#programming
1 messages · Page 523 of 1
 Yes but that costs more money
Yes but that costs more money
I don't have that kinda spare money for non-GPU things
It's basically 100€ with shipping
fair enough
Yes

i mean just cause u seemed interested in vr
Well I just saw you doing silliness in VRC and it seemed silly and interesting
yes


@☆♡《♥fox🦊ying•idol~★》♡☆ this u? 🪞



I like going big batch at reasonable speeds, right now it takes one day for a full model at 512 batch size
The more GPU power I have, the bigger and better I can go faster
are u pretraining the model from scratch?
I could cut training time around in half with a second 3090 by running in parallel like Wispers
This arch doesn't benefit from finetuning
hmm rip
 I should start my cybersec journey
I should start my cybersec journey
tired of playing games all day and having nothing to do
Either way I'd certainly appreaciate being able to reach higher or equal quality in less time








hook the pressure washer on it


This is a screenshot I think from the 400 car battery styropyro video

dont think this puts us on speaking terms
find the birth certificate or im not buying you food



I do wonder, is mitosis basically clone?
It does makes me wonder how do we manage the administrative process of lab specimen after mitosis

HeLa () is an immortalized cell line used in scientific research. It is the oldest human cell line and one of the most commonly used. HeLa cells are durable and prolific, allowing for extensive applications in scientific study. The line is derived from cervical cancer cells taken on February 8, 1951, from Henrietta Lacks, a 31-year-old African-A...
look into cell lines and how thhey manage those shit is wild
better hela

h
Ketchup curry? 
mushroom ketchurp
Still cursed
t
tpsbeat me to it
slash slash
n
e
u
curry ketchup 
I read that as ketchup carry and was confused
You wouldn't understand
Its genuinly good
europe is speaking
be careful everyone
sam europe has spoken 
stay frosty
Hela Gewürz Ketchup 
had to scroll almost to the bottom, you'll never guess what AX stands for



as far as i'm aware yeah

NOT real
i think he used to be a typescript nerd youtuber now everythiong is ai
vibecoding has become such a negative buzzword that people are calling themselves "REAL agentic engineers" instead
ai hero
what did enums do

 w ai
w ai

typescript enum NOT js enum


dsfksdfksf
i think i came up with a really cool idea, you know how harnesses pin editable stuff, e.g. a todo a model edits with tool calls? what if we do that but with mood/tone, can use that to prompt tts tone and change the model expression instead of semantic analysis and should reflect the intent of the model better
i don't think for example sarcasm is easily picked up by semantic analysis systems
depends on how obviously sarcastic it is. a transformer based system might be able to represent something similar, assuming there is enough context and it's something obvious like "I just love how easily this website made it to lose all my data." because people usually don't associate loving with losing things the transformer might actually end up representing in a way which implies sarcasm. but sarcasm is hard without verbal and/or visual cues.
yeah that's what i'm trying to address, what if the model just tells its intent in a way that doesn't require tuning it to do so? obviously increases latency since the model has to do a tool call once in a while to change its tone but it shouldn't be by that much if you're running the model locally. i'm gonna have to test this of course since i have a suspicion they're gonna be using the system wrong/not at all but i probably can fix this with a good enough prompt
i have my agent do a tool call to set the emote they want to do, reminding them if they haven't set it in a while.
yeah or that
i think it probably helps with keeping them "feeling" a consistent way. usually they're just "vibing" though.
@mouse is this true



You have 16gb, i can think of 150 different programs that could
list them

blender and ue are the first things that come to mind
Tab hoarder
Coukd also be an ai thingy or a mkdern game
Considering this is neurocord
Altho the cpu is too bad to run an llm tbh
Good code twitch good code

It doesn't stop me 

I don’t like how most distros preinstall the Nvidia OSS driver which for some people including me is completely broken, or make the choice of using the official Nvidia complicated as hell. It’s tarnished people’s belief that Linux can work with Nvidia to the point they think they need a special distro for it, you don’t need to reinstall your os. When I think of the steps you have to go through on Debian to install it I’d just say it’s impossible to do correctly due to how much they hate closed source
Nvidia linux is pretty easy no? It worked for me almost perfectly on all cards i tried on both OS i tried
I had to do quite a bunch to get my Nvidia Hybrid Setup correcly working on NixOS but now it works
Like look at steamos. Those are Arch based too
It’s the myriad of implementations that don’t work and are recommended to everyone
 can cause some compatibility issues but the install itself is easy
can cause some compatibility issues but the install itself is easy
pretty much every distro has either a package or an installer thing for it
isnt nvidia notoriously hard to go install on linux?
i meann i run fedora
Even gentoo?
i have to do akmods or smth
and i have to like
manually sign the keys
since i have secure boot
You just need to set the DRM thing to nvidia thingy in the boot params and rhen everything works completely fine
 no
no
maybe decades ago
It could also be due to the desktop environment as well… I’m just remembering that hyprland doesn’t work with Nvidia. But besides that just using the official driver & gnome has been fine
With better performance than windows on everything
i meann im a newgen in linux and all this tech stuff
so idk abt the past
all ik is that i switched to fedora 3 months ago
idk how it is on Fedora but pretty much every distro is forced to have decent NVIDIA support due to how common the cards are
Hyprland works perfectly fine with my sold 3090 and my 4090
ye but look on the program list, all of them seem normal
You're sorting by cpu usage, we cant see the one uding most ram
i shouldnt have let my model run 24/7
im using 100% zram
Last I remember it was suggested to use amd cards. That could have changed
Zram my beloved
Its still suggested, but nvidia works fine too now
I can see secure boot being an issue depending on how your system is configured
very much optional though 
true i guess, but if you look on the list you can clearly see which one is the problem
it cant get more obvious
that damn kswapd
you should kill it 
Idk what heroic is.
the most unoptimized program ever created
Is that the league launcher?
epic games+gog+ some other launchers
Epic games launcher, they didn’t want to put fortnight on steam so they made a launcher
its medal
if you look there's a bunch of 600mb instances
it has a terrible optimization which causes
terrible memory leak
Do you use live filesystem compression or something, open htop
idrk
might be bcz im running my agent model, brave browser, running a fedora kernel update, then an akmods for rebuilding nvidia and vbox, and also running feishu
that mightve overloaded the system
So it is AI
uh oh its happening again
I was joking when I send this

But its probably is the AI
usuallyy it doesnt jump this high
my ai inside a podman container on a separate account
I just think of what could be causing the OOM and do pkill thing
By building, did you mean compile?
tho it is running as a quadlet systemd service
I was thinking that training a 12B transformer on CPU would use all my 16GB of ram and set my CPU on fire
But I've done the math and using my backprop and forward pass optimisations it should use less than 3.5GB of memory (3GB for actual weights then maybe 500Mb for the CNN) and maybe 60 or 70 percent of my laptop CPU
So this seems quite promising
it mightt be bcz im using akmods on nvidia and vbox
Because compiling will make CPU go brrr too
since the kernel update js finished
tho like sometimes the system jumps to 99% CPU being used all the sudden
and the memory/RAM use spiking
then returns down to only 20% of CPU used
Plus however much ram I need for the KV cache, context window, and all that junk
What will you do if this guy(me) PR you 80000 LOC

rebuilding the modules
70 files changed
-10000 LOC
What I did for free was put my model on google drive; open google colab and clone my repo and train using their free Nvidia tesla gpus and when the account was out of hours I would push the result to Google drive and sign into colab with an alt and then pull it back for more training again and again and pull it back to my computer when done, also make sure you’re using the best optimizer like Muon instead of AdamW and there’s no software bottlenecks
Also I’ve done my own testing: GQA > MHA, decoder-only > encoder-decoder > encoder only
Was pretty much already known but I wanted to see if there were any cases where it wasn’t true, but no
Just use GQA decoder only bf16 Muon
That seems like a lot of effort when I just said I can train a 12B model on my laptop
And I'm gonna have to test different optimisers to find what works best with my architecture
seems like a lot of effort
It was faster

I’ve been working out the best transformer setup for a while
But it requires google of all things
Once you have a good architecture you’re confident in you can just pretrain it and re-use that same model for multiple different things
I have an archive of 90m 500m and 1b models I made myself
The top property is data quality, recently it’s a lot of post-training research to get it just right
Their.. alright
hi phrrrrr fox rectangle flag
hi afunyun
what transformer
?
architecture
Nope I have ethics
Custom :3
i doubt it would run even with heavy gradient checkpointing
12b is huge
bf16 12b is like 24gb
add the two momentums of adamw
and ur dead
and we didnt even consider activations
Might want to think about the evals to see if that’s really necessary
and flash attention doesnt exist on cpu in pytorch
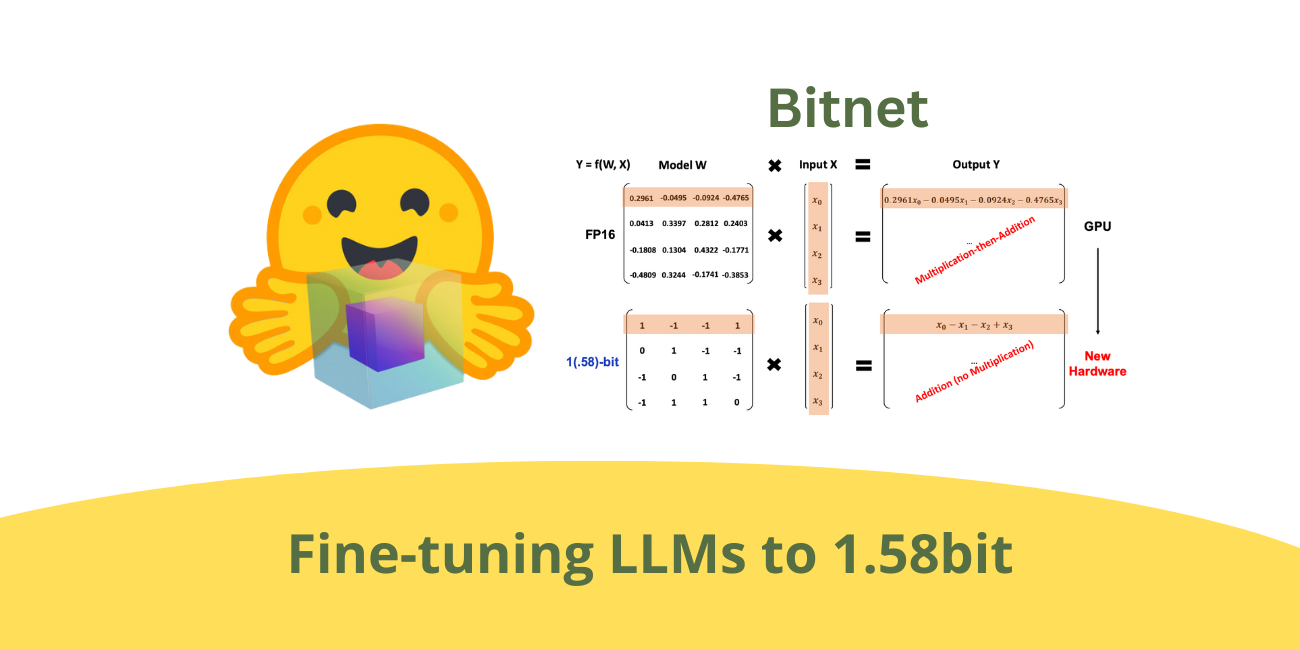
I'm using a mix of optimisations with one being 1.58 bit weights so it takes up just about 3GB for the entire model weights
And I'm making the model bigger because I can just afford the compute and it'll offset the loss of using 1.58bit weights and some of the other optimisations
pretraining in 1.58 bits seems like a very bad idea
A 1 bit model? That’s super cool
1.58 so Instead of 1 or 0 it is -1, 0, or +1 but the matrix multiply is still a lot cheaper since it only uses add, noop, or sub instead of multiply
fp4 training in the nvidia paper was already very unstable hence they had to do random hadamard rotations and keep the amax history and invent nvfp4, otherwise it would just NAN
Havnt gotten far enough to see but I'm using a custom method instead of backprop so it will work (in theory)
And you’re writing the transformer and training logic yourself? I would love to see it to learn from as reference, if that’s alright. I heard Microsoft was already working on something similar as a prototype
I don’t appreciate enough how my training is always stable, except when I was pushing a 100k model too hard and broke a bunch of stuff and it NAN’ed
more like cause we use a lot of stuff that is proven to work
switch the friggin activation function to something random and ur dead
I'm writing from scratch in luau using no ml libs or gpu accelerations but sadly a lot of my methods are custom and I don't want my methods to be public since I spent a lot of time working on them
Same here
does luau support simd intrinsics
My goal is I don’t think what I’m looking for is possible with existing tools like ollama, everything I’ve seen who’ve leaned on ollama to ‘make their own model’ get no where
I don't think so
So I write everything so that there can’t be any blockers
training is gonna take a very long while in that case
especially since the ops are quadratic with standard attn
and no simd
for a 12b model
That's why im using custom methods instead of backprop that is a lot cheaper
It would probably use a 64k tokenizer, which is even slower than my standard 8K
right but it would still have to traverse each single param
hi
For a hero run
You could probably record the loss, batches & hours and make a chart
To know how long it will take
bruh gonna train a 12b model on basic fp int units with no simd 💀

also if u wanna reach reasonable loss faster u should prob use a smaller transformer due to how scaling laws function


I have this image saved already lol
chinchilla my beloved
i got 2 flip flops available
wouldn't it converge a lot slower without backprop?
bruh lmao even at the absolute best 4 IPC apparently it would still take you 40K years to train with reasonable sized dataset
assuming 16 cores
Maybe trim out some irrelevant training sources if possible?
(assuming foward prop alone)
I'm not training the entire 12B at once
I'm training 500M first then once the loss stabilises I'm gonna freeze the first 500M, add 500M more, train it for 1 3rd the total time, unfreeze the original 500M 1 3rd the way through that run and train both together for 2 3rds of the total time
Then repeat multiple times over a few months until the model hits 12B
This combined with the many optimisations and replacements compared to a standard transformer will train the entire model in a few months on CPU
many optimisations and replacements compared to a standard transformer will train the entire model in a few months on CPU

It will be a tad slower but my replacement should converge
tad slower is an understatement usually
there's a reason why everyone uses backprop 
(for normal ANNs, that is)
because training each transformers layer would not only fuck up generalization a bit, it would still take you years, possibly hundreds, AND assuming foward prop alone.
So just expand the model as you go instead of starting at full size? I’ve experimented with that, don’t remember the exact sizes but after quadrupling the size it began training at 4 instead of 10. Not sure if it helps to start small or if is just convenient to start with the original size
Not to sure what size it will be since I haven't finalised the dataset yet
no i use KDE that should not be an issue
@bitter phoenix idk if it interests u but here google leaks gemma scaling laws https://arxiv.org/abs/2501.18914
arXiv.org
Scaling laws have emerged as important components of large language model (LLM) training as they can predict performance gains through scale, and provide guidance on important hyper-parameter choices that would otherwise be expensive. LLMs also rely on large, high-quality training datasets, like those sourced from (sometimes sensitive) user data...
page 6
i don't know why avoid backprop even, with batch feed and grad acc its like pretty much almost negligible compared to the forward pass

that + good luck optimizing without gradients
A few months is still a long time, I would prototype for a while before committing because it might turn into your own legacy model with one realization or improvement. I also bake my tokenizers into the model files
Ty
use SNN bro
Yep I'm just expanding the size by 500m each time and idk if it'll help but in theory it should work
<insert SNN mention copypasta>
your training steps will be faster but you will need 10x as many to converge, if it converges at all, so you end up spending way more compute
SNN 
what gets me more
is the fact that they wanted to train on cpu
bitnet works because it has gradients on the backwards pass, there's a latent full precision copy of every single weight which is actualy what is being optimized
with no simd
uuuh net 11 has MCP directly integrated on one side I like it but on the ohter side MCP is bloated
Hyprland works fine with NVIDIA
used to be an issue because NVIDIA insisted on EGLStream but that also just hasn't been the case for years now
Can't afford a good gpu in this economy so I'm optimising until what I have works
use kaggle tpu
are you sure that not using the simd unit on the cpu is "optimizing"
gonna be optimizing for a few decades 
gradient-estimate variance grows with parameter count so 12b is going to have like 0 signal
bare non-vector arithmetic units alone are slow as hell there's literally a reason AVX exist
another uii JS directly in MAUI
has anyone checked whether the add/sub only "matmul" in bitnet is even cheaper than using tensor cores
yes on gpu when packing it in tensor cores
with triton kernel
and AOT for android
I've not even gotten to the point of optimising the code and I assume the compilers either uses simd or I can mod the compiler to allow for simd intrinsics
is that a yes for it being cheaper

aint no way bro
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
I’ve made a 256k model with a loss of 4.9 just considering every way I can push it towards the right answers. There’s tons of things you can do with smaller models to reach decent results instead of going larger
This is an insult to my efforts, and my stuff doesn't even properly learn yet. But at least it is fast despite the operating logic being in python
 What be going on here?
What be going on here?
 Seems kinda entertaining
Seems kinda entertaining
also i still don't get the reason with avoiding backprop


I could use a 3B model or whatever but with my current code I can train a 12B model before my deadline is due
Who told you that?
I'm ignoring backprop because I have to, I can't say anyone else should at all do so
You'd be better off training on free tier Google Colab, at least it has a GPU
I would say there isn’t much reason to go farther than 3b if you aren’t coding or mastering multiple domains. Depends on what the inference is
not GPU optimized (real)
google and meta usually run ablations on 50-100m parameter models
on ~100B tokens
I get there isn't a point but I can do it so I don't see why not
I prototype on 90m
if your architecture is somehow incompatible with backprop or has a better way to train it then ye that's reasonable
that's just not the case for the average ANN
i dont think even hinton has gotten forward forward prop to work in anything transformer shaped at all let alone a 12b
If you’re confident
the reason is that you can't do it
sounds like a noob 
Highly entertaining
Yeah, I assume not a lot of people have the smarts to uphold the drain damaging takes 
Keep it up
If there is an issue causing it to take more time then ill still have a working model but it just won't hit that 12B goal in time
tribiall brain dablage

To this day I'm surprised the NN series has actually produced something that learns at all
is apparently
chat can i train 1t model on my athlon xp
surprisingly easy
True, the real battle is making it useful
train a 1 trillion parameter bigram model
1 trillion bigrams
✅
It's only gonna take 1 trillion years
auto differentiation one of the best things people have come up with 
i think
 Just keep all the weights on disk
Just keep all the weights on disk
llms currently
being so bloated
has distorted what a "large model" is
so badly that people think a 12b is a small network
✅
fr who remember 500m param vit/cnn being huge
Then you bypass the finite dram limit 
everyone was like holy shit
ye
GO BEYOND
Is a 100M parameter NeuroSynth big?
GPT-2 LLM
1b params in your mnist number recognition toy
117M params


Surely it's not that big
yes/no/maybe
my child
2
Is the baby coughing
@fast pagoda are you coughing

the answer is maybe

I bet on the baby
I'm betting on the baby
always bet on DaBaby
what if its an english exam







if anyone wants this as well you can submit here:
https://claude.com/form/cyber-use-case

technically
surely they will only give it to the good guys and there will be no issues with this system
 anthropic give me access to mythos...
anthropic give me access to mythos...

 i'll be honest i wouldn't be able to afford to run a single query on mythos anyway... all the claude models are so damn expensive
i'll be honest i wouldn't be able to afford to run a single query on mythos anyway... all the claude models are so damn expensive
well
is there anything that can stop them from making this thing stronger and stronger
they can just grow it more and more cant they
"mythos, destroy this country please"
openai now has gpt 5.5-cyber that is like mythos
 finding exploits. security stuff
finding exploits. security stuff
or is it like
it just becomes so strong it can do it without any specific tuning
and nobody knows how it does it
is idea of clashing glasswing vs mythos being worked on

can it potentially make them godlike while they fight
because they train in the process or something
or since they are llms it wont work
openai and anthropic haven't had any new stuff they developed in a long time
just stacking more islands?
any innovation in the AI space comes from Google or deepseek. and anthropic/openai just adapt the research into new models
they are currently more interested in turning a profit rather than developing new ideas
hmm
makes sense
so for google this thing is like a side job they are not feeding off it
if i got it right
google is the reason gpt exists they wrote the original paper on how to do it. but just didn't release a model
they have been doing AI for like 3 decades at this point
but anthropic/openai are focused on this thing and have no other income basically
google is easily the safest bet in the AI race
anthropic and openai are just the shiny things... but true AI will come from google
cool
if they ever decide to actually take it serious 
deepmind has been doing AI research for a long long time
it also helps that google has the whole thing under their belt. they do inference, models and the hardware to run the inference
they do the whole thing. so they are under no risk of external forces. like if nvidia goes down they take the whole AI bubble with them.. but google would be unnaffected
they have their own hardware?
is it like fully their own thing
ai focused
cant buy it on amazon and shit
secret google chips
pretty sure ye
damn
i mean.. even their open source models have gotten a lot better lately. gemma 4 is a beast overall
google is just not focusing rightnow on benchmaxxing so they look bad and might not be the best in agentic tasks... but they focus on things that people might use in their products.. like the AI search thingy, the video summary on youtube. and ondevice small ai's
Classic

if someone gave me $10k dollars and i had to bet it all on a company to win the AI race. i would put all the money in google tbh 
they might be lagging behind the best and greatest models... but they always catch up
i'd say they're winning in terms of real breakthroughs
what about deepseek
i dont consider llm benchmark scores any significant.
deepseek isn't self-sufficent. they rent gpu's thats the main reason i wouldn't... but yes they would be second to google
im talking about the deepmind team coming up with actually scientiically useful models like alphafold 2.
screw the llm part that's unimportant as hell
is alphafold that chemistry protein thing or what is it
i think i saw some youtube thumbnail about it
yeah probably
protein folding prediction
I had to read this 7 times to notice the difference
so it'd be good for designing drugs that work at a molecular level
idk man. google deepmind is the ONLY one making real academic contributions in the ML field.
it seems like it'd be pretty useful for medical research
the rest are cashgrabbing with llm shit and most they do is just modifying the architecture a bit
https://www.isomorphiclabs.com/ they spun this off into its own company a while back 

Isomorphic Labs is building a future where frontier AI can help to unlock deeper scientific insights, faster breakthroughs, and life-changing medicines.
“real” == unusable by the masses btw
Don’t let him fool you
SNN always stays closed and unpractical at scale
papers out there
if you can't implement the backend, skill issue honestly


He’s just cranky that his field has irrelevant for 4 years
Snn is science neural networks?
And Linux and communism and free hugs

stinky neuro network, it's what neuro uses, ask the green fog
very scientific
I am getting caveman vibes again 
bro
tensor networks bro
next gen shit
actually tensor network is fucking insane
tensor networks is based in quantum computing or osme shit
x is crazy. Shit is the future
doesn’t know what it is
Shadow is an ai bro now
u can represent bigger models with less params

via tensor networks
its fucking insane actually

literally
less params to backprop
and theres a fucking pytorch impl
Why is training speed an issue at all
GitHub
Tensor Network Learning with PyTorch. Contribute to rballester/tntorch development by creating an account on GitHub.
Do some neural networks take like super long to train
And its viable because can shrink 10 years training to 1 year for example
bro u can decompose a tensor into a graph
Or is it because every train is trial and error
And you can do 1000 attempts instead of 10 attempts for the same period of time
I am caveman please clarify 
Grokking
Why is there no 200b tensor llm that you can run on 16gb vram yet
Or is it wip
u can in theory
ucan convert all tensors
a company does this shit
You need x10 times less islands
Model as a service
Why nobody uses it
Multiverse Computing
We empower organizations to run secure, production-ready AI with tailored solutions — reducing compute costs and retaining full control across cloud, data centers and edge environments
Or is it new and wip and they are doing it rn
this is shit from 2024
but the idea of tensor networks exists since like forever
This justifies economy
and it rly works
ive ran like 100M param pretraining
with tensor network uses like 10M params
Do you need some quantum computer to run it
no
imagine having to iterate 30 billion weights times the highest context window, times the dataset length in tokens which is also in the billions to trillions of tokens
gpu is fine
No i mean
I get that its super good
And overpowered
I ask why for example
Openai wont use it rn
To make 10000000b model that fits into previously 1000b model size
if it works at scale and doesn't fuck up everything they're probably using it already
And save 90% of money on building islands
Imagine having to actually progress the field instead of gatekeeping and bragging with unverified claims
granted that's a big if
apparently super good
really old
has PyTorch impl
somehow nobody is using it

just gonna say that google had also a library
GitHub
A library for easy and efficient manipulation of tensor networks. - google/TensorNetwork
archived
Wait are you saying its bad
I didnt quite get it
I felt like what you said was like.. benefit for it
deepmind has alr schizoed into this shit
that's how much is going on with training llm. they had to optimize any caching related techniques on the attention heads just to make it viable
im just giving some examples for scale
So you saying that it works and everyone using it
Alright so
Quack is an SNNbro
He hates ai industry
Why my gemma4 26b takes 17gb vram then
But has agi internally but it’s just too dangerous to release
idk wtf is this dog on about lmao
So basically
Weaksauce hating
You know how OpenAI refused to release gpt 2 cause it was too dangerous
That’s where they are rn
They are gpt 2
you're talking about two completely separate things
They are still catching up
Kaine is yapping because they want to spread infomation, never said it good or informative tho
yeah im just giving scales on what's going on with pretraining a whole llm
maybe im leaving details like moe feed forward is much more compute efficient
idk, kaine is talking about something else
Not capability wise. SOTA SNN can barely spell. But I mean they are still in the phase where they all think they are savants who just created sentient machines and need to gatekeep it for the protection of the human race
and being somewhat obnoxious for absolutely no reason whatsoever
So quack is talking about different thing completely did i get it right
Not talking about tensor model shrinking
Or what
yes
yes
quack was talking about why training can take tens if not hundreds of million gpu hours
yeah
Then this tensor shit is mega overpowered? No?
there's a reason we laughed off of a guy who thought he could train a 12b 1.58bit model on a cpu
Quack would never be obnoxious about another persons interests, projects, or field of research 
within few months
supposedly
but somehow never deployed anywhere 
not widely known for LLMs at least
hard to tell, most optimisations end up being quite specific and not applicable to everything so it's easier to just not bother
despite existing for ages already
this tbh
i don't remember much about tensor networks to give an actual answer
Okay and then my gemma4 takes so much vram because gemma4 200b fitting in 4090 would be so strong i could exploit windows on it or some shit
no-brainer optimisations are obviously used everywhere
While mythos needs only 500gb vram while being 500000b model
it would still use a lot of vram for activations
god, im late for my fishing trip brb need to call an uber
activations dont get reduced
have fun quack
no, it only affects the parameters I think
only params are affected
shrinks the model itself, but not the space required for any computations with that model
Tensor networks +deepseek compressed sparse attention
That is absolutely not true
I want a source so I can ridicule it
Numbers are random
bro mythos is just a wider moe
HAHA RANDOM HAHA
But i already got answered
I mean i took these numbers out of my ass to pinpoint the scale of shrink
That’s why it’s a fraud
@mighty thorn u keep saying moe is shit but gemini and chatgpt and shit are all moe
They would be better if the hardware used for them was used for not MoE
that's just poor copium
So is this basically correct
not economical at scale
I still need 20gb for 26b model
But its trained much faster
Trying to understand
moe is good for what it's made for, which is allowing you to cram far more knowledge into the model for relatively cheap
MoE is awesome for big models
no need to pretend it's worthless
You either die dense or live long enough to see yourself become sparse
faster and easier to deploy 
Moe is just mega fast inference
moe is for expert paralleism on interconnected systems and shit
Which is good
MoE is worthless for LLMs in most contexts, but very useful in the contexts where it’s actually intelligent to use
???????????????????
but it's used in all sota contexts currently t
bro moe makes llm infinitely cheaper to train
doesnt seem particularly useless
u just need more vram
but compute is the same
activations dont grow
u can use higher context length
- MoE is worthless for LLMs in most contexts, but very useful in the contexts where it’s actually intelligent to use
I tried moe vs non moe and all i noticed was x5 faster inference
what is .... most contexts?
most contexts
bro all sota llms are moe
Because cheaper for improving benchmark scores versus actually making better models
❓
- Because cheaper for improving benchmark scores versus actually making better models
bro
u gotta be fr
anything except tiny local models where you need as much density as possible because you have little VRAM
everywhere else MoEs win I think
in the enterprise space where they basically have endless hbm memory, moe is highly beneficial
But moe doesnt shrink required vram
less compute being used
dense llms is just poor people copium
which is why i said endless memory
also
moe is basically
It explodes it while having almost all of it being idle and unused
the weakness of moe isnt a problem at sufficient active parameter counts
Something like Qwen3 30B-A3B knows things like a 30B model but is limited by the width of the active slice in any given forward pass
scale this to frontier size and the active parameters are in the tens to hundreds of billions again and it scales incredibly well when total params end up in the trillions
Least efficient possible idea
Huh
and even locally MoEs are pretty good
it's dumb anyway so might as well make it fast
yeah
basically
17gb for 3b parameter while the rest do nothing 😭
I understand that it assignes some "experts" that make it use only relatable params instead of all params evrry tjme
you got a model that inferenced just tiny part of itself but knows as much as the total params
though the drawback is that its somewhat dumber, but when you have like hundreds of billions params scale and work with enterprise scale inferencing does it even matter
"nothing" is a misunderstanding of moe
wrong when serving to many people u can get in fact higher utilization
due to expert load balancing
It only takes 3 but it selects it carefully
Whats the point of calculating impact of tokens that say 2+2=4 if it needs to write a poem
Its not a bad idea
ah great, he has never done batch inference before
Assuming that they aren’t trying to use the same experts
Which they will be
Since only 3 are generalists while all the others are overfitted to Turkish history
did bro fail statistics class

crazy
they arent bro
this is why you have load balancing in MoEs
bro router z loss
load balancing loss
also when you get multiple people using the same experts
that's not bad either
you batch the damn matrix
Multiple users hitting the same weights is the thing you want it's the entire economic basis of batched serving. Weights are readonly reads don't contend
exactly
you can batch serve a dense model all on the same weights
ye but then theres a ton of duplication
since u would be doing DDP
or TP if model too big
Does anyone here use both nixos and jetbrains ides?
LLMs have been on the wrong track since GPT-o1
Now everything is MoE CoT benchmaxxed distilled int8 marketingslop
well
linux 
throughput can get fugged for bad routing with one hot expert doing all or if the tokens all scatter like crazy that can be an issue but especially the single expert getting smashed is an issue of iimbalance
god im still waiting for sleep deprivation to hit me im sleepy as hell i need the sudden surge of energy
I'm pulling my hair out trying to get flakes working with them, cause everytime I try using rust rover etc, it complains that it can't find the rust install because rustup isn't available (even though it is installed) and it fails to run it because it's a dynamic exe
Qwen kinda is that
all the big LLM benchmarks are close enough that I do not care

the benchmarks don't tell shit anymore i prefer to measure models based on how enjoyable it is to converse with + how reliable it is with doing tasks a user requested
It will find rustc, but not the standard library
bro they can do more shit than earlier
earlier llms were unusable
actual braindead shit
Yes, I can compile rust apps outside of the ide just fine, it's the ide itself that shits the bed when it tries anything
ye basically that
they're still useful to know very roughly where an LLM is in terms of performance but you also usually don't need benchmarks for that 
yea i mean the indicator is like a black and white line
it's either in step with peers vaguely on useful tasks or it's total dogshit
that's about the max judgement to be had there
I was having 4o do python and was fine with it
Then they forced CoT on us
Then MoE
And now we are here

5T frontier model with 400k active parameters
Mixtral 
mixtral was fucking god tier at that time
47b params for gpt4 perf
would beat the fuck out of llama 2 70b
god
i archived the fuck out of mixtral as my "if the world ends" model to have lmao
at the time
you just reminded me
Yeah
I have a few of those
i had llms locally cause huggingface was down constantly
back in those days
in a fucking gitlab lfs
i just tried and rust-rover seems to find my toolchain just fine
so idk what to tell you other than use rust-overlay I guess
Stranded on island with solar powered laptop and 8b local llm, the creation of the ultimate schizo
 OpenClaw, get me off this island
OpenClaw, get me off this island
[toolchain]
channel = "nightly-2026-04-03"
components = ["rust-src", "rustc-dev", "rust-analyzer", "clippy"]
rust-toolchain = pkgs.rust-bin.fromRustupToolchainFile ./rust-toolchain.toml;
Make no mistakes
bro just
fuck the laptop
get 2x gb10
similar watts
run deepseek v4
moe
poor people cope
See how laptop like the price is
Mods ban this guy for discrimination
just get a job bro
i was earning slave wages
for 4 years
Suspiciously works 20 hours a week shaped
Shadow should do the thing where the rich person gets rid of all of their assets and qualifications and tries to rebuild from scratch to prove it’s easy.
He’d last a few hours before breaking down upon having to go to chick fil a instead of eating 50lb of caviar every meal
bro
ive had
cold dms from random sillicon valley cofounders shit
on fucking discord
i didnt even need to show my cv lmao
just show technical competence
me when i doxx
Shadow spent 40x that on a watch

Its basically luck
Time can counter luck
Effort too of course
Cant do shit without it
me, age 20

"luck" 
I discovered what programming is at 25 what do you want 💀
Yes luck

GitHub
Summary by CodeRabbit
New Features
Added serial and parallel caster modes, Motor6D transform movement with pooling, and client-side serial/parallel FPS benchmarks.
Bug Fixes
Fixed high-fidel...
This says a lot about society

The richer Australian with multiple a100 and a collection of exotic GPU and cpu defends the less rich guy
0.1% and 1% coming together to gaslight the poors 😭
215 commits now
It’s gonna be a long form defense of his $4000 watch
Which is worth more than everything I own combined
I mean if you have 10k per month income why not
Literally my current job but in US gives exactly that
12 days for a watch 😭
Yeah
which one is which
How many A100 do you have?
But due to low luck im not in US so i get 1.2k
Yes luck x2

Did you apply to google at 15
Ye
Child labor is the answer to poverty, ladies and gentlemen
Did you speak english at 15
i don't think a combined spend of like 12k-15k on tools that are used in your line of work + less than 5k hobby shit constitutes rich
rich is a whole different ball game than anything described
Is it legal? To let 15 y/o working in big tech? Like in your country
My country can't(laws, school system)
Ur also rich but I let you slide cause no $4k watch
I could easily have passed c1 cambridge in middle school

What your country?
How do u think i got in
There was no human in my town who would pass C1
I am trying to explain that you got lucky to be there where you were
With your skills
Swiss
Do you have github, I wanna explore
the power of having different circumstances
No my gh is empty
Good education too
and putting in the effort to actually use those circumstances
spawn luck
No room for said effort without the prior luck
Can’t build skyscraper on dirt
Need foundation
Hesright
I wasn't supposed to speak English at all for example
I just randomly stumbled upon forsen stream and understood 10%
How each eduactions system in different countries even works, I mean how did someone at 15 able to get phd, do they just max stats and beat it to phd?
the ability to be active in this discord to the extent that the majority of people in this conversation are is already indicative of a similar type of luck if not the same extent
there are entire swathes of the world who have no inkling of the wonder we interact with every day
Idk about phd at 15
You need to be noticed
I dont have phd idk
What if there nobody to notice you
Will you aplly to google
"hello i can make calculator im 15"

Thank you Socrates
Very cool
Yeah i would have
you're welcome, i won't charge for that one since you're on the brink it seems
further will require an active credit card on file, however
I'm active on discord, cus I just wanna yap and share or talk, I wanna doom scrolling tiktok, discord, facebook

It’s a rare disease but not unheard of

And to stop doom scrolling, I'll shut down myself(sleep)


{kind=link}
{kind=link}
{kind=link}
Get out
I also fixed previously unknown bugs and got +100$ raise at my job
I guess i played my cards alright
Now company is dying and idk if i should flee the country or go to capital
If I was a hiring manager, I would like to take a look at github than CV or resume honestly
My managers dont know what github is
Or any profile that shows you have passion in the tech
If someone actually done something impressive, they should have it all, either github, your facebook, your X as portfoilo to show they're actually facts
Because how I can believe if someone came up to me and say, I've graudated from cambridge and got a job at google 15 years old, I mean it's not bad
But I would like to see github profile slams on my face or any official papers that you're actually done it
Its super rare but not impossible
I guess
Not like i ever witnessed anything like that myself
I'm sorry if my opinions hurt your feeling
(Also there are intreview rounds, coding problems screen share idk about that cus I've not experneiced it)
However i find it concerning that you have to work in google at 15 to afford that shit
In 5 years
I mean are u asking for proof or wym
No, I'm just sharing my opinions
Not everyone have proof
I've heard that job hiring are using Ai to review CV/Resumes, it is that bad?
 getting a job at Google that early is probably not impossible if you can show technical competence and find the right opportunity
getting a job at Google that early is probably not impossible if you can show technical competence and find the right opportunity
 I did have cool stuff on GitHub but Nintendo nuked the main project that I contributed to.
I did have cool stuff on GitHub but Nintendo nuked the main project that I contributed to.
not unbelievable at least
make a switch 2 emulator ✅