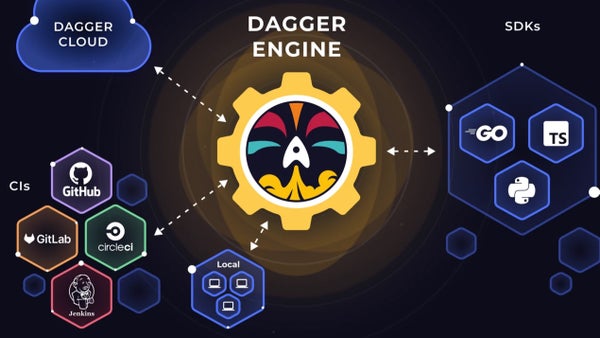
This channel could get interesting, because there are three ways to use Dagger and Kubernetes together:
-
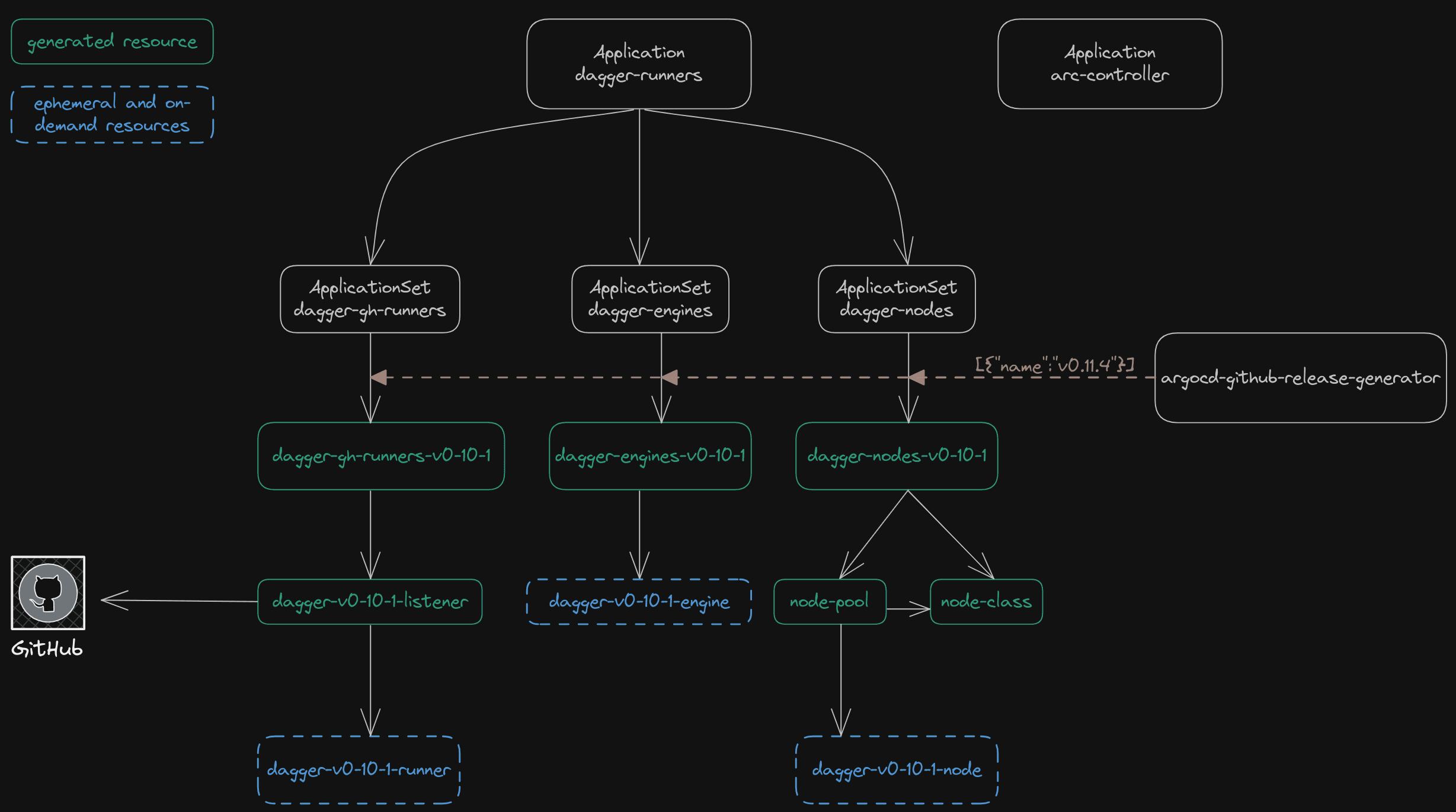
Dagger on Kubernetes. This is the most common, since many CI runners run on Kubernetes these days, and in that case we recommend running the Dagger Engine as a "sidecar" to the CI runner, using a Kubernetes Daemonset.
-
Kubernetes on Dagger. This is less common, but very cool. You can run an ephemeral kubernetes (or k3s) cluster for testing purposes, on Dagger itself.
-
kubectl on Dagger. Regardless of where your Dagger engine is running, sometimes your pipeline may need to deploy to a remote kubernetes cluster.
This channel is a good place for discussing all of those things 🙂