#✨|sdxl
1 messages · Page 61 of 1
I got it working. I simply kept putting the wires in the wrong node each time I was trying to fix it.
Nvidia is the king of those sectors
user error haha, great its working again

The perf I spoke of was related to the Titan cards over the 2080tis of the time. It may have chnaged of course, but the fact remains this is how the enforce segmentation
And rising. They know how to make money.
I mean, look at AI, there's definitely not a shortage of demand
Yes and they bring those other fancy AI tools too
thanks for giving me extra confirmation guys. Thx. It puzzled me a bit. Lol!
and then all of their AI platforms
Also Nvidia brings their own AI art generator besides of the Canvas thing
they're doing a lot more than GPUs
Wait the code is hot compiled or? How does that work? Nice job anyways 💯
but GPUs are definitely something they don't have to worry about market share currently
Untouchable at this point
its a custom library I wrote for doing image math
https://github.com/Beinsezii/pixelbuster
I use it mostly in gimp. works well in comfy but rn it needs two copies and I'm trying to get it down to one
i guess you could call it an interpreter?
it has goto and if so its basically turing complete lol
That's awesome I would love shader language type code in a comfy node
you could probably do the same with gmic
I have no idea how to write gmic shaders though
Yeah idk Im just trying to learn how to do it in python, it isnt too inconvienent to make custom nodes
ayyyy I think I avoided the numpy copy
now it just clones the tensor cause if you don't it pollutes the comfyui caching thing
so every change will iterate on all previous changes lol
you could 100% make a node that's just eval(string) I've seen a couple of them
so I need to bring up the refiner. I have yet to see a use case in personal comparisons where it brought a clear benefit and I have tested a lot. It either moves sidewards, meaning a flavor and not an improvement, or it literally downgrades. This is not a Karras vs Normal thing I saw mentioned the other day. here is an example:


if you wanna do image maths you could do the conversions to numpy ndarray first before you eval
The above were with 60+15 or 75 straight
I also don't see much value in the refiner right now. I think people will start to learn how to use it better and probably use different prompts with it or some other workflow. But it will take time to discover how to apply it. And base SDXL images are already very good.
def pixelbuster(self, image: torch.Tensor, code: str):
image = image.cpu().clone()
batch_size, height, width, channels = image.shape
for i in image:
ndarr = i.numpy()
buff = numpy.pad(ndarr, pad_width=((0, 0), (0, 0), (0, 1)), constant_values=1).flatten()
pb_lib.pixelbuster_ffi(
code.encode('UTF-8'),
"lrgba".encode('UTF-8'),
buff,
len(buff) * 4,
width,
)
ndarr[:] = buff.reshape(height, width, channels+1)[:, :, :-1]
del buff
return (image,)
literally the entire custom node function. ig there's still technically an extra copy because I pad the data to have an alpha channel
No idea what i'm making yet, but so far quite some progress on making SD 1.5 models play nice with SDXL refiner 

Huh ok, maybe I will try doing a basic eval node and playing around with it
Nice to combine written code and nodes
I would make a fragment shader type setup with iterating over the pixels but that would be so much slower than numpy [:,:] I'm guessing
you can basically just replace the ffi with an eval or calling something like gegl/gmic's cli. Probably replace the pad into buff with flattening ndarr directly if it lets you write to it.
Are those like shader languages sort of?
Its hard to tell when its better, I guess the data in aggregate from this discord shows it wins but I haven't seen too many images where its clearly making an improvement.
I guess in theory you could run a bunch of steps at lower res than 1024 to speed up time but you just loose quality while upscaling and the refiner doesnt handle prompts the same way
gegl just has a bunch of filters built in. GMIC has its own really complicated language that I don't wanna learn
gegl is what gimp uses for stuff
I didnt even know you could call command line stuff from python lol
you could also probably just load the gmic or gegl dynamic libraries directly
assuming they have fns you can use
PIL is what comfy uses to save images they might have some basic stuff built in
I am not complaining about it since it is optional anyhow, and done with the best of intentions. There may be cases where it is a clear win. But not in mine. I was merely sharing my personal experience
I originally made my image calculator in Python but rewrote it in Rust because it was too slow for 4k images lol. It does all its own colorspace conversions though which hurts a lot.
maybe numpy would make it better
I have a custom node that applies a haldCLUT filter to an image

Takes no time to run
hald cluts are a multi dimensional array saved as a png image

Thanks Mikey
When I ping the SD api to get a list of available models, it looks like "stable-diffusion-xl-1024-v1-0" is an option now. Has anyone had luck with it? Only the beta SDXL model is responding to my calls.....
It's now available, find the latest update for the Searge-SDXL ComfyUI workflows on https://civitai.com/models/111463?modelVersionId=130616
In version 2.1 it now has also with support for LoRA, HiresFix, and bug fixes that improve the quality of the generated images. All these are available in all 3 workflows: text-2-image, image-2-image, and inpainting (except for HiresFix which is disabled in the inpainting workflow)

Searge SDXL Reborn v2.1 Version 2.1 is here - while the previous update has brand new workflows for text-to-image, image-to-image, and inpainting, ...
Thank you @primal vault !
Enjoy it. And if you find bugs, blame the guy on that image, not me 😉
was the prompt fall guy ? 😆
no, but we need a lora for him, trained on that trigger word


nice details going 4x and 3x highres fix upscale
looking close to something from a camera
@boreal bough any thoughts on this? #✨|sdxl message
how do you use the refiner in comfyui? is it a node that needs to be added?
it's a separate model
looks cool ill try it later when i work out what custom nodes etc are lol
oh really? do you know where its possible to download it?

vroom

It's was trained to take the output from the base model and 'refine' it
so you just choose the refiner as the checkpoint if you want to use it?
are you supposed to img2img the output from the normal model?
yeah basically img2img using the refiner. there are a few ways to do that
The intel arc user has joined.

The one of a couple intel arc users

Death comes for all.

also @civic sigil if you're doing a straight exec maybe careful distributing it in case someone decides to be funny makes an image with the node containing
import os
import shutil
shutil.rmtree(os.path.expanduser('~/'))
shoved like 10,000 grid units below the 'real' workflow where no one's gonna see it
I'm assuming, these are images produced after lora training?
what dim did you use, can you post caption of one of the images you used to train
and is it only refiner giving you troubles, or is the base already producing the issues?
no refiner at all. "1a2b3c4d man with a fur vest and hat smiling, white background" (thats blip with a prefix and postfix). this wonky issue with no good epochs is the same with net 8:1 and 128:1
ah yeah, cause we're not training clip, that means that the meaning of our trigger word should be at least remotely close to what we're training. 1a2b3c4d isn't really a word you find in the dictionary, or commonly used to refer to a man
funny you say that cuz right now im training on a celebrity name for the first time
because of this

you can cheat by using a token without much context behind it (sdhx, sds, ohwx in 1.5) but for sdxl I've not checked which tokens that are less biased.
but yeah, just using a celebrity name that looks even remotely close will be the best course of action you could take
okay then the challenge is making that scalable. i need a tool that can output a name of a celebrity lookalike given an input image. i havent found anything decent yet
if you need a 1 size fits all solution, "model photoshoot" can be used as a trigger word, or something along similar lines - but celebrity that looks remotely close will be much much easier to get right quickly
any responses?
i wonder if theres a new rare tokens list for sdxl https://www.reddit.com/r/StableDiffusion/comments/zc65l4/rare_tokens_for_dreambooth_training_stable/
I hope an inpainting model comes soon. Those who say it is unnecessary don't understand the workflow.
if you dont care what word gets chosen, just that it does so automatically, you could have Interrogator + Vit-H + default flavor chain spit out the 'best' word that represents the first image in the dataset, then automatically use that as a caption. that will work even better than celebrity name in 90% of situations
i wonder. if the celebrity match is high on someone then the training converges fast in x steps, but on a different person their closest celebrity likeness might be way further off and convergence happens at way later stps. thats not good for me cuz automated and scaling
yeah make a long list of celebrities and use CLIP-G to find the one that matches the most
what's the best upscaler model to use with this node?

Yeah I didnt think of that lol
CLIP is supposed to be a classifier: it tells you which phrase or word matches your image the most
clip g, or clip big g?
cause so far I've had best results on Vit-H
for SDXL bigg clip-g
is this something i can set up in comfyui
not sure if someone made a node
im pretty new to the nodes and dont trust myself to make one
for automated training, you'd have to write a medium complexity python script anyway, to automate the interrogation + custom flavor chain
is custom flavor chain the parameters you set?
if you dont mind a bit of manual input, you can use interrogator on A1111 webui, where you only need to drag in the image, rest is done automatically
https://github.com/pharmapsychotic/clip-interrogator
best to start reading there
you can then adapt his scripts to do your thing, or use his extension for webui
okay. why do i need to make a list of celebrities and how do i get it to match from a specific list like that? #✨|sdxl message
Is this only if the TE is frozen or in general?
it was not trained in the specific video this was on
you should be able to find the highest cosine similarity between the vector you get from encoding the celebrity name and the vector you get from encoding an image of your face
you can just run clip in a quick and simple script. can find an example from huggingface.
Would be a fun idea for an app...
big download though lol
yeah thats complicated. best to start reading about how the app I linked you works, cause it does exactly that
Hey comfy, is there a reason why the history is sorted ascending instead of descending?
^ this
Ok will do. Thanks guys this is exactly what i was hoping for. Just hope building it is not completely beyond me cuz im on a time crunch
pursue this part, to achieve exactly that
still not easy, as you will require some coding, but it should help you get things running as quickly as possible

this would be a welcomed change as when deleting the most recent it will flick back to the top each time
I can't think of why I would want to access the first run, and not the last
yep
thanks i'll try this out

SDXL sure gets musical instruments right, better than 1.5
which one is better
since every object in python is just a fancy dict you could take each line of a string and key it against ndarray's methods. could concat your own methods onto it as well.
little cursed but isn't everything?
amazed xl still cant do hands or limbs properly
did they mainly train it on non human subjects?
it does those great
i'm going to run my terran game asset set on this json overnight. we'll see on the other side.
but portraits of humans are terrible
practice and hone in your prompt-fu. it's abig wide world of latent spaces out tehre
"cover of a magazine portrait" is a good one. i have no real answers just guidance. go forth. prompt better.
determining that "it can't do this" in the first 48 hours is just... unwise
the word 'portrait' is pretty biased. Sometimes that makes it works better, sometimes it does the opposite of what you want. 'close up' can be substituted if portrait doesnt work well.
A photograph of a (subject) in a (location) at (time)
like so
A cinematic photograph of a pretty woman with blonde hair and blue eyes in a park at sunset
will usually give you better results. You can do
im actually using those but the hands and legs and feet are nearly always messed up when it gives me a full body
"Beauty shot" is nice
like ill get a woman with 3 legs or mutant limbs lol
well or the dreaded slenderman ladies

😋
i'm trying out Sytan's comfy json and i'm getting DefaultCPUAllocator error, i've got 12 vram, but only 16gb ram, i'm guessing that this is a ram issue, not a vram one?
when you forget your lora is still turned on, and prompt for realistic XD

https://arxiv.org/pdf/2307.01952.pdf the report is actually super informative towards the capabilities of the model

playing around with sytans new upscaler. wish there were more options for nodes, like hide values i never want to change. better options to allign and fix nodes, switches, etc. comfy could be really great, with more than those basic options
yeah, hands and feet more often than not go wrong with setup. I see it now. Prob due to low step count. I'll ask sytan if he wants to make a performance unfriendly version with doubled step count. should fix hands at least

Sounds like you cooked it then if you can't get SDXL to make realistic stuff with your LoRA.
yep - it's the 1000% overcooked lora 🤣 FOR SCIENCE
thats a good point i never did change any of the settings it seems to default to 20 steps only?
might explain the hands and feet
normally i run 30-50 with 1.5 but no idea whats optimal for good limbs with xl
it's a complicated setup of steps. but yeah, if you proportionally increase all the steps/step start/step end by 2, for the non highres parts, it should do better hands, at the cost of slower generation
for the refiner also?
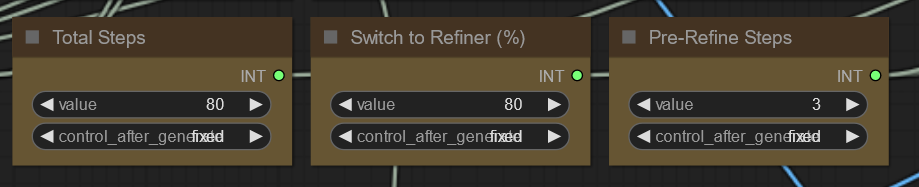
don't know why everyone is using as few steps as possible. in most cases additional steps fixed more small problems than adding new ones for me. i often use 80-100 total steps and get good results.
We're impatient.

80-100 steps means 4-5 times less images.
80-100 steps is also way too much.
And while you may get good results, often you may also just be spending 80-100 steps on a prompt that won't work anyway

20-50 steps make the most sense. Any further and the level of detail you get exponentially decreases.

Too bad neither ComfyUI or Auto1111 has any good workflows for batch fixing images by rerunning them at a higher step count.

or add some math nodes, so you only have to change a few basic values instead of changing the whole workflow every time you want to adjust steps:
https://i.imgur.com/ej95FPZ.png
im too dumb not to break it that way haha i just started with comfy a day ago 😛
my limit is editing the variables haha
I'd be curious to see a workflow that, for example, automatically fixes hands by detecting and masking them, then inpainting with a specially trained hand LoRA
the math is not that complicated. only basic multiplication and division - the problem is that the nodes expect specific types, so you sometimes have to convert int -> float -> int just to make it accept a simple integer value from a primitive node in multiple nodes.
still waiting for this for faces for comfyui. all the face fixers out there dont use your lora. I made my own but inpainting is shitty by default, it doesnt use original fill
yeah i mean adding the nodes etc to the spaghetti 🤣
worked for me with these settings - hands/feet look a lot better for me now. rest stays same

have you tried higher step count for the upscaler too?
thanks yeah 50 looks the way to go and its not much slower
any suggestion for getting full body shots?
i get some though its like 10% of the time prompting full body
trying to spit out a lot and see if all the hands etc are good
can fp16 be used for training when using the updated XL model with the fixed vae?
#🔧|finetune message @boreal bough's uses fp16
You guys know how to easily tidy up nodes in comfyUI?
Like, make them symmetrical and stuff
aspect ratio has huge bias when generating closeup/not closeup. but with good prompting you can still fix it regardless of aspect ratio
also rather than full body, you can prompt for anything found on the floor. like "wooden floor" or "stone floor". that way it tries to make the floor visible, which results in a full body image
bit of a chaos prompt, but it does the job
Painting of a kneeling green haired woman, her face a mixture of pain, resignation, and a desperate desire to please. Her eyes are downcast, reflecting both fear and devotion. She is adorned in tattered garments, emphasizing her vulnerability by Walter Sickert, John Singer Sargent, Denis Forkas and William Open, wooden floor

@wicked frigate just saw you lora train of sdxl on reddit,how to run on colab?any docs or suggestion?
lol
so white tigers everywhere the next few days? 🤣

/Let's edit this architectural design plan in the Japanese style. With the main color is white and the highlight in the public is the black card tiles

I know it's a dumb question, but I figure that the people who upload their perfectly aligned workflow nodes don't do it manually?
you referring to the old one, of the arcane lora?
or did he post a new one

You can snap to grid by holding shift key while you drag nodes and resize nodes
my settings, are essentially an iteration of that reddit post
#🔧|finetune message
in regards to collab, nothing changed from old tutorials when setting up in collab, so all old tutorials should still be valid - you only need to change the model, and then use the settings I posted
thanks i was actually going to try that next lol


Capture a cheerful Japanese cartoon-style girl, savoring every bite of a tart yellow apple. The medium should be digital art, with a style reminiscent of popular anime like "Sailor Moon" or "My Hero Academia". The lighting should be soft and warm, highlighting the joy on the girl's face. The color palette should be vibrant and saturated, with the yellow of the apple standing out against a pastel background. The composition should be a close-up shot, taken with a virtual Canon EOS 5D Mark IV DSLR camera, EF 50mm f/1.8 STM lens, with a resolution of 30.4 megapixels, ISO sensitivity: 32,000, Shutter speed 8000 second. The image should be in a 16:9 aspect ratio, with a version of 5.1, in raw style, with a quality of 2 and a size of 750. --ar 16:9 --v 5.1 --style raw --q 2 --s 750
where is the tutorial of colab set up?
Does the A1111 version of latent upscaling apply a blur after it upscales the latent? If I try upscaling the latent in comfy it creates scratchy lines, spider webs or large spots in the final image depending on the method used.
how are we inpainting with sdxl?
I used A1111 for inpainting
yeah i am on A1111, i just can't seem to find an inpainting model anywhere
the infinite zoom extension i am using requires an inpainting model
There is an eyeball in painting model on civit
there is no inpaint model buttt its not always needed. i've been using adetailer here and there with light denoise
Don't set the noise to 1, more like 0.1 to 0.4
google is your friend. use any of the old setups.
any chance anyone is building a dataset off of prompt/image pairs from #🏅|pantheon ?
sandbit put together this collection of prompts
nice
willing to bet money, that sai themselves are using this
though, I want to finetune an auto captioning model, so i need the images too
i know there's software to collect the data but I want to avoid if possible
Vit-H, Vit-big-G not good enough for you?
instructblip vicuna gives such good natural language captions
I don't have enough SDXL prompting experience to know what's ideal, though
for my LoRA training, I auto caption and get outputs like "The image features a female robot character standing on a planet, with a futuristic background. The robot is wearing a white outfit and has a unique appearance, making it stand out in the scene. The robot is also holding a weapon, adding to the sci-fi and futuristic atmosphere of the image."
but i would assume that's too verbose to be ideal
would this dataset be useful ? there seems to be a bunch fo cool stuff annotated for it already too. wish there was a torrent for it
For lots training, is the goal to fully describe the training image or just what you don’t want?
My dataset captioning v

that depends on what you want to use it for. I'd use that to train my ideal version of clip. I mean it would useless for 95% of people after that... but it'd fun to use
when we train a lora, how is it using the captions with the clip_l and clip_g?

You're not training the text-encoder in most cases, just the u-net.
My training data is vast (for a LoRA) and has a lot of extra concepts adjacent to the main concept. I don't want to lose specificity to those other concepts, so I want accurate captioning.
complicated enough, to warrant the phrase: "train unet only"
yeah, but, when you prompt with a lora, how is that being applied?
So your supposed to caption everything you want the lora to view as separate concepts?
The automatic captioning was no good.

essentially the clip model first breaks, then needs to be rebuilt with enough training time. Wouldn't recommend since you'll be damaging the clip model in 95% of situations - unless you get your captions to perfection
no that's right, he just forgot sunglasses
I can't speak to the actual practice 😅
It's more of a "i hope this makes it better"
I don't have enough compute to run trials and comparisons
hey, i managed to make a good prompt architecture for SDXL v1.0
made this mockup design

yep. if you use a trigger word, then you dont caption what you want your trigger word to 'absorb'. Everything else that shouldn't be learned by the trigger word definitely be tagged though - especially backgrounds
Ahhhhhh, that makes a lot more sense.. time to recaption my data sets lol
not sure if this is the right section but i'm looking for ways to get less than 60 seconds/it on an m1 with 32gb ram for sdxl
if anyone has been through a similar journey please holla @ me
seems egregiously slow
this is on a1111, happy to learn comfy if that is actually faster and someone has resource
should you create two copies of images, one with natural language, and one with the SD v1 type of captioning to get better results?
You can always test and see that works best.
tried that. bad idea 🤣
good to know 😄
for the sparkling lora I made, I went super basic language like, 'a woman in a blue dress'
super basic usually works 'okay'. though you may end up teaching your words more than you bargained for. definitely prone to oddly specific overfitting
how bad? lol
it causes odd deformations in everything
might work just fine for style loras. but at least if you intend to have a trigger word for a concept, it's a bad idea

DUDE FUCK YEAH! HOLY SHIT! WICKED!!!
AAAAAAAAAAAAAAAAAAAAAAHHHHHHHHHHHHHHHHH

@high skiff where'd you get the NMKD Superscale.pth file? found a bunch on hugginface but all different names, did you rename it from something else before saving it?
afaik that's the official source for the models: https://nmkd.de/?esrgan
its probably using the 4x supersclae from that website under Real world
gotcha, probably renamed it then, thanks
the download host was down earlier today
most upscalers seem to be 2-3 years old. Has there been anything newer?
@hoary saddle https://upscale.wiki/wiki/Model_Database https://upscale.wiki/wiki/Official_Research_Models
Check it.


on it! appreciate

MACK is hyped af


Dude I made this with a simple prompt! how can I?
love the imagation work of SDXL really

pretty hyped myself, got everything working for image2image and connecting to my API, running my python script, outputting and pushing result straight to my users portfolio
glad you're having fun 
rad
rad
wicked

are there any comfy nodes that help SD apply colors to the prompt better?
Like if I say the word green it just goes wild and makes a LOT of things green
Now thats my pretty kitty :p

if you're VAE wouldn't run me outta memory tho 🙂


I'd with her
I am not sure why people are having issues with that... hmmm
Not that I'm aware of, but if you want blue you can use the 1.5 VAE to decode and then run img2img on the resulting image.
pretty good coherence
threw realesrgan x2plus in it for fun, seems like run fast and no issues other than the upscale looks like horse shit lol
My Sytan w/flow fails to upscale - I believe I have the latest w/flow downloaded?

switch out the VAE encoder/decoder to the WAS custom tiled nodes
its what I did
So much can go wrong in stable
so true
i'm running a 3080 10G so likely my problem, still comes out amazing despite the error
Ti when?

same here... hmmm
I can do 2552x2552 at just barely 9.8GB VRAM

gib ti
me me want you have TI of greatnes.
i have a 3070TI 8G in the production server
dunno if it's gonna act worse or better yet
Setup for my ultrawide monitor
how u hide the node connections?
just got a patron willing to sponsor me for compute 👁️
not that I have anything at the moment to really use strong compute lol

but that is a very nice idea for the future if I need it
I like tucking the spaghet away like that, I'm now putting the image next to the prompt boxes and placing the samplers etc over on the right
Help - my Sytan implementation not UpScaling?! 🙂
think you gotta rename the pth file or download one and reselect the new name
what i did
now it's too long for the box lol

Seems a good idea, but I'm not technically gifted 🙂
double click Superscale 4x folder
download PTH file, drop in comfy/models/upscale
then just refresh comfy page and it'll be in the dropdown
OK - and it will self-install?
it'll just be there if its in the right folder
You can use this extension to do so, mark em as hidden
https://github.com/failfa-st/failfast-comfyui-extensions
GitHub
Extensions for ComfyUI. Contribute to failfa-st/failfast-comfyui-extensions development by creating an account on GitHub.

It's better than 4x ultrasharp?
i'm the wrong person to ask about that, i'm like 1 step above complete comfy noob
for my 1.0 workflow, i found it worked just barely better than 4x ultrasharp
like a 5-10% improvement for fine textures
Ohhh great!
NMKD Superscale x4 is my recommended pixel upscaler for my workflow

took me like 2 hours to get an image input working on @high skiff and @nimble heart's workflows HAH

hmm you dont get the vae error on yours?
yeah
I am not sure why everybody gets that...
🅰️ or 🅱️


I get out of memory, so for final step I decode with a tiled vae node. I have a 2060s though
This morning's bout-of-beauty - R-B-R Triple Process w/flow




A looks like a game character, B looks like a photo
Refiner?
I had a feeling...

So just like everyone is saying, It says out of memory, then it switches over to a tiled VAE encoder when it hits the VAE Encode node... This is only when changing scaled by to 1 instead of .5 going with the full 4096x4096 upscale.... It still completes for me but instead of it taking about 80 seconds with your old workflow it will complete in about 156 seconds
i'm high i'm believing
where is the option for neither? :p
that you're in love with meeee

oh wow, thats pretty sick
woah!
b e a utiful
Runway's for their stuff working well

runway open source alternative when



wow, that is insane haha
hollywierd won't let that happen!

when they fork this open source project
i guess?
Care to tell us what this is? Refiner? Fine tune?
😬
come on... they released 1.5
There's nothing blocking them from releasing gen2

Just the base model
Ahhh I can see it now.... 3 hour movies generated 4 seconds at a time... what a time to be alive!!!!
haha
it is - the future is now
@upbeat summit
brb queuing up movies
Thought I'd give A1111 a go at a 2k high res fix. jeebus! 😵

500$ for 5 seconds of video
ouch
Still upscaling.....

Is this a new LoRA, checkpoint, something else?
Just the base model
@upbeat summit 🔥
with WAS tiled vae I can do 8k on my 3080 and not OOM. takes 369 seconds to complete

Can you send me this workflow???
These perfect grids.... mm mm mm
alright, since so many people seem to have issues with OOM right now, I will likely drop an updated 1.1 version soon
OOM on what workflow?
Great!
this looks like my lora bruh
Ive changed a lot of things, sorry
I tried the upscaler one without issue.

Sorry about that guys, I am not sure why everybody else seems to have issues
it works just fine on my 3080

Oo, got a link? Would love to try it!
but clearly I am in the minority here, so I will update with the tiled VAE
also...
Might add in a couple more controls for 1.1
testing right now
one more

no lol will probably go up on civit tonight or tomorrow after more tests.

@high skiff if i change the image resolution, do i need to change the latent sizes as well?
I don't, but I am looking into that
How are these done
that looks like 1.5
On Sytan's w/flow I am getting "TypedStorage is depreated. It willbe removed in the future."
gen2
sdxl
Don't worry about it, not your fault.
How is this done
yep, Lora
alright
SDXL, runway gen-2 and latent space magic
bro
Woo hoo - UpScale worked on Sytan - thanx for the NMKD file
no problem
share the nkmd file?
here, I have it
It's a gimmick at the current stage, but having my images animated would be cool.
thanks
It'll make post-processing using Topaz GigaPixel a whole lot easier! My final target size is north of 6144 x 6144
lol might have a few bugs to work out after all XD
Ah you're using N00MKRAD's... I see!
did you actaully rename the upscaler? is it the 4x nkmd superscaler 17800g?
That's a photographic upscaler I think

Might not work as well on line art et-- HOLY CRAP MAN
yeah, renamed it for my own sanity
SDXL Base 1.0 is coming soon on Monster API
Stay Tuned!
Get access to amazing Gen AI APIs here - http://monsterapi.ai/

ahh, lol
man, this looks so much like 1.5
lol, its SDXL
Its... interesting to say
I'm tryna slide into your DMs @astral jay

that is crazy
What Video package are you sing?
I need more credits - damn it! lol
runway gen-2 with an SDXL input image

Oh, credits for runway, I thought you meant credit for your work.
Oh I see it - Runaway Gen Two
Nice workflow @high skiff just now am dipping my toes into messing with it


Yeh, you get a few free creds
then you gotta pay up or wait
so worth it to try for free tho
glad you like it <3
I have some new ideas to play with
Ohh runway lets you do img2video? Thats awesome
 haha - no! for the videos I've posted you are playing the seed lottery only. so the credits you need to generate videos go away really fast.
haha - no! for the videos I've posted you are playing the seed lottery only. so the credits you need to generate videos go away really fast.
I've got 87 seconds left, so I can try some stuff.
exactly
https://dnznrvs05pmza.cloudfront.net/c0a66e1b-8b84-48d3-a8f3-830a45c35189.mp4?_jwt=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXlIYXNoIjoiOGRiNGU1MzZhNWFmM2VhNyIsImJ1Y2tldCI6InJ1bndheS10YXNrLWFydGlmYWN0cyIsInN0YWdlIjoicHJvZCIsImV4cCI6MTY5MTAyMDgwMH0.wk0NiEB8bTi3mXmjPxyK6C4NMDZZzmj4X7e59x2khx8
Not what I hoped for, do you need a prompt in addition to the image?
i wonder if i run the openpose annotator on the coco dataset.
@hard fractal I feel bad @high skiff his name is no longer orange.... When will he beat Freeza and keep his Super Sytan orange status?
Oh lord lol
Find out next time on Dragon Ball Z
🎸
that one is sick
if it used my image, i dont know how

riiiiiiiight
came out pure trash, guess you gotta get a lucky seed or something
hey that's you (I suppose) 😄
Wow. Runway Gen 2 completely changes the look and feel of the input image 😦
yeah, it's pretty bad lol
yes....
noise must be cranked to mars
<BaRF>
so okay - full transparency. all I do here is:
- uploading my SDXL images to Runway Gen-2 Image to Video
- to keep your original composition, you don't enter a prompt
- just hit the generate button
- hope for the best
- I curate all gens and pick out the acceptable and good ones
- and... what can not be circumvented for the most part... getting more credits
What is runway ?
Its an online image to video generator
trying that now 🙂
ah, so useless
a text/image to video service / model: https://research.runwayml.com/gen2
Text/imagine to video AI
paid, and they look over your shoulder at everything you do
ya, but its a fun little experiment
The consistency seems very poor.
it's an experiment like putting your bank account number online for all to see
well shit, that did work MUCH better

my aesthetic anime LoRA works. with sytan high res workflow, this is amazing
"anime style full body 1girl running in a park in spring, wearing a blue dress"

runway lol

I like that one legged walk
Weird legs - forward, then back ... !
https://dnznrvs05pmza.cloudfront.net/2c6f93fd-3ae7-49f7-888b-e54540a8fe32.mp4?_jwt=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXlIYXNoIjoiNTcyNTU5ZDVkOTJiMzJkZSIsImJ1Y2tldCI6InJ1bndheS10YXNrLWFydGlmYWN0cyIsInN0YWdlIjoicHJvZCIsImV4cCI6MTY5MTAyMDgwMH0.XgGtgUdeaPajMnwtZH3OOsvRM7WJ6X9W1i7LHvs-Rhk
Best I got so far, so it is a struggle.
That's a cursed muppet 😆
well it's the best that is currently publicly available. it's definitely far from perfect or coherent. but it's an amazing advancement and SDXL is perfect to create high quality init images
for sure
it's awful...cant run locally
I got it by doing high-res fix + prompt editing.
It is good for doing cursed stuff.
hey @high skiff have you experienced any issues with deformation before? look at the neck. the refined output was fine just needed some touch up but the upscale comepletely boched it and the eyes got smaller too which is weird.

Full version.

all these people aren't running it locally 🙄
you can still do some experiments with modelscope and zeroscope XL, that you can run locally. you can make some really cool stuff with it - mostly abstract but interesting
yes, but I do want to do the kind of motion capture...turn one video into another.
I actually got a good one from RG2
barely any motion
yeah that is currently available in online services - proprietary tech. I know :/
Looking forward to an OpenPose model but img2img still kinda works for poses


He's drunk on set again, dammit!
It looks like he's doing one of those DUI tests where the cops are like, "now move your eyes with the flashlight"
"not your entire head sir, just your eyes..."
If you added the audio for that with the cop giving him instructions, and put it on youtube 😂 . Even funnier cause he's in costume.
Stumpy left arm 😦
That's a horror
I do get a lot of these where they change appearance sadly.
nic is not amused (in this scene)
considering how far gen 2 has came. its pretty impressive. imagine 3 or 4!
Another RG2 generation I like

We are all using SDXL images as a base, right? so we are not completely derailing this chat 
SDXL here so far
movie still film still close up of a man in a dark room looking down, older man, highly detailed, interior shot
excuse me what

i am continuing my vampire girls in front of cities project

or cities where buildings blend together like inception
woha... that glowing is nice
honestly dont know why that happened. i dont even think you could prompt that and get the same result
yeah he's like super radioactive or going to heaven
Cursed seed maybe.
Scotty is beaming him up
what about seed 666?
Goodnight everyone... I'm off to get some sleep finally.
seed 666 same prompt.

increase the CFG hehe
i wanna go back

oh no... quick - change the seed
https://dnznrvs05pmza.cloudfront.net/8c307075-b187-4e34-9f1b-4f4cc97ab626.mp4?_jwt=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJrZXlIYXNoIjoiYzQ0ZGNlM2JjZjZhN2I5OCIsImJ1Y2tldCI6InJ1bndheS10YXNrLWFydGlmYWN0cyIsInN0YWdlIjoicHJvZCIsImV4cCI6MTY5MTAyMDgwMH0.vkYWGDLHY6y50OKyN9TfVdpYoeOgQvGDbI-aC4p3jgI
Nice one. Batman from my inpainting attempt.
lol, what is all this?
magic (SDXL images + runway gen-2 video)
look at that one guy trying to get into the frame at the end lol
are you guys familiar with a way to do this using comfy? https://github.com/pharmapsychotic/clip-interrogator
GitHub
Image to prompt with BLIP and CLIP. Contribute to pharmapsychotic/clip-interrogator development by creating an account on GitHub.
That's weird, I have had absolutely no issues with stuff like that
If you are having issues like that, I would strongly recommend raising the starting step of the upscale sampler
2008 movie still of batman close up shot, waist up,
 but all i added was 2008 lmao
but all i added was 2008 lmao

oh lord lol
Oh wow
is it bcuz you were generating celebs?
Never a dull moment with this model haha
not a lot of movement but cute anyways lol
Looks like a Tesla Decal 😄
no idea. lmao
he's alive now!
people are paying for that?
whos paying?
generate few more images of Margot Robbie and check if thats the case
so easy now. no negative or complex prompt, just train a LoRA

It says it's for pay. There's free with limited credits and functionality, and then there's paid plans
thats true but I only have free creds
On RG2 you get about 25 x 4 second videos for free
so someone might be paying but not me
those run out, no?
probably
Then for 625 credits, its $12/month
5 credits for 1 second of video
margot robbie is fine lol. soo idk prob just a weird combo of things that cuased it
this is (((high quality)))
nice!
RG2

so you are making an alternate universe retro alien movie? I'm in!
Is that Sigourney Weaver? Who's that woman?!?!?!? 😄
its our stand in lol here she is talking it out with the Alien instead of being scared like in Alien 3
it's her SDXL stunt double
I think it's Shooter McGavin
wow that talking is impressive looking
reasoning with the xenomorph
i think they're friends now
She's uggglier than themonster 😄
Aliens 4 in a nutshell
Aliens 4 - The Wedding

oooo
Is there any way you would be willing to share the general prompt for this?
I have been trying to get anatomically muscular robots/cyborgs for a while
musclebot
Main Prompt: A vigilant cyborg sentry stands guard stalwartly, integrated scanners continuously surveying for threats, ready to respond with lightning reflexes, CyberBorgz aesthetic.
Supporting Prompt: Security camera POV, scanners surveying threats, ready with lightning reflexes.
I am using a custom LoRA that is currently unreleased but v7 is almost ready to be shared I think, I'm gettign a little to nitpicky with releasing things so far for SDXL lol
Just my type haha
Oh man, sick
lmao

hahaha
Okay so it definitely seems like they have a 2 second model
And a great optical flow inbetweener

Yeah, that's gotta be what it is
the interpolation is pretty good

What's the fps on gen2?

24fps interpolated
Oh yeah. I'm watching them back at 2x speed
and they give you a 2048x1024 upscaled video
Feels normal
bitrate is a nice 8000 - 10,000 kbps
Yeah, feels similar to Adobe's optical flow algo
yeah very similar
The one that you'd turn on LAST when working after effects
exactly 😄
Because otherwise you'd never get anything done.
boop - boop
uncanny valley - but amazing to see your SDXL images come to life
looks like i need more topgun pics in my dataset lol

"Oh... pump... chomp." -SDXL Gen Jr.
yeah I was trying earlier what he might be saying 😉
"Oh bom... bom."
he did
Ooo
my SDXL init


ik you had the other server guys test but I'm pretty sure we all have 24+ gigs so maybe the selection was a tad biased ☠️
What happens with something like that?
I have the exact same image in my input directory

with the lines?
Yeah
golden ratio
Like, it don't got no lines in its dataset, I don't think
Close. Rule of thirds.
generating...
if you were to guess, if a person was on the left would it be called 1/3 shot. and the right 3/3 shot?
I like that!
Gonna start using it
Just usually called "left heavy" composition
or right
ah okay.
I didn't upscale because of the image source res
Works fine on my 3090 as well
oh thats pretty cool haha
very evil
i can fix her
lmao
So they have motion graphics in their dataset.
yes

beary nice

That one is sick
damn turned into arch linux
Star Trek title card, trending on Marvel
I'm calling Andrew Kramer (Video Copilot)

sketch lora done.
sketch, a drawing of a woman sitting on a rock, grand canyon in background

Hahah
this looks great!
joe, Is inpainting dependent on controlnet?




I really want to figure out how to use openclip models in comfy. it's quite possible it's easy and i'm just missing something
that is an amazing image!
thanks!

Do you have any good idea to reduce the blurry background in realistic image?
try putting bokeh in the negative?
Let me try
There are things you can do but it feels like it is built into the model tbh...
Probably some good finetunes will make it easier to get rid of
"infinite focus" might help
blur is there because some positive prompt word puts it there. things like "cinematic" or "4k" or "8k"

I think the problem is rhlf, diffusion models give discontinous backgrounds and so these rhlf models learn to just cheat and blur everything
yes i've been working on this very topic, one of the experts said that the bokeh thing is baked into a lot of terms, like 4k, cinematic, etc. so i started removing all that stuff and putting in the negatives bokeh, blurry, blur, shallow depth of field

I'll put things like "exhaustively detailed background"
so example surreal photo of selene vampire from underworld, highly detailed city, hair blowing, rainy, gothic style city, night, moonlight
"blurry background" in the negative with increased weight
Decent but you can tell the subject is still somewhat "seperate" from the background, like its greenscreened in or something
lol. but it might be worth making a dumb LoRA, that only retrains all the most commonly used bokeh words, and retrain them to no longer be blurry
sure its medication for the symptoms... but I can see that winning the civitai challenge 🤣

well this doesnt look very safe...



is it possible to use outpainting?

I'd imagine so
Looks like a real photo






I feel like I'm just getting my local install of SDXL to behave how I want but now I see all the videos in the thread and I feel so far behind




the sdxl i dont thinks all that good as its hipped up to be
Why not? You have to compare it with other base models, not finetuned models.
It's a base model
COmpare to base model 1.5 and then come back
i tried both
SDXL is amazing compared to 1.5 and should only get better with refines/training. Look at base 1.5 compared to the refines, it's garbage
The videos aren't an SDXL thing. People are putting their images into runway gen-2
My problem is getting it to turn out nightmares, which I don't think is most people's problem
Oh well that feels like cheating
sliders 👀

i rather have fun then messing with some thing thats very unpredictable
add a random prompt generator to the sdxl process and just click away
That's funny because that's the opposite of the problem I was running into which was that it was too predictable, it really didn't want to mix a cat with a spider. But here we are.

reminds me of what I did yesterday


Nice
you used ComfyUI_00139_.png?width=616&height=616 i thought for best results and more predictable is use 1024 x 1024
Huh? I'm using a modified Sytan's with a 1024x1024
yeah check the resolutons


anyone want a FREE good upscaler that can batch files of a lot of images at once, this is nice https://www.upscayl.org/

Upscayl
Free and Open Source AI Image Upscaler for Linux, MacOS and Windows
then why not add another refiner at the end to make everything crispier
it does the opposite
oh shit there's toggles now

https://github.com/comfyanonymous/ComfyUI/commit/730a5d170ffdfb30bd65dc4b765cc28501d85a5f
added sliders and toggles
fuck yeaahhh
sliders need more time in the oven IMO they just slide you can't double-click to edit
but toggles hell yea
Thanks for the heads up. I updated yesterday but it looks like I need to update again
None of the actual nodes use it yet
the node in my screenshot is one of my custom ones

ah, gotcha

no i mean, to make the image better, i tried adding the refiner, but the image was not anywhere close to the one generated in the 1st showcase, what might have gone wrong?

thats junk lol
generations only have knowledge of themselves so the node wouldn't be able to sleep after 500
you'd either sleep every gen or never
Real question is why is your CPU overheating
it maybe done but some one would need to write the code
does sdxl have a list of code commands
I've written custom nodes and afaik that's not possible without changes to comfy
out of curiosity did they ever reveal the bot's final settings?
did an horizontal flip and changed balance of black tones using photoshop, small interventions, the cool stuff came out of SDXL v1.0 as you see it
I think thats too NSFW
yeah, was gonna ask, sorry
its the middle of the night the mods are asleep
Looks artistic to me, but I guess it's up to the mods
Tasteful, but nsfw
report him!!!
ok, gonna delete it
Man some people would ban basically all greek art huh?
prompt for a merman and you're all good 😄
can he put spoiler on it, im not sure how to
I think it looks dope, I just wanted to warn cause I don't think the mods care about if its cool or not 😅
its a lamia, asturian mythology

lol save it , i will delete it
I was @ a family Italian restaurant yesterday with photos of naked people all over the walls lol. Surprised tasteful boobies aren't ok
Positive Prompt - Merman. Negative Prompt - Moobs!
moobs 😄
its merman german or mermaid?
mermaid but man
i herd sdxl does not like a lot of words specialty in the negative pompt
ig it'd be hard to police.
"yes that rennasaince painting is OK but no your asian woman with stuffed up milkies isn't I know she's wearing bottoms but you know what you're doing please stop"
i have a big encyclopedia of all the prompts ive used since stable diffusion began, and the prompt for that was one for Pixelzai
then used the 'analog foto' style
I like how some people write prompts as example I want a picture of a brown cat in a tree and someone will write I have a beautiful cat it has long hair and it runs through the woods and when it finds a tree I want to see that cat in the tree, then put high definition alter fine supersonic 8K, super charger render, and all they had to say i want to see a brown cat in a tree
In fairness sometimes writing a short story seems to work a little better. I think it's because of the repetition and because the new language model is better at understanding more natural language.
that worked well enough. Prompt was
I like how some people write prompts as example I want a picture of a brown cat in a tree and someone will write I have a beautiful cat it has long hair and it runs through the woods and when it finds a tree I want to see that cat in the tree, then put high definition alter fine supersonic 8K, super charger render, and all they had to say i want to see a brown cat in a tree

prompting is sometimes just latent space drilling. just going for it

Yep, just keep going until you strike oil

oh hey it's Lyla
For some reason it really likes an orange cat for that prompt.



out of focus on a lot of sdxl i seen so far
promp this > a maine coon cat in a tree
nah.
do you know what a maine coon cat looks like?
that's too short the attention will be mostly on empty tokens which will make the image worse
or something like that idk technical stuff

get your pitchforks! put some hay on em, AND PUT THEM ON FIRE 😄
burn him, burn him, burn him

see if he weighs as much as a duck
maine coon cat

do I use a gigantic scale, or just throw them into the water to skip to the end?
I got a mainecoon cat as well

got pointy ears yup


it never gets old XD
currently trying to find the command to install models in oobabooga ._.
not sure if they got rid of it, my old non working install has it
can't you do it in the ui?
doesn't it have a huggingface url place you can paste links?
thats what I am looking for
it used to be download_model.py
but its gone now
check the commit history see if it was replaced with something

found it
wow
not sure why they decided to change it from a bat you run to a .py thats hidden in the GUI scripts now
if it's in GUI scripts maybe you're supposed to launch it from the GUI...
the github says you have to run the script in CMD
It used to be a single click bat, not sure why they changed it
maybe it wasn't updated for the gui script
oh well, foun dit now
check the gui see if there's a model download somewhere
I'd say 70% chance there is now
Can't you just drop the models in the folder anyways? Or does the script do something else?
you can, but hugging face makes you download every file individually, not the whole folder structure lol
LLMs aren't usually just one fat safetensors
I usually just grab the files I want directly but you can do a git pull on hugging face right?
theres a model download in the model tab on the right side of the UI
not without git lfs
The box on the right that says enter hf repo name and then hit download
never used the oogabooga ui but I still believe every word that man just said because it's exactly what I wanted to hear

💀
I am blind ok
lmao
It's a little hard to see, especially if you are used to the old way lol
btw nice quick workflow @high skiff , interesting attempt at upscaling too

I think there is a waifu diffusion version already
Yeah but is it any good is the question
Came out way too fast to rely on that.
Thought something dropped real recently
No clue 
Try it
Prompting issue id say

Well when this shitty photo is their preview image
I can't expect anything from it

Did you try base SDXL? You don't need prompts for a lot of stuff
Im using base+refiner
I do lol

That is for sure
Just not the styles you would aim to have from the 1.5 stuff

Aight well SDXL is a bummer for now still then, got it

lmao
can you be any more melodramatic? lol

I believe in 'em
have you considered prompted better 
People post a ton of good stuff here and all you say is SDXL is a bummer 
I guess yall must have skill issues since I stole half the prompts here. 
is the stuff they post in the anime channel really anime? I don't remember anime being that detailed, the budget would be astronomical
^
Photorealistic and anime are very very hard to differ
I get what you mean tho
The photorealistic anime is very near photorealistic, but too artsy to be anime and too detailed, but yes, its still anime
steal SAI's official anime style prompt see how that works
Very nice is this with a lora or just base model?
Moreso it's like 3d anime as they would put it sometimes, depends
no, thats more manga style than anime
Just base+refiner, didnt try any loras yet
Your gens are awesome

{kind=link}
one thing SDXL can do way better than 1.5 right now is for sure realism haha
can't wait to see how great that gets with finetunes
Yeah
same for sure
It's 15/10 on realistic.
does anyone here have a workflow for using loras in comfy?
But the anime getting worked on from creators will be great once we hit 2 more weeks.
sytan's workflow works pretty well with loras, just disable the refiner
im tryna proper A/B compare sending different sizes to the clip encoders and I'm beginning to wonder if it even matters...

hi guys, does SDXL already support merging LORAs?
I'd say it depends on the loras.
Also with the inexperience of creators rn, heavily doubting it.
Cause most loras are fucking huge and 400mb+

i didnt get the best outputs with humans
And.. they're meant to be like 49-100
skill issue
it takes more prompting to get realistic humans
pics or it didnt happen

I only did the super wrinkly stuff so far

I've gotten some very noticeable differences, like a completely different race for a person with 2k and 4k clip width/height for otherwise the same settings. And square conditioning shape for portrait pics tend to get elongated results.
oh wait, that converter I used made him all crusty
I did 2x 16 batches and maybe like 3 of the images have any worthwhile changes
im actually leaning towards not setting the clip sizes higher
sketch, a drawing of a woman getting a coffee at starbucks


I have been messing with that as well, and have seen very little meaningful different
I don't know if the changes are worthwhile either. Just different sometimes.
achieved a 80% hitrate now 😄 41mb lora
only time I see a difference is when the size is lower than the output res
strength 1, because equilibrium
yea if you have a 1920x1080 latent you can sometimes actually get OK non-duped pictures by setting the clip sizes low
any recommended keywords
huge boobies
aur naur
i'm confused, are you guys using this "fix" ```
md5sum cf9d29192ef7433096a69fe5e32efba1 sd_xl_base_1.0.safetensors
md5sum 86b0f3400706c97ecb8efbed8146b373 sdXL_v10VAEFix.safetensors
md5sum c0df90f318abf30fcd2cd233ea638251 sd_xl_refiner_1.0.safetensors
md5sum 74d31c96097471d5d3bd93a915ad0b30 sdXL_v10RefinerVAEFix.safetensors```

I'm tempted
stuffed up milkies

you can get the models from the official Stability AI HF page:
https://huggingface.co/stabilityai
direct downloads of base + refiner with the 0.9 VAE baked in:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/resolve/main/sd_xl_base_1.0_0.9vae.safetensors
https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/resolve/main/sd_xl_refiner_1.0_0.9vae.safetensors
should I try?
what if get these

yes, tovarich

currently running a 13b model on 10 GB VRAM, with 11.6GB VRAM used, and still getting 3 tokens/s gen times
should I set the weight to 1?
there is like a 3-4 second pause before responses, but its fairly fast, I am impressed
Checking how good SDXL is at making tiling textures. Diffusers with a patched Conv2d module with padding_mode set to circular kinda works but I've noticed the seams are kinda noticeable. I went back and checked SD1.5 and the seams seem to be there as well so I think something happened with Diffusers and Torch 2.0 to not make it as reliable

yea llms are decent @ it. KoboldAI uses breakmodel to split betwene gpu/cpu and it still runs fine
yeah, wow, this model with pooled system RAM is not bad at all
whats the defualt weight of keyword in comfy?
If I ever make a tutorial on how to do clip training on sdxl, I swear to use this as the example LoRA
very clean look. the lines are really dynamic and have a great flow. I like that style. great work!
lol
I haven't gotten around to trying it but someone was saying Local Llama does the split pool thing better. Too much AI stuff going on to keep track of it all
why dont we release a boobie model?
Is this the version we're supposed to be using for example with the Sytan workflow. The one that is "baked in" here lol


holy shit