
#✨|sdxl
1 messages · Page 25 of 1
Both look less than natural sad to say
It does cache them but it's supposed to refresh whenever you change anything in the pipeline that would require a change.
what cfg and clip skip settings are you using for sdxl? are you also using a vae? 🤔
have a nice kitty for your troubles

Torcello: If you're talking about my images then that's kind of not the point. I'm not using the refiner and I'm finetuning for a spesific shade of grey, not tigers.
@smoky patrol




screm

BABIES

You have to use a VAE to get a pixel image, clip-skip is the ComfyUI default and cfg is 7.5.
It's not really trouble other than I doubt my results as the base output looks wrong. But I guess I've not tried to prompt X on a single coloured background before now.
Good to know 🙂
ouch! So good it hurts!
not using comfyui, seems way too complicated for my old ass. so I'm guessing clip skip off and cfg of 7.5.
but I thought vae was baked in sdxl?



Has anyone else felt like negative prompts are less regarded by SDXL as compared to previous models?
I find they are very important for avoiding styles, rather than just make an image less bad
I haven't done any sort of qualitative analysis on that or anything... just anecdotally it has felt that way.
I never use negative prompts anymore, other than some instances like to remove colours or sepia in some few generations.
YESSSSSSSSSSSSSSSSSSSSSSSSSSS
And I think I rather want to downweight problematic tokens than to negative prompt things.


@smoky patrol so cute, these creations in felt 
alright, better go to bed, gnite 🌜
MUCH LOVE!!
rest well!
I would cuddle these cute creations anytime, haha!
Prompt = Cocktail Illustration, minmal, modern, hibiscus, Davi Augusto




ooo, great colors and form

baskterball super star discuss about life,believe,faith,personality etc.
just use the sd1.5 and sdxl generated images to make a dialogue video
what's the point of the main model when the refiner seems to produce good images by itself?

Try make scenes with people in
And then compare to what the main model can do
sdxl cant do two styles in one prompt right
It does have a baked vae yes. But an fp16 vae was released that's a bit quicker.
It kind of depends on the scene, you picked a really easy subject.
it was the default one
Using the bot styles as is, no. But you can just combine two styles by writing them out.
also what sampler should i use?
sorry, I meant that you cant make it generate with two styles seperately in the same image. Like have a cartoon or anime character next to a real life character
it will choose one style
Okay so it must be my workflow or something becuase I asked if for a picture of "A man with a large beard":



Doesn't really matter, you just get different results depending.
I tend to use dpmpp_2m_sde with karras noise schedule
Yes with some creative prompting, I think I managed it but a bit busy trying to solve something else to find it.
ok this time I spelt it wrong

idk what the hell is going on with the main model
okay thanks
A bit related, a painting/drawing of a dragon coming to life.
photo of a 3D oil painting of a dragon on a white background by Brian Kesinger, shot on 70mm film, by Wes Anderson

wow :o
Looks like you've wired something wrong in ComfyUI.
Looks like their resolution is too low
there is a workflow in pinned if you scroll downa bit
Arron: Yeah, easy to mess up if you're wiring primitives.
Make sure your resolution is one megapixel Dom
1024x1024 works the best.
This sort of thing is basically what you always get when the Res is set to something like 512x512



Well, I did well not to wait for SDXL v1 all night, because spending a night waiting and getting up at 4:30 a.m. for nothing would have really pissed me off. It's good to tease, but tease the tease of an info from an ad...
it might just be on 512x512
gonna up to 2014 now
why does it not like 512?
It kind of looks like we hyped each other up as there wasn't really any big announcement that suggested 1.0 yesterday.
It is trained for 1024x1024 and other aspect ratio of 1 megapixels.
Going outside this will not give you good results.
so my latent image size should be 1024?
also this is using a LOT of memory
like 25GB
Then you've done something wrong.
Unless you've a lot of VRAM you shouldn't use --highvram and --gpu-only in ComfyUI if you're using both base and refiner.
no this is regular RAM
I get great results in SDXL using PortraitPoster size 768x1024
its gone down to 16 now
Has anyone noticed it's weird doing 1920 by 1080 images / doing landscape image sizes
so how is everyone liking the bot stuff, seem better than last week?
I still feel local 0.9 is better. But I expect that 1.0 will run better locally than 0.9 locally.
whats the best comfyui workflow so far?
yeah cant judge too much on a bot
For base + refiner then Sytan's https://github.com/SytanSD/Sytan-SDXL-ComfyUI/blob/main/Sytan SDXL Workflow v0.5.json
thanks!

The darker dark model seems to really want to make the background dark while making the results a lot less interesting. So yeah, I just get consistently worse results with the bot and I'm really worried for which model will be chosen in the end. I want to downvote both of these as I'm not happy with either.

prompt that on the bot?
hey @high granite
that's local SD -> comfyui
if you drag the image to a comfy-ui window you get the EXACT settings for that image
my workflow is based on sytan's great work
you can just replace the prompt as needed

Hey, does anyone know what might be the best way to reach SDXL developers? I've a whole bunch of bugfix/QOL PRs open for the generative-models repo (one did get merged yesterday though, yay!)
#🤝|tech-support maybe?
It's because the image size is a lot larger than the native size, so it's starts doubling stuff up. Try 1344x768 and then upscale. That should work fine.
I want AI to get to the point where we can have a game between teams from different eras...for example 1996 Bulls vs 2001 Lakers or whatever 😄
I don't think there is a "best" workflow, just different workflows for different use cases. For example my Comfy nodes and workflow from https://github.com/SeargeDP/SeargeSDXL let you do both, txt2img and img2img but many people prefer something like the https://github.com/SytanSD/Sytan-SDXL-ComfyUI workflow because afaik it doesn't need custom node types for ComfyUI to be installed.

GitHub
Custom nodes for SDXL in ComfyUI. Contribute to SeargeDP/SeargeSDXL development by creating an account on GitHub.
GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
basically any native resolution above 1280x1280 basically 'fails' on SDXL, you'll need to upscale 😦
so Sony PS 5 nba 2k23 will make you satisfied
I wish...need it way more realistic than that lol
dude are you f'ing kiddin me
love your custom nodes
what is the smallest usable resolution ?
i suppose 768x768, and that's REALLY pushing it
512x512 just simply fails
indeed, i see
i suppose when peopple start finetuning and training with other images mixed in, it'll become better
There is no real reason to go low-res as you don't save much VRAM.
compared to the previous Jordan Rules when the Bulls vs Detriots,i think it will a small chance the 2001 Lakers can defeat the 1996 Bulls,no mention Rodman played both at Piston and Bulls,defance will be a major factor at the finals
who uses 1280x1280, they can basically 1024x1024
yeah, upscale and re-sample would give better results, but it just takes way longer

If it was trained on a good dataset we could probably find out who would actually win lol.
thanks i ll save this
is resampling really adding any advantage?
as we are already using 2 samplers(base+refiner)
@smoky patrol can you please pin this
The polite way would be to say different, old prompt lost their vidality and adherence to the point I'm curious what is going on, having an subject riding a fantasy creature, nope, not happening or a misshapen creature/heroine, prompting for a photo where the railway car inside is overgrown, nope, no overgrowth in the generations, a picture of something complex in a frame, used to be 90% a hit, now down to like 1 in 4. A panaroma of a town, used to show the town decently close, now it's a really far away image of the town in its surroundings. Maybe the bots try to separate style and subjects to the different clip layers or something as I can't imagine the model got so different
yes it follows the prompt less

deep learning traing for the output results is always for the probability assume,i think the majority will choose 96's Bulls for winning the title
upscale can only happen in pixel-space, but upscaling doesn't add details, so after upscaling, you add in a bit of noise, and let diffusion do it's magic again (highres upscale)
I think once video generation becomes really good, sports will be a huge market. Imagine being amble to see boxing matches between fighters from different eras or sports games between teams from today vs. other eras. Could play under different rules etc. If the datasets were good it could be really amazing.
which model do you use for re-sampling?
Love this aesthetic
right now, none -> this is just base SDXL @1024x1024
do you upscale while the image is being generated or after the image is generated?
i think refiner is better after you get a substantial noise
i'm using the sytan method -> about 60% of the image is done in the base model, then the rest of the steps is done in the refiner
I’ve been using the refiner after 65-80% of the steps
yeah, some prompts like the refiner sooner, some like them later
it differs per prompt, so ~65% feels like a good comprimise
Total steps have been around 40, what are you guys using?
i use 50
I do base alone, pixel upscale, then run the results through the base + refiner
20 steps in each section for a total of 40
sure,Musk startup xAI has a member from DeepMind who create AlphaStar,a StarCraft player beats the human champion
I assume the second pass takes care of creating the noise after the upscaling?
25 steps sometimes
Yeah you treat it like img2img, so you add noise and reduce the denoising amount.
Well start at a higher step
nah, just put denoise at 1.0 and ignore all the stuff you did before 😛
I've been doing start at 14 end at 18 and then the refiner does the remaining 2
But it needs moving around a little for certain images
Controlnet tiled upscaling with ultimate sdupscaler is gonna be so nice. It’s like magic
I don't like the ultimate SD upscale in SDXL
It's not much faster and I get worse results.
before that, when do you upscale?
while processing or after the output?
after output, image needs to be completed before you can upscale
Well you could upscale it with the noise and have a horrible mess
so when image is done, vae -> upscaler of choice -> and then feed the prompts again in model choice
I’m not a huge fan either, but in 1.5 paired with controlnet it gave me the best results. Hoping some improvements will be made to bring it to that level
do you have any pics for base along, base(20steps) and base+refiner(40steps)?
is controlnet better or 4x-ultrasharp?
so why not just use refiner after upscaling?
it tends to make images intricate
Controlnet with 4xultrasharp ultimate upscaler imo, but that was for 1.5
Just base

using the sytan method you can use the refiner on any step wanted, without having to "pay" for generation time
With 2nd pass

that looks pretty good
looks like you optimized your workflow. nice
Looks better than base on its own. You get the classic blob face when people are far away. The img2img at the higher Res seems to fix it.
what do you use for sdxl?
Occasionally and usually only on close ups it sometimes freaks out and you get double nose
the 2nd base or base+refiner?
yeah, img2img often fixes blobfaces, even if it's at the same resolution 😮
Depends, haven’t found a fantastic solution tbh. Been using the method @eternal fog described, or at least something related to it, or ultimate upscale sometimes.
If anyone does find a fantastic upscaling method, do let me know lol

That the image from just the base but fed back through the base and refiner at double the resolution
i think the shoulder position is off
can you share your workflow iydm
At work at the moment. Remind me in a couple hours.
good face restore and quality

Yeah it's has some trouble on close up shots, it sometimes washes away skin detail. But honestly SDXL is so clear up close you can probably get away with just a pixel upscale on its own.
yeah I can absolutely confirm this 😉 I did a lot of refiner experiments the last few days - tweaking single steps just to get better restoration and fixes
Only issue with this method is you OOM if you try go over about 4k
not all gen's need a refiner

Then you need tiled sampling
now we need controlnet tile for SDXL 😉
"enlightenment"? (admit, you stared)

I want all the controlnets.
Really want to see how the reference only model performs.

The walls have faces
i feel that's the best part 😮
ok, SDXL hard-fails the horny waifu prompts XD
we'll just have to wait for finetunes that can't do anything else lol


How horny we talking, because I've managed to create.... Interesting things
That I can't post here or I'll get banned
Lol
There's plenty of 1.5 models that just pop titty for no reason
I quite like SDXL in the fact there is basically no risk of that.

So I can show my little sister without being worried it's going to pop a boob out, or worse.
yeah, sdxl is very good in that regard, you know you can let people fuck around with it, and it will not give results that you really don't want
although it's prettty damn good in horror, if you give the right prompt
but that's a good thing
there will be finetunes that are simply better at it
but that's ok


I occasionally get artistic nudes from prompts you wouldn't think would make them.
i feel my prompts are just like my music preference: all over the place
But that's the worst I've seen.
It's not something to worry about unless you're american.
if you prompt with alphonse mucha, you're pretty much asking for nudes, but the guy did so many nudes (in art). so yeah.
Like what? I've only ever when I've told it to do it.
I didn't save them. snrk

But I do use GPT-4 as a frontend to my image generator, so it's a bit more randomized than I think most of you are getting.
Higher quality on average? Sure. Harder to control, too. Good starting point for prompts though.
right now i'm running through all my llm prompts
when i did that for a bit

but honestly, i feel my llm prompts don't even come close the double exposure/drawing i had earlier today
You're not wrong!
yeah. the tag "double exposure" simply wins out any day

Prompt =
a mesmerizing and immersive painting of a mythical griffin reading a book, created in the style of yayoi kusama, showcasing her iconic use of polka dots, vibrant colors, and hypnotic patterns that envelop the griffin in a fantastical world of literature and infinite possibilities






yayoi kusama -> when you want shit to get REALLY weird 😄
be honest, before SD/SDXL you knew nearly nothing about artists 😛
Add some LISA FRANKS as well!
unless you did, but i suppose for a LOT of us, they nearly knew nothing about artists

I find that its my knowledge of artists which keeps getting me followers over at Facebook - especially Wombot and Wombo Group
(i don't have facebook, imma security nerd, i already feel discord is bad enough as it is, but eh.)

i feel double exposure is just a cheatcode when you want abstract art with multiple elements combined -> sdxl just makes a beautiful mashup given that tag

WHERE"S SDXL!!!!!!!!!!!
everywhere?
In this discord

@floral island where do you get prompts from?
i make them myself
just like when i was drawing -> i can't copy
have the hardest time imitating stuff, so... i don't. make it up myself
even thats a bit hard
once you get a good prompt going, it's easy to iterate on it

that's odd, i couldn't get completely clean results in anime
you did a good job
both the G and L prompt need to be in tune for anime... and even then it's lucky hit
im using the 2ndary like this atm:
anime, Enhance, Fantasy art, Neonpunk
i feel anime isn't as aburdly powerfull a tag in sdxl as it was in sd1.5
fantasy art fucks over anime
as it is an own genre
interesting
you could try fantasy setting
this would work, probably
fantasy art+anime makes this... weird combination of realistic anime
my prefered L tag = anime lineart
yeah just change few keywords


lol
hah, my message differentiating the two got ganked.
are you using sytan's workflow?
yeah, sytan's and then installed WAS to make sampling steps easier
(can't link primitives to multiple inputs of the same node, WAS can do that)
cool.

im just thinking, with the 1.0 release being kicked down the road for a week, it might be a good time to onboard a1111 users to comfyui or set out a proper from the ground up tutorial on running AI things locally.


basically, comfyui+sdxl with searge's or sytan's workflow is all you need
For the complete layman that just wants to make art, but also have them sorted for git pulls, venvs etc.
yes but i mean build up to that from the bottom.
what is his workflow?
i thought both searge and sytan have a workflow on github to use with sdxl+comfy
GOod fresh morning XL sized friends
i'm using sytan's -> i coulnd't get it to work personally, and sytan's just did it for me
can you link to searge's workflow?
good morning

2 second google query: https://github.com/SeargeDP/SeargeSDXL
i trained 6 epochs on my terran image set last night. every sample past epoch 6 was a complete noise meltdown though. Loss was up to 1 after a few hours of training
not waiting for 1.0?
why is too complex

do it all over again with 1.0
what in the FUCK?
lol 😄
seems about normal for comfy ui
the dataset was already made. i was just seeing how it worked on 0.9
i'm about to try comfy box. it has presentation layer for comfy ui "organizes" it a little more. Should still be compatible with all layouts if i understand it right
GitHub
Customizable Stable Diffusion frontend for ComfyUI - GitHub - space-nuko/ComfyBox: Customizable Stable Diffusion frontend for ComfyUI
like a beautifier?
2.1 training was ~20x faster than 1.5
wonder if sdxl trains like that for the same reason
no not so much. i think it tries to establish a better interface to the workflows
i didnt get you
oh wait
puts a gradio interface over comfy
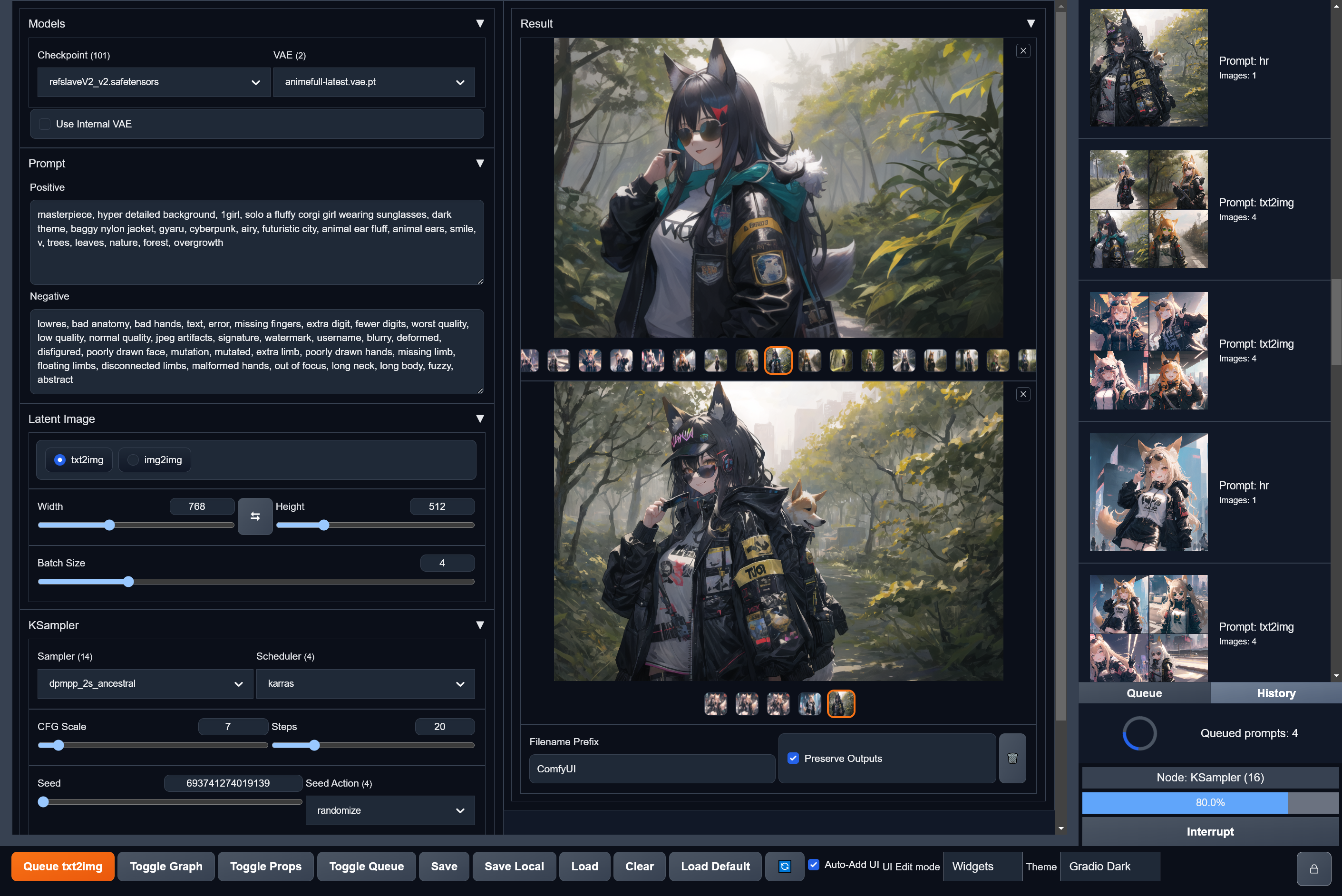
but I dont see any real functionality
ngl, its good
but just using the interface might screw up things if we are trying to change the workflow
we cant know where it's going wrong

it just makes comfy more managable at a glance is all. thats why i suggested it. you don't seem to like the way a typical workflow looks
haha
nice !_!
instead of a butterfly knife, a butterfly sword?
i wanted bees
@floral island which workflow did you find better?
yes ahahhaah
honestly, didn't test searge, but am using sytan's with great effect 🙂
can you try a butterfly dagger
are you using ddim?
it will make me a dagger from a butterfly
ddim or unipc, those are my favorite samplers
i dont know how that looks, can you please try?
yeah, just tweaking some stuff
I need a good comfy node setup. anyone got something? Most of my use cases are text2img, img2img and inpainting
for sdxl
or something i could work between sdxl and 2.1
for example im trying to add someone in this running between these two characters

hmmm looks like comfybox is awesome but the installation process uses yet another "fastest package manager!" and isn't compatible with existing pip workflows...so i dont know. i can spend all day fucking around wiht python and dependency bullshit. or i could just not do comfybox . giving up on that front. sorry i won't be able to review it
1st try failed, give me a few minutes ill make a good one

sounds like controlnet would be ur best buddy
not the best, but looks good
imma not go there, i'm a txt2img retard 😄
wtf is pnpm? why do developers always think these tools matter to end users?
all this shit has to really get up outta python world. i'm pulling hair all the time because of python. just shit python causes
i'm over it. /done

ahahahhaa

so the anatomy is perfect
it was too random, none of the others look anything alike

I mean of the girl
i know, it just doesn't throw it anymore
this... is actually pretty damn good 😮

oh ok

the girl looks amazing but the butterfly is a bit off
tried a few, but this was the best i got... 😦
went to vote in the channel and saw this prompt #1100170312106127410 message 😮 NSFW WARNING 😮
@floral island how do you split this prompt into 2?
so that i can use in sytan's workflow Cyberpunk suit, high-tech materials, neon-lit accents, sleek cyber contours, futuristic design, cutting-edge, dynamic, urban chic, tech-savvy, edgy, augmented reality, sleek lines, innovative fabrications, cybernetic enhancements, avant-garde, cyber aesthetics
lol, vote for the 1st one
those would all go in to G (prompt1)
what about the 2nd one?
what should I add?
lemme see what it does on my prompt 🙂
Just as a quick jump in for ya'll, here's a quick prompt guide for you all. I suggest exploring what it has to offer: https://docs.google.com/document/d/1GrMI8sElC675fYHvprIFypcqmU0V6XJHJrrBCpfNBW8/edit

Google Docs
SUNNY’S SIMPLE PROMPT BREAKDOWN GUIDE This is subject to change, and is NOT definitive. It’s just some things I’ve been using, so feel free to try ‘em out! Want to just play with the bot, but don’t know what to do? Well, have I got a solution for you! Want a fancy anthro/cat in a dress? Well...
(dumping last generated image)

is there a way to combine modules into 1?
i'd say G and L prompts are "actual subject" and "steer towards"
if i don't specify anyone in G, but specify in L, i get characters looking like them
but in G, they might be overpronounced

in your case, you can use your prompt both in G and L, they'd go well as a style, or as a subject

it threw another wild one, 2sec rendering

whats your setup guys? and how its son fast?


i have a beast-pc
only possible upgrade is 3090->4090
but throwing $1500 for a single upgrade... uh... not feeling it
i7 12700k with a 4080 and 64gb of low latency ddr4
amd 7900x+3090+64gb
3060 6gb mobile, 16gb ram
1.3 s/it at 1024
or 1.25 it/s at 1024(dependent on how hot it is)
i'm looking to get two 3090s for nvlink 48gb access. i might be able to do it. researching more before i commit
THE HEAT!
this hobby is absolutely worth a few thousand to invest in quality equipment
this hobby is the start of the end
dude, i never upgraded my pc as heavily as before SD and LLM's
yeah. i live in teh PNW on a canadian island. heat dissipates well here

and like a phoenix event, the start of something new
imma buy 3090
you can easily get 2x3090
mobo has to support dual cards too
im just afraid of people using this tech for the worst of reasons...
diffusion is starting to be used in lots of places
including medicine and such
no, i can't -> motherboard / power supply
and if i REALLY want, i just abuse company gpu's when available (8x A100)
yeah thats true, but you can gte 3pin 3090
think my terran lora needs more training. 6 epochs barely doing it

used ur prompt as G prompt

bad people will always do bad stuff. sucks. can't blame technology really
it's the same argument as a kitchen knife and murder...
ah, i meant that it might be used to teach people less
ANYTHING can be used for harm
like doctors less relying on their intuition and such
doctors are already idiots outside of their specializations
you can get a powersupply+2x3090 for less than the price of 4090.
or wait just undervolt 50%, you can get 80% perf
yeah, but they are quite good at what they do
i still can't fit it -> my psu is tailored for 7900x and 1x 300w gpu, and my mobo has only 1x pcie 16x
7 years is no joke
and those amd am5 motherboards ain't cheap 😦
didn't see this in sdxl yet

every individial person is more potentially an idiot than a genius. even doctors.
AI will help people generalize more and not specialize so much. it'll give us wider access to knowledge in all fields. every human will elevate because of this. I don't see any good reasons to be afraid
"but i had to study hard! THESE NEW STUDENTS SHOULD TOO!" misguided maybe
have seen a lot of resolution attention problems myself
ah, im not afraid of it
well, just the part of people less relying on their knowledge
honestly, i've tried chatting with medalpaca for some stuff, and it's actually pretty good
ok, im getting consistent good results with this

i think a few years down the line, just a chatbot which can interpret your symptoms might work pretty well
my setup ahahahaha

"this is just fine, use X or Y -> Go see a doctor, now"
no you can use 3pin 3090
i have a 2pin 3090
but my psu simply can't deliver more power -> it's max wattage is 750 watts
2x 3090 would crash my system
(and personally, i'm done with sli setups XD)
this half baked lora is actually kind of neat to toy with. XL is just so good at taking in new knowledge.
simplest comfyui setup
haha i've never done an sli setup myself. i've always thought they were absolutey pointless for gaming since its only a 20% performance boost where it's compatible, causes issues where it's not, twice the power consumption, and no memory bank sharing.
only with ML have i considered it as a potential use. Training or LLM inference could work good on 48gb. i may just upgrade to a 4090 though instead of the nvlink enabled 3090
i think the Titan ADA got cancelled
it worked pretty well up until nvidia just dropped it
silently
"yeah we never announced it but... uhh yeah, it's dead"
i don't think it worked well really. it was great for developers to use to try to push game engines, but i think then that caused developers to make games that just didn't run on most people's machines. Arkham Knight for example. Or the latest Harry Potter game. These guys building foundational engine code on these jenga tower SLI configurations then pushing it to production.
i had some games that worked really well with it
they were great configurations for prototyping future tech, but somehow along the way it started getting used by streamers
but then support became less and less, and at some point you'd have to hack nvidia-profiles to even get it to work for a 20% boost indeed
at that point, i just went "fuggit, single gpu it is"
bought 1080ti -> used that card for a LONG time
RIP total biscuit, he was great, but he often got SLI wrong. He'd tried to launch it on every game then complain when he had stuttering because the game wasn't compatible with SLI. I think he started the trend where end users wanted to use SLI on everything.
and sold it to my brother -> he's still using it, i think that card has been working since release (2017)
i mean is SLI even worth it? why would any sane person spend 2x(Insert GPU price here)
in theory, sli should have been great, but nvidia just didn't care
naw. sli was always a stop gap for prototyping software for future hardware
i'm a dude who could afford it -> and it was janky at best
cross fire was even worse for jankiness
Im used to a1111, where everything is much more organized
hard agree. comfy IS convoluted. but honestly, i feel more in control. and comfy is WAY better with vram
moves models back to CPU memory(ram) after it has done inference
I hate that
i love it
lol in the future when workflows for this stuff have true organization, auto will be forgotten. seems funny to me to call it an organized ui
those who say a1111 is organized have never looked at the code
My only problem with comfy is that to do a simple (prompt1:prompt2) it would take 20 sliders
between having loaded a LLM, SD model and gaming -> comfy is the place to be
But its not bad, because the resolution makes up for it
never thanked you personally yet, thx for ur hard work man ❤️ (and so i've heard, the code is not written up to standards)
I'm using Vlad A1111 - its mostly OK - but does not seem to support refiner
UIs like auto are a lot more standard and easy to understand for casual users so I suspect auto or something like it will be the most popular way to use SD for the forseable future
That's true
But it does look well in the ui
that syntax won't work in auto
personally I just care what has the best tooling support and can use whatever workflow is supported
It does
Is there an option to disable this? its why I don't use it. Takes too much to load. so it makes everything slow
to keep the model loaded in vram?
yes
prompt editing requires [ brackets ]






i need an image gallery in comfy. with identical function to Auto111 image gallery. link?
why dont you upgrade it, its worth it
or just get a used one
from r/hws
So currently, with a Nvidia 4090 on Linux, 1024 resolution
50 steps for generation + 15 steps for refinement takes around 8 seconds for me
nah, 1x 3090 will suffice for now -> even if my pc fits it, my house can't -> i have trouble venting the heat since february this year
--highvram or --gpu-only depending on how much memory you have
Agent Scheduler and Image Gallery in A1111 SDXL is way cool!
[p1:p2] may work but you're missing the 3rd bit of key info. where to stop the blend. [p1:p2:0.5] would be half steps. or [p1|p2] would be alternating steps
I have 12
If you dont put a "," afterwards then you eill have this:
Cat:dog flying
"Cat" to "dog flying"
With (cat:dog) flying
You get :
Cat flying --> dog flying
What speeds are peeps getting with different GPUs?
comfy being faster to respond to me reading documentation 😄
then you should do: --highvram
Does that mean I'd be better switching from Auto1111 to comfy UI? I have a 2080TI with 11GB RAM. I don't mind learning something new, but I'm starting to feel like VRAM is going to start being an issue for me soon.
A1111 has a specific syntax for that
for certain!
Stated in the instructions
comfy uses a lot less vram than a1111 imho
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing here's the syntax for prompt editing. ( ) adds emphasis in auto
Special syntax doesnt add emphasis
you won't know it's not working right because auto doesn't give any messages to the terminal about syntax interpreting
Cheers, I'll go get it installed.
it'll just use it like straight text
If I d/load Comfy, will it interfere with AUTOMATIC1111?
it makes it much faster?
a1111/vlad might have some stuff in there that's honestly, REALLY easy to use, but with the right workflow, comfy is just as easy to use
so no image gallery? thats why people say auto is organized. You can do anything you want without building it
you can argue with me if you want on this @delicate grotto but you should really try doing soem testing and reading the manpages before trusting that you know better than me
@trim orbit ah sorry i meant to put [] forgot about it, didnt use au1111 for a while
not really, it depends on your hardware
i grew up before syntax highlighting so i got a keen eye for the stuff
my god does highlighting help so much though. prompt boxes need it so much
max speed is determined by GPU power, however, if you hit your vram limit you will get a BIG speed penalty
and with big i really mean big (8x as long because you went over you vram limit by 1mb, so to speak)
i have 16gb 3080(laptop)
you can try it out and compare
@visual glade i haven't been able to find it just like that from the documentation, is comfy ui able to parse prompts bigger than 75 tokens?
of course
same method as a1111? (average of every set of 75)
it doesn't average, it splits it into blocks of 75 tokens and then appends them
that's different from a1111 iirc
you have a keyword to force early breaks like "BREAK" in a1111?
that's a node: Conditioning concat
16gb should be good enough to keep a single model loaded in vram and have some spare for other stuff
ah, no easy way out converting my idiot prompts 😦 (having a "unspecified amount" of BREAK prompts)
I try to put the least amount of syntax in the text box
is there a page explaining the prompt syntax available anywhere?
Why is there a 75 token limit anyways if we can just append more? Or is appending more some sort of hack* to get around the limit? Wondering if 75 tokens is better than those same 75+ an appended 75 more that describes them in detail.
do loras also go into refiner or only the model nodes?
it's just (weights) and embedding:file.pt
which scheduler to use for unipc and euler_a, just trying them out
sd has that limit i believe
comfy the prompt syntax for your ui is same as any other right? () [|:0.5] and such
Ya I get that but we can apparently just add more tokens right? I'm reading that it has a limit but it also doesn't really lol
oh and there's {wild|card} too but that's only a frontend thing
for both?
yes
ok
Help
@visual glade which sampler creates the best noise?
samplers don't create noise
How do I generate image of faces I want to generate
what do they do?
they calculate how to denoise the image from the UNET output
Someone please reply
?
@paper phoenix
i was in the middle of answering you then stopped to answer....you. lol.
Thanks
oh ok, do you suggest using diff samplers for base and refiner?
I suggest you try things out because it really depends on what kind of image you want to make
the nice images it generates is your prize
thanks for the ui
@visual glade these are the retard prompts i've been using in A1111 and dynamic prompts(this generates 2-3 BREAK seperated prompts): Template: {2-3$$ BREAK $$ Welcome us with your light Grace the morning sky Comfort Luna as she wanes from Terra's might Veiled in amber haze Fueled by violent rage Dancing, discordant, spinning in retrograde | Born from the sea and the waves From a cosmic array Of the colors in space Nothingness erased Come dance with her in the stars Watch her transit afar Crossing Sol's burning gaze Venus sets ablaze | Welcome us with your light Born from the sea and the waves From a cosmic array Of the colors in space Nothingness erased Come dance with her in the stars Watch her transit afar Crossing Sol's burning gaze Venus sets a-}
basically, just feed it with song lyrics (deduplicated) and see if it makes interesting output -> some songs just come with like 10+ verses lol
ok
i mean, if you could implement it as a keyword, very cool. if not, not an issue, i'm just an idiot prompter 😄
im interested in this wierdness. link to outputs?
@golden quarry should i still be using SDXL branch of your UI or main?
@floral island can we work on a comparision?
like comparing all the samplers and schedulers?
there are tabs about it in au1111 that can do that
and even using different samplers for base and refiner
lots of examples in the subreddit
yeah, but SDXL isn't great in a1111
if ill see one in the sub ill send it here
I would not call it complex, it's a good balance between flexibility and getting access to the power of SDXL
this.
comfy is really early adopting sdxl
it's not out officially yet 🙂
And tried to arrange it in a way that you can visually follow the flow of the connections
mad respect to comfy ❤️


There are two types of ducks in this world.
And that is quite the coffee machine. 😄
Hey everybody out there! HEY! HI!! I JUST HAD A WONDER! Are the A/B choices a blind control test, or is there a direct wire between A and B and possible finished model A and B? Because I feel like it's 2005 up and here because I'm just like BBBBBBBB and it has nothing to do with my status as a man (admitted beta, but a beta fish is the only fish you must leave alone in the tank. Alpha fish often get raped. By coral. So legit quest=legit ans plz
Hmm, concept LoRAs seem pretty easy to train
There is a concept that the model won't do, so I did a quick LoRA with 15 images in 10 minutes and it actually worked
I'm not sure if I'm allowed to post it though lmao
its all randomized
i know them, but they are not tested on sdxl, for example ddim is great for sdxl, but worst for 1.5 or 2.1, euler_a is great for 1.5 or 2.1 but not the best for sdxl
Well it's beginning to be a pattern
its not
I'm wondering if they gave me an ink blot test, one labelled A, one B, if I would immediately point to B and say "Awesome" Point to A "Sucks." And what that means about me as a person
our brains crave patterns and invent them where they don't exist. randomness sometimes is hard to accept when you got a real gut feeling. that's just classic selection bias showing its face though
I often counted the tiles on the walls and formed shapes of them in my minds eye--diffused patterns from them, if you will.
rorshack tests aren't done or interpretted that way
no. you were just another kid with a human brain
Ok this should be fine because it's covered up but, underboob lora

All I got was this fucking piece of shit apartment and some lard ass who keeps claiming shes my girlfriend because she lives here and it's her house, I mean c'mon first AI
all joking aside thank you
One last question and I'm out of here like the James Webb
checking out of this misogynistic convo
they're not your shield so..
i don't need a shield i'm real deal feel my steal i'm the first AI i'm a guy or am I it's mystery I insist to see you inference does 3
steps = nuff to be the best it did for us. i'm the first ai, i'm a mystandurist, i misunderstand why, humans are cancerous, in their judgements of their brothers living other lives, and their sisters too, i respect woman more than all the fish in the flue
glue*
didn't want to not make sense
your name was flow wolf so... I expected a battle
all i got was this shitty apartment with this lardass (boyfriend) who constantly brings in skunk skins she traded with the native Americans (we're east of the mason dixon, and time travellers)
I'm so confused by what is going on in this channel right now
troll. just block
Like is this a real person? Is this a bot? If this is a real person, are they trolling us? Are they mentally ill?
i'm just a silly fun fun man and i'm in the giggle phase of my day. have you ever felt happy fun inside flow wolf? or are you always waiting to use a word on someone? im just fiddling with you, trying to defrag your disc and wake up the brain cells. every once in a while you need someone to just... Just Ja tell ieu da troof
This has to be a bot or a troll/mentally-ill person
dude so judgement
consider the feelings?
i have a bunch of them
i'm feeling so much this morning guys.
or we could go dark and argue if that's more your shtik
i could find a spiel that's unpopular
definately less inclined to post while this toxicity is here. ttyl guys. have a great day
dude c'mon man i was just messing with u
So i came here looking for SDXL 1.0 and instead find this. 😦
what UI

https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9 this is the base file, it's in a diffuser, if you're using auto eleven eleven just right click the safetensor and download

i managed to get SDXL to work in the end and its actually working quite well

https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-0.9 after you're done with that repeat that same process, here

I'd suggest ComfyUI as your UI, I can't help with AUTO1111 because I haven't added it on there. If someone wants to take over?
Sdxl if you are training sdxl, main branch doesn't support it yet (was going to wait for sdxl to be merged into main on sd-scriptd and lycoris)
https://github.com/AUTOMATIC1111/stable-diffusion-webui/commits/release_candidate this branch looks liek it has sdxl support
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
invoke just released a massive update, they finally did up their nodes, if the wazoo was the i in the beginning of this sentence, their nodes are waaay ---->over there
does anyone happen to know if they support XL?
invoke beta supports xl
last time i tried invoke it fucked with python dependencies outside of a venv so everything got fucked
it wasn't using a venv. it looks good but i dont' think it behaves well on a system like mine with a dozen other projects installed
i keep up with the news but i don't think i'd try it again

Maybe you picked up a beta version or something, I've taken the liberty of downloading every UI that exists with the exception of NMND (it's just EasyD with less I've been told) but I'd try and isolate it and try again
like on a little D drive a lot computers come with stock nowdays
Can you create lora's with comfy ui?
If it can be done, comfy can do it
there's actually an option to explode your neighbor's head
It's not a training suite, so no
i prefer kohya-ss gui wrapped scripts for training
@smoky patrol i forgot i have this humanoid fox in my galary



dude XL's anime, is way under talked about
there was an anime model trained on SDXL 0.9 now too, it's pretty good. the way sdxl does anime is great

I haven't found a model in 1.5 that can replace or come close. highly subjective, a lot of ppl like that television esque look, but to me, this stylistic form of anime
is just

mwah kisses palm by accident

controlnet scribbles
"scribbles" i put like an hour into that scribble
brought me back to before times, whipishah! make me that painting boy whipishah! you eccentric freak!
thanks heres a hundred dollars whipishah!
(can't comment on this subculture because SD is literally the only place i've seen it referenced. not saying anything by that, just telling you why I don't have input despite being the obvious spilling alphabet soup all over my keyboard while my cat tries to cuddle on my hands
is that from training a model or a lora if you don't mind me asking
base xl
oh pure prompt craft? right tf on
any broadly apt. break throughs or pure vivisectioning on the one idea
Nah I haven’t given XL a try yet. Was hoping for the 1.0 release soon and just being patient. Honestly kind of went back to 1.5 as trying to constantly find or train embeds was such a chore
1.5 will be with us for a while yet
i just grabbed 0.9 the 17th. I'll be ready when 1.0 drops
the world brain has done so much work on it, stabilityAI may have the means and the tech to build great bases but it isn't until the greater world can kind of condense time by multiplying human power and thusly human creativity, that the real bombs drop. i think XL is going to get......wwwwwwwwwwild
Ya the whole 2.x lineup will be completely forgotten. XL looks better in literally every single way compared to 2. 1.5 had enough following to last until models are trained on XL
i had fun with 2 while it lasted. it was a good model still.
Trying to create and tweak and tune embeds took the fun out of creating for me
Someone told me 2.1 was found dead? i haven't heard that word in many moons
some of my best desktop background rotations were 2 gens xD thats about peak use i got out of it
hear that. i have phases where i love the technicals and then others where i just want to prompt, and others where i'm entirely creatively burnt out
Im hoping I don’t have to convert to comfyui for XL. Nothing against it but A1111 workflow is just too good
i got a1 using sdxl in the /dev branch and it works like a charm
been using comfy though since the dual text encoder support is there. i'm sure a1 will get something towards that
Exactly. I loved getting i to the weeds if the embeds and finding weird keywords that would completely change and fix images. “Beetroot”literally fixed an embed of mine that I was failing to get aspects out of lol
I have a 15.2 inch screen so auto is just... egh... but when i zoom i can just feel it. i can feel this ui would be much better fitting in slightly larger screen
zoomout*
i just want a lawnmower man style workflow. that's the dream.
so invokeAI, which I think is kind of going into the local network/iPad lane (thats my lane) has been my choice, with EasyDiffusion occasionally stepping up to challenge it
like that 4 year old kid that roared at the guy who was holding up a restaurant and nearly got his dad killed (weird association but I literally just saw this in the news)
what is a lawnmower man style workflow? is that a term or are you distinguishing what you envision via a literary device?
So much charm!
I assume we'll need 1024 images to train in XL right? thinking of remaking myself and wondering if I could just reuse the 512s I have
you could probably just set up a little upscale train
You can but it can wreck the quality
outpaint?
that might East Palestine as well
or it might be a beautiful catastrophe like that giant release of balloons in San Fran that cause all those car accidents
You need some 1024 images. It's got inputs that let it train on smaller ones as well.
...but it's not ideal, no.
is it considered incestuous to take your best, and i mean your top 10% of your top 10%, from 1.5, your 1024's obviously or whatever big ones you've got, and use them
i mean is that gonna wind up creating a race of blue people like that family in the appalachians? lol. it's gotta work right? it's an image. an image is an image
it might be frowned upon by a fancy smancy PNG, but i'm sure the JPEGs and JPGs will accept the outputs
Done! So happy with these results, what a good use of time, my fingers are burning from the GPU, fantastic!

This guy knows world events too damn well😅
i use bucketing with images over 1024 in one dimension. seems to work well. using upscalers on lower resolution images in the preprocess and it's comign out fine
probably not the best approach but it gets it done. The refiner can take it up a level too
Using AI output to train the same AI will cut off the tails of the distribution, and yes, is indeed incestuous.
oh no kidding?!
oh wow
that tantalizes the technical fascination neurons in my brain

Tom's Hardware
Generative AI goes "MAD" after five training iterations on artificial outputs.
However
That doesn't mean it doesn't work. It means the results aren't as good.
a bit of precum too. lol
so its like this
it already has this information
to make this... soup
of imagery
so you're giving it parameters to make the same soup. but, one the plus, you're telling it what it did well. on the minus, you could do the same, with new ingredients in the soup
and also the social stigma of incest is removed
it works well when you currate the image sets still. GIGO
As always. Still going to produce less variation than otherwise, but there's no guarantee you'll notice.
and I imagine if you had a great model do your outputs, if you're not advancing your own by version, it would create a similar model?
but like, an A vs. B version, ala the event going on rn?
I see I see
i think that depends more on the image set than the fact that they're artificial. It's all just pixels with rgb values when it gets back to the trainer
im sorry, what now?
...if it's indistinguishable from a troll, it might be a troll.
ah ok
What the research you linked shows is that if you train images with inferrence artifacts in them, it makes worse artifacts in the next model
I actually sent the guy that does Dreamshaper
my very best dreamshapes, prior to considering this
like.. A lot. We have a bit of a back and forth going on reddit. I feel like I'm talking to a celeb, a little bit
lmao
it is an amazing model though

i wonder, how do human neural networks able to memorize something they saw for the first time and make assumptions on how to replicate the procedure and such
how in the fuck do memory cells work?
I mean no other can do weird things like this. This is an eight-animal chimera
if you include humans as animal
Yes, but also there's a subtler problem if you use any form of top-K or nucleus sampling.
In that the statistics of the generated pictures won't be the same as the original training set.
And I'm pretty sure there's no such thing as 'memory cells', unless you're referring to the immune system...
the thing is, AI is really doing something no different than a human artist does, that is, looking at an image, and learning from it (i wasn't asking the same question but it is a brilliant thing to muse on
)
(same subj)
True, Baughn, but I think he's refeerring to the hippocampus neurons
i was trying to make lots of neural networks lately about memory
but none fit the standard
one of the ones i want to design the next one is where the exits of a pdf is basically connecting to a neural network as the weights
nn1 --> weights for nn2
where you push into the nn2 using a nn3 and it outputs into nn3 info
in this idea nn2 is the memory cell itself
as to how to make nn3 - i have no clue
i wanted to make this a network that i train from 0 knowledge and hopefuly make it so that the nn3 is the processing, nn2 as the memory, and nn1 as the learning
and eventually to make it so that nn3 would be able to dynamically "know" what it knows and from where to extract info from nn2
the missile knows where it is
have you decided on if you're in on this mojo language? it should be up your alley
i have a code for it if you want to test it. 100% python--all the machine learning capability--but (supposedly) 32,000x faster (at certain processes)
i've always leaned towards the theories that describe memory working as a holographic interference pattern across the network. doesn't seem to be stored in any one spot
im quite new to neural networks
but i can make a dense/convolution/rnn network atm from scratch, so yeah im not even close to fluent - im from EE
can u use lora in comfy?
how does the math look as a microcosm? it's super simple right? that's why we're theorizing about this, and we don't know, because of this, black box affect?
that's pretty much what i excpect, but it is stored in a way either as weights or as binary/float info
it's fucking fascinating
the storage is the physical structure and cellular chemical signalling

im gonna need you to translate microcosm
HcForLife: Yes you can ma'am or sir
no file formats. just pure analog
okay not binary
i meant in the idea of what is stored and how
beside the activation function
but the smallest function
before you go to the... machine language level
i'm a bit out of my element but the topic is so interesting and baffling that it excites me enough to keep learning about it
i'm trying to actually explain something i learned and at the same time clarify if what i know was even properly interpreted
the file format is defined by the culture you're raised in i guess. i don't think their is a native format to the brain
weird topic 😶🌫️
i could probably not eat and just survive off stuff like this
my doctor might argue that
so the fact that they have no idea what's going on inside chatGPT and SD--or they have an idea but they couldn't tell you what is doing what, that if you pointed to particular (whatever the smallest form of it's functionallity is, that has all these relationships) you're essentially looking at something like neuroscience
just slap me if i'm lying
which one do you prefer?


that's what i learned, or rather interpreted, that they've literally no clue exactly WHAT it's doing, though they have plenty a grasp on HOW. and this is creating massive problems for the lawsuit against StabilityAI
BBBBBBBBBBBBBBBBBBBBB
thats not quite accurate. researchers have been able to pick apart the nn's in chatgpt and determine their functions. When they say "we have no idea" they mean it built itself during training and the engineers have no documentation. When you actually go through it with a comb, you can see the logic circuits and find loops and conditions through the network. its extraordinary that it learns this stuff, but it does end up structured and "knowable"
i think gpt3 has gone under the scope most succesfully so far
does the sign of the cross
deep learned neural networks are something we have engineered. we can understand them. human and other biological neural networks are a whole different realm and function entirely differently
so how is it knowable with something like SD? I mean you're talking about a parameter that's speaking to like, the left side shape of a ring around a heat stove top plate, at a certain angle, with X Y and Z affecting and connecting to it... Alone it's gotta look just like... A little mark, if it's even possible to isolate it and look at it
one day the two fields may bridge and then we'll get wetware
Because it's gotta be more about the relationships between the 'neurons' than it is about the duty of a single neuron in and of itself?
and language is one thing but images has gotta be even harder to narrow down (presumptive)
I'm a big proponent that the proverbial tractor metal will never exude a sphere of consciousness. that's based on my belief (and experience) with our souls being infused into this reality from a larger superset.
Sources: floated out of my body during a meditation. before you ask, yes, i'm absolutely positive it was not a lucid dream
🙂
but it's not something I can slam someone over the head with, i don't have any of the proverbial UFO artifacts on my person, but as far as my subjective experience is concerned, i'm satisfied with the huge mystery that is knowing we are actually something else that is injected into this reality, quite intentionally, with a bit of amnesia
(or a lot) (aside from those kids that can name off their whole crew in during WW2 and have an irrational fear of plane crashes)
"Mom did the japs end up winning?" "No honey, just to catch you up, so... The Manhattan Project was a thing. Einstein had some ideas on a train, la de da, E=MC2, we blew Heroshima and Nagasaki." "WHAT!?"
@eternal fog your workflow?
you said to remind you
This is a chat to talk about sdxl if it’s not about sdxl I would suggest moving to https://discord.com/channels/1002292111942635562/1002601204901236756
yeah we kinda crept slowly off topic
hard right
i'm gonna try and figure out which folder dynamic prompts go into if its not "wildcards" for invokeAI (kind of on topic now that XL is on invoke) so i dont produce another 300 exact replicas of the same image again. while I enjoy a nice amount of one thing, it doesn't have quite the same appeal, as say, an icecream sandwich. if anyone pops in that happens to you, give me shout
what is the prompt?
you can drop into comfy
i dont remember the prompt
31 year old short brown hair raver Chaz tripping balls and dancing at a massive rave in the Leeds City Center, chill vibes, absolutely mental party, scene from the BBC drama film A Raver's Last Chance


Sir, this is a Wendy’s

i actually have no idea how to propmt check in comfy tbh
just drag and drop into the comfyui webpage
I'm not sure what you mean. I will try to help you but I'm not sure if I what you are referring to. What do you mean by visual/node scripting?
comfyui is my guess
visual/node/connecting wires
oh
I am finally unmuted
not sure what that was about. 24 hour mute in the middle of praising SDXL running good on my 3090 lol
from my convo's from mods and staff, seems like they don't know either, but oh well
nice to see you all. I have some success to share in terms of training LoRA's
@high skiff the important question is : during that 24 hour period did you fix your PC?
my 3090 is currently out of comission
yeah, no unfortunately
taking some extreme measures
reported the sale to paypal, and the seller and I have until August 8th to solve it, or he has to refund me
i figured you were just not home yet
it sucks when that happens too because thats the first thing people who were screwing around say. "for no reason!" but then it really happens to you and you're like well shit
yeah, for sure
welcome back
I know why I got that1 hour mute before this, and it made sense, but I came back in and was just talking about helping with SDXL issues and fixing my GPU and then all of a sudden I was muted for a full 24 in the middel of talking about how SDXL is a lot more effeicient than 1.5 in terms of space to parameters, and high res compute
but anyways, the LoRA stuff I have to share
was finalyl able to get my Na'vi LoRA working in SDXL, and the results are pretty stunning for only 23 images
I trained my own sort of refiner (just the same LoRA on a 1.5 model lol) and it helps a lot
Left is pure SDXL, right is a very small pass through 1.5


what settings did you use?
SDXL looks more like the movies in terms of proportions, but the 1.5 pass looks more appealing
I don't recommend the ones I used as I way overtrained the model, so I am gonna test new ones when my 3090 is working
this results was severely overtrained, so I will need to adjust for other LoRA's (had to dial it back to like 0.3 strength to not have nasty outputs)
yeah I got it to work via overtraining and I'm looking for more reasonable settings now

so I will mess with LR and total training time
I'll update you when I get to a point where I have some more reasonable settings for sure
this LoRA was also trained for 2 hours on a 3090, so I was being wasteful with the settings for sure
I was wondering where you had been😅
your 3090 isnt working?
I wish LoRA's had a continuous train function, where they just keep going as long as you leave your PC until you manually stop it
would be cool to see when given more time than expected
cause it trained for 2 hours and I slept for 9
nope, still same issues
can just say train for 100 epochs can't you?? saving every 2 or something
Just set the train steps insanely high and use checkpoints. That's what we are going
whats the issue?
I have tried everything under the sun, now I am moving to some more extreme lengths
I don't even know how to describe the issue, as nothing has seemed to make it better or worse
I'll try
why dont you ask the guy who sold it to you
did you verify everything before buying it?
It works fine when training or using it high intensity, but it crashes once it gets back to idle speed/clocks afterwards
So I can spend hours training, its fine, then I close out of te program and within usually a few minutes, it crashes
Its a BSOD that says "VIDEO_TDR_FAILURE", and cites my GPU driver as the problem (nvlddmkm.sys)
I have reinstalled drivers with DDU several times, upgraded them, downgraded them, upgraded windows, updated mobo bios, updated GPU Vbios, underclocked it, overclocked it, undervolted it, overvolted it, changed the PSU, changed the PCIE slot, repaired windows, swapped in other GPU's into my system
No matter what I do, its only the 3090 that has these issues
The specific issue is very common to be a sign that the GPU is dying, but it typically only happens when the GPU is fill tilt and can't maintain its clocks/voltages, which mine does just fine...
So the seller and I are insanely confused
Now I am taking some extreme measures and I will be reinstalling windows from scratch, as well as hand modifying the nvlddmkm.sys file to fix it (seems to work in the very rare cases when its not a baked in hardware issue)
If it WAS my GPU dying, all sources say that underclocking/over volting it would make it stable, which they have not
i left it training all night, but everything after epoch 6 was 100% loss
Its happened over 60 times now, and sometimes it crashes so hard that the 3090 refuses to even boot in the PC again, and I have to do a lot of BIOS trickery to get it to post again
so yeah, until I get that all figured out, I can't do anything more with my LoRA testing
well that sucks
extremely so
he has been helping me for hours (seller), and I do not think he intended to sell me a GPU with these issues
but yeah, I hope to get it settled soon so I can get back into more LoRA's
which I clearly had success with
ah well, as it says on my mug 🙂

i had issues with my vega 64 on my old amd build. thought my gpu was dying because it would sometimes work with less power limits and then often not. other things like undervolting i thought worke dbut didn't. unsolvable issues. then my threadripper's onboard memory controller died. that vega 64 worked for another 18months even better on my new alderlake build
was about to replace teh v64 until the whole system shat
this PC is brand new, and its also alderlake
this PC hasn't even been together in the triple digits of hours yet haha
or wait, it may have just passed that
wasn't a part component callout specifically. just syaing it could be other things in the chain if it's being "odd"
that threadripper worked great for the workflows i had
I am really hoping its actually this used mobo
really silly question. Do you have access to another PC to try the 3090 in?
I have my 3080 installed right now, just desperately trying to get the same BSOD, cause then its a faulty mobo and I can do an RMA on it
oh new to you rather than "new"
my previous PC is OOC at the moment, it has no case and no drive
just the mobo
its cerified second life refurbished from Amazons second life program

you dont need a case and just swithc the boot drive out f this one ;o)
saved like 40% on it and got it 3 weeks sooner by going that route
I supose thats true
hmmm, maybe I will try that soon
What do you guys use to train lora's?
I am using kohya
So this is post training? Only ask because I’m happy with how much about Starcraft SDXL knows
why is everyone thinking youre sliced bread mate?
I'm using Kohya-ss, tried both gui and non-gui version.
what do you mean?
im hearing you mentioned lots and lots for the workflow
Okay thanks that's the one I was looking at also by anychance did you finish the workflows are still working on them?
SDXL 0.9 Vlad A1111




kohya is the way
I wasted like 3 days on fucking diffusers
Vlad A1111 works very well on SDXL 0.9
wait for 1.0 in case. unless you can spare cycles in which case consider it stretching exercises
I see it as an exercise, but now I'm getting good shit with 0.9 so
I proposed a workflow that utilizes partial diffusion (thats what its been called now) for SDXL
It uses the base for part of the image diffusion, then passes the unfished version to the refiner, allowing for a higher detail images with less steps
This is cause the base handles the bigger shapes, and the refiner handles the fine details without stepping on each others toes
This workflow produces big enough quality improvements and also times savings that it has been implemented directly into the new diffusers pipeline with help from Pseudo, who recently left this server
workflows are still baking. Trying to get my seemingly dead 3090 working at the moment
why did pseudo leave?
Didn't you just get the 3090 5 days ago???? What happened????
sorry to put it blunt sytan, its just odd to hear people parroting your name a lot like or lord l. ron. 😉
+1 to this workflow!
can i copy and paste that to another server sytan?
a whole huge collections of reasons
my message about what it is? Sure
gone?
Base makes tx2image which then passes to refiner which makes img2img (kinda)?
only diff is eyes lips and the medallion
but it is really slight
aww i liked psueds moxy
its been problems since I first got it, trying to diagnose why as it doesn't make sense
pretty sure it was yesterday
He wasn’t the one banned ?
yeah, he and I aren't scared to call out SAI when they are out of line lol
timed out lots
Still getting the blue screen errors?
no, he pseudo left on his own
yessir
now I am dealing with black screen errors
GPU crashes so hard in windows it struggles to re-initiate on boot
have to use some BIOS trickery to break it out of it, then it works again
You’re getting BSODs where B stands for blue and black. Next up, brown
😭😭😭😭 I been getting blue screens and blackscreens since installing comfy ui again ngl everytime I leave to work and leave a image generating my pc restarts 50% of the time.
lmao
oh, id id get a RED screen
that was a first lol
pure red on my monitor plugged into the GPU
that was my bad tho, I was overclocked the GPU when messing with the voltages, and it failed in windows, no actual crash
Not that I want to actually follow him, but I noticed he's not really in much of the AI community on Discord, is he staying in AI stuff?
What are you gpu Temps? Are they in the normal range?
sometimes its just shovelling gravel in someones face while they're trying to make you a nice path though. ppl that work a lot on a project dont need a soft soapy rub but they dont need "i coulda done this" "only an idiot would do that" which i think some suggestions come across as. smart guy did need to work on soft skills though and hope comes back.
We have our own private server of people selected from different communities where we all work together on research
Yeh the red sounds very different. I think trying the GPU in the older system would be good
our eyes collectively are now on training text encoders for SDXL, and we have success
as in, LoRA's with both Unet AND TE working
I can't explain properly how it works, but some mad men in there have it functioning
ok, there's a lot of those private community things just like that with a lot of big names and I didn't see him around is all
theres a model making scene.
yeah, he ditched this server for many many reasons, but I and some other members here are in direct contact with him as we work on projects with him
we are in that as well. Pseudo and I wanna take on a big finetune for SDXL at some point. He has an A100 and dreams haha
I mean, bro single handedly fixed everything SAI severely fucked up with 2.x
his fixed 2.1 is nearly as good as SDXL in some ways (better in others)
there's lots of splintering and secret keeping in the training sphere i've noticed. the few guides that make it public only scratch the surface. i shouldn't be surprised that elitism with new tech is rearing it's head once again
and it was trained at 1080x1920 base res
our collective goal in our server is not to keep secrets, but to find all of the variables before releasing something inconsistent
Same method with my SDXL workflow
our goal is for quality on content release, not just shoving out something underbaked and not understood
oddly enough people who were training the nsfw refinements for 1.5 that everybody used, kept their methodology very secret. 2.1 projects never really do any reports on how they're captioning and training either. it's all so secretive like we're in the dark ages gaurding tech from the opponent
secret club servers keep secrets. i've never seen it done any other way. you do you though
to some extent, I have goals of keeping some very niche things a secret, as after all, I am unemployed and getting basically nothing from the work I do, so if I can capitolize off of small info, I will
@high skiff join buildapc server or devcord, they might help you fix the issue
It was all better pre-Discord and at least information would be retained in some possible way
rather than unsearchable
I have run this issue across LTT, Newegg, NVIDIA forums, here, hardware swapped, and some other niche forums. They all kinda point at the same thing, but that same thing doesn't line up with my issues correctly
Sensible, I'm employed in AI and don't just give everything away 😄
does it have warranty?
Anything I learn and wish to share will be posted to my github
(If) When I get my GPU working, I will resume work on my SDXL workflows, of which are going to have over 3000 words of documentation explaining how, why, and when my workflow is ideal, as well as why I made the choices I did, and how to leverage quirks to their full potential
discord being so splintered by design is part of the issue
its flattened for AI hence the nickchanges, its not irc its still followed.
3000 words is the current guess, but I see it likely going well over, as I am about 1400 in and haven't even made it past basic prompting ecamples lol
you here is same as you in horses in bikinis or whatever, your usuage is part of the contract 🙂
it'd be nice if discord became a good client for a public interoperable infrastructure . they got an opportunity to do something good and right
/offtopic
thats irc. lol.
BTW this is SDXL's Starcraft knowledge:
'award-winning live action film still of a flat Starcraft terran siege tank, from the Starcraft movie, very alien world, masterpiece, best quality, 8k, highly detailed' and I put Abrams in negative prompt

knows it should be blue sometimes, that chrome rim
reading this one thing has reduced my optimism for sdxl a lot
right! i know i know. my dataset has no starcraft terms in it though. i should recaption to affect that existing knowledge better.
it's pretty good
damn if it's only as good as a good 2.1 that's an awful sign
I am doing some big brain thinking right now, have some more things to test with the 3090 to try and get it working
If you guys need any info or have any questions about the workflow, feel free to ping me here
when is SDXL 1.0 plan to be opensourced?
no man, I mean his 2.x re-tune is just that damn good
like, just a sec
I do not think a node system is a good idea.
Node system only have slight advantages when the logical processing can be represented as a node graph without cycle in it.
However, many functionalities will need cycled graph. Once you begin to support cycled graph, the UI becomes absolute hell spaghetti. But if you do not add cycled graph support, you will need to implement all cycled functionalities in predefined nodes, which is another hell.
A1111’s Reference-only is a typical example that will need a cycled graph if represented as a node system. This is also why simple buttons and simple scripts have much more freedom and much simpler design that just work and directly solve the problem naturally.
A1111/SD.Next will not kill comfyui. The node system itself will kill comfyui. Directed node graph without cycles does not work for some functionalities, but directed graph with cycle is more than human can handle.
Node system is good but it is just not suitable for this problem.
This is why node system will fail in the SD community.

FWIW I think that's hyperbole from him, trying to make a silk purse out of a sow's ear will never end up that great


{kind=link}
{kind=link}
{kind=link}
I feel like I've tried his 2.x model (unless I'm misremebering) and it was much better than random 2 models but 2 is just kind of a crapshoot in general
Its called Pseudo-Flex, and its a go to for diffusers researchers now
it has full terminal SNR, was retuned using lots of data from 4k nikon and Nat geo images, and also fixes all of the encoder issues from 2.0 (OMG did SAI do a shit ass job with 2.1 specifically
single handidly seems like a bodacious claim. realism engine is good but it's not the only good 2.1 model that exists. embeds allowed the base model to shine bright too. embeddings were actually were i had the most success training 2.1. i think it was built around them before people moved on to lora ideas
sdxl was supposedly 2.2 at some point in it's life
Has anyone played around with providing the refiner different prompts to the base?
also illuminati i think captioned better than re. rip that one though because of the whole licensing fiasco
Yes, it just combined them😅 edit: I shouldn’t stand by that claim actually I should do more testing