#✨|sdxl
1 messages · Page 87 of 1
screenshot what the nodes look like
haha, that's gonna be fun.
Hey guys!

nice, does it work well for stylized animation / low poly characters?
what's up
They connect to the base just fine, if I mute the precon ksampler (using the refiner model), and change the steps to 0 for base, it works just fine. If anything hits the refiner from controlnet, I get the mat1 and mat2 error
Nothing much how about you?
just runnin some generations
I've been playing with it for a while. It seems to work well.
Though I haven't done a proper blind test.
It cannot. I do not believe it was trained specifically for in-painting.
what is inputted into the controlnet conditioning there?

Tried several iterations and they all just give the same mat1 and mat2 error.
In the screenshot it's the base SDXL text encode conditions, which I expect would not work.
So tried duplicating the apply controlnet node and using the refiner text encode conditional outputs, but also the same mat1 and mat2 error
lol i know, this one isn't tidied up yet, was waiting for COntrolnet to get these nodes introduced, then pretty it up 😆

I'm trying to find an ai art maker that I can download to make some nsfw art. If I can I'll send the UI, if anyone could help me that would be great
hahaha, not where it came from, someone designed it for me based off my prior image I had

In the screenshot it's the base SDXL text encode conditions, which I expect would not work.
this was my suspicion and what you followed it up with was my suggested fix but im unsure why it would also throw up those errors
Makes sense. I can't stand the simple looking shit they have.

oh wait
i dont think you would even need to apply controlnet to the refiner
I guess I'm just curious if someone even has controlnet working on a refiner.
I'm mostly just testing. The results I got using the preconditioner method, then controlnet base, was pretty shotty.
but mitigating the preconditioner and just starting with the controlnet base, worked well. Just wanted to see how it would work if I had controlnet precon
ya the refiner by itself doesnt change the image much except adding details so i think controlnet isnt necessary even if it worked flawlessly together
Yeah it's the first ksampler, before base. So it wouldn't be doing much, but keeping it applied gave bad results
because the precon is kinda like laying the foundation, but then the base has to fight against that
as such

thats strange, the effects shouldnt be fighting eachother that much. imo the precon's effect on the workflow is essentially equivalent to just another controlnet with guidance start 0.0 and ending at 0.03. in my experience that's always work flawlessly with other controlnets
Yeah, I've got more tinkering to try out, just d/l controlnet today, so this is my playing with it inbetween stuff loading during my actual work lol
May end up scrapping the preconditioner method if I plan to use Controlnet, because the disconnect between the two doesn't seem to play nice for that style of image generating
precon refiner left, base pass right with controlnet. Can see what the refiner was laying the foundation for, prominant figure to the left of the frame, but the controlnet then took over and made it where the controlnet should be applying the prominant figure.
If I could get CNet on the precon (left)refiner though, could work. But I don't think it works with the refiner at this point

ya the precon method sounds to me like just a workaround of not having controlnet to do guidance start/ends in the early stages of gens. controlnet is much better at doing exactly that, especially since you can slide the strength of the controlnet around and also with the many different controlnets that you can (eventually) use
Yup that would make sense. I'll see what comes of it all, probably will just get some sort of logic setup in my nodes which would make the switch off of the precon easy. Will take some fiddling
Because that does make some pretty images

isn't there a command switch to keep models in memory so the load times aren't so long between workflows?









which model?
He’s referring to AIT and @indigo carbon workflows
oh




Business cat thinks about the choices he's made that resulted him being where he is at this moment. Suddenly, the decision not to become an ordinary house cat weighs heavily on him.



does anyone train SDXL with a 3090? im trying to figure out if my speeds are normal or kind of slow and im doing something wrong?
One-shot generation for the Hulk. Nailed it.

nice. that's clean


That lighting is mighty fine






I like this one specifically
It wrote out "Draconic Knight"
Or tried to at least






Hi, I just installed SDXL, I thought I could get very nice results like you but I get very ugly results.
I wrote "disney style panda zombie hyperrealistic" and I got this:
I am sorry for my creation but I think it is ugly.
What did I do wrong?







What resolution is that?
I am sorry for my creation but I think it is ugly.
😂 😂 😂
yep 512 res is too small


there a way to keep models in memory with comfyui? a1111 seems to switch much quicker
some models/loras should never be combined...lol


Hey guys, I'm happy to announce the release of NightVision XL Alpha 0.5.2.0 on CivitAI!
NightVision XL is a lightly trained base SDXL model, refined with community LORAs. It produces touched-up photorealistic portraits, ready-stylized for social media. With nice coherency, it avoids weird body issues and biases, offering rich deep blacks and great evening/night time scenes. Capable of both SFW and NSFW output, NightVision XL prefers simple prompts, letting the model do the heavy lifting for scene building. Easy to use and versatile, it's your new go-to tool for creativity. Check out the Civit page for a full gallery of demo images and styles, including NSFW output. I would love and appreciate you all if you could shower it with your art, fill the gallery with your wonderful creations and give me all the feedback you can, both the good and the bad! It ain't perfect (yet) but I think it's the best photography model you're going to find out there right now!







***HELP ME WIN THE CIVITAI MODEL CREATOR CONTEST - SHARE YOUR ART IN THE GALLERY BELOW AND LIKE RATE AND FOLLOW ME FOR MORE SDXL GOODNESS - THANKS!...
Looks great SCG. Thank you for making these
I suck at art, but I'm good with making tools. it's kinda like my art I guess 🙂

oh its definitely an art form to craft a model
borrowing a prompt from the DynaVision gallery - this is NightVisionXL 0.5.2

this is from the DynaVision listing, just to compare


any suggestions for sdxl models that would facilitate me putting together beautiful images like this?




Looks like my neighbor and her kid
demon would be scared away from that
honestly haven't had much luck with the old vintage photo look with sdxl. I'm sure it's possible. wish I could find a lora that did the trick
Been waiting for a SDXL model capable of photo realism, can’t wait to test this out, thanks for the hard work.
indeed. I do appreciate all the work put into them
need to start inbreeding some myself
Have you tried the SDXL prompt styler?
yeah. maybe I need to work on emphasizing it more or something
it definitely changes the image, not denying that. but haven't got that same old analog photo feel

Hi Guys I really need a comfy workflow for achieve similar results in fooocus. I have been investigating different workflows for weeks, but none of it can beat fooocus. But fooocus cannot do img2img so we really need it
Some workflows can achieve similar results to fooocus, but those workflows sometime output garbage and I need to pick a lot to get good ones. But fooocus always give super good results. A equivalent workflow can help a lot.
well just figure out how to do this in comfy https://github.com/lllyasviel/Fooocus#list-of-hidden-tricks

GitHub
Focus on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub.

reading the git, it looks like he has combined the base and refiner into one ksampler process
Yeah it's just a simplified method after reading it.
It works, but not utilizing the separate clip function to the full extent also reduces the available latent space you can migrate in.
Can someone just translate that to english that I can understand
why don't you?
TLDR:
It will make pretty images for someone who doesn't care to really get super specific with their image generations.
Ooh, gotta learn that, one sec
I demand service, cater to my whims
the plug and play pretuned services are great and all, but it almost feels like a driverless car to me
are the control net models working on auto1111? or only in comfyUI?
I realize not everyone is going to be into putting it all together themselves, and that's all good. no hate on that


that foocus thing is basically just using a regular workflow with dpmpp_2m_sde + karras
I still haven't worked out exactly how those impact things
so theres no real secret sauce?
the secret sauce doesn't really change anything in practice
I still like euler a myself. might not be the best for high quality images though
heun is great if you want it to take twice as long for a boring image
Comfy, is there a hidden debug log feature i can turn on? still getting random system locks after a few dozen renders on 2 ubuntu systems with a 3080 and a 4090 and 32g ram each
basically he does 30 steps total, 20 steps base, 10 steps refiner
that's a refiner heavy approach
not sure how people pull that off. it's never worked for me
i thought he uses only 1 ksampler and thats whats different about it, does he not actually?
steps=30, cfg=7.0, sampler_name='dpmpp_2m_sde_gpu', scheduler='karras', denoise=1.0
that doesn't actually change quality in practice
yeah i didnt think it would
I mean, if you're running them in succession I don't see how it'd be different
it's more mathematically "correct" and would be better at very low steps like 4 but at 30 total steps you won't see a difference
though it might even be worse in practice because it's a different model so
masslevel, I made that node moderately useful, lol

it actually gives me all the aspect ratio/ resolutions that the stability website recommends
yes I've seen and I've already dowlnoaded it 😄
but then I can do 40 to 1 AR
did you read my quote from AI enthusiast Mahatma Ghandi?
I don't know, it was good practice. learned a few things.
yeah I have (now) 😄
my opinion on fooocus is that the sytan workflow is better
I just want to know what it would take to implement something like this in comfy https://github.com/mcmonkeyprojects/sd-dynamic-thresholding

GitHub
Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI - GitHub - mcmonkeyprojects/sd-dynamic-thresholding: Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI
Native refiner swap inside one single k-sampler. The advantage is that now the refiner model can reuse the base model's momentum (or ODE's history parameters) collected from k-sampling to achieve more coherent sampling. In Automatic1111's high-res fix and ComfyUI's node system, the base model and refiner use two independent k-samplers, which means the momentum is largely wasted, and the sampling continuity is broken.
does this have any merit to it in terms of optimization @visual glade?
me when comfy praises my workflow

Hey, comfy. It's this time of the month for me to say thank you again for all your work.
I cannot understand why, but for some reason I can't load your workflow files. it doesn't make sense to me. I can load pretty much every other one I've tried out. it kind of bums me out
Same
I am not sure why, I worked hard with the restrictions of just stock nodes for like a month in order to ensure reliable compatibility
it's been a game changer for me. I feel like I know a little less, or a lot less, than a good portion of people here, but I'm learning pretty quickly

GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
sytan, it's not that it's missing nodes. it just doesn't load. I don't get it at all
maybe I'll implement it because it's technically more correct but don't expect it to change quality at all
I guess I could manually recreate it, lol
does it load if you copy paste the contents of the json?
right, i just know comfy is literally as optimized as can be compared to a1 so it was surprising to see someone come up with another workflow thats even more optimized
might be a worthwhile endeavor tbh. I create some wacky workflows, but wouldn't necessarily call them top notch
ok, ok, ok
I am about to drop my boiling hot take on SDXL after some further testing
and expect this to be in the 1.1 release of my workflow
you know, I really should have tried that, lol. ugh
I see 0 point to use the refiner anymore, and I think its hinders more than it helps in 95% of cases
thanks

and you need to scroll up a bit or you might not see his workflow
all of my excellent realism images are from just base
oh yeah we want to get rid of the refiner eventually
let me try sytan a bit, i think i already have it
refiner is overfit, and introduces weird blurry artifacts that get exacerbated through high res fix sometimes
only 1.1? searge is up to like 3.0 or so now, gotta catch up
I can't decide if I like it or not. and I have no idea what to put in the refiner prompt
does his have high res fix?
kinda funny to see how often he updated his workflow tbh
and I don't think anyone does know
i have no idea, i just saw him constantly update it since i saw the 1.0 release
I know nothing about him or what he does
wow, I had no idea I could copy the actual text from the json and paste it into comfy like that. sytan workflow achieved

missing the downscale and contrast fix nodes. I could most likely substitute for those. is there an efficient method of determining where to get missing nodes?
they are all stock, I am not sure why it doesn't work
when was the last time you updated comfy?
or wait, did you just make them red like that?
I updated it a couple days ago, but I do have a few errors when I load
sounds like your install is incomplete
I lower the denoise everyday
I am at the point where my daily driver for SDXL is refinerless
I really see no reason for it, it messes things up more than it fixes it
and with my newer better realism prompting, as well as my realism LoRA, its completely obsolete for any form of realism gens
The only time I've liked the refiner output was when I was intentionally going for a very detailed and busy background. But it's such a small change I don't really need to use it.
I guess it's debugging time
de-erroring
well isn't that nice
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_v.weight shape '[640, 640]' is invalid for input of size 1638400
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.attn1.to_out.0.weight shape '[640, 640]' is invalid for input of size 1638400
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.0.proj.weight shape '[5120, 640]' is invalid for input of size 13107200
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.ff.net.2.weight shape '[640, 2560]' is invalid for input of size 6553600
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_q.weight shape '[640, 640]' is invalid for input of size 1638400
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_k.weight shape '[640, 2048]' is invalid for input of size 983040
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_v.weight shape '[640, 2048]' is invalid for input of size 983040
ERROR diffusion_model.output_blocks.4.1.transformer_blocks.0.attn2.to_out.0.weight shape '[640, 640]' is invalid for input of size 1638400
my friend is making a massive realism dataset for a finetune of SDXL, and he is gonna be sharing some images forwith me, so I will be contuning my realism Lora with much more data soon
my current tests with just 90 images are already damn promising, which is so good to see
your weight shape is invalid for the input size
what is the Lora?
its a LoRA for realism. Its not out anywhere, I am still early in dev
unlike a lot of people who rush out incomplete LoRA's, I spend a ridiculous amount of time trying to get the small things right lol
I see
I need to get a several times bigger dataset
and I need to optimize some settings as well

the dataset has to be very large for realism?
anyone got an open pose workflow for ComfyUI? These nodes are driving me crazy
Also, is there an open pose editor for it?
I still cannot get as good results as fooocus. My prompts are: Warriors fight monsters in front of a castle in the wilderness. Cinematic and chilling
Negative is: anime, cartoon
I am using sytan. This is the best on after 10 attempts

I’ve been struggling with this too, I didn’t have the wherewithal to remove refiner cause I thought I was just using it wrong. But it’s been lower steps, lower denoise every day for me. Glad I’m getting some confirmation
not very large, but several hundred images us the ideal, yeah
This is fooocus two random results in one click

hooray high quality taesd sampler previews are back when using AIT
src: https://github.com/FizzleDorf/AIT/issues/25
Caith does LORA's on like 3k+ images


my current realism LoRA is just 90 images, and it already works so damn good
wayy more detailed
I know the guy who makes the crystal clear realistic models uses 300 or so
of course, he also suckers people into helping him, claiming he has a commission and they will get paid, and then when the model is done...nada
base SDXL vs with my realism LoRA
Identical everything, just without vs with the LoRA


I really want to train a lora on some images I'm gathering but still haven't worked out my approach
the realism lora is on the right?
without vs with


yes
odd eyes
its a small dataset lol
need more vintage loras. old pictures, old maps, etc. but I guess that's not what most people are into so might have to make my own
That one is good
how can I use open pose in comfyUI


cant compare because one is black and white
without vs with


I asked for black and white specifically, so I hope that gives some idea haha
On the right is Tommy Lee Jones
also, this is not to say that SDXL base can;t do incredible realism, cause it can
but the point of this LORA is there is no need for realism cramming prompts
like, you can see here
I see
some people put out the unfinished in order to get feedback
get lots of people making images with them
someone needs to create a better refiner. that's the solution. or better yet, two refiners that work in tandem
the prompt is "a tiger"
No negative
without vs with my LORA


each with their own prompt
as you can see, my LoRA does definitely push realism haha
very much so
too much pattern in the background of with
its accurate to what real jungle portraits look like, so I am happy with that
tho, my LORA does support simple background tags
the leaves are in a circle pattern...of different trees
you don't like patterns, bro?
what? You mean bokeh?
no, looks like they make a circle
and tiger's right ear is messed up
like it's a botched perspective
I am not sure what you mean about the circle
yeah, the animals are a part I need to improve for sure
I only had 10 images of animals in my dataset
just to see if it could apply what it learned from other portraits, which it could
I know tigers very well...their ears are not flat like that usually...certainly generally not different like that
it has its ears back in aggression tho
real images of aggressive tigers



granted, the ear placement is a little high, iw ill say
it looks like it's trying to be back, but not placed back, just the shape
Wait, those 3 are real images?
yes

alright, having pip scan all the requirements.txt folders.
Wow. I would have said they all look like AI. It's getting so hard to tell.
it's attempting to install about 5 million things
looks like some node types were not found
I trashed the venv folder and started anew a few days ago
and there it went again, 4th lockup today mid render, 2 diff machines 2 diff gpus, everything git pulled and updated
but might have to just start over completely. I don't know

lock up as in won't ever go, or pauses for a while?
how much ram do you have?
hard lock, gotta hold power button to kill it
is open pose working? I can't get it work
32g in both systems
ah...sometimes comfy eats up resources and won't give it back. Now and then I get a lock, and I have to restart
32g 3080 10gb / and 32g 4090 24gb
how old is your ubuntu?
I downloaded the workflow from the open pose hugging face page.
22.04 fully patched
it could be system ram or vram
doesnt matter if i'm using sytan, searge, my own, just mid render for whatever reason
someimes my system locks after only a few generations. Sometimes it goes for a long time with no lock
last time I did this when I loaded comfy Ievery node was red, lolol
usually the first sign is my browser slows to a crawl.
it's always some aiohttp nonsense
Once you get it working, make a backup without the models
can't find anything in /var/logs
then if something goes wrong, at least you have a cl;ean starting point
somebody, somebody, somebady, can anybody find meeeeee. some open pose preprocessor to looveee
what does this mean?

is open pose working or not?
when you mix a goat lora with a truck lora

a1111 is running on the 3rd system with a 3070 8gb without sdxl and has been going for several weeks without a crash
watch out, one of these "I have dozens of systems all with better GPU's than most people have on one system" guys
does sdxl care what version of nvidia drivers it uses?
I care
try installing pytorch nightly
using 525 on all 3
does it change nightly?
yeah there's a new pytorch nightly build every day
wow
what are you prompting? I've never seen base XL make that fake of an image unless i put painting in the prompt or something
fake image
completely bare bones prompts
A pretty woman standing in a forest wearing a black dress
stuff like that
@visual glade what is this?

When I click on install custom node, or anything it appears that
comparing that simple prompt on SDXL vs with the LORA
and I can't load a open pose workflow
just wait for the manager to update
that's the manager I believe?
sudo apt install -c pytorch pytorch-nightly this look right?
no need to add all the flares of
"A stunning realistic analog photograph by national geoghraphic of a gorgeous young woman in her 20's with a beautiful face standing in a detailed and intricate forest while wearing a stunning designer dress at twilight, textured skin, photorealism, blah blah blah blaahhhhhhh"
my manager never updates. it says it needs to update. but it just teases me and never actually does it
I've accepted it
Yes, whatever I clickl on the manager that happens
it might be prudent to just start this install over. but hassle\
but still not working
god damn scipy taking 10 inutes to install
ah, always forget they got that nice install table, thanks
release when?
youre not satisfied with it?
no, it needs a lot more data
in the meantime, release what you have to get lots of people using it
I am at about 90 images, I want at minimum 400 images
And since I tag them by hand
ugh
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
NativeCommandExitException: Program "pip.exe" ended with non-zero exit code: 1.
do you say DAY ta or DAH ta?
game over
yeah civit has an update system so you can release updates as you make em
I interchange them
i SEE
i had that. i had to get rid of nightly
I have no plans to release it until its done and ready. I don't do incomplete releases
that's called testing, not incomplete
cause shit is gonna change a lot, and you have to hold this LoRA's hand
it's still running through other things so I'll see what happens. if and when I nuke the install I'm going to be much more mindful about install nodes
reguardless, I don't want my name on this in the public eye. I have a decent reputation for quality, and I would like to keep it that way 😅
too many dependencies
keep backups when it works
trainwreck,lol
where can i see your stuff?
okay I manually updated manager, but still the openPose preprocessor node doesn't load.

when you see people's stuff online, it's called "stuffs"
I don't have much released as of now. I make most things for myself, but my SDXL workflow is my most used/known thing
on a sidenote, the new 4090 24 renders a 1024x1024 with x4 upscale on a @indigo carbon AIT workflow in less than 15 seconds, jaw dropped
speaking of reputation, i gave up at least on civit. back when i was dreamboothing styles I had insanely good feedback but the moment Loras came out, i got a bunch of bad reviews and ratings because "you didnt make a lora version" 🙄
dont worry about ratings
manually clone this into your custom nodes folder
https://github.com/Fannovel16/comfy_controlnet_preprocessors

GitHub
Contribute to Fannovel16/comfy_controlnet_preprocessors development by creating an account on GitHub.
I don't, and was quickly hired so i stopped releasing anyways. Still it was fun chasing the #1 spot
python3 main.py --listen --port 37860 anything else i should add to startup command?
quickly hired?
--preview-method auto if you want previews on the samplers, --auto-launch if you want your browser to automatically opened when ComfyUI has been started
thanks. I deleted the installed folder and installed that. I don't have a red message now but still the preprocessor doesn't load. :S
very nice to see my LoRA is introducing easier support for non standard paired features, like a darker skinned person with blonde hair and freckles

that's a rather unconventional look
also, my attempt at training in dappled lighting is also seeming tow ork
I need to get more images of it tho for the dataset
Yeah, AIT is actually insane
the whole goal is to be able to make random mixes of characteristics, cause everybody is unique and diverse
Most people I was dreamboothing with back before civit existed got hired very quickly for their training skills. Nitrosocke got hired to SAI after making the Elden ring, Modern disney, classic disney, etc. models.
I did some freelance stuff after my Tron, JWST, Cats, and Van Gogh models, but now been developing an app for 6 ish months
I see
I think it's great. keep up the good work, man. do you have a lora tutorial anywhere, or would you be able to suggest one? I know how to use the tools, but not really how to optimize anything
I am honestly winging it, and my settings are far from good 😅
@boreal bough is a plethora of knowledge tho
he helps me in my manic training sessions lol
I mainly finetuned entire models using dreambooth quite a while back
then extracted loras from those models
for controlnet?
for me? yeah
The only downside or rather, unpeculiar property of AIT is that it doesn't decrease VRAM usage as much. If AIT would decrease VRAM usage on the same scale it increases performance, I am confident we would be seeing people running stuff like LLaMa 2 70b on normal 4000 GPUs
I can run llama 2 70B on my 3090, it just takes a bit
I did falcon 75B at 3 bit IIRC, and it used 38GB memory, but I was still getting like 1.7t/s, which is not much slower than ooba was in its early days for just normal models lmao
@high skiff flow on 4090 vs 3080, only 1 sec faster


thats peculiar, that makes... no sense
If by a bit you mean 0.08t/s then sure.
unless you have a very fast 3080 and a very slow 4090
no, likely about 1.5-2t/s
3080 (not a TI 10gb), 4090 24gb
which is still usable
Sure, its slower than the like 50t/s I get with wizcuna 13b, but still
probably CPU bottleneck on the 4090
that definately could be, 4090 in an older machine (card is facking huge and wouldn't fit in the newer case)
I tried this stupid model today on my 4070ti, it loaded the model, pretty fast I might add, but it didn't respond. I left it running for a few minutes and it only wrote 2 words.. pathetic, pathetic "efficient" model
my 3080 I have is bigger than a lot of 4090s
its the most overbuilt card I have ever seen lol
thats also a huge issue with the 4070ti and its pathetic VRAM bus unfortunately
fast GDDR6X chips with an anemic 192 bit buss straight off a 2012 midrange card
I'm so angry, I can make high quality SDXL images in about 15-ish seconds, and I can't make a few words?!?! This is so stupid
take it up with NVIDIA. They are the ones that decided that they would push back the VRAM bus on their cards by nearly a decade cause they felt like it
its not even like they saved really any money doing it
which model?
looks like @delicate kelp is cranking out some bangers🔥
do you deepspeed?
No, should I? Is this the AIT of LLMs? Heard that name before
hell, the GTX 460 from 2010 has the same bus as the 4070ti
Its pathetic
it sped things up substantially for me
testing the next update 😉



Huh, I'll try that out. Also EXllaMa, right?
my favorite bit of info is that the GT 8800 from 2007 has a bigger bus than the 4070ti, and it only has 512MB of VRAM lmao
Man Nvidia really ripped me off with this one, didn't they?
hmm, I haven't tried that one. I used it with oobabooga https://github.com/oobabooga/text-generation-webui/blob/main/docs/DeepSpeed.md
GitHub
A gradio web UI for running Large Language Models like LLaMA, llama.cpp, GPT-J, OPT, and GALACTICA. - oobabooga/text-generation-webui
oh yeah, for sure
They cucked lower end 4000 series so fucking hard lmao
it went from unusable to at least acceptable speeds
hell, the 4060 has an 8 lane bus
I don't think thats like... ever happened before
4070ti isn't low-end..(?)
that means if you have an older 3rd gen PCIE mobo (which is likely if you are buying a budget card), you only get 4x gen 4 speeds on your GPU
Its disgusting
I'm generating insane images with AIT on SDXL at speeds close to people with 4090 get to
its the first one that gets mega shafted by NVIDIA
specifically the Anemic VRAM bus that makes it really shitty at high read/write tasks
Fuck them, I'm probably getting a refund
if you can, i would
I would just buy a used ampere card
how much did the 4070ti cost you?
The CUDA cores themselves are amazing, no denying that. But man, the VRAM is something I would make out of playdough in 1999
how much did you pay?
I paid 750$, I was satisfied with it until I tried to use LLMs with over 13B params
bro, just get a used 3090 for that price
my 3090 was $700, and I have a top of the line EVGA FTW3 Ultra 3090
24GB VRAM with a 2x faster bus
Fuck this
Maybe I can create beautiful images, but I can't run a damn LLaMa model?!?! I am going to smite Nvidia
welcome to the party lol
i got that same card for 600 in April😁 love it
its been a great card so far
I just had to rip it open and clean it out cause got damn was it dirty from the previous owner
headbutts the wall
honestly tho dude, used 3090 is 100% the way to go for AI
anything the 4090 can do in terms of training, the 3090 can do, just slower
you can give something more time, you can't give something more VRAM
and 2x the VRAM over a 4070ti is also sexy AF

you can traing LORA's like a beast for SDXL on 24GB VRAM
I'm returning this piece of junk and saving up for when 5000 series comes out
The state of my card when I got it lol


dirrrtyyyyy
took 2.5 hours of elbow grease but...
Kleeeeeen


i droped, and I kid you not, anywhere from 15-25C depending on what part of the card you are monitoring
you say this like 5000 series won't be similarly predatorily priced and specced as 4000 series
what is your iteration speed when training SDXL?
depends, I train a wide range of BS, with TE, without, with buckets, without
I'd say at BS 10 or so, about 6s/it with SDXL at 1024x0124
which means with simple settings and about a 30 image dataset, a LoRA can be done in like 30 minutes?
ok im definitely doing something wrong then. i used BS 5 and got 60s/it
my bigger LoRA trained at BS 5, it was about 3.2s/it, and withj 90 images, 30 epochs, and 5 repeats, it took about 2.4 hours
a lot of the images in my dataset are higher resolution than 1024x1024 and maybe that's why
oh, are you not using buckets?
yes, im using buckets.
i copied Aitrepeneurs SDXL json config file so i havent messed with any settings, other than my dataset of images are varied resolutions
huh? at BS 5, 1 repeat, 120 epochs, 16 images takes a full hour
for me
let me do some math
I am doing basically 13,500 steps (30 epochs x 5 repeats x 90 images)
and you are doing (120 epochs x 1 repeat x 16 images) which is 1920 steps
that's a bit different
You aren't actually using all those images with BS 5 and 16 total images, one is being dropped


it took me 30 hours or so to do 1500 steps on a rtx3090
ok, something is very much off
are you using gradient accum?
It takes me an hour and 35 minutes to go 12400 steps at BS1 for an iA3 on my 3090. 2.16it/s
if not, thats why
i am
gradient accumulate steps? it's set to 1 which is the lowest on the slider i believe.
optimizer is Adafactor
Just gave Nvidia a nasty letter
Your steps may be set to one, but do you have it enabled with the checkbox?
Ohhhh, I think Ada factor explodes with higher BS
Some optimizers use more or less VRAM than others
For example, with the prodigy optimizer, you can only run BS1
BS1 uses about 13.9 GB RAM, but BS2 uses about 39 GB
any free SDXL site beside Clipdrop?
i trained with BS 1 and it was very slow too. oddly enough it was using 23GB/24GB VRAM on BS 1 which didn't make any sense.
free forever not 25 images perday stuff
ah to bad, why nobody put the model here https://aqualxx.github.io/stable-ui/ ?
Create and modify images with Stable Diffusion - for free! With the Stable Horde, unleash your creativity and generate without limits.
its not out yet for the masses is it?
Not many sites are keen on throwing money into fire
it still Delibarete model on aqualxx
I dont think images get dropped, but the last batch would be only 1 image, so not ideal anyways
The way I was told by caith and other good fine tuners is that your batch size should always be evenly divisible into your image account
is it possible the amount of buckets i had was causing the slow down?

How many images did you have in the data set?
it definitely should. but i dont think the leftover gets dropped entirely
500 or so
Wait a minute, that data set is terrible
Why do you have so many images above and below 1024^2 eq?
All of those low resolution images are really going to throw off your latents
If you are going to train SDXL at a lower than optimal resolution, you should keep the lower than optimal resolution continuous
Should I really get a refund for my 4070ti? Or is it not necessarily an issue of NVIDIA using a decade year old memory bus
i could never get an answer here on what resolution the data set was supposed to be, so i just winged it.
ooh, that link hsa a furry mix model. just wonderful
1024x1024, or as close to equivalent as possible
Just gonna put this here for convenience

@queen adder honestly, my guess is that you went severely over your VRAM limit, which led to the additional memory pulling in your system memory, which led to a significantly slower training session
I made an infinite aspect ratio node

sweet, this is the answer i was looking for lol.
i also saw a tutorial saying varying up the aspect ratio gave better training results, but what they left out is that every resolution used probably added up to 1024x1024^2
well maybe not infinite
You don't want 1024 X 1024²
You just want 1024²
yeah my bad
Or 1,040,000 IIRC
lol 1024^3
If you set the resolution to 1024 X 1024, and then provide it with images at that resolution or higher, it will figure all the math out for you
Most of my images for my realism data set are actually 4K or higher resolution
Even have some 6k, and maybe even a couple 8k+
Oh, you mean set the canvas size in photoshop to 1024x1024 and then just process each image in there
No, I mean if you set the maximum resolution in kohya
what about if an image is too small? upscale or trash it?
It will still automatically bucket them, but it will bucket them to where they are the maximum resolution that is equal to 1024 X 1024
I am soo angry at Nvidia rn, how DARE they have the AUDACITY to use a decade old memory bus for all cards under the 4080? I think I'm going to get a refund, this is unacceptable
ohhh, so you think it was just the images that were smaller than 1024 x 1024 was causing the issue?
yeah!
yes you should upscale the smaller ones. but only if it comes out looking amazing after
Why the fuck did they think this is a good idea?!?
if you give is a 2560x1080 image and tell it to bucket to 1024x1024, it will downscale the image to the resolution that is closest to 1204x1024 total pixesl while being the same aspect ratio
Do we know much more than what’s on report on how the refiner was trained? What was the dataset that was used and resolutions of images in that dataset? Did they also use the other conditioning parameters mentioned for the base?
perfect. i will just weed out my smaller resolution images and trash them, or AI upscale the good ones.
as somebody who is one of the leaders in workflow processing and premade workflows for th emasses, I am ditching the refiner as a whole, as I have found it hinders more than it helps, especially when you get better at prompting fundementally
does it round to 64 pixels?
awesome, best of luck
I heard it was trained on openclip only, while base was trained on openclip and openai clip. all i know
@gloomy barn also, here is the single tiger image in my dataset which it was pulling from hard for that "tiger" image lol

it rounds to whatever you set it to
Maybe we need to get better at implementing refiner too?
I god popular specifically off that
its just not something that should stick around
its extra issues, extra requirements, and actively damages most images
and it makes using LoRA's a waste of time
I assume finetunes will make refiner obsolete in every way
But I agree at least for now that ditching refiner might make lot of sense especially if we want community trained stuff - LoRas, fine-tunes. Refiner just ruins them
Does the 4090 also have those old memory busses?
@hardy cipherKohya advanced setting

no
the 4080 and 4090 are fine
just the 4070ti and below are cucked
or well
actually
the 4080 is kinda cucked too, but its not as bad as below cards
16GB GDDR6x on a 256x bus
the GTX 560ti from 2010 has a 320bit bus
and what... 2 GB VRAM?
GDDR3 IIRC too, so like 1/16th the speed?
ahh, thanks. as soon as I put together a decent set of images I'll try it out. but having a hard time with this one
best of luck man
Wait what are the specs of the 4070ti's memory bus? Am I yelling at Nvidia for no reason?
thanks. I'll get there. just sifting through a lot of non-win images
thx, I wish we knew more
Hi guys! I would like to know if someone could share a Workflow for image-to-image conversion. If anyone could point me to a link with resources on this topic. Currently, I'm using Sytan's SDXL 1.0 Workflow for image generation. Thank you in advance for your assistance!
can you share what you are training? I might be able to point in the direction of some good image sources
thats me!
:D
I'll be going for a refund or at least an upgrade when asus rma team eventually gets back to me about my 4080 for sure
Oh, I guess I should get to work on my img2img workflow as well haha
its not specifically an old bus, its just smaller due to the size of the gpu chip. older cards had larger buses as the silicon was larger. Its a physical limitation
where do I find this famous Sytan's workflows?
4090 minimum, keeping an eye on the new cards they announced but those are so pricey
GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
there you go <3
I've seen this node with a "longest" value in the "side" field. Why do I only have "width" and "height"?

Sytan, I'm using your Workflow but I don't have an image to image option, sorry for my lack of knowledge, I'm new to ComfyUI
I'd like to tain a model on things like this. old technical drawings, da vinci sketches. but I'm finding a lot of really basic, faded stuff and then a lot of midjourney generated images for some reason




no promises on when guys, but I will have 2 new workflows at some point hopefully soon
One for even more efficient SDXL usage as a base
And another dedicated to img2img workflows
both should run more efficient on all GPU's, as well as take less experience to prompt, and also upscale a little easier
Also, full built in LoRA support from text encoder to upscale result

internet archive has a bunch of stuff, but so much of it is just not worthwhile for training
no hate on their sketches, lol
yeah haha
thats gonna be an interesting LORA
let me see if my go to site has anything
I have been waiting to make that cough drop joke for over a year
Tag me when you do this, I'm learning a lot with your workflow.
I appreciate it.
there are already probably a thousand plus weird nsfw loras for sdxl. but kind of lacking in some of the stuff I want
hmmm, doesn't seem to have much in the way of technical style drawings specifically unfortunately
for sure, thats why I am being meticulous for realism
all good. I didn't think they'd be so elusive
Can anyone help me with an image to image workflow?
I could throw one together really fast, but the problem is it needs a lot of math
I'm just wondering how many images I should use
I guess it depends on the method
honestly, I think a few dozen should work, at least as a proof of concept
I don't want to take up your time, I just wanted something to help me understand the knots, everything is new to me.
yeah, I might have 10 or 12 that I think are passable.it's going to be a chore tbh
maybe start with 24? BS 6, 6 repeats, 10 epochs?
see how that goes, then see if you need to change anything?
thats um... an image

and then images like this that are cool, but midjourney

I could probably incorporate it tbh
what you really need is a single subject in that style
that's what I was wondering about
well I wasn't originally going to span so many areas
but it's surprisingly hard to find these images. I mean, in my head I thought they'd be in abundance
explain what the subjects are
It figures out what it has to do to its fundamental understanding of said object to get it that way, then it should be able to apply it pretty well to other things
This is crosshatching style draw
yeah, you might be able to augment your dataset with some cross hatch stills

Nightvision alpha - no refiner

||looks straight out of every 1.5 model to me  ||
||
yeah, I'll definitely try it out. do you tag manually or do you use any kind of model for that?
i really need help trying to come up with an AI image it is so specific in detail
like these

@high skiff what if I challenged you to replicate what fooocus (or whatever) has done with the sampler mix

not even sure what you are referring to
maximum croshatching.
definitely not pointilism lol

well my original idea was using vintage technical/mechanical drawings, but then adding weirdness to them
This sounds good
digital crosshatching
the way they combined the refiner into the same sampler as base because "a lot of latent gets dropped when transferring between samplers" or something
eh, i wouldn't waste the time. Its pretty agreed upon in the training and high level prompting scenes that the refiner is kinda dead weight
all of my fantastic images said bye bye to the refiner
can i get some help with making an AI image?
I think I got a good result at some point with the bot, let me see that.
want to make stuff like this, but mayb ea bit more vintagy

but thats part of it, if the refiner performs way better the way they're using it then its less of a dead weight
i was told looking into sdxl since i had something so specific
all base SDXL realim with the refiner kicked to the curb





use "schematic"

plague inc
I think I might have found some help @hardy cipher
but definitely would be cool to have something a bit less futuristic
"Design draft product sketches"
nice. howd you come up with that?






Looked for even one good image relating to what you mentioned, looked through the result, found words it used, strung them together
btw, both schematics and "design draft product sketches" are giving me good results

that's some smart thinking, lol
Certainly, I've corrected and clarified the text for you:
Using the term "Crosshatching," which is the correct terminology, the bot wasn't yielding very promising results. However, when I used the term "engraving," I think it worked to generate something similar to crosshatching

that's a nice one

some fun results


but I made it, lol
your workflow is completely outside the blue box 🤣 opened it and saw nothing
@hardy cipherproduct design concept sketches is also dope
oh that workflow is rather unconventional. but what's the blue box? lol. is there is actual center to these things?
lots of gold here

you cant see it? blue outline around center
tbh I never noticed,l ol
lots of good shoe schematics

nice. I have all these search terms loaded. I'll surely have sufficient data here shortly

community sourcing lol
I come here every so often to community source some needed materials for my workflows
you know, now that I think about it I was wondering why some of my workflows were out of view when I loaded them
specifically pixel upscalers
just working outsid ethe box
ohhh, industrial design concept sketches is pretty dope
man, I was kind of at a standstill there. I would have figured it out eventually, but thisvery much expedited things
I have an idea a while ago. Use the model to generate sketches. Use the sketches for img2img to generate the realistic image.
I would be scummy if I didn't help other people lol
it's much appreciated. I have been doing all of this stuff solo until recently. and sometimes it'd be a grind
Ive used colouring in book line drawings in controlnet. works really well. same applies to drawings
for sure
maybe include the bean comic?

I had to rely on my research partners for good image sourcing sites for my images
took me 3 days on google to put together a pretty ass 24 image dataset cause google image search has been so massively neutered
that's what it is. every image I was finding was either ai, low resolution, or watermarked
yessir
google has monumentally stepped down its image search engine to hold a big lead in data sourcing
this discord taught most of the training pros the majority of what they know, prompters as well probably. the open source energy of sharing info is what propels SD at light-speed. never stop sharing info and never stop asking questions.
websites might be adding google image scrape to their block lists
I guess that might be true
man, I evolved in relative isolation so I have some strange approaches. but tbh I just wanted to feel like I sort of knew what I was doing before I started trading ideas with people
I doubt that free stock image sites are actively trying to not be accessed, as they get money from ads and clickthroughs
even unsplash results are getting rare
and even then, google only embeds their high res images at like 600p
i wonder if other browsers have more now
how come I can generate stuff like this in ~17 seconds and I can't generate more than TWO WORDS with LLaMa?!?!?!!11!

llms are pretty complex stuff tbh
need more like this, lol

well not more cars per se
but that's the kind of structure I'm looking for idealy
there is no way, when I run a 30b LLaMa model I get 0.034T/s and with SDXL I make awesome images in under 17 seconds
fuck that, "efficient language model", so stupid
wow. you should check out "vintage organ schematics"

jesus lol
cutaway 3d blueprint diagram of a race car

that cold be an entire lora by itself. why so many images?
really? with 12B I get ~41.3T/s, why is it unusably slow when I go 30B? is this because Nvidia are fat fucks?
no... its cause 30B models need at least 18GB VRAM
but your very cucked VRAM doesn't help with pooling
I'm looking for some image to image workflow in Civitai, but everything I see there seems complicated, can anyone recommend a noob-friendly workflow?
This SDXL focused Image2Image process utilizes your desired SDXL base model with the SDXL Refiner. To ease the process, all steps are automatically...
like here, on my 10 GB 3080 with a 30B LLM, i would still get like 8t/s
4070ti should be a little stronger than a 3080, and it has more VRAM, why the fuck is this happening?
I will try this one, thanks buddy
likely VRAM bus being shitty
4070 has bad concept, yeah
the VRAM bus on the 4070ti is nearly half the bandwidth on a GPU that is decently faster GPU
jesus
and once you get past the minimum required compute time in latency, it slows down like crazy
do ADA cards need specific drivers or dlls - similar to A1111 etc?
wait, so why do I get more than 40T/s on 13b models?
cause a 13B model can fit inside 12GB VRAM
the issue shows up much worse when you need to load from outside VRAM
so cause a 13B model fits all on the card, it doesn't bog down the anemic VRAM bus as much
But then a 30B model is way too big for 12GB, so it caches like 6-8GB in system RAM, which is much slower, then it has to send that info into the GPU while echanging out info it doesn't need at the time, which is a huge VRAM bus hit, and then additionally it also has to read and write to the VRAM in real time for every token as well
So its a massive amount of reads and writes happening per token, which chokes the hell out of the 192 bit bus on the 4070ti, subsequently making it fall behind its clocks and basically computing, then waiting for a long time for all the right info, then computing, and waiting again, so on and so forth
on my 3090, its a fairly small hit for LLM's
Like I ran a 3 bit 70B model on my 3090 using about 36-38GB GPU memory, so 24 on GPU, and about 12-14 GB in system pool. Even then, I was still getting like 1.7t/s I think?
guys, where do I get these nodes

impact pack
installed it but no luck
hmm, I think I could modify that node I made a bit to quickly resize all these images to the proper resolution
make sure it's updated. at least for ultralytics
decent
you downloaded missing nodes?
it may need restart.
this is true
some nodes you can refresh, some you need to restart
yeah, its way faster than auto
I installed latest build of impactpack, how can I update it for ultralytics?
anyways, my 4070ti seems to run SDXL extremely fast when with AIT. So I guess this doesn't screw me up that bad because I'm not that into LLMs

dude, I nuked a couple auto installs when it would take 5-10 minutes
sytan, what were you saying resized the images? does the kohya program itself do that?
Is it a generated image?

Here's his github. In a recent update he added the ultralytics node which will replace the MMDET nodehttps://github.com/ltdrdata/ComfyUI-Impact-Pack
GitHub
Contribute to ltdrdata/ComfyUI-Impact-Pack development by creating an account on GitHub.
I kept reading bucketing and just didn't know what it meant. and didn't really want to ask since I could look it up
it's possible. but the website gave no indication of that
we're at the point where pretty much anything could be ai generated at this point
I said point a lot
why does my comfyui suddenly have a chicken on it
I don't see a chicken
im guessing searges nodes?
that's a bit odd

that's an anime girl
delete

you know, I didn't even notice that was a chicken or an anime girl
must undo this
I can't even think of what it was before. I saw that and just assumed I hadn't noticed it before or something
back to normal

I"mfinally just noticing the blue box over here. I feel like it could perhaps be a bit easer to see.
true is very faint
I wonder where that setting is hidden. probably pretty easy to alter if I could find it
add a little brightness to it

that boy ain't right
man, I like how easy it is to do text in images now

Anyone else no longer generate sample images when training?
@hardy cipher bit like that?


mine stops randomly, and randomly starts again later
I don't mean as an issue, I meant like it just not being useful for determining when its done. I found the graphs tell me a lot more and I just save more often, then test when I think it isn't going to get better
indeed. it's sort of deviated a bit from my original idea, or expanded rather
oh yes i agree, mostly useless. no epochs show likeness and then i use the exact same prompt in comfy and get perfect likeness
Yeah that's what I concluded, though sometimes its nice to see something more visual as it goes, but I haven't generated samples for my past week of training
I only did for the very first time last week

Has anyone tried a multi-concept LoRA that uses the same class token for all folders?
they were talking about that here
Thanks, I'll check it out
@high skiff This is strange, i upscaled all my images but when i look at the buckets readout the resolutions look wrong?


It downscales them again
To fit in the range you set
which is probably 256 or 512 to 2048
the range I use is 640-1636 IIRC
you mean this range?

Yeah, 4096 is really high btw, and it tries to fit them around the 1024x1024 you set above that
what do you reccomend minimum and maximum set to when training SDXL?
Sytan's range of 640-1636 isn't bad, the default is 256 to 2048 in Kohya_SS or 512 to 2048 in SDXL branch of Darrien's easy training scripts
I leave mine at 512 to 2048 usually
@queen adder
thanks, i will run it again with these settings. maybe the speed will change. I was getting 3it/s on BS 1
the buckets still look exactly the same but whatever. 2.3s/iteration
You were technically already fit into that range by coincidence lol
it's strange to me that 19GB/24GB VRAM is used up training with batch size 1. how the heck are people using batch size 3, 4 or 5?
What optimizer are you using?
Adafactor
That one uses the least iirc, but I haven't tried anything over 4
I usually use Prodigy so am stuck on BS 1
I use adamw8bit of the time
Sometimes I can get up to BS12 on 24GB VRAM, but it depends on what my dataset is like
I sit at 18GB with Prodigy on BS1 but anything more will OOM for me
No checkpointing though
adamw8bit doesn't run for me, gets some kind of python error when i try to run training
I used it on 0.9, so not sure what that would be about without seeing the error

ohhhh, i should wipe all those extra arguments then.
comyUI official discord ?
SDXL OOM issue with COntrolNet.
Well scratched my head last night and I'm still none the wiser.
Card is a 1080ti with 11GB Vram
ComfyUI is running at standard OOTB settings and has never OOM'd on any other workflow I run on it (execept to switch to tiled VAE on Hi ResFix)
Trying to run the accontrolnet workflow in the screenshot however get the dreaded red wall as sonn as it starts using the Base Ksampler.
Also included on the picture i s a meory graph showing a standard 3 psdd tun (Pre Con-Base-Refiner)
*torch.cuda.OutOfMemoryError: Allocation on device 0 would exceed allowed memory. (out of memory)
Currently allocated : 9.60 GiB
Requested : 80.00 MiB
Device limit : 11.00 GiB
Free (according to CUDA): 0 bytes
PyTorch limit (set by user-supplied memory fraction)
: 17179869184.00 GiB
Prompt executed in 31.26 seconds*

Hey, anybody using AITemplateVAEDecode in ComfyUI with SDXL with 8GB of VRAM? I mean does it working? Getting black images probably have not enough memory, but tried on 256x256 as well and black as well.
Thank you!
I have a 2060S with 8gb, but that series isn't supported yet, hopefully it will be eventually
i have 3070, probably same issue. Thank you @crisp owl
I believe the 3k series is supported
AITemplate loader is working, not perfect, but working. Just VAE is too slow. And node giving black picture
ah I gotcha. I wish I could fiddle around with that, but alas, my hardware situation won't allow lol
i believe official support will make it for all.
Yeah, just more "hurry up and wait" situation
I guess it's more impatience because this AI stuff is moving swiftly
just read this youtube comment SDXL 1.0: it is recommended to use smaller network ranks, such as 16 or 8 to reduce file sizes
does this seem right? i'm using network rank 256 on Lora training and maybe that's too high
@crisp owl if you put it that way, you get error or is it terribly slow?

I can't use AIT at all
o.k. Because in my case first run is horibly slow sometimes it can take up to 3 mins. Then it starts working.
Will have to next time set first run steps to very low, to get rid of this pass.
Just asked.
change keep loaded to :disabled
was just gonna mention that, I usualaly see people with that disabled, not enabled
if enabled it hogs vram
o.k. thank you, but i think it didint work. Going to test thank you @heady vale
would it be possible to export the prompts in json format later down the chain .. this could facilitate in creating NFT
need a scripting node
Hey working great and VAE is quick as thunder
meant to respond to this, dunno why it didnt 😒
the creator of LORA on DIM from https://www.reddit.com/r/StableDiffusion/comments/1223y27/im_the_creator_of_lora_how_can_i_make_it_better/jdqv9ik/ :
It's possible we don't need to use dim=128 and adapt all attn layers. I suspect that we can reduce the size by quite a bit if we are careful about which layers to adapt.
Interesting.
If I run the same flow as standalone (minus the Condition Switchers) It completes although noted it does use all of the memory with no overhead

does anyone know if it's possible now with a1111 to train textual embeddings?
Ok so adding --lowvram to the comfyui "run_nvidia_gpu.bat" helps
(first chunk was standalone with --normalvram then theres a succesful combined run with --lowvram enabled)

and another question: is it possible to remove the comfyUI metadata somehow again from an image?
is there any good anime models for sdxl
huggingface have some excellent LoRA trained anime style models
if you use the WAS Node Image Save you have an option to not wirte the metadata to the file on save or if you prefer you can use something like ExifCleaner to strip the data later
FREE Desktop app to clean image metadata
i am here
any bro's wanna check my messy control net setup, feel like ive done it wrong o0


You can compare it to mine, that works. https://civitai.com/models/119257/gtm-comfyui-workflows-including-sdxl-and-sd15

The SDXL workflow includes wildcards, base+refiner stages, Ultimate SD Upscaler (using a 1.5 refined model) and a switchable face detailer. Now wit...
The controlnet part is just the light blue area, bottom left of the flow.
Cheers man



Tyrannosaurus rex
got a link? 
hi guys, does the existing textual inversion from 1.5 can be used with SDXL?
nope
Min-SNR-γ 3.4 times faster convergence
you can train TI with kohya
i want to use the A1111 process, since i want that "save every trainign step" set to 1 and save every image
i think this cant be done with kohya
it can
in the same way like a1111 did?
is there some easy way to set kohiya up ? 🙂
I'm currently not on my computer, but you can more or less copy& paste the train command
the train setup itself is easy: make a directory with the name "1_keyword" where keyword is what you want to train on
the rest ist just the parameters. You can basically use same parameters as with lora training
can i stop training in the middle, change training images, then continue ?
I think there is a checkpointing option to stop and resume training
but it's easier to just stop and restart training
you can give a parameter --weights that points to a pretrained embedding


kohya training arguments set save_state=true and resume=true
you'd better run on highly RAM,otherwise it will be OOM
it will not offload any occupied RAM usage
how can i create a LORA that effects skin-texture ? i need to get better/realistic skin on my portraits
but i dont know ( a ) what kind of pictures to put in the training picture set for the LORA, and ( b ) how to describe the pictures so the LORA will learn only the skin texture
anybody got ideas here ?

how much work do you want to put into this?
15 pictures, or 150?
as much as needed, its gotta be good
but rather 30 pictures 🙂
hey, if 150 are needed, i ll do 150 though
@high skiff is working on this very thing at the moment, he has some examples in chat but he thinks it will be a while before its ready/out
you could try to do a "quick and dirty" lora using 30 ish of photos you think look good with texture, it might work decently at lower lora strengths
Do you have your photos already?
Once you get your photos start with BLIP captioning to get you a decent head start
The captioning might take a while
You will need to caption everything that is NOT what you want
my first question is: what kind of images do i need for training
and how exactly would i have to tag them?
describe just ANYTHING but the skin ?
pretty much
i suppose you are doing close up portraits?
gotta find something you like in the ether
actually i take back what i said, 30 isnt enough, refer to this guide, it will give you substantial detail on how to accomplish your goal

i hope you have 24gb
this looks decent however the quality of the picture will be important
yes, got 24gb
when you finish lora training with base model,you can render more details with refine model and upscaling nodes
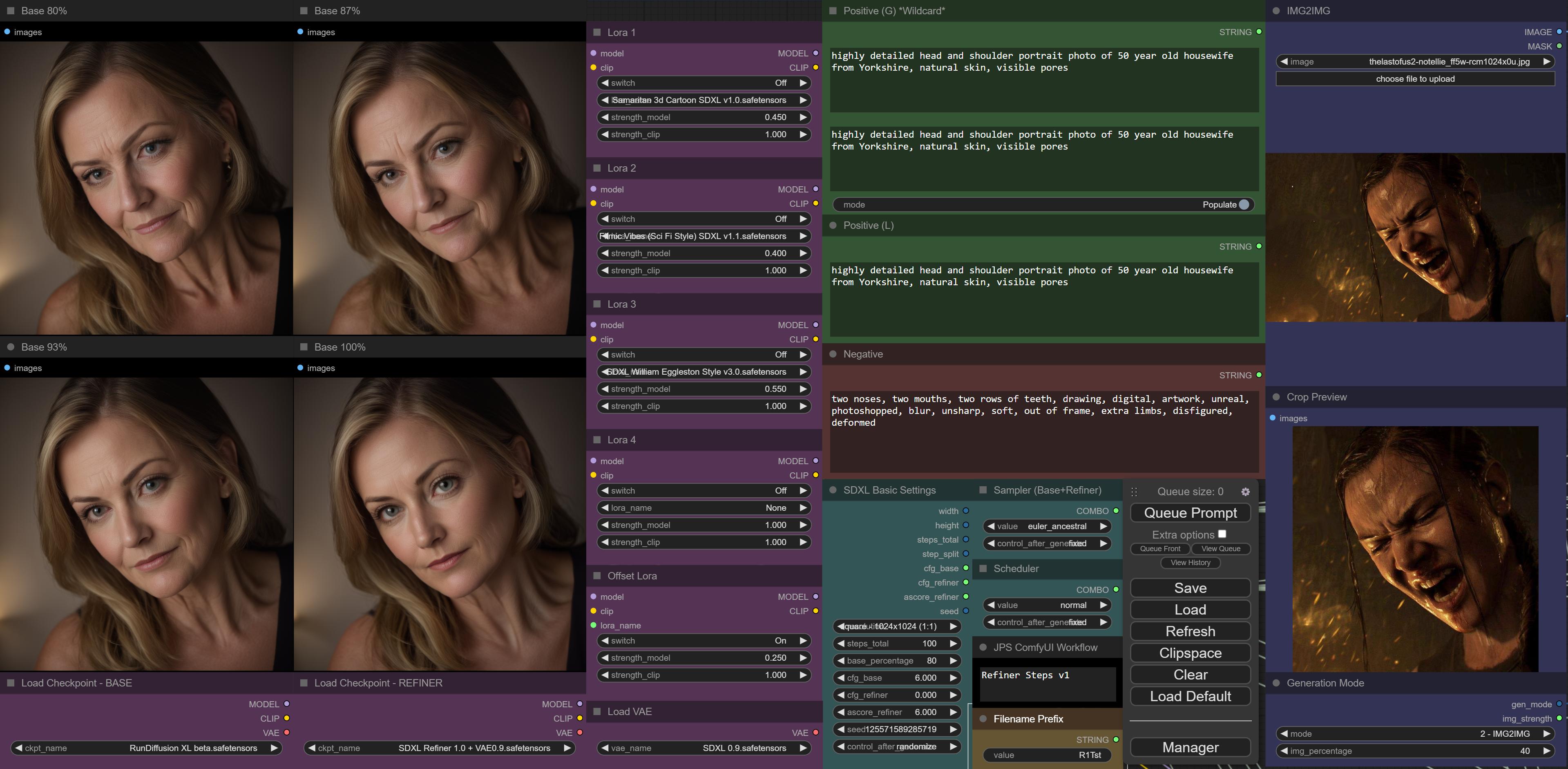
why do so many people dislike Refiner? it helps in many cases imo - without refiner i get a 35 yo woman, if i ask for 50 yo for example:
https://i.imgur.com/f0MvLDT.jpg
I would say this is not a good training imsge
Obviously I don't wish to give away all of my secrets, as I am already training what you are trying, but I would not use that image
My current dataset it's 90 images, and while I get some good results, it's inconsistent
My goal, if I can get there, is at least 500 images
That's really all I will say, everything else I would respectfully say is up for you to figure out in order to compete honestly
Any hint why it’s not a good image ?
I felt the same way before, but I now realize it was more of an inconsistent and unreliable crutch to lean on for sub optimal prompting, reslly
Too close and not really high quality skin detail in general
the main problem are the eyes imo - at least at 80/20 split they often come out bad with refiner
Yeah, the refiner trashes eyes
I suggest ditching the refiner and messing around with prompts until you get good results
When you do, they will be far better than the results you would normally get even with refiner
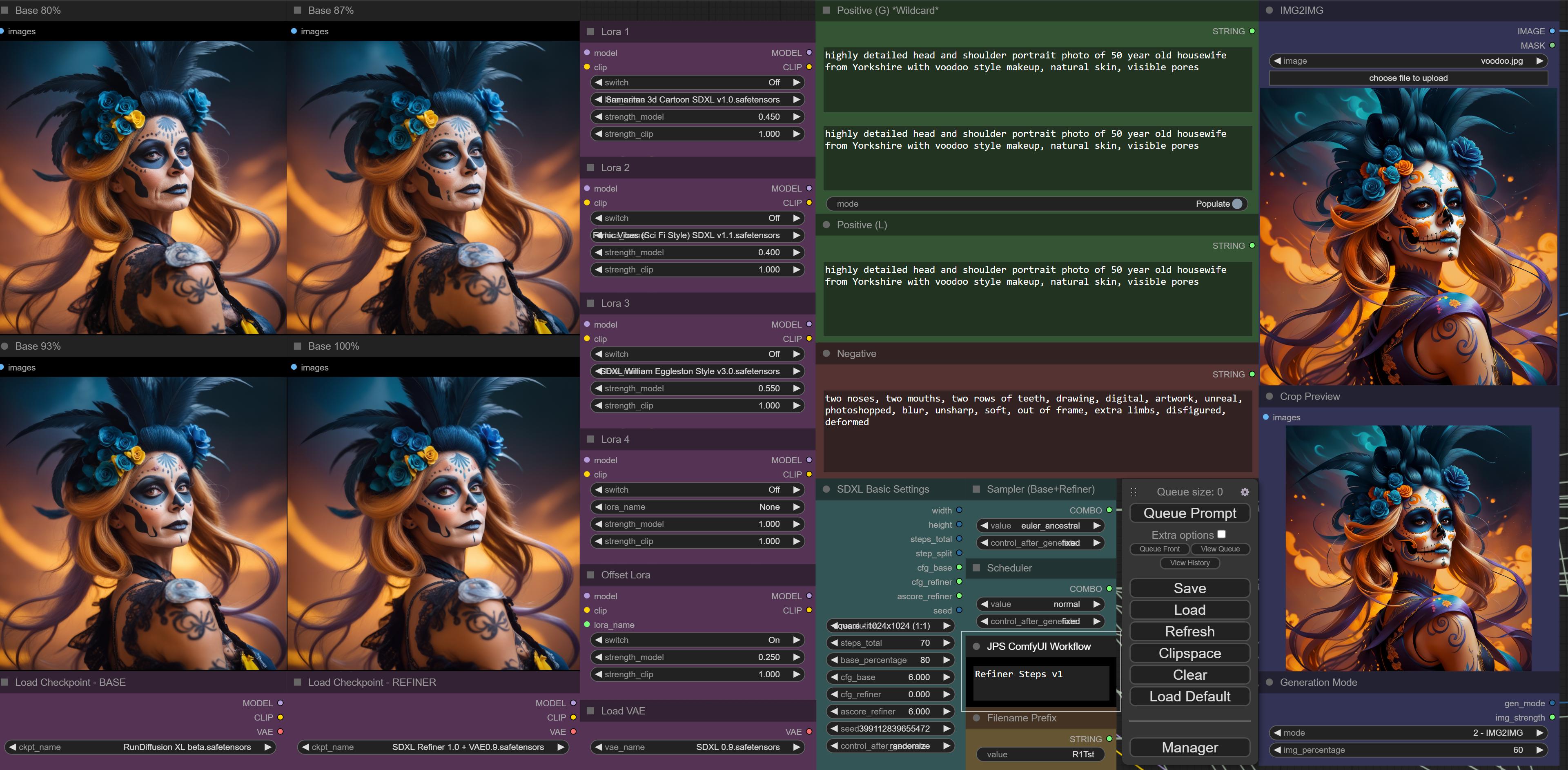
i made a workflow that generates 4 versions: 80%, 87%, 93%, 100% base. so i can pick the best one - and it doesn't take that much longer, because i don't generate all of them from 0% and continue from the last step instead. so only the last 20% have to be done twice and the vae decoding 4x.
{kind=link}
{kind=link}
I will really honestly just stick to my assertion that the refiner is more of a negative crutch for bad prompting than it is any form of reliably better result
Especially for photo realism and painterly images, as the refiner kind of mangles fine details associated with brush strokes and skin texture
Okay I am trying yet to use control net open pose... but the workflow says I am missing the preprocessor, then with the manager I click on get missing nodes and it leaves me to this:

My 1.1 release of my workflow will be ditching the refiner entirely in favor of just using the base, which is faster, more efficient, requires a few less steps, maintains consistency and compatibility with LoRA's from the first step to the very last step of high-res fix, uses considerably less VRAM and is more accessible for people on lower end GPUs, and overall improves pixel level quality considerably
this is stressful
i like the concept of expert models and splitting models at x%, but other aspects have to be worked on. refiner is problematic if things like loras don't fully support it.
I am sure people's dependency on the refiner stems from my earlier releases of my workflow, where I sung my split technique as being optimal, which four a workflow that it is using the refiner, it is optimal
But I have now found that the refiner is more deadweight than useful weight
means the missing node is not registered at comfy manager i guess
okay after 1000 tries it loaded, wth
I don't know why when comfyUI loads it opens up my audio driver though 😛
see generally speaking I'm happy with using refiner although I would agree there is no magic bullet and prompting helps.
Personally I use a 3-5 step flow with the last 2 being optional
Precondition
Base
Refiner
Upscale
Face Detail
NB I 've also tweaked my flow so I can use it with SDXL or SD1521 Models
Mind you this is the joy of it all, there is no right or wrong way, its what you;re happy with IMHO and yes YMMV
This is STable Diffusion, This is The Way
🙂
I will likely have to provide proof of my assertions that the refiner does more damage than it does good, and I'm prepared to release example images along my workflow, as the faster we can remove people's reliance on the refiner, the sooner we can get people who know better how to prompt, and subsequently rely more on the base which is more compatible with additional networks
That's my view on the matter at least
In Fariness many of the Custome XL models do say not to use the re SDXL refiner although all I sdo there is use the same model in the refiner step as I do in the base step.
(minor note I now refer to them in my workflow as Step 0,Step 1 & Step 2 rather than Precon.Base,Refiner as I ve found its fun to mix and match models at different stages 🙂
That's right, I forgot you still do preconditioning
Preconditioning is pretty neat, but I found that it has an absolute mind of its own, and often explodes some subjects lol
But when you do get something interesting with preconditioning, it an be pretty cool
Aye, I just like it 🙂
But anyways as I say in my own mind (and in my workflow) I have now moved away from the terminology I was using to a (in my mind) more accurate method of describing it it
I use multiple Ksamplers in a sequence which are rcounted starting at 0
Hmm should I rename Upscaled as Stage 3 & Face Detailed as Stage 5 I wonder lol

these are the 3 outputted images for completeness 🙂



u can control and easily generating darker or light images by offset the noise when fine-tuning the model,it's very interesting when you set noise_offset_num with different values
i prefer pre-conditioning with img2img at a very low percentage - this gives you some control over colors and composition.
and same prompt & seed through the DynaVision lens 🙂

that image looks aggressively 1.5
in the foreground possibly, less so in the background
Its this one
https://civitai.com/models/122606/dynavision-xl-all-in-one-stylized-3

***HELP ME WIN THE CIVITAI MODEL CREATOR CONTEST - SHARE YOUR ART IN THE GALLERY BELOW AND LIKE RATE AND FOLLOW ME FOR MORE SDXL GOODNESS - THANKS!...