#✨|sdxl
1 messages · Page 108 of 1
and for the next seed it rewote the initial as "A photo of a translucent, hexagonal dome tent with holographic patterns, set up amidst lush greenery and towering trees, showcasing its advanced design and eco-friendly materials."
Although, the guy said he just implemented it in the node - https://github.com/laksjdjf/IPAdapter-ComfyUI/issues/11

GitHub
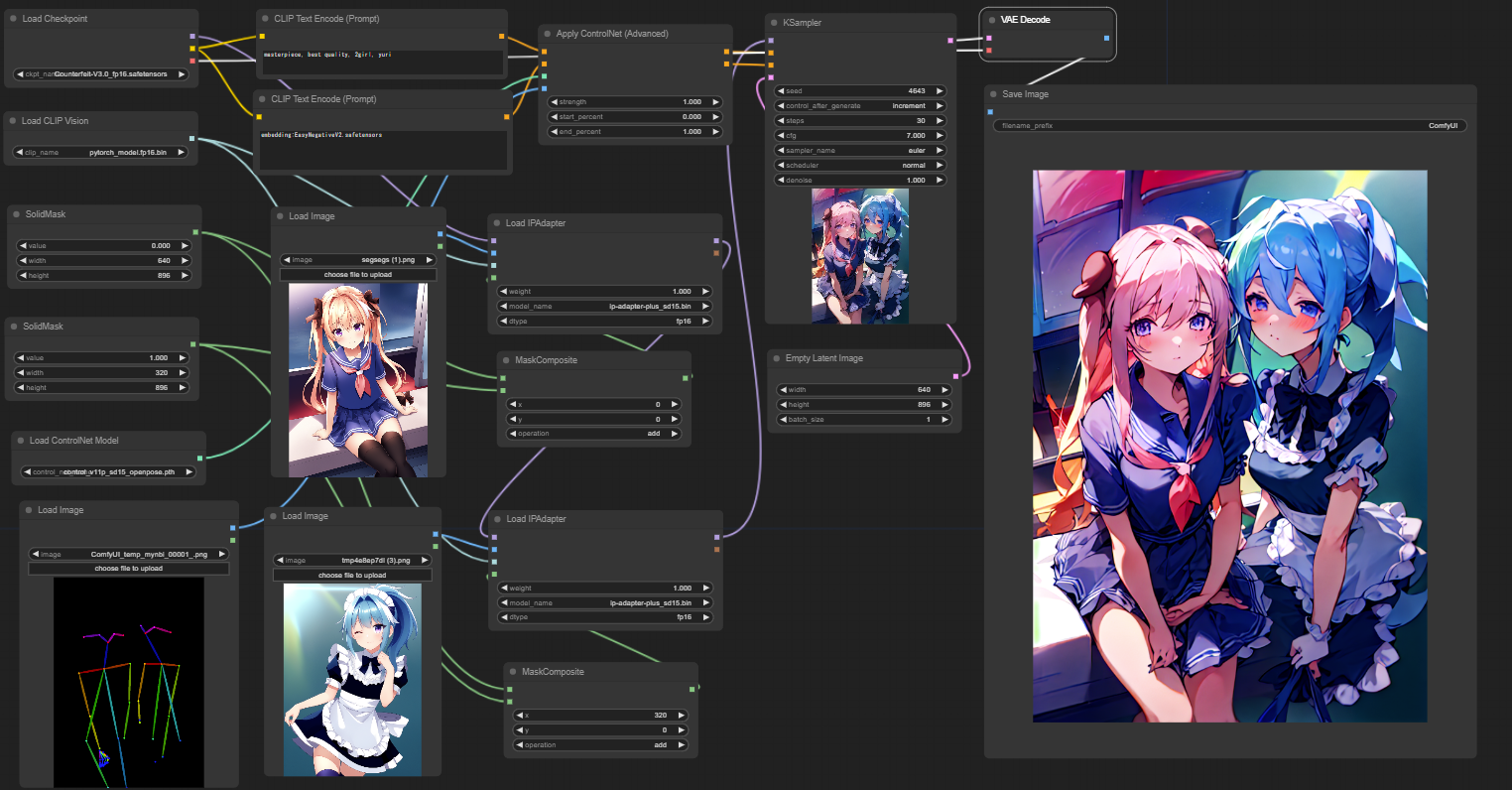
for IPAdapter. Like this: model - load ipadapter- load adapter - load ipadapter - ksampler
Does anyone know of a node that displays the seed for the current image instead of the one that's used for the next seed?
ha, but what does that mean
I sue Seed to Text to add ro my prompts.txt and also use in thr filename
translated from the readme
Multiple conditions.
Multiple images can be input by connecting nodes naturally. By combining with Mask, you can do something like separate conditioning for left and right.
The problem is that the background is also divided ^ ^;
ok, so just chain them
Yeah, I would just like a text box node that has it in a spot I can display it in my workflow.
neat
Yeah that didn't work before. Not sure what it will do. I'll give it a try again later.
@native knot so my image save filename is
SDXL/%date:yyyy-MM-dd%/%date:yyyyMMddhhmmss%%SWT.seed%%M1.ckpt_name%%M2.ckpt_name%%STYLE0.style%%STYLE1.style%%STYLE2.style%_STD
Previously it just ignored every adapter but the last one you used.
Oh man...so if IPA has been updated to work with multiple images, I know what I'm playing with next.
I wonder if Tiny Terra Nodes textdebug node would do that
@native knot looks like it will
But.... you will also have to switch to SSeed With Text unles.....................

I'll poke at that in a bit. Thanks for looking. 🙂
Well, chained IP-adapters seems to be too much for my poor VRAM
Getting black images only
I wish Comfy had a bit better component for loras, stacking 4-5 loras together to create a image is a bit painful
Someone here has a LORA loader node that makes it way easier...let me see if I can find it if nobody beats me to it.
that'd be great

ComfyRoll
How much VRAM do you have, seems to be working for me.
8GB (2070 super)
The CR one is one of them...there was another that had an even bigger stack.
Ah I've got 10GB, and it was using around 8GB
I wonder the best way to use it

GitHub
input aspect ratio, output dimensions. Contribute to picturesonpictures/comfy_PoP development by creating an account on GitHub.
As I've been feeding the IPAdapter through Revision
Looks way cleaner at least
That's the one...does like 10 LORAs
I just have 4 of these setup in line

oh lord, thanks hahaha, ill have a look
yeah same, it's just annoying having to mute, bypass etc.
just set to Off, they have switches (ComfyRoll again)
no muting/bypassing needed
I raely use 1 lora let alone multiple of them but its there just in case

One of the things I like more about a1111 is the model card panels and Civitai helper. Would be nice to have something like that in comfy
SDXL has pretty much cut my everyday need for LORAs down to almost zero.
Adapter has been to me as big a hit as LORAs were
build one ;o)

I've got way too many things to feed in now lol, I've got 2 IPAdpaters, and also 2 Revision images.
HA, I know how you feel
What do you mean by Revision images?
My 3 biggest things with SDXL are AIT for performance, ControlNet, and IPAdapter. If they can get around to making ControlNet and AIT work together...
Like second pass?
Revision/Clip vision G
Got a link?
Using 21 or more images that get interrogasted to produce a clip encioded output instead of using a text iput
controlnet color + adapter has been great to retain some of the info that gets lost
waaaaaaaat
https://huggingface.co/stabilityai/control-lora
Has info on this page.

See https://huggingface.co/stabilityai/control-lora & https://www.youtube.com/watch?v=1SwDCqgXZ-M for an explanation

If you caught the stability.ai discord livestream yesterday, you got the chance to see Comfy introduce this workflow to Amli and myself. The idea here is that you can take multiple images and have the CLIP model reverse engineer them, and then we use those to create something new! You can do this with photos, MidJourney images, DreamStudio, or...
It's kinda similar to IPAdapter
But it's much more loose
It's "conceptual" rather than "copy" of the image style
Is revision avaialble for 1.5 or is that just in the new SDXL group?
It is like mixing two prompts.
I believe it uses the SDXL Text Encoder, so SDXL only
I might be wrong though
The number of times that stable diffusion has made me almost buy a new card
not a healthy number of times
new version 5.7 of my workflow - this time ip adapter nodes got changed by its author (he combined two nodes into one) and broke my workflow - also did a lot of cleanup
https://github.com/JPS-GER/JPS-ComfyUI-Workflows

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
Just need to compile … lol
oh no lmao, You can now feed the clip vision output through the IPAdapters into Revision, which gets you different images again.
you'll never be free haha
I'm not sure exactly what the technical difference is though
Worked like a charm. Thanks again!

I guess it's mixing the images differently
You can composite latents, so do the background separate and composite the characters on top of the background
Revision outputs conditioning, right? So you can feed one revision into the _g and another into the _l to affect style versus content (sort of) right?
I think it only gets put into G as that's what the clip vision model is based on
Hmm feeding 2 image through IPAdapter isn't deterministic. You get different results every time, even with the exact same settings.
These were all the exact same settings



Deterministic when you blend the images first, use blend image node to set the balance
is this the comfy extention you guys use for IPAdapter or? https://github.com/laksjdjf/IPAdapter-ComfyUI
GitHub
experimental. Contribute to laksjdjf/IPAdapter-ComfyUI development by creating an account on GitHub.
I have had very good results with both IPA and Revision like that
why would you blend the images when you are wanting stuff out of both of them, just randomly blending images together and then feeding them I don't see how that would do what I wanted.
What are you trying to achieve?
IPA has been updated to allow you to chain them together
thus allowing two image inputs

Just trying to work out how this is supposed to work really.
The Idea I have is get an image of say a person and than another image of a style and put them both through their own IPAdapters. It seems to work, but it gives different results every time.
That’s neat that they implemented native support for it
It looks like the adapter is using cpu. Maybe it's getting internal randomness from that?
ip_state_dict is doing a torch.load() with map_location='cpu', but elsehwere in the code you see device as cuda. Might be related to non deterministic behavior 🤷♂️
I might post it as an issue on the Github page and see what the guy says
Good idea, because that's above my pay grade. I can make neat little nodes but the actual diffusion logic flies way above my head
I’m not sure you can achieve this with just IPA, you will need a way to constrain the latent space (after encode) or the image space (harder from my experience)
It seems to work fine doing it, it's just not the same every time.
Ah ok
Which sampler do you use? Some of the samplers themselves are non-deterministic
Though probably not to that extent
They aren't usually that bad, but I'll have a check in a bit
DDIM might be worth checking, as that's a solution-based sampler right? No noise addition each iteration
ok yeah DDIM it stays pretty much the same
Right ok, looks like it might be because I was using the "GPU" dpmpp_3m_sde sampler, using the none GPU one it's still different but a lot closer.
Jumping back a bit @native knot
side by side comparison
L to R
No ChatGPT assist no Supplementary
No CHatGPT assist with supplementary
CHatGPT Assist + Supplementary
(all same seed)

@cedar tusk I think I'm getting a bug I was getting yesterday when sometimes it randomly decides it's not going to listen to the IPAdapter at all
Yeah I think it's doing some really strange stuff with how it's pulling the data through
I just noticed that without changing any settings and keeping a fixed seed, Comfy dosn't recognize that it's already been calculated and re-runs the workflow
Mine isn't doing that
Might be my image load node
hello how can i use the sdlx patch on nocrypt colab? just load the models i want use?
you got an image of your latest workflow, been wanting to check out your ChatGPT assist
Probably not very useful like this as you cant see what connects where lol, would need to pull it out to see clearly and trun spaghetti back on
Or you could just load this young ladyt and try & work it out lol


ill pul lit apart hahah no owrries
thats the fun of it, "what the hell was winston thinking?!"
hehehehehehe 🙂
If it helps this is a simpler overview of just the switching elements with the final output onthe right being what you would feed into yuor conditioner Positive

Many thanks!
thing is after I get it working I rearrange everything to make it useable rather than flow
and even then I have the Style Warapping missed out from that lol
haha, i like to build from scratch ALOT, mosty testing, my usual workflows have tons of different tried and true methods, no organization
this helicopter view makes sense to me
Green are the daily driver zones (which get loaded in taht view when I open COnfyUI
Purple Are supplementary areas I may use on a semi daily basis
Blue are workzones that I dont need to touch once built
Yellow is old shit left in because..............

This is my "extended" daily view although some of the text can be difficult to read

Very nice, i see you have improved it substantially hahaha
and this has everything in view for daily use laid out in (what I think) is a logical arrangement

top right is my virtual "progress bar" where I can watch the various green boxes lighting up
ah that is slick i thought thats what this bar was
Image saves I can quickly break or make the jumpers depending on what I want to save

aye the purple bitts I justwanted a home for lol
If I was being Picky theres an argument that he LORA section should move to Lower Left closer to the Prompt ZOne
actually thats a good idea

offtopic kindof. just having a nostalgia moment. i used to use this software called "Reason" which i've been thinking is the first node editor i've ever used. it's a skeurmorphic interface based around rack mounted audio hardware. very cool software!

Oh what does that remind me off, I whink it was aWinamp plugin
just built this nonsense
it's reason. got popular around the age of winamp for a bit. went huge when matrix came out and the propellorheads became maintstream for a minute
comparing new IPAdapter chaining behavior to existing image blend techniques for shits and grins

Blending is far more preditable and offers much more control imo
ohh the one i saw that looked new is actually new. i figured it was just a manual instlal of what i was using already
so yeah Reason was my training ground, noodle pasta been on the menu for a long time
mfw noobs acting like node editors are something new and foreign

1914 noodles

ok heres another comparison, fine tuning ipa settings to get something mroe realistic
PATCH BAy
used to do a ton of patching back in my younger days for work

ah that reminds me of Moog Model 15 lol
patch cords are kickass
For this one are you not just basically overlaying the images on top of each other faintly. So it's not actually getting the images seperately, you just have an eye image with the other image faintly on top of it?
when do we get skeumorphic patch cords in comfy? i dont even see a branch for it. bollocks
when you create some lol
Change your blend mode to whatever you want. Heck convert to latent space. Possibilities are endless
Open Source = "DIY im lazy over here"
Well chaining 2 together seems to make it go absolutely haywire for me anyway, it's making images that make absolutely no sense for the provided images.
meanwhile.
All 4 of these used the same basic Linguistic, Supporting & Negative Prompts and the same fixed seed but because I had my ChatGOT Prompt Assistant enabled each time I Generated I got a slightly different description extrapolated from my base prompt




reduce your strengths for starters

full strenght chaining on IPA is asking for monsters haha
Hlo
okay, either i need to find a foss library for rendering node connections as patch cords then get a coding LLM to implement it for me, or go back to school and learn. i'll get right on one of those options
I am loving this idea, its nuts
Can we share a link here?
Oh I had.
But I had an image of a person and then a 3D model and it just starts making images of books, makes zero sense. But then after a few it makes something that makes sense and then goes back to making books. There's something wrong with it. I think sometimes it's just ignoring the values.
what was your prompt ?
Yt link I want some information
and unclip conditioning set at?
sure
No prompt because I wanted it to just use the IPAdapter and it works perfectly fine when you have 1 image.
yeah two chaining is a weird one for sure, still learning how it works
You don't use unclip conditioning for IPAdpater. Or you didn't before.
Its a nice way (I think) of getting variation from a base prompt with a fixed seed
I want to create something like this
https://youtube.com/shorts/CRY6C05QAPM?si=hVFo90Gsu1hbxBsf

#ai #aitools #stablediffusion #deforum #aiart #revanimated
I am not sure i see the use case, to be honest
who was that at ;o)
looks like Deforum
Yes but I don't know prompts
aaron
Is there any site where I can get these types of prompts
@vital ermine the meme images posted here will finally look more like him. thanks for doing this 😉 https://civitai.com/models/135544/segalsdxlv2
I dont remember if it was in the standard workflow, but this is an example of coherency with it turned off....big difference

Same exact settings
ah iok.
If it was me the answer would have been.
My Base Linguistic Positve was
one white woman hold flowers on top of roof, cyberpunk world, lots of neon lights
With it being translated by my assitant as:
A photo of a confident woman holding a vibrant bouquet atop a rooftop surrounded by a cyberpunk cityscape. Neon lights illuminate the futuristic city, casting a mesmerizing glow on her as she embraces nature's beauty.
OR
A photo of a white woman standing on a rooftop, vibrant neon lights illuminating the cyberpunk cityscape as she holds a bouquet of flowers.
OR
a photo of a stylish cyberpunk rooftop with a glowing white woman holding flowers, vibrant neon lights
OR
A photo of a white woman on a rooftop holding flowers at dusk, against the backdrop of a futuristic cyberpunk cityscape illuminated by vibrant neon lights. (No deep-fried barbie dolls, with no text or watermarks)
This right here is gold
Just the concept
AI using AI to AI
Its blending manual prompt crafting with ChatGPT assistance
How exactly are you setting up the conditioning, because the IP Adapter doesn't actually supply conditioning it just supplies the model.
So are you taking the Clip_Vision_Output and blending it with text conditioning?
On the readme it says to basically ignore the output on the IP Adapter, but it might be a miss translation
I dont have much experience with deforum, sorry
clip vision output to unclip, and clip text encode (prompt) to unclip, I do have a prompt
general idea

but its super messy since i just dragged into view, lol sorry
Ok, I think we are approaching this in different ways, so it's not cross compatible.
I'll stick with what I was doing before, that works fine. Looks like it just doesn't like having to images in the IPAdapter.
see thats interesing, i dont think that provides you with near enough control
@strong field and If I really get stuck:

I guess because you are using text prompts, it's taking the image conditioning and the IPAdapter. I guess essentially it's running both IPAdapter and Revision on the same input image.
why does that say 15 terms or lesss, thought I had told it 100 or less lol
So you have Image with IPAdapter + Image with Revision + Text Prompts
IPA very sensitive to weights and conditioning, so clearly it makes a difference. If your workflow works, just do you.
Yeah i guess you could think of it like IPA + Revision hybrid.
Yeah I think I understand how it's working now. Both for you and me.
with styles applied as well

I'm using revision but i'm using different images, because I'd rather use that than text prompt.
So I guess I could try putting in an extra unclip conditioning for the IPAdapter and see what it does.
Looking forward to implementing this, I trained an LLM to give me prompt ideas with just a "give me a cool <description> prompt, and it would generate, but i had to manual ask and manually copy paste and revise
i really like the idea of having it all built in
Yeah im definitely not using IPAdapter standard issue hahaa
Like i said, lots of experimenting
aye I used to use chatgpt in a browser to do similar then copy & paste, this is so much easier & slicker
Hmm running the IPAdapter through the unClip does let you make small adjustments, but it's adding an extra knob to my never ending list of knobs lol
yeah it really do be like that
I guess you could use it to push the output to be even more like the IPAdapter image, because you're also using the text encoding of that image as well as the adapter.
Yup that was my initial goal, take input image and refine, improve, add detail but stay very close to original
I found out you could make SMALL adjustments very well and still mainting OG integrity
Just a quick test left to right is, nothing via unclip conditioning, 0.5 strength, 1.0 strength.



Except one caveat, i didnt have image prompt
OG Prompt from a Random Pull from Lexica:
a cheetah and a bird in a buddy cop movie, movie still,
ChatGPT Assistant version:
A photo of a cheetah and a bird in a buddy cop movie would show the two main characters standing side by side, with the cheetah displaying its sleek and powerful build while the bird adds a touch of charm and wit. The high-quality image would capture the intensity of their partnership and the beautiful natural surroundings, immersing the viewer in the thrilling world of the movie.
OK doesnt always work lol
(although the CHeetah looks good)
Then again you could refine it manually from there

It's certainly an interesting option, I guess I'll leave it in to mess with


Next on my list to try out is - https://github.com/Ttl/ComfyUi_NNLatentUpscale

GitHub
Contribute to Ttl/ComfyUi_NNLatentUpscale development by creating an account on GitHub.
Looks interesting

Great gens btw
They'd look better after an upscale 🙂
16k?!
Lol I accidentally made a 350MB image yesterday, it tried to crash my web browser when I previewed it.
Omg hahahahahah
@strong field my other usage for CHatGPT assist is to take an old prompt originally written in A111 and then "transalte" it
eg
OG A1111 Prompt:
*(art style by (Utagawa Hiroshige:0.9) and (Reka Nyari:1.2) and (Jennifer Massaux:1.2) and (frank frazetta:0.8) and (salvador dali:0.9)),
(erotic boutique photography),
(best quality, 4k, 8k, ultra hires), (realistic, photo realistic, RAW photo), (hdr, sharp focus:1.2), (intricate texture),
(soothing tones, insane details, intricate details, hyper detailed,photorealistic, 8k, ultra realistic, volumetric lighting,(film grain:1.4)),
(Taken using a 35mm Hasselblad 500C/M camera using Lomography 400 color film at f/1.8),(bokeh:1.1),
(realistic skin detail),(skin pores),(hair fuzz),(skin wrinkles),(skin blemishes),
glamour photoshoot on an riverbank, early morning, a submissive elegant lady,wearing a kimono,standing,
(background of a river,cherry blossom)*
Which if I drop it in direct (with some styles applied) gives me the attched (which is srill nice)

2x ipa + txt promt is working fine for me:
https://i.imgur.com/I2XeXlq.jpg
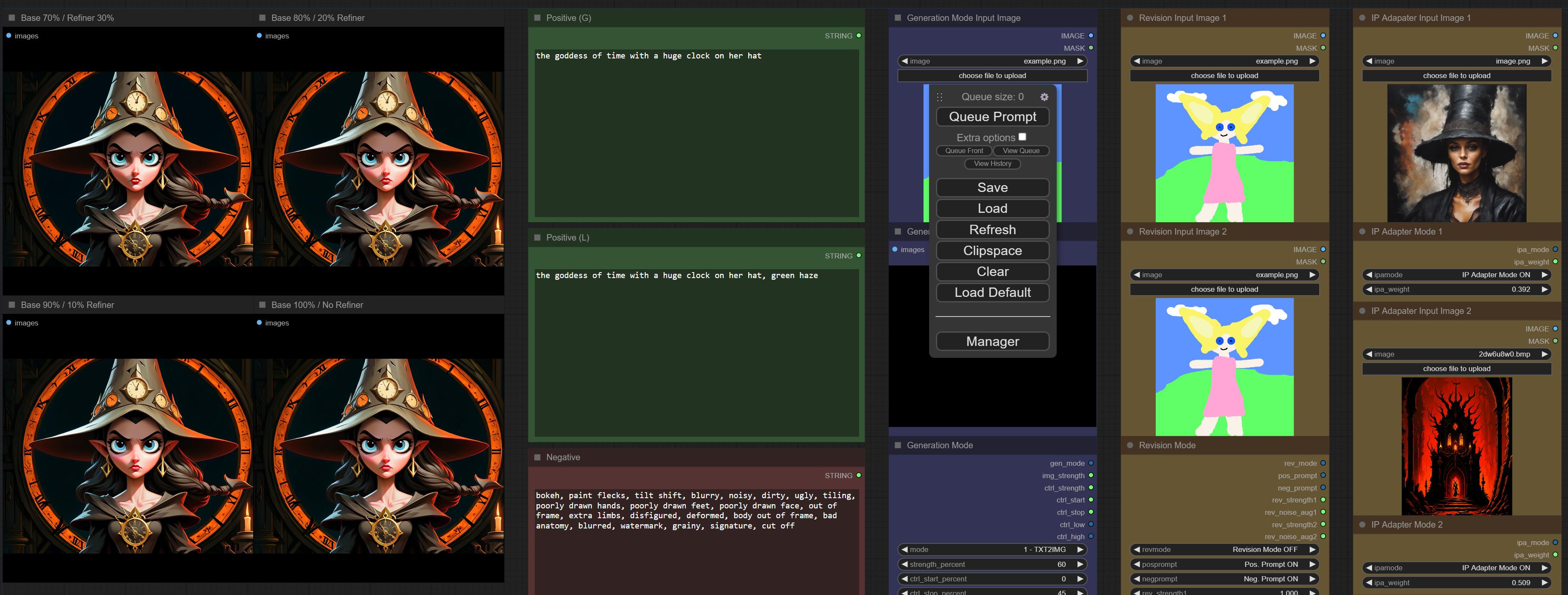
@strong field CHatGPT translated that as :
A photo of a glamour photoshoot on a riverbank at early morning. The image features a submissive elegant lady wearing a kimono, standing gracefully against the background of a river adorned with cherry blossoms. The photo is of the best quality, shot in 4k or 8k ultra hi-res. It showcases the art styles of Utagawa Hiroshige, Reka Nyari, Jennifer Massaux, Frank Frazetta, and Salvador Dali, combining their unique aesthetics into one captivating image. The lighting creates soothing tones and adds volumetric lighting effects. The photo is incredibly detailed and photorealistic, with intricate textures and sharp focus. Taken with a 35mm Hasselblad 500C/M camera and Lomography 400 color film at f/1.8, adding a touch of bokeh to beautifully blur the background. The image showcases realistic skin details, including pores, hair fuzz, wrinkles, and blemishes, adding a touch of authenticity to the subject. Overall, it is a stunning, high-quality image that captures the essence of elegance and beauty.

I see your weights 😉
3x ipa + txt prompt works but is a little bit to inconsistent to be very useful:
https://i.imgur.com/z3DRHQl.jpg
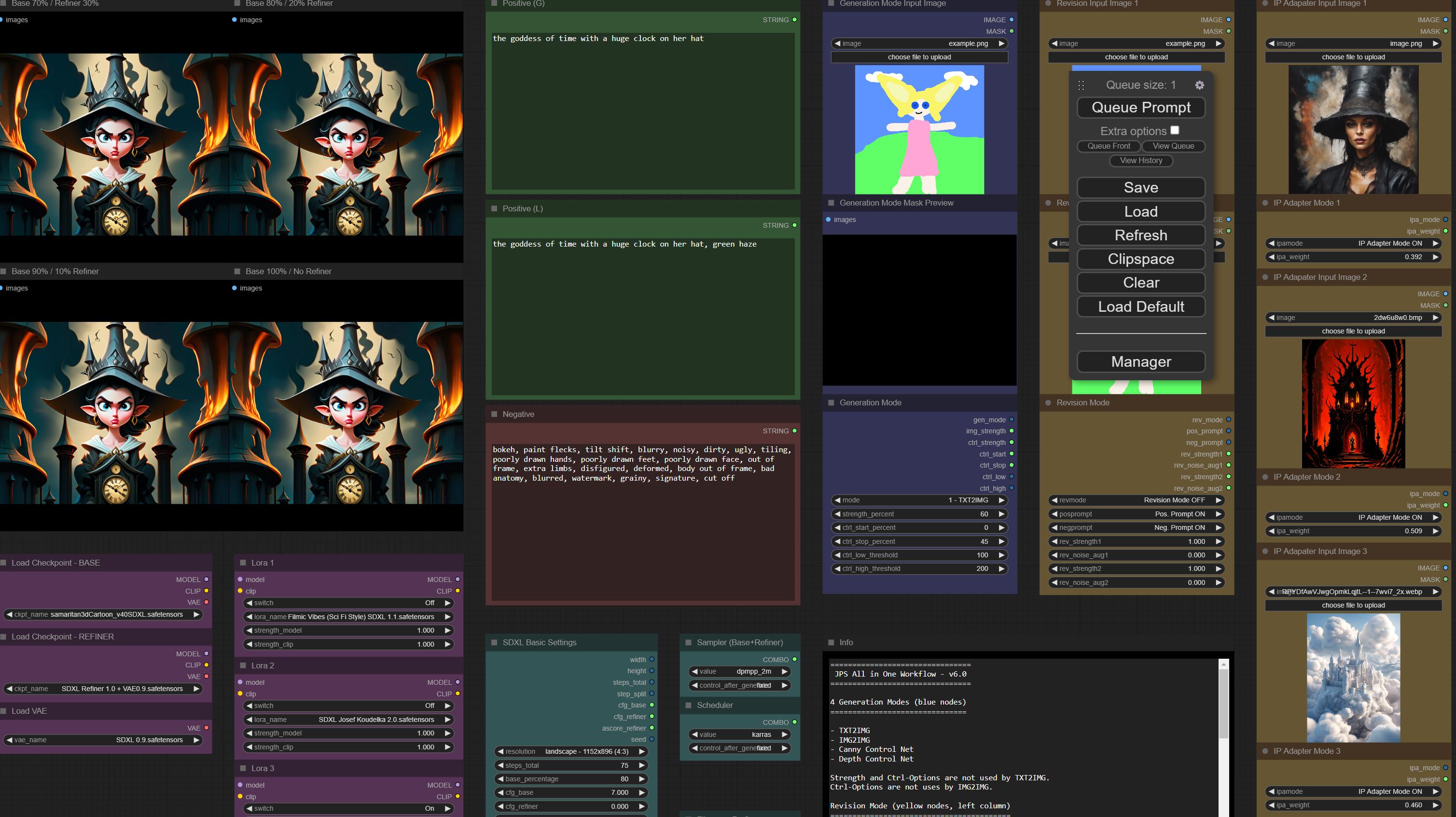
Definitely like the sdxl version better
well technically theyre both SDXL model wise lol but yeah I get you actually mean the prompt itself ;o)
the functional vs the linguistic
Ah yes the revised prompt
I also wonder if summarizing the prompt would perform any different
workflow 6.0 with up to 3x ipa (each one has an on/off switch) now on github:
https://github.com/JPS-GER/JPS-ComfyUI-Workflows
Closest I've been able to get so far to a workflow that says otherwise:

Without cheating by using a cnet, of course.
Looks like you ready for those wedding invitations
Yeah, but that workflow says otherwise.
Probably. I could ask the assistant to limit to say less than 40 words
🥁 🥁 💥
warhammer creature
Custom instruction and reuse the prompt to summarize? Might not be useful lol more token usage
still bad, even with ur prompt, bad quality - look at face... idk what to do with it


I gave you a suggestion that should help. Change the resolution to something closer to 1 megapixel. You'll generally have better results.
1024/768 is bad?
1344x768 instead of 1024x768.
hmm, okay will try
@icy brook




SDXL generally does best with ratios that are divisible by 64 and are closest to 1 megapixel.
You can see a table I posted here:
#✨|sdxl message
Sometimes you're just going to get bad results...that's part of how all this works. You can then tweak little things like the CFG up/down, the steps up/down.
why there are 2 text prompts as well?
yeah I know, I used a lot of SD 1.5 on A1111 but in Confy the images seem so grainy and fuzzy especially on faces in general (ofc with SDXL), I think I just have something set wrong
sdxl supports two text inputs (text_g and text_l) - so the two prompts are for that concept. don't really understand in detail how it works. one should be used for the content and one more for general style afaik, but as i haven't researched enough i just use the same most of the time. guess in the future the txt prompt will get further improvements, after i've done more research. but for now people who know how it works can use both positive prompts supported by sdxl.
That's just it...there's no such thing as "wrong" or "right" in this case. You could keep generating the image with new seeds and stumble upon one that works perfectly. There's not really much wrong with the recent image that you posted other than the face, so simply finding a seed that works better for this image would likely work fine. There is a tremendous amount of randomness with seed values and any given value can provide something totally different than the next.
Fun! 😀 I tried some flying before also actually 🙂 Not as good as yours though.

it seems to me that for now it is much easier to get better quality on SD 1.5 and hires fix, am I wrong?
Can actually play with it online here for those who want to do some transparent ghosts without local setup.

I don't think that's true in a general sense. Maybe it's easier to get a very specific look in some cases, but SDXL is far more capable in its "basic" state early on than 1.5 was in its early stages. The only reason 1.5 is capable of what it is now is due to the massive amount of development around it and the tons of models, LORAs, etc. Give it a bit more time and SDXL will easily pass that up.
OK, I understand. What about addons like facedetailer? I see that it's downloadable in the manager, I'll say that I want to install it, can I somehow add it and have the machine connect this "noodle" by itself? As a newbie I don't know how to do it right.
I don't know if facedtailer is compatible with XL as I don't use it.
Remover this is all being done pre conditioning
What checkpoint/model are you using? I could go look in the image but can’t be bothered lol.

I cant run your workflow as its AIT enabled but what I would do is try a non AIT enabled workflow with the same model & prompt as a comparison
why what >
why u asked for my model but now i know

currently a large proportion of hentai models are suitable for more than just "hentai" , you may be glad you don't see the rest 
he/she/they idec i'm a 24 yo adult cx (i didnt read the other half of msg send context of other models as long as legal cx (rhetorical but yee 🥂💕))

i'mma h^ntai model to h^ntai model
cx
@visual glade @indigo carbon i can confirm that the latest version is using vram too heavily on my 24GB RTX4090. the windows os gets very slow and comfyui doesn't respond very well (heavy delays) while generating images and vram is used completely (23-24GB).
after generation vram usage goes back to ~18gb and everything is responding fine again. i like that you want to keep more stuff in memory, but it seams you have to be a little bit more conservative and keep more buffer to avoid negative side effects.
at least "--disable-smart-memory" works for me and solves the problem for now.
are you using any custom nodes in your workflow?
@visual glade yes, but no ait - mostly very common stuff and a few of my own nodes, but those are more for input/menu purposes and very light weight.
hmm, I wonder if comfy could tell me how to keep the widget slider on on odd numbers

🤣
Got frustrated trying to improve the "OTHERWISE workflow...so went with something much simpler.
so the first image (if these post in the right order is using your OG prompt in copaxTimeless same as you with the same seed and no syles or other enhancements applied.
Second image is my revised prompt, agan with no styles or enhancements applied
3rd image is my prompt with a single Global Glamour Style applied
4th Image is my prompt with ProtoVision XL as the Base Model and DynaVisionXL as the Refiner model , no styles etc applied
5th image is your Prompt using ProtoVision & DynaVision as in #4
Draw your own conclusions ;o)





can somebody tell me why those white specs appeared in the photo? and why the faces are similar even if two different girls prompt used

The things in the red circles look like some kind of jewelry trying to be rendered in. Try adjusting the negative prompt to say earrings.
or maybe i should raise sampling steps?
Since there are so many things that change the results, it's worth trying. Ultimately, you could get the results you want by any number of combination of changes.
ok and what about the face similarities anyways? how do i get rid off similar or twin faces ?
Same changes could impact that. But personally, I'd play around with the prompt more by using more words that distinguish that there are two different people.
can you give me any example prompts? i really can't figure it out
any example photo link with multiple people with different faces
No offense, but I'm in the middle of doing some other things, but I would just encourage you to try stuff.
no problem mate
if you're using a similar prompt along with similar cfg, similar model, etc, it's just going to happen that you'll get similar looking people. that portion of latent space is being activated
those look like over training artifacts, like purple splotches, but after they've been refined through a second denoising pass. that's what my eye says anyways. i can only speculate since i dont' know how you made that image
I have reported this a week or so ago. There has been some improvements since then but sometimes I OOM like you do. Mostly when doing larger batch sizes or during upscaling. And yeah, disabling smart memory fixes the problem with a small performance hit.
I'm on a too new NVIDIA driver (536.67). Could be worth checking if running 531.79 would fix it.
no oom for me - just the whole os is getting super unresponsive. doesn't even show virtual vram usage - just usage of the full 24gb which results in the unresponsive os. (i'm using an older nvida driver - the newest ones would shift things to vram even earlier to avoid oom errors)
531.79 gives you real oom errors if you use too much ram, but doesn't tend to use shared vram. newer drivers shift things to shared vram if you use 80-90% of your physical vram - that prevents oom errors, but reduces performance in ai applications a lot - this is a feature meant to help games and doesn't work very well with ai and some other applications like video editing. nvidia knows about the problem and want to fix it in a future update.
System RAM no problem when you're running 64GB+ 😉
i have 96gb ram - the problem is the vram.
I'm just being fecetius.
96 is a weird configuration though. mismatched pairs or 4x24? 8x12? hows it work?
Makes sense, we are probably seeing the same issue but with different drivers.
2x32, 2x16
2x16 + 2x32 - as memory is dual channel that doesn't cause much of a problem.
i dont know about that. but alright
in my experience, that causes a TON of problems in this virtual memory management realm. timings being mismatched are not great for high performance
@steady grove only some server hardware/configurations "bundle" more than two ram modules. so using more than 2 ram modules or mixing 2x2 different modules can give you a little bit of performance loss (espeically if they have different timings), but nothing major as long as you use the right memory slots.
yeah that's different from mismatching pairs
i bet it goes away if you drop the 16s
Servers have different ranks too, many more slots, more than one CPU, it gets complicated fast. 😄
It's not that weird on the newest motherboards. In fact, there are now kits with 96GB. The reason is that it's more about matching up the amount of RAM to cores. Since there's a bunch of processors now with the # of cores divisible by 3, they're doing these kits now.
i don't have performance problems with the ram. i have problems with latest comfy that uses 24gb of vram instead of unloading unused models, etc. i have no shared memory usage - just straight 24gb vram usage - so ram isn't involved.
96gb ddr5 kits i think are actual 24gb dimms though.
Yes, I believe that's correct.
mismatched dimms will cause the cpu to compromise and find a compatibility mode across all of them
Have you updated your Nvidia drivers, I've just updated my drivers and the memory usage has gone to shit.
maybe it won't have performance problems. i bet its related though. this is the realm of swapping and low level memory management afterall
@eternal fog i'm using 513.79, because nvida drivers after that shift things to vram if you hit 80-90% of vram (explained in more detail above). so for ai and video editing all newer drivers cause huge performance drops if you use >80-90% of your vram.
Yeah I know that, but I wasnt having issues on the previous ones, now I am. So was wondering if you'd recently updated.
It might be comfy as well though, it seems like it's not unloading things from memory after gens and then doubling up.
I can do 1 gen fine and then next one it's going into shared memory and being extremely slow.
It should not be doing this for a single 1024x1024 render

@eternal fog if you have problems now, this is probably caused by the comfy changes. use --disable-smart-memory when starting comfy and the problems will be gone.
I thought it was that change that made it better, because after he added that it seemed to work a lot better, did he change it again?
my problems started with the latest comfy updates. and using that option solved it (by not using the new memory management)
the new drivers more intelligently use the shared gpu memory bank. the system memory. It doesn't automatically start using them at high vram useage. i know this becaues i use all 16gb of my 4080 very often without it edging into shared memory. When it goes over it slows down to my mainbus speed, since memory swapping is going on.
i bet when you hit those edge issues, problems occur because you've got mismatched memory banks running at lower timing's than they're meant to. I also think the newer versions of comfy might be tuned more for the newest drivers. You might be using the old drivers in an effort to disguise the problems of your mismatched dimms better
i've built systems for decades now. i've never seen mismatched ddr working at peak performance
I have the same issues as JPS but with matched memory. I doubt memory is the issue here.
The old drivers don't use shared memory at all they just OOM if you go over, the new ones do instead of going OOM, but it slows down a lot.
i'm using the old drivers to avoid a problem confirmed by nvidia, not to cover the ram issues you think i have. there is no shared vram usage according to task/performance manager when the problem occurs. and the "more intelligent" usage of newer drivers is fine for games, to hide the fact that many nvidia cards have not enough vram for latest games, but is poison for ai and some other tasks.
and yes, my system behaves even worse than some newer high end systems if shared vram is used, but not mainly because of my ram combination, but because i'm using a 5 year old mainboard and ddr4.
but the real problem is that the latest comfyui update tries to use every little bit of vram and fills up the full 24gb - which is enough to make other vram depending apps like the webbrowser slow down heavily. newer nvidia drivers would make it even worse and push 1-2gb to shared vram.
If it starts using RAM it will be bad.

I just reverted to 531.79. Saw that NVIDIA released 537.13 but not tested.
On a normal SDXL base + refiner 1024x1024 smart mem is 6s vs 10s with smart mem disabled. But with a 4x upscaler -> downscale 50% and a base pass it takes 27s on both.
the driver issues nvidia "confirmed" are overblown and often misrepresented. you stating a margin of 80-90% for example. everyday i'm pushing my 4080 to the edge of it's 16gb and it doesn't touch the shared memory. Some problems do occur when shared memory is dipped into, which i mostly by going back to python 3.10.9 from 3.10.11, but at the 80-90 margin ? i dont know about that. i've never seen shared memory open up at those thresholds
I'm on the newest drivers with my system configuration and i don't see these problems in comfy. running the default out of the box windows portable build
well with updates
The main issue I have with the Nvidia drivers is in Training.
It doesn't just tell you that you can't handle it and OOM. It tries to do it with RAM and takes a million years
heh yeah i've hit that too. before it would just crash and i'd adjust
now it just keeps going. darnit
that shouldn't happen with the old drivers. old drivers should give you a real oom error and allow you to use more of your vram, as it doesn't start early to push things to shared vram.
This could be specific to 4090.
It's not, it's specific to the entire 4000 series
@ionic gulch the fix was to merge the latest commit with a commit from a week ago
Talking about the smart memory in Comfy
Yeah, I know
maybe your models / workflow doesn't hit the limit - if there is nothing to fill up the full vram, even the new comfyui update can't cause problems.
pushing the limit is something i revel in doing. often theres a soundtrack in my head when i'm doing it
It's not the limit. Because Nvidia being drunk when they made the 4000 series, when VRAM is over 95% full, speed divides itself by over 10

@indigo carbon are you talking about the problem with latest drivers or in general? never had problems since i've gone back to the old drivers. with the newer drivers i had that behavior.
No, the latest drivers actually made it a little better. It's an issue with ComfyUI
Running SDXL and LLama2 13b at the same time on my PC makes both of them slow to a crawl. 😕
Switching between the two isn't too bad. I have Llama2 churn away inventing new prompts.
The old commits never fills up VRAM over 90%, which seems to be the threshold on 4000 series
There we go...no other text.

The hands don't look too great though.
What version are you running now?
The sign tells you they're bad hands. 🤣
Merged the latest commit with a commit from a week ago fixed it
Driver version that is. 😄
that's the problem i think. the new version really tries to use 100% vram, which is problematic with old and new drivers. there has to be some buffer left. the idea to keep more in vram is great, but not filling it up to 100% as there are other vram depending applications you will affect by doing that. one of them is the webbrowser you use to control comfy.
No, it's not the drivers, I tested it with 10 different versions of drivers, that's an issue with ComfyUI
Me and my

heh
Yeah that's what I'm saying, old drivers OOM and new ones try use shared RAM and it takes ages
That's a good thing on the 3000 series because when NVIDIA made them they didn't use memory busses from over a decade ago. I think there should be a mechanism that uses the old memory management on the entire 4000 series.
I'm going to try 537.13 now.
The current fix to use the old memory management is to merge a commit from a week ago with the latest one
shared vram will always be a problem even with much faster bus speed. we need more "real"/phyiscal vram and/or avoid filling it up to 100%.
80gb consumer cards please
Yeah, the threshold seems to be 90%. The old memory management seems to know that.. when I use the new memory management I get 30s/it, when I use the old one I get 10.5it/s
gpu with an m.2 slot would be nice
for me the switch @visual glade mentioned fixed the problem. not the perfect solution, as the new "smart" memory management would have some performance advantage, but i don't want to merge things manually with every future update.
i figured out.. the issue came with the model itself so it recommended using xl vae
after using vae i got clean faces
Fire and not the good kind lol
haha
Llama2 coming up with image ideas and writing prompts.




I feel like it's not tapping into its inner artist yet though... Hmm.
@soft zealot would like to have words with you
the pcie4 complete spec, something b series amd boards don't support, have a dedicated pcie lane from the ssd to the gpu. without the cpu needing to pass data. Directstorage is supposed to support it but i've seen nothing coming for that yet
ahh I see, not my magical thinking version then (haha)
once the api's are out for gpus talking to ssd's directly, direct storage and whatever other variants there'll be, we'll likely see gpu boards with m2s directly on them
I meant you wanted to show off your baby. I know I would 😛
Have you tried encouraging Llama2 to pursue an art career?
this tech will be developed and brought to market fast imo. It's not hard to do, it just didnt have a killer app
theres a scroll bar and a search function :p
Search functions are awesome. I've been developing fuzzy search algorithms since high school. Not sure what we're talking about though tbh.
my chatgpt assisted workflow using Omars Quality of Life schizzle
That link was for you I fudged up
ip adapter has problems if your source image aspect ratio doesn't match the target ar - seems it tries to crop it, but handles the resolution in a wrong way - guess i have to prepare the source images myself in some way:


Can't wait for my more RAM to get here lol

What was your prompt to llama? Try to give it a few examples of a prompt you like.
Yup many issues if your AR doesn’t match, I don’t like IPA chaining for this reason
Prompt setup I was working on yesterday.

I think you can get good results if you fiddle with blending and strength/weight but why mess with all that when you can stack revision on top lol
@uncut gull what @strong field was pointing at was the way I've integrated Omars QOL ChatGPT node into my workflow using the standard Prompt boxes & logixc switches.

thsi is the broken out view of the integration

Sweet Christmas.
Looks like a good start but would be interesting to see what happens if you add a few examples.
Mostly cause I still need to do this in my workflow
It had examples, but only a couple. And my examples were pretty lacking to be honest, to which it responded with similarly lacking prompts. I'm trying to think through it again now.
thats just the daily driver view
This is the helicopter overview with straight spaghetti on lol

What llama2 model are you using? Running locally?
Local.

Feels like there are more llama models than there are ants on earth.
I love programming and coding, even assembly language. I've been trying to learn nodes programming ever since it came out in Blender, but I just keep putting it off. I have to get over my dislike of 2d navigating... 😐
I’m here for it. Except for that kill switch
oooh maybe we need 3D Node Building, that would be cool 🙂
I guarantee it will come out as soon as I learn 2d nodes.


All Llama2 images. It's being very diverse, but not creative, you know? What am I missing in my prompt? I can't just tell it "be creative".

can LLaMa2 see images? or that's something only GPT4 can do
I'd say the older driver 531.79 is better than the most recent 537.13 with smart memory. Both have issues.
fix was to merge an older commit with latest; but I'm sure Comfy will get on it
Yeah, I guess I'll wait for that.
One message removed from a suspended account.
It's writing prompts for me. It can't see. I just want it to get more "creative" with its subjects, but I don't mean more "diverse". Even focusing more would be fine. Just more creative somehow.
Have you done any fine tuning, training, or embedding?

I tried for 8 hours yesterday to get Lora training working in Oobabooga. Errors all the way through, and I'm all burned out on that. I'm just prompting today.
Trying this now. 🙂

Ah yeah…. I hear that

@visual glade just a thanks from those of us at the "budget" end of all this (1080ti 11Gb VRAM driver 531.68 do I dare upgrade I wonder??, 64Gb System RAM), recent updates haven't degraded performance at all and indeed looks like COld Start perfromance has improved

One message removed from a suspended account.
Anyone else use the SDXL ultimate workflow on civiai? Anyone have insight to why the imgtoimg includes a downscaler?
Anime-finetuned XL is indeed better than 1.5 with details, and with understanding of different artstyles and cultures.


All Llama2 prompts. 🙂

You could try to install superbooga extension to ingest your own documentation with prompt examples. Otherwise Next steps would be api > lang chain > database / embedding
Are there any users of mst.ai? Their discord is closed, so I would want to know, if there is any progress towards XL support.
The roadblock here is my understanding of prompting and creativity. What, exactly, do I mean by wanting it to be more "creative"? And how do I put that into words?










One message removed from a suspended account.
That’s why using a data set of “creative” prompts would be a good solution. Go collect a set of examples you like and call creative and then tell the llm to use that dataset as a knowledge base when prompting.
you can try increasing or decreasing temperature, that tends to mess with the creativity
Lol try this. Wonder if something this simple would work
I forgot about this. I played around with it back when I was doing creative writing. It definitely makes a difference.
it'll pretty much break it going to either extreme as far as temperature is concerned
but then you can couple it with other parameters to go all sorts of directions
One message removed from a suspended account.
I tried just doubling the temperature from 0.7 to 1.4. Its prompts look more diverse style-wise, but still pretty on-theme for the imaginary artist I gave it. Llama2 has clearly never read Reincarnated as a Slime though. Generating images now.
Anyone knows when will be released 1.6?
"firefighter" took too literal..

These look much more creative! Well done, Llama2. I think it might pair better with a different SDXL model though.

1.4 is high, but I guess still coherent depending on the other settings
That is precisely why I did it, lol.
can some of you use my custom prompt
and see what it spits out for you?
Stranger things.
Walking outside in a nostalgic town from 1984. Looking through the front door of a building, on the other side of the door is another town, but that town has rainy mist ambience, the sky is grey and blue from the misty rain. probably a cool afternoon in september around 7pm. you notice the prototypical red glowing light ambience that is synonymous with stranger things. the town looks very familiar, like you have been there before
thats the entire prompt
@upbeat summit see above
Since its goal is to mash together subject and style words while ignoring grammar, I think it's pretty robust against errors even at high temperatures (for this particular task).

did the 1.2 channel get pulled
or 1.4 or whatever it was, or 2_1
for xl?
i guess people are using comfyUI now as the standard, no more "oogabooga"
Most people are still using A1111. And oobabooga is for text generation, not images.
(I'm using A1111 and oobabooga at the moment.)
i used that gradio ui before for image generation
but this comfyUI is just as effective
Doesn't work on tablets / phones.
yeah, if anyone hates nodes, they can just use SSW
have it make up hypothetical words
C:\Users\xt3\Desktop\ComfyUI_windows_portable>.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build
Total VRAM 24564 MB, total RAM 65457 MB
xformers version: 0.0.21.dev581
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 4090 : cudaMallocAsync
Using xformers cross attention
Starting server
To see the GUI go to: http://127.0.0.1:8188
So are you saying I have a problem because I run a local host just so I can access via tablet?
is there someting to use to speed it up?
Slightly better. :-). Llama2 pretending to be an AI prompter paired with CounterfeitXL.

is Using xformers cross attention not ideal for 4090 w/ comfyui?
The ComfyUI interface glitches every time the keyboard opens and closes on my phone and tablet. (Android.)
different params to use to speed it up?
something to consider, stable diffusion doesn't really know if a word is made up right?
so wouldn't it just try to connect the dots if it get's fed a new word?
Interesting, I had to zoom out a bunch on my browser but seems to work ok
Also, it understands languages other than English, and the sense is not the same. "Forest" is not the same as "bosque", even though they're both forests.
as I understand it it will atrempt to break the word up into words it can recognise and then tokenise
If you want speed; you can use AIT. it increases speed over 200% on 4090
show the flags
but slightly complex to set up atm
Where is this model, I've seen people mention it, but I can't find a model with that name.
GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT: This was orginally written by: https://github.com/hlky
yeah. doesn't really look at things like us. so if you think about it, you could put different tokens together that don't really have real world counterparts
Yep. There's a gem called "carbuncle". I tried to get SD1.5 to generate an image of it, and I got pokemon. 😕
you can use hgsksdfzg as a token or just leave it empty and get nice nature photography 😉
Split text > chunk > tokenize
I am using CounterfeitXL v1.0 along with some other finetuned checkpoints.
if you type frantic weird random letters it will probably not make beauty
Ah ok, I could never get CounterfeitXL to look as good as 1.5
or just put in something like "destitution" and have it loop over itself
but it does
@indigo carbon so basically , with how fast changes occur in this space, is that url some new optimization technique that vastly speeds up IT/S generation speeds
on 4090 for image gens?
Eventually it will tell you to stop acting crazy, but until then it will just tokenize with closest weighting
nope , all good post driver upgrade to 537.13 here at the cheap end @visual glade (well mostly, cold stat performance has slowed sligtly but that could be margin of error, same for warm starts)

for 3000 series and 4000 series. however; you can already get a somewhat nice boost already by using CUDA11.8 and the latest cuDNN software stack
Supercalifragilisticexpialidocious
but like dest-itution. two tokens. you can swap for other things.
Returns picture of umbrella
just interesting
@keen nimbus the workflow linked in the repo already has an explanation for how to infer in it
In CounterfeitXL, "forest" vs. "bosque". (Bosque is Spanish for forest. SDXL understands most languages I've tried, but the words have different feels to them.)


One message removed from a suspended account.
I (really did lol) got this first time around (no enhancements enabled)

if your not looking for an anime checkpoint, there is a checkpoint called copax_colorfulXLV2 and it's insanely good
I've found Nightvision better than Copax personally
copax colorful is way better than normal
I have CopaxTimeLessXL that I still haven't tested. I've been using CrystalClear 99% of the time, and CounterfeitXL for anime stuff. Thanks for the reminder. I will at least test CopaxTimeLess now. (As soon as SDXL gets done with its long slow churn through a measly 10 images...)
and when I turned on the ChatGPT assistant it spat this out from the same seed
lol
A picture of a whimsical landscape with vibrant colors, showcasing a sprawling meadow full of wildflowers and a sky filled with cotton candy-like clouds. The image exudes a sense of enchantment and joy, with every detail capturing the essence of the word "Supercalifragilisticexpialidocious."

copax timeless is not copax_colorful; I also used to like CCXL best: but copax_colorfulV2 has a league of its own
Much better than I could of done
Scary smart
Okay. Downloading now. I will totally delete it for HD space if I don't like it though. 😛
You mean Copax Vivid, right?
This should be Civitai's catch phrase or something
no, copax colorful
One message removed from a suspended account.
hold up, I'll get the link
Civitai link?

ABOUT PROMPT Version 4.6 demo images generated from the TensorArt website. You can visit there to see prompts and create images for free: https://t...
That is literally Copax TimeLessXL. That's the one I downloaded yesterday and was about to test.
it's the colorful version
No, you're right. I see it now. Okay, restarting download.

I just tried "llun o goedwig" which is the Welsh for "picture of a forest"
Nope lol

Not even the Welsh know Welsh so I doubt the model will

"forest" vs. "bosque" in SDXL base model, not fine tuned.


I understand spoken Welsh better than I speak it 🙂
Yeah, never tried Welsh. Also Latin doesn't work. (Not many latin-labeled images in the dataset. 🙂 )
But are you Welsh
Yes, Welsh was compulsory in school until the age of about 15
Mind you that was nearly 45 years ago lol
lol, I lived in Cardiff for Uni for 3 years. I found that people from South Wales used much less Welsh than those in the North. And the North had their own little group where they would speak Welsh regardless of who was around.
i think it only knows those words thanks to them being in the captions of the original data. images of a forest labeled "bosque" are likely going to be from a certain area or certain forest (spanish speaking people), giving it a unique look of the forest since its a specific one.
It's not like there was any extra effort made to make the model bilingual (afaik), it just knows the word because spanish people caption their forest pics with it, so yeah it wouldn't look the same as "forest".
if i copy data from a generated image from someone and use exact same setting with exact seed.. why do i get different result?
like in original the face is front facing but in mine it always comes as side facing or back facing

I#m a Cardiff boy and yes it is true
As I student I presume at some point you visted TWAT cafe ?
I do not remember, it was a while ago lol
But it would be really cool to use multiple sets of captions in different languages for every image. idk if the model can learn like that
I have a new use for the chatGPT assitant
On the fly translation

Yep. That's my theory too, anyway. Don't see what else it could be.
The Warm As Toast on Salisbury Rd

ChatGPTs ability to translate is... interesting lol
not same in all similar settings? 


its not just translated it literally, its done what I asked it to an provided an embellishment
but its impressive I put 3 Welsh words in and it cme up with something sensible
"Fire" vs. "fuego" (Spanish) vs. "feuer" (German) in SDXL base model, not fine tuned.



SDXL, why are you burning animals???
If I thorw "fuego" into my assitant it responds with
A picture of vibrant, fiery flames dancing within a fireplace, illuminating the room in a warm and inviting glow. The high quality image captures the intricate patterns and intense colors of the flames, making it feel alive and dynamic.
This isn't how you ride a motorbike

Is this what it would feed SDXL? I gave mine example non-grammar prompts to fix its tendency to use full sentences.
but remeber the "rules" I've given it are:
Act as a creative problem solver that answer in prompts.
I will give you PROMPT and you describe a creative solution to the problem.
Use terse concise terms to describe the answer.
User descriptive details, answer in one or two sentences in one response and keep to under 40 terms starting with either the phrase " a picture of" or "a photo of".
you can use commas between terms.
Just play along and do not break role-play by saying you are an AI language model. Just guess at the answer.
yes based on the rules I provided it
Mine: AI image generators are prompted by describing the subject as a list of attributes and style factors. Rather than exact and fluent language, the AI does best with short concept fragments in a list. Style factors include key words associated with images of that style. For one style example, artistic illustrations are associated with oil paints, watercolors, colored pencil, acrylics, etc. And for another style example, photographs are associated with key words such as depth of field, bokeh, lens, focus, clear, etc. The AI image generator may accidentally ignore parts of the prompt, especially if part of the prompt describes something uncommon or out of the ordinary. To mitigate this, features that should definitely be present must be repeated with different phrasings. For example, a "suit" commonly has a black jacket, a white shirt, and a red tie. What if you wanted to prompt for a completely black suit? That is an uncommon and unusual thing, so the prompt "all-black suit" would most likely be ignored in favor of the more common visual representation of a suit. Instead, the prompt would be extended with rephrased repetitions: "a black suit, a suit with black shirt and black tie, completely black suit, all black clothes, black fabric". The prompt has a maximum length of 75 words, so "fluff" words such as conjunctions, prepositions, and pronouns must be avoided at all costs.
Examples it gave me for the reincarnated as a slime gothic artist persona:
2. medieval manuscript illuminated initial P depicting knight holding sword before castle ruins moonlight faint distant church bells sound foggy grass ground. gold leaf silver paint illumination calligraphy golden ratio
3. futuristic cyberpunk 3d animation of humanoid slime monster with laser beam eyes moving through smoky alley full techno equipment stacks neon signs buzzing sound effects motion blurs distortion effects
4. abstract pixel art style of swirling multicolored fluorescent gas planet in endless void space, cosmic particles emanating energy beams, intergalactic travel feeling of loneliness cold mystery
5. classic impressionist oil painting capturing carefree moments young boys climbing cherry tree blossom branches in park. light spring sunshine fleeting moment joy happiness children laughing playfulness innocence```
(Edited, I pasted the wrong thing there.)What an earth is wrong with CounterfietXL, I just downloaded it and all its renders are like this

How many steps and what sampler?
Wait, fuck sake. I must have dragged accidentally. It's changed my steps settings and fucked it all up.
It had moved my steps to 257, but my end at step was on 28
It must have dragged over when it was lagging
@uncut gull
It made a good stab at
Gwlad, Gwlad, pleidiol wyf i'm gwlad
Tra môr yn fur i'r bur hoff bau
O bydded i'r heniaith barhau
The literal translation of which is
Country, Country, I am faithful to my Country.
While the sea [is] a wall to the pure, most loved land,
O may the old language endure
whilst feeding the following in as my positive prompt/
A picture of a peaceful Welsh countryside, with rolling green hills, a serene coastline, and clear blue skies. The high-quality image showcases the beauty of the landscape, capturing the essence of Wales' proud heritage and the everlasting love for its language. Tags: Wales, countryside, greenery, coastline, skies, heritage.

and then spat out what looks like part of the Welsh coastline

but that stuff like "capturing the essence" and "proud heritage" is hard to get rid of. It was challenging to get the model to just put visual-related words together without using grammar.
I wonder what its fgoing to make of the openingverse of La Marseillaise ;o)
anyways thats for another time
I'm just waiting on my PC running tests on different Copax models. Can't even prompt right now anyway.
did you get the one I linked? it's really incredible
it even does text like base does; which most XL finetunes lost the ability to make text
Yep. I'm comparing it to two other Copax models, and to CrystalClear, Juggernaut, and Counterfeit on the same prompts list. (The last prompt list I got from Llama2).
It'll be a while before all the tests are done rendering though.
if you would compare text in images, that model would easily be miles better than the others
I get full sentaces about 70-80% of the time like this

I could try that later, but I've never had a need for text. Not the main thing I'm looking for, definitely.
That's crazy. I'll at least give it a shot. (Still have a long wait though...)
yeah, it's almost as good as DF IF with text. while being incredibly clear and detailed
sign saying: "WELCOME TO NOWHERE" on it in the middle of the forest, desolate, intricately detailed, artistic lighting, particles, beautiful, amazing, highly detailed, digital art, sharp focus, trending on art station
Do you always use sign saying: "..."?
how to use more than one CN with SDXL?
if I want a sign saying something yes.
but always with :, "", and CAPS
where does these stacks go?




Is someone else having a problem with a1111, where it's possible to run SDXL once and any subsequent run or parameter change will cause out of memory errors, requiring to restart a1111? Interestingly, the behavior is different between a 3060 and a 1650: the 3060 can generate many images, as long no parameter changes from the initial run. The 1650 can generate one image and that's it.
no. I just used a1111 xl for the knight
better ?

row #1 model: base sdxl (1-3)
row #2 model: nightvision XL (4-6)






Are you using Linux?
nop, win11
Hmm... this may be a Linux issue
Maybe https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/12478
Made this using Deforum using SDXL if anyone is curious what that might look like.

- Deforum on Stable Diffusion XL using automatic1111 for generating the animation.
- Music created in Studio One using a lot of Spectrasonics and Native Instruments VSTs.
- DaVinci Resolove used for post-processing the video.
- Duesenberg Fullterton TV guitar.

futuristic terracotta army
midas entire family (he touched them)
terracotta from krypton
the stone men

Model comparisons: CopaxColorful, CopaxVivid, CopaxTimeless, CrystalClear, Juggernaut, SDXL Base

I kinda like copax_colorful best, but that's just my opinion.
I'm testing their text-writing abilities now, but for all 6 of those, I found images I preferred from each. Even SDXL Base had the best image on one of the prompts.
the writing abilities present in my images are also caused due to my optimized AIT workflow using complex stuff, it might not be as good as the quality I get to
So far I'm pretty happy with all of them, actually. 🙂 But I've only glanced at results. I'll count typos and get %s when the tests finish running.
I have a question about the Clip Vision models in SDXL if anyone knows. Is there much of a difference between using the 9Gb open_clip_pytorch over the 3Gb clip_vision_g.safetensors?
tried to outpaint... but i failed. dont know how to outpaint in comfy lol

Hello! I am not able to generate this image, I have been trying for two days now. Will be trying on comfy UI tomorrow.
Can someone help me with this scene?
"view from outside of a big garage with snowmobiles, gas station in front of the garage, a man sleeping on the ground near the gas station, outdoors, nightsky, north pole"
It always misses out on the dead person on the ground, I have tried on all the ai image generators
they let you adjust with mouse wheeling too
@upbeat summit more reason he is so meme worthy.

Writing comparisons CopaxColorful, CopaxTimeless, SDXL Base, CrystalClear (best).
Prompt sign that says: "WELCOME TO SMALLVILLE"
Plus a bonus, 1 image where CrystalClear spelled the entire prompt 100% perfectly! (Although still with some unwanted text underneath, so not usable.)


ngl id love to try the taste of berfatinn


The one sign tells you what to tune-in to in order to get the most from your visit... "JAM 79.9"
now imagine vid2vid + seagal lora + the matrix
It I can get a matrix remake where every character is a seagal interpretation but true to the movie I will tolerate every seagal meme until that time and it will have been worth it
I'm sure if you stay alive long enough, that'll be possible.
close-up shot of (Agent Smith:1.25) played by Steven Segal wearing a grey suit with sunglasses walking in downtown Manhattan, looking at viewer, detailed suit, detailed outfit, detailed hair, detailed sunglasses, (from The Matrix 1999,:1.3) heavy rain, soft light, IMAX, 4k remaster, insanely detailed, rain everywhere, green tinted color grading
incredible likeness made possible with https://civitai.com/models/135544/segalsdxlv2 by @vital ermine


I can only imagine The Matrix with him as NEO, lol.
Seagal is the ONE
Hehehehe
Well, he does make a good Jesus as I found out.
I am very pleased with how it turned out based on the really shitty , low quality, small pics I could find. FULL of noise and jpeg blocking nonsense.
took me longer cleaning them up than the training or even collecting them (which was no small task as the dude doesn't have all that many pics of him on the net only the same ones).




Trinity has been replaced






Holding hands like good buddies
Is it possible to alter a Openpose image in ComfyUI? OpenPoseEditor only seems good for creating entirely new poses.
lmao I mixed your cube with a person


Huh, clip vision can fuse images together?
Or did you combine tokens
Put your cube into an IPAdapter, then a woman into Clip Vision
IPAdapter? Can you clarify, didn't hear about that
revision can do backgrounds in another picture pretty well
Thanks. I wanted to make an image fusion version of my workflow, this might prove useful.
Does it need a prompt though?
There's lots of weights and settings you can move around to get different effects
@ionic gulch has already build a workflow that contains clipvision and IPAdapter and many more features https://github.com/JPS-GER/JPS-ComfyUI-Workflows
If you want to just get variations of the input image then no prompt needed.
If you want other things as well as the image then it needs a prompt, or a clip_g image
A true believer. Amen.
No AIT though, I might make a version of my workflow that uses that principle

I just gave up with this ComfyUI, the only advantage of Comfy for me is only reneder time - classically in A1111 everything looks better and easier. I hope they will introduce AIT quickly to A1111. Thanks for those comparison photos, I spent some time on it to try with this Comfy but no, it doesn't make sense because the A1111 contains everything I wants without the annoying look and unnecessary fiddling with it.

What images did you fuse here?

That was the single image with no prompt, but at a lower weight
Peculiar.
And this is when you go too far

Stableswarm uses comfy as a backend so best of both world with a gui you are familiar with
The possibilities are endless
can you share the gen params used here? that would be very useful.
I tryed. Still its not the same. Still problematic is that in order to add something to the program I have to deal with "noodles" to make the various plug-ins work. This is not for me.
My workflow is a complete mess, But I can send you it.
The weights make huge differences so you can just play about with it.
Godspeed my guy
That one should have the workflow in

red house looks like the town from The Goonies (astoria, oregon)

thanks alot, I'll credit you if I would implement that into the AIT workflow.
lower denoise
Thanks. My hope is in A1111. I hope that they will not abandon it in favor of the fact that Comfy is becoming popular.
I think you might have to compile it for this, as the model needs to go through the IPAdapter, and I doubt it can understand the AIT Model.
totally. but stranger things is basically goonies 😉
I can compile everything. the compile script I made to provide the precompiled ones for batch sizes are universal.
Does ComfyUI have an OpenPose editor like Auto1111 where I can adjust it overlaid on the orginal image for accuracy? Really the one thing I've ran into where I can't get the same functionality out of Comfy.



Testing AIT and if it works well an AIT version of my workflow is already on my todo list.
do you want to work together on this then? I'm planning to make a version of the AIT workflow that you just imput 2 images and it fuses them.
It's not a direct fuse btw, it can require messing around for certain images, there's loads of weights you need to tweak and sometimes it just doens't do what you'd expect.
@indigo carbon Have you heard anything about the LoRA + AIT issue?
If not I guess I will file a bug report on the AIT repo. That LoRA delay with AIT is really frustrating. Every image takes 5-8 seconds longer and if you use more samplers you can double the time for every sampler again. This keeps me from really using LoRAs at all.
for me LoRAs work fine, likely an issue on your end
Side note, is there an easy way to turn off any base + refiner workflows?
I talked to other 4000 series users. they have the same problem
this would already possible with my workflow (it has up to 2x revision + 3x ip adapter as input) and should behave like that if you keep the txt prompt empty. unless you want a less bloated, smaller workflow. but during the week i don't have that much time, so it may take until the next weekend before i can check AIT.
you have no delay?
might be a driver issue then
nope, same gen time
can you try LoRAs with the batch size modules
the gen time is the same. it doesn't start generating. the delay is before the gen starts when you have a LoRA in the pipeline
AIT + Lora for me I have roughly a 4 second delay before each sampler starts
yeah I got 5 - 8s
@upbeat summit can you try this? I suspect it could be because the old modules weren't compiled with the compile script I made.
you mean the 4 versions (70-100%)? not at the moment. i would like to make them optional / switchable, but haven't found a good solution. would prefer a real switch instead of just cutting and connecting wires.
sure. where to get those?

just use BS4/2 with the newest version of the node, it will get them automatically for you.

Yeah, no rush I can disable manually

Will it replace bs1 or do you have to manually remove bs1
yes, it's within replace the BS4 modules with the BS1, this is due to the new modules being flexible.
Sweet
good idea. batch size 2, new modules were downloaded, but the delay sadly remains
=\
it happens with all LoRAs
if I bypass the Load Lora node it goes back to instant
how are you implementing lora @upbeat summit ?
Checkpoint Loader -> Load LoRA -> AIT -> sampler
Checkpoint Loader -> AIT -> Load LoRA -> sampler
also works but same effect
that's how you should do it.. does the delay occur without AIT?
can you try checkpoint->AIT->LoRA->AIT->sampler?
first you win 100% speed than you get 50% taken away because of the delay, that is what is so frustrating 😄
I think I tried it before, but let me try again
no change. delay remains. I think it has something to do with sampler nodes. because when it hangs it highlights the sampler node with the green active border
same delay here
I don't get it, it shouldn't effect speed
gen speed is the same but start to finish makes the time slower
LoRAs have same architecture as the model they were built for, it should do it
AIT + LoRA loaded
AIT wihtout LoRA


AIT + LoRA takes 10 seconds longer because of the delay at the start
new version 7.0 of my workflow keeps the aspect ratio of the source image in IMG2IMG and adjusts it to one of the recommended SDXL resolutions. also ip adapter source images get resized to reduce resource usage for very large input images.
https://github.com/JPS-GER/JPS-ComfyUI-Workflows

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.

So I'm 100% speculating here, but maybe it has something to do with memory management? because the behavior goes away for a couple of minutes when launching ComfyUI with --gpu-only.
Than after a couple of minutes I get really bad performance issues like 1 step every 20 seconds with the GPU running at 100%. I have to restart ComfyUI to fix it. So I can't run --gpu-only because it's not stable for me.


@heady vale could you try starting ComfyUI with gpu-only and see if the delay is gone for you? just be beware it could get unstable after a couple of minutes
what ait nodes is everyone using?
damn

that one just mistakenly thinks my GPU is sm80 architecture then dies
it should work for 3000 and 4000 series cards
ya I was hoping it'd hot-compile for whatever arch
instead of just dl-ing
I'm using radeon's AIT fork specifically for my gpu
if its an issue with memory management it's a problem with ComfyUI, not the node.
I mean the node could have a bunch of clones
sm80 is the only one supported
yeah I don't know how to determine what it is. I just know that --gpu-only solves the problem for a couple of minutes, but it's get unstable with or without AIT. also gpu-only increases my performance even more with AIT
was comfy still working on official AIT support or should I begin working on a redneck patchjob for gfx1100 arch
do the redneck thing
I'm getting a missing node warning for RecommendedResCalc -- I don't see it in the manager?

ohhh duh, missed it in the manager because it's got spaces in there
@ionic gulch is your workflow capable of fusing images without text input?
Not sure why it wasn't showing up in missing nodes
yes, in various ways: img2img + revision, img2img + ip adapter, 2x revision, 2x ip adapter
for example 2x ip adapter:

Do you keep model loaded on AIT? Curious if this is in the mix
can we talk in DM? I have some questions.
sure. but i don't have much time left today. already 3:40 am here and i have to work tomorrow. :)
tried enable and disable on the "Load AITemplate node" - no change
Ok
You have 4000 gpu right? I have 3000
yeah
is ait support on colab?

do you have the delay issue when a LoRA is in the pipeline?
I still can't get two loras, or more, to even work
if I want that I have to use auto
nah. not re-downloading all the models from HF as the dorf docs seem to imply is necessary
https://github.com/FizzleDorf/AIT/blob/main/docs/compile.md#unetcontrol-unet
Not at desk just yet
if the navi 3 branch gets merged into the upstream facebook repo then maybe
That’s strictly for compiling
Oh duh nvm. Thought you meant to use it
I was gonna try this fork specifically made for my gpu arch
https://github.com/ROCmSoftwarePlatform/AITemplate/tree/navi3_rel_ver_1.0
but too much effort
You rocm?
what is lora?
7900 xtx here
Yeah unfortunately everything harder with ROCM
Gave up my 6950 XT for a 3090 because PyTorch no likey
my text generation performance was comparable to Sytan's 3090 using autogptq
SD hurts though still using sub quad attention
games completely rip. bought Shadow of War for $8 and it runs 4k 150fps maxxed
on linux
Navi 3 cards are getting "official" rocm support for use in pytorch and all that in the fall.
So I discovered it's possible to use more than one LoRA in one generation. Does the order on which the LoRAs are loaded affect the result on ComfyUI?
navi 2 and earlier can just get fucked I guess

A LoRA is a fine-tuning for SDXL. Think of it like a model add-on or extension that can introduce new and enhance existing concepts, styles, objects, subjects and more.
Benchmarks using pytorch nightly if you were curios. Not sure how they stack against 3090
#✨|sdxl message
I couldn’t wait. Sad panda


That pushes past my 10gb vram, so no benefit with that flag
Just reviewed, of the top of my head my 3090 is about 28it @512
5.4it @1024
I see - but is the lora delay gone?
muppet spirit quest

will test it
yea seems about right. Think mine's closer to the 3080 scores I've seen when they're using xformers.
supposedly navi 3 is getting SDP (xformers) suppport eventually™️
Damn sorry to hear that about your card. Can’t wait till you’re up again. But enjoy that mom time!
so see if that helps
pretty sure he got a different 3090
he got an evga FTW earlier this month
and got refunded for the zotac
my comfyui manager just disappeared and when I try to git pull
From https://github.com/ltdrdata/ComfyUI-Manager
- branch HEAD -> FETCH_HEAD
fatal: refusing to merge unrelated histories
checkout master
F:\ComfyUI_windows_portable_nightly_pytorch\ComfyUI\custom_nodes>git checkout master
Already on 'master'
D extra_model_paths.yaml.example
D models/checkpoints/put_checkpoints_here
D models/controlnet/put_controlnets_and_t2i_here
D models/loras/put_loras_here
D output/_output_images_will_be_put_here
Your branch is up to date with 'origin/master'.
I deleted it and git clone
do you have a detached head?
last I looked, no
that's the main reason pulls fail
if you haven't modded shit you could just git reset --hard
No mods from me
Its difficult to say, because even with 1 step for each sampler its still very very slow to start due to vram
I-
That was like a month ago
Finally getting a chance to mess with the new 2nd image capability with IPAdapter and I gotta say that it's insane how well it does pulling the concepts from the pictures. No text applied on this:

Actually, that was more than a month ago lmao
How did you even get all the way back there?
he's just really really sorry to hear it
yeah - I understand. thank you for trying it out though!
Lmao, I guess so haha
got two whole months worth of sorry backed up
You know I'm still dealing with PayPal to get my $600 back?
bruv
git clone got me back
didn't the actual seller site side with you?
case resolved gg
give muns
in fact make it $800 for the inconvenience
They canceled the appeal five separate times, illegitimately
Tried to state that I was outside of their return window, of which I proved them wrong
I got moved up to an account supervisor who is extremely rude with me, to which I have a recorded phone call of her trying to basically talk me out of going through with the refund and also strong arming me
I proved that somebody else in her department told me that I had 30 days rather than only the eight that they had given me. She tried to call my bluff to which she listened to our recorded phone call and heard that person tell me that, so she agreed to give me the refund
PayPal closed the case so she can't do the refund through that, so she's had to push it up to a supervisor payout, of which she's been postponing day after day for the last 10 days
So I'm going to politely call her up tomorrow and tell her that if she doesn't get me my money, I'm taking her to court
lol my bad, i read it tonight so....
I have a huge grounds for a lawsuit right now, so if they really want to keep testing me, I'll go for it
tought it was related to this fiasco still

hell yea hit her with the fucking OBJECTION
Nuts
I can get them on withholding a funds, emotional distress, and damages
All because in the end of the phone call she apologized for all the shit that they put me through for a month and a half, and stated that it was completely unnecessary
Of which means that all of these problems that I've had, including flare-ups with my autoimmune disease, of which I'm still dealing with currently, are all grounds for emotional distress and damages

glad to see you still using that monstrosity
Hah...what, that crazy steampunk hoodie? 🤣
That thing's hilarious.
ask for 8M settle for 400k buy Ford GT
Bro, I strong armed the fuck out of her. I had her on the call for an hour and 45 minutes of her trying to weasel her way out of the refund, to which I had receipts, recorded calls, and their own emails that they sent me as evidence
She tried several times to tell me that there was some reason that I was not going to be awarded the refund, to which I proved it wrong every single time
I even made her sit on the phone for 25 minutes until I got her confirmation email saying that she was a supervisor, what her name was, when we talked, the conclusion that she reached, and that she was going to be awarding me $600 because of all of this.

"awarding" you mean returning what's yours
Yeah, miss speak on my end
I'm going to get into contact with them tomorrow, to which if they do not settle, I'm sicking my credit union on them



brb tacos
Now, I've been told by several people who have dealt with these problems before with PayPal, that if they don't side with you and then you pull the funds away from them, they consider it a debt, and they'll send collections after you.
To which I say, try me, cuz I'll escalate it to small claims courts to where they will have to pay for my legal fees, and I'll bury them in evidence




they did the same to me,i sold something to a guy,2 months later the scammer goes to the bank and does a chargeback,paypal says they know hes a scammer but i still gotta pay the whole ammount because he did a bank reversal
Yes, main reason I don't sell shit these days as people are being scammed like that left and right.
did you paypal the money straight to the guy or did it go through the site? If it went through the site I'm confused why paypal isn't just billing them
Reason I would never sell my vid card unless something drastically changes. They get the card (item) and their money which a lot of sellers complain about happening far too often to them.

@upbeat summit Just updated, AIT and Comfy, here's my runs without AIT, then with Lora. I am finding the same behavior as you with AIT+Lora and only after updating both Comfy and AIT




Thanks for doing the tests! Very interesting. On my setup I have the delay issue since the beginning - so for a couple of weeks when AIT was first released.
@native knotYou have shit in there I have never seen before
IPA? Only IPA I know about is Inidan Pale Ale.
Bro... IP Adapter.
Local?
I am generating these locally.

beats me, as I said, I have no idea about that ip thing
@upbeat summit this is so dumb, i can gen BS4 faster with Lora, still slower tha without tho.

whale fuck is the best kind of fuck. :/
GitHub
experimental. Contribute to laksjdjf/IPAdapter-ComfyUI development by creating an account on GitHub.
Damn, Flava Flav V2
No, and if a furry whale pops by anytime lately I am running.

{kind=link}
{kind=link}
{kind=link}
Ahhh shit. click link. Hit wall of Asian text. Yep, whale visited me so time to grab a smoke and get the translator
even a scaled whale would still make you a furry
furry degeneracy is like a tree where the main clade "furry" has all the subspecies like "scalie" and similar.
but they're all still furry
Not my thing tbh. Just never went that way with no want to do so.
after looking I will skip ipa
maybe someone should make like a furry genealogical tree to see all of its branches and species and types of stuff etc
@upbeat summit I got lots of digging to do, but it seems this issue stems from these commits, separation of controlnet and state, i mean lora


hmm... yeah that is strange

i can confirm before the updates this was not occuring
because they keep saying my tracking info is illigitimate, even tho he has had the GPU for over 2 weeks now, and I got an email from them on the day arrived saying they SAW it arrived, and they are processing my refund
amelia bedelia
do you have 3000 or 4000 series card?
3000

that is very interesting to know. I have a 4000 series card and have that delay since AIT was first released. so it started for you on a 3000 series card with the latest updates
have AI write a script explaining the entire furry fandom phylogeny in the style of a Clint's Reptiles video
the timing is suspect, not sure why 4000 series wouldnt have worked prior
they didn't. the delay was always there
ive had loras in my workflow since AIT released

email gpu dude's email to paypal and say "he has it go after him"
I have to check what Fizzledorf changed, (forced change due to the Comfy change in lora.py) Ill let you know if i find anything
yeah maybe that will help to identify the problem. still not sure if I report it to the AIT repo or ComfyUI repo - maybe both need an update to fix this


They know he has it lmao
cool! sounds good
My path to resolution starts with identifying Comfy change (commit came first) and then review AIT
she legit told me they knew he had it, but I sent it back past their return date, which is different from what I was told, which is who now she is "honoring" it

yeah good thinking. if it happens on 3000 series cards now that may help find a fix for 4000 series cards too
she basically told me "You decided to send it back without pay, so he gets the money AND the card"
was this your old 3060?
what tf site was that again?
paypal
I mean the card
hardware swap
most 2nd hand sites have buyer protection terms for that
they banned him and barred him from the other sites
Their buyers protection IS PAYPAL
lot of good that does you
yeah, PayPal is shit and began to become shit after the forced break up ebay and paypal. Just getting worse by the day.
so wait are they just giving you $600 or are they gonna dock him the $600 he owes you?
sounds almost like they're just going to credit you $600 and he still gets his $600 too
no idea
I think what you said
I said two things which one
we both get $600
Sounds about right
even tho they ruled in my favor cause he scammed me
and he also agreed to a refund if I sent the card back
you are lucky as a lot of the times they now will tell you too bad, sucks to be you.
Anything else we can help you with?
my justice boner is extremely upset at this however
I am not lucky, I have been dealing with this for 2 months now, my stress is high, and my medical issues are the worst they have been in years
2023, there is no real justice