#💬|general-chat
1 messages · Page 70 of 1
That's the great thing about open source though. They made it easy for geeks to finetune this one. Curious to see what we get in comings weeks.
what did you do for optimization besides the usual --opt- args in the webui-user.bat?
cuDNN, specific pytorch and python versions
did you try out multiple versions to see which ones worked best or use a suggested "best" version?
yes, this is the best setup if you have a 4000 series card: pytorch2.0.1+cu118, latest cuDNN, python 3.10.9/3.10.10, (if you like xformers) latest xformers
What if they ask me if it's A or B and the answer is yes? Some of these generations are really amazing.
That happened to me during the beta, only then none of the devs knew anything about it. They said it might have been an automated suspension.
I still to this day have no idea why I was suspended. They thought maybe I had a generation that was flagged later that I didn't report. But not sure.
its just too much people, if entire governments cant handle this "too much people" problem , discord servers and mods are even less effective, relax , dont invest emotions on such a minor incovenience
government regulation is the only mechanism that can stop capitalism from steam rolling the populus
governments need to act fast because multinational corps sure are
For me, it was during the period where it didn't auto filter results. So I may have had some generations that were a bit too risque. But yeah, I was using SFW prompts too. I think my suspension was 48 hours though. Or maybe it just felt that way...
3 sides to every story
You were muted for prompting little girl in a bikini.
Please don't single out staff and be aggro towards them.
the blame i've put was on "too much people", sorry if i made you think i was blaming you directly
Will the Lora with created with the 0.9 model be compatible with the 1.0 version, given that the model comes out tomorrow, I guess the question is solved?
totally sfw
it depends, i would not be at my work seein "little girls in a bikini" , so not really safe for work hahaha
You'll probably want to use swimsuit or swim dress.
rules shouldn't explicitely define what consitutes child sexualization because then pervos come along and walk those rules right on the line. in this case it looks like mod discretion was a huge success and they succesfully disciplined a user for trying to "walk the line".
f around and find out.
little girl in a bikini is not NSFW?? LMAO
Yes, we filter through especially when it comes to specified "little girl" or "young girl" in bikini, because typically this phrase is often abused to yield specific results, and is deemed as not very sfw friendly. There are filters in place for this and we are alerted of these phrases. Our server has rules for this and is a safety net for pedophilic content, thus we crack down on it.
Picking at our devs who are NOT mods to reply to your dm is not the way to go, and I apologize for any confusion, but the above is likely why you were flagged.
it's about a bigger picture than just you
Why are users having to use qr codes without any other means of authentification offered?
Like they're trying to say, it's not just against you. It's hard to moderate so many people, and so they need a deterrent. People getting suspended is that deterrent so that people are more hesitant to do the same thing.
can someone tell me what aesthetic score exactly is?
does the automod not inform a user of why administrative actions are taken against them?
where can I test my own lora online?
if not, might need to do so otherwise disciplined users dont improve and are simply confused
an AI that classifies a score of an image according to it's training. many of them are trained towards a "chad" kind of aesthetic. many of them are trained on laion's aesthetic subsets.
wait, SDXL is nsfw filtered?
that was specifically about the bot in #1100170312106127410
i don't use them because so often the popular recommended ones look for chads and donnas
Filters for words used on our moderation end
ah, I see. so most of this server won't be upset
the bots are. obviously. they're using discord as a platform afterall. that's even before any ethical considerations
i contend only a small vocal minority are upset about censoring. they seem like a bigger crowd than they actually are. less than 1%
can someone help me with the install of sdxl, i have the base and the refiner model, is there needed anything more? the vae for sure, but there are some other high GB data.
Thats all you need
Some of the A and B options are so close now, I don't know how to answer.
You dont have to vote if you dont want to, its just to improve the outputs down the road. If youre happy with both thats fine too
Which is a good thing, I guess. Means it is generally looking very nice.
Anyone else being requested to use an authentification application now? I can't use it, so I can't use Dreamstudio now.
mhh im not really able to generate something with a1111 , my gpu isnt the best one but in comfy it works perfect
1 image takes like 40-50minutes in a1111
What GPU?
gtx 1070, in comfy it works fine
Yeah comfy is a smoother experience for me as well with SDXL
Downloading VAEApprox model to: D:\stable-diffusion-webui\models\VAE-approx\vaeapprox-sdxl.pt
100%|███████████████████████████████████████████████████████████████████████████████| 209k/209k [00:00<00:00, 9.49MB/s]
17%|█████████████▊ | 5/30 [03:49<18:00, 43.23s/it]
Total progress: 17%|███████████▏ | 5/30 [02:56<15:30, 37.24s/it]
Yeah... when you can commission an artist to make you something faster, that's not optimal.
1070 isnt a very capable GPU these days tbf
i could do anything with it on 1.5 so its fine, i cant upgrade bec. i would need a new monitor aswell, mine dont have a displayport
XL is more demanding
sure i know, but on comfy it worked out really nice with the 1070 😄
might get a 3060 in the future, or the 4060 ti
but for gaming my 1070 can play anything i need so its kinda useless upgrade in that case 😄
Yeah for 1080p its probably fine
using a benq 144hz monitor, and dont wanna upgrade its fine, and i hate ips panels 😄
wanna stay with my tn
I upgraded to the odyssey g9 oled recently and having a blast 
i just dont like ips bec of the reaction times
had 2 monitors here, and they just perform kinda same with my tn when they had terrible ghosting
like i had to activate all that overdrive stuff to get a similar result to my tn
oh i bet 😄
 together with my new 4090 liquid x i am very much gaming
together with my new 4090 liquid x i am very much gaming
i just play csgo, valorant and some retro emulator stuff, so it would be just overkill especially on 1080p 😄
i still hope they bring out some fixes, comfy works great for me, but auto just really takes hours
There already is a hotfix for auto in the works 1.5.1 from what ive seen
It will only improve
yeah i heard, but no idea if it improves the overall performance
We shall see
True or false. More art has been made in the last year than in the entirety of human history before then.
Sorry, you must answer true or false. 😉
tralse
Actually you didn't answer true or false, so clearly my last statement is false.
Good point though. I guess I should say anything resembling art. But you can count in bad art people make too.
Updated my A1111 and slightly overclocked my GPU, 1.0 can come 
With torch, xformers and all the fun stuff that spits errors at you

You're allowing the update now? lol. Alright, guys. Boto is ready for SDXL 1.0
prepare for cuda launch blocking 😛
Noooo 
Took me like over an hour cause I tried to also update python to the newest version, but it refused to work
python 3.10.11 ?
normaly its just running the installer and reboot. sometimes deleting the venv helps too
with my new desktop Ill finally be able to run SD at a good speed
I tried 3.11.4 and then the webui refused to launch whatever I tried 
SD wont work with 3.11 xD
not supported
Yeah I learned it the hard way

version: v1.5.0 • python: 3.10.9 • torch: 2.0.1+cu118 • xformers: 0.0.20
Went back to 3.10.9, since that worked for me before
He i use a111 and can i use multiple lora models in 1 image or not
Just got it so still new
Yes you can
yes u can
Oh ok nice
i really hope a1111 gets close to comfy performance, would be really nice, 25mins vs like 2-3 mins is huge xD
Comfy is just way more lightweighted, hard for A1111 to go that path now
If you talk about generation apeed mine generate in a couple of seconds
but u are probably not using the sdxl model
i dont think that has something to do with the overall generation speed
Not sure, im not super deep into that
Join us for the Stage tomorrow 👀
Is the 1.0 public model available tomorrow?
definitely
are you definitely being sarcastic? 🙂
no, i'm pretty sure they're releasing it tomorrow
oh ok lol, had to ask 🙂 thnx
What's the best resolution for realistic photos of people?
does anyone know what min gpu I need to run Kohya_ss
@wise stratus I already have 2 factor authentication setup on my Google account. Adding this QR code step to dreamstudio is unnecessary and will just be a pain. Now I need to use the authenticator app and save the recovery code somewhere. Extra complication for no benefit. There should be an option to skip it.
anybody got any experience with lora training? how long it usually start after clicking start training?
ten minutes to a week
Do discord bots that generate pictures on this channel work on the sdxl model?
Why does my inpaint keep drawing small versions of the overall pic, instead of just redrawing the thing I colored? I've got only masked. Got masked content original. Etc.
I inpaint a hand and it puts a face.
Maybe cause I had a seed set by accident?
Do you have it set to "inpaint only masked" or "inpaint whole image"
Only masked
No seed
Masked content Original
Restarted Stable and it's still doing it
Set it to inpaint the whole image. That way it will use context from outside the mask,
Or if you don't want that context, increase the padding on the mask, so it can see enough of the original image to realize there's supposed to be a hand, etc
Lmk if it helps
Comp is slow. Trying. Inpaint whole picture seemed to work. Thank you. Never had this issue before with only masked.
Best of luck
👍
Can someone tell me why I got this kind of format ? #1100170312106127410 message
🥬
Hi everyone, I'd like to know if it's possible to download the models we use in the bot channels, and where can we get these models? Thank you
Bot models are SDXL 1.0 candidates (not yet released): #🗣|artisan-support-feedback message
@faint nova Please don't self advertise in general chat, you can post in #🌶|off-topic instead
thanks
Guys where I can find the notebook file setup in civitai / github pages?
any tamil people here?
hey! does anyone know how to update Gradio to 3.23.0?
I got an error message when trying to use an extension that told me to update it. I have searched online which brought me to GitHub where it shows me a specific workflow/pull-request, but I have no idea how to work it ;-;
Did you update your A1111 install?
Hi, any news about official release of SD XL 1.0?
Its enough to ask in one channel 
Check out the next event and find out more
okay thankjs!
In almost every image with a person on stable diffusion the background is blurred out as the focus is almost completely on the person but that makes a very unrealistic picture, is there any way I can get a detailed background with a detailed person also to make it look like a real picture
cherubs was monsters with a lions body, eagles wings and a human head, but uneducated people started to use that name on Putto so now when I write "cherubs" I get ugly babies. So what are the original cherubs called and how do I get them in AI SDXL?
Hello I want to know can I use the bot of stable diffusion in other Discord servers??
Use Adobe Firefly
Nope
Good morning, everyone! I hope we are all well today!
Hey Sunny. The same to you!
Thanks! What are you up to?
I've made a reddit post with some of my SDXL experiments including the prompts: https://www.reddit.com/r/StableDiffusion/comments/159rio2/some_of_my_sdxl_experiments_with_prompts/
I've also shared my SDXL prompts here on the discord server over the last couple of days if you search for my name.
I shall take a loook!
I really love the one with the spell casting!
And that you shared all your prompts!
that's really cool!
Woohoo
Right? I joined this server after the delay to see what was up. Now I'm glued to the channels hoping there isn't another.
It’d be hilarious if that presentation is an announcement of the future release date of SDXL 1.0
I heard that they are also doing some new tool kits for training. Is this true? And will they be released at the same time?
is there a way to /describe with SD like midjourney does?
I'm not familiar with /describe or MJ that much. But initial search seems that it works like img2img
So yes.
its basically img2text, just going in reverse trying to predict the prompt
ah ok cool
Image prompting would be nice which is kind of like a blend of controlnet reference and clip, but dang Mj does it well
I think there are some more extensions that could make it better? Like a search and test token thing...
Who knows. I don't really focus on image prompting as much as controlnet and then inpainting.
I'm still struggling with the character consistency, any advice? 😬
Lots. I think the easist way is to find textual inversions on civit.ai. You find a few that are close and start blending them in the prompt
Is it better than img2img textual inversion?
Textual inversion is a specific way of fine tune training to create a token that represents a thing. So I don't really understand the question. I'd say it's about the same.
Same. But I have used MJ image prompting though to make fairly consistent material for rounding out Lora training sets.
I've got some examples one sec
I mean Img2Img have deapboru and the interrogator which should do the job
https://huggingface.co/spaces/fffiloni/CLIP-Interrogator-2 this worked pretty well just now
I'm suring Roop for the face, which is great and grant me the same aspect for the character, but keeping consistency on cloth is a real, real, mess 😕
Okay here's a short tutorial using automatic1111.
Say I want a consistent character. I find 2 to 3 TI(textual inversions) on civit.ai that i think are close to what I want the character to look like.
In this example I'll be using https://civitai.com/models/36147/veronica-cipher and https://civitai.com/models/23511/shay-mitchell
not sure if they've announced but im wondering if theyre working on freewilly 13b
Then I use the prompt to blend between them. like [x:y:#] x is shay, y is cypher.
https://media.discordapp.net/attachments/1060269382728683671/1133783524407787741/image.png?width=1268&height=106
the # is when it switches from one training to another. You can see the progression from one TI to anther here. I find a spot that looks good and then I use that.
Hey guys! Any tips on how to upscale images to 3x and keep realism?
Mine get too oversharpened (noticeable in the eyes, curls in the skin look sharp, double eyelid is like a line).
Turn down cfg, up the downsampling, or go in stages(like 1.5x then 1.5x that)
Then I added in some https://civitai.com/models/48104/sarah-shahi to switch inbetween steps.
Then finally I get [[VeronicaCipher:sh4ym1tch:0.79]|s4r4hsh4hi] as a good merge for a consistent original character
https://media.discordapp.net/attachments/1060269382728683671/1133785430609895465/image.png
https://cdn.discordapp.com/attachments/1060269382728683671/1133786139841548500/image.png
This is not the most straight forward but it is def the easiest with no training required
Also might be an upscaler issue... Try other ones?
So today is the day they announce the release date of 1.0?
Either they announce the release or they announce the delay. Well seeeee

Is there anything I can use to generate prompt from an inserted image
Thanks, Sunny! Really appreciated 🙂
hmm... announcement says 1.0 was released on github, but the Releases still only has 0.9 🤔
fr
Was it all just a lie?! 😭
how do i download SDXL model? i can't see it on github!
I suppose I can wait a few more hours XD
They probably don't have gigabit internet. Takes a while to upload. Might be on 56k modem.
until its, u know, "released released"
Back in my day you had to wait 60 seconds for an image to load on a website.
given it succeeded to load*
you remember logging into net, opening as many websites as you can, and disconnecting from the internet
It will be made public in the links mentioned in #📣|announcements soon! Please be patient ❤️
👍 👍
anyway i still have some time to watch the UAP congress hearing so thanks for delaying it!
Oh yeah! I forgot about that! Insane.....
i would be torn in two halves if you released it now
np!
Disclosure happening now so i quit my job because soon we will join the galactic federation and live off of alien tech
wait so sdxl 1.0 will not have a public release? only api and amazon?..
also, link please
(apparently they are uploading it now)
No clue
lol
ive been looking at github nothing yet
Soon! Things are rolling out 
If Aliens are revealed to be real, as exciting as 1.0 is, the alien reveal would be 1000x more interesting.
No offense to the stability team but we're talking about a world altering event.
When using the active bots, is there an automatic CFG value applied to the prompt?
I see a new vae on hf, will there be a new refiner model too? 
what is sdxl

{kind=link}
{kind=link}
{kind=link}
post scarcity civilisation, here we goo!
SD but big
Vanilla SD is small in size, probably SDXL is midjourney V3 level
{kind=link}
so its a model or a totally new environment?
new enviroment i presume
So it is SDXL today?
God I love Emad
Emad?
I'm trying to download the juice, but I'm getting a 404 error.
That's what the prophecy says
Ah, now it's a prophecy

CreativeML Weights, API & more coming today 🤞🏾
Fine tuning API preview launches today, #SDXL tunes really well, great job by team.
The hugging face pages are still 404'ing. Anyone else?
What exactly is SDXL and is there any reason for users of Automatic 1111 to switch over at this time?
Head over to #1005545148211527800 and find out 👀
Is there some information that I can read about it instead? I'm not good with the whole talking thing.
We have an announcement & a blog post: #📣|announcements message
i have this too
where model?
does SDXL change any of the requirements for generating images, like system resources (16GB VRAM etc)?
Very soon!
Are there anyways to load the info to find the prompt for a zeroscope generation, my computer crashed and didnt save the file i had written it in. Is there a way to bring up the data either in the auto1111 UI or on cmd where it appeared when it generated the initial video so i can use zeroscope XL?
404
?
Still 404'ing on huggingface.
oh hi again castor
yes good evening
nice pfp, i'm not sure if it's a pokemon or an astronaut helmet
Ha, it's the ship from Heavy Metal, the movie.
Waiting on the model drop while listening to the alien hearing is indeed a very interesting experience
right?
I ran this scripts: while true; do curl --fail https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0 && say Model Released; sleep 5; done
😃
the timing with AI is quite bad, now that we can have perfect UAP AI generated photos.....
it will be hard to believe any of the legit photographs are real!
Haha definitely. Creating an image out of text isn't going to seem so cool when we learn that teleportation is possible or that there are vehicles that can defy physics as we know them. I feel bad for the stability team today.
The aliens probably have tech to type something and then have it 3d print that thing.
Real living lifeforms or inanimate objects.
Link at the end still 404's
<t:1690399800:R> 👀
it will be activated soon
LOL
does anyone think the title of the blog might piss off mid journey
i will still be using midjourney for specific stuff. it's the right tool for the right task situation
Ehhh I don't think so. Mid-journey is still extremely good for certain things. I find the discord stuff annoying, but it can produce cool images.
discord stuff?
You have to create within discord. No dedicated app.
Sharing stuff is great, but they are limited because they don't have a customizable UI.
Seeing a 404 error on the Hugging Face download page for 1.0
25 min
Got it!
Stay strong
{kind=link}
Waiting for weights. https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0
On my screen it says No Access
ye cuz it was a link to stage chat which is now closed for us
Ah ok
I'm just currently using Automatic 1111 because I'm kind of use to that
so I'm just gonna wait a bit if it's not working like in the next 2 weeks I'll try out Invoke or comfy
GitHub
StableSwarmUI, A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - GitHub - Stability-AI/StableSwarmUI: St...
Why is there no channel for FreeWilly
what's sd_xl_offset_example-lora_1.0.safetensors?
StableSwarmUI have a local API like auto1111?
hmmm i'm trying to use SDXL in auto1111 the way i use other checkpoints, but it doesn't work, is there a different way to do it?
size mismatch for model.diffusion_model.output_blocks.5.1.transformer_blocks.0.norm2.weight: copying a param with shape torch.Size([640]) from checkpoint, the shape in current model is torch.Size([1280]).
i was using the SDXL .9 branch of A1111, had to use --no-half-vae in the webui commandline args, might still need to use it ? not sure
and 1024x1024 res
it just won't load so 1024x1024 won't mean anything i guess
oh dang
do you do anything differently ?
lemme load up the sdxl branch of a1111 and check it out see if it works
not really, paste into models and voila
What version did you install?
but i did use a different brnahc
i just got update, let me check
You can checkout to v1.5.0
i'm running it with --no-half-vae now
Anyone had luck with using a colab?
how do i check version of automatic? 😅
down the bottom
Stable diffusion model failed to load, exiting.... IN AUTOMATIC1111, WHY?

SDXL 1.0 model is out ?
Hi, for general use, would you rather recommend base or refiner? Or do both go together?
both
SDXL to load will use a lot of memory, like a TONNE mine used 29gb just then, so it will take a while if you have less, by packing it into local storage once memory is full, you may have to wait but i just launched it fine
ok, so when i try to update it says:
error: Your local changes to the following files would be overwritten by merge:
[here is a list of some files]
Please commit your changes or stash them before you merge.
Aborting
any idea?
ah thank you i will check
you have to use command line to get the specific branch from github (still a1111's github), if he has updated it im not sure if it will still be available
i'm using automatic1111 easy installer https://github.com/EmpireMediaScience/A1111-Web-UI-Installer
it has updating option in it which i'm trying to use
set COMMANDLINE_ARGS= --opt-sdp-attention --no-half-vae --theme dark --autolaunch
git pull
set ERROR_REPORTING=FALSE
IS THIS RIGHT?
any website where people can use and host multiple stable diffusion models?
hmmm not sure, i think i remember mattvidpro mentioning it in a vid, but i think it wasnt a showcase video so not searchable. Might have better luck with google sadly or maybe the stable diffusion subreddit
sadly there was no availability of the refiner for that branch but the generations were/are still amazing
Stable diffusion model failed to load, exiting, please help
not sure, i use the separate branch sorry mate, my command like args are --xformers --autolaunch --no-half-vae
iirc --xformers reduces vram usage and speeds up generation
i am also using a gpu with 24gb vram and have 64gb of normal ram, so not sure if its a technical issue youre running into related to hardware, so many variables
but during generations this model only uses around 9gb vram in combination with windows also using some
scratch that, increasing steps and resolution it jumped to 16gb
Maybe I'm a bit confused but are there safetensor versions of the model to download? I'm not quite sure where to download the actual models on the huggingface page.
I have downloaded the 2 files XL and VAE XL in the usual folders of my Automate 1111 but when i try to generate : it write : TypeError: must be real number, not NoneType
the safetensors 2nd from the bottom, click the download icon in the middle of the row
thank you friend, it worked
i think it was devil that did mention some issues with A1111 as of up to a couple of hours ago, i think for the next 24-48 hours the updates for it will be touch and go
i'm not sure why it's not straightforward though
youre VW, glad i could help someone else xD bigger thanks goes to coderx for the walkthrough video, shame it was so hard to find it
😩
i would spent today and whole weekend trying to figure this out if you didn't tell me
and would probably get sick of it and went back to the old version
😂
xD yeah that was how it was for me when using 1.5, nearly bricked my pc multiple times because im not versed in using git lol
i will try to run animatediff now, it didn't work for me before either
maybe it's just that
but wait... it probably doesn't work with xl
i would say within the next month there will be some crazy stuff coming, especially if 3rd party devs got early access to the model, by the end of the year our minds will be blown i reckon
yeah
it's interesting how people get used to the current state very fast
so, even though the progress is incredible
people just get used to it
there will be logo specific models, vector models, realistic models, waifu models, camera-specific models. Exciting times 😄
"oh yeah of course we can create amazing art in almost real time"
and noone remembers disco diffusion that was taking like 1.5h to create an image
😄
which was already mindblowing
i remember my mind being blown with disney using the LED projector dome for the mandalorian, then this came out....just huge strides bro lol
but what i really like (personally) is people and even some websites now, using parallax separation with generated AI images, gives such crazy depth
that method is used a lot on stills for intros and stuff but for AI it makes me feel like a kid again with a pop-up book lol
do you know if after preparing automatic1111 for SDXL it doesn't support 1.5 anymore?
because 1.5 don't show in my drop down menu
hi everybody. does anyone know how to get perfect tiled pattern? I try but the images doesnt match
i created a separate install folder and basically did a new install for the branch, if you didnt back up that folder i would recommend doing maybe a system restore to a previous date/time, that will restore those files that have been lost/changed. Thats the best method i can think of if backups were not made
i learned my lesson multiple times in the last 3 decades 😂
but im pretty sure either works fine by itself but i imagine the updated A1111 as of today might have issues because it is trying to provide flexibility between those models
right
anyhoo my dragon (wife) is now awake, gotta go tend to her 😄 very glad i could help out 🙂
Is there a way to save jpgs instead of pngs using ComfyUI?
thanks again !
sorry returned because i think i remembered where might be able to do that, runpod iirc
do your generations also have a weird texture in all images?
only if i dont use the 1024x1024, because thats the minimum it was trained on
people in comfyui got pretty good results at 4k with some tinkering, because it uses less vram with certain settings and nodes, but ive never used it
hi boys
i did upload my lora for alex from minecraft and i would like to share it with u all
how can i share my lora ?
thx
there may be a channel here, but people also have shared stuff on the models community page of the huggingface site
thx homie i did share it
im glad you said something i was doing gens in 512x512 and was like what the heck is going on lmao
haha yeah reminded me of when i used low res in sd 2.1 xD
just euler a, because im base as hell lol, but Olivio Sarikas has a great video showing different steps and samplers for SDXL, quite interesting with the difference in generations, high steps can make some of them look cooked as hell
I'm seeing that as well, the usual 30-35 steps seems too much.
yeah i noticed in longer prompts you had to find the "goldilocks" range of samples, too much, too little then after an hour or 2, just right 😄
i really need to upgrade my gpu though, get about 3 it/s on a 3090 with 80 steps when batching 100
how do you correctly use sd_xl_offset_example-lora_1.0 lora in comfy...? There's no trigger word or anything
might try comfyui, some dude said he was getting much faster results but i dont like speghetti that nodes-based rendering is lol
my 4080 is flexin hard on these gens i can feel the heat lmao
hey, thats a good thing, free space heating during winter 🙂
bet theres some lurker in this discord with a 48gb card just having a grand old time generating 5120x1440 wallpapers
Can SDXL 1.0 be used for commercial?
I know there was something akin to a eula/licencing for the closed beta of SDXL, you might need to check out huggingface if they dont have that provided here
but iirc it was more along the lines of "dont carbon copy known brands" etc
can anyone tell me how to get perfect tiling with sdxl? the tiling doesnt match
would the refiner work on images generated with sd 1.5 ? my peasant brain is trying to understand the research surrounding it lol
whats the difference between base and refiner for automatic1111?
the way i'm reading it , sdxl generations are a 2 step process equivalent to essentially a text-to-image from the base model followed by an image-to-image by the refiner
Is there a guide on how to use this new stuff with automatic1111? I guess it will take some time to implement.
I downloaded four files. The base model. The offset-example-lora (no idea what this is), the refiner, and the vae
i just grabbed a fresh copy of a1111 as i dont want to mess with my current setup too much and the only thing i had to do was add the no half vae flag thats mentioned in the latest release notes
but so far ive only got the base model working not the refiner
https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9/tree/main/vae cannot get that bottom "diffusion_pytorch_model.safetensors
" to save as default vae in A1111 (newest version), keeps defaulting to the 1.0 SDXL vae, as soon as i click apply settings it says 0 settings changed. Any idea what is causing that ?
that's a vae in diffusers format, won't work with auto
ah gotcha xD
you mean Xeet
my stablediffusion automatically tried to install SDXL just now with the "git pull" in my bash file, is that normal
idk but i will switch to sdxl just as soon as they support 4gb vram or i get a new computer
Can you generate nsfw with the released models now?
Yes
Hi, i got Sdxl 1.0 but i cant seem to make a good anime style but the bot could? How do i add theses Styles
does anyone know the analog film style prompt?
like what to type in to get the same results as using the style
anyone has a comfyui workflow that works well with sdxl
sent
gracias
no worries, glad to help. paying it forward, as it were.
how would i go about adding the new sdxl vae to the nodes? hmmm
ahh i think i see it now let me see if this works
nope didnt work lol
That particular workflow has blocks. Put the Base model in the bottom one, and the refiner in the top one. You will need to link the refiner model and the VAE. Also the clip to both of the upper joints.. I think that one was modified and broke a bit.. I may try to fix it real quick.
gotchaa
Hello Everyone!
asked this on a few reddit threads and couldn't get an answer - is there a reason I can't see the two safetensor files in the git repo?
I'm just looking to download the two new safetensor files for 1.0
not sure.. I found the on huggingface
oh are they not just in the git repo? that's what everyone was referencing on reddit
ah ok yeah I see them on huggingface, thanks
they said it's supposed to add offset noise (ie better contrast) since 1.0 has less of it than 0.9
Can anyone please help me install SDXL? I am pretty good at all of this. I know how to install extentions. I know about this video here which helped to install the demo. Via this link https://github.com/lifeisboringsoprogramming/sd-webui-xldemo-txt2img
https://www.youtube.com/watch?v=SVBOL_ukFqE
But is there a new link since this is no longer the demo?
I think I just put in an extension link into Automatic 1111
And than go download the models with my huggingface account. Do the activation for the permission or whatever generate the activation key etc.
But if anyone has a step by step guide, or can walk me though it quickly I would love that. Thank you.
So I have to use that lora with all of my creations?
ehh not really, I tried it but didn't really feel like it improved anything
Cool thanks for the help!
you might still find it useful, I dunno really
Wait. SDXL 1.0 does not need an extention anymore unlike the demo?
It installs like a regular model?
i think you can just generate with the model and then image2image with the refiner https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl
I can't wait until we can generate an image with SDXL Automatic 1111 and have them automatically refined in one click.
All in one process.
Yeah, it is too much of a pain to split it up into two steps. I'm not wasting time doing that.
I have no issue waiting days/weeks until it's a one click option.
Yes I still have not figured out how to set it up. Found two guides that give completely different steps. lol
in comfy ui you can do it
I am not learning comfy UI yet.
Sorry. lol
I can't wait for Aitrepreneur to put out a SDXL setup video. As I find his guides are quite good.
can i ask a question how much do you now about tiled diffusion/multidiffusion
I see. I know the alternative methed of hiresfix.
that would be
tell me more
It's like an alternative way of using highres fix in Automatic 1111.
the thing is i dont exactly know whats in latent space and what isnt
It's best you watch a video as I am not completely fresh on it. I can't teach it. Also it has a few ways to do it.
Let me find you a very good video
im a mad man i want all the detail
just cant get it
im currently upscaling an image to 9k just to see where diminishing returns begin
im so sorry but would anyone be able to DM me and help trouble shoot me through whatevers not allowing me to start generating images?
i tried my best to install SD from the instructions on github lol
whats your gpu ?
how do you check again?
I've spent too much time setting up automatic1111 to make the switch. All of my extensions are set up in automatic.
uh device manager or task manager will do
I have a RTX 4080. Here is the video I was referring too. https://youtu.be/A6dQPMy_tHY ULTRA SHARP Upscale! - Don't miss this Method!!! / A1111 - NEW Model by Olivio Sarikas
comfy also doesnt support all extensions i think
ULTRA SHARP Upscale! - Don't miss this Method!!! / A1111 - NEW Model by Olivio Sarikas
1660 is on the lower end.
bearly making it
6 gb is bearly enough
i know all of that
just need someone to explain the latent space to me
Yes that's my peak of knewledge likely more tricks now since this is 4 months old but useful.
yes
okay well can someone trouble shoot me through it?
the best way i found currently is image 2 image with controlnet tile resample and sd ultimate upscale
im sorry lol
multidiffusion doesnt work for me
Quick question can all that be done on 16GB of VRAM? I have not tried that yet in control net etc.
thats it it can be done one any vram
Hey I have some refs either I found them online or I had them custom drawn since I either still can't or wasn't at least then or didn't know I could get an A.I. to create the refs exactly how I want for an erp. Now I created those refs have a good PC and have found stable diffusion but idk after setting it up I can't seem to find a way to get it to make something that looks like my character, nothing that could pass as a sister. I was told by someone in DMs it be easy to do that can I DM someone some images and get some help with setup and prompts?
Yes 9K is extreme.
and i hav 24 gb
aay fr can someone help me lol
maybe later currently helping sanzaru
Lol then I'll go 16k
Ping me but just warning the refs are 18+ and she isn't fully human half dragon but not like half humanoid like I've been able to get it or weird skin and not right you know?
using stuff like automatic1111 in the past, where did it install everything? including like github related things
How can I know the best promot for the model I choose? For example I chose mistoon_anime how can I know the best prompt?
How do I use a specific style or modal? I was going through the galleries and would love to test a style with a prompt.
??
🧠'nt
?
Hi guys, does the checkpoint selected affect img2img?
In automatic1111 it does. Because normally that's where I will choose an inpainting checkpoint.
i was using sdxl 1.0 and whenever i type in a prompt it generates a sign that says "no" (different picture every time but same idea) what do i do
yo boys
i did a simple guide on how to use stable diffsuion on google colab for free
i would like to share it where to share ?
how is this server’s banner generated? The 2 astronauts
Can we generate images to the bot in our own private server?
This is a serious question and I would greatly appreciate an answer.
#✨|sdxl message
Hi, I am looking for a trained model to do product photography. What civtai pre-trained models will be best for that?
Hi goodnight
I have a question
How would you prompt something like this?
Ow
Where can I send images-
Nvm I'm dumb when I'm sleepy
Hello, everyone! How do I use the refiner model for sdxl in automatic1111's webui?
Is SDXL 1.0 allowed to be used commercially?
Yeah
hello!
Can I use the same ComfyUI workflow of SDXL 0.9 with the new model 1.0?
Can anyone tell me how the training data for sdxl was captioned? Captioning isn't mentioned in the sdxl paper on arxiv.
There was a lot of interesting work done on variations, mixing and clip inversion on the previous architecture and I'm just looking for more information.
lichess is the app my man, it's great.
you want to play?
thank you but no, I mostly just do random pairing, 3 min blitz, sat on the loo.
Guys we all agree that the model understand way better our prompts than 1.5 based models ?
Guys!!! Wtf am I reading in this article?
GPT 3.5 for open release? 
Isn't gpt 3.5 there's whole business?
.
I am new here, and I would need help to update my automatic1111. I am stuck on v1.2.1. I have setup the "git pull" in my "webui-user-bat" and disable all my extensions but still it is not updating.
What does it say in the console? A Screenshot in #🤝|tech-support pls
I posted my images on Adobe's Discord and was informed that sharing work generated by other engines is not permitted. Isn't it interesting?
Could it be a hint of apprehension about acknowledging the true potential of FREE STABLE DIFFUSION?
does anyone use comfyUI? i dont find DPM++ 2M Karras sampler? Or what is it called in ComfyUI?
also does anyone have a good workflow for comfyUI i kinda wanna get into it
I asked this question yesterday but no one answered (perhaps no one actually knows)
when using the SDXL discord bots, you can specify a separate "Style" tag from the "Prompt" tag.
Is there a special syntax for that when writing prompts? Or does the bot literally just add for example "photography style" to the prompt? or ...?
@trim ocean pretty sure there is a dropdown for DPM++ 2M as sampler and a separate dropdown to select Karras as scheduler
why do i need to wait for showdown to end to generate images thats yucky. most of the time its just 2 bozos comparing catgirls
jep i found that out lol ty!
hello
In Ksampler node:
sampler_name = dpmpp_2m
scheduler = karras
also you can finde soe tutorial on my youtube chanel for ComfyUI https://www.youtube.com/@ArchAi3D
Is it possible to use refiner in SwarmUI?
awesome ill check it out i wanna get good with comfyUI!
PS: is there a way to easily open the folder of outputs with comfyUI?
I think No
ah too bad but thats ok i love comfyUI its so performant
but you can config the output folder name and file names easily
Display the pixel image in the node frame and output/save it as a PNG file on the server below. It cannot handle latent images.
The input port is named images , but only one edge can be connected. If the number of batches of input is >1, each will be saved as a separate file.
Saved files are named with a 5-digit sequential number, and by default ComfyUI_01234_.pnghave a format similar to . filename_prefixComfyUI allows you to change the beginning (part) of the filename .
Within filename_prefix you can use some preprocessor variable strings:
%width%: image width (number of pixels)
%height%: image height (pixels)
%date:<format>%: Date and time of enqueue. It becomes like Nara %date:yyyy-MM-dd%. The contents to be replaced with are as follows, and the rest remains as it is. 2023-01-23<format>
yyyy: year (4 digits)
yy: year (two digits)
MM: Month (2 digits)
dd: day (2 digits)
hh: hour (2 digits)
mm: minute (2 digits)
ss: second (2 digits)
:doesn't work on Windows or Mac (Linux is mostly fine). to make sure.
%<node>.<widget>%: Widget value of the specified node. For example: %KSampler.seed%. <node>If there is a node with a matching Node name for S&R then that node is used, otherwise the node with the matching title is used.
TitleAfter creating a CLIPTextEncode titled
%date:yyyy-MM-dd%%Title.text%/%date:yyyyMMddThhmmss%%Title.text%%width%x%height%%KSampler.seed%_%Load Checkpoint.ckpt_name%
It is also possible to specify an overkill, such as Directory separation /can be used without problems on Windows. If the directory does not exist when saving, it will be created.
oh ok not sure i understand that all but i start watching your videos 😄
is there a way to easily set another folder as output?
or was that the explanation?
yes, change the name in (save image node) to this: (XX/image) it will creat a folder in output folder with name of (XX) and it will save the images with name of (image.png) in that XX folder
ah ok but i cant tell it to use a folder outside of the comfyui folder like on my desktop for easy access?
TensorArt is sketchy AF lol. they paying model creators / lora trainers on their ko-fi/patreon to go upload their model on their site.
one employee just dm'd me asking if i could upload my models, pretending he's new to AI and would like to learn from me despite having no idea who i am and what my images look like. 3 day old account too.
no, i don't think
{kind=link}
{kind=link}
All good i make a link to the folder to the desktop 😉
Playground for Hugging Face models, GPT4, Stable Diffusion, Whisper: https://lastmileai.dev/workbooks/clkjugr5g0036phc1ri5g517n
the photoshop plugin download link is broken on your site. Can you guys please point me a mirror link? Also, where do I pay for the SD api usage?
What do we need to do to use SDXL 1.0 with Auto1111? I tried just putting it in my model folder but it results in errors when i try to load it
nvm, if anyone gets the same issue just update auto1111 to latest release, that solved it ^
Hey guys. My 3080 10Gb pauses between image gens, while running SDXL 1.0. Is this normal?
(using Auto1111 btw)
how can I delete my image?
If I generate an image with stable diffusion and it looks good but the hands and faces don't look quite right how do I tell it to go back and just fix that?
is there a way to load custom nodes into comfyui in a colab setting
I have a general question. Back when SD first released I somehow was told or suggested to use --no-half. I have an RTX 4080 16GB. So I have been using --no-half. SDXL 1.0 does not work well with --no-half. So I removed it. I noticed if I re-run some of my seeds without --no-half my output is different. But I'm not sure if it's worse or just different.
My questions are should I be using --no-half with an RTX 4080 for 1.5 based models? I also heard of --nohalf-vae I do not and have never used that. What are the pros and cons of --no-half? Should I do away with using it?
I think I used --no-half as a way to eliminte black generated images that were all black?
Whats your thoughts on the room temp superconducting material? is it B.S. or is the world about to change as we know it.
bro this is a chat about ai image generation
there's #🌶|off-topic
where do you put the refiner model fro auto1111?
you can only do a img2img which dosent give you the same quality
wait for an update or learn comfyui or the other one
is there a way to put the comfyui manager in colab
I don't see why not
Is there a recording of yesterday's launch somewhere?
@rotund portal comfy colab notebook:
https://github.com/comfyanonymous/ComfyUI/blob/master/notebooks/comfyui_colab.ipynb
if there is I hope it's like that video of the windows 98 launch with steve balmer and the gang dancing enthusiastically.
Fast Stable Diffusion got updated and can run SDXL now but as a Google colab user im pretty disappointed: the compute units per hour went up from <2 to 5.45, because it need more ram and vram, and this makes colab too expensive (at least for me). So the options are to switch to runpod/paperscape or to go with Comfyui(it should run on lower ram machines, correct me if im wrong).
I like colab because of the ease of storing everything on Drive.
I would like to hear from users that run SD on web services what do you use, what are your experiences, etc.
I take it its pointless trying to run SDXL on a GTX 1080?
sup bois
i made a tutorial on how to import models from civitai straight to SD and how to run Sd on google colab for free where to share this link ?
i use clipdrop and pay monthly it takes only a second or two to generate the images.
i just timed it about 8 seconds for 4 images.
i hate google colab. its so clunky and slow.
had such a bad experience on VQGAN+clip a few years ago on google collab that i would never go back to that crappy thing
all that programing code and shit
hey guys, any recent advancement in generating proper hands?
or any techniques to bypass bad hands? i'm already using the badhandv4 embedding btw
bruh
i just asked where to share my guide,and i feel bad for u but there is people who deos not mind google colab because they can't afford to buy a new gpu
but i agree with u kinda
i understand... But whats the point in running on a google collab notebook when you can use a webservice? like clipdrop
because i didn't know about clipdrop
why would i want to hire a virtual machine from google and have them spying on everything i do
XD
oh right... ive been using clipdrop for ages, £7 a month for about 5000 images every day.
must be a way
i tried almost everything
what about using cryptocurrency?
Im thinking about using SD (again) for very specific usage
banned in egypt :((
governments hate cryptocurrency with a vengence.
to generate segs XD ?
i hate my life
wait no i hate my country
i had crypto on binance and then the British government threw a tantrum at them and practically banned binance
but i funneled my crypto over to coinbase
welp screw it i will just accept the fact that i can't pay outside
btw if u are planning to visit egypt the first thing to do is leave
No, more like filling the gap of Adobe Firefly for fun stuff with celebrities
i always wanted to see the ancient runins.
sheeesh nice fr
u will see it
your country has massive potential for tourism if its ran correctly
Literally just for fun
but u will see hell
For serious i stay with Firefly ofc if
Well there are going to be new solutions popping up in the near future imagine, for running SDXL
like peer to peer, i imagine.. because they are doing peer to peer for LLMs
i dunno, i guess to you 🙂
I dont have plans to switch when it comes to FF, but SD is free and i can play with copyrighted stuff and therefore its only for fun for some stuff
I mean i use FF also more for fun atm tbh
does FF ban copyrighted characters???
Yes, unless they are part of their Stock and therefore basically also theirs
knew there would be a catch with Adobe.. they think they own everything.
control freaks.
That is for a reason
Its targeted towards artists and professionals and companies, they dont want that stuff there
let me guess, everything anyone creates with adobe software, Adobe owns the rights.
No
but have you read the TCs
They dont own your stuff
They can train on those tho depending on some circumstances
For generative AI they dont own any of your images copyright
But companies like Autodesk own your stuff, that you create with their software like 3DSMAX
Nah
its true mate.. its all in their terms
I use 3DS Max from them
you may think you own your work like renders.. But if you dig through the leagal terms you will find they own the rights.
Its actually my main tool besides of ZBrush and Photoshop
i know its true because Ton the creator of Blender talked about it in an interview.
Its limited on what they own on your stuff
you still use Zbrush after the aqquisition then
They dont own your assets in sense that they can resell it etc
They might make ads with them tho
Etc
Or likely train on thel
them
did Zbrush survive the Maxon thing?
doesn't generative AI make you disenchanted with creating in 3D?
They could afford themselves that
Disenchanted?
The text to 3D model is looming
Sry have to look up the word
np
Generative AI made me appreciate those more actually
I just integrate gen AI eventually as part of the workflow
In one way or another
Because i want and need far more than generative AI tools are capable of right now
But you know its going to catchup to all the stuff it cant do
then what.
if i had a talent for sculpting right now, i think i might consider sculpting out of physical materials and selling the models.
Thats speculative to say the least and id not want to put a bet on that and wait for something that might not even come
sculpt something great out of marble, i bet you'd make a fortune, and then wonder why the hell you were doing it in zbrush for years
because im more a digital artist 😄
For money i will look later but there are (good) ways to do something and eventually earn on the side at least
Because as of now i already have a full time job
Otherwise i couldnt afford myself the huge amount of money spent in hardware and software
Got to have plans for when AGI starts taking most jobs.
yea, thats a lot of software subscription you are paying.
But i worry about the future... although i have one thing up my sleeve.
If it comes
And that is im a guitarist and ive been in a band for a while, and when AI takes all jobs,, nobody is going to want to go to a concert to watch robots play
But as said i dont want to bet and wait for something that isnt necessarily coming
But if you enjoy playing it you will continue playing?
well its just that AI wont replace that job..
watching a live band is a human thing, and an artform people appreciate, and dont want to see machines do
so when everyone is running about like a headless chicken because AI has replaced their job role, i know i have the gear, and the years of practice and experience to keep playing in a band.
But eventually getting paid back with secondary incone
income
But id do it without that still
Kinda like established artists
just my advice on what i think is coming with AI.. i would switch to physical artwork, because art collectors are always going to appreciate art made by human hands... But digital stuff might get swamped by AI generated content
Im between 2.000€-3.000€/year right now for software costs
Zbrush looks addictive.. it looks very rewarding.
Or more like at least 1.700€
and ive tried Blender sculpting, it cant touch Zbrush, but i see why people like it
Digital stuff is still not replacable by AI, the only issue is spamming of those AI images
But for the industry itself it isnt relevant since they want skills from artists
When they look at your portfolio they will know the potential candidates
yea but you have to be realistic about automation.. The game comapnies the movie compaines, will automate as soon as the technology is possible.. which will be soon.
Blender is free which is already a reason for many to use and its still powerful
Automation is already a thing, but its not there yet and some things are extremely hard to automate and replace
To compare, some no name company would more likely do that compared to those like Riot Games
For art and what i mean it is
art wont get replaced... that is true. like i said it dont matter how much AI content there is, people want to buy human made art.
The generative AI cant even touch the established artists in the industry. Thats why you see beginner artists being much more scared than those
It can be used there tho
But not to replace the complex workflow
Where you might see those are low companies
its only years off though.. a decade flys by
That are amateur like
Have less money
And dont give that much damn abour details
about
I personally am not realls worried about myself there and i also like art without earning money as well
Otherwise i wouldnt pay this much
Theres not many skills that people can be confident will survive the AI apocalypse.
Btw which SD model do u use?
Clipdrop so its still 0.9
Oh okad
Okay
I will have to look up agaik
i dont need fancy tools for SD because i will edit in Firefly and Photoshop anyway
its just a gimmick to me really, just something to do to relax..
watch what it comes up with
I just need to generate specific stuff
In a easy matter
No more no less
For SD
Ideally id use some web UI for SD without installing anything
yea why bother with the hassle.
I have already enough to bother with my pipeline xD
Back and forth between softwares and add ons
well have fun.. sounds like you are in a phase where you are really deep into creating...
im currently bored with life and have creative block...
I always loved being a creator, but my motivation was crushed by other people and partially myself
I did paint in youth for example and as a kid, but got demotivated by others
Plus had a very dark phase of life
yup.. that can easily happen.
Oh, i hope you find the track again 🙂
i hope so.
There are people who find enjoyment in art even late in their life 😄
of course, i think the mind just has to be ready for it. sometimes life gets in the way
Agree
When i try to generate images in clipdrop in mobile browser the file size is coming out around 1.5 mb where in the pc browser its coming out in 200kb. Why is this happening with the change of device thats being used to generate? Any idea guys?
im using the same prompts that i used for 0.9 in the latest 1.0 , the images looks bad and low in quality. speaking about clipdrop
in PC browser when your account has lots of credits you click on a generation and it will download full size image.. then after a few thousand images it seems to disable upscale and gives a smaller image size.
then when it renews again the next day you can get the larger images again. either that or the way you are downloading you are getting jpg rather than PNG
ok i just noticed this after your explanation, that when i download the image in my mobile browser its in PNG in 3-5 mb and when i download it on PC its in JPEG in 200kb
On PC, if you right click save, even before you left click to enlarge, then it will do the PNG thing
in PC theres no way/option that i can download the image in PNG, i tried right clicking to save the image and also the direct download button that appears on top of image...both ways are downloading the image in JPEG but not PNG. This is wierd
odd because in chrome, if i right click save from the grid it definetly saves as PNG
PNG just gives a bit more color gamut.
im trying it in every possible way to download the image in PNG from my PC browser and its not happening🥲 . still downloading in jpeg only. In my mobile its downloading in PNG but the issue is that earlier with 0.9 the default images were downloading in 2048x2048 ~ 5MB. But now after the 1.0 update even in my mobile the default image is downloading with 1024x1024 resolution ~2MB. Not sure what i must do to get the best quality...
I'm new here guys - can somebody help me understand what the main difference(s) are to midjourney? sorry if its a stoopid question?
ignore what i said, i just refreshed my browser and it changed to 1.0 from 0.9 so its probably different now.
in Auto1111 is there a way to save a template with resolution,neg prompt etc so you dont have to retype after loading everytime?
1024x1024 is native... 2K was just their to be honest crap upscaleer
or mediocore upscaler.. that any upscaler could do the same
lol... can you now check the downloaded image is in png or jpeg? and also if there any difference in resolution and file size?
nahh, with 0.9 the default download resolution was 2048x2048, im sure abt that. with the update it dropped down to 1024x1024.
i clicked the blue download button and it gave 1024x1024 184kb PNG 96dpi 24bit
so thats small for a PNG must have been maximum compression
i guess
looks good i dont see any artifacts or color banding
is it! now im confused🥲
actually the edges of things do look compressed. but it could just be the image
can you compare with your previous generated images that were in default aspect ratio 1:1 and see the resolution difference?
SDXL is native 1024x1024 anything above that is just a standard upscaler. so put it through what upscaler you like
not got anymore time its midnight here
The most obvious difference is that Midjourney is basically ready-to-go/out of the box AI image generator. You have a few options for generating. With Stable Diffusion you have much more customisation options but its also way more harder to setup
also you can use SD locally
with MJ that doesnt work that way, you only generate via Discord as of now there
is there any way that i can use the clipdrop 0.9 back again?

dont forget clipdrop has its own upscaler
i does but the 1024x1024 images that are generated after this update are not great. before the update im sure the default download resolution without upscaling was 2048x2048 and the images lookd more crisp and sharp.
Guys do i use the same sampler and steps for high res fix in comfyUI? Whats a good denoise strength, 0.3?
thanks mate
You are welcome 🙂
can anyone tell me where to put this in Auto1111 'detailed_eye-10' its not a Lora?
hey can anybody tell me how to set remote local access for stables warm with windows?
also what is this when using Loras RuntimeError: The size of tensor a (2048) must match the size of tensor b (768) at non-singleton dimension 1
is anyone able to help me?
pytorch_lightning should be imported after torch, but it re-enables warnings on import so import once to disable them
lovely thanks can't open firefox rn; misconfigured my proxychain
discord is dying right now how long until someone thinks it's just this server
anyone have troubles after installing temporal kit? im getting this error:
ImportError: cannot import name 'auto' from 'tqdm' (C:\aiii\system\python\lib\site-packages\tqdm_init_.py)
and i cant find anywhere on how to fix it
anyone have issues getting sdxl base to load in Automatic1111? The progress bar loads and then it goes back to the previous ckpt I had loaded
I'd ask in the github of the extension, the developer is your best resource for 3rd party extensions
Anyone know what SD puts in the watermark on images it generates? I can't seem to find a definitive answer anywhere...
what things need to be in the extensions file? do we need moviepy in there if we are going to be using temporalkit?
Is any1 using kohya on Collab to train SDXL content yet ? I have a question
me sitting and waiting for the generation to come back on because i already voted on everything: 
guess theres no point in asking questions here...nothings been answered in hours FYI
Anybody still using colab? Just me?
Like it works, its free (0$), and uh it has alot of features, it runs on your phone
Maybe its laggy as hell
Colab is the way for the people who can't afford a 4090
I sure can't
or a 3090, 80, 70, 60
But like its free you dont have to pay a cent
People tell me "don't worry you will get one in the future"
But in the future the 4090 will be obsolete
8 years ago my dream build was a GTX 980 + i7 6700
And look at that now
Completely obsolete
Well I don't even dream of that tbh
Ok cool
Why do people choose runpod or stuff over colab? Is it less laggy or sumthing?
Me neither dont have us cash
it's because you're doing it in the wrong channel lol
I pay $10 for colab and another $10 to Google One for 2tb's GDrive . I know I could colab free but I think it's worth $
where is controlnet on stable diffusion now?
are the bot -1 to 10 now running SDXL 1.0?
Dont use 1.5 loras with SDXL
comfy ui looking kinda basic rn guys how do i upgrade it to show the refinery options and base instead of the "load checkpoint"
For peoples info. The lowst gpu yet I tried to succesfully run sdxl fluently is a 3060 laptop/mobile gpu with 6gb vram!
and it was on auto
does InvokeAI have a feature similar to auto's hires fix?
$10 per month for a 2 TB drive?
For $190 approx, you can get a 10TB segate external hard drive.
For $60 approx you can get at 2 TB external drive.
So after about 6 months google should send you the physical drive, because basically you've paid for it.
So RTX 2070 would eventually work?
How, i get not enough vram on R5700 8gb
Also question
If buying new gpu for SD, probably better gp nvidia, instead of amd, even amd might get more vram?
Dont buy a new GPU its a scam currently.
Nvidia are still messing around scamming consumers.
Its hard to know when it will change but they plan on sticking to the same B.S. of releasing a gigantic over priced 5090 and then probably wait an entire year before the affordable varients come out.
well technically speaking yes
amd gpus are mostly not useable or at least harder to use
Intel is adding new instructions to their CPUs... would this allow SDXL?
word is the RTX 5070 will cost $1500 and have 8GB VRAM
and will release xmas 2025
is there any workflow on comfyui with roop and controlnet together?
If vram is true, its just insult to buyers
And suggestion is to do? Buy second hand?
I think maybe a 3060 12gb v4am would b3 good enough for now for sdxl
My suggestion would be just to wait. until a true option becomes available due to consumer demand
I will likely get RTX 4090 next year if 5090 doesnt come out
Nvidia still needs to wake up and smell the coffee after the bonanza they had during the crazed pandemic era buying of gaming cards.
People are struggling to afford to pay the energy bills let alone go out and buy an overpriced gaming card so they can game all day
But then issue is, my r5700 seems not running sdxl, option is using something like runDiffussion, and paying monthly and its cloud, so dont like it as my generations are there :/ so maybe a 3060 12gb is a good placeholder, till.good options come.out or amd gets better support for ai generations
is it really worth it? just generate in the cloud. and if you want NSFW stuff just view others work.
Its not about nsfw stuff, its general all workflows, like i generate image, in cloud i need to download or might get lost in rundiffusion or pay 35eur a month, not great price.
clipdropio is £7 a month for me, and its like 5000 images every day and loads of other tools
i already have 10500 SDXL images on my computer now.
it would have been drastically more expensive to buy an nvidia card and generate it all manually
Im on a GTX 1070 and still waiting for Nvidia to release an appropriate viable upgrade. But still nothing worth a buy.
invokeai and comfyui are great tools for inference. is there something with a ui for finetuning/training?
kohya_ss gui, onetrainer
thank you. i will have a look at them.
Hear me out instead of paying a cent
Use colab (except if you dislike lag)
guys how do I install stable diffusion on google colab
I've been following several tutorials the entire day
https://www.youtube.com/watch?v=0GXGnGp-2g0&ab_channel=EXNOZGAMING ---This one doesnt work for me
depends what UI for it you want to use? If you like SwarmUI, https://colab.research.google.com/github/Stability-AI/StableSwarmUI/blob/master/colab/colab-notebook.ipynb
https://www.youtube.com/watch?v=sHxv24ySgyk&ab_channel=AIMarvelverse -- This one works for me, but the problem of this is I cant put in my own models
out of all the things that get in pantheon it's my stupid little gamer chihuahua
im using stable diffusion
stable diffusion is a not a UI
oh fr
The hochiminh logo webui?
both the videos you posted are Automatic1111 WebUI
eyyy patrotic:))
ah alright
I didnt know that
so what do I do now? 😭
=)) dm me
Does anyone know if i can use Clipdrop: Stable Diffsuion XL for commercial uses?
soneone here using a 3060?
How to use free sd, if u no have pc:
Option1 : Colab
Option2: Playground ai (1000 imgs per day theres no fking way u would run out)
Hi, do anyone know where to download SDXL beta (2.2.2 version)? I found good results from that model
You wouldn't download a car
what are the new best anime models
I would
nah it's a service. my own HDD wouldn't be as convenient especially as a colab user. models that take minutes to download to Gdrive would take hours on my home Internet
colab is more then SD too. RVC, local LLM's. lots of models and training files to store in my Gdrive
are you on a paid google collab account? google stopped allowing SD for free accounts a while back
Nooooooo
how is ur performance with sdxl?
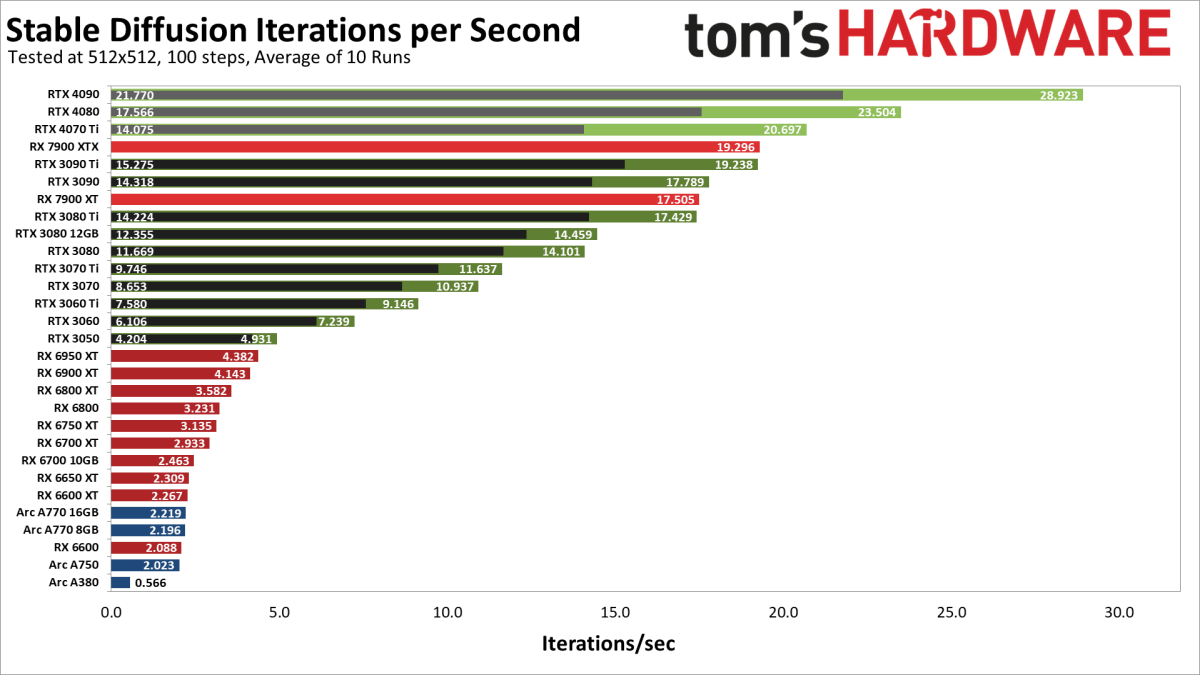
Outta curiosity. I was having a discussion to someone on GPUs and noticed that the AMD 7000 series performed quite good on this benchmark relative to 6000 series, is there a specific reason for this? https://i.gzn.jp/img/2023/01/26/stable-diffusion-gpu-benchmarks/01.png
{kind=link}
whats your guys favourite sampler for base image and high res fix for SDXL? Using the new Dreamshaper model
where do i put the refiner ? In with the model?
good question lol, let me know if you find out
Would a 3060 12gb be enough to run sdxl at 1024x1024?
As my r5700 8gb is not enough it seems, failing with mem out error also its very slow
As 4070 cost 2x has same 12gb vram :/
Hi everyone, I need to find a model for flat illustrations. I tried using lora:Drawing combined with deliberate_v2e, and lora does a great job with faces and animals. However, it doesn't work well for objects and other things. In the example, I want to illustrate fruits in a classic style using hatching and outlines. Currently, the test model's bot does an excellent job with the hatching style, but it's not available yet. Does anyone know of a model or lora that works well for this?
style LoRAs should be possible, but the captioning techniques might be different than they would be for objects. not sure if you accounted for that / how much you've played around
failing that, maybe Dreambooth ?
I`ll try to add my prompt to the images, give me a few minutes
Yes easily
Hi, I am trying to understand if SDXL can be used to create art that can be used commercial purposes like online ads. Please clarify if you are certain of the answer. Thank you
how does the vae fr mse 840000 ema pruned ckpt work
cut your prompt down!
what is the token limit?
what specifically did you put in the negative prompt that shows up more now?
hi @karmic brook i wanted to make a link to Stable Foundation in the deforum discord
we were thinking of sharing the invite link and a cover image

would you be interested in helping me with this?
Sorry if I'm misunderstanding-- What exactly is there to help with?
The link and img together are both here: https://discord.gg/stablediffusion
or do you mean formatted something like we have in this channel: #1072229057707659404
yeah the #1072229057707659404 stuff looks really good
we were thinking of using the new gallery channel
so it would be like a cover image then info inside when you click
oh, thanks! I made that channel using https://discohook.org/