#✨|sdxl
1 messages · Page 85 of 1
1.5 has a lot of utility built around it, and can pump out good quality images quickly. More than enough for casual users.
SDXL will far exceed what 1.5 can do, but doesn't mean 1.5 is gone
and the fact that the more popular platform, a1111, cannot even fully support SDXL yet
yeah it's amazing what the latest 1.5 models can do. fidelity, coherence - on a very high level
that's not really the point. "better" is relative. I prefer xl, but doesn't mean I think 1.5 is suddenly useless now
people still play nintendo
damn right
people still buy vintage crt televisions

and 1.5 still has it's strengths. uses fewer resources. versatile, etc
Well, thats true. I still have my vinyls.
how else should I play retro games?
I need my real scanlines
Trousers?
sony trinitonics still sell for quite a bit actually
But u think SDxl images are consistently better in the same conditions. (Not Controlnet and such)
they have a higher win rate
because they were the pinnacle of CRT TV tech - just the best
Both. LoL
with all the tools and accessories surrounding 1.5 I just don't see it going away. if anything I could see it being more integrated into workflows with sdxl as time goes on
yeah. multi-model processing is definitely the way to go imo
I've seen some SDXL upscale workflows using SD 1.5 models - it works quite good
1.5 can create quick rough drafts
The SDXL workflow includes wildcards, base+refiner stages, Ultimate SD Upscaler (using a 1.5 refined model) and a switchable face detailer. Now wit...
Exactly 😄
everyone into those low contrast images though. not my preference
I love contrasty images, those are my jam
yes, hdr is all good. but when the high and low are so close, that's what I'm not a big fan of
and also that highly blurred background thing
cinematic
not really my thing. it has it's place. but I like everything to pop

yeah sdxl pushes the bokeh pretty strong if you let it
people think it's stuck in bokeh just don't know how to prompt though


you have to tell it what to do
yup for sure
It's still so disappointing at hands though 😦
yep
so if it decides the random noise needs 7 fingers, then you get 7 fingers

it's just a broken pixel on the latent space cam sensor
This image too
Probably just a bellybutton ring shining 😆
I find people's acclimation to the incredibly quick progression of text-to-image AI almost as impressive as the progression of the technology itself.
stable diffusion hasn't even been out for a year, lol
15 months ago text to image was weird, uncanny horrors
just a bunch of daydream images, or super janky dogs and cats
man, I started on deepdream, lol
and then image on image. you had to earn your wins back then
I tried using it, but wasn't a fan of the outputs, so just abandoned trying anything further really.
is there a way to send a request to my locally running comfyUI server to check if it's still processing something or not ?
Check if the queue is empty?
I started using MJ about 13 months ago and then switched to SD the day it became available. Been prompting pretty much every day since!
you mean if you're not home?
I just have my outputs folder synced with google drive
Great job civit

no, i m starting the thing via my python script, but it returns immediately (asynchronous)
and i want to create a second image once the first is done
but i want to wait until the first is done
but i dont know how to figure out if its done
My very first AI image, created on MJ.

an epic battle between heaven and hell, cinematic
That was 13 months ago 😄
Does anyone know what kind of settings do the bots on this discord run?
The same prompt from SDXL

let me see what my first ai image was. it was a real winner I'm sure


anybody got an idea regarding my comfyUI problem ? 🙂
yeah. still blows my mind. from 30 minutes for an image, down to a few seconds locally. there aren't a lot of advancements like that
Not a clue

Gone a bit nuts with the upscaler denoise there! 😄
that was like 2 and a half years ago
That looks like something straight up out of an Escher painting.
Definitely! lol

how long are these images taking?
my cats and colored pencil scribbles. the image on image was better than deepdream by a lot, but still a chore

Some of my old MJ prompts are amazing in SDXL!


images take a different amount of time, depending on size for example, the last ones like 28sec

mount doom?:)
which one?


neither
malicor, so what is the situation exactly?
Supposed to be a Phoenix hovering over an erupting volcano
i call "python runme.py", which will then call the comfyui server and generate an image
that all works fine
but the "python runme.py" exits immediately (it seems to send the call to the comfyUI server asyncronously)
now i want to do a loop and generate 5 images
but i want to do the second call once the first image is finished processing
question: how do i figure out when the first image is finished processing?
@hardy cipher
The first one, because 2nd has slightly distorted eye...but base SDXL creates better versions 😄

I've determined it's not worthwhile to even try loading checkpoints off my external hard drive
why not request a batch size of 5, then all 5 complete at once

prompt pls
no, sdxl base isnt creating selena gomez's face

how many images of ms. gomez ae you using, qwerty?
you think this is great?
she doesnt even look like selena
for training?
are you using them for other things as well?
yeah, just curious how many you're using
i can look for the prompt later, it's somewhere deep within the code and a pretty complex workflow
and i dont want all images to be sent to the comfyserver at one time, since it could potentially be hundreds

me and my friends generating this in 2020 for like 4 hours and thinking the result was cool af

it's not bad for 2020. I actually didn't see your comment at first and thought it's something someone just made, lol
this was the best we could get out of shrek prompt

and we were truly thinking this was amazing (in a funny way)
Anyone tried this? It's really easy to setup and use, great for beginners and MJ fans:
https://github.com/lllyasviel/Fooocus

GitHub
Focus on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub.
well that's what I'm saying. any of our random generations now would have taken some serious skills even a year ago
also the fact that it took hours to create
Just created these using Fooocus




These are beautiful!
So Fooocus uses some post processing stuff in the background
Yes, it's listed at the bottom of the readme/main page in the repo
Does something different with samplers
the negative ADM guidance sounds interesting
160
dang, son. did you tag all of them?
I'm looking at the code. not really understanding what they're doing though 
and how can I go back to such a minimal interface now that I'm working "under the hood" in ComfyUI 
nodes satisfy me
I mean it sounds like that they have some ideas, so let's see

nice hologram star map table 👌
yeah, just doing my normal thing
is it possible to create a json data of difference traits of images generated
proly some python coding
would be nice to have a node for it
testing out same parameters with different last layer

that does sound reasonably useful



nice t23
SDX is really good at low poly

you should try this out https://civitai.com/models/118536/voxel-xl
Voxel XL Lora Hello, here is my first Lora for SDXL. I tryed to enchance the voxel style of the original Model. I hope you enjoy. Trigger words is ...
Look the name of the autor of this lora
oh nice
well good job
I use that one too
that's pretty awesome,l ol
how do you train something like that? I'm curious
yeah
I make voxel stuff with magicavoxel, so i generated some images and trained on them
how many images did you use?
I'm just curious. doesn't have to be exact numbers
just want to start making things in that realm
Come, i am ready

how is this?

but not sure if I need to tag them, or what methods to use
mostly just did loras of people in the past
Coming!

that's good

I used not many images, the important thing is variation, 2 cars, 2 buildings, 2 persons, 2 animals...
that makes sense
But if i found Voxel artists who like AI (here is not many) we can surely make a way better lora working together
magicavoxel
cool
but i also have an UE4 voxel project for landscape
using voxel plugin to generate procedural landscape
now how do we make a magicavoxel node?
I'll catch you 😛

this is a whole new realm for me. didn't even realize it was a thing. just thought that lora looked cool
What ? Magicavoxel is an app to make voxel asset, and then you can render it

well yeah, didn't mean it'd literally be the fully functioning program in a node

Sylvester stallone and robert downey jr's love child?
I see Tom Hanks in there
extremely art deco a hyperrealism photo portrait of a (upset:1.25) pilot played by a person looking like Tom Hanks waiting for someone at midnight during pre-winter, power auras, sigils, (dark and gritty:1.35), face symmetry, intricate accurate details, cinematic color grading, cinematic, artstation, 8K
using the upcoming NightVision XL model
please make image of wholesome hollywood actor
@unreal plover Cought ya



Are you sure ? You can't beat me, little wolf

I should try out another seed. I just get so attached to them sometimes. and it's not likely we'll meet again by chance
How about silver bullets?

decent
Or lasers! 😂

i like your prompt style






Mostly they are just ready made styles or combinations of them. Nothing special 🤷♂️



@late marsh do you train loras?
Nope. I know nothing of training this stuff








Few days ago


the likeness is pretty good here
hands are always the final boss

I started looking last night and got annoyed with it (and in the poocess may have annoyed others)
Having come back to it this morning.
Pros:
Its a clean simple interface with very few options even in advanced mode
Cons:
Its a clean simple interface with very few options even in advanced mode
Feedback:
Should make it clear in big letters at the start of the page that this is locked to one model only Should also ideally ask during the install if it's ok to download specific files rather than force downloading them. (NB have added an apology on the issue I riased regarding that point https://github.com/lllyasviel/Fooocus/issues/31)
**Summary:
**Produces nice images and almost gives an MJ like experience running locally , which is fine if thats what you 're after
EDIT Added 11:30::
It does allow use of additional models which makes the forced download of specific models even more annoying however given the target demographic.....
Thanks for the review, Winston!
Is it locked to one model? In advanced mode you can choose other models.
TBH f that is the case then I am even more annoyed that it foces you to download a specific model to start with.
You can copy models into the directory before you start it, like it says in the readme, and then it doesn't download them.
you have tpo copy the specific models they list, if those models arent there thenm it force downloads them
Oh, ok. Easy workaround with some empty files with the same names...but you shouldn't have to. I think they're just making it easy for beginners, which it does a good job of.
see pros & cons and summary


was that finetuned on SD and MJ images?


eh??
Its a UI that uses the base SDXL1 with 0.9 VAE model by default.
THe question seems "odd"

oh, then how is it generating MJ quality images?
Iss it ??
Who says it is ?
Wasnt me

The experience of using it isn't the same as the quality of the images.
mb
Tried and I think it is just a custom workflow of models with selectable style and aspect ratio.
hence the "hidden tricks"

which is all stuff the authir has hard coded as it is their opinion these are the optimal settinsgs.
Which is fine if you want the MJ like experience of having little control ;o)
and in case anyone thinks I'm dumping on it i@m not.
This could be the perfect solution to point newcomers at that want to dip their toes in the water of generating images Locally rather then being forced into an online only environment..
I've put this what I hope to be a fairly straightforward workflow together using some custom nodes I made. The sampler does a base -> refiner -> upscale -> base process. There's also a tiled version of the sampler which does the 'hires fix' using a tiled approach

Its a real shame you cant define multiple colours in one node (or can you?) then you could colour the Prompt With Style say Grey witht he Positive Prompt Input area Green and the Negative Input area Red
That would be cool
actually thats a thought. Can Widgets not be given Titles that display above them?
I think the text input is the only widget without a label

very clean
thanks
Does anyone try using different prompt for base and refiner?















Neanderthal chicken man 😆

which sampler and scheduler recomended
for mixing
why does my layer turns to cartoon

add negatives so it cant do cartoon
any ancestral based sampler will chnage more than a non ancestral based sampler
did
try using (as a test cos at the end of the day its down to personal preference) DDIM & DDIM-Uniform
same seed problem ?
what are you trying to achieve at the end of the sequence? maybe its too high denoise




betrayed by discord's auto gallery crop
sdxl controlnet canny is good

you get the ides o f the sequence though lol
hehe yep - good sequence 👌
I'll be honest, it wasnt planned and that wasnt the order they got generated in but I'll take happy accidents 🙂

well a film isn't shot in order as well, but you still try to tell a coherent story 🙂 it's great


That’s a lot of buckets lol. More buckets you have the more vram is used. But I haven’t experimented with that many before.
from the tutorial i was following it said you don't need to crop or adjust the resolution because it self sorts into buckets automatically.
but is the issue that the resolution is too high? or that there are too many different resolution ratios?
bruh

price and name check out
WIld though. 48GB VRAM is three 4080's plus it's DDR6.
30% faster vram than a 4090... I guess that will go into the rtx 5000 cards
It'd also come out to $2,200 per 4080 to get them in one pcie slot
was trying some experiments using SDXL fine tuned as base and SD1 fine tuned as refiner. thehive takes it as midjourney always

Well, per 16GB VRAM
I think that leaves little room for doubts about how midjourney works
or people is training with images from midjiourney. 
MJ simply can't provide the flexibility of an open source project no matter what they do, so they supplement with convenience.
sdxl controlnet make a shock on architecture


midjourny has zero interest for me.
It was fun when it was the new kid on the block, but I knew then I wasn't going to keep paying them a monthly fee for limited generation speed and rush hour congestion on requests.
Wow didnt know has been released. Downloadaing...
Cries in GPU RMA
MJ prompting is much easier imo
youtube guy doing western to asian face
ahh Olivio. I see
aside from training, why would you need this much VRAM?
commercial uses
so cool


I like the detail it managed to pull from the eye despite the shaded feathering
LoRA with controlnet,then upscaling with refine model,compete with midjourney
is SDXL refiner model still not working properly in A1111?
the resolutions are fine. the amount of buckets will cause a slowdown. are you training a full model im guessing? also could just be the amount of images lol. it takes me 1 hour for about 1500 steps or a little more.
for lora training that is. with adafactor.
i'm dreambooth training using SDXL as the base model. 750 images because it's a style and not a single character, otherwise Lora probably would have worked. adafactor as the optimizer
tbh, styles are very easily done with loras and you could merge that with a model that is close to it. or sdxl base. but straight dreambooth training may make better results. but i havent done a full dreambooth train before. just loras. you have sooo many pics so im guessing 5 repeats? whats is your batch size?
batch size: 5
training images repeats: 3
regularisation image repeats: 1
epoch: 1
okay maybe its the batch size then? i do max 3 so i can still use my computer. lol. anything more and it maxes out vram and takes forever lol. i hope you can figure it out! im sorry im not much help
thanks
Nope. There is an extension though. Doesnt support controlnet either. A1111 must rise its game or is going to be eaten alive by ComfyUI
i mean sdxl controlnet
yes im thinking of learning comfyUI. i wonder if the Loras trained on SDXL you are still expected to use the refiner model with it?
No problem with sdxl loras afaik
usually not.
The refiner is kind of hit or miss. Never expected to use but you can. Works great with base sdxl but sometimes not so much with custom models
i'm dreambooth training on SDXL model now. from my understanding it will still retain the previous characteristics of the model and wont be a completely new model from scratch?
the reason i ask is because the images i'm training are of people. so if i want to generate a car or a house that will still be possible?
It just seems incredible!
I've just updated the models, and this particular model continues to astonish me. (it is used by +700k people)
Yes it will still retain characteristics of the model. Your basically just continuing the training I believe. Like adding onto it
Looks anime ish to me, but just not enough steps so it’s a bit noisy
I am here
I can ask questions
HMU 🤙
what kind of questions?

Nice
@indigo carbon btw launching ComfyUI using --gpu-only and AIT the LORA lag is gone - instant generation. but after a couple of minutes the performance when using --gpu-only totally breaks down on my computer - like 1 step every 5 seconds with GPU at 100%.
but this also happens without AIT. I need to restart ComfyUI to fix it.
if you use a LORA in your chain and AIT it takes up to 4 secs for the generation process to start
every time
the refiner is like an img2img pass with another model. So if you fine-tune the base model and apply the refiner, you might lise details the base model was trained on
and it adds up if you chain multiple loras together
I was saying last night, it's not even worthwhile for me to load checkpoints from my big external drive. I've started to transfer models over to my primary drive and then load them
I wonder if it's an issue of where you have them stored? or maybe I'm totally off base
canny model for SDXL is so creative, lol

my best guess is it's likely because ComfyUI likes to keep LoRA in CPU RAM, --GPU-only forces it to place the LoRA in VRAM, which AIT modules are kept there in an efficient way which the LoRA isn't, so it's likely we need to compile modules for LoRA as well
yeah. just wanted to let you know that --gpu-only fixes it. other people are not having the "performance breakdown" problem as I have.
I'm going to try that out because the lag is very noticable
the one place my 64gb of ram actually helps, lol
it's 100% gone for me but I can't leave it running :(. be aware there might be other side effects when you use --gpu-only. I had a Out of Memory message when I switched to many models. looks like with the option more stuff is kept in vram
was that a reply to me, pictures?
yeah
does it ever clear the gpu cache?
good question
but sounds like it might be a ram thing then?
I have all my AI stuff on a nvme. so it's not a loading problem I suppose
it's a processing thing especially with AIT
without AIT Loras are much faster
comfyUI image previews not updating
likely because AIT doesn't support LoRAs yet.. this personally doesn't effect me because I don't use LoRAs
yeah I do lots of testing for other fine-tuners and I guess it is really needed for the scene 😉
I'm generating stuff like this in 18-ish seconds without LoRA, I'm happy with the quality of my images, and I never use LoRAs

is speed the deciding factor with this stuff though? are you needing 100s or thousands of images like that?
I mean, not knocking your images. they're pretty on point
finally it works.. layering

just saying. for me it's not all about speed. maybe when figuring out my approach speed matters more
yes, and the details are already amazing. LoRAs don't improve that much when you use a proper workflow..
no it's not all about speed. I want image fidelity. but having 200% speed is great too 😉
@hardy cipher, however, if you're so arrogant about needing LoRAs you can just wait until we compile AIT modules for SDXL LoRA.
arrogant? lol
you're the one acting like your workflow is top notch, and you post the same 3 images over and over
just saying
I didn't say anything negative about you. I was just curious
but if you want to be rude
Settle down guys/gals, we're all just her to have fun. Just stop and post some pics 😄
this is just not true. I never claimed my workflow is "top notch", but speeds are factual; aesthetics are opinional..
yeah, please post super soaker and see through gelatin cube things
ahh, heres an example, if you que say 20 imgs
and just before teh 2nd image initiates, you change settings, does it change to the new settings on the 2nd img?
I could render 6 step images in a couple seconds
No, once it is queued it has all of the settings and prompt determined already.
and I can generate 111 steps upscaled images in the same amount of time..
but no loras because speed?
thats what i thought, i have moar btw
anyway, I really don't care. I just wanted to hear your reasoning, but seems I've offended you, lol
so forget I asked
no, it's just we haven't compiled LoRA AIT modules yet. will be soon though.
LoRAs won't effect speed after AIT supports it..
gonna roll one, but im here for q's if ya'll need
I don't think loras have much of an impact on speed anyway
at least not for me
maybe a few percent slower if I'm running several
they take almost no time to load initially
actually, know what? I'm going to compile LoRA AIT modules rn, the compile script is universal anyways atm, so yeah
right on. well go ahead and do that so you can start using loras
canny
eww
my workflows are mostly trash, not gonna lie
I'm sure someone somewhere has something else going. but I haven't heard about it
this one was interesting

if you are able to do that - AIT speed boost for loras. that would be awesome! 🙂 there are different methods how loras are used. some are loading them in the prompt field and comfyui's default method is using the lora loader and chaining it after the main model.
I tried:
base model > AITemplate Loader > Lora > Lora > Lora... > Sampler
base model > Lora > Lora > Lora... > AITemplate Loader > Sampler
but it didn't made a difference
Not sure if every Lora would needs its own AITemplate Loader?!

my training on faces don't get good resemblance OR get overtrained. How can avoid this?

i was trying to get it to render subatomic particles, lol
for captioning images, is there a clean UI setup where you automatically have the image and caption prompt side by side? im tired of having to open the image, then the txt file, and line them up side by side.
that is tedious
tbh ive tried that prompt alot and whatever model that was did guud i think
prompt, model, a couple styles, juggling loras, skipped a few layers, proper noise offset. it's always a bit more than I can really handle
I just try to make things I've never seen before
btw, if you ever want to see any of my goofy workflows they're normally attached to my images in here
what is your workflow, GTM? so good
almost all of them these days
I just noticed the blue guy in the background
Supes 🤷🏻♂️
I'm using the one here https://civitai.com/models/119257/gtm-comfyui-workflows-including-sdxl-and-sd15

The SDXL workflow includes wildcards, base+refiner stages, Ultimate SD Upscaler (using a 1.5 refined model) and a switchable face detailer. Now wit...
hey I know that person 😄
awesome
a scene from "The Boys" netflix series, an angry looking Erin Moriarty as blonde starlight in her white superhero outfit. __location__
Wildcard location at the end there
I'm so stupid - sorry. You have posted it many times :D. It's just too many stuff going on.
did you see last night/this morning when I suggested this lora to fictiverse? https://civitai.com/models/118536/voxel-xl
Voxel XL Lora Hello, here is my first Lora for SDXL. I tryed to enchance the voxel style of the original Model. I hope you enjoy. Trigger words is ...
LOL
anyway, then noticed this

I'll bet he loved it
yeah, I'm glad. it's quality. and it opened up a whole new world to me as I didn't really know what voxel even was
at least not by name
I think anyone that creates these sorts of things should be proud of themselves. whether 5 people like it or 50,000 people use. it. I support anyone putting themselves out there like that
@upbeat summit I looked into it, AIT uses the same modules for base on LoRA, and it works! it's same architecture, so no need to compile for LoRA xD
idk about the delay you mentioned though, didn't experience that
even if it's not my thing, still support it. that's one of the reasons I've stopped looking into the stable diffusion subreddit. so many people hating on others that are putting things out for free
did you read my info here #✨|sdxl message
I need to read up on the ait thing. I only vaguely know what it is
I can make a LoRA version of my AIT workflow if you guys want, it's very simple to do
I talked to a couple of people who experience the delay...
- you start a queue
- than it loads the AIT module (shows the module guid in the console)
- it hangs for exactly 4 seconds
- than it starts to generate
this is on every image
it doesn't do it if you use comfy with --gpu-only
than it's instant
odd. this sounds like an issue with ComfyUI itself
you can open an issue on the AIT PR though
you will get answered very quickly

back to some gens =]
Yeah I don't think that's AIT, it does it normally as well. For me the first time I load up a LoRA its so bad it tries to freeze my PC, but once I've done it once it seems like it's alright. It looks like it tries to load up RAM the first time, hits the maximum and pages. And then next time it doesn't do that for some reason.
so is it maybe a ram issue?
I did discover though with AIT you can't blend prompts, like have 1 prompt for 5 steps and then another prompt for the remaining 20.
It just errors if you try that
fancy
Maybe, I have 16GB RAM and pretty much all the issues I ever have with SDXL are because it runs out of RAM
I see. for me it's with every gen. every time before the diffusion process
AIT seems good if you have a simple setup and you want more speed. But if you are trying anything fancy, it just causes issues.
I just upgraded from 16 to 64 because it was really a nominal cost difference
32 vs 64
How were you loading the LoRA, I was doing Model into LoRA into AITemplate

that's how I did it, works just fine =\
It does freeze on lower RAM setups, but so does regular LoRA, so it's expected.
I'd get more RAM but it feels annoying to buy more DDR4, when I'll probably upgrade at some point and then need to get DDR5 anyway
I just like to be able to run ram hog programs like photoshop and still be able to do other things without my computer slowing down
I tried both and it didn't make a difference
base model > AITemplate Loader > Lora > Lora > Lora... > Sampler
base model > Lora > Lora > Lora... > AITemplate Loader > Sampler
although comfy honestly does a lot of the things I do in photoshop in a more efficient way
Are you always using multiple LoRAs? Have you tried just 1?
blending and things
of course - same thing 🙂
Let me double check what my setup does
I also encounter issue using AIT. After a serval gens, I need to restart comfyui to let it work again.
when I was doing SD2 images I used up to 8 - 10 TI embeds in one image and I'm sure I will do the same with Loras at some point
Oh yeah a major issue I have with AIT, it's the actual Comfy Module. If it ever crashes, it doesn't unload the model. So then I run out of VRAM if I try render again without restarting.
8-10? that's impressive
I manage to get AIT working with Sytans workflow
yeah. TI embeds were to me like ingredients and I mixed them in the latent space
Yeah, it's not difficult to do that. I have a workflow that I made that's very similar to his and it works fine.
It sometimes goes a bit strange on img2img
Steps and denoise are very important AIT
yeah, my issue with the LoRAs after a point is it seems to get exponentially more complicated to get them to all work together properly
yeah, in the workflow I made it's already set on very nice settings.

I also forget what's what with them since they're all named random nonsense
I’ll do more testing with img2img, it’s not typically part of my workflow atm
For sure but I’ve managed to improve it :p
So yeah @upbeat summit first run with a LoRA, it maxes out RAM and takes ages
Prompt executed in 76.39 seconds
But if I run it again after
Prompt executed in 17.10 seconds
Slower than without a LoRA, but it doesn't take "ages"
some of my SD2 stuff - all raw txt2img outputs using TI embeds and prompt magic 😉 (a1111 metadata is included)






yeah, those are good
Wow those are great
Without a LoRA it's Prompt executed in 9.28 seconds
very diverse
Thank you 🙂
hmm interesting. as said it hangs 4 seconds on every gen for me.
Yeah does seem like it's a little slower with a LoRA.
Ran it again without AITemplate with the LoRA and it's 3 seconds faster
Prompt executed in 14.05 seconds
my image gen is not slower with or without lora. it's on the startup of the gen. when it says Using c102dk095kjmfoi29834... in the console / the AIT module guid than it hangs for 4 seconds. after 4 seconds the image is generated and it does it every time

Yeah, I mean that accounts for the entire process with AITemplate and a LoRA taking 4 seconds longer.

Are you talking about first green load into ram?
ah I see. if I bypass the Loras there is no delay.
Hmm interesting
nah it's on every run for me
if loras are in the chain it takes an extra 4 seconds for the image gen to start
as said before if I start ComfyUI with --gpu-only the delay is gone when using LORAs, but in this mode ComfyUI doesn't run stable for me
as Tdg8uU said I will debug this a little more and open an issue on github
My current workflow has Loras, two of them in chain but I haven’t noticed slow downs
Sounds like maybe the delay is it moving the LoRA from VRAM to RAM or RAM to VRAM
It's hard to say which factors play a role here. could be my hardware, maybe the python version, maybe a node in my workflow
yeah, but moving a 200mb file from ram to vram wouldn't take 4 seconds? well I don't know the process really
also running ComfyUI with --gpu-only gives me almost 2 it/s more when using AIT. that is super great, but it's not stable
you mean 2it/s more than AIT without --gpu-only?
those numbers are half of what you should be getting when using the AIT workflow
It's in my workflow. I can try with yours
but --gpu-only fills the vram at some point and it almost freezes for me after a couple of minutes - so not sure what's happening
sounds like memory leaks, I thought ComfyUI didn't have memory leaks issues?
I talked to others having the same GPU and they didn't have the problem with the slow down, but also Out of Memory errors when using --gpu-only
very odd. this sounds like an issue with ComfyUI rather than AIT, I suppose you should make an issue on ComfyUI repo?
yeah that issue is ComfyUI or related to my setup, because it does happen with or without AIT
the lora thing is AIT related
It appears that there is an issue with LoRAs using AIT- the fix for it being --gpu-only .to fix --gpu-only I suppose you could open an issue on the Comfy repo.
Canny is out for 1.0
just used your workflow, with the water gun. base model looks normal I guess but the refiner runs at 1.33 it/s ?!
base 67/67 [00:05<00:00, 11.75it/s]
refiner 44/44 [00:33<00:00, 1.33it/s]
Prompt executed in 49.45 seconds
guess I do a reboot next 😉
I should see if sdxl canny would even run on my computer
wtf, that doesn't sound right. try to release VRAM
why only the refiner is slow - I don't understand
I'm trying to find the person that made the workflow I'm using to politely ask them to add it in.
close ComfyUI completely, then try again. my bet is this is caused by memory leaks
OH WAIT
which workflow?
is this --gpu-only @upbeat summit

@mossy canopy hey do you think you can at some point add the new official canny to your workflow?
On average I think refiner is slower for me, not as slow as @upbeat summit Do you experience this too?
Maybe 1-2it shower
by how much, that's a vague question
how long does it take to execute prompt? @strong field
4096 in 20s
and on my unaltered workflow?
load this

This might be a good place to start for understanding a workflow idea. https://youtu.be/_f0qrHQs0jk
@mossy canopy

Introducing ControlNET Canny Support for SDXL 1.0, especially invaluable for architectural design! Dive into this tutorial where I'll guide you on harnessing ControlNet to craft AI images via SDXL 1.0 within ComfyUI. ControlNet empowers you to use an input image, directing the pose, composition, and other facets of the resulting Stable Diffusion...
shouldn't be too tough
ok apologies for the confusion. without --gpu-only and your water gun workflow
base 67/67 [00:05<00:00, 11.78it/s]
refiner 44/44 [00:04<00:00, 10.99it/s]
Prompt executed in 14.37 seconds
4090, Windows 11
yeah, this looks right
Yeah that looks right
it's so awesome we got to a point where we make stuff like this in less than 15 seconds

Pioneering
I have a small brain and also currently literally sick.
I need others to help me so that I can have fun.
oh, I'm not knocking you
I get that
I didn't mean to make it sound like that
I'm joking with you.
I am sick though.
I'm looking at it now. I'll see if I can get it to work for myself. if I do and you're still around I'll see if I can maybe help out
bummer you're sick 🫤
I'll send you the other UI I'm using by the other user to see if you want to try and fanagle it into that one as well.
that works. no promises, I'm not the best at this stuff but I'm persistent so should be able to figure it out
as long as my hardware allows it. might be pushing it a bit but we'll see
When I do send it just unwire the upscaler nodes and find a way to route the nodes to it.
The upscaler can take up to a minute plus just due to how he has it set up. Not at all hardware intensive for that portion from what I understand.
I'll send it in soon.
cool, I'll check it out
something seems off for me

thats using your workflow
pretty sure it used to be faster
i have some ideas
What scheduler should be used with euler_ancestral?
normal or karras work well
Does anyone have a workflow they are willing to share that works well that uses all the different components? Such as model, refiner, lora, and upscaler?
do you know how to install custom nodes using comfy manager?
In other words making my own workflow with an advanced configuration still elludes me
@hardy cipherHere it is.
thanks. might be a minute. we'll see. I'll let you know if I figure it out. or if I don't, lol
I get ya.
any idea what i could add to my new node? (things that are always required for SDXL TXT2IMG)
https://i.imgur.com/jlj0vVo.png
(the node calculates end_step, start_step by the percentage value and sets cfg_refiner to cfg_base if "0" is selected), also offers all recommended resolutions for SDXL)
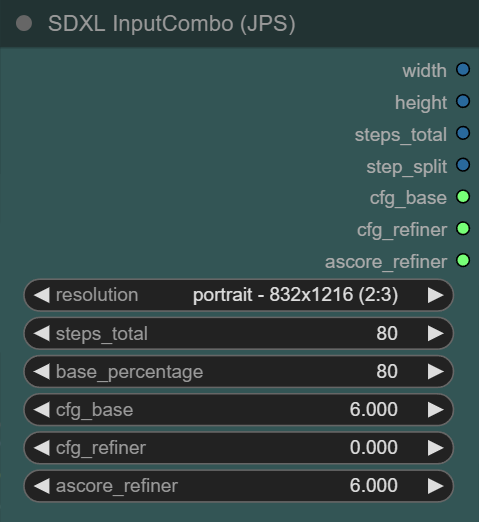
seed number?
@hardy cipher will have a look if this is possible with my limited skills :)
another nice node will be able to multiply resolution by a factor (without the int to float and float to int nodes required with available solutions):
https://i.imgur.com/TtJDspZ.png
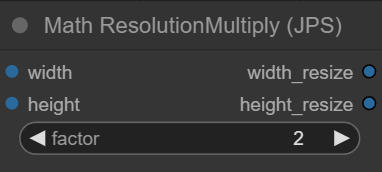
well I think if you'd got this far you can do it 
I need to learn how it all works so I can make a node that it seems no one else is really interested in, lol
@hardy cipher depends if it needs some includes from comfyui base (haven't figured that one out)
guys I had a dream where my comfyui went to 200 it/s
whoa
next step will be to find out how to make it available on github and comfyui manager
do you have a github account?
I had a dream where I met Kanye and talked about movie ideas with him.
i have one, but never used it for own projects.
I wonder what he'd be like in person. he's obviously has some mental health issues, but might be alright in person
or maybe a huge scumbag
also have a node for just the resolution (it's similar to some existing nodes but doesn't have manual inputs, as basic variation, that takes less space in my ui:
https://i.imgur.com/uaYgBxK.png
cobined with the math node it gives you height, width, height x2, width x2 - the only things you need most of the time
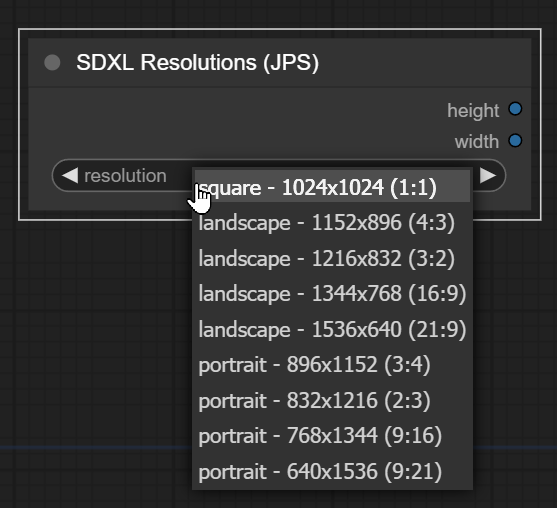

if you would like to be pedantic, to keep the same exact number of pixels as 1024x1024 at 4x3 the dimensions would be 4*(512/(sqrt(3))) X 3*(512/(sqrt(3)))
He's literally someone that is lost in regards to thinking that they need to have a larger than life goal that can barely be met.
it's unfortunate his mom died when she did. I think she probably kept him in check in that regard
That's what most people think too.
that's not right. I remember you showing it being faster?
That’s what I thought too
I need to experiment a bit with this. I have it running, but can't tell if it's having any impact on output
try to reset comfy entirely, you might have messed something up. or even restart PC.
never actually tried to use controlnet in comfy, lol
this node is default or extension node?
it's a new node i'm working on. just have to make some final adjustments to some other node and find out how to share it on github and comfyui manager.
Yeah been trouble shooting
I think I got it back to normal lol
is the speed back to 15 seconds/gen?
Does it look right for your workflow at 20s. I forgot which card you have
I had done the nodes.py tweak and I think I screwed something up
Reverted the file

I'm using ComfyUI with SDXL 1.0 and It is creating black images. I tried using --xformers but that doesn't seem to work with comfyui... Does anyone else know of a fix for this?
What’s your resolution settings
768w x 1024h
Not quite but I’m back to 6.9it/s
how long in total?
Can you screen shot your workflow real quick
20s
Its the one you sent scorp
GPU? that's the exact speed I get on my 4070ti
why pixeleted when zoom

OH FLICKITY F*
I’m running my undervolt profile
Low resolution?
You have any issues downloading the modules
?
X formers works fine with comfy
1024
You are 193% zoomed in, obviously it will be pixelated
Now it all makes sense, I’m ok sacrificing a little speed for the power reduction but I forgot I had it on lol
No and it was working before. Then I used the searge 3.4 workflow you sent scorp now I get black images
try it without lower power, I think it should get faster?
Yeah definitely, I’ll double check what my max is
Are you getting errors when you run it or just black images
I understand.
it's weird. it seems to be changing things but not in the way I'd expect
Is it overhauling the image more than it should?
not exactly. just creating seemingly random things. can't really say exactly what's going on. I'll let you know if/when I figure it out. just trying to troubleshoot it atm. I'd like to get it working for myself sa well. it'd help a lot with keeping complicated workflows cohesive
Makes sense.
Eh it’s only like 1-2 seconds faster. Not consistent either
So my others issues were workflow
huh. at least it's still incredibly fast
Seems right now
Great optimization on your workflow, I keep having to come back to it when I break it
8k in 25s is about my best benchmark
Hi there, I'm pretty new to the party and having great fun with comfyui and the Searge SDXL v3.4 workflow.
I'm not really understanding too much of it tbh, but so far, I got it running. I still get deformations on hands and sometimes faces, any noob-proof tips?
I'm not sure how to fix this does anyone have any suggestions?

I was getting just black images but not I cant even run comfy 😦
You could just use this too. https://github.com/lllyasviel/Fooocus

GitHub
Focus on prompting and generating. Contribute to lllyasviel/Fooocus development by creating an account on GitHub.
seed number was easier than expected:
https://i.imgur.com/AdhD1DP.png
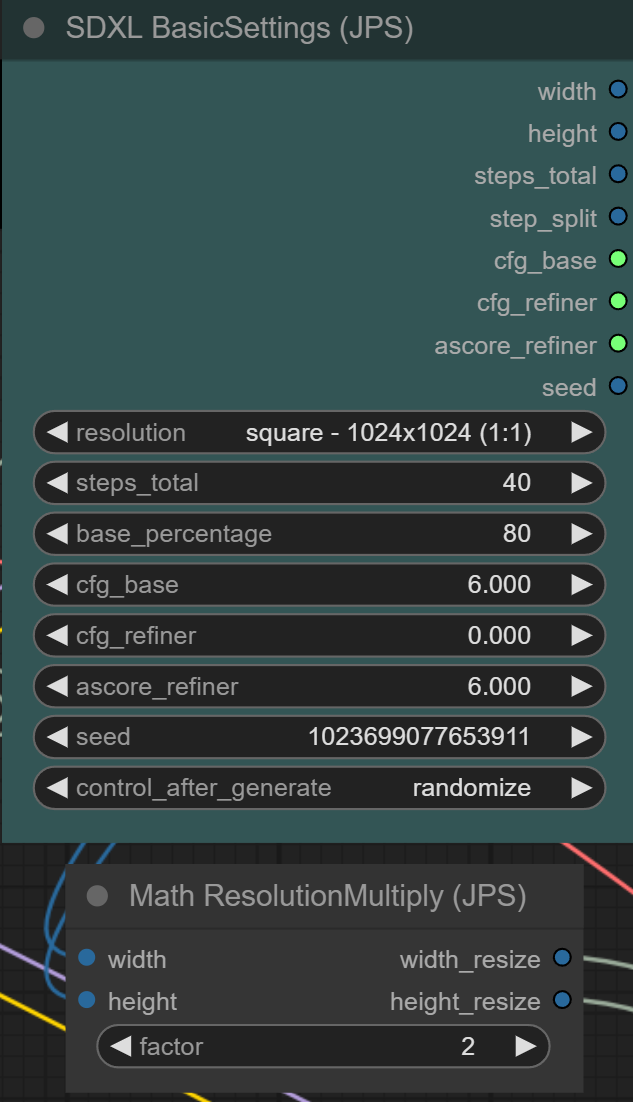
nice work!
I really don't understand what aitemplate has to do with controlnet or why it's causing errors. ugh
What gpu do you have and which PyTorch version
3080ti and currently reinstalling cuda and torch
Yes those are next steps, un install torch and install 118 whl
does this process change if I used venv in my .bat file?
Yeah that venv needs to be redone. Will most likely have a different configuration of requirements
so how do I do that I'm really new to using venv all together
Did it automatically generate the venv last time, if so you can just delete and when you run it will redo
so just delete the venv folder
Are you running windows portable comfy
yes
Yes delete venv
Do you think that you should watch the end part of the video where he goes back and shows the node set up from start to end?
You could possibly deconstruct it and.
Introducing ControlNET Canny Support for SDXL 1.0, especially invaluable for architectural design! Dive into this tutorial where I'll guide you on harnessing ControlNet to craft AI images via SDXL 1.0 within ComfyUI. ControlNet empowers you to use an input image, directing the pose, composition, and other facets of the resulting Stable Diffusion...
It will rebuild when you run comfy

maybe, I don't know if it's a memory issue or what. works fine when I switch to 1.5 models. I realize they're different things, but seems like it's the same concept
still getting
raise AssertionError("Torch not compiled with CUDA enabled")
AssertionError: Torch not compiled with CUDA enabled
what's weird is I guess 1.5 controlnet models kind of sort of work with xl?
In a way I think that's true.
never tried it, but they're giving me the general shape of the canny input
It was proven a while back that 1.5 net was working with very specific workflows in 0.9
not sure if it'd make anything pretty, but definitely works
what i wanted to upscale vs what i got😂

I'll take a look through the base setup he made.
using the 4x-ultrasharp method
run python interpreter on windows ( windows search: python 3.10 app)
import torch
torch.zeros(1).cuda()
then run those two commands, what do you get back?
more lens the better!
sure😂
More Asian woman the better too.
are you using tiled upscale?
yes
that's it
what it
in my experience does weird things with xl. like it renders each tile differently
its the normal sd1.5 actually
ahh, well I don't know
deonoise is very sensitive
More anime woman the best!
i think that ive done something wrong
so using SeargeSDXL broke comfyui? That is strange to say the least
I'll go over that video. I think I'm just the only person on the internet that prefers to just read this sort of stuff. but everyone making videos so I have to click through hoping to catch a glimpse of the workflow,lol
nah, your not the only
just wish someone would put a picture of their workflow instead of talk about something something for 5 minutes, subscribe this, like that
subscribe to my patreon to see unblurred images of my workflow

some people prefer to watch a video u know
you know who makes good videos? dudes that show you how to fix cars. they barely know how to video themselves a lot of times. no creepy uncanny weird face thumbnails. they don't spend 10 minutes explaining a minute worth of things
no doubt
im not knocking the format, to each their own
and those videos are legit worth watching because it's hard to visualize a lot of that stuff
or to understand it from an image
"imagine"
u mean like when they show u an almost naked women?
what is up ? it becoming cartoon image

Resolution?
can't tell you much without seeing the actual workflow
it was working fine earlier
maybe needed restart ?
I guess
something not right


I'll have to come back to it later. Have other things to do now. Hopefully you find a solution before I do 
working on a crazy new controlnet 👀

wat?
huh. that's impressive. I can't even conceptualize how you'd train for that

oooo

What model?
If sdxl is trained at 1024 so 512 will break a lot
Is this the new more efficient controlnet that were discussed previously?
im curious what the use case of this would be lmao.
I guess not everything must have a clear cut usecase at first, but imagine if you had a v2 of this where you used coloured text to colour the different part in the final output.
then youd have to make a picture with colored text and what not lmao, that just seems ummm time consuming. but im sure thats not the only use case, maybe its like a 1 size fits all kind of control net.
idk just speculating
With a good workflow that's not really an issue.
could maybe be combined with unclip models?
Unclip is just a worse version of reference_only "controlnet".

Speaking of SDXL does anyone have a good IMG2IMG/refine workflow especially interested in adding detail/fixing faces for SDXL in ComfyUI

SDXL 1.0 ComfyUI ULTIMATE Workflow Everything you need to generate amazing images! Packed full of useful features that you can enable and disable o...
Maybe this?
Dang discord full-size that’s why don’t you
weird, I could hardly run SDVN6-RealXL with A1111. I ran out of memory before it even started with 12gb of GPU and 16gb of RAM. But with ComfyUI it runs like any other model
weird indeed
wonder how many of these colour names Stable Diffusion "recognises" ;o)
when training SDXL on your own dataset images there is no need to bother grabbing 2k images as the max resolution is 1024,1024 right?
I have a bunch of 1280x720 images and i could get their 1920x1080 but im assuming that would slow down the training with no upside?
what is the best workflow in order to generate high resolution images with A1111 on SDXL? I mean above 2400 pixels
Start with 1024x1024 images and then upscale your favourites to 2400x2400 afterwards as this saves you a lot of time by not having to upscale everything.
Hi guys! With just 16 GB of RAM, I've installed SDXL and ComfyUI on my system. During the VAE pass, memory usage hits 99%, causing minor stuttering. I'm wondering if it's possible to limit memory usage to around 90%, even if it slightly extends rendering time. If not feasible, I'm considering using Google Colab, as I have an unused premium account there.
Also, I'd like to know if working on Google Colab is a good idea given my current setup.
My current setup features a 2070 Super FTW3 with 8 GB VRAM, a 5700x processor, 16 GB of RAM, and a 1 TB Kingston SSD 7300mb.
Thank you for your assistance.
thought about using tiled vae?
Or buying more RAM...
I want to replace my Hires workflow but in SDXL, so I need the native image resolution above 2K because end result should be above 16Mpixel (I use other AI tool for 2x upscale in an additional step)
I do not know how to do it
VAEDecodeTiled is the node name. maybe it will help? takes longer tho
oh, I'll look into that right away, thank you very much. I'll try to find a video explaining how to use it. Thanks buddy
hope it helps! i dont usually use it so i dont know the implications exactly but it may work
If it reduces ram usage by 10% or something like that it will help a lot with stuterings.
@autumn forum I found it, but I'm not sure where to place it. Could you assist me? Sorry if this seems simple, I'm new to ComfyUI.


so youll need to open the vae decode at the top of that first save image node by clicking the left grey dot, then replace the connections on that with the new vae decode tiled
hope that makes sense

It seems to have worked, I just need to organize things now.

nice! below 90% ?
are you using the upscaler? if not maybe try changing out the other ones too
yes, I will try to organize everything. Should I also do the same in Upscale?
wouldnt hurt hah
Thanks for the support Via

not a problem.



me over here trying to find the best upscaling method with the least artifacting and contrast issues. smahing my head against the wall but i feel im close.

Just ask the operator to patch you through to the best method 🙂

@autumn forum I managed to reserve 1GB with the adjustments, in addition to VAE decode (Tiled), I also replaced VAE encode (Tiled). Before this, memory was consuming the entire system, and there is no more system stuttering. Thank you very much for the valuable tip.

nice! glad to see it.

Can someone link me the guide that explains each official node in detail?
that would be good
I think it's a real thing is the issue.
I havent seen one
Thanks

the info on the page is just expanding the node title slightly it doesnt really say what they might be used with
Stock dynavision?
yep
I am disappointed now. I just clicked a link and thought "YIPPIE!"
gonna need a translator
What are you using for a browser?
FF
if you click on it you can see an explanation, we'll need a beer to translate that
Same here. Do I maybe have an extension? https://addons.mozilla.org/en-US/firefox/addon/traduzir-paginas-web/

Download TWP - Translate Web Pages for Firefox. Translate your page in real time using Google or Yandex.
It is not necessary to open new tabs.
Now works with the NoScript Extension.
This seems good too actually.
bing have translator, I like

That's rad actually.
Did you mean Edge?
I don't know, where I'm browsing, microsoft always changes things, until today I don't know if it's bing or edge
bing is a search engine like google but I guess both their own translate page abilities
I never use edge or bing
I LOOOOOOOOOOOOOOOVE EDGE!!!!!!
I will never use it unless I want to try experimental sites.




When I generate I get black images and this is what is says...

sourdough

i use edge for video streaming since its the only one that is usually fully compatible









Does anyone know some kind of node that allows batch count to create a grid like A1111 does? I kinda miss that feature
Have you tried searching for a node like that?

yes, couldn't find anything
Can you tell me the places you looked? I might know another site if you tell me the sites you searched on already.
HF, Reddit, here, CivitAI, Tensors,
Efficiency nodes has an XY plot, but Ive never used it

I'm looking for a feature that behaves like how A1111 behaved when doing batch count, the batch size on the other hand does make that grid, is there any way to have batch count make a grid like that?

Wait, which version of searge did you download? And from where. There is an issue with nodes that are updated with in old workflows. You need to make sure you are using the workflow that came with whatever you downloaded
dynavision + voxel lora


anyone know if there's a token limit when running sdxl on local machine?
Efficiency XY plot is the only thing I know

can someone help me with the code of a simple custom node?
code:
https://i.imgur.com/BdcR5vK.png
results in:
https://i.imgur.com/GAtVRCP.png
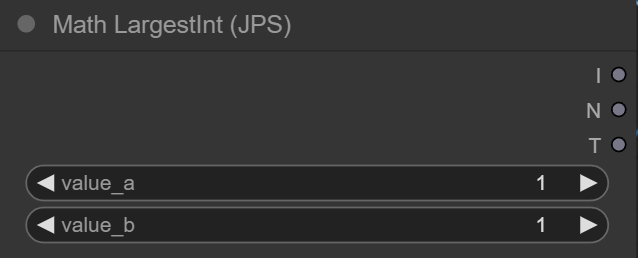
why does it show "I"," N","T" as return values?
i did much more complex nodes without problems, also tried to build it again from scratch, with the same result



HORROR

have you tried connecting anything to the outputs? if I were that's what I'd do first. drag from the node output and then let go in empty space. it should list the most common? nodes it can connect to, then you can click "search" to see everything it would connect to



OK, I like this. I confess that now, after 24 hours of using SDXL, it is countless times better than the previous options. I'm loving it!



yeah if you want to make berries
Or kickass pixel art of kaiju alien tech

I have to start somewhere, don't I? 😎
curious, did you have kaiju in the prompt? i did it with an animal and it didn't seem to work but i wonder if sdxl knows it with other subjects
No. But I'm actually trying some iterations of that since I thought of that word when responding.
hah gotcha


Imagine the berry fine tuning


i solved the node problem (imo that's a bug in comfyui) in a way that doesn't need the additional node.
workflow v13 is working fine in my first tests (img2img and txt2img):
https://i.imgur.com/WJOwCgJ.jpg







I had this idea of having pages that had a "prompt" and images would be generated and the pages would be endless galleries, but I had to give up


u could do a scale and resize with no filtering to get actual pixel art
Mack, can you send me this prompt? I love vintage art and would like to try something with it.
gothic (demented:1.8) smear dry vintage illustration of knight in bone armor holding spear
Thanks buddy
yea
and dont forget ur negative embeddings
idk if theres any on sdxl actually
it looks fine
That doesn't "just work" for everything. Pixel art tends to be drawn in certain ways with limited palettes and specific styles.
Lots of things lose important details when you try just scaling/resizing, like eyes, etc.

I meant as a fix to the model not getting pixels correctly square
but yeah you are right
because the model doesnt exactly put the pixels on a grid
Ah...yes. Actually, I am using that trick. The final step in my workflow is a nearest-neighbor resize.
It corrects the exact problem you're describing.
yeah thats what I meant
but when you upsize it, you need to use no filtering or else it looks blurry
unless the res is just rly low
Final res is 640x360.
On ComfyUI, what is the difference between latent and LATENT?
It's not blurry, tho.

oh must be my browser



How do img2img works on Comfy? I have a LoadImage and then a VAEEncode, but I didn't get how do I set the strength, it seems to change everything
look at the example
I think you are looking for denoise in ksampler
So it's not usable with the other ksampler that has the end_at_step for the refiner? Because the ksampler with the denoise parameter don't seem to have the end_at_step

you can use steps and start_step for sdxl for img 2 img - the higher the start_step for base, the more of the img will be kept




I think this is working, let me test a little more
should work without problems - here i start base steps at 35% for example:
https://i.imgur.com/WJOwCgJ.jpg
(right side is the original - left the result)
Can confirm it works, thank you
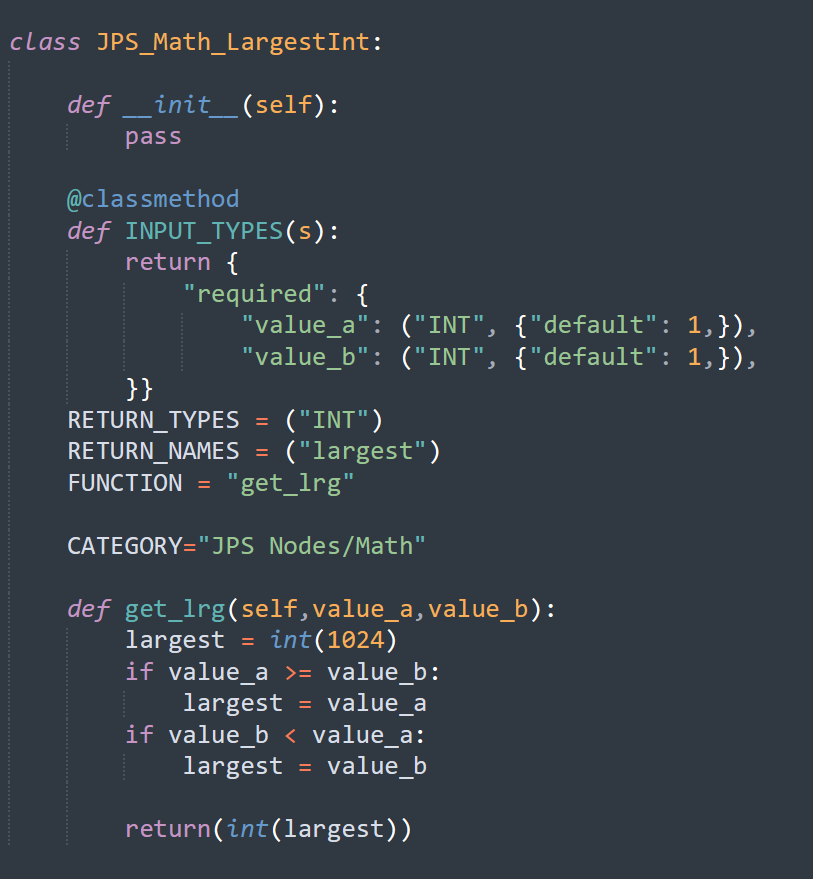
JPS, could you tell me what the deal was with that I N T thing? I'm really curious. I looked into it a bit and couldn't figure out what was going on. t

obviously it spelled INT, but then I could be integer? N number? T ???
yeah me too, i looked over the code for like 10 minutes an couldnt figure
I actually have no idea, lol
you want to do
return(int(largest), )
bruh was it just the comma?!
for some reason it didn't show the name as it worked for all other custom nodes i made and showed multiple outputs instead of one / also it didn't calculate the values and always gave me the default value - don't understand why, as much more complicated calculations work fine in other nodes i made.
looks like it
i checked and double checked all the brackets lol
i was thinking it had to be syntax related but damn, a comma
the comma doesn't make a difference. i tried with and without commas on multiple places - if there is nothing after the comma it just gets ignored

I was trying to figure out if those letters actually meant something, but I barely know enough about python to fix little errors that pop up. that was a bit beyond me
you still need it where i had it so it must be another issue.
ok, let me try again
well it had to have a reason to think each of those letters was an output. I want the flawed node so I can see what the outputs would connect to
I guess I could just use that code
so this should work?
https://i.imgur.com/kLtKFeW.png

I hope this isn't a dumb question, but with the fine tuned sdxl models, should I still use the 0.9 vae, or would I be able to use the vae output from the checkpoint loader?
you can copy the code:
lass JPS_Math_LargestInt:
def __init__(self):
pass
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"value_a": ("INT", {"default": 1,}),
"value_b": ("INT", {"default": 1,}),
}}
RETURN_TYPES = ("INT")
RETURN_NAMES = ("largest")
FUNCTION = "get_lrg"
CATEGORY="JPS Nodes/Math"
def get_lrg(self,value_a,value_b):
largest = int(1024)
if value_a >= value_b:
largest = value_a
if value_b < value_a:
largest = value_b
return(int(largest),)
I've been using the 0.9 vae, but I don't know if that's correct
think my new prompt generator is smarter than i am now


nice
I've been making some cool comic book stuff
you should download the ussr propaganda lora
also try def INPUT_TYPES(cls): instead of def INPUT_TYPES(s):
it adds flair
here is the result with comma:
https://i.imgur.com/kLtKFeW.png
https://i.imgur.com/jDfZfNl.png
for some reason it takes each letter of the "RETURN_NAMES" and creates outputs for the first three letters
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
they officially released one with .9 so i think you are good

well I'm using dreamshaper, and I've been testing out using the vae output from the checkpoint vs the vae loader
not even sure which is better, they're different though




I've been doing fine just using the regular vae though so I'll stick to that
if it aint broke.
also try:
largest = int(largest)
return(largest,)
btw, I don't just ask these questions when they pop in my head. it's just hard to find this information online
like trying to find a definitive explanation on how to construct the refiner prompt
scott detweiler is laughing at his cocktail party righ tnow