
#✨|sdxl
1 messages · Page 77 of 1
generative AI?
thought we were going to talk about amazing CEOs again
Jensen Huang, our savior
gpus
if the company has grew up to a state, where they there isnt much innovation further, then business CEOs are better, like Tim Cook
but in semiconductors, the field isnt at its peak yet, a lot of progress is yet to be made, and as said, tech CEOs can really dig deep into something and work their shit off to get everything working, but non-tech CEOs dont focus on their shit, rather just get tech people under them, but that wouldn't always be the best, as they might not always understand the potential of something techy
Intel is trying to get in. They might have some success in the gaming industry but AI is a lot harder to break into due to software support. Look at Pytorch. It has "cuda" hard coded in the library.
Acer is trying
buy it

what is this guy's deal?
lol
pretty sure he trollin us
but cant lie those gens are pretty good
what's the latest on her? one of those people that burnt the candle at both ends
Skim reading chat history, seems someone doesn't know that CEO does not equate to product knowledge or development
i cant have a word on their gpus, but as far as compared to their cpus, they have skyrocketed from nothing to everything, they dont even have a fab and yet they managed to overthrow intel, i mean that outsourcing takes a lot of time, like if they want to test a partiular thing it would take months for them, but intel with a fab can do it within weeks
I guess trolling. but seems a bit of a strange thing to troll about
lol pretty much
nvidia from wish.com

so elon layoff staff at twitter,Zuckerberg is struggling now
Hey you got the eyes right, sick gen, looks perfect
zuck is struggling just bcuz he completely transitioning his business from social media to ar/vr

maybe i will lora training of a realistic Jenson lol..
and elon is just playing with x, he isnt really looking to make profit from it
CEO LOVERS.JPG
damn, google shit itself lol

now Bard is doing rogue gens and uploading them to image search results
better :

these images are the same, so if you click on tghe first and use the arrow keys to the second, it forces that weird graphical glitch lol


needs more tentacles

omg thats hilarious
the hands really sell it
shoot if i had the time i would inpaint his hands and make them spaghetti
this is what you guys need https://civitai.com/models/124773/morphed-muscle-sdxl

Used for making men hyper-muscular. It seems to pick up on any use of the man concept, and greatly enhances their muscularity. Trained on a hand-ca...

bahahahahhahaha
I didn't knew you need a Lora for that ^^°°°
I thought thats default SD behaviour
lol
there's a "bulked up" xl model, but realized it's main images contained huge dongs
oh?
Can I have a link? lmao
and discord seems a bit sensitive to such things


lol
/models/26303
ah, jensen, the bulked up dong
I mean, they look unhealthy
oh, nevermind, I thought it was for SDXL
nevermind
thank you tho
all of my mature men based models can already look like that if you prompt it, thats way too much for me lol
oh, I thought there was an xl one
citvitai has been messing with me with their new menus though
"here, let us randomly suggest 1.5 models when your settings are sdxl only"
I should probably stop looking for degenerate loras anyway
based
who cares?
chip war is a book worth while to read
SIGGRAPH 2023
arent all those stories the same
the customers
great tech gets invented, somebody steals it, and when the chips fall everyone fondles over the victors?
rich guy vs rich guy, rich guys doin' stuff. rich guys talkin' about rich guy activities
pretty much
so I'm assuming you educate yourself on the ceos of all the companies you buy from then?
here we go again
lol
by educate you mean what exactly, knowing the history of their company and CV?

CEOsAndTentaCruels.png
yeah, you sound like you know a lot
How is SDXL inpainting ? Are you like me and think it is not as good as 1.5 inpainting model ?
use the 1.5 model
There is no SDXL inpainting model yet. An inpainting model will always produce better results than a non-inpainting model.
people acting like a model that's been out to the public for like a week is supposed to have all the accessories
i dont know a lot of things if you are about to be sarcastic 😄 To talk about what i mean above...its not like every customer of those above "need" or do know about every single new fancy technology or feature
but there is a niche of them that very well want to know more 😄
@hardy cipher Someone tell me that we don't need inpaint model for SDXL it is why i asked
for me personally im excited for things that may give me a productivity boost 😄
will i capitalize on those? Maybe, dont know for sure
dude, thats too cringe
You don't need an inpainting model if you only send the whole picture to the model. But if you want to inpaint a small area only you need an inpaint model.
I keep seeing it be hinted at, but same with controlnet
People love their influencer, their youtuber, instagram model, but if we like the CEO of the most innovative tech compagny we are the bad guy of the movie
I'm sure there are some setups that work at a certain level. but probably not ideal or optimized
think they said control net was pretty much done but it takes a ton of resources so not practical
im literally just regurgitating something i heard somewhere and dont remember from where so.....grain of salt
I don't care about influencers or CEOs. I guess I'm a psychopath
I mean, I care about ceos in the sense tha tthey're probably almost all scum
i guess too

and they exploit the labor of the common man
something tells me you dont get to that level without burning a few bodies
You never use ubereat ?
The CEO of Nvidia is a convenient target because a lot of gamers and AI enthusiasts don't like the way Nvidia treats gamers and AI enthusiasts. Beyond that it's pointless to argue over how much influence he really has. He's the leader to criticism is directed toward him. He doesn't care.
intelligent people can do well in this world. but intelligent people with no moral compass? they win. simple game theory
so sociopathic/psychopathic intelligent people run the world I believe
yup
no, I have. I realize I'm just a little fleck of dust in this world and I don't have the power or influence to change much if anything big
who says those dont have "moral compass"
we can accuse all each other not to have a moral compass
That is the way

k
well anyway, I never said that aobut an individual, or about the entire group
anecdotal evidence doesn't discount trends. and describing the likelihood of a trend doesn't speak of individuals
the issue is that moral is subjective so thats why i said everyone can accuse each other of not having a moral compass
you are not talking about the same thing as me
look up cluster b personality disorders. specifically antisocial personality disorder
lol yall talking a different language to each other
well CEOs have a higher chance of being psychopaths, but thats it
yes, hence what I said
This defeatist attitude has never led to anything decent in life ever
and psychopaths aren't an official diagnosis. it's antisocial personality disorder
we may get to the other channel for that i guess
If you are over sensitive you see everyone like a sociopath, while they are juste normal
before a mod steps in
its always that way. you download a model thinking it's general purpose, but it's actually very acutely focused on smutty images because the author thinks thats general and normal.
it's not defeatist, it's realist. our ablities don't give us power. it's resources. normally resources we're born with
ideas are the real power. any individual can only spread ideas.
wasn't actually going to download that one, lol. but I went on a clcking spree of cringe loras and now civitai thinks I probably like them
lol
merge them all into a megacringe
It's much simpler than all this. How many here own an Nvidia GPU because it's the only one that does what they want? Nvidia knows this and they have no reason to change any policies because people will continue to buy.
I'm more looking at it from a stoic perspective. worry about the things we can change. don't pollute your mind fretting over the things you can't. there's no benefit to you
so game theory it is then?
i've been told i'm stoic so i looked up what it was and i thought "ok i guess"
people are ready to bend their moral compass or what they tolerate, dont forget about that either
which i guess is stoicism in itself?
it's about being pragmatic
and not allowing your internal self to be dictated by external factors

I prefer to just call it reality.
People want games and AI. Nvidia is the only one selling that right now.
Imma hit you with that what is real Q and walk away
did i just get told game theory is just gaming?
where am i right now
If there was true competition (meaning the same or almost the same) people would buy other things. But there is no substitute for Nvidia right now. Sort of like the whole Reddit protest that accomplished nothing because there is currently no substitute for Reddit.
even if there is a competition
i'm personally a great example of this. last nvidia gpu i bought had less than 1gb of vram. i've been buying amd gpus since just after they rebranded ati. Why? because i love games but had less money around so i compromised since AMD ran games just fine.
over 10 years later i bought the first nvidia card in a long time solely because i wanted to do more than gaming this time, and the AMD vega64, despite working through rocm, just had limits everywhere i tried to use it. no xformers was a big deal. looking at how much research is done for nvidia vs amd was telling too. AMD was doing nothing in this field and only making broken promises.
i just gave up trying to get my 6950 xt to work with ROCM
nightmares
There is power in a trillion things, not just resources. Community and cultural power are two examples of things you can absolutely influence as an individual. Countries with lower pollution/waste rates got there, primarily, with cultural and community pressure (as an example).
Also, a self identified realist is almost always a pessimist.
Same here. I would accept a 10% performance reduction to get away from Nvidia. But reality is 90-100% performance reduction in AI and a lot more troubleshooting. Which means Nvidia has no competition right now. And when there is no competition they can do what they want. Forget about the CEO. It's the whole company because there is no substitute for Nvidia today.
That is how Jensen make GPU, please respect this guy

so i've heard. it worked well with the vega64 but newer architectures not so much. vegas aren't RDNA. They're their own thing.
figured out how to use AIT on base stage of workflow:

RDNA2 and 3 supported but kinda, only on linux, but mostly through docker, but sometimes, no pytorch, also, HIP SDK Cores, and then some
no competition in this field. AMD is competing hard in the 1080p and 2k gaming space. so many gamers are building fresh AMD pcs' for the current gen games. They'll stay relevant yet
newest window driver says they support it now i saw
AIT? whats that
When AMD performance and stability with SD is within 10% of Nvidia on Windows I'll switch. But I don't expect to switch any time soon because Nvidia has such a lead.
How?
x3 speed
im having a little dumb problem

i dont know how to load a upscale model with stable swarm ui
code that compiles AIT to SDXL's base architecture, it works only on base stage for now.
worry about the things you can change is all I'm saying. no need to fret over the things you can't. but we all make our own choices so do what brings you joy
@soft zealot any idea from where this node is from? been hard time finding it, even asked in comfy matrix, coundt get help

But will Pytorch properly support this? Or will it require unstable and troublesome translation libraries that introduce slowness and instability?
it takes a lot for me to switch because i don't like reconfiguring my software platform and tooling. now that i'm back in nvidia's ecosystem, i'm finding it a lot more comfortable than AMD's has been for over 10 years. AMD will have to move mountains to get me back i think
Thanks for share. I would take a look.
This statement and "I realize I'm just a little fleck of dust in this world and I don't have the power or influence to change much if anything big" this earlier statement are not compatible.
But this is substantially off topic, im intrigued with this AIT update
rocm is just cuda basically, so the pytorch that is compiled for cuda should work for this. but there's going to be some dependency issues here yet.
as I said yesterday, I did a clean install of ComfyUI with a clean Install of all the Accitional Nodes that werre listed in my workflow and it all worked as adverstised , if its doesnt work for you sorry but not my issue
Thank you. I'm still not familiar with AIT, but will read up on it. For anyone else:
https://www.cerebrium.ai/blog/improve-stable-diffusion-inference-by-50-with-tensorrt-or-aitemplate
this won't work on SDXL. it's way more complex than they say in that post.
i've got a 4080 and this sounds like amazing numbers to me. ❤️
even i did delete all my nodes and did reinstall but couldn't get it working, anyways thanks, will find a some way to get it running
could that be simpleeval ?
oops, these numbers
that article is about ait...
what about them?
on 1.5 models
they're very nice yes
dk, will try
2 new things for you https://www.reddit.com/r/machinelearningnews/comments/15l93t2/researchers_from_nvidia_and_tel_aviv_university/ and this: https://www.reddit.com/r/StableDiffusion/comments/15l9onu/its_possible_to_train_xl_lora_on_8gb_in/

reddit
22 votes and 2 comments so far on Reddit
reddit
59 votes and 35 comments so far on Reddit
the guy is only reading up about what it is. Do you have any articles demonstrating what AItemplating is for SDXL specifically?
why do i get the feeling that an argument is being manufactured here. i'm just going to walk off from this one.
look at efficiency nodes
that makes more sense actually
https://github.com/FizzleDorf/AIT if you look thoroughly in this repo, it should explain itself. optimally, when AIT is compiled on your specific device it should be a ~2.7x boost. on SDXL it's ~1.8x boost, still huge, but not as optimized.

GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT: This was orginally written by: https://github.com/hlky
bud, you don't need to tell me about manpages. i think you've lost the plot.
just look in the repo and try it yourself. I already demonstrated on this very channel how it works.
@rovo glad you caught that one
it's listed here https://github.com/LucianoCirino/efficiency-nodes-comfyui/blob/main/efficiency_nodes.py

GitHub
A collection of ComfyUI custom nodes. Contribute to LucianoCirino/efficiency-nodes-comfyui development by creating an account on GitHub.
In case I forgor though (which is entirely possible) its part of https://github.com/LucianoCirino/efficiency-nodes-comfyui
Which apparently is all over the place ATM
GitHub
A collection of ComfyUI custom nodes. Contribute to LucianoCirino/efficiency-nodes-comfyui development by creating an account on GitHub.
yes, exactly
how do i load a upscale model in stableswarmUI
yeah found it, but there's something wrong with my comfy, couldnt get it, still figuring out
make suer your requirements are all installed?
if you're using comfyui find a node pack that has upscale?
yes i have the node, but i cant select any model, but i have 4 models in the upscale_models folder
refresh comfy so it has the file directory
don't want to leave you hanging, but I don't really know
did it a hundred times
i had to create the folder
you named it wrong
upscale_models?
mine is ComfyUI\models\upscale_models
StableSwarmUI\Models\upscale_models
is that the folder the node looks in?
how do i know that
i'm not sure how stableswarm ui installs comfy
but you should have it in comfy's folder. stableswarm is a layer on top of comfy
when using StableSwarm or StableStudio with comfy, comfy still acts as the backend. StableSwarm is just a frontend as far as I know. therefor it shouldn't really matter where stable swarm is located as long as you specify directories.
figure out where the node you're using came from. look it up on google. read about how it works. it's hard to say what the issue is as there are a lot of unknown variables
I realize it can be confounding at times. I still have nodes I can't figure out myself
i'm not the one that needs this explained to chief. you seem to be really hung up on me and i don't appreciate this passive aggressiveness. Didn't I already express that you offended me earlier?
walk away
StableSwarm uses comfy backend and will do a fresh install, need to find that install and drop em in there
the best is when you use it online with google drive. and google drive will low key create two folders if you copy a folder with the same name into a directory with the same folder name. but it won't tell you that. it'll seem like one folder, lol
I've been dealing with this trying to get colab comfy and swarm working
I never offended you. I don't understand how you feel offended, but sure I guess. you just said you're not sure how stableswarm installs comfy, so I just explained it.
While doing batch I always get this kind of image that has absolutely nothing to do with anything, anyone else?

so had "models" "models (1)" listed in colab
but my google drive app just had them combined as "models"
as did the google drive website
it's pretty ridiculous tbh
Batch? Batch what?
a bread roll or a barm , depends where yo ulive
someone needs to make a "lowra" lora for xl. or maybe there is one and I missed it
batch is when you generate several images at once
That's not what I meant.
if it's always that image, it could only happen if it's the same seed and parameters everytime you run a batch. are you sure you're describing the problem accurately and finding a way to reproduce it?
Are you talking about ComfyUI? A1111? What?

I have the noise offset lora. but for this particular combination of things it just keeps coming out soooo bright. I realize I'm pushing it with all the loras I'm using
google designed drive early on to not use folder structures and instead everything is a label. but then it never worked because file systems use folder structures. so they engineerined in folders on the backside of google drive, but the front end is all labels because i geuss thats what users want? It's dumb. Google labels have always been a dumb way to be different for no reason.
not necessarily there is Batch Size & Batch Number
Batch Size is doing multiple together
Batch Number is how many Batches you run
ie a Batch Size of 1 with a Batch Number of 8 is 8 images
A Batch Size of 8 with a Batch Numberof 1 is also 8 images
There'll likely be others eventually then
yeah, I've been learning about that. and I realize I goofed. but I jut wish there'd been an indication of that in their apps and interfaces
These images were generated in the same batch (same parameters), batch size

I just need to adjust some things. maybe lower cfg or something
not your fault really. i'ts entirely google's poor design. the only reason people use drive is because they force it on us
In A1111 or one of its deriratioves or in COmfyUI?
comfy ui
Fixed it
You can do the image blend method for your final output image to bring back some contrast
that's wacky jacks man. i haven't a clue. cool conundrum though.
This is Stable Diffusion. This is The Way.
i'm trying to search civit but it's doing it's thing where it spins forever. anyone else seeing civit hosting fail today or is it just me?
Yeah it’s been a little slow to load at times over the last… week or so? Assuming they’re just a bit crunched with the SDXL hype
I decoded the latent after the first pass, added an effects node and adjusted some things. might do the job
This is how Sytan has it. Super basic, super quick. And doesn't necessarily change anything in the image. Just increase the number to bring back some more contrast

ahh. I've done similar things in photoshop
makes sense
I'd use multiply a lot
actually one layer multiply, the other inverted and divide. all the same image
You can pull the latent batched index from each seed.
I can reproduce every time 😁

it's really the gamma values that need to be checked and adjusted, gamma toooo low
ahh its not the "exact same" image. it's a styled version. That's just your prompt journeying far into latent spaces for one off

he's talking about how every batch, there's one image thats an illustration
I like it when it ends up in liminal latent space
the gateway to infinity
liminility is an awesome concept. core to the human condition imo
sdxl really dont know how do you ride an animal 😄

the bike handles are a dead giveaway this is in the futuer
that puddy cat looks like he's been zoomin
I went down the rabbithole when I found a liminal space 1.5 lora
and the room numbers, all that. I realize that the concept exists outside of the fan fiction stuff. but it's a trip
you might like a short miniseries that might've been an inspiration for all those room number style liminal spaces
I often feel liike I'm sitting in the train station of life,l ol
nice. thanks. I'll check it out
I used the lora to make some interesting things. hopefully someone makes one for xl
yeah all this AI stuff has my world view very disillusioned and i'm saturated in liminal ideas lately.

linear node paths are the way

looking good
thanks. I get so ocd about the organization,lol
that little reroute group on the left is so I can easily adjust how many loras I'm using. just move it up or down to connect to different lora nodes and cut out the ones below
and then the pipes. I suggest everyone start laying pipe
you ever use the lora stacker node?
getting somewhere! argv's and fstrings, dynamic prompts (python array), layer mask, layer overlay, user input image uploads
now for the new gpu to get here friday
Oh nice, an NFT generator :/
i really love knolling style paths. not sure if thats what thye're called. hard right angles.
yeah, the efficiency node? my issue is that it seems to only connect to the efficiency sampler
without end step in the left node there is no noise left - so the right node starts with no noise:
https://i.imgur.com/ZjsAC49.png
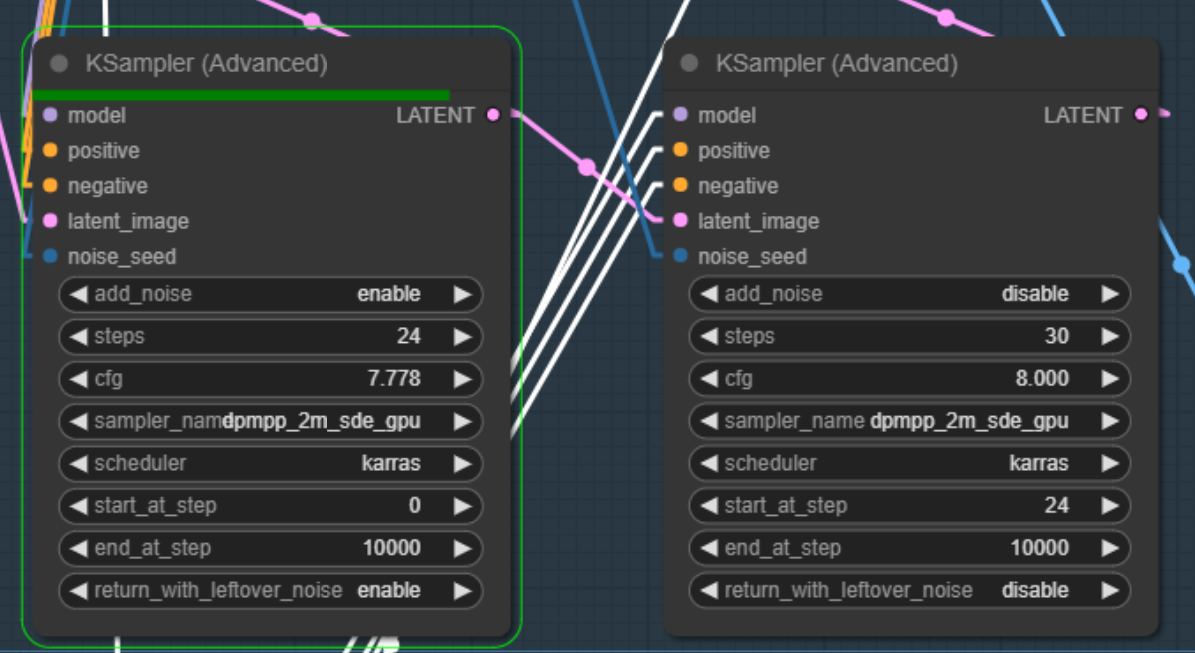
sort of, nft changer
Anybody else having problems training SDXL all of a sudden?
shhhh. just let it happen
regardless, still related to NFT's
I am not sure why, but SDXL training is way more ass all of a sudden
let's them build their own art for a change, not just buying someone elses junk 🙂
My statement still stands
do I want noise though?
yesterday i was training and it wasn't going well in the samples and i was all "wtf!?" and couldn't figure it out. i had scrolled my mouse wheel while moused over the setting for DIM, and took it down to 0.1.
i fixed that after wasting an hour but it worked fine. maybe unrelated to your issue
I don't know, maybe I'm missing something. I barely know what I'm doing
Its just suddenly... bad
like, unusable
identical settings, getting worse results
hm. i don't think it would've just suddenly changed how it trains.
like, my training for this new LoRA, loss has been consistently rising
started at 1.05 loss, now at 0.125 loss
no settings changes
afaik everything is based on removing noise with every step, so i think you want noise left
clearly there is something wrong here

it makes 0 sense for the loss of a LoRA to raise every epoch from starting
I really don't even get what that end step setting does anyway. seems like if I tell it 24 steps it gives me 24 steps. and I don't think it needs to send noise per se. everything is noise in a sense. I'm just trying to refine what's there
Even if the setting / captions are terrible, it should still lower, at least some
using your new gpu?
is it really removing noise though? or just adjusting it and turning it into something we want
throw prodigy at it. i never dont use prodigy these days. i got the resources that allow it.
if you set 30 steps and end step 25, it stops after 25 steps and has noise for 5 more steps left for you next phase.
i should run an over night batch training loras with different settings and running a grid on each. i need to figure out if prodigy really is my best option for my datasets
i use it cause its the newest and new is always better
ahh. I'll see what sort of impact that has. I just remember trying that before and having some strange results. but might have been doing something wrong
i can't get it to run no matter what I do
results are trash, and VRAM usage is astronomical
diffusion is a denoising process. training takes an image, adds noise to it, asks the network to predict what goes there, compares it to the original. doing this many many many times.
I can't seem to find anybody that can explain to me what I am doing wrong, as I am completely confident I have it set up incorrectly
I do get that to a degree. but in this instance I'm not necesasrily trying to add noise and have it create anything new. I'm trying to take something that isn't very refined and add structure
you went from a 3080 to a 3090 right? i dont think that woulv'e caused significant configuration problems
the scheduling part of denoising really has me wondering whats up. Comfy has a thing where it returns latent without any noise left and i'm like "how?"
I trained on this 3090 before
its only suddenly now having these issues
I'll try the other approach and see how it compares
so yeh not that then. are you using kohya gui i mean
My only potential thought is that batch size mixed with the bucketing is fucking something up
well it's not like it really says "this is noise, this isn't noise" it's just pixel values. and I don't know that the model really differentiates per se
another alternative would be to select "add noise" in the right step, but that is not the way base+refiner are meant to be used - it was something that was done before we had sdxl nodes as interim solution.
but my BS is a factor of the repeat count, so I am not sure
yeah, kohya
Anyone have luck with running AIT in Google Colab and Comfy UI?
i don't think batching would cause higher denoising like that. maybe it's a bucketing thing where there's too many buckets and only 1 image in each bucket?
I'm not sure what you mean
ok, now suddenly over half way through training, my loss is steadily decreasing
when it calculates the buckets at the start of training, it tells you how many different aspect ratios it's making and how many images are in each bucket
hurray heh!
what in the everloving fuck is this lol

it definitely changed the image structure. not saying they're winners, btw


whats that high value?
but you don't necessarily need to add noise to an image to run it through another sampler
loss still higher than when I started lol
.134
that aint bad. i find anything riding under 0.15 is typical
yeah but like... Raising for several epochs? I don't understand haha
yeah, that's not good
what is going on lmao

well sometimes the training hits plateaus right?
I am gonna assume it is infact something to do with bucketing
areas where it's harder to work through
@hardy cipher your previous solution doesn't seem to have any change between the two nodes. (at least on the small preview i could see in your screenshot)
and then it breaks through and resumes it's previous work
i'll see loss hover up and down around 0.15 to 0.1 often. i usually do 15 epochs and i don't start catching results until about 6 or 7. lately been generating a sample image on every epoch
sample images tell me more than loss charts have
interesting
second and third node are base and refiner. so no large change between them
so weird, by now on my nearly identical settings with my first LoRA for SDXL, I was at 0.07 loss
i think the missing noise is causing the little to no change

I am at a loss (pun intended)

but I don't want it to change, II don't want to send a bunch of noise to 6 steps of refining
i'd love to show off my loras. i haven't really bothered with asking for consent from people i do them of to share though. all my loras are friends and family. i'm trying to learn this way since i know their faces the best. celebrities i only know warped reality versions of.
i've also done a couple instagram models in an effort to speedrun a model, and have got good results. but i deleted those after.
both situations i can't share results for lol. not without permissions.
same. I made a few decent ones. made about 30 trash loras before I started getting the hang of it though
i like to think i know what i'm doing somewhat. i've gotten pretty wicked results. i'm trying to hone it in where promptcraft is less needed
@trim orbitdo you happen to have any info to share on how to use prodigy? I really wanna use it, but Caith has been gone all day
it's an adaptive learner so it does the lr itself. set learn rate to 1. I think 1 would be a multiplier, so whatever prodigy decides the learn rate is, multiplied by 1. The documentation isn't clear here but i think that's how all the adaptive trainers work
i use bf16 with it
thats not so much my issue, as much as all of the command line arguments and optimization tags everybody crams in for "the good results"
yeup. none needed from what i've determined. just the one for all sdxl loras. --network_train_unet_only
without the tags, it worked just like a normal trainer, but with the tags, it used a disgustingly high amount of memory
disgusting
but by normal trainer, I mean it did nothing
good lord
I'm still waiting on gpt-4 to give me proper schematics for a dual a100 laptop
it seemed to think it wasn't a reasonable idea
I'd probably have to cdarry around a large external lithium batterypack. but worth it
Caith made me realize that I don't have to cache the text encoder outputs and can shuffle captions.
I have been wanting to test that
but it seems as tho my buckets are more like fucketing me lol
oh, let me see how many aspect ratios it did
i took the settings i ran last night an sanitized them . an 896,896 run i tried. looking to try to fit more into my 16gb of vram without using shared memory. it's so much faster when i do that. gradient accumulation set to 5, but i often adjust this to the dataset size. so that batch * accumlation == a nice round number that divides into or close to the imageset size.

more buckets means more opportunity for batches to not fit

one batch can only do one bucket at a time
such a shame
accumulation helps here too though. so it can accumulate 5 batches together
guess I have to run at either lower BS or flat out BS 1 then
how would you recommend I go about this with that in mind? Also, thank you for the help, I appreciate it
i am a heavy employer of gradient accumulation. it's basically bigger batches at the cost of speed.
I use gradient accumulation as well
but I think I use it at one step
so in this case I should do BS1 at like gradient step 8?
just set your repeats to your batch size
pretend I didn't just botch the word "Gradient" lol
I did that
or well, a multiple
if my imageset was 50 images, and my batching was 2, i'd consider 5 or 25 gradient accumulation. 2*5 is 10 which divides into 50 nice. 2*25 is 50 which also does
this is the easiest solution except when you only want to train a single epoch (which only makes sense if you have thousands of train images)
my BS is 8, my repeats are 16
square numbers satisfy me
but then your buckets won't be a problem
8 epochs
12 wouldn't be so bad it. 2*12 is 48, which then leaves an oddball short step with less accumulation
why use repeats instead of just doing more epochs?
I am not sure
I have messed with ti with Caith, they can result in very different results
that helps too. i stick to 10 repeats and 15 epochs. it's kind of divisible
can't really explain how they differ, they just... do
because if you have a bucket with size 1 and a higher batch size the bucket won't fit into the batch
^
so if my BS is 8 and my repeats are 16, my buckets shouldn't be an issue?
yes
more image repeats gives bucketing more margin of error
oh snap
I have never used buckets before, I think I should note
every other time, I have manula cropped
cripped lol

oh man i gave up cropping soon as i figured out bucketing. it was such a pita process haha. bucketing can be a pita too but i'll trade that
cropping means murdering pixels
for the LoRA I am doing, I think having bucket's is very important
lol
it is not! do not order it!
it will arrive and you will be dissapointed /mitch hedburg
ok, I tested the LoRA
its a portrait LoRA
no LoRA, Epoch 1, 2, 3, 4, 5, 6, 7, 8









I like 5 the most
i need to get something like one button prompt script from a1111 setup in comfyui. i really love that little script.

I prompted for that lighting specifically
its specifically prompting for lighting on her face through slatted blinds haha
nice
Its a little unfair, cause I am picking the seed to test based off of how good no LoRA looks lol
i will skip 1-3 cause they look similar
Idk what the Lora is trying to do but I like number 1 the best 😬
Maybe cuz it kinda looks like a younger version of my mom lmao
its a very cherry picked seed for the original base image, tho it didn't listen as well as image number 6
you gotta do a "she's all that" and freddy prinze jr that lora like she's rachel leigh cook
pick the most random ugly seed you can and turn it into the prom queen
is it for faces?






Portrait photography
this LoRA trained like shit, but the results are still interesting
if you could, that would be amazing. I am very picky about my dataset images
i prefer 6 but for no reason other than subjectivity
image 6, or epoch 6?
i got them from unsplash and pexels, so the quality is great, can you please drop your gmail in dms so i can invite you

i've noticed that calling the lora trigger matters less when training unet only. it stilil helps a lot but i don't train with class images so the loras just hit hard whenever they're active
the refiner is not that suited for upscaling
what i posted is no refiner at all
using automatic so the refiner is a checkbox that i alwasy forget about. and when i use it it's like 3min longer.
@trim orbitWoah, this one is different
refiner is adding more details to the image. it's like img2img with low noise strength
refiner is meant to refine the final stages of generation by taking over the last few steps
epoch as you listed them





it's really bad in composition though and I also have the feeling it's not that good on upscaled images. But you can tr
crazy crap
almost looks underfit
you trained it on portraits? Do you have some trigger words?
epoch 6 and 8 look very similar, but 5 and 7 are very different
I honestly just tagged it and didn't even look at captions
just wanted to prove it was viable this way
dunno, it might be just normal variations
and it is clearly changing something
some seeds are just a bit unstable
gonna try seed 666 lol
does it? I wouldn't be able to see if its different seeds or different models
does what?
even tiniest variations in the weights can lead to different image compositions. This ist just due to the stochastic nature of diffusion
if all images have some common word like "portrait" this definitely speed up training
i dont have any good mononoke quotes for this one. so uh, yeah. psy animated does loras good too

what lora is this?
the big tree roots are my favorite part
none, 5, 6, 7, 8





the LoRA is clearly doing something for sure, I think I am onto something here
custom one i made. instagram model so i think it'd get dmcad if i posted it
I need to get more images and hone in my captions/tags along with settings
I wanna see how it upscales
I mean, the skin looks more realistic
how are you captioning images, are you only describing the style of portrait photography, or the subjects and backgrounds as well?
just auto tagging with Swinv2
just wanted to get something out as a proof of concept
upscaled

ah, how many images total?
oh wow, then that's a nice improvement
yeah, I could be onto something for sure
i just tried to do 'flash photography' one last night
i tagged them all the same 'disposable film flash, a person photographed by guy aroch'
i'm not liking what its doing so far, going to have to tag them different, i have like 80 images
and or get better more diverse images
why not caption with vit-g or big G? the actual encoder the unet was trained with
CLIP cannot caption.
caith was saying big-g fits into 24gb
my dataset is pretty diverse

you can just do clip interrogation, but thats not the same
i might give it a go, but i hear all this 'custom by hand talk' is 'better' or 'can be'
any info on how to do that? if so, I will 100% do that
there's an extension that builds captions in automatic1111 using various models.
what am i looking at

yes, but thats clip interrogation
working on a workflow for AIT. which one of these 2 images are better? one of them took half the time to make than the other.


it uses a very different model like BLIP to generate the caption
and then it repeatedly adds single tags to the caption, compares if that improves the similarity to the image, and search for a combination of tags with best similarity

GitHub
Stable Diffusion WebUI extension for CLIP Interrogator - GitHub - pharmapsychotic/clip-interrogator-ext: Stable Diffusion WebUI extension for CLIP Interrogator
one on the right has finer details, but the one on the left (minus the wires that stop) is fine too
oops thats a different one
to be honest, the results are not that good in my opinion, as most flavour tags are rather strange
in the end you don't want to give the model for training super strange captions that somehow maximize similarity
because you would never use these captions in inference
oh no it's the right one. the screenshot example doesn't show the batch mode
one thing too is that with automatic tagging you don't really get a say on what the model should pay attention to and what it should 'figure out on its own', this is what i hear at least

great, this means it worked 😄
thats what I use with Swin V2
doesn't matter. I wrote my own clip interrogator in a few lines of code. They all work basically the same
pro
where do I download the clip G model from? I will totally caption with it
i dont know why it doesn't matter. you're not explaining anything and just shutting it down. i'm annoyed now. i really loath when people get excited about what people aren't allowed to do.
even if it doesn't fit on 24GB VRAM, I have time for an improved image
"can't culture" i call it. all this can'ting
thats the big baddy?
when you select it in that extension it pulls it automatic
yeah, the default caption model is so weird. what time I used it and it captioned: "bruh moment"
the G encoder of SDXL?
fire
where do I tell someone whats allowed and whats not? I told you why clip interrogation is not that great for captions
yes, as far as I know
clipG=CLIPModel.from_pretrained("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k")
clipL=CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
I literally gave it a picture of waffles or what ever then it said- "waffles on a plate, food photography, bruh moment"
does open ai tool only verify or does it even generate captions?
or different: you asked why not using the same text encoder for making the captions which is used by SDXL. I just explained why CLIP cannot make captions. Clip interrogation is just a workaround
comfy suddenly says my text encode inputs cant be strings... finally found a system-breaking bug in comfy
clip can only compute similarities between images and text
oh ok
clip interrogation is a trick where you have a program that generates automatically thousands of captions by some algorithm and you then use CLIP to choose the best one
and you can do that iteratively, by using the best one as basis for creating longer captions and again ask for the best one
let me check
it doesn't seem to be in there ._.
their whole list

I checked it. It is the exact same one
my version. maybe update ?

Even "good" hands needs to have nightmare fuel elements

i do love a nice pair of nails
which extension do you use?
quoting you was an accident, sorry
its missing big g for me, and I am not sure why
i use auto's dev branch but i doubt that matters. i've had bigG in there since 2.1 days
i do mostly manually captioning. i shoulds ay i don't rely on that at all and i can't even load bigG with my 16gb. i use the other vit-G models when i do
But during the center stage they were like we didn't use laion
i'll try the one you were talking about
gimmie your big G
it gets the model names from the open_clip library
you don't even need it >:C
so you might try to update that one
someone know how to setup auto1111 to auto select vae when i switch to SDXL model ?
so much easier to do it through hugging face like before then lol. i'm not gonna leave a discord file transfer open for 8 hours.
fair enough

I just have no idea where to install big g, as the extension has no model folder
downloading it is no problem
yeah but like, I have nowhere to put it
can you check which version of open_clip you have installed?
pip list
@rustic garnet laion uses blip, but SDXL's text is very good, how was it possible with SDXL and not with 2.1?
smart to check anyways
GitHub
An open source implementation of CLIP. Contribute to mlfoundations/open_clip development by creating an account on GitHub.
the big one is definitely in there
so you have to0 get the up to date version of open_clip
ouch
which is __version__ = '2.20.0'
lol
you can still try to download open_clip and install it
thats what I have
oh wait. You use auto111?
are you in the auto111 venv?
oh, no, let me try that
actually I don't know how that works in windows ;_;
I always forget about venvs lol
in linux you would write source venv/activate
and then you can check the version of open_clip again. probably it has a lower version there
ah, its the same open clip
wuut?
this is really strange X_x
then download it from github and install it again
git clone `https://github.com/mlfoundations/open_clip/
cd open_clip
pip install .
in windows a useful script is usually /venv/scripts/activate.ps1 or .bat
ok, wait, what should I do with this?

i love short little concise pip commands like this. it feels like "pip pip cheerio" level pipping
thats clip_interrogator? I thought you use the clip_interrogator_ext in auto111?
ah okay, seems you can use it without starting the webui
but the problem seems that it doesn't know about the bigG model
yeah ._.
ironic that me, 16gb unable to load it guy can see it. sytan, 24gb guy can load it fine but can't find it. the gods work in mysterious ways.
it's like we're ants and they got a magnifying glass

did you tried reinstall open_clip within the auto111 venv?
If the gods would intervene with human existence at all, the advent of machine learning would certainly hail it.
world changing tech
So... I tried training a SDXL LoRA on my laptop. It took 30 hours. 12 hours of all failures possible, even permission denied to save the checkpoint, and then a 18 hours run that generated a file. I'm trying to use this file to generate pictures and I'm noticing that its effects are very small by default. If I set the LoRA weight to 2.0, the effects are noticeable but still small and with a weight of 4.0, then it's actually much closer to what I expect.
With that information (that a higher weight of the LoRA makes it actually apply the effects), can I know what parameter should I fix on training? Because "just set the weight to 4.0" seems a bit silly
uh, changing weight is dangerous
if it does not work with weight 1 you did something wrong in training
what is your learning rate?
I tried big g on my 3090 and it didn’t like it lmao maxes out my vram immediately. But then again there might have been another that I used that worked
and optimizer?
I got it run on my 3090
I am so jealous
you might've done what i done and set the alpha to something low accidentally. thats eactly how my lora turned out when i had the alpha at 0.1 by mistake
i'm still so sour about that and i'm seeing the problem in everyone else's workflow now
what is dim 0.1 oO
Hmm then maybe I used a bigger big g that didn’t work and the smaller one worked idk. Either way it was very impressive. Way better than vit l or h for basic descriptive prompts
in kohya, rank and dim. i usually put dim to 1.
yes, but its a discrete number, not a floating point
newer versions of kohya make it a float
but what does that mean? Do they use it as relative number?
in this case 0.1 would be a lot
my bad. it's not dim. Network rank is the dim. (dimension). the other setting is "network alpha"
i'm so sour about it i can't even talk about it right
ah, okay
Might be you just trained wrongly. The lora didnt learn much from the training.
could've been a low learn rate
I'm happy it sort of works at all. Next week, I'll have access to my desktop again and then I'll have a GPU to train things. This is the command I used:
python3 sdxl_train_network.py \
--pretrained_model_name_or_path=/path/to/sd_xl_base_1.0.safetensors \
--dataset_config=/path/to/toml.toml \
--output_dir=/path/to/output/lora \
--output_name=theLora \
--save_model_as=safetensors \
--prior_loss_weight=1.0 \
--max_train_steps=360 \
--learning_rate=2.5e-5 \
--mixed_precision="no" \
--cache_latents \
--gradient_checkpointing \
--save_every_n_epochs=1 \
--network_module=networks.lora \
--max_bucket_reso=1152
learning rate is too low
and you should train with mixed precision (bf16)
learning rate should be something between 2e-4 and 1e-3
but 2e-4 only if you have A LOT OF TIME
Does mixed precision works on CPU? Because I'm training on CPU right now (because the ISP unregistered the modem  )
)
otherwise, use 8e-4 to 1e-3
uuuuuh. No, it doesnt make sense on cpu
This is what I expected
just don't waste your time on training with cpu
I'm surprised you can even train on cpu, as xformers does not work there, too X_x That explains why it takes so long
--learning_rate=2.5e-5
this is low. i am used to 4 decimal place learn rates. if you look at adaptive trainer's actual learn rate, it often takes it to 0.0005
.000025 is like , a 40th of that
20th
yeah
final answer
quickmafs
2.5^-3 would be OK?
should be 0.0001
I'm glad I set up Stable Diffusion on a container. There are some unfortunate side effects (can't copy images directly and permissions can always cause trouble), but the resources can be limited, avoiding deaths of the host system
So how does LR work with gradient accumulation? Is the learning rate per image equal to LR / batchsize * gradsteps?
this is why i use the adaptive systems. all this math with batch sizes and image set sizes for the most optimal learn rate. they're all just rules of thumbs that someone came up with early in the dreambooth days. it's hard to say what works best without testing. A rule like that sort of gives you a general idea.
And then people like caith come along that just throw 0.001 at everything and it works.





for automatic, i've been using the hires fix on the base model fine. 30 steps first pass. 30 steps second pass. 0.5 denoise. latent upscale. ++ sde karras. not even flipping on the refiner extension at all.
LR is always per step. If you have larger batches or more gradsteps they are averaged
How many images are done in a step? Is it batch size * grad steps?
yes
yeh haha, happened to me to
I don't wanna think about my co2 footprint 🙈
yeup. winter it'll be a boon. summer time, it has me running ac so hard
Anybody know any good way to condition sdxl with depth information? I've tried out this controlnet https://huggingface.co/SargeZT/controlnet-v1e-sdxl-depth/tree/main and the results are not great. Any pointers regarding any good source of conditioning information would be much appreciated

controlnet still being developed
better way than that is to wait and see what comes out from stability when they've rebuilt the cnet architecture
i've used that controlnet myself and it's just not ready
Ah I see, thanks for letting me know of this. Do you know of any ETA stability has put out regarding cnet? Is there a good information source (beyond this discord or their twitter) that is being use to update regarding progress on it
good luck. SAI is very sparse with any information

the controlnet that we're used to was not developed by SAI. we also dont know the priority on their inhouse controlnet model for SDXL since they have other models to develop as well
they just released an LLM model geared towards coding for example
between all the potential models projects that they could be brewing, controlnet for SDXL could be pretty low priority imo
they promised to release control nets soon after sdxl release 🤷♂️
It's really only been like 2 weeks at most
yes. I haven't suggested to start a riot... yet... maybe next week...
lol yeah, tomorrow 2 weeks since SDXL release
Could the controlnet training scripts available in the diffusers repo likely train a good controlnet for sdxl given the right data or training parameters, or is there reason to believe the whole architecture of cnet will need to be significantly different? Wondering if I should invest the time in trying to train my own cnet given the resources available today
could anyone explain what "NUMBER" means in comfy? I understand int vs float. but not sure how number is different

yeah that didnt even come close for me. had to drop to .0003 to get believable details
the scripts exist but I think you have to train on a large dataset to get decent quality
thats what sarge used i think
he has 2x a100 for it
J
colab seems to only allow access to one, at least from the options I've seen. only ever used that option for training a few things
Working on a custom Blender addon

https://wandb.ai/patrick-e-shanahan/sd_xl_train_controlnet/runs/kwi429e8/overview?workspace=user-patrick-e-shanahan my bad. he has 2x rtx a6000
well, thats what he used on this service


cyberpunk life
https://youtu.be/8TToLgW7zuc the soundtrack to that pic

Music video by Glenn Frey performing You Belong To The City. © 1985 UMG Recordings, Inc.
lovely
this AI video looks so real, this truly the future

is it possible to set it up so a sampler value would vary by step number using external nodes? or would it have to be done within the sampler itself?
what do you mean?
I'm trying to figure out how to have cfg value vary by step, but I'm not sure where to start
I mean, you can do that with chaining samplera
ahh, I guess that's true
setting start_at and end_at accordingly
basically trying to emulate some of the things this a1111 extensions does https://github.com/mcmonkeyprojects/sd-dynamic-thresholding

GitHub
Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI - GitHub - mcmonkeyprojects/sd-dynamic-thresholding: Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI
Don't use A1111?
I do have a simple standalone Upscaler based (again) on @high skiff 's work at https://github.com/SytanSD/Sytan-SDXL-ComfyUI
If I've done this correctly it should be embedded in this picture

creating 30+ samplers is a bit tedious, but perhaps there's no simpler way at the moment
uh, but that's clamping latents
well clamping, but also scheduling
it's not changing the cfg
create on clone, then clone 2 into 4, 4 into 8..............
are you sure? there's a cfg scheduler
haha

true, I guess that is an option
yeah, I think thats this cfg rescaling from the terminal noise paper
if your cfg is very high, then your noise prediction can get very high, too. So you have to shrink it down a bit
but its not changing the cfg directly. The formula is a bit more complicated. Its more or less normalizing the gradient
you would have to change the sampler accordingly. Do you really need it?
cause I never needed so high cfg values that I got contrast issues
animals bleed

well it really adds a lot of variation to the image with the different schedulers. I'll give you a screenshot of the options if a1111 actually loads. the readme on that github is very subpar

@trim orbitI desperately am trying to figure out how to get big G working
lol you got that hunter instinct fired up. the chase is on. hard to make a hound let go of a scent.
i couldn't ever because of the 16gb i'm limited by. i heard it was tough to get it into 24 too
it seems as though it is varying the cfg by step. also doing the mimic cfg which I admittedly don't really fully understand. but with those two values working together in the right way it makes things that really pop more than they would with just setting the cfg statically. but I am not sure how to emulate any of the stuff it does
if I knew where the model folder was, I would just install big G and paste it in there
i thought it would be in appdata so i took a quick look but couldn't see it
models/clip-interrogator/
but I don't think that helps you
yeah, its not helpful at all lol
models is the same directory where your webui has all its models
the problem is that the right model won't appear in your dropdown list just because you downloaded it
only got these in mine right now

anyway, seems like the two choices would be chaining a bunch of samplers or creating my own. and not really prepared to make my own, lol
where are those?
I have an idea
here
WHERE
why didn't i go look there first
MODELS WHERE LMAO
webui model folder
go into the venv directory of your webui
and then you go to
venv/lib/python3.10/site-packages/open_clip
there is a file named pretrained.py
you open it with a text editor
no youwere right. it goes to the default model folder for webui
there is a large dictionary containing the models
_PRETRAINED = {
"RN50": _RN50,
"RN50-quickgelu": _RN50_quickgelu,
"RN101": _RN101,
"RN101-quickgelu": _RN101_quickgelu,
"RN50x4": _RN50x4,
"RN50x16": _RN50x16,
"RN50x64": _RN50x64,
"ViT-B-32": _VITB32,
"ViT-B-32-quickgelu": _VITB32_quickgelu,
"ViT-B-16": _VITB16,
"ViT-B-16-plus-240": _VITB16_PLUS_240,
"ViT-L-14": _VITL14,
"ViT-L-14-336": _VITL14_336,
#....
I am not sure how I should download it in here
like, download the folder and drop it in here?
ohhh thats what you were getting at. why his extension doesn't even show the models?
here you have to add the line
"ViT-bigG-14": _VITbigG14 = dict(
laion2b_s39b_b160k=_pcfg(hf_hub='laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/'),
),
yeah i guess if the extension doesn't show it, selecting it would be tough
lol
tbh I wouldn't need to do every step. could just vary it every 3-5 steps. maybe I'll mess with that a bit. I have a lot to learn here, and not trying to waste your time asking silly questions.
sytan... it does not pick the models from the folder. If you use the extension flowwolf posted then it will just put a predefined hardcoded list of models into the dropdown list
ok
so you are suggesting I go into that file and paste this?
yes, if you want to use the ui
alternatively, you could also try to use this REST api... but I think getting it working in the UI would be more comfortable
another day working 24/24? 😅
no, but my sleep is all messed up right now 😅
woke up at 3Am today, and its 2:30 PM, but I only slept 5 hours
am eepy
eepy
very eepy
go to eep then
bro, my best friend just informed me that today is national vore day
8/8
ate ate
I am deceased

well that was a new word for me I had to look up....
I have no clue what a vore day is 🥴
I use video mixers to influence IMG2IMG for results and this is a sample from my most recent session:

DONT
RIP

anyone watch neil gaiman's american gods on prime video?
tech boy was fun
manson twas not
kind of wish it concluded in all it's oddly horrible glory
ok, I added this and restarted it, but I am not seeing it... hmm...
you think there is a special fetish for getting swallowed into the *** of a living godness?
nooooooo
oh 100%
10000%
its like
let me try myself
yes
anyways, reason i bring it up is bilquis has a scene involving similar vore like vore things
what a fun show
I thought after watching "bonding" I know all the fetishs xD
ahhh, i think I migth know how to fix it @rustic garnet
this needs to be in a different location
I am just not sure what to add here

what I posted:
_VITbigG14 = dict(
laion2b_s39b_b160k=_pcfg(hf_hub='laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/'),
)
ilike:
_PRETRAINED = {
"RN50": _RN50,
"RN50-quickgelu": _RN50_quickgelu,
"RN101": _RN101,
"RN101-quickgelu": _RN101_quickgelu,
"RN50x4": _RN50x4,
"RN50x16": _RN50x16,
"RN50x64": _RN50x64,
"ViT-B-32": _VITB32,
"ViT-B-32-quickgelu": _VITB32_quickgelu,
"ViT-B-16": _VITB16,
"ViT-B-16-plus-240": _VITB16_PLUS_240,
"ViT-L-14": _VITL14,
"ViT-L-14-336": _VITL14_336,
"ViT-H-14": _VITH14,
"LilaluLoeffelstiel": _VITH14,
"ViT-g-14": _VITg14,
"ViT-bigG-14": _VITbigG14 = dict(
laion2b_s39b_b160k=_pcfg(hf_hub='laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/'),
)
}
laion2b_s39b_b160k=_pcfg(hf_hub='laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/'),
)
this part goes above
alright, I'll try it



yeah, I mean, you can do it both ways
if you put it up there
then you have to add
"VITbigG14" = _VITbigG14
ok, I think thats what I needed, lets see
I just wanted to keep it simple, so I gave you the code for doing it in one line
the _PRETRAINED is the dictionary which is later used in the dropdown list
AAAAAAAAAAAAAAA
please tell me it works

Do all that work for it to max out your vram and you can’t run it lmao
you can try tomorrow ;D
psy animated is way better for the loras i'm throwing at it. heres one i made on base model #1 and psy animated #2. same seed and settings. barely any resemblance on 1. all the resemblance and a better character portrait too . psy has been the best of the new models yet.



Sorry, I am VERY code illiterate
in the same place as the predefined file?
yes
2.7.0
is it really 2.20.0?
aha!
^^

so something didn't worked with the updating
ok, so it looks like the extension has its own open clip
I think the venv somehow messed things up
probably you have the up to date open_clip, but an outdated one in your venv
I eventually went for the original

nice. that's pretty spot on

hey guys, anybody know how to force auto to unload its resources?
I am trying ti fit clip big G in my VRAM, and I am off by legit like 100MB, and Auto chugs 4.3 GB VRAM when idle
I just need an "unload model" button or something
shouldn't bother the extension
I would be golden
Auto likes to hold on to your resources, it's annoying.
I legit need to squeeze out just the tiniest bit of VRAM
Switch to a really small model I guess lol
I'm finally testing ComfyUI on my laptop
Somehow, it uses the same amount of RAM than a1111 on it
a couple of times during training iv turned my desktop display resolution down to free up extra vram ahah
https://learn.microsoft.com/en-us/sysinternals/downloads/process-explorer you can use this nice little upgrade to the task manager to spot which apps are using the most gpu memory

Find out what files, registry keys and other objects processes have open, which DLLs they have loaded, and more.
@trim orbitI got big G working
thanks to @rustic garnet
only unfortunate part is... its kinda ass

{kind=link}
I was expecting much better captions than this
caith told me they used it often i thought. hmm
maybe they do, but these captions lowkey kinda suck
#✨|sdxl message were smoozching about it last night
If you find a caption model that doesn't suck let me know 😄
thats weird, it runs just fine on my 3090, uses about 17GB VRAM
I am actually annoyed right now
these captions are horrible
a woman sitting under a palm tree with her hand on her head, aesthetic portrait, girl in a suit, black scars on her face, afternoon lights, portrait of a sharp eyed, in a jungle, infp young woman, an olive skinned, beige, michal, close scene, a young asian woman, make - up

you know what the worst is?
like, those captions are terrible
"a woman sitting under a palm tree with her hand on her head" <--- this is BLIP
damn, this was all such a waste of time on all parts
the only part of the image that makes sense is not from clip-g
sorry for the waste of time
learning experience
as said: its still usable if you want to mimic styles
Feels like they pretty much all offer the same basic "a woman is standing in a blue outfit" then they tack on a bunch of random "picture by blah blah, takashi, yamamoto suzuki afrofuturism"
nothing is a waste really
I really would have thought clip g would have been a lot less bad
i thought it was a good watch
but its not good in captioning training data
yeah
i dont know about that because caith is pretty good and he's using it to great success he was saying
that was literally all I cared about too
but thats how they work
maybe you had sytan set it up the way that wasn't working that you had
haha, I'm diabolic
it does run much faster for me than kai
but thats how clip interrogation works. You take a caption and randomly add words to it and check if that improves image similarity somehow
wouldn't say it was intentional, just bad configurations proliferating. my point is is that caith uses it and he works with large sets
that doesn't explain how clip works to me. i'm not sure why you expect it would?
my point is: its not a captioning system
sorry for wasting yoru time sytan
clip is just a function that takes an image and a caption and outputs a similarity score