#ML Performance Reading Group
1 messages · Page 2 of 1
maybe, in that specific sense. but their perf numbers are probably real. and they have a V2 version that likely did work
i see. i'm planning to try to implement it using the new cute 4.0 python DSL
I think Comet V3 does not even have a backward. my MoE gradients are empty, and claude code cannot find the backward
claude says:
The backward implementation for forward_gather_rs in GemmGroupedV3GatherRS does not exist in this repository. The implementation only provides forward-only CUDA kernels without custom backward passes, relying on PyTorch's automatic differentiation instead
but if the grouped gemm is cuda, torch autodiff can't handle it. so my deduction is that there isn't any backward
could u link me the grouped gemm kernel?
Wow!!
Lots of room for better implementations then…
Does flux support backwards?
In the doc., it says that Flux supports training scenarios. However, I couldn’t find any details about backpropagation in the source code or examples.
response:
you may write the backward as magetron TP parallel does, does not use auto backward.
https://github.com/bytedance/flux/issues/139
knowing this earlier would have saved me a lot of time
More companies doing that now, open sourcing enough stuff to provide some credibility to their paper’s claims, but keeping enough closed source to still keep some competitive advantage
very sad ngl
They released the qutlass library -> https://github.com/IST-DASLab/qutlass

GitHub
QuTLASS: CUTLASS-Powered Quantized BLAS for Deep Learning - GitHub - IST-DASLab/qutlass: QuTLASS: CUTLASS-Powered Quantized BLAS for Deep Learning
Cutlass devs are very much into rhyming words and homophones it seems  .
.
We now have cute, qutlass and maybe soon qute lol.
hmm- seems like there is no gemv? 
Wdym?
Bruce-Lee-LY/cuda_hgemv: Several optimization methods of half-precision general matrix vector multiplication (HGEMV) using CUDA core. https://share.google/KolRiHlvqmXWzfR9X

GitHub
Several optimization methods of half-precision general matrix vector multiplication (HGEMV) using CUDA core. - Bruce-Lee-LY/cuda_hgemv
Bruce Lee himself has written gemv kernels
yes but what about gemv for fp4
You should create a GitHub repo with such issues and send them here or something.
I'm sure there will be many people like me looking to solve problems of practical significance while learning.
Like there's FP4, Blackwell support, etc.
Or just share here like you're already doing and I can create a GitHub repo lol
yeh- though yeah- mainly gemv is important because tensor cores don't work with vectors without being very inefficient
and llm inference uses vectors if batch size 1
the MLPs only see (1, hidden)
after prefill
(which is why LLMs can run so fast on macbooks)
it's vector @ matrix
I like so much detail, I'm gonna make a github issue now. we need more such detailed/concrete and accessible ML sys problems for people to learn and develop some "aura" lol
question: metal doesn't have tensor cores, right? it has a group_matrix instruction but not really dedicated cores for matrices. Is that the reason why it's faster for inference, cause everything is vector ops that are heavily optimized?
also: tracked here, I might give it a shot, or anyone else who sees the repo. https://github.com/vipulSharma18/Concrete-Industry-Relevant-MLSys-Problems/blob/main/niche_kernels/gemv_fp4.md
Well they have simd ops, which are sort of like tensor cores but for cpus heh
yeah, simdgroup_matrix. i was trying to understand how vector@matrix product makes apple better at inference. for nvidia tensor cores, i can get that they'll perform badly on v@m products.
nono it's not that- the reason why it makes apple good at all is because it's very low flops
flops for matmul are 2 * M * N * K, and if M=1 (for vector) then it's only N*K*2 flops, which is very small flops.. basically same number of flops as active parameters in model (.. well x2)
hmm, it's very low flops so the inference is memory bound and apple is good at memory. nice! got it, thanks for explaining!
one of my courses had us compute flops for all operations involved in a transformer block and then GPT2/nanogpt, it was error correction and verifying hell 
make sense yes
though can just use torch flop counter 
yep, at that time I was not aware of it and spent hours calculating the FLOPs and memory accesses by hand 
rip
though you can do most of it with just matmul flops
since attention is basically just 2 matmul and softmax
and if causal then just matmul flops / 2
yeah the quartet read me said mxfp4 kernels (including a gemm i assume are "coming soon...")
@uncut monolith do you still want to present soon
@hoary summit you also should present the paper you were looking at (USP?)
I'm working on implementing parallelism at different layers of abstraction, all the way from PyTorch DTensors to a custom NCCL implementation.
I could go through that by using TP as an example  . It's not a paper, but rather a showcase of my own educational "nanoParallelism".
. It's not a paper, but rather a showcase of my own educational "nanoParallelism".
We could finally have a toy example of how to do a fused communication + computation kernel, especially since a lot of papers are using it nowadays.
I had a brain fart, my bad. I think a better topic would be the internals of nccl since I'm doing that as part of above parallelism stuff.
Are you just reading nccl code to do the above
Sort of, there's a few papers that deconstruct nccl and prime intellect created their alternative
Those are my main references. I think it will be done in iterations, with each iteration going more in depth and less relying on existing nccl code.
The goal is to make collective APIs and just learn. So whatever helps with that.
Although TLDR is I'll know when I've done the first iteration. I don't know enough currently to be able to give a good picture of what the end product will be like.
I'm working on implementing parallelism at different layers of abstraction, all the way from PyTorch DTensors to a custom NCCL implementation.
do u push it to a repo
It's mostly empty now, but it's public
I'm still getting over the initial daunting and freezing experience that one gets when exploring something new
I have almost none experience with C++ and C professional development, so that's a barrier for me...
nicee, what resources do u use to do the NCCL?
I need to get to my laptop to do bibexport of zotero, will send in around half an hour
Do you have recommendations for fused communication+computation kernels in CUDA+nccl that I can look at to make the initial ramp up easier for me
I know the conceptual stuff, but very little development experience. (Hence this project)
Just need boilerplate code to get done with so that I can actually do the core part of it
Actually @unborn heart any recommendations for small fused communication+computation kernels that might be there in torch or made by bytedance?
Just looking to abstract away the project setup and integration with pytorch part.
looks nice https://arxiv.org/abs/2502.19811
arXiv.org
Mixture-of-experts (MoE) has been extensively employed to scale large language models to trillion-plus parameters while maintaining a fixed computational cost. The development of large MoE models in the distributed scenario encounters the problem of large communication overhead. The inter-device communication of a MoE layer can occupy 47% time o...
Yeah, we recently went over this paper (led by Daniel) and I know it has some code as well. That's why I asked Daniel.
GitHub
Triton-based Symmetric Memory operators and examples - pytorch-labs/kraken
Earlier this year, I had the fortune of joining Perplexity AI, where I finally got to use servers with the most powerful configuration—AWS p5 instances equipped with 8 NVIDIA H100 GPUs interconnect...
Oooh, nice! Thanks, couldn't have ever found it on my own!
@forest terrace this is what i have currently. I'm sure I'll remove nvshmem type extra stuff and add on more stuff as i go through the current list. It's very early stages currently.
[1] C.-H. Hsu, N. Imam, A. Langer, S. Potluri, and C. J. Newburn, “An Initial Assessment of NVSHMEM for High Performance Computing,” in 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), May 2020, pp. 1–10. doi: 10.1109/IPDPSW50202.2020.00104.
[2] Z. Hu et al., “Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms,” July 07, 2025, arXiv: arXiv:2507.04786. doi: 10.48550/arXiv.2507.04786.
[3] “NCCL vs NVSHMEM · Issue #679 · NVIDIA/nccl,” GitHub. Accessed: July 06, 2025. [Online]. Available: https://github.com/NVIDIA/nccl/issues/679
[4] “NCCL: The Inter-GPU Communication Library Powering Multi-GPU AI S72583 | GTC 2025 | NVIDIA On-Demand,” NVIDIA. Accessed: July 23, 2025. [Online]. Available: https://www.nvidia.com/en-us/on-demand/session/gtc25-s72583/
[5] M. Keiblinger, M. Sieg, J. M. Ong, S. Jaghouar, and J. Hagemann, “Prime Collective Communications Library -- Technical Report,” May 20, 2025, arXiv: arXiv:2505.14065. doi: 10.48550/arXiv.2505.14065.
[6] “Scaling Scientific Computing with NVSHMEM,” NVIDIA Technical Blog. Accessed: July 06, 2025. [Online]. Available: https://developer.nvidia.com/blog/scaling-scientific-computing-with-nvshmem/
Yep i can present it
did you get a chance to code it?
Yeah
nice! it will be nice to look at the code instead of the looped collective einsum notation
Can you link the paper
I did comparison with it. Talked to the authors. I will share the details.
niceee! talking to authors, and them actually responding, is really cool. I'm sure I'll get to learn much more than when I read the paper/skimmed it on my own
Haha not really i just asked them details about its behavior in practice. Looped einsum is implemented in xla. But i was not seeing the decomposition in my workload will share the caveats that xla has for pattern matching and decomposing.
@everyone here's the invite for session on Unified Sequence Parallelism (https://arxiv.org/html/2405.07719v5) on Sunday at 10am PST!
i've seen people use mostly pattern matching in torch compiler, rarely decomposition into the canonical ops stuff. let's see, seems like a lot going on in the paper when you actually implement it
Async comp paper authors are part of the xla team. They implemented it. I was surprised as well. I asked amit how to implement it but he told me xla implemented it and gave me some flags to turn on. I was surprised as well. But in xla world this is actually kind of the paradigm, compiler does lot. But you can tickle compiler or bypass it with kernels but thats not the norm. I inplemented usp not loopedeinsum xla works mostly fine. I like usp more though more flexible
Torch compiler does async TP with micro pipelining option in inductor backend.
I think it's loopedeinsum and not USP though.
Loopedeinsum is more fundamental and for TP, unlike USP which as the name suggests is for SP
Like, even torch compiler supports automatic async TP nowadays, just like xla compiler backend
I'd be interested to see if you're using copy engine in USP implementation or not.
If you're not, it's an easy paper/PR to xDiT
Maybe we can talk more in the call today afternoon, if you're interested in creating a PR/paper out of it.
Disclaimer: I'll definitely not have the time for that but talking about it cause it's interesting lol + I've been wanting to see how torch compiler gets new rules for a while and this seems like a nice opportunity for that.
@here reminder we'll be starting the meeting in a few min!
@unborn heart this is what I meant. I think nccl optimized their communication primitives which might help ring attention. They haven't profiled ring attention yet, just profiled the primitives by themselves.

hmm, ring attention uses p2p comms thoughh, not all-gather or reduce-scatter
that is interesting though, what video is that
I think I confused ring attention with ring all reduce
This video
NCCL: The Inter-GPU Communication Library Powering Multi-GPU AI S72583 | GTC 2025 | NVIDIA On-Demand https://share.google/8P48MwPX2hjPSXuFF
USP recording is up! First 20 sec or so are blurry but then it sharpens up. thanks again @hoary summit for presenting https://www.youtube.com/watch?v=tQzZ7oDKi6Y

Paper: https://arxiv.org/abs/2405.07719
Presenter: Kunjan Patel
Hello everyone
we should do a RoPE + MLSys session, just as an excuse to finally read up on it for everyone who's been wanting to lol
there is no interaction between rope and ml perf
RoPE is more or less free. There's nothing to optimize.
I was hoping for an excuse honestly . A cursory google search found this, which is less ML Perf and a bit "hacky".
EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection
https://arxiv.org/pdf/2503.01586v1
" Experimental results show that with minimal uptraining on only 0.6% of the original training data, RoPE based models achieve a 75% reduction in KV cache size while preserving performance within a negligible margin"
this is like a new flavor of quantization almost
question for folks, my impression is HF / transformers is not commonly used for groups doing MoE pretraining, due to scalability issues and these groups generally just being more sophisticated and using their own arch + implementation. for pretraining, it seems people usually fork off of a pretraining framework like torchtitan or megatron, or just do their own thing entirely.
however, it is more common to use HF models for people doing either (1) serving only or (2) fine-tuning + serving.
does this align with others' understanding as well? @pale rune curious what you've seen
mm i should ask in this in implementation details actually i think
Nobody uses HF's libraries for pretraining at scale
I don't know statistics for different libraries but I know our GPT-NeoX is used by a dozen or so labs around the world and that several people switched off of Megatron to it
this is really good to know, thanks. moe implementation in gpt-neox is interesting, i see it is representing experst with 2d nn.Parameters of (rows per rank, hidden) and using megablocks grouped GEMM
would you be amenable to a PR that supports using torch._grouped_mm (instead of megablocks gmm), if perf looks good?
Probably, that's a better question to ask Quentin in #gpt-neox-dev though. I'm minimally involved in the libray's development
the benefit is it would then be compatible with torchao low precision MoE training conversion util, so using fp8 rowwise, mxfp8 etc for MoE training can be a one liner
sounds good, will check there, thanks
Yes this my understanding and observation as well. We use parts of diffusers and transformers like the encoder for inference.
There's some discussion about this in twitter :
https://x.com/eliebakouch/status/1949398309346394518
TLDR: It's either Megatron, Torchtitan and fork them or build them from scratch
Notable framework : LLM-foundry, Nanotron, Olmo as well
Same question but for training stack, a fork of megatron-lm is used by the Kimi folks I think, but idk about other labs or how far that fork is from the original codebase. Another question is if you're starting a big lab rn, do you start from scratch or fork something like
I'm appreciating how cool this is, the more I make progress. I'm realizing I'm doing something like this and what @river lintel 's doing with OpenMPI. Very very similar to these 2.
Also, PCCL (Prime's internal communication library) sorta aims to make what this guy has already done...interesting
I could...are you guys interested in NCCL? It might be too low-level though...
it's like very basic, how different collectives are implemented and how buffers are managed
actually, I might need more time to polish it up. Don't want to hurry it...
I’m interested in nccl internals
hmm...what about next to next weekend? that should be plenty of time. I could talk in detail about the buffer registration and pipelined v/s non-pipelined nccl collectives
it's stuff that most people would not use honestly . I could also talk about fault tolerance and dynamic work group management limitations of nccl, like focus on that
ft and dynamic node addition/removal might be more interesting.
PCCL does it: https://www.primeintellect.ai/blog/pccl
i think it is good to have some level of understanding of the internals of critical tools you use
yeah, i do think it will require me time to "grok" and come up with the important concepts to discuss instead of talking about everything in nccl lol
Im interested in nccl too
I noticed that @OpenAI added learnable bias to attention logits before softmax. After softmax, they deleted the bias. This is similar to what I have done in my ICLR2025 paper: https://t.co/kmexsNx8O3.
I used learnable key bias and set corresponding value bias zero. In this way,

Interesting
I was wondering how they managed stable mxfp4 training, since Quartet only recently came out they must have some other technique
I guess they could have done bf16 or fp8 training then used QAT fp4 fine tuning
To prepare for mxfp4 PTQ
Using bias in attention for sink purposes is pretty clever, nice!
does the packing 2 fp4 into a single uint8 matter? it was pretty new to me
Maybe because various ops aren’t supported for these new dtypes, and for uint8 they are
hmm, weird. need to dive deep into how the gradients propagate as you pack a float into int. they're just breaking all dtypes "norms" lol
I will volunteer to present next if no one else wants to
it's going to take me time for sure, i'm moving/have interviews
i could present the paper, but i'd rather implement it before presenting
Which paper
[1] Z. Hu et al., “Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms,” July 07, 2025, arXiv: arXiv:2507.04786. doi: 10.48550/arXiv.2507.04786.
and my implementation, which has a long way to go .
there's a roadmap in the readme if you want to check if it's good for reading group. it has big picture view of things that are there in the paper/i could present
you know, considering i started this on july 31, the progress ain't that bad. i didn't even know makefile syntax back then, now i can write one from scratch and compile nccl code with multiple version in a docker container etc. etc.
nice... 
I am very interested in this
I'm still cooking, but seems like it will be fun to discuss it!
Also GPU mode is having a bunch of similar talks over this month. Maybe we can join them and then have a reading group on similar stuff
More value out of the reading group imo
Where is the schedule
GPU mode's events tab.
It will actually be pretty cool to follow those presentations for me cause people will know what to be interested in and why. The big picture motivation part will be done by them.
#1189640399476764692 message
I'm sure they're going to be confusing  . So people would actually be interested in diving deep into nccl in our reading group
. So people would actually be interested in diving deep into nccl in our reading group
https://arxiv.org/pdf/2507.04786
This is shared in GPU mode discord
Wait, it's not embed, the title is -> Demystifying NCCL: An In-depth Analysis of GPU
Communication Protocols and Algorithms
Oh lol, I'm implementing the same paper...ok, weird.
Let's see how it goes and if there's point to repeating it in our RG.
I think this is the best resource I've seen on nccl GPU communication yet.
just realized NCCL doesn't have a FP4 dtype at all...
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/api/types.html#nccldatatype-t
this might be related to why fp4 are packed into uint8. maybe it's for communication.
@unborn heart any chance you know how torchao is dealing with this?
We don’t do any comms in fp4 currently
If/when we do it will likely be with triton + symmetric memory
I am trying to look into what is symmetric memory, I found this if anyone interested :
and this https://github.com/yifuwang/symm-mem-recipes?tab=readme-ov-file#symm_mem_all_reducepy
It remind me of this tho : https://github.com/ByteDance-Seed/Triton-distributed
GitHub
Distributed Compiler based on Triton for Parallel Systems - ByteDance-Seed/Triton-distributed
Does triton allow dynamic slicing of refs?
No, if you mean tensor slicing
Yes
Turns out my question was bad. The better question is how CUDA handles FP4 since C++ doesn't support any such dtype.
And then the answer is here, custom structs and packing multiple FP4 together.
Edit: I'm now starting to think maybe it wasn't that bad lol. IDK, FP4 seems pretty early/new.
At least the mxfp4 and nvfp4 things are starting to make some sense, i.e., why we do all of that in the first place anyways.
ByteDance seems to be leading in terms of low level ML Systems optimizations. I always see their papers for the newer things.
Yeah, they are really fast running, it's insane
https://github.com/ByteDance-Seed/Triton-distributed
They just create a mega triton kernel for qwen btw. But seems like it's only for forward pass?
https://github.com/ByteDance-Seed/Triton-distributed/tree/main/python/triton_dist/mega_triton_kernel
https://zhuanlan.zhihu.com/p/1938959469439620849 Article about it (I usually use built in webbrowser translation btw)
gpu mode's nccl is this saturday, will give me a nice idea about what to not repeat and what to elaborate on.
would be cool if we attend that and you guys could let me know what specifics you would want deep dive on.
this is the 2nd work from bytedance (first is comet for MoE fused comm-comp) where someone has said that they only have the forward kernel released, not the backward one
do you know if they have something for qwen image as well?
@unborn heart what tool did you use for your async TP diagrams? I'm hoping to use the same for nccl diagrams
Excalidraw
Is there any resource folks recommend for host offloading?
i might use this as an excuse to get my hands dirty with inkscape (supposed to be used for paper figures)
nvme offload?
I meant like paper or blog especially for parameter offloading, not sure of its complexity i always imagined its one api call but been told its not lol
yeah, i doubt it's simple given the limited support it has (also limited use cases so there's a confound)
Share if you see any papers
https://github.com/deepspeedai/DeepSpeed/blob/master/blogs/ulysses-offload/README.md
paper here: https://arxiv.org/abs/2408.16978

GitHub
DeepSpeed is a deep learning optimization library that makes distributed training and inference easy, efficient, and effective. - deepspeedai/DeepSpeed
arXiv.org
Large Language Models (LLMs) with long context capabilities are integral to complex tasks in natural language processing and computational biology, such as text generation and protein sequence analysis. However, training LLMs directly on extremely long contexts demands considerable GPU resources and increased memory, leading to higher costs and ...
"With our dedicated sequence chunk pipeline design, we can now train 8B LLM with 2 million sequence length on only 4 GPUs, while also maintaining over 55% of MFU"
Very impressive
Is there a tentative date for the next meet?
We don't have a topic yet. You should volunteer 😄
i have been interested in diffusion based language models lately
Which one?
I implemented ring attention in pallas. And can give talk about it if people are curious about it
Llada to start
That would be great
Thats cool i have dream on my to go through list
I'm not expecting nccl to be done in less than a month fwiw. Busy with job search currently ... 
I'm collecting cool introductory topics though, stuff like interpreting profile traces. They're not a full paper, but they're also complex enough that they might be of interest.
Maybe I write blog post and then present it... It's going to be a long time in the future though 
For someone looking at Diffusion Transformer library that can scales (I think it's here no?)
Here's the paper Diffusion beats Autoregressive in Constraint Data, they just released their codebase which uses Megatron -> https://github.com/wmn-231314/diffusion-data-constraint

GitHub
Official PyTorch implementation and models for paper "Diffusion Beats Autoregressive in Data-Constrained Settings". We find diffusion models are significantly more data-efficient ...
Thanks!
What library do people use to train using AMD (large scale training)?
I know the OLMo codebase used to support AMD since they ran some runs on AMD not sure if they still do
NeoX also supports AMD
Maybe torchtitan as well? Not sure about this one
Gotcha, thank you for the information
@silver swift what do you use in your day job for large scale pre-training on AMD hardware?
I recommend torchtitan but I use our own framework which has a lot of things straight from torchtitan though
Thanks. You're the only person I know of that actually does AMD pre-training lol.
I want to learn more about diffusion bases LLMs and their performance characteristics compared to traditional transformers
there's an asap seminar on something slightly related (https://arxiv.org/pdf/2507.15857) at 2pm ET if you're interested
this paper is why I got interested in llada, etc
Hmm, pretty cool. I need to read the paper. I tried to listen in for the duration of the ASAP seminar and got frustrated at how slow it was ...
unrelated personal musing: A year ago I would've taken a seminar over reading and skipping sections any day, but now seminars are too slow and I'd rather read cause I'm impatient and like to skip ahead lol
there's another related asap seminar at 10pm ET tonight. It might just be late enough in the day for me to actually enjoy listening to it and not feel like i should be working instead ...

another one? I can't found the announcement
yeah, i see it in my calendar + got an email
https://asap-seminar.github.io/
it's here
ASAP Seminar Series - Advances in Sequence modeling from Algorithmic Perspectives
Hey
You're on the token order prediction paper right?
Yes
Pretty cool work!
Im thinking to share it here after the final paper finished .-.
Oh yeah please do
I do think you could've polished a bit more with the baselines etc but I really like the direction
I guess you guys were worried about being scooped but did you know anyone else doing this?
Not so far
But we have experienced of getting scooped lmao
So we and my lab in general dont want it to happened again
Oh nice
Im a master student there on NLP
Ooo where are you right now?
I'm at MPI-SWS
Dude thats really cool
Haha thanks 🙂
Mbz is pretty cool too
GPU mode is doing a cool multi-GPU kernel competition; related to the papers discussed in the group in the recent past...
I am scared to do it lmao
yeah...it's already giving me a reality check . nothing better than a competition to make you question how much you actually know something lol.
Any interesting VLM MLsystem paper? I am thinking of like Prefil-Decoding Disaggregation new technique type of paper but in VLM
I found this paper but it seems like they did not really designing for the VLM itself. Like they designing mainly for the decoding of the LLM and the vision stuff just happened to be there -> https://arxiv.org/pdf/2507.19427
surprised at the timing of your question. ByteDance seed just released a paper on it yesterday
wait which one? Is it the Taming Chaos paper?
Yeah. I think it's still mainly for LLMs though
I read them for a bit already, and I found that it's more about autoscaling (eg. when you're using kubernetes)
Hey Edd, if you end up doing the AMD competition, do you want to check-in before the registration deadline (around mid Sept) to see if we can collaborate on it?
@unborn heart food for thought, what do you think about a session on quantization?
I would be for it
I’m just so busy with work right now, crunch time for PyTorch conference
Ohh, good luck with it. I wish I could attend, still trying to find a way.
Anyways, I'd be up to do the session on quantization. That's what the bulk of my time is going in nowadays
I'm thinking 2 sessions, one theoretical and one practical. The theoretical one would be a survey of quantization methods, and practical one would show different tools and how it gets done irl.
I'd definitely appreciate your help on the practical side.
Theory session paper:
A Survey of Quantization Methods for Efficient Neural Network Inference
https://arxiv.org/abs/2103.13630
and any new methods post this paper.
arXiv.org
As soon as abstract mathematical computations were adapted to computation on digital computers, the problem of efficient representation, manipulation, and communication of the numerical values in those computations arose. Strongly related to the problem of numerical representation is the problem of quantization: in what manner should a set of co...
And for practical, the torchao paper has a bunch of libs listed in the appendix. I'm exploring them in my own repo so hopefully I'll have some idea.
Torchao paper:
https://openreview.net/attachment?id=HpqH0JakHf&name=pdf
My small exploration of these methods which is still a wip:
https://github.com/vipulSharma18/low-bit-inference
Do you want to schedule the theory one for next weekend? And the practical one...I think I'll dm you or something to ensure I can do quick exploration of all the different tools or something. Or at least figure out how torchao is integrating them and accessing them via torchao.
Sep 20-21?
Yep! I'll try to run the slides by you if that's fine. Just to ensure they're a good use of everyone's time.
Perfect yeah let me know, are you confident about the 21st date? If so I’ll schedule it
Yep! 21st should be good.
hey, I went through this paper, and it doesn't cover the OCP MX formats. So I'm adding this paper as well, which is a short review of MX FP.
arXiv.org
Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency...
@everyone invite for session on sept 21 by @uncut monolith on quantization methods and MX formats! https://discord.gg/eleutherai?event=1416138865772724355
@uncut monolith just confirming you're still planning to present at 10am PST tomorrow?
Hey, yep!
I couldn't get the ppt to you, but there's not a lot to in it lol.
I've been trying to get simple torch code demonstrating the quantization methods
I'm a bit worried it might be too simple, let's hope not 🤞
awesome, sounds great!
i think it will be fine
simple is ok, some folks may have never seen anything quantization related before
regardless of how simple or deep/complex, there will be people who get value out of it 😄
I never considered that lol. I was comparing it with mobicham's mxfp formats in triton presentation.
do you have a link for that
From GPU mode:
It's gonna be available on Youtube, but I can already share the slides with you, here: https://docs.google.com/presentation/d/1KLz3NisvrmTLuIPVb4yiP0z5WWlh9gTMm-Ms-kCc6fQ/edit?usp=sharing

@unborn heart lemme know when you want to start
I am running a bit late sorry!
nw
10:30 ok?
So sorry! Taking longer than expected to get back from morning breakfast date
it's fine with me, yeah. if it's quick, it might be nicer to update the event time. but yeah, low priority
ok i'm back
updated to 1030am
@everyone meeting is starting soon, @uncut monolith will be presenting "A Survey of Quantization Methods for Efficient Neural Network Inference" (https://arxiv.org/pdf/2103.13630) today!
Can anyone hear me
i can't hear anyone
let me restart discord @uncut monolith
@uncut monolith also try looking at discord settings and looking at audio
source
thanks @uncut monolith for the awesome presentation on quantization methods and low precision dtypes! i will upload the recording and share a link once it's ready
btw, here is the mxfp8 moe training blog i mentioned: https://cursor.com/blog/kernels
Cursor
Built to make you extraordinarily productive, Cursor is the best way to code with AI.
thanks! I'm going to try and make more progress on my mini-NCCL implementation so that I can present its internals soon as well.
This is like a nice learning experience for my own projects lol.
uh I missed it already
recording is up: https://youtu.be/NpQv0R0w_qY

Paper: https://arxiv.org/abs/2103.13630
Presenter: Vipul Sharma
Thanks for the opportunity again!
I'm going through this and it's pretty insane; completely unexpected for me. I didn't imagine they had such a strong engineering team.
Yeah I was impressed, from the blog they are clearly training in house models and have hardcore ML systems eng
I finally completed my first reading, and it's definitely the most technically in depth and modern CUDA blog I've read in a while.
Also, the author is part of hazy research lab, so definitely a good team.
I'm thinking of how to repro it without spending weeks or months on it. Please let me know if you have any ideas!
Would anyone be interested in doing a walkthrough of torchao mxfp8 MoE training code / kernels? Instead of a paper like usual?
like we just open repo, try to run it and break it down together?
I can prepare some slides for conceptual stuff, perf numbers, etc and then we can look at key parts of the implementation
That'd be really cool. I'm interested in it.
modular also did something similar 
I am interested as well. 4090 should be able to do it as well right?
FYI FA4 breakdown from modal shows that FA4 does similar use of warp specialization and warp groups for chunking different parts of the pipeline.
FA4 is like an easier version of this with only TMA and no TMEM shenanigans (although there could be scope of performance from there).
@unborn heart really looking forward to when you present your MoE training code.
I've seen the same pattern used in three cutting edge performance engineering problems now.
Someone should present FA4 😄
Depends on your timelines, I'm going to implement it in CUDA+PTX "soon" anyways 
I need to do FA in triton today, maybe I'll also give a shot at FA4... (edit: i will regret these words/short timelines)
@unborn heart do you want to try adding fa4 to torch or something? like, i'm trying to find someone to do this with so that it's not that much mental load lol
No i'm not planning on implementing, just want to understand
Hm, lucky you, implementation is another hell.
Do you mind presenting your mxfp8 MoE training work before FA4? They have a lot of similarities and I'd like to present FA4 but after implementing it myself to ensure I actually know what I'm presenting lol.
Honestly FA4 might be easier than mxfp8 MoE training from cursor blog lol
my mxfp8 moe training is different than cursor blog, their code isn't oss and sounds like they did everything in CUDA + PTX
i used pytorch, triton, CUDA for quanitzation and cutlass for the grouped GEMMs
Yeah, the blog was mainly about warp specialization, producer consumer model of work, and PTX instructions.
Interesting, you were able to use cutlass instead of having to do PTX by yourself, that's cool.
I think it would still help cause you would introduce the tensor core and memory jargon and concepts with your presentation.
FA4 is all about that.
The TLDR on FA4 is decomposing the kernel into different stages and assigning a warp to each stage via warp specialization. Then they do producer consumer model to manage different types of warps, with a barrier sync between each stage.
The MMA warp is all about tensor core instructions with soft max scaling using CUDA cores, just like we do fp block scaling. Like the same process.
It would be cool if I do a ncu trace and show it step by step when I present 🤔
Daniel, TLDR of the modal blog. I think it will be worth it to take it apart and focus on core things like tensor core instructions, and warp scheduler and persistent grids+blocks.

Which modal blog
this one
Yeah nice
That will leave us time to dive deep into tensor cores stuff if you want @unborn heart . Same stuff about sfu and tensor cores is used in quantized training/inference and FA4.
Do you guys already talk about the optimization on FA3 before?
seems like they did, and it was a really in-depth one. i wasn't there on this server at that point but saw this:
https://www.youtube.com/watch?v=Lys0TpsLIEc&list=PLvtrkEledFjqOLuDB_9FWL3dgivYqc6-3&index=13

ML Performance Reading Group Session 2 recording, in which we covered the original Flash Attention paper (https://arxiv.org/pdf/2205.14135), as well an example Triton kernel implementation of it.
Presenters: Ben Schneider, Daniel Vega-Myhre
they actually went through details like warp scheduler doing latency hiding for wgmma and stuff
someone should prenent sparse attention from new deepseek paper
or anything else in it
the presentation yesterday was really good
I am not familiar with like warp and stuff before. Now I have a slight clue on it??
Do you want to try asking smerky? He seems to be closely following it.
Which one?

Speaker: Charles FryeFrom the Modal team: https://modal.com/blog/reverse-engineer-flash-attention-4
@next rose would you have time some day to go over the new sparse attention things and deep seek paper?
im actually not following it as closesly as I should, tho I am following it - partly bc im so busy w/ stuff, so it might be quite a while sorry!
Completely understand! Do you know of anyone who works on this full-time in academia as a PhD student probably?
Maybe we could invite them @unborn heart . I can do the scheduling if it's fine.
on topk attention? no
Hm, no worries. If you ever get time, you know where to find us lol.
afaik no one was working on it except deepseek, me, and carson poole - all in somewhat different ways
but maybe others were and just didnt publish anything (yet?)
Yep, that's very likely
its an old idea
Cool, thanks anyways. I need to find some time to play around with implementing attention methods in CUDA, and triton soon. Maybe I'll start with that (top-k).
But probably a few weeks away for me as well, too much stuff to do.
Edit: ^ don't quote me on this lol. Everything takes a lot of time.
@crisp karma just in case he might be interested in presenting the work of deep seek... Which I doubt cause he seemed busy
What are people’s thoughts on doing some deviations into non-perf/systems topics sometimes
I want to dive into RL and DLMs for example but don’t want to start another group, lol
Do you have any examples (papers or suggestions) in mind?
There are generally 2 types of papers: building intuition for RL/Diffusion, MLsys+RL/Diffusion.
I believe there's pretty cool async and multi-gpu training stuff in RL, and many optimization in diffusion inference.
Examples I've thought of in the past:
https://github.com/vipulSharma18/Theory-and-Engineering-of-Diffusion-Models
It will take me a few months to get there, but I am hoping to do something similar in the future.
I am fine too
Are you looking on the OpenMoE 2.0?
Haven’t heard of that before
Here, they scale DLM even further for MoE
I've been reading some of optimization in hopper and blackwell architecture. Some keyword that I found is TMA and Warp Specialization
CMIIW and Triton cannot express the Warp Specialization part, therefore they created the Gluon and PyTorch team create TLX for that.
There's this blogpost from JAX team which express that their Pallas was able to do it as well : https://docs.jax.dev/en/latest/pallas/gpu/blackwell_matmul.html#warp-specialization
Some links:
https://github.com/facebookexperimental/triton/tree/tlx
https://pytorch.org/blog/fast-2-simplicial-attention-hardware-efficient-kernels-in-tlx/
https://github.com/triton-lang/triton/tree/main/python/tutorials/gluon
I know there's the CuTe DSL, but I kinda abit sad to leave AMD behind yk? .-.
Well I am not sure too that AMD has TMA or not. Not sure as well if this TDA is TMA equivalent in AMD : https://github.com/triton-lang/triton/pull/8333
Do you want to do a half hour meeting to discuss this?
Warp, warp groups, and warp specialization.
TMA, distributed smem, tensor memory (TMEM).
Hardware supported mxfp8, FP8, mxfp4, nvfp4 v/s simulated.
These all are very recent features and rapid changes across sm89, sm90, sm100 and sm120.
I want to discuss and get the details right once and for all.
We can do support in triton, gluon, cutedsl, cutlass, pytorch, and Jax.
And parallels across AMD and Nvidia.
Sure
@unborn heart impromptu one today lol?
We can honestly figure it out together while on the call lol.
Go through datasheet, CUDA and PTX isa docs, and micro-benchmarking papers.
I have some idea of where to figure it out for Nvidia. But not sure about AMD at all.
I'm hoping Edd will know where to look it up for amd.
I don't know yet lmao. I tried searching it but no luck :/
Ohh, nw. We take help from someone in GPU mode probably
But it will be nice to do it for Nvidia as a start!
Edd and I are just going to do a short impromptu searching and discussion on the above in 2 hrs in the voice chat if we can.
Everyone's welcome to join obviously.
Time: 1 pm ET, 17 GMT.
@hushed girder , do you want to jump in the voice chat?
wait
if you want, i can present this weekend on MQA, GQA, MLA, Decoupled RoPE, DSA and NSA.
basically everything in this doc and the papers in the reference: https://docs.google.com/document/d/10iF1856jdy-VcnsEXwIAAFcUvRBNlbEkrlPfZO8VMJ0/edit?usp=sharing
That’s be cool, we have already done MQA and GQA I believe
And MLA from dsv3 paper
I don’t mind review though
I’m interested in DSA and NSA
When do you want to meet
Nice! I can look at the old videos to check what's the best continuation.
I can do this weekend anytime... Unless I get a job and have to move, unless  (joke to clarify)
(joke to clarify)
Can you please share the old video for me to revise and get an idea of what worked in the past?
@next rose @crisp karma any of you have an hour this weekend?
Would be really nice to have you be present to correct or contribute additional insight into the topic.
Daniel, it seems like the code is divergent from what's described in the papers in a significant way.
If we want to go through the code, I'll need till next weekend.
If just the paper, this weekend is perfectly fine.
Also, RL book of around 200 pages.
This weekend with just the paper is fine!
Awesome! I'll see you guys on Sunday if that works.
The DSA and NSA papers from deepseek.
[2502.11089] Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention https://share.google/l3eX4cz6ODUKjmXVn
DeepSeek-V3.2-Exp/DeepSeek_V3_2.pdf at main · deepseek-ai/DeepSeek-V3.2-Exp https://share.google/ZD8ZJjmjSPt0liI4v
The old deepseekv3 video for people to review things, although I'll go through them quickly as well.

ML Performance Reading Group Session 7, where we covered the DeepSeek V3 paper. We also discussed some parts of the DeepSeek V2 paper for comparison.
Presenter: Daniel Vega-Myhre
Papers:
- DeepSeek V3 (https://arxiv.org/abs/2412.19437)
- DeepSeek V2 (https://arxiv.org/pdf/2405.04434)
@unborn heart unrelated to this, but do you have any pointers on getting started with cutlass and cutedsl?
i'm targetting triton, cuda c++, and cutlass+cute dsl for my toolbox of ml sys things
I only really use triton and CUDA
I have modified cutlass stuff but I hate when I have to work with it
it's nice that you can get done with most work by just those two!
@unborn heart i think papers like these would be cool if you want to branch out of pure ml sys topics for the reading group.
you get the chance to talk about diffusion + what's really the bottleneck in making diffusion work nowadays, i.e., the systems challenges.
link doens't load for me
https://arxiv.org/pdf/2510.02283
maybe this one will
also, the paper might be too advanced as a first paper  . it mixes GRPO, clever attention and kv cache, and diffusion all together
. it mixes GRPO, clever attention and kv cache, and diffusion all together
i envy how much time you have time for learning
the past 3-4 months i have been full steam building mode
no time for papers
😢
i want to get back to my roots
i know right, lol. it's one of the good things of not being in a job. i think i'll only be able to squeeze in like 1 paper a week when working full-time
i sometimes think i'll practice so much and be so good in my job that i can do things quickly and have time for other stuff in the evening, but i'm also early career lol 🤞
Thanks for sharing
@unborn heart can you please schedule an event for tomorrow 1 pm CT?
For MLA and DeepSeekv3.2. it will be nice to go through the paper and the code together. The code has been described as very confusing by 1-2 people lol.
Any chance you can do today?
Tomorrow I have plans
I’m free all day today though
Strangely, I have meetings all day today till at least 5:30 pm CT. Pretty unusual for a Saturday, but yeah.
I can do it sometime over the week if you'd like. At least as of now, it seems like I can make an hour in the week.
But I can confirm by tomorrow cause that might change.
Meetings?? lol what
It's just a long interview so I can't skip it...
Maybe it will end earlier than expected. I'll let you know if things change!
@unborn heart Should I give @uncut monolith reading group manager perms (make discord events, pin and delete posts in this channel)?
Sure that's fine with me, @uncut monolith do you want to be able to create an event yourself sometimes, esp when i am super busy with work?
Yep, that would be really convenient!
I need to fly to SF tomorrow though. So seems like I'm also unavailable tomorrow.
welcome @hot socket . He has kindly volunteered to present megablocks on 10/19 @unborn heart
Can you create a event
Will do, thanks for volunteering to share!
@everyone Meeting invite for Sunday 10/19 where we will cover Megablocks! https://discord.gg/eleutherai?event=1427086561870348382
Looks pretty cool!
I can do automated cuda codegen in the coming weeks. I'm working on it this week for an interview/take-home sort of.
so i have:
- deepseek sparse attention, and hardware native sparse attention
- sakana and meta's cuda code gen papers.
bcsr format in megablocks confused me for a bit ...
if you ever write a blog on the scaling challenges of MoEs based on the scaling laws of MoEs and the mixture of a million experts papers, let me know (we could collaborate)! I had that idea but i doubt i'll get to it on my own.
I want to write something purely from a ml sys perspective, laying out the challenges of MoE scaling.
also PMPP has a whole chapter on the CSR and COO representations, pretty approachable and simple language
i figured it out, damn though maybe it's time to finally get PMPP 😆
how much of the book have you read?
Yeah, it's just a really good book.
I'm on edition 3 iirc, and I have around 4 chapters left I believe.
it seems like the majority of the 4th edition chapters are just various applications / examples?
I just skimmed the table of contents for the fourth edition and it looks similar to the 3rd edition. And yeah, the book is split into 3 sections. Basic foundations, parallel programming patterns and application case studies.
The 4th edition seems to have replaced the 3rd part with the 2nd part in more details.
The parallel programming patterns sections are worth reading for everyone I think
worth the $70?
I got the 3td one for cheap and There's a PDF which details the difference between edition 3 and 4
Also, soon edition 5.
But yeah, the parallel patterns make it worth the cost
oh how soon is edition 5 coming?
I don't remember. I think it was early next year
yea i noticed it only discusses ampere from what i can see in descriptions
At least for me, after reading that book, the only thing left was tensor core features after Ampere. Maybe they'll cover it in the new edition
TMA, thread block clusters, DSMEM were all introduced in hopper. and TMEM was introduced in blackwell as well, i.e., tenscore accumulation (tcgen05.mma.*) happening in TMEM instead of registers
Yeah. I haven't found a reference for those except cutlass code and PTX isa.
The matmul blog from Aleksa something also doesn't cover everything
For a newbie like me, PMPP was definitely worth it.
For someone like you, I wish you can just get the parallel programming patterns part of the book
I mean PMPP got me my interview at Stanford and hopefully a job. So I'm very biased in favor of it lol
Can you share the pdf
I got the physical book. I do think there's first and 2nd edition PDFs online, but difficult to find
yeah this is really cool
@uncut monolith can you share the link or remind me of the concept you mentioned about NCCL implementation that could explain why sending N fp8 elements takes same amount of time as N bf16 elements?
note: you really should be profiling the nccl kernels using a proper nccl profiler.
answer:
-
the fp8 and bf16 elements might be using a different underlying protocol, causing discrepancies and unfair comparisons.
-
I saw an if else in the nccl kernel where the dtype of transmission might change based on the dtype of the packet overhead (metadata). I can't find it quickly now.

how sure are you that the bandwidth of the network interface and the latency per hop and per packet transmission are similar?
Maybe the fp8 has more network contention because of rapid packet sending in the link, and that leads to exponential back-off and ends up being slower than the bf16 due to the link going empty due to contention and cool-off/back-off time after packet collission?
how sure are you that the bandwidth of the network interface and the latency per hop and per packet transmission are similar?
pretty sure, it's the same devices on the same machine
yeah, but the protocol picked by nccl autotuner might be completely different given the dtype size. also, if the kernel is too fast given small dtype, the profiler might just be measuring the time required for synchronization after each packet, or after whole transmission, and launch overhead like cuda kernel.
@hot socket reminder
@hot socket just checking in, you still good for Megablocks @ 10am?
definitely!
@everyone reminder we'll be covering Megablocks in a couple minutes!
@unborn heart
megablox slides: https://gist.github.com/rdyro/8f08e74689a9cb0160c3a73c50057c87
Recording is up! https://youtu.be/tWkMj6lUp1c Thanks again @hot socket for presenting, very interesting to see how the Jax/Pallas/TPU ecosystem is thinking about MoEs!

Paper: Megablocks (https://arxiv.org/pdf/2211.15841)
Presenter: rdyro
Hi guys, is there a list of potential future papers to review. Looking back the past session there are number of topics not covered yet, these include:
- kv cache
- speculative decoding
- prefill
- megakernels
- decoding
- scheduling
- memory optimization
Do we mainly rely of volunteers to step up, or do we have list somewhere?
Any of those would be great to cover, and we rely on volunteers mostly - you want to cover one of these?
I am looking into KV caching for a system I'm working on now, might need a couple a weeks to prepare a decent presentation (maybe 2-3 weeks).
That’s fine, no need for it to be super polished or anything though, it’s fairly low key. Up to you!
Any specific paper related to kv caching you’re interested in?
I was thinking of this one:
https://arxiv.org/pdf/2510.09665
But I have a couple of others which are somewhat more specific (e.g. compression)
This is a hard thing :/
MoEs are tricky yes. Feel free to ask any questions
Hmmm it's more about the JAX and TPU world that's tricky for me since the topology is different with GPU. Currently watching the recording
What aspect of it? I find it easier lol shorter memory hierarchy sequential except for newer generation with 2 cores
Looks interesting, want to tentatively plan for ~2 weeks (Nov 1st)?
Yes, that would be great
What about your torch poster talk as follow up to robert’s work on moe gmm.
Im ok with being bumped to the next session after that if it helps
I don’t have a poster, it’s a slide deck lol
I could do it … would like to make a longer more detailed version though
I started doing experiment on multi-node, now I am facing a case where the training loop randomly stuck, sometimes it can escape after like 200s (normal iteration took 1s)
The network topology is a bit weird but we can't control it since it's rented machine and the machine that we got is not consistent. and we also want to test it on as many topology as possible so we want the solution to be working on any topology.
I don't even know where to start debugging this, one thing that I imagine that maybe would fix this is to put torch dist barrier()? but idk where to put it. How do I learn on where to put it?
Btw the framework that I use is Megatron
Thank you in advance!
>Btw the framework that I use is Megatron
why not torchtitan? simpler pytorch native code, supports all common parallelisms, model archs, fp8 etc. Megatron has a bunch of unnecessary abstractions and complexity, imo
>I am facing a case where the training loop randomly stuck, sometimes it can escape after like 200s (normal iteration took 1s)
I would try to first validate that a simple dist primitive works w/ torchrun. Write a script that just runs a simple collective or barrier. Use the minimal possible repro, not the full model. Validate the inter-node IB comms are actually functional first before diving deeper.
I can also suggest using torch.distributed.breakpoint() and stepping through the code with pdb.
our use case is currently on finetuning on scheduler system, we want to test it on as many architecture as possible. After we playing with megatron, we realize the bloat and we almost change to torchtitan lmao. but yeah torchtitan did not support many architecture. ofc we can implement it ourselves but yeah...
got it, thanks for the advice on the debugging tips. I keep forgot about torch.distributed.breakpoint()
Do you think you can do the more detailed presentation within the time, or shall we go with the original plan and I can take the next session and you can do the one after that?
If you are open to using jax you can try maxtext. Naive question whats a scheduler in your context i know offlow schedulers for diffusion models. Is it the same?
We’ll keep the current plan, I meant I would present adhoc this weekend
Btw i'm at pytorch conference today if anyone wants to say hey hmu!
I'd be down to doing one for speculative decoding.
awesome, any particular paper you had in mind? or a general session on the topic?
@here meeting invite for session 16 on LMCache with @cosmic kraken ! https://discord.gg/eleutherai?event=1430654005503332412
I was working my way towards lookahead decoding and I need to catch up on spec decoding. So I can give a general talk on that.
Is it same as multi token prediction?
in other words:
you can always constrain dynamic range, whereas (precision) errors accumulating can be fatal

This is crazy
btw batch invariant means then something like using FA without the varlen right (use batch with padding)? what other batch invariant kernels out there?
Yes using fixed reduction strategy to avoid rounding error due to floating point non-associativity. See here: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/

Thinking Machines Lab
Reproducibility is a bedrock of scientific progress. However, it’s remarkably difficult to get reproducible results out of large language models.
For example, you might observe that asking ChatGPT the same question multiple times provides different results. This by itself is not surprising, since getting a result from a language model involves...
Oh cool, I got the “regular” badge / green name! Life goal complete.haha
Just checking in, are you still good to present LMCache tomorrow at 10am PST?
Yes, I'm still planning to do that as scheduled
@here reminder we'll be starting a session on LMCache in 5min!
ugh I can't join the meeting since voice call discord is banned in my country. Will watch the recording instead
Hi guys, here is a link to the presentation.
https://docs.google.com/presentation/d/1X4SRkWBgRNSZ2b_B0N9Wkmi8h1RIwTVuwSCWJF8s6fM/edit?usp=sharing

Google Docs
LMCache: An Efficient KV Cache Layer for Enterprise Scale LLM Inference Yihua Cheng, et al 2025 https://arxiv.org/abs/2510.09665 A. Mahmood, SpinorML [email protected]
Recording is up! https://youtu.be/3KJXzYBDZFg

thanks again to @cosmic kraken for the great presentation!
@here would anyone be down to meet again tomorrow to cover MXFP8 training for MoEs? i just presented this at the Pytorch Conference in SF so i already have slides etc. We can also wait til next week if more people will be available
Created the event invite for tomorrow: https://discord.gg/eleutherai?event=1434250646131048479
May reschedule it for next week depending on how many people are interested!
Is there video of your conference talk?
it's not uploaded yet but will share when it is! btw i was wondering, would you potentially be interested in sharing Muon/MuonClip sometime? i think someone with a strong math background like you would be best suited for a topic like this. i have some questions about it 😄
Sure, I would love to. I'm not familiar with MuonClip, but it sounds up my alley.
MuonClip is just a slight variant of Muon introduced in Kimi K2 paper I believe, that helped with scaling
OK. After thanksgiving week would be best for me.
Cool maybe Nov 29th or Dec 6th?
Let me know if you have a preference. I can also just follow up later when we get closer to that time
To see how your schedule is looking around then
Yeah, Dec 6 should be good.
And please LMK any questions you think of beforehand.
just fyi all i decided to schedule the MXFP8 MoE training session for next weekend (Nov 7th)
we should talk about this https://arxiv.org/abs/2510.26692
arXiv.org
We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that ex...
big if true
Yeah in general ssm we should cover
Whats interesting is the performance comparison in the report is on short context pretraining
Yeah, will be interesting to see if anyone can try it on a decent sized model. There is also the native sparse attention paper from DeepSeek which might be worth doing too. Is there anyone willing to take this up, if no one volunteers I can probably do it but it would have to be in December as I am super busy at the moment.
I may volunteer, I need context on gated delta net first though
my PyTorch conference talk on MXFP8 MoE training is up! (my part starts at around 17min): https://youtu.be/h6LjH6Jkaf0?si=vy7ye0UmqoAbzvDf

PyTorch APIs for High Performance MoE Training and Inference - Daniel Vega-Myhre; Ke Wen & Natalia Gimelshein, Meta
With models like DeepSeekV3 and Llama4 rising in popularity, there has been an increasing demand for PyTorch-native APIs and tailored performance optimizations for MoE architectures.
This will be a joint talk between PyTorch Core...
QQ: is this MXFP8 using higher precision for the activations with fp8 for weights? or vice versa? or fully fp8?
this is dynamic quantization to mxfp8 for both activations and weights.
- both inputs to grouped gemm (activations and weights) are fp32/bf16
- dynamically quantize both to mxfp8
- perform mxfp8 grouped gemm which returns result in
out_dtype(bf16 or fp32).
gotcha, thanks! out of curiosity, what aspect of this is limited to blackwell? and does this dynamic quantization prevent the issues with outliers in activations? or do you have to do tricks to avoid that as well?
what aspect of this is limited to blackwell?
microscaled dtypes (mxfp8, mxfp4, nvfp4) have native acceleration for certain operations on blackwell. specificallytcgen05.*family of PTX instructions ("tensorcore 5th generation") have single instruction ops for doing things like block scaled mma (tcgen05.mma.*) that require the scale factors be (1) in TMEM (new layer of blackwell memory hierarchy) and (2) in blocked swizzled layout (see talk for details on that)
does this dynamic quantization prevent the issues with outliers in activations?
i discuss this in the beginning of the talk (i had to talk super fast to get through all the content so you may have missed it) - scaling granularity of mxfp8 is 1x32, so the impact of outliers is limited to only a 1x32 block of input data, rather than a larger chunk of the tensor (which you'd see in more coarsely grained quantization strategies like blockwise, rowwise, tensorwise)
for this reason, mxfp8 implemented properly has identical convergence to bf16, and some studies (including our own!) have shown slightly better convergence / lower loss at same step - implying the amount of quantization error /information loss provides a helpful amount of implicit regularization
There was another talk on mxfp8, mxfp4 and nvfp4 that was really interesting too, pytorch 2025 conf. I was looking for yours too, it must have gone up today
Great talk Daniel, looking forward to the deep dive 👍
Does this make some of Cursor's efforts https://cursor.com/blog/kernels obsolete?
Not at all! The difference is (1) ours is open source - this is the biggest one lol, you can’t use Cursor’s kernels - and (2) ours is natively integrated into torchtitan,and (3) we also have quantized/mxfp8 comms (all to all)
for tomorrow i was planning on going through the slides but pausing to look the kernels / implementations of certain parts. would that be interesting to folks or too much detail?
I'd prefer to look into kernels as well. Since it's MXFP8, the one that will be supported is hopper GPU right?
Blackwell
ah alright
Any chance of moving these sessions to a Sunday in future, here in the uk its 5pm on Saturday which is trickier to attend @unborn heart
we can do sunday this weekend, i actually usually prefer that when i present
let's do sundays from now on, i will update the invite
Thanks! Really looking forward to it
Thanks, better for me as well. Looking at the implementation as well sounds good 👍
hey @pastel sapphire is it ok if I share the reading group discord meeting invite link on Twitter? Not sure if there are server rules/norms about this so just checking
@here reminder we'll be talking about MXFP8 training for MoEs in 5min!
per group scale conversion to blocked format when groups are along M: https://github.com/pytorch/ao/blob/main/torchao/prototype/moe_training/kernels/mxfp8/quant.py#L221

GitHub
PyTorch native quantization and sparsity for training and inference - pytorch/ao
wgrad scale conversion for groups along K. /contracting dim: https://github.com/pytorch/ao/blob/17867e6788e4889b294449770f0275045384eab2/torchao/prototype/moe_training/kernels/mxfp8/quant.py#L488
GitHub
PyTorch native quantization and sparsity for training and inference - pytorch/ao
triton + symmetric memory example: https://github.com/pytorch/ao/blob/17867e6788e4889b294449770f0275045384eab2/torchao/prototype/moe_training/kernels/mxfp8/comms.py#L318
GitHub
PyTorch native quantization and sparsity for training and inference - pytorch/ao
Appreciate your time and discussion! 🙏 I'll be around in the future 🙂
Side note for the Blackwell stuff I mentioned, tcgen05 is only available on SM100 and SM110, and Blackwell consumer/workstation is SM120 unfortunately. PTX ISA deeplink (under Target ISA Notes) https://docs.nvidia.com/cuda/parallel-thread-execution/#tcgen-async-sync-operations
that sucks, yeah luckily i have b200s to do development work on for work ... for those doing personal projects / learning out there, may be tough / cost $
I'm picking up some AGX Thors which you can get at like 3500~ brand new which do support this
Some weird stuff with sm110 but it's mostly the same. Just way worse memory bandwidth
Still not cheap, but not "luxury car for a single GPU"
Also worth noting to prevent someone else from going down a rabbit hole, but if you're working on B300's at all, sm103 does support larger K dimensions for mma. Slightly different silicon
wait do 5090s et al not even support MXFP8 then?
oh wait I see that the mma.sync instructions (not the tcgen05) do support those dtypes w/ scales
does that work with the torchtitan stuff @unborn heart is presenting on? I would assume cublas would just target those instructions instead of the tcgen05?
also as an aside, Daniel, why do you think getting ~2x the FLOPs from MXFP8 results in still only getting 1.2-1.3x the speed? attention? just the requirement for the matrices to be so much larger for the full throughput to matter? do you think eg doing relatively less weight sharding (ie clos_er_ to DDP) would make that tradeoff better (ie bc larger weight matrices per GPU -> higher FLOPs)?
I suppose the on-the-fly scale calculation and whatnot does add overhead
Yea and just a note make sure your compile target is 120f not 120a. For whatever reason not supported at the arch level
- torchao + torchtitan mxfp8 MoE training has some CUDA kernels which we build for sm100a only right now.
- the mxfp8 grouped Gemm in fbgemm (integrated into PyTorch core via third_party) is only built for sm100a atm as well, I believe.
makes sense. does the scale calculations happen inside of the gemm kernel or is that a step that happens before?
before, we have quantization kernels that dynamically quantize inputs to the grouped gemm
might be able to contribute some SM_120 mxfp8 kernels if I can find some time
i have some (small M) gemm kernels that are pretty performant for (regular, ie non MX) fp8
could spend some time getting those a bit better for larger Ms
they're unlikely to be quite cublas perf (for large M especially), but at least they're be something for those devices
- the mxfp8 grouped gemm kernel achieves on average 1.8-2x higher flops/sec than bf16.
- add in the overhead of dynamic quant, the net speed up for llama4 shapes is 1.6-1.8x (for local batch size 16, seq len 8192 - need large M dim).
- measure the whole MoE layer with all the other ops, speeding up just the grouped Gemm results in 1.4x speed up.
- now measure the full model e2e training, using dp2ep parallelism, which is notoriously comms heavy all2all, speeding up just the grouped Gemm nets 1.2x throughout (and convergence) speed up
that could be useful, are they triton
no they're pure cpp cuda
I see, those are a pain for us to integrate, build, ship etc but we have them. You can loook in torchao/csrc
is there a need for non-grouped gemms as well?
or is grouped really where things are difficult rn
yes for linears, shared experts
attention
we have mxfp8 for linears as well
but no sm_120? or do you already have those?
No sm120 I believe
i can try to find some time over thanksgiving for this, could you ping me then if there still is nothing for those?
for sure, that would be awesome
Just curious, is anyone in this group planning on doing the GPU Mode NVFP4 competition?
link?
It's announced in their discord: #1189640399476764692 message
lmk if you need a invite, grand prize is a dell gb300
with some sparks and 5090/5080's thrown out along the way
also was thinking more about this and it might be doable to fuse some of the quantization in with the actual gemm kernel
if the baseline is two separate kernels it might be advantageous (obv it will be slower than a precalc'd scales)
you could tune the block size(s) of the gemm kernel to be the same as the MX spec's block sizes to make the reduction more optimal
What about symmem? What architecture supports it? I tried pytorch API on symmem on my 2x4090x but seems like it doesn't work? .-.
Is this what you are referring to? https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#data-movement-and-conversion-instructions-multimem:~:text=assumed by default.-,PTX ISA Notes,-Introduced in PTX
Seems like you need >= sm_100, the 4090 is I think sm_89. But the whole thing is super confusing, I wish nvidia would streamline the numbering. So if you're on a later sm version you can rely on the instructions, and have only family specifics at each level for extensions. The consumer 50x series are marketed as TC Gen 5, but they don't support tcgen05
Can you clarify what you're looking at? I'm seeing nvshmem when looking up symmem but those appear to be higher level APIs wrapping on device APIs
That would be neat. The gemm is in cutlass though and not sure how to add a custom prologue like that, would have to look into it
oh I was just talking about this : https://docs.pytorch.org/docs/main/symmetric_memory.html which also being used by daniel's code on the all_to_all

btw will you upload your yesterday presentation?
I guessed that, because there was no symmem instruction. I didn't look at the pytorch internal implementation to see the kernels that do that. But Blackwell seems to have these special instructions for cross device memory transfers.
I will look into further. I am not really familiar with instruction stuff and which feature are being supported in certain arch so what I did right now is just do it empirically (eg. try it in the code)
Thanks for the instruction tho (no pun intended)
Looking at this, it is the multimem instruction thats needed - https://dev-discuss.pytorch.org/t/pytorch-symmetricmemory-harnessing-nvlink-programmability-with-ease/2798

PyTorch Developer Mailing List
PyTorch SymmetricMemory: Harnessing NVLink Programmability with Ease with Horace He, Luca Wehrstedt TL;DR We introduced SymmetricMemory in PyTorch to enable users to harness NVLink programmability with ease. SymmetricMemory allows people to easily perform copy engine-based P2P copy with tensor1.copy_(tensor2) and write custom NVLink/NVLS collec...
yeah the intution is just that if you've already loaded the 16 bit values all the way down to registers, then you can do the quantization without having to store back out to gmem and then reload down to tmem for the gemm
seems conceptually doable
sorry forgot to reply I’m on vacation lol but yes I will upload, I wasn’t happy with some of my sleep-deprived explanations so might re-record it idk
Thank you so much 🫡
Any shot anyone would want any specific tests on the t5000 to see how sm100, 110 and 120 stack up against each other?
Getting a second one in today I could throw some tests at
in torchao? hmm we don’t build for sm110 or 120 so you’d need to update setup.py and validate various inline ptx used for mxfp8 works
It supports basically everything that sm100 does just with slightly fewer threads/warps per SM. https://docs.nvidia.com/cuda/cuda-c-programming-guide/#compute-capabilities
The programming guide to the CUDA model and interface.
also supports all the same stuff as SM100 under PTX 9.0
I believe certain instructions are only available on the “a” variant (e.g., sm100a)
I'm not seeing anything that sm110 doesn't get that sm100 does in the PTX ISA, but correct me if I'm wrong. sm110a was actually previously sm101a, and then renamed in PTX ISA 9.0, so earlier features that were sm100f (certain arguments, mostly), would have covered sm101a. Would be surprised if sm110 lost support for those arguments during the rename.
Actually I found the singular thing that is not supported here and it's stochastic rounding
Thats b200/300 only
From the tcgen05.alloc section of the PTX 9.0 docs, it would have been great to have a simple compatibility index for the different sm versions since 90 with a summary of support as a matrix:
Supported on following architectures:
sm_100a
sm_101a (Renamed to sm_110a from PTX ISA version 9.0)
And is supported on following family-specific architectures from PTX ISA version 8.8:
sm_100f or higher in the same family
sm_101f or higher in the same family (Renamed to sm_110f from PTX ISA version 9.0)
sm_110f or higher in the same family
Should be straightforward to make that matrix if we wanted to
i want to discuss KDA from https://arxiv.org/pdf/2510.26692 next
pretty interesting, i haven't looked at linear attention methods in much detail until now
anyone down for ad hoc meeting tomorrow to discuss kimi linear^?
Depends on time but yea!
I'm down
ok I’m super jet lagged but hopefully can nap and do something later today
If not then next weekend
okay no worries both cases for me
Let’s do next weekend
@unborn heart Was going to run a test using https://github.com/pytorch/ao/tree/main/torchao/prototype/moe_training, since a lot of it is your code, is it in a reasonable enough spot to do an experimental pretrain on? Any shot you know if you're using stochastic rounding at all?
yep! no stochastic rounding, that is just for nvfp4
also just to clarify, for mxfp8 there’s a couple rounding modes for the scale calculation (rceil, floor). For nvfp4 training we plan to use stochastic rounding as part of implementing the recipe in this paper, but it’s not done yet: https://arxiv.org/html/2509.25149v1
meeting link for sunday 10am PST: https://discord.gg/eleutherai?event=1443638926496632872
Makes sense. Was mostly asking because I figured stochastic rounding would help in other low precision data types
@junior ore any chance you're interested in joining this session? KDA involves more advanced linear algebra than i've done, and i'm learning as i go, so it would be useful for someone with a stronger math background to join to tell me if i say anything incorrect and/or discuss some of the details
in particular the WY representation and UT transformation i have not seen before ... everything up until that point i feel ok about
Thanks for the ping. I will check out the paper.
Is it worth moving over to Google Hangouts the sound quality on the recordings is not great with discord.
Also I wouldn't mind presenting the alternative Native Sparse Attention paper from deepseek in a couple of weeks on a free slot (I think muon was next week as I remember).
which one has bad quality? and NSA would be awesome, want to do dec 6th?
I was started listening to the playlist and I listened to flash attention and zero the first two. Sounded a bit garbled, not terrible just not great
I can do 13th, 6th is a bit short notice
can you check the more recent ones ? i had adjusted the recording software at some point
@everyone session invite for NSA on dec 14th! https://discord.gg/eleutherai?event=1444377551953985748
btw here is the recording for the session on mxfp8 training for MoEs, there was a problem with the original recording unfortunately so i rerecorded: https://youtu.be/MlLofYn8Ae0?si=9YqeiGHposIt4XG2

@unborn heart , where does the meeting take place?
Gotta drop, thanks for the presentation!

Recording of kimi delta attention session is up: https://youtu.be/HEFM4NXsWpQ?si=FM0jcqTef_WvWFYG

Presenter: Daniel Vega-Myhre, with part by wave_function
Paper: https://arxiv.org/pdf/2510.26692
They did open-source the KDA kernel, so I guess the answer is in there. I'm not fluent in triton, though. https://github.com/fla-org/flash-linear-attention/tree/main/fla/ops/kda

GitHub
🚀 Efficient implementations of state-of-the-art linear attention models - fla-org/flash-linear-attention
Hey Daniel - just getting back from NeurIPS but I wanted to follow up on this. I had volunteered for spec decoding. I can still do it - do we have a few dates in mind in Dec/Jan?
Nice yeah we can do
December 21st?
10am PST?
Yes - I think that's a bit tight, but I should be able to get that done. Let's do it
Can you link the paper you want to cover
I'd say these as an overview:
@unborn heart are we still having the session today?
Guys, it looks like daniel is offline today. So we will re-schedule this session for another time.
Crap sorry I’m here, I thought it was next weekend for some reason
I can start it up really quick, or can we reschedule for next weekend if that’s ok?
I’m working this weekend trying to get something done by Monday
Rescheduled for 21st! Sorry about that. @dire bronze can you do 27th for the spec decoding? Or Jan 3?
Hey @unborn heart - I thought it was Dec 21 - next weekend!
I'll be traveling from 23 Dec until the 7, so how about after that?
Jan 3 is probably doable, but I would prefer Jan 10. Is that possible?
We could potentially do 2 sessions next weeekend. Saturday and Sunday. To avoid pushing yours back
Okay with keeping next week, or pushing.
Np, I'm flexible so I'm ok for the 28th, as I'm working over the holiday period. Or early in the new year when everyone is back at work.
@dire bronze @cosmic kraken how about spec decoding 21st and NSA on 28th?
Sure, I'm ok with that
Sure. I'm okay with that too.
Actually can we push mine to sometime in Jan either 4th or 11th, looks like I might be a bit occupied over the holidays.
done! updated the event for NSA
@here here is the event for speculative decoding this Sunday the 21st: https://discord.gg/eleutherai?event=1450363719606468639
You're missing eagle and mtp, which are arguably most of what modern speculative decoding looks like in most AI labs
is this true? that would be very interesting then.
I thought Eagle is lossy and people did not really use it bcs of that
Hmm, I've got Medusa and Eagle there in that list. As I understand it, MTP is related to spec decode, but is still different. Medusa has multiple heads and predicts multiple tokens in parallel so that's where MTP would overlap.
TiDAR is pretty cool, too. https://arxiv.org/abs/2511.08923
I think he's probably got enough papers to talk about, though. 🙂
arXiv.org
Diffusion language models hold the promise of fast parallel generation, while autoregressive (AR) models typically excel in quality due to their causal structure aligning naturally with language modeling. This raises a fundamental question: can we achieve a synergy with high throughput, higher GPU utilization, and AR level quality? Existing meth...
arXiv.org
Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up language models without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher...
That looks like a really cool paper, I've been meaning to get up to speed with what is the latest in MoE. It will be interesting if they do a blackwell version which uses the clustered SM's and DSMEM.
They discuss Blackwell in the paper
Some tricks for still being able to use 2 CTA MMAs while having cross-CTA dependencies
Cool, although that is low hanging fruit since these instructions can be plugged in pretty easily.
10am pst tomorrow, be there or be square !
good morning everyone, we'll start in 12 min
just confirming @dire bronze you'll be ready?
Yep!
@everyonewe'll be starting a session on speculative decoding momentarily in the voice channel!
Thank you for the presentation! Very cool to know especially about Medusa and Eagle
Thanks for hanging around for the really long presentation. I hope folks found it helpful.
@unborn heart Here are the slides: https://docs.google.com/presentation/d/1iD0ud3Otd1VbB4Q-G7_UQDFgRfVrIEQr3XDyKkcy-xc/edit?usp=sharing

Google Docs
Speculative Decoding 12-21-2025 https://arxiv.org/pdf/2211.17192 https://arxiv.org/pdf/2302.01318 https://arxiv.org/pdf/2401.10774 https://arxiv.org/pdf/2401.15077 https://arxiv.org/pdf/2406.16858 https://arxiv.org/pdf/2503.01840 UDIT SAXENA
Recording is up! https://youtu.be/1XDi8_VPCDU?si=-IS3vCDa7EU2wEM7

Session covering an overview of speculative decoding and several seminal papers in the space, including Medusa, Eagle 1/2/3, and more.
Presenter: Udit Saxena
Slides: https://docs.google.com/presentation/d/1iD0ud3Otd1VbB4Q-G7_UQDFgRfVrIEQr3XDyKkcy-xc/edit?slide=id.p#slide=id.p
@unborn heart are we still ok for the reading group session on the 4th Jan
Yep!
@here reminder we have NSA presentation by @cosmic kraken in 5min!
meeting is open in the voice channel
@cosmic kraken are you joining?
Recording is up! https://youtu.be/HS5FJbif5A0

would anyone be interested in a short session on Mxfp8 expert parallelism in forward / backward
Cool stuff I’m working on right now I thought others might find interesting
I am very2 interested
ok cool would be focused on torch and kernel implementation
not theory or research
pretty interesting though I think
I’ll schedule something when it’s ready
erghhh 2D block tiling in CUDA easier to conceptualize than actually implement…..
forcing myself to implement each technique here with no AI or peaking at the authors solution until I have a working one: https://www.kapilsharma.dev/posts/learn-cutlass-the-hard-way/
Kapil Sharma
Walkthrough of optimization techniques for GEMMs from a naive fp32 kernel to CUTLASS bf16 kernel
got it working
got warp tiling working now... strangely i get better perf with smaller thread tile sizes (2x2). if i try the author's config of 8x8 perf falls off a cliff. maybe register spillage in my impl
That's a weird result the memory reads from hbm should have had a massive impact. What kind of gpu are you on. Also you might want to check the ptx to see which instructions are being used for mma
i'm still doing coalesced vectorized loads, just each thread is responsible for computing 2x2 subtile of output in each warp subtile, and each warp iterates through 4 warp subtiles. so reallly it's 4*(2x2) per thread
no documentation or anything since it's just for myself so far, but here it is if you're interested: https://github.com/danielvegamyhre/gemm/blob/main/warptile/warptile.cu

GitHub
Contribute to danielvegamyhre/gemm development by creating an account on GitHub.
Oh I thought you were doing cutlass, you should be able to get register spillage info from the compiler. You're using syncthreads too which won't work great on hopper or blackwell.
I'll try and look at ut tomorrow
Have you tried running it with ncu, that report is usually pretty good
yeah this gemm is designed for ampere
i am iteratively going from the most naive possible gemm, working my way through different optimizations, with the end goal being blackwell gemm with 2 cta mma, tcgen05 ptx, pipelining etc
next up is using tensorcores via wmma
Are you following Alecsa Gordics blog
yes aleksa's and this one, and Simon's as well
at each step, i read the description of the kernel design, then implement without looking at the code or using AI to practice and internalize more deeply
will refeerence this one lastt for blackwell (very good read, recommend it): https://gau-nernst.github.io/tcgen05/
gau-nernst's blog
tcgen05 is the set of PTX instructions to program Tensor Cores on the latest NVIDIA Blackwell GPUs (sm100, not to be confused with consumer Blackwell sm120). At the time of writing, I couldn’t find a Blackwell tutorial in plain CUDA C++ with PTX, even though such exist for Ampere (alexarmbr’s and spatters’) and Hopper (Pranjal’s). So let...
Amazing how bad that works on modern hw, gets 30 tflops when theoretical maximum is 1 petaflop
yeah max i have is 40 tflops w/ warptiling
strangely if i run torch.matmul it gets 63 tflops
seems like it isn't using tensorcores either
Yeah, on ampere I think tgd tensor cores are 2x2
I am wondering is pytorch is just using the sm better and your current approach is not optimally using the available sm. The ncu report also gives stats on occupancy.
oh there's no fp32 tensorcores huh, only bf16, fp8, fp4
so that's why torch is also so low
when i convert to bf16 i bet torch perf will skyrocket
wait, am i tripping, i am seeing conflicting things online

no i think i was right, ok
https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth/ is the definitive source. Also you have to distinguish fp32 and tf32

Today, during the 2020 NVIDIA GTC keynote address, NVIDIA founder and CEO Jensen Huang introduced the new NVIDIA A100 GPU based on the new NVIDIA Ampere GPU architecture. This post gives you a look…
did double buffered mma now too. finished all the kernels in that blog
moving into hopper optimizations next … then Blackwell
finished ampere with a pipelined impl with cp.async + mma
feel like i am getting fast at this
ok now moving onto cp.async -> cp.async.bulk.tensor (tma) 👀
it is very cool seeing the tflops actually increase as they "should" with each optimization
TMA so annoying to use though
cuTensorMapTileEncoded ... 🤡
craz the complexity increase moving from wmma to wgmma
(I hope you're going to eventually to someday present about all the recent stuff you've been talking about - sounds quite interesting!)
i’m just going through the exercise of implementing gem kernels in CUDA + PTX. First, starting with the basics, then doing optimizations for Ampere, the Hopper and Blackwell.
It looks like wizardry to a bunch of us, FWIW. 🙂
Any good RL system paper? Trying to find a good paper for our reading group (irl).
I am looking for SGLang/vLLM type of RL system paper. But system algorithm is fine too (eg. PipelineRL)
We did verl paper already before. Currently thinking for PipelineRL but still not sure about it.
The openrlhf paper is also fine though I didn't like the library much
Got it. So far I got OpenRLHF, PipelineRL, AReal, Magistral, and Ant Ring 1T paper. Will compare them
present one here too 😄 i have been wanting to learn more about this
Sure, how about 31st Jan or 1 Feb?
Let’s do Feb 1
Btw it's about PipelineRL. Forgot to mention that.
https://arxiv.org/abs/2509.19128 (PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence Generation)
It is a system where they tried to both increase the utilization while also keeping the staleness intact. They are doing this by doing weight transfer during generation while also transfer the current available data for training. By doing so, both training GPU and inference GPU keep running all the time (see Figure 1b). What is surprising for me that KV staleness is okay to do.
I found on other model's paper such as Slime framework (SGLang's official RL framework), Longcat, and PrimeIntellect's model using the same technique with a bit modification. I may be talking about the difference between them as well abit.
arXiv.org
Reinforcement Learning (RL) is increasingly utilized to enhance the reasoning capabilities of Large Language Models (LLMs). However, effectively scaling these RL methods presents significant challenges, primarily due to the difficulty in maintaining high AI accelerator utilization without generating stale, off-policy data that harms common RL al...
@hushed girder is this reading group somewhere in SF? I'm based in SF and am looking for IRL groups.
On RL systems - I've been reading and gathering as well. I think there's RLHFuse, RollPacker, but there's a lot of details hidden about systems in tech reports from neo tech labs (longcat, olmo3, nemotron etc). There's also a pretty cool theoretical+systems paper IIRC in AsyncRLHF.
not irl, i would go to a irl one sometime though, could be cool
sry i have been spending all my free time writing kernels lately instead of reading papers
almost at a good milestone to pause and read sonicMoE though!
maybe this weekend
i can read it
Do you still want to share the RL systems paper Feb 1?
yes I will still do it
awesome, 10am PST work for you?
that's 10pm GMT+4 right? yeah that works
@here meeting invite for Feb 1st! (topic: Pipeline RL): https://discord.gg/HF9NkEqv?event=1466131147380625533
got 2 CTA tcgen05 mma working finally
in warp specialized Gemm
After much anger and struggle with cuda-gdb
Yess
Sounds like you've got a great sequel to your original CUDA Gpu talk, I would be interested in your journey and how you used the tools (ncu, cuda-gdb, etc)
@here meeting is open we are starting soon!
@runic shale here
thanks!
Training LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models: how TPUs (and GPUs) work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and infer...
tpu section: https://jax-ml.github.io/scaling-book/tpus/
This section is all about how TPUs work, how they're networked together to enable multi-chip training and inference, and how this affects the performance of our favorite algorithms. There's even some good stuff for GPU users too!
thanks everyone for joining, will post meeting recording shortly for anyone who missed it
Sorry for some heavy breathing. In my mind I am not nervous but my body is nervous
I didn’t notice this lol I’m sure it’s fine
recording is up! https://youtu.be/pkcWmgQBc9I

ergh
got persistent kernel working finally and perf is flat vs non persistent …
🥲
persistent kernel?
yeah
launching a kernel with num blocks == num SMs, and having each thread block chug through computing multiple output tiles.
in contrast to launching num thread blocks == output size divided by output tile size, with each thread block computing exactly 1 output tile, which results in multiple waves of thread blocks being scheduled on the SMs one wave at a time, since num blocks >> num SMs
sure, so ig this shows that time gain you pay for having n waves of smaller blocks is much smaller than the parallelism you get from saturating cuda cores within each SM with one giant block
isn't the limit of max threads per thread-block smaller than the total max of theoretical threads you need to saturate an SM? so that would make sense if your workload previously was flop dense since you're now leaving flops idling
Maybe the chips you're implementing this on are heavily optimized for the non-persistent case, somehow.
the blocks are the same size in both persistent and non persistent
it's just a matter of how you schedule them
sure. how do you force each block to go to one SM? If the block sizes are too small, they could double up
Hmm good question, CUDA runtime schedules in “waves” distributing as many blocks as possible across the SMs per wave, as efficiently as possible based on register usage, smem usage etc per block, as well as current resources available on each SM.
So if you have same number of blocks as SMs, it naturally schedules one per SM. (If there’s no concurrent kernels running)
this is my understanding and the pattern I have observed in other kernels, but I wish I knew a little more detail here..
hmm, what you're saying makes sense but is also kinda speculative based on the block sizing. put concretely, say we're lucky enough to have N thread blocks and N SMs. each threadblock has a size of (# of threads per SM) / 2. how do we know that we are using all N SMs without a profiler? we could have two threadblocks double up on an SM and still run concurrently.
I think what you mentioned about scheduling in "waves" makes sense. but if we have N = # of SMs, my guess is that we'd have few enough threadblocks to be in the waves = 1 regime, i.e trying to still fill up the first wave. so the question isn't "how many waves do I need", but moreso "how do we fill up each incoming wave".
and for that question, at least I don't really have a convincing argument for why a scheduler would pick an even spread of blocks across all SMs versus cramming into one SM fully. perhaps on a mem bound workload we distribute so that we do more parallel gmem loads/stores? but I'd imagine each SM would have enough load store units (the things that actually handle memory fetches) for 2 blocks to make 1 vs 2 negligible.
cool discussion anyways!!
Another more practical reason we will end up with one thread block assigned to one SM in a persistent gemm kernel is that in the warp specialized design, we are using a huge amount of shared memory for the queue of A and B tiles in shared memory. You generally get better performance by increasing the queue size so we get a longer duration of thread block execution time in the pipeline “steady state” where load latency is hidden and epilogue is overlapped.
In fact, in the kernel launcher host code, you have to manually override the maximum shared memory per thread block limit in order to do this. Otherwise you’re limited to only 48KB per thread block rather than the full 227KB on the SM (B200), which would give you a tiny queue and provide little benefit, if any.
Given this, we literally cannot schedule more than one thread block per SM. Just 1 barely fits, by design.
you are likely right that in an arbitrary kernel that does not follow this design pattern, we don’t get this kind of guarantee
Let me put this here so I won't forget lmao : https://x.com/vega_myhre/status/2018521302383132802
Wrote a short post "Debugging deadlocks in warp-specialized GEMM kernels with CUDA-GDB" with some tricks learned through doing battle with CUDA+PTX and the complex synchronization logic in Blackwell GEMMs: https://t.co/tNGs4I3iBT
(I might be late to the party here) I can recommend the Helix Parallelism paper to anyone who’s interested in more on TP+Context Parallelism specifically for inference/decode (as opposed to training/prefill). Interesting as a follow-up on Megatron and RingAttn. https://arxiv.org/pdf/2507.07120
looks interesting… you should present it sometime!
New here (and to ML perf in general). What should I do to start attending (and understanding) and perhaps making meaningful contributions to the reading group?
welcome! Feb 8th and 22nd are both open for anyone who has a paper they want to share. fyi @runic shale who also expressed interest
And more generally feel free to chat about anything cool you come across or questions etc
Can I claim Feb 22nd? It would help me out to give a relatively faithful presentation of a paper that I was somewhat involved in just to put a damper on first time jitters. Probably this: https://arxiv.org/pdf/2511.17127
When does XLA hit its limits? How do you write the TPU Pallas kernel that the compiler cannot automatically find? Why can't XLA generate Splash Attention?
I recently discovered the ML Performance Reading Group sessions by @AiEleuther and was surprised by how little they're mentioned online, given the quality and depth of the discussions. It's a great resource for learning modern perf. optimization techniques used in AI/ML

for sure, I’ll create the event. 10am PST on 22nd ok? And don’t worry it’s pretty low key lol nobody is gonna grill you
btw I forgot to mention if you’re new to ml performance, this blog by Horace is a good intro to some foundational concepts: https://horace.io/brrr_intro.html
Hey! I'm also kind of new to this reading group. Are there any books/good resources that you would recommend, except this blog post?
it depends on what you're interested in. there's a few main categories: GPU architecture and kernel development/performance? distributed/parallelism strategies for training/inference? Efficient model architectures? Quantization? sparsity? etc
I'm mostly interested in efficient training/inference strategies, but also in efficient model architectures
His website seems to be down. Or maybe it's just me?
I can access it
Weird. I'll try later. Everything else works for me just the website doesn't load.
Ok, i will say that having a firm foundation of basic chip architecture and performance characteristics, including interchip networking, is essential to properly understand any of of this. It defines the problem constraints in which all of these parallelisms, efficient architectures, etc exist, and the motivation doing "X instead of Y" in the first place
for example, flash attention is an efficient/innovative design and implementation of a core piece of the model architecture, but you will have a bad time trying to understand it without understanding GPUs first
Stanford's CS149 goes into this a bit I think. Would you recommend starting from there?
Sure, or we have this intro video in the group playlist: https://www.youtube.com/watch?v=Cp7g1Ll4v0M

ML Performance research paper reading group session 1 meeting (2024/11/29). This was an intro session covering prerequisite knowledge related to GPU architecture, CUDA, NCCL, and common performance bottlenecks in ML workloads.
Presenter: Daniel Vega-Myhre
disclaimer: this was at the beginning of my "ml perf journey" a long time ago so hopefully i didn't say anything inaccurate ... lol
"Introducing KVTC: A new KV cache transform coder (think JPEG for KV caches) that solves the "recompute vs. offload" dilemma. It achieves 20×-40× (up to 88×) near-lossless compression, redefining how we handle long-context memory."
https://x.com/AdrianLancucki/status/2019748151209476587
https://arxiv.org/abs/2511.01815
🚀📉 Storing KV Cache just got 20-40× cheaper
#NVIDIAResearch #ICLR2026
Introducing KVTC: A new KV cache transform coder (think JPEG for KV caches) that solves the "recompute vs. offload" dilemma. It achieves 20×-40× (up to 88×) near-lossless compression, redefining how we

arXiv.org
Serving large language models (LLMs) at scale necessitates efficient key-value (KV) cache management. KV caches can be reused across conversation turns via shared-prefix prompts that are common in iterative code editing and chat. However, stale caches consume scarce GPU memory, require offloading, or force recomputation. We present KVTC, a light...
Are you actively working on AMD environment? Is working on AMD environment usually very hard to set up things? Especially maybe old generation (eg. MI210)?
We have cluster of MI210 but people rarely use it since it's very hard to do things (eg. installing vLLM, veRL, Megatron etc).
In your experience, do you maybe need to have some kind of container that's been built by AMD engineers to do stuff?
Can't say too much at this stage, but will say to check out these docs - https://rocm.docs.amd.com/en/latest/how-to/rocm-for-ai/training/benchmark-docker/megatron-lm.html?model=pyt_megatron_lm_train_llama-3.3-70b# re: rocm containers
How to train a model using Megatron-LM for ROCm.
What sort of challenges do you face on MI210 that you can share?
If your experiments only rely on pure pytorch / Huggingface models, you are generally fine. Common libraries like flash attention, xformers, bitsandbytes etc. have rocm specific builds, sometimes you might need to build those libraries from source.
Oh we just wanted to setup verl there. We cannot use docker, hence we are using Apptainer. But it's still failed on MI210. Seems like these container is being built for >MI300
I will take a note on this. Thank you for the suggestion.
This will be a nightmare 
Hmm, try with older versions of ROCM? I.e pre 6.1?
But yeah it would make sense if they're trying to aggressively push MI300X
or MI300A
Speaking of MI300A, did anybody spot a matching AI / ML problem, in which this particular architecture would shine over others?
For those who do not know: MI300A is an 'APU', where CPU and the GPU processors sit on the same silicon and share the entire HBM memory. For ML, this means your worker processes would eat the same memory as your GPU's. This conflicts with the basic design principles of many ML libraries, where one assumes there is a huge amount of host memory out there for the CPU.
The particular ML problem this architecture should shine would be the one where the I/O between host memory (the RAM of the CPU) and the GPU memory is the main bottleneck. If anybody is aware of such ML problems, I would be grateful to exchange! For example, maybe some online RL training with hard-to-parallelized simulations as supervision could be a nice culprit. Or student-teacher style learning paradigms where the teacher would better run on CPU.
When I check MLPerf works, I see them focusing on the bottleneck between GPU global memory and GPU shared memory. There is almost no discussion whether there is any bottleneck formation outside of this area of focus. If you are aware of literature in this direction, or keywords, please feel welcome to share!
Probably very clean shared memory abstractions to start. I wonder how crazy it would be to have this, and then expand memory via a standard like CXL and get a VRAM instaboost (at the cost of lower speed DDR bandwidth).
I wonder if there is some custom pytorch backend already, such that operations like:
x.to('gpu').to('cpu')
model.to('cpu').to('gpu')
resolve efficiently. As a person who is not so much aware of the internals of pytorch backend, I am a little afraid of getting lost trying this 😅
Of course, no one would do .to() twice. A more realistic case would be:
model0= model0.to('cpu') # will execute only forward() on CPU
model0.get_all_params().requires_grad = False # only fwd for this one
model1= model1.to('gpu') # will execute on gpu, will do fwd + bwd
for x in batch:
x0 = x.to('cpu')
x1 = x.to('gpu') # same thing on memory, this operation should have very low cost
# concurrently run:
y0 = model0(x0) # This runs on CPU cores
y1 = model1(x1) # This runs on GPU cores
# Now we are done with model0 for the current batch. model 0 can already start processing the next batch.
y0 = y0.to('gpu') # same thing on memory, this operation should have very low cost
optim.zero_grad()
loss = loss_fn(y0,y1)
loss.bwd() # Happens on GPU only
optim.step() # Happens on GPU only
Edit: The above idea sits on an assumption: CPU is preferrable for some cases. I had the chance to investigate this assumption on MI300A. For tiny models below 500k parameters, CPU inference speed is faster on fp32. But this was on batch size=1. As batch size or number of parameters increase, there remains no reason to bother touching CPU. So the above idea turned out to be impractical in the end.
https://arxiv.org/pdf/2602.06036v1
DFlash: Block Diffusion for Flash Speculative Decoding
Abstract:
Autoregressive large language models (LLMs) deliver strong performance but require inherently sequential decoding, leading to high inference latency and poor GPU utilization. Speculative decoding mitigates this bottleneck by using a fast draft model whose outputs are verified in parallel by the target LLM. However, existing methods still rely on autoregressive drafting, which remains sequential and constrains practical speedups. Diffusion LLMs offer a promising alternative by enabling parallel generation, but current diffusion models typically underperform compared with autoregressive models. In this paper, we introduce DFlash, a speculative decoding framework that employs a lightweight block diffusion model for parallel drafting. We show that speculative decoding provides a natural and effective setting for diffusion models. By generating draft tokens in a single forward pass, DFlash enables efficient drafting, and by conditioning the draft model on context features extracted from the target model, it achieves high-quality drafts with higher acceptance rates. Experiments show that DFlash achieves over 6× lossless acceleration across a range of models and tasks, delivering up to 2.5× higher speedup than the state-of-the-art speculative decoding method EAGLE-3.
that is a super interesting idea. haven't looked at the paper yet but i wonder how this impacts quality. fyi @dire bronze who is interested in spec decoding
If you could present this would be awesome
I am a beginner right now so I do not understand all the nitty gritty yet 😅 @dire bronze would you be interested in presenting this?
big fan of the reading group! just discovered it on youtube recently and randomly... really great content and discussions! wonder why there is so little information about it on the internet and why EleutherAI doesnt mention/promote it
When our fearless daniel here started this reading group he encouraged me to present in week 3 when i was an absolute beginner and i think I definitely made quite a few rookie mistakes. Feynman technique works learning and gaining clarity by teaching others
welcome! yeah idk I never really shared the videos widely, I did it mostly for my own learning
heading good feedback like this maybe I’ll share them more often going forward 😄
next topic is on pretraining on AMD at scale https://discord.gg/yZyauAM32?event=1469725804983226519
I really wanna present/discuss sonicMoE and latentMoE but I have been insanely busy the past few weeks…
You should give it a go, maybe gets an llm to help by summarising the paper to help you. The paper itself is not too difficult, all theyre doing is using the hidden state from the prefill to drive the smaller model. The main drawback is you need to train a custom diffusion llm.
Thanks for the encouragement @hoary summit and @cosmic kraken.
@unborn heart Can I claim the date after 22nd for this? Of course, if you wanna go for sonicMoE and latentMoE first thats fine!
Sure, Sunday March 1st at 10am PST?
Works
this paper right: https://arxiv.org/pdf/2602.06036v1
awesome, here is the meeting invite: https://discord.gg/eleutherai?event=1471909697152876696
Please dont spam with non performance related stuff, there are other discords and channels (such as Yanic Kilchers) which is more suitable for this
Hey, guys! I only see papers on the topics being treated in the YouTube videos descriptions.
I think it’ll help if I can lay my hands on all the Google Slides docs used in the discussions.
I’ll appreciate any reply to this.
the github repo for the meetings has slides for some of the presentations: https://github.com/danielvegamyhre/ml-perf-reading-group
GitHub
EleutherAI ML Performance reading group repository (slides, meeting recordings, annotated papers) - danielvegamyhre/ml-perf-reading-group
@runic shale you still good to present tomorrow?
should be, yeah. let's see how this goes!
@here reminder everyone we'll meet in ~7 min to discussing Training foundation models on AMD stack!
great discussion, thanks again to our presenter @runic shale ! i will share the recording when it's uploaded
Maybe you can share your slide? 🙏 @runic shale

Paper: https://arxiv.org/pdf/2511.17127
Presenter: Ansh Chaurasia
mb, had the link copied and then forgot to drop it. here's the slides! thanks for taking the time to come out!! https://docs.google.com/presentation/d/1mjFM7RPNuHMsKeDF4Arr-y2YhkMBJztqp1NzRfETP7U/edit?usp=sharing

Google Docs
Training Foundational Models on a Full Stack AMD Cluster Ansh Chaurasia
I am straight up having a bad time with mxfp8 CUDA + ptx gemm impl with 2 CTA mma, persistent kernel with static schedule
🤡
that's why you have sleep deprived last time? 👀
Hi everyone! Unfortunately I have gotten food poisoning and it would be hard for me to give the presentation I think. Would it be possible to reschedule today's presentation for next Sunday? If rescheduling won't be possible, I can still try to push through.
Take care, hope you feel better soon! I am personally okay with coming by next week (I suppose others can react with 👍🏻 to your post if they agree as well)
Thank you! My apologies to those who had set time apart for this today.
Take care @slow shore
Ahhh ok no worries, hope you feel better that sucks
I will be out of town next weekend so how about the one after that?
i rescheduled it for weekend after next
Yes that works too!
🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
A bunch of cool ideas make this possible: [1/n]

Jay Shah and Co, released a new paper on FA4
https://research.colfax-intl.com/flashattention-4-algorithm-and-kernel-pipelining-co-design-for-asymmetric-hardware-scaling/

Modern accelerators like Blackwell GPUs continue the trend of asymmetric hardware scaling, where tensor core throughput grows far faster than other resources such as shared memory bandwidth, specia…
I wouldn't mind presenting this paper on Sunday 22nd, unless someone else wants to do it
yes!! please do
i am interested in learning more about this as well
should i create the meeting invite for this? sunday 22nd at 10am pst?
Yes, please
Meeting invite for FA4 on the 22nd! https://discord.gg/eleutherai?event=1479293472513986571
congrats @unborn heart
may I ask what's the biggest challenge of the development? esp for the _to_mxfp8_then_scaled_grouped_mm?
Also, for the selection of which layer is not using mxfp8, that's purely empirical right?
Yes we micro benchmark layers to determine which will provide a speed up with mxfp8. Wk/wv are too small to get a benefit. The output proj is huge and would get a speedup but it is numerically sensitive and hurts model quality / convergence, so kept in high precision
There were many challenges one was reverse engineering how the hierarchical scale factor layout for each token group should relate to each other in memory, given they are all in the same tensor/buffer.
There are Nvidia docs on how these scale factors for a single tensor for a single gem should be laid out in memory. However, no examples for group gems where we have l scale factors for logically independent GEMMs all in the same buffer.
So I had to figure it out myself, lol
Got it, I always wonder how the big labs doing this. I thought it's some fancy interp stuff 😄
I think I get what you mean like 50%? .-.
Can't wait for the follow up blogpost then 😄
@slow shore is having discord issues so we may use Google meet today
ML Performance Reading Group
Sunday, March 15 · 10:00 – 11:00am
Time zone: America/Los_Angeles
Google Meet joining info
Video call link: https://meet.google.com/jpb-pqne-mmw
Real-time meetings by Google. Using your browser, share your video, desktop, and presentations with teammates and customers.
in 8min
fyi @here ^
@everyone we are starting in the Google Meet link above shortly
@fickle lark we are in this google meet channel today instead of disord voice
thanks for the great presentation on DFlash @slow shore ! please feel free to share a copy of the slides here when you can and i'll include them in the youtube description as well
Just wanted to say, great job with the group! Discovered it fairly recently and have been going through the videos. Will join starting next week.
awesome, welcome!
Dflash recording: https://youtu.be/jdNcR9urMxw
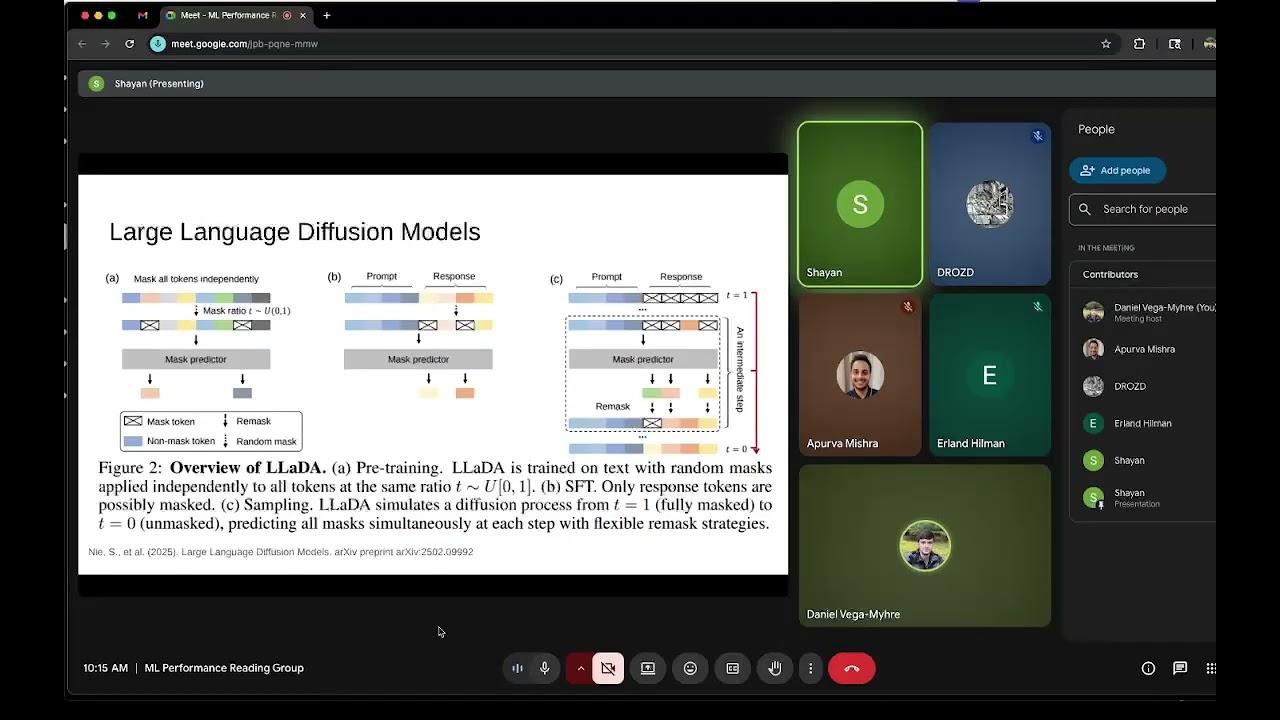
Paper: https://arxiv.org/abs/2602.06036
Presenter: Shayan Shamsi
Link to the slides:
https://docs.google.com/presentation/d/1V33oJL9o23Mb7_xABhDIFsSR68GQZXopGfBUlPQDiV4/edit?usp=sharing

Google Docs
DFlash: Block Diffusion for Flash Speculative Decoding Jian Chen, Yesheng Liang, Zhijian Liu Presented by Muhammad Shayan Shamsi for the EleutherAI ML Performance Reading Group

DFlash⚡ meets OpenClaw🦞 = FlashClaw
Same Claw. >4X faster or cheaper.
DFlash support for Qwen3.5 is live — outperforming native MTP by up to 2.3X.
More to come! 🔥
They just did something with OpenClaw .-.
OOT but anyone here used openclaw here? Is it good?
wdym this is about DFlash more than openclaw, but I am using qwen3.5-4B so lets see if DFlash can work for me. Wait wait, I thought Dflash was for diffusion models. I couldn't watch the presentation thanks for the slides! Going through them I understand this is some exciting stuff. Will implement this asap. NVM Flash Attention3 required 
wow lol
I haven't, but I've been thinking about it. Today, I saw the Jensen on the GTC Keynote mention it a lot, and maybe I will after I finish my round of interviews.
We still on for FA4 tomorrow?
yes, should be ok
Has anyone here looked at fla?
I am keen to find list of optimizations and corresponding code
@everyone we are starting the FlashAttention4 session momentarily!
I miss the session .-.
Hey
If I want to benchmark FP4 matmul what API should I be using? I don't think PyTorch supports it so I see Transformer Engine and TorchAO as things to potentially use but don't know what is preferred (if any)
Whats the fastest algorithm for inverting a lower triangle matrix? i am beating xla with just block decomposition + substituion
torch has nvfp4 gemm
is this for linear attention
example usage for mxfp4, you can modify inputs/args for nvfp4 too: https://github.com/pytorch/ao/blob/fe986580eaafc87f532534a8f222c7d11af18702/benchmarks/float8/bench_matmul.py#L166
Thankss
Thanks for sharing
Yep
Unless you absolutely need to invert it, you just use forward substitution to solve linear system. It's O(n^2) per solve and you can apply it to columns of the identity matrix to compute the full inverse
It's not gpu friendly though
Look at how they do it in kimi linear
Yes saw this seems more efficient than blockwise forward substitution but seems you have to write code for different powers of 2 chunk size
that should be fine no?
Yeah was hoping to have something more flexible. On tpu 64x64 the recursive doubling makes not much difference over blockwise forward substitution . But i will give it go see how it performs for 512 and 1024 chunksize
https://x.com/ezyang/status/2037002567658488201
I just thought this is cool
Cool pure Python implementation of CuTe layout algebra: https://t.co/P1tVXrzYZ7 -- with it, it only took a few minutes for Claude to make all of the CuTe paper https://t.co/4QV4wIdJk7 have executable Python code with it too https://t.co/fCyEjLzOeQ
The robots are coming. https://x.com/bingxu_/status/2036983004200149460
This may be one of the first real signs of superhuman intelligence in software. On some of the most optimized attention workloads, agents can now outperform almost all human GPU experts by searching continuously for 7 days with no human intervention inside the optimization loop.

Hi @unborn heart
Do you know why this view is in fp8 here when doing nvfp4 matmul?
https://github.com/pytorch/ao/blob/fe986580eaafc87f532534a8f222c7d11af18702/benchmarks/float8/bench_matmul.py#L144
GitHub
PyTorch native quantization and sparsity for training and inference - pytorch/ao
Also the mxfp4 codepath uses this https://docs.pytorch.org/docs/stable/generated/torch.nn.functional.scaled_mm.html while the nvfp4 code path uses https://docs.pytorch.org/cppdocs/api/function_namespaceat_1a2902105d8aed3fa448a0da42f90e2cbf.html
I see that both support different args. Is there a reason why 2 functions which identical names but with extra _ prefix in one are being maintained?
_scaled_mm is the original, private function, without BC guarantees. The other one is the new public one. I think the old one will be deprecated
Probably because the scales are fp32 scales used for fp8 rowwise benchmark, and naively viewed here as fp8e4m3 for running a nvfp4 gemm with them
In real life you would run a nvfp4 quantizer which produces real scales
This script just measures the gemm itself though, so the author must have not cared
so if I were to benchmark a realistic nvfp4 gemm what dtype should I be using? Is there any recommended one?
It should be realistic, I’m just saying the way the scales were constructed is artificial, not a real quantization kernels
Gotcha
Thanks!
Willl you let me know what results you get
I have been deep in the mxfp8 trenches not as tested nvfp4 yet
Oh yep will do
I'm trying to benchmark fp4 on spark and b200 to see how much faster is it over fp8/bf16
Btw i posted this in #implementation-details channel but will share here as well since it is very relevant to ML performance:
Wrote a post some folks here may find interesting: “MXFP8 GEMM: Up to 99% of cuBLAS performance using CUDA + PTX” - https://danielvegamyhre.github.io/2026/03/29/mxfp8-gemm.html
tweet/x post: https://x.com/vega_myhre/status/2038293614204445039?s=46
ML Perf Notes
I recently did a deep-dive on writing GEMM kernels with just CUDA + PTX for Ampere, Hopper, and Blackwell GPUs, culminating in a MXFP8 GEMM kernel which achieves up to 99% of cuBLAS (torch._scaled_mm) depending on the problem shape - see microbenchmarks below, measured with: B200 GPU, 1000W power CUDA 13.0 PyTorch version: 2.11.0+cu130 K-major i...
New blog post: "MXFP8 GEMM: Up to 99% of cuBLAS performance using CUDA + PTX": https://t.co/HFcCcKnNja
As someone who works on MXFP8 training, I was interested in deeply understanding GEMM design for this numerical format. In this post, we write a MXFP8 GEMM with CUDA + PTX, and

Now that i am done with this, maybe i'll finally have to time present SonicMoE 😂
@unborn heart i think we recorded the FA4 session, any chance you can publish it
Thnx
FA4 recording! https://www.youtube.com/watch?v=W49k837lm_g

ML Performance Reading Group Session 24 meeting recording
Paper: Flash Attention 4
Presenter: arshadm (Discord user)
thanks again @cosmic kraken for presenting!
🚀 Linear Attention is unlocking million-token context windows by dropping computational complexity from O(N^2) to O(N), but software is increasingly bottlenecking the hardware.
Meet cuLA (CUDA Linear Attention): hand-written kernels using CuTe DSL & CUTLASS C++ to extract
that looks very coooolll
https://www.alphaxiv.org/abs/2604.15039v1
KV Transfer across data center? whattt

alphaXiv
View recent discussion. Abstract: Prefill-decode (PD) disaggregation has become the standard architecture for large-scale LLM serving, but in practice its deployment boundary is still determined by KVCache transfer. In conventional dense-attention models, prefill generates huge KVCache traffics that keep prefill and decode tightly coupled within...
I could present, but maybe in about 2 weeks from now. How soon does it have to be?
I think that's cool. I need to read it as well first too
Sure anytime works, pick a Saturday or Sunday at 10am PST
I watched @cosmic kraken 's FA4 talk last night, and noticed that he didn't have time to get to the backward kernel in detail. I was studying that closely this week (just the paper, I'm trying to dive into the cute code now, but I'm a bit out of my depth, there), and could present on that. It would be a pretty rough presentation, just walking through the paper and explaining my understanding. I don't have time to make slides.
I would also like to spelunk through the cute implementation with people who know GPU programming better than I do. Claude and gemini are giving me seemingly sensible answers, but I don't know what I don't know. I want to write a backward kernel for my own attention mechanism, which is currently dog-slow.
Would be really interested in this
Saturday 2nd of May works
Awesome, the cross DC kv cache paper?
yeahh
@here event invite for next time, May 2nd! thanks @cosmic osprey for volunteering: https://discord.gg/eleutherai?event=1495853026080981052
Looking forward! Seems TogetherAI came up with a similar idea as well: https://www.together.ai/blog/cache-aware-disaggregated-inference

Serving long prompts doesn't have to mean slow responses. Learn how Together AI's CPD architecture separates warm and cold inference workloads to deliver 40% higher throughput and dramatically lower time-to-first-token for long-context LLM serving.
Wonder how it affects goodput given the use of slow interconnect; they only mention the throughput benefits
DSv4 paper next? 🙂
we need several days I think lmao
or we reading and analyze together instead of someone preparing it alone top down?
Yes!!
@cosmic osprey could we move this to Sunday (May 3rd), same time (10am PST)? i am traveling right now and won't be able to host until sunday
Heyy!! @unborn heart Sundays are tricky for me (this is why I've not been attending the group's meetings on Sundays). How about next week Saturday/Sunday? I was about writing about the possibility of shifting the meeting to Saturday, actually
Ok I will push it back
to next week Sat/Sun? Either is fine for me actually
updated to next sunday!
@unborn heart rg still holding today?
Running late due to Mother’s Day, can we meet in 25min
Ohh, shoot! If we meet in 25 mins, there's about 30 mins left for the presentation and I won't be able to stay for much long because I have another meeting 🙁
It's okayy if we reschedule though
Ok sorry let’s reschedule for next weekend, sorry Mother’s Day activity running longer than expected!
Just saw the message.
good article: https://research.colfax-intl.com/dynamic-persistent-tile-scheduling-with-cluster-launch-control-clc-on-nvidia-blackwell-gpus/
This blog post discusses Cluster Launch Control (CLC), a hardware-supported feature on NVIDIA Blackwell GPUs that facilitates optimal tile scheduling, in particular with respect to load balancing. To provide context, we first survey a few common scheduling strategies and the deficiencies CLC is designed to address. We then walk through the imple...
Heyy all! Reading group session is starting momentarily!
@unborn heart are we still meeting today?
I am so sorry I need to give someone else hosting powers to help me with the logistics from time to time, my life has been too busy for reading group recently and I forgot! My sincerest apologies
I’m down to reschedule through!
I can help here - happy to help with hosting.
I have to travel this weekend so I won’t be available but you could do this session without me or wait til the following weekend!
Do we need specific discord priveleges for hosting? Or should I just start a google meet and record and upload to you?
Nope, yep that works !
I'm down with rescheduling if possible
Are we still on for this Sunday?
I’lll be out of town but I can schedule something if you want to host and record!