#Reverse geocoding remote locations
1 messages · Page 2 of 1
Makes sense I guess as it'll make the queries much faster for them
Doesn't really help me though 🤣
I do wonder if this ranking thing is only a problem in major cities
In London the results are much more reasonable
Maybe I shouldn't be just keeping administrative boundaries, hmmm
Time to load up all the data again because it went missing when I rebooted my server 🤣
So it seems to me that the way notanim does this is they have both the administrative zones and the other place data, then they prioritise one over the other if the search ranking is the same
I’m really happy about that! I use the geocoded location a lot for filtering and just for remembering trips we had.
So I’m happy that I got the ball rolling and you can dedicate time for this!!
yea I also use it a lot
How much storage do you need to load North America? I want to download it and take a look as well 🙂
My 30GB available docker space wasn’t enough 😄
I think that should be big enough, hmmmm
North america is 14.5GB for the download
Not sure what it is after ingest
Yeah it failed during ingest… I’ll just increase the size to a lot more lmao
Alright, I think a good middleground to this is going to be what I suggested before
Lets build our own mapping from administrative zones to
- city_block
- suburb
- city_district
- city
- state
- region
- country
That's what notanim has it seems
Not all countries will have that, but if that's what we store internally we should be able to have a mapping for most places to that or some subset of it
For display we will de-duplicate the string, so if any components are the same, they won't appear twice
Sounds good
I wonder if chat gpt can do this for us lol
It probably has a better understanding of those terms than I do 🤣
Can 4o access the internet?
Ah I think only if you pay, right?
Duckduckgo has something afaik lol
Using 4o but without an account?
Never used it lol, just saw it somewhere
You can use 4o on chatgpt without an account
But I think it doesn't have internet access
Ah I see

Just use the immich ML! /s
If you want to be mean ping mert lolololol
I think I will need it in JSON and then ask ChatGPT to deal with it 😛
Boet > chatgpt change my mind
Glad to see that you're dealing with it 😛
Slowly getting better lol

Of course south korea has to be awkward with two definitions for the administration zones
Dammit lol


I'm kind of leaning more towards your idea now tbh @wanton ibex lol
Just store a tiered list without particular associations
:P
And then we just make displaying that nicely on the frontend Alex's problem right?
Well I think it should be reasonably easy tbh
Just display all the fields, in reverse admin level order, deduplicating any sections that repeat themselves

I mean, you can just display the highest level as that top one
Basically, looking at the OSM list
I don't see a good way to reliably get the information from there
Take afghanistan for example
They only list 2 admin levels with any relevance
But if you check their capital, that exists in admin level 7
(they only list levels 4 and 5)
Dang
A lot of them are just "proposed"
I just feel we will cut off a lot of data doing it this way
yeah indeed
I feel like anything that relies on some understanding of the meaning of each level is bound to mess up :P
This does again just massively increase the scope of this change though lmao
Now we're into search changes, UI changes for assets 🤣
I guess I will go into a hole for a couple weeks
😅
Right, well, going to try and get all the data re-imported again, this time with english locale 😛
I think for the first pass, everything will be english where translations exists
I need to limit the scope somewhere lmao
With the plain list approach, how do we handle the places view?
This is just a bottomless pit of scope lmao
Hmmm
I mean you could just have the lowest level and the highest level or something
Personally I don't know if the places view is even very useful right now 😛
It's already a bit of a mix of what you get
Though also probably just showing every level is also reasonable 🤷♂️
Could just show it for places with > X photos
Nested would be neat too, but scope creep goes brrrr 😛
Yea, nested could also work
I'm waiting for europe to re-import
Then I am going to run the nesting processor on that data and see what it gives me
Ideally having nesting on the reverse geocoding data directly would be the best option
If you want we can spin up that db on mich and load all of the everything into it, then take a snapshot
Yea maybe, might be better than doing it on my server lol
I realised yesterday it backed up like 100GB of OSM files to my backup servers lmao
Oof 😅
So.....
Impacts of improved geocoding
- Nested location structure instead of city, state, country
- Search will need to handle this nesting
- Places will need to handle this nesting
- Asset view will need to display nested string correctly
Do we write up an epic at this point? /hj
lmao
It’ll be tricky to search by city and state if there’s no consistency in admin levels
Do you wanna take a quick look at https://github.com/immich-app/devtools/pull/72 while I add a node port to that so you can access it, and then we can let it populate overnight & get a snapshot tomorrow?
I'm thinking we just drop those search fields
And have just one with typeahead
Yea, just have one field that sorts by match and then admin level
So more specific results showup first
This is what notanim and OSM do
I was thinking about that yeah. It’d be easier if we didn’t need to care whether it’s a city. Getting good autocomplete for that will be its own rabbithole though
Probably won't be toooooo bad
What if you want to search by a state or country that shares the name of a city somewhere else? It might not show up in the dropdown
@gray plover I can easily up the database volume size by quite a lot, the 100G was just a somewhat arbitrary pick, so if you want a higher number lmk
Yea idk, it's probably fine for our initial stuff, but once we're ingesting everything on repeat and maybe with multiple languages, it may be pushing it
Maybe go for 250GiB?
It’s kinda the opposite situation with the location search for adding a location. There we can let the user type more to get the specific result they want and more specific = more good. But for normal search specific can be worse
We could maybe partition the drop down so it shows different admin levels
We could, but also that'll likely mean nothing to a user
It doesn't mean a whole lot to me lol
Idk I’m just spitballing here
Yea
It's a difficult problem
It's kind of annoying that boundaries don't have some hint of what they are on them tbh
There's other data types for these type of zones, but then our data size will balloon massively
The solution is to manually sift through each row and tag it as a city or state /s
It's only 800k
@gray plover can you merge the db PR? I'll let you know when it's up and then you can start throwing stuff at it whenever
Done
Cluster.postgresql.cnpg.io "geocoding-database" is invalid: [spec.postgresql.parameters.full_page_writes: Invalid value: "off": Can't set fixed configuration parameter, spec.postgresql.parameters.wal_level: Invalid value: "minimal": Can't set fixed configuration parameter]
Damnit lmao
lmao
Just need to drop those params I think
cnpg won't let you set them?
Yeah they have a few params that are controlled by the operator
For WAL streaming backup stuff etc to work
Should I drop the other wal params as well?
No those help speed things up
oki
So North America wanted more than 100GB during import, so I moved to Australia
👀
You're using pgosm-flex?
Yeah
Tbf I haven't really been keeping an eye on that stuff, but that seems insane
Looking at the DB, I see that the place_polygon has the osm_type field, which has values such as city, town, village, municipality, etc... I believe each one has a corresponding polygon
Could we use those? Just filter on the types we care about
Or am I totally missing something?
The problem is those don't exist everywhere and we'll end up with duplicates
Basically we want to just use administrative zones
And those don't include those fields sadly
I've been considering if we could map between them somehow to include that extra information, but it'd probably be extremely unreliable
Ahh I see... Well that does complicate things
Yeah I was wondering the same. Some sort of join with cities500, or a larger DB which will have the info
I'm going to see what happens with this nested stuff
And keep only those entries
It's possible that we could pull that information out once that nesting is built
I was meaning joining the OSM data with itself
So like join the administrative entry with the city entry if they overlap and share the same name
Alright @gray plover db is up
I'm still waiting for europe to re-import 😛
Neat, I might not start imports tonight, I will have to see
Whenver you want
Throw the creds in 1password though and I might get round to it
Creds are already there
👍
Just ping me whenever you've loaded it up and I'll snapshot it, after that you can destroy it to your hearts content
Alternatively if there's a simple script call you have for loading it, I can put that in a kubernetes Job and it'll just chug away on its own
I don't have a script yet but I was planning to make one
Then I can just set it to import all countries and forget about it
👍
I s2g this is the sorta stuff people spend entire lives trying to understand
There are tons of research papers on this kind of thing
So in the OSM data, Paris boundary is related to the Paris POI, which is labelled as a city
Perhaps if those relations exist in the pgosm-flex export, I could do a similar thing
Tomorrows problem now 🤣
Nice! I wonder if smaller cities and towns will also have such POI
Not everywhere is Paris 😄
I'd expect there to be at least the places we already have in the geonames data rn
So I think the way this should work is
administrative zone should have an "admin_centre"
And the admin_centre should have a place tag
Perfect
I think that applies for cities and towns, but not necessarily for state level stuff
But even my reasonably small town has that
So does my parents even smaller village
I'll try to figure out how tf I would join all that tomorrow lmao
New Zealand is an an example of a country we could have an issue with.
Admin boundaries are only until the district level 😦
So for towns we could have issues
Currently this maps in Immich to the town of Oamaru, but not here…
pgosm=# SELECT osm_id, osm_type, admin_level, name
FROM osm.place_polygon
WHERE ST_Intersects(geom, ST_Point(170.9704, -45.1251, 4326));
-4420809 | boundary | 6 | Waitaki District
-15954189 | boundary | | Pacific/Auckland timezone
-556706 | boundary | 2 | New Zealand / Aotearoa
-3986157 | island | | South Island / Te Waipounamu
-1640138 | boundary | 4 | Otago
Browsing in OSM it looks like the towns are “Node”, not how to get those in pgosm flex
And they probably won’t have polygons
Hmmmm, I mean yea, we'll probably have places where there is missing data
I agree nothing will be perfect, and that’s okay.
But this would be a whole country missing city and town level mappings
I’m checking out the documentation to see if there are more like this
Yea but that's a point, not a polygon
Is there a POI for Oamaru?
Can we get the polygon and then the closest POI inside that?
Yea there is a point
That requires
1.) always searching for a poi
2.) storing those
That'll be substantially slower than the current search we are doing
From a Quick Look at the country admin level docs seems that New Zealand is an exception and most do have city/town admin levels
Yea so notanim calculate the spherical distance to that point
And as it's closest they assume that is the location
So like a special case for certain countries? Cause* it’s admin level 6
For some countries that would be a town
Damn this dynamic leveling is tough
Yea....
Idk what the solution to that is really
It's potentially worth us including all the "place" boundaries too
In OSM those are lower level boundaries that can't be verified as administrative
So for new zealand you could potentially resolve this by updating the data to add place polygons for the places that are missing them
OpenStreetMap
OpenStreetMap is a map of the world, created by people like you and free to use under an open license.
Like for example this place
No administrative boundary, but has a place boundary
There are 4k of those in europe
How much more data is it if we include these?
I doubt it's much
Are these exported in pgosm? Would it have shown in the query I did on osm.place_polygons ?
We're at 850k ish total
Yes, new zealand doesn't have those
It was kinda unrelated to that 😛
Ahhh okay!
I focused on NZ cause we traveled there lately and I was wondering how much of an improvement we’d get! Was surprised to see it would be otherwise 😄
Any help is more than welcome! The whole world is a lot of places to check 🤣
So true lmao
I'm not really sure what to do wrt NZ though right now 😛
If we could somehow “know” there’s an issue we could fall back to some sort of point geocoding (cities500 or osm)
But due to the admin levels being different I don’t see how
I mean, if we know there's an issue we could pull in the points data from OSM for that place/country
I don't have NZ in my dataset right now
But what do you get back?
How many with boundary=administrative?
Say city is a KM. If we get polygons which is 3a we map using cities500 or osm points
a is a variable, sorry for choosing a bad name lol
Yeah I get that
I would kind of prefer to just figure out a solution for NZ, then wait for reports for issues with other places
Fixing NZ may literally just be telling people to go add polygons for those areas lol
Is this what you were thinking?
SELECT COUNT(*) FROM osm.place_polygon_nested WHERE 'New Zealand / Aotearoa'=ANY(name_path) AND osm_type = 'boundary' AND admin_level IS NOT NULL;
151
Used nested as there’s Australia and such in the DB as well
The boundary column will just say 'administrative' for those
non administrative boundaries can have admin levels 😛
Really the question is, do we prefer accuracy over returning more data
We could probably include the POIs for all cities/towns/villages in our data with not a huge amount of increased data
However then how and when do we match against those
And what distance do we decide is acceptable?
The problem I envision is something like this
You are stood outside of a city, but not in any other administrative zone
So the lowest level info is the state boundary
We detect that (somehow) and then decide to match by closest point
So we find that city we originally correctly identified you as outside of, and then place you inside it instead
Personally that sounds good to me. I’d take more data over perfect accuracy.
I’d rather have the closest populated place than a huge district
But limited to some distance from the populated place, similarly to current code
Now I get 160, but a few have no name so that’s not ideal
SELECT COUNT(*)
FROM osm.place_polygon
WHERE ST_Intersects(geom, (SELECT geom FROM osm.place_polygon WHERE osm_id=-556706)) AND boundary='administrative';
Right, but then just use geonames lol
And whack up the distance
The ugly intersection is to limit New Zealand
I'd prefer if I am not in a city in 90% of the world that has correct zones, it doesn't match a city I am not in
Like, the whole point of these changes is to make everything more accurate
This is was my initial plan when starting all this 😄
I don't want to nerf that accuracy in order to account for a small amount of places that don't have polygons
IMO we just special case areas where we know this is the case like NZ
I'm honesly tempted for the solution to this to be "Go add the bounding area to OSM"
If we can master the “somehow” you mention, then we won’t affect those
Theoretically
I'm absolutely down with this being one of the answers we give
But if we have a whole country that we can handle with a special case (maybe we can do the case upfront in the processing somehow) then IMO that's also fair
True, but if there are more countries like this it could escalate
If it escalates we can always fallback to saying go fix the data
nice
I was going to see how long it takes but we could even do it daily 😛
Like realistically incremental updates should be pretty fast
My current plan is something like this, though this is only in my head
Data processing runs daily and computes the diff between yesterday and today
It publishes SQL scripts to update the data in your DB since the last run
It also publishes full dumps so you can start from any day
These will live in github releases and we will publish a manifest file onto cloudflare pages that instances can request to get details on if a new dataset is available, size, stuff like that
Then they can calculate what downloads they need to grab and apply to get back to "live"
Sounds good!
If we do want to support NZ better we could add this dataset:
https://data.linz.govt.nz/layer/113764-nz-suburbs-and-localities/

NZ Suburbs and Localities describes the spatial extent and name of communities in urban areas (suburbs) and rural areas (localities) for navigation and...
Okay so the euro football match ended, meaning I’m off for the night 🙂
Who did you want to win? 😛
Yea we could absolutely just take the NZ dataset
I'm happy to monkeypatch datasets together as long as they're polygons 😛
Germany but that’s not happening 😛
This being directly from NZ land registry is great
Yeah and seems to be updating as well
Their export tool is pretty extensive too lol
Ooh shiny
Why isn't that getting piped into osm though?
Probably politics lmao
Not sure if osm has ocean data as well. If not we’d to monkey patch that as well
OSM has ocean data
Just haven't looked at it yet
That’s good
one subsection of the rabbit crater at a time
Totally!
Let's do the same for that nz data, let's just validate if it's usable and if so leave adding it in for later
Yea for sure
Didn't touch this today, but needed to give myself a break from all of this lmao
Will be back to it tomorrow 🙂
Yeah very understandable lol, no worries
Well deserved 🙂
So... todays learnings are that place_polygon_nested appears to automatically remove everything that isn't relevant anyway, so we can just use that as our filtering method
I'm currently trying to get tags imported to see how I can link those together
I probably should've done this on a dataset other than europe 🤣
Sweet
The downside is it took my machine a day to process those lmao
I'm not sure why... their docs say it shouldn't take anything like that long
The docs only have timings for NA, wasn't Europe quite a bit more complex than that?
All I'm reading here is "I need to buy new hardware" 🙂
I think you're running similar specs to Mich right Zack? What sort of disk do you have pg on?
Mich has mirrored nvme, that might be quicker?
It's not even that, idk why it was so slow
This is mirrored NVMe but BTRFS
hmm gotcha
But I doubt it's making that much of a difference

👀

Tags finished loading earlier
You have to load them along with the place data for it to load all the relevant tags
I only had 129 million when I loaded them alone 😄
So after importing a bunch more data, and comparing it all...
It appears that the admin_centre members don't get linked with pgosm-flex
Idk if this is a bug with their implementation or not, because the admin_centre exists in place_point table, but does not exist in the member_ids column of the place_polygon table
Pretty annoying
Dang
I'm tempted to attempt doing a full Nominatim import and see whether the data from that would be more useful
Were the SSDs on Mich 1TB or 2TB @wanton ibex ?
IIRC 2, I'll check
Might just get a full planet install rolling so we can at least start to take a look at what data exists in there
About 1.6T of disk space available
Alternatively Night might have a full planet sitting around you can get access to
True, let me ask
Worst case I can still use pgosm-flex, we just can't get those name tags
So for australia_oceania, it took like 10-15 minutes to import the file from like a week ago
Then like 10 seconds to process the updates since then 😅
Pretty great
Is admin_center a tag which can be found under place?
Similarly to village, town and such?
admin_centre is a type of node
Which then has a place tag on it, which indicates what type of place it is
Sometimes those places tags exist directly on the boundary, but it seems quite often they don't
Ah okay
I’ve been taking a look at importing directly using osm2pgsql instead
Seems to load it all, creating tables for point, line and polygons… so not more useful than using flex
What do you think about merging my PR for the next release?
Seems like using osm could take some time
In the meantime the PR could reverse geocode, and then we could drop the data and replace the code
Then when metadata refresh is run it would replace with osm geocoded locations, no harm done
Yea, if we are gearing up to another release I will get that merged, do not worry 🙂
If any change is needed please let me know!
So, deeper into this rabbit hole we go 🤣
So now I believe that OSM is actually pulling the data for what type of place it is from multiple places
Lots of these entries have wikidata links, which have "instance of: town" and such in there
We may need to pull that data and infer the type of place from that
So I think the ideal structure would be
1.) Check for place tag directly on the relation
2.) Check for admin_centre with place tag
3.) Check wikidata for instanceof with a filter for certain types
And we just do that in the preprocessing and spit out a single value right?
Yea exactly
Sounds great
God I have to actually write all this at some point 😅
I think it might be cool to actually include the wikidata link potentially
There's so much cool data in there
All as stored procedures right? :D
WTF TIL you can actually write those in a whole bunch of languages https://wiki.postgresql.org/wiki/PL_Matrix
Turns out that the nominatim wiki export includes the instance_of parameter
As a reference to the wikidata article

type of ecclesiastical subdivision of a diocese
So like it'll reference this
Annnnddddddddd the data ALSO includes that reference, with all the languages for that too
Damn lol
Feels like I'm finally nearing the end of how we get all the data we need lmao
Need to get an ingestion pipeline setup for this at least locally, and then find how many places don't have a designation after that ingestion is done
Hopefully won't be that many
I'm thinking Nominatim might be the way to go though, depending what data they have in there
I think they pre-compute all the address rank stuff
So we can basically leverage that for everything we need
So we just spin up a full nominatim instance and then pull our output from there?
Might just be generally simpler than trying to monky patch everything together
Yea that's what I am thinking
Sounds reasonable
Would you mind throwing together a second postgres instance with all the required extensions so I can get an import going? 😛
Does the existing one not have everything needed?
No it has a bunch of random requirements it seems
Other than disk space allocation ofc but that's an easy fix

Actually, I am not sure how many of those are postgres extensions
And how many just normal requirements lol
They don't have a seperate list
afaik, only postgis is lol
Alright, fair enough 🤣
fwiw I think this should fit on mich but only just about lol

If we go prod with it we might wanna consider asking Thomas for a beefier box
Yea, we could probably spec something to live over in the "DC"
Though, this import should realistically fit on Mich
It's not supposed to be more than 1TB
It should, yeah, it's just gonna be getting close to full
We really using like 500GB already? 👀
No :P
I also mean in terms of ram etc
Unless nominatim really calms down after ingest?
I'd imagine RAM usage for this will be pretty minimal after ingest
Also we can just shut this down between ingest cycles if we need to
FWIW you can run this on like 2GB of RAM 😛
That's the "minimum"
They want 64GB minimum for a full planet import
But again, I imagine this will be just the stuff that happens during import, I would expect updates to be much less intensive too
Cool cool
Alright, going to go finish taking lunch lol, then will look at getting an ingest started
Job execution time - Each job in a workflow can run for up to 5 days of execution time. If a job reaches this limit, the job is terminated and fails to complete.
Workflow run time - Each workflow run is limited to 35 days. If a workflow run reaches this limit, the workflow run is cancelled. This period includes execution duration, and time spent on waiting and approval.
So we can totally run this through GHA 🤣
😂
Did you want me to apply these tunes?
Yea, please
Did just find this, as a side note 😛
I guess that'd be annoying with k8s probably lol
That's a thing that runs the ingest? Or does it also embed pg?
I think it does everything
Getting to use the cnpg-run cluster is nice cause then we can easily do snapshots and such if we want
Other than that though, spinning up some random container is really nbd
Idk if we'll be doing snapshots of this tbh
We'd then have to store those 1TB snapshots lol
It's running on zfs so the snapshot shouldn't take any extra space
idk if we need them for prod but I figured at least right now it'd be a good idea to snap after you do the whole import
Are you sure that applies with postgres data?
I mean the operator literally just takes a volume snapshot
So idk how it couldn't :P
I mean going forwards
Ofc immediately it'll be no extra data
But once we update, idk how postgres modifies that data on disk
I'd expect most of it should stay put
At least enough to not be an issue during dev right now
Side note, apparently on zfs we should always have full_page_writes turned off
Better for performance and ZFS doesn't need it
Looking to run Postgres on ZFS? I've gathered some of the information and sage advice out there to give you a head start on figuring out how to do it safely and efficiently.
A fun read if you want it 😛
🫡
Might be worth going through that and setting a bunch of the tunable stuff up
If you're willing 😛
I'm too lazy :') But feel free to throw specific ones you want set at me (or just add them yourself)
Is it possible to tune the zfs volume from the k8s config?
That I don't think so I'm afraid

fancy
@gray plover can you approve https://github.com/immich-app/devtools/pull/85 and then after the volume resizes I'll (try to) enable lz4 on it
Oh huh
Apparently zstd compress is already on
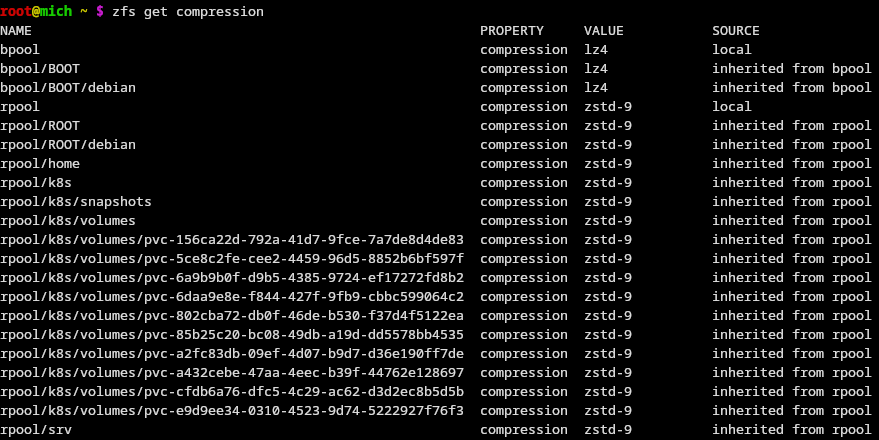
I think lz4 is supposed to be the best for this stuff
Is that something we can configure per volume?
A cursory google tells me zstd compresses more but trades off more cpu to do it
Yes
The compressratio on the tf db volume is 7.5x right now :P
Huh
Apparently zstd will be even better yea
Some people reporting 4x vs 2x for lz4
Pretty neat
lmao nice
Tbf a lot of that is duplicated data lmao
Man, there is so much performance tuning you can do with ZFS for postgres lmao
Yeah I’ve gone down that rabbit hole
Can’t remember half the stuff I changed now lol
I have a nominatim import 👀
Time to start digging shortly 😛
Also @versed condor I will look to merge your changes today as there will likely be a release tomorrow 🙂
Oh god
:D

🚀
👀

Fancy

So this should directly relate to this kind of thing
So we can just take the top result for each section to get the full address
Side note: I feel like I am going slightly insane staring at this all day every day 🤣

So for that address it would resolve to
That's how I picture you most days tbh
When keeping your UPS hydrated
When doing TF magic
...
Oh each output row already includes a full path?
Neighbourhood: 4th Arrondissement
Suburb: Paris
City: Paris
County: null
State: Metropolitan France
Country: France
No, I mean for each one of those ranges, we could have multiple
Ah I see what you mean
So we can take either the highest (less specific) or lowest (more specific) for each section
That dataset does not include POIs, correct?

This is what nominatim returns from their API for the exact same point
Looks like they might be doing it the other way, so taking the more specific part
Hmmm
Or their docs just don't match the actual implementation anymore 😛
Time to go code diving
Nope
Slowly getting closer

Oh no
It's in python
It used to be in php
So, could be worse
Apparently they took a pretty big performance hit switching to python though 😛
Is PHP so quick?
Though while looking at that I also found out that if you're just using nominatim for reverse geocoding, the database can basically hold all the indexes in memory all the time
So it just always responds in like 10ms 😛
The DB does at least, most of the processing time is actually in python lol
That's crazy
So we're going to be faster than notanimnominatim? 👀
Now I got it mixed up lol
I thought you were still writing it the wrong way
🤣
First query constructed 😅
SELECT * FROM (SELECT *
FROM placex
WHERE rank_search BETWEEN 5 AND 40
AND ST_intersects(geometry, ST_Point(2.356494, 48.853659, 4326))
AND (ST_GeometryType(placex.geometry) in ('ST_Polygon', 'ST_MultiPolygon'))
AND rank_address BETWEEN 4 AND 25
AND type != 'postcode'
AND name is not null
AND indexed_status = 0
AND linked_place_id is null
ORDER BY rank_search DESC
LIMIT 50
) as area
WHERE ST_Contains(geometry, ST_Point(2.356494, 48.853659, 4326))
ORDER BY rank_search DESC
LIMIT 1```I just set a high number, as we don't want to limit on rank
My thoughts are basically if we can reconstruct all the queries that Nominatim does, we can use those to pre-filter our data to only what we care about, and hopefully get the exact same results Nominatim does
I like that
Did you think about running nominatim and querying it? Could simplify things, and the db can be not huge

If we keep only the admin and do the drop
That's the plan, we just spin up nominatim and then process that into an export suitable for immich
I have nominatim running right now
Ah OK, I thought you were going to use it to generate the data and then do it all ourselves
Did the ingest last night 🙂
I’m thinking about running a docker with immich and the querying it using the api
Ah, no we want to avoid that if possible
In addition to immich that is
Running it within our own DB is preferable and we can probably significantly trim the data down from 20GB
Ah interesting, so nominatim does the geometry lookup first, so only finding things with polygons, then it looks up the closest node within the smallest polygon it found
So for the paris co-ordinates I am using, it then finds Le Village Saint-Paul
Last week we mentioned doing an approach like this as well right?
Yea, but I didn't consider the possibility of constraining it to the outer bounding area
I'm currently a little lost at where it is doing some logic lol
God help me

Ah good, it runs some sql function it doesn't log in the debug output 😄
if ($aLine['isaddress'] && $sPrevResult != $aLine['localname']) {
$sPrevResult = $aLine['localname'];
$aParts[] = $sPrevResult;
}
}```Well their logic to construct the address is actually pretty simple lol
Still need to figure out how they classify them though...

Lol are you serious

Definitely lunchtime after that discovery lol
Oh, they use their rank_address and divide it by 2? 🤣
wtf
Found this as well

So I think they only count specific nodes if they are within this distance away, in degrees
ₙₒ
:(
@pale aspen could you do me a favour if you don't mind and double check @versed condor's PR? 😅
I think if I look at that right now all this PHP madness will be gone from my head forever
I think the only thing was a merge conflict in the base-image because we moved where the files are located
Currently I'm at the uni but I can look at it later, yes
No worries 😛
Isn't that a good thing? /s
Maybe I will be out of hell by then
I do not want to do this twice 🤣
I think I am close to the end
I hope so
Look at this amazing SQL query

There's a bunch of stuff way off to the right I can't screenshot 😛
That is the final query though
Is this how hell looks like?
It runs that, then runs this query to get all the parents
FROM get_addressdata(2712940, -1)
ORDER BY rank_address DESC, isaddress DESC;```Oh that's better!
Then it constructs this address object, which contains every parent of the place
Then using that address object it can calculate the <addresspart> xml block
Basically what I take from that is, all we need to calculate that is this
'osm_type' => 'N'
'osm_id' => 9492497453
'name' => '"name"=>"Village Saint-Paul"'
'class' => 'place'
'type' => 'neighbourhood'
'place_type' =>
'admin_level' => 15
'fromarea' => False
'isaddress' => False
'rank_address' => 24
'distance' => '0.00041273765275298224'
'localname' => 'Village Saint-Paul'```Wow that formatting
We need that for each parent object
isaddress and rank_address are the important parts
No worries on my phone it looks even more awful lol
So if !isAddress, we never include that in addresses
So we can essentially nuke all those from the database 😛

Then it uses this lovely logic to calculate the part -> name
So which ones are that?
When do you not have an address?
It's not that it doesn't have an address
It's that the ingest considered that part not important for addresses
So for us, we don't ever care about it
Nominatim would never include that in their reverse geocoding, so we can just delete it and forget about it in the SQL
Their code is pretty complicated because they use the same code for both reverse geocoding and normal geocoding/search
Ah I see
So a lot of stuff is irrelevant for what we want
Something that is irrelevant for addresses, might be relevant for search, for example
Ok I am going to grab lunch and forget all of this then smash my head into my desk when I return 🙂
Sounds like a plan! :)

Similar size with what I think we need currently
I haven't added the points data yet, need to figure out how to convert that
That looks very sensible!
This is more detail than before btw
But presumably we're binning a bunch of stuff we didn't need before

Before we only had administrative
👀

actually wut
There isn't even a comment to explain why
if rank_address is 0, set to 100
if rank_address is 11, set to 5
?????
The first I understand
k

Looks like they've just completely binned that lmao
That returns 0 rows
Think my brain is done for today lol
Just staring at this now and making no progress 😅
The name tags for stuff are pretty horrendous lol
Need to reformat them ideally because right now it's just paiunful
This just reaffirms we are starting with english only lol
'name:en-US','_place_name:en-US','name:en','_place_name:en','name','_place_name','brand','_place_brand','official_name:en-US','_place_official_name:en-US','short_name:en-US','_place_short_name:en-US','official_name:en','_place_official_name:en','short_name:en','_place_short_name:en','official_name','_place_official_name','short_name','_place_short_name','ref','_place_ref','type','_place_type'
These are all the tags you have to search for when looking for english
In order
Current table generation SQL
CREATE TABLE nominatim.non_postgis.placex AS
SELECT place_id,
parent_place_id,
rank_address,
rank_search,
class,
type,
admin_level,
get_name_by_language(name, ARRAY ['name:en-US','_place_name:en-US','name:en','_place_name:en','name','_place_name','brand','_place_brand','official_name:en-US','_place_official_name:en-US','short_name:en-US','_place_short_name:en-US','official_name:en','_place_official_name:en','short_name:en','_place_short_name:en','official_name','_place_official_name','short_name','_place_short_name','ref','_place_ref','type','_place_type']) as name,
country_code,
coalesce(extratags -> 'linked_place', extratags -> 'place') as place_type,
POLYGON((ST_Dump(ST_Transform(geometry, 4326))).geom::geometry(Polygon, 4326)) AS poly
FROM placex
WHERE (ST_GeometryType(placex.geometry) in ('ST_Polygon', 'ST_MultiPolygon'))
AND type != 'postcode'
AND name is not null
AND indexed_status = 0
AND linked_place_id is null;
Lol that looks painful
I think I will be able to get a PoC working tomorrow
With two caveats
Not going to have single point data to start with
It's all in english or the local language of the place 😛
FWIW though, when we do add support for multiple languages
Seems that's only about 100MB of data
Note for me for tomorrow, I can move the place type processing to the ingest procedure and then drop a bunch of the other data
Just some thoughts while I was cooking dinner 🤣
Love it when that happens 😛
@versed condor Apologies for leaving this so late, I just got the brain power back to quickly look at your PR. I am just fixing the merge conflicts right now, but would you be able to throw an e2e test in there that is a location in the middle of nowhere that resolves the country using this data?
I'd also just have time now in case you need me to do anything
Sorry I've been busy the whole afternoon/evening
I guess the test should ensure that it gets a country but doesn't get a city
That would ensure that cities500 isn't being used
Just somewhere out in the middle of a desert or something 😛
Haha k that works
This would be fine?

Yea I expect so
K cool

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Tests are failing, are you working on that?
Can you fix the linting pls too? xD
At least you see the issue yourself :P
Is it enough if I update existing geodata or should I upload a new asset with those coordinates?
Ah because we need an asset 😅
Yea just modify one I guess?
Yup, can't go with unit tests
Right, modify an asset or just PUT the changes
like, we basically could use this, await the job

and then check city
Btw tests still fail

Am I blind or is it not creating that file anywhere?
That's in the base image
I'm working on getting that updated atm
Ah I see
It's building the image atm
If you need an ide lmk
Yea, this is fine imo
So just manually kicking of the job again as soon as it's merged should do the trick?
that's what I have now

Yea
Noice
Unfortunately latitude or longitude cannot be 420
Lol
But I'm still happy I found a combination that wasn't in a city lol
I want runners that go brrrrrrrrr :(
runs-on: mich
Or we can bully Thomas into building us a crazy build farm in Austin /s
Isn't e2e running no mich?
Why that /s? :)
I've been waiting for hours for e2e
Nope
Well, like 5min lol
Do you think it'd make a difference?
IIRC we did that for a bit but then the mich runners froze once & Alex killed it by hard resetting the whole box, and we went back to the github runners after :')
Something like that anyways
AFAIK only the baseimage build is on mich rn
There was something, I remember....
Just saw the messages, anything I can still help with?
Cool!
@gray plover does rerunning a test use cached images?

If you're hitting the try again button on a job, there's a good chance it reuses the cache yes
I don't know how far github actually goes to reproduce the same environment, but it at least does something in that direction
So ideally I'd push something instead?
Yeah
K, waiting for 7 minutes again 🙂
Am I blind or is updating an asset not queuing geocoding?
Like, it's calling this but that's only setting lat and lng

Doesn't the sidecar write then kick off metadata extract after?
Oh?
Ah you're right
Oh, I get why my test is failing lol
I'm not fetching the asset again
There are still broken motionphoto paths :)
The branch probably just needs rebasing 😛
You merged changes like an hour ago no?
Oh, I see
It may just merge the changes to resolve the conflict
But not the entire main branch
Well let's see if that helped
Noooope
How bad would it be if I leave it for now? Need to do some other uni stuff still and it's getting kinda late :P
Maybe I come back at this afterwards
You're not chained down lol, you can take off whenever
Doubly so if you have other actual stuff to do
I know :D
But if this is important I'm happy to continue working on it
Yea no worries lmao 😛
All good
I can finish it up tomorrow morning
Appreciate the help 🙂
Wasn't much :D
Ok, the other stuff went surprisignly painless
Any ideas why this stuff is failing? The paths seem to be correct to me
I've not checked the job yet, I will take a look shortly
It seems the submodule reference got updated/downgraded when the rebase was done 😛

I also believe that the lat / long of Kazakhstan is reversed in the test
Oh that's sad. I double checked it even but apparently I am lost :/
Happens to me all the time 🙂
And it’s not consistent as well! ll_to_earth has different ordering than when defining a point
Yea it's painful lol
Sadly it's worthwhile as it means the logic in the app will be very simple
Also reduces data stored in the database 😛
Are these SQL funcs we run during processing or ship with the app?
Just preprocessing
Basically we can pre-calculate the place type for every place
Awesome
Then I can drop the address rank, extra tags and other fields from the final data
Thanks guys for getting the e2e tests working and merging!
while doing backup if one of the asset fails to upload, in the iOS immich app remainder stops decrementing even though assets keep getting uploaded
I think you're in the wrong thread - but yeah, that counter being wrong is a known issue
oops 😬
After the new release 2,611 / 3,190 of my photos with missing location now have a country!
The missing 579 are only 13 unique locations (lat/long pairs rounded to 1 decimal places)
Still room for improvement, which OSM data will hopefully bring (missing country mappings and adding state/city)
Awesome! 🎉
cries in SQL functions
Yup, things can escalate quickly 😄
👀 table building

Hmmmm, still something wrong
Getting there though 😛
type

🙌


Halle-fucking-lujah 🤣

Response from their API
In our table

All the different types

Should be easy to fit those into a segmented system now 🙂
Making search and everything easier or at least similar to what we have now 😛
Just need more columns
The next thing to figure out is this is just the polygons
There's also the single point centroids
But I am thinking of ignoring that to start with maybe
Dumping this here because if my PC sets on fire and I somehow lose this, I might actually lose my mind
CREATE TABLE nominatim.non_postgis.placex AS
SELECT place_id,
parent_place_id,
rank_search,
admin_level,
get_place_type(rank_address, extratags, class, type, country_code) as type,
get_name_by_language(name,
ARRAY ['name:en-US','_place_name:en-US','name:en','_place_name:en','name','_place_name','brand','_place_brand','official_name:en-US','_place_official_name:en-US','short_name:en-US','_place_short_name:en-US','official_name:en','_place_official_name:en','short_name:en','_place_short_name:en','official_name','_place_official_name','short_name','_place_short_name','ref','_place_ref','type','_place_type']) as name,
POLYGON((ST_Dump(ST_Transform(geometry, 4326))).geom::geometry(Polygon, 4326)) AS poly
FROM placex
WHERE (ST_GeometryType(placex.geometry) in ('ST_Polygon', 'ST_MultiPolygon'))
AND type != 'postcode'
AND name is not null
AND indexed_status = 0
AND linked_place_id is null;```CREATE OR REPLACE FUNCTION get_admin_boundary_label(iAdminLevel INT, sCountry TEXT,
sFallback TEXT DEFAULT 'Administrative') RETURNS TEXT AS
$$
BEGIN
RAISE NOTICE 'get_admin_boundary_label(%s, %s)', iAdminLevel, sCountry;
-- Norway and Sweden custom labels
IF sCountry IN ('no', 'se') THEN
CASE iAdminLevel
WHEN 3 THEN RETURN 'State';
WHEN 4 THEN RETURN 'County';
ELSE -- No custom label for this admin level
END CASE;
END IF;
-- Default labels
RETURN CASE iAdminLevel
WHEN 1 THEN 'Continent'
WHEN 2 THEN 'Country'
WHEN 3 THEN 'Region'
WHEN 4 THEN 'State'
WHEN 5 THEN 'State District'
WHEN 6 THEN 'County'
WHEN 7 THEN 'Municipality'
WHEN 8 THEN 'City'
WHEN 9 THEN 'City District'
WHEN 10 THEN 'Suburb'
WHEN 11 THEN 'Neighbourhood'
WHEN 12 THEN 'City Block'
ELSE sFallback -- Return fallback if no match found
END;
END;
$$ LANGUAGE plpgsql;
Don't you back up your computer? 👀
CREATE OR REPLACE FUNCTION get_place_type(rank_address INT, extra_tags hstore, class varchar, type varchar,
country_code varchar) RETURNS varchar AS
$$
DECLARE
label varchar;
rank INT;
BEGIN
rank := COALESCE(rank_address, 30);
IF extra_tags IS NOT NULL AND ((extra_tags -> 'place') IS NOT NULL OR extra_tags -> 'linked_place' IS NOT NULL) THEN
IF (extra_tags -> 'place') IS NOT NULL THEN
label = extra_tags -> 'place';
ELSIF extra_tags -> 'linked_place' IS NOT NULL THEN
label = extra_tags -> 'linked_place';
END IF;
ELSIF class = 'boundary' AND type = 'administrative' THEN
label = get_admin_boundary_label(rank / 2, country_code);
ELSIF type = 'postal_code' THEN
label = 'postcode';
ELSIF rank_address < 26 THEN
label = type;
ELSIF rank_address < 28 THEN
label = 'road';
ELSIF class = 'place' AND (type = 'house_number' OR type == 'house_name' OR type == 'country_code') THEN
label = type;
ELSE
label = class;
END IF;
return LOWER(REPLACE(label, ' ', '_'));
END
$$ LANGUAGE plpgsql;```Nope
Everything is on nextcloud or git
Which are then backed up
My PC is intentionally not backed up so I don't get reliant on that 😛
I can quite happily wipe my OS at any time
And know it'll all be in nextcloud or git
Oh yeah that actually makes sense
Makes sense, the points will add some complexity to the calculation (like how far away do we want to count, 25km like geonames?)
They already have some distances in the nominatim code
So I'll steal those 😛
But yea it'll make it more complex
So going to ignore it for now
This will be significantly better than what we have already
Today's fun is trying to figure out how to calculate the diff between two tables in postgres 😅
The problem being we don't have a unique column 😢
Because the multi-polygons become multiple rows
Is the diff for updating the table when new data is added?
Yea
I want to provide incremental updates rather than requiring the full 6GB be downloaded and ingested every time
Would it be possible and easier to do it in postgis tables before expanding the multi polygon to multiple rows?
Potentially but that's probably an even bigger rabbit hole 🤣
I think I'm going to change the table layout to reduce duplication which will also help here
I'm going to make it into two tables, one with the geometry and then a reference to the actual place data
Right now Brittany has the same data 1.5k times lol
Sounds like a good plan 🙂
So I am going to use the osm IDs as the reference, but the OSM IDs aren't unique
They are unique within each type
For which there are ways, relations and nodes
So the ID for each entry will be like R102394012
or N12498123
Getting better 😛

Well, I am done for the day, maybe this'll finish running by tomorrow 😅
EXPLAIN ANALYSE SELECT g2.*
FROM non_postgis.geometry_2 AS g2
JOIN non_postgis.geometry AS g ON g.osm_ref = g2.osm_ref
WHERE g2.poly::varchar NOT IN (SELECT poly::varchar FROM non_postgis.geometry WHERE osm_ref = g2.osm_ref);```I'm considering generating a hash for every polygon and using that for these checks, should at least be able to do that with an index then 🤣
I do have working diff commands though now 😄
Tested for a specific osm_ref
Just need it to work over the entire table efficiently now
Awesome
The diff generation doesn't have to be particularly efficient
Nice!
Got a command now that takes 10 minutes to calculate the updated or new entries to geometry
Sweet
It'll presumably take the same amount of time to calculate deletes
I think I may still add a hash column that is pre-computed
Most of the time here is probably casting between types and running those comparisons lol
hey folks
just read through most of the thread, apprectiate the work :))
and I think I understood what you were saying about how now the remaining work is infrastructure related
which is def not first time contributor friendly 😄
if I understand correctly, with the lower administrative level polygons imported, even polygon edges close together would be resolved correctly - right?
the example that made me notice the issue is that my city Budapest is surrounded by many smaller towns
and any time I take photos in districts further out from the center of the city (e.g blue circle area) my photos are tagged with the towns outside of the border

Certainly much much better than now
Depending on the resolution we use there might still be some small edge cases
I tested borders down to 1 meter in each direction and seemed to be very solid
It'll vary slightly depending exactly where on the border, but the new method will have actual border lines rather than just a single point
woah, awesome.
are there any news in this regard as we've hit 2.0? there are still recurring mentions of this issue in github too, e.g. #22325
[Issue] Immich v1.143.0 giving wrong locations name (immich-app/immich#22325)