#✨|sdxl
1 messages · Page 101 of 1



Hello people, I have a question, I want to use SDXL, but I don't want to run it on my hardware, besides clipdrop, what are my options?
vastai or runpod have a look at them
isnt there some solution unlimited pictures 7USD/month? or is it clipdrop?
clipdrop actualy good pricing
1500 image a day is really good
imo
makes 45k month
it is good
ComfyUI 1221 too old - where do I get an update from at all?! 🙂
go to github tor
use the update bat file in the comfy folder
There’s only main version, you could just use git pull in the comfyui directory
Or run the bat as above, guess it does the same thing plus updating the python modules.
I am using Manager to update - even after an update this way - still says 1221 is an old version?!
OK, .bat file

So ComfyUI Manager does not actually Update ComfyUI?! The mind boggles!!!
Which .bat file, to be specific?
OK, found it 🙂
Found 3 items not on PATH ...
Prompt Queue - is it now hard-wired to the right side of the screen?




Moobs!!! And what beauties they are!!! 😄

How do I make PROMPT QUEUE in ComfyUI free-standing again?!
1330 is latest version? @peak dove update it as Pure-fire suggested.
Yes, I discovered the .bat update files - especially confusing as ComfyUI Manager suggests that the way to Update is via Manager - yet I've had to do it manually ... ! I've learnt something at least 🙂
Some results this a.m. on newly updated CUI













Coil whine shouldn't be an issue. It's just components humming at a frequency you can hear.
GPU manufacturers seem to have gotten lazy in recent years dampening them.



I think the "fax machine" noise is just down to how it loads the GPU. Mine does the same.
I think each step is a short high load on the GPU. So you get the buzz-buzz-buzz sound for each step.
Hi
Hello
Hey can i use stable d.. Model in my app if i don't brake the usage agreement
mack do you use comfy ui? can i have your workflow
Drag and drop any of my images into the UI itself.
aah i see, thanks mack
yee
do you know how to remove previous load photo list?
nope
@cold cargo Hey how are we on tasteful nudity? My nudity gen was by chance and I really just like the way it ended up.
\





how do you combined those photos
With weights
using clip, any tricks?
yeah just use clip
I don't combine. Combineing to me is still re tardedly broken. I can't figure that out yet.
I use clip just for art styles right now.



do you fill all the box with image?

not sure i will ever learn this...
haha
sooo, you are using auto11?
No comfy, just very basic workflows 🙂


/
haha cute
dont know anything about image input, so combine it, its behind my horizon 😄




the first one is very different of course. but coherence is best in no 3

they all used the same gen params, only difference is the SDXL finetune checkpoint
well than in my case I would further explore the checkpoint of no 3
@shy kelpTry to undesrand it like this. I use three images that all have the same art medium becasue I want realism. I do not mix mediums (for right now) because I have found worse results when trying to even out the weights.
I use three images becasue I found that I get the style I want more often by having that third image. I include the fourth image because I might try to see what I can do with it one day in regards to making it look good.
If you want to blend images without a prompt then you will need to use the "strength" value. When blendeing you want to mentally understand what you want to see the most of. I don't often go above the values of 2 because it doesn't mix well on the putout from what I have tried.
Moving onto prompting with the images. When using the posative prompt you want to describe either want you want to see that involves the images you have chosen or any other subject at all.
When I first started using it i tried to use the prompt to get what I wanted to see from the images. I quickly learned that doing that wasn't always the best idea. I now only use it for making a style. I grab images that are photos of faces and sometimes locations because I want hyper realism.
And if you want that fourth image then click the nodes that have the purple covering it and press ctrl + b. This is bypass those nodes. When you have them back on you then wire the "unCLIPConditiong: "CONDITIONG" output to the "KSampler" "positive" sinput. You'll also want to rewire the last node of the unCLIPconditioning so that the "CONDITIONING" is wired to the "positive" input on the "KSampler"
Pay attention to where those wires are going so that you don't get confused when tinkering with it all.
Be sure to save a lot when you don't really know what you are doing.


it need undo/redo 🙂
wow mack, nice thank you so much for the tips!
yea agree, as 3d artist it is like blender, i hope i can layout the keys as blender,
which one this time?


i like on the right one
snowboarders



Yeah no problem.
So, i think i have found a solution to my Reroute Switch problem. As it turn out, that you can't mute a reroute node to break the process chain and you need to make a switch out of 2 reroute nodes to connect them to make a switch. i have figured out another way by making "passthrough" notes. Maybe it was obvious, and someone figured that already out, in this case feel free to call me dumb 😄 . Those "Passthrough" Nodes can just be muted with ctrl + m. And they break the chain and stop anything after them from processing.





that is not dumb - it's great that it works for you. I've been using the "jumper" technique for some time. some nodes can be muted, others can be bypassed
Yeah, i basically get rid of my jumpers now
crazy good
I know I sound like the SDXL beta bot, but A or B?


b its grungier
A is CCXL and B is copax_colourful
A
Cool!!!
idk which I like better, both are very detailed and unique
both are SDXL though, so my final conclusion is whichever is more coherent will be better imo
is dynavision any good?
ComfyUI - I used to be able to move the Queue Prompt to any position I liked - now it seems stuck to right-screen?!
I kinda like copax_colourfulv2 rn. for me it's a tie between CCXL and copax_colourfulv2




this is batch of dynovision, good it all had moreles well made standing on snowboard.




Totally cool!








try the copax colorful model, I tried everything, the copax model has the highest average aesthetic score
o.k. thank you @indigo carbon will try!
Mr Trump drives himself to Fulton County, Georgia ... comfyUI






@indigo carbon there is v 4.2 some numbers version and then OK going with colorful V2
one thing I notice, copax_colorful seems to be slightly grainier than CCXL sometimes
possibly requires higher denoising strength with refiner
You all with your highres images. And i am here with my newly trained 32x32 pixelart lora 😅

I don't really get pixelart tbh, can't you just make normal images then downscale?
firefox says this is a 747x598 image tho
can't they just take a normal AI image, downscale it massively, then upscale using math(no upscaler, just resize)?
Pixel art has to do with very deliberate placement and colors of pixels, chosen by an artist for aesthetics.
Basically it's very stylized. So downscaling won't get you there.
nah, worst case scenario just make a LoRA for that
Yeah that's a way
@indigo carbon Here is what you get with your downscale upscale techique 🤷

that's how pixel art usually looks like..
it seems to have worked
I appreciate you, Tdg8uU, for giving your respect for other artstyles. Thank you for your valuable contribution in this conversation.





I agree a proper generic "switch" would be nice.
I m not a big fan of muting simply as I always seem to ignore the greyed outedness of them lol.
Ah well stick with my "Enablers"



Does anybody know some tokens how to prevent jewelry chains in realism photography? They keep popping up and are rarely coherent.
I tried chain, chains, jewelry chain, metal in the negative or wearing no jewelry in the positive






@upbeat summit how to put on jewelry or jewelry chain, more attention in negative prompt?
(neck chain, jewelry, jewellry, jewelry chain, jewellry chain, chain, chains, snake chain:1.3)
trying this in the negative right now. it has improved it and I get way less chains now. before it was like 2 -4 or more - now it's mostly down to 1
or (jewelry:0.1) in positive
good idea

i am using 1.5 and it is still somehow o.k. don't broke prompt very
Tried to make space suit helmet cubic shaped, or not wear it and it still does same suit with same helmet

adding (jewelry chain:0.1) in the positive adds massive amounts of chains to the image 😄
the mysteries of the latent space
(jewelry:1.5) in the negative? Maybe
in ComfyUI you use (brackets)
o.k. not squared brackets or how they are called? Going to try on my own 🙂
tried it - it does reduce the amount of chains though but you can't get rid of them. might be the overall prompt build though

so a short while back (2nd june to be precise) I got a load of data from the test results at https://vladmandic.github.io/sd-extension-system-info/pages/benchmark.html (nothing to do with me) to draw up a Relative Performance Ranking of various GPUs.
Data for the 4060ti was added on 25 July.
Again I want to stress I'm more interested in Relative performance rather than whether or not the absolute it/s are correct for each GPU (and again all the names come from the site referenced, not my data)
Should also be noted that these would have all been tested/created using SD1.5 or 2.1 models but again, its a relative ranking.
So for no particulr reason I've now also splitthese into Three Tiers with each Tier subdivided into a further 3 tiers

SD WebUI Benchmark Data; Author: Vladimir Mandic
that you are using orange space suit 😄
This doesn't work. Putting jewelry into the positive at any strength will add jewelry more than it not being there.
benchmarks on a1111 are invalid because the unet code has autocast on
oh hey comfy
as I said its all relative rather than absolute
in other words I wdont necessarily disagree however if every test is wrong to the same degree the relative positions will remain the same
@visual glade can you push the compile AIT code to the custom node? we can't seem to figure out batch size with AIT
which error do you get when you try to compile with different batch size?
I set batch size as a IntVar(values=(1, 16), name="batch_size") and it works
msbuild errors, hold up- I'll find the exact errors
consitency over accuracy 🙂
but there's a few things wrong like the H100 should be on top
and the different A100 should be pretty much the same
I just crunched the numbers. It's not my data and I have no bias 🙂
how comfui is working, is it difficult to add undo redo?
@visual glade would you consider building a standardised benchmarking node in COmfyUI that autofed backinto a DB that was publically accesible

GitHub
ComfyUI extension that adds undo (and redo) functionality. - GitHub - bmad4ever/ComfyUI-Bmad-DirtyUndoRedo: ComfyUI extension that adds undo (and redo) functionality.
@crisp owl thank you!
It ain't perfect, but works when you need it
neato
I don't know if it's fixed now, but in an earlier version that I've tried if you use Ctrl+Z + Ctrl+Y (undo/redo) and are in prompt text boxes you also reverting to an older version of your workflow. They were not excluded from it. And I use undo/redo a lot when doing prompt engineering.
But I guess text input boxes could be technically excluded from it
I never looked into the code behind it, but from what I understand it basically keeps a cache of each change you make, and that's what it's bringing up each undo.
Something along those lines.
yes this is how it works
but CTRL+Z must be excluded from text input boxes, otherwise you are reloading an older version of your workflow every time you want to just undo a change in your prompt
otherwise it works - but this was a deal breaker for me. if it's not fixed yet, I will take a look at the code, because having an Undo function would be great of course
Yeah a simple undo button would be phenomenal, but good things come with time haha
currently trying this. is set AIT_USE_CMAKE_COMPILATION=1 required for batch sizes?
oh yeah I set that to 1
True, I’m really looking forward to the future of comfyui. Hopefully it gets a little more. Comfy😛
thanks, will update if compiling succeeds or fails.
 RIP the rabbit
RIP the rabbit

for me compiling anything just failed completely without that on windows
Well, it's already worlds more customizable than other platforms, and for that, I'm hooked
heh, for me it worked without it. but it appears to be required for BS
yeah it's compiling, don't see any issues yet
@indigo carbon has anything new been found out how to accelerate LORAs in combination with AIT?
it works, it goes- model->LoRA->AIT->WORKFLOW
@visual glade how long did it take you for a BS 1 16 module? when I compiled for BS 1 a few days ago it took over an hour
comfyui patches the model weights with the loras so it should work with AIT
didn't take too long for me, maybe 10-20 min
jesus, did you do just the UNET or something? when compiling the entire model it takes an hour or 2 lol
yeah I only do the UNET
that explains it
well, it's still going, it's now doing text encoder2
wait, is there a --flag for just the UNET?
it does work since the beginning but it takes 4 and up to 10 seconds every time before it starts generating an image if you have a LORA in the chain. model->LoRA->AIT->WORKFLOW
at least on my system but others have experienced the same. Adding this much time (it's like frozen) for every gen is of course not optimal.
If I bypass the Load LoRA node the speed is back to normal and the delay is gone
the delay is also gone when using --gpu-only on start up, but this tends to get really unstable after a couple of minutes on my system (freezes and slowdowns)
My ComfyUI is going crazy. Started off at a good s/it rate ... then really slowed; then added in all by itself an Upscale (which node was completely disconnected to begin with!!!) Ghosts?

And I don't really know if this is an issue that I report to the ComfyUI repo or the AITemplate repo heh
it went smoothly at first, when it finished the 2 text encoders it started UNET and spat out this error. this error doesn't occur when doing bs1
has somebody tested anty of the Kappa_Neuro Loras at Civitai?
They doesnt seem to make any effect at all!
i loaded a lot of styles and none seems to work
is it some kind of scam?
you can add or delete the lora of the prompt and it will no affect to the final result at all.
aquarium fish for dish 🙂

Which one? Is it for SDXL?
Not sure what the scam would be. I mean, the images definitely look AI generated
this hand was not painted by a rococo master heh

he has versions for 2.1 and XL. I am trying XL
the images are AI generate, but you obtain the same image with the lora and without the lora. It looks rococo because the style is already in the base model
they all definitely looks like empty loras. Most absurd thing i have seen.
Oh kappa neuro is an account name, I was looking for a lora named that lol
yes, he has a lot of styles. Pretty amazing if they were real
two submarines for cats


i doubt about the watertightness of those designs though. :p
Oh well he's got a few

Yeah I mean the volume would make me wonder what they're training all that on?
i have no doubts 😄 i am sure it wont work 😄
Where does the default config hide for comfy?
I keep getting tripped up with the default being 512x512
I think that is a node thing
yeah, shouldn't be hard to find
On nothing. So i downloaded 30 gigas de crap. Deleting...
Most silly scammer ever
lol you're not kidding. it's not the same image it is pixel exact
I had downloaded some of these but hadn't played with them
yes those loras are like ghosts
Lmao that’s crazy, have you tried turning it to wumbo?

I was looking forward to the craig mullins one
Loved him back from the marathon box art days 😂
you can for instance change the loras weight to any number with zero effect
lol

Any advice on a sampler to use if I want to render out some final, print-worthy pieces? 🤔
So that is the secret of Bill, he can count up to 12, two more than us.
have you used their tokens?
if they're trained with good regularization, they won't come on without tokens
yes, he is 20 percent better at everything, including counting

That is the thing. You can use the tokens without downloading the lora of civitai and will get the same result
I used one of the prompts directly from a sample
identical results with lora/clip 0 and 1
Also given the sheer volume of these
it raises a question
Is the guy tring to get some record uploading trash?
yeah i went and tried it. first test got unstunning results. looked at the prompts and the prompts are doing all the lifting
might just be enthusiastic and thinking his loras are doing it all
or maybe he dont know what is he doing.

trains for 5 steps. fires off a very styled prompt. calls it done
a decent finetune takes what, 10 hours on a 4090?
for a style lora? naw. if you're blowing out your memory then yeah over 10. smaller batches so that the vram doesn't over flow into shared helps a lot. Smaller batches does better with gradient accumulation which takes time, but takes less time than blowing into shared memory pools
but someone will come up wiht some kind of magic
Just talking practically about how many this dude could theoretically crank out
I have just seen some Magic in LLM with llama.cpp
could be using cloud
2 hours for a style lora first version i'd say. If its popular then do it better. if i were trying to mass produce that's what i'd do.
this guy though. kind of sus. neat find.
loras don't seem to be doing jack at all. i've tested 3 now
he has fun uploading these things apparently
Yeah if they seemed to work I'd think "sure he's training on cloud and just loves art"
but since they don't work, and there are a ton of them
🤔
🤔
Given the amount of crap on civit I guess I should not be surprised
"mind blowing realism lora!" and the example pictures are plastic skin with 12 fingers per hand
https://ko-fi.com/kappa_neuro heres the grift

Ko-fi
Become a supporter of Alexander (aka. Kappa_Neuro) today! ❤️ Ko-fi lets you support the creators you love with no fees on donations.
has actually caught some
well even outside of training time entirely
how do you find all those pictures and put collections together like that?
wonder if each file has the same hash
gotcha
the hashes on civit are at least different based off a quick spot check
no its different each time
meta data can do that. i bet it's the same lora each time though
civit has remote upload too iirc
well if you report it to civit let us know if we can +1

how can you see the hash od a file in wiondows?
yeah with tools. i used civit though
i think civit doesn't really facilitate reports too well since the whole ai trolls would use them
just this

Gill Bates?! 🙂

i threw up "needs moderator review" and explained that i think the styles are automated prompts and the loras are blank templates
i honestly think they dn't read them though. How many of these do you think they get?
soemthing like that?

We Are Borg - or We Are Tylda Swynton!
they're all the same size, lol



wait, one's 435.6
~can you guess which ones are from this guy?~ nm there are ones from other authors with the same size
to be fair, I didn't look at all o fthem
I had explained the prompting were doing all the style work. I think that's a key since it appears in the examples at a glance that it works
there's hundreds i estimate
so is he cheating or just exploiting what's allowed?




looks like bot. all his posts have hundreds of likes.
hundreds of mundane style loras all being hyped so hard? i unno
"all kappa_neuro loras seems to be empty. It is the prompt who does all the style work. The Loras does not affect at all"
coo
and saw some of them on a "featured" list
i also said i reported based on this discuussion on this server
reported
lol, well whoever is doing it created a very prolific system

the guy has been uploading nothingness for months
will try with one 1.5 to see what happens
i think he's using the one button prompt script. all his examples have automatic1111 metadata
it's pretty good for doing random artists and styles
i wish it was stand alone actually
this is why people can't have nice things




So he has just wasted 47.5 tb of civitai's traffic since today.
i have used one button for months and having lots of fun. Didnt imagine it could be used to do evil things. LOL
i've been using it pre work. i'll go in an theres a mode to generate prompts without using them. do that, pull the list into a txt file. take it into comfy.
scammers lovvvve to automate

well, he at least has shown us how amazing the base model is
leveraging people's blind spots for donations
grimy
civitai should curate content a bit better. And clean some hentai crap too
grew up in a tourist city. there'd be guys who walk the block "scuse me i don't have money for the bus, could i borrow $2, $3?" and then bam, move on. they do this 300 times and 10 people help em out because its a good story and a person needing bus fair is more helpable. blind spot beggers.
most street beggers weren't even homeless people. lease cars and condos and shit. a good day can see $1000 cause tourists all think they can make a difference
man, just make a "beware, degenerate content" section or soemthing
There’d be nothing left 🙃
real homeless people look too hard up to be allowed downtown. police take em on a trip to the shelter on the other side of the hill
there was a guy that'd work mlb games near me. follow people along, begging begging begging like he was a crack addict. just pathetic. then when he'd get done he'd go back to normal
get in hius car and drive home
there's a ton of good will in the world and the people who are most generous have a lot of blind spots
seriously it's just an act a lot of the time. 9-5
a lot of times people don't pay them because they feel bad, it's more to get them away
if you're following some family with little kids or something begging
not like the parents want to deal with that
but yeah, with the lora thing
people just don't know any better
Some recent ComfyUI SDXL




there's a lot going on. can't really expect people to know the intricacies of how traing and all that works. I've been using SD quite alot for about 9 months, and I stiill don't know how a lot of it works
another city near me, it's less of a tourist city. guys will drive around picking up homeless people and then take them to highway exits and intersections to beg or wash windows. these are like wayyy out in the woods with no facilities near by. keep these guys hydrated and fed then take half their "earnings" . they're basically homeless people pimps.
it won't be long till ai waifu pimps show up. these sort of advantage seeking people love to organise hierarchies and cults
lol, that's messed up
its not the real messed up part. to shine light on just how much of a human traffiking operation it is, you'll notice that they never have women at the intersections begging. Women can generate cash for these operators in other ways.
The guy keeps uploading no-loras at one every hour aproximately
and in alphabetic order
anyways. long story short, don't underestimate people's capacity to abuse good will
we are in Jo- now
not sure it's a thing there, and not disparaging anyone, or ethnicity or whatever. but do you have any of the "roma" folk around there? because there aer a few that show up around here. and they all have the exact same approach
the first company that trains an AI classifier for data intake that can be used at an enterprise level has a huge position
signs with identicdal hand writing
something that can determine scams like this at intake
show up, I mean like one lady will show up to big events with her kids and a sign with very clean, perfect hand writing
but then, saw another lady with the exact same hand writing on her sign
and then a post online in another city, same hand writing
if i were on the marketing team, i'd call it "hopper" and the logo would be an obey style stencil of dennis hopper
well the 1.5 lora seems to work
well, i mean, gypsies kind of come from romania no? there's a lot of stereotypes about gypsies for many reasons.
I kind of love their culture. They're kind of grifters but they seem more like robin hood an his merry men about it.
its about familia
yeah, I just navigate some things with caution. not sure who might get offended by what
I have no hate on them. I'm just impressed that I've seen the same woman with her kids at least 100 miles apart
kind of low to exploit her kids like that
i used to always say gypped thinking it was just normal. had no idea it was a gypsie slur for a long time.
but might not be her call
well they really have it figured out
you want to look down trodden, but not low class and scummy
just like you lost your job a couple months earlier and you're running out of options or something
a good sign is powerful! the art of sign making is something homeless culture runs with. i'm not surprised that those trying to maximize the begging career are using mass produced signs
the key is a sign that makes people actually read it or look at all
tougher to do than it sounds
well it's all the traveler folk with these signs though
maybe they have a sign syndicate we're not privy to
they probably printed off 100 and got a pile of em
"hand written"
the same lora in the xl version doesnt make any difference though
maybe the guy simply doesnt know how to train XL
And doesn’t know how to do basic testing?
well I've just seen the same ones in dallas and houston. and then I saw something online inn like st. louis or something, same signs. LOL
kind of blew my mind for a minute
naw i think he did train loras on styles the models already knew before. easier an efficient. probably used a collab to automate it too.
collab stopped working. now he's got a new script deployed.
yeah, he is too silly or too clever




it is a syndicate. a homeless one. these "homeless pimps" don't operate in just one city. they take their gems to the hot spots all around the country. a mother with kids for instance
or just a bunch of kids in general. probably not even related. human traffiking is so common unfortunately

the city i grew up in, i used to volunteer a lot of homeless outreach. going an talking to them basically. i'd have pamphlets about resources. was a small effort and i'm not bragging about it. i bring it up because during my time with that, i'd meet literally recruiting agents. They'd be offering these young kids who were just kicked out of their mom's house a trip to toronto to "work" for them. just street begging where its more profitable. and away from support networks. happens all the time
they've got scouts going all over the country
again, long story short, don't underestimate the capacity of people to abuse good will

tried to see latent space, and it seems i broke my model 🙂 something should be hidden probably. Seems architecture first.
Oh got it, it is latent SPACE, therefore architecture.




cats are my favorite! 🙂
nice
@visual glade did UNet2DConditionModel added to import diffusers resolve the BS issue? I just did and it seems to do something
maybe. but they definitely don't look homeless. I guess that's not saying much though. most homeless people really don't look homeless. it's just the shameless and mentally ill ones that we tend to recognize as homeless
🅰️ or 🅱️ ?


B
B
freckle dots to me look too fake in B
People have all kind of shit in the skin. A seems too plastic
it's hard to decide with that stuff for me. AI has goofed my perception, lol. real life sometimes doesn't have the same realism as AI
Another seed:


Tbh if I were doing a final, I’d throw them both into photoshop and do a manual blend
B seems like it has details turned up
A looks like a Terminator
A has some “too perfect” elements, B looks overcooked
and I was going to say the same thing as xyrrus
I'd blend them if I was going to be meticulous about it
One day I will get off my ass and learn how to build a frequency separation node using image magic and python
hmm, what would a frequency seperation node entail?
you keep the parts you like and blend or discard the rest
the TLDR is it’s a photo editing technique that tries to separate out fine detail from broad detail. So when retuouching a photo, you tend to do it, then do your editing just on the fine detail to remove things like blemishes
hmm. I wonder if you could do that with existing nodes?
There’s some convolution and blurring that need to be done
editing the mask you mean?
Sec let me find an article that’s decent so I’m not talking out of my ass
I'll take two images that are close, use the "difference" filter and then use that result to blend back in
Is there a setting to tone down B slightly?
isnt it part of krita, wavelet things?
been like this for a while. still happy no errors =]

problem with that is there is not a universal solution, each image is different
We’d basically want to do the opposite though. Retouchers use it to remove detail (blemishes) w/o making an image look edited.
We’d want to add detail by amplifying texture
I'm currently compiling batch 1-16 res 64-2048
I've used the frequency separator in audition
reverse polarity for different pitches
makes things interesting
Anyways I am not sure how much futzing would need to be done with the node but it seems possible
An in fact the exact sort of thing comfy was built to do
But my coding skillz are, uh, rusty
same. well I've never really programmed in python before recently. but getting acclimated. really just need to figure out how the photoshop thing works exacrtly. then it wouldn't be that hard
I also have no idea if it would work. Been meaning to overcook an image and then see if I can create a photoshop action
If I can do that, easy to break down and see what’s available w/ existing nodes
But if you can do it in photoshop it’s pretty likely you can just string together a bunch of imagemagick commands
I'm sure they're using some fancy algorithms though
that might be beyond what I could even really understand
Photoshop has a lot of new hotness that’s proprietary
But all their basic shit is just math
Would be nice to have nodes for being able to quick retouch images manually in Comfy
Free Krita got it as well

Are there good models for Space stuff?
@cloud dove TDG8UU making nice pictures with copaxTimelessxlSDXL1_colorfulV2
But others can you suggest better models
okay thx
it's still going.. did I actually manage to resolve this lol

if this works- I might be the one providing the precompiled modules lol
I like this, not finished images, but helping imagination
Latent space is emerging real life world. BREAK
photo-realistic.







would love to have a bit of ice there 🙂
just seeing it's a guy surfing/boarding down that haha
CCXL used to be my personal favorite. today I discovered copax_colorful and I like it kinda better

ill take freebies, and wont complain




Very ice
contrast to ideal icy world. Bit of reality



how do you upscale ?
Damn
it managed to compile something called UNet2DConditionModel.dll which I'm not sure is the right component- but it is compiled for bs1-bs16, 64-2048 res
Idk how to infer it though
hate .json
why?
Hi, why cant we enter long prompts in the bot?
Is there any way to enter long prompts?
this is the prompt "concept art for a research laboratory attached within a modern facility, wooden furniture, intricate laboratory equipment, surrounded by a snowy North Pole landscape, glass apparatus in the center table with shimmering green liquid, computer workstations, files on the shelf, 8K concept art, Octane Render and Cinematic Lighting, "


ever read the book sphere? one of crichton's best from before he went mental. what if we showed the latent space to that device? oooOoo
movie was okay too i guess
really like these, man. I've been making blueprinty sorts of things latelt
author of that rat?
jurassic park
o.k. rat out of stainless steel will be somebody else, going to check it
Harry Harrison
strong name
Aye think its kick ass.
the middle one i should keep for some competition 🙂



started off with regular blueprints from google image search. then used those to make weird things with clip vision


I made a lora out of it for XL so it helps a lot.
well the blueprint is from clip vision
then that second one is controlnet
I've been thinking about making a lor with them myself
It is fun to play with any concept tbh. 🙂
but haven't really done the work to sort through and figure out what I'd like to use
SD is one big magic box.
am i supposed to generate my image then inpaint it using the refiner model?
that's a new approach but if you can do it I support it
what's the standard approach
i've got a sudden urge to test, "blueprints for a human" but i'm scared to go over that edge

Oh it will do it.

@steady grove like mentioned Schwarzenegger and elephant in one prompt?
@vital ermine Hi!
man, depends on what you use. depends on what you want. you really don't need refiner. you can run it for 20 percent of the steps at the end. no one actually knows how it works. it's a big mystery
Hello. 🙂


how do I do that?
run it for 20 percent of the steps

well, you run the base model for a number of steps, then you divide that number by 4 and run the refiner over the image

green print


Sorry Im new to this, how exactly do I "run" the refiner? Do I change to inpainting tab and mask the whole picture or something?
peak performance


I really like this style
oh wow til rip roop

I'd suggest looking at some tutorials and things. I'm more than happy to help people. but it'll be complicated for both of us if you don't have some of the base knowledge required to understand what we're talking about. I'm assuming you're using a1111? first tab is text to image, second tab is image on image. not exactly inpainting, although that's an option. you create the image, then send it to image to image/image on image, whatever that's called, and you run the refiner for the final 20 percent of the steps

or if there's a more streamlined approach now, I haven't heard about it
hands, the bane of all
whoa, those are nice
alright
but yeah, not trying to be dismissive. I was there too, it's a learning curve. but you'll be a lot better off if you read about it a bit
and do some experimenting. if the result isn't what you want that's fine
I think it can be daunting for new people because they see these ridiculous creations made by more experienced users and they compare their results to that

but thing is most of what almost everyone makes is either poo or so so

then a few gems in the mix
personally I like poo gems
I wonder if stable diffusion knows who daddy long neck is


hehehe










I'm super eager to get Revision working on Colab. I'm following this vid: https://www.youtube.com/watch?v=1SwDCqgXZ-M, but as a nube with ComfyUI, the first thing I'm stuck on: in the vid he describes getting a specific CLIP model and placing it inside the model folder (in a local installation). How does one do the equivalent when running on colab? Alternatively, is there a comfy colab that is ready to go with all the necessary models for Revision?

If you caught the stability.ai discord livestream yesterday, you got the chance to see Comfy introduce this workflow to Amli and myself. The idea here is that you can take multiple images and have the CLIP model reverse engineer them, and then we use those to create something new! You can do this with photos, MidJourney images, DreamStudio, or...
so revision is just clip vision,, right? or is there more to it that I'm missing?
I can put together a simple workflow with clip vision in a couple minutes. but not sure what else they might be doing in there
if you used a1111 it's a similar model concept. put it in the model folder

thanks very much for your reply: haven't used a1111. Should I place it in the standard colab AI/models path?







you're using colab for it? well it's the same concept. find your comfy folder on your google drive and put the model in there. now if you're not using google drive either. I really don't know.

but yes, standard model folder. I think there's a specific clip vision folder
ok, I see it now on the drive, thanks very much for the help!






microwave houses








I'd be alright with it. but I'd always feel like some creeper wsa watching me from below
yeah
but fuck having to wash them every single day cause you just know how dirty they would get.
Need a crane for it
future electrostatic windows that repell materials when charged. and can become opaque. perhaps even stenciled


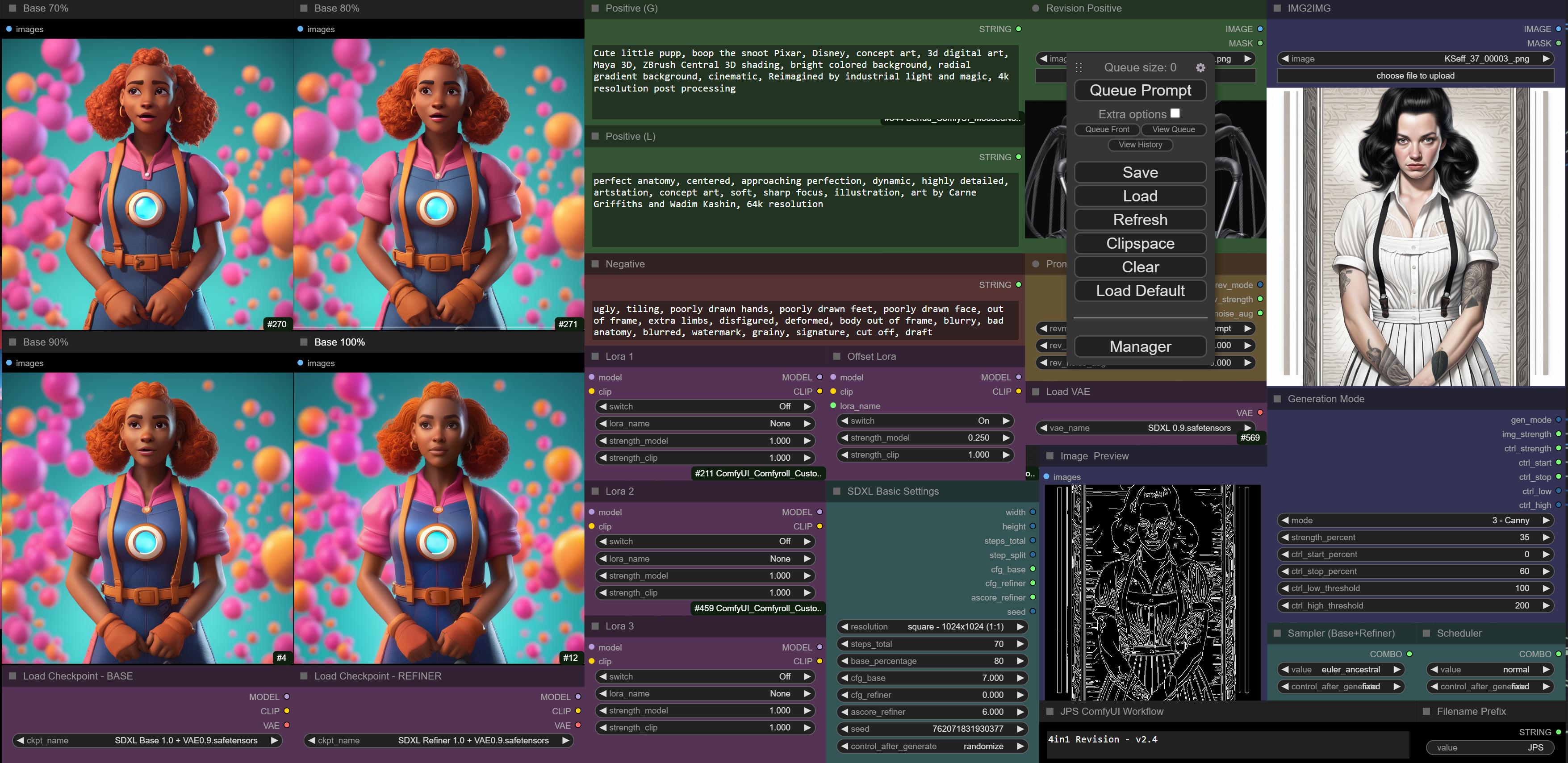
new version of my workflow online: https://github.com/JPS-GER/JPS-ComfyUI-Workflows
https://user-images.githubusercontent.com/142158778/262469111-88ff5603-5b51-4668-abed-9aefc6b42f08.png

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.




Thanks for sharing it, JPS!









so everyone here still uses refiner?
So I have the model in the specified folder, and the LOAD_CLIP_VERSION node sees it. I've got the graph all connected up as per the vid, but when I try to run, I get this error: Error occurred when executing CLIPVisionLoader:
invalid load key, 'v'.
Does this ring a bell?
According to my-debugging-partner-GPT,
From the provided traceback, it appears that the problem arises when trying to load a PyTorch model checkpoint using torch.load(). The error originates from this line:
pl_sd = torch.load(ckpt, map_location=device, pickle_module=comfy.checkpoint_pickle)
Here, ckpt is the path to the file that's causing the problem. The error suggests that when trying to unpickle the file using pickle_module.load(f, **pickle_load_args), an "invalid load key, 'v'" error occurs.
The immediate file in question is referred to by the ckpt variable in the function load_torch_file inside the file /content/drive/MyDrive/ComfyUI/comfy/utils.py.
my workflow creates four variants with 70-100% base, so if refiner doesn't help you can pick the 100% base version. for many styles refiner helps IMO.
you workflow looks amazing and scray at the same time 🙂
it's easy to use. everything you need on one screen - here is a simple txt2img with little bit of canny for example - only the pose is taken from the voodoo girl, the rest is txt prompt only:
https://i.imgur.com/nUW8R7v.jpg
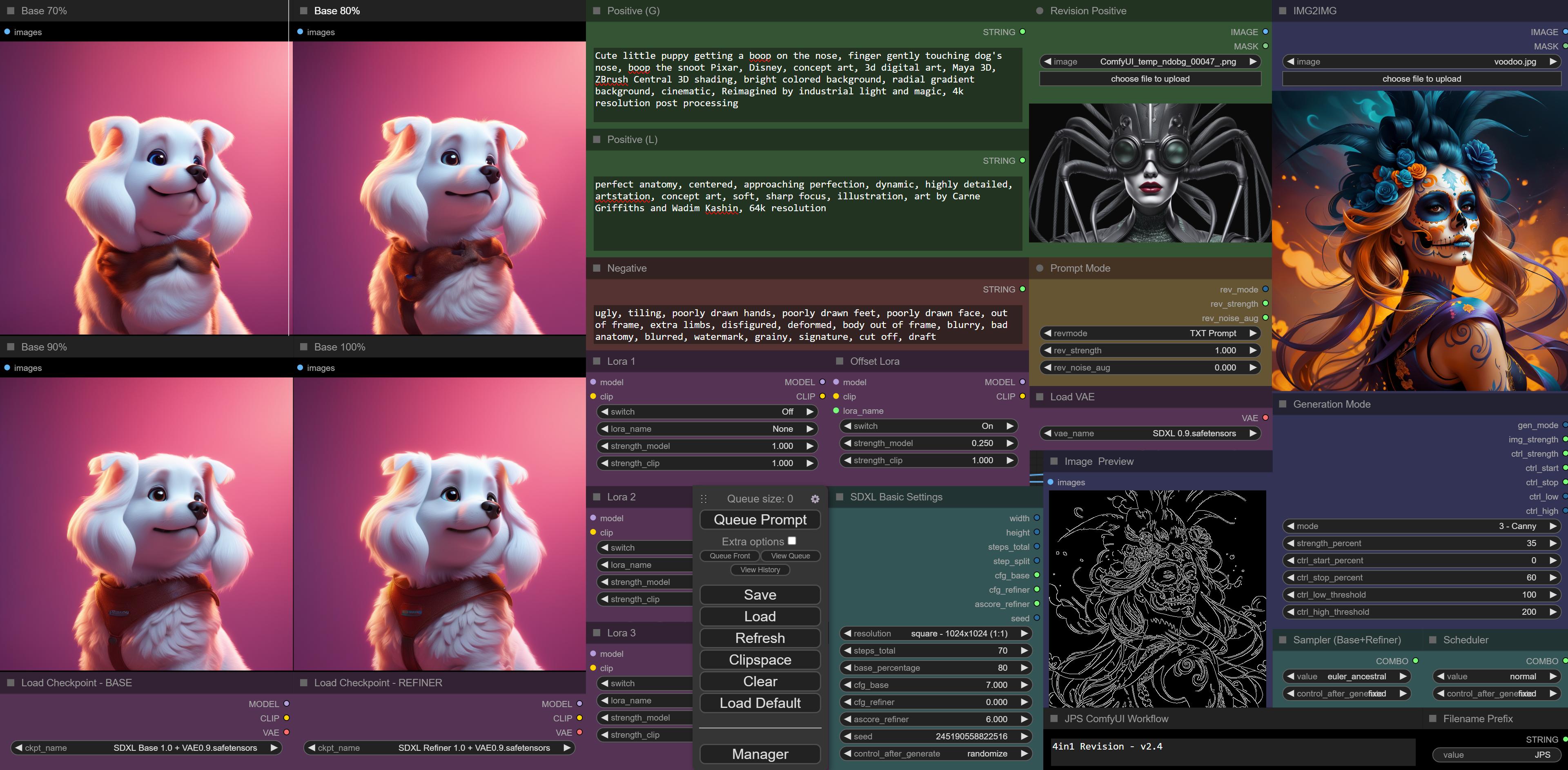
i enjoyed canny today 🙂



I still use the refiner.
I did a test of 100 images with and 100 without and based my own personal feelings on those, comparing each simultaneously. In the end I felt there were better results using it still. Regardless the checkpoint used.
i need to start keeping thing tidy in comfy

I'm obsessive about keeping my lines clean 😅

i use pipelines on top and bottom to keep it "clean":
https://i.imgur.com/m2xQ8yK.png

That's hot
dont show us your factorio screenshots!
was better in the past, but i had to add the revision featre, that messed it up a little bit
both 2 and 2.4 does not load for me.
also the png from github
@zinc cargo without any error message?
try this one:

did you download the raw file from github? it's a bit tricky do download files from github. you have to right click "raw" and choose "download file form destination" or something like that
oh, i just right click and save
the refiner is a very tricky thing.
- the concept sounds really good and there are some great use cases for it
- it depends on the prompt, because it is heavily style dependent
- it depends how many steps you let it run, because it should be used as a finalizer. so I would never use it for more than 30-40% of the image. For a 40 steps image I let it run for a maximum of 5-7 steps.
- it depends on the sampler you are using
- I have used it a lot and I think it can help in certain situations. I try the refiner in experiments often.
- but almost all images I've posted since the before the launch of SDXL 1.0 don't use it
yes, my own nodes are in manager and the other ones are from very popular node packs.
@zinc cargo someone had problems with one node from impact pack yesterday. please try it if it works for you

did "find missing nodes" in manager work in the past for you?



yes
yes
i'll do an update just in case
usually solve stuff
you can find my own nodes if you search for "jps" in manager
if i would ever made something for comfy, it would be to restart from withtin the gui
how did it go when you submitted them?
I mean, obviously they're there now, lol
the rest are common packs like
- ComfyUI Impact Pack
- (WIP) ComfyUI's ControlNet preprocessors auxiliary models
- WAS Node Suite
- Comfyroll
- Derfuu
i made a fork of the manager, changed the file with the sources and made a pull request.
ahh. I was reading about it. seems simple enough. just hadn't used github before now so new concepts to me
well I'd downloaded things from it, but never really interacted
was my first time too. not too hard. took me 10-20 minutes of google/youtube to learn how to fork and make a pull request.
lol, DO NOT ask an llm how to do any of these things
fyi
not sure if they're getting "dumber" or if I'm just used to them now
i would explain it to you, but as i'm a n00b github user myself, i guess a youtube video will be better than what i remember from the process :)
ahh, nah, I think I have it. it's not that complicated. I just get anxious about the idea of missing things
https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models_XL
These are now supported by ComfyUI

how do they differ from the ones that stability released?
which one is CR? the comfyroll one?

never quite figured out the differencece with the t2i stuff
I'm pretty sure
did you try the missing nodes button?

yes, it doesnt work for me.
the comfy roll is installed, but doesnt load

lol, how is the code indented incorrectly?
this doesn't look right
I think there's some other conflict
that would make more sense
I just had a custom_node that kept UltimateUpscaler from loading
so conflicts do exist
I had an error last night that caused me to end up deleting a few big node packs
turned out it was something entirely unrelated that wasn't showing up in any error
well, it was related. wrong word I guess
just hiding
how did you find out which one was it?
both for @upbeat summit and @hardy cipher
pooled output was my error
here is a list of nodes i'm using without conflict at the moment:
https://i.imgur.com/SrD7Ww4.png
https://i.imgur.com/QUy12VY.png

well, need to see more of the error tbh
I just thought of what new nodes I was using. not new node packs, but specifics I hadn't used much before
so first I check what's up in the console. but for the UltimateUpscaler thing the node that was responsible didn't even throw an error. so I just removed the node packages one by one, till I found the one causing the problem - or just start from scratch and copy each one back one by one
becaause I'd get the errors, stop getting the error. then it'd reaappear when doing something seemingly simple

last line got cut off in that screenshot, but that was pretty much it
pretty obvious it has something to do with the sampler, or something that had connected to the sampler, so just kind of had to do deduction work
no stability nodes?
simplest solution normally is to update everything
is there like a git . i can run recursvly ?
no, i don't have them installed on my system.
for what?
are you using a virtual environment? if you want to be a mad lad you could run this in your comfy folder in powershell
Get-ChildItem -Recurse -Filter 'requirements.txt' | ForEach-Object { pip install -r $_.FullName }
well I only did that because something got goofed and a bunch of python packages didn't get installed
even matching your nodes, i get the same thing
and everything is updated?
yes
have you tried just restarting and refreshing the browser?
it really does help 😄
the error is at the server level
what server?
i know, i'm that guy who everyone calls to help about their pc as well 🙂
try to remove my pack (JPS) and check if the others work or show the same error
hah same
the comfy server loads from terminal...
so move all nodes out of the custom_nodes folder
and move them in one by one
find the culprit
@zinc cargo just did an update and get the error now too - so my guess is that the comfyroll-pack is broken at the moment.
that is a possibility too
it works as a standalone
it may conflict with a node we all use
well what node is it?
WAS, efficiency etc
no wait!
File "C:\Users\User\SD\ComfyUI\custom_nodes\ComfyUI_Comfyroll_CustomNodes_init_.py", line 1, in <module>
from .Comfyroll_Nodes import *
File "C:\Users\User\SD\ComfyUI\custom_nodes\ComfyUI_Comfyroll_CustomNodes\Comfyroll_Nodes.py", line 1572
class Comfyroll_LoadAnimationFrames:
IndentationError: expected an indented block after 'else' statement on line 1566
Cannot import C:\Users\User\SD\ComfyUI\custom_nodes\ComfyUI_Comfyroll_CustomNodes module for custom nodes: expected an indented block after 'else' statement on line 1566 (Comfyroll_Nodes.py, line 1572)
yeah
yes, indentation error
still that ident thing... no nodes other folders
so comfyroll broken
should i just ident it?
well indent that mofo!
i mean, it's just pressing tab, right?
I mean, just undo it if it doesn't work out
could be as simple as a tab instead of a space


I made that mistake last night editing something, tabbed, broke it, then realized it expected 4 spaces instead of a tab. easy correction
dude, what kind of psychopath came up with the space/tab thing?
this python thing is crazy
in notepad++ there's a make all tabs to spaces button, so that comes in handy
okay i cant i love the generations im getting from comfy.. but i want Auto gui and features... with comfy workflow backend.. and somehow magically they work cohesively.. comfy generations are better also.. but i just cant node system workflow is a bit messy sometimes
I like that I can also highlight a bunch of stuff in notepat++ and tab it all at once

stableswarm works until it doesnt with some workflows because idk
here is the line with the eles
actually didn't know about this though
and comfybox..has potential but the dev left it
what are you talking about?

generations aren't different depending on user interface?
If that's the code that's erroring it's probably doing it because there's no actionable code in the Else statement. With it commented out, there's no reason for that else to be there.
comfy generations are different than autos
so i can just commnet it as well?
also speed is better than auto
its not a opinion..
python needs indentation to work, which is crazy, but this is how it works
WE are all in crisis mate
also whats ur issue tho
ComfyRoll will probably be updated in T-X min 😄
Yeah comment out the Else, or just delete it
comfy with the same settings generates a different image on auto
if it were me I'd just delete the comfyroll install and git clone it again
yeah, because you're probably using a different scheduler or something
maybe yes and maybe no
It's not just that Auto does some different stuff with the images that it doesn't present to the user. There is no way to get identical images between Auto and Comfy
maybe you're assuming things when you're not sure about them. that's all I'm saying

im assuming my assumitions are correct
which im pretty sure they are
okay, I've seen people say so many things like this, and then they're not accounting for something simple
did you try to chatgpt it?
he fixed it
Comfy has said something about it before. I don't remember the details, but there's something that Auto's code is doing differently, which means it's basically impossible to get the same images, even if you use the exact same settings between the two.
not a fan of accounting ngl..
alright, you've deflected a few times meaning you probably don't have the details of what you're doing
which is fine
i remember it was that comfy generates noise using the cpu somefing like that
I just wish people wouldn't spread misinformation
while auto idk does something else
this is the fix:
https://i.imgur.com/f9aIuZg.png

The fix would be deleting those lines
add # in front of else
thanks i did exactly that!
so proud of myself
and now, to generate some stuff
There's no point in commenting out lines that don't do anything, just delete them
He's clearly put that in for debugging and forgotten to remove them
it's already hard enough for people to understand this stuff. don't need to have other people going around planting little seeds of half truth
but before that...






heh sdxl makes fun creatures
they look kind

mike wazowski
doesn't really mater for a quick local fix while waiting for an update. but it seems the update is already available, so updating through manager is the real fix :)
I did some as well the other day







Yeah it just causes problems, like the one you were trying to fix.
I know I've done it before
I like how in each one he looks like he's really holding in a poo
holdin diarrhea lora
@zinc cargo so my workflow now works for you?
i just hit ctrl enter for the first time

That did the trick, thanks! Now that I have it working, it is interesting to compare to image prompting with MJ and also Kandinsky. Of the three methods, Kandinsky comes the closest to matching the features of both input images, and not adding what seems like its own spin. For example, when I used two b&w images with Revision, I received color images as output, something that never happens with Kandinsky. I'm certainly eager to experiment around some more, though.
COuld be as simple as the weights for them
so trye bcz i have 0 idea what goes on in this glorious beast of yours
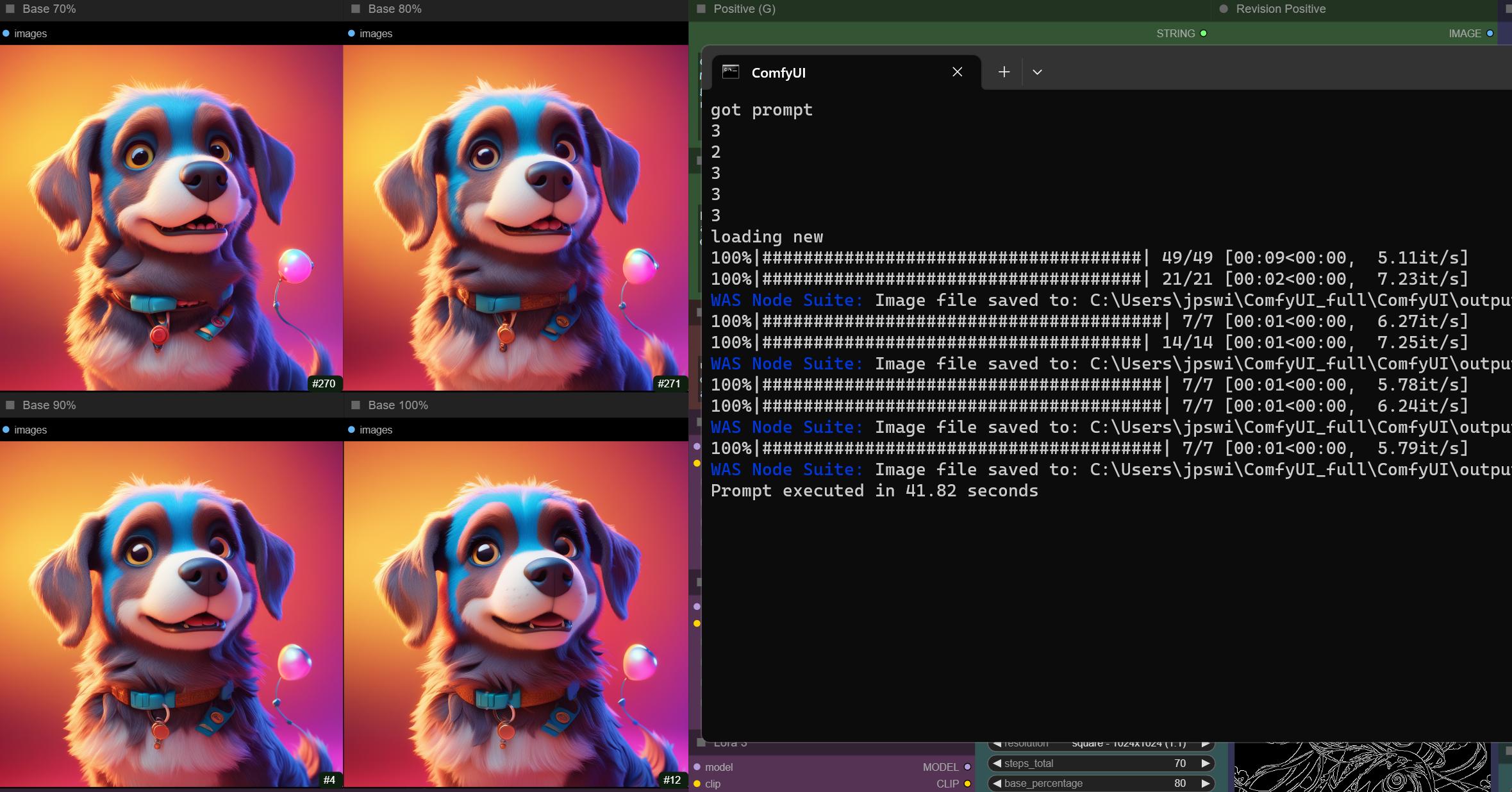
txt2img + canny with 70 steps takes 42 seconds on my system for the 4 versions:
https://i.imgur.com/qbShbRC.jpg
working on batch size for AIT, base works- now compiling refiner
And then sm75 support!
don't have SM75 to compile on. FizzleDorf might though
they said they will add easy compiling scripts to the node's files so everyone can get the highest boost possible
What's the compile process? Is that the only thing holding back currently sm75 support?
canny with low value is nice to get a girly dog:
https://i.imgur.com/fJoEsXs.jpg

yes. it's the process that AIT does when it makes a specialized module.
theoretically, it can all be precompiled.. but that's a job for someone like Comfy that has access to all that
Ah ok, so nothing i can really do on my end
you can, compile yourself using AIT
that will become easier eventually
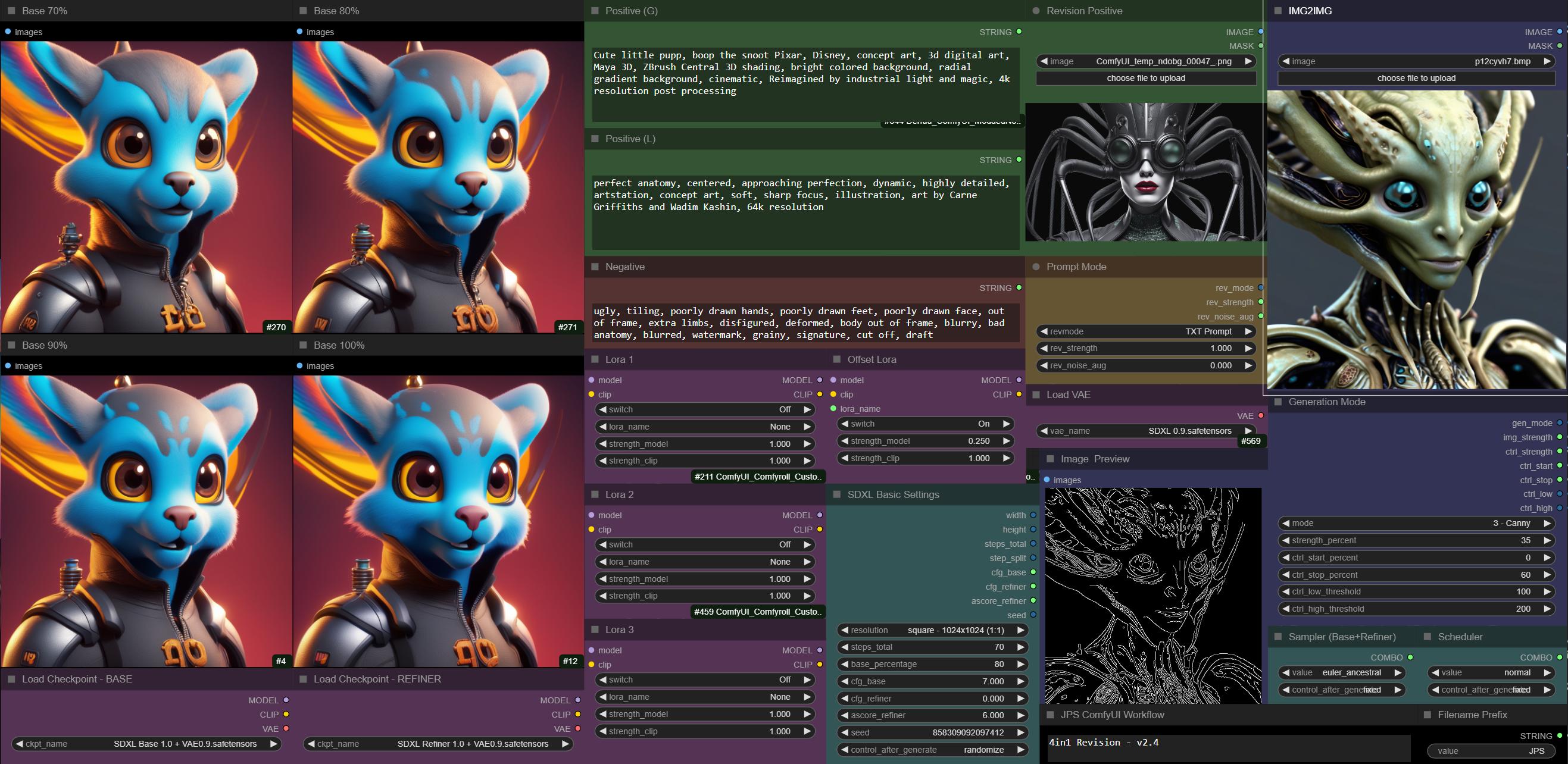
or scifi dog:
https://i.imgur.com/zZDmrWT.jpg
Yeah Unless there was something that specified what needed to be done, that seems out of my current realm
or house wife style:
https://i.imgur.com/KTqoORK.jpg
or spider-alien-dog:
https://i.imgur.com/Ourqdty.jpg





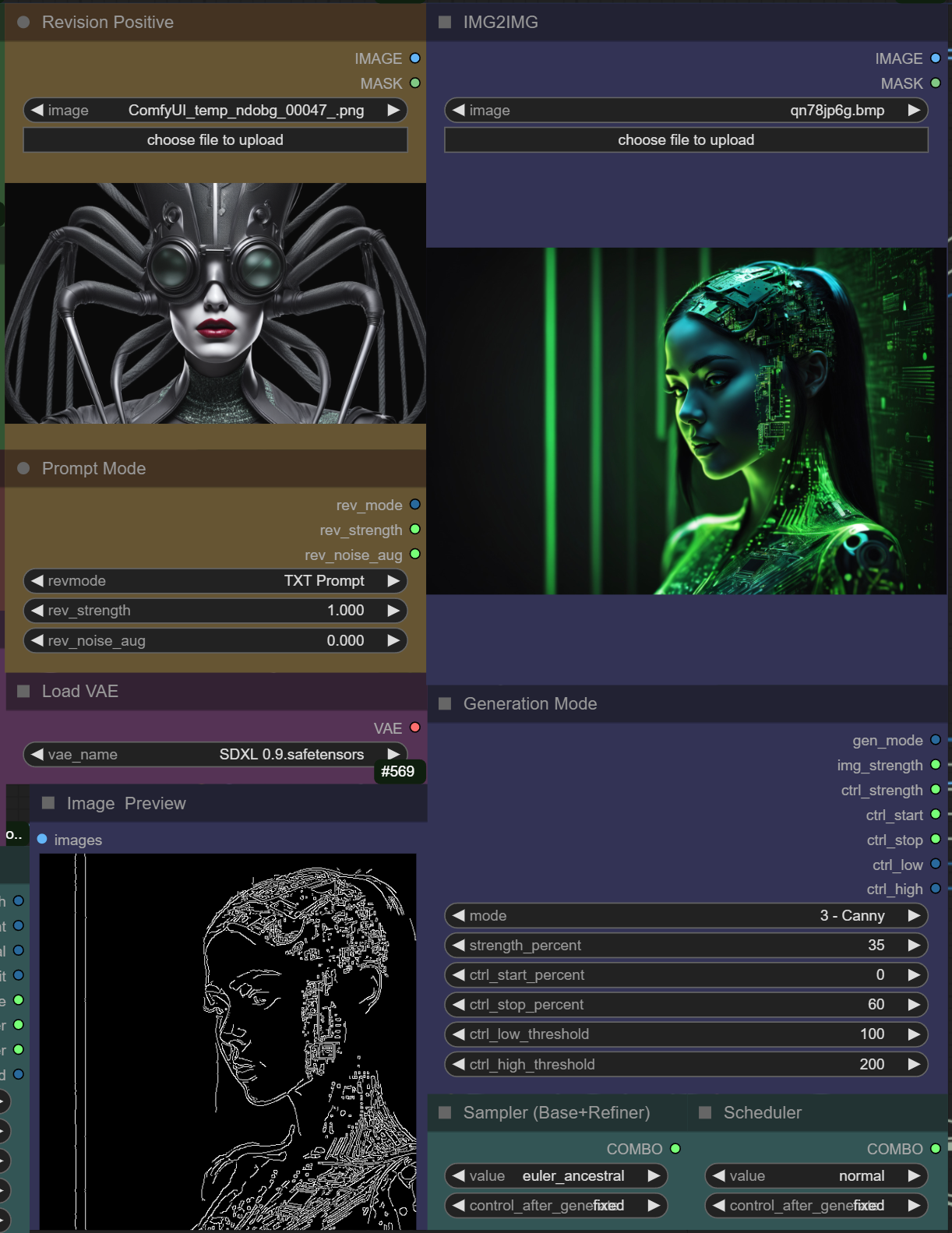
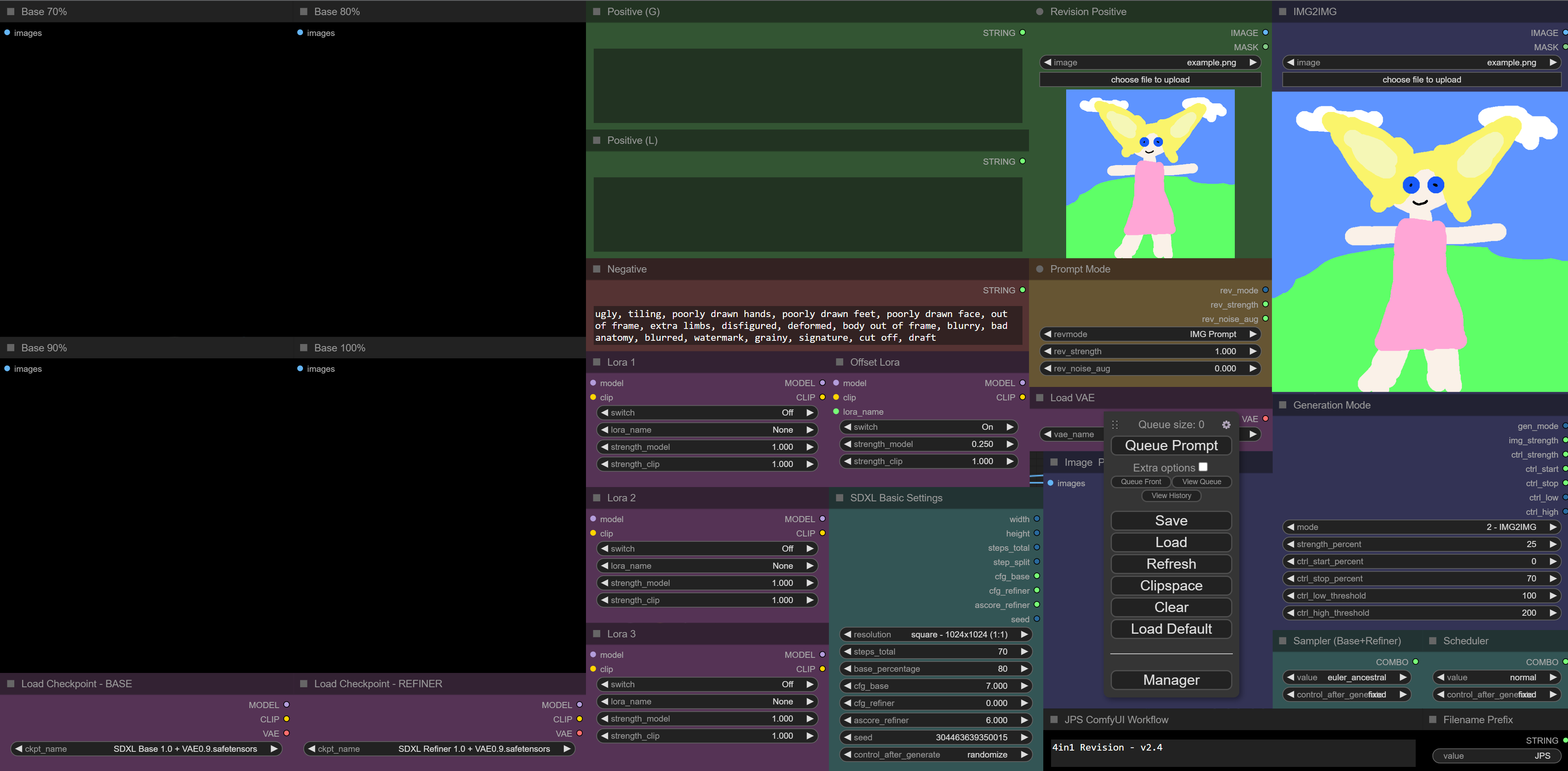
already looks good. if you have questions just ask. basically you have to switch between txt promt or img promt and one of the four generation modes
@JPS i tried with canny, to make the ones above...
so i chose 3, made but i'm not sure if which one should i put the input of the canny to. img2img or revision?
does revision keeps working for canny?
the revision positive img replaces the text prompts completly if you switch revmode to IMG promt, if you use TXT Promt the image is ignored and the text prompt is used.
for canny, depth, img2img you use the img2img image and it shows you a preview of the canny, depth mask on the bottom
so the left image is only for the promt mode and the right image for the generation mode
should make the revision node yellow i guess, so it's more clear
what about canny settings?
also sorry about these 🙂



canny settings are in the generation mode node (blue):
https://i.imgur.com/ZXfuc4r.png
strengh + 4 ctrl options. i mostly use strength and ctrl_stop
i've changed the colors and titles of the nodes to make it more clear:
https://i.imgur.com/D559oPm.png
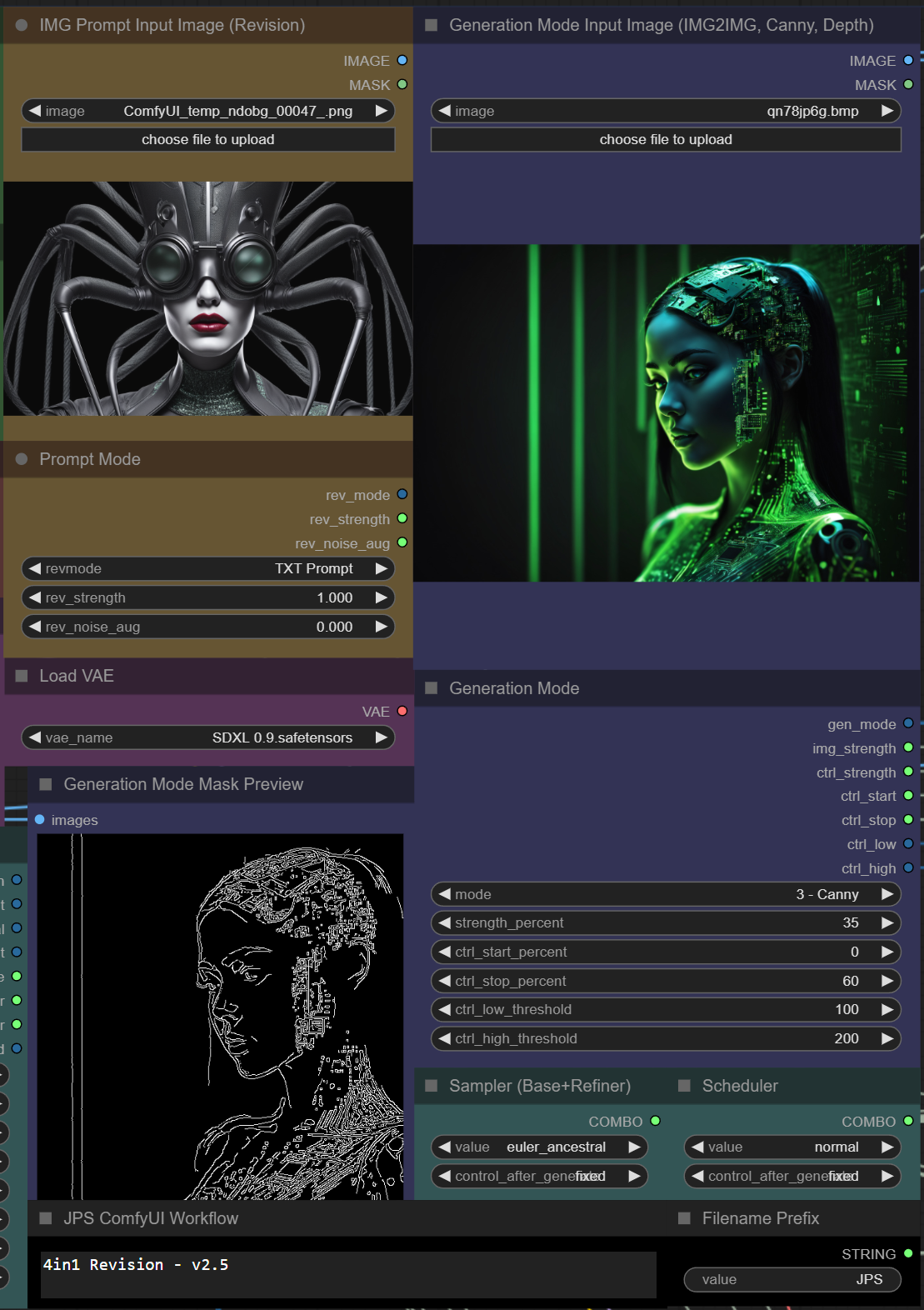








is this img2img?
naw

This is all from these images. @zinc cargo
@visual glade I think I might have found a code issue in comfy UI, but I am looking into it. Running some huge tests for my 2.0 high res fix. I am starting at step 296/300, going to step 300
That should be only 4 steps, yet its queuing 40 of them, and its also slowing down considerably over normal
or sorry, 294/300
so 40 instead of 6
DONE
ok, its an error with setting the end step above 300
I have it set to 1000 to stop at, which causes it to do 40 steps instead of 6. So weird
refiner is compiled for BS1-4




res 64-2048, this module should be universal for any gen params as long as you're on windows with SM80
and text prompt ?
i think there is a rounding problem with ksampler and high step values. i've reported it here:
#✨|sdxl message
yeah.
blue and pink candy neko boy wearing maid outfit at a bar, by hiro mashima, akira toriyama, Masashi Kishimoto
interesting, thanks!
also, little tease for the public
I redid some settings on my v2 high res fix, and it now pulls out even MORE texture and detail over my previous 2.0 candidate
Left is base SDXL, middle is my old 1.0 high res fix, and right is my new 2.0 candidate





here is another example:
#✨|sdxl message
this one is best

gold
Yes, I did try playing with the weights, still getting color, and also imagery that isn't in either of the two sources. The strange thing is that both are b&w images. I haven't taken the time to try to understand the flow of the graph yet, but it looks sort of what I'd imagine you'd get if you used Clip Interrogator with both images and then used those descriptions as text prompts, whereas with Kandinsky it is very close to the style of the source images.
Ah interesting.
Yeah I've only done a handful of images through the new cvision method, currently trying to resolve another issue, if possible.







@ionic gulch thanks!












I'm curious how the technique for image prompting in Kandinsky differs from this sdxl workflow.
Beats me. I've used A1111 and now Comfy
This looks like my Cinemax model. Is that the model you’ve been using for you pics? Love your generations btw.
kadinsky is a whole entirely different model architecture from stable diffusion
like dall-e
yeah it's just the one I've always been using for hyper realism. I can get better texture detail if I weren't using these images or this workflow, but without these images I wouldn't get this style either.

Ooo nice. The model does need some help, hopefully I can get it lookin better soon
Does anyone making ComfyUI nodes have an idea of how to get a custom node to show an image preview like the LoadImage default node does? I fear that the feature is hard-coded based on node name...
you have to do something like this
hmm
That’s a cool idea like preview preprocessors or preview image upscale basically preview anything. Rn it seems to be just samplers
I know that works for output nodes like image saving
Does it also work for input nodes*?
Dialing in my new highres fix even further
Left is base SDXL, middle is my old high res fix, right is my new textured high res fix


(Please excuse the weird right band on my comparison images there, its a funky seed issue)
not sure sorry, haven't made a node like that
was curious what that was lol
Yeah, it seems to be an issue on some seeds using my LoRA
Think I need another coffee

evidently, one of the images in my dataset seems to be introducing it
dang
which is weird, cause they are all super clean images, and I only seem to get it with this prompt
I have seen it a couple times
got even faster.. batch size>1 support soon =]


If I just outright copy the LoadImage node from the base code but rename it to something else, no image preview and no upload button 😦
I think it is hard coded
this didn't work?

Because it's an input node, it's returning other things (image, mask, and a bunch of metadata)
give me a workflow if you think you found a bug
Oh, hey, there's someone who probably knows!
will do, just need a bit
@visual glade Is the ability of a node to display an image preview hard coded to the LoadImage and LoadImageMask nodes? I have a custom node for loading images but it doesn't show a preview
@glad grove

Girl what you really want all night
Me want the buddy, make me feel nice
Boy what you really want all night
Me want the poonani, see for make nice
She want the buddy
Him want the poonani
And me know it nice
When the girls start to strut
you could look at her but you shouldn't do that
Think about just that because her clothes are just as pretty
...
sensei 🙇♂️

Also, @visual glade , the fix was adding import UNet2DConditionModel to the beginning of the code. Just compiled for XL and XLR on SM80 with bs1-4 res64-2048.
@cedar tusk Hey, had a question about one of your nodes. Specifically the positive-negative with text node
sure
For some reason, I got this error when using it last night. Have you seen it before? Last line was cut off, but didn't have anything specific in it

let me check it out, I haven't used that node in a while (I made it before I was aware of primatives and being able to change toggle inputs and widgets, haha)
The node wasn't listed in the error, but figured out it was at least facilitating it


Great, thanks!
A little more ominous

I just tested a basic workflow using that node and it seems to work. I'm seeing no error pop up BUT I did just find a seemingly different bug with the filename using timestamps...
But anyhow, if you remove that node from your workflow does it still error out?
Also, are you using SDXL with it? I think that SDXL requires a different CLIP text encode node due to internal differences, right?
Only got that error with that node. Never saw it otherwise. And yeah, used xl with it. Not a big deal, just thought I'd bring it up with you
Ah, I'll see to spooling up an XL version then



these are the voyages of the starship d o double g
@hardy cipher So what do you think about the positive_text returning combined pos_g and pos_l?

And then telling it to not generate those images!
neat
Sorry if this was already posted. It's pretty interesting. They intentionally generated a bunch of crappy SDXL examples, then trained a LORA with those to use as a negative prompt and it works better than you'd expect
I thought the base model was already RLHF'd but maybe it didn't get enough negative reinforcement

@hardy cipher Okay, SDXL version of the CLIP Positive-Negative nodes are now up



Get that chedda

hrm no safetensors version of it though 😭

Sounds decent to me. I've been exploring different options in that regard





LOL


I think this locon was a success.
although lycoris locon has a bug now so I had to use kohya

Damn, those are legit. What did you use for training?

comfy_extras


my problem is I can't think of any prompts to try it on
the lexica prompts are meh
@vital ermine I just start writing something from a small base idea and add random stuff to it as I move through and just switch subject matter here's a prompt for you: a 1970s album cover in the style of grand funk railroad featuring a photorealistic tyrannosaurus rex playing golf with John Lennon in the landing bay of a large space station orbiting a gas giant
or you could try to get it to create a photorealistic image of a scuba diver wearing a scuba tank... which 1.5 nor any refined 1.5 model I have tried can, I know cannot do at all for some reason and others tried sdxl earlier I think, and said similar problem lol




here's an img2img upscale of whatever prompt I use, I forget

actually that may be a 1.5 i need to organize this stuff
here's a few I made earlier with sdxl



that one is 8k though :\






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I've successfully integrated 3 new color transfer methods into a custom node. Now to incorporate the old method on the bottom into it.

The big picture is to get GroundedSAM in as well to segment out masks and edit masked regions with color transfers from different images
what a long road

Once GroundedSAM is in, this could possibly be added for automatic openpose MoCap

GitHub
[CVPR 2023] Official implementation of the paper "One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer" - GitHub - IDEA-Research/OSX: [CVPR 2023] Official implem...
I just want what I know is mine

