
#✨|sdxl
1 messages · Page 54 of 1

i hate making even tiny changes to comfyui layouts . it's always this kind of stuff. mb

Well it won’t break break it.(I don’t think) just means the seed won’t get written to the file named or into the prompts txt

i've got a lot to learn about comfy yet. think i want simpler and sexier layouts. efficiency nodes seem to be my jam
comfy would benefit from "collapse" setup where you could just make new functions out of bunch of nodes

GitHub
Adds a feature to ComfyUI that lets you nest nodes under a new node for better organization and simplification of repetitive patterns in workflows. - GitHub - ssitu/ComfyUI_NestedNodeBuilder: Adds ...
ohh
yes i know it's saturday. saving money requires compromises. also, living on an island makes it easier.
yo we'll see you all late.r i got a work thing called my job to get to. good luck generating generators!

SDXL makes my 8Gb RTX2070 look underpowered when using A1111
Yeah i noticed vram usage is quite insane, even for my 4080 i get it filled quite often 😂😂
Anybody using Dettweiler's triple refiner-base-refiner setup in ComfyUI?
I e tried it But hit and miss Depends a lot on what you’re generating
I learnt a lot about the workings of ComfyUI, its an interesting insight
What does it mean that SAI made finetuning easier on SDXL?
What comfy nodes are people using for XY graphs?
GitHub
A collection of ComfyUI custom nodes. Contribute to LucianoCirino/efficiency-nodes-comfyui development by creating an account on GitHub.

same prompt & seed, one with pre conditiong and one without (see file name).


drat forgot to take the 3 out f the no preconditioned
Yes, its a good setting off point for experimentation

Anti AI people want to ban AI images on this sub. i need your vote https://www.reddit.com/r/Avatar/comments/156x3cf/poll_should_this_sub_remove_all_ai_art/
this is what I should have added as the Non Preconditiooned however first time I left the start step in First Pass as 3 rather than resetting to 0




is it something he posted or from a YouTube video of his?
yes

Since we have released stable diffusion SDXL to the world, I might as well show you how to get the most from the models as this is the same workflow I use on a daily basis at stability.ai. In this video I show you some of the basics on how to get the model from the models to generate your best AI artwork from our models. You will need some of ...

Interestingly for these videos hes not using the triple prompt input method, maybe he's going to bring that in in a future video with an explanation of why/how it works




Example one also doesn't use triple input.
The video I posted above, he adds a 3 step refiner to the normal base/refiner setup almost at the very end of the video. 3 step refiner; then base step 3 to 12; then refiner again step 12 to 20...
I wasnt referring to that, I was reffering to the fact hes just using a simpple Postive & Negative prompt rather than Linguistic Positive, Supporting Terms & Fundamental Negative
Hmm weird, keep getting refiner out of memory errors in 1111 :/
I'm not sure if it does anything valuable, but it certainly opens up possibilities in the use of ComfyUI ...
OK, I understand 🙂
L8r
Another example of "Non PreConditioned" (on the Left) and "PreConditioned" for the same Prompt & Seed


what does this mean? base model genning at 128x128?

is there a reason why comfy has bad hands all the time and a1111 doesn't?
no, latent images are kind of a different thing. it still generates at 1024.
i see lol
sorry for asking elementary questions but how does one "train" the ai?
i believe if you were to pixilate a latent image it would theoretically look like 128x128 random colored pixels. if you were to do a 1024x1024 latent it would either take forever or oom instantly lol
you can train it by training the whole model itself or making a lora. Lora's are great because you dont have to have that many images 10-1000+. most people use Kohya GUI to train loras.
@wicked frigate what do you mean that training has been easier on SDXL?
wait the latent is 128x128?
thought sd 1.5 had a latent 256x256x4
does anyone have a link to the sdxl 1 with the 0.9 vae inbedded?


thanks m8
it looks like sd1.5 may use 4x64x64 latent space
but im not sure im still learning about this stuff.
pretty sure latent is 8x smaller vs base res so 64 for 512 model and 128 for 1024
that is impressive
thank you, question about the training. if i feed it images, does it go to a cloud? or will my model remain local?
there has to be a way to make pictures come out more rugged, right know the generations look to perfect and I kinda hate it ngl
yep, probably why sdxl isnt that much better than 1.5 with small details and far away faces, has much higher latent res but vae pretty much same as 1.5 just trained more
can u give me advice for more complex prompts?
kohya_ss is all local on your computer. given if you have a decent gpu with sufficent vram id say 16gb vram is good enough for lora training. yes the files stay on your computer and its up to you to set parameters and such. i would suggest watching a couple youtube videos to get a better idea
i wanna generate a dragon which skin (body) is out of thousand eyes
but i cant figure out how to do it
thanks friend. i will definitely watch some videos. i appecriate you.
no problem hope i helped a bit!
yeah i can see that being difficult. ima give it a shot by trying to weight the eyes part higher than the dragon
hey @autumn forum what UI are you using? Im currently using auto1111 but i see a lot of people here using comfyui.
The refiner prompt helps in allowing hires fix for odd resolutions.
comfy, i tried using a1111 but seems lackluster with how well comfy speeds up using sdxl. very low vram usage comparitive to a1111.

i will make the transition to comfy. thank you!
nodes just keep adding up huh
better extension for "link render mode" (shape of the cables)
Now you can change it when you need it (saved to storage)
drop into ComfyUI/web/extensions
https://gist.github.com/pixelass/0518d56d62d7b8ad19281eb032bde330




yup
feel like its super hard generating complex stuff with sdxl, doing basic prompts way better but when u wanna add a lot and doing fine editing its hard
did the refiner have the vae problem too?
using 42 inch oled as monitor is a godsend for comfy, gotta have the extra screen realestate
🔥
im getting.. somewhere? lmao

i want more like a full shot
95 inch projector next lol
hope u know what i mean, like the body (tail) skin where comes a lot of eyes out 😄
but yeah its getting in a direction 😄
i know man its so hard haha. maybe there will be a model for more artistic outlandish concepts one day
hehe depends on how crazy your workflow is, the comfy wall in your computer room/office
Would you have any idea on how I can replace my ksamplers by advanced one in order to have my first 20 steps with base and the last 5 with refiner? I can't figure out how to gen img2img with this technique, only txt2img. How do I add a certain amount of noise on the original, for example?

mee...tooo?

i give up lmao. its difficult haha
Personally I would start with @high skiff 's work and extrapolate your won workflows from there.
Its what Ive done and then added in pinches frm wherever else I need too
use ksampler advanced. For example you can set steps to 25 in your refined one and start from step 20
Yup, It's the one I'm using for txt2img, but I don't get how I could set the denoise for the original image
🥲
it uses latent to latent rather than img2img or are you wanting to add an img2img step after?
yet it can do a dragon made of sparkly gems lmao

🤣
Yes sorry, it's latent to latent you're right. My objective would be VAE encode -> advanced ksampler with a denoise of 0.5 for the 20 fists -> Another one with no denoise for the 5 lasts one -> VAE decode. Maybe there's a node to add "denoise"?
wha
ugh.

I use my 65-inch TV
Maybe those two?


what are the best res for sdxl?
Is there a spot people are sharing Comfy templates/workflows?
I'll be honest, I think Comfy's workflow is far superior
1:1 [1024x1024 square] | 8:5 [1216x768 landscape]
4:3 [1152x896 landscape] | 3:2 [1216x832 landscape]
7:5 [1176x840 landscape] | 16:9 [1344x768 landscape]
21:9 [1536x640 landscape] | 19:9 [1472x704 landscape]
3:4 [896x1152 portrait] | 2:3 [832x1216 portrait]
5:7 [840x1176 portrait] | 9:16 [768x1344 portrait]
9:21 [640x1536 portrait] | 5:8 [768x1216 portrait]
9:19 [704x1472 portrait]`
at least in terms of result
warning, lots of eyes, i can give you this prompt if you want to try it out. using no negatives.

I did say it was like a tyre or oil thread lol
yeah would like that and maybe try to work with that 😄
I mean, for using the combination of Base and Refiner I find the results better
I hate the endless panning and moving about to render and make changes, but I cannot argue with the results
(dragon made of eyeballs:1.3), realistic eyeballs, full body
ty
No Panning around needed here on a daily driver basis
Everything comfortably in one place

admittedly if I want to delve under th hood its different lol

your workflows itches a good spot in my brain. love it winston!!
I will happily acknowledg that I wouldnt want to try and reverse engineer from it if I was anyone else lol
For curious people, here's what I'm trying. Hopefully it'll work.

so you use the refiner for the first few steps? have you noticed a benefit to that at all?
its very much a case of YMMV
For more abstract ones such as #✨|sdxl message IMHO the preconditioned output is much better.
When it comes to photorealism.................... hmm jury is out.
This is Stable Diffusion, This is the way

Can I just download SDXL and use it as a normal model? Or I need some cfg to A111?
@autumn forum another example Of Non PreCondtioned (LHS) v PreCOnditioned (RHS) for same prompt/seed



hmm interesting ill have to try that out
anyone knows if you could fuse characters in stable diffusion??
Hey, is this discord about the sdxl version on clipdrop?
I think its a general sdxl channel
preconditioning is pretty interesting, might even be worth while to try finetuning some models just for pre conditioning, maybe pre condition with a line art or monochrome vector art model to get cleaner lines , and finish with a color model, probably need to toy around with the right amount of initial steps
Non Preconditioned LH Image, Preconditioned RH Image , same prompt & seed


how many steps do you use for it? I've found anything over 4 kinda blows it up
thats a clear difference!
Scott in his vide said to keep it to 3 for the PreConditioning step so I am (and hes a QA guy at SAI so who am I to argue lol)
makes sense. it seems 3 is the sweet spot

thats where comfy really shines, just making weird model daisy chains, especially if you start finetuning custome models for it
thats an interesting idea
In Principle COmy also allows you to merge models on the fly to use in your flow
Hmmm, I wonder if in Comfy on my 3090 (system has 32 gigs) if I could have a 1.5 model/SDXL base/SDXL refiner all loaded at the same time and just pipe from one to the other etc without having to load/switch models...?

Can you fave your generations and prompts in Clipdrop so you can use them later again?
cant see why not, previously on my 1080ti 11Gb I was piping srom SDXL to SD1.5 Img2Img
hmm thats actually interesting for cooking up model merges..Comfy's kitchen
I guess I will have to give comfy a try. Feeling cramped in A1111
(nb I also have 64Gb system RAM)
Comy offloads from VRAM as soon as it can to System RAM so it does increae System Ram usage but then again RAM is cheap and upgadeable unlike VRAM
yah, but this is a work machine and it is a pain, lol, wish I could just go buy 100$ of ram and toss it in but nope
Reqyuest extra RAM for work, say you need it in order to manipulate large Excel documents more efficiently

haha, oh my job is AI cool so no worries there. but yah I guess I will request a 32g drop soon
I asked for more and they upped me from 16-32... dont think they get it heh
stuff is so damn cheap but many mouths to feed and art is not a high priority
Another comparison this time with a more photo feel
Non Pre COnditioned on LH, PreConditioned on RH


anyone have a saved inpainting flow I can use to try to fix bad hands - like load an image and a mask, have it pain only over the masked area inpaint without me having to set up all the nodes? I see images of such a workflow, but can't tell where everything connects
It's too bad SDXL is still piss poor at multiple conceps/characters
great, that gives me a few months to save for retirement
same. I wanna know how I can fix these hands

OOH! Someone who gets that filenames can be have dates and folder locations can be different! Is this the workflow in your PNG images? I tried dragging this image into Comfy but it didn't do anything
The image in the post you replied to looks like a screenshot of the comfy window.
wow, i get the feeling that comfy is a pain on 1080p

zombie vampire?
does anyone know if there's a node for saving the prompt (in the filename) in comfy?
no lora used but it really look like lora already.....



Really? On my system, this the default it loads (left) and the SDXL one from the example page on the right


I added "crooked teeth"
Wow, I thought it was just a screenshot
Bro , which platform are you using to run xdxl ?
colab only with comfyui
Ha, all good 🙂 Doesn't matter anyway, I got the workflow from one of the PNG he posted, but even using the workflow manager still results in many missing nodes, so I'm gonna hunt them down

Those are all WAS Suite nodes
Negative prompts are still very important in sdxl.


Left is with and right is without
Yeah, it goofs on installing 😦

You are using comfy portable I guess? What OS?
Windows 10, so now following the instructions on WAS page instead of going through the install manager
i had to give my pc requirements and did somethig with --user idk
I have full admin rights on the PC, but I'll keep that in mind
i do too... sooo yeah lmao, i thought the same thing but still had to do it for whatever reason. but that error doesnt look like the one i had so maybe its fine
Yup si I used it as an excuse to add a 32" 1440P monitor to my dual 22" 1080p set up lol

may bring out the ol 4k for workflows.. lmao. i use a 1440 for daily and a side 1080 for discord. maybe i should add a 4k uptop hmm

"Loooking Good" - Chico and the Man - Freddy Prinze with Jack Albertson.
I have seen one but cant remeber where.
My approach is to write to a text file in the same directory



liminal space vibes
Indeed
Imagine how much better it could be with a liminal dreambooth model.
now winston got me playing with preconditioning...odd results from preconditioning with the same base model, alot of change from just 4 extra initial steps. pre conditioned on the right with 4 steps of base model , same seed

i think it can be done with a primitive node, i will try it like this and see what happens:
- convert filename_prefix to input,
- link it to a primitive node
- copy the prompt text into the value field like this
I am missing LahMysteriousSDXL v10
Gah. I tried all three methods (recommended, legacy,and install bat) and still get an error. Oh well, I'll figure out another way to add partial prompt names and dates to the file and output it to a UNC path

has comfy responded to you yet?
having installed comfy just now as a total noob to it, what is a good point to start off?
No, it's not the Comfy workflow, nor does the WAS suite belong to Comfy, so nothing to respond to
i feel like xl still isnt quite there. idk i was impressed more with the bots and clipdrop than everything ive done or seen post its actual release. feels like a step up from 2.0 era but still not really a game changer idk, wont be a popular opinion here im sure
ah okay
If it's sdxl you're wanting to use them you can just load this workflow and prompt from there https://github.com/SytanSD/Sytan-SDXL-ComfyUI
GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
like this (i took the sdxl example workflow to illustrate) @soft zealot
nah, that doesn't make it easier. i hoped i would get a bigger input field, but it's the same as the prefix

Different strokes for different folks I guess. I can get these quite adequate results from a local install





As a base model it's by far better than 1.5's. I'd wait for fine-tuning for actual polished content.
I'm getting this weird SyntaxError: Unexpected token '<', " in comfyui
I'm using the simple example workflow given in github
nice biff
do I understand that correctly that I have to adjust start and end steps on the passes if I adjust my overall steps node?
Thank you, what kind of output quality issues do you get on your local install?
its decent, it just doesnt wow me as much as I thought it would. i thought itd be like on MJ level at least with how much some of the stable people were shit talking MJ but I find it pretty weak comparatively
but we'll see how things look in a few months or whatever with some fine tunes, 1.5 base aint all that either
Yep it's fairly straightforward enough to use. If you have any issues that pop up then just ask here about them.
thanks man appreciate it
favourited ^^
Yes, people forget how poor SD 1.3, 1.4, and 1.5 could be at the beggining
This is a good one too... https://github.com/wyrde/wyrde-comfyui-workflows/tree/main
GitHub
some wyrde workflows for comfyUI. Contribute to wyrde/wyrde-comfyui-workflows development by creating an account on GitHub.
and also

GitHub
Examples of ComfyUI workflows. Contribute to comfyanonymous/ComfyUI_examples development by creating an account on GitHub.
The second is the one I use for great effect
the second workflow
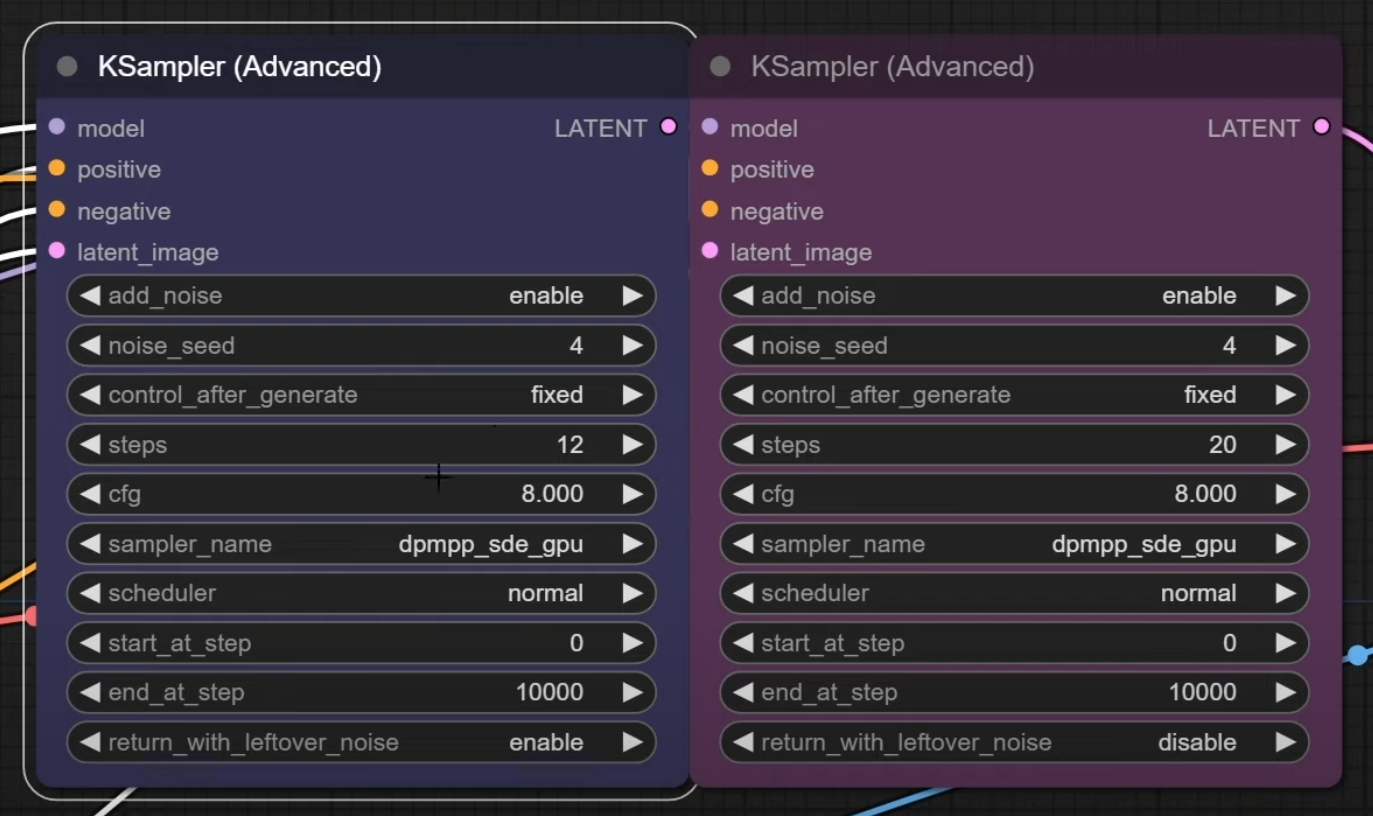
Why is Scott Detweiler not using the "end_at_step" parameter in his ComfyUI workflow? Doesn't that result in removal of all noise, making the "return_with_leftover_noise" option useless, which would go against SDXL documentation?
https://i.imgur.com/Pkk0uZ7.png
(Source: https://youtu.be/2Xe79Nl_6jA)
Since we have released stable diffusion SDXL to the world, I might as well show you how to get the most from the models as this is the same workflow I use on a daily basis at stability.ai. In this video I show you some of the basics on how to get the model from the models to generate your best AI artwork from our models. You will need some of ...
it will end at 20 steps of whatever you set the steps to
@tender timber @autumn forum You might want to ask here: https://github.com/WASasquatch/was-node-suite-comfyui/issues?q=is%3Aissue+is%3Aopen+sort%3Aupdated-desc
I just asked WAS it's not a known issue yet at least apparently
Thanks, will do!
he sets steps to 12 for base, which from my understanding would result in 12/12 steps with no remaining noise. after that he adds new noise and does another 20 steps with refiner.
all that is not how sdxl should be used by documentations i've seen. refiner should be less steps than base and carry over the noise from base instead of creating new noise.
I also wonder why he isnt usng the Positive, supporting, negative triple prompt method however..............
.................I wonder (base don his last 3 videos) if hes going to introduce those other elements.
Ie is he doing this in a building blocks method rather than a one shor wham bam thank you ma'am
Unless I am not undrestanding, I see it say enable noise at end of the 12 steps, i.e. return with leftover noise
@brazen patrol if you don't use end_at_step, there is no noise left, as shown by the preview image he does from the base result. that's why his refiner node needs to add new noise. that's not required if you use end_at_step.
i would understand that as simplified solution or his personal way, but he says that they use that workflow internally at stability ai.

anyone know where I can get a copy of NKMD upscalers? the links dead ?
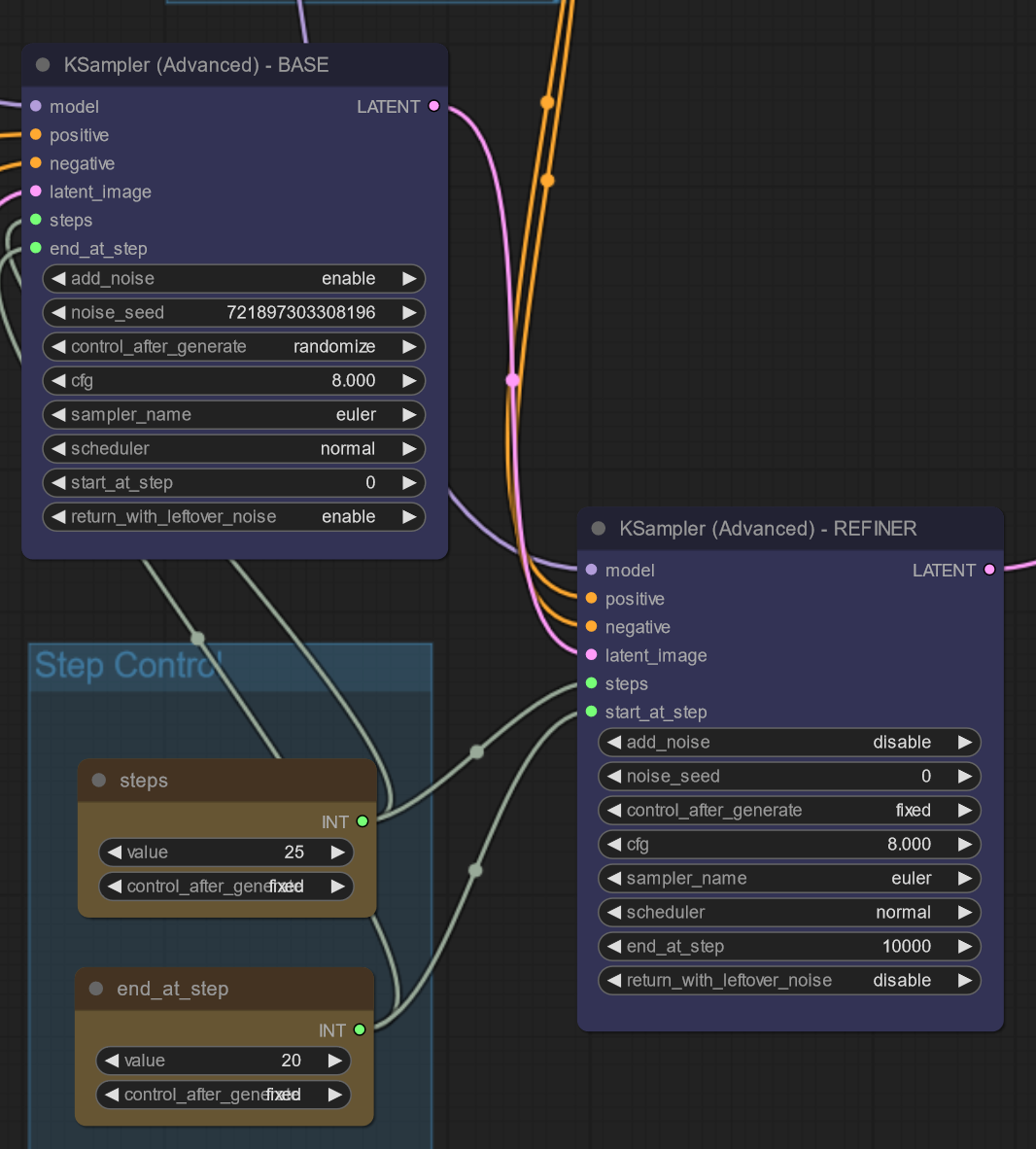
This is the standard ComfyUI workflow for SDXL:

There is no end at step for Base
There is no option for it even
Mind you, this is not my workflow design. It is Comfy's
your screenshot doesn't show where end_at_step is coming from. at least it seems to be not kept at 10000 as in the video i've linked above.
do you have a link to the complete workflow?
is there any information anywhere about prompt weighting? I recently heard that you can use a picture of a ((red)) (((cat))) to add weights? or something?
GitHub
Examples of ComfyUI workflows. Contribute to comfyanonymous/ComfyUI_examples development by creating an account on GitHub.
@brazen patrol thanks for the link. that makes much more sense. they use end_at_step in that example and end at 20 of 25 steps and do the remaining 5 steps with refiner:
https://i.imgur.com/gFcfPKg.png
refiner is used for step 20-25.
so why does Scott Detweiler tell us they use his (totally different) workflow internally as default base sdxl workflow at stability ai?
@soft zealot so it works, but it's the same as pasting the prompt in thestandard prefix field. no need to use the extra node
so this just gives you a stupidly long fine name ?
Yes, sorry if my shot was not clear. I reorgnaized the panes to keep it ll in one screen
well i pasted the prompt in the field and that;s what i got
More precisely, I organzied them so the ones I typically modify are all there.
are you referring to this?
So each time you write a new prompt you need to copy & paste it over to the primitive to include it in the filename?
My method of writng a matching prompt .txt file automates it and adds everything from my orompt inputs automatically

@brazen patrol i do the same on my workflow. would be great to have a way to create a real user interface and hide the nodes in the background.
how?
using a series for text manipulation boxes as shown in the screenshot in this post
Agreed, but for now:

stupid me, i overlooked it thanks! 😅 ❤️
I'm also using WASNodes Suite Image Save rather than the default

Anyone tried ✨ as a prompt? Like ✨Isometric✨
i tried was nodes, but i got an error
not sure though if it was WAS, i installed a lot at the same time so i'll try it again
i'm using a very simple setup right now
would be nice just to add that one @soft zealot
Seems to be working, guess it's not a fluke that ✨ is the icon for the channel. 😉
does comfy have support for post processing a step, like being able to sharpen ala photoshop between an img2img step?
Unicycling Giraffe was difficult in 1.5, but SDXL seems to grasp the absurdity of things and make better inferences. *A giraffe riding a unicycle, giraffe, ((unicycle)) *


help.

look under image of the right click context menu oer just dbl click any where on the canvas to bring up the search box and satrt typing


Ahh sweet, all right, I have run out of excuses... will install it today hehe, much thanks!
I think refiner model shouldn't be used for generating in a1111
apologies but my workflow is wrtten for my personal use, have no intention of adding to it for other people.
Its in all the images I post if people want to use/adapt it but its not an "offical" supported thing and subject to chnages on a whim
no it wasn't your workflow, i just downloaded a lot of those custom nodes and tried them on sdxl 0.9 (not recently)
I changed to base model and its still broken

do you have the latest version of a1111
yeah i think so, i use a launcher that automatically updates it
Ok, back to the SDXL 1.0 release workflow grind
1.5.1? and maybe set the canvas size to 1024x 1024
still kinda broken

could these be the issue?

Maybe, try launching with the xformers check turned off?
Can you use sdxl model in auto1111 img2img to upscale?
yes, ultimate sd upscale extention works as well
Nice! Do you get higher res results?
Just the model, check around, its up on the civai...or however you spell it
yeah definitely some tweaking to get it to work but it works well
Cool adding it to auto now...we'll see. Upscale 1.5 gens with the new model seems it would be the way to go until the new model is fine tuned
yeah models are pretty crap right now, we just have to be patient. SDXl is going to be great in a couple months
are there good tutorials for fine tuning SDXL?
manually pick the VAE instead of usingthe automatic
on further inspection I think it might be your torch version not working properly, try putting --reinstall-torch here

I reinstalled torch and xformers and picked the VAE and while its generating it looks fine but it fucks it up at the end result


I think you're torch version should be above 2.0.0, that's what I can think of.

found it, it's in mikey nodes
you just convert the pos en neg prompt to input and then link them to the text node outputs
does anyone know of a way to adjust refiner settings in sdnext? i'm getting pretty good results with dreamshaperxl10+adetailer+refiner

So I got SDXL running on the webui and I can generate images, but everytime I try to use the refiner model I run out of VRAM, I'm already using xformers and lowvram, does the img2img just use way more vram or am I doing something wrong?
sorry probably wrong channel
did someone tried this depth controlnet model already? https://huggingface.co/SargeZT/controlnet-v1e-sdxl-depth

try settings to unload model to ram when switching between base and refiner
I have the same issue and I’ve seen other people also mention this. Sdxl doesn’t work in automatic 1111 very well right now so many people moved to comfy which it work so much better on.
Honestly, you're not. A1111 is quite memory inefficient.
I tried running 0.9 but keep getting a black image.
i moved to sdnext. it's closer to a1111
Can anyone tell me what I am probably doing wrong?
what are you running? a1111 comfy?
Comfy
thanks and also thanks @fast vector, I'll setup comfyUI I guess, doesnt seem too cumbersome
can you make a screenshot of your comfy ui?

are you running it with any options?
I am using your Pytorch build
THough with 3.10.9
since 3.11 was slow as molasses
love me some alicia vikander...
Best parameters were tested with the bots here right? Were the results ever released?
However, the UI and nodes are pure Comfy SDXL refiner setup
why does it take almost 3 mins for an image with 20 steps? what gpu are you running?
Or the ideal parameters, if not the full results?
RTX 3070 8GB VRAM
yeah I have the same one, that shouldn;t take 3 mins but tabout 25 seconds. so something is really wrong there.
I would try to reinstall a1111 in a seperate folder to see if that solves it. Or does it give something in the command prompt on generation?

would anyone here happen to know why my primitive nodes in comfyui doesn't save the custom size I've applied to them? when loading the workflow they just go back to default size
If I swithc to plain 0.9 I get a black pic. If I use the 1.0 it works fine. I have tried wit a separate VAE model and not
why would you use 0.9?
I mean have you tried both refiner and base? Or just one?
I am now 99% of the way there after a clean install... just missing one node. I"ll see if I? can grab it manually somehow

mind sharing json?
I can't take credit, it's from @soft zealot and is available from any one of his PNG output files
it's this. save the raw file to your /custom_nodes/ directory:
https://gist.github.com/alkemann/7361b8eb966f29c8238fd323409efb68
make sure its name is .py and not py.txt
Hi, do you think it's worth re-downloading the model to get the 0.9 baked VAE?
Thank you sir/ma'am!
ah, I see
greetings all 🙂
https://cdn.discordapp.com/attachments/1089974139927920741/1134917403856347217/SDXL_20230729193500_318187109389229_000001.png should have it within the PNG



My cousin's been in Texas for a decade, she now says "all y'all" without irony 🙂
That’s seed to text. Link in the credit and notes of mine
yeah just pointed him to it 😉
We are nearing completion for release :p

Syan's 1.0 SDXL workflow with built in 2048x upscaling
Just have to check some more things, should be able to submit it to the comfu UI wiki later today after I cut out the upscale nodes (the upscale version will be available on my github)
wot no "Pre Conditioning" ;o)
har har har
oh wait
Just disconnect the node that goes to upscaling
half a day away and civit is flooded with SDXL content
Hey, are bracketed weights and :1.3 etc style weights still working with SDXL? i've been trying but don't think they are working, what about prompt timing, is this meant to function as like with old SD or is there a new format? thanks
I forgot to look into that @soft zealot Would you be willing to help me with that in DM's? Maybe I could include it in the workflow
or use a jumper ;o)

I usually upscale with Topaz, so this sort of thing was never on my list anyhow
the jumper idea is a good workaround for not having options or settings
I have a jumper for the workflow

but Comfy prefers I upload a version with no third party nodes, so I will do that with a link to my github for the one WITH the upscaler
Success! Thanks!
Winston is building LHC level machines in comfyui 😉
have fun!
Hi, is the 0.9 VAE model worth it?
All I really wanted was custom file names and folder paths, but many of the other nodes are lacking or buggy. Will tootle around with this one and maybe grab bits and bobs to make my own Frankenstein version
Small update to my linksRenderMode extension: Just select the mode you need. (saved in browser storage)
For installation guide see comment below the gist
What does this do? It toggles the render mode of the cables/lines mode (straight, slight curve, curve)
https://gist.github.com/pixelass/0518d56d62d7b8ad19281eb032bde330

Woah woah help each other out here so everyone else gets to learn, I want in on this too
put this one into custom nodes?
@visual glade Are you still planning on releasing a reference_only node with img2img support? If not I will start trying to hack it in myself but I'm not sure if I will be able to
I reinstalled A1111, eta is still like 2-3 mins, waiting on the result
Is there a simple way to have flexible workflows in comfy where I can enable disable certain parts with one click?
images seem to turn out correctly now but it still takes like 2 minutes
So I tested it, and it is the Base 0.9 that doens't work. If I ask it to run the refiner only I get a picture. So I will redownload the Base in case it got corrupted somehow
Yeah I’m not quite sure what to make of that, definitely taking to long. You should put your sampling steps around 40/45. Are your drivers of the gpu updated?
drivers are updated yeah
Do you get any type of error in your command prompt?
Ctrl m mutes selected nodes is all I can suggest
Hoi, just a questionary as i'm curious if i should continue using comfy as a AIO click, or manually got fetch, install requirements and such, as a few extensions is missing modules, and i can't even install the modules as it's not cmd'd into it's venv, so it's stuck at missing modules lol
1: Stick to 1 click?
2: All manual, and can effectively add modules :P






nope
Settings > System > Disable memmapping for loading .safetensors files. (fixes very slow loading speed in some cases), Maybe turn this on?
or maybe enable low vram, I heard not enabling that can cause issues
how can i enable that
during startup of a1111 you can check it
I am messing with it right now to see if it has any place in my workflow or not
Its veryyyy weird lol
@lethal tusk

LETS GO THAT FIXED IT
Thank you so much for helping me
Someone promote this guy
I hope I ask in right place now, after a stroke I forgot somethings, bur I have the "sd_xl_base_1.0" model and Img2Img I want to use a old 256x256 image and upscale it to 1024x1024, but i get a long error and I hope some can say what I do wrong.
"NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check."
I have a Nvidia 3090 that was a gift and I think it will be okay, but do I need to change something in the settings to get this to work or have I just missed some step?
Hi everyone, I want to know if my GPU RTX 2070 Super FTW3 with 8GB of VRAM is capable of running the SDXL model. Complete setup includes 16GB RAM at 3200MHz, AMD Ryzen 5700X, and NVMe Kingston with 7500MB/s read and 6000MB/s write speeds.
😃 Awesome, always enable low vram, makes life a lot easier
I had the same error happening to me, I restarted a1111 and after a couple times it worked. If you're using the ultimate sd upscaler make sure to leave the tile width on 512.
yes should be able to, you need -medvram option
i always forget to switch between base and refiner lmao
so many character loras are showing up in civit cuz of contest lmao
Just now I am in a episode where my brain skip logick, I removed all scripts for many did not work with SDXL that I mainly want to use, so I just dropped a 256x256 image in the image tab, added a description and pressed generate and hoped it would give me an image based on the smaller image.
I will look into that script and test it... when I find it 😄
My brain do racover but it work slowly.
Thank you, can I set up the low GPU through Automatic1111 & ComfyUI?
I understand, You wanna go to extensions and click available then on the load from button, You want to look for ultimate-upscale-for-automatic1111 and click install. click on installed and then apply and restart ui. after that within img2img under script it should now say ultimate sd upscale. you have the settings for that as follows
@void skiff

Ty. That is what I needed, I feel a bit stupid when miss simple things like that, ty again.
You just have to know where to find it :), It could be you still get the error after I'm not really sure what that means but for me it just started working after a couple of restarts
Btw I was able to use just the refiner alone in auto 1111 for both processes
@visual glade @fast vector So just an update: I narrowed the issue down to th SDXL 0.9 base, and redownloaded it on the long shot it had somehow been corrupted. Long shot was a short shot: the new download fixed it.
with 8GB vram?
I have 16 gb but I have xformers and medvram
Stroke is odd, I wanted to say something, I typed, forgot what and.... BUNNIES!
what are the prompts for these
That sucks man I can only imagine being good at something and then just forgetting it, Take it one step at a time man.
It takes my RX 6800 XT roughly 3 minutes per image generated by SDXL 1.0 in 1024x1024 on the official workflow for SDXL 1.0 in ComfyUI. Is that decent?
So I noticed that loading one of the latest Loras for SDXL take much longer to be processed in the sampler
How many steps?
yes for windows

Is that a very slow card?
no its just amd perf
or old? I dont know AMD
Feels like it lol
I have 6900xt and get about same speed
I wish I had a better GPU and more ram for this :c
6800xt beats 3070 in raw perf
but windows amd has no rocm, so you need directml, which is like 5-10x slower
Is that the 'simple example?
huh.. extension needs bitsandbytes, i install it, but then cuda suddely doesn't exist  ,
,

yes I think
Hi, I'm using Comfy with SD XL 1.0, and I'd like to know how to see the seed of an image, knowing that I've generated 4 here.
But most of the time I generate 20 images, and in that case I'd like to see the seed of the selected image, in my example among the 4, how can I do that please?

click on one and save it. That should do the trick

try clicking on one of the images
I see, however I upscale my images and I'd like to avoid having to download an image that interests me and that I want to upscale, and then go looking in its metadata to find out its Seed.
Isn't there a simple solution on the interface to view the Seed?
is there any new news on controlnet?
So I ran it on my laptop here (which is my daily driver anyhow) with a 2080 Super and got 25 seconds
😩
I bet the 4090 is blazing fast for Stable Diffusion
reddit
18 votes and 27 comments so far on Reddit
I have no doubt. 🙂 I bought this for a varety of things, but SD was not one. as it did not exist yet
Idk what to think of that I can make batch 12 at the same time 896x1152 images on 2070. Literally how :D
So annoying that the reroute can only go left, or down 

is there any custom node/plugin for comfy where you can load loras in the prompt? I think I saw it a few days ago but completely forgot what it was called
GitHub
A collection of ComfyUI custom nodes. Contribute to LucianoCirino/efficiency-nodes-comfyui development by creating an account on GitHub.
Hey guys, i can manage txt2img, img2img and loras in the same Workflow?
I saw the cool superhero looking "drugs" by midjourney, attempted badly at making one for my adhd meds, i ended up with paracetamol instead 

Img2img is simply just one ksampler shipping it further to a second one. Or of you wanna upscale, upscale base image, then resample it with more details

Does anyone have a workflow for any of these two images, but with the use of Efficiency nodes instead? - https://comfyanonymous.github.io/ComfyUI_examples/sdxl/

does anyone know what causes this to happen?
Using dreamshaperXL 1.0 on a111 with a 12gb 3060 and 16gbs of ram

am i just runnning out of vram?
Is 1024x1024?
ya
I need to test with other lora's, but seems to work fine. This was with base, refiner and 4x upscale with ariel lora

Or even with the vae enabled
enable low vram check when starting a1111, it has a big issue with vram and sdxl
What's denoise and steps at?
Oh amazing
Lemme try ichigo and see how that goes :P

How do ya'll get the right angle wires in ComfyUI?
Is not 1024
Or no. This one, one of my favorite characters in it. Gonna try one with and one without lora

numbers are totally undependable
ill try with low vram
You want base being 1024 if you use SDXL
low vram will fix the issue bro someone else came in here with the exact same problem today
how i can set the steps on sytan workflow?
Is there a node to simply turn off/siderail process if i wanna do before and after images without having to replug node threads all the time?
Someone said Ctrl-M
Back in SD 1.4 and 1.5 I asked it to make me a new logo for my channel on YT based on Chess and tech. I was not stuck on perfection, but I couldn't get anything remotely usable. Logos were a dead end, and anything with chess gave me pure gibberish
Now? I first asked it a very offbeat idea:
beautiful company logo of (chess and circuit board), AI, court of Louis XIV, intricate, sophisticated, extremely detailed, 4k
and it gave me:
I run a 4090.
Comfyui -> batch 3 is max for vram
takes about 8~14 seconds per image depending on your steps & settings for base+refiner+vae (running in batch cuts time down by around 30%)
Training: batch 10~12 is theoretical max. 8 is good if you still want to use your pc.
If you run an optimzed workflow, training a lora with a dataset of 30~100 images needs about 14 minutes to reach its ideal state. (though I usually go 50~100% over the ideal, so I have more options to choose from after I finish training)
Is it the best value?
No 3090 wins every time in money/performance ratio.
If all you do is inference, or occasional training. 16gb vram will give you access to everything that sdxl has to offer.
(In case you're wondering about finetuning - it's a complicated topic, but even if 24gb vram can do it, you should just do a LoRA instead. If you plan to make something on the level of waifudiffusion XL, rent a proper 8stack A100 on runpod)
Used 3090s are cool for now, I will buy new when there's a > 24gb Vram card
anyone got a 3090? how many it/s do you get with the base model?

i get about 3 it/s to 7 it/s
I do rather like this 🙂

WHich was kind of cool and well themed with gold Lousi XIV ideas. but I added the word FLAT to get something less picturesque and it again delivered
hmm I get only 2.3 with base and 4 with refiner 


it starts out 2.6 then climbs to 7 with my setup. what ui? comfy?
Super impressed
yep, comfy
and "neonpunk" ified


yeah sounds about right. i heard you can use --bf16 or something to speed it up. or --gpu-only or something. but im also doing 1024x1024. but i also 16:9 ratios as well
with 1024x1024 I'm at 1.8  damn
damn
These are all handy tips, but I don't even know how to train a lora or make my own custom model (I'm also not sure if the two are the same). You could leave your message up for others though, as it may help. I'm very new to SD.
bf16 is in theory out-of-date, due to the automatic fp16 support now
only relevant if you're working with 0.9
ah okay.
okay just did a test, 2.75 it/s base, 2.45 it/s refiner. dpmpp_2m_sde karras
hmm
2m sde still working for you in 1.0? O:
I had to switch to standard 2m, as the results were otherwise less than ideal in my tests
Yeah it's important to specify the sampler. Although some of samplers take fewer iterations for a good image.
doesnt do to bad. should i change to standard 2m? lol

When training faces in 1.5, the model usually extrapolated the body form fairly well. For XL it doesn't do so as much. Have you found a solution for that yet? Wonder if you @boreal bough know
I'm using the timestep hack. But so far this gives me a hell of a lot more detail on faces again, and reduces the background blur a bit, that's baked into some of the prompts

It is finally ready! The latest update for my SDXL 1.0 Comfy workflows and extension: https://civitai.com/models/111463
Now with text2image, image2image, and inpainting workflows. All of them using base + refiner!


Searge SDXL Reborn v2.0 Version 2.0 is here - improved text to image workflows, the image to image workflow is back and completely overhauled, and ...
do using that many steps help with faces and eyes? im usiung 34 max on both. seems to be doing fine
switched to dpmpp_2m and I'm at 3.3 now. I guess the dpm ancestral was slowing it down
Small collection of ComfyUI extensions: https://github.com/failfa-st/comfyui-extensions
I hope these are helpful. Enjoy.


yeah samplers make a big difference
sadly none of the big fixes I was hoping for, happened in 1.0 😦
faces got the smallest bit easier to train now - but nothing that I would call "easy"
Still trying different methods to find one that is both easy to explain, and doesn't take an eternity to train
yeah those 256 dim LoRAs are bullshit haha
404
like 2gb for a LoRA??!!
page not found
might end up making a 'community training data' which is pretrained on a 5k dataset, which you then put into kohya as an unfinished training thingie, and continue from there. Essentially a pre-existing offset. That way I can stick to 43mb + default sdxl base
still hoping I dont have to resolve to that though T.T
thats a good idea!
try again (forgot to publish)
I'm willing to help. Is the idea to train on 5K images of faces? What's your hypothesis?
Sub SDXL loras does not work great lol. Trying to generate this guy's lora lol


perfect and thank you for sharing it 🙂
the screenshots still give a AccessDenied
so I'll prob need to do one folder all cropped, one folder all uncropped
that or block weight training - just that I haven't tested which blocks now occupy face data, as its a lot more than before
fixed.
an additional thing that may end up working as an 'easy' solution, is TI for refiner only.
Essentially unet lora for base + TI for refiner.
Haven't tested it yet, but in theory it should work\
and you can't do a TI for base? Because of the 2 text encoders?
I think TI was what understood the body based on the face if I had to guess
for the 1.5
nice QoL features 🙂 thank you. much appreciated
should I downgrade to WIN10 from WIN11? I'm getting compatibility issues sometimes
TI for base works - but from tests from others, it usually does too much damage to the clip model to be worth it
hmm I wonder why
for upscaling the image, should I use the base model or the refiner for the second pass?
Well I hope something for the refiner works out. Is there any problem with training a lora for the refiner? Because it's annoying to train a lora for a likeness and have the refiner change lip/nose/eye shapes and ruin the base model's work.
No it's basically the same OS just with some different appearance. Win11 works properly.
clip was trained in a very specific way - unless we perfectly duplicate it, we essentially have to train it for a fair amount of steps to stop it from self destructing. But this inevitably causes overfitting.
I am getting compatibility issues I didn't have on WIN10
What issues exactly?
environment variables
they don't function the same way as in 10
Environment variables have existed since Windows 1.0. Windows 11 is not causing that issue.
Yes they do.
So you need to explain your problem exactly so someone can help you.
they don't. it works with a naming system, programs just assume it's a blank name- which doesn't exist in win11
when I run programs dependent on environment variables- it doesn't see the library. each time I use a library located in the system's environment variables I have to manually insert the directory, which wasn't an issue with win10
I can assure you that environment variable behavior is unchanged between Windows 10 and Windows 11. Also Windows 8, 7, Vista, XP, 2000...Something else is causing your problem. You need to give the exact example with exact names.

i really feel like auto 1111 is handling my prompts for sdxl better than comy, the usage of refiner is kinda useless in auto and anything else is better in comfy aswell
but i feel like in auto i get most of the time more what i want
Are you using the same sampler, same scheduler, same resolution, same steps?
Also same seed for testing.
yes
oh i didnt test yet with same seeds
i just generated a lot of images
and overall it felt like
Be sure to use CPU for seeds not GPU so you can be more reproducible. Results should be the same.
no. in win10 you didn't have to specify the library's name, in 11 you need to do so. programs assume it's just in PATH without any titling. for instance- I ran Nvidia's code that converts checkpoints to TRT, that program relies on environment variables. it didn't see the library. I have set it up on the correct directory.

especially humans are always super deformed in sdxl for me, dunno why
If you want to downgrade to Windows 10, you do you. And if you keep asking someone will eventually tell you to do that. But I'm telling you that something else is causing your problem. I can't really understand your sentences so I can't help beyond that. Good luck.
Are you using same CFG?
another picture of my moviestill lora!

yes
that lora looks like something I totally have to try!
basic English? what's wrong with that?
dunno i just feel i need all those extra nodes to get really good results, and thats hella overwhelming for me
Very strange. Everyone else seems to think that Comfy is better than A1111. You probably need to show screenshots of your Comfy workflow and your A1111 settings.
i really hope sdxl will be better implemented in auto 1111. especially the refiner
its hit or miss, lmao, ive realised that 1.0 does a good job already but this adds a special ✨ touch ✨ lol
this is default behavior if you go too small in resolution.
You sure your resolution isnt off by 64, and accidentally 'defaulting' to like a 300px small in the background due to that
Have you tried SD.Next? It's supposed to be like A1111 but supports SDXL better. I haven't tried it yet but I might try it soon.
is it yours or can I test it somewhere?
AUTOMATIC said he doesn't know when he will do that.
which resolutions u recommend
its mine. ill be uploading it to civit when i think its good enough. im close. with this round. may try a couple more trainings with different settings
i feel like 1024x1024 is not the best
he currently doesn't seem to work on anything
@upbeat summit heres another pic

nice! I'm looking very forward to it! If you need testers let me know 😉
try 1024x1024 just to make sure that things are okay. if people disfigure here there's a problem somewhere else. If this resolution does work, then at the same time you know that your resolution was at fault
will do i may take you up on that offer!
It will be difficult for him to adapt his code for a new workflow. His code is not maintainable.
this is the res i always use, but people tend to have 3 arms, no fingers etc.
yeah, and Vladmandic's UI is just kind of unstable.
SDXL is made for 1024x1024. You should use that or one of the other supported resolutions. Any other resolutions will give bad results.
@boreal bough I just pushed an update (a few actually) to the UI, to add support for full bf16, and do a bit more error handling
keep in mind full bf16 isn't possible on windows
ddim 50 steps, cfg 6
(not ideal, but great for testing if the error was in your sampler/step choice)
because bitsandbytes 0.35.0 doesn't work
and any newer version on windows causes issues
❤️
also fp16 is now working again - since 1.0
working and recommended
I put together a basic beginners guide for both sdxl and comfy ui Incase anyone is interested.
I am still learning myself so I compiled my recent learnings into a guide. If I’m terribly wrong at anything please also let me know.

Huggingface links for models:
https://huggingface.co/stabilityai
Comfy UI configuration file:
https://drive.google.com/file/d/1ksztHBWDSXYzCF3pwJKApfR536w9dBZb/view?usp=sharing
Patreon:
https://www.patreon.com/EndangeredAI
This video is a begginer friendly guide to the new SDXL model for Automatic 1111 and Comfy In this video, we'll show you ...
that's also very disappointing. many people are used to his UI so switching to ComfyUI is not going to be easy.
isn't vlads close enough to make the jump?
cause diffusers are long term supportable
i feel like i did way to complex stuff in the past for sdxl, thats why i probably need more trained models and kinda disappointed
Vladmandic's UI is unstable- memory leaks all over it
ComfyUI is a fundamentally different system and is better for some workflows but much worse for others. It is not really a replacement for A1111 or vice versa. It is like saying that Notepad is a replacement for Word. It's two different things.
ah. oh well 😦
Or saying that Elden Ring and CoD are the same because they are both video games.
StableStudio is the A1111 equivalent, which while running comfy in the background, saves you the trouble of actually interacting with it.
Same goes for StableSwarmUI - which just needs a bit more styling, but is functionally already better than any alternative
My workflows fit well with A1111 and don't fit well with Comfy. I understand Comfy and I know how to use it but it's not efficient for my workflows. Some other people it might be very efficient.
however, if there would be an A1111 extension that replaces all checkpoint instances to Diffusers, then there is hope for A1111 to live on.
mostly seed luck (not stable yet) but I'm always experimenting on film and video prompt builds 😉



in other words- if vlad's ui would be stable, it will be the replacement
Any inpainting method that works? This one doesn't

also the way that it handles prompts.. not even close to A1111.
or A1111 would make a switch to diffusers, IDK
ummm... comfy talked about it recently. its already well supported XD but no one wants to go through the trouble of building it, and writing a mini guide for the keyboard + mouse shortcuts that are needed to make (quick and low effort) use of it
StableStudio will also add proper inpainting support on top of comfy in the 'near' future. But obviously not a solution right now
The nodes look right. I've tried a similar workflow and it worked but didn't give good results due to not having SDXL inpainting model yet. If you want a cat face on the woman, just specify that and don't include any other background info in the prompt.
@upbeat summit heres a nice before and after, same seed, same prompt


nice hehe. the hair improved 😄
this just looks like the death of A1111 webui, unless he pulls something off

everyone knew that the programming debt would catch up eventually.
instant 78/80s film vibes
was just a matter of when
He will need to do a lot of work to make the code work with the new models. And also VRAM usage is inefficient.
yeah. we had those talks when SD2 came out and had the same conclusions
as much as I hate using ComfyUI, it pretty much is the only way. I personally prefer A1111 over ComfyUI, but it seems AUTOMATIC is slowly starting to abandon it, sadly.
I am looking at the code in another window and I still can't make very much sense of it.

how to make 1 subject o0
I was very hesitant to use Comfy but went from 90% Auto1111 to 98% Comfy within 2 days

his commits are insane. He's definitely working full time on it though. even had the 1.5 release recently, which fixed a lot of old issues that hadn't been addressed.

I think he's working on it but it will be a lot of work.
I hope he doesn't give up.
yeah. it's not a realistic task for a one? man operation
Auto should be moved to an org with a larger number of core devs. With the current userbase and number of issues that's the smartest thing to do.
comfy, mcmonkey and multiple solo devs joined SAI. I say that the lack of A1111 says more than anything else.
I don't understand what his priorities are. SDXL has been available for over a month for people like A1111, and still acts like the refiner or diffusers or any new breakthroughs exist.
Even though I don't use either comfy or automatic1111, I think I would pick comfy from the fact that the workflows are deterministic and shareable. Don't you have to bounce an image through multiple pages to tweak it in automatic? I would forget everything in about 10 minutes


I also love node networks so I'm biased
anyone got any success with latent upscaling?

it was always intended as a backend solution.
And now with the first frontend iterations produced, it shows just how much that payed off
Comfy workflow is better for creating a workflow to generate one image or one type of image based mainly on prompting. A1111 is better for iterative workflows such as geneting a bunch of images, picking the best, sending to inpaint, and then inpainting small areas many times to fix details.
sure, everything has to be done manually in auto, but it's buttons, simple buttons to click. People love buttons. Clicky clicky
Gotta respect those hard clickers
like, I feel like if A1111 would accept to switch to diffusers all of his struggles with trying to load multiple checkpoints and making the VRAM want to kill itself- the WebUI might return to its former glory.
for now using comfy as a backend and swarm or something like that as a frontend seems to be the way.

congrats! that one would pass for a genuine photo XD
no background blur either
thats a good photo. but i wish sd could do better on wheels lol
I relaly need to mark down what prompts i need for X thing. As i pretty much only use prompt info from civitA.I and generate SDXL from there lol. don't know squat of artstyles, cameras, techniques or anything lol

There are loras for 2.1 that do wheels well

oooo.
I have finally found the actual code that runs the txt2img process in A1111. Trying to figure out why it uses so much VRAM.
Offroad Corvette

part of the issues is(unlike comfy) it doesnt release anything from VRAM after its used it
Trying to load LoRAs in diffusers but getting key errors atm :/
The issue I've seen is more related to peak VRAM usage. Especially with the SDXL VAE. SDXL 1024 generation uses only about 9.9 GB but this goes up to 14.3 GB during VAE.
Are there any instances of torch.cuda.empty_cache() in the code?
a1111 has always had issues with memory all SDXL did is make them more apparent
and that , it does like to spike at the end during image save
The code is giving me a major headache. I might give up on this project.
no idea, not looked
It spikes during the VAE step. I just don't know why or if it is normal.
of course the code is bad, if it was good someone would have fixed it already
you get a spike in the VAE step with comfy as well, its just better managed
you could try my inpainting workflow: https://civitai.com/models/111463
That's what I use in my Unreal script to make sure that I've flushed the model before I init a new one. I let diffusers handle loading/offloading the individual model components to and from CPU as needed and I never run out of VRAM, it'll just slow down
A spike makes sense since it's using another model. I just wanted to see if there was a reasonably simple explanation for the difference (a detailed technical explanation, not just "one code is better").
i feel like every zombie horror stuff got those white lines in sdxl 😄
white canals
dunno how to describe 😄

i still like it
but im trying to get rid of it 😄
How do you feel about SDXL 1.0? High contrast? High saturation? Is the age settings of the character too high?
Hey everyone, is there any website or document to get the best prompts and appropriate resolutions?
@visual glade Question:
Is this pale blue box supposed to indicate where ComfyUI will open up at ?

yes
Is it possible to use diffusers controlnets in comfyui?
I think one I downloaded is glitched then
hmm If ive managed to create everything completely outside of it is there an easy way to find it cos if I zoom out its so fine and pale I cant see it lol
ok found it
it's something I added recently so make sure you are updated

this is like in every horror picture xD
dunno what sdxl likes about those white canals
😄
same here

I think that worked, seems to be running 👍
fixed that (ok maybe a bit too aggresively lol

Add "in focus, hyper detailed" to it, wanna see if it makes your more detailed :P
could give u like 10 horror pictures, every of them has those white sceleton
canals
i really love this one here 😄

what is the best rez for a full body portrait picture?
1024x1280?
I need a reroute node that does that

 Branching is illegal sir
Branching is illegal sir
hey great SDXL output  . yeah that would be good
. yeah that would be good
easy eat stuff directly right in your tummy? just get a zombie with a extra mouth



Looking at the A1111 code at least showed me how --medvram works and I realized it would speed up SDXL on my 12 GB card by getting stuff out of VRAM to make room for the VAE. 1024 generations went from about 40 seconds to about 25 seconds (20 steps).
@soft zealot How did you get the 90 degree corners on your wires?
Someone posted a document with a list of model prompts for XL, but I can't find it. Can someone repost it? Thanks.
the model have styles pressets
Any guidance on what the height/width and target height/width for the base and refiner clips should be in Comfy SDXL? Should I match the ratio of the target image? Is there a best ratio between the height/width and target height/width for the base clip? Does it matter?
you mean this? #✨|sdxl message
oh Thank you buddy
Wait hold up how do you route the paths to perpendicular bends??? My workflow looks like a bad day in an Italian kitchen
put this in comfyui/web/extensions folder
Thanks
Is there a guide to train lora on kohya ? I have 12GB of VRAM and it says it can do it.
But I don't even have it installed. I would love a tutorial for training sdxl Lora
that really cleans up the spagetttt. nice one!
man, I sometimes make some really wacky iflows as far as editting and finetuning the image between renderings. it's pretty much impossible to make it look good. lol. well as far as I know
Should the height/width for the SDXL CLIP be a square ratio?
yes
width and height refiner and base i have at 4096. the target width and height i have set to 1024
what about for the refiner? nevermind, misread what you wrote
lol
Guys, my 8GB RTX 2070 Super wasn't able to run the SDXL model. There are freezes when loading the model, and even the minimum resolution of 1024 takes 29 minutes to render a single image. Fortunately, it works very quickly with other models. Let me know what the ideal Vram is to run the XL model.
Mine works on Comfy but not on Auto1111.
For A1111 at least 16 GB. But try --medvram or --lowvram.
Is there ever a reason to change it from those?
I have determined by reading code and by testing that --medvram increases SDXL generation speed by 25-35% on A1111 due to less swapping to system RAM during VAE step.
ive never had a reason. even when changin the resolution of the image.
Without --medvram 40 seconds, with --medvram 30 seconds per generation.
I think I'll stick with other models until I upgrade my GPU someday. I don't have the patience to wait for long minutes, but what bothers me the most is that the model freezes my GPU for a few seconds during the load. I believe there's not enough memory left for the rest of the system during those moments. It's better to wait for a future upgrade. For now, I'll work with other models.
How much normal Ram do you have??
I have 8 gb in total 2070 Super
if you want the best possible chance of using sdxl. use comfyui and do a simple node setup with just the base
How much system ram
16 gb
I wonder of ComfyUI unloads more things or moves more things to CPU when not in use compared with A1111. Maybe that's why it uses VRAM better.
Yeah Comfy should be able to handle those specs, idk about A1111
looks like it mostly sits in system RAM then is queued to the GPU when needed. Ive noticed it unloads VRAM after its done. A1111 would just keep it in VRAM
That could explain it. A1111 moves stuff around more with --medvram and that makes SDXL faster on 12 GB card even though it seems like it would be slower.
Due to less RAM swapping during inference.
i went from 20 minutes to 2 minutes with -medvram
I didn't think it would help until I read the code and then it made sense.
The reason for speedup made sense I mean. Not the A1111 code. A1111 code makes no sense!

Nice!

So, how do you stop the refiner pass in Comfy from taking the work a LoRA is doing and hucking it in the trash?
i believe thats what you do, if it doesnt work try the others lmao
i dont think anyone knows yet. if we could train the lora for both that would be awesome but i dont think anyone has found out how to train refiner yet
Hmm
you dont
*queue Invincible meme*
A.) dont use refiner
B.) give refiner different prompt, to not touch some areas
C.) research for more options that we haven't discovered yet. (lora training refiner is currently not possible)
I was able to 'cheat' it by basically giving the refiner 2 steps only and then set denoising to a very low number (modified the KSamplerAdvanced to make that visible)
if its a face lora, then A is your only option
D - sell caith to me
🤣
I'm currently writing a comprehensive guide to lora training - after that I can simply link it everytime 😄
has someone tried training the refiner on 512x resolution?
Do we have any recommendation for Lora training that isn't faces?
'full'. pruned, right? cause we officially dont have access to the full 1.0 weights
Just asking if there's already a few examples/guides on the optimizer, LR, and such
the most popular ones are for faces right now
ya the pruned model like 2.1 and 1.5 etc
With an 8GB 2070 super, will I be able to do LoRA training for SDXL 1.0? I keep seeing recommendations for 12GB, but some have said 8GB...
is what I'm wondering as well. even when pinged, sai staff ignores that question for now. might be a legal thing as well - essentially we just dont know, and they have no obligation to provide us with knowledge. might show up randomly in the following weeks, might be partner program only 🤷♂️
12 is the lowest we got working with 0.9 - which wasn't optimized.
in theory, 8gb should barely be possible now -but will definitely take a lot of tinkering.
I'd rather recommend google colab + kohya, as that will work without any issues, nor do you need any weird hacks that may impact final quality
SAI said that training on SDXL is easier. So in what terms is it easy?

I've had pretty good results from just 1 epoch when looking at the sample images
for a lora
to answer in his place - yes its become a lot easier.
just a very few aspects became like 10 times harder, but in return 90% of loras are now 10 times easier
I think they meant you dont need to fight the model to get results
the fact that faces are one of those aspects is just unlucky XD
style loras are essentially fool proof to train now - even bad datasets + bad captioning + bad training settings will give an average quality lora - when compared to what 1.5 loras provided in terms of results
@boreal bough wanna see a cursed image
concept loras are a lot easier to train now - only captioning stays equally important - so if you mess that up, its still a garbage lora

From examples on CivitAI, there are already some pretty good loras for faces though
glad to know styles are doing better, as that's what interests me
I'm going to try a style lora. Just taking a while to get decent images from the 1.5 model I'm using to create the training data
faces/anatomy lora got 10x harder. definitely doable if you have a lot of experience, but dont do this as a first lora.
^ while its easy to 'get results' with sdxl, you are essentially damaging the model significantly if you make it badly. Many tutorials going around that do just that sadly.

overfitting is how most do it - it's also the only option I'll include in my guide for now - as its beginner friendly. but as you see in the picture above, that is the cost of doing it this way\
that donut looks good. fruit loops donut yummm
i still dont get how u all get so great results, my results are "ok"

try way longer prompts, but written with natural language
Fair enough. I feel that we had to take that overfitting with a lot of character/styles loras of 1.5 too
less commas = good for generally good images, even if not very accurate to the prompt

still hoping to get a good anime finetune

but I want to start trying to train anyways
Many tutorials going around that do just that sadly.
That's true about much more than SDXL training. Too much Dunning-Kruger in the world of tutorials.
here are some pics from my 'grumpy style' lora, it makes people grumpy 😄
never gets boring seeing the grumpy faces

needs more lens flare 😄
this is cursed
i mean the concept was ok, im just missing details, hard to describe them in natural language 😄
eyes look generally kinda bad
yall look at the bottom right hand corner haha

Now its asking me again:




should I do any optional steps?
Uh, 5?
Looks like it already did those steps just from the small logs you showed.
3 and 4 not necesary?
Look in logs and see what it already did.
elon and mark
oh yes you are right


why am i not getting photo realistic images
@visual glade So sorry to bother, just wanted to ask if you could help me with something.
I am wondering how to remove images that have been uploaded to the image load node, cause its getting really full of things
found the folder, nevermind!
pinged then found it literally 2 seconds later 😅
yup, thats how I roll lol
when typing out questions, it can help to figure out solutions lol
where
nm sorry misread
be cool if there was a --dont-copy-inputs or something
ummm... I think there was?\
something soemthing right click + keyboard shortcut
someone ask comfy when he's on again
Which aspects?
SDXL better understands a subject?
- is it possible to train on 10GB of vram?
- what batch size is possible on a 4090?
did you change anything to achieve that? my 4090 doesnt go above 1 batch without ooming
training a car for example, now takes around 14~21 min to get a damn good lora
I tried both LETS and bmaltais kohya, both oom above that, are you using the studio drivers or game ready?
game
So it takes less time to train too?
But the min vram is 24 😢
What does conditioning the noise do? (as described in https://youtu.be/2Xe79Nl_6jA )
Since we have released stable diffusion SDXL to the world, I might as well show you how to get the most from the models as this is the same workflow I use on a daily basis at stability.ai. In this video I show you some of the basics on how to get the model from the models to generate your best AI artwork from our models. You will need some of ...

I mean lora training, not generation
i have't trained lora for SDXL
fair enough, sorry forgot to mention it haha
16gb vram for super quick training
12gb vram for no-compromise training
below that should be possible now thanks to fp16 support - but haven't had the time to test it out yet
it should handel more than 1 tho
Oh ok
training at lower resolution is possible - but don't. it does more damage than good if you train anything that isn't a style lora

been messing with this for potential release alongside my 1.0 workflow drop, but I found its extremely unreliable and leads to tons of issues
Yeah, we would need 1024x1024 images or atleast the dimensions specified
The supported res
What’s it supposed to achieve?
for example, on one seed it looks like this

☠️
on another it looks like this

its unreliable and often leads to some very messy and artifact filled results
@soft zealot and I were messing with it in DM's


Thanks!
supported res is built in. just use bucket 512 ~ 2048 (same file "resolution" as 1024x1024, just other aspect ratios)
what res/batch is using 20 gigs?
4090
yeah, but that's pre vae decode XD
huh. you have --high-vram?
yep
Ah.
Is multi res supported?
For 1.5 and 2.1 supports multi-res through EveryDream2
assuming you ignore vae decode, you can go up to batch 49 on the rtx4090
for 1024?
yep
damn
how can i ignore vae decode
doesnt help you though, since vae gonna get stuck
I'm @ like 18 gigs batch 9 using base+refiner on my 7900 XTX
tiled vae - but you do so at cost of color accuracy
@high skiff any more key aspects to make outputs better?
took 90 seconds for 30 steps, so 10 secs an image
jesus the VRAM usage on AMD is high
Original Post:
So how efficient are batch sizes? using @nimble heart .json
Here's the table that absolutely no one asked for! 😄
RTX4090 running full model + tiled vae + cli argument --dont-upcast-attention
batch 1 = 10.9s per image
batch 2 = 7.7s per image | 09.6 GB vram + overhead | 15.44s
batch 3 = 7.2s per image | 10.0 GB vram + overhead | 21.50s
batch 4 = 6.9s per image | 10.4 GB vram + overhead | 27.39s
batch 8 = 6.3s per image | 11.9 GB vram + overhead | 50.41s
batch 16 = 5.9s per image | 12.0 GB vram + overhead | 95.32s
batch 25 = 6.0s per image | 14.9 GB vram + overhead | 151.00s
batch 32 = 6.0s per image | 17.4 GB vram + overhead | 192.95s
batch 36 = 6.0s per image | 19.9 GB vram + overhead | 215.71s
batch 49 = x.xs per image | 22.1 GB vram + overhead | xxx.xxs
squared numbers provide peak efficiency - but I also included some off-peak examples for science!
(I just barely ran out of memory for 49, since I have too much overhead on my win11 machine)
batch 1 is 13 secs/image for the same settings
just saw, I even did it with the workflow you posted 🤣
yup. don't think it unloaded anything though

if you unload base/refiner when you're not using them it'd probably go down


what in the hell did you mess up lol
which .json
he would have had to do a lot more than that
i've got like a dozen floating around now
BS8 with SDXL runs fine on my 10GB 3080
I think it was the first one you ever posted
The one you used for your 2b lora?
not that it's a relevant test - I just wanted to see number go up
yep!
imma try 16 see if my DE crashes
gonna take a hot minute for the kernel to compile a 16k square lol
fp16 on the attention or the vae
since both are pruned, both? I think that's by default now though - if you use the 1.0 model
Sdxl loras don't use the text file??? For training??
if you're using the 0.9 vae, not the 0.9 built in, then use the 0.9vae with the community fp16 fix
bad tutorials. yes they do, and caption files are very important
seems stable @ 20 gigs batch 16. I saw it hit 23.9 before dropping so it might've unloaded the refiner model while it's doing the base pass

both pruned? officially?
it's why the new 1.0 checkpoints are so much smaller, and use less vram
is that new? I'm still using the 1.0's from first release day
as a downside, it's why 'full' finetuning is kinda not possible XD
check size. they're not 13gb, right?
also get the new one, with the vae fix embedded. then you dont have to load the (big) vae separately
I went to bed with my generation time optimized down to 30secs (which was fun)
I woke up and it's 170 secs again, hanging at the vae decode and before starting on the first steps with the k-sampler
same settings, same comfyui w/ nightly pytorch, and even less RAM used by system than yesterday
AHHHHHH
for reasons I don't know it seems to be getting RAM lockup again and I've spent hours trying to figure it out, I've even tested crazy small things to try and replicate the smoothness of how it was running yesterday.
base 6.5gb refiner 5.7gb
0.9 vae 320mb
so guess im gucci
dont forget windows uses vram too. every additional monitor uses vram, chrome uses vram if hardware acceleration is on, adobe apps use vram
yeah i signed out of steam and I'm using a tiny monitor and I close chrome when I'm generating
my windows desktop has gone on a whole diet 😂
rip ❤️
On rocm 5.5 I was running out of vram decoding a 1536^2 image.
5.6 reduced it enough I can at least do that lol. Still gotta tile for 2048 tho


@boreal bough I trained a character lora but when I used the workflow like base+lora->refiner, the refiner made the output less similar to the lora. Do you have any idea to avoid this? I could only use base+lora but it kinda makes the refiner useless.


that's close enough
yes. exactly
it figured out ratchet&clank too tho which is kinda impressive


{kind=link}
{kind=link}
{kind=link}
its from the flavor chain. It might figure out rivet as well if I add a custom flavor chain
the what
only first sentence counts, as that is from Vit-H directly
batch 16 in 152 seconds, < 10 secs an image now for 26 base and 4 refiner steps.
maybe when the winter rocm release comes and my gpu is "officially" supported I'll finally beat those 3090 bois 🔪
the first part, comes from Vit-H - which is the caption that reads like normal text.
Remaining tags come from a custom text file called 'flavor' - where it compares all words, and sees which 'fit' the image best.
But interrogator in A1111 comes presupplied with a custom flavor text of questionable quality.
If you add your own flavor text, then it uses the words that you yourself supply
what do those images look like? Id rather have a bit more quality over the fastest gen
just using my principled sdxl node's default settings

I like the extra quality of 30 total steps over 20
I have a fast enough gpu it doesn't matter too much until you get to like 3 megapixels
does anyone got a 1024 regularization images of woman?
For some reason the interrogator extension in A1111 was ignoring my settings not to put artists in the caption
artist comes from flavor chain - which is 1 single txt file, so it 'can't' tell them apart from all the other captions
it seems to separate them properly on the analyze tab
I've found somewhere around 30-40 is the "safe" zone where a lot images start to become somewhat convergent. 20 -> 30 steps over half of your images get like major composition changes
training a new lora now, fingers crossed 🤞