
#✨|sdxl
1 messages · Page 96 of 1
does that message pop up when you run the automatic1111 setup?
big memories
I run webui-user
time to acquire more ram to do way larger gens, as sure, takes pretty much 2x longer for larger gens, but ram acts as extra video memory 
Kindly take some action against people generating bikini pictures in SDXL bots, its so uncomfortable generating images there, with my young brothers behind me
after following these steps right?
Automatic Installation on Windows
Install Python 3.10.6 (Newer version of Python does not support torch), checking "Add Python to PATH".
Install git.
Download the stable-diffusion-webui repository, for example by running git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git.
Run webui-user.bat from Windows Explorer as normal, non-administrator, user.
Bikini Images are hardly NSFW, if you dont want your younger brothers to see them kick them out from behind you
I used 3.10.11
are they wearing pasties?


I mean, that's pretty cringe to do. but not sure if it breaks any rules
in bot 10
And yes @terse pewter I appreciate there may well be (based on yuor name) some cultural and relisgous iidfferences but as the olde rbrother you need to take some responsibility for what you are showing yuor siblings
lol
actually, even my parents are behind me 🤣 we have a small home so
Oh, I’m not sure of that works let me do some digging
thanks for helping
thats a "you" problem not a "me" problem
it's like looking up crude images on a computer at the public library, lol
yup, definitely cultural/religious difference
i'll try another bot
I don't know, not sure anyone here could do anything even if they wanted to
Hilarious that people aren’t ashamed in a public server

unless someone here is a super secret mod


i think people would be able to soon, once sdxl gets open sourced, and run it on our machines
60mb?!
Ahem
8k image?
That's why I download it
Jk
this is joke
we know what chii gonna be doin
im a girl

i said i was joked

Got an idea for it, pooh's jar floating down the river next to him




girls also have needs #justsaying
it should work with 3.10
C:\AI\stable-diffusion-webui\scripts do i put copy of python exe in here?
i dont think it will work
shoot sorry
copy and paste it, see if it does anything lol
ok
ive had trouble creating venvs on windows before its always been a hit and miss thing for me
Dont work






1024x1024



woa these are awesome
Thanks



which version?
glad to hear it
latest, since i think i will use fooocus instead
WTP the hacker diary

@shell pilot not sure if stable diffusion isnt problem, not UIs
sweet, now you learning the joys of python
yes and i think it doesnt matter what UI, that python problem is with stable diffusion
I am going to study C++ and python in free time
ye but i download latest
and latest dont work with one of the one i have

python more important than c++ for this stuff

Nice mark zuckerburg

ye for AI phython better, but I want to learn c++ too
I want to be software engineer or something
2 y
years until uni
ok
thatsthejoke.jpg
That's the joke too igga
still keyboard is oposite to programer, why!!! 😦
then we on the same page
true true
I actually want to see what I can get from doing mark though. These colors are great!

I actually might use clip_vision as more of a art style type thing for a bit. Not great a making subjects yet.
Looks like a StarCraft 1 portrait render

Something very uncanny
TRUE

!!!!!!!!
😐

Some people have found great ways of blending subjects. I have not found that yet.
naw
That's the character Morgana from an old game
this dunder head

Prompt for Morgana

Write the word "Morgana"
Yes
But when I try to generate other people oc

@steady grovebroooooo

Why is it like this?
No. Even AI won't be your gf. 🫣



Someone's mother is neglecting then again. Log off @void zenith go live your best life. Forget your mother's neglect. She's not worth it

Let's be honest. It's all because of mommy issues


k kool?
Is he trolling? 🤔

seems like it 🧌

You doing well this morning?


I meant the other dude 😅
I'm fine. I gave fooocus a go. it was pretty cool.

Naw I got that.
Yeah fooocus is really kool. I used a community model and built a small prompt that forced hyper realism throughout.
Tbh
I would rather use 1000x1000

It's perfect for me
ngl

I hate this
for fuck sake
generate only 1 person PLEASE
It's ugly
It's not cool
It's not perfect.
use 23x45590 for all I care. just telling you what it should be
and you should use 1024x1024
unless you want extra arms

But why am I so unlucky when I use SDXL?
He's actually just using 1000x1000
you're not
odd
do what brings you joy


@wet nacelle do you think ksampler approach implemented in fooocus is the proper way to do it? 🤔
Ah, good old 23x45590. That's the best resolution.
i keep getting black sqaures when training
I really have zero idea. It could be though.
It might just be me or does he have a different method of denoising? It just seemed different.

looks betteer right?
😐
Dude, we know now that you hit puberty. Congrats
I guess yes
@shell pilotDid you click a link or were you actually hacked?
Maybe change something in here might do

link lol
Because i was retard

he does something different with the sampling


Unlucky. I two times did that. I actually joined a server and then accepted a friend request by a user I didn't know.
I now which server have the bots that spam you with groups.
Oh yeah I remember reading that now. really interesting stuff.
wow
What is that foul language you use? Are you talking about woman like that?
A.I. sometime being stupid




even tho my prompts explained everything
sometimes it just happens. use another seed number




wow
I don't really understand all of this... as long as it gives me pretty pictures 🤷♂️
Same here
He looks here as real toy.





maybe seed 0
Can we ping a mod to let them know of this guy? He is adding nothing to the table.
I am up for that idea
there are lots of seeds, bud. just try any of them

strange vibes in here today, lol
yeah, 123456
Here. send in the prompt.

Tragic.
WICKED
Why does this take forever?

I waited like 10 min now
maybe it's becuz the randomizing seed cause the problem for me
Do i wait or reload
Close the cmd and reopen it.


It's a furry
you are not a mother fuckin centuar

I am not
I am a furry hunter
😕


anyone here runs swarm?

Bragging about being degenerate 🫣
I love taking images and running them through my lora
Never know what is going to be spit out

Seems like it makes yours flowers
FUCK the "allboymix_v20" this piece of flumery of a.i. generating image industry
such a mother fucking disappointment
I hadn't and would never in a million years figured that out. Thanks!
I'm so fucking done
Well, at least this one didn't make flowers for me.

still dont work


it is stuck on processing text encoding, it seems it doesnt generate image at this stage
I'm so sorry to hear this
@shell pilot try post what cmd error it show
No, that is a good thing

it just wont load fast
Can you check the advanced tab to see if the base and refiner are selected properly?



What gpu did you say you had?

2060 rtx
its stuck
@polar epoch Made this abomination for you









Have you tried to just uninstall it all and reinstall it?
I hate doing that with this tech but it might help.

idk how i just ran bat file
how do i unsintall that?


or you can try delete only venv folder
How to not make A.I. become stupid even tho I applied so many prompts
Such a impossible dream
yeah
I did everything you told me
Interesting take on The BatGirl using the ReVisioned technique @strange mist @native knot


but a.i. still not being cool with me
that's how it works out sometimes
Where is this addon and where can I get it.
I want to be able to control LORA weights.

Is that a LoRA?
Btw is the thing that guy is using up there
LoraCTL?
What's the name of that extension?
No. I'm using clip_vision
you just need this

Hey quick question. Does anyone know what class prompt to use for a style in Kohya? For my last analg photo style i have used "style". I am talking about LoRa training btw.
well, you could be using a 10 stack, bud
Well no, I couldn't.
ComfyUI is slower on Intel Arc than it is on Vladmantic
And half-broken as well
I don't want a 10-stack.
I just made it a while ago because I could. might actually use it though
What is this extension?

that's the extra models extension or something along those lines

sd-webui-additional-networks
Clip vision is indeed interesting
unclipXL


How to stop A.I. switch colors?

ask politely
ok the filename prefix there almost made me spit out my coffee 😂
I have many figma files with layers named something along those lines

a few more "ReVisioned" takes on BatGirl @strange mist & @native knot & @crisp owl







that's some clip vision there
Any South Africans in the room ?
Damn they can play some good Rugby (and yes I'm Welsh & currently depressed lol)
Hi guys, good morning! I'm happy to announce the release of ProtoVison XL 0.5.2.0!
This version of ProtoVision has had some additions to add more variety and complexity to scene backgrounds, more facial and skin detail to subjects, better coherence. Eye and hand improvements. PVXL should also be more responsive to cinematic prompts. Facial variety has been improved, and racial biases are less prominent. - See listing for full changelog details and sample images. Thanks so much for all your downloads, likes, stars, and shares, I LOVE seeing all your art filling the galleries for my listings, it really is amazing!!! 🫶





***HELP ME WIN THE CIVITAI MODEL CREATOR CONTEST - SHARE YOUR ART IN THE GALLERY BELOW AND LIKE RATE AND FOLLOW ME FOR MORE SDXL GOODNESS - THANKS!...
this looks amazing!
Got updates for Dynavision and NightVision in the pipeline as well, testers have been creating some pretty amazing stuff with them, can't wait to show you all what we've got coming next!




what SD? It is only model. Comfui, you can update with manager
Stable Diffusion
i am telling you. SD is just and only model. You know what model are you using, comfui or a1111 UI version you are looking for, and you can install update of any of them
any good textual inversions like easynegative that work with sdxl?
Oh oke.
What's yall GPU btw?
3070 only
i used to have 1070ti, and switched to 3070 because not needed changing PSU 550w
very cool for learning how stable diffusion work

daaaamnn
that's drip
very cool drip.
GTX1080ti +5600X +64Gb system RAM

what's the prompt?



Get iced
Is there a comfy node that'll pull metadata out of a png
I recognize that there would be quite a few issues with it, including the sheer amount of MD in a large workflow
But it'd be rad if there was a node that would let you grep/search for an output by name and then use it
a tower unit with green lighting sat on a desk that has 3 monitors and a Mandalorian Helmet

and a tardis!
and a Dalek

This is my second attempt at creating a sad story through ai images of stable diffusion
I am trying to create stories, that would make us cry, for tiktok
You need to max out the video for full view
Why is it so wide
It's tiktok resolution, 1080x1920
if you aim for social, try to do 16:9 resolution (unless you want to put captions above and under - then never mind)
this is how we see it in discord
that's why i've commented

yup, if you press on the rectangular button below, it will show correctly
to expand it

oh, okay
dont
I see
show me

modules dnt count

dang, what will you do now?

That’s not the problem
i am
What modules are you missing
Manual install.
@strong field gimme yr best CN,
CN?
need a prompt and a preprocessed img?
if you look at the red nodes you don't have installed you can see what they're called, then just find the node packs with those nodes and install

yea right click on node
get it


For Comfy nodes, is there a way to pre-define the names of the outputs of a custom node in the code? So instead of saying "INT" it might say "height". I know you can rename them after in the UI
you could do it in the code for the node
shush
Can you point me to how? If I do a custom RETURN_TYPES() entry then it'll limit what that can connect to
need to get bk to production

Problem is that only works on my local saved workflow. Not if people load in the node on their own workflow
Bruh what is happening
bro
RETURN_NAMES (tuple):
Optional: The name of each output in the output tulple.
same q's
he spelled tuple wrong, lol
Gotta hard code

ah, thanks! I had no idea I could tuple that

serious, avoided blender nodes ast all costs, dove into sdxl open hearted, bt...

god why cant comfy be easy to use for people like us
why can't this free thing that I choose to use cater to me?
whats wrong here?
Using Comfy and developing for Comfy are two different things. I think using comfy is pretty easy if you just drag in a workflow
bro, im bitching for all normies,
this is how I node

creating nodes are simple too.. but it's so time consuming
aight, so it looks like that doesn't work. If I have something like:
RETURN_TYPES = ("INT", "INT")```
the node has outputs of "INT" and "INT"honetly, b4 you devs make yr workflow, send it to me, i haz teh dumbs, we can simplify
indeed
pcs showing off again

from a non node creator, this is very confusing, well done, you missed the point, you kept it selfishly
is GA a bot?
Last time I check no, but who knows.
going bk to auto at 1.5
sad story bt fun'er
AI is a thing, so mebe the response is not = (will delete this)
At least I am not running around in here asking for anime chicks to have sex with like that other dude did this morning, lol
if you want your Lora training to really affect your base model, how high on the network rank would you go before considering it to be too much? i tried using 128 and felt my Lora didn't make too much difference on the underlying model when i called the instance.
k wait, ya'll got anime girls inhere. i might stay then
jk
super upset though, thought more devs wld congregate
SD is in a state atm, ngl
gimme decent rsrcs and i will learn
every 2nd person has a generation that has red blocks that isnt fixable
??
red
Yeah, well I am not doing comfyui for reasons.
I guess you probably shouldn't use it
i envisage openness, not selectiveness
Alright, so another question: how can I get Comfy to load an image preview on a custom node like LoadImage does? It looks like it might be hard-coded
very strange people coming in here today
well, I can hear SAI now. "Then for you we have the simple web interface for xx per month."
dont you dare
hmm, that's a good question. I should figure that out
name appropriate, haha
all this apprehension about comfyui reminds me of when governemnts made leaded gas illegal and many people were pissed about having to put less toxic gas in their cars
its what they've always known and they don't want to change
then don't use it
there are manuals and guides
or dont
you don't have to use comfy if you dont' like it. it's not like it's legally mandated. it existing doesn't harm you
i want it
it existing doesn't make a1111 suck right now either
this conversation is very predictable. I agree
no a1 just sucks on it's own usually
You could look at something like StableSwarm. That's got a comfy backend, but an easier to use front end.
people are acting like comfy stole it's a1111's soul or something. like they're outlanders and there can only be 1 stable diffusion UI
that's different too though. so much change
some people like to make their own problems and manufacture their own roadblocks. it's weird
people that complain about things that are free and that they aren't obligated to even think about make me sad
wish i cld code
complainign about no manuals and docs is just lazy too
,(excuse AGAIN amirit)
complaining about free things can be valid, just needs to be actionable complaints
wots yr gpu?
that's fair
not saying it should be immune from criticism
but vague nonsense
bro
lol yeh. That's just nonsense
send me yr best img2img CN
lets talk
i think a lot of it is fanboy logic. Because stability is paying comfy, that means auto isn't getting paid 😦
well, I wouldn't mind if they both got paid
Do you no like maths
no
a1111 taught me a lot, but then it kind of sputtered out
“Load default”
im a non coder, non math'er
you just linked someone trying to helpyou figure out comfy, and you sarcastically treating them with an attitude similar to "Yeah okay. sure buddy!"
Not sure what the point was
entertain me
pikachu, i choose you!
Well, for now I'm just using a preview image node. And with that I now have a node that can load in an Auto1111 image and let you grab the metadata to deliver to other nodes!
how so
ooh, that's pretty awesome
yusss the angled hate to join in
I've been looking at the code for nodes that have some of the features I want. and then looking at it again and again since I barely know python, lol
but figuring it out
it's pretty straightforward compared the C and C++ or java
Hey that’s a great idea
python is a scripting language. it's leagues easier than c++ or java
thinks he's trolling. I guess he is
Python gg ez level compared to those
frustrated he can't noodle so he's lashing out
no
again, you're focusing on drama instead of actually using the UI.
this isn't looking for assistance. it's looking for attention and dragging things out.
Hey I get it, I’d be sad if I couldn’t noodle
comfy got them noods everyone wants
sj\how me yr assistance, you literally went to dramas bro lol, read bk, you pushed it
people's insecurities often manifest into aggression
is true
thats a great way to ask for help after you've spat on a lot of it being offered
hoooowwww
JC

kkkk
I'll help pretty much any doofus that seems to sincerely want to know about things
you right
I did my best
but I think some people don't want answers
yup
yuuuup
anyway, doofus here
nah, I don't know what you are
wot is top model?

they're all different tools for different purposes. there is no best
those are all 1.5 controlnet models
there doesn't need to be a best either
fk my "m" is going bust
shhh
tried to offer advice and then this. okay
the top 1.6 works with sdxl base and refiner, so it works
"i've changed guys. help me!" /acts the exact same way
If you mean what is the top model, as in what is the one on the top of the list. It's hard to tell because it's not named very well.
This checkpoint is really meant for me

i need a workflow
I love male anime character
if i explain then you'll spit on my answer
I did not know that was a model
yeah
ill wait for some1 elser
I'm searching for stuff like this
lol
i'm not worried about other people failling. i think they're the most worried about that one
\llloooooollll
but not 3d anime tho
a lot of people when failing will blame anyone but themselves

like i sai, avoided nodes in blender,
avoiding them now \
just think it could be easier
Here's another question: what's the trick to getting a node's input to default as an input port and not be in the node. For example, having a STRING type be an input point and not a text box?
DID HE JUST GIVE ME A MIDDLE FINGER?
that one is really good
HELLO?
this is my favorite model right now https://civitai.com/models/128456/pe-shitty-fanart

Sick of perfect AI Images? Then use this Lora to make some terrible FanArt! Weights 0.8-1 If you want to donate: https://ko-fi.com/proomptengineer
that lora is also potentially super useful if you're going for photorealism
just send it negative
make one then copy paste it
ctrl c ctrl v
or alternatively, ctrl shift v to paste with connections
Ah, I mean in the code. So that the first time a user loads the node it's showing ports not boxes
hmm
Not sure about that. I think you'd have to recode each node.
setting it up once and pasting it seems a lot easier for new users
I don't know about that
maybe we'll get an option when importing new nodes. "all values as inputs"
I see they're more on realistic side 😄
top middle is my fav. amazing detail on the costume.
You mad fuckin lad, i love it Now to tandem up 2 or 3 

still haven't gotten around to uploading it, lol. but I will shortly
Strad Grandgaze
Is there a server rule about at'ing the comfy themselves?
wait, wallish, what exactly were you wanting to do?
Aye, ping me when it's ready lol
will do, keep getting distracted by various things
I have "STRING" inputs to a node, but I would like them to default to 'input' type (node inputs) and not to widgets (like multiline)
On first load via the node definition in code
oh, well that's easy I think. unless I'm misunderstanding you
Why don't you look at another node like the Save Image node that only has an input and look at how it's coded.
Should be able to get an idea what way
you admitted to not respecting what I say. Why would i engage that?
i do though
So it looks like some types default to having widgets made
That's me as well every damn day from everything lol
this feels like troll bait and you'll just string me along saying my generation isn't good enough
you tend to be negative, is okei, a challenge if you will
But also I've accidentally had it where I turned an input into a non-widget on load, but I'm not sure what the syntax was that did that and it isn't consistent
its just an opportunity for you to act as an arbiter towards me. no thanks
can't you set it up as input?
i'll challenge myself
well one second, I'll look at the code
okay well, no thanks
return {"required": {
"model": ("MODEL",),
"clip": ("CLIP",),```then it shows up as inputs, that format
I realized a while ago I actually don't care about anything this guy is saying
here's an example:
def INPUT_TYPES(s):
return {
"required": {
"prompt": ("STRING",{"default": '', "multiline": True}, ),
},
}```
This will start with a widget for the 'prompt' value, but you can turn that into an input port in the UI. If I remove the definition parts (so it's just `"prompt": ("STRING",),` for example, it may not even load the nodeAs the "STRING" entry is needing to know the type, I think
use this as an example
def INPUT_TYPES(cls):
return {"required": {
"model": ("MODEL",),
"clip": ("CLIP",),
"switch_1": (["Off", "On"],),
"lora_name_1": (cls.loras,),
"strength_model_1": ("FLOAT", {"default": 0.0, "min": -10.0, "max": 10.0, "step": 0.01}),
"strength_clip_1": ("FLOAT", {"default": 0.0, "min": -10.0, "max": 10.0, "step": 0.01}),
"switch_2": (["Off", "On"],),
"lora_name_2": (cls.loras,),
"strength_model_2": ("FLOAT", {"default": 0.0, "min": -10.0, "max": 10.0, "step": 0.01}),
"strength_clip_2": ("FLOAT", {"default": 0.0, "min": -10.0, "max": 10.0, "step": 0.01}),
"switch_3": (["Off", "On"],),
"lora_name_3": (cls.loras,),
"strength_model_3": ("FLOAT", {"default": 0.0, "min": -10.0, "max": 10.0, "step": 0.01}),
"strength_clip_3": ("FLOAT", {"default": 0.0, "min": -10.0, "max": 10.0, "step": 0.01}),
}}
RETURN_TYPES = ("MODEL", "CLIP")
FUNCTION = "apply_loras"
CATEGORY = "loaders"```model and clip are inputs
The problem is with the "STRING" type, mostly
ahh
I always just look for other nodes that have whatever it is I don't quite know how to do
see how they do it
probably my favourite as well.
On the realism point its intersting because as you can see I wasnt particulalry prompting for it

this is the way
yeah, unfortunately I'm not seeing anything in the default nodes or in the sets i have installed
it's probably nightvisionXL, must have a higher bias towards realism.
what's this Revision technique btw? are you using two images as inputs alongside your prompt? 😮
something SAI announced yetserday. Yes uses one or more images that get clip encoded and added to the prompt
See the lower part of this link:


Thats a big eye

Ooh just reran that top middle one back thru but this time using ProtoVision

Interesting

I'll look around and see if I can find anything in mine. curious now
Which is intersting when you see what he inputs were lol

still realistic but in a different way. the mask needs inpainting. other than that def a good one.
looked up the revision thingy, mindblowing stuff.

those are nice eyes 👁️
which model are you using?

Newest ProtovisionXL model for those
https://github.com/wallish77/wlsh_nodes Feel free to check out the Auto1111 importer and mess aroudn with my nodes to see if you can figure out that STRING input thing. I gave up for now.

GitHub
WLSH ComfyUI Nodes. Contribute to wallish77/wlsh_nodes development by creating an account on GitHub.
wow, no prompting or after detailer?
hmm, I think I might have them installed actually
No just that Revision technique
lol, didn't even make that connection
@strange mist These as the input images

Wasn't what I was expecting, but looks cool and if you push the weight more towards the earth image, it starts to make eye based space scenes
this is one from when I was playing with the original SDXL0.9 release

It's not always a win though

cool stuff. I'll give revision a shot tomorrow 😄
once I get a few put together and am confident they'll be useful to people I might look into having them put in the manager list. haven't really looked into how that's done though
yeah, I think I use them actually
yup, got em
I tend to delete the node packs when I keep getting dependency issues and realize I don't really need them
but seems yours passed the test, lol
Anyone else working on getting a setup for ComfyUI to do animations? :3
I wish
FYI you can do this into an OOTB Image Save node using built in S&R fuunctionality.
Eg I use
SDXL/%date:yyyy-MM-dd%/%date:yyyyMMddhhmmss%%SWT.seed%%BML.ckpt_name%%RML.ckpt_name%%STYLE0.style%%STYLE1.style%%STYLE2.style%_STD
WHich piut it in a ime dated Subfolder of Outputs/SDXL with a name like
20230819203614_3347873819_protovisionXL.safetensors_protovisionXL.safetensors_base_base_base_HRF_00001_.png
Co BML.ckpt_name is Base Model Loader (yes I know Im using a WAS NODE witha Name_String on it, just not using it, OOTB S& R & WAS Tokens dont plauy nicely, reasons) you just need to edit the Node Name in Properties

oh dang, I had no idea
Its all about learningthough so its never a waste 🙂
Well it's too late to undo the dev time, haha
Plus i wrote a PyQT tool that lets you drag in images and get prompt info from Auto or my nodes, which is super useful and wouldn't work with the default save, so not a waste
GitHub
PyQt program to extract prompt metadata from SD-generated images - GitHub - wallish77/sd-prompt-inspector: PyQt program to extract prompt metadata from SD-generated images
was wondering why this upscale was taking forever. turns out I had somehow stacked two upscalers on top of each other and they were both in the chain
FizzNides, WAS Node Suite & MTB Nodes seems to be a good starting point so far but once I figure out something more full I'll throw the set up in here
hey, I'm trying to make an image fusing workflow, final image has nothing to do with the 2 images provided. any idea?
Maybe let them get to know each other first? Get them some movie tickets and dinner reservations? (Sorry I have no idea)
there might be something like Interpolating latents
I might be making a technical blunder saying that but like vae encode the images and then some lerping thing

See if this works
currently messing with the image weights
I hope so he image didn’t get stripped of meta
no metadata
Darn on mobile so I don’t have my goodies
I got u tho 2 seconds
Did you stay here, he’s got the weights preset
Prompt also matters here, empty prompts can get random
love it when I inadvertantly srun a 1.5 model in the xl workflow
Two heads are better than one
huh, I'm trying to make it not prompt dependent, gonna look into this
man, I spent about 20 minutes adjusting clip vision and various other things. then realized I hadn't even thought about the model
ugh
Ah I misunderstood
ok not a traditional look but I am likingthe way the suit has been rendered

Decided to make some ComfyUI app icons
thought you were cracking joes at my expense. which would be fair


I should just stop typing for now

those are pretty cool
Isn’t clip dependent on text anyway, not sure how to give revision direction without a guiding prompt
my other approach is to maybe use interrogate and merge tokens, I know that's possible
a grittier re-imagining of batgirl. the color scheme reminds me of the awful titans show.
I like the expression on her.
Revision can be used without any textual prompt what soever and can generate a LIP encoded COnditioned output 100% from input images
oh god that was dire
oh I like the image 😅
the show is bad, but the costumes are kinda good. gritty and grounded.
I watched season 1 then stopped
yeah, but when you don't give it any prompt it makes SDXL's incoherent instinctual image
Without clip text encode you get random tho, could be unrelated to source images because of the way it works
just a tile of fruits and leaf
I think I watched a bit of season 2 as well.
This sounds like the right direction
Use the ConditioningZeroOut node
a few more variations onthe grittier looks. I like th eidea of a painted on Domino mask and no cape, its mor e"functional"



is it a built in node? or a custom one?
Pretty sure it's built in, I didn't download anything to get it.
huh, that's also dependent on text though
it wants a tokenized prompt and outputs conditioning
It zero's out the text conditioning, so it sends zeros, rather than an "empty" token
ohhh, nice! I'll try this rn
are you prompting something for the facial expression? 🤔
there was a response last night from , damn it forgotton who now from the SAI team) about the Zeroing node and waht it does
I'm trying to figure out the best way to use a negative prompt as well as using Clip Vision, without the negative massively overtaking the prompt, as the text prompts have way more strength than the image prompts
depends on if you think its "cute & sexy" lol
NB dont forget that im using the ReVision Technique so its also influenced by the 2 input images
a cute and sexy picture of The BatGirl in aan aggresive fighting pose (clenched fists) in a dirty, dritty street,she is wearing a head covering mask that has pointed ears on top of her head,she is wearing a black cape that is blowing in the wind, she is wearing a dark blue one piece leather suit with black fabric inserts , she is wearing with flat soled boots
,art style by (frank frazetta:1.3)

FWIW & IMHO with SDXL you can keeep or completely omit the negative prompts most of the time
True
Yeah it's for things like, it always seems to make women with earrings, so I want to remove them with a negative. But at the moment it completely changes everything in the image.
yeah no, that is a fierce expression. I wouldn't want anyone to give me that look 😁
image 2 has a high strength and it has a sort of determined expression. that has to be the source.
Does a node exist to retokenize clip ?
meanwhile a ReVisioned generation with 0 textual input


Lol I guess that’s kinda related
same seed but with added style info



Notem the way I have it confgure in my workflow is that the ClipVISION ddta is to BasePrompt G Positive only
Dont care if that the right way its the way I'm using it 🙂
I wing it and do what I want
That’s clever
Lol is there a right way? Only comfy way.

is there an xy plot that works with SDXL in ComfyUI?
wouldn't any xy plot work with sdxl?
ok wtf, it got way more coherent when weight is 3
I think it depends on what your input images are
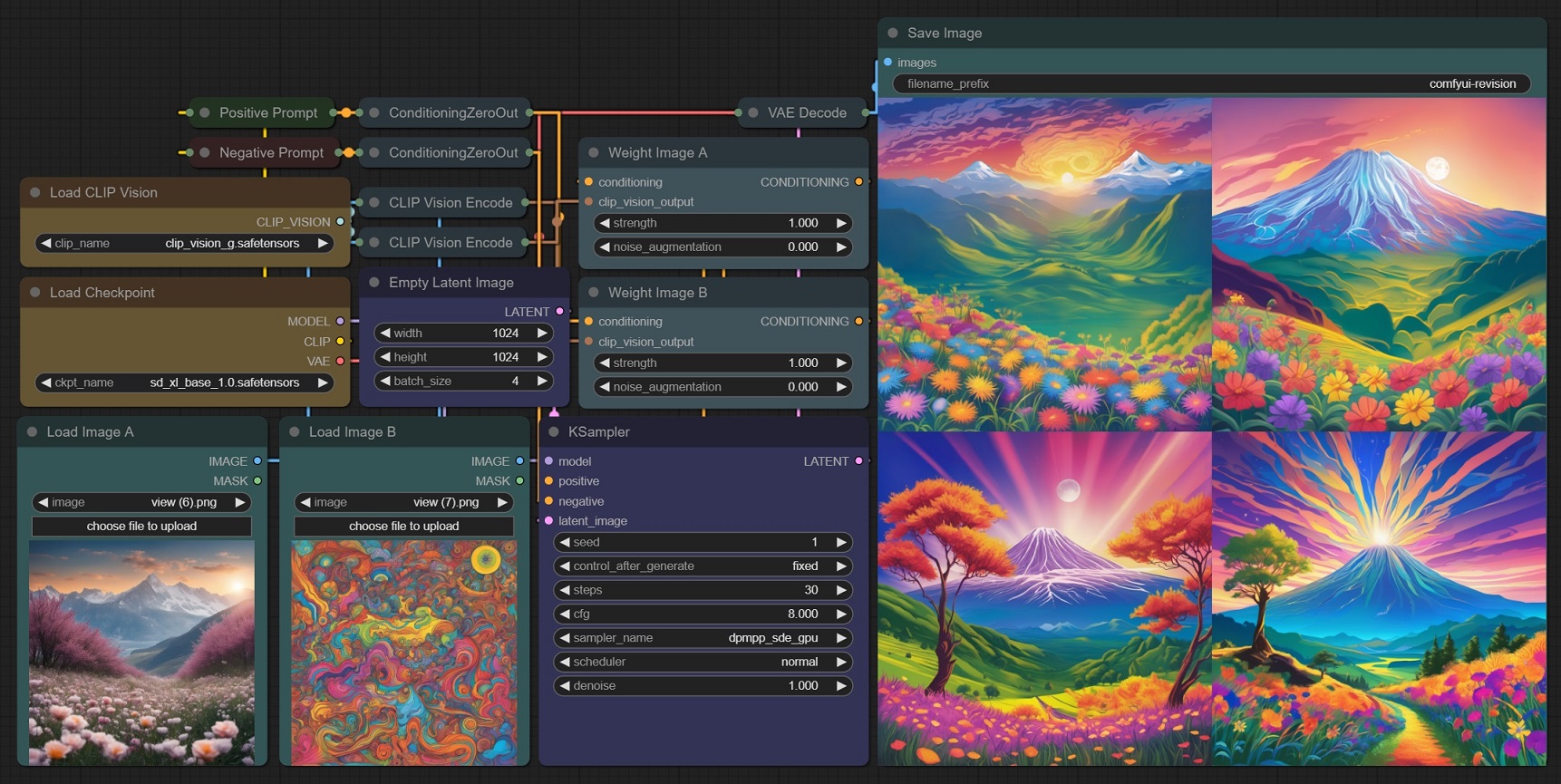
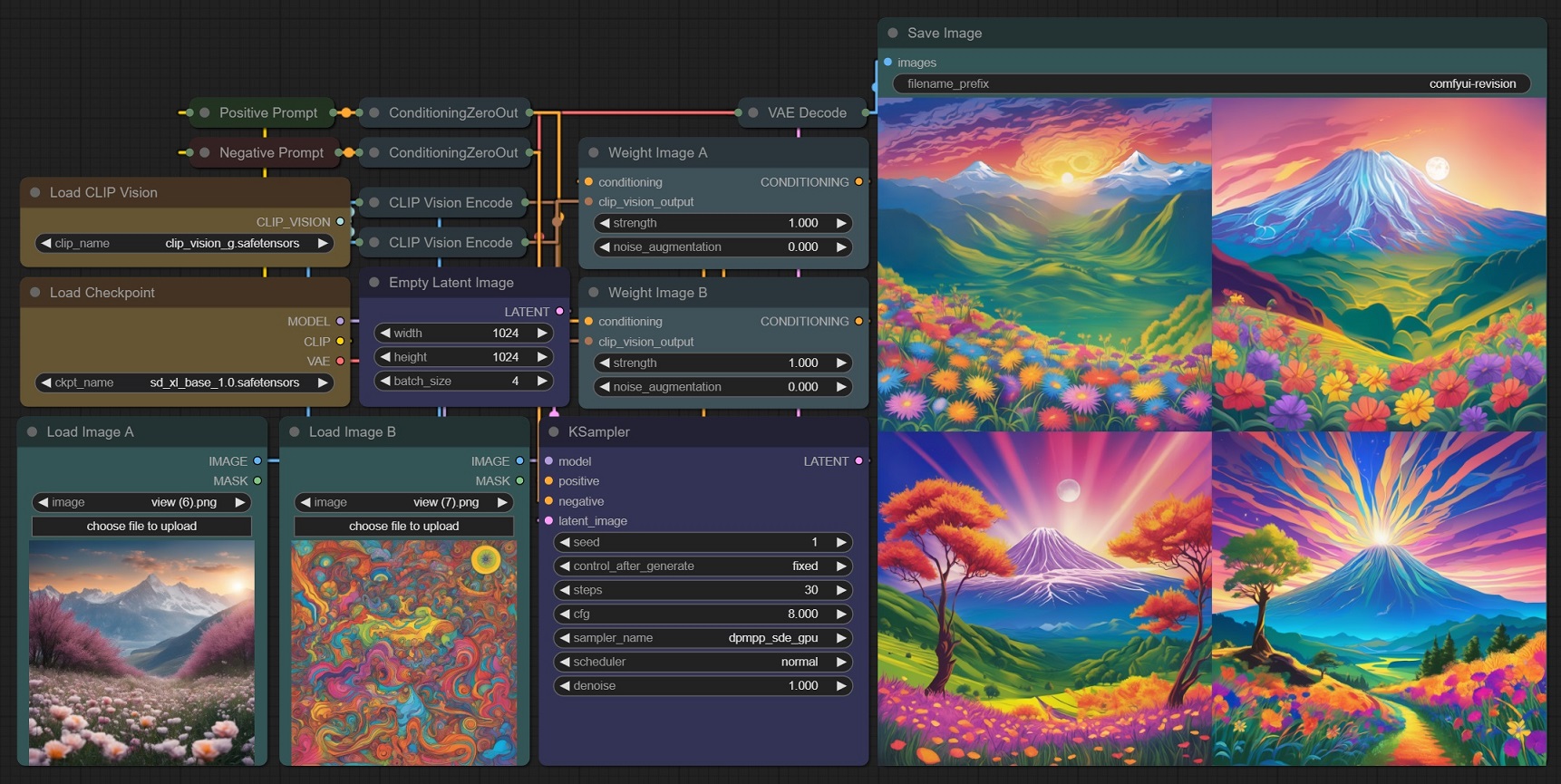
Overview of the data flow in my workflow
Orange is Text
Yellow is COnditioned
Blue Are Switches to siwtch between Normal, NormAl + COntrolNet, Normal + ControlNet+Revision or Normal +ReVision depending on where they are thrownsiwtch

https://civitai.com/models/31126/imagesgrid-comfy-plugin-xy-plot i used this once. worked ok

ImagesGrid (X/Y Plot): Comfy plugin A simple ComfyUI plugin for images grid (X/Y Plot) Preview Integration with efficiency Simple grid of images XY...
Damn nicely done, you always have great workflows
Cheeers, theres other stuff in there as well to do with textfile generation but thats a simplified view
I saw that one, but i didnt quiiiite see how to integrate it with Searge
Scrolls out firther and turns lines back on lol

nah, it looks like clip_vision isn't the way to fuse images- even with 2 identical images and CLIPZEROOUT the final image had nothing to do with the first 2
Why do all these mega workflows have options to load a separate vae? There aren't any available on civit and it seems like it's always just best to use what's in the checkpoint
used to use the straight lines but i've gone back to splines because i canmore easily tell where lines are coming and going. the straight ones all blend together. makes it really hard to follow with an eye
It doesn't really fuse the images, it's supposed to take the concept of them. I don't really understand how it works, but it can get interesting results. But I don't think it can "fuse" images.
what about revision?
Clip_Vision and Revision are the same thing
remind me, how many different Seeds can SDXL potentially use?
2.1 trillion (my educated guess, that number is the max on most computing stuff)

and trust me, tested multiple times
and you're basing your statement on a sample siize of? 'o)
It's the size a FP32 variable can hold
Anyways from my sample ssize of 1 where I have 2 identical images it does appear to have generated an image related to them with Zeroed out Prompts

my question was rhetorical
/shrug
For some reason people seem to be expecting that they can put 2 images in and it's going to sort of merge them together. Not that it's going to use that concept.
did over 20 tests, none had anything to do with image.. if it will after the ENTIRE 2.1 trillion it will make a few good images I don't give a shit- I'm not going to wait for an infinite amount of time -_-
less about the seed and more about initial noise. so possible combinations of all pixels as a starting point equals xres*yres*8*8*8 possibilities. 2^24 * the pixel count essentially.
seed just is used to generate initial noise
Seems to work fine for me



I'm wrong anyways a 32 bit is 2 billion, a 64 bit is... a lot more than that 😆
if people want t merge / blend inages theres a node for that 🙂

that overlays them without even using AI. it can be a base for redirecting to sampling though
17,592,186,000,000 at 1024x1024
yes and I never said it was AI influenced did I ? @eternal fog merely pointed out (correctly) that some people ar ecionfused about even at a basic level ReVision works.
bottom line its a shit load
when i looked at joe's revision post it showed a lot of multiple images being used
but these 20 tries shows it can't do it i guess
joe must've done it wrong
what does "ecionfused" mean?
he doesn't understand it doesn't work
TBH I dont really care how it works, all I know is based on my BatGirl images its prodicing sme rather nice images that I can see are tied to the prompt * source images
my internal typo recognition figured it out. maybe you're just ecionfused
it means I have sausage fingers and the girls love me ;o)
I cant write the word I want to write as its banned so I'll settle for the one that sounds like a snack bar instead.
snicker
big ol dongus fingers
and yet I can happily wirt Scunthorpe
wirt
oh damn, didn't notice I guess I am ecionfused, and maybe even and maybe even ar
which for those that dont know is a seaside town in the North East of England

Revision does do odd things sometimes though. And the weights seem to matter a lot.
Like? lol. Not sure how these concepts exactly merge.
I guess maybe, dirt on the ground, soldier(armor/space), but not sure where the tiger comes in


note some people would argue that as its South of the Humber its isnt the North East
No one cares about Scunthorpe anyway
I think the better approach is to interrogate an X amount of images and then fuse the tokens- seems more reliable
well this is true, it is a dump
This isn't using tokens from what Dustin said yesterday.
As someone was asking how to get the tokens out that it uses.
It does something on a conceptual level, rather than just generating tokens from the provided image.
I guess I'm also curious, what is everyone's favorite SDXL workflow with comfyui? I've tried Searge and Sytan
yeah, but for consecutive image fusing the best way is likely interrogate->token merge->conditioning->sampler
just one piece is missing for that
No idea, once you start getting into the details and all the maths that goes on for generating the images my understanding stops.
well ask a silly question, of coutse I'm going to say my own (which starte dlife as being based on @high skiff s and then "eveolved a little lol

me
nice lighting
What's it called? And can I integrate an xy plot with it?
same question, i didnt quite see how to do an xy plot w/ yours

for ref, i'm just trying to have a side by side of several loras i've trained
I am not sure I am in the right headspace to help right now, I am really anxious right now. My mother and I are just 3 miles away from the direct path of Huricane Hillary right now
I dont actively publish it cos I get irrated by inane questions espeically when people ask where do I get such and such a node from even though Ive included a credit & notes file with all the information in.
I do howvwever leave it in all images I post here (that have been generated in Comfy)

ooof, no worries at all. we're in LA, so not as bad. stay safe
we live 120 miles away from the ocean, at a mile in elevation in a desert, and we are on expected emergency evacuation watch right now
tie to batten down the hatches
we live in the high desert, but we are only 3 miles from the projected center of its path

we are all hunkered down right now, hoping that our elevation and our mountain bowl shields us, but the local mountain communities were just emergency evacuated
This is the first time in the history of California this has happened
@high skiff just as a point of reference the furthest any point inthe UK is away from the sea is 84 miles (or it might be 70 depending on the source)
Hurricane Hilary is expected to reach all the way past Las Vegas, its insane
We also don't really get hurricaines
neither does socal.... but here we are
Its not that socal "doesn't really get hurricanes", its that we never have
idk what y'all use, the workflow I made does stuff like this in ~14 seconds on average

only thing we have ever had was a tropical storm in 1931
tell Michael Fish in 19827that lol

yeah, its wild times
Hilary just got downgraded to Cat 3, so I hope so much for San diego that it keeps going down, cause if not, there are going to be unprecedented casualties
Before I was born, doesn't exist clearly.
Point of interest , whats the difference berween a Typhoon & a Hurricane?

I would have been 23
why was he a fish
probably about the same age (or older) than many of yo u here are now 🙂
because his dad was a Fish, and his Dads dad before that
You are older than my Parents. And I'm not "young" lol I'm 32.
also, @high skiff, @strong field successfully compiled 3090 AIT modules on windows, they can probably give you the module
hey I have 2 grand kids and 3rd on the way
OH?
Yippie!
thats dope! I would really appreciate it
now all we need is an AIT module forth e1080ti and oither cards that would benefit form a little boost more than a 23090 does :p
I am trying to distract from the huricane fear ATM
Not at comps but I’m definitely send when I can
not sure non tensor cards will benefit
isn't AIT based off Tensor RT?
it was mostly tongue in cheek 🙂
you wish, TensorRT is SO unfriendly and less beneficial for performance
I thought AIT was just a better optimized and made version of Tensor RT
plus, TRT modules can't move from CPU RAM to VRAM and back while AIT modules can
plus bigger boost
so theoretically it may be possible at some point to compile it for older cards such as the 1080ti ?
@high skiff Hurricane Hilary has weakened to a Category 2 storm, so that's good news
much love <3
https://huggingface.co/stabilityai/control-lora/resolve/main/samples/revision-sample.jpeg maybe the documentation is wrong
just 40 minutes ago it was demoted to 3, not 2
Clip(Re)Vision AIT when? 
It was 4 yesterday
10 min ago it was down to 2 according to cnn

CNN
Hurricane Hilary, a Category 3 storm, is expected to bring "catastrophic and life-threatening flooding" to Mexico and parts of the southwestern United States. Follow here for live news updates.
maybe someone will do it in the future (soon)
i thought with storms, cat 4 was highest
it is
there was a little rascal who was cat 5
serioulsy it would be good if older cards could be given a boost
oh we've got into cat 5 storms now. nice
also AIT is universal and doesn't need some stupid conversion like ONNX for TRT, you don't have to rebuild the code if converting different architectures. AIT learns the specified model's architecture and makes a ~100mb MSVC module, making it not checkpoint specific
Yeah, I get that its much better, but I swear I was told it was the same base idea implemented in a much better way
nah, it's just inspired by TRT- but executed better and relies on much more universal languages
@high skiff if you want I can guide you how to compile yourself in DM. it's somewhat simple after figuring it out
I am too scatter brained for that at the moment, but thank you
the thing with the pacific coast is it has a lot shorter of a shore till the continent's edge. Deep ocean is really near land. Atlantic has huuuge shores. the sudden cutoff near the pacific coast really changes weather patterns. systems make landfall like it's a 45 degree incline suddenly.
its the main reason we don't get a lot of massive storms hitting the west coast and systems are a lot more localized
you can do it right now infact, but doubtful it will profile any better than without optimization, but you can try it
AIT is very new tech, so it's just common sense it performs best in newer cards such as 3000 series and 4000 series
but if TRT does anything for a 1080ti, I'm confident AIT will do better when compiling on your own
heh, I like SDXL's waterguns

is water wet?

there is no wet without water
yeah, that's true. but the definition of wet is "x with water on it"
does water have water on it?
very philosophical question

I may have to look into that then
why is my revision not working properly can anyone help??
whats it doing?
i give the 2 images and the generated image isnt related at all
use my workflow
the workflow comfy has doesnt really explain how to us it well. this workflow solves the issue.
Issou
ill try yours this is mine, using stabilities workflow weird output



you are using zerouts so it should work. i mean try mine if you want. clipvision is interesting some concepts dont blend well. its not really going to add the 2 together but it takes elements from both and creates a brand new image out of it.
yeah it can do odd things sometimes
Depends
also, am I the only one that gets weird fruit drawing tile when doing no prompt on SDXL?
I do wonder though when you have a zeroed out conditioning, why there are differences between 0.5 on both and 1.0 on both, what is that strength used against
its a multiplier of sorts as comfy mentioned.
that isn't safe

SD cannot use http links as reference in a prompt. ?
sd doesnt use the internet

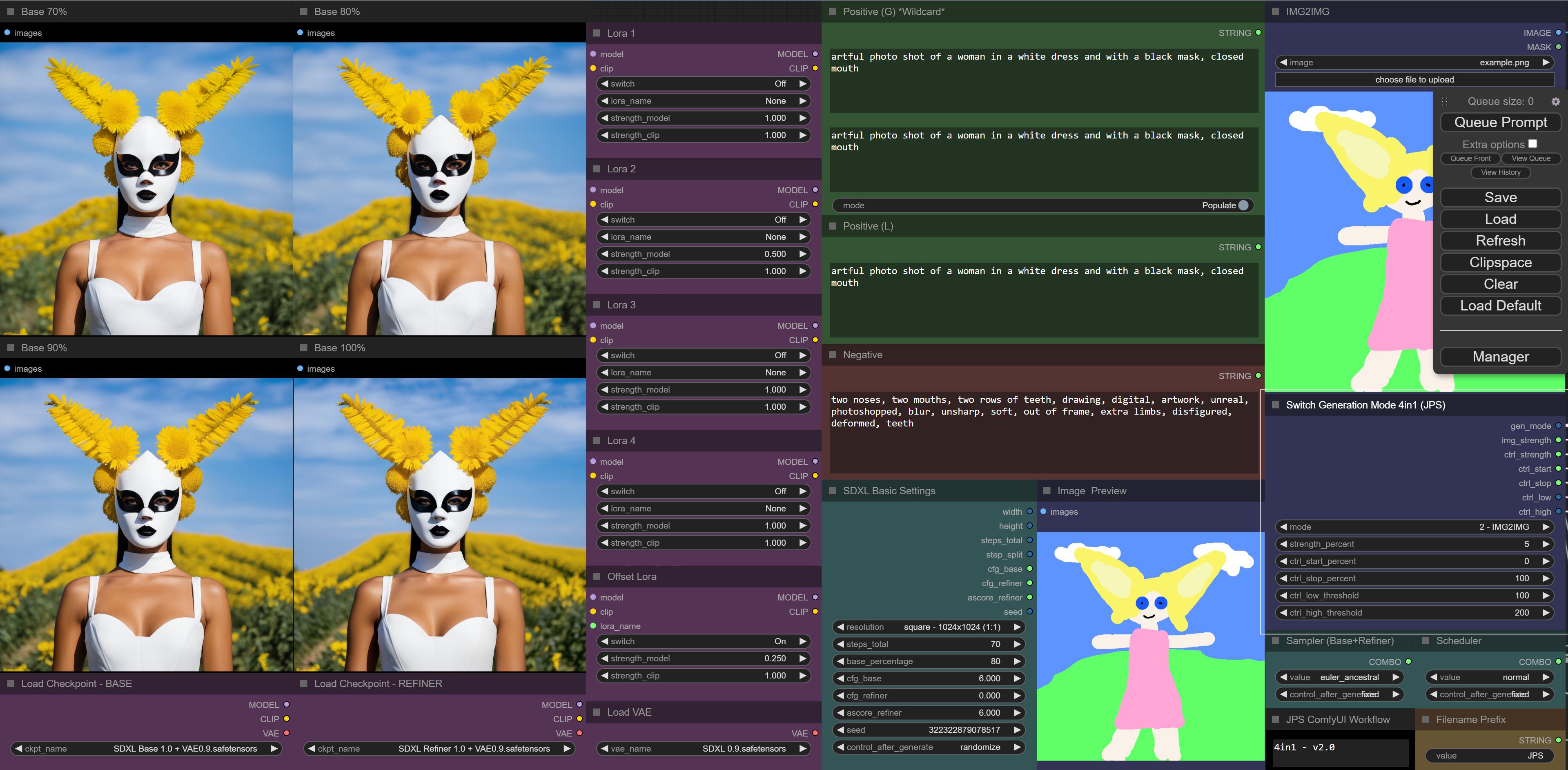
who wants to test my 4in1 workflow (txt2img, img2img, controlnet-candy, controlnet-depth)?
https://i.imgur.com/D9Yz1DS.jpg
{kind=link}
{kind=link}
hand🖐️
wow