#RWKV-papers
1 messages · Page 4 of 1
and i think maybe we should upweight SRU paper in the next version? I know Bo is deeply inspired by AFT. But the one core ingredient to scale up RNN is lightweight time-relevant operation and RWKV follows exactly two principles in SRU: (1) lightweight recurrence(hadamard product) with customized cuda kernel (2) other modules computed in parallel
Can we presume that v5 will supplant v4? Based on the differences, v5 appears to address the "true parallelization" concerns, especially given the modifications in time mixing. Have I grasped this right?
i have no idea what you mean by "true parallelization" ?
but yea, v5 will presumely supplant v4 (when its trained finished : there is no fully trained model yet)
Pardon. I looked at the code better; I thought there was no longer a loop in the TimeMix.
they thought there were no loops in matmul lol
Any plans for rebuttals? Could clear up questions for the committee.
i can deduplicate the contents from figs 2-3 that a reviewer complained about
^^
Oops that's on me
Here's a skeleton: https://docs.google.com/document/d/1J4ofU5Of0WIi5uAUT5BYxEnNTUIV2idKXkUm9EV0kk0/edit?usp=sharing
To avoid people stepping on others' toes, it's comments-only right now. If people can help write responses as comments, I'll try to play arbiter
Here are the current TODOs. Grab an item or two:
1.~~ (HIGH-IMPORTANCE) Fill out rebuttal section for reviewer Zd3h~~
2. (HIGH-IMPORTANCE) Fill out rebuttal section for reviewer rSzx
3. (HIGH-IMPORTANCE) Fill out rebuttal section for reviewer 85wr
4.~~ (HIGH-IMPORTANCE) Fill out rebuttal section for reviewer HDNB~~
5. Update the text to have a sentence defending the following from reviewer rSzx: Two specific tasks (ReCoRD and Winogrande, as shown in Figure 5) see the model underperforming other models. This underperformance requires further investigation.
6. Fix the following typos found by reviewer rSzx L126:a computationally efficient alternatives. L136:Simultaneously with this work, (Poli et al., 2023): citep -> citet
7. Add a sentence to the text defending against reviewer 85wr's confusion on: My understanding is that RWKV is roughly equivalent to the AFT local model that was previously presented. Yet this is not mentioned in the paper and the table does not include this key property. Is this an oversight or am I missing something?
8. Update figure 1 to fix reviewer 85wr's comment: Figure 1 needs to have actual references to datasets and calculations. Having unlabeled graphs is not okay in a published paper. Languages need to be provided as well (BLOOM is multilingual, are these English tasks?)
9. Add tables in an appendix to address reviewer 85wr's suggestion: All the main information in the paper is shown in graphs in terms of scaling. While I understand why the authors want to show their model in this way, as a reader I want to see standard tables showing tokens / ppl (or bpc). Please include these tables in the paper so I can understand the data efficiency without trying to extrapolate from tables.
- Update the fonts to address reviewer 85wr's comment:
Generally the graph labels are much too small to read, please increase these to be similar to the text itself. - Add a sentence or two clarifying the inference experimental setup, addressing 85wr's comment:
Can you provide more details on exactly the inference method / software hardware used for the text generation results? From the text it is unclear whether it is even cpu or gpu. - Table 1 is overlapping the middle margin. Needs fixed.
@tropic minnow -- Do you have time today to write some initial rebuttals? Feel free to take whatever help you need. I should be able to work on this later tonight, but the rebuttal is due tomorrow August 28 AoE so any help is welcome
6 is fixed
Added AFT-local (conv) row to table 1 for (7). Think that's what 85wr wanted
Point 11 - Added
In figure 6 we can see the cumulative inference time of different models when generating a sentence of 1000 tokens on a NVIDIA A100 80GB GPU.
For all our experiments we use float32 precision and generate the sentence using sampling decoding.
to the inference results.
Didn't anyone write an answer yet or can't I see the current answers?
Nobody has written anything yet in the rebuttal (besides you. Thank you!!)
I'm writing it now.
which part are u working on? maybe i could help with others
Currently I'm doing a second pass over @snow zealot's rebuttal for Zd3h
Can you start on rSzx in parallel?
sure, i would make a draft first
Finished Zd3h. Moving to 85wr
> My understanding is that RWKV is roughly equivalent to the AFT local model that was previously presented. Yet this is not mentioned in the paper and the table does not include this key property. Is this an oversight or am I missing something?
How do I respond to this?
> While the pen-and-paper FLOP calculations are interesting, would be curious to understand how the actual training time compares on real hardware. Some graphs in the main paper would help.
Can we do this? Maybe infer the training time using timestamps from our logs?
Finished a draft on 85wr. Moving to HDNB.
I don't know if we should write something in the paper comparing both models, but I think the difference is that AFT learns a decay for each pair of locations, where in the local approach if the distance between two locations is higher than the kernel size this decay is 0. RWKV uses exponential decays that decreases with the distance.
So like we said in this paragraph

AFT learns a parameters for each $t, i$ pair, RWKV learns one W that is multiplied by $t, i$ to produce an decay
SSamuel

We have a few statements in the paper explicitly comparing AFT and RWKV. I'm thinking we say something along the lines of:
AFT and RWKV are indeed overall similar, but differ in a few key ways. We compare these exact differences between architectures in section 4.1, but at a high level AFT learns a decay for each pair of locations, where in the local approach if the distance between two locations is higher than the kernel size this decay is 0. RWKV uses exponential decays that decreases with the distance.
@fickle hare and @outer vine -- Do you think this response to HNDB is reasonable:
Recent large language models are using float16 or bfloat16 precision, it will be great to see RWKV also works in these precisons.
RWKV now supports bf16 training and inference, and evaluating under this precision type is left to future work.
RWKV also explicitly was tested under fp16/bf16 as of June right? We kind of have to say something along the lines of "yes it works, but doing it now is too costly for a revision"
How's this going? Just finished HNDB, so rSzx is the last one pending.
sorry, been occupied for a while. u can start now, I would see what can i do later
ok
i think we should emphasis that the key difference between RWKV and AFT is the relative postional information, and this very change make everything different--it make the model have recurrent form
I'll make this more explicit in my response
From reviewer rSzx:
> A significant potential benefit of an RNN-like formulation is its applicability to longer contexts, but Figure 6 appears to limit this method to up to 2^12=4096 tokens. Further exploration of context length scaling is desirable. Additionally, most of Figure 6 is unsurprising, as more context naturally results in lower perplexity within the context window size. The figure's x-axis should start with the context window size being trained on. Clarification on the context size being fine-tuned up to would also be beneficial.
I'm thinking our response should be along the lines of:
- We'll explore longer context than 4k tokens in future work
- (not sure how to respond to
...most of Figure 6 is unsurprising.... I kinda agree? Am I missing something?) - We need to add explicit details on the fine-tuning context length strategy and also respond on the rebuttal with it. @tropic minnow and @obsidian quest -- Who can tell me this?
rSzx says:
> The time mixing component, while parallelizable along other dimensions, is not parallelizable in the time dimension. This lack of parallelization could become a training bottleneck for very long context windows.
I don't think this is accurate since we have time-parallel mode in 4.2. Is it sufficient to just say "we solved this, look at 4.2" or am I missing something? I need someone to double-check me here.
we already have ctx 128k models such as https://huggingface.co/xiaol/rwkv-7B-world-novel-128k
and we have infctx trainer https://github.com/RWKV/RWKV-infctx-trainer
"more context naturally results in lower perplexity within the context window size"
previous LSTM LMs are unable to utilize ctxlen beyond ~100 tokens
all RWKV models are trained using bf16
and https://github.com/saharNooby/rwkv.cpp has INT4/5/8
GitHub
INT4/INT5/INT8 and FP16 inference on CPU for RWKV language model - GitHub - saharNooby/rwkv.cpp: INT4/INT5/INT8 and FP16 inference on CPU for RWKV language model
The performance of AFT-local is bad, and it cannot be rewritten as an RNN.
RWKV has an RNN form because we explicitly use exponential decay as kernel.
RWKV-4 14B BF16 = 114K tokens/s on 8x8 A100 80G (DeepSpeed ZERO2+CP)
yeah that's one way to put it. another factor is we have token-shift.
Attention is not parallelizable in time dimension (I mean going beyond O(T)), unless we use FFT-style / prefix scan-style designs and reach O(log(T))
Recently the RetNet paper claims that it can achieve time-parallelizability, however if we expand the formulas (by looking at the hardware implementation) we can see that's not true. One still have the loop over T.
So it can only claim usage of tensorcores. And then the difference is between [GEMM on tensorcore] vs [GEMV without tensorcore].
And the second case is faster, because GEMV has much less flops than GEMM. It can reach bandwidth limit without utilizing tensorcore.
This should be explicitly stated in the paper then (I've added it)
So we're not parallelizable over the time dimension. In that case, why are we claiming:
RNNs require less memory, particularly for handling long sequences. However, they suffer from the vanishing gradient problem and non-parallelizability in the time dimension during training, limiting their scalability
in the intro when RWKV is also subject to this problem?
RWKV is parallelizable in the sense if we consider GPT to be parallelizable.
Note there is "loop over T" in GPT attention formula.
do we have the comparable results of self-attention? On my side, on 8*v100 32G, RWKV with customized kernel lags behind Transformers about 7%~8% in terms of training speed
So if we consider GPT to be parallelizable, that means "loop over T" is totally fine.
are you using RWKV-LM to train it
It trains xx% faster than GPT on my A100s
Set ctxlen = 4k and compare speed & vram.
RWKV training speed is independent of ctxlen.
Some more comparison of optimized implementations: https://bellard.org/ts_server/ts_zip.html

Ah I think I'm grasping what you're recommending then. So is it accurate then to say:
Neither RWKV nor attention-based architectures GPT can improve in the time dimension beyond O(T) where T is the sequence length. Therefore, either both RWKV and GPT are parallelizable in the time dimension, or they both are not. We note that RWKV has a notable decrease in time and space complexity as T increases compared to competing architectures (see table 1), and this is a key strength of our approach.
i write my own, and since v100 couldn't afford longer context
maybe longer context would give more advantanges
if we could put that number in the paper, it would be much stronger. would you mind share ? tokens/s for transformer on your A100?
with comparable setting(bfloat, model size, context length)
@obsidian quest -- I want to be explicit since I don't think we're noting it anywhere in the paper: What is the pretraining ctxlen for all the models pretrained in Table 2?
Pile models - ctx 1024 (and then finetuned to 8192)
World models - ctx 4096 (and the community finetuned it to 128k)
Ah I see 1024 in Appendix D now. I'm going to add this detail to the main text as well since I think it's important.
8192 though conflicts with what we say in the paper:
Specifically, we double the sequence length and finetune for 10B tokens from the original pre-training corpus.
i finetune them to 2k and then 4k and then 8k
Hmm, that also needs updated in the paper then :/
What is your exact ctxlen finetuning schedule over the 10B tokens
I will update this
Vanilla RNN / LSTM are considered not parallelizable because they are not parallelizable in C.
So the real criteria is whether we can parallelize in C. We can saturate the GPU if we can do that. And RWKV4 is good at it.
Ok I will provide some RWKV vs GPT training speed numbers soon
@last mauve I will finetune a World model from 4K to 8K and show the positional loss changes
What I need is a detailed ctxlen schedule for the experiment here:

Because what we have now is not accurate if it's actually 8k
Firstly, RWKV can be finetuned from small ctxlen to large ctxlen using very few tokens
Example: 4K to 128K in 1.4G tokens here: https://huggingface.co/xiaol/rwkv-7B-world-novel-128k
However, we had spare compute at the moment, so we did this:
1k -> 2k for 10B tokens
2k -> 4k for 100B tokens
4k -> 8k for 100B tokens
And those were repeated for both 7B and 14B in Figure 6. Got it.
Thanks! We also need to put the exact software versions (torch, CUDA, etc)
Ok the rebuttal is in a good spot I think. I would appreciate if someone did a pass and left comments before tonight.
Also, there are still a lot of work items that need done before the final paper version can be published. See #1103039376184852622 message and #1103039376184852622 message. I would appreciate help with these over the next few days.
I didn't use a static version of torch
pip install torch --index-url https://download.pytorch.org/whl/cu118
So the cuda was 11.8 and torch was 2
@last mauve Do you want me to write a phrase stating this?
@outer vine @last mauve
L=32 D=2560 VocabSize=65536, params count = 3.1B
Here all models are using the same FFN (RWKV-style, with sigmoid gate)
DeepSpeed ZERO2 + gradCP on 4x8 A100 40G, bf16
ctxlen=4096, bsz 4x8x6x4096 = 0.78M
RWKV, speed = 229kt/s
GPT w/ rotary, 20 heads, speed = 103kt/s
GPT (FlashAttention2) w/ rotary, 20 heads, speed = 210kt/s
I'm going through and posting the rebuttals now
They'll be posted to reviewers today AoE, so if there are any glaring issues feel free to edit through openreview
this is crazy... the results look so good
No architecture can improve beyond O(T) lol, just inputting requires O(T) computation
Have a suggested edit?
i believe that all current experiments runs in bf16 already
wkv in timemix is currently sequential in time. it can be improved with a parallel scan without changing the math, left to future work - in current seqlen wkv itself takes too little portion of time, so it don't worth the effort to implement a new kernel
All matmuls in RWKV TimeMix are parallelizable just as in Self-Attention; the only difference is the current non-parallel-scan-style WKV is not yet parallelizable through sequence dimension. But it doesn't hurt, because:
- in timemix the hotspot is in matmul instead of WKV, due to WKV is already sufficiently parallelized through the channels dimension;
- if we hit the scalability issue in the future (like over 100k seqlen, distributed over multiple GPUs), just do parallel scan and it becomes parallelizable through time dimension.
I don't really have the time to work on the rebuttal, hope the above comments help. Let me know if anything still not clear.
We should emphasize that the training speed (token/s) of RWKV is constant regardless of seqlen. So seqlen scalability is never an issue.
It's reasonable that a 100k seqlen sample trains 100 times slower than a 1k seqlen sample, because the token/s is still constant.
@fickle hare @last mauve
Just like any other RNN, RWKV cannot directly look back previous information, and have to answer questions solely based on its state (memory). The Winogrande task explicitly requires at least one lookback of the reference of the pronoun, while the ReCoRD reading comprehension requires recalling information from the previous passage. The underperformance of RNN and the need of special designation of prompts is further studied in Section 10 and Appendix I.
note the gap narrows as model grows, because of the larger state in larger models
😅 if there is a follow up paper for v5 (and its much larger state), i have mountains of data on how the lookback is a huge jump and quantified - doubt thats usable in the current paper though
RWKV-5: Watch out the Revenge of RNNs😆
RWKV podcast on latent space is out : https://x.com/swyx/status/1696920942033981674?s=46&t=sF1AtA14XiYn538Irne_XA
Any signal boost would be appreciated. As their audience is primarily from outside the usual rwkv sphere (aka transformers)
Just putting this thought out there. Looks like an average score of 3 (soundness) at EMNLP, even after the rebuttal/response period. The soundness score isn't the only factor for acceptance, and the excitement score is quite high, but I think it's a very borderline assessment meaning it's definitely possible that it ends up being rejected. Based on reviewer responses it seems that the presentation is what needs to be improved most, and I think the work has been out there long enough that we have new ways to explain the architecture which are clearer, and additional experiments to address some of the issues that have been raised since the paper was first released.
So, my question is: Is it worth spending 2 weeks to improve/update the paper writing/plots to address reviewer concerns, and then submit to ICLR (abstract deadline sept. 21, paper deadline sept. 28) with a version of the paper that will be significantly improved?
Some considerations: We can't wait and see what the outcome of EMNLP is, we would have to pull from EMNLP before finding out the decision. But, if we end up getting rejected from EMNLP, then we won't be able to submit to anything until ACL/ICML in january/february. If we get into findings at EMNLP, it's unknown whether we'd get a spot for a poster presentation as they did at ACL, so we could just end up with no opportunity to present at all.
Thoughts? @young sparrow @last mauve @obsidian quest
ok maybe let's go for ICLR?
I think it would be wrong to assume that a paper that recieves all 3s for soundness won't be accepted
I don't have any info one way or the other, but that seems to strongly determine your analysis and unless you have a reason to beleive it is disqualifying I would shy away from that.
In my opinion, the paper has a high chance of being accepted based on the reviews, and withdrawing would be premature.
I suggest that we work toward arXiv version 2, once the anonymity period is over (accepted or rejected), we can submit arXiv version 2 with better presentations.
Just to stay prepared in case there are any changes
I'm not assuming it won't be accepted, but my opinion is that it's highly unlikely to be accepted to the main conference, and possible that it will be accepted to findings. Also, the soundness weren't all 3s, it got 3 3 4 2, and 3 4 5 4 for excitement. So a lot of this judgement is up to the AC/SAC who will determine if a high excitement is enough for a paper to get accepted to main conference.
I hear what you're saying though. I don't have any extra information one way or the other either. I'm just concerned that if it does get rejected, the next conference deadline after ICLR is ~4 months out, and we currently have the capability of significantly improving the paper quality.
Sounds like everybody else is pretty confident it will get in though 👍
Try this tool 🙂 https://github.com/changmenseng/accept_prob
GitHub
Calculate the probability of a paper being accepted by EMNLP2023 based on score distribution of ACL2023. - GitHub - changmenseng/accept_prob: Calculate the probability of a paper being accepted by ...
Input:
python accept_prob.py 3 4
Output:
Main: 0.4592064544731725
Findings: 0.20714542818067555
Reject: 0.3336481173461519
This is just a rough estimation. Given RWKV's influence, I believe that RWKV has a much higher chance of being accepted.
I agree with this. I can compile a list of TODO items for this over the weekend unless you want to take a crack at it.
We'll have to do the work anyway for arxiv v2 + camera-ready if accepted, and resubmission if rejected
Also, I think RWKV would really benefit from adding an entry to https://nn.labml.ai/ via a PR to https://github.com/labmlai/annotated_deep_learning_paper_implementations/tree/master
If you are a co-author of the RWKV paper (or any other EleutherAI research paper) and you live in a country not colored green or blue on this map please let me know.

btw, while its not peer review citations - you can already see them happening on arxiv (for the RWKV paper)

RRWKV makes an architecture change but doesn't even benchmark to show it does anything useful over the original implementation.
Are you referring to v4 vs v5?
ahhh
no sorry
RRWKV
The paper ^ citing it
yeah sorry for increasing the entropy 🙂
Google Scholar is tracking 31 even!
This will likely be a 100-citation paper by EOY
guess we are on track to a small 9000 😉

Someone can conduct the experiment to check whether RRWKV is superior to original implementation
I just saw the video on Yannic's channel! Congrats guys this is super cool!
Is there a simple pytorch implementation of RWKV? The implementations in the github are naturally super optimized

GitHub
The nanoGPT-style implementation of RWKV Language Model - an RNN with GPT-level LLM performance. - GitHub - Hannibal046/nanoRWKV: The nanoGPT-style implementation of RWKV Language Model - an RNN wi...
Hm, it still uses a custom Cuda kernel: https://github.com/Hannibal046/nanoRWKV/blob/7d025958a85fb77475a90edb9ba6d7ed94995946/modeling_rwkv.py#L162
GitHub
The nanoGPT-style implementation of RWKV Language Model - an RNN with GPT-level LLM performance. - Hannibal046/nanoRWKV
There's a "raw wkv function" but I'm not sure whether it does the same thing, since it says "only for generation"
The raw function is just a conv1d.
Is the raw function not like the RNN for loop over the sequence length?
Could I use the raw function for training as well? (Just slower,) or is it fundementally different?
The Good Minima
I go through and explain a minimal implementation of RWKV in detail.
My intuition is that RWKV is much more easier to comprehend than GPT if you already know LSTM 🤔
Probably, but I think it's more common nowadays to already know GPT rather than LSTMs
you can choose not to use custom cuda kernel
GitHub
The nanoGPT-style implementation of RWKV Language Model - an RNN with GPT-level LLM performance. - Hannibal046/nanoRWKV
it does the same thing. The reason behind "only for generation" is that if you don't use custom cuda kernel for training, it would be much much slow and inefficient
Ok, but the cuda kernel still contains some equivalent of the for current_index in range(seq_length) loop?
I'm asking because I'm trying to understand to what degree RWKV can be trained "in parallel" like a transformer or Retnet
I think the answer is that RWKV is parallelizable, but the code is actually not currently written in a fully parallelized way. Instead, it's written in a sort of cascading parallelism, as demonstrated in the gif here (https://wiki.rwkv.com/advance/architecture.html#how-does-rwkv-differ-from-classic-rnn), which I believe in practice is very similar efficiency to if you wrote it in the "fully parallelized" method
I could be wrong, so somebody correct me if needed.
see #1103039376184852622 message
moreover the training speed (token/s) of RWKV is constant regardless of seqlen.
Do you mean it's parallelizable the same way an RNN is? That is, you can handle each "diagonal" line of cells at the same time. I guess this would roughly be as efficient as transformer-like parallelization, if the number of layers is of the same order as the sequence length
why it was constant?
it is computed sequentially, with a very light weight recurrence
GitHub
The nanoGPT-style implementation of RWKV Language Model - an RNN with GPT-level LLM performance. - Hannibal046/nanoRWKV
if you check how CUDA works, you will see that RWKV is perfectly parallelizable
In Hannibal's gif there's a sequence of wkv computations that look like it's going to take time proportional to the sequence length. Is this not so, even in Cuda?
I can see how you can do O(layers+seq) parallel time, but not O(layers) like transformers. Is this not right? I'm not saying it's a problem. In practice the number of layers is probably not that different from the sequence length.
"take time proportional to the sequence length" is expected. that's how you get constant token/s regardless of ctxlen.
Yes, but when people say transformers are "parallelizable", in this context, they mean that you only need a number of steps proportional to the number of layers. Every cell in the sequence dimension can be done in parallel/batched.
I'm not saying this means RWKV is bad, or that this is an important difference. I'm just trying to understand if RWKV is like transformers in this way, or like RNNs.
The operation that takes place in the sequence dimension is a tiny operation, essentially a complicated cumulative sum (RWKV 4)
While this does impact the training, its by a very negligible amount.
Where it matters is that where transformers requires the recomputation of the entire sequence for each token during inference, RWKV does not.
for easy understanding, you could simply take RWKV as an RNN
Thanks, this makes sense. Is that similar to the "Recurrent representation" of the Retnet (Figure 3b in https://arxiv.org/pdf/2307.08621.pdf) which also has just a scaled addition onto the state vector
btw major news for RWKV:
https://twitter.com/picocreator/status/1704916066491826517
🎉RWKV is the worlds first #opensource #AI model to join the Linux Foundation🎊
Ensuring that RWKV continues to grow as a true OSS model (Just Apache 2 license)
By the community, for the world 🌏
Thanks @LFAIDataFdn for welcoming us on board #ossummit

not sure if im allowed to post this in the general channel haha
( any mods, let me know where i can repost this )
Is there any interest in submitting a slightly shortened paper (4 pages) to a NeurIPS workshop? https://neurips.cc/virtual/2023/workshop/66532
You can't.
Submitting to two conferences simultaneously is against the rules everywhere and grounds for rejection from both
This workshop is non-archival
I'm fairly confident that it is within the rules of EMNLP
It doesn’t really fit well with the NeurIPS workshops and as far as I can tell this is a conference track paper in caliber anyways.
Submitting to a nonarchival and archival one is also against the policies of a lot of workshops
I won't push for submitting to the workshop if others don't want to. But just to clarify, many workshops with non-archival tracks do allow you to submit papers that have already been accepted to a conference
Wait, are we still in anonymity period? Anonymity period lasts until the final results (accept/reject) are out, on Oct 6, 2023.
I’ve the same understanding of the anonymity period
Yes
Yes
Some friends of RWKV at Frontier super computing clusters, is asking "RWKV under the Linux Foundation" to apply from SummitPLUS : https://www.olcf.ornl.gov/summit-plus/
So that we could potentially use this to train larger foundation models for RWKV v5
As it would help the application process if we have a PI / CoPI of
prefereble someone from a University or research center. And in US
Would anyone be interested in doing a joint application with me and blink ?

Oak Ridge Leadership Computing Facility
The OLCF was established at Oak Ridge National Laboratory in 2004 with the mission of standing up a supercomputer 100 times more powerful than the leading systems of the day.
if no hits here, you might try #general and #off-topic too, but maybe give the people in this channel preference - i'd put money on someone being available though
EleutherAI can do that, and have a track record of winning computing grants from OLCF. I can be the co-PI with you
Great! I just realise your name was on the reference project they sent me - “Scalable Foundational Models for Transferable Generalist AI”
Yes! We were very excited to win the only INCITE grant for pure AI research last year with LAION and Mila 🙂
will circle back once i figure out the basics of the application process (everything is new to me, and the frontier fellow is guiding me through)
Tagging @last mauve for his awareness as he also has experience with OLCF applications
I do!
Would love to help on this! As @young sparrow mentioned, I have a lot of experience writing OLCF applications and helped write the eleuther/mila INCITE grant as well as its followup. I can also be a CoPI through my ohio state university affiliation.
I would love to help as well. I have NYU affiliation and helped with v4 paper.
https://github.com/BlinkDL/ChatRWKV/blob/main/run_lm_eval.py lm_eval for RWKV

GitHub
ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source. - BlinkDL/ChatRWKV
@void quartz FYI: If you and blink are seeking for discounted computing resources for v5, it might be a possible choice to apply a competition to use Japanese government's computing cluster called ABCI whose price of single node is 6.64 USD/hour. (up to 60 nodes and 8 A100s(40GB-RAM) and 480GB CPU-memory per node) This is less than 1/4 of 32.77 USD/hour of p4d.24xlarge . Someone in an academic institution or a corporation inside the state is needed to apply the competition.
Sorry for the delay, i drafted the following - after bouncing some ideas with the folks at oakland - they felt it was best to highlight RWKV energy efficiency
https://docs.google.com/document/d/17JBx_h-8k5S36Z5d1rggLL3wFL8iLXSGjvLUNm0F5AM/edit?usp=sharing

Google Docs
Project Information Project Name High Energy Efficiency Scalable Foundation Models Project Duration 9 Months Research Area Machine Learning Funding Source DONATIONS Abstract / Project Summary This project aims to train and evaluate highly energy efficient yet performant large...
@last mauve i would need your real name (DM me if you want to keep it private)
Also i was advice specifically not to add @young sparrow / EleutherAI - sorry 😦 you have won enough compute, and this wave they want to specifically priotise groups they never gave compute before
His name is Quentin Anthony, he's at Ohio State University
thanks, will keep note and consider
thanks! - do let me know if there is anything i should be amending in the draft that might be erroneous / essential
@obsidian quest - what was the largest number of nodes * gpu per node that you have ranned? / if anyone here has ranned for RWKV training
(asking for the HPC application)
current code can support lots of nodes. i only tried 12x8 A100 40g
what was
- model of the gpu, (A100/40G?)
- tokens trained,
- dataset used
- and time used for training
- param size
sorry for back and forth
i think they want to project how long it would take on the HPC cluster
RWKV-4 14B BF16 ctxlen4096 = 114K tokens/s on 8x8 A100 80G (ZERO2+GradCP)
RWKV-5 is a bit slower because of suboptimal CUDA kernel
If we are trying to build 30B or higher, IMHO, I think that A100-40GB and zero-3 is required.
Experimental zero 3 is already supported in both trainers
Thanks!
Is the RWKV paper acceped?
Might be Not yet because of time zone
When that happens it means peer review process is completed?
Email will be sent to blink and Anthony
We will be finding out today (hopefully) if the paper was accepted
Is it okay if I leave some comments on the proposal?
Of course! That’s what I would like
we can work on an RWKV-5 paper

We should definitely add all the memory experiment data to show how much it improved
@misty cedar try Retrieval experiment https://lmsys.org/blog/2023-06-29-longchat/
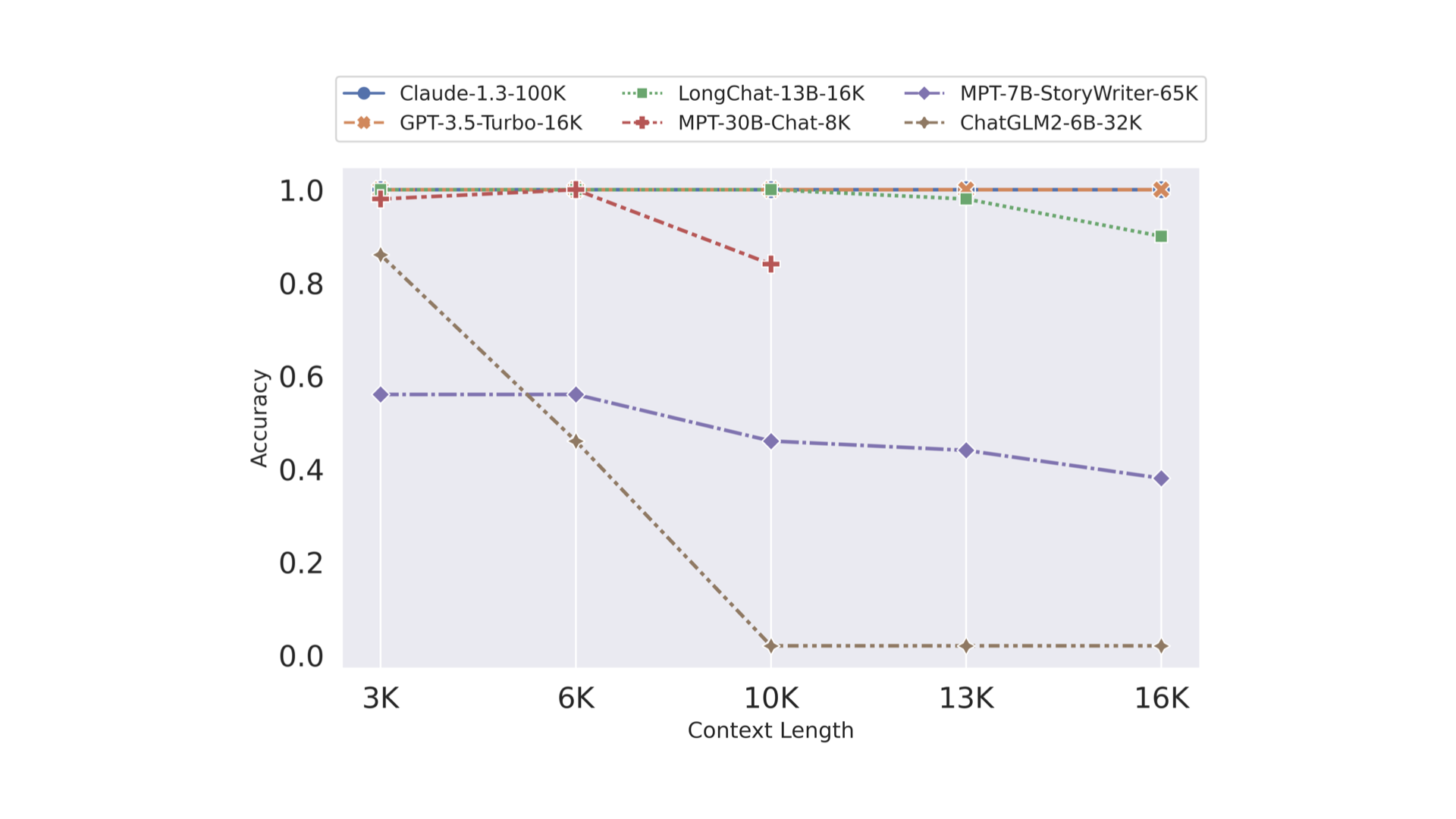
In this blogpost, we introduce our latest series of chatbot models, LongChat-7B and LongChat-13B, featuring a new level of extended context length up to 1...
looking into this
also
after a small amount of testing
I have found that almost none of the information for rwkv5 is stored in the time_shifts
also
the state is huge
state is 32x of rwkv4
for 1b5, does
32*64*64
=131072 values per layer
seem right?
absolute insanity lol
I'd love to help with an RWKV5 paper. Been writing and experimenting with my own related models and modular system for comparison training of similar components since the retnet paper was released, so I'm very familiar with both it and related architectures.
@obsidian quest where can I find a detailed breakdown of the training data?

How did you see that?
You can see revision of our manuscript
And you will find the submission venue ID has been changed to rejected..
😦
Github 18k+ stars project rejected by EMNLP😅
That’s a joke haha
Maybe we need to wait the meta review to see what happens…
There's a trlX paper under review at EMNLP that shows this too
Oh yeah I find that
My reviewer console also shows that, all papers change to the Rejected🤣
Oh yeah same. I suppose it's a bug then
I reviewed 3 papers and the Meta reviews showed that these papers should be accepted to main conference, but now all in Rejected
Yeah I think it’s a bug haha
EMNLP is killing me
Delayed results, no communication, then this bug that gives everyone a heart attack with no announcement, forcing us to compare notes
Can you summarize what's different between RWKV-5 and the RWKV-4 arch we submitted to EMNLP?
We need to decide whether we want a bunch of small followup papers, or build them up into a big paper like our first EMNLP submission.

Congratulations to everybody 🎉 !!
🥳
Awesome!
false alarm! we're in🌟
there will be a chance for a poster it seems!

It is a bug hahhaha! Congrats!🎊🍾
Just to confirm, @obsidian quest are you okay with EMNLP Findings?
Or do you prefer a main conference?
Findings means we cannot present the work at the actual conference
afaik only wkv replaced with that new mechanism (named wkv5 in the code)
#1083107245971226685 message
My opinion matters less than Bo's, but I think that findings are fine. I think we'll fall into the "highly-cited findings papers" (context: https://twitter.com/gneubig/status/1451317435278270466?lang=en), and the primary benefit of being accepted into EMNLP is the stamp of approval that the RWKV arch is technically sound and can withstand the scrutiny of peer-review.
Presenting at the main conference would be a nice-to-have, but we don't have the issue of people not knowing RWKV exists like many other papers do.
I agree with this too. I see the current publication as a credibility stamp and the number of citations this is accumulating would help us with any further academic-ish grants
wkv is now w*transpose(k)*v so it's a matrix rather than a vector, and the numerator/denominator in rwkv1-4 no longer need to be tracked separately
The matrix version of wkv lets you store way more state data, so it has much larger memory abilities, and is more analogous to how you can adjust traditional attention's softmax(q*transpose(k))*v into linear attention style q*(transpose(k)*v) via associativity if you remove the softmax
(yeah, but remember the exponentially decaying 'position embedding')
V4 was a legitimately terrible architecture, it's a miracle it did so well.
V5 is going to decimate other similar models
it's fine. let's work on v5 paper 🙂
Great. Let's goooo 🚀
@obsidian quest Did you ever run the extended scaling laws grid we had discussed? I think there's a good chance that that could turn into a paper too.
we can try that on slimpajama data
IDC which we do it on 🙂 But I'm very interested in seeing if optimal data:param ratio is the same for transformers and RWKV. It looks like it could be, but we need more data.
Is there a reason to not use the same data we were using before? Seems like a waste to change the dataset
The x axis in this plot is hilariously clearly wrong. Tbh it's very unclear if there's any pattern here at all on the high side to me
I don't see why the x axis is wrong here. Enlighten me.
The plot is clearly non-cumulative, but the x-axis is. I had several hypotheses about what the issue was that don't really fit but now I'm if there's an implicit a < x <= b when the label just says <= b for space reasons
It's just for space reasons. The x-axis isn't cumulative.
Yeah for some reason I thought that didn't work but it does
I got some interesting feedback from sasha rush that we can include in the next paper 👍
What kind of feedback?
Do tell
Now that we're accepted, time to work on the following (in order):
- Prepare the camera-ready for EMNLP (by Oct 20)
- Update the arxiv version with the same changes. I suspect this will be the last time we touch this submission so that we can move forward.
- Announce on Twitter with a thread of major results?
- Create the poster for EMNLP
- Start brainstorming on the next RWKV paper's outline. Can contain completed (e.g. v5) and in-progress work items. I suspect this submission will start crystallizing around EOY
I'll send out the latest work items for #1 and #2 on Monday.
I was fiddling with the author block, alphabetizing authors and adjusting formatting a little. It needs a little more love but I'll be done by the end of the day
Looking over the reviews, I don't understand what this is asking about
All the main information in the paper is shown in graphs in terms of scaling. While I understand why the authors want to show their model in this way, as a reader I want to see standard tables showing tokens / ppl (or bpc). Please include these tables in the paper so I can understand the data efficiency without trying to extrapolate from tables.
What is supposed to be measured in tokens / ppl?
( Context size training -> accuracy ) relationship?
Wow I forgot how much of a crab Reviewer 85wr was.
Figure 1 needs to have actual references to datasets and calculations. Having unlabeled graphs is not okay in a published paper. Languages need to be provided as well (BLOOM is multilingual, are these English tasks?)
It's labeled "average across 12 tasks" and in the experiments we list... 12 tasks. Surely it's not beyond this person's reading comp to figure this out...
The big picture of the feedback (my words, not his), we need more science.
Specifically, he asked for ablations on individual portions of the architecture to try and tease out what role each part contributes to find perplexity / flop savings.
Also, he suggested (and I agree) that it could be written a little less like marketing material. Meaning that we should have more description of what we did, and why we did it. So things like, an explanation of which parts of the architecture were chosen for speed vs. accuracy. And more here is where it improves over the transformer, but here is where it lags behind, discussing the tradeoffs.
Some of these may have been improved in the version submitted to EMNLP, but he only had access to the ArXiv version
Specifically, he asked for ablations on individual portions of the architecture to try and tease out what role each part contributes to find perplexity / flop savings.
I don't really view this as viable, nor is it a very common thing to do. The level of rigor we hold ourselves to here is comparable to other LLM papers IMO (GPT-NeoX-20B, PaLM, LLaMA).
Also, he suggested (and I agree) that it could be written a little less like marketing material. Meaning that we should have more description of what we did, and why we did it. So things like, an explanation of which parts of the architecture were chosen for speed vs. accuracy. And more here is where it improves over the transformer, but here is where it lags behind, discussing the tradeoffs.
I'm not sure what parts you think read like marketing material, but those should absolutely be cut. Can you point them out?
Maybe you mean the chat stuff? I had assumed we had run out of time with that. I agree that at present it doesn't add anything to the paper, but think that's a reason to improve it not delete it. Rather than compare to ChatGPT-4, we should probably be comparing to other OS models.
Some of these may have been improved in the version submitted to EMNLP, but he only had access to the ArXiv version
No, they had access to the EMNLP version when reviewing a submission to EMNLP.
I noticed that there's a lot of experiments in the appendix that aren't even referenced in the main text, such as the wikitext perplexity and LRA evaluations. This was because we ran out of space, though I continue to think Sec 2 is unnecessary and can be removed and/or merged with Sec 3. These results may need to stay in the appendix, but they should absolutely be referenced in the main text when talking about long contexts.
What kind of negative ratings could decrease the score level from main-conference accepting level to findings one?
- Component wise detailed ablation study at pre-training phase ??
- Significant margin of benchmark performance against other LMs against other competitive models like RetNet ??
- Or any other aspects to be improved ???
- Ablation studies: possible, but I don't believe that it's the key reason. It would be better if we add some ablation studies, since there are tons of new tricks, like WKV CUDA kernel, token shift, small init embedding, etc. These new tricks might be of interest to someone, but it's still unsure how they really work. (For example, I once questioned the coefficients in the token shift about its numerical instability)
- Significant margin of benchmark performance against Retnet: This is really unlikely, since Retnet is later work than RWKV, cited RWKV, and is posted after EMNLP deadline.
- Other aspects: I suspect that it's the nature of extreme competitiveness of top AI conferences. Of course, there are many articles better than RWKV with better soundness and presentation (i.e. Story-telling).
my previous experiment, data = SlimPajama
retnet official repo ("torchscale", gray) vs older and weaker rwkv5 ("r2r3", cyan)
it will nan in fp16 too (the small circle on x-axis around 0.6 G tokens)
my implementation of retnet wont nan, and performs better, but still no match for rwkv5
probably that's why they havent released any models

I think it's mostly bad luck with reviewers. We got shafted pretty hard, and many of their complaints are extremely unreasonable. I expect that this is going to be one of the most cited papers coming out of EMNLP this year.
The paper isn't the best written thing and could present our results in a better or more compelling light. But in my mind the most compelling version of this paper is award-worthy, not just main-track worthy.
IMO the things we should change for the camera-ready are:
- We need to do a better job with the experiments for long-context. We have LRA results in the appendix that are never mentioned, but we should eval on actual long-context benchmarks for text models and extend our analysis to much longer sequences than we did. If this is actually "infinite context," let's show evals with 100k+ sequence length. I'm also still unsure what the long context evals in the main body are supposed to show.
- We should add the S4 variant that's been scaled to > 1B params to our primary NLP evaluations
- We should eval on MMLU
- The stuff about the chat model in the appendix seems largely irrelevant to the paper. We should either cut it or work it into the narrative better. If we keep it, we should be comparing against similarly sized models not GPT-4. IIRC Raven was at the top of the open model on some chat benchmarks... we should show that off!
- General principle: everything in the appendix needs to be at least referenced in the main body.
I largely agree with @spiral minnow and we can take a less improvised approach for the paper describing the v5 (which I assume is the v 5.2).
5.2 ( aka revision 4 )
is the finalized rwkv v5 algorithm
Is this comment meaning a kind of ALIBI like position bias is given via exponetial decaying?
yea, kinda like that
it's already the case in v4, where the softmax is taken on a decayed k, after the exp it becomes exponential
I proposed "time-weighting" back in 2020 https://github.com/BlinkDL/minGPT-tuned
Another reason is that the topic of RWKV is a little far from the main focuses and topics of EMNLP. EMNLP does not really suit RWKV.
Look at this (Mostly in Chinese, just see the titles): https://mp.weixin.qq.com/s?__biz=MzI1ODI2ODI1MA==&mid=2247484873&idx=1&sn=00fe41a7da8f0544d050c84a2ee0fbff&chksm=ea0b88fcdd7c01ea815c3a44620279f457d6821b39e7d9ec96260952f9234ae782fba9471061&mpshare=1&scene=23&srcid=1009TP3yfdFSLUtUYr0q66Pu&sharer_shareinfo=3d763bdae0c3c483c1a7643fafe6d90d&sharer_shareinfo_first=3d763bdae0c3c483c1a7643fafe6d90d#rd
There is not so much related to model architecture, just using models to solve problems like speech transcription, multilingual translation and some more. Therefore, RWKV seemed to be of little interest to EMNLP.

I don't really view this as viable, nor is it a very common thing to do.
That's a fair point, I'm not sure how expensive it is to run the main experiments with more variations on the architecture. But maybe we can do some smaller scale experiments? I don't have a lot of concrete ideas here, just passing it on from Sasha.
I'm not sure what parts you think read like marketing material, but those should absolutely be cut. Can you point them out?
I think his point on this wasn't that any specific section was written as marketing material, but more suggesting that not enough of the paper was dedicated to analysis.
Directly from him: "I think a lot of the experiments could be trimmed down to a less marketing version of how do RNN models work on real language that is honest and clear about what works and what doesn't".
I see both sides of this, I think a lot of the paper is spent on background and methods, which makes sense because there are a lot of details to the method which the reviewers/readers may not be familiar with. On the other hand, if I were reviewing this, I would agree that evaluations section really only touches on the high-level results and includes very minimal discussion. It feels like there are so many results and there could be some analysis of all of it to better understand when RWKV improves over transformers and when it does worse, and then trying to propose reasoning for why we think that happens.
Maybe this paper is a better fit for a journal because 8-10 pages isn't enough space to go into much depth.
Just read this. And I 100% agree, there's so much data/results to present, but not enough space. Moving some of the background to appendix (or shortening it in general), and bringing more analysis into the evaluations (possibly even creating a discussion section) makes a lot of sense
Start brainstorming on the next RWKV paper's outline. Can contain completed (e.g. v5) and in-progress work items. I suspect this submission will start crystallizing around EOY
Could we split paper's ideas of v5 (or later) into narrower scopes, RQs and desirable supporting experiments including ones that should be conducted in the future? And could we consider the venue to be submitted for each portion of ideas??
Relatively smaller and specific portions could be better to submit to the conference length.
Any overleaf links for new papers? I have more spare time this semester to help with the article.🤔
I think that it's not yet. It's still in brain-stroming according to Anthony.
I think splitting also makes sense cause it allows us to go more in depth on particular segments tbh
Right now one of the common criticism was how we lack more details and depth for each segment. And I’m like - at that point it’s a book
yeah, a text-book is a structured and assembled collection of many papers.
arXiv.org
Recently, self-attention-based transformers and conformers have been introduced as alternatives to RNNs for ASR acoustic modeling. Nevertheless, the full-sequence attention mechanism is non-streamable and computationally expensive, thus requiring modifications, such as chunking and caching, for efficient streaming ASR. In this paper, we propose ...
Their font sizes are too small 🤔
Related to our Oakland HPC compute application.
We are trying to frame it as an worlds most energy efficient model at 40B param scale
So a possible paper path is comparing the energy consumption on inference between various models with different input and output context length
Would be nice to have something like https://arxiv.org/abs/2310.06839 side-by-side comparison with RWKV vs GPT
arXiv.org
In long context scenarios, large language models (LLMs) face three main challenges: higher computational/financial cost, longer latency, and inferior performance. Some studies reveal that the performance of LLMs depends on both the density and the position of the key information (question relevant) in the input prompt. Inspired by these findings...
RWKV doesn't really provide much of compelling case (aside from memory saving) for just simple chatbots that can keep prior context mostly in cache
What is the evidence for this claim?
Current benchmark for 7B models put us well ahead on a joules per token basis compared to other models


An Energy Leaderboard for LLMs
Huh
This should still hold on higher param count, due to the lower gpu usage on inference (compared to models of same param count)
That's quite interesting
Though I'm a little suspicious about the amount of variability that's shown for 7B models... those are mostly basic decoder-only models and should be the same right?
I suspect it’s the lower vram usage
Why is StableLM substantially lower cost than Alpaca? Aren't they literally the same architecture?
Ahh that. We’ll have to investigate further I suppose into their methodology
Since none of us @ rwkv were involved in this benchmark
Yeah sorry. My skepticism isn't about RWKV, but all the transformers are nearly identical algorithms but show variance of ~ 20%
TBH considering how we observed perf difference in inference libraries even within rwkv and llama
It might even just be that
I suspect it is, or minor implementation differences in the HF library leading to different efficiencies
If that's the case, it's "not real" in the sense that if you are running at scale with an optimized implementation the difference goes away
Heck, our advantage could just be from custom CUDA kernels
Yup HF has its own optimisation. And our libraries has a difference between custom cuda optimised and non cuda optimised code
Hmm. I guess there is lots more to explore on this angle then I expected
RWKV and a transformer are the same number of FLOPs for a forward pass. So while it's certainly possible to be lower energy my prior is that it wouldn't be if you optimize them equally... unless there's something in the architecture that's a better fit for GPU computing
Lower vram usage?
Does that equate to lower power draw? I don't know.
somewhat, but it's not really that strong case
it translates indirectly due to having clear the cache and recompute the prompt, then you burn a lot of co2
As much as I understand gpu and shader code. I never looked at it from a per watt basis before 😂
Game development never really cared about that
Yeah, that wouldn't be savings in excess of 10% I don't think
there's some hard numbers for this for consumers GPUs if you look around, but its been mostly issue with older GDDR5/6, not the ultra efficient HBM2s
That said, if the goal is to get the ORNL grant there's a sense in which it deosnf matter. If the independent benchmark says you're way better you can cite that without feeling bad about it
For a 3090 gpu:
Vram is 60 watt
GPU is 230 watt
Of the total power budget

igor´sLAB
Well, meanwhile there are several leaks of "pre-release" models of the upcoming GeForce RTX 3080, but I don't really trust the roast published here, because I just assume design validation samples.
I also wonder how much of that 230 watt is to transferring data from vram to gpu and back
it's a bit tricky to quantify it because power saving on memory is done mostly via clock
and it doesn't matter how much memory you're using when you're inferring, it will always dial the mem clk, and subsequently power usage, full throttle
I also wonder if there is big difference between consumer and DC cards
yes, huge
As the vram is tuned very very differently from what I understand
entirely different memory architecture, for starters lol
😂 we keep getting more questions at every layer we peel of this onion
best data you can get is if you look around hardware forums with people troubleshooting idle power usage
turns out its just clk spiking due to desktop tasks and what not, and their giant radeon/nvidia with 16gb eating 30w doing nothing
Yea cause I know a100 idle is huge. And 7B is definitely underusing the gpu
Their numbers are A100, making these mostly irrelevant
Yea. Just using it as an approximate of how big of an impact vram can possibly be
A100 memory frequency is just locked to 1ghz. DC cards are just made with the presumption of running full throttle at all times (meaning you burn all your flops doing parallel inference tasks, too), a reasonable assumption.
Then the numbers advantage makes less sense 😂
@silver leaf You seem to know your shit. Are you a CUDA or data center engineer by any chance?
A good life lesson: just because you can assign a number to something doesn't mean that number actually means anything.
If you have no idea how far off your number might be or what factors effect that, it's meaningless.
As I said earlier, I'd focus on the angle using less memory -> you can cache more/run more inferences in parallel -> which can be useful for a lot of specialied tasks like QA retrieval and other sorts of prompt engineering, but translates poorly to just plain chatbots.
Crypto rigs. Blunder years.
I might be wrong on this. But AI models are somewhat constant energy usage on a per token basis (assuming same input token length) ?
There's also the issue of plain GPT models being ultimately memory bandwidth bound. No matter how you parallelize inference, you end up with all that K/V cache traffic on your hands.
I think we can validate this train of thought by simply initialising empty models at a specific param count.
And just measuring energy usage across X K token inference
which implementation should I be looking at to find parallel inference server for RWKV?
I think this one : https://github.com/cgisky1980/ai00_rwkv_server

GitHub
A localized open-source AI server that is better than ChatGPT. - GitHub - cgisky1980/ai00_rwkv_server: A localized open-source AI server that is better than ChatGPT.
Looking at the repo - for the benchmark - it’s huggingface TGI based : https://github.com/ml-energy/leaderboard
GitHub
How much energy do LLMs consume? Contribute to ml-energy/leaderboard development by creating an account on GitHub.
So for better or worse it includes all of huggingface optimizations for each models
this is the llama (opensource) SOTA you'd be against head-on it seems, https://www.anyscale.com/blog/continuous-batching-llm-inference

Anyscale
In this blog, we discuss continuous batching, a critical systems-level optimization that improves both throughput and latency under load for LLMs.
Is it possible to measure an architecture potential efficiency?
Cause down this path it can end up being who writes the best cuda/Vulkan code
ye, its sort of do you really want to be in this race, theres a lot of resources thrown to microoptimize gpt inference
There will probably be different numbers for batched and unbatched modes lol
but then again, most of it can be reused, ie adding rwkv into vllm
And we might just end up being more efficient because we can cram in more batches in same number of vram lol
ye i'm pretty certain rwkv could be huge win in large model / low vram situation
even 40g A100s probably
Ok my plan tentatively is
- proceed with the compute grant application
- do some benchmarks to replicate in non batching mode (HF implementation), using empty init model for larger models if we dun have one
- (stretch) benchmark batched mode
- when the training completes rerun with trained model
I agree that the numbers do seem off for models which should be the same architecture. So replication seems to be the only route to figure this out further
Besides the grant if given is for next year. So there is time in between 😂
Could we derive the big-O of J/token in generation length with no specific hardware dependent benchmark??
If the order is much faster, the optimizations for hidden constants are theoretically ignored.
Ideally, J would be estimated a function in the number of operations and volatile utils.
FYI:
Energy efficiency depends on tasks or kernels.
https://arxiv.org/pdf/1906.11879.pdf
I need someone to confirm this for me. If I have 2 different prompt of same length which output same token length (but different content)
The energy usage should be the same right?
I agree to this statement.
I assume that the J depends only arithmetic operation type and data type (float16, float32, int8, int16 etc).
An example of worst case scenarios (very very very unlikely) is as follows:
1: If RWKV is quantized via 3-bit int, task accuracy inevitably decreases largely.
2: Someone invented a novel 3-bit operation which is extremely (pays quadratic number of operations) energy efficient than the other operations (fp, or int8, int16) "only" for 3-bit arithmetic.
3: Quadratic attentions with 3-bit quantization can keep good task accuracy.
Then, energy drawbacks of quadratic attention are paid off...
I think we can approach it without quantization first haha
Cause quantisation techniques in concept applies to all models
I think that bio-computing with brain-cells 🧠 in glass tubes is the best for energy. 😉
Yea we are like < 20 watt haha

how can this statement be true? relative to context length, rwkv is constant O(1) flops cost per inference token regardless of context length while transformer attention costs O(N) flops per inference token where N is context length
it's a bit apples to oranges in the sense that RWKV has limited memory space, but it's not limited by a fixed length like a transformer is
there's a reason they charge a lot more for inference on chatgpt4 long context edition 🙂
@everyone the camera ready deadline is in one week. The major to-do items are:
- Do a better job with the experiments for long-context. We have LRA results in the appendix, but we should really evaluate on an actual long-context benchmark and compare with other recent technqiues for extending the context length of a transformer.
- Compare to S4, if possible. I've contacted the people who claim to have trained a 1.3B parameter S4 model as they didn't release anything larger than 125M.
- The stuff about the chat model in the appendix seems largely irrelevant to the paper. We should either cut it or work it into the narrative better. If we keep it, we should be comparing against similarly sized models not GPT-4. IIRC Raven was at the top of the open model on some chat benchmarks... we should show that off!
Maybe some other things? These seem like the main areas of concern to me, but maybe @obsidian quest @tropic minnow @last mauve disagree.
Who has bandwidth to volunteer to work on these items as soon as possible. We should have a target deadline of Wednesday for getting the results in.
RWKV-5 World v2 1.5B Demo: https://huggingface.co/spaces/BlinkDL/ChatRWKV-gradio

temperature of .8 seems to be a little better, with fewer 4th wall continuations
We need to see under which conditions has this S4 1.3b happened. If the authors of S4 (or anyone related) have not pushed scaling the arch further I am quite suspicious tbh, and we should be comparing apples to apples
imo chat stuff is highly subjective and hard to assess scientifically as it's very easy to 🍒 pick. the way i see it is more for showcasing applications and for a "shock/PR/marketing" for scientific community. An example that RNNs can also be assistants/chat interfaces; not just transformers. i think RWKV is the first to show this at sufficient quality. After all, RWKV community is alive bc people are interested for its "industry" applications given its efficiency, etc.
I agree we should try to integrate the narrative better and compare to similar sized transformers
an actual long-context benchmark other than LRA? i've seen avg ppl per token but not sure if that is more rigourous... seems highly dataset dependent; and many of those methods involve some finetuning / adaptation for long context, something that RWKV did not undergo, just up to 8K in late stages if im not mistaken ( @obsidian quest pls correct me if im wrong )
There are long context benchmarks that measure standard NLP stuff like QA, summarization, NLI

Scrolls Benchmark
SCROLLS is a suite of datasets that require synthesizing information over long texts. The benchmark includes seven natural language tasks across multiple domains, including summarization, question answering, and natural language inference.
arXiv.org
Although large language models (LLMs) demonstrate impressive performance for many language tasks, most of them can only handle texts a few thousand tokens long, limiting their applications on longer sequence inputs, such as books, reports, and codebases. Recent works have proposed methods to improve LLMs' long context capabilities by extending c...
This is probably easiest to do quickly, from https://arxiv.org/abs/2309.00071

arXiv.org
Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, r...
What's the difference between V4 and V5? Just wider hidden state?

Is there a link to code? Unclear how the matrix valued adjustment is being done.
the matrix difference is instead of k*v it's k.transpose(-1,-2)@v
Thanks. This basically adds a lookup like attention. https://github.com/BlinkDL/ChatRWKV/blob/cb2480682a47c0bff854ca79db78263587da2a6f/RWKV_v5_demo.py#L183C18-L183C18
I wouldn't characterize it that way. But it does work more like linear attention this way, with r replacing q in q@(k^T@v)
What is the difference? It's an element-wise comparison across the entire sequence which seems to use group-norm instad of softmax at the end?
softmax is only applied at the (q@k^T) part in traditional attention, and group norm doesn't perform a related function
softmax causes negative dot product (cosine similarity) results between and query and the keys to become nearly zero, while emphasizing ones that are aligned
and that resulting set of attention 'weights' is used to select from values
That's mostly semantics. Changing Softmax to ReLU or just using the raw linear dot product with a final gate multiplication still yields comparable lookups. #research message
it's not semantics at all - this math doesn't do anything like that
I agree that other functions that squash the negative dot products can work well (I've tried)
as for using the raw linear dot product with final gate, I don't agree that works the same
I've seen plenty of linear attention papers that use it raw, or apply nonlinearities to q and k before multiplying, but my experience is that it's way less effective
and not the same kind of thing, mathematically
I completely agree that it's not the same mathematically, but functionally the models seem to learn and perform very similarly.
not in my experience! (don't get me wrong, I love rwkv)
but everything I've ever tried, which is a lot, points towards linear attention learning much more slowly than traditional
my description of the difference in this attention part of the models would be:
traditional attention is a mushy hashtable, where similarity betweek q's and k's chooses a mush of v's to return
rwkv5 style attention is a mushy decaying memory storage device, where 'k' chooses what address lines to store 'v' values in for later consumption, and 'r' selects a mush of address lines to return
hopefully we can get the rwkv5 paper to give that intuitive understanding - I think it's really useful for understanding why the model works so well
see https://github.com/BlinkDL/ChatRWKV/blob/main/rwkv_pip_package/src/rwkv/model.py
att_one_v5_1 (same as 5_2)
att_seq_v5_2
GitHub
ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source. - BlinkDL/ChatRWKV
rwkv learns fast. try it
our brain is more like rwkv style
Hey, you have any idea how that ouroboros experiment is going?
That seems like it could have crazy potential
I've tried it many many times, but my attention based models learn much faster per token IF they're given the same advantages like tokenshift, smallinit embed, etc.
I know you've also tried this comparison and I've seen your graphs - I'll do another run using mine vs the latest rwkv5 code at some point soon and report back
depends on your model size and data too
I always use the pile for both.. same # parameters (usually L12D768) - i've tried bigger models but never a direct comparison on bigger ones
this is always rwkv5 (past versions with per head decay instead of per channel decay and headsize 64)
Your final design is shockingly close to my RNN design. I ended up not using the k@v scan since I didn't see it performing much better than the other mechanism I came up with. I also norm by head but using a different method.
I assume we're not going to get a paper on that...?
Probably not but I might just dump the code somewhere. I'm training it to make music on my personal setup. It's not any better than RWKV/Attention (comparable), it's just a lot simpler.
I didn't like the dependency on all these custom kernels for numerical stability so I built something more accessible 🙂 I did also swap out the Pytha attention modules with my RNN version at one point and freeze the rest of the module and just tune those. Can be used as a drop-in replacement but still doesn't do super well at long-form QA in few-shot learning.
rwkv5 doesn't require custom kernel for numerical stability, just speed
Yes, this new version is similar to what I came up with. I am referring to V4, sorry for the confusion.
lol i accidentally happen to be working on a non-cuda kernel version of the latest rwkv5 right this second
due to trying to upgrade my whole codebase to support MQA
Using FFT or conv1d? (I used FFT since it's pretty fast and supported on everything)
not sure I understand... maybe you weren't referring to blink's custom cuda kernels used in rwkv?
i dont use fft or conv1d for anything at all in this model
V4 could be implemented using both FFT and conv1d, haven't looked super closely if V5 can be.
you could implement tokenshift with conv1d...
but id love to know how u implement the rest with FFT! (for V4)
#research message
thanks!
oh like the same trick hyena uses
gotta think about that some more
I could use long-kernel convolution to apply the decays to a whole slew of keys in parallel, which would at least save memory (and memory bandwidth) versus applying a giant decay matrix like retnet does in their parallel implementation... don't even necessarily need the FFT for that
other problem w/ FFT in terms of speed is you can't use torch.compile with it bc it involves complex numbers
I have several concerns:
- The formulas in time-mixing and channel-mixing modules are presented in a mixed manner, rather than listed sequentially. It's therefore difficult to understand exactly how time-mixing and channel-mixing modules work separately, especially if several formulas only differ slightly by an apostrophe. Anyway, it is not as clear as the ArXiv version.
- Due to token shift, the channel mixing module is also an RNN module. Could the channel mix module be added to figure 8 of Appendix D too?
- (Small) Add more details about the structure of RWKV internal states, including the total size, wkv numerator, wkv denominator and last token embedding.
This is using data-dependent decay which is likely what xLSTM (search for it on twitter) is doing
https://openreview.net/pdf?id=AL1fq05o7H
I planned to do this too, so now I will try it for RWKV-6 lol
p.s. I predict all these are similar to RWKV-4 performance when model params > 1T
I like that they used the selective copying task -- it's funny how badly non-attention models fail on this one especially when the target is 1k-2k tokens away (a common occurrence for any sort of document processing task like the now popular "chat with your PDF"/doc qa)
Okay lets try this. Our aim will be to replace the Figure 5 plot with more thorough and comparable results. We expect RWKV to not exhibit this blow-up effect seen in transformers for longer lengths. Doing this with @snow zealot


Sounds good!
It's probably worth making sure you're using the same 10 documents. @proper raven @compact pulsar do you know which one(s) you did?
I also saw that the SCROLLS benchmark was implemented in the eval harness. It should be easy to run.
@tropic minnow Do you know how much sequence length finetuning has been done? Both in terms of # of tokens and in terms of total length. Doing an apples-to-apples comparison will likely require some care.
i think the best is not to finetune RWKV further. just the RWKV-v4 we had @young sparrow
So the ones that have been finetuned to 8192, or the 1024 ones we used for most of the paper?
I think that the explosion in perplexity is connected with the particular PE / PE Extension used in those papers, and wouldn't be seen with other PEs
You can test this by running evals on BLOOM, which uses alibi
if rwkv is trained using the correct method (chunkwise BPTT), it will naturally have infinite ctxlen
@obsidian quest But you didn't train the models we evaluated in the paper using that method right
no i didn't
https://github.com/RWKV/RWKV-infctx-trainer use this (don't know if they coded it correctly)
GitHub
RWKV infctx trainer, for training arbitary context sizes, to 10k and beyond! - GitHub - RWKV/RWKV-infctx-trainer: RWKV infctx trainer, for training arbitary context sizes, to 10k and beyond!
If you don't know if they coded it correctly, we can't use it
Also, they don't seem to have pretrained models at this scale?
we can finetune existing models
We can't introduce a new technique after the paper has been accepted for publication. If we were going to use this we should have trained the models with it originally
certainly we can do so for rwkv-v5 or in future papers. for now, just evaluating V4 as they were trained is the right thing to do imo. It shows that "you dont need to worry about ctx len extension methods that much if you use RWKV architecture" and that rwkv can handle very long context lengths by default.
Thanks for these @gusty condor and @young sparrow! Time to buckle down for the camera-ready and arxiv-v2. My understanding is that our outstanding tasks are the following:
- (HIGH IMPORTANCE) Long-context experiments (see #1103039376184852622 message) - (In-Progress by @tropic minnow and @snow zealot)
2. (Stretch-Goal) Compare to S4 (see #1103039376184852622 message). This would be a nice-to-have for the camera-ready, but we can push it to later work if necessary imo.
3. Massage the chat appendix M section. I think that we should both reference the appendix where appropriate in the paper, and add a short paragraph at the start of the appendix justifying its existence. - Clear up our time-mixing and channel-mixing modules as reported by @gusty condor in #1103039376184852622 message. I agree these have become less clear.
- (Stretch-Goal) Add the channel mix module to figure 8 of appendix D as reported by @gusty condor in #1103039376184852622 message. I agree this would be nice to have, but it's not necessary for camera-ready
6. (Stretch-Goal) Add more details about the structure of RWKV internal states as reported by @gusty condor in #1103039376184852622 message. Not sure about the specific shortcomings here, so whoever picks this up will need to check with @gusty condor (or you can pick this up yourself @gusty condor)
(To clarify, all items I labeled (Stretch-Goal) are important and should at least go in the arxiv-v2, but were not explicitly pointed out by reviewers and are not absolutely necessary for the camera-ready)
Here are the rest of the work items that we haven't addressed yet for camera-ready:
7. Update the text to have a sentence defending the following from reviewer rSzx: Two specific tasks (ReCoRD and Winogrande, as shown in Figure 5) see the model underperforming other models. This underperformance requires further investigation.
8. Update figure 1 to fix reviewer 85wr's comment: Figure 1 needs to have actual references to datasets and calculations. Having unlabeled graphs is not okay in a published paper. Languages need to be provided as well (BLOOM is multilingual, are these English tasks?)
9. (Stretch Goal) Add tables in an appendix to address reviewer 85wr's suggestion: All the main information in the paper is shown in graphs in terms of scaling. While I understand why the authors want to show their model in this way, as a reader I want to see standard tables showing tokens / ppl (or bpc). Please include these tables in the paper so I can understand the data efficiency without trying to extrapolate from tables.
10. Update the fonts to address reviewer 85wr's comment: Generally the graph labels are much too small to read, please increase these to be similar to the text itself.
11. Add a sentence or two clarifying the inference experimental setup, addressing 85wr's comment: Can you provide more details on exactly the inference method / software hardware used for the text generation results? From the text it is unclear whether it is even cpu or gpu.
12. Table 1 is overlapping the middle margin. Needs fixed.
13. Several missing references in the contributions section
rSzx: Two specific tasks (ReCoRD and Winogrande, as shown in Figure 5) see the model underperforming other models. This underperformance requires further investigation.
I think it's a stretch to say we underpreform on Winogrande. In particular, RWKV and Pythia (which are trained on the same dataset) seem to trade off which is ahead.
We do underperform slightly on ReCoRD, but I don't particularly see what there is to explain. We're a little worse at ReCoRD, a little better at OpenBookQA, HeadQA, ARC (challenge), and nearly identical on the others. That's what happens though... all of the models have some tasks they're better at and some they're worse at. I think it would be irresponsible to posit an "explanation" based on such little data and don't think one is necessary at all.


**Also, many of these changes need to be applied to both the EMNLP camera-ready and the arxiv-v2. If you pick up an item that needs applied to both (e.g. #3 but not #4), make sure you edit both overleafs before I cross it out. **
@young sparrow -- Can you link the arxiv overleaf so that I can pin it?
RE: "Can you provide more details on exactly the inference method / software hardware used for the text generation results? From the text it is unclear whether it is even cpu or gpu."
I think they just missed it. We write:
Specifically, we evaluate text generation speed and memory requirements on typical compute platforms including CPU (x86) and GPU (NVIDIA A100 80 GB). For all our experiments we use float32 precision. We include all model parameters in the parameter count, including both embedding and non-embedding layers. Performance under different quantization setups is left to further work. See Appendix H for more results.
It would be good to mention that this is thetransformerslibrary specifically though
I don't have an archive-v2 overleaf? I only see the EMNLP one actually
You're the owner. It's listed as just "RWKV" in overleaf
I made two notable changes to the EMNLP overleaf:
- I moved the related work to the appendix, in anticipation of needing the space for our extened experiments. We can move it back if that doesn't turn out to be necessary, but we're already half way down the ninth page.
- I added a second way of formatting the related work that doesn't lead to nearly as much wasted space (namely grouping by activity instead of lisitng each author individually)
oh I had archived it.
To clarify, when I say "arxiv-v2" I mean "our arxiv paper + the emnlp edits applied + any fixes along the way we couldn't make due to anonymity"
The arxiv version is here though I recommend we put the camera ready version on arXiv as well
An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
How should we differentiate the longer arxiv version with our EMNLP camera-ready in that case?
The difference is just bumping a couple things to the appendix for page limits right
I would do the EMNLP version, submit that, and then just move the sections to the main body
I'm of the opinion that the EMNLP and arxiv versions are separate retellings of the RWKV storyline for different audiences:
- Arxiv: Broader audience, where we make things longer and more detailed, and advertisements like the chat appendix are OK
- EMNLP: Academic audience, where we keep things brief and purely technical
It's not as simple as bumping entire sections. Many of the sections themselves were reworded or shortened for EMNLP. The two versions have drifted a bit and I'm proposing we keep them that way.
I see
I fixed all the missing refs
This is the last warning but I can't find an actual instance of this

Got it
@last mauve I have handled 8, 11, and 12. I don't think we need to do anything about 7. I've concluded that the big S4 model is unreleased and have reached out to the authors. I would expect this to not come to anything, but it's probably worth explaining that that is why we don't compare to it.
I think for 9, they're looking for how quickly the model improves over the course of training? So, something like training loss over time vs Pythia's would make sense? Is that your read too?
ReCoRD & WinoGrande are solved in rwkv5
That's nice, but not particularly helpful to this paper 😛
or you can simply scale rwkv4 🙂 i predict the gap will be filled just like what happens to lambada. probably need 100b params for that lol
my intuition is rwkv will spend more efforts on easier tasks when its capacity is limited by state size, and that's why it's doing better than gpt in some other benchmarks
p.s. we have lots of intermediate checkpt here https://huggingface.co/BlinkDL/rwkv-4-pile-3b/tree/main

😂 I would gladly welcome a third pair of eyes on my bptt implementation - however, I do think the infctx part can be a followup paper
Sure, I was saying that we can't use it in this paper
Great! Can you compute pile validation loss for all of them?
@hushed flare @misty igloo Try my RWKV-6 first step: dynamic TokenShiftMix (likely works for RWKV-4 too) #1083107245971226685 message
My understanding is that mixing coefficients are added a LORA term of current x.
Original RWKV-6 is postponed to RWKV-7? Or will they be implemented together?

My opinion toward long context experiments is to leave it afterwards (so just remove the LRA experiments and say sth in future work). The relationship between trained length and practically available length in inference is still unknown; while there are some reports from the community about seemingly extending to much longer once trained to ~100k, we have no formal result on that.
InfCtx is just a cheap method tuning to >100k on consumer cards, which backed up the abovementioned community reports.
I think we could focus on the "transformer equivalent RNN" narrative and it would make the paper better in abstract, but the context length stuff was very important to @obsidian quest
I'll try it on both rwkv and traditional attention models - tokenshift works very well on those in my experience. Let's discuss on rwkv discord instead, so we can leave this channel for paper publishing related work
- I have done it
The total size of the RWKV internal state can be computed as $4DL$ in mathematical theory or $5DL$ in practice, where $D$ is the model dimension and $L$ denotes the amount of layers. The internal state in each layer consists of five vectors of size $D$. The five vectors are respectively listed as follows.
\begin{itemize}
\item The current input of the Time-mix block $x_t$;
\item The current input of the Channel-mix block $y_t$;
\item The numerator of the $WKV$ value $a_t$ in \eqref{eq:statea}, or $a'_t$ in practice \eqref{eq:stateaa} for numerical stability;
\item The denominator of the $WKV$ value $b_t$ \eqref{eq:stateb}, or $b'_t$ in practice \eqref{eq:statebb};
\item A helper state $p_t$ in \eqref{eq:statepp}, which is implemented solely for numerical stability.
\end{itemize}
Can you elaborate about the distinction between theory and practice? This will confuse readers, who are used to it being the same for model sizing.
The RWKV model has an internal state that stores some previous information. In each layer, the internal state consists five parts, each of which is a vector with $D$ numbers, where $D$ is the model dimension. The five parts are:
\begin{itemize}
\item The current input of the Time-mix block $x_t$;
\item The current input of the Channel-mix block $y_t$;
\item The numerator of the $WKV$ value $a'_t$, as defined in equation \eqref{eq:stateaa};
\item The denominator of the $WKV$ value $b'_t$, as defined in equation \eqref{eq:statebb};
\item A helper state $p_t$ in \eqref{eq:statepp}, which is used for $WKV$ computation to maintain numerical precision.
\end{itemize}
Which yields a total size of $5DL$ parameters. It is worth noting that in an algebraic context with infinite precision, the helper state $p_t$ can be ignored, and the $WKV$ numerator and denominator can be computed directly using equations \eqref{eq:statea} and \eqref{eq:stateb}, reducing the size of the internal state to $4DL$.
It would be good to mention that this is the transformers library specifically though
Added this
Thanks! Updated the task list.
Yep I think they want a table of training loss over time in an appendix to accompany the graph
@tropic minnow and @snow zealot -- How are the long-context experiments looking? Are they on-track to be included?
I have the data for the 7B model
However there are some details we need to talk
So the plot is like this

@everyone -- Does anyone know who "Jiaju Lin" is? They're listed as an EMNLP author but their contributions section is empty, they're not on the arxiv verison, and I can't track down anything they've done -- Resolved!
the data I collected is the cross_entropy at each token for a sequence of 128k tokens
Yikes. Discuss details with @tropic minnow and keep us on the loop, I suppose.
They appear to have been added to the authorship list by you in the same edit that I was added.
Another thing, figure fonts should be increased.
**All **-- If you contributed a figure (Figures 2, 3, 8, 9, and 11 are fine and don't need updated), please bump up the fonts a bit and reupload the updated figure to the EMNLP overleaf.
Yesterday someone proposed that CoLM https://colmweb.org/ is a good conference for RWKV. The deadline is March 2024, so we could prepare for RWKV-5 or even RWKV-6.



i cant tell which orange line is RWKV =x
(figured out, we are the lower winning line)
Wow, that's really interesting. RetNet seems to do well on "easy" tasks (not sure how the authors define easy vs hard), but does significantly worse on hard tasks
didn't expect this one

LLama2 is the weakest LM?? 🥹

Strongest, it's the same color as the weakest for some reason
Oh, NO!! 😆 I see that rwkv is the 2nd place 🤗
I'm curious how they used RWKV, only with the WKV recurrent unit or including all the tricks
I'll be submitting a version tonight for camera ready
If ppl can update figure fonts if they haven't already, that'd be great
@snow zealot and @tropic minnow did those long context results get resolved or are they unable to make it for camera ready?
hey hey so @snow zealot got good results imo
rwkv-4 (trained on 8k at most) compared to transformers 7B transformers trained on 8K ctx len ( https://github.com/jquesnelle/yarn/blob/master/data/proofpile-long-small-8k.csv ) from YaRN paper on proofpile (long docs), rwkv has its perplexity explode around 14k whereas transformers explode at 11K10K.
GitHub
YaRN: Efficient Context Window Extension of Large Language Models - jquesnelle/yarn
this, coupled to RWKV not having pos_emb, [[which means that length dependence is entirely driven by training. thus training on longer sequences might make it "grok" on longer term memory and address this effectively for virtually any ctx (but this is more speculation); ]] imo makes the argument that RWKV handles longer ctxs better
this would be the summary. wonder if its best displayed as table or as plot

@tropic minnow Okay that's a positive signal, but there's a lot uncontrolled for. In particular, I would expect LLaMA 2 and the derived models to be much better than RWKV in general. If we can confirm this, that would be good evidence that we aren't just leveraging a more powerful model
Is the 16384 score for RWKV correct, or is there a missing decimal point
im afraid its correct, no decimal mistake
What happened there
good Q. RWKV ppl just seems to blow up past a certain length around 14k-16k. at 18k and 20k it looks even worse lol
What is this from?
hmm i wouldnt focus that much on the absolute numbers as it's quite dependent on the document used, and we dont know which ones were used in YaRN: We selected 10 random samples from Proof-pile that were at least 128k tokens in length and evaluated the calculated the perplexity of each of these samples and ppl is quite document dependent
These long-context results are the last pending items for camera-ready. I'll leave it up to you on when they're ready to be included. I'm happy with them.
From this preprint : https://arxiv.org/pdf/2310.08049.pdf
Okay, I think this table makes sense enough. I can take a stab at massaging the narrative a little this evening or in the morning
Should we present a plot so it occupies less space and fits in the 2 column part? Or is a table better?
Which model is it tested against? Cause this is consistent with user feedback of the v4 base model which was trained to 8k
Where performance degrades past 2x the training window somewhere
We have community tuned 32k+ and beyond model since then which might do better? (Maybe?)
Not sure if there is time to retest against the longer context tuned models : https://huggingface.co/xiaol/rwkv-7B-world-novel-128k/tree/main

Is it unfair?
- This model is trained after EMNLP submission deadline.
- This model is not Pile model, vocab size V=65536 rather than 50277. If this model is listed then previous descriptions should be modified too.
- Shouldn't compare this model with other 2k or 4k pretrained context length models, which is extremely unfair.
Yes and this should be studied but i think not for the camera ready as no models trained for longer-than-8k cyx are shown elsewhere in the paper. We can followup with newer rwkv versions or very-long context len tailored rwkvs
I’m slightly worried that it end up being quoted as proof of rwkv being unable to scale past 16k tbh 😅
But agree that the newer models is out of scope for the reasons listed above
I at least can confirm ur observation is consistent with what we know of the older models 🙂
Well we can include a sentence saying that rwkv shows superior capabilities in ctx len extrapolation and given theres no pos-emb this is better bc implies ctxlen is entirely driven by training.
Thus basically
Yea. Framing that this model was trained only up to 8k is fair
If our all the models were trained to 8192 then I think this is a strong argument in favor of it
Mathematically it's actually not possible to maintain accuracy for arbitrary sequence lengths beyond the train set on sufficiently complicated test sets
What's relevant is a) the memory usage as you lengthen the sequence and b) how quickly performance falls apart
@tropic minnow Can you also quickly make a plot showing memory usage as sequence length increases for both Llongma and RWKV
will try
well actually we already have a plot comparing memory consumption and time as seqlen increases for RWKV and transformer models dont we (opt, pythia, rwkv) in figures 10, 11 of the arxiv version
New camera-ready deadline Oct 22 AoE
Or just cherry-pick to ctxlen 8192 or 12288 (Actually 8192 is not cherry-picking, because they are trained as ctxlen 8k, the behavior above 8k is undefined)
i dont think cherrypicking is valid bc we're not using the exact documents that were run in the yarn paper (they didnt say which) and it's quite document-dependent. the relative trend is more important than absolute numbers
The result is essentially presenting the extrapolation IMO. Extrapolating from 8k to 14k without any changes is already impressive.
IMO it should really fair compare with original llama, instead of those long variants; I think the table can list as two parts, one llama & rwkv, the next those long variants
and we can claim RWKV to be naturally extrapolating (nearly same quality to 10k, not “exploding” up to 14k)
yes, (edit: but) we dont have the results for llama, would have to run them ourselves and its quite time intensive (rwkv took around 20hrs for each document and with occasional memory errors)
Wait what
That's outlandish
How did it possibly take that long
yea i was like that at the beginning. we just followed the original code from https://github.com/jquesnelle/yarn/blob/master/eval/perplexity.py . @snow zealot knows the details
GitHub
YaRN: Efficient Context Window Extension of Large Language Models - jquesnelle/yarn
@proper raven is the something seriously wrong with the efficiency of this code?
What I understood from this code is that for each context length you do a sliding windows (with the size of the context) using a step size of 256
This for a sequence of size 128k for 10 sequences
You could try to batch this but it is a trade off between memory and speed
it compares sliding window results to full context ones? that does cost a lot then...
Just submitted the camera-ready
We can submit v2 of the arxiv this week once the long-context results are in
Then we can begin brainstorming the followup paper
Stretch-goal 5: add Channel mix block as a figure too.
Which application did you use to produce those figures?
This figure (from arxiv version)? I used lucidchart. Can share it with you or adapt it if you want to change something

Yes (I mean figure 8)
Have to study Lucidchart (I was using Powerpoint)
Quick question: as the training of the smaller RWLV v5 models is getting close to the end, will the datasets used to train them be available somewhere ?
@snow zealot @young sparrow @tropic minnow -- what are we doing from long context? I don't see any actionable conclusions from your previous discussion.
I was under the impression we were going with what we had
It's not my first choice but it's pretty good and running more apples-to-apples models appears to be prohibitively expensive. It would be nice to augment with one of the long context evals I linked to earlier but I don't have bandwidth to do that and nobody seemed interested.
Gotcha. Ok let's get the table into the arxiv overleaf then @tropic minnow
World = Some_Pile + Some_SlimPajama + Some_StarCoder + Some_OSCAR + All_Wikipedia + All_ChatGPT_Data_I_can_find
Thanks. Any chance this set, along with how it would have been deduped would be released? It's hard to compare different techniques on bleading edge dev when we can't do it on the same data.
Some data are from people PMed to Bo Peng, which are not released
Will do in about 2hrs
on the arxiv (https://www.overleaf.com/5467634575mjghxcgkfqzs) version🙂

An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
We restructured / reorganized Sections 4 through 6 between the arXiv preprint and the EMNLP version. I think that the structuring in the EMNLP version is better (though I'm open to disagreement!). We should make a decision about if we are going to back-port that to the arxiv version or not
we used FA2 for inference which made it better, but yeah sliding window is extremely inefficient since you're recalculating perplexity for the context size (so like 8k, 10k token inferences) every 256 tokens. you end up calculating the entire document several dozens of times, but it corrects for the first tokens having outsized weight on the ppl since essentially all tokens (mod 256) get to be "first" at some point
Could this brainstorming contain ideas about training methods which are extended version of autoregressive causal LMs (e.g. UL2 like denoiser) or only contain stuffs related to pre training ?
I think the next paper is about RWKV5
Anyway, I think this is clearer
Legend:
- Circles: operators
- Arrows and rounded rectangles: vectors (dimension D unless bolded or explicitly stated)
- Squares and rectangles: matrices (with respect to their shapes)
- Purple: trainable parameters
- Red: internal states
(Note that this is solely a mathematical implementation)


Any suggestions on it?
Ah yes I am not sure what kind of training methods are conducted for the latest RWKV5 paper.
what does LN1, LN2 mean in the layernorms? weights and bias of the affine transform?
i think it is quite correct, but found it quite hard to read at first glance😅 maybe using different line styles for the vertical (GPT) and horizontal (RNN) modes? maybe grouping the items under different sections (token-shift, etc) could help as well
Should we add a sentence or two referencing RWKV-1-3? The paper started with 4, and moving to 5 might confuse some readers.
Or actually, just pointing the GitHub link to the v5 folder should be fine.
@steady ether I thought we removed all reference to "4" from the paper, but we can footnote it if not
Yes, I will correct it
Not now, in the next paper we can add more about RWKV history
V5 is now in the V4neo folder, and the files in the repo are constantly changing, so it's not fine
Is this diagram better?

is it drawio? can you share the file?
Yes, I can
This is the original version of RWKV5, slightly better than RWKV4

Pretty good, but your missing the time-mix->lerp->gate-linear->silu->mult between group norm and the output for time-mix
This is for RWKV-5 revision 2, 3 and 4, not the original version
RWKV-5.2, revision 4

Due Nov. 12. Everything is optional, but it probably helps.

Ah yes. Does anyone want to head any of these up? I can head up one myself but more than that will probably kill me.
Happy to help with the slides and/or video. Can start on the slides this weekend.
My diagrams might help in that poster
sure lets coordinate for the poster
Howdy, I am working on a labml entry on RWKV, and I was hoping someone might have the answer to this. Why is the else branch of https://github.com/Hannibal046/nanoRWKV/blob/main/modeling_rwkv.py#L162 only for generation? How can I adapt this for training as well?

GitHub
The nanoGPT-style implementation of RWKV Language Model - an RNN with GPT-level LLM performance. - Hannibal046/nanoRWKV
Generally with rwkv, the lack of a cumsum with decay operator in pytorch means that custom cuda code is needed for training models, as the looping generally explodes the time and memory complexity during training due to the back propagation through time during auto backprop
Here is a quick draft of the slides. Anyone with the link can edit them. Please feel free to make updates.

Google Docs
1 RWKV: Reinventing RNNs for the Transformer Era Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Xingjian Du, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Jiaju Lin, Przemysław Kazienko, Jan Kocoń, Jiaming...
I don’t think the intention is to make something performant. Just functional and informative. But what I’m taking from this is that the code I linked would work as is for training as well, but in a slow and primitive state. Is that correct?
Possibly not,
Torch gets weird about autoprop with accessors[:,i] = tensors
You may need to do some .cat or stack tricks
Hmm. Ok. Thank you for the help.
What are their requirements? For example, horizontal and vertical ratio? Size and format?
Inline link: https://blogs.lse.ac.uk/impactofsocialsciences/2018/05/11/how-to-design-an-award-winning-conference-poster/

A0 is so large

Howdy again. I've submitted a draft here: https://github.com/labmlai/annotated_deep_learning_paper_implementations/pull/222 with @last mauve and I was hoping someone could help me implement a minimal training loop here: https://github.com/jahatef/annotated_deep_learning_paper_implementations/blob/master/labml_nn/RWKV/experiment.py#L136. The code there is nonfunctional. We've been looking at https://github.com/Hannibal046/nanoRWKV/blob/main/train.py, but this training script is fairly complex, and it would take us a long time to boil it down

I think this is a tittle obscure
https://arxiv.org/abs/2311.01981 nice trick to boost rwkv4 performance

arXiv.org
RNN-like language models are getting renewed attention from NLP researchers in recent years and several models have made significant progress, which demonstrates performance comparable to traditional transformers. However, due to the recurrent nature of RNNs, this kind of language model can only store information in a set of fixed-length state v...
To be more clear, can someone either:
- help me implement the training loop here to complete the labml submission. or
- commit to completing this loop, and I can add you to my fork so that you can work with us on this.
Appreciate the help!
Interested, would like to work on this.
Great! Would you like to be added to the gh fork?
Sure, that will be great
This might look like an alternative of ghost attention of LLAMA2 which is a trick not to forget instruction through putting instruction texts as the header of system utterances for each user-system interaction.
Would be cool if @obsidian quest can go wow everyone and answer people's questions 😍

Will there be a workshop? I really want to join
I'm not sure. Don't think we submitted to any workshops.
It looks like they might email us
Should this poster be vertical or horizontal?
Horizontal
so @gusty condor has made an amazing work with the first draft of the poster and we'd like to ask for feedback / suggestions (mine are annotated in purple and i'll be adding them in the next hours)

Wow, that looks amazing. Just a few nitpicks in chronological order:
-
Shouldn't it be 'Attention-Free Transformer (AFT)' instead of 'AFT (Attention-Free Transformer)'?
-
Not sure if 'tricks' is the best word here to describe our improvements over AFT: "Although RWKV is inspired by AFT, this is not the final form of the RWKV model, which includes many additional tricks explained below."
-
Words in titles can be capitalized. E.g., 'RWKV Architecture: Summary.'
-
In the diagrams, we used 'Time Mixing' and 'Channel-Mixing,' but here we use the hyphenated 'Time-Mix' and 'Channel-Mix.'
-
We called it 'output gating' in the paper but 'self-gating' here.
-
Maybe we can bold the Left/Right/Middle text in diagrams to make it more readable?
Hey, can someone share the code that was used to evalue RWKV and the other models from the arXiv paper?
Also was the base model tested or the falcon variant, cause we're unable to reproduce the results, we are getting 35% on ARC-Easy instead of the 48% claimed for the smallest model.
Someone please correct me if I'm wrong but I think we used
Code: https://github.com/EleutherAI/lm-evaluation-harness
Pile models: https://huggingface.co/RWKV
I just ran it and got:
hf-causal (pretrained=RWKV/rwkv-4-169m-pile), limit: None, provide_description: False, num_fewshot: 0, batch_size: None
| Task |Version| Metric |Value | |Stderr|
|--------|------:|--------|-----:|---|-----:|
|arc_easy| 0|acc |0.4752|± |0.0102|
| | |acc_norm|0.4150|± |0.0101|
Yeah this is what we ran, and indeed gives 48% +/- 1% as reported.
Which documents is the loss tested on?

From the Pile. I think it's the validation set, but don't recall off the top of my head
@obsidian quest you ran the loss calculations and sent me the numbers to use right? Are these train, validation, or test loss numbers?
training loss
Alright thanks!
Hey so I just ran 'RWKV-4-Pile-169M-20220807-8023' from https://huggingface.co/BlinkDL/rwkv-4-pile-169m/tree/main with that exact script and it gets 42% acc on ARC-Easy. Is the huggingface model different?

Here is the command I used. Could you provide a .txt file of your command line output?
python main.py \
--model hf-causal \
--model_args pretrained=RWKV/rwkv-4-169m-pile \
--tasks arc_easy \
--device cuda:0
I'm running it directly using the lm_evaluation.py file but I think I figured it out, thanks a lot!
- Done
- Deleted
- Done
- I intended to use shorter names to save space.
- Corrected
- I don't own these diagrams
did anyone fill this? otherwise i'm going to do so

Anyone plans to be in singapore for EMNLP? @void quartz @paper dove ?
I'm not in the registered authors of RWKV-EMNLP, so it's not convenient for me to fill that
Filled to present virtually
We can work on new articles such as arxiv-v2 or even RWKV-5
I'd love to work on a rwkv5 article
Can anyone pick this up? I think it'd be quick work for someone knowledgable on the project.
if it can be later this week i can help
yees

Yup! No problem. Would you like to be added to the gh fork?
=[ it abit too close to ai.dev conference, so i would be in SF : https://events.linuxfoundation.org/ai-dev-north-america/
Naive unfused wkv5 module

The RWKV-5 article/paper draft on overleaf is here:
https://www.overleaf.com/project/6554f20d4d10a35cdff3b448
I believe that we can finish this article once RWKV-5 training is complete, within the year 2023.
This link doesn't grant read permissions to people who didn't previously have it.
Ok now that the poster is in, we have the next two broad targets:
- arxiv v2 that's in-sync with the EMNLP submission
- Update the author list (Can anyone pick this up?)
- Merge in changes from EMNLP draft. Varies by section and I've been putting it off, but hope to finish it by Monday
- Push to arxiv
- Start setting up for RWKV-5
- Create an overleaf (looks like @gusty condor already did this for everyone, but this link is not shareable. Also, @gusty condor -- are you using an overleaf premium account? If not, I can put this under my account so that we get more compile time)
- Come up with a list of new contributions that RWKV-v5 introduces, and what results we want to include given those contributions. @obsidian quest and others, do you have a list of v4 --> v5 differences you can point me to? If it doesn't exist, let's add one to the new overleaf so that we can start planning design sections
- Once the above two tasks are done, I'll start creating task lists like I did for v1 and we can start working on the writeup together.
Here is a list of the main changes I'm aware of from rwkv4->rwkv5.2:
- now multi-headed, with per-head [decaying] state
r@(wk)@vinstead ofrwkv, so the [decaying] state is now a K channel memory bank of values <- this is similar to retnet- per-channel learned decay and boost (w and u) <- retnet does not have this, but rwkv4 did
- per-head grouped normalization <- various other models have this, including transnormer and I think retnet
- added a silu gate in WKV <- other models use gating as well
I'd be happy to integrate those whenever we have an accessible overleaf
The biggest question is what kind of claims to make about them, since they're excellent together but individually they are largely pieces that exist in other models that all fit very nicely into the rwkv puzzle and improve its performance dramatically
hard to say any of them were 'invented here' - the specific usage in concert with the underlying recurrent rwkv4 mechanisms is what's new
the only one I would think might have been 'invented here' independently is #2, the r@(wk)@v part which is like a recurrent decaying version of linear attention
and is probably at most concurrent work with retnet
As long as we motivate why these elements are suited to RWKV, I think that's OK. Bringing existing pieces together in a unique way with solid motivation is still a new contribution and requires enough insight to justify a paper submission.
We'll only face paper review scrutiny if we make it look like we're randomly throwing things at RWKV. Since that's not what we're doing, we just need to make sure our writing reflects that.
An online LaTeX editor that’s easy to use. No installation, real-time collaboration, version control, hundreds of LaTeX templates, and more.
Sorry for confusions, It's not me who created, it's Eric Alcaide
@gusty condor I'm confused, this looks like it's the previous paper?


Ah it default compiled v4 for me
Possibly hot take: a history of RWKV would make a great blog post but doesn't make sense being crammed into the "background" section of a paper
- I think some of the improvements in RWKV-1 in August 2021 are still pioneering even compared to the current transformer architecture.
- There have been some debates questioning the originality of RWKV. We can post out entire history of RWKV to resolve the debate.
- If architecture evolves so fast, at some time in the future we have to review the history again.
we have token shift, and not using rotary/xpos/etc.
https://github.com/BlinkDL/minGPT-tuned goes back to 2020 (check commit history)
haha added to things i need to write on list 😄 for the RWKV blog
(will crawl through blinks repo history)

I also don't think that framing these as a historic subsection would be appropriate. We can point to prior internal RWKV works in the "related work" section if we want to establish ourselves.
We can explain the previous RWKV in the background, but we should frame those as "getting the reader up to speed on what the architecture is" and not "a trip down RWKV memory lane". This reframing is as simple as taking "history" out of the name and replacing with "the RWKV architecture" or something, and the content should be purely on the architecture. No personal or organizational stories should be included
OK, I agree with that
token shift is really amazing, but this was just a list of new items in rwkv5.2 that were not present in rwkv4 so people know what to put in the new portion vs background
Also Zhihu history, the original idea of RWKV is posted here https://zhuanlan.zhihu.com/p/397985790
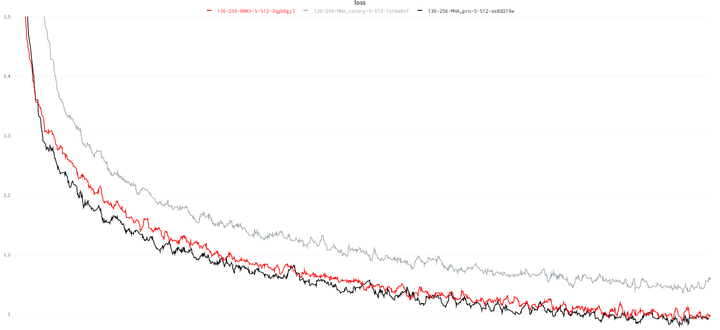
知乎专栏
本文提出一种 RWKV 语言模型,类似线性注意力,适合长 context,运行速度较快,拟合性能较好,占用显存较少,训练用时较少。 模型由交替的 Time-mix 和 Channel-mix 层组成: \begin{align*} \text{Time-mix :} &a…
Just to clarify in case there was any misunderstanding, I am not questioning that rwkv is original work 🙂 (Also, I think it's amazingly great!) My question about what can be considered to be new inventions for the purposes of a new paper was intended to be specifically regarding what makes version 5 different from 4. My apologies if that came off badly!
No problem, I understand, it's the
- improved WKV module
- with head size 64 and matrix valued larger states
- removal of denominator for numerical issue
- addition of an extra group normalization
- extra SiLU gating
- reduced dimension of channel-mix in exchange
Do you know if the matrix valued multi-headed module was developed/discovered concurrently with or following retnet? My impression from seeing the rwkv discord at around that time was it was immediately following, but I'm not at all certain about the timeline. It's of course part of the whole rwkv5 model improvements either way - I'm just asking if it could be additionally claimed as an independent invention on its own.
iirc, it was after reading retnet paper
Following RetNet, the proof is here: https://zhuanlan.zhihu.com/p/645094812
知乎专栏
首先 AFT 和 LinearTransformer( https://arxiv.org/pdf/2006.16236.pdf) 都是旧论文,区别是:AFT的headsize=1,LinearTransformer的headsize > 1。然后RWKV最早做了加ExponentialDecay转RNN方案(在RWKV-2-…
Actually, RWKV and RetNet followed each other. RWKV-5 followed RetNet, and RetNet followed RWKV-4.
I think to add on to this, we may want to be careful about phrasing anything as "we've previously done this...", for anonymity purposes. I added this as a comment in the overleaf as well
Do we have experiments (or theory) to support these new changes?
I think we can use prior works to motivate these changes, or we need to have experimental evidence that they each improve the architecture in some way.
I would expect that reviewers will want to ask about each individual portion, and how we came to the decision to make all of these changes.
That was BlinkDL's experiments
it seems that they are all able to be motivated by other prior work
matrix valued states from retnet
groupnorm from transnormer and maybe retnet
gating from various others
Yes! Token shift is not however, therefore might need an ablation study
good point! btw ive been adding some rwkv5 and 6 formulae to the paper
not quite done yet but it's a start
I figured as long as I was putting in the formulas for 5 we might as well have 6 ready to go... also, who knows when this gets published so maybe by then we'll want to show 6 as well
Within 2023
@gusty condor notation style in your edits is a bit different from the rwkv4 paper, probably more precise but not sure if we want it to be standardized between the papers?
one other question, do you think it might be easier to read if we keep everything specified per-head throughout the main equations since that way there would be fewer subscripts?
Style:
- All matrices are bolded, vectors are not.
- \cdot (or written together) is matrix multiplication, \odot is element-wise multiplication. Two operands of \odot must have the same shape.
- All vectors are row vectors, unless explicitly stated, so matrices must operate at the vector's right side.
These conventions make it easier to track the shapes of matrices and vectors, which helps sanity checking.
matrix valued states were used by the original linear transformer
retnet = linear transformer + exponential decay (i was doing it first) + xpos. nothing new 😉
let's go for 5+6. v6 1.5B in 26 days. results look good
What's new in V6?
data-dependent shift & data-dependent decay
That's going to be an interesting flow chart to draw for the architecture.
Yeah the formulas are a bit intense bc of lots of lora weightings. I guess I gotta make functions for all that
I wrote the rwkv6 calcs three ways... let me know which is the least annoying to read or if you have other ideas on how to express this complex combination of lora and shifting
Guys if you need some help I can give my contribution
Yes, I think introducing new operators is necessary if we want to save spme space, otherwise we have to use single column
We should use single column regardless
Is your opinion about the what's new at the v5 compared with rwkv (< v4) and the other related models ?
Yeah, I was asking if any mechanisms added in v5 were new inventions and not combinations of preexisting inventions. To figure out what claims to make in the paper
just describing the full architecture and clarifying what changed in v5 and v6 (and why) seems fine so far
@obsidian quest what factors do you use for the LoRA reduction in v6 right now? I know it might change, I just need something to put in the paper as a placeholder
fixed size 5*32 for time_mix (32 for each of w/k/v/r/g), 64 for time_decay
So, not D/4, Since D* (D/4) is a large amount

Yeah, I only put in D/4 as a placeholder until we heard back from blink
okay I updated that in overleaf
pls show a similar table so everyone can see v4 v5 v6 are natural evolutions
sounds good. We can add a table in section 3.1 to illustrate the changes. (I might not get to it for a couple of days - holidays here)

cool! also, thanks for noticing and fixing my mistake w/ lambda vs W on DDlerp
it seems like the formula for rwkv6 w got changed and lora_\omega became missing but I somehow don't see the changelog on it. I tried to put it back to what I think it should be. not sure if we should change the d naming to something else since omega is now a little odd
see https://github.com/BlinkDL/ChatRWKV/blob/0f9fd50b7a8b4d317a87e4f1ad7e713a275df11e/rwkv_pip_package/src/rwkv/model.py#L846C5-L846C5 for reference
GitHub
ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source. - BlinkDL/ChatRWKV
per my above comment, this graph appears to be missing the second lora (the 64 sized one) on the results of wx
the initial lora that's shown is still size 32 in blink's code, it's just missing the second lora on the result of that
Not missing, I have taken into account
I added "width 64" below the fourth DDLerp from left to right, which is for \omega
Let's see if this looks better

the timemix lerp part is wrong 🙂
should be x & x_prev == [ lerp ] ==> xxx == [ lora ] ==> w/k/v/r/g lerp factors => xw/xk/xv/xr/xg
and then xw == [ lora ] ==> w
That fourth red one is still 32 wide in the actual model and there's supposed to be an additional 64-sized Lora above it (see blinks comment above and the code I was referring to)
extremely complicated 🙂

Hehe it really is! Took me several read throughs of the code and I still got it wrong when I added it to overleaf 😂

How to add these data? As tables or plots?
Also, I'm not entirely sure about the model parameter count. I counted 13D^2L + 598DL + 4D + 2DV, but the actual number might be different
I prefer table, personally. Hard to tell what's going on with so many values plotted. Would be nice if there was a clean separation of model sizes - it's unfortunate that our sizes don't match others very cleanly
Maybe we can also plot some figures like this in first RWKV paper and put them into appendix? it makes the scaling more clear maybe...

Added a subsection to introduce the tokenizer
not using lora in channelmix
oh you changed it back so it's same as v4 and v5 now?
I see that here https://github.com/BlinkDL/ChatRWKV/blob/0f9fd50b7a8b4d317a87e4f1ad7e713a275df11e/rwkv_pip_package/src/rwkv/model.py#L579
so the only difference really is that k_maa is the amount of x_t-1 to use, while in v4-5 k_mix is the amount of x_t to use, correct? which is really just an implementation detail
GitHub
ChatRWKV is like ChatGPT but powered by RWKV (100% RNN) language model, and open source. - BlinkDL/ChatRWKV
yeah just implementation details. less operations
which versions use the new tokenizer?
sorry, I was mistaken and blink apparently isn't using ddlerp in chanmix any more so your chart can revert to v4-5 chanmix
I updated overleaf accordingly
(was originally going off old comments in rwkv discord, and hadnt seen the actual new code for it)
Have you experimented lora in channel mix?
seems redundant after training for a while
All new versions with World endings
RWKV-4-World, RWKV-5-World and RWKV-6-World
I now added a table like this at the end, maybe for inclusion in an appendix. Not happy with the way it looks yet tho...
Also, just to make sure: you stopped using data dependent time_first (u) in RWKV-6, correct?
on a different note, Stella was saying we should move to single column layout, but I'm too new to latex to understand how to bridge the incompatibility between \onecolumn and \maketitle - maybe someone else here knows?
@obsidian quest one more question, I realized I made an assumption that w_maa, k_maa etc. in rwkv6 are learnable... are they parameters or fixed values? We have them listed as learned parameters currently
learnable
Add \onecolumn after \maketitle will start a new page
The problem is due to our template (which is EMNLP2023). Feel free to change a template.

Neurips_2023, but with line numbers? Trying to remove that.
Done.

Matrix-valued states

@misty igloo I found this article interesting: https://arxiv.org/abs/2207.02098
Can we try some on RWKV-5 and 6?
My expectation is that RWKV will outperform both Transformer and LSTM on these tasks, but if you want titles like this:
% RWKV-5 and 6: Towards Neural Turing Machines as LLMs
% RWKV-5 and 6: Enhanced Neural Turing Machines as Recurrent Attention
% RWKV-5 and 6: Modified Neural Turing Machines are All You Need
Then the evaluations on Chomsky Hierarchy is crucial (which shows how powerful a neural Turing machine is).
arXiv.org
Reliable generalization lies at the heart of safe ML and AI. However, understanding when and how neural networks generalize remains one of the most important unsolved problems in the field. In this work, we conduct an extensive empirical study (20'910 models, 15 tasks) to investigate whether insights from the theory of computation can predict th...
i'll take a look! It's possible I misunderstand NTMs, but I thought the latest RWKV memory state acts extremely similarly to them
also, not married to any particular title... was just suggesting ideas on what might make it more interesting (and still hopefully be accurate and descriptive)
but you're right that we need to validate it experimentally
my hunch is that the current state mechanism acts as a fixed-size random access memory for the purposes of the chomsky hierarchy
especially in v6 where we now have a real data-driven forget mechanism
from a theory perspective, what mechanism(s) is v6 missing that an NTM contains? for writing they use erase and add, where in rwkv6 we have decay and bonus
but I suppose while we do have content-based addressing we're missing the location-based addressing mechanism
@obsidian quest rotational location-based addressing might be interesting for v7
Adaptive computation time (https://arxiv.org/abs/1603.08983) and reusage of parameters (https://arxiv.org/abs/1807.03819) (Turing machine is the same function iterated over and over again on a tape)
arXiv.org
This paper introduces Adaptive Computation Time (ACT), an algorithm that allows recurrent neural networks to learn how many computational steps to take between receiving an input and emitting an output. ACT requires minimal changes to the network architecture, is deterministic and differentiable, and does not add any noise to the parameter gradi...
arXiv.org
Recurrent neural networks (RNNs) sequentially process data by updating their state with each new data point, and have long been the de facto choice for sequence modeling tasks. However, their inherently sequential computation makes them slow to train. Feed-forward and convolutional architectures have recently been shown to achieve superior resul...
We can make a Universal RWKV or something, but that's another article.
can try adding [pause] token first
yeah still seems like an interesting direction
Thanks, that's helpful for my understanding of the remaining differences.
imho the problem with reusage of parameters is that a single function/layer isn't a lot of 'algorithm' for the machine to run... it's like having a very short program that can run on a long tape. We've all written programs and the code often needs to be longish even if you have lots of RAM available
[pause] is one way of keeping the program code longer while allowing multiple iterations but I'm sure there exist other alternatives
and traditional software of course allows loops for specific subregions of the code, not just the whole program
maybe each layer needs the equivalent of repetition until 'halt'
this is of course going way off track from discussion of the rwkv5/6 paper 😉
sorry hehe
No, Universal Turing Machines are extremely simple.
very true. But for language modelling (or any specific task) there still needs to be a program of some sort stored somewhere - that could be on the tape, or it could be in parameters
my assumption was that it was going to be in the parameters, since the tape usually doesn't start out with anything extra on it that doesn't come from the input text [embeddings]
RWKV 6: LINEAR RECURRENCE NEURON TURING MACHINE IS ALL YOU NEED
I think that its analogy is like "right-foward-move" only Turing Machine or "One-Way Streaming Turing Machine".
@misty igloo Could you explain location based addressing in short and how does it help? Thanks!
If anyone wants to mention Turing machine, I think it's necessary to benchmark the Chomsky Hierarchy since it quantitatively tests how powerful an Automata is.
I strongly recommend not mentioning it, as it's extremely irrelevant to DL despite people's obsession with it.
I am just saying as an analogy. hehe
I updated the paper to use the authblk library as I find that for papers with many authors it's the easiest and cleanest way to manage an author block
@void quartz is "the RWKV Foundation" an entity? My understanding is that the actual org is called the Generative AI Commons
No the actual entity is 深圳元始智能有限公司 (Shenzhen Yuanshi Intelligent Co., Ltd.)
I don't understand. I'm talking about the non-profit research foundation that RWKV joined.
see 1410.5401 section 3.2
But I agree with Stella, let's drop the NTM discussion for the purposes of this paper 🙂
my understanding is, RWKV Foundation is now a virtual entity under LFAI
@void quartz let's find the best method to say this
It is under the Linux Foundation. More specifically the gen AI commons
Been using “RWKV project under the Linux Foundation” in compute grant application. And I cleared that phrase with the LF team
I actually have a call with Matt White and Lucy Hyde tomorrow and can ask them
Didn't mean to open pandora's box with the NTM mentions. But I still think we need a better title, since a) the models do more than add larger internal states and b) retnet already uses similar matrix valued decay state.
The other ideas I wrote in as comments were:
RWKV-5 and 6: Enhanced Recurrent State Mechanisms for LLMs
Matrix-valued and LSTM-like States for LLMs
RWKV-5 and 6: 2D LSTM State for LLMs
I'm not necessarily recommending these in this form - they are just spitball ideas to get things rolling.
I know that there's a hierarchy of:
LF -> LF AI & Data -> GenAI Commons -> RWKV
I'm just not sure what level of that hierarchy makes sense to use to refer to an entity (this was promoted by seeing "RWKV Foundation" as an affiliation on the paper)
Yea that’s the full chain. Since it’s a paper, it can afford the space for a longer title?
Another question: WKV6 is very similar to GateLoop, though it started training way earlier than the GateLoop preprint. How to treat that work?
2D LSTM is reasonable, but it's still different, since nonlinearity is mainly from the Channel mix module
Never heard GateLoop
arXiv.org
Linear Recurrence has proven to be a powerful tool for modeling long sequences efficiently. In this work, we show that existing models fail to take full advantage of its potential. Motivated by this finding, we develop GateLoop, a foundational sequence model that generalizes linear recurrent models such as S4, S5, LRU and RetNet, by employing da...
Its title accurately describes RWKV6 as well
I see, but they didn't even cite RWKV
if they were to cite, it must be RWKV6, but there're nowhere to cite RWKV6 up to now
unless you'd accept a reference pointed to a github commit
As to the title, I'd prefer one mentioning multi-head linear attention and data-dependent decay/gate
(over NTM)
So it’s gonna be one paper for v5 and v6?
that's what blink asked for, so the current draft contains both, but we could easily split it back up if necessary
Or ur intending to just focus on the state size increase and compare them side by side
How is the compute grant application going? https://docs.google.com/document/d/17JBx_h-8k5S36Z5d1rggLL3wFL8iLXSGjvLUNm0F5AM/edit

Google Docs
Project Information Project Name Shaping the future of sustainable AI: Innovation Advancement through Scalable Energy-Efficient Foundation Models Innovation Advancement through Sustainable and Scalable Energy-Efficient Foundation Models Sustainable Energy-Efficient and Scalable Foundation...
We are working with them to get scaling numbers. Final decision is next year
So far we gotten 2M tokens / sec on a 3B for 160 nodes. But can’t seem to go further due to some sync issue
That's so fast
PS: that’s technically their AMD mi100 cluster not the cluster we applied
that's only <40 TFLOPS per GPU...
Yea driver bottlenecks is a real problem
That's what I can only imagine 🙂 RTX4090 90TFLOPs
Anyway since there is still time till decision. Pushing to go past the 160 node barrier haha
All the numbers were from <1hr test runs
no it's 165.2/330.3 for bf/fp16
My concern is the title sets up the expectation that we do the comparisons across v4 / v5 / v6 - with that framing - and that bloats the paper. When we can focus on v4 to v5 in one paper then v5 to v6
On that note. To compare the models …. Do we need a v5 pile?
Not sure how we plan to compare v4 to v5 - different tokenizer and dataset
Around specific evals like memory it can be very clear its architecture change. Beyond that, a criticism could be the change in dataset
No, if we have intermediate checkpoints
Compare with World models
I thought v5 world is not trained on exactly the same dataset than v4 world?
Did we fail to get NVIDIA GPU accesses??
Simultaneous work, mention it in passing
If we are going to pump out new model variants faster than papers, we should start using minor version numbers so that the major version numbers line up with the papers.
e.g., v5 -> v4.1, v6 -> v5
(Or v5 -> v5.1, v6 -> v5.2)
IMHO, the latter is better because matrix valued decaying seems to be crucial in the memory features which v4 totally lacks.
v4
vs.
v5.2 (w/o time-decaying depending on data) is what we are calling v5 now.
v5.3 (w/ time-decaying depending on data) is what we are calling v6 now.
I guys, I would like to give my contribution to this project. There is something I can do?
You could check RWKV's discord server rwkv-x channels for architecture discussions.
See blink's github
The genie might be out of the bottle for rwkv5 at this point, since it's already publicly available under that version nomenclature. What if we put only RWKV-6 in the title, and describe both incremental changes within? Or we could split into two papers... but that might force us to double up any new experiment runs required
or I guess the RWKV5.3 idea works (there was already technically a 5.1 and 5.2)
I'm a little worried about this minor versioning idea though, since to end users it may not be at all obvious that the model weights are totally incompatible
likely to cause significant support problems
haha, i think we need to have a discussion on verisoning numbers, cause likewise i think folks are confused as well
since genie is out of the bottle, maybe we can do something like nodejs or many other projects Stable / Unstable versioning (added to the agenda for TSC later)
v5 can be stable, while v6 is still unstable, then v7, when its out should be stable when its out
Indeed, the difference among GPT-1, 2, 3, 4 is just increasing the parameter size. 😆
ours is still define as having code changes, so its not compatible (without conversion)
i like your idea about unstable
none of this addresses Stella's concern about paper numbering but I think the compatibility is more important to signal properly
technically the AMD cluster is an upgrade
( the nvidia cluster is the much older v100s, the only benefit is they have scale )
uncertain what we will actually get at the end (if any) - they tested both, but it seems like the direction they are testing towards is the new AMD cluster
Does AMD's middlewares like cuda or cudnn or drivers are sufficiently supported ?
https://www.reddit.com/r/MachineLearning/comments/wbdq5c/d_rocm_vs_cuda/

Reddit
Explore this post and more from the MachineLearning community
My concern is about public communication about your great work.
I personally agree to this concern.
ML/DL model "versioning" seems to be different from the stricter semantic versioning of usuall software like python 3.11.x
Even just increasing the # of params gives GPT's "major" versions.
I personally think that huggingface's transformers numerous foo_modeling.py shows the difficulty of "strict semantic versioning" of DL models.
We tried to make GPT-J and GPT-NeoX the same model type on HF and they were like "no you're calling it something different it's a new thing"
not out of the box, there is literally unreleased driver code changes being worked on with AMD. I mean they work, but the default is really slow
it took like 3 month back and forth to hit 50% gpu usage
So do you think we should change 6->5.3? I'm just worried it's going to cause support problems for people actually using the models (vs researchers)
On an unrelated note, I think it'd be useful for accept all changes on the overleaf so we can start seeing new differences easily but I didn't want to do it without asking first
Why would it cause those problems?
only because people expect minor version numbers to be in some way compatible
i have already met folks in person who are confused about v6, when they thought we are launching v5 😅 and asking if they should wait and use v6
and this is for them to play with the model (not evals)
yeah but imagine the confusion if 5.3 (previously 6) is like totally incompatible with 5.2... we actually already have that problem with 5.1 which is much less different but still have to support in the same codebase everywhere since there's a small model in the '5' range that relies on it
request. can we move this convo to the main discord
not sure if its paper related anymore
the fundamental related questions, in terms of the paper, are:
single paper for 5 and 6?
name it differently to avoid confusion?
i like chrome style versioning 🙂 lets reach rwkv v100+
does anyone think we should NOT press 'accept' on all revisions on the paper at this point? I think it will help us track actual changes going forward
I think it's okay to include the changes for both, as long as all the information fits into the appropriate paper length.
I can imagine the paper setup to be something like:
Methods:
RWKV-5: Improvements made up til this point
RWKV-6: Improvements made on top of v5
Experiments: compare all of RWKV-4, 5, and 6
Of course, it may be complicated to fit all the details into 8-10 pages, so we should be careful that we're not overloading it
I think it's still ok to mention it, as long as it's relevant to cs.CL
okay I went through and accepted all the changes to date - should be a lot easier to see what changes from now on
regarding versioning
Details to be finalized, but we will be splitting versioning on two tracks. A more experimental branch (rwkv-x-???), and a more stable branch (rwkv-vK)
So in this flow, the current v6 will be renamed to an -x variant, till it is finalized, stable and gets promoted to the stable branch. This allow blinkDL and others to make as much changes as they like in the "experimental branch". And promote to stable when its finalized
This allow a clearer, more stable release, with clearer communication / coordination.
This would also reduce the confusion like V5, R1, R2, R3, and R4 varients
current models will be like
rwkv-x060-3b-world-v2-14%trained-20231129-ctx4k.pth
rwkv-x060-1b6-world-v2-42%trained-20231130-ctx4k.pth
p.s. x061 is coming 🙂
can x061 switch back lerp to work the same direction as v4, v5? hehe
current mix is faster than pytorch lerp
i know, I just mean the direction of it - not the mechanism
it switched directions between v5 and v6 when you changed the code to be more optimized
see #1097928558309036042 message
(We can talk about this in rwkv discord if needed)
I thought we had a 169M model.

Rwkv-4, but no 5 or 6, looks like
V040(the new versioning)-Pile has 169M
V040-World is 193M
V050-World is 193M
V052-World starts from 462M (the article is currently describing)
X060 is under development (estimated at 197M and 473M)
It seems not to be uploaded 463M V052 at https://huggingface.co/RWKV


{kind=link}
{kind=link}
this is cool https://bbycroft.net/llm we need one for rwkv
A 3D animated visualization of an LLM with a walkthrough.
woa

Did anyone see this paper?

I would email the author with a correction
Also the performance grades look incredibly suspect
Yeah RetNet and this paper seems mostly from Microsoft and they just inflated their own product…
Any seen the Mamba paper yet? https://arxiv.org/abs/2312.00752 They incorporated a gating mechanism similar (in purpose) to the updates in RWKV-v5/6
arXiv.org
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to addr...
this was posted here back when it was in review here
#1103039376184852622 message
yeah mamba has great numbers but i still cant get it to run yet
why? some installation issue?
i've been trying to figure out if there's a way we can try their combined FFN idea in RWKV without blowing parameter budget
installation issues
have you tried this?
https://github.com/state-spaces/mamba/pull/2

GitHub
Issue: Using pip install . was failing with the following error:
Building wheels for collected packages: mamba-ssm ...
ok it works now
love to know how it compares w rwkv x6 on same dataset, even in early going
RetNet is MsNet, 😉
The definition of parallelization have to be considered... As picocreater mentioned in GH issue of unillm.
We support 3D parallelism though
rwkv has same kind of parallelism as mamba
tipping works for v5 (but not for v4)

That looks like a joke but we got one more citation 🙂
By derogating other products that might be competing against them, which is not OK
Yeah a common used trick in deep learning papers... lowering the baseline
To be fair, none of the RetNet authors are on this, so maybe they just cited other papers directly without checking.
Yeah maybe just ignore the detailed checking and just using the RetNet results, sorry I just guess
https://arstechnica.com/information-technology/2023/12/ibm-meta-form-ai-alliance-with-50-organizations-to-promote-open-source-ai/ haven't checked for Eluether on this one yet

Ars Technica
What's the opposite of OpenAI? IBM and Meta devise plan that includes 50 members.
from community

Ravens, Mambas and Transformers
By the way, let's hurry for the RWKV-5 article (Mamba is still citing RWKV4)
The retnet paper claims was used against us (not by the author) in a recent compute grant application. Thankfully, I was given the opportunity to clarify citing the author here https://web.archive.org/web/20230916013316/https://github.com/microsoft/unilm/issues/1243
But it’s hard to say how often do I not get the opportunity to clarify
Even if retnet paper refused to change. You can push the other papers to clarify what they mean, and push for amendment
Oh boy I forgot how much dicks they were about this

The promised "next version of our paper" never happened
do we mostly just need the experiments? rwkv-5 3b and 7B still haven't finished training... and neither has RWKV-6 1.5B 🙂
Hey, have you guys tried any softmax variations like sigsoftmax or multifaceted softmax? It seems like this would be a natural enhancement, with a potentially big impact.
Why do you think this would be better than the current set-up
Might not be, the attention-like benefits could already be achieved - having multiple categories held in memory for places where softmax is used might be a boost, though, especially with data driven decay if I'm understanding how things work?
Seems like it could give you flexibility in how high level concepts are prioritized over time and directly tied into decay and attention gating
https://aclanthology.org/2022.acl-long.554/ this paper for reference
Agreed. I'll be more free next week and can start pushing for this again.
Emailed and also asked for additional clarification on +, ++, and +++.
Got a very quick response. They will update arXiv in late December.
...
The term "parallelization" is meant to refer to parallelization within sequences or chunks. To avoid any future misunderstandings, we will omit the parallelization column in our revision.
As for the performance indicators, they are majorly sourced from Table 5 in RetNet (as the attached image), which reports perplexity numbers on both in-domain validation sets and various out-of-domain corpora. From Table 5, we can see H3 slightly outperforms RWKV and Hyena in general, thus we assign it with one more '+' sign.
...
The table ^

That's a really stupid standard to use, but also doesn't H3 underperform RWKV on all of these tasks? RWKV also outpreforms RetNet
Not too familiar with these benchmarks. I think lower is better for perplexity
even their limited claim is annoying - you absolutely can parallelize rwkv within chunks by using parallel scan, it's just not necessarily desirable to bother
This evaluation is just weird in general. Each model is trained on different data, their performance on each individual "out-of-domain" corpus is a function of the data just as much as the architecture. Unless I've misunderstood and they actually trained each model from scratch on the same data
I was going to say this but stopped myself because I wanted to look at the paper again. If the evals are framed as being about the architectures you're correct that they're entirely invalid. If they're framed as being about which model artifact to use that's mostly fine. However in such a context it's still the case that comparing in-distribution loss (does that mean validation set from the training corpus?) is meaningless
mamba paper showed more results on this
at 2x10^20 flops in their test:
hyena < vanilla transformer < rwkv4 < retnet < h3+attention < mamba < modern transformer
however the slope of rwkv4 is the best among all models, so it may catch up and surpass more models, similar to how it surpasses vanilla transformer

all papers should mention they are comparing with RWKV-4
They may not know that there's a V5 and V6 yet 😢
Also, I think it's generally the standard practice for academic papers to compare with the most recently published works rather than the most up-to-date versions on github
Yes, this is considered best practices in part because people can't be expected to know about everything on GitHub
BTW, I live in Japan not colored green or blue.
Thank you!
Have their article been already published as the first version with no modification?
Probably not
Do we need a long-context FT models for 8k, 16k, 32k ( or more even 64k, 128k) ?
IMHO, the answer seems to be yes.
I think that comparison with RetNet, Mamba and the other SSM like models are needed.
We should do experiments on 1.5B and 3B first, and on partially trained versions, for a full comparison.
Yes, but we can do experiments on the 4k versions first. The current 4k models have the ability to exceed context length even without fine-tuning.
@tough crane @gusty condor
BTW, what's going on at EMNLP, is somebody presenting the paper? It would be great to see how it's going 😄
Just found the schedule here: https://docs.google.com/spreadsheets/d/1CB9fsADV_U2Dce6Pe47AT-OlmyTOXkEmYqEqt8RMH5c/edit#gid=0

Google Docs
Tutorials Schedule
Date,Time,Room,Tutorial Title ,Authors,Presentation Mode
2023-12-06,9:00 - 12:30,Pisces 1,T01: NLP+Vis: NLP Meets Visualization,Shafiq Joty, Enamul Hoque and Jesse Vig,Hybrid
2023-12-06,9:00 - 12:30,Pisces 2 & 3,T02: Security Challenges in Natural Language Processing Models,Qi...
It seems that the time has passed
On a side note, we expect the RWKV-5 7B model to be trained by year's end. After running experiments, we can aim for an ICML submission and release a preprint for benchmarking.
If i remember correctly, @tropic minnow registered to present the paper online
When is ICML 2024's anonymity period?