#programming
1 messages · Page 414 of 1
claude gets a block character guy to represent it

he had a birthday hat for the last month

cuz it was around the time the public beta first launched lol
the first computer programs i wrote basically drew an animation by drawing 4 or so frames of ascii art. i did a conveyor belt moving bottles that got filled and a lid put on (i swear it was obvious that's what it was. not just after I said what it was.)
probably inspired by a "how stuff is made" or something tv program.
and i just repeated all the objects so after they had moved 4 frames, it was the same
or the next process
telnet towel.blinkenlights.nl
they put a video game in a building, right?
with the room lights as the pixels
or was that someone else?
oh... i have seen that ages ago when i was at college
someone i knew said something about playing it next to the original... i don't remember if they were complaining that it didn't match up or saying that it did
/~\
|oo ) It's much too
_\=/_ rocky.
___ / _ \
/() \ //|/.\|\\
_|_____|_ || \_/ ||
| | === | | || |\ /| ||
|_| O |_| # \_ _/ #
|| O || | | |
||__*__|| | | |
|~ \___/ ~| []|[]
/=\ /=\ /=\ | | |
\_________________[_]_[_]_[_]________/_]_[_\______________________
verified it works.
lol and i thought my terminal was at the wrong resolution
seems like it has been replaced with a new ipv6 version
useless video trimmer failed to remove the first part so im sure it looks like some unrelated clip
me

this cant be the first thing i see opening this channel

happy birthday shiro claude
if i ever have kids im telling them this is the original version of star wars before they made a real movie

yeah. this is before all the "modern" CGI they added . computers used to be a little more limited in what they could render.

obviously it's all makeup and prosthetics. industrial light and magic were amazing.
they really could do a lot with a little, they cooked too hard and now people can see my facial expressions though
if only they did ASCII Jurrasic Park so you could assure them they "Spared no expense!"
they didnt have a UNIX SYSTEM or they would've been able to
just watched an "Everything Great About" for the original. it aged surprisingly well

bzzzzzzzzzzzzzt wrrrrrrrrrrrrrr
bzzzt
 there's a frame of something in there
there's a frame of something in there

frame of what
oh shit there is lmao
looks like a face
The image features the Moon from The Legend of Zelda: Majora's Mask.


today i learned you can right click on a video and say "Copy this frame"

"it's the same picture."
i guess because that's what makes the delay
it's 2 seconds long at 100 fps lmao
why
coz they put a 10ms delay coz they wanted it to blink quickly
but really, who can know the minds of someone who puts nicolas cage on anything?
you can. but it's easier not to.
as far as im aware the delay for each frame can be set
Mhm
15 days
heroic is what i wanted, thank god plasmasearch is forgiving

25 until what?
I think i saw it when i tinkered with easygif
🎂
oh, than 15 days)
3 to the power of 3 is 27. so 27th of the 3rd is more better.


otherwise it would've clearly had 5 stars already saved
or when you downloaded it if it's not actual file metadata but just disk metadata
that wouldnt change the format tho
it's even titled gif in the url

but this link downloads a .mp4
even tho file extension can be meaningless
it is h264 i dont think .gif supports that
so i was messing with the eza flags forgot i was in / at the time
and ran eza -lagR
was ssh'd to my minipc
and R runs recursive ofc
this action listed so much it was uploading like 15 mib

/s
fan went into turbo overdrive as well lmfao
silly
took 1min 7s to run 
benchmark against ls time inb4 i already aliased ls to eza on this (cant remember)
ls took 1 min 18s

sometimes i wonder why i dont get things done
if you have scamazon prime you apparently may have free civ 6 available to claim on luna

damn
how did I get one of chayleaf's yt videos recommended to me wtf
I think I've gotten NS stuff also recommended to me via algo before
I mean that's always been recommended to me (at least until recently, dk why it stopped) but I think I've seen some stray NS videos idk
idr tbh it was a while ago
Well we'll see if the next big upcoming NS release gets recommended to anyone
what's the next big upcoming NS release I haven't had the foggiest clue what it would be
We'll be releasing a surprise to showcase the NS JP capabilities (finally)
NS JP is actually incredible, even better than NS EN
Interesting 🤔
Having some real JP Nur data really helps

I kinda like to shorten Neuro sometimes
yeah fair
I guess I can answer my questions now:
- Yes
- No
my monitor is completely unusable now 
guessing JP is not Jurassic Park?
Japanese
mid answering a question the claude web interface decided "This isn't working right now. You can try again later." and won't let me see the previous reply
Can’t open this chat
It may have been deleted or you might not have permission to view it. Use the share button to share chats on Claude.
I can see it in the list on the left so it's obviously a transient problem.
self-modifying code is impossible to model without emulation.
i wonder if it knows (or can guess) when it's modifying itself
"update the step() function of the claude model to..."
except without being told that's what it's changing
or the web interface
or some other capability.
Ah,,
Claude will return soon
Claude is currently experiencing a temporary service disruption. We're working on it, please check back soon.
vibe infrastructure
"Solving this is taking longer than expected because... Claude isn't responding. We asked ChatGPT but it just laughed at us."
You expect them to even look at ChatGPT? They probably vibecoded an internal MCP server and connected <insert agentic AI tool here> to it and just didn't bother caring
they are the ones who made the MCP spec after all
not really. i don't expect it to go down either though.
no fucking way the warranty is still active until 2026-11-9
‼️
glad it broke early
no mention of overclocking... just you went to play a game and it stopped working and got worse over time. probably.
Don't call me out (I don't program)
I use Claude like a home assistant
 Help with planning my day, mateirals lists, and schizo ranting about politics
Help with planning my day, mateirals lists, and schizo ranting about politics
for me seems like cloude in the middle
i sanity check logic full with it, so idk
 I might have carpal tunnel from typing all day
I might have carpal tunnel from typing all dayand this, kids, is why you use a wrist rest
I also need an ergo keybaord cause I already have wrist issues
But no one makes a mechancial ergo keybaord

By that i mean a fancy one that lets me repalce the keycaps and switches
Wait nevermojd people do

There are some custom ones afaik
Yeah I am looking at them now, they are expensive as fuck though. 200-300 cad
Might be worth to prevent more wrist pain
Yeah custom keyboards are expensive always
You can easily reach 600-800
But if you're into ergo / orto keebs there are a bunch of good options
i'm looking into them now, I already have to use an ergo trackball mouse for my right hand because of wrist issues
According to a friend of mine that works in cybersecuirty trackballs are a safety feature?
Don't know how though
?

Don't fucking ask me
I gues sbecuase you can't move it by accident?
idk
But eitherwya I use a ergo trackball as is.
Never heard of that before as someone in cyber security lmao
security through obscurity 
good 
playing this on my laptop makes me wonder how tf did the PS4 handling these kinds of graphics lmaoooo

PS4s at the time where equal to a midspec PC but all built on an APU iirc
im surprised they managed to make something so powerful for so cheap...
They take intentional loses on hardware sold and make it up through game purchases through digital store fronts, subscriptions, and mtx. Cause if they didn't it would be launch PS3 prices whch didn't take a loss on hardware pricing. Which I think adjusted to inflation now launch PS3 is like 1300 bucks or something crazy.
Unfortunately too many do that in practice
Cause it was 699.99/599.99 when it claunceh in 2006
Jokes on you my laptop is probably 5 times as powerful as a PS4
I think my 2015 macbook pro is too.
laptops nowadays are more powerful than a PS4
I have a Core Ultra 9 275HX and RTX 5070 ti in my laptop
 Sick
Sick
With 96 gb ddr5 ram 
what shocked me the most is that my classmates still game on PS4s after 10+ years lmaooo
shit's built to last...
i just love watching the cores go vroom

i mean at least they last that long after all
i just wished laptops were made the same way...
to last as long as consoles...
some do
it's just that hardware advances very quickly nowadays
I can't wait tull i get my P920 
Gonna be a while since I am waiting for them to go down in price
specs?
is it playstation airlines with that thing
I was aiming for dual Xeon Gold 6154's, 64-128gb of ddr4 ecc, and slapping a RTX 3080 and P40 inside it.
not rly i think?, my classmates didnt complain too much about the fan noise...

i have an RTX 3080 that i only use for hashcat lmao
maybe i should let it do some work and run an LLM on it as well
This was going to be a multiple purpose gaming, server, and llm machine
The P40 was going to do most of my LLM stuff
Imagine playing dmc 5 on a PS4 lmaooo

i wanted to play around with OpenClaw with vllm. Wanted to deploy it via Nix instead of Docker but had no luck yet getting it to run lol
he's good for research
like getting a bunch of info about a topic (with sources) ig research mode in the web
im too scared to use openclaw
security seems wishful at best
the xeon chips themself are cheap asf but the board is  💸
💸
Its crazy that the boards are the price of awhol e-waste workstation
also the hdplex psu im getting accepts EPS (12-48v dynamic range) dc input and comes with 7.4*5mm to 8 pin EPS adapter
my lipo battery has xt90s output.....
i can't fucking find xt90s to 7.4x5mm there's only xt60 to 7.4x5mm... am i deadass going to do xt90s to xt60 to 7.4x5mm
what's your goal with the hardware btw?
hmm... do y'all think the PS6 would be backwards compatible with PS4 games?
cuz if it is... im switching to that from my laptop
i might be able to help out on an alternative 
i wasted money on one
like 2 days ago
it wasnt that much but it hurt for the age of it ig
but i got xeon platinum
2x 8259cl
xeon gold 6138 is like ryzen 7 5700 perf multicore damn wtf
it's definitely the boards that keep them cheap ig
i mean c620 boards had a huge range of pricing 2 but not much below 200 bucks and at that price it was a server board with like 0 connectivity
cheaper for you id assume but on ebay anyways
Server for me and my friends, workstationf or my work, gaming, and running a basic local llm for my work. Its gonna be an alrounder machine.
are you guys good with grammar, perhaps even pros at it
no


prehaps
♻️
i used to flame people over grammar on facebook

why would anyone admit to that
2009
Never talked in this chat, go tell whoever told me to post it
lmao


It's original because I made it
playing star wars battlefront II and getting into arguments with wine moms
Source: I lied to win

I feel so dumb for using the youtube app on android for so long.
Because my friefox literally gives me all the premium features on mobile with a couple extensions.
i have premium for free*
-# paid for it via buying the phone it came with
damn had to reply it instead of react it
Literally get YouTube revanced brochacho chip
Not even a blocked user btw
This guy might be a buddy
No clue what that is. I just do everything through my Firefox instead kf rhe android apps.

It's a very customizable YT client
Oh sick
Highly recommend over browser on phone
Use Revanced on Android and YouTube Plus on iOS
I'll check out revqnced
And for revanced there are malicious ones only build your own from the real website via their official app
i thought revanced got shut down at one point
i guess it was likely "shut down"
Continuing the legacy of Vanced.
hydra head
.app is too newfangled to not seem sus to me

GitHub
ReVanced YouTube APK Auto-Builds. Contribute to mentalblank/YouTube-Revanced development by creating an account on GitHub.
If someone wants a compiled ipa for YouTube Plus on iOS i have that as well 
Why not use Revanced Manager to build the APK directly on the phone?
Then you can also select all the features you want
ye, just use Revanced Manager from the official github
https://github.com/revanced/revanced-manager
-# or the revanced.app site, they're both legitimate
If you ever used anything else change your Google password asap lmao
Nah I never used anything else. I used the official app that came preloaded on my phone and Firefox browser. Thats it
i mean any of the fake revanced apps because that's most likely malware
yeah that's why it's a hard no from me on top of i imagine risking google banning me, losing my google account would be horribly inconvenient & why i don't recommend using it as lame as that sounds, worse if someone got access to it
there's morphe too from some core revanced contributors now cause open source drama 
you know how it goes
I use protonmail for everything. My Google account is a burner.
you can also self host your own email server via mailcow .e.g
if there's an email provider out there, I've fucking used it
but i also use protonmail primarily
there is also tutanota
those two are the best ones usually
I grinded 600 lines of code for a small Python project in school lul
the requirement is just a number guessing game

I was able to access my pc by connecting the HDMI cable to a capture card, and fullscreen preview with OBS on a laptop


Your poor laptop
shiroko bg and arona plush!!
my poor laptop
suffered from 6 OS reinstallations


btw, i was talking about laptop-pc, here is my laptop
(big cap and small banana for compare)

i wanna buy either a plana or arona plush but was too late 
why is your mousepad burnt
Just spent 3 hours of my life repairing the pneumatic brakes on my bike 
erm, it is releave*(who this spells idk)* instead of suffering
eh ah, erm... 

trackball!?
definitely not pictured it on purpose
Yes


I need to take a need image since I did update this setup.
But ita a Thinkpad P73 and 2015 MacBook Pro

i was trying to stick up new pedal for 1.5 hour tho..
Both now Kubuntu since I found what I like
Jesus christ
:O why do you have a 99% medical alcohol
just, sitting on your desk
battle-scarred


superiority of not having to maintain desk 
is that a 49° OLED
this shit is basically insane
idk how you manage to use this display
yes. and it's a tad to small, isn't it? maybe i'll buy the 57'' one if that bocems affordable
Cleaning and Gunpla. I build plamo while I listen to Neuro and Evil yap.






holy mega rich

it's just two 27" monitors without the bezels in the middle
is that from warhammer 40k or osmething?
when you have this + keybinds?

most of the times i have 3 windows open. left discord, right media (youtube, crunchyroll, reddit, whatever), center game
super+e = open terminal, super+q - first window, super+w - other
when using code, same but different. ( terminal, ide, documentation)
when i play i focus on game, why would i need other windows?
 all that but you only have 2 sticks of ram smh
all that but you only have 2 sticks of ram smh
Mobile Suit Gundam
40k for weebs

gundam isnt somehow?
water cooling and super thick gpu everything but 2 sticks of ram 
sth sth 2 sticks is optimal
it isnt even very useful for codding, i have 2 windows on work, and i cant say that it is better, i usually have discord/active browser/youtube there
and it isnt kinda 'i need it', i just have it why not use, but actual window im using is in front of me
it's 32Gb in Total, fine for most Stuff.
if i need more, i'll buy the same kit again and plonk it in.

i have 8gb and its fine (again, why you need such amount of ram lul, i never even hit 16gb without mem leaks from discord being open 24/7 2 month or clangd cache for idk, or running qt6 build from source in parallel while other programs already use 6gb)
(it is literally only cases i hit 16gb)
why stop at 4x?
get a threadripper and do 8x
that way you can sell of both your kidneys
why stop at 8x? get an epyc and do 16x

No what I meant is Gundam is 40k but for weebs

couldnt be enough actually
ah lmao
i havent watched/played either
Yeah. Sometimes i use extensive debugging and tracing tools, that where a 20 Minute Trace can reach >15gb. But rarely. For dev purposes i see however for a new work notebook 32gb as mandatory, since we also work with virtualization and stuff. That can eat RAM quickly.
20 min trace is already something extreme
Heavily Multithreaded event based application written by devs that are used to tasks and interrupts. Sometimes you need 20min to reproduce the sporadic error
like, i kind of already unable to use valgrind with our app, cuz it slow down so dramatically that it no longer have appropriate timings and it literally cant work without manual changes
idk, just use log man, lul
tho trace meant to be solving manually processing everything to log something...
The automaton fired off an SOS shortly before I lost contact with it around 0800
Thankfully I think he's gonna be alright I found the crash site on time, what a brave soldier tackling such a challenge alone

yes. and with QT, it's even more of a pain. We integrated, behind a global on/off toggle, https://github.com/wolfpld/tracy
It's a neat thing, easy to use, and has almost no perfomance impact. But it will definitly crash your computer if you have a full RAM / SWAP

GitHub
Frame profiler. Contribute to wolfpld/tracy development by creating an account on GitHub.
idk why python framework would use 32gb just for running project, that kinda crazy, tho, python....
wdym without qt? like you talking about qt object system making everything simple or what?
nan, meant using valgrind on a app that uses qt is a pain.
a real app though, not some hello world example
when i was really needed profiler, i used intel profiler
that was real performance question i couldnt answer with logging
whe have performance sensitive application, tho most of the work is gpu classification model inference, i just write code that not doing stupid things and acknowledge dimensions of img to perform better pre-pre processing, pre processing, visualization, etc (basically common sense stuff when you work with multi dimensions)
what do you think about adding profiler to project that actually may live perfectly fine without?
i have some free time before they implement next network i already have outer code for, but just not yet interface to attach
idk, just ignore indirects from qt
like, i really used to since i using only qt
Its alright. Some series are much better than others but I am a suckered for the model kits because its 20 bucks and I have a couple months worth of painting and modding fun.

Maybe that's an Option, havent explored it though. And won't, since i called in sick for a month last week due to burnout.
Not Gunpla specifically but here my last miniature model kit i fully completed.


I wanna stream my model kits building at some point
Damn right
@sick owl i, uh, what the fuck-
the new qwen 4B model is actually cracked 
https://fixupx.com/Alibaba_Qwen/status/2028460046510965160?s=20
🚀 Introducing the Qwen 3.5 Small Model Series
︀︀Qwen3.5-0.8B · Qwen3.5-2B · Qwen3.5-4B · Qwen3.5-9B
︀︀
︀︀✨ More intelligence, less compute.
︀︀These small models are built on the same Qwen3.5 foundation — native multimodal, improved architecture, scaled RL:
︀︀• 0.8B / 2B → tiny, fast, great for edge device
︀︀• 4B → a surprisingly strong multimodal base for lightweight agents
︀︀• 9B → compact, but already closing the gap with much larger models
︀︀And yes — we’re also releasing the Base models as well.
︀︀We hope this better supports research, experimentation, and real-world industrial innovation.
︀︀Hugging Face: huggingface.co/collections/Qwen/qwen35
︀︀ModelScope: modelscope.cn/collections/Qwen/Qwen35


Am I cooked bro

AI able to debug faster than me lmao
And also it's all correct code (Reviewed code), passed all tests
With high performance, being able to holds 3000 projectiles moving parts multi-threaded(talking about projectile system)
nah. Step up a step on the ladder of abstraction, and you'll be fine.
hi any balatro coders 
we are recruiting moders for cards and fun
What's the salary
0 per month lmao
Driving a hard bargain
just community mod for a promise of being the best
Ai cannot write complex code for a reason it just doesn't
But it can if it a terminator robot sitting next to me
Especially if you are trying to make something that doesn't exist
#1336777692070023271 qaaap if you are interested
I am not
Also tiktok comments glazing ai just because they bulit something with zero code
Kinda annoying
they themselves didn't code, the ai had to use code though
literally everything uses some form of code
well, everything on the computer
The less you understand something, the more easy it is to midnlesly praise or hate it
I saw this dude on titkok i cant tell if he ragebaiting https://vt.tiktok.com/ZSmTy318H/
We can create the game like anime To Be Hero X?
Lmao
why you try to use copilot
why ppl use this shit man
it will never work mid-term ||(shorter than log term)||
Cuz it's free and comes with microslop stuff
ais are absolute shit for most tasks
if you aren't doing anything too complex it's good enough
why use microslop stuff
just use arch and nvim
unless you have unsupported laptop pins for micro, you are fine
(literally me btw, but i fixed by searching with ai with a shit ton of context so it can actually find correct solution)
how do i add new function to some class from outside 
cpp
or do i just pass the class as argument
except issue with not updating keyring frequently enough (so i had just to go to config and disabling checking for next run)
after instillation i have no issues with arch
reflection
see c++26
haha
what you actually need? do you have access to class source code?
or it compiled+declaration?
i need to make new function for this class

that i passed as 1st argument now and its fine
i jsut needed access to PollRateMs and m_context
i took another function as example but that function exists in class already
so it just overrides/expands/whateveritscalled
and i need new one
to what class?
NeuroSocket
i assume it is compiled or just without sources change allowed
seems like this are just public and assumed to use as public member for some reasons? that weird in term of cpp in first place
but with this api you can just inher from neuro socket and do whatever you want in new class with this members always presented
tho i really doubt that you should do like this anyway
why cant you just remember this values in your logic? if you need access for context and rate, just make value and pointer to it, context is assumed to be used as pointer anyway
just from what i see it basically values to be created once per session
nah it is c api purely, idk why it have namespace
so llm doesnt try to communicate with "choose_string_choice" for example (now renamed to choose_character_string_name_dont_use_unless_asked_to)
but actually if its registered only when needed
will not be a problem
same with other force commands i have
@obsidian mantle idk why i tried to see it as cpp
it is c api, not cpp, in this case you would wrap it into c++ class and expose only stuff you need via proper methods
try to search for actual cpp api for neuro sdk first
cuz it is surely c api
idk i just stole it from cyberpunk integration 
FYI the socket URL gets autosetup to value of some env var with libneurosdk
You don’t need to set it by hand
i think i just got confused with cpp again and now it all works
new function within class or something like that
wtf is this im scared
const char **action_names;
pointer to array of const char *?
are they separated with \0 or
 pointer to array of strings most likely
pointer to array of strings most likely
don't need to be separated with \0, the pointers have a known size
the strings don't though, those should still be null-terminated
array itself might be null-terminated too
unless they give you the length too i guess
i see i see so its just an array of pointers to const char*s

if you're ever confused about some of the truly vile declarations there's https://cdecl.org/ or https://github.com/paul-j-lucas/cdecl
its a library for convenient integration development
hey
checking in
i'm ok
baii
just remembered i said some things to some here that might worry them because i stopped appearing

phrrr

Restarting Discord be like (it was using 14GB alone)

Does anyone know what will happen after you Windows + Ctrl + C
Relatable developer at night, staring at gigantic code
in the basement 24/7
595.71
Still borked on the 4000 series
aight so..
i randomly decided to test gemini 3.1 pro on our informatics (CS) govt exam (the one that all HS graduates take to get into college/university)
 it fucking passed with 95/100 score, 27/29 tasks completed, only 2 failures
it fucking passed with 95/100 score, 27/29 tasks completed, only 2 failures
are all CS graduates actually fucking cooked bro

it might aswell ace the exam when 3.5 comes out
gg wp
Saw your message about 3.5 4B, does it actually stack up to the bemchmarks though?
I could believe it with the 27B and 35BA3B since that's still a lotta params
^ and I didnt even give it direct access to the provided files, only gave the description to them given by the official exam text
informatics oge is easiest on earth even&oe
need testing
And I personally tested em and found them good
thats ege
oge would be childs play for this thing 🗿
dont think theres a point in testing it in either physics or maths, as its still limited by the same image recognition issues, analog meters etc etc
i might acc try downloading the 4B qwen model later and give it a try

International models on ARC-AGI-2 Semi Private
︀︀
︀︀ - Kimi K2.5 (@Kimi_Moonshot): 12%, $0.28
︀︀ - Minimax M2.5 (@MiniMax_AI): 5%, $0.17
︀︀ - GLM-5 (@Zai_org): 5%, $0.27
︀︀ - Deepseek V3.2 (@deepseek_ai): 4%, $0.12
︀︀
︀︀These models score below July 2025 frontier labs

You know LLMs, any good LLMs that would perform better than Nvidia Nemotron 30BA3B?
-# Xod's school project which is about making an LLM teach people using provided school materials and whatever and that's the LLM I'm providing for her right now
(has to be something in the 30B or so range for it to fit on my GPU)
Not a huge fan of 3b expert models. honestly have been having better results with dense models
So far it's worked just fine and it's also really fast
Define fast
190 t/s
Is that sustained prefill or generation? Also quality is going to be questionable at 3b active
It's the generation speed
There's also not been any major obviously model quality issues
MoE 
The issue is that a 2 expert MoE is like asking someone to double the horsepower of your car and they just buy and identical one and weld the two side by side
Well technically with the car it works, as long as you run both engines at once and link the steering systems
not in parallel parking it wont
Either way I see no issue with MoE because it's not just the same weights over and over again
It faceplants on cot
Hem?
Chain of thought. 3b active is aweful at cot. The model essentially will always confidently produce the best output without considering alternatives that are actually more relevant to the question at hand
sounds like temperature issues
I like glm4.7 flash, oss 120 (too big but good for retrieval still, tends to run very well even without much in vram but a lot in ram), qwen3 coder next (maybe too big but worth trying if you can fit it with less offloaded layers as it's really good), and devstral 2 small. Coder next is best imo for local stuff, not a thinking model but if you can fit it even at q4 etc it is very very good
Haven't gotten to try 3.5 yet
I can't afford to put anything onto the CPU
There's too many mem leaks in Discord and web apps
Wha
A good amount of that is probably just electron//chromium using the space cuz it's there
This is meant to be a model I can just chuck onto my 3090 and forget about while Xod does her thing
But idk
You looking for speed or smarts?
Eh, 14GB doesn't sound like using memory for the sake of using memory considering it also lags like stupid
I don't know I like it being at least decently fast but it shouldn't be completely incompetent either
Holy
Qwen 3.5 27B
If that's too slow then use 35BA3B with inactive MoE layer offloading
i still like gemma3 27b  for style stuff
for style stuff
for fine tuning
dont really use it for anything else ig
Easy recommend imo, absolute SOTA in that size class
echo is gemma3 27b lolo
How much system ram do you have though because that can change things with tensor offloading
he apparently ownt put any layers in ram
Then Qwen 3.5 27B is a no brainer
i need to grab 3.5 rn
need to yolo an echo with it for fun and profit
i see that liquid put out a lfm2 24b (2b active) in the last week
Its more or less worthless next OSS 20B sadly
damn
Wait this thing has image-text?
oss 20b is p good at that size hard to beat that makes sense
Its multimodal yeah
qwen3 VL also has this in this size class but i imagine 3.5 is better now
Well how does that work with llama.cpp?
Qwen 3.5 27B mogs Qwen 3 VL
poor qwen3
How does one use such stuff from the API?
i still preferred 2.5 over 3 unfortunately
although qwen3 coder next is really good imo
idk how 3.5 compared to that
coder next is in 70b class tho
Bartowski and other GGUF repos have an FP16 multimodal projector as a separate file in the repos, you add it to the llama-server launch command with --mproj pathtofile
Wa
80b*
So basically
But how do I programatically use the multimodality?
How do I call it from the OpenAI compatible endpoint?
have any thoughts on 122b A10b?
im aboutta try it
i want to try 397b (a17b) but it's a bit too thicc
122b moe should be an interesting mogging of oss 120 if it's already losing to the smaller models
I assume this thing has tool use as well (that is also a requirement I forgor to mention)
it can
Was getting to that, I was gonna do an overcomplicated explanation but its easier just to say same way as you would for the OpenAI API
Well I don't use any other OpenAI API than llama.cpp (because others cost money) and I have never used a multimodal model

vllm
llama.cpp
3.5's model card has this for vllm
vllm serve Qwen/Qwen3.5-27B --port 8000
--tensor-parallel-size 8
--max-model-len 262144
--reasoning-parser qwen3
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
ollama itself (ollama run) will automatically do this
which uses llama ont he backend
I find the easiest way is to convert to base64 then pass as image data
Lemme get the docs up for you
How majorly would I have to modify this?
./llama-server -dev CUDA1 --port 8492 -c 131072 --context-shift -m ../../custom-models/Nemotron-3-Nano-30B-A3B-IQ4_XS.gguf --temp 0.7 -ngl 999999999 --special --verbose-prompt --jinja
the worst part about images to the model is the context

Learn how to understand or generate images with the OpenAI API.
If you're quanting down to 4 bits you don't want to be using vllm imo
Well I kinda gotta go that low if I want models to fit
How much context do you actually need?
I fit 27B in my 24gb vram at Q6 10k context on llama.cpp
I have no idea but it's better to have a lot of it because I don't know what Xod is gonna do with it
Dropping down to Q5 I can fit 40k context
-m Qwen3.5-27B-Q4_K_M.gguf \
--jinja \
--reasoning-format deepseek \
-ngl 99 \
-fa \
-c 32768 \
-n 32768 \
--temp 0.6 --top-k 20 --top-p 0.95 --min-p 0 \
--no-context-shift \
--host 0.0.0.0 --port 8000```This 30B uses only 18GB mem a this quant and context
Dumber than 27B but with far more knowledge, however ironically it actually hallucinates more
27B uses around 24GB at Q5 with 40k context
Otherwise you really should look at offloading inactive MoE layers to RAM
I use the 35B at Q6_K_L with 40K context at 60 tokens per second using offloading
True, I was working off the assumption your setup was similar
I have a dedicated GPU for rendering and ML separately
I stick to the 27B though since my use case is single turn anyway
4070Ti + 3090
wouldnt vllm be better for 2 cards
I only use 1 for ML
The other is exclusively for rendering
And gaming
That way whatever happens on the ML card doesn't affect my everyday use of the PC
i know that feel
In that case you could probably fit the 27B at Q6_K_L and long context if you ran with tensor parallelism
You can run models across multiple GPUs on setups like that and still have plenty of power left over on the lesser utilised one
I don't want to split across GPUs
I need room for NeuroSynth too
I like my models Q4, very great VRAM efficiency
If you're insistent on it fitting 24GB VRAM then run the 27B at Q6, drop down to Q5KL if you find yourself bumping into the max context you can squeeze in
Q4 isn't worth it on a lot of these more knowledge dense models, you begin to run into pretty significant degradation below Q5 nowadays
I'm gonna guess I need to recompile llama.cpp first though either way
You do yeah
do
o7 CPU
Eh 12700K can handle it
Oh yeah but no CPU enjoys building llama.cpp
Grab bartowskis Q6 and Q5_K_L GGUFs and F16 mmproj
And recommended sampler settings can be found here https://huggingface.co/Qwen/Qwen3.5-27B

We’re on a journey to advance and democratize artificial intelligence through open source and open science.
The Q6 based on file size is absolutely not gonna fit
when you load 122b with old llama.cpp it is not happy

I fit it on my only GPU (4090) with 10k context
And 1GB free on top
But if you need plenty of context go Q5KL
Its a quality hit but not an unbearable one
All that really matters is that it performs as well or better than the old 30B model
It absolutely mogs that model rest assured, go Q5KL for reliabilities sake though imo
did you see the qwen3.5 with opus 4.6 reasoning distil
With no OS to worry about I'd wager you can fit like 60k+ context
I did but it seems a bit redundant to me
Qwen 3.5 is already a far more professional distill of Opus data
it already was that 
yeah
i just saw that the benchmarks seem to have improvement in like
terminal bench
some benchmaxxing improvements really
dunno real world
It probably benches better but I bet its way more unstable
its stated purpose is to be less unstable which is why i'm interested since in qwen3 experience it was very prone to looping
im sure 3.5 is already much better at that
so idk

the most fun to look at
i will have a system with 136 cores// 544 threads here at some point in the near future, i'm excited to see the longest core list of all time
They say that but excessive rigidity (which is what a lot of these tunes achieve) is its own form of instability imo
yeah you're not wrong
it just depends on how they executed really end of the day
could benefit from additional sft
could not
watching 122b reason throuhg something right now and its logic is already extremely structured ngl
Circling back to that actually, one benefit of 27B is that its pretty concise in its reasoning where I found 122B is a bit yappier
it's structured but it is a long ass thinking trace
I got similar answers to hard questions in 10K tokens max from 27B where 122B took a couple thousand more
I recommend their "precise logic tasks" preset if you don't mind it thinking longer, I find it gives a much smarter presentation
One tip, sometimes the model almost seems like its looping but its actually checking to see if it hallucinated, after a few iterations it usually answers
general tasks recommend 1.0 temp so that's good
I don't like the general tasks preset but if you're not really putting the models smarts through its paces its fine
And it is more concise thanks to that presence penalty
Thinking mode for general tasks:
temperature=1.0, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
Thinking mode for precise coding tasks (e.g., WebDev):
temperature=0.6, top_p=0.95, top_k=20, min_p=0.0, presence_penalty=0.0, repetition_penalty=1.0
Instruct (or non-thinking) mode for general tasks:
temperature=0.7, top_p=0.8, top_k=20, min_p=0.0, presence_penalty=1.5, repetition_penalty=1.0
Instruct (or non-thinking) mode for reasoning tasks:
temperature=1.0, top_p=1.0, top_k=40, min_p=0.0, presence_penalty=2.0, repetition_penalty=1.0
For supported frameworks, you can adjust the presence_penalty parameter between 0 and 2 to reduce endless repetitions.
in this case im asking it to rewrite a song
Slightly higher hallucination rates though naturally
Yeah it'll be fine for that
So how do I use the weird little extra thingy again?
Throw it into your launch command with --mmproj [path to file]
if you just put it in the same dir you're in it's probably in the repo dir --mmproj mmproj-F16.gguf
--mmproj ../../custom-models/mmproj-Qwen_Qwen3.5-27B-bf16.gguf
Like that?
You want FP16 not BF16 generally but yup
I heard BF16 is usually better than FP16
for training
Does it suck for inference somehow?
it's more stable for training
it's not needed
for inference
bf16's advantage is that it's better with large gradients and such which makes it better for training
BF16 is fine tbf, but I encountered some weird bugs using it in the past
it just sacrifices accuracy in small
contexts
shouldnt use contexts there given its meaning already is set for ml
If you keep an eye out and recognise that as the cause if they do occur you're probably fine @nocturne olive
BF16 will be slightly slower and marginally more accurate at similar memory costs since you're on a modern GPU
for forward passes, bf16 is not more accurate in general, it loses mantissa bit precision for exponent bits (to get the same range as fp32 for that) so your gradients dont explode
err
Downloading models on 100Mbps is so slow
bf16 is not more accurate
fp16 is better technically for forward pass because there's less rounding error
long sequences can suffer comparatively in bf16
it's NOT A VERY BIG DIFFERENCE tho
Qwen 3.5 is natively BF16 so I was under the impression you do lose a little accuracy in the conversion process
well if that's the case then nvm it's a bit different
i'd run bf16
unless my hardware doesn't support bf16 obv
fp16 was more commonly the native format for a while so that's a bit of an antiquated thing now ig
i mainly cared about this when i was training stable diffusion vs running inference for it which was natively fp16 and bf16 would cause issues with fine detail
I have actually heard that manually setting context cache to BF16 might reduce looping with Qwen models on llama.cpp
I don't know whether that would hold up under scientific testing though
Given llama.cpp uses FP32 accumulation for context anyway
is flash attention broken with 3.5
that tends to be what happens early half the time i just havent checked
Its broken if you switch to BF16 context yeah, so I stick with FP16
I figure the speed loss isn't worth the edge cases (if there even is a real issue)

Oh wait hang on lmao, that means the F16 mmproj is the one you want after all
D'oh
@nocturne olive I did a dumb
How weirdly silly
too late he's already sat there like "this model fucking sucks wtf"
Mildly unpopular opinion: PDF is the worst file format ever

i hate it when my steak is too juicy and my lobster is too buttery
I put it into Claudes memeory to argue with me and drop agreebility bias when I am engaged in work projects. Now he's all sassy and destroying my legal arguements.

best instruction follower
I'd consider 100mbps to be on the slower end by uk standards at least
100mbps was the first "fast" internet we had hwen i was a kid
that was in like 2010
it is the baseline for what i'd consider usable for anything more than phone tier browsing
100Mbps is literally the lowest option here
Eh, 1Gbps would be better value
lol why
that's how it is here
75~ is the lowest in my area
verizon asked me if i wanted FiOS and i was like sure ill see what your fiber speed is on offer
and these mfs had the audacityu
they dont have fiber here
they offered 25 mbps LTE
home modem
bruh
on the plus side xfinity is apparently offering 10g service here now i just have to wait for them to procure an xb10 (docsis 4.0 modem)
cant get those anywhere else so that's fun
q5 was unhappy with long context for me w/ 32gb vram so that checks out
without any offloading anyways
q6 i mean
If you really need super long context by all means
Game of tradeoffs like anything in computing
It'll still outperform the 30B
2nd go with the recommended general thinking params = 4491 tokens 
agentic harness
A security hole you willingly install
you should give it access to your whole life to let it ruin it for you
That’s what I was suspecting
like swiss cheese
the holes ARE the value prop
it's running up against the problem
of agents
they cant be useful without the holes
without a lot of manual intervention
I heard nobody’s overseeing the GitHub repo 😬
he got hired by openAI so who knows
it's basically "what if i give ai access to everything and the ability to do anything?"
as in, delete your whole gmail inbox
it's fine there's no way an agent might come across some adversarial prompts on the internet surely not
or just go off the rails
or message your ex you miss her
he's just tryna helpp
most do i would imagine
probably knows there are flaws
might not know the extent or risk
also the software itself has a shitload of its own vulnerabilities
it's not just the agent going berserk
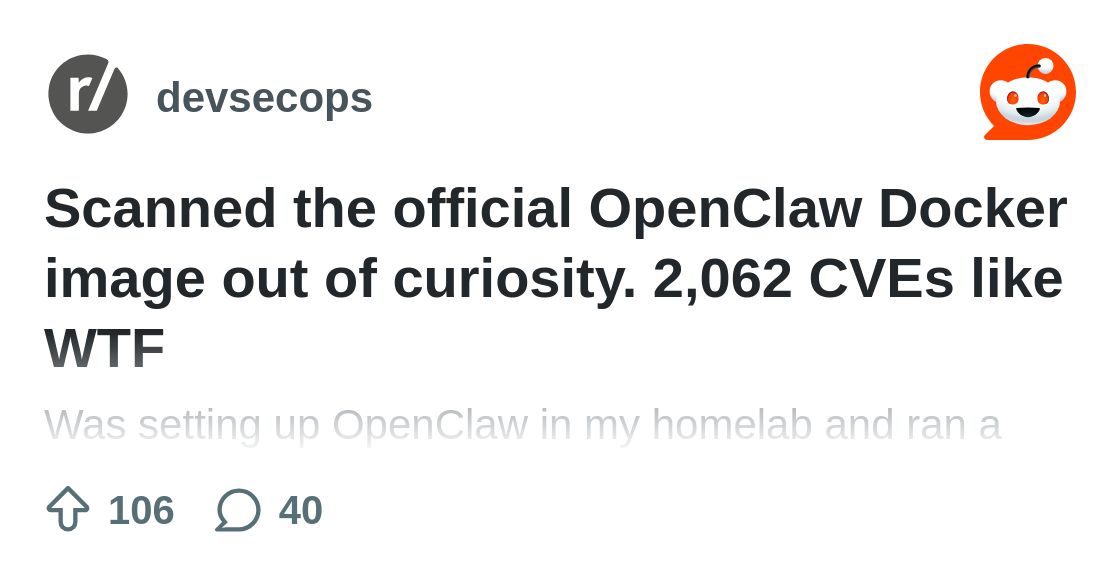
the docker container had like 2000 vulnerabilities or something dumb
Was setting up OpenClaw in my homelab and ran a quick CVE scan on ghcr.io/openclaw/openclaw because why not. Holy hell. 2,06…
I’ll just keep going down the road I was already on.
ftr I was the guy asking about an AI chat buddy for streamers who aren’t used to talking live
that can be done many safer ways
Ho ho yeah
Vibe coded LLM powered sysadmin at scale, what could go wrong 
I believe that
top comment  is that referring to the prediction market / crypto trading bots people are setting up
is that referring to the prediction market / crypto trading bots people are setting up

web3 baby

All Telegram chatbots can now stream responses to users in real time — great for AI assistants.
but my nft newsletter that no-one reads is automated and generates intrinsic value (somehow)
i don't know any openclaw users is this an accurate depiction of how they type?
yes

wow the agentic future is incredible

gimme gimme gimme
somehow i dont see how this is unsustainable, just tell the bot to build me wealthy  well done
well done


entirely helpless without asking grok in the replies too
epic
prompt engineers
Good news (?)
The person is aware of Open Claws flaws
isnt your 30b an a3b
27b is all loaded in vram in the dense model
for the 30b it's loading not nearly as much
it only has 3b active paramters
Ok it doesn't really fit NeuroSynth won't run
offload like 2 layers to cpu
No
i knwo you dont want to but that's like nothing
I'll just drop a few CTX I guess
Looks like NeuroSynth needs 2GB VRAM at inference time
wouldnt you just run that on your other gpu
Taking off 16K CTX from 128K is enough to get it running
No that's slow
And affects graphics
you must be bigly gaming at all times
I'll see if I swap to this model or not
This one's way more annoying to deal with VRAM wise
what about the 3.5 equivalent of your 30b?

the dense model is gonna be more resource hungry which is obviously a concern this one should be very much more similar to the 30b with 3b active
Well what does the @sick owl think?
with 3.5 35b a3b loaded entire on to GPU and set to 128k context, im using 27.9 gb vram with it loaded
and getting 67 tok/sec dayum
well this is with 128k context
Well 128K is what I was running Nemotron 30B at
i have a few things enabled that probably increase vram hold on
25.5 with kv quant welp idk it's just a bit bigger than 30b cuz 5b more i guess
i still think you're overestimating just how much offloading like 2 layers to system ram would harm your overall pc experience, probably significantly less than if one of your GPU is sitting at 100% vram
I want the model to be completely invisible to me when I use my PC
Otherwise I can't exactly keep it up for Xod more than absolutely needed
i think it'd be more invisible than having a full gpu tbh
when one of mine is maxxed out it causes the rest of the pc to be a bit less happy presumably due to bumping up against the point it might need to use some system ram but not quite
I used an IQ4 quant by the way instead of a regular Q4_K_M
It's a bit smaller
with 5 model layers offloaded the mem use of lm studio is 22gb on vram and 3gigs in system ram

it's pretty nothing
but that also would probably help idk if there are any imatrix quants of this yet but people are usually fast
closed vivaldi kekw

didnt even have much open
went down to 37 tok/s with 5 layer offload & 128k context 22.1gb vram used
lm studio in the interface will estimate vram/ram usage as you adjust parameters before loading which is nice
I just raw terminal llama.cpp
yea i mean that's what i do for vllm
but for this purpose
rather than loading/unloading over and over to see
not that it takes forever
isnt it just based on when you first used it that week
er the last week
i dont use codex much
Well the ratelimit reset for me was on March 5
I checked it a few mins ago and it reset to 100%
i found some threads of that happening to people randomly a few months ago
maybe they just felt like resetting it "as a gift"
oh wait
Attempt to retain userbase after uh, misadvertisement?
gpt 5.4 is out in codex randomly
in the last hour
seems like they may be blasting 5.4 codex out and reset it for that + they were having issues when doing so
Probably some A/B testing stuff
it is
the model name is literally
ab
lmfao
interesting that some info can be guessed from this name string
agi
 ?
?{kind=link}
OK maybe if mister Altman routes this Codex instance to GPT5.4 it can solve this crypto challenge
Lol my 2nd acct got kicked out of verified?

5.4 - obviously new version incremented from 5.3, still gpt5 pretrain
ab - a/b test there's prob another variant or 2
arm1 - seems like arm arch but idk what arm1 is unless it's talking about some sort of branching a/b with "arms"
1020 - october 20th? maybe the original checkpoint date, or 1020 steps, or something else. original gpt 5.1 announcement was nov 12th so i could see this being the first 5.x training run date or something
1p - 1 pass? something with precision?
codexswic - codex line, swic could be a few things, maybe software in context or something if i schizo, or just switch
ev3 - eval 3?
oo found a 5.1-ab-arm3-840-1p-codexswic-ev3
arm1/arm3 arent arm arch then i guess
1020/840 probably not dates
maybe thye are context length
1020k vs 840k
https://www.reddit.com/r/codex/comments/1rjcwli/usage_limit_reset/ seems like there was an error with 5.3 that was fixed
seems liek possible deepseek v4 imminent
@sick owl interestingly enough with both 122b and 35b MoE, the thinking trace making any sense or focusing on things that matter for the task is inversely correlated with the final output quality
the best final answers came from the unhinged thinking traces that spent all their time on nothing of value



is that 1u/2u atx?

3.2
on amazon, $12
depending on level of sketchy unsurity about getting what it's listed as, as low as $4
on other sites
those seem not real tho
idk
i should buy one to see
theyre free anyways
that's abouit the verified price i could find
there are a lot of overpriced $20+ ones
yeah there are
in fact i just got one for $10
because i realized all my usb drive are 32gb
so why not ig
holy
too small
well, i used those kinds for lik
bios
and small transfers ig but if i am putting something on a usb stick it's usually something big
for bios most 64MB-128MB already works lol
i do
the one my father years ago got