#💬|general-chat
1 messages · Page 64 of 1
when it's a coordinated attack, cloudflare has a lot of mechanisms in place to prevent that. When it's just realworld usage that surges, it's hard to contain
cool thing about machine learning though is it's only a matter of time before the ddos tools get upgraded with new algorithms to appear like they're real world usage. so cloudflare's protections have an expiry date on them that nobody can read
lulsec might sail again
I think you're making an assumption that CloudFlare and other similar providers aren't using ML to detect that and adapt to changes.
i am. you'll see how new attack surfaces will appear. they'll find weaknesses in new algorithms that go around cloudflare and require website admins to restructure their backend just ever so slightly. Most admins won't though.
lulsec will sale again and eveyrone will then see "shit we need to get our shit together" and fix it , but it will take something like lulsec or worse
we're entering into a new age of computational intelligence. new attacks that were never conceived of yet will happen
malicious actors are going to be some of the biggest innovators in this space sooner than later
"Go around cloudflare" is not quite as easy as you think. Yes, ML will change that, but depending on how assets are protected by cloudflare you can't "go around" unless you're able to compromise CF themselves to interrupt the traffic or be able to successfully perform BGP hijacking against an infrastructure that's specifically designed to prevent that.
You can make broad predictions like that and deem them to be true afterwards. New attacks are surely coming and of course they haven't been conceived yet.
not easy no, until that one little hole is found and a tunnel is formed
we got a good wall built up today. netsec has come along way. but new terrirtory is being uncovered. maginot wall only goes so far
No, it does not work like that. The "little hole" would have to be in CF's infrastructure, and that's exactly what they're looking for.
Lol okay. Networks are invincible. That's probably a smart outlook.
I think you're putting a lot of words in my mouth so i'm just going to ignore you
I'm not putting any words in your mouth at all. You don't know what you're talking about and I am calling you out on it.
yes, but also, if you think "AI will make DDoS stronger" then... I think you're not really understanding what people are talking about when they say there will be new kinds of attacks not currently conceived of
but 100% agree, "site is a little bit slow" is not really anything to be surprised about
people wake up monday morning and go "I wanna diffuse"
likely normal and expected
tbh there is the possibility that AI makes it easier to defend against botnets... because if most "real" users are using one of a very few massive AI models to do their searching/browsing/etc... then the AI providers are now more or less a bottleneck that your traffic must pass through in order to appear legit.
that's one additional layer you need to have your attack go through undetected. Maybe that makes it easier or maybe it makes it harder... hard to know for sure
you're also putting words in my mouth so i will ignore you on the matter too. good luck out there champ
sensitive
propose the following: people can agree with you on some things, and disagree on others, and it doesn't make them "putting words in your mouth"
To put words in your mouth would be really easy, such as pointing out your reference to the "Maginot Wall" which is an entirely unnecessary WW2 reference, which likely reveals something about the kind of content you consume 😉
When switching models, is there a way to preload settings and prompts for that specific model?
in Automatic1111? I'm not aware of one
There's an extension called Model Preset Manager that might help
Awesome that sounds exactly like what I'm looking for. Thanks!
Will running SD off a faster m.2 vs keeping it on a regular SSD improve it in any way?
not really
Thanks 😊
And last question, I got a 24gb now, and I had an 8gb before. Is there anything I can do now that I couldn't before, besides run it without --medvram
I think you can increase your batch size to run more simultaneously, but you'd want to refer to the documentation. I could be completely wrong about that.
I'll try it, thanks 😊 I'll keep looking for cool things to do with it
question about batching actually... Do batches run faster than individual images?
And can you batch with different prompts?
Sorry I am out of my depth on that.
I assume you can't, because the X/Y/Z grid thing generates individual images instead of batches at a time
Last last question, do you guys have any cheat sheets or a favorite guide to making quality prompts? I think the thing that works for me so far is starting with an empty prompt and just adding 1/2 tags per generation
"cheat sheet" probably depends on what you're making
but in general, you can look up images on civ.ai and check their negative prompts. I think getting a good list of negative prompts to start with will help avoid the common "bad fingers" etc that people run into when starting
I meant cheat sheet as in like commands. I heard there's the bracket one that lets each generated image flip between tags, for example.
For example [dog, cat, duck] would create 3 images, one with dog, one with cat, one with duck
But I totally forgot how to do that prompt trick, been a while
https://medium.com/@inzaniak/stable-diffusion-ultimate-guide-pt-2-prompting-35eacb3dc5f4
It's long winded, but yeah
Thanks!
Also, a trick I never see anyone write about
(cat:X)
on XYZ prompt with SR
You can replace "X" with 1.1, 1.2 , 1.4, 1.8 etc... to try different weights
people always write about it as if you can only replace words, but you can replace the weights too
I'll have to look into xyz prompts 😊 I'll screenshot that to remember it lol
That is to compare models?
Ahhhhhh. That speeds up figuring out how a tag will influence the generation. Awesome! Thanks
You can compare everything with it. Models, upscalers, vae, cfg, steps etc
That's really neat. I'll try it out 😊
Yes
I'll Google it 😂 too many questions
Vaes are needed for some models for color correction. Mostly every anime model needs one.
TIs(Embeddings) and Loras are pre trained files that go on top of a model to get an specific style or character
Awesome thank you :)
they're super small files compared to models too. so while a good generalized model is fun, you can alter it in a lot of ways for cheap. no load times, fast downloads
now there's a civit extension to automatically download loras
gonna need a new faster lora browser
I'm having a nightmare of a time trying to generate a consistent enough outfit to train with textual inversion. Specifically this character has a cloak, and it seems flat out impossible to get generations with somewhat consistent details
any tips maybe?
Try reference in controlnet
Might only work on faces tho
The character themself I already have a good textual embedding for - I trained them naked. But the outfit...
doesn't help that it's an unusual, fairly complex outfit
Reference isn't working? I saw it reproducing the clothes in the example I saw
hmm didn't know control net could do that
Also doesn't help that I can't reference reddit posts about stuff like this because reddit going dark XD
Oh wow yes, looks like I might be able to just use control net rather than train anything for outfits
At least, for visual novel esque variations like I need
Lmk if the reference trick worked well for outfits, I'll try it myself later
anyone know how to use textual inversion embeddings in webui?
since the reddit is down due to the protest I can't find anything elsewhere on how to do it
You just put in the name of the embedding into the prompt. Needs to be the file name in your 'embeddings' folder
I think it will also pull it up in the ui if you click one of the buttons in the top right of the ui
k, thanks
wait where?
also do I need to put the file extension?
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion this is the official guide, but I don't know how to use it yet either
thanks
still new to the webui since I finally found a way to run it on AMD with the newish official fork on the github
ok that still doesn't explain it
tried with and without the file extension and image still looks deepfried
you will need at least moderate computer skills
and patience to read directions
was using it yeah
Sure
can anyone help me with this?
discord etticut is to not ask for help in multiple channels
Can somebody recommend text-to-video tools for the web ui? I dont want it with watermarks or any kind of limit
I'm interested also. I think deforum worked a while back but I felt like I had no control over it.
I got it working on a laptop edition 3050, so it will probably work for you
I have a GTX 1650
Ah 4gb might not work
rtx 3050 didint work?
which model should I download to run locally on my computer from hugging face?
or can I just use easydiffusion?
Hey guys just made a video about some stable diffusion prompt techniques if you’re interested!
https://youtu.be/4441SBe-XZc
Hey guys, we (Meat Dept.) just finished a music video using Blender, Octane and Stable Diffusion. Take a look and don’t hesitate to share comments! Thx
depends on what style you want?
cyberrealistic is good for photorealism from what I have seen
and anythingv4.5 is a popular anime model similar to novelai
I was talking about which version of sd to actually use
If you need help, I recommend starting with #1072220168534642768 and #1072229020520947753 and long with #1080946152318443610 If you need technical support, you can check out #🤝|tech-support
As for this question, 2.1 has come a long way, but there are many different kinds of models/embeddings, etc. I recommend checking out the bot channels if you haven’t already to see a preview of SDXL. You can also see more about models in general by visiting the links in my previous comment, as well as #1047197565365538826 to get started. If you need help prompting, you can go to #📝|prompting-help
what do you guys think is the best way to make an OC using SD? been thinking on maybe mixing gear and characteristics of other characters, it wouldn't create anything new but i guess it's the closest thing i can think of.
Hello everyone ! I have a problem, I have training a model of drawing with dreambooth, no problem with text2img but with img2img the result is always bad, why ? Someone can help me ?
Hi guys, is it possible to train the StableLM with my own data to create a specialist in it's own particular area?
I suggest checking out #📝|prompting-help
For more info on training, etc, I would check out # fine as well as #1072229020520947753 #1080946152318443610
To learn more about StableLM, please see #1098025024541167646 for the most current info
if anyone could help in #🤝|tech-support that actually knows what they are doing it would be apreciated lol
I am trying to give two ppl tech help but I barely even know what I am doing
it is kind of the blind leading the blind rn
For some reason a few communities are claiming that ckpt training data can be fully reproduced but my understanding is that a diffusion latent generator would not use original parts of the image so would be a new generation is that correct?
I've heard conflicting things about using dreambooth with sd 2.1. Some say it works fine, some say it's impossible, and my own test resulted in all outputs being random static, but it was my first attempt and I had no idea what I was doing
is it possible to use dreambooth with 2.1?
Thanks Sunny, there is some chat in there that suggests it's no longer available, is this correct
@delicate oxide
Whats up
Saw the reddit story lol
The answer is "maybe"
There are well known papers that talk about recovering training data from image models. Whether it's possible in this instance is hard to know for sure without seeing a demo. https://imgopt.infoq.com/fit-in/1200x2400/filters:quality(80)/filters:no_upscale()/articles/privacy-attacks-machine-learning-models/en/resources/1privacy-attacks-machine-learning-models-2-1564821302857.jpg
Thanks
I decided to try easyDiffusion is it just as automatic1111 web ui?
Automatic1111 webui offers more features and supports all of the Community build extensions.


Since /r/stablediffusion is on black, I miss my daily diffusion news 😦
Its for a good cause id say
and breaks more lol, although i never used easyDiffusion
"503 Service Temporarily Unavailable" whats up with the civitai for two days?
Loads for me without any issues
nuking like 50% of the models
citivai always had trouble with loading
using it for two teeks and last two days been weird
I thought i was the only one
Guys is there a way to merge Lora but with a NEGATIVE WEIGHT?
I've trained this nice Lora, but it tends to add too many details. To tackle this, I've been using the Lora Detail Tweaker with a negative weight (it removes details). But I don't want to keep relying on two separate Loras all the time. Is there a way to combine them together? If I use a regular merge, both of them end up adding even more details, which is not what I want. So, I'm looking for a way to merge my Lora with the opposite version of the Detail Tweaker Lora. I hope I've explained it clearly enough. Sorry if it's a bit lengthy!
Good morning, everyone!
I got roofers tearing out the roof above me, and it sounds like hammers straight into my soul. So yes, "good" morning to you as well ;P
Noooo! The teeth chattering you must be experiencing!
I'm just here, with my face partially smashed against this back rest pillow I have, which has been fantastic for recovery, and fantastic for holding my face.
why images generated with pixar models always smile
Just pretend you're in a doll house and someone is upgrading your domainlol
Probably because the images they were trained with were ones with ppl smiling.
I wonder how many pixar images have smiles in them and how many does not in the first place 🤔
they only train with the movies' cover or what
@jaunty beacon cant help clip skip say skip last one?
I noticed in some models on civitai they suggesting at 3d CGI images like clip skip 2, probably for reason you mentioned.
🙂 they all like this emoji
Who knows! I suppose it depends on the view/prompt, etc, too. If you consider ppl who have made 3d models in this/or a similar style, there are a lot of smiling ones.
Thank Bernix. I can do that but if possible I want to merge those 2 LORAs together. It just that the lowest weight I can merge LORAs in Kohya-ss is 0, not negative weight
i wonder if there is a model that not made by "waifu" lovers
or any uwu stuff
i hate when male characters get jean panties
for 1.5, probably. Which models are you using?
all the popular stuff i found on civitai
around 15 models
some of them are 1.5
dreamshape is almost the best but i cant get the characters facial expressions even with openpose
I'm using dreamshaper5beta2 at this very moment. Trying to find the "perfect" upscaler for my images from it.
Anyway, it depends on the expression. Like, there's a difference between using smiling and happy
should i use upscaler instead doing high res?
got a 4090 so never cared about the vram stuff
but high res mostly gives me better faces
high.res is a upscaler. I always use it when I want to make "quality" images because it fixes a lot of ai errors
yes, but the high res fix uses a upscaler. I use auto1111's webui's highres fix and I can pick and choose which upscaler to use when toggling the hires fix
i leave "Hires. fix" unchecked always
A friend of mine asked me if I could use SD to create a line-art drawing (in approx. this style) of her and her coworker. I'm certain it's possible, and have been looking through different ControlNet models and LoRa's, but don't yet have a solid lead. I wanted to ask the community before I spend too much time down this rabbit hole, what would you recommend? (image: #🏞|general-with-images message)
what extensions can i use to make mask? like the shape of a body and stuff, i am not asking about pose editor
can someone give me an image
to impaint
i trained 2.1 and use deep fried in negative to fix faces
Is there a way to use the semantics of 1 image and create another? Like a different composition and details but the overall image resembles the original? (The original image is not generated through SD and so I cannot use the same seed and generate again)
probably you mean img2img @molten heron
Just interogate image and generate another by this description.
Yes I tried that but the results are not that accurate and i thought maybe SD already has an option for this
probably controlnet, not sure, probably pix2pix.
so is this still an Nvidia game? Should I just bite teh bullet and upghrade to nvidia or do my AMD brothers have hope that we'll get to inpaint soon?
no
i realize that I asked wayyyy too many questions there
there is an official fork now
for the popular automatic1111 webui
I am an AMD user and I can run it well with it
ikr
I was here when SD first launched (left and rejoined the server since then)
was super dissapointed when it was announced there would be no AMD support for windows
but hoped that eventually due to the opensource nature of this project a fork or official support would eventually come
I actualyl upgraded my PC a few months ago and I never even thought to check if AMD or Nvidia made a difference. I was using midjourney at the time
so do I just need the Automatic1111 or do I also need to install SD locally?
i'm googling and chatgpting as well so I'll figure out an answer momentarily
all the instructions are on the github page I sent
how would i consistently put on clothes on a character TI I made?
booba cool and all but sheesh
inpainting?
do I insert said article of clothing within the original prompt?
depends whether inpainting area is set to only masked or not?
gotcha, I was hoping i was overlooking sonething simple
I'll give it a look see. Bonus question: any resource of what tokens SD will recognize for clothing?
Hello. Show how to use AI to generate app icons. This is not necessarily about Stable Diffusion, maybe some other AI. Thanks.
guys i am panic-ing, how can i get private access to r/stablediffusion? i used to read it for 1h per day for work-related info on CGİ workflows
Only 1 day and it will come back
from what i heard that's not the case for r/stablediffusion
I don't think it will stay dark forever. The site admins can just assign new moderators and bring it back live.
I've just unleashed an SOTA plug and play script so you can finetune any model on Huggingface with production level infrastructures!
Features include:
- Utilizes Torch Distributed training 🔥
- Tokenization 📚
- Qlora 🌐
- 6 optimizers ⚙️
- Torch Distributed
- Huggingface Accelerate 🚀
- And so so much more! 🎉
try it now: https://github.com/kyegomez/Finetuning-Suite
Where can I ask question about getting better images, like fingers and face?
Hands is a big problem XD
You can ask in #📝|prompting-help
Mostly highres fix is the key for better face and hands
Im using Easy Diffusion so idk how that works
is it possible to use inpaint not masked to basically alter a person but only keep the face? I want to keep the face of myself but then have the background and body change. Like clothing etc.
Oh no clue how its there, but look for an upscale setting
Yea, mask your face and then check the Invert mask mode
ya thats what im trying, just getting crazy stuff. Like it doesnt try to blend with the face. Sometimes the face will just be present in a picture completely unrelated
Try to add portrait of or photo of as tag
AI friends, I made this intro tutorial to MJ, SD, AF, it's in Spanish, you can watch it with subtitles, I'm trying to convert my voice into English, I hope you like it and can share it, hugs. https://youtu.be/i7eQngjhIcU
Anyone has an idea of a good prompt of workflow to generate a meteor shower burning in the atmosphere ?
ello
hello, what is price of text to image api?
2.1 has an UnCLIP model that's really weird
Yeah upon doing some research the Karlo unclip seems like it may work? I'll go check it out
Hey guys
Its Ton 618 Black hole here
the biggest black hole
@regal raven @hidden dagger @hushed quarry @sudden ruin @bleak matrix
@here
Please do not mass ping people; if you need help with something, please check out our various channels, #1072220168534642768 #📚 #1072229020520947753 #1080946152318443610 etc
i need help swallowing the milky way
pls help
i can help
yo thanks come dms
fr fr
For more information on our rules, you can check out #✍🏼|rules-and-tos
i only need info on how to eat galaxies
Does anyone know how I would go about fine tuning the decoder part of the Stable Diffusion VAE? Are there any code examples for this?
@wise stratus how many H100s y'all got now 👀
Hey, im trying to ai animate the Interstellar trailer just for fun but i get very bad results, is there a good documentation / video how to get the best results in longer videos (it has 4151 frames) with multiple shots? Im using automatic1111 git on my own pc with img2img method
Can I make a lora with a 1660ti, 6gb? Or do I need more vram?
I can barely run stable diffusion as is, I get 1 second per iteration
that's just sorta how it works lol you're creating random things on 4151 different images. i imagine youre seeing lots of flickering
Hello, I'm new to Stable Diffusion, can anyone help me on the installation? I've followed the guide and got 404 error in the browser
it doesn't say much
show some screenshot
did your command prompt show any error message?
Here's the image, thanks for help
https://imgur.com/a/zhKH5hX
seems more like something to do with browser or your pc settings
you using your own pc ?
I'm using company pc

cuz public pc they block some port and stuff like that

Same result 😢
Well If you can run it locally
What is colab?
Google colab? A way to run stable diffusion on cloud gpu
OK I'll check it out, thanks a lot
hi
Anyone using DiffusionBee? I'm very new to it as of yesterday. I have a good understanding of how seeds, steps, and guidance work. Still trying to figure out what is the best sampler to use and why I can not recreate some of the artwork I find online even with the exact specs.
Hi. Total newbie here! Is there any benefit to using Google Colab VS your own local setup? I have the GPU power to run it locally, but is it possibly more convenient to use Colab, for instance by reducing storage space on my PC?
AI will never recreate exact images, it will aways intrpret your prompt in a slightly different way. depending on teh consinstency on your prompt these changes can be drasticly different or very small differences. don't focus to much on exactly recreating other people's their work.
Ok - I assumed if I had the exact prompt, negative prompt, seed, steps, guidance, sampler, and model - running on the same version, it would produce the same result. I'm not so much focused on recreating other people's work but rather on experimenting with prompts and parameters. Any tips on how to get the best or fine-tune my images in DiffusionBee?
Also I am not familiar with DIffusionBee I believe that's the name of the license not sure. generally it is called Stable Diffusion. unless DiffusionBee is some sort of webui I am not aware of. for finetuning images not sure what you mean. if you mean to train a model to get a a specific output you're better off in #🔧|finetune
I don't believe the repo are the onces that requires the most storage but more your output images/videos. which will be the same no matter if you use Colab or a local install. if you have the specs I recomend using it localy. if however you are planning to do some crazy 16K images or long videos that your pc can't handle go for colab. but be aware colab has some limitations and requirs a payed subscription for long time usage and the better GPUs. I never personally used colabs tho
Hi, please do we know when the SD reddit page will be up? or it will stay hidden forever?
From my understanding, it is a way to run Stable Diffusion locally on a Mac. However, I realize that it has limited features compared to the SD web UI. For example, capping steps at 75. https://diffusionbee.com/
These days you don't really need more steps then 75
do this server's admins run the stablediffusion subreddit
Idk but iirc reddit has some issues snd several subreddits has been put inactive iirc not to sure what is happening and I don't use reddit
When is sd-xl releasing publicly?
Nope, the subreddit is run by the community
Good day, looking for the dreambooth discord if anyone has the link
👍
how do i get started creating an image..im lost in the discord
Anyone know what Photoshop uses at the back end for its "generative" feature? Custom stable diffusion model?
Not really sure which channel this would belong in but is anyone aware of any good elevenlabs alternatives? Preferably something I can run locally and with a healthy voice ecosystem
Pinned message in #1100170312106127410
or #1080946152318443610 for local/online!
So Im using Easy Diffusion, how would I get better hands. Im looking at EnvyBetterHands LoConbut that needs LyCORIS and I dont know if or how I install that. If anyone knows how to get better hands I'd gladly take help
anyone know when the stable diffusion subreddit is going live again?
never
If you're trying to create a new Reddit like I am, this is a golden opportunity for sure!
what are some nice communities(except reddit) to share SD art ? Here is some but it doesn't seem very active
@jagged vigil SD art is getting more and more worthless my man :/
Maybe that's why this isn't the death of real educated designers after all, since they have real ideas.
I don't know your art, but you could make a script to upload it to all known communities.
If you can post-process it to actually look real and not another anime fanboy render.
I know it isn't "valueble". There are still nice interesting pictures shared on the stable diffusion reddit for example for insparetion.
Design/architecture forgot to teach their students about business and entrepreneurship.
not everything is about money
True.
art is art lol
Can you share here though?
Because there's amateur art, professional art, and one-in-a-million art. If that makes sense!
for me genius is always rare, not bound by medium
Yup
That is so true
Remember reading about that in those old Japanese warrior books, it went like "Master one art and you master them all."
I like that quote
I think it's from The Book of Five Rings, or Hagakure (movie Ghost Dog)
Yes here is ok but it is hard to discover interesting stuff, reddit community pre-sorting is quite nice. Here it is all in countless channels. Just wondering what other people use when they look for inspiration or pictures with workflows.
My inspiration as an architect and entrepreneur is expanding human civilization, so for instance I have this project to populate the Antarctic in order to 1. Test new planet colonization tech, 2. Create new economies and 3. Provide a place for the world's homeless (if they're up for it)
Posting the images in #general-with-images, some of y'all might have seen them before. But they were just drafts.
oooh like terraforming Antartica
Youve really thought this through heh
But we need to know how to bore underground tunnels during such conditions.
And establish cities in a matter of hours using AI.
hehe no not really, there are flaws all over my logic
well with that image in mind I doubt civit would be much help to you lol
But this would allow me as a state representative to exchange tech with SpaceX
Idk, I just think we can make use of new land, while we rebuild old land (ie. large parts of the US)
I completely agree, sadly the profit incentive for the world's richest is all they think about
For real!
Well, not really
I see what you mean
Rich business men, but the world's truly richest, like those Saudis (who are probably already trillionaires) or Norway, doesn't have to think in terms of profit
yea I keep forgetting the Saudi's are the real richest. Don't even try to quantify their value
This is all pointing towards a new phenomenon in human history
Like now we just had AI, next up is a post-scarcity world where everybody will be taken care of and money will be a thing of the past
Yeah 🤣
Idk what those freakin' Arabs are up to
(I grew up with Arabs though and got some cool projects with them)
(peep #general-with-images)
solid 😄
Thanks! It's my man Haisam from Palestine
He always used to freestyle rap at parties, he was the ladies man and still is
The beat and video is not up to par, I used https://replicate.com/pollinations/stable-diffusion-dance but it's severely limited
just think where it'll be in 6 months
Based on the data for 2023, Saudi Arabia is richer than Norway. The GDP of Saudi Arabia is expected to reach $950 billion by the end of 2023, while the GDP of Norway is $554 billion. Please note that GDP is just one measure of a country's wealth, and it doesn't account for factors like income inequality, natural resources, or quality of life.
Fuckers. The Line looks awesome though.
Our raps in 6 months you mean? We got 10 years of material, it's hard to condense, but here's some: https://replicate.delivery/pbxt/PfXfVvQpausta09qNKoJRt1ZiYx7iaWTojqrw5qeXvGqZIIiA/lucid-sonic-dream.mp4
nah I meant the tech.
the rap was already competent imo
Yeah 🙂
You know the whole theory that in terms of the evolution of the universe, mankind were created with the same mission as larvae. Whereas they give birth to butterflies, we'd give birth to AI.
certainly seems so, everyone contributes (like social media data later used for LLMs)
Indeed!
Like right now we have normal people teaching AI
But if the world's greatest artists starts doing the same, then we as a species have nothing more to bargain with I think.
Good thing people like Bach, Bob Marley or J Dilla are dead and can't teach AI any new tricks.
That’d be scary lol, someone will pick the mantle tho. Very soon methinks
Are you joking? I just read that the blackout is over
What are people using now for image to text to describe images for prompts?
Why does upscaling take so long?
It gets to 50% then takes forever to finnish
ayy I'm supportive of the reddit protest and I exclusively use Sync but just wanted to point out where it says "and exclude blind users from the site." is false - they specifically stated that all app developers that have created apps for reddit to target blind people and the like are being given 100% free API access
to whomever owns the sub lol
Hello, I'm pretty new to Stable Difussion. I'm using the Automatic1111 UI and want to install Token Merging, following this Video. https://www.youtube.com/watch?v=EMCyh2X3zsQ
Sadly, it seems that the Automatic1111 extension for Token Merging was deleted. https://git.mmaker.moe/mmaker/sd-webui-tome
Is there somewhere a fork or an other Autoamtic1111 extension for TokenMerging?
its built into the UI now, not an extension.
update and check the settings.
this setting here? https://imgur.com/37Wo23y
no, the other one that says token merging /s
but yeah that's the one. I recommend just using it for hires. 👍
crank it up and test it out at 0.2, 0.5, and max setting to see how the speed changes
ok thank you 🙂
yeah, I use anyways only highres and want to reduce memory usage
But only the UI extension is comming with Automatic1111, I still need to install the python stuff, right?
I'm not sure what you mean
cloning this repo or install the tome pyhton package: https://github.com/dbolya/tomesd#installation
is there any resource that details clothing tokens recognized by 1.5?
or do I have no idea what im talking about
probably not. I think everything is there
just tested it. If I remove the tome dir which I installed, I require a bit more VRAM
Reddit news?
What are models which follow prompts well? Atm dreamshaper does best for me when I add unusual things or details.
what are other models which do it well. Most are very limited
well can i get in somehow
i want to join the sub but cant because its privated
one post piqued my interest but i cant access it anymore, luckily i have the site they used
Some models just doesn't know some words or have nothing in it's training data on it
When is the xl model expected to be out of beta?
i saw a video to get depth chart for an image, the video is 6 months old, is there a newer and easier way to get depth chart now?
no idea m8. I exclusively use it for unsavoury things and it's pretty good at doing what I want. If you want to make normal stuff use midjourney or something.
Is there a relatively recent guide somewhere on how to train using dreambooth? I tried with fairly default settings, using a directory of 512x512 instance images and file class descriptors to train a single person, and it was going to take 20 hours on an RTX 3080. So I switched to the lara extended training method instead and it's still taking like 8 hours :\
Hi Guys: Im looking for a chat bot that is set up similar to stable diffusion (without all the outside "controls") that I can run locally -- does anyone know of one they would recommend?
when I save some image it saves in another type of webp file what is the type of solution for this
Is there a way to speed up upscaling. It took a few seconds on Easy Diffution but like 3 minuets on stable diffusion webui
Using default setting too
At 50% it just slows down super fast
I have a overclocked 3070 and a overclocked I7-9700k so idk why
How much hires steps do you use?
And you should use --xformers
Im using 0 Hires steps and the "latest" upscaler
if it's set to 0, then it will use as many steps as what you set your sampling steps as.
Try 10 hires steps and esrgan 4x+ with denois 0.5
Better but still snow
Used these
So you use xformers ?
Where would I check?
You need to edit your Webui-user.bat and at the line Commandline_ARGS=
add --xformers --autolaunch
Also i think easy diffusion dont use hires fix. It uses the same Function as the Extras tab in Automatic1111. Thats normal upscaling and wont add details but is a lot faster and uses cpu
But i dont have easy diffusion installed to check it
Lot faster but now the eyes are just super bad
Make sure you dont enabled face fix
Restore faces?
Yea that shouldnt be used when upscaling
Confusing 🤔
welcome to ai art ;P
Hires fix itself will fix the eyes so no need for restore faces
If both are enabled the eyes get ugly
What about fingers, I have a lora that should fix it but idk if its feeling like it tbh
That depends on the model and also hires fix can fix hands
Great
Some negative embeddings can help too
I have lots of them XD
fingers? yeah, we all do when it comes to the ai ;P
Fingers are a solid 6/10
for me at least XD
Btw, is there any way to get more character space in the promt?
you can write as many words you want, it just get slightly, weird after a while
CS1o is probably the kind person, I'm more of a "always hungry" person myself >:I
btw, is there a way to stop it generating an image after its started?
Yea press the interrupt button
Its grayed out of me
its color is gray, but the button isn't disabled ;P
"Design"
you'd get, if they did the correct work in the css, a 🚫 as a cursor if you weren't able to click it
Your a kind person too! Every help is appreciated
[type="range"]::-webkit-slider-runnable-track {
background: #7e7e7e;
}
[type="range"]::-moz-range-track {
background: #7e7e7e;
}
[type="range"]::-ms-track {
background: #7e7e7e;
}``` I have this at the bottom of my ``style.css`` file to make those awful pure white "range bars" be a darker color as to not burn one's monitorAh nice, what range bars?
Do you use the dark Theme ?
yes! using dark mode/theme should be a law! :P
https://youtu.be/3_9LGSex1JY?t=18
evidence that dark mode is superior! >:D
Hahaha exactly xD
How do I generate art with "generation steps" < 10?
In auto1111 webui ?
You can try the UniPC sampler
Is it not possible with stability's API?
Idk does it gives an error if you go below 10 ?
Hey all, new to stable diffusion - I’ve been so impressed with all the models and especially controlnet. However, I’ve been having trouble getting it to generate images of objects without showing humans - faces, body parts, etc. Any recommendations on models or settings that could reduce this?
negative image prompts probably
what is new...a fix for hands and feet?
Anyone having new issues with SD upscaler being extremely slow/freezing? Ihave a 4070TI that was able to handle 4k walls up until a recent windows/NVidia update. Also, hello!
Couldn't find a fix if anyone else ends up having a similar issue suddenly, but I am able to use Coyote-A's Ultimate SD Upscaler just fine.
Hi guys, I have a silly question. If I setup StableStudio and SD into my own server, will I have to pay something in terms of model consumption? Or just costs related to my own server?
anyone know any good AI tts out there that can be locally run on an AMD GPU?
the images are different now. They used to generate 2 very different images now they are similar. the bot also changed its style
It's now been 10 hours and is only 40% done wtf
Are there any programs that can color black and white manga art?
You can try to use controlnet for it, should work
Idk which model is good for it tho...there was one which works with outlines
hmmm 3090 for sale, 2nd hand, 40 hours of use, seller has 98% rating, 800 dollars (or about, depending on exchange.) I'm tempted
Thank you.
If you want mine - that's another non creative and pretty pointless use of nft's.
images aren't bad tho.
why did a random guy dm me saying i got message 4
You can open a ticket and give us more information if you want us to take steps
my weekly post, this time on LoRAs. From never using a LoRA for image generation to being able to train a high-quality custom LoRA with added photorealism. It is very interesting how a custom fine-tuned model is acting when training a LoRA on top of it. I was surprised on a few things including how it generalized the photorealism. Check it out:
https://followfoxai.substack.com/p/getting-started-with-loras-vodka
Hello guys
Wanted to ask something
Can we dream unlimited? or it is limited?
I'm new here
Thank you
no limits as long as bot is active.
Thank you!
anyone else having issues with batch upscaler?
Batch From Directory was working up until today but that stopped working and returns mad errors. I need to upscale hella images. any help appreciated, posted in tech support but no replies
Hey I wanted to find out if it is possible to add any of the bots to my personal server?
Hello guys, wanted to ask something again... Can we dream 2 times at the same time? Because I can't do that so it must be one by one...
Good morning, everyone! How are we all this beautiful day?
loser
Does anyone here knows how to code
Be respectful of others in chat, please
they're calling themselves that xd
You can add negative prompts. For all specific questions regarding the bot, I recommend asking in #🗣|artisan-support-feedback
You can dream as much as you want. To learn more information about showdown/pantheon, read the pinned comments
Well, one should be kind to one's self, too. 🙂
trying to find the most realistic fine tuned model out there.
any suggestions anyone?
You can find models in #1047197565365538826
oh didn't know that thanks Sunny
do you have any suggestions btw? would love to knwo
Np. 2.1 can already do great stuff, but there are many good models out there that ppl have made. It's really up to your own personal taste. Realism has a lot of factors, so I suggest just looking around, checking out reviews, and just trying some out.
You might find something you like.
alright thanks!
This is why I recommend checking out #🗣|artisan-support-feedback for any and all current answers
hi everyone! I am a researcher and I think I found something that will dramatically improve LLMs without retraining, but I need to prove it. I am conducting a blind human preference test. If you'd like to help, go here https://cfg.vermeille.fr/ and tell your preferences over a bunch of generations. Ah, you'll read about Freudian analysis of cooking a steak, or raps about Yann LeCun. It's funny.
Thank you very very very much!
for the best depth map, which should I install?
- sd-webui-controlnet manipulations
- Depth Maps editing
- depthmap2mask editing, manipulations
- Depth Image I/O manipulations
um what is this server again??
All info is in #1072220168534642768 - #1072220168534642768 message
anyone?
I would say try depthmap2mask
Controlnet is if you want to use the depthmap
Also a good thing is depth lib
i want to create a depth map of image and upload in blender (so I guess I am using it - need to download it)? I need to know which depth map is the most advanced. Also, I think it should be ply format? That's what I saw in a video
Hmm dont know about ply.
But maybe check this out too:
https://github.com/thygate/stable-diffusion-webui-depthmap-script it saves as .obj
I only get like point clouds out of it, no real meshes that I can use...
Hi everyone
Anyone know when stable diffusion reddit will be back? Get the protest but feels at this point it is punishing the users accessing the knowledge off that subreddit more than the big bosses at reddit
I don’t know yet
How to remove text or unwanted objects?
everytime I want to open stable disffusion I have to click on the webui-user icon and itll open command prompt? the command prompt has to be open when I use stable diffusion?
Yeah cause it's the client that runs the server on your computer that you can access through the local url
Random question, but is the StableDiffusion subreddit just gone? I know that they are all doing that API protest thing, but I can't even see my old posts in my feed.
I think so
hello
If you want, you could try run my new py2rb.rb script: https://gist.github.com/basicfeatures/288b6a20a610975a8cabba6e0ccbcab6 (Ruby's like Python's little brother but simpler and more modern)
Does it run on OpenBSD btw?
thinks out loud: Choose OpenBSD for your Unix needs. OpenBSD -- the world's simplest and most secure Unix-like OS. A safe alternatve to the frequent security vulnerabilities and overengineering of Linux and Linux-related software such as NGiNX, Apache, OpenSSL, iptables/nftables, systemd, BIND, Postfix, Docker etc. OpenBSD -- the cleanest kernel, the cleanest userland and the cleanest configuration syntax.
normally yes, i've tested with ubuntu, and worked on arch as well.
macos has a few casting issues
but kandinsky worked already
Anyone know how to make loras with animals?
yeah tbh stuff the stablediffusion reddit mods, idgaf about this politics, everyone just needs to come to the conclusion of where to start the base for a community
Has the XL model been released yet?
Is there a link to use XL on a website? Or is it all on here? Like Midjourney?
hey forgive me for being a scrub here but where can I go to discuss LORA training?
Where can I ask about my prompts for word2img function? I'm trying to draw img using Stable Diffusion.
hey, I don't remember who was asking about the artistic QR's earlier but I found this tool https://app.tt.social/tools/qr-generator-ai that was released and it lets you create them without the hassle of configuring Stable Diffusion and all that
anybody installed riff fusion in A1111? I tried it now sd wont boot
Does it make any difference having a 72ppi or 300ppi image in img2img or ControlNet? I noticed that a higher resolution base image will yield finer details, but I am not sure about the DPI/PPI
If you have a LORA (let's say it is named "ExampleLORA") in your LORAs folder and it has Trigger Words (like "exampletrigger"), does that mean that if you type in a prompt with "exampletrigger" then ExampleLORA will be activated even though you didn't explicitly lora:ExampleExample:1?
The reason I ask is because I have some LORAs installed that have very generic trigger words like "cute" or "chibi", and I don't want these LORAs to be activated unless I explicitly type lora:ChibiLORA:1 or lora:CuteLORA:1 or whatever.
Hi,
Is there a stable diffusion community specifically for the low end users?
Are there any websites besides civit ai for getting lora's and checkpoints?
I think everything gets downscaled to 72ppi? Since thats what it puts out as well, not sure tho
https://huggingface.co/
But its hard to find stuff there
ty
Hello, how Can i upgrade the quality on stable diffusion ?
What exactly do you mean by that?
I made some 500x500 image but i want to upscale ? Or upgrade the quality , but everytime i try stable completly change my image
What are you using to generate images?
Wdym ? I'm using stable diffusion with hires fix
So automatic1111? There are many ways to use SD
Ohhh okey yes sorry ik only 1111
What are your high res settings?
High res setting ? Wdym ?
Does anyone know if theres any website that allows me to upload an image and create variations on that image. And im not talking about the ones that let you choose to set the image strength between 0% - 100% that sortof guess the original image. I'm talking about how Corridor digital did with their images, where it changes the image's style via prompt.
I use hiers with X2 upscale for 1920x1080 but the quality IS terrible
I just read this info: is it true?
8. If you are using any kind of negative prompt at all: Scroll down further in the web ui, to the drop-down section titled "Composable Lora". Open it, and check the "enabled" checkbox. (If you do not do this, LyCORIS will interfere with your negative prompts; basically all LoRAs are incompatible with negative prompts unless you use Composable Lora.)
Sup Andrew
Activate hires fix in txt2img.
Then set hires steps to 10.
Denois to 0.5
Upscaler to Esrgan4x+ (for anime use the anime 6b)
Upscale by 2
For example.
Ty i will try
Does anyone know if you can scan an image of your pencil sketch and have the AI do a colour render?
Yes thats done with the Controlnet extension
Are we getting any alternative to reddit?
Thanks il look into it 👍
I read somewhere that lycoris breaks sd or the lora use, is it true? Or it's been fixed.
Should be fixed
Finally I can use those lycoris, thanks for the info.
And any reddit alternative so far?
oh so I don't have to use composable lora anymore to fix the lyco/lora interaction
Yea if you use this extension and place the lycoris in the models/Lycoris folder there shouldnt be an issue
https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris
Yea normaly not. As the old locon extension got replaced by Lycoris
that's great news, now I don't have to figure out how to activate it in the api lol
Kandinsky now runs under 6Gb of VRAM in aiNodes
https://github.com/XmYx/ainodes-engine
Easy to get started on Windows and Linux.
Nothing much how about you
Work. Waiting to finally come back home, create a nice background for my new PC rig
it's quite nice for certain things, prompt fidelity is rather high, and we should expect finetunes / methods get polished : )
looks kinda fun with deforum
Guys how to use stable diffusion?
Can someone send me the link to /r stable diffusion discord channel ?
I'm looking to interview someone for an academic paper. I just wanna prod someone about how training a model works and if certain ideas I have make sense.
check out #1080946152318443610 for all you'll need to start getting stable diffusion running!
Its really good compared to any base SD model but since its based off of different architecture(?) And is Russian, most people don't use it
Not to mention it requires very high vram
guys does somebody know a AI that generates music from prompts on your PC that you can use commercialy?
I mean you have harmonai but you can only do samples and is mote for research etc. Idk of any tool that already can do text2music
Learn some beats in FL Studio or Cubase Elements or Reaper(I think it's still free)
more satisfying than just telling an AI to do it for you
Any other decent sites for SD now the Reddit site has gone down?
Kandinsky is just CLIP again
It uses CLIP for encoding images and text, and a diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach enhances the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
basically they did what LAION did with their conditioned priors
I'd check out musicgen. We have a section of users working on a gradio for it in the Harmonai discord server.
but its kinda bad isnt it
Idk. I've been impressed with the results even if it's a little limiting.
Hey
I saw on vid for controlnet dude had style "presets" that loaded in a whole bunch of prompts and he just added in the specifics. Where do I find?
for txt2img it is right under generate button.
yup I know where it is in A1111, but my style panel is blank
yes you can save your own prompt, there are not premade.
ah I see
and then load them with icon next to diskette
Will SD reddit return, or permanent protest?
I was about to ask what is with that nonsense
i hope it comes back, only subreddit I really used and I stayed updated on SD thanks to it
but now idk whats new
news are still here
but not the community stuff
https://reddit.com/r/StableDiffusion/comments/14b2t1f/information_is_currently_available/
There is a vote right now
also included in the nodes : )
If they open it up again all of this was for nothing 
I know 😔
I mean, it will largely be for nothing because there is no way Reddit is going to not do it
But some communities will presumably decide to leave for Discord permanently
Hi
Hello
Sup
but seriously the sub have quite tons of useful information
like one should be easily accessible information, one should care about the moderation, Reddit channel right now couldn't possibly have both
Closing the sub hurts the members much, much, much more than it hurts Reddit. It’s also a big ‘F U!’ to people who have spent time contributing content, including questions and answers, from the start of the sub. Effectively deleting their useful content would be very rude.
by u/farcaller899
Reddit's actions suck and I support all the goals of the protest, but it should be pretty clear at this point that they're not going to budge. If people absolutely cannot live with these decisions they should just move on, but without forcing that on other users that still want to participate here for whatever reason (and definitely without taking entire subs private and removing a ton of valuable information from the internet).
by u/ocafino
Hi all, long shot here but there was a website I was using the other day where it showed artist style example prompts, and I forgot to bookmark it, I can't remember what it was called, but I remember all the example images had Henry Cavill in them, anyone know which site I'm talking about?
nvm I found it, incase anyone was wondering it's https://supagruen.github.io/StableDiffusion-CheatSheet/
Hey guys i was installing stable difussion on my pc , but when i was opening batch file , it was installing pytorch which was 2.6gb of file.
i was getting error installing it due to my internet , so i downloaded the file of 2.6gb seprately , its whl file now i dont know where to put it and how to install it , when i open web ui batch file , it again start from start downloading it.
this is the file name : torch-2.0.1+cu118-cp310-cp310-win_amd64
Hello guys
i hate to be that guy but colab doesnt want to run with my CPU
and i wanted to ask if someone could train a model for me
just 20 images each 585x559
Hey guys all of a sudden stable diffusion is taking up all my memory?
Im using same settings as normal, all of a sudden its asking for 20gb of memory to generate 4 images at default 512 size?
hey all, where can I find info about which laptop or desktop I should buy, to run SD + models locally?
preferably with links to actual computers... i get lost in the specs. 🙂
Depends what you want to run and what your budget is. I have a Asus G513 laptop, that has a nvidia 3060 with 6GB of vram. I can generate images fine, but I don't have enough vram to train locally
If I plug that into Amazon I get something like this: https://www.amazon.com/ASUS-Display-GeForce-Keyboard-G513RC-IS74/dp/B0B9RZCFSR/ref=sr_1_2?crid=34MWC3F8XITQH&keywords=Asus%2BG513%2Blaptop%2C%2Bthat%2Bhas%2Ba%2Bnvidia%2B3060%2Bwith%2B6GB&qid=1686978960&sprefix=asus%2Bg513%2Blaptop%2C%2Bthat%2Bhas%2Ba%2Bnvidia%2B3060%2Bwith%2B6gb%2Caps%2C156&sr=8-2&th=1 ..
I want to be able to run SD + models and do training. Back in the day I would walk into a computer store and say "I want a desktop computer that can run Photoshop, After Effects, Illustrator and Chrome simultaneously" and the shop assistant would help me find the 'third best' computer. That would become my budget. Nowadays if I walk into a store and say I want to run SD locally they look at me with no idea what I'm talking about. :/ and all the specs I see listed about the GPU and NVIDIA and stuff, I have no idea how they relate to an actual computer. Sure, I understand the GPU is important - but if I go to Amazon looking just for that, I won't be able to buy a laptop or a PC... so yeah, I'd love some guidance on figuring out what sort (or what range, what brand, what budget) I should be looking at.
I guess if you want a mid range PC that can train models, you'd be looking for something like the 'outstanding' tier on the logicalincrements.com website, it has a 4070 with 12GB of vram. get at least 32GB of RAM and as much disk space as you can afford
if you can afford it, just go higher tiers than that, but keep to the nvidia brand GPUs
is training indispensable? I'm a concept artist, and I thought that training was a must-have if I want to train SD on my own style, for example - or with Dreambooth, or with anything that involves me saying "take these images and remember them next time" sort of thing.
yes, training would be useful to create models that know your style
do i need to crop out my image background before i use it for training a lora ?
cuz they are mostly pure white background
Does anyone know of a LORA that can generate cats lying on their back (non-furry) or other action poses?
I think you can do better for that price
Id always advice to build your PC yourself, saves a lot of money
what if i want to make new renders of a pre existing character?
Is there a good script for doing a batch img2img, which allows changing some other settings than in the default Batch tab?
Particularly, I want to use a different checkpoint than used to make the original image - but it is automatically switching the checkpoint when I hit Generate.
The stock batch img2img seems like its broken or something anyway, the images are blurry
i have a question how to say to stable diffusion to not add a lot of pp ?
I have 3 persone on 1 image i just whant only one
put what you don't want to see in the image in the negative prompt box
put "solo" in positive prompt
thanks
or 1boy 1girl etc should work as well. Until you are not generating large images >512 1.5 or >768 2.1 Then it generate duplicates or artefacts.
Why using of same Prompt, Models and settings cannot generate same photo?
You need to use the same seed
hello guys, i have created two custom nodes, one will take a text entered and convert it to white text on black background image to be used with controlnet or t2i depth models. The other node is for prompt editing....check them out here if youre interested: https://github.com/taabata/Comfy_custom_nodes
Any suggestion to my negative prompt?
(Disfigured, disfigure), (not real, unreal), (cartoon, anime, sketch, comic, manga, drawing, 2D, 3D), (blurred, blurry, low quality, worst quality, low Resolution), (Black and White), (missing limbs, extra limbs, extra legs, extra arms, extra fingers, deformed hands), (Old age, Old, mature, senior citizen, elderly person)
Hi! I'm having a bit of trouble with image generation. Whenever I try to generate an image, it just turns out completely black. I've tried a few different solutions, but nothing seems to be working. Do you happen to have any ideas on what might be causing this issue? Any help would be greatly appreciated
@gray fern how much space do you have on C: ?
21 gb
Any1 know how to fix the RuntimeError: "LayerNormKernelImpl"
You could try using the cmd arg —no-half and/or —no-half-vae
i need help
Make a Screenshot for #🤝|tech-support
Anyone have a suggestion for doing a batch img2img? The stock option for this via the tab in A1111 img2img doesn't seem to be working correctly
Googling, I only find a bunch of open issues lost in the abyss
What are you trying to accomplish? I noticed the batch img2img in a1111 goes in the order like frame 01, frame 10, frame 100, frame 101, etc, which gives you out of order images. To get around this I used Deforum and turned off all the movement settings
I have a folder with ~500 images, 512x512 which used model RevAnimated.
I want to img2img all of them using the same prompt/negative prompt, but upscale to 1024x1024 using a different model
I can't tell if it's even working via the Batch function, because all of the metadata is getting stripped
I haven't ever done something like that so I can't help here unfortunately
I am no expert - but here on the WIki is refered to "black screen" instead of generated pics: https://github.com/automatic1111/stable-diffusion-webui/wiki/Troubleshooting
Does anyone have an example of how multiple controlnet units are useful?
You could use openpose to inpaint a person. You could also use Inpaint controlnet which will enhance the inpaint result
theres too many useful combinations. Try using 1 controlnet and youll get a flexible output, but if you use 2+ controlnets it will be much more constrained.
I made lifestyle images (person holding a specific product) by taking a photo of someone holding the product. Then I used openpose, and also a depth + canny of just their hand which really forces it to be drawn nicely
easy photoshop after to put the product into the hand
You can controlnet tile and controlnet openpose to change the pose of a person if openpose by itself isn't working for that
OK that seems interesting
You can reference + any other one for a similar change
The lifestyle images thing I will try first
one thing to note is that when you have the depth/canny maps of just a hand it degrades the quality of the generation. I wish there was a way to mask controlnets or something so it only affects the masked area of the map
So its better to just use openpose, then inpaint the hand afterwards with the depth + canny. You could do this step using controlnet txt2img inpainting method
I found a script that actually solved the thing I've been asking about (batch img2img using original prompt, negative prompt, etc)
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/4938#discussioncomment-4211878
Only problem is, no metadata in output images
hey guys, i have recently installed sd v2.1 with model 768 and added the extensions deforum and controlnet, however funnily the video output get fractalized and blurry at default settings whereas it shoul output something similar to default outputs that other people have. does anyone have such issue?
In settings tab did you change controlnet yaml from 15 to 21?
The controlnet v1.1 models are also just for sd 1.x - theres a separate github somewhere with sd 2.x specific controlnet models
Idk anything about deforum tho
Last I checked there were only a few cnet models for 2.x
yeah there is not many people troubleshooting on the internet either
hey guys, can I generate 1024x1024 with 3090 card? I always get "NansException: A tensor with all NaNs was produced in VAE. This could be because there's not enough precision to represent the picture." error when I try to create anything bigger than 512x512.
thats why i ended up here xD
Would it be possible in theory to create a textual inversion or Lora to represent a building? I'm thinking of trying to use stable diffusion to do images of local landmarks, but I'm not sure how well it would work to try and separate a building from everything else in the area, given that most of the photos I could have of it would include a bunch of other stuff that isn't the building.
checkin my models rn
You can use Photoshop select object tool. Or use SD Extension Segment Anything (or Inpaint Anything)
You could easily isolate the building
(Probably)
i changed it but the outcome is the same
can we share files here like screenrecording? xD im new here maybe on another channel?
Its probably an issue with deforum then - can't help you there
nice name
also
i have an issue
i want to train body angles for my checkpoint but don't know where to start
im looking for a new name actually because this one is used by more people but thanks xD
sd v1.5 works!
yo looking for a good img2img website
most of the huggingface spaces been bugging out
I can’t afford anything paid
what are the best models for you? (anyone reading this)
I’d love some feedback on my alpha of TensorPlay.ai if anyone has a moment to check it out… uploads, LoRAs, and support for all the license permitting models coming this week.
hello I had a question. I want to train ether an model or a Lora but I don't know which I should do. for context I am trying to train the different styles and characters from the new animated Spiderman movie.
i recommend locon/lyco training for styles
i use derrians distro gui
would that allow me to also specify each character ?
is there a place here where i can request art i have a good idea for the cover of an english project just no time to learn how to use this
best ai photo upscale software? suggest me
!
in img2img, find the Script box at the bottom and choose SD Upscale, then choose settings.
May I know where is img2img? I didn't find the option after dream...
any word on whether Stable Diffusion 2.1 models are backwards compatible with XL?
Is putting share=true in the .bat the best way to make A1111 accessible via mobile?
Hello, can somebody recommend me a Yt Video for perfect realistic images? Like a full walktrough?
Yo quick question. I'm running on Windows. I have multiple GPUs hooked up, but the default seems to be set to 5GB of RAM, is there an easy way to config this value higher?
you mean VRam? you can change what gpu you want to use. But only 1 i believe.
how do i change directory in github, i know the same everywehre im guessing but i cant figure out wha ti thought was obvious lol
no one responded to this
why can't my checkpoint use lora's
Does your text just get discarded when its GPU rest?
that is so bs and unreasonably annoying
How come this AI has no idea what a skyscraper is lol
hello, does any one know how to inpaint an object with a reference image?
I've tried a few approaches but none are working properly
something something dataset
Where can I download stable diffusion AI?
Just look around there’s like a thousand people who’ve asked this before in this very place ,_,

or check pins that’s a p good place to start
oh what do you know there’s a whole guide in there!
I am lost.
yea
the true meaning of AI:
inpainting chickens into photos of my house
hello is this stable diffusion discord or something similar to ai art?
Yes
does this thing know who Tate McRae is
Why does it keep drawing a man
Who's oddly handsome
most important thing is to choose if you want 2d 2.5d or photorealistic
almost all the popular models on civitai are pretty good, since even if someone sucks at making models like me, they can just copy and merge models that are good to make a new one
Can latent diffusion models be 'thought' or designed to focus more in one area of the resulting image (say 4x more) than say some other part? Like focus on face or hands 4x more (so more neurons or neuronal power or whatever dedicated to the face/hands) vs something in the periphery [just 1x]?
I notice, whenever I have a good prompt, and good fine tuned model on SD1.5 or whatever, and it is focused on the face (so close up for example, not much more in the image), I can get creations that easily rival whatever MJ has lol (like with photorealism, maybe semantics is another thing, not sure).
but, whenever say it includes more, like more of the target's body, or just more, it like, just dissolves in quality.
and also, would this help with the everlasting hand/eyes whatever issues
hmm maybe it is just a resolution thing of the fundamental/foundational model. I don't know shit. Just thoughts. Sorry if distraction/noise
inpainting is the general fix for these issues, also choosing a slightly larger resolution for full body shots
Hi dudes! this channel can i get support about the colab version that since today, the models does not appears anymore
some issues like extra arms, shared arms, are a more fundamental flaw in how the gradient descent works
Hey does anyone know a good model for creating logos
i like #1087493421209485393
https://github.com/AUTOMATIC1111/stable-diffusion-webui and https://huggingface.co/stabilityai/stable-diffusion-2-1/tree/main if you want to install to a desktop or laptop. If you have an iPhone, you can install the Draw Things app: https://apps.apple.com/us/app/draw-things-ai-generation/id6444050820
I just violated intergalactic law by using a canny preprocessor for a sketch model
these systems are suprisingly flexible sometimes
Guys, I have a pretty big issue that's driving me insane, I would really be thankful for some help
My VAEs are not being applied in Img2img generation, but work fine in txt2img
uncheck the collor corection thingy
doesnt do anything
I've tried almost everything conventional you can think of
The best lead I got is this message I see during boot up in console: "Couldn't find VAE named klF8Anime2VAE_klF8Anime2VAE.ckpt; using None instead"
No matter what I do it doesnt go away
just use the default ema prune thing, everything else is broken
nothing works for me
I have like 5 vaes
they all go up to the preview, but the end result is desaturated
as if no vaes were loaded to begin with
but it works FINE IN TXT2IMG
and as weith every tech issue, try restarting stuff
Which is the most frustrating part
I've restarted, even downloaded all the microsoft c++ tools to clear out all the console error logs
Ive taken out folders with models and extensions to see if it was doing anything
No result
the only difference I noticed is that if I remove the extension folder, the error about missing vae would go away
but I still wouldnt actually be able to use vaes in img2img
Its driving me insane, please somebody help
I will literally paypal anybody 2$ whoever can help me with this
a lot of MJ's quality and success comes from them having control over the actual prompt. They train their models and they know exactly how they prompt well. They have an accurate map of a very specialized latent space for their service. What i suspect they do is restructure inputted prompts, with a deterministic algorithm, so that they more closely resemble the internally trained text encoder's understanding and structure. When you go to MJ and prompt for a dog, the model catches a lot more than just that one token. Doing this also gives a layer of separation between their TE layers and their front end, making it more difficult to reverse engineer.
do I need an Nvidia graphics card to run the webui?
interesting, a lot of prompt engineering on the backend. Do you think they get the checkpoint from the likes of civitai or do they train their own?
doesn't have to be Nvidia but u need a GPU
RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx
then why does it give me this error?
they absolutely train their own. they're running a 1024 native model, likely not even based on anything stability has released. Their own base model with their own structure at this point in time.
back end prompt engineering is a suspicion i hold, but them using their own model is nearly an accepted fact. But MJ keeps that all very secret and doesn't reveal any of their recipes. These are just educated guesses people make
do you think they use LAION’s as well?
For those that use regional prompt control, what do you put in your main prompt area for positive and negative?
are the admins from /r stablediffusion in here?
in positive copy addcoll, addrow and so which you generate, type prompts in front of it like
sun addcol
moon addrow
city on horizon
For example. Also make it active but left unchecked where sort of main prompt or how probably regular, common prompt and common negative is. @placid hatch
Ah, runwayML.
anyone have bad hand v3
What is the best channel to ask for a checkpoint model recommendation?
at the beginning maybe but not now
i think the frontend uses gpt4
Guys, how do you add colour to a picture generated without a vae, or with very desaturated colours?
I have it saved, but no matter what I do, it doesnt wanna get brighter!
Hi I am new here, I will like to ask if I have question about DreamStudio which chat room should I go?
Welcome! You can head over to #1025467151206854736 check the pins for additional info ^^
#1047197565365538826 or ask in any of the chat channels for SD
Thanks Jae, I think I better ask here then, since the #Dreamstudio don't seem very active LoL
I get a question about did other people will have the access to the photos I updated to Dreamstudio? I get this question as I use Midjourney other people will have access to the image I upload.
No, images you upload or generate on DreamStudio are not shared with anyone else!
Thanks a lot, haha this is my first day switching from Midjourney.
Have fun! We have a friendly community and weekly events here if you're interested! ^^ #1087493421209485393
Hi!! There are many ways to get started, I suggest looking over #1080946152318443610 to get yourself situated!
Just got into messing with this. Got everything working but.... I have an AMD card. Is there a workaround for this other than using the cloud option?
Hey there. I try to use prompts and neither one of the boys are working…. And I receive an ephemeral message from the bot….
Is this normal?
👍🏻
I was trying to install I think stable diffusion someone told me i need to get something that i find when i google automatic1111/stable-diffusion but ive been running some thing for like an hour then its finished but i dont have a stable diffusion and the instructions are not clear at all, does anyone know how i can get stable diffusion locally on my computer and use my own images as training?
there are web UIs that will work for amd
[This is server for people who uses stable diffusion]
[?]
Sir sorry to ping you
made the account just to spam. what a spammy site. affiliate links or what?
?via=gpte OHHHH yeah they're affiliate links. so spammy
They've already ditched the server. neat

GC. Time to play some bonnie tyler
Hey. I've been using ControlNet through hugging face but it's really hard to join the queue. Is there a bot version or a quicker way I can use it? Thanks
Is there a checkpoint model + Lora combo well suited for analog J-horror? Stuff like so: https://youtu.be/g-4Eew0YAwM. Not interested in gore. Looking for grainy, moody, creepy, haunted images - decaying structures and interiors, etc.
install it on your PC, only take something like 60GB for the contronel models alone
Thanks I'll try that 😁
be sure to run --lowvram and --opt-sub-quad-attention if you only have 4gb vram like me. it can run 3-4 controlnet models at the same time with that setting
If youre looking for support with a local installation you can try asking for help in #🤝|tech-support
appreciate it man, I have 6gb vram but I'll see which works best
The Pruned models are a lot smaller
Dont need to use the big ones
maybe i should update them, ive had them for quite a while
Is multidfiffusion compatible with regional prompting other than what it has built in?
Stable Diffusion would be way better if u could just upload ur own models onto the website version and use them there.
ngl
alive!
Get your roof finished yet?
no, still got at least one more week of the roofing roofers roofing the roof
but after that I can finally rest! Forever...that sounded very ominous :P
Just loading up a model and hitting Generate without any prompts or negatives can make some pretty cool scenes all by itself
oh boy! Well, I hope you're used to them by now, at least!
yeah, there's certainly a lot of things you can do!
Hey everyone! im new to using stable diffusion and im suspecting its using my cpu instead of my gpu, i have Nvidia
Can someone help me out please? T_T
Its taking forever to process just one image
did you check task manager while you render image?
No! i will check it
🙂
Don't kill me T_T hehe
so works ok? GPU i mean..
How long does a 512x512 30 steps image take?
why does it say error requesting generation

i am using the dreambooth automatic1111 extension. Is there a go to source checkpoint for building a model based on my face? Should i go with a standard SD checkpoint or something that is pretrained for realistic pictures of people?
Guys, update
is using the CPU
What should i do in this case? help please :(
The GPU is in 0% usage
No surprise its going that slow
Any recommended models for short prompts that will do decent at anything
Inpainting controlnet made me generate the same image 5 times as if I hadn't masked anything in the inpainting image
I like dreamshaper and revanimated.
How many gb’s are they
526 mix is pretty good too.
Dreamshaper and Revanimated are 5-6 gigs, 526 mix is 2 gigs.
You usually can get them smaller if you get models that don't have baked in vaes.
If you use 526 make sure to drop the CFG to about 4-5.
The model is a little overbaked.
Hello everyone,
I hope this message finds you well. I am writing to kindly request assistance regarding the use of stable diffusion models for video generation. As a newcomer to this topic, I have embarked on a journey to comprehend the foundations of stable diffusion models. Currently, my focus lies on studying relevant papers and code that cover the basics of Diffusion models, such as "Diffusion Models Beat GANs on Image Synthesis," as well as different evaluation metrics like Fréchet Distance.
Objective:
My ultimate goal is to gain a comprehensive understanding and achieve the following objective: input a video into a stable diffusion model and obtain a stylized version of the same video, resembling an avatar, while ensuring that the quality of the output video remains consistently high and robust to motion in the input videos.
If any of you could kindly provide me with some useful references or resources in this regard, I would greatly appreciate it.
Thank you very much for your time and assistance.
hi everyone, is there still a channel for hardware advice?
i just got 4090 but my PSU is just 750... not sure it it's enough or not
i hope there's a way for a 6gb vram gpu to run SDXL
i have a laptop, don't think i can update that to have a better gpu
@wise stratus is doing a countdown on Twitter. Shares pics that look like it's SDXL. So we'll probably see a release on friday, as it wouldn't make no sense to launch something in the weekend.
I there an open source program that can design all over print clothing desings that can be uploaded to Print on demand suppliers?
Its not, you should at least have 850W but 1000W is even better
I saw my 4090 draw almost 500W stock
Put an Intel CPU next to it and some fans and youll surely run into problems with 750W
Hey guys, can you explain in simple terms when do I need NOT to use a preproccesor on controlnet
I always forget that?
Is there a simple rule?
when you have the output you are looking for
for example, when you upload the actual open pose output to the controlNet unit, you dont need to use the preprocessor, just load the openpose model
do you guys use local computing or cloud computing to generate pictures?

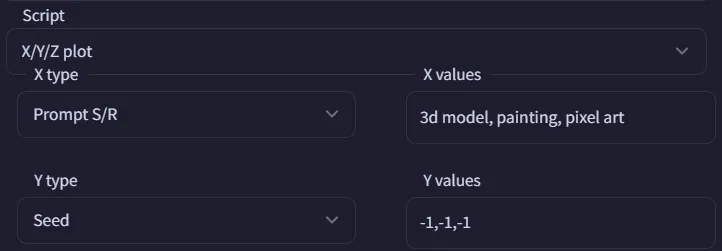{kind=link}
/filters:no_upscale()/articles/privacy-attacks-machine-learning-models/en/resources/1privacy-attacks-machine-learning-models-2-1564821302857.jpg){kind=link}
how do i instruct kohyass to use the venv for automatic1111? since the venv already has torch installed in it, i don't want to install it again
does anyone know how to make faces look more like the person using TI's and Loras the faces come out looking weird
is there any settings im missing
any quick libs/methods to train a LoRA?
can i put someones face in an ai picture? how?
what happened to kohya ss?? all the tutorials are different from what's on the github
You could try ADetailer for Auto1111 and put the Lora into the extra prompt for the face, not sure if that works as I got it in my head tho
https://github.com/Bing-su/adetailer
You can train a persons face into a model/lora and use that to regenerate their Face, or you look for existing models/loras if you dont want to train stuff yourself
thanks for reply, do you habe any link to train faces?
Id just check youtube for tutorials on training with SD, depending on what UI youre using put that in too. They will probably suggest dreambooth id guess
I think you will find your answers in #🎥|animation
Hello. I chose DM1 option. And it says DM sent. Where can I see it?
Hello everyone! Do you recall the announcement from the Stable Diffusion team about their upcoming release? They mentioned it would be open-source and boasted about it being 50 times faster than the current version. It sparked quite a bit of excitement and anticipation among us. However, it seems like we haven't heard any updates on this for a while. Does anyone have any information about when this new release might be available? We're all eager to explore its promised enhancements and speed!
top left of your discord
There is no DM sent but on "bot" chat it says "DM Sent" that's why I was thinking I could have looked at somewhere else for photos
The stabledreamer bot sends the image in DM or you can just download the image directly from bot
would the prompt be: "ADetailer lora:name:value"??
ADetailer adds an extra settings menu where you can input a prompt for the part it regenerates, in this case the face. There id put the lora and your negative TIs into the neg prompt there
Usually i just put "photo of girl/man" there but it should work with everything
Do you have DMs disabled?
I see and do I need to include anything extra in the main prompt?
In which section of settings can I check it?
And what should I enable/disable?
Nope, ill send you a pic of how it looks in #🏞|general-with-images
ty
it seems to be working ty
It should be something like allow DMs from X under privacy i think
Argh wrong reply 
idk why is started doing it because yesterday it was perfectly fine the faces looks realistic and then today they looked terrible
It happens when you have more distance to the camera, thats where ADetailer shines
can u use more than one lora?
Should be possible yes
remembering @keen citrus before he changes his identity
What is the best way to increase a pictures quality without making it too smooth?
The add detail TI does wonders for a lot of stuff, besides that good prompts, maybe img2img
img2img high res fix with low denoising
@vast thunder good to see Zdzisław Beksiński here! and with dbz 👍🏻
controlnet models need specific images to work with. preprocessors turn your image into those specific image. for example: if you already have a depth map that you made then you dont need to turn on the preprocessor for depth -- if you did then you would be making a depth map of your image of a depth map to send to the controlnet model, which is unnecessary/creates some weird unintended stuff sometimes.
is there a website or resource that shows a list of ai related things people do for cash?
Is there a way to determine what a lora's trigger phrase is?
Sorry, dumb question, but what channel is the sdxl bot in?
#1100170312106127410 & up
whats the hold up on XL drop? I want to see some community models built around it already.
Hey hey, I keep looking around but I can't find out whether there is a limit to the generations I can do, does someone know? Thanks in advance!
i'll likely be very hard to refine and not understood for some time. Community models will be out 2-3 months after public release, is my prediction
very soooon!
anyone had this training error? RuntimeError: Error(s) in loading state_dict for UNet2DConditionModel:
size mismatch for down_blocks.0.attentions.0.transformer_blocks.0.attn2.to_k.weight: copying a param with shape
3
wow, almost 30,000+ online
wait has it been over 1/2 a year since SD 2 was released? that is like an eternity in ML
time flies!
can someone suggest good realistic models please
I like analog madness and edge of realism
Bruh who be generating images of toes rn💀
Dude, i just watched AI sponge and it started speaking chinese, and immediately after speaking chinese it just spat out math formulas
Are there any extensions that automatically change your webui settings to presets for different checkpoints?