
#🏞|general-with-images
1 messages · Page 167 of 1
cat
I'm new to Comfy, I haven't try upscale yet, it seems I have to set a lot of things
what workflow and resources do you use?
https://civitai.com/models/549838/phoenix-dota-2-sdxl-pony Do you guys think it'll be possible to get a humanoid girl out of this lora or no?
seeing how image 4 is a female body and phoenix face id say yes
actually most of them are bru

Idk lol
There's not much art out there of a humanoid girl like this unfortunately so I think it'd be hard to train a lora for this
idk, you can generate a bunch that look like it and use that for character training, probs low quality end result tho
Ah
I'm gonna try this and see how it turns out

Ah shoot I meant to make hi res steps 20
Oh well
Maybe if I make the lora less than .5 it'd work out?
Idk?
Uhhhhhh 

What happened here??
74 sampling steps? Bro what
Tune it down to like 28 max
I have been in the studio all dang day. Working on some new live music till my eyes crossed looking at screens. Feel free to jam to this unreleased stuff and I hope it helps the creativity.
I use my own built workflow.
But in reality, it's just Flux Dev + 4 anti-burn nodes to allow me to use a cfg above 1
I would use dedistilled but dedistilled takes more steps

le squid
Is dedistilled really worth it for the better comprehension?

I wonder how strong the text comprehension is when you use dedistill with anti-burn nodes
with the dedistill you can use dynamic thresholding mimic scale cfgs of around 2-14 and max out base cfg to 100



14cfg outputs are fine it seems
Interesting that I can mimic scale 14cfg and unlock it entirely in ksampler using dedistilled
Flux here takes like 5 min to generate so I'm just testing loras and some workflows like img2img there I play a bit with denoise and steps, but not much.
it was much easier to test stuff with SD XL for example
With Flux it is like Interstellar time
I haven't try different samplers for example... in my experience I could only tell about something like that after generating ton of stuff, and here I'm not able
IDK if flux is worth waiting 5 minutes
if you can find a flux look you like and train an SDXL checkpoint on the output, you can get kinda close
I'm actually waiting 10-12 minutes for an image, but it's for a different reason ofc
lmao

\

Nvidia Cosmos, 768².
Img2Vid

Please help me
Extension not available due to error below



A1111 on colab... 🤮
What are your PC specs? You maybe don't need it
Graphics board is NVIDIA GeForce GTX1660 6GB.
CPU is Ryzen7 5700G with Radeon Graphics.
Stable Diffusion is not a specification that works in a local environment.
I don't quite understand, I guess your translation tools have trouble translating from Japanese to English.
You think Stable Diffusion doesn't work locally? Of course it does x)
You should know, even with your PC specs, you can use A1111/ForgeWebUI/Comfy_UI, with lightweight models such as SDXL, Pony, Illustrious, and probably even with quantified Flux models which are very lightweight. Like Flux1Dev Q2, or Q3, for example.
I tried it a year or two ago and it was impossible, so I have been using it as a Google colab.
I will try the lightweight model once, thank you





اسے پن کرنے کے لیے کلپ کو ٹچ کر کے دبائے رکھیں۔ 1 گھنٹے کے بعد پن ہٹائی گئی کلپس کو حذف کر دیا جائے گا۔
Does it looks like arab language Discord server?
People dont check what channel they are in too, so many english speakers posting their problems in general
Like dam
fr, no need to be a dick
Oh in not nm trying to be like i meant the techsupport channel
I realize i hit sent before finishing and forgot about it
Apologies
People dont check what channel they are in too, so many english speakers posting their problems in general instead of #🤝|tech-support ***
Ah but still. My comment sounded a bit rude
It’s a bot anyway. The message translates to “Touch and hold a clip to pin it. Unpinned clips will be deleted after 1 hour.”
Anyone got a good way to generate DND maps ?
With stable diffusion of course!

could someone take my trash server logo and animate it with ai? Trying to make a gif for an animated verison of this.

Youd be better off having the background as a separate image, animate and then plop the text on
Ai will make the letters into a mess











Man, what model it is?
SD 1.5 models with "Mix" in the name can look like that
has there been much changes in the last 3 months ? i didnt watch the news kinda
i can't seem to find improved pictures in any of the channels here sadly

but that's still 1.5 based ?
SDXL
but not 3.5 ?
not that im aware of
there's not much going on with 3.5 ,right ?
or with stable diffusion at all ?
there's not much progress in the last months ? at least i couldnt find any


can't tell if you know about flux or not

ok everything kinda moved there


flux / sd3.5 realism wasn't cutting it for me, i prefer illustrious and its sweet aesthetics better

especially for anime

i hoped that sd3.5 would be used as base model and finetuned / trained into infinity
but that doesnt seem to have happened ?
might work with sd3.5 medium but i havent' seen much happening

dunno, but i personally got bored with those styles




what do people want with all these anime girls ? they look so replace-able to me ?

cos its hard to understand why to fine tune SD3.5 instead of flux
they are not the same, i think variations with sdxl breed models are captivating
because flux has a veeeeeeery limited range of styles
but we're talking about fine tuning so you are replacing the base style with your own
flux is isolated in a way that not every consumer can use it

i found that you can't push flux beyond some things, no matter how hard you try
it was very annyoing
flux body variations are a struggle

how the hell do i remove ears from image
i tried putting it in negative prompt, i tried writing in prompt "no ears seen on image", i tried drawing hair and using low and high strength, theyre always here


on the one hand yes, but on the other hand SD 3.5 anatomy issues seem to be even worse than Flux
so I am not sure it is a good trade

withdrawn: try in your prompt not to write what you DONT want, but what you want instead
medium hair also doesnt work
what is your prompt?
all flux has to offer is highly detailed texture but within a limited variation

i stopped using flux / shuttle3/ sd3.5
try with "earless male" in the beginning, instead of "male"


i'm not trying to down those anime girls, but i m honestly curious what you are trying to create
i personally try to create new forms of art, new combinations of styles that haven't been done before (with more or less success), that's my goal

for me those last two pictures are exactly the same
doesnt work



which model are you using


tired 4 and 3 with different strengths, doesnt work
instead of 7
show your workflow pls
its krita with SD plugin

its basically every other workflow but in app created for drawing
i m using comfyUI stuff
like that last image is this workflow:

model was epicrealism_naturalSinRC1VAE
plus flux with ipadapter
plus sd3.5large
wow 3 different models
they're in a pipe
i generate something with the first, the use the input as partial base for the next
(for example let the next generated image not start at step 0 but at step 5 or so)
yeah that's good, I do that with Flux followed by SD 1.5 or SDXL sometimes
another thing that i'm trying is to create one workflow that will create vaaaaastly different results with the very same prompt
like i got this here:

this


all with the same prompt (just different seeds)
hmm yeah that's cool
I would recommend CADS https://github.com/asagi4/ComfyUI-CADS
makes SD and SDXL more variety



a bit of a different style here 🙂
(still same prompt)

but what are you trying to achieve, @wispy nest ?




are you just doing random anime girls for fun ?
or are you trying to create something specific ?
playing
other than merging some models now and then
but this is mostly for fun recreation
but you#re not looking for something specific ? do you create images that you yourself think of as "wow, that's a great outcome" ?
I don't know anime but apparently its very complex, there are lots of subtle differences between anime art styles
i have specific expectations thats why i try specific models

like we have one word for "anime" but something like Studio Ghibli and Dragon Ball Z are super different
so what -are- your expectations ?
because i see that a -lot- of people put a -lot- of effort into this
and i dont understand it
but i would like to understand
this is mostly for fun
i like the aesthetics of it

to be more specific, im always amused about feminine traits of girls
so to be creating such art through prompting is quite fun
i did a lot of portrait stuff, too, thousands of pictures, but i was always going after different styles, like charcoal/drawings/photography/whatnot
i think everybody finds it fun to explore new styles and techniques
i do too
these illustrious models are interesting for me atm
i do like that art style, too
but now that that one's done, i would already now look for something new

Illustrious is a kind of model, not a model

i have very specific goals of what i seek actually

no, that's a too general question @vivid widget
to generate something like this ?
i cant find one tho
i m quite sure that most models can do that, and it's a question of prompt/setup
okay, do i need a lora or models are good enough on their own ?
models should be good enough for this
cool thanks









@wispy nest man, would you please tell me.. 🙂
Use a illustrious model that catches your fancy :-)
Well, I'm looking, but I can't find any that give results that are less manga, and more realistic like the Torqx photos.
I'm just asking for the model eh, I'm not a prompt scratcher
something like this
?

No, its not 3D render like this. Its more realistic, like this one :
SD 1.5 🤮
we were talking about Illustrious one.

yo @wispy nest man tell the name bro
Wait, you're asking him for an open secret here. It's very precious to give the name of an open source model.
ohh my bad man
in my experience some people don't give prompts or model names out
or any workflow details
have you checked this one ? Vauxz Merge 2.5D - 3D
We are talking about a model man.
fair enough
the license of the diffusion model allows stuff to be kept secret
licenses exist that stop you from keeping anything secret, but so far the diffusion models don't use them
Let me remind you that the basic ideology behind SD and others is sharing. So I'm all for keeping our prompt and our methods. Everyone keeps their personal touch.
But stalling on a model's name, that's lame.
this is like
one of the biggest and oldest debates in open source
whether open source licenses should allow closed and commercial usage
or whether they should force all usage to be open
in the end isn't it upto every individual if he wants to share on not, regardless if the license allows it

no not necessarily because a license can force people to share stuff
but it doesn't apply here cos the models don't have a license like that
Don't ask me what model I used, it's a CIA-defended business secret.
If I give it to you, the whole Western empire will collapse, and I'll lose all my talent.
i mean if its a private merge or hes using it for a patreon income etc
i can understand keeping certain things a secret
Oh, this kind of dogshit
it's true that the license can force people but all i was saying is one people can choose to tell out of good faith bro, we aint dealing with sum high stakes to follow the license line by line
the merge or patreon? the merges mean it wont be on civit ai at all (if done locally) but patreon is good money
hell even some slop posters here get like 20-30 a month
a bit like those people who take open source, make a few changes, and ask for a donation patreon when they've changed almost nothing.
Special dedication to Aitrepreneur
i can understand if money is involved
if someone is willing to pay for it i dont see the harm. ( i was talking about image outputs tho)
theres this cool pixel sprite lora id love to get but he asks 25 for it
If someone has broken their back to do it, and a ham comes along, and just because of his notoriety, makes money off the back of the REAL dev/creator who did the work. While the REAL dev/creator earns nothing... I'm not sure that's any better.
Another special dedication to Aitrepreneur, who steals Github's code, and creates an almost identical clone, and forces its viewers to pay to see the content, whereas the real Github is accessible to all...
finetuning a model (and especially getting to really good) is quite a lot of work and were honestly blessed to have so many models accesable for free
posters on civit ai could easyly have asked for money for the model download
Question, so I am using a negative prompt list that I was told to use for all of my images
Here it is: BadDream, badhandv4, BadNegAnatomyV1-neg, easynegative, FastNegativeV2, bad anatomy, extra people, (deformed iris, deformed pupils, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation, signature, watermark, airbrush, photoshop, plastic doll, (ugly eyes, deformed iris, deformed pupils, fused lips and teeth:1.2), text, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, masculine, obese, fat, out of frame, caricature, body horror, mutant, facebook, youtube, food, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature
Are the ones in the beginning some sort of Lora?
are you using this on SD1.5 or SDXL?
because daym thats a LOT
I believe it's SDXL if it's pony?
are you getting the desired results/

Yup! I'm just in #🤝|tech-support figuring out what's wrong with my Lora though
well personally id shrink the negative prompt
Isn't the bigger the negative prompt the better though?
nooo
i use like
(low quality, worst quality), displeasing, ugly, poorly drawn, displeasing, very displeasing, worst quality, bad quality, oldest, deformed limbs, bad anatomy, frames, watermark,
nothing more
but since its pony
nope
you can add the obvious child tags and the slow scores like score_1 score_2 score_3 etc
Score?
yeah pony works with this cursed score stystem
theres also embeddings you can use
7 to 9 iirc
Oh
i used control net for the pose hence im missing many pompt tags for this one. but as you can see my negative is small (holding a big ass hotdog odd request from a friend) (edited some secret model data)

original was like a man trying to eat a oversized hotdog
but bigger prompt doesnt mean better result
I see
also im messing with sebl4rd. the model i use is waiNSFW illustrious

I've tested it, and personally I think it's a load of rubbish.
i mean its a 7b model its pretty good for its parameters
Mistral and llama3.2 do much better
possibly but once more finetuning happens it will be better i think















guess the SD model I used for this one

do you guys have a go to upscale model?
this is a good balance for anime and realism 4x_foolhardy_Remacri.pth
https://huggingface.co/uwg/upscaler/tree/main/ESRGAN

if you want to focus on specific style between realism and anime you could try 4x-UltraSharp.pth and 4x_fatal_Anime_500000_G.pth
the spelling is wrong bro




If I saw this thing in real life, I'd probably play soccer with it.

@scenic yew spammer alert
yeah these spammers are so unbelievable as well, how is "x-token" even related to image gen.













For some reason, Flux drew a blank food-based void all on its own. I think I can see an alien staring at me through it.










That’s a mighty weird-looking alien, I gotta say.
she likes pizza too











Why dont you post these in #🍥|anime . They look great btw








How much lol. If its a decent pay ill even do the letters
But imo your better off going on fiverr or something similar and hiring a small time artist for that
The trick is to use both ai and photoshop
But yeah I'm not staying unless i know the € range (also adviceable to just mention it here in advance so other people might want to but idk upto you)
You don't have the time to mention a pay range?
26
Don't see how it's relevant though
hey man
i can recommend you a few sites to try
where the words are correct^
its what i use for my own stuff
heres an example
heres another example
@viral shadow


mes premiers essaie sur stable-diffusion si vous avez quelques conseil sa ne serais pas de refus
^^
Do you guys think this was made with Stable Diffusion? It's my friend but it's a jacked version of him. Can't ask the person who made it.

Impossible to say from all those low quality jpeg compression artifacts and the "cinematic" editing
It could be a real photo that's been edited or an AI generated one.
@modest delta

Personally i think there could be a hint of ai in there BUT you could use a ai image checker
well i know it was ai just not sure which
Those are fairly accurate as they flag 70% of my images as AI and 30% made by human
Hmm
Thats hard to say honestly
Probably flux or sdxl realistic model
i want to add batman in behind him in the same style. i tried diffusion bee and it went horribly wrong
Well if your pc got a decent graphics card you could add batman behind him pretty easly
Personally id just photshop him in, mask batman and use img2img to clean up any dispensary's
@copper matrix is it easy enough to do that u wouldnt mind doing it for me? I have no photoshop skills lol

look at this sugar model https://civitai.com/models/1110156/majicflus
but too bad it's flux which i dont run


Are there any italian speackers?
use google translator.. there is no restrictions to conversing between english and other languages
you can also just use chatgpt, copilot, gemini
Yes no problem, thanks, i speack a little. My AI suggest me to try here for help choosing my bar logo
people share their gens here, for tech support there is a channel #🤝|tech-support but if you are looking for ideas you can ask , and if anyone's able to share idea they will
I've got many ideas but i'm not a graphic
Ok
if you already have some local setup to generate images that's a good start to experiment with your prompts









generator

Cant im not home for the coming 2 days. But what ? You just throw a shitty batman behind him. Then go back to ai. Mask the batman and run it at a very low weight (0.2)
Like copy pase a png. Use the eraser so it looks like he's behind him






























I had an interesting showdown between FLUX and SD3.5 using the same prompt, and the results were quite revealing... I've compiled all my results into an 82-page PDF, and you can grab the free download link from my X profile: https://x.com/JPdeBeerAI




Visual Prompt Mastery for Creatives | Bringing the power of AI to your brand visuals.
i have been using hiabrid concepts to make transitions and animations for my streams and thumbnails
Used SDXL to generate an image of a guy, then used Kling to animate it and get different facial expressions and poses





ouu, its a free viewer/sub generator for YT
why does it have fans tho xd, surely the phones themself arent getting that hot
there was a conversation involving running SD on a phone 😆




ahh .o.
ig its possible, i mean, at least androids, have linux capablities, if u can get one rooted, then flashed, provided the CPU is oki with it, and u can find appropriate drivers, that would be pretty interesting
Stable Diffusion is the foundation behind Riffusion. Instead of generating images, Riffusion uses Stable Diffusion to generate spectrograms (visual representations of sound). These spectrograms are then converted into playable audio using an algorithm that transforms them back into sound waves.
Riffusion essentially adapts the text-to-image model of Stable Diffusion to create music in different styles based on prompts. This is why it can generate a wide variety of musical genres, instruments, and even vocal-like effects.
vocal transition of riffusion seem more polished and fine tuned compared to suno...
or rather less robotic
and its completely free to use, unlike suno, udio that have subscription fee
holy.... sense of melody is so good with riffusion
pretty obvious riffusion perfected some of the lacking suno still has
how is it possible that one company with a selective team for developing all these AI based technology happen to spread so widely across many other companies, that could only mean one company insider is selling ideas to other companies, OR all of them have been holding back technologies and releasing them once the elites of society gave the go
also the news media have long been posting perfect pictures for the news and magazine covers .. how did they do it? They already had all the Ai tech to recreate stuff
I'm both amazed and pissed
And where does alien technology fit in
no such thing is alien
some ppl might have superior intelligence and have been living in isolation

Riffusion
(Verse 1)
Snowflakes fall, the world slows down,
A quiet hush, the only sound.
Wrapped in warmth, the fire's glow,
Outside the frost, inside it's slow.
The sun peeks through the icy haze,
A golden touch on winter days.
I press play, the music flows,
A gentle stream that softly grows.
(Pre-Chorus)
The rhythm sways, it pulls me near,
A melod...
riffusion was broken last i saw, which version is this?
still in Beta, but works fine

its own now, interesting
why do you think they are running sd1.5, xl and all that, those are for image gen
is ok for music
instead of channel being colour a channel can be a sound thing
really that's interesting
but i'm trying it just now, and i see fuzz model
the exciting part is no song limits with paid bs
i already have reason now not to use suno
imgine getting stuck with 5 songs / day with suno and dopamine rush stopped from flowing
yeah need open source
this is really good with what i've discovered in the last 2 days
first the deepseek, now the riffusion
oh and alibaba released qwen that's full blown modal from text-chat to image-gen to video-gen


hey could someone explain the "resource used" section on civitai? did he use first SD XL then Game Icon?

Simple as the name riffusion and some models where already available 3 years ago. In the github you can read that the project is not developed anymore. ...
are you saying they abandoned the riffusion project 3 years ago?
No I said that they started (Open Source) with a Model based on 1.5 SD

ok, sounds good to me, their recent development is as good as suno which they achieved only a year ago

you seem to forget that audio can be visualized
as is the basis of this tool youre raving about
🙄
not forgetting anything, i have no idea how to visualize sound
also im raving about riffusion its completely open source with 0 pay
Sdxl isnthe model they use, a lora is a addon for the model. Could be a style or character or even a concept
the only way i visualize sounds is through senses and feelings, not optically, and ways to bridge between mental world and physical world idk how, except you are existentially a conductor between those two worlds
oh i see, if it doesn't bother you, do you know a video where i could learn more about it?
i have sd xl and game icon but i don't know what do to to make them work together 😂
i am on automatic1111





I’m creating a lot of images with Flux now. Some of them a little bit unsensored.
cool, i stopped using flux/ sd.3.5
Really? Why?
Wow do you have examples?
yeah all thsse images im posting

i know

i can spot a flux gen from a glimpse
the plasticy look and having to refine it was too much
well you know flux and sd3.5 are better at realism than sdxl but my personal take on realism is bit different, i love creating anime themes more other might prefer realism flux offers for their projects
Oh I Understand
I like the Anime too. I’m not an expert of course.

This isn’t an Anime image anyway hahaha

Plastic as you said 😦
one draw back about flux / sd3.5 are those dont work too well with poses unless you use controlnet
Ufff you are right
upper body pics can look great, but nowhere as flexible with anatomy as pony
Do you have the link for pony?
this is pony

Wow
lots of good models on civitai
just filter the search for pony have a look under checkpoints

Do you have a server where I can see your work?
no, i run stuff locally
Ok. I hope to see more of your work over here.. 😛
look at that image @dry crow just posted, very crisp and radiant
thanks, its illustrious + adetailer + upscale
its possible if the character has a very good unique description (and is more anime like)
or if you use controlnet and with that you can use the same face and stuff for the next images (works for realism and anime)

Select the checkpoint (model) sdxl. Then use the loras tab and select the game icon
Thats it really
Put in a prompt and your ready to go

Do you know where I can find the bot on discord (if available).

Riffusion
[Intro]
(Ooooh, floating away)
(In this space with you)
[Verse 1]
Paper people pass
Through my open hands
Can't make you stay
Can't make you understand
That I see through
Your painted smile
Just a projection
For a little while
[Pre-chorus 1]
Each step I take
Makes you fade and blur
Reality breaks
When I reach for her
[Chorus]
You're just a dr...
the bot is not free but here is the info:
https://discord.com/channels/1002292111942635562/1237461679286128730

I really like bro… amazing.

Hey, anyone have a good workflow with a XL being used as a refiner for flux?
thanks. I will try it out




Do you know if this picture is a SD ?





Hahaha


scam link


anyone using deepseek with comfyui yet?
Why should we do that? Deepseek is just dogshit, specially small models
GUYS

Most people only talk about Wavespeed to improve their generation speed. Problems: Wavespeed doesn't work with GGUF models, and it greatly distorts images.
Here, at a guess, I'd say the image remains 98% true, it works with GGUF, and -50% s/it.
I was experimenting with TeaCache the last couple days with Flux (bf16) and an adaptive RK sampler. Unfortunately, I don’t have a very high opinion of it so far. Yes, the speed increases, but the quality decreases just like if you had relaxed the sampler tolerances (i.e. reduced the number of steps). Tightening the tolerances will get you back to a similar quality as the default tolerances with no TeaCache, but then the generation speed reduces again back to about the original time. So there is no free lunch here.
The node repo mentions the ability to losslessly reduce the generation speed, but there is no setting that does this. Below a certain TeaCache tolerance threshold (maybe around 0.15), there is no change to the generation time. The final result still looks slightly different than if the node is not part of the graph, though.
TeaCache also seems incompatible with tiled diffusion. It didn’t break anything, but it didn’t do anything — the generation time for my high res pass didn’t change regardless of the TeaCache tolerance setting.


X tiling only

i dont know whats in the image though, just prompted grass texture
can u pls check if this works with flux pretty pls? I dont wanna install it just to find out it doesnt work with flux

There is already tiled VAE support built into comfy.
I just installed it but cant find the damn node 😿
here is my workflow without the tile
i hardly use flux since its a bit slower then SDXL but it should. seamless tiled does seem to work. so you can use it


You need to refresh your browser window after you restart the back end.

yea but when I right click I get a gazillion nodes with no order and I cant figure out how to find it 💀
Double-click the node canvas to open a search box.



use it ollama on comfy, quite good

im actually using florence2 to interpret images, not 100% correct but works
thats a good caption model, deepseek is a reasoning model
so itll display its "thought" process
deepseek janus pro has image understanding node native to comfyui
but so far i didnt feel a reason to switch or replace florence2
i tried the janus pro 1B model few mins ago
also i love florence2 for it's versatile features, it can give you detailed caption and it can give you booru style tags
latter is quite useful with pony




Hows the janus model?
not bad, but nothing extraordinary for what i was trying it out
and low Vram usage
I really want to get a decensored llm hooked up to my own SD models for generation and image recognition but llm's arent there yet

this is quite uncensored and can generate explicit prompts

Oh yeah hmm i meant more like when interacting with the LLM and i say "make me a image of" but instead of it using janus it uses like my illustrious model
Possible in comfyUI? If so i need to get into it
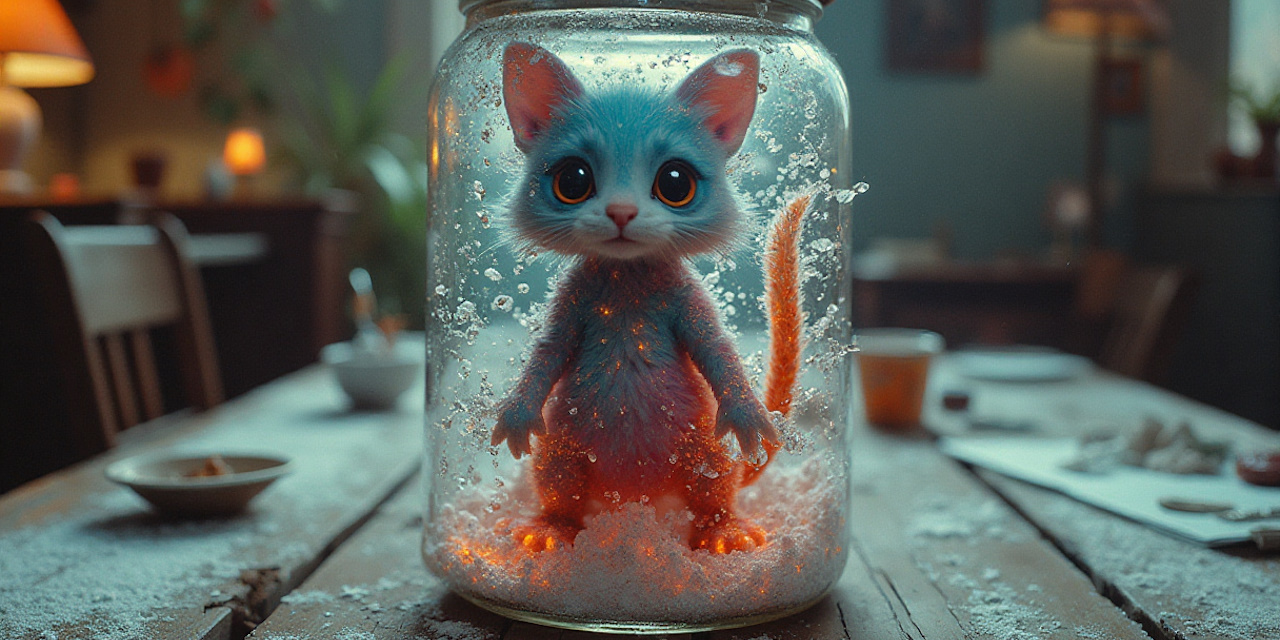
GitHub
Custom nodes for ComfyUI that utilize a language model to generate text-to-image prompts - SeargeDP/ComfyUI_Searge_LLM
Nice, ill dive into it. Its not fully what i want but does the trick partially
Diffusion models like flux can do this with Flux Redux, or IPAdapter for SDXL
The ability to clip vision encode them basically instead of getting an LLM to describe it in words




guess who placed loras in checkpoint folder 😂

judging by the above images
this is the server i didnt know i needed
excellent work lads, keep it up


is that Wii Sports?
I can never remember if she's 17 or 18.
18



Can someone edit it to look bit ai




Thank you sir


Bro you are great



















Could you share the prompt for the second image?
I actually cannot. It was made in like 2 seconds by an LLM.
In this case, it was Openrouter's free rose LLM 100b model
🤷♂️
I didn't have job data per image on.
Thats why.

Haha

Interesting. Are you using the API or on the website? Did you pay for the service?



your model wrong

ok can u explain why mine is wrong and why i should change to this
I had bad results on this model, or did I misunderstand? Explain what’s wrong with your picture?
how i can help
my picture is wrong cause it aint a man with black hair
so i understand that my model might be wrong but why should i take epicphotogasm more than another
its one of good models
😅
bad?
, prompt is wrong(too short and no negatives), its SD1.5 so its gonna come out cursed a lot regardless
can u give me an example of good prompt and neg prompt pls?
it can differ per model but since your using Sd1.5
Negative prompt (might wanna add some embeddings once you know what your doing): low quality, worst quality, low quality, worst quality,
for positive:
(Upper body photo:1.2). Detailed eyes, Detailed face. Photorealistic, Natural atmospheric lighting, intricate details, 35mm photograph, film, professional, 4k visuals, highly detailed, elegant, studio quality. (your prompt here)
remove some stuff you wont use maybe like upper body photo
then try again
Or,
Try different king of models, try Comfy.
Depends on your hardware specs.
@naive roost
i wont recommend comfyUI to someone who doesnt know how to prompt yet
maybe swarm but that might be complex too since there might be a lot of documentation there are hardly any video tutorials
i recommend any XL model over SD1.5 provided they can run it
I wouldn't recommend anyone to train on a model as old as Herode, which will disgust them more than anything else.
true lmao but he can use any other SD1.5 but if hes someone who cant run a heavy model theres still some OK 1.5 ones
out of most 1.5 models i prefer Based64 with one of the many style loras. decent results for 1.5
a bit more qualitative 🙂

yes i recommend flux and SD3.5 if he can run it but we dont know
but for what its worth 1.5 can still do ok images



except for noodle fingers or hiding hands altogether
im not saying its great man. but if you got a potato pc its the best one could get




this is perfect
can you make my character LOL

the two blondies :3
THE ART STYLE IS SO GOOD OMG



i wonder if all illustrious models are this weird, or the model im using...
blonde woman, orange abstract background,

not sure but its fantastic
love the character model













its cake frosting




Teach me master! how should I start doing this art? Can I do it on the web page or should I get this installed in my own computer?
not a master at this, but I use local setup with comfyui on a system with 12gb vram, 32gb ram, but these illustrious model would work fine with 8gb vram and 16gb ram too, just an idea
Hey o// Can someone please post an SD 3.5 benchmark on a 5090?
let me know where i can buy one and ill show you asap!
A black haired girl with a realistic image
That's oddly generic yet specific.. is she holding a realistic image?
literally blocked torq because all I've seen him post is girls

You can do so much more.

There is no real limitation with flux other than the time you take to make the image you want
Want to make an alternative of an already existing image? Use Flux Redux.
Want to inpaint? Flux Fill.
Depth and canny models, and just the amount of more common good flux finetunes
and just antiburn nodes in general and their ability to allow you better prompt adherence
hello, anybody knows how to replicate this artstyle?

2nd one isnt my favorite and i very much messed it up in prompting, but it's still pretty


imagine such hideous mindset. never the less I prefer to block them too. only annoying thing about discord is that it shows when blocked users show up in channel message as blocked instead of completely muting them.
Believe it or not, some people don't want to be assaulted with soft porn whenever they visit the discord.
you're painting a different scenario, those images are not explicit
i also have 0 regards for your worldview when you fail to appreciate life aesthetics

@viral frost you keep up your toxic mockery as you like, i'd have to be banned from server by SAI moderator before you can expect me to stop posting what i like posting which btw has nothing to do with explicit content. this hideous game you play is not confined to discord servers, its an issue that will be eradicated in real life.


Believe it or not, but the world doesn't revolve around you. I have young kids. I don't want to have to shield their eyes when I hop on discord, not knowing what might show up. And the last thing I need is my wife banning my use of AI image generation because she feels threatened.
you seem to assume the world revolves around your social constraints, that's a pretty loaded assumption, the fact that you oppose perfectly aesthetic aspects of life itself shows enough of your conditioned mindset and your circle of influence.
Nice rationalizations you got there.
i dont have to play word games with you, i know where you come from, and who you are in social sphere, there is nothing reasonable about your worldviews
You don't know me. Get gone.
you can back off








after playing with Illustrious and Pony for about 2 weeks and comparing the output images, it seems like Pony has more substance and texture than Illustrious





















SwarmUI now supports Lumina 2, a medium scale image model with an LLM (Gemma 2) as its text encoder, and the Flux VAE
Docs here: https://github.com/mcmonkeyprojects/SwarmUI/blob/master/docs/Model Support.md#lumina-2











@viral frost make a picture of the oscar statue 2025
Id just ignore, people cant be bothered to read the #artisan-faq
Usually the bots don’t ping a specific person.
Could also not be a bot. People can be really clueless
Yes, I’m assuming it’s a real person and they are just really self-absorbed. That’s what I was challenging.
Its somewhat of the same situation what i ranted about in off topic lol
Might come off as rude but it's what i deal with for work 8 hrs a day


Wth🙉
what model is that? The hair is so detailed
Size does not matter !

look for cyberrealistic, one of the best realism pony model out there

i'd hope the author is here so i could shower him/her with compliments
in either case the author is breaking boundaries with sdxl breed model / pony and merging all kinds of sugary worlds














which cute model is this

wow






ollama takes heck lot of vram compared to which Searge LLM is lot less memory hog
no clue what youre talking about
literally comes down to quantization

ollama keeps models loaded in vram/ram also
which can be disabled via OLLAMA_KEEP_ALIVE="0"
you probably dont have the brain to understand what im talking about, and btw werent you suposed to block me?
because what youre saying makes no sense logically lmao
that's with your brain, not my issue
Elaborate on how seargeLLM is less vram dependant than ollama
Like actually explain
I want to understand how you got to that conclusion
and im done wasting time talking to someone as obnoxious as you who acts like pompous, obnoxious cause of someone who appreciate feminine beauty, here something for you, im trying hard to be nice to you, just dont talk to me, dont address me
LMAO
So offended for nothing but me criticizing the fact you mostly only post women.
Go ahead. Not my problem.
you are stupid as you are rude
still havent explained anything, just insulted me the entire way instead
dont twist this around, you freak.. DONT address me
No, chief. You are in a general images chatroom.
Either block me and continue on or just don't talk.
how cheap can you be





your blackholes and portals miss life, there is no point in having a vast universe w/o girls




SD 3.5 large. prompt: a snowy owl, perched high in an oak tree on the edge of lake at sunrise. in the background we can see snowcapped mountains and on the other side of the lake are lodgepole pine tree covered hills

i hestiate to say ty, but ty, i've been discriminated by many for no rational cause for loving feminine aesthetics
bro you got me inspired rn to make a waifu if you saw my femboy collection bro youd see true degeneracy I cant judge waifus bro.
lol well thats nice to hear, at least someone understands the life aesthetics, its not about judging anyone but appreciating beauties of life
bro you got twitter youre making these alot that kinda stuff murders on twitter bro
well i do post here and there
looks good but they have channel moderation to not show too much skin, cause of minors might be watching
shit i cant share anything on this server thats crazy
yeah its crazy cause there is a fine line between acceptable sexy and going over that line
thats my boy
Waifus all day all the way thats how the pros do it. Just sit around and generate waifus all day theres a skilled future involved in that
Waifu

i see a lot of good 18+ pics on civitai, and also the civitai discord has nsfw channel but the problem with that channel is they post too much gore
also remember if you wanna do something more lucrative you can always jump into programming and take all your homework and pump it through ai tools and only study in the days following the test just to get by then cheat your way through the entire career or you know what fuck college. Just ai generate everything
big changes with AI for sure, automation is inevitable
Dont do anything that isnt gonna make money boys cuz its not gonna be easy to make money in the future boys you gotta really scrape the depths of deviantart interests to get away with those ai tools
yea man that shits not gonna happen and even if it does its gonna be 1000 dollars a month. You only bring it up because andrew yang and asmongold tell you its gonna ever do fucking anything but its not.
it will take a bit of time to develop a good system around it
but its coming
btw since we are discussing this in SAI discord, did you know they released Riffusion?
nope were just fucked bro go make money however you can
stop gargling asmongold bro i get it hes funny but he also cant clean his own house hes not a bright guy.
not into bitcoin btw
even before ai the entire economy was rigged to hell and back with nepotism now its just gonna get worse. Also thats good that you dont have a gambling problem that gambling problem never gonna make you money.