#✨|sdxl
1 messages · Page 131 of 1

i have a variation of those in my pack:
difference is that off is left and on is right, which is more in line with many other on/off switches. comfyroll nodes do some things i don't like. for example the switches have a=1 and b=0 which always confused me.

I just stuff 10 loras and switches into one node
I don't think I've ever used 10 loras in one workflow
if i need more space in my menu section i would do that too. for now i like the flexibility of 4 separate nodes, even if they overall take a little bit more space. for example i scan spread them horizontally.




pipe-like nodes are nice for menus. as they only have one "pipe" output and take less space in the menu section. other than that i don't see much use and using too many pipe-type nodes was part of the performance problem i had a week ago.
example - menu node + output node in a different part of the workflow:


with normal outputs the menu part would be twice as high - wasting menu space and looking bad
I'd really like if they offered the pipe option but didn't require it's usage
would require complicated "real-time" code, to hide the outputs you don't use. that is a thing that can also cause the lost wires problem i had. had to replace all the impact pack xin1 switches for that reason. made simple 5 in 1 switches for almost all types for that reason.
well image loaders have mask outputs they don't usually use and they don't appear to be very complicated
hi! having a lot of ai generated png images it would be useful to be able to convert them to jpg to save space. Problem is losing the prompt. Is there some util to batch extract prompts from png images?




extremely cursed

yes not sure it can work with already generated images, but there is chance it somehow can.
I know. The interesting thing would be to apply it to 1000 or 2000 images. Generate a txt file with the same name as the image, convert the imag to png and delete the png. All done automatically. I can program some simple scripts in python (with help from chtgpt) but this would be beyond my capacities i think.
uhhh...

well it's all in the metadata
i read it already 🙂 Converting images to jpg is for xnview question of few minutels. You can as well keep metadata, but i think it is not in those one can keep.
why uhhh... seems o.k.
@uncut fiber well,tried absurdism, it's totally awesome 😮
formulaxl workflow 
i love gertrude abercombie work, can work together probably.
art by <random artist>, absurdism, cute




lemme run 4 on that 🙂
🙂 we all have different tastes 🙂 dont be dissapointed!
it for sure is something!










horror warning




lel









he looks like beholder is next in pot 🙂

imma eat you after this.
done! chatgpt is fantastic.
congrats!

because if so, and you don't go over it, you're going to have a very bad time
in a block you mean?
like this?
yep
the little hash thing to the left of 1 on the keyboard `
alredy tested
repeat 3 times above and below
fat zombie hamster... very underwhelming

from PIL import Image
# Directorio que contiene los archivos PNG
input_dir = "D:/SD-outputs_storage/convertojpg/aa"
# Itera sobre cada archivo en el directorio
for filename in os.listdir(input_dir):
if filename.endswith(".png"):
file_path = os.path.join(input_dir, filename)
try:
# Abre el archivo de imagen
image = Image.open(file_path)
# Obtiene los metadatos (EXIF) de la imagen
metadata = image.info
# Crea un archivo de texto con el mismo nombre que el archivo de imagen
txt_filename = os.path.splitext(filename)[0] + ".txt"
txt_path = os.path.join(input_dir, txt_filename)
# Escribe los metadatos en el archivo de texto
with open(txt_path, "w") as txt_file:
txt_file.write(f"File: {filename}\n\n")
txt_file.write("Metadata:\n")
for key, value in metadata.items():
txt_file.write(f"{key}: {value}\n")
txt_file.write("---\n")
# Cierra el archivo de imagen
image.close()
except Exception as e:
print(f"Error procesando el archivo: {filename}")
print(e)```input_dir change inputdir to the folder where your png images are obviously
all the LLMs are psychopaths. I wanted gpt-4 to give me advice on some code and help me figure something out and it kept messing up my code
they'll do little subtle things you might not even realize until way later
you need to explain it very clearly
well it kept messing up the math
I said
do not touch the math do not touch the math
Yes 59% of code it do is wrong, some recent tests, but for ppl that know language properly it can be very helpful
it seldom do it at the first attempt
it would apologize, say it understood now, and do it again
Probably somebody already did it before?
no no, they will never get it right because their entire existence is a calculated hallucination. they have no idea when they're lying or messing something up
I'm not saying that's a bad thing per se
just that I understand it's limitations, at least for me
in this case i used a code from reddit from a guy that also used chatgpt to write a code to extract all metadata in a single txt file. Copied it, pasted it in chatgpt and asked for a modified code, so that each metadata would go in its own txt file with the img name
so it was a AI-human1-AI-human2 interaction. 😄
i just dont know. In xnview it showing metadata, but not those you are looking for.
redbull clown mecha... uhhh

Chatgpt is better at modifying code than making it from scratch i think
well there are approaches that can work, but they require human interaction to a degree. run it by bing every so often. but don't bother with bard. he's a bit tarded these days
well, just lies about EVERYTHING
hey bard, can you help me with this thing?
sure I know about that thing and I'd be happy to help
cool, so here's my issue with the thing we just discussed
an an AI language model I'm unable to assist you with that

have you tried to run llama model locally?
there are some that code acceptably well, not so good as chatgpt though

well if you want actual programming assistance just get something like github copilot. but then, that thing doesn't have any clue about anything. it knows code real good, but it definitely misses a lot of other things
people want these things to be binary or like switches. but that's not how it happens
for amateurs like myself chatgpt is just enough.
if you say so. but as I said, if you don't go over everything it does you're going to have a bad time at some point. it'll do something so subtle you won't recognize it. use a deprecated library, forget a comma in a place that rarely comes up. who knows what sot of hidden frustration mines it will leave
maybe?

like, I'm in no way trying to discourage you from using it
just want to let you know what I've found it's shortcomings to be. it's still a huge help to almost anyone


i know. There is some times it gets exasperating. But for using it ocasionally is nice. It has solved me more of an issue.
i wonder what the promt was for this. Sadly i converted it to jpg before having my brand new metadata extractor script.

it's just a new kind of tool, like a hammer that thinks real good. but any tool has it's limitations
is that a butt to butt shrimp centipede?
dont know. All i know shrimps are less appetizing now

i use one button prompt script to generate a bunch of images with random subject, i only stablish the style and loras to use
man, I have something like that sort of
except instead of random prompts I use images for the prompts
it generate garbage but sometimes some pearl appears, si it is interesting to keep prompts somewhere
you mean clip interrogator?
this one rarely makes garbage. just doesn't always turn out eactly the way expected
it's a combination of a few things
which ui are you on?
well it's clip, blip, ipa, controlnet, etc
i use both a1111 and comfy
all balanced delicately
and I don't think there's a one size fits all for the settings and parameters, but I have done some goofy things with conditioning data whch seems to have made it less susceptible to the black boxes I was getting at fiirst
have been disconnected for a couple of weeks and didnt remembered IPA
comfy is limitless
dude, this combo I have going never gets old. just need 3 images and it's on
yeah, but it's a bit sloppy as I've been moving things around
will try it anyway. :p
love the space monsters chasing children images

the monsters always look so full of joy
I have some examples of what the same images look like in different orders too
each slot has a different role
first image is ipadapter with interrogater running to clip g
second is two different types of clipvisions plus clip l
SDXL Bot




third image is latent base and controlnet
might have to install some nodes if you want to use it properly
dont get any workflow when loading the images in comfy. 😦
ahh
give me a second. I know why
I was just copying and pasting rather than dragging them from the folder
I'll make a new one and send it your way
ok ty



deconstructing 


let me know if you see anything that's obviously not the way it should be
got the workflow 👍
excellent
has to update everything after two weeks not using comfy zzz
these thigns happen. and that ipadapter is so finicky and needs updating constantly




(haven't added the lora stack but it's working  )
)


which flow is this?
frankenstein'd the formulaxl workflow
stuff on far left is from first image on this page: https://comfyanonymous.github.io/ComfyUI_examples/sdxl/
what are these switches?  if i had like, 3 loras, do i have to move the switch to on? hmm
if i had like, 3 loras, do i have to move the switch to on? hmm

or even 1 lora, does switch need to be on?
Hey can i use stable diffusion 1.0 using api
You need apply Lora stack.

so many jumps and previews..
maybe mine is old or something, idk, just confused on where it says switch_1, switch_2

what goes on with the face?
is this a public workflow?
face fixing, i just deconstructed formulaxl workflow #✨|sdxl message, the facefix, hires 1 & 2

Can your prompt do that? 😁
Practical applications of the overlay prompts I've been working on. Her face is actually inside the helmet!
Steps: 50, Sampler: DPM++ 3M SDE Exponential, CFG scale: 7, Seed: 3784295722, Size: 1024x1024, Model hash: 0b76532e03, Model: SDXL-CrystalClear, VAE hash: 551eac7037, VAE: sdxl_vae.safetensors, Version: v1.6.0```
nice.
i remember the other day, we were trying to get this woman's face behind some glass, pretty tough
Yeah that was me. But check out how short my prompt is now, and the results are much more consistent. 🙂
 turned out great!
turned out great!
Veils too.
Steps: 50, Sampler: DPM++ 3M SDE Exponential, CFG scale: 7, Seed: 2151636245, Size: 1024x1024, Model hash: 0b76532e03, Model: SDXL-CrystalClear, VAE hash: 551eac7037, VAE: sdxl_vae.safetensors, Version: v1.6.0```
And of course... the holy grail of fine-structure overlays... 🥁 🥁 🥁
Portrait rainfall coverage! 🥳 🎉 🌧️
...With a pretty convoluted prompt though...
Steps: 50, Sampler: DPM++ 3M SDE Exponential, CFG scale: 7, Seed: 1538189682, Size: 1024x1024, Model hash: 0b76532e03, Model: SDXL-CrystalClear, VAE hash: 551eac7037, VAE: sdxl_vae.safetensors, Version: v1.6.0```
Basically, SDXL sets up an internal 3D scene at the very beginning of the render, in the first 20% of steps or so. Within that 3D scene, it has the concept of a background, a foreground subject, and a screen-level overlay. Using prompt-switching lets us prime that screen-level overlay with large-scale structures that resemble the final effect we want. Once the 3D scene is primed like this, we can switch to a description of the prompt we actually want, and SDXL will convert those large-scale structures into fine details.
The screen-level overlay in general is very fragile. SDXL will just discard the entire structure in most renders. For that reason, we have to prime a special kind of scene: One with a background and screen-level overlay, but no foreground subject. Then, only after 20% of steps (once the 3D scene is well-established), we insert a foreground subject. At this point, the screen-level overlay's structure is so solid that it will not be discarded in favor of the subject.
honestly, not entirely sure
im not sure with a lot of things lol

it's weird, with formulaxl, my gen was failing due to memory issues but then i set it up exactly how it was and no memory issues now 
did you share the formulaxl workflow?
i only find its' model
ok, just got it that i can copy paste a workflow off civit.ai website


It's the ComfyUI bottle! 🙂

This is the Tooth Furry. He sneaks into your room while you're sleeping and takes the teeth of children who don't brush their teeth.

Really though, SDXL struggles so much with teeth...

He will eat your fat daemon! 😄






going to rest, will try open his mouth later 🙂

Gremlin?
idk what is going on

Nah, just some alien creature
Fatal battle of humankind vs evil beasts. Last part 🙂
it found a face in there 


I am starting a new series called "Sports done wrong"


Id like to request soccer icehockey.



Id like to add deap sea tennis diving.


Would play. 👍



Prompt a hand with 6 fingers, six fingers, polydactyl. I guess you just can't have it both ways. 😮💨

Well, I mean, if SDXL knew how to COUNT, now that would be AMAZING! Seriously, Stability, text is awesome, but please teach it how to count next!
@uncut gull That was the request, right?

LOL maybe. But are you saying they're "female" just because of the way they look? Do you want to get cancelled? 😱
Female was part of the request. Where do i need to sign the cancelation form?
I have tried "Hand with a huge amount of fingers" and it doesn't look so healthy

It's interesting. I'm trying right now to work out an experiment that will investigate how well SDXL can count. E.g., "four cars", "eight cookies", "three houses". How often does it score a hit on the number? It seems to be doing better than chance from my early tests. Does it have a generalized concept of counting, or is it memorizing??? I suddenly have so many questions.
Oh, try "thousands"
You can't visualize a "thousand" in your head, neither can it. Also, human counting doesn't generalize perfectly to all scenarios. Just because you can count change in a cash register doesn't mean you can count beats in a musical measure. The question is: Can it count at all, or does it only have some numbered-pictures memorized?
(But it'll take a while to work out how to set this up and then run it.)
If i would take a guess, than i would go for "only have some numbered-pictures memorized"
I guess so, too ^^°
LOL that's why it's one of my two hypotheses. Obviously that would be the boring answer. The other answer would be awesome.

Can SDXL count?
To get a real answer, you would need to do latent saliency probing.
That would mean: SDXL would need to show an embedding that activates on the prompt "four". But, when you prompt for "cookies" and SDXL generates an image with four cookies, that "four"-embedding activates even though "four" wasn't in the prompt.
What I can do... Is at best, just check how it scores across a random sampling of subjects. I'll have Llama2 get me a huge list of countable things, then pair them with random numbers between 2 and 10, and measure the hit-rate... Oof. That's one long experiment.
Humans can barely count. Have you tried working a cash register?
The question is not "can it count well", but "can it count at all?"
What the hell are you talking about? My finger picture is flawless.
well I'm saying, their training didn't necessarily give them an understanding of the concepts we take for granted as simple
that's because you have a special relationship with sdxl
But they do learn real concepts. We have multiple papers demonstrating that now. Everything from board game rules to theory of mind.
they learn them, but not flawlessly
You might be onto something
hae you ever tried having chat gpt give you a list of x number of something?
gpt 3 will fall off the rails quickly
3.5, whatever
4 does better, but it starts breaking down soon as well
they can do insanely advanced things in an instant, but struggle with computational tasks that most 5 year olds could work out

I honestly only use Llama2 on my local PC. It can count lists fine as long as you don't make them too long. Same for humans. You can count chairs or coins or whatever fine if there's just five or six. You can group them into stacks if there's a few hundred, but tens of thousands? Forget it. Humans can't count that without messing up. (We use technology, as old as wax and styli, to make up for it. 🙂 )
But... Can SDXL count at all? I will have evidence one way or another soon!
neural networks in general can barely generalize mathematical functions
you can train a DNN to interpolate a sinus function, but it will still struggle to extrapolate the very same function no matter how many neurons you use for training
same for large language models. There is a funny anecdote with large language models couldn't get finetuned on larger context windows, because the model was initially trained on a fixed size context window. The problem was not that it could not be generalized on the larger window, it could not learn the positional embeddings because it has never seen such large numbers.
same is for SDXL. We know that it struggles if we generate images with unusual aspect ratios
the problem is not that the underlying unet wouldn't be able to generate these aspect ratios
it just doesn't understand the numbers
768x1344 is fine cause it was trained on these numbers. 1080x1480 is weird, cause it never seen these numbers in its training data
That's some interesting information. Thank you.
SDXL likes to only make things that look right. if you ask for 4 fingers, you will likely get 5. same goes for other logistic things
It's been over-trained on five-fingered hands IMO.
Like the scene from 1984, "How many fingers on on this hand?" 🙂
yeah, I hope that NeXT-GPT gets released soon, I can't wait to have instructive editing and such using SDXL
it just replicates the patterns that it learns. and sometimes when denoising it'll see an opening for 7 or 8 fingers on the one hand. so that's what it'll give you.
I'd imagine a lot of it's logic also comes from the clip models right?
The repo you found said they'd release the weights. Hopefully works out!
I think they said the weights already exists. it's like gluing expert models of certain things together, right? it says it uses SDXL for the diffusion and LLaMa 2 for interpretation (I think?)
an ensemble of experts, interesting
it's just how to make all the weights work together in a single inference
this

They're using ImageBind, a 1.2B parameter multimodel encoder. https://arxiv.org/pdf/2309.05519.pdf
ooh, an all in one LLM team
so idk if they really train anything. it seems they just glue together diffusion and LLM, etc..
this tech is moving at warp speed
well that's what I think is going to keep happening
train specialized models that are really good at their one specific task or few tasks
then link them up with other models that are experts in other tasks
They did, they trained two things they call "linear projection layers". They have little 🔥 emojis on that pic you posted.
The 🔥 means these weights are live / updated parameters during training. The ❄️ icon means these weights are frozen and just used for forward propagation during training.

ah, yeah. I think that kind of inference can allow image blending and instructive editing, right? that's likely just the tip of the capabilities when using SDXL and LLaMa2 together and such..
But also, hold your horses there. They've been working on this for a long time, and they're using SD 1.5 and Llama 1 (Vicuna). That's what their weights are trained on, so you can't just drop in SDXL and Llama 2. 😕
well once you get the first then you move to the second
I don't see why that won't be compatible with stuff like SDXL and MythoMax. LLM is LLM and Diffusion is still Diffusion
they have a demo
https://989c787409ca0e66e1.gradio.live
And you might be right. I doubt it though. Even prompting for SDXL is not the same as prompting for SD 1.5.
well yeah, but the framework is there
basic inputs and outputs are comparable. they might differ in some of the specifics but they are largely the same
It didn't mention that she's feeling "wet".

Got no solid workflows for sdxl (control'd), Auto1111 cant produce (for me) = sad bois club, heart broke island, waterfall of tears, depression cave vibes
I feel your pain. I love that my A1111 install works. Good luck.
so cool 😂
bro 👌
that's still crazy.. can you get it to blend images?
😮💨 It really doesn't know what it's looking at. The LLM just has a very vague understanding of what's in the image, and zero understanding of the images it creates. (It never "sees" its own output.)

damn, so I guess we aren't there yet, huh?
LOL no wait. After you post the next message, it gets to see what image it outputted. Not super helpful. 🙂

We're not there yet though. Not with this exact setup, anyway.
oh, so I guess that's a limitation of the diffusion model then. I bet SDXL would follow the bot's description
Yeah. SD 1.5 here is like a "filter" on the LLM's imagination. The filter is bad, even though the imagination is fine. SDXL would be better, but still not perfect. After all, I'm not even sure it can count.
when it comes to diffusion, SDXL is by far the best.. the only issues is it's lack of capabilities such as instructive stuff and blending. honastly idk where this is going
I don't know what MJ does for blending, but it's not IPA for sure.. I think when it comes to pure txt2img SDXL destroys stuff like MJ but again, the lack of capabilities
AUTOMATIC1111 DynaVision XL for a model




MJ has a finish to die for. Comparing SDXL and MJ is like comparing salt and sugar imho
android to apple
Chalk2Cheez
rounded corners and censorship
only thing left is for SD to do pistachios and im good.

Bad news guys... SDXL can't count! 😭 At least that's what all my tests are showing so far.
best image made by sdxl thus far?


Idk what do you mean by "finish" but the quality of the images made with SDXL is miles ahead of MJ. the only advantage MJ has is the image input capability
Woah there. I wouldn't defend it that strongly. (I've never used MJ though, so I can't weigh in here.)
MJ has an esthetic flavor that is very... MJish...
SDXL can't count at all. It doesn't even have a few numbered-pictures memorized. 😐
The prompt was {two|three|four|five|six} against a white background, and only the two ever succeeded.

(I'm testing now whether it understands the difference between 1 and 2.)
idk.. I never saw MJ get to this quality, when it comes to the images themselves I don't think MJ stands that much of a chance tbh

Yeah, I really have no idea. I feel like if MJ was actually worse than SDXL, couldn't they just switch to SDXL behind the scenes and not tell anyone? But people still use Yahoo, so...
We can agree to disagree 🙂
IMHO these are the equal of MJ
why don't you prove it then? mj won't get to that kind of detail if its life was dependent on it. it would be able to blend the images though
the blend thingy is impressive, but txt2img is not as good as SDXL

As any opinion is subjective, there is no proving 🙂
well some opinions hold more weight than others
dunno, I can't try MJ myself, but I sometimes see images other people generated with MJ that look extremely good. At least it seems that MJ is better in doing human anatomy right than SDXL. What's noticeable, though, is that all MJ images I saw so far look all "the same", as if MJ can only do one style (or all people who use MJ and post images all do the same style?=
Objectivity is the democracy of subjectivities.
All subjective opinions are pooled and the objective emerges ...
mj seems like it produces amazing results with minimal effort. which is great. but in that same vein it also feelss like the user is in no way controlling the real outcome
it's like taking a train somewhere
Somebody's using SD for captchas.

or having a driver
That tendency to sameness a wise and careful prompt-wrangler finds as a challenge to surmount
Anyone have a problem with the just updated comfyui? My nodes sticks to the cursor and you cant put them down. Even when you click on screen starts draging the screen and does not let go....
stable diffusion give you a pwerful engine but you need to know what to do wtih it



I laterally wrote "cube made out of water in rainy cyberpunk city" and it made this is 30 seconds. if this isn't minimal effort idk what is

I am back to AUTOMATIC1111 - just for the sake of a "tidy screen!" 😄
This is cool!
yeah, and what accompanying tools and fine tuning did you use?
to be honest: this looks totally like a MJ image 😂

bruh
I'm not putting it down. what I'm saying is that a lot of powerful tools really aren't plug and play
I agree - I couldn't tell MJ or SDXL?!
hm, SDXL generates great images without fine-tuning imo. I sometimes use other models, but in many cases the base model still produces best results
someone gimme dumb prompt quick, wanna test my new merge
A camel eating a banana

just loaded a workflow, then wrote those words. that's it

A serpent in silk pyjamas
person observing extremely muscular monolithic rubber duck
why do you have to make it THAT hard?!
naaaa, "just" loaded a workflow 🙂
This is a good prompt - (To a girl: If You Were A Booger, I'd Pick You!)

lol


I mean, I did use the workflow I made; but that's all I did, really..
that's a nice looking camel
and spock
A snake in silk pyjamas
well General, we havent spoke in a while now
No turning back, Comfy is so much faster, and versatile...
man i saw your workflow about 2 weeks ago and my butt still hurts since
ngl, i picked up comfy a few days ago and love it so far
been on a1 for like 1+yr or something, too long

#1 and #3

I tire of expanding Comfy just to see the text, and then reducing again so as to see the whole thing!!!
had to put it in midj... it's not so bad 😛
before upscaling etc

looking at the previews i can only say "what is wrong with you"
OMFG
actual prompt: This is a good prompt - (To a girl: If You Were A Booger, I'd Pick You!)

Okay! In some circumstances, SDXL can tell the difference between one and two with a 100% hit rate. That counts as counting! (Because I said so.) However! It can probably only count animals and flowers???
Prompt {one|two} against a white background. 100% accuracy, and it is obviously not pasting in pictures that originally had two subjects. (Some of these are clearly not pasted pictures.)

not as good. plus, MJ isn't free like SDXL is


@indigo carbon you're preachign to the quire, we are all team SD here...
of course mj is not free. It also does not have this amazing ecosystem of tools, plugins, extensions, controlneta and workflows. There are so many reasons why SDXL is better than MJ. But if you just look at text2image I would say MJ is not worse than SDXL
but, MJ has it's strong points, it's a wonderful tool with pleanty of stuff that doesnt require the GPUs and serious knowledge.
it simplifes alot of the stuff we actually enjoy - so like SD, it's a tool. not a way of life. you can still use both
L8r
this reply was used as the actual prompt. I like this new merge

idk what y'all want. even though MJ is paid, it's still not as good when it comes to txt2img. that's all I'll say.

MJ really making a case for the face

what's the prompt? i'd love to try on my model mix

Do you know what I'm missing with this error? Using AItemplate nodes on this workflow?

cube made out of fire in rainy cyberpunk city
to use AIT you need either the latest Comfy and latest AIT node or a specific Comfy commit and a specific node commit
I use commits from a week or so ago because it's faster on my 4070ti for some reason
Then it must be specific, as I just updated everything to the latest.
including the nodes?
Yeah...
I see. then you need the specifc commits
@lusty wolf
https://github.com/FizzleDorf/AIT/tree/ca8f0627992649eb2211bbdc2f269484b054e62b
https://github.com/comfyanonymous/ComfyUI/tree/bc76b3829f5fbba7c5a439c7833d313a3ca87398
GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT at ca8f0627992649eb2211bbdc2f269484b054e62b

GitHub
A powerful and modular stable diffusion GUI with a graph/nodes interface. - GitHub - comfyanonymous/ComfyUI at bc76b3829f5fbba7c5a439c7833d313a3ca87398
Been trying to use the AI templates for the last week, (that is why I updated) even on the old it gave me the same error. So I give up.
this is what I use
Thanks.
Can one see the commits in the manager, or where do one see that info?
lol

git rev-parse HEAD in directories with repos

A tribute to Tdg8uU


banana cubes

that's pretty good tbh
Okay... SDXL can count "birds" specifically! Why birds? Why not.
It can count "one" and "two" birds with 100% accuracy, and "three" birds with 75% accuracy.
Prompt {one|two|three} birds against a white background

How far does its concept of "one" and "two" generalize? Stay tuned.
well think of it like this, they can count, sorta kinda, but not in the same context that we can
they don't understand what it all means, probably don't recognize larger numbers, etc
they are simply trained to recognize patterns. and sometimes things have numbers attached to them

couple loras attached and a custom model

how about tags 1girl and 1boy ??? @uncut gull
Oy. I'm talking about real results here, you know? Does SDXL have a baseline concept of "one" and "two"?
But here's OthelloGPT. I point people to this when they say NNs just "recognize patterns". https://arxiv.org/abs/2210.13382
Trained only to predict the next move in an Othello game, a GPT learns to predict the next move in an Othello game. No surprises there.
How does it do this, under the hood? It develops the concept of an 8x8 board, and learns the rules of Othello. Why? Because that's how you predict the next move in an Othello game.
How do you count? By understanding numbers. And I, as a human, do not understand the number 1.23 * 10^60 in the same way that I understand the number 5.
arXiv.org
Language models show a surprising range of capabilities, but the source of
their apparent competence is unclear. Do these networks just memorize a
collection of surface statistics, or do they rely on internal representations
of the process that generates the sequences they see? We investigate this
question by applying a variant of the GPT model ...
Lets keep it SFW. 😛
SDXL can count cats more accurately than it can count birds.


I don't know if these results are very scientific
depends if 3 cats are where 3 cats realy should be.
the main reason I jumped to 2.0 is that it could count up to 5
got it to count up to 5 knives and people were shocked. Never looked back
Yeah, I'm checking every image one by one. So it takes a while.
well what I'm saying is that it's not a binary concept
o.k.
tried 355/113 today, it changed theme 😄
And I'm saying: "How far do experiments show its ability to generalize 'one' and 'two' to different subjects?"
It cannot count cookies. Flat out.



It can count Kermits as accurately as birds and cats! 🙂
(Each one of these is tagged "one" "two" or "three", and all of them are accurate.)

how does it know what defines a "cookie" from our perspective. those are weird angles. how could it know what one cookie is visually?


cookies are probably difficult know where it starts and ends, if it is one or two cookies.
@hardy cipher i read it now, didnt noticed before 🙂

I wonder if it could count something like Oreos though? I'm starting to suspect it can only count things with faces.

It can count "two" and "three" Sailor Moons with 100% accuracy, but not "one"? Or is it because I prompted "one Sailor Moons" (plural)?

sorry, mom called, that's a call i'll never not take (this on my model merge)




I kinda still like Copax_colorful better, but nice!

Fixing the prompt for plural / non-plural, we get {one Sailor Moon|two Sailor Moons|three Sailor Moons} against a white background, and now it can count Sailor Moon with 100% accuracy. 🙂


i think i had it in my initial model tests, but decided to drop it -> it doesn't work well with nonsensical prompts, and too many artifacts

all 3 prompts combined!



It is 100% accurate with "one Oreo" and "two Oreos", but definitely not "three Oreos". It is generalizing at least a little bit to things without faces.





a matte grey cube in rainy cyberpunk city


that's not a fiery cube prompt tho
1 cookie

I wrote water here, but it still nails it
made of wwater?
Yeah, my prompt was "one cookies" technically.
It is counting 1 and 2 Excaliburs, and 3 with better-than-chance.

@uncut gull it all depends on model, which models "learned to count"
usually 1, 2, 3, 5 and multiple are the things you can rely on
this is with fire in the prompt

for example elysium anime model learned what 'punks' are
True. I'm using SDXL CrystalClear. These tests do not necessarily apply to any other models, but it would be straight-forward to repeat these tests on another model.
cube. matte. rainy




don't have to test it too much, usually 1 and 2 are decently understood
anything above will be 'guesstimate levels'
anyone using rtx3060, how long does it take for you to render a 1024px image? kindly include sampler use and step count.
That in itself would be amazing to me. If SDXL had a concept of "one" and "two" under the hood that it could generalize to any subject. (Including subjects that had never shown up with "one" or "two" in the training data.)

sdxl doesn't have the concept
the checkpoint needs to associate the tag "one/two" with similar elements
that's a training thing

mine's aren't floating =\

obviously, worst timeline to live in.
So you're saying it associates the tag of "one" or "two" with its internalized concept of "one" or "two" elements? 😛



yes, this is the 2 cubes concept
it TRIES to make 2 similar elements
Depends on which side of the globe you are... floating here too.

but one image failed
three, will probably have even worse results
why?
because one and two are the most common numbers used in tagging images
three, lot less common
the rest, even less common
run

you'd have 'thousands' or 'a group of'
Yep. That's how number concepts work. That's why you can glance at three chairs and know it's three chairs. But glance at twenty, and you have no idea. Then you need an algorithm and a process.

so after 2, they already start to fail
Yes! But I promise, what you just said has society-ending implications, and there are philosophers who profoundly disagree.
2 out of 3, three cubes. my model is pretty smart, but i like it that way



can it do. 5 cubes?!
have you ever tried.... 5 cubes?
exactly 20 chairs lol

well, color me impressed, again 2/3



this is what you guys need to be doing

now. ipadapter merge that shit, and show us what it becomes!

uhh... what am i looking at XD
here is a guard tower

this is glorious!
IPA doesn't really blend that well. when used on SDXL, SDXL looses a lot of its aesthetics and coherency, sadly.
just gotta treat it right
@uncut gull this is 'millions of cubes' -> the model tries to resolve the request and 'decided' that it sub-cubes would suffice



Mine are also not floating. But they are made out of skin

It can count Einsteins as well as Kermits and cats. It can consistently make "one" or "two" {things with faces}. "Three" is ~75% accurate across the board for things with faces.

Mmm. Pork rinds.
i have not been able to recreate that skull in the sky

either model preference, or flavour text doing you favors
meat. cubes. (technically prompt was : cubes made of meat)



was BLIP the solution? I don't see how we would achieve instructive image editing and blending without SDXL loosing its qualities though. I'm thinking the ultimate solve might be to make SDXL work with something like LLaMA to give it image input abilities like MJ has



tbh I think the blip thing really does help. just kind of stumbled onto the idea. might not be ideal but it works
They're made out of meat.
oh. i still have bismuth in my prompt
Steps: 50, Sampler: DPM++ 3M SDE Exponential, CFG scale: 7, Seed: 1920749068, Size: 1024x1024, Model hash: 0b76532e03, Model: SDXL-CrystalClear, VAE hash: 551eac7037, VAE: sdxl_vae.safetensors, Version: v1.6.0```
meat cube, but it also has neon glass bismuth cube in the prompt. no wonder i get these packaged meats



plus I kind of stopped trying to go pure ipadapter because that seemed to fizzle out a lot. but using it with accompanying tools seems to work alright
this is epic
 the skull has to be made out of smoke!
the skull has to be made out of smoke!
The Impossible Burger supplier had a container fall off the ship, basically.
sigh. i hate it when prompts listen too close.



I think the solution for image inputs might not be IPA tbh, SDXL's txt2img destroys MJ but IPA makes SDXL loose quality in my experience. I think going forward the goal should be achieving multimodal inference that doesn't make SDXL loose quality. idk if IPA is the way to do it, but it sure is progress
steak block, now farmable in minecraft

not sure what's going to happen, but I bet it will look delicious

oh my
good idea, eface
when doing stuff like IPA it makes a whole lot of new issues like speed decrease and compatibility issues with optimizations, so multimodal might be a solution
war

I believe the concept will go through a lot of refinement over time. when it doesn't work out the way I want I have to remind myself the paper on it was just released a month ago
he angy

lol "how do you want your steak done -> blocky"



steak

yeah, I heard about something Facebook is working on that's called "CM3LEON", but they said it's closed source, unfortunately.
is there a prompt for this? it's soo nice

this looks as raw as possible xD




Add bone.

adding "minecraft block" help make it a defined block, i just noticed
mostly non-text prompting stuff. I have blip doing most of my prompting, and then have style overlays

Every good meat cube needs a little bone.
reminds me of my last spareribs
you look at the ribs -> they just fall out
good spareribs ❤️


Too small.
those blocks would cost $10000 a piece
think of the cow they'd have to be cut from
lol
1000 feet cow

333 non-freedom units
Imagine the size of Salt Bae you'd need.
Salt a-AI
@nusr_et and that marbled-marbled meat 😁
#saltbae #aivideo
@robosapien_renaissance
I wonder if he'll ever see and like this.
asked for electronic pork chops -> am dissapointed in my model



they've evolved
Too much minecraft influence there.

that's the economy beef cube
This even has vents

here is where you get that 1m cubes of beef get from

Massive unit, that one.
the size of that lad. geez







full meat


look skinny
Ate already all recources
oh he just donates 0.1% of his body mass for all the world so they can eat for year
universe scaled cow, your move atheists

that cow actually dictates the physical laws of the known universe.
meatball star lol xD





meatball star. capable of feeding a civilisation for a gazillion years

or 5 years, because nestle be like 'yeah it's gone to waste'
been there for 1000000000 years, but went bad in 3 months
meat ball star gave me this lol




meat gundam?






meat gundam.



oh yeah!



more meat robots!

going through things I made recently, lol. don't always look at all of them initially
comes with integrated salad. lol this is a walking meal xD


space cow

"i'm ur dinner"




wet meat gang

finding out the hard way that using a photorealistic lora on a photorealistic model is just overkill





meatpocalypse
wardog

somehow, i'm not giving this guy much of a chance...



My eyes are up here, buddy!
 dog is hungry
dog is hungry

not res'd but i liked this gen





wonderful!
Delicious
and glad you didnt put sausage into the prompt
MEAT. GUNDAM.


imma keep going till i get the ultimate meal gundam



did i just invent the ultimate meal?
what is that green stuff?! 
the stuff you don't eat.



whats in its hands??
the the thing which either makes him, or you, dinner

i feel close

fern gully!!!
will always remind me of sea of thieves



this is how i feel...
the fabled eye of the storm

"so uhh... what are we going to do about that?"


"bullshit inspirational quote"

she speakin fax tho





















Hey fellas...any of you done something with comfy where you point it at a directory full of images (or in my case, one with subdirectories full of images) and then have that run through the WD14 Tagger? Trying to get a bunch of images tagged and I figured comfy might actually be useful for that since I can otherwise build the workflow how I need. I just can't seem to find a way (yet) to load a directory of images in for processing.
No idea, sorry.
You want to use WD14 to caption?
Card backs by faction.

Use Kohya.
I'm using pythonssss WD14 tagger and it does a good job pulling them in. I'm dropping them off into a custom script that then adds the tags into my Lychee server when the images are scraped in.
I here for my stuff both BLIP and WD14 and then go over them by hand and my love. 🙂
I only need to do it once through for all the images that were generated prior to now. I've got new ones saving the tags off and being processed, but I've got thousands of images I want to pipe through the WD14 tagger and it'll be trivial once I can figure that part out.
Oh well this is for when I make a lora.
The both free caption methods give me a free start to edit each caption and merge them.
I give up. It's not consistent, and it's always just somewhere between bone and cloud, never really a cloud shaped like a skull.
Steps: 100, Sampler: DPM++ 3M SDE Exponential, CFG scale: 7, Seed: 1629730332, Size: 1024x1024, Model hash: 0b76532e03, Model: SDXL-CrystalClear, Version: v1.6.0```
If you want a new challenge, go do the most recent in #🔆|dailies
🙂
I tried one, but it worked on the first try... and it wasn't as interesting either. But I'm gonna sleep now.

New from Burger King?
Yes, with authentic blue cheese
Your way, right away, as you die, from Burger King now.








Could someone reccomend a comfy workflow for generating with upscale and use of loras?

Thanks, could you advisae me what to put in the clip?

or open this image

download again, i added clip node 🙂
this one
Thank you prompting now, could I ask, why is there no refiner in this workflow? trying to get a better understanding of nodes.
Am I to assume generated images contain meta for the nodes?
just the default comfy workflow
some use refiner, some don't, was more needed with sdxl 0.9 i think
loras good a good job in my opinion
yes, if they're saved correctly, sometimes discord will remove it, but yeah they have workflow embedded into the image
if you save image it will retain it, if you right click copy image it won't
I needed this info, thank you so much.
I was wondering why people dropped images here.
You've been extreamly helpful so I don't want to take up more of your time, but final question (as I clearly know nothing about comphy). I currently don't have this checkpoint after testing the image load, do I need to search HF for the model or is there a built in way to get any dependencies such as this in the UI?

dunno what that one is either, i use civitai website mostly for checkpoints and lora's (make sure to check sdxl 1.0 in the filter), download and copy to your comfyui/models/checkpoints and loras folders and refresh webui to load them in dropdown

perfect, yea hwas just wondering if there was a similar thing I may be missing to

as you load in others workflows youll come across tons of errors as most are using custom nodes, that button will help you figure out which addons to install




yeah its a bit tough! 😭




I give up on people as I can't train them


Got that tagging workflow figured out. Took a bit of ingenuity, but:




Basically spit an output from find into a text file, used that with an incremental loader paired with load image from file path, then a bit of string manipulation to extract the file name so that I can re-concat that with where the tag file needed to be saved and boom. Tested with a small batch of .png files to start, then thousands of .webp files are next.
nice work 🙂
4675 webp files to get tags for, then a quick script to inject those into the mysql database for lychee. I've already got most of that written in a different way for images moving forward. Once all these get injected, finding an image on my site will be so much easier.





ghostly hershey kisses












Nearly 2000 images have tag files created for future integration into the database already. This will do just fine.

Nice





dang




if i combine a pre-existing sd 1.5 (i think) model with sdxl, will it gain anything from it?
or should i just not bother until someone trains an sdxl model that has roughly the same style that i want
You mean into one checkpoint?
yeah
Don't think you can
unfortunate
They're trained on different sized images, have different parameters. Just wouldn't work.
But believe me. Sdxl models are quickly surpassing the best the peak for what could be done with 1.5
i know, its just that there aren't any available in the style that i like


Big dudes are back






info: my nodes (and workflow) are fixed for linux users now. someone reported it on github and i've noticed that my paths didn't work for linux users:
https://github.com/JPS-GER/ComfyUI_JPS-Nodes
also included is the current version (WIP) of the movie styler.
GitHub
Contribute to JPS-GER/ComfyUI_JPS-Nodes development by creating an account on GitHub.
XL is fighting me for training a person yet every vid makes it seem so easy
is the process still the same as with 1.5 but just a bigger resolution src image?
pretty much
for styles I have that down pat
funny, as styles is supposed to be harder, lol
2 days of about 30 trainings
with 1.5, i didn't even bother tagging and got pretty good results
wonder if i could do that with xl
:(
they say yes but damn if I could pull it off
if you don't tag it should make a hard coded image cause tagging/captioning is just telling it what you want to be able to change.
brown hair then I can change the hair colour

Anyone have any suggestions on more realistic?

@glad grove
Found it

Reddit
Explore this post and more from the therewasanattempt community
sensei 🙇♂️

hlo anyone here
i want to create a clothing graphics for a website which software should i use











there all wearing one outfit
their cousins

Must be fashion Week
good call


I've tried my hand at some very, very, very basic nodes for ComfyUI. Have a look if you want:

GitHub
Some basic custom nodes for the ComfyUI user interface for Stable Diffusion - GitHub - tusharbhutt/Endless-Nodes: Some basic custom nodes for the ComfyUI user interface for Stable Diffusion















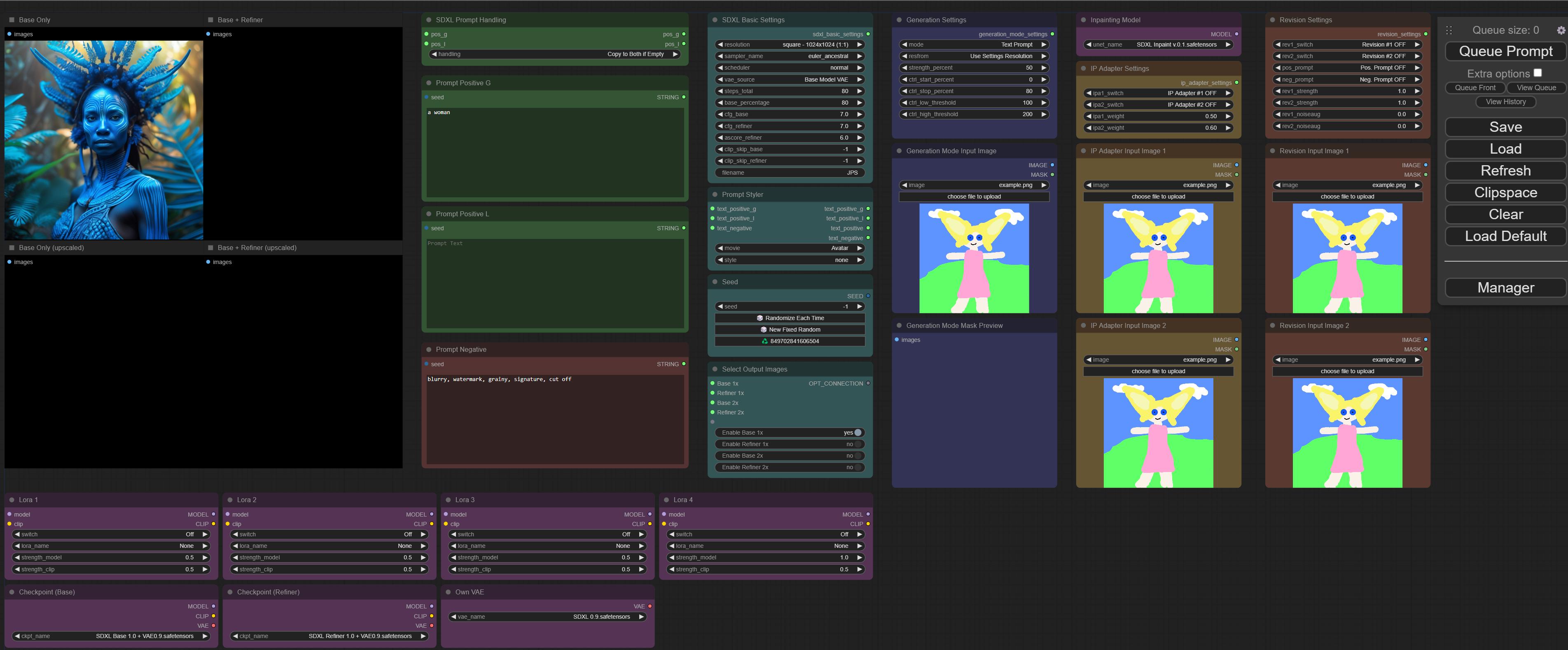
Version 12 of my workflow - now with real "on/off" switches for Base, Refiner, Base Upscaled and Refiner Upscaled:
https://i.imgur.com/h98OyZA.jpg
https://github.com/JPS-GER/JPS-ComfyUI-Workflows
Features:
- Easy-to-use menu area that fits on a single screen (if your screen is big enough)
- Generate images with 100% Base model and/or Base + Refiner (selectable percentage for base and refiner, default: 80%)
- Generate upscaled versions (2x)
- On/Off switches for enabling/disabling generated images and/or upscaled versions
- Easy selection of resolutions recommended for SDXL (aspect ratio between square and up to 21:9 / 9:21)
- Switch between your own resolution and the resolution of the input image
- Automatically adjust input images to the nearest recommended SDXL resolution
- 5 Generation Modes: TXT2IMG, IMG2IMG, ControlNet Canny, ControlNet Depth, Inpainting
- Use the VAE included in your model or provide a separate VAE (switchable)
- 4x Lora - use up to 4 Lora models, menu area offers an on/off switch and all necessary parameters for fine tuning
- 2x IP Adapter - use up to two input images, menu area offers an on/off switch and all necessary parameters for fine tuning
- 2x Revision- use up to two input images, menu area offers an on/off switch and all necessary parameters for fine tuning

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.


version 12? prolific workflow production
usually each "real" update gets a new major version. only bugfixes get smaller steps :)
so next week i have the workflow with the highest version number available :)
finally having a solution for turning on/off parts of the workflow with real switches may result in some other updates in the next days
do you have it on civitai? or just github?
only github
what do you mean by real switches though? I have switches on my things. too bad I goofed on some of them, lol. but they're fixed now
they looked like they worked, but when you don't use matching variables things tend to not work right
before you had to cut wires. now you can choose the four output images with a switch (shown in the first screenshot) and really turn off that part of the workflow
ahhh, an entire part of the workflow
gotcha

I've had to change four words total so far. well in the last 2 or 3 weeks. and those four words broke 2 nodes
I guess it wasn't that bad. but don't like being sloppy like that
he looks like some of his ancestors were cats
one of his grandparents was a khajiit
@hardy cipher it was this



I just keep throwing things back in the pot. it's kind of like the upton sinclair book "the jungle" where butchers used to throw the old sausages back in the mix when they would make new sausages
gets weird after a while
the usual xin1 switches with for example 4 inputs, 1 output and a value to select the input will still run code for all 4 inputs. the new switch used for the 4 output images will set one node to mute which prevents unneeded code from being executed. you also couldn't turn off some things, because missing inputs throw errors that stop the workflow. so for that use case there was no solution other than cutting wires (that were rerouted to the menu section). now as it mutes the vae-decoder you get no error and everything "left" of the muted node is not run.
ugh, that missing inputs thing is annoying
is there a qr code control net for xl?
impact any switch with execute on prompt option
@hardy cipher what the root of the frog people?
told a guy in another channel to give me a random picture and he gave me hypnotoad. and then hypnotoad's frog babies started showing up in other images
and it just went from there
it looks like Wes Anderson, mixed with like Vogue Magazine
well I added some style of course. I really liked the frog girls. this is where it all began

the patriarch


I don't know about size per se, but I do like to have them similar sizes. I know that the shape can matter for some things
that's one of the reasons things get cut off with ipadapter I believe
I just try to make sure they have similar pixel counts though


So I worked on Giant Spock for way to longer then I wanted to, even editing in photoshop and rerunning 10 total maybe

lol. well got em at least

More like: stop right there!!!
honestly if 2005 fashion 80 foot tall spock told me to stop while i was on the freeway, i would








I love the meat helmets
wet meat gang
Those are MeatBoys I think they fought the Warriors
they look so comfortable in their own meat skin
no worries or strife
this guy is a different story



Hypnotoad frog girls you say?
https://youtu.be/TiFlMspJvN0?feature=shared




great The Warriors, really looks like the film
Ha, its to generate
they're hiding, one moment
As cast of SNL ? kinda


alright, still trying to remember what folder they're in. in the meantime tried to bring some kool keith fashion into the mix

aged them a bit






lol, this is genuinely perplexing. I tucked that whole folder of images into some weird corner somewhere and cant' find it. I'll find it as soon as I stop looking. but that's unacceptable
its all good
nah, it was something smart like "new folder 3"

Internet decided to go down right in the middle of my search






FrogoWarriors
whoa

Were from France

Because you cant lose a body paint vest

yeah Im done before I unearth a demon
think I did already
I was just mixing them with spinoff rainbow goblins

their shoe game is on point though
if they can get those goblin faces ,is that them too
you want the goblin faces?
Yes




{kind=link}
There really Good , all of them .A+
that time they found the end of the rainbow


these ones are so grimy
little skittles colored street urchins

no demons here

3rd maybe demon, ha
might have to work this one in too

Give them Pepsi
