#💬|general-chat
1 messages · Page 178 of 1
How can I speed up stable diffusion and can I save the images that generated ones?
do i learn tech or video editing if i wanna do entrprenuership?
It should already be saved if you use a1111. Check your a1111 folder for a "output" folder. And in your case you can speed up by upgrading your graphics card so you have more then 4gb vram
Really asking the same questions over and over huh
I was about to ask a question about img2img but suddenly I figured out the answer right after finding this thread just by mere coincidence. is it possible someone redirects me to a thread or external discord servers where the discussion on combination of params for generation is discussed?
Hi, I have a proposal regarding marketing and business. Since you don't have a ticket system, may I ask who I should contact?
@still glacier
@bleak matrix
@jade wren @odd cloud @hidden dagger
This discord is meant for public/community usage.
For direct contact with stability team it s probably best to go through their mail.
https://stability.ai/contact
There is no output folder
how do i generate ?
go to tech support and check the pins for guides
really dumb question, i assume the answer is yes, but if i close the web browser while i'm generating images, the genertion is still working right? Since the CMD is still open
it should still work yes.
Is the website down just now stability.ai ??
what UI are you guys rockin for local generation
Hey, do you know what dynamic thresholding does
nope, sorry
K
swarm ofc
is it easier to use than comfy? 😭
yeah definitely, https://github.com/mcmonkeyprojects/SwarmUI
also i recommend checking this one out:
https://github.com/mcmonkeyprojects/SwarmUI/blob/master/docs/Why Use Swarm.md
is there a way tomake the swarmui models folder point to my forge one?
yes in the server configuration tab
these prompt are making me go crazy... was doing fine this morning, had the effect i wanted, now trying it again tonight, doing the same prompt (i copy pasted it), and it refuses to give me the results from before, i don't get it
when all else fails, symlinks
how would i set up something like adetailer or the scripts from forge? (if youve used those before)
https://schinagl.priv.at/nt/hardlinkshellext/linkshellextension.html install this an make symlinks right in explorer
Adetailer is for face editing right? Theres a extension for adetailer in the extensions tab (server? Not sure out of my head) and theres segment:thingyouwantedited prompt for the automatic impaint like best quality, blue eyes, brown eyebrows etc
thanks! im in the extensions tab and it looks like theres only 12 available. is that all of them or is there a list im missing somewhere
No that's all of them. Many features/extensions in forge are either already in swarm or got a comfy backend fix iirc. But if there's something really missing you could hop onto the swarm discord to ask on how to do a specific thing
What are you missing?
forgeUI had this cool prompt search and replace script where you could run multiple generations back to back replacing part of the prompt automatically
i could live without it but it was a cool feature 😂
guys
is bluesky popular in us and europe
swarm has macros
and grids
https://github.com/mcmonkeyprojects/SwarmUI/blob/master/docs/Features/Prompt Syntax.md
lots of nuggets in the docs. this is a good start point
thanks ill check em out
anyone use pioniko here?
idk my pio use fp8 only .. i download fp16 and delete fp8 for replace but cannot run.
when training an image ai would uploading just comic strips be okay or would it end up having the ai make a mess of an image
training set is 90% of the effort for what the model becomes. it'll learn to draw comic strips then. It'd be better to get high quality crops of each cell
depending on your goal
a specific artist's artstyle
Train a lora
if the artist is famous chances are there already is one
have you checked if there is a lora for that artist?
a lora is like a plugin for a full model
there is but it still seems to have that generic ai look to it
what's the artist's name?
jlullaby
https://stablediffusionweb.com/image/25622118-robot-woman-with-removed-face-plate what for checkpoint is this ?
You should try "Jlullaby style PDXL, Illustrious" Maybe with the right lora strength and good prompting you could get the style you want.
so would just comic strips still confuse it and have it end up making a mess of an image or would the civitai trainer recognize the details from the body
"Trained on art by Jlullaby, got some help with this one ;getting rid of as much text as possible, specially watermark logo."
well i just dont know how many images they uploaded to train it because the most images used the better right?
the art i can find already looks very inconsistent. it's gonna be difficult to train on an artist that uses lots of different styles.
Hello, I have a short question. I have took some photos from my last shibari session but in my living room. So there is a lot of stuff in the background. Is there a good free (and best local) tool to remove and normalize backgrounds? I have tried the MS Picture editor but it doesn't work well. My plan is to remove the clutter from the background and after that blur the background. Any tipps what tool would be good to use. I do this for hobby and not comercial reason so freeware and easy to use would be nice since it is not my main focus ...
can try a remove background workflow
I am new to a1111 so I am not firm with that workflow.
could use layer diffusion extension for forge, but it probably doesn't work anymore since trolls started sabotaging that project in the name of GPL
theres an extension for a1111/forge called rembg
OK, I will look at it. Unfortunatly when you google "a1111 blur background from image" there are only results for commercial tools, no tutorials ...
But is that not only for removing background? I want to blur it a lot or make it look more cleaner but it should be the image of my room but maybe without that clutter and extremly blurred. I wish I could show you more what I want 🙂
You can use gimp to remove clutter and blur a background, you dont need ai to do that for you
Gimp is free and theres plenty of tutorials that can show you how
I have done that now. But it is semi good 🙂
When I get clearance from my friend aka model in this case I maybe ask for some kind of guidance on that as an example ...
Everything I tried seems to look unnatural though
What kind of photoshoot are you talking about?
We took some fotos of her in my living room. Just for fun and also so I can test or better "simulate" as if I want to upload them somewhere and also for us to look at. Nothing nude if you mean that 😉
Simulate? You want to make a ai model of her?
But yeah for your original request to remove clutter and blur it is still a manual job unless you hire someone to do it. Gimp is a nice tool that can do all of this
No. I mean more that I don't like to try things like working on something with dummy pictures. So we made some photos of her in shibari and took some nice photos. The idea was that we get some experience in such photos - how to take, blur the image, make them look appealing as if we want to upload them on some platforms like reddit or social media (I have no social media) and use those photos as the guinea pigs.
I have done that for other photos I took in a greater hall so the background was kinda clean. Now with my living room when I review the pictures I see that in the background there are cupboards, some shoes on the floor, the tv and such and some plants. That all is a) diestracting even if I blur that out a little and b) could (for my own feeling) reveal to much about my living room and also looks kinda messy when blurred.
Yeah the end result here is still manual photoshop bud
Ai cant do what you want from it unless you transform the room into something else entirely
But then the lightning will look off and the image turns messy again
I think you. My idea was more like
- Use AI to hammer out the outstanding details like the brown shoes on the lighter floor, the black TV in the background and details in the cupboard with some kinda ok looking substitute. And then blur the whole background to blend it in.
Its a whole project your gonna take on that would be easier in gimp. Just add a png image to substitute to blur. But lets say you insist on using AI
What are your computer specs?
a gtx 1070 and 32GB RAM.
As said it is more to get some practice and not for effectiveness.
But I agree, GIMP is faster and easier.
With a 1070 its gonna take a whole bunch of time
Maybe a sd 1.5 model could get ok speeds but from my experience its not gonna be a great one
if there's not a subreddit for cursed stable diffusion abonimations there should be
hello
Anyone able to help me configure stabel diffusion using AMD gpu
running into a brick wall here.
A full log can be found at C:\Users\kidfo\AppData\Local\Temp\pip-install-6cvo7hm3\scikit-image_3b9981ff0af24673bb8227e0a045d1d8.mesonpy-537bo4m6\meson-logs\meson-log.txt
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
damn pip
Someone has the info. please help a brotha out
video call with screen share maybe?
Ill give you 10 sheckles
😦
there are pinned messages in #🤝|tech-support that have all the info's, and helpful people
HI, I'M NEW HERE. WHO CAN EXPLAIN TO ME HOW I CREATE THE IMAGES HERE? PLEASE HELP ME.
How might i go about creating 2d game assets with local ai and most importantly chacarter movemtent spritesheets, is there a easy way to achive this?
Why exactly can't we use cfg with flux? I tried and it worked! Even negative prompts worked. And I mean out of the box and not with any trickery. Damn I wasted so many image generations fiddling around with loras because I thought using cfg with flux is taboo.
anyone looking at the new 50 series cards?
performance for gaming isnt that big of an upgrade but nobodys talkin about how much better theyre claiming that theyll be at image generation
5090 will be a solid upgrade but we gotta wait for the cards to test
gm⛅
has anyone figured out how to make AI comic books? im an artist working on a comic, and would love to use AI art to speed up the process but its been churning garbage for me for a year now. i even tried making a lora with my characters
Comic book consistency has always been junk, it's far more reasonable to generate panel by panel, using controlnet for scene control/blocking etc.
helo11
So I was reading through all the executive orders and saw that Trump rescinded Biden's AI Executive Order
Executive Order 14110 of October 30, 2023 (Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence).
It's listed here https://www.whitehouse.gov/presidential-actions/2025/01/initial-rescissions-of-harmful-executive-orders-and-actions/
The whitehouse page with the text of the original order no longer shows up so here's a web archive link https://web.archive.org/web/20250106193611/https://www.whitehouse.gov/briefing-room/presidential-actions/2023/10/30/executive-order-on-the-safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence/
I read that illustrious is good for prompting details to multiple characters, but I can only find guides on how to prompt multiple characters that the model knows.
For example I want to prompt 2 girls with no names, one with blonde hair, another with pink for example. Both have different body types, etc.
How do I do that without contamination?
I would rather do it without regional prompting, it doesn't work great for me
Can someone summarize what Trump's inauguration means in terms of China policies? Does europe get cheap materials soon?
bruh this is a stable diffusion discord
I know, it would help tremendously if the compute costs went down.
This could seriously impact the trout population
why do people keep thinking tariffs would make things cheaper? 🤔
because the average person is uneducated unfortunately
Tariffs increase costs, locally.
for the consumers
Tariffs don't just increase costs locally, they increase costs globally because the economies of the world are not in isolated bubbles that don't interact
Yeah it does work, just not as well as undistilled models.
De-distilled flux models are going to be the best option if you want to use cfg.
So I realize today that there are a lot of people who don’t like the idea of AI art, did y’all know this?
It depends on what country. Because in America 51% if I’m not mistaken, have a degree. ( this doesn’t they know anything) but technically, they are classified as education😂
yeah - they've been screaming about it for 2.5 years now.
i was once told to kill myself when found out i used ai
Yeah, basically got told the same thing today lol😂
Talking about how we’re stealing work from true artist or something like that
It works good enough for me, I don't think I need de-distilled models. Using a negative prompt helps the model to have better prompt adherence. It's just weird that every workflow and every youtuber I ever saw always sets cfg to 1 and "disables" negative prompting.
Yeah it should help, only thing is that it takes 2x longer.
There are alot of people who don't understand that AI is just a tool and whether or not something is art depends on the artist and not the tool.
Yes I know. I use it in a first low resolution pass to get good composition and prompt adherence and set cfg to 1 for upscaling. Flux doesn't have good composition above 1 megapixel anyway.
hello
People here are predators they support discussion of grape and politics
Look at #🌶|off-topic
Full of illegal discussion that violates discord TOS
All saved and will be shared.
So what exactly is this? I don't understand what I'm doing?
Discussion of real life events in off topic is fine but okay
Has anyone got automatic1111's webui working on an AMD 5700xt, on windows? Or am I still stuck to Linux? (Getting back into it haven't installed it in a year)
Yes it works on Windows with ZLUDA
You'll find a guide in the pinned messages of #🤝|tech-support
hello
@clear fossilYou mean this place? Its a place to talk about Stable Diffusion, an AI image generator.
i really don't get why some lora don't replicate the artstyle at all, even with the right model and wieight
even tried with like just the lora and prompt included with it, and nothing
lots of lora works great, and some other it just doesn't do anything
hellow [:
@proud thistle sup?
G Morning
must have been a bot cause I got a DM as well.
Kinda figured tbh. His join date was a bit sussy, and a random dm..? Extra sussy
it's like they're not even trying anymore.
Why would they? They got quantity.
Also... Who the heck uses their "real" name as a user name?
What about someone called angel same thing happened yesterday to me but with someone username called Angel. Probably a bot to
They asked for my address and where I lived, that’s literally the first thing they asked
🤷 I've seen too much spam by users incapable of own thoughts, who gets hacked cause "Free Steam card - Totally not fake". Unless i know you, I ain't adding you.
nope... that was a message from god... they wanted to tell you you had a free gift.
Lol bro like I think about two weeks ago my other account someone tried to offer to talk to me for $399 e-pal and gave me a link, just out of nowhere on discord. Like what!
Who does that
Scammers
Notice: I’m not trying to say they’re willing to pay me they’re asking me to pay them
Like I didn’t even know what e-pal was, I seriously thought it was a slang name for PayPal
Jokes on them. I'm broke 23/7
😭😂 same
would 1.5 still be the best choice for creating minecraft textures?
Yea I talked to that guy. I got him really upset.
😂
i useally play along nowadays. get them far enough that i speak to an actual person and then weird them out
is citivAI down for anyone elese?
They do maintenance a few times every day
anyone know how to get started with fixing faces in swarmUI? do i use refiner?
short questions 🙂 Am I allowed to make a job offer somwehere in the groups here?
no
Man i wish there was a way to know which prompt or lora breaks another lora
when you have a lot, it's too annoying to test all of them
lol
I'm on a mission on binan wallet, where can I get my test tokens
In the past, for instance when 40 series released, was there any wait between the release and when the new cards worked with generative models? Or did it simply work straight out of the box immediately?
Thinking as i'm planning to acquire a 5090, just more curious whether proper support within pytorch is needed and such.
with 40xx it took a few months, for a while there were weird hacks of copying driver files around to weird places to make it work
That's perfect then :) As i am upgrading my server from i5-7400 to 5900x next week, so that's 500 bucks "out the window", and most likely by the time i maybe acquire 5090 by norway's "no tax june", i can use that, plus other financial strategies to acquire 5090 somehow lol. One of the strategies will be to sell my 3090 lol
... basically any? nothing physically prevents copyright violation, it's the law that prevents that (eg if you include a replica of a copyrighted character in a commercial work you release, the original owner can sue you)
Stable Diffusion is a family of models, not just one.
Most people these days use Flux.1-dev (isn't SD, but is a derivative of SD3)
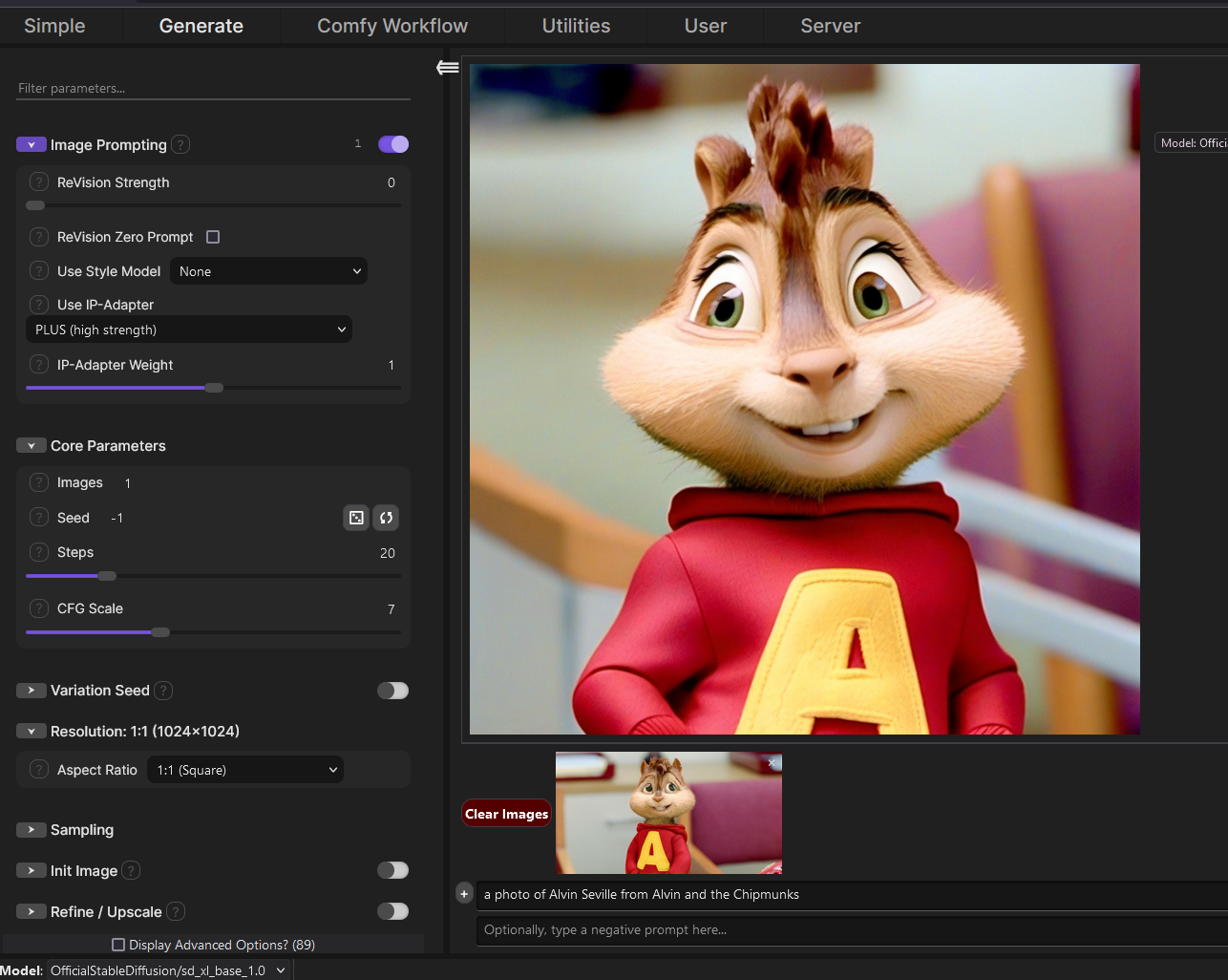
I typed the prompt a photo of Alvin Seville from Alvin and the Chipmunks in with Flux as my selected model, here's what it generated: https://i.alexgoodwin.media/i/misc/0022dd.png which isn't quite perfect but it's pretty dang close
{kind=link}
at a glance on civitai, there appear to be Loras for this too https://civitai.com/models/981021/alvin-seville-alvin-and-the-chipmunks-movie
You can also do image-prompting. Here's an image prompt for Alvin (using random picture off google) using SDXL (older, weaker model relative to Flux, probably can't do Alvin on its own, but with an image prompt it gets very close... albeit kinda wacky lol) https://i.alexgoodwin.media/i/misc/294172.png
{kind=link}
last example, here's an image prompt + flux + a unique situation https://i.alexgoodwin.media/i/misc/551ef5.png
{kind=link}
I ve started a collective SDXL GPUs benchmark. Please consider testing your GPU:
only ComfyUI, fp16
create a template workflow (menu Workflow - Browse Templates - left one) and change the model to ponyDiffusionV6XL_v6StartWithThisOne and the resolution to 1024*1024.
calcute the average it/s of 4 generations
do you think I should calculate price-performance on used or new cards?
i literally linked a model trained on the movies
so, not hard lol
to do it yourself mostly just requires a decent GPU and some time to run it
(eg a 4090 can do a small lora train on SDXL in ~30 minutes, or Flux in a few hours)
uhhhhh enough for SDXL? Yes. Flux? probably not
... fun fact, an RTX 2070 was one of the first GPUs to ever be used to train SDXL. Purely just to prove it was possible lol https://www.reddit.com/r/StableDiffusion/comments/14jck90/finetuning_sdxl_on_an_rtx_2070_consumer_tier_gpu/
SD3.5m might be a better base nowadays to fit on a 2060? not sure
scroll through this page for info about the various image models, has comparison images and all https://github.com/mcmonkeyprojects/SwarmUI/blob/master/docs/Model Support.md
I can't personally give much info about training, but there's a lot of people out there who can. OneTrainer is a pretty nice training UI that supports just about everything
what is clip skip? I see it a lot of civitai where it's recommended to be at 2, but i can't find the option
it's a legacy setting from the SD1 era that a lot of civitai users in particular for some reason seem to mistakenly think is still relevant. You can ignore that
I'm still overclocking my 5090.
I can't wait to see how fast that shit is gonna gen with all those sweet new tensor cores omggg....
5090 is around 20-40% faster but uses 30% more power so its not amazing yeah
the B100/B200/B300GB200/GB300 and NVL72 are the impressive parts of Blackwell, not so much the consumer chips this time
I want to generate (AI) ice text. But I need to use a specific font. I create a text with this font, for example in Inkscape, and export it as a black and white mask. Now I need to give a task for ice generation using this mask. Is this possible? I use SD on my computer via the web interface. I know that I need to use Img2img but I don't understand exactly how.
probably just canny controlnet would be enough if you tile up to a large enough resolution
You don't have to use a mask. You can make the text ice colored and then simply do img2img with denoise < 1.
You will also need to prompt for ice.
I can imagine that there's even a node in comfyui so you don't have to use inkscape to create the text (unless it's a custom font)
I use Ukrainian text. Without the sample of text it don't work properly
img2img can work yeah but you may as well add a control net it would help
Adobe firefly does something similar too for your specific use case if you own a adobe licence by any chance
hi
beep boop
Was is das
Hello
how do i tell if an image is poisoned or not?
is there a model optimized for 16:9?
What is the go to opensource AI lipsync now?
I always do a lick test.
has someone ran the hunyuan-video model yet?
many people have yes lol
yes it works even n 12 GB VRAM
Is it perfect no, is it close? yes. Will it be good enough with image to video? yes.
kling ai is kinda nuts, for local, is the closest option to quality hunyuan?
Yep, it’s even comparable if you can wait long enough. The main problem is no image to video yet which is very very useful and important.
aw man, i only really use image to video, i hope that update comes out soon enough, idk if my 16GB Vram card can handle it though
Yeah one of the hunyuan devs said supposed to come q1-q2 this year, not sure what’s the exact time.
Looking for some help. This the right place? Stable Diffusion related. My mental health help is coming from another discord (bad joke)
If someone sees this and is willing to shoot me some quick advice on a settings fix, please ping me. I will love you forever and may send you a gift basket
"When I try Google corabo, install the extension, and start it again, it says ""An error occurred while loading the script"" in the code."
If you know how to solve this problem, please give me some advice
Why not use the dedicated tech support channenl?
I can do that
Yeah and i recommend describing the problem while mentioning your pc specs, what UI you use and a screenshot of what's going wrong
👍
Hello... Yesterday my stable diffusion webui was working fine.... today i get a torch error, unable to use gpu or something like this... what happened? Like I used it 10 hrs ago and now something broke?
Now I deleted the venv folder to see if maybe it fix itself... but this is strange.
Webui forge is working using flux so... I don't think it's os or hw related
can you shwo your cmd log in #🤝|tech-support ?
Hello, can anyone help me?
with? please post in #🤝|tech-support
Hi everyone, I’m looking for the vae-ft-mse-840000.vae.pt file. Does anyone have a working download link or know where I can find it? Thanks in advance for your help!
Dont answer any DM from the scammer who DMD you
There is no support server
Why does it have to be .pt?
Oh, i dont know 😂 just got the advice from someone to use vae-ft-nas-840000 to Improve image quality in Stable Diffusion
but you can easily find the file by just googling. It's .safetensor though
or .chpt
did that person write the advice ~2.5 years ago? cause that's about when that made sense
that's an SD1 VAE tune
there's been 3 versions of stable diffusion and several competitors since then
Does anyone know where I can find a list of API parameters for Forge? The FastAPI docs are not extensive enough for me.
Hello
is there a place where I can download upscalers? I like latent antialiased, mainly because of the slight blur which makes my stuff look very nice, but it doesnt allow me to go beyond 1080x1080 upscaled by 1.5, since at that point it deforms bodies and limbs quite a lot. I tried some 4k upscalers which work fine even when i go to 2160x2160 (after upscaling x2), but theyre way too clean and i dont like it much. is there some latent upscaler that goes to higher resolutions without deformities?
tried it, there's nothing there that im looking for ;<. unless you know one on that website that fits what im looking for
Have you tried https://upscayl.org/ free to download I use for quick upscales.
nah, I generate hundreds of pics a day, I need something that work in stable diffusion on every single generation
is it normal for images in a batch looking nearly exactly same ?
Did you lock the seed / low seed variation?
Cause it shouldent
i believe it stays on the random value, do i change it ?
nop, just artstyle lora and adetailer for face
Hi guys, can anyone please point me to where i can learn to edit images using Stable Diffusion using code and not a webUI? I want to create a tool to help me in my Design work. Thanks in advance!
Assuming the tool is a image to image comfyUI can do it or has a node for it
Or its yet another starting business with a unrealistic expectation of ai
yea lol typically is
Hey everyone!
I’m planning to create something exciting—maybe a bot, an app, or a tool that solves real or fun problems ! 🤔
What’s one thing you’ve always wished existed or a problem you face that you’d love solved? Let your imagination run wild! Drop any ideas, and feel free to bounce off each other’s suggestions!
For people to stop coming in and having unrealistic expectations and asking others for their ideas on furthering fueling these ideas
this cant be a real person. the bio
tech talk and coding convos? screams bot
hello ^^
hii
how are you ?^^
I am trying to build a computer that will locally run an LLM like llama 3.2 90B.... Would a computer running with 5090 and 192GB of ram be able to run that large of a model locally?
3.1 70b and llama 3.2 90b have the same text model. you don't need 90b if you're only using chat
Option 1(very cheap): 64gb ram - run Q5km with 1t/s on CPU
Option 2 (mid): 2x P40 (2x 24gb VRAM) - run q4km with 6-7 t/s, llama.cpp only
Option 3(top): 2x 3090/4090 (2x 24gb vRAM) - run exl2 with exllamav2 - faster prompt processing and generation, also can train diffusion and text models.
(source 2 reddit posts)
I am going to input pictures/video into it, so the 90B model seems like a perfect fit. If I go option 1 route, would an intel i285k or a 9950x be a better options?
i was wondering if it can run on 32gb, or what is the lowest amount of vram I need to run the 90B model
hi In which chat should I ask about the possibility of generating women using Automatic1111 Web UI
Hi, in #📝|prompting-help as long as its sfw
Is there a node that can do 4k depth anything v2? controlnet aux is very limited. I already hacked together a working node but I'd rather use something more professional.
generally you'll want to install a webui anyway, and then use it as an API. For example, SwarmUI's API docs are here: https://github.com/mcmonkeyprojects/SwarmUI/blob/master/docs/API.md
Most tools that integrate SD into new places work this way.
can i ask you something please
sure?
about 40GB would be the lower threshold. can easily be double that depending on the setup.
But do note - you can run partially in RAM, and heck - you can theoretically run the whole model of SSD if you want. It's just going to be painfully slow if you do
90B is very large though. There are smaller versions. Choose wisely if you actually need that high complexity. In a more focused set of roles, a much smalelr model can be as good as the larger ones
Does anybody know how to add noise to a latent in comfyui so it still converges with 100% denoise? I'm using KSampler (Advanced) with flux dev. I tried multiple different noise nodes but no matter what parameters I choose, the image will not converge when the starting step is set to 0.
using RF-edit from Fluxtapose node pack to add noise can be good
unsampled noise is calibrated by default
if you are just wanting to add stuff like gaussian, perlin, laplacian, simplex etc then its a case of noise scaling, specifically that it has to be variance preserving, as in the variance preserving SDE from Song 2020
if you are able to set the variance by hand it is not impossible to calibrate by hand
I only want to add the default noise, nothing fancy. I found out that KSampler (Advanced) will always return the same bad latent when adding noise is turned off and start step = 0 and end step = 1, no matter the input latent. Is this normal or a bug? I thought I could use this node in a loop, doing one step at a time. But it looks like it's impossible because the first step always returns a garbage latent.
if you use sampler custom advanced with either random noise node or disable noise node it works fine
No it doesn't when the steps are 0-1. It returns a garbage latent that will not converge when denoised any further (leftover noise is enabled). Mind you that I'm using Flux dev, maybe it's a Flux specific issue?
I'm talking about a different node, rather than ksampler advanced I am talking about sampler custom advanced
skipping penultimate sigma can help, a node in here does it: https://github.com/blepping/ComfyUI-bleh
some of the stock sampler+ksampler combos will add a ton of extra noise to the image without it
Oh interesting. Do you know how do I set that up or can it automatically configure that for me?
I am going to have 192GB of ram, a 5090 + a 2070Super (this is the best I can manage for now lol)
How significant is the 9B model compared to the 90B?
I want it to be knowledgeable on various topics of course
Not specialized, but at minimum surface level
It does require a bit more setup - because you have to install some load balancing systems and allowing chunks to be loaded on demand (if running from disk any)
for running in RAM, that should pretty much just happen automatically if you allow it
192GB should be ample - and even though its an order of magnitude slower than VRAM - it's probably more than enough for a single user to be happy with
the latency on the start of the answer might be annoying if integrating into voice commands or whatever - I don't know what you are using it for
Yeah but I'd like the responses to be generally quick and not take minutes for a response. A couple seconds to have it think while it loads and a reponse is fine
Inputting photos
I'll be converting voice to text and input that as well
well there is a visual llama3
The 9B/90B models
not sure how small it comes in tho
I don't have much experience with visual input. It's a different beast - and while very useful, the AIs aren't god-tier at it yet like with text
Well it's going to be provided some sort of text so it will know atleast a littlke context of the photo
They will add noise even when it's disabled? Unfortunately sampler custom advanced has the exact same issue that I mentioned when noise is disabled (with the disable noise node).
I don't think the node you mentioned will help in my case. I use plain old Euler simple.
I'm starting to believe this is a bug
yes even when add noise is disabled
the penultimate sigma issue happens at the end of sampling though
yeah it could well be a bug
everyone has different setups so its hard to compare
I was able to narrow it down. The issue appears when the first sigma is exactly 1. It doesn't happen when the first sigma is 0.999
flux too?
yeah
its possible
same for LLMs
@fervent thunder i have a 7900xtx what would you recommend me to get for anime generation(or any art rrly)? also one for chatting with llm bot
because there is like so many options 😭
dumb question, but can any ai help to make a pcb bored or something of that nature. im just curious.
probably Flux Dev for image
LLM is tricky but Qwen 2.5 14B or 32B would be fine
yea probably but it could make some mistakes
it could have absorbed some hardware books or something
hello
Heyy guys , I wanted to build a headshot generator app using open source model .
( Without finetuning)
Which model can I try out ?
Not stable diffusion. Maybe a closed source version somewhere
Probably any sdxl realtistic model
But if you want to get your own picture into a ai image you would need to use face swap, a dedicated server (because its for an app) so you need to finetune!
No it can't. If one exists, then it could give you something like a prototype of a board, but you would have to debug it anyways. So you would definitely have to be proficient in electrical engineering. But you can certainly make one as a beginner if you learn some basics about electronics, follow tutorials and work off of a template board.
There are auto complete algorithms for extremely simple ones but tbh a stable diffusion discord is probably the wrong place to ask
Since there are pcb communities
No I want to generalise the headshot for all .
Example :- if you loaded your image and choose a style like professional or anime it will create that style for your image and give it .
Is that possible?
Youd need a few models. Or flux with a few loras. But then you need to create a few workflows within comfy to facilitate that
But i see that this is yet another million dollar idea so my advice ends
Okayy thank you !
But wait , that means flux can handle my usecase properly right ?
If you got the face swap nodes and the know how to configure it so it works like you want it to
I still don't get what's the advantage of Illustrious
When I prompt for it to sit reclined, it does it consistently 4 out of a batch of 4, whereas pony hits maybe 2/3 times, sure. But it can't seem to shift the style away that very specific anime look
you save so much on tokens cos you dont need all that score bloat crap
ive always been an advocate of pure prompting power, i find embeddings and such to be a hindrance
So is the use of illustrious better when the pormpt has less than 75/150 tokens?
Neither one is really great with natural language as far as I can tell, Illustrious has a little bit of edge
on that front
Is it mostly because visual styles? As pony is obviously fixated on that broad jawline stuff
God i hate natural language prompting
"the background is jubilant and serene but her gaze is deterministic. She stands confidently " and other bs
Illustrious doesn't need score tags and is better trained on the boorutags than pony.
It follows these tags really good.
Well s--t
I don't know much about booru tags
I just prompt whatever, for pony, by cutting my language into tags
Anyone got some good example prompts for Illustrious here? I can't figure out the right way to use it
Get the boorutag autocompletion extension.
That helps a lot with prompting
OK, I will give it a shot, thanks.
BTW, would you say that Illustrious is better at booru poses than Pony?
Yes would say so
Hello fam, been away from AI image generation for a lil while, what is the best way to run stabil diffusion these days?
Hey, still localcy if you have a good GPU
But if you mean UI its comfy, swarm and forge
Is there a way to put real life object on image generation?
Flux Redux
or Qwen2vl-Flux
or ACE_Plus (is also Flux)
I want like my stuffed animals/toys to show up on my image.
Will it work too if the image we going for is non realism?
embeddings are still prompts they are just in a weird alien language lol
yeah still works
You dont need flux, you can train a lora of a specific item or person

Does ram amount mater a lot with running stable diffusion locally?
yeah at least 64GB, or otherwise at least 32GB is good
you can get away with less but it gets trickier
Okay I have 7950x3D, 64gb ddr5 and a 5090 soon, so I guess next upgrade I’ll make is my ram amount
16gb can work but 32gb is recommended
I have a rtx 3060 now, i want to try my hand at better llm models, ive tried 32 sized models but they are slow. is there a way to run bigger models locally and have it be at good speeds or something?
Qwen2.5-14B-Instruct-IQ4_XS.gguf https://huggingface.co/bartowski/Qwen2.5-14B-Instruct-GGUF/blob/main/Qwen2.5-14B-Instruct-IQ4_XS.gguf
what interface can run this type of model?
For SD you can run sdxl good and flux with a lower speed
ok good to know, but im also curious about language models think of chatgpt but locally.
you can use the bolt diy script from pinokio
ollama with deepseek reasoning model
ollama is fine ye
with GGUF 5_K_M and IQ4_XS do extra well for their size for some reason
so if you can find 5_K_M or IQ4_XS versions of things then that is good
Is the deepseek model uncensored already?
who knows
i dont use it for those purposes
😛
but its a reasoning model, itll display its though process
so not great for immersive conversation
that being said, still a dang good model
for a side hustle project
maybe someone uncensored it
Oh me neither lol. Tough some guidelines are a bit too strict
when people say uncensored they can mean different things though
can someone guide me thru this whole AI thing? i got 7900xtx and i want to generate stuff locally
hi. seeing as you have a AMD card i recommend Forge (follow the AMD guide)
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides#amd-forge-webui-with-zluda
but you need zdula to run it properly
this the best i can generate locally right?
the best would be comfy but i think it could be a bit too complex for a beginner
but for you i would recommend forge as theres more tutorials availible
the thing is my internet slow so if am going to download something it has to be the best thing i can get so i dont have to go back for it, plus i can follow instructions well
still i recommend forge webui or swarm. both are really good options for beginners
comfy just has big learning curve and its not everyones piece of cake as its mostly puzzling lines together and if you dont know what your doing its more frustration then anything else
oh alright then i will go with webui
Has anyone been able to train a good flux finetune for style? I mean full finetune not a lora. On style it's easy to train on a single subject. I'm trying to train a style with 200imgs, but no luck.
Uh what?
Oh
How do I know if my pc can run the 671b deepseek model
ah hey there i got the awnser for you
you cant
ill tag you in the list of requirements in general with images
you cant. not the 671 billion parameter lol. thats like 400 gigs and needs serious hardware. you can use its 7-9b with 12gb vram really easily. anything else above gives me issues
youd need like 4 or 8 a100s lmao
It seems like once the 5090 with 32gb comes I’ll be able to do the 60 one at least
yeah lol
How are you liking it? I haven’t had a chance to use it yet, waiting on their new image generator to be posted to ollama to use it
im hoping they do a chat version or something cos reasoning models display the thinking process which is nice but i cant incorporate in my workflow because of it
non-chat LLMs are rough yeah
Deepseek V3 or R1 need over 1.3TB of VRAM to run at full precision 😅
My friend has 6xA100's, and he runs it at low precision
goddamn, i was just making an educated guess too, wasnt too far off it seems 
Does anyone have an NVIDIA GeForce RTX 4090 and has created video with it?
lots of people have. whats the question that comes after?
ya, im sure most can
frfr
Hello
beep boop
So what is our opinion of Janus
-googles what a janus is-
looks to be a british investor thing
dunno tbh, i do wanna invest in sum, but'll prolly be a savings account
Janus pro, im waiting for some more examples but promising so far
Yeah i wanted to know the best UI platform for it.
Which is better of the 3, i have a spect pc.
Need to reinstall all the stable diffusion stuff and wanted to get the best possible UI and way to use SD 😄
I have not used SD in over 1 year
generate a photo on this topic: Basic methods of primary surgical treatment of wounds
Theres no better. Just preference. Swarm has both. Forge is easy and comfy is hard
Seeing the question, forge is best for you
Check pinned in techsupport for guide
Ahhh okay i used to use Automatic1111
Yeah then forge-webui
I need to download Python to use Anaconda3 to use Pytorch to install torch-directml to use comfyUi to use a training ai to use a model to generate pics
(am never leaving my room)
I used 16GB before with Stable Diffusion - It WORKS but uses your swap file a LOT. and if you have that on a SSD, not ideal.
You mean you want to pay someone for a ai job? I recommend civit ai for a bounty or fiverr
If you just want a few Images, once im home i can help you with that (free)
No, you just have to follow my install guide to setup Comfyui with zluda or any other webui with zluda.
Anaconda is not needed
i know, am following different guides so i get more than one to use
?
My guide covers multiple webuis with zluda.
Directml is not recommended
If you mean more than one python version. Most if not all ai stuff with AMD works with Python 3.10.11 64bit
hello
hello new person on discord.
"person"
Has anyone run Deepseek locally here?
Is that shit really the next best thing for uncensored LLMs or is that just hype
uncensored? its censored for now but its pretty nice
but if you want The NEXT BEST THING you need about 1.3tb of vram but the 7-13b models are okay
ok but not revolutionary?
cuz we already have tons of 7-13b llms
so Im wondering what makes this one special
its comparible to OpenAI at the full model
so small deepseek = full ChatGPT 4?
and actually opensource instead of "open" just in name
what no
at the FULL model
oh
we can run small models
so its just hype. got it
its good but not WOW. the Janus model is pretty nice tho
as its comparible to DallE
given the fact that it tanked Nvidia stock I was expecting something crazy
the only thing crazy about it is its price and thats it
stockmarket is bad thing to look at as its a giant bubble and investors are twitching
make model
nividia stock drops
people realize they need nvidia cards to train etc
nvidia stock rises
rofl
it makes me wonder why if China is so advanced technologically as the media wants us to believe, they still can't produce their own GPUs.
we need someone to compete with nvidia's shite business practices
nvidia is both a goldmine owner and selling pickaxes, they make a ton of money
I can guarantee you the real price for 5090 will be closer to 2600 pre-tax since it will sell out in the first 6 seconds. AMD nowhere to be seen. We need new players
we got AMD but people didnt give it a fair enough chance
and they fell behind
and the problem in computers is
we litterally made a rock think (not to oversimplify we used lightning to help)
good luck trying to improve on that
as a startup? nearly impossible youd need investments of trillions for a chance
the machines alone are a gigantic investment and youd not be there even
china has the money
and the interest is there, look at the recent shortages there have been
but not the technology. lithomachines are resticting htem
them*
and for chip production you need spesific conditions
they are catching up slowly though
but not any area is simply suitable witch also limits advancement speed
well there are fabs in taiwan, israel, costa rica
what do they have in common
all owned by the same companies
there was an interview not long ago that mentioned china has more honor students than the US has students
if there's any country that has insane talent it's china
but they dont get the oppertunities and get crushed by the insane work culture
that is true given that probably half the country is still in poverty. but just give it some time
now we all get mad at a printer right. how much babysitting it needs
now imagine instead of paper its 10 micron spheres being shot around 50k times in a vacuum at a very fast speed being shot by a laser
im lookin at upscalers and it looks like people have been using the same ones for like 2 years
is that right?
people got their favourites
I have some credits I bought before artisian came out can I use those or do I need the membership?
I used them on dreamstudio
ive never really looked into them so i thought they would be like regular models where they get updated like every week 😂
thought i was just couldnt find the new ones
i prefer using 4x-AnimeSharp.pth - 4x_foolhardy_remachri.pth and 4x_NMKD-superscale-SP-178000_G
both are on civit ai but the anime sharp not iirc
What's the utilities to make stable diffusion work on amd cards? I just dropped $1800 on a 128 ram PC with two 7800xt for topaz and running local llms
check the tech support channel pinned messages! theres a AMD guide there for a UI of choice
personally i recommend swarm UI or webui-forge
Alright sick
you NEED to follow the AMD guide or its going to be slow
I have a 3080 that I use a ton for this but I have zero clue how to do amd
128 ram is an absolute waste of money
you are better off getting 32gb of VRAM for less than half of what you paid
128gb ram doesnt even cost that much if youre planning on rocking 2 video cards
its like what 300 bucks?
only if your sole purpose is to run turtle-speed llm's which most suck compared to subscription-based models
ai isnt the only use case to have high ram lol
especially with deepseek pro being like 1/10th the cost of GPT pro
it certainly is
I have 32gb and never ever do I use it all
maybe only in minecraft lmao.
unless ur running a server or sum shit
what did you spend the $3 you saved on
thats your use cases yeah. virtual servers, processing large amounts of data (3d animation etc)
a 5090
as 3d animation will use any ram you give it
vram is worth its weight in gold. ram is useless except for super niche cases
this man is high
so some can be more capable instead of hitting a wall, sounds like a good reason
of all the things to hate on, why hate on having more ram than you need? lmao
im jelly of his build lmao
because unused ram is wasted ram
= wasted money. you are better off getting multi-quadros
you say wasted. i say he might have other use cases as he spent a lot of money on that build
should of got a tablet
Does ComfyUI work the same way where it has an API that i can serve to make a tool for myself?
yes. Though note it's a fair bit more complicated than Swarm's, expect a lot more troubleshooting if you directly interact with comfy's api
If you read for once more sentence, I am
Two 7800xt = 32gb vram
What is Janus good for? Is it only image captioning? I'm not impressed by the image generation capabilites. And the 7B model is terribly slow.
Speed is mostly on specs your pc has no?
Most base models are mid ( personally ) you're just gonna have to wait till its matured, I'm still using sdxl because of this rather than flux or sd3
Hello, what is currently the best checkpoint in forge application to generate very realistic images and characters ?
flux1-dev-bnb-nf4-v2 ?
i love the way you prompt for pony models
but im pretty sure you can use the same language for sdxl now right?
last time i use sdxl you had to write a whole dang book for a prompt
no clue i also use pony or pony based sdxl models
i forget which pony based model i use let me check
autismmix confetti
yo is there any alternative to reactor?
If you modify the comfyui node for Janus image understanding you can pass a batch as input and make it choose a favorite. Could be handy for automatically picking the best seed. Just a tip for anyone interested.
Hey does sd have a vanish brush to like scratch things out of a pic? I can’t find anything regarding that, maybe an extension?
my old mate used to use the inpaint thing
to do exactly that
how tho, beats me, they was jus good at it after practice, id give u their ID but, um, we're not on good terms anymore so, cant xd
will someone help me ? I would like to generate a character from a prompt but want to later create more pictures with the same character (face hair eyes body) to then have a lot of pictures for fluxgym
in forge( stable diffusion)
Are there any good models for virtual clothing try on? eg. user provides photo of custom model and garment. Something like Kling.ai?
Preferrably one that is capable of handling graphics on shirts and such as well
Are there any RTX 5000 series Stable Diffusion and other AI models performance tests out yet?
No, youd need a custom workflow but that would require some work on your part. Any sdxl/flux realistic model would work but youd need to have the right nodes or even make it your sefl
Its not out yet (and the drivers) so its sucky hard for people who got it early
You need to make a lora 👍
Where can I learn to do that? Im new to stable diffusion
Do you know python?(Programming)
Unfortunately no
Its an million dollar app idea again so honestly its gonna take a lot of learning or paying someone
Theres a app thats in beta rn thats trying to do exactly that but its costing them a pretty penny
Infact last week we had someone with the same idea lol
You could try a mix of a controlnet canny model + inpaint with automatic segmentation and hope it transfers properly
I've been looking around for something I can run locally on hugging face. Theres a few that I've tried directly in my browser but the results arent promising. I just want to try on some things Ive made but I get what you mean, if there was one it probably would be million dollar idea.
But running stable diffusion localy, its not that hard in its self
But what you want? Thats a challenge
Right lol
You could lookup a controlnet impainting tutorial on youtube for comfyUI but its missing over half the things youd need
I sent you a pm about another question, if you have a second please check it out
In a bit, preparing to leave for work
This was one of the ones I tried. Its does a good job fitting the garment to the body but falls very short on retaining details
Saw that one yeah, but i wasn't happy with the results either
But thats the current state of image generation .its impressive but were not there yet
there's flux ones
Could someone recommend a more recent model, SDXL or Pony that does Fantasy / Dark Fantasy / Armored characters well?
I can't find a model willing to do lots of blood, even for dark fantasy purposes
Latest breakthrough of AGI! TL;DR: It is all about money and evolution. You can read my latest Cybergod paper at: https://james4ever0.github.io/Cybergod__God_is_in_your_computer.html
ive just been jumping around using whatever model pops up under the most downloaded for the month 😂 i think i should settle on one and learn it inside and out
Try out image to image for that maybe it'll help
tried it just made a blob of tomato sauce.
😭 I mostly just use autism mix confetti and it does everything I've tried
It's just a wallpaper machine at this point
Good morning, everyone! How are you all today?
terrible!
Is there another gradio based platform other than auto1111 and forge that's getting popular or did everyone just move to the trash heap that is comfyui? Both haven't been updated since last summer.
how exactly forge wasn't updated? i see some commits 2 weeks ago: https://github.com/lllyasviel/stable-diffusion-webui-forge/
even yesterday.. just update it after downloading. i'm still sticking to forge
btw, i got a question... how does Adetailer picks "top K masks" ? i'm getting some random inconsistencies in img2img, same image, different seed, two people - sometimes the top 1 k mask is person on left, sometimes person on right... whats going on there?
trash? comfy ui? what also swarmUI is pretty popular
comfy gets updated near daily and its one of the most advanced ui there is. It may seem trash because you lack the knowlege and skill needed to navigate it.
i get disliking the noodles but comfyUI is the most sophisticated ai software availible to the community tbh
hey i want to install stable diffusion
but there is still the error that couldnt lounch python
but i installed python 3.10.6
does someone else know what the problem is? thank you
hi!
can you hop over to #🤝|tech-support with:
what UI are you using?
What guide were you following?
i will write on techsupport
Is self-promotion even allowed? Also I read a little bit of your paper and it's complete nonsense. It reads like a kickstarter scam.
print("Hello world!")
From the point of view of classical textbooks, this process is simple, as if the meaning of the execution of
the program is completely within the code itself, without any further connection in real life
So you think "print" needs no further context about the printing press, modern printers or monitors? Sounds like dialogue for a bad sci-fi movie. Did you even write this yourself or is this an LLM?
Sorry to sound so harsh, but don't sell your blog post as a scientific paper.
It being advanced doesn't mean it's usable and streamlined. In factquite the opposite. Try actually working on it, using different models, multiple lora, changing options on the fly, controlnet, upscaling and inpainting, I promise you you're going to do 3x more work for the same time in forge or reforge
Haven't tried swarmui yet, hopefully it doesn't go the way of Invoke
i dont know invoke. what happend to it
Ive been using comfy as my mainline tool for the last year and a half.
This arguement is flawed
You dont seem to know about workflows
Maybe try seeing what the tool can do before disparaging it
in swarm once you get a workflow going to the point where you only need to edit the prompt you can even save it as a "simple" tile to use
or well just save the workflow you made once? its not that much work and it allows for much greater results then forge ever could
Yup
I got a whole folder full of workflows for specific tasks
It boils down to people having unrealistic expectations with ai
Also, comfy allows for more complex workflows that produce interesting results
Workflows are exactly the reason why it's slower to work on than forge
But it's pointless to argue about it, you do you
Comfy has two major problems. First, it’s fundamentally a backend tool that enthuasiasts are trying to force on people who want a front end tool. Second, workflows result in combinatorial explosion.
Comfy is basically a UI to connect code snippets. It's great if you want full control over what you're doing. Which assumes that you know what you're doing. I wish there were better image editing features, but other than that, it's great. And almost every new model will be supported very quickly.
And assumes you’re ok with having to manually connect every single little detail. As opposed to ”yo, what I just generated but now with better faces” (adetsiler) or ”same thing but higher res” (hires fix)
But you only do that once. Or not even once if you use an existing workflow.
See my comment about combinatorial explosion. Those "yo, what I did but now with X and Y" result in a whole bunch of different combinations that it makes no sense to force on 99% of users when they could just be buttons in the UI.
That's what I mean by "backend tool". It's something that should be used behind the scenes but not forced on the user for 99% of situations (IOW, don't do anything ridiculously limited like Fooocus).
Under the hood Comfy works no different than other UIs. I don't know what you mean by combinatorial explosion. You can bypass nodes, you don't have to create a new workflow for every combination of steps. You can even convert part of a workflow to a group node, which will get rid of all the node salad. I can do things with Comfy that I can't do with other UIs. For example in Comfy I can make a XY plot for absolutely every parameter imaginable. I other UIs I'm restricted to the supported parameters.
The problem is comfy forces the user to deal mainly with the generation process. Most people couldn't care less about the generation process (unless they really need to fix some specific thing) and care about the results. Basically, for 99% of situations I don't want to have to see a single node or have the UI spend any space on any of them or force me to load some random workflow when I just want to enable a setting. I just want settings in a convenient UI that's been optimized for settings and prompts instead of for connecting nodes. I want a frontend UI, not a backend UI. And I specifically want a frontend UI that hasn't been dumbed down (see Fooocus).
A1111 / Forge are janky but they (almost certainly accidentally) ended up finding a rather good balance between presenting the relevant things while having quite a bit of flexibility. Under the hood Comfy approach is good but I really really really don't want to have to care in the slightest about the flowgraph when there is no reason a decent UI couldn't fully handle that for 99% of situations.
how does the artisan work?
i rmbr back in 2022 it would message you the result
but its been a while
new account btw, nice to remeet yall
Yeah same
Yes If you have a user friendly UI with all the features you need then use that by all means. The advantage of Comfy is that you can do more exotic things with it because you don't have to wait for the devs to implement every new functionality or feature. Or if you have a crazy idea you can just do it in Comfy, even if it means that you'll have to create your own nodes. I think everyone should start with a simpler UI and only switch to Comfy once they feel the need for more control.
Yes, the 1% of situations where you do need to touch the backend to make something work. And that's good that it's available but it very much shouldn't be the default (ie. Comfy is very much the wrong tool for me and most others).
Because it's an added step, especially since you still have to tailorthe workflows somehow to your current needs, as there is no workflow that is truly universal. It's a useful tool if you want to experiment, it's a hassle if you know exactly what you want to do and you have to add-connect-bypass nodes and whole sections or swap workflows entirely to make it work instead of just checking a box.
I'm not mad at all, despite your best efforts
i mean if you use specific settings for realism or for anime so you got two workflows
and you can just
workflow > open
done
but id like to think forge as a jack of all trades but comfy workflow a master of a trade
some like to fill out forms some like to connect noodles
But you can add check boxes if that's what you need. Or you can just save multiple workflows for multiple purposes. It sounds like you're working off of one workflow and constantly rearranging it for different use cases.
You came out swinging insulting me for not liking comfy and you're still going despite me letting it go, are you sure you're not the mad one?
Well, that was quick.. I lasted 8 minutes with Invoke before I got fed up and ctrl-w reflex hit (not helped by the fact that it kept showing distracting animations on the screen with no way to turn them off from the UI)
You didn't like being forced to inpaint inside a 1024x1024 square and not being able to adjust it or focus on a specific part of the image without modifying the resolution? Weird
I didn't even get that far. The compeltely pointless flashing animations were enough to drive me away.
Speaking of which, that sort of shitty inpainting UI design has been my pet peeve with everything I've tried. It's ridiculous that the UIs don't let you separate "this is the inpainting region within a larger image that I want the model to see and consider" from "this is the model visible image dimensions and the actually affected mask within the inpainting region"
The crazy thing is people praise invoke's canvas method because it integrates a couple of basic ass features like layers, but ANYONE working on it seriously already uses free photoshop alternatives like krita because they offer so much more on top of that
Can you run ComfyUI/Flux on a Mac these days?
The two sets of data you mention here are the image you feed into the model and the inpainting/denoising mask. You cannot tell a model to focus on a certain part of the image. What you do is crop the image, add a mask and then denoise. After that you have to blend the denoised image back into the full image.
Cropping is exactly what I mean by "focus". Say I'm working on a 2048 x 1024 image. I want to inpaint a small region with good details but it needs some context so I have a 256x384 area I want the model to see for context. Currently it requires way too many hoops instead of just selecting a rectangular focus region and drawing the mask. openOutpaint almost gets it right but doesn't understand non-rectangular regions once you decouple the generation resolution from region size (and also lacks regular controlnet features).
swarm has a fantastic impainting tool
You can do that in auto1111 or Forge. I can do that as well in my Comfy workflow. I paint a rectangle which will be the outline for cropping. There are nodes that will convert a mask to a bounding box for cropping.
I have to wait until tomorrow for the vast people to update their Swarm template. I'll give it a try then.
i happen to have the UI open if you want to see the impaint window
I can if I jump through way too many error prone hoops. There's absolutely no reason why that couldn't be handled automatically (as I said, openOutpaint almost does it perfectly).
Yes you can, go on forge, mask the image and then add a little piece of mask wherever you want the model's attention to stop. It essentially upsamples the image
i am working on a shitpost however so yeah
It's essentially what adetailed does
But you can do it manually and adjust the attention and make it as big as you want on inpaint
I'm not sure what you mean. It is automatic in auto1111 and Forge. Maybe not in the UI you use.
Nevermind I guess we're talking about the same thing then
Are you talking about a UI specifically? Because that's quick work on any auto1111 based UI
Yes, with the requirement that I get full use of controlnets (eg. I want to add a person to a scene and need openpose for that)
Yeah it works with controlnet too, I use it with lineart all the time
How?
Hey, if I showed you guys an image, could an expert tell me if it was made using Stable Diffusion? I am trying to figure out which software was used so I can download that one but don't want to waste my time until I am certain.
would really appreciate
skoomadentist has been typing for 10 minutes lol
Now add the step of generating a controlnet preprocessor preview (properly aligned and without downsampling) so you can do trivial edits to it (eg. clean up scribbles or make space in lineart). At least my A1111 and ReForge don't let me do that without copying the original to-be-inpainted image elsewhere that can run preprocessor on it at full res, copying the result of that back and so on. And the frustrating part is that all of the sub-tasks have already been solved, it's just that nobody's bothered to make them actually work (I suspect most people are fixated on generic "pretty" images instead of goal driven generation tasks).
nooooo it wasnt for me
5090 drops tomorrow woooooooooooohoooooooooooooo
How much does it cost?
2,000 if and only if you can get one at msrp.
suspecting it will sell out in <6 seconds
my bot might not even be fast enough.... we will see. hyped af rn
I'm curious, why the hype? Is the extra 8 GB really that important over just renting a 48 GB vram VM from cloud?
boatloads of extra tensor cores
ppl say it's lackluster bc it's not a big jump from the 4090 but since Im upgrading from the 3090 for me it will be night and day
How much do 4090s cost nowadays?
well they will cost less by tomorrow. fyi you still cannot buy any new gpu at msrp except during launch
See, you could make all of this automtic in ComfyUI if you were willing to invest the time. You wouldn't even have to manually inpaint, you could add a segmentation model that would automatically inpaint the face for example. And you can clean up the controlnet image with the mask inpainter.
amazon still scalps them and they are almost always sold out on newegg etc
I specifically do not want to automate any of the manual inpainting and cleanup. I'm doing it manually precisely because I can use it to work around the models' limitations by guiding them with controlnets in a way automated solutions can't (eg. liberal use of Photoshop's excellent remove tool)
This is what you're trying to do, right?
Yes. When I do the preprocessing, A1111 runs the preprocessor at the inpainting resolution instead of image resolution so the results are too blurry (unless I do the preprocessing in txt2img or extras tab).
I'll give swarmui a try tomorrow when the new template becomes available. Hopefully it can solve that better.
Just send me a dm
What I meant is that you don't have to edit the preprocessed image in another program, if you're fine with only using a simple brush tool. Also in A1111 you can add a separate image for the preprocessor (at least in Forge you can).
You can set the preprocessor resolution so I'm not sure what you mean. I left it at 512 but you can go up to 2048. It's not gonna make much of a difference though
Short side
yup! i switched from forge to swarmui after forge stated they'll start going into unstable experimental territory last year
I still hate using comyfui but since it's built in swarm I still use it occasionally, mostly for upscaling to 8k as some random comfyui workflow i ripped off the web made it fast in comfyui where it took multiple hours in every other ui
The UI in ComfyUI is ironic /s
^
Hey guys! I’m new here (relatively new to ComfyUI). Lately, I’ve been wanting to make a profile picture of myself in the design style of Marvel Rivals artwork. Is there a way using style references, Loras, etc, to achieve this? If so, could you walk me through what your process would be for this kind of thing?
?
Insight on any barriers I might face using this set up: https://www.dell.com/en-us/shop/all-deals/precision-5540-mobile-workstation-1-year-of-prosupport/spd/precision-15-5540-laptop/xctop554015us2ps to run stable diffusion locally?
For that price, only having 16GB of RAM is a scam! My 5 year old $800 laptop has 16 gigs.
They want $400 to upgrade to 32GB? Holy cow leave this website immediately. Buy a laptop from a company that doesn't rip you off.
it's a dell - right there is a red flag. it's a laptop, that's another red flag.
Its definitely not my first choice just what I have on hand at the moment
go look up 'marvel rivals' on civitai
there should be plenty of style loras for it out by now 
Its about 4-5 years old. Has the 32gb
For real. Even this ~2018 era second hand laptop came with 32 GB.
I think I paid 400-450e or so for the laptop, including that ram + 1 TB ssd
Dude that gpu has 4gb of memory and is a few years old and has a price tag of $2.7k????
does anybody know of any sd android apps that ACTUALLY work? the ones that i find crash or don't work 💔
Guys, where can I find a workflow for working with flux generated icons?
Hi, I am Lee from India
Does anyone know what tools and workflow these types of videos use? Music, I get. Then, image generators to video generation. Then using a video editor to put the clouds and foreground in planes and loops, but how do they get the trees to merge so well into the sky, the butterflies flying around and pool water movement? https://www.youtube.com/watch?v=pvxUHpf1pxQ
masking model for the trees
the butterflies and water are likely traditional CGI not deep learning
Thanks for the input. I was more curious about what the workflow is to integrate a specific face, while also using a style LORA. I’ve done both of these things separately but couldn’t wrap my head around a workflow for this specifically.
mmmmh
100 batch count usually took me like 1 hour, been that way for month since i've been using around the same settings
i started a new one and suddenly it's 2 hours?
i don't have anything else open, or i didn't change the resolution
what gives
can certain LORA make generation longer?
it never happened before
what is happening... now the generation is not doing anything anymore, it stopped at 11 %... it's still running but it's not using VRAM anymore, like it completely stopped
NEVERMIND
somehow i turned off tiled VAE
my bad, lol
How do i change a lora's name? as well of the prompt itself
there's one lora who has __ in the name, but that messes with dynamic prompt
i changed the name to just one, but selecting the lora still gives me __
Does anyone know what's happened to reActor? Their GitHub page has been taken down
Got used for too many deepfakes so it got taken down iirc
Sad af, was a proper useful tool. Is there anything else like it?
if i wanted to train a lora for sdxl what gpu is worth getting, 5080 looks kinda good, its also for gaming, im a student so i aint got that much money
@atomic mortar
Reactor got taken down because it got no nsfw filter.
The dev updated it and reuploaded it with the filter.
For auto1111:
https://github.com/Gourieff/sd-webui-reactor-sfw
For comfyui:
https://github.com/Gourieff/comfyui-reactor
Ah same thing ish
I think i still have the original because i never updated my swarm that had the extension
Does anyone here know if Mistral-Small 3 24b competes against deepseek's distilled models?
It just got updated literally half an hour ago.
- 24B params, 81% MMLU
- Latency optimized: 150 tokens/s
- Competitive with Llama-3.3 70B, Qwen-2.5 32B, GPT4o-mini
- Apache 2.0
Brilliant, thank you very much
Good morning everyone, sorry to be a bother but I’m looking for a solution to getting rid of an issue I’m having. It seems all my art is coming out with nothing but gray images. Is there a way to fix this?
use a vae
Thanks Ellie
I just found out that Override settings are a thing
Uh what do they even do
who do I tell about a spam bot from this server?
Pretty sure you just report them by userid? If mods dont nuke em first
welp today was a total letdown
looks like another 2 years before 50 series becomes viable to purchase. god I hate this world
Are you inable to go into financing for products like that?
The point of that I thought was to lower the cost at once by spreading it across payment dates
viable as in availability
Damn.
Well, I'm a unique one since I'm on arc still myself.
Alchemist, too.
🤷♂️
oof
Not oof. I can run flux no problem at 3it/s
And deepseek 14b
its been heavily improved since there's now pytorch 2.5.1+xpu and intel xpu branches for torch 2.7
I think the main thing arc suffers on now
is the fact it's a 32-bit architecture. This can be bypassed by slicing the tensors under a 4 gigabyte rate.
what is the performance of that GPU comparable to?
I have a 3090 so I can live but man I really really wanted to taste that 5090
interesting
Halo World
i know whoooo i wanttt to take me home, i know whooo i want to take me home, take me homeeee 🎵
Apparently there were only a few thousand 5090s shipped in all of NA was sold out everywhere for me, anyone here able to get one and wanna flex on us? Lolol
A few thousand? My country got 0 fe's and only a handful of em
My local pc enthusiasts/expert forms were pretty mad and only a few managed to buy them
Is there a tool yet to convert safetensor models to tensorrt models in parts/chunks yet? Where it'll combine the model at the end, as flux is too eavy, even when using shared memory, or ram as vram extension, it eats just too much.
Hey peeps! An AI novice here. Need some kick starter insights and advice on where and how to's for starting with Stable Diffusion for Architectural Visualization. I have never used SD earlier except for a few times in hugging face.
Hey yall. i'm looking to learn and improve my skill. all tips tricks and walk throughs are accepted.
Remove the thotbot please.
I mean, its just someone asking for advice despite the nsfw profile
No it's a bot. So obviously lol. The comment is generic and posted in 100s of gaming servers trying to catch victims.
The server i used to run had (real) profiles like these by the dozen
Staying neutral till i see links or dm requests
- Just joined the server
- Posts a generic comment that incentivizes people to contact "her"
- Has attractive profile picture and heart emojis and claims to be a women "seeking help"
100% Scam profile. If you leave this stuff in you just expose people to risks.
I getchu, you don't have to explain it to me. But as i said i know and seen a lot of people who act like that
Especially in servers oriented for an older audience
I have too, they're all scammers 😂
The ones i had meetups with didnt lol, still yeah odd profile for this kind of server but some people just have the npc energy
And this one didnt respond to any of this@compact knoll
Ill bait sec
forgive me.. i'm on the phone but also confused. did i do something wrong?
Your profile has a lot of red flags (looks like a bot)
Do you know what this server is about?
And to use it on your pc locally
What specs does your pc have? Or are you looking to use a cloud based solution?
well my pc is rather up to date but ... i do ai mirror edits of my imvu toon and i want to make them better
What graphics card do you own?
If you open task manager (control alt delete) the second tab (looks like a graph icon) shows you the model name
rtx 5080
lol no way
? Can you post a screenshot of it in general with images?
If it is i would be incredibly jealous due the shortages of any 50 card rn
Had a 5090 in my basket and the store crashed so i couldn't buy it
Hmm and youd be looking to ai mirror videos or still pictures?
i do still photos
You could probably run it albeit slowly
What UI are you using right now for your current images?
android .... apple made the ai mirror images more pixalated
Hmm you used an app for it then i assume
that is what ai mirror is love
I mean you can make ai mirrored images on other platforms/apps too so just asking
i'm still learning love.
Do you have Android on your PC?
no .... it's my phone
Well i would recommend following one of the guides CS1o made in the pinned messages in the #🤝|tech-support channel
thank you
Webui forge is the better one for you. Image to image isnt hard but you need the proper models for it
Lmk once you get to the step where you have installed it
is that pc or phone
How slow lol, 50min slow?
not sure
not neccesarily
people run fairly big AI stuff on mac
but modern iphone and modern mac are similar chips
The base silicon sure but the vram amounts are still gonna bottleneck it
O iphones dont even have vram
Its not gonna be able to load in even too lol
the way apple silicon works is that
it has neither VRAM nor regular DRAM
it has a unified memory
These things exist on a smaller scale already, Samsung Galaxy AI Sketch To Image, Google Pixel Studio, Apple no idea neve even heard of that brand
IDK if they are gonna use them but OPPO and Samsung posted diffusion models and upscalers on Arxiv
they are not open source but I am not sure if they are coming out closed source either
If you can run AI on a raspi you should be able to at least run it on an Android phone.
I mean I'm sure someone has already done it.
I mean theres a difference between a 1.3b llm and a fully fledged image generation model called flux most full pc's cant even run smoothly
Since his claim "a phone can run flux"
i use telegram sup
"22.3 minutes from submission to output, and my phone felt like it was melting"
doesnt sound ideal
but add image to image and a possible control net
wew
Does stable diffusion 3.5 have to run on comfyui? kind of miss the layout i played around with in 1.4 tutorial i followed lol
No way a phone can run flux. The thermals alone wouldn't allow it. I was thinking of basic stable diffusion at low resolution.
why stable got more expensive
can i use stable diffusion on an amd?
bots, bots everywhere
geez, we need some bot-be-gone spray
put a roach trap by the front door of the server anroud the walls and windows
maybe a new way of verifiction on the server would be handy, a way to like, make it effort intensive so as to drive the bot deployers away, like, those new ReCaptcha things that make u have to solve a friggin puzzle
that method on the reddit post was cool, but it wasn't proper
it needs to be done using Qualcomm AI Engine Direct API
it would be a ton of work though to do it properly I don't think its worth doing
My phone gallery is insanely big
It's almost at 40k pictures and it's a nightmare to find anything
Is there any ai image search thingy that can accurately find what I am describing
Not on your phone but iirc clip + on the nvidia llm app can index and search your pics for you locally
nope but you should definitly backup your images xD
selfhostes tools like Immich have build in Contextual Search which can do what you want
Ok thanks
Does stable diffusion create a completely unique name every single time it generates an image or can two different images have the same file name
It gives them names like 00039-2127574113
go into settings and set Image Filename pattern to [datetime]
so they will only have that as the name and are unique
example: 20250201135213.png
Is there a way that I can automatically remove all unused nodes from a comfyui workflow for an image?
In the time it took you to ask this question you could have manually deleted all unconnected nodes.
If you hold control and drag your mouse, you can select multiple nodes at once.
I have hundreds of images I want to do this for
I don't understand. You want to edit the workflow that is saved in the meta data of an image? But why? The workflow saved in an image is there so you know which workflow created that image. Editing it would be pointless.
Anyone know how to do a tiled texture on either 1.5 or Flux? I remember A1111 had a checkbox for tiled, but it's gone now.
i mean you COULD just wipe the metadata of a image gotta look for a tool your self tho
The way I understand it, he doesn't want to remove the full workflow, but only some nodes.
its a web-ui thing not a SD checkbox. in swarm its under "sampling" checked there?
oh yeah unused nodes mb
yeah manual labour bud
I want to make it look cleaner for upload, because there are multiple inactive workflows present alongside the active one
swarm?
yeah swarm webUI has it under sampling. you could look for something similar within A1111 (tough i recommend using forge webui or swarmUI)
Oh I see
Does anyone know if this is a thing for Flux? Its just that Flux blows everything out of the water at this point
also wondering if anyone has trained a lora for flux and if it can be done on 24gb VRAM
i think i mentioned it above but:
its a web-ui thing the seamless tileable
flux is only on comfy tho
nope lol
You could just upload a separate clean workflow. The alternative is you would have to code a script that would remove all unused nodes from the meta data.
swam UI and i think forge web ui also supports it
A1111 is pretty outdated
damn yeah I havent used this in a while
does forge have any speed advantage over swarm
You can always make an image tiled texture by just blending after each step.
how? which UI?
Swarm is pretty fast since it has a comfy UI backend but its a preference thing
some like the UI of forge
You can do it in Comfyui. Basically overlap the sides of the latent after each step and blend.
hes on A1111
i do NOT recommend comfyUI as a person who isnt really familiar with this/noodles
as its node based
Im already on comfy but yeah I have no idea how to do what mario is saying
SwarmUI lets you not use the noodles while still having its advantages
I would check if there is a specialized node first. Chances are somebody already made a node for that.