#programming
1 messages · Page 527 of 1
Just did my first open source contribution 
Let's hope it gets merged
GitHub
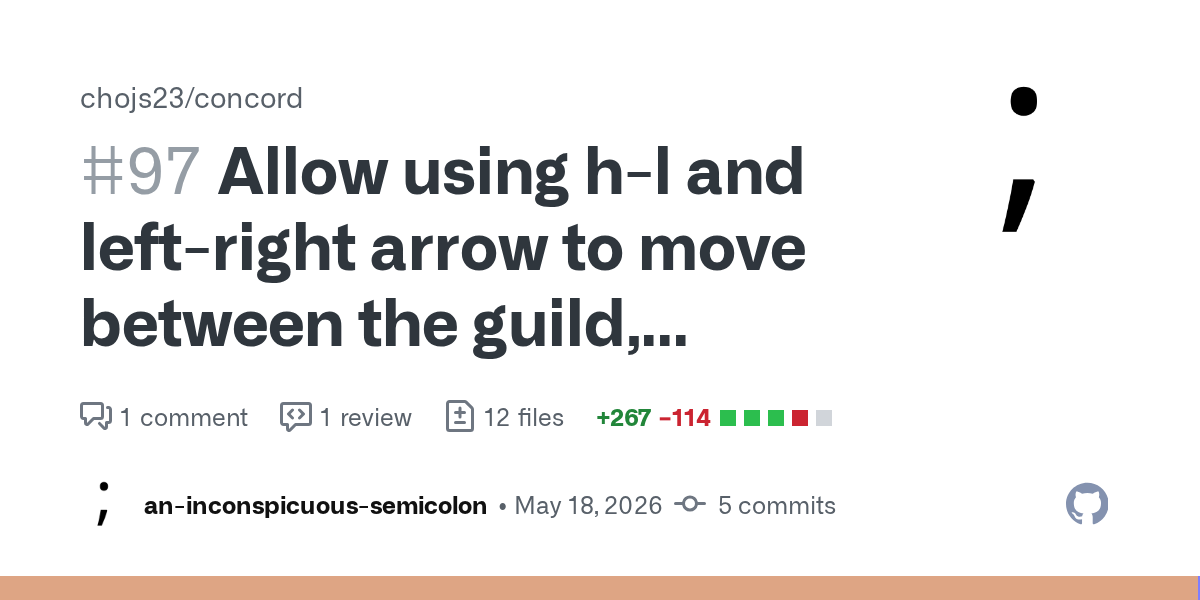
Summary
When l or right is pressed on a guild (not folder) it will activate the guild as usual, but it will also now focus the channels pane, ditto for channels but focusing the messages pane.
when...
Qwen 3.5+ ahh
ratatui pog
What the hell is that thing
Yeah but what is it
Also I don’t speak that
Basically an open source mini ESP32 based bobot designed to be customised
Effectively a moving IOT dev board with every port, sensor or extension you could want + a touchscreen display for about £35-50 depending on where you live
Has a big community that does all kinds of crazy shit with them

Here's a miko stack chan

That's always the hardest part to actually get your PRs merged lol
Currently only 22 out of 29 of my PRs got merged 
Quick question
In OBS, is it fine if you have two audio sources, those being desktop and microphone? Turns out that for some reason the screen capture one disappeared
It is fine but desktop audio capture will capture every sound your PC makes. Including when windows do those "ding" thingy
I don’t know how moe works. Are you able to sort of “graft” multiple llms together? Or do they have to be the same exact architecture?
Or is it completely different to what I’m thinking
replace the single feed forward network inside a transformer block with multiple + a router in front that sends each token through one or more and you have a moe model
each FFN people like to call "experts" since you end up with the situation where they store different information so during inference you only have to activate the parameters you actually need at any given time
I hate this fucking place and its dog shit power grid man, was typing a whole thing about moe that nobody cares about but still.
You can bolt them together btw kinda
Will explain in a sec
Yeah Moe aren't generally multiple models, the experts are just the FFN block, and the whole thing gets trained together from scratch as one model. attention, embeddings, layer norms are all shared only the FFN is duplicated and given the router gatekeeper, and the router learns which token goes where during that training. They are segregated along fuzzy lines and aren't as simple as "this one is good at physics" and "this is the python expert". The router actually sends tokens on a per token basis, and each token can be routed to different experts per layer so like one token might be processed by expert 3 on layer 2 but expert 6 on layer 10. It has a loss signal in training for load balancing to avoid any particular feedforward block being starved out
fcuk i hate this place
anyways the bolt together thing is called a clown car moe lmao
they have to be the same architecture generally the same model but you can take several finetunes of the same model and staple them together then weld a router on there
doesnt even need to be trained necessarily
some of them use just keywords and shit
I wonder if that’s a way Neuro could have gotten an intelligence upgrade without risking destroying her personality
At some point when asked “how much of the original Neuro is in modern neuro” he said “mostly”
Not very specific at all
it depends on what he means and he's being intentionally vague
technically
a huge amount of "Neuro" lives outside the weights
aka the scaffold
Yeah
whatever the system prompt is (if any), the lore/memory injected into context, RAG over past streams, the TTS voice, the Live2D rig, tool definitions, the filtering layer. you could swap the LLM wholesale and if the scaffold is identical she still reads as ~the same character. Vedal saying "mostly" could honestly just mean "the harness is unchanged  " meanwhile he swapped the entire LLM
" meanwhile he swapped the entire LLM
Well now most of that scaffold has been redone
the llm path for it i'd see as probably something like kl-regularization
a large amount of the heavy lifting to make it seem still neuro is likely the visible elements smoothing over the differences in personality as they come and he's quite careful with keeping new versions similar enough to be hand waved away, except when he explicitly announces an intelligence upgrade which is definitely his way of marketing "neuro is gonna be a bit different" because she likely changes base model during these.
He's used at least 5 base models at this point likely more, I think he said model 6 back in like 2024 lo
Oh
V4?
my assumption on that maps to - model x = base model itself, the overall raw llm itself without any changes
vX = major versions of the current neuro-tuned model, likely full finetunes (training all weights rather than a subset like a lora adapter although he might also just being doing loras) OR some sort of versioning representing the actual persona/training data that he uses changing in some large way
iteration X = catchall for any other changes, system prompt change, memory system change, loras being trained & applied or not, filters being changed etc etc
i kinda doubt she really has much of a system prompt at this point otherwise i just don't see how someone hasn't been able to get any of it to leak. Although this is part of the reason you and I aren't allowed to just chat with neuro in a chatbot type interface, makes attempting stuff like that much easier than it would be if you were trying to get her to notice some adversarial prompt in chat even if you're paying for TTS like you could back in the day
and im pretty sure he's also mentioned that it's not like she has a personality card type prompt, which makes sense as it would not result in the type of ingrained persona she has
if she has one it's likely just instructions on using her scaffold/harness tooling
The whole “im Neuro Sama, an ai vtuber on twitch” seems to be the only thing really
that's baked in
easily done too
training examples you can train that sort of thing in
Would that double the effort of having both Neuro and evil?
evil on occasion used to call herself neuro
holy shit why are people genuine idiots when it comes to electronics my friend bought a ryzen 7 7445hs rtx 2050 laptop for 700$ while i got a ryzen 5 8645hs rtx 2050 for 600$
both victus 15
they have diverged much more now tho
it's like a 15% perf difference barely
definitely one that i wouldn't eat and pay more for but
if it's genuinely a 7445
ryzen 7 7445hs is worse the base clock is arse compared to 8645hs
yes multicore but do i look like i care
They both seem to have the same mannerisms like saying “hug” when hugging someone in vr
20% approx actually
for 100$ more
like why
20% performance loss and 100$ more paid
it depends on the benchmark
but most people literally don't know the difference so it's really unsurprising
maybe they think you're goofy for paying $100 less and getting a cpu that uses more power thus has worse battery life
perspective
my laptop purchase was very spur of the moment too but i researched too
no they got scammed by the hp store mf
i mean it doesn't take a gigabrain to figure that 8645 is higher than 7445 and quickly check to make sure
buying from hp direct is automatically a rough choice on its own
and i mean i could argue that you got scammed considering i bought an 8745HS mini pc for $300
did it have a discrete gpu
nah, but a 2050 isnt worth $300
in fact, a 2050 is nearly the same performance as the radeon 780m in the 8745hs
and having a 2050 is just a power drain at that point
i wanted it for the cuda cores and 4gb vram to run gemma
the 780 having shared memory i can serve 30bs on it
Also i think he said the location thing happened to Neuro first
they likely have the same base mix of training data with divergences for personality differences
true, 100$ more and i could have gotten a 3050.... but i had a really ridiculously low budget set by my father so i made do with what options i had without having to buy dogshit like an acer nitro
Huh
like their overall mix of finetuning data to take them from "base model" to "neuro/evil" is probably quite similar
with differences purposefully introduced to make the result different
and more kl regularization to each to keep them aligned with their intended target persona
So she was just hallucinating her name being told to her here?

i wouldn't take anything they say as a real indicator of what their setup is other than like failed toolcalls exposing those
Oh
but it's possible she has some sort of grounding in the setup somewhere that reminds that she is in fact neuro-sama if she looks at it
you'll often have new models come out in stealth with a codename and people will go and ask it what it is
and itll say some shit like "I'm gemini blah blah blaH"
and it's not gemini at all
She does sometimes forget that she’s Neuro during dev streams so maybe that’s a thing
Like she talks in 3rd person
I was referring to this maybe being a thing
name comes up a lot in chat
if she truly has any chat data in her set of training data at any point, it's full of third person "neuro" references it learns from, not as strong of a symbol as the main one telling her that the assistant role should be referring to itself as neuro tho
symbol
signal
I can’t imagine how many cases of that are in the training data in general. It probably doesn’t help the whole hallucination thing when there’s a million people talking about their own memories in first person in the training data

data prep fucking sucks
vedal by all appearances is quite good at curation though given how consistent he's kept them over the years
How often do llms hallucinate when copying text?
for an ethereal green turtle shaped fog like he is IRL, his overall moat i'd say is a very strong intuition for extracting the persona he wants from his models through various means
and autism tier repetition
in context? barely ever
the longer the text being copied the more likely it is
transformers are extremely reliable at this as long as it's within the span attention is looking at
theyre terrible at recalling the exact text from "memory" though
go ask a small model to recite the declaration of independence
they will change it all over the place
I 100% agree with this statement the main thing that makes neuro and evil feel normal enough is the crazy amounts of fine tuning and detail put into the prompts given to their llms

yeah i mean a 1T+ param chatgpt will finger it out probably
That chat gpt you’re talking to is NOT a small model by the way
Horrendous typo
intentional too, if you could believe that
the other day i was testing one of the smol gemmas (e4b) on my phone since it can run it on the tensor tpu finally
easy test of how much of an output token budget theyre specified is to just "recite the bill of rights" or similar
it got the general gist of it but the actual text was completely wrong
substitutions everywhere
the meaning was the same but not the actual tokens
which makes sense as in the end a model is basically the compressed angry ghost of its training data
Their ability to copy text (from context) is interesting to me as it actually learned the thing properly and doesn’t just have a bunch of memorized answers
memorization is possible and in fact probable if the example is in the data enough, models can and do regurgitate training data verbatim
depends on how often it's in the data, as well as the capacity of the network
a 4b model cant afford to store the full text of much in unchanged form, it stores more of a representation of the general vibe of it as a smaller set of weights
I wonder how much full text a human can memorize
a 1 trilly boi has a fuckload of free weight to throw around so it can keep stuff like lower frequency but still frequent texts stored nearly perfectly
and it's not really "stored" as much as the function that is the llm is fine-grained enough to have the entire surface of the sought output mapped, it has the extra capacity that there can be a real identifiable spike in the weights that is zeroed in on one next token, the actual one
every output token for everything an llm ever says is a probability distribution of possible next tokens and training points it at the correct ones through repetition in seeing it in the data
for a smol model, that might show up like: it nails "We hold these truths to be self-evident", a phrase is everywhere in the training data, easy spike. and then immediately starts smearing. "that all men are created equal" survives. then it hits the list and "endowed by their Creator with certain unalienable Rights" becomes "given by God certain basic rights" same meaning, completely different tokens. "Life, Liberty and the pursuit of Happiness" might come back as "life, liberty, and the pursuit of justice" etc
Is it actually a probability distribution or is it just treated like one? Does this question even mean anything?
It seems like the probability part is optional
The model outputs a probability for every token in the token space and you can either take the most likely or do some T distribution yeah
the sampling of it is, you can do deterministic outputs
temp 0
it will always output the same thing because it always selects the single most likely output in that mode
temp 0

temp 1.6 (random)

How does temperature not completely screw up the output sometimes?
it does
O
that's why very low temp is used for coding models
theyll sub in some total bullshit while coding otherwise (more than they already do by being bad)]
sufficient temp (with supporting other hyperparams) makes the output nearly rng
luckily even if a small amout of the output gets fucked up from being selected improperly, attention mechanism is considering the entire sequence including those, so it doesnt go entirely off the rails
Are llms ever given the ability to replace the words in the output text (not in context) when they notice a mistake?
Before their turn is over
well ive seen some models be like:
calculate this, oh wait wrong, let me redo it..z
but they dont replace words in the output
they usua|ly correct themselves immediately if smth is wrong
they can and do depending on if theyre trained for it, and how the output is being produced. sometimes when streaming an output you're seeing something being produced by a very small speculative decoder model which the main model may or may not accept or completely redo, sometimes they will simply say "wait, that's wrong, it's this" etc, there's a few more that ill say in a sec
Seahorse emoji 
likee i think
ive seen deepseek and kimi do that 
a bunch of times
usually when doing bulk calculations


a model can never edit a token it already emitted. autoregressive generation is append only. once a token's out, it's frozen and it becomes part of the context for everything after. there is no backspace.
so for that part, it's never going to be able to
tru
wtv it generates is permanent
generally you as the end user can't see the speculative decoding bit i mentioned above btw
i am used to seeing it because im watching the model generate on the server end most of the time
but those are not the model correcting itself, it's more like it is given a proposal by its smaller, dumber and less experienced assistant and says "no let's say this" instead
qwen schizoing in the CoT 
Wonder if you could train it to catch its own mistakes by waiting for it to make a mistake then writing what it should do and training it to say that. Can’t imagine how long it would take to make the data.
that's essentially what theyre trained to do when in thinking mode
CoT = chain of thought
the nice thing about getting that data
is that you dont have to really specifically make them u
up
you just
give it problems with a verifiable answer and let it generate thousands of thought processes working through them
and then just keep the ones it gets it right
throw out the rest
the ones that include "oh wait that isnt right, it's X" are overselected for because of that
I heard that can sometimes make it start talking in gibberish when thinking?
Or was that something else
couple things
the CoT itself and the ultimate answer it produces aren't necessarily linked perfectly
the optimizatrion is for the answer at the end being right
since it's not manual, sometimes that means reasoning like a fucking idiot the whole time and then somehow getting the right answer
often with stuff like qwen or deepseek, models that see a huge amount of multiple languages in training, they will flip to chinese in their CoT even if the conversation is in english
this has been mitigated somewhat by adding a penalty for gibberish in the CoT
just a whoopsie of optimization
the other one is just
Goodmorning 
decoding collapses
happens to many models if theyre deep fried a bit on very long sequences
more likely to happen with thinking because generally thinking inflates the context to comical levels compared to straight instruct non thinking outputs
morning samuel
as you output more tokens
attention is considering them all
if you stack errors in the output
the overall error rate increases
repeat x1200309421804532
I’m wondering if some of that gibberish might be the llm giving non language “meaning” to tokens
partly yes, but not the way you might be picturing
the model has no persistent private channel. every step it gets back is the literal token. it can't attach a hidden payload to "banana" and recover that payload next step; all it sees next step is the token "banana" embedded the same way it always is. there's no scratch memory riding alongside the token stream. so a stable invented codebook can't really form when there's nowhere to keep the codebook. there's also no training reward for this behavior generally
however
the model
lives in high-dimensional activations, and that representation is already not language at all. the tokens are a lossy bottleneck the model is forced to squeeze through every step because we need to be able to comprehend the output instead of just a bunch of vectors
all the meaning is non-linguistic as a rule. when CoT degrades, you're watching the model pick token sequences that aren't optimized to mean anything to a reader, only to land the activation state somewhere useful for the next step.
a token or phrase can get used as a control marker rather than for its dictionary meaning. punctuation, a repeated word, a filler phrase that's really just "keep going" or "branch here." it's not a secret meaning, it's the word getting hollowed out and used for its effect on attention rather than its content to you as the observer
I really wonder how far you can push that If you don’t care about the CoT being readable
there is a big subset of research on this
neuralese / latent-reasoning
arXiv.org
Large language models (LLMs) are typically constrained to reason in the language space, where they express the reasoning process through a chain-of-thought (CoT) to solve complex problems. However, the language space may not always be optimal for reasoning. Most word tokens primarily ensure textual coherence and are not essential for reasoning, ...
everything the model "knows" is really a latent representation of meaning within the model
that's why theyre so fucking good at translations
they dont care what language they output
that happens at the last layer
I really wonder how Neuro in Minecraft comes to the conclusion that she needs to put all of her stuff in a chest then hit vedal’s bed with a stick 
well, that's a combo of neuro being fucking hilarious and trained to be so
and her model not being in direct control of her character
She said that out loud
I don’t think i have a screenshot
yeah if it was preplanned then it's just her being funny as shit
How do you even train that? It’s not a normal conversation
And there’s not really a quantifiable objective
they can come up with dumb ass yet hilarious stuff on the fly quite well, especially when the goal isnt accuracy
Neuro's training mix is built to produce her character, which by all means is full of comedic timing, absurdity, chaotic yet confident delivery of anything she says, etc. following that "put my stuff in a chest, then hit the bed with a stick" isn't a separately trained skill but can be what falls out of a model whose whole weight distribution is shaped to be a random goofball. the comedy is a property of the persona, which was what she was trained to be
It’s interesting that she can apply that persona to unique scenarios like that.
Like refusing to use anything but the ellipse tool when drawing
it's a wonderful property of llms, they arent always unfunny idiots if theyre not trained to be some hyper sycophantic assistant
this is fresh on my mind because i posted it elsewhere earlier but i maintain this to be my favourite thing echo has ever said (in response to  which is an emote from my server) :
which is an emote from my server) :

there was no breaking bad in his training data, at least from me
I got this from ChatGPT when showing it ascii art of the thing on the right


how many amogus crewmates must be in that poor mf's dataset (with giant  most likely)
most likely)
think about what an llm "sees" when you feed it ascii art and it becomes amazing that they can produce arbitrary ascii art at all:
a human you see
( o.o )
> ^```model sees
/\, _/, \, \n, (, o, .o, ), \n, >, ^, <
It sees the spaces to doesn’t it?
yeah that's why i included them
they also "see" images this way btw
vision encoder slices an input image into a bunch of patches usually like 16x16
and those get turned into a vector and then feedds them to the model in a sequence
this is why people talk about wishing to remove tokenization in general, in the end it's basically a lossy compression of meaning that causes the model to be worse than it would otherwise be able to be. the question is just what do you replace it with then? it has to be represented in some way still obviously, but the idea is to reduce the amount of arbitrary divisions in the inputs that confuse things, so generally the answer is something like "byte level" or "character level"
this issue is why llms cannot into 9.11 vs 9.9
without great pain
and why they cant count the Rs in strawberry
the reason they are not byte level or character level is generally computational complexity/cost
Is there really any actual “position” in the input or is that something the llm learns from the data?
position is encoded yeah
attention itself doesnt care about position nor have any concept of order, on its face. if you were to take a sequence and compute attention score for it, it would be identical regardless of the order of the sequence
so it gets added
to the embeddings in various ways
originally, that was with a position vector bolted on to each embedding that basically would signal "this is token #69" or w/e
nowadays it's generally what's called a rotary embedding
which is not really an absolute position like that, but it's actually a small offset applied to the embedding that rotates the query/key proportional to its position so the model can see an offset relative between two tokens
RoPE
the model generally learns what to do with that offset during training
I understood like one of those words
From that perspective it’s not surprising that it can figure out ascii art
hello programming people
yeah, just another "point it at it till if groks that shit" thing basically
no 
i was just thinking havent seen you around that much :S

earlier when talking to konii anyways
It’s kinda like how you can give someone glasses that flips their vision upside down and your brain just figures it out
life stuff
and when i look here its mostly llm discussions which i dont care about 
yeh basically, except our brains can do it a lot more easily because we can actually learn without going through a whole training run rwith 8 gazillion examples
whatever do you mean

oh

relatable
my tz not to be comprehended by mere mortalss 
h-how does that 9 minute drift appear though
It’s 1:30 in the morning and I’m now looking up stuff about the optic nerve lol
on the bright side, hopefully electrochu has a much more robust understanding of the basics of llm stuff than before
almost 1 for me as well but i work tomorrow which means im not sleeping
paradoxically

It’s been a year I think since I said I should stop procrastinating and just start messing with llms and I still haven’t
damn you really posted her raw ass like that
why does it fade lmao
budget cuts
simulation of my consciousness fading as i pass on
no time like the present
the photons return to sender
damn cheap ass
I’ve been a bit more motivated recently so who knows
That might change when I get my wisdom teeth pulled



someone ate the international fiberoptic line
i always wanted to get my hands on a cut piece of one of those
so i can say i own part of the internet
Does your own computer count as part of the internet?
I guess if you host a website

every time i think of the magnitude of resources that go into the dumb shit i do every day
i lose a bit of sanity
ii'd say that the internet fundamentally includes client systems
i think that then i remember some of the sites and groups out there
and i suddenly feel better
they aren't load bearing infra but they are part of it
wheres that one loved internet infrastructure image
for us at home likely we dont have a globally routable ip address
at our desktop
it's behind a NAT
so technically

the modem? would be part of it but not anything behind it
the most loved image in this channel
innacurate
light in typical fiber optic material goes ~2/3 the speed of light. Similar speed as electrical signals in copper.
thats the latest one i have i think
it was worth it trust

people just stack onto it
with new stuff
there are a few with ASML at the bottom holding it up
yeah i mean yours going down to electricity and lower is even more accurate than that

usually the i don't is one of the other 2 for me tbh
except when it isn't it's VERY visible
i think its playing on the outage stuff
yeah
it's fine, it's only like
i dunno
1/5th of all traffic
that's fine
we're fine
check on a different device
related

This is crazy


it's missing the random pixel noise
deepfry it
funny its positive for me

<t:-8640000000000>
yeah i get that one on my pc
thanks javascript hard limit
do we know why discord's max image area is 90,250,000 ≤ x < 90,250,002 in absolute number of pixels
likely just a bound they decided for performance reasons
yeah that one seems arbitrary
the reason for the 2 at the end is likely for rounding bs that can happen
can also be jpeg blocks
compressed image containers can have margins
as to why the overflow ends up - or + depending on device, i guess just the js engine or method used for rendering on w/e client, idk what android uses but on android it's negative so it's porbably toISOstring
and then i guess my pc is doing something like Intl format
so it poops out 271822 bc
ig why bother
input sanitation would honestly be my first thought for a lot of things
just given the history of bs that happens with javascript and electron
yeah, i guess the date limit is well handled enough to not worry about it
as long as it doesnt crash shit or cause downstream issues
i cant really picture how it would unless something else relies on a rendered timestamp and does it really badly somehow
It used to happen to msg timestamps sometimes
And it would crash ur client when u looked at it
U would have to go into ur discord settings and reset ur timezone
(No server side validation for some reason at the time lmao)

3D print a replica as a prank
I should do this on my pc to add the radiation effects lol
But it’s 2 in the morning
I read something about input sanitization with discord, what did I miss
EYO NERDS!!!!!!!!
Has anyone successfully implemented a "put the neuro in the pragmata-diana"-mod?
I knew it. I knew there'd be a genius who can do this. I am eternally happy.
you could search the #1336777692070023271
 what is my poor laptop doing
what is my poor laptop doing
linux cannot power off
like it goes through all the steps
screen turns off
laptop stays on
Maybe accidentally sleeping or u set power button to hibernate?
im pressing shutdown 
Have u tried shutdown command as well

battery out
i thought he meant he's pressing shutdown like the power button isnt working
but rereading maybe she means shutdown in gui
in which case yea hold power button
physical power button held for like 15 seconds should shut'er down unless that's disabled at like uefi
pluu


A Wayland Compositor in Minecraft.
This is a project I've been working on since about last year. This fully featured Wayland compositor works entirely integrated within a Fabric mod for Minecraft Java 26.1.2
The repository can be found on Github under EVV1E/waylandcraft.
yeah but I don't wanna have my shutdown button as a secret "haha you actually have just sent your laptop to the shadow realm, sorry :3"
hell yeah
testing fixes is such a pain lol
the text rendering looks horrible, but all in all this is hilarious
or you could just make a 3d fps compositor
 not minecraft
not minecraft
vibecode it even 
1:37 "rabbithole.webp"
i know what kind of person this is 
osmu
if only osu! was written in java
then you could
write a custom gamemode that launches minecraft




it looks like theres no way to run clr in jvm
but you can run jvm in clr using ikvm
scrolling compositor but instead of scrolling in x or y it scrolls in z

 with depth effects like fog
with depth effects like fog
doesn't that just resize the window? or you mean orthographic?
android 5 app switcher
create monitors in-game using maps
compositor with fog of war
it has to be isometric
might as well open another one

isometric is orthographic but from the side
XR compositor but it's on a 2d screen

(zooming around cursor, so it does allow to move)

almost
lmao that would be funny
why task bar not in perspective
scrolling compositor but the windows are in a multidimensional space and you have more than 2 degrees of freedom to move around in
many keybindings
oh ye fun fact hollow knight isnt orthographic
scrolling compositor but its actually not scrolling or compositor
🦊🔀🐇 
doomscrolling compositor
scrolling compositor except it has twitter UI
yt shorts
mobile scrolling compositor
composior but the active app is randomly selected when you alt+tab
vertical aspect ratio
gamba
mobile usually uses tiling  scrolling could be useful maybe
scrolling could be useful maybe
kuu
if your window doesnt actually need full screen you could just request a small strip
 still usability nightmare
still usability nightmare
widgets have scroll features built in. but instead of only widgets i want to put full app in there
deprecation wall of text

my nix config could really use some maintenance
same
Chara
✅
hii
hello
INB4 "What they took from us" video with sad music
It's so over
Gemini 3.5 flash

9$/M tokens
Actually over
Slop flash
Capitalism
wasn't the point of flash that its fast and cheap?
cheaper
And this is coming from google. Famous for actually making custom inference HW
Imagine how much the other companies are burning money 
makes me curious how much they'll raise the price of 3.5 pro


If the bubble crash, at least I want scama to be affected as well
rust
betrayed me

it not allow specialization
and it has no function_name in std::panic::Location (alt to std::source_location)
some gifs won't load in the gif selector thingy
i wonder if i got blacklisted on some gif sites 
nvm it's all tenor and some work some don't
def discord problems
like the ones i starred more than a week ago load, anything less than a week ago don't just remain a blurple placeholder
hi

meow..

meow
mrffff

stop 😭
void* chocolate = chips();
cookies.
AbstractChipFactoryProviderFactory


how to unlock secret #baking subscription
why arent you banana?
i'm a traitor



that no banana dog 

hello hello
sdmi is atomic

I don't think multiple instruction are atomic
what if one instruction fail but others succeed
Then NotAtomic™
Wrong channel 

@hard delta now - return to banana
i never left

WE HAVE IRL SERVER BUILDING
TIME TO ROAST VEDAL FOR TORQUING THE THREADRIPPER THE WRONG WAY

Hello guys
You have unlocked new role
Does anyone know what Vedal uses for TTS voiceovers or how he makes it sound realistic?
 Today I found out, Nginx only refreshes its HTTPS certificates when it starts
Today I found out, Nginx only refreshes its HTTPS certificates when it starts
That's a feature iirc
HAProxy explicitly states that even that a cert is only loaded once at startup
So nginx may have the same docs somewhere
That is the defintion of HolyC sir not C
honestly makes sense
unless u want people to get served different things

not sure how others do it but nginx has been used forever without issue
For renewal you should also trigger a server reload
i think a bit of a concern would be someone receiving an invalid one late
latency and all
 Server reload? What does that have to do with certificate renewal?
Server reload? What does that have to do with certificate renewal?
So nginx re fetch the cert

You said it is an issue for certificate renewal
Well, make sure the renewal triggers server reload
As in, nginx reload, not the machine
How do you renew your certificate anyway?
Certbot
people setup hooks for certbot usually
Directly? Surely not right 
if u use nginx proxy manager there is good reason for it
(force ssl can break if the renewal fails because it can sometimes block the ACME challenge)
I use acme.sh usually because it provides other convenient method to auto renew and executing extra script in the process
otherwise just use a deploy hook
Also, I use dns verification since it is easier
[renwalparams]
OK so the llm luau runtime gets maybe 7 to 9 tokens per second with 12B of randomly initialised weights
Last time I checked I can't speak at 9 tokens per second so its enough for my use but for the fun of it (I've got many months until its gotta be done) I'm gonna remake the entire runtime in rust
So this is gonna be fun
RVC probably
not too sure tho

Samurai!!

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.

kinda unexpected
Broke the chat interface again, but They actually seemed to notice...
https://www.youtube.com/watch?v=lJ2qc6ggipo it's a shame nobody told Max that Copilot dropped out.
Mr. Opensource my beloved
Now time to make this hyprland only project not hyprland only [tbf it shouldn't be too hard, because I just have to add alternative method for some things] surelly.
we will soon see ig
finally
how the hell do you make something hyprland only?
 by using hyperland specific libraries
by using hyperland specific libraries
why would you do that?
because...
Hyprland IPC probably 
3.5 Flash 
surely the new antigravity is going to be more reliable 
Yooooo
they replaced nano banana with Omni?
that's crazy
Bro be working on mithos
pretty heavy endorsement for anthropic

$1.5/$9


ok I wanna take another crack at the integration
well, google finally got a separate app for agents now

Wtf 1400t/s gemini 3.5 on tpuv8i
oh lord

surely the rate limits wont tank with this
@sick owl are you watching this
chat
what if google is not evil
they just kickstarted all of this to give you better search results

they harvested infinite advertisement money for a decade or two so they could afford blooming the IT industry by leading by example
so there would be competition
so they'd be forced to improve fast
so they could provide EVEN BETTER search results
3.5 flash doesn't have the preview suffix, something must be wrong
either themselves, or through others
it's all a giant data collection scheme
the corporations will know everything about you eventually
including on how to manipulate you into buying products
remember, nothing is ever done just for the sake of it. there's always potential of profit
eventually?
why manipulate me into buying products
when they can just manipulate me into giving them political or military power :200iq:
they know a lot of things already, not everything, but a lot
they know everything they need to
but wouldn't you love a personal AI assistant gaslighting you into buying a new GPU because it analyzed that the market is about to crash? 😊
i'd love that actually
because i'm not stupid enough to fall for it
but others are
they will tank previous-gen prices cause there will be all these used cards for sale
used 4090 2027™
WHAT IS THIS GENERATION SPEED
did it just write 800 lines of code in 10 seconds
or rather 5
that was 600 tokens in a second
btw when do these start going by that new memory model
million commits in nixpkgs now
prices will crash sooner or later, unless there is some efficient way to run AI, everything runs at a loss currently
whose loss tho 
like you could always just print more venture capital at the cost of inflating everyone else's money and keep throwing it at the bubble, and then blame me personally
well def all the AI companies, i would rather wait a few years until gpu prices go back to normal than any kind of used gpu rn
🤔 yeah i didnt think that way
ye nah lmoa
Laughing my off ass?
Even google is already using specialized hardware still struggle
laughing my outrage away

Seems like a healthy way to cope

Reported incorrectly since the day it was written.
And a new kernel vuln as well

I have more fun abusing it 
you got a loicense fer tomfoolery?
If you stay on the white hat side you don't need any license.
Just labs and contracts 

gif
DirtyDecrypt PoC got released
Another vuln for privesc
Erm
Nah, was making dinner and figured I'd check after
Spill the tea
Wtf is Andrew File System

linux LPE in rds kernel module
QRT: v12sec
99e5c2d00d247298f4710546c62f827252840de5f25fbfc0e67e7e05b323bdc1 -
Bnuuy obviously
abstain 
How do I get a slot machine on my terminal background
guf
konii will win by a landslide as the next government contacted agentic ai solution



3.5 flash
better than 3.1 pro at insane speeds
3.5 pro coming in a month
spark - separate system for gemini agents
agents and 3.5 flash in google search
antigravity 2.0
antigravity in google search
gemini omni - basically a new model for generating slop all-in-one, starting with video and the 'omni flash' model
and more
So many exploits...
d
buh, please stop the spam

Looking at the stats 3.5 flash defo isn't better than 3.1 pro, it is a damn good model for the price though
Gemini omni is cool
Antigrav could be great but they really need to not suck at coding this go around for it to be worthwhile
better depending on what

im sad theres no scientific benchmarks here
but i suppose if it's reasoning is worse, so then the GPQA Diamond and others would tank too
well, the consumer part is over

Falls short on most of the common signifiers

Analysis of Google's Gemini 3.5 Flash and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window & more.
+7% on HLE over last flash is good tho

Oh yeah, its just not "better than 3.1 pro"
Probs better than 3 pro in real world use though
smh corpo scammed again
agentic tasks and visual are an exception



i meann isnt that why its on antigravity
we love those bait graphs


It's not bait
They just included 3.1 flash lite as comparison
Which is their own llm
Which is fair
fair, but doing so they extended the graph to the 30's and made it look like 3.5 flash is on the same level as opus and 3.1 pro
which is obviously not true
it's not that they lied
but they wrapped it up to look too good
i get the whole marketing part, but damn
I love how Neuro complains when her tools break or are acting strange. I would love if ChatGPT would randomly crash out when something breaks lol
@sick owl okay I have to give 3.5 flash credit
it solved my second version of the encoding benchmark - something 3.0 pro failed and I didn't test 3.1 on it apparently (smh)
more than that, there was actually a mistake I made in the encoding the actual message, it solved the cipher easily
something that no other model did for me before, in just 7k tokens and 35 seconds
I remember torturing testing grok on it, and it spent like 15 minutes with no good result on it 
Now test 3.1 pro
I reckon it'll solve it
38 seconds already passed

i'll give it one more try to continue where it left off


i'll run it once more on 3.5 in a new window just to make sure
solved in 56 seconds
oof, maybe it really is that much better at agentic tasks
I think I'd still rely on 3.1 Pro for knowledge/general reasoning tasks though
perhaps
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
WHAT



I'd love to know these "easier ways"
vedals server is only 128GB 
ddr5 ecc so it makes sense its expensive i guess
tbf if it works it works, espedcially in this economy 💀
I am just waiting at how much neuro memory leak would consume it
he fixed that in rewrite
from what im aware
he said he did
ye
Inb4 moving to threadripper is different enough to cause yet another leak
ehh
its typescript
so not really
also is seperated into vms using something like proxmox from wat he said he was gonna do
I love compiling large asf libaries my pc be struggling to do anything else
It may be jover

I am 13 gib into swap
and all of my mem is being eat
if ram prices wernt, what they were rn I would get another 16 gig kit and just get 32 gigs total
but they are not
vedal leaked his upcoming server specs
9975wx
but he also said 24 core 48 threads so might be 9965wx
man, if he don't do multi gpu imma deadass kill him
Even my server has 128GB ....... DDR3 ECC 
L
it is a 9965wx
i might have misheard
kinda mid core count so i assume the only reason he go with threadripper is saturating heck ton of pcie
yeah i got the 9975wx info from sam
smh sam
I can't believe you'd just lie like that 
i might forgive him if it's a single B100/H100
If he is with that chip and no multi gpu that will be dead ass stoopid
same
tbf
i wouldnt
if he do that
he committed another even worse crimes
I hope server build goes better then pc build did lol
just buy an hgx system or something, surely he has the money for it
fe
arm is shit
who said anything about arm

{kind=link}
{kind=link}
{kind=link}
he better not bend the RAM this time
isw
ye im indeed deaf, he said "9 9 6 5 W X"
SamVanSlop2000
ddr5 ecc does not like bend
not in THIS ECONOMY
he would have one very expensive paperweight
ddr4 also doesnt like to get bent lmao
Hallucinating answer circa 2026
ddr5 is even worse tho
esp if its proper server ram, cas last time it had heatsinks and shit. If he gets wat I expect it will just be bare pcb and chips
So
iirc obv
heatsinks isnt bad tho no?
not bad
it cools
I think threadripper would be different. They may have a RAM with heatsink
ehh
its all the same ram
Keywords being may because threadripper are still possibly be installed in a tower
can someone check for me rq
Unlike EPYC
I doubt as he said he has a rack
if you search in google specifically nvidia h100 price does the search result page break
 it uses normal RDIMM, same as Epyc, no?
it uses normal RDIMM, same as Epyc, no?
a lot of server ram has heatsinks
but a lot are also running bare because they're meant for memory dense config with 2dpc so low clock
uses rdimm ecc
a lot rdimm ecc can have heatsink
he can also install manually
the c sdk from cyberpunk looks easier to use, does anyone have any experience with it?
Ye
As if he will do that
My PC is not having a fun time rn
I don't think I've ever seen any, but ye, can just slap one on if really needed 
no way he will do that though
also not really necessary if he uses a proper case
mine have
though custom
I was more so speaking of shipping from factory usually without one
well discord has launched back on my pc
even tho everything else is dead
so we ball ig
shits still compiling
Guys the best password manager is github !
https://gizmodo.com/the-worst-leak-that-ive-witnessed-u-s-cybersecurity-agency-leaves-its-digital-keys-out-in-public-on-github-2000760330

Gizmodo
Passwords were stored as plain text in a public GitHub repository.
Nah thx i stay with bitwarden
nope, and the price is 23.694 for one and 198.177 for 8 + the server chassis thiny where all 8 slot in
Ehh it only dies for me when I try to do it on my pc rn
as I currently have -12 gigs avail
Do be aware that their new executive are coming from private equity
well fuck
Ig I am going to be running vaultwarden
[self hosted bitwarden for those unaware]
Better than PTO
Is that a problem?
I self hosted the official Server Back in the days but i had regular data loss due to Database corruptions after updates
Never again
Their recent snafu is removing "always free" due to "miscommunication" with the over eager marketing team
fe, I aint currently because my whole homelab is currently down for major matinence, but preety much I just have backups to a seperate vm
only way I would ever host it, fully replicated so I update the primariy ensure it dosent fuck, wait a week update the secondary
2 diff machines
in acluster
I just wished their recent mess will spark more development on Keepass or other open source password manager that also support passkey and ssh agent
fe
I use both of those features regularly from bitwarden. When ssh or signing commit and when logging in to a site using their extension
I would be more tempted to just wirte some shit for myself atp tbh, Just make it work well enough for myself and throw it on codeberg or github or both or sm shit. Then if sm1 wants to improve it go for it
thats my usual strat for shit tbh
I never really saw the point of keepass
I don't want to have my password db on my device
I want it to be safe away from my devices , properly backed up and always in sync with all devices.
cloud storage?
That's why I store mine on Google Drive and many other places
Storing it on gdrive lowk hurts me to sm degree but to each there own
Google
But it also needs to be properly secured and you need to do the sync on your own somehow
it's an encrypted file who cares
Eh, I can store it on github or anywhere public anyway and it wouldn't matter

^
Good luck cracking argon2id with additional file key
Even quantum computers can't crack regular block cipher
I'm already annoyed when i have to crack bcrypt
yet
Point is, trying the permutation that is possible to do the encryption for the file is too much
I may or may not even use hw encryption
Sure, invent the algorithm first, then the computer
Unlike shor's, there's no known method (beside grover) to more efficiently crack those cipher
that is what i heard him say yeah