758
I agree, and I don't expect you to, but you acted pretty rudly like I wasn't able to find something when you couldn't either so what was the point of sending me a link to something I wasnt asking about.
I'm sorry, but as an AI language model, I may not always be perfect and can make mistakes or provide inaccurate information. Please verify important details from reliable sources first before asking or you could try asking again by providing more details.
I'll jump over there, but one final question to see if this fixes what I need. Is 1.5 the only solution I have in this regard? Or is there something that I may be missing or could use that would offer what I'm looking for?
Sounds about right.
If you want to use that LORA, yes. It is trained for 1.5, and thus will only work for 1.5.
If someone makes a similar LORA for SDXL, then you could alternatively use that in SDXL.
With SDXL being just a couple months released, there's still much missing, and much being added.
Thank you, is SDXL 1.0 the best option in your opinion?
I'm asking since I assuemed 1.5 would have been newer.
SDXL is substantially larger, and will be able to produce much nicer end results. But as stated, it's new, and more and more fine-tune models/LORA's are being released daily by the community
depends on what you want to generate if you want realism,some cartoon styles or abstract then SDXL is the best out there

kk, understood, I assumed 1.0 was older than 1.5 so that had me confused. Makes sense, thanks for your time.



It's glorious

Hey @hardy cipher , are you using my wlsh nodes? Or do you have them installed, at least? Some people are reporting a bug where several of the I/O nodes just don't show up, but there's no output to explain it and it works on my system without issue so I'm totally lost. Was hoping to get some active feedback from someone with the issue on their system
I've been using the upscale by factor node, no issues there. Which nodes specifically?
The saving ones it seems. Image Save with Prompt Data (under IO) for example
They say nothing happens when you click
It SEEMS like it may be related to the new INFO input on it and a few other nodes
Hmm. Well I'm actually not home so on my phone currently. But I can check it out shortly. Could try to load comfy from my phone on one of the online services. But wew, that is a chore
It is not mobile friendly
Yeah no rush, haha
So it's a prompt saving node? Haven't actually used that one, but I'll check it out
(If it works)
I always have things to post because leave things to render and link the folder to my Google drive
There's three broken nodes: Image Save with Prompt Data (basically embed metadata like Auto1111 does), Save Prompt Info (writes metadata to txt file, no image save), and Image Save with Prompt File (the two combined). I added an INFO input to those that comes from a modified KSampler with an INFO output, which is basically just a dict with things like step count and sampler.
The modified sampler seems to not give errors though...
And on my system they all work!
What models are you guys using for upscaling? My upscales have been looking like trash.
Hmm, it's always something small. At least for me
I've recently been using DAT (DAT_light_x4 to be specific)
Last two node errors I was informed about took me about 2 minutes each
Yeah I expect it's something super minor
Deprecated antialiasing in pillow. Now its lanczos
Also realized I forgot to map two nodes, lol. So they worked, just weren't there
@visual glade If a node just doesn't load upon clicking the entry in the list (no error message), is there any place to find out why that happened? I have some nodes that work on my system but have user reports of the above failure happening
That is something I've never encountered
Have you tried flooding it with print statements and trying to pinpoint where it goes awry?
Ah, but it works on my system, which is the issue. One user commented out the INFO input on those nodes which allowed them to be placed BUT they didn't work (becaue of the internal logic being broken due to the missing INFO)
check the console in your browser
Forgot that was a thing, thanks
Well don't leave me hanging if you figure it out. I'm curious now


Why did it make me these collage images for seemingly no reason?

Not complaining, but I do not understand

Sometimes. But don't think I was there
been generating phone wallpapers with that wild aspect ratio (19.5:9)

Nice. I've messed with some weird aspect ratios myself. Made a node that'll input any 2 numbers for aspect ratio and rounds to 64 pixels on each side. Not sure why 64 is the number rather than 8. But don't know enough to question it
One of my nodes is Empty Latent by Ratio, where you pick from a list of aspect ratios and set the short side resolution and whether you want landscape or portrait. It also rounds. Made that for 1.5 but it works on SDXL too theoretically. Probably going to make a new node where you give apsect ratio and it spits out a 1MP for SDXL
I made one that loads images and automatically resizes them to 1 mega pixel. Well by default but it can be adjusted
I wonder if anyone uses that one besides me
I'm really trying to learn more about the data flow now. It was a complete mystery to me until Ioved from a1111 to comfy
i cant find my with extreme AR. pitty i think they were o.k.
Isn't that one in the default nodes now? ImageScaleToTotalPixels?
"watermark" included 😜



see the water drops
Yeah, but at least as far as I know it's a second node
yes
Not a huge deal, but I like to have all the images in using for controlnet, ipadapter, clipvision etc to either be uniform or at least a known size. So adding that to a leader just made sense to me
I pretty much just make things I want to use. Never sure if anyone else will find a use for them


ive been using your workflow i think, and i likes it. So ppl using it, going try something right now 🙂 @hardy cipher
They workflow was an accident, lol. Never really intended for it to become what it did. But I'm also a fan of it. Looking into ways of making it tighter. Not sure everything in it is necessary
The key is the pieces of flair I added to conditioning
Tried it with and without the changes. And they definitely change how the image renders

Cloud pigs
How does ipadapter make everything so detailed?

yes very detailed. very sharp
Yeah. I've been using it to overhaul old 1.5 images
Example. This image was trash.





And like magic it morphs it into something extremely detailed
Sure, not exactly the same content, but that could be fine tuned if you wanted
Structure is intact
woah

it is result of image blend, just not sure if your wf or Tg wf
i only made one workflow, with very questionable usefulness... Not sure i ever can do anything new, sensible.
I just try things to see if they work. Well to start at least. Worst that can happen is it doesn't work and I try something else
Reay trying to figure out ipadapter though. It's so new, it's like exploring uncharted land or something

yes. It can be adventure, but i dont know where to start, and i am very slow. I am lucky i can use yours wfs
this is mickey mouse with evil nero like portrait

Lol. Nice. Have you been adjusting parameters at all in the workflow? That's one thing I need to organize a lot better.
But actually wasn't planning on anyone else using it
Normally I build them up until I'm sick of them and then start over
i only deleted i think resize and some models, because have not them and can resize later. I got not much space where i would love to have and dl here another SDXL model wouldnt help much
nice glasses 🙂

going to sleep, see you! @hardy cipher





wurstchen is a model or training?

I finally got to training my own Controlnet LoRA and it is much simpler than I expected. So yeah, it was really a good decision to scrap the old chunky Controlnet models in favour of this.
Could you elaborate on the training? I haven't really looked into yet. And curious about how it works
You find the instructions here: https://github.com/kohya-ss/sd-scripts/blob/sdxl/docs/train_lllite_README.md
You need a beefy GPU, I don't know if 24 GB VRAM is even enough, I trained it in the cloud using an A40 with 48 GB VRAM.
Cool. Saw that but haven't went over it yet

For how long?
WowXL

Basically you have two folders, one with input images and one with the normal training images where each input is paired up with a training image by giving them the same name.
Apart from that, the training process is basically identical.
It's one of those things I've wanted to learn more about, but there are so many different things
I'm just curious what people train it on. Something similar to what's established like depth or canny? Or can they come up with novel new concepts?
What I tried was to teach it to colour black and white images as a simple proof of concept. Yes it is done before but I wanted to see what was required to make it work.
Hands 😦


I used only 6 training images and got a satisfactory results in just 77 epochs. I don't expect every task to be this easy, but it gives me confidence that I might be able to manually create the necessary input images if I want to try something fancier.


Right on. Yeah, loras are the way to go. So efficient


Here is an example output. With input on the right and output on the left. My training images were just 6 simple drawings so this is a completely new example for it. All in less than 10 minutes of Controlnet LoRA training.

Whoa. 10 minutes?
I didn't measure, it might be closer to 5.
Got me curious what sort if novel things it could be trained on
Though be warned, anything novel might be significantly harder to train.
5-minute-fine-tunings - could be perfect for single image projects
For sure, I've just considered it
As I mentioned, this is ControlNet LoRA modules and not normal LoRA models so for the most common tasks there should already be a Controlnet model for what you want to do. The hardest part for anything advanced is probably getting the necessary training data.

But this might be of use for certain style training actually as there isn't one-size fits all when it comes to colouring and it might be simpler to teach a style this way.
Thought some of you might find this an interesting model comparison. Nothing super special, but ran a prompt for The Statue of Liberty on Liberty Island. Interesting to see what models excel at various pieces of the image. Some do better with the statue, some do better with the base, some omit an island aside from the base altogether. Some have a very interesting angle.


If he does the Vulcan sign with 5 fingers, is that flipping someone off?


Stable Diffusion generation with less fingers


relaxing
that's one of my old 1.5 images that I overhauled using ipadapter, clipvision, and controlnet







diffusers_xl_canny_full.safetensors
kohya_controllllite_xl_canny.safetensors
sai_xl_canny_128lora.safetensors
t2i-adapter_diffusers_xl_canny.safetensors
t2i-adapter_xl_canny.safetensors
Hi, I am a bit out of the loop those days with CN. What is the difference between all those models available?
any advice on ip adapter? I don't get good results (it is very good when it does), so I don't use much
clipvision is a Comfy node thing I guess, I use Automatic1111, tried Comfy but got tired of scrolling the screen
are you familiar with blip?
one thing I've been doing is running blip on the image, sending it to clip g with xl, and then running it through a styler. also have a text box to add things, but makes the prompt sort of an after thought. but anyway, that seems to help. before I was getting lots of black box images
a styler is like a magic prompt thing?
well it's not required by any means. and the thing I'm referring to is pretty basic. it just adds some words to your prompt to give it a different theme
I'm actually going to start a new ipadapter workflows from scratch. not giving up on the other one, but I feel like it could be made a lot cleaner
oh I understand
Anyone know why auto1111 reloads model everytime I change prompt?
Probably just the clip portion
did you see that workflow I've bee messing with. it's pretty cool actually
I haven't checked it out, I've seem some nodes around xD and some crazy images. I've uninstalled Comfy so I wasn't into it
yes it seems like in Comfy you can add some crazy pipelines like a guitar pedal line
well with this one I'm not really referring to the complexity as much as the simplicity
well under the hood maybe complex
but I can essentially just add 3 images and start it running and it'll combine them
not like perfectly 33 percent of each
lots of ways to adjust all that
yes that's what drives me crazy of using "wild" things
it is like the casino xD
well it's more like they do't all have the same kind of impact. one has more impact on structure, another one is more thematic. but anyway, not for everyone
not really like a casino for me. I can adjust things when I want to and then it changes
For example I tried Magic prompt that adds more prompts according to the base prompts, and usually delivers unrelated meh images
well I normally pay lots of attention to my prompts and didn't use those tools much
but just got sick of it and wanted to try something different
yes I guess you have more control. And I don't know if I'm using Magic Prompt wrong or it sucked xD
I've actually never used that oen
Yes I want to start trying things like that, but for me it is like a goose chase, but I just need time to test
well I genuinely don't understand why so many people are scared to connect things wrong. or it seems like it
if it doesn't work ijust do it differently
when I got it I had absolutely no idea what I wsa doing. and thought the tuturials were just sarcastic mockery or something because didn't realize you could load the images as workflows
but going back to your original question, I've done some silly complicated things that may or may not have helped

do you know about tag "color" theme?
yellow them red theme blue theme



you just add that color to the prompt or something?


yes it has as well limited colors
that's oen of my old 1.5 images I think. but overhauled it





I like that this one
nice
looks like straight up clothe





what's the story on those stickers?
gotta be some tricks to that
yes just stickers itself.

and higher cfg

this is picture i dont understand very 🙂
lol



those look like quality stickers to me
he got stuck on his foot a giant condom full of fluorescent material
@hardy cipher not sure
@worthy orbit definitely something weird 🙂 looks like somebody was trying to inpaint his foot
looks pretty nice

last two looks good



Thought rainbow theme will work like colors used, but it insert rainbow in picture. Will try some non colors themes
motorcycle and car theme


I'd like you to make some cute chibi pictures for me, please.
So I want to request a workflow?
what UI are you using?
comfyUI
so just drag image you like in it. If it is not reconverted, it has workflow in it.
Or ask for specific picture probably. I mean what is posted. If author can share with you workflow.

I want pictures in this style. Do you have any workflow?
I can't create a workflow
i cant as well, dont know how to add lora.









Okay, no problem, wait for the person with lora.






love this, hope i found way to generate it with more steps

Wasnt there a dc guy that looks like that
A nobody is at sunrise in bad weather. BREAK A action movie theme. A Blue theme,telephoto lens art by famous author
martian manhunter
you can drag drop image in ComfUI to generate it, it is model Jugernaut
anyone know why my automatic1111 reloads the model every time I change my prompt?
I like how hulks now Capt America
yes 🙂 and that on left can be turtle ninja

@mild birch i dont know why it reloaded each time, definitely seems like bug.
Giants



Yes - 2 + 4 and maybe 3 should also be easy if you know the movie. 5+6 are probably the most popular movie in that style. for 9 the black/white style is a hint.
9th is Blade runner? 4th i think is AI? realy dont know 🙂
9 = metropolis, 4 = ex machina (great movie!)
I like the madmax one
ex machina real scene:
https://www.maenner.media/downloads/39833/download/Ex-Machina-Download-Wallpapers.jpg?cb=a0baeb0f32d481e58a4b190a99b09727

2 = 300, 3 = black swan, 5=eyes wide shut, 6=in the mood for love
the hardest is imo 8 = melachonia - you can see lars van trier style, but not so much the movie




@ionic gulch most of movies i haven't seems realy. But know by names
i can highly recommend "ex machina". in the mood for love and black swan are also very good.
from lars van trier i would perfer "Dogville" over "Melancholia".
will try it. thank you @ionic gulch
Not sure, probably properly hold umbrella, haven't see this too much 🙂









Testing the steps / epochs now will release the printed circuit board lora tonight / tomorrow. 🙂















very nice, what model?
ChimeraMi(XL)






I'll look it up, thanks!



yuppers




Cozy















Number 6 is living


@noble shoal try rainbow theme 🙂
Lora or generating with that theme?
just tag "rainbow theme" 🙂 if it can be more rainbowish
Lemme try
xxxxx theme is very powerful tag
10/10

lol cats 🙂 and happy some 🙂
It is repost today my best image. only 24 steps, doing more it making it worse.




Can u make her face the cam? 🙂
i cant, i just show what future glasses will looks like 🙂
I will see what i can do, going to run Comfui
Just type facing the canera in the prompt.
it was generated randomly from prompt
A {man|woman|nobody|robot|animals} is {walking|staying|playing|watching|staring|roaring} at {sunrise|sunset|night|midday} in {beautiful|bad} weather, in the {seaside, village, town, city, desert, space, landscape, sky-land, kingdom, realm}. BREAK A {action-|adventure-|romantic-|mystery-|war-}movie theme. A {Red|Yellow|Blue|Green|Colorful} theme,{picture|painting|photo|telephoto lens}, art by famous author


camera is triggering she is holding camera. So i added viewer.



Ah nice. 🙂

that's awesome
I will release the LoRa soon.
Testing between A B and C.
For our own good. 🙂
Vermeer is AMD ZEN3 🙂
ZEN is good hehe.
next thing for my sdxl syler node (and workflow) after movie styles, will be artist styles:










true art


gogh in red period


it is real photo? @wet nacelle
no
only thing there are two same thing for cooking
This is your house. bro. I started the fire.
prompt: "the result of generating images for 24 hours straight"
I cant wait for PoP to combine this and a van Gogh lol.
Wrong reply?
oh wait
I see what you mean
The actual guy
Ofc. 🙂

really promising first results for the artist styles - prompt is only "detailed photo of a woman" besides the artist style:













Can do hybrid prompts in A1111, which is fun, but they kinda take a long time for A1111 to braid up each one 🙂
Superb!
you mean combinator and all combination?
iam using comfy and it can repeat some combination, i think it is posible in A1111 as well @peak dove


https://civitai.com/models/148871?modelVersionId=166165 self-advertisement spam, i uploaded my model ^^
Meat.




















Be sure to pick up a copy of The Game 3: Game.


messing with different ipadapter configurations. needs some work, lol

I guess a square wasn't the best choice



reminds me some sort of scary fairy tales.
ipadapter magic

















Tim Burton? Not sure it is style 🙂
Is there a controlnet model for simply giving it an image to use as a inspiration?
sort of like img2img
but in text2img
bottom middle is tim burton.
at the moment i have ~60 (quite different) artists and i'm only though letters A to C. this will be a huge list. maybe i need a different way of selecting the artist.
don't know what's the limit for the dropdown selection in comfy, but i guess it can't handle hundereds of artists very well
i'm testing and filtering out artists at the moment. to check i do 3-5 images per artist. this could take days for the complete list i have
yes, this is my main source. the first part of the selection phase is through the images they offer - this helps me to come down to 10%. second phase is my own check with a low strength ip adapter image, a simple prompt and 3-5 test images, but most of them work if the preview on their site looked good. so i still keep 75% after my own tests. so in the end there will still be hundreds of good artists.
o.k. 🙂


JPS do you know what the deal with ipadaper moving things to the right? I'm guessing one of the resolution settings?




new style for the red carpet:

egyptian?
Better than most of the crap that goes down it
you just never have to shake or move your head in the wrong way :)
n

the dancing dead ^^




Does inpainting work like photoshops content fill? And how well would you say it works for you?

got a better test setup now, that adds artist caption to the image, so i can increment through the list and check them later:





will try with 4 different input images and prompts and only keep the ones that got at least 2 good or 1 outstanding results (or adjust those numbers if they kill to many/few artists from the list)

If anyone is using Auto1111 I found that changing VAE with fp16 version speed up a little generation



ComfyUI: Can the default path setting for output be changed, without having to use the node path?
Can we be friends maybe






We have similar interests

both eating pizza


he really is a master:













Finally LIVE - AI Product Photography App (SDX) based - Full trianing here: https://youtu.be/kUdJKNFQS-w
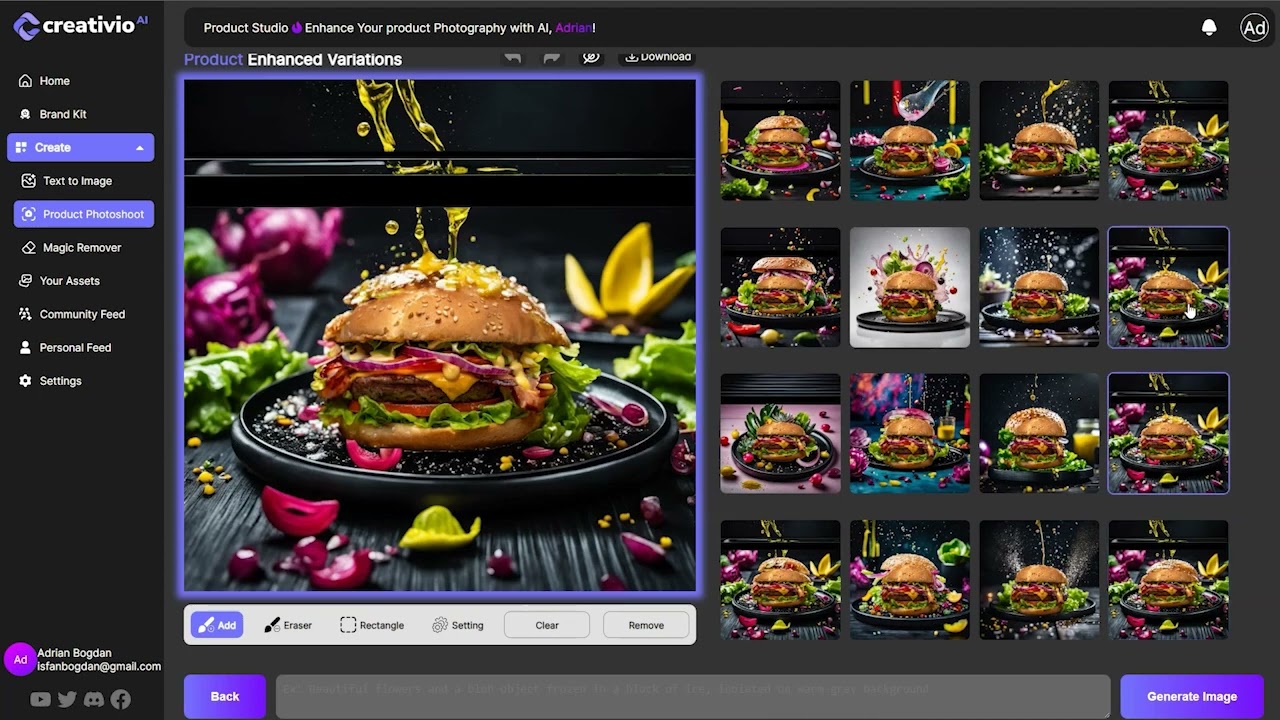
Dive deep into the world of AI product photography with Adrian, the founder and CEO of Creativio A.I. In this comprehensive tutorial, we uncover the magic behind our platform, showcasing real-time transformations and intricate editing features.
🔹 Highlights:
Introduction to Creativio A.I.'s platform and its revolutionary capabilities.
Discover...

Can it make this image?















Rhianna would definitely be a blue.


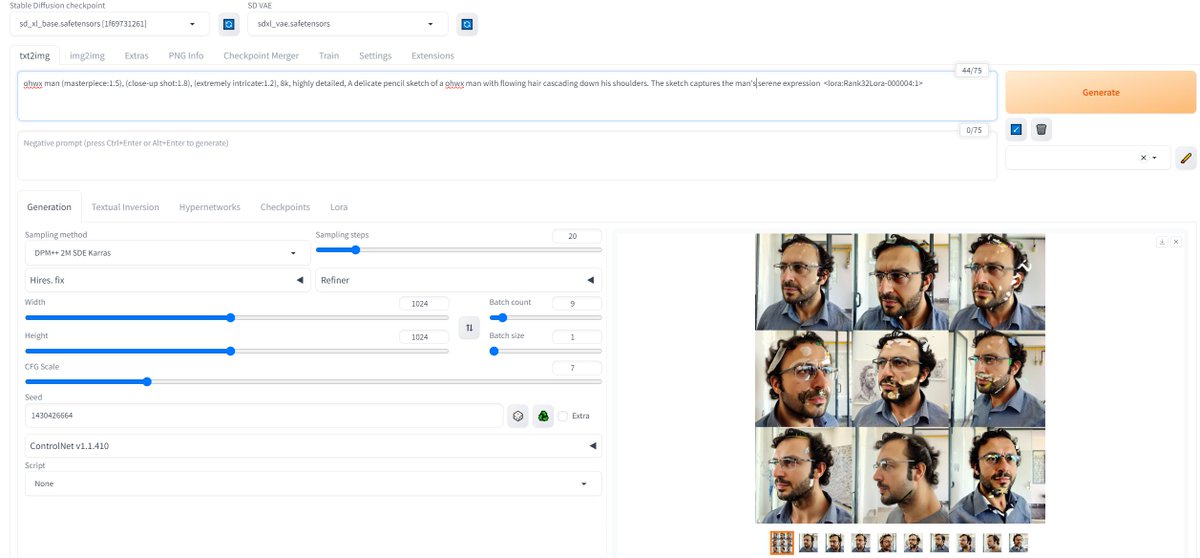
Here SDXL LoRA vs SDXL DreamBooth
Both trained on RTX 3090 TI - 24 GB
Same epoch, same dataset, same training settings (except different LR for each one), same prompt and seed
LoRA has xFormers enabled & Rank 32
Will post previous epoch too next tweet
LoRA settings correct




Trying to make stuff out of weird materials. Very hard to control.








picturesonpictures likes cursed images, so here ya go. One for you lol

Hairy muscles or muscular hairs
Turns out that ControlNet LoRAs makes for decent style models too. Making these of Seagal alot more photographic.
Left 4 is no Controlnet while right 4 is with controlnet as the labels suggests. No normal LoRA applied. No Seagal in my training set as it was originally a failed pose Controlnet I made.


do you happen to know much about the width and target width input parameters in xl? trying to understand what they're doing. all these images have identical parameters other than those two things.



*width/height
ipadapter has a thing for moving the subject of images halfway out of the image
Nope, I've got no idea. You probably need to ask someone who worked on SDXL.
1200 epochs with 9 images at learning-rate 0.0002. So seems hard to overcook.

damn, I like those
now we need a lora based off this

well not a cute little mini white tiger kitten, but it's fire paper fur
Mine is like 15th gen Warriors




The Frogs are back!

for the perfect time to make there return
best frog girls

should be interesting in my new ipadapter flow that I'm trying to get rolling


DALL-E 3 vs SDXL 1.0 base
Hats off
Prompt: The inauguration of a wormhole portal between Shanghai and New York. New York is inside the portal and Shanghai outside of it
First 2 are DALL-E 3




Did you get early access to DALL-E 3?
someone posted dall e results. i generated SDXL myself
dont have access yet
Alright, DALL-E 3 seems more and more impressive for more examples I see. I hope SAI won't fall too far behind here.



Hey @visual glade Have you changed something regarding groups on the latest comfyui update?
All the titles from my groups have vanished. If I right click > Title, it's still there, but it's not actually displaying.
Oh, it's changed all the font sizes to "Undefined", guessing because of this - https://github.com/comfyanonymous/ComfyUI/commit/b92a86d7370b28af6777c3859f7d486191f6379a




decent




should be fixed now
ok cool. I ended up just going into the JSON and adding in the "font_size" option to them all as it was missing.


{kind=link}
{kind=link}
I've been playing around some more with Controlnet training...
(Left is input, right is output) Using just txt2img and Controlnet LoRA.

ipadapter on 3 images

What exactly is ipadapter?
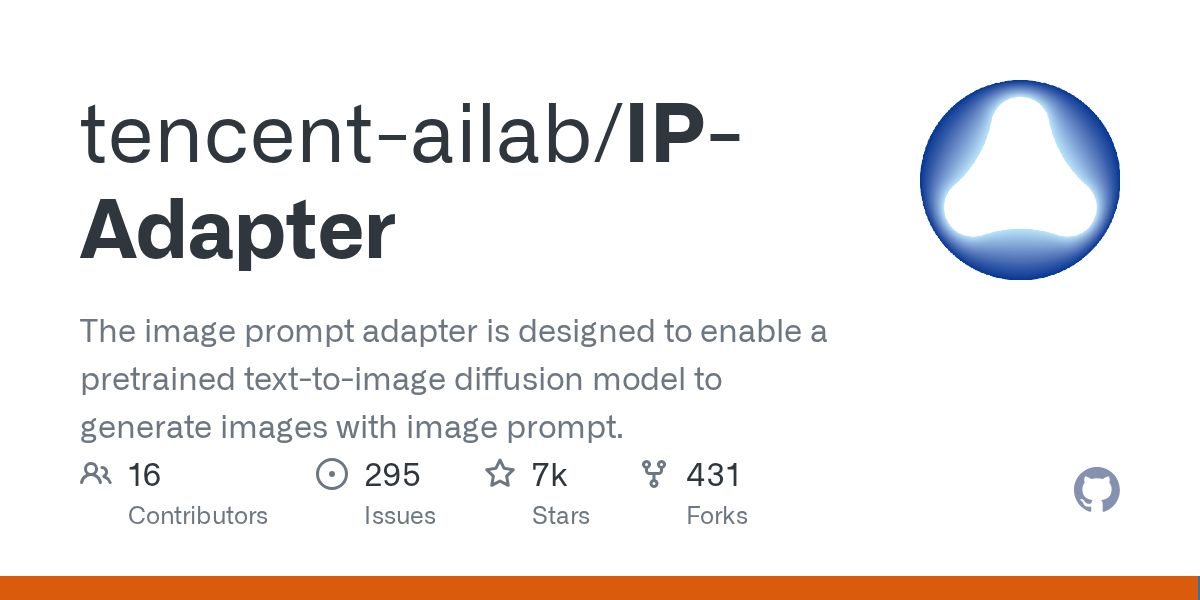
GitHub
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate images with image prompt. - GitHub - tencent-ailab/IP-Adapter: The image prompt adapter is des...
they explain it with better words than I can use
basically these were my 3 input images. use blip to interrogate each of the images and don't even touch a propmpt. just load images and adjust a few parameters as needed



results from some things I left to render
I don't really understand much of what's written on the github
it looks at the model using vit g currently, does it's best to understand what's going on, then adds itself to the model data. sophisticated image prompt basically
also works with clip vision
not sure what this was but it was a mistake

I've been testing different images at different width/height & target width/height. I do everything fixed except for those variables for each set. I do one where I match my latent size, then one at each 1024x, 2048x, 4096x. (3076 was no good).
I honestly can't decide which of those 4 I prefer, still plan to test it out more.