#✨|sdxl
1 messages · Page 62 of 1
cause that actually needs clip training to avoid damaging the model - except I've not nearly tested clip enough to pull that off yet
I could load massive models this way
I wonder if I could do 30b on a 3080 like this, cause I have 42GB total GPU RAM
flat color go brrrrrrr ❤️
when I get my 3090, I till have 56GB RAM to play with
normal weight

No 4090? 
no, 3090 can do everything the 4090 can do, with less power, and WAY less money lol
I don't care about speed, just functionality
Fair
much rather a $700 top of the line 3090 over a $1900 top of the line 4090
technically, a restricted 4090 does what a 3090 does with less power



this man diffusions
Only had to buy one of those myself so its fine 
sketch, owl sitting on a branch

lol sometimes it actually understands it

I mean I have a lora with my usual 80% hitrate 😏
My workflow takes about 100s for a 2048² image on a 4090, not very optimal but I like the outputs 
thats a long ass time how many samples is that?

You can check it yourself, its embedded in all my images
I just switched it to use wildcards right now
lol at some of the prompts from sandbits prompt compilation file: A male fairy with dragonfly wings runs along a beach holding up a fishing net. He is chasing a flock of flying shrimps creatures. The fairy wears a wide-brimmed hat, thai fisherman pants and has a beard. Graphic novel illustration by Alphonse Mucha

Im running through that one too
My fav from his file so far


sketch, drawing of boto waiting on his computer to finish the high quality drawing by the man stuck in the unet
(lora is gender friendly! #biasFree)

the mushroom is downright adorable


2048^2 is 70s @ 26/4 + 15/5 samples for me. For 100 on a 4090 that must be like 50+ samples low and high
Do you use leco to extract the concept in the model?
Well I managed to crash comfyui somehow. That's a first
leco?
This one, https://github.com/p1atdev/LECO

GitHub
Low-rank adaptation for Erasing COncepts from diffusion models. - GitHub - p1atdev/LECO: Low-rank adaptation for Erasing COncepts from diffusion models.

1 or 2?


I like 2 more
2
2
eyes feel more not dead
2
Hi, anyone know how to use an input reference image in sdxl with the same way like midjourney(midjourney can get style, object, color from reference and generate creativate related image) ? If this can be true, sdxl could replace midjourney!

SDXL loves that concept 😉

hi-res fix work so good using @high skiff workflow
yeah - sorry for reposting. emerging patterns are always interesting

really like the artwork you've been posting. beautiful stuff
that's about how much sauce they give you at a pasta restaurant
It's called an Italian restraunt, show some respect
there is a large difference between pasta restraunt and italian restraunt
I hand masked 1800 images in an hour while listening to other stuff. Here's hoping the masked lora training code actually works.


no sdxl support yet. but cool method of doing it!
I did it by essentially bombarding sdxl with 41mb of extremely biased input.
OhIsee
got cha
o no i forgot about that
So I've been messing with anime styles since the complaints about it not working and I think they work great... with the right prompt




I think we really need to learn how far could the base model reach.
who's really sitting on the throne 👀

same. if you use vit-h on any anime image, then put that exact prompt back into sdxl, you get amazing anime images. but I get that that isn't really userfriendly
I'd say further than most of the finetuned models already. Maybe not better than the best 1.5 finetunes, but pretty up there. Maybe TOO far.



What's vit-h?
I uhm... 🍄


A man with one butterfly wing for an eyelid, so accurate!

he looks very... strong 😳
maybe this one won't be as easy. A or B


light does look better in B id say

B looks better in general, but both have odd eyes
yea im working on pure latent upscaling and I'm tryna figure out if an iterative approach is worthwhile or not

due to the latent nature it's gonna be a lil jank
ummmm that is not a bird eating a worm!

I gave up on pure latent upscale
In both tests one image goes straight 1024 -> 2048 while the other increases over multiple steps by a factor of (2048/1024) ** (1/3)
I feel like the pixel upscale has issue on background. It is doing pretty well on the subject and ruin the background a bit.

latent does OK for me @ 1536 but anything higher is going to need inpainting I fear
Cat Vador
stupid idea lemme test it real quick
hope to god it doesn't fucking work cause it'd be stupid



I have like a zillion images of anatomy for artists (not they are that you think :p) can I use them to train SDxl with a 3090ti?


yes, idk about legally
o no he got the armpit pics
but functionally, you can
does (word strength:1.4) still work? with SDXL?
hey wait, i generated something similar few hours ago


there's a chance it actually helps a little ☠️


Yours do look nicer, mine is a little on the blurry side
can you? yes
finetune? ehhh... technically yes with gradient accumulation. but it's gonna be race for if the heat death of the universe occurs first, or the finetune finishes
LoRA? yes - but bigger datasets make training harder, as you have to get your captions real good. which comes from lots of practice on small datasets
Face in A but details of B
i used sytan's workflow, workflow in the image too
I had a look at his workflow earlier, interesting approach to upscaling, but not too sure if its really that good
It's hard to tell how well an upscale process is working on busy images. Like I tried for ages to get a latent upscaler working, and got it to a decent looking image, but as soon as I changed the style I could see all the faults the other image was hiding
So it is not like throwing the images into the model (haven't done it before obviously lol) but a bit more complicated.
essentially, anatomy is currently the hardest thing to train by far, with the most pitfalls. I'd highly recommend starting with something easier, like the style or feeling of an artist
much easier to train, and you need a dataset of like 50~150 images
Yeah I've been thinking the next revolution in AI image generation is probably going to involve a better understanding of 3D space and how objects fit in it. That seems to be a big limitation in how the AI currently function


Dr Stranger Man?
Would be nice to make the basic scene in 3d and then render it using an AI engine instead of traditional render engines
Fantasy Artwork style is awesome


I think some of these high quality render assets like Unreal's textures and whatever their human generator are called mixed with real photos would be a good start. Start with comparing images of the 3D model to the 3D model, then mix in pictures and try to get a 3D model out of that. I know there's been some work in that space but the results have been mediocre
Balls



Dr Stranger Vampire!



For some reason these remind me of all the women attached to some villain in James Bond
definitely. it's like the glamour photoshoot version of a james bond film intro 😉

Eva Green ... Bruh ! 🌡️ 💥🍆
You remember Gold Finger? Well get ready for Gold...
sdxl has very big opinions about "woman from james bond movie"

lol. this causes more boob focus than when I tried with boobies earlier 🤣
I think a different ai generation technology would be needed. One really understanding 3d figures in 3 dimensional space, not working on denoising images only. Such thing exist I think as there are AI generating 3d models already but it is still in very alpha stages. I think diffusion models are only the beginning.

I've actually been wondering about a system of merging specialized AI with one 'overseer' to distribute tasks. It's something I've thought about alot and apparently there was a recent-ish paper called 'Mixture of Experts' or something on the topic. There's also speculation GPT-4 might be exactly that.
sketch, landscape from shaun of the dead

That almost looks like a panel from The Walking Dead comic
Yes we need more ultra wide stuff, I need a new wallpaper for my 5120x1440 screen 
what a artwork ....



if I do a google image reverse search on it, will I find it? 
That would be basically getting closer to a general AI, which is unavoidable probably. Next year's will be awesome, if chatgpt 8 doesn't go skynet and decides to exterminate humanity in a nanosecond after getting self awareness. 
I keep forgetting not everyone thinks AGI is the goal of AI. In my mind they're one in the same but that's probably because that's where I want things to go.
Probably not 

has SD ever put out a text2img result that could be reverse searched?

besides like the mona lisa i guess
"I have these shoes in my mind - let me quickly generate them and look if somebody sells them"
yes. absolutely yes XD overcooking can even happen in the base model
$1337 dollars lol 
I think AGI is the only logical way for AI to develop, unless people gets scared or something and try to forbid it , which would only make AI development secret.
ah. All those examples I saw of supposedly re-creating some deviant artist's piece was clearly img2img so I didn't think it was actually possible
guess if you just fry a single image of your waifu into a lora that'll do it
I agree but we can already see people getting scared. At the same time I don't know how you'd really stop it, I think the best you could do was slow it down.
I think in one of the ongoing lawsuits one of the image generators was able to spit out almost exact copies of some movie posters. I don't remember if it was stable diffusion though. They were trying to use a statistical artifact to 'prove' AI is just copying and remixing existing work.
"copy and remixing" make it sound like automatic photoshop lol
oh yeah that has been around for a while. if you read the study they did nothing is really clear about it
If a human spent a lot of time in a museum with 5,000 Iron Man 2 posters they'd probably be able to draw it pretty well from memory
It's dumb but they have to prove it's a 'derivative work', which means being substantially based on an existing work. But it's impossible to store the amount of information used to train AI Image generators in the model sizes used so I guess it's going to come down to how dumb the courts are about it.
Yep, first lawsuit came from artist. Don't know whenor what will the court rule but will be interesting.




if greg rutkowski sues, I wouldn't even be mad if he wins though
I read the one on the 'secret keeper' or whatever it is by google about extracting numbers. I just skimmed the lawsuit because it struck me as kind of stupid and copyright law is subjective.
0 steps kinda looks wrong

Only if every artist (or their estate) with a similar style to his that came before him is allowed to sue him in turn.
Looks like one of my prompts - excellent work 🙂
Also don't you dare ask artists about using 'reference' images, they get real mad
genial sdxl and refiner with comfyui , but I can’t use the (Loras sdxl) and (style model with load image). if anyone has any info?

Which is dumb itself since any human artist dies exactly the same as AI. Copy other artists work and mix them up to build his own style. Being a real medium artist myself I only see these lawsuits extremely dumb and arbitrary
https://civitai.com/models/117635/greg-rutkowski-inspired-style-lora-sdxl
what a convenient name change that page had


Not a huge fan of this, he even links his patreon in the first sentence of the description
Eh it's the same thing. You can't copyright a style, somebody probably just got a scary letter about it.

less about the style, more of a 'specifically targeted and impacted' thing
Right but it specifically says 'style' in the earlier version so their bases were pretty well covered.
I don't know when AI will take over or surpass us in everything but it will definitely play a big part in entertainment and visualization
SDXL image

runway gen-2
adding 'inspired' doesn't really change much
Bet ya this guy's doing ddim-u

Yeah weren't a bunch of people upset because Secret Invasion used some ML/AI Art? I haven't seen it but I've heard there was some controversy
yes the intro had lots of ai generated imagery. most people who are not familiar with it just thought it was a cool art style, but if you know how AI art works and looks there's no question that they used it
Im doing 2S ancestral for base and upscale and 2m karras for refiner
I thought it was pretty sub par tbh
I heard a couple other people disliked it but they might have been biased cause its AI art
I've been using UniPC and my animals have come out great. I don't know what the complaints are about.

Have a non cursed cat

What's cursed? They're just chilling

its got chinchilla hair
I think 0.9 had a higher success rate for coherent elephants, from what I tried a few days ago
hi guys, it's kinda off the track but there was a trend for this Korean profile picture generated with AI. I was wondering if it's possible to train using SDXL LORA to achieve this kind of result? i also noticed when i generate using SDXL with asian woman prompt, it has the tendencies of korean beauty style (which is from the datasets i presume).
user upload their face and got this template images


maybe their dark skin worked better with its stronger offset noise


can confirm. cats look great with UniPC. 10/10

seriously though I did have to take a break from generating cat spiders because it was starting to upset me and that doesn't happen often 🤣
Can somebody do a furry octopus? That seems to be the ultimate challenge for SDXL. The most I have achieved is a furry cuddle toy in the shape of an octopus but not a real one. Dall-E otoh makes it wonderfully at the firstborn attempt.
instruction unclear. send halp.

If you grab some of my images I think you can just drag that into comfy UI and see what I did to get the spider cats if that helps.




I'm not using any custom nodes so the workflow should just work
best my lora can do with its few lines XD

this makes me so uncomfortable. I love it
Thanks! Uncomfortable is sort of my specialty.



sketch, drawing of a car in the city at midnight under the lights of streetlamps

Octopus covered in layer of fur

Looks like the ink preset in Wombo Dream
That looks like a mix of elephant and octopus. Still closer than I got
An octophant
Pretty amazing, but not much hair there
Since sandbit's file is so massive, I added word search to my wildcard pattern matching

That is Dall-E first attempt.

I will try "obvious fur" "long fur" "heavy fur" ... 🙂

Does anyone know if the controlnet dev team is working on SDXL ? Or if there is a place where we can follow their progress ?
a furry muppet octopus, from a 1980 tv series

Now add "under water"
Yes, muppet furry octopus work. But put in under water and hair will disappear. (It is only evolutionary logical anyway lol)
Octopus covered in heavy fur/long fur


nice
my specialty with SD 2.1 was putting fish above the water
there. did it properly now

I think that is a winner
a extra furry muppet octopus underwater, from a 1980 tv series, national geographic


A head on portrait photograph of a furry octopus covered in thick fur at sunset in a reef
Supporting: hair, pelt, thich hair, fur, thick fur, head on, fujifilm, bokeh, f1.8


I've done some of that too!

What made SDXL sit up and do FUR properly? 🙂
Did he finish ravaging the diner? 😎
Lol love the curly hair
Nah getting home from work.

the meatball rebellion

An entire series about an angry shark who think he's a person








enough messing with sketch, time to do ink lora next

This was my attempt of generating a furry octopus from a few days prior. Call it a success or not.

We need some pics of him doing chores around the house and sleeping
hybrids are always a success
perhaps getting into a dispute with the neighbor
Mine keep coming out like cartoon characters



sketch, cutest friendly pet octopus I have ever seen!

First one is perfect, second one is more a mushroom octopus

why doesn't primitive nodes size get fixed with higher priority? makes it impossible to create good looking "frontends" and should be an easy fix, if other nodes already save their size:
https://i.imgur.com/uMlrcGA.png
also some kind of on/off switch to turn on and off sections like lora, upscaler or switch between txt2img and img2img would help a lot. other great features would be an option to hide values you never want to change in a node (set value once, then hide) and input nodes that allow to define a list for a dropdown selection without editing the code externally.


I think it's supposed to be a bowl cut, in hindsight I probably shouldn't have used the word hair 😄
yeah that would be good if they didn't automatically shrink
omg mikey.. this is great!
Here's a decent one.


are there any sdxl loras yet? I'm looking for something to create better hands. Thanks!
This one is 4000×4000 done with SDXL and ultimatescale. Gives an idea of how much richer and variated xl is compared to previous models. Only issue is anatomy imo.

lots

can you tell me where for example? TY
give her/him a parachute!
go to civitai and add a filter for sdxl 1.0
I mean ultimate-upscale
what did you have the denoise value set to and tile size? There's a lot going on!
Tile 1024 x 1024. Denoise 0.2 or so. Did a little inpainting too to eliminate some nonsense .

my settings

The most fluff i can get atm

I did it in a1111. An important thing I found is to put 1.1 or more in the img2img noise multiplier to create extra things which did not exist on the low res image. Don't know hom to do that in comfy.
I created a tile size calculator node for dividing up the image evenly. didn't like how sometimes you get a border of weirdness




usually doesnt happen for me
That is a proper furry octopus I would say
Thank you.
Now i want to pet him
wait... I just had an idea

this is with denoise set to 1.0 just to illustrate. first image you can see if you don't evenly divide the picture, it creates tiles with the leftover space. 2nd image has the tile size calculated to get evenly distributed tiles


I think this one is my favorite
sophisticated furry octopus muppet
so cute with the goggles!
Interesting idea. Let's give aquatic creatures unnecessary diving equipment.
Yes, it is necessary to divide it evenly. In my case the high res image was the low res one multiplied x4 both width and height


i am loving comfyui , never going back to automatic1111. i have reduced image generation to under 1 minute even with 40 steps and 1024 resolution, and gpu v ram never takes ,more than 6 gb with rtx 3070
Man I love mixing two things together



feels weird going back to A1111 now
increase ur pc ram its cheaper, because i saw comfyui takes some huge amount of pc ram compare to automatic1111
Perfect.




Those spiders are like a 20% of octopus. I wonder if SD understand percentages

plushy!
I just remembered I had a felting style
It might be because I was trying to swap the tentacles with spider limbs, rather than doing a full hybridization. I got either octopi standing like spiders or spiders with tentacles. I'm sure I could get it exact if I messed with it enough but I'm happy with the results.


octopus with plasticine brain


That is looping the loop
I think it's because it understand the prompts so much better so it's easier to get consistent results
that's exactly it


Yep, you can ask chatgpt, bard or whatever to write a history and SDXL will summarize it wonderfully in a single image

that's really cool 🙂
Even better than Dall-E in that aspect
I can't wait for someone to get control nets trained on this thing. It's already so good at just understanding the prompt, with controlnets it should be easy to get the perfect image pretty consistently. It will probably take a few months though.
Which reminds me I think my next step needs to be practicing img2img and inpainting, I haven't even touched that yet because I wanted to get my workflow right.
Anyone try the reference only node that is pinnedd?

There are depth controlnets
inked, drawing of a girl sitting on a rock, grand canyon in background
inked lora coming along nicely c:
(40/200)

Interesting I'll have to take a look. I've seen some people asking for them and hadn't heard any were released. Thanks for the heads up.

Img2img is where real control is. I have got my own real world drawings perfectly finished with minimum denoising and continuously retouching the results in Photoshop. Not controller at all. It is laborious but I get exactly that I want
That's really cool. My art is decent but my proportions and perspective tend to be off so it sets the whole thing off.
Although in fairness that was 1.5, still haven't tried on XL
Alright I've been at this too long, I should take a break. Here are some of my 'failed' cat spiders for anyone I've traumatized.







not a single chainsaw man prompt in sandbit's file, and only 1 with saitama 😦
a meatball playing electric guitar at a spaghetti concert


which genre do you think left and right meatballs are playing?
left gives me wedding band vibes, but right looks like he could be playing nu-metal
righty could deffo play static-x riffs
lefty would play something self indulgent, like an hour long santana riff nobody's ever heard of
oh god, why do these things have headcanon now?
May i ask what the sandbit file is? I think i missed something.
I had to strip out the double new lines before I could use it as a wildcard file
Thank you very much. Now that's some file.





where can i see your stories man?

I just did, and it feels like an img2img with 1.0 denoising ,which behaves controlnet like and keeps the subject in place? I actually have no idea what it is suppose to do but it could be helpful.
do weights in ComfyUI work the same way as A1111? example (((red hat)))
can you suggest a good workflow for img2img?
I think it's supposed to help guide the generation. Found this example on reddit

use (red hat:1.3)
which one do you prefer?


Left side
right
now i am confused
Depends on what you want to achieve. If it is about retouching your own art I recommend using Photoshop and some Photoshop SD plugin like stable.art which uses a1111 API mode.

actually i dont have a set goal, i just want to expriment with img2img as i've never did
Totally agree, Stable.art is really great
Some rare beauty Sytan's w/flow




whats the prompt?
love the orange and teal colour pallette
PROMPT = a vivid watercolor depiction of tinga tinga art, diverse Rococopunk Afrofuturist women with beautiful and bold head wraps walking toward a huge moon in the background, holding hands, walking away from the camera, collaborating in a creative and productive environment, women empowerment poster, photography, inspired by the styles of tinga tinga art, victo ngai and vladimir kush tinga tinga art
@thorny frost did you try Stable.Art with SDXL? Its working?
how did you divide it, like this?a vivid watercolor depiction of tinga tinga art, diverse Rococopunk Afrofuturist women with beautiful and bold head wraps walking toward a huge moon in the background`````` holding hands, walking away from the camera, collaborating in a creative and productive environment, women empowerment poster, photography, inspired by the styles of tinga tinga art, victo ngai and vladimir kush tinga tinga art




All in primary positive prompt - in secondary positive prompt = warm colors, translucent, glow
Then I don't know, feel free to experiment like the possibilities are infinite. Try different models over the same image, if you use a1111 set noise multiplier >1 to add details, use Lora and inpainting for changing faces. Don't know so much things...
oh ok, tq
But divide it up as you like ... see what happens - a creative accident might arise - serendipity!
Some facial features benefited after upscale; but a lot of detail gets lost after upscale ...

Not yet. But since stable.srt is nothing but a1111 rendering inside photoshop I suppose it works exactly the same. The base at least. Don't know if the a1111 refiner extension will work too. I suppose it does
does anybody know where to put your args in oobabooga?
seems they changed that as well
session tab?
Yeah thats what i was thinking too
MAD MAN
thank you
I am not sure why they make the standalone and manual installs so massively different
Love the prompt @peak dove

Yes, the watercolor is so soft ...
I'm still really new to the oobabooga


I used it monts ago, and they changed it so much
would be nice if the refiner didn't turn the grass into little strings
hm, could this possibly happen if I used too high denoising?
I tried over a hundred different step settings with this image and could not get away from the grass looking like green fur or strings

Pomegranate Girl




so, I inferred the refiner correctly?
this is with the new A1111 branch
I find it's hard to get blades of grass like this

same gen, lower denoising strength.

some pics generated with the improved Blame lora I finished training a while ago





the girl is supposed to be Emma Watson lol
love the inky style
SDXL interpretation of Bing prompt-story: "After a deadly virus wiped out most of humanity, only a few survivors remained in isolated bunkers. One of them was Mia, a young woman who loved plants and flowers. She had a secret project: to create the last garden on Earth, using seeds and soil she had collected before the outbreak. She hoped that one day, she could share her garden with someone else. But she was not alone. There was someone watching her from the shadows, someone who wanted to destroy her garden and her life."

It is amazing how well SDXL understand normal text
Would exchange that for correct hands any day though
i passed that prompt to my lora lol


First one is spot on. Second one where is mia?
somewhere in the latent space most likely
try this workflow I've been working on today. it upscales to 2k and fixes faces and hands pretty well
Pomegranate Girl





some nodes missing. Working on it...
you also need the detection models. if you have the manager extension installed, you can find them in the install models menu
"a robot sitting in a Greek marble throne room by nihei tsutomu" upscaled x2, see original to see the details

i already did. manager cant find UltralyticsDetectorProvider though
that's in the impact one

GitHub
Contribute to ltdrdata/ComfyUI-Impact-Pack development by creating an account on GitHub.
amazing



working now

that is ok? i lack the sparkling lora

Oh don't need that for your prompts
looks great!

🎇 Add sparkle to your images with sparkling and bucket load of sparkle with sparkling and stars . Adds glitter to clothes and surfaces and adds lot...




"he doesn't care about the backdraft"
ty. looks pretty nice workflow. Will be my default for now. Will add some intermediate preview image to know what is rendering before finished because it takes a while. 🙂
yeah, it's pretty thorough 😄 good idea

no more tears!

I think my sparkling lora helps a bit with hand poses since it was trained on outputs from a 1.5 model that had predictable hand poses

i tried combining my lora with pixelart xl lora 🤔

nice

When I have a queue of prompts in ComfyUI - is there any way to see the names of the prompts as they are passing thru at all?
you can click load
you can get the worflow of that specific execution
and you can view the prompt in prompt nodes
that is interesting. preview of the default prompt with sparks lora. Will try anatomy now.

you could output them to the console with the Text to Console node or I use the show text node from https://github.com/pythongosssss/ComfyUI-Custom-Scripts. you connect it to your prompt source node / or processor (can even contain wildcards) and it will always show you the current processed prompt
um truck driver hands, but those are the sdxl best feet i have got till now

have to go now, will try more later
How do you setup wildcards?
you could use Mikey Nodes by @west breach. The Prompt With Style node does have support for wildcards, wildcard files and more options to do dynamic prompting: https://github.com/bash-j/mikey_nodes
Oh I guess I missed that, thanks!


...
tq
@west breach I think I inferred the refiner correctly here?

best I've seen 👍
thanks! I made it so the refiner stays in CPU RAM and base stays in VRAM and when it's time for the refiner to stop/start it swamps the UNET in CPU RAM with the UNET in VRAM and back.
Does anybody knows a tool, workflow or tutorial to get pixelart outputs pixel perfect? 🤔


@west breach is that smart or stupidly complex?
sounds pretty smart to me!
The real question to me is: regarrdless of not having the refiner hurt the result, did it actually help it over the non-refined version?
Can you say: oh this is so much better with it
yes, what ever it did it's better than what I did before. see: scroll up in this chat


THat's the point: I did. I compared this last result with the original one labeled 'no-refiner'. I canoot even see one iota of improvement. Maybe I am missing it?





they are both the last one I uploaded. this is the one I was talking about:

refined

this is without refiner, labeled wrong
I am talking the result aftr you claimed to have solved it
here
refining works by having the base render at X steps then the refiner rendering the rest of the prompt.
You should only have one output image.


are the workflows in tose images?
the refiner did improve it; and in the way I implemented it doesn't effect performance that much.
Looks like it's not useable without the refiner model 😦
If you're talking about the examples on the git then no.
I have two comfyui workflows that I can share that use it properly.
pretty reasonable hands and feet from @west breach workflow!




so the secrete is in the sparks?
Each of them are using the SDXL-VAE and an upscaler setup as well.
They look awesome! Dunno if my lora is doing all the work, but I think it's nudging it in the right direction
I'm confused. I thought he was the author of the pink cubes, not you
the statue looks perfect
I'm just confused here I think.
If you are using the refiner as a way of getting an output image after having the base already rendered then you are using it wrong.
I don't know what you guys are doing I think.
I am not using the refiner at all. I already explained I get consistently worse results or sideways, and demonstrated this
That's wacky man. Sad to know that you're having issues when I and most other people aren't.
i have lots of reference images for artists. Will try to train some lora on anatomy. Never have done it though before, so probably will get crap.
I haven't had a single example where the refiner was a clear win over not using it.
I mean are you rendering the base as a blob and letting the refiner render the blob out into a full image?
@west breach It takes some coaxing sometimes, but nice when it sparkles 😄

comfy ui?
it either gives a different flavor, but not better, or it hurts the result
100 people give 100 different opinions on which workflow works and which doesnt
My first images didn't sparkle at all.


Blob? I just use the standard work flow with 80% Base + 20% refined
and then compare it to Base 100%
yeah dunno what happens sometimes when the don't show up, but loving the sparkle in that image 🤩
so 60+15 vs 75
This is why I'm getting confused still.
Are you rendering the base image fully and then letting the refiner literally refine the smaller details of that output?
@brazen patrolAre you using ComfyUI
It wasn't trained on daytime images, so less effect usually with those. I can see it added glitter texture to the jacket on the second picture. It can add glitter, sparkles and stars
can i post nude marble stautes i will get banned by the spanish inquisition?
got some amazing anatomy
Yes, standard ComfyUI setup
I was getting some of the glittery tops without the lora though. I think it just takes the trigger words from the prompt and creates it.
If you do, it'll be unexpected 😉
nice workflow, what is __sandbit?


a massive text file made by user sandbit who scraped the showdown channel for prompts

sorry for not reading what you sent while I was typing. My bad.
I'll tell you this. I have a workflow that uses a full steps of 40. I render the base to 20and then refine the rest at at again 20 (to equal that 40)
I don't let the base image fully render out.
i think the classical pose contributes to the perfection of the srtatue
Interesting, what's the significance? Are you somehow choosing all keywords with this wildcard? Sorry this is a new concept

The steps depends on your sampler, but I use 30 steps and base ends at 21, where the refiner starts.
I am well aware of how it works. The ideal balance is not so much refiner though (20+20), so in your case it may completely change the end result since the refiner also interptts prompts differently. Hence refiner as a term
That too makes sense.
The node detects the __sandbit__ and opens the txt file and inserts a line from the sandbit.txt file into the prompt
Awesome thanks
so if I shut off the refiner, I also disable the end with noise setting
@west breach is it possible to use your v3 without the refiner?
I'm done with this. I clearly don't know what I'm talking about.
yeah, it just needs any clip input into the refiner clip, so just feed the base into it
oh great, thanks!







The devs used some system to poll people on Base vs Base+Refiner. I only wonder about how they did this. I used their bots, enjoyably, but often would get two very different results, and not always remotely what I wanted. A or B? wel.... A? but hard to really know. I never was shown an A or B where the diff was subtle or small, indicating a genuine Base vs B+R comparison. So if randomly throwing in with or withouts and mixed results, they would have a huge amuont of noise in the results
correct way to render in sdxl is to render the first 70 or 80% with the base and then finish it with the refiner, not to render the whole imagen with the base and then do img2img with the refiner. I think stabilityai said it. In case someone dont knoes it yet.
Oh you're fucking right.
Oh shit. It can be much more difficult to get what you want when the model itself is built for something else while also being talked about as an everything model.
That is hard to read


It's ok, I parsed it well enough. 🙂




I doubt this is a problem, since most people will be using pre-baked workflows such as Comfy's, which come with it already set up correctly.
@west breach Any chance of adding a dropdown menu, to your v3 node, for the styles? Like "SDXLPromptStyler" uses?
Makes life so much easier when selecting
only satying, just in case somebody didnt have it clear.
I had this in the original and the v2. But my list of styles was getting so long, plus when you type it in you can add multiple styles
I hear you. I mean, I see these reports about wacky combinations such as Scott Det's R+B+R, and it is not that I doubt the end-result was enjoyable. I just question whether this was not just random noise as a result of multiple unpredictable sequences. In other words: could I not easily get as good results without such an elaborate setup?
With such a long list, it's impossible to know them all to make use of them, without having to refere to a seperate list all of the time. It may as well then be an embedded list you can choose from, with also the option to type it in.

Maybe I'll just use v2 🙂
i think it is ok to try weird not official things anyway. Maybe there are workflows not even stabilityai knows that gives amazing results. That is that makes comfy great. We can experiment without really knowing what we are doing .
Anyone used the diffusers library to load in SDXL on Google Colab? Getting 3.67s/it
what LR is this

I'll see if I can add it to the bottom of the node without it breaking the workflow. V2 won't have the lora:lora_name syntax support
I'm not worried about that, I have lora options all over the place already 😄
tinyterra nodes
Oh absolutely. I love it! Please don't misunderstand me. I know the caveats of this node setup, mostly in appearance and figuring out what is doing what, but love the power it gives to experiment. No, what I meant is this: suppose we see an image. Any. and I tell you this was the result of R+B+R+ 123 steps at Karras+ 15 with... whatever and so on. And then conclude: this is thanks to my absurd sequence. Now, this is not false mind you as it DID come from it. But it leaves the impression that you could not get this without it. When maybe just Euler at 45 steps and the right seed would get the same thing.
Sure but mabey the sequence leads to it more consistently
i could be wrong but that should be how the refiner came about -- SAI didn't need to include it but they did it anyways to try it out
in the paper, they mentioned that some results werent clear and from here probly had a several options to proceed forward in solving this problem, refiner was probly just 1 of them
absoplutely. BTW talking about steps, yesterday i found that doing 125 or more gives a totally different image, like a new seed. Bet stabilityai didnt know that.
let it be known, I deeply respect this.
Going straight for the endboss of LoRA training XD
protip, overfitting is the easiest solution - just get 50 images of different people in the same pose. done & anatomy learned (only results matter, right?) XD
But if you wanna do it properly, then you'll be doing a lot of manual tagging + getting equally distributed datasets of all the anatomy parts you wanna train/improve.
(unknown anatomy parts take longer to learn, so you'd have to eventually train those more than everything else)
Do you guys know how to curb this kind of concept bleeding? My starting prompt was just "photo of curious little (mechanical robot humanoid:1.2), standing next to a (large fluffy dog:1.25)" Or another example, if I try to give someone red hair, they'll end up having red everything.

gasp, sounds like a lot of work!
Or not. How much detailed testing was done? I am a super methodical person as a rule for such. So for example, in the last two days, not having the benefit of the time powerusers here already enjoyed, I put a single seed through its paces. Meaning every sampler, then tested numbers of steps, then permuted a single word, the order, in parentheses, and so on, and ran it all again and carefully compiled the results. HUndreds of images were done this way to really see what was happening. Oh, and yes, with and withut refiner, and varying it with few steps, more steps and slight variations of %. I.e. Refiner for 40% or 30, 20, or 10 (and of course zero)

it was super instructive
this isnt an sdxl exclusive thing, https://github.com/hako-mikan/sd-webui-regional-prompter is one method of solving it
idk if comfy has an equivalent tho
did a quick search and came up with this for comfy
https://github.com/BlenderNeko/ComfyUI_Cutoff
Yeh, any kind of composition or "art direction" gets difficult... I think I saw something like that in the custom nodes in the manager too
Thought to ask if I'm missing something obvious to help it even a bit. "Just do this dummy" -type of a thing 😄
kohya contine beiung the best way to train things, isnt?
your best option is to find a single or 2 prompt words that essentially define the act of both animals being present in one frame
"cat chasing a dog"
"cuddling"
"friends with"
Hey friends, has anyone seen a good consistent technique for legible text?
other than training a lora? no
there are some words that clearly exist often enough in the dataset that it works, but you can't actually "write" text.
with the word "dog" would be the way to prompt for words. ('text' doesn't work at all, 'word' makes the magic happen)
ahhhhh, will try word, was using text :)
and roger that on Lora
thank you :)
why we are keep voting A and B in bot rooms?
its supposed to continue improve for a better model training or something?
yes
I am thinkg about training a text lora with specific words. Do you think it is posible in SDXL?
this seems clearly untrue #1100170514670039070 message #1100170514670039070 message



I've seen this with 20-40 steps on some samplers. You don't need to run so many steps to see it 🙂

Here we combine this exquisite mansion with a dorm room style "sleep on the couch" theme
ha
and it also works without 'text' or 'word' if you use sign.
basically 'text' feels a bit like a garbage collection tag, where everything texty looking was put it. Yes it can work, with the right context.
'word' however usually can be made to work more often than not in out of context situations.
like making the word "sdxl" neon glow and float in the air in a dark forest


sketch, While cleaning her room, teenage girl Yuu discovers an old book containing a stunning map with glittering stars indicating an unknown island. The map is very detailed and hand-drawn, with intricate compass roses and sea monsters, as well as a red cross reminiscent of the maps of ancient explorers. The artwork is classic and vintage in style, with warm colors and soft light evoking curiosity and adventure. The image should be ultra-realistic
+sketch lora XD

in the first example it's only picture with text, not sign with text


DreamShaper XL1.0 gives me better results than the default base consistently. And it is in alpha... There is a lot of room for improvement.
i think SD will got better than midjourney. 
This is taking forever, it got stuck here for like 5 minutes

I am using a 3060 12GB with 16GB RAM
I tried it last night and got some good results too. Have you tried XL6 -Hephasitos? I saw a video showing results so i gave it a try.....pretty good at people

downloading......
I have the same card and while it's not as fast as Comfy, it's far from 5 min freeze. In options, stable diffusion, check that you have "Checkpoints to cache in RAM" and "VAE Checkpoints to cache in RAM" set to 0
i keep seeying people with that card have issues....some have said that you need to revert drivers to previous verson

How to force comfy ui to use xformers? Mine is not using it and there is no flag that turn it on. There is a disable xformer flag no enable xformers flag tho.
has sort of a strange face fix mixed in, but people's bodies and clothing looks good......and you almost dont need to run refiner

if its still processing, i'd check the console to see if it hung. it could also be that its trying to load both the base model + the refiner into your RAM and its stuck waiting for more space
Hmm
this is how you manually install it btw, shouldnt need to do that
lets see how it combines with mike workflow and sparky lora...

It hung on the "creating model" part
I do have xformer installed, that is not the issue
Comfy is just not using it
ah okay sorry then
should be able to just input --xformers into run_nvidia_gpu.bat but i have yet to use comfy with any args so i could be wrong on this
now is a face with personality
@visual glade hey i love comfyui and it is nice to play with it around. I woder if u also had the idea of adding node conection to all the numbers and settings. And math nodes. Simular to blender. Thus you coud use math nodes to calculate something and controle for example the power of a lora or how many steps a sampler does. This would be soooo cool . And another cool thing would be loop node setups. With these you could loop throgh a generation and each time changing a setting or maby even more complex stuff like shifting the noice imput image.🤔
check your task manager (ctrl shift esc) and see if your RAM or vram are full
idk too much about a1 and sdxl but i do know that it is awful in loading the models in
curiously always paints the same woman, but feet and hands are nearly perfect

not bad right?
Does the terminal on startup say this?
Do you see the exformers here?

i did get repeated likenesses too. I hope this gets merged and used for more looks because there is something good in there
yep
Now we're talking lol
No, it used to but then I started experimenting with flags and it does not show it any longer

Ah okay I see. I don't know what that is and hope that you get the help you need.
RAM usage at 96% and the VRAM is barely being touched
Thanks anyway
yeah looks like its stuck hahah
your best bet is to kill the whole thing, mabey restart it and try again, or mabey try another ui
a1 is kinda awful with sdxl
Simba's kingdom is looking a little... urban lol

I guess I will try comfyUI instead
male hands look really good too in a consistent way. Only some minor errors.


yeah!! 😄

correct number of fingers but too many laser sabers. Cant get everything ok! 🤣

finally, sdxl 1.0 lora training works on 16GB GPU RAM,params optimization is so important with convolution network

moar loras!
yep....the newer models are still not quite there, but pushing the needle a little bit at a time
i just saw a flood of new ones on civitai since yesterday....have you tried any of the brand new ones
things are going pretty fast indeed, much faster than with previous models. It is only a week since xl1.0 released and we have a number of custom checkpoints already and loads odf loras! I havbe tried most of them and i think the better most equilibrated adn "proffesional" one is dreamshaper, which was launched first btw.
most look pretty weak by the preview pics, and comments.....but i think those two models do give better results for humans.....but for other things, i dont see much of an improvement
i dont care much about celebrity loras, but there is one that The Last Ben did for a photography style that is pretty good
IMO XL is great in almost everything except humans.

Trying LORAs in my workflow with the voxel LORA


And the DFunk Lora

And the cyborg Lora

Can someone generate examples created with Tiled Diffusion vs Tiled VAE, and what is the difference between them? Which one of these methods generate faster images with SDXL? I tried running Tiled diffusion on my system it took way tooooooooo long time which produce 2 tiled split screen result and turned 1 dog into 2 dogs in each tile split horizontaly 2 + 2 = 4 dogs 🤔
oh, love it

CAT!!!
pure coding no UI lora training,loll.

estimate 1.5 hours finish 10 epochs for training lora,16G RAM runs so well

why is there still voting going on? how will the data be used?
Yes, Euler A does it a lot - often multiple times if you increase steps - that's one of the reasons why I prefer different samplers even if results with Euler A are good in general.

There are addons for math, the real problems are ways to switch different behavior by addings switch nodes and allowing nodes to handle empty input.
Comfyroll addon has switch nodes
Thanks, I will check it later when I get home.
are they general switch nodes or only for a single purpose?
ComfyUI is really fast lol
use Euler A for my lora sdxl sampler training, loss 0.13-0.15,good result
The hands are kinda wierd though, maybe it is me who forgot to put the negative prompts lol


Leopard Lady etc






reroutes are just sooo big, therefore I made this (can be toggled and allow moving and connecting while in dot mode)

Pareidolia
how can you toggle the connection routes to a boxy style like this
Hi, I would like to learn more about mashing various styles for generating images. For example Barbie movie style applied to Harry Potter scenes. Do you know good resources to read/watch?
also part of my extension: https://github.com/failfa-st/failfast-comfyui-extensions
GitHub
Extensions for ComfyUI. Contribute to failfa-st/failfast-comfyui-extensions development by creating an account on GitHub.
perfect thank you





oh fucking wicked
are you using the voxel lora so far?
yes
an alien skull face medieval knight action figure riding a horse, castle in the background, extremely detailed,natural lighting,film grain,((voxel syle)),lora:VoxelXL_v1:1
sdxl lora training of hitokomoru successful, prompt:1girl, aqua eyes, baseball cap, blonde hair, closed mouth, earrings, green background, hat, hoop earrings, jewelry, looking at viewer, shirt, short hair, simple background, solo, upper body, yellow shirt

I'm afraid of going back to A1111 at any point in time after using Comfy
you can't comfortably use refiner with a1111

heard you can use it as a highresfix now
but you can't use hiresfix then 😄


would be cool if people would post their prompts and seeds alongside the images  you know.. for educational purposes
you know.. for educational purposes
yeah putting it into comfy isn't worth the hassle most of the time


prompt?
Copy image directly from the context menu "Copy Image" 🙂


 I just finished training my 400 image style lora, it can do almost anything and is only 40mb!
I just finished training my 400 image style lora, it can do almost anything and is only 40mb!
loras are really cool like that ❤️
prompt: (LEGO tiger:1.1) sneaking through the jungle, orthographic view, color graded, wide shot

my previous one was 800mb and was essentially taking over the training pool for SDXL. It was having a ton of difficulty generating variety -.-

they're easy to over train with sdxl
I mean, I think thats just because of the way people are training atm, I used DIM 8/1
my inpainting isn't transitioning very smoothly right now in SDXL 1.0. Any tips to make it blend better?

Prev I used 128/128
yup. i've found no need for more than 8/1 too.
use generative fill in Photoshop or Firefly
thats sort of what i mean. because sdxl is very easy to overtrain, people are stumbling all over those pitfalls
I want to do it in SDXL purely lol
oh, then i dunno xD
Unless you want to only produce your dataset yea LMAO
lora vs original


I'm so hungry ....


Should I cancel my Mid Journey subscription.
I don't use it that much anymore and I've completely moved over to stable.
answered your own question. if you're not using it why pay for it
I've had it for over a eyar now
saas' biggest caveat
It's just difficult
do it!
I'll archive all of my prompts. You aren't allowed to view your prompts a while after you leave. @trim orbit
will you ever look at them ever again?
Yes. I use them for when I have nothing else I can think of.
I've made 40+ thousands images.


cancel it all. the whole plan. all the prompts.




https://github.com/topics/midjourney-download these might help
Thanks.
MidJourney still has a finish totally unavailable in SDXL, especially Niji
What does that mean?
midjourney fans might not like to hear this, but sdxl is a better model than what MJ uses. all objective tests reveal this.
Subjectivity YMMV as we all have preferences of course. Where ever objectivity can come into play, SDXL wins. Simple as that.
What did you train it with and any chence u could share your config?
Kohya and I used the config @boreal bough posted!
Original vs Lora


This is lora after hi-res fix :3

where was it posted? can't find it
anyone know what would cause a "pooled_output" figured out it was the efficient loader causing the error. but can't figure out why.

Has anyone figured out an effective way to reduce twinning in resolutions over 1024x1024?
Use a supported SDXL resolution.
1152 x 896
896 x 1152
1216 x 832
832 x 1216
1344 x 768
768 x 1344
1536 x 640
640 x 1536
^5
TYVM ❤️

Peekaboo!


If you want bigger the best thing to do would be to upscale the resolution from the trained sdxl resolutions, then run a base pass over it again, or just use the upscaled as your final image.
An action figure of a cyberpunk cyborg cop controling a punk group of muscular bad guys, cyberpunk street in the background extremely detailed, natural lighting, film grain, ((voxel syle)), lora:VoxelXL_v1:1

So the first few results of SDXL were really good although it took some time to render
And m laptop even lagged for a few seconds

I also didnt have to install Pytorch etc
when the memory usage overflows the vram into the system ram, the entire main bus will be saturated and you'll get obvious system latency
pretty cutting edge stuff
I took the settings from a youtuber maybe thats why
well you've got a laptop so i'm going to assume 8gb vram
4096x4096 width and lenght to 1024x1024 target and then i changed also to 4 batch which results in 4x Base images, 4x Refined
8 images alltogether
I dont have any clue what those other changed settings where tho tbh
with noises etc
I just followed along
I tried the DreamShaperXL checkpoint, it's actually really nice !

does anyone has good upscaling method ?

cool


What is the purpose of the lora? You say it can do "everything", which seems a bit general 😄
to make psychedelic imagery, I wanted something to encapsulate my personal taste. I also wanted it to have depth in its scope.
"Ultimate SD Upscaler" is good. It's in my workflow, here :
https://civitai.com/models/119257?modelVersionId=129558
The SDXL workflow includes wildcards, base+refiner stages, Ultimate SD Upscaler (using a 1.5 refined model) and a switchable face detailer. **Note:...
thank you !


Okay, here again tryna ask for some help.
was-node-suite-comfyui always bugs out and won't load certain nodes. I've tried everything from fresh installs to manual installs to asking for the nodes themselves. I'm looking for TEXT MULTILINE and a few others. If anyone knows what to do please help. It's so annoying because half the workflows use was-node-suite-comfyui and I can't get all of the nodes to install!
i tried tech help. no go there
someone tryed 1.5 + xl refiner ?
hmm, have you?
i will try on auto1111
ok i might as well try too
but first .. im installing the refiner extension so i can use refiner in txt2img w/o having to go into img2img
Is img2img available on XL? Didnt look uo
and with that ext you can also load up base and refiner inside txt2img with one click output

Thats okay, i use SDXL only for specific purpose



Experimenting with upscaling with the SDXL refiner model, starting to get a better understanding of it. The number of total steps effects how much gets denoised each step, and you can change which step you start denoising


loving the speeds today

In this picture I did 50 upscale steps total, with the start_step at 20. I set the base model to stop and the refiner model to start at step 40.
Its sort of like a denoise at .6 with 35% of the steps being refiner
but does going above 30 steps show any visible difference?
YO
30 steps with base and 5 steps with refiner


does anyone have a workflow with only one checkpoint loader+lora+vae+upscale+hires with multiple prompting section?
Searge is tinkering with something, can be found in Civit
oh, I will wait for it then.
but it has refiner checkpoint
True
you can remove the refiner by setting the start at to the equal to the total steps
oh
also, i can't change the lora in searge's workflow
it's fixed to offset lora by SAI
when i clock on it, only offset lora is being shown
*click
insert lora loader into sytan's





Any ideas what I can do to get the same image results as DreamStudio? I get much better results on DreamStudio than in Automatic1111 using the sdxl 1.0 model. Width, height, steps, and seed are the same accross both.
Does DreamStudio add additional details to the prompt or negative prompt?
I don't know if they use the refiner, surely, so try to install the extension
they're using their style prompts in the back
Thank you. In DreamStudio I did not select a style. Does it select one by default if I don't select one?

probably not. but i think they might have a permanent negative. they also might be using loras, i know they've developed in-house style loras that the bots have used in the past
dreambooth has the style selector, which adds styles passed to clip L iirc. you can get this from an a1 extension
i heard that on the bots the style prompts were passed to both l and g
i'd like to look into that more. maybe you're right
i really dont like having to divide my prompts. i hope a guide comes out explaining the advantage of separating them vs passing same text to both
or comparisons at least
They're like having two separate actions on the latent space rather than just one for invoking images. You want them to act in concert, but you can also divide their attention across a wider scope of latent focus. Sytan's workflow has a nice bit of text about it. Well, i haven't seen the 1.0 yet but his first one did.
What are the GPU requirements for XL model?
I really need Controlnet working with sdxl



Is there something better than WD14 tagger for interrogation? (It's good enough not great) Something more like clip interrogator that works inside of comfyui?
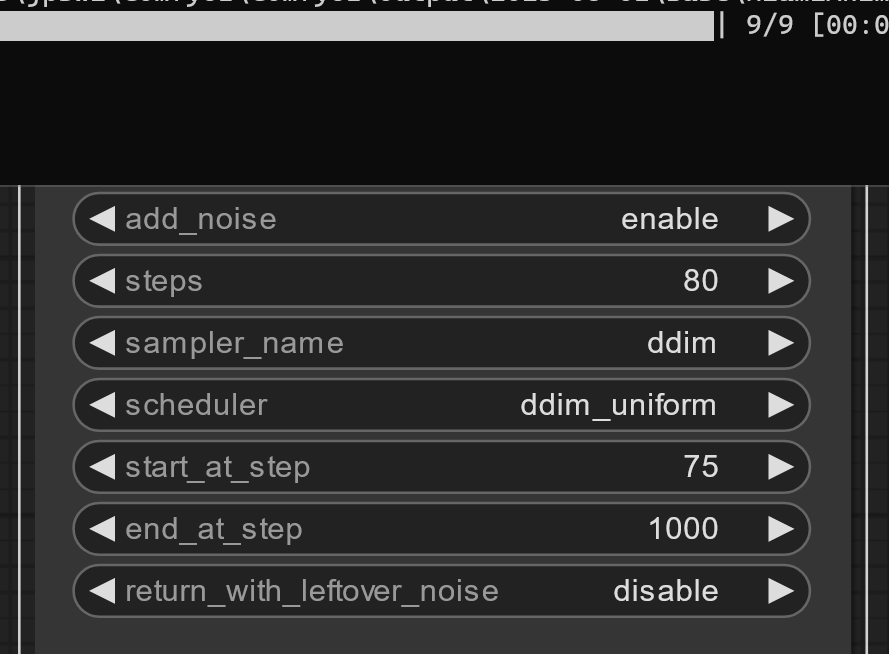
is there a bug in step calculation in KSampler(Advanced) node? steps and start_at_step don't match the actual executed steps. works for lower numbers, but if you go higher with your steps, the actual steps (14) are a lot higher than what should be the right amount of steps (11):
https://i.imgur.com/ng78t4r.png

Outside of comfy, just tried a cool project. blip2+wd14+flamingo and summarize with llm.
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/commit/91704abbae38a0e1f60d433fb08d7f7d99081d21
Look what got commited an hour ago

same thing for 75/80 - should be 5-6 steps, but it does 9 steps:
https://i.imgur.com/sKJUJ1E.png

What was the reasoning for making 1.0 use 0.9 vae now?

Looks like they finally admitted there was an issue. On the first day of release they were very dismissive about it and even claimed it was supposed to be that way. So I'm glad to see they changed their stance.
Artifacts in generated images with 1.0 VAE, especially when using refiner in Comfy. Artifacts not seen with A1111 base model only.
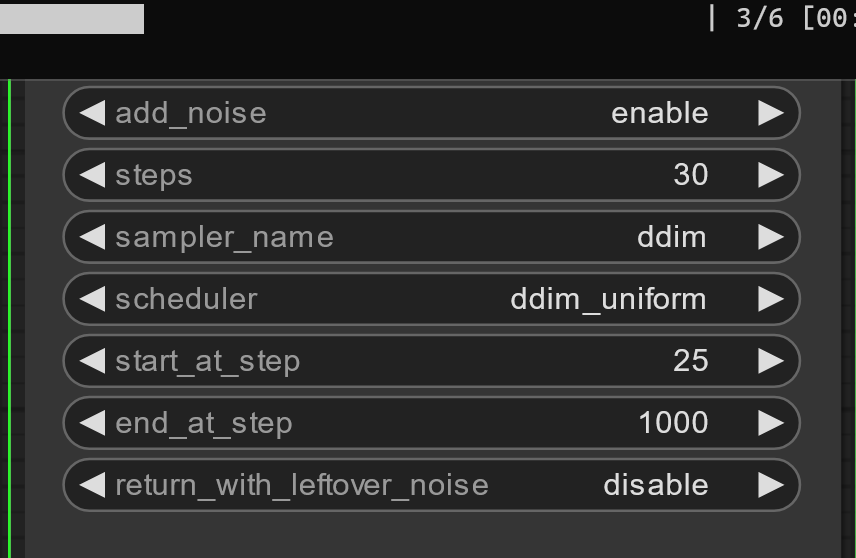
for lower values it works and 25/30 gives you the correct 6 steps:
https://i.imgur.com/jcPsAgw.png
o.0 how can the vae be this big?

Oh thank you 🙂
That is not a VAE. That is a base model. The name indicates that it has the 0.9 VAE baked in.
ahh ok
That's pretty cool, I'm trying to refine detected faces in a conditional stage of an SDXL workflow, I wanted to generate descriptions of the face on-the-fly with interrogation. WD14 does well, but I would really like some better quality automated text to influence the generation more. I'm sure more options will be available in the coming weeks.

GitHub
GIT/BLIP/CLIP Caption tool. Contribute to theovercomer8/captionr development by creating an account on GitHub.
also i put this together if you want to use instructblip https://github.com/briansemrau/kohya-ss-sd-scripts/blob/sdxl/finetune/make_captions_instructblip.py
I get well written captions like "The image features a young girl standing on a hillside, looking down at a house. She is wearing a yellow shirt and has a backpack on her back. The house is situated on a hill, surrounded by trees and a stone wall. The girl is standing near the edge of the hill, with a view of the house and the surrounding landscape."
I also have a question for anyone who may help. I'm trying to find a way how to prompt SDXL to replace part of an object with something different. Is there a way to use something like "instead" in prompt? I know I could go for inpainting or regional prompter (once it's working with SDXL), but I'm searching for a way to do this within the prompt itself. An example would be "a photo of hamburger, cigarettes instead of meat". No matter what I do (give more strength to keywords, use negative "meat") it renders normal burger with meat in it.
I think wd14 is not that good at training a SDXL lora or model. I used 15 images with hand made prompts. Only 1 epoch and 10 repeat, it could get pretty decent result in 150 steps. Therefore, I tried that mixing tagging project.
A dozen cigarettes, sandwiched between two brioche buns (?)
Could also try prompt editing… to get the composition of the burger the switch it to cigarettes between buns
Trying it now. That would mean that "instead" wouldnt work, I'd have to find a way around i guess 🤔
Might have some effect if used afterwards… dozen ciggs between buns, cigarette burger with cigarettes instead of meat
SD doesn't understand sentences the way ChatGPT does. It just sees words, actully tokens. That's why if you say a prompt like "cat with dog's head, dog's feet, looks like a dog only in the head and feet" you will probably get a bunch of dogs and a bunch of feet in addition to your cat.


the workflows are just getting so good

Yes, now I'm getting bunch of buns. Mostly I'm going quite simple. I'll try to find a way around. I mean, impainting would be the key then i guess
Yes, inpainting is key. SD does not understand complex relationships between objects. That is written in the documentation.
anyone know what method CLIPDROP uses for their background removal? i'm sure it's ffmpeg related
Might come eventually tho since its possible to do so and there is something that does that already
I assume you mean Midjourney?

can anyone help, how to make a prompt to put subject a little further from the "camera", it always crops the bottom and the top of the subject... negatives like "out of frame" don't help really
with sd1.5 don't have these issues. it's sdxl issue, can't get it no way. and no controlnet yet. maybe some "field of view" trick or something?
there's some level of relationships between tokens with CLIP but yeah, for the most part, its nothing like LLM
what sampler do you use?
The Voxel Simpsons!

ymmv but ive had good luck with rule-of-thirds photography as a positive prompt. SDXL should actually have this happen less than 1.5 because of how it was trained, autocropping was the issue and sdxl had sort of a workaround to help prevent this issue
it's probably your prompt or the resolution you're using why it frames it like this. try mid-shot portrait of or just portrait of
i usually put full body as the second or third term in prompt. then anything that gives you detail on parts you want to see like shoes etc
how can we add hires fix into Sytan's workflow?


its allready in there
i just recommend to set the steps in the highres fix higher than recommended
tried... it works 1 in 10 times
I mean Firefly/Photoshop generative fill. Midjourney doesnt even have inpainting ^^
is there hires fix?
i dont think so
MJ is out of the equation right now. it's not even close to SDXL.
In terms of image quality or all in all/general?
it also helps to change the resolution like more of a portrait style to help it give you full body shots
both
i think so
For image quality MJ is very well toe to toe, for customization...well needless to say

thank you, but maybe you're right, the resolution im trying is 456x1472 upscaled by 1.7 to 775x2502 ... but already the first pass cuts the legs
imo thats a highresfix
DPM++ 2M SDE Karras
yeah, try a different resolution. SDXL works most reliable if your resolution fits into 1024x1024
nah, midjorney doesn't even get close to this level of image quality.

if for you it's not, you're not using SDXL correctly
From what i have witnessed and also used myself definitelly disagree there
But also depends always
Where MJ definitelly will remain behind is customization and advanced tools
MJ doesn't even have 1024 base resolution. Your quality comparisons are likely thumbnail glances
Until they bring out their web UI SD and Firefly will be much further eventually

yeah, which is a little problematic for people, who are tall and narrow... if you need just the people, no need to make it rectangular... that's how I see it... so I use short width and long height, and I keep adding height but it always cuts the legs... at some point it starts making double legs or something, rather than making one person whole 🤣
fuck no, mj isn't even a match. I NEVER saw MJ get to this level of quality and/or detail. if you disagree with this you're most definitely biased

subjective biases can be very strong and hard to seperate from
MJ and SD are different tools for different use cases. No need to defend one or the other.
for example, a simple prompt like centered full body photography of a woman in boots at 456x1224 upscaled to 775x2080 results in this, which would be acceptable if the hat was 20 pixels higher and if the feet were visible.

i woudln't call MJ a tool as much as it is a service
a very limited service
MJ and SD are different things for different use cases. No need to defend one or the other.
I bet more like you are biased man lol
That is true
You will find those three have different target audience
oh, please. do you really think MJ is capable of producing an image with this quality?? and don't even get me started with text

Across all technical and objective categories, SDXL succeeds. This is just something MJ fans need to contend with. The MJ SAAS business model is only going to succeed for a blip. They've suceeded well but if they don't pivot, they're done.
Wouldn't be surprised if something like deviant art ended up acquiring whats left of MJ in a year
What is the best upscale model ?
no. I think MJ uses old technology for their current version. A very refined and capable form of those older papers, but nothing like SDXL and can't compare to SDXL at all
yeah, it's not even close
I think he'll sell to Adobe in a year lol
could someone explain me how i could add a save node to comfy?
Adobe doesn't need MJ at all
MJ's business model is hyper exploitive, and their real competitor is Adobe. Adobe will break them.
Stability will just keep pumping out open models. They're competing in a different way .
In a matter of week's after launching adobe's generative userbase doubled MJ's
tried adding rule of thirds as well, still cuts the legs at ankles height... 
Tried another lora training last night. File size and training speed were significantly improved, but it couldn't generate my dog like before- only random dogs. A couple settings got mixed up, caught in them review.
Made one wrong setting during overnight lora generation, lead to another model at 1.7GB. Currently retraining, not any faster sadly but this file size is lookin' real good and the sample images confirm it's able to recognize my dog when prompted with the unique text identifier.

final product quality remains to be seen
describing the photo rather than the position of the camera. "magazine cover photo", "rule of thirds", "perfect composition", "professional portrait" "studio photograph", "patterened backdrop" all give a context to where a photo isn't cropped. Without context then anything goes. Selfies are always cropped tight because most people suck at composure when doing selfies
thanks @trim orbit i'll give that a shot
"magazine centerfold" gives good full body compositions



it works, not every time, but every 2nd or 3rd it makes full composition

I’ve found the dimension rank is what leads to large file size higher the dim higher the files size. Dim 8 leads to 40mb file haven’t tested if higher ones were better yet tho

it's a helper is all. i'm trying more to describe the frame of thought for building prompts.
well thank you, it's a good starting point


would a prompt be able to remove artifacts? I actually don't know
I'm not sure what's caused this but for some reason it looks like SD pasted a new image of a shark over a completely different image

It's following the prompt, it's just a weird render I should say
naw thats just one of those there bioluminscent air sharks
I got one yesterday where it literally pasted different images in? not sure how to describe it. let me see if I can find it
I should mention part of the prompt was trying to turn the shark into glass but... that's not what that would look like 😂
no, just a weird workflow. unclip models and whatnot
I think I was just using one of the two ComfyUI stock workflows with minimal changes. Although I haven't run into it with Sytan's so maybe there's something to that

.... what?
those are beautiful artifacts
No way
unclip models are very interesting. I still don't know how they work. made some interesting stuff though
@trim orbit i agree, i mean SD, MJ and Adobe with FF have different audience target
like what sort of fever dream did this come from?

Gotta test more with SDXL on friday

What is the main advantage of sdxl?
gets better results with less finetuning?
resolution
with all the loras and tools with 1.5 I can make things that can compare with what a lot of sdxl does. but with just the base model I've been exceeding the quality of about anything I did previously. basically a much higher percentage of results are wins
https://i.imgur.com/Ik8OqeC.jpg (SDXL, no refiner, just finetuned upscaling)

resolution improvements always kick ass in any it field

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}