#bevy_replicon
1 messages · Page 14 of 1
I like of_n! Will rename, thanks 🙂
About of_ids, do you need this for your crate?
Because I expect users to know the types 🤔 And this probably requires using reflection of the component and its Hash impl since I need to dynamically query for Hash.
Ah right .. Hmmm, well it's not uncommon for me to type erase stuff in my game, so I'd imagine I'll run into it sooner or later ... But maybe we can find a different API once I get there. Perhaps it'd be possible to merge one I'd try to insert with one I can require
Needing to pass a fn pointer or hash could also work though
Since almost every time I do this I need some type register anyway
Maybe just use from in such cases? 🤔
Yea, could work for now
And maybe later we can swap it for using Hash as an ECS trait
Components as Entities when 
Yep, this would also work.
The suggestion about reflection is doable if we wrap the fns into enum.
But I'd probably advice to use from in cases like this. It's just simpler.
Renamed
Added Clone and Copy derives.
Since the component itself is not generic, you can store it somewhere. I think this might be more convenient than storing a pointer to hash 🤔
Could also be useful if you decide that from is not enough.
I’m open to expanding this further.
We could add reflection to make it work via ComponentId or accept user-defined pointers.
However, I'd wait for a concrete use case for it before adding complexity. If you find one, feel free to ask - I'll be able to include it in a patch release.
I'm trying to figure out how to replicate sprites (or anything with an asset handle). i dont want to include asset handle logic on the server, but i dont want to sync between an asset-less component and the sprite either...
I'd usually use the blueprint pattern.
The idea is to send a component that describes the player and load the corresponding asset.
The same approach will work for your savegames.
that is what i am doing rn. syncing that into sprites is just kinda weird tho
i feel like having a server and client representation of the same (logical) component with to/from functions would be much cleaner
What is weird exactly?
If you know the component statically, you create a type or enum. If it's dynamic, you serialize a path (or better a hash of the path to save traffic).
Then on insertion you load the visuals using observer. That's basically your "from" function with world access. It will work the same way on both client and server.
my program allows users to change size/color and potentially texture of some sprite. so i will have the actual sprite holding the real data, and then a component that is really just "the values of the last update message". and this component has some of its values copied (OnAdd/OnChange) over into the sprite (e.g. color tint). it's just not a good architecture in general, cf single source of truth
Then it's easy, you just replicate the mentioned component that changes the sprite.
that doesnt solve the fact that i then have two instances of the same data living on the client
Could elaborate on it a bit more?
Imagine it's a singleplayer, forget about networking for now
The sprite has other relevant properties, in my case pub color: Color,
so my "message component" becomes something like SpriteRef{color: Color, asset_id: MyAssetEnum}
in my mind, the ideal solution would be to have some SpriteRef on the server and Spriteon the client
Makes sense. You don't have to create a separate component for adjusting the color.
What you need to do is to enable replication for Sprite, but with custom serialization and deserialization. In these functions you define that you serialize only color and possibly other properties and leave everything as is.
On the lastest master you actually do have something like this 🙂
We provide replicate_as
This works on the latest release.
But on the latest master I'd use replicate_as for this use case.
if i replicate Sprite the server needs to instantiate an image handle
You can replicate it with the default handle. And once your asset loads, you update it with real handle.
and i'd prefer the server to not bother with that (stretch goal, but still)
I'd suggest to handle this uniformly on both client and server. This way you will be able to serialize the state in the same way. You serialize only your SpriteRef and MyAssetEnum, no need to serialize handles and such.
yeah that is the current solution
So, the ideas is:
app.replicate::<MyAssetEnum>().replicate_as<Sprite, SpriteColor>().
And then you impl From<Sprite> and From<SpriteColor>.
And defined an observer for MyAssetEnum insertion.
I planning to draft a new release soon. You will need it for replicate_as.
On the latest release you can use replicate_with, but it's not very ergonomic... It has it's own use cases, though.
well i would do app.replicate::<SpriteRef>().replicate_as<Sprite>()
Just to clarify: SpriteColor is not a component. It's just and intermediate struct.
i'll check master
It's just how you send it over the network.
yeah that makes sense
Hi there! Using the high level replication is great for when new players join the game and they get the whole game state automatically, but a system I am currently using this for needs to happen ordered. Is my only option to then use server events/triggers and then manually sending the begin state if a new player joins?
Would be nice if I could still have the initial replication, but I understand that this might not be possible.
Maybe for some context, I was now using it to sync the position of enemies and players in the world, but everything is kind of moving on a chess grid so I also have a function that updates these positions as the positions are updated:
fn position_changed(
mut q: Query<(Entity, &Position, &Transform, &mut ViewDirection, &OnIsland, Option<&Character>), Changed<Position>>,
mut islands: ResMut<IslandMaps>,
){
for (entity, position, transform, mut view_direction, island, character) in q.iter_mut() {
islands.get_map_mut(island.0).map(|map| {
position.previous.map(|pos| map.remove_entity(pos));
map.add_entity_ivec3(position.current, Tile::new(tile_type, entity));
});
}
}```
But this has issues as it is does not have the same ordering as on the server, also is it correct on the client side that ```trigger: Trigger<OnRemove, Position>,``` Does not trigger?Hi!
No, it's not possible to do the initial replication because of how deltas are currently calculated.
But why would you need something like this?
Yes, ordering is not guaranteed. You need to adjust your algorithm somehow if it depends on it.
trigger: Trigger<OnRemove, Position>,
It will be triggered on the client when you remove Position on the server.
Thanks for the response! Probably a mistake on my end then with the OnRemove, will test tomorrow.
The initial replication would be nice as people can join into the game at any time, so I hoped for an easy way to sync all the positions using replicate, but as I need ordering in the movement for keeping the grid consistent I will have to use triggers/events
Replication itself works for clients that join later.
But you will have to avoid using it for things that require ordering since we can't guarantee it.
Working on suggestions from Koe, many good catches.
the tl;dr of building your own backend is just sending items from Replicon{Client, Server}::drain_sent() in PostUpdate and putting them into Replicon{Client, Server}::insert_received() in PreUpdate?
That's what i'm getting from the example backend at least...
Almost. I documented the process here:
https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/backend/index.html
API for messaging backends.
kinda oof. what does " This can be done via an extension trait that provides a conversion which the user needs to call manually to get channels for the backend." even mean? Is there such a trait somewhere? if i call this manually anyway why do need a trait at all?
where does the example backend create channels (looking at latest release)
It's a common pattern in Rust when you create a trait to add new methods
The example backend doesn't need it.
But renet does: https://github.com/simgine/bevy_replicon_renet/blob/e639540f5fa3a15c3e365b5b6822106245b093f3/src/lib.rs#L142
GitHub
Integration with renet for bevy_replicon. Contribute to simgine/bevy_replicon_renet development by creating an account on GitHub.
i mean yeah but that's an implementation detail unrelated to the requirements for a backend afaict
It's just a suggestion how to do this.
Took quite some time becase I had to re-think how to make it work nicely with visibility.
It's possible. Check out one of the examples for replicate_with (you will need to scroll a little bit):
https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/replication_rules/trait.AppRuleExt.html#method.replicate_with
We don't use TypeIds, we have our own special identifier. But you don't have to deal with it, you just need to provide a function.
In postcard you have "flavors". It's a special modifiers for serialization and deserialization.
The mentioned BufFlavor is our custom flavor for bytes::Buf trait.
To put it short: it's basically a reader/cursor over bytes to conveniently stream from Bytes.
A deserialization flavor for a borrowed buffer.
Serialization via refelct serializes the whole type name and on deserialization it matches by it 🙂
Dynamic serialization/deserialization is not very efficient 😅
But sometimes useful, yeah.
Why not use std::io::Cursor?
It's slow, it's much more efficient to shift Bytes pointer, which is what BufFlavor does (was about 10% faster according to my benchmarks).
And it's also requires std.
Received replication messages represented by Bytes. We unpack data from it by streaming from them.
Deserialization functions accept the message and need to advance "where we at"
Instead of wrapping the message into something like cursor that stores the array and current index, we shift the beginning of Bytes.
Feel free to ask more questions if something is unclear 🙂
In that case you need to manually implement DeserializeSeed additionally. It's tricky 🙂
Let show you an example...
Foo is the component in your case?
This will be terrible to write 😅
If it's 3 levels deep, it's 3 levels of manual impl.
I working on an example, so you could see the problem.
@vocal violet check this abomination:
https://github.com/simgine/bevy_replicon/pull/576
It's for a struct that contains a reflect. If your struct also contains a map, you need to do the exact same thing 2 levels deeper:
- Custom ser/de for Bar
- Custom ser/de for FooBar
It's not specific to Replicon. That's just how serde works with Bevy reflection.
So I'd suggest to split this multiple components / entities 😅
@spring raptor Would you recommend to grab latest version from main instead of what's available in crates.io?
Yes, but if you are okay with using the example backend or this branch of the renet backend: https://github.com/simgine/bevy_replicon_renet/pull/46
GitHub
Each commit is a separate change with a detailed description.
Yeah, I figured that would be the case.
Works for my expriments of trying to move away from Unity :)
Opened a small PR to replace our hasher:
https://github.com/simgine/bevy_replicon/pull/577
Should be ready for a release after this.
GitHub
rapidhash is fastest and produces high-quality hashes. For benchmarks see SMHasher and SMHasher3.
While migrating I realized that Hash and Hasher aren't portable. This can be reproduced by ...
Migrated to 0.17.
It works, but *_trigger_targets does nothing since the entities now stored inside events.
I think I'll re-architecture how events work in general. We no longer need to have custom methods for events (former "triggers").
Hi, I'm quite new to replicon.
I have an app where I'm going to replicate some image data. I have two scenarios:
- I run the server and client on the same machine
- Server is somewhere else
For scenario 1, is there a way for me to use a transport layer that skips networking? I took a look at lightyear and saw that has a crossbeam layer, something like that would probably work.
For scenario 2 I will likely downsample the image e.g. 4x or 8x such that the data is much smaller.
Hi!
For this case you want "listen server" mode. It's where server is also a client, but without any networking (even no serialization). If you also don't want for anyone to connect - it's also supported. You even even need to run a server, we call it "singleplayer" in our docs.
Our API designed in a special way, so all these modes (including also pure client) works seamlessly. Check this part of the quick start guide:
https://docs.rs/bevy_replicon/latest/bevy_replicon/#abstracting-over-configurations (you need "The recommended way").
Great news, thanks a lot for that!
You can also check any example, they all showcase this approach in action.
Ah sorry for the lack of due diligence- I was just looking at some crate at work which now uses replicon and asked before I looked at official docs/examples (except I saw the messaging backends didn't have e.g. a channel impl so I made assumptions)
It's okay 🙂
Migrated to 0.17.
Logically, it was a trivial migration, and the Bevy team did a great job with the migration guide.
But renaming "event" -> "message" and "trigger" -> "event" was so painful.
It blew up the diff to +3,731 −3,934 😢
https://github.com/simgine/bevy_replicon/pull/581
GitHub
I put each logical change into a separate commit. I'd recommend to review them separately.
Some of them are just incremental module renames to make it easier to review "event&q...
And here I am just barely getting around to updating bevy_bundlication to unblock using the new stuff in my game so I hopefully get my game working again and can release before I update to 0.17 🤣
Hopefully with some of our new features this is the last time I need to update bevy_bundlication
Because iirc we have the features to make it irrelevant now 👀
You may not need to update it because I released all the new features for Bevy 0.16.
The release for 0.17 is a pure migration to the new version of Bevy.
It seems my game broke after I migrated to 0.35 ... There is just no connection happening anymore ... Event aren't being sent ... Is there something new I need to do? 🤔
What backend do you use? 🤔
I use bevy_replicon_renet now since renet2 hasn't been updated yet and I don't use any of the features of it anyway 🤣
The API didn't change 🤔
Maybe it's a bug? Could you run with RUST_LOG=bevy_replicon=trace?
The change that might be related is the migration to states.
I did but I see nothing unusual, is there any specific logging wrt state changes that I'd want to look for?
I don't log the state changes 🤔
I can add logging here if you want:
https://github.com/simgine/bevy_replicon_renet/blob/366652d30223aa460436600226f80ab876ee5e83/src/client.rs#L44
GitHub
Integration with renet for bevy_replicon. Contribute to simgine/bevy_replicon_renet development by creating an account on GitHub.
These systems run when you insert/remove renet resources
@dire aurora actually, I think we just don't have any state change logging at all.
Previously it was logged on the Replicon side.
I probably should add logging on the backend side.
You could possibly log on the replicon side too in the systems in the OnEnters or something too
I didn't want to add a systems just to log, but think I can add them conditionally.
Let me create a quick patch...
@dire aurora the patch on crates.io now
The PR itself: https://github.com/simgine/bevy_replicon/pull/585
Now we just need to figure out what is the problem 😅
Do you see state changes at least?
Gets stuck on connecting 🤔
Hm... Examples work. Maybe something renet-specific?
Yea, my rewind example works too with the example backend
I just tried renet examples - they do work.
What's the condition on connecting -> connected?
bevy_renet::client_just_connected should return true
It's a run condition.
pub fn update(
&mut self,
duration: Duration,
client: &mut RenetClient,
) -> Result<(), NetcodeError> {
if self.is_disconnected() {
return Err(NetcodeError::ClientNotConnected);
}
client.set_connected();
```Kinda hard for it to not be connected I guess 😅I wonder if it misses the connect because it's not just_connected because it was already connected the first time 🤔
Weird. Run conditions have their own state. So if it wasn't connected before for the condition and now becomes connected at some point, then when the condition runs it should see it.
Could you manually check the state of RenetClient resource?
2025-10-03T21:13:24.268029Z DEBUG bevy_replicon::client: connecting
Requesting time, connected? true
Requesting time, connected? true
Requesting time, connected? true
```The code printing it:
println!("Requesting time, connected? {}", client.is_connected());
Those prints are only twice a second too 😅
Maybe it somehow becomes connected and connecting at the same time, but it becomes connecting goes last and overrides the state?
Let me create a branch
@dire aurora could you try this?
https://github.com/simgine/bevy_replicon_renet/pull/49
GitHub
If the inserted resource is already connected
This works ... Though I think this isn't ideal either, since the Connecting state gets skipped entirely now. What we'd really want is to make sure we always go disconnected -> connecting -> connected
Makes sense, I pushed one more commit, what do you think?
Strange that I can't reproduce this problem locally.
Doesn't seem to work, I think the run conditions run regardless of the one before it failing, thus it still fails that "just" part of the check
Weird, it works perfectly locally 😢
There's probably also system ordering involved, I'm surprised it didn't work by chance at some point
Also do you have a transport that connects instantly or not?
I just use netcode
Ah, yea, I have a custom transport that sets connected to true on the first update, that's not normally possible I think
Ah, I see
(Because there is no connecting state, you get everything you need before you even connect, IP, port, and a pre shared key)
Could you try one more time with the latest change? 🙂
Works! Clever solution 🤣
Great, I drafted a patch!
Other than that, how is the migration going?
0.34 -> 0.35 was pretty doable, though the ClientId change was a bit of a pain
Also the migration from ClientEntityMap to Signature on my rewind example was a bit silly, but only because I was too lazy to find a good solution
Still need to start using the new features
Also realized I can't actually use the replicate_as for my original example, since I can't implement a From when I need access to the tick to make it relative, but it should still help when I inevitably do some cleanup to my code
Well if it does become a problem I guess we could use a different trait for the conversion that allows some limited world access ... There's also the issue that modifying in place doesn't work optimally if you say replicated transform without the scale, but the scale isn't possible to know in the From impls
Because now you need unwrap an entity from it?
Yeah, not ideal... Still think it's an incremental improvement from the old SERVER entity as placeholder 😅
I hope we get entities as resources soon. This way we can assign server an entity too.
Ah, you are right.
Yeah, it's quite ergonomic for simple cases, I really like it.
Yea, though I don't unwrap it, I just put anlet Some(client_entity) = client_id.entity else {continue}
But there's also the cases where I need to pass ClientId now instead of the entity from before, etc
Not too bad, just a lot of places to change
Yea. Ideally if we had specialization we could have this super simple approach and make a more specialized API that's still as simple
Maybe we already can, idk if implementing a custom trait, then blanketing that where there are Froms/Intos is valid 🤔
For cases where it could be the server it's good. Otherwise you would silently get a placeholder with the old API 😅
I'll explore this path, thanks!
Will focus on the component visibility next (decided to shift interpolation, it's a much bigger feature, requires quite a lot of coordination).
"Now how am I going to use these signatures"
"Wait a second ..."
https://github.com/NiseVoid/bevy_rewind/commit/c44a22eca4eb1165c7132001892e768813a12545
Definitely gonna have to make it nicer later, maybe by using the signature directly and removing the Reason stuff, but for now this should work
(Obviously this change isn't all I'll need to do, since my game currently uses Entity in some of these reasons, which would not hash correctly)
Yeah, I actually assumed that you will use from for a more graduate migration 🙂
#[cfg(feature = "client")]
source: *server_map.to_server().get(&*cast.skill).unwrap(),
#[cfg(not(feature = "client"))]
source: *cast.skill,
```😈(This is still going be a painful refactor)
Really going to need to rewrite my skill system so I don't have to copy paste logic like this everywhere 😅
Or wrap this into a macro 😈
I mean that would clean up these few lines, but it doesn't fix the overal problem that I need to do this correctly for every single entity a skill spawns 😅
Hmmm, ServerEntityMap gets removed in the loop of applying changes so I can't access it in my hook ... Hmmm ... How am I going to work around that one
Yeah :(
I can wrap it into an Arc if you really need it. Similar to the type registry in Bevy.
But it was always like this.
Hmmm, I can see if I can apply these changes later 🤔
Since the replicon logic runs in PreUpdate that should be doable in some way or another at least
What I dislike about "message" naming is that in cases like this it looks a bit weird:
I can rename this into ServerMessage, but it's quite ambiguous.

(migrating renet)
It's renet, which is not related to Bevy. ServerMessage would be just a bad name.
Yea, it's definitely not a server message, even server event isn't great, since it's more of a connection-specific thing
I guess it's like a ConnectionChange 🤣
Hmmm, when switching server instances I seem to be getting stuck in connecting now ... I wonder if it's because of that condition 🤔
2025-10-05T16:25:59.228513Z DEBUG bevy_replicon::shared::event::client_event: sending event `net_sync::Disconnect`
2025-10-05T16:25:59.245786Z DEBUG bevy_replicon::shared::replication::signature: removing hash 0xa43c8848fa3e3678 for `193v1`
2025-10-05T16:25:59.261460Z DEBUG bevy_replicon::client: disconnected
2025-10-05T16:25:59.262094Z DEBUG bevy_replicon_renet: creating channel config ..
2025-10-05T16:25:59.277838Z DEBUG bevy_replicon::client: connecting
I guess logically speaking if we aren't connecting then we aren't updating the last status, thus from the perspective of that system it goes from connected to connected
Maybe remove the requirement of going through connecting -> connected?
If the transport reports connected right after disconnected: go into connected.
Hmmm, actually I think there might be a better fix here, if it only runs during Connecting
Why check for just_connected
If it's connected at all we can go to Connected
Then we still hit every cycle and we no longer rely on that fragile state change there
I guess we never had the ability to do this before since we had no states, but we do now
Could you try this?
https://github.com/simgine/bevy_replicon_renet/pull/51
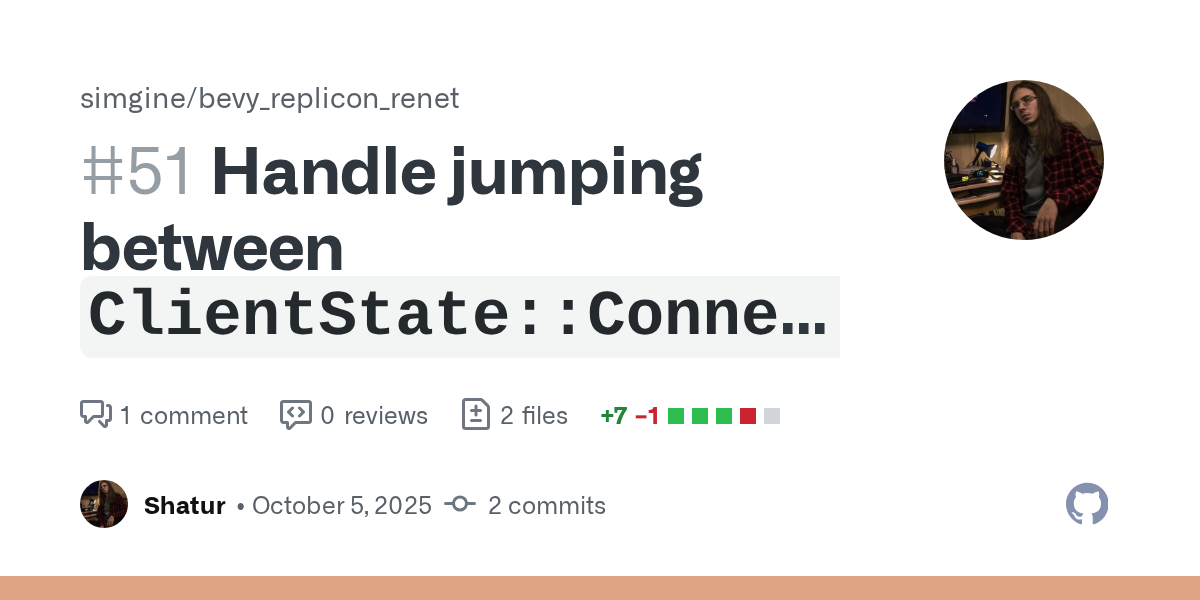
Yea now the switch works. Alternative solution would be this:
set_connected.run_if(
- in_state(ClientState::Connecting).and(bevy_renet::client_just_connected),
+ in_state(ClientState::Connecting).and(bevy_renet::client_connected),
),
Which I think should always be correct 🤔
Yes, I think this will work too!
It's a bit tricky, but will encorce "disconnected" -> "connecting" -> "connected".
But do you think it's worth it? If the transport immediately reports "connected", why wait extra frame? 🤔
Because users might want to use Connecting for something, and skipping it could cause unexpected failures because of that, though we could ofc document that it can be skipped
But I think it's possible only for transports like yours, right? 🤔
Any other transport will report "connected" only after at least one update call.
Hmmm, might be possible with QUIC and an open server too, but otherwise there's probably some sort of handshake happening
Maybe if the transport just blocks until it's done though (not ideal but very easy problem to create)
Yes, so only for custom transports?
If I write a custom transport, I'd probably expect it to go into "Connected" immediately if the transport says so 🤔
Or other backends if they copy bevy_replicon_renet's code
Okay, let's go with the safe option 🙂
Pushed this change, could you try it locally?
Thanks, drafted a patch 🙂
I think right now only bevy_renet is compatible:
https://github.com/simgine/bevy_replicon_renet/pull/50

GitHub
Based on lucaspoffo/renet#189. Will draft a new release once merged.
Because renet itself is not updated.
But you can use the branch, it's fully functional.
I.e. it's the only reason 🙂
Maybe just help the author to update it?
It's trivial, pretty sure the diff will be identical to the linked PR
Ah, it wasn't updated to 0.35.
Then you also need https://github.com/simgine/bevy_replicon_renet/pull/46
GitHub
Each commit is a separate change with a detailed description.
Most of the diff comes from examples, which you copy-paste and undo changes in parse_cli specific to the backend.
Sorry for the noob question here, but I couldn't find it in the docs -- is there a convenient way to tell a client that it "owns" a particular entity that was spawned on the server? Is the best way to just replicate a component storing the relevant backend client ID (as opposed to the replicon client ID which I'm guessing would not work as it's world-dependent), and check against our own?
No need to sorry!
I usually create a component like Owned and an event MakeOwned.
Then on the server just do:
commands.write_message(ToClients {
mode: SendMode::Direct(your_client_id),
message: MakeOwned { entity },
});
Then on the client you observe for the event and insert Owned.
Thanks :)
Finished my migration to 0.35 + using the Signature feature. As expected it made my status effects work way better. Still need to make a bevy_bundlication release though so I don't reference some random commit 😅
36 files changed, 286 insertions(+), 168 deletions(-)
(The extra code is mostly to make sure the client/server actually create identical hashes, since I was using Entity and ComponentId in some of what I would've been hashing)
I'm toying with GBA for the last few days 🙂
I might implement a networking backend for it in the future just for fun. We currently lack the necessary abstraction for it on agb side, but someone started working on it recently. Once done, integrating it with Replicon should be trivial. Just curious if it even runs 😅
While waiting for it, I'm starting to work on actually useful features.
Hi, I can't see any obvious mention of whether resource replication is supported?
I searched this chat and I see some talk about resources as entities, is it waiting for that?
Yeah, we are waiting for resources to become entities.
I just don't want to duplicate the replication code for entities 🙂
But you can just use a singletone entity already. It works nice with Single.
Fair, will do.
Would it be an idea to add an example to bevy replicon which has the structured mentioned in the docs for headless servers?
That's my use case. Specifically I would want to split it server, client, and shared crates, and I'll run it both in "singleplayer mode" natively but also split into server headless and client wasm
Would be nice to have an example which shows best practice for setting up this structure
Yes, it's planned!
Just a bit busy with other stuff right now.
It's explained it in the docs, maybe you could try to figure it yourself and PR it? That would really help.
I may find time to do that!
Hello! Is there an API to artificially introduce some latency in order to test my prediction/correction code?
Maybe in renet?
Your best choice would be something OS level
Example backend provides this: https://github.com/simgine/bevy_replicon/blob/master/bevy_replicon_example_backend/src/link_conditioner.rs

GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
But that's because we need it for testing.
Actual backends usually don't include stuff like this because there are os-level tools.
Thank you
What's the correct way to model something like a UI slider using bevy_replicon?
The client owns the UI, but the server should be authoritative on the value.
I imagine if I drag the slider then there are potentially large bursts of small changes.
Should I client_trigger each of these?
Further, if I have a UI state struct on the client for >1 slider, for example:
struct MyUi {
slider_1: f32,
slider_2: f32,
checkbox: bool
}
then the first thing I would try is to:
- Add serde + replicated to let the server be authoritative
- Use it directly on the client to render the ui
- Add an event derive on it such that a client can client_trigger it to request committing new values
I want to know if this is a bad approach.
I'm using egui which would want to use &mut my_ui.slider_1 directly.
I'm thinking perhaps the client experience will be choppy if replication overwrites the actual state the UI is trying to modify.
The "problem" is that e.g. bevy_egui wants to mutate some state locally and update the UI immediately.
While the server which holds the real state runs at a relatively low tick rate. How do you reconcile this elegantly
Let's say you keep holding the slider and quickly dragging the value back and forth, when the server starts replying with ACKed values these will be a bit delayed, which I think would cause conflicts if I try to apply it to the client state while it's dragging
Should I buffer the server replies until the user stops dragging the slider, then apply?
Since the server is authoritative I need to apply what the server tells me to at some point, else the client is out of sync
The point is that the UI is a control panel that is displayed on the client, but the server is going to own the real state it represents
I know, but at some point I'm going to have to write back what the server replicates to the client side UI state, since the client doesn't own it
Maybe I'm simply confused 😬 I'll try to implement what I thought was problematic then see.
I see, you want a client-side prediction for the slider. Otherwise when you send an event for it to the server, it will replicate the value back, but you don't want to apply it because value on your machine might already be different.
Yeah!
I'd probably send event with the end value when the client stops using the slider 🤔
Only thing I don't like is if the slider represents something with scrutiny, e.g. some fine-tuning of something you might want to use the egui hotkey to change the slider very slightly without letting go
So being forced to let go of the slider is a bit unergonomic then
For the hotkey I'd make a 1 second delay before sending the end value.
I think the server ultimatively interested only in the end value
Another option is to create an "apply" button or something like that.
The slider represents inputs that control GPU work on the server, producing an image that is sent back to the client.
So the client wants to be able to use the slider to see changes applied to the image as quickly as possible (replicating the image efficiently is a separate problem from the slider)
In this case I'd probably do the trick I suggested 🤔
I assume producing an image takes quite a lot of power, so sending a request for every move doesn't sound like a good idea
Right, so make some kind of debounce on the client side
or you put a timer on the "x time since the last change"
Yeah I think I'll want some sort of rate limiter or similar.
Maybe something like this could be a good contender for an example in the repo.
The current examples as far as I can tell have discrete infrequent updates, so there isn't anything showing how to properly do continuous fast updates
(which need to be rate limited or similar)
Right so having general support for it in bevy_replicon is probably hard if use cases are very different, but an example of a specific use case might help similar use cases still?
Since I have these questions I'm sure there are others in similar situations out there
Yeah, an example would be nice!
@dire aurora I left a small comment about per-component visibility - could you take a look and share your thoughts?
https://github.com/simgine/bevy_replicon/issues/304#issuecomment-3392119767

GitHub
I'd like the ability to not only be able to define which entities are visible to specific clients (possible with the bevy_replicon::server::VisibilityPolicy) but also be able to define what com...
Bit confused on where these masks go
They are stored inside VisibilityMasks component on the entities that represent connected clients.
But after writing this, I wonder if we can use components instead of masks 🤔
So instead of doing something like this:
const GUILD_MEMBER: u32 = 0b1;
app.set_visibility_mask::<C>(GUILD_MEMBER);
We would do something like this:
app.set_visibility_component::<GuildMember, C>();
Drafted a small patch with recent improvements.
I think I have even a better idea, let me write it down.
I don't see how this could work per-client, since being in one guild doesn't make you everyone's guild member
Yes, I didn't think this through at the time of writing, but I expanded on this:
https://github.com/simgine/bevy_replicon/issues/304#issuecomment-3393406488

GitHub
I'd like the ability to not only be able to define which entities are visible to specific clients (possible with the bevy_replicon::server::VisibilityPolicy) but also be able to define what com...
So it's like bitmasks, but dynamic. But not entirely sure if the complication is worth it.
After calling TrackAppExt::track_mutate_messages, I'm panicking with the error telling me that ClientMessages resource does not exist... docs and source both say it is inserted by ClientPlugin... not really sure how to troubleshoot this
Hold on there's actually an earlier panic in another thread, let me try and resolve that one and see if it fixes the other
The panic is caused by the call to Bytes::advance in client::apply_mutations. The assertion that data_size <= message.len() is failing. I will have a deeper look later, idk if this is a bug in replicon or in my code
Are you working on client-side prediction? 🤔
I'm asking because it's quite an advanced feature.
Do you use custom serialization?
- Yes, 2. No
Could you try to temporarely not to call this function and see if the panic can still be reproduced? 🤔
We have a ton of tests, but I feel like I might've missed some combination of this and other things.
Can confirm, I can't reproduce the panic without calling the function
The panic caused by serialization error. I.e. the message have X bytes left, but we are trying to read more.
That's why the message is so cryptic.
Could you tell me a bit more about your setup or create a minimal repro?
I have a custom WriteFn when associated with a marker component Predicted<C>. We expect that an entity with Predicted<C> also has a History<C>. The history component is updated for all entities that have it at the end of each physics tick. The custom WriteFn checks the deserialized component against the one for the corresponding tick in that entity's history and if there is a mismatch it inserts a flag that indicates we need to initiate a rollback from (at least) that tick. Right now the only component that is registered to be predicted is Bevy's Transform component
I can try to create a minimal repo in a bit
Maybe it's somehow cause by your WriteFn
That would be nice
I'm not sure where else the problem could be, but I really can't see anything suspicious in it
fn write_actual<C>(
ctx: &mut WriteCtx,
rule_fns: &RuleFns<C>,
entity: &mut DeferredEntity,
msg: &mut Bytes,
) -> Result
where
C: Component<Mutability = Mutable> + PartialEq,
{
let c = rule_fns.deserialize(ctx, msg)?;
let Some(history) = entity.get::<History<C>>() else {
error!("no history for predicted component on {}?", entity.id());
return Ok(());
};
let Some(expected) = history.get(&ctx.message_tick) else {
error!(
"no history for tick {} for {}",
ctx.message_tick.get(),
entity.id()
);
return Ok(());
};
if *expected != c {
match entity.get::<DesyncTick>() {
Some(DesyncTick(t)) if *t < ctx.message_tick => {}
_ => {
entity.insert(DesyncTick(ctx.message_tick));
}
}
}
Ok(())
}
Yes, this looks correct 🤔
I probably need a minimal repro 🤔
@lean thunder are you sure you enabled it on both client and server?
Oops, I definitely did not enable it on the server!! 😅
My bad. Sorry for wasting your time there
No, no, it's actually good because I noticed that I didn't include this flag in the protocol hasher. You shouldn't even be able to connect when the protocol differs 😅
Added the check: https://github.com/simgine/bevy_replicon/pull/591
GitHub
This feature affects the serialization format.
Playing with this. I really like this system.
It basically allows defining visibility seamlessly without maintaining a separate source of truth.
Want your client to see only Health for components of team members? Just call app.add_component_visibility::<Team, Health>(), where Team implements PartialEq.
So if a game entity has Team(1) and the connected player has Team(1), Health will be visible to them.
It is quite expensive to compute though. I need to dynamically fetch components from clients, and FilteredEntityRef provides checked access (which I need to avoid).
I could write my own QueryParam, but maybe there is a different way.
When I collect changes, I basically need to know things like "Is this entity/component visible?". So maybe I can split this into two layers:
- A low-level mechanism that directly tells me what is visible when I iterate over entities. It's managed by the higher-level.
- A component-based API with observers that cache the data for the low-level mechanism.
Still exploring which path forward will be the best.
Yea this approach seems better. One thing I'm not sure about is if component visibility as a single yes/no is enough. Like for this example, what if we want to still send a full or empty value to people on other teams?
In this case we can certian work around it, but I'm wondering if we can always to so easily 🤔
Also we can potentially optimize things here in cases like: the entity has a Team, but no Life, and no other components that need Team for visibility
Also VisibilityComponent needs to match between client entity and game entity? I think that would be limiting for say physical rooms, you can see rooms that are connected to yours, thus need a list on the client, but a single id on the game entities
In that case you might want an associated component that the client has, and default it to Self (if that's even allowed)
That might require too much bookkeping. I'm not even sure how we would express something like this 🤔
For cases like this I'd probably opted for a workaround. Like splitting the component or handling Option<&T> on user side in queries.
Not necessary match. That's why I introduced ComponentVisibility trait. We will have a blanket impl for PartialEq for convenience, but you can implement a custom check such as bitmask comparison.
Blanket impl might not be a good idea. This will prevent users to implement PartialEq for components with custom ComponentVisibility impl 🤔
Is it possible to preserve relationships from server to client?
I have a parent entity on the server that is replicated.
Some time later in the program I spawn a collection of children on that parent.
The client receives them "flattened out", not as children but at the top level.
I tried sync_related_entities::<ChildOf> on the server but seems that's more about not splitting up replication I think.
I'm on 0.34.4 if it matters
Ah I just needed replicate::<ChildOf> on client and server, saw there was some notes in the guide for that.
It works now
Yep, sync_related_entities needed only if you want for changes to their components to be replicated together.
Opened a draft for the new visibility system:
https://github.com/simgine/bevy_replicon/pull/595

GitHub
With observers, we can finally provide an ergonomic visibility API. This works similarly to collision layers in physics: users insert filters into both the client and gameplay entities.
An entity w...
It's fully working, with tests, docs, and examples.
It's a draft only because I am considering changing the internal tracking from hidden entities to visible entities. This should avoid awkward checks in the code, since I can't easily distinguish between an
entity despawning and gaining visibility. It will also be more memory-efficient for games with many players, which is where memory usage actually matters.
So you can already check the API and give me feedback if you want.
It's only entity-based visibility for now, but I'll implement component-based visibility in a follow-up by extending this API.
After giving it some thought, I realized that I have to track hidden entities - there's no other way.
But I optimized how they are stored.
@echo lion marked as ready for review 🙂
Most of the code comes from tests, there aren't a lot of code.
This will break bevy_replicon_attributes, but you should be able to port it by turning VisibilityCondition into a visibility filter.
@spring raptor where can I find the bit of code that handles the client receiving an out of order replication message?
for example receiving a mutation for tick 1 after already receiving a mutation for tick 2
GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
I feel that I read somewhere some time ago that mutations for replicated components on the same entity are applied on the same tick, but I now can't find evidence of this -- did I dream it?
We network things per-entity, but priority and send rates could break that guarantee
Entities are "atomic", so you can't receive half of the entity mutations.
Constant ID of a channel for sending data from server to client.
Yep, that's exactly what I meant. Thanks!
We no longer have send rates; the new prioritization system replaced them.
And it's per-entity, like in other engines, so nothing breaks this guarantee right now.
So you don't need to handle it in bevy_rewind 😅
I can see how it could be useful to have a different send rate per component,
so we might reintroduce it later, but we need more bookkeeping to implement it properly.
This is something that will be possible after per-component visibility.
(becase per-component visibility requires more tracking)
We still have once vs always right?
Yep!
It's now called ReplicationMode.
Hi, I get
23v1 exceeded memory limit, disconnecting log.target = "aeronet_transport";
log.module_path = "aeronet_transport";
even though I have increased the transport mem limit to fit messages of at least the size I'm sending.
My guess is that the websocket transport (or somewhere higher up) queues up more messages than I'm able to send.
Is it likely this is the case? Is there a way for me to control this?
You better ask in #1354455157596880906.
One thing to try is temporarily swap the backend with bevy_renet and see if it works.
It should be a simple swap, only the server and client setups are different.
If the prediction only takes weeks it's pretty fast 
It's pretty simple prediction and I was working several hours per day
Exciting!
Are you planning to publish a crate or will it be specific to your game?
I would like to battle test it a bit more first but I'm thinking I'll publish a crate
I still need to implement interp and lag compensation so I might see if I can include all of that
Looking forward to it.
It's all quite an advanced topic, pretty sure you find edge cases 😅
It's also requires a remote input manager to send inputs efficiently. Are you planning to implement it too?
I'm not sure what you mean by that, is there some resources you could point me to?
Here is a really good video that explains the approach:
https://www.youtube.com/watch?v=W3aieHjyNvw&t=1528s

In this 2017 GDC session, Blizzard's Timothy Ford explains how Overwatch uses the Entity Component System (ECS) architecture to create a rich variety of layered gameplay.
Register for GDC: https://ubm.io/2yWXW38
Join the GDC mailing list: http://www.gdconf.com/subscribe
Follow GDC on Twitter: https://twitter.com/Official_GDC
GDC talks cover...
Ohh, I have seen this a few times actually
So you are talking about input buffering and timeline dilation or?
Yeah, input buffering 🙂
I see
In bevy_rewind we have https://github.com/NiseVoid/bevy_rewind/tree/main/crates/bevy_rewind_input
GitHub
Server-authoritative rollback networking for bevy. Contribute to NiseVoid/bevy_rewind development by creating an account on GitHub.
It's probably worth unifying the effort.
I put off implementing it for the time-being due to the complexity and I wanted to get onto other areas of my game, but I'm definitely interested in it
The rollback approach in bevy_rewind is usually more costly than classical rollback, but it works better for physics-based games.
I assume you're working on a classical approach, where rollback happens per-entity, right?
Right
I was thinking about unification. Mainly, these things are independent of rollback approach:
- Input buffering
- Component history buffering
- Clock sync
In networking, games usually rely on fixed updates. To make things smooth, interpolation is incredibly common.
There is https://github.com/Jondolf/bevy_transform_interpolation, which is planned for upstreaming into Bevy. Currently, it interpolates between fixed ticks. This works for listen servers (where the server is also a client). But for pure clients, we need to interpolate between network snapshots. I inspected the code, and it's a very simple change: just allow control of overstep via component. I talked with the author, and he agreed to extend it. This way, we will get interpolation, Hermite and extrapolation “for free.”
But to control overstep, we need component history buffering and clock sync. So I'd probably "upstream" this into Replicon and provide interpolation out of the box (behind a feature).
This should also reduce the amount of code needed for rollback crates, such as yours and @dire aurora's.
As for input buffering, I'm not sure if we need to move it inside Replicon. Probably fine keeping as a separate crate. However, @dire aurora's implementation needs a bit of work: we need to integrate it with https://github.com/simgine/bevy_enhanced_input (my another crate 🙂). That's a crate for high-level input which is planned for upstreaming in 0.18.
Component history unification could be a good first step.
@dire aurora already have efficient implementation (I used some of its bits to insert components in batches during replication), I just need to extract it and make a proper review 🙂
@lean thunder you probably also have your own implementation too. Once you publish, I'll be able to check it as well.
So we'll replace track_mutate_messages with something like buffer_component<C> which automatically enables sending all mutate messages and provides a component that holds history.
I'm planning to get to it right after per-component visibility. But if you want to help - PRs will be very welcome!
Just sharing my plans. If you want to focus on the crate - it's totally fine.
We can always upstream common parts to Replicon later.
All sounds really exciting!! Hopefully I'll be able to help 🙂
What a great time to be working with bevy
I am currently migrating, everywhere where i used to have client_trigger_targets i will now have to change the trigger to include the target like below right?
#[derive(Debug, Deserialize, Event, Serialize, MapEntities)]
pub struct ClientShipPosition{
pub position: Vec3,
#[entities]
pub entity: Entity
}```Yes, and you also need to register it using the _mapped function.
Merged. Will start working on extending it to per-component visibility.
Do you think it's reasonable to have > 32 replicated components on a single entity? 🤔
Definitely not an issue in my project for the time being, but admittedly it doesn't seem entirely unreasonable to me
Or at least reasonably out of the realm of possibility
I can imagine scenarios where that would happen
That's what I thought, thanks!
Asking because I'm planning to use bitmasks to track which components client received (needed for per-component visibility).
I'll go with https://docs.rs/smallbitvec/latest/smallbitvec/index.html then. For 62 components it's pointer-sized and on 63+ components it will dynamically-allocate (on 64-bit systems).
SmallBitVec is a bit vector, a vector of single-bit values stored compactly in memory.
@dire aurora @lean thunder But do you think it's reasonable to have up to 32 components that affect visibility or it's a bit too limiting?
Not on a single entity, global.
Hmmmm, layering 32 visibility things would be hard ... Maybe in a complex game if they are required to be compile-time known?
In my game I could configure them per server instance type if that's supported so I could work with that even if I end up with many such systems
Might cause bitmask mismatches if that's networked though 🤔
My reasoning was that if you need more, each component can be a bitmask on its own.
So I went with u32 masks since it's only 4 bytes per entity.
But I can switch to SmallBitVec, which doubles the size on 64-bit platforms but allows having any number of visibility components.
Since I'm planning to use it for per-component tracking, I'm just wondering if it's worth using it for visibility tracking as well.
I.e., since the dependency will already be in the tree, the only downside of using SmallBitVec is the increase in RAM usage.
Memory is pretty cheap. Always the possibility of feature-gating it but I'm guessing that will add a lot of maintenance complexity
If this exists purely in the server I think 32 or 64 would be fine, the overhead of having a smallbitvec is probably more noticable
Ah, yes, there is definitely a tiny overhead in checking the upper bits.
Also I'd worry about all the overhead on checking if there is crazy number of visibility systems, so combining those that you can would be the way to go
Like you can't combine party status + distance + room, but do you really need 7 different room systems? Doubt it
It's cheap, but if you have a lot of entities, it might be noticable. For example, if you develop an MMO.
Yea, the dynamic case seems concerning since MMOs are also the ones most likely to have enough features for this
And they shouldn't accidentally create massive overhead like that
It's backed by observers. Visibility components must be immutable and I update bits on insertion. I.e. they are cached via these bitsets.
Thanks for the feedback!
So I'll keep u32 for visibility bitmasks and use SmallBitVec for tracking sent components (since 32 or 64 components on an entity might be limiting).
Sounds very reasonable :)
Spent last week making optimizations and refactoring needed for this. The component tracking should be the last piece. It's useful on its own because it adds support for entities that starts to match rules incrementally. It's a niche use case, so I had explicitly avoided supporting it earlier due to the extra bookkeeping (no one complained 😅 ). But since we now need this tracking for component visibility, this case will start working automatically.
"support for entities that starts to match rules incrementally" ... Wait, what?
Yeah, I probably should explain 😅
For example, you have a replication rule for (A, B).
You spawn an entity with A. And on the next tick you insert B. B will be replicated, but A will be wrongly considered as sent.
So if you have a replication rule, the insertion can't be split across ticks.
Oh
Ooooh
This has caused me a few rare crashes I think 🤣
Though I'e never had cases where that was supposed to happen, it just shouldn't have caused a crash, just an undesirable 1 frame delay
Yeah, it's weird behavior... Even though it's rarely needed, handling it like this isn't great.
But it should be fixed when we start tracking which components were sent.
I guess it could cause even sillier behavior with filters?
Like you have A, With<B>, and add A, then B, and send nothing
Ah yeah, with filters it's even weirder 😅
Luckily, the approach I'm currently working on should work for filters too.
GitHub
Objective
We'll need this for per-component visibility, but this change is useful on its own because it fixes replication for rules with multiple components that were inserted on different ...
I actually had something like this because my entities have sub-entities that act as inventory e.e
Does anyone have a simple example of using this crate with client auth movement I'm stuck with wondering how to handle networked players and the local player simultaneously
You need to send inputs, and the server will replicate the position back.
If you are making a fast-paced game, check out bevy_rewind.
I'm making a social presence mmorpg structured in a way where other players position is not important for any real gameplay mechanics so I was thinking having the client control there own movement would lead to a better experience
Ah, in this case you probably could just send positions via an event.
Just do this with some interval and apply interpolation via https://github.com/Jondolf/bevy_transform_interpolation to make it look smooth
GitHub
Transfom interpolation for fixed timesteps for the Bevy game engine. - Jondolf/bevy_transform_interpolation
thanks
hey! was wondering if anyone had an examples of using avian-based physics on the server for checking for collisions? i'm used to just having the physics in non-networked games, so curious how this would work with a server authority and replication 🙂
There’s bevy_rewind, which provides server-authoritative physics.
By the way, @dire aurora, are you planning to finish it, or do you want to focus on the game?
I mean I am ofc planning to finish it as it is important for my game, but there's a couple of design requirements that are still a bit up in the air right now so I'm trying not to mess with it too much atm
Besides some wrong handling of edgecases and missing data it all works fine atm. Main is on 0.17 too now
Makes sense. I just phrased it poorly 😅
Right now, the integration with Avian and input is manual. Is this an intentional design choice, or are you planning to simplify it?
That's probably what I actually meant to ask.
And if you plan to change the API, are you currently focused on the game or on your crates?
Just curious 🙂
Ah, the input stuff is actually very easy atm. You just add both plugins and set up the schedules the right way, can't improve that much until we get better FixedUpdate input stuff
As for avian, I might make a crate just for avian integration at some point, though tbh my current integration is still a bit of a hack so I have no clue if it works for every game
Currently on my game, though I will do a cleanup pass on some of my crates. Combine the SDF ones into one repo, make relrases for everything, and get my avian branch merged
But it's easy only for the raw input? I think people usually use LWIM or BEI, for which integration will be harder, right?
Yea, no special integration for LWIM or BEI currently exists, I'll have to see how viable the latter is once I switch my game over
I'd suggest trying to migrate to BEI now to see how it performs with a complex game like yours.
More importantly, evaluate how well it can be networked. Lightyear's author has already implemented an integration, but it would be really nice to have a second opinion on it.
Alice is planning to upstream BEI in 0.18, and before the upstream, I can make changes much more quickly 🙂
But no pushing, If you're busy with other stuff that's okay. We can make breaking changes after upstreaming. It's just not as fast.
Ah, I should probably try that soon then ... My whole input handling has some technical debt I need to tackle anyway
Worst case ofc, the same strategy I do now is probably still possible, but I do hope I can make something prettier, because I have some really ugly input systems
This is the code for generating the inputs for combat ... This luckily only runs on the client, and everything in my simulation deals with a simpel component with 3 fields having the exact relevant info ... But damn is it annoying when there's bugs here 🤣
Ah, BEI definitely should simplify this
The BEI approach differs significantly from how input management is usually done, that's why I had to create a separate crate instead of just contribute to LWIM.
But I suspect that the migration will be a pain 😢
The input handling part. The networking might become harder 😅
Luckily I can start by just generating the correct data into my input struct, which doesn't require migrating as I can just delete this function and write something new 🤣
Then see from there if I can make something without room for worsening of desync (some examples can be seen if you look at the 2 todos and generally the number of ifs before an input is set) or cheating if I network at the BEI level
Great!
I'm open to make changes to the crate if necessary.
We now have a better quick start guide, I'd highly suggest to give it a read first 🙂
I have also seen claims of it benefiting from BSN, is it worth grabbing cart's branch first?
It just makes defining hierarchies nicer. I'd stick with the current release.
But we provide actions! and bindings!. So if you're used to children! macro, it's fine 🙂
I noticed that in docs we reference deprecated event names.
Since they are hidden in the docs, it results in incorrect links. But this doesn't trigger a warning, we check docs on CI 🤔
How would I handle players with signatures and prevent hash collisions my player component is just a marker struct does replicon have builtin client IDs that are synced between the client and the server? or does that depend on my backend
Depending on the backend you can access a NetworkId iirc
Hmmm, actually getting a funny class of inputs that aren't coming from user inputs, this might make something like LWIM or BEI integration impractical 🤔
Basically an input might merely put the client in a state where they start sending input based on something that happens (eg where the camera is aiming)
But don’t you need to send an input for it? Or do you just send the camera position directly?
With how my game handles it right now this specific example can be one of 3 things:
- A direction (this is just the direction from the player to where the camera hits a collider)
- A position on the ground, this might just be where you aim, or the point on the ground from where it hits or where the range limit of a skill applies
- An entity that you targeted (this one is especially nasty since you could target an entity between ticks)
-# I mean this specific input can also be in the states "clear" and "unchanged", but those aren't that special
But if you send the direction or position directly, do you even need to buffer it? 🤔
Well yea, the direction is essentially what I'm sending (with some minor details that are left up to the client cause it could be a setting, eg that "the point on the ground at the range limit" could be a client setting)
thanks
But the direction of the camera isn't really an input, is it? 🤔
-# I mean it is for the simulation in this case ofc
Yes, but aren't you usually buffer inputs? And in case of the direction you don't need to buffer it, right?
I do always buffer my inputs with how I process them yea, the code just writes to components and accumulates data there until the simulation clears it after it's done
But you probably don't need to buffer it for the direction? Just trying to understand it better.
Well, I do still need to send the direction as a valid part of an input for a simulation tick
The logic in my game is that once you release the skill button the client can generate aim inputs, and they get accepted until the skill has locked its aim
They need to be identical between client and server for that entire span of ticks
For some skills the input for accepting aim changes iss the entire skill long, until the effect ends and the recovery animation plays (I mean I have no animations but the code has the concept of them)
Got it! Maybe it makes sense to avoid coupling BEI actions with what you send over the network.
And I think it might be even more efficient.
Yea, the efficiency is definitely highest if you manually pick what you network
Some fighting games fit their entire inputs in a single u16 after all
Sending the past few frames of input is very cheap at that point!
Yeah, it's much more efficient than using syncing actions. You'd need to send the entity, state, and value.
But the downside is that on the client you need to react on the logic from BEI, but on the server you react on client data 🤔
Or do you handle it somehow?
Currently I just collect inputs into this struct (and another one for movement):
pub struct ActionInput {
/// When `true` cancel the current action, if possible
pub cancel_action: bool,
/// Activate an action, if possible
pub activate_action: PlayerAction,
/// The aim for the current action
pub aim: SetAim,
// action_event: ActionEvent,
}
Then the simulation always reads this component and uses that to run the simulation
Ah, makes total sense.
Though my current logic for creating these inputs is all very brittle, the aim thing is clearly a seperately calculated input, gated on an input-based condition, but right now it's implemented more as a sort of state machine 😅
But the input itself seems fine for the most part
I think it's all great, then!
Do you think that the migration to BEI could simplify it?
Using observers can probably simplify things yea
LWIM's design kinda makes it easier to write highly coupled systems
You can still use systems just like with LWIM.
While BEI encourages you to consider just what needs to happen for an action, not how that ties into everything
Yea, but you can't use LWIM like BEI 😅
Yeah, sometimes observers are more convenient, but sometimes coupled systems fit better 🙂
I'd say observers usually more convenient 🤔
But there are cases where I'd use systems
2025-11-04T20:34:00.798071Z ERROR bevy_panic_handler: Fatal Error
Unhandled panic! at C:\Users\~\.cargo\registry\src\index.crates.io-1949cf8c6b5b557f\bevy_ecs-0.17.2\src\error\handler.rs:125:1:
Encountered an error in system `(bevy_ecs::world::filtered_resource::FilteredResourcesMut, bevy_ecs::world::filtered_resource::FilteredResourcesMut, bevy_ecs::change_detection::ResMut<bevy_replicon::shared::backend::client_messages::ClientMessages>, bevy_ecs::change_detection::Res<bevy_ecs::reflect::AppTypeRegistry>, bevy_ecs::change_detection::Res<bevy_replicon::shared::server_entity_map::ServerEntityMap>, bevy_ecs::change_detection::Res<bevy_replicon::shared::message::registry::RemoteMessageRegistry>, bevy_ecs::change_detection::Res<bevy_replicon::client::ServerUpdateTick>)`: Parameter `ResMut<ClientMessages>` failed validation: Resource does not exist
If this is an expected state, wrap the parameter in `Option<T>` and handle `None` when it happens, or wrap the parameter in `If<T>` to skip the system when it happens.
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
error: process didn't exit successfully: `target\debug\quinnet-testing.exe client` (exit code: 101)
I'm getting this panic but it seems to be a replicon issue any way to fix this?
This looks like you disabled client plugin, but kept ClientEventPlugin enabled
if matches!(mode, Mode::Server { .. }) {
app.add_plugins(MinimalPlugins)
.add_plugins(bevy::log::LogPlugin::default())
.add_plugins(StatesPlugin);
} else {
app.add_plugins(DefaultPlugins)
.add_plugins(EnhancedInputPlugin);
}
app.add_plugins((
RepliconPlugins,
RepliconQuinnetPlugins,
PanicHandlerBuilder::default().build(),
));
these are my plugins
This looks correct. How do you handle features?
wdym?
this is my cargo.toml if thats what your asking:
bevy = { version = "0.17", features = ["serialize"] }
bevy-panic-handler = "6.0.0"
bevy_asset_loader = "0.23.0"
bevy_enhanced_input = "0.19.2"
bevy_quinnet = { version = "0.19.0", default-features = false }
bevy_replicon = "0.36"
bevy_replicon_quinnet = "0.15.0"
bevy_rand = { version = "0.12.1", features = ["wyrand"] }
rand = "0.9.2"
clap = { version = "4.5.51", features = ["derive"] }
serde = { version = "1.0.228", features = ["derive"] }
I assumed you disabled client via a feature.
The panic you facing says ClientMessages is not initialized. But it's initialized here:
https://github.com/simgine/bevy_replicon/blob/115d02e7e6e3a21b84fff59f08cadb775caf3170/src/client.rs#L42
From your code I see you initialized all plugins 🤔
It's from this system:
https://github.com/simgine/bevy_replicon/blob/115d02e7e6e3a21b84fff59f08cadb775caf3170/src/client/message.rs#L202

GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
ill check
You can try to call init_resource::<ClientMessages> manually, but it's sus... Ensure that ClientPlugin is actually initialized.
I manually added Client plugin and now this error happens instead:
thread 'main' panicked at C:\Users\~\.cargo\registry\src\index.crates.io-1949cf8c6b5b557f\bevy_replicon-0.36.1\src\client.rs:86:40:
Requested resource bevy_replicon::shared::AuthMethod does not exist in the `World`.
Did you forget to add it using `app.insert_resource` / `app.init_resource`?
Resources are also implicitly added via `app.add_message`,
and can be added by plugins.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
error: process didn't exit successfully: `target\debug\quinnet-testing.exe client` (exit code: 101)
Looks like RepliconSharedPlugin is also not present
But if that's your code, it should be added with RepliconPlugins 🤔
same error even after adding it ferrisThonk

btw the server works fine its only the client getting these panics
GitHub
Contribute to PizzaLvr49/quinnet-testing development by creating an account on GitHub.
heres my code btw
ik its really messy but I've just been experimenting with bevy replicon and quinnet
This is weird because it's initialized here:
https://github.com/simgine/bevy_replicon/blob/115d02e7e6e3a21b84fff59f08cadb775caf3170/src/shared.rs#L118
GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
Ah, I see the problem. You have 2 versions of Bevy in your project.
bevy_asset_loader wasn't updated to Bevy 0.17
oh yeah forgot to use the rc
When you pull 2 different Bevy versions, plugins register resources for 0.17, but your main might use 0.16 and the resources simply won't be available.
kk ill try running it now
Unhandled panic! at C:\Users\~\.cargo\registry\src\index.crates.io-1949cf8c6b5b557f\bevy_replicon-0.36.1\src\shared\replication\signature.rs:311:10:
Requested resource bevy_replicon::shared::replication::signature::SignatureMap does not exist in the `World`.
Did you forget to add it using `app.insert_resource` / `app.init_resource`?
Resources are also implicitly added via `app.add_message`,
and can be added by plugins.
Encountered a panic in system `bevy_replicon::client::receive_replication`!
2025-11-04T22:21:50.330998Z ERROR bevy_panic_handler: Fatal Error
Unhandled panic! at C:\Users\~\.cargo\registry\src\index.crates.io-1949cf8c6b5b557f\bevy_ecs-0.17.2\src\error\handler.rs:125:1:
Encountered an error in system `(bevy_ecs::world::filtered_resource::FilteredResourcesMut, bevy_ecs::world::filtered_resource::FilteredResourcesMut, bevy_ecs::change_detection::ResMut<bevy_replicon::shared::backend::client_messages::ClientMessages>, bevy_ecs::change_detection::Res<bevy_ecs::reflect::AppTypeRegistry>, bevy_ecs::change_detection::Res<bevy_replicon::shared::server_entity_map::ServerEntityMap>, bevy_ecs::change_detection::Res<bevy_replicon::shared::message::registry::RemoteMessageRegistry>, bevy_ecs::change_detection::Res<bevy_replicon::client::ServerUpdateTick>)`: Parameter `ResMut<ClientMessages>` failed validation: Resource does not exist
If this is an expected state, wrap the parameter in `Option<T>` and handle `None` when it happens, or wrap the parameter in `If<T>` to skip the system when it happens.
Encountered a panic in system `bevy_app::main_schedule::Main::run_main`!
error: process didn't exit successfully: `target\debug\quinnet-testing.exe client` (exit code: 101)
nope still panics
it appears to be something with my code because reverting my main.rs file to an earlier commit fixed the panic
Check your Cargo.lock, you might still have a duplicate Bevy version
If you see "bevy <version number>" in dependencies, it's the problem.
I just checked and i dont
also this ^ which is weird
Maybe check what changed?
kk
I cant find anything that would change how the plugins or resources would get initialized
If you share the code, I can take a look
you can look through here
last working commit was https://github.com/PizzaLvr49/quinnet-testing/commit/4f61edd016ea7085515cf20a44b81130072e886f
Ah, I see what's happening.
You have a Player entity that requires Signature. But you spawn it on the server and replicate it to the client. When replication is applied, the SignatureMap and a bunch of other resources are temporarely removed from the world (via resource_scope).
Since the insertion of Player inserts Signature, it tries to access SignatureMap and panics because it doesn't exist.
But since you use a panic handler, the application loop continue and you encounter a panic in other system because now other resources are missing.
I definitely should handle this nicer, will turn into an error logging message tomorrow.
TL;DR; Remove Signature from required component on Player. You don't want to automatically insert it and replicate the player.
You need to either spawn them separately on client and server or receive replication from the server.
oh ok thanks
Hey just to confirm, there is no support for replicating Bevy states right?
And the reason is probably because states are backed by resources (which are not yet entities in Bevy)?
Correct 🙂
As a workaround, you can sync them via events.
what would be the equivalent of that but for the client getting its own network id I cant seem to query it on the client
I think on the client you retrieve it directly from your backend
I don't think my backend exposes it so for now I just send the client an event containing their id when they connect :/
I mean that works too, client entities are one of the things you need to prespawn the least since you could just have the server tell you which is yours
Alternatively the client can tell the server what identifier to use (like how in the past the client sent their local entity and the server then mapped that)
The latter is how I do it in my bevy_rewind example, the client just sends a timestamp ... Not ideal for production games but good enough for an example
having the server tell the client their Id isn't much of a hassle just would've been nice if my backend exposed it since it does log it when the client connects
2025-11-05T21:09:34.812132Z INFO bevy_quinnet::client::connection: Connection 0 connected to [::1]:5000 with client_id Some(1)
bevy_quinnet itself does allow you to get the client and from that the client id
how?
Afaict you get the QuinnetClient, then call .connection() then .client_id()
is there an event that can be used on the client side for detecting when the client successfully connected because that returns None if the client isn't connected yet
Hmmm, the ConnectionEvent I guess?
ill try
bevy_quinnet::client::connection::ConnectionEvent is not an Event
the trait bevy::prelude::Event is not implemented for bevy_quinnet::client::connection::ConnectionEvent
consider annotating bevy_quinnet::client::connection::ConnectionEvent with #[derive(Event)]
the following other types implement trait bevy::prelude::Event:
AcquireFocus
CheckChangeTicks
Fire<A>
FocusedInput<M>
FromClient<T>
ProtocolHash
ProtocolMismatch
ReadbackComplete
and 14 others
:/
It's actually a Message 🤣
😔
Uh, yes, I might rename those or make them derive Message and Event. When updating to bevy 0.17 I just thought that ConnectionMessage would be a confusing name for a network crate 😫
Btw you can also use Replicon 'ClientState' which is properly set by quinnet to 'Connected'
Or use the run condition 'bevy_quinnet::client::client_just_connected'
In Renet they also have ServerEvent, which is actually a Message. ServerMessage would be too confusing.
Same thing even in Bevy itself - for example, WindowEvent is a Message 😅
Originally, I used hash sets for simplicity, but I pushed a commit that switches to SmallBitVec as I originally planned. This significantly improved performance.
It's still not as fast as tracking changes per entity, but it's not that much slower. I think it's a worth price to pay 🙂
how would I send a response to the client like this:
fn on_message(message: On<TestMessage>, mut commands: Commands) {
commands.server_trigger(ToClients {
mode: SendMode::Direct(???),
message: TestMessage(format!("Recieved: {}", message.0)),
});
}
Idk where to get the client ID that sent or if I should include it in the message
nvm
forgot to read docs
How would I split players into 'rooms' like for matchmaking
does replicon have anything like that or should I just make it myself
ig this is more of a question for #networking
Yep :) We don't provide a matchmaking abstraction.
It's usually a separate server that provides an authentification token for players and request a server start.
And the server is where replicon runs
Im getting this error with Replicon 0.34.4 and aeronet_replicon 0.16.1
ignoring event `bevy_replicon::shared::event::server_trigger::ServerTriggerEvent<shared::SetLocalPlayer>` that failed to deserialize: unable to map entities `[270v1#4294967566]` from the server, make sure that the event references entities visible to the client
The server triggers an event on ConnectedClient:
fn spawn_clients(
trigger: Trigger<OnAdd, ConnectedClient>,
mut commands: Commands,
mut visibility: Query<&mut ClientVisibility>,
mut client_player_map: ResMut<ClientPlayerMap>,
) {
let player = commands
.entity(trigger.target())
.insert((
Player {
color: *fastrand::choice(PlayerColor::all_variants()).unwrap(),
},
Transform::from_xyz(250.0, 0.0, Layers::Player.as_f32()),
GameSceneId::lobby(),
Owner::Player(trigger.target()),
Health { hitpoints: 200. },
))
.id();
client_player_map.insert(player, player);
for mut client_visibility in visibility.iter_mut() {
client_visibility.set_visibility(player, true);
}
commands.server_trigger(ToClients {
mode: SendMode::Direct(player),
event: SetLocalPlayer(player),
});
}
and on the client:
fn init_local_player(
trigger: Trigger<SetLocalPlayer>,
mut commands: Commands,
camera: Query<Entity, With<Camera>>,
) {
let player = trigger.entity();
let mut player_commands = commands.entity(player);
player_commands.insert((ControlledPlayer, SpatialListener::new(50.0)));
commands
.entity(camera.single().unwrap())
.insert(CameraFollow::fixed(player).with_offset(Vec2 { x: 0., y: 50. }));
}
How can i fix this error message ?
Are you sure the event is registered via _mapped?
It's also quite an old version 🤔
Ah, you probably not migrated to 0.17 yet. But this shouldn't be a problem.
Thanks for the quick answer!
Yes
.add_mapped_server_trigger::<SetLocalPlayer>(Channel::Ordered)
and
visibility_policy: VisibilityPolicy::Whitelist,
Or could it be a race condition between the visibility and the sending of the event ?
I didnt had this error with replicon 0.33
It shouldn't be, we ensure that replication is applied first 🤔
The error means the client knows nothing about this entity.
And MapEntities is implemented for the event properly?
#[derive(Event, Clone, Copy, Debug, Deserialize, Serialize, Deref, DerefMut)]
pub struct SetLocalPlayer(Entity);
impl MapEntities for SetLocalPlayer {
fn map_entities<M: EntityMapper>(&mut self, entity_mapper: &mut M) {
self.0 = entity_mapper.get_mapped(self.0);
}
}
Looks correct to me 🤔
I can also try version 0.35
Ensure that aeronet is available for that version
Could you try with VisibilityPolicy::All?
it works with VisibilityPolicy::All.
But VisibilityPolicy::Whitelist worked in version 0.33.
Interesting... So visibility definitely causes the problem.
Can you update to Bevy 0.17?
I just completely reworked the visibility system recently 😅
I'll need some coffee for that.
If everything works, you wont hear from me :).
Thanks again and also for this amazing crate !
I haven't released it yet, but I'm planning to release it soon. Right I'm working on extending it to per-component visibility. This new API is so much nicer.
But if you can update to 0.17, you can try this new API by patching with the latest master.
Sure, that would be nice!. We really rely heavily on the visibility system to reduce bandwidth.
Do you have a https://buymeacoffee.com/ link or something familiar ?
We want to give something back for your lifesaving work.
I'm glad you like my crate 🙂
I don't have anything like that, but your kind words are enough 😅
It's always nice to hear when people appreciate what I do.
Are these supposed to ever happen?
2025-11-08T13:36:02.317989Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 298v1
You shouldn't receive the same mapping twice 🤔
I'd assume you have different signatures have the same hash, but you're mapping the same entity.
Ah, so it's because I somehow spawn duplicate entities with the same hash ... Yea, that's possible, I seem to get desync now that I'm porting to bevy_enhanced_input, so it's very possible that causes extra spawns
Would you prefer to define filters via trait or via functions?
Via trait:
impl VisibilityFilter for TestVisibility {
type Kind = Entity;
fn is_visible(&self, entity_filter: &Self) -> bool {
// ..
}
}
For components:
impl VisibilityFilter for TestVisibility {
type Kind = (A, B);
// ..
}
But for a single component I need something like this:
impl VisibilityFilter for TestVisibility {
type Kind = Single<A>;
// ..
}
Via functions for entities:
app.add_visibility_filter::<F>();
For components
app.add_components_visibility_filter::<F, (A, B)>();
Single component:
app.add_component_visibility_filter::<F, A>();
I think via functions it's a bit too verbose and difference between pluaral ans single too subtle 🤔
But Single for trait approach is a bit ugly... But maybe it's a lesser evil?
Is this for registering components to a visibility filter?
Yep. A component can be either an entity-level filter, or a component-level filter.
You always need to call add_component_visibility_filter for both versions.
The difference is wheter to add Kind to the trait or additional registrational helpers.
Ah, I think I'd need to see a bit more of a complete example to make a propper judgement then
I like the via trait example you showed
Why would you need to do Single<A> and not just A
I can't define a blanked impl for Component and have an impl for tuples.
It's a Rust limitation.
It's possible to do this:
type Kind = (A,);
But it's very ugly 😅
Another option is to get rid of Kind and have different regitration functions for entity, single component and multiple components. But it's quite wordy...
Oh

I'm pretty confused and would love an example that actually shows an is_visible implementation...
For example, how would I express that I only want the client that "owns" entity x to be able to see component A on x?
It's already in the latest master:
https://github.com/simgine/bevy_replicon/blob/a1fa75c4e3dd648261be83012b91a010a98a189b/src/server/visibility.rs#L16
I was asking about configuring which filter gives visibility to entities and which one to components.

GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
My bad.
It's not released yet 🙂
I just reworked the visibility system first (with a bunch of other related internal changes) and now I adding per component visibility to this system.
Nothing is final, and the documentation will also be improved.
The trait seems like a good way to do it
Since it's merged into master I'll give it a go in my project and let you know if I have any API feedback
It would be great!
Don't forget to use patch because you want your backend to use this replicon verison.
Oh, I just saw this is entity visibility that's merged (not per-component). I was wondering how I had missed it. I have to admit I'm extremely tired this evening
It's less immediately useful for my game but if I think of a use-case I'll for sure try it out
You interested in per-component visibility specifically?
No problem; I think I'll open a PR in a few days.
It's a follow-up to the new visibility system.
Hmmm, looking at the example, the only thing I'm wondering is if it's preferable to define the filters in one place, then define which filter components use, or the other way around
The latter would look nicer with the trait I think, the former wouldn't work like that at all I think? 🤔
Not sure if I get you, could you elaborate?
So lets say I define my filter in one module, and my components that get the visibility applied to them in another module
Or even multiple crates
What would the dependencies look like between the filtering logic and the replicated components
Ah, I see.
The approach when you define components in a function is more flexible.
But I can't come up with nice and distinctive names for them.
Im trying to get my networking to work but im confused with how im supposed to use like signatures for having consistency on the client and server the repo with my code is linked here #1437634489441456341
Im kinda confused with trying to find whats wrong but I think someone else taking a fresh look at my code might help
What about Signature is unclear? But more importantly, what behavior are you trying to achieve with them?
hmm curious does rewind impl interpolation?
Nope, though the design of rewind and bevy_replicon should allow another crate to do interpolation alongside it ... Iirc Shatur was considering making interpolation either a first party thing or as an official add on crate
In theory it shouldn't be too hard if there is a good extensible interpolation crate available after all
Yes, my plan is to integrate https://github.com/Jondolf/bevy_transform_interpolation
It can already be used as is in listen server, but for clients we need to interpolate between the received snapshots. Jondolf agreed on extending the crate to support this, but I'm busy with per-component visibility right now.
GitHub
Transfom interpolation for fixed timesteps for the Bevy game engine. - Jondolf/bevy_transform_interpolation
I dont really know whats wrong with my code but its not working I dont see any reason it wouldnt though I was wondering if you or someone could review it and see what im missing
Looking into someone else's project is quite time-consuming, and "not working" is quite vague 🙂
I'd recommend asking specific questions. We also have extensive logging - you can try enabling it to see what's happening under the hood: https://docs.rs/bevy_replicon/latest/bevy_replicon/#troubleshooting
I'm having electricity outages, and when I have both free time and electricity, I want to focus on implementing features 😅
A server-authoritative replication crate for Bevy.
It will take more time. I have a somewhat working implementation, but it's very inefficient because of how removals are currently handled (I need to calculate function IDs for all components to properly handle rule layering).
While it was okay-ish for removals, I don't like using it for visibility lost.
But I know how to optimize it using archetype information. It will improve both removals and handling of component visibility lost.
turns out I was spawning a new entity with the player data component instead of inserting onto the actual networked entity
I love bevy inspector egui now ❤️
now i just have a problem where when a player joins it doesnt show the players that joined before it
You mean the snapshots of certains components? Like transform in this case
Can you just replicate players like normal, but use marker fns to disable replication for the owned player specifically, and send to the server authoritative state every tick for the owned player? This way previously joined players will be replicated
Yep
I think Transform is 99% of what is usually interpolated 😅
Honestly, I can't even imagine a use case for interpolating something else 🤔
So I'm considering using bevy_transform_interpolation instead of rolling my own. It includes extrapolation and Hermite which is neat.
- it's planned for upstreaming.
true
i think i am gonna make a clone of ror2 with your crate and rewind ought to be a funny lil project
Perhaps as I get more familiarized with it I can make the interpolation logic.
Clone of ror 2 doesn't sound like a small project to me, but definitely fun 😅
Feel free to reach me about this, I can give you some pointers about what needs to be changed.
In both bevy_replicon and bevy_transform_interpolation
Or just temporarely set the tickrate to 60 and wait until I get to this 🙂
But help with this is definitely welcome and definitely accelerate the process. I'm currently busy with the new visibility system.
Hmm interesting, rewind example feels a little brokeish. When two clients are connected it just doesnt seem to match the client states and colliding with the wall is very weird, just wondering if this was mapped
Ask @dire aurora about this ^
Okay yea there's definitely something wrong there 😅
hmm clever
Looks like my physics are just very broken, even with just the server you can create behavior that shouldn't be possible
but how can I get replicon to replicate players from before they joined? also can you give an example of how to do the marker fns
Replicon will automatically handle replicating previously joined players if they are correctly registered. As for the marker fns I'll send you an example when I get back to my desk 👍
Kk thanks
Just a double check because I'm getting some cursed issues with the client receiving old data ... Regardless of the tick schedule, we only gather changes in PostUpdate, right?
@spring raptor When it comes to message sending, do you recommend to utilize the same channel for esporadic events/messages such as user click on and so on, or should i make use of more than one
Correct, it's done in this system: https://github.com/simgine/bevy_replicon/blob/master/src/server.rs#L154
GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
It's up to the backend how the messages are handled, but they usually add an identifier for the channel in each message. So it doesn't matter whether your message have channel 10 or 42 in the header.
Just see what reads better or convenient to use for your specific project.
Something weird happens on CI recently 🤔
error: linking with `cc` failed: exit status: 1
...
= note: PLEASE submit a bug report to https://github.com/llvm/llvm-project/issues/ and include the crash backtrace.
collect2: fatal error: ld terminated with signal 7 [Bus error], core dumped
compilation terminated.
And it happens sometimes.
Hmmm, yea looks correct ... Do we have a way to debug a specific component being sent/received? 🤔
Because oddly enough the client gets a state for a tick that doesn't match the server's state on that tick
Enable tracing and first see which component corresponds to which ID and after that look at "sending insertion for ..."
That only works for insertions and not updates, right?
For mutations it's "sending mutations for ..."
There is an example here in the docs which shows how to do it: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/command_markers/trait.AppMarkerExt.html#tymethod.set_marker_fns
What I am suggesting is to just use like |_, _, _, _| Ok(()) for your custom write.
Not seeing it, but it might be behind a flag ... But I'd really need to see the actual values ... I guess I can log values in PostUpdate to make sure the data isn't somehow reset first though 🤔
Should always be present: https://github.com/simgine/bevy_replicon/blob/a1fa75c4e3dd648261be83012b91a010a98a189b/src/server.rs#L684
But yeah, if you want values, just log after PostUpdate.
GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
I found the source of the bug
I apparantly had an issue for quite a while where I double incremented the tick on the server 😅
But only the RepliconTick
Weirdly enough still getting these:
2025-11-14T20:44:39.739579Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v1 to 323v4
```Just a lot less, and now it always happens
Oddly enough the warnings happen *after* the spawns though 🤔Would disabling/reenabling entities trigger that message?
Glad you figured it out!
Hmmm... You disable entities on the server?
No, this is on the client
I don't think it the source of this warning.
It happens when the server sends a mapping and client already received it. If the client know about it, it shouldn't send it at all.
Huh, so something on the server causes the signatures to get resent? 🤔
The server sends a mappings if the signature is inserted or the entity is considered new for a client (gained visibility or just spawned).
Hmmm, neither of those should be happening, so that's strange 🤔
Set the log to debug and look for inserting hash
Player spawn, player casts a skill, skill spawns a projectile:
2025-11-14T20:59:45.908653Z DEBUG bevy_replicon::shared::replication::signature: inserting hash 0x76038a003006384f for `194v0`
2025-11-14T20:59:51.908868Z DEBUG bevy_replicon::shared::replication::signature: inserting hash 0x0e397180d8a93194 for `195v1`
2025-11-14T20:59:52.108900Z DEBUG bevy_replicon::shared::replication::signature: inserting hash 0x381dbf3cd2b90a9c for `199v0`
2025-11-14T20:59:52.308919Z DEBUG bevy_replicon::shared::replication::signature: removing hash 0x0e397180d8a93194 for `195v1`
2025-11-14T20:59:52.459119Z DEBUG bevy_replicon::shared::replication::signature: removing hash 0x381dbf3cd2b90a9c for `199v0`
Looks fine.
Could set it to trace and look for writing mapping?
You can filter by bevy_replicon::server
Not seeing anything 🤔
2025-11-14T21:04:31.677188Z DEBUG bevy_replicon::server: client `192v0` connected
2025-11-14T21:04:31.693814Z DEBUG bevy_replicon::server: marking client `192v0` as authorized
2025-11-14T21:04:37.594286Z DEBUG bevy_replicon::server::related_entities: connecting `194v1` with `193v0` via `Affects`
2025-11-14T21:04:37.594299Z DEBUG bevy_replicon::server::related_entities: connecting `194v1` with `193v0` via `Affects`
2025-11-14T21:04:37.595581Z DEBUG bevy_replicon::server::related_entities: rebuilding graphs
2025-11-14T21:04:37.994442Z DEBUG bevy_replicon::server::related_entities: disconnecting `194v1` from `193v0` via `Affects`
2025-11-14T21:04:37.994452Z DEBUG bevy_replicon::server::related_entities: removing orphan `193v0`
2025-11-14T21:04:37.994456Z DEBUG bevy_replicon::server::related_entities: removing orphan `194v1`
2025-11-14T21:04:37.995228Z DEBUG bevy_replicon::server::related_entities: rebuilding graphs
Also odd how the related_entities connecting thing gets duplicated
You need trace for it
RUST_LOG=bevy_replicon=trace cargo run -p session 2>&1 | grep bevy_replicon::server
Pretty sure it's enabled
This means you don't send any mappings at all 🤔
Try spawning a projectile
Hold on let me double check that the log flag to limit it to debug doesn't affect things
I do see some trace but I know that flag is very inconsistent 😅
Still nothing
The related entities are status effects which spawn projectiles already 😅
Technically that projectile doesn't actually get replicated right now, so it doesn't really need the hash, but the status effect definitely gets sent since I got desynchronized spawn messages before I fixed my input scheduling for the newly changed tick logic that is no longer always wrong
Which entity has Signature?
The player, the status effect, and the projectile
But the projectile is not replicated?
Yea, I'll probably fix that at some point but not now
Maybe it's considered new for a client every time somehow?
The warning is for the status effect
Does it spam with this warning?
2025-11-14T21:19:22.495034Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 323v1
2025-11-14T21:19:22.511634Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 323v1
2025-11-14T21:19:22.528374Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 323v1
2025-11-14T21:19:22.544989Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 323v1
2025-11-14T21:19:22.561657Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 323v1
2025-11-14T21:19:22.578308Z WARN bevy_replicon::shared::server_entity_map: ignoring duplicate mapping from 198v0 to 323v1
...
```Many of them, roughly until the status despawnsFor some reason server thinks this entity is new for the client 🤔
Do you see writing mapping on the server?
With trace
Nope, no messages with mapping in them at all
I just get this spam on the client, and a single message about inserting/removing each hash on the server
Could it be that it spams because it doesn't register it as sent? 🤔
Yes, but it's also a bit weird because if the hash is inserted and removed and client receives a mapping, you should see the message about writing mapping 🤔
Yea, idk why there is no such message
Also this is in visibility policy blacklist in case that matters at all
Could you set a breakpoint here and try again? 😅
https://github.com/simgine/bevy_replicon/blob/622b0f3a06649f2ce7f392ca44d00df3677bd416/src/server.rs#L505
GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
And above, for client-specific singatures.
I forgot to recompile after this 😅
I wonder why some trace logging still got trough
Oh
Ooooh ...
It is the projectile that fails
That's ... interesting 🤔
It's not replicated, why does the server send it?
Ah, of course I didn't include Replicated in the query
I didn't expect Signature to be used for non-replicated entities 😅
I insert it in my spawn reusing logic, since I use the hashes from that API for signatures
I'll fix it. I should just skip sending it.
But you are planning to replicate projectiles?
Yea, if someone joins the server after the skill got started they'd miss projectiles otherwise afterall
Need to set up some better logic for that though
Just ignore this message for now.
I'll fix it in the upcoming release 🙂
Okay 👍
Time to continue my input rework now that I fixed the random issues that got unearthed by this
I'd fix now and draft a patch, but since it's also a temporary solution for you, I'll focus on the current release

GitHub
Requires #609.
Added Replicated to the query filter. Also realized we don't need the addition check. Verifying that the client received the entity is enough.
Looks like other people also facing it:
https://github.com/tensorzero/tensorzero/actions/runs/19314725039/job/55243387915
So it's not my cursed code.

GitHub
TensorZero is an open-source stack for industrial-grade LLM applications. It unifies an LLM gateway, observability, optimization, evaluation, and experimentation. - Add check-python-schema job (#45...
Looks like Bus error basically means no disk space left. I wonder why the error is so cryptic. On my machine, I see a proper error when there's no space left. Maybe it's because on CI it's in a VM?
Anyway, removing some of the preinstalled junk fixed the problem: https://github.com/simgine/bevy_replicon/pull/611
Left my comment on corresponding LLVM issue: https://github.com/llvm/llvm-project/issues/167785

GitHub
We're running into a space limit, which causes ld to terminate with a bus error.

GitHub
Here's the build log: https://github.com/tensorzero/tensorzero/actions/runs/19314725039/job/55243387915 It looks like there's a memory access error from ld somewhere.
Now I wonder if I couldn't collect test coverage from my example backend because of the same issue.
It was it! I can finally collect test coverage from it.
Why I'm getting?
Trait EntityEvent is not implemented for `FromClient<LootCommand>
on
commands.spawn(....observe(on_loot_command);
This worked before now it seems it wants me to not put FromClient on entity observers.
I guess it will be fine moving it to .add_observer(on_loot_command); and everything else stays the same.
Ah, right, after 0.17 it needs to be an EntityEvent for it.
I think I can easily fix it, hold on

{kind=link}
Also, this part worries me a bit. The changelog says “Rename FromClient::client_entity into FromClient::client_id.”, but in reality client_id is now a ClientId, not an Entity like before. I don’t mind the change, I’d just like to understand the idea behind it, and whether there’s a shorter or simpler way to get the client player entity for basic use cases.
fn on_kill_me_command(
kill_me_command: On<FromClient<KillMeCommand>>,
mut player_health: Query<&mut Health, With<Player>>,
) -> Result {
if let ClientId::Client(player_e) = kill_me_command.client_id {
let mut health = player_health.get_mut(player_e)?;
health.kill_mut();
} else {
warn!("Received KillMeCommand from server, but it's not from a client");
}
Ok(())
}
I also tried this in another place:
let player_e = loot_command
.client_id
.entity()
.expect("LootCommand player entity not found");
Any advice is welcome!
Yes, we previously used Entity, but it's quite error-prone because if the server is the sender, it's Entity::PLACEHOLDER.
When resources become entities, it won't be a problem. But right now it's better to have it strongly-typed.
Archetype-cached removals using a dynamic observer done:
https://github.com/simgine/bevy_replicon/pull/613
It's both simpler and much faster. We just didn't have observers back then.
GitHub
Requires #610.
Use archetypes to get IDs and listen for removals via a dynamic observer. This is not only faster but also much simpler.
Needed for component visibility. But a cool change on its own.
@dire aurora oh so the example now works? Just curious really wanted to try out the cool rocketo league
how so
So my game had a weird bug, that I recently discovered. I fixed it, but the same case isn't in my bevy_rewind example, so that's still broken in a different way 
does replicon support wasm?
Yep, we even test wast target on CI.
You just need a backend that supports it. Check renet2 or aeronet.
@spring raptor i was thinking about the Reflection usage for serialization.
Doesn't it only work with the same architecture since the AppTypeRegistry is not stable between architecture/machines ? it uses type_id and typename right ?
We use special identifiers before we call functions. So we always call the correct fn.
You can use reflection inside it.
The reason we don't use reflection under the hood is because it's incredibly inefficient. For both bandwidth and performance.
what does this mean
If you override serialization, you can use reflection inside.
We provide you correct ComponentId in the serialization context.
I.e. it's handled for you
i speak about PartialReflect serialization/deserialization like.
fn serialize_dynamic(
ctx: &mut ClientSendCtx,
dynamic: &InputMsg,
message: &mut Vec<u8>,
) -> Result<()> {
serialize_dynamic_with_registry(ctx.type_registry, dynamic, message)
}
fn serialize_dynamic_with_registry(
registry: &AppTypeRegistry,
dynamic: &InputMsg,
message: &mut Vec<u8>,
) -> Result<()> {
let mut serializer = Serializer {
output: ExtendMutFlavor::new(message),
};
let registry = registry.read();
ReflectSerializer::new(&*dynamic.0, ®istry).serialize(&mut serializer)?;
Ok(())
}
fn deserialize_dynamic(ctx: &mut ServerReceiveCtx, message: &mut Bytes) -> Result<InputMsg> {
deserialize_dynamic_with_registry(ctx.type_registry, message)
}
fn deserialize_dynamic_with_registry(
registry: &AppTypeRegistry,
message: &mut Bytes,
) -> Result<InputMsg> {
let mut deserializer = Deserializer::from_flavor(BufFlavor::new(message));
let registry = registry.read();
let reflect = ReflectDeserializer::new(®istry).deserialize(&mut deserializer)?;
Ok(InputMsg(reflect))
}
#[derive(Message)]
pub struct InputMsg(pub Box<dyn PartialReflect>);```Ah, you probably asking whether reflection will work across multiple machines?
this code work on my test, but it's on the same machine
The answer is yes because the reflection is text-based.
#[cfg(test)]
mod tests {
use super::*;
use bevy::reflect::Reflect;
#[derive(Reflect, Clone, Debug, PartialEq)]
struct DummyInput {
value: f32,
}
#[test]
fn serialize_dynamic_roundtrip_preserves_payload() {
let mut registry = AppTypeRegistry::default();
registry.write().register::<DummyInput>();
let payload = DummyInput { value: 42.0 };
let msg = InputMsg(Box::new(payload.clone()));
let mut bytes = Vec::new();
serialize_dynamic_with_registry(®istry, &msg, &mut bytes).expect("serialize");
let mut buf = Bytes::from(bytes);
let result = deserialize_dynamic_with_registry(®istry, &mut buf).expect("deserialize");
let reflected = result.0.try_as_reflect().expect("reflect access");
let recovered = reflected
.downcast_ref::<DummyInput>()
.expect("downcast concrete value");
assert_eq!(recovered, &payload);
}
}
For ex
This will work across machines.
text-based on typename right ?
which is not stable across machine
Yes
It's stable, type names are the same across multiple machines.
really, any source for this, just to be sure my architecutre is not false
Bevy uses it for remote protocol
Ok i will trust that then.
For my usecase it's doesn't matter the serialization is text based.
But i wonder if you have thought about the case of dynamic serialization alternative to reflection for the future, the main reason we have to use text reflection is that we can't access the world for alternative as serialization/desrialization for reason idk since i haven't yet looked at how replicon work under the hood.
I will not need it but i'm just wondering what was your thought on that.
we can probably already bypass this issue for message by serializing the message content before sending the message itself, but it's not possible for component
For dynamic serialization reflection is a good option. Having 2 kinds of serialization would increse the complexity too much.
It's already quite complicated with all specializations and such.
specializations ?
Yeah, you can have different serialization for (Transform, StaticBox) and just Transform.
It's a very useful feature.
Like you don't need to send rotation for boxes
Or you can reduce the precision for non-player characters
i see
well, my dynamic data repliction is not a hot path for now so as long it's stable accross compilations/machines it's fine if it's text based
Exactly!
but there's usecases where it can be an issue i think
There is nothing wrong with using reflection if you need it.
We just don't use it by default because it's a library and we can't assume users won't build an MMO or something like that.
nah it's just a graph with nodes which has inputs of a dynamic type i have to replicate
that why i need dynamic data replication
btw, reflection its only needed for component with dynamic data, for message you can litteraly just replicate it yourself before sending the message
https://doc.rust-lang.org/std/any/fn.type_name.html
It's not stable accross compiler version apparently.
feel like it could be a footgun
Returns the name of a type as a string slice.
oh
The returned string must not be considered to be a unique identifier of a type as multiple types may map to the same type name
yet bevy remote uses it ? feels like i'm missing something
I don't exactly know what Bevy uses, but they serialize names. Can't say for sure what is used under the hood for them, but it's stable.
so the classic typename is not stable but AppTypeRegistry is stable ?
i doubt they haven't fixed this issue yet but they don't use type_name then
Compile-time type information for various reflected types.
ok thanks you for your help, that all i needed to know
i think the only issue this has outside the hotpath is that version has to be the excat same.
just food for thoughts
If you change things in your code, it could break, of course.
But you can reject clients with different game versions using a single line of code in Replicon.
Per-component visibility is up:
https://github.com/simgine/bevy_replicon/pull/614
GitHub
Closes #304.
Includes a minor refactor for ComponentMask in a separate commit to make it consistent with FiltersMask in the next one.
The VisibilityFilter trait now includes an associated Scope typ...
@dire aurora you were interested ^
See the docs in visibility module for API details and examples.
Any feedback is very welcome!
Once it's merged, I'll draft a new release 🙂
Can anyone point me in the direction of a client server setup with both udp and webtransport for the backend? I seem to be getting issues with self signed certs for webtransport
You better ask in a backend-specific channel, such as #1038137656107864084 or #1354455157596880906 with details about what exactly went wrong.
i've gotten this working using renet2. can ping offline if you want some help/pointers
Appologies, I keep forgetting the seperation between the two
No problem!
Out of curiosity, what is the reason that everything must be registered in the same order on both client and server as opposed to just the same types?
(reasoning: currently going insane trying to prevent what I can only guess is llvm involuntarily reordering my function for me cuz it's the exact same file)
We need to have unique identifier for each registration and the most efficient way is to increment a counter because small numbers can be serialized compactly.
If the order is messed up, you will get a different hash and the server will reject the connection.
You can also enable logging and the assigned ID in order.
Most likely you have something different between client and server, I don't think the compiler reorders anything.
Ended up nuking my whole target directory and that seemed to resolve things. Bizarre
My client and server run the exact same codebase; it would connect, but authentication (also based on the protocol hash by default iirc) was failing; client didn’t get disconnected though, just didn’t get any replication or events
The client should get disconnected in this case. You just might not properly check for it in your codebase (or it's a bug on the backend side).
Pushed a small change that exposes the direct bit API in addition to automatic filters.
I played with it, and I think it's better to have both. For example, updating visibility based on distance works better when setting the bits directly.
See the added doc example for details.
@spring raptor It's me again.
I updated to bevy 0.17, Replicon 0.36 and Aeronet (including all packages) 0.17
My messages are working as before, but the events triggered from the client to the server are no longer being received by the server.
Do you have an idea, what the problem could be
Can't say for sure, but I'd try to enable debug-level logging and see what's happening:
https://docs.rs/bevy_replicon/latest/bevy_replicon/index.html#troubleshooting
A server-authoritative replication crate for Bevy.
ill try thanks
Okay i got the problem @spring raptor . Im sending an empty struct.
mpl Plugin for InteractPlugin {
fn build(&self, app: &mut App) {
app.add_client_event::<Interact>(Channel::Ordered)
.add_observer(interact)
.add_message::<InteractionTriggeredEvent>()
.add_systems(
PostUpdate,
send_interact
.before(ClientSystems::Send)
.run_if(in_state(PlayerState::World)),
);
}
}
#[derive(Event, Serialize, Deserialize, Debug)]
struct Interact;
fn send_interact(mut commands: Commands, keyboard_input: Res<ButtonInput<KeyCode>>) {
if keyboard_input.just_pressed(KeyCode::KeyF) {
commands.client_trigger(Interact);
}
}
fn interact(
trigger: On<FromClient<Interact>>,
mut triggered_events: MessageWriter<InteractionTriggeredEvent>,
players: Query<(&Transform, &BoxCollider)>,
interactables: Query<(Entity, &Transform, &BoxCollider, &Interactable)>,
client_player_map: Res<ClientPlayerMap>,
) -> Result {
let player = *client_player_map.get_player(&trigger.client_id)?;
let (player_transform, player_collider) = players.get(player)?;
let player_bounds = player_collider.at(player_transform);
But when i changed to
#[derive(Event, Serialize, Deserialize, Debug)]
struct Interact(usize);
Then it works
Ah, this looks like a bug in the backend. Could you report this to #1354455157596880906 or to https://github.com/aecsocket/aeronet ?
Because we have a test for it.

GitHub
Set of Bevy-native networking crates, focused on providing robust and rock-solid data transfer primitives - aecsocket/aeronet
sure!
Hi! I'm not sure whether this is more of a replicon or a renet problem but I'm leaning towards replicon; I set up bevy_replicon_renet as a backend as in the examples, and swapped out my old backend (aeronet) with it. Aeronet mostly worked with some bugs I want to avoid, so I know I can get things working. But for some reason the renet backend manages to trigger an On<Add, ConnectedClient> event and then the client never gets authorized and receives no warning about e.g. failed protocol matching. I also disabled protocol matching in case that was the issue; it was not. I'm really not sure what else to check, or could be a problem?
Found the issue: Was a mix of some logic that no longer worked quite right without aeronet, and leaving some actual aeronet plugins in that seemed to interfere with renet. Works great now!
Glad it was solved!
But I'm curious: what bugs did you encounter with aeronet?
I see it wasn't updated to the latest version of replicon yet, so maybe version missmatch was the issue?
it mostly worked, so I doubt it was a version mismatch; mainly:
- if I alt-tab, it would instantly run out of some memory buffer and disconnect
- it doesn't handle zero sized messages right now, which is easily worked around but just one more thing to forget and have go wrong
I was also leaning towards switching to renet since it's what you use, and you maintainbevy_replicon_renet, so I figured it would probably be overall more likely to be smooth development with renet over aeronet. Also happened to be about 100 less transitive dependencies and simpler setup, which was nice
Yeah, it's definitely not a version missmatch 🤔
@raw idol you might be interested in this ^
Luckily, switching between backends is trivial 🙂
Hey @spring raptor, thanks for your networking crate. Its really a pleasure working with 😊 Thanks also for the thorough documentation. I often find myself going back to it when I'm stuck.
I'm trying to get bevy_transform_interpolation working. Just adding bevy_transform_interpolation::prelude::TransformInterpolation to the entity does not seem to work as described in the crate 🤔 do you know if it is related to the update schedule required by the transform interpolation?
Glad you like it 🙂
About bevy_transform_interpolation, see this discussion: #1124043933886976171 message
To put it short, it requires adjusting bevy_transform_interpolation and write a small integration for it.
I just didn't get to it yet.
What IO layer is this using? I know Steam has issues with zero-sized messages, but I haven't had reports of it on other IO layers. Also would appreciate a github issue on this since I don't really check discord anymore
Also I really should update aeronet_replicon
Was using webtransport. I tried both webtransport and websockets for the alt-tab bug, both had it so it seems to be more of an aeronet_io issue. Not sure what the zero sized messages one applies to, but definitely webtransport
On WASM or native?
the transitive deps is interesting. should have a look at pruning the tree sometime
Should be just a simple version bump for you 🙂
native. I'm not 100% certain that aeronet actually has that many transitive dependencies, this has been a long project with a lot of dependency movement so maybe something just got unlodged in the lockfile by chance when I switched to renet and dropped a lot of dependencies, but I did go from 700 to 600 for the client executable.
Can't seem to reproduce the alt tab thing, I suspect that it's Bevy pausing systems when alt-tabbed, but I can reproduce the empty event thing. trying to diagnose now
The alt-tab bug might be related to https://docs.rs/bevy/latest/bevy/winit/struct.WinitSettings.html configuration.
Settings for the WinitPlugin.
alt tabing out of the browser, or just changing browser tab ?
No browser, native
using renet2 and its stays connected during alt tab (ws or wt). using the default WinitSettings. so its probably aeronet yeah
could u supply a repro and open an issue pls?
found out why zero sized messages are breaking, will be resolved in https://github.com/aecsocket/aeronet/pull/74
GitHub
Fixes #73.
When pushing a message into a Transport for sending, we split it into fragments. If the message is zero-sized, no fragments will be made, so the SentMessage will have a Box<[Optio...
im not using aeronet even tho i would like too, its @distant hazel that had this issue about alt tab
Thanks for the fix! When is the released to crates.io planned ?
Does Replicon have transform interpolation and extrapolation?
Not yet. But it's possible to integrate it with bevy_transform_interpolation, but I haven't gotten around to it yet.
Thanks for the answer 🙂 I ended up writing a simple lerp one for now
are you confused with #[require(Replicated)] maybe?
I also think it's actually great that we don't require a trait because this allows us to replicate components from third-party crates 🙂
How is the replication interval controlled in replicon? By specifying a tick_schedule that specifies how often the RepliconTick is incremented?
Yep. If it's not flexible enough, you can manually increment ServerTick, which will trigger replication at the end of the frame.
Thanks, will try that. I'm mostly thinking of how to integrate this with lightyear tick. Lightyear's tick is incremented every FixedUpdate run, and replication runs every few ticks (specified by user).
For example when I receive a ConfirmedTick, I would like to know the fixed-update Tick that I should rollback to. I guess I need to maintain a mapping from RepliconTick to lightyear Tick?
I'm curious why FixedUpdate is separate from the tick?
I'd expect it to be tied to the FixedUpdate directly.
But yeah, I think mapping makes sense. Or you can just store the RepliconTick directly 🤔
What do you mean?
Sorry, I wanted to write why FixedUpdate is separate from replication sending?
I expected it it be tied to the update. But I guess it make sense if you want to send traffic?
I think we can make it work similar to Lightyear, so you can convert ticks simpler without any mappings.
I'm not sure I understand, sorry!
Tick is incremented every FixedUpdate; and is just used as convenient way to measure time, even between replication intervals. For example i need it for input-handling, prediction or interpolation.
Replication sending is done in PostUpdate, and I just include in the message the current fixed-update Tick. The user can specify a replication frequency (for example 100ms)
I saw that in Replicon you include the RepliconTick in the message; but that is only useful for replication, I cannot compare that tick with other fixed-update related timestamps (inputs, prediction, etc.)
It's okay, I'm not a native speaker, so maybe it's also a language barrier 🙂
Quick question, are you talking about https://docs.rs/bevy/latest/bevy/ecs/component/struct.Tick.html or you have your own?
A value that tracks when a system ran relative to other systems. This is used to power change detection.
Ah right, i have my own! https://github.com/cBournhonesque/lightyear/blob/main/lightyear_core/src/tick.rs#L10
bevy's Tick is only used for replication/change-detection purposes.
My Tick is just incremented by 1 every time FixedUpdate runs, and is what I use to do time-synchronization between multiple peers + as a way to track time in general

GitHub
A networking library to make multiplayer games for the Bevy game engine - cBournhonesque/lightyear
Ah, makes sense. So RepliconTick is basically the same thing.
Except, we tied the tick mutation to the replication. The replication happens in PostUpdate every time the tick mutates.
But in your case it replicates not every increment, but every X increments, defined by the user. Is this correct?
Yes; in my example RepliconTick would get incremented once every 100ms in PostUpdate, but lightyear's Tick gets replicated every FixedUpdate
Got it!
But even though you send replication every X increments, the tick itself gets sent every increment. Is this correct?
Sorry for long responses, a bit busy rn 🙂
We also have a size difference: u32 vs u16.
I used u16 originally, but @dire aurora suggested a valid use case: in games that track time in ticks, u16 might be too short. With 30Hz it's only ~36 mins. In some MMOs buffs could be active for 1h+.
Would you consider switching to u32?
No, the tick gets incremented every FixedUpdate; and whenever a replication message gets sent it include the current value of a tick.
For example the tick could be 45, and then on the next message it is 50.
For u32 vs u16; yes i might switch to u32.
I originally used u16 because i include a tick in a lot of packets (for example Ping/Pong packets) for time sync so reducing the size is nice.
I have a bunch of extra complexity where I currently have to clean up stale sticks every ~10 minutes to avoid wraparound issues, it might be easier to just switch to u32
Ah, I think I understand it properly now.
We can add the same configuration setting to Replicon and your Tick will match RepliconTick.
But there is a small problem.
First, let me describe how replication is sent by default (it's relevant!).
We have 2 kinds of replication messages: mutations and updates. Mutation messages only include entities and mutated components. Update messages include everything else. And both messages include the tick.
I mentioned that we send messages every tick, but if there is no data to send, we simply don't send anything.
This works well for games that don't need tick synchronization.
But we have a special switch: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/track_mutate_messages/trait.TrackAppExt.html#tymethod.track_mutate_messages
This function needs to be called by rollback crates that use Replicon. This way, mutation messages will be sent every tick. If there is nothing to send, the message will only contain the tick.
This allows not only synchronizing ticks, but also distinguishing between predicted and received data. I documented the API here: https://docs.rs/bevy_replicon/latest/bevy_replicon/#ticks-information. It's very low-level, but we went with it for maximum storage efficiency.
But if we don't send mutation messages every tick, how do we distinguish between what was predicted and what was interpolated? How is this done in Lightyear?
API documentation for the Rust TrackAppExt trait in crate bevy_replicon.
A server-authoritative replication crate for Bevy.
We can add the same configuration setting to Replicon and your Tick will match RepliconTick.
you mean thatRepliconTickwould be updated every FixedUpdate, but we could still send replication updates every 'send_interval'?
I'm not sure I understand why track_mutate_messages is necessary for prediction/rollback. Could you elaborate? Why do we need to send mutation messages every tick?
But if we don't send mutation messages every tick, how do we distinguish between what was predicted and what was interpolated? How is this done in Lightyear?
Component values received from replication are inserted asConfirmed<C>, and the predicted/interpolated value is the componentC.
Each entity has aConfirmedTickwhich tracks the latest tick where a replication message was received. I don't use anything likeServerMutateTicks, I only need to know the latest confirmed tick for the entity.
Whenever a mutation is received on a predicted entity, I would:
- rollback to the earliest confirmed tick of any predicted entity (currently all prediction entities are in the same ReplicationGroup, so there is a guarantee that there are all at the same tick, but I think I want to relax this constraint)
- re-apply history from there.
you mean that RepliconTick would be updated every FixedUpdate, but we could still send replication updates every 'send_interval'?
Correct! That's how yourTickworks, right?
For the clarification it's better to ask @dire aurora directly. Could you explain? Because I don't remember the details, only the fact that we need to distinguish for which tick the value was confirmed and for which predicted 🤔
Sending every tick allows to check was the mutation missed or the component just didn't change.
The case we wanted to solve was not receiving data for an Entity, because nothing changed, but the client not having a clue if it changed or not. The client would assume it's missing and just load a prediction and never the old value (which might've still been the correct authoritative value)
Makes sense, I think that's why @viscid jacinth have to use the same replication group.
But I think it's worth using the bevy_rewind approach. But this will require dropping the ability to set the mentioned delay.
Yea that's what I thought. It's independent from replication groups.
The client might mispredict something, and if the server doesn't send any updates then you never know what the correct value is.
In which case do you need the full history of ConfirmedTick instead of just the latest value?
Yes, but you mentioned that you're using the same replication group because without it looks weird? Maybe it's the missing piece?
Yep, you need the full history. In Replicon we have ConfirmHistory component.
But we also have MutateTicks resource that track for which ticks mutations were received. It needs to be checked additionally if ConfirmHistory missing a tick.
It's for performance reasons. Would be slow to update ConfirmHistory on all entities every time we receive an empty message.
Received ticks from the server for an entity.
Received ticks for mutate message from server.
you mean that RepliconTick would be updated every FixedUpdate, but we could still send replication updates every 'send_interval'?
Correct! That's how your Tick works, right?
Yes, but i guess if you store aConfirmedTick(RepliconTick)I would still have to map to my own lighyear tick since they might not be the same; I update the lightyear tick to do some tick syncing. Or I guess I could just update the RepliconTick to match my lightyear Tick? (and I update it only when I want to run the replication systems). That should work, right?
So plan would be:
- maybe add a
set_tomethod inServerTick - switch my lightyear tick to u32
- everytime I want to run replication, I manually update the
ServerTickto be equal to my lightyear tick
Yes, but you mentioned that you're using the same replication group because without it looks weird? Maybe it's the missing piece?
I haven't tested it; without it I don't think it would necessarily look weird, but there's more chances of mispredictions. I will change lightyear to be compatible with all predicted entities not being on the same tick.
Yep, you need the full history.
Why do you need the full history? I don't think I ever use the full history.
It needs to be checked additionally if ConfirmHistory missing a tick.
How come?ConfirmHistorycan be lossy?
ServerTick is used for replication, I'm not sure if it's correct to change it. Maybe I can rename it into ReplicationTick or something like that and you can have your own custom resource?
But i thought that modifying ServerTick is the way to tell replicon to trigger replication.
Also i looked at the code, I don't think it requires consecutive replication system runs to have consecutive ServerTick. It just needs to be monotonically increasing, like in lightyear. i.e. we run replicate once with ServerTick = 100, and then later when ServerTick = 120.
I think it would work. I can actually test it now since increment_by is basically the same as set_to
Why do you need the full history?
If you received a mutation for tick X, it doesn't mean that you received the value for X - 10 to which you might want to rollback.
But just to clarify - when I say full history, I mean only the last 64 ticks.
How come? ConfirmHistory can be lossy?
Imagine you received update to tick X. Now on the next tick there are no changes. We send an empty message. But instead of iterating over all entities withConfirmHistoryand set this tick, we just update aServerMutatTicksresource.
It's simply for optimization. So the logic is this:
IfConfirmHistoryhas tick X - it was received.
If not, you need to check whether the message for tick X usingServerMutatTicks. Mutations could be split in multiple parts and this resource allows you to check wheter all parts where received.
This is correct. It's just in my mind set_to could be used to decrement which might break things. increment_by will always work.
This would allows you to emulate the delay.
You won't be able to use the mentioned tick API, but you're saying it's not needed for Lightyear? Strange, this sounded essential for rollback to me 🤔
We also discussing adding client authority in https://discord.com/channels/691052431525675048/1449832649240612946 and I would really appreciate your opinions.
It's in #networking since it's related to both Lightyaer and Replicon. Please, join us if you have suggestions or thoughts!
Ok i see how ServerMutateTicks can be used to avoid iterating over all ConfirmedTick on empty messages.
I still don't think I need the history; everytime I receive a replication update I just need to rollback to the latest received ConfirmedTick for each predicted entity, so there doesn't seem to be any need to store confirmed ticks past the latest one
So would it be possible to not have any tick_schedule so that I can increment the SreverTick manually?
The visibility system is interesting but also somewhat unintuitive?
For example if I want to replicate an entity to all clients except one, if I understand correctly I would have to add a
AllExceptOneMarker(Entity) on both the entity itself + all clients except the one I don't want?
That seems a bit tedious
Ah i guess another approach would be that each client entity has a
Marker {
behaviour: Only/Except, // not used on the client entity, but only used on the entity to replicate
entity: Entity, // the client entity itself
}
then on the entity to replicate you can add the Marker.
It just seems strange that on the client entities I have to add a Marker component where all the information is either unused or redundant.
Maybe the API should allow settings a VisibilityFilter with 2 distinct components: one for the replicated entity and one for the client entity. And maybe there could be a default case where no component is required and the check is done on the Entity itself? (but that might be expensive)
Ideally I would:
- add
ExceptFilter(Entity)on the replicated entity - this triggers a visibility filter check against all entities with the
<ExceptFilter as VisibilityFilter>::ClientMarkercomponent; in our case the marker is (), so we check against all entities; and we use theEntityitself - I can compare the
Entitystored inExceptFilteragainst the clientEntityto decide if I want to send or not.
Or if you don't like the Entity part, I could have a ExceptFilter(network_id) on the replicated entity, which uses the NetworkId component on the client entity.
Ah it looks like I can have more fine-grained control with ClientVisibility; I think I can just make things work with that!
You can just ignore the tick history API then. 🙂
But let me clarify why bevy_rewind uses it, just in case. Entities can have different confirmed ticks. When a rollback happens, it rolls back to the last confirmed tick among all entities.
This API allows us to distinguish between a missed update and a value that simply did not change.
For example, you have an entity for which you received an authoritative update on tick X. On ticks X+1..=X+5, nothing happened. So on X+5, you still have a valid authoritative value.
So the last confirmed tick for this entity is X+5 and not X, which is important because the crate rollbacks to the last received tick among all entities.
Without this API, we would not be able to tell whether the value simply did not change or whether the update was not received.
It is low-level because it was designed for rollback crates and prioritizes efficiency.
Sure. How about to wrap it into Option, so you can pass None and control the tick manually?
(I answer slowly because I'm still at work)
Yes, I think for this use case the component-based API just gets in your way 🙂
Just toggle visibility manually with ClientVisibility.
The component-based API works best for something like: "my entity belongs to X, and I want to make it visible for all clients that also belong to X".
We could maybe make it possible for the visibility API to handle an Option on the client side for the component, so this case is easier, also helps with things like party visibility on clients that aren't in a party, etc
I actually ran into that same thing before, though I just fixed my case with a minor change and some new scheduling constraints
Yes, I think this makes sense 🤔
Will implement after the release for 0.18: https://github.com/simgine/bevy_replicon/issues/626

GitHub
Right when the filter component is missing on the client, entities with this component will be hidden. But it's not always desirable. Users may want to express the reverse behavior - make entit...
GitHub
I'll merge this after a release for Bevy 0.18 because these changes are breaking and we try to avoid breaking API together with Bevy update.
Updated to the latest RC.
I also updated bevy_replicon_renet, but it's not on crates.io yet because it uses my renet fork.
How can
- stop replication without despawning the entity? simply remove
Replicated? - despawn an entity without replicating the despawn? just remove
Replicatedand then despawn?
Also is there a way to have a component A on the sender be received as component B on the receiver?
I'm close to having a testable version of lightyear using replicon for replication, btw
When you remove Replicated, it will despawn the entity on clients 🤔
It's because I watch for Replicated removal. We didn't have a Despawn lifecycle event back then.
I think it should be an easy fix: just replace On<Remove<Replicated>> with On<Despawn>.
The only thing I'm not sure how to handle is entity mappings. Right now, I remove the mapping from the list on despawn. But what if you stop replication and then despawn the entity? In that case, the mapping will remain in the client map forever.
Yes, we have markers API for it: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/command_markers/trait.AppMarkerExt.html
You register a marker and associates a writing function for a component.
This way you can write A as B.
Marker-based functions for App.
See this example: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/command_markers/trait.AppMarkerExt.html#tymethod.set_marker_fns
Marker-based functions for App.
So to be clear we are suggesting that
- removing
Replicatedjust pauses the replication (instead of sending a despawn) - a despawn while the entity has
Replicatedwill be replicated - a despawn while the entity doesn't have
Replicatedwon't be replicated
I guess we could have an infrequent message sent that lets the client know about entities that were despawned but not replicated, so that the mapping on the receiver side gets cleaned out?
Yes, does this sound reasonable? How was it handled in Lightyear?
But we don't know which entities are replicated. Are you suggesting we remember which entities were marked as replicated?
@viscid jacinth wait, we also have the ability to override despawn handling on the client: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/registry/struct.ReplicationRegistry.html#structfield.despawn
Maybe that's what you want? 🤔
Stores configurable replication functions.
No, I want to despawn an entity without any message being sent to the receiver.
in lightyear I had a distinction between Replicate and Replicating, but I think what I outlined above is better.
I didn't have any handling of the entity mapping memory leak, though
Thanks, I opened https://github.com/simgine/bevy_replicon/issues/629
Is this a blocker for you? If you need this right now, I think you can quickly hack without bothering about mappings cleanup.
No none of this is urgent!
To track if the client received ANY replication messages I need to:
- enable
app.track_mutate_messageson both sender and receiver - check both
ServerUpdateTickandServerMutateTickson the receiver?
It looks like i can't access the last tick in ServerUpdateTick
EDIT: nvm i can deref
Yes, but checking ServerMutateTicks is enough.
Yeah, just deref it.
I'm still not sure how to get the last confirm tick for an entity. Let's say ConfirmHistory tells us 'not-confirmed' for tick 17.
How can I use ServerMutateTicks to know that we might have received an 'empty' mutate messaage for tick 17, and not a non-empty message?
Why? ServerMutateTicks is also updated when we receive an Update message with mutations?
You just call ServerMutateTicks::contains(tick). If it's true - the tick is confirmed.
When update message is received, all entities affected by it will update.
However, it doesn't mean that all mutations were received. It's possible to have an update message with insertions for entity X and mutations for entities Y and Z. And mutations will be applied only after the update message.
So checking ServerMutateTicks should be enough.
All mutation messages include the minimal required tick from update messages to be applied. Until the update messages for the minimal required tick is received, the mutation message will be buffered.
So if you received a mutate message for tick X, everything before and including tick X is confirmed.
ServerMutateTicks::contains(tick) is global. I want to know for a specific Entity the latest confirmed tick
Yes, and if it's true - tick was confirmed for all entities.
I see; ServerMutateTicks is true only if the tick was confirmed for ALL entities.
So it's possible that ConfirmHistory's last_tick is higher than the tick in ServerMutateTicks?
That's because of how replication works.
We scan for changes and include everything that wasn't acked by the client for tick X. The message split into parts (if necessary) and parts can be applied serparately.
If all parts for tick X was applied - the tick is fully confirmed.
Exactly!
So the strategy is to check ServerMutateTicks first. It's a very cheap check. If it wasn't confirmed, check ConfirmTicks.
To check for a specific tick? I was planning on just doing confirmed_tick = max(server_mutate_ticks.last_tick(), confirm_history.last_tick())
Ah, yes, this also works 🙂
I still don't get why we wouldn't check ServerUpdateTick. Let's say C is insert at tick 17, then the confirmed_tick for the entity is 17, even if it didn't have any mutations
Sure, ask as many questions as needed!
It's because we bump ConfirmHistory on every entity change: mutations, insertions, removals, etc.
But the entity might not have any mutations on this tick. In this case ConfirmHistory will return false for this tick.
This is why we need ServerUpdateTick. If for this tick we received all mutations, the entity can be considered confirmed because there was no changes.
I probably should clarify this in the docs 🤔
Updated: https://github.com/simgine/bevy_replicon/pull/631
Hope this makes it more clear.
GitHub
Remove suggestion to check ServerUpdateTicks, as it is not needed. This API should likely be removed from the public surface in the next release.
Fix confusing documentation for ServerMutateTicks::...
Ok here's my understanding, is it correct?
- ServerMutateTicks contains the information of 'were all mutation messages received for a given tick'
- if a tick is confirmed there, then ALL entities are confirmed for AT LEAST this tick
- some entities might have a more recent confirmed tick, even though all entities for that tick were not confirmed yet, in which case
ConfirmHistory.last_tick() > ServerMutateTicks.last_tick()
- ConfirmHistory contains any tick where we get an Mutation or Update. (but only if it was 'explicit')
- with MutationTracking, we also send empty packets if there were no mutations for that tick.
- these can only be seen in ServerMutateTicks; in that case we would have `ServerMutateTicks.last_tick() > ConfirmHistory.last_tick()`
- ServerUpdateTick is useful to globally check if any Update was received, and also because you could have:
- entity 1 has an insertion but not entity 2. In which case `ConfirmHistory` will be false for entity 2 for that tick,
but we know that entity 2 is confirmed for the tick thanks to ServerUpdateTick
And for prediction:
- we need the oldest tick that was confirmed among all predicted entities
- the most recent of `ServerUpdateTick` and `ServerMutateTick.last_tick()` is the OLDEST possible confirmed tick across all entities
- it is possible that the Predicted entities are a subset of all replicated entities, in which case we might want to check
each Predicted entity's `ConfirmedHistory` to see if the oldest confirmed tick among them is more recent (but in most cases `ServerUpdateTick` + `ServerMutateTick.last_tick()` is enough
Your PR mentions that ServerUpdateTicks is not needed but your previous message just said "This is why we need ServerUpdateTick" haha
I don't know which one it is
Oops, I wanted to write ServerMutateTicks, sorry!
Forget about ServerUpdateTicks 🙂
But why is ServerUpdateTicks not needed?
Let's say we receive an Update message which spawns entity 2 at tick T, but doens't include any mutations. (and we have an existing entity 1)
That means that all entities are confirmed for tick T.
I would need to check ServerUpdateTicks to know that since:
- the information is not present in
ServerMutateTickssince there are no mutations - the
ConfirmHistoryof entity 1 was not updated.
Since we use track_mutate_messages (I def should mention it in the ticks information!),
we send empty mutate messages even if there are no mutations. And they update ServerMutateTicks.
Yes I understand that, that's why I included
- with MutationTracking, we also send empty packets if there were no mutations for that tick.
- these can only be seen in ServerMutateTicks; in that case we would have `ServerMutateTicks.last_tick() > ConfirmHistory.last_tick()`
But for the case I described above, I think we would need ServerUpdateTicks, no?
the information is not present in ServerMutateTicks since there are no mutations
But it will be present.ServerMutateTicksupdated every time we receive a mutation message. Even if it's an empty message.
the ConfirmHistory of entity 1 was not updated.
This part is correct. This is why checking forServerMutateTicksis necessary.
But it will be present. ServerMutateTicks updated every time we receive a mutation message. Even if it's an empty message.
But that was not an empty mutation message, that was an Update message (since another entity was spawned).
Or are you saying that in this case we would send 2 messages:
- an Update message
- an empty Mutation message?
I was under the impression that we never sent mutations at the same time as Updates since they were merged together
Yes, you'll get 2 messages 🙂
On tick N it's possible to receive an update message with insertion for entity X and mutation message with changes for entity Y. The mutation message will be buffered until the update message for tick N is received and applied.
Another thing I'm curious about; the example you showed earlier suggested that you want history enabled for prediction.
@dire aurora may I ask how you're using that?
Don't you want the most recent tick for any predicted entity?
Or is the thought process that it would be useful in the following case:
- predicted entity 1 has latest tick 7
- predicted entity 1 has history-ticks 3, 7, 11. The message with tick 7 was received after the message with 11, so if history was enabled that update would have been lost. However with history enabled we get a more correct rollback because we can rollback to the exact value on tick 7?
https://github.com/simgine/bevy_replicon/blob/e7fa5364d8a5ee3bd2e6aa68b612b96ed82cd617/src/server.rs#L758
Doesn't this mean that whenever there is ANY update, then all mutations for all entities are included in the update message? Or is that only for that one entity that has updates?
So the rule is:
- all updates are sent together as a single message. Any mutations for those entities are included in that update message
- you can still have mutations for other entities. If track_mutation is enabled, then we send an extra mutation message even if there were no mutations

GitHub
A server-authoritative replication crate for Bevy. - simgine/bevy_replicon
Finally I have last question 😄
Are the confirmed ticks (ConfirmHistory and ServerMutateTicks) updated for past/historical messages?
For example I receive at the same tick a Mutation message for tick 7 and a Mutation message for tick 11 for the same entity.
Will ConfirmHistory also say that tick 7 is confirmed? same for ServerMutateTicks ?
Doesn't this mean that whenever there is ANY update, then all mutations for all entities are included in the update message? Or is that only for that one entity that has updates?
Not all entities! Only this specific entity.
You can receive mutations for other entities in a mutate message if there was any mutations.
So the rule is:
This understanding is correct!
Yes if you enable history for the entity via marker config: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/command_markers/struct.MarkerConfig.html
You set it when you register your markers on the entity. For example, your Predicted marker component will need to enable history to bump ticks and receive all mutations, including past mutations.
Parameters for a marker.
See https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/replication/command_markers/trait.AppMarkerExt.html for more details about the markers API. I provided an example for history.
Marker-based functions for App.
Feel free to ask as many questions as needed 🙂
It's not the most intuitive API. But we tried to design it in a way that allows you to avoid paying for what you don't need.
This markers API basically tell "how to write this component on this entity". By default all components have default writer that just inserts the component.
But sometimes you want to apply it as a different component. Or write into a history buffer that might need previous values.
That's why it happens yea. The use in my crate is that if entity A is at tick 7, and B at 6, and A6 was received after A7 wel still need it to correctly predict B7
(Unless they never interact ofc)
But you don't need history for that, no?
The history is only for a given entity.
Even without history, you could receive an update for B at 6, and for A at 7
Yes I understand that the marker api can customize how the component is written. But in general are the confirmed ticks updated for past mutation messages?
Or only the latest mutation message is taken into account for ConfirmHistory? And does enabling history change anything>
Without history A6, needed to predict B7 properly if they interacted that frame, would be lost if A7 arrived first. This isn't a big issue on one frame, but with slightly bad network conditiond the effect is noticable
But again, only relevant if entities interact with eachother but don't get networked together
But in general are the confirmed ticks updated for past mutation messages?
Yes if you enable history. Otherwise old mutations and tick confirmations will be ignored.
Why would A6 be lost if B7 arrived first? Past mutations for A are only ignored if we received a more recent mutation for A, not for other entities, no?
Because if you receive A7 first and later A6 (due to network fluctuation), we discard A6. It would be weird for A6 to override a more recent A7.
But if the history is enabled, I apply everything to let you write all values into the history.
Summarized my initial thoughts on client -> server replication based on https://discord.com/channels/691052431525675048/1449832649240612946 discussion in this issue:
https://github.com/simgine/bevy_replicon/issues/634
If you're interested in this feature, I'd really welcome your opinions!

GitHub
Use cases Originally, I wasn't sure about this feature. I thought it's a very niche feature for VR games to avoid rollbacks (which might cause player nausea). But I was wrong! For example, ...
Fully agree to just keep it server client model. And for entity spawns I think that can be good to have. It would definitely need a validation/auth middleware on the server before sending out to other clients
But its also not hard to set up a message like that
Also I don't think you should ever allow more than one client be the authority of something. Not sure if you have that in there or not. So maybe you just need the client Id on a component which says who gets to control that.
That's one the reasons I didn't suggest adding client entity spawning with validation.
Clients can send game-specific messages that can be validated on the server in a system and spawn entities.
And if a client wants to spawn before waiting for confirmation (similar to how client-spawned entities would work on the server), we have the Signature component, which allows entities to be matched via hashes. So when the server confirms the spawn, the client will match the local entity with the server entity using the hash. And If on the server you immediately give the client the authority, it will work exactly like client spawning, but with validation.
Describes how to calculate a deterministic hash that identifies an entity.
Ah, I actually forgot to mention it while writing the proposal! I'll update it.
I described ClientAuthority with a single client entity, so this way only a single client can have authority. I think in Lightyear you can also have only a single authority over an entity (which is reasonable).
However, I can imagine a use case where an entity owned by client A can be moved around by anyone, but only client A can change non-transform components (was suggested by NiseVoid) 🤔
I'm not sure about this, though... Maybe, to keep things simple, we can go with a single client authority over an entity - mainly because I'm not sure how to implement this efficiently.
Thanks for the feedback!
Is there a way to check if any replication message was received?
You can check messages inside ClientMessages for replication channels. I didn't expose received_count though. I can make it pub if needed.
Or you can check ServerMutateTicks. But the tick is confirmed only if all messages received. If you're interested in "any message received", we'll need to expose the API. In addition, you will need to check ServerUpdateTicks.
I wanted to have this so that I could do something like: only check for possible rollbacks if any replication message was received.
But now I'm thinking I could do this other approach: every time I receive an mutation/insertion for a Predicted entity, I will:
- compare the component with the previous value in the prediction history
- insert the new component in the prediction history
- trigger a rollback if there is any mismatch
For this I would need to have World access in WriteCtx and RemoveCtx; what do you think of adding a UnsafeWorldCell there (with safety comments) so that I can directly update the world when receiving an update for a predicted entity)?
(right now i insert the replication value in a Confirmed<C> component, and I compare Confirmed<C> with PredictionHistory<C> to see if there is a mismatch. But it would be better if I could skip that step and directly do the mismatch check in WriteFn<C>
I guess one issue is that this only checks for rollbacks when an entity receives an update. But when ServerMutateTicks's last_tick is updated, it's also equivalent to 'we received an update for all entities that did not send muations' that their component value did not change, and I should also check for rollbacks for these
Yes, I can give you the world access, but it's very easy to trigger UB. Users can't spawn/despawn entities with it and shouldn't alias same components that deserialization fn.
Maybe we can do something better? Could you explain more how the comparison works?
I.e. on the server the value might not change, but they could move on the client?
If there is a mismatch between the component to be inserted and the existing value in the history I want to update some internal prediction-related resource that tracks rollback state.
Another option would be to have access to Commands, so i can trigger a command that updates the rollback state.
i.e. the client might have mispredicted something, but the server tells us that the component value didn't change so we should trigger a rollback
Ah, I see! This shouldn't cause UB.
Not sure about Commands... I think they alias Entities? If yes, it will be UB.
Yeah, makes sense... Not sure what to suggest to make it efficient.
Wait, the access is read-only. Yes, I can expose Commands too.
I opened an issue here: https://github.com/simgine/bevy_replicon/issues/635

GitHub
It would be useful to have a way to check if 'any replication messages were received', so that I can skip rollback checks if no replication messages were received this frame. Maybe ClientMe...
What is the easiest to check if a component is registered for replication ? Is there any public method in the Registry?
Get ReplicationRules resource, it derefs into a slice of ReplicationRule.
Each rule has components: Vec<ComponentRule>. Each component rule contains id: ComponentId.
Collect these component IDs into a HashSet to dedup. It's because we can have a rule for Transform and (Transform, Player), so the ID of Transform will appear twice.
But I think you don't need all of them for rollback, right?
Because In rewind you register what to rollback (and I think it's the same Lightyear), so only these components are affected?
Yes but i want to know which of the rolled back components are replicated, as there might be different behaviour for components that are rolled back but not networked. Thanks
If you'll have suggestions how we can make the API nicer for you - let us know.
For bevy_rewind it's simpler because they rollback the whole world without checks. If you have many entities or they interact with each other, there is a big chance that rollback is needed.
So they optimize by removing the checks. At least that's my understanding 🙂
Hello, is there an example and instructions on how to run it for a client host (aka listen server) setup locally ?
I looked at the getting started guide but it seems more about adding it from scratch, but maybe I just missed it
All examples in the repo work in listen server mode.
The quick start guide explains how to use it, it's backed in the crate.
Thanks I had missed the README inside example_backend, I think it was because of the "unconventional" structure, is there a reason it's not just an examples folder ? Anyways it works great !

Replicon just doesn't have any I/O, that's why I had to put them into the backend folder.
I don't understand why that would prevent having an examples folder, examples can pull special dependencies if needed, but I don't know much about crate structure and such.
Btw what would you recommend for adding my firestore signalling based webrtc transport for replicon since making a connection is not quite as straightforward as just opening a tcp one.
Would it make sense for it to be it's own backend or use another (like aeronet) for proxy
Backends depend on Replicon, so this would create a circular dependency.
But I mentioned where to look for examples in the "Getting started" section.
Can't say for sure without looking at your transport 🤔
Maybe check other backends to see whether their API fits yours. If it does and you like the backend itself, creating a transport plugin should be simpler. Plus you will get other transports from the backend "for free".
But creating a backend for replicon is also quite simple.
Thanks, Ideally I would build my transport over matchbox since it is built for webrtc so it would save me some trouble. Right now I managed to make a working matchbox example that uses firestore for signalling, but in truth all of these networking layers (replicon, replicon_matchbox, matchbox, bevy_matchbox) are making it very confusing for me to know where my implementation would exist and how I would wire it all together to use in my actual game.
If I were to go the "replicon backend from scratch" route, how would I know what needs to be implemented for replicon to work correctly ?
Do I just have to just go off the existing implementation or is there some more comprehensive list or way to thing about it ?
Nice to see!
About crates, it's actually quite simple:
backendis pure networking crate that doesn't depend on Bevy. Some backends, such asaeronetskips this layer for better ECS integration.bevy_backendcrate integratesbackendwith bevy. Usually it just allows you to send bytes via resources.bevy_replicon_backendcrate integratesbevy_backendas an I/O layer intobevy_replicon.
To put it in more familiar terms: bevy_replicon is like serde. It's just pure replication (serialization) and you can plug any I/O (formats) that can sometimes function on its own (usable without serde).
Yes, there is a documented list of what backends need to do: https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/backend/index.html
The linked types include more details about each step. And there are 2 reference implementations: the example backend and the renet integration.
API for messaging backends.
Do you have an idea of how I could keep a mapping from RepliconTick to Tick?
On the transport side, I know the Tick of the remote when they sent a packet. But i'm not sure how to use that to keep a mapping from RepliconTick to Tick, since the messages are just inserted on ClientMessage so I lose the Tick information before the message gets parsed inside Replicon.
This might be needed in client->server replication, since the client's Tick might get modified (even go backwards) to keep the timeline in sync with the server timeline.
@spring raptor PR that changed the world flush requirement?
The Replicated component is the same on the send and receiver side?
Would it be possible to split it in to a send-side component and a receive-side component? (for example Replicate and Replicated)
Are you talking about Bevy tick or yours?
Bevy's think Tick is different for each system. And since the replication is split into multiple system, there are no specific mapping from RepliconTick to Tick 🤔
If it's about your GitHub comment, I answered there 🙂
about mine
Aren't you incrementing RepliconTick manually? If so, you can create a mapping there. Another option is to create a mapping in a system after sending replication.
Or is there some kind of way to react to a newly replicated entity so that I can insert some receiver-specific components when the replicated entity is spawned?
I was just about to answer 🙂
Yes you can create an observer for Replicated and check the state. If it's ClientState::Connected, you're on the client. There are plans for filtered observers, but right now you'll need to do a manual check.
I'm also fine with splitting. But maybe instead of having different components on client and server, we can just add special component for entities received on the client?
For example, Remote. So Replicated will be on both and Remote will be only the client. This simplifies logic, such as state serialization. I.e. I can have the same code that serialized game state for both client and server due to Replicated component, but can have special behavior for the client if needed (like the one you suggested).
Sure that works for me! It's just nice to be able to distinguish between Sender/Receiver
Could you open an issue?
Also is this a blocker for you? It should actually be a simple change in the client.rs - just add additional component alongside Replicated.
I guess i'll wait until things are refactored from Client/Server to Send/Receive; if that's something you're still open to?
It's not a blocker, just things I notice while porting to replicon.
I just know that in a lot of my examples I use filters like With<Replicated> to filter out received entities (for example on shared systems between client/server)
Of course!
I'm currently just waiting for 0.18 to release and right after that I'll start implementing all your suggestions.
But the client->server replication may take some time... It's quite a huge change even with the proposed simplifications (like avoid client spawning for now to avoid touching entity mappings). And I'm also working on my game.
I remember you mentioned that you want to try to tackle client->server? Or is it fine to wait?
Hello, I finally got replicon to work with my firestore + matchbox backend on native, but I can't test it on wasm since the bevy_cli doesn't support this mix of args bevy run --example tic_tac_toe web -- server (basically the web and extra server arg don't mix), did anyone encounter something similar and have a solution ?
You better ask in #web to get the answer faster 🙂
They are working out a patch in the bevy_cli thread I think, thought that someone might've encountered in similar replicon usage
I think @thorn forum uses replicon in browser 🤔
But the question is not replicon-specific
hey sorry im not using bevy cli to run my game in browser, only use it to build then import the package in my web app @lilac mantle
thanks still 👍
hello ! im migrating from bevy 0.16 and replicon 0.34 to 0.17 and replicon 0.37.1.
im using renet2, and to re connect player to a running game i was re using NetworktId, it was working great.
now, the client reconnects correctly with renet2 like before, but it's "invisible" to replicon:
on reconnection, a entity is spawned with NetworkId and ConnectedClient but AuthorizedClient is never added back, and manually inserting it doesn't work either, so no events or replication are sent to the client.
thanks :)
AuthorizedClient usually added after authorization. What authorization method do you use?
default's. it's working on first connection, and it was working on 0.34. thanks
Hm... Could run your client and server with logging (RUST_LOG=bevy_replicon=debug cargo run ...)?
there's 4 paragraph.
- server startup, two client connect, game start normally.
- one client manually disconnect (using
renetclient.disconnect()), tries automatically reconnecting, its connecting, its NetworkId entity exists, but replicon doesn't acknowledge it from what i understand. - i entirely quit the client that isn't reconnecting, and launching it again, it works.
- tried again 2., manually disconnecting and auto reconnecting, same as 2.
by "auto reconnecting" its just a system on client disconnect that get a new renet2 ServerConnectToken and re connect the client.
tested with a 1s delay on auto reconnecting, doesn't work. i dont understand why connecting from a fresh client works but not re connection.
looking at the log it seems the client is not sending the ProtocolHash event when connecting ?
thanks for any tips, or things to test :)
tried with AuthMethod::None, Authorized gets added alongside other components, but it ends up at the same place when i added authorized manually on reconnection, events are not send.
the main event send on reconnection is ManualSync, as we can see in the 3. paragraph in the logs.
Maybe it's because you re-use your original client resource? 🤔
Can you try entirely removing it?
Also this log is for the entire app. I'd suggest to limit it to bevy_replicon: RUST_LOG=bevy_replicon=debug <- yes, that's the value of the variable.
It would be interesting to see the client log.
I suspect that renet2 don't handle reconnects properly 🤔
omg its reconnecting after waiting 1min !
sorry for the logs level i thought adding more context from my app would help.
ive tried removing RenetClient resource on disconnect, and im inserting a new one anyway on each creation, same problem.
it seems renet2 doesn't disconnect the client when they disconnect, but with a 1 min delay (timeout?) ! and then it handle the new connection. so its a renet2 problem ?
edit: closing my bevy client window instantly disconnect the client server side, but using renetclient.disconnect() doesn't, even when removing renetclient and netcodeclienttransport resources.
when i connect a client i send a payload, user_data for unsecure, token for secure auth. how do i access this payload from the server if i'm using replicon? i can't figure it out. none of the examples use it. they just use unsecure and None.
hey ! https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/struct.RepliconSharedPlugin.html#structfield.auth_method there's a example here, i think its what you want ?
I see. I thought there would be a way to hook into the handshake process, possibly to validate and/or reject a connection attempt before it actually connects. Seems here we are already connected because we are sending events?
yes, bevy replicon build upon a transport layer like renet/aeronet. they handle the socket connection, underlying communication etc. bevy replicon use a already created channel/connection between the client and server.
i think disconnecting client in bevy replicon is ok for most use case, but if you really need to reject connection in a earlier stage of connection, you need to do it with your transport layer.
i know renet2 has some auth with tokens that i am using, other transport layer probably also have some way of doing that.
yeah im just confused how i would do that since replicon is already consuming all socket input data on the server
Interesting! Yes, based on the server logs, the server never receives the disconnect message from the client and later disconnects because of the timeout.
I suspect it's a problem with renet2 iteself (not even the backend integration layer) 🤔 Could you try to reproduce this problem with their examples?
If you want to intercept the backend handshake process, you need to look at what your backend provides for it.
Replicon's auth operates at a much higher level: it allows you to connect and exchange special messages before marking the client as authorized (which then allows it to receive replication and send all kinds of events/messages).
the server wasn't removing the disconnected client because i removing the RenetClient/NetcodeClientTransport resources in the same frame, and so the disconnect wasn't sent.
i tried waiting 500ms before removing then, 500ms before trying to connect again, and it doesn't work again, ill try to do a reproduction
Let me know if you need any help
I think we had already talked about this but I forgot; removing Replicated currently sends a 'despawn', right?
Would it be possible to change this to "removing Replicated pauses any replication messages"?
That way:
- if you want to despawn and send a message: just despawn the entity
- if you want to despawn without sending a message: remove Replicated, then despawn the entity
- if you want to not despawn locally, but despawn on the remote: this is what removing
Replicatedcurrently does, I guess we would have to find an equivalent?
Or what was the solution for despawning without sending a message
Yes and yes 🙂
I opened https://github.com/simgine/bevy_replicon/issues/629 for it.
I'll implement it after 0.18 release.

GitHub
Right now, removing Replicated on the server removes the entity on the client. It's not the most convenient behavior. I suggest the following: Removing Replicated should just pause replication ...
thanks :)
update, im still working on a reproduction with an llm, its struggling lol.
on another branch, another llm is migrating from renet2 to aeronet. just got it working now, and instant reconnect is working with aeronet ! so its renet2, or renet2 integration with replicon.
will update again when i get a reproduction.
For once I don't need help, just wanted to say thanks since I got my "serverless" firestore webrtc lobby backend to work as a replicon backend. I'll do a few tests (mostly latency, stability and edge cases) and probably make a crate out of it if it turns out okay.

Awesome!
If you make a crate, feel free to submit it to the Replicon's README.md 🙂
hey, im switching to aeronet anyway i think, but i fixed my problem with renet2.
just needed to remove the resources before adding them back. when i tried it previously, it was done at the wrong moments.
commands.remove_resource::<RenetClient>();
commands.remove_resource::<NetcodeClientTransport>();
commands.insert_resource(renet_client);
commands.insert_resource(transport_client);
in bevy_replicon_renet2/src/client/plugin.rs, the system responsible for starting the connection transition is gated by the resource_added filter:
set_connecting.run_if(resource_added::<RenetClient>), which doesn't run if the resource is overwritten.
maybe just better documentation on the bevy_replicon_renet2 examples can be added.
thanks for the help debugging
Ah, yeah, this makes sense.
With resources your can't detect replacements right now.
Resources as entities will land in 0.19 which should solve the problem.
hey i was using SendRate::Periodic(TICKRATE * 2), to replicate update for a specific component only every 2 seconds, how to do that now ? PriorityMap is per entity, not per component from what i understand ?
This didn't work properly. First, if you lose the update, we didn't resend on the next update. And since the tracking logic was per-entity, it sometimes might be incorrectly considered as acked.
We currently have accumulation which does work as you expect, but it's per-entity.
After recent changes I can re-introduce it per-rule 🤔
(We now track changes per-component as we should've)
that would be useful thanks :) my use case is for the position component of troops, which is updated on both server and client so i dont have to repliate to save bandwidth, but just updating every few seconds to re sync the position if any desync happened.
i guess in the mean time i can manually sends the troops position via an event every few seconds
Yeah, I think it's a reasonable workaround.
Could you open an issue, so I won't forget?
Hello, is there a built-in way to get metrics (latency, etc...) or do I have to make my own implementation ?
There's a bunch in a resource
RepliconStats or something I don't actually remember
But you don't have to make your own you can find it
Correct, we have https://docs.rs/bevy_replicon/latest/bevy_replicon/shared/backend/struct.ClientStats.html
It's a component on the server for client entities and a resource on the client. It needs to be populated (optionally) by the backend.
Statistic for the current client when used as a resource, or for a connected client when used as a component on connected entities on the server.
By populated, you mean that I need to insert the component on the specific connection entities ?
No, it's already inserted. It's a required component for ConnectedClient
so what did you mean by need to be populated optionally ? is it on by default ?
You need to populate the values inside it.
You can take a look at bevy_replicon_renet
Ah I see, populated by the backend