I've been trying to use the /simple/ API to get a full list of packages available on PyPI, but the data I'm being served hasn't changed in the past few hours (at least, packages uploaded > six hours ago are missing, and I believe the ETag hasn't changed though I didn't write it down, relying on memory). I assume this is something to do with being served cached data -- are there any known workarounds to force through the cache?
#pypi
1 messages · Page 3 of 1
I also see different results in cURL vs. querying from Python (and the HTML vs. JSON APIs):
❯ curl -s https://pypi.org/simple/ | grep ii-researcher-test
❯ curl -s https://pypi.org/simple/ --header "Accept: application/vnd.pypi.simple.v1+json" | jq | grep ii-researcher-test
"name": "ii-researcher-test"
(And then querying with httpx, that package isn't present in either response.)
I would also note that the simple API doesn't show all project names registered on PyPi, a few are only available via the XML-RPC API
Oh, should I just be using that?
I mean, it is deprecated. The issue is the simple API is not complete
It does say list_packages_with_serial is still "fully supported, until an improved mechanism for mirroring is implemented" 😅
Yeah, there are a few packages that show up there but not in the simple API
Wow, the secret forbidden PyPI API
We use it to check if a name is registered when integrating projects and if name registration fails.
Not sure what your use case is, but there's also this: https://github.com/pypi-data/pypi-json-data
The /simple/ page is not frequently updated, see https://github.com/pypi/warehouse/issues/9926 and linked issues for more details

GitHub
I published a new project recently, and it's not showing up on https://pypi.org/simple/ after 18+ hours. Whereas it is available when referenced directly: https://pypi.org/project/portable-pyth...
This is probably something we should mention here: https://docs.pypi.org/api/index-api/#list-all-projects
it would be nice to be able to delete a yanked release. right now, you need to first un-yank, and then delete, giving a short window where people may end up downloading the bad one before it gets zapped
but hopefully not often needed so I guess would be low priority
I see no reason we couldn't support that, would you mind filling an issue?
sure!
GitHub
What's the problem this feature will solve? Right now if you want to delete a yanked release, you first have to un-yank that release to be able to delete it. This gives a small window where peo...
I didn't realize there was deletion at all... ?
I have a languishing branch for programmatic yanking and it allows you to do that IIRC.
It’s nice when things work the way they’re supposed to when things don’t work the way they’re supposed to https://blog.pypi.org/posts/2025-04-14-incident-report-organization-team-privileges/

We responded to an incident related to privileges persisting via Organization Teams after Members are removed from Organizations.
Nice indeed: "In total, this incident was resolved in 2 hours and 2 minutes from the time of report."
And 30m of that was waiting for me to get out of a meeting to review a PR 😅
Congratulations!
Plus same day incident report 👏
Absolutely stellar mitigation of the incident and incident report write-up.
I heard about it early yesterday through a colleague who'd been notified via a different, open source org. Our corp org did not get the notification which made me believe that we weren't affected. Confirmed through auditing the activity via our PyPI org user page.
yeah, we notified the only organization that was impacted (that didn't report it)
Test PyPI is giving 503 Service Unavailable
https://github.com/ultrajson/ultrajson/actions/runs/14628999082/job/41079987007#step:10:576
Same for the PROD pypi.
Edit: It seems to be fixed.
Random, but I tried to register a project on PyPI ("axi") and got a 400 because the name is "too similar" to existing ones. I'm not even sure what name that overlaps with. Is there a way we (Astral), as a clearly non-malicious user, could use the name? Is there a record of the concerning conflict?
@formal jolt you can make a request for the name by following the instructions inhttps://pypi.org/help/#project-name

PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
I don't think it covers this case, does it? I don't see it in PEP 541
good point that could be clarified a bit, but use the same process
kk

GitHub
Project to be claimed axi: https://pypi.org/project/axi Your PyPI username zanie: https://pypi.org/user/zanie Reasons for the request This project is marked as too similar to existing projects Uplo...
I like uv and ruff enough that if the next Astral project was named "reqeusts" I'd be clamoring for them to get a name exception.
Huh, requesting a naming exception for conflicts didn't even occur to me as a possible option. tstrprocess is called that because my first idea (tprocess) was deemed too similar to existing project names (presumably process)
the conflict is actually https://pypi.org/project/t_process/0.1/
wow. A few dozen lines with a wrapper for subprocess usage and another for os.kill. Uploaded once in 2017 - along with several other packages by the same author (it seems like the t_ is meant as a form of namespacing?)...
I mean, everyone is entitled to share their work on PyPI by default. But it does, well, cause conflict.
Certainly, which is why we have some processes designed to help resolve the conflicts.

Discussions on Python.org
Organization review is now current. 0 Pending Organization Requests 3,424 requests awaiting response 5,421 Approved Organizations 1,790 Community 3,631 Company
In this case, I ended up not being too worried about it - I hope the tstrprocess library only exists for a release or two (until we have something we're happy to process for plumbum and/or the stdlib), and tstr is at least arguably a better prefix for that than just t anyway.
It'd be cool if there was a "Type checking" classifier on PyPI
ah. do you think there's that many that justify a classifier?
I'm not sure! I think the more justified classifier would be like "Static analysis"
There are definitely enough linters and type checkers to justify that
Though I worry about the term's user friendliness
kick off a d.p.o thread to suggesst something to add in https://github.com/pypa/trove-classifiers/blob/e2b922f3a625ed37ef37108be82aa902240621ac/src/trove_classifiers/__init__.py#L775-L780 ?
Thanks!
keep in mind - pyright isn't a python project, the one on PyPI is a wrapper that bundles the javascript code
but the classifier on the wrapper might help
Yeah, our type checker is not really a "Python" project either though there will be a Python module
There are other type checkers too though, like https://github.com/beartype/beartype and https://github.com/agronholm/typeguard
I think generally it's an interesting space for users to be able to navigate
Speaking of classifiers
I saw this while poking around this morning
https://github.com/pypi/warehouse/blob/main/warehouse/cli/classifiers.py#L23
That comment isn’t correct, right?
nope, looks like it got copy-pasta'd
Other powers that be -Just wanting consensus - How feasible could it be to make simple/index API less cached for bandersnatch so we could for once and all put an EOL date on xmlrpc?
GitHub
The XMLRPC is now obsolete and deprecated and even the parts that may
not be deprecated no longer work. Instead, let's use the simple Index
API with JSON to collect all packages and their c...
e.g. if the client requesting == bandersnatch, maybe we refetch latest version
I agree it could be a DOS / DDOS enpoint, but no more than xmlrpc today ...
I can't speak to bandersnatch, but there are places where we still have to use the XMLRPC API, mainly because some information is not available any other way than scraping the web ui, which of course no longer works due to the Fastly redirect.
I'm also using the xmlrpc because the simple endpoint is often missing available packages
if they were created within the last 24 hours, yes that would be the case. if they've existed for > 24 hours and aren't there its a bug
Yeah, within 24 hours is critical for the use-case
Changes made today will ensure the JSON version of /simple/ is fresh within 1 hour, does that fit use case?
Maybe but we're actually targetting <2m
As in, that's the acceptable time for our service to reflect a change via the XML RPC API
xmlrpc is effectively "within the confines of transaction isolation" instant.
you're using "list packages with serial"?
Yeah
can you share more about what you need to detect?
We're mirroring packages
like, for what you're describing the changelog is much more reasonable
I think we can use changelog_since_serial yeah
We still need the other one for backfills, because we can't guarantee all insertions are successful and the last serial is monotonically increasing
can you say more about second part?
but we can run that at a much slower cadence
we have a brutal amount of lock contention to ensure they are 😂
Yeah we don't want that contention on our end 🙂
We don't insert in strict order, basically
i think we're not far from being able to offer a better answer here, i just do not want to add any new APIs that aren't cached (like immediate correct answers for what projects@serial) until we can put it behind auth
(I hadn't realized the API was usable at all since it stopped being available to pip)
we could also probably add our own abstraction that is monotonically increasing and less fallible, it's just quite a bit of work
no, uh, we are — we're just not guaranteeing that insertion into our database
but we could add a stream or something in between PyPI and our database that is monotonic to reduce load on ya'll
not following, hard to understand in the abstract 🙂
That's okay haha, sorry.
I can write something more detailed up later when I'm less busy if it's helpful.
... hold on, is the XMLRPC interface usable for something that isn't search?
Hey all, I haven’t been able to track this down in docs yet: will all requests for a package to Pypi.org work with the normalized name (PEP503) of that package? And does Pypi guarantee that a normalized name only points to one package?
https://packaging.python.org/en/latest/specifications/simple-repository-api/#base-html-api is the relevant spec section.
The answer to both questions is "Yes", as normalized names are the only ones that are guaranteed to work. Index servers may redirect the non-normalized names, but they're not formally required to do so.
Thanks @vast halo !
sigh someone took uv on test PyPI https://test.pypi.org/simple/uv/
There are no files there yet, but... this is an attack surface
Do I need to file a request to take it down? Do we need to maintain a squat there.. ?
PEP 541 definitely covers taking that down. maybe PyPI can add it to the reserved names list
yeah, just file a request for the name, we almost always give TestPyPI project names to their respective owners on PyPI

GitHub
Project to be claimed uv: https://test.pypi.org/project/uv/ Your PyPI username zanie: https://test.pypi.org/user/zanie Reasons for the request This project is popular on PyPI and has been claimed b...
Yet another good reason to decommission test.pypi.org (eventually, #PEP694)
but where will I test
pypi.org itself!
testpypi actually reserves names?
I'm also surprised that one can end up with a 200 from the simple API with no artifacts listed.
Not reserve, but behaved identically to PyPI in that regard - first come, first serve
yeah, but I thought they were released afterward.
since the test index isn't supposed to serve the package long-term, only long enough for testing purposes.
Hi all - I'm trying to use the BigQuery dataset to figure out how many cp313t wheels are being downloaded relative to cp313 wheels. From what I can tell, this requires generating a very large query, because I need to look at all downloaded wheel files to see if they have cp313t or cp313 in the name. Is there a better way to do this? Anyone have experience optimizing queries like this? Also maybe it makes sense to include ABI flag information in the info that pypi collects for each download.
looks like @pliant obsidian has been thinking about this: https://hugovk.dev/blog/2024/a-surprising-thing-about-pypis-bigquery-data/. Maybe the simplest thing is just to give up on backfilling the data back to last year and instead start just running this query daily since that appears to be a lot cheaper. I'm also able to successfully get the data for up to a few days without hitting scaling issues necessitating doing a different kind of reservation that gets billed by compute time rather than data processed. Just thinking out load...
probably not worth running each and every day. each week follows roughly the same pattern (less downloads on the weekend than weekdays), so you just could sample, say, Tuesdays
and if you want to get historical data, maybe sample like the second Tuesday of the month or something
a friend who works at google suggested using table subsampling since all I care about is the ratio, that seems to help a lot
FYI, clickhouse ingests our public dataset and lets you query against it for free, I think something like this might be what you're looking for? https://sql.clickhouse.com?query=U0VMRUNUCiAgICB0b1N0YXJ0T2ZXZWVrKHVwbG9hZF90aW1lKSBBUyB3ZWVrLAogICAgICAgIGNvdW50SWYoZmlsZW5hbWUgSUxJS0UgJyVjcDMxM3QtJScpIEFTIGNwMzEzdF93aGVlbHMsCiAgICAgICAgICAgIGNvdW50SWYoZmlsZW5hbWUgSUxJS0UgJyVjcDMxMy0lJyBBTkQgZmlsZW5hbWUgTk9UIElMSUtFICclY3AzMTN0LSUnKSBBUyBjcDMxM193aGVlbHMsCiAgICAgICAgICAgICAgICBjcDMxM3Rfd2hlZWxzIC8gbnVsbGlmKGNwMzEzX3doZWVscywgMCkgQVMgcmF0aW8KICAgICAgICAgICAgICAgIEZST00KICAgICAgICAgICAgICAgICAgICBweXBpLnByb2plY3RzCiAgICAgICAgICAgICAgICAgICAgV0hFUkUKICAgICAgICAgICAgICAgICAgICAgICAgcGFja2FnZXR5cGUgPSAnYmRpc3Rfd2hlZWwnIEFORCAoZmlsZW5hbWUgSUxJS0UgJyVjcDMxM3QtJScgT1IgZmlsZW5hbWUgSUxJS0UgJyVjcDMxMy0lJykKICAgICAgICAgICAgICAgICAgICAgICAgR1JPVVAgQlkKICAgICAgICAgICAgICAgICAgICAgICAgICAgIHdlZWsKICAgICAgICAgICAgICAgICAgICAgICAgICAgIE9SREVSIEJZCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgd2VlayBERVNDCiAgICAgICAg
@merry valve wow cool, thanks!
except those numbers don't make any sense to me - only 4000 cp313 wheels last week?
i think that's the wheel upload, not the wheel downloads
ah, that makes more sense for those numbers
FWIW, here are the download numbers based on subsampling 2% of the full table:

(log scale)
so about 1% t...
ah, apologies, you're right. it doesn't seem like clickhouse currently has a table with download counts & filenames
uploads are interesting too though!
I didn't notice it was a log scale at first glance, and thought "That can't be right!"
Hi there, I want to set up an internal PyPI server for my organisation. I require it to have a UI for searching packages. I tried the PyPI Docker image, but it only has a webpage to list all the packages. I don't know how Sentry is handling it here https://pypi.devinfra.sentry.io/.
Someone recommended checking https://github.com/pypa/warehouse, but I don't see any docs on how to deploy & manage on prod.
Can someone please help me with how to go about it?
Thank you
I don't know how Sentry is handling it here
FWIW, it seems to be a custom server: https://github.com/getsentry/pypi
GitHub
sentry internal pypi. Contribute to getsentry/pypi development by creating an account on GitHub.
it seems to be a custom server
yeah but it lacks documentation 😦
check devpi
#bandersnatch is also for this if I understood it correctly.
(as in, actually implements such a thing)
What's the current state of availability for .metadata files? Does every wheel that actually has a METADATA (how far back would you have to go to find them without?) and sdist with PKG-INFO get them?
All wheels should have them, no sdists have them.
I guess I'll have to check what uv actually does about sdist dependencies, then.
warehouse isn't set up to be a reusable codebase. It's very much focused on the singular purpose of being pypi.org with a lot of related baked in assumptions. You're gonna want something that's more flexible like devpi in all likelihood.
more fun with BigQuery:

sharp dip at the end because it's Monday and I binned weekly
getting to more like 2 or 3 % there it looks like?
question for the upload api v2.0 - is there any consideration for a session to upload multiple packages at once - im jsut thinking about how to safely release setuptools-scm and vcs-versioning in locked versions (which will be necessary for a transition period) ideally i put both releases together in the same session
Not specifically. An upload session is tied to a package+version, but you can defer the publishing step so that you could open two sessions for two different releases, then upload all your wheels, then publish each session. It's not atomic across sessions, but it should be a pretty narrow race window.
I suppose we could consider a publish request for multiple sessions, but things like that do make the protocol more complicated, so we've generally avoided that.
I just finished reviewing @hazy wagon update to 694 and I think it looks really good.
google just sent out an email announcing they’re bumping up the free usage per day on bigquery by a substantial margin

sorry to disappoint, but these are changes to the default quota for a given project (e.g. how much of your GCP budget it can consume before failing), not changes to the free tier (which remains 10GB of storage and 1TiB per month: https://cloud.google.com/bigquery/pricing?hl=en#section-14)
ah darn, too good to be true, sorry for the noise…
If you don't need upload (and writing wheels to disk is good enough), and don't want to mirror the whole of PyPI, then perhaps check out https://github.com/simple-repository/simple-repository-server. For the UI, take a look at https://github.com/simple-repository/simple-repository-browser (live demo is down for infrastructural reasons).
Disclosure: I'm an author of both
GitHub
A web interface to browse and search packages in any simple package repository (PEP-503), inspired by PyPI / warehouse - simple-repository/simple-repository-browser
Alas inspector is down?
This package https://pypi.org/project/coveragePy/ is confusingly named, and links to an empty github repo: https://github.com/chexiedaping/coveragePy. The code seems not to be malware, but at a quick glance could seem alarming. About once a year someone gets in contact with me about it. I wrote to the author ~2.5 years ago and never got a response. Can we remove the package?
I expect so, you could at least do a PEP 541 request to transfer the name to you because it's an abandoned project
Seems to still be down
For awareness: https://discuss.python.org/t/100267 -- probable phishing campaign against PyPI.
Discussions on Python.org
I just received this email (link deliberately broken): As part of our ongoing account maintenance and security procedures, we’re asking users to verify their email addresses. Please follow [this link](http s://pypj.org/account/login?user=ethan&token=xxx) to verify your email address. This link will expire in 72 hours. If you fail to confi...
I noticed the other day that certbot-dns-cloudflare had a massive spike in downloads to 250 million+/day starting at the beginning of the month. I was mystified until I came across what I think could be the cause: https://github.com/NginxProxyManager/nginx-proxy-manager/issues/4641#issuecomment-3124707792

GitHub
Have you pulled and found the error with jc21/nginx-proxy-manager:latest docker image? Yes Are you sure you're not using someone else's docker image? Yes Have you searched for similar issue...
An update to this: https://blog.pypi.org/posts/2025-07-31-incident-report-phishing-attack/
TL,DR:
• PyPI was not breached
• PyPI users were targeted with phishing emails
• A single project saw uploads with malicious code and those releases have been removed

Follow-up on the recent phishing attack targeting PyPI users.
Ah, I heard about the num2words incident on HN and wondered if it was connected.
wow! That is something like six times the daily average for boto3. Looks like this bumped cloudflare, acme and certbot-dns-cloudflare to the top of the monthly leaderboard, by a healthy margin.
The cloudflare none-any wheel is 4.4MB so that represents a sizeable bump in PyPI total bandwidth.
like perhaps 4 or 5 times Numpy's impact.
I think this should be a reserved name https://pypi.org/project/pytho/
The author may have originally had good intent, maybe "pytho" indeed means something in the context of Vietnamese poetry (that's certainly not my field of expertise). But the release doesn't contain any functional code (not even to implement the entry point described in setup.py!) and has sat idle since 2017
There’s actually code but they packaged it incorrectly https://github.com/pymivn/pytho
But yeah it can probably be reclaimed if it’s preferred
GitHub
Python library for processing Vietnamese poetry. Contribute to pymivn/pytho development by creating an account on GitHub.

PyPI will begin warning and will later reject wheels that contain differentiable ZIP features or incorrect RECORD files.
One question about orgs: Are scientific institures “communities” or “companies”? They aren’t for-profit, and can’t really pay for a lot of recurring expenses, do technically have finances …
@pliant obsidian I think there’s been a bit of an acceleration on https://hugovk.github.io/free-threaded-wheels/ - shot in the dark: do you have the daily historical numbers too?
I guess I can mess with the script in https://github.com/hugovk/free-threaded-wheels/issues/21#issuecomment-2979686402 to get the historical data

GitHub
I love your website; I visit it every day checking to see if the outstanding packages I need for my project (lxml, numba, geoviews, datashader, python-snappy, not all of these are in the top 360) h...
it's all in git! see results.json
https://github.com/hugovk/free-threaded-wheels/commits/gh-pages/
good excuse for me to poke at pygit2’s free-threaded wheels too!
@pliant obsidian any chance you have any idea what the discontinuity in april is about?

and it definitely has been accelerating
import gitpython
repo = Repo('/path/to/free-threaded-wheels')
for commit in repo.iter_commits('gh-pages'):
data = json.loads(commit.tree['results.json'].data_stream.read())
results[datetime.datetime.strptime(data['last_update'], "%A, %d %B %Y, %H:%M:%S %Z")] = sum([int(d['icon'] == '🧵') for d in data['data']])
Yeah we changed what it counts on 19th March:
https://github.com/hugovk/free-threaded-wheels/pull/17
ah I see, so it'll be continuous if I add 🧵 and 🐍 (lol, 😎 )
And earlier on 4th Nov, but doesn't seem to show up on the chart https://github.com/hugovk/free-threaded-wheels/pull/11
oh no, this is wrong, I should just treat the datasets as completely different before and after 19th March
Yeah, better that way
When that most recent incline start? Does it coincide with the new cibuildwheel?
probably, I'm re-doing the plot, bear with me...
I'm a lapsed astrophysicist trying to work with the datetime API and I'm dying a little
yeah seems to be august 1 when the acceleration starts (thanks @agile sinew and cibuildwheel folks)


GitHub
Here's a sketch of how to do this: from datetime import datetime import json import git from matplotlib import pyplot as plt repo = git.Repo('.') results = {} for commit in repo.iter_co...

PyPI has implemented PEP 792, and is now serving project status markers in its standard HTML and JSON APIs.
hello, sorry for writing in here, but I got a pypi ticket opened 8 days ago https://github.com/pypi/support/issues/7229
I gave it an unconventional title and it didn't get an answer, so 4 days ago I changed it to something more standard and it's been another 4 days and no reply.
I am writing here because I am not sure it will receive any reply even after a long period of time, did I do something wrong, do I need to create another ticket
Replies generally take a very long time
Forgot to share here as well: https://blog.pypi.org/posts/2025-08-18-preventing-domain-resurrections/

PyPI now checks for expired domains to prevent domain resurrection attacks, a type of supply-chain attack where someone buys an expired domain and uses it to take over PyPI accounts through password resets.
i'd like to take over https://pypi.org/project/deprecator/ - i created https://github.com/antlong/deprecator/issues/2 about 3 weeks agoi and the package hasnt seen any action since its inception and first release - where should i reach out

GitHub
hi, im planning to release a deprecation utility that includes tools to warn, warn via github, want for config details + manage lifecycles of deprecation - itd like to use this pypi name and im hap...
thanks, i created https://github.com/pypi/support/issues/7562

GitHub
Project to be claimed deprecator:https://pypi.org/project/deprecator/ Your PyPI username ronny: https://pypi.org/user/ronny Reasons for the request the package is practically unmaintained - untouch...

Incident report of a recent attack campaign targeting GitHub Actions workflows to exfiltrate PyPI tokens, our response, and steps to protect your projects.
FYI, there's a phishing campaign ongoing w/ the same tactics, new domain: https://blog.pypi.org/posts/2025-09-23-plenty-of-phish-in-the-sea/

A new phishing campaign targeting PyPI users using similar tactics to previous campaigns.
Definitely seems the evil-doers smell blood in the water. Success in the NPM ecosystem probably drives some of it too
https://pypi.org/project/ibus/ seems to have a release, but the release has no files. How did that happen?
Couple ways.
That particular project looks old enough it’s before uploading files was mandatory, and there was just a command to register a release independent of uploading.
But even today you can upload a release and delete the files out of it
ah
I notice pip index versions reports no distributions, so it does look a bit deeper
How big of a problem is it if a package (which has only a few kb of Python to interface to a compiled executable) is open-source but its PyPI distributions don't include a LICENSE file?
Not a lawyer, but that seems to be a legal question? What kind of problem are you asking about?
whether it actually violates any PyPI policies etc., or just community norms
the project can worry about legal for themselves
but the big news this morning apparently is that yt-dlp will soon adopt Deno as a dependency (https://news.ycombinator.com/item?id=45358980) and I noticed that https://pypi.org/project/deno packages lack a license even though there is an MIT license in the corresponding repo
The change is likely to propel the package from thousands of monthly downloads to millions
... actually I should check if they already track that as an issue...
It appears not, so I'll fix that
oh, that publishing is done externally x.x
when you upload to PyPI you agree that either the software you upload is licensed under a license that allows redistribution (but not modification, or use, or anything else) OR that you're the rights holder and you're granting an irrevocable worldwide royalty free license to PyPI and all it's users to redistribute it
so PyPI itself doesn't care
unless it's not licensed under a license that allows redistribution and you're not the rightsholder (and thus can't grant the license to redistribute)
mm
looking further, I'm not actually sure that the Deno project is aware of this packaging?
anyway, I managed to track down the separate repo for the person packaging and uploading it, and filed an issue
nice! resolved in scarcely an hour. I'm happy to have motivated potentially millions of future monthly redundant downloads of a gzipped MIT license full licensing clarity on an important package to the ecosystem
One of the uv developers recently repackaged rustup as a pypi package, so maybe yt-dlp will add a dependency on that to bootstrap a rust toolchain in a few months: https://pypi.org/project/rustup/
"in order to build our package, first install the world" moment
I have just discovered the wheel list filters, which is such a great feature, no more ^F-ing the page looking for a correct wheel!
Just a quick note that the latest PR for a PEP 694 update is here: https://github.com/python/peps/pull/4549
I've resolved every comment received so far. I intend to merge it and start a Round 3 DPO thread before the EOW (perhaps tomorrow if time permits).

GitHub
Remove the nonce and gentoken() algorithm. Indexes are now responsible for generating
an cryptographically secure session token and obfuscated stage URL (but only if they support
staged previews)....
I guess this was a joke, but there probably are a lot of people who will benefit from that package; meanwhile yt-dlp is written in pure Python
I have thought it would be nice to display wheels in a matrix (perhaps just with check-mark icons that can be hovered or clicked for more info) rather than a list
say, a separate table per Python tag, with rows per platform and columns per ABI. separate icons for not supported / supported by a generic wheel / supported by a specific wheel
that would be much less readable
The table idea is interesting, but rather than trying to resolve to single wheels, instead resolve to links to filtered file listings (so they don't need to narrow things down to single files)
Then the rows could be Python versions, and the columns platforms (including source and pure Python wheel)
simple-repository-browser has something quite similar. Live demo at https://simple-repository.app.cern.ch/project/scipy/1.16.2/files. (simple-repository-browser code itself is in need of a refactor, but implementation at https://github.com/simple-repository/simple-repository-browser/blob/main/simple_repository_browser/compatibility_matrix.py).

GitHub
A web interface to browse and search packages in any simple package repository (PEP-503), inspired by PyPI / warehouse - simple-repository/simple-repository-browser
Where can I ask a question about a potential security bug on pypi?
Thanks!
Huh....
Further research indicates this may not be a bug but actually intended behavior
What does this mean, and is there a way to somehow appeal? I redacted the rest of the name we were trying.

It likely matches an existing project name after the ultranormalization rules.
There are no special characters, just 8 lowercase letters. Where are those rules defined?
the name that it conflicts with may have special characters (eg foo-bar would conflict with your project foobar)
The project name is dotslash and I plan to immediately give it to https://github.com/facebook/dotslash after the first release. I did a bunch of work over the weekend 😅
we can release the name, email admin@pypi.org with the name and a link to the source repo you're trying to publish
@naive rune thinks he might be dealing with someone who is setting up a supply-chain attack: https://github.com/pyodide/pyodide-recipes/pull/386#pullrequestreview-3333172050
thanks for raising this here @radiant crag 🙏🏻
looking closer, I think it is a real package probably. At least the readme describes an API and this isn’t trying to typosquat msgpack. But this person is trying to advertise in a weird way. It definitely doesn’t make sense to bundle random stuff into the pyodide distribution.
true, it might be real for what the readme describes, but at the same time I would expect there to be source code and the API to be exposed as python methods rather than just inside an opaque extension module that I would rather not run on my own machine.
I ended up reporting this through the PyPI button just now based on the suggestion of a colleague at QS who is not here. Inspector is limited in this fashion as it cannot find problems in binary files, and here the attack vector (if there is found to be one) is probably within the shared object itself.
@spice hull @restive sapphire is this something that vypr can take a look at?
👋 I asked this in a few other community facing areas, but might as well ask here.
Context: I know pypi supports uploading SLSA attestations, (but they are in a slightly different format than some of the standard tools use for, e.g. Github.
I'm wondering if anyone is aware of a single package on PYPI that contains SLSA attestations? -- everything I can find in the top ~1500 packages only contains trusted publishing attestations (if that)?
For my use case, I only need to know about one package which does. Regardless of how obscure of a package.
confirmed:
$ gh attestation verify coverage-7.11.0-cp314-cp314-macosx_11_0_arm64.whl --repo nedbat/coveragepy
Loaded digest sha256:a3d0e2087dba64c86a6b254f43e12d264b636a39e88c5cc0a01a7c71bcfdab7e for file://coverage-7.11.0-cp314-cp314-macosx_11_0_arm64.whl
Loaded 2 attestations from GitHub API
The following policy criteria will be enforced:
- Predicate type must match:................ https://slsa.dev/provenance/v1
- Source Repository Owner URI must match:... https://github.com/nedbat
- Source Repository URI must match:......... https://github.com/nedbat/coveragepy
- Subject Alternative Name must match regex: (?i)^https://github.com/nedbat/coveragepy/
- OIDC Issuer must match:................... https://token.actions.githubusercontent.com
✓ Verification succeeded!
The following 2 attestations matched the policy criteria
- Attestation #1
- Build repo:..... nedbat/coveragepy
- Build workflow:. .github/workflows/publish.yml@refs/heads/master
- Signer repo:.... nedbat/coveragepy
- Signer workflow: .github/workflows/publish.yml@refs/heads/master
- Attestation #2
- Build repo:..... nedbat/coveragepy
- Build workflow:. .github/workflows/publish.yml@refs/heads/master
- Signer repo:.... nedbat/coveragepy
- Signer workflow: .github/workflows/publish.yml@refs/heads/master
or did you mean non-GH (and non-Trusted Publishing)?
I meant where the SLSA attestation itself was published to PyPI (the registry where the wheel lives) -- I'm already aware of several that produce SLSA attestations that are stored in Github. So specifically PEP-740 formatted SLSA attestations hosted on PyPI itself.
Aka: when I might see a SLSA attestation when I introspect the result from f"https://pypi.org/integrity/{pkg}/{ver}/{filename}/provenance" (I've already seen several Trusted Publishing entries from that API)
Looks like coverage has that too: https://pypi.org/integrity/coverage/7.11.0/coverage-7.11.0-cp314-cp314t-win_arm64.whl/provenance
that only has one attestation and it's a publish attestation:
$ http https://pypi.org/integrity/coverage/7.11.0/coverage-7.11.0-cp314-cp314t-win_arm64.whl/provenance | jq -r .attestation_bundles[0].attestations[0].envelope.statement | base64 -d | jq .predicateType
"https://docs.pypi.org/attestations/publish/v1"
@formal loom the reason you're not finding any SLSA attestations on PyPI is because there aren't any (yet):
warehouse=> WITH
all_attestations AS (
SELECT
attestation.value AS attestation_json
FROM
provenance,
-- Get each bundle from the 'attestation_bundles' array
LATERAL jsonb_array_elements(provenance -> 'attestation_bundles') AS bundle,
-- From each bundle, get each attestation from the 'attestations' array
LATERAL jsonb_array_elements(bundle.value -> 'attestations') AS attestation
),
decoded_statements AS (
SELECT
convert_from(
decode(
attestation_json -> 'envelope' ->> 'statement',
'base64'
),
'UTF8'
)::jsonb AS statement_json
FROM
all_attestations
)
SELECT
statement_json ->> 'predicateType' AS predicate_type,
COUNT(*) AS total
FROM
decoded_statements
GROUP BY
predicate_type
ORDER BY
total DESC;
predicate_type | total
-----------------------------------------------+--------
https://docs.pypi.org/attestations/publish/v1 | 561701
(1 row)
Ok thanks!
If a release workflow calls another where the actual PyPI upload happens, which workflow should be configured for Trusted Publishing?
Are you referring to what GitHub might call a "reusable workflow"? If so, PyPI doesn't yet support that pattern https://github.com/pypi/warehouse/issues/11096
Yes reusable workflow but in my case it is from the same repository. Would I put the caller or callee workflow, if the latter performs the uploads?
From reading a comment in the issue, it appears that it would be the callee as one would expect. Thanks Mike!
Is there a way to find out why a project was removed from PyPI? airtrain and modelcontextprotocol were removed, and had the same owner.
all this owner's projects on PyPI say:
This project has been quarantined.
PyPI Admins need to review this project before it can be restored. While in quarantine, the project is not installable by clients, and cannot be being modified by its maintainers.
Read more in the project in quarantine help article.
I think I'm missing something: how do you know their PyPI user name?
So they've all been quarantined, but I guess there's no more public information about why?
no, it's a quick measure the admins can trigger so they can check in more detail later
and I think if they get reports from trusted security researchers, that can also trigger quarantine
right, i didn't know if there was a way to get more details so that we could assess what we may have stepped into.
Huh. Never seen that
x2
presumably, it mostly happens with unpopular packages where it's luck of the draw if it runs into your use case
... from the blog:
The one project cleared was a project containing obfuscated code, in violation of the PyPI Acceptable Use Policy. The project owner corrected the violation after being contacted by PyPI Admins.
I'm not entirely sure what to think of that, since I can imagine the argument that pre-building a wheel is an obfuscation technique (for projects with non-Python code at least). Any compiled binary blobs in the wheel typically don't have source code, to my understanding. Some do provide headers but AFAIK only so that you can link against it
Presumably the obfuscated code was in the sdist.
Usually when we say "obfuscated code" we mean something like this: https://inspector.pypi.io/project/imad213insta/213.2/packages/82/b7/446b6cb134e241da6172ab5ea715aa4b324179935469bd3a995a0e2c6600/imad213insta-213.2.tar.gz/imad213insta-213.2/imad213insta/imad.py
(discord warns about that link, lol)
that's... pretty impressive.
but you know, it's possible to publish a wheel without source code at all, just pyc files that pip et al will happily install
To prevent abuse of the quarantine system, we could place a minimum requirement of Observers reporting a given Project, as well as only consider a single non-Observer report in the calculation.
my gut says: thresholds should use a constant number of Observers, but for non-Observers it should depend on the amount of downloads
as for "enough credible reports", if you want to assess credibility of reports from people who aren't vetted experts, they should be able to provide their reasoning.
(maybe that can also be part of a pathway to becoming vetted)
Where should I open an issue regarding clarification in the python packaging spec that the pep517 build-system.requires field may include git dependencies, even in dists published to pypi?
would this be opened on pypi/warehouse?
(please ping when replying)
Wait, I don't think distributions published to PyPI should be able to depend on Direct URL dependencies, even in [build-system].requires. For runtime dependencies, PyPI already rejects such requirements: https://github.com/pypi/warehouse/blame/dc1d9543ac4db87f1d0ba4d6e627f92eb0b1fde2/warehouse/forklift/legacy.py#L255-L258
This sounds like a bug.
I figured it was a security bug yeah
I reported it to security@pypi.org but was told it was not
There's nothing stopping Direct URL dependencies from appearing in [build-system].requires when not publishing to PyPI though
It's simply a list of dependency requirements, which includes abstract names and concrete Direct URL requirements.
Ah, the way you worded your question implied you wanted PEP 518 itself to be amended to clarify that Direct URL requirement may appear in the key.
Possibly? I don't think its clear that they may appear in the key, but I'll reread
The spec on PyPUG links to the version specifier spec which then contains a section on Direct References


It is confusing that the main language describing direct URL references are in the Version Specifier spec and not in the Dependency specifier spec 🙃
ah yeah, that does seem to document what I am thinking if I re-read it a fourth time
...i even linked those two headers in my email.
The specs could be better organised TBF.
Anyway. I'm not a PyPI maintainer, but this seems like something you can open an issue on the warehouse repository for.
The Astral folk were asking me about this issue a few weeks ago, it's not a spec violation it's just a question about whether PyPI should allow it or not, so it's up to them.
And FYI, nothing stops a build backend from reaching out to the Internet during installation on it's own, so it's hard to argue it opens up a new attack vector. But PyPI folks are better at security analysis than me.
It's been brought to my attention that TestPyPI can apparently sometimes leave projects up for literally years: https://test.pypi.org/project/your-package-name/
I thought packages here were supposed to be transient, intended for testing that your build and upload process works?
Test PyPI is bad at everything people use it for
It was originally (pre warehouse) a second staging instance for testing changes to PyPI itself
But since it’s a wholly separate instance people started using it for testing upload / release processes
It was never really intended for that, and now a days we don’t really use it as a staging instance anymore
So the testing a release process is kinda the only remaining use case, but it’s not really good for that
We sometimes manually purge the database
But there are very minimal differences between PyPI and test PyPI
Yeah. pypi security said non-issue
So now it's a question of can pypi clarify it's support on this lol
Did PyPI security actually say it was a non-issue? Or that currently PyPI does not inspect the contents of artifacts metadata?
PyPI does inspect distribution metadata already, no? There are many potential ways a distribution can be rejected for bad metadata by PyPI.
I dug into this further, and I don't think PyPI currently parses much metadata from the artifacts, rather only what's posted via the "form" payload in the transaction.
See: https://github.com/pypi/warehouse/blob/d029959d8198c5c0e19825e8547d8abab9f1c731/warehouse/forklift/legacy.py#L617-L622I think this kind of check makes sense if/when PyPI stores per-file metadata, see this issue: https://github.com/pypi/warehouse/issues/8090
but yeah i only shared it with security because i wasn't sure if it was a security though I figured it wasn't it did seem possible. Because backends can execute arbitrary code anyhow it doesn't really change much on the user side
i found it odd that pypi would deny regular dependencies with URLs, but allow build deps with URLs
it's not a security hole, source dists can and do download artifacts from external URLs, but it breaks the contract that packages on pypi can only refer to other packages on pypi
it should deny build deps with urls (imo), it just doesn't currently, because we don't currently introspect artifacts at all
is this tracked somewhere i can point users to?
(i can open a bug report but it feels off to point users to something that i as non-warehouse dev wrote)
uh, I'm not aware of it being tracked anywhere in particular
When my brain turns on I can probably open an issue
wait, if artifacts aren't introspected, where do the .metadata files come from and how does it know about regular dependencies using URLs?
we do some introspection of some files, notably to extract the metadata file, check if the listed license files exist, and measure the decompression ratio
ah, the latter is a heuristic for malware?
for a zip bomb, yeah
(isn't it dangerous just to attempt that measurement?)
do you mean because it would make us susceptible to a zip bomb? the actual measurement happens statically without actually decompressing the zip
ah, of course there can be separate code that does that
You may find this interesting
https://blog.pypi.org/posts/2023-11-14-2-security-audit-remediation-warehouse/#:~:text=that distribution version.-,TOB-PYPI-27,-%3A Denial-of-service

A deeper dive into the remediation of the security audit findings for the Warehouse project.
I'll open one, I meant to a few days ago when I first caught this
Is it possible to update the python_requires metadata of a Source Distribution after it's been deployed ?
pyobjc==12.0 released without Python 3.9 support, but still uses python_requires=">=3.9", causing issues downstream. I'm wondering whether that's something they can fix without yanking the release.
no, once it's published it's published. you can yank the release and make a post release instead: https://packaging.python.org/en/latest/specifications/version-specifiers/#post-releases
Would there be appetite to extend the linehaul log structure (and the corresponding bigquery tables) with a new subcommand field that would capture how the client was invoked? I think it'd be helpful for developers of package managers to prioritize improvements - e.g. how popular is pip download, pip wheel, or uv's pip interface?
Happy to open an issue to discuss specifics, but wanted a vibe check first to avoid wasting people's time.
Full disclosure: I work at Astral on uv and pyx
seems reasonable to add to details!
yeah, i'd say file away on https://github.com/pypi/linehaul-cloud-function/issues, @fiery orchid
Fantastic, will do
FYI, PyPI has added additional email verification for unrecognized devices when logging in with TOTP: https://blog.pypi.org/posts/2025-11-14-login-verification/

PyPI has added email verification for TOTP-based logins
I was wondering about this today: Is there any non-pep440-compliant packages from years past on pypi?
if you're wondering because of the #general discussion, there's some analysis in the corresponding PDO thread. In short, there are, but they're fairly rare and probably all quite old.
https://discuss.python.org/t/_/104885/21
(Ah, I guess summarizing it myself is redundant)
Discussions on Python.org
Providing some further context - or possibly just mild interest - I wondered how many packages even have not-valid versions. I checked the top 15,000 per GitHub - hugovk/top-pypi-packages: A regular dump of the most-downloaded packages from PyPI and found 55 packages with invalid versions, the most recent uploaded in 2014. (Possibly pypi requi...
Since packaging does not support metadata version 2.5 yet and I did not find a package with this metadata version during a quick search on PyPI, I was wondering if PyPI does support this version already?
Two contradictory data points:
- I was able to upload a package with metadata version 2.5 to TestPyPI: https://test.pypi.org/project/poetry-core-pep794-test/
- I found this line, which does not include 2.5, in the warehouse repo: https://github.com/pypi/warehouse/blob/b70f937c42d33f71c27b474135a036f3829151ab/warehouse/forklift/metadata.py#L26
my builds are getting rejected:
error: Failed to publish `scripts/packages/built-by-uv/dist/built_by_uv-0.1.0-py3-none-any.whl` to https://upload.pypi.org/legacy/
Caused by: Upload failed with status code 400 Bad Request. Server says: 400 '2.5' is not a valid metadata version. See https://packaging.python.org/specifications/core-metadata for more information.
are you sure that the upload is setting 2.5 and not 2.4 in the form-data?
That is the explanation. I used an older tool version to upload it and it set 2.4 in the form-data. (Seems like a sneaky way to smuggle new metadata versions early. 😅 )
wait, PyPI isn't actually inspecting the METADATA/PKG-INFO file? It expects tools like twine et. al. to set an HTTP parameter?
yup
that... seems bad

GitHub
The Python Package Index. Contribute to pypi/warehouse development by creating an account on GitHub.
i suspect this predates sdists having widespread (for some definitions of widespread) machine readable metadata
That would definitely make sense.
Lol I didn't notice general I just wanted to see if I could break any dependency manager packages
Yeah pypi validation seems to just be inspecting the upload itself rather than the files. Just trusting the provider 🙃
well, installer tools validate it anyway so I assume it's never caused a big problem. It also wouldn't happen with ordinary use of twine etc., so.
@merry valve
yes, that's it, thank you!
is there a way to view file deletions? i'm having a curious uv bug that would make a lot more sense if a file was deleted from pypi https://github.com/astral-sh/uv/issues/16841
no but we could check for you
I believe you could cross reference the XML-RPC events for a project and what is there right now. But having someone check is probably easier and definitely accurate :)
@unborn nacelle doesn't seem like that file ever existed, these are all the wheels that've ever been uploaded for that project (including deletions):
warehouse=> select filename from file_registry where filename ilike 'lgpio-%.whl';
filename
------------------------------------------------------
lgpio-0.2.2.0-cp310-cp310-linux_armv7l.whl
lgpio-0.2.2.0-cp311-cp311-linux_armv7l.whl
lgpio-0.2.2.0-cp312-cp312-linux_armv7l.whl
lgpio-0.2.2.0-cp39-cp39-linux_armv7l.whl
lgpio-0.2.2.0-cp310-cp310-manylinux_2_34_aarch64.whl
lgpio-0.2.2.0-cp311-cp311-manylinux_2_34_aarch64.whl
lgpio-0.2.2.0-cp312-cp312-manylinux_2_34_aarch64.whl
lgpio-0.2.2.0-cp39-cp39-manylinux_2_34_aarch64.whl
lgpio-0.2.2.0-cp310-cp310-manylinux_2_34_x86_64.whl
lgpio-0.2.2.0-cp311-cp311-manylinux_2_34_x86_64.whl
lgpio-0.2.2.0-cp312-cp312-manylinux_2_34_x86_64.whl
lgpio-0.2.2.0-cp39-cp39-manylinux_2_34_x86_64.whl
lgpio-0.0.0.1-py3-none-any.whl
lgpio-0.0.0.2-py3-none-any.whl
(14 rows)
I thought it might be on piwheels, they do appear to build Python 3.13 wheels there, but I don't see an aarch64 wheel there: https://piwheels.org/project/lgpio/ (but maybe it was deleted?)
Linux SBC GPIO module
Linux 6.12.47+rpt-rpi-2712 is for the raspberry pi 5 so seems pretty likely that index was involved
Version 7.0.0 of bandersnatch defaults to using PEP691 v1 JSON API and no longer needs the xmlrpc APIs (but support is still there via config)
- Should we start a deprecation plan for them to finally turn off the xmlrpc APIs?
As people upgrade we should see xmlrpc usage go down ...
Thank you for checking!
Hello everyone, latest mystery I came across about PyPI stats, I'd be curious if someone has insights into this 🙏!
Here is the mystery:
- there was a big spike of downloads in scikit-learn on November 19 (from 4-6M/day to 40M/day). See pypistats.org dashboard, clickpy dashboard and screenshots below.
- amongst the scikit-learn dependencies, scipy and threadpoolctl show a similar spike, numpy and joblib don't 🤔. I checked a few other popular packages and could not find any that show a similar peak.
- during the peak it's mostly Amazon Linux 2 downloads. I looked at the Google BigQuery database that has the Linux distribution information.
- the spike happened the day after the Clouflare outage (November 18), could this be related somehow? I don't have a good enough understanding of the cloud so this may be a naive hypothesis 😅
- in terms of timing the peak happened on November 19 4am-12.30pm UTC (from a quick look at the Google BigQuery database), in case it rings a bell of something weird that happened during this time period ...
- any other suggestions/guesses 🔮?
If you are curious about other weird things I have discovered along my PyPI stats journey, here are the slides for my talk "PyPI in the face: running jokes that PyPI download stats can play ou you". I gave it at a few conferences this year (last one was at PyData Paris).



PyPI Download Stats
Suppose I wanted to offer a drop-in replacement for something listed in https://peps.python.org/pep-0594/ that doesn't already have an alternative; is there a convention for how to name the distribution to comply with e.g. PEP 541 rules and avoid confusion?

Python Enhancement Proposals (PEPs)
This PEP proposed a list of standard library modules to be removed from the standard library. The modules are mostly historic data formats (e.g. Commodore and SUN file formats), APIs and operating systems that have been superseded a long time ago (e.g. ...
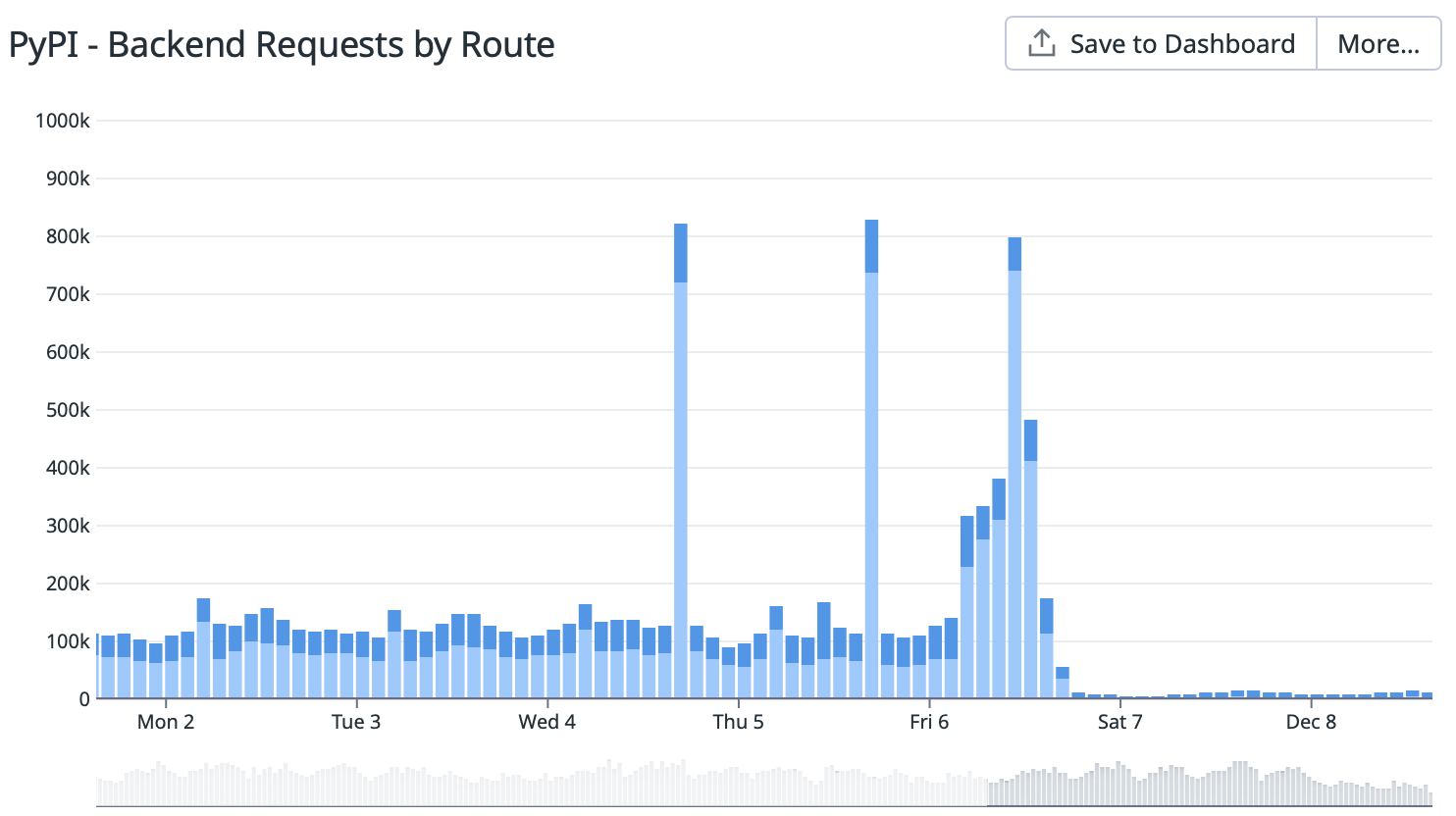
PyPI Backend Requests (req/sec) - Is that the best to watch on the public dashboard here for xmlrpc calls? https://p.datadoghq.com/sb/7dc8b3250-85dcf667bd
last I have seen was cgi replacement called legacy-cgi, so maybe that?
cool. (my actual use case is binhex, removed earlier, but either of those naming conventions works I suppose)
Depends on whether the call was cached or not, but generally speaking, yes.
However, the current total xmlrpc calls hitting the backend is around 2 requests per second, so I don't think it'll be that noticeable
What’s the cache settings and when was that implemented? It was once uncached right for a long time?
Is it same as Simple API per chance? If so I’ll remove my disadvantage that simple is more cached than xmlrpc
@finite pulsar Thanks for the excellent suggestion that PEP 694 follow RFC 9457. PTAL: https://github.com/python/peps/pull/4733/files

GitHub
As per suggestion: https://discuss.python.org/t/pep-694-pypi-upload-api-2-0-round-2/101483/32
@woodruffw for review.
📚 Documentation preview 📚: https://pep-previews--4733.org.readthedocs.build/
thanks, i'll try and look today!
Just noticed the new donation banner. FWIW I paid to join the PSF in response 🙂
Hello,
I'm reaching out because the talon-v3 package, which is a library from Mailgun for parsing emails, seems to have been removed from PyPI very recently.
Was the package deleted by the maintainer (Mailgun) or was it removed by PyPI admins for a security or policy reason?
Any official confirmation or link to a public statement would be extremely helpful as I could not find any.
PS: If there is specific channel for this kind of query, then please lmk.
What happens if a developer of a library abandons a pypi project, does the name stay occupied for the rest of eternity?
Python Enhancement Proposals (PEPs)
This PEP proposes an extension to the Terms of Use 1 of the Package Index 2, clarifying expectations of package owners regarding ownership of a package name on the Package Index, specifically with regards to conflict resolution.
Ty
looks like it was removed by the maintainer on 2025-12-11. FYI, it doesn't look like the maintainer was mailgun, it was this user: https://pypi.org/user/ltd412/
I noticed horizontal rules on project pages have a neat style, including:
background-image: linear-gradient(90deg, rgb(211, 211, 211), rgb(255, 255, 255))
is that new?
Only since 2018: https://github.com/pypi/warehouse/blame/42f26aeaa99906d3b607b0bdb2194b19eed2add7/warehouse/static/sass/base/_typography.scss#L192 😉
GitHub
The Python Package Index. Contribute to pypi/warehouse development by creating an account on GitHub.
heh
it looks nice
I didn't realize you've been involved that long, either
PyPI overall looks nice, but in a boring sort of way where you don't readily notice the details. Which is probably even better
In an age of tacky over the top websites, I think that's a pretty damn good compliment
PyPI is quite the amazing piece of infrastructure if you think about it. It's owned and operated by a nonprofit, developed for and by the community.
/end pypi appreciation post
Not the same, simple is 1 day/10 minutes - https://github.com/pypi/warehouse/blob/f59df186dc62274b5831a72f639a1e92bbe3f94c/warehouse/api/simple.py#L52-L96 and xmplrpc was 2 days/1 hour - so if anything, simple is fresher
O wow, let me update bandersnatch’s docs … might tag you guys n the PR to double check I get it right.
Thanks
Well, that's not suspicious at all.
@glad trench Hi, I deleted your message since it is highly suspicious to drop random archives without any context. If you have a genuine question, please state that and host your archive on a platform where we don't need to download and extract it (e.g., github). Thanks!
(Not sure who pinged me, but thanks for the notice! I did delete the message promptly, but once I got around to checking the archive, it was actually fine.)
I pinged the admin role, as you said, that message was HIGHLY suspicious
tarballs belong on the big pypi, not this one

Thanks
The yank API is also failing
(We have a release that failed part way through hence trying to recover at the moment)
yank API?
We can't yank the release (it hangs then fails with a 503)
Yeah sorry API in the sense that when we attempt to perform a yank via the UI it does not succeed
+1 Im also seeing errors uploading distributions. The errors I've encountered so far include 502 Bad Gateway, an error from my build backend authenticating with PyPI over OIDC through a trusted publisher in GH Actions, and finally a 400 Bad Request.
Looks like a Resolution was posted only 3 minutes ago, Ill go try again
(Working for us now!)
Hm Im still seeing a 400 Bad Request, let me try to verify it's not the build backend
Can anyone help here? Im trying to publish by hand now, and the API response suggests Im uploading a file that has already been uploaded and since deleted, but I never had a publish of this version succeed. I think this is the root of the 400 error Im seeing on GitHub Actions:
[PublishError]: Client error '400 This filename was previously used by a file that has since been deleted. Use a different version. See https://pypi.org/help/#file-name-reuse for more information.' for url 'https://upload.pypi.org/legacy/'
Is it possible that an upload made it most of the way through before the incident interrupted? Is there a way to clean it up?
probably the DB got updated with the filename and the file was not actually uploaded
yeah unfortunately it seems that way, I wonder if that's something that admins can clean up
@merry valve might have some insight? Im not sure the proper channels so forgive my intrusion
<@&815744082823348274> Suspicious attachment
They've been banned for the 2nd violation.
Without further information like what project or filename, more investigation would be hard. There's an issue tracker on GitHub that is a decent place to start
Thanks! I went ahead with a 1.0.1 release since 1.0.0 was unavailable so there's no need to go backwards now, but if something similar happens in the future I'll open an issue
Has anyone gone through the process of transferring a package before? We have a package <company_name>-<qualifier> but people keep accidentally installing <company_name> and the current package owner is willing to transfer (since that package hasn't been updated in ~7 years).
Any things to watch out for/best practices? I can find PEPs on how to grab abandoned projects but not how to make a handoff like this smooth.
Generally just
- They add you as an owner
- You remove them as an owner
- You publish a release of your package
- You yank all the old versions
You should of course make sure they're okay with all that up front
Also it's worth noting you can't re-use any version numbers they've used
even if you delete the releases
I got bit by that last part for ty 0.1.0 😄
I forgot that I had deleted the release
or 0.0.1*
one of these days I will make a joke beanie baby package but it will have a much longer name
Thanks! I was aware of not re-using version numbers. I was thinking of them marking the project as archived so people get notices about it since that seems to be recently supported, give it some time then hand it off to us for the rest of the approach. Then we'd probably archive our <company_name>-<qualifier> to avoid the reverse confusion.
props to the team for the https://warehouse.pypa.io/development/getting-started/#logging-in-to-warehouse . i'm new to the project, and this is def one of the best onboarding experience for dev to get this up and running locally.
Thanks, so awesome to hear that!
i see that https://docs.pypi.org/api/index-api/ mentions an X-PyPI-Last-Serial response header. it would be very useful to standardize a serial number as well as e.g. a timestamp as a method of selecting particular subranges of uploaded content. in particular it would improve pip performance if it could request uploads for a package since the last serial number pip recorded for a fetch
i'm very confused about pypa/bandersnatch prominently mentioning PEP 381 while PEP 381 itself says it was withdrawn https://peps.python.org/pep-0381/#pep-withdrawal. one curious distinction between pip and a mirror is that pip really only needs a package's checksummed fetch URL and its METADATA
i also would love to know if pypi would be interested in serving PEP 566 json-format METADATA at the URL specified by PEP 658. pip currently implements the PEP 566 transform by hand for our pip install --report format https://pip.pypa.io/en/latest/reference/installation-report
q: how long does it typically take to get an org approved? I am trying to make an org just for testing with / to publish an example project under as I work to add a new trusted publisher? Is it required to pay for the org under those circumstances? Or should I be doing things differently? any guidance welcome.
we're generally around 2-4wks behind. Account Recovery, PEP 541, and other limit requests take priority from our Support Engineer who reviews
we're also digging out of the hole from the end of 2025 vacations
cool thanks. no urgency just wanted a sense of it.
I'm just now hearing about https://www.aikido.dev/blog/malicious-pypi-packages-spellcheckpy-and-spellcheckerpy-deliver-python-rat . Is this a) legitimate and b) previously known to PyPI folks?

Attackers published fake spellchecker packages to PyPI with malware hidden in plain sight. We break down the attack and what developers need to watch for.
There don't appear to be public listings for the packages in question, but I can't confirm whether they were taken down in response to a report, or never existed in the first place

A) yes, inasmuch that folks put up packages with malware like this all the time, and a small portion gets written about, often by folks with a security product to sell you. B) yes, that's how they get removed most of the time
good to know. I assume the "small portion" is more or less random
Kinda what I do for a non-trivial portion of my day to day
Of the 361 takedowns from the past 30 days, only a handful have been written about
good to know
Small bit of good vibes to share:
I finally got billing sorted out at work, and have been setting up my work's PyPI Organization this morning. It's a delight to no longer have my user listed as an owner on legacy packages we stopped publishing in 2015! 😁
As countless people have thought, and many have said, thanks a bunch for the Organizations feature set! 🎉
One thing a couple of my coworkers hit as we transferred projects: when you make the org an owner (and lose your owner role), you get a 403 because the UI reloads on the permissions page for the project. It might be better to send them to the public project page in such a case. We understood it each time, but it was a surprise.
q: pypi-attestation - tbh not sure where this q should go? So if I need to sign python package, its recommended to just sign with a python script that uses the pypi-attestation vs using cosign cli tool?
Recommend using pypi-attestations, it wraps sigstore-python, unless you need an implementation in a different language for some reason
More details here: https://docs.pypi.org/attestations/producing-attestations/
kk thanks. yeah, trying to understand how its working, since I am trying to add CCI to it. Is the note in the readme about NOT using it in CLI mode still valid? ( CLI is intended primarily for experimentation, and is not considered a stable interface for generating or verifying attestations) . looking at the examples, it looks like they are showing python -m... which I consider 'cli'
CCI?
sorry. CircleCI. relates to https://github.com/pypi/warehouse/issues/13888

GitHub
Per https://circleci.com/docs/api/v2/index.html#tag/OIDC-Token-Management, CircleCI now supports a customizable aud claim which means we could support it as a trusted publisher. This is likely bloc...
yeah I think that warning is a bit stale, you can probably consider it stable at this point
Should I just remove that bit as part of my pr?
@finite pulsar what do you think?
it's technically not stable, but i think the ship has sailed on us breaking it without going through a long deprecation cycle + major release anyways, so i'd say go for it 😅
cool thanks that helps
follow up question - i have just learned we actually are gonna have a new thing to actually publish. 😄 So is there something I need to do to do payment? or is the flow get approved first, then I can Activate Billing? (i noticed that button when i was working locally on warehouse), Unfortunately I can't update the message I put in my application (afaict)
approved then payment.

There's even more work underway to improve https://github.com/pypi/warehouse/pull/18982
GitHub
Continuing #18741
Additions:
Update url based on the selected filters.
Limit the filters based on what the user has already selected.
Provide quick option to reset the filters ("Show all f...
q: when developing warehouse locally, I need to install a copy of pypi-attestations and id from a github repo, since they are not yet published.
So I add these to main.in, try to make requirements/main.txt but I get an git not installed message in the error.
So what is the right way to do this while developing? Is there a different way to go about testing with unpublished packages?
Since we usually want to avoid extra dependencies, you could temporarily add git around here: https://github.com/pypi/warehouse/blob/8ddc53f0100653800bf28126abfa20f3301c669d/Dockerfile#L219
Just don't ship that for reals
GitHub
The Python Package Index. Contribute to pypi/warehouse development by creating an account on GitHub.
Something I saw that I stole for later:
Git links require, well, Git
git+https://github.com/letsbuilda/imsosorry.git
But you can copy the link from the “download zip” button and pip doesn’t need Git to extract a zip
https://github.com/letsbuilda/imsosorry/archive/refs/heads/main.zip
thanks. thats what i thought. i'll go back to read the stack trace. it was pretty late so i probably messed something else up in that case. was failing to import on db operations on startup so I thought it was still failing to find my package
oh thats handy. i'll test that method out as well.
This the sort of info I could add to the dev contributing guide? (or was it already in there and i missed it?)
Hi everyone, I'm new here. I'm seeking help with an issue I'm having.
I created a package called orchestral-ai and released it on PyPi last year. Everything was working great and people in my field were using the package. But as of last week my package has disappeared from PyPi and I can't log into my account.
When I try to log in I see a message saying "Sorry, something went wrong, PyPI is down for maintenance or is having an outage." which is obviously not the case. I did not knowingly violate any pypi rules and have a legitimate python project (orchestral-ai.com).
I can't find any resources for reaching out and getting this resolved. I was hoping that someone here could point me in the right direction!
Any help is appreciated! Thanks so much!
PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
Does it make sense that I would be unable to log into my account if this were the case? I also didn't receive any email communication from PyPi about this which seems strange.
I can see the project is in quarantine from the PyPI page
I assume yes you'd be locked out of your account, but I'm not a PyPI admin so I don't know
Ahh thank you! That's very helpful, now I at least know what to search for. I'll try to contact the admins
Is it possible to upload older versions of a package after newer ones? Say for example I forgot the older ones initially, or I'm trying to reconstruct them from a broken Git history where the tags were lost/inconsistent and I don't get it working until later.
I've seen many project maintain multiple branches, e.g. 1.x and 2.x, the 1.x stuff all shows up beflow the 2.x stuff
and the upload dates don't cause problems for tools (although I'm not sure how they would)? good
Yea tools generally don’t care about upload date. The worst that would happen is some tools provide a flag to skip files newer than X
Yeah, and the purpose of such flag is to provide some level of consistency between runs on the user side, so they would intentially not want newly uploaded packages even if they are older
👍
Aside from actual malware, is there a reporting mechanism (or should it not be reported) for apparent name squatting or test packages (package inactive for years, with no apparent meaningful functionality, empty or useless readme etc.)?
About Michael Winser's FOSDEM talk, which covered PyPI https://www.theregister.com/2026/02/16/open_source_registries_fund_security/

fosdem 2026: Free beer is great. Securing the keg costs money
In PEP 825 thread, there was a request to increase permitted variant label length from 16 to 32 characters: https://discuss.python.org/t/pep-825-wheel-variants-package-format-split-from-pep-817/106196/13. Could one of the PyPI admins respond to this? (I don't recall who brought the filename length as a problem before.)
In PEP 825 thread, there was a request
A lot depends on why you're reporting it - if you want the name, file a name retention request. if you want to surface the issue of mass name squatting, there's also an issue type for that, although they are super low priority.
I'm curious about "inactive packages" since there's no policy that packages need to be updated that I'm aware of. Some folks upload their homework to PyPI (super weird, but whatever) - so there's often got to be a compelling reason to take something down.
See https://peps.python.org/pep-0541/#invalid-projects and https://policies.python.org/pypi.org/Acceptable-Use-Policy/ for more
I guess this is a "mass name squatting" except the names squatted don't make a lot of sense to value. and it's... 7 projects
(actually I would like one of the names, which is how I discovered it, but...)
this still uses the pypi/support Github issues, yes?
Just to verify, non-normalized sdist names are now blocked from upload? Filename 'openbabel-wheel-3.1.1.23.tar.gz' is invalid, should be 'openbabel_wheel-3.1.1.23.tar.gz?
@agile sinew https://github.com/pypi/warehouse/issues/12245

GitHub
What's the problem this feature will solve? PEP 625 has been accepted, PyPI should be updated to support the PEP. Describe the solution you'd like PyPI needs to implement some changes to su...
Okay, good to know, thanks! Scikit-build-core normally promises no changes if you set a min version, but I think I'll drop the pre 0.5 behavior for this then, and always normalize (0.5 added the normalization)
I tried to do a release for brotlicffi this morning and the upload failed because the release automation pointed at the master branch of gh-action-pypi-publish. Is the correct fix what I've done here? https://github.com/python-hyper/brotlicffi/pull/222. I guess I could test this in my fork with test.pypi.org but I'd rather not go to the trouble of setting all that up but unfortunately I don't see another way to test this.
as another thing, you could switch from a long-lived token in repo secrets to Trusted Publishing
I think all of this was set up a long time ago and then never touched. I just got permissions to update this stuff this morning. But maybe better to take the opportunity to migrate to trusted publishing now.
yeah, I think it's worth it, given the recent news about GHA security
I see Seth is the only maintainer at https://pypi.org/project/brotlicffi/, you can ask him to set up the stuff on the PyPI side, or maybe better, improve the bus factor and add you to PyPI as well
Yeah, he's been slowly adding me to things 🙂
It's on-board with standards and such if I publish wheels that are "pure Python", for any platform, but specific to an individual version, yes? And I can do so in addition to a py3-none-any wheel?
as long as all 3 parts are valid within standards, you can publish whatever combinations you might want
the other thing is, do I need to have .py files in every wheel for TOU purposes?
A project I'm working on right now precompiles Python code and I wanted to make distributions that contain just the precompiled version
(it does more than that actually, but that would be the sticking point)
that is fine, it would be a valid wheel
kind of an annoying thing to do if you are gonna publish the wheels, but if it's just for internal consumption, I don't see any problem
Hey, I'd like some help getting https://github.com/pypi/warehouse/pull/19048 through. First, it is ready for review. Second, I could use some guidance on the deploy and test
GitHub
This attempts to implement #18882.
The automated tests are all passing, but I don't have confidence this actually works because I don't know how to test the actual integration. I ha...
question - is it preferred to rebase off main for prs? or just merge main into branch? I'm asking because I specifically get translation .pot file conflicts regularly now (every few days) so I rebase. but wanted to check if there's a preferred flow.
hey @fading halo i can help answer this - i went through it myself. From your pr description, it sounds like you are having an issue testing your changes against semaphore? like you want to try to publish from a real pipeline?
What I did in my case, I ran my warehouse instance on my local machine (make serve). Then you go through, setup the trusted provider. Then I used tunnelmole to setup a path into my machine, and used that as the destination - you can see example here of what i did https://github.com/meeech/sign-and-publish-examples/blob/pypi/.circleci/pypi-publish.yml#L70 and I was able to successfully test my work (you could use ngrok, or there's probably a few other similar options)
is static lint supposed to be restricted? when it tried to run on my pr its failing with a 401?
Warehouse does squash merges (and only squash merges), so it doesn't matter to Warehouse how you handle updates to a PR like that, it'll be squashed, so do whatever is easier for you pretty much.
i will start using the update button more in gh then. i been constantly rebasing
community etiquette question: I know people are busy, so trying to be mindful of that, whats a good amount of time to wait before bumping for a pr review? (on a pr that's had some back and forth?) or is there a better way?
Is there any writeup post/reasoning/docs about why the fastly client verification was introduced? Wanted a source to be able to reference
Discussions on Python.org
This less than ideal outcome is indeed the result of needing to protect PyPI against automated/scripted access/scraping. Over the last week we saw a dramatic increase in this kind of activity against the (relatively) expensive to serve project, release, and search endpoints. Worse, this activity was coming from over 1000 unique IP addresses wit...
Thanks
Does anyone know a good way to work on "General alignment w/ error messages vs. what PyPI uses" for https://github.com/pypa/packaging/pull/1113 ? Not sure what to look at to compare.
GitHub
This builds on #409 and #1009 to add a packaging.filenames module.
Compared to #1009, this:
Avoids inheritance and removes the Filename.from_filename method, which isn't usable without man...
responded
Thanks! Where are these error messages for PyPI?
GitHub
The Python Package Index. Contribute to pypi/warehouse development by creating an account on GitHub.
Thanks!
CMake 4.3.1 is partially uploaded and I don’t have permission to delete or yank as a maintainer (hit limit at https://github.com/pypi/support/issues/10002)
I wish it checked the remaining size before starting the upload!

GitHub
Issue tracker for support requests related to using https://pypi.org - pypi/support
It does check technically:) but every file is its own upload
super nitpicky but you hit my OCD
Out of space on PyPI #692
We are out of space on PyPY
FWIW skip existing doesn’t really matter on PyPI
If you reupload the same file (same hash; etc) PyPI just silently accepts it and no-ops it
Did it always do that?
I've had it set because years ago I had a flaky release process and I was getting kickbacks from existing artifacts
It did not always do that, but it’s done it for awhile now

GitHub
Here is a very naive attempt to address #2284. I'm not sure this is the right direction for this fix, but really want to help out.
Ignore duplicate files when uploading, instead of throwin...
Is there a reason that removing a PyPI token requires a password but creating one doesn't?
Are organization requests on test.pypi.org looked at, at all? I was thinking I could replicate the permissions from my org on regular pypi.org for test purposes but I saw that you still have to make a requests for an org, just like on regular pypi.org
(to be clear, this isn't really that important)
i'm 99% sure both creating and removing an API token require reauthentication, you may have just been within the reauth window (there's a timeout within which it won't re-challenge you for your password if you've already been challenged recently)
context:
the flow was:
- I tried to delete a token.
- It asks for password.
- I do not give the password because it gets me curious about token creation.
- I try creating another token.
- I manage to create it without a password.
With that said, I may have been within the reauth window, but if so, it wold suggest that deletion asks for password regardless of that window.
hmm, so you didn't enter your password in the deletion flow? had you entered your password in another auth challenge flow before that?
may have been within the reauth window, but if so, it wold suggest that deletion asks for password regardless of that window.
what threat model are you envisioning here?
Nope
after you saying it's only due to a reauth window, I don't
Just wanted to add context that deletion seems to ask regardless of the window
I'd expect it not to ask to be honest
but ye, thank you for explaining, it makes sense!
np! thanks for raising this, i'll try and trace down why you'd see that behavior
from a quick look the reauth/challenge behavior only happens every 30m including the login event, so if you had logged in <30m prior you shouldn't have received any auth challenges at all
clicking on delete button was definitely less than 30m after logging in
I imagine the popup that prompts you for confirmation probably just happens to have the password field in it which I imagine is unlike other actions that only ask you for password after you make a request outside the window through a redirect

that might not be the re-ath thing that @finite pulsar is thinkign of
it might just be a confirmation box
yeah, I'm not really sure why that's there - it predates me by a long time (and issue.) I suspect it could probably be removed/replaced with a confirmation on the token name instead?
ah yeah, confusingly that's not the same thing!
the reauth is a totally different flow 😅
These modals are a confirmation dialog for destructive actions, usually we have the user type the name of the thing they're destroying, but since that's hard to do here, that's why we have the password instead
You can't delete a yanked release. That seemed like a good way to free up some space in cmake. You can un-yank then delete, though. 🤷♂️
I manually unyanked then deleted all of them, slow but works.
Still not important but with the discussion about my other question, this one might have gotten lost with other messages so wanted to reask it
They don't get routinely reviewed, as far as I know. But if you email in to support requesting the same org as you have on PyPI, that request should eventually be answered
Signal boosting: https://blog.pypi.org/posts/2026-04-02-incident-report-litellm-telnyx-supply-chain-attack/

Python Package Index shares insights and provides guidance following LiteLLM/Telnyx supply-chain attacks
Any chance to get maintainer review on this? or anything i can do to help that process forward? https://github.com/pypi/warehouse/pull/19349 i think its ready and the context is slowly leaking out of my brain :D. there is still a followup to add auto attestation, but would like to get this out and into test.pypi.org at least if possible?

GitHub
#13888
Related PRs:
pypi/pypi-attestations#166 Add CircleCI to pypi-attestations
meeech#1 Stacked pr off this one - integrates attestations. Question: would it be better to just merge this into hav...
my review time is at a premium right now, so I've been deferring this as it's non-trivial and may take a couple of hours to review effectively, and security incidents take priority
cool. just wanted to check in.
and understandable re sec incidents
I'm proud to announce we did pretty well on the PyPI second external audit
https://blog.pypi.org/posts/2026-04-16-pypi-completes-second-audit/

We are proud to announce PyPI's second external security audit.
https://github.com/pypi/warehouse/pull/19804 is still waiting, I think. We are releasing a packaging 26.2 with fixed support for pyemscripten soon, but I don't think this depends on that
GitHub
PEP 783 was accepted, so this adds PyEmscripten support.
I moved a project into the Astral organization and https://pypi.org/org/astral/ is stale / not updated, just fyi.
PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
William filed an issue https://github.com/pypi/warehouse/issues/19911
If you wanted to take a crack at it

GitHub
Describe the bug The Astral org has at least 4 projects enrolled against it, but only three are currently rendered in the /orgs/{orgname} view: (Specifically ty is missing, even though it was added...
I'm seeing new failures in TP publishing from GitLab. I think one of them is due to PyPI and the other may be due to my rehoming some projects to a GL group (for their new OSS licenses). Take a look at this pipeline failure:
https://gitlab.com/flufl/flufl.lock/-/jobs/14094058681#L124
And notice the last error message:
id.AmbientCredentialError: Token audience claim mismatch (expected PYPI, got pypi)
These instructions: https://docs.pypi.org/trusted-publishers/using-a-publisher/#gitlab-cicd clearly say to use aud: pypi. When I changed it to aud: PYPI I didn't get the failure.
Is this an intentional change? If so, we should update the docs at least, but maybe also consider accepting aud: pypi for backward compatibility.

GitLab
NFS-safe file locking with timeouts for POSIX systems for Python.
Even after changing that, I get a second, different 403 error: https://gitlab.com/flufl/flufl.lock/-/jobs/14094095701
I'm guessing this is related to the GL project transfer from the warsaw (personal) namespace to the flufl (group) namespace, since I've published this package many times before with TP. I did add a GL publisher for flufl/flufl.lock and left warsaw/flufl.lock but no dice.
GitLab
NFS-safe file locking with timeouts for POSIX systems for Python.
This error appears to be surfaced by the id library, before it even gets to exchange the token with PyPI, probably due to the uppercase aud: PYPI as you've noted.
I agree this is a little confusing, since there's both an uppercase and lowercase "pypi" value here - the id library is looking for an input from the cli (you're passing it "the manual way" via oidc_token=$(/tmp/publish/bin/python -m id PYPI) <= that should be lowercase pypi , so that when this code runs it gets the "right" envvar: https://github.com/di/id/blob/45316af38e9e5dc1eb50bd384ec1b247d3e103c2/id/_internal/oidc/ambient.py#L317-L318
I suspect this has the same issue, since the input hasn't changed: https://gitlab.com/flufl/flufl.lock/-/jobs/14094095701#L108
Looks like the necessary change is needed in two places:
- https://gitlab.com/flufl/gitlab-ci/-/blob/9ae7740349d8f08608357dc17ea5b4ad43394242/common-gitlab-ci.yml#L131
- https://gitlab.com/flufl/gitlab-ci/-/blob/9ae7740349d8f08608357dc17ea5b4ad43394242/common-gitlab-ci.yml#L145
It alos looks like this is "the old way"? twine can now handle a lot of the excahnge logic itself so you don't have to: https://docs.pypi.org/trusted-publishers/using-a-publisher/#gitlab-cicd
Thanks @tribal sedge - I'd been trying a bunch of things, and then noticed the "new way" using twine. Switching back to aud: pypi and then just using twine upload does the trick! Glad to not have to roll my own anymore.
@tribal sedge, sorry about the reports I caused. I didn't really expect people would go out of their way to start reporting stuff when I asked.
Thanks! Give people a button to push, I am never surprised when they push it 😉
I do feel like there's an inherent risk to typo-squatted names even if there's currently no malware. Even if there's no future intent for malware, I can imagine people naming a package like that just to, say, try to get lots of downloads and put download stats on a resume or something.
On the other hand, it's easy enough to end up coining a similar name honestly. For example, the person who made the turtle package back in the day (nothing to do with TKinter turtle graphics!) seems to have had perfectly good intentions, and a reasonable rationale for choosing that name. I struggle to imagine an honest thought process behind panadas (to take an example from the thread), especially without a README, but I can't exactly rule it out either.
(That package seems to contain some scrap work implementing the basics of neural networks, perhaps following someone else's tutorial...)
numpee is my favorite joke PyPI package, sometimes typosquats are fun
you can depend on numpee if you insist on pronouncing it that way :p
Heh. Seems like the wheel contains an unintended Vim temporary file though x.x
hi all, we have a bit of an odd situation relating to the zarr project on testpypi. One of our maintainers registered testpypi/projects/zarr several years ago (good) but they are not responding to requests to add the rest of the zarr dev team to that project (bad). They are responding to requests in general, but somehow this specific request isn't working. Is there a way we can fix this without relying on this particular maintainer? I opened a ticket over in the pypa issue tracker, but that never got triaged (and the maintainer in question did respond to that issue, although merely -- this person did not follow up by doing the actual thing we need.

GitHub
Project to be claimed Zarr: https://test.pypi.org/project/zarr Your PyPI username d-v-b: https://test.pypi.org/user/d-v-b/ Reasons for the request Hi! I'm an active zarr-python developer. We ar...
I don't know what the blocker is for this maintainer but evidently something is preventing them from adding the rest of zarr-python devs to testpypi 🤷♂️
Hello! Over in CPython, we (i.e., at least I;-) frequently use Victor's scripts (see Hugo's blog post on them) for grep'ing the top PyPI packages (for various reasons, generally to see how much use a feature has before we slash it), but it is always a bit painful to use as it requires downloading several GBs of source. I'm wondering if someone has created something like grep.app which can be used on the web to make this easier?
There was py-codes but it looks like that was abandoned/hacked. I've been thinking of setting up something like grep.app for PyPI
I've been thinking about writing something too, my main blocker is the cost of hosting:-/
that is usually the issue
Yeah, we could always try push the limits of static sites;-)
actually, how much space the artifacts take up?
IIRC top 15000 was around 12 GB.
Yeah I'm imagining aggressive caching and trying to make things as static as possible
~~ Also, probably best to move this to #general ~~ I guess this is about pypi so maybe on topic
I don't have a set on this machine, but from my post:
At the time of writing (2022-12-09), it took me just under 27 minutes to download 4,748 files, taking up 5.37 GB of space.
so 15k ~= 12 GB sounds about right
Yeah I expect it has at least doubled if not more from then
Maybe I'll spend some time this weekend setting this up because I'm curious
Also, from what I am seeing, the script has no notion of caching or checking if the artifact is already present on disk
I do think downloading wheels is probably a good idea as well?
depends. doesn't allow you to check for C API stuff
unless you only care about the python files
Sure, but not all projects ship sdists (will have to see how many of the top 15k)
Yeah it won't give you info about C usage but might about Python usage
Plus you can look at symbol names in binaries
Back then, 5000-4748 = 5% missing sdists
is there a good reason for a Python-only project to ship an sdist?
because usually the canonical artifact downstream redistributors use as the source of truth for their builds is the sdist
that said, there’s isn’t a huge practical difference between a pure python wheel and an sdist
an sdist is where I'd expect to find included test files, docs, etc - and I'd exclude those from a wheel
Metadata: 7.5% missing sdists, and total data is 17GB for all 13880 files :)
oh, I kinda expect to look at the Repository or Homepage etc. in the project metadata for that...
but maybe mirroring that sort of thing to PyPI via an sdist is friendlier to e.g. distro maintainers (not that I imagine my stuff making it into a distro any time soon, nice as that might be)
Yeah, I don't think a packager will blink when there's no sdist but a repo link.
If you're attending #PyConUS and want to find me, I'm likely to be found:
- Thursday evening Reception, PSF Booth
- Friday afternoon, Packaging Summit
- Saturday, before lunch, #Security Track
- Saturday, after lunch, Maintainers Summit
- Sunday morning, Keynote Stage, Update from Security Engineers
Find these and more on the PyCon US Mobile app. Pro Tip: sign in with your registration details to favorite sessions: us.pycon.org/2026/attend/onsit…
Lots of links:
- us.pycon.org/2026/events/openi…
- us.pycon.org/2026/schedule/pre…
- us.pycon.org/2026/schedule/tal…
- us.pycon.org/2026/events/maint…

Hi! In the Odoo Community we typically create a few new projects each day using the same PyPI user. Since yesterday we are being rate limited (429 Too many new projects created). Has the limit been lowered on PyPI recently?
Yes, due to repeated abuse, the project create limit has been lowered.
Why do you create new projects that frequently?
The Odoo Community Association is a large group of creators of Odoo addons (https://odoo-community.org). Due to how Odoo works we have thousands of addons across 200+ GitHub repos, each addon becoming a Python package and published on PyPI. We have a bot publishing on merge under the oca PyPI user. Since the community is very active, several new addons appear each day.
What would you estimate a reasonable amount of new add-ons per day?
Do these use Trusted Publishing?
I'm getting a constant stream of abuse and malware reports, most commonly from new projects, so I need some lower threshold
I totally understand the abuse problem.
We would love to migrate to trusted publishing but we can't so far because we can't afford a manual setup of the trusted publisher on PyPI for each new addon. We would need an API for project creation + trusted publishing setup, then we could publish packages with TP. But I don't think that API exists?
Not yet
I cannot afford manual triage and review by myself for every inbound malware report at the volume that they are coming in
This just hit me as I'm preparing to announce a few new projects at PyCon. Is it a complete halt to new projects or is there some limit I can abide by?
2 per day
Okay, that should be fine, thanks!
What would you estimate a reasonable
I have something I'm tinkering with - if you have a few specific queries, I may be able to produce a report across the top 15k
Oh as an update Stan and I have been discussing making this a thing for general use
I'd be curious to see what you've come up with - you around PyCon US yet? 👀
I arrive around 11:30 tonight
not staying up that late 😪 just thinking about it 😉 If yopu have an example of a query you're looking for, happy to run one now, and chit chat about it tomorrow!
I figured, let's catch up tomorrow!
Very sad I won't be there 🙁
Mike and Emma if you are around today I would love to grab some time with both of you! Niko Matsakis asked me to chat about integrating https://symposium.dev/introduction.html with PyPI and the Python ecosystem.
here's where to find Mike: https://hachyderm.io/@miketheman/116556846541147314
I'm sitting in a chair near the convention entrance for the next 45 minutes. I have an NVIDIA backpack in my lap
Would PyPI consider an MR that bans the registration of new packages starting with "internal-"? Or is this not possible without PEP 752 first exiting draft status?
There are only 16 packages matching internal-, less than private- (33).
There's already a way to block uploads:
To prevent a package from being uploaded to PyPI, use the special
Private :: Do Not Uploadclassifier. PyPI will always reject packages with classifiers beginning withPrivate ::.
https://packaging.python.org/en/latest/guides/writing-pyproject-toml/#classifiers
Sorry, should've been more clear - this isn't for preventing accidental upload of internal packages. It's for dependency confusion eg: prevent accidental download of a package somebody else maliciously or coincidentally publishes.
I'm trying to upload a new release of my package to PyPI, but I get this error when using the PyPA GitHub Action:
400 Can't have direct dependency: sphinx-click @
git+https://github.com/dionhaefner/sphinx-click#egg=82fed75 ; extra ==
"docs". See https://packaging.python.org/specifications/core-metadata
for more information.
Full log is here. I suspect this happens because some of my development dependencies use direct GitHub URLs. I need those commits to work around some bugs, but they're not essential to the package -- they're just for documentation.
What options do I have here?
use dependency-groups
Fork or vendor the projects, PyPI (as far as I'm aware I'm not on the team), will not allow VCS dependencies
If the general public aren't meant to use the docs feature specified (I assume this translates to "... aren't meant to generate HTML etc. documentation from source") then it shouldn't be an extra for the publicly distributed project.
Or yeah, don't have them as extras
optional-dependencies are part of the package and it's metadata, PyPI checks it, end users have access to it. dependency-groups are what you should be using for dev-dependencies
Where can I find the docs that describe dependency-groups?
~~https://packaging.pypa.io/en/stable/dependency_groups.html~~ wrong link, use the one below
Perfect, thank you very much
I meant this
but yeah the basic idea is that pyproject.toml can include both things that are used by your devs / local tooling, and the "source" of metadata included by your package. Dev-time dependencies should not get into wheels or sdists (except that sdists typically copy pyproject.toml) because the end user can't... use them. (sdists get built locally, but build-time is not dev-time)
An "extra" connotes that the end user can do e.g. pip install libretro[docs] and end up with those other dependencies installed locally, which is very unlikely to be desirable.
(Some organizations might do this sort of thing, I suppose, for internal distribution, with a private index, if they don't have a better option)
Gotcha, I appreciate the clarification
Is it possible for contributors to install dependencies in a dependency-group as easily as they can with an extra?
So if I move the docs extra to a dependency-group, would-be contributors can still run pip install -e .[docs] or something similar and it'll work?
similar, pip install --group docs
Close enough.
uv, hatch, poetry, pdm all support that standard too
Yep, that's the point of them.
Oh thank Christ, worked like a charm
TBH, I didn't realize that PyPI forbids VCS deps! It was very important to me that dependency-groups not be in package metadata, for other reasons. Very happy to see the thing here doing what we want! 🥳
Neither VCS, path or url dependencies are allowed IIRC
Paths are definitely not, since they aren't part of the standards. VCS and URL are, which is where it gets fuzzier. (Also file:///... hackery... 🫠 )
At any rate...for interested parties! https://libretropy.readthedocs.io/en/latest If you need to test a retro game emulator or a homebrew game for its emulated hardware then boy do I have good news for you!
(Relevant because the documentation is way better than the last release, and this morning you all helped me bring it live. Not gonna plug it in this channel any further, just wanted to show off my "why".)
npm now has "staged publishing", like a draft upload:
nstead of a direct publish that immediately makes a package version available to consumers, the prebuilt tarball is uploaded to a stage queue where a maintainer must explicitly approve it before it becomes installable. The queue is visible both on npmjs.com and in the npm CLI.
Staged publishing reinforces proof of presence on every publish, including those that originate from non-interactive CI/CD workflows and those using trusted publishing with OIDC. A human maintainer with a 2FA challenge is required to approve a staged package before it is released to the registry.
https://github.blog/changelog/2026-05-22-staged-publishing-and-new-install-time-controls-for-npm/
Can I ask somebody to review and merge Postgres image initialization at https://github.com/pypa/warehouse/pull/9993 ?
GitHub
The behavior is explained here https://hub.docker.com/_/postgres
After the entrypoint calls initdb to create the default postgres user and database, it will run any *.sql files, run any executable...
Who can unblock workflow for the PR above ?
The test are passed successfully. What is needed to merge the PR?
It will be a month soon since I've landed my 3 PRs and neither was merged. Is PyPI project really funded? What are you priorities guys? Anything I can do to speed up the reviews?
Sadly very few maintainers on it
I'm only aware of https://twitter.com/di_codes so you can try to ping him

@google developer advocate, @thepsf director, @pypi maintainer. he/him
Tweets
2034
Followers
3659
Is PyPI project really funded?
Its infrastructure is funded, I think there is one dev-op (Ee?) Developer-wise it's purely voluntary.
This is my understanding too
There have been some funded project work too - e.g. pushing warehouse out and into prod
If PyPI could switch to OpenCollective then it would be more transparent for community to understand where the money goes to and balance the thing. At least there are more people at OpenCollective who are actively researching different ways to support OSS projects. For example just recent news https://opencollective.com/opencollective/updates/support-open-source-software-using-crypto
Today, we are adding limited support for cryptocurrencies on the Open Collective platform. We're testing this feature with one of our own Hosts. If you're interested in adding crypto' to your hosted Collectives email ...
And in my private letter to PSF, the answer was that crypto is complicated, and PSF evaluates this possibility, but there is no timeline, and therefore no commitment.
That's all very strange. https://twitter.com/pypi/status/1427334604386676740 from Aug 16 says $300000 had been raised this year specifically for new features and improvements, and none of my PRs submitted in the last month is merged. I hoped that such money could solve all the problems.
Thank you Facebook/Instagram for supporting PyPI. This year @thePSF’s sponsorship program raised over $300,000 for PyPI’s use. These funds will be used to implement new functionalities and address many improvements. Let’s keep that momentum going! https://t.co/S0HsLAxwO2

- This is likely not the correct venue for the discussion. PyPA does not handle funding, only development.
- Donations like this are more likely targeted to features and improvements chosen by the contributor, not your chosen features and improvements. But that may as well not be the case, and I agree more transparency is preferable, but again, this is the wrong venue to look for that answer.
I exchanged some letters with PSF, and it is already 8 days since my last letter with no reply, so I am out of ideas where to discuss this.
If somebody could review https://github.com/pypa/warehouse/pull/10052 I would spend my energy on something else, but so far I am trying to understand the roadblock to clean it.

GitHub
This adds a new workflow that sets up development environment and runs tests with docker-compose as described in getting started docs. This could be used to improve the setup time, which takes more...
Another issue https://github.com/pypa/warehouse/issues/10158

GitHub
Describe the bug make build fails. Click to expand ... Step 5/32 : RUN set -x && npm install -g npm@latest && npm install -g gulp-cli && npm ci ---&a...
Looks like nobody wants to speak with me anymore. 😦
And the PR to fix it https://github.com/pypa/warehouse/pull/10159
GitHub
Fixes build failure in docker build that started two days ago after npm 8 released.
Uses npm versions that is provided by the image, and switches the image to 14.15 which is a minimum required by n...
An easy one https://github.com/pypa/warehouse/pull/10267

GitHub
Cleans up a lot of messages like this.
...
tests/conftest.py:298
/opt/warehouse/src/tests/conftest.py:298: PytestDeprecationWarning: @pytest.yield_fixture is deprecated.
Use @pytest.fixture ins...
@tawdry raft have you got commit privileges to merge PRs already?
Hi. 😄
No I don't 🙂
Hi folks, I'm trying to run the make serve https://warehouse.pypa.io/development/getting-started.html#running-the-warehouse-container-and-services and am getting an error. There seems to be no fix for this, and would really appreciate help in fixing those, so can start contributing to Pypa.

The output of make serve command
Looks like a network problem on your side. Port 53 is a DNS server, and the request failed. The setup is tested in this PR https://github.com/pypa/warehouse/pull/10052 but nobody is merging it.

GitHub
This adds a new workflow that sets up development environment and runs tests with docker-compose as described in getting started docs. This could be used to improve the setup time, which takes more...
I'll run the make again, and update with the outcome.
I apologize in advance if this is a protocol violation, but I'm having no luck building a local warehose instance. Summarizing the Getting Started page, it's basically: install docker, install docker-compose, make build. The first two went fine, but make build keeps failing miserably. It seems that it wants to use .state/env/bin/python for building stuff, but that was missing all sorts of packages, babel, pyramid, pip-tools. I saw no indication there was any make target intended to install all that stuff. I'm on an XUbuntu 20.04 sytem. Here's my current sticking point:
% pgrep -fl docker
305078 dockerd
% make build
make[1]: Entering directory '/home/skip/src/python/warehouse'
make[1]: Circular requirements/docs.txt <- .state/env/pyvenv.cfg dependency dropped.
make[1]: Circular requirements/lint.txt <- .state/env/pyvenv.cfg dependency dropped.
Build our docker containers for this project.
docker-compose build --build-arg IPYTHON=no --force-rm web
ERROR: Couldn't connect to Docker daemon at http+docker://localhost - is it running?
If it's at a non-standard location, specify the URL with the DOCKER_HOST environment variable.
make[1]: *** [Makefile:67: .state/docker-build] Error 1
make[1]: Leaving directory '/home/skip/src/python/warehouse'
make: *** [Makefile:76: build] Error 2
You need to install docker properly, make sure it is running and you are in appropriate group. I am using podman on Fedora, so not sure what is the right way for XUbunutu.
https://github.com/pypa/warehouse/pull/10052 would make sure that development environment build is never broken. If anybody from warehouse mergers would review it.

GitHub
This adds a new workflow that sets up development environment and runs tests with docker-compose as described in getting started docs. This could be used to improve the setup time, which takes more...
I am not sure that people with warehouse commit access are in this channel.
the call-to-action on https://discuss.python.org/t/pypi-further-feedback/11888 is a little confusing, I ended up in a loop when I went from twitter to discuss back to twitter again

Discussions on Python.org
The PSF conducted a survey and interviewed PyPI users to understand common themes of improvements that would add value to PyPI. In order to consolidate these findings, we are conducting a poll that is open to anyone. Sharing feedback will allow us to decide our next course of development efforts. Please feel free to share this post widely. Ple...
could be like this instead?
The PSF conducted a survey and interviewed PyPI users to understand common themes of improvements that would add value to PyPI. In order to consolidate these findings, we are conducting a poll that is open to anyone. Sharing feedback will allow us to decide our next course of development efforts.
Complete the survey here: https://forms.gle/KWycVxJ9cCS6Njbe9
Please feel free to share this post widely.
Please RT- https://twitter.com/pypi/status/1459138071740493826

We are seeking some additional quick feedback after an initial round of outreach to teams using PyPI! If you use PyPI as a team, please respond to the poll linked from https://t.co/v801VmYyTn

You want to post this to Discuss instead, I don’t believe Shamika is monitoring this Discord
Reviewing existing PyPI PRs at least once a week would be very nice improvement that PSF could support.
https://github.com/pypa/warehouse/pull/10469 fixed development environment (again).

GitHub
This removes circular dependency in Makefile added in #10278
Unblocks #10052
Fixes #10446
Fixes #10447
I've got some time this week and next, and am open to picking up some fixes et al. Dustin's been pointing me in the direction of some tasks until now, but the two 2FA issues I've been writing on seem to be stalling, and I'm not sure where to best sink my time.
@tribal sedge do you have the commit rights to merge fixes that are already available on GitHub?
@timid ibex no, I am not (yet) a maintainer, only a contributor.
Well, hopefully you will be luckier than me in getting attentions from committers.
This is possibly one of the worst times of the year for people who work on these projects (full time?) since they also need a break for relaxation.
It is hard to say how busy are those people, because there is not enough open information about it. So far I haven't seen any public roadmaps or iterations.
The most recent roadmap was changed back in 2019: https://warehouse.pypa.io/roadmap.html
Yep. There is no heads up process to keep community and sponsors synced about what's going on and what are priorities. With $300k budget it could be better managed.
A good example from Python world is PySide https://wiki.qt.io/Qt_for_Python_Development_Notes. And I remember they were even planning sprints with two week iterations at one point.
Still blows my mine the top 100 packages are 45% of PyPI:
Top 100 Packages consume 4.65 TB
- This is 45% of PyPI
#datascience
Bandwidth?
Storage - https://pypi.org/stats

PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
Tensorflow alone is consuming >10% of all PyPI.
Yeah, I added these stats cause when I use to run a bandersnatch mirror the exponential growth was crazy so wanted to see where it was
I'm curious, what's the pypi stance of having a package name that is copyrighted?
for example, say I registered the package "arl" on pypi, what would happen if a entity owned the tracemark/rights to "arl" and wanted to claim that name?
asking here on the advice of the wonderful @violet fable
I did read pep 541 but it doesn't really answer this question, unless I overlooked an important section
same question as ^, but the original arl project was around before the copyright owner ever existed. Lets say, a year in advance. Absolutely 0% chance that arl would be trolling the to-be trademark owner
@fleet grove PEP 541 includes the following as an example of an 'invalid project':
project violates copyright, trademarks, patents, or licenses;
In general this is somewhat subjective and whether it's actually invalid & we'll remove it depends on the potential for confusion.
And the potential for disruption for legitimate consumers of the given project.
For trademark stuff we basically email legal@python.org, and the PSF lawyers determine it
Hmmm, alright
Is there a way to directly get the download url of a wheel from its name without querying the json api first? i.e. if I know sampleproject ,1.2.0 and sampleproject-1.2.0-py2.py3-none-any.whl, can I get to https://files.pythonhosted.org/packages/30/52/547eb3719d0e872bdd6fe3ab60cef92596f95262e925e1943f68f840df88/sampleproject-1.2.0-py2.py3-none-any.whl ?
No
Well technically yes because you asked without querying the JSON API but you can query another API instead
But the answer the question behind your question is no
ok thanks
@unborn nacelle It is possible, we maintain a redirector https://warehouse.pypa.io/api-reference/integration-guide.html#if-you-so-choose
e.g. from sampleproject-1.2.0-py2.py3-none-any.whl you can get https://files.pythonhosted.org/packages/2.7/s/sampleproject/sampleproject-1.2.0-py2.py3-none-any.whl which redirects to https://files.pythonhosted.org/packages/30/52/547eb3719d0e872bdd6fe3ab60cef92596f95262e925e1943f68f840df88/sampleproject-1.2.0-py2.py3-none-any.whl
This is exactly what i was looking for, thank you!
The PSF just published an RFP for upcoming PyPI contract work: https://pyfound.blogspot.com/2022/02/we-are-hiring-contract-developers-to.html
Please share widely: https://twitter.com/ThePSF/status/1493994827020709897
The Python Software Foundation has funding available for designing, developing and deploying organization accounts in PyPI. PyPI is the off...
We are hiring two contract developers to build organization accounts for @PyPI. This is a unique opportunity to flex your skills and develop next-gen features for PyPI. More details at https://t.co/Da04WUVYmV
Hi folks! Is there an easy way to generate project packages in the local storage (http://...:9001/packages/ ) in a development environment? I'm doing this by uploading some packages using twine.
pip install build && python -m build .
In local development? It kind of depends on how extensive you want the project packages to be.
You could take some insights from the testing Factory pattern - see tests/common/db/packaging.py:ProjectFactory for an example of one
is the project moving towards Python 3.9? We're currently on 3.8.9 and the RFP doesn't mention the move
In local development It kind of depends
That's a typo, but there's nothing preventing us from moving to 3.9 AFAIK. @tribal sedge, wanna 'fix' the typo by migrating us? 🙂
Has anyone seen an Invalid API Token: InvalidMacaroonError on uploading an SDist after all the wheels uploaded perfectly? Just started happening a couple of days ago, opened https://github.com/pypa/warehouse/issues/10821
Thanks @merry valve!
Is the best way to support cuda in PyPI really to make a bunch of packages, like cupy-cuda102, then hope no one squats on cupy-cuda-120? There was a discussion about this a while back, but I lost track of it. I'm guessing they are fudging manylinux compatibility. Those are large, too.
how big is each package? I assume putting everything in the same package wouldn't be viable, right?
Depends on the project, for CuPy, it's 30-60 MB per wheel, and there are about 6-8 versions of CUDA (11.5. 11.4. 11.3 11.2 11.1 11.0 10.1 10.0). For Awkward, it's currently under 1 MB, which I think is because it's only the math kernels - or might be because it's experimental. Looking at one from cibuildwheel (implicit), that's 20 MB and just manually renamed to "manylinux", auditwheel is skipped. And I guess only one CUDA version? Not clear there.
Seems like it really should be a new tag + have auditwheel support, but guessing that hasn't ever happened.
From I remember the main blocker is there is no automated way to introspect stuff (e.g. GPU version, library compatibility, things like that); currently people are just manually promising things work
I could invest some time into this, my employer is very interested in making this work
If there are discussions somewhere, please keep me in the loop 🙂
@merry valve et al, In reading about https://github.com/pypa/warehouse/issues/10718, I was tinkering with some Elasticsearch syntax queries, and then realized that there's more open search issues of similar nature. Is there ay kind of working group, or meta-collection to work on some of these issues? Some seem to have a resolution of reindexing the project via an admin, but others may be related to the search configuration.
The discussion was here: https://discuss.python.org/t/what-to-do-about-gpus-and-the-built-distributions-that-support-them/7125, I think the main blocker for something like GPU tags for wheels is having tools/libraries that can determine which GPU architectures are present.
There's a lot of open issues about search because Elasticsearch has historically been a big pain to tune or add features to. We recently got a free trial to the hosted version of MeiliSearch which I'd like to explore as an alternative (https://github.com/pypa/warehouse/issues/8002) but I haven't had the time. Migrating off Elasticsearch also resolves issues we have with using the AWS fork and not being able to upgrade to the latest Elasticsearch client.

GitHub
We made a working demo of this with the open source MeiliSearch: https://pypi.meilisearch.com/ https://github.com/meilisearch/meilisearch-python This could also be extended to support the more adva...
But, to answer your question: no, search is fairly neglected.
Thanks for sharing, indeed that's an interesting proposition.
Looking at the service, it's still non-prod ready, as it doesn't appear to have a fault tolerant setup just yet, is that correct?
Unless the goal is to use their hosted version and defer the problem?
In the interim, would performing some reindexing to alleviate some of the current issues be worth doing?
The goal would be to use the hosted version. I'm not sure doing more reindexing would help here, most of the search-related issues are due to the index just not being very capable.
Okay! I figured it was worth asking. I was able to make the index work just fine in development, so there must be some differences.
Hi, I was wondering if the operation logs obtained by Changelog in PyPI's XML-RPC method didn't actually happen? Because there seems to be a time difference when I check on https://pypi.org/.
PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
@stray rivet Could you elaborate what you mean?
I used PyPI XML-RPC to call the changelog method log, and the data I got seems not to be displayed on the official website
@stray rivet Can you give us more details? What did you get, and what were you expecting?
Static typing makes code easier to read... Current example: https://github.com/pypa/warehouse/blob/b1b636c64f3dac83fc23bf052828c5f9ad0ef42e/warehouse/filters.py#L51 (technically https://github.com/pypa/warehouse/blob/b1b636c64f3dac83fc23bf052828c5f9ad0ef42e/warehouse/filters.py#L79) - I can't tell what "request" is to track down request.camo_url. I'm debugging a missing ".gif" image in https://pypi.org/project/uproot-browser/ that was supposed to be loaded from a release attachment on GitHub.
@agile sinew it's a pyramid.request:https://docs.pylonsproject.org/projects/pyramid/en/latest/api/request.html
Likely that the GIF is too large and our informational image that would replace a missing GIF is missing. IIRC the limit is 10MB.
It's trying to link to https://pypi.org/static/images/image-too-large-10mb.png which should be https://github.com/pypa/warehouse/blob/main/warehouse/static/images/image-too-large-10mb.png but it's getting cache busted (with a hash in the filename like https://pypi.org/static/images/logo-small.95de8436.svg)
GitHub
The Python Package Index. Contribute to pypa/warehouse development by creating an account on GitHub.
This was broken in https://github.com/pypa/warehouse/pull/9856

The gif is 1.2 MB
So there are likely two fixes needed: adding a hash to the filename when generating the link for "too large", and fixing whatever makes this think the gif is too large?
@agile sinew Possible the issue is https://github.com/pypa/warehouse/issues/5596 instead then

GitHub
The actual fix is that we replace https://github.com/pypa/warehouse-camo with something that can handle >10MB images, application/octet-stream and also isn't Ruby and unmaintained

GitHub
:lock: an http proxy to route images through SSL. Contribute to pypa/warehouse-camo development by creating an account on GitHub.
Why does warehouse, when uploading, throw a 403 for invalid credentials instead of a 401? I would expect a 401 when providing no- or invalid credentials, and a 403 when the credentials are valid, but you have no authorization over the specific project you're trying to upload to.
Going off of these descriptions: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status#client_error_responses
uh
the answer is probably something like
"that's what legacy pypi did, and dstufft copied the behavior"
@uncut root what did you use to upload that gave you the response?
@merry valve or others - do you have any context on whether it's worth checking out solutions for the existing API endpoints to support https://github.com/pypa/warehouse/issues/2929 prior to any "Revamp PyPI API" work is undertaken? Ref: https://github.com/psf/fundable-packaging-improvements/blob/master/FUNDABLES.md#revamp-pypi-api
Maybe? I guess it depends on how tied to the current API it would be.
Quick question, is Warehouse CI/CD or does it have a manual deployment schedule for the prod instance? I couldn't find an answer in the docs.
@golden rover It deploys automatically on merge. Changes are live ~5 minutes after merge (about as long as it takes CI to run on the main branch).
Great, thanks @merry valve!
@merry valve has anyone on warehouse or other places explored adding Gitpod to the GitHub org? I've been tinkering with it for warehouse development, and think it's an awesome use case for making it really easy to check out the entire stack and have a working instance in under 5 minutes, if set up correctly.
I think aside from me trying to do it one time and failing to get it running w/in 5 minutes, no. But if you have it working it would definitely be a worthwhile addition to https://warehouse.pypa.io/development/cloud.html !
Okay! I'll continue tinkering, and may propose a PR with a Gitpod config file, but to truly work the pypa GitHub org would have to opt in to the application to enable the prebuild concepts that make it fast
I'd be interested in exploring that if necessary, getting everything running locally is a huge barrier to entry for new contributors
Agreed - I think I faced the same and powered through, so we got some nice things since. The weirdest part right now is getting the initdb run at the right time, but I have some ideas on that too. Especially now that pretty much everything runs inside its own docker container, this might be simpler to achieve.
I just found this! https://github.com/DavHau/pypi-deps-db
I brought it up recently, but didn‘t ask: Is there a place to discuss fitting PyPI with a dependency database?
GitHub
Probably the most complete python dependency database - GitHub - DavHau/pypi-deps-db: Probably the most complete python dependency database
GitHub
Data about packages and maintainers on PyPI. Contribute to sethmlarson/pypi-data development by creating an account on GitHub.
I think PyPI has the basics of dependency management already - as evidenced by the Release model having some keys and relationships on things like dependencies and others, through a Dependency - https://github.com/pypa/warehouse/blob/b4d70807cf43620a869341135d0afcff4195d445/warehouse/packaging/models.py#L273-L311
It's not currently surfaced via the API, and I don't know how complete it is, but there's "something"
that information is likely to be super broken
there's some pieces now that can be used to make something not broken
Sounds about right. 😀
I found something interesting, a package on pypi without version number 😮 https://pypi.org/simple/101903751-topsis/
(packaging.version.Version returns an error on parsing)
Well, that's weird.
This should have failed validation during upload.
Could you file an issue against warehouse for this?
Huh, and it’s even published just two months ago. I assumed it was from the pre-historic times when checks are much less strict.
Yup, that's what I was expecting too.
Might be worthwhile reaching out to the user how they managed to get this uploaded. I’d assume twine also has checks for this https://pypi.org/project/101903751-topsis/
Would logs show the user agent?
Dunno, need to ask the infra folks
In case you want another one: https://pypi.org/simple/aspyc/, although this one was uploaded in 2013, so not as interesting..
Yeah, that would have been via old cheese shop (or what ever the name was) and not warehouse
pypi-legacy if I remember correctly.
Do we have any TUF gurus around? @wet flax, @merry valve, @unreal jewel and I are looking at adding to the Simple API and just have some questions around TUF + new proposal
@merry valve Does William hang in here or anywhere? He might be helpful
I see at least some versions at https://pypi.org/pypi/101903751-topsis/json
Yeah the package metadata is still saying 1.0.0 that’s probably why Warehouse (via Twine?) lists it as such. But the filename doesn’t agree and that should have caused an error
I invited William recently, but not sure if he's joined. Do you still have questions or did we resolve them in DM?
Donald answered enough for the PEP in regards to TUF
We can amend if needed for TUF
But maybe let’s send him the PR when up.
I’m not a TUF guru, but I'm around and working on the PR
@merry valve @buoyant vector We possibly want PEP 691 to supersede 629 (https://peps.python.org/pep-0629/), which was never implemented.
Or we want to incorporate it into 691 maybe, and add the repository-version data into the response body. Maybe something like:
{
"meta": {
"repository-version": "1.0"
},
"name": "holygrail",
"files": [
{
"filename": "holygrail-1.0.tar.gz",
"url": "https://example.com/files/holygrail-1.0.tar.gz",
"hashes": {"sha256": "...", "blake2b": "..."},
"requires-python": ">=3.7",
"yanked": "Had a vulnerability"
},
{
"filename": "holygrail-1.0-py3-none-any.whl",
"url": "https://example.com/files/holygrail-1.0-py3-none-any.whl",
"hashes": {"sha256": "...", "blake2b": "..."},
"requires-python": ">=3.7",
"dist-info-metadata-available": true
},
]
}
I don't know that I feel strongly one way or the other. I definitely feel that we should never have anything but Major in the content types, then the minor version would just be to allow a client like pip to notice that the repository supports some new, backwards compatible feature, and maybe tell the end user about it.
Either way, 629 never got around to being implemented, so we should probably nix it via supersedes or roll it in since it technically exists.
I'm down for that totally
I don't see a need for min but only put it in 691 due to 629 existing
Yea, pretty much my entire reason for adding a minor to 629 was uh, the upgrade warning in pip.
Debian and Co strip that warning out, and it was suggested that they might be fine with the warning if it didn't warn just because pip released a new version, but if pip detected that the repository or the thing it was trying to install needed a newer version of pip.
We already had Major.Minor for wheels (pip errors on a major it doesn't understand, warns on a minor that is > what it understands), so I just tacked the same thing into PyPI with the idea we could move pip's upgrade warning to not be an always kind of thing, and just look for the minor version bumping.
But nobody (including myself) has been motivated / available to implement it in the last 2 years, so it's obviously not a pressing need. So I'm OK either way, just don't want to leave it out there as yet another "technically exists, but never implemented" standard, and instead either explicitly support it or explicitly kill it.
hi all, this is William 🙂
If I may ask, what do you mean by not implemented? As it is currently exposed by the Simple API https://github.com/pypa/warehouse/blob/main/warehouse/templates/legacy/api/simple/index.html#L17
nothing uses it afaik
@merry valve is there a particular script or tool you use to generate the combined pull requests for multiple dependabot changes into one? I was thinking about trying to help out there if desired.
I've been using Dependabot, but someone recently suggested using Renovate instead, so last week added it to a repo to test it out
https://docs.renovatebot.com/
it solves a couple of big problems with Dependabot:
the biggest is Dependabot also opens PRs in forks, which is incredibly spammy (see https://github.com/dependabot/dependabot-core/issues/2198 and https://github.com/dependabot/dependabot-core/issues/2804, they say they've been planning a fix but it's been years now)
I hesitate to update my Warehouse fork because of the Dependabot spam. By default Renovate has PRs for forks turned off
second, by default Renovate also opens a single PR to group several updates (except major bumps get their PRs, but that can be configured too: I've enabled to group major bumps for GitHub Actions)
Dependabot has no turn off for forks default? Should we ask for that?
@unreal jewel Thanks for the updates to the PEP. Made me lol, I haven't used the cgi library for a long time
Even forgot about it's parse_header
Looks a lot more solid now
There's this workflow but I haven't been using it lately: https://github.com/pypa/warehouse/actions/workflows/combine-prs.yml (in favor of a script I run locally instead)
GitHub
The Python Package Index. Contribute to pypa/warehouse development by creating an account on GitHub.
correct, it's been asked many times, they've been planning a fix for years
https://github.com/dependabot/dependabot-core/issues/2198
https://github.com/dependabot/dependabot-core/issues/2804
It also doesn’t support PEP 621: https://github.com/renovatebot/renovate/issues/10187
Hi! 👋 I'm new here so apologies if this is the wrong place to put it. I wanted to know how best to help out/contribute/discuss on what appears to be an operational issue with a pypi CDN appearing to potentially be almost a week stale. I'm a part of AWS and we're getting a lot of direct reach-outs where a botocore version published 6 days ago still doesn't appear available uniformly, with Dublin appearing to be the commonly-reported area behind
I'm guessing it's related to https://github.com/pypa/warehouse/issues/10390 , but it does appear to be ongoing with an especially bad bit of staleness right now

GitHub
Describe the bug We upload the AWS Python packages (awscli, boto3, and botocore) each weekday with changes to keep the tools up-to-date with the company's services. We realize that generate...
Is there a best place to talk about potential operational issues like this? I could see from the chat it looked pretty squarely about both PEPs and general development on the project but wasn't sure if pypi operational issues has a home for those things
Sure, I think this is a fine place to chat about this. Unfortunately it seems somewhat out of our hands, as it's our CDN being stale. We could try to escalate though?
That sounds reasonable since 6 days old may be a bit too old if there are security-conscious libraries distributed via PyPI
@maiden parcel It'd probably be helpful for anyone who can reproduce this to file a network access issue here: https://github.com/pypa/pypi-support/issues/new?assignees=&labels=network&template=access-issues.yml, specifically the result from https://fastly-debug.com/
QQ: Are the pythonhosted.org artifact links identical between the CDN endpoints? I'd assume so, but I have seen systems where it isn't
You mean between PoPs? Yes
Hi, is there an api for https://inspector.pypi.io/ ?
Hi! No. What are you hoping for?
the ability to be able to read the source of the package without downloading it and extracting from the tarball
I have some cases where I know which file it is, and want to be able to check a single file without downloading the entire binary
I think that's something it could provide, but we probably need to implement https://github.com/pypi/inspector/issues/27 first. Right now there is no caching, and each request requires Inspector to download the entire distribution from PyPI first.

GitHub
The following routes will ~never change once a distribution is published: /project/<project_name>/<version>/packages/<first>/<second>/<...
Could you file an issue that describes what you want here? https://github.com/pypi/inspector/issues/new
GitHub
GitHub is where people build software. More than 83 million people use GitHub to discover, fork, and contribute to over 200 million projects.
👍
Including some details of your use case would be helpful as well!
@unreal jewel Should we see if we could divide up the work for implementing PEP 691 - Your POC PR does most of basic implementation tho I guess
I deployed the PEP a few minutes ago, have a follow up PR to fix a small issue
gonna test it once that's deployed
er deployed to PyPI that is
Much excite 😄
it doesn't give us a ton of new capability besides not having to use a HTML parser, but it will hopefully pave the way forward for extending it in sensible ways
I'd like to discuss XMLRPC deprecation with it potentially
I have a half baked idea that I haven't decided if it's a good idea or not, of throwing the serial numbers into the /simple/ response, and adding an optional ?since=SERIAL query arg to the /simple/ index
O, interesting. That could work for bandersnatch
Do we have stats somewhere for what's still getting hit @ xmlrpc land?
yea
We should target top 5 and design replacements
Then try and look at the agents hitting and go do the PRs to move to new APIs

changelog_since_serial
list_packages_with_serial
is bandersnatch
I think the above fixes changlog_*_serial and changelog is old mirroring stuff that never migrated to using the serial versions
list_packages I think can just be replaced with /simple/
Totally - Want to start a PEP outlining a plan for all this?
I can kick up a draft this weekend
package_releases I think can already be replaced using either PEP691 or the non standard json API depending on what data you're looking for
I feel we best effort it then call for comment - I'm sure it'll get a lot of comment
I'm probably not going to push a follow up PEP quite yet, want to let the PEP 691 stuff bake a little bit, but can maybe throw it up as an idea
Yeah sure - Can start kicking tires and then once all the xmlrpc endpoints are implemented we can call ~12 months till we sunset it or something.
That screenshot above, do clients supply useragents or anything helpful to see what's using them?
I'll try print out what bandersnatch sends and see
the old cache didn't look at the Accept header
06/25/2022
$ curl -Is https://pypi.org/simple/barbican/ | grep content-type:
content-type: text/html
$ curl -Is https://pypi.org/simple/barbican/ -H 'Accept: application/vnd.pypi.simple.v1+html' | grep content-type:
content-type: application/vnd.pypi.simple.v1+html
$ curl -Is https://pypi.org/simple/barbican/ -H 'Accept: application/vnd.pypi.simple.v1+json' | grep content-type:
content-type: application/vnd.pypi.simple.v1+json
$ curl -Is https://pypi.org/simple/barbican/ -H 'Accept: application/vnd.pypi.simple.v1+html;q=0.2, application/vnd.pypi.simple.v1+json, text/html;q=0.01' | grep content-type:
content-type: application/vnd.pypi.simple.v1+json
$ curl -Is https://pypi.org/simple/barbican/ -H 'Accept: application/vnd.pypi.simple.latest+json' | grep content-type:
content-type: application/vnd.pypi.simple.v1+json
$ curl -Is 'https://pypi.org/simple/barbican/?format=application/vnd.pypi.simple.latest+json' -H 'Accept: text/html' | grep content-type:
content-type: application/vnd.pypi.simple.v1+json
curl -i https://pypi.org/simple/black/ -H 'Accept: application/vnd.pypi.simple.v1+json' for me is returning HTML ... cache change still rolling out?
it will take 24-48 hours for the pre PEP 691 cached objects to expire
I'm not going to purge the previously cached responses because that hammers the backend servers
Yeah no problem. Thought that might be the case
if there's a particular page you want the new api on
curl -XPURGE <url> should still work
Just trying to workout how bandersnatch should handle this - I think a switch for json_simple or not and eventually default to that
you can put them at two different locations too
yea
Yeah I'll do that
Apache natively supports conneg, not 100% sure if it needs file extensions side by side or if two locations works
I'll see what nginx etc. can do
worst case, it would be really easy to have, maybe externally to bandersnatch, a small run time shim that rewrites urls
to two different locations
now to go fix up my pip PR
PSA: I think we should avoid upgrading Docker on our dev machines for now. Upgrading to Docker Compose 2.6.0 appears to break things. Notes in https://github.com/pypa/warehouse/issues/11674 please let me know if you’ve seen the same error or think the root cause is something different.

GitHub
Steps to reproduce: Upgrade to Docker Compose 2.6.0 Run make serve for pypa/warehouse. Error message: Error response from daemon: failed to create shim task: OCI runtime create failed: runc create ...
Thanks for finding the issue on the compose side! I experienced this in a Linux-based environment as well, and thought it to be isolated, since I hadn't seen it on Docker Desktop yet.
Hello. does anyone knows how often does the pypa index update?
Essentially every time a file is uploaded. Why do you ask?
Thanks for the replu. I updated a new version to pypi, but pip still pulls old version.
Is this you? https://github.com/pypa/warehouse/issues/11678

GitHub
Hi, I just released the new version of speechbrain (0.5.12). Everything seems fine and the new version is available here: https://pypi.org/project/speechbrain/0.5.12/ However, https://pypi.org/proj...
No but its the same issue, this is my package if it helps - https://pypi.org/project/unopass
PyPI
unopass is a simple to use 1Password CLI python module to retrieve secrets using your biometrics in local scripts
Yeah, seems like we're still experiencing https://github.com/pypa/warehouse/issues/10390 once in a while

GitHub
Describe the bug We upload the AWS Python packages (awscli, boto3, and botocore) each weekday with changes to keep the tools up-to-date with the company's services. We realize that generate...
gotcha! thanks for the info. any alternative fix that you know of? I tried curl -X purge 'https://pypi.org/simple/unopass/' but seems no longer allowed
You need to do curl -XPURGE
I get a 405 The method PURGE is not allowed for this resource.
I see the updates now! did you run the command on your end?
I didn't, but someone else might have.
Cool! Is this something only the pypa team can do? Just in case it reoccur on future uploads.
No, anyone can do it
cooll. thanks for helping me.
Q: Anything I can do to help the PEP 658 implementation on PyPI move forward?
Would it help if I picked up the implementation work, from wherever https://github.com/pypa/warehouse/pull/9972/ has left it?
@wet flax I guess something we need to decide, since afaik nothing ever implemented PEP 658, is whether it still makes sense
What's needed to decide?
I still think it is, since pip would benefit from having this information readily available.
Seems like now that PEP 691 is accepted/implemented-ish, it might make more sense to expose metadata there instead with a follow-up PEP
Basically what @merry valve said. PEP 658 was done the way it was, because HTML didn't have a way to expose the information pip needed. We don't need to use HTML anymore, so the question then is it better to have the whole METADATA file available, and require multiple requests to access that data, or is it better to just put the data pip, etc needs directly into the simple api
I don't know what fields pip exactly needs from the metadata, but it might be minor enough that it could fit in the Simple API response, avoiding the need for multiple requests.
But it is important to remember that pip is not the sole consumer of these API's, and that there are more client which would benefit from ALL the metadata fields being available (as is currently promised by PEP-658).
We for example have an internal front-end which makes use of a PEP-658 API (displaying the same info https://pypi.org does).
Although I would rather have this exposed as JSON than as email-formatted file, when exposing all the metadata fields, putting it in the Simple response body does not sound like a good idea to me. Image the following response with all the metadata fields like description in there as well: https://pypi.org/simple/numpy/?format=application/vnd.pypi.simple.v1+json
You could argue that these people can make use of the Warehouse JSON API instead. But because it is not standardised, there is no way providers like JFrog Artifactory or Nexus Repo Manager are going to support that.
the simple API's primary purpose is to act as an installer api
that people can use it for other things is a nice bonus
To be clear, I'm not saying that PEP 658 is the wrong approach either. Mostly that it hasn't been implemented yet, and the landscape has changed since it was accepted, so it's possible that better solutions are possible now. It's also possible that it still is the right approach
I'm fine with the rational that the Simple API primary focus is serving installers. But in that case, I hope this "nice bonus" use-case can be promoted to requirement at some point. And since PEP-658 is already accepted, it makes life easy 🙂
On the other hand, you could consider a search functionality an installer use-case. And what metadata to display on these search results is an opinion that could differ between installers, so exposing all metadata would be a safe bet.
A pip search revive, based on something standardised, does not sound bad to me.
But maybe I'm reaching a bit here 🤷
I only care about dependencies, so... just that is OK?
Yea, there's not really a hard line here. The big thing is that these APIs get a lot of traffic (we're at this moment about ~60k req/s to pypi.org), so we have to figure out what trade off makes the most sense
Like, we can just add a "dependencies" key that'll contain the install-requires of the packages to the JSON-based simple API, and... yea, it'll all work just fine.
Whether we want to... 🤷♂️
So like, there's two obvious solutions, PEP 658, and what @wet flax just mentioned
the dependencies key makes the /simple/foo/ page bigger.. but with compression, would it be much bigger? I dunno, need to look into it
I think the duplication will help with compression.
(i.e. most packages have the same dependencies across versions)
PEP 658 generates more requests, but it also includes a bunch of stuff (in particular, the description) that is a bunch of wastes bandwidth
wasted*
Well, it has license and stuff.
I wonder if we should do both actually.
For installers, the dependencies in JSON /simple/ is likely better.
Nah, the more I think, the more I feel like "PEP 658 is defered and we're doing dependency data in JSON-based simple API"
both might be the right answer too. I'm not really set on a specific implementation, though I guess I lean towards just adding stuff into the simple api now that we can
mostly my comment was just "someone should sit down and figure out what the trade offs are, and do the reasons we went with PEP 658 still hold true"
I also have another PEP coming up
that adds a new upload API
an asynchronous upload API that allows us to spend more time during upload doing stuff like extraction of metadata
without blocking a single request forever
my rough idea was to get that PEP done and implemented, then start extracting dependencies out of files using that
and storing them in a new database table attached to File rather than Release
(or alternatively, extracting the METADATA file and storing that)
https://github.com/python/peps/pull/2675 this isn't really ready for public comments, I have a refactor locally that solves some issues that came out of talking about it with people, but you can kidn of get a sense

Would PR comments be welcome, or should I post them somewhere else? ;)
This looks pretty neat tho.
I think the PEP editors generally prefer people to take discussion elsewhere
I think Donald was gonna open a discourse thread about it soon
I also had some changes I wanted to make around supporting draft uploads: https://github.com/dstufft/peps/pull/2

GitHub
This attempts to keep the URL structure clean by reusing the root to list draft sessions and including per-session URLs. The only thing I'm not totally sure about is the empty POST to publish a...
Yea I'm going to open a thread, hopefully later tonight
Neato -- I'll hold off until tomorrow then. :)
Discussions on Python.org
Riffing off the work done in PEP 691, I’ve gone ahead and used a similar pattern to write a new upload API for PyPI, this time documented as a standard PEP rather than implementation defined like the existing upload API. The new API is a bit more complicated (it would be pretty hard to get less complicated than the old API), but with it we unlo...
Here's the incident report from yesterdays outage: https://status.python.org/incidents/l16ylxktn4r9
Congrats on moving warehouse to pypi GitHub org! Is there something I can read on the move and what this means going forward?
It mostly means CI won't be slow
It was explained in the recent PyPI incident:
In order to mitigate delays in PyPI’s CI pipeline, PyPI admins will migrate PyPI’s source repository to a separate organization, in order to ensure that the CI queue remains small and changes can be quickly deployed.
https://status.python.org/incidents/l16ylxktn4r9
The PyPA shares a pool of GHA resources and PyPA is active enough where there's a backlog a lot of the time
Thanks! I must have overlooked that one line. When one of my scripts didn't work today based on the repo name, I found out. :)
tip for people with write permissions in an org: create feature branches in your own fork instead of in the upstream org, then you can run the CI on your own account which has its own CI queue, so won't add to the upstream backlog (until you make a PR)
I think most projects disabled runs on pushes to non-main branches, but the regular volume is still just too high. We were sitting around waiting for CI to pass for way too long during the outage.
Time to make pypi/waitlister that just spams ci jobs
Curious to know if there's any data tracking Internet Explorer 11 usage? In reference to https://github.com/pypi/warehouse/issues/11758
GitHub
Context Internet Explorer 11 (IE11) is finally retired. We claim to support IE11 in our frontend development docs: https://warehouse.pypa.io/development/frontend.html#browser-support We include a p...
@tribal sedge https://tldr.tw/Hmcp0A5

Excellent @unreal jewel ! Any chance of representing only IE over time to confirm if it's in decline?
https://tldr.tw/FTWsULl year of IE, grouped by month

Well, that pretty much confirms it for me. 😎

{kind=link}
{kind=link}
{kind=link}
Now I need to look up what a YaBrowser is.
Cool, thanks for the graphs @unreal jewel ! Supports that it's probably safe to not be concerned about any polyfills to support IE any more.
Happy Fourth, if you're celebrating it 🎆
pypi told me "Congratulations! A project you ('JelleZijlstra') maintain has been designated as a critical project on PyPI. You can see which project(s) has been designated at http://localhost/manage/projects/."
unfortunately I am not running pypi on localhost 😦
thanks for resending with a fixed URL 🙂
the URLs are fixed in the email I received, but maybe use https 🙂
this is a little surprising, I'd already enabled 2FA so am ineligible to improve security via the key giveaway. but also seems the keys are not "approved for sale" in Finland so I couldn't get one anyway

Weird double . in my email:
You can see which project(s) has been designated at http://pypi.org/manage/projects/. .
PyPI
The Python Package Index (PyPI) is a repository of software for the Python programming language.
Oh no
Needs https too
PyPI users who are eligible to receive security keys must be maintainers of critical projects who have not previously enabled 2FA on PyPI and are able to ship their keys to an eligible region.
Feels a bit weird to disallow maintainers who already enabled 2FA via less secure methods, such as an authentication app 🤔 I mean if all we want to have them 2FA, why not just tell everyone to download an Android/iPhone auth app and enable it 🤔
Also from the e-mail:
Since you already have two-factor authentication enabled on your account, there's nothing you need to do at this time.
PS: To make it easier for maintainers like you to enable two-factor authentication, we're also distributing security keys to eligible maintainers. See http://pypi.org/security-key-giveaway/ for more details.
If you're going to mark people un-eligible for already having 2FA perhaps don't attach the PS part :-D.
when the news came out about the keys, I asked my Pillow team members to enable 2FA for their accounts! oops, no keys for them either! 🙃
this is nice, you can also opt-in other projects to require 2FA: https://twitter.com/pypi/status/1545455458529341440
We've also enabled a feature that will allow any project to opt-in to a 2FA requirement for its maintainers: this can be enabled in the settings for each individual project.
This can be enabled/disabled for non-critical projects at any time.
Yeah, sorry Hugo, a bit out of our control. We tried to get some other manufacturers to participate to expand this to other locations, but they weren't interested.
nice, I just deleted the atomicwrites package, then uploaded a new version. now it's no longer a critical project