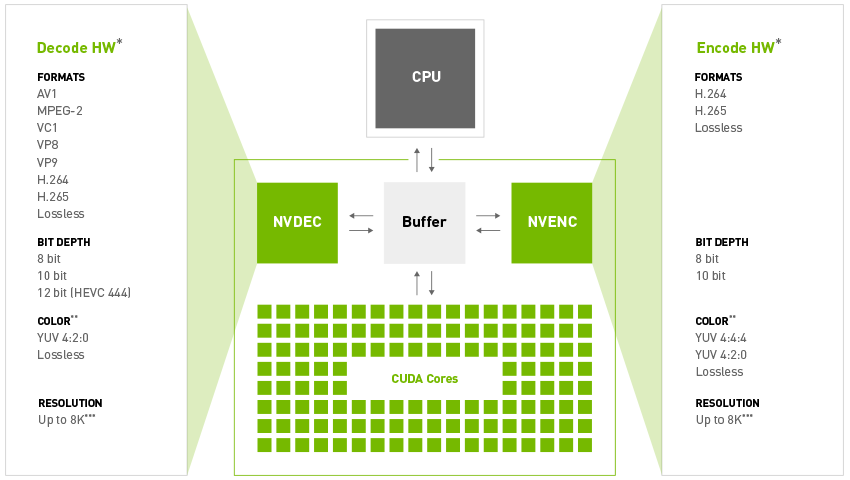
DC:US-NC-1
GPU:RTX 5090
I have switched data centers to US-IL-1 in addition to US-NC-1, but the results remain the same.
cmd
-f lavfi -i testsrc=duration=5:size=1280x720:rate=30 -c:v h264_nvenc -pix_fmt yuv420p -t 5 /tmp/test.mp4 -y
ffmpeg version 7.1.1 Copyright (c) 2000-2025 the FFmpeg developers
built with gcc 13 (Ubuntu 13.3.0-6ubuntu2~24.04)
configuration: --disable-debug --disable-doc --disable-ffplay --enable-alsa --enable-cuda-llvm --enable-cuvid --enable-ffprobe --enable-gpl --enable-libaom --enable-libass --enable-libdav1d --enable-libfdk_aac --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libharfbuzz --enable-libkvazaar --enable-liblc3 --enable-libmp3lame --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libopus --enable-libplacebo --enable-librav1e --enable-librist --enable-libshaderc --enable-libsrt --enable-libsvtav1 --enable-libtheora --enable-libv4l2 --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvpl --enable-libvpx --enable-libvvenc --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzimg --enable-libzmq --enable-nonfree --enable-nvdec --enable-nvenc --enable-opencl --enable-openssl --enable-stripping --enable-vaapi --enable-vdpau --enable-version3 --enable-vulkan
libavutil 59. 39.100 / 59. 39.100
libavcodec 61. 19.101 / 61. 19.101
libavformat 61. 7.100 / 61. 7.100
libavdevice 61. 3.100 / 61. 3.100
libavfilter 10. 4.100 / 10. 4.100
libswscale 8. 3.100 / 8. 3.100
libswresample 5. 3.100 / 5. 3.100
libpostproc 58. 3.100 / 58. 3.100
Input #0, lavfi, from 'testsrc=duration=5:size=1280x720:rate=30':
Duration: N/A, start: 0.000000, bitrate: N/A
Stream #0:0: Video: wrapped_avframe, rgb24, 1280x720 [SAR 1:1 DAR 16:9], 30 fps, 30 tbr, 30 tbn
Stream mapping:
Stream #0:0 -> #0:0 (wrapped_avframe (native) -> h264 (h264_nvenc))
Press [q] to stop, [?] for help
[h264_nvenc @ 0x5b844ea0d440] OpenEncodeSessionEx failed: unsupported device (2): (no details)
[h264_nvenc @ 0x5b844ea0d440] No capable devices found
[vost#0:0/h264_nvenc @ 0x5b844ea0fdc0] Error while opening encoder - maybe incorrect parameters such as bit_rate, rate, width or height.
[vf#0:0 @ 0x5b844ea2afc0] Error sending frames to consumers: Generic error in an external library
[vf#0:0 @ 0x5b844ea2afc0] Task finished with error code: -542398533 (Generic error in an external library)
[vf#0:0 @ 0x5b844ea2afc0] Terminating thread with return code -542398533 (Generic error in an external library)
[vost#0:0/h264_nvenc @ 0x5b844ea0fdc0] Could not open encoder before EOF
[vost#0:0/h264_nvenc @ 0x5b844ea0fdc0] Task finished with error code: -22 (Invalid argument)
[vost#0:0/h264_nvenc @ 0x5b844ea0fdc0] Terminating thread with return code -22 (Invalid argument)
[out#0/mp4 @ 0x5b844ea0f540] Nothing was written into output file, because at least one of its streams received no packets.
frame= 0 fps=0.0 q=0.0 Lsize= 0KiB time=N/A bitrate=N/A speed=N/A
Conversion failed!
This is the result I got running on my RTX 4090. There are no issues with the container image and command.
docker run --rm -it --gpus=all \
-v $(pwd):/config \
linuxserver/ffmpeg:7.1.1 \
-hwaccel cuda -hwaccel_device 0 -f lavfi -i testsrc=duration=5:size=1280x720:rate=30 -c:v h264_nvenc -pix_fmt yuv420p -t 5 /tmp/test.mp4 -y
...
encoder : Lavc61.19.101 h264_nvenc
Side data:
cpb: bitrate max/min/avg: 0/0/2000000 buffer size: 4000000 vbv_delay: N/A
[out#0/mp4 @ 0x619f0fd1afc0] video:196KiB audio:0KiB subtitle:0KiB other streams:0KiB global headers:0KiB muxing overhead: 1.333094%
frame= 150 fps=0.0 q=8.0 Lsize= 199KiB time=00:00:04.90 bitrate= 332.2kbits/s speed=27.8x