#pip
1 messages · Page 3 of 1
I'm not a committer and can't edit your issue description, heh :)
Hi all, I finished writing the draft of my pip 24.2 post, I'd appreciate feedback before I share it more widely: https://ichard26.github.io/blog/2024/08/whats-new-in-pip-24.2/. Please enjoy and thank you!
@jovial jasper I'd especially appreciate a review of my discussion of the legacy editable deprecation (as I plan on using its contents to provide more context to the pip issue). I know you're on vacation, so if you can't, no worries.
In version 24.2, pip learns to use system certificates by default, receives a handful of optimizations, and deprecates legacy editable installations.
Good writeup! My only suggestion is to capitalise Poetry and Hatch
just a nitpick, poetry-core is the backend, not poetry itself

I assume that no one actually cares about that distinction. I can add another footnote since you care :p
like I said, a nitpick
Thanks @dapper laurel and @stuck girder for reading it and providing feedback! I made sure to acknowledge you two in the summary :)
So I posted that additional context. I ended up rewriting the entire issue description. I'm not entirely sold that my approach is the best approach, but I do think it's better than what we have right now. This stuff is confusing, so more detail is good IMO. https://github.com/pypa/pip/issues/11457#issuecomment-2313932318

GitHub
There is now a standardized mechanism for an installer like pip to request an editable install of a project. pip is transitioning to using this standard only instead of invoking the deprecated setu...
Anyway, I think that's all the time I can allocate to pip for the time being. I got other things to do! Hopefully that helps!
In a src layout for a package that has CPP nanobind code
Where do I put the CMake and the CPP headers and sources?
https://github.com/wjakob/nanobind_example might help
GitHub
A nanobind example project. Contribute to wjakob/nanobind_example development by creating an account on GitHub.
@hidden flame pip self check message will be an ongoing saga from now till the end of time 😜
is there some docs for the API of extension modules builders classes? If not, maybe I could get some help. I would like to use setuptools for building extension module, but without passing the build through the setup() method. What is the API there?
I think this is probably best to go in #setuptools. Are you asking about the CCompiler subclasses? There are docs from older versions of CPython that cover distutils, which define the interface for a lot of this https://docs.python.org/3.9/distutils/apiref.html#module-distutils.ccompiler
if you mean setuptools.core.Extension, the docs for that are here: https://docs.python.org/3.9/distutils/setupscript.html#describing-extension-modules
Huh, that's how asking questions at 4am ends. I was sure I asked on #setuptools lol
I've been working on doing some installer version analysis for background on wheel 2.0 migration planning. Thought I'd share this chart about pypi.org downloads by installer version for pip. It's great to see almost half of users are on 24.x!

9.x!?
py2.7 legacy users
It still works?
Why wouldn't it?
note that pip makes up ~87.5% of all donwloads on pypi.org, so this is really more like 1.6% of all downloads over the past 6 months
pip 9 was the last to support 2.6, pip 20 was the last to support 2.7
(there was a pip 10, and then it switched to calver for pip 18)
I'm surprised you don't have, like, 1.5.6 or whatever in there.
I'm surprised there's no pip 9 on the chart, or 18 and 19
https://pepy.tech shows ~700k for 9 vs. ~2k for 8
(edit: ignore this comment, I misread it 😅 )
Oh I limited to only versions >1%
I think some really old ones weren't reporting their versions?
Ooooh! What does the sum(%age of <1% versions) come out to?
got full data (from installers other than pip) too?
Yep, here is the raw data:
24: 47.699604%
23: 19.881506%
21: 13.928024%
22: 10.457457%
20: 5.390142%
9: 1.883370%
18: 0.171540%
19: 0.513196%
8: 0.039315%
10: 0.028705%
1: 0.004430%
6: 0.002084%
7: 0.000627%
240: 0.000000%
2019: 0.000000%
I did a bigquery to get the data so I have raw download counts, but moving to percent to make comparison easier
Not sure where 240 or 2019 are coming from 😅
Is this the last month?

Oh, nice.
How much does that cost?
Yea, I figured you need to pay for 6 months, but you also have a corporate card that this can probably end up on. 😅
1 month is actually juuust over 1TB, so you'd need to pay either way (you get the first TB free per month)
~20 USD, I think if it's the highest tier of pricing?
the cost per query has been going up a lot recently: https://github.com/hugovk/top-pypi-packages/issues/36#issuecomment-2320919458
Oh wow, I wish PyPI didn't have an exponential rise only because of the bigquery numbers. :(
The embed was nice!
yeah its a bummer
take 2...

btw to debug that I've started a 90 day free trial so have ~$300 to use up in that time. let me know if you have some queries to run (not right now, another time)
I remember querying the entire year of downloads to decide on Python 2.7 removal numbers.
Yeah, I think the numbers I gathered make me pretty content with a 4 year window to get users on newer installers for wheel 2.0.
I have to imagine that pip 9 being higher than pip 10, 18, 19, and 20 has to do with some LTS version of RHEL or something similar?
Ubuntu, RHEL and pip 9 being a long lived version too.
I think pip 9 was the latest version for multiple years, whereas we've had releases ~every quarter since.
I remember the calver jump but only really started paying attention to pip versions when pip 20.3 didn't work with any of my environments by failing to resolve any of them, aha
oh and I have the data for non-pip installers, here's a chart of downloads by installer name (again only those >1% of total downloads to avoid cluttering the pie chart)

nice
Wow, uv already bigger than poetry, makes sense, it's a lot easier to move over from pip
huh, uv being that big is actually a big deal
It's also making more requests to PyPI per download, since each individual package counts as two downloads.
Over what time period is that?
I was gonna suggest.
so it literally causes double the workload vs pip?
it took over for pip first, only now it starts to bite into Poetry's piece of cake
Workload?
maybe i misread, it sounds like it's making more requests than pip normally would make
if it needs to do that, then that's more work pypi has to handle
why does it do it twice?
They do range requests for metadata, which PyPI counts as a download, at least last I checked.
So separated resolve vs download.
uv only makes a range request if there's no metadata file
Although, it should be better now with PEP 658?
Yea, which still counts as a separate download IIRC.
But modern versions of pip are doing that also
And pip is worse because it doesn't cache metadata, whereas uv does
We do at the http layer, no?
If not, we should really fix that.
Man, I should find some time to clean up our half cleaned up prepare step.
Hmmm, I thought pip wasn't doing that for transitively found metadata files, only for wheels, I thought that's what one of cosmicexplorers PRs fixed
I wonder when PEP 658 is going to become a standard in extra index providers, not just on PyPI
Also, uv has only been public for just over 6 months, I wonder what the last 1 months statistics looks like, uv could easily be at 10 or 15%
I have plans to implement it on NVIDIA's index
yep, this is past 1 month data

Rightfully so! I am using uv myself. 😅
Yeah, I moved most parts of our work projects to uv a couple of months ago.
This week I leveraged the hatch/pipx like tool feature to decouple our dev tools and our dev dependencies, making the environments simpler to resolver.
that's amazing, thanks for compiling these statistics!
sure thing! I'll share a link to the blog post when I have time to write it up
TLS 1.2 EOL would kill it dead
Not been announced, I know so much infrastructure that it would break 😄
trends would possibly suggest 1.2 could hit deprecation either somewhere near 2026 (fitting with 5-year average deprecation gap) or 2030 (following 1.0's 22-year support). my guess is 20 years at 2028
2020 should've killed py2
RHEL8 only ended Python 2 support this year, in June, I've worked on many projects that use software 10+ years after support ended
The fact that the corporate world does that continues to disgust me.
I have a whole rant about the fact that it's easier to get paid for bad ideas in software than it is to get paid for good ones (since someone will probably publish the good ones for free somewhere along the line) 😛
Software? Pfft. I've definitely heard of banks relying on machines older than me.
did you read this about the fun world of Bank Python? https://calpaterson.com/bank-python.html
talk version: https://www.youtube.com/watch?v=tCIkncZrfes&list=PLguFXrFRjbcPPzVaQ7Wy0kj10B_269y2P&index=7
source code stored in a database instead of a filesystem
As soon as they clicked that "vouch" button - bang - your new change was in prod: after all, there is no such thing as a deployment step when your code is stored in a database.
I have a lot of stories about Python in Bank Tech, or particularly how it was a reaction to many devs not wanting to maintain Perl code, I should write a blog post on it one day
How do folks feel about a pip install -r pyproject.toml that mirrors what uv pip ended up implementing in that spot?
I'm meh on auto detecting the file type. It should be a different option. The feature itself seems useful, though.
OK, that's how I'm feeling too. We have --only-deps in an issue but I'm feeling like avoiding the build-system build is worthwhile.
Minor note that I think detecting the file type would be weird if it was just *.toml but since pyproject.toml is a standardized name and it's an exact match it feels like less of a big deal.
We're kind of on the fence about how to do this for scripts with inline metadata
Yea, I'm leaning towards an exact match for that basename.
(Like -r foo.py might be too much, but it is an easier UX and we'll probably need a special cased error message either way)
I'm not gonna touch that blue touch paper in pip.
Haha fair enough 🙂
@shy echo do you think pip run is something that would be accepted or do you want to leave that with pipx?
I want it. I also don't want it to look like pip-run for a few reasons and... yea, I don't have bandwidth to maintain even more code. 😅
My calendar has been poking a bit red "TOML 1.1.0" in my face for a little while.
pip-run has a specific use and was only made for its author imho
There’s some people strongly against it apparently, me and @gloomy briar did think about implementing it as well
FWIW, my work has a messy monorepo, so any tooling which requires an exact name match I just can't use, we have files like pyproject.{team}.toml. I'm sure others will face this situation also.
ok, but that is non-standard anyway.
Yes it's non standard, so is a front end tool reading requirements from pyproject.toml, strictly it's up to the build tools to do that (which we don't use because we don't build any of these projects)
since we had that discussion (and in fact since @shy echo and I last spoke about this even more recently) I've discovered that uv pip install -r pyproject.toml does handle the case where the project's dependencies are dynamic, by invoking the build backend to generate the metadata. So, when we last spoke I thought this would be a quick win that implements something simpler than the proposed --only-deps flag to pip install, but my new understanding is that it's not simpler but rather isomorphic. Based on that updated understanding, the only reason to implement pip install -r pyproject.toml instead of pip install --only-deps . is for interface compatibility with uv, rather than having two distinct interfaces for the same operation.
I do think some users would value a flag that meant "install these statically defined dependencies from this pyproject.toml file, plus these optional dependency groups".
If that were to exist I definitely don't think it should be using an existing flag. Or try to follow what uv is doing.
I don't think any of this is an easy shortcut to "--only-deps" while following standards.
hm, i think the added complexity of the implementation is worth the cost to standardize -r inputs for both pyproject.tom and requirements.txt
At this point I'm pretty ambivalent. pip install --only-deps . would meet my needs just as well as pip install -r pyproject.toml would, as long as both can work with static metadata without invoking the build backend. I'd expect that to be the case for you, too?
my use was is not having to make sure both requirements.txt and pyproject.toml are synced and avoid deduplication, so yes, it does, but the pip install . is still done, i don't quite like that behavior, hatch does that (not installing the package locally) behavior via dev-mode = false i believe
I don't know what you mean by "the pip install . is still done". The whole feature being proposed as pip install --only-deps . is that the package does not get installed
oh, seems like i misread your message then, then yes, makes me happy
Hey guys are there any good resource that could help me diagnose a ResolutionTooDeep error? I'm looking at a really convoluted pip error log no idea what is happening
Can you share a reproducible example?
I'm looking at https://github.com/chflame163/ComfyUI_LayerStyle/blob/main/requirements.txt on pip 23.0.1 Python 3.10.11
let me try in an isolated env
Linux, Windows, or Mac?
Windows
Taking a look
weird this resolves in a clean env despite lots of backtrack still
Yeah, I see the same thing
This is usually because pip tries to use the already installed version of a package rather than getting a new one, but if there is a combination of package versions installed that are difficult to resolve on it can send pip on a long backtracking journey
I am working to improve the situation, and significantly reduce the chance of anyone seeing ResolutionTooDeep, so if you can post a reproducible issue as a GitHub issue I would be highly appreciative.
There is also an alternative tool called uv (https://github.com/astral-sh/uv/?tab=readme-ov-file#installation - and your commands becomes uv pip install ...) which can usually handle these situations better.
I have an error log that captures the environment state on the instance that triggers the error though it would take some effort to turn it into a reprod
Feel free to share the error log, if there's enough information in it I might be able to reconstruct it myself far more quickly
I've been noticing that lately I become agitated or annoyed whenever I read incoming pip issue tracker emails. The whole "open source made me a worse person" is 100% a thing.
In fairness, I also am probably not in the best of moods as of lately so that's affecting my patience, too.
yeah, I've definitely chosen to take breaks from looking at incoming issues because it can be annoying to read through e.g. entitled issue filers (even if they make up a small percentage of issues)
I've always been a grumpy irritated person!
One thing that really improved my disposion with dealing with people was watching Twitch streamers that I like, they answer the same questions over and over and over, and never get irritated
I've always been in awe at that, and tried to take the same attitude when I can
I think part of it is that I'm rarely in the position to do anything about it. When I used to have lots of time for OSS, I'd see a more negatively toned notification and think "I can fix this" but now I can't and I end up frustrated.
There’s a phase some people never managed to get through and burned out eventually. But if you do get through and realise you don’t need to fix anything (even if the issue is not irritating) you end up a better person than when you started
@finite perch I've never thought you were grumpy haha
🤨 not sure if sarcastic
ahaha, that's good to hear, I just try to keep in mind I can be abrasive about things and get frustrated
Also not sure I will be around quite as much, I've simplified our main work environment to use uv tool install for lots of the dev tools we use, so their dependencies no longer get tied up in knots with airflow dependencies, so between that and uv knocking out issues quickly, not finding any more bugs in uv pip compile --universal
😭 we'll release new features for you
I'm not quite sure when I'll move over to uv's project tools, I am very used to messing about with the pip API to get my stuff done
It's important to keep in mind that this isn't always a once-and-done thing, though, since emotional energy reserves can wax and wane based on other things that are going on in our lives (e.g. my own multi-year mostly-break from active open source participation had a whole host of contributing factors).
But yeah, it's a matter of finding a balance point of "invested enough to want to participate and help out, but not so invested that the sheer scope of the available opportunities for improvement becomes overwhelming" (and filtering our incoming data feeds in a way that works for us plays an active role in that process).
So what's the merge policy for pip? Is merging supposed to fall purely on the release manager?
Particularly in the context of release 24.3 https://github.com/pypa/pip/issues/12941, if the next release manager is not going to merge pending approved milestone PRs, do I need to be pinging all my PRs I think should be merged soon?
there really isn't a merge policy, it's just that as a group, we tend to be quite conversative.
approved PRs tend to wait until a second approval is given
I was looking at enabling the pycodestyle rules for pip, and it quickly become apparent I have never read PEP 257 before
I feel like there are maybe a few rules that are worth enabling that catch easy stuff, but assuming the first line of a docstring is a summary line, and is not in an imperative mood is a lot of work, and perhaps difficult to explain to contributors
Is there a name for the feeling where you've finally gotten round to writing a good unit test for something and you slowly realize you don't know what the intended behaviour is?
sadness
does someone know which PR this person is referring to? https://github.com/pypa/pip/pull/12388#issuecomment-2305226619
perhaps https://github.com/pypa/pip/pull/12816 ?
I saw that but it's about installation rather than downloads
nice thanks!
I reported the person, could a maintainer delete this spam review? https://github.com/pypa/pip/pull/12923#pullrequestreview-2246655047
FYI, I also reported them about 20 mins ago, don't know how quick GitHub is on reports
Can't delete the review but I did block the user from pypa, to lean on automation making their comments as spam.
Wow TIL you can’t delete a review…
I also reported this user, but I'm not sure if we're getting a response very soon...

I got a response 30 minutes ago

Same here, hope everything gets better now 🙂
And their reviews are gone
Finally starting some work on some pip benchmark scenarios, so I can prove a bunch of my upcoming resolver changes have a general positive impact, trying not to get distracted, trying not get distracted...
What is this https://github.com/ddelange/pipgrip ??? Wow, someone straight up grabbed the mixology resolver and wrapped it around calling pip in a subprocess...
looks like initial implementation of Poetry's resolver
which is now much more optimized
You could try using the strategy the package manager shootout uses: https://lincolnloop.github.io/python-package-manager-shootout/ (although I don't think pip has a "locking" command, that could measure the resolver perf)
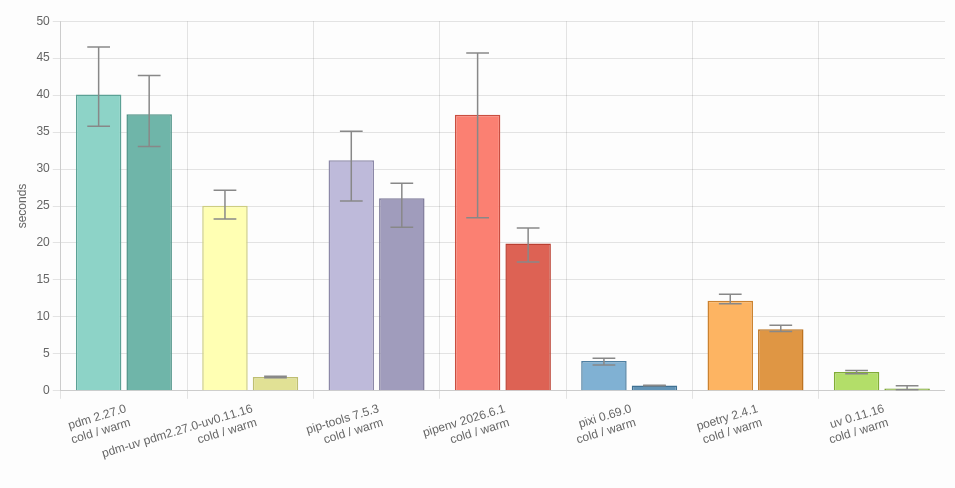
Python Package Manager Shootout
Benchmarking the performance of various Python package managers
I'm not too interested in wall clock timings (although I will be grabbing them to make the results compelling), I'm more interested in how many packages did pip have to visit to solve a complicated resolution (if it in fact was able to solve it at all)
And I want my tooling to be able to: 1) Install and run against any version of Python, 2) Install and run against any commit of pip from any git repo, 3) Run against PyPI for a specific date and time
and now Damian is blowing up my inbox 🧨

😂
I have some free time (finally!) so it's time I catch up on these
TBF, it's mostly coz I was sick and didn't handle some resolvelib button clicking and the only times I saw it were when I was away from all my Yubikeys. 😅
I think we all knew going into Q4 that "nothing" was going to get done anyway 😅
I hope you're feeling better now!
Oh dear, I probably have in real life things I should have been doing instead...
I was also very sick a month ago, hope you're feeling better
I think uv should probably do the same, but they would need to do their own testing. But, like, if uv could hold off for a bit, I might be able to brag I made a PR that made pip resolve faster than uv in a handful of extreme edge cases 😉 .
lol, what a quote
Aha, I just like to inject some humour when I can, especially into threads where someone is playing the "this free software doesn't do exactly what I want" card
I was hoping to catch up all of my pip notifications today, but I don't have the energy to read through the extended discussions of things I'm not even particularly interested, heh.
I'll get my inbox to stop screaming blue but otherwise, I'll look at things I want to look at.
I skip threads and topics I'm never going to act on
If started an OSS project that became popular I would be tempted to make the bug issue template:
- Read the error message
- ???
- Profit
(was just checking on an issue @hidden flame closed)
(no lemons included)
I'll take a look at your PRs sometime tomorrow @finite perch. Overall this is likely going to be a pretty small release :)
I'm going to try and get 1 more PR ready for the release, it should be a big win for complicated resolutions, it's a very small code change, but I really want to prove it doesn't cause problems, so I'm working on have it be able able to automatically run through 100s of scenarios. Anyway, I've got all of Sunday free, so either I'll have it ready by the end of Sunday or not this release
Release is not earlier than next week end, so there is still some time.
I'll need feedback on https://github.com/pypa/pip/pull/13010
GitHub
On python 3.13+ we don't support the fallback to the pkg_resources metadata backend, and don't attempt to detect .egg installed distributions (#12330).
In effect, this means pkg_res...
Is it a bit too late to change it for 3.13?
We've already got a stable release and this seems like something that Linux distros might complain about. 🙈
But why would any recent distro debundling pip use the pkg_resources backend, which is deprecated since quite a while now?
AFAIK, no major distros is debundling pip anymore.
yea, it's just that my availability is going to be very hit or miss later on this month
Fun fact, if you just take the top 20 most downloaded packages in the last month (https://pypistats.org/top) and try to install them with pip:
python -m pip install --dry-run --upgrade boto3 urllib3 botocore requests setuptools certifi idna charset-normalizer typing-extensions packaging aiobotocore python-dateutil s3transfer six grpcio-status fsspec pyyaml s3fs numpy cryptography
It causes pip to do a whole bunch of backtracking to old sdists that it has to download and build to extract the metadata
It's sad that six is in that list
hmm, requests.adapters is surprisingly expensive...

The fact that requests is in maintenance mode and none of the other HTTP libraries have been able to reach its level of popularity makes me sad 😦
I'm just glad it's still maintained.
isn't httpx catching up?
https://pypistats.org/packages/httpx
https://pypistats.org/packages/requests
Yeah, but still less than 4x as much, and anecdotally I don't see beginner guides say "install httpx"
TIL requests is in maintenance mode
TIL requests exists in node
https://nodesource.com/blog/express-going-into-maintenance-mode/
got that when googling the info

The NodeSource Blog - Node.js Tutorials, Guides, and Updates
Request is going into maintenance mode, find the implications for the Node.js ecosystem and the best-supported alternatives to replace it.
That's Request not requests, popular word to pick when making an HTTP library in a language though
Rust went with reqwest: https://docs.rs/reqwest/latest/reqwest/
this is the proper thread for pythons requests
https://github.com/psf/requests/issues/5149#issuecomment-523105187
urllib3 is 3 places above requests https://pypistats.org/top
Makes sense, every requests install depends on it, and so do other tools that don't use requests, in fact I've seen a trend for users to directly use urllib3, especially since 2.0
But I would still guess 80+% of the downloads of urllib3 are because of requests
It's very very rough, but I've written a tool for measuring improvements in pip's resolver algorithm on real world scenarios: https://github.com/notatallshaw/Pip-Resolution-Scenarios-and-Benchmarks/tree/main
If any maintainer who is confident enough to review resolver code would like to look at https://github.com/pypa/pip/pull/12982 and/or https://github.com/pypa/pip/pull/13017 (which is built on top of 12982) I promise you these are actually quite small changes
Hey all, I've created a tool called pip-timemachine: https://github.com/notatallshaw/pip-timemachine
It allows you to install packages as they were on a specific date, this is similar to the existing pypi-timemachine but uses PEP 691, PEP 700, and passing through metadata files, yank status, etc. So it ends up being quite a bit faster.
My main purpose in creating it is to support my Resolution Scenarios scripts, but may help some other people. I just made it today, so I may end up tweaking the API, but I suspect it's fairly close to done.
Cool!
Well, uv has this built in, and maybe some day pip will too, but using pypi-timemachine was starting to be a real blocker for running these scenarios
I have a draft PR for this sit there for quite a while now :(
UV_EXCLUDE_NEWER is one of my favourite uv features, so cool to see a comparable capability available for pip too.
That's good to know, thanks! But then why would anyone still want to use the pkg_resources metadata backend with modern Pythons?
Backwards compatibility reasons. IIRC, the pkg_resources backend and importlib.metadata backends didn't have 100% functional parity in behaviours and we needed to do a slow burn transition there.
It's probably worth double checking this tho, I'm basing this off if memory. 😅
Do we have a way to know if _PIP_USE_IMPORTLIB_METADATA=False is actually used in the wild?
Doing a search for the env var surfaces a bunch of projects.
(I'm using Kagi, so can't easily share the results link)
But, that's somewhere in docs and stuff, so maybe Google finds them too.
There's definitely real world uses of it in public code, and to me it seems like one of those options that has a lot more uses in private code
I dunno about private vs public on this... I lean toward thinking that basing this specific judgement call on just OSS stuff is sufficient tho.
And, even that tends to suggest that we should do the slow transition for this.
Not many in public repos actually, if you exclude copies of pip source code. And those seem to refer to some perf issue that was resolved since.
I'd be enclined to log a message (warning or info level) to ask users to report use cases on a pip issue. We need to find a path to get rid of pkg_resources at some point.
Yeah, I'd say there looks to be about ~10 non-vendors in that github search, could raise an issue with each project if someone wanted
I think if anyone is still using eggs for anything, pkg_resources is the only option that works. I'm not sure why anyone would still be using them, but, well, software.
It was one of my very first requests to uv shortly after they went public, and turns out they already had a hidden API to do it: https://github.com/astral-sh/uv/issues/1358
Funny enough, we do get complaints about the error messages 😄
If anyone has any passing knowledge of resolvelib and would like to help speed up backtracking I point you to take a look at: https://github.com/sarugaku/resolvelib/issues/171#issuecomment-2439135036
I think if this could be solved at the resolvelib level it would make backtracking much much better in pip. I'm going to keep taking a look at it, but I'm sure some fresh eyes would help.
Before pip 25.0 I think I'm going to have a lot of resolver optimizations ready, some of them are going to depend on others. Does it make sense to break them down in as small as possible PRs where one depends on the other? Does it make sense to collapse all the ones that depend on each other to single PRs that are doing multiple things?
The 2 I already have open could really be broken out into 5 PRs, but I'm not sure how much sense that makes.
A single PR with easy to review commits would be my preference. That said, I don't know how much bandwidth I'd have to do reviews. 😅
Okay, well once 24.3 is out the door, and resolvelib 1.1+ is vendored I'll look at working a new PR with very clean commits, I'm going to work on that resolvelib issue I linked above in the mean time, as I strongly suspect that will be a massive improvement to backtracking if I can figure out how to do it
Yeah, so I think the logic in https://github.com/pypa/pip/pull/12877/files is wrong, it doesn't consider that you can receive many requirements files and they can reference each other as a DAG
I think to fix it you need to build a Directed Graph and show there are no cycles, I suspect that's not a minor code change
I can't comment directly on that PR because I'm not a maintainer 😢
git bisect points to that PR
https://github.com/pypa/pip/issues/13046 is the right place to comment, no?

GitHub
Description I have three requirements files, as follows: # requirements.txt ... # test-requirements.txt -r requirements.txt ... # lint-requirements.txt -r requirements.txt -r test-requirements.txt ...
This seems like a relatively cheap revert FWIW.
Commented there also
Why does my pip 24.2 blog post rank so high for for the legacy editable install deprecation? 

I mean, I purposefully wrote it to be an informational resource for those encountering the message, but there ought to be better more authorative resources than mine...
High quality user facing written authoritative information on this topic is extremely sparse
On python-trio We've been having trouble with our pip cache on PyPy on windows: https://github.com/python-trio/trio/actions/runs/11628353435/job/32383357312?pr=3112#step:4:211
GitHub
Trio – a friendly Python library for async concurrency and I/O - don't use f_locals for foreign async generators · python-trio/trio@8fdaaf5
https://github.com/python-trio/trio/actions/runs/11642251222/job/32421639471?pr=3127 this also happens if I split the pip and UV installs
GitHub
Trio – a friendly Python library for async concurrency and I/O - install pip and uv in separate pip calls · python-trio/trio@abe70be
I'm also seeing something odd with PyPy on Windows: https://github.com/python-pillow/Pillow/actions/runs/11601085499/job/32303003010?pr=8514
Not near a computer right now to check, but pretty sure you get that unhelpful error when you put multiple requirements or constraints on a package that isn't available at that version on your platform
Yeah I thought that, but I'm pretty sure it is available. It was reported that the tests pass with an empty cache
Built Distributions
uv-0.4.29-py3-none-win_amd64.whl (14.9 MB view hashes)
Uploaded Oct 30, 2024 Python 3 Windows x86-64
uv-0.4.29-py3-none-win32.whl (13.2 MB view hashes)
Uploaded Oct 30, 2024 Python 3 Windows x86

But also it should try to download the sadist if that was the case
I'm not near a computer till tomorrow, I'll try and look then
I tried running with -vvv and it looks like it gave up checking for links at 0.4.27 https://github.com/python-trio/trio/actions/runs/11650146282/job/32438530991?pr=3127#step:4:2608
This is a bit weird, it seems to be skipping py3-none-win32 and using py3-non-win_amd64 - but it's on arch: x86
Skipping link: none of the wheel's tags (py3-none-win32) are compatible (run pip debug --verbose to show compatible tags): https://files.pythonhosted.org/packages/9d/f6/cf0b29eb54add073342690a98997a376a51753ca9bd403577dee45d5565d/uv-0.4.27-py3-none-win32.whl (from https://pypi.org/simple/uv/) (requires-python:>=3.8)
Found link https://files.pythonhosted.org/packages/07/3a/c593aead3e8e08b7df35120e9c0d4961ea509e27aabc8464e10f80691b4e/uv-0.4.27-py3-none-win_amd64.whl (from https://pypi.org/simple/uv/) (requires-python:>=3.8), version: 0.4.27
Found link https://files.pythonhosted.org/packages/d0/5e/4e5044bfa5cc2b3ae4fbb0cb903680a3f3db99e21d5f626dcfc89c8f2af4/uv-0.4.27.tar.gz (from https://pypi.org/simple/uv/) (requires-python:>=3.8), version: 0.4.27
What's the output of python -m pip debug --verbose on that box?
(throw it in a gist and paste the link here, coz I expect it'll be long)
also A5rocks investigated this a bit:
Since it looks like you are investigating it a bit, I've investigated a bit here: https://github.com/python-trio/trio/pull/3118 (check specific commit actions runs) -- I enabled pip verbosity and manually inspected the files pip would use in its cache, and found those files to be incorrect. I wasn't sure how pip determines a file is out of date so I couldn't check that.

GitHub
updates:
github.com/astral-sh/ruff-pre-commit: v0.6.9 → v0.7.0
ok it's here: https://github.com/python-trio/trio/actions/runs/11650344039/job/32438958945?pr=3127#step:4:210

GitHub
Trio – a friendly Python library for async concurrency and I/O - add a comma, as requested · python-trio/trio@5b03326
here it is in a gist https://gist.github.com/graingert/39bc4c1ef508939347d0ddde23d0bc45

here's the version from the x86 build https://github.com/python-trio/trio/actions/runs/11650344039/job/32438958817?pr=3127#step:4:247
GitHub
Trio – a friendly Python library for async concurrency and I/O - add a comma, as requested · python-trio/trio@5b03326
It turns out setup-python falls back to the os architecture if the requested architecture is not available, so we're just running a redundant PyPy windows build that duplicates the x64 build
@hidden flame I'm not sure how to organize/handle ResolutionTooDeep errors, I understand your merging of https://github.com/pypa/pip/issues/12754 into 12305, another ResolutionTooDeep error, but what's slightly problematic about this is that 12305 will be fixed when resolvelib 1.1.0 is vendored, but there's a good chance 12754 won't :/
Ah, I took your word for "it's essentially the same root cause".
Feel free to reopen it. I'm not a dependency resolution expert :)
It's the same root cause in the sense that "resolution is hard"
And that "better resolution heuristics" will likely fix it, lol
What's life without random heuristics?
Yeah, so I accidentally broke one pip's heuristics in resolvelib 1.1.0, I've been running tests all weekend and found that 1) Breaking it significantly improved performance in lots of problematic examples, 2) Removing it altogether will slightly reduces performance compared to leaving it in it's broken state 🙃
I envy the patience you must have to be doing this all weekend, haha
I rarely get chance to do any more than a few minutes here and there during the week
And sometimes I just need a couple of hours of coding, or to kick off multi-hour tests, to really make any progress on this stuff
Depending on how much of a penalty it is, I'd honestly prefer simplifying the resolution logic, although perhaps it is already beyond any hope of simplification.. 😅
Yeah, I'm going to make the case to drop the heuristic altogether rather than leave it in in a broken state that happens to be marginally faster in some cases
It's actually problamatic for other reasons, and could be argued the logic should be in resolvelib if it's worthwhile, not pip
However, I'm soon going to be arguing for the need to vendor https://github.com/pdm-project/dep-logic to have any chance to take on some of these more complex ResolutionTooDeep examples, I was hoping to get a working demo this weekend of using it, but I ended up getting stuck on this resolvelib 1.1.0 / heauristic issue
At some point, I'd love to chip away at some larger project (better no distribution found errors, mayhaps), but I really do need to sit down and start seriously reviewing PRs.
Any luck with this or should I open an issue? I'm not really sure what's going on or if it's pypy's fault or pip's fault. Pretty sure it's not uv's fault
So it's going to be a vague issue if I do open it
ChatGPT seems to have already invented pip's use of tool.pip in pyproject.toml, that's nice!

I would make an issue, I read your last message as though you had solved this problem as an environment issue, and it's hard to follow long chains of issues on dicord without creating a thread
TBH, why not?
Ah I see, whoops. There were two issues!
People have thoughts: https://github.com/pypa/pip/issues/13003
I'm writing a quick post for pip 24.3. There's not too much to talk about, but I'd like to ensure that there are links to the proper resources for anyone encountering the legacy editable install deprecation.
I've realized that communication of pip changes, especially of deprecations, is lacking. I do hope these write-ups are helping to communicate changes in a more digestable way.
I should write these before the release, but time is hard :)
I'll try to have this out when 24.3 is more broadly announced, pending a potential 24.3.2.
I agree, it's really lacking, and the modular architecture of package installation doesn't help UX
I think we've made a development on the "pip install uv with constraints on PyPy on windows with cache" issue: https://github.com/python-trio/trio/pull/3127#issuecomment-2466160938

GitHub
[investigating pypy pip cache issues]
also I noticed you don't detect ResourceWarnings in your test suite - eg using filterwarnings = ["error"] in your pytest config
the bug is a missing with in cachecontrol
GitHub
The httplib2 caching algorithms packaged up for use with requests. - psf/cachecontrol
should be with self._load_from_cache(request) as resp: ...
Oh you can't put the with there as _load_from_cache could return None
I've done some more investigation using BigQuery free trial credits (and have spent €181 of credits so far!), in an effort to find how many projects I can query per month to keep https://hugovk.github.io/top-pypi-packages/ going with the monthly 1 TiB free quota, and have found some surprising results
first of all, the not surprising result:
the estimated cost and billed bytes go up ~linearly with the number of days queried

the surprising thing: I was looking into adjusting the limit of projects queried, to see how that affects cost
I compared 1000, 2000, ..., 8000 projects. and it turns out it makes absolutely no difference -- they're all the same cost!

I also checked factors of ten from 1 project, up to 1 million (which covers download data for all ~500k projects on PyPI) and still the same flat cost!
(note: this was ran the day after the others, so a different flat cost in comparison)

one other thing: I was using @limber ore's pypinfo CLI to run the queries, and by default it filters to only show installs from pip (AND details.installer.name = "pip") . that extra clause makes the query cost an extra 25% or so in cost and bytes. the above charts are without that filter, so for all installers (using --all for the tool). here's one with the filter, so only pip:

my conclusion: if I want to stay within the free 1 TiB/month quota, first I should fetch for all installers. next, it doesn't matter how many projects I fetch, I might as well get all half a million(!), but as the cost gradually increases over time, I'll need to reduce the number of days from 30 to some unknown number
This is quite cool @stuck girder! Thank you for investigating and sharing.
Have you considered putting this somewhere publicly, such that this information can be found by folks not in this Discord? (eg: a personal blog or something like that)
yeah, will stick it up somewhere!
I also have €96 of credit to use up in the next 16 days, were there some pip queries you wanted to run? like for pypa/pip#12989 (comment)
I wonder how many projects would be happy with daily sums instead of one entry for each individual download, and how much cheaper that would be to store and query.
You can't strictly do that, since there's a ton of metadata captured in each row.
You are loosing data, sure, but even if most of the interesting metadata is still preserved, the dataset would probably be small enough so it can be dumped as a compressed CSV on a CDN once a day, and many projects can fetch those once a day and put the data into their own local databases for cheap. I'm thinking about something like the result of SELECT count(*) as sum, project, version, installer, python FROM pypi.file_downloads WHERE DATE_TRUNC(DATE(timestamp), DAY) == $yesterday GROUP BY (project, version, installer, python) (pseudicode), dumped once a day and made publicly available via means cheaper than BigQuery.
I mean... Yea, I agree that most projects are happy to just have download numbers.
But there's a bunch of ecosystem level decisions that can't be made without that metadata.
I'm not saying we should get rid of the original BigQuery table, just to offer cheaper ways for downstream projects (science \o/) to use a subset of that data
I mean, that's what pypistats and pepy.tech are, no?
https://pypistats.org/ for example should be happy with the grouped data I just described.
PyPI Download Stats
I think what bugs me is that there are probably multiple projects paying money for the exact same or very similar queries, and those queries produce a manage-able amount of data that does not need to be in BigQuery. Sharing those results could save money and spawn new interesting projects. pypistats already has this exact dataset, but it's API is also rate limited and not suitable for fetching "all of it". If the daily sums were available directly from pypi infrastructure then, maybe, less people would need to pay for BigQuery and more people would do interesting stuff with it. Ignore historical data for now, just dump daily (and maybe also monthly) sums somewhere as flat files and remove them again after a month. Interested projects can fetch those files daily, ingest them into their own databases, and do stuff with it.
I don't think that storing this data is sufficient and Internet bandwidth isn't free. That said, I do understand what you mean tho.
I don't think #pip is the right place to advocate for that, and pypi/warehouse issue tracker is probably where you wanna be poking people about this. 😅
It was just an idea sparked from "and have spent €181 of credits so far" 🙂 But if this still bugs me tomorrow, I might start writing a proposal.
FWIW, that's after 1 TB/month of byte processing quota.
(you get that for free)
yep and I'm only using up so much because you get $300 of credit in the free 3-month trial, so I'm doing my best to waste it use it up. I definitely wouldn't be spending that much in real money 😅
So, getting daily sums for "everything" once a day would fit into the free tier?
Cost seems to depend on timeframe more than on result size according to your findings.
Slight counterpoint: never generate CSV ever.
Instead, use anything that
- has the data types you need (e.g. if floats, strings, and null are enough for you, you can use JSON)
- was standardized before every language and library under the sun has committed to their own mutually incompatible defaults
You cannot believe the horrors I've seen. Careers ruined, PhD students crying because all their work was based on an assumption that came from a corrupt CSV read.
Don't generate it, ever. And if you really really have to read it, quadruple check the data after conversion.
It cost -USD$100k to reship several hundred packages after Python took the leading zero off my postal codes
double check your data!!

Yeah thanks for supporting me in that. I rarely get preachy anymore, but when someone says “CSV” I hear the alarm bells ringing
@finite perch by the way, someone's curious to how your wheel filename deprecation is going to affect them. https://github.com/pypa/pip/issues/12938#issuecomment-2469681012
I would respond, but I'm tied up in work so can't at the moment
I'm writing a response right now
ah, awesome
I just not been near a personal computer in a couple of days
great minds think alike :)
Honestly, I should do a digital detox (is that what we call it?) at some point.
lol, whatever I'm doing it's not that, it's just been a logistics issue, I don't really use a laptop much, so when I'm not home I don't get much OSS done
So I'm finishing up my pip 24.3 post. I can't remember the details of the wheel filename deprecation clearly even though I reviewed your PR and read the relevant specs..
Hmmm, the basic difference is that you can currently include extra stuff in the version "2.4.2_stuff" in the filename, and now that's depreciated, a version should be PEP 440 compliant, and should put that extra stuff in either the build tag or the local version segment
The full answer is there was a custom regex before and now we parse the wheel name using packaging's standard function
I think I got it.
It's not quite that simple, something like 1.2.0_post1 is still allowed.
_ is still allowed as a separator for pre/post/development segments, but not for an implicit post-release. Anyway, it's also ambiguous in a wheel, as it could be denoting the build tag, too.
I know nothing of the historical context, but I'd bet that a version like 1.2.0-1 (valid) got normalized to 1.2.0_1 (invalid) when being placed in a wheel.
Makes sense
Wheel filename segments can't include dashes, thus this normalization is needed, but normalizing versions is not trivial. Care needs to be taken.
If you're hit by deprecation it's likely to be very noisy, because it'll warn for every wheel filename pip collects
Unless you're using ancient packages, it seems exceedingly rare IMO.
Yeah, just that 1 user has reported so far
My PR to move over does seem to be causing an unexpected test to consistently fail in CI (but not locally 😭) that I need to figure out how to fix
@finite perch if you have time, I'd appreciate a quick review on https://ichard26.github.io/blog/2024/11/whats-new-in-pip-24.3/. Otherwise, I'm not worried to getting feedback on this as the release is small and I shouldn't have gotten anything major wrong.
pip 24.3 is a small release with a truststore bugfix, QoL improvements, and one minor deprecation of noncompliant wheel filenames.
@jovial jasper if you're interested ^
Is PIP_NO_DEPENDENCIES a real flag? It seems like it should be PIP_NO_DEPS? (conda-build sets this)
It does seem to work
no-deps is a shorthand for no-dependencies; they do the same thing.
Nice!
ugh, I like that when I immediately start to share my post, I realized that I'd totally missed that get-pip stopped installing setuptools and wheel. I just reread your announcement post.
I got to go to work so there's no fixing that, but oops. Haha.
https://discuss.python.org/t/announcement-pip-24-3-release/69350/4, it's frustrating how difficult doing good communication is here. I appreciate any help though!
I should probably update my 24.2 post given it ranks high on Google Search Results for the deprecation of legacy editable installs.
Or rather, the GitHub issue since I try to redirect users immediately there to avoid fracturing advice across various pages. Would it be worth it to also include a point that the setup.py file itself is not deprecated? I'd also want to include some links for further reading (probably to the PyUG)
I can't edit the issue description myself as I'm not a committer, so yeah.
Spent a few hours this last few days working on what I thought would be a big speed improvement to resolution when you end up significantly backtracking on boto3 and friends. Finally got to the point where I was confident it was logically sound, put it to the test, was barely noticeable 😭
amazon is doing python ecosystem dirty with daily releases....
Yeah, several uv optimizations are built around boto3 and friends, good for stress testing resolvers I suppose...
Let me know what change you'd like to make.
@shy echo do we still need the news file GHA workflow? https://github.com/pypa/pip/blob/main/.github/workflows/news-file.yml Can we mark the PSF Chronographer check as required and delete our DIY workflow?
FYI, I'm thinking of making the ResolutionTooDeep error a diagnostics error and opening an issue and pointing users to it, to both help them and track problematic resolutions, I'm worried this happens in the wild and isn't well reported. Especially now I have https://github.com/notatallshaw/Pip-Resolution-Scenarios-and-Benchmarks/ to track problematic resolutions, which I've been improving on the resolution statistics it collects.
did you switch from towncrier to something else?
With a diagnostic error, you can include a dedicated error code. The plan was to at some point have the code link to the documentation with further guidance
I'm not so keen on including a link to a GH issue but as long as you're willing to manage it, it's fine. We can always remove it once the algorithm improves sufficiently.
nah, we still use towncrier, but we currently use a github app and a custom workflow to check for new entries.
Yeah, it's more than just giving users good advise, it would be good to know what resolutions are causing this issue, I'm a strong believer in validating against real world resolutions, not theoretical improvements
Speaking of diagnostic errors, I do think https://github.com/pypa/pip/issues/13078 should probably give a nice error to suggest increasing the timeout, it seem there's some code to try and catch network errors and raise pip specific errors, at least I see that in the Response class, but it appears to be completely missing this stack trace
I think this PR of mine covers that already: https://github.com/pypa/pip/pull/12818
It doesn't include guidance to increase the timeout, however.
I think it might make sense when urllib3.exceptions.ReadTimeoutError is raised
From the PR. It's very similar to when a read timeout error is raised. Both are handled by the PR>

Super, I totally forgot about that PR, glad I didn't try and raise it myself
Of course, is anyone going to review the PR? Probably not, no.
It'll be stuck in limbo :/
I may break out the network diagnostic errors out into their own PR since they're less controversal than the retry warning rewriting, but /shrug
I'll try and take a look before 25.0 if I'm able to help move things along
would any maintainer mind hopping on a call with me to explain at a high level the pieces involved in the resolver? I also don't mind just chatting here if that's better. I'm working on pip this quarter now and the first feature is cross-platform resolution. I thought I grokked the code base but actually I think I've confused myself even further
Can do in about 18 hours from now
awesome thank you, I'll come back here tomorrow around 1:30 PM New York time
Can you ping me, I'd love to listen in
+1, would love to listen
I won't be available then, but yeah, it'd be neat to listen in too :p
+1
We can probably chat on #pip voice channel, but I'm probably gonna need another hour before I'm ready to hop on a call. 😅
just @ me when you're ready
Any chance I could join? I am also interested in being a fly on the wall 🪰
Oh, we just hopped off call. It'd have been 100% OK to hop in. 🙈
I guess I should have clarified that. Ooops?
No worries! I didn't see a pip voice channel, or any channel under voice channels with people in them, so I thought there was a hidden channel perhaps
Hmm... That's interesting.
Time for me to go use admin powers and figure out what we're set up for.
I think that channel might be behind a role or something.
Ah yeah that does make sense
Yeah, it has a little locked symbol, I didn't see, maybe use the empty general channel next time?

Whoops, yup.
ahh makes more sense!
Sorry @ripe shoal (and anyone else who wanted to join!) -- didn't realise that the channel was behind some permissioning situation.
Super secret channel!
I sort of figured I was missing something, I was also curious to listen in.
All good, I was late to it anyway
Yea I had no intention of doing this in a "secret" place. 😅
lol, I'm just now available
😂
Is there a brief summary? 🙂
We talked through the way pip resolves packages at a relatively high level... how the separation of concerns works between pip vs resolvelib, what the initial round of resolution looks like, where the wheel compatibility/filtering happens in the codebase, what simplifying assumptions are made in uv/Poetry etc (eg: consistent metadata across name+version combination, etc) and how they simplify things, the sdist dynamic metadata stuff, how pip might end up supporting the lockfile PEP and... I think that's all?
Did I miss something @limber ore @finite perch?
Oh, and cross platform resolves + what metadata is needed to do them with only-wheels as well as what marker environment stuff could be reasonably inferred (I think uv has some prior art around the assumptions that can be made, as well as examples of when those break down).
That sounds right
Great thanks!
just a suggestion for the next time:
we use granola AI at work (and sadly it's macos only) https://www.granola.ai which listens in to our meetings and generates notes / sumaries based on what it heard, very useful for stuff like this and gives a shareable link for when you're too lazy to write stuff up
heads up: it looks like pip cannot cross resolve for PyPy like pp310-pypy310_pp73-win_amd64 because it determines the allowable set to be the following {<py311-none-any>, <py38-none-win_amd64>, <pp312-none-any>, <py310-none-win_amd64>, <py38-none-any>, <py310-none-any>, <py35-none-win_amd64>, <py33-none-win_amd64>, <py3-none-win_amd64>, <py35-none-any>, <py30-none-win_amd64>, <py33-none-any>, <py3-none-any>, <py30-none-any>, <py37-none-win_amd64>, <py37-none-any>, <py36-none-win_amd64>, <py32-none-win_amd64>, <py36-none-any>, <pp312-cp312-win_amd64>, <py32-none-any>, <py34-none-win_amd64>, <py31-none-win_amd64>, <py34-none-any>, <py312-none-win_amd64>, <py31-none-any>, <py312-none-any>, <py39-none-win_amd64>, <py311-none-win_amd64>, <pp312-none-win_amd64>, <py39-none-any>}
Does pypy310_pp73 match the ABI tag spec?
For implementation-specific ABIs, the implementation is abbreviated in the same way as the Python Tag, e.g. cp33d would be the CPython 3.3 ABI with debugging
It's not clear to me thatpypy310is a valid tag fragment?
that's whatever pip parses as the tag for the cryptography wheel during resolution
Given the cp312 in there, I'm gonna guess something doesn't plumb the information about the changed tag down to packaging.
I don't think it's a viable path forward in any circumstance but it's conceivable that a complete rewrite of the pip-specific resolver bits would be the best long-term strategy. I'm very new to the code base but that's what I think so far after some time with it
and extras are handled in an odd way that I can't quite articulate, seems like there is unnecessary indirection/complication/complexity because of the interface of the backing library resolvelib
it's essentially the same problem that I'm encountering with environment markers, I think it's the same root cause
ah indeed, unfortunately https://github.com/sarugaku/resolvelib/issues/14
I totally forgot about mousebender... https://github.com/brettcannon/mousebender/issues/105#issuecomment-1712884765
so actually that's awesome, no rewrite is necessary and we should instead (imo) make mousebender achieve feature parity and then switch to that internally
Here's a fun question: should files in subdirectories of <name>-<version>.data/scripts have their shebangs rewritten? Like <name>-<version>.data/scripts/foo/bar.py?
I have no idea
I have a real example of a package that includes a directory in scripts
And we currently error on that in uv intentionally
It's not even gonna be on PATH even.
(protobuf-protoc-bin)
My instinct was an error, so that tracks.
It looks like pip does move the directory, and my guess from the code is that it would also rewrite the shebangs (but I haven't tested it -- that package doesn't contain any such Python files in that subdirectory)
Ugh, that looks like a packaging mistake on their end.
Those seem to be files that should be in the include directory.
Yea, in data is what I was thinking.
Pragmatically, uv mirroring pip is probably fine. Ideally, I'd want pip to flag this as an error honestly. 😅
Yeah... tough call!
Thanks for the input 🙏
It is fun to decide, though, whether this means files directly in scripts or in any subdirectory of scripts:
In wheel, scripts are packaged in {distribution}-{version}.data/scripts/. If the first line of a file in scripts/ starts with exactly b'#!python', rewrite to point to the correct interpreter.
Probably a good idea to amend the spec to ban directories entirely
I'd be on board for that!
I read the spec that directories are banned/ignored already. "scripts are packaged in {distribution}-{version}.data/scripts/" (not "below")
Congratulations @hidden flame on becoming an official pip maintainer, well deserved
And likewise! As I've said before, it's great to have another resolver expert on the team! It's been overdue. You've been around longer than I have, heh.
I was confused about how you knew that I got the commit bit before I heard anything from anyone else, but then I realized you got the commit bit as well :)
@shy echo @lunar gyro what's our general policy on merging PRs in-between release cycles? With the recent releases, we've done most of our merging near the release date. I don't think that's the optimal strategy for contributors (it sucks to have your PR languish with no progress for weeks or months on end) or us (landing so many changes all at once is likely to introduce issues or incompatibilities we fail to foresee). I'd like to merge things earlier if that's alright.
I think that we've shifted to merging a ton in a short window mostly as maintainer time is limited, but I wasn't certain whether it's also a project custom now.
I agree that the current PR merging cycle hasn't been ideal, and I was specifically planning to approve and/or merge earlier in the release cycle (shortly after a previous release is consider closed)
Also /cc @jovial jasper
When I have bandwidth to do so anyway
- https://github.com/pypa/pip/pull/13063
- https://github.com/pypa/pip/pull/13085
- https://github.com/pypa/pip/pull/12659
I was thinking of merging these PRs at least. They've been approved by several individuals and/or are a relatively safe merge.
One thing I would advise though, is if a PR has been languishing for a little while, and it is a non-trivial change, is it might be worth to merge main and let tests run one more time
Another reason why I don't like to leave PRs languishing, but yes, that is a good point!
Welcome both of you!
I don't think there is a policy for that. More like that's how life goes and there is more attention close to release time.
Except for vendoring updates which I think it's important to do early in the cycle.
Did a new CPython release break CI again? https://github.com/pypa/pip/actions/runs/12206893115/job/34057333229?pr=12659#step:5:3406
I haven't looked carefully to figure out which one of these bugfixes is breaking us, but man, there were lots of changes to url2pathname in CPython 3.13.1:
- https://github.com/python/cpython/issues/126766
- https://github.com/python/cpython/issues/127078
- https://github.com/python/cpython/issues/126766
- https://github.com/python/cpython/issues/127217
- https://github.com/python/cpython/issues/120423
- https://github.com/python/cpython/issues/126212
- https://github.com/python/cpython/issues/126205
Ah, you dealt with similar breakage earlier, am I correct @finite perch?
I remember this recent fix: https://github.com/pypa/pip/pull/12964, I wasn't involved
408 pytest.param(
409 "git+file:///T:/with space/repo.git@1.0#egg=my-package-1.0",
410 "git+file:///T:/with%20space/repo.git@1.0#egg=my-package-1.0",
411 marks=skip_needs_old_urlun_behavior_win,
412 ),
I vaguely remember you writing this marker though.
Not impossible, but I do not remember
Ah, I had the wrong person, haha.
commit 5c389ec91fa178ec3897f5b9522441f4d3922662
Author: Matthew Hughes <34972397+matthewhughes934@users.noreply.github.com>
Date: Tue Jun 25 13:04:26 2024 +0100
Split up Windows tests relying on urlunparse behaviour (#12788)
There was a behavioural change to `urllib.parse.urlunparse`[1] that
affects some of our tests on Windows. With the understanding that the
new behaviour is indeed desired, split up some tests relying on this
behaviour depending on the version of Python.
The sample URL used to check this behaviour was taken from a test in the
upstream change (with the new behaviour this URL will round-trip
parsing)
[1] https://github.com/python/cpython/pull/113563
Whoops. Anyway, I'm filing an issue. Will try to take a look but I don't even use Windows day to day anymore.
I use Windows, but I almost exclusively do dev work inside WSL2
It makes me really happy to see my posts be used as a reference for users dealing with the deprecation of legacy editable installs: https://github.com/zopefoundation/Zope/issues/1239#issuecomment-2503257765 😄
I still think some more (and better) communication is needed, but at least there are accurate user-facing resources out there.
Surprisingly, I can't find a SO question on this deprecation warning.
Maybe it would be worth it to repackage everything I've said into a more targeted post that would rank better SSO wise (than a pip 24.2 post).
Maybe this will work 🤞 https://github.com/pypa/pip/pull/13105
- https://github.com/pypa/pip/pull/12898
- https://github.com/pypa/pip/pull/12869
I'm also planning to merge these two PRs once main CI is no longer red.
Pradyun sometimes pre-emptively wrote an SO question and answer, for example: https://stackoverflow.com/questions/70914876/get-pip-py-fails-with-modulenotfounderror-no-module-named-dataclasses
We've used the "self-answered question" trick on SO for CPython changes, too (I still occasionally get rep notifications for https://stackoverflow.com/questions/25445439/what-does-syntaxerror-missing-parentheses-in-call-to-print-mean-in-python)
Ah, yeah, I should probably write one myself.
Thanks @finite perch for attempting to reproduce that bug!
Fortunately my past self left enough information to check if it was still a problem
I've basically not used pycharm since that post
I've never used pycharm :P
Alright, I'm going to call it a day with pip development work today. I'd appreciate reviews on the following PRs:
I've hit somewhat of a snag with cross-platform resolution. basically, the way others (UV, Poetry, etc.) do this is recording the entire allowed set and assume that it's also the installer. this is not the way pip handles things and therefore unless I'm mistaken would require either the exact same type of lock file they do or the user specifying an extremely large amount of data (https://github.com/pypa/pip/issues/11664), even down to the target version of glibc, or else the wheels could be incompatible. I'm not sure the latter is desirable for UX nor am I certain that the former we would want to tackle before Brett's proposal is finalized
I would appreciate any feedback from maintainers, based on going deep through the code it looks like pip (and also packaging) currently is very much incapable of cross-platform resolution without significant changes (far more than I thought at least)
I was going down the path of the recommended solution to that issue and realized what we think we need to supply is more than just environment markers and so much data being ad-hoc supplied by the user IMO is a very poor user experience
I would agree with your assessment
I didn't think cross platform compilation would be possible without big changes, and either ignoring standards or poor UX, but didn't want to be pessimistic
Are you talking cross-platform like, solve for this single different platform or solve for all platforms?
for a single to start with
I see now you talked to Charlie a bit on our server, but presumably there are things to learn from the --python-platform and --universal options to uv pip compile.
i.e., we implement single and multi cross-platform resolution with a requirements.txt output format there
I believe uv pip compile makes several simplifying assumptions to get these options to work nicely for the user. I think such options for pip are not going to be as easy to design where everyone is happy. But maybe I'm wrong.
Yes definitely we make some assumptions around the options — I'm not sure why they'd be harder in pip but it's certainly possible there will be more strong opinions 🙂
For example, I don't think there would be agreement on making assumptions about non static metadata from sdists, so it wouldn't be possible to extract that information from a different platform
Mmm welcome to intractible universal resolution 🙂
Yeah, I agree that to do universal resolution in a way that's useful to users you have to make some simplifying assumptions, I just don't think there will be agreement for pip to make those assumptions without new standards that enshrine those assumptions
What additional data is needed beyond environment markers for a single platform resolution?
Compatible platform tags
There is no way to compute these from environment markers?
no
for example, if you want to resolve for Linux with a particular maximum version of glibc
only the installer has such information and would require the entire resolution set as the input
I also thought I could cut out certain edge cases and make this work but really pip is not designed for this and I'm going to open an issue later detailing this and asking for advice. I don't know what the maintainers want to do actually
and if Brett's proposal goes back to the original way of "requirements.txt v2" rather than the standardized full resolution approach it's conceivable that pip would either never cross resolve or it would take many years because of the work and adopting a lock file
FYI, I've enabled auto-merging on the pip repository (so I can let CI pass in the background while I'm doing something completely unrelated and not have to come back to press merge).
I'll send an email to everyone when I get the time to do so.
where do discussions for the roadmap go? here, a FR issue, or a Discourse thread?
pip's roadmap? Issue tracker!
feature request?

Yea
it gave me "we have a roadmap?" vibe 🤣
I mean... yea. That's basically correct.
#pip is no longer a private voice channel, FWIW
I found the button for that!
there's no time for a road map if you don't even have the gas (maintainer time) to make the trip (review large changes) because of inflation (our lives have gotten busy) :p
everyone is still recovering my from my github notification inbox spam
I've merged so many PRs recently that it seems almost second nature now
@hidden flame full auto on the merge gun?
I'll leave the pip cache filesize reporting PR open for another day just in case others have something to say
I am indirectly responsible for this flurry of activity. I "only" merged 7 of these PRs, but I think I kicked off the rest.

My goal is to have ~130 PRs open by the end of this year.
I think that's doable given that there are still a few simple PRs that only need a bit of work to land, but of course, the rest are either totally unready (or should be rejected, probably) or require a nontrivial amount of discussion.
https://www.repotrends.com/pypa/pip is handy to see changes over time
Oooh, I like how it shows when I'd made a concentrated effort in 2019 to get the number lower for open issues.
And why it felt like a try to hold sand. XD
😭

That's pretty impressive
can see the big releases in February and August 🙂
Can't complain that we have lots of users haha
It's funny we get so many questions now
Like "how do I Python package"
That's a good sign!
I think I got frustrated with answering the same question every time at some point. 😅
hahaha
I have https://ichard26.github.io/ghstats/ for that already :P
What happened 20, March 2017? Stalebot?
No idea.
I plan on reviewing and merging the following PRs this weekend:
- https://github.com/pypa/pip/pull/13063 (my own, I am waiting for community feedback, but it seems no one is interested)
- https://github.com/pypa/pip/pull/13050 (docs only change)
- https://github.com/pypa/pip/pull/13075 (similar to my PR)
^ if anyone wants to look at them as well
I'm looking for some feedback on vendoring resolvelib, resolvelib 1.1 is ready to vendor, it has some important correctness fixes where pip currently says some resolutions are impossible when they are not (and gives spurious errors), it even improves some resolutions performance, but it will cause other use cases to perform much worse (especially stuff involving boto3 / urllib3).
I'm fairly confident I can fix these other use cases in a new version of resolvelib, but I have very little time over the next few weeks to work on OSS. So, if I push resolvelib 1.1 to vendor now, there's a chance a resolvelib 1.2 will not make it for pip 25.0, and it will fix some issues and cause others, but if I wait for to push vendoring resolvelib 1.2 it means these correctness issues might not be fixed until pip 25.1.
You should probably post this as a comment on the PR or issue as well. Not everyone is here or keeps a close eye on Discord.
I wrote this up but think I forgot to share it! https://dev.to/hugovk/a-surprising-thing-about-pypis-bigquery-data-2g9o
🤯 ... more than a billion downloads with pip every month ...
no, every day
Eep, even more 🤯
And those are only the ones that pypi reports - it's likely far more for internal mirrors
So much traffic and energy burned by uncached and probably mostly useless CI/CD pipelines
Yeah, I imagine at least a few % points of that is people putting pip install pip --upgrade after a COPY on their dockerfiles
if you have time I would love to improve the default to include every actual non-mirror installer!
Alright, time to sit down and work on pip properly now I have some actual free time
I made the last set of changes I wanted to make to improve the legacy editable deprecation issue write-up: https://github.com/pypa/pip/issues/11457.
It could probably do with even more work to be more beginner-friendly, but at least, it should be comprehensive. It's so long, gosh, I wish this stuff was easier to explain (but it's really complicated under the hood).
Actually, I do want to make one more change to state that it's not like when pip 25 rolls around, any project still using the legacy mechanism is guaranteed to break.
Coolio, I'll finish up the actual removal PR next. That's a task for tomorrow though as it's getting late.
Annnd I broke 32 tests by removing the legacy editable mechanism. This will be fun to patch...

you think tests will be fun to patch? imagine what fun it will be to answer all those issues about people not being able to work on their projects for some reason (I am sure there will be some special people that will have a crazy setup that will complain)
I can't tell if you're being sarcastic or not.
@rare umbra are you aware of an easy first-party way to use ReFS/DevDrive in GHA CI? I'm looking at https://github.com/astral-sh/uv/pull/3522/files and it looks a tad complicated 😅
Actually, it doesn't look that bad digging into the PR more carefully. I'll try to port this over to pip's CI (as I'd prefer avoiding a third-party action even if it would make my life easier).
And it doesn't give us a speed up anyway (trying both a custom implementation inspired by uv's and the 3rd party action available to set up a dev drive). That's a disappointment.
@hidden flame please let me know if you need help (or a review), it's not too bad / we haven't had problems since setting it up.
I'm surprised it doesn't provide a speed-up, but perhaps we're bound on different things.
We used to have a RAM-based disk for pip's CI at some point but that got broken by GH a few times, and we removed it at some point. 😅
Some time in January I plan to upgrade to Windows 11, create a dev drive, and do a performance test locally, to at least see what that turns up. Maybe GitHub are already doing something with their VM runners that negates this need though?
I recently learned that anything relying on pth files won't work in notebooks or similar systems where you interactively install package at runtime, because those are only interpreted during runtime startup :/
Yea, site is responsible for that and is imported at startup.
I don't think GitHub is investing in it, but 🤷♀️ https://github.com/actions/runner-images/issues/7320 is the only tracking issue I know of
Less of a tracking issue and more of a shared misery issue, lol
Haha indeed
notebooks could run site.main() after install to run new .pth files
But they don't automatically as part of the %pip macro and most users don't know that
right, but it might be a good idea to open an issue proposing it
Is site.main() really idempotent? Is it save to call it multiple times?
It's definitely not necessarily idempotent because .pth files can cause arbitrary code execution
Then there is no proper and clean solution for this issue, unless site keps track of pth files it already executed and offers a way to run only new ones.
if you want to take a look: https://github.com/pypa/pip/pull/13123
I think the only main way to improve CI times is to literally make pip faster and simplify the tests where possible.
I really would've thought the dev drive would've netted a noticeable improvement, but I guess not.
I'll try locally in the new year and report back if I saw any gains or not
I dual boot Windows 11 and Ubuntu. I could test it out myself, but I honestly don't have the appetite for trying this again given I've spent a few hours for nothing.
Well, I would like to see if I can run the tests locally, I boot into Windows but then usually do my dev in WSL2
But there are occasionally disadvantages to not running directly in Windows
This is what https://docs.python.org/3/library/site.html#site.addsitedirsite.addsitedir() is for:
Ah, you want to run the .pth files newly added to an existing site directory. Yeah, there's no stdlib support for that - installation is expected to happen while the process isn't running.
You usually need a couple of tricks to make sure all your disk IO is running on the dev drive. Redirecting TEMP is a good start (just set the env variable early). You might also be on an OS that doesn't have it yet and so it's disabled (ReFS on a separate drive should give you most of the benefits though - all Dev Drive really adds on top of that is reducing Windows Defender's impact, but that'll be turned off on GHA already).
I believe GitHub will start using Dev Drives automatically once they're running Windows Server 2025, but don't quote me on that.
Heh. There are so many things I'd like to work on:
- prototyping replacing the build environment provisioning to install deps in-process instead of via a subprocess
- cleaning up the test suite, focusing on making it faster
- reducing the PR backlog
- improving error messages
- continuing the pip communication work I've already started
There are only so many hours I can spend on pip though, so I have to choose carefully.
Anyway, I'm just thinking out loud :P
This is promising. I seem to be shaving 30s to a minute on the Python 3.8 jobs. The Python 3.13 jobs don't really care though.
Checking last 50 runs ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 50/50 100% 0:00:47
[3.8 (1)] mean: 0:17:37 min: 0:16:40
[3.8 (2)] mean: 0:14:59 min: 0:14:04
[3.13 (1)] mean: 0:11:15 min: 0:10:29
[3.13 (2)] mean: 0:10:39 min: 0:09:55

I kicked off a second rerun to see whether this was just a spectacularly lucky and speedy run, or actually maybe the result of the ReFS drive.
It's probably best to graph the CI times on a scatter plot or something and then see if the lines trend down with the change, but I really don't feel like this running this 50 times over. If this potentially improves the times, it may be worth it to merge and then observe CI data over time, reverting if it turns out to be useless.
Yeah, I do think CI run times can be pretty noisy 😕
So the same time could still end up being an improvement
Or visa versa
mhmm
I know a way to get 3.8 times down to zero 😉
but then we have to test 3.9
and 9 was eaten by 7 sooooo, that's impossible, thus imploding the python support matrix
I know that's a really awful joke, but I had to make once I thought of it
While you're here @stuck girder , is --numprocesses auto really necessary on GHA? I thought pytest-xdist would recognize that the worker has multiple cores available without that...
Hmm, I don't remember off the top of my head, would be easy to test and find out
I'll remove it then :D
hmm, while I further micro-optimize CI, I'm tempted to work on https://github.com/wntrblm/nox/issues/710
I don't know whether to only land the uncertain/definite improvement OR just land all of the optimizations I've worked on.
If I land both, it will be fairly difficult to isolate the impact of the uncertain change (ReFS drives), but I also don't want to wait that long between improvements.
I guess the answer to collect as much data before merging them.
I combined all of the optimizations so far (ReFS drives, faster pytest test collection, elimination of redundant nox session build/install work). This is of course only one data point, but it looks rather promising. These numbers are on average better than only the ReFS drive and are noticably better than the last 50 CI runs on main (only losing out on the minimums for 3.13).

I think the last testing I need to do is to collect before/after results within the same run. That way, I can hopefully eliminate some of the run to run variability and figure out whether there is actually an improvement. Measuring that improvement is IMHO impractical, but as long as there is one, I'd say it's worth it.
Stepping back though, even the best results (comparing this one run to the 50 run averages), it's still at most a 11% improvement (3.8 - shard 2) which is admittedly small 
If they simplify/remove things I think it's a no brainier, if they add stuff probably less worth it
11% is pretty good 👍
I was hoping for a bigger improvement since apparently dev drives were shown to significantly help with the test suite in microsoft's own marketing materials (although they took it out as it was too much of an outlier).
But it's windows, you can't argue with it too much :P
Marketing numbers from anyone with an incentive to lie... are basically always unreliable. 😅
fair!
I've tested that, it actually seems to be faster than the ReFS drive, but I will actually kick off a run to figure that out soon.
probably could combine both
I already did, seems to be slower
I see
Here's a test run: https://github.com/pypa/pip/actions/runs/12495659590/job/34866614422. The first test suite run is using the D: drive, the 2nd is main, and the 3rd is the fastest ReFS drive set up I've managed to write.
D: drive is fastest, ReFS drive (which is created on the D: drive) is middle of the pack, and as expected, main is the slowest.
On the one hand, I'm pissed that I spent so much time on the Dev Drive/ReFS, but OTOH, I'm happy that a simple change is all that's needed to majorly improve CI times.
I mean, building the infra/context meant you knew how to check this quicker.
Another question... Did you try a ram disk? I'm 80% sure what we used to do had stopped working at some point.
Yeah, the ram disk was turned off because it was causing problems and there wasn't a significant performance degradation after turning it off
I started to take a look at installing build deps in-process. Writing a prototype doesn't actually look too bad. There is a lot of refactoring to do though as pip's codebase is not designed to resolve/install in separate chunks.
Of course, the devil is in the details. The tests, the edge cases, and getting the reporting and error handling right will be a pain, heh.
Is this something spinning up a subinterpreter to do the build dep installation could help with? That would let you keep the Python level state separated without having to launch a whole new OS subprocess (which can be particularly expensive on Windows): https://pypi.org/project/interpreters-pep-734/#description
Would be a hassle to maintain, though, since you'd still need to fall back to out-of-process builds on 3.12 and earlier (the pure Python PyPI backport needs a supporting binary extension module on 3.12, and doesn't work at all on 3.11 and earlier).
Honestly, there are other problems with calling pip in a subprocess:
- passing all of the state, there are a lot of flags that are simply ignored
- friendly error reporting is difficult
- in-memory caches aren't used
anyway, I quickly wrote a prototype. Installing build deps in-process saves like 300-350 ms on my system.
most of the time penalty is still from querying PyPI for the backend (in my case, setuptools) index page to see if there's a new version of setuptools available
Reducing having to query for setuptools would be a big win, there will be millions of HTTP calls per day because of that check, however having an isolated build step in process does seem tricky
writing the prototype made me realize just how many flags pip has, there was so much configuration state where I decided "eh, screw it, this is supposed to be a demo anyway, I'll just hardcode this value"
So many tools grow to be https://cbx-prod.b-cdn.net/COLOURBOX10672202.jpg?width=1600&height=1600&quality=70

sadly we don't have a budget of $insert-boeing-market-valuation
That's fast! @shy echo

I mean, it's still sharded over two jobs, but now the Windows jobs are firmly not the slowest jobs in CI. macOS and the zipapp jobs are.
this is very interesting! May need to steal this for mypy 😛
:sigh: there is no D:\ drive on the larger Windows runners, apparently
That's a shame
Yeah took me a while to figure out why it wasn't working
I'll see if moving from ReFS on a larger runner to D:\ on the default runner is a speed-up for us, but I seriously doubt it
tests / 3.10 / macos-latest -> mean: 0:06:25, min: 0:05:44, stdev: 0:00:34 (8%)
tests / 3.11 / macos-latest -> mean: 0:06:40, min: 0:06:03, stdev: 0:00:39 (9%)
tests / 3.9 / macos-latest -> mean: 0:06:57, min: 0:06:03, stdev: 0:00:55 (13%)
tests / 3.13 / macos-latest -> mean: 0:06:59, min: 0:06:15, stdev: 0:00:37 (8%)
tests / 3.12 / macos-latest -> mean: 0:07:09, min: 0:06:14, stdev: 0:01:01 (14%)
tests / 3.8 / macos-latest -> mean: 0:07:11, min: 0:06:32, stdev: 0:00:31 (7%)
tests / 3.11 / ubuntu-latest -> mean: 0:09:33, min: 0:09:08, stdev: 0:00:10 (1%)
tests / 3.10 / ubuntu-latest -> mean: 0:10:04, min: 0:09:43, stdev: 0:00:14 (2%)
tests / 3.12 / ubuntu-latest -> mean: 0:10:34, min: 0:10:16, stdev: 0:00:14 (2%)
tests / 3.13 / ubuntu-latest -> mean: 0:10:35, min: 0:10:10, stdev: 0:00:12 (2%)
tests / 3.13 / Windows / 2 -> mean: 0:10:39, min: 0:09:55, stdev: 0:00:20 (3%)
tests / 3.8 / ubuntu-latest -> mean: 0:11:02, min: 0:10:41, stdev: 0:00:14 (2%)
tests / 3.13 / Windows / 1 -> mean: 0:11:13, min: 0:10:29, stdev: 0:00:24 (3%)
tests / 3.9 / ubuntu-latest -> mean: 0:11:44, min: 0:11:20, stdev: 0:00:19 (2%)
tests / 3.10 / macos-13 -> mean: 0:12:10, min: 0:08:53, stdev: 0:02:16 (18%)
tests / 3.11 / macos-13 -> mean: 0:12:59, min: 0:09:09, stdev: 0:02:34 (19%)
tests / 3.13 / macos-13 -> mean: 0:12:59, min: 0:09:54, stdev: 0:02:41 (20%)
tests / 3.9 / macos-13 -> mean: 0:13:10, min: 0:10:09, stdev: 0:02:42 (20%)
tests / 3.8 / macos-13 -> mean: 0:13:34, min: 0:10:09, stdev: 0:02:30 (18%)
tests / 3.12 / macos-13 -> mean: 0:13:55, min: 0:09:54, stdev: 0:03:23 (24%)
tests / 3.8 / Windows / 2 -> mean: 0:14:58, min: 0:14:04, stdev: 0:00:26 (2%)
tests / zipapp -> mean: 0:16:53, min: 0:16:27, stdev: 0:00:15 (1%)
tests / 3.8 / Windows / 1 -> mean: 0:17:37, min: 0:16:40, stdev: 0:00:30 (2%)
whelp, this script has possibly gotten out of hand 😅
With the C: -> D: PR and moving the zipapp tests to macos-latest, we should have 15 minute CI (*although all of the intel macOS runners experience a LOT of run to run variation)
That's much nicer!

I think that's enough CI shenanigans for now.
@lunar gyro I'm trying to optimise link parsing as it can be rather expensive.. is there any meaningful difference between urllib.parse.urlparse and urllib.parse.urlsplit for pip? It may make sense to introduce an URL wrapper class that simply caches the result of urlparse or urlsplit, but for that to be effective, I'd need to converge on a single url parsing function.

(I sent the message to the wrong channel previously, hence the double ping, sorry!)
hmm, it may be easier to simply slap a small LRU cache on urllib.parse.urlsplit, this is tricky
CacheInfo(hits=54861, misses=53265, maxsize=10, currsize=10)
yeaaaaa
I don’t think we use anything special that’d cause problems if we use urlparse or urlsplit. It should work if we always use one of the other.
FYI, the arguments here are quite technical but maybe being worth aware of: https://discuss.python.org/t/deprecating-urllib-parse-urlparse/35028
oh, urlsplit() already has its own caching: https://github.com/python/cpython/blob/64173cd6f2d8dc95c6f8b67912d0edd1c1b707d5/Lib/urllib/parse.py#L455-L456
simply by moving to using urlsplit consistently, we can benefit from that 🎉
@obtuse lagoon should probably continue here. Ah, I simply copy and pasted the list of redistributor contacts from the old "technical debt, debundling" pip issue. I wasn't sure if it was up to date, but I've never interacted with any of y'all before so I had no idea where else to look.
good to know that arch has no concerns 👍
gor gentoo I'd recommend pinging https://github.com/mgorny instead
no worries, this is mostly a me issue, I am not in a great mental state and feel uncomfortable interacting with him
frankly, as an ubuntu-forever-and-ever user, I don't understand the difference/relationship between Gentoo and Arch, but ¯_(ツ)_/¯
which is something I have to do for $dayjob anyway, because of meson
eh, it's mostly just different packaging infrastructure
I understand. There are people I'd rather avoid interacting with as well. I just wasn't aware. I knew that you were probably busy/not in the best state, but didn't know about the history between you two.
Not that I was expected to know that, but it definitely would've been nice 
I was having a look at https://github.com/pypa/pip/issues/13120 and from what I understand: the constraints file doesn't handle Git (or any VCS) links? I see is_satisfied_by firstly does link comparison https://github.com/pypa/pip/blob/dd6c4adb2e3a4dd2d99b9854d41ae9d3ce783cfb/src/pip/_internal/resolution/resolvelib/base.py#L50 which would fail for e.g. git+https://host/some/path and git+https://host/some/path@some_version since the final path components (path vs path@some_version) won't compare equally. Have I missed anything? Could that issue then be considered as a feature request?
That sounds right, there's a design issue around constraints and the resolver which limits what it can figure out without having to download the and in this case build the package, I was going to take a look at your issue once I was back from visiting the family for the holidays
I'm going to be busy again so my pip activity will slow down. The remaining items I want to get to are:
- Finishing an initial draft of the legacy editable removal PR. I won't be able to fix the test suite (as it involves some truly incredibly hard to follow test helper code) so I'll need someone else to pick up the rest of it
- A first pass review of the aliases PR
- A bit more communication work in preparation for the release (technically, I don't need to do this now, but it'd make my life much easier).
Reviews of anything in the milestone are of course appreciated. There isn't anything left that I feel comfortable merging without further reviews/eye balls.
I'm still on vacation, hope to start being able to do a little work and reviewing in January
Vacation comes 1st, enjoy it! ☀️
On that note, I totally forgot it's New Year's Eve. When the hell did 2025 start knocking on the door? 👀
Oh yay, a bunch of tests that fail because of the number of slashes after "file:" on 3.14: https://github.com/pypa/pip/actions/runs/12582388693/job/35067982563?pr=13138
file path tests are just the gift that keep on giving 🫠
it's the tech equivalent of receiving coal for christmas 
I'd honestly pay money for someone else to deal with them. This is super annoying, ugh.
In all seriousness, perhaps we should just ignore leading slashes because I've lost track of how many expected variations there are across our platforms now...
Yeah, I've not looked at why they've kept changing, but it would be nice to have a test that was less fragile, maybe a test helper function that can produce a bunch of possible valid outputs given the current platform, if no one else does I'll start working through them in a couple of weeks
would normalization help at all: instead of comparing strs in tests, compare e.g. pathlib.Path objects? That idea was just from a glance at the _get_url_from_path tests, not sure how helpful/appropriate it would be elsewhere
Possibly, not read the code or it's history yet
$ pip check
uv 0.5.13 is not supported on this platform
hm, is that supposed to happen? I built uv myself and it's working
oh, something is writing wrong tags into wheels, fun
oh no, build backends are hardcoding these 😦
not fun times for non-official Python distributions with different tags
Yeah, this is https://github.com/pypa/pip/issues/12884. A PR improving our error messaging when dealing with improper or unsupported tags would be welcome, but that's a nontrivial patch.
thanks for the pointer. For maturin I worked it around for now via:
$ export _PYTHON_HOST_PLATFORM=$(python -c "import sysconfig, sys; sys.stdout.write(sysconfig.get_platform())")
Do the folks in here happen to recall why/how the choice for PIP_USER_AGENT_USER_DATA to be a JSON-encoded string? (cite: https://pip.pypa.io/en/stable/user_guide/#using-a-proxy-server)
There's nothing that I could find that validates JSON-encoded string, passing pretty much anything ends up as a string.
It seems that it was tacked on to an existing json blob as to avoid adding something new, the chain I followed to find this out:
https://github.com/pypa/pip/pull/5550
https://github.com/pypa/pip/issues/5549
https://github.com/pypa/pip/pull/5424#issuecomment-393119615
Thanks - I was also able to follow the commit trails, but was trying to understand the notion of a "JSON-encoded string" as it appears that anything passed in will be escaped anyhow
Curious to how the test suite spends its time installing build dependencies so I wrote in some logic to measure the durations and save them to a DB.

The functional test suite (excluding all of the keyring tests) spends 80 seconds installing build dependencies. Hmm.
That's actually lower than I expected. There are still obvious improvements though. The test suite should really not be hitting PyPI nearly as much.
Unfamiliar with the CI yet, but setup-python action has a flag to enable pip caches - is that of interest?
Here's a PR that enables caching: https://github.com/pypa/pip/pull/13141
But the impact of it would only be seen post-merge and subsequent runs
Here we can see that caches are generated against a platform/OS/pyver/hash-reqs-file https://github.com/pypa/pip/actions/caches
The test suite disables pip's cache by default.
I haven't thought about this too much, but I'm leaning towards cleaning up and refactoring the test suite to eliminate all of the unnecessary network requests (using local data as much as possible).
A lot of tests already disable the usage of any remote indices and use a local filesystem index, but not all of them.
Does the test suite disable pip cache, or do (almost all) tests disable using pip's cache?
The PR I sent would at the very least prevent the test setup installations from needing to reinstall stuff like nox itself
We have a globally applied per-test pytest fixture that isolates the pip under test, disabling the cache among its other effects.
The log I sent is misleading. Almost of these pip installs are occuring during test execution, not setup.
I'm not sure why it's being recorded as part of the setup phase, but I don't feel like debugging a potential pytest bug or quirk.
So yeah, I don't think we will benefit from pip caching. We don't install that many dependencies during CI setup. For example, for this Ubuntu job, only six seconds is spent installing nox and the test dependencies. The rest is spent on installing Ubuntu system dependencies and pip itself (from source).
I mean, every little bit likely helps reduce the load from PyPI 😉
I'm honestly surprised that GHA or whatever doesn't cache PyPI requests. I get that would be a logistical and admin nightmare, but the amount of external traffic it'd save would be significant.
Agreed - but that would be an unexpected behavior that might violate end users' expectations. Having the ability to slap a cache: 'pip' directive into a workflow pretty much does the thing. We use dep caching pretty heavily in warehouse
Also: my question about user_data was motivated by thinking "is there something dependabot could add to help identify how many requests come from them?" but it seems like the chocie to disallow that data from linehaul make the question moot
Right, but now we have to maintain this caching. If it breaks randomly, then it's a net negative. If someone wants to merge it, then sure, but ¯_(ツ)_/¯
Oh, I'm happy to retract - especially since it appears there's no dependency locking for nox - it's get latest always. without a reqs.txt / pyproject.toml with depency versions to hash against, the nox version and depencenies would never be updated
We have a tests/requirements.txt, it's just almost totally unconstrained :)
Ride the lightning! ⚡
Using nifty lil pytest-socket, I identified 9 tests that make external network calls (on macos, others might be skipped).
There's 133 pytest.mark.network decorators in place, and conftest will mark those as rerunfailures .
Yeah, we could probably benefit from a cleanup of the network marker.
I'd much prefer using that over an additional marker if possible.
@ember shuttle I'd probably want to look into how coverage/pytest-cov handles subprocesses since IIRC they have pretty good (and even automatic zero-config) subprocess support.
My understanding for coverage and subprocess is that every subprocess runs its own coverage wrapper process, and dumps the coverage data to a hashed filename, and post-tests combines back to a single coverage file.
I got a little too deep into that, and we ended up having to add a sitecustomize.py to enable coverage "early enough" (not pretty, but it worked)
I have no idea how pytest-socket works, but I'd imagine that as long as you can run some code at Python startup to install a shim for socket.socket, you can filter the calls as appropriate, probably using envvars to pass state.

hmm that's interesting...
This is how pytest-cov collects coverage information even in subprocesses without any configuration. You can run arbitrary code at startup using .pth files.
(yes, this is a known, but probably not well-known-enough security hole, I didn't invent this :P)
Thanks for the pointer, filed https://github.com/miketheman/pytest-socket/issues/401
unlikely to get to it anytime soon, but that's definitely an area this library doesn't support yet
yeah, I'm unlikely to get to it either, but I can tack it onto my wish list.
It's possibly documented incorrectly, I've not played around with it
Off topic, but I remember this from a few months ago about doing wild things with .pth files: https://pydong.org/posts/PythonsPreprocessor/
do you know if this can be disabled?
The .pth file processing? Kind of, in that .pth files are only processed in "site directories", and you can turn the default site directory off with the -S switch. However, you then have an interpreter that needs app level sys.path manipulation to make regular package dependencies work.
https://github.com/python/cpython/issues/78125 has the ongoing (6 years and counting) discussion of what would be needed in order to separate the startup code execution behaviour from the path extension feature.
The Ubuntu jobs are remarkably consistent. (the number of runs varies as the exact job names stop existing at different points in time.)



Interesting
The Intel macs OTOH, they're an absolute mess :P
This script has grown into a 240 LoC mostly uncommented and unorganised mess as well...
My favourite kind of script, I made a couple of those recently at about ~500 lines, and I was curious if any of the AI tools could do a good job of doing a refactor, keep the logic the same but apply a bit of organization and DRY, so far everything I tested fails miserably (either removed large chunks of important logic or just refused to do the tas)
I've had decent success with a "tell me how you would do it" followed by a "do it".
For simpler stuff, but somewhere around 400 lines when the script is quite dense with different concepts I haven't had any luck, Gemini Ultra literally just tells me "I can't assist you with that, as I'm only a language model and don't have the capacity to understand and respond.", and ChatGPT deletes about ~50% of the logic
LOL
#off-topic maybe? 👮
Yes.
As a meta comment, we should probably get in the good practise of making threads for topics, so not to spam people with notifications turned on for this channel
I'm looking at resolutions on main since Packaging 24.2 was vendored, and I've found a couple of packages from Google have tendency to write their dependencies like proto-plus<2.0.0dev, which can result in proto-plus==1.24.1rc0 instead of say proto=plus==1.24.0 (at least it would have on 2024-10-07), this brings Pip in line with the spec, but may be surprising behaviour, would this be worth adding to the release notes? (even though it's a vendored behaviour change)
I find that threads have terrible visibility, but then again, once they're all archived, I guess they have better searchability so YMMV.
If other maintainers are good with this I will merge https://github.com/pypa/pip/pull/13152
I'm also pretty sure that bzr was missing on Ubuntu 24.04 despite being installed explicitly via apt if I read the logs correctly.
Pretty annoying in all. CI is seemingly frequently on fire.
Yeah, I agree
Time to deprecate/drop Bazaar support? Maintenance burden is a good reason to consider it, along with its tiny usage, plus last release in 2016!
The homepage http://bazaar.canonical.com/ doesn't have https and won't load for me

It seems that GNU Bazaar is no longer maintained and that it was forked as Breezy: https://en.wikipedia.org/wiki/Breezy_(software)
The last email in the mailing list was in 2023 about the website returning 503s, it was brought up, but it seems like it is run off someone's local machine: https://lists.ubuntu.com/archives/bazaar/
People have few bugs to their bug tracker in 2024 though (the breezy one, not the Bazaar one)
And I've just tested, the version you get installing from Ubuntu is breezy, not bazaar: https://www.breezy-vcs.org/
I think at the very least, for our test cases, we are using the wrong website, I am going to ask the breezy developers if they have a suggestion
This developer dedicated a lot of time wrestling with legacy versions and specifiers, tirelessly adding tests and refining error messages. They clearly wanted everyone to use PEP 440-compliant versions. Like, really wanted them to. 😅
Well... No, that dev just wanted to do the vendoring upgrade for packaging 😂
AI writing can be hilariously out of context
Yep quite apt at summarizing, but not anywhere close to understanding the why of things...
I have a small patch that improves pip install startup time by ~10% on my system (220ms -> 200ms). The vast majority of the gains are from eliminating an extra SSLContext.load_verify_locations call which are very expensive with OpenSSL 3.x. (~16ms).
I'm reaching the point where the next easiest way to shave a few more milliseconds is to probably start deferring regex compiles since some regexes are just never used. It's a shame that the majority of the potential savings are in the stdlib.

FYI, there is any ongoing thread about stdlib slowdowns: https://discuss.python.org/t/make-more-of-the-standard-library-import-on-demand/76311
The other big problem is that rich is heavy to import, but that's out of my wheelhouse.
Seems like CI is generally a few minutes faster as intended 🎉

@jovial jasper I'll take a look at the trusted publishing PR sometime in the week. I'm happy to postpone the discussions for how to manage access and security policies to after the release in a dedicated issue.
The only remaining item in the milestone that I'm not sure about is https://github.com/pypa/pip/pull/13051. There seems to be a fair bit of history to the issue, so it's not immediately clear if it's the right approach. I also removed the env-var docs PR as that's still under discussion.
I think the legitimate issue here is there is a name collision between --no-proxy and the (in)famous env variable NO_PROXY, I don't have a strong concern about this collision, but 🤷♂️
We import a lot of modules from the stdlib, definitely most of the common ones that the lazy imports would target.
The one thing I would appreciate is being to use urllib.request.pathname2url() and url2pathname() without importing urllib.client, ssl, etc.
It's honestly tempting to install a global shim to defer regex compiles, although that is quite dodgy admittedly.
Maybe we need Regex literals like JS
FYI, GitHub is having issues if anyone else was confused why their git commands were returning a 5XX code: https://www.githubstatus.com/
ty
Probably the weekend. I'm busy all week.
@hidden flame is that CI benchmarking script you were using around somewhere?
Seems useful 😄
benchmarking? do you mean CI time graphing/averaging script?
yeah
When I'm back home at my computer, I can share it. Warning though, it's pretty jank :p
the best kind of script 🙂
@azure heron https://paste.pythondiscord.com/6OBA. You'll definitely need to update the CACHE_DIR and JOBS constants
You can delete the rest of the commented out code, however.
The WORKFLOW constant plots the whole workflow run times instead on a per-job basis.
Thanks!
I just updated the paste link. Use the shorter URL, not the long one :)
That includes the table printout.
You can pass the number of previous runs to include as argument while running the script.
I'm sure you can edit it further as you wish 📊
If I can remember how to write Python...
Really? You don't write much Python anymore?
You'd think you'd still write Python working on uv/ruff
Well, not really — I remember how to write Python. I don't write very much anymore though.
Very little!
We need opportunities to write more.
Even my recent CPython work is all build systems... autoconf and C templates
fair enough, heh. It's been a while since I last worked with another language.
I need to set up a newer JS toolchain at some point to fix a bug in Refined GitHub that's been driving me nuts, but I haven't gotten around to it
I used to write some C for mypyc, but I've essentially left that project since.
Looking at that script the data juicy bits are in the api and fetch_run, it's 'just' logging and graphing after that, I'm sure it would be easy to look at those two and rewrite in any other language
after having looked into this for cygwin. I don't understand how that is supposed to work in the first place. Build tools encode sysconfig.get_platform() into a platform tag. sysconfig.get_platform() is documented to include a version number for some systems. So every time you update the system to a newer version pip will start complaining about all installed packages.
Should sysconfig.get_platform() be changed to not include version numbers?
Or should sysconfig be extended with a sysconfig.get_platform_tag() returning a stable tag for the current system, so build systems can switch to that?
I've patched Python for now to strip versions from get_platform(), which fixes things for cygwin at least (and I'm happy with that... just still trying to understand things..)
Wouldn't that mean that pip would also refuse to install said wheels as the system would require too new platform tags?
I understand the fragility of platform tags when the OS version is included, but this seems like a problem bigger than pip check...
@jovial jasper how was the new release flow? Sounds like it worked well! 🎉
Yes all went well at the first attempt. ✨
I didn't realize you could check the release artifacts before approving the deployment. I guess I didn't check how the deployment was used that closely :P
https://github.com/pypa/pip/blob/984c399f6e6045748ec4eedac82d88660c039d83/.github/workflows/release.yml#L31-L33 ah of course, it's only the release step that needs approval.
Good question. pip refuses to install ("python -m installer" on the other hand installs just fine). I guess that's usually not a problem on systems not hosting on pypi, as wheels get build and installed in one step. And if they are cached they are just rebuilt. In a distro packaging scenario it's usually building the wheel, installing it into a prefix, throwing away the wheel.
FWIW, installer is meant to be a "you know what you're doing" kinda tool, so it'll happily let you break your system and stuff like that. 😅
tbf I didn't expect that installer cli would be so popular with distro packagers
I did, that was the target audience for bootstrapping reasons.
I'd love to get pip to stop running itself in a subprocess. Too much state to pass that is easy to forget/screw up: https://github.com/pypa/pip/issues/13186#issuecomment-2616081930
Yea, not to mention the overheads of non-reused memory caches and subprocess call.
TIL pip runs itself in a subprocess
any tl;dr what exactly is being run that way?
Subprocesses for building sdists
oh, right
I have a proof of concept for install in-process, a quick and dirty test seems to show a 600ms savings on a pip install . for pip itself.
Noice!
isn't that what build is for? maybe it would be a chance to add build to pip? or would that be a bootstrapping whack-a-mole?
There's an open issue about that over on build.
IIRC, we'd ended up concluding that it'd be more complexity in both projects, compared to having pip use pyproject-hooks directly (which it does today, with additional quirky things like not-a-virtualenv isolation).
- build has/had hard-coded pip install commands (which are now pip/uv install commands).
I lobbied for that CLI to exist, because I was convinced that it was the ideal tool for packaging Python dists as e.g. Arch Linux packages.
Using pip for that was always problematic since that use case needs so many flags to make it work. But it's just python -m installer --no-isolation!
I've never understood the differences between all of the location/scheme flags pip install has.
TBF, I've also never really cared, but if I start to refactor pip to install build deps in-process, I will need to fill this gap in my knowledge.
I think this is something from before the times of venvs
well I hate it
Welcome to the club.
I've said before that I want a Python 4 that redoes all the import stuff to make things work better from a packaging perspective. I also know that it's not gonna happen because I asked for it and the phrase Python 4 is a taboo anyway. 😅
Could we just remove all of the flags and then say "sorry, but you gotta write your own installer, have fun"?
looks at the Astral people
reminds me of this deprecation: https://github.com/pypa/pip/issues/13154
part of me wonders if it was a bad idea to deprecate this flag if a Python 4 ever shows up, but if that did happen, we'd be stuck in the 3->4 transition until 2100.
I was like, wait, that's too high a number. 😂
Oh, I never saw that. Yea, I'm surprised we deprecated it.
Man, I've been out of the loop on a lot of pip things for a while now. 🙈
it's basically been Stéphane, Damian, and I for the past few months 👀
*with Paul here and there
It comes and goes in waves 🎵🎶
I was very confused at why we had a flag that we never used and seemingly referenced Python 2 ¯_(ツ)_/¯
It was probably not worth deprecating in hindsight. I'm surprised how many people still pass it, but I was never around for the Python 2 transition so I guess I underestimated its historical importance.
I don't mean to be demanding, but do you think you'll have a bit more time for OSS lately? IIRC last time we talked, you said you'd hopefully have more time ~roughly soon-ish.
yes please, there's a number parts of uv that i'd want to get rid of. we currently have to spawn an interpreter and run a half-documented script to figure out the whole location/schemes logic
I'll know in a couple of weeks. 😅
This issue might be AI spam: https://github.com/pypa/pip/issues/13187
See the issue that Airflow has been having: https://lists.apache.org/thread/2vmvv429sowq90x96d5w2fxpc298cy3l
If they don't respond reasonably in the next week, I'll close it out.
cc @finite perch
oh my god, I didn't realize it was you who said that
I thought you were @dapper laurel or someone else 😅
That's why I pinged you, not because I thought you stepped away from the keyboard.
me? what? huh?
I think I saw the blue username and I thought it was you who said that
I must've been too tired then.
btw I have just noticed that pip index command is missing from the docs: https://pip.pypa.io/en/latest/cli/
want me to open an issue?
so only non-experimental commands are documented? I would expect it to be documented with a big EXPERIMENTAL notice
honestly, I'd like to take a proper look at the command before stablizing it. I realize it has effectively been stable for the last four years, but I think were some open design questions.
It's not policy if you're asking about that. We just never documented it as yeah, it was experimental, and then we forgot about it.
Maybe the admin colors should be less prominent. 😂
but then how can I power trip by flexing "do you even know who I am" in a feature discussion
anyway, is anyone up to review a 2000+ LOC diff? :P

😅
Is it atomic commits?
I did not create a commit per file touched by pyupgrade. I could automate that, but I'm going to need a few more lemons for that.

They are
some of them are definitely on. Ruff was complaining a bunch after I bumped requires-python in pyproject.toml
And then I had to fix another 50 violations that pyupgrade/ruff didn't address automagically.
I wonder if it makes sense to pass --no-compile while installing build dependencies. The environment is never reused across pip runs and it's very possible not every python module installed will end up being imported/compiled.
Seems reasonable to me
I've seen Tensorflow be listed as a build dependency, certainly going to be faster not to compile all of Tensorflow
yikes
if anyone has opinions, please redirect your strongly worded email to https://github.com/pypa/pip/pull/13192
Things like PyTorch require building against the same ABI (hence version down to commit) for extensions, so there are practical reasons why this is needed. I think an escape hatch for build isolation maybe be the most ergonomic way out of this
why pyc compilation is necessary? sure you don't mean that?
OH sorry my mistake. I thought you meant compiling libraries, but of course it would be pyc compilation 🤦♀️
still, people would need to list PyTorch as a build dependency for PyTorch extensions; I expect the reasons for Tensorflow are similar, so it would probably be a good optimization to not compile the Python files since they are going to be thrown away
I'm pretty sure we do this in uv
uv doesn't compile by default, does it also ignore any compile flag when building source?
I think so, we only compile as a post-install step
Like, it's in the uv pip install implementation not passed through to our build context
I didn't look very closely though 🙂
I'm finishing my 25.0 blog post. Holy crap there are a lot of things scheduled for removal in pip 25.1.
🌈
annnnd it's up: https://ichard26.github.io/blog/2025/01/whats-new-in-pip-25.0/
Richard Si
pip 25.0 adds support for SPDX License Expressions (PEP 639), build environment bugfixes, and further optimizations among other changes.
feedback is of course welcome before I share this more widely
Coolio. I'd like to pick up some larger projects (better error reporting and installing build deps in-process) but I don't want to do that unless there is going to be enough review capacity.
Realistically, I'm probably going to be the bottleneck on those projects, but having somewhat-prompt-reviews would be beneficial.
One more thing I'd like to investigate, reintroducing parallelization to pip. I thought it was blocked until we upgraded to urllib3 2.x, but having checked again, it turns out the thread-safety fixes were backported to urllib3 1.x.
I'd like to start small, readding the parallelization of the --outdated flag of pip list. If that doesn't blow up, we can move onto more impactful areas (such as index page collection)
I'll open an issue about this tomorrow.
I would think about making sure it's easy to globally control concurrency
This was an early issue uv faced, and introduced several control variables for users
Yea, we went through the same thing with Black.
People have weird systems where os.cpu_count() reports like 64 cores, but they actually don't have that many cores. Others where their system does actually have 128 cores which then breaks multiprocessing on Windows (as there's a limit of 64 processes, -1 for the server process in the background).
TBF that's with multiprocessing. I'm just talking about multithreading for pip for now.
There was an example on uv recently where the system had something like 128 cores but individual users were limited to 4 GB of RAM
Honestly, it'd be pretty reasonable to set a decently low concurrency maximum to avoid resource exhaustion. At a certain point we're going to be bottlenecked by the network or filesystem stack.
Also, I really don't like the idea of spinning up 128 threads to query PyPI. That sounds miserable, lol.
Actually, I'll kick the can for opening that issue, it seems like a broader plan is in order, and there is a fair bit of reading I'd need to do first.
Hmm, packaging.version.Version parsing/construction can be a bottleneck in certain situations. I'd wonder if caching would be feasible. The main problem is that a good chunk of the calls are within packaging itself.
This was discussed a bit in: https://github.com/pypa/pip/issues/12314
Also see:
https://github.com/pypa/pip/pull/12316
https://github.com/pypa/packaging/issues/729
https://github.com/pypa/pip/pull/12453
I don't remember the details
querying the canonical name and version from the importlib metadata backend has been majorly optimized since then, and it is cached at some layer IIRC
Yea, the problem could very well be that pip has O(n²) logic.
Yeah, it does during resolution, and maybe in collection
Pip has been growing a lot of caches, which is definitely not ideal. At some point, I may take a look at the existing caching and see if any of it can be removed.
the caching has been very ad-hoc so far
A lot of uv's performance problems have been solved by caching / pre-calculating, resolving often requires doing the same operations over and over again, I agree it's pretty ad hoc though
If anything, it'd be at least nice to compile the caches in a list and explain why they exist. We don't have to remove any of them.
I imagine that even if the underlying logic was optimized significantly, since some logic is called very, very frequently, even a small reduction from slapping a LRU cache would result in a nontrivial improvement. For example, importlib.metadata name/version querying.
I'm going to be inactive for a little bit. I got some personal commitments that are going to keep me away for at least a week.
Has anyone else seen this error going around? https://github.com/astral-sh/uv/issues/11397

{kind=link}

It's probably not related to pip, but I saw there was a release yesterday (and this is new)
Nope, and I don't have a good understanding of setup-python, I see 2 weeks ago setup-python updated that error message and updated their actions/cache, which was apparently totally rewritten, and old actions/cache are expected to fail
mm I guess it could be a change in actions/cache
Whatever, I just turned off caching there — it just doesn't make sense in the first place.
I'm thinking of repicking up https://github.com/pypa/pip/issues/12712
I've implemented most of the obvious (to me, at least) optimizations so improving the UX is the next logical step.
I simplified the progress bar even further as I thought it was too noisy before. (I also believe keeping it simpler will help ensure not too many people take issue with the bar.)
I like it
I'm going to try to "delay" the first draw of the progress bar so the transient progress bar doesn't flash for small installs (which IMO is bad UX) but that may be impossible or impractical.
Eh, a proper solution is likely going to be way too complicated. A simple bodge of disabling the task visibility until the first refresh (which occurs ~150ms after starting due a refresh rate of 6/s) is "good enough".
I finally figured out the proper GHA syntax to conditionally exclude certain jobs. My gosh is this syntax unintuitive,

What would that be?
strategy:
fail-fast: true
matrix:
os: [Windows]
python:
# NOTE: don't forget to update middle versions below!
- "3.8"
- "3.9"
- "3.10"
- "3.11"
- "3.12"
- "3.13"
group:
- { number: 1, pytest-filter: "not test_install" }
- { number: 2, pytest-filter: "test_install" }
scheduled:
- ${{ github.event_name == 'schedule' }}
exclude:
# Only run Windows CI across all Python versions during a scheduled run.
- { python: "3.9", scheduled: false }
- { python: "3.10", scheduled: false }
- { python: "3.11", scheduled: false }
- { python: "3.12", scheduled: false }
I have no idea why matrix.scheduled needs to be an array.
The syntax is great for simple stuff, but what I really struggle with is groking the documentation or finding a complete reference for all the stuff you need, I recent wanted to do some fancy exclusions based on files in the commits for work stuff, I resorted to chatgpt o1 and then hacked away at the stuff it gave me
you should also be able to have an initial job to generate the matrix, which you then use on the next job
We don't have such a job yet, and that seems like more complexity...?
This is the only matrix customization we need to do (exclude certain jobs depending on the triggering event)
GitHub
Arch Linux Multi-version Python Repository. Contribute to FFY00/arch-python-repo development by creating an account on GitHub.
eg.
might be more complexity, but it's more intuitive, I think
so, eh
oh yeah, that's true
either way should be fine
I'll push this. If other maintainers consider this too magical, I could be convinced to set a dynamic matrix.
FWIW, I prefer the dynamic matrix because it's all in one file and I don't need to understand another language, but maybe it's because I've already spent a bunch of time reading them and understanding github's matrix concepts
Not saying pip needs it, but here's another example of generating a matrix via a Python script: https://github.com/astral-sh/python-build-standalone/blob/440cedcf54c990067479bd0b716ca411704138ff/.github/workflows/linux.yml#L150
And we just changed some complex change detection in CPython to a Python script https://github.com/python/cpython/pull/129627
It was quite the boon for us to switch to generating the matrix
I don't think my solution is particularly pretty, but it's functional
yep, the CPython change detection was getting tricky using ugly regexes against file paths. turns out Python scripts can be pretty useful!!
Install progress bar PR is up: https://github.com/pypa/pip/pull/13220
i'm wondering if rich.get_console wouldn't be more appropiate here:
but then idr if it accepts an argument to which console obj to get
It doesn't. We need a stdout and stderr console.
For parallelizing bytecode compilation, the naive solution of using compile_dir() is likely too simple. Trying your old branch @finite perch actually results in slower pip installs, probably due to subprocess creation overhead. I'd like to try creating a set of "server" subprocesses that compile files from a queue.
Yeah subprocess creation overhead on Windows was massive, it wasn't worth it till you had >100 files per process
I'm on Linux and your branch was still slower for the 40 packages I installed (same set in the install progress PR demos).
Oh, locally Linux was faster for me once you hit 4 or 5 files, clearly depends on environment
May be easiest to disable any sort of parallelization on Windows until further refinement, for better or worse ¯_(ツ)_/¯
Well, I would hope that free threaded Python will eventually come to the rescue here
I think we're still a few years away from that being mainstream...
Yeah, I'm thinking in like 5 to 10 years 🙃
Python itself would likely be significantly faster at that point.
Did you look at ours?
your parallelization approach? no