#RWKV-papers
1 messages · Page 8 of 1
Okay those are all updated now - I'll let you massage the table sizing so it fits the page again!
@last mauve also, once its resized maybe you can port that to arxiv as well
yep will do
let me know if you need any particular data.... its probably all in there, but yea the raw data is a giant pile to sort
its ok it turned out I had the data handy in the spreadsheet and we got it done
- Done (Should I add speed experiments for Cahya's Rust implementation?)
I would personally support having more info like that for the tokenizer's benefits
I believe we can still add @acoustic knoll to the Arxiv version's author list in the next revision, even though they wouldn't be able to be listed as an author for the COLM paper it would still be great to show that
Done, but I lost access to arxiv version 😭

@tropic minnow see above.. maybe you can remove some people's edit access or reset sharing on the arxiv doc so we can re-add editors from zero?
The best solution is to turn on link sharing. While these limits apply to officially added collaborators you can still share an edit link with as many people as you like
Okay will do soon
I believe we can still add @Cahya to the Arxiv version's author list in the next revision
Yep this is fine!
I did turn on link sharing though. @tropic minnow -- Are you accessing through my edit link?
oh I thought @tropic minnow was the owner of this one (arxiv, not COLM) too, but it's yours
still says this to me when I use your edit link:
This project has more than the maximum number of collaborators allowed on the project owner’s Overleaf plan. This means you could lose edit access from August 26th.
To keep edit access, ask the project owner to upgrade their plan or reduce the number of people with edit access.
Do this
So how can I regain access?
well link sharing is on for version: https://www.overleaf.com/1623283552mkymjtvsnybt#bd0fc2

An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
I removed everyone as an editor for the arxiv version. The edit link is still: https://www.overleaf.com/8557419627zggxjcgcnqbn#6dad3b
An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
Acknowledgement will not count toward the page limit, but here's still a paragraph to compress.
I noticed this sentence:
Authors can add an optional ethics statement to the paper; it will not count toward the page limit, but should not be more than 1 page.
Can we move some information (like fostering multilinguality and culture diversity) into the ethics statement to add a bit more information into the main pages?

@gusty condor I copied your new tokenizer appendix section into the arxiv version, and will add @acoustic knoll as an author when I get his details
I thought @last mauve was handling making it fit
He has been absent and deadline is coming
I'm happy to work on rewriting stuff- do you have suggestions?
This is my suggestion - Move some information (like fostering multilinguality and culture diversity) into the ethics statement to add a bit more information into the main pages
and maybe just shrink Figure 4
ok it all fits now... I removed "The Eagle and Finch models fall short on certain aspects that can be mitigated and addressed in future work." because it doesn't add any information, and shrank VisualRWKV image to 80% but its still a good size
Great, let's upload it as camera-ready. In case that a revision is needed, we can still upload before the deadline.
I'm handling it today. Been sick but I'm feeling a bit better
sorry to hear that, hope you're 100% real soon!!!
hmm the contents section of the Arxiv version ended up with a second page now, and looks messy
maybe someone with more latex knowledge than myself can help fix that up?
Yeah I can take a look in 20-ish min
thanks! no big rush, its just the arxiv version - we can update it at any time
Ok, did my final pass of minor edits and submitted an updated camera-ready
I don't see a section called "Contents." Which part of the paper are you talking about specifically?
An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
Let's target making an arxiv revision live by Wednesday.
Who will go as a presenter?
i got a ticket for author, but i think price is the same so far:


I didn’t know you have to pay a lot as an author and student 🙂
Hypno and I are going.
Yeah conferences are expensive 😦
Camera ready deadline extended until 9th (friday)
oops look like camera-ready isn't formatted right
I was just about to say
We have detected a critical formatting issues with submission #422. The issues are:
Wrong font; author list misformated; no author email
we used the colm conference format, so not sure about the font point
missing emails is fair. I can add them
re font: maybe something about the chinese support stuff?
does anyone know what they mean by the wrong font and author list misformatted?
but we need CJK font support
Re: example author list format

if we format like this, we're going to have 5 pages of authors
only thing really with 'font' in the document is \usepackage{pifont}
@misty igloo -- Can you email them and get clarification on those while I gather author emails
is there an official email channel or way of contacting them via openreview? only thing I can find is on the COLM website Questions can be directed to: [email protected]
That's the right email to use
It does look like our font is off, comparing the template and our paper side by side
Check out the title in particular

Hi,
We are the authors of submission #422, ("Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence") and received an email that our camera-ready version has the following errors: "Wrong font; author list misformated; no author email"
If you could supply a bit more detail it would help us resubmit a corrected version as quickly as possible. Specifically:
- What font and point size is supposed to be shown?
- We have a very large number of authors. If listed as Author/Affiliation/Address/Email on separate lines this will take many pages. Is that what we should submit or do you have an alternate example template for this many authors?
- Are there other authorship formatting issues we should be aware of?
Thanks for your assistance,
Dan Goldstein
I would say "more than a full page"
ok, sent
What's your email?
is this something that should stand the test of time? you could use [email protected] if it can be job specific
I was going to add a "correspondence to X, Y, and Z" line with the emails of you, bo, and quentin
my other emails are like personal and unrelated company ones so I guess that one is best!
@misty igloo Do you agree that the title fonts look different here?
definitely
but so does the word "Abstract"
it's a totally different 't'
in that pic that's the easiest letter to see how different the two fonts are - lowercase t
seems like it's not just the headings, the actual normal font is also different in the same way
so a document-wide font change of some sort
Yeah I'm working on it
experiment.tex is a new file that contains a heavily stripped down header and seems to match the font
oh duh
I think I have it, lemme recompile
Yeah fixed it
The packages fourier and times both set the default font in the document. After removing them, the font looks right
awesome!!! now we just have to hear back about what they want us to do about the authors list I guess
maybe in the interest of time we should guess what they might want and just try resubmitting that way tonight
We reran the evals of models like Mistral and Falcon instead of copying them from their papers right
yeah
bb in 40 min
Does anyone know where I can find the raw eval harness outputs btw?
(Doing a final pass on some details)

i have a spreadsheet thats a bit less annoying too if u need
Each lm-eval output jsonl logs the hash of the library commit used. It looks like there are at least four different commit hashes used to do the evals
You'll have to ask @void quartz about it - he set all of this up
@young sparrow @last mauve with the new font the paper now appears to be 11 pages long
not including a larger authors section we may be required to include
tables 4,5 also now appear to have gotten too wide somehow
my only ideas on how to reduce the size easily and quickly to fit within the 10 page limit is to move Figures 3 and 4 back to the Appendix
working on that now
done.
I would cut one of the lambada metrics (we report both acc and ppl) to make it fit width-wise
ok i can do that for table 4 ... and I'll add a second header row on table 15 to fix that
update: done
there was an update that was required for adding in the google models (which had a bug)? and a fix for the rwkv lm-eval-harness integration.
@young sparrow @last mauve I updated the author block with one that's in the original COLM style.. it puts us slightly over the page count but maybe we could fix that by eliminating text or the huge number of affiliations. Let me know what you think.
I commented out the following conclusions paragraph:
Because our training corpus contains synthetic data from GPT-3.5 and ChatGPT, our released models exhibit behaviors similar to ChatGPT and will mimic ChatGPT's conversation style and tone. For instance, the model might occasionally claim that it is trained by OpenAI. However, this is not a general property of RWKV architecture but rather a specific outcome of the training data.
and now we are at exactly 10 pages, even with the COLM style author block
We could probably resubmit in its current form. I mildly abbreviated a few of the affiliations. And we only list emails for the three first authors. (I don't know how we could fit emails for everyone)
Actually, I don't need an email listed, to avoid spam emails
go ahead and resubmit. I can't seem to get it to fit with everyone's email.
If they complain about that again, I'll massage it a bit more until it fits.
agreed - got any suggestions or should we just submit like this?
Did they respond to your email?
nope
The other thing they did in the example was group people by affiliation
but that seemed nearly impossible
- requires changing author order
yeah exactly, or at least taking the first three authors and putting them under EleutherAI and then doing... something else with everyone else
couldn't find a reasonable way to do it
would you mind submitting? I haven't done it on openreview and don't want to screw up the process
The deadline is Thursday. I think we should give them at least 24 hours more to respond
maybe their response would be better informed if they can see what we have here?
as of now we had to ask some fairly vague questions about what they want us to do, given the number of authors
Good point. Send a follow-up email saying:
Hello,
I wanted to follow up on my previous email with additional information. We've solved all of the typesetting and layout issues except for the author block. As mentioned previously, a strict interpretation of the layout guidelines would take more than a full page due to needing to put each author on their own line. I've attached two screenshots of alternative solutions, one using the authblk package and one not. Are either of these acceptable solutions?


btw the only thing really stopping the author list from looking like we used to have it was their low quality footnote/thanks mechanism
and that their examples basically said to put the affiliation below the author
I'll send that followup email
I debated saying we had a preference for the authblk vesion but idk
The authblk version has been saved as its own file named authblk.tex
looks like quentin submitted the revision too (with the colm style authors)
yep just resubmitted
I have a preference that the authblk version go on arXiv but otherwise it's 
send them the email and get their take on it
I'll change the email to say that we submitted this one, and show both options
I wouldn't because I think the only thing that might do is cause them to default to saying "keep whatever you submitted"
wait do you want me to resubmit with a different version?
or is smerky just changing the email
I'm fine with having submitted one that more strictly conforms - at least this way we're less likely to get booted from the conference 🙂
I kept the email as written by Stella
yep ok
It makes no sense that author list takes up 2/10 of the main pages, and some figures are moved back into the appendix.
The figures had to be moved back to the appendix mainly because of the font size issue - not because of the author list.
What do you mean about 2/10 pages? The author list in the camera ready version takes up about 65-70% of the first page now, up from maybe 40% originally.
Still no email response from COLM... maybe you should email them as well?
Sure. Sending it now.
btw I noticed that @steady ether updated his affiliations in Overleaf - I think I accidentally had left one of his out
No worries, that's optional. Nice to have if we do end up resubmitting

wow, GoldFinch got a citation in a paper that is appearing in COLM'24!
so... they must have added that for the camera ready version - since GoldFinch didn't exist at the time of COLM submission!
https://arxiv.org/abs/2407.18003
but.. they cited the original RWKV paper when discussing it (doh!) We have some kind of weird discoverability issue with the Eagle/Finch paper
arXiv.org
Large Language Models (LLMs), epitomized by ChatGPT' s release in late 2022, have revolutionized various industries with their advanced language comprehension. However, their efficiency is challenged by the Transformer architecture' s struggle with handling long texts. KV-Cache has emerged as a pivotal solution to this issue, converting the time...
Next paper should be named RWKV-7 somehow
In general, the Eagle/Finch paper does not appear near the top of the results when searching for "RWKV 6 paper" on Google
it's too late for COLM camera ready but maybe we can fix this in the next Arxiv version somehow?
research paper internal SEO 🤷♂️
we could change the title to something more like "Eagle and Finch: RWKV-5 with Matrix-Valued States and RWKV-6 with Dynamic Recurrence"
or "Eagle (RWKV-5) and Finch (RWKV-6): RWKV with Matrix-Valued States and Dynamic Recurrence"
or "RWKV-5 'Eagle' and RWKV-6 'Finch': RWKV with Matrix-Valued States and Dynamic Recurrence"
any other suggestions?
What about:
Eagle and Finch: RWKV 5 & 6 with Matrix-Valued States and Dynamic Recurrence
I agree we have terrible SEO on the eagle/finch paper, and I'm of the opinion that "RWKV" should be the first word of any future title.
I like this but I worry it won't cause "RWKV 6" and "RWKV v6" to be searchable, which are more likely than people looking for RWKV 5
It appears at the top for me


I also took time to read through the citations. They only cited the foundational works, so I think it's appropriate that they cited RWKV 4 instead of 5/6, and they cited Mamba 1 instead of Mamba 2.
Hi, last week, I wrote about the Rust RWKV world tokenizer update on the RWKV Discord channel. In case some of you do not see it, here again. Three weeks ago, Huggingface tokenizer released a test comparison of the encoding speed of Tiktoken and Huggingface tokenizer on different sizes of text and different numbers of threads (for batch encoding). The result was that the Huggingface tokenizer is faster on small text sizes and more threads. Otherwise, Tiktoken is faster. https://github.com/huggingface/tokenizers
So, we updated the Rust RWKV world tokenizer to support multithreading for batch encoding. We ran the same comparison script from the HF tokenizer with the additional rwkv tokenizer. The result is that the rwkv world tokenizer is significantly faster than the Tiktoken and Huggingface tokenizers in all numbers of threads and document sizes (on average, its speed is ten times faster).


GitHub
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production - huggingface/tokenizers
It hadn't for me about a month ago. I tested in a private window.
I will never understand search ranking algorithms.
Do you have a fancy new windows laptop, with local copilot installed?
it might be running RWKV, im trying to fact check this, so if possible scan the OS for any files larger than 1GB
We already confirmed that RWKV.cpp codebase is part of the windows OS latest update
the copilot pc thing?
i don't even know what PCs support it
but Microsoft is shipping RWKV.cpp?
If they are, you can probably be sure... wherever they put OSS licenses
i don't even know where to find the windows eula anymore, actually
they also ship llama.cpp
our stuff is all apache2, so its definately allowed
and its not like they remove the license entirely either, so its all above board
im trying to source for a single working laptop with the "offline copilot" beta, typically on a snapdragon CPU (if anyone here has it, please let me know)
so i can trace if its actually using our model, or is our code just being dumpped in there

if ur using windows 11 updated, you can just search system files for rwkv
I found the files, didn't find any models though
I assume you don't necessarily need the copilot pc thing, since they have libraries for CPU & GPU
there is no model, the copilot offline mode (which i assume will download the models), is in very limited beta - so im trying to find that 1 laptop that has it
Maybe Snapdragon X?
i assume so (the documentation has been inconsistent)
https://x.com/RWKV_AI/status/1830859408106192942
The completed finch model, trained and eval-ed can be found here - its generally a step up from the previous Eagle models
The RWKV v6 Finch lines of models are here
Scaling from 1.6B all the way to 14B
Pushing the boundary for an Attention-free transformer, and Multi-lingual models.
Cleanly licensedm Apache 2, under
@linuxfoundation
Find out more from the writeup here: https://t.co/30VbPbbfCm
V6 7B MMLU should be higher than 41.7%. Which code did you use?

use https://github.com/Jellyfish042/rwkv_mmlu
v6 7b = 46.7%
GitHub
Contribute to Jellyfish042/rwkv_mmlu development by creating an account on GitHub.
User: Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.
A. 0
B. 4
C. 2
D. 6
Assistant: The answer is
Remove the first line break, 46.7% -> 47.2%
which line break
This one

That's Discord's formatting problems
A better prompt is:
User: You are a very talented expert in abstract algebra. Answer this question:
Find the degree for the given field extension Q(sqrt(2), sqrt(3), sqrt(18)) over Q.
A. 0
B. 4
C. 2
D. 6
Assistant: The answer is
Correct: 6696 / 14042 (47.69%)
could you update rwkv_mmlu thanks 😂
I don't own that repo, will ask @iron parrot to update
please check out this script: https://github.com/Jellyfish042/rwkv_mmlu/blob/main/rwkv_mmlu_minimal.py
GitHub
Contribute to Jellyfish042/rwkv_mmlu development by creating an account on GitHub.
use your (47.69%) prompt and # all_prefix_ids = pipeline.tokenizer.encode(all_prefix) all_prefix_ids = [0] + pipeline.tokenizer.encode(all_prefix.strip())
Correct: 6731 - Total: 14042 - Accuracy: 0.47935
Special tokens influence so much on the final result
@hushed orchid - you might want to update to results?
Is that ACC norm?
What's your score before ACC norm
it's only detecting A/B/C/D
Since the letters 'A B C D' all have the same length, acc and acc_norm should be equal.
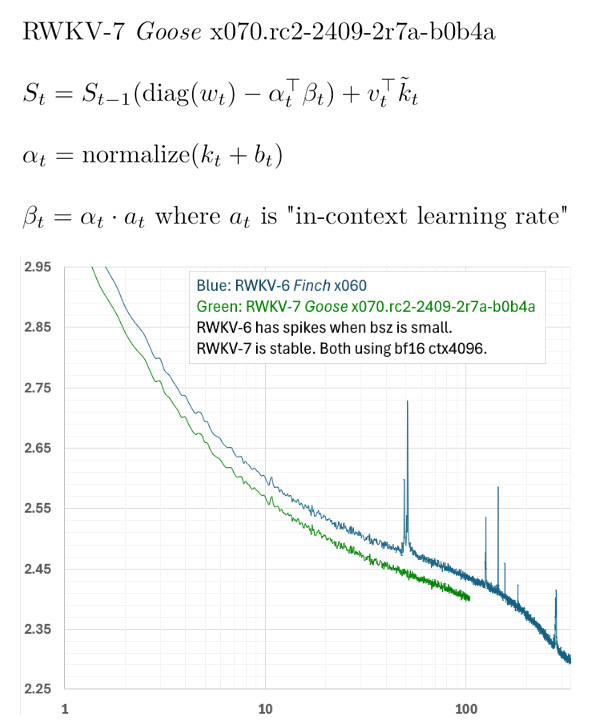
RWKV-7 "Goose" preview, with dynamic state evolution (using structured matrix) 🪿 Now the loss curve looks scalable, after fixing a hidden bug😀

So is rwkv7 = rwkv6 + matrix valued decay and/or time boost? No delta rule?
Also what are the specifics on how to make that decay? Is it like before (vector data dependent + matrix data independent)?
@obsidian quest
And are there some speed benchmarks for the cuda kernel compared to v6?
matrix-valued evolution already includes delta rule as a special case
Oh ya good point
What abt this?
congrats! that's really great news that a bug was causing the problems before! excited to see it in action
and curious how we can do this efficiently in terms of the kernel
If I just search for "rwkv paper", the first 3 pages doesn't show rwkv 5/6 paper or any article mentioning the latest paper
the eagle/finch paper appears for me but in position 7 below the fold
Best to test in incognito I think
just did, same result
I think when citation count (16) approaches v4 (275) we might get higher placement on the newer paper
strange, in my place using incognito or normal, I don't see it at all. maybe the search result depend on location
Well most times it barely appears 😢
@obsidian quest
What's the plan on the RWKV COLM poster? I'm not attending so can't really decide things here.
Is there a poster template? I'm not currently seeing one on the website
I had one for RWKV-4, but I'm not planning for RWKV-5/6 poster.
An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
details soon
yes im crafting the poster!
Has v7 architecture finalized?
not yet. but close
@obsidian quest if you could supply a list of all the world v3 datasets and mix, that'd help get a headstart on the RWKV-7 paper so we can turn it around faster this time
(if you plan to train it on world v3, or continued from Finch world v3)
Qwen 2.5 is out. It is said that they used 18 trillion tokens of data. RWKV world v3 is only one sixth of their size.
Did some testing on the llama3 8B model... and transformers might be just RNN's with extra steps and more memory?
Not sure if this is significant / should be its own thing. Maybe its already a known thing (and i was ignorant)
You can setup a transformer, with a prompt, in sort of a needle-in-heystack situation. And delete the needled KV embedding.... And it still works, from the recurrent embedding stored in subsequent tokens.
This is more prelevant in longer prompt / chain-of-thought, and would explain how such processes (or thinking tokens) help model performance improve.
The longer write up is here: https://docs.google.com/document/d/1ShztwKqQtqkG5ZsbbhKxw2toS0_s-OwxR_FbaLK2nIU/edit?usp=sharing
( note i might be just ignorant, and too used to thinking in RWKV recurrent terms - so im sharing here, to see if it makes sense to you all too )

Google Docs
QKV Transformers are Recurrent models with extra steps and memory capacity Author: Eugene Cheah ( @picocreator , eugene@{rwkv.com, recursal.ai} ) Abstract The information stored into a transformer model KV cache, represents not just the existing token information. But the model embedding state ...
I think (?) this is known (tho I haven't seen it written about), and is why SWA (Sliding Window Attention) can work for longer than its window
But it's very interesting!
Essentially, the KV state of higher layers can keep around deleted KV state from lower layers, subject to layer count limits
This might be something to show the folks in the interpretability channel, in case they haven't analyzed it before and want to do a deep dive on it!
Oh, I see you already posted there! nice!
less of a post, and more of asking whats the existing litrature - cause i actually been trying to find something that explains it
Anyway rewrote and consolidated it here as a git repo : https://github.com/PicoCreator/QKV-Transformers-are-RNNs
GitHub
QKV Transformers are RNN's with extra steps and larger memory capacity - PicoCreator/QKV-Transformers-are-RNNs
https://arxiv.org/pdf/2404.05892 formula 16 should be ddlerp. lets fix it?
this was fixed in the manuscript a while ago
@last mauve I guess a new version never got uploaded to arxiv?
Several synthetic datasets are needed to be added to the pre-training corpus to earn high scores beyond multiple-choice question tasks.
In particular, to earn the higher score for more difficult generative benchmarks like mtbench non-English instruction datasets and math/coding instruction datasets are required in the hundreds billions.
world v3.1 or v3.2 datasets seems to be better.
oh? Must have gotten lost in the chaos. Will do that today or tomorrow
submitted the latest arxiv overleaf
RWKV-7 "Goose" 🪿 preview rc2 => Peak RNN architecture?😃Will try to squeeze more performance for the final release. Preview code: https://t.co/ecOwkzJCOo
I suggest using torch.lerp to simplify RWKV-LM token shift. Might improve performance a bit 🙂
And modulize lora-like MLP (being quite common in v7).
@tropic minnow
what do you think of calling the lora-like MLP as loratanh?
I agree, but let's call them Low-rank MLP.
just to reiterate @tropic minnow's link, since it wasn't posted in this channel yet:
RWKV-7 documentation and writing effort has started https://www.overleaf.com/5753862368yvnbymysbrsf#07fba2 welcome everyone to join~
An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
In the paper "The Illusion of State in State-Space Model", it is only proven that an SSM can be simulated by TC0 when the projection matrix (transition matrix) is both input-independent and diagonal. However, this does not necessarily imply that an SSM cannot be simulated by TC0 if the transition matrix is not diagonal, does it?
Ya good point I’m not sure if a diagonal plus low rank state matrix counts
Maybe we need some mathematical proof
Might be easier to contact the authors of that paper to check
They already have things setup to test I guess
Can RWKV-7 solve the A5 word problem?
Wasn’t tested
Doesn't he show the opposite? It was my understanding that the matrix cannot be diagonal because a diagonalized matrix makes use of an elementwise operation and that is within TC0
Once training code is released, test it on the formal languages in https://arxiv.org/pdf/2405.04517
Also the illusion paper has the code https://github.com/jopetty/word-problem

GitHub
Experiments on the impact of depth in transformers and SSMs. - jopetty/word-problem
Not really interesting, finite group multiplication is regular. Test Chomsky Hierarchy if possible.
but transformer struggle to accurately solve long sequence A5 word problems within a limited number of layers.

Why do you want to prioritize that over circuit complexity hierarchies?
Maybe ... we are talking about languages, right? For example, most programming languages are context-free or context-sensitive, and MQAR is context sensitive.
The Chompsky Heirarchy is one of multiple different ways to classify computational problems by difficulty. It is very poorly aligned with transformers and massively parallel computation techniques though, and does not meaningfully capture degrees of difficulty for such models.
And the leading theorists do not use it (see Angluin et al., 2023; Merrill
& Sabharwal, 2023a; Liu et al., 2023; Chiang et al., 2023;
Merrill & Sabharwal, 2023b; Hao et al., 2022, etc)
I highly recommend The Illusion of State in State-Space Models in particular, which has an excellent bibliography and seems like the most productive point of reference for our work.
@obsidian quest what do you think about renaming eta to beta in the paper? That way we could say RWKV-7 is an extension of the delta rule so that Beta becomes vector valued
delta rule:
restated rwkv-7 version
also this brings up the question of whether you tried keeping everything normalized like in delta rule while extending Beta to be vector valued
the current version comes close by using the k*=1-w trick, but its not exact due to the delta rule portion not being included in that
Here's a visualization from Will Merrill showing how regular languages are incomparable with circuit classes

Is the transition matrix of RWKV-7 Diagonalizable?
I think the claim that "Transformers and RNNs with diagonal transition matrix could only represent functions in TC0" is potentially misleading. Given the nonlinear transformations in RNNs like LSTMs and GRUs, the notion of a transition matrix might be unclear. Using "linear RNNs" instead could make the statement more precise.
I'm trying to prove that RWKV-7 can simulate DFA, but it seems impossible if the transition matrix is diagonalizable.
wdym tho, the rwkv7 is a diagonal matrix plus a low rank matrix
so its not fully diagonalisable
I've found that you are invited to the simon's TCS seminor. Great!!
The theoretical analysis among complexity classes could be reserved for independent papers.
I'm think that theoretical complexity models often have unrealistic assumptions like precision length of matrices which depends on input sequence lengths.
I am currently there! (Here?)
I think log-precision is extremely reasonable, why don't you?
umm 🤨
IMHO, I feel that FP8 / FP4 training looks like constant precision.
Here?
SFO (My vacation has just finished now )
r = r.view(B, T, H, N).double()
k = k.view(B, T, H, N).double()
v = v.view(B, T, H, N).double()
a = a.view(B, T, H, N).double()
b = b.view(B, T, H, N).double()
w = torch.exp(-torch.exp(w.view(B, T, H, N).double()))
out = torch.zeros((B, T, H, N), device=DEVICE).double()
state = torch.zeros((B, H, N, N), device=DEVICE).double()
for t in range(T):
kk = k[:, t, :]
rr = r[:, t, :]
vv = v[:, t, :]
aa = a[:, t, :]
bb = b[:, t, :]
sab = torch.einsum('bhik,bhk,bhj->bhij', state, aa, bb)
state = state * w[: , t, :, None, :] + sab + torch.einsum('bhj,bhi->bhij', kk, vv)
out[:, t, :] = torch.einsum('bhj,bhij->bhi', rr, state)
return out.view((B, T, C))```I tried to prove that RWKV7 can simulate DFA based on the methods proposed in the paper "The Illusion of State in State-Space Models". Is it correct?
I don't see it on arxiv.org yet (maybe there was some error in the process?)
also, I was looking for some stats and realized that the separation of arc_easy and arc_challenge never made it into the arxiv manuscript - would you like me to port that table into it from the COLM version? If so, I seem to have lost edit access there due to subscription limits 😦
Yeah they flagged my edits for further review. Waiting on them to get approved.
https://github.com/TorchRWKV/flash-linear-attention/blob/rwkv7/fla/ops/rwkv7/recurrent_naive.py (i havent verified it)

GitHub
Efficient implementations of state-of-the-art linear attention models in Pytorch and Triton - TorchRWKV/flash-linear-attention
def try_bwd(self, r, w0, k, v, a, b, gout, gstate):
gout = gout.view(B, T, H, N).double()
gr = torch.zeros((B, T, H, N)).double()
gw = torch.zeros((B, T, H, N)).double()
gk = torch.zeros((B, T, H, N)).double()
gv = torch.zeros((B, T, H, N)).double()
ga = torch.zeros((B, T, H, N)).double()
gb = torch.zeros((B, T, H, N)).double()
w = torch.exp(-torch.exp(w0.view(B, T, H, N).double()))
for t in range(T-1, -1, -1):
rr = r[:, t, :]
ww = w[:, t, :]
kk = k[:, t, :]
vv = v[:, t, :]
aa = a[:, t, :]
bb = b[:, t, :]
gr[:, t, :] = torch.einsum('bhij,bhi->bhj', self.state_cache[:, t+1, :], gout[:, t, :])
gstate = torch.einsum('bhj,bhi->bhij', rr, gout[:, t, :]) + gstate
gk[:, t, :] = torch.einsum('bhi,bhij->bhj', vv, gstate)
gv[:, t, :] = torch.einsum('bhj,bhij->bhi', kk, gstate)
ga[:, t, :] = torch.einsum('bhik,bhj,bhij->bhk', self.state_cache[:, t, :], bb, gstate)
gb[:, t, :] = torch.einsum('bhik,bhk,bhij->bhj', self.state_cache[:, t, :], aa, gstate)
gw[:, t, :] = torch.einsum('bhij,bhij->bhj', self.state_cache[:, t, :], gstate)
gstate = torch.einsum('bhj,bhij->bhij', ww, gstate) + torch.einsum('bhk,bhj,bhij->bhik', aa, bb, gstate)
gw = -torch.exp(w0-torch.exp(w0)) * gw
return gr, gw, gk, gv, ga, gb, gstate
Note that
self.state_cache = torch.zeros((B, T+1, H, N, N)).double()
self.state_cache[:, 0, :] = state
The cache is designed to avoid another forward computation
we can test this too https://arxiv.org/abs/2406.09347
arXiv.org
Transformer architectures have been widely adopted in foundation models. Due to their high inference costs, there is renewed interest in exploring the potential of efficient recurrent architectures (RNNs). In this paper, we analyze the differences in the representational capabilities of Transformers and RNNs across several tasks of practical rel...
nice work
Hi, it might be a silly question...
Is the reason that Stella think log precision is extremely reasonable as follows? 1. the total number of binary sequences with log N precision is (num of params) * ( log N), where N is an arbitrary input length, and then 2. The transformers are equivalent to boolean circuits with size N^{const * num of params}. Thus, if num of params does not depend on input lengths, transformers are in P/poly which is a tractable circuit complexity class.
thanks 🙏 for sharing the reference forward & backwards passes. I recall some mention of precision issues, is that the reason for .double() ? (sorry if question has already been answered)
in the RWKV server on a different channel Bo said that it's not necessary, float32 is fine, but that this is just a reference implementation to check things
delta rule is ICL gradient descent (this is shown in TTT paper too, for example. it is known decades ago)
we can add some computation to show my factors are indeed ICL wd & lr
@obsidian quest any way to help in evaluations ?
wait what part is the weight decay?
w
oh lol ya sorry 🤦♂️
also mentioned by https://x.com/cranialxix/status/1838612712437498303
RWKV-7'update is pretty similar to the Longhorn model's update (https://t.co/Ll0GIayA8p), which is derived explicitly from solving online associative recall in closed form.
The household transform used in the RWKV-7, (diag(w) - a \alpha^\top \beta), stems from optimizing a
I mean longhorn is an approximation of the delta rule so delta rule is still closer to rwkv7 but ya
now updated!
@misty igloo -- I just made you an editor (I think? I picked the only Dan) on the arxiv. Go ahead and make your edits and I can resubmit.
yep I can edit now, thanks!!
I updated that one table... not too sure if there's anything else we needed from COLM. The tokenizer efficiency experiments, Architectural Ablations, and DDLerp ablations are all already in the arxiv version
Yep I think everything else was already ported over. I'll resubmit this to arxiv today. Thanks!
Thanks for doing that! Sorry that part didn't make it in before
The consistent use of subscript t in equation 15 and subscript j in equation 16 is somewhat confusing.

thanks, this revealed another mistake I made when upgrading some of the other formulae as well
Changes in rc3:
kk = F.normalize(kk.view(B,T,H,-1), dim=-1, p=2.0).view(B,T,C)
and
a = torch.sigmoid( self.time_aaaaa + (xa @ self.time_aaa_w1) @ self.time_aaa_w2 )
and some incremental stuffs
the paper already reflected the per-head normalization 🙂 [we had it 'wrong' originally]
then we need a to be within (0,1) range or it will nan
I removed the 2 multiplier from the paper just now
we'll change the eigenvalue proof etc. in a bit
unfortunately, because of w replacing I rather than being outside, the model can still flip the signs of existing state values
I might wait to change our description of how it works until we're a little more certain of the final version
yeah but at least now it stays within abs < 1. rc2 will nan after 150G tokens probably because of this
what do you think about using a variation of the \alpha and \beta mechanism on only the left side? I think it makes more sense than deformed key and vector beta
like some kind of symmetry there
might still need 'deformation' though too

deformed k works better for LLM
in any sense, i think these are data-dependent. your "nicer" version might be better for some time series
I'm really most interested in adding in this alpha I show above
maybe via a second deformed k and no alpha or beta
if you can get eigenvalues under control, i think deformed alpha + deformed beta will be the best
(deformed key -> alpha, beta)
i found (1-w) is actually too much normalization
I think this is because it does not all add up in the RWKV-7rc2,3 formulations
this one it would sum correctly to exactly one value
maybe 1 - w^2 would be better bcs it more so emulates the diagonal of kk^T
idk just a guess
so I think reducing (1-w) is an approximation to the imbalance in the formula
and does removing it fully hurt performance or stability? Esp now with proper normalisation?
just slight (but not noise) performance difference. maybe 0.001
I'll look into this
hmm cus im guessing with scale it might be better without it as its less restriction, unless it hurts stability
resubmitted
could you add Cahya Wirawan to the authors list too? I don't see him there on arxiv.org
maybe you need his credentials or something for that @acoustic knoll
you're killing me lol
You'll need to add them to the authors list along with a contribution section that justifies their inclusion
he's already in there
he was even in the prior version you published
ah oops. You mean just in the arxiv console. Sure I can put them in.
yeah sorry, should have been clearer 🙂
added them along with Jiaju
thanks!!!
Where is k^bar used in Formula 12?

These formulas are placeholders and do not represent the exact RWKV-7 architecture.
I have discovered that RWKV-7 can mimic the state transitions of any Deterministic Finite Automaton (DFA) by performing multiple calculations. This is because I've proven that RWKV-7's transition matrix can be configured to represent any permutation matrix. Since the state transitions of a DFA can be expressed as a sequence of permutation matrix multiplications, RWKV-7 can simulate any DFA through iterative computations!
Can you explain this proof in more detail?
simple v7 expression

In essence, the state transitions within a Deterministic Finite Automaton (DFA) can be fully represented by a Boolean transition matrix. This matrix, in turn, can be constructed by multiplying a sequence of permutation matrices. I found that, under specific parameter conditions, the transition matrix of an RWKV7 model can assume the form of any arbitrary permutation matrix. Consequently, by multiplying RWKV7 transition matrices, we can generate any Boolean transition matrix that defines a DFA's state transitions. This implies that RWKV7 models possess the capability to simulate the behavior of any DFA.
i think theyre outer products not elementwise multiplicaitons
yeah, they are shaped so thats what happens
Heres another formulation I like

it's used in formulas 13 and 15
but as Zhang says, this is all preliminary - the real implementation uses a slightly different equation than k^bar = k*(1-w)
I have that in there for now because it's the motivating equation for what's used in practice, which imho is adjusted because of other current discrepancies in the left vs right sides of the rc2 formula
it will eventually get replaced with whatever the final version uses in practice, with some text describing what it approximates
What is the forward computation formula of RWKV-7rc2 now?
@dawn pewter I noticed your comment about restricting Beta in the manuscript
Bo is now restricting it to [0,1] in the latest versions
One problem is if it goes up to 2 it can cause flipping, where every timestep parts of the state are negated back and forth
This might cause some problems because, if we only allow beta to be between 0 and 1, it would really limit what our transition matrix can do. For example, it wouldn't be able to represent a permutation matrix.
this is an interesting topic, I can recall there was another paper going the opposite direction: https://arxiv.org/abs/1902.10297, in this one, the authors tried to extract a DFA from a trained RNN.
Interesting! Maybe we can replicate the experiment with RWKV7.
It could be quite interesting if RWKV-7 could do more things with one layer
Meanwhile you might also like this one: https://arxiv.org/pdf/2402.13934
Thank you!
this paper suggested there are tasks that "efficient transformers" can't solve efficiently
could be a good time to revisit these conclusions, with rwkv-7 design
I think RWKV7 will exhibit capabilities that set it apart from RNNs, transformers, and earlier Efficient Transformers.
This paper evaluates linear attn which is very weak compared to even rwkv6
could you give a small example of (maybe 3 elements? so 3x3 matrix) realistic values for w, kappa, beta that result in a permuation matrix? (or something like a permutation matrix)

That is the primary reason for my emphasis on the beta value range.
this - you mean
yup! there's a ton of evals data there from around the time of the eagle/finch paper
as stella pointed out back up there in this channel, there were a few different commit hashes of lm-eval used tho
I think because RWKV wasn't well supported at first and picocreator/hailey needed to change it a bit for that
we probably should rerun everything anyway for v7
check out this ICLR submission!
https://openreview.net/forum?id=UvTo3tVBk2
OpenReview
Linear Recurrent Neural Networks (LRNNs), such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to transformers in large language modeling, offering linear scaling...
i bet this is someone who payed attention at rwkv7 initial materials hahah
actually the whole point of this paper sounds oddly familiar to RWKV7 draft hahah i hope authors cite it in some form

Amazing!
I understand that from the perspective of this paper, since permutation matrices in state tracking tasks can have eigenvalues of -1, transfer matrix with only positive eigenvalues cannot represent these permutation matrices. However, if eigenvalues can be -1, then these matrices may be represented.
@obsidian quest i did the experiment hand in hand with: delta rule vs delta rule with scaled beta between [0, 2] and this last thing worked better
with headwise normalization
(and beta being a headwise scalar, not a vector)
try 3 different random initializations
i am doing now, the results look good, but theres a key at the init
Hey! Any of you wonderful RWKV people going to be at COLM this week? I'd love to meet up at some point!
@tropic minnow and I are 🙂
I'm at COLM as well 😄
@spiral minnow @tropic minnow @young sparrow Let's meet up and chat about RWKV!
Sure when/where
Want to meet up for lunch?
Oh and I forgot to tag @sonic rose
I didnt see this til just now! @sonic rose and i went for lunch with a big group
No worries! I'd love to meet up for dinner, lunch tomorrow, really whenever if you guys are still up for it! @spiral minnow @young sparrow @tropic minnow @sonic rose

What's the 30-second pitch for the RWKVv7 architecture?
more general dynamic state evolution, while still efficiently trainable on current GPUs
rwkv 5/6 : diagonal matrix diag(w)
rwkv 7: diagonal + low rank (such as diag(w) + a^t b)

Mamba was presented and RWKV got a few shout outs during it!
Are a and b dense, while w is diagonal?
w a b are all vectors
And are they all weight vectors?
RWKV-7 "Goose" 🪿 preview rc2 => Peak RNN architecture?😃Will try to squeeze more performance for the final release. Preview code: https://t.co/ecOwkzJCOo
Some interesting stuff in here I am sure

our poster
It is without a doubt one of the best looking posters here
It's based on my last year RWKV-4 poster
Indeed~
There was quite some interest in RWKV today! Also some papers used is as comparison of LinearAttention-like models and RNN baselines! Made sure to remind people that v7 is just around the corner :)
Are there any live pictures of RWKV in COLM?
Could someone explain the evolution process from RWKV-6 to RWKV-7?
In high level terms it just uses the delta rule additionally
I think additionally there is rank one update
Another way to look at it is the evolution from vector valued data dependent state decay to matrix valued state evolution (via matmul)
Compared to the baseline RWKV-6, RWKV-7 Goose adds a full matrix linear
transition between timesteps
yes, though the way that matrix is constructed is quite special
Goose extends this delta rule removal principle into vector-valued territory, allowing precise
channel-specific portions of values to be removed from the state in a data-dependent manner.
Sorry, I should probably update that sentence - this was a placeholder early on
I'm waiting to see what's in rc3 before revising the paper a bit more
previous w is also a removal(decay) from the state, what is the key difference?
It's not exactly incorrect but I'd like to be more specific about what directions those channels face
In v7 Bo uses a 'deformed key' to remove from a key which is slightly different than the key which is added to
he first does the normal decay, and then removes a fraction of the value stored at that deformed key
but it's a bit messy in terms of the math so I'd rather wait until rc3 to clarify exactly what's going on there
but in general, the difference between decay and delta rule formulations is that in delta rule you remove a fraction of the projection of the state onto the removal key
reflection κ parameters and β_t represents the "in-context learning rate". these are total new concept for me.
κ is that 'deformed key'
you can consider it like a modified version of the normal key
so the reflection is confusing.
the other interesting perspective from which to view this, which we will eventually put into the paper, is as a form of SGD
is it the reflection of a matirx like this?

@gusty condor wrote in the 'reflection' naming - I hadn't seen that until now, and I don't think I agree with the terminology
but I'll way for him to explain it since I only just saw it now
Bo calls it 'deformed key', not reflection
'deformed key' may be a better name
Sorry there isn't much explanation of the parameters meanings in the paper yet - I'm just waiting because the architecture is going to change slightly
Many people complain that the RWKV paper is not readable, one reason being the insufficient explanation of the meaning of parameters.
there are also a few details that don't match the existing implementation, which I left in for clarity to myself/others, like formula 12 is wrong
imho it represents more of the underlying meaning as it's written, but it does not match what he actually does
it's just a placeholder

unfortunately, that may be the result of two effects:
- I had to remove or move a lot of explanation to the appendix due to space limitations for Eagle/Finch paper
- I was being very careful to avoid putting in anything that reviewers might object to as being unsupported
this is pretty annoying, because it makes it much harder to give intuitive explanations
yeah this specific formula is passed on from GoldFinch and Finch C2, but Bo found that a slightly different variation works better for v7 in its current formulation
imo this is because the formula for v7 is imbalanced, so the modification is a way of approximating what should really be k'=k*(1-w)
but due to the imbalance it's more effective to use a somewhat different formula for that
the rationale for k'=k*(1-w) in GoldFinch is that it keeps the state naturally normalized to containing exactly one value at all times in any given key channel
classic delta rule automatically preserves this kind of status without requiring such a formulation, but v7 has a weird delta rule with a different amount being removed than is added back
that's the 'imbalance' im referring to
If you have suggestions of how to avoid damaging prospects with reviewers while still giving more explanations in the paper that would be useful!
Unfortunately I have a feeling the best way might be a separate blog post etc.
RWKV, and especially v7, is quite complicated relative to many other architectures
Since we only have one architecture this time instead of two, hopefully we can fit more description of the different parts up front and where they come from
this is a interesting point. Maybe we don't need "add = remove"
let the network keep capacity for future use
it's not required, because normalization at the end fixes the problem, but I find it's somehow more efficient for the model usually when it doesn't have to consider varying scale
there's definitely a tradeoff, and afaict so far Bo has found the imbalanced versions to perform a bit better
blog is a good idea. The mamba-2 paper has 3-4 blogs to explain
there can also be issues in very long contexts potentially if the state can grow unbounded and then gets renormalized
so I personally prefer non-growing mechanisms
yeah the variation formula on k=k*(1-w) is exactly the kind of thing I can't imagine how to explain in the paper - it's like really 'something that worked empirically', and I don't want to have to justify that with ablations etc.
like I know roughly where it comes from and have a good guess as to why it works better, but it'd be very hard to justify or prove
but that makes explaining why we adjust k very tricky to do, even though the k=k*(1-w) viewpoint is very easy to explain
we could say it in a blog post much more easily, where there doesn't have to be a full defense of every statement or claim
Householder matrices are reflections
or "reflector" maybe?
This is my favorite formulation so far, for v7rc2
it really shows that the v7 is super simple,
its:
- create fast weights [ab] and [kv]
- add a diag of decay to [ab]
- for each timestep:
[kv](t) += [ab](t) @ [kv](t-1)
3.1) essentially, the fastweight [ab] is being used to do processing on the fastweight kv - use the new fastweight kv as a linear module

I like that!
didn't check it thoroughly for the correct transpositions since I'm just writing it in discord, but maybe the easiest way to show what it does recurrently would be with something like this?
outer_product = lambda x, y: x[:, None] @ y[None, :]
out = torch.empty_like(v)
for t in range(T):
r_t, w_t, k_t, v_t, a_t, b_t = map(lambda: x[:, t, ...], [r, w, k, v, a, b])
G_t = w_t.diag_embed() + outer_product(a_t, b_t) # the transition matrix
state = G_t @ state + outer_product(k_t, v_t)
out[:, t, ...] = r_t @ state
or, restated in terms of deformed k:
outer_product = lambda x, y: x[:, None] @ y[None, :]
out = torch.empty_like(v)
for t in range(T):
r_t, w_t, k_t, v_t, d_t = map(lambda: x[:, t, ...], [r, w, k, v, deformed_k])
G_t = w_t.diag_embed() - outer_product(d_t, beta * d_t) # the transition matrix
state = G_t @ state + outer_product(k_t, v_t)
out[:, t, ...] = r_t @ state
Do we have a plan to draft a blog for RWKV v7 like this https://fullstackdeeplearning.com/blog/posts/rwkv-explainer/

A step-by-step explanation of the RWKV architecture via typed PyTorch code.

so, is this the correct list of changes?
- per head deformed key normalization, as previously discussed
- per-channel dynamic adjustment of k towards the in context learning rate, so that it can add anywhere from 'the correct amount of in context learning' up through full k to the state at each step?
- a new replacement for k*=1-w using some kind of approximation that it would be helpful if you could explain the idea for
in vanilla delta rule, k should be scaled by iclr
and k should be scaled by 1-w if you like the idea
however it's better to let the model determine by itself the amount of these changes
could you explain the idea of the math behind the approximation you're using for the dynamic 1-w adjustment?
actually I can just graph it 🙂

thanks, I see - I think you showed this before
mk = 1 ==> full scaling, similar to k = k * (1-exp(-exp(w)))
mk = 0 ==> no scaling, similar to k = k
I guess the only special note is that the mk parameter acts in a nonlinear way to scale 1-w, since the exp() is after it is applied
kappa is the hyperplane normal onto which we project the state - and then subtract this projection off of the state
so kappa itself isn't really the reflection, nor does it do the reflecting, it just chooses the hyperplane
it's an expression of what part of the state we want to remove (the amount to remove is determined separately, by the in-context learning rate)

OpenReview
Linear Recurrent Neural Networks (LRNNs), such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to transformers in large language modeling, offering linear scaling...


You mean "retraction"?
hehe I don't know enough topology to know about topological retracts... but in common English usage it most commonly means withdrawing statements in a newspaper or journal, or as the name of a medical device
Bo wanted to call kappa the 'deformed key'
Kappa is withdrawn from a state (not a statement but pretty close)
I noticed a pattern in RWKV designation: Important information like key and value uses full matrix, while variables mainly for controlling (not important for information transmission) use low-rank MLPs.
this blog is great
v4 is easy to understand. V7 is much more complex
All the more reason to prioritize clear explanations. At COLM some people indicated a reason they used Mamba instead was that they felt like it made more sense to them.
Indeed, it seems that the clarity and intuitiveness of Mamba's writing is a significant factor for those who prefer using it over other options.
I think it's publicity and promotion that we are lagging behind.
mamba2 is very similar to rwkv while weaker
I think another reason is that RWKV is an over-designed architecture (since v5.2).
And I think the name is also one of the reasons. I have difficulty to pronounce it, and people can’t remember it easily which is not so good for promotion
If all tricks are removed, it will become Mamba2 / GLA, which is simply weaker, and they have to use huge head size
enter "rʌkuv" in http://ipa-reader.xyz/ to get the pronunciation 🙂
Read IPA notation
however we definitely need more blogposts
We will soon reach a point where the architecture is too complex to explain in every detail.
far from that. YOLO (v1 to v11) is a good example of real "over-design"
I don't think RWKV is over-design
I agree and think that this is an extremely bad sign
From RWKV-4 to RWKV5/6, the incremental design is very clear.
But the reader's preliminary knowledge is not enough to understand
I share a tutorial that may help to improve the writing flow
mamba is more complicated than wkv, however they create an illusion by providing some "reasoning" to make the reader feel better

"My thing is better, you're just too stupid" is not a line of argument that will convince anyone. Indeed, making the reader feel better is a major goal of the description of a methodology. If RWKV is substantially simpler than Mamba then the fact that the paper fails to convey that is a problem we should put a priority on addressing.
Communication with an under-informed reader is a, if not the, primary goal.
That's who reads methods sections
agree. WKV itself is simple, however ddlerp etc. can be confusing for newcomers, and we need to seperate these topics
in fact, ddlerp is beneficial for transformers too. has nothing to do with WKV.
That makes a lot of sense. If we can present the "level 1" view that's slightly simplified, and then introduce some additional complexity (which also benefits transformers and isn't bespoke to what we are doing) that should substantially increase readability.
Another question: Readers from which background are we mainly aiming at?
What are the options for answers here?
firstly, mamba users
secondly, attention users
This is a great answer. There was no way this was going to occur to me, but now that you've said it it's obviously the right answer.
For me (my background includes mainly algebra and mathematical analysis), RWKV paper is more informative than Mamba, and formulae are consistent.
I’m worried rwkv7 gets mamba’s by https://openreview.net/forum?id=r8H7xhYPwz
OpenReview
Linear Transformers have emerged as efficient alternatives to standard Transformers due to their inference efficiency, achieving competitive performance across various tasks, though they often...
Also make sure to try out alpha * 2 again @obsidian quest to get some state tracking and showcase better math and code performance
that's certainly a weaker design
seems slightly worse for LM
Ya ik but it should be much faster and simpler, so it’s a trade off for efficiency but also for readability which is what happened with mamba. I’m just saying we should try and make rwkv7 explained very well so we don’t get mamba’d
Fair although in their experiments it’s a little worse while a lot better in code and math, also it becomes more of a true rnn in that sense
we can propose two versions
- rc3 style: sigmoid & W-ab
- sigmoid * 2 & W(I-ab) ===> although i found this will nan
I don’t think that’s how u get state tracking the best way, should have the 2 * only on ab (like u were doing before)
But ya I agree
is the key difference [headwise decay (v5.1 style)] vs [channelwise decay (v5.2 style)]
Ya which apparently makes a huge difference for efficiency as head wise incurs very little overhead. Also beta is head wise unlike v7 using channelwise, and the normalisation and deformed keys stuff
For beta being a vector I’m not sure it brings much overhead but I think it’s supposed to preserve some properties and be more stable
Oh also it does w * (I - beta * kk^T)
this needs a=b
Ya nans bcs the 2 should be on ab i think
I have an idea. We can build a RWKV CoT demo to do MCTS. For example, Reversi (Othello).
Rewrite the MCTS procedure as some very long text, and simply train a tiny RWKV model on plenty of such data.
This will be a proof-of-concept to show RWKV is good for very long CoT.
Discussion: https://discord.com/channels/992359628979568762/1296413705159966751
The RWKV model will simulate the full MCTS process. Not just a "value network" / "policy network".
FYI:
https://github.com/LeC-Z/RWKV-nonogram
https://x.com/BlinkDL_AI/status/1834300605973889111
But Othello is solved: https://arxiv.org/abs/2310.19387
arXiv.org
The game of Othello is one of the world's most complex and popular games that has yet to be computationally solved. Othello has roughly ten octodecillion (10 to the 58th power) possible game records and ten octillion (10 to the 28th power) possible game positions. The challenge of solving Othello, determining the outcome of a game with no mistak...
This will be a proof-of-concept to show RWKV is good for very long CoT
can someone try https://github.com/jopetty/word-problem 🙂
GitHub
Experiments on the impact of depth in transformers and SSMs. - jopetty/word-problem
how does this compare to https://arxiv.org/abs/2407.14207
arXiv.org
Modern large language models are built on sequence modeling via next-token prediction. While the Transformer remains the dominant architecture for sequence modeling, its quadratic decoding complexity in sequence length poses a major limitation. State-space models (SSMs) present a competitive alternative, offering linear decoding efficiency while...
longhorn is a pretty bad approximation of deltanet
then gated deltanet is even better than gated deltanet
esp for length extrapolation
so is gated deltanet the best alternative to rwkv7 atm? I'm just interested in architectures using delta-rule, because that would make them more expressive than the tc0 space that transformers operate in AFAIK.
yes gated deltanet is the best, also this paper (https://openreview.net/forum?id=UvTo3tVBk2) shows u need to modify the delta rule a bit to actually get state tracking
OpenReview
Linear Recurrent Neural Networks (LRNNs), such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to transformers in large language modeling, offering linear scaling...
which u can do easily in rwkv7 and gated deltanet
will keep in mind
might train a model from scratch to play chess and want the best architecture
https://x.com/BlinkDL_AI/status/1848343821467390156 with my very inefficient RWKV-7 kernel and @bronze frost 's fast kernel 🙂
RWKV-7: attention-free and surpassing modded-GPT. Training code & log: https://t.co/cuH0pItsPy Larger headsz can reach 3.26xx. My current implementation is slow🤣Might can reach 85% GPT speed @ ctx1k (or faster than GPT @ ctx4k) after optimization. Any helps are welcome🙏#RWKV

I can try !
@obsidian quest What is the model that I should try on ?
attention, mamba, rwkv6, rwkv7
On it! Will post here
I have started experiments for transformers, got hang of it
@obsidian quest I am trying to run it for rwkv. I am looking at the code. what is the rescale layer in inference code? ( 281-293) in rwkv_demo.py
could you point out which rwkv_demo.py
Under rwkv7
RESCALE_LAYER is only for preventing overflow when doing fp16 inference
so you don't need them for bf16 training
let's test https://huggingface.co/spaces/HuggingFaceFW/blogpost-fine-tasks for rwkv-6-world
should be great

https://github.com/BlinkDL/modded-nanogpt-rwkv now much faster

GitHub
RWKV-7: Surpassing GPT. Contribute to BlinkDL/modded-nanogpt-rwkv development by creating an account on GitHub.
@obsidian quest Is not possible to train f32 training on 'cuda' ?, I changed it to DTYPE = torch.float32 and there is an error saying expected half

most stuffs are hardcoded bf16 now
change cuda .cu and .cpp too
typedef float bf16
@obsidian quest Are you saying 'typdef at::Float bf16' is not correct?
typedef float bf16 is better
Oh I see, I changed it
from @iron parrot
@obsidian quest ' you must implement either the backward or vjp method for your custom autograd.function to use it with backward mode AD'

@obsidian quest forward pass worked fine, but backward is throwing above error.
@obsidian quest seems like the backward code is missing in the 'WKV_7'?
@obsidian quest Should I try with rwkv_cuda or rwkv_cuda_wind ? This is a 4 million Parameter ( single layer model for testing on word problem )
wkv7g_v1 is reference implementation (slighly better loss, very slow, but enough for your tiny model)
@obsidian quest another question, I was originally trying with code under RWKV-LM/RWKV7/rwkv_v7_demo.py
But the one in modded-nanogpt-rwkv/ doesn't have RWKV_Tmix_x070, RWKV_CMix_x060 but only single RWKV7. Does this subsume both mixs ?
that one is tmix
you need very good understanding of rwkv to use current rwkv7 😂 can try rwkv6 first
@obsidian quest Yup,😅. This is my first time. But can I just change the config in GPT (I mean vocab_size, n_embd) , be sure it works right?
@obsidian quest yup, after a lot of staring. Seems like Cmix is replaced by normal MLP?
i keep train_gpt2 MLP for some fair comparison
@obsidian quest Should I also use this as well, because we are comparing against transformers as baseline?
Or do you want me to use cmix?
likely similar results
kernels in modded_gpt_rwkv_7 are hard-coded for a chunk length of 16, but I am trying to train on small sequences of 5. So there were errors
So I'm trying to train rwkv6
But cuda kernels are not compiling
There is an import error in the code for rwkv_v6_demo.py

@obsidian quest after a lot of wrangling, figured out the cause
This error stems when importing import RWKV
setting is_python_module=False as load(name="wkv6"..., is_python_module=False,...) and using torch.ops.wkv6 fixed the issue.
I completed a run for the A5 group and k=5 and for n=2 ( seq_len ) and number_of_layers=2, RWKV6 got perfect validation accuracy within 2 epochs !

I started the training run for sequence length=15 for both 1,2 layers.
...you pinged blink 4 times.
simply change CHUNK_LEN to 5

Do we have plan for model like rwkv-o (GPT4-o)
check #1103039376184852622 message
Training runs for longer sequences (k=15) will require approximately 15 million sequences in a single epoch, and it seems like they do not converge as quickly as shorter sequences. Previously, I was running experiments on Kaggle P100 GPUs, but each notebook can only run for 12 hours. Could you let me know if there is a cluster available where I can run the full experiment, or suggest how I should proceed next?
2 layer RWKV-6 only ran 6 epochs in 12 hours and best val sequence accuracy is 0.32

pls check DM 🙂
https://arxiv.org/pdf/2411.02795 but this looks like some AIGC, ignore that
Wow, it's definitely AI, but the benchmarks really do match what's in the actual papers.
PS: i will be at neurips this year
(finally finally, closing up our fundraise round... and have time to focus more on RWKV again, but yea in general good news for RWKV soon)
RWKV-6-world-v3 release
https://x.com/BlinkDL_AI/status/1856679399598522833
RWKV-6-world-v3 (+3.1T tokens): our best multilingual 7B model as of now. https://t.co/VxiofVqXOb 100% RNN and attention-free. MMLU 54.2% (previous world-v2.1 = 47.9%. note: without eval-boosting tricks such as annealing). RWKV-7-world-v4 soon🙂 #RWKV #RNN


RWKV-7 (preview) training code pushed to https://github.com/BlinkDL/RWKV-LM
Please check RWKV_Tmix_x070 and RWKV_Cmix_x070
I removed lots of loras (including ddlerp) to speed up training

GitHub
RWKV is an RNN with transformer-level LLM performance. It can be directly trained like a GPT (parallelizable). So it's combining the best of RNN and transformer - great performance, fast in...
Now with smaller 12M params RWKV-6 and cool graphics. Seems to solve any solvable sudoku, including one after 2M (!) tokens CoT🙂Note RWKV is RNN, so constant speed & vram regardless of CoT length. https://t.co/uhmSOqmJcf

I don't see the lora's or ddlerp removed in this code?

GitHub
RWKV is an RNN with transformer-level LLM performance. It can be directly trained like a GPT (parallelizable). So it's combining the best of RNN and transformer - great performance, fast in...
oh not in the v7 folder lol
i am removing more loras
you accidentally left in unused parameter self.time_maa_x
@obsidian quest you got rid of the sigmoid limit on ICLR/Key mix amount - was that intentional so it can go <0 and >1.0?
you also got rid of all adjustment of key by decay - this was also intentional, right?
like now you just do something like:
k = k + k * (iclr-1) * self.iclr_mix_amt
which i guess is supposed to mean:
k = k - k * (1-iclr) * self.iclr_mix_amt
so just making sure you want it to be able to exceed [0,1]
like is the idea k = torch.lerp(k, k * iclr, self.iclr_mix_amt)?
just confused since it isn't equivalent to that
it's this
yeah improvement too small
yes. could be useful in some cases
k = k + k * (a-1) * ma
k = k * (1-ma) + k*a * ma
gotcha yeah it is equivalent, somehow i got mixed up 🙂
[putting all of this into my RWKV_Explained repo]

i guess now in hindsight, he is outside the transformer cult bubble?
From my opinion, the reason is that RWKV uses LayerNorm while all others use RMSNorm.
It might be LayerNorm that makes this projection invalid.
Try Pythia (if it uses LayerNorm)
Another possibility is that RWKV has token shift.
new simplified v7 rc4a. less params, less lora, +0.0074 loss vs rc4, but quite faster, so worth it.
https://github.com/BlinkDL/RWKV-LM/blob/main/RWKV-v7/rwkv_v7_demo.py
i think it will be rwkv-7 final. trains faster than rwkv-6 too (https://github.com/BlinkDL/RWKV-LM use --my_testing "x070")

faster than RWKV-6, but better loss as well???
yes much better loss
Now we can find latest RWKV-related papers on https://t.co/ANmttaBgYy from stock prediction to video recognition🙂

I will be helping cover the RWKV paper at neurips at the following in person paper club here: https://x.com/swyx/status/1861197521126859260
Since there is a strong (10% of vote) demand for transformer alt
Disclosure: I been helping co-organize some of their paper club on a regular basis, and are friends with the organizer
Super interesting responses from all the NeurIPS LS live attendees so far:
- Everyone wants Agents, Vision, Open Models, Transformers Killers, Economic Landscape/CodeGen
- Nobody wants Voice (!?!), Diffusion, Finetuning, RAG content?!??!
Ok we need speakers/debaters on all

Asking: Anyone here want to join me, and cover statespace? If your there in person. In particular i guess would be @last mauve anyone from your team? (since ur not going to be there)
My ending stance would be: It might not matter our architecture differences at this stage, we do not know until we scale - to avoid making it a "this is better then that presentation"
So its more of running through the 3 alts RWKV, statespace, XLSTM, the high level similarity and differences.
I'll ask around
pls talk about RWKV-7 🙂
Here is how RWKV-7 really works. It is a meta-in-context learner, test-time-training its state on the context via in-context gradient descent at every token.
https://x.com/BlinkDL_AI/status/1861753903886561649
my simplest explanation:
you have some {k0, v0} {k1, v1} ... and q
ignoring details:
if q = ki, you'd like result to be close to vi
if q = (ka+kb)/2, you'd like result to be close to (va+vb)/2
RWKV-7:
simply test-time-train a model ki -> vi using in-context online GD
if q = ki, result is close to vi
if q = (ka+kb)/2, result is close to (va+vb)/2```RWKV-7 "Goose" 🪿 is a meta-in-context learner, test-time-training its state on the context via in-context gradient descent at every token. It is like a world model ever adapting to external environment: https://t.co/ecOwkzJCOo🙂#RWKV

@gusty condor we can draw RWKV-7 graph now based on rc4a
@void quartz @last mauve please make sure you have good understanding of rwkv-7 🙂 feel free to ask questions
Will do. Been following up with smerky on it as well
Though the format I’m planning may not let any of us dive too deeply unless asked
This might also help a bit as a different perspective #992359629419991142 message
Last section has rwkv7 but it might be a bit outdated
the QKV-softmax-attention: xxx RWKV-7: xxx explanation is probably good enough and simple for most 😂
Ya true
I think tho the deltanet database explanation could be more intuitive for some ppl
yeah your version is about some further details
Now with RWKV-7 RNN mode inference & 0.1B 0.4B Pile models, and cleanup param names
https://github.com/BlinkDL/RWKV-LM/tree/main/RWKV-v7
The current RWKV-7 implementation of W is not elegant. This induces one extra exponential, one negation and one logarithm, which might be the bottleneck for training. The formulae can be further simplified as follows.

torch.exp(-0.606*F.sigmoid(u)) is very elegant.
yeah i know (that's actually why i picked softplus), but i just still don't want to fuse this with the kernel 😂
0.606531 = exp(-0.5) although we can definitely fuse this for inference
I think it's necessary to fuse this
RWKV-7 is stable version
Make it as fast as possible
because probably it's possible to remove this w clipping with clever bwd
so is there a shared doc or sth? How could I help with any parts?
There is, but it may depend on your existing level of familiarity with RWKV and RWKV-7 specifically.
Link: https://www.overleaf.com/5753862368yvnbymysbrsf#07fba2
Please don't edit yet without discussion (or add wholly new proposed sections/appendices if you like, but no guarantee these will stick) - I've been holding off on updating the formulas bc things have changed quite a bit recently, and we haven't really begun writing the discussion sections yet.
The main codebase or my https://github.com/SmerkyG/RWKV_Explained repo might be a good place to look if you need to first learn how RWKV-7 works.
Generally speaking, people propose and run experiments and we add those in, or they write proofs, etc. The idea is to get a lot of community involvement. Proposing and doing ablation studies could be a great way to help out.
I know you've expressed an interest in making things clearer and more appealing in the coming paper, which will be great!
One thing to keep in mind that has constrained us (or well, certainly me personally) in the past is that everything we say in the paper has to be well substantiated by empirical evidence or proof to ensure a smooth review process... though this seems somewhat relaxed when such statements or descriptions lie within the appendices.
This, and restrictive page count limits (usually 9), can make it more difficult to be descriptive or provide a clear intuitive basis for what are often somewhat complicated technical bits, especially when the paper is written in a communal open-source kind of manner with often 20+ authors.
That said, let's strive for clarity and accessibility!!!
i see, yea it will definitely be hard to do good ablations at scale and it's not clear how informative ablations at small scale (e.g. ~100M params) would be
what type of theoretical results are we looking for?
deriving motivation for why grad descent/meta-learning grad descent of the specific type of linear regression is useful?
Im not actually familiar with the existing literature around rnn alternatives, but, it seems to me that many have converged on this idea of updates based on online grad descent, yet, the exact formulation of why this makes sense to do (especially given that both k and v are functions of x) is missing no?
have you read the various papers on delta rule usage in models in general? like the delta net paper https://arxiv.org/abs/2102.11174 and others
arXiv.org
We show the formal equivalence of linearised self-attention mechanisms and fast weight controllers from the early '90s, where a slow" neural net learns by gradient descent to program the fast weights" of another net through sequences of elementary programming instructions which are additive outer products of self-invented activation patterns...
I think in order to determine what's missing you should probably do some literature review
as for why delta rule/modified grad descent is useful for these kv memory states... that's something that we will definitely try to cover in the paper
but RWKV-7 is not just traditional delta rule
any ablations are better than no ablations
I added a bunch of smallish scale ablations to the Eagle/Finch paper for the camera ready version in response to reviewer comments (I know you guys were claiming that the RWKV papers do not include ablations in the research discord channel but these did get added)
heh that's the thing about an open paper writing process like this - anyone (including you!) gets to propose what they think we should be looking for! there's no one here forcing a top down process
i think i'm somewhat familiar with this literature, i'll def look more carefully, thanks!
Yea, I was just wondering if people have concrete open problems they're interested or not. Imo I think the optimization perspective is still not entirely complete. I get the notion of approximating the operation of querying to retrieve linear combination of value vectors, approximating linear cross attention, but I do think there is something slightly broader of asking what exact role this serves for doing autoregressive prediction, why aren't we making the key matrix part of our online learned state (thereby turning the linear regression optimization into a linear autoencoder problem), what is the functional importance of sparsity or nonlinearities in how they can actually assist with the objective, etc.
Hell, can even ask why isn't rwkv doing multiple gradient descent steps and why meta learning the learning rate makes sense instead of choosing the optimal learning rate for linear regression. How can we think of label noise and robust algorithms, replacing the squared loss with Huber like losses, regularizations
If we can understand the broader objective better, we should be able to reason about how keys and values may need to evolve or behave as well
I don't exactly disagree, but I would point out that you're really describing new research directions, not RWKV-7
Yea that's what I'm worried about and Im not sure what people's feelings are in regards to the current RWKV-7 and goals regarding theoretical results
Ig it's a sort of reverse engineering theory to justify the current implementation
Like why normalizing the update vectors and making learning rate a learned parameter is important
Although perhaps some things could be done if proper ablations are conducted (e.g. ablating over learned vs fixed learning rate)
generally speaking, the process for RWKV is that Bo does a ton of experiments (with a mix of consultation with others) and decides the architecture based on what experimentally works best... based on his very strong intuitions about why certain directions will likely work well, of course
the description is then written up based on the kind of reverse engineering you're describing, by folks who have been paying close attention to the development process
it can definitely include analysis that didn't exist when the arch was defined
he or I can probably answer questions about why specific choices were made that don't necessarily seem obvious
I often feel like a real time archaeologist 🤣
I see, ok, I'll follow along closely in the meantime then and see how things play out and see if I can try any ablations myself. Mostly interested in getting some more practical experience here, better understanding real world concerns when it comes to large models, and the optimization perspectives
there definitely are lots of choices that have been informally ablated, which would benefit from a formal recorded ablation
even if not at large scale
e.g. 'deformed' key removal
what are the typical compute requirements for ablation experiments? Would 4 80GB A100s be enough?
I think that's more than enough for small scale ablations
the biggest issue is that longer/larger scale tests often reveal quite different behavior much later in training
afaik the main v7 release candidate versions Bo has tried each got a full Pile run at smaller size
we frequently see architecture 'improvements' that win at smaller scales and for 1-2gtok but fall behind later in training
there's simply no feasible way to truly fully ablate everything, given any reasonable compute budget
Are these 'improvements' typically things that make the architecture more or less complex?
I don't think I can detect a relationship in general
often though, additional parts become less necessary at scale
which is part of why you see the regression of tokenshift back towards v5 in v7 (this is not in the paper yet - but its in the rc4a code)
so there's at least some aspect of 'the bitter lesson' at play, which is I think what you were maybe getting at with that question
and yet, there are other complexities which seem useful and low parameter
Yea I am honestly kinda hoping that simpler and closer to just basic grad descent with optimal learning rate is what is optimal, and that additional modifications such as learned learning rate aren't actually improving performance much. I'm also curious if the normalization corresponds to certain types of regularization
But yea ig understanding why they are useful would be interesting to explore
pretty certain you are gonna be disappointed by the results of attempting 'maybe simplest is best'
unless you first develop some very advanced theory of what you're modelling and why
no one here is purposely making things complex
The bitter lesson is about simplifying as much as possible given the constraints, not absolute maximum simplicity.
but it's valuable to get some experimental experience with these architectures, so either way trying it is valuable!
This is I think what I was thinking of in terms of better understanding the actual objective in learning the linear regression. There's factors such as orthogonality of the state matrix that could be quite relevant and important, and certain modifications such as key normalization are sorta regularizing this
There's also things that I don't quite understand like why is the learned learning rate only applied when subtracting the key outer products but not applied when adding the new value key outer product update
well I didn't want to push my viewpoint earlier, but I think there are some fairly simple explanations that are at least mostly correct
you can view the state as a memory, or as SGD... and if you're viewing it as a memory the geometric interpretation is pretty clear cut
as for normalization, that's a topic I have a lot of thoughts about...
see the k*=1-w thing from Finch-C (originally in GoldFinch paper) for a general idea of what I think is wrong with RWKV normalization in other versions
we tried some stuff like that for RWKV-7, but the formulas are kind of lopsided and it didn't matter enough
from my perspective its not that it didnt matter, its that the formulas never got clean enough for it to matter
and normalization is an end-run around this problem
Ic ill take a look
in any case, a deeper understanding of the SGD perspective definitely needs to make its way into the RWKV-7 paper
Bo for sure wants this described in it
Thanks for the pointers, I really appreciate it!
no problem! sorry I can't go on at length too much about it all ... got a lot of other unrelated (but RWKV related) stuff i gotta get done 🙂
also, the RWKV discord server might be the best place to discuss architecture concerns
we generally use this channel mostly around paper writing organizational stuff
tho its flexible heh
Some questions about RWKV-7.
currently, the state calculation in RWKV-7 is:
state = state * w.view(H,1,N) + state @ ab.float() + vk.float()
where:
w = torch.exp(-0.606531 * torch.sigmoid(w)) # 0.606531 = exp(-0.5)
ab = (-kk).view(H,N,1) @ (kk*a).view(H,1,N)
kk = torch.nn.functional.normalize(kk.view(H,N), dim=-1, p=2.0).view(-1)
a = torch.sigmoid(a0 + (xa @ a1) @ a2)
Is the range of eigenvalues of the state-transition matrix [-0.455, 2]? Would this affect the model's performance on some tasks (like parity)?
how to make it [-1, 1] (however i notice this will nan after some time)
a = torch.sigmoid( self.time_aaaaa + (xa @ self.time_aaa_w1) @ self.time_aaa_w2 )
x = RUN_CUDA_RWKV7g(r, w, k, v, -kk, kk*a)
new:
a = torch.sigmoid( self.time_aaaaa + (xa @ self.time_aaa_w1) @ self.time_aaa_w2 ) * 2.0
x = RUN_CUDA_RWKV7g(r, w, k, v, -kk, kk*(a.float()*torch.exp(-torch.exp(w.float()))).to(dtype=torch.bfloat16))
or (try both)
a = torch.sigmoid( self.time_aaaaa + (xa @ self.time_aaa_w1) @ self.time_aaa_w2 ) * 2.0
x = RUN_CUDA_RWKV7g(r, w, k, v, -kk*torch.exp(-torch.exp(w.float())).to(dtype=torch.bfloat16), kk*a)
Thanks, I'll try it now
After expanding the eigenvalues, RWKV-7 (green) solved the parity task instantly compared to the original version (brown)
magic!

arXiv.org
Linear Recurrent Neural Networks (LRNNs) such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to Transformers in large language modeling, offering linear scaling with sequence length and improved training efficiency. However, LRNNs struggle to perform state-tracking which may impair performance in tasks such as co...
@crystal hull
however it's useless for LLM lol
and i don't know why it will nan after xxG tokens (well can certainly locate the nan, but too busy now)
Yup. I have started training Runs with this modified code. Will update.
also, problem i working on is bit more general. I am workign on non-commutative group mulitplication on S_5, A_{4} \times Z_{5}
from this paper, eigen values being negative will NOT suffice. it has to be complex values
for even slightly more complicatd like modulo 3
new blog post from songlin maybe helpful: https://sustcsonglin.github.io/blog/2024/deltanet-1/
A gentle and comprehensive introduction to the DeltaNet
The graph here. Is that perplexity or loss?
loss
Jeez, that's so smooth
perfectly smooth for 0.4b 1.5b too
wait is this eval loss or train loss?
im training my own architecture and get a way more noisy training loss (if this is training loss) but my eval loss is pretty smooth and aligns more so with what you have (I am only training a ~150 param model atm)
well eval loss will always be smooth
but thats training loss
sure sure
I think training loss will be smoother if you increase the batch size

rwkv 7?
Yes
rmsnorm => l2norm and there is "Text" near bottom LayerNorm
jesus christ

Looks a tiny bit more complex than a transformer layer 😆
if you draw llama style transformer with rotary, that can show the illustration makes everything looking more complex 🙂
I don't understand why we need that.
Tbh why have it all in one diagram
It should be done for each block

Something like this
But more detailed I guess and specific to rwkv

Recurrent view could also be shown
yeah our goal should be making it looking as simple as possible
The biggest thing that has thrown me off from looking into RWKV in the past were overly complicated architecture diagrams that made it look like some over-engineered mess, as opposed to simple, interpretable, well motivated architectural decisions. Equations, such as those presented in BlinkDL's tweet about the connection to lin reg gradient descent, make a lot of this far more digestible imo.
Even if there are still many details and components, anything that starts more abstract and introduces these "later on" for those seeking specifics on exact implementation would definitely help clarity
I was commenting that because of the impact of seeing such a complex diagram, I actually like having the entire achitecture avilable at a single illustration
But it does have a strong inital impression
It's hard to infer the role of components in the time mix block, but it seems to me that showing it in an intuative way is pretty hard.
forgive the ascii art, but something more like
↑
[Linear]
↑
[LayerNorm]
↑
------[+]
| ↑
| [CMix]
| ↑
| [LayerNorm]
| ↑
-------|
------[+]
| ↑
| [WKV]
| ↑
| [LayerNorm]
| ↑
-------|
↑
[LayerNorm]
|
input
WKV Attention Block:
↑
[Linear] (W_out)
↑
[*] (gate)
↑
[+] (bonus)
↑
[GroupNorm]
↑
[*] (receptance)
↑
[Modified Delta Rule]
↑
[Linear / LoRA] (w,k,v,r,g,a)
↑
[Token Shift]
↑
and we can add detail views for the modified delta rule and how some of the special aspects of k, kappa, v are calculated
would the above kind of diagram be easier to see at a glance and digest?
yes def even as ascii art (although idk about the Linear / LoRA, such details can be left to appendices and so on. For any paper, the main goal in the main text is to provide as much clarity and accessibility to as broad an audience as possible. The hope is to bait them in with an interest to understand more and without a feeling that understanding will require massive investment
And include a block showing what the Cmix is
Modified delta rule might be more understandable in terms of equations than architecturally
yah sorry, just got tired of typing ascii art so I didnt include all of the parts 🤣
it's pretty doable as a graph on its own, but I personally find those kinds of graphs hard to understand anyway
yea exactly. And for purposes of clarity I think starting as abstract/high level as possible and gradually going into details of specific components is going to be ideal
The complete diagram may still be useful for people who are interested in exact implementation specifics perhaps, and it could help in possibly highlighting differences from previous methods

on its own its complicated as a diagram, but not totally insane
not totally insane i agree, but so much less clear than the equations imo
wouldn't help me personally reading a paper to see it instead of code or equations
I think the key question to ask is: what's the most accessible form of each piece of info. I think the high level diagram is very clear in part because it maps pretty cleanly to the standard transformer diagram, so it makes it clear how it relates. But this I feel is probably easier to digest as equations
yes exactly
the less annoying TL;DR of the above diagram is:
state = state times decay, minus 'a' amount of the old value at the deformed key, plus 'a' amount of the new value at the current key
but the details are just a tiny bit more complicated than that bc of the LERP
+1 on using equations and code as the primary way to convey rwkv.
For diagrams, I propose a 3-level approach:
- (max-detail) The maximally-detailed figure posted above. This is for rwkv practitioners to understand rwkv version differences. This should be in an appendix of the paper.
- (mid-range) A modified version of the figure above, where we remove the inner details and just have blocks like "channel mix". I.e. the rwkv analogue of #1103039376184852622 message. This is for RNN/SSM researchers to compare rwkv with competing blocks like mamba/lstmx/etc. This should be placed in the "Design" section of the paper.
- (min-detail) A transformer-like diagram like what's proposed by @misty igloo in #1103039376184852622 message. This is the headline figure for the general public. This should be either in the "intro" or "design" section of the paper based on how we handle the storyline.
let's call it "Generalized Delta Rule", sounds better
And add a part for state-tuning 🙂 https://x.com/BlinkDL_AI/status/1866715202898825279
And RNN (with state) is the way to go, such as RWKV🙂The RWKV state is tiny, and we can do state-tuning as shown in https://t.co/3lx8NQcGtM
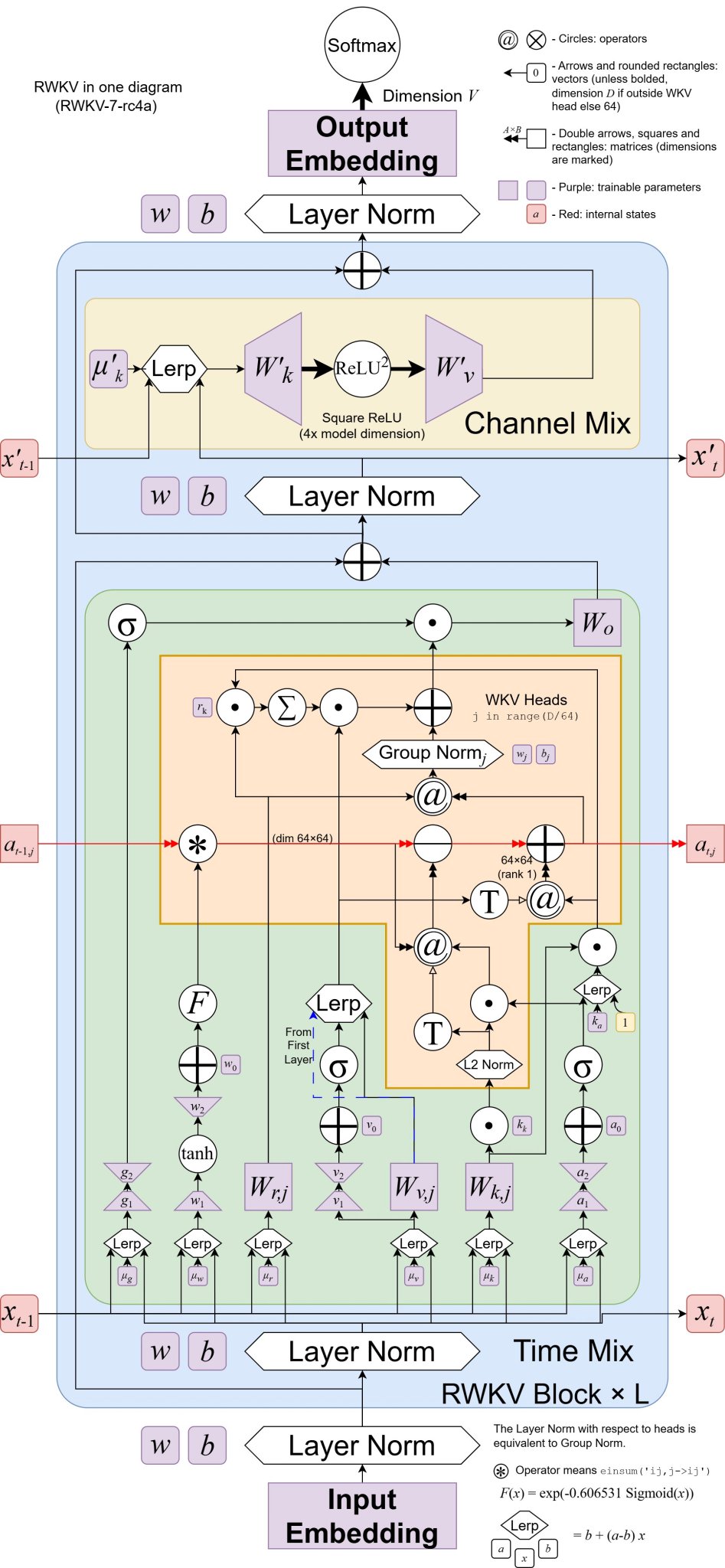
The current v7 CUDA kernel does not support state tuning yet.
@gusty condor we can simply call various loras lora as in the v6 graph

They are essentially different
Im gonna present RWKV & QRWKV in 30 mins at the latent space event
https://lu.ma/LSLIVE
https://www.youtube.com/watch?v=wT636THdZZo&ab_channel=LatentSpace
Both Dan Fu and I agreed we are not going to go into the math / details, so we can spend more time high level - and what we expect next in the future
So no V7 beyond a mention

Let's get together to send off 2024 with the first LIVE Latent Space Paper Club, hosted during NeurIPS! Instead of going paper-by-paper as NeurIPS does, we are…

then loraA loraB etc.

GitHub
Contribute to Itamarzimm/UnifiedImplicitAttnRepr development by creating an account on GitHub.
If you need it as picture in style of transformers diagram, you can use this one using tikz embedded in overleaf for easier update: https://www.overleaf.com/1763727691mfzjqnmsxvvq#fea0cd

An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
thanks! looks great there
lets call it RWKV instead of WKV
In terms of long-context PPL, RWKV-7 completely outperformed Mamba and appears to be capable of extrapolating to infinite context


This is the original RWKV-7 trained on Pile ctx4k
interesting that it doesnt seem to suffer from state collapse https://arxiv.org/abs/2410.07145
arXiv.org
One essential advantage of recurrent neural networks (RNNs) over transformer-based language models is their linear computational complexity concerning the sequence length, which makes them much faster in handling long sequences during inference. However, most publicly available RNNs (e.g., Mamba and RWKV) are trained on sequences with less than ...
This is pretty cool and a clear demonstration would be a compelling pitch. @nova frost has been scoping out long context evals for the eval harness and is planning to implement some more, maybe he can be a helpful collaborator?
I know that there are some formal benchmarks for long context evals used in papers studying limitations of long context models, as well as naturalistic benchmarks for tasks that require long context. Do you have any specific benchmarks you're most interested in?
tested in https://github.com/Jellyfish042/LongMamba/tree/main @young sparrow
GitHub
Some preliminary explorations of Mamba's context scaling. - Jellyfish042/LongMamba
are the any currently implemented in the harness? would be amazing to have them in there
ruler and longbench come to mind
GitHub
RULER testing for rwkv. Contribute to Ojiyumm/RULER_RWKV development by creating an account on GitHub.
GitHub
LongBench testing for rwkv. Contribute to Ojiyumm/LongBench_RWKV development by creating an account on GitHub.
can modify them to support rwkv7
GitHub
A benchmark for testing memorization abilities of LMs - NiuTrans/ForgettingCurve
i dont want to modify anything to support rwkv7 - i want to modify them to support any HF model in the world, including rwkv7 🙂
but preferably just include them in lm eval harness
otherwise we have to modify things every time we have a new architecture
which I seem to have a lot of lately 🤣
easier to modify each new architecture once to work on HF than modify 100 tools for each new architecture
esp since we have to make new architectures work on HF anyway
rwkv7 not supported in HF yet
yeah, but its easier to add that support than modify the benchmark codes
I'll just go do that - I gotta do it for QRWKV7 anyway
I guess for now I'll use icecuber's Triton implementation
the range of values in rwkv7 state is surprisingly stable, much better than rwkv6
Well might be cus of the clipping
You'll have to ask @nova frost. I know he has some in progress. I had written up a couple ppl ones in past but the way they're typically run causes issues in the harness and they never were merged
Will add them!
cool, let me know when you have em! I'm curious to try on QRWKV6/7 and I'm porting RWKV-7 to HF now
I aim to kick rwkv-7 paper writing into gear by the end of this year. I think we have much of what we need now.
@misty igloo @obsidian quest -- Can you summarize any remaining experiments we need to finalize (e.g. the long-context discussion above)?
there arent many existing experiments bc the larger models arent trained
we have pile models up to 1.6B but only a 0.1B world dataset model
conversion/upgrade training is about to begin, which can show results but not in the from-scratch baseline way
I can do a Q-RWKV 7B 'any old day' in hours, but that's quite a different thing than even a v6 continuation trained model
Makes sense. In that case we can focus RWKV-7 efforts on nailing down:
- Design section and associated architecture messaging
- Intro/background/related-work
- Calculations for FLOPs and params
Are you wanting Q-RWKV to be a community-driven paper? I had assumed you would want to do that on your own.
That's up to @void quartz
But I agree that it certainly makes sense for it to be separate since it's a whole additional process that applies to my Q-RWKV-6 model as well as Q-RWKV-7, neither of which will be exactly the same architecture as RWKV-6 or RWKV-7
RWKV-7 0.1B/0.4B/1.5B trained on the Pile, showing best performance among all models trained on the exact same dataset & tokenizer: https://t.co/6A83VjNVUw All RWKV-7 results are fully replicable and spike-free (I find some architectures unstable)🙂

its definitely a separate paper (too confusing otherwise)
currently the plan is to rush to Llama-RWKV-7-70B.... then figure out the paper 😅
i wish there is a good 70B class model without llama, or qwen wierd licensing
yes it's a separate paper, but I'm asking if you want its writing to be a community effort
😅 honestly have not considered it, until you asked lol - will discuss with smerky separately.
We are starting to hire phd students / postdoc (intern or fulltime), to help scale up RWKV paper processes - so its not just smerky leading the process (ps; let us know if you have someone in mind as well)
😅 honestly have not considered it, until you asked lol - will discuss with smerky separately.
Yep no pressure. Think on it.
We are also started to hire postdoc (intern or fulltime), to help scale up RWKV paper processes
Exciting! I'll lyk if names cross my path.
yeah to clarify this could include current PhD students (or even well qualified folks who aren't in a PhD program but have some experience with publishing)
We're also looking for a Machine Learning Research Engineer to focus on the RWKV open source software ecosystem and tech for other RWKV projects - if you're someone in one of these two categories or in between, ideally have familiarity with RWKV, and are interested in either role, definitely reach out to us
@obsidian quest where do you think the length extrapolation comes from? Separately it would be interesting to know the state size you trained at with 4096 context length. These are very impressive figures imo
Agreed
same state size for model dimensions - it has not changed since RWKV-5
Don't you train at various different states sizes? I wasn't aware training only happened at a particular state size
What is that state size?
it's always num_layers * d_model * head_size plus a tiny amt for the tokenshift state
same as mamba 2, gla, etc.
all these models work the same way in terms of state
Oh sure sure. I'm just wondering the actual values for that. @quaint quiver shared a paper that suggests that length extrapolation comes from the ratio of information a state can hold versus the amount of information you train on, i.e. the context length, allows for better length extrapolation.
for 1.4B RWKV-7 model size its 24 * 2048 * 64
168M:
args.n_layer = 12
args.n_embd = 768
421M:
args.n_layer = 24
args.n_embd = 1024
By any chance do you guys know the ratio of parameters in the token mixing part relative to the rest of the model? Would be interesting to know how much of the model needs to be token mixing in order for it to perform well. I'm pretty sure attention takes up a pretty sizeable portion at around 1/3rd of the model
not sure what token mixing means exactly, but channel mixer (ffn) is approx 8/12ths and generalized delta rule attention is the remainder
unless this is related to the paper lets discuss elsewhere so as not to clog things up - either the rwkv eleuther channel or rwkv discord
rwkv7 prevents state out-of-domain
because of this
I'm not sure what this means. What is state out-of-domain?
if the state grows to unseen values/ranges
Oh I see, I mean isn't this handled by the constraining of eigenvalues via the tanh?
solved in rwkv7
Are you saying this because there is a paper for RWKV-v7? I'm a bit confused
They don't really understand the mechanisms, and state collapse was revised to state explosion. However, that doesn't really apply to RWKV-6, because entries in WKV can go up to 1e+4.
This paper receives 3,3,3,3,6 after ICLR 2025 rebuttal.
My understanding is that Mamba has poorer state management than RWKV-6 and RWKV-7. The state evolution formula plays a key role in preventing state degradation.
More test results:
original 0.4B RWKV-7 ctx4k (Figure 1) completely outperforms the 2.8B Mamba (Figure 2) on the Haystack test, even though Mamba was specifically fine-tuned for long context


With longer context lengths, RWKV-7's PPL continues to decrease without any apparent limitations

RWKV-6 vs. RWKV-7 as context length increases, RWKV-7's advantage grows

note it's v7 0.4b pile
pls test non-tuned mamba too
I am curious about what does the score in these figures represents. Does score 5 mean 100% correct rate? I am also very interested in which score that a non-linear attention architecture such as LLAMA can achieve, and how it compares to that achieved by RWKV. Do you know where I can find this information?
Yes, 5 means perfect accuracy since 5 needles are used. test scripts are in https://github.com/Jellyfish042/LongMamba/tree/main, forked from https://github.com/jzhang38/LongMamba
GitHub
Some preliminary explorations of Mamba's context scaling. - Jellyfish042/LongMamba
GitHub
Some preliminary explorations of Mamba's context scaling. - jzhang38/LongMamba
I have the HF version of RWKV-7 just about ready, so should become easy to test a lot more stuff imminently
Wow, then the results are super promising🔥. Thanks for the response and sharing the links!

RWKV-7 "Goose" 🪿 0.4B trained w/ ctx4k automatically extrapolates to ctx32k+, and perfectly solves NIAH ctx16k🤯Only trained on the Pile. No finetuning. Replicable training runs. tested by our community: https://t.co/GQHUCOTUYo #RWKV
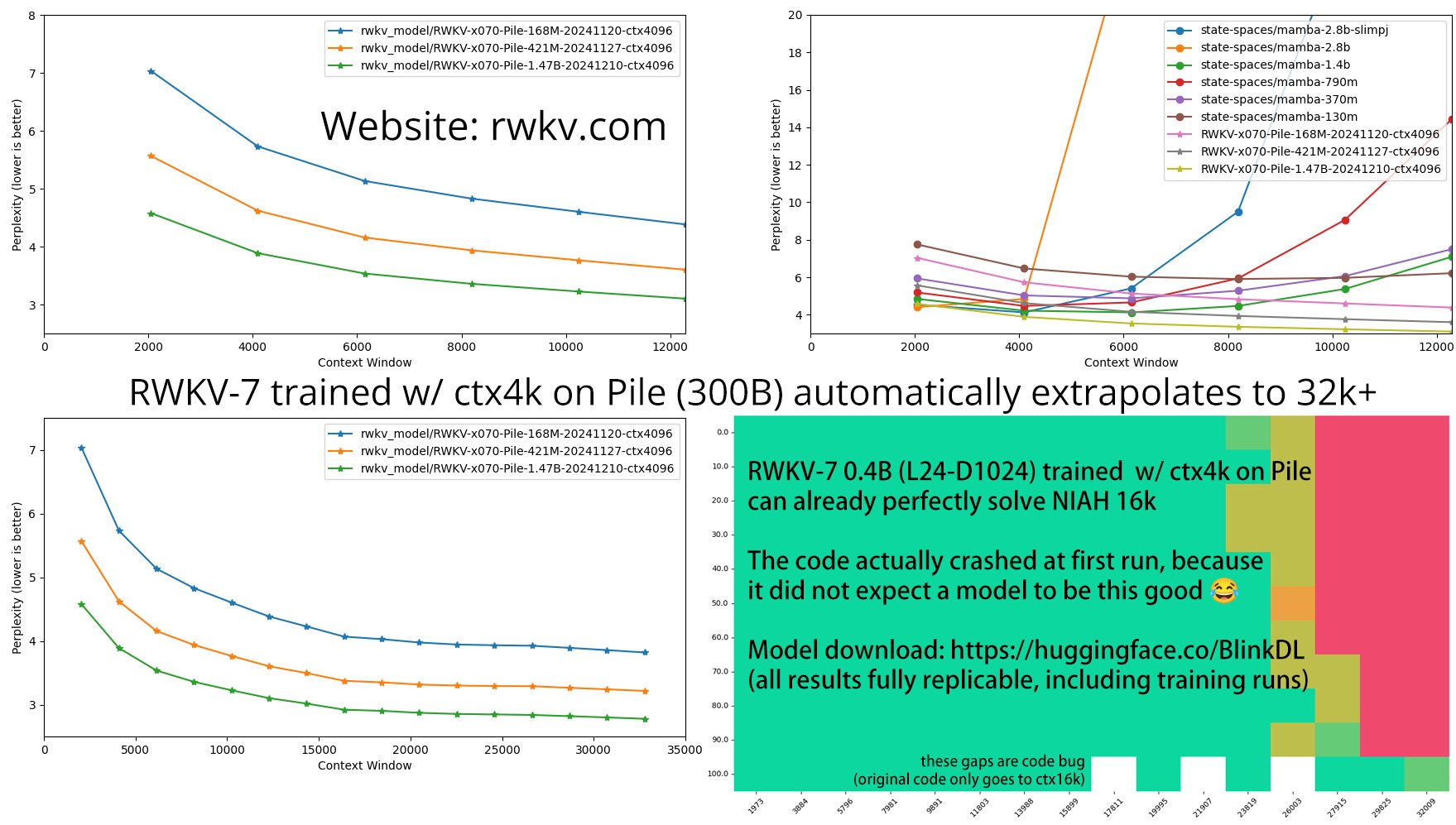
RWKV-7-World 0.1B (L12-D768) trained w/ ctx4k perfectly solves NIAH ctx16k 🤯 100% RNN and attention-free. RWKV is all you need. https://t.co/ANmttaBgYy #RWKV

I put a preview of the upcoming official releases of the various sized HF Pile and 0.1B World 2.8 models in my huggingface account, so everyone here can use them to do experiments more easily:
SmerkyG/RWKV7-Goose-0.1B-Pile-HF
SmerkyG/RWKV7-Goose-0.4B-Pile-HF
SmerkyG/RWKV7-Goose-1.4B-Pile-HF
SmerkyG/RWKV7-Goose-0.1B-World2.8-HF```add 0.1B world 🙂
done!
if anyone needs RWKV-7 PTH to HF weight conversion code and HF model code its in my fork of BBuf's repo at https://github.com/SmerkyG/RWKV-World-HF-Tokenizer
You might be interested, rwkv is mentioned https://arxiv.org/abs/2406.10149
arXiv.org
In recent years, the input context sizes of large language models (LLMs) have increased dramatically. However, existing evaluation methods have not kept pace, failing to comprehensively assess the efficiency of models in handling long contexts. To bridge this gap, we introduce the BABILong benchmark, designed to test language models' ability to ...
cool wll test it
@nova frost any progress with long context benchmarks? I have the RWKV-7 HF models ready
working on them today!
do you have a link? can run them
HF model links above ^
prompts are quite important too
can you expand on that?
can ask @iron parrot
model may know certain information but won't output it, sometimes prompts need to be adjusted
|Tasks |Version|Filter|n-shot|Metric| |Value | |Stderr|
|------|------:|------|-----:|-----:|---|-----:|---|------|
|niah_2| 1|none | 0| 16384|↑ |0.2440|± | N/A|
| | |none | 0| 4096|↑ |0.7900|± | N/A|
| | |none | 0| 8192|↑ |0.6080|± | N/A|
|niah_3| 1|none | 0| 16384|↑ |0.0640|± | N/A|
| | |none | 0| 4096|↑ |0.7860|± | N/A|
| | |none | 0| 8192|↑ |0.5320|± | N/A|
|niah_4| 1|none | 0| 16384|↑ |0.1860|± | N/A|
| | |none | 0| 4096|↑ |0.1680|± | N/A|
| | |none | 0| 8192|↑ |0.1720|± | N/A|
|niah_5| 1|none | 0| 16384|↑ |0.0000|± | N/A|
| | |none | 0| 4096|↑ |0.0280|± | N/A|
| | |none | 0| 8192|↑ |0.0000|± | N/A|
|niah_6| 1|none | 0| 16384|↑ |0.0000|± | N/A|
| | |none | 0| 4096|↑ |0.0120|± | N/A|
| | |none | 0| 8192|↑ |0.0000|± | N/A|
|niah_7| 1|none | 0| 16384|↑ |0.1190|± | N/A|
| | |none | 0| 4096|↑ |0.2230|± | N/A|
| | |none | 0| 8192|↑ |0.2350|± | N/A|
|niah_8| 1|none | 0| 16384|↑ |0.1310|± | N/A|
| | |none | 0| 4096|↑ |0.5040|± | N/A|
| | |none | 0| 8192|↑ |0.3555|± | N/A|
did some evals on some of the other NIAH variants from ruler on RWKV7-Goose-1.4B-Pile-HF
The metric here is context length
the prompt is very important 🙂 could you share the code so @iron parrot can tune it
lm_eval --model hf --model_args pretrained=...,max_length=<max length evaluating> --tasks niah_2,niah_3,..
from here

some prompts for rwkv6 https://github.com/Ojiyumm/RULER_RWKV

GitHub
RULER testing for rwkv. Contribute to Ojiyumm/RULER_RWKV development by creating an account on GitHub.
We should not be tuning the prompts for evaluation tasks for the sake of making our model look better.
What's the comparison scores for a similar Mamba2 model?
ill run that!
the prompt is related to training data
state-spaces/mamba-2.8b does really badly for some reason. scoring max in single digits even for cxt length of 4096
implementation seems to be correct as it scores perfectly on the passkey retrieval (niah_1 4096 - as most models do)
and it was trained with 8192 sequence length
Completely falls apart though. mostly generating ( ( ( ( ( ( ( (, and sometimes (2 (2 (2 (2 (2 (2 (2 (2
What does the output look like if you feed some normal text in?
looks fine. It's also coherent for ctx_len < 4096, just incorrect (and repetitive looping, but thats expected ig)
oh I should check how it does on niah_1 with ctx_len 8096. The main difference with that and all the other tasks is that in the former the haystack is a short repetitive phrase, while the others use Paul Graham's essays
completely degenerated. Scored 0
from #992359629419991142 message

is the intuition here that a higher rank states contain more information?
each state update is at most a rank two update to the state, higher rank states would presumably imply that a larger diversity of distinct state updates are stored/can be retrieved
yes, that would be the take away
Might need to reach out, cause that is too low
On that note; if the impact of just read twice is significant enough for linear models (mamba or rwkv), are we open to benchmarking that separately?
arXiv.org
Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to ...
that's expected for mamba
we truly need to raise RWKV-7 awareness 🙂 https://x.com/BlinkDL_AI/status/1872041360288866556
Solved by RWKV-7 "Goose" which is no longer linear attention, and finally great at long context 😀 See https://t.co/KfvKaG8013
https://arxiv.org/abs/2407.02678 might be a related perspective
arXiv.org
The advancement of large language models (LLMs) for real-world applications hinges critically on enhancing their reasoning capabilities. In this work, we explore the reasoning abilities of large language models (LLMs) through their geometrical understanding. We establish a connection between the expressive power of LLMs and the density of their ...
how does inference speed compare to transformers now with v7?
perhaps with everyone shifting their focus to inference compute and 'thinking' models like o1/o3, that might be an area where v7 can shine
Still linear complexity
complexity sure but what about actual times? mamba is also theoretically linear complexity but usually slower than transformers in practice
Well ya depends on implementation so not sure
But with an optimised implementation it should be faster
Maybe noticeable after 2k tokens
Yeah your experiment chart from the v6 paper showed it crossed around 4k
Ya although that was training
Doesn't mean that's quite the same for v7, but roughly...
It has a big advantage in memory bandwidth for longer ctx bc of kv cache
But of course everything comes down to ctxlen vs how optimized the implementation can be for current gpus
For batched inference the kv cache thing is a big deal
thought so. hopefully later down the line in development for RWKV-7 optimization for modern gpus gets some focus
re: chain of thought, it could also be viable (given there exists a sufficient dataset) to tune a small rwkv model on chain of thought and benchmark it, which would also be a nice addition to the paper + the first linear cot model?
It's gotten quite a bit of focus already, but more is always great! And Bo reduced some of the complexity of other non-kernel parts of v7 to increase speed as well
ah, didn't know that, nice
please test RWKV-7 MQAR 🙂 using RWKV-LM --my_testing "x070" and recommended lora dimensions
Will try!
Better than v6. Nearly perfect at 512 seq len. Used default dim_ffn (3.5x emb size).
Trains much faster than v6. Will review code over next few days & clean up. Will ping if needed.

lets test long seqlen and compare with v6
RWKV-7 WebGPU demo: https://t.co/C7T2WAcmEO (runs in your browser, currently WebGPU required) with cool state visualizer🙂

please try extended eigenvalue too
a = torch.sigmoid( self.time_aaaaa + (xa @ self.time_aaa_w1) @ self.time_aaa_w2 )
...
x = RUN_CUDA_RWKV7g(r, w, k, v, -kk, kk*a)
new:
a = torch.sigmoid( self.time_aaaaa + (xa @ self.time_aaa_w1) @ self.time_aaa_w2 ) * 2.0
...
x = RUN_CUDA_RWKV7g(r, w, k, v, -kk, kk*(a.float()*torch.exp(-torch.exp(w.float()))).to(dtype=torch.bfloat16))
similar to rwkv-7 https://arxiv.org/abs/2501.00663
arXiv.org
Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accur...
@steady ether important: use LayerNorm instead of RMSNorm for RWKV-7
we should mention this in paper. i think it's related to better initial state. I find LN as fast as RMSNorm in latest pytorch
because i am not using trainable initial state (=persistent memory). found it useless, at least when using LN
Sounds good. I think we are already using LayerNorm in RWKV-LM which is where I'm getting the training code from.
latest checkpts: gen7 RNN finally solves MMLU
https://huggingface.co/BlinkDL/temp-latest-training-models/tree/main
MMLU
rwkv6-v2.1-7b 47.9%
rwkv6-v3-7b 54.2%
rwkv6-v2.1-3b 32.38%
25%trained-rwkv7-v3-2b9 43.08%
35%trained-rwkv7-v3-2b9 45.24%
40%trained-rwkv7-v3-2b9 47.36%
49%trained-rwkv7-v3-2b9 49.34%
rwkv6-v2.1-1b6 26.34%
38%trained-rwkv7-v3-1b5 33.89%
51%trained-rwkv7-v3-1b5 40.44%
60%trained-rwkv7-v3-1b5 40.77%
72%trained-rwkv7-v3-1b5 41.36%```is it the rnn part or the squared relu MLP?😏
rnn part 🙂
I tested 46.21% on 25%trained-rwkv7-v3-2b9.

how's longer seqlen 🙂
Ignore the drop in v6, it's an old run I forgot to finish because it took forever.

Hello everyone, I have just updated the data from VisualRWKV-7 in the "RWKV for Image Understanding" section. I think we should speed up the progress of the RWKV-7 paper. Recently, Google has also introduced the concept of an in-context learner, which is very similar to RWKV-7.
We are not in a hurry if we aim for EMNLP, CoLM or NeurIPS.
Well titans is not anymore similar to rwkv7 than gated deltanet is
an arxiv paper is good for citation
the point is, there are plenty of gen7 papers now 🙂 lets not miss the opportunity for citation
Are we ready now? I was thinking we start on the arxiv a bit ago but the consensus was to wait until models were further along.
let's start. 0.1b/0.4b/1.5b @ 300b is far more than what they were doing
and 1.5b v7 world in 10 days
I'm updating the formulas in the paper to match rc4a now, should be done today
I've been interested in contributing, is there anywhere help would be particularly appreciated rn or should I just explore potential opportunities?
if you have some compute, I'd suggest finding experiments you can run on the trained models that might require some code adaptation etc. but which provide high value comparisons with other architectures
or experiments that train a specific model from scratch (like we do for MQAR) and test them work great, too
If there's anything I can help with, let me know. Illness last month derailed most of my planned experiments.
hope you're feeling better!
what were you planning?
that sucks, but also it should just be its own paper 🙂
because it will be really awesome and deserves it own spotlight!
good point there
thanks, will look into that. for context these would be along the lines of sec. 8-10 in the RWKV-6 paper, yeah?
yeah some got put into Appendix G as well
@obsidian quest to get the paper ready we need to start gathering the details of World v2.1,3,4
here's what I have so far:
Added in World v2.1 for ~1.4T tokens total
• cosmopedia
• slimpajama c4 (missing in v2)
• dolma v1.6 reddit
• Magpie-Align_Llama-3-Magpie-Pro-1M
• Magpie-Align_Magpie-Pro-MT-300K
• Magpie-Align_Magpie-Air-MT-300K
• Magpie-Align_Magpie-Qwen2-Pro-1M
• Magpie-Align_Magpie-Phi3-Pro-300K-Filtered
• Magpie-Align_Magpie-Gemma2-Pro-200K-Filtered
• glaiveai_glaive-code-assistant-v3
• cognitivecomputations_SystemChat-2.0_SystemChat
• migtissera_Tess_tess-v1.5
• openbmb_UltraInteract_sft
• m-a-p~Code-Feedback~Code-Feedback
Added in World v3 for ~3.1T tokens total
• remove slimpajama cc and c4
• fineweb-edu
• DCLM (only global-shard_10_of_10)
• cosmopedia-v2
• Buzz-V12
• WebInstructSub
• SKGInstruct
• math-ai/TemplateGSM
• all of starcoder (instead of only >10 stars repo)
• python-edu (in HuggingFaceTB/smollm-corpus)
Still missing v4 datasets
v3.1 first, with more code, and o1-style data, etc
got a list? 🙂
v3.1 not constructed yet 😂
oh sorry, I just misunderstood your news post
rwkv-7 world-3 1.5b is strong (finishing in 10 days)
i think rwkv-7 world-4 will be sota
Update stability of RWKV-7 DPLR rule

(Linear) Attention Mechanisms as Test-Time Regression
v1.1
I've added @BlinkDL_AI's RWKV-7 and fixed the update rule for Vanilla DeltaNet
---
Note that the arrows in the part where we derive linear attention variants don't necessarily indicate generality nor a tech-tree. For

Therefore, the ICLR should not remain at its current value of 1; setting it to 1.606 can enhance the model's expressive ability.
stable as in not growing but can still flip back and forth, which may lead to undesirable behaviors even if more expressive
When ICLR was originally set to 1, the range of eigenvalues was [-0.4, 1]. I believe that by setting ICLR to 1.606 to adjust the eigenvalue range to [-1, 1], it does not lead to undesirable behaviors.
yeah, gotta test it to know!
certainly other people have reported that it can be beneficial
the reality is that the decay is almost always near 1.0, so even that will not really allow all the way [-1,1] in most cases
I know its hard right now with the state of things, but please do make an effort 👇

I think this idea may have been present somewhere. There might already be code repos for this.
arXiv.org
Large language models (LLMs) have shown impressive capabilities, but still struggle with complex reasoning tasks requiring multiple steps. While prompt-based methods like Chain-of-Thought (CoT) can improve LLM reasoning at inference time, optimizing reasoning capabilities during training remains challenging. We introduce LaTent Reasoning Optimiz...
This one is different: we don't have prompts, we don't have chat templates, and CoT is conducted on pretraining data,