#general
1 messages · Page 3 of 1
PSA: there's a new terminal UI for viewing your Dagger runs! Just wrap your command in dagger run (after setting _EXPERIMENTAL_DAGGER_TUI=1 in your shell*).
Instructions/feedback here: https://github.com/dagger/dagger/discussions/4942


GitHub
In Dagger v0.5.0 we shipped an experimental new feature: a terminal UI for dagger run. (#4522) Terminal UIs are notoriously difficult to implement, so there will be quirks, and there may be times w...
thanks a lot for guide.
Reminder: the new Dagger+PHP guide is looking for reviewers at https://github.com/dagger/dagger/pull/4913 - thanks!
Was building a Go app using Dagger's Python SDK when it failed (crashed?) with this error in the engine logs:
time="2023-04-16T10:17:50Z" level=error msg="/moby.buildkit.v1.Control/Solve returned error: rpc error: code = Unknown desc = process \"/app/api data collect-migrations ./migrations\" did not complete successfully: exit code: 1"
process "/app/api data collect-migrations ./migrations" did not complete successfully: exit code: 1
1 v0.0.0+unknown /usr/local/bin/dagger-engine --config /etc/dagger/engine.toml --debug
github.com/moby/buildkit/executor/runcexecutor.exitError
/go/pkg/mod/github.com/moby/buildkit@v0.11.0-rc3.0.20230322213239-deba8768c675/executor/runcexecutor/executor.go:327
Anyone encountered this before? I'm hoping it's not another m1+qemu bug. The api data collect-migrations line can be removed in the script and it would fail with the same thing somewhere else still. A bit lost at this point for how to continue.
EDIT: Looks like I might've found a bug, filed https://github.com/dagger/dagger/issues/4965
Was building a Go app using Dagger s
Would it be totally weird if dagger could could do something like client.Container().FromLLB(llb)?
Any Dagger maintainers happen to be at KubeCon EU?
@calm mulch it didn't line up for us this year, but we'll have a crew at KubeCon NA. Happy to meet you virtually any time! Feel free to DM me. 🙂
Just FYI, I've been incredibly busy the last few weeks so dagger-rust haven't gotten much love. I should be back next week and I hope to get dagger run to work with dagger-rust =D, that and fixing a few bugs that has piled up over the weeks 😄
Thank you! I’m curious if anyone here might be interested in helping you maintain a Rust SDK?
Does anyone using Mage here use a yaml file as input for constants, or do you stick with just setting as const ( ) in your Magefiles?
faster ⚡
Any Elixir fans? 😁 https://twitter.com/wingyplus/status/1649084079344877569
Start porting Dagger SDK from @dagger_io into Elixir. Now we can bring Elixir into CI/CD domain. :)
See https://t.co/PjBIURVUUw. Not complete yet, code gen may change and have bugs. :P
#myelixirstatus
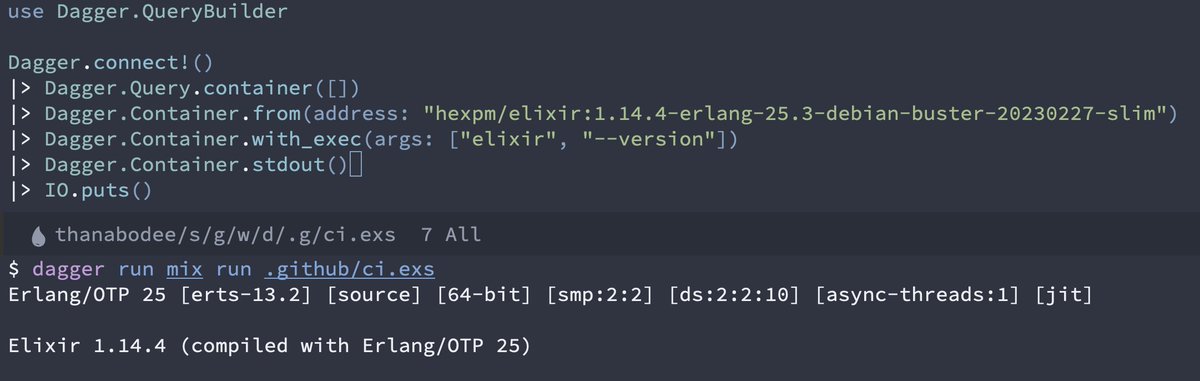
ohmygodyes
And in case you missed @empty jay awesome demo: https://twitter.com/solomonstre/status/1649098623534219267
Now @sameoldaweris shows us Github Actions running on @dagger_io unmodified! 🤯


Thank you for sharing 😊
Came across this while trying to support a clients concourse implementation. Is concourse on lifeline support? Im really enjoying its remote dependency hooks for triggering builds and don’t see an alternative.
Came across this while trying to support
quick question. In specific regards to the SDK's, are there any operations you can do without spinning up an engine container? We were interested in perhaps using some of the Git parts of the dagger client sdk outside of dagger as there are some contexts that we might want some of that information that don't involve spinning up an engine. Or is this basically counter to the design and not really achievable with dagger right now? cc @scenic ridge
quick question In specific regards to
Got an interesting question for my buildkit homies. If I run a dagger build pipeline... Could I somehow extract information about all files that were read over the course of the build?
I think I could do some type of syscall evaluation here and log all the files that were opened, but I'm curious if this is available through buildkit more directly
What's a reasonable way to retry a docker build task in the Python SDK if the underlying command fails? Just re-call the sequence that generated the error if exit_code() != 0 or are there other things I need to also do? .
CORRECTION: there no .exec_with so the build fails before .publish is called if that changes anything
So I'm doing some funky stuff...
I'm spinning up a qemu VM inside a dagger container and exposing SSH.
In another dagger container I'm trying to consume that ssh service, however everything just seems to hang.
I have confirmed that the port is available from the dagger engine container (exec into dagger-engine container and nc <ip> 22.
It does not look like dagger is even running the container that is trying to consume that service (nothing in the process tree, just the qemu vm.
It shows the pipeline name and nothing else (ie. runner.Pipeline("stuff")).
Retry in Python SDK?
Hi, does running infinite process with dagger is suitable ?
my use case is dev server (npm run dev / uvicorn --reload, etc)
Dagger supports running service containers, but it’s most useful if you’re also connecting to those services from a dagger pipeline - for example for e2e integration tests. If you use them only to manually connect to them from your host, it should work, but it may still be missing a few features to be super smooth. Primarily filesync and host-to-container port forwarding: those are still work in progress
thanks, I found https://docs.dagger.io/757394/use-service-containers/ which speak about that (I suppose it's that ?)
I'll share a trick I just did about handling cancelation of multiple cts

Introduction
Hi, is it possible to do hmr with dagger ?
I mean to access to the container from the host I can do some networking stuff with port forwarding & ssh but for reload file I'm out of idea
for other folks, this question got address here: #1099247946106675221 message
@here For anyone that missed the community call last week, you can find the recording here. Sorry for the delay. Demo snippets in the demo forum are coming shortly.
Thank you to @warm temple , @stuck wyvern , @wheat agate , and @empty jay for presenting!

It'd be really nice if the TUI worked with vim-like controls.
I personally have pgUp/down mapped to my volume control because I never use it for anything else.
Plus search and such would be really nice.
what vim-equivalent keys would you prefer for that? also feel free to drop feedback on the UI here 👉 https://github.com/dagger/dagger/discussions/4942
I have some good ideas from k9s (https://k9scli.io) that could fit quite nicely in our TUI. I'll leave some comments tomorrow.
FWIW k9s has become a de-facto tool in every k8s user at this point. cc @winter linden
K9s provides a terminal UI to interact with your Kubernetes clusters. The aim of this project is to make it easier to navigate, observe and manage your Kuber...
good timing!
I have been thinking alot about the TUI today, going through the k9s source code and the pattern used there, specifically in terms of search.
I use ripgrep and friends for everything related to search and found this Go pager lib that bundles ripgrep
https://github.com/vrothberg/vgrep
With large pipelines and huge monorepo builds, log search has to be blazingly fast and ripgrep is still lightyears ahead of other search libs given that benchmarks are correct.

GitHub
a user-friendly pager for grep. Contribute to vrothberg/vgrep development by creating an account on GitHub.
I have no idea if this library makes any sense but bundling Rust libs with Go linkers seems trivial, or just using the whole binary like they do 😄
Yep, vgrep could fit quite nicely there as a search lib. I've contributed to it sometime ago and the maintainer keeps the project quite active.
ahh! 💪
yeah, I just looked at the Makefile quickly and they dont even bother with any fancy C header linker stuff, just bundle ripgrep bin straight up
does anyone know if i can perform a non-shallow or fetch-depth: 0 clone using daggers client.Git?
Currently doing this but appears to not fetch entire history. Might need to switch to running git clone in its own container and passing that around?
dagger.GitRefTreeOpts{
SSHAuthSocket: client.Host().UnixSocket(sshAgentPath),
})```would be great if depth could be added to GitOpts
https://pkg.go.dev/dagger.io/dagger#GitOpts
I am following this thread now
I can't recall if buildkit's clone operation allows specifying the depth... let me check really quick
I would also +1 this feature. Shallow clone is very common, especially in monorepo setups. Any time you are dealing with repo's with larger size or longer commit history it has the potential to save lots and lots of time. Another somewhat common usecase is working with repositories that store blobs. Shallow clone significantly speeds up working with those types of repositories
Still using old dagger release here, 0.2.32. when trying the latest release, it can't find build when using dagger do build command. Also this workaround is painful https://docs.dagger.io/1224/self-signed-certificates/. Is it possible to volume mount internal CA into moby/buildkit:v0.10.4? I tried but could not get that to work.
@real kite just to clarify, the clones that the Gitoperation currently does are all shallow
Still using old dagger release here 0 2
Thanks!
Hey there! Tried submitting job-application through Greenhouse but getting Oops! We were unable to verify your Captcha response error without seeing any Captcha. Is there a possibility to connect with your hiring team here in Discord? 🙂
cc @wraith niche
Please pm me on discord or email sam@dagger.io, I can add you manually and we can have a quick chat.
A few updates:
- Rust sdk has been updated to the newest 5.1 dagger release, and now supports
dagger runas well 😄
I am struggling a bit with removing the .id() param from directory, file etc. structs: https://github.com/kjuulh/dagger-sdk/issues/26, tl;dr; rust is even more strict than go with types. I am gonna experiment a bit with it to see if I can get something reasonable up and running, it isn't a deal breaker, but it is ergonomics I'd like to fix, I haven't sunk that much time into it yet, so there may be an easy solution, but this should be the last difference between the rust sdk and all the other sdks.
I also want to enable opentelemetry and better error handling for better debug-ability mostly from my side, but also to help users report errors if they occur in the sdk specifically.
- I've implemented golang support in shuttle: https://github.com/lunarway/shuttle/pull/159, it is a pretty long pr. But the tldr is that I've added magefile like support for our organization tool, which makes it possible to share golang packages as commands (
shuttle run ci) shuttle -> golang -> dagger [build, scan, test, etc]. We're currently building our catalogue of tools built on dagger internally (closed source) but I will probably a blog post / video on it at some point. it is pretty cool 😄 this is the thoughts behind it if interested: https://blog.kasperhermansen.com/posts/distributing-continuous-integration/ again tl;dr; bringing developer tools software engineering for organizations into the 21st century 😄
You know what would be really fun... if in addition to the TUI you could also have it spin up a web UI.
This is a feature of Dagger Cloud 🙂
It's already available in preview, in case you're interested, just saying
Would love to see it.
I recall pre-cloak there was a Dagger Cloud.
I imagine it is similar?
Yes, it's a continuation of that earlier version, adapted to the new multi-language engine, and expanded with better visualization (including a DAG view, and a tree view with logical grouping a-la TUI); and other features beyond acceleration as well 😇
Oh I'm interested
i’m not seeing much search results but i’m curious if anyone has used dagger to target builds with go-libvirt/go-qemu to target local VMs?
Nope but I've used cross in rust quite a bit which uses qemu for cross compilation. And actually also some go for cross compiling binaries in github actions. Not that much locally as qemu docker etc can be a bit buggy on a mac
We'll be giving a special demo on this week's community call... Recording won't be shared. Just FYI 🙂

Zoom
Join the Dagger team and community to learn about the latest features that we've been working on, see neat demos from community members, and ask any questions that you may have.
No question is too small!
If you'd like to add a demo or topic to the agenda, please submit it here: https://airtable.com/shrj9zf66QYXAxauy
I have built a whole host of small tools on top of dagger would this be interesting in a community call something? It goes quite outside of what you would normally do ci wise
cc @chilly arch. I'd personally love to see some of that. Reminds me of the early days of people running everything in containers 😄
Absolutely! Seeing what others are building with Dagger (regardless of use case) in the community calls are always fun. I'll DM you @main spear to coordinate.
Is there any plan for dagger to support docker-bake files? I have some really complex build definitions defined in HCL and was hoping that dagger could consume them. I mean I could try and recreate them but figured if Dockerfiles were supported, bake might possibly be on the roadmap?
docker bake compat?
Hey everyone! Looking forward to seeing you all at the community call tomorrow. We have some great demos planned. Register here - https://dagger-io.zoom.us/webinar/register/4416686668409/WN_USQjVBGXT0SWhNMvqYVvCA#/registration

Continuing the conversation from community call over here 🙂
I might try a weekend project to do a vscode plugin. I don't know TypeScript or vscode API but might be fun.
There is a VSCode extension for Dagger, but it's specific to our CUE version. It's limbo as we didn't know if there would be a need for a VSCode extension in the new architecture. Feel free to fork and experiment 🙂
Or did we discontinue the extension? can't remember @slender star
It's still in there.
My thought was a way to run with tui enabled and keep history around without having to use the terminal.
Likely answered many times by now, but is there an env var or anything i can set to cache bust so all WithExec() are re-executed?
cache busting without changing code
Is it possible to copy files, from a container onto a host machine, and run commands via ssh using the Go SDK as we can do in the CUE version?
Yes, in the same way.
Great! Is there some example code that I can take a look at?
Just created a branch called dagger-spike and that's probably the most metal branch name I've ever typed
I submitted a few Dagger talks here and there (OSS EU, KubeCon NA). The new service container and dynamic secrets features make Dagger more and more impressive.
All we need now is extensions. 😄
Next stop: entrypoints. This train goes all the way to extensions, last stop: extensions.
Going to update the description of my entrypoints POC PR later today with all the new stuff I pushed, really excited with how it's starting to shape up. Not full blown extensions yet, but all the groundwork is being laid 🙂
Shameless plug for the next community call (May 18th) - @pseudo stream will provide a summary of the latest entrypoints work during that call 🙂 Don't forget to register, so you get the reminders! https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA
Too bad I'm gonna miss that one. I'll catch the record!
We'll miss you, but yes, will share the recording!
Here is the recording from yesterday. Thank you to @warm temple , @elfin frigate, @sacred crypt , @hushed cosmos and @winter linden for presenting! https://dagger-io.zoom.us/rec/share/JJGBajnMbCQN5GRwZSJXYg3KMR9Tv2ogCRSPha1bH3FFK2H8FIh5PHu2uamJP0_C.jvo3bNwyPosbc2gK
At the end, Solomon shows a sneak peek of what we've been working on for Dagger Cloud. If you are interested in learning more, click the "contact us" button on the top right of https://dagger.io/. It will go straight to @slender star, so he will follow up to get you a demo!
Hello, I'm trying to keep the colored output of an utility that tests for a terminal (test -t). I'm able to keep the colors using unbuffer / script but all the lines are displaying a B at the end of each line.
changing TERM=ansi, worked. The issue was related to tput sgr0. 
Any clue on what can I possibly do to configure buildkit to accept our registry mirror?
https://discord.com/channels/707636530424053791/1105045640989388800
Anyone have any experience using dagger in a k8s job?
We definitely need the docker socket but I'm wondering if there's any way to make those containers adhere to the requests/limits set in the Pod or have buildkit create Pods or something?
Dagger is listed on the Stack Overflow survey question for "developer tools for compiling, building, and testing" 🙂
I know we've worked with some projects like Actions Runner Controller for k8s GH Actions runners and we have users that are using GitLab runners in EKS...I bet we can help figure it out @wary peak .
cc @turbid tulip
Any suggestion here? I am really confused on why Dagger completely ignores any /etc/buildkitd.toml configuration or the Docker daemon settings for pulling the images from the registry. This is unfortunately blocking us from adopting Dagger
+ docker pull alpine:3.17
3.17: Pulling from library/alpine
f56be85fc22e: Pulling fs layer
f56be85fc22e: Verifying Checksum
f56be85fc22e: Download complete
f56be85fc22e: Pull complete
Digest: sha256:124c7d2707904eea7431fffe91522a01e5a861a624ee31d03372cc1d138a3126
Status: Downloaded newer image for alpine:3.17
docker.io/library/alpine:3.17
+ go run ./ci/
...
#1 DONE 0.1s
#2 [internal] load metadata for docker.io/library/alpine:latest
time="2023-05-09T16:02:34Z" level=fatal msg="unable to get stderr: input:1: container.build DeadlineExceeded: alpine: failed to do request: Head \"https://registry-1.docker.io/v2/library/alpine/manifests/latest\": dial tcp 34.194.164.123:443: i/o timeout\n\nPlease visit https://dagger.io/help#go for troubleshooting guidance."
exit status 1
Why would Dagger ever ignore the Docker / Buildkitd settings?

Docker Documentation
Setting-up a local mirror for Docker Hub images
👋 just replied in the help thread 🙏
I know we ve worked with some projects
At Open Source Summit Vancouver with @fossil pine !

FOMO intensifies
We need your help deciding which terminal UI to make the default: “interactive” or “inline”? Too much awesomeness (courtesy of @elfin frigate) is making it hard to choose… See https://discord.com/channels/707636530424053791/1105631313198841956
Hey everyone, I'm currently working on debugging pipelines and I'm looking for a effective way to connect pipeline. Is it possible to do something with ssh socket . Does anyone have any experience or suggestions on how to achieve this?
👋 Hi! Just read the blog post about Grafana (thanks for sharing your experience, @wary peak). I was amazed by how much the pipeline was improved (75%!). I'd like to learn a bit more about how you managed to achieve such improvement. My assumption is that the CI node is using a single persistent volume that is mounted in the Dagger engine container at /var/lib/dagger? Or are you doing something fancier?
👋 Hi Just read the blog post about
Since we have a bi-weekly team meeting in our company at the same time, I have to miss every Dagger community call. 😢
hi all! Just a reminder that @slender star is at the Open Source Summit NA today, so reach out to him if you are there! He'd love to say hi, and give you a sticker!
Join the Dagger Community Call
The moment Gerhard pitched rewriting buildkit in rust 😛

Not my prettiest moment ❤️ pretty mind blowing
All three of us look awesome in that screenshot.
Although I have the coolest shirt.
If you want to help Dagger, the new StackOverflow Developer Survey has a way to show your interest in Dagger at the "developer tools for compiling, building and testing" section: https://stackoverflow.az1.qualtrics.com/jfe/form/SV_czLVsbnGnF4Q04e?utm_source=banner&utm_medium=display&utm_campaign=dev-survey-2023&utm_content=take-the-survey

Stack Overflow is the largest, most trusted online community for developers to learn, share their programming knowledge, and build their careers.
Hey guys, I descovered dagger a view days ago and love the concept. Im trying to buld a pipeline that can deploy code from remote repos. I would like to run a node server with some tool (maybe dagger?) That gets the code from an url and runs a defined pipeline for that code. Later uploads the image to an artefact. Would dagger be a good fit for that? How would I aproach this?
Is anyone able to help me with running a set of commands in a .sql file within a Go SDK please?
Sure, let's go to #1030538312508776540 . I'll be there in a bit. Making breakfast here
Yes, Dagger seems to be s very good fit for this use-case. Do you have an idea on how to start? Or you need some help?
I have some ideas. But I could use some help when it comes to the exact application flow and the coresponding dagger functions i need, to build that
Edit: A short description of our Idea: https://sempex.github.io/cloudwave/notes/sgxlnynp7wmo4nqyldvdjbm/#concept
Personal Knowledge Space
got it seems to be straightforward. Let us know how can we help!
Sure let s go to 🙋help I ll be there in
Cool! Now we know that it is a good fit i think we try some stuff and reach out to you when we know a bit more. Do you know of some recourses that would lead us in the right direction? Thx alot!
Welcome to the Dagger community! We're excited to see what you build. Please keep us updated on your progress, and reach out to us on the help forum if you need anything!
new tui is 🔥
love the TUI! Would it be possible to remove red color as an option for the lines on the side? It makes me think something failed when it didn't.
Inline. Going interactive should always be an opt in for cli tools that are used in automation purposes IMO.
that's fair - and actually the reason it doesn't start with red (which is the first numeric ANSI color). i'm not 100% sure about removing it entirely though, since you could make a similar argument for yellow = warning, magenta also = error, green = success, etc., but I'll keep an eye out for similar feedback. the advantage of having a broader spectrum is being able to distinguish more things happening concurrently, i.e. minimizing color reuse.
FWIW git log --graph uses red too, and seems even less afraid of using it as the 'first color', so I think it's just a matter of getting used to it
Makes sense, it's just that, from running a CI pipeline standpoint, I am very used to seeing RED as a error. For something like git log I understand the colors don't really signify much. Another reason seeing the color RED is confusing to me is that the TUI doesn't give me enough of an indication that it was successful. It returns to the prompt but I end up confirming with the output that everything was ok. Maybe if the SUCCESS indication was more apparent the red lines will be less of an issue.
If anyone is at KubeHuddle today, make sure to say hi to @warm temple and @elfin frigate ! https://kubehuddle.com/2023/toronto/
I am calling for comments, from anyone interested in the intersection of Dagger and Github Actions.
There is a very interesting and promising project getting started: Project Gale by @empty jay . Its goal is to support running Github Actions (unmodifed!) on top of Dagger. Very exciting, and even in its early stage, it works 🙂 I encourage you to check it out.
I am requesting comments on the question: what should Gale prioritize?. There are two ways to leverage Gale's core capabilities. Which should Gale focus on? I know some of you have opinions 🙂 I would love to read them.
Here is the thread: https://github.com/aweris/gale/issues/18

GitHub
Sorry for the vague title. I'm hoping to continue here a conversation that started live. The topic is: what should Project Gale prioritize? I see two options: A better alternative to nektos/act...
**Reminder - Dagger Community call is tomorrow at 9 am PT. **
We'll have an exciting demo from @main spear, and @pseudo stream will share the latest on the highly anticipated entrypoints. See you there!
Register here - https://dagger-io.zoom.us/webinar/register/4416686668409/WN_USQjVBGXT0SWhNMvqYVvCA#/registration

Thank you to everyone that attended the community call today, and to @main spear and @pseudo stream for presenting! It was great to see all the interactions. You can find the recording here: https://dagger-io.zoom.us/rec/share/qivnhWSSeTKIcJmbP60PE85HIJ2JbS3X_5P397Y9JVp-HqlKZ2pC2fae7q1tgrPh.wMLuldpgMjBu8d4Z
Is there an easy way to identify why a stage wasn't cached?
Hello, I had a look at the recent project entrypoint work and I’m wondering if there will be a way to enable users to just type dagger do at the root of the repository to discover the entrypoints (currently one has to type dagger do --config ci to do so)?
Yeah, right now it's necessary to specify --config when the entrypoint code isn't directly in the root dir of the repo. But I think that's going to be the case more often than not, so agree we need to make this nicer.
No decided on solution yet, but two possibilities are:
- When you run
dagger do, it searches all subdirs recursively and finds all entrypoints (unless you specify one explicitly with--config) - You can put
dagger.jsonin the root of the repository and specify in there all the subdirs with entrypoints
We have an issue for this in our internal tracker, but if you or anyone else want to have a public issue to comment on or follow for progress, I'm happy to make one.
Thanks for your answer, 2 sounds nice to me.
are you running locally or in a CI runner?
if you're running locally, the TUI is very helpful for that. We're also working in Dagger Cloud, a web based service that gives you more visibility about your pipelines. If you're interested in a trial, please DM @chilly arch so we can get you started!
Unfortunately I can't send data out of our Network so that may not work right now. In TUI how can I tell which exact thing actually invalidated the cache?
here's a very basic example:
func main() {
ctx := context.Background()
client, err := dagger.Connect(ctx, dagger.WithLogOutput(os.Stderr))
if err != nil {
panic(err)
}
defer client.Close()
output, err := client.Pipeline("test").
Container().
From("alpine").
WithExec([]string{"apk", "add", "curl"}).
WithEnvVariable("CACHE", time.Now().String()).
WithExec([]string{"curl", "https://dagger.io"}).
Stdout(ctx)
if err != nil {
panic(err)
}
fmt.Println(output[:300])
}
You can see from the image that curl is not cached even though apk add it is. That gives you a hint that WithEnvVariable is causing the cache to be invalidaed.

having said that, there's still areas of improvements towards giving more visibility about what is causing the cache invalidation. cc @pseudo stream IIRC there's a discussion in the OSS repo 🙏
This is great! I didn't know you can invalidate individual Execs like that. My previous understanding was that the entire container is invalidated.
sure! np. Maybe we can document this in our cookbook? WDYT @heavy karma ?
Yes! This was on my list to add this week, didn't have a chance yet but will do it early next week
is it mandatory to install dagger cli to use dagger graphQL api or can we directly call dagger graphQL api through curl?
Dagger session
Lots of great participation in the Project Gale issue I shared the other day - thank you! Here's another one for everyone looking at Github Actions compat for Dagger: https://github.com/aweris/gale/issues/22

GitHub
Problem When discussing Github Actions, and Act, I problem I keep hearing about is "the big fat image". In order to reproduce the original Github Actions environment in a container, you n...
is there any way to clean cache in dagger automatically? like after 30 days or something? And i would like to know how dagger handles cache like when dagger get new cache for same repo or path or depeendency then does it remove old cache automatically? or is it being overwrite?
Hi all, I noticed that if I run dagger run with the --debug flag, none of my pipeline secrets are masked in the output. Not sure if this is already a known issue. I couldn't find anything related in the issues so I opened one - https://github.com/dagger/dagger/issues/5171

GitHub
What is the issue? Running the TUI with dagger run --debug exposes the secrets otherwise masked in the logs. I can observe the withSecretVariable being exposed in the listing of stages. Log output ...
hi, we are trying to use graphql with dagger cli but not able to use secret variables. we are getting Error: failed to solve: secret not found if we run our sh file. Here is sample code how we are trying to store and use secret in container. Please help how we can solve this.
S_APP_ID=$(dagger --debug query <<EOF | jq -r .setSecret.id
{
setSecret(
name: "APP_ID",
plaintext: "1234"
) {
id
}
}
EOF
)
output=$(dagger --debug query <<EOF | jq -r .container.from.withSecretVariable.withExec.stdout
{
container {
from(address: "node:latest") {
withSecretVariable(name: "APP_ID", secret: "$S_APP_ID") {
withExec(args: ["-v"]) {
stdout
}
}
}
}
}
EOF
)
echo $output
Secrets in the CLI
Nothing I've reproduced, but running the first run with dagger run go run main.go build:all had a big image to download and seemed to timeout. The first run seemed to timeout. Never ran into after that first run. Might be a known issue or maybe you can reproduce by calling the https://github.com/goreleaser/goreleaser-cross image in your test.
If I can reproduce I'll let you know

GitHub
Docker image for Golang cross-compiling with CGO. Contribute to goreleaser/goreleaser-cross development by creating an account on GitHub.
unrelated... I honestly think one of the things I'm most excited about is dagger run build etc with auto discovering of commands and a better command line interface that is improved beyond what mage offers.
I just realized I could run dagger run mage build:all and it worked where I was providing this before dagger run go run mage.go build:all before and definitely digging the shorter version 😆
next up: dagger do build:all 😇
do
Hi, i found dagger blog site layout display only half of my mobile screen. I guess that probably because of mapping table that expand to the screen width and the table cannot scroll. 🙇♂️


@last pine @glad jolt 👆
Pretty bad indeed. I'm going to open an issue for that. Thanks for the reporting 🙏
Hey all, we're using dagger for everything in the company right now and are pretty happy with it 😁 but we're mostly doing local builds from the dev machine (we have a lot of small-ish projects) and are, just now, looking to actually add a real CI/CD server that would build every git pushes as it should be.
What's everyone using right now for CI for your dagger-based projects?
Also have this crazy idea, since every repo already have a build.py file housing the CI code, we're really only missing an HTTP server to receive webhook from github and then from './build.py' import build to build it.
Has anyone done anything similar to this? Dagger is a "toolkit" after all so I think this approach is kind of perfect.
Hi. It depends a bit on what hosting platform you use. Right now github actions is the preferred option as far as I can tell. But it should be relatively easy to setup others as well.
You could also roll your own like you mention with the http server. But in general you get a lot of benefits from an actual ci platform. Isolation being one of them.
I don't think anybody has built a roll your own github ci for dagger. But you could probably find something out there xD.
I'd recommend github actions though, there are quite a few guides in the dagger quickstarts
CI with Dagger
Hey, I was experimenting with new entrypoints and get input:1: pipeline.pipeline.pipeline.pipeline.host.unixSocket eval symlinks: lstat /run/docker.sock: no such file or directory. I wonder is there a way to load unix socket to my entrypoint? cc: @pseudo stream
Ah no that's not possible yet, it's in the backlog though! Not really any great workarounds in the meantime. It's technically possible to run docker inside dagger as a privileged service, but I don't recommend going down that route unless you really need to get unblocked immediately.
Oh understand, fair enough. Nope it's not that urgent. I'm using dagger run to workaround for now. it can wait for entrypoints
Nice work ya'll !

HI everyone, many thank to have me accepted in this group. I'm experimenting dagger CLI, but I'm facing install: cannot create regular file './bin/dagger': Permission denied error during the installation on Ubuntu22. Anyone else had the same issue?
sudo curl -L https://dl.dagger.io/dagger/install.sh | sh
Hey there! That's because sudo is currently applying only to the curl command and not sh. Try with
curl -L https://dl.dagger.io/dagger/install.sh | sudo sh
Thank you Marco, worked like a charm
I have a question regarding the SDKs, specifically the go SDK. Is it possible to statically link and compile a single binary that represents all the pipelines for easier running on external CI systems? An example would be instead of using the node.js sdk and then having to do npm install before doing node build.mjs or whatnot, or requiring the go toolchain on the CI server, we statically compile a linux binary that we commit and directly run on the CI (for example gitlab, github etc.)?
Apologies if the question is worded badly or the answer is easily implied, I don't have any experience with go
I have a question regarding the SDKs
Hi folks! I am very Dagger-curious, and trying to figure out if it would be useful to incorporate into my next project. I think I understand the basic ideas -- it is a container-native CI-agnostic abstraction layer for workflows that can be represented as a DAG. This is very appealing to me since I hate that none of my existing CI tools can run locally, and I would love not to be so tied to one CI platform or another. Two problems I have are that I primarily use Bitbucket Pipelines, and secondarily have some CI work I would like to automate involving Windows platforms.
Hi all! @heavy karma is working on a few different guides, and we'd love your thoughts. If you have a moment to test drive them and provide feedback, please do 🙏
- Dagger+AWS Lambda: https://github.com/dagger/dagger/pull/5202
- Dagger+AWS Codebuild: https://github.com/dagger/dagger/pull/5188
- Dagger+Azure Pipelines: https://github.com/dagger/dagger/pull/5165
Anyone running kafka as service container?
Well, I guess I'm going to be the first then...this is going to hurt 😄
Anyone running kafka as service
No worries! We're here to help out!

We have a great demo lineup for tomorrow's community call! Thanks to @strong wyvern , @warm temple @heavy gazelle and @wraith niche for presenting. See you at 9 am PT !
Register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA

Hi, I have tested dagger on very old release with dagger cli and cuelang. I look now there a framwork to build ci pipeline on golang. If I right understand, dagger no more use buildkit, but now docker engine ? I have tested a simple sample from quick start guide. It's seems not working behind coorporate proxy. I have local docker cli that point on remote docker engine (DOCKER_HOST=tcp://...). The remote docker engin can pull image behind proxy, but when dagger (it seems use local docker cli) try to pull image it not use the proxy ... (I think I soesn't understand how dagger use the local docker...
Dagger is just starting a container in docker which has the dagger engine in it.
dagger-engine still uses buildkit.
Hi I have tested dagger on very old
In case you missed it, here is the recording from today's community cal. Thank you again to @strong wyvern , @warm temple , @heavy gazelle , and @wraith niche for presenting! I will post the demo snippets in the demo forum soon. https://dagger-io.zoom.us/rec/play/0OoJj6vqVRFQJWJIUwzX6bs4ARbvOnA7MpT3xJFtSYY8W1uhDDSBjpnIosNdWFA_De5rfDFla4d6nyTF.M9A2w96UTu705vE5?canPlayFromShare=true&from=my_recording&continueMode=true&componentName=rec-play&originRequestUrl=https%3A%2F%2Fdagger-io.zoom.us%2Frec%2Fshare%2Fis8jtV2HQvjW_ac8uBho9C3_GShkN_lAdKYvsx2Bd2KIgH3Op-Rz_oDnCdvKmTYK.MQMYCSRegGvpbUsl
first of all — i’ve been playing with dagger and it is amazingly well done! — been lurking in issues/discussions and you have some super interesting projects in the pipeline — a stellar team for solving the ux in this problem space — looking forward to seeing where this project would be taken within the next year!
now … on the topic of debugging in a post-docker world;
what is the easiest (shortest? 😁) way from a failed step in a pipeline, to debugging it interactively in the same environment, so you could run commands/inspect filesystem and such? — basically, mimicking targets in a dockerfile, and being able to exec into the failed container state? — preferably using go sdk — but any pointers appreciated, i’ve been mucking with nsenter from the buildkit host — but hoping for something along the lines of earthly -i if possible 😄
I’m loving what I’m seeing in the latest blog post about the new CLI TUIs. When you use dagger run, does dagger care at all about the underlying command as long as it outputs a compatible output stream?
This is 100% going to happen- we even had a live proof of concept shown in a community call I think? Just a question of “when”. Unfortunately I don’t have the answer to that question 😅
@heavy gazelle #maintainers message I've been pondering what a simplest-possible production dagger engine could look like -- was exploring a bit with controlplane.com, but I'm not knowledgeable enough to know if it's properly suited to it, or to try to get it working. Fly.io sounds very enticing
Maybe this is a silly questions but can I build a binary using my main.go (Dagger pipeline) and execute as a binary on a machine that does not have Go?
I am just reading the Go SDK doc btw.
Yes, you can.
Hey folks, I’ve been really enjoying Dagger for almost every use case except for… spinning up a Kubernetes cluster as a Dagger Service.
Both kind and k3d seem to be hard to get running. The whole Kubernetes in Docker in Dagger feels so nested and hard to set up. I ended up not using Dagger because of this complexity.
Would be nice to have a clean example of how to do both kind and/or k3d in Dagger. Or something else like built-in Kubernetes API support? Would love to spin up Helm charts locally and in CI for example to run tests
Hey question... what is the easiest way to introspect the graphql schema? I am noodling with writing a kotlin SDK, and would like to use the apollo plugin https://www.apollographql.com/docs/kotlin/advanced/plugin-configuration/ to codegen the queries, but trying to yoink the schema from the playground leads to a jwt token error.
Basically want to be able to run this command from my terminal
./gradlew downloadApolloSchema \
--endpoint="{{ dagger_schema_endpoint }}" \
--schema="app/src/main/graphql/com/example/schema.graphqls"

Apollo Docs
Dagger requires to have session token to do authentication with dagger server. You may see an example in go https://github.com/dagger/dagger/blob/main/sdk/go/internal/engineconn/engineconn.go#L73

GitHub
A programmable CI/CD engine that runs your pipelines in containers - dagger/engineconn.go at main · dagger/dagger
Yea, unfortunate that it requires that just to inspect the schema. Would be nice to just point the codegen tool at the playground and be able to yoink the schema. Ultimately I had to load the web playground, inspect the network tab, grab the response payload, pass it thru an introspect to sdl converter, then paste the hard coded SDL in my repo.
Guess I could use dagger to spin up a pipeline, just to run this request against the local server inside of a dagger context eventually. Having a rough time getting dagger to even spawn a gradle daemon. posted abt that in the help channel
You get the authentication params as environment variables when using dagger run:
❯ dagger run -s env | grep DAGGER
Connected to engine 9351479b0c81
DAGGER_SESSION_PORT=63597
DAGGER_SESSION_TOKEN=1aab3152-4a0c-48d2-8fde-5353ede8e8f7
very cool, i should be able to do this then, when I can get gradle to run 🙂
You can use dagger listen as a convenience for this FYI. Just be careful to not use it in production or on a shared system
oh neat! how do you get the token then?
No token needed. It just exposes the graphql api on a local port. That’s why it’s a dangerous command if used incorrectly - the address you listen on is basically a remote shell with your privileges. I believe the command is hidden and we might deprecate it in the future. But it is convenient 🙂
Ahh gotcha. Once I can get gradle to work via dagger run, that should be enough, then I can run something like
dagger run ./gradlew downloadApolloSchema \
--endpoint="127.0.0.1:{{port}}" \
--schema="app/src/main/graphql/com/example/schema.graphqls"
--however-this-gradle-plugin-does-auth
Hello everyone !
I'm new to Devops and CI/CD, and just covered Dagger!!
I have a few questions about it, if someone more experienced can answer me!
- What is the update frequency and more generally the product life cycle!
- Is it compatible with Kubernetes? How to run a Dagger pipeline with Kubernetes?
- are there training tutorials on dagger?
- How are the stages of a pipeline and the results stored (logs, states, ..
Thank's
Hey folks I’ve been really enjoying
Heya, I have a tiny question about the new TUI; how can I interleave output from other parts of my pipeline? For example, in some cases an error from a pipeline step might be expected, and I want to output some nice logging/debug info for the user. At the moment it seems (if I just use e.g. rich.print) that the TUI swallows that output?
the tui should automatically capture stdout, and stderr. it should be visible in the top most node of the tui =D. I don't think you can set explicitly which pipeline steps it should output it in though.
Sorry, I realise that was misleading; this output comes from the glue code / scaffolding around the calls to the dagger API. So, handling return values, etc!
@radiant talon Yep. The tui should capture both the stdout/stderr of the program, i.e. your printf statments etc. And the output from the dagger engine itself, ie. the pipelines steps, with buildkit output.
That said it depends a bit on which type of TUI you use. There is the full editor kind of mode, and the streaming one.


@mild flame Regarding training tutorials, check out the Dagger Quickstart https://docs.dagger.io/648215/quickstart
Introduction
Hello everyone
@rose sage Continuing here. Yep, an easy way to start is writing multiple jobs and calling them as needed in your CI platform
An example (I'm on Gitlab using Python): https://docs.dagger.io/145912/ci#gitlab-ci
Introduction
In this example you simply change the main.py bit to whatever job you want to run
There are more options for this coming down the feature pipeline however, there's a very cool demo from a recent community call: #1110799740322463744 message
I have a Go program, hof, where users hof create github.com/org/repo myapp. This command creates a tmp dir, copies files around, runs some commands, and then copies some files back to where the user ran it from. This seems like something that I could port to Dagger and ship within our CLI, which would mean that the user would need docker|containerd|podman available to use the command. The goal would be to do the same steps in an isolated container rathern than on the host system, until the end when we want to actually write out to the FS, from a final Dagger FS.
Does that sound right? Would I also be able to get the same experimental TUI experience?
- Yes that sounds right 🙂
- At the moment the experimental TUI experience requires wrapping with
dagger run. We're considering the option of allowing you to embed that experience in the CLI, but it's not decided yet. And if we did it, it would be a complete takeover of the user's terminal, not necessarily what you want either
Nice, we have thoughts around (T)UIs for hof anyway, so we might put something higher up for all the features that may or may not run in dagger, so passing it directly through might complicate things as you mention. In the meantime or in isolation, it could be nice
Is there a better channel for asking questions specific to the Go SDK?
Here is fine, or you can use #1030538312508776540 with the appropriate tags
What API is the Go SDK calling when I run dagger code via one of our commands?
(point 3) from Understanding the basics of Dagger
Do I even need the dagger CLI any more?
Everyone, we need help with an important matter: choosing our next silly codename.
As some of you know, we started working on the next major improvement of Dagger, featuring 1) a new CLI-driven UX, 2) standardizing project entrypoints to reduce the amount of dagger boilerplate each project needs to write from scratch, and 3) finally! the beginning of an extension system.
We need to choose a silly codename for this exciting new project. Help us choose one!
In the past we've had:
- Europa, which later became Dagger 0.2: a complete redesign our CUE APIs
- Cloak, which later became Dagger 0.3: a new architecture based on GraphQL and generated native SDKs
- <YOUR SILLY CODENAME IDEA HERE>: a new user experience based on the Dagger CLI and cross-language extensions
Hello Everyone,
I came across your project on hacker news - I'll be using dagger for my upcoming CI needs. Great project.
Thanks for the kind words Andreii! And welcome to our discord. Let us know if you have questions, we're always happy to help.
Thank you Solomon
@winter linden can we see TUI in github action?
Hi all, is the functionality on this PR (https://github.com/dagger/dagger/pull/2805) available for dagger-cue? if so how do i install it?
thanks

GitHub
Add global dockerhub_auth_user and dockerhub_auth_password env variables, to enable login to docker hub (only) and avoid being limited by rate-limiting free accounts.
Fixes #2804
Signed-off-by: gui...
Hi 👋 , this is how we used to be able to rely on this feature: https://github.com/dagger/dagger/pull/2805/files#diff-81b03936d20067e15354dba72e031dca8d5a5852118849dc8c5f65fc2c2057c1R17-R18.
export DOCKERHUB_AUTH_USER=foo DOCKERHUB_AUTH_PASSWORD=bar
dagger-cue do -p ./your_pipeline.cue
thanks @swift inlet , will try it
solomon 4104 can we see TUI in github
All of the SDKs are built on top of the GraphQL API
Technical Preview
I hope this question is appropriate for this channel - What are the differences between Dagger and Actuated-CI?
I hope this question is appropriate for
Hello, I'm interested in understanding the technology that Dagger employs to generate documentation from .md files. It seems very intriguing, and I'm not quite sure how it works. Could you please provide some insight into this?
Hello I m interested in understanding
why dagger-buildkitd docker container using huge amounts of disk space? it seems to have one associated docker volume, which uses huge numbers of snapshots.
That’s probably the cache
yes. I am trying to do "docker volume rm the-volume-name", and now it is hanging for a very long time. will it eventually be able to delete this volume? I want to start up the container after deleting this large volume.
ok after 25 minutes, it finally removed this volume.
is there way to avoid the cache, if later we just want to start the container in the pipeline, run dagger script, then destroy the container and its volume?
Hi all, I am testing Dagger since 3 months now and it looks awesome. I did not replace the CI yet. I would like to replace bash scripts to Go code (to add unit test). Bash scripts manipulate many files. I can run them in a WithExec inside a container...but like I said before I would like to write go code. Is it possible to execute go code inside a container ? (Without recompiling another project and execute the binary). Or is it possible to have io.Reader and io.Writer to files inside container to modify them in the go code. Maybe I missed a design, could you give me some points on that ?
Hi all, is it possible to use private image registry as cache on dagger-cue? also, when running dagger with docker-dind (i'm currently running dagger inside jenkins worker pod), where should you put the credential?
Usage:
dagger-cue do <action> [subaction...] [flags]
Flags:
--cache-from stringArray External cache sources (eg. user/app:cache, type=local,src=path/to/dir)
--cache-to stringArray Cache export destinations (eg. user/app:cache, type=local,dest=path/to/dir)
Dagger-cue caching
Hey guys, sorry if this is often asked but:
I found dagger when it became public last year and thought it looked awesome. I especially loved Cue. The language SDKs do seem awesome for many workflows, but the simple declarative nature of Cue, while being more advanced that alternatives, attracted me.
Is there a specific reason for it it not having been updated and might be deprecated (quoting solomon)? Or is it purely demand related?
I could find no specific announcement of tradeoffs, only the introduction of multilang api
Old topic but just to let you know @sudden ocean that this has been fixed ;).
Hey guys sorry if this is often asked
Is there an actual "server" running somewhere, like do I have to be connected to the internet to use Dagger? What domain would I have to allow in the firewall?
Or is that GraphQL string just passed around in the Go SDK (to possibly internal code)?
Hi @stoic knot ! 👋 No, you don't have to be online. The Dagger Engine (distributed as an OCI container) will get started (and stay running) when your run a program using a Dagger SDK. That's where in the neighborhood where the GraphQL server lives 🙂
- offline mode
- local mode
- works in any CI
all superpowers
Architecture
Confirm it is fixed. Thank you. ❤️
Hey @winter linden just listened to the podcast you did about Docker, and it reminds me ... Huge ❤️ to all of you for all of it, ideas, changes, and everything that is to come.
Thank you Sven! Lots of memories good and bad… But mostly good 🙂
Always retell the good! At some point any bad just fades away 🙂
Hi, i open the guide page on my iphone (12) and found search input is quite small and it can touch only in grey area. The problem is it’s hard to touch to typing a little bit.

Docs - Guide search bar size on mobile
If you missed the community call today, you can see the full recording below. Thank you to @green leaf , @empty jay , and @sharp marsh for presenting!
The demo snippets will be added to the demo forum soon.

Hey there folks! I'm back to Dagger after sometime. I previously used cue-sdk and I loved using it. I can not find it anymore, can someone give me a tl;dr of the changes since then? I can not find any updates/blogs to read about the changes
Hey! I am trying to use Dagger in my buildkite CI pipeline. I would like to enable having a base pipeline CI js file which then can spawn other jobs with the containers so that jobs aren't all running on the same machine. Is there anything like that or does that make sense?
Dagger in Buildkite CI
quick question - does attaching a service binding to a container automatically invalidate the cache for everything that happens after that?
quick question does attaching a service
Hi everyone, was just wondering. I've played around a bit with dagger and I like the idea of debugging and running a pipeline locally. However running docker in a pipeline is cumbersome. Especially with tools like Gitlab and Bitbucket, where you have to set up services that run the docker daemon. To make matters worse this not only is unwieldy, it prolongs build times significantly (in comparison to build the "raw" application on the runner without docker). At least thats my experience.
Now, my question is, are there plans to make dagger work with podman, kaniko or some similar tool that can create the image on the runner itself? I think we could get quite a build time boost from this.
Check the guides, I'm certain there is already a dagger-with-podman guide
Thanks man, seems like I've overlooked this. https://docs.dagger.io/541047/alternative-runtimes
Introduction
Hey evryone, anyone can give sample repo or example to run dagger in docker container with base image of ubuntu and running any language code to build or ship?
https://github.com/dagger/examples/ > there you'll find a broad set of examples

GitHub
Contribute to dagger/examples development by creating an account on GitHub.
there is no example of using dagger in docker with base image of ubuntu
Oh I misunderstood your question. I'm not sure what you mean by using Dagger in docker with an Ubuntu image
Are you looking for a Dagger engine image that's based on Ubuntu?
Yes but i think to run dagger in that docker image we need to install docker also because dagger runs on docker so...ultimately it will become dagger image with ubuntu and docker installed in it, right?
in short we dont want to run dagger at os level, we want to run dagger in docker container only
let us know how to solve this
How to run dagger in docker and not at OS level? Please help to solve this

From: https://docs.dagger.io/541047/alternative-runtimes
Is this mostly about Dagger being able to start the BuildKit container which it then later talks to directly?
Context, we are using the github.com/docker/docker/client to start an container (server in background) and were thinking about how to support other OCI runtimes like dagger to start a container that runs in the background. If we use the Dagger Go SDK, would we be able to abstract away this problem letting dagger start a container and then tell us what ip:port to find it at? Or should we just follow your pattern and shell out to the executable to life-cycle and query?
Introduction
I want to test our hof cli with dagger because we want to have clean user like environments, which we hope to get with containers via dagger, also all those other great docker optimizations.
Thing is, our cli wants to talk to docker (or podman | nerdctl), among other tools. docker stands out because it would be docker-in-dagger. Is this possible? Can I get some guidance?
Our current problem is using the testscript tool from the Go source, via the rogpeppe/go-internal. It does to much directory manipulation and env var rewriting that it's making our code more complex than it should be. Our hope is that using ephemeral testing containers via dagger can give us a purer environment.
newbie question:
is there a way to use dagger to spin up a multi-container long-running dev-stacks? E.g. spin up a posgres+redis+with a nextjs node.js server and then being able to open that next.js server in a my local browser? (similar to what you could do with docker-compose up ) . Or is dagger purely designed for pipelines? If the latter is true what tool would you recommend instead for local dev environments?
It looks like the v0.7.2 Go SDK started the Dagger v0.6.2 engine. Is that expected?
Is there a way to get a host directory and have it use my nested git ignore files?
I'd like to get something of a "fresh clone" from my working directory, while still having unstaged changes
Is there a way to get a host directory
Is the Dagger Go SDK safe to use with concurrency?
Yes 🙂
I see #<n> in my output, which seem do be akin to steps or layers in a Dockerfile, is that a good analogy?
I see certain step numbers multiple times, could that be related to how I organize my code, as a tree of containers?
where does the named Pipeline fit in?
It's logical grouping for visualization
We've just released the first version of a new Open Source project: https://github.com/openmeterio/openmeter
I'm only sharing because it uses Dagger for CI. 😉
This is where I'm gonna need Kafka (and ksqldb) for integration tests. I'll report back when I manage to set that up.

GitHub
Real-Time and Scalable Usage Metering. Contribute to openmeterio/openmeter development by creating an account on GitHub.
Nice, congratulations on launching and thanks for sharing!
Happy to report that after staying up way too late playing with dagger, we did achieve our goal!
We were able to run our existing tests in containers via Dagger and remove some nasty hacks in our code for dealing with $HOME shenanigans in our current testing regime. Bonus points because we are essentially running the same test files without modification in a mode that works on the host system. We are also able to use docker during these tests, and also POC'd using dagger-in-dagger for when we adopt more Dagger to support actual functionality in our tool, rather than just testing
It was a pretty easy experience with the help I got here, the existing examples on the docs, and minorly from my dagger-cue related experience that.
- (main) https://github.com/hofstadter-io/hof/blob/gen-path-simplifications/test/dagger/main/hof.go
- (lib) https://github.com/hofstadter-io/hof/blob/gen-path-simplifications/test/dagger/hof.go
- (current tests in dagger) https://github.com/hofstadter-io/hof/blob/gen-path-simplifications/test/dagger/testscripts.go
In theory, that last link should be easy to replicate for most other test groups
More than one test frameworks rely on Docker (or increasingly Podman) being available in the test environment. One such framework I used recently: https://github.com/kubernetes-sigs/e2e-framework/
Is this something that Dagger could support at some point? In some cases it would require a significant effort to rewrite those tests.
GitHub
A Go framework for end-to-end testing of components running in Kubernetes clusters. - GitHub - kubernetes-sigs/e2e-framework: A Go framework for end-to-end testing of components running in Kubernet...
yes you can run docker engine privileged inside dagger 🙂 a compat shim is also possible but only a POC today
Sounds great! Dunno when I get to playing with that, but it's on my short list.
I'm working on this right now, we have some POC of docker-in-dagger here: https://github.com/hofstadter-io/hof/tree/gen-path-simplifications/test/dagger
We are running into the issue that we need to be able to talk to the containers we start over http and they cannot be reached
Yes, it's quite possible. Already done something similar in my previous work and we had an POC with dagger as well.
This is https://github.com/kinkgo/kinkgo in my short list as well. I'll finish it, if I'm able to return it 😄

GitHub
Contribute to kinkgo/kinkgo development by creating an account on GitHub.
few months later, at least now took like 30s before first example responding with line
"Connected to engine 125b8a1b1a16"
running this helloworld: https://docs.dagger.io/593914/quickstart-hello
Write your first Dagger pipeline
Write your first Dagger pipeline | Dagge...
I see nestybox/sysbox has been mentioned a couple of times. (https://github.com/nestybox/sysbox) I came across it while trying to alleviate my dockerd-in-dagger issues.
Has anyone run this as their base container runtime on which they run Dagger?
GitHub
An open-source, next-generation "runc" that empowers rootless containers to run workloads such as Systemd, Docker, Kubernetes, just like VMs. - GitHub - nestybox/sysbox: An open-s...
It occured to me that I meant to ask about nestybox while watching the k8s-in-dagger talk
it was mentioned a few times but I don't think anyone tried Dagger in nestybox yet, no.
Dagger on nestybox/sysbox
with a new tool brewing at systeminit.com how useful will dagger be?
with a new tool brewing at systeminit
Removing the /usr/local/bin/dagger symlink hack
tl;dr How can I mix SDKs like python and javascript from multiple teams into our pipeline without requiring knowledge of every programming language? Cue files? Something else?
As am SRE team - we are currently POCing dagger. The question I expected and did get when presenting to the devs was "Why would we want to adopt this - our current pipeline works" One of the big takeaways I got from the talk at KubeHuddle - was that anyone how knew go, python, javascript could write part of their teams pipeline, while inheriting libraries written in other languages. This is a crucial capability for selling the company on dagger. It looks like the only way to do this is through a cue file. The SRE team (by that I mean myself) could build the current steps in our messy yaml in python - and our frontend team could extend their pipeline in javascript. I think im missing something obvious - but it looks like the cue documentation is missing from the current version.
How to mix SDKs from multiple languages in a team setting?
Looking forward to seeing y'all at this week's community call! @solar raptor will demo " Fine-tuning stable diffusion using LoRA with Dagger", and @arctic grove share the latest updates on GPU access for Dagger.
Register here - https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA
Want a sneak peak? Check out @solar raptor demo teaser here 🙂 https://youtu.be/uhcsBTf0mqQ

Great case and post! dagger is getting popular among alchemists. @sudden ocean @chilly arch @winter linden https://elixirforum.com/t/case-study-using-dagger-elixir-sdk-to-refactor-a-script/56748

Elixir Programming Language Forum
In this post I’d like to share my experience working with Elixir SDK for dagger. dagger positions itself as a “programmable CI”, but I used it to re-write a shell script: using Elixir SDK for dagger, I was able to simplify my write-only fish-shell script significantly. I’m impressed with the results, and intent to use it as my go-to approach fo...
Thanks for sharing @inner remnant !
Love it ❤️

GitHub
Since we shipped SDKs in November 2022 - 🐹 sdk/go/v0.4.0, 🐍 sdk/python/v0.1.1 & ⬡ sdk/nodejs/v0.1.0 - we announced numerous deprecations and discussed few breaking changes in 🐙 GitHub issues &a...
@solar raptor is doing a live MLOps demo right now: fine-tuning of stable diffusion using LoRA with Dagger.
He tried it with Dagger’s branding and we thought it would be fun to create some swag from the result. We set up a storefront to show off an example, but haven't pushed it live yet. If enough of you are interested, we will set up the option to purchase them. https://2be4fa.myshopify.com/
So, who wants to buy some AI-generated Dagger merch? 😁 Add an emoji if interested.
Credit to @chilly arch for this idea
note, I don’t think we will be able to sell the battle axe 😅
Looks like the check-out actually works (which wasn't working last night), so go for it everyone! It might be restricted in some countries, but I'll look into fixing that.
this was the best image from "magic the gathering socks" 😂

Those demos were great, thank you @solar raptor and @arctic grove
Very nice session today! I'm still processing the impact of the LoRa on dagger demo.
and @arctic grove really took one for the team dealing with Alpine images (for Cuda)
(Backstory: using Alpine for python projects makes you speak python with a go accent. https://pythonspeed.com/articles/alpine-docker-python/

Python⇒Speed
Alpine Linux is often recommended as a smaller, faster Docker base image. But if you’re using Python, it will slow down your build and make your image larger.
That's less of an issue (in Python projects) today because of PEP 656.
Just so I understand, if we switch the dagger engine image to use glibc instead of musl (regardless of how we do that, new distro or alpine+hacks) then it can bundle the nvidia runc tooling without issues and all dagger clients connecting to the engine can cleanly exec containers with gpu access - regardless of the distro those clients use, and regardless of the distro inside the containers they create?
that's right - I didn't manage to get it running with Alpine 100%, I would say 80%, but it was better than my initial tests where it wouldn't even reach the first init steps.
also from comments I've seen on NV repos, seems they're working on supporting other distros
We won't know until we try. 🪓
Ultimately it all depends on how the dependencies were built. In Python, most of the scientific and statistics packages were built with Debian and glibc. PEP 656 makes it easier to support multiple build libraries. IDK how much traction it has in your target use case.
Quick question about clean up in general. A lot of our dagger pipelines are pretty big and each mount / export at least a few gb of files.
sudo du -h /var/lib/docker -d 1 shows 306G /var/lib/docker/overlay2 which is a lot and seems to have built up quite a bit over a few weeks of running these pipelines over and over. Is this a directory I can just remove or is there a command I should be running to do that?
Assuming this is the same docker daemon that is running your dagger engine, then you can wipe the cache by simply nuking the dagger engine container (I think it's called dagger-buildkitd by default? Which by the way we should change..)
For the record, there's also a apk add gcompat that i haven't tried. But it's probably better to just use a debian based one for max compat.
yup. gcompat in combination with libc6-compat made it almost work, I mentioned it here: https://github.com/dagger/dagger/issues/4675#issuecomment-1609549492
output: https://gist.github.com/matiasinsaurralde/96c4568bb533bd7f9c01b77344ae5f1e
Is there a Dagger pattern or best practice around making our own functions of the form WithX(*dagger.Container) -> (*dagger.Container)? possibly with an additional error return (I'm referencing the Go SDK, but assume this is more general). This "with" pattern seems to be consistent with the SDK and creating reusable components.
One question I have is how to know which point (layer?) an error occurred, given they are really only realized once a pipeline is actually run
Another pattern question, how to have a make <rule> like experience with Dagger? It seems I need to either have a main for each or build what might amount to a CLI wrapper (if only one command deep for most cases). Is either of these the recommended pattern?
We use urfave/cli in github.com/grafana/grafana-build and it's been ok. Not amazing but it does enough for us.
Here's an example where we did something similar to mount a cache directory for yarn install https://github.com/grafana/grafana-build/blob/main/containers/build_frontend.go#L50
nice, seems like we need some common libraries in the ecosystem, for example we are also writing similar gcloud auth wrapper code
@stoic knot the proper ultimate solution to this is what's being cooked in #daggernauts which addresses exactly this as well as some other cool stuff. In the meantime, what we use withing Dagger's CI ourselves is mage (https://magefile.org/). You can check some of that code here: https://github.com/dagger/dagger/tree/main/internal/mage https://github.com/dagger/dagger/blob/main/internal/mage/engine.go
Hi all! If you missed the community call this morning, you can check out the full recording here: https://dagger-io.zoom.us/rec/share/yFXl6qKieV4crpWwME4-0M0zcIwFc44p0naWo3-hiRmmKeN-Fpj_xOfQXM8WOO9X.LHE_tWceakd2R17a
A little off-topic, but Is there a dagger person in the DC metro area? I just saw a car with a ton of stickers of the Dagger astronaut on their car
I must say, If Luke got in front of the Dora community and opened up with:
And what I've seen time and time again is that if you just kind of try and start doing it, then you'll you'll end up with like AI engineers just Ssh into a machine that has a Gpu installing some python libraries and running some scripts.
He would immediately get everyone's attention.
https://dora.community

DORA Community of Practice
The DORA Community provides opportunities to learn, discuss, and collaborate on software delivery and operational performance.
cc @solar raptor 🙂
The doit project seems a lot like mage, but in python: https://pydoit.org/
doit comes from the idea of bringing the power of build-tools to execute any kind of task
Hey everyone, I wanted to add my part into popularizing Dagger. Check out post I just released!
I hope you'll like it 🙂
https://bakson.dev/2023/07/03/deploy-azure-webapp-dagger.html

bakson.dev
Continuous Integration and Continuous Delivery are an extremely important part of development lifecycle. Unfortunately, due to the lack of local environment and debugging features, pipelines development can be a bumpy road of frustration. Learn how Dagger solves these challenges!
Thanks for sharing Piotr! What a solid, detailed post. I especially enjoyed how you used the new dynamic secrets API to integrate with Azure "service principal" identity. I learned something about how Azure works 🙂
Thanks, great you like it! To be honest the previous secrets handling version was holding me back a bit, so I was really glad when you released a new API recently 😀
can dagger runs pipelines on wasm without docker?
not in the current state since that'd require some custom OCI workers with the corresponding WASM runtime which we haven't hooked up yet. Come to think about it, this is the first time I've seen someone asking for Dagger + WASM
haha, it will be future...rather than someone implement such things we should explore this asap...to be futuristic tool...let us know if any help required from our side for testing. Thanks
👍. If you have experience in the topic, it'd be awesome if you could help us out by outlying how could Dagger potentially work with WASM. New contributors are always welcome
not that much of experineced person otherwise i could have submitted PR already. thanks
Dagger builds on BuildKit, wouldn't that have to be changed to support WASM?
@swift barn @stoic knot @sharp marsh There's one route to using WASM already today, which is to create a Container that has a wasm runtime installed and then execute whatever wasm bin you want with it using a WithExec. Not the most elegant but should work perfectly fine in practice.
We can also add support for the WASM platform and plug it into our existing multiplatform support (same way we support different architectures and to a very limited extent different OSes: https://docs.dagger.io/406009/multiplatform-support). Buildkit probably wouldn't need many updates (if any); it supports configurable backends (which oci bin to use, which containerd runtime to use, etc.) and we also have our own dagger shim where we can implement custom stuff as needed too.
The funny thing is that if we had that "official" support, it would underneath the hood be almost exactly the same thing as doing it in user-space: just create a Container that has a wasm runtime and execute wasm bins with it. So it would just be a little bit of sugar.
OP asked about Dagger without docker, which I also assume means any container runtimes available. How realistic is that?
It's possible by creating a symlink to the runtime executable.
https://docs.dagger.io/541047/alternative-runtimes/
Introduction
I think you missed the point. The OP sounded like they wanted to use WASM instead of OCI runtime. No docker, nerdctl, or podman.
Hmm, that's where my knowledge ends unfortunately lol
Yeah that’s technically possible in theory too, you would just swap out the runc binary for an oci compatible wasm runtime binary. I don’t know the state of the ecosystem well enough to say if anything like that exists yet or is planned, but on a purely theoretical level it’s possible and would be abstracted away from buildkit specific support
Yeah that’s technically possible in theory too, you would just swap out the runc binary for an oci compatible wasm runtime binary.
^ this is what I was reffering to when mentioning he OCI workers in my initial comment.
Seems like there is an issue with the quickstart guide:
https://docs.dagger.io/593914/quickstart-hello/
Not sure if this is the overall error its printed in the console a lot?
framework-d51ece3d757c7ed2.js:1 Error: `Tooltip` must be used within `TooltipProvider`
at 3822.a39f1827fba86b73.js:1:151307
at nf (3822.a39f1827fba86b73.js:1:323486)
at Eo (framework-d51ece3d757c7ed2.js:1:63193)
at xi (framework-d51ece3d757c7ed2.js:1:120433)
at bs (framework-d51ece3d757c7ed2.js:1:109369)
at gs (framework-d51ece3d757c7ed2.js:1:109297)
at vs (framework-d51ece3d757c7ed2.js:1:109160)
at as (framework-d51ece3d757c7ed2.js:1:105940)
at is (framework-d51ece3d757c7ed2.js:1:106331)
at jl (framework-d51ece3d757c7ed2.js:1:46914)

Write your first Dagger pipeline
cc @glad jolt
On it!
Should be working now ⚒️
Thanks for reporting!
Yep all good thanks!
that was fast, Thx Julian! 
Are there any updates on the topic of distributing builds across multiple machines? Or are people using CI provider semantics to acheive this? Like matrix's etc?
If i have serviceA and serviceB and i want to run them on diffrent runners/workers etc?
not yet. Users still relying on CI semantics for this pretty much. We've been focusing on other core areas line global caching and Zenith #daggernauts
so potentially easiest way would be adding flags or something to the build so we can do:
go run ci/main.go -test
go run ci/main.go -build
go run ci/main.go -lint
and then using normal CI semantics to do the distribution right?
yes, exactly. We do have target flags in Dagger's own CI by leveraging on mage (https://magefile.org/) currently which makes it quite convenient. However, we're planning to enhance that soon what #daggernauts will bring
Mage
Awesome, yea just having a read over to try and understand exactly what zenith is.
The way ive ended up doing this in the past in github actions/gitlab is using code (go, python or even bash and jq 😂 ) to "generate" the final output of the pipeline so people dont have to write very complex pipelines and they have a much simpler abstraction to say "there is a binary here which you should do the standard things too (lint, test, build, publish, sign etc..)"
Would be nice if this was solved without being specific to a CI provider or with some horrible bash/jq 🤣
I see the new release but I don't see detailed release notes like previous releases. Am I missing something? Surely there's a lot more going on than bumping the engine dependency for example for Go SDK?
Looks fine to me, I think there just haven't been any SDK changes since the last patch.
Can we write a step by step guide in docs for this?
i have one more question can dagger run it self in wasm, if yes then how? and we should write step by step guide for this also. Awaiting your responses
I think buildkit already support wasm

Our first code -> production with Dagger! https://github.com/hofstadter-io/hof/blob/458c1f7d1236b67ea76103c27d252d4df62d6e5d/next/ci/dagger.mts
- uses the Node SDK for a javascript project, I normally write Go and Python
- app is nextjs + react, this is the basis for our next documentation stack
- multiple images (nextjs, nginx, gcloud)
- publishes images & deploys to GKE as a pod with 2 images
Still needs some upgrades, but it was really nice that the publishing just picks up on my credentials on the system outside of Dagger. Sneak peek, while I'm not thrilled with this particular code component, https://codehike.org is pretty nice for MDX based docs. https://next.hofstadter.io/dagger (this doc is out of date to the file above)
Our first code production with Dagger
Thanks for the clarification! I think the SDK changes I was expecting to see were actual engine changes. However, in the email I got for the release, I didn't see the notes, I had to click into the release in GH. Maybe they were updated after the release
Yeah likely - I think @heavy gazelle is trying a new tool for automating release notes so maybe there were some bumps in the road.
Thanks for the ping @elfin frigate! Yes, we are in a transition phase re release notes, going towards changie.dev, as described at the very end of https://dagger.io/blog/how-dagger-releases. I still need to finish https://github.com/dagger/dagger/pull/5408 which will expand on what the changes are.
Which of the following Engine changes did you expect to see in the Go SDK release notes @cunning jolt ? https://github.com/dagger/dagger/releases/tag/v0.6.3
I think that core: Improve image publish/export format compatibility by @sipsma in #5365 is the change that you were expecting to see in the SDK release notes. This makes me think that: #1126155953436373042 message
Hey @heavy gazelle , I am okay seeing the changes in either the engine changelog or the SDK changelog. I posted here because I didn't see the notes in either place when I first looked. Now I see them under the engine changelog which is sufficient. In the future, it may be useful to link the engine changelog in the SDK changelog for engine speicifc changes.
Here's what I see in the email I got. I've subscribed to releases in GH

Yes, there was a longer delay than normal between the release going live & the release notes being available. Going forward, there should be no delay since the release notes should be already done before we publish.
that is super helpful! I see exactly what you mean now.
That is a good point! Anything that would make this better?

This is what we have now:

hey My demo went great today. I've converted 10 gitlab steps into 6 python files and was able to use dagger to allow for an option for a OS independent image rather than a centos image. That all being said - I wanted to leave this question:
TLDR: how can I share my dagger connection and / or container outputs across multiple files with the python sdk?
build_artifact.py -> container
build_docker -> build_artifact's container output -> build the image.
having done my Due diligence I cannot figure out how to share my dagger connection across multiple files. All examples, PRs, Issues, Docs - and I can't figure out how to keep a connection alive. Which kneecaps any part of the pipeline that needs output from another one, without saving that output to the disk. So how do people split their pipeline into multiple files? Go has a defer close - but python does... not. Maybe I'm missing something really obvious with python itself, but I have been at this for 3 days and cannot figure it out. No matter what I try I always get ┃ dagger.exceptions.TransportError: Connection to engine has been closed. Make sure you're calling the API within a `dagger.Connection()` context. Thanks again to this community. I am very excited for the future of our pipeline.
hey My demo went great today I ve
It might be valuable to add a new #terraform channel, I can post the first snippet 😄
Really nice work you have done with improving the error output in v0.6.3 🤩
before
29: [4.53s] err Error: spawn /app/node_modules/optipng-bin/vendor/optipng ENOENT
29: [4.53s] at Process.ChildProcess._handle.onexit (node:internal/child_process:285:19)
29: [4.53s] at onErrorNT (node:internal/child_process:485:16)
29: [4.53s] at processTicksAndRejections (node:internal/process/task_queues:83:21) {
29: [4.53s] errno: -2,
29: [4.53s] code: 'ENOENT',
29: [4.53s] syscall: 'spawn /app/node_modules/optipng-bin/vendor/optipng',
29: [4.53s] path: '/app/node_modules/optipng-bin/vendor/optipng',
29: [4.53s] spawnargs: [
29: [4.53s] '-strip',
29: [4.53s] 'all',
29: [4.53s] '-clobber',
29: [4.53s] '-o',
......
After
30: [24.3s] error /app/node_modules/optipng-bin: Command failed.
30: [24.3s] Exit code: 1
30: [24.3s] Command: node lib/install.js
30: [24.3s] Arguments:
30: [24.3s] Directory: /app/node_modules/optipng-bin
30: [24.3s] Output:
30: [24.3s] ⚠ spawn /app/node_modules/optipng-bin/vendor/optipng ENOENT
30: [24.3s] ⚠ optipng pre-build test failed
30: [24.3s] ℹ compiling from source
30: [24.3s] ✖ Error: Command failed: /bin/sh -c ./configure --with-system-zlib --prefix="/app/node_modules/optipng-bin/vendor" --bindir="/app/node_modules/optipng-bin/vendor"
Is there a channel for dagger cloud discussion?
Big gitlab outage today, and this HN exchange about it made me think "Dagger solves this": https://news.ycombinator.com/item?id=36634959
panzi
It's git, so everyone has a copy of the repo. You can continue collaborating with send-email or some random SSH server. That's the beauty of a DSCM.
I wonder if project-gale will allow for GitLab local executor in addition to the GitHub one?
I don't think we have one but please feel free to post a #1034366157156790293 topic 🙏 . cc @winter linden
I don t think we have one but please
hi all, in python sdk, i see function named project and pipeline . Is there any explanation on the functionality? i can't find it in dagger docs website
👋 project is something legacy which is going to be mutating and integrated into #daggernauts soon. Regarding pipeline, it's a logical grouping you can give to your pipeline so you can then have better observability using the TUI and Dagger Cloud
Thanks @sharp marsh 🙏
Hello everyone, i'm new here. I needed to confirm something first, is it the same DAGGER model NASA is using for solar storm prediction?
No (but that's a cool one to learn about https://www.space.com/ai-program-dagger-predicts-solar-storms). Dagger.io relates to the Directed Acyclic Graph, or DAG for short: https://en.wikipedia.org/wiki/Directed_acyclic_graph

In mathematics, particularly graph theory, and computer science, a directed acyclic graph (DAG) is a directed graph with no directed cycles. That is, it consists of vertices and edges (also called arcs), with each edge directed from one vertex to another, such that following those directions will never form a closed loop. A directed graph is a D...
Hey. anyone knows? which dagger image of docker can be used in both amd & arm architecture in pipeline? if no then how to create such image which can work automatically in pipeline with detected architecture?
is there any dagger method to install both binary for arm and amd and it will automatically run whichever needed in pipeline or in docker where required?
is there any dagger method to install
**Join us tomorrow for Dagger's Community call at 9 am PT. **
We'll share the latest updates on reusable Dagger environments, and demo how to use Dagger on Kubernetes.
Register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA

Hey! 👋 I'm digging the work you all are doing. I follow along on Github. I'm curious about what the future looks like in pricing and/or licensing of the SDK and Dagger Engine.
I think it will remain free for personal use
Hey 👋 I m digging the work you all are
What is the prefered way to fail pipeline inside of the dagger.WithContainerFunc?
is yesterday's community call recording available yet? I had to leave for a meeting and didn't catch the end
Here is the recording from Thursday's community call. Thank you @slender star for hosting and @pseudo stream @elfin frigate @heavy gazelle @warm temple @turbid tulip for presenting 🙏 https://dagger-io.zoom.us/rec/share/9tE48ZxV0GwOaImuuA2yT3jtZRX3EyQmVzqQs9quKrRZTyvwcpzVoh4WtYjwHZgb.TgGeObfPVYNmPncZ
there is still no complete story for container-to-host networking in Dagger correct? Only container to container networking is officially supported? Are there any workarounds like host.docker.internal if not?cc @elfin scaffold
@elfin frigate 👆
Right, h2c and c2h have been on the backburner for now. We've made some plans and had a false start but other priorities took over. You can mount a Unix socket in for c2h, but there's no TCP yet. I can take a look tomorrow and see if it's a good time to revive these, there's certainly a lot of interest
Implementing h2c/c2h would also solve my issue here https://github.com/dagger/dagger/issues/5382, right?

GitHub
A programmable CI/CD engine that runs your pipelines in containers - Issues · dagger/dagger
I don't think it's related - I would expect the second change, adding WithServiceBinding("echo", echo) to the proxy, to work. You could try running it with --debug
just had another case where dagger (almost) filled my disk and I started getting unclear / alternative errors like failed to find image
just reclaimed 50GB
how do cached volumes interact with github actions runner? Will the volumes automatically persist between pipelines runs and if so, how exactly is that achieved? If not, what do I need to do to make sure they do?
Cache volumes will not persist in ephemeral VMs like Github Actions runners. That is one feature we added to Dagger Cloud (our managed control plane). It’s not yet launched but we rolled it out to several teams in early access. Let me know if you’re interested.
I'll preface that this may be a uncommon request, but is it possible to get inside a running container created by dagger interactively? e.g. docker exec -it containername?
I am trying to debug a pipeline that is failing for unclear reasons. I can exec into the dagger engine and see the overlay filesystems.

GitHub
It would be amazing to have a way to add "breakpoints" to the DAG, and interactively inspect the state at the given point (via an interactive shell for example). This has been requested a...
Hi, are there any known projects that integrate dagger with the GitHub checks API? We are in currently in search for a student project and that topic came to mind. Thanks for a pointers
Yes, that's it! 😄 thanks
Hi, I may be wrong, but if I understood correctly, that’s something #project-zenith wants to address.
Thanks, will look into it
+1 for me too. Having just wired up a project to run an integration test (using service containers), was poking around to see if I could also run this for dev orchestration - the missing piece being about to make requests from the host.
Going to see if I can get a crude proxy running through the sockets.
hello, what is the typical workflow when using dagger in production in a large team ? Employees build locally with dagger, and then send the docker image in another CI tool like GitlabCI ? I try to plan myself onto the future using it.
hello what is the typical workflow when
Hi. I was curious if there are any plans to include support for docker-compose? I am trying to build multiple similar Docker containers, just need different ARGs. I know that I could just loop thought array or something and do it this way, but docker-compose would be much cleaner.
courtesy of @elfin frigate. Current stage is "working prototype" but most of the heavy lifting is there ❤️
Looking forward to seeing y'all at the community call tomorrow! @stoic knot will share how he is using Dagger and we'll share updates on the latest Dagger Cloud features. See you there! https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA

Community call happening now - Join us! https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA
I missed it! 😦 can't wait for the recording!
For those who missed it, here is the full recording of the community call. I will add the demos to the demo snippets to demo threads soon! https://dagger-io.zoom.us/rec/share/luG_9xS5p_GorFTMsNOhpPvkW8LsA1-zJm4GMTF6PVRm00f8E_v1nXODGMNnacwT.-3ofWVM8UA7L9kAP
v0.8.0 will be coming out next week, on August 3, 2023. It contains a bunch of breaking changes that you will need to be aware of before upgrading: https://github.com/dagger/dagger/milestone/18
We shared https://github.com/dagger/dagger/discussions/5374 one month ago. It explains why we are doing this, what is the expected timeline & addresses some common questions.
TGIF! 🙌

GitHub
A programmable CI/CD engine that runs your pipelines in containers - 0.8.0 BREAKING CHANGES RELEASE Milestone · dagger/dagger

GitHub
Scope https://github.com/dagger/dagger/milestone/18 Why are we doing this? Since we shipped SDKs in November 2022 - 🐹 sdk/go/v0.4.0, 🐍 sdk/python/v0.1.1 & ⬡ sdk/nodejs/v0.1.0 - we announced num...
For those who want to know how to access tailscale from within a container run from dagger: https://discord.com/channels/707636530424053791/1134878180566646814
I 100% think this should be added to the cook book, it took me a few hours to figure out how to do this
Re: cookbook, yes, I agree! 🙌
cc @heavy karma for cookbook
Will add it, thanks!
I have had two different friends say, "Have you heard about Dagger?" in a single day. The Changelog podcast worked!
request for a thorough walkthrough of replacing Goreleaser with Dagger, with GitHub uploads, changelog, sbom, checksums, etc... we hit an issue where it worked locally, but not in CI again :[ (though gale could catch this instance)
I may not have the complete vocabulary here, so please correct me / ask for clarification.
When using the clients, which seem to be wrappers around GraphQL gen, when does the resolution of the container execution order happen?
I have this example where one container references the directory in the previous container. The resolution appears just based on the order I've declared things in the main.go. Which might just explain what I was looking for. Since it is reference the Directory object.
I might have confused myself based on this doc talking about where the DAG happens. There might be complex examples that use that, not the one I shared here.
Hey. The execution happens when you ask for a value. In Go this is anytime you need to pass a Context and handle an error. Until then, everything is lazy. In your case, second.Stdout is what triggers execution. The DAG starts to solve, and dependencies are executed first. Since second needs buildPath it solves first until first.Directory(path) and passes the result to second.WithDirectory.
You can see this visually with the TUI (notice the flow on the left): dagger run go run main.go

That's what I thought, but I didn't see Directory have a call to Execute for the graphQL call. I also didn't see one within the WithDirectory either.
Yeah, no need 🙂 Being a dependency of something that needs solving is enough to trigger it to execute.
Under the scenes the Go SDK will resolve first.Directory(path).ID() and send that to the API since directory: DirectoryID! (https://docs.dagger.io/api/reference/#Directory-withDirectory).
But the .ID doesn't execute anything, it's defining a lazy "sub-dag" (or graph). Everything is solved in one go.
Oh... #build has reference to #marshal which evaluates the Directory.ID.
Got it.
If anyone missed the latest product demo from @fallen temple last week at the community call, I highly recommend watching it! If you are interested in a trial, click the "request demo" button on our homepage (https://dagger.io/) and our team will be in touch to discuss your use case further - https://youtu.be/atxwhqVd26U

Also, all the demo snippets from last week were added to the demos forum, so check them out!
I haven't been as active in the community as of late, just relaxing and enjoying my vacation (I will pick up and update the rust-sdk, when I've rested a bit more =D, I expect to make it before the 0.8 release). Anyways, I was working on a small tool I was building a found a solution to a problem, I couldn't have solved without dagger, so I decided to write a small blog post about it 😄
https://blog.kasperhermansen.com/posts/superior-caching-with-dagger/

Kasper Hermansen's Blog
Kasper Hermansen's blog is a hub of insights on platform engineering
This is great, thank you for sharing!
Does the buildkit wrapper use buildx and binfmt for qemu.
Rust builds using Platform is incredibly slow
Like 50x slower so. My amd64 build finished in 20 seconds my arm64 is running at 1000seconds atm
(Arch linux btw)
Yes it does, if you pull a container for a platform different than that of the engine container, emulation will kick in if you run any Execs on top of them. Which is generally better than just not being able to run them at all, but it indeed is extremely slow.
If you want to instead use cross-compilation but then publish a final image (or export binaries, etc.) that is multiplatform, you can use the pattern outlined here: https://docs.dagger.io/406009/multiplatform-support#use-cross-compilation
The example is w/ go, but I imagine the general outline applies to rust too
Introduction
Yep, i realized, I am going with normal cross compilation instead. I hoped that Qemu would emulate fast enough, but doesn't seem like it.
It is a bit of a mess, with compiled languages, on musl, and gnu etc. Statically linked vs dynamically linked. Which is why I preferred running under qemu originally, as it would allow the dependencies to also be the proper platform.
But hopefully it will work fine with just cross compiling and sticking to gcc (in a debian image) after I am done compiling
Seems to be much faster, now I am down to 60 seconds instead ❤️
Hitting some unexpected behaviour as I test the dagger waters: when I bring in a cache volume, later steps of the pipeline appear to be skipped. Log messages are not output and yet the exit code is 0. Thought the node.js event loop might have drained or something so I added a referenced timer handle and that didn't seem to change things. Commenting out the mount of the cache volume restores the previous behaviour. Adding the cache back in results in the first run (I assume a cache miss) having the desired output and then all subsequent runs (presumably cache hits) exit early.
Hello, I just heard about Dagger, sounds great. Would like to ask for your opinion on a use case if it would make sense to implement with Dagger.
I have a system where user of the web app fills a form then submits it. Based on the form I trigger a "google cloud run jobs" job. This job consists of a docker image containing a build script which compiles a mobile game based on the configuration then uploads the bundle to google cloud storage. then writes to database that the job with id is complete.
However build script is a combination of bash and nodejs scripts hacked together. Not really happy with its state, not very extensible and testable. development is quite cumbersome.
So my question is since this task is not really a deployment, rather more like a long running background task that ends up producing a file. then user downloads it. Would dagger be useful for this use case? Many thanks ahead.
Dagger certainly can fulfill this task, I do something similar with renovate. Where I schedule renovate jobs depending on a webhook trigger.
You simply create your rest api, and run dagger behind the scenes, you also shouldn't need to worry about multi-threadedness, as the client sdk is basically stateless.
You can choose how much you want to do in pure dagger, or if you just want basically a docker build on demand =D.
All the rest can be handled in a pure go or whatever language you prefer.
Dagger would function as just another part of the business logic you're having 😄
thanks for the answer!
ok then I won't even need cloud run jobs to run the jobs, if dagger can run tasks in paralel stateless then task runner and web server can co-locate in a cloud run web app delpyment even? I was using GCP cloud run jobs so that tasks can run paralel and stateless.
I also understand that I can incorporate dagger into deploying the task builder docker images into google's registry, is that so?
at the moment I'm just using google's cli to build and deploy the images locally.
Yep, you can just do a classic deployment of a webapp with docker installed. you also benefit from extra caching, as your different builds if running on partially the same builds, I.e. only source files changed, dagger will reuse the earlier layers. The only thing I would be careful off is resources, you may want to limit the amount of resources docker can pull otherwise your web api can become starved of cpu and memory, and may become unresponsive.
The only real requirement is that dagger needs to able to talk to a docker host, I.e. a machine with a docker engine installed. Either locally or through DOCKER_HOST.
Just note that this is outside of what the dagger team is focusing on right now (I am not affiliated with them, just answering here, because I do something similar)
Yep, as long as the cloud registry is docker api compatible. I.e. you can do a normal docker push to it, it should work just fine.
I may write a small blog post and open-source my renovate setup if anyone is interested (golang based)
Thanks so much once again, excellent! Are you running the web app in a EC2 vps-like situation or is it aws fargate / app engine kind of “we run your docker thing” system? Sorry for the lack of terms :)
Would be looking forward to the blog post! I’m well aware of this use case is rather odd but awesome that dagger is useful this way also
I am running it on a classic vps (Hetzner 4 core 8gb ram). But it could just as well autoscale on fargate, or something similar, if I needed the extra performance, we're currently considering adopting it to solve our needs in my current company, because we've got too many repositories for a single VPS to handle.
Great, It will probably take a while to prepare and write. But hopefully it will be of use to you 😄
Alas, our work policies (😡) have the playground blocked, so I can't use that to post a repro.
👋 @sullen ridge have you shared a snippet to repro? Not sure I missed that
Happy to share that. On my personal laptop now. Lemme see if I can get it spun up on the playground.
playground is mostly only graphQL. If you have the node code, we can check directly 🙏
Dropped it here: https://gist.github.com/ggoodman/e0f5b905e99d8ffefb0d84a8f59d15f9

Gist
Reproduction of cache hit re-entrancy issue using Dagger - run_tests.mjs
Gimme one sec and I'll share the different outputs as well
@sullen ridge wanna jump quickly to #911305510882513037 to chat about it?
I have a few minutes
Just hopping into team sync 😬
np.. if you have time later feel free to ping. I'll probably be around and have my evening quite open
I updated the gist w/ 3 scenario outputs: 1) no cache volume; 2) cache volume run #1; 3) cache volume run #3
I'll 👀 in the meantime
Hitting some unexpected behaviour as I test the dagger waters: when I bring in a cache volume, later steps of the pipeline appear to be skipped. Log messages are not output and yet the exit code is 0.
I'm just re-reading this
this is expected because of cache if you haven't modified anything
if you run the same pipeline twice without modifying any files in your local directory, you'll get exit code 0 and dagger will skip the whole execution
since it already did it the first time and there's nothing to do if nothing changed
the clearTimeout shouldn't be necessary
if you want dagger to re-run your build / test, you need to make some modifications to the files you're adding in the withDirectory operation so the cache gets invalidated and the opreation re-computed
This was a bit surprising to me. I thought that the .stderr() Promise would resolve to the cached output. I (wrongly) assumed that since I was not seeing anything getting logged that control flow was not reaching that point. Adding a static log at the end shows that the promise is resolving but just with an empty string.
In other words, as a user of Dagger, how can I draw conclusions about the outcome of my workflow if that promise sometimes resolves to an empty string and sometimes to the actual output?
Feels like there's an opportunity to tweak the API for interacting with the 'outcome' of a pipeline's sub-graph. AFAICT, there are .sync(), .stdout() and .stderr() that result in evaluation being performed. It seems like under the hood, these are all components of some logical outcome of running this graph of workloads in their respective containers. Could there be an objected returned that encapsulates this instead of this sometimes fluent, sometimes not api?
I'm imagining:
import { connect } from "@dagger.io/dagger";
// initialize Dagger client
await connect(
async (client) => {
const nodeModules = client
.container()
.from("node:20-slim")
.withDirectory("/src", client.host().directory("."), {
exclude: ["node_modules/", "scripts/"],
})
.withWorkdir("/src")
.withExec(["npm", "ci"]);
const testResult = await nodeModules.run(["npm", "run", "test"]);
assert.equal(testResult.exitCode, 0);
// Log interleaved output if I want to. This output is consistent whether the
// step was a cache hit or cache miss.
console.log(testResult.interleavedOutput);
// Log stdout. Same re: cache hit / miss
console.log(testResult.stdout);
// Grab a reference to a file from that layer
const coverageReport = await testResult
.file("./path/to/coverage.cov")
.contents();
},
{ LogOutput: process.stdout }
);
Not certain how to include another other dagger go developer in an older help request, so I didn't use the "AtGoDevelopers" group for now. Posting here before I generate noise.
Could really use 5-10 mins of help to know if I should shelve that effort or if I'm missing something. Any help appreciated.
https://discord.com/channels/707636530424053791/1115404536400584704
Geoff experiments
I noticed the latest dagger v0.8.0 is not printing underlying output when there is an error
$ dnr ./ci/dagger.mts
┻
• Engine: 4ffb547fb177 (version devel ())
• Duration: 1.122s
exit status 1
vs
$ node --loader ts-node/esm ./ci/dagger.mts
(node:15388) ExperimentalWarning: Custom ESM Loaders is an experimental feature and might change at any time
(Use `node --trace-warnings ...` to show where the warning was created)
Usage: dagger [options] [command]
... output I expect ...
(dnr is an alias for dagger run node ... $0)
Hi, thank you for reporting this!
Yes, it is a known regression, fixed by https://github.com/dagger/dagger/pull/5564 . We are aiming to get v0.8.1 out today.
FWIW, a few more improvements coming: https://github.com/dagger/dagger/milestone/19
@sharp marsh @slender star branching off our caching discussion with @warm hawk ... Once again we encounter confusion around the use of "caching" for two related, but distinct features: 1) dagger operation caching and 2) cache volumes. Which brings back the topic of possibly changing what they are called, to reduce confusion... @warm temple floated the idea of renaming "cache volumes" to just "volumes", which would help with this confusion but possibly create another... I'm curious what everyone thinks. Starting a thread here, then I can formalize the discussion in Github if there's enough interest. 🧵
Don't want to interfere w/ the team thread on caching but hoping to understand a bit more about what the cache volumes are. To me, they seem to have a couple key attributes: 1) they are named; 2) they may persist across runs. I wonder what their other key properties are from a user's perspective. In this way, the remind me a bit of persistent volumes in the k8s world. But on the other hand, am I right in understanding that w/ dagger cloud they are bound to this 'environment' concept instead of the host?
Surfacing this for discussion, it is related to important UX and architecture topic. https://github.com/dagger/dagger/issues/5583
cc @warm temple @pseudo stream @slender star
Short-term impact is to get rid of the docker run; ... ; docker stop wrappers we're seeing in more and more CI snippets, and collapse it all into a single dagger run.

GitHub
Overview There is increasing demand for customizing the dagger engine, including: What version (this carries specific problems because of the version compat matrix, but I will ignore those for now)...
maybe I'm missing something obvious but is there a way to use a remote repo for caching build layers? I see docs about remote cache but all seem outdated and don't really see anything recent about configuring the build environment
Cache + remote repo
**Dagger 0.8: Big Summer Clean Up **
Dagger 0.8 introduces various breaking changes. This blog post explains these changes and provides additional information, including the actions required to integrate these changes in existing Dagger pipelines.
https://dagger.io/blog/dagger-0-8
If you get stuck during your upgrade process, let us know here: https://github.com/dagger/dagger/discussions/5584
Hello all! I just threw up an intro, but I had a question. I was wondering if there are thoughts on using Dagger to mock AWS deploys.
Some context; My team keeps running into issues with our AWS deploys. Random issues, like character limits for resources, permission issues, etc. I'm wondering if Dagger can be used to mock deployments to AWS locally to check for issues rather than sorting through GitHub action logs.
I'm gonna mess with Dagger anyway since it's cool. But the above is a real-world use case.
Dagger could definitely be used to run those pipelines locally, but I don't think it would work to mock AWS deployments by itself. Have you looked into using something like LocalStack? https://localstack.cloud/solutions/cloud-emulation/
Utilizing Dagger + LocalStack might get you what you're looking for.
Thanks for sharing your use case! If you try it ou Joel's suggestion above, please keep us updated on your progress or reach out to use in the help forum if you need support. We'd love to hear about it!
Our community demos are a great way to see how others use Dagger for their use cases too. Here are some helpful resources:
Community Call Demo playlist - https://www.youtube.com/playlist?list=PLyHqb4A5ee1tEgcr7KsNFzQSPN-R3fPs2
Demo forum in Discord, which is great to use if you want to ask the speaker any additional questions - https://discord.com/channels/707636530424053791/1075928318802657340
We do these calls every other week, so we'd love to see you there! You can register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA
**Community Call Demo Tomorrow **
We look forward to seeing you all at the Dagger Community Call tomorrow. We'll have a quick update on the status of Project Zenith from @pseudo stream , Pulumi demo by @verbal berry , and a Java SDK demo from @honest pebble !
Register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA

I just a shiny new m2 macbook pro - nice right? For dagger builds were so slow that htey seemed to hang. After looking through discord - I tried colima with colima it was painfully slow. Podman was the same. Docker desktop no different. So for speed on M1 Macs or M2 Macs I found https://docs.orbstack.dev builds are so very fast. Its a drop in docker replacement. Orbstack for the win.
Say goodbye to slow, clunky containers and VMs.
yayy thanks folks for helping get my tests going w/ Dagger - much better local-to-CI experience than ever before. love that it enables an iterative progressive improvement development style from simple early local tests to adding CI / dependencies / multi-system-component tests

Hello, is there already a known/documented/integrated way to visualize a run? Something that shows the actual graph and which nodes are running/skipped/cached?
Will this be recorded? Can't make the community call but very interested in hearing about Pulumi + Dagger.
yes, it will be 🙂 I will share each of the demos from the community calls in our demo forum, so I'll be sure tag you there when I add the pulumi one https://discord.com/channels/707636530424053791/1075928318802657340
hey there! the dagger CLI (https://docs.dagger.io/cli/465058/install) currently has an undocumented TUI feature that allows you have better local visualization of your pipelines if you wrap them with dagger run. Having said that, we have a private beta of a SaaS based cloud product which enhances this experience. If you're interested, happy to chat for you to check it our. cc @slender star
{@include: ../partials/_install-cli.md}
@here community call starting now - https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA
Zoom
Join the Dagger team and community to learn about the latest features that we've been working on, see neat demos from community members, and ask any questions that you may have.
No question is too small!
If you'd like to add a demo or topic to the agenda, please submit it here: https://airtable.com/shrj9zf66QYXAxauy
Good call. Thanks for pointing that out!
Thanks to all who joined the community call today, and special thanks to our speakers @honest pebble and @verbal berry !
You can check out the recording here:
https://dagger-io.zoom.us/rec/play/SeTQCSbAZeF-FozkVcNbnVoFROllv9ySNxPffUm5TM3TQ4t7ubAqSnJtVKh668hUT2CO2yT5qSMGNLP-.wFvHFcYR2iycc_1_?autoplay=true&startTime=1691683210000
I will upload the demo snippets to the demo forum soon 🙂
If I clone a random repo - is there (currently) any way of determining if that's a dagger based project, and how one should invoke dagger? i.e. my current small project I'm running dagger run go run ci/main.go - but is there a way of abstracting the go run ci/main.go portion? Is that something coming in Zenith?
Was wanting to update my small Gerrit CI server to trigger a detect/trigger a dagger based build.
Excellent question! Not yet possible but there is a major development underway to add that.
Problem statement: https://github.com/dagger/dagger/issues/4414
Solution: #daggernauts

GitHub
Problem TLDR: Dagger does not define a standard interface for project entrypoints, which limits what it can do for users. Dagger works by writing an entrypoint for your project: custom software tha...
Big thread there - will read more later.
I actually recommend starting here: https://discord.com/channels/707636530424053791/1129800905798193263
(video update + demo at community meetup 2 weeks ago)
Was watching that earlier - looks nice!
Thanks for the feedback 🙂 In the meantime already watched the video about the cloud version. This looks really nice and something I was looking for. Preferably also available on the local machine directly or at least some static output directly from the engine. But I will definitely come back to you after my vacation 👍
have a good vacation! 🏖️ ⛰️ 🌴 🥥
Has anyone run Dagger via Argo Workflows? It seems like it should be straight forward if you already have Dagger running in k8s. Any gotchyas?
I know @coarse anchor has a similar use case, but I haven't had a chance to check-in. Seems like this might be a good demo for a community call, so I'll work with the team on that!
@coarse anchor , have you had a chance to set up an argo workflow yet?
https://discord.com/channels/707636530424053791/1135600635065159713
Is there a premade container with the latest Dagger cli in it?
not yet! but the cli is easy to get via curl | sh
I ended up wget the file from github
Anyone else having probems running dagger with go sdk 0.8.2?
after updating the sdk and the cli client the connection to the engine hangs, rolling back the client to 0.8.1 and it works, with the warning of mismatching versions.
i already tried removing the dagger engine container and couple other things
Hmm, I seem to be hitting this too with Python
Yep, rolling back to 0.8.1 works
Are you on macOS by any chance? I am, seems there's some related buildkit issues if I dig through the github discussions
SDKs v0.8.2 hang while establishing a connection to Engine
Is last week's demo uploaded somewhere? I don't see the part I'm interested in uploaded to #1075928318802657340 yet.
Plain old Linux, Fedora
Which part? 🙂
Project Zenith updates?
Hi! Solomon just made a forum post for the update specifically, but you can find it as a comment here as well if anyone needs additional context on project zenith - #1129800905798193263 message
Shout out to @strong wyvern for sharing his Dagger experience with the world! https://dagger.io/blog/discern-use-case

Random question, does anyone have experience recording discord calls?
We'd love to switch our community meetups from zoom to discord, but the ability to record in zoom is holding us back.
are there any established patterns for pre-caching images needed for a dagger run? … or what is the currently preferred method for optimizing dagger runs in ephemeral environments?
The main thing you need is persistent cache. In a persistent machine (like a laptop or a long-lived server) this works out of the box using the machine's local storage. In ephemeral environments (like most CI runners), you need an external service to persist cache data, and orchestrate the movement of data between each runner's "hot cache" and the centralized "cold cache". This is a non-trivial distributed systems problem. One feature of our commercial control plane (currently in early access) is to implement this out of the box.
is there any prior art for the case of pre-populating the dagger engine with base-images required for a ci run?
The simplest and most reliable way to pre-warm a pipeline is to run it beforehand, and rely on cache persistence.
Since Dagger lets you run pipelines dynamically, from code, it can't know in advance what your pipelines will do. Only you (the developer of the pipeline) can decide what you want to pre-run. Whatever you decide to pre-run, Dagger will make sure it's cache optimally.
As part of #daggernauts (a planned improvement to Dagger to make it more approachable) we are considering something like dagger warmup which would let the user "pre-warm" their environment. This would basically be a hook to attach the parts of the pipelines you (devops engineer scripting the CI environment) want to pre-run for caching purposes
Random question does anyone have
thanks for the reply — i’ll probably have to resort to restoring a buildkit instance or some other gnarly solution in the interim 🥸
we can give you early access to the caching service if you want 🙂
Yep. Let me know @fossil halo and I can help with that. 🙌
Not sure if right place, but would love some updates on the discovery/running of tasks
https://discord.com/channels/707636530424053791/1141439367169200309
About to proceed monday with some new work and knowing where it stands would be great
I've fixed the .id().await? requirement in rust. A pr will probably be published tomorrow (I need to fix the codegen first).
I've created some truly cursed code, but it works 😄

Hey all, I'm having a bit of difficulty figuring out how caching works with the Dagger engine and the Go SDK. Do I need to pass some config to the Engine container (we manage the engine container as part of our Go CLI), or do I need to pass something to the client constructor, or both? It's not exactly clear.
Ideally I'd like to be able to configure both the local and GHA caches
Hello I'm pretty new here and I have a question. I'm considering to migrate from Jenkins, and need to ssh, execute some bash commands in the other VMs and get response from it. Is it achievable with Dagger? Thank you.
SSH VMs
#1141511080166830100 message bringing this out to the channel
What is the story for being able to use matrix or multi-arch pipelines, but have the different work run on different, real underlying hardware? I kind of think of k8s node taints & tolerances, but at the BuildKit level. Where does QEMU fit in here? Ideally I'd like to avoid the overhead of arch emulation
At the moment Dagger can't distribute a DAG across multiple machines - you need to rely on an external orchestrator (typically your CI control plane) to do that. We plan on adding that capability in the future (distributed caching is the first step - horizontal scaling isn't super useful if you dispatch work to machines with empty caches).
This means that, at the moment, Dagger's support for multi-platform execution is always backed by qemu (except for the native platform of the host machine of course)
Cool, that is inline with where I thought it was probably at. Thank's @winter linden, maybe I can work this into my Argo setup
is it possible to run a dagger on gitlba ci
Possible, it requires docker and may requires compiler/runtime depends on SDK that you use.
We are a devops team that writes Makefile and Jenkins pipelines for all our Go devs. About 600 different repositories all using the Go language. When we update our Makefile targets, we distribute them to the main branch in all these repos. How do people/teams in a similar situation to ours use dagger and distribute updates to the dagger code to all the repositories?
I would make your dagger pipelines a Go module they import, and then put a very minimal main.go somewhere in their repo that imports/uses this. Your updates to the 600 other repos could then be a go mod edit ...
We use a monorepo, so have a package and multiple main files in the repo
Pushing Dagger changes to many repos
So I had a bit of time and the need this weekend to spike out a working GHA marketplace shim for Dagger.
What do I mean when I say GHA marketplace shim? I mean that, within a dagger pipeline, from an sdk, I want to be able to use an off-the-shelf github actions marketplace action and run it in a dagger container as a standalone piece of code.
I have only done this for Typescript for the POC, since that's the action type in particular that I wanted/needed for my pipelines to work - but the approach should be broadly applicable to all types of github actions (ts, container, composite)
This is actually simpler than I thought it was going to be, because the context of what is passed to actions is not super heavy. Here's how I implemented it in aircmd:https://github.com/airbytehq/aircmd/blob/main/aircmd/actions/environments.py#L23
The TL;DR approach is:
- Create an object that contains the following: Settings that every GHA needs, Env var that every GHA needs
- Create a dagger container that has what the action needs (files, env vars, nodejs in this case) and inject the settings and files into it
- Execute the action as normal (in the typescript case this means simply running
node dist/index.jsin a node container)
How does this work? Interestingly, the design of a github action is well-formed enough that you can trust environment variables to hydrate the GHA context. Typescript actions do that here: https://github.com/actions/toolkit/blob/7b617c260dff86f8d044d5ab0425444b29fa0d18/packages/github/src/context.ts#L6
Composite and container actions can presumably work the same way, though there may be caveats that I'm not aware of yet.
GHA Marketplace Shim
How do you plan on monetizing Dagger? We would like to know before we get to deep into it.
https://overcast.fm/+HZUdZQ1IU Solomon gave a talk on this here

This week we’re joined by Solomon Hykes, the creator of Docker. Now he’s back with his next big thing called Dagger — CI/CD as code that runs anywhere. We’re users of Dagger so check out our codebase if you want to see how it works. On today’s show Solomon takes us back to the days of Docker, what it was like on that 10 year journey, his transit...
From Docker to Dagger — The Changelog: S...
In regards to sdk development.
I've been doing some work in which I'd like to benefit from stacked prs(stacked diffs) https://benjamincongdon.me/blog/2022/07/17/In-Praise-of-Stacked-PRs/
It doesn't necessarily have to be this exactly. The gist of it is, I'd like to do some work, i.e. fix a bug, then move on to building a feature, then a bug again, all on top of each other. However, I can't post prs for each, because if I post a pr for each, changes will be duplicated, I can post a pr to point to another pr, but that messes up with squash commits.
All in all, I am curious how you go about developing software using the open source model, i.e. forking the repo and doing work from that.
Managing sets of small, dependent PRs enables faster review and increased developer velocity
In case anyone missed the note in the thread above, we do have an early access program available for Dagger Cloud. If your company has a use case that you'd like to share and discuss, please fill out this form. It is also accessible from the top header on the Dagger.io website under "request demo".
Request form: https://dagger-io.typeform.com/to/RDGtJLic?utm_source=homepage&typeform-source=discord

Turn data collection into an experience with Typeform. Create beautiful online forms, surveys, quizzes, and so much more. Try it for FREE.
Shout out to Daggernaut @stoic knot for taking the time to share his Dagger story with us! Check out the link below to learn how he is using Dagger to improve the consistency and accuracy of Hof's test suite. https://dagger.io/blog/hof-use-case

Will there be somekind of "free for single private person" package? Perhaps similar to what GitLab does? Or free for "open source" projects?
I see a few murmurs about it, but is the old dagger-cue and cue SDK actually abandoned? Is it time to start migrating old builds to using dagger via python or go?
Dagger Cloud free plan?
not officially abandoned, but that’s the most likely outcome given the lack of traction compared to all other SDKs. So yes I would recommend looking at another SDK
Hope everyone is having a great week. We have a great lineup of panelist ( @hot yarrow , @cosmic moss , and @wraith niche ) for tomorrow's community call, so we look forward to seeing you there!
Register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA

Liking the new summary output!
(although, it looks like some double counting going on, I am currently getting 7 reported, but only see 3 (and maybe a fourth that is only counted once, while the others are counted twice))

Liking the new summary output
Hi guys, the company i'm working for is migrating from an old fashion CI system to a more modern one (can't give names).
we have a couple hundred repos, lots of which have CICD pipelines that need to be translated in the new CI system and i'm currently working on a POC that would include Dagger in the tech stack to help us transition smoothly ( i also love the As a Code paradigm and the fact that pipelines are running locally but i'm advocating for the tool because we could start rewriting our pipelines even before the migration starts)
Do you have testimonies/ blog posts/ post mortems about Dagger used in production ? i would love to keep it purely technical but the project is still relatively young and i know i'm also gonna have to please the people in suit at some point 🙃 .
Dagger case studies
Hi guys, you can see all FluentCI codes (Dagger+TypeScript/Deno) here https://github.com/fluent-ci-templates , still experimental project 🧪, any feedbacks are welcome 🙂

Git branchless looks nice! Need to play with this - we use gerrit for code review and it's patchset model works similar, but want something that works with Github PRs.
This looks good
Hey, I am trying to lint my code and running into some very minor issues like adding two space on line x.
There is a --fix flag to solve this but since linting using ./hack/make sdk:nodejs:lint I couldn’t find a way to solve this issue.
I tried npm run lint or yarn run lint inside ./sdk/nodejs they doesn't seem to cover the snippets.
help pls
Since that is what was suggested here: https://docs.dagger.io/204441/contributing#how-to-run-linters-locally
Inside sdk/nodejs there's a yarn run docs:lint and yarn run docs:fmt.
fmt is the one with the --fix.
Is there a Dagger story for ephemeral dev environments?
Thanks again for presenting at the community call last week! For those who missed @cosmic moss's demo, you can check it out here https://discord.com/channels/707636530424053791/1145564127448805466
feature request, given the output without the dagger cli, add a command to generate the pretty version
feature request, dagger run github.com/hofstadter-io/hof/path/to/daggerfile arg1 --foo bar
I want to ensure no one misses the latest Project Gale (GALE - GitHub Action Local Executor) release notes. Check out the latest in the Project Gale channel message below.
Thanks for all your work on this @empty jay!
Project Gale release update: #github message
Hey 🙂 Sorry if the doc is a very obvious place and I just missed it, but is there some kind of high-level document that describes what dagger.cloud offers (and potentially even a roadmap for features that it might tackle in the future)?
I asked the same question earlier, the answer your looking for is here I think, #1143358533233037363 message.
Discord
Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Thank you!
Hello Dagger Developers,
I've been delving into the functionality of the Dagger Engine, understanding it as the pivotal hub for build and workload operations, based on my recent learnings. As we integrate with Kubernetes, we're contemplating deploying the Dagger Engine as a DaemonSet to ensure its presence on every worker node. However, this strategy reminds me of obstacles we faced prior to our transition to Jenkins Kubernetes Agents.
Historically, our reliance was on a singular VM, robustly provisioned with memory and CPU, designed to accommodate a fixed quota of simultaneous builds. While memory wasn’t always the bottleneck, job queues often formed because we maxed out the build count for that VM. Given the variability in resource requirements across builds, our strategy inclined toward a conservative simultaneous build quota estimate.
Our shift to Kubernetes offered a more adaptive approach. It provided us with a clear view of the unique resource requirements for each build. Starting with conservative resource allocations, we were able to set precise resource requests and limits for each repository. This gave developers the leeway to adjust resources to align with actual demands. As a result, the Kubernetes scheduler made more informed decisions, balancing the distinct needs of every build with available resources, which effectively reduced build queues.
Now, with the Dagger Engine consolidating builds in a single, generously provisioned Pod, I harbor concerns about reverting to a less transparent and efficient build paradigm. I'm curious: could we run Dagger pipelines within the actual build Pod to uphold the resource optimization strategies we've cultivated?
Your expertise and perspectives on this would be invaluable.
👋 this really depends on what strategy you're pursuing and if you're planning to use a managed control plane (Dagger Cloud) to help you scale horizontally across your fleet. Generally, as you know, the main reason to use hefty stateful VM's is to keep the architecture simple and take advantage of a persistent volume across runs which will improve your CI performance but will very likely have a vertical scaling limit as well as contention bottlenecks. Additionally, you can design your system in a way that can better scale horizontally, but that would require a lot of moving pieces and orchestration to make sure that storage volumes are correctly attached to your ephemeral VM's.
Having said that, the way we do this ourselves in Kuberentes with Github Actions is to leverage Dagger Cloud caching capabilities along with ARC (https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners-with-actions-runner-controller/about-actions-runner-controller) and Karpenter (https://karpenter.sh/) so we have a predictable horizontally-scalable solution since both ARC and Karpeneter allow setting fine-grained quotes in the amount of CI jobs and the type of compute that we want to allocate for our CI projects. cc @turbid tulip might have more inputs here.
@inland pivot the problem with relying on your existing per-pod resource allocation, is that it's too primitive for a DAG model, you'll end up wasting tons of resources by re-running the same computation for no reason
Kubernetes / pods are a great layer of logical orchestration. But for resource allocation and accounting, the underlying machine (VM or physical) remains undefeated
That being said, there's nothing keeping you from running the Dagger engine as a sidecar pod, and benchmark 🙂 From a technical point of view, both will work.
I may be missing a piece of the puzzle, how will the DAG save computation? Other than the build and module cache being persisted (which we do today), if someone pushes a commit the code must be linted, tested and built over again against the new commit.
If I can use the same persistent storage in each instance of a dagger engine sidecar, using a sidecar may be a good solution.
How does DAG save computation
I'm reading the Dagster, the python data pipeline. And see that it can run on any executor, like docker, k8s, etc. I'm just curious if it can be uses dagger as an executor 🤔
Here is the executor reference https://docs.dagster.io/deployment/executors

Executors are responsible for executing steps within a job run.
@pseudo stream can I join you people?
feature request, more git options like depth and filter
a single var like GIT_FLAGS would suffice
That’s could be great. Depth option could help cloning large repository more faster.
By default the Git operation does a shallow clone. I don't think buildkit supports passing options to this type of operation. I think we'd have to make the changes upstream first
or implement our own git operation in userland?
Thanks for the docs contribution!! 🚀
Looking forward to ore such contributions!
How does Dagger think about itself as a complement or alternative to BuildPacks?
i am not from dagger, but isn't buildpack just for packaging "apps" in container images, where dagger is a more complete build abstraction to allow for complex ci operations within ci-environments?
I think the buildpack ecosystem covers some of those things too
I was partially thinking that the user doesn't have to set the image, they just provide some vague details about their stack and app, then a bunch of things are figured out / done for them
I do not see it being used to build a bunch of images, deploy them to container registries, talking to vault, starting kubernetes pods
but with enough devops magic-sugar anything is possible
I'm part of the evil sugar industry :]
It's a valid use case and one I've been interested in from day one. Essentially you'd need to create functions to look into a source code to detect what files it has and use that to build a container. That's as a replacement. As a complement, you can also run BuildPack's lifecycle binary (https://buildpacks.io/docs/concepts/components/lifecycle/) from inside a container in Dagger to delegate all of that to the BuildPacks ecosystem. In this case Dagger replaces only "pack" as the platform (https://buildpacks.io/docs/concepts/components/platform/).
there's been some members in the community which experimented with Dagger + Buildpacks. Here's two demos about it:
#1076019869784490074 message
In summary: Dagger and buildpacks can play nicely together. There are some small areas where they overlap, but all in all, they can leverage each together
would like to know the following
- is dagger still considered beta
- is there support for docker-compose projects
- is there support for kubernetes buidkit installation so that dagger installed on jenkins can use it
- is there a migration guide from Jenkins
- what features are still yet to be baked or will be removed. I used the cue version before
We look forward to seeing all of you at the community call tomorrow!
If you haven't already, you can register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA#/registration

@here Dagger Community Call starts in a few minutes. See you there! Register here to get into the call: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA#/registration
Hi All, anyone joining in-person DockerCon in LA next month on 4-5th October?
happy to meetup
We would love to, but it’s the week of our yearly team retreat in Lisbon…

Working for me right now (US east region)! Is it still down on your end?
Nah, it's me. It's like this on my WiFi, not on 5G. I guess I'll have to dig into my router logs. -.-
Any video on line yet of this mornings community call?
Stupid question regarding named sub-pipelines - are they meant to dangle down there own separate path, or is there any intention of them "completing" and the main pipeline continuing on.
I was setting a sub-pipline for "building", "testing", "deploying" - but there really just stages of the pipeline - do I care about labelling/identifing what stage I'm in? Probably not....
Is there a way to share dagger caches between GHA builds ?
Or do I totally misunderstand how dagger works ?
IOW, if my dagger script defines a volume, can this volume be cached by the Github cache action in order to be reused by a next build ?
hey there! This thread will probably give you more informatoin about caching in Dagger
TL;DR:
- Use the default buildkit cache exporters which are known to have some issues and don't scale very well for large projects
- We can extend an invite to our distributed caching solution.
https://discord.com/channels/707636530424053791/1141511080166830100. Let us know if you still have any questions 🙏
Discord
Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
I am trying to use dagger for Open Source software (Plone CMS). Would I still be allowed to join the distributed caching solution ?
Our service is not publicly available yet and we're figuring out how sponsored plans will work. We could still onboard you to Dagger Cloud if desired, but there's no guarantees that we can keep providing that service free of charge in the near future.
Makefile vs Dagger
Today I got this question from a colleague. "How is it beneficial for me to adopt dagger over writing a makefile?". I gave a general answer and explained some of the benefits of dagger but I am not sure I convinced them yet. I think it would be helpful to have a comprehensive comparison between the tools in dagger docs. I am also curious how other daggernauts would compare and contrast the two tools.
Here is the recording of yesterday's community call. Working on adding the snippets to youtube shortly - https://dagger-io.zoom.us/rec/play/_lvKTMYpvIAMb7856TuKU_HM81eBczW2i_NKj4w7HBGudhxX9kWCixAiA4tj3h3wtRlpqbbDlnoVKOpl.vUmfx2gklPA9yuuG?canPlayFromShare=true&from=my_recording&continueMode=true&componentName=rec-play&originRequestUrl=https%3A%2F%2Fdagger-io.zoom.us%2Frec%2Fshare%2Fj7rL-c3HR_46UHZ5G9EMEAOkm-H66X9c0otOQjgdt7GWV5I_nTLIofsNLbsjD-d_.jUT21UVR-698ICE0
Makefile vs Dagger
@arctic grove neat progress on dagger for GPUs. I noticed that your APIs focused on Nvidia GPUs (understandable), but have you given thought to how the API might change with other kinds of accelerators. I’m thinking of GPUs from other vendors (Intel and AMD), non GPU accelerators like FPGAs, and accelerated non IP accelerated networking devices (eg infiniband). How can the API be extended by users who have these devices?
sounds very interesting. do you have any samples of code that's compatible with other vendors?
PyTorch code is generally “interoperable” between vendors. You need to use a different version of it that matches your device, but the code doesn’t change.
CuPY (despite it’s name) is also interoperable
Is there a docs page that explains what "creates a named sub-pipeline" means? (client.pipeline() eg) and why it's also present on Directory and Container? I'm experimenting, but curious about the intent
I think I understand that client.pipeline() gets you a Client to build a sub-pipeline with, but I'm confused by how Directory.pipeline() and Container.pipeline() return a Directory and Container respectively. Is it kind of like "forking" the DAG at those junctions?
It’s a logical grouping for visualization purposes - an annotation.
It’s available in several core types purely for convenience.
How do you “end” that grouping tho? I couldn't see anything for that…
it only lasts for the current “chain”
It’s not super intuitive… But still quite handy when visualizing larger DAGs 🙂

GitHub
Problem Dagger has an API for logical grouping: the Pipeline step. Developers use it for nesting pipelines within other pipelines. But the Pipeline step relies on chaining semantics, not nesting. B...
Thoughts about tradeoffs between (e.g.) calling AWS via the aws-cli docker image in a Dagger pipeline vs. calling AWS via the AWS SDK in the same language you're using to host Dagger (e.g. Node)? I think if I'm using a platform whose CLI doesn't have an equivalent SDK, then using the CLI in a container with Dagger is a no-brainer, but if I'm trying to idempotently configure AWS state, then using the Node SDK is potentially less clunky than trading commands and outputs back and forth between my node program and dagger containers.
Hi All. This is my first time using dagger. I am trying to figure how to use the dagger cli on an existing project like booklit / bass but i still cant figure it out. Can someone point me to where this is documented please ?
i am not trying to create a new project. I want to use it on a large existing project to see how it behaves.
https://news.ycombinator.com/item?id=37481513 [Earthly shutting down post, I'm shilling Dagger in the comments :]
A few threads have asked for examples of how others are using Dagger at their companies. @smoky magnet took the time to explain how he is currently using Dagger at Classmates, so this summary is worth a listen! #1151410359463313478 message
Is there a story for Dagger "hot-reload" whereby, when I change (my app) files on disk, the relavent parts of the pipeline are re-run?
basically a watch on the host directories loaded up
Dagger doesn't do that at the moment. I could see that feature being added in the future. But probably not until a few third-party tools implement it first, so we can see patterns emerge.
I'd imagine that Zenith comes first, that seems enabling
Oh yes 🙂
But it could happen in parallel. For example someone could write a wrapper tool that watches a directory, and re-runs a particular Dagger pipeline on change. From there, we may get a clearer picture of what is missing in the Dagger API
the watching is the easy part, know what to run is the part I'm hoping could happen by some Dagger magic
That will get much easier with Zenith. Once there is a standard entrypoint, there will also be a standardized way to reference that entrypoint in a third-party tool.
In the current iteration of the design, it would probably be something like: "Run $FUNCTION from $MODULE with $ARGUMENTS
yeah, and having some watch semantics, even if crude, doesn't seem like such a heavy lift after Zenith is in place
every time I show off some new hof stuff, it seems like the first request is a hot-reload watch, the consistency is 🤯
You could also try to introduce a convention, for example: "To use hof's hot-reload feature with your Dagger module, add a Dagger function to your module that takes a single directory as argument. Then configure hof with the name of your module and function."
Or one step further:
"To use hof's hot-reload feature, add a Dagger function to your module called hofWatch. It must take a single directory as argument. Then configure hof with the name of your module.
we have watch natively, because two-levels (1) CUE, cause it can take a long time (2) non-CUE, always fast. They now want it in the new Hof TUI (it's not even released yet), to refresh the code they edit in their IDE
I mostly ask because I'm going to be deep in DAG land, working on a Dagger inspired hof/flow visual for our TUI
https://youtu.be/XNBqBWO4y08 (Hof TUI demo for the curious)
once I get flow in, I can think about how to rethink Dagger on CUE, it will be a lot easier to see how they operate
Dagger CUE got a shout out by another HN'r in that Earthly thread, that person misses it, not a fan of SDK based CI, or turing complete languages for CI
Curious what you are thinking in that recent tweet about moving beyond our current thinking in CI @winter linden
I'm not sure how we escape Turing in turning commits into running stuff
is there any way to use dagger through wasm only and in browser?
Join us as we go into the Daggerverse
- Learn how to build a module
- Share what you're building
- Share feedback and ideas
A friend of mine is a bit skeptical about Dagger, so I'm gonna try "selling" Dagger to him. To make it more of a challenge, I'm gonna do it live:
🤣🤣🤣
Wish me luck!

My friend Márk Sági-Kazár is coming on the stream again.
He is an avid Dagger.io user and he is happy to introduce me to Dagger. This is a perfect time for…
Nice! I can't access the link for some reason. Will this happen in English? would love to join and help if the chat if needed
Hm, weird. Here is the link again: https://www.linkedin.com/events/7109835660592656385/comments/
Yes, the plan is to do it in English.

My friend Mark is coming on the stream again.
He is an avid Dagger.io user and he is happy to introduce me to Dagger. This is a perfect time for you to get to know the platform.
You are more than welcome to join and correct me 😄
happy to join and help with clarification if needed. Just realized that this is scheduled for Oct 9. You'll very likely have some new cool stuff to show Laszlo by then to make him part of the Dagger cult
This is amazing 😂
Mark sellls Laszlo on Dagger
Hi everyone, in 45mn we have a special event that will NOT be recorded 😇 See you there! https://discord.gg/G6h7UdPF?event=1153881957478973440
Everyone, please go to https://discord.com/channels/707636530424053791/1154104516225015880, not dev-audio
Discord
Discord is the easiest way to communicate over voice, video, and text. Chat, hang out, and stay close with your friends and communities.
Thanks everyone for joining! Dagger Cloud is now live in early access, you can try it out at https://dagger.io/cloud . Feel free to send questions and feedback here, or on the #1030538312508776540 channel. Thank you all for your support!
Dagger.io | Dagger Cloud
Curious about the price. The 0.05/min $3/hr is 10x the cost of the VM we rent for builds <0.3/hr, which run multiple at the same time, so we are talking at least an order of magnitude cost increase. How can I square this circle? I totally expect that to be an hourly rate. Looking at hour our build hours, this would be 3x our total cloud cost
So.. hear me out... have there been any considerations around a YAML sdk? With zenith/modules making it possible to hide complexity behind a low cognitive load interface, I think YAML could be useful for those users who just want to stitch together a couple of modules with a few args. YAML is generally more familiar than GQL syntax. It could also be a good entry point for those using a language without a Dagger SDK available.
I'm going to be looking at writing a CUE SDK, which could totally support Yaml and Json too, my hope is that you will prefer to write them in CUE with time. One thing that CUE has that will be helpful, is language support for references, so I can naturally write that "the output of this Dagger pipeline FS becomes the input to this pipeline over here"
I'm trying to rationalize this myself. If we think about GHA, their lowest cost runner is $0.008. If we use 6000 minutes in one month that's $48 from GHA and $300 from dagger cloud. If Dagger does improve efficiency of just CI system by 40% that's 3600 CI minutes which will be $28.8 from GHA and $180 from dagger.
So we're really going from $48 to ~$208 per month. Does Dagger Cloud add $160/month of value to not just the CI system but also developer productivity and satisfaction?
I mean maybe? But that is all before the local development aspect of Dagger Cloud, which I expect my team to use a lot of.
That's also a big if on dagger improving efficiency that far, historically for us, operations running within containers on GHA have been slower than operations ran directly on the runner VM
If you run Dagger on a single VM with persistent storage, you don't really need distributed caching, so may not need Dagger Cloud at all?
For this I would love to see a telemetry only Dagger Cloud offering
we typically have about a dozen workers running during the workday, it autoscales real nice, Jenkins is solid
Starting a thread for pricing bikeshedding 🙂
some of them are packed with 20+ driver jobs
Congratulations on launching Dagger Cloud! Looking forward to give it a try!
Unfortunately I couldn't attend the announcement call (I'm at OSS EU this week).
I do have a question about the distributed cache though. Is that something that could be used with Buildkit? One of the challenges of running a Buildkit infrastructure right now is scaling it properly. There are solutions (like making sure the same image build would always go to the same instance using some sort of consistent hashing), but they aren't perfect.
Dagger obviously takes care of the problem, but Dagger may not be an option everywhere (or it may take a long time to introduce it). I've seen many cases where a centralized Buildkit infrastructure could have taken the load off of let's say Jenkins, but due to the scaling and addressing challenges, it's not a trivial solution either.
So, coming back to the question again: could this distributed cache be used with Buildkit to allow scaling it and using it behind a load balancer for example? I'm guessing that's what's happening anyway, but I it may not be open source right now?
I love this question.
@winter linden BTW I was thinking about this yesterday in our discussion about the future with modules, it would be slightly ironic and delightful if we had a YAML "SDK" for this specific purpose haha.
Hi @fossil pine ! We missed you. We will share a demo during the community call tomorrow, which will be recorded, so we will share that recording with you too.
We don’t plan on extracting parts of the Dagger features to be used with “just” buildkit. If you’re using Dagger you’re using buildkit. If you have an existing buildkit infra and you want the benefits of Dagger, the easiest way is to switch to Dagger and get the best of both. There are compatibility bridges (native dockerfile support being the obvious one). If you have a dependency on raw buildkit (rare but it happens) porting that to dagger API is the easiest path to getting it to benefit from Dagger. In the future we will ship compat layers that make this (almost) seamless
Pulumi is somewhat of an example of the same development. They provided real SDKs to a world with only a declarative DSL. But now they also have YAML that can consume modules written with SDKs to provide the "low code" option to the end users. This is essentially what I would want to do with CI in our internal platform. I don't necessarily want to have to sell devs on a dagger SDK (potentially in a different lang). The idea is that they would not mind YAML that much if its 10 lines instead of 100 (we're already doing this, just not with Dagger as engine)
I'm interested in this more from a theoretical perspective.
Let me rephrase then: does the distributed cache solve the load balancing/addressing issue with Buildkit within Dagger.
If so, it's kinda cool and may be interesting to people who for some reason wants to stick to raw Buildkit.
This problem has been around for a couple years now. If this is indeed a solution for that, it's kinda cool. That's all.
My guess is that the “YAML pseudo-programming” market is pretty saturated, I would rather make sure the 1000 existing tools like that work well with Dagger…
But if you see an opportunity for a YAML Dager SDK I want to make sure you can build it and have a great experience doing so!
tagline: "replace your YAML hell with YAML heck!"
That would be cool indeed; My guess is no in the short term. But if there’s enough demand that could change.
My guess us that there aren’t enough “buildkit but not docker” deployment out there to justify the effort. Plus those tend to be built by teams that like to, or have to, build everything themselves anyway (why else deal with the pain of targeting buildkit directly)
You can also potentially solve the distributed caching problem with just buildkit export cache. We run buildctl stateless in K8S and export the cache as OCI to a cluster-local OCI registry. It works alright but you may need good disk throughout and some CPU to make sure that pulling the cache doesn't become a bottleneck for low-delta builds. Depends on your Dockerfiles too ofc.
I don't necessarily want to have to sell devs on a dagger SDK
I think this area is evolving pretty rapidly, our vision with zenith is also that you don't have to sell devs on a dagger SDK.
Missed the announcement. Anyone ask "how soon is 'soon'?" on the Daggernaut?
Next week roughly
Oh excellent
There was one question from @zinc pewter during the event that we did not answer.
Our Go build cache grows to multiple terabytes per month. What controls are in place to manage ever growing build caches?
I am not quite sure but wanted to capture it here in case soemone has a good answer handy 😇
The good news (for you @zinc pewter) is that Dagger will eat the cost of storing that go build cache 🙂 This also means that we are highly incentivized to keep storage under control. Initially we will have crude controls, then over time we will be able to be more precise with pruning (with telemetry data we can make smart decisions about which data is used where, when etc). Over time, as we better understand the available optimizations and tradeoffs, we will be able to surface some manual controls to the user. But very important to not rush to do that - the wrong manual controls too early can ruin performance and create unnecessary headaches for the user
See y'all tomorrow at the Dagger Community Call!
Register here: https://dagger-io.zoom.us/webinar/register/9716685521713/WN_USQjVBGXT0SWhNMvqYVvCA

Hey everyone! Community call starts in 10 min. See you there! 🙂
Not sure if this is the best place to report it (couldn't find a UX dedicated channel), but I noticed that the CLI output sometimes uses a red color which suggests an error while there is none.

That always sticks out to me too. +1
I've noticed that too and heard it once before, but I'm on the fence still; you could say similar things for other colors ("green means it succeeded, yellow/orange means [...]"), and there are only so many colors available. I already tried to dodge the issue by making it the last-used one in the rotation, but maybe that just makes it worse. 😅
It gets really good when you get 15 deep 😉
Sspeaking of UX, I'm impressed with the status page on dagger cloud:
https://status.dagger.io/
it says a lot about the organization that accountability is backed in from the outset.

Welcome to Dagger status page for real-time and historical data on system performance.
Anyone got video links to todays community call?
That was me who reported it way back :D. Although I've gotten used to it, it still makes me double check sometimes whether I'm seeing an error or not. I think making it the final one in the rotation makes it worse. How about making it the first? IDK honestly if that's any better.
lol, here's a particularly cursed example (red ones succeeded, green one failed, but has the error text in red)

Quick poll:
1️⃣ remove red
2️⃣ keep red
3️⃣ switch to only red/green for success/failure
4️⃣ something else?
cc @cunning jolt @warm temple @fossil pine
3 + yellow 🙂
I may have asked this before, but have you considered functional options for the API?
Instead of this:
return client.Container().
From("scratch").
WithNewFile("/hello", dagger.ContainerWithNewFileOpts{
Contents: "hello world",
})
We could write this:
return client.Container().
From("scratch").
WithNewFile("/hello", dagger.Contents("hello world"))
It's probably too late at this point (although I imagine it could be possible to implement a semi-backward compatible solution, where the function signature changes, but the above could would continue working), but I'm curious if it's been discussed and if so, what where the factors in deciding to go with the current API instead.
Is there a dedicated space to give feedback on Dagger Cloud?
I'm just going to leave them here for now, before I forget:
When I'm looking at a "run" or logs, I'm usually interested in two things:
- If anything failed, where AND why
- If everything went well, I probably just want confirmation of that
In the first case, I want to see where things failed and then work my way back to the root cause (for instance: a test failed, because the service it was talking to returned an error, so my next stop is looking at the log for that service).
In the second case, I want to check the output of the "primary" function of a run (eg. test output).
Now on the current UI these are all doable, but it takes some time to get used to.
For example, the order of different pipelines/steps is non-trivial at the moment. I guess it's not random, but it's not in a linear order either. It's kinda weird that build comes before test. It's possible I'm doing something wrong here, but the test pipeline clearly comes after and relies on build, so 🤷♂️
Another thing I haven't been able to figure out is how to start a new pipeline with a container that's already in a pipeline. For example: I'd like to have a separate pipeline for building the test container (installing dependencies, etc) and then another one for the actual execution.
I also find it a bit weird that all pipelines are expanded by default on the UI. Referring back to my earlier use cases, I'm usually interested in a very specific part of the whole run: something that failed or the "primary" pipeline.
I wonder if that init -> connect step should be tagged as internal as well.
I also noticed that once in every ten runs a service continues to run until it hits some sort of timeout. (this is happening locally)
On the positive side, I like that I can hide cached and internal steps.
I like that I can visualize local runs on the UI, but it would probably make sense to tag these local runs somehow, so I can filter runs from the CI for example)

One thing that would be a killer feature is comparing runs (ie. how long each step took). Maybe even generic some metrics on a regular basis to show if runs became longer or shorter. I know it's still an early product, but I already started dreaming. 😄
cc @fallen temple
Another thing I haven't been able to figure out is how to start a new pipeline with a container that's already in a pipeline. For example: I'd like to have a separate pipeline for building the test container (installing dependencies, etc) and then another one for the actual execution.
you can do this to accomplish that:
func main() {
ctx := context.Background()
client, err := dagger.Connect(ctx, dagger.WithLogOutput(os.Stderr))
if err != nil {
panic(err)
}
defer client.Close()
output, err := client.Pipeline("Test").
Container().
From("alpine").
WithExec([]string{"apk", "add", "curl"}).
Sync(ctx)
if err != nil {
panic(err)
}
cid, err := output.ID(ctx)
if err != nil {
panic(err)
}
output, err = client.Container(dagger.ContainerOpts{ID: cid}).
Pipeline("Build").
WithExec([]string{"echo", "foo"}).Sync(ctx)
}
^ in this case both Build and Test will be independent pipelines
Here is the community call recording for anyone who missed it. The demo snippets will be added to the demo forum shortly: https://dagger-io.zoom.us/rec/share/K0UDbiCo5QX8dgnEENPr7BPLugewfXsjhaco1yCKi7xQ1GibxL86mr9qt1x8Bri9.82Q4p6r9dM_mEKRS
Thanks, that worked!
Kudos to the "Getting started page" !
https://docs.dagger.io/quickstart/593914/hello#write-your-first-dagger-pipeline
The Time-to-first-success is really short and free of decisions.
Write your first Dagger pipeline
Branch filtering doesn't work on the Cloud UI.
It would be great to have this as an example in the docs. Maybe a cookbook entry?
Hey 👋 ,
What are you trying to filter? What happens exactly? Thanks for your feedback, very valuable
Here is what happens, when I click on filter for a branch name.
Hi @fossil pine , we're working on this now. Thank you for reporting the bug! Do the other filters work for you?
Sure, no problem. Yeah, the rest of the filters seem to be working.
@fallen temple I shared some feedback about Cloud in general above. Also reported an issue regarding local runs timing out. (It's also visible on the above video: roughly one out of ten builds timeout even when they run locally)
Going through the "Getting Started" (via the python track), I got a traceback and I filed an issue:
https://github.com/dagger/hello-dagger/issues/3
LMK if I need to do anything differently

GitHub
What is the issue? The python track fails in the second lesson (Test the Application) Traceback at: https://paste.ofcode.org/pKgDXLDxK8u7V64xgWk8eS Log output https://paste.ofcode.org/pKgDXLDxK8u7V...
For people new to Dagger and familiar with Dockerfile... is the recommended approach to start off wrapping the dockerfiles and then refactoring ?
For people new to Dagger and familiar
Many people have asked about how to run Dagger on Kubernetes, so @heavy karma, @heavy gazelle and @turbid tulip created a guide! https://docs.dagger.io/194031/kubernetes/
Let us know what you think!
Introduction
Thanks for reporting this @timber crater . I will look into it today
@timber crater Can't reproduce, there must be a diff in your code. I replied in the issue.
Question about service bindings: can one use a distributed dagger daemon and control which nodes get what services (or at least that services get different nodes)? The use case that I have in mind is something like bazel remote build execution or distributed c++compilation with distcc to horizontally scale compilation . Essentially I would like to have a fleet of service containers that are compiler nodes, but depending on what I am building they need different headers and files installed so I don’t want to have the remote build nodes separately controlled if possible.
Second how would dagger caching invaldiation work in this case? I would never want the service to invalidate the cache unless the services image changes.
Additionally depending on available resources I’d like to use different numbers of service containers. Does that change the invalidation story?
@fossil pine - I opened a support issue to track the problem with the branch filter. I'm recording your feedback now as well. I'd love to get time with you and our team to discuss your feedback. We're working on some revisions to this tree view and a reimagining of the DAG view (it's an experimental feature you can toggle on and off today) and are looking for input on our UX prototypes.
I wonder if that init -> connect step should be tagged as internal as well.
Yes, I agree that this should be internal.
I also find it a bit weird that all pipelines are expanded by default on the UI. Referring back to my earlier use cases, I'm usually interested in a very specific part of the whole run: something that failed or the "primary" pipeline.
I agree. These should be collapsed and you should be taken to the first error, if there is one.
Thank you for your feedback!
Yes, this is planned 😄
@fallen temple the next couple weeks are packed for me as I'm transitioning into a new job.
Feel free to book something in my calendar from the second week of October: https://calendly.com/sagikazarmark/short-meeting?back=1&month=2023-10
I'll be at KubeCon as well, so we can chat there as well.
I looked at the DAG view and it looks interesting if you want to understand the dependencies between different steps, but even for a relatively simple build it can become complex enough to not fit on a screen. Also, the way the whole graph is formatted it's not easy to understand where things "begin" and where they end.
Interestingly though, the DAG view helped me understand a bit why the tree view is ordered the way it is.

My OCD can't help it, sorry: there seem to be a pattern emerging in the community for sharing Helm charts as OCI artifacts: oci://registry.dagger.io/helm-charts/dagger
dagger-helm just bothers me, but I can't really say why. 😄
Feel free to ignore, just needed to get this out of my system. 😄
Question about service bindings can one
Thanks, @fossil pine! I set up time for us. I'll also be at Kubecon NA. 🙂
Thanks for the feedback! @turbid tulip , I'd love your thoughts on this.
I like oci://registry.dagger.io/helm-charts/dagger. @heavy gazelle, how hard would it be to create another proxy like this?
I chose dagger-helm because github container registry doesn't let you create any namespaces beyond the org and the package name.
I don't think that it would be too hard. FWIW: https://github.com/dagger/registry-redirect/blob/main/pkg/redirect/redirect.go
TIL. 🙂 Thank you!
Is it possible right now to be the member of two organizations on Dagger Cloud?
Hm, okay...next question then: how do I create another organization? 😄
It looks like I can't create multiple orgs right now. Do I have to ask someone to register and set one up then invite me?
Yeah I went through the same thing... It's possible but not intuitive at all
Basically you go to https://dagger.cloud/signup
At the moment if you're logged into one org, there's no way to click to that. We'll fix it, I know it's on @fallen temple 's radar
Now that I never would have figured out. 😄 Thanks @winter linden
Uh, can't have dashboard for two different orgs open. That's....weird
Do you mean in different tabs?
yeah.
Hm, could you tell me a bit more, what happens when you try that? I just tried to reproduce it and did not see an issue.
If I switch to an other org on another tab and hit refresh on the original tab, it switches to the new org
Oh yeah, I see this now, thanks for raising, I will file a bug!
I've heard that a few Daggernauts will be at QCon next week, including one Daggernaut, @real kite, who will demo Dagger! Don't forget to attend his talk if you are going to be at the show https://qconsf.com/presentation/oct2023/cicd-beyond-yaml

QCon San Francisco 2023
Go Conor!
QCon San Francisco 2023
You can also file these right within the app via the Intercom messenger - there's a workflow for giving feedback, filing a bug, and submitting a support issue.
Wish I could be there!
Hi @fossil pine, this issue has been fixed. Thanks again for you feedback 🙏
Is there a command to replay the journal file in the interactive TUI?
I'm running dagger from within vitest and right now I'm just outputting text logs to files, but I'm thinking outputting the journal files too would be really cool.
replay
I pop in from time to time to check on this project. Have the dagger flags/variables that allow some level of offline support left experimental status yet?
That’s the biggest hold up on my use case for adoption 😦
Hey all, I am one of the organizers of PackagingCon! It might be an interesting event for some of you? The idea is to bring folks from as many different package manager ecosystems together as possible. We have a nice variety of talks. It is in Berlin 26-28 of October and it's hybrid (remote attendance possible!)
Website: https://packaging-con.org/
Schedule: https://cfp.packaging-con.org/2023/schedule/
PackagingCon 2023
Hi @wooden cape , can you share your use case so that I can better understand your need?
I just need ideally to be able to use dagger in an offline lab environment without having to manage a lot of orchestration and configuration to get it to work on runners or user workstations.
Any Daggernauts here based in Lisbon?
PackagingCon
Interesting observation after trying out a bunch of js testing frameworks with dagger. Vitest is by far the easiest to set up and use but has an interesting issue where wrapping it with dagger run stalls out the inline and interactive TUI. Jest and playwright don't have the same issue, but jest is a pain in the butt. Playwright seems alright, it's made for e2e, but it's not exactly the intended use case.
Going to test a few more from https://2022.stateofjs.com/en-US/libraries/testing/
Just noticed there is no "Dagger and node" channel. Would love to contribute to a channel like that instead of spamming general 😶
Heads up, the entire Dagger team is at a team retreat in Lisbon this week. We are converging from the US, Canada, Argentina, Uruguay, Azores, France, UK, and India.
Apologies in advance if we are less responsive on discord.
That sounds like an amazing gathering! 📸 Could you share some pictures from your team retreat in Lisbon?
playground just gives me the message { "errors": [ { "message": "JSON.parse: unexpected character at line 1 column 1 of the JSON data", "stack": "" } ] }
Hey!
Thanks for letting us know. ❤️
I'll look into it in a bit
Not based in Lisbon, but based in Porto. If you come to the North do tell.
Cheers
I love how most of my build problems are with drone rather than dagger. most of my build failures are principle of most surprise issues coming from my so-called "orchestrator"
can't wait to replace all of drone with a top-level dagger build 😄
Hi everyone! I am excited to announce that we've kicked off Dagger Meetup groups to help unite Daggernauts worldwide! We are starting with our first meetup in Paris since Solomon will be there next week, but I'd love to work with any Daggernaut who would like to host a Dagger meetup elsewhere! DM me if you are interested 🙂
You can become a member of any of our meetup groups here: https://www.meetup.com/pro/dagger/
If you'd like to attend the Paris event, you can RSVP here: https://www.meetup.com/dagger-paris/events/296415861/
Fixed, sorry for the delay and thanks for the heads up!
works for me now. Thanks
Is it too meta to test dagger in dagger? 🤔
Nope, we do it all the time 🙂
Dagger's own CI runs in Dagger
I'm guessing I just need to map a unix socket back to the docker socket on the host?
Finally got my large dagger based IT project running in AZDO:
Progress (2): 38 kB | 1.7/1.9 MB
Progress (2): 38 kB | 1.7/1.9 MB
Progress (2): 38 kB | 1.7/1.9 MB
Progress (2): 38 kB
41: [2123.0s] [output clipped, log limit 2MiB reached]
``` - is that truncation limit a dagger thing, or likely an AZDO thing? 45k lines of log and that was just bootstrapping/dependency downloading 😦 Never hit that locally so I suspect AzureNice! I’ve never seen that message, I don’t think it’s a dagger thing, but could be wrong
I think it's Azure Devops - something in my pipeline is hanging/stalling it seems - but works fine on the laptop. Turns out azdo kills the job after 60s minutes also 🙂
It seems to be a docker thing? Do you have a dependency on docker engine in your pipeline? https://stackoverflow.com/questions/66212253/docker-build-throwing-a-error-docker-output-clipped-log-limit-1mib-reached

Stack Overflow
While Building my docker Image in Docker Desktop for windows,after some sort of time It throwing a error:
=> => # [output clipped, log limit 1MiB reached]
I tired configuring the log file s...
ok nevermind it might be a buildkit thing
Indirectly - tho the pipeline hadn't gotten that far AFAIK - I have dagger running a Maven/Java build, and it's tests in turn use TestContainers to lauch adjacent containers which are under test. I did note the maven process was generating a tonne more logging (it updates a progress bar, which just logs each line in when not in a real console) - so may need to configure that differently

GitHub
concurrent, cache-efficient, and Dockerfile-agnostic builder toolkit - moby/buildkit
note that log clipping should not prevent the pipeline from running
I suspected as such - and also found maven now supports -no-transfer-progress which will help lower the a chunk of logging
is that clipping likely to be per-step, or the entire pipeline?
Not sure , but my educated guess is for the entire run (it’s at the “print human-readable bytes”) level. Also means that https://dagger.cloud should be unaffected 😇
I'm so sad that I can't attend this first Dagger meetup  But unfortunately, I have Japanese classes at the university every Tuesday evening.
But unfortunately, I have Japanese classes at the university every Tuesday evening.
We have a mini-hackathon during the day , if you want to join us for that 🙂
I can probably arrange to come during the day
I had this in my calendar but is it correct to assume the community call isn't happening today?
batch flag works for this too. -B. We use it in our CI.
Correct - we are currently spread throughout various parts of Lisbon 🇵🇹





Hey Daggernauts! Sorry for the slower responses this week. The Dagger team has their team retreat in Lisbon this week ❤️
Fom where do I get those dagger t-shirts? 🙂
Interestingly - for some reason javac is just hanging - enabled diagnostics on javac - the build was locking/hanging after a compiler some inner class - split that out and it still hangs:
35: [35.8s] [loading /root/.m2/repository/org/concordion/concordion/4.0.1/concordion-4.0.1.jar(/org/concordion/api/extension/ConcordionExtender.class)]
35: [35.8s] [loading /root/.m2/repository/org/concordion/concordion/4.0.1/concordion-4.0.1.jar(/org/concordion/internal/FixtureType.class)]
35: [35.8s] [loading modules/java.base/java/io/FilterOutputStream.class]
35: [35.8s] [loading modules/java.base/java/util/Locale.class]
Oddly, no errors, just - hanging.
Not sure I can even SSH into the VM to try and do some digging - tho not sure if I can connect into a dagger/buildkit image even if I can get another VM from our ops team?
I’m sure we can arrange a T-shirt drop 😁
On Linux you can nsenter the container with the pid of the process.
I’m hopeful that some more robust interactive capabilities for debugging running can be added to dagger in the future (maybe dagger shell from Zenith will off this eventually, or this could be added to the fancier interactive tui)
Note we have dagger shell coming soon 🙂 Open an interactive shell in any container in your pipeline
awesome, I spent like 30 minutes yesterday looking for it. I was thinking it just had to be feature....

Awesome - I suspect the harder part will be getting my ops team to build me a semi-permanent VM for testing.
It looks like the event is in-person only?
kinda solved my issue - thankfully it's not a javac issue - tho it looks like Dagger/buildkit maybe isn't flushing all logging properly - got our ops guy to create me a VM from the same image we use in our AZDO runner - looks like it was hanging inside the maven exec plugin spawning my code - when running TestContainers and an embedded LDAP server.
Looks like we only have socket access to Docker setup, not network API access so my TestContainer launch from inside dagger was... problematic. Need to look at a better way to kick off the TestContainers images, somehow passing the socket into the dagger/buildkit container doesn't feel right?
Gonna discuss that further with our ops team tomorrow morning
Yes, sorry. We will work on hybrid events in the future, but this one is last minute so not very high tech. Just a few hackers in a room with pizza and (hopefully) working code 🙂
That makes sense, there is no reliable & portable way to connect to a container from the host in docker engine. So it’s all duct tape with host-specific dependencies. That part of the docker client is harder to containerize. There are definitely solutions, but I don’t know if there are any short-term workarounds. let me think
Sorry @runic heron I don’t remember if we already discussed this, have you tried running the docker engine itself as a dagger service container? in theory that would solve your problem
At least on my local setup - I just have network access enabled for localhost - and assume the container is local, and use host.docker.internal in URL references, tho TestContainers gives you an API wrapper that uses docker APIS so I can use:
apiBase = "http://%s:%d/api".formatted(SMX3_CONTAINER.getHost(), SMX3_CONTAINER.getMappedPort(8181));
``` which seems to also work.I haven't yet - i've seen other people commenting on their own pains of Docker-Inside-Docker - but that might be viable. At this point I need to convince our Ops team Dagger is viable and possible change some of our infr - i.e the azdo runner image is also emphemerial, and dagger's caches keep getting wiped out. cough dagger cloud cough
I understand. For what it’s worth, docker-in-dagger seems to work better than docker-in-docker 🙂
I can not attend at the meetup in the evening but I'm could make me available for the hackathon Solomon was talking about. But I was wondering where and at what ime should I come?
just sent you a DM 🙂
I tried it and docker-in-dagger really worked better than docker-in-docker. The only downside is if you need to access host-level data like cgroups then it is not working.
this will also bust the Docker engine cache as well, correct? or does your ephemeral runners have some custom behavior to persist the docker engine cache?
OG Daggernaut @fossil pine is pitching Dagger live right now on the livestream of his friend Jason 🙂 Go Mark! https://www.linkedin.com/events/dagger-io-ademoofdockerfounders7109835660592656385/theater/

My friend Mark is coming on the stream again.
He is an avid Dagger.io user and he is happy to introduce me to Dagger. This is a perfect time for you to get to know the platform.
Huh, I hope I did Dagger some justice. 😄
it was great Mark, solid presentation. The ball is in our end now to improve our messaging and product so more people can relate to our vision
Probably- i may have to resort to using AZDOs fs caching and just mount the dir into dagger (the biggest issue atm is alllllllllllllll the maven dependencies being downloaded, and slowly (a third issue I'm facing in out network stack).
this is independet of Dagger, correct? Since the same issue would happen with standard Docker builds.
you could sign up to Dagger Cloud's free trial and show your team how our distributed caching actually helps with this without having to rely on the AZDOs fs caching which has its limitations
I have this pipeline:
import anyio
import dagger
async def main():
async with dagger.Connection() as client:
ctr = (
client.pipeline("test")
.container()
.from_("python:3-slim")
.with_exec(["apt-get", "update"])
.with_exec(["apt-get", "install", "-y", "make", "gcc", "python3-dev"])
.with_directory("/src", client.host().directory("."))
)
await ctr.with_exec(["cp", "-r", "/src", "/app"])
await ctr.with_workdir("/app").with_exec(["echo", "-- app --"]).with_exec(["ls", "/app"]).with_exec(["echo", "-- src --"]).with_exec(["ls", "/src"])
anyio.run(main)
I expected /src and /app to be the same (given I copy using the -r flag). But there is nothing copied over. What am I missing?
Is there a non-linked in link for that at all?
You need to reassign ctr:
ctr = ctr.with_exec(["cp", "-r", "/src", "/app"])
Honestly, not sure. I believe so. That's where we streamed it.
When trying to activate a venv for pythong I get a permission error: fork/exec venv/bin/activate: permission denied on a physical machine the build is activate venv, pip install requirements and wheel. activate venv is not possible
I tried sourcing but that doesn't work either
In containers I don't recommend doing the venv/bin/activate thing. That's for changing your shell in your host. To activate the venv in a container, just set VIRTUAL_ENV var to the path of the venv, then add $VIRTUAL_ENV/bin to PATH. That's it.
You can see an example of that in our own Python SDK: https://github.com/dagger/dagger/blob/28e09abe14bc4b27ed7515d22d59191c42194229/internal/mage/sdk/python.go#L220-L228. Check out https://pythonspeed.com/articles/activate-virtualenv-dockerfile/ to learn more about it.





Paris Meetup
is there any way to spin up the GQL playground locally?
@frozen basin for dagger v0.8.7? or Zenith?
yes, with Zenith it's easier since the engine has an option to enable cors
I’m trying to see if I can redo the acorn build process in dagger. In order to do this I need to be able to create oci indexes. Acorn actually creates an index that points to an index. This is allowed by the spec but never seen in practice (except acorn images). I don’t see a way to create an oci index that points to an index. The only way I see to create indexes is one is implicitly created as part of a publish. While probably too advanced it would be nice to have an API to directly deal with oci indexes.
Great meetup in Paris tonight 😎
I used directory.exportwith_mounted_directory("/build", client.host().directory("./build")) to add - as I thought - an output folder to the mix. When I run the pipeline, I can ls /build and see the file, though it never appears on the host?
I’m gonna try running Kafka in Dagger for an e2e test and I thought I’d stream it so others can find some joy in my struggles.
Probably on LinkedIn or YouTube (or even here on Discord if there is a place for that?)
Nice!
Hey Dagger team/community.
I'm trying out Dagger for the first time now. I'll let you know how I get on 🙂
Rather than running a SDK locally (installing python or php natively on machine) can I run the SDK from inside a docker container? Any issues/changes to the workflow here?
In the current version of Dagger, the SDK simply provides a client library. The pipeline developer is responsible for developing a complete tool that uses the library. And the end user of that tool is responsible for running it somewhere that can open a Dagger session.
So, in the current version of Dagger, the SDK developer (you) and pipeline developer (users of your SDK) do not control whether the SDK will ultimately be running in a container or not. It's up to the end user.
In the future Zenith release of Dagger, this changes, and all SDKs are containerized automatically, by Dagger.
just got into using a service container within one of my builds and 😄
it's unreasonably easy next to using some sort of yaml stuff
I've also been speccing out my mixable things (certain clients, etc) in as WithContainerFunc so I can have general builds and then have extension to the container to insert the dependency
❤️ a good with pattern
Anyone interesting in Zig? I have a prototype on Zig (https://github.com/wingyplus/dagger.zig/blob/main/src/main.zig) a few weeks ago to test Elixir SDK Dagger and Gradle issue. The prototype can only query to the graphql to Dagger with dagger run command.
I have no time in this month because needs to preparing internal company hackathon and addict in the Zenith. The work might update on the next month.
GitHub
Experimental Dagger SDK for Zig. Contribute to wingyplus/dagger.zig development by creating an account on GitHub.
You’re on a roll! I know @spiral plank is a big Zig fan 😇
Hey @winter linden okay, got it, thanks for clarity
I see the Javascript SDK and typscript SDK are using await or async ...
when building a SDK do you have to implement dagger called in async mode, or can we do standard sync calls here?e
@sand gorge that is entirely up to each SDK. Whatever you think will be the best native developer experience. The Dagger Engine itself is fully concurrent, so if you make 100 queries in parallel, the engine will process them all in parallel.
In other words how to handle concurrency is purely a client problem
Next question, as a first time user, I'm installing a Dagger CLI, and use a SDK to "connect to dagger" ... but doesn't Dagger engine need to be running already, somewhere? like a Dagger Daemon?
maybe dagger is connected to the Docker Engine running on the same host, so it can do Docker Build/Push?
Does the SDK just make calls to the dagger-cli? or am I missing something and there's a space in the docs for "runing the dagger daemon"
In the current version of Dagger the SDK
To answer your original question, from "how it works" in the docs:
Using the SDK, your program opens a new session to a Dagger Engine: either by connecting to an existing engine, or by provisioning one on-the-fly.
Conceptually, you can think of the Dagger Engine as a CLI tool (dagger) which spawns a companion worker in a container. It does this automatically, by default by calling docker run, but this can be customized
understood, this answers my Q - there isn't a running Dameon, it will spawn containers/engines on the fly as needed. 🙂
Yes, but note that while we are aiming towards a stateless ephemeral worker container, at the moment they are left running by default (so that you don't have to re-run a container at each run of the CLI). So by default, if you run docker ps after running a dagger pipeline, you'll see a container called dagger-engine or somethign like that. If you nuke that container however, nothing will break: the next run will just take a little longer to start (and it will start from an empty local cache)
I understand, it's a "warming" container technique, to avoid cold-boots in the future of this engine 🙂
similar when invoking a CI pipeline and there's no underlying workers, the first person has to take the hit, and then that worker can be re-used for future CI runs
You can get more context from this (wip) guide: https://github.com/dagger/dagger/blob/main/sdk/CONTRIBUTING.md
Fully read it now, the python examples were useful.
Q1 - withExec() is running commands as root, how can I tell it which user to use? basically the same as
docker-compose run --rm --user=www-data /run-some/tests.sh
Q2 - are these all ran in one Docker Layer? or are they individual docker layers
if it was native dockerfile, they'd be separate layers, but this is Dagger, so unsure 🙂

There is the withUser command that you can use to change the user.
I am not 100% sure but each withExec is cachable and failable so I believe its its own docker layer. I think withExec is essentially RUN in a Dockerfile.
This doc provides a good overview of how Dockerfile translates to Dagger https://docs.dagger.io/205271/replace-dockerfile/#introduction
excellent URL, i'll be sure to familairize myself with how Docker translates to Dagger 🙂
If you have not already seen it, there is also this really nice playground that you can use to try and learn things https://play.dagger.cloud/playground
Welcome to Dagger API Playground
I did exit 1 in one of my bash scripts just to see what happens
the bash script did exit 1, yet the dagger run line is an exit 0
This is probably by design, just sharing what expected vs actual
It's got a little red cross to tell me stuff tho, just don't know what errored I guess, just that something did

SUCCESS! got my own baby PHP pipeline running, with 1 unit test 🙂
withUser(name: "www-data") {
withExec(args: ["./cicd/run-unit-tests.sh"]) {
stdout
}
}
withUser worked 👍 🙂
If anyone wants to see the true power of caching I suggest trying to use Dagger in a starbucks wifi. 😂
Build went from 1hour to 3 seconds. 🚀 🚀🚀


I want to say this is expected because the dagger process itself did not exit nonzero, its a bit of a shift of mental model because in this case you can look at dagger as the CI runner and when a build fails its not true that the CI runner process itself failed.
completely logical tbh
How does the package in nixpkgs get updated? Is it just manual or is there any automated process? Looks like @fossil pine might be responsible for it? Seeing his name on the 0.8.4 to 0.8.7 update.
I found this document very useful btw! 🙂 https://github.com/dagger/dagger/blob/main/core/docs/d7yxc-operator_manual.md#dagger-session-interface-dsi
great write-up 👏
I submitted the package to nixpkgs, so I'm technically a maintainer, but anyone can send a PR. 😉 (I always get the nudge to review it though)
0.8.8 upgrade has been merged today: https://github.com/NixOS/nixpkgs/pull/260684

GitHub
Automatic update generated by nixpkgs-update tools. This update was made based on information from https://repology.org/project/dagger-ci-cd-devkit/versions.
meta.description for dagger is: A porta...
Are there any reasons why I want to do withExec() approach, versus me just putting all these commands into 1 bash file, and doing withExec(args: ["./setup-environment.sh"]) ?

I think it caches differently. Do you want multiple caches or one?
Nixpkgs
I'm not sure, I haven't looked into that yet. I just need the basics, it's on my local machine. 🙂
Less granular caching, less granular visibility. It’s up to you really.
In 1 bash script .. I guess due to cache layer invalidation, if I change anything inside the file, then all commands get invalidated .. right?
The one thing that might matter is if you want to call the equivalent of ‘dnf clean’ (I don’t remember the Ubuntu equivalent). Then dagger would cache extra stuff if you don’t put a clean at the end
If you don’t call clean they should be image content equivalent, but the one with multiple with execs would have more layers
But layer metadata is pretty tiny
I think eventually with hundreds to low thousands of layers their might be some overlayfs overhead
I guess what I'm asking is if you guys can confirm if my theory is correct. 😄
assuming withExec() works like docker RUN commands, in a Dockerfile..
nested withExec() will cache individual layers for each command, and if you only change the 10th command, then commands 1-9 are cached
whereas if you only have 1 withExec() with a single bash file with 10 lines in it .. and change the 10th line, then it will invalidate the entire layer because there is only 1 layer, and you won't have a cache for commands 1-9 anymore
micro vs monolith
Right? (hope that made sense)
yes, this is correct
hey everyone! We have a new support-ai forum, and we are excited for y'all to try it out.
What is this new forum channel?
Similar to help🙋, but connected to an instant-answering AI bot named <@&1151945210213969943> (https://kapa.ai/)
How does it work?
Post questions in this channel and <@&1151945210213969943> will answer instantly. Supports follow-up questions and discussions as well when you mention <@&1151945210213969943> in your reply.
When should I use this channel?
If you want an instant reply from a bot that has read our docs, SDKs, and GitHub issues/PRs, this channel is for you.
Perfect for quick questions that don't necessarily need an expert human's eye (or a great place to start if you're unsure where to post).
If you're already familiar with the docs and think you've encountered a bug in Dagger that doesn't match the docs, #help may be a better place to post.
Try it out here: https://discord.com/channels/707636530424053791/1161349676751126528
Hey! Are there any licencing reasons why we can't use a code snippet that ChatGPT convered from NodeJS to PHP, for me ?
https://docs.dagger.io/api/reference/#query-container
I'm having some inconsistency with container() on the GraphQL docs
I see code around the place that does
container()
some
container(platform: xxxx)
and some
container(id: xxxx)
The docs here say only platform is an argument (see screenshot)
My point:
- Looks like maybe
idis missing from the documentation? - I can run container without
platformso what is the default value? - Is it correct that container() can have 3 variations of arguments here ? (none, platform, and id?)

looks like maybe an outdated API reference doc. Let me take a quick look
That's recently been changed on main. I'm guessing main is being published there.
@sand gorge found the issue, that's because the id argument has been deprecated (https://github.com/dagger/dagger/blob/main/core/schema/container.graphqls#L9). Seems like we're omitting deprecated fields in the API reference docs
GitHub
A programmable CI/CD engine that runs your pipelines in containers - dagger/dagger
Oh. Yep, deprecations should show and marked as such. In any case, this breaking change is in main, it's not been released yet.
For context: https://github.com/dagger/dagger/pull/5881

GitHub
This is an assorted set of sweeping changes that fix the longstanding bug involved with traversing lists of ID-able objects in the SDK. We've worked around this issue about 10 times in the past...
Just created a PR to handle args deprecation. Previously only fields marked as deprecated were being rendered.
https://github.com/dagger/dagger/pull/5895
https://deploy-preview-5895--devel-docs-dagger-io.netlify.app/api/reference/#query-container
cc @sharp marsh @sand gorge
Thanks to @sharp marsh we have a new Dagger Meetup location! If are you near Buenos Aires, join the group 🙂 We are hosting our first meetup on October 25th https://www.meetup.com/dagger-buenos-aires/

Meetup
What we’re aboutDagger Buenos Aires is a place for the dagger.io community to meet in person, learn, and build the future of devops together.Everyone is welcome, no matter your expertise or familiarity with Dagger.io. The only pre-requisites are an interest in devops, the desire to learn, and willin
You can RSVP to the event here: https://www.meetup.com/dagger-buenos-aires/events/296724798/

Meetup
The primary language at this event will be in Spanish.
Join us for the very first Dagger.io meetup in Buenos Aires!
One of Dagger's very own engineers, Marcos Lilljedahl,
Nicely done!
Hey! So basically I've inherited the graphql from a PHP post that @heavy karma put together.
It used container( "id" ) on nearly every graphql.
So I've learned a deprecated feature 😄
Now I'm wondering if there's an example how to "keep making graphql queries" on the same container.. without passing the ID between queries?
Hope that made sense, just trying now to unlearn id and be taught the new thing.
Thanks 🙂
It's not possible in GraphQL since it doesn't support the primitives for that. That's why it's more convenient to use the SDKs for that since we can hide that ID passing and wrap it with proper language primitives
We generally don't recommend using the raw GraphQL API since it's generally more low level and requires more intricate handling
Hi! Just found dagger, and I love it and think it may very well be key to the future of CICD, now with that brown nosing out of the way, I have a very beginner-level question.
I create a ci/ folder with a main.go and I can run my pipeline via either dagger run go run ./ci or go run ./ci directly. I am trying to understand the difference between both? The dagger version has a lot of UI but seems to create a fresh session each time, and takes a long time to execute relative to running the program directly via go. When running with Go, everything is cached and runs instantly if no changes have been made. What am I not understanding, and what are the recommendations?
Is there a remote option for the Buenos Aires meetup?
No, there won’t be a remote option, but we are working on some virtual meetups soon and a few more meetup group locations are in the works as well 🙂
Mark your calendars for this week's Dagger Community Call! We have some great demos lined up from @wispy tapir , @earnest prawn and @solar raptor. If you have't already, you can sign up for the community call here: https://dagger-io.zoom.us/webinar/register/4416686668409/WN_USQjVBGXT0SWhNMvqYVvCA#/registration
See you there 🚀

gonna move this to #1030538312508776540 🙂
Hi! If I want to run the dagger engine using Github Actions and I create an ephemeral engine, is it possible to connect that engine to some S3 Bucket with docker layers caching? Or to export the built layers to an S3 bucket once I am done?
My concern is that if my dagger engine is ephemeral then I never benefit from any caching. Is there a way to export the docker artifacts or do I need to host a dagger engine to benefit from cached layers?
Hi If I want to run the dagger engine
Thanks to @main spear for sharing his Dagger story with the world. https://dagger.io/blog/enabling-platform-engineering

does anyone know if there's a way to stream the stdout from a running container inside dagger?
Hello everyone. Is it possible to suppress the output (stdout/stderr) of service containers?
yes, you can use WithExec's redirectStdX to /dev/null (https://docs.dagger.io/current/sdk/nodejs/reference/modules/api_client_gen/#containerwithexecopts)
Enumerations
Okay so in go I would leave the actual command argument of WithExec() blank like this serviceContainer.WithExec([]string{}, dagger.ContainerWithExecopts{RedirectStdout: "/dev/null"}) ?
IIRC you can pass nil instead of a blank command
alright many thanks!
@chilly arch are these recorded somewhere?
hey everyone! Here is the full recording from this week's community call. I will add it to the Dagger events page now. I will add the demos to youtube and add them to the Demo forum shortly.
Thank you again to @wispy tapir @earnest prawn and @solar raptor for the demos!
Thanks you all the speakers, demos were awesome!
Hi All!  Project Zenith Community Call happening in #911305510882513037 channel!
Project Zenith Community Call happening in #911305510882513037 channel!
@deft wyvern are you still going to show us an insane demo today?!
I had another good week in dagger land. I was able to create a test of my database migrations by defining a postgres to my specs, loading my migrations on it with goose. If that build passes, my migrations are good!
i can take that same database and now feed it into my other services so i can pull that migrated database in, apply some changes, then integrate with it
A newbie question. From the documentation, I understand that Dagger uses containers to perform what is asked. Are there use cases without containers?
What are the prospects of long running services external with the new 0.9 release. Any direct limitations and/or is it only meant for ephemeral environments?
hey there! not currently. Even though some users have asked about it, the current vision and design of the system is very dependent on the "container" concept
Quick Q about how cache volumes work in Dagger/Dagger Cloud. Terraform plugin cache has a warning that it is not guaranteed to be concurrency safe and that running multiple terraform inits on the same plugin cache is undefined behaviour. Do volume caches make this any safer? Or is it safer to just let the various terraform inits cache as a buildkit layer cache?
when turning a Container into a Service - is there anyway of controlling when Dagger perceives that service to be live? Looks like it waits for any .WithExposedPorts() to respond currently.
I'm reworking some code using TestContainers in which I have:
.waitingFor(forLogMessage("INFO Successfully applied \\d migrations to schema.*", 1))
as a check condition. The docs at https://docs.dagger.io/757394/use-services/ mention they're health checked, but doesn't say how, or if that can be customised? ( or does that use the standard docker healthcheck process? )
Dagger v0.9.0 includes a breaking change for binding service containers. The Container.withServiceBinding API now takes a Service instead of a Container, so you must call Container.asService on its argument. See the section on binding service containers for examples.
It waits for the exposed ports to be available as you correctly mentioned.
oh, another reason to ditch my current method of pinging with a second container. I was curious about what makes it available to the build graph
Hi all, was searching for a bit but couldn't find the answer: is it possible to run part of the pipeline on another host running Dagger Engine? I have a performance test as part of the pipeline and I need to run it on a specific machine to get consistent results. So far I have achieved this by having a dedicated GitLab runner on that server
That's a shame - cause that doesn't guarantee the service is actually fully ready for use. Interestingly, that so far doesn't seem to be an issue - altho, usng service containers seems to double my pipeline runtime ( as opposed to having TestContainers start the service containers ). mmm
Well... This is the eternal dilemma of who should be accountable for the service being ready. In your example above, it looks like that logic is closer to the service itself. The way that I'm used to handling that in my CI/CD pipelines is to move that closer to the app. The only thing that my app cares about is for the service to be up and have a valid set of credentials, it should be the app responsibility to make sure the service is "ready" (i.e have the right schemas) so tests can run
In this scenario - the IT tests start the DB image, then run a server process that applies the migrations to create schema, then starts the main server. Of which I will need to add another in to start an LDAP server and something to import its schemeas.
it does seem to be working fine tho - tho I suspect thats cause it seems to be slower than not using services. now to figure out why the IT tests fail under this model, than the internally starts services ( sadly the pipeline takes 30 minutes, so a pain to diagnose issues ).
thats a ME thing tho 🙂
(the pipeline in question starts 2 postgresql containers as services, the application under test as a service, a migration process to setup a database/schema , then runs the main test compilation/execution. I'm quite impressed with out clean/easy it is to setup this up, and is pretty much close to what I was doing with TestContainers - only running at the dagger layer which means this should work when run in our AZDO environment, which TC was having issues with.
Today I am speaking at National DevOps Conference - London. I'd like to feature Dagger. I have around 2-3 minutes, max, to talk about Dagger.
What are the key things I should be saying to them, to convince them to check out Dagger.
Any good code snippets to show "common usecases" and thus showing them how they could do it, would be a great idea.
Hi Paul! Given my west coast usa time zone, I fear I've missed the chance to give you a timely response.
Hello. The today's event finished, I'm speaking at a larger event on Wednesday.
That's a better suited talk and audience for Dagger, so don't worry @slender star you've not missed me yet 😀
Feel free to drop me things 🙂
My question is "how would you like the community to perceive Dagger?"
Let me know, I'll be your messenger 👍
cache volumes and terraform init
What are the prospects of long running
Hi all, was searching for a bit but
Hey, what do you guys think about potentially adding buildpack support?
There is already an experimental project for buildpack compatibility already 🙂 With the upcoming reusable modules in the future Zenith release, it will be a perfect opportunity for a buildpack module
Past discussions and demos of buildpack support:
has anyone done anything with profiling pipelines? Having switched a my pipeline from custom launches containers via in-process TestContainers calls, to using Dagger Service Containers - things seem to be about 50% slower (tho I should really reboot and test this from a clean machine state - altho - I wonder also if that's more an issue with the dagger CLI rather than just running go run build.go: 6.8gb for the process?
thats certaintly not going to help this laptop 🙂
has anyone done anything with profiling
KubeCon is less than two weeks away! We are so excited to meet current and future Daggernauts there.
If you are going to be at the show, please DM me. I'd love to secure some swag for you! I have a feeling this swag is going to run out quickly 🙂

Socks! So unique 🙂 Bless them little feet.
@winter linden and others. Can we update the Discord questionnaire to include "PHP" ?
These devs aren't doing JS or Python so want the DX to be perfect 💙
Secondly, when you join the discord it auto joins you into some channels, and #php is not on the questionnaire so you don't join #php channel automatically
..
And can we make the #php channel visible on the left panel? Otherwise people don't know it exists ..
T minus 2hrs until the unveiling of dagger 😄
I appreciate timezones might not align here.
Hi! I can update this right now. One moment
Done!
Shout out to all the Daggernauts in Thailand! @wary cave will be doing a talk about Dagger at the PyCon Thailand 2023 event on December 16th. Make sure to say hi if you are attending! https://twitter.com/pyconthailand/status/1716667067376734567
Hello folks! We did it 😎 I blew many people's minds.
It was great to see their eyes light up ✨️ and be inspired
Special thanks to @slender star who made some GoLang examples of a PHP Drupal app the night before.
I took snippets from your repo, Jeremy, to help them understand the power of dagger! Super helpful
The PHP community are excited for the SDK, so as of next week I will resume coding on it and get it finished, for. November launch
🙂

Hello folks! We did it 😎 I blew many