#✨|sdxl
1 messages · Page 57 of 1
for me sdxl is a tool in the toolkit and an amazing one at that. sure life could have froze at 1.5 and I would be fine but sdxl just makes things better quicker for me
its 10x slower tho
there is no loader for refiner in workflow
black cats = best cats

yes there is, it's an A1111 extension
does it take significantly longer to generate like switching between models?

PMSL
first_nsfw_for_sdxl_v1
"use it like usual, read prompts and add the words ... i cant write here"

use it like usual, read prompts and add the words ... i cant write here have fun ;) usual 32steps ok, better are up to 60 (be patient first try, bu...
with the supposed dreamshaperxl workflow i guess yeah
then it should be explicity mentioned 🙂

found a way to eliminate that issue by changing TOURCH arguments
usually you would feed latent into the refiner straight from base with noise leftover but dsXL seems to work different?
ah thats cios I renamed the title, WAS doesnt advertise what It does, its somehwere under Was Suite |Text IIRC

it's not writing it in the metadata, it's a very new extension that keeps the refiner in the CPU's RAM and switches the UNET with the refiner UNET for the last few steps(you choose how many steps)
ohh, nice
I could never get 1.4 or 1.5 to do this kind of frame, I'm really tempted to clean a bunch of them up and add it to my personal clipart library but to do that I'd have to make a to-do list and open GIMP instead of generating more stuff

this way, it doesn't effect performance, just takes ~3 seconds extra every gen
LOVE art nouveau decorations, hate the time it takes to draft this stuff by hand
I'm suprised by how well sdxl handles pixel art, that's progress for sure

yea, sdxl does create higher quality image
yeah, no noise with that extension whatsoever

got it

what I need to do to use Swarm to create alterations of the image?
I can't connect image from Load Image with KSampler
different nodes
anybody care to explain CLIPTextEncodeSDXL or paste a resource for some information


More than that. I used to try to make logos witha chess theme in 1.5 and gave up. Not only was it clueless on the idea, but its chess themes were just endless garbage. Not anymore
try putting base on lower steps
Doesn't even need lora's to work either, I used to strugle with that in 1.5
yes, it was one of the first things I tried, and I was quite amazed

Compare base model to base model. Compare SDXL to base 1.5 with no LoRA, no TI, no hypernet.
this was something like "innovative web design with creative use of gradients, screenshot of a website"

will take time for sdxl to take off, a lot of the popular 1.5 models are just mixes of the NAI leaked model and they don't have that for sdxl, very few people do actual finetunes, most just mix models
hi, i'm using Comfyui SDXL to test out a few different things. is the official offset LoRa suppose to change the image fairly dramatically from the none LoRa image? i'm using the same fixed seed for both lora and no lora. I'm including my test images + an image card to drag into ComfyUI to show my workflow.
edit: oops the first image is like this Base -> with lora -> refiner


BRUH I THINK IT WAS WILDCARD PROMPTS IN COMFY THAT WERE CAUSING THE SLOWDOWN!!!!
I'm back to 29 second generations 🥳
download1 = w/o refiner
download2 = with refiner
this is with more refiner steps

wildcard prompts such as {option1|option2} were apparently doubling to tripling my generation time in comfyui, I've been trying to figure out what the problem is for a whole day now
did I use the refiner correctly here? there is no significant difference- I used 17 refiner steps here
i set 10 max steps for refiner to do it's job
Refiner doesn't do a lot for that sort of image. It seems like its more for faces/eyes


sdxl might be onto a new better helicopter design 🤔





the first one looks really good
oof i accidentally replied to something, sorry
Damn I think it's on to something

Here is a gallery with more in that style: https://imgur.com/a/4P8FNpj

damn are those done in comfy or a1111?
https://www.youtube.com/watch?v=P-DCgzFbo_o found this channel, with a unique artstyle think a lora might be nice for this one ^^

The Ultimate Militairy Showdown! Watch as 10 Countries Unleash Their War Tactics.
Laugh Your Way through the Battlefields of UK, Germany, Russia, Vietnam, Switzerland, China, Somalia, Iraq, USA, and North Korea. Join the Hilarious Hype and Don't Forget to Subscribe for More Laughs!"
Visit our store for cool Mitsi merchandise:
http://www.mitsis...

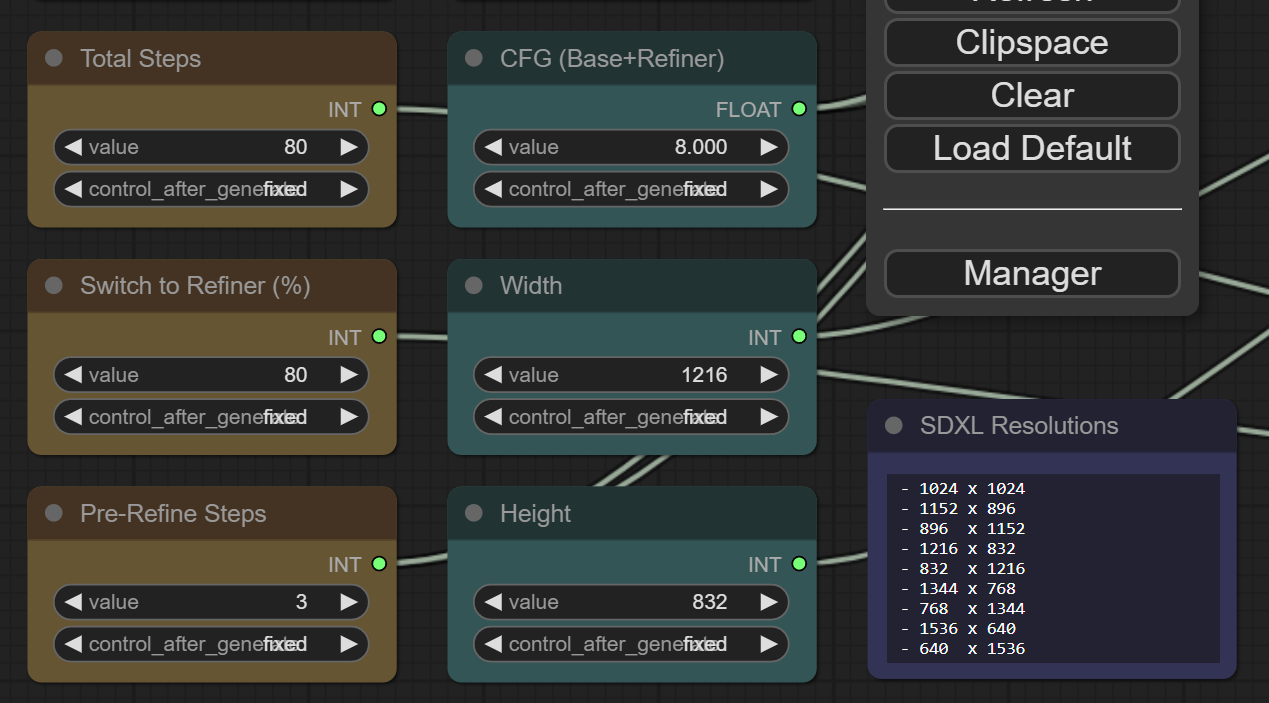
Comfy - all with DPM++2M or Euler a and 80-100 total steps (80% base + 20% refiner, a few with 3 extra refiner steps in front of the base)
"innovative web design, website about frogs, screenshot of a website"

Really cool, It might be because this is my favorite style but those are awesome
Definitely
It just changed one corner of the cube





art nouveau ornate web design

this combined with chatgpt would be great
I've been trying to generate CSS with chatgpt and it hasn't been great 😂
Tree textures and overall background vegetation textures are straight up bad. Anybody else?
Othervice getting damn pristine stuff out of that sdxl 1.0
🤔 post example?
But those textures make me grimace
Sec

Simple bs prompt, but still exemplary of the general phenomena Ive encountered



Make a primitive with required dimensions
can i make a primitive with height and width combinations and use those values for two different inputs (height + weight)?
I get similar texture problems with realistic fur, sometimes adding to the prompt can help
yes, but i need different values. i want to get a selection of the combinations in the blue box as dropdown or buttons or in some other way that allows me to pre-define multiple height/width combinations:
https://i.imgur.com/EURCa2C.png
well, +1 for negative prompts. This next image is all identical except negative prompts: "distorted, bad geometry"

Prompt was: flat company logo of chess and motherboard, electronics, elegant, gorgeous design, minimalist
not quite logo, but I had not expected such a radical change from those two negs
LOL, I love how the bottom right kind of stutters "MESS" while the other laptops say "CHESS"
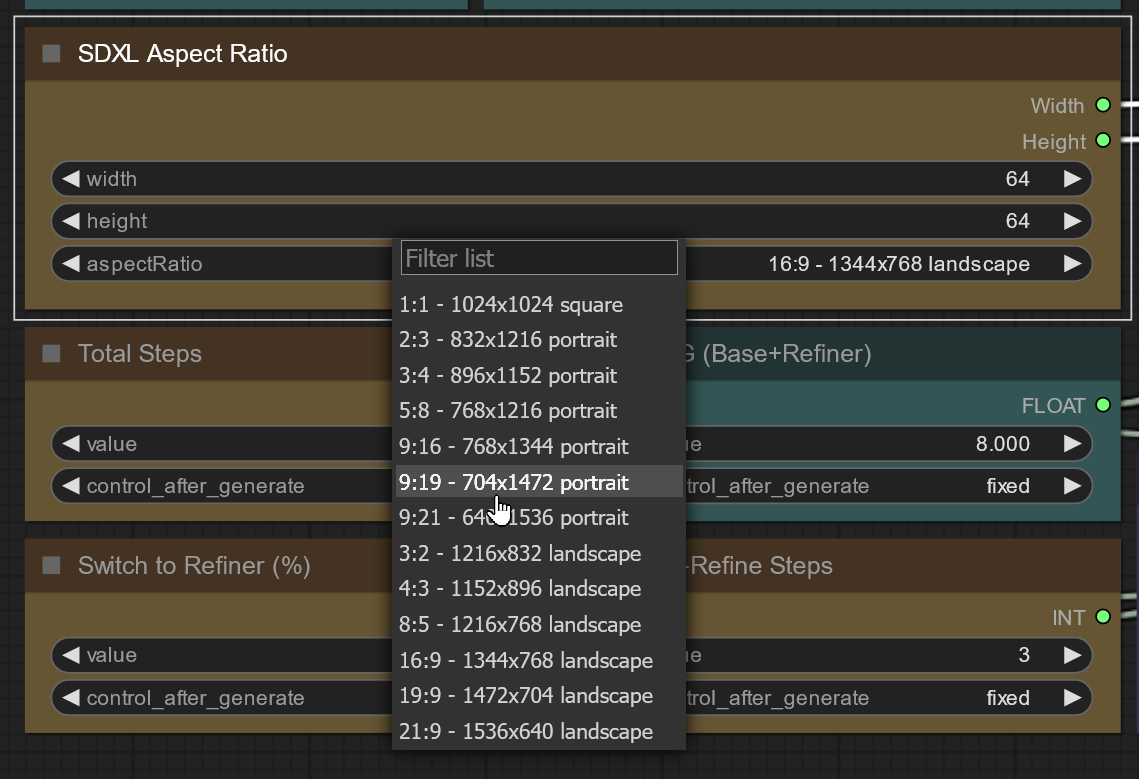
I have coded myself a custom EmptyLatent node with a buidin Ratio/Dimesion selector. Quite handy
Yes, I was caught offguard by its choice to add the words. Funny how the original tried to use 'motherboard' instead



new color modes for comfyUI:
plain, color by type, rainbow and positive/negative
Positive negative will color nodes depending on the title
via: https://github.com/failfa-st/failfast-comfyui-extensions


using serge cutom node 2.0 inpaint....after running it once, it doesn't run a second time. Seems the images have to be cleared from intermediate output, but how?
I have turned to saving it unrun, then reloading it to run a second time. It runs once, then runs very fast subsequent times - around .1 second - with no output
I take it back. Even if I save it before generating, if I reload the unrun saved workflow, it still runs in about ,1 with no output. I have to re-load the blank workflow...start from scratch
well someones making a statement XD
nothing to see here that was for somehwere else lol
Is this yours?
If so then a "Make selected nodes the same size" option would be nice please 🙂
besides, it was misspelled. It is written "Seeks"
Mister MeSeeks
The dynamic promtps built into ComfyUI is very barebones. A ComfyUI port of Auto1111's dynamic prompt extension was just released - https://github.com/adieyal/comfyui-dynamicprompts. It supports wildcards, combinatorial mode, I'm feeling lucky, magic prompt, jinja2 templates and the majority of the features available in Auto1111.

feel free to pen a feature request on GitHub.
I'm still trying to find out how to do things in a clean way. A lot of reverse engineering.
But I think it should be possible to add such a feature.
@soft zealot do you know anyone who trained an LLM before?
well its not an issue and I dont see a discussion page or a featre request page 🙂

ah ok use this
Name this

in GitHub, everything is an issue. I added a new type "feature request": https://github.com/failfa-st/failfast-comfyui-extensions/issues/new/choose
god dang it, after I added some
is you node available through comfy manager?
i found one for sdxl resolutions, but i don't know how it works, because it has some predefined resolutions, but still has seperate inputs for height and weight
Did you get an answer to this? i'm looking for the same thing. mostly as how the "ascore" works
dang it, started playing witht e COlour Options and now I cant get it back to COmfy Default
nope sadly not
@zealous horizon grrr mutter mutter
So not only does it do nothing when I slect "Default" even after deleting yuor folder & restarting I stil have a fruit cocktail on the screen

I've just done this. Those are Searge integer pair nodes. And just drag whichever width and height pair to those reroute pins.

how it started VS how it's going
september 2022 stable diffusion 1.4 vs SDXL 1.0 today


because the state has been saved in the nodes by Comfy. I'm still looking into supporting that. You can choose "plain" to get the default uncolored mode back
I've been trying to recreate some 1.4 prompts
Damnit.. how do i tell it to make a tiny shark to bite him in the finger lol

Ive reset everything manually for now and reinstalled your extension but Im not toouching the colours agian lol
what are some crazy things you made with dreamshaperXL?
this has to be changed to 1024,1024 for lora training right?

Thanks, nice idea. Maybe I've found a better solution:
https://i.imgur.com/d4rMHee.png
This is using a node I found in Comfy UI Manager - will have to test it - if it doesn't work I may use your solution.
Should be easy to add new resolutions to the code yourself, you want other / different values.
Ah yes, well that looks like a more production ready solution 😄
just don't know why it doesn't update width and height if you use the dropdown menu. but from a frist test it uses the values selected via dropdown.
@wise edge the name of the custom node is the same as shown in the picture - if you want to try it yourself
Thanks! I`ll be checking that out
You mean "realistic fur"? In my case would you suggest "realistic leaves" etc.?
Unfortunately not. At the moment it only lives on my PC

i've found something similar in the comfyui manager (see screenshot above). just has some useless width/height fields that don't get updated by the dropdown menu
anyone have a way to unload comfy, without close/reopen the whole app?
If someone is interested in this node: https://drive.google.com/file/d/1iKMydI_uKv1k2PDswH3EBFfGm9hrPvd4/view?usp=sharing
sometimes it's adding adjectives like "lush foliage", "majestic" to the entire prompt or adding interesting negative prompts
idk, you just have to experiment until you find what works
one time I added "itchy" to a negetive prompt and it helped something
thats a sampler issue
I have a pic for that. gimme moment
bit big, but it shows exactly what you have - and how to resolve it

either switch sampler, or go up in steps. both options work
oh yeah, I forgot my texture problems were way worse when not using euler
@visual glade
is there currently a supported way to unload the vram? my lora training pushes it just over edge T.T
if I could just unload the models, then I could leave it open while training
where do comfyUI's history is saved?
unload the vram from comfyui?
output folder - if you save images
and in the ui, if your instance is still open
the history isn't saved anywhere, it's in the software memory
but you can get the workflows by loading the images you generated
Check for updates. both features you requested are implemented.
basically set it back to the state before I generate the first image - when it uses up 0 vram
that should be the default right now
O_O
how much is it taking after a generation?
in comfyui you can open a new tab and drag that image in
a new browser tab
thanks,
recently reloading UI to test some stuff, so wanted to load previous queue query to compare with generation before reset/update
pre closing/after closing



oh that's the amount pytorch takes by default
it works right now apparently. but sometimes it occupies 7 gb vram for hours
but clearly not always
you're probably running with highvram and it's not unloading the unet to cpu after generation
try starting with --normalvram
RuntimeError: Sizes of tensors must match except in dimension 1. Expected size
56 but got size 55 for tensor number 1 in the list., Anyone know what this means?
Gracias
I see the Option and Ive selected it
And it works a treat 🙂
will try 👍
Dang. No options for samplers in the service I'm relying to
can you adjust steps? issue solves itself around 50~60 steps
also to add to this, if you have fewer than 8 (iirc) cpu threads it will try to move the text encoder to vram, no idea why it's the default
Can't dabble with steps either 😦 but good to know that this ACTUALLY is not an issue. Thanks!
Is there any way to get comfyUI to use more vram??? I have a 4090 and it seems to be pegged at under 8gb vram since the update.. Would allowing it to use more vram get it to have more its/s right now I get about 6.5 its/s
batch size to 3, should 95% utilize it
@visual glade Could the threads check here be lowered? I only have 6 but the text encoder still works much faster on cpu than moving it back and forth, I think 4 would be reasonable, or maybe it could just always stay on cpu with normalvram
https://github.com/comfyanonymous/ComfyUI/blob/master/comfy/model_management.py#L367
thanks
done
most of the time you can just use the same prompt in main and secondary, making them different only helps with fine tuning the image in the last iterations of improving it
I always start with using the same prompts there until I find a nice seed, then fine tune the prompts if needed while locking in the seed

is there a way to prevent nodes from changing size? especially primitive nodes always reduce their size if i save a workflow and reload it at a later time (pinning doesn't help for the size, only for the top left corner)
also SDXL has been amazig so far and SAI definitely was right that lower weights on keywords that affect styles can improve the results quite a bit
primitive nodes do currently not remember their size
I'd say it's up and down. Sometimes the reduced offset noise in 1.0 can wash out art if you don't cram the prompt full of tokens
@visual glade remember when you claimed you managed to convert SDXL into TensorRT? how did you convert the safetensors to ONNX, as far as I know- ONNX doesn't support SDXL's shapes?
why wouldn't it support it?
ONNX isn't supporting SDXL's shapes, they are different from SD1 and SD2
i think ur referring to the a1111 extension
that specific one doesnt support it
nor did it support 2.1's unless you did something iirc
yeah of course I didn't use any of the code from that extension
when they built the latest version of ONNX they specified what architectures it's intended to support, I am certain SDXL wasn't one of them. did you change ONNX's code?
I have no idea how would you do it otherwise.
I suggest you go read what onnx is and how it works
First finished version of my XL Animation workflow, would like to add reference_only and more controlnets as they roll out tho

yes, I did. the conversion scripts on the HF diffusers repo mentions that SDXL isn't supported. I have no idea what kind of black magic script did you use for that conversion. the ONNX->TRT onversion is the simple part. however, I have no idea how would you convert SDXL to ONNX.
Reference only is here - https://gist.github.com/comfyanonymous/343e5675f9a2c8281fde0c440df2e2c6
However, from what I've tried, it's usefulness is limited
Doesnt support img2img
by simply following the documentation
im more interested in how this is coming along tbh 😉
which one? NVIDIA's?
oh I started working on it, I'm trying to make the AIT and pytorch code the same
the documentation that explains how to convert a pytorch model to onnx
by the way, how's AIT performance wise in comparison to TRT?
Do TensorRT models just work with Comfy then? Or do you have to do special things.
no and I don't plan on supporting them because they are not useful since the weights can't be swapped out
What's the actual speed difference like. I never bothered trying them before, because you have to convert every model you want to use.
can AIT weights be swapped?
if there's an official trt engine file that gets released for SDXL I might make a custom node to load it though
TRT files are system specific
of course and in case there's issues it's open source so I can fix it myself
not really
nice! is it as fast as tensorrt?
ive seen reports of some crazy it/s's
as crazy as TensorRT? I managed to get it to ~35it/s on 512x512 with SD1.5 (I have a 4070ti)

oh jesus
i remember looking it up a while back, someone managed to get like 90+ it/s on their 4090 but i cant seem to find the thread in my history
oh shit, also, the conversion is straight from safetensors to AIT, trying this out now.
oh i take it back, i confused it with this from yesterday https://old.reddit.com/r/StableDiffusion/comments/15clbwi/boom_99_its_batchsize1_with_torchcompile_on_a_4090/
The documentation for that says it requires Triton and I believe that only works on linux
really? =[
Unless it's changed recently
The Kohya trainer can use Triton as well, but it won't install on Windows
I'm getting MVS errors when using AIT hahaha
They claim for that AIT it uses less memory as well
Finally gettig ComfyUI going locally. If I move it to another location do I need to update any absolute paths other than the ones in the venv scripts?
the venv itself can't be moved easily
when it's created all its references are absolute
Yeah if you move the venv it will break
Even if you try change the config, it still seems to break
OK. I'll re-create it in the new location then. I was hoping I just needed to update the references in the venv scripts.

I tried that using a sed regex replace and it still broke
so I just remade the venv
maybe there's a shady python script for it on git or pip somewhere
@marble dew @hard fractal i propose everytime you get a new question of a upcoming feature, you tease us with a Picture or a Vid 👀 of "SOON™"......using that feature, like controlnet 👀 👀
just just a lil tease
of
SOON™
What am I doing wrong? 😦

so whens videoLDM for sdxl coming out 👀 ?
ur picture isnt supposed to be white.. thats what wrong
have you checked the messages in the console?

And if you look in the outputs folder, is it actually saving a white image.
Yes, it is saving a white image.
i successfully managed to get my lora to do a reverse shot. albeit not consistantly but it did it

@visual glade are you on linux? AIT is spitting OS compatibility issues at me
tbh you might have cracked the code in producing perfect white pictures
can anyone do that with SDXL?
Do you get an image if you don't do the upscale step
ill try that
Also how the fuck do you get all your lines at right angles?
Ill find that for you
Enabling the TAESD preview for each sampler might help you narrow things down.
I'd like to remove my spaghetti mess
This here
if you use ur Lora trigger word at the start of the prompt, it will almost always be consistant
I did that and it gives straight lines
token placement in prompts is important... especially for loras
a lora at the mid or end of a prompt is utter trash
but if its at the start it works almost always depending on the weighting sometimes
i know. lol. the lora is for moviestills. it has many features imbeded to it. weighting them all correctly is the hard part.
@eternal fog https://github.com/failfa-st/failfast-comfyui-extensions is probably better as also allows you to do other things include set the line width to 1
GitHub
Extensions for ComfyUI. Contribute to failfa-st/failfast-comfyui-extensions development by creating an account on GitHub.
i found weighting the lora node.. to be a bit of you either get it right or its shit, weighting the trigger word and class is a bit more lenient
I got an image this time

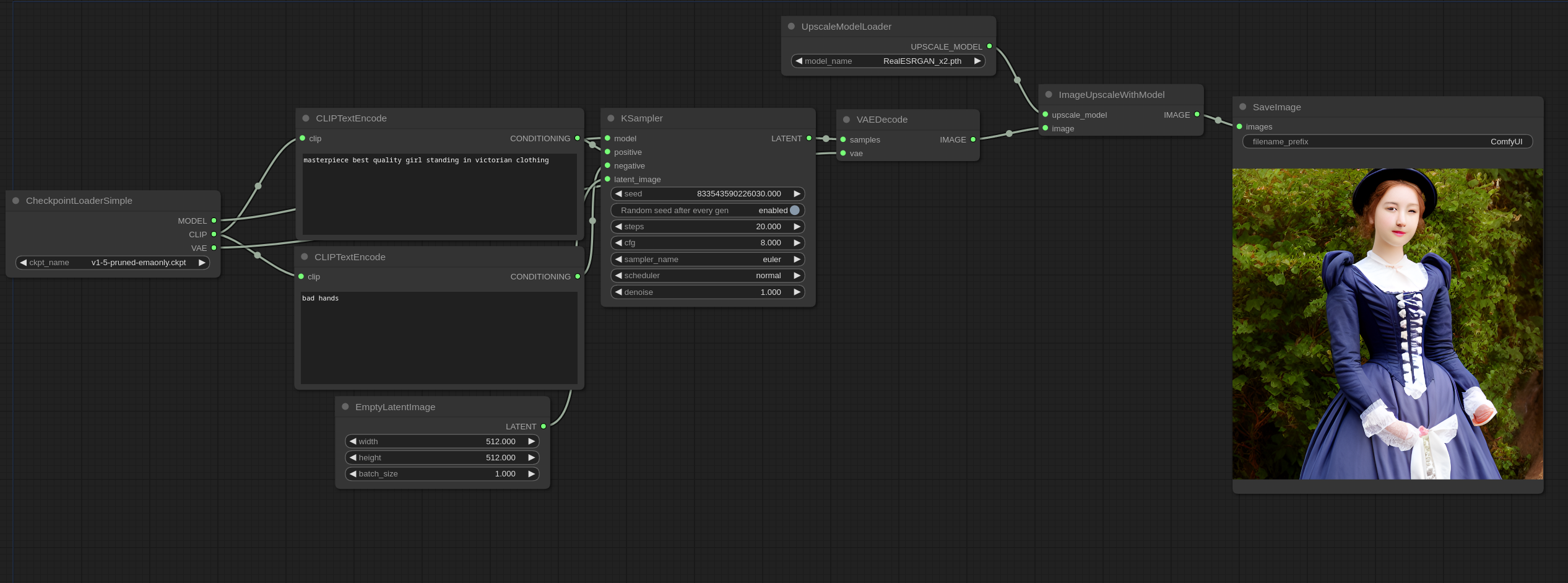
Is it because the upscale model file is not in safetensors format?
no it doiesnt need to be safetensors. non of mine are
I was kinda going based off of this here: https://comfyanonymous.github.io/ComfyUI_examples/upscale_models/esrgan_example.png
mam you need to turn around.. 😂

But kept the default SDXL 1.0 workflow and trying to add upscale to it
that is the correct way to implement the upscale nodes
yeah using this since yesterday. really nice QoL features
@visual glade does AIT only work on linux?
I can see the different VRAM memory management strategy between A1111 and Comfy just by watching the VRAM graph. I can see where it loads and unloads models in real time whereas A1111 without --medvram just shoves everything in there until it overflows.
@visual glade is it possible to use like --share on my pc to connect to my laptop? or is there another method or still not implemented?
@quartz sequoia excuse the bad face but turns out it is pretty consistant

Look Ma, No Spaghetti ;o)

I think you just type --listen 0.0.0.0 as part of your startup command
looks like a computer chip die haha
Lol
Even more so with straight lines at size 1

dope
i shall attempt thanks
won't that only be relevant to Linux users though?
Hmm I tried to install Roop with the ComfyUI package Manager and now ComfyUI will not launch, looks like it has broken the Python version
" RuntimeError: Failed to import transformers.models.clip.modeling_clip because of the following error (look up to see its traceback):
Descriptors cannot not be created directly.
Downgrade the protobuf package to 3.20.x or lower."
Anyone had this and know how to fix it, please?
did you install roop's dependencies?
there could be a shortcut to just hide the link cables. but this goes a bit against what a node interface is. I understand having a simple interface with a compact overview makes sense, but I think UI projects like comfybox or mentaldiffusion that put a simplified UI on top of it could be overall a better solution.
but there's no right or wrong. if it makes sense to someone, it makes sense ;).
hmm, I remember now, that I did try that the other night and it came up with a Windows file permission error.
There seemed to be 2 versions of Roop avalible so I just tried the 2nd one and that is when it broke ComfyUI.

hehehe this is getting me gitty with how well this is working

This is interesting. Now that I'm using Comfy I finally saw the VAE artifacts that I'd never seen before. Biggest difference is that I am using refiner in Comfy but not using refiner in A1111. I wonder if the VAE artifacts are mainly a refiner problem?
is it a lora or prompting? I tried over the shoulder shots, but have not yet figured out a good prompt structure
my lora!
nice! looks really good
of course AIT works on windows

it's spitting compatibility errors at me. am I supposed to use Docker?
no, you can try: https://github.com/FizzleDorf/AIT
GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT: This was orginally written by: https://github.com/hlky
Does anyone have a working XL 1.0 for control net workflow for comfy? If so can you send an image that uses it so that I can have the metadata attached to it?
has anyone released controlnet weights for XL?
if they did you can just use it like a regular controlnet
does this do the conversion? the errors I get are during the conversion process.
I don't have a comfy control net workflow though. That's why I also need the workflow.

https://huggingface.co/SargeZT/controlnet-sd-xl-1.0-depth-zeed/tree/main
haven't tested it yet, tho (too few vram for it)

The main Repo suggests updates need to be made for it to be able to do SDXL https://github.com/facebookincubator/AITemplate/issues/851

GitHub
Hello! It would be super cool to accelerate the stable diffusion xl models, as they are pretty slow because of the 1024x1024 res. I think it could work pretty easily, the only problem seems to be t...
Updates to the code in the example, so if you know how it works, then you can probably just update the conversion code.
@visual glade claimed to have done it on SDXL
Probably because he knows how it works and can code it himself.
yeah if you stick that .bin in the models/controlnet folder and use it like in my examples it should work
Is it my imagination or do the examples not match the depth input?
no they don't, so I'm not sure what that's actually doing
oh wow, I'm getting 33it/s with https://github.com/FizzleDorf/AIT
GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT: This was orginally written by: https://github.com/hlky
no SDXL support though
what was your speed without it?
anyone can give me an idea of what I should be getting with a 3090 and SDXL in comfy? I think I hit a weird bug, used to be 3it/s, now 3s/it 😦
~20
Should be more than that. Check console for any errors. Did you change anything?
nicenice
I got to ~40 with TensorRT though
Nothing in console, but I might reinstall comfy just to be sure
did you change any generation settings?
so it would be faster if the engine would be created on local machine, correct? @visual glade
Also watch Task Manager if on Windows to make sure it's using your GPU and that it's not using unexpected amounts of VRAM.
some samplers are slower than others and there might be some other generation settings that affect speed
probably but those AIT files might not be the most optimized
will the final version you're working on create the engine itself?
no, the engine will be compiled separately and shipped with the standalone
and the engine isn't model specific, correct?
so basically, everyone will get that insane boost
it is model specific but not checkpoint specific
that's amazing!
it didnt work
anyways to use my pc? and share the webui to run it on my laptop?
when controlnet for sdxl realsinf
on LAN use --listen, make sure it's unblocked in your firewall and access the LAN ip of that computer
oh my, wha tdid I miss?
is it secure?
as long as your LAN is secure
so no pass required?
ur webui isnt technically gradio
that makes sense
also i have no idea if my ur ui is updating for me
everytime i run the update / comfy manager update also
its always upto date
i never see it take in any pull requests when i start it up
when I first started using comfyui recently I thought the tutorials were super lame and uninformative not realizing I could load the pictures to get the workflow, lol
as I just (unluckily) found out, some prompts in sdxl are out of the box insane disproportionally weighted - so if you add those words to your lora training, they make essentially zero impact unless you equally disproportionally add them to your dataset 🥲
guess you just have to be jedi and know ahead of time
I need to figure out how to use the boolean commands to automate things. I haven't really seen much of that but I know there are lots of possibilities
how do i unblock it from my firewall? since --listen isnt working for me
'coffee shop' being one of them. trumps most other weights XD
that makes sense. that sucks. finding which keywords they are is probably pretty difficult
Idk what is going on with SDXL but I was making things like this.... the dark one with the golowing eyes, now they are coming out like this.... Can someone please help me???
.
.
Does the new SDXL 1.0 model need more steps to make good images?


poor comfy, probly has a million pings from various servers for tech support

using a lighter latent image to start?
he the realest mvp for actually responding tho
or whatever it's called
'view from behind' is one of them, and its one I often used for tagging - and also automated by vit-h. not sure what to do about that right now, as I have no good 'solution' for it
what are you trying to get and was is it giving you?
yeah i'm curious have been toying with the idea of trying to make some styled loras for sdxl and would love any time saving knowledge
did my proper captioning, and all views of rivet from behind, I tagged with 'view from behind'.
lora works great - but the moment I add 'view from behind' I just get photos of men from behind. as if my lora stopped existing. even if its the last prompt XD like wth

i see completely what you mean now
maybe try giving it a different keyword? lol like facing away or something?
right, like some community 'hard to train' phases would be killer
view from behind vs same prompt, without view from behind


a lombax!
right, like it almost got it, but then forgot about the subject
hmm. maybe you could word it differently? not sure how exactly
'back'
there are definitely ways to get around it - but 'view from behind' shouldn't be incredibly biased towards men, to the point of ignoring 90% of the remaining prompt
its a core sdxl problem T.T
yeah you could try "back towards viewer" "back facing", "turned around". and yes i agree its like all the ones from behind were trained on men and it kinda stuck with that
@boreal bough what program is that first screenshot from
could be solved with TE training - but once I add that in, I can forget about making a 'newbie friendly tutorial', cause this is getting complicated
hydrus network. hard to learn the first time, but scales well from small till 5k datasets for manual tagging
I claim innocence!

its for sfw tutorial XD
app lets you organize tags real well
lolol
can SDXL outpaint?
anyone know why I would get a "header too large" error when trying to use a safetensors vae? switched to ckpt and it worked fine
Sounds like it's not really a VAE file but maybe a full model or something else? Or else it's a corrupted download.
ahh. well it 's vae-ft-mse-840000-ema-pruned.safetensors. used the ckpt version and no problem.

Maybe try downloading it again in case it's corrupted.
yeah, that could very well be the case. I'll do that
thanks. sometimes these errors are kind of hard to figure out without doing some digging or having someone clue me in.
SDXL is not as the other AI kids, not long ago I did not like Euler and Euler A, but now SDXL can give okay but very random result. What have become your (any who read this) favorite sampler for SDXL?
what's wrong with euler A?
this is a cool question. my favorite was dpm++_2m_sde karras in 1.5 and now it seems to be a mix of euler and dpm++2m karras. sde seems to have kinda shit the bed lol
(base only)
but refiner doesn't change composition, so it makes for a good comparison
I haven't found the samplers to make that much of a difference. Maybe Euler is a little "softer" and some of the DPM are a bit more intricate detailed. But I could never guess what sampelr was used for an image.
I love sde in 1.5, but in SDXL Euler is friend
Eurler A was jumpy and changed result as fast as Sampling Steps was altered
That's because it's an ancestral sampler. It never converges.
is it possible to copy an entire group of nodes in comfyui?
I guess you can try a seperate LoRA for just behind and then merge them...
Yes, control drag to select multiple nodes in ComfyUI, I think.
Does sdxl require more steps for a good image? I used to use 0-13 base then 13-20 refiner then 10 upscaler steps. Has this methodology changed since 1.0 released?
I do the opposite, 13-20 base, 0-13 refiner
yep. I can definitely solve it - in multiple ways. But while writing a guide I'm doing my best to not turn it into an endless flowchart that takes multiple months of lora training to understand T.T
depends on the sampler, no?
There are cases where the Refiner is actually counterproductive
and if it's too complex, it ends in "too long; didn't read" when a youtube video (looks like it) gets them 80% of the way there in 15 minutes. Even if that's not true at all
does that... work?
Oh, maybe they mean "13 to 20 steps on the base and then 0 to 13 steps on the refiner". Not actual step numbers.
YEAH LOL
i thought you were talking about number of steps
somewhere my old high school teacher is taking a nap, woke up and screamed something about units, and fell back asleep confused
poor man had a revelation from an alternate universe self. tried to warn yall!
I downloaded this SEARGE custom node. Run the inpaind. Once it's run one time, it runs in about .1 seconds every other time, outputs nothing. I have to reload it - either blank or saved with what I want to do before running it.
Is there a way to get it to run more than once?
anyone here using comfyUI API? curious if anyone else experiences it freezing the PC after a couple dozen renders, after a bit the queue shows "Prompt Executed" but fails to render, then system locks up and have to hard reset

mine doesn't freeze, but as I explained above, it won't run inpaint more than once
every time I have issues like that it's because something isn't installed or updated
check mic is controlnet gtg yet mic check check 1 2
As far as face fixes go, what works best with SDXL? Photo real faces all look weird in the eyes with SEARGE SDXL workflow and another that I tried. I've tried using a facedetailer node setup that I recreated from a 1.5 workflow but the results weren't great because I have limited knowledge on which model to feed the DetailedDebug node now that there are two different models to consider. It'd be nice to pass the image through codeformer or GFPGAN within the node network.
yeah pretty clean fresh install

we've taken such a huge step back with sdxl...
only thing erroring is stage_model_clip, whatever that is
doesn't effect it via web ui
Sorry if this is a dumb question - are the settings for this discord's bot image generator(s) shown anywhere?
I finally downloaded the sdxl models for my local stablediffusion installation and the images it's generating are just really, really awful compared to what the bot is generating. I'm just using default settings from the automatic1111 web ui, and using exactly the same prompt as I am with the bot, and it's not even close (like child's drawing in mspaint vs a nice painting.
in the past, people had answers and fixes. Now...nada. Faces look weird, workflows won't run more than once if at all
In what sense? It seems a lot better than base 1.5 or base 2.1. But you can't compare it with finetuned models. Only base.
That's not a model issue. That's a UI issue.
codeformer still works
I don't even really know what you're asking? why inpaint only runs once? why things look weird?
SDNext and Auto 1111 not generating clear images....look like at best refiner isn't really applying. Comfy running something once then never again unless it's reloaded
prompting is a new vernacular to learn too
Clothing styles are lost...inconsistend or not there
"can't" is a bad attitude to approach these systems with
A1111 SDXL images are clear enough for me. Also ran many Comfy gens with no freezes.
I mean, maybe go back to what brings you joy and wait until people figure xl out?
Compare with base 1.5, not finetuned.
But yeah, if SDXL doesn't work for you, use a model that does.
base 1.5 if I prompted a certain clothing, it was somewhat consistent
inpaint ran more than once, images weren't blurry in A1111 and SDNext
SDXL has more training data, so if you say "pretty dress" it will have a lot more different dresses.

if I say shorts....it does long pants, baggy shorts, one leg long and one short, one leg missing of character,
lol, those shorts
When you try to make images of people playing tennis or basketball in the 70's, you need shorts
Use old model for waifus while learning new model. Problem solved.
not the baggy shorts they wear today
I dont do waffles\
I tried to make an image of a tennis player with standard, not baggy, shorts
SDXL is blowing my mind that I can have a whole cityscape + vast landscape with Maxfeild Parrish influences, and then add "and blue pineapple plants" and it doesn't tint random things blue or have a giant floating pineapple, it actually tries to incorperate pineapple. They aren't always blue, but sometimes they are, and it's amazing lol

out of the box with no loras or anything else sdxl can do a lot of things as well or better than most of the stuff I could do with 1.5. and I'm not bad with 1.5. I just think it's one of those things that takes time to get used to
I want to try to inpaint in Comfy,.,,but can only run inpaint one time...then it stops outputting anything
I think the SDXL base model is better but it will require time to learn how to use it and more time for people to finetune it.
Build your own workflow so you know it's built correctly.
instead of re-loading the flow?
I am not clear on how to build it for inpaint, so I am using searge
I think you need to use a load image node, then a VAE encode node.
just as with 1.,5 I wouldn't have known how to do it, so I used a1111 and sdnext
There's no SDXL inpainting model yet so I haven't really done much with SDXL inpaint.
Might also need a mask encode node. I can't remember.
but with sdxl, those give what look like unrefined images. Comfy has face issues...maybe there is a face fix somewhere for comfy
I think there is a face fix
The model is the model. Comfy and A1111 use the same model. It's just more complicated to use Codeformer in Comfy.
I like to have the freedom to make my own mistakes and mess everything up
right. I have started using comfy because a1111 and sdnext arent giving good results.. not sure if they're actually applying the refiner
bro, just use other people's workflows. and if they don't exist yet I guess just wait
A1111 is definitely not applying the refiner. Comfy and SD.Next are applying the refiner if and only if you configure them to do so.
I am
Which is why I asked if there's a way to make it run over and over again
\rather than just one time...then it has to be reloaded
I'm really trying to figure out some new things myself. lots of things that don't work, lol
but that's how I learn this kind of stuff
I add the imagte, the inpaint image, inpaint, run it...it outputs., Hit QUEUE again...it goes for .1 second, claims to be done...outputs nothing. Then I have to reload the workflow
if I'm using a 2.1 unclip model do the other models in the workflow need to be 2.1? I hope this isn't a dumb question
that's how you do it 😉
and you ask if it's already been done
might be a problem with the node?
Don't you have to generate an image before it can be refined?

happy accidents, and all that
Crazy that just 1 year ago someone would have probably paid money to buy that and hang it in a gallery.
they're my favorite
And someone would have spent many hours creating it.
searge has some kind of discord alternative link to live chat about his workflow...but that won't create an account, so I can't get into it
people still will, lol

For a little while longer until AI gen goes fully mainstream. Once it's as easy as Word or Excel no one will pay for anything other than highly specialized art.
another recent happy accident for me

Ah, if I change either the initial image or the image in the inpaint node, it runs again


I like when they sort of render in liminal latent space. on the precipice of different concepts
for me a bad generation used to be body horror where it looked like someone's face melted off and the subject of the portrait used to stare at you with dead blacked smeared eyes
This usually happened to me when my prompt was really complex in 1.4 and 1.5 and I wasn't using a LORA or anything for correction
In SDXL my bad generations are usually just too generic and rarely there's some floating object or something. Sometimes things are just "too perfect". It's hard to prompt back in that vintage look and the quirks that come with it.
These images look like the subject of my 1.4 and 1.5 prompts died of tuberculosis and are now in heaven


Got themselves a case of the vapours
I thought we were talking about number of steps LOL
my bad renders are basic and dont pop. not sure how to describe it
show one
ya but if you use the refiner at steps 0-13 wouldn't that mean you are starting the refiner before there is an image? then if you use the base at steps 13-20 thats when it starts to create the image itself? Maybe I don't get how this works.
a bad one?
yes
nah I was confused and thought we were talking about how many steps we were using, not which order
getting closer to a good workflow after adding the offset lora - using -0.08 for offset lora works great for that style of pictures:
https://i.imgur.com/CMatwx7.jpg
anyone have a good workflow for inpaint?

like to fix handy pandies?
looks like no vae applied
well it was more than that
I moved a bunch of nodes when zoomed out
not realizing I was still changing parameters
yes, but it's washed out
Some VAE had to be applied. That's the only way to get a human-readable image out of the latent space.
so that took a while to undo
we=ll...then the wrong vae
in sdnext, I was getting washed out images until I changed to default VAE none
but didn't realize because never meant to set it
I ask the same thing
how do you get straigh lines in the workflow instead curves lines, thanks !
VAE "none" means to use the VAE built in to the model. A VAE is always used.
right. well,. it's odd
when I used the sdxl vae in sdnext, everything was washed out
when I did none to use the baked in, it was fine
if you drag a node and let go in empty space there will be a "reroute" option
on comfy, I used the sdxl vae....looks fine
or rather, from the input or output
SDNext generations look blocky, unfinished. Comfy looks better, but issues in the eyes
SDXL inpainting model wen? 😎
cutting an unclip model's output off a few steps early produces some strange results
I have a workflow for inpaint, but it only works once
meant to put the cutoff on the sdxl base model, not the unclip, but either way
So what's the skinny on refiner prompt versus base prompt? I usually keep it the same

I have two prompts, one is for refiner, both go to the original image too
how do you structure them?
I haven't figured out what my approach will be. still experimenting

I've decided most of the online advice is pretty much. people saying all sorts of conflicting things
*pretty much nonsense
Any of yall played around much with SDXL on the StableStudio tauri build?
I don't know what that is, but I wouldn't mind knowing
One person says it and 1000 copycats repeat it as gospel without understanding.
I'll take note of what people say, but I don't just believe it. and a lot of it is subjective, so there really isn't a right or wrong way per se
Are you talking about SDXL, Social Media, or what?
The best is if you learn enough about how it works so you understand it. And not just doing "magic spells" and incantations.
yes
however, many things will start off as magic spells and incantations. we must put in the effort to demystify them
Following tutorials without understanding counts as incantations.
Understanding at least on some basic and honest level what the steps are doing.
Some basic understanding of all those. Just the basics.
well you have to be bad at something before being good at it. we were all born knowing basically nothing
thats completely missing the point here
what is the point?
Yes, but the information is out there to learn by researching. Not to say anyone knows it all. I don't. But some learning is needed for any new technology.
that people shouldn't follow totorials if they don't have a deeper understanding of how it works?
Learn by doing will often result in wrong learning.
This, you're not going to learn anything by not knowing how it actually works
well okay
but how do you learn if you don't get experience in it?
should a person just read about it for a fdw months before looking at tutorilals?
I disagree. I have no clue what each sampler does, and yet have experimented to geta feel for them and choose three that I rotate
No, but maybe a few hours.
I know how things work because I used them when I didn't
because you can learn 'cfg should be 4-6[or insert whatever]' and 'learn' that... but you're not learning anything by following a guide that doesn't explain why that is 4-6 vs, 8-10. for example
and figured it out
I don't agree at all, but okay
this just seems like some strange quasi-gatekeeping to me. I don't care what someone else wants to understand, lol. it's their choice. doesn't impact me

I like to learn everything I can about whatever I'm doing. but I realize not everyone has that want. and I don't see any reason to really be concerned with that
https://civitai.com/models/119038/sdxl-controlnetinpaint-workflow check this out. currently working on V2.0

It's a WIP so it's still a mess, but feel free to play around with it. Basically, load your image and then take it into the mask editor and create ...







extremely long frankensteined prompt
sometimes I'll just put two completely different prompts together to see what happens
or 3

ooh. made that on dreamstudio. mess with that sometimes on my phone when I'm out doing things
ah, that's why i couldn't import anything lol
yeah, I noticed that. kind of annoying. you'd think the people that make the model would be all about having the prompts in the metadata

man, this unclip workflow is stuck in some weird nether region, but kind of making cool things

Not necessarily, not like they intend most of them to be made on that, and with the pace of development it adds extra layers and more work


haha nice
some of my first ones for the prompt, and not too upset by that


all searge's workflows are the same...they run once, then won't run a second time unless I remove the feeder image and add a new one, even the same one

does any seeds change or is it laid out to generate the same result each time? because comfyUI will skip redoing stuff
true
personally haven't used it but sounds like that's the issue if other people are fine
No idea. it';s the searge inpaint and searge img2img
so are you changing things int he flow before trying it again?
no, when I inpaint, it has to generate lots of images to get one that's good generally
the first one isn't always fixed...in fact, almost never
well what he's saying is if the inputs or whatever are identical it won't rerun them

so it doesn't change it each time like a111 or sdnext
So it's one chance to inpaint...that's it
Only if you set the seed to fixed or such
seed number?
I have seed set, and then random variance
random variance?
feel free to post the workflow, could solve a lot
it is the searge inpaint and img2img workflow
yeah, haven't used that one myself
I dont know how to post it. An image is unseeable...the workflow is huge
I understand that, but it very well could be a connection being wrong
post the image
it contains the workflow
To get the image in one screen, the names disappear
erm... post the generated image

tilt shift?
I have to load the json - the workflow doesn't always load from the image
That's for img2iimg...note there's nowhere to load the initial image
so I have to use the json
Here's one I made with it.

I don't think mine willload it because it's rendering something. wanted to check it out. not sure I can help though. but curious
you can, just gotta go into your history after or queue and select load from that and it'll be back
that's fine. it'll just be a few seconds. are you trying to make peaky blinders there?
The seed is set to random, but it doesn't generate a second time. If I change anything, then it will generate again

just change it manually then
also, that seed is set. It doesnt change with the uploaded image
So I cant generate the same image over and over to try to get good hands, for example
doesn't it say "fixed" right in that screenshot?
yes, but I mean when I set that to random
well...now its working...generating over and over whether it's fixed or randomized
Ah., no
no idea, a lot didn't load for me because i don't have those plugins/extensions but glad its worki--
bruh
it generated 3x, then wouldn't generate again
what are folks using for easy training right now?
in sdnext, sometimed generate over and over until it gives one with good hands...each generation is slightly different\
in comfy, cant do it
,,,,sometimes
Just did it again...it generated twice in a row, then wouldn't generate again
no idea why the image won't load for me, but it's not
I'm using Kohya-ss gui for training, it works and I'm too lazt to look for something else.
anyone try onetrainer?
heard of this, cmdline or .. nvm you answered. ill check it out again. it's been months since i looked at that.
i am here
wot did i miss '
this is a shitty sdxl gen. we have really leveled up

that would be a good idea
no one knows. I'm just over even trying to figure it out, lol
I've read completely opposite things about it both being stated as valid
surely refiner is anything not forcing a change, anything positive..
so like "detailed" doesnt have a shape and wont affect a space
read it's not needed. read it's vital. read it can be the same as base prompt, then not. then that it should just include base prompt and a few words for fine tuning, etc
I got mask upscale working now.

that is a clusterific mess, lol
Eventually someone will really understand how it works, and then they can explain why it is or is not needed with evidence to back up their claims.
Yup. Trying to keep it tidy but i need to get rid of wires and find out how to name parameters
Right now you just have people randomly spouting things without understanding.
believe me, I understand. I like to do lots of image modifications between renders and it can get twisted very quickly
If anyone wants to play with it. Nested Nodes, Masquerade Nodes, and WAS Suite is required.
I think I have all those. thanks. I'll take a look
for controlnet and SDXL?
No controlnet or inpainting model required. It has edge detection and a negative blend in the inpainting mask to help keep features
sweet. I'll load it in a fw minutes when this thing is done
well done, nice
trying to figure out the unclip models. or at least sort of grasp them
https://www.youtube.com/watch?v=lVSNJYfvO9o&t=2s Anyone know this channel? Comfy workflows and custom nodes

The functionality of the detailer wildcard has been improved.
Previously, you had to use the [a|b|c] syntax for dynamic prompts, but now you can use the {a|b|c} syntax.

I'm apparently one of the few people on the internet that does not really like watching tutorial videos
looks slightly better with straight lines

lol
dont 😂
you don't
To blur a mask, use radius

how do you get the straight lines?
it dont
like, not saying they're the most mind blowing thing ever
but very interesting
I think I'm zeroing in on a sweet spot of some kind.
cant remember 😂
tryna find it
hey anyone have good settings for lora training?


not really there yet, whereever there is
ooh, last image of that round got borked,lol. stupid edge filter
I erally like how it just runs what's needed, so when it's something at the end it's super quick
control mask contrast with black_level and white_level

alright, I need to check this out
Working on mask by prompt, but it's getting late
@vast galleon think it was this one
https://github.com/pythongosssss/ComfyUI-Custom-Scripts
lol
When loading the graph, the following node types were not found:
Model_Inputs
Text_Encoders
VAE_Inpaint_Encoder
Inpainting
Edge_Detection
Blend_Node
Samplers
Mask_Upscale
Nodes that have failed to load will show as red on the graph.
I thought I had most of the nodes, but missed those I guess
Is there a way to know if a model knows a specific term?
same same
looks greatt. im gonna pick it up
You will need masquerade nodes, nested nodes, and WAS suite
I don't think so unless you have access to the original training data. By the nature of the model, it "knows" all words. The words will have some impact on the generation even if they are nonsense.
hmm. got another error. I'm sure it's resolvable
Loading aborted due to error reloading workflow data
TypeError: Cannot read properties of null (reading 'type')
TypeError: Cannot read properties of null (reading 'type')
at ComfyNode.inheritPrimitiveWidgets (http://127.0.0.1:8188/extensions/ComfyUI_NestedNodeBuilder/nestedNode.js:186:26)
at ComfyNode.nestedNodeSetup (http://127.0.0.1:8188/extensions/ComfyUI_NestedNodeBuilder/nestedNode.js:84:14)
at ComfyNode.onAdded (http://127.0.0.1:8188/extensions/ComfyUI_NestedNodeBuilder/nestedNode.js:124:18)
at nodeType.onAdded (http://127.0.0.1:8188/extensions/tinyterraNodes/ttNwidgets.js:392:49)
at LGraph.add (http://127.0.0.1:8188/lib/litegraph.core.js:1453:18)
at LGraph.configure (http://127.0.0.1:8188/lib/litegraph.core.js:2232:22)
at ComfyApp.loadGraphData (http://127.0.0.1:8188/scripts/app.js:1199:15)
at http://127.0.0.1:8188/extensions/ComfyUI_NestedNodeBuilder/nodeMenu.js:193:17
This may be due to the following script:
/extensions/ComfyUI_NestedNodeBuilder/nestedNode.js
trying to think if there are any requirements I might have forgotten
well I have nested nodes and thought I had all that node packages
a short story 😂



I'll figure it out and let you know
maybe some of them have been updated?
Check out #✨|sdxl message
install missing custom nodes
I'll look when this thing finishes
I just odn't even know what to think of these results, lol


it takes some finangling
Boolean will invert the mask. But I just realized blur won't work if the mask is inverted, so I will have to fix that.

and now this guy? what?

did this but there were no options to install, got all the ones you mentoned, WAS etc
bare with me. gonna un-nest and try to see what's missing. everything is working for me
I have all those node packages though, I use a lot of them
I'll just restart. that usually helps
well restart the comfy
done that already
once these apparent updates finish I'll restart
also not the 1st time, might be a comfy thing
these are the only extensions I have

I wish it said which node the error was coming from

Oh, ok. those are all of the nested nodes I built. how do I make them available?

put these into \ComfyUI\custom_nodes\ComfyUI_NestedNodeBuilder\nested_nodes
oh yeah! that does make sense
I have mixed feelings about nested nodes, or maybe i'm not using them right. sometimes they're great, but other times they'll do things like swallow a parameter adjustment or output display or something
I am not fond of them either. I plan on going through and trying to build my own custom ones, but I'm trying to build it first
yeah, how do you go about starting that process? I'm curious. I have some ideas floating around in my head, but pretty new to this particular interface so not really planning on diving in immediately
youtube tutorials lol. also I have experience with blender and houdini so I'm learning quickly
only started learning about python because of stable diffusion, lol. but I'd taken a few random programming classes in the past so the logic is still in my head
and nodes satisfy my weird brain. and allow me to quantify some of the strange things I'll do with photoshop
not so much any particular single thing, but I've done so much as far as layers and filtering. but these nodes get out of hand quickly
Thanks, is anyone else getting a weird primitive box underneath the "Image Source". It's already has a list of files that were in the JSON but not files i have
so it won't run because the "file doesn't exist" type thing
* LoadImage 131:
- Custom validation failed for node: image - Invalid image file: NINTCHDBPICT000270813068 (1).jpg
maybe modify the json?
🤷♂️ just seems unintended, you upload a picture
File "<frozen importlib._bootstrap_external>", line 1073, in get_data
FileNotFoundError: [Errno 2] No such file or directory: 'C:\Users\34\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI_NestedNodeBuilder\init.py'
Cannot import C:\Users\34\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI_NestedNodeBuilder module for custom nodes: [Errno 2] No such file or directory: 'C:\Users\34\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI_NestedNodeBuilder\init.py'
alright. I'm going to restart browser as well
That's a test image. You can load an image through the load image node in the inpainting group and then select the image with the primitive under image source so you have a view of the source image after the mask is painted on the one in the inpainting group
it loaded fine but got some errors. scanning them to see what they are
Trained my first lora on one of my dogs today! Pretty solid results, but two "issues". My lora is 1.7GB and the execution time jumps from about 20s to anywhere from 300-500s
try that one, maybe it changes when you make a nested node?
ooh, zinger ModuleNotFoundError: No module named 'global_table'
You upload a picture to the 2nd node and it should show up in the 1st node primitive?
It works, but I was expecting a smaller file size from a lora, and not sure what common causes might lead to extremely long load times
I wonder if there are any others
yah i just made one too, HUGE! Wonder how the citivai ones are much smaller
high five!
(i saved it after adding the mask)
it should, but I don't know how without using the image primitive underneath
that makes sense
ModuleNotFoundError: No module named 'comfy.ldm.models.diffusion.ddpm' tbh not exactly sure how to resolve that one
use network rank 8. the network being high will make huge file sizes
Ah, I went with 256 same as the tutorial I think lol
What's the rank tradeoff again?
the tutorials are wayy wrong. lol. network 8 and alpha 1.
Thanks bud. Yeah, I made some personal tweaks along the way as well.
But only when I was confident it wouldn't hurt
sdxl is very good with loras just dont go much heigher than network rank 8. cuz itll make huge files that you dont need. mess with learning rate and unet learn. i went from 0.0001 to 0.0004 on both learning rate and unet learn rate it made differences but not like a complete burn so try as you wish.
I might be able to mitigate the lower rank training tradeoff if I increase the subject sample image data set size. I want more variation in blankets and background for him organically anyway.
LoRA is low-rank adaptation. Apparently 256 isn't low enough. 😆
I converted image back to widget for the first one? seems to be working now. without that primitive. i'm not super familiar with all this yet
I took the primitive out. I like your method better
I also normalized each of the learning rates to 0.0004
whats the difference between a checkpoint and a Lora?
i mean for a first generation with adjusting nothing 😀

A checkpoint is a whole model that can generate images by itself. A LoRA is extra data that changes the images a model generates.
loras tend to be smaller, and can be used in tandem with any checkpoint
dope
Lol face of hulk hogan
i just threw a random image i saw on here in there lol

that's funny that it brought some of my test images into it
yeah it must save the history for some nodes
offset lora is helpful to hide problems with faces and hands:
https://i.imgur.com/Z3y448w.jpg
https://i.imgur.com/cFKHaLe.jpg



that red sash thing looks great
more red sash:
https://i.imgur.com/nqR5rXv.jpg

it would look even better with less offset, but you can see the broken faces without the heavy contrast.
i have seen the offset lora in ComfyUI but with the weight set to 0, is that correct? not sure how to use it right
lol RuntimeError: Added route will never be executed, method HEAD is already registered
ugh
@urban breach to get the dark sillouette you have to use negative values.
the 3 images use -0.8 to -1.5
is that for the model or clip strength or both?
i've made a simple workflow that changes both values at the same time - so both for those pictures.
maybe you can get better results if you try to change them separately.
very small negative values help in a lot of cases. even -0.05 can make a difference, if you just want a higher contrast in regular pictures.
and if you set it to 0 the lora isn't used. so you can keep it in the workflow all the time.
cool where do you put that in the workflow, right after checkpoint?
yes and only for the base model at the moment. haven't tried refiner because people said lora doesn't work well with refiner.
ah interesting
i still use refiner for the last 20%, but without a lora node.
with small negative values you get "glowing" effects like that:
https://i.imgur.com/JFzpTKG.jpg

at last a good way to hide the 6 fingers on my snowy vampire girl 😂

actually it looks more like an assortment of random fingers under the gloves now lol
in 22 minutes we will see if my lora training of UnBlurTool will work! time to squash the pesky blur everyone has been annoyed with
any good solid updates from @nimble heart or @high skiff with their node examples?
Submitting 1.0 workflow to Comfy soon for approval for the wiki
have some full quality image examples of what my new upscale workflow can do
These are all 2048x res






This one is 4096x

@high skiff do you use "target width" and "target height" for your upscaler?
I do, but not in any particular way
can't wait to test drive it!

Tried making a ultrawide image.. well, made a meme instead lol




@high skiff I really hope you drop that sooon... I am pretty much not using SDXL until I can work with a better workflow.
Here, have the workflow lol.

Goal is for later today, early tomorrow
Don't mind the 80MB size, it's just native 1440p upscaled 4x lol
squiiiiiiiiiiish
You are awesome... thank you
here is some information about correct values for target height/width: https://arxiv.org/pdf/2307.01952.pdf - just using 4096x4096 works but it should be better to use values caclulated by that information
most high res cursed image ive seen. i love it
Got a better squish for ya

oh god why XD
failed diffusions needs to be more active lmao

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
I and many people have messed with it, it doesn't make much of a reliable difference across different prompts and stuff
when you forget to tell your lora that you're describing a game character - and sdxl decides that it's a cat/labrador mix XD

#notEvenMad

that is too cute haha
Now to find the right CFG to not have face slaps all over lol


Oooh I wonder if that's why it spits out so many errors but still produces something
Is there a benefit to have leftover noise with comfy? 
Did that with the base sdxl offset lora and my new one
I'm still getting good results, but if it speeds things up that'd be great
Granted, mine's a character lora not an offset lora
I just add lora for both base and refiner, somewhat works with sub SDXL loras 
for style/offset it shouldn't matter too much if you don't use lora for refiner. for faces/celebs it's more problematic, because the refiner without lora will remove some of that information.
When i attempted zaraki kenpachi, a 1.5 lora with SDXL. Didn't get it quite right at all, but close enough lol

didn't realize you could use 1.5 lora's with it, i gotta try that
I just throw around different loras and see what sticks
Ariel for instance


How did you get this. I am right now trying to get characters facing away from the viewer. Can't get it to happen.
I've tried walking away, walking away from camera, walking away from viewer, pitching to a batter, serving to an oppoent in the distance, - always facing the camera/viewer
that one was just random. Drop it into comfyUI and you can see it's workload and prompts. But generally just
Positive: "facing away", back towards camera
Negative: Looking at ccamera, facing camera, eye contact
And such
When I put facing away, it usually works but they don't look back
I'll try the negatives
i use "rear view" and "rear side view"
"view from behind" <- but biased towards men.
or "back view"
This is gonna take forever  ultrawide native res with 80 steps
ultrawide native res with 80 steps

This is incredible.
One last attempt, then bedtime at this damned 6am's..

I like making cursed images
tried all of those...still facing the camera
"back turned" but it can impart thematic coldness to some prompts
a weird hack can be adding prompts that focus on "hairstyle", especially for women characters
I have (rear view:1.4) in positive, forward view in negative along with facing the camera, eyes to camera, looking at camera
I accidentally found out (at least in 1.5) that trying to specify hairstyles ended up with a character with their back completely turned some of the time
Oh me too! Have a toothless kitten i tried to give shark teeth, well, chimera happen

Have a kid eating beans with his soul leaving his body

Have a cricket i made earlier today that i gave a hat, but also half turned into a slight cat lol

tried each one and then all in the same prompt...still facing the camera
it's not ultra ultra wide until it's 512x2048 XD
goold old 1:4
Rookie numbers

3440x1440 x4
Well I'll be damned
of course when I make a simple prompt "man with back to camera" that works
offset lora?
I'll be honest, it was less painful having a broken neck than trying to get this walking away from camera
dont forget that many prompts are biased towards front facing, so trying to overthrow front facing, by using more backfacing words usually just leads to worse quality. better try trimming, or rewording the original prompt
I put "faciong away from camera" in the front of the prompt. It made the torse facing away, but the legs facing to the side
wait a minute XD

Finally. 1440p divided by 2, then upscale by 4x

maybe when there's something like controlnet for sdxl 1 it will have the ability to rotate something - we'll all be pleasantly surprised
So what do people think about 1.0 refiner?
True...I see the quality is down when it has the torso facing away
Is it bad to not do any upscaling? Biggest I make is 1920x1080
here we go. Wallpaper worthy

if you go the way of loras, then you're stuck with base only.
Ideally I wish I we could use refiner for everything, as it definitely is worth it when used right
Hi guys having some trouble. Whenever i go less than 0.4 de-noise on high res fix i always get a weird result with the picture quality? Meanwhile others using it just fine. What am i doing wrong?

you cant use refiner with lora?
I guess you can, but the LoRA would apply to base only
custom models like dreamshaper dont need refiner
high res fix is great if it works
does bascially the same job
ive seen best results with Base: 20 Steps, CFG 7, DPM++ 2s a
Refiner: 15 steps, CFG 8, DPM++ 2M,
I'm using dpmpp 2m karras for base
issue is low denoise fucks the image quality for me for some reason
But I've heard dpm is not good if you use <15 steps, apparently it can fuck it up with few steps
try DPM++ 2s a most use it results are the best imho its euler a for sdxl
both ancestrals converge pretty fast, between 35~50 steps.
as for the steps before, their difference is genuinely minor (base only experience, where I generated enough comparison grids)
refiner may be a different experience
Yeah was rather meaning euler a was the popular rockstar of SD 1.5 now i feel its DPMPP 2s ancestral
ok
I've ended up with DPM++ 2M for both base & refiner
With lower_order_final=True
ii use whatever and it's always coming out good. hard to determine whats best. even old ddim is fast and great
50 steps base, 15 steps refiner
Alrighty, time for a break for tonight. Gonna go wilder tomorrow lol

without lower_order_final, 15 steps fails with DPM++ 2M on refiner
orly?
if you ever have to go base only, then use this though
(steps 25 or 50, depending if the extra bit of quality is worth the double time for you)

If only this page was finished https://blenderneko.github.io/ComfyUI-docs/Core Nodes/Sampling/samplers/
is that so?
you can use the infinity grid from mcmonkey to make your own comparisons
or use this for reference
#✨|sdxl message
There is a lot of information here: https://stable-diffusion-art.com/samplers/ although not for sdxl.
Yeah saw that but doesnt have dpmpp_sde_gpu, which Im curious about
oh yeah that ones new XD wasn't there when I generated the graph
Do we have something like xyz grid in comfyui?
StableSwarmUI - then give that the port of your comfyui. then you can gen all graphs
https://discord.com/channels/1002292111942635562/1134546054872842290
Has its own channel as well, if you get stuck on how to use it
pretty simple though
Does anyone know how to get ComfyUI to save images to a folder outside of the comfy folder? I would like to save my images to a folder on a server I have and it is not in the Comfy folder to say the least... Is that something that can be changed in the python file "folder_paths.py"?
lora I trained on one of my dogs
edit the bat file and add something like this at the end of the first line
--output-directory D:\SD_Output
Awesome, that's easy enough to do... Thank you.
just checked code. it calls for the output path variable... so it should be configurable somewhere
That worked perfectly... Thank you
The new Marvel series, "Electric Dog". Coming to a streaming service near you!
how much gpu mem is needed for sdxl base 1.0?
Anyone have a pun for Electrocute + Dog
something to do with davedevil comics
around 8
6 should be barely possible now, though I haven't tested it
He's got a thunderous bark, but that's nothing compared to the bite.
hard to resist those eyes
Google Docs
You're telling me! I spent 6 hours deciding which ones to cut and what to crop out of the sample set!
Like having to say no to that face a thousand times
dataset building is a dogs life
Scott Detweiler's Refiner-Base-Refiner Workflow - Triple-Proces R-B-R
the payoff though
does anyone knows how to run sdxl lora training on colab?
That is pretty impressive. My first go has been very satisfying too. Can't wait to make a bunch of these and start mixing them. strange amazing times.