#Best Vector DB for Local Use
1 messages · Page 2 of 1
So how will it be queried on words?
You have substantial overlap between groups
Computers overlap with history and math
History can be literally anything with a date
example?

Hey @meager siren there are two sets of categrories in the xml. one is main category like computers then you get subset mainframe as an example and then you have articles with titles. You could extract those and make a trie of it?
yep
You know the tag where that’s at?
I saw them when scrolling through the data but not confirmed i'll check and see
haven't looked too much myself ghost would know I am busy elsewhere
true...
I gotta go back and check too
Invert index words to categories and then use that to get a set of documents
categories has sub categories if needed we generate sub sub categrories and they have documents is that the plan?
index words = nodes
I think there were sub categories as I said computer is main and mainframe computer is sub
Not confident about generating additional data but I follow the rest
so sub sub will be generated if needed
I understand I'm giving example
mainframe itself has many sub catog I presume but I dont think I saw anything in metadata.
[[Category:Kansas State University academic buildings]]
[[Category:Architecture schools in Kansas]]
[[Category:Landscape architecture schools]]
[[Category:1908 establishments in Kansas]]
[[Category:University and college buildings completed in 1908]]
this is how it is.
It’s structured XML data with the documents inside a tag
Jackpot
More blind meta meta data analysis
I was wondering the same
Hard to visualize in a notebook with 95 GB of data
Looking at just the meta meta data like the category words takes a while because the script has to load so many files
Kinda
195 files but each one contains 150,000 documents
Yup but not by category
Just chunked by whatever they were when i downloaded them from these big bz compressed files
okay so some of them have categories in title tag
<title>
Category:Mark Eitzel albums
</title>
words
Yeah, I’m also assuming lexicographically sorted
It’s not
But that’s how they came
tf-idf was calculated for corpus and then you make them as nodes and add documents under the respective nodes.
No
data was downloaded
in chunks of files
one file has 150k articles
no idea about catog here
just downloaded it
then extract articles
find tf-ifd
idf*
yep.
in what sense?
Ahaan good idea.
That's why I asked ghost to keep a higher threshold for tf-idf values any word below it will discarded
that was one way of doing it
now catog are introduced they are better
nope
I am talking about the words
you only discard the words with which the trie will be made
Already built tries for the inverted index, word frequency for each document, document frequency for each word, and word IDF for all words. And again, scale of the data would make any sort of analysis difficult to verify.
Verify, no build
I know hence the new method of using catogs
…. No it’s probably in the order of a few GB depending on what you’re looking at
Word IDF when stored in msg pack is like 4 GB
can you limit the byte size of the stream?
python should have it. many other langs normally do.
So @meager siren limit how many bytes are read
and output to terminal
seems to be for online stuff
if you dont limit the read bytes it will load everything in memory
he said 4gb in msgpack unpacked would be much bigger in ram.
not by a lot
but still
what are we talking about here lol. Outputting metadata to stdout?
batch load would be slower then just loading the file.
well I am gonna leave and install some different OS now. Cause I feel like arch is getting old
will meet up with you guys some time later.
what data is being generated?
site unreachable.
hey @meager siren @inland lynx I see short description tag as well
which gives little know how about the article
here is the dataset
@inland lynx ^

It's not my dataset, it's just a copy of the data I pulled from Wikipedia (which is updated frequently) and I am just storing one copy I pulled from April.
The FULL wiki data though?
Clarification here. This is specially formatted from the document/article text. It's not its own metadata tag from xml
English wiki, but yes
Create search engine to run in reasonable time (ie 5 minutes per query) to allow me
- get experience building search engines at scale rather than using langchain or llama index
- plug in as part of a RAG system and replicate experiments done in WikiChat paper from Meta AI using TinyLlama 1.1B instead of Llama 2 7B
If you can use small LLM to replicate wikichat, it emphasizes you dont even need 7B models to be effective at simple tasks like QnA.
Leave it to the nerds in Meta or OpenAI to figure out how to make LLMs "smarter"
I'm just trying to get it to not hallucinate with knowledge that can be stored offline
Not really
it's about hallucination reduction using a generally decent ground truth dataset
Well, that's why I said "generally"
Are you saying that the generative part of RAG is going to obscure or destroy the truth that is retrieved from the knowledge database or are you looking at a more philosophical question?
look, let's put the thought experiment aside
This project is primarily for fun and for hands on learning
I have yet to add in optimizations for speed such as using Rust or multithreading
I'm assuming single core processor for the sake of min specs (consumer level PCs/laptops)
Dont want the system to take up all cores and RAM
Systems can have limited number of cores
ie raspberry pi is only 4 core ARM processor
I could have designed this thing to just run on my server
but then no one else could go over and replicate my results, build upon them, or even tested the program
It's not but it's an example of an "offline" usecase
Imagine something like a robot that has a 1TB HDD with this program and data on it. You have a mobile and semi competant machine that is portable
They're all relatively the same documents
But using a hierarchical grouping system does seem like an interesting approach. Downside is that not all articles have explicit categories like mentioned before
On the plus side, RAM usage is pretty low ATM for search

No
It's a server, but like I said, single thread single core ops
It shouldn't be
It's just a mail thing on Ubuntu I set up for easy stuff'
small batch high variance doesn'ts speak to much confidence
Did you find the algo that would be good to build the category trees?
Another thing I found. Some of the data (articles/documents) are just category data. In other words, they have a “Category:Some subject” in the title and the rest of the text body is just “[[Category:Category data]]”. I gotta filter those out now too.
Not sure if I can use them as a way to aggregate different category labels under a few larger categories and build a category tree that way.
@west pagoda Setting and IDF filter threshold to 1.0 did seem to help cut back on some of the documents returned from the trie inverted index. Went from around 10M to 9.5M. I'm still not sure what I can be doing with the timetraveler's idea around using categories to construct the inverted index. Also perusing the links he sent above
500K articles removed does help but I agree that it’s not great
I’m looking through them now
Remind me again how I go from bag of words to inverted index with the category tree?
Right but what about queries that are not key words but rather an actual text that was just preprocessed into a bag of words?
How is he using a different TF-IDF? The formula is the same regardless.
Is he weighing documents based on the cosine similarity between TF-IDF vectors of the query and document?
If so, then this is fundamentally what my current search engine does
Nevermind, I just read the paper
FAISS probably for local use
Ok, let me see if I understand the general idea of what you've been proposing @inland lynx :
- Create a clustering algorithm to group words with different categories
- Use a category tree to organize the categories.
- Our inverted index now maps words to categories
- Once we have the categories/sub-categories isolated, we get the mapping of categories to document IDs
- We aggregate the results into a list and then run TF-IDF on those documents and then get the top best results from there.
does that about sum it up?
And for the word -> Category mapping, we have some limit/threshold so that we don't accidentally pull ALL categories for words that are common across many articles and we do the same for Category -> documents?
Why is the tf-idf weighed at step 5?
I assume so
do a set union and use tf-idf would be my guess
for straight TF-IDF, we vectorize the query and cosine similarity the query against the doc vectors
for BM25, we still have parts of TF-IDF but BM25 does not require cosine similarity nor vectorizing the query
The query still influences the search because of how it still uses the query term TF and IDF
you want to remap query to just the terms in the (sub) categories?
yes
TBH, I have both implemented for the sake of comparing results
But the flow of data is expected to be similar across both
The flow of data is as follows: the query should map to a list of documents (via the inverted index) and we perform the algo search (TF-IDF or BM25) for which documents are relevant to the search
Current issue is the inverted index is returning too many docs and so we're investigating a mapping to categories to shorten the results
BUT we are finding that the mappings may not be effective in theory.
well, we already have trie index mapping
straight up word to document ID inverted index with tries
Currently working on figuring out how to classify words to categories
Right but how to take a word and search through a category to get the sub categories
unlike the trie inverted index in which I can organize things to be roughly O(1)-ish per word, I'd have to traverse each category trie O(n) for every word to get the correct categories
It's not about the levels
It's about how many categories I have to sift through in general per word
I can build a trie that maps word to categories/sub-categories. But that doesnt help me much more than my current inverted index
Just like I mapped each word to a document, I just pull the category data from the document
thing is that still doesnt help eliminate options as efficiently
particularly with words that span a large chunk of (unrelated) documents
It's building right now
the trie for word to category
No, it doesnt
tf-idf is just a sparse vector scheme for sparse vector comparisons
nothing has pulled actual key words from the query
calculation is based on the words in the query vs words in the document. Take the matching words and create a vector to perform cosine similarity
It doesnt
the inverted index doesnt prioritize words over others
it treats all words equally and aggregates the document IDs of each word in a set union
No weight to documents based on return frequency across words or weight based on word IDF
that's kind of the hope with the ideas for the inverted index
to figure out how to prioritize words in a way that is fair and wont accidentlally kill valid documents from the search
yes
we need to short list the inverted index without using calculations form there
the edge case is the inverted index step
ie the word "plot" expands to 10M articles around stories and movies and land and schemes
when the original query was "who started the gunpowder plot"
depends on the context of the query my guy
that's why it's a problematic word
right
but when we look at the documents returned, we get documetns for "gunpowder", "plot", "start", etc
hence, we get A TON of documents (like half the corpus)
because we do a simple aggregation of set union
I told you, the trie for tha tis still being built
and this was more of an example
You can run the code yourself man
links to repo and data are in the thread
It does
taking a raw query and putting it into bag of words, and doing a word level inverted index is returning a lot of documents
Well no kidding, the tree is still being built
Check the actual example I have in searchwiki.py
That's downstream
I have a class called rerank that handles exact passage lookup with vector search
But yes, we also need something simple up front

GitHub
Contribute to dmmagdal/WikipediaEnSearch development by creating an account on GitHub.
Hope you got enough storage space
?
Huggingface hub for backup
but I have a 1TB external hdd as another backup
and my server storage is 1Tb large
Server wise?
56 cores total (2x Xeon CPUs), 68 GB RAM, and 1 TB storage
Idea is to get it to run on any consumer level system. Server offers maximum parallelization for preprocessing scripts
You're fine to scale it as needed
Just have more than 8GB regular RAM
Anyways, just get an idea for the number of texts in the corpus vs the number of texts are returned from the inverted index
and then you see the problem I'm having
It's hard for python to scale the TF-IDF or BM25 compute across all files quickly
@west pagoda I think I found an interesting issue with one of the modules I'm using, specifically msgpack. I noticed that there was A LOT of cache/buffer memory usage after I had finished running scripts. So I went through all the packages I used and settled on msgpack. I assumed msgpack was implemented in C given the speed and since it's a third party package that is used a lot. And I found an open issue on GitHub related to this.

GitHub
Hello, I think I've found a second Python 3.12 memory leak (having read the issue for the other one, and tried upgrading to msgpack 1.0.8 to fix). This issue occurs with dicts, and key uniquene...
Ahh I see...
yeah I have had issues with python 3.11 and 3.12
so I settled with 3.10 for now. Cause there are some packages that don't work in 3.12 due to inter package dependency and one package not being upto date cause issues in another.
3.11 had issues with llama index not running properly
this issue is from may... that's a long time ago. It means it's still not fixed given you are facing it.
Yup. And it’s even on 3.10 Python
Have you been implementing stuff in rust? I wonder if it would be better loading in that data with rust instead of the map hack pypi package
msgpack doesnt seem to be maintained last commit is 3 months ago
and there are 2 PR still un-merged
I would say try doing this in rust if possible. do file manipulation in python like extracting metadata or articles from xml
etc
then for preprocessing you can move onto rust.
it'll be faster as well
I figured that the search functions can be converted to rust and called from Python
Things like the inverted index and computing TF-IDF or BM25 and returning the best scoring entries
what does this mean converted to rust then called from python?
ahh
sorry
I get it
Yup
so rust binding for python
Keep to Python but offload the heavy compute stuff to rust
Cuz Python can call rust code
With maturin or something like that
got it. yeah send msgpack to rust as well. I just don't see python msgpack being a good package
i saw the msgs for category issue. You can't grab the category from the xml file?
It’s some extra parsing. Just having the problem of figuring out how it would best work in the inverted index component
If I’m understanding timetraveler correctly, the bag of words component allows the current inverted index to return too broad of a search and we can’t figure out how using the categories would help the issue
instead of words being the node the category would represent nodes and then you can add relevant documents under each category
although you may use sub categories within categories
categories will help better filter and group articles
so you most likely wont have 10 million under each category
Right but figuring out the logic for that is a bit hard for me to grasp
Turning words to categories isn’t too hard
Could just build a map for that
and if you make more sub categories then you'll have even better grouping hence even less articles at once
According to time travelers research, Wikipedia has shallow category trees
yep they do. given that's how they structure their data.
Question is to turn categories to documents without returning too many
have you looked into this?

Recall that using set union for the word to doc tries inverted index returned a lot of documents
that would be to group them effeciently, use a cluster algo
Any suggestions?
one minute i'm thinking on it
here's the parser btw
this is basically what I am thinking
OpenGenus IQ: Learn Algorithms, DL, System Design
In this article, we will demonstrate how we can use K-Nearest Neighbors (KNN) algorithm for classifying input text into different categories. We used 20 news groups for a demo.
it uses tf-idf method to create vectors
I’m not sure how I like the amount of ads and popups on the site
lol.
I use brave so I don't see them
@meager siren what was the dimension size you were using for embeddings?
768 for BERT vector emebeddings
when using encoders
and the size of text?
were you using the whole articles or chunked?
so the max size was 512 tokens and 768 sized dimensions
Yup
Vectors are not a compressed representation of data but an abstract one that just makes it easier to operate on instead of words
I am reading an articles that can scale the dimension size by 32x smaller
so you get lots of memory benefits
I feel we might be able to go back to the vector db version of this project
lemme read further
okkk
this is it
@meager siren
42 million vector embeddings how much space would those take? take a guess
At how many dims?
yep yep go on
4 bytes x 1024 x 42,000,000 so probably around 42 TB?
4bytes from one float32 value per dim
wait
wrong calc
it's 160gb
are you dividing by (1024*3) for GBs?
ohh sorry not
that
Float 32 -> 4 bytes
yep
Per number
4*1024 = 4096
X 1024 dims is 4 KB
4096* 42000000
172032000000
172032000000/1024 = kbs
168000000
168000000/1024 = mbs
164062.5mbs
164062 / 1024 = gbs
That doesn’t seem right
160.217
I think you double divided the KB
nope
it's correct atleast on the calculator im using
check on yours
i'll use online version just in case
But you are also assuming 1 embedding per article
yep for now
that's not the point
this is
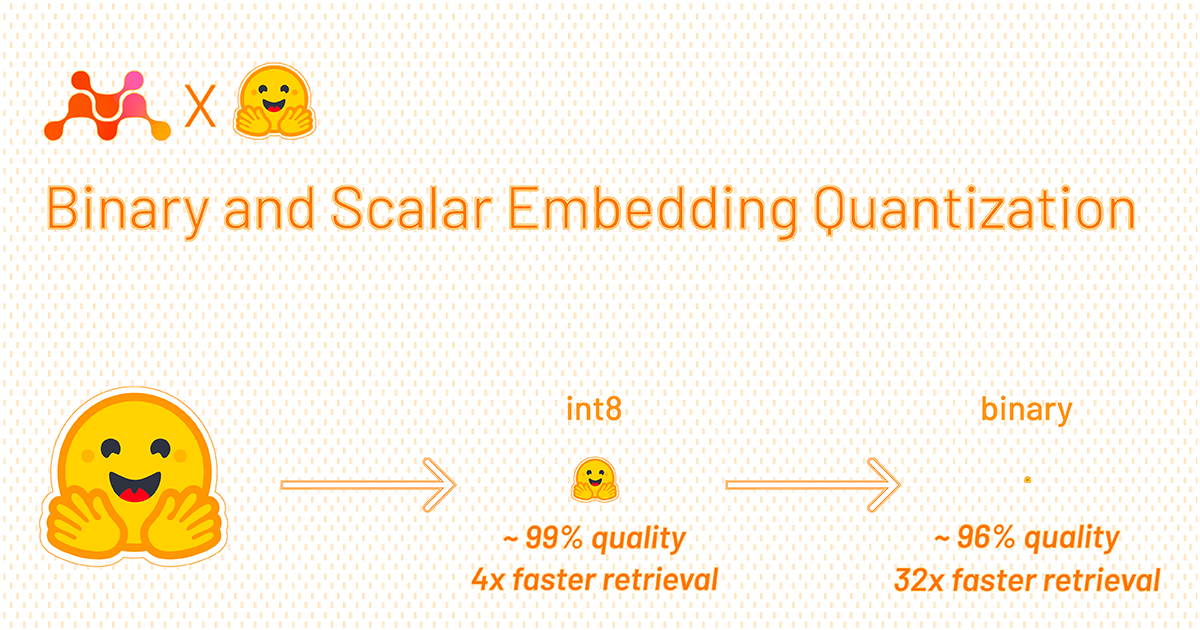
so 42 million takes 160gb
the stats here are for 250 million vector embeddings
which is:
~937gb
now
if you use binary quantization you can scale this 250 million embeddings to ~29gb
29
just 29
from 937
lol

Here is the steps:
Combining binary and scalar quantization is possible to get the best of both worlds: the extreme speed from binary embeddings and the great performance preservation of scalar embeddings with rescoring. See the demo below for a real-life implementation of this approach involving 41 million texts from Wikipedia. The pipeline for that setup is as follows:
The query is embedded using the mixedbread-ai/mxbai-embed-large-v1 SentenceTransformer model.
The query is quantized to binary using the quantize_embeddings function from the sentence-transformers library.
A binary index (41M binary embeddings; 5.2GB of memory/disk space) is searched using the quantized query for the top 40 documents.
The top 40 documents are loaded on the fly from an int8 index on disk (41M int8 embeddings; 0 bytes of memory, 47.5GB of disk space).
The top 40 documents are rescored using the float32 query and the int8 embeddings to get the top 10 documents.
The top 10 documents are sorted by score and displayed.
Through this approach, we use 5.2GB of memory and 52GB of disk space for the indices. This is considerably less than normal retrieval, requiring 200GB of memory and 200GB of disk space. Especially as you scale up even further, this will result in notable reductions in latency and costs.
we've lost the plot though.
here's the full article:
sparse vector retrieval via BM25 and TF-IDF reduces the amount of storage and compute you would have to do in comparison to full vector search
yes and nope. since they both produce vectors you would still have float32
in this case vectors are int8 or binary
most likely int8 for results
so even with less vector count in tf-idf the resulting sizes are roughly equivalent but one will give better results in top k
Right but the first vectors are dependent on the length of the search query vs the dense vectors are dependend on the model output dims
I'm just saying, if you can use sparse vectors to isolate the correct articles of interest, the amount of compute to do dense vector retrieval is drastically reduced
that's why people have been looking at this two stage rerank system for RAG
any link?

In this Video we discuss advanced retrieval techniques from Vector Databases with Query Expansion and Two-Stage Retrieval with a Cross Encoder. We use another Reranker on top to take the famous "lost in the middle" problem into consideration.
Code: https://github.com/Coding-Crashkurse/Applied-Advanced-RAG
Timestamps:
0:00 Two-Stage Retrieval i...
but most vector retreival are already in secs range with this approach it would be 32x faster

AI-powered search is heating up, but it's nothing new. Google, Netflix, Amazon, and many more big tech companies have all powered their search and recommendation systems with “vector search”.
In this video, we'll talk about sparse and dense vector search, their pros and cons, and how the latest sparse embedding model called SPLADE can help us e...
Sort of. Depends on the scale of the data
It's seconds for a handful of documents
More like hours/days for all of wikipedia
doubt that hours part.
which vector db bench marks are you quoting?
lemme send some links
Looking at lancedb since it's using disk storage
milvus can do 10248 queries per second with 1 million vectors
standalone is 7522
which is local
1.2 seconds for 1000 retreival queries among 1 million vectors 128 dimensions
for one query it's 0.0361 seconds
doubt your single user on a laptop can bunch out 1000 queries a second which will cause 1 second delay in his life
also I don't know if these are float32 most likely they are maybe... cannot confirm. but that means binary quantization will work faster
I mean, be my guest if you can scale this. I wanted to do a vector search benchmark but I would have to clean up the data by remove redirect and category documents from the dataset
soka.
One thing that I love about open sourcing this project here is that I've gotten a ton of feedback from you and other devs on how to approach this problem given the scale
everyone can build their own version given the data I have consolidated and made available
we can still technically go the trie based way and it still would be faster than using vectordb. However the main use of vectordb is where you dont get metadata such as category/short description etc
then you can't rely on much other than vector search by using vector embeddings
I mean, right tool for the right job
if yo can filter our the target documents the vector DB can do its job on the limited amount of data quickly
dont forget that vector DBs take time to process all that data into vectors
yep very long
forcasted about 2 months to store it all but that was unoptimized
and I ran out of space very quickly so....
that's when I decided that the compute of vectors on the fly at inference time, as long as the number of vectors was limted, makes more sense
yep that's why the binary quantization would help in memory.
Does transformers support binary quantization?
if the vectors are dynamic and limited, I could use faiss which does support binary quantized vectors
nope an extra step does. it'a quantiation function in the transformers library by hugging face
and yes faiss supports quantized vectors and a few mainstream vector dbs as well
ok then, I have to go to sleep will talk when I wake up.
ghost can
the vectors made by them become very large
that was the conversation I had with ghost
he can use quantized vectors to scale the memory consumption down by 32x.
and that will also increase the lookup speed
he does want a trie based method.
so we're going with that
@inland lynx ^
quantization of vectors would not loose information to such an extent
quantization is just using lesser bytes to represent the value with less precision
so yeah loss of data but not much given the vector can be safely quantized to such a level with good retrieval.
so what you said was transformations.
quantization of vectors is more like scaling.
so you represent the same vector on a small scale.
say if the vector was (10.010201, 10.103020) then we can represent that as say (10.01, 10.10) so we reduced the precision. But the information in 3 significant digits will have similar accuracy to 8 significant digits
the benefit is mainly memory, if memory size is reduced than the speed is automatically increased in terms of vector calculations.
i'll definitely look into this.
@inland lynx can you give a step by step super simplified diagram of the logic flow and mappings that are needed for the category based inverted index for the bag-of-words search (TF-IDF, BM25)? I think something like that would be tremendously helpful (at least for me) wrapping my head around what you've been trying to communicate
I'm not being confused. I said what you explained "If you quantize the data, we loose Accuracy as we are using data in an encoded" <-This is exactly what I said but you are wrong to say encoded. It's not encoded. How is using float32 vs float64 encoding. I see that as precision scaling. If say you had a vector represented by both fp32 and fp64 and plot it on a graph you would see no difference at all in their location. however one is computationaly faster. But scale the float point even less say fp4 which is float point using 4 bit then the graph looks somwhat same but with large number of vectors it's going to be harder to distinguish since only so many values can be represented in 4 bits. That's why I said precision scaling.
"As its binary quant, the vector is similar to a Boolean yes or no, in terms of one characteristic" <- For this i'm not too sure. I haven't acually run the code to see if it outputs binary yes and no, even if the name implies it. But if that's the case we can simply use int8.
And yes int8 is a encoding since you went from decimal points to whole number. And yes you loose quite some accuracy but in terms of vector angle difference it isn't a whole lot. say you have 10 million vectors and you try to find top-k = 10 meaning top 10 closest values to some query vector X, then you can good retrieval but it doesn't scale all too well after a few 100 million vectors
Problem with using pure transformers is that you have to consider the scale of the KNN search on consumer hardware. I think we already had a discussion on the time it would take to embed all vectors as well as performance of retrieval from the vector DB. From what I recall, we pretty much said "yeah, the metrics look good but it's untested on the wikipedia data with regular hardware so.... 🤷 "
The goal of the project was to narrow down the list of possible valid articles to some top K with the sparse vectors like TF-IDF and then find exact passages with BERT (that should keep cost down). I'm still re-reading the paper to see how the weighted TF-IDF would work/look
so I say
@meager siren
you are doing tf-idf in rust correct?
what type are you using? float32, float64 etc
also how many articles were left after duplicates?
Not sure. I’d have to remove the articles that are just categories mapping to other (sub) categories
I suggest to use even lower floating point
They have lower than float32?
or some sort of quantization that's int 8 based
that should be some good optimization on it's own
I think they might otherwise you can try using int8 they have very good ML libs
otherwise you can use another thing
they have pytorch/libtorch binding lib you could use the fp8 that pytorch provides
Not sure how int 8 helps given the TF IDF of a character is a float
basically tensors
Yeah I'm not sure either.
but I am just assuming there might e a way of quantization on tf-idf
I think it’s good to keep memory low
And most vectors are pretty different by the first 6 digits after the decimal
multiply those by 1000_000 and you got ints.
lol
Int8 and float32 are the smallest size dtypes in the vanilla rust library
wow
@meager siren just found this
idk how useful it is
since im working on my own thing
check it out and tell me
https://scikit-learn.org/stable/auto_examples/applications/plot_topics_extraction_with_nmf_lda.html#
scikit-learn
This is an example of applying NMF and LatentDirichletAllocation on a corpus of documents and extract additive models of the topic structure of the corpus. The output is a plot of topics, each repr...
@inland lynx I finished the paper on utilizing the categories, keyword extraction, and TF-IDF to give a more streamlined search. It's pretty interesting though that it heavily relies on the categorical mappings. I see a lot of the logic they used for the weighing functions and it sort of makes sense (I wonder if I can swap out TF-IDF with BM25 to compare results).
I am working on building the category to category map from scratch. The only reason I'm not using the repo you suggested is because I'm not sure if key categories overlap or are missing from my current dataset. Current script takes a few hours (primarily because it reads the original xml article files and those files take time to load (more time to load than it takes to actually process the article data).
I can speed this up with multiprocessing but it will take some time to work out. I still have to break up the current graph to remove cycles and identify starter nodes
Ok this may actually be much more helpful than doing it by hand
Still have to build the TF-IDF data in such a way that data is properly propagated up the graph/tree(s)
The paper you shared earlier had used TF-IDF to determine which categories to go down. You need word freq & number of documents per category in order to determine this. The wikicat repo does organize the categories into a tree/DAG structure but you still need that metadata propagated up to all the categories (my code only has that data at the leaf nodes of the tree/DAG).
No, we are
but the metadata for that child has to get propagated up to the parents otherwise there is no way for the algorithm to know which category to go to
@inland lynx hang on let me break it down
wikicat gives us the categories structured in a tree right?
And the paper you shared, it used a modified TF-IDF to determine which category & sub category to traverse in the tree
It does not
wikicat does not have that metadata
Or at least, I'm not seeing it
right, that's not the problem
the problem is that, in order for the TF-IDF to be used, each level of the tree needs the metadata useful to compute that vector
we have the metadata (for TF-IDF) in the leaves
that metadata has to be propagated up so that the next level (parent categories) have it aggregated
the paper does a BFS implementation but yes
kinda
there is nothing wrong with the algo from the paper nor the structure provided from wikicat
We have to populate the metadata to the tree bottom up (leaf to root)
Yo have to
because it's cheaper to precompute that before inference
than to do this at every inference time
You read the same paper as I did, right?
kinda
it talked about document but we can do the same for query
right, that's true
But the paper builds that vector based on the data from the children/leaf nodes
that's wat I'm saying the problem is
right now, I'm trying to give the nodes enough data to build the vector from the child nodes
and store that to file
I understand that
you have to populate parent categories with vectors from the metadata. That metadata is coming from the sub-categories
You are assuming that wikicat already has that vector info precomputed
Your description doesnt line up with the resources you've provided
It's not that it's computationally efficient
It's that I'm having trouble finding a way to build the tree they did from the bottom up
they gloss over that heavily
I'm not talking about the relations
the graph structure is already made with wikicat
I'm talking populating the structure such that the traversal described in the paper is ready with minimal compute
stop talking about relationships. We already know the relationships have been established between categories
yes
but you have to move the data up the tree to parent nodes in order for that vector to be created
Information has to be moved bottom up for you to create vectors that go top down
aggregated vectors
Ok, but how do you take a query like "who ran for president in 1992 in the United states?" and go category by category down the tree?
That is not how the paper did things
If i were to do what you just suggested, you know what I'd do? I'd use word2vec to get the category label that closely matched my query bag of words.
My point is that strategy is tangential to the paper you had me read
I guess I'd just do a BFS traversal similar to the paper and use the highest cos similarity of a word in a bag of words against the category label
no
whatever
yeah, it's fine
Summary of inverted index schemas that have been proposed thus far:
- Plain inverted index using a trie to store the information/mappings in a compressed manner. For each word, get the documents that the word is found in. Aggregate the documents in a set union operation
- Plain inverted index (like above) with a filter against words with low IDF scores (given an arbitrary threshold).
- Weighted inverted index. Similar to 1, each document gets a weight that is computed from the sum of the IDF values for all words that returned that document.
- Category search - Word2Vec. Do a BFS style search on the category tree where you choose the branch that is "most similar" to the query based on aggregated Word2Vec scores between the query and the category for that node
- Category search - modified TF-IDF. Similar to 4, except the comparison uses a modified TF-IDF for the vectors instead of Word2Vec.
Looks promising but given the scale of the data (10 - 20 million articles with a corpus vocab of around 40 million) I dont think the sklearn vectorizer is equipped to handle that much data.
possibly yes.
@inland lynx Tried using wikicat.... Downloading the data dump has not been fruitful



@inland lynx I just had a thought. Since the original files are broken up into 195 files, each with 150,000 articles, why not have the search engine run on each file instead of building monolithic stores that contain metadata per some arbitrary chunk size?
Pros:
- Conceptually easy to parallelize
- No worries about load time in fileIO
- Possible reduction in memory overhead
Cons:
- More fileIO operations
- Possible (likely) data redundancy
And before you ask, no I still have not implemented categorical hierarchy inverted index yet. It's something that's taking a long time to hack together.
More like if we have 1 file for a search engine to process, You lose the compression of storing the inverted index in a trie because you would have 1 trie per file rather than the 50 or so tries that have coverage for the entire corpus.
Alternatively, we can still keep 1 trie per starting character found in the words for a file but I'm not sure if having extra files would help or hurt.
I also agree that searching the entire file is not ideal. But also consider that the files are pretty small (1.6GB token max but most are 700MB). Loading will be slow but just as slow as all the other file loading that's been done so far (ie load tries, redirect files, IDF files, etc)
Simplicity
Right, but it's also been compute (RAM) intensive
Running on my server, we used up 24 GB RAM easily when doing search
that's with iterating through tries that account for the corpus
virtual memory readings are unreliable due to the memory leak in the python msgpack module
On a run my cache memory is like 40GB
2GB MAX, mean is more like 700MB
The 24 GB was also including a few other files
7GB can be accounted for via the doc to int /int to doc mappings
IDK
remember, the metadata files I've made are for the entire corpus
I figured that sharding the search engine could help keep the overhead load and help reduce the number of documents I have to read into memory
entire file is only needed for final retrieval
No, sharding based on the file splits of the data (the 195 files)
The only metadata file that wont be sharded would be the IDF metadata, since that is corpus wide information (overhead/file size is still around 2 GB)
It's actually kinda against TOS to use it for metadata storage
I wont tell if you dont though
No hard limit but I would suggest keeping it below 500GB to avoid detection
Also, i think that still qualifies as metadata
what's the threshold for high weights? What are the weights based on? IDF?
Sounds like word2vec
Or TF-IDF with some extra steps. Either way, the term extraction/isolation from the query is a bit iffy without an algo.
hey im confused about LangChain and Weaviate support
Weaviate release v4 client api and make v3 depreciated
But
from langchain_community.vectorstores import Weaviate
Doesn't work with v4 client
i found topic from June that is not resolved yet
https://github.com/langchain-ai/langchain/issues/23088#issuecomment-2268069252
i just startet my RAG project 2 days ago, should i search for some workarounds or just change VectorDB?
update: i will test this solution:
https://github.com/langchain-ai/langchain/pull/20443#issuecomment-2080199607
Use TF-IDF to create an inverted index to filter out/reduce how many TF-IDF operations you have to do on the actual corpus

😕 wait correct me if im wrong
to run RAG app with vector search i need running Embbeded model every time i perform a query, not only when prepared data to populate vector DB
🤔
Correct
because you query also needs to be converted to vector space so the vector DB can do KNN and return the closest results
thanks 🥹 i would try to find small embedding on HF model to run locally on CPU to finish my project
It was a joke. That being we're using TF-IDF twice but one is for the inverted index to filter/narrow down our search

At this point you guys should consider making your own vectorDB and retrieving algorithms
No I know idea must be good thats why this thread is still alive
That's one of the reasons why the repo is public. If someone can do it better, they have a place to start from
I switched the TF-IDF to do a file level search (in other words, you have multiple threads where each thread processes a chunk of the 195 files). Spawned 32 threads for the process and waiting on results.
I had a few bugs which got my hopes up (I thought the return speeds I was getting of 100s per query were good but there were entire sections being skipped). Still hoping that the multithreading and chunking brings the search time really far down from 2 hours per query.
Inverted index trie was also split by file (and then by starting character). It reduces the savings on storage but keeps the inverted index still relatively compressed.
File search
Figured that threads processing around 100,000 articles per thread would be more fruitful than doing the inverted index to get 10M articles and then sharing the TF-IDF process to threads
Preprocessed articles in each files into tries. Preprocessing skipped redirect and category articles
Same stuff I used to build the Tries previously
Still using bag of words atm
I am doing per article
I’m just allocating threads by file
195 files splits across 32 threads puts 7 files per thread. For each file, I get the relevant files via the inverted index trie for that file and pass that on to the TF-IDF/BM25 algo for scoring. Scores are kept in heap that has a max size.
Heap from each thread is aggregated and again, that has a max size.
That final heap is returned/passed to a function to retrieve article text.
Note to self, num-workers value for threadpool is capped by the memory alloted to the PC. Each trie folder is about 200MB on average and doc_to_words map is about 400MB on average which gives overhead of around 600MB to as much as 1GB per thread.
Fewer threads means less parallelization (and thus slower inference/search) BUT that is all dependent on hardware so there's not much more I can do in terms of optimization (until I do the Rust conversion of the source code).
OOM issue due to worker count
Each thread has to process a chunk of files in serial. Overhead for that is about 1GB memory. Across 32 workers, thats possibly 32GB memory usages.
No risk of deadlock since each worker gets its own unique files
32 workers means each thread has to do max 7 files. BUT because of the OOM I'm trying 8 workers right now (puts the count to around 25 files).
I'll also try with 16 and 12 workers on my macbook and see how that goes. I'm sure my server will be able to handle this just fine (maybe even handle it as multiprocessing). Kind of a downer because the whole point was that "any" PC could run this reasonably but you do have to consider the scale of the data and.... yeah, it's just a lot.
Not sure
Assuming rust provides something wild like a 10x speedup and we take the 2 hours per query (from my previous runs under serial load/no parallelization) as a benchmark.... That would be around 10 - 15 minutes per query...
Oh, I forgot to mention to you is that the category tree stuff failed to build on my system. Ran for so long and I think my system was rebooted after a few weeks from an update
No, I built from the category data in the dataset
Heap for my bag of words does this
stdlib from python
heap entries are the following tuple (TF-IDF score * -1, document filename + article hash)
Pretty much. I did everything I could to cut back redundancy and reads
Even put in calls to delete variables and use the garbage collection to clean them up.
Only memory wastage is the memory leak from the msgpack module
and the TF-IDF score for ordering
document name is going to take up some space, but because the heap has a set limit before it starts poppushing, it should be fine
Because I'd have to spend more time on getting category key working
I'll give the thing a try, but remember that 1) this is a hobby project and 2) I have other things to do so progress will be slow.
Since I'm away from my server, I wont be able to do any have processing for the category tree, so it would have to be a prebuilt tree that gets downloaded.
I’d starts where I got the wiki dump.
Downloading enwiki-latest-category.sql.gz-rss and enwiki-latest-categorylinks.sql.gz to try and see what I can get. Downside is that I have to use sqlite3 to explore it. I may consider swapping to sqlite instead of xml because I can interface easier on python. Not sure about the speed though.
Code/links?
Did you get the entire category trie?
Not bad. Can parse it since it’s XML format
Well, if I can implement the TF-IDF search via the category tree, it may eliminate the trie all together
Also, I just finished downloading the two sql files from the wikipedia hub. the latest category sql file is about 200MB but the category links is at abou 30GB
sigh looks like I'm on the right track with this dump:
https://stackoverflow.com/questions/27279649/how-to-build-wikipedia-category-hierarchy
https://stackoverflow.com/questions/17432254/wikipedia-category-hierarchy-from-dumps
https://kodingnotes.wordpress.com/2014/12/03/parsing-wikipedia-page-hierarchy/

Stack Overflow
I'm trying to build the treegraph of wikipedia articles and its categories. What do I need to do that?
From this site (http://dumps.wikimedia.org/enwiki/latest/), I've downloaded:
enwiki-latest-p...
Stack Overflow
Using Wikipedia's dumps I want to build a hierarchy for its categories. I have downloaded the main dump (enwiki-latest-pages-articles) and the category SQL dump (enwiki-latest-category). But I can'...

Wikipedia is a set of pages that has relationships with one another. For example, the Anarchism page has a set of categories (located at the bottom of the page). Categories group related pages toge…
But TBH, with the shear scale we're looking at... I dunno if I wanna do it
Primarily for the ability to take a dump and parse it when it updates.
The categories oerall wont shift from year to year but there are new ones that might be added in accordance with major historical events or scientific discoveries
in which case, that static graph would be out of date
ok then, let me look again at the repo one more time
Alrigh alright
Just give me today to look it over. I'm not by my server today and I have to drive back home later (It's a 2 hour drive from my current location)
I'm afraid that is gonna be compute intensive
since you have to work bottom up from the tree to build the TF-IDf word vectors
For their scale, it's not compute intensive
they have a budget for CDN but I imagine they have an entire server dedicated to search
It's interesting to ponder
most people entere wikipedia via Google search, not via the main wikipedia homepage
so most people dont search wikipedia via wikipedia search engine
No no
I’m doing a dumber search engine
One that can take in raw queries like goog but outputs the Wikipedia articles
Via that max depth parameter in your graph builder?
Mess with the max depth to get a slightly taller tree. Something either 4 deep or 3 deep. Smaller depth means more articles per leaf
Each category maps to a set of articles
Higher categories are just aggregations of sub category articles
Well I. That case, let’s see what happens
If the category tree can return something like a few 100K articles l, then we’re in business
I’m just saying. If we can filter out from 10M articles down to 100K, it would be nice
We still doing the TF IDF BFS search on the category tree, right?
Thinking about it, the vocab is also huge…..
Top level category is gonna have a HUGE vocab
That cleanup is no big deal
I’m just thinking of once each category’s aggregated word frequency is done it needs to be stored and pulled into memory for searching through the tree
Group subcategories by number of articles then
If a sub category has less than 10K, group as one
More like throw something out and seeing what sticks
What about this
Ignore overlapping terms words at a level?
Nah, no go for that. If the query consists of overlapping terms, then you get nowhere
New thought: train a Word2Vec model on the data and use cosine similarity between the words and category labels?
This only falls apart at sub categories that are multi word
No you’d just train 1 model on the whole corpus to get the relative vector embeddings
Yeah
And the problem is that the multi word query and categories also won’t work well
Maybe BERT embedding the query against the category?
Thought our graph was relevant categories
Not sure
Didn’t you have networkx in the code? You could print it out to see the tree
Kinda. I think they did more NER or classical methods
Ok
So to recap
Query and the graph labels (categories)
Why not vector embed the query and categories with BERT and traverse the graph (category tree) until the cosine similarity becomes worse
Think about it, it’s handling multi word texts
No pretraining on our end
How “many” are we talking? Is my question
If we can get shorter than 500K, then we’re golden
If not, then we need further refinement
Give mean, median, and mode
Most give mean when they do this
Just thought I’d specify
Running at max depth 5 right now to see what happens. There should be a conceivable level where max depth returns "too fine grain" of search. I guess we're just finding it at this point
To be fair, the DFS algo in your code should be able to handle that, no?
And I did see in my own code (when trying to build the tree from the actual data dump) that indeed cycles were detected.
Then encountering cycles should not be a problem I think
🤷♂️
Probably 20 levels is all we'll want to explore IMO. Thinking from a high level, there should not be too many ways to categorize one article that isn't already covered by other categories
Have you been able to save the graph to a png instead of a pyplot?
I'm currently doing that for my depth 5 run right now
I have it set on mine
Is there a save to svg then?
OR something that wont blow out the canvas limit?
How long did it take for you to get a max depth 5 graph?
Damn
Well, unless chat jippity gives a source, I'm not inclined to believe it for something like this
Should do incremental runs. Depth of 5, 10, 25, 50 and compare results. I can leave the script on my server to run.
Plus, chat gpt was only talking about articles, when we're talking about the categories

So what we know now:
C = category
P = page (articles)
F = ?
Some categories overlap/crisscross and there are probably cycles in the graph
Got HTTP error on my run for depth = 5

Could not tell
Side note: running search on multithread for pages was not as fast as I was hoping (8 threads)
Search returned in 17078.927761 seconds
Also RAM jumped to 18GB for some reason (probably the memory leak - cache is at 47GB)
Let me try
It's the msgpack module
Gonna convert that loading in the search engine to rust
It's not, but some of the msgpack items that are serialized (ie tries) have to be handled in case we use them
I dont want to even deal with that. I'd have to submit a PR to the msgpack module repo
Running script again for depth = 2
Ran no problems. WOW that's a lot of text/fields

Rerunning with max depth = 5 on server
Thinking about it out loud, we probably wont get a better depth lower than 10/20 because of how much RAM you'd need to process the number of categories.
Breakdown of the data: https://en.wikipedia.org/wiki/Wikipedia:Size_of_Wikipedia
The size of the English Wikipedia can be measured in terms of the number of articles, number of words, number of pages, and the size of the database, among other ways. As of 16 September 2024, there are 6,883,665 articles in the English Wikipedia containing over 4.6 billion words (giving an average of about 681 words per article). The total numb...
Only around 7M articles out of 61M possible pages.
C = Category
D = Draft
F = File
P = Portal
Template
TimedText
User
Wikipedia
Help
MediaWiki
@inland lynx I think we need to look at parsing the damn sql file for category links
Running your script for depth 5 and it's still going
It would probably be easier to parse the sql tables
Not sure. I have Max depth at 5 and it's still running. Memory usage is at around 28GB (with 38 GB cache). I feel like it should have stopped by now. Part of me wants to suspect network issues (since we're using API calls) but those would have given timeout errors.

Not yet
I wanted to keep the run going rather than restart
For depth 2, I get a completion time of maybe 10 to 15 minutes (or less)
I'm killing the depth 5 run. 24 hours is long enough
So the categorylinks and all other sql files are MySQL format. Kinda dont want to have to install mysql on every machine so i need a way to convert it to something like SQLite
I think it’s worth going back and exploring deriving the category tree from the articles. We have some category to category data so it may be worth exploring.
@inland lynx I have an idea for how to build a (mostly complete) category tree. It will combine both the wikipedia API AND the categories from the article data dump.
- Compile a list of all unique categories mentioned in the data dump.
- We use the categories listed in the data dump to seed queries to the API. Each category is queried from the API, and should give us a subtree shard that we can use to build the bigger tree (we should be able to see subcategories and parent categories).
- We attempt to stitch as many shards as possible with the tree we get from querying the
Main Topic Articlesfrom the API
This comes from the fact that querying the APi is taking way too long and the data dump is somewhat incomplete when it comes to category data just from the XML containing articles\
Also, I (think I) figured out why the download category script was taking so long. It was because of the saving the graph to png component that was taking forever
You dont think so @inland lynx ? I managed to get the depth = 5 to run in under a day on my machine. I'm currently working on depth = 10 to see how long that takes.
So far I got remote connection error after some time
Also, current file size of category graphs
depth 2: 1.8MB
depth 3: 14MB
depth 5: 112MB
depth 10: 490MB
Took around 24 hours for gathering the depth 10 information. Should I try for depth 25?
Number of unique categories captured by wikipedia API at depth 10: ~1.6M.
Number of unique categories captured by dump only: ~4.6M
I think I'll just run the depth 25 run and see what happens. Fingers crossed it only takes 2.5 to 3 days.
im running the code w/o drawing the graph and it takes equally long I think the time is spent on loading the entire page
page = something
This part needs to be optimized
I thought it was only grasping links to other categories, not (article) pages?
Already kicked it off... might as well see what comes of it.
I scrapped the sql dump idea because I'd have to set up a docker instance to host mySQL and do the querying. Effectively, it would be a lot of work to set up and maintain for when newer dumps came out.
How do you propose we do that?
Also, depth 25 category tree download failed (got HTTP 443 timeout exception - not surprised). I guess I'll just look at the depth 10 to see how many categories from the text fit.
need to use a different wiki api (or) figure out how to create a new WIKI APi which is more efficient
Would it be too much for me to ask you to explore this part?
Also thinking out loud here. Would it make sense to do unsupervised clustering on the articles and build a tree that way?
Had another thought. We have the categories of each article in the dump. We have the category tree/map to at most a depth of 10 from the wikipedia API. What if we used BERT (since we cannot directly use word embeddings for multi word texts) to create links between the article categories from a dump and the leaf categories from the retrieved category tree? We have some sort of distance threshold so that you can have multiple mappings but there is a limit to that number. After that, prune the tree of all leaf categories that have no correlation to a category from a dump.
This is sort of like creating a weak connection between categories to "fill in the blanks" where the tree was unable to be populated.
This may be an interesting thing, since there are around 1.5M categories in the tree but are ~4M categories in the dump (not included category to category articles).
So around 6M embeddings total (1 embedding per category, 4KB per embedding.... gonna be a lot of data)
Agreed. I'm kinda wary of doing that too. Lot of resources look at TF-IDF to create the vectors but the vocab is gonna make the vectors large as you compare more and more articles and groupings.
I'm saying more like we use BERT to map categories from the tree we made from the API with the categories from articles that were not captured in the tree.
I had a script running take inventory of what was covered and what wasnt by the category tree (API, depth 10).

When you consider there are 4 million categories, having a gap coverage of 2M is not bad (especially when you consider the tree also had around 2M categories). Also, only 1M articles being completely unreachable is crazy good all things considered.
Of course, that would be ideal but there is a lot of processing that would have to be done to gather those categories
A lot of waiting for gathering the entirety of the category tree
I thought about using abstracts to aid the search but the information within them can be either sparse or dense relative to the topic
They do but like I said, the info is sparse
even metadata is minimal
Not even that
From what I recall, you get title, abstract text, and maybe one other metadata bit but that is it
And the abstract text itself was something like 1 paragrah tops
For persons, it was 1 short line like date of birth and region of birth
So I dont think those texts will provide any meaningful assistance
i feel like actual search engines have multiple layers of condensed information before the actual article
starting from tags -> more metadata -> summary -> node link of actual data
We could have an LLM like llama 3.2 1B try and summarize the articles to create our own abstracts. See if that 128K context length is true.
It's just a thought
Can we maintain category weights separate from an LLM summary?
More like summary based on the article text. Ignore categories
We keep category map but we confine our TF-IDF/BoW analysis to the summary instead of the whole text
Unfortunately, I dont think anyone will have an answer for that.
Honestly, the lack of relative control and traceability is always a good reason against using LLMs
yeah exactly
Lowering parameters like temp can help
I can do that, no problem
Should I use the instruct model?
we want to minimize "creative liberties" the model may take in the summary
I'll just generate 5 summaries and send you the original articles as well.
Also sharing the screenshot of my idea on "filling in the blanks" for the category tree.
I know we just discussed it but I'm leaving it here for notes

I got something stiched together for a few articles
took 50 seconds to generate for 6 articles
not great when you have to scale up to like 7M
that' the summary generating
there is no article that has an explicit map to that category
they are from the category tree
and make up the tree for traversal
yeah
like I said, we discussed this
we can prune some but not all. Prune away all non-direct reports andthe tree falls apart
well, I dont know what you mean by "short" but depth of 10 is pretty short to me. Depth of 2 will have no overlapping categories
Most immediate idea is lack of batching
gotcha
It was just for proof of concept, so no multiprocessing/batching
let's evaluate the summaries first
📎 pages-articles-multistream10_288ec473bfbc27d7686cfee3396c7ea4db31c2f7b2b967778e1e3a21c08a583b.xml9mhbv5bb1ouszwwbe7tnk4cmndmhtcx_summary.txt
📎 pages-articles-multistream10_288ec473bfbc27d7686cfee3396c7ea4db31c2f7b2b967778e1e3a21c08a583b.xml77dc02ek2x5qlza7dplrjdgi4smmbso_summary.txt
📎 pages-articles-multistream10_288ec473bfbc27d7686cfee3396c7ea4db31c2f7b2b967778e1e3a21c08a583b.xmlalpwsbm4z7vc9d1f18qe92c2sf5tpqz_summary.txt
📎 pages-articles-multistream10_288ec473bfbc27d7686cfee3396c7ea4db31c2f7b2b967778e1e3a21c08a583b.xmlf792aqy9mdauyvzbihq89rg2n05xa72_summary.txt
📎 pages-articles-multistream10_288ec473bfbc27d7686cfee3396c7ea4db31c2f7b2b967778e1e3a21c08a583b.xmlfbc9mind2xijdhy7hzwm32ne7larvfz_summary.txt
📎 pages-articles-multistream10_288ec473bfbc27d7686cfee3396c7ea4db31c2f7b2b967778e1e3a21c08a583b.xmlqfvznvvpcm96bch35yagim92oetkgx2_summary.txt
Damn, you gotta parse through it a bit. But it's not that bad
This isn’t search, just summary. I can send you the code in a bit
I think with the way the LLM is prompted for the summary (and things such as the temperature of the generation), it is staying as close to the original material as possible. It does not seem to do anything with the classification categories that are attached at the bottom of the original article
Saw this article (Use freedium to access it). What if we trained a document embedding model? https://freedium.cfd/https://medium.com/@evertongomede/doc2vec-understanding-document-embeddings-for-natural-language-processing-ba244e55eba3
I was looking back at this Medium article on the people who did a similar project (Wikipedia search engine). They operated on a much more limited scope, choosing to grab articles from the Health category and diving depth 10 down the tree. They ended up with about 650 articles and filtered it down to 450 after some additional processing around document similarity (used Jaccard Index + some arbitrary threshold for similarity and removed documents that were too similar).
It honestly got me thinking about how "easy" they got it for their project not having to deal with the vast scale of the corpus of millions of articles....
https://medium.com/@akleber/developing-a-search-engine-framework-for-wikipedia-articles-81fcbd95a928

Medium
André Kleber, Trevor McCalmont, Julien W
It’s more of a comment of envy at the simplicity of their dataset
Just putting it out there as another alternative
so where are you with your summaries?
I was thinking,
- you generate summaries for articles in a few catgeories
- do a cosine similarity between query and summary vs query and article
Q) is there any difference? If we do similarity with summary vs article itself
Probably will be a slight but noticeable difference
I want to know does it affect the query result
That’s all. It should not be that summary returns different set of x documents
I'll generate ~100 summaries for that then
Is this a dense vector cos-similarity or just BoW (TF-IDF) cosine similarity?
tf idf
If its possible, can you do both?
Want to know how much difference in using different vector similarity also
What is the expected gain you're hoping out of this compared to how we're trying to set up the search engine?
My ask is more around how does this tackle the scaling problem we're having
oh right
We just want to be sure that summaries are enough
summaries will reduce data load by a ton
We are doing vector comparison between query and article also right
so yes less tokens
i feel like for sparse vectors, the cost difference is minimal
hmm but you dont havr the processing memory right
we started with how much load everything was on yout servers
also think of 50 articles at a time right?
right, we want to reduce the load by introducing a condensed version of the articles
atleast thats what I thought we were discussing before
I thought we were looking at the document filtering based on query.
I'm not sure about the necessity but I already have the script to generate them.
So I should do the following:
- Generate summaries for all articles and store them
- Compute Word Freq of all article summaries and store them
- Use the summary Word Freq for...... TF-IDF inverted index?
And we are going to tackle part 3 via the method covered in the category tree traversal from that one white paper. Am I getting that right?
which paper? Sorry to ask
Rust has me convinced. Preprocessing took 30 seconds on something that was going to take tens of thousands of hours
Not sure if it’s doing what I want it to do but it was damn fast compared to Python
what did you do?
Remember how I was talking about filling in the gaps with the remaining categories by loosely using BERT embeddings?
I am going to try to minimize the number of categories used while still ensuring total document coverage
I abstracted that problem (least category for full doc coverage) into a state space problem
Downside is that generating a space is compute intensive. There are two sort operations (to give preference to certain properties)
And the number of missed categories and documents are around 3M and 1M respectively
Essentially solving the problem would have been very slow for python without some high performance library written in C or Rust because the algorithm I had implemented (while efficient) was going to take 10,000s or 1,000s of hours to compute
Notes for myself:
I was able to implement code in rust that would search for the minimal number of "missing" categories to get complete document coverage for "missing" documents. I converted the problem to a state space problem and implemented a modified BFS algorithm to return a solution. Even after several optimizations and greedy strategies, the search space was so wide and expansive, OOM issues were persisting even on my server.
I am currently investigating the option of breaking down the problem into sub-problems and iteratively building the solution. I've already made some optimizations by taking the category to documents map and removing/ignoring categories that are not missing (only focus on "missed" categories) and for those values for those remaining categories, I removed the documents that are not missing as well (only focus on the "missed" documents).
Now, rather than try to solve the whole problem "fewest categories to cover all documents", what if I broke the problem down to "fewest categories to maximize document coverage". The difference is that in the sub-problem, we look at subsections of missed categories, while still keeping the missed documents list the same AND we strategically start our iterations by:
- sorting the missed categories list by number of documents covered in each category
- chunk the sorted missed categories list such that each chunk generates a solution
- for each chunk, we pass in the previous solution state and the use the modified BFS to solve the modified problem statement ("fewest categories to maximize document coverage")
- continue until either the end of the chunked list or we have found a solution to the greater problem statement ("fewest categories to cover all documents").
This will probably be costly in terms of compute (even with rust speeding things up) but hopefully the OOM issues will die down.
@inland lynx I have my incremental script up and running. It took a bit but I got a depth 15 graph together (it should be cleaned). Funny enough, the size seems to be roughly the same as the depth 10 graph, so I have to audit the two and see what the difference is. It's over here https://github.com/dmmagdal/WikipediaEnSearch/blob/main/download_category_tree.py
GitHub
Contribute to dmmagdal/WikipediaEnSearch development by creating an account on GitHub.
if its the same size, I doubt it ran beyond depth = 10
https://github.com/rx-112358/Wiki-Category-Graph/blob/main/createGraph_append
use this its easier
How far did you run this?
depth 10
depth 15 - its failing a lot on the cluster / i am looking some alternate means
Your original implementation was able to work at depth 10. It appears that anything above that depth causes issues of some kind
my suggestion would be to run from depth 10 to depth 11 and first verify anything is there beyond that level
I’ll test it in a few days. Trying to get a depth 20 run finished right now
Every 100,000 nodes I have a 4 hour pause to give the API time to cool down
so there are some properties which someone can set at the server side to stop x number of requests coming in a short span of time
i think better is if you add a sleep in between the parsing
Yeah. Just FYI, 4hours between every 100,000 subtrees seems to be the magic number
And an inconsistent LLM. Yeah
Ran mine for depth 11 and 13. Both came out to be the same size. Ran a diff on the two files, also got no changes between the two. So there is something about my script that's not saving the data properly.
Did you get the bugs out of yours for depth > 10 ?
what?
That is not the point
We are labelling the answers and collectively weighing the correct web results
Thats how atleast google gen AI works
You can try to replicate the same by asking for a code snippet or answer to a topic which is rarely searched such as adding a ceritifcate to a request since nowadays everything is handled by some SaaS or kube
so the inference is there is nothing beyond depth 10?
I will be running for depth 10 to 11 and see if anything is there
seems fishy
we can verify manually by going and fetching in a code snippet pages of categories with depth=10
I think I found the snippet that's causing the issue on my script.
subcategories = get_all_subcategories_bfs(
category, intermediate_max_depth - depth
)
The depth that it is looking at is intermediate_max_depth - depth which would be a negative value if depth > intermediate_max_depth.
I'm re-running my script again but with just depth - intermediate_max_depth for a depth 11 graph.
Saw that the "for" loop wasnt running when I ran my stuff so I think I found another bug in my code
4.9 GB to store category tree data (depth 10) as vectors. Despite being very abstract and in numerical format, the dense representation is costly in terms of space.
you can try some condensed version of each word
I have noticed in some Microsoft services they dont store words directly, they store it as a long int
This saves a lot of space
No, the issue isnt the word storage (categories are like sub 50 characters). It's just that the vector embeddings are going to be heavy because you are dealing with around 1024 float32 (while each float 32 is 4 bytes) puts you at around 4KB per embedding (multiply by around 1.6M embeddings or 1.6 categories in the depth 10 graph).
Its the same design for the vector storage
Ideally the vectors should be in such a way that 1922,1922 War are not separate but structured in a way words with same prefix/suffix are related and not stored as seperate vectors
we can explore run time vectorization, keeping only some level nodes as pre-computed vectors
we discussed about a possibility that we match by metadata till last level and in last level only use the comparison
I plan on keeping the graph nodes pre computer in a vector DB
Right now trying to find the fastest way to process the remaining vectors
It took 2.5 hours at 48 cores to run the depth 10 graph
But my server is showing 13 hours to finish the remaining categories that map to documents.
I’m investigating batching the inputs on top of the multiprocessing now
Wow, batching is a wild fast at least in terms of processing data and keeps memory usage low compared to batch size 1 + muliprocessing



GPU 0 is working with the 48 processors + batch size 1 job (~40 GB RAM + 16 GB VRAM usage)
GPU 1 is working with the 8 processors + batch size 32 job (~16 GB RAM + 3 GB VRAM usage)
So batching really helps (though I found something from Huggingface that shows that there is a limit https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#pipeline-batching)
I restarted it and am running ike 16 processors + 64 batch size. It is blazing
P.S remember RDD
Thats how data should be processed - utilize as many parallel compute
Not yet. I'm hitting CUDA OOM errors from the amount I'm trying to parallelize
I think I over-estimated the "power" of the GPUs. I saw all of that speed increase that I was happy about was primarily under the condition that there are no additional embeddings to generate. When starting from 0 (no embeddings), the resource usage becomes more apparent. I am effectively limited to some combination that puts, at most, 256 text categories on a GPU at a time. This means 16 processors + 16 batch size, or 8 processors + 32 batch size are going to be the cap for what my machine is able to handle right now (I cannot distribute on all 3 GPUs without some extra work).
I know 8 processors + 16 batch size was able to do the first half of embeddings but the second half I may not know. This also is putting embedding times for each half at around 8.5 - 10 hours and around 13 hours respectively (again, assuming you have to generate all new embeddings).
yes
that's the categories that map directly to documents. The ones that were not captured by the download from wikipedia
I'd still have to generate all embeddings because I would have to group the categories from the second half into the graph downloaded in the first half. The pruning would have to be done post "merge".
Is there a way to generate the embeddings for a partial tree?
That is what I am trying to say
Not without doing more extensive computing (ie recall my efforts to trim the number of categories that map to documents while still maintaining 100% coverage. That effort was computationally intractable). Embedding both "halves" is just faster.
I had an interesting thing come up with the embedding for the last "half" of the categories. Apparently, there is a category detected that exceeded the 512 BERT token limit and it caused an error for the program (didn't find out until after it was supposed to finish). It's probably a line that got caught up on accident from the main body of an article but interesting occurence nonetheless.
@inland lynx I figured it out with the GPU. I had some stuff in the code to try and save intermediately. Additionally, I had lines in the embedding function to verify that a category wasn't already in the DB table. So the reality was that the check was probably going to cost a lot of time BUT it probably wasn't going to be 120 hours.
I did the following:
- consolidate node processing. Combine node list from downloaded graph and category-to-documents map. Eliminate duplicates by converting it to a set.
- check table in vector db. Remove nodes from the list that appear in the table.
- pass the filtered node list to the embedding function. Also added an argument to bypass the category check in the embedding function too.
This is much more straight forward I think and should bring the process down to maybe around 6 hours if I'm right.
Ok, I really over estimated on the 6 hours. It's looking more like 21/22 hours. But since everything is on one loop (for the embedding), I only have to wait once.
damn, 21 hours for what exactly?
Can you breadown the timing for what processes
Stage 1: load all nodes and clean the texts. Use set operations to get first and second half node list. Combine to one list. Iterate through and identify nodes that already exist in the table. Remove those words from the node list.
Stage 2: embed node list and update table. There are 4M nodes to embed. This stage will take 21 hours if starting from nothing.
After 1 full run yesterday, I found out that there is a limit to what pyarrow is able to handle. Apparently, objects over 2GB in size will cause it to error out. So I think I’m kinda forced to do an iterative saving along the way. That kinda sucks because it will still add time (to stage 1) if the program was interrupted or were to crash and I don’t know how much that will affect performance.
yeah you can do some checkpointing and save the obj part by part at a timestamp
Well, I might as well write it to the DB where it's going anyway
Stage 1 should filter out already stored values.
hmm partial xml s
That said, it will probably take much longer to complete stage 1 as it goes up
oh
uh dont store it as a pair together
do it like a hashmap
Store the embedding in its suitable form and categories in a suitable form

Analytics Vidhya
Learn to efficiently find content similar to queries using vector embeddings and LangChain. Understand embeddings, implement LangChain models.
I think you should try using some existing frameworks for your hashing and embedding management, the way your doing rn isnt that efficient
any thoughts ghost?
The interface and setup for lancedb is pretty straight forward. Search seems to be pretty fast too (on my mac, I'm getting 200 items/second with lancedb) for looking up already stored categories
so what is the best way to manage embedding s? Any existing frameworkd
Yeah, I let lancedb do all the work because it also does handles stuff at a disk level, not just memory.
too many writes per pair may not work efficiently maybe
Try keeping a temp batch where you push x pairs
Once the total max count is reached write at once to db
Way ahead of you there. Doing a batched writes periodically during the embedding process in Stage 2
If you do one big write to the db, you'll get a errors (if the data is over 2GB large)
I did the math
assume 6 kb per pair, I would have a max of 250,000 pairs per batch write to the db
I would suggest you do some dummy testing to test the limits with your h/w to find the optimal write batch size
We dont want to write MAX limit if it s costing efficiency/time
@meager siren is this what your doing?
https://lancedb.github.io/lance/read_and_write.html
Batching and merging is natively supported in lance
I see bulk update but nothing for add
Ah I found it
yeah I hope that makes everything more faster
Note there are many insert types, which does the checking if embedding exists
Try to use all the native methods instead of your code
Have you seen my code
no
I mean, I'm not denying it's probably inefficient
but I wonder how this will handle the scale
?
We have 4M entries to put into the db
Your doing everything in a batch
hmm true
isnt it supposed to scale to that level?
I mean otherwise using that db makes not much sense tbh
Right but what I'm saying is "how efficient is that upsert if it has to check by category name ?"
embeddings can be organized into a hierarchical tree based on similarity
but if you store 1M pairs into the db, and you have 3M left, how performant will that upsert be?
internally does it not do all this?
i mean they would be internally managing the data in a different way thats why your search is fast
Right but if you are using the category name as the primary key, you dont get that benefit
Youd have to do something else to account for that variable in the db (though I guess they probably would be able to figure something out since they can infer/use the types defined in the schema)
why dont u just try it and see
ideally they should be storing as some sort of hash maps internally
so that embedding is stored efficiently
its probably just interfaced as a db which you can query out like SQL
yes you can pass out a schema
Already defined the schema
they have the option to infer it based on the data or define it.
dont infer
depending on the initialization method one uses
I know. I have the schema explicitly defined
one problem with upsert
if you upsert, you have a constant runtime of 21 hours since you would be updating entries already seen/stored
use merge insert
not upsert
i just mentioned upsert in the case we want a scenario where we update Catgeories, like the label changes
Ah, I see
hmm actually we should have stored some page id
Why?
we dont have anything to uniquely identify an article
it makes it hard to update existing article nodes
this is just the vector db to allow for semantic search across the category graph.
yeah as time passes wiki changes
the Category name may change for the same article
anyways … carry on
As it stands, the DB would only get bigger since it uses the categories found in the tree and category-to-document mapping. Writing a "clean up" function to remove categories not found in either should be easy
its un necessary and in efficient in the case ppl are allowed to change name
thats mean we end up doing pre processing multiple times for the same article
Not true at all
But if the article itself changed then it makes sense
if the category name changed what do you find in the graph?
today my article was 1977 War tmrw its The history of 1977 and war of an era
consider this. The data (wikipedia and the dump files) are updated periodically
yeah but we end up doing un necessary inserts when the name only changes
Do you get what Im trying to say
We identify by a category name which may change
if the category changes, then the embedding changes because the embedding is tied to the category, NOT the article
If there is a new category, it has to be added to the db with its own embedding.
but the category is the same right why change the embedding
They probably made it sound fancier or some synonym crap
No, that's not correct at all
the embedding model is tied to the category because it was generated as a function of the category string
embedding = model(category_string)
that is true
new category -> new embedding
uh ok makes sense
update the category to document map, those new categories from there will be captured and stored to the vector db
but we need to update only the category node and upsert
Exactly!
but how do you map to the original category?
did u add any id or metadata
no
uh ok its possible needs a little more extra effort
We query the article history and do search and see what has changed
or whatever stores category audit history
insert categories unique to the category to documents map into the downloaded category tree via the semantic embeddings to match the categories
we dont have article history
its there actually whn you hit the API
We have TRIED to hit the API
lol calm down
and we have no good way to download the whole graph
this is only when we want to update some categories
It's interesting. The vectorDB is operating at a pace of around a little over 1 query per second when trying to search the table with SQL querying for known categories. I've tried what I can to speed things up, including mutliprocessing and even batching items into one query but still I get long estimates for this function (after there have been a large number of category, embedding pairs committed to the DB).
I even looked at using lancedb rust package to create a helper function in rust but ran into some issues with building and installing dependencies.
Update to that, I figured a way around that. Setting a bigger batch size for that (ie 1000) works well. Downsize is that the RAM usage really goes up a lot
@inland lynx Something I noticed is that I was getting really inconsistent results with my vector db. Like, why is it that, after 1 full run, I still have vectors that need to be embedded? Why is is it that each time I run a search on the db to get vectors already seen, I get different results? My program logic is right.
I'm thinking that perhaps multiprocessing could be the cause behind this issue. So I am running the script again, this time with single processor, to see how many vectors it finds in the db.
Could be the situation that, since lancedb is written in rust, it cannot handle multiprocessing well.
I use "spawn" instead of "fork" in my code but maybe it's just safer to go single-thread/single-processor

Ok, so after running that part 3 times, I was getting some solid consistency.

The number is concerning because that means I have around 4000 unique embeddings out of the entire 13 GB stored there which allows me to deduce that there are A LOT of either duplicates or corrupt vectors in the DB
So that means, for the sake of stability, I should run the program on single processor (and single thread I guess) and see what happens.
makes sense, might be a LOT of WRITE hazards
if your dealing with a ton of read/write hazards, we need to handle the number of threads optimized to lance
instead of multiple threads failing and we need to again spawn a new thread for all the data lost by the previous one s
so basically what is the commit limit? are you following the same?
I feel there is something fishy going on with your h/w also, is it supposed to handle these many concurrent writes?
so they mentioned they have a certain limit to how they handle write hazards
you need to follow the same, hope its not a huge limitation in terms of number of threads
I went back and ran diagnostics. H/W was fine. I forgot the specifics but the problem lie in the way the code was executing. After I changed the workflow of the program, haven’t had the same issue since.
I haven't checked multi-threading yet and despite the info I saw on the FAQ saying certain kinds of multiprocessing are supported, I dont think it's work the risk right now. Downside right now to running single thread/processor is that it is taking A LONG time to run the program (create and save embeddings) even with batching/chunk insertion.
No more 21 hour runs.

Uh but does that mean your number of write hazards reduced?
Yes
hmm how are you checking that