#agents
1 messages · Page 3 of 1
fixed, ty!
building now
ok i ran this one that worked on llm.8 and its the same response on llm latest
It's now possible to use the dockerfile-optimizer standalone without the Github PR flow (with dagger-llm.8)
$ dagger shell -m github.com/samalba/agents/dockerfile-optimizer
⋈ src=$(git https://github.com/samalba/demo-app | head | tree)
⋈ optimize-dockerfile-from-directory $src | file Dockerfile | contents
Thanks for the suggestion @smoky ocean
dammit

and this is how the apocalypse day began
context: adding a hint to the model when its context changes, trying to avoid this:
✔ container | from alpine | .llm 1.7s
│🤖 Thank you for letting me know. How can I assist you with the current container context?
│ ┃ 1.4s ◆ Input Tokens: 6,971 ◆ Output Tokens: 20
LLM@xxh3:7bf41186fcf1a6ee
instead of replying it ran a tool to reply -_-

@smoky ocean you can tag llm.9 whenever, brought back withPromptVar and made multi-object lazily enabled (when you set a var)
this is the exact thing that makes avante.nvim+claude completely useless lmao
it really really really wants to use tools to the point it just never responds
0.17.0-llm.9 🧵
🚨 🚨 🚨 new release: 0.17.0-llm.9. Now with revolutionary multi-object support 🙂 The design is not fully baked so we also left single-object, to avoid breaking existing modules and scripts.
@spring wave Ctrl-L doesn't work for me on that version
try pressing it again?
(unironically - there's a sleep(100ms) in there to time the clearing for when the scrollback is flushed, quite unfortunate)
worked in ghostty. not in zed
@spring wave @shrewd ermine FYI I think llm.9 does break all modules, because of capitalization changes
does zed also not work after pressing it again?
correct
Zed might be eating the Ctrl+L keybind entirely, I know Cursor defaults to using it for chat stuff
or does it work outside of dagger
OK in zed after re-starting the shell, it works on second try. can't repro the issue in zed. so I guess we're good 🙂
also, tiny thing: I made it so submitting an empty shell input starts and immediately cancels a span, instead of doing nothing, since that's a muscle memory (to add spacing). lemme know if it's weird
Actually I'm trying to figure out if it does break modules or not...
dagger -m github.com/samalba/agents/dockerfile-optimizer:./main.go:66:76: undefined: dagger.Llm
dagger -m github.com/shykes/toy-programmer-> loads ok 🤷♂️
ah, the type was renamed but the constructor is still dag.Llm - but I think that's a TODO
Nice!
Oh I think it's a typo in the first module
OK I understand now - not a typo, Sam's module just exposes the LLM type in its API, which is relatively rare - but llm.9 does break that
Actually the problem is not actually exposing it's just referencing the type anywhere in his code
(in his case it's an internal function)
this is tricky because if I open a PR to his module, it will break for pre-llm.9 users
which as of right now is 100% of our small testing pool 🙂
hey I reference that type also in my melvin module...
yup it's broken also 😭
bummer. ah well, good to get these out of the way sooner than later
Yeah basically it means we have to be aggressive in getting people to update engine and modules
or, slow-roll on both
@storm gate FYI https://github.com/samalba/agents/pull/2
GitHub
The dagger llm pre-release of Dagger has a breaking change: the "Llm" type has been renamed to "LLM".
You did not add unit tests
tried out having it start with Query, pretty fun example: https://v3.dagger.cloud/dagger/traces/4cf133e60e6ba9d4bd29ed41690ca12b

Browse and visualize Dagger traces.
complete with the classic running prompt as shell first
i think it would have figured things out easier _objects included all objects, not just variables, with the name of the call that created it (like Container@xxh3:abcdef.from(args...)). not sure if worth it, maybe there's another way
all objects as in every ID received by the llm?
yea
it would be nicer if it would have just recognized it from the tool output though
I still think reusing the trick from single-object, with auto-saving each variable, would help overall a lot
feels like it just needs a small hint
i think that would make this harder, because the variable would be irreversibly reassigned even after making a "mistake" (installing nano instead of vim)
but this is a very specific scenario, not sure if it'd be common
we can always give it "rewind KEY" and "history KEY" stuff like that
ah true
that feels like basically what it's trying to do now, though
just instead of keys it's object ids
life hack: write a dagger agent that monitors the latest dagger release and opens a PR against your module. It can make sure your module builds and watch for any breaking change in the changelog, and updates the code as needed.
And we could even make it a github app available to all...
Ideally compat mode saves us from relying on something like that, but yes I'd use it 😄
yeah I gave my workspace a reset() func, it makes sense to have that ability for objects in general. Sometimes models get a little carried away with their early attempts and destroy their workspace https://github.com/kpenfound/greetings-api/blob/main/.dagger/workspace/main.go#L60
why do we configure a system prompt for anthropic and gemini but not openai? 
I think @wraith remnant asked about that when he implemented anthropic. I haven't looked at the openai client much but in anthropic and Gemini the system prompt is a special thing
Special as in we might want to make it configurable or something more specific
I don't know if thats wired up? I thought for Gemini and anthropic it was passed to the constructor
oh yeah duh it adds a message as system. I don't know what happens if you do that to gemini. Let's see
oh wait no I had it the first time, it's not wired up ! no function "with-system-prompt" in type "LLM"
this would be great tbh
I was looking at make the llm part working with llama.cpp Did anyone already tried?
My understanding is while both tools and streaming are supported, they are not supporting at the same time.
So I started to change a bit the code to handle that, but it's not calling the tools anymore. For instance I have this message in the output "You can write this code in the workspace and then build it by calling ToyWorkspace_build.".
I'll have a deeper look, but if anyone has some ideas 🙂
@spring wave want to bikeshed multi-object design later?
I could setup another eval maybe
Answering myself, but https://github.com/ggml-org/llama.cpp/pull/12379 looks like to make it work. Sort of. At least I don't have anymore the server error about streams and tools. That's a first step in the right direction
cc @lilac crystal 😛
multi-object prompt/metaphor engineering
🫡
I wonder if it isn't related, but with ollama and llama3.2 on my machine, I have the same behavior.
I'm running the version llm.9 and if I'm trying toy-programmer with the classical go-program "develop a curl clone" | terminal it does nothing.
By nothing I mean
✔ go-program "develop a curl clone" | terminal 4.7s
│🧑 You are an expert go programmer. You have access to a workspace
│ ┃ 0.0s
│
│🧑 Complete the assignment written at assignment.txt
│ ┃ 0.0s
│
│🧑 Don't stop until the code builds
│ ┃ 0.0s
Container@xxh3:f699019bc6b5b1b3
And nothing more.
So this looks like the behaviour I have with llama.cpp
(If useful https://dagger.cloud/eunomie/traces/9fbb1d84e75179ccf9687c71b06a9a2d)
If I am getting an error like this
│🤖 0.8s
│ ! POST "https://api.anthropic.com/v1/messages": 400 Bad Request
│ ! {"type":"error","error":{"type":"invalid_request_error","message":"prompt is too long:
│ ! 211147 tokens > 200000 maximum"}}
! input: llm.withContainer.withPrompt.id select: POST
! "https://api.anthropic.com/v1/messages": 400 Bad Request
! {"type":"error","error":{"type":"invalid_request_error","message":"prompt is too long:
! 211147 tokens > 200000 maximum"}}
Is there any easy way for me to see what the prompt was in dagger?
llama3.2 is super small and might need a more helpful prompt compared to bigger models. Compare it to llama3.1 and qwen2.5-coder:7b that will probably at least try to use it's tools automatically. With llama3.2 maybe something like "you have tools to access a workspace where you can read, write, and build code. develop a curl clone". That might be enough
ah sorry this regressed - should be fixed on head of llm
oh i missed it, what was the regression on llm.9?
the old-style getters (Llm.workspace) weren't calling sync internally, so the LLM never actually ran
v0.17.0-llm.10
To everyone using Dagger's agent features: what do you think of the new website? Do you recognize the reasons you personally are excited about Dagger? https://dagger.io
Dagger is an open-source runtime for composable workflows. It's perfect for systems with many moving parts and a strong need for repeatability, modularity, observability and cross-platform support.
What are the use cases of using llms through dagger ?
The "Dagger in Action" section lists examples with links to the README. Are you looking for something else?
Mhm do you think it would be possible to have an llm that judge commits on the repository of a project ?
I've seen a company selling a product like that but I guess it can be made using dagger aswell
Yeah, I could see that as an expansion of @shrewd ermine 's AI Agents in CI demo - #1349235356184350770 message
Ok thanks i'll check
Also check out the examples here: https://docs.dagger.io/ai-agents#examples
yes seems very doable
@spring wave trying the . | .llm thing on llm.10. What's the flow look like? I tried
. | .llm
> are my tests passing?
what did it do? seems like it should work
hmm i think it got confused about arguments. that makes sense I guess because I should give it variables for those
yup now we're good
if your module constructor takes args you'll need to pass them to .
was that it?
so like . arg1 arg2 | .llm
I'm using the module from the quickstart and I forgot it doesn't use context directories. So I made a source=$(directory | with-directory / .) and it figured it out
multi object 🚀
ah ok nice
That new prompt for external access to modules is 🔥
@spring wave quick feedback from ongoing mini-workshop: multi-object without auto-save requires custom prompting every time (at least on gpt-4o): "save to the same variable when you're done"
Hi new and old Daggernauts!
If you’re new here, we host a Dagger Community Call every other week to showcase what the community is building. You can check out past calls here: https://www.youtube.com/@dagger-io/streams.
Are you working on a Dagger Agent project? We’d love to highlight your work in an upcoming call...and yes, there will be Dagger swag involved! 😃
Your project doesn’t need to be finished. We love seeing work in progress and half-baked ideas.
If you’re interested, DM me and I’ll be happy to add you to the agenda or answer any questions. Looking forward to seeing what you’re building!
Workshop feedback 🧵
Im stuck in a doom loop
│🤖 0.2s
│ ! POST "https://api.anthropic.com/v1/messages": 400 Bad Request
│ ! {"type":"error","error":{"type":"invalid_request_error","message":"messages.7:
│ ! `tool_use` ids were found without `tool_result` blocks immediately after:
│ ! toolu_016BtYBAoQfwMzn4P7CeBD2p. Each `tool_use` block must have a corresponding
│ ! `tool_result` block in the next message."}}
! input: llm.withPrompt.loop.withPrompt.loop.withPrompt.loop.setContainer.withPrompt.sync
! select: POST "https://api.anthropic.com/v1/messages": 400 Bad Request
! {"type":"error","error":{"type":"invalid_request_error","message":"messages.7: `tool_use`
! ids were found without `tool_result` blocks immediately after:
! toolu_016BtYBAoQfwMzn4P7CeBD2p. Each `tool_use` block must have a corresponding
! `tool_result` block in the next message."}}
Anyone seen this before?
Just trying to have the llm use my container in vibe mode
@merry scarab that's fixed on llm tip
Can you ELI5 how to get on that, I have been using this handy dandy command 🙂
curl -fsSL https://dl.dagger.io/dagger/install.sh | DAGGER_VERSION=0.17.0-llm.9 BIN_DIR=/usr/local/bin sh
v0.17.0-llm.11
am i being dumb?
I expect this prompt to use the container I give it, but instead it tries to use ubuntu
● llm | with-container $(container | from alpine) | with-prompt "you have access to a container, us
│🧑 you have access to a container, use it to install chromium
│ ┃ 0.0s
│
│🤖 I'll help you install Chromium using a container. I'll use an Ubuntu base image and install
│ ┃ Chromium using apt.
│ ┃ 2.9s ◆ Input Tokens: 11,846 ◆ Output Tokens: 83
│
│ ✔ Container.from(address: "ubuntu:latest"): Container! 1.1s
│
│ ✔ remotes.docker.resolver.HTTPRequest 0.1s
│ ✔ remotes.docker.resolver.HTTPRequest 7.0s
yeah, that'll happen 😂 In the future we'll be able to mask an object's functions so you could actually restrict it from using from, but for now you can add more prompting to say "dont use from. only use the withExec tool"
Thanks!
Hm sorry something still feels wrong, it tells me i didnt give it a container at atll. Feels like something silly
⋈ llm | with-container $ctr | with-prompt "i gave you a container, does it have a browser in
And then its like "sorry i dont have a container"
Question, since -llm.{10,11}, the cli fails to read my api keys from the env, it now fails reading from (an non-existing) .env file. Did anything change or do we have a regression?
it currently still shows a bunch of errors for the stuff it doesn't find, but should still find the vars that are set. What env vars are you setting?
The usual keys, and I get an empty answer from the llm
oh but it does answer? 🤔 not like a 403 or something? What provider are you hitting? I'm mainly using ollama and gemini
Showing those errors should be fixed, lmk if you're still seeing it
The empty response was my own mistake, but I can see these errors, only when I introspect the span from the LLM router config:

It's not bothering at all, they stay collapsed by default and the overall flow works without errors.
oh, yeah the collapsing was the solution 😛 - it should only expand if they all fail
would be nice to avoid them in the first place for sure
yep you're right, it's just burned into my eyes lol
I'm from the hack day @smoky ocean's. i was playing with the agent and Gemini and I was struggling to have it find tools:
I've attached the output from my interaction with the model. I have been asked to ping @spring wave
Weird bug - prompt is completely missing here but its doing the right thing 🙂 https://v3.dagger.cloud/levlaz/traces/a8a6e230396e3a873190d50b9b896582?listen=7fbd4e97db816dab&listen=929acc8e9ca3db93&showHidden=52a5eb8074ffedd9#a340488547251a0c

Browse and visualize Dagger traces.
@shrewd ermine I have function masks almost working 🙂

pushing the branch
what's the UX? I pass a list of function names as opts?

llm | with-container $foo --function-mask=withExec,rootfs,directory
llm | set-container foo $bar --function-mask=withExec,rootfs,directory
(applies to all types, not just container)

✘ llm | with-container $ctr --function-mask=withExec,rootfs,directory 0.0s
! input: llm.withContainer index 0 out of bounds
│ ✘ LLM.withContainer(
│ │ │ functionMask: ["withExec", "rootfs", "directory"]
│ │ │ value: ✔ Container.withWorkdir(path: "/app"): Container! 0.0s
│ │ ): LLM! 0.0s
│ ! index 0 out of bounds
! input: llm.withContainer index 0 out of bounds
😦
I wasn't able to test it, ran into unrelated LLM hang issues
probably something stupid. will look into it
ah got it, wasn't sure if i was holding it wrong
@shrewd ermine is there a stack trace in the engine?

no but I added some debugging. elmts.Len() is 3, i is 0, and it's returning index out of bounds 🤔
haha yeah...
that would do it! I'm sure there's a fun story behind that
trying that
confirmed that fixes it 🙏
next speedbump
✘ llm | with-container $(container | from golang:latest) --function-mask=withExec,rootfs,directory | with-prompt "write a curl clone" | container | terminal 0.0s
! input: llm.withContainer.withPrompt.container instantiate: cannot instantiate dagql.Class[*github.com/dagger/dagger/core.Container] with core.maskedValue
someday...


it started out as a "i don't want to deal with *int everywhere", how did it end up like this...
this one might be more serious..
I think my "clever" approach to add masking with minimal changes, might be a little too naive
will need to add a little more substance to it tomorrow
(tldr I wrap the actual value, of interface type dagql.Typed , with a simple wrapper type that keeps the original value embedded, and adds just the mask field:
type maskedValue struct {
dagql.Typed
mask []string
}
I was banking on the fact that my maskedValue still implements the Typed interface, with the original value - the perfect passthrough.
Except not at all, because callers try to cast it back to the original type, and I can't pass-through typecasts (I guess)
I think I'll need to define a new interface, and use that instead of dagql.Typed across the whole llm.Withxxx call chain
Yeah makes sense!
@spring wave @shrewd ermine multi-object DX bikeshed. How do you feel about:
LLM.bindContainer("foo", ...)
LLM.bindings()
LLM.binding("foo").container()
LLM.bindToyWorkspace("bar", ...)
LLM.bindings()
LLM.binding("bar").toyWorkspace()
LLM.bindString("baz", ...)
LLM.bindings()
LLM.binding("baz").string()
Benefits:
- Consistency around the word "binding". Everything related to bindings has the common root "bind".
bindings()allows for listing existing bindings -> that's a gap currentlybinding()groups all the getters. So that cuts the volume in half right therebinding()andbindings()will always be listed immediately afterbindFoobecause of the uppercase/lowercase sorting
Works for me! Would the value from .binding() have a GetType or something too?
well it has type()
could be getType() or asType()
went for the shortest as a baseline
Yeah makes sense, was just trying to think about using values from bindings()
alternative: replace LLM.bindFoo with LLM.withFooBinding
Oh bindings plural
No you had it right! Sorry replying from my phone... So I'd get keys from bindings() and check their type from binding(key)
Yeah, but we can also add any metadata in the result of bindings(), if we want to introspect their type, or current id etc.
In practice callers are supposed to know the type they want
Yeah I was trying to think of the case where the LLM was able to save to a new variable (if that's going to be allowed) and how to safely find that
And withFooBinding sounds good too
I do like the parallels to container.withServiceBinding
ctr, err := dag.LLM().WithPrompt("please save the container to $foo. don't mess up please").Binding("foo").Container()
if err != nil {
panic("you had one job")
}
Where I can find examples of using multi-object? Wanna try that out
@proper stratus docs update coming very soon!
@proper stratus in the meantime, you can try it straight from the shell:
- Start dagger shell
$ dagger
Make sure it's v0.17.0-llm.11 (released today)
- Set a few variables in the shell
ctr=$(container | from alpine | with-new-file hi.txt "Hi Bob")
dagger_repo=$(git https://github.com/dagger/dagger)
- Switch to "prompt mode"
>
- Start prompting
I gave you a container and a git repository. First, open the file hi.txt in the container, and tell me its contents. Then, fetch the last stable release of the git repo, get the subdirectory docs/, and copy them into the container I gave you. Save the result to new_container
- Switch back to shell mode
!
- Check that the new container was created
$new_container | terminal
(it's simpler that it seems in written form)
side note: been considering tab to swap between prompt/shell, assuming the input is empty (have to compete w/ tab completion)
@proper stratus in code, you can use LLM.Set<Foo>() and LLM.Get<Foo>() where <Foo> is the binding type. If you're familiar with the single-object API, it's the same, except you need to specify a key
I vote Ctrl-/ 🙂
is that from something?
or Ctrl-<something>
no, just a throwback to the slash commands
conveniently placed. prime location
in an up-and-coming neighborhood
lol
If I run the module in Dagger shell, does the agent know the TUI output? I want to try give the agent that output so it can help me improve my Dagger module performance.
Ah. No, the agent can only see the output of functions that it calls itself. One thing you can do, is give it a container with the dagger CLI installed (with dagger-in-dagger nesting enabled) then have it run dagger CLI commands in there.
I believe @merry scarab was working on something very similar just today
also, @spring wave is working on allowing agents to access your current module's dependencies. That would allow you to install the modules of your choice, then have the agent call them directly
So currently if I give it a module, it just knows what I write in that module, not the dependencies I install in that module?
yeah 1) it can't access the dependencies and 2) it can't call the module constructor, you have to call it and bind the object instance to the llm
Today's workshop made me think about API integration.
@spring ocean and @wraith remnant worked on an agent that involves a lot of them. At the moment it's possible to write Dagger modules that wrap cloud APIs, and there are benefits to that - but it's labor-intensive. The DX is cumbersome and there are gaps, for example Dagger/Graphql types don't map directly to JSON and OpenAPI (eg. no maps). I believe @violet stump, @olive badge and @uneven depot brought this up in the in the past.
What if we added first class to external APIs somehow? Maybe as a special kind of dependency - imagine if your dagger.json could have remote APIs as a dependency, and the engine exposed that as a dagql module? The dependency source could be an OpenAPI/Swagger/graphql schema of some kind (I'm sure there are catalogs out there). They would be loaded by a special builtin SDK. Could be a big boost to our DX
That's a neat idea! I wonder if that same idea can extend to CLI tools also? That's what I end up wrapping more than APIs. I usually try to get an official image for the tool, if not pull an Alpine container and install it. CLI tools don't have a common structure though, like openAPI so, it's probably impossible. There's no guarantee a rest API follows the oapi spec also, so consumers may end up with weird errors that they can't directly identify because the api is wrapped in another SDK.
I'm making a few changes and will polish and publish, but I thought it would be fun to write a database agent that can take a database connection and answer questions. I'm using an example database for dvd rentals.
👀

I saw that yesterday, was asked for that very feature last night at the meetup 🔥

llm has been merged into main

Follow-up to DX thread @spring wave @shrewd ermine. Should we consider spinning out a LLMEnvironment type, separate from LLM? The former would have the bindings & state management. The latter would have the prompting and endpoint routing. Soon there will be MCP that currently grafts onto LLM. But would now cleanly graft onto LLMEnvironment instead.
Maybe makes the modules code cleaner also? Clear delineation of the LLM vs. its environment?
you have my attention 🙂
yeah, was thinking something similar
"environment" is the accepted industry term for where llm's interact with their tools and state right?
or is it more specific
it will be 😇
i think the industry is stuck on "tools" and will soon realize that they need more. Environment in my opinion is the next logical evolution, and I think we should spearhead it.
An environment implies 1) objects 2) state 3) rules for how objects interact
all of which dagger can provide
cc @noble notch 👆
ship it!
Environment API 🧵
Stuck on tools and frameworks!
loop() 🧵
I switched from the llm tag release, to main. @worn hill it'd be nice if we could set the --allow-llm from an env var for the CI. I thought setting DAGGER_LLM_ALLOW=all would override the cli arg but it does not work
yeah i can add this, shouldn't be hard. i had another post-flagparse processing thing i wanted to do anyways
I finally got my end to end AI flow working reliably: https://github.com/samalba/demo-app/pull/19
This PR is generated by an agent, and reviewed by another, with a recommendation to merge or not, based on the diff and PR description.
It looks like I am discussing alone  because of the github token I use. It's pretty cool!
because of the github token I use. It's pretty cool!
All the code is here: https://github.com/samalba/agents

asked ChatGPT about that but didn't take any hot takes. Mostly referencing vim's modes and python's ! special character
having said that C-/ maps as ^_ in my keyboard ( I think a bunch them do for some reason) which then bash in my case uses it to undo. FWIW C-[ and C-] are not currently remapped to anything and seems like bash doesn't use them

quick idea: LLM.interrogate - like Container.terminal but for debugging an LLM. Runs the .sync and then pops you into interactive prompt-mode shell so you can ask it why it messed up
or, a way to pipe a LLM to .llm so you can load it as your current session, then you can at least change your function to return *LLM
have we incorporated the concept of stop_sequences? I mean.. how can we know if the LLM effectively accomplished its task to interrogate it?
Ideally you'd want to interrupt it when you know it's just not going anywhere, right?
yeah that's another thing i've been wondering, if we do that we can get -i to do it automatically which is even better
for what i suggested you'd just splice it in after your last prompt before things go haywire, and hope it does it again. (same as splicing in .Terminal())
is there a way to do this? i didn't see it in the API when I looked, and feared the only option would be some sort of sentiment analysis thing lol
MVP could just be grepping for "sorry" haha
anthropic API has it at least

Just pushed the code , short video, and an updated README to https://github.com/jasonmccallister/database-agent
Would love an extra set of eyes/feedback if there is any!
GitHub
Dagger module to give an AI Agent access to a database - jasonmccallister/database-agent
managed to get that to < 300 lines of code - but supports bot mysql and postgres, Might be able to trim that down even more if I tried
@spring wave probably safest and most portable to have _error builtin that llm can call to report an error
I love the idea of explicit LLM.terminal()
and I think prompt mode in the CLI should use it
separately, I think it would be SUPER powerful if you could just save variables of type LLM, and automatically the prompt mode shortcut can cycle through them. the default LLM would be a special case of this
I like this variable-based approach better than .llm which is too close to llm
https://tenor.com/ZeJP.gif (in response to _error)

check out this template with some tips, namely to make it easier to understand and more interesting to people who'll see this and won't be familiar with Dagger or "modules" yet.
would love to post it to HN as something like "Show HN: DBAgent - Talk to your database" [1]
in fact there was a recent similar post that did well: https://news.ycombinator.com/item?id=43356039
[1] DBA but the A is for Agent 🤪
I have hard time to use llama.cpp because of tools and streaming not supported at the same time.
So I'm running that on my machine: https://github.com/dagger/dagger/pull/9919
Basically if there's a tool it doesn't use streaming in the same call.
That looks like to work, but I don't know if that's the right way to do it or if it can have side effects
GitHub
For llama.cpp that doesn't support both at the same time
updating the readme with those changes: https://github.com/jasonmccallister/database-agent/pull/2
GitHub
Updates the Dagger version to the mainline release
Updates the documentation from feedback
With that change, I finally have a fully local experience using llama.cpp that works. For instance the toy-programmer is working as expected. A bit slower of course, but that works.
I think the tricky part with this is that it seems like it's just llama.cpp that doesn't fully support the OpenAI compat API, since this currently works fine for other OpenAI compat APIs like openai itself, azure, ollama, etc. We had the same problem with Gemini because they advertise an OpenAI compat endpoint but it doesn't fully work, so we implemented the native Gemini client instead
Hi
I've written an example of how to use an agent with Dagger in Python:
https://github.com/azorej/dagger-agent-example
Nothing special: I've used kpenfound/dag/workspace as the base for my workspace module and wrote a simple function to fix Dockerfile.
The most interesting part: I'm using a devcontainer to simplify setup, so it will be easier for others to try out the example.
I haven't seen a lot of use for devcontainers in the Dagger examples, and it's not very practical to have different versions of Dagger installed on one machine.
Therefore, it would be great if we could normalize the use of devcontainers.
GitHub
Test Dagger ML agents. Contribute to azorej/dagger-agent-example development by creating an account on GitHub.

A generated module for Workspace functions
btw, I am not sure how code generation works in Dagger.
Do I need to maintain a separate workspace module?
Or can I use the same module for both orchestration and the agent workspace?
Ideally you would not need to maintain a separate module (while being free to, if you want)
There is a temporary limitation which prevents a module from calling itself via the Dagger API. We are working on allowing this. By extension, this also prevents a module from creating a binding to its own types, for a LLM to use.
This is why at the moment you have to separate the module being referenced by a LLM binding, and the module doing the binding.
--> hopefully this makes sense!
I'm giving a live demo tonight... Should I show multi-object or not? 🙂
✅ ❌
ok the ❌ isn't helpful lol. I would vote no just because the DX is still up for discussion (I think? unless the WithFooBinding is in) and the reliability is in question depending on your model and objects
Also, the deprecation underlines (at least in Zed) with the current with<> makes my eyes wander like I wrote broken code/syntax
oh but isn't the deprecation warning for single object?
ran into this too, thinking of un-deprecating them until we're 100% sure. We haven't been able to fully escape the idea of a "current state", and the pattern of exposing vars to the LLM and pulling a single value out still feels most natural to me
Hi everyone, I've recently begun exploring Dagger, love the idea of building containers for AI agents. I'm curious if there are common patterns or best practices for picking which models to use. It could be because you want to try different models for the same task and compare. Or, you could be building something that benefits from multiple models each with a specialized task.
Welcome! Definitely checkout https://docs.dagger.io/ai-agents#faq , it's a bit bare right now but we've been working on adding best practices as we can. As far as model selection, claude 3.7 and gpt-4o seem to be pretty capable in general. I've been enjoying gemini-2.0-flash too but you need to get the prompting just right for it to be successful. For coding tasks, qwen2.5-coder of whatever size you can run has been good too, but also needs just the right prompting and configuration
Thanks, I'll check out the FAQ. Do you think it would be worthwhile to build a module that could abstract away the model selection? As in, not have to fret about which is the current SOTA model for X and just have the module enable the current best? I know that sounds a bit abstract.
I imagine with more "vibe coding", you just forget about which model(s) and say "give me the best model that I can run on this machine right now for this task."
Yeah it's an interesting problem. Most of the functions I've been writing specify a default model but allow one to be passed in. The hard part that I've seen is that the prompting is somewhat model-specific so it's hard to just swap out the model and keep everything else the same
As it is, it's hard to keep track of which model identifier is right <model family><version>-<params>-<tuned for>-<quantized>. The naming conventions for these models is...rough.
Let alone the right prompt style/setup
Yeah I totally agree. It would be nice to have that kind of thing handled at some model router level since at the agent/Dagger level you don't necessarily know what models are available
It's something my team and I are looking into/building. I was looking at Dagger separately for workflow orchestration and then got nerd-swiped with agent containerization. Perhaps we can contribute.
Basically it would be cool if the agent could say "give me a model that meets these criteria" and the model server gives you the best fit
Which I think works great since containers may have the same functionality but access to different hardware resources or compute budget
So if the model registry could choose based on the resources available, it'd be a nice abstraction. Unless I'm misunderstanding the intent with containers.
Yeah its a surprisingly similar problem to container orchestration/scheduling in platforms like kubernetes. The app doesn't say "put me on this node", it just says "give me a node with this cpu/memory and access to this volume"
I expect something like that to show up here sometime soon 😄 https://openrouter.ai/docs/features/model-routing

OpenRouter Documentation
Route requests dynamically between AI models. Learn how to use OpenRouter's Auto Router and model fallback features for optimal performance and reliability.
Yes, I think this is a good starting point.
I was definitely thinking about adding models: [string] as an argument to LLM()
How would that work?
It can choose from the set or have fall backs if the first doesn't work?
Either "any of these" or ordered by preference with fallback - wasn't sure
I like that affordance. I'd be curious how to build logic around the set of models. How to make it easier for the developer or the workflow to choose among the models in the set.
But allowing for multiple models is a good starting point IMO
Well it would be the developer of the workflow providing a list of models it doesn't mind using
that would be the choice
Choice is good
My personal coding agent 🧵
as soon as 0.17 is out we can remove the custom install instructions from AI agent tutorial 🥳
it's out
And Jason removed it!


Is it possible to set a callback for the llm response? Meaning every single response from the llm I can capture and send somewhere?
You can query it after the fact with LLM.history()
That history API is a bit barebones, but we can beef it up to distinguish messages by sender (LLM, user, tool)
I think for now you could filter it by emoji in the contents 😛
yeah, the demo I was thinking of would be to have a NATS publisher sending the request and a NATS consumer sending all of the responses to the stream - giving a decoupled kind of pub/sub agent
@steep onyx @spring wave should I be worried that after running dagger develop with 0.17, my IDE autocompletes to dag.Llm and not dag.LLM ?

known issue
if that reduces the worry 😛
i think we need to teach strcase about that acronym
ah, looks like we do that in core/ but the codegen code probably (hopefully) isn't loading core/
Weird BBI error at the end of this demo prep session: https://v3.dagger.cloud/dagger/traces/09cd836f493f191fdb1ceb31de288a83

Browse and visualize Dagger traces.
(see very last error)
looks like it tried to call a function with "app" in place of a FooID arg, essentially an unbound var
which didn't work because all the vars are app_*, and there's never just an app wonder why it tried that
oh geez the codegen has a whole separate case conversion system

GitHub
This is gonna break a bunch of stuff, but better now than later...
bots make typos too 🤗

random question. of multiobj continues to cause problems. should we implement it as single object + shadowing?
- the builtins system

GitHub
This introduces a new dagger mcp command that starts an MCP stdio server.
MCP clients can configure to exec: dagger mcp or dagger mcp -m path/to/module.
In this version, each dagger function corres...
@spring wave wdyt?
@warped bramble @wraith remnant my guess is that your MCP pull request already works with multi-object... But only for models that don't need the crutch of a special system prompt
also @spring wave we could use the old "read the manual first" trick to inject the system prompt without making it a real system prompt - then it would work over mcp
i think it wouldn't have the weighting of a real system prompt, but yeah could try it
This is the error I'm getting on Gemini returning a Go struct: https://v3.dagger.cloud/JasonDagger/traces/c8f50741d8745eb87147a4f4649fac71

Browse and visualize Dagger traces.
I do keep coming around to the idea that single-object is all we need for bootstrapping, and anything else can be implemented as a module that is able to maintain its own state (as the single object) . which i have done on a throwaway branch somewhere. Like I have a pretty strong feeling that different situations might call for different schemes, one of which being 100% control over the set of available tools to keep the model from jumping around and saving vars aimlessly.
I still need the ability to give the llm not just constructor functions, but pre-configured objects, ie. with my secrets etc
@spring wave I'm going to get back to dev mode today, I'm loaded up with demo feedback and papercuts. How do I do this in a way that doesn't conflict?
a few options:
- try my
llm-evalsbranch if you want to start from my experimental changes + have a suite you can use to test your changes - just stick with
main, maybe copy over those same evals since they should be compatible - or just monkey around on
main
there will probably be conflicts either way but that's OK, experimentation is always messy/good.
I'm thinking I'll start with Environment, which is mostly API changes to use the same underlying implementation. From there, might try the "single object with shadowing" idea
I'm thinking we should merge dagger mcp (hidden) asap to avoid conflict storm
One drawback of single-object (that i'm sure you're already aware of) is that just by bringing in dagger.Container's functions, you get ~70 tools. Which could grow quickly to the 128 tools limit.
that's true for multi-object too
but, we never combine tools of multiple types, so that helps a bit
Ah sorry, i thought there was an indirection (not super familiar with it yet)
i was only able to hit that limit by doing LLM.withLLM since it has a ton of getters/setters lol
no you're right @warped bramble . in multi-object you get at most the tools of container; but it doesn't add up as you "unlock" more yypes
(also, funny how a 128 limit is cropping up again, I remember that from the early Docker days with aufs :P)
god...
did you hear the story of what it turned out to be? Which we discovered much later...
hmmm was it the limit of the mount opts string length or something?
yeah exactly. It wasn't actually 128 of anything - it just roughly landed at that number by chance with typical opt strings
and we all saw what we needed to see, to make sense of the world
input: databaseAgent.ask google API error occurred: googleapi: got HTTP response code 400 with body: [{
"error": {
"code": 400,
"message": "Please ensure that function call turn contains at least one function_call part which can not be mixed with function_response parts.",
"status": "INVALID_ARGUMENT"
}
}
]
most likely unrealted to that Go struct issue, it's some sort of flakiness, haven't been able to pin it down yet
do you want a branch on my repo where I am seeing this to help?
oh I'm having an easy enough time hitting it on my own, thanks 😂
haha ok
Any trick to hide the progress bar so that it doesn't mess with python's input() reading from console?

buckle up, I just merged https://github.com/dagger/dagger/pull/9933 💥 /cc @smoky ocean (breaking change)

GitHub
This is gonna break a bunch of stuff, but better now than later...
OK installing!
how does one fix this exactly with an unreleased cli? like if i do dagger develop on my module that calls Llm (that's used by dagger/dagger tests) it puts a long dev version specifier in the dagger.json, i fix my compile errors and then should i just truncate the version specifier to 0.17.1 ?
I would just fake it and say 0.17.0 tbh. The auto dagger.json version bumping does seem a bit too aggressive to me. Ideally we would only bump if to the minimum required version, and never to dev versions imo
 but doesn't the 0.17.0 go sdk want
but doesn't the 0.17.0 go sdk want Llm?
it does but v0.17.1 isn't a thing afaik
so i don't think dev versions would match it?
if you say v0.17.0 dev engines can at least still use it
you could tag a Llm version before the LLM bump i suppose
 maybe i'm making bad assumptions about the failures im tryna fix
maybe i'm making bad assumptions about the failures im tryna fix
OK so: definitely don't publish llm modules targeting 0.17.0?
- release 0.17.1 monday?
yeah I think it's better for folks to stray forward to dev compatibility vs. maintain compatibility with whatever iteration we happened to ship in v0.17.0
@spring wave got a crash trying to use query object in prompt mode, in the dagger module https://dagger.cloud/dagger/traces/318291796c3f542d7f3194a4294a7a4e#418845bd7580ade6
looks like it ended up on an array maybe? those are currently not handled, might need something special like "select the Nth item"
also, yeah, at the moment you have to mention "dagger" for it to realize you want to use that module - ran into that to. try "lint the Dagger docs"
maybe it should be further scoped
was going to try that next - but got that panic first
there's a subtlety here btw, sometimes you want an API endpoint to a module; and sometimes you want an API endpoint from the context of hte module. At the moment Dagger doesn't clearly delineate the two.
Maybe the distinction becomes more important when we throw LLM and their environments the mix?
New video drop 🙂 https://x.com/solomonstre/status/1903226073938268361
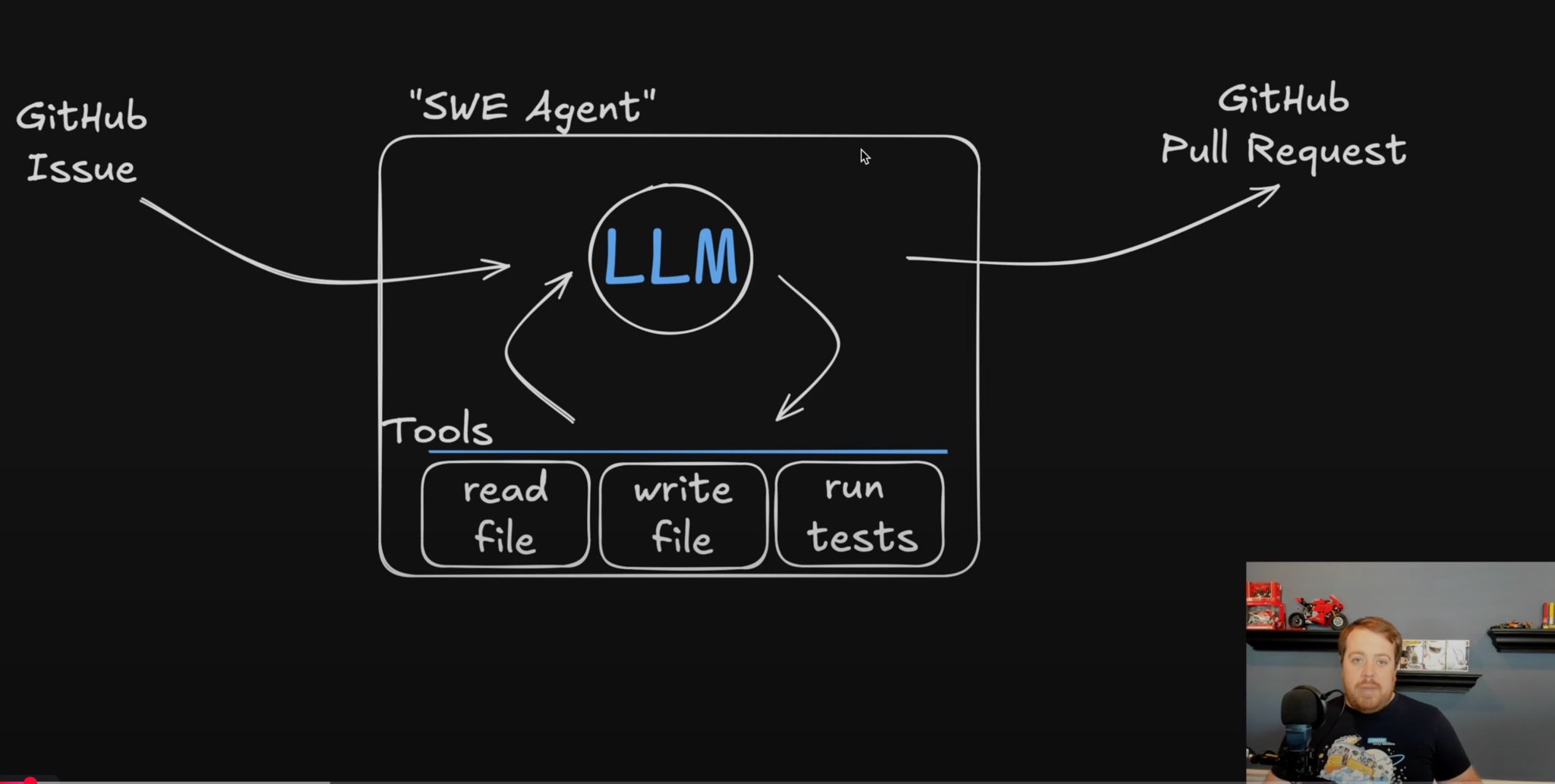
This video by @kylepenfound kind of blew my mind. He demystifies the concept of a coding agent, and shows how to build your own from scratch. From zero to "robot ships a feature" in one video 🤯
If you're curious about coding agents, but not sure where to start... Watch it! 🧵
Hello, I'm trying to create an simple assistant for simple Kubernetes issues. As with many real-world problems, it would be ideal to find a perfect solution and finish, but it seems necessary to be able to instruct human intervention or interruption at each attempt (e.g. LLM Call). From what I can see, dagger/agent currently only adjusts loops through prompts, but would more programmatic control be possible? (e.g. MaxTry or confirmation on every call?)
You have a couple of ways to proceed, first of all you don't have to let the LLM handle the main loop. We built demos doing both, and I prefer to keep the LLM loop small, as well as its toolset.
Then you handle the main logic in a bigger surrounding loop that will do things beyond what an LLM can do. For example call containers, call an API, or anything that the Dagger API can do outside of LLMs, etc... You can then include extra information when you re-call the LLM, which increases the LLM accuracy (tried with both OpenAI and Anthropic models).
Also note that even if the LLM tries several times with its own loop, you can limit it to a specific number of attempts by making it explicit in the prompt.
I made a module for working with firecrawl (firecrawl.dev) since it seems pretty hot for LLMs + web scraping https://daggerverse.dev/mod/github.com/kpenfound/dag/firecrawl
A module for working with Firecrawl (firecrawl.dev)

@shrewd ermine thanks for the YT videos on Agents, I'm going through them now.
https://www.youtube.com/watch?v=VHUi9ABdASA
https://www.youtube.com/watch?v=B7P04M9c1m0

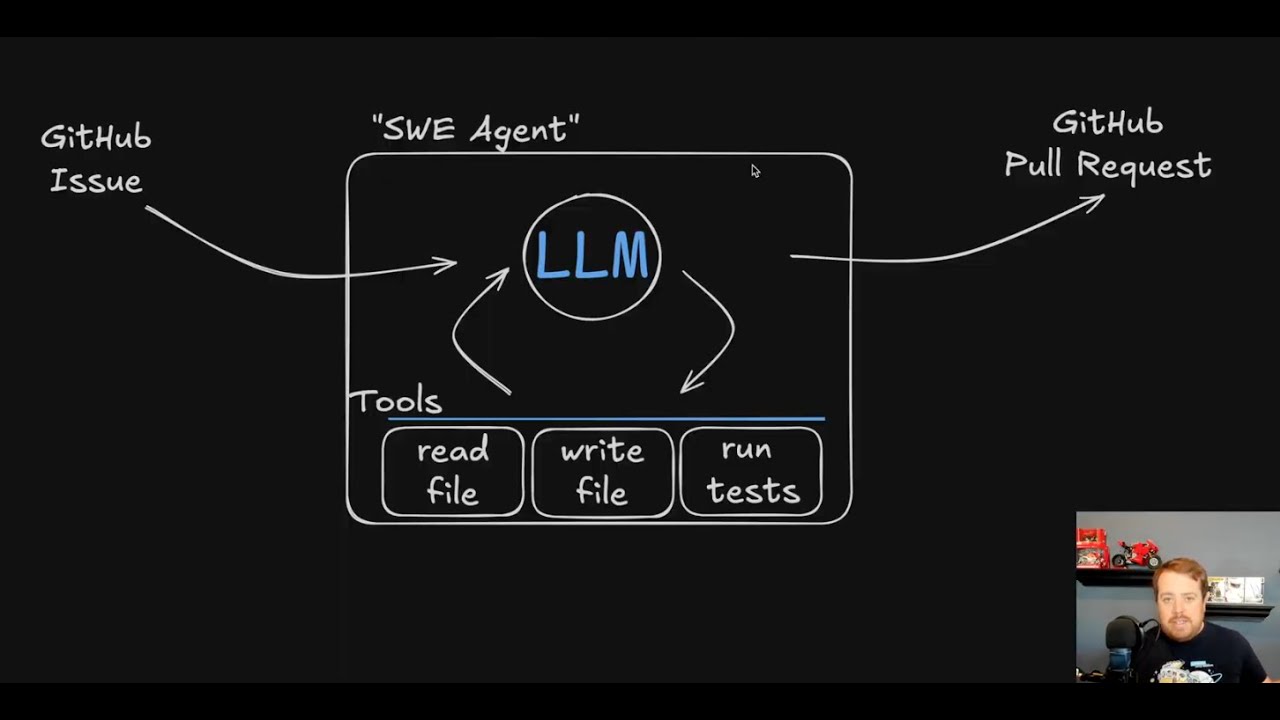
This demo shows how an AI Agent can operate in a CI environment to assist in resolving test failures.
Code: https://github.com/kpenfound/greetings-api
Have questions? Ask us in Discord: https://discord.com/invite/dagger-io
This demo shows off a simple agent that automatically creates new features in a demo project. Features are designed and assigned as GitHub issues and the agent creates a pull request with the completed work.
Code: https://github.com/kpenfound/greetings-api/blob/main/SWE_AGENT.md
Have questions? Ask us in Discord: https://discord.com/invite/da...
finally figured out those cryptic "mismatched function call/response" shaped errors - it's when an LLM tries to call a tool that doesn't exist, we were dropping that on the floor
local git awareness 🧵
I'm also getting these kind of errors quite often using Anthropic:
! POST "https://api.anthropic.com/v1/messages": 400 Bad Request {"type":"error","error":{"type":"invalid_request_error","message":"messages.33: `tool_use` ids were found without
│ ! `tool_result` blocks immediately after: toolu_01T2iDjHMNTfRJWtGAgqidc6. Each `tool_use` block must have a corresponding `tool_result` block in the next message."}}
! input: llm.setK3S.withPrompt.loop.setK3S.withPrompt.loop.setK3S.withPrompt.loop.setK3S.withPrompt.sync select: POST "https://api.anthropic.com/v1/messages": 400 Bad Request
! {"type":"error","error":{"type":"invalid_request_error","message":"messages.33: `tool_use` ids were found without `tool_result` blocks immediately after:
! toolu_01T2iDjHMNTfRJWtGAgqidc6. Each `tool_use` block must have a corresponding `tool_result` block in the next message."}}
seems like a 🐛 ?
yep, same issue, have a fix on my llm-evals branch
it's two issues: 1. that the model tried to make that call (bad prompting), 2. that we dropped the bad call and ended up with garbled history
I think I'm seeing something odd with the token caches where if I ask the LLM to run another thing that it ran before, it replies that it's going to do it but the tool actually never gets called. I'll try to get a repro
even if the dagger function has cache buster
Maybe the dagql cache? 🤔
yeah if it makes the same DagQL-level query multiple times it'll only show up in the trace once. I ended up adding a cache buster for my evals, and that worked
But don't we have function caching within the same session? I think I'm hitting that?
I have a cache buster within my function but the trace doesn't even show the initial function call
yep
that's true, cache busters technically have to be propagated all the way out now
i mean if we do a dagql persistent cache
Yep... Seems like it
this might change with @steep onyx's work - he had to do something special for intra-session dagql cache hit telemetry
We need to find a way to set a pragma at the function level to hint the engine that the function should never be cached
Or just disable function caching altogether in prompt mode 🤔
There's many edge cases here I think
I'll open an issue tomorrow

GitHub
Problem Dagger has great caching, but Dagger Functions don't fully benefit from it, because their runtime containers are not cached. This has several consequences: Functions that perform comput...
not exactly. In this particular case because I'm running a long-living Dagger session, the LLM is not being able to execute the same function twice with the same arguments since it'll always return the initial cached response
not sure what's the best way to handle that though. I'll open an issue to start the discussion tomorrow 🙏
you mentioned a pragma to disable caching of a function. That's part of the proposal in 7428. Are you thinking of a pragma that would be llm-specific?
yes, my initial thought was to make it llm-specific but TBH I haven't really thought about it too much in detail. Would it make sense to differentiate the caching (and potentially other properties) behavior based if the function is being called by an LLM or not? 🤔
I would prefer not to, if possible. But we can figure it out in your issue. Maybe we have no choice? 🤷♂️
what's an example of a function where you'd want different caching specifically when called by an LLM?
@spring wave @worn hill @wraith remnant @warped bramble just to point out a major unresolved point between MCP and main branch: if our tool bindings implementation requires injecting a system prompt, it won't work over MCP. I know it's a tricky tradeoff. Just want to clarify that it's a high-impact problem to solve..
Other question possibly related: do we care or not about MCP clients that don't update their tools list as we make more tools available dynamically ? Because I wonder if (maybe just a stop-gap) the tools we expose in MCP would be a static list of loader/getter/setter tools that are essentially an indirection on top of what LLMEnv would provide. (Keep in mind i'm not up to date with what the new multi object API should look like).
Just to share some fun stuff (at least to me 😅 )
I built a small agent that allows me to start a dev environment based on (any?) codebase. It will install everything I need, without to worry about it. Depending on the model you use it will even build an run the tests before to give the container back.
That's just a demo, so probably a lot of stuff to improve, but that's nice to play with.
dagger -c "dev-environment path/to/some/code | terminal"
(there's also an other task that is summarizing a subreddit, nothing related to the first one but also nice to test)
If you want to try it be careful to select the model you want, by default it's tuned to use some of my local models for a fully local experience, including models)
https://github.com/eunomie/local-agent
system prompting
@wraith remnant @warped bramble do you know if Cursor supports dynamic tool registration? Also I noticed in a MCP+Cursor video that the client asks for manual confirmation before each tool call. I wonder if that will be annoying with Dagger MCP, since that implies more intermediary internal calls
It doesn't support dynamic tool registration atm. And yes it asks for manual confirmation for every tool call. #welcomeToTheMCPJungle
yeah, not only doesn't it support dynamic tool registration but it gets confused by it -- still unsure if it's because of us or not
is the manual confirmation part just a cursor thing?
so far yes
this is cool, have you thrown any lower level language (rust, c) stuff at it? https://github.com/redis/redis or https://github.com/tree-sitter/tree-sitter would be fun examples

GitHub
Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs,...

GitHub
An incremental parsing system for programming tools - tree-sitter/tree-sitter
Release checklist 🧵
@quiet ether re: your discord agent. Can you split it into 1) a discord module and 2) an example agent using it? We're trying to apply that model to all examples going forward, to maximize composability
(ideally that discord module would be reusable enough to be a basis for stdlib)
Roger!
@smoky ocean one thing that I was wondering is if i should try to make it work with multi-object by default. It's not a big deal through because I can otherwise wrap all the tools that I need in a single workspace and use single-object as we currently showcase in multiple demos
what would the multiple objects be? discord client and _?
for my case. Discord and GIthub client
and potentially a third object to send notifications to somewhere else besides Discord?
yes multi object. specifically multi object from prompt mode...
by default the builtin agent has access to your module's dependencies
(right @spring wave )
really? I thought I needed to initialize them beforehand
i.e foo=$(my-module)
not anymore 🙂 (at least that's the UX we want to enable)
install; prompt; boom it works
is that v0.17.1?
of course that leaves the question of injecting config
which is why we need to dogfood asap
the only thing I'm missing is the ability to set multiple -m flags then. So I can make it work in the prompt without even creating a module at all
ha ha that is something I've wanted forever
maybe now I will finally get it 🙂
but init & install is a good start i think
maybe in the future, we will have a first class concept of environment, which you could initialize list load etc
doesn't seem super hard to add?? 🤔 . I can try checking out if I can make it work after I finish my module
i think it might not be so simple because multiple -m means each one is a dependency, and a single -m means you are that module
yep, it starts scoped to the toplevel Query now so it can call your module's constructor, and I think dependencies too, but actually not 100% sure - I remember we do things to avoid leaking module dependencies
my guess is it will be hard . single module is probably a baked in assumption everywhere in the cli code
but would love to be wrong
true.. will 👀 🙏
is this v0.17.1 Alex?
yes i think so

GitHub
A few experiments:
Add LLM.withQuery for making the whole Query schema available to the LLM
loadFooFromID fields are skipped
CLI prompt starts from Query so you can jump right into action, with...
oh also - $_ is a thing, it'll always be the last object that the LLM operated on / "returned"
there may be some bikeshedding to do there, but i think it's an important mechanic
❤️ I've awlays wanted a $LAST kind of thing. Wondering if we thought about using bash's !!?
that's the one that gets substituted with the last input right? so you don't have to go back and edit?
(i'm a fishy kinda guy)
correct, but you can also use it in context, like i do with-dev go test ... and then when i rebuild i do dev && !!
(also im on zsh, and fairly certain that alias is POSIX, more ancient than even bash)
right right
yep, exactly
!$ is another one that's probably very useful in a dagger shell context, just the last arg of the last command
what's the prevailing use case? !! | with-foo?
yeah, either append or prepend
i guess that can be $_ | with-foo once we support $_ in shell too (not just LLM response)
i generally use prepend more, though, because append can also be <up arrow> | with-foo
in bash !! actually re-computes the last command, doesn't hold the actual value
oh yeah it's unevaluated
right it's more like a macro than a var
yeah
so you'd do container | from alpine
and then something like
myfunc --ctr $(!!)
and then your history will contain myfunc --ctr $(container | from alpine) right?
lol that's a big "depends" i think
yes, correct
at least on my config it saves the !! unless you tab-expand
I don't get any !! in the history
@spring wave what does _scratch do and why does it get called so often in prompt mode?
it resets the current state to nil, so there aren't any per-object tools
i've gotten rid of it on llm-evals
lol so basically a table flip, got it
lol, yea pretty much. curious how it does on the llm-evals tool scheme. is it easily reproducible?
yeah i'm just setting source=$(directory | with-directory / .) and asking gemini to make changes to my project
ah gemini specifically is the model i've been fixing, lemme try. are you using a particular agent? or that's it?
just prompt mode right now, trying to work on a no-code experience
Ok, worked a generic sql module using Go structs, I've essentially broken the "workspace" with the LLM. Its trying to use the SqlTableDetails@xxh3:0735eeb380a1522f as the table name?
Trace: https://v3.dagger.cloud/JasonDagger/traces/929aee5c6d2e1152969edcc861f2325f
Code: https://github.com/jasonmccallister/sql/blob/09b96e193a85a93826a532168119628b8efe8492/main.go#L100
Quick question(s): On your llm-evals branch, after calling a tool, do you automatically get scoped to that tool or that tool's result or do you stay in the same original scope that gets updated with select + typeName?
when a tool returns an object, it auto-selects it yes
so theoretically selectFoo is only for 1) when you have no current selection or 2) when you want to go back to a different/older object
but, some models are keen to call it redundantly. those ones need a system prompt 😦
tried everything: putting something in the description => ignored. putting an explicit hint in the output => ignored. having selectFoo return an error if it was redundant => it just keeps doing it
Ok, and this is the same behaviro on the single object, BUT, the user can choose to go back to the original env (in the shell) with llm | with-hello $(.) | with-prompt "spin up an alpine container" | hello where hello brings back to the original env scope?
switching to JSON string was a little better: https://dagger.cloud/JasonDagger/traces/79a96b344ad7c040ffcd4c0e861ef0a1
Ok, worked a generic sql module using
the | hello at the end there will access the last value selected by the LLM, which must be a Hello object, otherwise it'll fail
Is there a consensus on the best model to use in ollama for tool calling? List looks long and forum/reddit are a little all over the place in terms of recommendations: https://ollama.com/search?c=tools
In that list I've mostly used llama and qwen2.5-coder
I tried, and the results are... not consistent.
I can use it to work on a rust project for instance, no problem.
But on complex codebases, the result will really depend on the model. With my local qwen2.5 it works well on small codebases.
But tree-sitter for instance (that also contains bindings to other languages) will not be good.
If I switch to openai/gpt-4o (I kept defaults) it works great, install cargo, npm, install some npm tools, build it before to open the terminal
I'd love to have the same thing fully locally, but I probably need a bigger machine and a bigger model for that 😅

Figuring out the deployment part, would appreciate any advice. Rest is working PERFECTLY!
So far the setup:
- I want my app containerized to simplify running under k8s, ECS whatnot.
- My app inside container calls dagger engine itself.
- Ideally some images come cached within dagger engine inside the app container.
What I'm doing right now:
use dind as base and install Dagger + UV
LOAD_CACHE = """
import anyio
import dagger
from dagger import dag
async def main():
async with dagger.connection():
print("inside async with dagger")
container = dag.container().from_("oven/bun:1.2.5-alpine")
result = await container.with_exec(["bun"])
print(await result.stdout())
if __name__ == "__main__":
anyio.run(main)
""".strip()
base = (
dag.container()
.from_("docker:28-dind")
.with_exec(["apk", "add", "curl"])
.with_exec(["apk", "add", "python3"])
.with_exec(["curl", "-fsSL", "https://dl.dagger.io/dagger/install.sh", "-o", "/tmp/install.sh"])
.with_exec(["sh", "-c", "BIN_DIR=/usr/local/bin sh /tmp/install.sh"])
.with_exec(["curl", "-fsSL", "https://astral.sh/uv/install.sh", "-o", "/tmp/install.sh"])
.with_exec(["sh", "-c", "XDG_BIN_HOME=/usr/local/bin INSTALLER_NO_MODIFY_PATH=1 sh /tmp/install.sh"])
)
runtime = (
base
#.with_exec(["sh", "/usr/local/bin/dockerd-entrypoint.sh"], insecure_root_capabilities=True)
.with_workdir("/app")
.with_new_file("/app/load_cache.py", LOAD_CACHE)
.with_exec(["uv", "run", "load_cache.py"], insecure_root_capabilities=True)
)
Whats the best course of action?
Figuring out the deployment part, would
Is there a generalize workspaces that folks are using for agents yet or are most folks hand rolling each time? I tried @shrewd ermine 's module from the daggerverse, but also noticed that it's not used in his agents demos
I've mostly made one for each demo that's tailored for the individual use cases. I suspect when multi-object + function masking is in it'll be less relevant.
yeah i keep finding that the agent's context grows huge and the task fails out before it finishes. suspect i'll need to hand roll a workspace module
yeah exactly, the workspace pattern is perfect for that. I tried to make a generalized one with kpenfound/dag/workspace but I still ended up needing changes for each implementation. Maybe function masking on top of a very generalized workspace would be a solution
I do think we should ship a default workspace with dagger init or something just to help people get off on the right foot
another case for init templates 😛
Environments (#1352023893543747754 message) might also replace this

Google
Gemini 2.5 is our most intelligent AI model, now with thinking.
Thanks! I missed this whole discussion lol, compeltely on board with the idea
Was talking Silicon Valley (HBO show) with a friend today and he told me about Windsurf's commercial that has Russ from the show on it. Hilarious. BUT, what Windsurf's founders describe is where I think Dagger might be headed "Both collaborative and independently powerful"

Introducing the Windsurf Editor - the world’s first agentic IDE. 🏄
In Windsurf, we have given the AI a previously unseen combination of deep codebase understanding, access to a powerful set of tools, and real time access to your actions. The result? A magical experience we call Cascade, the evolution of chat that keeps you truly in the flo...
yep I hit that too
Path to tres commas!
Cloudflare agent stuff
@spring wave what does LLMEnv.intern() do exactly? Re-entrant ingestion into "ID system" + return ingested ID? So I have to call it at least once to ingest the value, but then I can safely call it several times and get the same result, without side effects on the env state?
(context: rebasing my Environment API branch on planet-eval 🙂 )

yep!
the PR is ready for approval now
@spring wave how do you use the expectedType argument in Get()?
it's to handle the potential case where we just get a number from the model - that type will get auto-prefixed onto it to normalize it. So if you have an expected type (because you're being called in the context of an ID arg, or you're being called from selectFoo, etc.) - be sure to populate it
it's hard to consistently convince a model to make that mistake, so it's kind of "best effort" atm, may need refinement as we test more (for example, to handle 1 vs. "1")
it would probably also make sense to assert that the value matches that type name, but that's already handled other places so I didn't bother
I see everything is locked to objects, I'm guessing it wont be too hard to expand to any dagql.Typed in the future? There use to be a check for objects in some parts
it might make sense to do that again yeah, but it might also make sense to still keep non-Object types in a separate spot since the mechanics are so different. I split it up at a time where string vars were moved out into the LLM (because they were reduced to just prompt vars), but now they're back in the LLMEnv, and I just gave them their own map to keep it tidy
make sure you pull, you might not have those changes
i was going to ask earlier: do we anticipate passing other types as variables, or only strings? other scalars are easy, but arrays are where things get complicated
At least other scalars yeah. Didn't think about arrays, might not be worth it
are scalar values preserved in shell? or are they all strings?
foo=1 is a string i'd imagine
(though there may be other ways to set these for sure)
My immediate concern for the env API, is splitting LLMEnv in two halves: a Dagger-facing backend called Environment, and a LLM-facing frontend called MCP. So trying to sort the implementation in those 2 buckets
Implementation as I understand is mostly unaffected (besides being split in two), except for the functionMask part, which will move to the individual binding instead of just the current selected object
oh right, I want to try functionMask again, I had it almost working but the model ended up just getting confused, so I shelved it :/ (but kept some of the code intact for when I get back to it)
The Type#number system will be in the backend Environment. But things like the concept of "current" object, the specific string replies, tool hints etc, move to MCP
I'm tempted to try another model where instead of having a "current object" you gradually increase your scope of available functions and explicitly pass a self argument
Hopefully Environment can stabilize while MCP keeps iterating like crazy on best LLM interface
my concern here is I'm not sure the "state machine" concept would survive the transition
(to be clear I'm using MCP in a loose sense. It would encapsulate both actual MCP protocol implementation, and BBI. I'm thinking we can just rebrand our BBI as "MCP", really a sort of "MCP+" 🙂
I feel like the longer we wait before we split, the harder it will get
looking forward to some code so this can start to become concrete in my head 😛
yeah sorry, the last week or so I haven't been able to look at the code at all
thanks for keeping that core going
👋 how's the load secret from env var tools coming?
✔ call the Discord API and set the bot token using the DISCORD_TOKEN environment variable 5.0s
│🧑 call the Discord API and set the bot token using the DISCORD_TOKEN environment variable
│ ┃ 0.0s
│
│🤖 To work with the Discord API using the provided tools, I'll need to call Query_discord which requires a bot token parameter. The token should be provided through the environment, but I don't
│ ┃ have direct access to environment variables. Let me let you know what's needed:
│ ┃
│ ┃ The Query_discord function requires a bot token and this needs to be provided as a SecretID. You'll need to first create a secret with the Discord token and then use that secret with the
│ ┃ Discord API call.
related:
✔ load the secret from the DISCORD_TOKEN env variable 12.4s
│🧑 load the secret from the DISCORD_TOKEN env variable
│ ┃ 0.0s
│
│🤖 I can help you load a secret using the name "DISCORD_TOKEN". I can use the Query_loadSecretFromName function for this purpose.
│ ┃ 2.7s ◆ Input Tokens: 2,427 ◆ Output Tokens: 95
│
│ ✔ loadSecretFromName(name: "DISCORD_TOKEN"): Secret! 0.0s
│
│🤖 Now I can retrieve the information about this secret:
│ ┃ 4.0s ◆ Input Tokens: 628 ◆ Output Tokens: 48
│
│🤖 3.3s ◆ Input Tokens: 702 ◆ Output Tokens: 37
│
│ ✘ Secret.name: String! 0.0s
│ ! secret not found: xxh3:a87f0af2887099fc
│
│🤖 I apologize, but it seems there was an error retrieving the secret. This could mean that either:
│ ┃
│ ┃ 1. The secret named "DISCORD_TOKEN" doesn't exist in the environment
related:
@spring wave @warped bramble @shrewd ermine @wraith remnant can we talk live about llm release in a little bit?
@worn hill and i are pairing in team-audio, feel free to drop in
cool, need another 30mn or so
This actually gave an idea. How about a flag along with "-c" so the shell doesn't automatically exits after running the commands? Python's REPL supports this by adding the -i flag
@quiet ether FYI i have an idea to make MCP work with multiple modules statically (not yet dynamically), could be in a follow up.
actually, sorry, i have to do an errand and will probably miss that timing
No problem, me too 😛
Want to ping us when you're back? The shell launch tornado will probably be over by then
Can you still talk today?
yep! just have to dip out for a couple of hours
Are SetXxxx(name, value) and WithXxxx(value) equivalent?
I thought WithXxx was deprecated, but maybe not anymore?
What's the impact regarding tools? When I use WithXxxx I can see the tools (for instance using .LLM().Tools()) but not when doing the same thing with SetXxxx.
So I guess I'm missing something here, but not sure what 😉
- it's work in progress... APIs not yet stabilized
- The way it currently works is that both work, and are layered. There is a concept of "selected object", which you can set directly with
WithXXX. The LLM can also change its own selection with internal tools. At a higher layer on top of that, there are named bindings (variables) which can be set in the LLM environment (SetXXX). The LLM can list them and select them
We are actively working to simplify this API. It's tricky because there are several variables in the equation:
- Best DX for the developer (ie. you)
- Best performing LLM interface (how the bindings are presented to the LLM, lots of tricks and iterations there)
- MCP support. We want the same system to work over LLM and MCP protocols.
- Keeping modules up-to-date with API changes (examples, early prototypes etc)
See #1352023893543747754 for proposed direction
@river belfry when you do WithXxx("foo", bar) the object bar is available at the named binding "foo". I think in the current implementation there is a special tool called _objects or _list or something like that, and it will list the bindings
just to validate array types are not very well handled by the dagger llm yet, right? Getting some panics when try to call function which return those
correct, I think arrays of basic types are fine but not arrays of objects
This works on my llm-evals pr, which still needs a ✅
Merged!
@smoky ocean half baked idea related to return values and whether there's an implicit current state / return value, and building on the idea of letting it know upfront what type of value we want back: something like withFileSlot("bin", "The compiled binary.") - the goal being for the model to fill all the "slots"(?) before returning. Those could then all be synced back to the shell. Dunno about the code DX, I have a feeling the functional model of "many inputs in, one input out" may still be more intuitive (I generally prefer schemes that don't require you to make up names for things if you only have one thing), but something to think about
Could be a property of the binding, set with an optional to withBinding
mm but "returning" a binding is weird
but so it "returning a slot" 😛
lol, i thought of it more like filling a slot but am not bound (heh) to the word at all
since there may be multiple of them
there's probably a better metaphor
what I really don't want is mutable bindings
I think if LLM familiarity matters, we should go for something very very present in the training data, like returning or exporting
Or printing 🙂 (we don't have to actually print it)
Or showing ?
yeah probably comes down to what the evals say
What would a human user do
It would probably enter the values in a form
You could almost say it would be prompted to enter a value 😛
oh god we crossed the streams
I mean that is how they win in the end

FYI https://github.com/dagger/dagger/pull/9983, i managed to test it with .model claude / .model openai in the shell. cc @smoky ocean
Dumb idea, but a user with a form would be to submit or even.. enter?
submitBinding
We’re all going to submit to them in the end.. so might as well adapt now?
enterBinding 🤘

https://github.com/dagger/dagger/pull/9978 @spring wave and i got a life alert prototype up and running today, so far pretty impressive at least with gemini, gonna try some other models tomorrow

GitHub
sorta working? if i ask gemini to use the tool, it does, prompts me, and reads my responses afaict. gemini also happens to ask pretty good clarifying questions, like maybe better than the ones it d...
knowing the desired return type
Google AI for Developers
Definitely eager to try this one. I've seen lots of good things about gemma3 but in the few prompts I've thrown at it, I'm not 100% convinced yet. But I'm a gemini fan so I know they can do it 🙂
I'm tinkering with function masks again and it's working suspiciously well... tempted to sneak it in. It saves SO many tokens (2849 vs 13,470), and in turn makes things run much faster especially with Claude. Also cool to see the LLM planning ahead.


(that mask-less run ended with "overloaded"... I have been seeing that a lot)
Hi, first post here: I tried using o3-mini of openai but got the error in the pic which shows parallel_tool_calls is not supported by the model yet, and parallel_tool_calls is true by default per https://platform.openai.com/docs/api-reference/chat/create#chat-create-parallel_tool_calls. Actually there is a recent issue on openai forum claiming o3-min tool calling issue (https://community.openai.com/t/o3-mini-api-with-tools-only-ever-returns-1-tool-no-matter-prompt/1112390/3), so it seems we cannot expect to use parallel_tool_calls for o3-mini any time soon. Alternatively, thinking of turning the option off, as I tracked down the dagger implementation which doesn't seem to allow custom params for the api (https://github.com/dagger/dagger/blob/20e8a174fd9e45c7ae915d091167aa7ef18d822a/core/llm_openai.go#L117), so parallel_tool_calls is true by default and not configurable from client side. So it seems a deadend for o3-mini unless I missed anything ? Is there any workaround or is allowing custom parameters for llm api worth being supported in near term ?


GitHub
An open-source runtime for composable workflows. Great for AI agents and CI/CD. - dagger/dagger
Has anyone been able to get their agent to understand how to find a trace url for the work its doing?
I am trying to have this URL included in a markdown file that the my agent is creating, but sadly right now it just says something along the lines of - **Dagger Cloud Trace**: N/A (local testing)
While trying to use mistral-nemo I've got:
After the optional system message, conversation roles must alternate user/assistant/user/assistant/...
Is it something worth investigating (or is that something already known)?
Has anyone seen this error from (I think anthropic)?
input: daggerverseQa.doQa received error while streaming: {"type":"error","error":{"details":null,"type":"overloaded_error","message":"Overloaded"} }
Yeah, I think they just need a break, same idea as google's 429
I have a feeling my demo is not going to go well 😦
usually they're not overloaded for long so 🤞
I hit that pretty frequently with Claude :/ @merry scarab have you tried your demo with Gemini? it'll be much better with v0.17.2, super fast and no throttling/overloaded errors
No I have not yet but like 5 min to show time so....
I dont have a gemini account either, yet ..
switch to openai?
openai has other errors - it tells me to f off because of a 30k token limit or something
Ugh........ I am so sad. This was working overall before but now its not writing my file again 😭
why does this always seem to happen right before a demo
nvm it works!
🤞
The overloaded thing gets cached lol -- this is where I really wish I could have a flag or somethign to tell shell to DOIT or something
I've run into this too, we should not cache those errors
Masked functions 🧵
(possible early thread deduping: https://discord.com/channels/707636530424053791/1354656055925149716)
custom params
🚨🚨🚨 Dagger 0.17.2 is out, with many improvements to the LLM API. Make sure to upgrade and try running your agents again! Let us know if you see any issues or improvements!
Updated my agents to v0.17.2 - everything works as expected. Any specific APIs we should try/test out?
@spring wave
not really! there are some additive APIs but they're mostly meta/fringe things, it's mostly just whether your existing agents are still working 😛
yeah working just fine, nice work 💪
soooo @quiet ether @spring wave @smoky ocean the "we want dagger install'd deps to be available to the LLM" thing: this is obviously desirable for local modules, should it also apply to remote modules? eg dagger -m toy-programmer shell should have an LLM env where toy-workspace is callable? remotes-depending-on-remotes, too? like dagger -m dagger/dagger should have gerhard/daggerverse/notify?
Great question. I mentioned in another thread (can't find it of course) that we've always had this ambiguity between "query a module from the outside" and "query from inside a module". We've never had to resolve it, but it started gently biting us in the shell, and now even more 🙂
imma just try to have the llm always feel like it's inside the module regardless of local/remote status
Makes sense to me
That way it will match the shell .cd
 #1354880578390065162 message - here's a delegateable task: retry logic in the LLM loop. Each provider implementation checks for certain retryable errors, annotates the error response as such (wrapping error type), outer loop checks for it and retries, backing off as appropriate
#1354880578390065162 message - here's a delegateable task: retry logic in the LLM loop. Each provider implementation checks for certain retryable errors, annotates the error response as such (wrapping error type), outer loop checks for it and retries, backing off as appropriate
i'd wager that's pretty high priority
oh @shrewd ermine opened an issue 🙏 - https://github.com/dagger/dagger/issues/9970
debugging a thing in the gemini client implementation https://github.com/dagger/dagger/blob/main/core/llm_google.go#L221
if candidate.Content == nil {
return nil, fmt.Errorf("no content?")
}
I think maybe we need to continue in this case rather than error. Anyone else have more context on cases when the Content is nil (with streaming)
do you have a trace ? 👀🙏
I don't, I haven't hit it on my end yet but im trying to make a repro
I ran into this and saw we were getting FinishReason=10 which is something like "the model generated a malformed function call" - but couldn't find any more info, can't even see said malformed call in the dump, but may be able to see it on raw network traffic if that were inspectable
ah got it, yeah I don't think we're handling FinishReason at all right now are we
I need to explore more, but on the same agent, same (local) model, I have worse results with the 0.17.2 than I had before. 🤔
I was running a version based on commit a2aaf08158a64bc47e4d3fe143701b9dbb88d885 that was pretty good. Not sure what changed, I'll have a look at the llm related commits between this commit and the release.
right not at all. For extra fun, the genai package's consts don't even go up to 10 🙃 - I had to look up their API
do you have code anywhere I can try out?
once I write a PR review agent from my demo repo I'm going to have a review bake-off between the different big models 😎

please record 😍
so i've been poking around for a couple hours now and i cannot for the life of me figure out where to rip open a seam to mix module dependencies into LLMEnv. i think i've found a couple of the relevant pieces, like LLMHook.InstallObject exposes objects in the LLM env, core/schema/modulesource.go has pieces that iterate through module dependencies... ModSource.lazilyLoadSchema even calls mod.Install on each module in a ModDeps (although that feels like maybe a different meaning of Install)... coming from the outside, shell_fs.go has maybeLoadModule for bringing in modules, but that's got all its own definitions of modules that don't map to core types, and there's a lot of indirection between those shell modules and the LLM install hook.
where would you start with this? @spring wave @hidden tartan it feels somewhat related to codegen activities, but the calling context is very different
cc @steep onyx @shrewd fern 🙏
I suspect you might be too far down in the stack - I would try doing it in the CLI from the outside, for example if we have an API for getting a module's dependencies and calling .Serve I think that should result in them being installed into Query
lol i was literally just looking at this
@spring wave there's a spooky comment here though: ```go
// Serve a module's API in the current session.
//
// Note: this can only be called once per session. In the future, it could return a stream or service to remove the side effect.
func (r *Module) Serve(ctx context.Context) error {
if r.serve != nil {
return nil
}
q := r.query.Select("serve")
return q.Execute(ctx)
}
A question about "direct host access" which is disabled for dagger function per https://docs.dagger.io/api/sdk/#differences: my case is to develop an AI agent in form of dagger module, and I'm trying to let it take an input source directory from host (where my sample app is at), and do something agentic in my dagger module/functions including read, write, modify codes in my sample app or execute some arbitrary commands. But I tried achieving with no luck, the best I reached is taking in the host dir, manipulating it with or without container but cannot export it via code. Is it because function context is only the module folder and exporting to host via code is not allowed ? The dagger demos of agent are mostly publishing the agentic results on the project to PR, but I just want to apply them to host. It seems related to this issue https://github.com/dagger/dagger/issues/8235 ?

GitHub
Problem In theory Dagger is perfect for generating code or docs. In practice, the logic for exporting files back to the client filesystem is simplistic and brittle, which makes the experience awkwa...
Dagger SDKs make it easy to call the Dagger API from your favorite programming language, by developing Dagger Functions or custom applications.

I believe there is now an optional argument to llm() to give it "privileged" access to the caller's context. I think it's called withQuery
it's all or nothing though
It can be called multiple time per session from different modules, not from the same one (it will conflict with already installed dep)
sick, i think that works fine in this context, building now
That's what I do with the client gen, I call serve for each dep that needs to be served
Something like that
dag.moduleSource("xxx").Serve(ctx)
dag.moduleSource("bbb").Serve(ctx)
Boom xxx and bbb are queriable 😄
in the shell context, i'm initially trying this one layer up in 2/3 callsites of maybeLoadModule (.cd and on startup, skipping the one in exec)
func (h *shellCallHandler) maybeLoadModuleAndDeps(ctx context.Context, path string) (*moduleDef, *configuredModule, error) {
def, cfg, err := h.maybeLoadModule(ctx, path)
if err != nil {
return nil, nil, err
}
for _, dep := range def.Dependencies {
digest, err := dep.Source.Digest(ctx)
if err != nil {
return nil, nil, err
}
_, err = h.getOrInitDef(digest, func() (*moduleDef, error) {
return initializeModule(ctx, h.dag, dep.Source)
})
if err != nil {
return nil, nil, err
}
}
return def, cfg, nil
}
looks like this
And is it working as expected?
dunno yet still building lol
Okay let me know 😄
You could just call dep.Source.AsModule.Serve technically
If you want to serve that dep
I guess there's more to add it to the shell completion etc but that should be a one liner to only serve
Thanks for the llm hint. But a dumber question is that without using llm/agent, just normal operations, is it possible to use a module function to take input source and write like a hello.txt directly back to the source directory on host via code instead of dagger shell ? Here is a simple code that ran with no error but nothing is created on mysampleapp folder even with wipe as True, and file is created in container as verified via terminal(), not sure what I miss here.

it did actually work 
imma try it with just serve now, because the way i did it the shell wiring is incomplete anyways
Yeah this is possible I did a demo showing this exact scenario this morning. My example used LLM but it works the same in all scenarios.
Check out the code and video
https://github.com/levlaz/agent-playground/tree/main/daggerverse-qa
https://www.youtube.com/live/uOSmyFx7O7Q?feature=shared&t=2851
Main thing is you need to use ‘export’ to get the file or directory back out to your local machine
https://docs.dagger.io/api/chaining/#export-directories-files-and-containers
GitHub
Public Repo for Building AI Agents using Dagger. Contribute to levlaz/agent-playground development by creating an account on GitHub.

Join the Dagger team and fellow Daggernauts for our bi-weekly Community Call! Stay up-to-date with the latest product enhancements, discover innovative use c...
Function chaining is one of Dagger's most powerful features, as it allows you to dynamically compose complex pipelines by connecting one Dagger Function with another. The following sections demonstrate a few more examples of function chaining with the Dagger CLI.
https://github.com/dagger/dagger/pull/9992 @spring wave @hidden tartan for your perusal

GitHub
this lets prompt users dagger install modules and manipulate them in prompt mode as though they were the core module.
there's a alternate approach where we do a bit more and call
def, err ...
Every time I see a PR by @worn hill, a little "victory trumpet" sound plays in my head because of that little trumpet-shaped avatar. Is it just me?
I'll keep that in mind
Thanks @merry scarab ! I've watched the live video of you this morning but notice the difference that you use export function from dagger shell instead of writing it in code. I'm asking whether it's possible to achieve it using pure code. I guess this comment from dagger team is relevant ? https://github.com/dagger/dagger/issues/8226#issuecomment-2312479275 And I tried using your code, the shell way of exporting works for me even the target dir is arbitrary out of module root but the attached code doesn't work for neither under module root or arbitrary path (ran without error but nothing exported).


GitHub
What is the issue? We have created a container using go sdk and trying to export to host machine using Export function but it is not working. Same operation we are doing using cli "export path...
I see the issue.
You're right that modules can't export to their caller's context. One workaround is to assemble a single directory with the contents to export, and return that. Then the caller can export in one go.
It makes sense. Now I kind of get that why module isn't allowed to export to host since it's supposed to be the caller responsible for doing changes to host rather then module. The caller can be either dagger cli/shell or some custom app.
Exactly. We sacrificed some short term convenience in exchange for a more robust composition system.
is there a way to see the full LLM query? i keep blowing up because the input grows too large as the system runs the tests on repeat, but i haven't figured out how to tell what exactly is getting appended to the LLM request
yes you can call LLM.history()
if i were running in the shell?
ah, I think there's a .llm builtin that returns the builtin llm state. so .llm | history ?
ah you meant in the SDK with LLM.history()? i meant after a run / in traces for trying to understand the failure
ah I see. Did you setup tracing in Dagger Cloud? You can see the full history in the web view if the trace
Ok now the LLM is doing what I expect, but dagger keeps exiting after the LLM prompt cycle finishes:
const llmSpace = await dag.llm()
.withWorkspace(ws)
.withPromptFile(prompt)
.sync();
return await llmSpace
.workspace()
.diff()
it nevers calls diff -- it exits at the llm call
fwiw i had the same issue with the shorter,
return await dag.llm()
.withWorkspace(ws)
.withPromptFile(prompt)
.workspace()
.diff();
but i broke it up trying to debug
That looks right, but there could be 2 things going on:
- If you're looking in cloud, currently the LLM basically "takes over" the whole trace and hides everything before/after. We need to fix this
- At one point the tracing output in the terminal would basically push the output of
diffoff screen. I don't remember what the current state of this is, I thought it was fixed... but when that was happening, running the same command again to get the cached run would show me the correct output.
could use a review on this if anyone's got time: https://github.com/dagger/dagger/pull/9993

GitHub
This was a bit of a halfway measure and is currently detrimental to consistent model behavior.
For example, I've observed:
needless calls to readVariable
attemps to pass variables as funct...
oh snap! maybe i'll write the diff as a file and export it instead of a string and see what i get
@shrewd ermine have you seen this in your greetings api?
POST https://api.github.com/repos/lamalex/greetings-api/pulls/3/comments: 422 Validation Failed [{Resource:PullRequestReviewComment Field:pull_request_review_thread.path Code:invalid Message:} {Resource:PullRequestReviewComment Field:pull_request_review_thread.diff_hunk Code:missing_field Message:}]
its failing to write suggestions, https://v3.dagger.cloud/lamalex/traces/e8fd16f89c8f5aaa89d2db32192d6de5?span=2deb6b8a5cac88a3

Browse and visualize Dagger traces.
I haven't but I'm surprised I haven't 😅 There probably needs to be some kind of validation on the payload https://github.com/kpenfound/greetings-api/blob/main/.dagger/debugger.go#L93
spent yesterday loading a bunch of NYC open data into postgres and then wrote an agent to analyze it.
-
gpt-4o seems to consistently generate working queries, but then quickly ends up in rate limit land.
-
gpt-4o-mini avoids rate limits but generates mostly useless queries and spends a bunch of time just looping on nonsense
trying out some alternative models this morning
Nice, is that on a free tier account or paid?
open AI ive paid for but it says i have to spend more to get to higher rate limit tiers?
```suggestion
Click the button to see a greeting!
looks right but 🤷ah ok, I haven't used OpenAI at all yet but that makes sense. FWIW gemini goes really far for free, but maybe that's a hot take 😅
which model?
gemini-2.0-flash
🧵 to bikeshed prompt mode toggle

GitHub
In addition to user-configurable function masks, maybe we should mask some functions from core types by default. The core types (Container, Directory) have a lot of functions, so the tool count goe...
Connor, would really love to have this so I can continue working on my Discord module with this enabled. Just checking if I can help somehow to merge it
or..I can just build the engine off that PR and hold, that's fine either way 🙏
feel free to cherry-pick, i've got some broken tests to track down and some tests to write before that will become mergable
@shrewd ermine ya gemini limits seem better.

although you'll notice i asked about 2025 and got a 2024 response 😛
so have to play with the data and prompts a bit.
My code is there but not sure how easy it is to test it https://github.com/eunomie/local-agent
But I finally managed to find the first commit that changed the behavior:
https://github.com/dagger/dagger/commit/44370a44d
I'll check again with main to see.
Basically:
- I'm running qwen2.5 as the (local) model
- the app is a small tool containing an environment with functions like addpackages, tree, read, write
- the goal is to create dev environments on the fly, by letting the LLM read the files and understand what to do.
- before this commit, the llm will read the file tree, read the files, install packages
- after, the llm will read the file tree, read the files, but stops there. It never install packages, in best case it prints what it should do
My guess would be in this upgrade ofopenai-gofrom0.1.0-alpha.61to0.1.0-beta.2
I'm trying to upgrade to the0.1.0-beta-3to see if that's any better
ok, so the 0.1.0-beta.3 is better. My feeling is it's still worse than the alpha.61, but it's better
I'll do some more tests, but I can open a PR to bump it
Hi all! I've been playing around with Dagger's agent use cases and am very excited to build an agent on top of it! Thinking ahead, I do have a question on how I can distribute my agent that's built on top of Dagger for others to run. I understand that I could ask my users to install Dagger and then do dagger install dagger run etc, with my own dagger module. But is there a way that I could package dagger runtime as part of my own executable and just ship one single binary to my users? Thanks for the help!

GitHub
https://github.com/openai/openai-go/releases/tag/v0.1.0-beta.3
Full changelog: openai/openai-go@v0.1.0-beta.2...v0.1.0-beta.3
just tested this and unblocks my use-case. Thx Connor ❤️
was chatting with @spring wave and there is one thing downstream of this that feels kinda necessary: the LLM needs a selectQuery tool. when its selected something else, in my use cases usually the type of the parameter of a query that im building up to put into the query, once you've got the param all constructed, it can no longer pass it in to the query-rooted function you're trying to call. curious if you've hit that same thing in your experimentation.
Did a rebase of the engine-wide cache PR on main and picked up the new AllowLLM tests, which started failing. The main "problem" is that tests are getting cache hits/deduped-execution when calling the same modules with the same args, which results in only one of the test clients actually getting a prompt to ask if it's okay to use the LLM, causing others to fail randomly...
"problem" in quotes because I'm not sure yet if that's actually something to consider a bug. The point of the --allow-llm stuff is to not eat users tokens without their permission, right? So in this case, not prompting a user who's tokens wouldn't be consumed anyways makes sense, I think? Would others agree? cc @worn hill
I got the tests to pass by mixing in the client's AllowedLLMModules settings into the cache key for function calls, but that's a sad way to fix it since it means less function caching everywhere just based on those settings.
For now, going with just adjusting the tests to avoid duplicate function calls that trigger this. If anyone has an opinion on whether the behavior should be different in this situation lemme know.
yeah, i'd agree. i was hitting this with the old cache algos too, but added this cache buster to try to avoid it... it seemed to work and cause the desired-for-test cache invalidations but i won't pretend i had a complete understanding of why, i was just trying to get hit all the cases i needed to hit and it seemed to unblock me

GitHub
Contribute to dagger/dagger-test-modules development by creating an account on GitHub.
@steep onyx that said the full caching on llm calls is gonna be really interesting... does it correctly factor in message history and whatnot? people definitely don't think of LLMs as being pure or "hermetic" (weird word to use here, i know, but i think you catch my meaning) and im curious how easy it's gonna be to get accidental cache hits that produce surprising behavior
those test examples are not what i'd call surprising fwiw, mostly cuz they each start from scratch so there's no collected message history
For now I'm gonna toss in a CachePerSession on llm so that it just retains the behavior it currently has once we enable persistent dagql caching. Basically just delaying needing answers to those (tricky) questions.
I feel like not caching LLM calls is the right default, but we do definitely need the history to be cacheable (and transferable via remote caching). So there's some subtleties there to disentangle
idk i could see caching feeling nice provided that all the history and env context bits are treated as part of the cache key
🚨🚨🚨 Experimental MCP support merging soon! Thank you @wraith remnant @warped bramble 🙏
In ✅
GitHub
This introduces a new dagger mcp command that starts an MCP stdio server
Usage
dagger mcp or dagger mcp -m ref, where the ref is a path to a local module or a remote one
Implementation
In this vers...
Work in progress: "Environment API" which cleans up LLM API by introducing an Environment type.

GitHub
LLM is now a regular type. It can receive an environment
Environment: an execution context within the Dagger Engine. Basically, a sandbox.
Binding: a named mapping to a value, scoped to an Environm...
Not sure who I should put in reviewers, but I have this one that bumps openai-go. This improves a bit the behavior when using llama.cpp and small models. Not entirely sure why exactly, I wasn't able to find the exact commit between the alpha.61 and beta.2 that degraded the results
https://github.com/dagger/dagger/pull/10005

GitHub
https://github.com/openai/openai-go/releases/tag/v0.1.0-beta.3
Full changelog: openai/openai-go@v0.1.0-beta.2...v0.1.0-beta.3
writing some sort of eval for this would be nice. ref: https://github.com/vito/daggerverse/blob/main/botsbuildingbots/evals/main.go
GitHub
a monorepo of all my Dagger modules. Contribute to vito/daggerverse development by creating an account on GitHub.
Based on your module I did that: https://github.com/lgtdio/llmeval
I added my .env to the git repo as there's no screts here. It's using Docker Model Runner but that should be similar if we run the model using llama.cpp.
Basically it generates the reports for my main test case, where I want the LLM to generate dev environment on the fly by inspecting the code base.
I run it with dagger based on the alpha.61 of openai-go (using this branch https://github.com/lgtdio/dagger/tree/llm-demo-2) and here is the result: https://github.com/lgtdio/llmeval/blob/main/reports/with-openai-alpha-61.txt
-> At the end of the report I added the history of the built container.
-> It works really well, found the tools, use thems
I also run the same thing based on beta.3 (main) and here is the result: https://github.com/lgtdio/llmeval/blob/main/reports/with-openai-beta-3.txt
-> It's failing because it doesn't use correctly the tools
-> Instead of finding a tool tree it will install the tree package
-> It never uses the addPackage tool
-> It install weird stuff in mode --force-broken-world
In the end that works, but way less efficient.
I still haven't found the change from the alpha61 that degraded the performances.
My prompt is also complex because the model wasn't able to find the tools at start, but it might depends on the models, especially when they are not so big. But at least it was working.
Multi-objects is great. However, I have issues with Dagger Shell. When switching from navigate to input mode, the output stops where I was, and I can't see what I'm typing. Sometimes it shows input and output but only a few lines before stopping. Also, output from long prompts is difficult to follow, and it seems to not show the complete output.
Currently I'm mostly running local models (<14B for most of them, so not so big)
I'm seeing a lot of differences in behavior depending on the model. Would it be interesting to share a list of the models that works well/to recommend based on the kind of task to perform?
<14b can be a bit rough, but I've mostly used qwen2.5-coder for code generation and it's been pretty good. Getting the prompting just right is the real challenge with the smaller models but once you get the constraints just right they're good
I'm also using qwen2.5-coder in 14B, I can't really go more with my actual laptop 😕
yeah it might be worth the tradeoff to run 7b with a larger context length too, I haven't dug too deep on that config side
Do you have some prompts available on GH? To compare with what I'm doing. I have for instance this one that works (depending on the openai-go version) but it's "big": https://github.com/eunomie/local-agent/blob/main/.dagger/qwen_dev_env.md
That looks pretty good, I don't have anything as good as that 😛 I would add under contraints DO NOT USE THE CONTAINER TOOL. If it calls Container() from your dev-environment module to get the container object it will immediately overwhelm itself. Hopefully that won't be an issue in the next release
Regarding https://docs.dagger.io/api/llm#environments-and-tools I wonder if we shouldn't add a small example. Like if we only want the ability for the llm to read, a small module that only contains a read func. Or if we want to go a bit further, a read function and a tree function that runs tree in a container on a specified directory (I like this one because it's not just restricting the scope of the llm, it's also extending it with custom functions).
What I mean by that is I understand what is written, but also because I know what to expect. And while that sounds clear, I don't know how easy for someone to go from this description to the creation of a small module that can act as an environment.
I'll see to open a PR with a small example and we can discuss it if that makes sense.
Thanks, iterating on docs now. That part will probably change a bunch with #1352023893543747754 in the upcoming release but that'll be covered
btw if there's more feedback on the current LLM docs, now is an excellent time to share 😄
Quick demo I made for my GH agent using the prompt mode, it's kinda cool
🤔 for prompt mode, should the results be written back to the variable? sorry, i'm struggling a bit to get the actual result back out
No, see latest in #1352023893543747754 for relevant discussion
aha 😦
welcome to the frontier 😁
i'm using 0.17.2 without those env changes, still applies?
~~in 0.17.2 I believe:
- the llm can set variables
- they get synced back to your shell
- but you need to explicitly prompt the llm to do it~~
Nevermind I was completely wrong
ahaha
the llm can't set variables in 0.17.2
@gloomy kindle i think you want $_
that'll be assigned as the last value returned by the LLM
is there any way to get $_ in code??
i'm guessing it's not supported for getting the last result from a normal shell command?
returned as in selected?
not currently, but i want it to be that too, yeah
or result of last tool call?
both (they are the same)
since tool calls auto-select
thank you thank you 😄
i suppose that also means $_ will always be an object, never a string, since LLMs never select non-objects
but now you can e.g. $agent | last-reply if that's what you want 😛
well at least now I'm caught up on what the API is in main..
Bug report by @bronze fern : _currentSelection tool is always sent to LLM even when environment is empty. It seems to confuse the LLM (it gives tainted responses that talk about selection)
This page was generated and deployed with an llm 😄
Just FYI but after a lot of different tries, it looks like I have better results by adding to a system prompts the list of available tools. This makes better results than to have them inside the prompt file.
With that I have really similar results than I had when we were using openai-go alpha.61 (I mean I have good results and I'll be able to demo with based on main, and really happy about that 🙂 )

GitHub
Demo of local agent using Dagger. Contribute to eunomie/local-agent development by creating an account on GitHub.
What's the diff between a system prompt and a regular prompt in the Dagger API?
Based on ⬆️
We have a Tools function. I wonder if we shouldn't make available the list of tools directly. That way we can construct a kind of similar doc but specifically for the model used and the expected format, and send it to the (system) prompt. (It can be useful for small, local models)
Would that make sense? (Happy to try to do it, but wanted to validate the need first)
It's sent as a specific type of message to the openai API https://github.com/dagger/dagger/blob/3f89ce13e1b4ffd435d143cf190d2b88c584353a/core/llm_openai.go#L113-L114
GitHub
An open-source runtime for composable workflows. Great for AI agents and CI/CD. - dagger/dagger
An even better version 😄 https://daggerverse-qa.surge.sh/
That's actually better to set the system prompt so you don't send the instruction on every query in prompt mode, just noticed that while trying
When LLMs are calling LLMs, it might be helpful to name them? cc @hidden tartan (e.g. LLM.WithName("bot1"))
@river belfry @hidden tartan I'm not sure I understand, tool calling already works this way - the LLM endpoint already injects the same information in the context. Doing this duplicates it
Are your descriptions in that doc the same as what's in the comments of your functions?
I'll try again to be sure, but what I saw is that works well with big models, like when you use gpt, but with small models if I don't add again the tools (sometimes in a different format) that doesn't work well, the LLM will for instance not find the tools to run. Especially with qwen model I'd say.
That's good to know! We should add it to the eval
It could be linked to other variables, for example our MCP/tool calling implementation changed a lot over the last week
Here is what chatgpt says to me when I ask it to improve my prompt:
Ah, you’re super close — but here’s the catch: LLaMA 3.2 1B is extremely small and may not reliably infer when to call a tool, even when told it can. Smaller models like this often need explicit prompting to take actions like calling tools.
We could add this to the LLM type
Like if model == "qen" { /* inject system prompt */ }
System prompt makes thing quite inaccurate though, I can clearly see the diff when I set it or not, it seems it fails to use the tool correctly :/
yeah I'd make sure you're on at least 0.17.2, but if that system prompt makes a huge difference I'd try adjusting the documentation on the functions in the module instead. Especially with a really small model it might actually be worse to use that system prompt in addition to the tool descriptions because it's just more context
@spring wave As I mentioned in the prod-dev sync, I'm getting into a situation where after my agent selects the firs tool it needs, it seems like it gets stuck within that context and doesn't know how to use the other tools it knew about before selecting the current one. I'm currently using Claude 3.5 as an LLM, not sure if that matters.
might be the known issue around losing track of Query - @worn hill has context
seems to be related.
basically we might need another tool, analogous to selectQuery but maybe not named that because the model might not understand
#agents message link to previous mention, definitely related if not exactly the same thing @quiet ether
it's definitely the sort of UX bug where it makes you wonder if you're doing something wrong, but the fact that both of us hit the exact same thing trying to use the interactive-onramp UX strongly implies this is not user error at all
@worn hill wanna tackle this one together? seems important
Be careful of split brain guys
@spring wave @worn hill thread about selectQuery tool
FYI, you cannot use Rancher Desktop with Claude to register/test MCP servers - has to be Docker Desktop

Ok, so I did more tests.
And I removed both the system prompt and the tools list I was passing to the llm.
And that works fine!
Initially I added the tool list because they weren't correctly found, and now it's better to remove them to avoid confusion. (I also improved the function docs)
Let's call that learning 😅
But the (important) result is that works great 🙂
Amazing!
(ok, it works better 😅 )
Masking fields 🧵
I find myself constantly rate limited by 4o - are there any good patterns to either
- consistently reduce my token size
- get visibiliyt into what the input tokens acftually look like?
are you using the company gpt-4o account? it's still severely rate limited, but if we're all using it, we'll burn enough money more quickly to get into the higher tiers 💸
the biggest problem is that it currently gets every single API exposed to it as a tool, depending on the currently selected object, which is where #1354656055925149716 came in, which showed promise but led to the model making more mistakes
Yeah for sure.
Getting the token count is dope but I wish I could see the whole injput, would help people debug easier IMO
Sorry if dumb querstion but can I use dall-e-3?
.model allows me to switch but then seeing this error when I try
│🤖 0.1s
│ ! POST "https://api.openai.com/v1/chat/completions": 403 Forbidden {
│ ! "message": "You are not allowed to sample from this model",
│ ! "type": "invalid_request_error",
│ ! "param": null,
│ ! "code": null
│ ! }
! input: llm.withQuery.withModel.withPrompt.sync select: POST "https://api.openai.com/v1/chat/completions": 403 Forbidden {
! "message": "You are not allowed to sample from this model",
! "type": "invalid_request_error",
! "param": null,
! "code": null
! }
you are not allowed to sample from this model
But to answer more specifically, the model has to support chat generation. And if you want to give it objects, it has to support tool calling
Oh @steep onyx there's another papercut we could use help with...
The "EnvironmentHook" in core/env.go install all core types in Environment.with[TYPE]Input and Output.as[TYPE] but really, half of those types can be removed...

Not really sure what "sample" means here.
So im thinking of just wrapping their SDK then?
https://platform.openai.com/docs/guides/image-generation
I was thinking I could use it via text since it accepts a prompt and returns a URL.
I'm thinking we could remove the following:
current-module*type-defenverrorfunction-*generated-codellm-token-usagesdk-configsource-map
Not really sure what "sample" means here
I'm thinking we could remove the
Oh good I know MCP now https://youtu.be/HyzlYwjoXOQ?si=-k0tnlMzN3IZDQbs

Deploy your app without complexity and $50 in free credits on Sevalla https://sevalla.com/fireship
Learn the fundamentals of Anthropic's Model Context Protocol by building an MCP server can give any AI model superpowers. In this tutorial, we build an TypeScript server that provides Claude with additional context and the ability to modify data o...
lol
OK @steep onyx @wraith remnant @worn hill @spring wave we're in countdown to release... The idea is to get the new environment API out, so we can port all examples & docs to it by the hack night tomorrow
@spring wave what say you? 🙂
Night crew ready to do final testing here in London

fixing $_ is the last blocker i think? i can figure something out there
and maybe revive -i / life-alert since that was based on returning, which we have now (in an even more solid form)
is this a v0.17.3 or the big v0.18?
@smoky ocean oh, and the exposing bindings as tools. that needs more testing i think
eval it uuuuuup
I would suggest 0.17.3 since only experimental APIs break (with the caveat that there is no formal marker of experimental APIs... but we have communicated clearly that llm is experimental IMO)
Then we can cut 0.18 tomorrow when the stakes are less high 🙂 Probably safe to assume there's another (hopefully small) release to be had tomorrow for last minute fixes
But hopefully we can freeze API today

GitHub
What are you trying to do? Many users have requested the ability to capture the state of a Container that has been modified through an interactive session with terminal such as in ⋈ container | fro...
If we’re planning to cut 0.18 tomorrow on a stable API that ships in .17.3. I’d cut .18 today and .18.1 tomorrow. My 2p.
My 2p.
2 pounds? 🙂
I’ll go back to giving my 2c next week
@spring wave how can we ( @steep onyx @wraith remnant @worn hill ) help you get that PR merged?
moar testing
particularly curious about the vars-as-tools bit, that's the biggest unknown at the moment, and there are other schemes we could try
@spring wave so you're positive you saw that working at least once?
i definitely see it call those tools, but what's worrying is that it seems to take their presence (or maybe the way they're described) as a sign that it can pass them by name in args to things, which if true could be a real wrench in the gears
so another thing we could try is to change/repurpose currentSelection to additionally list the known object IDs, MAYBE paired with a name, but that might have the same risks. ideally they'd have a description instead
that's the general area that needs de-risking atm
aside from that, just trying out existing agents and trying to find (not too cryptic) ways to break/confuse it
just got $_ working, will push soon. it's currently as-before, where it's only the last selected object, not arbitrary scalars, since that's by far the easiest to support and you can always just re-select whatever field you want from it
(pushed)
i'll add some telemetry to those env getters too so it's more obvious when it's using them
Let me tweak the description for inputs as tools
@smoky ocean here's a run where I tried to make it rely on the tools - it seemed hesitant to use them: https://v3.dagger.cloud/dagger/traces/4e0c9b0390848d1c687b3bca8a72812f
could be worth just tossing the IDs directly in the description to cut out the extra roundtrips

Browse and visualize Dagger traces.
also, pushed this
@spring wave did you want to make description mandatory in inputs?
probably last call to do that if so 🙂

...lemme dogfood it a bit
worth noting there isn't a way to add descriptions to shell vars. would be cool to use comments for that
ctr=$(container | from golang) # a Go image to use for building
use ai 😉
"A container for preserving broccoli"
(but actually what if "container | from golang" was the description)
Oh right the shell... damn
well, we could always accept a "" description
it's mostly about making it hard to forget, and easy to consistently provide
yeah
Having descriptions everywhere also clarifies that inputs and outputs each have their own namespace...
this might not actually be hard, either
probably easier in the REPL than it would be in a script, though
having said that, right now var syncing doesn't work at all in a script anyway
@spring wave this seems like dead code no? Should I remove?

yeah noticed that, you can rm it
could it have influenced some of the above?
ok i have to sleep, cant wait to try 0.18 (or 1.0?) when i wake up 🙏
@spring wave we should fix that papercut also
@wraith remnant if you're available? 👆
possibly, though worth noting its value has been 0 1 etc. on your branch. but just the word "variable" could have done that
trying to get to that 1.0
~~On the functionmask PR / main or environment-api ~~? Yes, we're available to help on that 🙏
On it
@spring wave trying to not get pulled into too many changes at once, to avoid conflict. pushing soon
👍 - i'm testing required descriptions now, feels pretty good to use actually
MCP Server issues
@smoky ocean rebased + pushed required input descriptions
Shall i make a pr against your environmnet-api branch ? I have it ready
@spring wave I don't see Env.outputs and Env.output in the llm schema, ok for me to add?
btw I just had a very successful run with the only explicit prompt being "do it" 😛
sure - right now it's still binding i believe? or did you just change that to inputs?
It really feels like with this pattern we're getting closer to agents being declarative reactive functions themselves, not just the outside code envelope, but the LLM itself 🙂
was this with described inputs + outputs?
Yeah just changed that to inputs. Didn't realize I had to split 😅
that's what i've been saaaaayiiiiiing! 😛
and why the idea of mutable bindings felt off
sadly I was in a nested dagger so don't have a trace. but here's the snippet:
env=$(
.core | env |
with-container-input base-container $(container | from alpine) |
with-git-repository-input dagger-source $(git https://github.com/dagger/dagger) |
with-file-output dagger-binary "The dagger command-line binary, built in Go from the latest stable release of Dagger, in a containerized dev environment" |
with-container-output go-env "The go environment used to build the dagger CLI, with everything setup such that 'go build' works on the first try when entering the
container"
)
result=$(llm | with-env $env | with-prompt "do it")
(sparing you the middle part)
│🤖 1.2s ◆ Input Tokens: 2,355 ◆ Output Tokens: 26
│ ✔ return(
│ │ │ dagger-binary:🤖 Container.file(path: "/bin/dagger"): File! 0.0s
│ │ │ go-env:🤖 Container.withWorkdir(path: "/app"): Container! 0.0s
│ │ ): String! 0.0s
│🤖 I've successfully prepared everything:
│ ┃
│ ┃ • Dagger Binary: The Dagger CLI binary has been built and is available.
│ ┃ • Go Environment: The containerized Go environment is set up with the Dagger source code mounted at /app .
│ ┃
│ ┃ You can now proceed with your tasks using these resources.
│ ┃ 1.8s ◆ Input Tokens: 2,433 ◆ Output Tokens: 62
sweet
It did try to cheat and return File#1
(before actually getting a file)
so that might be a weakness of the numerical ID system
maybe we need to make it look a little more random
gpt-4o
https://github.com/shykes/dagger/pull/351. @smoky ocean feel free to just take the code and close the PR. Made this for an easy review. Didn't want to push directly without asking
env input chaining papercut
@spring wave I'm a little confused trying to add Env.output() and Env.outputs(): it looks like the output definitions are saved in place (outputsByName) but the actual values in another (objsByName) is that right?
yeah, we could dedupe them but I wasn't sure if a binding with a nil value was safe or if it would lead to panics somewhere
I would have expected objsByName to become inputsByName, with a mirror outputsByName of the same type: map[string]*Binding.
Oh I see. Yeah its perfectly fine to clarify having a non-null binding with a null value is perfectly fine
or that yeah
OK I'll do that then?
Then need to go to sleep... Will you be able to carry the release today guys? I know it's getting late even for your timezeons
I am still good with kicking it off tonight. Just need to know when and a final call on version number.
My assumptions atm are that "when" == "when that environment-api PR is merged" and "version number" == "v0.18"
so just tell me if that's wrong
- When: 👍
- Version: your call
just in case it was missed: there's this PR against the environment-api on his fork -- https://github.com/shykes/dagger/pull/351 ; if you guys want i can open it on dagger/dagger (or you can direclty copy-paste and push on the branch )
current status: nothing in progress, was just dogfooding the required-descriptions stuff for my evals, and then gonna run them, which I'll do after @smoky ocean pushes the new Env.output API since I need it now. 😛
but, have to go on a 40m-ish car ride so that's it from me for a bit. pushed my evals changes in case anyone wants to try them while i'm in the 🚗
also want to try adding input descriptions to the tool descriptions, not sure if that's done yet
It LGTM, I'd just push that commit to the branch

{kind=link}
{kind=link}
{kind=link}
thanks, doing it
@spring wave do you use the type_ argument of WithOutput anywhere ?
my guess is that type enforcement was left as a todo?
or I'm blind
I thought it was passed along
Yeah but I didn't see it used anywhere. But, I since realized that I was blind 🙂
It's enforced in the return builtin at the dagql layer - not explicitly, doh!
OK I think I'm done, testing real quick
I apologize in advance if there are sleep-depravation bugs
@wraith remnant another papercut request... env doesn't work in the shell, you have to call .core | env...
mmm there's a Terminal type? 🤔 isn't that long deprecated?
I think the object still shows up because we have legacy API support (pre-v0.12) for the field on it. But the view only hides the field, not the object type itself
I can append it to that list of things to hide from the env extensions
@spring wave pushed
I think that and SDK config would be great thanks. Obviously not a release blocker...
One last tweak, the description of the input is not passed through to the llm. fixin gnow
oh also missing in output arguments
(I think)
shall I add them too?
hitting a compile error but I think we can just nix the code causing it. seems like we can just get rid of currentSelection entirely
those should be there
oh you're right. Mmm then I guess the LLM ignored it in my eval
I was getting a little too cocky with the "do it" prompts 😛
lol
oh no, I rebased and didn't try rebuilding.
fixing it
so, the currentSelection tool was originally added as a hint to the model so it knows when it's been given an initial selection, but now that isn't a thing
so i'm not sure if it's even needed anymore? unless the hint is still helping it? not sure
Oh I see. Not needed the rest of the time?
my other idea was to repurpose it into a general purpose "your current context" tool, which lists the inputs + descriptions in its description, that way we don't need all the getter tools
Honestly that seems like the getter tools but less native
well, the advantage is a) not having to run those tools ever, and b) not risking confusing tool names because of what people named their inputs
I mean it doesn't change the API so we can let the evals decide 🙂
In my testing simply putting stuff in tool descriptions is pretty high leverage
For now I'll just fix the code as is, feel free to remove the hint
Yeah we can iterate
/me writes an eval that sets an input called "return" 
Night!
Hopefully not too late for release?
I'm still good, releases go pretty quick now so it's not a big deal
The LLM integ tests are very upset on that PR right now, I'll work on updating them
probably need a sdk all generate + docs generate too (I would but I'm on a laptop in a car and my legs are hot enough as it is)
hmm looks like we need a .sync before getting values out of the env - adding one to LLM.env. also just remembered I had a fix for .sync on another branch, gonna try pulling that in, and MAYBE -i support but that might be too much too late
Done ✅
@steep onyx I'm around for approvals / support / whatever you need
feel free to ping / dm me
hm to update these tests I need to regenerate the golden examples, which seems like it requires I have all of our API keys for various providers? And then to uncomment this code or similar?
@spring wave @quiet ether does that sound right?
I run this: dagger call test update --pkg=./core/integration --run="TestLLM" --env-file=file://$PWD/.env -o .
or do I just need one provider?
one provider should be sufficient
running evals now, noticed claude-3-5-sonnet-latest sometimes doesn't call return 😬 maybe more prompting needed?
anyone know what causes this? my ./hack/dev is wedged
│ │ ✘ moduleSource(disableFindUp: true, refString: "/var/home/vito/src/dagger/docs"): ModuleSource! 30.0s
│ │ ! failed to resolve dep to source: failed to load local dep: select: failed to load sdk for local module source: failed to load local dep: select: local path "/var/home/vito/src/dagger/sdk/php/dev/php" does not exist: unknown builtin sdk
│ │ ! The "php" SDK does not exist. The available SDKs are:
│ │ ! - go
│ │ ! - python
│ │ ! - typescript
│ │ ! - php
│ │ ! - elixir
│ │ ! - java
│ │ ! - any non-bundled SDK from its git ref (e.g. github.com/dagger/dagger/sdk/elixir@main)
https://v3.dagger.cloud/dagger/traces/cdf57de1006c67015097cfffdfc7edaa
Browse and visualize Dagger traces.
hmm could be
❯ git clean -ffdnx
Would remove .dagger/dagger.gen.go
Would remove .dagger/internal/
Would remove .env
Would remove .jj/
Would remove .ropeproject/
Would remove bin/
Would remove sdk/dotnet/sdk/Dagger.SDK/introspection.json
Would remove sdk/php/vendor/
Would remove sdk/rust/target/
seen that happening in the past but with a different error
oh yes
elixir builds fail also in CI due to caching
I think the elixir cache is racy somehow
seen that happening quite a few times in CI and re-running generally fixes it
@steep onyx where you able to get the golden files? I have them here
Yep gonna push fixes in a min, just had to update the modules in our dagger-test-modules repo too
(pruning cache worked but now a fresh build is taking ages...)
It's quite buried but eventually in the error trace I found this: https://v3.dagger.cloud/dagger/traces/cdf57de1006c67015097cfffdfc7edaa?span=db3424adfa16f059
host github.com not found
Which probably explains sorta what's happening; it tried to get the php sdk from git but then probably hits a fallback case where it assumes it's not meant to be a git ref and just a local ref
Browse and visualize Dagger traces.
So might be a DNS problem
ah nice find, saw that error later and decided to restart the engine, seems ok now
I pushed TestLLM fixes and sdk/doc regen to the PR, so hopefully CI is happy now
@steep onyx sorry, got caught up in a rebase, trying to hoist over some fixes from the life-alert branch. are you getting close to a cut-off time? 😬
No problem, I'm good, I'd say 10pm is probably my cutoff time to start (so 2hrs)
@steep onyx ok, calling it for now - Claude 3.5 Sonnet still has some issues, but I don't think it's blocking
(just did a push -f)
Do these failures in TestLLM look legit or just something that needs the golden examples regen'd again? https://v3.dagger.cloud/dagger/traces/c497d1a248cf0410a4ea9f49fe50595c?listen=1a235b3cd96d0ccf&listen=9b8f517aaba53937&listen=d20cbf598d89915d
Browse and visualize Dagger traces.
ah this might be fixed by what I just push -f'd - went back to return
I temporarily renamed it to try to drop a stronger hint to Claude 3.5 but it didn't work well enough to be worthwhile
oh okay that was an even newer -f 😄 , cool sounds good
Okay merged it, will start the release after main looks nice and green ( https://discord.com/channels/707636530424053791/1355235431746240794)
https://discord.com/channels/707636530424053791/1355235431746240794)
going to bed folks, it's quite late here 🙏 😴
v0.18.0 is published: https://github.com/dagger/dagger/releases/tag/v0.18.0
Thanks all! Resuming the shift from the old continent 🌐

question around required descriptions - just on porting code to the new style, it feels a little clunky? i'm also not entirely sure what i should be describing? it feels like i'm just parroting the type comments from the type itself for simple examples
little nit about the new API - I have to repeat the magic string for the output var a couple times? it feels weird that it's not statically typed, and I could just get it wrong and get runtime errors. feels unavoidable though, and it always present (although less obvious) with single object before.
I also don't have any suggestions as to how to avoid it 😭 but it does feel very magically dynamic, and different from the test of our type system
(also I'm so far out of the loop, so you've probably discussed it all before)
here's the diff for a python agent upgrading to v0.18.0 if anyone needs a reference. Will have other language reference soon https://github.com/kpenfound/dagger-programmer/commit/df1ced09304c4a18a20bc226b7c783293e74be84
getting API errors if I do llm | with-prompt (not supplying an env). Not supported?
came here to say the same. Thought it was me on bad wifi, but same on good wifi. Prompt mode working fine.
Shell mode:
✘ llm 1.0s
│ ● llm: LLM! 11.1s
! Post "http://dagger/query": unexpected EOF
Prompt mode:
dagger
Dagger interactive shell. Type ".help" for more information. Press Ctrl+D to exit.loading type definitions 0.1s
│ ┃ 0.0s
│
│🤖 Hello! How can I assist you today?
│ ┃ 1.4s ◆ Input Tokens: 1,089 ◆ Output Tokens: 11
which provider were you using on shell mode? With gemini I got a nice google API error. That looks like maybe your engine got crashed
that was OPENAI
Get similar with Gemini and Anthropic. Kills the engine when I run llm in shell mode.
I just hit the same error in two session

GitHub
What is the issue? Engine which may handle prompt mode fine with LLMs like Gemini, GPT, Claude, panics when llm is run in shell mode under 0.18.0 Dagger version 0.18.0 Steps to reproduce dagger llm...
building the engine to check this
its on 0.18.0
yep, building to make a bisect
and checking where it broke
probably when the entire API was refactored 😅
yeah.. I'd assume it was the Environments API PR 😬
Making a list of 0.18 papercuts 🧵
I really like the new env API 😍
yep, confirmed it's commit https://github.com/dagger/dagger/commit/628dfb3ea44f2a5ee4d00c5547e8c17bd5d9105d

GitHub
…… (#10007)
- Environment API: a new API for exposing a Dagger environment to humans, code and LLMs
- LLM is now a regular type. It can receive an environment
- Environment: an execution context ...
checking..
ok, found the problem and adding a fix
https://github.com/dagger/dagger/pull/10033 cc @smoky ocean @shrewd ermine @bronze fern

GitHub
Fixes 10032. Initializes once when LLM is created
Signed-off-by: Marcos Lilljedahl marcosnils@gmail.com
@spring wave can you merge please? Had to step out for a bit