#💬|general-chat
1 messages · Page 55 of 1
I would just use my name
ho
the best way to know is to run the initialisation text as a prompt
try to find a prompt that makes people resembling you in that dataset
that's the best you can use
run this in the txt2img on the same model you are trying to train
I would add the ethnicity, like country. age too
this helps a lot the model usually
yeah it works, but origins, ... yeah, putting for example "half irish half japanese american"
try to just run this in the model, in txt2img
and see if it gives things around this
also adding "a photo of"
or "a selfie of"
"taken on my iphone6, RAW photo, 8k"
usual photorealistic tokens
nice init text then
yeah, the 8k token is just for photorealistic quality
not really saying it's using 8k pics
as a token though, it is
the pics that were trained on 8k token are mostly made in 8k, so have very granular details, like face pores for example
so this token gets associated with that : level of granular detail
sampling steps, it should be a factor of your dataset size
like on batch size at 8, sampling steps 100, you have a total of 800 pictures that will get trained
I usually try to go around 100 repeats of the dataset myself
in your case, that would mean, on 22 photos if I remember well, 275 steps
let me explain simply the maths here
1 step = a batch is trained.
total pictures trained = batch size X steps
so if I want "total pictures trained = 100 X dataset size"
that means steps = 100 X dataset size / batch size
5 to 8 is what people tend to use for this use case scenario
8 is better quality usually
5 is better for using less token when you'll prompt with this embed later on
when you'll use the "token" you are training on, it will cost this much tokens for real in the prompt
it's quite nice
instead of having a binary file, you get an image as output. it has all the training data stored inside, and it shows an example of what this embed does
hi it's been a week since i started ai art and i'm loving it
It's quite the fun thing to explore yeah ! what type of things do you do ? mind sharing some in #🏞|general-with-images ?
yes, it works the same but is for us humans to use them easier
sure, i'm mostly focusing on anime and also a specific animated style (arcane) lemme show you
GAS (for short) is the "same" as batch size, but serialize. it does train multiple pictures before modifying the model, but instead of doing them in the same batch and costing VRAM, it does them one after the other and costs time
it multiplies with batch size
lower batch size ^^
or restart
yes, a lot
I can train dreambooth max on batch size of 6 personally
and I can go higher than 20 in batch size in image
yeah, try 4, 3
this is the default size, i'd say you always go higher cause it impacts a lot on the quality
they are training an embed, it works a little differently there, you can't really up the size like that without upscaling your dataset too, and it costs a lot more VRAM in training too
oooh okay i see
restart your auto to see if it frees some.
remove hardware acceleration in discord so it runs on RAM and not VRAM
you can also move windows itself to the motherboard by changing where you plugged your screen and restarting
nah, they reserve about 1.1GB on my VRAM, OS + discord, if I don't do those steps
windows 11 itself takes about 0.9 right now
and yeah, when torch takes that much, it's nice to get those bits back
let's move to #🏞|general-with-images ? funier to be able to share pics
hi sorry dumb question, the open sourced stable diffusion is a LLM or just a ml mode?
model
Stable Diffusion is a ML model, a diffusion model to make picture. It's not an LLM (large language model) that are meant to make text
thanks for the clarification
Guys can I upload a deforum video here? Cause I messed up settings and cant restore it back?
#🤝|tech-support or #🎥|animation will be the best place for that
nicer !
well, not sure about all your other settings
but the time jumps a lot at the start
it goes slower/faster
and the time will become stable in a few minutes
it/s vary
I don't have the 4070Ti in the community benchmark, not sure if your it/s is good or not sorry
https://docs.google.com/spreadsheets/d/1Zlv4UFiciSgmJZncCujuXKHwc4BcxbjbSBg71-SdeNk/edit#gid=0 benchmark (pinned in the #1011228477954998273 channel)
be sure you are ventilating correctly. if the it/s drop so much it could be your computer limiting processing speed to reduce heat production
I know it did that on my laptop before
ask in tech support if they know more to help you on this, but I'm not even sure there is any problem there
training is long
and 4070 is good but not the highest cuda core count either
Hi guys! I'm building my first PC in 20 years, for SD. Can you tell me which windows 10 or 11 is better? Is there a problem with 11? Build 7900X + 4090 + 64GB
should be all good. most people on that kind of system are really happy. you'll get better tips on such things in #1011228477954998273 where the Computer builders tend to go
(don't forget to mention those are training it/s but Trex knows his 40XX series stuff 😄 )
My 4090 trains at 6 it/s. The 4070ti should be at a minimum of 4 or 5. Seeing as my 3080 used to hit 4.5
It sounds like you aren't using xformers nore have.... yeah xd
You need the cudnn dlls.
40 series isn't supported native.
I'm not sure if it is different on ubuntu, as I'm entirely unfamiliar with the platform. But I know that you need xformers and the latest cudnn.dlls from nvidia to make the most of SD. It shot my 4090 its from 7 up to 40 for batch size 8 image gens.
A gatekept nvidia developer download
Pulling up my install to show you the folder directory, sec
stable-diffusion-webui-2\venv\Lib\site-packages\torch\lib
The following files need updated for 40-series compatibility: cudnn_adv_infer64_8.dll through cudnn64_8.dll
how to use
^could just be looking for the easy to use online version 
I bet your perf quadruples
I.. hm. I think I had to go to 10.9
Prompt: Clean page from a coloring book for children, with dog running with a butterfly in front of house and park background, black and white, high quality, high resolution, clean image, white background, ad ink outlines --v 4 --q 2
This isn't a bot channel, and there aren't currently any bot channels available. Check out #1072220168534642768 to see how you can generate images.
I assume that's an improvement


Higher performance 
In other words idk
This is relevant how 
Sounds narcissistic 
But also self-destructive
A new record
I've run some img-img on myself for sure. Haven't tried training a lora yet.
I've been merging models all night and I got work in 4 hours. I'm out 
if I read "use the base 1.5 SD vae"
is that this one then?:
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
vae-ft-ms-840000-ema-pruned?
correct
Hi guys, so this negative prompt '[(badhandv4:1.2):0.1]' that I found online. They said 1.2 is the weight of the embedding and 0.1 is the step on where it will be used so e.g: 20 steps * 0.1 so at step 2.
My question is what is the default step it begins? step 0?
yes
by default it's active for every step
that works on any token, in positive prompt too
here is the detailed wiki on this feature https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing
Speaking of Covid I was anti vax until I got very serious delta virus. After that I run to the doctor to get boosters not because I believe everything or deny the risk but I genuinely thought I'd die after getting Delta unvaxxed
So I hope you feel better Clueless I get it
Sorry if this is a wrong chat to ask this, but can anyone please help me to transform a picture of a painting to look like a real human similar to the painting?
Or please direct me to the correct tutorial.
Again sorry if wrong place to ask.
you're in luck, I tried to do a guide on this about a month ago : #1011634831467221033 message
Thank you, I have webui installed, will that be a problem?
+ an extension, controlnet
how would I get that?
just search for it on google and download it?
Thanks, will find it on the net and download it, then follow your tutorial
well controlnet is a nice extension, that you can download in the extension tab.
It requires to download some models too.
I just answered this with a little more details, and a link to a good guide on it, there : #🤝|tech-support message
Thanks again, just watching a video how to download that controlnet
Hello guys, what is this function for: Clip Skip?
CLIP is what makes your prompt into tokens, to give to the model.
It works in layers, 12 layers total
Using clip skip higher than one is saying to skip some of those layers. This makes it possible for the model to ignore a little your tokens and can bring higher quality.
In particular, people praise a lot Clip Skip 2
👍
would clip skip dampen the attention issue with color keywords ? I should experiment there. I always thought i was only intended for anime models because of something nai did to train it
no in fact it's quite good with photorealistic too
don't push it too much or your prompt goes ignored almost
but it's really cool for some artistic results or very realistic results
especially if you use very long prompts, at least it feels so
does anyone know where can I find some good fnaf model?
The only two on civit are just updates from each other and are full on ponybro smut
Anyone know any really good book style illustration checkpoints?
any AI music generators that can make good classical music?
Anyone knw how to run Blip2 with less vram? I'm using this extension. https://github.com/Tps-F/sd-webui-blip2
Hi
I just finished my exam and wanted to get my hands dirty and images beautiful with stable diffusion
is there any course or something like that which can teach me how to get good with ai art generation?
If you really want to delve into the weeds, go check out Aitrepreneur's videos on YT.
The #🍥|anime community is a great place to get prompting ideas and support. Though if you want to avoid our fabulous anime friends ig #🤝|tech-support works too.
uh, google colab doesn't let me use GPU anymore, what did i do wrong?
guys want ur insight on these prices, anything that stands out as exceptionally good worth a buy?! :
zotac gtx 3080 trinity 10gb 594.17$
msi rtx 3090 gaming x trio 871.45$
msi rtx 3080 gaming x trio 10g 653.59$
gigabyte rtx 3090 vision oc 24g 871.45$
asus tuf rtx 3080 gaming oc 10g 673.40$
asus geforce rtx 3070 ko oc gaming 475.34$
gigabyte geforce gtx 1080 ti aorus xtreme edition 11gb 297.09$
evga gtx 1080 ti ftw3 gaming 11gb oc 297.09$
if you're not paying for it - it's limited.
up to 6hours if you're not using it everyday and if you're lucky, usually less.
~2-3h if you're using it everyday
I just started yesterday to train a model, and sudennly went idle and closed stable diffusion 
The training was working perfectly
now it doesn´t let me use it, like I was banned or something
anyone tried aZovyaRPGArtistTools_sd15V2 model? which VAE is the best for it? since if i put it on auto or none, the results are washed out and desaturated...
uggh i want to try control net's style transfer but i always have issues trying to run SD on google collab since i have a mac :/
anyone know a good model that can design a logo with letter?
or prompt maybe
(fantastic logo lol, for minecraft server..)
"Please reinstall the torchvision that matches your PyTorch install" lol why is this an error in google colab, like this stuff just breaks my brain 
Im using the stable diffusion webGUI. How do I use a safetensor file with the program? It only takes .ckpt files
Anyone have any success with and can recommend a good four GPU motherboard? Along with four PCIe x16 slots, the mobo has to have them spaced appropriately to accommodate the 3x slot width of some of the heftier GPU's. For example, NVIDIA x090's and x080's are 3 slots, the NVIDIA x070's and x060's are 2 slots. So far I've found Asus, Gigabyte and MSI motherboards with up to 4 PCIe x4 or better slots, but looking at the spacing I believe they could only accommodate 2 of the 3 slot GPU's. Recommendations, experience? Thanks ~
Automatic1111s? Put them in your stable diffusion/models/ folder. They should work the same as ckpt files.
Hey guys it might kinda sound stupid but how can i tell the generator to take the picture for a distance? I tried telling photo taken from distance, candid shot or capture surroundings but almost all the time the main object takes the majority of my screen
So how should I write it? Just 1 meter or 2 meter or is there any other commands to write.
Thanks a lot I’ll try it for sure
Stability AI is on shaky ground as it burns through cash and looks at a management overhaul: https://www.semafor.com/article/04/07/2023/stability-ai-is-on-shaky-ground-as-it-burns-through-cash
Are there any good models for generating textures? I've found https://huggingface.co/dream-textures/texture-diffusion but it seems to only be trained on like dirt and brick so it can't make organics and then there is https://withpoly.com/browse/textures but there's no access to the actual model
I replied to this silly article here https://twitter.com/EMostaque/status/1644476969298345986?s=20
@PaoloDalprato What a crazy headline.
Our main cost is compute that is not available anywhere that we get at a massive discount to market.
We are inundated with folk wanting their own models and more.
Could even just do consulting and make stupid $$s
awesome, thank you for the response!
any eta for the next model release? think we'll see something before May?
Announcements start next week. Very nice!
next week for soem models (not sdxl, still tuning)
awesome! and damn thanks for the reply, i didnt actually expect to get one lol
hey, i have a question,controlnet is awesome,but how create models normal map from blender or camera 4d to controlnet
so next week should be pretty dope for sd fanboys lol
Hi
Hi
Hi everyone, can anyone change the aspect ratio on the new website https://beta.dreamstudio.ai/ ? I can't x)
How to get the prompts from images posted here on discord?
discord removes all metadata now.
Any other space apart from CivitAI that has well documented image library?
CivitAI is a mess to search on.
for SD, not really
how to use this
hey, we are a group of students trying to create a 3D model of an aged-up face by taking photos of the face, passing them through SD to age them up, and passing those images into another program to generate a 3D model. Does anyone know how to use Stable Diffusion to modify existing images like that?
Holy, you're back!
IMG2iimg and controlnet
tysm!!!
There's also InstructPix2Pix which works with something like GPT3 to fine tune edits with human language - such as take a photo of a person, write "make him an old man" to get an old man version. I haven't tried it, and the img2img and controlnet work well - I made a zombie version of an image.
for example
"@wise stratus did you hear, Stability just dropped BaLM?"
"what's BaLM?"
"Big-ass language model"
"Damn.. Stability dropping BaLMs over here"
sir, i implore you to consider the meme potential here
An explosive new LLM drop from Stability
Stability is really blowing up
Emad's on fire
.... the headlines write themselves
How would we use controlnet? Would we train the network on photos of this person, adding an image, and using a prompt to age the person, or would that be going about it wrong?
So I made my first Lora today. It was based on real images. But when go back into a1111 and try and make something. it comes out as a cartoon. No idea why.
hi u know where can i create my images on AI?
did you train it on a custom model, that was perhaps fine-tuned on cartoon-ish images? try adding "cartoon, animated" etc. to the negative prompt
I tried it twice on custom models that specialize in realistic humans. I'll have to check what negative prompts I used.
Here is my negative prompt.
--n cartoon, 3d, ((disfigured)), ((bad art)), ((deformed)), ((poorly drawn)), ((extra limbs)), ((close up)), ((b&w)), weird colors, blurry",
too many brackets. start with no negative prompts, add them back one by one. start simple and adjust 1 variable at a time
I copied this from an image I generated that worked really well. No idea why this was bad for LORA. Does it work different than SD?
you are changing the latent space when you add a LORA. the same prompts won't behave the same way, you have to create new prompts for what is effectively a new model
Understood. Thank you
https://www.etsy.com/in-en/listing/1456809415/colorful-fury-a-digital-print-of-a-angry?click_key=ba2eefedd338855f84de693a852703a80f81eb48%3A1456809415&click_sum=0fe2b1f9&ref=shop_home_active_1
Check out my store on etsy, i have some amazing graphic designs.
oh shit
actually new stable diffusion model?
been cooking for a while now.
wonder how they've improved.
midjourney has been improving at a very steady pace since SD's release, and gpt-4 is going multi-modal and can even understand images.
wonder how SD is going to catch up. CLIP is not exactly intelligent by comparison.
i wonder how long before enthusiasts can train their own SD2.0 level models for <$1000, from scratch
@hidden dagger ^
SD 2.0 is crap
1.5 vs 2.0 vs 2.1?
is it available?
by try, I don't mean make an image on a server someone else controls
Not as an API, but it is on DS
Because the local install is far more customizable and perfect for those of us who want to train our own models.
Thanks, that makes sense
I'm on it, sorry I was sleeping... damn the guys....
nobody can change it at a whim, censor what I do, take it down without notice, increase the cost
Does anybody know how or if I can prevent CUDA running out of memory over time (30 minutes)?
Again not to sound like a bitch but
I wish all AI stuff could be written in Ruby instead of Python
And run on OpenBSD instead of Linux 😢
hello, I am new to this but I am looking for a way to use LORA model in API mode. I am using the newest version of automatic1111 and everything with the loras is working fine in the webui. For the /txt2img endpoint in API mode the text for lora activation lora:model:1 doesn't seem to work. Any help would be greatly appreciated!
Do you guys know how generate a batch of 100 images with same exact settings, only differing in miniscule noise patters resulting in ancestral samplers?
i am doing so "by hand" right now, and its painstaking
hey guys, is there any open source AI Voice changer? which can do things like change current voice into a old male voice or little child voice or female voice.
If NVIDIA actually gives a shit about OBSD
Even FreeBSD has Nvidia gpu support
hey I'm new to stable diffusion Is there a place I can go to browse for diffusion models
anyone know a good model that can design a logo with letter?
or prompt maybe
(fantastic logo lol, for minecraft server..)
hello, an information; is there any good tutorials/online course to start learning stable diffusion? pay course also if need
If i may ask you directly. What kind of consumer hardware setup will we need for SDXL? Do we need more than 10GB of Vram for example?
Do someone know how to install lama cleaner from github on windows ?
it was free but now you have to pay 5$
Blue ocean competition. SD are operating in a space that others can't. Training models for clients while providing open source foundations for the public.
I'm no employee, that's just my conjecture based on what i've seen them doing. DStudio doesn't seem like it's meant to compete with MJ. If i understand it right, SD bootstrapped MJ to get hype for ML alive, and it worked. MJ is a huge Stability success story.
Why are the images generated with anything v4 looks so washed out? They lack contrast. Any way to remedy this?
using vae.pt's often improves color
Hello, I've been training a model but I'm not sure if I'm doing it right, the drawings looks like a kid drawing, like the model if missing something, what I'm doing wrong?
oh sorry I think i loaded the wrong model
#relatable
Can't wait for SDXL now.
Got the automatic webUI fully operational on Intel Arc now, and it's working well.
thanks dude, i tried using vae and the image quality improved
Hey everyone,
I hope this message finds you well. I've heard great things about your programming skills and I was wondering if you could help me with a project I've been working on.
I used to work in e-commerce and have recently been exploring the world of AI and machine learning. I came across the website pebblely.com, and was impressed with the accuracy of their product backgrounds. I'm interested in creating a similar or even better AI model that can achieve the same results.
Since I don't have any programming experience, I was wondering if you could help me with this project. Specifically, I would need somebody to program the AI model and then push it on replicate.com for API use. If you have any suggestions for a better way to approach this project, I'd be open to hearing them as well.
I'd also like to discuss compensation with you guys. Please let me know how much you would charge for this type of project and we can discuss further details.
If you are interested, feel free to dm me
Best regards
if you have atleast 4gb vram, its best just to download stable diffusion to run on your pc
Its 2.5x size of SD
DreamStudio is just a reference implementation tbh, we will have big changes soon and be more open
2.2.4 does tasty food

we help devs all the time in the community, grants, getting them lots of GPUs when stuck and more
hii
hello
You’re a strawberry
how much time does stable diffusion needs to learn a certain style?
is XL still a long ways from release?
Is it possible to still change the size of the generated images in DreamStudio?
Bumping because I want to know too
The XL custom models are going to be insane
bring em on lol
I'm ready for SD to get a little ai hype back haha
i think they lost some shine since 1.5, but now they can strike back
and say "How you like me now?"
Well, it's mostly shameful that mid journey has them beat.
We really shouldn't even be jumping to conclusions because it's possible that the XL model will suck dick just as much as the 2.x did.
we just have to wait and hope that they learned from their mistakes.
I am trying dream studio - diffusion model there is limited? i want to make a comix where people are getting killed

i dont understand why there are some limitations its ai - when people paint they paint whatever
guys, do you know what algoritihim does Dall-E and midjourney use?
if stable diffusion uses a latent diffusion model, is it similar with DALL-E and MidJourney?
and/or other open source image generation AIs?
You can make your own using base data
and it will be unrestricted
services are limited, AI itself isn't, you can do whatever on your local machine
ok
a
a
b
whats this server about?
AI art generation
Yeah, SD is completely free
For a local installation it will require a sorta strong GPU.
But you can run it via resources like Colab as well.
where ai art
All art is ai art. Real artists don't exist
Gifs don't work in here so I deleted
where ai art channel
guys
I SWEAR I FELT SMTH WAS CLIMBING MY LEG UNDER THE BLANKET
cant post
Is there a website that has a gallery of stable diffusion images and prompts with users upvoting the best ones, like lexica.art but with more recent images?
if i'm conjecturing right, i feel like dream studio is about to be open sourced soon and we might have a new webui on the block.
local install DS webui?
hey, going through an installation guide from nov 28 2022, in it they edit a webui-user.bat file, looking through my download now that file doesnt exist. in the file they linked python and added a git pull to automatically update stablediff whenever it runs, is there an alternative file to do this in now? or is it unnecessary
hasnt changed. its still there on every install
if you're running it on a mac or something, it's probably webui.sh
running on pc, strange that its not there
ik this isn't stable diffusion but its p powerful
connects gpt-4 correctly to your command line to search the internet and make files and stuff
if i'm conjecturing right
When is sd XL releasing open source for local running
wish we knew
This is is even more annoying then waitlist now adays not knowing anything
the only thing you've posted in this server is that link three times over the last few days 👀
emad be like "soon"
probably be a while
after everyone complained on 2.1 we are using feedback to optimise it
so its awesome out of the box
ooooooooo
some images from feedback input on XL

impresssive! ...what about text ?
by the time it is released I reckoon we can get the text just about perfect
about to test some new text condiitoning
would it be also capable of like uploading custom font and make it to render in that image in future
DALL-E uses a pixel based approach that is similar to DeepFloyd which we are about to release
MJ uses a diffusion variant
yeah thats not hard, its not in one model tho
gonna be really cool

ohk i see thats a good initiative 👌 good luck for release
we are working with all our partners so we will get many millions of pieces of feedback data
another last thing is would there be sd xl inpainting model ?
damn looks incredible
perfect!
🤞
wait, so theres xl, then version 3?
yeah
and something before xl?
3 is.. different
you think there is a chance for 3 this year?
there is XL in dreamstudio now and the above is a variant of it we are working on
yeah defo
very nice
this might be a bit off topic but will sd release a language based model ?
chatbots
laion
already doing it
someone said first version this week
gonna be needing huge vram ig
could we run offline i wonder like stable?
well gpt4all and vacuna seems to run in cpu now
I haven't seen the details of the model, I'm not sure. it wouldn't be impossible to run locally, they will probably release the weights.
sure
I hope to release 100s literally
every nation and sector needs their own
plus we are working on getting them to the edge for our education tablets
with a bunch of hardware folk for specialised hardware
stable lm best ! we dont want a bit copied name we gotta be our own :))
an AI that teaches kids and learns from kids in each culture is the best food output for national language models
we also funded https://github.com/BlinkDL/RWKV-LM fully
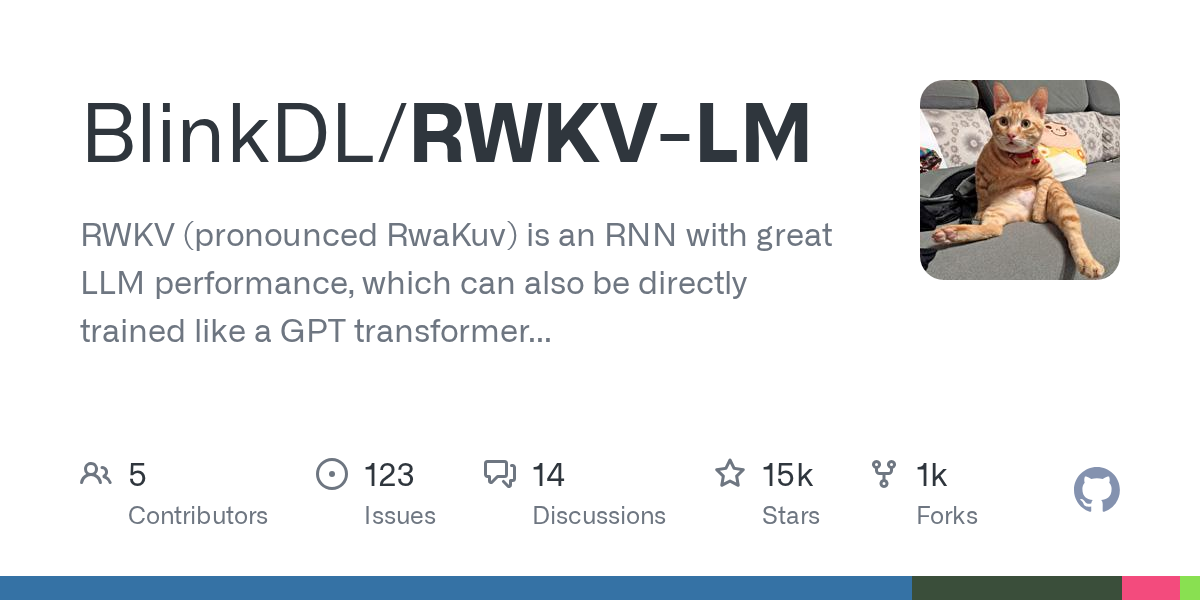
GitHub
RWKV is an RNN with transformer-level LLM performance. It can be directly trained like a GPT (parallelizable). So it's combining the best of RNN and transformer - great performance, fast in...
which is a different type of language model that is highly performant
this will work better on offline devices tbh
Do you think we will continue to have these exponential evolutions until what year?
what checkpoint do yal use when training anime girls 
About AI in general
we will start a blog series of all the crazy stuffs we do
s curves all the way up
It looks like this year is going to be BIG.
It already is, in fact. The first four months have already been bigger than all the 2022.
I didn't even want to sleep and have a social life anyway.
did you say a model will release this week or i misinterpret that?
Do you remember what color the sun is?
grey, like my closed stores
StableLM ! GPT is so overused right now
ye fr
was the gif made by a.i too ?
I think it was done in like 3 minutes during one of our mod meets
we needed to have a "red emad alert" x)
indeed
(just joking Emad 😉 don't ban me pls)
yeah the collective mind already assimilates GPT with OpenAI
in the other hand, people know what a GPT is and what it does

hopefully
idk I keep poking legal

it will be easier to get people to try the text model if theyre familiar with "GPT"
Emad I know in the grand scheme of things this is trivial and a waste of your valuable time, but if you could ask Fruit to give me back the Hatsune Miku role, it would put a very big smile on my face. Thanks for pioneering AI for the free world 
fruit does as fruit does
Next best thing after AI would be a hat that read what I envisioned in my mind and output it to the screen using AI imo
From brain to text then to AI, it lost quite a bit of detail. Directly from brain to AI would be neat
modules.devices.NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
I got this error when i am using orange mix 3 model... all this options does not help, how to fix it?
I got some error message last night, i just reload the thing. Maybe you should reload too if you haven’t tried that
this error shows up constantly with some models, no matter what I do. for example with abyssorangemix2 it's ok, but with abyssorangemix3 it has this problem. when I launch with --disable-nan-check i just get black rectangles instead of images every time
i have rtx2070 super
"Upcast cross attention layer to float32" didn't help though
Maybe you should undo the disable nan check command in the bat file
I think you misunderstanding, I mean when there is no disable nan check i got "half type not supported" error, when I disable it there is no error, but i got black images.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/6923
It seems like this is sort of common problem without clear solution
So only these model got the error? If so it is best to use other models for now
well.. this model is one of the best so I want to try it. and I am looking for some sort of solution for this error
What are you trying to make with the model? There might be alternatives
I just want to generate images with this model, because i like how it does it.
Question is not what i want, question is how to make it work
#🤝|tech-support would be the place to discuss that
but also you are right, it's currently an issue that seems to be spreading, from the reports I saw recently in tech support, and as you saw too, that is not really identified nor fixed yet
lol is it normal to just be updating xformers and then everything else have to be updated too cuz they dont support the version?
yeah, xformers has to be built to the same pytorch and cuda drivers being used. it's all a dependency chain. welcome to dependency hell 🔥

Camera cup
Yeap
/imagin
I hate all the hate for 2.1. I'm afraid we'll getting a new version which your unable to run local or on (free) colab, because of that. 😒
--no-half --no-half-vae
good
Hi Everyone,
How's you all?
hey everybody! I'm just testing Lora and it's super powerful...I was just wondering if there was a place to download .safetensors file with Lora already trained for famous people. A place where you can find Lora for Athletes, actors, politics... I'm just asking! Thank You in advance!
is it possible to stop rendering image instantly? sometimes canceling takes 5-10 seconds, sometimes it takes minutes
i don't think that just kill rendering thread and free gpu memory is something that needs any time
how do i actually use the batch upscaler in automatic1111? it give me error with the same setting as the single file: UnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x00000172D6B7D270>
Time taken: 0.00sTorch active/reserved: 552/564 MiB, Sys VRAM: 1837/4096 MiB (44.85%)
nvm, i just use the tab next to it, seems to work well
so true thanks emad 🫡
fruit giveth and fruit taketh away

where do i get help with instalation?
thank you
the future is now
hi, i have 6gb vram. I want to train my father through dreambooth, but I could not succeed. it says "No executable batch size found, reached zero." I tried many settings but I couldn't succeed. I guess I need to get a more powerful gpu. i also tried with Lora. But when i select my .safetensors, nothing changed. my model is not working...
well, you are too low on vram, that you got.
But since you are aiming for just 1 or 2 tries at it, or a few over a few days, I would suggest to do it on google colab. Using your google drive and a notebook, you can train 1 to 2 models per day on the free plan
upgrading GPU is a solution too of course
but yeah, just using a notebook seems the most advisable
for example this one should work quite easily
https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
Thank you for the answer. I'm a complete novice at these things. i will look into it.
#🔧|finetune is usually where you'll find the most help on this subject
Is anyone else here a little disillusioned with the AI hype cycle?
Most of what I saw weeks ago was quality content from artists and dev, and now there is so much noise and chatter on the topic, so much bullshit as well
I swear most of my timeline on Twitter or LinkedIn is filled with the most random or idiotic hot takes on AI, it feels like NFTs all over again
In fact it seems that many accounts that were bullshitting their way through the NFT gold rush are now doing the same with AI
It feels so scammy and fake
i've got lora's of my friends made right? i won't share them here because they're their personal photos and that's a confidence i don't betray. Anyways, so today's easter and i decided to try to generate a few of them as Jesus. I decided not to proceed as it could be offensive to some and i don't want to cause problems. Just the circles a few of us are in is all. No harm done by just generating them for a laugh then moving on.
MY POINT THOUGH. Sorry to get there the scenic root. Blasphemy or not, people with short hair styles, if you do "Person as Jesus" prompt, they get a sick looking mullet. That's the tip. Cherish it forever. Happy Easter!
fun bit ^^ happy easter to you too!
bonjour.]
Anyone know why my "restore faces" option is missing in txt2img tab of webui after updating webui?
hey whats the difference between all the stable versions ? I see stable diffusion 1.4 up to v2.2.2 XL Beta ?
Dude how do I generate images 😭
@proper furnace
FAQ: How do I generate images? Is there a bot on the server?
Currently, there is no bot on the server that generates images. However, there are plenty of other ways such as the official https://beta.dreamstudio.ai/ website or by running Stable Diffusion locally using your own hardware! Check out #1080946152318443610 for more details! You can also stop by #1025467151206854736 for any issues you experience while using DreamStudio or #🤝|tech-support for any problems you encounter while installing it locally!
hi, again me. i think the training is finished. it says "DONE, the CKPT model is in your Gdrive in the sessions folder" then it gives me new whole SD file. now i dont know how to use the trained model in my sd.
oh i see the session folder now.
oh i saw ckpt folder now. I'm moving forward. :D
soo, don't worked for me. my model is not working. i think I'll give up
anyone else have an issue with sd on diffusers?
all of my parameters are correct, the output image is just terrible
you can observe on the respective huggingface spaces
aswell
Hey, I am looking for a way to upload an image on SD and get a van gogh's starry night style painting version of the uploaded image as an output. Does anyone have any recommendations how can I do this on SD?
does anyone have any idea if there is a local alternative to something like studio.d-id for making something like the balenciaga meme and make a static image blink or move?
Hey, i'm new to these things, is there any tutorial that i can read?
I don’t see v2.2.2 XL beta anywhere in the docs
Hi guys, check this out https://youtu.be/enfZ7do8CTs
120 steps on euler a ...wtf he's doing
as comparison works, I guess, but I'm still mad for 120 steps at Euler a and "It's not similar to mj"...
Why he's trying to get mj results...want to get mj - go mj...like...why do you even... 
But yea, mj better at understanding prompts rn
and why noone ever compares amount of tools and control over gen in mj and sd, since it's kinda main thing there
^
I wanna ask about training regarding Dreambooth. How many steps shall I set per image ? Are 200 too many per image ?
I do 120 steps sometimes, it's really not that bad if u know what ur doing. Not to mention Euler A is lightning fast so it's like 0.3 seconds more to do those extra steps on my 3090 lel
Can we just settle the debate once and for all that MJ v5 wins best model but SD wins best toolset?
If things go according to planned, the XL model will blow v5 out of the water so we just have to be patient and hope they don't screw this up
I personally would never fathom using SD without dreambooth so for me, I'm never going to be sold into MJ
My motto is also "if it's not local, it's garbage"
absolutely.
40 steps is a good place to start I fink
any extensions for text models available?
it seems like the official extentions lack that
Hello Hello, sorry stupid question: dream bots are offline, no? no more image generation from discord?
for now, no, we don't have any bot on the discord.
The ways to generate are :
- on public websites like https://beta.dreamstudio.ai/generate
- installing it on your computer => check in #1080946152318443610 and #🤝|tech-support
- running it in the cloud in google colab or something => check #1080946152318443610 and #1011228442399883294
thanks a lot 🙂
Ive seen so many insane pictures but no prompts on how to get them, is there a place where they post both ?
Hi guys, I need some inputs on how to improve this
keywords used: Harry potter on the ground, casting levitation spell on Donald Trump, Donal Trump in air, voldemort laughing on the side
no negative keywords used
How would i make specific changes to a picture without chaging the whole ?
inpainting
what preprocessor should i use with control_mediapipe_face_sd15_v2
ty where can I read about that in here ?
check out #1080946152318443610 for a massive list of tools you can use. For inpainting specifically, I can recommend an external link and a youtube video. https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
https://www.youtube.com/watch?v=MDHC7E6G1RA
If you have specific questions you can check out #1034602544263090268
thanks a lot trexdel
is it much better to use the software he uses in the video over dreamstudio ? Is it expensive to run it on your own pc ?
Automatic1111 is free. It does require that you have a decent PC to generate images.
If you tell me your gpu/cpu I can let you know if running locally is feasible.
Hi. (sorry very new I think I posted, but can not find my post anywhere..) I want to start editing some of the frames that are generated on stable diffusion. And I understand that how to do this is through img2img and inpaint. I was looking at tutorials. But do I enter img2img through a stable diffusion notebook? or how would I do it? I am using Colab. Thanks!
any one from Canada?
nvidia gtx1060 6gb - what about that software/tool he is using in his video ? Is that the original stable diffusion software or how does this work ? CPu Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz 3.60 GHz
Thanks bro
怎么玩
does anyone know what the different version in dreamstudio do ? From version 1.4 to SDXL Beta is there a best version ?
something i've noticed is base 1.5 does crowds and dual people not so poorly. it seems to have less attention problems. But when you start using 1.5 merged refinements, you'll get a lot of same face syndrome. I think this is a symptom of over training and over merging, destroying nuanced knowledge in the base set that actually gives it better attention over a wider knowledge plane
How fast is AMD Radeon 6800XT at image generation in stable diffusion? How it can compare to Nvidia RTX 3070 in terms of image generation? Currently i have GTX 1070 and it is usable, but I am rather hesitant due to only 8GiB on RTX one, while RX has 16GiB of ram. (I am running Stable Diffusin on my pc, R5 3600 with 32GiB and GTX 1070 @ 8GiB)
best method to confirm that question is to search for any posts that describes how many iterations per second that people are getting with both cards (on the same sampler and batch size, since those do affect it). Then compare the numbers that you see.
rtx 3070 here it takes me less than a min with my settings
Hey all, I'm Kenso
Building DallePunkz "use AI to build digital avatar based web3 communities"
https://www.twitter.com/dallepunkz
Background, university physics and AI, UK.
Great to be returning to the AI space after a few years in web2 mobile and web3 now
🙂
Looking to switch from Neural Love to Stable Diffusion
i heard AMD cards stinky
- "euler a" doesn't converge
- there's no reason to go that high on it
It's not bad , it's just waste of time.
"if you know what you're doing" - so...what exactly you're doing?
(edited to less passive-aggressive variant lol)
Eluer a results look completely different on different amount of steps.
You'll just get different results with different amount of steps, but it won't make them "better", just different
25 steps, 50 steps, 100...whatever
So...you might want to do that if you want to do changing subject in prompt
Like 60 steps on one thing, 60 steps on another thing
I do high amount steps too sometimes, but not on "a" samplers
Is stable diffusion inferior to midjourney ? Made lots of pictures with dreamstudio but there is allways some imperfection with it , how can i fix those ? Like wierd hands or unsharpness on some parts of the picture ect ?
While on the things i saw from midjourney they look good on first try
weird hands => controlnet, sharpness => img2img?
im using dreamstudio dont know wht these commands are or if i can even find those in dreamstudio ?
I'm going to be a little pedantic but there are lots of different things in your question.
Dreamstudio is one of the different implementations of Stable diffusion you can find around. It does has some nice art, but it also has its weaknesses like the one you are underlining here.
Out of the box, I think Dreamstudio is a little worse at art, but a little better genericaly, able to make more real life pictures for example, where MJ tends to struggle going out of the artistic zone.
Lots of other ways exist to use Stable Diffusion, with lots of custumization, and that will make it on par if not miles ahead of MJ. Takes a little more effort though, but it's free
Controlnet for example, or sharpening in upscale, can be easily accomplished in comfy or automatic. but it sure is a lot more work than just prompting in MJ
Thanks for that big response, there are a few things that i didnt understand yet so I will do some more research on that with the info you gave me
ask if you want, no problem
I forgot to link to #1080946152318443610 , we have quite a lot of those different flavors to access Stable diffusion there
Stable diffusion is the "software" and dreamstudio and controllnet are just interfaces were controllnet is the one u can finetune a lot while dreamstudio justoffers basics use ? So if I want to create commerically usefull "art" I would have to use controllnet ?
big response incoming 😂
Stable diffusion is the concrete that builds the pictures.
Controlnet is a tool that helps make the concrete the right shape for you, it's a conditioning method that can for example force hands in particular positions, or bodies, or ...
Dreamstudio doesn't have controlnet, but it has different "models" and "styles". Models are the memory of Stable diffusion, the gravel used in that concrete, and it keeps on evolving.
Fine tuning means making a new model, training it to learn special things for you. This is a complicated process and requires other softwares. but it is usually quite useful to perfect the quality of professional renders even more.
It all depends on your professional goal here, what to go for. I would say yes, the optimal way would be local installation and custumizing it to fit your needs
After all, even MJ is running only on Stable diffusion, with their own models
sorry yeah I do walls of texts :p
thats great those walls have been very insighftul so far for me ty 😄
Do i get it right that mj is just running a different model of stable difussion which is trained on art things which is why it performs better on those ?
different from the models that are in dreamstudio aka 1.4- 2.1 ?
it's hard to say exactly what pipeline they have, they don't disclose it. They just announced they used stable diffusion as base, but I do feel like they add hypernetworks, they also seem to preprocess your prompt so it better fits their models even if you don't know how to prompt.
And yes, they sure do have trained their own models
and where could i read what models in dreamstudio are best for the things I want to do ? A also saw a version called sdxl beta which costs a lot more
Ah i thought so too that they allready use some prompts beforehand , so I could achieve the same commerical art focussed style if i just used the right prompts?
there has been multiple waves of models for now. I say waves because same gen models are "compatible" to train and merge between themselves, but not cross generation.
- 1.2 to 1.5 have been the first wave, trained from a first dataset in 512x512 pixels
- 2.0 and 2.1 have 512x512 and 768x768 variations, and have been trained on another dataset to better fit regulations everywhere
- SDXL, we don't know a lot for now. it seems quite a lot more powerful but I can't say more, it's still cooking, it's in beta
if your type of commercial use is selling good art, then yes, you can focus on improving your prompt. but don't try too much on details like hands, prompt don't fix that that much
Since dreamstudio is mad expensive , could I run that sdxl model on my own pc for free ?
I see quite a lot of people integrating SD in other types of professional pipelines nowadays ^^
so just negative prompt hands ^^ ?
not yet, SDXL isn't released yet
what do you mean ?
it's a beta only and only on DreamStudio for now
In dreamstudio you can use the beta , looked the best out of all things i tried
yes but it's been here for not even 2 weeks I think, and last news Emad gave around here he said it was not for a while probably <#💬|general-chat message>
i read about inlining where u can change spefici parts of the pictures is that possible in dreamstudio too ? Cause often times i had some promising pictures but there were allways some minor things that I dont know how to change without changing the whole picture
You can definitely run locally, but gens will be pretty slow on a 1060. You're looking at a couple minutes for a 512x512 image iirc.
ho I missed that question
yep, it will run but slow
but one thing that you open when you install
it's the list of models available
all of a sudden, you can download almost any model on hugging face or https://civitai.com/
what does gens and iirc mean ?
ah I see do you have some art portfolio of yours ?

well, the banner of the server is my last win at our contest here. you can see all the submissions in #1023999442338201721 if you want to check a little what people do.
I mostly train models, I don't have an instagram or something like that
I'm noticing new models mention "Dynamic Thresholding" as recommendation, what exactly is it?
https://github.com/mcmonkeyprojects/sd-dynamic-thresholding google seems to say, not sure either yet, let's look
which models did u train ?
Check out #1047197565365538826
are these made with dreamstudio ? They look so much better
Most of entries are made with web UI of Stable Diffusion
hm, interesting
Every week we do an art contest on the server, and I train a model out of the submissions, but those aren't really the best general purpose models, quite artistic but mono subjects. https://civitai.com/user/guizmus all the ones starting with SDArt
My prefered one was Dark Souls or Death note before that (same link)
Which is free
are those models like the ones i see in dreamstudio 1.5 ect or is that a diffrent meaning of model ?
I use mainly Automatic1111 https://github.com/AUTOMATIC1111/stable-diffusion-webui
and comfyUI https://github.com/comfyanonymous/ComfyUI
for my pictures
Automatic is the most popular currently.
The second most popular is invokeAI https://invoke-ai.github.io/InvokeAI/
all have a different UI and focus, depends on your tastes what is the best
those are the tools to use stable diffusion on your own pc right ?
Sounds interesting, although usually going too high on cfg doesn't really change anything at some point
they are fine tunes of models from dream studio yes. I take a base model, and I train it to be good at making funny cats for example.
It gets really good at it. but the problem of any specialised model is that, you can't just learn. it takes from other things it knew. so for example, my cat model is a lot worse at making tables
yep, those are the 3 tools I would invite you to look at, or ask around, to see the one that fits you the more.
I would show you the UIs but we are in the only channel on the server (almost) where there is no pictures allowed x)
there are screenshots on each of the links I sent though
You can find personalized models at https://civitai.com or https://huggingface.co to use with WebUI
I recommend to check YuTube how to install WebUi 1st
(people tend to call Automatic1111 WebUI for short too)
AH i see is there a list of which model is best for what task ? Like a model for adobe stock fotos ?
There are a lot of tutorials to do that
I'd recommend installing using actual a1111 docs instead , it's just faster and up to date
https://github.com/AUTOMATIC1111/stable-diffusion-webui#installation-and-running
did those guys in the contest use finetuned tools or what is the most common way to create these amazing pictures ?
not really a list, it's a big thing that keeps on growing more every day.
But lots of people on this discord share recommendations around.
personally, my prefered model is RealBiter https://civitai.com/models/16592/realbiter
but I would also recommend https://civitai.com/models/4201/realistic-vision-v20 or https://civitai.com/models/4823/deliberate. but there are tons
Most of us did
and to create a good img you just need to experiment with prompts and find the good ones
You can always check https://prompthero.com for prompt help
I used 3 different models in the making of my picture. <#🚀|pow-discussion message>
but I use complicated things
WebUI is a lot simpler
Do we have new "stable" a1111 version btw?
Wasn't updating since it was broken
ah so you use multiple models and attempts each changing the pic a little bit ? Waht prompts did u use for that ?
a different tool ?
it seems to work yeah. all extensions seem to have caught up, it works ok for me and it was a "go go go" in #🤝|tech-support recently on that subject
comfyUI, one of the 3 I linked.
You don't just really have a prompt, you wire nodes to build your image pipeline.
In some of those nodes you can put prompts ^^
https://cdn.discordapp.com/attachments/1023999264885588089/1093530677061898320/image.png
the complete configuration is given around there : #🚀|pow-discussion message
did you black out the prompts in those brackets or how does it work without words^^ ?
"SDArt phol, an abstract close up of a cup of coffee filled with music,synesthesia sensory,anime line art, epic splash art, abstract,surrealism, highest quality, 8k"
" elem flowers, air, an abstract close up of a cup of coffee filled with music,synesthesia sensory, ((music) note), chocolate, honney, swirling smells, music, sounds, smooth delicate texture, soft fur, delicate, exquisite, superb golden engravings,anime line art, epic splash art, abstract,surrealism, highest quality, 8k, spiritual, food texture, lettuce leaf, tomatoes, pickles, delicious, appetizing"
close up of a cup of coffee filled with music,synesthesia sensory, (music note), chocolate, honney, swirling smells, music, sounds, smooth delicate texture, soft fur, delicate, exquisite,epic splash art, splash paint, abstract,surrealism, highest quality, 8k
those where the 3 prompts
I didn"t black them out, they appear when I zoom, I just unzoomed to have a complete screenshot
the 2 first prompts are specificaly crafted for the models I was using
like the "phol" is a specific token that makes artistic cups
"elem" ? does it work better then elemental?
or it it specifically on your model?
same, it was trained on elem
do you know exactly what words has what impact or is it a bit random what outcome u will get and u just decide at some point of trying around when its enough ^^ ?
for those 2 first prompt, I know for some specific tokens, because I trained models on those specific tokens
but the rest is try and retry and experience, and understanding what works and what doesn't in your model
this changes per model
for example, SD 1.5 and 2.1 don't respond the same to the same words
so with dreamstudio it would just become very expensive if i just tried it out all day long ^^ do you know especially on dreamstudio if I chose a style if any prompts for the style of the picture are still needed or even usefull ? Like there existing styles like digital painting that u can chose
could u say 2.1 is better than 1.5 or just different ?
I can recommend https://playgroundai.com if you want to play with images and check if you want to go further in
does it use the same models as dreamstudio for free or whats the catch with it ?
you wouldn't be able to dreambooth on 6GB VRAM I think, even all day long ^^ but there are lots of good models to take out there, or if you need to just train 1 or 2, you can do it for free in google colab too.
I'm not sure how the styles on Dreamstudio are done. it could be through prompts addition, it could be through post processing or other type of conditioning, I can't say really, outside of testing
it's different. I prefer 2.1 results, but I have a lot harder time to train 2.1 models, so I tend to stick to 1.5
Lots of people never made the switch to 2.1 because 1.5 training scene really blew up. there are some really really good and aesthetics models out there for almost anything now on 1.5, and like I explained earlier, it's not directly compatible with 2.1 models. going to 2.1 is a little like a "clean slate" for all the trainers that merge models
training my own models is a whole diferent science ^^ i just want to learn how to use the existing ones for now , so far my results are not what I want to have
It uses basic SD 1.5 and 2.1 + Dall-E 2. I have started from using this one so I could check how things work with the prompt thing and all
do you have to traing 2.1 models or could u achieve those contest winning art just with the dreamstudio defualt 2.1 ?
and its for free or why is it better than dreamstudio ?
It's free and you can generate 1k images per day
I don't have to train, I love to train. And those models I train are with the community art, and for the community, I share them each time.
Most people don't train, it takes a bigger computer, lots of time, and lots of other knowledge. plus there are really good models already trained out there
Dunno if it's better, never used Dream Studio so I cannot compare
damn no catch ? I like that you can see the prompts of other pictures
dreamstudio u got like 9-25 pics
what size do you do ? I thought it was 1k pictures on the base size (on dreamstudio)
Yeah, it's great for beginners
it depends on the models you use and some other parameter i forgott
does it have some preprocessor as well like midhourney ? the pictures i see on fronpage look verry art heavy allready
It has filters which can change generated images by a lot
You can still edit them tho
but i need my google account :/ ?
Well yeah, you have to register with an email 😄
you'll have to ask them "why they don't do better", but I think the focus of Stability (the one behind DreamStudio, and behind Stable Diffusion tech) is more on developing the new models (XL, 3.0, ...) than focusing on the website, even if the steam on that side seems to change now with that nice line of features for #1084896022368624640
to me it just allow registration with google ^^
Well, I'm already logged in, so did not check 😉
^^ its great to see the prompts as well with the pictures
Yup, you can explore and learn from them
if you like to see prompts and pics, it's not always the best prompts but it's full of ideas to try : https://lexica.art/
oh nice ty
Hello guys
hey there !
welcome around 🙂
it's getting late for me, time to make pictures and share stupid things
How are you there
tired but good, lots of nice new people around today. And you ?
What brings you around here ?
Am just chilling with my friends here in discord while am trying to join stable diffusion discord community after my friend recommend it to me
well,we have DJ cats and waifus by billions, and not afraid to share
it looks really good in here i didn't know that stable diffusion had already a discord community
its just so impressive
it opened with the alpha I think ? I joined when the software just went out in public beta. it's been quite the trip around here, it keeps on moving
hey, I'm getting a weird error when using model 2-1 says "NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check." i've tried ticking the options anyone know whats up with this?

I heard about the software when it got released but not its discord community
#🤝|tech-support will be in a better spot to help you there mate
no i saying from a video
oops is this the right chat for that type of question?
a guy maded a anime with the a.i
ah sorry thanks mate @vast ingot
you've been playing around since then ? trained some things ? what's your history with it :p
corridor crew ?
just made a awesome one where can i show you ^^ ?
yeah look really good
this thing really can make a big change in how animations are maded
some animations can be done in half the normal time
for sure
even just helping on backgrounds already, on stills. it has a problem with temporal consistency though, details tend to change, frame to frame
for now
Oh I didnt see that one, looks cool!
yeah but mading 70% of the work is aready insane
they can just fix the problems
still really less time
https://www.youtube.com/watch?v=GVT3WUa-48Y
this is the not comparison version, better for just the spectacle
I've tried Midjourney's bot and DALL-E's but I've never got the opportunity to try stable diffusion, cuz I don't know what configs it needs to run in my pc , but my friends are telling me that it's quite good
the most easiest way to run it is to have an NVIDIA card with 6GB VRAM.
It runs down to 4, and you get more fun bits around 8 and more though
it also runs on other configs with a little more work sometimes (AMD)
Alright then i've been kinda confused with this
it would be a lot good if it existed a discord bot for stable diffusion with some options to modify on
there has been at some times, but not currently on this discord.
there are some ways to access for free, but we don't provide a bot for it yeah
I'm excited about all this, but hard to say where it's going. and it's going there faster and faster.
like my most recent workflow runs a GPT like at home and creates prompt dynamicaly, feeds them to SD and makes the pictures
and when I chatted a little too much with it it started say it would break into my house and f me up, so not sure
(true story but lol, just an LLM doing LLM things :p)
lmao
It's just going to blow our minds you know just what happened in avengers with ultron, its really hard to maintain control over something that we never experienced this fast as we all were exited bout this innovation and how it'll simplify our jobs in the future
I'm trying to find the data to prompt it to act as Samantha, the AI in "Her" movie
whats the best way to upscale a 512x512 pic from dreamstudio ?
y we def gonna fuk it up if we didnt fuck it up allready and dont know about it
complicated question, I'm not sure. I upscale while generating but I don't do it on dream studio. #1003034183716835418 may be of more help
where can I share a pic I just made ^^ ?
yes yes you know that when I finished from watching that movie I really went out to google and YouTube searching for a why to build the same as that AI LOL
ye we must do somthin about it we let it we go to hell
I'm not sure where to stop in the movie, because she changes a lot, but the first half of the script should give a lot of examples for some character maybe. never really tried those sorts of things yet
Yeah but it's quite great inspiration for silicon valley's tech companies to build a prototype of that AI
@vast ingot every image i see on that site u send me for prompts lexica art is using the Lexica Aperture v2 model ? Is that the best one for art like that and how would be the easiest way for me to use it ?
can see his artworks
@vast ingot
I'm sorry guys, it's about 1 am and I'm falling asleep right now. i'll need to let you in the hands of others around here
woops a ban first
^^
Kek
hahahaha
top kek

see ya have a good night
👋
exactly
So does it or does it not make a difference?
the image wouldnt be refined with extra steps, so no difference, other than waiting longer
He literally just said it does make a difference, and it does, it's one of the many ways you can get a variation of a source image which is especially good for dreambooth source material
sure, but for a single image its not worth it
Plus, it may stop making a difference after a certain point, but based on what I've seen there are still tiny nuances enough to justify the few extra milliseconds of processing power
If this was karras then yeah I definitely wouldnt bother since that one is slow as balls
I go to 30 steps usually and get nice gens. not much better after that
I am super new to stable diffusion AI but I have seen incredible results that people have made over the past few months. Can anyone tell me how good it is compared to midjourney / Dalle etc.?
it won't stop on euler a. That's whole point of that sampler - it will keep changing - more steps you add.
Nuances aren't tiny, they are pretty huge, I had matrix on each 25 steps.
My point is - with that amount of steps(120), you're just wasting time doing a single image gen, while you are suddenly talking about variations
Stable Diffusion is very different from MJ and Dalle in that it is incredibly customizable. Because SD is open source and available to everyone, developers around the world have been able to create custom user interfaces and implement new technologies to diversify workflows. As far as I'm concerned, stable diffusion is vastly superior to the competition for that reason alone.
Arguments you see in favor / against SD are generally about the ease of use and capabilities of the default models. Midjourney is much, much better if you're not tech-savvy and need a quick way to generate images. Same with Dalle.
SD gives you unparalleled control over your outputs though. It's my personal favorite :V
Who the hell makes a single image of anything? lol
Perhaps my standards are high. For me to get a masterpiece on the first click of a button is just not something I usually expect
My initial message you replied to - was exactly on that - I made a comment on a guy doing single image gen with Euler a on 120 steps.
That is an amazing answer thanks so much
I can't believe this is free tho. Thats the power of communities like this
so if you do 50 images in a batch and all are 120 steps, all 50 wont look any better than if you used 30 steps
"better" is subjective
I do 90 steps about 95% of the time since its the sweet spot for me
I know u can get decent results with low steps but my question is... why?
Im not getting charged for GPU time here lol
I mean...some will be better, some will be worse, they will be just different...
They dont always necessarily change
Sometimes its just extra detail to shadows, skin details etc
And sometimes its a completely different image
It's always different details...some details might be missing , some might be added , some might be changed
I knew this dude who claimed he used 300 steps for his gens lamo
too unpredictable for my taste. you could go over by 1 step and bam its a totally different image
Stick to 90 if u have a decent GPU
I'll stick to my 25 lol
Its not just a random number, thousands of gens of work have led me to that number
maybe to 50 on DMP++ SDE
Yeah only on euler A, all else are too slow to bother
Some of them are about same speed as euler a tho
like DDIM, UNIPC...there were more that's pretty fast
Ive watched enough of Aitrepreneur's videos and boards to know u can't go wrong with Euler A lol
eh...
Its good to have those for variations but it's really more of a luck of the draw than anything
2M karras is actually slightly faster
Ive seen shit euler A gens and ive seen shit karras++ gens, and viceversa
Oh btw. I have a godlike seed for portraits I wanna share as a gift to the community
1755153404
For any other portrait freaks out there, thank me later. That is my golden seed
ai
there has to be some coherence. The model I used is a blend of popular models like vision etc
i use this server as a meme server
try using "cyberpunk background", high quality, fujifilm XT3 and ur guaranteed a good result



but...my demon girls
wut
i licked my finger
We have cows , cats, cow girls , cat girls...and my thing - demon girls 😄
okaaaayyyy...


Hey guys! Sorry if this sis not the place but looking for some help with Automatic, everytime I try to cope the ip URL to launch the UI it crashes.
more context?
Is A1111 ever updated anymore?
A few UI restarts fixed the issue but when Im generating img2img I get this: A tensor with all NaNs was produced in VAE. This could be because there's not enough precision to represent the picture. Try adding --no-half-vae commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
Where would I do that?
right click the .bat file that u start up a1111 with and edit it
Howdy! I haven't tried this, but on 6gb of vram (assuming a 1060 or equivalent) you're looking at about a minute per 512x512 image. Multiplied by 24fps, and a 3 minute video, it could easily take your system 3 days to crank out all those frames.
Just my rough estimates. I primarily do txt-img and img-img.
GM all -- seeking SD artists and prompt engineers
@robust frost GM! For general advice or a related project?
Both ser. We're switching out Neural Love (not delivering such consistent results) for SD. So baptism of fire.
Roadmap
- trial a web based API to SD
- integrate into our project
- implement an instance ourselves asap in the cloud.
my macbook GPU is 2gb and old 😦
https://www.twitter.com/dallepunkz
Anyone with experience of coreml stable diffusion on macOS?
that seems like a nice project. you should create a post in #1092446741984444416 !
How to inpaint and generate supersampled photos?
Well, you definitely don't want to run gens on your laptop. As for getting computer hardware that can run sd, I recommend services like google collab or runpod. Further than those recommendations I don't think I can help.
Thanks I will ask there
Oh hey, OK -- ill check this thread and write a super quick description!
Many thanks!
Top tier? 137/900k, 4090, 32/64/96gb ddr5 at 6ghz+, several TB of nvme ssds...
You can spend between 2 and 5 grand (usd) on a rig like that.
it's where you may get the most visibility medium/long term. it's still quite new, but we try to direct all community projects there now
Heck, the 4090 alone is 2 grand. It'd be between 3.5-5 grand.
Oh that bites
Portability i guess
Ok great thanks - so we boot an instance in the cloud and then connect to it - is all art generated via a GUI?
Looking for a rest / API based service to the SD instance running.
Will check these services and read some docs! Thanks again.
NL has a simple web based API, looking for equivalent to make the switch painless
Ok makes sense, will head over to this channel 🙂 thanks!
Afaik its all gui-based. Not sure how to go the api route and derivate instances out.
OK, assumption is - if you run your own instance on your own kit you can set it up however you want.
but for now -- its GUI based
@uncut junco the rig I mentioned is prosumer territory. If you were looking for industrial power, you're headed the route of A100s. Orders of magnitude more expensive 
Check out workstation GPUs ? Teslas ?
A single A100 gpu has 40 or 80gb of vram and costs tens of thousands of dollars.
The 4090 is rock solid, I run one regularly and am quite content.
Maybe wait for 50 series to launch
Early leaks say 2.x gains over 40 series
the ADA Titan will have 48gb
How long does it take to generate a photo of 50 iterations size of 512*512 for you?
Not more than 2 or 3 seconds.
one 512 ? should be less. but yeah. FAST
^
Depends on sampler and cfg. For testing I run euler a at 25 steps
Pretty standard
@vast ingot Gm .. just DMd re community-projects channel
https://imgur.com/wNJpM05 my 4080 speeds
At batch size 8, euler A, 512x512, I get 6it/s. That's effectively 48it/s per image.
sd is optimized for cuda
Any going to Stability AI London meetup?
https://london.meetup.wandb.events/
thats about right. my 4080 is bottlenecked by shitty ddr4 dimms i haven't upgraded yet
Im pretty happy with my laptop 2060 for SD, it not the fastest but its fine, it can do up to like 1300x1300 or so resolution which is fine most of the time. If i need anything better i just spin up a webui on colab or kaggle. Obviously if you can buy a better gpu that will be a much nicer experience.
you should have about 80-90% over me with a 4090
but you're more than double right now as expected
here i am, sloggin away with 2 second gens

{kind=link}
{kind=link}
I’m waiting for better performance coming to my Mac since they are improving the core ml implementation
think of all the poor souls generating images on free stable diffusion websites
i might buy a macbook for the first time ever. because its a good portable ML box now a days
hires fix is a 2nd resolution increase pass. its slower usually
Highres fix is its own category of speed test.
For finding your base numbers, run w/o it
HF is more-demanding, not less so.
my hires pass speeds suck right now. it pauses for seconds before it starts the next pass. like sometimes 20 seconds
Whats your it/s look like
bruuuh i only get like 3.9it/s its good enough but damm i want a fat gpu
Iterations per second. It/s. It shows in the cmd window.
/hugs my fat gpu. these adas are the fattest ive ever seen
4.5it/s ?
Ada Lovelace always been my favorite computer scientist too
4.5 sounds about right for a 3060 anyways
Child of Lord Byron, her mother hated that he was a rockstar sexy poet that left all the time. so she kept her out of arts and gave her nothing but math an science education.
She flexed that by translating papers, including the difference engine, and wrote programs for it
fun facts
man im just waiting for amd to make a gpu decent at stable diffusion
yeah but its still not close on price to perf
I mean, I'd have to run the specific test you ran. You did like 50 images.
Generate 1 image at 512x512, euler A, 25 steps
he did say he got like 48it/s, thats like 10x faster, 24 seconds. obviously benchmarking it would be more accurate.
launching my UI now 
Time taken: 1.24sTorch active/reserved: 2618/3054 MiB, Sys VRAM: 5162/24564 MiB (21.01%)```well thats only batch size 1 tho
Here's batch size of 8, so 8 images at a time:
Time taken: 6.31sTorch active/reserved: 3140/3478 MiB, Sys VRAM: 6180/24564 MiB (25.16%)```6.3s
0.78 seconds per image :V
yo when we gonna get 60fps stable diffusion gaming
literally
it mostly shines in training and in making big pictures, the difference. because I also do around 0.95s per picture, but you don't really need more speed on those 512
a customizable stable diffusion img2img shader that can run over games would actually be amazing
I can run a 3840x2160 gen and see how long it takes 🙂
bro please stop im dying over here
I think an engine that generates more detailed meshes and textures as you get closer, storing locally so many layers of different distance models, that would be awesome
isnt that just nanite
not sure ?
3840x2160. 8.3 million pixels.
Time taken: 1m 46.76sTorch active/reserved: 19346/22462 MiB, Sys VRAM: 24564/24564 MiB (100.0%)```50 years? bro in a decade we will all be jobless
I was meaning like diffusing more than what the devs initially made
https://www.youtube.com/watch?v=yF1bZiH-wJQ stadia had done this
yeah this is cool
thats exactly what the new unreal engine 5's nanite is all about
ohhh. that'll plug into nanite like systems very easily likely
i mean yeah if you have a highly skilled job you are safer, but nobody is safe. and 10 years is a long time in AI development nowadays. id give it a good 50/50 that ai will do your job better than you could by then.
there's a simpsons episode about this isn't there? where the truckers have all been using ai driving the whole time
yep 🙂 I can just imagine all those higher res of just nothing really interesting, like food on a plate in a tavern, or the detailed mesh of a cup on the counter. And if you just want to focus on something, no more "blurry texture" or "polygons the size of the screen", past a certain threshold, more of those get made on the fly
Now the chat gpt is exactly what is depicted in the terminator movie
I mean the skynet thing
I can see where its going
lol chatgpt isn't whats in terminator
i mean nobody really knows what the future is gonna be like at ALL, im really scared of what its gonna look like.
skynet in terminator 1 was described as a military strategy system. if anything wargames was the closest real depiction of early skynet
Hi. (sorry very new I think I posted, but can not find my post anywhere..) I want to start editing some of the frames that are generated on stable diffusion. And I understand that how to do this is through img2img and inpaint. I was looking at tutorials. But do I enter img2img through a stable diffusion notebook? or how would I do it? I am using Colab. Thanks!
lol were not gonna get nuked by AI. but what happens when we cant do anything better than an AI can. When people can no longer contribute to the economy how can people guarantee that they live a good life.
also, skynet was brought online and launched every missile seconds after it got self awareness. portal parodies this quite well
Yeah I do think there is still some time before we cut the human part out of truck driving, but it may come faster than we know
Yeah, my local untamed chatGPT does threaten me too when it bugs. I don't really care, it's just a language system that is tripping balls for a second. it's still new and in development
But when will it be good enough ? the thing is, since it's a self improving tech, it's starting to go faster and faster, it refactors its own code or at least helps with that fact, and it gets more efficient on an exponential curve.
So it's really hard to predict where the curve will slow down. From what we see, it's just speeding up every day currently
wait you can download gpt4?
I do like the gpt4-x-alpaca-13b-native-4bit-128g
Aitrepreneur - Uncensored GPT4 x Alpaca
yo what
got it running and it's impressive
imma pick it up right tf now :DDD
oobagooba as a webui to run it is really good too
it's just missing the ability to look up the internet for now
wait hahahha i tried gpt4all yesterday and was unimpressed, i didnt realize it was actually gpt4
chatgpt4 can write nice code but it also writes really error prone code. it learned from github after all. i doubt they're using it to write model code
it's not GPT4. it's alpaca model, fine tuned using answers from GPT4
oh i see, didnt read closely enough
yes but it can run an agent that tests code, gives feedback and asks the first agent to fix it, until the specs are correct
I think now the problem with the current gpt is it doesn’t know if what he’s saying is correct or not
alpaca got some ways to go. theres some neat looking llama projects too. could be useful but i dont think we'll see openai levels there. just neat home user toolsets if you use them right
Sometimes he will say something with great confidence but actually it’s wrong
Also check out AutoGPT. It is crazy neat - you just need an API key if you want to use gpt4.
thing is just like stable diffusion the way LLM's can be used is HIGHLY customizable, we are only just starting to see what these models are actually capable of.
How i make a porno on the ai
sigh
You should ping one of the community mods, they will tell you how you can achieve this
just go to #1045349359044280360 and type the prompt in chat, an image will be generated. jk this wont work.
^
 #✍🏼|rules-and-tos
#✍🏼|rules-and-tos
this is not the discord to ask for this
stable diffusion or?
or?
follow the guides for a normal sd setup. then do ur own research from there lol
or what ? I mean this is the official discord and as much as we can help make animations and things like that, it's a purely SFW discord and we won't be letting tips about making porn just be traded here. other discords and PMs are here for that
but you can learn all the bases for what you need here for sure
try midjourney
lmao
just keep it tame and find the good resources you'll need to achieve your end goal
now we've all generated bags of sand now and then but really guys, guys, come on
now and then?
I don't like sand
it's course and rough and irritating
and It gets everywhere
Everywhere
makes neat computer chips tho
🤔
does it also install all the python crap, anaconda/extra copy of pytorch/etc?
yep
ugh i hate python packages
it's about the same requirements almost
i saw automatic has a new optimziation if you install pytorch 2, thats faster than xformers
damn i got no free space left, all my hdd(s) filled with SD models 😐
if you have auto running you may have already all you need, it will just make its 5GB venv on the install part
yes please download 20gb worth of packages, oops the versions dont match up haha have fun
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Optimizations --opt-sdp-no-mem-attention