
#✨|sdxl
1 messages · Page 117 of 1
What interrogator did you use? Are you using Comfy? Automatic1111? What checkpoint? I'm trying to understand what influences the "interrogator"...other than the image itself which is being interrogated.






Watching...

watching you watching






















Lets jam.







Mr. Hightower



Official Video for "Jam” by Michael Jackson
Listen to Michael Jackson: https://MichaelJackson.lnk.to/_listenYD
Shot on location in Chicago, the “Jam” short film paired Michael Jackson and NBA superstar Michael Jordan for a one-of-a-kind one-on-one match of basketball and stunning dance moves.
Follow Michael Jackson:
Facebook: https://MichaelJ...





he looks angry. somebody probably stole his prompt 😄
is that the nightvision model?
Lets cook some vram. 🙂


Noice one.
we have controlnet\inpainting working with sdxl yet? was away on vaycay
we have both
nice. time to pull on auto1111 and go hunting the model files.

yes
overfitted..
probably a bit, can't quite tell yet where it's overfitted the wrong way
but overfitted models (like any anime model) can be used
it can't do artistic very well.. just photoreal
it can't do artistic?
oh the nightvision?
protovision can do realistic and artistic
not very well compared to others..
and in my brief testing it does photoreal NSFW the best out of what i've downloaded and then smack with custom trained lora's via adetailer
use protovision 😄 (you vs the girl he tells you not to worry about)

protovision is a lot more creative
although i like the realistic output from nightvision you've shown
look at the details here..

add 3d render (or 3d,render) in your negatives

🔥 ❤️



model remembers what e30 looks like. I am pleased!




Thats nothing place that back pff.
ketchup is involved




Now thats boombastic. 🙂

Very nice broski. 🙂
Help...I'm using automatic1111 and I've followed instructions for activating CLIP_stop_at_last_laers. I restarted stable-diffusion/automatic1111. Nevertheless, the "control" at the top of the UI has not appeared as expected. Ideas?

Recheck settings if everything properly there. If you did it somehow and pasted here, there is missing Y.
Easiest way is in setting display all and there activate it @wild ice
i know therefore ✅
Les go.
just going through old prompts


very nice
😦 I don't understand what you are saying. "There is missing 'Y' "? Maybe you are asking me to paste a screen shot?

yes that is proper way how to do it, but they mess with UI, so it probably can affect this
@uncut fiber Ugh! Well, never-mind. I have now refreshed the UI for the 3rd time...and THIS TIME the setting finally appeared.
❤️

CLIP_stop_at_last_laers <- here is missing y 🙂
those flowers, impresionist expresionist and abstract, not technique mentioned 🙂
???


Now my ultra bad question. I still don't understand 'y'. Is that letter short for something? I'm new to all things AI-art.

still working on old prompts... at 20k out of 80k or so...

nice emerald eyes
sdxl based models slap hard
80k prompts?
something around there
the amount of images i generated before i got to sdxl or so?
thats a large number if each prompt is unique
well, i switched to my randomizers at some point
so having a lot of text prepared makes everything unique, and not at the same time
yes me too using it, sometimes with for me very nice results
but trying old prompts really gives me a feel what sdxl models like and not

my randomizers being my own wildcard scizo prompt fueled with verser.ps1 song lyrics lol



i tried add price tag, but it was completely ignored.
Use the force. 😄
Best goddam sneaker ever seen in my life fr
Well, this is an artistic community! I still don't know what you mean. I think you are saying 'y' is short for "layer".
@floral island GN!
#justonemore!
simply, what command you posted, there were missing y in word layers. Thats all. My english is bad, so i cant better describe it 🙂 @wild ice
Ik zal morgen aan je denken als ik een jj op de bank rook slaap lekker gap. 😛



@stone fossil you've been posting some great stuff tonight 🙂
Thanks heh, I am being supported by you and @sturdy abyss , @floral island , @dapper dragon .
Lets cook some more VRAM.

A love letter to SD.
🙂



This one. This one right here. 

In this youtube video. The fella is making a primitive hand "sketch", then de-noising. However, in my automatic1111...the "sketch" doesn't let me hand-sketch as he demonstrates...I can only mask. What am I doing wrong?
Stable Diffusion allows you to sketch with AI. You draw something and tell it what your drawing is of, the AI figures out the rest. I ask my Twitch chat to decide what to make! Follow me on Twitch to join in on the next one: https://www.twitch.tv/Greenskull
In this video I use the artificial intelligence tool Stable Diffusion.
Join my FREE AI ...
Hehe yeah some are very emotional heavy.
🙂




Been screwing around with PPF noise and using combined latents to get some interesting results. Essentially, if I generate the same info for with and without combining the latents I can get similar poses but simpler backgrounds with the PPF mixed in. For instance, here's a knight. Top image is with PPF mixed in and bottom is without.






@upbeat summit - What do you think about this?


it's looks very interesting. I'm not sure yet if perlin is the way to go for detailed compositions but it might be great for textures or complex patterns - how it's used in the industry. for a couple of days now I wanted to do some experiments with perlin noise - but haven't come around to it yet. I just saw that WAS updated his perlin noise node so I have to try it out very soon.
There's a great Blend Latents node here:
I'm trying a third box with different operations just to see what kinds of outcomes are there. The top result from earlier was done using a Latent Composite.


Dance some pictures. 🙂
Dance with me.
New workflow with all 3 images, plus the 3rd upscaled knight image


heh yeah. need to make some images - but still have to do some work but I just finished including a new prompt building workflow in my setup. so looking forward to try that out
That was using "difference" as the operation, which is interesting.
there's some interesting stuff going on for sure

I think this could be a pretty nice way to make some very small tweaks as well. The PPF noise can be refined very very finely.
now I just need to try it out with revision, IPAapter and ControlNet 
Yeah...a lot to do there.
Oh, and just as an FYI, the blend and composite are combining fine while I'm using AIT, so no issues there.
yeah. I have experimented with different noise latent images and it should be definitely explored
are you still on the old commit to use AIT or is it fixed now?
I'm currently running on up to date builds and I think the only thing that's not currently working for me are TTN's nodes.
YMMV, of course
cool. thank you. making a backup now and then git pull 😉
(((cracks knuckles)))...time to stage these into passes.
is there a snap to grid option for comfy?
it drives me crazy that i'm not placing the nodes aligned






there is
what am i missing?


found it

thanks!







https://i.postimg.cc/NfSjFxHH/6-Q3g-C9651u-KQAPo-P3l-VK-1-2wgxn.jpg
https://i.postimg.cc/zXVfqQVN/8u-ZHy4f-Lxc332-Y3u15za-1-pgcnu.jpg
https://i.postimg.cc/x1mTzbvF/Xp-Cyq2-ILcv4-Mvt9-YQz0c-1-cxokh.jpg



The same prompt in Adobe FireFly creates more or less the same thing, except that there is much less reflection on the ground and Adobe doesn't place houses at the borders. I don't want the houses, but SDXL placed them thinking that I wanted a street crossing a village. I said a village at the distance, far away.
SDXL also understood "chinese light poles" better than Adobe. Adobe placed lanterns hanging from the trees or lens flare floating as if they were fireflies















reminiscent of Kingdom Hearts
Aye









How, presumably with a prompt, do I control how close or far an object is? Or its position? I want "forest surrounding wise man" and I want the man to be somewhat centered and consuming perhaps 30% the height of the image.

Just experiment. There's no one right approach. You can literally type in anything. Make a prompt out of what you just typed here. You can use terms like medium image, centered, etc. Be as descriptive as possible. The better you describe the scene the better the ai will know what you want

Sometimes I make up words. People need to do more of that
Stable diffusion always knows what to do
I've done that a few times...usually I'm merging a few words together that make up what I mean...it's odd how well it understands that.
Well I've thought about creating a node or something that will pit prefixes and suffixes and things together in ways that are syntactically correct but aren't used in the real world
But in latent space anything goes
I wonder how well it grasps latin
When do we all get to realize that we live in latent space and can fly?
Hopefully soon
plzI'mdyin'ovahere
I just checked my hands, 6 fingers on one hand and 7 on the other.
I think that confirms I'm in SD Latent space
pix or it didn't happ....wait...
Oh I responded to the wrong post lol
But you still got it haha

Perhaps Peele was right in his "You Can Do Anything" video. He knew back in 2012 that we can do anything, we can literally fly
Hey, i'm having this issue a lot of time meanwhile i do nothing and it appear for no reason. Anybody know how to solve that ?

Sounds like a bad extension in A1111.
Take a look here:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/12155
Maybe it helps. 
"pip install tqdm" perhaps?

GitHub
:zap: A Fast, Extensible Progress Bar for Python and CLI - GitHub - tqdm/tqdm: :zap: A Fast, Extensible Progress Bar for Python and CLI
or install tqdm_auto
a1111 really taught me a lot about troubleshooting errors
making some conditioning modification nodes. not sure if they'll be useful, but you know, they'll be something
Problem narrowed down. It looks like a conflict with https://github.com/failfa-st/failfast-comfyui-extensions

GitHub
Extensions for ComfyUI. Contribute to failfa-st/failfast-comfyui-extensions development by creating an account on GitHub.
what's the problem?

follow the message link
#✨|sdxl message
ahh, didn't even notice that you quoted yourself and a youtube video. nice. I've not had that issue myself. but I guess that would make sense since I don't have those nodes either.
had them, but when I clean installed I didn't download as many things
quick question, Is there any news on controlnet for a1111?
There was one that looked cool called "DW Pose "
has a1111 kept up on anything in the last few months?
nah, but the latest update fixed a lot of things for sdxl tho
that's cool. kind of a bummer to watch them drop the ball with everything. it's always had lots of errors and all that, at least for me. but I always reminded myself that it was free open source software, new technology, lots of things having to work together, etc. but when I realized they were falling behind in everything I had no incentive to keep using it
yeah I change to Comfy UI
yeah all true, I still can't deal with comfy. It's just not my style of program. All those custom nodes and none of it makes any sense. Just let me use my a1111 in peace lol
I'm not one of those weirdos that cares what other people use. but personally I wish I'd tried comfy sooner. but stupid redditors naysaying it, and that had been my main day to day source for stable diffusion information in the past
But once you learn it , It show your more under the hood. and the images png have the meta data of the node in it. so can load a Comfy UI thur a png image made
it just satisfies my brain
yeah, thing is, you literally never have to create your own workflow if you really don't want to
but as soon as I acclimated myself to it I immediately started creating workflows that probably didn't ever need to be made
Any idea how to put the render image in progress under KSampler ? I saw someone have it in a video

there you go
Not necessarily that one I'm hovering on, but those turn it on
Thanks, Oh But its Slower,Ill test thanks
Yeah just see how you like it. I ended up sticking with just preview nodes for the time being.
yeah, I don't run the live preview. I like to delay my disappointment
What is badge and channel for?
we get badges?

do you use the refiner when using a lora?
no one knows the right answer, marksouls
My refiner is on for every run. But I don't use Lora's hardly. Just the offset.
I would probably default to keeping it on for using others though, then adjust if needed
why there is no reference for best parameters we should use for training a model on SDXL dreambooth ? 😦
But there is lots of content for LORA SDXL.
badge :looks like it counts the nodes , is nickname if someone add a nickname to a Node?
well it's to help you figure out where you got it




I'm not sure if I can use the same parameters that we use on lora for dreambooth as well.
does dreambooth not train loras?
Sick Helmet
Good question, don't know 🙂

not sure, the human centipede one?
maybe. I think it had martha stewart in it
and she ate an entire thanksgiving turkey in an unconventional manner
Theres some AI south park project out there
like entire shows? or images?
There a episode written by AI, and a Automatic Run one which is like ChatGPt linked to text to speech and the cartoon. there a similar one on twitch of Rick and Morty
impressive

Anyone tried making youtube videos with sdxl? It's pretty good even with creative prompts https://www.youtube.com/shorts/dpLSKQroYCk

Get ready to dive into the wildest and most surreal memes about dat boi! 🐸🚀 From space adventures to quantum realms, time travel, and multiverses, these scenarios will blow your mind! 🌌🌀 Join me on this wacky journey and witness each scenario getting crazier than the last. 🤪 #shorts #surrealmemes #datboi #unhinged #wacky
Did you know that this...

Any good image to video apis out there yet?
gen 2 is always some kind of slot machine
can you make a video with this?

yes for sure, mama little baby like short bread
@hardy cipher

Subscribe for the best vintage music http://bit.ly/35VAEKV
Best Vintage Travel Songs For Any Journey https://bit.ly/35y6iz0
Vintage Big Bands Playlist: 1930s & 40s Big Band Orchestras. Toe-tapping music to 'cut a rug' on the dance floor - https://bit.ly/3vBUBmV
Dreamy Vintage Love Songs Playlist: https://youtube.com/playlist?list=PLIvacmZCzEbAg...
grease bread. I forgot that I knew that song, lol
@hardy cipher So in Pika I put in prompt :looking, blinking, smiling gen2 will do something crazy with this ill try it
not good, my buds
decoded (tensor([[[[nan, nan, nan],
[nan, nan, nan],
[nan, nan, nan],
...,
[nan, nan, nan],
[nan, nan, nan],
[nan, nan, nan]],
[[nan, nan, nan],
[nan, nan, nan],
[nan, nan, nan],
...,
more inpainting
@hardy cipher So Gen2 found image NSFW and didn't process
idk its all automatic
well I appreciate the effort
yeah, just wondering how it triggered the algorithm or whatever
I get better results with pika and its free
I wonder if either of these would make it through the filter


Are those Sea Monkeys?
rainbow goblins, silly
yeah I already see the NSFW, they need pants
fair enough, well rainbow goblins are free range and they choose not to wear pants
Pants Lora
the bottom right one in both images is extra special
hmm, maybe. I have a few more. I just cursed those ones
ill try it in pika
they're wearing clothes here

@hardy cipher




thank you, gentlemanscholar
I keep an eye on you!





i dont know. Would send it to extra tab and try esrgan or swinIR probably. It will keep picture unchanged. Hires fix will change it a bit.
Thanks a lot!

two different rain-snows 🙂 many thanks to Thaevil1



Does Automatic1111 run super slow?
I am trying to switch from ComfyUI to Automatic1111
but it's really slow
Idk how to make it faster hm

ok
Deforum is fun, till you do it 8+ hours in a row and your head explodes. 🙂
how realistic is this?

just sun and shadows on shirt? Dont know
trying dithered color, not sure it is working....

https://followfoxai.substack.com/p/part-4-advanced-sdxl-workflows-in
my weekly post - this time about building workflows in Comfy

Step-by-step guide to build up to a powerful workflow








Could be real inspiration, bell tower in the middle of the square 🙂

anybody have a better idea how to implement the stage design?loRA or controlnet?i'm afraid the stage lighting is an obstacle and disturbing of final render









new lora?
yeah
nice!
I love the style of it
i posted different 😄

it has some issues still so needs more training (steps)
me too. looks a bit like TV Funhouse 🙂
tv funhouse?
animated shorts as part of saturday night live
yeah
this is what it did to my robot 😦

retrofied


very nice 🙂
Very much like a childrens cartoon

Lucky Luke!
Yep lora by @dapper dragon

Not using Lora, only one tempting me a bit is Audrey Hepburn ❤️


how is it that no matter how much memory I have I am still getting a huge page file?
I crashed due to it yesterday with a WHEA uncorrectable error. Ran a mem test etc... all good

Does anyone still use Lexica to gen?




any originality here?


you made it - so it's an original 😉

and is artgerm in your prompt?
nope


sdxl has nice steps and banisters.

i have with signatures issues as well, once i had impresion that blur corners helps, but not sure now.
I lost those issues when I left 1.5 for 2.0 then 2.1 now they are back


got it
@vital ermine How?
(signature:3) killed it
o.k. very strength value
and no impact on picture?
2.7 is the magic value
2,718 🙂

2.718 is e 🙂
Working on a book cover, and I decided to ask SDXL to render the title, just to see what would happen. I didn't think it would work, because there's no way that these title words were anywhere in the dataset. So, here's my question: How does this work, exactly?
Does SDXL understand the concepts of spelling, letter-joining in words it has never seen, line breaks, and even typographical balance?
(Title "The Heavenly Ruins")

Diffusion has issues with text, period.
To be clear: SDXL can accurately spell words it has never encountered before, and make the text look beautiful in any style. Not with 100% accuracy, but I only rendered 20 to get a perfect render.
How is this possible?
It understands how to write.
It's not copy-pasting words its seen.
no, never
it is an issue with diffusion that is being worked on for all types of various diffusion based schemes
It is using an internal world model governed by rules. That's the only way this could be possible. 😕 (But I need to get back to work.)
messing around with the comfyui mask editor. got a zoom function working kinda/sorta. still some functionality breaking bugs to work out.






Can you post same picture with and without (signature:3) ? I think it washing detail a bit.
I did it was the one before with just signature
o.k.
you will never ever get the exact same picture if signature, or whatever, is in the neg as it is a filter
yes


🕯️
ERROR: LOW VRAM MODE NEEDS accelerate.
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 4090 : cudaMallocAsync
VAE dtype: torch.bfloat16
I guess i need a better graphic card for sdxl
we all need 128GB cards now



even better

Oh, wow this is the 1960s TV Godzilla

try Gapa 🙂
gapa?
or gappa


nice text 😄
LOL, yea


Ahem

that is Mr. Fabulous


2.7 not enough

5

must be listed as something not signature






I'd like help with a prompt (or some other tool/extension?) that would cause an image to have an overall increase in firelight-orangeness added...as if an orange-like cellophane was overlaid on top. Ideas?



only sdxl pro get this type of photorrealism.

I had to make another account to try again.
SDxl pro? What is that @shy kelp ?
1.0 "pro users only"
hm... "a car with (donut tires)"









SUCCESS!

this is way beyond what I can achieve with Adobe's FireFly. It's so life like.








lol













kappa_neuro is attacking again with his countless loras of artists already included in the base model. This time they work though.
i am downloading some, they seem to somewhat improve final results.


That would require training a noise offset lora. It's the same impossibility as trying to get a "bright" or "dark" image by prompting. https://www.crosslabs.org/blog/diffusion-with-offset-noise
The poorman's solution: I tried sepia orange vintage film, * subject * and that gave a reasonably good base. After that initial render, you would need to use photoshop / gimp / whatever to adjust the colors further.
(Prompt subjects courtesy of a Llama2 AI running on my PC. 🙂 )


Fine-tuning against a modified noise, enables Stable Diffusion to generate very dark or light images easily.

Is that Owen Wilson?
















Does anyone know if a workflow for weak systems has been shared recently? I haven't been following the chat in the last few days. @high skiff had said that they would make a workflow available.


sorry, my lightsaber whiffed

I LOVE SPAM! I LOVE BEING ON AN EMAIL LIST!!!!! YAAAAAAAAAA!!!!!mnbj we rtfljkhlvbhferjl;jhkv ewf

This is not a stable thing. BUT FUCK ME MAN!!! WHAT DO I FUCKING DO!!! I CAN'T DO SHIT HERE!!!
YEARS OF THIS!!
Alright I'm done with the caps
🤔
a little more progress made on the zoom functionality. drawing is still buggy, but it now has a pretty background canvas.






tf is going on with sytans workflow..

she's a scarred fire survivor?
give me ur workflow.. mine is broken for some reason..
mine is A1111 + protovision (probably overtuned) model

sorry my dude/dudette ❤️
not sure if its the model

she quite literally stole his heart

which model u using?
How to get rid of donuts sticking to car, any idea on negative prompt


it might be that ur prompting style just fucks the model over....
what is the pos prompt?
simple one sentence prompt.. no nonsense
mmnt
Real car, (tires made out of donuts with toppings:1.6), seen from side, solid background.
turn down 1.6 do not help
o.k. will try thank you!
just to make sure the model understands what i'm trying
some models have better comprehension, some have worse
"homer simpson" as a positive token
my personal 1.5 model had great comprehension (but is a toddler compared to sdxl)


the worst part of SD in summer? the heat.
taylor swift vibes
p.d. official desktop 🙂



i feel this image has 5kg of botox injected lol (perhaps not far from the truth nowadays, but what od i know)



found the mistake. i have to use super low cfg with this model.. or else..
in my experience, that means the model is very knowledgeable
or overcooked..

that might be tho
glorious donutmobile


now you made her hide her face

getting better

clipdrop generates the same style that I get with nightcafe. Except that it doesn't put houses by the road's side.

However. I keep saying "negative prompt, aslphalt" and it insists on asphalt damn


clipdrop pushes default prompts style..
try asphalt 😄 @shy kelp or in positive cobble stone
I tried reimagine in clipdrop. Everytime I seem to get worse images.

not sure if they are using revision or just an unclip model
I'm installing sdxl. Installed python, then invoke ai
the photorrealism in clipdrop seems to be a bit too hyper real compared to nightcafe

With Comfy, why use Google Colab in your workflow?
good luck installing invoke
there are better options than invoke?
automatic1111, comfyui, sd.next, fooocus
countless
I went for invoke because it was mentioned first in the installation guide
comfy for sdxl at the moment is the fastest and still better
ComfyUI works great
when I install it. Is my PC generating the image as opposed to a remote service with much more processing power?
remotes better I mean they have server size room computers
But Im getting great results with comfyui local, You have a lot of control with your image
and what about official Stableswarm-UI?


#meme #memes #cat #cowboys #cats #aivideo #catboy
uh now I don't know how to remove invokeai
this trait is very beautiful
there's so many AI systems usually its all in one folder

well, clipdrop doesn't have weight control

what is the model?
And this is another Lora





PixAI - Anime AI Art Generator for Free
PixAI is an all-in-one AI art platform to generate and share your own anime characters, realistic portraits, wallpapers and assets with a huge selection of AI Models and styles.
are most of them waifu?


Generate prompts for AI images and media
why are lexica images too bad, like they are too polished
just take the prompt.. https://majinai.art/

Explore millions of AI generated images and create collections of prompts. Featuring Stable Diffusion generations.

lexica was always bad..
yeah
are the prompts good?


i dont use them.. i write my own or just clip interrogate it if its unknown to me ..

only problem is that the old prompts lose their relevance with new technologies really quickly.
remember when it was basically impossible to get decent weapons or tools from SD? now you just prompt for them normally and SDXL does the rest
just do your own prompts instead, describe what you want, and be a bit creative
e.g. this is "dark batman standing on top of a tall building at night looking over gotham city, made of bats, explosion shards frozen in time, cinematic"

i always used controlnet to get them properly..
too much work for me 🙂
i just prompt for new stuff and don't try to replicate existing work or finetune my creations
oops, cape on his front side, this will be inconvenient


what i like about SDXL is that you can use the style selector (basically adding stuff to the prompt and negs) and get a fresh look for the same prompt


whoa, psychedelic strikes

dystopian indeed - the batman sign shaped bats are a nice touch

and so on 🙂

where are u using sdxl?

"((flat 2d cel shaded studio ghibli style)) dark batman standing on top of a tall building at night looking over gotham city, made of bats, explosion shards frozen in time, cinematic"

ok last one 🙂


model?
sdxl + lora
My wife says she approves 😎😉
these are done with sdxl + Lora of my face


"mmmhmmmmmmm, yup"

show some abs
abs?
for his wife
😄 yes but I don't know abs what stands for


larger than 512 x 512 gives me out of memory error
gpu?
512x512 is not a good res for sdxl
invoke?
automatic1111
512x512 +sdxl = bad results
oom
yes but sdxl can't work with 512x512
A1111 can do SDXL 1024x1024 on an 8GB card though... I'm 90% sure.
Launch with --medvram or --lowvram
add some optimization arguments other peoples are using like he said..
For 8gb, use --medvram
I haven't used A1111 since SDXL came out though, so can't speak to how my 8gb 2060s works with it.
much lower quality than clipdrop


You're using SD 1.5. Clipdrop is on SDXL. (Also, your prompt needs some work.)

so there is no offline sdxl 1.0
make a mexican wrestler
coming up next

just prompt

Installed locally, yes.
Automatic1111, Comfyui, Swarmai, etc etc

what i was meaning to say is....
make her a mexican wrestler
whom?
dreamstudio is more or less the same result as nightcafe

https://tensor.art/ try this
AI model sharing platform, online run models to generate image for free. Your can upload or download models, include Checkpoint, Textual Inversion, ControlNet, LoRA. Also we offer some base model like Stable Diffusion 1.5 to generate.
it's funny that I say "village in the distance" but it places houses at the road's borders.
Las tone before going to sleep. DRacula and his castle

so I added "houses at the road's borders" to the negative prompt and it worked



the only thing left is to fix the excessive lighting. It's placing just too much light.
some results of ip adapter experiments with my workflow










It’s a pretty nice image as is. I’d honestly drop it into an image editor and adjust the lighting and color temp with curves if prompts aren’t getting you where you wanna go
this was perfect damn
what is going on here?






I got that in img2go. I asked for Elon Musk practicing moonwalk and it made two elon musk, one with three legs
what are those merged body errors?
these are all cursed images, my friend. that is the explanation
theres a red pepper with a human leg in the background 🤣

that collage randomly has a big bird/howard the duck demon on the left



you have to ask yourself what the incentive would be to create such things
give life to my ideas, and frustrations
use the bots on this server
it's giving a very annoying problem, when I try to use a prompt that I've already used it appears to download in BIN
then I have to rename it to PNG, but then I keep downloading a bunch of poorly made images and deleting them
VPN and multiple accounts
change the prompt slightly if this is an issue with you. add spaces or punctuation. problem solve. I really have no answers for you other than that
firefly is so lame

stable diffusion dgaf. stable diffusion will make images from the string of characters left when my cat naps on my keyboard
I am going to try
good luck with all that on discord
graphics card
my old account got banned because they didn't like my vpn and I was labeled as a spammer, lol
hallo, i was wondering if what the difference between controlnet rank128 and and 258?
never once spammed, but you know, that's not the important part
and their customer service people helped a lot by doing nothing at all to help me
did you ever start on that gmic node?
well, I'm figuring out the basic workings of conditioning. but I would say I'm not very far yet. I'm learning the arithmetic so I can move up to the algebra
I'll keep renaming the downloads, multiple accounts is even more annoying
that's it
I have a conditioning normalizer node. not sure what benefit that serves, but I made it
auto does something like that
see if your results are comparable when both using cpu seeds
#1100170312106127410 message the bot is also great. Except that I missed some parameters
my problem lately is I keep getting this sort of thing
samples {'samples': tensor([[[[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]],
in general or just with your custom nodes
man, I'm having a hard time telling. tbf I haven't had a chance to spend a bunch of time with them. but can't tell if it's a vae thing or the custom nodes. realized I'd been modifying the conditioning tensors themselves, and then trying to figure out if that carries over to new image generations or what. so just trying to get my bearings with it all before I step up to anything more complicated
it's like opening a can of worms for me. it's all stuff that will be simple in hindsight, but isn't yet
assuming you're using that new 0.9 vae, make sure you're not autocasting to fp16 when starting comfy
ahh, that could be an issue. because the 0.9 vae keeps giving me black boxes
beyond that idk. I've only NaNd a whole tensor in a custom node by mutating it directly without a clone which caused each subsequent run of the same seed to compound the modifications cause of the comfyui caching
so the numbers just kept growing until it broke lol
yes, this is what I did. in place operations, lol
but then I fixed it, or thought I did
if you're directly mutating a tensor using pytorch/numpy ops just clone it first thing in the function
else you mutate the cached version it seems
cause comfy doesn't clone its own version for the cache
which makes sense ig since python doesn't discriminate between read-only and mutable data
probalby why Comfy talked about rewriting the whole ui in C lol
yeah, I just have a problem with learning all the ins and outs of things in detail before I jump in
so end up breaking stuff sometimes
nah that's just how it is in the hacking worl
d
break things before you fix them
just like
back up your shit before you do something that could potentially brick your data
and you're good
I'll start it up and see what sort of issues it gives me now. keep tweaking things here and there
other thing that discombobulates me is all the different data forms and understanding what requires what. tensors, lists, tensors that contain lists, tensors that contain tensors, tensors that contain tensors and lists, tensors that contain tensors that contain lists
alright, adding "--force-fp32 "
hopefully that helps
I set it up to clone and create a new tensor when I realized what was going on. but what exactly was it even changing before?
Forcing FP32, if this improves things please report it.
...
VAE dtype: torch.bfloat16
wtf
so is it overriding what I'm tring to do?
so comfy doesn't build a new tensor every run. It only makes a new one as far back as the prompt changes.
so if the prompt doesn't change leading up to your node it feeds your node the same tensor every time, and if you mutate that tensor directly that's how you get the compounding effect
on nvidia 3000+ cards it adds --bf16-vae by default
idk how to remove it
if there's an --fp32-vae maybe? BF16 shouldn't make NaNs though...
I don't know. I'll see what happens now that I changed the code a little bit
sweet sweet errors. alright, I need to figure this one out now
TypeError: can only concatenate list (not "tuple") to list
boo hiss
hey. For some reason my prompt keeps generating straight roads
I even tried negative prompt "straight road"
hmm.... Swapped "sakura trees" with "willows" that made the whole image different. It seems that the AI thinks that if you want sakura trees, it means japanese architecture.
looks like sakura a anima character also ,try SakuraArchitecture

So SakuraArchitecture, trigger the Anime character for me

gta 7
sensei





theres a guy there with face made of fur 🤣
lots of perimeter fur in that one
hello, I have been away from SD for a few months. Can someone help me install and setup SDXL in auto?

A1111 1.6 brings awesome new updates. Especially the long awaited integration of SDXL refiner. Also meta data for Checkpoints. A easy way to edit and save Styles in A1111 and more. hires fix: add an option to use a different checkpoint for second pass. always show extra networks tabs in the UI . use less RAM when creating models. allow selecting...
Also, is SDXL pretty much better than 1.5 in everyway? or no?
its better in some ways but not everyway
well more training parameters or whatever, but it was trained on 1 megapixel images, so 1024x1024, vs 1.5 being 512x512. this means that in order to get good results that mostly lack things like extra limbs you'll need to render images that are around 1 megapixel vs .25 megapixel images with a1111. so 4x the number of pixels. basically takes longer to make images. but they're normally more detailed, and a higher percentage of wins. 1.5 is more of a numbers game, make a bunch, hope a few work out
Really, the only serious detractor right now is the time to process vs 1.5. All the patchwork and add-ons that were used to make 1.5 good are in the process of being brought over to XL, which will only continue to make XL better. Speed will come over time as there are new processes and new hardware. It's inevitable that 1.5 will become outdated over time. But hell, eventually the same thing will happen to XL.
yes but what about the porn
We have to go... deeper ...
so 1024x1024 for sdxl?
Also basic question but where is the checkpoint to download?
Also is the raw checkpoint best rn?
or are there good fine tuned models
Or any other resolution where the sides are divisible by 64 and the total pixels are close to 1 megapixel. I posted a table here: #✨|sdxl message
There are some really great models for XL out right now above and beyond base. Everyone's got their preferences...I like these (among others):
Copax Cute
Copax Melodies
Copax Timeless
Copax Vivid
CrystalClear
DeepBlue
Dreamshaper
Dynavision
Juggernaut
Nightvision
Protovision
NijiSpecial
huggingface has the base model and refiner
some people aren't into it, but you might want to download the refiner model as well
as soul just said

no one really knows what it does, but it refines, so there's that
maybe its like high res fix but laggier
I'm checking Civit like multiple times per day with my main view filtered to XL checkpoints...lol
man, whoever came up with the structure of things on there has problems. I set my preferences to only xl. and then I go there and it shows me all sorts of cool looking loras which I download not thinking. and they're 1.5 loras
what would be the benefit of doing such things?
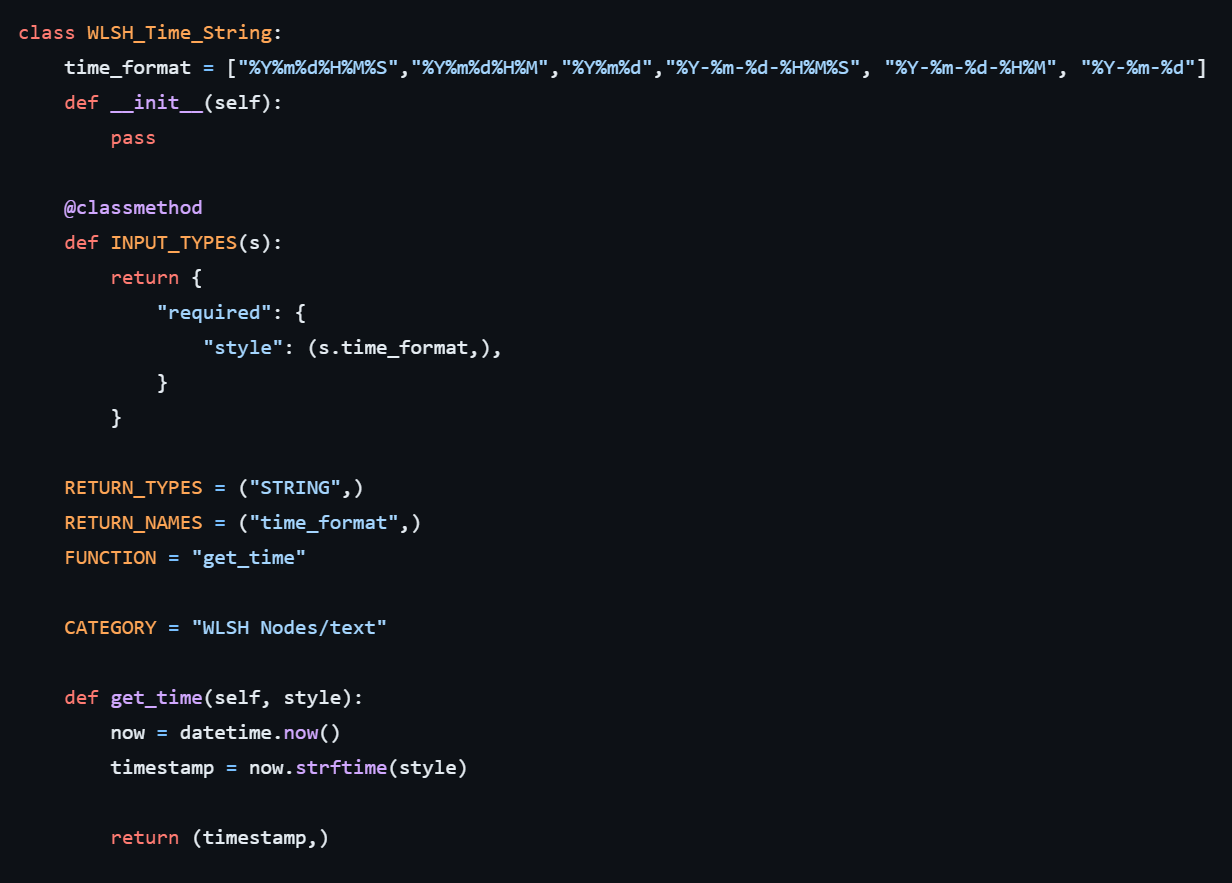
is there a way to prevent a node from delivering / using cached results? i wanted to use a node from "wlsh nodes" to get the time for a filename, but it somehow delivers cached values, so even if i generate minutes apart, it always delivers the time from the first start. this is the code: https://i.imgur.com/9LjfcSx.png
hmm
Are you filtered like this for LoRAs?

no, I just had it set to sdxl 1.0. but it had loras and checkpoints. I'm assuming 1.5 checkpoints as well
It shouldn't show you 1.5 stuff unless the uploader was stupid.
Sometimes there are releases where they've got both a 1.5 AND an XL version, so when you go to the page, you need to look at the top bar to see which one you're looking at and download the right one.
I think it caches everything until it's triggered to change. example being conditioning. if you don't change any of the parameters impacting the conditioning it runs off the cached version
I figured this out when I was modifying the original conditioning data rather than creating new. that gets out of control quickly
For instance, this one has both an XL and 1.5 version:

Does anyone know how many images SDXL was trained on? 2 billion?
but, perhaps you could just change the cached time?
but the seed somehow knows it has to run again. guess that kind of behavior must be transfered to that get time node
you can modify the cached data. but it won't overwrite unless it deems it necessary
well it was trickery. they weren't showing me what I had my setting restricted to. it was just "things you might like" or something along those lines. makes about as much sense as the search setup on there. I turned all that crap off though. or as much as I could
well I also double check what version it's made for.
it's not a big deal, but wasted my time
this is the model download right? https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0

yup
Using base for a bit will get you used to the way you should prompt.
might want a vae
can you train models with dreambooth with xl?
Just try things. That's honestly the best advise to start out with. Once you have it up and running, just try shit.
but they're also baked in sometimes
soul is correct. just get it working and then once you're acclimated and comfortable with the base expand to other things
Ive noticed the same thing. Look at the top left of the image if it has Lora XL before clicking
which one?

2
middle
3 is a lora
cool, thanks for the help
what is the lora version gonna do?
well that's not a version of the model. it's seperate.
basically it adjust the noise offset. just download it and play with it. it'll change the dynamic of the resulting images
but like I said, it's not necessary, just helps with finetuning your results
How to get the refiner?
should be on huggingface
4x longer. 4x the number of pixels
maybe a little longer than that actually. but haven't done the math
I'm running on a 3080.
well is interdimensionalplanetarytv on a1111?
I guess my lora weight is too damn high

lol
goodness 😂
by the time sdxl is done rendering i would have done at least 4 pics on 1.5 with high res fix on ( 1080p)
oh i think it was bc i had high res fix on


bro needs a new haircut
I think it looks alright

That one is nice, Mack.
So are most of yours.
what "switch at" setting is good for the refiner?
Okay. So I use a base step of 20 and then 5 for the refiner.
I don't know much and base my info from what I use of others.
When using base+refiner, it's a bit of a "play with it and see", but like Mack, I was running around 60-80% on base, then refiner for the rest. I did toy with a workflow that was base, then refiner, then base again on top...that gave an interesting and polished look to certain images.
I did the same here actually. I forget whose it was but it was a really interesting way of doing it.
Depending upon what you're doing, that may vary. You're using A1111, I assume?
yes
I get one every 20 seconds. I use COmfy UI
Ah...a lot of us are on ComfyUI.
i should probably switch
comfy is the way
With the right workflow, I can put out a really nice txt2img in under 30 seconds on a 3080.

{kind=link}
{kind=link}
{kind=link}
{kind=link}

Run that same thing but against the 640x1536 resolution.
I bet that will look insane with the taller res.
bro thinks I know how
lol

Seriously, though. Whatever that prompt actually is would look great on that tall aspect ratio.
cyberpunk exterior house art by barclay shaw
The issue is that I'm using a model that is forcing bullshit so the art style won't commit
Ah.

Nightvision, from what I can see, eh?
Yeah. It's a great model but is so not what I thought it was going to be. He made something great here for sure.

File "C:\AI\ComfyUI_windows_portable\ComfyUI\comfy\sample.py", line 42, in broadcast_cond
copy += [[t] + p[1:]]
TypeError: can only concatenate list (not "tuple") to list
stupid tensor
Yeah, I stopped using Nightvision for people and started using it for other things...a similar thought came to mind.
HEY!!!! HOW DID YOU MAKE THESE!!!