#What is learned, when?
1413 messages · Page 2 of 2 (latest)

should I try calculating the euclidean distance from its original initialization?
i guess the grad norm jump just after 100 can just be a normal oddity of training
i am trying to think what makes sense to measure
if the entire embedding space, every vector in it, were say rotated by some specific matrix, what quantity would remain the same?
oh, i guess norm could also be changing, either norm or angle should be different
the norm should be dependent on the rotation matrix (I guess?)
i think the relationships between vectors would remain the same if they all experienced the same rotation

maybe normalize them
but yeah
random sample bc there's 50,000 of them and doing them all sounds like a pain
I think I'm messed up but
since cosine similarity is also dot product divided by their noorm
shouldn't it be invariant to rotation?
it should be invariant if you rotate both equally
aha
if they are rotated differently it should not
if eg you choose one reference token preferably one of the ones that trains
and you take cos with every other one, i think that is invariant to "all embeddings get rotated over time" and then running that across time might be cleaner than cos similarity
that ... might give us a cleaner indication of if they effectively stop training early
in fact, the sheer uniformity with which embeddings converge towards their final representation sort of suggests this? they do follow very clean trajectories
it is probably smarter to random sample like clyde suggested
like, the same sample for each timestep and enough pairs that you guarantee each embedding is included twice
if you pick one token and its weird it messes up the entire result
this will give you a scalar for each sample and you can track how much it varies
it might similarly make sense to track ratios of pairs of norms since we are throwing out that info when we take cos sim
so we could get a pairwise similarity between a good bunch of tokens
and see how they change over time?
yes, possibly also ratio of norm but i no longer recall if we have a ln right after embedding for pythia
ratio is less revealing if so
hmm sounds a bit like a graph?
with each tokens as a node
an the similarity as edges?
yes
i am dredging for if this suggests a clever way to calculate the all-to-all divide and conquer, cosine similarity is not transitive
.... I do not see a clever way to avoid the all-to-all if we want to calculate them all
agree I guess we will have to calculate the entire pairwise similarity (or whatever)
yeah i think just subsample
it is some billions if you calculate all of them
oh, wait, only 400 million
still way high to do 150-or-so times
how should we choose the subsample? will random sampling be god enough?
i think random is fine
any oddities will come out in the wash give or take
if there's an easy way to exclude the tokens that don't train that would be better
i get it
my arr review ends by in a few days so I can try comparning the pairwise cos-sim of a subsample after that
or someone could just go ahead
I’ll give it a shot (I will fail miserably)
I've done cosine similarities on entire embedding matrices before, you just have to do it intelligently. You don't want to do it individually by item, you want to do it to the whole matrix at the same time. I believe I used the following code, and it took about two minutes to run when I did this last.

oh lol, yeah i was for some reason thinking of sklearn where this would take forever
torch probably does it in a reasonable span of time
iff the model is actually rotating and not adding information to the embedding layer we should expect the all-to-all cosine similarity to stop changing on a good set of indices


i'll more or less be able to run it on my gpu once my unrelated training project is complete. I am however, unable to download 100GB worth of embeddings. i'll write what's basically a proof of concept wrapped in a loop that i'll verify through downloading './pythia-12b-weights/embed_only_0-29000.pkl' and base it off analyze-all-embeddings.ipynb, someone else will have to figure out if what i wrote is workable or garbage, or workable garbage (most likely).
Guys. Good news. I am Gyges’ 69th follower on Twitter 
garbage here: https://github.com/Clyde013/pythia-embedding-analysis/blob/main/notebooks/embed_pairwise_cos_sims.ipynb
kernel kept dying on me, but the code works. someone else go ahead and rack up their internet and electricity bills on my behalf, because i'm a jobless NEET who doesn't pay rent.
I can make a PR if you want (once i wake up).
also threw in some pain in the ass visualisation code at the end. it should work out of the box no alterations necessary, except changing the ylim. and maybe definitely fixing bugs i did not catch.
ok it is 2:30am time to eep.
GitHub
Contribute to Clyde013/pythia-embedding-analysis development by creating an account on GitHub.
thank you
Once I’m free later in the day, I’ll work on improving the plot visualisation to generate multiple plots for multiple indices to make it more efficient. Unless someone already beat me to it.
Oh and I’ll also include the norm ratios I didn’t graph that out
Anything else I might have missed?
lgtm, i would spot check the norm to make sure output is reasonable but that's probably a me thing b/c my pytorch isn't perfect, i would also not worry too much about visualizing and save to .json because we can always viz at a later step
Yeah l pkl all the results so we can just read from saved files. I know you’re probably running some other tokenizer experiment to prove shmucks on the internet wrong and that clearly takes priority. So no rush. Maybe I’ll be able to clear enough space on my hard disk to download all the embedding checkpoints. @marsh sand is also busy, but I think you already have copies of the embedding files locally? If you could take 5 mins to just run the notebook cells they should work out of the box (just uncomment the correct file names).
other experiment has been pending for 6mo, it isn't a big deal, if you have a clean script that works i can just run it on my machine because i have all the checkpoints
or a notebook, equivalently
Should work ^
kk, will try to run through it
i will have to figure out ... infra nonsense
like, tiny details with file paths etc
Remember to uncomment the other checkpoint file names in the files list
That’s always the boring part

the boring part consumes, perceptually, 90% of the time
the interesting part consumes zero time even though it objectively consumes time
the other 10% is woolgathering
Unfortunately it is so. Thinking of ideas and debating them is intellectually stimulating and fun. Too bad we actually have to verify them 
(the one way it's time critical is that i have access to a good machine with a blank check right now and don't usually have that lmao)
You can rent my singular 4090 
Im suppose to be busy but..no reviewers are responding to my review so…
I can just try running jupyter file
Is segygs working on it or should i go ahead?
 no organisations gonna sponsor you (the one and only gyges) for your medium big Pythia project?
no organisations gonna sponsor you (the one and only gyges) for your medium big Pythia project?
I’m sure it’s because none of the reviewers are able to find a single flaw in your perfect paper bro 
You got this man
Haha thanks ill just go ahead an run it wont take long
Don’t sweat it bro. Mamba got rejected. Not copium at all to say review process is broken
Im redownloading the embeddings, and probably would be able to share the results by tomorroow
Rip your internet bro. At least I’ll be able to play league of legends on good ping since I’m not downloading it. O7 thanks for your sacrifice 
oops
im trying to running the codes and
the pythia embeddings+pickle files dumped from the notebook takes about 360gb in my storage
and im out of disk space lol
Maybe we have to compute the embeddings and graph their plots on the fly then.
If we save the precomputed cos sin embeddings it’s going to take up a lot of hard disk space
You are trying to create a visualization like that but for all embeddings?

We thank Eric Winsor, Lee Sharkey, Dan Braun, Carlos Ramon Guevara, and Misha Wagner for helpful suggestions and comments on this post. …
Lol wait a minute… @charred bluff
woah this looks coool
I have access to a h100 server with bigger storage ill try again later at night
I swear to god we even linked that article waaaaay back and just forgot about it
lol
i realise i forgot to respond to you. sorry, that's really inconsiderate of me.
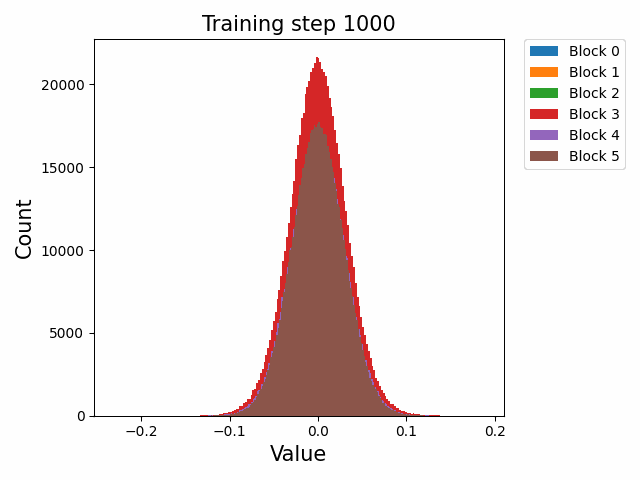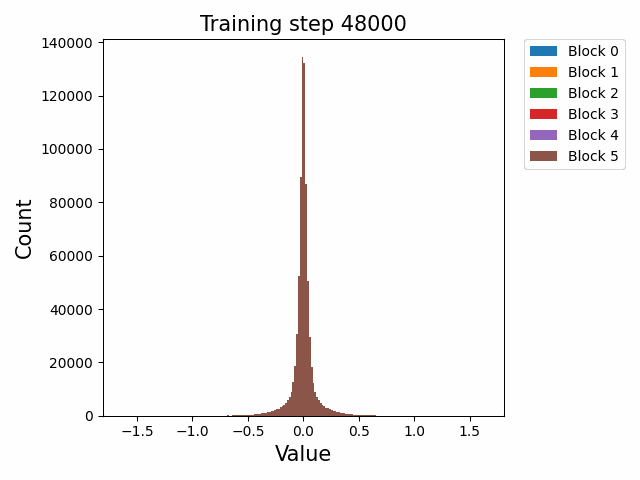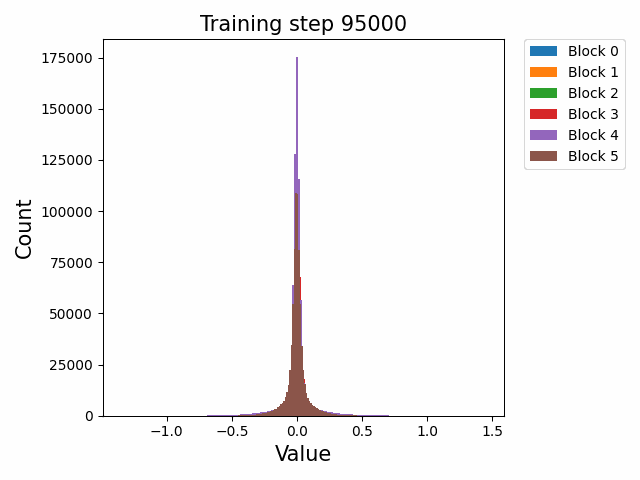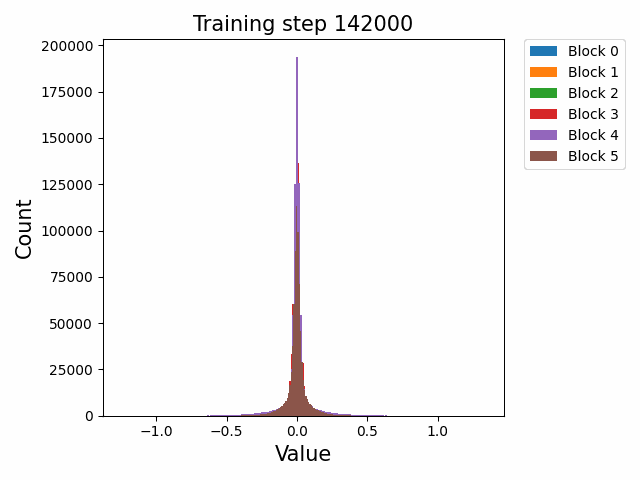
Yes we are doing something similar but on an individual embedding scale across training steps. Initially when we plotted the cos-sim between the current step of a token representation and it's final representation (fig1) you can see that the embeddings seem to converge towards the final representation throughout the entire training sequence. However, we used a linear probe (several different classifier models on a toy task) to determine whether relevant information to a token's attributes (in our case the task was part of speech classification) is learned in the embedding at which step (fig2).
Now note the discrepancy between our initial conclusion and what fig2 implies. At step 1000-2000 the embeddings seem to have gained a majority of the token information, and plateaus at 10,000 steps. In fig1, the embeddings only begin converging towards their final representation at 10,000 steps, but before that the embeddings remain "constant" (at least relative to their final representations).
As Gyges has pointed out, this might imply that the embeddings actually begin to just rotate in embedding space once it has completed its training, and we are currently trying to verify this hypothesis of rotation by plotting pairwise cos-sims between tokens, using a singular token as an anchor point (which we will repeat multiple times in case said singular token for some reason has a skill issue). If this is true, what we might see in the pairwise cos-sim line graphs, is many lines that zigzag wildly and overlap (tokens are updating their representations) for the first 10,000 steps, before the lines all flatten out and become straight (the entire space, and all tokens, rotate (fig3)).



at least, i think that's what we're doing 
ive started re-running, this time it seems fine
🙏
any reviewer responses?
got one and is keeping the original score lol
hope the original score is a good one...?
just finshed dumping the sim matrixs
awesome. do you want me to update the code to run for multiple embedding indices at once? i should right... more efficient.
what do you mean by multiple embeddings at once?
the current plotting code only creates 1 graph when it loads and unloads each calculated cos-sim matrix into memory
at the same time i am also really worried about overloading CPU memory by storing too many linecollection instances...
yeah i have seen that one
i have storage
i just uh have a poor well of spare focus rn
hows it going
im trying to push the extracted sim matrixs but its taking a while
this will help definitely
it is going ... okay
yeah i wonder why...?
good to hear man
i assume the extracted sim matrixes are uncomfortably large
1.5 tb? yeah that's a decent size
i think we're doing a random ish sampling but basically yes, and basically we want to see what the rate of change for that looks like over this entire thing
clyde's breakdown more detailed and good and also he actually wrote the code for this step
you know, if the tokens really are just rotating... why?
would freezing the tokens during their rotary stage impact the training in any way?
and after that... then what? any direction for the project actually, i'm starting to see the light at the end of tunnel here.

im not sure how this will help but
each line in the plot means the average similarity of token "i" and every other token in a given sstep
Im assumming the straight lines there are those the tokens that arent trained for the entire training loop
x axis being step?
no wait
yup x-axis by checkpoint
ah i see
oh no
interesting graph
wait a sec
i think you get values between -1 and 1
isnt it..?
assuming I have the right numbers... im just trying random things but this seems a bit interesting


the two images are the same plots with different scaling (the second in log scale) but it seems that actually the av cos-sim actively changes after the 10,000th step? this probably might be some human-set parameters
im still trying to push the calculated cos-sims to hf but its not working ill try again tomoroow
huh yeah it is my bad G
ngl its perfectly fine to be unable to do that. even i don't want to download it. maybe once i fix up the multi-indexing plotting you can run them locally for like multiple indices.
i haven't implemented norm graphing yet. but its getting late where i am as well and i have stuff to do in the morning.
hey what the heck @marsh sand isn't it 1am where you are
yonsei uni its in your twitter and ur in korea i assume
1 hour behind u, sg time
i really don't know what to make of these graphs lol. @charred bluff any ideas?
@marsh sand just pushed to my branch an updated version with n_samples parameter to plot multiple graphs at once.
https://github.com/Clyde013/pythia-embedding-analysis/blob/main/notebooks/embed_pairwise_cos_sims.ipynb
you might not want to set n_samples too high, its not memory optimized in any way, you might have to wrap the whole cell in a loop if you intend on running it overnight.
GitHub
Contribute to Clyde013/pythia-embedding-analysis development by creating an account on GitHub.
that is so incredibly weird
nothing special happens at 10k
thanks ill try it out tomorrow
i would 100% want to just do the calculation and do plotting separately but definitely cannot today
by seperately u mean one plot per token?
eyyy guess what my code cell does…
That’s right, plots every token independently!
Goodnight gson
Goodnight gyges
Use float16 instead of 32
And raw binary instead of pickle, help a little bit
fig1 is weird. Did you double-check if it is correct? Like doing the same calculation but comparing with the first embeddings instead of the last one?
figured this out. loss gets rescaled at increments of 1000 so we will sometimes expect to see discontinuities there

https://github.com/segyges/pythia-embedding-analysis/blob/main/notebooks/cal_cos_sim.ipynb it's pretty straightforward, i think

GitHub
Contribute to segyges/pythia-embedding-analysis development by creating an account on GitHub.
i guess maybe i am being fooled by the log scale
but like, it sure seems like no?
like: that does look like an actual discontinuity, we just can't see more than one of them at precision-scaling cliffs because everything past 10^3 gets compressed along the x axis
I don't get this code, what should it do exactly?
What is data.keys?
Got it, its the steps
But thats not the code for fig1, right?
for this one? it is. like, doesn't have the visualization but that is how that was extracted

But I thought the plot was comparing the current embedding of a token against its final embedding
And thats not what the code is doing, correct?
there are two blocks doing compares, one is current against final and one is current against next
I see
wait, no, i am wrong
the reason the line diverges at 1000 is the sample rate
points are further apart
this means inter point variation is much higher
Can you elaborate?
And what are the lines on the graph? All tokens on the vocab, random, or specific ones?
Because this plot is very weird by itself, I would say that something is wrong right away. But the point that the lines go up is different for each token, which indicates that it was because of a gradient update, not a problem with the code
pythia checkpoints at powers of two up to 512 and every 1000 steps thereafter
so resolution is much finer below step 1000
oh
I didn't know that
But still, that wouldn't explain the plot
it explains the start of the plot
The straight lines?
yes
yeah, it does
What else strikes you as weird about the plot?
Nothing
yeah i think that's what that is
This explains the straight lines
fwiw does suggest the plot needs rescaling along x-axis, that we have steps along the bottom mislabelled a touch because that looks further out than 1,000 on that graph
And the fact that the point is different for each line is probably because some tokens didn't appear on those checkpoints
so the x-axis label assumes constant distance per step, which is not accurate
So what are you guys doing rn based on that?
the current idea is to check if tokens' cos-sim with each other becomes much more constant later which would indicate that all embeddings are changing more or less uniformly
or "the embedding space is rotating, but tokens are not changing"
this is i think the last idea i have for why the fit with part of speech tags would be good when the embeddings are definitely still absorbing grads
the alternative is just "information is going into the embeddings, but it's information that is encoded in some way we can't read off easily"
there's some code upwards for that but i have not been doing much with it, you'd want to wait for clyde to be online for a better breakdown
So for example if the token cat cos sim with dog is changing the same as cat cos sim with house?
more if it's changing at all
If embeddings are changing?
all the tokens can be changing but their relationships can be the same
Ok
it should hopefully eventually end up as basically the same type of thing to analyze/visualize but it would have a lot more points so we are likely to need to sample
Well, they barely change actually
At the beginning they change a lot because of how attention works at the beginning
When the model starts training, attention doesn't know what to attend, so it attends to everything (or some heads to closer tokens, due to RoPE). So attention makes the model backpropagates the signal to a lot of embeddings at the beginning
oh, yeah, they almost totally converge like ... midway through the run? changes after that are very small. but, the "how well can we fit a linear probe for being a noun" converges way earlier
Way earlier
comically earlier. so if the relationships between embeddings stop changing that suggests that subsequent changes are basically noise, it's the embedding layer adjusting to keep up with the network itself
but not storing any additional info
but also: it can just be storing more info in some way that's not amenable to linear probe and that has negligible impact on cos sim
Well, they do change, just not as much. In simple terms at the beginning they realise what they are, after that, they enrich itself
so a positive result (cos sims continue to change) would kind of be more informative
because there's only one hypothesis fitting that, which is that embeddings are still training
i mean, we could also test this by freezing embeddings about 2x the number of steps it takes them to seem to converge to see if it harms the network at all
And nothing is that simple with embeddings. For example the token "dog" will contain information about the animal dog. But with attention it may change abruptly when it realizes the word is actually "underdog"
Now how much information of underdog is in dog, I would love to know
sure, but how much of that information is in the embedding layer vs the attn layer?
Or if it is mostly stored on dense attention weights
yeah
yeah
... actually, and I am trying to convince myself that I do not just think this because I have an ongoing grudge against embeddings, it seems like it shouldn't be stored in the embedding itself
I have some ideas on how to test that with checkpoints. You can use the embeddings of an earlier checkpoint on a later model. And see what tokens/words change the context vector the most
because: for gradient about that to reach the embedding it has to first go through all the dense layers, which have plenty of "space"
the early part when the embeddings are still training significantly the FC layers are all still basically random
oh that's clever
but: i think it neglects the "entire embedding space is shifted" possibility
Yeah, I generally avoid doing research on early checkpoints. I find the problems there too hard to solve
Wdym by shifted?
rotated?
rotated or rescaled, yeah
if you uniformly dilate or rotate the embedding vectors it will break the network totally but they have the same amount of information
I don't think that would be the case
Simply because mathematically there is no reason for that to happen
it would be interesting to test by doing your test and then seeing if you can normalize the earlier embedding matrix to align with the later one by a single pure rotation
eh, so figure the residual is at some angle wrt the origin
as the network trains this angle should basically brownian drift
because it's not under any particular pressure, it's not the goal of training
just all-ones vector
... i should not have called this the origin, whoops
"some basis vector"
Ok, but then they wouldnt rotate
they would a little bit
they wouldn't a lot but it can have basically noise rotation
i think that's actually testable
It is possible, but I would say that it is unlikely
And personally, I would do research without thinking about that
Too many problems already
yeah fair
the number of things you can check mathematically is absurdly high
actually i can think of a fairly amusing way of testing this
yeah, but models act in weird ways. because data is weird
yeah you cannot check all the things and only discretion keeps you from just running statistics forever
just give it a one-token input for some good stretch of common tokens. see if for any given common token the later model's residual is the same as the earlier one's with some rotation applied
but, yeah
i think after this specific check is done i am willing to try to put a bow on this one
For example, look at that
Dimensions values for q and q_rope, Pythia 1B
The model already has information of the position before RoPE is applied

... that is insane
Thats why I am very humble when thinking about models
that basically means the model is learning to reverse the rope transformation before going into it, no?
it 1) knows what the rope transformation will be and 2) can apply the reverse operation
Well, it encodes some positional information, but not entirely
For example here, this sample is actually three samples, separated by <|endoftext|>, and you can see that the model also separates the positional information per sample
Some dimensions have very clear patterns

anyway, Im going off-topic here
the big bro talks always have a lot to learn
think this is an easy idea to test?
we can just switch the embedding layers and run some evaluations to see how it changes
Augh I hate waking up
haha im already at class
I don't want to divert you guys from what you're doing, you know
It’s not like we’re doing anything particularly interesting. And that’s also relevant somewhat to what we’re doing. Actually what we’re doing kind of has no direction…
i actually agree i think we're roughly done
these are just interesting threads to chase
the original question was more or less whether embeddings contain part of speech information early in training, they do, while we have a big ole block of embedding layers there are other things it seems to make sense to check but none of those seem essential
ideally should wrap all existing files in a notebook and throw them somewhere sometime soon
Well I’m back from the dead
@marsh sand how’s it going
im trying to understand what happens after the 1000th step. just averaging everything doesnt seem to give much insight but im not sure what other things I can try
Can you run the last cell in this notebook
Unless you already did and I missed the plots
How’s the review going btw
the other reviewers didn't give me an answer so i guess ill just fix and re esubmit

sorry i missed this
these are the plots but they are look like a huge mess



Well that’s to be expected
Maybe subsampling for plots is a good idea
Gyges does seem to be correct, we do see lots of fluctuation at the start then flattening out at the end. So I guess the embedding space really is slightly rotating?
seems like it
as the attention learns better to concentrate on related tokens
it looke like tokens with lower cos-sim show lower fluctuation later in the training
i think the key metric would be comparing how much this changes vs the absolute cos sim with final
How would we do that
actually i dont get it what does "this" refer to
yeah come to think this isn't really easy to reduce to a rate of change per embedding
I’m gonna like “phone a friend”
i am gonna ... maybe get around to looking at this again at some point
Too busy getting .geese’d in #off-topic ?
I’ll ask around and maybe someone in another discord server provides a wonderful idea because I’m sure as hell not smart enough to come up with one
i just have insomnia at the moment so i am not doing anything very smart
Hope it gets better man
Is this still the TODO list? Is there an updated one?
I think the TODO on the GitHub README is the most updated one, but even that would be quite far behind
Going through the repo. Anything on top off your head that you all need more eyes on?
Read this ^
Look at these ^
Think like gyges ^
Because I can’t…
Thanks!
I guess we can try to see if we can rotate the embedding from the 1000th layer to get the final one?
Im not sure how though
Try decomposing?
Or dimensional reduction?
That’s a good idea

Mathematics Stack Exchange
Suppose that we know two real vectors with n components, which are linked by some arbitrary transformation/scaling/rotation/shearing...
Now, I think that it is possible to know which is the scaling

what the fuck
Ok is anyone able to decipher this into English

I just hang out in yannic kilchers yt discord
Yea the implementation doesn’t seem like the hard part, understanding what I write is the hard part, and unfortunately for me the latter part seems to occur too often
it’s weird that you’d get a response like that then
Nah zickzack is the GOAT man
Just depends on who you interact with in every server, there’s always good people. Just gotta know where to look and who to look for.
@gaunt plaza then i guess our future today is trying that orth. parameterizations or switching the embedding layer of different checkpoints to see if it works?
I haven’t the foggiest. I’m not home yet and won’t be until quite late.
I would like to try the SO(N) matrices, zickzack is pretty much always right about this math stuff
How’s the review. Resubmitted the paper?
Not yet im busy with other works so probably work on the paper some time next week
Then ill try the orth. parametrization thing im new to it but im basically new to most things so it wont really matter
@marsh sand I’ll get back to work tonight, any progress?
None is fine as well not like I’ve done jack shit either.
Totally forgot about this sorry
how’s the paper man
i might work on this the weekend/next week <_<
I just got the meta reviews its a 3/5. Probably will have to fix and resubmit somewhere
@gaunt plaza you interested in multilingual topics by any chance?
Erm, yeah I did some multilingual stuff before for a school project
I think…
Sorry I've been away for a bit. I'm not entirely convinced by the "it rotates" argument, at least for after around ~90,000 steps, because it is very much stable from that point:


when i have four spare brain cells i'm gonna try to wrap all these up in one block of markdown, i think for the rotaty bits there might be some postprocessing necessary because those graphs are nigh unreadable but
Interestingly, the results for token 0 (<|end_of_text|>) and token 1(<|padding|>) are very different from "normal" tokens. Note especially the different scales for the end of text token. I don't think they use the padding token much in training pythia:


i don't think they use the padding token at all
i guess they must if it's receiving grad but that looks like it's maybe just decay
It was probably in the data already
<|endoftext|> doesn't carry any information and can be used in any context, tokens like that need sparser activations. I bet you will see similar things on tokens like \n, comma, dot, parentheses and connectors like "and", "or", "from", "is", "a"
that would make sense
that would not explain why it looks different than any other arbitrary token
weight decay, as you said
i mean: the trajectory for "I" reflects that it's trained over because it's irregular, the trajectory for that one seems to indicate just decay as if it's not in the data, but if it's not in the data it shouldn't be in the tokenizer
i am also not sure weight decay would touch it if it's never activated, maybe?
depends on implementation
i am not extremely motivated to chase down these edge cases though
I don't know of a WD implementation that leaves un-activated weights alone
You'd know better than me
"but if it's not in the data it shouldn't be in the tokenizer"
Not in this case, since it is an added token, not one created by the tokenization process

I think I misunderstood an earlier bit
yeah, it's a special token added by hand.
also, and i may be totally wrong, but does it not seem maybe problematic if tokens not being activated are being weight decayed per timestep? if a token appears very rarely it will decay substantially between optimization steps
A token that appears very rarely should not be a token
But it is a good point. If someone creates a token that will only be used during fine-tuning, that could be a problem
assuming tokens are distributed sort of zipf-ily with no weird outliers you still have a pretty vast gap between how much of the token's delta will be weight decay vs gradient for the top and bottom of the distribution
they are in pretty different training regimes
To avoid that problem you could apply weight decay to the gradient instead
But it is rare that a token doesn’t appear for tens of consecutive updates
Interesting problem, needs more research
if it appears in every update once but another token appears in every update ten times, the less common token will have a much noisier grad relative to its decay, basically the question would be if noise + decay is higher than signal and if so how much higher
Your hypothesis is correct. Comparisons of the end of text token, " and", "\n" and " developers", noting the scales are different between the different tokens.




I don't know if this is helpful at all, but here is a gif of changing dimension values over time for the token " Mon", token id 4200. points on the 2d space are adjacent dimensions plotted as x and y. Not the most useful, but interesting nonetheless.

Back from the dead guys, finally POPd and will have block leave next week where I can spend all my days wrapping up the project. If you guys are still interested that is, because I’m definitely a bit brainrotted not having touched any code for the past 13 weeks