
#✨|sdxl
1 messages · Page 105 of 1
who here wants volunteer for this conversation? I don't have the mental capacity.
Yep. He was a joke in the general with images channel for a long time and no one watched him.
stray?
@native knot same prompt as earlier but I've used different models and style settings(theyre in the image filenames if you open in browser)



yes
Some days I didn't sleep and it christmas I was lucky they let me have 24h on colab.


Olivio (SEcourses) is active in this channel. Probably my fave youtuber as well, not that I use youtube for this stuff. But I got the best reg image dataset I've ever seen from his patreon

for god's sake I'm joking. Except about the comedy part. He cracks me up how excited he gets over simple things
Interesting differences. I like how the 2nd image has the flower in the hair due to where it put the color.
yeah I love his stuff. I just listen to him while I drive
He's very, I don't know, he is so happy doing it, it makes me smile lol.
Olvio is a good guy and so cheerful all the time.
yeah, exactly
good. I probably couldn't tell because of my condition
It's okay, text and sarcasm blindness is common among 100% of internet denizens
also the mr t stuff was intentionally bad, this my friend, is true art.

he does not like vegetables
Eons ago I got a ban because they mistook what I said. When I said I even used 🙂 to show I was joking they said that people do that even when they aren't. I gave up on the internet denziens after that.
yeah, very much. humorless limps are no fun, but a ban from such a place is no ban at all, but a gift imo
no, there is a child out of frame I had it generate, he's angry the child wants his vegetables
It was, but I got my just deserves when they went bankrupt a year or two later and shut down. Was cool, but when nasty people get power, if even in a limited capacity, nasty things happen.
whose child wants vegetables wtf
do u have a moment to talk about our savior Jesus Seagal

it is AI art, it need not be real
mine
meh, мені слід сказати, я дійсно не люблю Стівена Сігала. Він симпатизує росіянам і не є доброю людиною.


think diffusion got confused and thought jason segal
lol


100+ s/it
I currently have --disable-smart-memory flag on.
Would that effect your changes you just made?



how much are you upscaling to?


this was:
ProtoVision for 3 steps in a Preconditioning type stage (refiner prompt from attached)
DynaVision for 13 Steps in a Base type stage (Base G & Base L from Attached)
ProtoVision for 9 Steps in a Refiner type stage (refiner prompt from attached)






just x2
img2img process goes
upscale model 4x > upscale image by 0.5 > vae encode > ksampler for 10 steps > vae decode
Ok...so you're starting to approach Cruella DeVille territory, which is interesting to me. That's definitely a hot look, though.
Didn't even notice the glove until just now...haha.

I've looked but is there any no merger nodes, where I can set complete circuits within a node and combine them into a single reusable set
I don't know of any mixer nodes which would rock
Wait I just thought of a really easy way to do this actually, a three node set with an ID value, the input and output will correlate to a second nodes input and output, and the input and output nodes will be placed at the edge of the circuits outside of the primary area
would require parallel nodes though
come here my son

That's true, see I don't know how it works, I'll have to look. Maybe if within the code it replicated the structure by the number of nodes that are used for a single input and output. Creating non-visual node sets that are copies of the original
Got me as I have only just begun to really use comfyui
For example let's say you have no input a, and no output a, and they take and output a latent signal. For the first instance it would use the design that is outside of the primary structure, passing the signal remotely to the input a in and taking the signal from output a in the third node which is only an input and output.
Now while the input and outputs have an ID of A, the node could be A_1 which would be the first instance that is seen and designed by the user, whereas A_2 if it exists would copy 1 internally, not being displayed on the actual ui, to avoid the requirement of parallel pathways
heeeres steven

i remmeber someone a workflow with face repair for sdxl, right?
I will have to look to see how it works actually I'm going to do that when I get home because I really really need emergency. Because spaghetti hell...
I need to look at the actual API I haven't ever really looked into comfy yet. I've just been treating it purely as a node base system. But I wonder if I could create perhaps a API note of sorts that would allow for definitions via selected Python extensions. Plant without having to create a specific node for each and that method
it works best last, after upscale. At least when I tested it
segal as vorhees. he kills it imo (heh)

real





repent or else


I'm gonna need to enlist the help of a node wizard soon.
Impact Detailer node is great but there needs to be a way of attributing the denoise value to the whole image rather than the cropped+zoomed image, so that the further away the face is the more it denoises. Right now it's not scalable whatsoever. Auto1111 works correctly where "inpaint at full resolution" gets it's denoise from the zoomed fraction of detected face and not afterwards
If there was a way to intercept Detailer after it has zoomed, and say "if you zoomed by x amount, scale denoise value up by x"

So running all three different canny models, nothing else changed:
Control-lora-canny-rank128
1630.46 seconds
adapter-xl-canny
207.32 seconds
diffusion_pytorch_model.f16
170.8 seconds




some img2img testing


sdxl is bad for this. had to use 1.5 to turn it into a photography
sdxl tend to lose detail blur and mess it all 😦









That's odd. It worked well on my 3060 6gb. What upscaler model are you using there? I was using the 4x ultrasharp






is there an interrogate node for ComfyUI?

SDXL requires its own and it was hard to find anything to make my captions for training.
I settled on llama-7b
tf, LLaMa can describe images?
didn't know that
pretty damn well, yes
13b is even better but I found nothing that works with it
oob I gave up on
is there a node for that?
I'm making a version of the AIT workflow that makes an image, describes it, and repeat
from this to this. i still have work to do with the scar coz inpainting always seems to fade it out and im clueless on how to make it more noticeable instead.




metadata + workflow included


SDXL model CrystalClear. See the PNG info for gen parameters. (If you didn't know, Euler A doesn't work with SDXL. It always produces blurry images. You probably already knew that, but here's a working prompt for clear results you can edit for other stuff.)

Wait a min I use euler A all the time in Automatic1111 as it was the best of them with less noise.
figured out the interrogate thing. is there a node that takes the text from conditioning?
eh, it wants clipvision, definately not it
revision uses that node
close though and is doing the same thing. sees a pic to interrogate it.
might need to make our own node. I do know they have a chatgpt node
not what I needed. I needed something more similar to how A1111 used to describe stuff
that is broken af though for XL
There's this that does Booru tags, maybe you could pull it apart and use something else for SDXL with it? - https://github.com/pythongosssss/ComfyUI-WD14-Tagger
wd tagging went poof with xl too
seems for training wd tagging and xl is a hit or miss now
will check out
This also has some BLIP Analyse nodes - https://github.com/WASasquatch/was-node-suite-comfyui

1000%. wd tagging fixed all problems with clothing artifacts but fucked the perspectives and proportions beyond repair. I removed them and instantly got the model i was hoping for
Yep. I always used them now forget it

Losing them is why I ran to try and find anything that would caption to only find one thing that would work locally for me
I was super careful too. I pruned all tags of human characteristics and turned threshhold way down, so the only tags were the background, clothing, and facial expression. Still completely broken
I tried blip too though. For training faces on XL it seems captioning never really helps.


Yes, faces are bad many are saying and for me the first thing that hit me was the faces being smooshed in, missing, etc... that I never had in 1.5/2.0/2.1
I finally got it mostly sorted out but captioning was not an answer
same. spent a long time wondering why the hell SAI told us XL is "easier to train" when i was finding the opposite. I'm finally happy with my formula but it takes an hour on 18 images
@upbeat summit you home yet?
Yeah, I am lol'ing inside because a friend of mine I said EXACTLY the same thing to two weeks back.
i've been training loras in 30min with 16gb. i train at 896 buckets with batches of 2
I think one thing hurting us may be the two TE stuff, but not sure. All I know is XL has issues with training that I never saw in any version before.
20-30 images usually
I wonder how many actually touch TE now or is everything --train unet only?
Caith has been recommending TE training so most people active here are using it now. Even SEcourses and aitrepreneur are training TE
I'm training it too but only with token
--network_train_unet_only
You know I took my friend's training and used windows and OOM instantly. I have to train on Linux or else. On linux 18-19GB on WIndows 24+ GB




each time you raise dim, memory goes up by 2gb+. I recommend 64 maximum to train successfully on 24gb
Just saying that on Linux it trains fine while on Windows, changing only folder paths, no way no how. WHY?
Caith and Olivio seem to think higher dims damage the model on XL. It might, but it still helps with details
I never left? 
I use prodigy so it sets all that
i see dims as like the more info you are trying to fit in the higher the dim. but it donesnt take much. i could be wayyyy off but it makes it easy for my pea brain to understand
Oh, lol. You tried the locon? btw, I posted it on reddit and the bots hit me. Each time I refreshed the number was going down and up and steadily down.
i dont think the TE needs training tbh. it knows a ton of tokens very well already and training only the unet is faster and works.
i'd really like to see some comparisons. followfox might have something soon. 🤞
not yet - but I will now. is the post still up? let me upvote it!
Smaller modules
It's possible we don't need to use dim=128 and adapt all attn layers. I suspect that we can reduce the size by quite a bit if we are careful about which layers to adapt.https://old.reddit.com/r/StableDiffusion/comments/1223y27/im_the_creator_of_lora_how_can_i_make_it_better/
LORA creator thinks >128 isnt necessary either as long as you're careful of the other stuff
yeah, i see it as another way to control overfitting and detail amount. I want the actual freckles and skin pores of the real person to be present in outputs. That aint happening with "dim 24" as recommended
I didn't dare post it in the old sub reddit as they hit me hard last year so I can only imagine now
256 is definitely overkill for any case tho
I wish I could tell what my dim/alpha is at but it is automatic
idk ive never went over dim 12 and it got freckles and skin detail for sure. just dont caption the skin or anyuthing about the skin
accelerate command should say
I'll give it a shot. I remember my outputs being smooth af and i hate smooth
goes by so fast I never see that stuff. I will look next time but it is automatic past accelerate it isn't static set
I used to set all that by hand but it was a nightmare so I let prodigy, etc... set it with some long ass commands and optimizer settings
i didnt know schedulers could change anything beyond LR

Quick question. I have used the model in automatic1111 based on the github model provided. As well as I used the sample on clipart. It seem like clipart produces much better quality results? What could be the explenation for the difference in quality? Is the model I am running locally not working the same as the model on clipart?
Well, I used to use iA3 and forced to switch to locon. Love the iA3 as it trained way faster and did better for sub 1mb.
905k is now 43.5m








nah, I concluded the caption output is too close to the original- I just wanted to see the wacky results.

?

repent







I was making a version of my AIT workflow that makes an image like the original, describes it, send to prompt, repeat
oh i missed that
comment was just kind of - there
hmm I have yet to play with AIT
i should probably


sensei 🙇♂️
the AIT workflow I made is now excepted as the official one for SDXL with the AIT node, it's included in the repo

oi
uh

i guess it did as I asked
))))
@glad grove the masterpiece is complete. I can leave generative AI forever, and collab with AIpretenaeur in videos about uncensored language models speaking french

sd literally thinks wilfred brimley is mr potato head. thats all this prompt makes. a potato in the shape of wilfred brimley, russet potatos in a basket

lol
lol
so this is because you are using the As/Is dialogue, try "a realistic carving of a potato, wilfred brimley, etc. "

that is if he WERE a potato, not displaying a potato AS him
mine was "photograph of an unfinished carving in a potato, fat disgusting steven segal "

diabeetus

tried lora-FA yet? heard it converges twice as fast as standard

dia beeeet us

oh lord

brand new lora type available only on kohya dev2 branch
I was using -b dev then found out dev doesn't work with locon and he said to go back to master

git checkout dev2. locon works. 2 seconds to switch back if it doesnt
while we'pre on beets
apparently kim jong il as a bowl of borshch is not okay :\
cos openai right banned me
does it work in gui for training and more impotantly does it work in comfyui?
(during the beta long while back)
yes and yes
its probably the intent behind the image that they don't want their brand associated with, more than anything else
damn. my gui is updated and not even shown

The guy is A) dead, and B) a public figure and C) it's borshch, everyone loves borshch


it wont show unless youre on dev2
not sure what it happening, but it is.
I did finish building the AI telephone workflow, but SDXL's clip is too accurate it was useless, so yeah
basically, this would be entertaining on old models like 1.5, but because SDXL is so good, it's useless

idk what -b is i just do "git checkout dev2". is that a linux thing?

The FA stands for full attention ig
well, I will have log into linux and do the lycoris shuffle git clone -b dev2
if locon did 15 epochs at 1800 steps I wonder what FA lora would do?
i havent tried it myself yet



VERY cool
That lora will also do realism
yeah I just saw that and checked the settings if I was doing something wrong 🙂
I was doing it by accident
you can add realism, and ambient occlusion (that one is a great one) and it will switch away from cartoon
it is a great effect
It is a nice lora but so many people are back on 1.5 now
but SDXL can be fine-tuned so well
it's amazing what you can do
anime people are back on 1.5. They say 1.5 for anime and realism XL.
I could not change their minds so we have two groups now splintering the community
same as it was with 2.x vs 1.5
yea cuz theres not a good anime model yet
precisely
maybe later there will be a good one
they said thanks to NAI being jacked anime/1.5 lived
seems everything is a descendant of NAI if Anime related
they said if we can get an anime model training on millions of images like NAI did but for XL then they will come. Made me a bit sad and perplexed.
😔
Reason I stopped releasing for 2.1 is everyone run back to 1.5. Now I am getting the same vibes for XL.
maybe someone will figure how to transform training data from 1.5 models into XL ? or not possible?
not possible
SAI already said that with 1.5 to 2.1
now, what they could do is retrain and that would work
😔
a lot of those models came from people with 8-12gb cards and on XL it laughs at puny cards for training. 😦

use XL img2img and upscale to 1024 and then use those images as the dataset to train a new model 😄 or do you mean the already refined models to XL format?

YES, or straight to 1024 as the gen source as most of those models do it

I am laughing

well...
Currently allocated : 6.59 GiB
Requested : 5.00 MiB
Device limit : 8.00 GiB
Free (according to CUDA): 0 bytes
PyTorch limit (set by user-supplied memory fraction)
: 17179869184.00 GiB
I need more GiB

yup 🙂
it really is a good lora that will fizzle and die on the vine.
very very cool

Upscaling a dataset is a terrible idea
yep
I tried that once in a training and oh, my
it saw shit I never saw

that shit is like cocaine to a diffusion model

hence the emoji... I was joking
Seems XL likes drinks

and brussels

and potatos of course






i upscale datasets all the time to great result. only a double though. a ton of cheap photos around 600x to 800x sized photos of varying aspects. throw away everything with significant artifacts. i crop slightly only to minimise bucketing. so if i can shave 10 pixels to make it match another better i will. then i pretty much ALWAYS double from there. any image that is smaller than 1024 in any dimension.
after that, kohya sizes down all the images so they fit buckets built around the resolution i define. cropping is more about ratios than actual pixels because of this end step. i've never had any problems with gan artifacts showing up where they shouldn't and i actually pull great detail into the loras i train.
don't upscale shit though. don't even use it.

nah, I mean when I have, I just use CLIP out as prompt and img2img at 2x @ .6-.85 seems to have good results. upscale itself is garbage
wtf
it just put out a nude potato lady
:\
idk i feel want to go back to sd 1.5
OH you're still pumping it though, you're just not using the upscale models specific. cool!
hot potato means you gotta give it to the next guy
and then regenning something LIKE it
but usually kind of close, but it's good for a dataset
since the tags will be corrolated since it CLIPs
works not so bad
cheap quick and dirty, but works need be
not at all what i asked for, but k
what is the different sd2.1 and sd1.5? why many user using 1.5 insted of 2.1
@shy kelp it's... friendlier
Careful, I almost got banned for that and had a HUGE adressing to by a mod for doing the same thing.
wdym?
wise move.
oof, I mean it isn't like, dirty, it's clearly artistic style, but yeah
censored boxes is a nono it seems.
and really, they aren't even per se, what you see. it's smooth, no nips or any detail
just didn't wanna risk it
just weird because I asked for a woman carved into a potato with potato skin filagre
yeah, not worth it. Hell, I no longer show any children because I got a 3 day vacation when I did absolutely nothing wrong but a resdident pearl clutchers took offence at the showing of children and down I went. smh

@soft bonefatal: Remote branch dev2 not found in upstream origin
tip toe through the tulips
for a 1.25 Paul.
For SDXL, what's the current opinion on A1111 vs ComfyUI vs ??. Just looking for the best frontend to run it locally.
you a grease monkey or a Sunday driver type?
Somewhere in the middle. I can tinker but I do appreciate things that work easily.
Stick with the dev branch of Auto1111
until a proper frontend that is friendlier to novices is made. As Comfy said ComyUI was made as a backend and the ui it has was thrown on.
I was already building a brand new instance of that, so I guess I'll get it going and see how it is. I just saw someone else complaining that it didn't integrate the refiner very well.
I am sure someone is going to come out with a really good frontend soon
interesting result using a 2.1 embed with XL

most are not really using refiner anymore as Sytan has stated it is not good.
nice!
Oh, I didn't know this. I haven't used SDXL at all yet so I'm unfamiliar.
well, on auto it is implemented really bad and on master branch it will crash you to a BSOD if it runs out of page file. I have 48GB of ram and my page file was 128GB and growing. I limited it and BOOM. In the dev it loads base, then unloads it, then loads the refiner, then unloads it to reload the base. Really bad.
I think that was the basis of the complaints I was reading.
there is one other issue

they still havent fixed it? its been more than two weeks already
sure haven't
the other issue is that the images are foggy/lot of noise and the same prompt in Comfy is crystal clear
made me think my lora was jacked
Well that seems like a big problem.

it is and isn't. For me I finally gave up due to that but what was keeping me is the iA3 I trained in. In Comfy that will never be implemented so I stuck with Auto as long as I could.
If I am going to release loras/locons they need to be made for what people will use them on, if anyone is still around with XL

was that dev 2 of lycoris or of the gui?
no idea what you're doing. i use regular kohya on windows and dev2 has been there for months
dev2 of bmaltis kohya
see for iA3 you had to go into the gui, delete the LyCORIS folder. do a git clone https://github.com/KohakuBlueleaf/LyCORIS -b dev then venv and pip install .
Frankchieng talked about https://huggingface.co/stabilityai/stable-diffusion-xl-1.0-tensorrt
I am wondering if this is for 1080 Ti video cards or not

no TC in pascal cards @wet raven
they didn't come until Turing for consumers
literally all i do to switch is open command in kohya folder, type "git checkout dev2" and close
ok thanks
welcome
do you use windows or linux to train in?
windows
i set up linux once but too many hoops to jump through each time, considering i train all day every day
Linux is superior at this than windows but all my tools are windows only :/
even triton is Linux only the windows one does nothing but shut up programs complaining
accessibility vs. function. a tale as old as time. Comfy vs. auto1111, linux vs. windows, android vs. apple, pc vs. console
the only one i havent opted for function in is windows
should I install cudann? I know his versions are out of date
i believe its much faster

was no difference in Linux with them or without

A fatter adam sandler again
oprah getting in on the assasination of rasputin
I am just waiting for a new training scheme to hit to compensate for XL
nvidia is supposedly going drop something for 4090s but who know might have just been all hype talk from them
there we go

your pfp so cuute >u<
I wish i remembered who made it for me. Its a Toad + Snail hybrid.
My invention, but not my artwork.
Oh, and I tried deepspeed and that was a nightmare so I opted out
uwu so cute, glad you have it
There's a 4 inch long vinegaroon in my house somehwere. should i kill it
something I never knew is the last accelerate config option of no, fp16, bf16, or fp8 does it matter?
for mixed precision or save precision?
fp16 for mixed precision is causing problems

oh i did bf16 for that
my 4090 will do fp8 but kohya does not
RandomPower#3956 Made my Discord Avatar on Game Dev Underground server
i saved that as a note so i'll remember


welp im gonna kill it
bitch is bigger than the one in harry potter
oops dal_mac, didn't mean to DM you
Benito Mussolini, liked children's cereals.

its right there m8

exactly, I was showing you there it is
I have my previous iA3 model I trained and will redo it now in FA
ok lol. my first time switching i actually didnt see it for a minute
on Windows to see
yeah
I hate how it autostarts without the dark mode so I have to type the url with it. Annoying, and blinding
Just changing my paths and move that to FA


"Freeze A and only train full connection layers. In simple, better memories efficient and training faster" purpose of FA i guess
we do not need any special flags?
Reminds me of a side scroller type game
prompted for Terraria landscape
same
I went back to minecraft
but i cant even get into minecraft
it can get quite difficult
I can't now but back then it was alright
i had minecraft on pc alpha in 2011 or something and got bored
Ive been playing MC modpacks for years. I like the expert packs that take a few months to complete
never looked into modding it. I extensively mod tho, in skyrimVR and now Kerbal


I have been using vr for 6 years now, and to this day i keep my feet planted. the only room i need is for my arms to swing
when I train my case gets so hot while the card goes around 69-70c. Fans that came with the case suck so 140mm is OOS but is next.
well, nice thing is when it gets cold this is one heater for the room

the case fans that came with it are 120 and just can't push a feather at max rpm. New ones do almost 70cfm a piece at over 2mb/h20. Arctic makes good fans
now that we are headed back into covid masking and lock downs I need to get while I can get

lian li uni for aesthetic, noctua for power. I got an industrial 140mm that rivals my $140 room tower fan
my side glas right at the back where the actual gpu is blow so hot the glass gets almost too hot to touch
well, I need 4 but only come in a pack of 3 and I don't wish to spend 40-100 per fan
2400 pwm or some shit
I bet these fans aren't even for pressure so even worse
I finally went with a aio and I am in love. When it dies I want to go to a full on open loop but the block for this 4090 is almost 200 USD, sheesh
btw,
I am about to train but I am unsure what to do and how to test if it is as good? 17 epochs with 1 repeat 130 images
that was the locon/ia3 but for this?
i've never used a type other than standard before so no idea
i just know FA takes less epochs than standard
standard is 10-17 epochs for me with 120-130 images 1 repeat
i'd do 10 and save each one
damn, almost half? Yeah.
save each 1 sounds like a good idea
tensorboard is pretty useless I found
@vale eagle Said it was much less than half for them
i just ranted about that in finetune channel last night. changing the learning rate drastically didnt change the slope of my loss whatsoever yet people are using that to determine "overfitting"
No, I do another test which slower than normal lora but it have another effect
with FA?
Haven't post it yet
Precisely. Friend, and I, train a lot and can't determine a damn thing based off the nonsense of tensorboard. Change stuff and the graph stays the same,
good or bad?
yes, it is weird. The test conflicted with previous result. But it should be more accurate
well, we don't need a slower way to train
i wouldnt mind, if it fixes clothing artifacts when not using captions
thats my last remaining problem
what sort of artifacting?
@vale eagledid you use any special flags for it, or arguments?
if i prompt the subject into a context where someone would be wearing a certain thing, but dont specify what that is, i.e. "ohwx man at a fancy gala" it puts them into a tux, but their clothing from the input images messes with details of the tux, such that its not believable anymore.
It's overfitting slightly, sure, but to guarantee likeness I cant afford to overfit any less. captions solved this completely but as we know they have to be perfect or its fucked.
its very small details. things like too many buttons too close together, or a necklace not following the laws of gravity
perhaps lowering dim can help but I imagine anything that helps this would also hurt likeness
Lora-fa has more room for prompt even it's overfitted.
beautiful, always loved those kind of level map in game magazines
weird

Well, not sure I like the FA results
base, ia3 17 epochs, f4 10 epochs



base, ia3, fa



I wonder what dim/alpha I should use and is this using conv too?
yeah it could be for sure
btw is there a way to make the textures seamless
i made some textures but they ended up not totally seamless
Ive not tried seamless gens yet

We finally got to play Black Myth: Wukong, the gorgeous Unreal Engine 5-powered, next-gen soulslike that's inspired by the 16th-century Chinese novel Journey to the West. Find out our thoughts as we faced off against three different bosses.
#IGN


I upped the dim and alpha to 32/1 like a normal lora so it is over 4 times larger than previously and not a lot of difference.

Testing out new workflows and well im actually impressed

it must use conv since lora hides them but FA they appear
was trying to decipher the papers

you just have to put tiling option with texture style and check y n x tiling and it tiles in sd
now i don't need to manually fix my images
is using sdxl worth it?
m still using 2.1
for sure. you can gen a lot more things
i just make game assets
like fixing textures n such
mid journey was amazing for making concept art for games
depends if u want anime style or realism
I used 2.1 only for months and at the end felt quite restricted
no to realism never
seen enough of reality lol
i want something like hand painted like league of legends
sdxl is more realism?

BBRRRRROOOOOO

Hugging Face just raised a 235M / 4.5B series D!
8 epochs at dim rank 16 else I lose the ring of light in the middle on the bottom. It did not matter if I did 20 epochs it would not bring it back until I went from 8 to 16. I have not tried between those.

is the ring of light in the training data or something?
no, it is in the base image though
until finetuners have time to train. consider where 1.5 was at 1 month in (absolute trash)
this is without my lora

what exactly are you training
right off, regardless how low I went see the top of the saucer? it isn't smooth it is actually bulk plating.
it refined it.
I only train styles not objects
so the bulkhead plating is awesome

thats with FA? thoughts vs. standard so far?
against locon, or ia3? Not as good
base, fa, ia3



fa barely changed it even when I did 20 epochs
16 dim
or 32 dim
hm. different for faces im sure



FA is improving on base without changing architecture. looks best to me so far
not for styling as that is not what I want.
yeah impossible to judge your results without knowing your dataset
dataset is irrelevant as I am looking for the greatest changes when I use a lora/locon.
this, I lay odds, is more for objects/subjects.
thats dumb. for the greatest change you can just do LR of 1e-2 and overfit the shit out of it. plenty of change. shit quality tho
did you know the reason we have locon is for styles as a lora isn't really made for that
1 layer deeper which is where we get the styles from
so, for you and clothes on your subjects this would be good I think
i havent done styles since DB. if i wanted to do styles again id probably start with finetuning
could be. will try
if you notice it is refining the base image
still remembered the floppy disk drive and internet explorer DOS and office https://twitter.com/Rainmaker1973/status/1694597311723180089

#Today in 1995, Microsoft released Windows 95.
[📹 PC USER 486]
Likes
17119
Retweets
3223
i remember when games used to come in those big 8 inch floppy disks
i still remember games on those compact cassette 😄
yea i heard some of them are pretty expensive now ( only if they are sealed in mint condition) could be rich now 😔 💸
Hey, I still remember tic tac toe on a stone tablet. fun, but a lot of work when it was time for the next game.
fighting with a stone axe was my fav sport
head splitting. Damn, those were the days.
Quick question. I have SDXL model in automatic1111 based on the github model provided. As well as I used the sample on clipart. It seem like clipart produces much better quality results? What could be the explenation for the difference in quality? Is the model I am running locally not working the same as the model on clipa or their playground in terms of quality.




The first is cats can play as well and second is cat's bosses are playing too.


@pure crystal cfg, VAE if quality is realy poor. Feel free post image to compare



Could you explain? Not sure what you mean

it looks good to me. @pure crystal
CFG can be too high to affect image quality. And VAE is think that in some time can hurt quality as well.
what settings would you adjust in the prompt/settings?
i am not in A1111 and load sdxl models takes ages, can you make screen of your A1111 where prompt is?
i were at dentinst 😄

@autumn storm post some example images
@pure crystal sorry i mistaken you for @autumn storm






you have @pure crystal base model?

dynavisionbeta.safetensors
great i am using copax or sorach, dont know 🙂 @pure crystal
And comfy or A1111?
Comfy for SDXL for now. A1111 for everything else
yes seems right
Once I get comfortable with controlnet and inpainting workflows in Comfy I think I'll use it most of the time
he reminds me that ugly con from Galaxy quest 🙂


GAPA!
IP-Adapter + Canny:



third is canny source, second for ip-adapter and the first is the result?



yes
did ip-adapter need text prompt?
only some info for the style: 3d imax shot, 8k detailed photograph, centered, uncropped, dramatic lighting, cinematic, vivid,
If you use the same image of ip-adapter for clip vision g, would it be better?
you mean in addition to ip adapter or instead?
in addition
no with my first try - will try again later after work:
3d imax shot, 8k detailed photograph, centered, uncropped, dramatic lighting, cinematic, vivid,

How is control lora different from t2i adapters?

T2i adapters only run inference one time and have a lack of understanding of the prompt or timesteps so they are pretty limited in how far they can be used with the model, the benefit is they are very fast. ControlLora adapts the models own encoder (insteading of needing a whole 2nd one like controlnet) which then has all the generative knowledge to generate its own controlling context including the prompt and timesteps so it not only is better for simple tasks but possible to have it handle much more complex ones.
can some of you guys explain your current workflow of how to upscale stuff ? (or how to get more/better details into an image) ?
any plans to launch t2i adapters too?
what would be coming up in next sdxl release?
How is 3060 12gb for sdxl? Is it enough? With controlnet? And how much better a 4060 16gb would be?
Not really atm. We had some internally at one point but they really don't have the same strength or usability controlnet does and now with control-lora we arent trading off vram requirements anymore
i see
thanks
Hopefully stuff people like haha, nothing guaranteed atm. Lots of testing of new ideas going on (or old ideas in new ways)
@sour obsidian are you working on a tile controlnet?
Would love some better upscaling systems. Ill say its on the list to dive into real soon, as above though, no guarantees
was my favourite controlnet for SD1.5
is ipadapter and clipvision a different thing?
Revision is pretty impressive. Hoping for other great work.
Yea its pretty impressive, really like what it does conceptually
Im glad you like it 🙂
SDXL Good Morning Comfy-ists!







so controlloras dont consume extra vram as they are being used?
From a glance it looks like a modified transformer block that splits the cross attention and projects a clip image embedding in as a new input instead of text and then mixes the outputs cross attn for text and img. Hmm interesting. Wonder how a fully tuned revision would compare. Cool approach, I like the idea of the split. Is it slower for inference time running both inputs?
Much much less than reg controlnets since there is no secondary model like with controlnet
Its just turning the models own input blocks into its own controlnet
See SiliconThaumaturgy's sampler testing. Euler A doesn't work for SDXL. You'll get smooth, fake-looking skin / hair etc. and blurry backgrounds. https://youtu.be/JAMkYVV-n18

Support the channel and watch videos ad-free by joining my Patreon: https://www.patreon.com/SiliconThaumaturgy
This video will teach you everything you need to know about samplers in Stable Diffusion including how things change for SDXL and which samplers are which for ComfyUI.
First, I break down the differences between the samplers by compa...
so control loras use a technique where the seed starts with controlnet?
Kinda. It essentially has the model run its own encoder blocks 2 times. Once with the lora applied where its acting as a controlnet, and another time fully through like normal without the lora
oh ok
@sour obsidian any info about multi gpu training?
as its a very anticipated thing, as SDXL training consumes a lot of vram, it helps people to use multiple gpus so they can accumulate the vram
any plans on that
Yea, what you're looking for is sharded training. Id check out deepspeed or fsdp. They should work on any pytorch based trainer but of course takes a little know how to set up. Its not really XL specific using them as they are basically required for very large LLM tuning now haha. Check out this video for some info on deepspeed but should give a great gist of the concept (https://www.youtube.com/watch?v=pDGI668pNg0). Id imagine these could prob be integrated into something like kohya np with some initial configuration for anyone who has access to mutli-gpu

will check it out
We use sharded training though for basically everything internally, typically with our internal variant of this for SD stuff: https://github.com/Stability-AI/generative-models

GitHub
Generative Models by Stability AI. Contribute to Stability-AI/generative-models development by creating an account on GitHub.
hey @sour obsidian!
Heya 🙂
thank youuuu
@sour obsidian i dont see many community models coming out as much as 1.5 did, is it bcuz XL is OP?
Does the generative-models is a training tool? We could use that to fine-tune the base model?
Haha maybe? We certainly put a lot more effort into making sure the base model was really usable vs the older ones, im sure the model also being a bit larger and needing better hardware to train contribute as well
You totally could yea 🙂
yes and yes
its very gpu intensive and comparatively takes more time to train
maybe I should train a new Double Exposure SDXL version? 🙂
Does 24g vram enough to use the generative-model?
Great Idea!
I am back using A1111 in Base Mode only ... it works a lot better than at the outset of SDXL!
ComfyUI is great - but I miss my favourite A1111 Extensions (and .pt files!!!) (Latent Mirroring, Image Browser)
With the right config it should be possible. Ill be honest though, I only use it with larger cards so I am not quite sure how its low end is 😅
Likely kohya is better unless youre trying to train on chunkier datasets
A1111 in Base Mode only




this is from my 2.1 model




Cool!
OK. Used kohya already. Just want to know if it would be another option or not.




It is a large and very capable trainer. Lots of knobs and easy to dev on. Its built though with larger scale training in mind but not limited to it
This is brilliant!!
Thanks! Made with this I made yesterday:
https://civitai.com/models/133412/aether-ghost-lora-for-sdxl

Made a little ghost LoRA since I find transparent, translucent ghosts hard to get right on SDXL. It's trained on ghost people, but you might squeez...
would take a look. Hopefully, I would rent A100s to do something training with it. 🤣
wow, i dont know what was wrong with my prompt, but tried yours and the result is amazing, at the first attempt.


my prompt was: cinematic photography of a twisted dead tree in a deep forest background and sun rays coming through the branches, bluish fog , metaphysical, very detailed, intrincated . 35mm photograph, film, bokeh, professional, 4k, highly detailed
Negative prompt: drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly, low contrast, blurry, desaturated, drawing, painting, lines. I used copaxTimelessxlSDXL1_colorfulV2
oh wait, so this tool can be used to finetune?
and supports sharded training?
It doesn't natively support deepspeed or fsdp though it might be updated to have it natively in the future. It should support ddp_sharded though atm
the statement is too technical for me

that is pretty nice, specially the god rays, but the point is to make it similar to the original drawing
i didn't notice it image2image haha
trying to get similar godrays but it turn them on branches

noicee
sometimes it does a photo, sometimes a drawing, depending on the seed. It is curious.

how to use this node

no idea. it makes a new model from text and another model?

final result, only a slight sharpen in photoshop

looks good
openpose is fun

RIP

anyone encoutered this before?

prompt very long ?
looks more like something on your timesteps is causing the error
it was solved yesterday, that this is just warning, but should be solved.
but message he was answering was deleted. It was same screenshot as you are posting


actually, it was me, so sorry for the dupe 🙂
totaly forgot i asked it, and yes, i was answered as well. thanks!

got to love those realiastic models 😉




a bit more balanced and detailed. (last one, i promise)

what is doing to those tomatoes? nothing good probably
tomato core
What model is it?
i think proton... with some loras.
the info is wihtin the PNG
just drag it to your comfy
o.k. some are deleting it. And got opened my now, so probably later. Thank you!
i have no secrets 🙂
i've learnt from @upbeat summit's 2.1 images exactly like that, opened at my local SD and try stuff out with his prompts and settings.
i am learning now from magic prompts and so. It is part of dynamic prompt. Nice long prompts, but problem is i dont speak english well, so some basic words i have to find in translator.... 😦
recreate

what's your first lang.?
what's magic prompts?
cze. And magic prompt is part of dynamic prompt. You can find in manager and how to IT is on github
it enhanced your prompt
you feel it's required with sdxl?
what do you mean? It is working with comfui, so why not using it
Nice. Fog is gone and tree is having branch loss issues.
became bonsai

i mean that i thinkg that the prompting with sdxl can be simple and still give great results
That is pretty 😍
yes of course but i like for example randomize input to be surprised. Or it can your idea -> whisky and soda change to different prompt like vodka with chicken legs or similar. It is not limited to make prompts longer @zinc cargo
yea on sdxl, doesn't have to put a long prompt, and it'll create an amazing images
@thorny frost godrays seems to have more sources.
wrong person
Yes, too much sources
Many
Now I'm very curious. I feel like your prompt should have worked. The most powerful parts of my prompt are positive "Unreal" and negative "depth of field". I would have to experiment with your prompt though to see exactly what effect those negative art terms have on the result.
@uncut gull Are you using comfy? I am using a1111. May be that. I got very different results with different seeds. Some drawings, other more photographics.
Seems unstable
Otoh loaded the 1.5 model, and boom, 100% photo at first attempt
anyone good upscaler table site ?
like comparison for all
using LDSR at the moment good but slow
https://upscale.wiki/wiki/Model_Database
not sure it is what you want @tepid maple
yep perfect
lots of example I can look at
then
time to get a 1tb ssd
ssd is full
cant d oshit
rip
here goes 110 bucks to ssd 😄
spend 200 bucks on 3060 12gig too
That is going to favorites asap
yep
deleted all pics!!!
its just 240 gig ssd man it was never goign to survive
I have 4tb hdd but it is slow
time to go new ssd
give me some advice for my website
what do you guys want ?
every feedback is appreciated....

my aim is to make really easy prompt finding and sharing hd images only
all iamges will be HD or more
I use SSD for the checkpoints I usually work with the most, and a big ass mechanical hd for everything else, including less used checkpoints LORAs and such
my models and loras alone 300 gig atm
how about m.2?
Mine a couple of teras, included some LLM models. But you must be selective and leave the things you use daily in the ssd
Have my motherboard covered with them.
No place for one more
😄 i have only one, but it is truly high speed.
Yep, much faster than SATA SSDs
crazy how ai images can create a fake news, from peaceful city to apocalyptic city

controlnet?
we should start a challange creating utopia from places not disasters...
yup using canny
bit of peace 🙂

is there are reason why things like lora, ip-adapter and revision don't work well or even give broken result or console errors if used with refiner instead or in addition to the base model (in a usual 80 base / 20 refiner split setup)? this reduces the usefulness of refiner a lot, if the last 20% of the process work without and against the influences of lora, ip-adapter and revision.
yeaa, any suggestion?
because the refiner is a different network with different weights and slightly different architecture
do you know what would be needed to change for ip adapter and revision to make them work in the refiner part of the workflow?
you would have to train them again
you can't use them for the refiner for same reason as you cannot use an 1.5 controlnet on sdxl
so ip adapter and revision also are also based on some training? not only models and lora?
okay... maybe I don't understand what you mean with ip adapter and revision
alos none vanilla models...
https://huggingface.co/comfyanonymous/clip_vision_g/blob/main/clip_vision_g.safetensors
https://github.com/laksjdjf/IPAdapter-ComfyUI

GitHub
experimental. Contribute to laksjdjf/IPAdapter-ComfyUI development by creating an account on GitHub.
cool, didn't knew that one
but yes, the IPAdapter is trained on the unet of the model
do you know how to install the ip adapter
for comfyui you need the nodes and https://huggingface.co/h94/IP-Adapter/blob/main/sdxl_models/ip-adapter_sdxl.bin + https://huggingface.co/h94/IP-Adapter/blob/main/sdxl_models/image_encoder/pytorch_model.bin
i already have it working in my workflow since yesterday. so the next update of my workflow (released in 10-20 hours) will include an ip adapter section.
the current version of my workflow already has a revision section: https://github.com/JPS-GER/JPS-ComfyUI-Workflows


GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
I'm using A1111. 1.5 and SDXL behave differently, for sure. But SDXL is better overall, for all things like chair legs that don't fade into the ground, animals with four legs, buildings with windows that don't turn into billboards halfway through, and of course, hands with four fingers and a thumb more than 50% of the time. Learning to prompt for it is worthwhile IMO, and hopefully we'll have the full suite of controlnets in A1111 soon.
how did you create that, canny?
using canny node and controlnet
ok
Can IP adapter be used in Auto1111?

dont know how to make hamburgers smaller. When not mentioned size it was even larger, now tried Palm sized hamburger, still same. But love the mood.


I don't know either

SDXL just likes to make huge burgers

haha - nice
how to use this nodes

connect to an image you want as image prompt, connect clip-vision to a loader, insert between model loader and ksampler
This would be awesome in comfy https://github.com/naver-ai/DenseDiffusion

GitHub
Contribute to naver-ai/DenseDiffusion development by creating an account on GitHub.
Great question. Should post on the adapter github.

detail boost

can you give whole workflow?
do you upscale size whilte you're taking this step?
no upscale

Like a rhinestone cowboy.
Photographicographicographicographicographicographicographic
what a tag 😄
Thinking about Christmas.




christmas already??
Like a rhinestone alien.

🙂
@west breach yes thinking because atmosphere, peaceful atmosphere 🙂 I come to that mood doing snowy images.
LSTM can produce midi music after training, long time memeory and compose music
one of my short videos vistors traffic just over 400k
according to my analysis,the vested interest and the social class solidification is a big issue,the young generation is struggle for surviving
the comments and emotional classification is another key point of AI research,it can help predict the tendency of stock market or social life ,ppl opinions on e-commerce site products or social network topic bias or whatever









Interesting.
DPM++ 3M SDE GPU for the win.
Edit: karras > normal
Be aware the video started saying unipc, ddim, and PLMS can't be used with XL when that is true for the master branch on automatic1111 but 100% wrong for the dev branch of automatic1111 as well as ComfyUI.
Not even listed as an option on civit as I found out yesterday when I was filling in the info for my upload.
It's pretty new...but they really need to update to add that.
i tested ddim on a1111 and it told me it cant work with sdxl, so in some time it was true
Yeah, I had to lie when asked about which one I used for the images
smh, get off that master branch
i updated and it said something about RC, i got 1.5.2 but it say something about 1.6.0 so not sure. Will check it
it will say dev branch. You are 100% on the master branch which is bad
yy
that branch caused me my first BSOD in years
and how about devs and performance?
much better. not perfect but I was happier in it
they switched stuff around but I got used to it fast
i dont see the dpmpp 3 gpu in a1111
remote: Enumerating objects: 3, done.
remote: Counting objects: 100% (3/3), done.
remote: Total 3 (delta 2), reused 3 (delta 2), pack-reused 0
Unpacking objects: 100% (3/3), 353 bytes | 27.00 KiB/s, done.
From https://github.com/AUTOMATIC1111/stable-diffusion-webui
a6cedafb..4c678864 dev -> origin/dev
Updating a6cedafb..4c678864
Fast-forward
modules/ui_loadsave.py | 17 +++++++++++++----
1 file changed, 13 insertions(+), 4 deletions(-)
venv "K:\a1111xl\webui\venv\Scripts\Python.exe"
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: v1.6.0-RC-7-g4c678864
Commit hash: 4c6788644a367704d5dcb684a6c74a4ad1d1b078
Is that the developer branch? I think so
¯_(ツ)_/¯
custom lora?
say, can anyone tell me how to turn off previews from the ksampler efficent advanced?

hello, do any of you have a good json for kohja to train a style for sdxl with a 4070?
dpmpp_3m_sde_gpu. normal, karras, exponential, sgm, simple, ddim






https://github.com/Stability-AI/stability-ComfyUI-nodes This is the only node available that i can find


GitHub
Contribute to Stability-AI/stability-ComfyUI-nodes development by creating an account on GitHub.
Where do i get this?

have you tried with the manager?
what manager
there is a special node calledmanager which will dowload the missing nodes automatically, among other things. look for it.
GitHub
Contribute to ltdrdata/ComfyUI-Manager development by creating an account on GitHub.
well that didnt work right out of the box 😛
that worked thanks
change to None in Manager

it has many other functions. It is a must for comfyui.
btw Google Bard is pretty dumb, but can create some nice prompts
yeah bard is bad
But I imagine it's decent at prompts because it has internet access and can pull from other prompts formats now?
like very much first picture, may(j)or tom i believe, and David Bowie isnt so great 🙂


possibly. At least he knows what a prompt is, apparently
For example: "A young woman sits on a bench in a park, reading a book. The sun is shining, and the birds are singing. The woman is wearing a long, flowing dress, and she has long, flowing hair. She is completely absorbed in her book, and she looks happy and peaceful."
A sunset over the ocean. The sky is ablaze with color, and the waves crash against the shore. The sun is setting below the horizon, and the sky is filled with shades of red, orange, and yellow. The scene is breathtaking, and it is a reminder of the beauty of nature.
A cityscape at night, with all the lights on. The skyscrapers are lit up, and the streets are full of activity. The city is alive and vibrant, and it is a symbol of progress and modernity.
A forest in the fall, with the leaves changing color. The trees are ablaze with color, and the air is crisp and cool. The forest is a place of peace and tranquility, and it is a reminder of the changing seasons.
ok found a great upscaler for myself test almsot all of them
SwinIR is the best if you have a decent cpu
like a good Ryzen
it doesnt KILL your ram or vram uses cpu more
perfect






model?
in the file name
Buts its 3 steps dynavision
13 steps NightVision
9 Steps Dynavision






do the maths, thats 25 total split across 3 passes
how much time one image takes ?
plus a further 5 wuth a 0.12% denoise onwith NightVision on the upscale
thsi is a batch of 10 random seeds

do you use some special node for that?
and another batch of 10 random seeds with a mosdified prompt

uses the method in @high skiff s workflow https://github.com/SytanSD/Sytan-SDXL-ComfyUI

GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
although I have added an additional "preconditioning" stage which is the 3 initial steps
obvioulsy there was prior work on it, these are variations on a peompts I started posting yesterday
what benefit are you trying to achieve with 3 different models on a single image?
you mean 2 different models on 3 passes?
its a variation on the OG Base+Refiner pass for SDXL
only difference is I'm using 2 different models
@soft zealot your workflow is extremely complex! i am trying it but lack the seed with text node. Manager cant find it.
If you scroll out and go to the highlighted black box it has a readme


ok, ty. looking for my glasses...
its wonderful what you can do with copy & paste into notepad and then increase the font size
FYI if you refer back to my overview
Green Boxes are the only ones you need to use ona daily basis
Purple you may occaisonally need to use
Blue you are unlikely to need to do anything with
Yellow is old Shit I've left ibn for reference/
As Isay though its only there because I dont believe in stripping workflow out and f you want to follow along you really need to start with something way simpler first
ooooooor windows 11 ninja new awesome shortcuts. start + the actual + key. then start + esc to get out
What types of models/LoRAs are sorely missing on the SDXL landscape?
Styles, people etc.
I am interesting in training to fill the void 🙂
Maybe something practical like user interface stuff. SD1.5 had an awesome Button lora. 🤷
🙂

nice
hello stable people
^||unstable||





ooh those are neat
Thanks, but that are just photos from how i live.
better connected with nature than 99% of people then
Thats ture. Let me check if i can generate my PC setup 😜

I'm expecting potatoes
Nice steps imho, and second bearded woman or another issue.


That was a good idea!

Perfect potato pc 👌🏻
one step away from being a really good couch potatoe metaphor
my NMKD superscale doesn't work with SDXL. is there a close equivalent upscale that's compatible? i really liked that one

A Potato Couch?



hmmm this doesn't work for me either. must be the checkpoint of the SDXL model i'm using maybe.
Hmm yeah then something else is wonky inyour flow.
I use it on nearly 100% of my images

and how it would look to not scale exactly 2x or 4x?

yes my bad english, i mean workflow how it would be
Haha, nah i was cracking a joke
there is such think for say better to downscale, nearest neighb... bilinear and bicubic.
Yes, what are you trying to achieve, upscale the image by a set amount?
Or by a factor?

use this node, and downscale by .25
and then resample, with a decent denoise so you dont have artifacting
you making me give away my secret sauce 😛

here's an example
This i know o.k. on other hand it spend too much time to upscale.
Thank you 🙂
Yup exactly that above.
I always just upscale by 0.5, to achieve a 2x upscale using a 4x model

Thick paint 🙂
Thick cracking paint.
Now comes pseudo artsy images 🙂




cat made of liquid light 😛

Very nice heavy use of palette knife 👌
My character from old dnd campaign, tho I couldn't get eyes blue

Does anybody knows what is benefit of using upscale latent space by... ? Tested it and same results, and same performance with it or without it.
It's picky based on the sampler methods, so I tend not to even bother with it.
perhaps there's reasons to use it and it's best for, but eh, I currently couldn't be bothered with it.




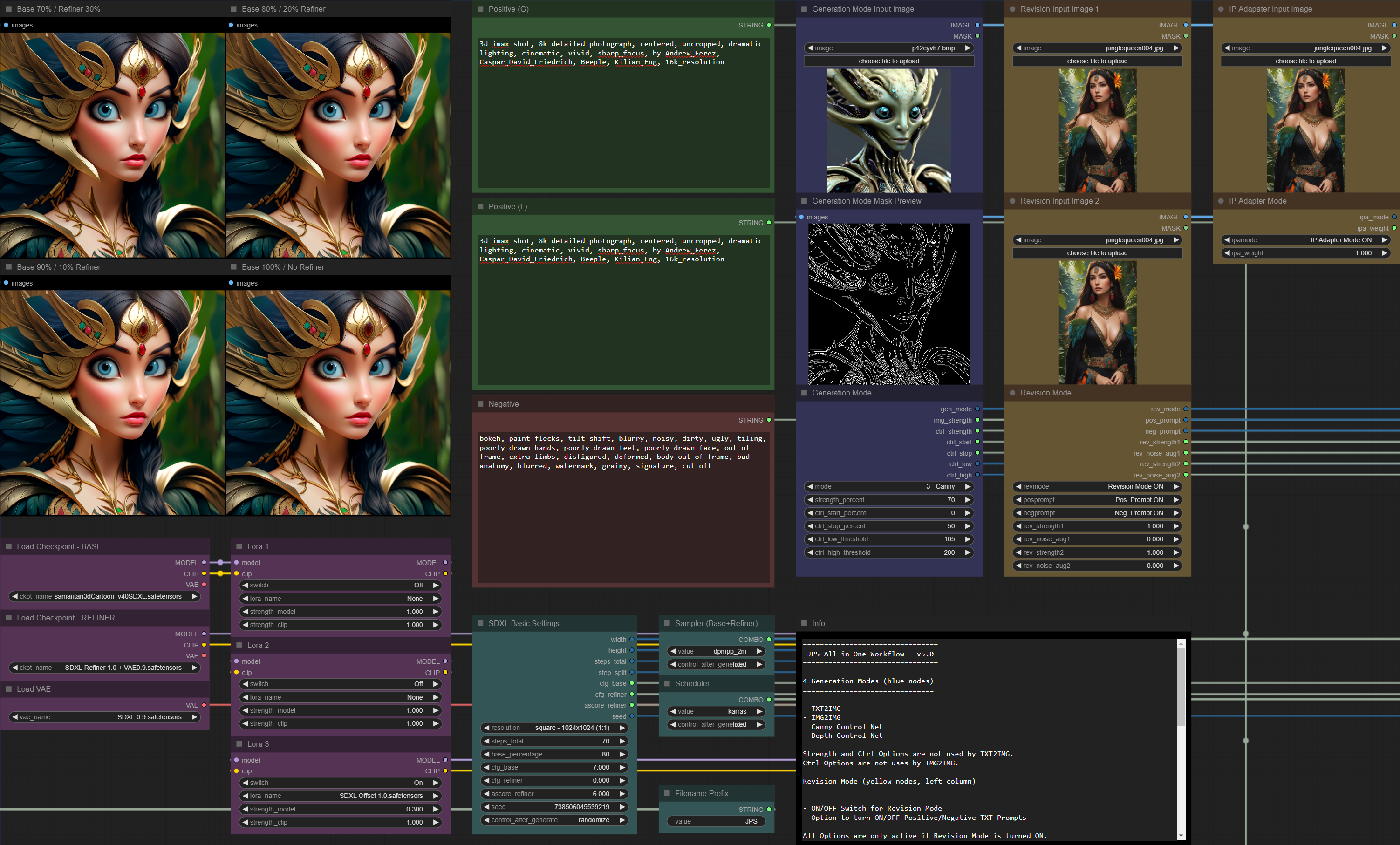
JPS All-In-One-Workflow 5.0 with IP Adapter, Revision (Clip Vision), TXT2IMG, IMG2IMG, Control Net Canny, Control Net Depth) now on GitHub:
https://user-images.githubusercontent.com/142158778/263359034-b000458e-9635-4ab4-97dd-4d0b0cac57f2.png
https://user-images.githubusercontent.com/142158778/263359221-86572383-f3a9-42a5-8fce-8122de7a6133.png
https://github.com/JPS-GER/JPS-ComfyUI-Workflows/tree/main


GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.





why it is s ohard to prompt this office

all of the models halucinating crazy when it comes to office
tar Puma? on white skin. Owners must be happy 🙂

so many twins so many weird looks





how about those @tepid maple




{kind=link}
{kind=link}
Hehehehe
that second from top @vital ermine too high cfg?