#✨|sdxl
1 messages · Page 113 of 1
desktop
Laptops are generally going to be shit compared to desktops on graphics. It's gotten a lot better over the years, but same "model" isn't really the same model in a lot of cases. Mainly because graphics cards have high power requirements which kinda plays against what laptops really need.
It's just a reality. You can do it on a laptop, it's just gonna take longer and/or gonna be more expensive.
cause i feel like the only way i can get access to this cool new technology is to jump through a million hoops with google colab and it'll never work well anyways
To be fair, it's still very early in the tech's maturity. Give it some time and it'll continue to get better, be faster, more accessible, cheaper, etc.
i guess
because u only want a laptop thats where the extra expensive price comes from
i know that
it's just frustrating
and i've had very little luck with sdxl on google colab and no one seems to be able to help me cause i always run into issues no one has ever seen before
When it comes to tech, saving up generally has a double-impact. Not only will you have more money to drop on whatever you're gonna buy, but the tech tends to get better and/or cheaper during the time you're saving up. So my advice would be to put some cash away for a bit and target a later date.
well the problem is i kind of need a new computer
So just get something that's minimally viable for the moment.
and i have way more important things to save up for (house)
eh
i'll try again to figure out colab
i tried stable swarm but it kept not working
same with the camenduru colab
it's whatever
this probably the cheapest https://www.bhphotovideo.com/c/product/1758502-REG/hp_6u715ua_aba_17_3_omen_gaming_laptop.html/specs

Buy HP 17.3" OMEN 17-ck1003nr Gaming Laptop featuring Intel Core i9-12900H 14-Core (12th Gen), 32GB DDR5 RAM | 1TB PCIe M.2 SSD, 17.3" 2560 x 1440 165 Hz IPS Display, NVIDIA GeForce RTX 3080 Ti (16GB GDDR6), SD/SDHC/SDXC Card Reader, Thunderbolt 4 | USB 3.2 Gen 1 | HDMI 2.1, Wi-Fi 6E (802.11ax) | Bluetooth 5.3, Gigabit Ethernet Port, 720p Webcam...
lemme see if there are any used ones
This is friggin wild—thanks for sharing!
https://www.hp.com/us-en/shop/pdp/omen-gaming-laptop-16t-wf000-161-76w28av-1
i assume this one is not the same and will not do as well?
all 4060's have 128 bit bus
ah

Reddit
Explore this post and more from the LocalLLaMA community
Been following GAN since 2018 and I think that is where the future is not with diffusion based algorithms.
well thank you guys for your help
It does look cool, yet my gens never look like the left side. So im curious what generates that image

I'm assuming the low res photos they used were downsamples of high res shots so they could compare the upscaler w/ ground truth
I'd be really interested to see if a downsampled SD generated image would upscale as well
Was thinking exactly that. I would imagine that you could do some really interesting things with that as a method combined with some conditioning.
guess that's why they didn't release the model 🙃

for my bike image at 1024sq I need to zoom in 1600% to see that same pixel level


Nvm, I'm dumb
the zoomed screenshot is the top of the gas tank
unless youre making masssssive images it doesnt seem worth it
what model is this 

It's from a research paper


creating beauty

oh, it's this guy again. I made him earlier

doesn't look like he won the genetic lottery
do you say that just because he's got a row of teeth floating detached in his mouth?
oh, that would point to superior genetics
but his gaze disturbs me a bit

A good checkpoint + good prompt work + fiddling with all the bits + a decent seed value = wonderful results
I still have a few small tweaks to make, but that is almost perfect.
just like this beauty

my waifu

you'll have to get past this fierce beast first

hmm. I think I should see what it'd look like if they had babies and the babies grew up and we took a picture of them
anyone know what this error is about? defniitely not moving models or dispatching them on multiple devices
WARNING:accelerate.big_modeling:You shouldn't move a model when it is dispatched on multiple devices.
WARNING:accelerate.big_modeling:You shouldn't move a model when it is dispatched on multiple devices.

Good enough to post up now.





so much to explore in these 🙂 nice
I like this one

could maybe be a bit more refined, but like the aesthetic
now this guy is definitely refined

who knew these two would make him?

wow...without uninstalling any games I reclaimed 50gb of storage on my C drive by removing crap that was just sitting there
I often hit numbers like that just clearing cached BS. so many programs be like, "oh, ya got some space? how about we fill it?"
exactly it was mostly cache
now I will acknowledge that my primary drive is only 500 gb which is undersized imo. but I store pretty much all media and things on other drives. I'll clear 120 gb of data and the next day it'll be down to 30 somehow
Im considering playing Starfield so that needs 125gb, then CP77 Phantom Liberty in less than a month probably another 40-50gb there
I should just get a 2gb M2 SSD and store all games on that
Plus two 16TB drives for the wealth of gens
surprisingly all my saved gens are under 20gb
I delete a lot
oops realised I typed 2gb, I meant 2Tb drive😆
16tb, lol. I mean, I'm not against it. but I've indiscriminately dumped things onto a 5 tb drive for the last year and it still has plenty of space



sadly it doesnt know Beaker or Swedish Chef from the muppets

hello ladies

close enough



real







this looks insane 🤯 https://magic-edit.github.io/

Don't let your SD blind you to what he was doing or saying. He was showing just how 128px became 1024pix etc...
even 8x upscale, I rarely ever do. I would prefer see a 1k image at 4x and see what it adds then. Im sure its so small that current upscalers are just fine
Couple randoms for you ❤️














Someone brought a gorilla suit to a gun fight
and hes pointin the gun down there 
It seems to be working






I've gotta say, I admire your tenacity in sticking to Steven Seagal images lol
well i gotta kill time while i generate hundreds of imgs on 1.5 😂







whats the different between this two?

if you don't know the difference I'd suggest method 2
it's more plug and play
option 1 requires more command line stuff
okay thankyou
with option 2 it should create a .bat file you can use to open comfy
how to download this

I'm assuming you're using windows?
yep
i can type in here right?
that's where it should be installed
okay then

next how
just paste this?

🙇♂️

it shows this

meh, not ideal but shouldn't cause anything to stop working
ohh okay
there are so many finicky little things with these libraries
witness him

but the file .bat doesn't show up
well where are you looking for it?


@toxic moss i made some IMG2IMG workflow just not sure if it works properly. If you want test it?
Some morning SDXL/ComfyUI surrealism





You can forget this. It's simply a note to the developer to change something later!
SO the image above was the ReVisioned output of my workflow
This is the IpAdaptor output of the same input images & seed & weights ;o)


I think I have some work to do on the IpAdaptor side of things 🙂
I shall call this one "Mr Hangover Cure"

nice
so how does the ipadaptor really differ? I still haven't gotten around to trying it. I probably should
dunno yet, from what I've seen elsewhere it does more of a merge (potentiallY) but it really depends how its configured. Only just started playing with it
This is slightly better actually using a Prompt to "guide" Ipadaptor . Not saying thsi is the right way but....
I can see how its taken my prompt & the info in the 2 images to produce the final output



happy with the way my ReVision setup is working though 🙂
yeah, I've been messing with clip vision a lot. not sure if that' revision, or unclip or what it's called these days. but interesting results sometimes
very strange how the exact same input can be so different depending on the prompt
like, not even remotely the same
dont forget that "ipadaptor" is different to "revision" even though they share some commonality
I think I'll download the model while it's in my mind
"Is iPad Aptor different to iPad Pro?!" 🥳
yes
Yes. It’s onion encrypted
that is a weird puppy XD (i missed my A1111 randomizer)


implications that dairy is good for bones?



lol
you trained johnny depp's lora?
probably can be done with prompting only on sdxl models
SDXL know depp well
does it do depp when prompting for pirate?

that's propmting jack sparrow




anyone know why is this happening?

Not I
it only render half way and pause















randomizer prompt going haywire ❤️




i just press generate, stuff comes out 😄
sdxl models are the best thing that happened to my prompting style





I am currently playing around with SDXL 1.0, coming from 1.5. It seems like all my pictures are soft / way to much bokeh in SDXL. Is there any way to avoid it?
enough steps/proper workflow or up to date A1111?
never tried it but I've seen this here on reddit: https://www.reddit.com/r/StableDiffusion/comments/15wgbwr/new_soap_photo_enhancement_lora_bye_bye_blurry/

Reddit
Explore this post and more from the StableDiffusion community
dog+birthday cake=..?

@indigo carbon when would you release your workflow with image blend? want to try it out and see what different between revision
I won't release it until I'm as confident with it as I was with the normal AIT one when I released it
1 difference right from the start is revision doesn't use AIT, so it's automatically better

how do you clip skip at comfy?
If you're on SDXL, you don't really need to.
But I believe you'd use CLIPSetLastLayer.
which node does it?
That is the node.
it will lose the ability to do text
agree. I tried it and found it made worse images
when clip skipping, coherency decreases
XL...ahem, excels at not needing it.
nvm ill find myself
i know, thank you
CLIPSetLastLayer is a somewhat useless node.. it makes SDXL lose its high coherency
I can see why it would be useful for 1,5 models though

Trigger word is flm
Just sharing a lora I trained on frames from documentaries filmed in the 1960s
seems alright even with clip skip, somewhat more coherent in some areas
text is lost when doing that.. try it
nothing lost, everything present
doesn't seem like a problem

hand/leg/machinery seems less coherent
text also
it can't do full sentences like it can without clip skip



try a cake without layers

THAT CAKE FLAT AS A FEMALE DOG!
I have recently found out that the word "bitch" is derogatory.

relax man
i'm just combining images, not offending anyone
No. I poorly conveyed my joke.
dang it.
Now I'm upset that I made you feel a way that is unintended.







That's just plugging a primitive into the clip_skip
clip skip -1

-2

Recommend me some good SDXL LoRAs? Please 🙂
it seems performance of A1111 is way better than it used to be, but still 1024x1024 almost 30 seconds. Still too much. Also getting back i felt bit confused 🙂
I just released a 1960s lora




Cool - if it's at Civit - I will d/l
Trigger word is flm The model was trained on 3000 frames from various documentaries filmed in the 1960s to try and capture diversity in people, obj...
Thank You, me got it - just introduce this new LoRA into Comfy here ...
1960's LoRA and Underwater LoRA together ...

The 1960's LoRA introduces a small amount of realism into my current w/flow - its nice

Hey guys, i tried to install TemporalKit with HuggingFace, but it corrupted my whole Stable Diffusion.. Do you know where i can find a clean version that work of the tqdm.py file ? From \venv\Lib\site-packages\huggingface_hub\utils ?





this is a weird pizza


I like it. Nice work

@peak dove you might also like my melting candles lora, since it's more 'arty' ;D https://civitai.com/models/127822/melting-candles

Trigger Word: mlt For basic prompts it will create a beautiful melting wax and candle scene. For more complex prompts with other style tokens, it s...

2 x 1960's LoRA in Sytan's W/Flow (no UpScale)




aight, imma do some groceries and leave pc on generate forever 😄
full random max mode is enabled, i'm sure some interesting stuff will come rolling out
I d/loaded - thank you
thanks mate


looks good!
It has definition - very well defined.
My arty stuff is normally a lot looser ...
is that the candles lora?
No, I'm trying Candles now, but mixed with 60's - 60's seems to be winning - no melts yet.
I will put both LoRAs to Candles ...


@indigo carbon you might be interested aswell

did you put mlt in the prompt?
No. I thought just the LoRA? OK, I will add mlt
yeah trigger word makes the effect much stronger, the trigger word for the 1960s lora is 'flm'
and the answer was?
hahha, well it depends what you are looking for. Clip vision interprets, with IPA interpreting more inconsistently, and IPA give you the best IMG2IMG bang for your buck
here's another example all at default weights

Just a reroll
Notice how #3 doesnt change
and how different #2 was
It seems to be melting the whole picture - which sometimes looks incredible!!!

It actually brings candy-colored supersaturation - also looks incredible!!!


Nothing outright melty ... yet!
Good hands limbs fingers etc'
added one more, Revision + IPA at the top RHS

My w/flow is not conducive to that melted candle wax look ... mebbe if I changed my prompt?
I am getting balloons - nothing in the prompt suggests balloons - but mlt seems to like them



mlt also "arraigns" the subject - bolt upright, to camera, centred, dark hair.
I will work on some prompts to see if I can encourage mlt to diverse and differentiated looks
The training images were melting objects on a table
Perhaps the balloons are actually blobs of wax - mebbe my prompts are too much work for the LoRA to easily deal with!
But if I ever need candy-colored saturation - mlt will be there!
Could be yeah. But I also like the effect it has on colour and lighting
Sharp, bright, saturated, outdoor - yes, its a cool look
If you do a basic prompt with only a few words you will probably get something closer to the training images
I've just posted the workflow that includes the clip skip on Civitai, if you want it.
Have you noticed the countdown at: https://fantasy.ai/comingsoon The SDXL workflow includes wildcards, base+refiner stages, Ultimate SD Upscaler (u...
Yes, some LoRAs respond better to a simpler prompt. I will try that!
L8r - and thaks for the LoRAs!
What is this? 🙂

looks like you've visualized gravity 🤔 while making it look like food...
i would like to hire you to write my prompts
lol
i uh, need to lie down





i dont know how i got here

so you've build a latent space kaleidoscope

Im getting lost

very nice 🙂
these are generated by recycling clip space
Those look great
This is random as well

I wasnt trying to build this, but now that its built, i cant stop

not sure yet where I ended up here, but let's explore it 😉

is it possible to keep the exact same angle with img2img?

can nmkd use sdxl models?/
do you mean, can you use nmkd upscalers on sdxl?
Yes mostly
nmkd sd gui

Pure Lucian Freud. While others upload fake loras, i completely recommend fr3u xl loras. They work great.



let me make the ones that we have seen and that come from the most advanced civilizations
not sure if 3 black blob are even hands
there are ofcourse less smart civilizations visiting us as well, like the ones that keep crashing
between you and me, i dont think they crashed. i think other aliens shot them.


Lucian Freud manga


technically if you threw a rock really fast to someone it become UFO for a bit

cuz UFO aren't necessity space craft
they're all unidentified flying object
technically underwear can be UFO if they didn't find out

awesome images 🙂
nmkd sd gui have you tried it?

No, sorry not familiar
once long time ago..
if it's in the sky and I can't identify it it's an UFO or UAP. if it's in the water it's an USO

what's USO? United Service Organizations?
👀
prob not right
Coffee spot Dali style

Unidentified submerged object
also here's my attempt at saucer

interesting interpretation




if you want realistic make ||chinese spy balloon||
🤣

Yay for causal racism, amirite guys?
hmm, im almost out of fruit, might need to go get some more

if it makes me scared then its a great concept
sure it's an ufo

nice barrier it got there










i um....yikes
supertornadoes

Legit those can exist.

Ive always wanted to see one, and then i got some sense, and now never want to see one
^
A curious facts about UFOs is now cameras are much better than in the 60s but UFO photographs are equally crappy
mines coming up
i would like some HD UFO pics



how have you done it, with revision?
have you seen that @EyesOnCinema channel that just popped up on youtube?
it's got all these reports, interviews and witness testimonies, as if someone from the u.s. government is behind it.
it's like one of the most remarkable channels on youtube.
let me emphasize credible. this ain't no history channel BS.
Revision, IPA Clip Vision Only, IPA + Clip Vision, IPA, Revision + IPA
Will investigate a bit. The only IPA i know is the beer
Pick your favorite of those pictures and focus on that, this workflow is just to demonstrate the possibilities

the end..

b&w ufo reminds me plan9 🙂
whats that?
lmao.. that trailer cracked me up ..
true classic indeed
The man has turned into a legend
check Tim Burton movie about him: https://www.imdb.com/title/tt0109707/
UFOs are UAP now!! https://www.cbsnews.com/news/what-are-uaps-unexplained-aerial-phenomenon-ufos-new-name/

A former intelligence officer-turned-whistleblower and two pilots testified before Congress about the strange, seemingly inexplicable objects.
Some more using the flm 1960's LoRA (inter alia)!






man, all these cases
like the ariel school encounter in zimbabwe, some 30-50 children saw it
colors spared by generating of AI images

it landed, and people came out
every child had the exact same story, its impossble they could have all lied
majority white children, few blacks

i'm trying to describe that ufo that was seen outside the coast of san diego i think?

like everybody thinks that the more advanced a civilization is, the more details are on their craft
it's by our observation the exact opposite
"a single transparent bubble sphere enclosing one solid dark grey geometric cube with its edges touching the inside of the sphere, in the sky outside california, high angle, few clouds, ufo, photograph, ultra realistic, otherworldly, void of details"




almost! nice bg btw
just noticing some checkpoints I've been using don't have the fixed vae baked in, so they have that vae issue still in the images




use the 0.9 vae
Yeah, I'd just have expected finetunes to know that and have that baked in
but htey clearly don't
I gave up on using baked in vaes a long time ago
always explicitly specify
even on sd 1.5 there's only like two people use
Yeah gonna for suure do that now.
Just thought I'd bring it up in here in case others don't know

What checkpoint?
I haven't gone through all mine yet, but checked Zavychroma and sdvn7RealArtxl
Protovision looks ok
nightvisionxl


ah, seems they used the right vae then, or you have the right one manually haha
i am using external vae..
agnes kittelsen 😁

nightvision got baked vae i think, depends probably on version
Gotcha, then yeah that'll mitigate the issue.
Again, I just had expected the finetuners to know to not use the broken vae
Just a normal group of people sitting around having conversations in a bedroom.

dim light
whats up with the faces?!
Why, whatever do you mean? Those are totally just hu-man faces.
👽
tf
cute animals on end 😄





I don't know about the rest of you, but I'm totally into hanging out, fully clothed, just standing around in someone's bedroom in awkward groupings.

sure... me too

I have it for sure, just didn't think I'd have to specify using it after the finetunes started coming out
sdxl baked vaes never gave me any issues.. may be u r doing something wrong
There's nothing to do wrong.
use baked in vae, get vae issue. use manually selected vae, get no vae issue.
haven't checked many other checkpoints, but again, Zavy has the issue, sdvn7Realart has the issue.
Not sure beyond those two yet
well.. comfyui?
yah comfy
image res?
832x1216
1344x768
412x 609
crop
i always do 2k or 4k . so i dont usually notice those small artifacts

Yeah I upscale 2x usually.
I hadn't noticed the issue until just now because I was messing with face detailer and actually zooming in on my images to check how it stitched. Then started to notice the pattern with the base images.
These are the two images for these eyes



so at a glance, not gonna notice at all
but the issue is there. Most won't care because it's hardly noticeable from general viewing of the images. But when it comes to being able to fix it vs not fixing it, I'll always opt to fix it
nice

this also looks like the same artifacts when using the broken VAE of SDXL 1.0 and not the working 0.9 one
Yup that's exactly it

sdxl original vae
Original 1.0 vae

The generally recognized vae issue they released the 0.9 vae to resolve
0.9 fixed vae

hmm
anyone know if there's a node similar to primitive which would loop back through the list once the incremental counting hits the end of the list?
Primitive counts up, then stays at the end of the list
decided to try out adobe firefly just to remove something from an image, and it plastered it with a huge bright red adobe logo. pretty top notch service there
May look at the primitive node code and see if I can add that loop in somehow
there's a WAS node where you can restrict a range. not sure though if it loops
"Oh, you want this removed? No problem, here you go!"
ADOBE™️
hmm, would it stick to the value it's connected to? Like in this instance connecting the primitive to a boolean_number, I just simply want it to go from 0,1,0,1,0,1,0,1 each time I hit queue prompt
I find it somewhat ironic that i'll now be using adobe photoshop to remove their watermark
there're over 100 nodes in the WAS package - so maybe, but you could definitely do it with the EVAL nodes of Efficiency Nodes (https://github.com/LucianoCirino/efficiency-nodes-comfyui) because you can just use SimpleEval python expressions.
so this could work as a workaround for what you want to do

Inpainting, depending upon what you're trying to remove, can be really good at getting rid of watermarks. I had a tricky gradient area that I had to clean up and it was able to navigate that very well.
yeah, I will probably do that in the future. but I haven't inpainted much with comfy. not saying it's complex, but also wanted to check out firefly
🤔 Hmm didn't think about that, I'll fiddle with this, thanks for the extra brain haha
tbf it did do a good job of removing what I wanted, lol
but didn't realize they'd add something else
I didn't end up using comfy for that job...just was a fast job in A1^4
I mean, it'll be super easy to fix. but just wanted to remove the logo from the gray scale image of the shirt so I could put something else on it


or check the Number Operation or Number Counter (which has a reset_bool pin) node in the WAS package
they basically just decided to give me a couple minutes of extra busy work
just use photoshop beta
I'd have been tempted to pad a ton of white space around the image so that their watermark wouldn't overlap the shirt
yes, that's what I'm doing. but does photoshop beta have the same tool in it? if so I haven't been able to find it
ooh that may work also. Gives me a few things to test out here
Appreciate it
well I have the original image so I'll paste the new one and then erase the logo. it's just dumb and pointless
I just joined their discord to raise a ruckus, lol. well not that much, but I don't really think it's a reasonable approach. put a watermark on if you want, but could be a bit more subtle
its there.. no way to miss it.. just select area type prompt or leave it blank thats it..
huh? I've never seen an option to type a prompt into anything but then I've never really tried I guess
okay, crisis averted


Is that good?
with text

Except it's not adjusting the letters very well for the way the fabric is sitting.
so what I'm doing is removing one logo, then adding another one. and using that image I posted as a displacement map
ideogram.ai is exceptionally good at text

told my friend I'd help him out with his silly little t-shirt business dream
phenomenal with text 😄
struggles with hand 



The Searge-SDXL v4.0 workflow and custom nodes for ComfyUI are now released on CivitAI and the projects Github page. There is now an install script that should make it easier than before to update to the latest version and get everything set up correctly.

Searge-SDXL: EVOLVED v4.0 Version 4.0 is here. I made a convenient install script that can install the extension and workflow, the python dependenc...

does anyone know whats wrong with this?

There's nothing "wrong" with it.
need to add that folder to paths in system environment settings
It's literally telling you what to do.
type "env" into search
you'll see system properties or something. click that, go to advanced
The path will be something like:
C:\Users\userrname\AppData\Local\Programs\Python\Python311\Scripts
But whatever version you're running.
and there will be an "environment variables" option
Actually...your screenshot shows your path to add.

i got those errors as well, as well i was puzzled.











1B-parameter GigaGAN
two minute papers video with some examples: https://www.youtube.com/watch?v=UyoXmHS-KGc
more examples:
https://mingukkang.github.io/GigaGAN/
implementation:
https://github.com/lucidrains/gigagan-pytorch
GitHub
Implementation of GigaGAN, new SOTA GAN out of Adobe. Culmination of nearly a decade of research into GANs - GitHub - lucidrains/gigagan-pytorch: Implementation of GigaGAN, new SOTA GAN out of Adob...





Hi, if I was wanting to do an animation using sdxl what would be the best way?
I’ve used an animation script with automation 1111 before, and messed with deforum, but that’s not available for sdxl I think
Yep, that is the future not this diffusion based stuff I firmly believe. Speed alone will win out.





I didn’t see it here, so here you go: InvokeAI has been spaghettified (aka now has working nodes)

GitHub
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an ind...





Just toying a bit around with ipadapter for 1.5 and sdxl, and the sdxl version seems to want to significantly want to copy the style of the drawing, and way to prevent that?






90s comedy sitcom cover





Reduce the strength to below .3
You can also use the clip vision > unclip conditioning to add weight to your prompt

do you have a workflow with the ip adapter nodes?
Headed off to bed now, I'll try it tomorrow thanks
I fixed it partly with sdxl text styles
At least it looked better
Not at desk but I can send something when I get back to it, what are you looking for. I have allot of workflows 😉


SDXL?
Have Fun

Play with the weights a bunch to get a feel for it

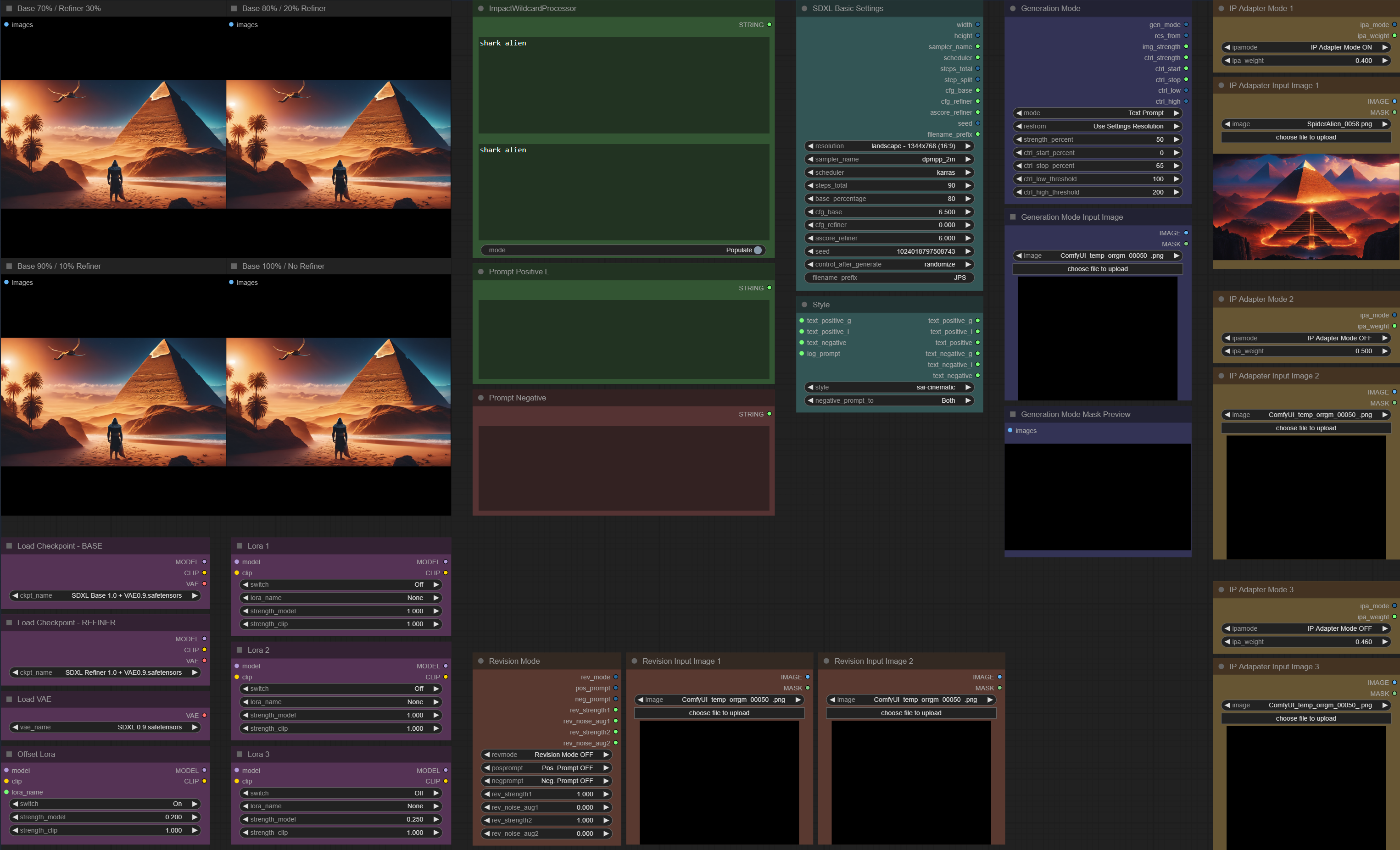
Major update of my workflow with many improvements (new layout of the menu, use image size or size from settings, wildcard prompts, style options, resizing of images to recommended SDXL resolutions, own nodes to reduce amount of nodes needed for some calculations, etc.)
https://user-images.githubusercontent.com/142158778/264802323-99d60e13-d150-4b04-af0f-27c0b80189fa.png
https://user-images.githubusercontent.com/142158778/264802453-19d867a4-6fb9-423b-915f-121a2484733c.png
https://github.com/JPS-GER/JPS-ComfyUI-Workflows



GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
Looking forward to checking this one out
There’s no model here though, right? Like—this is great if you’re interested in training your own 1B parameter model over the course of a month on cloud A100s but it’s practically useless to non researchers?
Yep

@strong field the styles feature is great. allows to create much better images in many different styles with simple prompt by using SAI styles and some others.
Ty! Not in my PC anymore. Will try it tomorrow!
Did some more testing of various checkpoints with the checkpoints included vae (I of course don't have all the checkpoints). Noted which ones contain the 1.0 vae issue. Mitigate by using a vae loader for the 0.9 vae instead manually.
altxl_V50 GOOD
bluepencilxl_V021 GOOD
cherrypickerxl_v20 GOOD
copaxvividxl_v10 GOOD
copaxvividxlv2 GOOD
counterfeitxl BAD
crystalclearxl_ccxl Strangely just a little, but considered bad
dreamshaperxl10_alpha2xl10 GOOD
duchaitenaiartsdxl_v09 GOOD
dynavisionxlallinonestyalized_beta0411bakedvae GOOD
juggernautxl_version1 GOOD
nightvisionxlphotorealisticportrait_beta0702bakedvae GOOD
protovisionxlhighfidelity3d_beta0520bakedvae GOOD
pyrosnsfwsdxl_v012e6 GOOD
sdvn7realartxl_beta2 BAD
zavychromaxl_b2 BAD
Excellent info here





you know a bit about the IPAdaptor stuff. I was wondering about a couple things
I've had a few outputs that were just black images. but seems like restricting image size might fix that? or am I imagining things?
also haven't really figured out what the mask input is for. I guess I coudl send a mask to it and see

Steven Z'Dar Seagal

alright, the IPAdaptor is pretty cool. should've got this earlier
Taylor Z'Dar Swift

I can't stop staring
malfoy

hes fightin cancer




]]a]]


STARFIELD Full Gameplay Walkthrough / No Commentary 【FULL GAME】4K 60FPS Ultra HD includes the full story, ending and final boss of the game. The game was played, recorded and edited by Gamer’s Little Playground team. We recorded the game in 4K 60FPS on Steam PC. In short, the video includes the full game, ending and all story related scenes. The...
full game

real picture



I keep getting that. I think it's an error error. Are you running more than one instance of comfy?
nope








How could I save an image in custom path outside comfyui folder? Just enter the full path?
edit the bat file and add this, with your folder
--output-directory D:\SD_Output
Could you add it to this? https://github.com/comfyanonymous/ComfyUI/blob/master/extra_model_paths.yaml.example

GitHub
A powerful and modular stable diffusion GUI with a graph/nodes interface. - comfyanonymous/ComfyUI




Thanks for your help. But I want to change the dir in process
Im not sure you can











I've spent some time upgrading the color transfer method even further. It now runs on GPU for batch processing (animation ready) and works by extracting, mapping, and swapping color palettes. AND it can be used with masks. The code is tested and working nicely. Now I just need to get it into ComfyUI.
Hoping to have it out this weekend.














A version of the AIT workflow, but this one does img+img, instead of text2img. [REQUIRED NODES/MODELS]: - https://github.com/FizzleDorf/AIT - https...
published, as requested.
appreciated

batch 4 isn't on linux yet
ah
change to 1
@hoary saddle if you want to contribute; you can compile the modules for linux yourself, people will appreciate that
the reason I decided to upload it, is because I'm confident with it now; it can blend images very nicely

the craziest part about this is; I managed to make this workflow in a way that it still uses AIT while achieving img+img very nicely
Awesome work. I am having better results not using the base XL checkpioint for some reason. Finetune models seem blend easier


@visual glade Is there a way to change the output image folder by chance? I need to keep some images from different workflows separate
I'm using Copax_colorful, but that also seems to work!
Just asked this question. LUL
oh shit, really? lmao
this is my workflow

test/ComfyUI in the save image node will create a new folder named "test"
You could set output-directory to a root folder. The save image function able to create subfolder
dope!
I remember doing that once, but I need these images on a different drive to save space
ah
You could use symbolic link (mklink command) to link different driver to a folder

you can also weight them accordingly to output if you want it to be more imageA than imageB
need a lot of E in D
not sure the weights were the problem as the blended image was totally different to both input images
on base right?
well, the finetunings are definately better than base anyways so..
lotta files to scrub

getting that with 3 and 4 on Windows
I need to get a big HDD to offload a lot of my cache files
I did that yesterday and reclaimed 50gb
lol. I feel your pain

so much cache garbage sitting around
you don't have the latest version of the node then. it should do BS1,2,4 just fine if you're on windows
google drive really takes a lot of liberties
I have like 300GB of caches
this one is a 130GB cache of my moms old drive

Well, cool to know cause I am not chasing updates daily. Get the update tomorrow if there is one. How do I even know what version I am using?
oh no, I mean I have caches for files I save
ahh, I have an external drive for that stuff. need a bigger ssd though
nodes get updates constantly, I think there is a button on manager to update all nodes
Would be nice to know what version it is though
I got burned a lot chasing updates so I am once bitten twice shy with this stuff
yeah, mine is 500. I'll clear up 150 gb then a few days later I'll have 100+ gb of trash cache garbage
I told it to fetch updates and all it said was there is a node that needs to be updated but didn't do it for me.
I have 2x 1TB NVMe Drives, 1x2TB NVMe drive, and a 512GB SATA SSD
I wanna get like a 4TB HDD
didn't even tell me which one either, lol
I have a 5 tb hdd. I dump any and all things on it and still have a couple tb of space left
yep, a lot of ones show update but funny how fetch updates doesn't actually fetch the updates
holy shit, I found my culprit
my old SD install

just deleted 31GB of just old VENV's
Rookie league
I had 1 venv of about 15GB. Not sure why that thing was so huge but buh bye to it
my oobabooga venv hit 95 gb somehow and didn't even work so I zapped that one
wait
that was wsl
lol
LOL, that one I did keep but it gets HUGE
wrong letters
ooba does work though I just barely use it
yeah, 95 gb would be a beast
I have it installed but haven't messed with it lately
gotta use deepspeed with it. not sure exactly how deepspeed works but sped mine up substantially
deepspeed I could not get to work
it's only for LLMs and it's only for Linux
were you running it in windows?
you would think Microsoft, and windows it would just work
yeah, wouldn't work for me except with linux
I don't think I have tried it on Linux but if I did it didn't work either.
it was for kohya_ss
had no issues with it in linux
come to find out for training a LoRA it can't be done. well, shit.
lol
I want to know how to train llm loras. I haven't found a solid source that explains it
I know training llm is being done but not sure if lora or not
they're a thing, but also really restrictive at the moment. you need to use them with the same exact model architecture they were trained on
Since I haven't seen anything with loading a lora llm yet not sure
and there are a thousand different architecture. open source llms are like weed strains
yes
they're named like them, there are countless crossbreeds
well, loras for SD is supposed to be like that and if it works on any other model great or it may do weird shit or not work at all. Probably the same in llm world
YOOOOO
wizard vicuna blue dolphin kush
go on
I found all of my 3D printer profiles backed up to a little folder I forgot I made!
I have been struggling so hard to replicate all of these profiles!
These took like 2 years to finetune


Nice find

excellent. put them on the cloud!
Once a 3d printer is finetuned those are gold
SOB, updating broke AIT
TypeError: cat() received an invalid combination of arguments - got (Tensor, dim=int), but expected one of:
- (tuple of Tensors tensors, int dim, *, Tensor out)
- (tuple of Tensors tensors, name dim, *, Tensor out)
Prompt executed in 7.50 seconds
Yep, I removed the ait nodes and it works
what was that about updating again?
you have some funky things happening regularly on your PC. I update all the time and never have errors
might be worth clean wiping your windows/linux and starting fresh
The newest ComfyUI commit is incompatible, merge with an older one.
looks like General Awareness isn't the only one with AIT problems after the latest update
Idk why Comfy keeps breaking AIT and requires us to change the code after every few commits
Wait, the update I did for comfy right before it broke it? Ugh. Thanks
Yes. It almost feels intentional LOL. Idk why would Comfy make the UI incompatible with AIT after every few commits..
Might make a fork that is compatible
Sounds a bit like what Auto did with his program that pissed off all the extension devs.
If it ain't broken, don't break it..
LOL

That's a moto that people like Comfy should consider before making updates that break important nodes almost intentionally(no offense, this is just how it feels..)
I might make a fork of a compatible merged branch or something, because this is just ridiculous at this point unless Comfy will fix compatibility
Why is SDXL so bad? It trains okay but leans too heavily towards realism
Auto is bad about that too but they gotta break stuff
Even perfect trains 3/10 times turn to realism if its another style
thats 30 percent
I know with Auto the extension devs said it was because their is no back channel for them to test and stuff.
GA you got an answer? You have a great style that keeps turning to realism so I know you get what I'm saying
Mine did as well. Change seed and it pops into realism but I never trained on realistic art.
Anyways @vital ermine the fix for that issue is to merge with a branch from a few days ago. I hope Comfy won't do this again
This channel loves to ignore questions they dont have an answer too 🤷♂️
Do you have a commit? do a hard reset to it?
No, just merge with the earliest commit from August 28th, that's the one I use
True, very true. I wish I had an answer as it bit me in the ass but I suppose I just need to erase my drive and reinstall Windows to fix that.
Lol fuck reinstalling windows, thats not a solution. If you have to reinstall windows, someone messed up their python code
Well, that is what a venv is supposed to be for so you will never need to zap the os
If it leaks out of the venv someones code is bad
Yep, and there are a lot of bad devs out there.
Most of these devs don't even answer github issues so  but Comfy wont even acknowledge features are needed, its all about the "back-end" and apparently this front end they made "to learn" doesn't matter anymore
but Comfy wont even acknowledge features are needed, its all about the "back-end" and apparently this front end they made "to learn" doesn't matter anymore
In this case it was comfy, but you have had so many things break it has to be more at issue.
Dude, for real? Okay, if you say so.
Bruh has brand new hardware, a fresh hard drive, and you're going to say its his fault when all he installs is SD related things?
half of them being made by comfy or Kohya et al
He has to be trolling or just pulling my leg for fun. No worries.
I never blamed anyone for fault.
GitHub
Leaving this PR open for now as people are on older commits and this would break it. When the memory issue is fixed with latest I will merge.
Well you did say he should reinstall windows, which implies that he fucked up somewhere
the reason this extension breaks is because it overrides a bunch of comfyui code
but that one was my fault
if you see it that way. whatever
How did you mean it? I'd love to be wrong
software isnt perfect. it doesnt mean he was at fault
Ah I see. So for now we just stay on older commits?
No but somewhere, along the way, someone did something wrong
Software doesnt break on its own once working
hey man plz help me a bit i have a question
can i use custom image at the end of deforum ?
under animation
Fact is venv's very existence is why what he said was full of it. It was made to protect the system so infection of bad code should not be able to escape into the main system, and besides if he could read code he would have seen that error was saying it isn't the end usersd fault. Got an int expected a tuple. simple.
Yeah int expected tuple is always a code issue
well I spent 2-3 hours not long ago helping him sort out software conflicts.. so yeah
pretty sure comfy himself mentioned this a long time ago
#✨|sdxl message
I help him daily, though he is very capable on his own, your point?
If iA3 breaks comfy code and is not implemented how did AIT code that breaks a good chunk of comfy code in this?
Why is AIT supported if iA3 isn't. Thats my question. AIT breaks more than adding an extra network type does
Not being Auto1111 is not an answer
But why did you even attempt to if iA3 isn't in the works?
AIT is more complicated than letting the unet adjust to the model instead of model adjust to unet
AIT is way more important than iA3 support
But Why?
because iA3 isn't an actual lora, it's a patch on the network
AIT, 50% speed increase is not better than something that trains perfectly with the same settings between styles, concepts, and subjects
iA3 isn't a lora but why does that matter
It's a new network
BINGO
Hmmm, good question.
lora just require modifying the weights
iA3 require modifying the network like hypernetworks
Kohya's official extension even had options for more networks, but never took off on that. I'm just genuinely curious why no one though outside of LoRA?
which HN rocked
What is SAI paying you?
Are you referring to the ComfyUI repo, or the AIT repo?
the ComfyUI repo
To not support anythign besides lora
Huh, you implemented it yet?
I know SAI doesn't want anything besides LoRA because SDXL is broken, and has a lot of issues, but someone needs to admit that
yes I just want to try reducing memory usage a bit before publishing my version
THe refiner is the main sayer of all that
What about speed? Is it as fast as the node?
yeah it's the same speed
I just want to try reducing memory usage a bit so that it can fit well on 8GB GPUs
Remember when LoRA was the start of "Additional Networks"? Guess that is gone
Nice to hear. Does it mean AIT coming soon with comfyui latest update when released?
We just have LoRA, DB, and FT, which is just a new model
Comfy, do you even know calculus?
cmon dude
You don't know this shit, and just learned the FastAI implementation of CNN's, admit it
why the salt
Because he won't acknowledge the ACTUAL questions being asked
Will it be shipped with compile scripts for people that want to compile on their own?
of course, there will be an easy compile script with instructions for windows
and it will let you compile every type of model that comfyui supports
I see. What about CLIP_vision and ESRGAN?
but not iA3, the best LoRA equivalent currently available
it already does but like I said I want to try to improve some things first
oh the first release is going to be for the unet only
I wouldn't either if someone was trying to talk to me that way 🤷🏻♂️
it will use the pytorch implementations for the clip and VAE
The custom node has CNET and CLIP vision, is it an issue with the compilation scripts or you just didn't compile the modules?
I'm asking in a factual manner, any REAL dev would aknowledge the questions but comfy wont because he is an SAI shill
lol blocks me
I'm just focusing completely on the unet because that's the most important part
and the part in the custom node that breaks every time I change something
You;ve never provided anything of substance to this channel, I was the first one to share my sdxl training settings and no one was grateful, so yeah, lol
ok 👍🏻

Yeah, I know. But will it be usable with CLIP vision and CNET? Or will it break when used with stuff other than K_sampler
It will break with anything other than ksampler because comfy is copy pasting code form the huggingface diffusers section
there's zero code from diffusers in my codebase
Jesus, leave Comfy alone. He is doing a great job and you're being rude for no reason. I advise the mods to step in at this point.
He doesn;t answer actual questions about his software, just the same rehashed questions from reddit and github, so no
yeah I'll make it work with controlnets/t2i
Will it be in the form of a node like the custom one is or something you select in K_sampler?
i want to add custom image at end of the animation
it's going to be completely transparent, that means you set it up and the regular sampler node will use it automatically
Yo sorry comfy but that was literally a test of the mods, thats sad that no one stepped in, I was being a dick

{kind=link}
{kind=link}
You're doing fine
So to make the workflows I made compatible just remove the AIT node?
yeah that's how it's going to work, just use the regular sampler node
Damn, I was afraid for the cat. :/
if you pick settings that are not supported it will switch to the pytorch implementation
Any plans for support for none LoRA networks? Not iA3 but just something new, things are getting stale imo
which commit do I do a hard reset to so I can finish making 650 reg images?
Could we know when it was AIT on or off?
Other than the generating speed
yeah I'll make it print something for debugging
cant be AIT by default keep in memory = disabled, as it cause lot of crashes when one forgot?
ComfyUI on Ideogram.ai


Does clip skip really do anything in XL as 2.x it did nothing due to the different clip being used and XL uses the same clip I think.
I know in 2.1 I tried it and never saw any difference then finally read why that was. Made sense but in 1.5 it did make a difference.
Is there a release date for when that's going to happen?

Using HumbleMikey's 1960's LoRA

I don't commit to release dates
I'm asking because I'm unsure if I should provide modules for ESRGAN due to you likely releasing it before