#✨|sdxl
1 messages · Page 118 of 1
lol
Come on PoP
do negatives work the same in xl?
Give him the sauce!
these are mine from 1.5: (deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation, cartoonish, inaccurate clothing, distorted face, unnatural lighting, unrecognizable, pixelated, watermarked, low quality, poorly composed, low resolution
I just wanna make hyper gore
man, I had bing give me a list of 50 latin words that were similar to "uncanny"
have less negs
I find that negatives are actually a touch stronger in XL compared to previously.
and then I pasted them all in
oh. interesting.
@dim steeplecheck it

I have been curating my negative list as I go and pretty much use the same one every time unless I really need to adjust it.
oh, I'm going to try to make a node that'll make picking your saved words and what not easier. unless that's already a thing and I just haven't seen it
I've been really lucky with the stuff that I get. I've used a few Loras and a few models.
I'm lucky to have gotten what I want from my positives rather than having to mess with the negatives.
something simple. I honestly tried to find something like that and haven't found it. I've only ever made nodes that I couldn't find in other people's stuff
and that I want to use

a lot of times in the negative I'll just put dumb stuff. "bad, stupid, failure"
SUPAMAN AND BAHTMAN!!!
things like that
Mack, add the word plastic to your negative and re-run that.
bro thinks he batman 😭
Which?
That last one
he must be using the muscle bro lora
lol
is 2048x1024 too high?
@native knotI honestly don't know how to keep my seed in Comfy after a gen.
what's your workflow?
If you've already generated it, click view history, then find the one that popped out that image.
That's another way

you can also copy the image and paste into comfy
Or you can open it in a text editor and search for the seed
or you can use a hex editor and sift through the metadata
Or you can print it out, fold it up, stick it in an envelope, and hold it against your forehead like carmack.
PoP & me...same energy


He ate breakfast before that pic.
needs to cut back on the salt intake
real

@native knot(1) neg
(2) without the neg


Definitely better with that in the negative...cuts some of that sheen from the costumes.

When I'm going for certain looks, I'm always trying to think about materials. It's almost a habit now. I fucking think about materials all the time when I'm looking at stuff around the house, around work, or when I'm out, now. I'm constantly on the look out for words that will describe how a material is visually.

Sounds intrusive

oh my

Poor Steven...really really let himself go.
What is the best way currently to train custom SDXL models?
The Death Star has entered the system...I repeat...The Death Star has entered the system.
Is Dreambooth still good?

I believe people use kohya these days. I have images for a lora but haven't got around to it. started making dumb nodes instead
hey baby

whoa
I got this from zeroing out conditioning

thought I'd see some sort of grayed out monster or something
The AI is not getting Naruto x Goku. It's drawing Naruto x Naruto, with one having Goku's clothes.
yeah well, it thinks you want to look at their offspring
feelin sexy tonight

got these dumb conditioning nodes to work

yeah, well firstly that image is 512x512 right?

ya
you need to render at 1024x1024
so thats like 10 minutes per render?
or 1 megapixel if you want to change the aspect ratio. so 2048x512 works also
probably
pc dependent
3060ti with 32 gb ram
since 4 times as many pixels
Goodness no not 10 minutes on that lol
I promise you it will take forever
I have a 2060s
unmodified conditioning, normalized, 2x conditioning



normalized seagal looking dapper
I'm doing 5x seagal now
feelin human today

jeez, fat forehead

hmm, 5x Seagal took on a strange form

turned into a dirty piece of fabric. his next form maybe


I can see guys we are deep in the latent space now
we have to go deeper 
I went too deep


"Any great warrior is also a scholar, and a poet, and an artist"

time to relax

You know you've hit a weight level over 9000 when gravity starts pulling your finger fat down
feetngers
new pants









he's about to open his third eye and see into the overground
you are looking into humanity's future with this - latent space evolution
I'm just messing with pooled output. need to learn more about how all these things work though
looks almost like the right have is the regular square and the left section was painted in. Probably from the high res non-square aspect.
supposedly you can adjust that using the CLIP crop x/y params but I haven't really monkeyd with it much

also the depth of field can sometimes generate interesting "compositions"
then on low res you have the opposite issue where it looks like it's a square that was overcropped so idk
well I'm doing pretty rudimentary changes. I'm sure there's a more sophisticated approach that would work better. just need to learn about how it all works
even adjusting the width/height params on clip seem to do very little
setting base width/height to the higher res then targeting low res turns it from total soup into only garbled mess so maybe there's something there
in my Principled node I actually set the clip sizes to the equivalent base megapixel for the provided latent aspect which kinda helps??? but feel like there's better solutions
clip text encoder width/height + target (bucket) values have a big impact on coherence, especially on subject proportions
yea I set width/height to the literal sizes (latent * 8) then target the equivalent aspect at 1024**2 megapixels
so if you feed in a 1920x1080 image it actually targets 1368x768
seems to very mildly help with duplicate composition at high res
hmm. well I only started learning about this stuff 6 weeks ago when I downloaded comfy. so might need a little more time to learn about it all
with a1111 it was pretty much just abstract concepts for me
yea. thats why im sticking to comfy even with a1111 supporting refiner now; it's nice to understand things
also speed
a1111 makes amd cards even slower compared to nvidia

humblemikey and I have build a node (Preset Ratio Selector) and the presets contain all the values following the current best practice that Stability AI suggested - at least like it was a couple of weeks ago. but it works. it's not 100% solving all the mutation issues, but it can greatly reduce them.
the longest side is always 4096 and the short side is calculated proportionally to your output resolution.
I created this preset file following this concept, containing all official SDXL Resolutions (from the paper), rounded all target bucket values to multiples of 16 and approximated the closest Aspect Ratios.
https://github.com/bash-j/mikey_nodes/blob/main/ratio_presets.json
so you guys don't use Crop either?

still exploring. also you can set it manually in the advanced node
have you tested it on > 1mpx resolutions? I found targeting lower instead of higher helps @ 1.5 -> 2 MPX if you're not upscaling
the Preset Ratio Selector and Ratio Advanced node were build especially to explore this part of SDXL. the presets help to quickly try out different configurations
I use crop if my resolutions aren't likely to play nice together.

Jesus, I can just keep upscaling.
yea. kinda interesting you guys came to literally the opposite conclusion as me lol
lemme make a quick demo of what I'm talking about
using 4096 on the long side and calculating the short side proportionally to your output resolution is something that Joe Penna discussed in the chat some weeks ago. he said it's their current internal best practice and I applied this to all SDXL resolutions for this preset file
must've missed that when I was out in the country cutting up trees
yeah I think many have missed it
there's almost no documentation about this and almost all workflows don't use it
but it clearly improves proportions for ex. subjects - especially in extreme aspect ratios
I'm still doing experiments how to best utilize it
🦶

After playing with XL for the first time I must say the quality in no way comes close to Midjourney 5.2



not as easy as mj but it could produce very decent images with dedicated workflow and prompts.
seems to make less of a difference now. in XL 0.9 the target low res trick reduced duplication quite a bit. Now everything looks like the same but you just used a slightly different sampler

just messing around, liked this




@crisp owl you know how you said it cant take 10 minutes?
Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [21:57<00:00, 65.86s/it]
Automatic1111?
What optimizations do you have selected?
you running off of a Voodoo 3 or something?
now we can be gecko friends

persistent cond cache
thats really it
In your bat file
Lol wow, haven’t heard that I awhile
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--port 2000 --listen --xformers
call webui.bat
more like 3060 ti
tf you doing on a 3060 ti to get minute long samples
Try to replace your xformers with this
--opt-sdp-attention --no-half-vae --medvram
want the prompt?
1024x1024
good test! thanks for doing it.
changing the values can alter the composition - depends also a bit on the prompt. I see the biggest differences when you do extreme aspect ratios like ex. 512x2048 or 2048x512 - things tend to be more proportional especially in realism.
that is at least my experience, but I'm also still experimenting. since I'm approaching this from a very non-scientific angle of not knowing what is really happening inside the model (can only guess and what I've read) everything could be different tomorrow.
batch size 144???
1
I noticed extreme differences even @ 16:9 with XL 0.9
Guess they improved it
is that training or inference
it was 1 image generated
did you just like not install cuda or something
is it running off directML?
nope i have cuda
Oh boy. I've found that if I create an image with SDXL 1 in some other site and use it as input in nightcafe, but generate using SDXL 0.9 which is not restricted to pro users only, I get an almost exact copy of the original image.
well they're almost the same model right?
I guess it just comes down to which images feel better. In my dozen or so renders that was usually the lower targeting ones. Someone would probably have to make a big 100-image grid to get something more objective.
Sytan was playing with it for a while and just gave up I think
pretty sure he just sets 4096 on both now
I made a couple of experiments with a custom node setup I've build to iterate through the target bucket values - some changes were interesting in the compositions - like a progression.
but right now I would say the changes look closest to the ones you get when slightly changing the seed or surfing "between the seeds" like you could do with an extension for a1111.
guess I could bear that cross. have 9 'save image' nodes each named differently for every combination of low/mid/high clip resoltuions, render it like 20 times then use Magick to combine everything into a supergrid
to me its looks almost like those subtle differences between samplers @ medium steps. Like how LMS/Euler/DDIM converge in the same direction but they all get there slightly differently.
in fact let me re-render that last one @ 2.5x samples
yeah or like xformers differences
maybe; can't use xformers
do i just say fuck it and reinstall automatic completely? it seems like its gonna be 20+ minutes for this render
damn the amount of contrast between 20 and 50 samples

See that deforum has a local install and can be used without a1111 I think. Anyone know if it can be used via command line via API or Python script?
do what brings you joy
just delete the venv and let it reinstall torch and everything
or conda if auto on windows uses that idk
yea pretty subtle again



50 samples for each this time instead of 20
I'll probably just leave my principled node targeting 1 megapixel like it currently is until it's thoroughly explored.
I guess I could add a toggle? "Target size: Base/Input/Max"
yeah. I let a sequence run from 1024x1024 and incremented to 30720x30720 for the target values - and of course I don't know when it's internally just ignoring my input (need to do more research), but the changes kept the same as in your image. there wasn't any coherence improvement really nor sudden bigger changes in the composition.
I thought they only trained up to 4096 anyways
of course, sure. but can't hurt to try all the possibilities
even if internally something else is going on
little unfortunate. I thought the sizes would be more powerful.
Been trying to make some kind of workflow to latent upscale to 3840x2160 but no combination of width/height/targets makes it any amount more coherent beyond standard variance
have you guys messed with things like negative_original_size or negative_target_size?
I even tried multi-step where it upscales 3 or 4 times in increments instead of going straight from 1368x768 -> 3840x2160. Helped slightly but not nearly enough
some parameters here I really didn't consider
those aren't exposed in the nodes are they?
is this layout of things normal?


yeah I also wasn't sure what to expect. some interesting observation I had with a couple of prompts were having a perspective change - like "zooming in" on a subject.
using ex. 4096x4096 and than 3072x3072 as target values + the same seed and prompt gave me a similar composition but a different perspective - like being closer / further away in the scene.
but it's not something that I would call controllable 😉
I've just been using 4x the latent size for the most part and haven't noticed any problems with stretched people or twins
that closer/further is what I observed in XL 0.9
That's why I always set the target to 1024x1024 or it's aspect equivalent to keep the subject center-framed instead of just like some malformed speck in the corner. Seems a lot more rare of a phenomena in 1.0 though.
not that I'm aware of, just looking at the list of parameters on hugging face


https://m.media-amazon.com/images/I/51vMImAd8lL._AC_SL1108_.jpg can sdxl generate this? multi pose image?

why not?
1.5 had a lora specifically for that
charturner
yes
I asked for Elon Musk performing moonwalk. One of the images cut off his head. lol

I'm trying to reproduce the zoom even once and everything's so similar now they look like the same image from the thumbnails

you know for just generating some random 1920x1080 images directly without any 2nd passes it does pretty good
you're getting clones every so often tho
but that just happens with those resolutions

just showing some love around here

yea normally I use 2 passes for everything above like 1.5 megapixels but I'm testing some clip stuff
1920x1080 @nimble heart is working for you well? Would suggest 1088 rather. I got more issues with 1080 then with 1088 or 1024
pretty sure it makes basically no difference beyond just changing the noise and therefore see
d
difference is /64 both w and h. And it matters very
but idk could be wrong. you could make a big like 40 image grid of 1080 vs 1088 and see if there's any objective difference
Why /64? Latent scale is only /8 from input
you are generating directly to this resolution, or just upscale. I must miss something if only upscale
I mean I normally upscale but those earlier images were all direct 1080p
that shouldn't make a difference either tbh
isn't it the same noise algo for upscale? It just doesn't start at 0
o.k. I just saying from my experience. If it works for you then superb @nimble heart
What leads you to believe that 64 divisibility specifically is important?
by testing images at high resolution. And watch them closely. Probably i had just bad luck...

you must watch them i believe closer. But seems o.k. i will send you examples with stones, once i get to it.
that's a full resolution jpeg so you can zoom in as much as you want.
unless I'm misunderstanding "watch closer"
you understand o.k.
Well... this certainly is a prompt.





boobs and skeletons and skeletons with boobs
but no mention of skeleton or boobs in prompt 😄
idk probably the "lust" part gives it the boobs
obviously 🙂
nudity in negative also pretty important tho, else boobage ensues
i like how it twitches back and forth between either pure skeleton knight or girl
is "occams razor" in the negative also important???

ah, that was a negative propmt i had for a previous prompt
why
there was some elements which did in fact, look like an occams razor
so that basically killed it
and how is it (often) visualized?
if you're getting razorblades just neg "razor blade" or "razor" why occam specifically what did he do to you
is ands even a keyword in auto I thought it was just BREAK/AND
is that an extension or something?
yeah
it targets the AND composition in various ways, which can be helpful to get a better steering towards a wanted output
heh.

one of these is not like the others...

which custom node pack has the node where where we can get resolution presets?
mikey nodes
ok
what is the node called?

tq

"empty segs"
i got many



should very much be there if it loaded in as I see it did
If you're in another tab you're keeping active, make sure you hit refresh also


remove the pack and install directly from here
https://github.com/bash-j/mikey_nodes
GitHub
comfy nodes from mikey. Contribute to bash-j/mikey_nodes development by creating an account on GitHub.
ok, or are there any aspect ratio nodes from different packs?
🤷🏻♂️
lots of them, bud
can you name one

He means like Mikeys where it has the preselected options
@nimble heart i recall what was wrong with images, there were clearly seen blends, but must be because unlucky seeds, today it seems moreless o.k.




asked bing to alphabetize some stable diffusion parameters and it seems to have put some of it's own parameters in. or is just straight hallucinating. or both

not this, i want preselected ones

were you using tiled vae or something back in the day? That's the only thing I can think of that'd make clear blend lines
man, I got some pretty wicked ones a while back
wicked blend lines?
no never. Still same, it is not so much ago, and in this installation of Comfui, must be unlucky seeds
let me find the image, or images.
@ionic dragon here are resolution sdxl should be trained on, so best ones.

bunny in danger 😄
why have separate portrait and landscape tables if they just have the same data but rotated?
yes, i didnt do it 🙂
probably for ppl quickly pick up, realy dont know
weird is there is missing AR 1024x576 = 16/9 so apparently not training w and h.
it wont, because not trained, just weird it wasnt trained. /64 as all others, and 16/9 which ratio is missing.
i know the resolutions, but i used a preset one few weeks ago
that table you just posted literally says
1344x768 │ 1.75 │ 16:9
but I dont remeber which one
o.k. i believed in ratio
still looking for the tiled thing, but I did find this

it is not 16/9
1024x576 would be half the megapixels of the base resoltuion 1024² so it would make garbage images
mine will give you 36/29 if you want
1368/768 is the closest you can get to 16:9 for one megapixel

is there a difference between "--medvram-sdxl and "--medvram ?
it is
I gues being that it's sdxl it wouldn't be old. but now curious what it is
you can approximate any aspect ratio in SDXL's native res by
X = (1024²*R)^0.5
Y = (1024²/R)^0.5
where R is your ratio, so 16/9 == 1.6667 or 3/4 == 0.75
it's what I use in my automatic resolution node and it works well enough
1,7777777777.... 🙂
Some day the number of fingers will be right. But today is not that day 😢

she's just a lil handsy
you also gotta round them to 8 so 16:9 would be actually be 1368x768

she's like those cats with the etra toes
I read you had to round to 64, but I never know what to believe so that might be nonsensse
the latent space is 1/8 res so I assume rounding to 8 works fine. Seems to so far.
comfy latent nodes step by 8 as well and he literally works for SAI so I trust him
can always round to 64 if you really want
@nimble heart i cant speak English properly. Which is my big problem, i am more guessing what who write and so... So i cant argue 🙂
that makes sense. I believe the encoder also does that for you right?
¯_(ツ)_/¯
so if your input image is off it corrects
comfy's latent nodes don't let you make an incorrectly sized one so
could probably look at the VAEEncode source and see if it crops the image to *8
not sure about img2img must try it
the encode just has the model load built in?
mine does
wouldn't be hard
in my Principled node I have latent and pixel upscaling but I could probably just check the upscale model paths and load it same way the node does
yeah, just look at the load upscale model node and see what it's about
probably pretty similar to loading any other model
I have to just do a full pass over my principled node again
probably remove some parts and try to add new ones

yea


that's a lotta node power
its that one I linked you the source to
to demonstrate using built-in nodes directly
so it just has a million params then chains together like 10 factory nodes to do everything for you
automatically splitting the base/refiner and some other stuff
oh yeah. I learned a bit more about them
but yea I wanna add more shit to it but I don't wanna make it too much longer...
I have a pretty long one myself
so like idk remove scale iterations cause it's jank, hopefully remove vae_tile once amd fixes its rocm issues, add upscale model options to scale_method, maybe add optional brown node inputs for clip vision?
since it has text it could parse BREAK/AND and automatically split the conditionings then concat/merge them
or maybe I could just go to sleep for once

brown nodes, aye?
yea clip vision data is a brown spline in comfyui
so instead of taking an image and a vision model it could just take the brown spline
ControlNets would be hard though
lora doesn't matter cause lora's applied directly to the model but controlnets are applied to the conditioning
not really to input would it?
just look at controlnet.py
that's no the issue
for every 1 layer of controlnet Principled has you need 5 values on the node
ControlNet Image
ControlNet Model
ControlNet Strength
ControlNet Start Percent
ControlNet End Percent
if you wanted to fully support it
and god forbid you wanted to use two at once
could maybe make some abstract base principled node then make two separate ones. One with like 15 controlnet inputs and the other without
I was wondering about stuff like that. how it could be dealt with. but not sure how much is allowed within the ui
I'm trying to at least have the node be able to fit on my screen

alternatively I could also make a version of principled that takes positive/negative conditioning inputs instead of text. Then you could just do whatever to the conditioning outside of the node itself
it'd mean the node couldn't automatically set the XL conditioning res though
that's why clipvision is nice cause the image encode is a separate node that makes a lovely brown spline
but idk how useful vision would even be
include ip adaptor
is that even in base comfyui or is that an extension
it's spelled out in controlnet.py. but not sure if the node is base or what.
ah
so do you just load it with the normal controlnet loader?
if so that's the same problem lol
ig you wouldn't need a start/end since it's just a reference image
but I don't like excluding things
actually, don't listen to me. I only thought it was in there. so you know, oops

hmm, I need to figure this out now
GitHub
The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate images with image prompt. - GitHub - tencent-ailab/IP-Adapter: The image prompt adapter is des...


well okay


disney fae








is there an inplaint sdxl version?
and does comfy support the stable-diffusion-xl-1.0-tensorrt model?



sweet, thanks!



it might call to skeletons too, depends on who you are




@delicate kelp new protovision is fire!
these might make my wife more into AI stuff...




anyone there can help me with refiner in comfyUI?

This is a simple, but extremely functional, replacement for SDXL's cartoon keyword and is now V2. It has a different feel, look, and general style ...
oh it's out! nice
Go look at its pics and give it a try

I guess they are anti Pork cause the other pics with blood are fine.


Legible text is hard for AI

trying programing like way 😄 Just asking for some sample to know it is not random, curious if it could work
yeah that was my sample 😄
oh you mean Legible text ... as example 😄
you know dreaming the way you can tell if you are lucid dreaming or stuck in a dream is to see if you can read something. I use that tactic alot to know because the way AI makes writing is how you see it in a dream but lucid dreaming your right side is more awake and you can read it.
yes ;). or if you want something shorter try: Stability AI
it's not that easy to get all the i's and l's right
it is bad

but it tried!
it is 1st test
It worked just temporary 😄 But will play with it

it is sdxl or that exterior thing anytime you want?
ok i can do glass hour, shorter, better
I guess it help that my name doesn't mean anything so it can't misunderstand and make smt else
o.k.
🤣

lmfao those face tho

anyone know why my images come looking out blurry and faded?

sorry, Using a1111 with the new controlnet
give me screenshot of the whole page...

sorry, these ar my current settings.
I keep getting blurry pictures.
is it because of the model or the new canny control net..
hold on getting screenshot now

Well...first thing is that you should follow this sizing table: #✨|sdxl message
Also, your CFG Scale is too high compared to the recommendations for that checkpoint. You might get something that works, but they recommend a much lower CFG at 3. (YMMV)
I think I've found a way to generate the same image again. Use image input with 0% noise and the same prompt that made the original image.
ah, sorry about that. Keeping up with current events is not my strong point
A lot of times it's just simply going to take a bunch of fooling with settings until you hone in on something you're going for.
Best thing to do is first understand what each setting does, then use that knowledge to tweak the image.
It seems to be a problem with controlnet, the more I tone down the strength the less blurry it becomes
When you are adding stuff that requires more to be processed, like cnet, you may have to compensate in another way. Have you tried making other adjustments? It's not really a "problem" with cnet.
Just switched model, not 100% but like it

Friend of mine wanted his Type R "Batmobileafied", so I gave him a few options.



I also gave him this just to balance it out:

why are 768x1344 better than 1024x1024 outputs?
I've seen a bit of the same, though I don't think that's a technical issue so much as it is just the subject matter and visual framing.
could be a lot of photos are either in landscape or portrait and not square
Exactly. Think of the idea that most subject matter isn't photographed/drawn/painted/etc. in a square format.
Yeah
Human potraits are great
Compared to square
I think my favorite one so far in portrait is Hugh Jackman:

Just straight up looks like a legit photo...even zoomed in it's really good.
https://creator.nightcafe.studio/creation/YsmllJ1j24fGykvRdAUx I almost got an exact copy of the original image.

NightCafe Creator
AI Art Generator App. ✅ Fast ✅ Free ✅ Easy. Create amazing artworks using artificial intelligence.

Where are you applying those values?
Because everything for SDXL has been trained against 1 megapixel input and each side should be divisible by 64. If you stray from the 1 megapixel dimensions, you're less likely to get coherence.
can you use the high res upscaler extention in a1111 with an sdxl model?



Correction, the problem was that is used the old vae, switched to the xl vae and it works perfect now 
Nice. Where do I put the decimal and ratio? Im using automatic1111

Ah...good find!
You don't...just use the values from the table.

You must be using or doing something different than me to generate .. so im not sure how to use that table when creating images. 😦

Literally just put the resolution values into width and height.



440 is too low for any model @weak saddle
you just have to generate it in 1024x then rescale it to 440x


@weak saddle screen is showing 440x728, it is not my problem 🙂 @mossy canopy
do y'all use the refiner on models other then the base?
Occasionally, but for the most part I don't use the refiner much anymore. Finetuned models tend to be good enough w/o that.

Hi all.
Who can explain why I have different images, although the parameters are the same?


There's a difference between wherever you made the left one vs the right.



I thought these models were identical: stable-diffusion-xl-1024-v1-0 and stable-diffusion-xl-base-1.0
Well...one has the vae baked and the other may not, but also, since we can't see things like cfg scale in the left image, perhaps there was a difference there.
what is the limit of dropclip free accounts? 400 gen per day?

stable-diffusion-xl-1024-v1-0?
The checkpoint name in the left screenshot.
on site: stable-diffusion-xl-1024-v1-0
localhost: sd_xl_base_1.0.safetensors (stable-diffusion-xl-base-1.0)
But I've also used vae baked. same situation
and cfg from 3 to 11
By chance do you have clip skip set to something like 2 on your A1111 instance? That would change the outcome.
ouh, and where is it?
My A1111 is modified and I don't have the setting buried in the settings screens, so it shows on the main A1111 page. But you'd have to dive into the settings pages to find it. It was a common setting to change to 2 in SD 1.5 but SDXL doesn't need it set to that.
same sampler? same gpu? if the seed was generated in gpu.
Samplers used k_dpmpp_2m and k_dpmpp_2s_ancestral (since they come as default kinda).
I didn't know about GPU. I did one picture on the site, the other on my own graphics card.
Now I realize that it's the GPU
Thank you

 \
\

But still, the seed does show which image to start with.
So it should still be the same image
Variances in cpu vs gpu hardware can impact results when dealing with randomness.
I tried to make some battle suit blueprints in ComfyUI.



Checked, you're right that SDXL doesn't need it.
These are great.
They did turn out quite well 🙂
But the starting seed responds to the final result (the image will be similar, but not 100%), and mine is not similar at all
also different sites apply different optimizations to get faster gens. and optimizations changes seed drastically.. . so that seed only matters on that specific site .. other than that its useless.
Exactly. There is some other setting difference for what you generated on that left image versus your A1111 installation...who knows what that is behind the scenes.
Thank you for the information





tbh I could watch him eat that carrot for quite a while


https://easywithai.com/guide/how-to-install-sdxl-locally/ I think I installed SD 1.5 then. I was following this

SDXL, also known as Stable Diffusion XL, is a highly anticipated open-source generative AI model that was just recently released to the public by StabilityAI. It is an upgrade from previous versions…




Oh it's gooooood to have to ControlNet back in Auto1111! (First image is control)









The fact that it used the fro to make a tree, the clown wig, and the hat/moon are amazing.
hey there folks I'm trying to play around with a logo I'd like to get tattooed sometime and trying to get different designs. What is the best way of doing this, right now i'm using the depth controlnet but it's just not working right.



I'll give that a try thank you





only prompt?
yes
canny is giving me the issue that the background is also being painted

can you share prompt?
If you only want the inside painted, you should use inpainting to mask it off.
Ofcourse, I'm an idiot. Inpainting was the answer all along lol.
1girl, solo, sky, wings, star (sky), blue bow, outdoors, short sleeves, bow, dress, shooting star, starry sky, closed eyes, blue hair, open mouth, hair bow, tree, night, smile, lake, ice wings, scenery, puffy sleeves, short hair, mountain, puffy short sleeves, night sky, ice, mountainous horizon, blue dress, facing viewer, shirt, standing, pinafore dress, cloud, reflection, blush, white shirt, :d, hand up, ^ ^, bangs, water, bowtie, red bow, grass, teeth, red ribbon, hill, collared shirt, cowboy shot, neck ribbon, hair between eyes, hand on own chest, upper teeth only, nature, blurry, ribbon
thanks. and for negative?
easynegative
easynegative works also for sdxl? The "normal one" ?
nope.. only upscaled with sdxl ..
so you start with 1.5 and then go with sdxl thanks. So the model of 1.5 influences final result

yes



I just released a bug fix update for Searge-SDXL to version 4.1 on CivitAI and on Github that addresses some of the reported issue from the v4.0 release.

Searge-SDXL: EVOLVED v4.1 Version 4.x is here. I made a convenient install script that can install the extension and workflow, the python dependenc...


Which model are you using for these?
counterfiet




Hmm maybe I need to play with it a bit more, I tried it briefly, but never got any good results.





The blueprints that were posted earlier made me want to try it with IPAdapter and Revision



anyone here train Loras?
yes.


your dim and alpha are too big


with lower values result are inconsistent
sounds like you did 128//128
Probably need better training data or different training values
you do not need it that big, lol
I have 96MB ones that work perfectly fine
from what I understand when they get that big they start taking over the checkpoint model
with 4090 50 images it takes 2hrs.... on runpod because on my 4070 it's infinite

can you share your json?
You are doing something very wrong if that is happening.
I've not done any training for a month, so anything I give you will be out of date.
Lora works very well after training, but they are too big and can do only on runpod 4090. But I can't understand where is the problem
I started based off of this that one of the SD Devs posted during 0.9 - https://gist.github.com/mcmonkey4eva/0f0bd074c17802213817a9a5a50098df

Gist
SDXL 0.9-ish LoRA Training Fit On an RTX 2070. GitHub Gist: instantly share code, notes, and snippets.
That uses 16 DIM
And I could get decent results within about an hour with around 30 - 50 images
on a 3080
with 16dim I get bad results....
But it's old now, so there's probably better settings.
reduce network dim
tried but don't like results
so here's the deal, buddo
either you lower the dim and all that, or it won't get smaller
so you can choose not to do that
but it'll be bigger
simple science



So I'll stuck with this files 😦
you should probably review your training images and how you're training the model
You'll likely need to change your training settings to get results you like with lower DIM
but if you want to keep them that is allowed
You need to spend time tweaking it until you get what you want.
10 epochs and 256 maybe it's too much but I like results
combining these two images

If it's just you using it then other than disk space I don't see the problem. But if you plan on uploading them to Civitai or somewhere people will bitch about the size


whoa, it made a nsfw image. tsk tsk
Half the custom models randomly pop a tit out for no reason
Ok I obviously didn't try use Counterfiet much before

I mean, it's not the most graphic thing I've ever seen. but still

BOTTOM
weird back skin on that one
And the shadow makes no sense
I think it's sort of tried to combine the person and the tree, but in the wrong way
Maybe it's... foreshadowing.
...I'll see myself out.



harry in wonderland?
Wes Anderson
lmao, sus

kinky I guess
What are the downsides to using SDXL based checkpoints, versus prior editions?


I need to make the openpose skeleton impact as strong as possible during generation.


best place for a firepit. next to the house
can't get counterfeit to work for me 😦
😄
In what way, like bad generations, or it just won't do anything?
then again, regular models are good enough for me 🙂

nah, it doesn't work well with my prompting style
I have found a use case for the nightvision model. Exterior house shots are really good.
I don't really use text prompts anymore
this is what my prompting style does 🙂 counterfeit just whacks out in that case









lmao
can't get that stuff working in anime models
except darkalfa which... well, it was my own mix
let me see what it does if I use IPAdapter
ipadapter exists for auto1111?
I don't use Auto, but I think it does, someone posted a screeshot with it in a bit further up
It kinda gets the idea, but not properly

i'm using neutral prompt too
so you might not get the best milage out of the AND_TOPK modifier
if you don't have it intstalled
closer







is that a hello kitty porcelain thingy with an m16?
yes
For those that use Lora's often, what's an avg amount you'd use in a single generation? Just 1, or more at a time?



Oh hope that you don't like Limited Run too.
I have a couple that I use often, and then I
I'll use maybe 3-6 total
normally
at a single time, or just cycled through?
sometimes go nuts with them, but it doesn't always work out well
0 lora's, all the time, i'm still stuck in the prompting only era 😄
at a single time, yeah. but I'll start with none, add 1 or 2
same lol
well I was doing it without loras for a long time
gotcha, good to know, thanks 🙂
but then I discovered how much they can do
No comment other than to say that I know Josh, (and Doug, but he's not with them any longer).
1 lora for me

???

I just know of the practices.@native knot
Josh Fairhurst, CEO of LRG.
🍑🔞👩❤️💋👩🌴💦 is my prompt... lets see what it brings us 😄
the business practices.
i mean,i couldn't not do that on my old model, lets see if protovision does give me something more decent
I LOVE STEAK!!!! OH MY GOD!!!!!

canny?
What practices? If you don't know the people behind the company, how can you speak intelligently about their practices? If you aren't involved behind the scenes, you probably don't know a bunch of context that you would need to know to not be making assumptions about their business.

no, pure prompt
From an in depth video I watched about them last year. https://www.youtube.com/watch?v=lS3ja5JnkAQ&vl=en

Subscribe https://youtube.com/reallycool?sub_confirmation=1 Discord https://crymor.tv/discord
Limited Run Games has absorbed me for the past months as I researched the issues, complaints, scandals, and more associated with them. Every time I thought I was done, another issue would pop up and I'd have to amend the video to stay as complete as po...
literally the thing i posted above 😄 (with some extra in the AND_TOPK for anime style)
Oh wicked.

The same applies to the person who made that video. They speak about things they don't have all the information about.
I'm not defending everything about LRG, but I also don't base my opinions on a youtube video.
Although the information they do share applies to the consumer. The consumer means a lot to a company and should not be put in a bad light that leads to lesser consumers.

death stranding much.


Then why base opinions off of articles or the newspaper?




@native knot
It's rather incompetent to see that a person has spent the time and effort into researching a topic just for someone else to say "I don't base my opinions on a YouTube video"
This person fully understands that the video maker has spent months researching a topic so that they can properly make an informative video. At the end of the day they don't base opinions off of YouTube videos even when the video itself has months of research put into it.
no. We don't do that here.

thankies
Probably pushes the line into NSFW when it's presented like that

That's what I'm thinking as well.

I'm not being a bully here mods.


lol that dog... thing




the only problem with SDXL and SD in general is that is a sort of drug
it is.


send in... THE FLEET!




with the new A1111 update is the refiner automatic?

I prefer space fleets

Yes, you have a voice
I don't see where to choose to apply it or not


go down and look for refiner section
I would assume it's ther "switch at" option. but I don't use Auto1111 anymore
that's it! thanks! it even says as much in the tooltip, which I didn't check
my bad
well then, now i'll have to run this prompt again!

I work in the industry. I've seen what goes on behind the scenes with my own eyes. I know multiple people that work at LRG as well as at several other publishers in the physical media space. I can tell you that there are aspects that I don't agree with in regard to their business and that there are other aspects that are perfectly fine. All I'm getting at is that what goes on behind the scenes versus what gets said in public are two different things in a lot of cases.
Apologies if it sounded as if I was saying you based your opinion solely on the video, that wasn't my intent. Also, I'm sure that neither of us want to continue clogging up #SDXL with an off-topic subject but I'm happy to continue conversation privately if you'd like. ☮️

kek








My first image here...


Thanks, I love the organic stuff.



I love what IPAdapter can do lol


























That is excellent.



















This are some really good images. Great Work!
Can you make that meme that does that face with the vein in this style
I don't make memes. Only serious art here 🤣
Is this with some kind of dressed / undressed lora? 😜
I didnt ether but youtubes got me taging every video memes
idk this is what I thought of when I saw the previous image




I don't think that i can manage that. I cant even get the vein on his forehead.

so THAT'S what was actually going on




Is there any kind of base line time it takes to train a sdxl lora? I know there are lots of factors but out of the box it seems like it is going to take some time. I have one now 1024,1024, 163 images, rtx 4080(16 gig), i9-13900K, 32gigs, is taking 5 hours?
With 4090 50 images for me is 2 hr
That makes me feel better. i have a triple the images
depends on network dims and epochs
looks about right. your big limiter will be the 16gb. i got the 4080 with a 12700k an 64gb. You could try improving those times by shaving it down to 896x896 resolution, with a batch size of 2
that should fit into 16gb still

the card ram is maxed out after a few minutes, but it is working. im over half way there with 6/10 batches done with about 2:21 hours left
Only other way would be rent space on a cloud based server to process
Groot 2.0

batch size 5, epock 10, Network Rank (Dimensions) = 1
learning ot max out the performance of limited hardware is good too. skills that can be used for efficiently using enterprise level hardware down the road

Rant about Secret invasion. ||They ruined groot by turning him into a genetic bottle that could be cloned. now he's not unique or the last of his kind. he's just a manufacturable formula now. Secret wars kind of sucks and disney should write it out of canon like they did with the EU||





Gorgu!
Now do Mogwai
Mogwai, Gollum, Grogu, E.T. - all cousins in the latent space



what would pika do with this image

lets see if i can make this look even more like a visual novel 😄



do you know what sdxl does to conflicting positive x negative prompts? It seems that wet road conflicts with negative "flooded", ending up in "dry road"

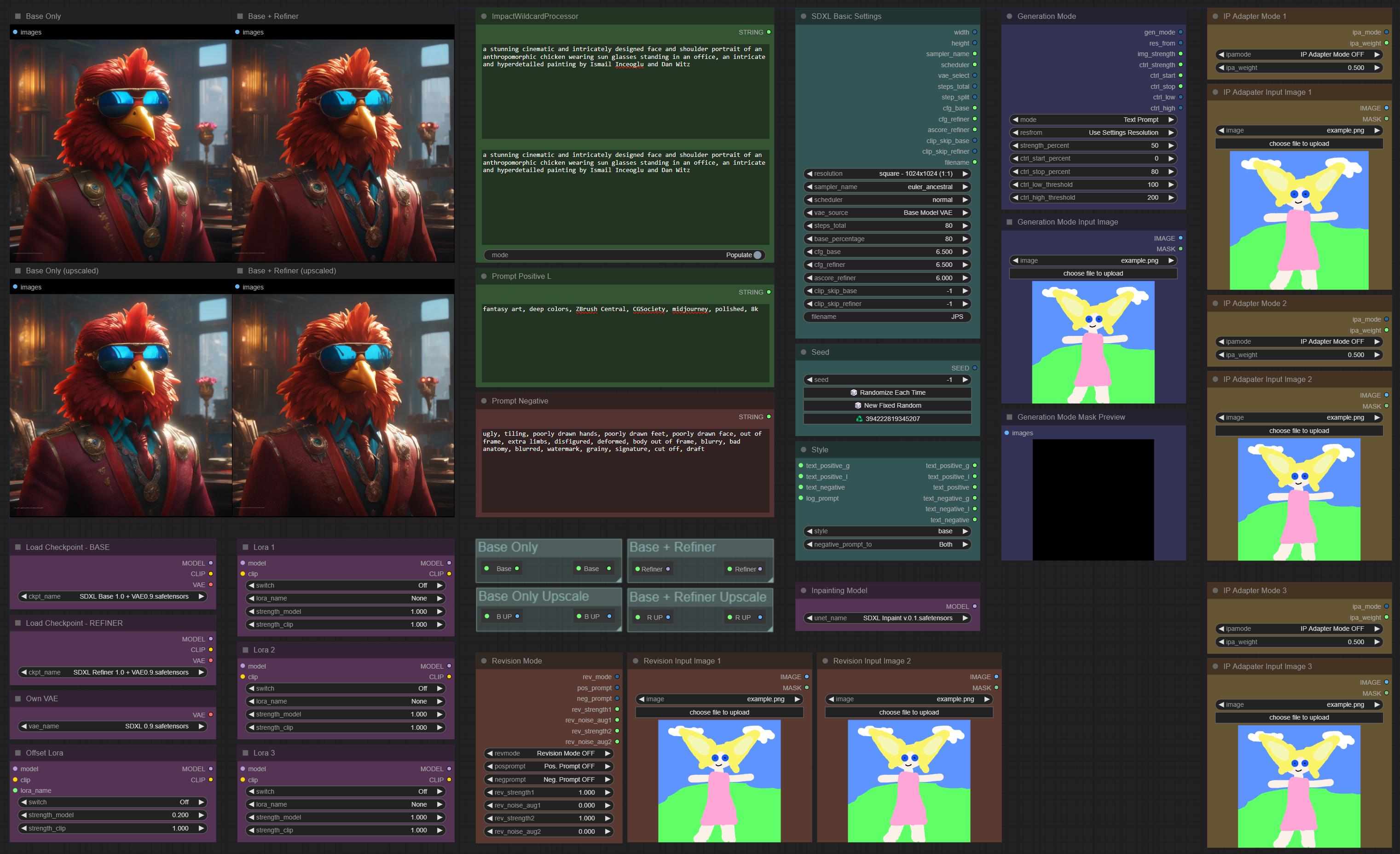
new version 5.0 of my workflow - better file names / directory structure, choose between own VAE and model VAE, clip skip, removed history, because it slowed down saving and ui too much, removed unused options from nodes, so you have to update both components
https://i.imgur.com/AeLm87h.jpg
https://github.com/JPS-GER/JPS-ComfyUI-Workflows
GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
Out of curiosity, if you add weight to "wet road", does it start to make the road more....wet?
the bots here lack weight
ah never used them here




I began to notice that the roads that SDXL is generating for me are, half of the time, kinda have a wrong perspective specially torwards the end of it.

{kind=link}
{kind=link}
I've a strange thing. All my lora works fine with ComfyUI. With auto1111 they all work fine execpt one that doesn''t. Any idea?
unet tenc separate strength?

partially from weight normalization I guess?