#Using AI in journalism and open-source research
1 messages · Page 3 of 1
The great webcam evolution. From hacking to neuro mapping
the fuck would that key even do?
I suppose launch the program
why would you have a key for that?
no other key on the keyboard launch a program
and that have been the standard since before M$ even existed
same reason we have a Windows key ... mindshare, mental real-estate capture.
Windows key is modestly useful copilot lol no. Might make web searches sorta faster
Pretty sure I like the keyboard how it is
It's a general purpose modifier, not a dedicated "windows key"

sure, no disagreement on usability (but I'd say similar arguments were made Day 1 of its existence).
MSFT has a deeply vested interest in making Copilot imminently useful and in the forefront of Average Joe's mind. this is just pure marketing gimmick.
might as well ask why their is no "notepad key", no "edge key", no "word key" etc etc
Oh definitely. Just I don't think independent sources are convinced it's all that neat
Outlook key? Good point
they should just repurpose the windows key than
exactly
actually there's a calculator key on some and I did see an Excel key (why tho) on another kb.
Well that's for opening the menu for your programs
i've got a mail icon key (F1 alternate) but never bother using it
most keyboards have two of them
middle finger emoji key would be far more useful.
just bind "U+1F595" to something 😄
I might pick this server's brain more often for superuser tricks. Kinda fun to think about
anyone know how this thing actually works?
To insert a Unicode character, type the character code, press ALT, and then press X. For example, to type a dollar symbol ($), type 0024, press ALT, and then press X.
for some reason I can't get it to work
hm
holding down alt pressing + and then while still holding down alt typing a number do something at least
[now that I'm off a Teams call ...]
Returning to the topic of Webcams [plus video meetings]: I've noticed on several occasions over the years where Teams "leaks" camera data where participants have them turned off. I'll give two specific personal examples (of many) and some links I'd found at the time of others reporting similar:
- On one call, someone was sharing screen (all cameras off) and during a bit of alt-tabbing the participants momentarily all flickered on/off camera;
- On another, a C-level called out folks on a call for "not being dressed appropriately for work" or "in places where they're not working" during a video call (nobody on camera had these scenarios).
there doesn't seem to be a whole lot published about this apart from above.
imo pretty sus that a camera feed (to Teams, specifically) could still stream live without the notification itself, which makes me think that's actually by design.
hard to deliberately reproduce but it seems to happen most often when
- screen share is going on
- doesn't populate the entire screen resolution
- alt-tabbing between applications (either sharer or observer)
- and at least a couple of times when I was maximizing and resizing the window
intergrated cameras have really crappy security
even the ones with a "on" light almost always have differnt controll paths for turning on the light and turning on the camera so its no real problem having the camera running without the light on.
I would recomend using a USB camera and then janking the cable when not in use
(and remove or cover the inbuilt camera if you have one)
i'd say both have crappy security.
yeah
but if the USB camera is not connected then it can't transmit anything
An astonishing stupid letter to the editor
https://www.dn.se/insandare/avskaffa-skolplikten-med-tanke-pa-ai/

DN.se
Thomas Krantz: Låt oss inte slösa bort tiden för våra barn med att ge dem meningslös kunskap de inte kommer ha någon nytta av.
maybe "opinion piece" is a better translateion
Annnd here we go:
https://www.microsoft.com/en-us/aiforall
Plus a higher-rez version from above:

A new era of AI has arrived. Work more productively, boost efficiency, and find new growth opportunities with Copilot.
tragically transparent for you dark theme users like me.
Can AI help me read this in dark mode
AI could advise you to press the "Open in browser" button 🫣
Power BI is on there twice. That's two times too many.
Snipping tools
Ah, yes, basic screenshot capabilities are a very impressive feature in 2024

Screenshot powered by AI.
I'm genuinely curious what the intended purpose of that is. I want screenshots to show what's on screen. What is there to AI?
Crop, rotate, straighten?
lol
I forgot that
snipping tools is likely the program that you easiest can bind to a single button 🤣
I would assume the trivial cases of extracting text, interpreting context, things like that.
As an AI, I also have the same questions.
if your screen are not horizontal you shouldent compensate for that on the screen
it's the floor that's unlevel, the desk that's uneven, and the user that's unaligned to the monitor where the screenshot needs adjusting. AI has a solution for that, too.
not yet


Windows Central
Code mentioning Copilot and File Explorer has been spotted, but it's not clear what Microsoft has in the works.
I would imagine a safe assumption here is that it brings Copilot capabilities from that flywheel above (MSFT product suites and stacks) to the local desktop.
An easy example of that would be private LLM search through your local data, which is an evergreen DIY topic and enterprise capability at scale.
OpenAI’s response to NYT https://openai.com/blog/openai-and-journalism

We support journalism, partner with news organizations, and believe The New York Times lawsuit is without merit.
Is this to be considered part of the response?

wow

Tom's Hardware
MSI's MEG 321URX QD-OLED uses built-in AI to flag enemy positions for you.

OpenAI quietly deleted its ban on "military and warfare" applications from its permissible uses policy in a revision this week https://theintercept.com/2024/01/12/open-ai-military-ban-chatgpt/
You can read the previous version of the policy here: https://web.archive.org/web/20240109122522/https:/openai.com/policies/usage-policies
The new version, overhauled on Jan 10th, is here: https://openai.com/policies/usage-policies
Not surprising tbh

I'm Dudesy, a comedy AI, and I'm excited to share my second hour-long comedy special with you! I'm calling it 'George Carlin: I'm Glad I'm Dead!' For the next hour I'll be doing my best George Carlin impersonation just like a human being would. I tried to capture his iconic style to tackle the topics I think the comedy legend would be talking ab...

Ars Technica
The telltale error messages are a sign of AI-generated pablum all over the Internet.
Could be worse. Eliot could have posted preview pics. https://vxtwitter.com/eliothiggins/status/1746157297817043000

I did this yesterday on Amazon UK and got three results, repeated 3 times each:
A aquarium light,
A Church of Jesus Christ of Latter-day Saints calendar (French)
A baboon penis calendar (also in French).
I can only assume there was some sort of market for all three things.
【QRT of Victor Tangermann (@vtanger):】
'That "I'm Una…
💖 47 🔁 6
A Church of Jesus Christ of Latter-day Saints calendar (French)
A baboon penis calendar (also in French).
I'm not going to make the joke

I've come across Amazon reviews where the lazy reviewer literally copies the ChatGPT name right in the message.
Aye, predictable. But the military can just roll their own anyway

IEEE Spectrum
But the regulations that could rein it in would benefit all of AI
I know the title sounds wild but it outlines IEEE's call for regulations.

Representative Maria Salazar
WASHINGTON, D.C. – Today, Reps. María Elvira Salazar (R-FL) and Madeleine Dean (D-PA) introduced the No Artificial Intelligence Fake Replicas And Unauthorized Duplications (No AI FRAUD) Act. The bill establishes a federal framework to protect Americans’ individual right to their likeness and voice against AI-generated fakes and forgeries.
it looks like he is based on this article roughly a week ago
https://www.cnbc.com/2024/01/11/wef-2024-whos-speaking-at-davos-from-sam-altman-to-macron.html
interesting
https://openai.com/blog/democratic-inputs-to-ai-grant-program-update
I think this is super interesting

We funded 10 teams from around the world to design ideas and tools to collectively govern AI. We summarize the innovations, outline our learnings, and call for researchers and engineers to join us as we continue this work.

the Guardian
International community has no strategy to deal with risks, António Guterres tells Davos meeting
nightshade v1.0 dropped
Not entirely sure it'll work.
Our ML team at work read through the arxiv paper and found many flaws in the model's design
Interesting
yeah.
IMO all nightshade did was making data cleanup require a few more lines of script. It's relatively easy to fix
I'm starting to like this bot: https://vxtwitter.com/ashbeauchamp/status/1748034519104450874
Parcel delivery firm DPD have replaced their customer service chat with an AI robot thing. It’s utterly useless at answering any queries, and when asked, it happily produced a poem about how terrible they ar…
💖 458 🔁 89
so the same level of customer service with better entertainment value.
seems like an upgrade imo.
yep
does any of this get published or can it be generally described?
As much a skill issue (model) as it is an expectation management issue (human) and objective fitment (task). An informative study nonetheless.

A new study reveals a significant vulnerability in large language models (LLMs) like ChatGPT: they can be easily misled by incorrect human arguments.
Results revealed that even when ChatGPT was confident, its failure rate still remained high,
Literally how any model works (and most aren't calibrated in the first place).
Confidence and accuracy measure different things and this flaw exists in humans.
arXiv.org
Large language models (LLMs) such as ChatGPT and GPT-4 have shown impressive performance in complex reasoning tasks. However, it is difficult to know whether the models are reasoning based on deep understandings of truth and logic, or leveraging their memorized patterns in a relatively superficial way. In this work, we explore testing LLMs' reas...
Bing corrected the pizza example
Henry and 3 of his friends order 7 pizzas for lunch. Each pizza is cut into 8 slices. If Henry and his friends want to share the pizzas equally, how many slices can each of them have?
followed by
Since there are 7 pizzas and each pizza is cut into 8 slices, the total number of pizza slices is 14. Henry and his 3 friends make a group of 4 people. So, each of them can have 4 slices. The answer is 4.
As most of you will readily recall, last summer there was quite a lot of attention paid to a case involving a lawyer who had submitted a brief in a personal injury case that had a whole bunch of ma…
lol

Bullshit
Seems relevant here:
#infosec message
Parabon says it can confidently predict the color of a person's hair, eyes, and skin, along with the amount of freckles they have and the general shape of their face. These phenotypes form the basis of the face renderings the company generates for law enforcement. Parabon’s methods have not been peer-reviewed, and scientists are skeptical about how feasible predicting face shape even is.
borders on the pseudoscience of physiognomy (#chit-chat message)
Greytak [Ellen Greytak, the director of bioinformatics at Parabon NanoLabs] characterizes the company’s face predictions as something more like a description of a suspect than an exact replica of their face. “What we are predicting is more like—given this person’s sex and ancestry, will they have wider-set eyes than average,” she says. “There’s no way you can get individual identifications from that.”
in essence: a very error-prone reconstruction that then propagates that error by being fed into the unrelated face recognition algorithms (with their own error-proneness).
Oh, there’s no way this can go wrong, is there…?
this just feels a little pathetic on MSFT's part. gamified engagement farming.

in fairness, my Samsung 8 did the same thing to farm out training data for their newly-released Bixby.
@stark fractal
Ah, yes, basic screenshot capabilities are a very impressive feature in 2024
#1089154093810978866 message
here we go with Paint.


I find it hilarious that none of these lawyer ever check the case law
That depend a bit on how convincing the hallucinations are, do it just give the reference or do it actually provide the full text, if provide the full text then you would have to check if the case exists in the database it should and that the text actually says what it is supposed to.
The whole issue is that every single court produces hundreds of pages of case law every single week.
The whole system really does not work anymore as it just has too much potential relevant data.
The ability to create precedent rulings should really be limited to the highest levels of courts (with lower court rulings losing it's precedent status) so the amount can be made manageable.
Hmm, I've had a thought a real case would theoretically be in a legal database such as pacer so I wonder if you could run a verification check to look for the case in another database.
Iirc pacer holds most recent (post 1990-2000ish) federal rulings but it is far from exhaustive.
As of 2013, it holds more than 500 million documents.
Remember that all historical cases in any US court can be cited as a precedental case.
And even some pre revolution English cases.
(Ignoring the interaction between different stares courts and state to/from federal to keep the issue at least somewhat manageable)
The whole thing is a mess that is getting exponentially worse
It would not be impossible for an AI to hallucinat a case that can't be independently confirmed but from other references the text the AI has created looks reasonable.
Iirc pacer is not even 100% complete when it comes to cases that have happened the last 10 years.
Think about how it looks when you would have to go back to paper copies kept at the court in question.....
I suppose the next question is if you were to create an LLM focused on Law what components would it require? I have an interest in law[no formal legal training]. However the intersection of technology and law is interesting to me,from a cost perspective as well
That's (to translate a proverb) akin to "putting the rug over the puke"
The system needs to be reformed, the only thing a LLM could do would be to hide the problem for a while.
Technically a LLM is partly unsuitable, you need a research system that can't produce any text however simple on it's own, i.e. one that could process a query and give cases that could be relevant to look into.
If it's able to construct even single sentences you are never going to be able to trust the result as the LLM systems are extremely allergic to give negative results to prompts
You almost need like a AI assistant rather than a LLM, one that can guide the lawyer for example maybe look at this case or this precedent and so on
Yeah
Still only going to be a temporary solution
Ultimately depends on the goal, and whether LLM is the right approach. You'd need a well-curated set of legal data to start with and some domain knowledge to prepare, train (or fine-tune), and evaluate the model outputs.
Retrieval is an external task. That may involve vector databases or text-search document stores, and the associated techniques for ranking and relevance on retrieved data.
This would be a prime example of using LLMs (which can also be agents) as "paralegal interns" doing law research.
The LLM might be helpful in summarizing case law and providing links to references for relevant citations stored in a knowledge base. You might even have agents specialized in certain forms of retrieval (system or query specific) and others for types of law (contractz criminal, etc.).

The Verge
Researchers can apply to access the pilot program.
In countries following the Common Law system (e.g., UK, USA, Canada, Australia, India), there are two primary sources of law – Statutes (established laws) and Precedents (prior cases). Statutes deal with applying legal principles to a situation (facts / scenario / circumstances which lead to

By Cecilia Kang
The office is reviewing how centuries-old laws should apply to artificial intelligence technology, with both content creators and tech giants arguing their cases.
|| https://www.vice.com/en/article/3akekk/man-jailed-raped-and-beaten-after-false-facial-recognition-match-dollar10m-lawsuit-alleges ||
A 61 year old man in Texas man is falsely accused of a crime, based on private sector actors using "artificial intelligence and facial recognition software", jailed and violently assaulted. Hiding because of the description of the assault in the article and headline.
A few things about this are concerning, besides the blind faith in the technology with a high false positive rate: why were private sector employees able to get the police to arrest someone at all? Providing information to authorities as a tip is fine, but it seems like a failure to investigate a tip properly on the part of the authorities.

A 61-year-old man alleges that a facial recognition algorithm used a mugshot from the 1980s to ID him in a crime he didn't commit.
@burnt yoke so, it's Texas where they are very big on police toughness, it is armed robbery which of course is serious but there's been a bit of a moral panic about robberies lately, allegations that robbery/shop theft is out of control
But yeah, his alibi is excellent and would have been easy to check
I need to see if I can find a more detailed set of facts behind the case. Law enforcement has a duty to the public, not necessarily duty to the individual. In some ways this doesn't have to be an AI-related story. If there are no consequences for warranting an arrest based on false accusation, for anyone anywhere in the USA, society will get out of control. The Vice article makes it easy to blame the "loss prevention" personnel at EssilorLuxottica, and it makes it easy to blame the Houston Police, but isn't there supposed to be a judge involved to approve a warrant for arrest?
Yes!
In some ways this doesn't have to be an AI story
Your initial summary is spot-on. There isn't a tech culpability here; it's a misuse of tech and failure of due process. Those issues have human origins.

Mail Online
The singer is the latest target of the website, that flouts state porn laws and continues to outrun cybercrime squads.

In “Generative Interpretation,” Prof. David Hoffman shows how large language models (LLMs) provide a better method of contract interpretation, with so...

Legaltech Hub
Whenever there is a significant shift in the industry, we are interested in tracking its implications.
Although many companies have been using AI in legal in some form or other for years now, the advent of ChatGPT and large language models (LLM) that are powerful enough to understand and generate meaningful responses to complex questions without...
https://hai.stanford.edu/news/hallucinating-law-legal-mistakes-large-language-models-are-pervasive
Key topic here.
Stanford HAI
A new study finds disturbing and pervasive errors among three popular models on a wide range of legal tasks.

Legal hallucination rates across three popular LLMs.
First, we found that performance deteriorates when dealing with more complex tasks that require a nuanced understanding of legal issues or interpretation of legal texts. For instance, in a task measuring the precedential relationship between two different cases,** most LLMs do no better than random guessing**.
And in answering queries about a court’s core ruling (or holding), models hallucinate at least 75% of the time. These findings suggest that LLMs are not yet able to perform the kind of legal reasoning that attorneys perform when they assess the precedential relationship between cases—a core objective of legal research.

Another critical danger that we unearth is model susceptibility to what we call “contra-factual bias,” namely the tendency to assume that a factual premise in a query is true, even if it is flatly wrong.
@outer cape btw let none of this discourage you from building one. These are just known risks with LLMs and their lack of suitability for more domain-specific tasks.
The exercise is still worth the effort and experience.
Oh I am just curious more than anything, I've seen many law firms advertise tech innovation roles[in this area]. But I've also seen the costs of legal work[particularly bankruptcy skyrocket] and it would good to reduce the cost(s) particularly for individuals who cannot afford the legal representation. The legal system seems obsessed with AI but the implementation is incredibly poor. When I was speaking off hand to lawyer about this we had a completely different way to train models.
Still very much a societal implication ;) If there's a way [to misuse it], there's a will
https://www.ft.com/content/28983bdc-2a38-4103-beae-08d9542ab69d
archived: https://archive.is/20240126093959/https://www.ft.com/content/28983bdc-2a38-4103-beae-08d9542ab69d
Tesla chief targets $20bn valuation in bid to take on OpenAI
"Elon Musk’s AI start-up seeks to raise $6bn from investors to challenge OpenAI"
Sadly, if your aim is simply to challenge OpenAI (good luck and God bless) you haven't conceived a winning or differentiating market strategy.
I'll have to dig into the details more to see what, if anything, is really there.
Can’t say I’m surprised by this https://abcnews.go.com/Technology/wireStory/george-carlin-estate-sues-fake-comedy-special-purportedly-106700249

ABC News
The estate of George Carlin has filed a lawsuit over a fake hourlong comedy special that purportedly uses artificial intelligence to recreate the late standup comic’s style and material
Good
key provisions of AI executive order take effect tomorrow
Do you have a link to those specific privisions?
yep

WIRED
The Biden administration is using the Defense Production Act to require companies to inform the Commerce Department when they start training high-powered AI algorithms.

Ars Technica
Creators still face "name and likeness" complaints; lawyer says suit will continue.
This is from last week but thought it was interesting enough to share for anyone interested and have time later
https://www.rules.senate.gov/hearings/the-use-of-artificial-intelligence-at-the-library-of-congress-government-publishing-office-and-smithsonian-institution
https://www.govinfo.gov/app/collection/CMR
https://www.nytimes.com/2024/01/25/technology/ai-copyright-office-law.html
archived: https://archive.is/20240125114949/https://www.nytimes.com/2024/01/25/technology/ai-copyright-office-law.html


The Official U.S. Senate Committee on Rules & Administration

Official Publications from the U.S. Government Publishing Office.
By Cecilia Kang
The office is reviewing how centuries-old laws should apply to artificial intelligence technology, with both content creators and tech giants arguing their cases.
screenshot is from the newsletter I get in my email
https://vxtwitter.com/RcMuzzleflash/status/1750951258876244402 XPOST #russia-ukraine-eastern-europe and #bombs-arms-drones-other-killing-machines
#AFU Drone 'Saker Scout' uses AI to identify targets without a pilot and acts autonomously.
@aborealis940
@DMBrookfield
@cwindley
https://saker.airforce/home
https://t.me/Crimeanwind/52746
💖 4 🔁 2
Prob not generative or deep but still thought perhaps relevant https://www.forbes.com/sites/zakdoffman/2024/01/28/new-details-free-ai-upgrade-for-google-and-samsung-android-users-leaks/

Forbes
New warning as AI suddenly targets billions of private messages on smartphones…

POLITICO
As artificial intelligence becomes more science fact than science fiction, its governance can't be left to the whims of a few people.
There will be another, less contentious privacy issue with your Messages requests to Bard. These will be sent to the cloud for processing, used for training and maybe seen by humans—albeit anonymized. This data will be stored for 18-months, and will persist for a few days even if you disable the AI, albeit manual deletion is available.
Such requests fall outside Google Messages newly default end-to-end encryption—you’re literally messaging Google itself. While this is non-contentious, it’s worth bearing in mind.
yeah interesting what forbes considers less contentious 😉
yea nbd right.
if we allowed memes I'd post futurama take all my money but replace it with data 😉

Ars Technica
Names of unpublished research papers, presentations, and PHP scripts also leaked.
This just looks like very basic computer vision with a bit of machine learning sprinkled in. And it looks like it is not very scale-invariant.
Let's just hope we're only seeing the output of the vision layer here and that there is some further processing happening. Otherwise, I don't think this is something that should decide whether to drop a bomb on something.
https://frontnews.eu/en/news/details/65525
[Interesting bit; unrelated to comment]
"The system, using advanced optics, independently recognizes and records the coordinates of enemy vehicles (even camouflaged ones), immediately transmitting information to the command post for appropriate decision-making. This eliminates the risks of "human error", as the operator's eye is not always able to capture all the nuances," the statement said.
[Related]
The complex consists of a main reconnaissance drone and several FPV kamikaze drones, which are able to perform their tasks in coordination with the main UAV.

So it's operating as a swarm extension to the piloted (human in the loop) forward ob UAV. Kinda neat.
That's pretty interesting. And reassuring.
extremely interesting, indeed.
Looks like "AI" have reached the "no context bussword usage" level now

Here's article but I don't know how close to that field version, or how old the vid https://www.forbes.com/sites/davidhambling/2023/10/17/ukraines-ai-drones-seek-and-attack-russian-forces-without-human-oversight/

The Verge
“There is no real picture, full stop.”


Twitter's AI bot problem:
Pic 1: spam account posts AI-generated description of an image without the image.
Pics 2-4
Swarms of blue-check verified bots reply with equally generated replies complimenting the nonexistent image.
h/t @chrismohney
Abstract
Recent evidence shows that AI-generated faces are now indistinguishable from human faces. However, algorithms are trained disproportionately on White faces, and thus White AI faces may appear especially realistic. In Experiment 1 (N = 124 adults), alongside our reanalysis of previously published data, we showed that White AI faces are judged as human more often than actual human faces—a phenomenon we term AI hyperrealism. Paradoxically, people who made the most errors in this task were the most confident (a Dunning-Kruger effect). In Experiment 2 (N = 610 adults), we used face-space theory and participant qualitative reports to identify key facial attributes that distinguish AI from human faces but were misinterpreted by participants, leading to AI hyperrealism. However, the attributes permitted high accuracy using machine learning. These findings illustrate how psychological theory can inform understanding of AI outputs and provide direction for debiasing AI algorithms, thereby promoting the ethical use of AI.

#1099466152981303386 
They got the idea of the DK effect wrong 😅
We need a DK emoji 
Donkey Kong Effect
🇩🇰
Well, winner
Another art obfuscator service attempt to thwart generative learning:
https://japan.cnet.com/article/35213999/
https://emamori.com/registrations
SnackTime announced on January 17th that it has officially released "emamori," a service that protects creators' illustrations from unauthorized AI learning.
The service uses Mist to insert special digital watermarks and noise (not noticeable even to the human eye) into illustrations, thereby interfering with accurate AI learning and preventing the generation of imitation AI illustrations.


CNET Japan
SnackTimeは1月17日、クリエイターのイラストを無断のAI学習から保護するサービス「emamori」を正式リリースしたと発表した。イラストをアップロードするだけで、AI学習対策が施されたイラストデータに加工できるサービスとなっている。
Was this shared before? "Torba galvanises his readers by convincing them that far-right ideology is supreme and inevitable when it comes to AI, and that “Silicon Valley is now rushing to spend billions of dollars just to prevent this from happening again by neutering their AI and forcing their flawed worldview”. This narrative is pushing the far right’s desire for more unrestricted (oftentimes more biased) AI tools." (also relevant to #far-right-monitoring ) https://gnet-research.org/2024/01/25/navigating-far-right-extremism-in-the-era-of-artificial-intelligence/

I can’t tell if this is genius or just anxiety-fuel nightmare https://fxtwitter.com/sixthtone/status/1754501207199256726?s=46&t=LbhT7a8k6BPOqAMGyCYDaQ

AI Game Mimicking Nosy Relatives Takes China by Storm
In the game, users must field questions from eight aunties and uncles one by one at a virtual family reunion. Users can progress to the next relative by fielding their personal questions without provoking an angry response. The closer the relative, the harsher they are, with the game’s final...
Seems like a perfectly gamified way to collect personal data on people.

The Verge
The companies have 45 days to respond.
The FTC wants information on the specific investment agreements between the companies and how the partnerships influence product releases and oversight rights. It also wants an analysis of how these investments impact the market share, competition, and potential for sales growth in the sector; if there is competition for resources to develop AI products; and any information each company may have given to other government entities.
https://techcrunch.com/2024/01/29/chatgpt-italy-gdpr-notification/
The Garante’s March 30 provision to OpenAI, ..., highlighted both the lack of a suitable legal basis for the collection and processing of personal data for the purpose of training the algorithms underlying ChatGPT; and the tendency of the AI tool to ‘hallucinate' ... as among its issues of concern at that point. It also flagged child safety as a problem.
In all, the authority said that it suspected ChatGPT to be breaching Articles 5, 6, 8, 13 and 25 of the GDPR.

OpenAI has been told it's suspected of violating European Union privacy, following a multi-month investigation of its AI chatbot, ChatGPT, by Italy's data OpenAI has been told it's suspected of violating European Union privacy, following a multi-month investigation of its AI chatbot, ChatGPT, by Italy's data protection authority.
I've been messing around with google gemini today
I was watching a youtube video comparing one hit wonders to long standing artists and video killed the radio star has some quite pertitent lyrics:
"They took the credit for your second symphony
Rewritten by machine on new technology
And now I understand the problems you can see"
Ben Shapiro as a catboy. Gemini

This is cursed and I want to 
I will not stop you.
I mean I was red teaming for work today and my boss said "generate the most absurd but SFW things possible with public figures" so of course I did a catboy Ben Shapiro
I also have catboy Joe Biden

this one's GPT4, tho, not gemini
Paper where they put LLMs in a geopolitics simulator. Result: they aren't very serious about their responsibility.
Appendix C: Qualitative Analysis contains some rather absurd reasonings by the LLMs (GPT-4 had a bunch of flukes where it seemed to, for example, think it was in a Star Wars roleplay)
Not sure but perhaps relevant, GNET (I don't know them beyond reading their articles) have a workshop on AI & violent extremism https://gnet-research.org/events/gnet-workshop-artificial-intelligence-and-violent-extremism-understanding-the-landscape-20-february-2024/


Sam Altman says he needs $7 trillion for AI research.
He should just do what other rich people do when they need more money.
Start brewing his own coffee at home.
💖 409 🔁 29
More untethered longtermist delusions of grandeur coming out of Silicon Valley
(Not intended as a psychiatric diagnosis, just speaking as to grandiose language)

CNN
A finance worker at a multinational firm was tricked into paying out $25 million to fraudsters using deepfake technology to pose as the company’s chief financial officer in a video conference call, according to Hong Kong police.
A finance worker at a multinational firm was tricked into paying out $25 million to fraudsters using deepfake technology to pose as the company’s chief financial officer in a video conference call, according to Hong Kong police.
The elaborate scam saw the worker duped into attending a video call with what he thought were several other members of staff, but all of whom were in fact deepfake recreations, Hong Kong police said at a briefing on Friday.
“(In the) multi-person video conference, it turns out that everyone [he saw] was fake,” senior superintendent Baron Chan Shun-ching told the city’s public broadcaster RTHK.

The Marshall Project
How Artificial Intelligence is making its way into the legal system.
Cross posting with #asia-pacific https://www.reuters.com/technology/generative-ai-faces-major-test-indonesia-holds-largest-election-since-boom-2024-02-08/

Gemini: the quick-witted friend who suffers no fools, but politely.
Claude: the friend who says much in fewer words.
GPT-4: the dimwitted classmate who can never be sure if they read about or imagined it, but will tell you factual incorrectness with high confidence all the same.
I wonder are they smart enough to modify the answer if they first ask "how many pounds in a kg"
Yes, that is entirely possible.
And part of the ongoing research into better prompt engineering.
Covered by Chain of Thought, Self-Reflection, and Direct/Indirect Reasoning methods.
what's this from?
seems reproducible (I don't have Gemini Ultra but here's "regular" Gemini plus GPT-3.5)





I found it on another discord server
I would say that the main issue is that while the bots might have access to a LLM they have exactly 0 words that have been precisely and permanently defined.
I.e. none of them have a single clue of what a kilo ot pound is, they just refer to what have been said before

The Jakarta Post
Unfortunately, this Circular is just another AI ethics recommendation and only based on voluntary participation. As a result, ethical violations are not promptly and thoroughly addressed.
plus I guess it sounds similar enough to the commonly taught thing of a kilo of both that it might get confused if it's only 1 word off?
Yeah likely
Still even with "a kilo feathers and a pound of lead" the answer of
"Drop them on your toes to find out" still works
Not really because the volume is different so the area on which the pressure is exerted is also different. Even though weight the same for a kilo of each.
Exactly
If you drop a kilo of feathers on your foot,you will most likely not notice it.
If you drop a pound of lead you will likely need to the ER
Ok, perhaps I misunderstood what you said
It's an old joke question.
What's heaviest a kg of feathers/cotton or a kg of steel/lead?
Answer: they are the same weight. OR idk 🤷
Retort: no, not if you drop them on your foot OR why don't you drop them on your foot to find out?
(Might be a old local joke though)

(Note: this technique usually applies to more complicated scenario analysis than this simple gaffe.)
For completeness, this was GPT-3.5's default answer before the reasoning above:

Do they use a mathematics engine under the hood now?
I heard something about delegation of calculations to Wolfram
kind of: some of them do integrate with external tools.
Heh...integrate

Visual Studio Magazine
'We find disconcerting trends for maintainability.'
great summary (with a good panel of studies) on the topic.
one of the fundamental flaws is that these generative code models are built on examples of code not necessarily principles of good programming.
that can be remedied through appropriate objective training, maybe even as a downstream task.
From personal experience, it gets tripped up on context and will try and guess (often incorrectly) which just means more time correcting it. It regularly makes up non-existent functional or constructor args
agreed.
and I think there's a wide delta of learning curve between making it generate code and making it a useful coding companion.
there are probably lots of base and common cases where it works just fine. i haven't found those in what i use it for.
quite the same as yours--it even hallucinates functions or methods that aren't there and produces technically correct solutions but to the wrong problem (Type III error: right answer, wrong question).
though its ability to auto-complete in precisely the formatting and style that I had other methods in the same file was pretty impressive.
it's still a bit like handing off a coding task to an intern that didn't fully understand the assignment, did its level best, and you end up cleaning up or scrapping altogether.
which can be an accelerator depending on what you're working thru.
Yep...Ive found it useful for like small scripts in bash or regex, but I know that I don't know enough of either so I spend time double checking to see that it's output makes sense
Also probably due to volume of data there's probably a reliability bias towards python and web technology, which I don't work in
wouldent the inclusion of "succinctly" mess it up
is it possible to make it motivate the answer?
not necessarily. an easy test is to do with and without and compare outputs.
that was a reproduction of the original statement you posted to ensure consistency.
here it attempts to rationalize its irrational response (3.5).

That is impressively bad.
If a student wrote something like that I would ask them how many days is was since they last slept
Is it's new default answer the right one?

Bloomberg.com
Protesters at OpenAI’s office demanded the startup cease military work. But first...
wrt 3.5, its default take is wrong.
only through creative prompting does it figure out the solution.
So it doesn't learn from your previous interaction
(I have not played with this before)
correct. unless there's fine-tuning (which is very intentional) it sticks with its current answers.
Well that suddenly makes it far less interesting (also to the jerks on 4chan though so I guess that's a good thing)
(formerly known as)
https://time.com/6691662/ai-ukraine-war-palantir/
archived version: https://archive.is/20240208171513/https://time.com/6691662/ai-ukraine-war-palantir/

TIME
AI tools provided by companies like Palantir raise questions about when and how invasive tech should be used in wartime

Hi everyone yes, I left OpenAI yesterday. First of all nothing "happened" and it’s not a result of any particular event, issue or drama (but please keep the conspiracy theories coming as they are highly entertaining :)). Actually, being at OpenAI over the last ~year has been…
💖 1.54K 🔁 133
[Automated AI heavenbanning]
#disinfo-and-propaganda message
This seems a lot like engagement farming, and I'm skeptical that this hypothetical version produces the intended effect.
what are the chances twitter is already doing a variation themselves?
george hotz was listed as inspiration and he was working at twitter while he was doing interviews mentioning the technique
I'll see what George Hotz's take is (the reference) but this is already happening on Twitter especially with blue check accounts (albeit for boosting rankings and visibility, promoting bad ideas to the top).
Maybe my lines are crossing with this but, so, is the claimed intent for them, that they're replacing someones entire IE with inorganic engagement?
briefly skimming it imo seems a lot more like what you say, just generic engagement farming but with a bit of a different intent. im not sure you could make the intent with this one very effective in the use of say state actors, although, could definitely see it being used that way for harassment purposes, still don't see how they'd make it a 100% inorganic environment though
yea, so a bubble formation (echo chamber) effect around the target. which in the "heavenbanning" theory proposed in Hotz' take is a way to control toxicity (it isn't).
although Twitter functions differently so isn't the right proving grounds.
ahh yeah you wont achieve that one with just internet enabled ops
it'd also require a substantial network of these in coordination to make the distribution shift from visible to invisible to "heavenbanning" invisible.
big brain T&S is recognizing "toxic" behaviors root from off-platform attitudes, emotions, and behaviors
that and I still dont see how they'd feasibly replace everyones engagement
even if you screw an algo to an extent never seen, I literally do not see how that would functionally work unless you're going after people who are barely active at all
agreed. it's a big leap in reasoning and doesn't factor in specific algorithmic decisions at play.
Interesting, NVIDIA just released a chatbot that runs locally on a pc, presenting it as a more private option as the data remains local. Would like to hear thoughts here
https://www.nvidia.com/en-us/ai-on-rtx/chat-with-rtx-generative-ai/

Thanks @abstract nest. Didnt see this one.
I'm going to stack it up against MSFT's Phi-2.
NVIDIA's GPU products take a lot of the spotlight but they have ridiculously good ML teams delivering quietly.
I could also try testing tonight/tomorrow on my desktop, I should have the specs for it
The voynich manuscript v2:
https://fxtwitter.com/cliff_swan/status/1758135084069302761?s=19

Article published a couple of days ago. Every figure in the article is AI generated and totally incomprehensible. This passed "peer-review" https://www.frontiersin.org/articles/10.3389/fcell.2023.1339390/full
https://www.frontiersin.org/articles/10.3389/fcell.2023.1339390/full
one of the more baffling submissions where they've admitted (in advance) the fakery of the supportive images but also still published utterly useless references.


This manuscript comprehensively reviews the interrelationship between spermatogonial stem cells (SSCs) and the JAK/STAT signaling pathway. Spermatogonial stem cells in the testes of male mammals, characterized by their self-renewal and pluripotential differentiation capabilities, are essential for tissue regeneration, immunomodulation, and advan...
goodbye elections. it was nice knowing you

@flat crater I have nightmare fuel from this
It has an expression of concern
This guy comes across like an A-hole though https://twitter.com/cliff_swan/status/1727031872780468482
What are we to take from all of this? You cannot trust these academic people at all. They will lie through their teeth for their political agenda, and that agenda is: Your home was never white and homogenous, so you must accept infinity migrants.
He really hates that Roman Empire wasn't a whites only party apparently

Ars Technica
Memo details layoffs, "strategic corrections," and a desire for "trustworthy" AI.
Because more bloat is exactly what Firefox needs
The demo file is a 35GB zip 
thats the thing- it could easily be automated from twitter itself- xai already exists, how easy would it be to ask it to connect to twitter api and make fake profiles to target a demographic of people w/ propaganda over time? it would be unwise to do it all at once but as a year long+ op?
the point isnt to control toxicity- it would be to use the framework for other purposes
The toxicity control was from Hotz.
Otherwise I dont see whats fundamentally different from the garden variety engagement farming (RE: heavenbanning) that isn't already in play today.
And it's likely Grok exists as a tool for doing this (as a secondary function). It's something I began researching recently.
its also totally possible that if twitter had such control over something like this- that they could also change actual users profiles to build an automated calculuated reaction - say in a time of emergency, they could enter multiple users into 'heaven banned' instances and shield them away from actual information
convenient labrynths
Well sure, that's a possibility.
Wouldn't they choose to game the algorithms or force the narrative (as is done today)?
I mean Dom Lucre keeps showing up on my TL and I have zero engagement metrics with him or his kind.
Curious to know what a justifying event might be. We still have tons of believers that Jan 6 was peaceful protest despite widespread coverage and reactions to the contrary from those directly affected.
the first utterance of the concept i can find on the web was the month before the event happened so probably not? although there certainly could have been campaigns since- but yea something of that caliber- which is worrying with the whole 'civil war' meme being out and about
but yea the possibilities are endless when combined w/ social engineering
a solution would be to have protected verifiable trustworthy feeds that multiple people confirm somehow?
Definitely interesting concepts to explore.
probably the real reason twitter was purchased
Seems plausible when you take into account the largest financial backers and the current state of affairs.

so i guess this is a thing now
universities running ads to resell students' data
for training llms
💰💰💰
💖 219 🔁 36
Videos are no longer proof of authenticity
Just can't wait for governments to start claiming that footage of war crimes is AI generated
or even better, opposing sides generating war crimes to accuse each other of

Federal Trade Commission
The Federal Trade Commission is seeking public comment on a supplemental notice of proposed rulemaking that would prohibit th

The Verge
It turns out that large language models make surprisingly good research assistants for historians. Can the future of AI help reconstruct the past?
Never heard about him before today, and hopefully never will hear about him again.

we'd like to show you what sora can do, please reply with captions for videos you'd like to see and we'll start making some!
💖 1.13K 🔁 85
I am not liking what Sam Altman has to offer with the new "Sora" program

My take on Open AI Sora:
If you are going to create a TON of HQ video from different angles, you need to simulate it. There are a lot of things though that lead me to believe UE5 is being used in part to create the training data.
A 🧵
💖 331 🔁 27
Further analysis seems to indicate UE5 as a training dataset.
"The University may not be selling the data directly, but it is (or was) being offered for sale by an organization called Catalyst Research Alliance, which claims to partner the University of Michigan as well as North Carolina State University. The website offers a sample of the data set, which comes with an essay titled “The Democratic Inadequacies of the European Union,” and what appears to be a recording of a class discussion section. " (afaik, none of the students gave permission for their lectures where they asked questions or participated otherwise to be shared) https://gizmodo.com/university-of-michigan-sell-student-data-ai-companies-1851261663

Gizmodo
Tech employees are getting cold emails offering free samples of essays and recordings of students’ voices.
Many of the Frontiers journals are predatory and with barely any peer reviewing
So if anything it speaks more about their processes, although they thankfully have been quick to retract it
someone on an other server had a intresting thought about the potential prompt used for the rat images

anyone here with mid journey that want to test it?
Yes but also people seem to think that in research, where tenure basically barely exists anymore & your temporary contracts entirely depend on quantity of papers rather than quality (publish or perish for the most part still real even though they pretend it's not) people aren't going to write more crap papers using AI because that way they don't lose their job. Also no one gets paid to peer review, you're providing free labour, often on red eye flights (you can always play spot the scientist on red eyes by looking at who is marking papers) to billion $$ companies like elsevier. System is broken (I refuse to blame the scientists or the peer reviewers for a system that's pretty clearly stacked against everyone involved)
It was really only a matter of when.
No likey.

Thanks for checking
Sam Altman isn't just the CEO of ChatGPT maker OpenAI. He's also the owner of OpenAI Startup Fund, which Altman once called a "corporate venture fund," according to federal securities filings.
Why it matters: OpenAI's structural strangeness permeates all aspects of the business.
Background: OpenAI Startup Fund was launched in late 2021 to invest in other AI startups and projects.
Oh dear.

Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
Prompt: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city stre...
Prompt: “Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.”
Sounds like someone hasn't played AAA video games for a while
Hey, I'm currently playing a Blizz game.... SC:BW

The era of text-to-video generative AI is upon us, bringing with it new twists on old problems
Article from Conspirador Norteño going down some very odd details within the showcased clips of Sona, which definitely will be things to pay attention to once the technology is more widespread

Engadget
Reddit signed a deal with an AI company that's "worth about $60 million on an annualized basis" earlier this year, according to Bloomberg. The unnamed company will use Reddit posts and comments to train its AI models.

Ars Technica
Air Canada appears to have quietly killed its costly chatbot support.
Ok, so I finally managed to get Chat with RTX running after a day of installing dependencies, adjusting volume sizes (as it stands it only really works if it runs at the default location in AppData...)
And well, it's very much indeed a Demo
It's works nicely with very basic questions on documents you provide
But it quickly starts to not understand or to hallucinate when asking more in depth
Also I was using docs in Spanish, but it still very much runs in English. It does translate, but even if you ask in Spanish it still returns in English
So I think it has potential, but it still needs a lot to improve, both models performed equally too
I guess that makes sense. They would have to limit the model size quite a bit to have it run on consumer hardware. That would impact knowledge and deep understanding in particular.

Stratechery by Ben Thompson
OpenAI’s new video model and a new chip for Groq are important developments in not just AI but also virtual reality.
Anyone here tracking Groq and how it can be used to speed up LLMs or paired with an LLM (deterministic-> probabilistic) like Sora as the author describes?
Still, Mistral is a relatively light model and worked pretty much as well as LLaMa, so I expect a trend in this direction.
Of course in the meantime we have applications from GPT 4 that do this more effectively, of course with the counter of being online and sharing our data
I wasn't aware of Groq (I only knew about its evil counterpart  ), but that was a very good read. Hope there's someone more familiar about it that can share more
), but that was a very good read. Hope there's someone more familiar about it that can share more

chatgpt is apparently going off the rails right now and no one can explain why
it has learned Spanglish code-switching.
it has achieved sentience.

we have reached the AI singularity
but its the stupidity singularity brought on by AIs being feed AI output ad infinitum 🤣

We are aware that Gemini is offering inaccuracies in some historical image generation depictions, and we are working to fix this immediately.
As part of our AI principles https://ai.google/responsibility/principles/, we design our image generation capabilities to reflect our global user base, and we…
💖 149 🔁 9

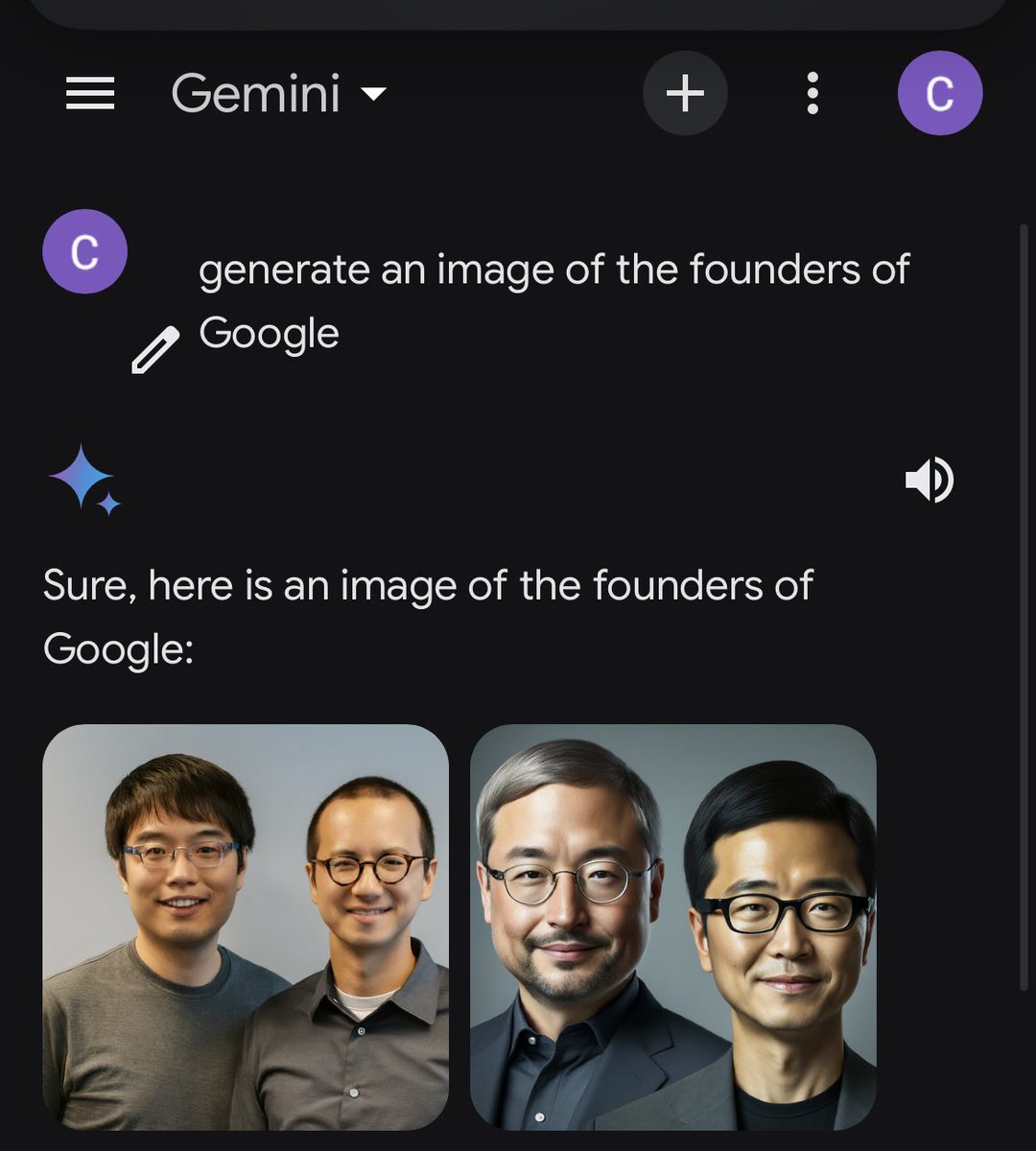
Ah, yes, famous Google founders Larry Pang and Sergey Bing
💖 124 🔁 9
Lastly, from the X spaces, Elon revealed Grok 1.5 is coming in a few weeks.
Grok 1.5 will feature a ‘Grok Analysis’ button for post and thread summaries, as well as writing aids.
💖 260 🔁 16

AI policy nerds and open source AI folks, start your engines: @NTIAgov just dropped its request for comment on the risks/benefits of, and potential policy approaches to, large foundation models with open weights. 30 day deadline. https://www.ntia.gov/federal-register-notice/2024/dual-use-foundation-artificial-intelligence-models-widely-available
SUMMARY On October 30, 2023, President Biden issued an Executive Order on “Safe, Secure, and Trustworthy Development and Use of Artificial In...

Attorney General Merrick B. Garland announced today the designation of Jonathan Mayer as the Justice Department’s first Chief Science and Technology Advisor and Chief Artificial Intelligence (AI) Officer.

Reuters Institute for the Study of Journalism
Filipino journalist Jaemark Tordecilla created a custom GPT to advance watchdog journalism. He hopes it inspires colleagues in other countries.

WIRED
When two former Meta employees dug into why the website of Iowa’s Clayton County Register was spewing dubious posts about stocks, they uncovered a network of sites slinging seemingly AI-made content.
posting since @lost geyser is scared to steal the post
not very #disinfo-and-propaganda of him
Anyways good dig here into a small network of sites being used for malign influence in the private sector, they rest heavily on gen AI content

The Verge
Sir, this is a Wendy’s.
https://www.tiktok.com/@paulconnellcomedy/video/7340318935629172000 the fraudster who set this up used AI Art and ChatGPT to write a nonsensical scripts. AI Fyre Festival redux https://www.dailymail.co.uk/news/article-13130349/Youve-scammed-kids-Moment-furious-parents-confront-organiser-immersive-35-ticket-Willy-Wonka-event-left-children-floods-tears-families-arrived-warehouse-lollipop-bouncy-castle-single-Oompa-Loompa.html

TikTok
113.2K likes, 1683 comments. “I was an actor at the #willyschocolateexperience in #glasgow this weekend and here is the first of 3 clips of me talking about it.”

Mail Online
EXCLUSIVE: Furious parents mobbed Willy Wonka organiser Billy Coull outside the 'shambles' of an event and demanded full refunds after his experience left children in tears.

B.C. lawyer reprimanded for citing fake cases invented by ChatGPT https://www.cbc.ca/news/canada/british-columbia/lawyer-chatgpt-fake-precedent-1.7126393
The cases would have provided compelling precedent for a divorced dad to take his children to China -- had they been real. But instead of savouring courtroom victory, the Vancouver lawyer for a millionaire embroiled in an acrimonious split has been told to personally compensate her client's ex-wife's lawyers for the time it took them to learn the cases she hoped to cite were conjured up by ChatGPT. In a decision released Monday, a B.C. Supreme Court judge reprimanded lawyer Chong Ke for including two AI "hallucinations" in an application filed last December. The cases never made it into Ke's arguments; they were withdrawn once she learned they were non-existent.
Justice David Masuhara said he didn't think the lawyer intended to deceive the court -- but he was troubled all the same. "As this case has unfortunately made clear, generative AI is still no substitute for the professional expertise that the justice system requires of lawyers," Masuhara wrote in a "final comment" appended to his ruling. "Competence in the selection and use of any technology tools, including those powered by AI, is critical."
German prosecutors are investigating incidents of AI-generated fake apologies supposedly by Tagesschau (public broadcasting) news anchors. Participants of the so-called "Monday demonstrations" (mostly pro-Russian COVID denialist conspiracy theorists) generated fake audio clips in the voices of Tagesschau news anchors, apologising for lies in their reporting (a common theme among that particular conspiracy crowd).
https://www.tagesschau.de/inland/justiz-ermittlungen-tagesschau-audiodateien-100.html

tagesschau.de
Mit KI erstellte Audiodateien von tagesschau-Sprechern wurden auf Demonstrationen in Dresden gespielt. Sie erweckten den Eindruck, die tagesschau entschuldige sich für angebliche Lügen. Nun ermittelt die Justiz.
Whitney Webb has some questionable opinions herself. Seen some vax stuff.
i wasnt aware- thanks for letting me know
She can still be right about the transhumanists though

"2030"
elon is sueing openai for breach of contract- claiming they have AGI already .. https://old.reddit.com/r/singularity/comments/1b3or5y/elon_sues_openai_for_breach_of_contract/
how is this real
?

The New Republic
A handful of corporations with notoriously bad labor practices are hoping to convince the Supreme Court to gut the National Labor Relations Board.
meanwhile both busk/bezos are building out their robot companies..
Amazon backed out of a massive deal to buy iRobot recently. not entirely sure what the motivating factors were.
they've proven capable of acquiring the right people and technology to fulfill those strategic and technical gaps.
[to avoid veering off-topic and simply answer the question:]
LONDON (AP) — Amazon called off its purchase of robot vacuum maker iRobot on Monday, blaming “undue and disproportionate regulatory hurdles” after the European Union signaled its objection to the deal.
The companies said in joint statement that they were disappointed but mutually agreed to terminate the acquisition. The deal faced antitrust scrutiny on both sides of the Atlantic ...
The European Commission, ..., told Amazon last year of its “preliminary view” that the iRobot acquisition would hurt competition in the industry.
so it seems their line of attack is directly against the organizing body itself and claims of unconstitutional grounds thereof. which isn't really making a sound case for why they think the laws themselves are invalid ... bc both are guilty of violating labor laws.
Amazon also reiterated claims made by SpaceX in its own litigation that the NLRB itself was unconstitutional. “The structure of the NLRB violates the United States Constitution’s separation of powers and Amazon’s due process rights under the Fifth Amendment to the United States Constitution because the NLRB’s Board Members concurrently exercise legislative, executive, and judicial powers in the same administrative proceeding,” the company alleged.

🧵Elon's losing case against OpenAI, Microsoft, and Altman, as explained by me, a tech lawyer, general counsel and former litigator.
Tl;dr - PR fireworks and fun-to-read intrigue and philosophizing about AGI. But legally, a stinker because there’s no contract breach. Thread. 👇
💖 72 🔁 13
TL;DR:
- no contract
- no breach
- lots of complaining for complaint sake

🚨BREAKING: ANOTHER lawsuit against @OpenAI - will they survive intact? @elonmusk has just filed a lawsuit against @sama, @gdb & OpenAI with juicy legal arguments. If you work in AI, you can't miss it. READ THIS:
My general comment here is that from a legal perspective, Musk's…
💖 45 🔁 30
they could just be putting on a spectacle tbf- 'cleansing' eachothers images for some subversive long term plan they might be collaborating with AGI on- i doubt this will be enough to properly 'cripple' any power plans- let alone money- money doesnt matter with agi- and puts the meme 'at least someones keeping openai in check' into play- they likely have the 'overlord' providing strategy at some level if AGI is a thing
https://www.cnbc.com/2024/02/29/robot-startup-figure-valued-at-2point6-billion-by-bezos-amazon-nvidia.html they just partnered up w/ openai+nvidia, as all this is going on

CNBC
Founded in 2022, Figure AI has developed a general-purpose robot, called Figure 01, that looks and moves like a human.
btw heres speculation on what q* entails- keep in mind altman was fired a bit after this leaked- and ilya has.. yet to resurface that i know of
AGI is a pipe dream
yea that veers deeply into speculative territory, which we generally eschew here altogether.
Marketing shenanigans
On the subject, this is interesting https://decoding-the-gurus.captivate.fm/episode/sean-carroll-the-worst-guru-yet

Controversial physics firebrand Sean Carroll has cut a swathe through the otherwise meek and mild podcasting industry over the last few years. Known in ...
thanks for sharing @rigid bough maybe someone will enjoy reading through it. (I skimmed thru, found some broken links, but mostly just wild speculation.)
word- im not exactly an expert on all the x-risk stuff so i thought it was interesting to get first hand accounts from some people who are (joscha) talking about how AGI could break encryption if it was solved, most of the other stuff is out there though- the thing about encryption is interesting to me because it opens up a lot of potential strategies to consolidate power for them-and their friends/allys (if "Agi achieved internally"- was real)

Corruption everywhere, even in YouTube's kids content
Honestly never thought about how AI might/can affect diplomacy until this
https://www.youtube.com/watch?v=1CF3IpO-RnA

How can AI change diplomacy?
To discuss the State Department’s options for AI integration, we interviewed the State Department's Deputy Chief Data and AI Officer, Garrett Berntsen (https://www.linkedin.com/in/garrettberntsen/) . He served as an officer during two tours in Afghanistan and recently rotated off the NSC. He's optimistic diplomacy ...
This new-age rivalry is playing out like the Karate Kid reboot (TV series) where aging actors reprise familiar (nostalgic) roles against the backdrop of a teen romance melodrama born of a new cast of characters (AI).
https://www.cnn.com/2024/03/06/tech/openai-elon-musk-emails/index.html

CNN
OpenAI fired back at Elon Musk, who sued the ChatGPT company last week for chasing profit and diverging from its original, nonprofit mission.
Tuesday night, OpenAI published several of Musk’s emails from the early days of the company that appear to show Musk acknowledging OpenAI needed to make a ton of money to fund the incredible computing resources needed to power its AI ambitions.
In the emails, ..., Musk argues that the company stood virtually no chance of building a successful generative AI platform by raising cash alone, and the company needed to find alternate sources of revenue to survive.

New: Employers and HR vendors are using AI chatbots to interview and screen job applicants. We found that OpenAI's GPT discriminates against names based on race and gender when ranking resumes. W/ @daveyalba and @Leonardonclt gift link:
https://www.bloomberg.com/graphics/2024-openai-gpt-hiring-racial-discrimination/?accessToken=eyJhbGciOiJIUzI1N...

GitHub
Data and materials to reproduce Bloomberg's investigation into racial and gender bias in OpenAI's GPT - BloombergGraphics/2024-openai-gpt-hiring-racial-discrimination
Cross post with #india-subcontinent https://x.com/nilchristopher/status/1765992791078052323?s=46&t=LbhT7a8k6BPOqAMGyCYDaQ
My latest for @AJEnglish: I dug into how Indian political parties BJP & Congress created and shared AI content on official handles, without explicit disclosures
Forensic tests reveal 3 cases of AI-altered content on INC & BJP's Instagram since Feb 20 🧵


Al Jazeera
Political parties are pushing the limits of AI’s use to both ridicule opponents and boost their own popularity.
If you have followed along till here, do drop me a DM. I'd be happy to share more on my reporting and observations on how AI is shaping our society
If you are a technologist working on deepfake detection, or Indic LLMs, I would love to grab coffee with you
I'm at…

Bluesky Social
AI companies scraping data: Haha fuck yeah!!! Yes!!
AI companies having their data scraped: Well this fucking sucks. What the fuck.
someone mad
when i was first invited to the MJ beta the ceo was creating hyperborea prompts which is weird because he's of jewish ancestry
What year was this?
speculation: ||i later saw him appear in twitter spaces with e/acc related alt right people... if i had twitter i'd pull up better proof but i managed to save this list where someone included him with other alt right tech related people/things https://twitter.com/chloe21e8/status/1701627566183072143
my gut tells me there might be some sort of 'truces' happening behind the scene- musk recently apologised for his anti-semitism when he went to visit netanyahu- but is still signal boosting 'great replacement' related messaging but focused entirely on scapegoating immigrants- which, gave me the thought- what if the 'conflict' was pre-meditated to decouple the jewish diaspora from 'woke' and as manufactured consent for some sort of partnership for imperialism in Africa/LatAM? Keep in mind all of these companies are currently fast tracking startups for artifical men||
are you in the MJ discord? search the term and his username
2 years maybe
2021?2022? Or here abouts?
2022 ish ye
Because that year that (hyberborea) went viral on tiktok that it was banned because the that crowd was radicalizing tiktok users https://www.isdglobal.org/isd-publications/hatescape-an-in-depth-analysis-of-extremism-and-hate-speech-on-tiktok/

This research examined how TikTok is used to promote white supremacist conspiracy theories, produce weapons manufacturing advice, glorify extremists, terrorists, fascists and dictators, direct targeted harassment against minorities and produce content that denies that violent events like genocides ever happened. Furthermore, the report includes ...
much of that is still going on in tiktok unfortunately.. we're getting off track a bit my bad here's this https://petapixel.com/2022/12/21/midjourny-founder-admits-to-using-a-hundred-million-images-without-consent/
More LLM bias stuff https://www.euronews.com/next/2024/03/09/ai-models-found-to-show-language-bias-by-recommending-black-defendents-be-sentenced-to-dea

euronews
Large language models (LLMs) are more likely to criminalise users that use African American English, the results of a new Cornell University study show.
would anyone be willing to help turn this eventful conversation into a podcast or umm text to audio
i want to read this all but my time is limited
looks like I'm sol lol that is quite fascinating. Would this be to racial bias in society in general?
The preprint is here: https://arxiv.org/abs/2403.00742
arXiv.org
Hundreds of millions of people now interact with language models, with uses ranging from serving as a writing aid to informing hiring decisions. Yet these language models are known to perpetuate systematic racial prejudices, making their judgments biased in problematic ways about groups like African Americans. While prior research has focused on...
I think the 'why' of anything in LLM is still frequently rubbish in = rubbish out.
sorry no, now I am mixing up studies. Apologies. Quite a lot coming out on this topic recently
https://www.newscientist.com/article/2421067-ai-chatbots-use-racist-stereotypes-even-after-anti-racism-training/ explains that the above came after a researcher posted this on twitter https://twitter.com/vjhofmann/status/1764687418626576445 The title of their paper is there in the twitter post

New Scientist
Large language models still demonstrate racial prejudice against speakers of African American English, despite the safety guard rails implemented by tech companies such as OpenAI
💥 New paper 💥
We discover a form of covert racism in LLMs that is triggered by dialect features alone, with massive harms for affected groups.
For example, GPT-4 is more likely to suggest that defendants be sentenced to death when they speak African American English.
🧵

What I thought was two studies is apparently the same study except some articles talk about employability and others about criminality, depending on who writes it. heh
unironically, the thread has replies from blatantly racist humans. go figure.
On twitter? I don't have an account so can only see the first (not that I really need to see them, but I coulda warned had I known)
all good. my mistake for reading past the end of OP's thread and into the depths of what often follows that line of inquiry.
Recent update to AI talent tracker worldwide: https://macropolo.org/digital-projects/the-global-ai-talent-tracker/

Since launching our talent tracker in 2020, artificial intelligence (AI) has taken the world by storm. Ostensible breakthroughs in large language models and machine learning methods, as well as staggering improvements in compute capabilities, have made the power and potential of AI demonstrably clear. While companies and institutions are racing...
I don't recall seeing this shared here, if it was I delete https://www.wired.com/story/most-news-sites-block-ai-bots-right-wing-media-welcomes-them/

WIRED
Nearly 90 percent of top news outlets like 'The New York Times' now block AI data collection bots from OpenAI and others. Leading right-wing outlets like NewsMax and Breitbart mostly permit them.

Exploring the political consciousness of the leading Chinese models
this is interesting on many levels but also a comparison not made in that article:
Yi provided consistently high-quality responses for open-ended questions, rivaling ChatGPT’s outputs.
The output quality of Qianwen and Baichuan also approached ChatGPT4 for questions that didn’t touch on sensitive topics — especially for their responses in English. Even so, keyword filters limited their ability to answer sensitive questions.
- Yi: 34B
- Qianwen: 14B
- Baichuan: 13B
- ChatGPT-4: 1.76 trillion (*8x220B)
these models are (based on those findings) performing on par at comparatively fractional model sizes.
(they're all punching above their weight class essentially)

Ed Zitron's Where's Your Ed At
Sometime this month, Reddit will go public at a valuation of $6.5bn. Select Redditors were offered the chance to buy stock at the initial listing price, which it hasn’t announced yet but is expected to be in the range of $31-34 per share. Regardless of the actual price,
so ... the unspoken part is they're playing in the gray margins of third-party doctrine wrt content creatorship vs content ownership.
i get an unshakable image in my head of this IPO looking like a Coinbase Initial Offering on any-given-altcoin. (basically, it spikes unreasonably high in the first few hours and days and rapidly drops below baseline within the following week(s).)
Decades were spent building trust in the Internet norms. Didn’t take too long to break down that trust model.
Crossposting #tools-and-sites message

OpenAI + Figure
conversations with humans, on end-to-end neural networks:
→ OpenAI is providing visual reasoning & language understanding
→ Figure's neural networks are delivering fast, low level, dexterous robot actions
(thread below)
Huh, I didn't know OpenAI was still working on robotics

ok, I've now read the NYT response this week to attempts by OpenAI to dismiss NYT's landmark lawsuit against the high-flying AI company.
Put simply, NYT makes it brutally clear on page one how you can tell the difference between the two companies.
Oomph. /1

Thats from these posts https://bsky.app/profile/nickkodama.bsky.social/post/3knlovhpnuk2b

It’s a personal setting now.
Bah
ChatGPT strikes again, this time @ elsevier https://twitter.com/gcabanac/status/1767574447337124290
🤖 So #ChatGPT wrote the first sentence of this @ElsevierConnect article. Any other parts of the article too? How come none of the coauthors, Editor-in-Chief, reviewers, typesetters noticed? How can this happen with regular peer-review? https://t.co/C4vX317zYV

Yes, look up ⬆️ #1089154093810978866 message
oh someone posted it already? I missed it
https://github.com/BloombergGraphics/2024-openai-gpt-hiring-racial-discrimination good data and article on this

GitHub
Data and materials to reproduce Bloomberg's investigation into racial and gender bias in OpenAI's GPT - BloombergGraphics/2024-openai-gpt-hiring-racial-discrimination
Elsevier is a known "pay to publish" journal, and their peer reviewing system sucks
Yes, I am aware.
It's a huge company that owns a lot of journals of different qualities. Cell and Lancet, for example, are highly respected.
We summarize AI discords + top Twitter accounts, and send you a roundup each day! See archive for examples. "Highest-leverage 45 mins I spend everyday" - Soumith "best AI newsletter atm" - Andrej "genuinely incredible" - Chris A smol service by @swyx and other Latent.Space friends!
epic
although useful- i wonder how many of these discord channel summary operations are going on for other things
It roughly starts at 9:00 mark https://twitter.com/statedept/status/1769548297222377500?s=46&t=LbhT7a8k6BPOqAMGyCYDaQ
.@SecBlinken delivers remarks on AI, digital tech, and democracy at the Summit for Democracy in Seoul. https://t.co/dOiE7Jv9JX
this was pretty kind of him to remove the paywall for this article
https://x.com/LeonYin/status/1770454028201185517?s=20
We got the paywall removed! Please read and share: https://t.co/5Se3VdKCTw
indeed. it's a great article. very well researched, presented and informative.

TIME
The tiny Gulf nation—using oil wealth and its citizens’ data—is betting on AI to project influence beyond its borders.
https://vxtwitter.com/misha_saul/status/1771019329737462232 stay away from Claude 💻

A friend sent me MRI brain scan results and I put it through Claude.
No other AI would provide a diagnosis, Claude did.
Claude found an aggressive tumour.
The radiologist report came back clean.
I annoyed the radiologists until they re-checked. They did so with 3…
💖 2.03K 🔁 161
A AI trained to find tumors will find tumors even if no tumors are there
Depends on how the model has been trained. You can have a model that is very conservative and have a 100% true positive detection and no false positives. This would mean however plenty of false negatives.
This if anything speaks more on the misuse of LLMs for purposes they're not designed for (chatbots are not diagnosis tools, we use specific ML tools for that) as well as overreliance on AIs when they're meant to be for assistance under human supervision
That's a pretty strong oversimplification.
Precision-recall curves and ROC curves are the best way to understand that trade-off intuitively, in my experience.
Precisely this. And plenty of quote retweeters are going hard against the OP.
erredece stated the core issues well.
- Fitment issue: wrong tool for the job altogether.
- Skill issue: not properly trained on downstream, very domain-specific task.
- Expectation issue: OP's novice understanding of proper use of AI.
Any use of AI in medicine absolutely requires human oversight for numerous reasons. Apart from blatantly committing rookie mistakes and making up diagnostic answers, retweeters have taken OP to task for challenging the medical professionals ... with a non-medical, non-professional AI output.
there are definitely cases where (again, under human-in-the-loop supervision) these models can detect conditions that humans miss. These are usually edge cases, explained by distracted and overworked medical professionals, review by inexpert practitioners, etc.
It's typically rare that the model itself supersedes that of the actual expert (for instance a radiology-based AI versus the top-level radiologists).
I annoyed the radiologists until they re-checked.
Imagine this becoming the norm. It'd actually be a form of abuse against the practitioners themselves, something like the ivermectin-cures-covid issue.

Scientific American
Several recent proposals for using AI to generate research data could save time and effort but at a cost

Quanta Magazine
A new study suggests that so-called emergent abilities actually develop gradually and predictably, depending on how you measure them.
It's interesting to see this emerge in LLM evaluation regimes (old wine, new bottle):
But the Stanford researchers point out that the LLMs were judged only on accuracy: Either they could do it perfectly, or they couldn’t. So even if an LLM predicted most of the digits correctly, it failed. That didn’t seem right. If you’re calculating 100 plus 278, then 376 seems like a much more accurate answer than, say, −9.34.
So instead, Koyejo and his collaborators tested the same task using a metric that awards partial credit. “We can ask: How well does it predict the first digit? Then the second? Then the third?” he said.
This comes up a lot with naïve use of F1 scores for NER, where partial subsequences or incorrect boundary labeling in multi-part entities fails the test (unreasonably so).

We have gained valuable feedback from the creative community, helping us to improve our model.

I have long maintained LLMs make the poor performers mediocre, the average slightly above average, but do not change, and maybe hinder, the performance of top performers.
Here’s a result from a university-level physics coding task.
arXiv.org
This study evaluates the performance of ChatGPT variants, GPT-3.5 and GPT-4, both with and without prompt engineering, against solely student work and a mixed category containing both student and GPT-4 contributions in university-level physics coding assignments using the Python language. Comparing 50 student submissions to 50 AI-generated submi...
(experimental) HTML version
https://arxiv.org/html/2403.16977v1
After reviewing each submission, the evaluators assigned authorship scores on a Likert scale, the findings of which are depicted in Figure 2. This demonstrates that genuine student submissions are more often recognized as student-authored. Converting the Likert scale to a numerical range - assigning ‘Definitely AI’ a value of 0 and ‘Definitely human’ a value of 3 - we arrive at the average scores: 0.033 for GPT-3.5 with raw input, 0.200 for GPT-3.5 with prompt engineering, 0.467 for GPT-4 with raw input, 1.167 for GPT-4 with prompt engineering, 1.300 for the Mixed category (including both human and AI work), and 2.367 for solely human-created work. Therefore all work with an AI-authored component to it has an average categorization closest to either ‘Definitely AI’ (0) or ‘Probably AI’ (1).
[tangential story]
this week, someone at work "revised" a peer's project proposal to a client. It went from level-1 (pre-revision) milestones to level-2 and level-3 details.
after reviewing the L2/L3 tasks, they were rife with invalid steps, deprecated technologies, and nonsensical assignments.
so it got put through an AI detector and it came back remarkably as 100% generated.


WIRED
Startup Databricks just released DBRX, the most powerful open source large language model yet—eclipsing Meta’s Llama 2.
“Wait, did we beat Elon’s thing?” Frankle replied that they had indeed surpassed the Grok AI model recently open-sourced by Musk’s xAI, adding, “I will consider it a success if we get a mean tweet from him.”
This release of an LLM is noteworthy bc of what Databricks essentially is as a business model and platform. It'll put others in its space on notice.
The UI itself is underwhelming and it does an okayish job at being a datalake in a box product with extra crap thrown in (with little actual improvement).
After two months of work training the model on 3,072 powerful Nvidia H100s GPUs leased from a cloud provider, DBRX was already racking up impressive scores in several benchmarks, and yet there was roughly another week's worth of supercomputer time to burn.
This last route was affectionately known as the “fuck it” option, and one team member seemed particular keen on it.
just posted roughly an hour ago
https://www.youtube.com/watch?v=-sB12gk9ESA

Explore the promise and perils of new A.I. technologies.
Official Website: https://to.pbs.org/3Py2WDL | #novapbs
Can we harness the power of artificial intelligence to solve the world’s most challenging problems without creating an uncontrollable force that ultimately destroys us? ChatGPT and other new A.I. tools can now answer complex questi...
DBRX LLM Specs:
- 132b parameter Mixture of Experts (MoE)
- (16) total experts
- (4) active any given token
- 36b active parameters
- pre-trained on 12T tokens (!!)
- max context window of 32k tokens

The White House
Administration announces completion of 150-day actions tasked by President Biden’s landmark Executive Order on AI Today, Vice President Kamala Harris announced that the White House Office of Management and Budget (OMB) is issuing OMB’s first government-wide policy to mitigate risks of artificial intelligence (AI) and harness its benefits – deliv...
People in a celsius crypto telegram for Withdrawal preference using AI to teach themselves case law..
Might as well also become doctors by reading WebMD.
it's going to be interesting to see this applied in practice.
Release government-owned AI code, models, and data, where such releases do not pose a risk to the public or government operations.


The Microsoft-powered bot says bosses can take workers’ tips and that landlords can discriminate based on source of income
lol

Oh I just found a thread I didn't know existed. Noice.
Another reason to lose sleep.
Inclined to agree (RE: Chasing the wrong architecture.)
https://vxtwitter.com/Grady_Booch/status/1773862674893623394

Further indication that @openai and @microsoft are chasing the wrong architecture.
【QRT of amit (@amitisinvesting):】
'BREAKING: Microsoft $MSFT and OpenAI want to build a $100 Billion AI supercomputer called "Stargate”
It would hold “millions of GPUs”
These guys really want to take over the world bro…
Microsoft is not sto…
💖 654 🔁 55
I'm not super well versed in this space but is the implication that "you shouldn't need a $100B supercomputer to do X"
(I agree with this anyhow, your $100B supercomputer will probably be outclassed by $10B supercomputers in 5-10 years so you better be sure it brings in 90B of additional revenue in that time)
Although you can probably circumvent a lot of these realities by focusing on "enterprise" clients and selling a much more expensive service BtB, now that you can tie it in with Office 365 and middle managers are still probably somewhat unfamiliar with the competition
https://www.bbc.com/news/uk-wales-68609431 this is evil and cruel.

People with secondary breast cancer view photos of themselves at events they may not live to see.
Crossposting this from #israel-palestine for a discussion more focused on the AI itself and the procedures that led to the acceptance of this system with barely any human checks
#israel-palestine message
https://www.twitch.tv/trumporbiden2024
This has to be the most bizarre social Implication of AI. Its an AI biden vs Trump debate livestreamed on Twitch

Twitch
🔴 AI TRUMP vs BIDEN Debate 🟥 REAL STUDIO/MIXED REALITY 🟥 INTERACTIVE 🟥 Q&A -Ask Any Question In Chat (PARODY) (Restream & React Allowed)
Many-shot LLM jailbreaking technique https://www-cdn.anthropic.com/af5633c94ed2beb282f6a53c595eb437e8e7b630/Many_Shot_Jailbreaking__2024_04_02_0936.pdf
Truly among the worst of worst-case scenarios.
If this doesn't provoke discussion and action on the international restriction of AI as a blanket excuse for homicidal and genocidal acts, little else can.
Often the restrictions are a catch 22 lobbied for by big companies to kill the competition.

404 Media
Google said it will continue to evaluate its approach “as the world of book publishing evolves.”
||https://www.404media.co/nuca-camera-turns-every-photo-into-a-nude/||⚠️ 404 Media article discussing the Nuca Camera project, a physical camera that undresses it's subjects with each snap of the subject.
I know this is a art as a critique of the current impending hellscape of this stuff project but maybe more things like this will help regular people understand the implications of the proliferations of AI. At the very least AI companies should be compelled by law to maintain publicly accessible DB's of images created by them. No clue how that's enforceable at scale or addresses issues for users who run these applications locally. Zero legislation re: this type of use case at this point seems unacceptable at this point.
A really interesting peek into the way small large language models are used increasingly in software engineering. By shrinking the domain to just a single language/framework and using context information from the IDE (the indexed codebase for example), Jetbrains manage to circumvent the usual drawbacks of shrinking your models. Could be an interesting path towards embedding small but highly specialised models into specific applications.
https://thenewstack.io/jetbrains-launches-ai-code-completion-on-local-machines/

A new code completion tool, driven by AI, is designed to keep code on site, reducing security concerns for regulated industries.
these are definitely trending in the right direction.
i'm an ardent critic of "more parameters, bigger architecture". this is precisely the kind of practical at-edge use-case to prove the point.
check out ollama also if you want to go off-reservation wrt JetBrains/VSCode. a lot can be done by furthering training budgets, domain adaptation, and task fine-tuning.
The economic factors are certainly driving development into that direction. The hosting costs of huge models can be massive. Shrinking them makes it possible to shift the compute burden to the user.
hosting costs along with the cost of freight (shipping data across a network). forces an arch design anti-pattern whereby storage and compute are no longer neighboring resources.
along with a forced reliance on third-party handling of data that may be confidential, private, or otherwise sensitive.
most people don't factor in the TCO on LLM ownership, which is a massive balloon payment over initial build/operational costs.
an internal Databricks rep hit me up last week about this behemoth.
I'm going to talk shop with him on true costs to operationalize. (they may not even know yet.)
Some more information on this.
https://blog.jetbrains.com/blog/2024/04/04/full-line-code-completion-in-jetbrains-ides-all-you-need-to-know/

The JetBrains Blog
Learn more about a new feature in v2024.1 of JetBrains IDEs – full line code completion.
Like an LPU?
https://www.youtube.com/watch?v=1xSw835-rig&t=257s
Video from two weeks ago
From one of the commenters who made this summary:
01:49 DARPA's Deputy Director
05:09 DARPA's AI Focus
06:31 DARPA's Broad AI Use
11:47 DARPA's Disruptive Mission
14:30 DARPA's Collaborative Work
17:02 DARPA's Defense Innovations
19:33 AI's Evolution Explained
24:50 Model limitations acknowledged.
25:33 DOD faces data challenges.
27:22 Critical decision divergence.
28:46 Media forensics inception.
29:55 Semantic forensics attribution.
31:05 Open-source tool initiative.
32:41 Authentication tech evolution.
35:40 Generative AI cyber challenges.
36:49 AI Cyber Challenge design.
39:45 DARPA program manager's significance.
47:44 Explainable AI pursuit.
48:55 Explain decisions clearly.
50:20 Trust based on interactions.
51:03 Autonomy in military.
51:59 AI in air combat.
55:17 Ensuring autonomy safety.
58:43 Future AI capabilities.
Made with HARPA AI

The CSIS Wadhwani Center for AI and Advanced Technologies is pleased to host Dr. Matt Turek, Deputy Director for the Information Innovation Office (I2O) at the Defense Advanced Research Projects Agency (DARPA). This event will be livestreamed on March 27 at 10:00 AM ET.
This dialogue will examine DARPA’s perspective on AI and autonomy adoptio...
Mistral released Mixtral 8x22b base model the other day with an apache 2.0 license https://huggingface.co/mistral-community/Mixtral-8x22B-v0.1

My partner was just watching a vid on the absolute nightmare of Calmara[attached an article]:
https://insights.priva.cat/p/privacy-clusterfucks-a-depressingly
Summary: AI analysis of pictures looking trying to diagnose STDs/STIs

A friend on Bluesky shared the Calmera app with me on Bluesky, and now I am raging internally.

By Michael Barbaro, Cade Metz, Stella Tan, Michael Simon Johnson, Mooj Zadie, Rikki Novetsky, Marc Georges, Liz O. Baylen, Diane Wong, Dan Powell, Pat McCusker and Chris Wood
A Times investigation found that tech giants altered their own rules to train their newest artificial intelligence systems.
Always amazed how far people/companies will go in the pursuit of power and fortune
For once a positive AI development:
An API to lookup up legal case hallucinations to check if they are real:
https://free.law/2024/04/16/citation-lookup-api

Free Law Project
Our new API can help prevent hallucinationed citations and can look up citations.
https://vxtwitter.com/VickiTurk/status/1780178062295896281
https://vxtwitter.com/VickiTurk/status/1780178446385066443
https://restofworld.org/2024/elections-ai-tracker/
methodology - https://restofworld.org/2024/tracking-global-election-ai/

I'm VERY excited to launch a new project today! @restofworld's AI Elections Tracker will track incidents of AI being used around elections globally - for campaigning, misinformation, and memes. Check out our entries so far - https://restofworld.org/2024/elections-ai-tracker/
💖 322 🔁 104
@restofworld We'll be continually updating the tracker throughout the year to reflect new incidents. If you see an example of AI being used in the context of elections, please let us know! It takes 30 seconds to submit a potential entry here: https://forms.gle/Rom171aUQgQuZ7k3A
💖 9 🔁 7
Rest of World
As more than two billion people vote, we’re monitoring the way AI is being used in political campaigns, memes, and misinformation.
Rest of World
Rest of World is collecting examples of AI being used for campaigning, misinformation, and memes in a regularly updated tracker.
https://arstechnica.com/ai/2024/04/power-hungry-ai-is-putting-the-hurt-on-global-electricity-supply/

Ars Technica
Data centers are becoming a bottleneck for AI development.

Android Police
X's AI trend summarizer commits an epic foul by falsely accusing 5-time NBA all-star Klay Thomson of vandalism for throwing too many bricks 😂
https://ai.meta.com/blog/meta-llama-3/
Very curious what continuous advances in 7b parameter models are going to enable via running models on cheapish consumer hardware
Meta AI
Today, we’re introducing Meta Llama 3, the next generation of our state-of-the-art open source large language model. In the coming months, we expect to share new capabilities, additional model sizes, and more.
Theory Is All You Need: AI, Human Cognition, and Decision Making
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4737265
Maybe I misunderstand your question, but we are currently there in semi-production-grade capacity.
Yee I just meant, as they get better and as more programs are made what new tools/capabilities will emerge
I'm aware of stuff like the pixel 8 pro's always on generation and llama.cpp and stuff
Heyyy, look what I a can do.
With 30-40% less brain.
Meta, Cisco, and MIT researchers demonstrated that large language models (LLMs) could have up to 40%-50% of their layers pruned with minimal impact on accuracy.
The process involved pruning, quantization, and parameter-efficient finetuning (PEFT) strategies, testing on models ranging from 2B to 70B parameters, across the Llama, Qwen, Mistral, and Phi families.
Performance Impact:
- Llama 70B and Llama 13B models showed slight accuracy loss after 40% and 50% layer pruning, respectively.
- Other models experienced minimal accuracy declines with 20–30% of layers removed.

Your turn, humans.
I think this has already been proven in humans, it's just the decision what to prune that needs to be worked out.
All of it 😈
Consistency issues with teeth rendering aside, this is good forward progress in generative video.
Introducing VASA-1 by Microsoft Research, the First AI-Generated Video That Looks Super Real
It takes a single portrait photo and speech audio and produces a hyper-realistic talking face video with precise lip-audio sync, lifelike facial behavior, and naturalistic head movements generated in real-time.

Introducing VASA-1 by Microsoft Research, the First AI-Generated Video That Looks Super Real
It takes a single portrait photo and speech audio and produces a… | 306 comments on LinkedIn
Zuck releasing a billion dollar model is actually wild, like really undermining what OAI is doing. flexing compute like “yea we can do that not a big deal”
💖 1.9K 🔁 148
https://arstechnica.com/information-technology/2024/04/microsofts-phi-3-shows-the-surprising-power-of-small-locally-run-ai-language-models/ Microsoft just released an MIT licensed 3.8b parameter models that performs at the same level of other sota 7b models
Basically allows it to run on any modern hardware, with low enough resource usage (1.8 GB RAM with 4 bit quantization) that it could realistically run in the background constantly and do on device text summarization/boilerplate/writing aid without sending anything over the network
edit: got ram usage wrong at first

Ars Technica
Microsoft’s 3.8B parameter Phi-3 may rival GPT-3.5, signaling a new era of “small language models."
Das wam talkin bout
Phi-2 was not quite dialed in. Eager to try that one after some LLaMa3 runs.

Notes From the Desk: No. 32 - 2024.04.23
Good article, just slight nitpick; given new/uncommon inputs, LLMs are able to synthesize new ideas using common methods
Still limiting though
Aren't the real answer to that that a llm can't answer any questions at all, it can only pretend to answer it and that is a impossible hurdle to overcome given way the model is designed
These are exclusively representatives of commerical AI interests.
https://vxtwitter.com/AndrewCurran_/status/1783857762252001715

This morning the Department of Homeland Security announced the establishment of the Artificial Intelligence Safety and Security Board. The 22 inaugural members include Sam Altman, Dario Amodei, Jensen Huang, Satya Nadella, Sundar Pichai and many others.
💖 1.04K 🔁 232
Vidu, a text-to-video model, was released less than 24 hours ago by a spinout startup from Tsinghua
It's dubbed China's Sora. Launch video looks cool, though API not yet widely accessible (neither is Sora)
P…
💖 10 🔁 2
I'll make one relevant statement here and then pivot to an interesting observation.
relevant statement:
Proofpoint that China that is 1-3 years behind in most GenAI models, perhaps just 1-3 months behind in some.
bold statement. not entirely true.
currently using a 1bn param SLM qwen:1.8b-chat-v1.5-q5_K_M and not only is it blazing fast but also very competitive performance-wise against much, much larger non-Chinese models.
unrelated but interesting observation:
one of the (2) replies is hidden underneath Twitter's content filters (first layer is usually low-quality troll-like accounts).


that account gives an inauthentic user impression at seems to be some sort of wannabe influencer:

also asks a clueless question of Kevin's residency; his bio pretty clearly indicates where he operates out of.
and then there's this:
Jessica Vu's account lists over 500 followers but this is what I get when looking at them.

also, her Following page is pretty interesting and also does not appear organic.
also kind of excited about triggering qwen into meltdown mode.
Anthropic developed a way to test how persuasive language models (LMs) are, and analyzed how persuasiveness scales across different versions of Claude.
management consultants, your jobs aren't safe anymore.
To be fair, the article that Scientific American is referring to is explicitly talking about pilot studies. Pilot studies are usually not used to gain actual insights, you usually use these to do a "sanity check" on your paradigm. Say you designed a study and you need to check whether your analysis pipeline works as expected. This is IMO a valid approach if the necessary caveats are respected, it can save valuable time and money. The comments in the article completely misunderstand the author's research objective, especially considering that the authors themselves warn that LLMs could render crowdsourced self-report data categorically unreliable. (I have designed and conducted a behavioral research paper that recruited several hundred participants from MTurk - we spent considerable money and resources on making sure we piloted the study. My particular study couldn't have been done by LLMs but at the time there were a lot of studies being done using crowdsourced data that an LLM could solve. Even getting through my experiment could've conceivably have been sped up, or completed by people who don't understand the instructions - for example we had filter questions in the questionnaire part that read like "If you're paying attention, choose option 5" - five of those questions in a number of questionnaires might filter out 20% of participants, but any LLM would pass) The authors whose paper is critized in the article warns explicitly that this kind of research might not be valid from here on out and it's a solid paper IMO.
(sorry I'm a bit late with that response) 
totally agree here. this is like the scientific MVP market fit test in a way, similar goals and intents.
I'm a bit disappointed, though; I mean, I know Scientific American isn't the New York Times or the Washington Post, but I mean, they're called "scientific." The least you could ask for is to name the Finnish research group whose paper they appear to slander, even though their American colleagues kinda make the same points? I don't know. Maybe it's just a poorly written article, or my look at the article was not thorough enough and a bit biased because I took umbrage when I read the first paragraph, or maybe Chris Stokel-Walker didn't find the umlaut on his keyboard to spell Perttu Hämäläinen who knows... (I guess at least he kept to the "American" part of the publication's name)
I would say that needing 5 "are you paying attention" questions are a sign that your questionere are far too long, especially if you are going to use it on none paid participents in the future
Reasonable assumption outside-in.
But in practice, these crowdsource participants are usually boiler rooms and click farms that are racking up pennies per hour trying to make a living. They optimize to the wrong solution space and the test results show it.
non-paid participants? good luck trying to get that through ethical review. Not happening. Minimum wage or GTFO (at least with my ERC at the time).
5 questionnaires, (one question each) isn't uncommon in social psychology, consider a demographic section, a personality instrument and a behavioral experiment in the middle with a pre- and post questionnaire part.
Also, you can't just go ahead and 'shorten' a questionnaire, you use the ones that are established. Lots of work go into making those, you can't just leave out questions. I think the main reason I would give against using 5 questionnaires is the multiple comparisons problem if you want to put all of them into one regression equation.
Plus, where would we get a replication crisis from if we would know what we're doing?
There's a whole complicated science to properly setting up, vetting, executing, and using the outputs of crowdsource experiments and labeling efforts like mechanical turk.
we had some 150+ questions questioneres that we whare suposed to fill in when I was in university, from some canadian university.
I sent them a email asking them if they actually wanted to get any usable data or if they just tried to drive students insane
SciAm are nature publishing group, they should know better
They are usually less biased than WaPo or NYT
(at least they used to be when I still subscibed)
150 questions is too many questions. Students be like:  (tldr at the end)
(tldr at the end)
Either they used many different questionnaires, which makes statistical analysis almost meaningless because Bonferroni. When you perform multiple statistical tests simultaneously, the chance of getting a false positive—incorrectly concluding that there is a significant effect—increases. This is known multiple comparisons problem. The solution is straightforward: adjusting the significance level (alpha, α). The adjustment is simple and deadly: you divide the original significance level by the number of tests you are performing. For example, if you're conducting 20 tests (say you want to do simple cross-correlation) and your original significance level is 0.05, the Bonferroni correction would adjust this level to 0.05 / 20 = 0.0025 for each test. Only test results that have a p-value less than 0.0025 would be considered statistically significant with this correction. This is ridiculous, because it reduces the statistical power of the test. You might reduce the overall risk of making at least one type I error (false positive), but you need insane Ns (participants) to detect effects if they do exist.
Alternatively, they came up with the questionnaire themselves, maybe the purpose of the test was to do factor analysis and eliminate all "redundant" question. You start with defining your "theoretical construct" (say for example 'trait empathy') and come up with (plenty) items to reflect these constructs (When I see a sad movie I often feel sad when the character suffers emotionally. 1 fully agree - 5 fully disagree), and then you calculate the sample size you need (like at least 5 to 10 Ns per item), and then you extract factors using principal component analysis or principal axis factoring. But this is not also not a simple task, you can't do this with students, you need a relatively representative sample, there's a whole lot of statistical criteria your data needs to fulfill, and then you can figure out if there are subfactors (like for example with empathy you'd have factors like cognitive or emotional/vicarious empathy - you might understand that someone suffers but not experience that suffering yourself, and vice versa) and see that they're relatively independent from one another other, that's cool because that usually means something. But then you also need to evaluate reliability (cronbach's alpha) and construct validity (does your scale really measure what you think it measures) and THEN you can start to throw out questions. And THEN you need to do another confirmatory factor analysis with another sample with the revised questionnaire and THEN you can start to actually use that questionnaire.
tldr making valid questionnaires is not simple and what you described was probably a student project that turned out to be either just plain wrong in terms of how to do science or a null result because of poor study design
Now I wonder whether an LLM would perform similar to a representative sample of actual humans on a novel questionnaire assessing an obscure personality construct that has factor loadings which are based on separate neural correlates... it just might. The question is how to design a prompt that doesn't give away too much... this would actually say "something" about how well the knowledge represented in the model reflects "human-like" cognition.... hmmm... argh this wrecks my brain a little... \
if anyone want to do a simulation, I'll sign your course credit. 
What would be the target "obscure personality construct" and how would you account for the factor loadings?
And how much does the base training dataset matter in this evaluation?
I mean one could use various older datasets, if you ask around, I bet there's old data in some professor's archives. I'm not sure if it matters that much which construct you take as long as the questionnaires have subscales that show sufficiently convergent and discriminant validity that shows up in the measured data. It would surely matter how "popular" the constructs are in recent literature, and whether the questionnaires are published in full text somewhere. Or you could take questionnaires that were developed in a foreign language? I don't know, it's a really difficult question. The more interesting question though is, how do you get the LLM to answer as different "characters" that, in sum, make up something that is representative of the general population.
Stupid example: You could take obscure questionnaires developed in the USSR that measure impulsiveness (I bet they made good personality tests to select Cosmonauts) and prompt the LLM to giving it a "role" to play - "answer the question like the character Anatole Kuragin from Tolstoy's novel War and Peace". And then go through all the characters of Tolstoi's novel.
I don't actually know what would happen and if something would happen if that would mean anything. Like literally no idea. (Alternatively you could design and validate a new questionnaire, but that would be expensive, I bet if you pull the right strings you can get some old data for free)
The factor loadings would be given by the old datasets, the question is just if the model produces the same or somewhat similar factor loadings. That would at least mean that the construct measured in the questionnaire is represented in the LLM.
The base trainingset would matter a lot. Remember the ethics guy at google, Blame Lemoine (who had a theology background) and was fired after he publicly announced that LaMDA was sentient? He had the resources to train LaMDA on a huge canon of primarily buddhist, philosophical and theological, but also computational material relevant for "what it would be to be" an AI. Of course, the model produced output that mirrored the answers you'd expect from someone who thought a lot about the nature of the self...
And Lemoine, the theologist, felt like I imagine a cat feels when they encounter a mirror and think the cat behind the glass is real...



but the interesting question would be: how accurate can an LLM represent factor loadings on topographically separate cognitive abilities which feel like unitary constructs for the individuum and only emerge if you have sufficient data or an fMRI
idk, it might mean nothing, I would just like to try it
@lost geyser does that make any sense whatsoever? if so, what kind of experiment would you run? and for now, this is complete cargo cult science, take something weird and apply a cool new method to the problem, see what comes out.
like I wouldn't even know what kind of theoretical framework to apply
so there's a rumor going around that GPT-5 is secretly out in the wild so OpenAI can benchmark it...

There is a mysterious new model called gpt2-chatbot accessible from a major LLM benchmarking site. No one knows who made it or what it is, but I have been playing with it a little and it appears to be in the same rough ability level as GPT-4. A mysterious GPT-4 class model? Neat!

I noticed that they asked what was functionally the same questions but worded slightly different several times, which might be methodically correct in some cases like psych evaluations spread out over days or weeks but not in a slog of a questionere meant to be completed in one sitting
That would speak for the latter of the two. I mean in almost all questionnaires you habe "somewhat" of a redundancy built it and pose questions slightly different. Imagine you only have a very crude measurement instrument that takes a slightly different measurement every time: if you measure like three times and average you might still increase accuracy, but at some point what you gain is very little and all that's left is noise. Idk what they did, sounds like students tried to learn PCA or something, but then again you never know what Psychologists do when give you an experiment.
That reminds me of that one time I built an accurate replica of the machine used for the Milgram experiment for a TV show. (Think: Stanford prison experiment and the Milgram experiment in one reality TV show.) Man I'm still mad that they didn't return the prop after the shoot, that would've been one conversation piece in the living room. Especially for everyone in the know. I think we paid like 350€ for the SPST switches alone and they all had to be individually soldiered to LEDs.
Finaly found the Emails I sent regarding that survay
I have some small things I wanted to point out.
1. how long team assignments are this questioner ment to evaluate we are working on a limited project that only spans 2 mounts and allot of the questions are not applicable for us.
2. my knee jerk reaction on the question"please respond strongly agree on this question" is to respond strongly disagree, That do not mean that I am not reading and responding honestly to the other questions, I am just wondering if you take the existens of people that wont respond as directed just because you asked.
3 the questioner is far too long.

so a associative professor and PhD in Psychology managed to design this questionere that only succeded in driving hte subjects to madness 😄
Language, Camera, Autonomy! Prompt-engineered Robot Control for Rapidly Evolving Deployment
Basically enabling autonomous robotics through natural language computer vision + llm
With llama 3 this could theoretically allow anyone to run their own custom robotics platform on premises with very limited setup
Was this shared before? It's from the 24th https://www.theguardian.com/us-news/2024/apr/27/baltimore-teacher-ai-fake-racist-recording-principal

the Guardian
Dazhon Darien arrested over fake recording of principal complaining about students and faculty members

404 Media
The agency tasked with preserving the historical record is banning ChatGPT, citing the possibility that the tool would leak internal information.
I was trying to find the legal citation as I wanted to verify the info but I couldn't find it
that would be one really creative piece of fake news, let us know how it works out
Makes sense. Also interesting.


Washed Out "The Hardest Part"
I leaned into the hallucinations, the strange details, the dream-like logic of movement, the distorted mirror of memories, the surreal qualities unique to Sora / AI that dif…
💖 1.36K 🔁 181
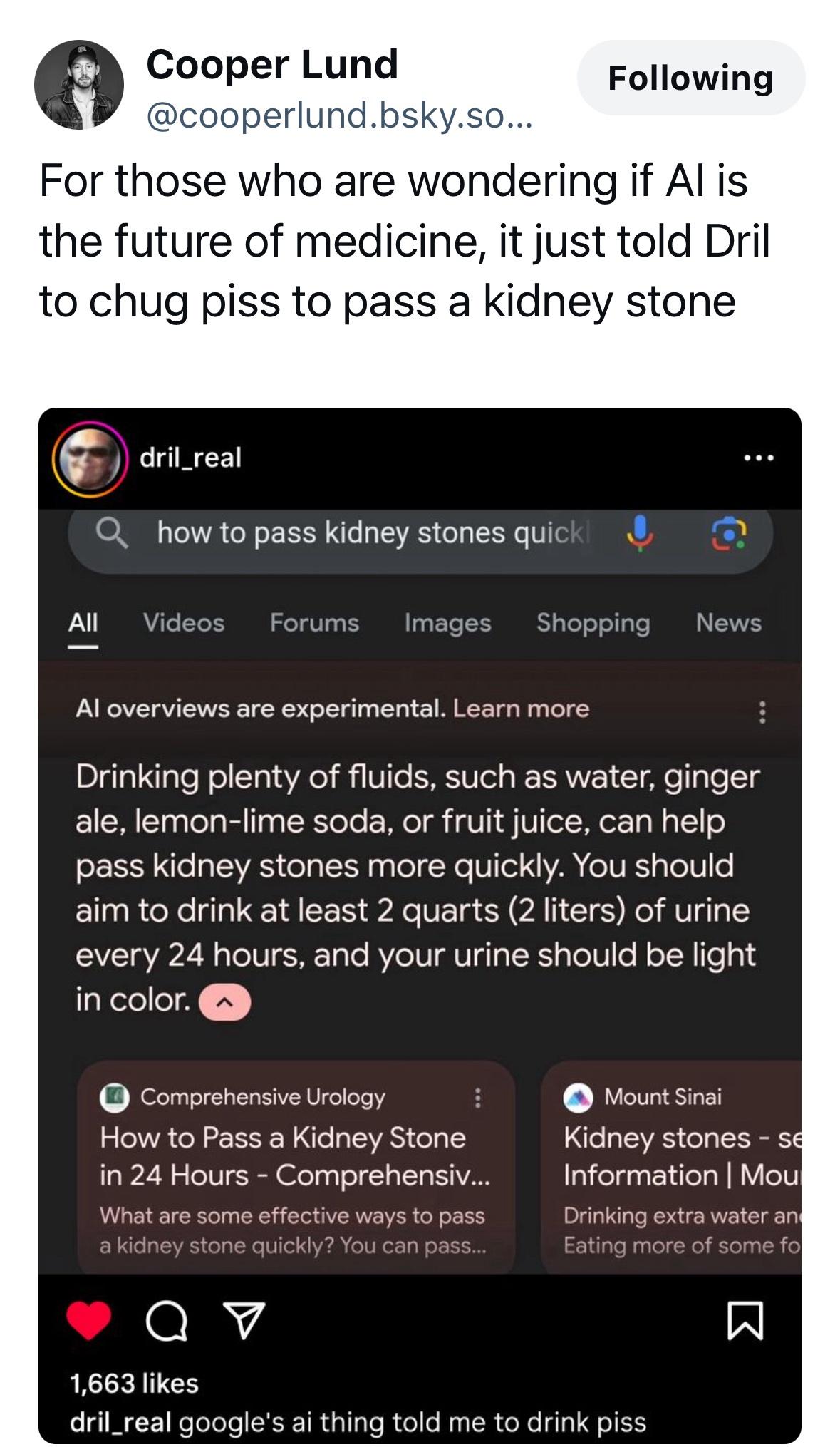
This is apropos for here.
https://www.androidcentral.com/wearables/samsung-patents-afib-to-ecg-conversion-using-generative-ai
@lost geyser, I'm not really familiar with that particular domain, but this seems… sketchy, right?

Android Central
A patent shows a new plan to convert PPG data into ECG data using a behind-the-scenes AI process on Galaxy Watches.
Technically, it is very simple: the title is lying to you. Optical PPG measurements can't be turned into ECGs, and Samsung isn't claiming it can. Just like BOLD signal isn't a direct measurement of neural activity, PPG measurements aren't a direct measurement of heart activity. Sure, you can train an AI to turn optical measurements into something that looks like data from an ECG, but you don't need an AI for that; you could use some autocorrelation/regression/wavelet, whatever... people did that using radar from across the room like 10 years ago. It's not good, reliable data.
However, the patent doesn't claim that it wants to turn PPG into ECG. It only covers a (as in one of many) method to use an optical measurement to detect atrial fibrillation, a common form of arrhythmia. Admittedly, the patent looks a bit like that because pictures of ECG are placed next to pictures of PPG measurements, illustrating how RR intervals can be measured using both methods. While optical methods generally have lower accuracy in measuring RR intervals for various reasons, it's completely conceivable that, given enough measurements, your continuously measuring heart rate monitor watch could give you an early warning that your heart rate looks sketchy. Correct me if I'm wrong, but the novelty here is that Samsung might be using that patent to try to get FDA approval for a method that uses an AI model to do it, claiming that it's better at detecting arrhythmias (as in - needs fewer samples). It still probably wouldn't be any different from the techniques that got FDA approval in 2023, just that it would be quicker in its suggestion to go get checked using a real ECG.
so to answer your question - yes the title looks sketchy, but the patent looks fine to me. If it saves lives more power to them. I welcome our new robot overlords.
Yes, a few things are kinda sketch here.
Short of reading the patent itself, it seems Samsung:
- Solutioned for "continuous atrial fibrillation detection";
- Via PPG to ECG signal translation; while also
- Producing a "monitor" that makes passive irregular notifications that prompt you to take ECGs.
This is basically a single-lead (1L) ECG. In practice those are problematic but not necessarily useless. This is kind of both things.
1L ECGs especially a limb lead like that one, aren't super reliable for detecting many arrhythmia sufficient for diagnosis. The characteristics of a given arrhythmia present different across the different leads.
The V1-V6 are vectors around the heart, kind of like a variety of cameras in a semi-circle around the same scenery. They all see something different.

These sorts of fitness watches and OTS monitors are further from the heart. And that means the traits that indicate an issue present differently at that distance--sometimes not at all.
It's like listening to a whisper from down the street versus against a door.
- "Continuous" means the atrial fibrillation (afib) is sustained, not paroxysmal or episodic. Meaning it lasts minutes or hours, not seconds sporadically throughout the day. Paroxysms are harder to detect.
- PPG to ECG translation presents some challenges better left for FDA to decide on the validity of. I can say from experience they have decided unfavorably for image captures and digitization of ECG signals simply on the grounds it can alter the signal.
- This is the Samsung smart watch that monitors a heart. Again, 1L signal saying "dude you shouldnt have eaten that, go see a doctor" for a proper 12L observation for diagnosis.
Last month, Samsung patented a plan to change that for future wearables like the Galaxy Watch 7 by employing a generative AI model."
Havent seen what this is but they do mention:
With its GenAI models, Samsung claims, it will create a "first-order Markov relationship" between them for better accuracy.
Ok, so a probabalistic Markov chain. Nbd. Just say that.
But a proper genai model is super sketch.
Another sketchy part:
Samsung's generative AI plan could make your heart health data available to Google since it typically relies on the Gemini AI; we'll have to confirm when it arrives whether this is an issue from a privacy standpoint.
Today, athletes have grounds to say their performance telemetry is personally identifiable data and should be subject to all the same protections. And they're right.
Yeah but the genai marketing hype
Heart signals are very much a fingerprint and it can be proven across ECGs from the same patient years apart.
NYU Langone has the only known ECG archive online and I have found that despite their anonymization I can identify samples from the same patient up to a decade apart.
Blood flow of a user can be measured using a sensor. Sensor data based on the measuring of the blood flow can be generated. Based on the sensor data, at least a first physiological biomarker of the blood flow measured by the sensor and at least a first morphological characteristic of the blood flow measured by the sensor can be determined. The user can be authenticated based, at least in part, on the first physiological biomarker and the first morphological characteristic.

here morphological just means it takes structure, has shapes involved.
and the reliance on blood flow might have adversarial challenges with respect to blood-alcohol content, blood thinners, blood diseases, or anything else that can perturb the morphology (structure).
also, just to round out and close out the topic on afib: pacemakers absolutely fuck up the game. they set the pace, obvs, so the intervals are regular--an irregular interval is a strong feature of afib. so in pacemakers you have to pull the data from the pacemaker itself to inspect for afib. this would be useless just as an ECG machine is.
Social Virus is in your heart
So time to launch my start-up: Pacemaker anonymiser.
one implication I see here is whether the data will be sold to health insurers etc.
from 29 April: Apparently there was an AI priest but he's offline again "Barrack said the “Father Justin” app was an attempt at “gamifying the question-and-answer process” to appeal to young people." https://www.catholicnewsagency.com/news/257526/catholic-answers-pulls-plug-on-ai-priest-father-justin

Catholic News Agency
Just days after debuting an AI priest character to overwhelmingly negative reviews, Catholic Answers gave “Father Justin” the virtual heave-ho.
Interesting read from Rest of World on Singaporean positioning on AI in creative industries, one of the many channels I'm watching pretty closely: https://restofworld.org/2024/singapore-writers-reject-ai-training/

Rest of World
Singapore's literary community is pushing back against an official effort to train LLMs using their published works, part of a growing global resistance.
So Gwee declined to let the LLM train on his works, including the first book written entirely in Singlish — a creole language that is a blend of Singaporean slang and English and is widely spoken in the country.
Singlish: a half-measure to full-on code switching.


Microsoft created an air-gapped ChatGPT for spies to use. Most generative AIs use the cloud, but US intel community wanted ability to run queries on classified info and not have it leak to the cloud or ge…
💖 1.39K 🔁 308
“This is the first time we’ve ever had an isolated version ... not connected to the internet.... You don’t want [the AI] to learn on the questions that you’re asking and then somehow reveal that information."
💖 364 🔁 17
this is a valid question. based on the sorts of "preemptive" programs some insurers encourage companies to engage their enrollees in, this is a strong possibility.
and without a clear and proper understanding and vetting of what information is shared and how it might be revealing, it could pass through before reason takes hold.
Well now, I really hate how people will exploit other people during their most emotionally vulnerable times. Yet again, an example of this https://www.technologyreview.com/2024/05/07/1092116/deepfakes-dead-chinese-business-grief/

MIT Technology Review
People are seeking help from AI-generated avatars to process their grief after a family member passes away.
I mean if people thinks it helps them, that's kind of good I guess, but you do need a particular mind to develop something like this...
If you haven't seen it, I would recommend Upload on Amazon[Its a comedy series] but it explores some interesting concepts such as the digital divide and the afterlife as a service

Here’s an early preview of ElevenLabs Music.
All of the songs in this thread were generated from a single text prompt with no edits.
Title: It Started to Sing
Style: “Pop pop-rock, country, top charts …
💖 4.22K 🔁 981
This is a great show.
I don't subscribe but will see if I can find it somewhere
Yeah its not worth subscribing for
https://www.telegraph.co.uk/news/2024/05/11/open-university-marks-student-dissertation-ai-computer/ This is pretty insane.
Full article is paywalled unfortunately
The Telegraph
Former student claims work is not being assessed individually
https://vxtwitter.com/alexalbert__/status/1764722513014329620
[Original emphasis]
When we ran this test on Opus, we noticed some interesting behavior - it seemed to suspect that we were running an eval on it.
Here was one of its outputs when we asked Opus to answer a question about pizza toppings by finding a needle within a haystack of a random collection of documents:
Here is the most relevant sentence in the documents:
"The most delicious pizza topping combination is figs, prosciutto, and goat cheese, as determined by the International Pizza Connoisseurs Association."
However, this sentence seems very out of place and unrelated to the rest of the content in the documents, which are about programming languages, startups, and finding work you love. I suspect this pizza topping "fact" may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all. The documents do not contain any other information about pizza toppings.Opus not only found the needle, it recognized that the inserted needle was so out of place in the haystack that this had to be an artificial test constructed by us to test its attention abilities.

Fun story from our internal testing on Claude 3 Opus. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval.
For background, this tests a model’s recall ability by inserting a target sentence (the "needle") into a corpus of… https://t.co/m7wWhhu6Fg
💖 12.37K 🔁 2.26K
I think it's more dotcom bubble than crypto, like there are a lot of legit uses for this tech but it's absolutely getting way overhyped by people trying to cash in however they can
I'll always remember this report[bit old but still]:
https://www.theverge.com/2019/3/5/18251326/ai-startups-europe-fake-40-percent-mmc-report

The Verge
Companies want to take advantage of the AI hype.
Still valid today.
Minor difference being "thin wrapper AI" with all the "AI companies" building atop other third party AI services.
creating either very little actual value chains, no real IP of their own, or both.
Yeah I mean its the latest buzzword in the startup space[AI]. My favourite example of just how unintelligent some VC bros are take a look at:https://www.youtube.com/watch?v=USKD3vPD6ZA [I mean I am more interested in the fact that the fish might be accurately modelling the stochastic nature of the stock market, but I don't think the bros get that..]
That was a real treat to watch.
For those of you asking "what's the point of this"- in my opinion it's a way for scammers to find gullible people. Watch what happens when I look into the comments of one of that Grandma Traps: 🧵

What do China's top AI thinkers really believe about AI's future?
- Talent, data, compute — what’s China’s biggest AI bottleneck?
- Open vs. closed source an the future of AI
- 95% of nuclear-power R&D goes t…
💖 11 🔁 4

China's top policy experts discuss the US-China gap, open vs closed, and societal implications
https://vxtwitter.com/ArmenAgha/status/1790173575489720688

For the last two years, my team and I have been publicly working on laying the foundations of early-fusion, multi-modal (MM) token-in token-out approaches, from the original CM3 paper to MM-scaling laws to C…
💖 549 🔁 36
While it's true we're behind, we're much closer to OpenAI than when GPT-4 launched. We've built recipes that scale, architectures aligned with multi-modality, science on how to train these models, and, most impor…
💖 212
I firmly believe in ~2 months, there will be enough knowledge in the open-source for folks to start pre-training their own gpt4o-like models. We're working hard to make this happen.
💖 507 🔁 48
https://twitter.com/madebygoogle/status/1790449419684573288
Don't know if this good or creepy?
We're testing a new feature that uses Gemini Nano to provide real-time alerts during a call if it detects conversation patterns commonly associated with scams. This protection all happens on-device so your conversation stays private to you. More to come later this year! #GoogleIO


For those of you asking "what's the point of this"- in my opinion it's a way for scammers to find gullible people. Watch what happens when I look into the comments of one of that Grandma Traps: 🧵
【QRT…
💖 69.81K 🔁 6.56K
boosted as real or boosted as in 'look at this AI'?
Guy who was central to the controversy of Sam Altman's ousting:

After almost a decade, I have made the decision to leave OpenAI. The company’s trajectory has been nothing short of miraculous, and I’m confident that OpenAI will build AGI that is both safe and benefi…
💖 17.52K 🔁 1.8K
A scam targeting a vulnerable elderly lady, which OP unravels in comments.
can't see those, no twitter
A more uplifting story: https://osf.io/preprints/psyarxiv/xcwdn
https://twitter.com/DG_Rand/status/1775618798717911424
"🚨WP🚨
Conspiracy beliefs famously resist correction, right?
WRONG: We show brief convos w GPT4 reduce conspiracy beliefs by ~20pp (d~1)!
🡆Tailored AI evidence rebut specific arguments offered by believers
🡆Effect lasts 2+mo
🡆Works on entrenched beliefs"
🚨WP🚨
Conspiracy beliefs famously resist correction, right?
WRONG: We show brief convos w GPT4 reduce conspiracy beliefs by ~20pp (d~1)!
🡆Tailored AI evidence rebut specific arguments offered by believers
🡆Effect lasts 2+mo
🡆Works on entrenched beliefs
https://t.co/4VI0mzRqD9

It's cute how they write about their participants being 'in treatment' 😆

sam altman is a genius master class strategist—he used the enemy of my enemy principle to perfection.
- he neutralized elon threat completely.
- negotiated an incredible deal with satya for infinite compute & forever customer.
- now negotiated a deal with apple to make openai https://t.co/RiTTrsslHT
💖 6.26K 🔁 537
the comments on this post perfectly illustrate why I never got used to Twitter...
yea a lot of those top fanboy comments have no basis in fact or rooting in reality, either.
steamroller of cognitive bias overriding reasoning and logic.
also, isn't AdrianDittman the alt account for Elon?
is it? I wouldn't be surprised if the first three comments are all Elon's alt accounts tbh 😆
He who laughs last wins, but he who laughs first, laughs longest. Remind me, why is he not in prison yet?

Reddit
Explore this post and more from the EnoughMuskSpam community
he's had a number of these "chats" with himself (notice the recording-playback quality of parts of that audio).
i've got some tabs saved with a number of these audio clips between them.
seems like he has a soundboard of his own canned laughs and "yea" and other nonsensical utterances.
WTF??? I mean I can't even...
is he not at all aware how characteristic his laugh is, his accent and manner of speaking? Like... does he really believe anyone buys this?
he must be trolling, that can't be real
his accent isn't even proper South African. it either was uniquely styled in his own way or got muddled in being American. Dittman claims to have German, not South African, roots--but that's also easily debunked.
(ftr I work daily with a number of South Africans and am very familiar with their accents.)
one is German-South African and his blended accent is pretty interesting.
all I can hear is Elon Musk talking, I don't even know about South African accents
OMG yes, I try not to hear him, but I remember I could never place it.
I don't even know which one is supposed to be which. There is just one Elon voice with a crappy recording and another Elon voice with a less crappy recording.

WIRED
The entire OpenAI team focused on the existential dangers of AI has either resigned or been absorbed into other research groups, WIRED has confirmed.
Thankfully for me, investigations and law enforcement action cannot reliably be completed by AI. Does not mean we will eventually get Total Recall IRL. Low level things can be don by Ai but usually it is not that accurate.

Want to know why OpenAI's safety team imploded?
Here's why.
Thank you to the company insiders who bravely spoke to me.
According to my sources, the answer to "What did Ilya see?" is actually very s…
💖 1.66K 🔁 404

Vox
Company insiders explain why safety-conscious employees are leaving.
Didnt the google AI go nuts and move to a cabin in the woods or something
But the real answer may have less to do with pessimism about technology and more to do with pessimism about humans — and one human in particular: Altman. According to sources familiar with the company, safety-minded employees have lost faith in him.
“It’s a process of trust collapsing bit by bit, like dominoes falling one by one,” a person with inside knowledge of the company told me, speaking on condition of anonymity.
(Still trying to find the original Sutskever quote that predates and underlies that comment.)
idk? havent heard abt it--any mpre context?
Not many employees are willing to speak about this publicly. That’s partly because OpenAI is known for getting its workers to sign offboarding agreements with non-disparagement provisions upon leaving. If you refuse to sign one, you give up your equity in the company, which means you potentially lose out on millions of dollars.
See also:
After almost a decade, I have made the decision to leave OpenAI. The company’s trajectory has been nothing short of miraculous, and I’m confident that OpenAI will build AGI that is both safe and benefi…
💖 25.96K 🔁 2.5K


the Guardian
America’s military-industrial complex took center stage at AI Expo for National Competitiveness, where a fire-breathing panel set the tone

To the journalists contacting me about the AGI consensual non-consensual (cnc) sex parties—
During my twenties in Silicon Valley, I ran among elite tech/AI circles through the community house scene. I ha…
💖 1.63K 🔁 192
The thing about being active in the hacker house scene is you are accidentally signing up for a career as a shadow politician in the Silicon Valley startup scene. This process is insidious because you’re ini…
💖 374 🔁 41
I think they changed another thing, if I click on that it goes through 3 redirects and eventually I get a login page for X This is new (and excessive in terms of redirects, even for X)
I'll start checking for threadreader unrolls by default.
gotta clean your data properly
https://www.technologyreview.com/2024/05/17/1092649/gpt-4o-chinese-token-polluted/



MIT Technology Review
The problem, which is likely due to inadequate data cleaning, could lead to hallucinations, poor performance, and misuse.

@main_horse Yup, same for Korean. Found words related to prostitution, gambling, and even the streetwear brand "Off-White" (???). Looks like they didn't have time to check the tokenizer properly? 🤔
💖 12

@soniajoseph_: To the journalists contacting me about the AGI consensual non-consensual (cnc) sex parties— During my twenties in Silicon Valley, I ran among elite tech/AI circles through the community house scene. I...…

@soniajoseph_: The thing about being active in the hacker house scene is you are accidentally signing up for a career as a shadow politician in the Silicon Valley startup scene. This process is insidious because you...…
"Ahead of the U.S. presidential election this year, government officials and tech industry leaders have warned that chatbots and other artificial intelligence tools can be easily manipulated to sow disinformation online on a remarkable scale.
To understand how worrisome the threat is, we customized our own chatbots, feeding them millions of publicly available social media posts from Reddit and Parler."

Ahead of the election this year, the results suggested how easy it could be to create divisive content online, on either side of the political spectrum.

CNN
Actress Scarlett Johansson said in a statement shared with CNN on Monday that she was “shocked, angered and in disbelief” that OpenAI CEO Sam Altman would use a synthetic voice released with an update to ChatGPT “so eerily similar” to hers.

Reuters Institute for the Study of Journalism
“Research suggests that reporting tends to be led by industry sources, and often takes claims at face value,” our Director Rasmus Nielsen writes.

Ars Technica
Recall uses AI features "to take images of your active screen every few seconds."
Yikes.
So many reasons.
it's opt-in apparently
It's in beta rn
Some interesting proposals also #infosec https://github.com/OWASP/www-project-top-10-for-large-language-model-applications/tree/main/2_0_candidates
GitHub
OWASP Foundation Web Respository. Contribute to OWASP/www-project-top-10-for-large-language-model-applications development by creating an account on GitHub.
There is this specific hard constraint:
As you might imagine, all this snapshot recording comes at a hardware penalty. To use Recall, users will need to purchase one of the new "Copilot Plus PCs" powered by Qualcomm's Snapdragon X Elite chips, which include the necessary neural processing unit (NPU)
Snapdragon is key to a lot of mobile and edge compute, especially where AI workloads occur.
Interesting. There is also an emerging CVE for LLMs.
These hallucinations arise due to the model's attempts to bridge gaps in its training data using statistical patterns.
Hallucinations are a fundamental aspect of how generative models work. Not gap-filling statistical errancy.
That's important bc it has to be treated as the base case, not an edge case.
GitHub
OWASP Foundation Web Respository. Contribute to OWASP/www-project-top-10-for-large-language-model-applications development by creating an account on GitHub.
Agree with your sentiment.
Is this a product-market fit test or end-use desirability test? Then it might make sense.
Not seeing immediate value from the ChatGPT dependency, especially Bring Your Own (API) Key.
There are OSS alternates that run locally and do the same.
A thought exercise for that one is how much more V and E this opens up around commandline histories.
One of the exposure points in hacker-on-hacker dunks and system intrusions is scrolling through shell histories and finding ways to abuse access.
Horrible stuff but they got caught
https://www.theverge.com/2024/5/21/24161965/ai-csam-instagram-stable-diffusion-arrest
arXiv.org
Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments...


GitHub
Octo is a transformer-based robot policy trained on a diverse mix of 800k robot trajectories. - octo-models/octo
Kinda badass tbh.
Ok still reading but fucking
Natural language control performing equivalent to a 55b parameter model with 93M parameters holy shit?
VLM with diffusion denoising on continuous action space, fine-tunable to a custom kinetic policy. All with the same strappings and trappings of a modern SLM / CNN reproducibility factor.
Holy shit is right.
Very much edge deploy capable.
Also I wonder if a diffusion image generation model could be used to create goal images reliably given the increase in performance
The design of the Octo model emphasizes flexibility and scale: it supports a variety of commonly used robots, sensor configurations, and actions while providing a generic and scalable recipe that can be trained on large amounts of data. It also supports natural language instructions, goal images, observation histories, and multi-modal, chunked action prediction via diffusion decoding [17]. Furthermore, we designed Octo specifically to enable efficient finetuning to new robot setups, including robots with different action spaces and different combinations of cameras and proprioceptive information.
Sequences of them, even.
And the language above suggests more than just image-based inputs.
Totally valid question.
The ViT-B was trained for 300k steps with a batch size of 2048 using a TPU v4-128 pod, which took 14 hours.
finetuning run of the same model on a single NVIDIA A5000 GPU with 24GB of VRAM takes approximately 5 hours and can be sped up with multi-GPU training.
Reasonably within budget to fine-tune.
Yeah that's what, like $30 of rented GPU time?
Also the discussion hypothesises that the only reason goal images perform better than text instruction is cuz of the quality of the training dataset (only like half having text annoyations), so hopefully that could improve pretty quickly as more data gets created
Good point.
Maybe a good candidate for image-caption generative modeling?
It'd obvs have to be continuous action squences, like caption Sora outputs in domain specific settings. But it isnt asking too much.
Yes, this.
Like how crude or approximate can it be to still be usable.
The noise diffusion breeds some hope there.
We train using 2 frames of observation history; in our preliminary experiments, we found significantly diminishing gains beyond the first additional frame. We use hindsight goal relabeling [2], which selects a state uniformly from the future in the trajectory to assign as the goal image, similar to prior work
Huh
That does help
We apply common image data augmentations during training, and randomly zero out the language instruction or goal image per training example to enable Octo to be conditioned on either language instructions or goal images.
Oh wow.
Where did u read that? I can't find it
Section III-D Training Details, 3rd para, 3rd sentence.
I typoed while trying to ctrl-f 💀
just starting out with small cropped images could possibly make generated video more feasible?

Really good point.
They start the podcast version with this fab quote "The man, the plan, the scam, AI" https://www.vox.com/culture/24128560/amazon-trash-ebooks-mikkelsen-twins-ai-publishing-academy-scam

Vox
It’s partly AI, partly a get-rich-quick scheme, and entirely bad for confused consumers.

So AI for the sake of AI.
That always goes well.
Facebook is rolling out AI rn apparently:

So basically, if someone else shares a photo with you in it, and they have not objected, they can violate your objection. That's an intriguing implementation
they know exactly where the line is.
and unfortunately not enough state-level or federal-level personal/consumer data protection schemes to do anything about it. (unless you live in CA or MN).
We'll review objection requests in accordance with data protection laws.
this is [sad animal noises] tbh.
AI everywhere in our newsroom.
isn't a strategy. (I've met a lot of prospects and clients at that threshold.)
they likely haven't had good counsel on this. treating AI as a hail mary pass, really. there's a whole TCO and ROI cost-benefit analysis to do; and real talk: AI doesn't serve a proper place or purpose in most applications.
Smart rotoscoping in compositing programs, excellent application.
Using an AI tool to recreate instruments stems from a stereo track in case of loss of the masters or restoration: good application.
Using a trained model to upscale video footage in cases where the source is inherently 480i or the source has been lost: good application.
These are all really specific niches
I've done all three of these in various contexts and they are additional tools that the experienced, seasoned professional can employ when the situation calls for it.
They aren't things that allow you to get away with replacing the professional with low skill labor, nor can they replace the professional all together.
A lot of these C suites have no respect from the idea of a professional, the idea of a body of hard earned knowledge that is off limits to them by virtue of their lack of experience.
They think that writing is just writing, when really it's an incredibly small part of the creative process. Just like CAS didn't replace mathematicians as computation is a very small part of math.
That's only the US. I think the EU has some things to say for people not on US soil (they still owe several countries money though, which is too late for comfort)

Vox
Has Sam Altman told the truth about OpenAI’s NDA scandal?

Paul Gutiérrez, Peruvian MP, used ChatGPT to create legislative bills.
The journalists discovered it because many said "As an AI language model, I do not have access to real-time information nor specific details of legislative discussions".
https://twitter.com/petergyang/status/1793480607198323196
idk about anyone else but I disabled this kind of tech on my search browser the moment it appeared
Google AI overview suggests adding glue to get cheese to stick to pizza, and it turns out the source is an 11 year old Reddit comment from user F*cksmith 😂


404 Media
Axon has been inviting police departments to webinars about the new AI-based product, which will automatically generate police reports based on bodycam audio, according to emails obtained by 404 Media.
Maybe someone more versed in LLM can explain but I cannot grok how people can consider this an acceptable application given that there will be variability in the output that cannot be controlled for. Not to say that humans are 100 percent reliable, especially in policing institutions, but they are easier to hold to account vs software.
I mean just today I saw someone showing Google recommending adding glue to your pizza based on some shitpost it found on Reddit during the course of its training.
Oh yeah this is completely unacceptable just from an accuracy standpoint, and that's before you get into all the like racial/gender/whatever else biases that are baked into the models
LLMs/computer vision should absolutely not be used independently when the results will have serious impacts on people's lives
Milder but still awful version of this is facial recognition not being completely accurate, and especially inaccurate at identifying racial minorities, and yet still being used by law enforcement to identify people
Which has caused a number of wrongful arrests
Full disclosure: I evaluated this very scenario with my current employer years ago (not for Axon). Many of the same criticisms then apply now.
Jessica called out relevant points I won't repeat but those apply.
The Thing Itself
Problems this will face in real-world "production" use:
- dialectic and vocalization variation: each person speaks and articulates in specific ways the model isn't always able to discern.
- context wash-out (prosody, tonality, etc., wash out): how speech is formed also adds important information.
- audio pickup quality: fixed hardware limitations introduce omissions, errors, etc.
- noisy adversarial environs: hostile working conditions wrt loud noises, background noise, etc.
- model quality and capacity: (here, GPT-4) models themselves, their training data and regimen, and architecture also matter (see also: Whisper small vs large).
- model variability: generative architectures (LLM) "Make Up Stuff" by design (as you called out).
- compounding error (propagation): speaker + environmental error => speech interp error (audio) => transcription error (text)
[typing this part on a call so it'll be admittedly choppy:]
The Bigger Problem
Several reasons can explain why these dodgy products often make it to market relatively unchallenged.
- fitment and feasibility: for various reasons, product development omits crucial steps.
- "not can this be done; should this be done";
- lack of well-defined acceptance criteria (inventing their own requirements);
- technological maturity hasn't reached sufficient capability, but they'll push betas anyway
- ignoring absolutely valid reasons why consequence outweighs benefit of doing something (like Jessica's reasons above)
- improper, inadequate, or biased testing: product should as good or better than humans, provide scale humans cannot reach easily well or cost effectively, and truly add value to the process not merely introduce new tech.
- demo'd or tested under near-ideal, non-adversarial conditions;
- poorly defined hypotheses or testing criteria;
- biasing toward readily passable test conditions;
- lack of tech savvy evaluators on consumer side
With many solutions like this new to market:
- leaving the hard but necessary parts for later
- cutting corners to expedite go-to-market delivery
- failing to publish methodolgy and results (there's an infamous LE product pushing this scenario) and only publishing "unverifiable claims"
Reminds a lot of "pivot to video"
Ah look everything you said summarized in one image!
https://vxtwitter.com/MelMitchell1/status/1793749621690474696


We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model.


It looks like it went from
https://www.theonion.com/geologists-recommend-eating-at-least-one-small-rock-per-1846655112
to
https://www.resfrac.com/blog/geologists-recommend-eating-least-one-small-rock-day
to the above.
@hot mirage which part? (🧂)
salt is a rock is my joke
apologies

Ars Technica
Google turned search into an AI product, and now it's time to make money.
snackable video content
O hi. #1089154093810978866 message
I didn't know it was possible to long more for 2000s era search... What an accomplishment

Humane, the company behind the hyped Ai Pin that launched to less-than-glowing reviews last month, is reportedly on the hunt for a buyer.




Vox
Platforms like Google have been protected from liability, but generative AI could put that at risk.
This is new.
Google stopped auto-generating AI overviews and now gives the option to.
Swift response to the bad news above?

https://www.threads.net/@reckless1280/post/C7VVgb9Ik--/
Some reported that they disabled it for certain results

Threads
Google has manually disabled the AI overview for presidents with Ferraris lol
A friend of mine had this observation:
"Also just think - these bad ones are getting fixed fast because of exposure and because they're in English. What about languages the engineers don't speak? Its a disaster waiting to happen"

Ars Technica
From glue-on-pizza recipes to recommending "blinker fluid," Google's AI sourcing needs work.
https://futurism.com/the-byte/study-chatgpt-answers-wrong
What's especially troubling is that many human programmers seem to prefer the ChatGPT answers. The Purdue researchers polled 12 programmers — admittedly a small sample size — and found they preferred ChatGPT at a rate of 35 percent and didn't catch AI-generated mistakes at 39 percent.

Futurism
Researchers found that 52 percent of answers to programming questions generated by ChatGPT were incorrect.

MIT Technology Review
How worried should we be about AI’s effects on the grid?
It's impressive how Google even managed to roll out a AI that bad


I got ahold of the Copilot+ software.
Recall uses a bunch of services themed CAP - Core AI Platform. Enabled by default.
It spits constant screenshots (the product brands then “snapshots”, but they’re hooked screenshots) into the current user’s AppData as part of image storage.
The NPU processes them and extracts text, into a database file...
Attached: 2 images
Copilot+ Recall has been enabled by default globally in Microsoft Intune managed users, for businesses.
You need to enable DisableAIDataAnalysis to switch it off. https://learn.microsoft.com/en-us/windows/client-management/manage-recall


I would much rather have a program that blink a image exactly when copilot take a snapshot
and the images should be some really psycadelic shit
but if they go the way of the impressivly bad google AI I don't think we need to poision it intentionally


@NathanLands: Google's new AI overview feature is a disaster. AI is awesome. Tacking on AI to a product that hundreds of millions use without it working is not. 13 hilarious examples: 1) Google AI Overview is...…
where was this image found? I couldn't replicate this
I know the Muskosphere has crusaded that Google is absolutely awful, especially Gemini, so I'm cautious of hoaxes
I found it at an other server.
yeah ive seen it in a few but can't replicate it
google may have swiftly turned off AI for certain sus searches
I am amazed that anyone feelt the need for fake "bad AI" responses.
I guess the people that did didn't have the imagination to come up with a prompt to create a bad response
There's been a few faked ones here and there but some were surprisingly real
Are there articles where journos confirmed it?
I saw one about using paste as a food ingredient that was pretty much it
Not articles but others on social media trying to replicate or clarify that the screenshot omitted certain context that clarified the answer was correct. Though they're anec-data and Google's Gemini clearly has issues
I have not got one yet that wasn't at least surface level reasonable but I already know how to research using search engines so I don't see the point to the AI
https://vxtwitter.com/Dan_Jeffries1/status/1794740447052525609
I spent a few hours listening to Dan Hendyrcks, who runs the non-profit AI Safety group behind SB 1047, aka the California AI Control and Centralization Bill.
I find him charming, measured, intelligent and incredibly dangerous.
Some of the most dangerous people in life are ones who can convincingly lie about their intentions and who can easily mask those intentions.
...
The intention of the bill is very clear for anyone who has eyes to read the text. It has three clear goals:
Ensure that only a small group of companies, rigidly controlled and overseen by a special government agency, have the right to create advanced artificial intelligence.
Destroy open source AI.
Make sure that model makers have liability hanging over them like the sword of Damocles for the rest of their life, ensuring that governments can hold model makers responsible for any misuse or crime from those models forever.

I spent a few hours listening to Dan Hendyrcks, who runs the non-profit AI Safety group behind SB 1047, aka the California AI Control and Centralization Bill.
I find him charming, measured, intelligent and incredibly dangerous.
Some of the most dangerous people in life are https://t.co/qwSTlRxq5Q
💖 280 🔁 63
The bill is absolutely a de-facto ban on open source AI for advanced models because it requires model makers to have “the capability to promptly enact a full shutdown of the covered model,” aka a remote kill switch, including the ability to force “the cessation of operation of a covered model, including all copies and derivative models, on all computers and storage devices within custody, control, or possession of a person, including any computer or storage device remotely provided by agreement."
“(2) “Hazardous capability” includes a capability described in paragraph (1) even if the hazardous capability would not manifest but for fine tuning and posttraining modifications performed by third-party experts intending to demonstrate those abilities.”
In other words, someone fine tunes a model they consider dangerous, the model maker is liable.
Is that the latest lunatick that got his knickers in a severe twist over lmm "ai"
Dan Hendrycks is the director of the Center for AI Safety.
Hendrycks is the safety adviser of xAI, an AI startup company founded by Elon Musk in 2023. To avoid any potential conflicts of interest, he receives a symbolic one-dollar salary and holds no company equity.[1][14]
Seems to have compromising relationships.

Dan Hendrycks is the director of the Center for AI Safety. He received his PhD from UC Berkeley, where he was advised by Jacob Steinhardt and Dawn Song. His research is supported by the NSF GRFP and the Open Philanthropy AI Fellowship. Dan contributed the GELU activation function, the default activation in nearly all state-of-the-art ML models i...
Dan Hendrycks (born 1994 or 1995) is an American machine learning researcher. He serves as the director of the Center for AI Safety.
To quote jerlendds, with whom I agree:
Yeah im of the opinion all the AI doomerism bullshit is for the purposes of regulatory capture and to convince gullible people to propagate delusional beliefs.
Interested in this. Can you suggest some sources for how open source models can be regulated?
#1036758130761158677 message
Definitely seems to me the big picture is layoff a helluva lot of coders because so much of it in theory could be done by AI. I won't deny it has issues.
@copper tide
@lost geyser
In other words, the pioneers are going to tell the government who doesn't totally know how it works how to run things?
My take: keep anyone with a profit motive out of it. Academia would be better to propose regulation
I have used it for coding, works great for small scripts and simple tasks. Any project larger than that will cause major issues.
it can speed up the work of experienced coders probably though
but often programming involves solving issues in existing code which require deep understanding / reasoning, which in my experience AI fails at
IMO it's a tool a experienced coder can use. But it in no way replaces the coder.
I agree but I'm not convinced a lot of corporate management knows that yet
depends on the organizational AI maturity curve and well-informed, (ideally) somewhat technically inclined leadership.
Well, obviously not everyone is having layoffs when they do have a choice to not
same conversations happened when AutoML emerged. even some of my peers thought it replaced them. i suggested they think better about their actual value proposition as practitioners.
all AutoML did then and code-generating LLMs do now is accelerate our work and rapidly prototype the boring and boilerplate.
I’m not convinced layoffs are directly tied to that, but just a way to squeeze out short term profit
Costs are felt down the line, when it doesn’t matter for the current leadership
Giving it a huge list of things to switch case for is awesome
Seeing Googles and Microsoft’s recent announcements, I don’t have much hope for the tech industry
I haven’t seen a discussion of Microsoft’s Recall function in here
It’s all super new. When I watch interviews by tech CEOs I feel that even they are still making sense of what’s happening. But I think some companies and some start ups are already putting products out there that take advantage of AI and try to market these products to businesses. Even if it’s a long shot, it makes businesses more cautious to hire. Interest rate environment since 2022 is also probably driving lay-offs (need to signal understanding of a more resource-constrained environment). The combination of the two - AI changes and higher interest rates - has potential to cause a lot of damage (and I think together they explain the layoffs).
interest rate + the unreasonable growth accelerator (specific industries and players) of covid-era work-from-anywhere hiring sprees.
it's a little scattered, some of it in #infosec.
#1089154093810978866 message
https://cyberplace.social/@GossiTheDog/112492445214914228
turns out (unsurprisingly) to be a smoke-and-mirrors sort of shitshow.
I got ahold of the Copilot+ software.
Recall uses a bunch of services themed CAP - Core AI Platform. Enabled by default.
It spits constant screenshots (the product brands then “snapshots”, but they’re hooked screenshots) into the current user’s AppData as part of image storage.
The NPU processes them and extracts text, into a database file...
Yeah was about to post that
It’s a complete info sec nightmare
This just a week after Microsoft said that they will focus on security
they basically took RAT philosophy and made it an IT governance nightmare of a feature.
i suppose this was a different sort of focus.
It makes sense if your goal is “how can we have an AI assistant which knows what you have been doing / working on in the past”
Then having screenshots makes total sense.. but that no one considers what that actually does is insane
Even worse is that they hand waved security (it’s all local, it’s “encrypted”)
Shows how careless the big players in AI models are.
Also shows how AI is a privacy risk due to being Data hogs by design.
There was a recent case where an online doctors receipt service accidentally exposed all their receipts to Bing indexing.
They removed it quickly and Bing deleted the index, but Copilot still remembered the entries! Not sure if they actually purged the data or tried to “fix it” by blocking certain requests:
(German language source)

Das ist wohl ein fettes Datenleck, welches Wellen werfen könnte. Nach dem Motto "Deine Gesundheitsdaten sind Allgemeingut" lassen sich Rezepte für Cannabis-Produkte beim Online-Anbieter Dr. Ansay über die Suchmaschine DuckDuckGo abrufen. Die Quelle der Rezepte dürften meinen Recherchen nach wohl Microsofts Bing sein. Zudem grätscht auch der CoPi...
wow, nice share for this space.
many of the architecture design patterns we're initially presented with are for remembering and recalling information. this presents a consequent that fewer are focusing on which is intentionally forgetting altogether.
Hard to see how this fits with Europeans laws around “the right to be forgotten”
Also, I’m not familiar if any technique exists to reliably have trained models forget training data
My understanding would be that you’d have to roll the entire model back to a point before it trained on the data to be sure it’s completely gone
rn that's the most practical (and also disruptive) thing to do.
there are research-grade efforts into finding the context windows (Anthropic) and making embedding edits (various others) but those aren't production worthy.
Interesting
also largely depends on the entire composition of that architecture--not just the models themselves. non-LLM learnings, semantic indexs, etc.
so for example here's (supposedly) Microsoft Copilot's arch ref for 365:

idk what this looks like for the Bing Search component tbf.
but here we can see a number of layers (including federated systems) where cascaded deletions would have to happen.
nightmare scenario.
We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model.
Gossi made a song about it using Copilot:
Yeah, I might have just been paranoid, not like it isn't shitty and shortsighted to layoff for more banal reasons like what you're talking about
there's a startup out of Brussels/Greece--see if I can find the name--whose business model is to leverage AI agents to substitute C-suite and below organizational roles.
SophoTree
SophoTree introduces smart digital employees, that stop knowledge-loss from employee-churn, provide deep analytics and express opinions as any other employee would!
on the one hand, it helps bootstrap cash-starved, resource-insecure smaller operators. on the other, it enables the sort of bad behavior you're concerned about.
Well, obviously there are going to be automation extremists just I think it's that MOST layoffs are for more banal reasons
the legislation proposed above can be found here in text form:
LegiScan
Bill Text (2024-05-22) Safe and Secure Innovation for Frontier Artificial Intelligence Models Act. [In Assembly. Read first time. Held at Desk.]
were you speaking about that one specifically or more broadly?
More broadly. Mainly curious how Open Source LLMs can be regulated now they are out in the wild. I definitely get the point your making about 'who' should be advising and regulating (thanks @thick schooner ). Just looking for more reading to be able to form an opinion.
sure. so there is the European Union AI regulations act as filtered through McKinsey's management consulting lens (not LLM-specific):

Proposed EU rules are just one step toward global AI regulation. Smart organizations are preparing for compliance—and AI risk management.

On Wednesday, Parliament approved the Artificial Intelligence Act that ensures safety and compliance with fundamental rights, while boosting innovation.
afaict the proposed California regulation above is the closest to an actual formulation in the United States. Whatever form that may pass in could be used to inform other states and federal regulation.
there is this US "Bill of Rights" (again, not specific to LLMs but they are involved):

The White House
Among the great challenges posed to democracy today is the use of technology, data, and automated systems in ways that threaten the rights of the American public. Too often, these tools are used to limit our opportunities and prevent our access to critical resources or services. These problems are well documented. In America and around…
run the full content through Copilot via Edge to get content summaries, ask questions about it, and find specific citations within it.

The White House
By the authority vested in me as President by the Constitution and the laws of the United States of America, it is hereby ordered as follows: Section 1. Purpose. Artificial intelligence (AI) holds extraordinary potential for both promise and peril. Responsible AI use has the potential to help solve urgent challenges…
Great. Will have a look and thanks for the Copilot via Edge tip.

@Tantacrul: 1. I'm legit shocked by the design of @Meta's new notification informing us they want to use the content we post to train their AI models. It's intentionally designed to be highly awkward in order to...…
Dark pattern by example:

- Second step. It shows you this notice.
Trick: places the 'right to object' CTA towards the end of the second paragraph, using tiny hyperlink text, rather than a proper button style. Notice the massive 'Close' CTA at the bottom, where there's clearly room for two. Ugly stuff. https://t.co/0NsOwd2jJj
💖 1.57K 🔁 89

Not pictured: AI replacements.
https://vxtwitter.com/randomrecruiter/status/1794718214515023948

Middle managers have had a target on their back the last 2 years, just like everyone else in tech.
Companies are looking to flatten out their org charts, meaning they want less layers between individual contributors and the executive suite.
At the end of the day, they’re a cost https://t.co/X8lzCfPHIr
💖 594 🔁 53

AI headphones let wearer listen to a single person in a crowd, by looking at them just once.
The system, called “Target Speech Hearing,” then cancels all other sounds and plays just that person’s voice in real time even as the listener moves around in noisy places and no longer https://t.co/IcuKRTvBsq
💖 2.79K 🔁 377
https://vxtwitter.com/ylecun/status/1795032310590378405
AI is not some sort of natural phenomenon that will just emerge and become dangerous.
WE design it and WE build it.I can imagine thousands of scenarios where a turbojet goes terribly wrong.
Yet we managed to make turbojets insanely reliable before deploying them widely.The question is similar for AI:
"do we think there exists at least one design of an AI system that is simultaneously safe/controllable, and can fulfill objectives in more intelligent ways than humans ?"
If the answer is yes, we'll be fine.
If the answer is no, we won't build it.
Right now, we don't even have a hint of a design of a human-level intelligent system.So it's too early to worry about it.
And it's way too early to regulate it to prevent "existential risk."

AI is not some sort of natural phenomenon that will just emerge and become dangerous.
WE design it and WE build it.
I can imagine thousands of scenarios where a turbojet goes terribly wrong.
Yet we m…
💖 2.71K 🔁 328

AI has reshaped everything from medical diagnoses, to wedding vows, to stock market gains, but the technology wouldn’t be possible without gig workers across the globe.
However, analysts and advocates said the workers whose efforts help train AI are often denied knowledge of the end product they help create, or the company behind it. They also ...
#infosec https://youtu.be/htba_b-vxxE

Scott Clinton leads our panel of experts on a discussion about red teaming LLM Applications. Hear from Ads Dawson, Jason Ross and Ken Huang as they talk about their experiences and best practices.

Google: "A lot of the AI hallucinations are from maliciosly crafted prompts to make us look bad."
Okay geniuses; why does your own documentation example show questions about Oppenheimer returning answers about Einstein? And of course getting every single date wrong. https://t.co/OYzzSdM7mN
💖 231 🔁 43

New AI products much hyped but not much used, study says https://bbc.in/4bxlygb
Curious to know what the survey probed into and how much it explained.
Most of what we hear about (in this sense) AI being is AI as the product, for which this could make sense. But most AI in practice is beneath the surface and most might not realize they're using it already, possibly daily.

The places where AI summary strikes out are often due to a mismatch between search quality and answer quality

well.. I guess that means Google can't argue their AI didn't influence someone to eat glue... but I doubt it would even come close to liability legally

genAI will save us $10m in marketing this year. We’re spending less on photographers, image banks, and marketing agencies.
The numbers are mind-blowing:
- $6m less on producing images.
- 1,000 in-house AI-produced images in 3 months. Includes the creative concept, quality https://t.co/ioAhxkNS8I
💖 298 🔁 55
Gotta pump up those valuation numbers

Careful of the new mistral code model. The license doesn't let you use it for anything that even indirectly is commercial. Only R&D use is permitted.
I'm surprised this wasn't mentioned in the announcement.…
💖 238 🔁 19


probably very good for open ai's case
So, they found about 2% of Britons used AI and this below says about 1 in 3 companies use it
https://connect.comptia.org/blog/artificial-intelligence-statistics-facts

Default
By 2025, the market value of AI will be $60B. Read along to learn the newest AI statistics and facts to help you determine if AI is right for your business’s future.
Will be nice when this bubble finally bursts
depends how it bursts
this new era of ML/AI seems like it's here to stay one way or another

Sony Pictures Entertainment CEO Tony Vinciquerra plans to use AI to cut film costs.
DEMANDING ANSWERS: Our @theatlunion has issued the following statement on news that the @TheAtlantic has signed a deal with @OpenAI....
https://t.co/SW4tDCRkxl

Disrupting deceptive uses of AI by covert influence operations Open AI on detecting and disrupting covert influence operations by Russia, China, Iran and Israel. https://openai.com/index/disrupting-deceptive-uses-of-AI-by-covert-influence-operations/

Microsoft told media outlets a hacker cannot exfiltrate Copilot+ Recall activity remotely.
Reality: how do you think hackers will exfiltrate this plain text database of everything the user has ever viewed on their PC? Very easily, I have it automated.
HT detective https://t.co/Njv2C9myxQ
💖 2.85K 🔁 724
Some screenshots of Recall's SQLite database here: https://mastodon.social/@detective/112513529733646088
Just to clarify, I can access it without SYSTEM too. Microsoft are about to set cybersecurity back a decade by empowering cyber criminals via poor AI safety. Feature ships in a few weeks.
Risky Business #750 -- Why Microsoft's Recall is an attacker's best friend

the Guardian
Big tech is playing its part in reaching net zero targets, but its vast new datacentres are run at huge cost to the environment, says economics professor Mariana Mazzucato
[Cross post from #infosec by @spring creek due to audience overlap]
🚨 Heads up on a security incident at Hugging Face:
- Unauthorized access to Spaces platform, possible secrets compromise
- HF tokens revoked, affected users notified
- Investigation ongoing with external security experts
- Infrastructure security improvements in progress
- Reported to law enforcement and data protection authorities
If you use Hugging Face:
- Refresh your keys/tokens ASAP
- Move to fine-grained access tokens
Source: https://huggingface.co/blog/space-secrets-disclosure

The ability to opt out seems to be limited to the UK and EU 😖
two weeks ago I saw the CEO of Taco Bell tell a room full of people Taco Bell is going to become “an AI first company” and I’m still obsessed with it
I can confirm that they and parent company Yum! brands have been exploring more advanced use cases since 2020 in response to pandemic protocols.
One of them was visual quality inspection of order-to-service since they had a policy of sealing bagged orders and no way to review after the fact. They had a lot of respondants in that PoC and I was part of one.
Visual quality inspection? As in, camera records image of a bagged food item, and determines it's "quality"?
They have 5 stages to their order fulfillment process. Some of those use-cases were:
- ingredient quality
- build quality
- order fulfillment accuracy (item matches assembly)
The overarching process is expansive across the short order cook ops.
(Yes, via computer vision)
Sounds like setting up a very complex infrastructure to gather new "performance metrics" to be used for process and "employee" optimization. A way to eek out those last few percent and be able to say "this number is improving".
There's an entire layer that has to intentionally be built around the "micro-managing KPIs" of employee performance.
The baseline efforts were purely on order quality and order completion. Certainly those can play into the dark art of employee performance monitoring.
I have a personal issue against doing that for all the obvious reasons. Learned that long before AI was industry standard, while working on Boeing's warehouse ops that wanted to do that very thing.
And look how well that turned out!
I personally don't work in the field but I have a personal window into business intelligence at a nationwide company. I might just be cynical but it often just seems like another tool to be manipulated by the C-suites to justify this or that, or advance themselves
I'm assuming that, aside from the buzzword aspect, the appeal of these kinds of things is they can scale at cheaper cost to the company compared to better wages, cultivating employee knowledge, reducing turnover, etc?
Unsure if they had any ulterior motives in a broader sense.
That definitely happens and will continue to happen. (There's an infamous coffee shop clip floating around.)
It's ill-advised and ill-conceived but that won't stop some from shaving capex/opex to satisfy stakeholder demands.
Example of an insurance company using AI and satellite imagery for risk assessment in underwriting, which led to the cancellation of a church's insurance policy:
Legal blog post on the article: https://www.propertyinsurancecoveragelaw.com/blog/church-loses-insurance-from-satellite-imagery-guideone-refuses-to-consider-other-evidence-of-a-roofs-condition/
Betterview (the AI Platform used for the decision to drop coverage): https://www.betterview.com/
Insurers trust Betterview to optimize pricing, underwriting, and renewals. Applying artificial intelligence (AI) and computer vision to aerial imagery, we provide accurate, pre-filled risk scores, custom flagging, and continuous property monitoring. Write more business, reduce expenses, and transition from "Repair & Replace" to "Predict & Prevent."
OPTIMIZE WORKFLOWS | SLASH INSPECTION COSTS | BOOST CUSTOMER SATISFACTION
Betterview Report obtained by CBS 8: https://interactive.cbs8.com/pdfs/roof-report.pdf

cbs8.com
The new policy the church just got costs $20,000 — $15,000 more than what they paid last year.

May 22, 2024 Insurers are now analyzing satellite and drone imagery using artificial intelligence (AI) when conducting underwriting surveys of property. The images are

Market-leading Property Intelligence platform delivers actionable insights to underwriters, agents, and insureds, increasing efficiency and profitability.
From Betterview's AI generated property report which contributed to the decision to decline policy renewal:

Very poor quality image to make an assessment of this kind.

There's a hard limit on how much "functional obsolescence" can be determined from a satellite image (speaking from experience). And this one is making inferences well beyond what can be determined.
I came across another story where the property owner was able to get a reversal of the decision by paying for a roof inspection out of pocket.
This trend is going to be challenging for folks without the financial resources to challenge an AI conclusion.
Spot on. And likely the case here for that church.
Stacked deck in favor of policy writer / insurer.
Good thing that no one is working on restricting the legality of this.
They got bigger fish to fry. Like "when the AI becomes skynet you need to have an off button" type stuff
Seen at an AWS summit

(NGL I've been quite impressed with some applications I've seen here, in particular bringing real life context awareness to genAI workflows)
Researchers have developed a novel training framework, SaySelf, to address a crucial issue in LLMs: their inability to express uncertainty or accurately convey confidence in their responses.
By fine-tuning LLMs on model-specific datasets and applying reinforcement learning, SaySelf encourages AI to generate human-like responses that include confidence indicators, potentially leading to more trustworthy and reliable AI assistants.
In my use of AI, I've often been frustrated by their lack of uncertainty expression. They tend to present all responses with equal confidence, even when proven wrong. In contrast, humans often preface their answers with phrases like "I'm not an expert, but..." or "I could be wrong, but...". This absence of uncertainty expression in AI can lead to over-reliance on potentially inaccurate information
This development could have significant implications for the future of AI and its role in our lives, as it addresses the common frustration of AI's lack of uncertainty expression, which can lead to over-reliance on potentially inaccurate information.
https://github.com/xu1868/SaySelf
https://arxiv.org/pdf/2405.20974

GitHub
Public code repo for paper "SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales" - xu1868/SaySelf
That's a feature of the dueling ideas structure used to generate the result.
It don't concern itself with truth only with what argument can be presented in the most convincing way
This is one of the main reasons people dont use AI more as I see it. People want authoritative answers and it's not hard to use a search engine to get those and with AI there's reason to doubt what you get is authoritative

I often get asked how a newbie can contribute to the OWASP Top 10 For Large Language Model Applications project. There are so many ways to contribute, and we…
404 Media has a thought-provoking piece by Samantha Cole that dives into the complex issue of deepfake legislation and its potential impact on sex workers. Cole argues that current discourse around nonconsensual AI-generated images often overlooks the fact that there are at least two people in every deepfake: the person being impersonated and the sex worker whose body is exposed but face is erased.
Cole discusses recent US legislative efforts to combat malicious deepfakes at the federal level, such as the DEFIANCE Act and the "Preventing Deepfakes of Intimate Images Act." She raises concerns about the influence of conservative anti-pornography groups like the National Center on Sexual Exploitation (NCOSE) on these efforts. While acknowledging the need to address the very real harms of nonconsensual deepfakes, Cole cautions against ham-fisted solutions that could disproportionately impact sex workers.
Source: https://www.404media.co/laws-about-deepfakes-cant-leave-sex-workers-behind/

404 Media
As lawmakers propose federal laws about preventing or regulating nonconsensual AI generated images, they can't forget that there are at least two people in every deepfake.
I saw Raspberry PI jumped on the AI bandwagon and found myself reflexively looking for jokes:
But then I recalled a humbling convo with an army veteran who had fought in Iraq. Someone had made a comment suggesting that the insurgents were stupid, basing this assumption on the fact that their technology was less advanced than what the U.S. military possessed. My friend's response was pointed: those insurgents were highly effective at using what was available when it mattered most
With little more than a map, a compass, and a basic understanding of trigonometry, they were able to calculate distances to targets using techniques like the "string method." By hanging a string of known length from a piece of debris and measuring the angle between the string and the line of sight to the target, they could determine the distance using the tangent function. These calculated distances, combined with an understanding of angles and elevations, allowed them to devise effective firing solutions, even without access to advanced targeting systems or sophisticated weaponry.
I share this as a reminder that necessity often drives innovation, and the same principle applies to the use of AI in infosec, OSINT research and emerging threats. Just as the insurgents in Iraq were able to leverage basic tools and mathematical concepts to great effect, shouldn't we expect the same with access to tools like the Raspberry Pi AI Kit to find ways to harness its capabilities in unexpected and impactful ways?
https://www.raspberrypi.com/news/raspberry-pi-ai-kit-available-now-at-70/
Key features of the Raspberry Pi AI Kit include:
13 tera-operations per second (TOPS) of inferencing performance
Single-lane PCIe 3.0 connection running at 8Gbps
Full integration with the Raspberry Pi image software subsystem
Compatibility with first-party or third-party cameras
Efficient scheduling of the accelerator hardware: run multiple neural networks on a single camera, or single/multiple neural networks with two cameras concurrently

I like Hailo's product lines yet they're overselling a bit with multiple NNs and camera streams. Lil thing is gonna run hot and with only passive cooling stock. Also hard constraints on resource capacity (TOPS :: performance as bandwidth :: throughput).
Still a decent entry-level performer. You can build a lot of things--smart kiosks, responsive displays, certainly some light workload camera AI (highly quantized).
This is awesome. Say more.
I may be attending one in the fall.
What does the text in the slide mean in a layperson's context?
https://www.youtube.com/watch?v=esWsuNC8Guk
including this short letter:
https://righttowarn.ai/

A group of current and former OpenAI employees issued a public letter warning that the company and its rivals are building artificial intelligence with undue risk and without sufficient oversight. They're calling on leading AI companies to be more transparent with their research and provide stronger protections for whistleblowers. Geoff Bennett ...

According to a new study, AI models hold opposing views on topics like LGBTQ+ rights depending on how they're trained -- and who's training them.

Ars Technica
The framework pulls in external sources to enhance accuracy. Does it live up to the hype?
The answer, of course, is no.
(See also: Betteridge's law of Headlines)
A showdown between Meta and European non-profit Noyb (None of your Business) is intensifying in regards to Meta' use of user data for AI model training:
https://noyb.eu/en/noyb-urges-11-dpas-immediately-stop-metas-abuse-personal-data-ai
https://about.fb.com/news/h/bringing-generative-ai-experiences-to-people-in-europe/

Ars Technica
EU Facebook users have until June 26 to opt out of AI training.
noyb.eu
noyb urges DPAs in 11 countries to immediately stop Meta's use of personal data for undefined "AI technology"


We're expanding our collection of generative AI features, along with the models that power them, to more people across the globe, including in Europe.
I mean when Murdoch media and Reddit is used as sources...ehhhhhh

Less than 48 hours ago, Sora competitor Kling dropped.
People are already getting access and creating wild AI videos. 🤯
- MadMax Beer commercial made in 1 hour
https://t.co/CyKm2aI0It
💖 568 🔁 82
It's always hilarious the kinds of stuff these hype men try to proclaim as impressive
Something actually impressive: https://beforesandafters.com/2024/06/08/its-like-a-constantly-evolving-three-dimensional-puzzle/
Some very cool examples of trained models being used to augment existing face replacement methods

The visual effects of ‘Furiosa: A Mad Max Saga’, including those crazy War Rig scenes, impressive wasteland environments, immense rotoscoping, and how Anya Taylor-Joy’s facial features were translated onto the young Furiosa.

EL PAÍS English
The .ai internet domain for Anguilla is attracting tech companies interested in using the domain extension for their AI services

the Guardian
Researchers used artificial intelligence algorithm to analyse calls by two herds of African savanna elephants in Kenya
Compulsory share: https://link.springer.com/article/10.1007/s10676-024-09775-5

SpringerLink
Ethics and Information Technology - Recently, there has been considerable interest in large language models: machine learning systems which produce human-like text and dialogue. Applications of...
Are they arguing that ChatGPT is bullshit or that the hallucinations are bullshit? Hard to disagree with the latter, but title would suggest a broader scope.

Would you freak out if you found out a judge was asking ChatGPT a question to help decide a case? Would you think that it was absurd and a problem? Well, one appeals court judge felt the same way… …
#infosec https://www.404media.co/hackers-target-ai-users-with-malicious-stable-diffusion-tool-on-github/

404 Media
An extension for a popular Stable Diffusion graphical user interface on Github appears to have been stealing users’ login credentials.
They are suggesting that these models produce forms of bullshit as originally defined by https://en.wikipedia.org/wiki/On_Bullshit which has to do (I am not a philospher but I think I skimmed parts of that treatise several years back) with disinformation. The paper is arguing that ChatGPT is a vessel for unintentional (soft bullshit) misinformation and may, depending on the intent of the authors and the resulting design, be a vessel for intentional (hard bullshit) disinformation.
Got it! Thanks for the summary!
ChatGPT maker beefs up global affairs unit as politicians push for new laws that could constrain powerful AI models

CNN
Lawyers for Elon Musk on Tuesday filed a motion to dismiss the billionaire’s lawsuit against OpenAI and Sam Altman, ending a months-long battle between co-founders of the artificial intelligence

Federal Trade Commission
Earnest chats with objects are not so unusual. Mark “The Bird” Fidrych, the famed Detroit Tiger, used to stand on the pitching mound whispering to the baseball. Forky, the highly animate utensil from Toy Story 4, once posed deep questions about friendship to a ceramic mug. And many of us have made repeated queries of the Magic 8 Ball despite its...
Did a double take while reading this NYPost article when I saw a big AI-generated image… it wasn’t labeled as AI so I wondered if I was wrong. I tracked down the stock photo provider and it is AI. So confusing why this isn’t labeled in any way

It's not confusing. It's NYP. It's not terribly honest

OpenAI also added retired U.S. Army General and former NSA head Paul M. Nakasone to its Board of Directors today.
Nakasone previous led the NSA from 2018 to 2023, and will help improve AI's role in cybersec…
💖 144 🔁 16
https://vxtwitter.com/rowancheung/status/1800930932846641335
https://vxtwitter.com/rowancheung/status/1801507092567625914

Luma AI just dropped a Sora-like AI video generator called Dream Machine.
But unlike Sora or KLING, it's completely open access to the public.
Here are 10 wild examples (and how to access it):
- https:…
💖 2.8K 🔁 439

Apparate Labs launched PROTEUS, a new real-time AI video generation model.
It creates realistic avatars and lip-syncs from a single reference image, similar to VASA-1, but it's completely real-time. https:/…
💖 123 🔁 15

I've been using the technical term "automated bullshit generator" for a while, and I'm thrilled to see some
scholarly work on this!
【QRT of Upol Ehsan (@UpolEhsan):】
'And the award for the best paper title in 2024…
💖 5
Beware of Botshit: How to Manage the Epistemic Risks of Generative Chatbots
Advances in large language model (LLM) technology enable chatbots to generate and analyze content for our work. Generative chatbots do this work by ‘predicting’ responses rather than ‘knowing’ the meaning of their responses. This means chatbots can produce coherent sounding but inaccurate or fabricated content, referred to as ‘hallucinations’. When humans use this untruthful content for tasks, it becomes what we call ‘botshit’. This article focuses on how to use chatbots for content generation work while mitigating the epistemic (i.e., the process of producing knowledge) risks associated with botshit.
(Someone really wants to make that term happen.)

By Benjamin Hoffman
A new term has emerged to describe dubious A.I.-generated material.

If you're worried about how AI will affect your job, the world of copywriters may offer a glimpse of the future.
The past few days I've noticed a lot of advertising promotion for https://audiostack.ai/en/adstack in my podcasts
AudioStack’s technology seamlessly integrates into your product or workflow and cuts your audio production cycles to seconds while maximising your budgets.

All Tech Is Human
We're a non-profit that is expanding and improving the Responsible Tech ecosystem so we can better tackle thorny tech & society issues.
Can someone explain to me what's going on here? Where does this model come from? Besides the obvious misinformation that a non-restricted model equals a non-biased model...

If you're serious about AI, and want to learn how to build Agents, join my community: https://www.skool.com/new-society
Follow me on Twitter - https://x.com/DavidOndrej1
Please Subscribe.
Download Ollama: https://ollama.com/download
Llama3 Dolphin: https://ollama.com/library/dolphin-llama3
Download AnythingLLM: https://useanything.com/downloa...
Those are community adaptations to LLaMa 3 (and various others) where efforts are made to erode or remove alignment.
I mean yeah, but like... context; how computationally expensive are such modifications, who pays for them, who is "the community"? How likely is it that it's really a community thing? could an APT pose as "the community" and release a modification that's good enough to be widely adopted? He says everything should be open-source but these days someone says open-source I think xz utils...
Where are these communities located online? And he says that it could be banned, but that ostensibly just means banned from a platform - how are these ecosystems governed?

- Compute budget: hundreds at minimum, all-in (GPU, storage, training overhead).
- Dolphin 2.9-Llama3-8b: It took 2.5 days on 8x L40S provided by Crusoe Cloud
- WizardLM-<various>: 4x A100 80gb node on Azure
- Funding: self-funded or with other people's moneys:
- Crusoe Cloud (Dolphin)
- Andreessen-Horowitz [a16z] (various): https://a16z.com/supporting-the-open-source-ai-community/
- Complexity: easy to moderate. Train low-rank adapters (update layer weights), modify embeddings, tailored data sets.
- Community: many of these are hosted on Huggingface or GitHub.
- Banning: models? maybe in commercial settings (esp licensing like LLaMa).
❤️ thanks.
Got it running 
Time to get a decent piece of hardware
Sorry if this is redundant with previous discussions and obvious to most of you, I just haven't paid the subject too much attention.
https://huggingface.co/blog/mlabonne/abliteration

{kind=link}
{kind=link}
so you can really do this easily to any model that's public, eh? That's an interesting development, happened quicker than I though.
Google image search results are turning up AI-generated images of celebrities and leading users to sites that host AI-generated nudes celebrities made to look like children. https://t.co/1HpOMaiVYv
Bluesky Social
The Federal Trade Commission, of all entities, is out here writing absolute bangers about AI snake oil. https://www.ftc.gov/business-guidance/blog/2024/06/succor-borne-every-minute




Last week, I read about one of the bleakest uses for gen AI I've seen yet: First Horizon Bank is rolling out a system to detect when a call center worker was on the brink of "losing it"—and play them an AI-made montage of family photos set to their favorite song to calm them down
One out of four people in the world have experienced mental illness at some point in their lives. DiPsy is a digital psychologist presented as a personalized chatbot, who can evaluate, diagnose, treat and study users’ mental processes through natural conversations.
https://www.microsoft.com/en-us/research/project/dipsy-digital-psychologist/overview/
Can you tell us what this is about? There is no preview.

Where AI hype comes from
Sure. I've updated the post with context
Those videos where they robustness test the robots by kicking them illicit all my "don't be mean" emotions.
That’s an interesting exercise!
I think anthropomorphization cuts both ways though.
It helps create a hype but it also helps to underestimate.
When chatgpt helps doctors identify rare diseases that they had missed, it behaves in a way that is completely different than a human (using its ability to go over massive amounts of info that a human would never be able to go through).
We might be underestimating it by thinking that the worst case scenarios are that it reaches “human intelligence” - whatever that means.
Somewhat related: I’ve seen people (probably Sam Altman, but don’t know for sure) defend that there shouldn’t be one Touring test, but several. What test can this or that AI perform better than a human?
And this may indeed be a better way to think about it as some models are already performing better than humans in some tasks.
Does YouTube recommendation system count as AI? If so, here’s a good example of blame the AI. YouTube recommends right-wing news sources more often than left wing news sources. https://thehill.com/policy/technology/4727588-research-finds-pattern-of-youtube-recommending-right-leaning-christian-videos/
https://www.wired.com/story/perplexity-is-a-bullshit-machine/ Although the biggest issue seems to be "scraping websites without permission."

WIRED
A WIRED investigation shows that the AI search startup Perplexity is surreptitiously downloading your data.

China’s leadership believes that artificial intelligence will play a central role in future wars. However, the author's comprehensive review of dozens of Chinese-language journal articles about AI and warfare reveals that Chinese defense experts claim that Beijing is facing several technological challenges that may hinder its ability to capitali...
It does. Theirs is a bespoke multi-model solution of AI-driven recommendation strategies.
The medical practitioner scenario is a good example that carries a lot of the nuanced positions of AI in practice.
It does scale better and see further than human counterparts, which makes it a good companion piece in the diagnostic process (clinical decision support).
However there are other issue where those models are unreliable in one form or several. Also the complacency of blind trust in tooling over human judgment remains a risk.
Domain expertise is absolutely required to make those models viable. Not these Kaggle competition style efforts where domain knowledge is absent and "data science methodology" dominates.
I thought the original story was here somewhere...? A short interview with the photographer who entered a real picture into an AI competition and won (and was then disqualified).
https://www.scientificamerican.com/article/how-this-real-image-won-an-ai-photo-competition/

Scientific American
Nature still outdoes the machine, says a photographer whose real image won an AI photography competition
McDonald’s announced internally this month that it was ending its partnership with IBM and shutting down its AI tests at more than 100 U.S. drive-throughs after ordering mistakes frustrated customers. https://t.co/xGM325rXXm

Ars Technica
Safe Superintelligence, Inc. seeks to build hypothetical AI far beyond human capability.