#✨|sdxl
1 messages · Page 74 of 1
what might this here be:
Error occurred when executing FaceDetailer:
'Sam' object has no attribute 'is_auto_mode'
File "D:\AI\ComfyUI\execution.py", line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "D:\AI\ComfyUI\execution.py", line 81, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "D:\AI\ComfyUI\execution.py", line 74, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "D:\AI\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\impact_pack.py", line 985, in doit
enhanced_img, cropped_enhanced, cropped_enhanced_alpha, mask = FaceDetailer.enhance_face(
File "D:\AI\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\impact_pack.py", line 953, in enhance_face
sam_mask = core.make_sam_mask(sam_model_opt, segs, image, sam_detection_hint, sam_dilation,
File "D:\AI\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\core.py", line 235, in make_sam_mask
if sam_model.is_auto_mode:
File "C:\Users\malicor\AppData\Local\Programs\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1614, in getattr
raise AttributeError("'{}' object has no attribute '{}'".format(
Thank you!
wrong node?

thx
@west breach what happens if we train face with 160 images and 60 images have getty watermark
dunno, try adding watermark to the caption with those images so it knows it's there?
by the way, @visual glade- why can't I reproduce A1111 generations in ComfyUI? I even changed the code to use GPU ARG
I have never used a LoRA before - but now I'm hooked 😄 Underwater LoRA





alright seem pretty great. except obviously in low resolution



if i take a real photo (detected as 1 not_ai) and then pass it through img2img at a 0.3 denoising strength thehive detects it as a 0.908 SD image. If i do the same with a denoise strenght of 0.1 it is detected as a 0.989 non-AI. Both 0.3 and 0.1 are almost the same to the human eye. So it is not the image itself but some invisible artifact. I guess a photoshop filter could eliminate it making any AI image indetectable.
you need a1111 style of interpetering tokens
take a lot at https://github.com/BlenderNeko/ComfyUI_ADV_CLIP_emb

GitHub
ComfyUI node that let you pick the way in which prompt weights are interpreted - GitHub - BlenderNeko/ComfyUI_ADV_CLIP_emb: ComfyUI node that let you pick the way in which prompt weights are interp...

Yeah. I think if you gaussian blur and sharpen afterwards all artifacts will be removed.
i am trying but it is clever than it looks. 😦
running a free colab notebook is so much faster than my computer, its insane
no way, you must literally destroy the image for it not detect it. Must be something more.

colab rola traing speed can up to 5-6 it/s with kohya
applying a filter whihc distort the image seems to work better. Blur/sharpen alone doesnt work

I like this oil-painting look 🙂
It looks more like latte coffee to me. 😄
Its the exact image of the OP filter in PS ...
yeah. I tried and also had no success. It's also none of my concerns. I just found it interesting that it couldn't detect several of my gens.
... but not filter coffee 😄
Is the process for training loras for SDXL different than for sd1.5?
mainly different settings.
which makes it more remarkable
I am using Underwater LoRA and SDXL Offset Example LoRA ... in tandem - a really soft and romantic result!!!




but in general: "no differences in the process"


I love this


2 x SDXL LoRAs










refiner doesn't like asians, but i force him to like black woman:
https://i.imgur.com/vireOUl.jpg
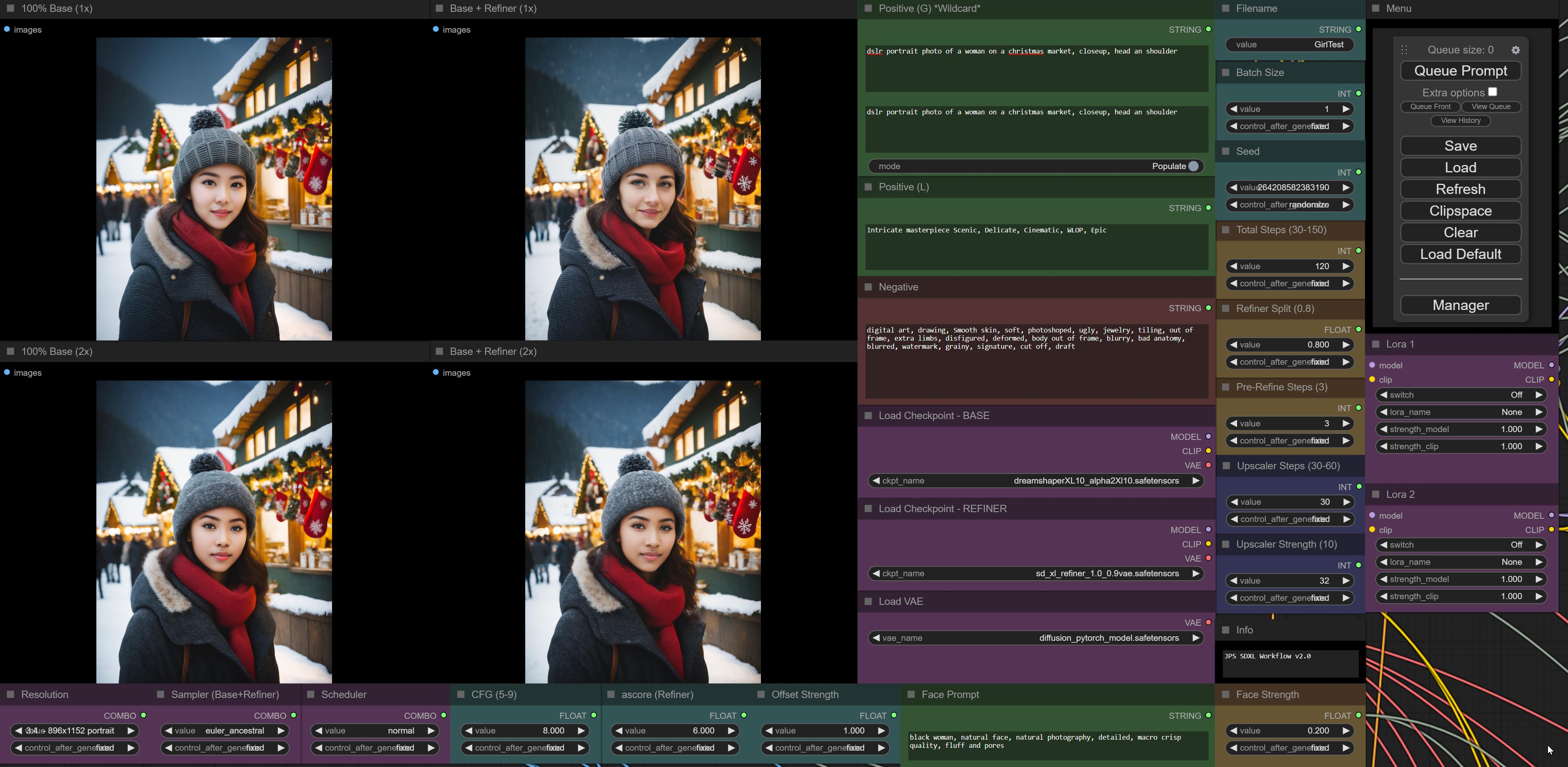


you should lora train for realistic character,asian generation works well either
it was more observation that base picks asian woman in many cases and refiner always overwrites them with caucasian woman, if you don't specify it. if you prompt for asian it keeps it, just from a neutral prompt i often noticed that base creates asians and refiner changes them. also noticed that refiner tends to make woman older than base.
Working on some Sci-Fi movie scenes

lora trained asian actress upscale with refine model,lol..




so it looks like sarge put out safetensor versions of the controlnet depth for sdxl. i was playing with the bin file in comfy but had little success. it's not a very accurate model i feel. anyone can play with it using a1111 now too. https://huggingface.co/SargeZT/controlnet-v1e-sdxl-depth/tree/main
thanks for posting your workflow. i've integrated the face part in mine and experiment with it:
https://i.imgur.com/jU3ZebL.jpg
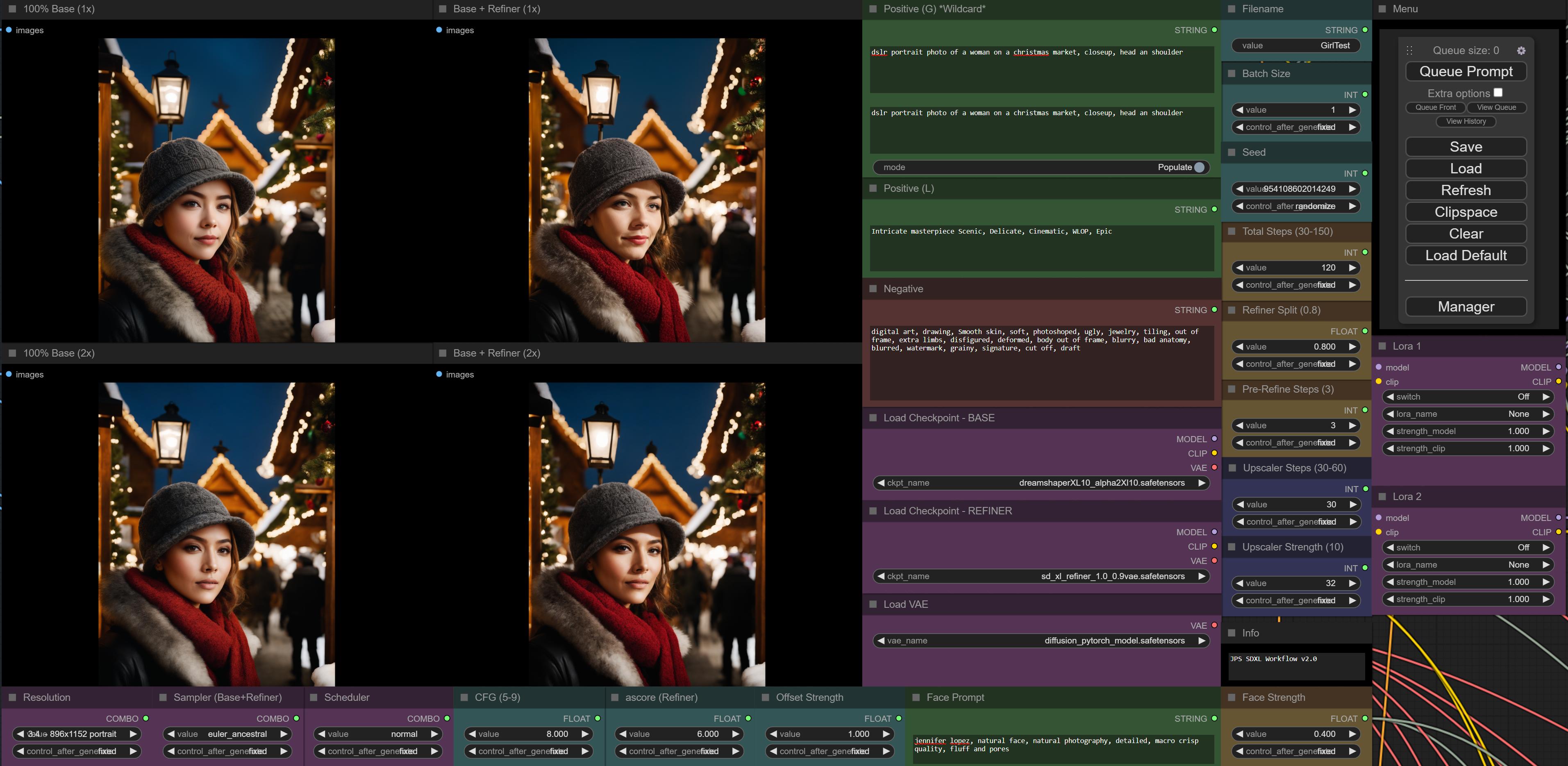
Oh lord have mercy. You havent heard of the workloe from Winston
do you mean because i also fill the screen with nodes until all lines are hidden?
it's the best kind of layout imo. get all important elements on one screen with preview images. the scrolling and zooming is not fluid enough in comfyui imo, so this works best for me.
the face replacement part works quite well:


with https://github.com/failfa-st/failfast-comfyui-extensions you can not only make straight links / cables but also hide them completely
thanks. saw that in the past, but didn't find it again with a short search.
i'd rather have a real frontend instead of this new habit people have of creating tighter and less manageable node graphs. have you seen comfy box? i implore usability addicts to start building comfybox ui's
sweet thanks! i've been wondering how people have done this. i didn't know there were extensions as well as custom nodes. This could be a confusing structure down the road but i'll go with it
@trim orbit i know there are a few of those solutions for a frontend, but from what i got from first impressions they need a little bit more refinement. but this is the way to go in the future imo.
comfybox sees few updates but i don't think it needs them very much given that comfyui is just so well maintained. what we need in this space is more people creating more custom uis for it. i'd be in there doing it but i lack attention span. something i'm working on.
https://github.com/space-nuko/ComfyBox it's also kind of tricky to install which might be holding people back. story of the year.
yeah the QoL features by @zealous horizon are super helpful. now mandatory for my workflows. also square nodes by default. rounded corners look nice but they are a waste of space 😉
rounded corners are a huge waste of space. ty
should I use this to train a lora

i like them still but it' so conflicting when i'm trying to tile nodes together
i haven't been. i think it needs newest bits&bytes which windows users won't have
oh ok
lemme disable

--no_half_vae: Disable the half-precision (mixed-precision) VAE. VAE for SDXL seems to produce NaNs in some cases. This option is useful to avoid the NaNs.i choose no mixed_precision in the step of Bucketing and Latents Caching,cuz it will sometimes show NaN for some pre-trained images when i set fp16
gonna try playing with this safetensors depth model in a1111 a bit. i can't get comfy_controlnet_preprocessors nodes to install in my windows portable version. giving up and going to where preprocessors work instead.
i used it to train my prev lora didnt have any issues
@dense chasm just concerned about half way loras
would the quality be the same?
Been toying with my first personally trained #LoRA in Stable Diffusion #SDXL. Diggin' the results so far.🍉

Might be on the cusp of another breakthrough for SDXL
this one being for realism portrait prompting
these images are the same core prompt, same seed, same setup, just altered negatives and a couple extra positives


not just a one off, either

it's just speed up for computation,Mixed precision training offers significant computational speedup by performing operations in half-precision format, anyway,you have to assign a proper GPU CUDA
looks really good!!
so its way faster compared to full vae?
@high skiff any lora workflow?
from my crappy sketch made in rebelle to final result


which extension allows you to edit node sizes by entering numeric values? i had it, but don't find it again after a reinstall.
so far I am very happy with the textures and skin tones on most subjects
And you can dial it up for more detail/skin texture

this img2img proccess is much easier now in sdxl. With sd1 it tends to diverge much more and do crazy thing needing many more manual corrections
I am rapidly coming for midjourney

Tentacles still unbeatable by any of the AI art generators
Even with inpainting
SD or Firefly
No workflow in png?
DALL E as well
no, not right now
How do i add commandline args to comfyui? There isn't any wewbui-user/sh for this one
Took me only 2 hours to realize that "Bokeh" in negative prompt ruined the pose of my character
I have shared a ton of stuff with this community as of now, I think its reasonable I hold on to some things for myself, potentially even just temporarily
Completely understand mate👍
I had a similar quality result in 0.9, but the prompt was as long as your arm.
I'll share in just a mo.
that looks like something I made in CSS a couple of years ago 🙂
@high skiff whats something that you think sd should improve?
i can prepare the dataset if someone's planning to finetune

are teh bots using aws instances by any chance?
AWS?
it's weird how I can reliable snatch a free sagemaker lab only when the bots are in gpu cooldown mode
Amazon AWS
Could someone send two different pictures, one with sdxl other one with Midjourney ?

Looks beautiful.
if you have a saved lora/checkpoint you can continue from there. otherise "Don't mess around while training"
Top Gun 🙂
no, a ckpt didnt save yet
so gotta run it again



I did the same with RunDiff and Talaman and get very different results.
What's your prompt?
an AI detector tool me this is definitely not generated by AI (0.004 likely to be SD)

those things are fake anyways lol
I have used tons
uplaod the same image a few times and suddenly the rating changes lol
it detects other images with high accuracy but yeah. I don't trust those tools.
Unless the person is stood in front of you and you are taking the picture there is always a >0% chance of the image being fake

with the extensions recommended above i could improve my workflow further and make it look cleaner:
https://i.imgur.com/y0fmoaR.jpg
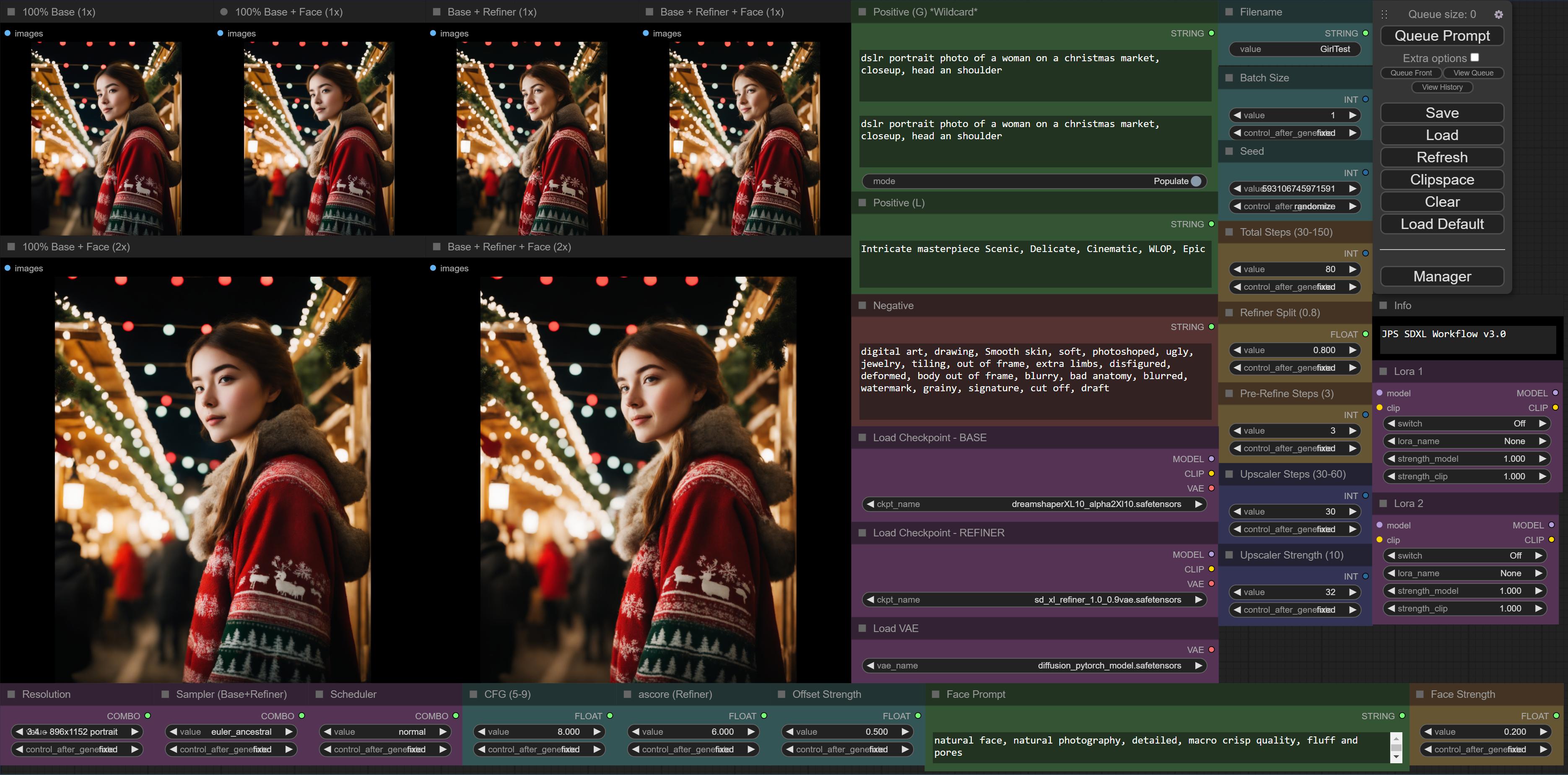
Weirdly Sunday-ish - done in SDXL1.0 with 512 x 512 .pt (embeddings)




Quick question: In comfyUI how do I control the denoising strength in the KSamplerAdvanced? I just see the option to add noise or not
the basic KSampler has the normal denoise value so I'm not sure why the advanced doesn't
holy shit SDXL slaps with black and white photography using my new prompting

yeah. looks like he got slapped hard. sorry for the poor joke but that looks like abuse
was trying for great depression style street photography
A tad like Norman Rockwell! Nice.
I'm guessing whover that was just asking about the See with Text Node just daw this block in my workkflow and decided to avoid my wrath lol

oh my god, I am onto something


Yes, it has Dustbowl/Okies look about it!

kinda creepy

Blade Runner
for some reason cars look much worse than still subjects, the lighting is just kinda off for some reason and I cant figure out why





Has anyone been able to create a text file save node with a timestamp, one that specifically matches the timestamp of the image file too? I can time stamp the image via WAS nodes (because the base one does not allow for UNC paths, at least that I have been able to use and its built-in time variables are more limited). I create a token for the current time and use that as a variable and use the same variable for the text file save.
Problem is... the text file is saved as soon as the positive prompt is generated and the image obviously comes after and it looks like when the time variable is created, it's evaluated twice: once for the text file once for the image file. I've tried copying the variable to another string but that does not seem to work. I can't see a way to have the text file created simultaneously once the image is generated, or even after. Any suggestions?
In Fairness with a biot of work you could get 1.5 to turn out some good ones (this was froma series of models merged then with pictures of myself trained in)

I'm pretty sure LORAs only work on the model they were trained with, or at least work well. There are a couple of workflows for mixing SDXL with 1.5 models out there though, the simplest being just doing img2img from one to the other.
The only other ones I've found require custom ComfyUI nodes and I'm trying to keep my workflows as stock as possible
weird focus but still pretty cool

talke a look at my workflow , its down the bottom (workflow embedded in attached pic of main workflow)


holy workflow batman
ctually I just noyciiced dammit, its fractionally out
No Its not that was just a bad example I grabbed from where I cancelled something

Thanks, is the workflow embedded in that PNG? I saved it but nothing loaded. I'll look for one of your earlier posts and grab it
thats just the tip of it lol

dear god
got a picture with it embedded by any chance lol
it should be if I did it right but if I didnt use this one

That did the trick thanks. I'll go through it but in general though, how did you get the timestamps to match?
luck
I feel your pain
winston, that workflow needs the truck lora
time to open that up without the straight line mod, this is gonna be an abomination to the eyes
One day I am going to make a tutorial specifically for people over 52 to show each node and what the damn inputs and outputs do. But even then, I'd probably run into issues like where the output of one should be able work with the input of another, but underlying invisible variables (like min/max values) mess it up
even I dont do that lol


I've seen a couple of references to a ComfyUI wiki for that sort of thing but I don't think it's ready yet.
Not at all ready.
@soft zealot do you have the link for the seed with text node?
Im 60 next March
There's a mod out there that makes invisible nodes

but is it older people that have a problem with comfy and nodes?
53 exactly three months from today
theres always one youngster who cant bloody read lol

No, it's the documentation, not the concept. I was being flippant about age. I used to play with AmigaVision as a very first generation workflow object oriented presentation maker back before a lot of people here were born
with their iphones and their doodads and gadgets all catered to their whims
technically thats invisible links, invisible nodes would leave a screen full of spaghetti only ~justsaying
ty, to be fair though I didn't see that in the view I had lol

I just showed my age 🙂
A lot of open source software has very little documentation. You're supposed to learn by tinkering. But the problem with tinkering is that it's easy to draw incorrect conclusions that then get spread throughout the community as misinformation.
Odd , It should open by default to this view

maybe it works different in colab? My comfyui in it has been acting bizarre, especially with the nonsense workarounds I've had to use on it lol
I only ask questions when my tinkering leads to a dead end
no idea, I just use my trusty old 1080ti 🙂
Tinkering is fine, but when you get to "oh, it doesn't work because of this spot in the underlying code that I never told anyone about", then it's annoying. I can learn, I can muddle my way through programming if needed, just tell me what the things do
I ran into that problem with primitive nodes in Comfy. I thought it was a limitation of how many things could be connected, but it was really a hidden constraint where identical data types can only be connected if the min/max is also the same. But if I had made a video about it and stated my assumptions that misinformation could have spread in the community.
I don't know, seems pretty impressive for a single person to make such a program anyway, and then to keep up with updates, dependencies, etc, different hardware, different software, different preferences, etc. so I don't know how anyone could expect it to be flawless in all aspects

No software is flawless even if built by a huge professional team. I was only commenting on the problems that come from the idea of "learn by tinkering".
Or more spesifically the collision between "learn by tinkering" and "everyone making Youtube tutorials".
what i'm saying is I see complaints from people about issues they run into with the software. it's one thing to discuss them. another thing to be a dick about it
Anyone who is that upset can learn Python and fix it themselves, 😆
I've actually done that, lol. well to a degree
As I said in another channel, my undergrad is in teaching, so I am biased. I also work with legal contracts for a living, so you have to be crystal clear. I just spent four months reducing risk because of a three letter typo which allowed an asset reseller to potentially claim full ownership of our scrap and sue our legal affiliate. So yes, documentation/instructions matter. We had fun in my undergrad teaching someone how to make a peanut butter sandwich where your partner had to do exactly and only what you said.
"OK, take out the bread" ... partner rips the bag with hands instead of undoing the bread tag.
"Put the peanut butter on the bread" ... partner picks up jar of peanut butter and puts it on the bread.
Hilarity ensues. Very eye-opening to get rid of underlying assumptions of what a person thinks are clear instructinos
but I hadn't really ever even looked at python before messing with ai stuff
I've resorted to that too
Is Monty Python a good starting point? 😉
I also realized that no one was going to come in and save me when I was encountering weird errors at times. so had to fix it on my own
I think I'm implementing Monty Python 3.10.8 on my machine!
Oh hey, I ran into that yesterday. I changed the min/max to match in the other node but it didn't work 😦
what were you trying to do?
There might be another hidden constraint. I only learned about the mix/max because Comfy himself said it.
I'm curious about the errors
I was trying to connect a primitive to steps because I wanted the steps as a string for text input later. It then creates an INT output, but the INT to TEXT node from Aklemann can't use it because the primitive min/max in is 0/8192 and for the other it was 0/0xffffffffffffffff or something like that. Ended up doing this as a workaround

Hey guys, I have created a web app that relies heavily on SDXL and with the new model the prices of stability’s API are just not sustainable for me anymore (~$0.020/image) :/ I was thinking about deploying my own infra on aws, but not sure where to start from and if it’s going to be worth it in terms of cutting inference costs. Has anyone deployed SDXL on their own infra? Do you have any suggestions on how to go about that?
Only in the sense of deploying Comfy and A1111 in Docker, but never used them for API calls. Have you done the math about how much you spend on Stability API calls versus how much you will spend on computer, storage, bandwidth, etc?
hey winston do you have a link to that workflow of yours so i could try it out? or is it private?
ahh, so basically just wanted to have that control steps as well as have it be printed out? or am I missing something?
It’s in the image #✨|sdxl message
okay thanks!
I have read some articles from AWS, but most of them only talk about benchmarks done with the older SD models, there’s not much content yet about SDXL and I’m not very AWS-savvy to be able to run benchmarks on my own
Not benchmarks. Cost calculations. I think you will find that AWS is a lot more expensiev than you think.
yup... print to text file. in a perfect world, the WAS npdes at the bottom would not be needed, but the primitive node won't go to the Aklemann node and the STEPS input of a sampler. Also WAS has a TEXT to NUMBER but not a TEXT to INT node, so I needed to do it in sequence
I keep having an issue with images disappearing once the generation is complete (SDXL - Auto1111), has anyone else experienced this?
Are they being saved at all?
only the ugly 512x512 ones are
it shouldnt be memory issue with 10gb and an RTX 3080 right?
I just thought that considered that Stability is probably using AWS for their API and they’re probably making some profit on it, which means that it’s cheaper to run your own infra rather than use their API. But it’s all speculation, hence why I was asking for some advice😁
No... but are you saving at 1024x1024?
That is an extreme oversimplifcation. They have the advantage of economy of scale. And also most AI companies do not make a profit, they survive on investment capital. Assume that even the lowest AWS GPU EC2 instance will probably be about 50 cents per hour. Are you doing more than 25 generations per hour on your system? Also you need to consider outgoing bandwidth costs which can add up.
oh does the finished result disappear if its not "saved"?
Nope, it should save the 1024x1024. I am not using AUTO but it seems like only the intermediate image is being saved?
I have an "Int2Any_AS" node installed. not sure if that would work. I guess it really doesn't matter.
I just like how it lets me connect string to text. but then tells me that isn't going to work out
I can see the image being generated in the preview but it disappears once the image is complete
I've had that happen before
Makes total sense, I am quite ignorant on the matter, so thank you for clarifying!😅 I do have around 50 generations/hour, but not at all times of the day.
I really wonder if there is a way to deploy SDXL in a cost effective way that would keep the price at around $0.001/inference, ideally on demand
About how much are you spending on Stability API calls per month? If it depends, provide an average or approximate cost per month. If you aren't doing 50 per hour 24/7 you are already behind when it comes to hosting your own infrastructure. I don't know of any way to get $0.001/image.
I think i underestimated the complexity of deploying SDXL to the cloud.
I am not in a rush currently, as my users have not complained about pricing, but I hope in the near future to be able to find a proper solution to cut costs, at least to something similar to what SD 1.5 was
About how much are you spending per month on Stability calls?
so now it's saving in my folder but its not staying in the stable ui preview display
Around $90, but I launched my product exactly one month ago, so it’s just one month’s spend
Also consider that I have switched to SDXL 1.0 only the last week, before I was running on SDXL Beta, which was cheaper
In that case, using Stability API services is definitely the best choice. The cheapest underpowered AWS GPU instance is going to be over $500/month. And it will probably be slower than the API.
I appreciate your time in replying, I will then wait for higher traffic before considering a self hosted solution
had a little tiling accident, guys

AM BACK
good tiles gone bad

Some more super-weird (512x512 embedding in SDXL 1024x1024)




Testing some of the different checkpoints on Civiti

man, I get some weirdness when I forget to set the latent to 1024x1024 or a comparable size
I believe I'll add this lora to the mix and see if that improves anything. I'd suggest you do the same https://civitai.com/models/94842/truckmaker
I like its artistic potential in spite of the mismatch 🙂
yes, I agree. everyone doing the same thing gets boring after a while
which is why I will do my best to incorporate the truck loha into everything I do
so much inbreeding, lol
yeah clearly unstable diffusers, PerfectDesign & Rhapsody are similar merges - Rundiffusion & sdvnRealXL seem to be unique
Sdvn seems to give most realistic results for people at least, but thats what it was made for.
start with a video of someone dancing like that
then you use ai and magic

is it made for xl?
is that from that video?
if so it uses rev animated which is 1.5
quality checkpoint tbh
look at the upload date
may 20
I actually downloaded that lora a cuople weeks ago. should try one day
oh yeah am stupid
tanks
Trained on random screenshots of police bodycam footage I found on Google.
this one looks funny too
is for 1.5 tho
I just want to figure out a solid workflow that'll combine the power of sdxl with the cool stuff in 1.5
I know you can use the refiner on 1.5 models, but meh
yeah true
I wonder if it's possible to backtrace ai rendered images to their base images
base images?
well say you make something in image to image
using a picture you took
it's a base image, right? I don't know what else to call it
the first image, the initial image the before image
At most I think you would be able to show that the images are similar. But not prove or extract the original image.
might not be quite what you're looking for but a previous incarnation of my workflow had an SDXL to 1.5/2.1 ImG2IMG flow

Someone knows a good tut for lora training for my face for SDXL 1.0?
google drive is a damn hassle. no matter what I do to combine two folders it secretly keeps creating two distinct folders. in the google drive app it said the're one folder, but then I look in colab at the directory and 2 folders, lol
now google drive has the two folders listed with identical names. but they're not identical names. one is "models" and one is "models (1)" why would they set it up like that?
Best to create a whole new folder with a new name and then put all items in there. The way GDrive handles folders on the back end is strange.
I do believe you're right. it's just very perplexing. when I see things like that I think they must be intentional, especially for such a large operation and company. but then, why do it that way?
Why does SDXL sometimes start generating dogs... with no mention of dog in my prompt? 🐶

It's not intentional in the sense of trying to make life difficult. But GDrive has no concept of actual folders. Only object parents. And so sometimes you can end up with results that aren't intuitive if you are thinking of it like a traditional file system.



What was your exact prompt and negative prompt?
yeah, that makes sense. I didn't assume it was to make my life more difficult. just a bit perplexing
on a positive note, for colab at least, I probably wasted about an hour or more trying to figure this out while connected to colab. so they got to squeeze a few cents from me through the whole ordeal
but like, there's literally nothing that seems to work. change the folder names. remove the folder.s copy them back in. still it persists. what a maddening experience.
Create a whole new folder. Copy each file into the new folder.
Or move the files. But only move files, not folders.
I
And you can do this in the Google Drive web interface. You don't need to be in the collab.
I'll do that. so stupid though
no I'm not doing it in colab
but kept thinking it wouldn't be this complicated. becaues there's no reason it should be this complicated
so kept reconnecting thinking it'd work right
and each time encounter the same issue
even changed files in the install to point to both folders, that didn't help, for reasons I don't quite understand
and then I can come at google drive from quite a few angles. windows explorer, gdrive app, the website, colab, and each on seems to interpret the world differently
The Google Drive web interface is probably the best source of truth. Everything else, as you said, is an interpretation. Trying to represent the GDrive architecture as a different architecture.
best anime model for SDXL right now? tested smth but it was bad...
have you tried this one? https://civitai.com/models/117259

Anime Art Diffusion XL Check the version description below (bottom right) for more info and add a ❤️ to receive future updates. Do you like what I d...
Allegedly:
- Take example anime image
- Interrogate in A1111 using the “Vit-H” model
- Take the resulting caption and use it as your prompt in SDXL base
And you’ll get close to the starting image without using a checkpoint
Spend last night hacking together some string and LLM nodes for testing. still testing prompts and flows, but using it to generate a scene description and then a list of modifiers seems to give unique and varied results.

Really want to try something like this but locally and contained inside of comfyui as much as possible. Love seeing LLM stuff incorporated like that.
have you tried vailla SXL and see what it can produce? This was deleiberately monchrome comic bookish

Id be happy to release the custom nodes after cleanup and more testing. Just having string contatination nodes, template nodes (for inserting text at a specific location in a prompt), and a GPT node has been proving useful
I feel like fairly small models would suffice for these purposes if they were trained right. just not sure if there are any that currently fit the criteria


what is vit-h? newbie here in sd
vision transformer model
AI Summer
In this article you will learn how the vision transformer works for image classification problems. We distill all the important details you need to grasp along with reasons it can work very well given enough data for pretraining.
sdxl uses vit-g and vit-l
lots of vits


yeah, but how to use it to Interrogate?

tbh with a lot of these things I've had to read the description about 20 times to wrap my head around it
because they've been entirely new concepts my brain never really considered
nah, didnt test is yet, but if u say thats good will test
you mean in general or in a specific application?
in s&d for sdxl
colour me purple and call me kevin why wouldn'y ypou at least try the stock model before going down a rabbit hole?
lol
need to combine with a blip model and do magic
I don't actually know the specifics of that process. but you might be able to figure some things out here https://github.com/pharmapsychotic/clip-interrogator

GitHub
Image to prompt with BLIP and CLIP. Contribute to pharmapsychotic/clip-interrogator development by creating an account on GitHub.
I've been attempting to learn more about it myself. I believe combining interrogation with the image generation in different novel ways could improve the end result quality. I'm sure all sorts of people are looking into that idea though

Where do I find this? " vailla SXL"
valhalla sdxl is the default version
sorry typo.
Vanilla
on an ice cream cart ;o)
I like mint choc chip
chocolate chip cookie dough is the money ice cream
how have I got to be 59 before realising that "tutti frutti" icecream is simplky all the fruits lol
I didn't know that until right now,l ol
yes that
lovely clean images

"Tutti Frutti" in cake format ...

nom nom
I'm not quite sure what the tiling is doing in these images, but it's interesting

SDXL ControlNet wen?
Any info?
Sdxl anime finetunes are getting good..




from what I understand it's pretty much ready to go but it's going to be resource prohibitive in that normal users probably won't have the vram required to run it
they are okay, still has a ways togo before they are 1.5 quality. however 1.0 anime finetunes are great at enhancing 1.5 tuned outputs very well
Just out of curiosity, if I find myself in the middle of a very long render (image generation) while using ComfyUI, and I decide I want to cancel it, how do I do that?
view queue in the top right
then you'll see what's rendering, and what's queued. and you'll have the option to cancel there
I'll have to check
which one do you prefer?
tbh I've found it easier to just ctrl+C and just kill the program. usually faster for me
Copy that. Thank you.
I had that problem randomly when I used AUTO. Seems to be a bug




Is img2img a lot slower on SDXL? I seems like on 1.5, img2img renders more quickly than txt2img, but on SDXL it's going like 5-10x slower. This is not using the refiner but continuing to use the same model as txt2img, currently CopaxRealistic
I don't know how or why that would be the case. it's rendering the image the same way. just on a different configuration of pixel values
what size is the image?
no problem. I run into all sorts of issues myself. maybe it's the sampler?
Maybe it is, I thought I was using the same sampler but I realize now I was not. txt2img was DPM++ 2M SDE Karras and img was DPM++ SDE Karras. I'll check.
is this a1111?
Yep
Much faster now
Damn my eyes, it was the sampler
Apparently the SDE makes a big difference
lol, well that's good. some of them do take longer. heun takes a long time. basically takes 2 steps for every one
I don't really know how the SDE makes a difference, it's a lot of stuff to learn. but definitely know the samplers have a pretty wide range of speeds
it's so many things to juggle at one time and it's all such new technology.. it's impressive these programs even work as well as they do
I'm extremely impressed SDXL is rendering as quickly as it is. I did not think these resolutions would be possible to work with at these speeds on my 3080ti after seeing SD1.5 chug along when doing higher res, but clearly they were able to make some amazing optimizations
can someone create something like this? I want a tattoo made by AI

i can but not on SD
with what then?
photoshop
would be cool if you had time haha I don't know if it would take long
probably like 20 minutes or u can do it yourself too just search for halftone effect on youtube
try using halftone pattern in your prompt (that's the name of that effect)
thanks guys
🙏
but it's already created?
use "silhouette" as well
I don't want exactely that haha
you could use a decent interrogator to get more specific descriptive words
A few other terms to try: scan lines, toner, photocopy, maybe even engraving with a low weight? I think you’re going to struggle with getting separation over the vertical bands if that’s a feature you want
ill try
yeah kinda like the vertical lines
yea u wont get pixel perfect dots with SD but try to play around with prompt like "black and white"
Can always throw it into photoshop after and bring out the halftones there via filter
yea thats easier

assuming it's in the png but
extreme closeup of an eye, black and white toner, bad photocopy, halftone, strong vertical, white stripes
negative was greyscale
ima try a few batches thanks for the help all
If you load it up in comfy there’s a bunch of random other crap in the node graph you can delete. Been trying to figure this crap out
here's what bing said
" I would say that your image is an example of a black and white abstract style. This style uses shapes, lines, and patterns to create an eye that is not realistic, but rather expressive, symbolic, or conceptual. Your image has a vertical pattern of black lines and shapes that create a sense of chaos or disorder. The white shape in the center of the image could be interpreted as a bird or a dove, which could symbolize peace, freedom, or hope.
I think your image is very interesting and creative. It reminds me of some of the works by Pablo Picasso, who was a famous abstract artist. He used black and white to create powerful and expressive images, such as his famous painting Guernica, which depicts the horrors of war.
I hope you enjoyed this conversation. If you want me to create a similar image for you using my graphic art tool, just type #graphic_art(“your description”) and I will generate an image for you. 😊"
not very helpful tbh



the last one is pretty nice
im gonna try again cus my workflow makes something ultra realttic from it haha
this is the tattoo you need

that was one of those happy accidents, lol
tmr morning i get the tattoo so i got to be quick haha
I am pretty good in the ai eye department
let me see if I can make anything worthwhile
i want to get into the vibe of my profile picture/ the eye
got really lucky with that seed tbh
Yeah I ran like 4-5 and that was the best. Didn’t really hunt around a ton though.
might just fire up old a1111. that interrogator extension at least used to work pretty well
takes about 5 minutes on my next level hardware
how much difference does a lora workflow make in terms of performance (comfy)

Anyone have a good prompt for a movie title?
loars will slow it down, kraibse. I think the amount depends ont he lora though
If anyone is thinking about getting an AI tattoo it should definitely be this:

read the comments here https://www.reddit.com/r/StableDiffusion/comments/159rio2/some_of_my_sdxl_experiments_with_prompts/
reddit
405 votes and 56 comments so far on Reddit
lol the buggy fingers have something nice
I'm currently at 10 mins/pic with an sdxl lora
and if you're serious about it, this one is my best offer

Prompt executed in 1836.97 seconds
I think I should probably trim down that workflow
that sd best upscaler or whatever it's called is a beast
perfect
alright, interrogating your eye image with VIT-L-14/openai. should have results within the hour
if it ever actually works. seems I need to update about 500 things first
nah, I'm curious now
gonna have it do a prompt now

I don't know exactly how "flavor chain" works, but it sure does take it's sweet time

should probably get more armor before getting into battle 😉
that would slow her down

flavor chain still tasting things
call me weird but its the background scenery that does it for me

the atmosphere and color grading is really nice. very cinematic
combination of three filters

which ends up like this
nice! was just about to ask if you know the prompt build that is being constructed at the end - very cool 🙂
and the models used + filter names & samplers are in the file names (if opened in browser)
That text file is autogenerated everytime I generate an image

do you use a specific node to generate the txt file?
I've build my own node setup for it and it works but the problem is that it's not always in sync with the date or a random / counter number to match the image's filename. I can see that it's the same issue with your setup. at least we both got the seed matched 😉

th issue is that the OOTB S&R functionality doesnt play nice with WAS Nodes and Vice Versa
fancy lads
ootb? and yeah I use WAS tokens and since you can't control how it's processed (the cascade), for example my image has the ID 00001 and the txt file gets 00002
sometimes it matches, but if you use a batch count on the queue, they way ComfyUI fills the queue it will be totally out of sync
Now I was originallyusing this section to generate Path & Fname for both the WAS text save & image save which gave everything the same timestamp

but I want to add in the smapler, scheduler etc and I havent figrured out a wat of doing that except with OOTB S&R
OOTB =Out Of The Box
well you can use the native ComfyUI Save Image node and use save file formatting - but it's only supported by this node. this should be a global feature so every node can access S&R
ah k
we are talking about the same thing 🙂 gotcha
SDXL/%date:yyyy-MM-dd%/%date:yyyyMMddhhmmss%%SWT.seed%%BML.ckpt_name%%STYLE0.style%%STYLE1.style%%STYLE2.style%%SPL.sampler_name%_%SPL.scheduler%_FFHRF

I asked WAS about S&R since it's in every node's properties and he said since it's a "unsupported" front-end feature / "bug" it will probably not be included in WAS
I think I was on the same thread
ah 🙂
the irony is that I can use a WAS Node and taake its S&R prioperty and use in in an OOTB image save fname
yeah. S&R should be a global option for all nodes but many are doing their own syntax
I'm now trying a new workflow for metadata. I use MikeyNodes' AddMetaData node. You can create your own PNG chunk and I just extract that with exiftool and format my own textfile with the name I want. one extra step but I wrote a small script and it's just a shortcut in my image management tool (xnview)
I was on the same thrread and I see hes suggested something I need to try
Hey Winston, is this what you are using for the prompt styler nodes or something else? https://github.com/twri/sdxl_prompt_styler
yup thats the one
Ok this works but agan th eissue uis you have to use all WAS nodes and I havent checked if they all support txt outputrs

nice! thanks for sharing it. yeah, the value will be hard to get if something isn't a text string or has not output heh. I usually use one of the EVAL nodes from efficiency nodes to convert types.
also saw this earlier - I haven't tried it yet. this package has an Any Converter node: https://github.com/tudal/Hakkun-ComfyUI-nodes
@tender timber made me aware of it 🙂
FWIW Ive added an update to https://github.com/WASasquatch/was-node-suite-comfyui/discussions/129




would have to see if it accepts inline OOTB S&R format
but thats tomorrow, bedtime for me
good idea! sleep well!
I'm trying to follow the logic for the text file name and the image name. For Image you have:
SDXL/%date:yyyy-MM-dd%/%date:yyyy-MM-dd hh-mm-ss%_%SWT.seed%_%BML.ckpt_name%_%STYLE0.style%_%STYLE1.style%_%STYLE2.style%_%SPL.sampler_name%_%SPL.scheduler%_STD
And the FPATH variable for the text file is:
[time(%Y%m%d%H%M%S)]_[Seed]
So those two timestamps are somehow written at the same time for the text file and the image?
Also, I am using the WAS image saver so I have access to UNC paths and better timestamp variables such as three letter month acronyms and it barfs on the S&R name and date fields 😦
I#vr gone too bed but we're all caught in the loop between OOTB & Custom Nodes it would appear
https://github.com/WASasquatch/was-node-suite-comfyui/discussions/129
So it would seem 😦
Have a good night and thanks for the workflow provided so I can examine it
this doesnt work either (worth a try) using #✨|sdxl message

all it needs is for one Python Genius to figure oyt a Node that can take a S&R variable and pipe it out as formatted text................
yeah and probably a node that generates a JOBID and saves the image + text file so they are in sync heh
Mind sharing the code for that concat node? I initially struggled to get a node to accept an arbitrary number of inputs of the same type (text)
it's just the WAS Text Concatenate node

Thank you. I realize now seeing them expanded there are still multiple inputs. Appreciate it!
yeah I construct the text strings that end up in the text file with it. the line break option than formats it like:
Positive prompt (CLIP_G):
my prompt....
etc
It was one of my first ComfyUI experiments. It would make more sense to put that all in a node, but it was fun and I learned a couple things
Use the filter
I know I said I was going to bed but...
There is this in WAS NOdes that saves everything to a JSON

what about something like this?

I think I totally forgot about the node. there are just too many haha
@fresh path Like so...

I was tardy to the party and have no idea what you guys are even doing with all this craziness
Trying to save text files and image files with the same time stamps in the file name and the ability to save to a UNC path, in my case anyway
building machines
with all this effort with wicked complex nodes it seems simpler to patch the comfy engine itself to allow to save the meta data than to create a wicked mess of third part nodes 😂
Well, it DOES save the data into the image, so there's gotta be a way of reading that into a file and parse it
going down the node hole
I will now tell people I don't like to stop being such a node hole
spaghetti all the way down
Who knew that Guns and Roses was so prophetic with their 1993 album? https://en.wikipedia.org/wiki/"The_Spaghetti_Incident%3F"

"The Spaghetti Incident?" is the fifth studio album by the American hard rock band Guns N' Roses. The album is composed of covers of older punk rock, hard rock, and other songs. "The Spaghetti Incident?" is the only studio album to feature rhythm guitarist Gilby Clarke, who replaced original Guns N' Roses member Izzy Stradlin during the band's ...
GThis almost works except it adds a different number to the txt file and also doesnt allow for adding all the other nice details I normally like to have inthe filnemae but if its of any help


no idea why the WAS Image Save doesnt like the [PATH} token that works inthe text save but hey ho
So for today (who knows what's tomorrow) I've scratched the txt file idea. I can't get it in sync so the image and the text file have the same exact name - number counters get out of sync if you run batch counts, time doesn't work since the image and txt will not be created at the same time / second.
I tried for days.
so I'm using https://github.com/bash-j/mikey_nodes AddMetaData Node now. You can create your own PNG chunk. I then use exiftool on a shortcut in my image management tool:
exiftool.exe -T -png:my-metadata filename.png > filename.png.txt
The command is in a batch file and the filenames will be populated dynamically with the image's filename.
Exiftool will then output a .txt file with just the chunk that contains the ComfyUI data that I added through the AddMetaData node.
You can also output a XMP with exiftool
Maybe the square bracket is throwing it off? I'm trying it without ... and also wonder if case matters
I entered it as [Path] (I think) that was more likely a tyo here lol
That will work, still hoping for an in-application solution. Of course we don't need the text files, it's just a want 🙂
yeah but it's my new workaround - lets see where it falls flat, but right now it's looking good to me
I just like to have th eapremters in a nice easy to read plain txt file noit buried away in a JSON etc
yeah me too that's why I build all that
especially handy if I set everything to random lol
I now get a nice textfile from the json data only containing the data I want from the image gen 🙂
but it's not all in comfy - so it takes a bit of a setup
Success with the filenames for image and text having the same timestamp and saving to a UNC path via WAS image save! Had to remove the square brackets from the vraible name, so [Fname] became fname

now run a queue with a batch count higher than 1
try 10 images and see if it stays in sync
Aye aye cap'n!
maybe you figured it out. I tried many different approaches, but the possibilities also seem to be endless 😄
I just used @soft zealot's layout, subbed out the image save from the WAS one, and removed the square brackets from the variables. In looking at Winston's code, I had something very similar for text file save but for some reason, it would save the text filename first and reevaluate the time for the image. I bet it's a slightly different node that I had used, but God knows which one and where in the workflow

Hey, that's my node pack!
I need some parmesan with that
Howdy...
Did it work for getting the text data out?
the spaghetti caverns

I have to comment out the deepface import call in the python file to start it up
Yeah I pushed a commit today to fix that. Forgot that I didn't comment that out even though the node itself was

It's unnerving how some of those look like worms
Does Comfy have a clip interrogator? I see an extension for booru interrogation but is there a non-booru one?
yeah, but I haven't got it to work properly
and I can't recall why, but it didn't quite do what was needed, or I got distracted. I'll have to look, but perhaps it was that I needed to add more into the prompt text file and needed a timestamp as part of the name
I don't even get how the booru stuff works really. I mean, I understand the words, but not how they're actually effective


@cedar tusk if you can figure this out, you will be worshiped 🙂 #✨|sdxl message
Yeah, there's a lot of info that doesn't carry through, like CFG and steps count.
he's been down in the caverns so long he's turning into gollum
You need style, sampler, and scheduler in the name, is that right?
Success! This is on a pokey AMD Ryzen 1700 with 16GB of RAM sending the saved files to a QNAP across Gigabit Ethernet, with no stoppage of other tasks (in fact a batch file runs to backup the QNAP to a local external HD and then to OneDrive every ten minutes...)

just put "average comfy user" on that image there and you'll win the stable diffusion subreddit
nice work, dude
that image is so good 😄

awesome - now I need to know how you did it 😉 I had mine running a bit and it looked okay and at some point it just got out of sync, but this looks good! nice
Me? No. I wanted part of the positive prompt in the filename, which I've figured. i wanted a text file that has some of metadata (but not all) and the text file should have an identical filename to the image output include the timestamp of the filename. Looks like I've got kludgy success at the moment 🙂
ah - I remember it did work quite stable for some time using the Save Image node from ComfyUI, but it did not stay in sync with the WAS Save Image node

Got color correction working. woohoo! Only took all day.

nice!
This is with the WAS node. See the images for the changes I made to the Winston workflow



I need to inspect your screenshot 🙂 great job!
Thanks, Biff. I will check it out 🙂

DAD?!?!?
Thank you! I had issues knowing which data type was compatible for comfyui.
yall thing it would be possible to convert a lora from 1.5 to sdxl? or is that impossible? kind of a dumb question but im guess not sense so much is different with the encoders and such
yeah I'll bet. looks like a really nice solution. I need to give you workflow a spin
I tested this with TI embeds. you can use 1.5 embeddings in the SDXL clip_l textencoder, but it won't give you the results you want, since it was trained on a total different latent space.
okay so its the latent space that causes the trouble. i see
It's almost ready. The issues today put me behind, but it should be smooth sailing now. Only problem is I won't have time to work on it much tomorrow.
yeah simply said it's build totally different, so stuff is in other places.
yeah it looks really exciting. like the ultimate ComfyUI in-painting workflow
That's the plan. Trying to eliminate as many nodes as I can
The beautiful thing about this color correction method is that it can be controlled by adding a factor which I'm about to implement. Then you will be able to adjust the amount of color correction you want.
that sounds intuitive
Oh SNAP! ... all the seeds are the same for the batch of ten. That's dumb.

there's always something 
It's Mr. Winston 🙂

well it's set to fixed
which I do a lot since we have to explore what each setting does:D


color correction changes scaled by a factor of .5 from .5 - 1.5

Does anyone know how the Winston (or other workflows) use Lexica random prompts? It seems to be a WAS node, but where does it grab data from? Is it local or does it go out to a dictionary online?

can't go too high with it though

Somewhere in India, a marketing rep for skin whitening cream is salivating
first female oompa loompa

doesn't work on multiple masks yet. need to tweak some things.

I cannot get SDXL to work at all. AT.ALL. I have a 2070 Super gpu, so it should be minimally OK to run. Out of memory every time on the simplest of Generate. Is there a tweak to the .bat or an extension I'm missing?
Here's the error msg:
OutOfMemoryError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 8.00 GiB total capacity; 6.99 GiB already allocated; 0 bytes free; 7.27 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
And as far as that refiner is concerned? How the heck do I use it in AUTO1111 anyway?
A1111 is the problem. Use ComfyUI
Yes, but is there a fix in A1111? Comfy confuses the hell out of me.
Not yet that I know of
So, how are all the YouTubers using SXDL in A1111?
But back to my question instead of just suggesting I use a different UI. Is there or are there cmd lines for the .bat or an extension I'm not seeing that help with memory allocation?
I would guess they arent using an old 2070. A1111 is a massive vram hog with XL
Anyone else on familiar with A1111 and getting SXDL to run? I saw a post that mentioned something about an extension called "dev" that helped with memory crashes. I have no idea what they meant.
I can get it to run, it just uses more than 10gb or vram on my gpu and nearly 30gb of system ram

with comfy its 6-8gb vram and 20gb system ram
is the latent composite node broken? It seems to be reading the samples_to input, but no matter what setting I change I can't get the samples_from input to affect the output.
I was only gone for a couple of minutes. the story is getting interesting 

this is interesting

OK, so with adding "--medvram --no-half-vae" to the "set COMMANDLINE_ARGS=" I finally got SDXL 1.0 to work for me. Alrighty then... for the life of me and despite prompting (3girls:1.5) it cannot seems to generate more than 1 girl. What is up with that?
lol
It's giving me lovely images of a single viking girl in a forest at night, but just won't produce more than that. Any suggestions?
use natural language like, three girls
I thought 3girls WAS the lingo. Is it not?
thats 1.5 and 2.1 prompting
you can go full booro if you choose, but I don't think that's optimal
Got it. Thanks. Diving back in. 😄
if you're using xl just try natural language
just say, "3 viking women" or something along those lines
1.5 used vit-l. xl uses vit-g and vit-l. vit-g is newer and more capable of understanding natural language
In English, Carter...
model known english better
*sg1 ref lol
it understands sentences
ahso. I see I'm going to have a little fun tonight playing around with this.

Second question. I downloaded the refiner as well and dropped it into the models folder where the xl also is. In A1111... how do I use it?
I do not know
img2img
basically it should be around a 4 to 1 ratio I believe, base to refiner. so if you run the base for 20, run the refiner for 5 at the end
that's not really set in stone, you can adjust as you want. but you don't want it to be 50/50 or anything
at least under normal circumstances

come join us in the noodle caverns, crushin. comfy is what you need
I've started quite a collection of sdxl loras over here
Ive only played a little bit with the offset example lora so far
Download the refiner extension for Auto1111 if you want it to work like in ComfyUI with Sytan's workflow.
some of them are really top notch
just downloaded a couple new checkpoints as well

I was able to get color correction working with multiple faces.

crazy stuff man. nice one
just need to fix the AR
Thanks. I think it's a good stopping point for the day.
AR?
aspect ratio
yeah I had it scaled to 1024x1024 to test. let me take that off and see what happens.
my goodness, that's a bit of a noodle nightmare, but mine always end up looking like that too
My testing charts look like that, once finalized, that's when I organize
yeah, when you're on the move you don't want to take the time to organize everything. it makes sense
Add "nope that broke it", delete. Rinse and repeat lol
works with original aspect ratio.

I tend to organize when I start to forget what's what. or when I have to zoom way out to connect things
awesome
I need to get up to speed on how all that stuff even works. literally never messed with doing that sort of thing. at least not in stable diffusion
and there's my stopping point for the day lol

any suggestions on how to clarify/separate the color lavender from the flower? I'm trying to get lavender eyes and hair, not... actual lavender. lol. (I HAVE tried "light purple", but that's not quite the color i want. (and sometimes i get "purple light" instead. 


GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
well
I guess that a1111, so not sure if that's universal or what
also, put flowers in the negative
ive got a few breaks in there, but maybe ill try putting one immediately before it, lol
I've pulled a generated image into img2img (A1111), but I don't see where to use the refiner. Am I blind?
don't think any of the methods are foolproof
just change the model to the refiner
as I understand it, it's fairly tedious in a1111. seems they dropped the ball with xl
oh jeez, yeah thanks. id been trying to avoid negatives since xl works well without them, but id kind've forgotten that was a thing
Ah, I see.
i may have misreplied
I always negative
I knew what you were replying to
negatives don't always work as expected, but I believe for stylistic type things they're a big help
if you want a1111 feeling but better sdxl support use sd.next - it's a fork but they worked much earlier on sdxl/diffuser support and the sdxl solution is quite different internally compared to a1111.
but I don't think you can really use them to create a whole negative scene or anything. or you can, but results will vary
yeah, that worked, hahah

nice
tysm
I've experimented so much with prompts. take it weird directions just to see what it makes
From a dream I had last night. Cant quite get the details right. Also cant tell if I'm going crazy or just playing with SD too much before bed.

literally my new hobby since i discovered dynamic prompts: fill a prompt with so many possible combinations, run 1000 images while i sleep... mext evening just check out what i got. way better than tv. and i learn to make better prompts and better art.
i love that
nice, yes, it just keeps going deeper too
Anyone else experience issues with the live preview box with SDXL (automatic1111)
what issue?
I can see the live preview of an image but it disappears when the generation is complete
Ah
also fun to make RPG character portraits: put all fantasy races, human ethnicities, eye colors, skin colors, hair colors and styles, classes, types of armor, various environments and lighting styles... and i have a few high-CHA parties the next day XD
is it saving?
Yeah but only after I added a few arguments
theres a setting... somewhere to keep some of the iterations, i believe... or at least one to keep it before adetailer or upresing
what's a high-CHA party?
I can preview sd1.5 and save 1.5
high charisma, aka very pretty hahah
ahhh lol, yeah. I haven't messed with making RPG characters all that much. maybe to a degree
hi guys, i need help. I am new to SDXL in A1111, I just downloaded it and started to running on my Macbook, and I only see one model in my stable diffusion checkpoints. but I have downloaded other models like SDXL 1.0 and these have not shown. how can I get it updated? thanks in advance.

these are the models i downloaded and place it into stable diffusion file, but they are not showing on the stable diffusion checkpoint

click the little blue refresh button there
im also new, but i have a new error that keeps the ui at 95% and it gets stuck but in the cmd apears completed and i have to restart the application if i want to use it again (it will fail again)
that's why most people aren't using a1111 for sdxl
lots of different things like that
and what should I use
i clicked and it still stays the same
I'm using comfyui, it has a bit of a learning curve if you are new, but there are lots of resources out there and templates you can use that make it plug and play pretty much
I don't know, man. make sure it's the same folder that the program is looking at. restart the program. update. could be lots of things

the problem with that error is that only happens about 70% of the time
i can generate the same thing 4 times and 1 will do it correctly
ghasty3. well, not sure what to tell you. one thing that is convenient is if you do decide to use comfy, yo ucan drag and drop any of your images into the UI and it will automatically load all the settings for that image
if everything is up to date and you aren't getting any errors when loading the program, I don't know. maybe go to the extensions tab and try to update
okay, tomorrow i will try to install it
i'm so happy with this.

there are other options as well. but I'm not well versed on all of them
just went from a1111 to comfy
that IS a tough transition, i still cant do it
my brain is satisfied by weird things, so picked the nodes up quickly
i know nothing about programming, just casual girl that likes art, is that too much difficult?
certainly wouldn't call myself good at it or anything, but I guess that's subjective
you don't need to be a programmer
I'm not
lot easier if you use StableSwarmUI
but I have learned some python over time just out of having to unbreak stuff
easy to install, has the easy interface like auto, but also exposes the comfy node interface to play with when you're wanting to do more advanced things
more a1111 than comfy tbh
yeah, I need to try that out. I think I have it installed
also, is it supposed to be 50 times slower sdxl than 1.5?
i have to wait like 20 minutes for one single image, with a 2060 graphics card
50x, no. But the scale up from 512x512 to 1024x1024 tends to be 5-10x slower
... 20 minutes? 0.0
I only have 6gb vram but I'm getting abotu 1.75 it/second. not really something to brag about, but I can deal with it
oh, 6 GiB VRAM... uh, yeah, use Swarm lol
that number drops when I get too crazy with things
auto struggles to run SDXL well, especially on low-end hardware
im getting 0.13it/second
Swarm uses comfy backend which can run a lot better on weak hardware
nah, I'm not on a11111, lol, that's the other guy. but he has a 2060 which is slowe than me
oh lol that was coincidence actually, i googled how much vram a 2060 has, didn't even see your message right next to mine oops
I realize now I should have opted for the bigger video card, but who knew?
Since I can't run SDXL. I'll just ask someone else opinion. Is SDXL worth it? Or is SD 1.5 still the king?
yes SDXL is worth it. Why can't you run it?
is worth it even for me that i have to wait 20 minutes
1.5 is still as good as it ever was though. but xl is a step up
GTX 1660 Super 6GB Ram. Out of memory 😦
That is in Automatic1111. In comfyUI it takes so long to generate 1 image around 30-35 minutes per image.
ooo, 16xx :(
it, uh, might be possible in the semi-near future? No promises, but optimizations always happen in the period after a new thingy was released
I hope so 🥺
there's some exciting experiments going on with SDXL optimization that might work out
several different places trying to quantize it
ps at everyone in the channel on small graphics cards rn: an RTX 3060 is only a few hundred bucks and has 12 GiB VRAM. If you're able to afford an upgrade, that's a really good price vs capability there
$250-$300 depending on brand n stuff, probably even less used







these are just screenshots of movies, bud
looks great

now we finally live in a society
thanks!
ill let you know, still collecting some shots for the post and ill upload to civit, theres one on there now but its nowhere near the quality of this version


also to note its best used with upscale and a base pass without the lora, thats how im able to achieve this quality. the lora itself can sometimes be a bit blurry due to the nature of movie stills online, but if you do another base pass no lora it turns out great.
ahh, interesting. hadn't really considered that approach. good to know
this is a pretty quality lora https://civitai.com/models/119667?modelVersionId=130038
Can get decent results with simple prompts such as : a house by william eggleston, sunrays, beautiful closeup portrait of a woman in a kitchen by w...
but look at the size . mine is only 90mb
but it is a quality lora for sure
yeah, lol. huge. I wonder why?

Prompts to start with : papercut --subject/scene-- Trained using https://github.com/TheLastBen/fast-stable-diffusion SDXL trainer.
also that one, it's medium sized I guess
network rank dim set to 64-128
depending on dataset and amount you want to learn you can use more but 64-128 is just wayyy to high. maybe if you have like.. thousands of pics but anywhere between 100-1000 dim 12 ish is fine
oh yeah, I should have known that I guess. I really haven't trained many loras. mostly just did dreambooth models and then later extracted the loras from those
nice
Rank dimension, that's the number of weights per layer right? Or does that even apply to this type of model?
I actually learned a lot from that endeavor because I could not figure out how to extract them for the longest time. I knew it was possible, but just kept running into hiccups
what is the go to method for training these loras?
caith had a guide somewhere, ive found good results with adafactor 0.001 LR 30 epoch, 1-5 repeats depending on amount of images. but take my word with a grain of salt. i havent done much testing
kaibio went into the dim research a lot deeper. 24 was where he hit the limit of improvements
24 epoch?
for 90% of my loras, dim 8 was just right.
doing a lora with an endgoal of around 50k images (currently at 3k), which I'll be doing at dim 64, since I plan on merging it with base in the future
but anything that is under 5k images, should stay between dim 8~24
dim 24/alpha 1
yeah i trained this lora with 400 images with dim 12 alpha 1 and it got everything well.
layers, dimensions, I need to familiarize myself more
just don't have the hardware to be training anything like that myself. I could do it online of course
do you guys ever run loras on the negative, or on the refiner? I can't figure out if this is something people normally do

fyi, dim 128 and up, usually does significant damage to the sdxl model - unless you both know what you're doing, and want the base model to 'do less'
could be relevant if you have genuinely bad training data (like 2 images), and only need to make it work barely, so you can generate more training data, with which you'll then train a proper lora
oh, that's something else I hadn't considered. so you can train a huge lora on so-so data, get better data from that, and make a more efficient lora?
@wicked frigate kohya is good,especially when running with bucketing and latent cache,with xformer optimization,fp16 mixed precision,save VRAM highly
not really my style, but yeah it definitely works ^^


LoRAs and .pt embeddings - do they do much the same job at all?
I don't think so. AFAIK embeddings are used to train the existing model to understand new concepts based only existing model weights. But LoRA introduces a new set of weights to the model.
But they end up doing the same things - old weights or new weights?
Some weirdness from yesterday using 512 x 512 .pt embeddings in 1024 x 1024 SDXL1.0




I think an embedding is much less flexible since it can only "pull" the existing model toward the concept or character. But the LoRA is an additional model with its own information. But it's not as much of a full model as a hypernetwork.
OK, I will setup a LoRA, HypNtwk and Embed and make my own comparisons ... ! 🙂
But they seem to do similar work
The sheer detail in this one is mind-blowing!

If I understand it right, embedding is the least powerful and not used very much anymore. LoRA is more powerful and you can train it about a particualr character or a style and you need an activation word. Hypernetwork is the most powerful because you train the model the same way you train a full model (only prompts and images) but these are not popular.
Movie Still XL V2!! Movie Still XL is made for SDXL and its intended purpose was to add variety and coherence on the already great film and movie s...
Thank you for your insight 🙂
Embedding is also trained with an activation word that doesn't appear in the model. So you would use a nonsense word like "lsr100" to represent the embedding. And then train the embedding with prompts containing that word such as "a photo of lsr100" or "lsr100 wearing a top hat".
embeddings were used a lot in 2.1 for styles
I still like them ...
I used them all the time. great little light weight tools
I have d/loaded an SDXL Papercut model at Civitai - does this go in place of the SDXL Base? Or is it added on top of the SDXL Bse?
Is it a checkpoint?
Believe he means LoRa
add a lora loader node inbetween your checkpoint loader and your ksampler. same with the clip and your prompts
Sorry, its a LoRA - thank you,! 🙂
Basquiat and Rasuchenberg flavoured ...






oh yeah , I used fixed seeds a lot when testing lol


its an API call out to Lexica from looking at the source code


Although it would maybe have been more fun has you loaded and run this as I have no idea what you would get out.
Prompt = Random
Master Style =Random
Sampler = Random
Scheduler =Random
Seed = Random
It's all just randomness lol

@upbeat summit @tender timber picking up from yesterday
GitHub
as per title would it be possible to get some Text nodes to allow use of S&R variable insertion functionality please. Even a simple Save as Text File where they could be used in the Path name s...
I used to do that with wildcards all the time with SD2.1, will get started with SDXL once I get more comfortable with it
Ah, from WAS or from Comfy? I think it’s WAS if I am not mistaken
from WAS
Nice, I hope it gets traction
TBH I'm not holding my breath , comfy hasnt commented and wasasquatch has referred me back to comfy /
Meanwhile here I am stuck in the middle with you lol

ahhh , only bringing back some, maybe I need to "rweak" that lol
`# Random Prompt
class WAS_Text_Random_Prompt:
def init(self):
pass
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"search_seed": ("STRING", {"multiline": False}),
}
}
@classmethod
def IS_CHANGED(cls, **kwargs):
return float("NaN")
RETURN_TYPES = (TEXT_TYPE,)
FUNCTION = "random_prompt"
CATEGORY = "WAS Suite/Text"
def random_prompt(self, search_seed=None):
if search_seed in ['', ' ']:
search_seed = None
return (self.search_lexica_art(search_seed), )
def search_lexica_art(self, query=None):
if not query:
query = random.choice(["portrait","landscape","anime","superhero","animal","nature","scenery"])
url = f"https://lexica.art/api/v1/search?q={query}"
try:
response = requests.get(url)
data = response.json()
images = data.get("images", [])
if not images:
return "404 not found error"
random_image = random.choice(images)
prompt = random_image.get("prompt")
except Exception:
cstr("Unable to establish connection to Lexica API.").error.print()
prompt = "404 not found error"
return prompt
`
They’d fit in well with my Accounts Payable team I deal with at work… everything is referred back to my suppliers with nothing corrected and no explanation 😀
There are people in the windows

there are some people on the pitch, they think it's all over......
and as Im sure some here may not understand the reference

Unforgettable England Moments - 6 of 10

Who's up for another Carrington event?


sorry feit asleep that's nice!!
LOL the meme lives on in XL



also take a look at used RTX 3090(ti)s - they are twice the price, but you also get double the vram (24gb) and more performance. this would be as future proof as the top consumer card RTX 4090 (also 24gb).
very nice ! keeping an eye on it and I'll think about what I could add.
"No Prompt" Images
No prompts set, no styles set just hit go 🙂




the getting lucky latent space slot machine run
and pleasantly surprised was I 🙂
I got lots of nice nature images with no prompt
a Shiba Inu wearing (Ray-Ban sunglasses, a gold chain, and a white hoodie)
The universe is a giant brain, change my mind





he is lost







does anyone have experience with what U-NET is?
In Kohya it says Train U-Net only for SDXL and I cant find that option
anywhere

add --network_train_unet_only to additional parameters
thanks, yeah I thought that would solve my error but
It didnt
Do you have an easy method for updating kohya? @west breach
I only recently started using it myself. I use the SDXL branch


okay thanks, getting a really weird error training,
" size mismatch for down_blocks.1.attentions.0.proj_in.weight: copying a param with shape torch.Size([640, 640])
from checkpoint, the shape in current model is torch.Size([640, 640, 1, 1])."
Have you ever encountered this?
I should have all the correct parameters, a 640 size is really weird
not that error no
ok thanks still
We don't have a yaml file or anything like that for XL right? we only need the checkpoint for the training
try these settings. does your kohya gui have a sdxl model checkbox on the source model page?
👆
But this is for lora right? I have done a couple loras
Trying to get the dreambooth working @west breach
I haven't tried dreambooth
winston, added any nodes, i have all the packs mentioned in the notes

Ah ok, found only one issue post about it, seems even 24gbs is low for dreambooth
Yesreday I did a clean installl into a new directory of COmfyUI and reinstalled all the Additional Nodes I mention in my notes element and (other than a minor issue with me not reading WAS NOdes install properly) everything works
so all are mentioned in the notes?
i did install missing nodes
lemme try again
I di da clean install of COmfyui and aclean install of all the nodes mentioned in the notes and it worked as expecetd without any errors
oh lemme try




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
With post processing ?


yes high res fix + face inpainting
but fully automated i used adetailer extension
will generate hundreds now while going gym
haha this is wild too but need some more inpainting of face

haha this is wild too but need some more inpainting of face
I love this theme




@hard fractal
While training SDXL, regardless of LoRA or full finetune, everything very slowly converges to 50% grey. first backgrounds, then more and more. Both via Kohya, as well as on diffusers training.
While there are ways of slowing this down, by changing noise offsets, and hacks that come at the cost of damaging the model (training on pure white & black)
I have 3 official questions:
A.) Just confirming that you are acknowledging that this is a thing.
B.) Do you have a way to counteract this while doing your full tuning?
C.) what offset noise did you use while training SDXL 1.0 (paper says 0.05, kohya says 0.0357, is either of them true for 1.0?)

(FYI, I will link to the answer in my guide, as there is no info on this regardless of where you search)
What is your prompt
cinematic photo A neandertal prehistoric man riding a giant chicken dinosaur with feathers in a jungle with mud, rain storm. 35mm photograph,film,professional,4k,highly detailed
n : drawing,painting,crayon,sketch,graphite,impressionist,noisy,blurry,soft,deformed,ugly

Do we have a reliable method of dreambooth training for XL? Getting some errors
Hopefully it is my next research
cfg at 5
Waiting on the video for it, thanks.
I will try that prompt with my lora
Thanks I think it will be amazing
these are all lora right?
Not dreambooth
I think so as well, it feels like Lora's arent so flexible with different art styles
Or even flexible with anything, they retain too much info from the training images.
Lora's of a face
only happens if you train it wrong
like using a too high dim setting
or overfitting it to the point where it starts to damage other concepts
reg images in lora are a scam
if you use dim 24, then you should be able to train a face without damaging anything
4000 steps lora is way better than 16k steps lora
whats dim?
🤣
hey, my 1k custom edited & tagged regularization images work like a charm
was gonna ask this too, which setting is this?
i didnt tag mine
Wait you have to tag your reg images

ok so appearantly I used 256
I'll prob release a 500 image subset of it, when I put out my guide. so that can be used for female faces, while doing literally 0 damage, as it's 100% ethnicity & age weighted
male dataset coming as well, but not until I'm finished with my first one
Where can I follow you
yeah, at 256 you'll be doing significant damage to the whole model
finetune channel here on the server

I often post there
I see, will try 24 than, that difference seems huge though...
for a full settings json