#🔧|finetune
1 messages · Page 16 of 1
Your total steps still feel s way too high
(1 * 39 * 20)/8 = 97 total steps
This is what the progress should look like

on a 3090
why so small amount of steps when training 5k+ steps on SD1.5 is no problem?
Different model, different lora training styles
having the same problem, any idea why?

what is your training image folder name?

40_lora
3 hours for 100 steps
113s/step is waay too high for a 3090. There is something else up here..
should be 1_lora
Where can I change that?
its your repeats
I have no clue, I am sorry..
are you changing any setting from caith?
in Caith's message, they recommend 1 image repeat. As you are using Epoch instead of repeats to change your total steps
if your SD1.5 LORA settings were:
40 images
4 Batch
30 repeats
1 Epoch
it is now:
40 images
8 Batch
1 repeat
30 Epochs
(estimated)
ah so this message referred to something else? in sd 1.5 it was recommended to name your folder 100_lora, so i was a little confused here

ah! Yes, when I asked Caith a while ago, they said you now use epochs as repeats
this is starting to make an awful lot of sense now
so like this then

yes
yeah buddy, thats more like it. Thanks for the help

for sure!
Dang it, ive been sitting here for hours trying to figure out why everything Caith said was gold but not working for me..Thank you
Running with caiths exact settings the estimated time is 9 hours
225s/it
costum model sdxl set?
yes
this one?

yup


Might be it 😄
Try running it with half the batch size, it could be a vram issue
4 hours estimate, 74s/it
batch size 4, epoch 20
are your images scaled to 1024x1024?
no
that might be it
ahh okay xD
thought the bucket would take care of it
very well then, saving that for tomorrow
thanks for the help
this looks exciting: https://github.com/KohakuBlueleaf/HyperKohaku

GitHub
A diffusers based implementation of HyperDreamBooth - GitHub - KohakuBlueleaf/HyperKohaku: A diffusers based implementation of HyperDreamBooth
If I remeber correctly, in ML the loss should be decreasing contantly over itterations. Is this True for diffusion models? Is it ok if my loss is going a little bit up then down though iterarions or it should always decrease?
When you are finetuning, loss is always going down if lr is right?
Depends. The loss landscape is very large, sometimes to get to global optima you have to go through suboptimal solutions. Do not know how exactly this applies to sd xl though. This is what my current model in training looks like, using cosine with restart, hopefully it will work:


Medium
An additional method that makes gradient descent smoother and faster, and minimizes the loss of a neural network more accurately.
@open merlin thanks, it helps
Has anyone had issues with their LoRAs doing very well on some prompts (simpler ones, typically), but struggling to reproduce the training subject accurately on others (usually larger and more complex ones)?
Train with transparent vs White background, anyone have an idea about which is better? I trained with transparent and its giving me alot of colorful background. Dont know if it had influence.
I can tell you that my properly captioned datasets, trained with my settings have no issues.
but if you:
• Trainet with clip on
• Used bad caption practices
• Too big dim settings
then yeah, the LoRA may have damaged the core sdxl model enough that it's no longer functioning right
For my settings -> #🔧|finetune message
did kohya now support alpha channels? O:
or is it just turning it white in the background, during import.
Cause from when I last checked up on that, it was still the latter. would be really cool to have transparency support though
Thanks very much for your thoughtful response! Here's one example of the caption I created for one of the 40 images in the training set. Any critique on its style/format?
"amcm, a woman wearing a black dress, smiling at the camera with a white curtain behind her, head shot"
I dont know, it does accept the images, but no idea how its interpreting it. Kinda what I was asking 😦
changing your trigger word, to something that the model already knows exists and is close to what you're trying to make - will significantly improve your experience. but this shouldn't really be causing any issue other than longer training time. (in the past, this was addressed by clip training, but since we're doing unet only right now, using proper fitting words as the trigger word saves you time)
other than that all good. "with a white curtain behind her" is good! always tag background 🙂
What kind of trigger word would work best for a woman? I assume "woman" isn't a good one, right?
Btw in kohya, should I add the trigger and class words in the start of all captions?
ummm... woman is a bit of a special situation, since 'woman' contains all the information for all women.
you could pick the name of any famous woman that looks even remotely close to your subject
If you need a 1 size fits all approach, then 'photoshoot model', or something on a similar level will work as well.
depends on training style.
if you want to do it properly, then this would be the way to go:
<trigger word>, caption, caption, caption, caption, caption, caption, <background description>
Oh thank you! It was not clear if I should add the trigger or it is already doing that behind the scenes.
anyone had any luck with SDXL textual inversion?
Dont know if it helps but, I used to work with TI in the past, now with the new inplementations of lora its doing pretty good on XL
i'd like to try a TI + fine tune unet/lora but the TI alone right now is not working right
it's currently working, but the method to go about it is different, so dont expect old tutorial to work.
expect there to be significan't amount of experimentation + longer training time, as the clip first breaks, before it rebuilds itself
ah ok good to know. i'll just keep playing with it
to get a bit of understanding, I'd recommend to do TI for something that isn't faces/anatomy. Then it's a lot easier to understand how it works
For some reason when setting --num_cpu_threads_per_process=2 with sd-scripts, accelerate deadlocks. Very odd. Anyone see this before?
I think i found the issue
max_data_loader_n_workers
Yup, don't use both. https://github.com/pytorch/pytorch/issues/75147
I noticed with --num_cpu_threads_per_process=1 and max_data_loader_n_workers=4 I had a single CPU core pinned, so hopefully swapping those numbers give better perf.
@hollow spruce do u still recommend vit-h for auto tagging datasets for sdxl lora training? i want to experiment with ppl/faces. i will check captions manually, but i want to auto tag the dataset first as a base
Vit-H is the second best option that exists, but by far the easiest. (vit-big-g is better, but good luck on getting it to run)
ok. because i tried vit-h yesterday the first time, and got some weird captions on nearly every image. like a lot of artist names and words i never heard of 😂. i removed them by hand, but was wondering if i chose the right model
that's the flavor chain. you do 'caption' only, to get only the first sentence, which is a neat descriptor
can anyone tell if this is something we can use in diffusion land? https://research.nvidia.com/labs/par/Perfusion/
Key-Locked Rank One Editing for Text-to-Image Personalization
What is a good upscaler for a image like this that needs to go from 512 to 1024?

try 4x-Ultrasharp
In which folder does the pth file go?
are you using a1111 or comfy?
a1111
models\ESRGAN
thank you
CUDA Unified Memory is saving the day for me with LoRA training on a 3070, it OoMs without it
Do they have to be 1024x1024 or is it good enough that one of the axis is 1024x(xxxx)?
I believe they need to be one megapixel. How you spread out the megapixel is up to you (1024x1024 or 2048x512 or anything else that equals 1mp)
can they be more than one megapixel?
Yes, but the model is trained at one megapixel and your memory usage may take a hit
But, I have had 100% success rate at 1.5 Lora’s and a 0% success rate at SDXL, so I may not be the best repo of information
have a question, when training an sdxl lora, why some people put the bucket max size over 1024px?
while I do not know, my guess would be because SDXL is trained at 1mp not at 1024x1024 specifically. So a 1:2 aspect ratio SDXL render should be 2048x512. Which would be past 1024 on one axis.
Or its cause people like to train above the base resolution
yeah i guess
with buckets turned on, and resolution set to 1024,1024 - everything that is too large gets scaled down to the best size for sdxl.
all aspect ratios work (but you'll save vram by not having all too many of them)
also although your images can be bigger, dont go complete overkill - if you have multiple 4000x7000 pictures, you'll get weird issues while the script is starting, and may run out of ram, or just have it run super slow. Keep the size at a humane level of like under 4000px in the largest dimension
is this considered fast? 🤔

2000+ images, or did you set your repeat that high?
172 img, 12 repeats
at 2k images, I'd say you're about averaged speed
cooking the new Blame lora :D
'cooking' well defined XD hope you dont burn it
improved the datased, all hand picked and edited + processed
gonna look better than before for sure
you better be saving every epoch with that high repeat rate!
Would it make sense to use an llm like llama2 to adjust the automatically generated prompts in the correct format? It might be able to distinguish background from main character.
Then you can just write a python script that goes over the folder with automatically labelled images and cleans it up. Then you can train the llama with the cleaned up prompts for a copilot. Is this project feasible?
@hollow spruce How do you make sure your training prompts are in the correct format? Do you really go through all images every time?
normally? yeah.
but right now I'm doing fun and lazy loras, where I do everything with just the trigger word
hmm, thanks. Do you think using open source LLM's could improve captioning?
https://discord.com/channels/1002292111942635562/1089974139927920741
is full with examples of my sketch lora
nop. peak efficiency is reached when you use Vit-big-G
How would one use it?
Any special tricks when captioning sketch lora? I am also making a sketch lora atm 🙂
my dataset is 50 images so far, no background in any of them only solid white color

All 50 images are similar to this
results of 2h and a half of taining my Blame! lora. Not bad!




"ryan gosling by nihei tsutomu"


@hollow spruce your finetune config works with bitsandbytes 0.35, once upgraded to 0.41 (when using dev2 branch of kohya) the loss would diverge after a few epochs, it's upstream bug but I think you should be aware
well that explains a lot. noticed that on one install it wouldn't work correctly - but on the other it did. couldn't figure out why though.
thanks for letting me know ❤️ helps a lot
Thanks for sharing the config. Any thoughts on using prodigy instead of adamw8bit? Assuming the optimal learning rate changed due to the bug, would adaptive method like prodigy help? Also, if I use a different rank (say 16 or 64), should I modify the learning rate?
16~32 should be fine. 8/1 ratio for dim/alpha should be kept though (so 16/2) - significantly increases the learning time. From my tests I can say it works great - but at the same it's not like I've run into any issues on 8/1 that weren't dataset or captioning related
but 64~256 you should take care to not accidentally overthrow the common knowledge of the sdxl model. Basically everything starts getting a bit worse if you use those sizes and don't take a lot of preventative measures
I was using rank 8 with 500 images, but after about 40 epochs it starts to forget some likeness of already learnt stuff, feels like it's trying to jam too much into the 40mb file. So considering upsizing to rank 16 and resume training
And how about conv dim? Keep at 4?
apart from adamw8bit, I've only tested adafactor - where I did 4 loras, once with adam, once with adaf, same dataset. adamw8bit turned out better/faster every time. But I'm assuming it will arrive at the same detail, just slower.
will be testing prodigy soon - as it sounds promising. just haven't found the time for it yet
conv dim?
I could swear that was lycoris specific
I tried adamw8bit yesterday and it said it was gunna take 3 hours lmao so I switched to adamw and it only took 1 hour. Is there a reason for that?
long captions?
the most I've tried to teach it was 100 concepts with a 5k dataset - which worked fine. But if your captions are good enough, and basically every tag gets treated like a concept, then I can see that happening much sooner.
with your 3090? nop not really :/
how many steps was it in total?
Yeah, and it was 1180 steps I believe. I used lower batch size because I can only do 3 max, 4 causes to much vram usage for me for some reason
Well I could probably push 4. I think 3 was like 15.8G of vram
Yeah it’s pretty long caption with tags, this could be why rank 8 gets filled quickly
also, at that point you've prob reached the limit of what constant scheduler will provide. best to move over to cosine with restarts
I found cosine hard to work with because when I use resume using last training state it just keeps decreasing lr instead of starting over
So the learning rate is stuck at 0
exactly. cosine with restarts is great when you know exactly where you want your training to end
Yeah but I train 10 epochs at a time and resumes if I feel need more. How would I resume the training state but reset cosine if it already ended it’s cycle in the previous 10 epochs?
save every 10 epochs. restart every 10 epochs. max epochs of 500. then go on vacation for the weekend XD
Sorry for the dumb question but how to set the restart to be 10 epochs? I see there’s “lr number of cycles” setting, so in this case I would set max epoch to 500 and “lr number of cycles” to 50? Also what’s the difference between “epoch” and “max train epoch”?
Looks Superb!. Please if possible upload it on CivitAI.
ur not putting --w 1024 and --h 1024 in the sample prompts right? that might be the problem
has anyone tried finetuning the XL unet instead of finetuning a LoRA?
waifu diffusion xl
isnt a lora a finetuning on the XL unet?
now this is overfitting 😎
Is there a way to get a fancy graph of my loss? I’m using kohya gui.
i think you can configure wandb
Start the tensor board thing
Idek how to do that😂
in the gui
got masked lora training working on kohya-ss/sd-scripts sdxl branch

(mask covers the text/drawing in the training data)
anyone have a masked hands dataset? 😄

I sent an image of it
Hi, does anyone know how to train on multi gpu devices with everydream2?
#✨|sdxl or #🤝|tech-support - but this channel is for training the sdxl model only



nothing functionally. some UIs let you see the comment if one was attached

No I didn't tried yet
why does training pull 450w from my gpu 🙃
What gpu do you have?
Your gpu has a 450w tdp

Some gpus have a way to change that with a switch on the top of the gpu, but I’m not sure about the ftw3
its not oc but pulls 420+. the problem is it's overdrawing and shuts my pc off every time i train.
my sensor logs say it's pulling 110% TDP
What PSU and CPU do you have?
r7 5800x, corsair 850w 80+ gold
550w between the two, it’s possible that you are getting a spike in your power draw causing it to shut down.
Assuming you are using caith’s settings, if you lower batch size from 8 to 4, you will lower your memory usage quite a bit and, in turn, wattage.
yeah i can always lower batch size but how are they doing batch 8 on 2070s with the exact same config?
By running way slower and offloading to system memory
The extra performance (on a factor of like 5-10x in this case) is what is drawing so much power
And as Caith notes, running batch 4 means you can check your training in ComfyUi while your training rather than relying on the not-great sample output
Which means you’d technically be running faster as you can check your work sooner
something else is off. i'm using caith's config file with no changes and getting crashes even on batch 6, while thousands of others are running it fine on worse gpu's and higher batches, and if anything they only get oom.
if i got oom i wouldnt mind
🤔
In that case, it sounds like there’s something up with the gpu specifically.. have you tried running stress tests on it recently?
yes a few today. I also use vr heavily and have never had problems. temps are good
Hoi, for training, do the images have to be 1:1 ratio? Like 1024x1024? And if so, how do would i say train one for a game character? AS most of them for the ingame character is in 21:9 ratio or around there. Just photoshop the images to have no backgrounds and just make image as wide as tall and make them a transparent png with no background? :P
You can train at different aspect ratios, just make sure of a few things:
1. The image size should be One Megapixel in total (1024x1024, 2048x512, etc). Here is a calulator for this purpose: https://www.scantips.com/mpixels.html (there are others aswell, just a hard thing to find). You can use Presize.io to crop your whole data set at once
2. Set max image size in the settings to your source image resolution
3. When testing in ComfyUI, make sure to set your CLIP resolution to the same aspect ratio as your generated image or else SAI staff may post your lora in the sdxl chat and call you out for claiming to fix double characters
Megapixel Calculator, what image size image from X megapixels?
You could power limit the GPU. The command is: nvidia-smi -pl 350 if you wanted to limit it to 350W.
I run my 3090 at 300W and lose about 3% performance in training compared to the normal power and it's much quieter as well (i.e. it's very worth it).
is there any drawbacks to this in terms of stability?
No. It's perfectly stable and I have done this for months.
Ah nice, so as long as pixel count is the same as model trained, then it works?
There's no clip res for loras as far as i can see. Used this guide https://www.youtube.com/watch?v=AY6DMBCIZ3A


Updated for SDXL 1.0. How to install #Kohya SS GUI trainer and do #LoRA training with Stable Diffusion XL (#SDXL) this is the video you are looking for. I have shown how to install Kohya from scratch. The best parameters to do LoRA training with SDXL. How to use Kohya SDXL LoRAs with ComfyUI. How to do checkpoint comparison with SDXL LoRAs and m...
Also, is it normal for when training a lora for it to use all 24GB and then some?  Training for SDXL
Training for SDXL

i dont trust that guide lmao
as Via noted, please use Caiths guide if you want to follow one, Caith has a guide based on what SDXL needs. This guide is a SD1.5 preset slightly modified to work in XL.
TLDR: The issue is LORAs are relative and training 10% of SD1.5 is a very different thing than 10% of SDXL.
I'll grab a link to Caith's guide
Batch 4: 10gb
Batch 8: 16gb
Batch 10: 24gb
or something along those lines
Thanks! Doing 8 batches now and that uses 18GB video memory :P
Will take 19 sec per iteration, so 15 hours for this quick test lol.
whats your repeats at o.o ?
A SDXL lora of any reasonable size on a 3090 should be 15-50 minutes
should be around 80 Epochs, 1 repeats and 8 batch
I used the config in the post you linked to. And for some reason, training just ceased for some reason

press space on the command prompt, but you have way too many repeats
The heck? Then why did it say 48k steps And 2 sec per iteration
repeats at one, 35 images, epoch 100, batch 8 takes about 2 hours


Ah, seems like i forgot this one. Gonna do a through folder structure tomorrow and do the deprecated folder part as well :P

Do you do 1024 or 512 training?
1mp @ 21:9
Huh, odd. And yeah, something is amiss lol

whats your img folder name?
(You can censor the prompt name if you want, just want to know the first number)
100_link. Testing making a game character lora.
rename to 1_link
you are using Epochs as steps per image with Caith's workflow
Ah, thought number indicated steps per image
Gotchu. Is there a tutorial video that explains what each of that stuff means? Like "epochs" :P
Not too good with text sadly, though the guide you linked to was fairly easy, just some terms i wanna dig deeper into :P
Steps = (Repeats x Img Count x Epochs) / Batch Size
Aim for 150-200 steps with Caiths workflow
I honeslty dont know what they mean either sadly. Hopefully one day there will be a solid video tutorial, but most today are either bloated or confusing..
changes depending on bf16 support and multiple other factors.
most 12gb vram gpus can run batch 2. Some are just over the limit.
Enabling full bf16 training should fix this, and allow for much higher batches - but I still haven't tried that setting as there's not much point on my rtx4090 - since lower end cards may behave differently
but I've seen the issue people run into with vram, so I'll be adding presets for 12gb vram, 16gb vram, 24gb vram in the next few days - should solve the first issue people usually encounter
added a lora for chappie:P works surprisingly well. probably would pair good with other mech loras in the future https://civitai.com/models/121549
oh damn those images look legit O:
thanks!
i just realized all of them are in the same pose. lmao
except one
why does training with regularization double the training steps even though reg repeats is 1 and img repeats is 20?
1reg image per dataset image is the general rule of thumb
I think kohya automates that
so reg repeats is ignored? strange cuz in the kohya dataset preparation tool it asks for reg repeats.
I havent tested it,but I suspect that reg repeats is repeats per data set image. So if you set it to, say, 2 it will do 2 reg images per data set image
ohh
guys what's the max batch size you usually put on a 24gb GPU when training SDXL LoRa?
8
damn stupid me using batch 2 lol
8 if I'm afk. 3 if I'm using the pc - so that I can actively continue using comfy & test my checkpoints while its training
Thanks so much for everything youve said on the topic, ive been stalking. (sorry) - Do you have any tips or a comfy setup you recommend, i ended up switching back to Auto but purely because my Loras are being mutilated on Comfy but not there, and i havent narrowed down why yet.
I made sure to include some notes.
This is the easiest way to test your lora in comfy. runs quick and easy using base only.
for a more "full" workflow, I can recommend sytans highres fix (since that uses the base again at the end - therefore more lora details
but for testing the capabilities of your lora - this is the most efficient way
whats the easiest/ best way to generated images of myself in any style?
thanks so much for this and all your comments, helpful notes, thanks for you.. basically.
I wonder when any actual good fine tunes will come about for sdxl. Dreamshaper is meh and all the anime ones are meh as of right now.
does anybody have a propper description on how exactly finetuning in kohyass works?
also is it possible to merge 2 lora models to 1 model?
I was very excited with sytans 3rd pass to bring back lora detail but it made details a bit too perfect. for my use case if someone is ugly irl they need to stay ugly in the output lol.
So i discovered that if a lora is sufficiently trained enough, the details of a face make it into the first base pass and arent removed for refiner pass. refiner does its job on details but doesnt remove any likeness. It's quite nice

What’s your refiner pass set to?
5 steps on 2m karras
DDIM for the base/upscale?
also 2m karras, no upscale. this is just 2 stage workflow not sytans
Ahh, I misread the post, tyty
does it make sense to train a 1.5 model with max size 768 by 768? i read that it can pick up more details this way? is it true?
I have usually trained 1.5 at 768x768 and everything always worked out fine. But I never compared to training at 512x512 with the same settings.
I mainly trained at 512x512 for faces, with a good starting checkpoint, the faces looked great.
I think 768x768 could help with more complex trainings?
Barely docu on this if you google, so I thought I'd post it here. Advanced settings in kohya
Dropout caption every n epochs
Usually, images and captions are learned as a pair, but it's possible to train just on "images without captions" every certain number of epochs.
This option allows you to specify "drop out captions every ○ epochs."
For instance, if you set this to 2, you will conduct image training without captions every 2 epochs (2nd epoch, 4th epoch, 6th epoch...).
By training on images without captions, it is expected that your LoRA will learn a more comprehensive feature set from the images. It can also help prevent the image features from being tied too closely to specific words. However, if you use captions too sparingly, your LoRA could become ineffective at prompts, so be cautious.
The default is 0, and in the case of 0, caption dropout is not performed.
Rate of caption dropout
This is similar to the "Dropout caption every n epochs" mentioned above, but during the entire learning process, you can train on "images without captions" for a certain proportion of the time.
Here, you can set the proportion of images without captions. 0 means "always use captions during training," and 1 means "never use captions during training."
Which images will be trained as "images without captions" is determined randomly.
For example, if you train LoRA with 20 images, reading each image 50 times for just 1 epoch, the total number of image learnings is 20 images x 50 times x 1 epoch = 1000 times. If you set the rate of caption dropout to 0.1, 1000 times x 0.1 = 100 times, you will train on "images without captions."
The default is 0, and all images are learned with captions
thx for the guide above and your commitment. First time I ever played around with SD in general and still got no clue about all the terms, but was already able to do my own training and create some nice images afterwards with your basic workflow
has anyone managed to get the refiner to train?
you can stalk the dev branch if you want, but so far, casual refiner training is not a thing yet
https://github.com/kohya-ss/sd-scripts/commits/dev
once it's supported, you'll see it via commit there first
Question, is there a nice automated way to generate captions, and a UI to edit them? I want something to work with initially, and then edit the captions myself.
Also to curate the dataset, delete some images, etc.
Question, is it possible to merge xl1.0 base with the refiner ?
@stone garden lol, sup
Interrogator on webui to auto-tag using the Vit-H or Bit-big-G model. (vit-big-g is better, but requires more resources to run)
curation, I recommend adobe bridge for the initial "delete, rate, move" part.|
resize all images above 4000px to be less (can be automated in many apps)
then move to hydrus network, where you can import all the tags, and efficiently edit them
I'll have a comprehensive guide up eventually, on how to do it. but this is it in a nutshell
How much do all these cost lol?
those are all free ^^
hydrus network is somewhat complicated to learn though. so if your dataset is like around 50~100 images, you could use this app instead (not as good, but much much easier to use)
https://github.com/lukemoore66/FastCaption
for the actual training, these settings are still valid if you're just starting out with sdxl
#🔧|finetune message
It’s 1000s, but of course many will be pruned for lighting, etc.
i've also just open sourced a tool I developed for myself for combined manual captioning, tagging, and masking. It also has a few handy scripts for moving/filtering datasets and scraping booru tags.
https://github.com/briansemrau/image-data-tool
Does anyone know if it’s possible to train to a negative amount instead of 1? Like, if I train a Lora I want to train the negative variant so the positive does the opposite? If that makes sense.
Haven't experimented much with this yet, but super interested in its impact (also the impact of training with a different scheduler). If you give it a try I'd love to hear what you find.
yes/no?
basically you can train the lora normally, but then use it with negative values
tried it with my sketch lora and got pretty weird (but not bad) results
Yeah I guess that would be the only way, but I think that would be an interesting concept to somehow add if it’s even possible.
you should be able to flip the weights after you're done. not sure about how to do that myself, but basically you invert the weights on the tokens, and then -1 = 1. so it should do what you want
The code in sd-scripts is fairly straight forward and makes sense in terms of just adopting the minimal required changes from 1.5. There aren't that significant differences compared to for example the training setup in the diffusers training for LoRA, and there's an open fine-tune PR for diffusers right now that also is very similar in approach (some things differ like inclusion of snr for example). Diffusers PR here https://github.com/huggingface/diffusers/pull/4401
What's still quite unclear to me is what the impact of all these slight differences are, there's not much available data. For example how good results people are getting with float16, bfloat16 vs float32 precision, snr or not, batch sizes, learning rates, etc. There's simple quite a lack of benchmarks and data still. Model trainers are noutoriously BAD at sharing details of their findings as well.
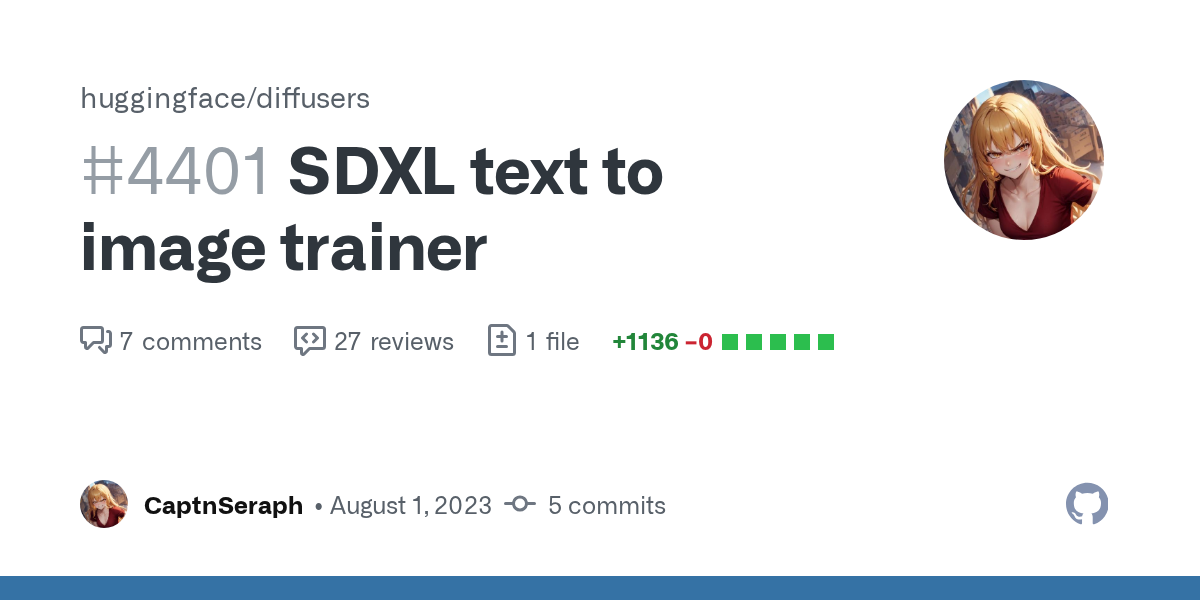
GitHub
What does this PR do?
This is a modified pix2pix that should enable a basic text to image trainer for SDXL
fixes issue #4366 as requested by @sayakpaul
theres some small todo in the code, and it do...
Hmm yeah I’ll look into that
oh shit. i REALLY need to load up my accidental youtube artifact compression LoRA
And do what with it? Invert the weights to see if it adds detail? Lmao
yes! XD
Do it! Lmk how you did it if you figure it out
I made an inverse aesthetic lora, but the results weren't obvious
Did you invert the weights? If so how did you?
you can just do weight = -1 to quick test it. results are the same as if you inverted it
and hot damn its working
my dumb accidental youtube artifact lora is now high detail lora

right is with lora applied with -1
Is that the same res? If so I’d say that did add some detail. Interesting
big image for the brave!
Artifact lora is using weight -1
BASE ONLY | Artifact Lora | Face Lora | Artifact + Face Lora

also some cherry picked results:

first of all, this makes using 2 loras at the same time a damn lot easier.
and the negative lora helps a lot with following the prompt XD which... I can't really explain
either way, this opens up a whole new box of stuff to research
For the vit-h captioning, should we use the caption preset on A111?
I feel like it always gives very simple captions to the images, but idk what an ideal caption length would be
has there been any proper research on negative prompting?
I know you said "More resources" but this is getting ridiculous. Am I doing something wrong?

neck is sus
in other messages Caith did (more or less) say "good luck running it lmao" so it may be very difficult to run
anyone got foolproof background removal i can run locally?
if you're running it yourself, you need the 8 bit version.
if you're doing it via interrogator app, then once the initialization is done, it should work even on a 4090 if you pick fast/caption only
but yeah, for properly running the flavor chain each time you'll be needing 48/80gb vram depending on 8bit or 16bit
it's not really a local solution, as the 3090/4090 can barely run it.
most that I'm aware of, run it via an A100 runpod or other hosted solution
Thanks for answering, it ran, just didn’t output anything to the console.
anyone messed with specified down and up weights when training lora? i get an error saying no perameters specified
prob worth checking if the number of blocks changed in sdxl - cause if yes, then you'd need to supply more parameters to statisfy all blocks
i looked it up, still 12, at least it should be. may have some hidden parameters that are not in the gui that are missing for me idk
Inpaint?
like automated tho
https://www.lightxeditor.com I use this. The AI background removal. pretty easy after a bit of fumbling. i use it a good bit now. If you find a better one let me know.

LightX
Create beautiful designs with thousands of editable and customizable design templates. Make social media posts, posters, ads, flyers, ebook covers and much more with LightX.
How are regularization images supposed to be created ideally???
If I just generate regularization images using "photo of a woman", I never get full body shots, face closeups, sitting or lying poses, or pictures from behind, while the training images include those shots.
On https://rentry.org/59xed3#hard-route I read:
"regularization images are reduced to latents and then trained on how to produce them back, using DDIM as sampler"
"You will want to generate an AI reg image for every training image you have. The names will have to match. So every training image will have a matching regularization image."
"Same prompt as the caption for the training image."
"DDIM sampler, resolution equal to your training resolution (not the same as the training image!), seed equal to your training seed (420 if you didn't touch it in the scripts below)."

Stable Diffusion LoRA training science and notes
By yours truly, The Other LoRA Rentry Guy.
This is not a how to install guide, it is a guide about how to improve your results, describe what options do, and hints on how to train characters using bad or few images.
Due to the higher prevalence of...
I would imagine the AI can learn the difference between training and regularization images best if the prompt is the same for both images, just with the trigger word in the training image!?
I am renting a 1 x A100 SXM 80GB on runpod. What are some good initial settings for dreambooth sdxl training that optimize for performance? I am using the huggingface/diffusers library with latest pytorch, latest diffusers lib, and the training pipeline from examples/dreambooth. I guess fp16 precision is a good choice for performance on a100?. I get something like 3.44s/it during training.
accelerate launch train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision="fp16" \
--instance_prompt="a photo of sks dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=1e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of sks dog in a bucket" \
--validation_epochs=25 \
--seed="0"
and ~/.cache/huggingface/accelerate/default_config.yaml looks like this:
compute_environment: LOCAL_MACHINE
distributed_type: 'NO'
downcast_bf16: 'no'
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
I guess I should try torch.compile
anyone have any good recomendations for a good tool to manage / tag / edit datasets?
use blip captions in a1111
seems like a good place to ask, but how can someone make a sdxl checkpoint? I can't seem to figure out... anything
quick question, what is "CV"?
"8bit Adam is slower but saves memory and results in a higher CV" - what does CV stand for?
I think it's limited to training loras until someone figures it out
how are people on civitai making checkpoints though?
Cross validation (score)
and what does that mean?
thats what i have been wondering for over a week now 😂 cant find any infos about how to finetune sdxl checkpoint (not lora), but obviously there has to be way, as there are already some fine tuned checkpoints on civit. have to try harder gathering i guess
It's a way to validate model performance for kaggle competition, nothing we should be concerned about for stable diffusion
ok, than i gues smy question is shall i use adamw oder admaw8 bit? i cant find too much about the difference
The point of adamw8bit is to save vram, if you are using a consumer GPU you should prefer the 8bit
i am wondering on what is the difference in the model at the end of the day
so far i allways used adamw
i am wondering weather i can expect the model to get worse with adamw8bit
No hard rule to tell, they will have different optimal parameters which you can only find by experimentation
took me 2 month to finde mine with adamw so better not touch that lol
Adam8bit will allow higher batch size which can train faster
doe sit make sense to train an 1.5 model with 768x768 max size? i read online that it can pick up more detailes this waay
Hi,
How deep should captioning go when training a person/character lora?
I have seen conflicting information on this and was wondering what results people here have had.
At the moment I am not captioning very deep.
Eg:
Uniquetrigger, man wearing tank top, close-up, from side
uniquetrigger, man wearing jacket and pants
Should I be captioning even less?
Eg:
Uniquetrigger, man, from side, close-up
Or more
Uniquetrigger, man with a beard standing in room wearing blue tank top, from side, close-up
Uniquetrigger, man with a beard standing on a balcony wearing blue tank top, from side, close-up
or excessive
Uniquetrigger, man with a beard standing in room wearing blue tank top, from side, close-up, white wall, cabinet, brown eyes, photo
Uniquetrigger, man with a beard standing on a balcony wearing green jacket with black sleeves, from side, close-up, trees, ocean, islands, houses, photo
tag or prompt is to descript your image. In training, it means your lora try to learn to use your caption to descript the training pair image. If less, you would able to produce the similar image in less caption. Something you are not mention in caption would be learned into your mentioned tag.
Correct me if I am wrong
The guideline I follow is to describe everything but the character. You can describe their clothing if you don't want the AI to associate the clothing in the training images with the character. I'd avoid things like hair, eye color, etc unless you want to be able to change those things in your inference
I've done lots of 1.5 training with higher resolution loras. it does help a lot. i think i even took it to 896 a couple of times.
my usual captioning strategy. i collect a bunch of tags i want to consistently use. like "muscles, shades, looking cool" whatever. Those might not apply to all your images but you want them to be consistently tagged where they are used. so you form a consistent tag set. thats step 1.
step 2. captioning each image with a template pattern. "token class, tags, clothes, background" so it could be "jack man, muscles, shades, looking cool, lumberjack flannel jacket, heavy duty jeans, in the woods"
step 3. there is no step 3. ez pz.
end of the day, just go for it. captioning is just voodoo imo
whenever i try using clip and blip to caption, it's always some junk like "man holding a beer and sitting holding a beer with a beer in his hand holding a beer sitting at a beer table with beer"
Thing i don' tlike about those is that there's no commas so they don't play into caption shuffles or dropout mechanisms that kohya uses
for me what i do as captioning is i create as @pliant drift mentioned my base catpions of the concepts i want to train, like, "standing, sitting, whatever" and tag all my images
then i use an automated tagger and add all the usefull tokes i get from it
and then i prefix my own tokens
for me DeepDanbooru captioner worked quite well, however you need to get rid of the nsfw tags afterwards
@pliant drift when you say you trained with higher resolution do you mean to change the max resolution settings higher or just use high res input images?
flowwolf you should try DeepDanbooru captioner, you get a comma seperated list of tags and if you enhance that with your own the results got much more flexible in my tests
i've never considered that app because i don't do anime or anything like what danbooru hosts. LOL only reason i know about danbooru is because i was wondering what all this talk about booru tags in anything v3 were
would an app like that matter to me? like, i'm training generalized styles for non anime models. I feel like the anime guys just got way better tooling. Booru tagging culture is actually a huge boon to this new field
i dont do animie either
but i have tried like 10 different taggers and overall this one worked be for me for lora on ppl
i even did testing for landscape and it did a good job
you can test it here
what i found most importaint is that you still create your concepts and tag the primary tags you want by yourself
but once you have that sorted you can just use the tagger for the details
@flowwolf regarding the sizes may i ask for more details?
can confirm. 896 REALLY paid off. the last lycoris model I did for 1.5 basically upped the resolution you can generate to 896, and gave consistent results more than 80% of all generated images -which is usually my target line
the amount of images I manually tagged in the last two days.
only 25hours of manual reviewing/editing/tagging
roughly 20k images were reduced to that
100% watermark free
@hollow spruce i am train a lora and i forgot to add these args to one of the sample prompts --w 1024 --h 1024 --d 1 --l 7.5 --s 35 --n blurry,text,watermark can I edit them in the prompts.txt file from the samples folder
yep
once the next image generates, it always checks the .txt file for what is has to generate
so you can change it like every epoch if you want XD even change prompt entirely
oh ok
but my main prob was that its just 600 steps away from generating samples
I've done that before when I had an unlucky seed for what I was training
i dont really trust sample images
same. which is why I've stopped them completely in sdxl. on 4090 I have enough vram left to run comfy on the side (normally at least)
but now I'll just wait it out
oh cool
after waking up from sleep I'll just test everything. if you're not in a rush, you can just load up comfy anyway, let it overflow into ram, and sure it takes like 10 minutes to generate 1 image. but if you're not using the pc that's little time to wait

@hollow spruce when using Kohya, does the training continue after waking the pc after sleep?
or will it terminate if we put the pc on sleep?
ah. may wanna try out the cpu only method. see if that works in the future. (not now though, when you just try if it works)
that's terrifying XD no idea
oh ok
I'd assume it crashes since it uses so many systems
not many apps are optimized for sleep
@tall condor sorry i've been wrestling with configurations . when i say using 896 images, i mean i'm bucketing and setting the resolution in kohya to 896,896. the training sets i have i try to do at the highest quality, and i let kohya downscale it to appropriate buckets. Common crops help here a lot
where appropriate i'll even double up the training data a bit, for people especially, i'll do high quality square crops of faces. If the closeup crop isn't decent quality at the training resolution, then i toss it. quality training data is paramount
high resolution alone isn't a magic bullet. there should be high quality imagery too and thats up to you to eyeball
and how many batches can you do with that? like 2?
i have 16gb. i guess maybe 3 -4. gradient checkpoints seeem to be a magical way of getting higher batches at the cost of speed. I use them to huge success.
thanks for the input i will try that
i tried deepdanbooru on a few typical photos of the sort i'd like to deal with. i guess the demo doesn't show the tag editing capabilities. it kind of sucks for photographic purposes and the only thing it does see accurately is the text. i hope the editing abilities are better

i use a janky script i milked out of chatgpt right now
i have something for that sec
its quite fancy
GitHub
Use miniGPT-4 batch to generate captions for a lot of images! You should be able to create the best captions you always wanted! - GitHub - pipinstallyp/minigpt4-batch: Use miniGPT-4 batch to genera...
it works quite well but does not produce tags, its more like the clip
will post more info on this eventually,
but if you're training a single face, then use DIM 24/alpha 1
that is big enough that no detail should be lost at all
emphasis on face only.
for essentially all other loras, dim 8/alpha 1 is still the way to go.
For face training, is it still ideal to crop as close to the face as possible? (Or is the 24 dim also for like upper body + face)
getting this error when trying to merge loras merge_lora.py", line 6, in <module>
import library.model_util as model_util
ModuleNotFoundError: No module named 'library
@pliant drift when i increase the max size to 768 my model turns into maximum crap
any suggestion on the settings?
Woah, a quick test (because your workflow allows for such quick tests) - and.. it seems to have made a lot of difference. 🙂... Im particularly honing on quick loras as i use them for reference so usually have about 10 face shots (which like, 100 odd repeats on each image for 1.5 and random crap tagging was fine. Looking forward to your detailed guide.. if you haave a buymeorcoffee or somesuch, let me know. Keenly following as you've been a massive help.
@hollow spruce Sorry to bother you, if we are not training the text encoder on sdxl, why would the trigger words work with the lora? As my understanding, the trigger was learned into text encoder in previous lora. When we loaded the lora with models, we use the trigger words to trigger related trained features. In my sdxl lora testing, I am still doing the same thing without training the text encoder. I dont understand how the model+lora could know my trigger word and trigger related features.
the clip is like a translator. it takes your prompt, and translates it into ai language.
if you are training a specific car, and give it the caption "car", then clip will take the image, and do its best to translate it from a car image, into car data.
if you give it an image of a monkey, and call it "car", then the clip will still translate it into car data, and the unet layer will just stare at the clip in a very confused way and mumble: "well if you say so...". causing all future cars to very very slowly converge into monkeys.
but if you used the caption "monkey", then it would make a lot more sense, and the unet will learn it much faster, since its data that already makes sense when the unet looks at the converted word
if you actually train the clip
then in the first instance, it will look at your car, and make the ai word for car also sound a small bit more like your english word for "car". It makes the whole translation process smoother and easier.
In the second example of telling it that monkeys are cars... its gonna REALLY mess everything up about both cars and monkeys XD but after enough epochs, and after having seen enough monkeys that are all called "car", then essentially the ai will learn the new meaning for the word, and translation will be smoother.
so why don't we do clip training for everything?
because just telling it that its translation is wrong, often does more harm than good. You only give it a word, with very little context. meanwhile the original meaning the ai had before you, was incredibly complex and linked to many things.
for cars, this isn't much of an issue, as it will quickly learn it. but if you dare to teach it eyes, neck, hands, feet or any such words, which are extremely complex when viewed in context of the bigger picture, then unless you're willing to provide it with around 5k images, you'll only teach it wrong things.
clip training is great. half assed clip training is bad.
here'

here's an example. I'm currently retraining "girl" since the clip understanding of that word is pretty wrong.
vertical is clip training, horizontal is unet training
basically, once my training is done, I'll be able to specify age groups, without bias from the words "girl" or "woman", since I'm completely retraining the meaning of those words in both clip & unet
but it comes at the cost of 4200 manually tagged images 🤣
still not nearly enough, as I'll need about 3000 images per ethnicity
I think I get the answer after seeing your explaination. For example, my trigger words is multiple characters, xeanlwan, the text encoder is freezed. The trigger word would be splitted into something like this xe, an, nl, w, and the unet got trained on those words leanred from the training image. When I loaded the lora, the text encoder also split my trigger word into same combination and because of that, te unet could load the trained features.
thanks for sharing
its usually best to change your trigger word to one that matches your content.
if you can't change it (training many many concepts, and you don't want to write a guide for how to use your lora)
then you have no option but to train the text encoder, to make all your trigger words work
Does it means if I change my trigger word to the closest word in the vocab would makes the training much faster?
For example, when I train an anime character call jianguo, rather than use his name as the trigger word. I should use male anime character to trigger the lora.
yes. absolutely
it's literally like a multiplier
if you're training a face for example, you should find out which celebrity looks closest to you, then use their name to train your own face XD
but does it means I need to input his name to trigger the lora?
lin the celebrity example
Thank you for sharing this useful information
did anyone tried textual inversion with xl model? im getting mixed results
if you're doing captions, then you want the first word in your caption file to be that name:
lin sheng, a man wearing swimming trunks holding up a gold medal, olympic stand, pool
and then have your settings like shown in the screenshot
if you have no captions, then you'd just have your folder name like: 1_lin sheng

I usually do that but if the text encoder is not trained. How would lin sheng represents to the person who I want to train. This is my question
ah, this was referring to if you know what celebrity looks like you
and I was hinting at gold medalist lin sheng

Oh, I didnt realize the name is a celebrity.Lol
you dont actually use your own name. you use the name of a famous person that looks like you! XD
Now I get that
adaptive optimziers. dadapt. adafactor. prodigy. use the learn rate of 1 and let it take the wheel.
which one worked best for you?
anyone know if you can get the entire codeformer algorithm into stable diffusion? THere is an extension but it seems it doesnt come with uber face upscale and enhancement
So LR 1, but what about Unet and TE LR's? Make LR=1 too for these? What if we want to turn down the TE? Does it affect the TE LR to lower it at all, or is adaptive completely automated on the unet/TE as well?
How are you training it?
Lora's have an essential requirement according to the kohya documentation. --network_train_unet_only (i think thats' corect) so keep that in mind.
now those other learn rates are optional. if they're both 0, then they both use the learn rate. But since you're only training the unet, setting the TE here doesn't matter anyways. Understanding what the settings are helps a lot. They're optional settings if you don't want the LR for both the TE and Unet to be the same.
As usual i'm always coming back to this. RTFM. I could've also mentioned --network_train_unet_only at the beginning too, but i thought it was implied and known already. I tend to trust people have at least read the manpages when they're looking for help.
@hollow spruce How would you find the closest celebrity for lora training? I have tried one but I think the celebrity I had chosen wasn't the closest one and it does affected the likeness to the lora.
almost like standard script
i changed to tune both text encoders embeddings and smaller size images (will try later on 512x512)
Which script
originally from diffusers, with lots of edits from myself
🤷♀️ i can share if you interested
Thanks dude. Yea, basic questions
• quick google
• use Interrogator + Vit-H on an image of yourself. see what words it says look like you. google a few of them, then be amazed by the fact that there is a famous doppelganger of yourself walking somewhere in the world! XD
• use a word like "model photoshoot" <- much less ideal, but avoids the research on yourself XD
Thanks. Where can I use Vit-H standalone?
A1111 webui -> addon Interrogator
you can also load it standalone via the github page, but that comes without the ability to batch interrogate an entire folder all at once
Thanks. I just uninstalled the webui. I will try the github.
I have a question, is Micro-Conditioning from the paper also related to training? or is it only related to generating?
If I select don't upscale buckets in training a Lora (train on the original resolution of the images) and then do Micro-Conditioning in generating in comfy does it know that it should use the quality of the images above 1024 px but still use the knowledge from the images under 1024px?
Do you know if it was ever working or if it broke? Do you know the commit that broke it?
it wasn't ever working as intended. i think it works it's just a little bit haywire until the devs sort things out and optimize things. sdxl has two text encoders so training them isn't as straight forward
to be exact, text encoder support was added just before 1.0 release.
but it's not about the training being supported - it's about it being nothing like training 1.5. which is the first thing people do - just pretend that sdxl is 1.6, which it is not
I talked a bit about training clip over here: #🔧|finetune message
I have tried to train with celebrity but I didn't get the likeness to replicate the original image using the training prompt. Does it mean it is undertrain? I usually able to replicate the image around 80~90% using the training prompt with unique token training.
probably. more closeup photos usually help speed this up by a lot]
the more uncropped they are, the longer it takes, and the more images you need
My dataset are 15 images, most are upper body.
I am trying 400+ images now with celebrity training.
I see now many fine-tune anime xl mode in civital , but all of them had a bad performance , even worse than 1.5. I think training sdxl not only just train base , refiner model is also even more important. That's why until now there is not good xl model of anime.
SDXL is good, 50% is because strong clip, 50% is because refiner model. No refiner model, the result of sdxl is not surprising .
It seems that most people still don't realize how important the refiner model is.
If there are a good anime sdxl model, it must have a related anime refiner model .
maybe try extracting a lora from the finetuned base model and plug it into the refiner? not sure if this will work but it might?
or the other way around maybe
refiner is not that much.

I do agree a good fine tune should has its paired refiner model, especially the anime model which is a total different things of current model.
SAI should provide insights on how to train properly or at least how they did it, it's kind of weird they did beta testing with finetuners yet no best practice being shared.
For example to this date we don't know if 1.0 uses offset noise or zero terminal snr.
They said they trained with huge dataset which is not compatible with consumer level equipment.
And the training method is also different
That's not the point, things like if./how much offset noise or if foundamental things like zero terminal snr should be used are invariant to the batch size
offset noise for SDXL is 0.0357
Maybe true for 0.9, probably not for 1.0, the two models look a lot different
Two my best knowledge 1.0 doesn't use offset noise, but we shouldn't be the ones to make guesses when such things can be easily explained by offical SAI
You prove my point, the community shouldn't be digging for pieces here and there when the team can easily put together a coherent piece explaining things
I do agree SDXL is kind of lacking well documentation. Many things need to be experiment. If dev team could provide more information which would be nicer.
Release shouldn't be "let's throw it out there and let people solve puzzles", documentation is important
Especially given the fact that there was a beta test
I could imagine 0.9 is rougher than 1.0 and they couldn't postone 1.0 again
prodygy and adafactor for me uses a way to high elarning rate. is there any way to control that
both of them should be auto adjusted in the training
Lora does tend to use high LR rate, nothing inherently bad with that
Could someone edit one caption for me so it’s in the proper format (I could work on editing the rest myself):
The image shows a woman with long red hair wearing a black top and looking up at the sky with a pensive expression on her face. The background is a cityscape with skyscrapers and other buildings visible in the distance. The image is well lit, with the sun shining down on the woman's face and casting shadows on her body. The overall mood of the image is contemplative and introspective.
what do you want documented?
it's a machine learned neural network. releasing it with documentation would mean 3 years of research into figuring out how to document it
these tend to be black box systems. even by the people who make them. it's sort of a key aspect of the entire field of Machine Learning.
Setting and processes that they used to trained it. Best practices during their training and beta testing. None require 3 years of research
also, due to the nature of open sourced fields, most of the components are all made by different people. the memory optimizers for instance. wnat to learn about dadaptation? the documentation is in the project. https://github.com/facebookresearch/dadaptation
how are they to determine best practices?
You think they didn’t do any research during training and just hit run and released one model they got? There’s a lot of trials and errors during fitting, a lot of learning during beta testing, not much of those shared yet
these complaints got strong armchair expert energy to them. you're coming in here demanding help and blaming the world why you haven't found it yet. lack of documentation on cutting edge software is kind of what's expected and always has been. There is so much information for you to search out and dig your teeth into, but you're instead coming here and wasting energy blaming stability for not releasing documentation about a black box system
have you read the paper they released for sdxl on arxis? they published
complaining about documentation lacking when you've not even studied the paper or put any notes on it
arXiv.org
We present SDXL, a latent diffusion model for text-to-image synthesis.
Compared to previous versions of Stable Diffusion, SDXL leverages a three times
larger UNet backbone: The increase of model parameters is mainly due to more
attention blocks and a larger cross-attention context as SDXL uses a second
text encoder. We design multiple novel cond...
Yes I did, but you can’t say docs are sufficient as of now
then why are you complaining about not knowing training settings?
Because a lot of those were valid for 0.9 not 1.0
Such as offset noise
I can say that because i've managed to find my way around just fine. i've not relied on any youtube tutorials at all since after the 2.1 release and i figured out that none of them really knew what they were talking about
the one i linked is for 1.0. hmmmmmmm
1.0 is a progressed version of 0.9 too so all the information in the former version of the paper would matter
Then good for you, you are talented. Why get so worked up about a user wishing such info are more organized and centralized?
It’s not like they don’t have the info, but not everyone is as talented as you or as patient to dig stuff out
i'm not very talented. i just don't have an aversion to combing through open source information
have you even read kohya's training manual? all of that informaiton still applies too
I use kohya and I train fine, what’s wrong with demanding such things are more accessible to everyone? I don’t get why you are so angry about this
because you're making unreasonable demands when we break it down. like i have.
believe me when i say i'm not angry about this.
I believe you.
"the community shouldn't be digging for information" feels really lazy and more about "i don't want to do legwork" since nobdoy researching any field will find all the information in one place. Research and learning will always require leg work. I don't understand people's aversion to research. learning is awesome. Spoon fed learning is just doing what you're told. Going out and discovering exactly the knowledge you need is what being human is all about.
Yes I’m advocating spoonfeeding because for good documentation you should always assume users are dumb and lazy. I’m advocating for those majority of users out there, nothing wrong about that.
users won't read the manual. always assume that. the lazy people will always want someone else to do it for them. that'll never end regardless of all of stabilities efforts. we are in the Eternal September
#oldmemes
example. LInux is arguably more documented than windows. windows costs money while linux is free. people still use windows because they don't want to read manuals, ever
i really don't buy the altruism schtick if i wasn't being clear
i understand that lora is using high LR but the models are so dominant
What do you mean by dominant?
i mean that as soon i add it it it becomes very dominant in the results, i need to turn it down to 0.4 or less to generate regular concepts - but if i turn it down so far it barely generates the face right
if this was a regular model i would say its very overfit
i have treid about 10 different settings with the lora but apparently its either too strong or too weak - it appears to be much more harder to get it right than creating actual models
also after around 50 epocs the loss move to <0.02 and so on
i think its just very fast overfitting
how many epocs do you guys run? usually
You could just save the lora more frequently and test which one is the best
yes obviousely i do that but i find it quite hard to find propper settings
If you have 50 epochs come to <0.02, you might try 10,20,30,40,50 and try to findout which one is overcook. If you find that, move to the previous one and testing out.
repeat the process you might find the perfect one
but even at 50 epochs some concepts tend to underperform so i cant just reduce epocs
what learing rate are you guys using and how many epochs and how many repeats in each epoch?
if your loss is less than 0.02, it should means you could reproduce the training image by the training caption at very high level similarity, let say 98%.
yes, how come some concepts underperformed?
well some concepts are just harder to learn and take more epochs
i try to balance that out with higher repeat count but you can also only push that so far because otherwise it will break the model
Does the concepts perform correctlly in 50 epoches result? If yes, you might try the 40 epoches one. If 40 is great, you could try to use 40 epoches in next time or run the same dataset with 40 epoches and see would it be ok.
with adafactor the resulting model produces allmost only the model arready at 50 epochs
i need to do some research on the behavior i gues
prodigy is even worse
And you don't need to run the full training if you could see the result is enough
what dim/alpha ratio are you guys using?
possible for a mod to pin this?
When training and I dont put offset noise on that number I get a warning that it was trained on that number so I guess I was
so for me it is very unexcpected that a rank 8 lora has allmost the same effect than a rank 256 - why is that
I need clarification on something. Online guides are very conflicted on this.
As I understand it: If my 20 training images are in the training img folder, "20_ronald", thats 400 after repeats. now if my reg folder, "1_man", also has 20 images in it, then there's one reg image for every training image.
BUT if I put way more images into the reg folder and keep "1_man" title, training still goes for the same amount of steps. So theoretically if I put 400 images into reg rather than 20, there would be one unique reg image per training image repeat, rather than 20 reg images repeated 20 times.
Correct? Why does this not lengthen training time? Why are people being told to use the same # of images in both? Is there even a benefit to putting more images in "1_reg" than in "20_img"?
My best guess is that it just finishes the epoch as if you had no reg images... Having 1 for every batch ensures a consistent benchmark for every image. If you put more, my guess is they get skipped
Unless you get the guy that wrote kohya_ss to comment, or someone that actually understands the code, it's just guess work
@safe pecan 🤔
The way I try to think of it, every comparison of your training image to the class results in a score, that gives you the loss. But the class itself changes as you fine tune the model. The reg images would serve as a stable unchanging representation
That's why people recommend 1 for 1
anyone know how to train a sdxl refiner model using custom data?
https://github.com/kohya-ss/sd-scripts/issues/640
explains the nuance of it a bit more
full finetuning - which isn't really a 1 man job anymore, nor are there any examples of other people who did to base your work off.
other than that we currently have no way to train the refiner.
yes i spoke with him (SEcourses) about it a lot today in sdxl but he still couldnt confirm. He's been using hundreds of reg and didn't know people have been using matching numbers. i just don't know if that's actually working for him or if 380 of the reg images get ignored
in short - your assumption is completely true.
the reason is doesn't take longer, despite all the uniques, is that only latent caching takes a bit longer. but if there are only 20 images, then they get auto-repeat to match the total steps of your training folder
essentially, the moment you declare a regularization folder, you multiply your steps by a total of 2. Images from the regularization folder are taken until they match this number, or multiplied until they match it
Thank you for the clarity, been looking for that answer all day. So there's no reason that people should be matching their image counts if theyre using repeats, because they'll get better preservation with less repeated reg images (more images in reg folder). In that case I'll just use a permanent 1000 img reg folder to ensure all uniques.
yep. it's why in the past people often had folders with 10k images. Because while having more often doesn't make a difference, if you're in a situation where you don't have enough, then thats actually a bad thing.
I've currently sidestepped this by using no regularization folder at all, and instead including it as an additional training folder. -while I can confirm that this works for big and more complex loras, trained on datasets of over 1k images (for the both the training images AND reg images), I haven't tested it with smaller datasets yet
what token should class images use if training a face? many in sdxl channel said they use the same instance token on both training and reg.. i cant see how that would be a good idea
same token defeats the purpose XD
I don't train faces enough, to have tested this properly. But I can tell you the 2 ideal theoretical ways.
Training token: <celebrity name>
Regularization: man (or woman)
option 2:
<celebrity name> man
man
option 2 follows the original dreambooth intention a bit more. can't confirm if it is better or not though
@hollow spruce I tried the celebrity method and I think it is less likeness then unique token method. Some celebrities features remain on the result compared same training with unique token.
I also tried to use your reg files. It kinda prevent my lora to learn the features from training image compare with no reg.
oh no D:
thanks for letting me know. I'll mess around with it tonight, and see what changes work best
In my recent experience, both of these things you just mentioned required me to extend my epochs but boosted quality and likeness in the end beyond what 'no name' or 'no reg' were capable of. Felt like lora vs. dreambooth.
but tbf my LR is .0003 so less relevant to caiths params
which makes sense
learning rate might be adjustable, so I'll try it from 5e-3 through 1e-4, and record how many epochs (steps) it took to learn all the features, as well as the quality thereof.
I was training on 400 epoch and the result still the same as 20-40 epoch with celebrity+reg
my regularization data is still biased towards standard caucasian, so maybe the reg data is having an adverse effect to that
Yeah, my training data is Asian which seems conflicted with your reg set.
I'd love to see the results of that. you should post findings here afterwards🙏
also some unusual features
Yeah. I realized that 'asian' isn't even good enough. I'll have to split that tag into chinese/vietnamese/philipino and so on
I finally got all the images though, so now its just a matter of filtering and tagging ^^
you do realise reg images get shuffled every epoch. In that Kohya issue about repeats, he asks Bmaltais if each epoch remembers what class images have been used in the previous epochs, so as to run the whole diversity of images. The problem is there is no way to spread all class images across epochs. It’s an open issue unfortunately
yes you can't spread across epochs but you can spread across repeats. if a 10 img training folder is getting repeated 20 times per epoch then there's 200 steps, which could be paired with 200 unique reg imgs rather than 10 of them repeated 20 times.
Thanks for simplifying and clarifying. So, if we can only randomize within an epochs repeats, it stands to reason to only use as many class images as there are in an epoch, in this case above, 200. Furkan from SECourses suggested to Bernard to implement a way to link class image randomization across epochs, but he said he didn't have the time to do it unfortunately. Think dreambooth extension solves this by using global repeats for randomization of class
Can I double check something with folks here? I've read a reddit post on SDXL lora training, and in the example they have 14 training images repeated 7 times, and 200 regularisation images, with a training step count of 3000. In their post they claim it takes 30 minutes on a 4090.
Now I'm trying a broadly similar setup using the same params (as far as I can tell) and it's estimated to be about 20 hours on my 4080. Is there something I've likely got wildly wrong? I can't imagine estimated training time is non-linear. There aren't so many posts on using sdxl_train_network.py so I'm having trouble cross-checking this with other sources.
How do I train a character LoRA? I tried making a character and style LoRA with 10 images and I got the style but failed on the character
By some miracle, I have access to my desktop again, so I should be able to train on a reasonable time
Do LoRA dimensions always need to be powers of 2?
no.
since 24 is the current ideal for faces.
can't talk about the theory behind it though
Thanks. I'm just playing around with values, as going from 256 down to 128 gives me an absolutely incredible increase to speed.
Caith - Kinda curious on why your posts arent pinned , .. its like, anything you say should be revered (IMO). But anyone poking about on the things youve said already would.. learn alot. Felt impolite to @ you welcome to ignore it or not even see it 😄
❤️
joe said he'd have the team review it. but I'm pretty sure I was forgotten 🤣
it's fine though. some day once my guide is up, I'll get them to link that!
Question, what are people's views on reg images? Also, in my LoRA, I can't get people's teeth to come out right. Any tips?
Ive yet to see anyone else produce something that could be proven to be gold (and at the least a high level base with you know, tweaking) in like, 14 minutes or less.. but.. really looking forward to your take on a guide - thanks again
yep
teeth need about 5 times as long to train as faces
still haven't found a quick way to solve it other than either bigger datasets or accept more overfitting :/
I mean, I'm not picky whose teeth they are, they should look like teeth and not one big blob.
I didn't solve it for my mega lora until I hit 4k images in my dataset 🥲 (essentially a finetune, but in a lora)
I had this theory for why reg images are not working properly, I personally think you'd have to generate images on the same seed you put your training to and the same prompts your captions of your training images are, not sure how accurate this is , didn't have time to properly test it yet..
reg images in dreambooth needed the activation word of your model (to target the right part of the model) so that might be the same if you use captioned images in lora
regularization is great for faces - but other than that, for literally any lora, I've not yet needed them
Ty so much. 😄
@hollow spruce i trained the lora
but i dont know if its really good
do you have any workflow and sample prompts to test?
depends on what you want to achieve?
if you wanna be genuinely partial, try random prompts from other people, which roughly include your lora subject
I usually mess with random civitai prompts, and generate an image without and with my lora
ok thats better
@hollow spruce can you share a workflow for testing lora, as i dont have any
Can you get over-training with a lora ? I remember over-training in SD1.5 Dreambooth and the subject's likeness was present in every single face that was generated
yep. that is called overfitting. and it is something you both do and and dont want at the same time
up to a certain point it's usually good, and after a certain time it gets bad
especially bad if you accidentally also trained things like low quality noise/backgrounds/a watermark present in all training images
Ok, and I guess that's why you have checkpoints generated every n epochs, and you manually test them to find the right balance
exactly! ^^
I haven't quite figured out the maths for a good epoch balance, so my current run has generated 18, which is probably a bit excessive 😄
yes and no
it will work, but if you have sidecar caption files, with the same name
then obviously "image.jpg" and "image.png" can't both have their own "image.txt"
that can lead to serious issues - but other than that, you're good to go ^^
Are the sidecar caption files suffixed with .npz ?
Or is that an intermediate cache of the latent values? (maybe this depends on your workflow. I'm using kohya-ss/sd-scripts)
yes those are latents
When I train my Lora after a certain number of epochs I just get black output. Is that overtraining or what is that? Any idea of what I am doing wrong?
I think you need to reduce the epochs or perhaps increase the dampening.
Is the loss going up a bad thing, and what can I do to control it? It goes up, but only slightly. I'm already using prodigy with ["decouple=True", "weight_decay=0.01", "d_coef=2.0", "use_bias_correction=True", "safeguard_warmup=False", "betas=0.9,0.99"], I've noticed it happens when the d*lr/d jumps.
What does increase dampening mean? I am using AdamW8Bit constant_with_warmup (5%) and a learning rate of 0.001
I'm getting it with other samplers too
You probably need a lower learning rate and a different sampler.
What's the recomended learning rate and sampler for SDXL Loras? (For a character)
I don't know, I'm still doing SD1.5 first.
the ones you're using are the only ones I've seen "recommended". There just havent been enough experiments yet. I'm using Adafactor and 3e-4, someone else used 2e-4, and SEcourses uses 4e-4. training times for those rates can go up to 2-3 hours. yet caith gets good stuff with 1e-3 in 15 minutes, but we're all doing very different things.
that's very interesting. Whats the theory behind how @hollow spruce can get good stuff so quickly?
i don't think he's focused on photorealistic faces so it can be more quick and dirty. those of us trying to make HD photos of real people all seem to be using 256 dim still, and 0.0005-0.0001. it does a deeper, more dreambooth-like style of training
styles, concepts, objects, animals, mostly anything can be trained much faster than faces if you're going for flexibility + likeness + photoreal
Thank you for the explanation. What's the best resources for best practice for captioning, regularization and parameters when it comes to faces? Any up to date guides that works for SDXL
I would try SEcourses youtube channel for a visual breakdown or Caith's message here. I haven't seen any other well-informed "guides" #🔧|finetune message
What would you recommend for captions for such a Lora? Prose or prompt?
Also what about the dim/alpha for 1.5?
i'm not even using captions anymore for training faces and it's perfectly fine without.
i've never made 1.5 loras, i was on 2.1 when they came out so idk
About loss going up? Do you check that in a tensorflow graph or in the training terminal data?
hello everyone
i just cant get this to run on google colab
no matter what i do, it throws the following error

Both
Has anyone tried to finetune XL 1.0 refiner for anime style?
If you really mean "finetune", then no, since even the base has only been finetuned 2 times so far:
https://huggingface.co/hakurei/waifu-diffusion-xl
https://huggingface.co/Linaqruf/animagine-xl
If you were referring to LoRAs, then no. Since we currently can't lora train the refiner.
How did those two guys finetune the base?
How is ANYONE training SDXL LoRAs? Which commit of kohya-ss do you guys use, the dev and sdxl branches are broken.
kohya-gui main branch - it gets updates from the dev branches, so you dont need to do anything complicated
anyone know how to find and remove unicode characters from the caption files?
Speed training for faces! it's time
Lora Training Settings - speed training faces edition
(24gb vram version for 3090/4090 or datacenter cards) - no regularization images - trains relatively fast
Use exactly 40 or 45 or 50 or 55 or 60 images (multiple of 5, and as close to 50 as possible)
Do we need captions for images? Yes! Because this is training the clip - hence the instruction are a bit more important to make this exact setup work
What captions?
- A trigger word (caith, sdxl_token, george, sara, ohwx, shirogane-sama <- can be anything, as we're clip training. no need for celebrity names. Just please dont use "coffee shop" or "toyota". Any normal names, or completely made up names will work though)
- Your class token (boy/man/girl/woman)
- any features that aren't present in all images (glasses/sweater/suit/outdoor/indoor/shower/red lipstick/black lipstick)
A few example captions for images from my dataset:
girl, glasses, indoor, shirogane-sama
cindy aurum cosplay, girl, shirogane-sama
asuka cosplay, girl, indoor, shirogane-sama
(order doesn't matter - since we use shuffle captions!)
Training Images setup:
- they don't need to all be 1024x1024 - its fine to have some lower quality ones, and it's fine to have like 2048x2048 images
- they do need to be perfect squares 1:1, as we won't be using buckets, to reduce the amount of things that can go wrong. (buckets work just fine, we don't use them to keep this as simple to follow as possible)
- images should be zoomed in on faces, similar to portrait shots. I'll include 4 sample images of my dataset, so you can see what level of zoom is recommended
- folder name should be your class token that represents your images. Choose 1 from these 4: boy/man/girl/woman
(my folder name was 1_girl in this case) - No need for regularization photos
- Repeat must be set to 1
- Caption files need to have the same name as the images:
1bec16d.jpg
1bec16d.txt - jpg/png/webp all work just fine - but obviously make sure they all have unique names
Settings:
- Make sure you're actually on the LoRA tab
- Change Source model path to your own
- Change folders to your own
- Under Parameters -> There's a VAE option. Link it to the 0.9 VAE (then samples are kind of working)
- Sample Prompt needs to update to match your own:
<trigger word>, <class token>, flavor text --w 1024 --h 1024 --d 2 --l 7 --s 30
shirogane-sama, girl, indoor, glasses --w 1024 --h 1024 --d 2 --l 7 --s 30
Expectations:
- This should work straight on the first attempt, as long as you follow the guidelines.
- Epoch 60 should be perfectly cooked. (but do try a few below and above that - just to be sure)
- Training time: 8min per 10 epochs with no samples. (so about 80 minutes for 100 epochs)
Explanations of Parameters:
Consider this training to be a bit more... aggressive... to put it mildly.
Essentially we're using Dropout caption every n epochs to literally nuke the model with our training info.
We are using Text Encoder training - hence what captions are used is important, as some captions will break the model quickly. Start out with my recommendations, and then slowly expand from there.
All learning rates are set to 0.0005. This slows down training a bit - but that's needed due to what we're doing to the poor sdxl model with Dropout caption every n epochs
Network Rank (Dimension) is set to 24. This is the highest you should need to go - while higher may give better results - don't mistake this for your lora getting better vs the whole sdxl model getting worse. Essentially our dropout setting should emulate the effect that that higher dim setting was giving. It's not necessarily the best option that exists - but it's certainly not more destructive than using dim 128 or 256.
F.A.Q.:
Q: Can I enable Buckets?
A: Yes! Just make sure all the buckets have images that are a multiple of 5.
Q: Can I use more images? (Like 100!)
A: Yes! It will most likely increase quality, but the epochs that this needs to run will change. Basically just try out your various checkpoints afterwards, and let it run for longer.
Q: Will this run on 16gb vram?
A: Yes! Batch size & caption dropout will need to adjusted. To what? That requires testing - feel free to try out various combinations and report back.
Q: Will this run on 12gb vram?
A: Most likely not. Text Encoder requires some vram as well - and that will probably push you above 12gb vram 😦
(But you can still train with other settings that don't use clip training)
Q: Why is it taking longer to train?
A: Cause we're generating samples. Feel free to turn them off for an almost 100% speed boost.
Q: For captions, can I write "a photo of a man standing inside a room"
A: No. Captions need to be simple words separated by commas. Simple but effective.
Q: Are more captions better?
A: Usually not. There are a lot of words we really don't want to train, so we're keeping it super simple on purpose.
Q: What if I want to train without captions?
A: Then this is the wrong setup - there are many other ways, just that this one relies on a few captions per image
Q: Should I save the training state?
A: Yes! It will let you pick up right where you left off. Meaning you can set training to 60 epochs, finish it in 48mins, and if you're unhappy with your checkpoint, you can just resume training again.
Q: Should I change the Save every N epochs setting?
A: You can change to it to like 10 if you want. But keep in mind that every 5th epoch is a 'big one', since that's the one that runs with dropout.
Q: Why is this using offset noise of 0, instead of 0.0357?
A: This... is a lot more complicated to answer. But in a nutshell, it will make our images less grey in the end.
4 training images for context (I used a total of 45, in random cosplays, random positions, random outfits & hair colors, random backgrounds)
I trained her face, and lightly the aesthetic of her images




without/with lora (base only - 1 sampler node only)






(images were made using random civitai prompt - so I can be impartial in how well the lora works)
And the json!
Amazing! Thanks @hollow spruce 
Can't wait to try it
@hollow spruce wrote "mages were made using random civitai prompt "
Or using random prompts supplied/inspired by the audience lol ( I recognise the 70's feeling)
also, in case somebody is wondering, this is what dropout even means
Dropout caption every n epochs
Usually, images and captions are learned as a pair, but it's possible to train just on "images without captions" every certain number of epochs.
This option allows you to specify "drop out captions every ○ epochs."
For instance, if you set this to 2, you will conduct image training without captions every 2 epochs (2nd epoch, 4th epoch, 6th epoch...).
By training on images without captions, it is expected that your LoRA will learn a more comprehensive feature set from the images. It can also help prevent the image features from being tied too closely to specific words. However, if you use captions too sparingly, your LoRA could become ineffective at prompts, so be cautious.
The default is 0, and in the case of 0, caption dropout is not performed.
Rate of caption dropout
This is similar to the "Dropout caption every n epochs" mentioned above, but during the entire learning process, you can train on "images without captions" for a certain proportion of the time.
Here, you can set the proportion of images without captions. 0 means "always use captions during training," and 1 means "never use captions during training."
Which images will be trained as "images without captions" is determined randomly.
For example, if you train LoRA with 20 images, reading each image 50 times for just 1 epoch, the total number of image learnings is 20 images x 50 times x 1 epoch = 1000 times. If you set the rate of caption dropout to 0.1, 1000 times x 0.1 = 100 times, you will train on "images without captions."
The default is 0, and all images are learned with captions
Consider this option going nuclear. Might be great for style loras, but anything else is technically seen a wrong application. It's working here since we're only training for a few epochs - and are fine with the little damage that is does do. It's still a lot less damage than using network rank 256
@hollow spruce I saw BMaltais write a review of Ai3 Lycoris where he had two dataset image folders one regular 10_busterkeaton man and 10_buster Keaton hat. Strangely no class name it seems. But I'd be interested to know if dividing central concepts in dataset preparation benefits training with decisive separation of the concepts https://www.reddit.com/r/StableDiffusion/comments/14low8y/lora_lycoris_ia3_is_amazing_info_in_1st_comment/
reddit
27 votes and 13 comments so far on Reddit
I've looked at the code. If the repeats are the same and every file has captions, it should in theory make zero difference.
Ok so, it would be like having them in the same folder all together. With the added benefit giving you a more simple organization of image type, say for instance to easily separate crop types (closeup, full and half body)... if you're dealing with 100 images dataset it can be a benefit
Thanks for your response
I'm loving what I read about Ai3 Lycoris. will definitely try it out once it leaves the dev branch
will be trying it out, since it seems to be working for sdxl
as for the separation of concepts - yes it works, but it was already hard to use correctly in 1.5
and even harder now in sdxl
I've done it a few times so far
especially for my big datasets, where I did this

it's also how I include regularization images, when I misuse them as training data rather than regularization data
Curious what your take on a small dataset is, like, on the lower end of 10 - 20 images. Its pretty easy to get, just photo style of the subject. You can pretty much do that with 1 image, or one image with a coupel of different crops. So i was about to try, your last method, with the real images i can collect, plus, generated photo images of that subject which i guess isnt ideal, but.. was trying to think of, the best you can do with the least.
1-10 photos is still doable - but it's not what I'd call beginner friendly - nor will the final lora achieve an 80% hitrate of 'good' images.
10-20 images is just about good enough, settings will be harder to get right
also depends on quality of those images
down to that snappy tagging? (+ good quality images)
keep in mind that with small datasets, you might accidentally end up training something like a jpg-compression artifact lora 🤣 happened to me once when I trained on not-so-high quality images, and since there weren't enough, I accidentally made a lora that added jpg compression 🥲
but yeah. 2 high quality images is the lowest that really "works"
Yeah i appreciate everything, Loras were always a side thing, i could just throw in before on 1.5, so having to learn a bit just to do what was quick mockups, but im in love with SDXL and i dont want to go back 😄
at 1 image, you're just building a weird controlnet lora to hopefully reproduce the right thing.
can only recommend to get it good enough to produce a few good images - then reuse those to train a good lora
fyi, generated photos work just fine.
sure you'll probably reduce skin details - but that's rarely the make or break point for if a lora is good
and can be fixed with a bit of prompting
not my thing, since my long term goal is to make a finetune that is trained on less than 50% professional photography
but I can vouch for a lot of loras trained on nothing but synthetic images, and the lora is 😘 chefs kiss!
(especially style loras suffer essentially 0 quality loss for synthetic training)
Im about to move into style training and my main use case, as I am a photographer by trade, is to train for specific photographic styles which include studio flash or very natural soft light, or composition and film look. Usually this is done by using in style of so and so. But as I want to refine the styles into something much more focused and specific, I wondered if you had some basic art style tenets. I suppose cohesion image to image is the most important thing. So the end result in the Lora is snappy. I wonder if art/fasjoon photographic styles as concepts are difficult. I shall know soon. Will test with standard Lora and prodigy Lokr @hollow spruce
Have had some excellent results with loha/profigy for character...
Has anyone tested the difference between training a lora on the base model vs a different model which images you like better? Like dreamshaperXL. Which is a better base for a lora
Here's an example of character LoHA. Dataset of 20


And gen

40 repeats, batch 8, 6 epochs
And yes, fully images are hit and miss as far as face accuracy though I suspect adetailer and impairing should be standard for full body

uff that looks cool and good
what network + Convolution ranks + alphas were you running on?
Pretty much all default on preset loha/prodigy. Except precision at bf/bf. Dim alpha 32/16
Nothing really changed but I did curate my dataset a ton
For the photo styles I guess I could organise image folders under film look, light, edgy (for stuff that is more complex to categorize). The first two are pretty standard and not much captioning to do. But the third would be more of a flavour thing. I wish it was possible to use yaml files to increase repeats on specific important subfolders recursively like in Everydream
at least in theory, 32/1 should give better results.
but in practice, I've not nearly spent enough time with LoHA
The Lycoris discord guys guys discuss it a little, though they are not especially always forthcoming with config settings. They talk math more often than not lol
Im just surprised how much more effective prodigy is than adafactor. At batch 6 I cooked the model much faster and nicely than with ada in batch 1 over a much longer period of time
yeah. prodigy for automated or adamW if you're confident about your training rate
how to get prodigy for gui?
Preset on Kohya
oh ok tq
i dont have 24gb vram, it uses 24gb vram, i have 16gb vram, what batch size do you suggest?
For outfits training any recommendations? How many per outfit?
But if I want to generalize from a variety of similar outfits from a same collection, should I fine tune a model rather than do a loha with several outfits and mix them up with a multiplier?
@hollow spruce what does this mean?

Then try batch 1. It's very ram consuming. I use an a100 with 80gb ram and it's like 3 hours
oh ok
Use bf instead of fp precision. And start with batch 1 and very small dataset. It might not generalize but at least you can check how much time it takes to learn the face
ok
did you enable fp16, anywhere other than for saving the lora?
yeah
i disable it rn
@hollow spruce

idk why even with basic settings the vram consumption is high
loha + prodigy + TE?
Can anyone offer assistance on the relationship between training images and epochs and steps? In Kohya LoRA training I have 33 images, set to train with batch size 1, no bucketing, learning rate 1 ... I'd expect epoch amounts to 33 steps, right? One step for each image? But some other setting is making that 1 epoch amount to 5445 steps. How do I make sense of this?
steps = (images x repeats) / batch_size x epochs x 2(only if reg images are used)
repeats? I don't see such a setting. And I am not using reg images right now so that should mean no doubling. I have all settings I can find to just x1 so I expect 1 epoch should equal my training set. 33. 5,445 is so weirdly huge I can't figure out what is going awry
-edit: I think I found it - just needed to type some things out and then do some arithmetic. Conflict arising between trying to piece together incomplete direction from multiple sources.
prodigy will always get you 80% of the way if configured right.
amaw can get you to 100%, but that doesn't mean that it will.
its in tools>deprecated
can you share adamw
i'll train it once this gets completed
for faces:
#🔧|finetune message
for others:
#🔧|finetune message
tq
@hollow spruce do you suggest loha or lora for characters?
the epochs is 100, i have 160 images
what should I set the repeats and epochs to?
I can only say that my faces preset works. Haven't tested loha with sdxl yet
ok, prodigy uses loha
repeat = 1
if you're doing the faces one - then epochs 60 will be finished.
I usually let it run to 100 so I can test various checkpoints - to see what heavy overfitting did
oh ok
but 100x160
i use batch_size of 1, so should I also use 100
the steps change, so asking
🤷♂️ might take less epochs, might take more. My preset was designed for 50 images. You'll have to try and find out
Hi guys. I was working with stable diffusion 1111 without a problem today but since I have copied the ckpt file version 7gig it stopped to work with SDXL refiner and even after I have deleted it it doesn't work when I push the generate button it gives me a black image 😔
Does anyone have any good information or resources on instance & class tokens for training SDXL? I have seen things such as "ohwx" recomended because its unique & 1 token? but also seen people say with SDXL just use the name of the person or something else? really trying to understand better.
just read though so much of this stuff above, thanks so much @hollow spruce for all the effort you are taking to help people so useful 🙌 . Still have much to learn. two questions if you dont mind - Are you guides hosted anywhere else except berried in the discord? 🥲 & any resources or further reading for going beyond your guide? eg training styles / multiple subjects / larger checkpoints?
One point it’d help is if you had no captions. Then you could use a different class token and template for each subset.
It helps if you want to re-use the images later.
I’ve found that with Prodigy min_snr_gamma has a significant effect. Set it low for simple Loras (like characters) and high for complicated Loras (style, for example). But outside of that, it’s really been the only parameter I needed to adjust for good results.
Don’t know about 100% of the way though. Never went that far.
And my dataset is pretty shit to say the least. The captions are good, the images are not edited in any way. Just selected/pruned.
@hollow spruce

I also has this effect using your preset. Does it related to dataset? How do you resolve it?
the samples are always half-working. same for me.
it's good enough to roughly know whats going on - but actually testing the checkpoints will give proper results
It has the effect in real run.🤣
wait what? XD that's not normal!
Maybe you have that setting which ends the steps early?

有美国人
If someone wanted to make a SDXL finetune with many concepts and ideas all in one, but can't because they only have 12gb vram, would making a huge lora or multiple loras then merging it with the SDXL model be any good?
I don’t know but you can test it out. A couple of tips: Use scaled weights to make sure the LoRAs are compatible. Test different orders as order matters. And finally, merge in the same order you test.
just realized SEcourses is training the text encoder with only an instance token and no captions in his video. and results look good🤔 trying it for myself, except his params for 16 imgs is 3 fkn hours
and results look good
do note what happens to the backgrounds in the images he generates
text encoder for single words work just fine - but if you pick the wrong one, uff does it go bad quickly XD
so use with words you've tested are ok
'2jF7' <- 4 letters only. might be worth trying
in your particular case, I'd rather figure out the perfect parameters for training on the 4 main class words for people though
boy/man/girl/woman
cause once you got those down, you can train them much easier
as in use "man" as instance token? I'm still using "man" reg
yeah. I'd try with a small amount of dropout + clip training on only the word 'man'. no regularization images
did a lot of tests the last two days, and it should work
I'm starting to get good results with less and less images
(much trial and error though)
network or caption dropout? and what value are you using
dropout every 5 epochs
that will work if you can get your training to finish in under 100 epochs (1 repeat)
so basically play with training rate, until 50 epochs looks 'perfect'
that way you also train much faster obviously
I've even pulled of a somewhat successful training on a single image - using that method
do u mean learning rate?
yes
ok I'll give it a shot thank you
cheers love
Hey all. I've been interested to train a lora. But my set-up of using Linux means I get a crash with the koyha_ss gui. Can anyone say if they have had success in just using the sd-script along (on Linux)?
weird. kohya should run better on linux O_O
@hollow spruce Your preset is good but I think the likeness is not enough. My caption is using nature language like this: {rare_token}, a {subject}..... Should I reduce token in caption? I think the result of this attempt is like 70-80% of original using default epoches with 60 images. If I extend the epoch, might be increase the likeness?
https://github.com/bmaltais/kohya_ss
^ you were trying to install this, right?
I get a crash with python - the Tk extension is not present. The other factor is that this is a headless EC2 with attached GPU. I have no idea why something with a web interface requires Tk!
yeah. more epochs should increase likeness.
'a' is wrong though. just {rare_token}, {subject}, {clothing}, {background}
and you're using 50 images? or less?
I should probably stop using epochs as a reference. essentially 3000 steps (600 steps at batch 5) is where my loras turn out ideal.
but the full range is 1500 steps to 4500 steps (so that would be epoch 30~90)
using 60 images
it's why I initially suggested 100 epochs - just to be sure
if you saved the training state, then let it run for up to 100 epochs
I would try the 4 token caption way
clothing/background only need to be mentioned if they aren't the same in all images
basically you write a word for everything that actually changes between the images in your dataset
how detail should this 4 parts be?
"glasses" aren't needed if the subject wears a glasses in all images.
but if they only wear it in half the images, then its important to tag it
like clothing, white t-shirt and blue jeans or t-shirt and jeans?
lin sheng, woman, fencing suit
lin sheng, woman, blue track outfit
lin sheng, woman, studio photograph



to give an example
jeans shouldn't be visible
cropping is important!
#🔧|finetune message
check there for crop examples
I cropped all as 1024 for testing
@hollow spruce L to R
No LORA
SDXL Offset Example at 0.65
Your LORA at 0.65
Nice 🙂

Repeats is the number of your img folder example 20_Subject, 20 would then be the repeats
Same 3 Images after Upscaling/HRF & Face Detailing

@hollow spruce would i not see any benefit from adding regularization to your method? considering I don't have captions, and many images have matching clothing, and training set is usually 12-25 imgs, and backgrounds are all white
if i can afford the time
I've not tried it yet.
If you do add reg images, then definitely double dropout chance, to once every 10 epochs
Not sure if that will mean it runs the same, less, or more epochs though. will be interesting to see
have you experimented with batch 1? I keep hearing quality is best one image at a time
batch size impacts learning rate & in case of clip training, how the actualy clip training works
so it's more of a case of people using presets designed for batch 1 - then having worse experiences after using a higher batch size - which makes total sense.
higher batch sizes can deliver better results, but that doesn't mean that training gets automatically better with high batch sizes.
Basically, one setting will never fit all vram options.
(but you can use batch 1 + Gradient accumulation 5, to get extremely close to batch 5) <- so that helps when you already have a good workflow that is designer for a higher end card
@hollow spruce "man" token worked surprisingly well but not even 100 epochs was enough so I may extend it. artifacts on clothing is WAY less than before with celeb and reg, but detail is lower for sure. Could I raise dim just a bit?
are you too zoomed out on your images?
but yeah. either increase learning rate, or try using dropout every 5 epochs after all
that was with dropout every 5. theres a couple waist-up but mostly closeup
interesting. then it's probably that you have 25 images, instead of my usually tested 50.
yeah, just increase learning rate until epoch 50~100 is well cooked
What about gradient accumulation on batch 10 on a 80gig A100 card. Is there any benefit to update weights less frequently if using a high batch size with a larger gpu? I'm running right now at batch 4 with excellent results but at 3 hours training. I'd love to bring time down. Would higher batch size plus grad accumulation combo = faster iterations (higher batch) + slower updates (less frequent updates)? What is the correct calculation to predict gains?
with an A100 you can do cool things.
I'd probably try a dataset of 50~100 images, and fitting the whole thing into 1 single checkpoint
(so like batch 50 with GA of 2, for exactly 100 images) <- will take a while to get all the settings right, but then you can pull of really cool things
also, you can train at 1536x1536 <- captures more detail, but obviously your images need to be high quality enough, to not accidentally train image noise found in low to mid quality jpgs
How does a model like SDXL cope with mixed resolutions? Could a LoRA encode higher resolution information than the base model?
That sounds like a very cool experiment. Is that a Dreambooth Lora type training or we talking a full fine tune checkpoint model training?
still a lora.
also, you can do finetune style loras with that gpu (training on 30k images)
which brings similar results to full finetune on SD1.5
^ that's what I'm currently doing, where my rtx4090 can barely keep up, by running for 20~30 hours
awesome. will do a test now
why would extending epochs make likeness drift further and further 🤔 i would expect it to start overfitting but it's more like it starts un-learning entirely.
Does this mean more images take more Vram? Can 30k images be done on 12gb vram?
You need to install it using the system package manager but it isn’t needed to train. What OS and version?
You can use gradient_accumulation_steps for the same effect on lower end GPUs, it has exactly the same effect, just slower.
Ok so to train within 16GB, one can follow Caith's writeup, drop Batch Size down to 1, and raise Gradient accumulate steps up to 5 under Advanced Config? Would there be any mileage in changing the Optimiser too? It's currently set to AdamW and am I right in thinking that AdamW does nothing fancy in terms of memory or lower bit quantisation ?
A higher gradient_accumulation_steps can usually get away with a higher learning rate, but not always.
Anyone has a dataset of regularisation images for faces that they can share?
Why does Caith not use bf 16 for both mixed and saved precision?
I am using an Amazon "Deep Learning" AMI. I can see the system installed Python, but they appear to have shipped a custom distribution in /opt/tensorflow thus my installation of python3-tk did not help. Given Tk is a GUI framework I'm not entirely sure how this works across a web interface either, but I cannot get that far. FWIW A11111 and ComfyUI both work fine but lack lora training options.
Which python version are you using? Try installing apt install python3.10-tk (adjust the version)
(For me, system Python was 3.10 but python3-tk installed a version for 3.8 for some reason.)
Looks like others are having the same issue (https://github.com/bmaltais/kohya_ss/issues/873 and others). Using a python that was not installed by the system package manager is going to cause all sorts of issues to be raised.

GitHub
Apologies, I don't have a particularly masterful understanding of python environmental settings. I'm on Ubuntu 22.04. I've cloned the kohya_ss repo, entered the newly created directory ...
to be honest, for that setting I'm just following the tips of those who actively study machine learning. Never questioned it.
(also, when I tried it - I saw no difference that I could actually notice, so I just left it on what was recommended to me)
might have been a fringe case though - so if you notice a difference, please do share ❤️
I'm saying something different: That we should install tk that matches system Python, because apt didn't installing the version matching my installation for some reason.
yep. but oh god it takes long XD
if my rtx4090 runs would run for 1 weeks straight - then how long would a 12 or 16gb vram card run for? 🥲
No disagreement there. 🙂 Just saying for those who really want to.
So the question I have is, how? Within koyha_ss I see:
lrwxrwxrwx 1 ec2-user ec2-user 30 Aug 7 21:28 /mnt/sd1/kohya_ss/venv/bin/python3.10 -> /opt/tensorflow/bin/python3.10
Which is clearly a different installation to the one yum is installing packages for.
I used apt install python3.10-tk, yum might (or might not) have something similar.
apt will only provide for system-supplied installs. Hence mine installs but has zero effect.
Wait, you're mixing apt and yum on the same distro? One comes from Fedora/RHEL and the other from Ubuntu. How's that even possible?
No.
You have apt. I have yum. I have no apt.
Did you try yum install python3.10-tk (instead of python3-tk) though? Worst case, you could use a conda environment and build a venv on top, I've done it before.
Oh -- forgot to say. You need both system and venv installations for tk to work.
There isn't one. There is a yum installed python-2, and python-3.7.
Inside /opt/tensorflow there is also python-3.10 which is clearly being used everything. When I installed python3-tk from yum it was version 3.7.xxxx.
Trying to figure out how to extend the tensorflow installation is the tricky bit.
Try pip install tk-tools inside the venv.
Do you have the option to use a different AMI? That one seems effed up.
Well this is the one Amazon have optimised for GPUs with python and the frameworks. But I'm guessing as it is a headless environment they won't have bothered with a GUI library like Tk. Docs: https://docs.aws.amazon.com/dlami/latest/devguide/what-is-dlami.html
Launch a AWS Deep Learning AMI (DLAMI) for deep learning with NVIDIA CUDA and NVIDIA cuDNN as well as the latest releases of the most popular deep learning frameworks.
I've usually had success just launching vanilla Ubuntu and installing CUDA toolkit inside. Optimization doesn't mean 💩 when you can't get it to work.
does anybody know if possible to resume training on kohya lora even if i didnt tick the save training state on the last run?

also, what is this path for, LoRA network weights

Hello, I've been wondering if I could replicate something like this for other architectural design styles? How should I go about making a dataset that would help me train a lora such as this one? https://civitai.com/models/25384/xsarchitectural-8japanwabisabi
Japanese wabi Sabi style Test phase It is necessary to cooperate with ckpt and VAE If you have any questions, please contact me at xsarchitecturals...
the proper way?
get enough dataset images with a high enough quality (100~500)
the easy way?
Use that lora (or any other lora) + highres fix to generate around 100 images. Then mess with sdxl until you also get about 100 good enough images.
then train on those 200 images. (this is called synthetic training)
the long way?
find whatever high quality images you can on the internet
then use those to train a v1 of your lora.
Then generate 1000 images using that lora, pick your 100~200 favorites.
Combine those with the original dataset -> then train the mix of original + synthetic images to make a really good v2 of your lora.
When you say high quality, you mean high resolution?
I'm thinking proper captioning is also critical? What should I be thinking about when I caption images?
high quality = 1216x832px or higher (with no jpg noise or typical phone quality like compression)
Once you have the dataset - you could try running it without captions, using only the class token of "room photography"
if that doesn't work - then you should worry about captioning
So the .txt files should only contain "room photography"?
only folder needs this name: 1_room photography
that gets loaded into kohya automatically
Ah, so I can train with the images alone? I was thinking captions are also required.
Sorry, I'm quite the noob at this. 😅
no problem ❤️ we were all there once XD
nop. while captions help with specific goals in mind, they aren't always needed. especially for your kind of lora
also actually training it will be relatively quick and easy - so just trying it, before doing the work of adding captions is worth it
Hey anyone, I want to trained an inpainting model on traditional dress. Currently working on scraping the dataset. Hoping to use 30k-50k images. Which model to used? and most importantly how to get caption for each images(clip, blip, or manually..) that will help get good training results. Last time have tried training a simple model on sd2.1 using manual caption on 30k images with plain background. The model trained was not good. Can anyone help?
I wonder if flipping face images horizontally would be good for increasing the size of a small dataset
no good cuz if the persons face isnt symmetrical it will ruin likeness
@hollow spruce Using your preset, same scheduler, same learning rate, same optimizer. 100 epoch, 200 epoch, 250 epoch, 275 epoch, 300 epoch.





I think around 275 is the sweet point for this type of training. 300 is a little bit overfit.
Hello, how is the stable-diffusion-inpainting model trained? and why do we need seperate checkpoint if SDEdit-based method (does not require training) used?

Around 4 hours on 3090. It could be the baseline. I would test prodigy and see if it would speedup the process.
keep in mind, prodigy changes the learning rate - so before that, it might be worth trying by just raising the learning yourself
loss around 0.15-0.13 in a few epoch. After that mostly around 0.13-0.1. In very last, it became 0.11-0.08.
I heard prodigy has an issue which always started to learn in very late.
? it shouldn't.
basically put all learning rates to "1", and make sure warmup is around 10% (or lower for a more aggressive start)
Thanks for advice
https://github.com/konstmish/prodigy/issues/3 refer to this issue. Seems prodigy has issue with cosine restart

GitHub
I am noticing a trend that has happened to my friend, and I, as we use CosinewithAnnealingLR and Prodigy, but it doesn't begin to really learn until it is almost done. I am wondering what is go...
I see it. but it seems they already have an official fix for it

Ok. 👌
but that is specifically for annealing
@latent charm just did a quick check - but the preset for prodigy seems to have everything set correctly - including the special optimizer settings, so probably use that if you really want to use prodigy

(it was updated a few days ago - so make sure your install is up to date)
Just updated in yesterday. It should be fine.
Are those loss changes broadly what anybody should see while training?
I just share what I saw in my training using @hollow spruce facr preset in 300 epoch with 40 images
I'm in epoch 194 and loss is around 0.12, so it looks similar (but I'm using Caith's original settings with Adafactor)
Ok thanks, I have not done much training so I don't know what to expect 😄
Even the loss didnt come down, The model still learned.
You could see the different in above conversation
@hollow spruce Regarding regularisation images, are there basically two choices in training, captions or regularisation ? I saw your comment somewhere above that the current LoRA tutorials on youtube which use regularisation images have a weaker ability to create detailed backgrounds. Is that the weakness behind the regularisation approach?
ah no, not at all. reg images are amazing.
the youtube tutorial uses dim setting of 128 or 256
also clip training can be destructive if done incorrectly
but reg images are always good for face training - just changes your learning rate & the length of your training to some extend
but quality should be better - at the expense of training longer
Aaah ok I misunderstood
I'm trying your above approach, but I had to reduce the batch size to 1 to fit my 16GB card. I've also changed to Adafactor for the optimiser. I think it's working, but my training images aren't as varied as yours, so many of my captions are the same, so I'm unsure of how successful it will be. All part of learning 😄
as long as they're not all copies of one another, you should be good ^^
Yeah but I don't cosplay enough, clearly. Need some more variety in my life 😄
Interesting. The sample prompt I'm using for every 5 epochs has created an image that's much more like the training set, rather than a slowly morphing face. I wonder if this is the start of overfitting
i want to make ai images from face of my friend which method should i use textual-inversion, lora, dreambooth, kohya_ss?
What kind of regularisation images would you recommend for a face/anatomy LoRA? Just other random faces? What about captions for reg images?
@urban halo
kohya_ss lora with unet only works best in my opinion
I have a question about the concept of using a celebrity's name for training instead of a the generic "ukj", etc...
I recently tried doing this with a friend of mine. I used "Tom Hanks" b/c he kind of sort of a litte bit resembles him. I trained both a Checkpoint and a Lora. It worked pretty well for the Checkpoint ... however, with the Lora (and I assumed this would happen), when I use the Lora with a different checkpoint (say, Photon), it creates a person who looks like a radiated blend of my friend and the actual Tom Hanks.
Am I correct in assuming that this concept does not work for Lora's?
small hickup with training, i am having trouble resuming from last saved State. Error message is Kohya script could not locate the State folder.... any ideas what could be causing this minor error? I am using the / in the path.



is it possible to merge checkpoints in kohya or is a1111 the only way?
@hollow spruce After 5 hours with 300 epoch, didn't learn enough.

Always bouncing between 1.0~1.4, sometime get 1.6~1.7
cosine forever decreases - which means you can leave it running forever - but at the same time you won't be seeing significant improvement after a while.
Either cosing with restarts or cosine with annealing restarts - to make that work
but really really odd :/
cause it should learn everything, even with standard cosine
(even if not as aggressive)
300 epoch. Left is cosine prodigy. Right is constant with warmup adam.


275 epoch.


100 epoch


prodigy with cosine didn't learn much at all.
No lora

Might be it is due to I didn't set the Optimizer extra arguments "decouple=True weight_decay=0.5 betas=0.9,0.99 use_bias_correction=False"
I'm just getting started training loras on 1.5, using kohya_ss. I looked around for guides but they all seem to be "just copy my example for this 16 image sample of a character! quick and easy!". Is there a more in depth guide that explains all the options/parameters and what they actually do? Like, what should I be thinking about when setting a learning rate? What are the 20 different optimizers and why should I use one over the other? etc.
Also training for a concept rather than character with around 200 images, so the endless tutorials with 16-20 images probably use settings that I should change. I just don't have the info on what and why to change, though.
Is there a way to change a body part shape and size using inpaint?
for a bit of a more complex explanation:
https://rentry.org/59xed3
^ goes into a fair amount of detail
https://hoshikat.hatenablog.com/entry/2023/05/26/223229#Rate-of-caption-dropout
^ use bing translate on that site, it explains all the settings you can find in kohya, without too much complexity
prodigy needs the special parameters to work correctly
https://rentry.org/59xed3#prodigy
^ this entry goes into a bit more detail on prodigy - and what the special parameters do and why they're important, if you're up for a bit of reading
Thank you
yeh. while i've been getting good results with prodigy, i've noticed it could be better when i look at lr graphcs. I found this https://github.com/kohya-ss/sd-scripts/pull/271
GitHub
Add argument --lr_scheduler_type and --lr_scheduler_args to use lr_scheduler from another library
For example, to use torch.optim.lr_scheduler.CosineAnnealingLR with T_max=100 as lr_scheduler, we ...
of course caith already on it too
these options just showed up in the gui recently. we can add cosine annealing now
hmm nevermind maybe not. the annealing is seperate and can't be used. i'll have to craft a command

seems like a pita. i'm going to go back to adamw
num train images * repeats / 学習画像の数×繰り返し回数: 2770
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 1385
num epochs / epoch数: 4
batch size per device / バッチサイズ: 2
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 5540
It's estimating 4 hours at 2.8 it/s for this lora. 270 images at 10 repeats each, 4 epochs, batch size of 2. I'm running on a 12gb VRAM RTX 3060. Are these normal speeds?
dim 24 vs. dim 256, from aitrepreneurs new video

You need a huge dataset and probably even reg images and captions for dim = 256.
Guys, do you have tips for tutorials on how to train your own embeddings for SDXL using google colab?
Well looks like resume was broken for Lycoris training but the latest Lycoris dev module is now working for resuming fyi "pip install lycoris_lora==1.9.0.dev7"
If anyone interested
Also... is LORA tied to a specific model or is it like an embedding that you can use on top of a model?
Just tried cosine annealing with T_max = to max steps. Not good results. Vanilla prodigy was better
LoRAs can be biased towards a model, but if they are created correctly they will work well with most models.
How can I make the learning rate decay over the repeats when using cosine with restarts? Every repeat returns to the initial learning rate though it would be better if every repeat is a little less than the one before.

unless I misunderstood it - constant should get you close to perfect results using prodigy?
since it already auto adapts learning rate. no need to double adapt it, right?
@hollow spruce Tried prodigy with https://rentry.org/59xed3 this suggested extra parameter. It is better than the default parameter in the gui preset.
Stable Diffusion LoRA training science and notes
By yours truly, The Other LoRA Rentry Guy.
This is not a how to install guide, it is a guide about how to improve your results, describe what options do, and hints on how to train characters using bad or few images.
Due to the higher prevalence of...
Prodigy 300 epoch cosine prodigy
decouple=True weight_decay=0.5 betas=0.9,0.99 use_bias_correction=False
Epoch: 100, 200, 250, 275, 300





Prodigy 300 epoch constant prodigy
decouple=True weight_decay=0.01 d_coef=2 use_bias_correction=True safeguard_warmup=False betas=0.9,0.99
Epoch: 100, 200, 250, 275, 300





But overall, I still think constant adam produce the best result over 300 epoches.
Yea this seems to be the case. Playing with the opt arts only makes the LR go wild so far
What was the difference in training time? Any gains?
constant prodigy seems to be 3.x hours and constant adam seems to take longer, 4.x hours
cause we're running adam at the lowest rate. adam with all learning rates at 0.001 should give similar results, at much much faster times
Oh really. I'll give that try
Worth turning off TE in arg?
How did your loss graphs compare for your two prodigy years? Can you paste here?
1e-3 is kinda the best 'value' of learning rates that I've found. best performance to training time ratio
5e-4 is the highest quality I achieved, but yeah, for some subjects it needs to run til like epoch 250~350. :/
my next test will be to do a small full finetune, and see if training speeds change on that finetuned sdxl model - where only the faces are easier to train
not sure if that will work out, but we'll see
Sorry, how many repeats on this range 250-350?
everything with repeat 1 - for simplicities sake
Batch 6?
I used batch 5
repeats are only relevant if you do unevenly weighted datasets - or are training a smaller amount of images on a specific face, and need a lot of regularization images to run with it
but for all other situations, repeat 1 is always the go to method, since it gives you more control over everything
constant adam


here are mine. prodigy cosntant then with annealing -- --network_train_unet_only --lr_scheduler_type "CosineAnnealingLR" --lr_scheduler_args "T-max=25" and weight_decay=0.5 d_coef=2 use_bias_correction=True

a little higher on the weight decay
constant was good, green. the adapt scheduler went a bit bonkers and didnt learn. Probably because my weight decay was too high
ok, i didnt know that.
but in my case, i am working on a character. 23 images at the moment (might go up to 50)
10 faces, 10 midshots, 3 full bodies.
constant prodigy (should be this one)


and i use reg with photographs, to inbibe photo style... prodigy constant

dataset:

@hollow spruce shouldnt we use the max_norm graph mostly to see the loss ?
basically there's no downside to just increasing epochs. but you have the advantage of using settings like 'dropout every n epochs' or the cosing with restarts with a lot more control
Not familiar with that. How to turn it on?
I'm the wrong person to ask for that - I work entirely without graphs since I almost always train multiple concepts at the same time - and graphs won't help much, if 3/5 concepts are trained perfectly, 1 does nothing, and 1 just crashes sdxl XD
it's one of the graphs on wandb. see bottom left

I didn't use wandb on the testing. Although I have the account, a little bit lazy to set it up.
oh. ok. i will try 1 repeat epochs then
Can you give an example set of concepts in one of your trainings?
I wonder if for instance for the above asian model, concepts could be:
- a certain hair style